
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-27 00:42:13
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 499
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-27 00:40:00
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
ilyass31/AI-negotiation-assistant | ilyass31 | 2025-05-02T23:56:32Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"conversational",
"custom_code",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T22:06:59Z | ---
base_model: unsloth/qwen3-14b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** ilyass31
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen3-14b-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
saramoncayon/sol | saramoncayon | 2025-05-02T23:49:36Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-05-02T23:36:40Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: sol
---
# Sol
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `sol ` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "sol ",
"lora_weights": "https://huggingface.co/saramoncayon/sol/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('saramoncayon/sol', weight_name='lora.safetensors')
image = pipeline('sol ').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/saramoncayon/sol/discussions) to add images that show off what you’ve made with this LoRA.
|
fats-fme/dbed360c-d31a-41b8-a639-f7200e835194 | fats-fme | 2025-05-02T23:49:22Z | 0 | 0 | peft | [
"peft",
"safetensors",
"qwen2",
"axolotl",
"generated_from_trainer",
"base_model:Qwen/Qwen2-1.5B-Instruct",
"base_model:adapter:Qwen/Qwen2-1.5B-Instruct",
"license:apache-2.0",
"region:us"
] | null | 2025-05-02T22:02:35Z | ---
library_name: peft
license: apache-2.0
base_model: Qwen/Qwen2-1.5B-Instruct
tags:
- axolotl
- generated_from_trainer
model-index:
- name: dbed360c-d31a-41b8-a639-f7200e835194
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: Qwen/Qwen2-1.5B-Instruct
bf16: true
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- 21c49dc937709928_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/21c49dc937709928_train_data.json
type:
field_instruction: en
field_output: fr
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
device_map: auto
early_stopping_patience: 3
eval_max_new_tokens: 128
eval_steps: 100
eval_table_size: null
evals_per_epoch: null
flash_attention: true
fp16: false
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: true
group_by_length: false
hub_model_id: fats-fme/dbed360c-d31a-41b8-a639-f7200e835194
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 5.0e-05
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 10
lora_alpha: 128
lora_dropout: 0.1
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 64
lora_target_linear: true
lr_scheduler: cosine
max_memory:
0: 130GB
max_steps: 200
micro_batch_size: 2
mlflow_experiment_name: /tmp/21c49dc937709928_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 10
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: 100
saves_per_epoch: null
sequence_len: 2048
strict: false
tf32: true
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 3817e1a8-ed6c-45eb-9aef-fd65e3afe80f
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: 3817e1a8-ed6c-45eb-9aef-fd65e3afe80f
warmup_steps: 200
weight_decay: 0.01
xformers_attention: null
```
</details><br>
# dbed360c-d31a-41b8-a639-f7200e835194
This model is a fine-tuned version of [Qwen/Qwen2-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3586
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 200
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| No log | 0.0000 | 1 | 2.9527 |
| 1.3482 | 0.0008 | 100 | 1.4766 |
| 1.3165 | 0.0017 | 200 | 1.3586 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
Afaf/arab-qwen2.5-3B-grpo | Afaf | 2025-05-02T23:45:09Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T23:37:31Z | ---
base_model: unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Afaf
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
AdoCleanCode/real_model_VGG_v3_060 | AdoCleanCode | 2025-05-02T23:40:25Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T21:29:03Z | ---
library_name: transformers
license: mit
base_model: gpt2
tags:
- generated_from_trainer
model-index:
- name: real_model_VGG_v3_060
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# real_model_VGG_v3_060
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4275
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.7172 | 1.0 | 3997 | 1.5437 |
| 1.5152 | 2.0 | 7994 | 1.4800 |
| 1.4495 | 3.0 | 11991 | 1.4483 |
| 1.407 | 4.0 | 15988 | 1.4328 |
| 1.3728 | 5.0 | 19985 | 1.4275 |
### Framework versions
- Transformers 4.46.3
- Pytorch 2.1.2+cu121
- Datasets 2.19.1
- Tokenizers 0.20.3
|
cwaud/3218bdd7-24fe-48a8-bdcc-a18831328e5c | cwaud | 2025-05-02T23:36:38Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:TinyLlama/TinyLlama_v1.1",
"base_model:adapter:TinyLlama/TinyLlama_v1.1",
"license:apache-2.0",
"region:us"
] | null | 2025-05-02T23:32:48Z | ---
library_name: peft
license: apache-2.0
base_model: TinyLlama/TinyLlama_v1.1
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 3218bdd7-24fe-48a8-bdcc-a18831328e5c
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.5.2`
```yaml
adapter: lora
base_model: TinyLlama/TinyLlama_v1.1
bf16: auto
chat_template: llama3
dataset_prepared_path: /workspace/axolotl/data_prepared
datasets:
- data_files:
- e1230b33949f9bdf_train_data.json
ds_type: json
format: custom
path: /workspace/axolotl/data
type:
field_instruction: question
field_output: chosen
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 4
flash_attention: false
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: false
group_by_length: false
hub_model_id: cwaud/3218bdd7-24fe-48a8-bdcc-a18831328e5c
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.0002
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 16
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 8
lora_target_linear: true
lr_scheduler: cosine
max_steps: 10
micro_batch_size: 2
mlflow_experiment_name: /workspace/axolotl/data/e1230b33949f9bdf_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 4
sequence_len: 512
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 0ace46bc-8f88-4e70-95b9-9502b5a4d1dc
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: 0ace46bc-8f88-4e70-95b9-9502b5a4d1dc
warmup_steps: 10
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# 3218bdd7-24fe-48a8-bdcc-a18831328e5c
This model is a fine-tuned version of [TinyLlama/TinyLlama_v1.1](https://huggingface.co/TinyLlama/TinyLlama_v1.1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6293
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- training_steps: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.3664 | 0.0002 | 1 | 1.7174 |
| 1.5623 | 0.0007 | 3 | 1.7129 |
| 1.5257 | 0.0014 | 6 | 1.6821 |
| 1.526 | 0.0021 | 9 | 1.6293 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.2
- Pytorch 2.5.1+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3 |
Yeongi/ppo-Pyramids | Yeongi | 2025-05-02T23:35:22Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] | reinforcement-learning | 2025-05-02T23:35:09Z | ---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Yeongi/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
ivangrapher/258a3a8f-d2b1-4961-9699-a77b3483edf3 | ivangrapher | 2025-05-02T23:34:37Z | 0 | 0 | peft | [
"peft",
"safetensors",
"mistral",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/mistral-7b-v0.3",
"base_model:adapter:unsloth/mistral-7b-v0.3",
"license:apache-2.0",
"8-bit",
"bitsandbytes",
"region:us"
] | null | 2025-05-02T22:01:38Z | ---
library_name: peft
license: apache-2.0
base_model: unsloth/mistral-7b-v0.3
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 258a3a8f-d2b1-4961-9699-a77b3483edf3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: unsloth/mistral-7b-v0.3
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 0bc216a74e5223ea_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/0bc216a74e5223ea_train_data.json
type:
field_input: system_prompt
field_instruction: question
field_output: response
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.55
group_by_length: false
hub_model_id: ivangrapher/258a3a8f-d2b1-4961-9699-a77b3483edf3
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 1.0e-06
load_in_4bit: true
load_in_8bit: true
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 150
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/0bc216a74e5223ea_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 2048
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 54f8b968-ef35-4e16-a7c3-fbecb65048c8
wandb_project: s56-7
wandb_run: your_name
wandb_runid: 54f8b968-ef35-4e16-a7c3-fbecb65048c8
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# 258a3a8f-d2b1-4961-9699-a77b3483edf3
This model is a fine-tuned version of [unsloth/mistral-7b-v0.3](https://huggingface.co/unsloth/mistral-7b-v0.3) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0589
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.9845 | 0.0063 | 150 | 1.0589 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
chchen/MentaLLaMA-chat-7B-PsyCourse-doc-info-fold7 | chchen | 2025-05-02T23:34:37Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama-factory",
"lora",
"generated_from_trainer",
"base_model:klyang/MentaLLaMA-chat-7B-hf",
"base_model:adapter:klyang/MentaLLaMA-chat-7B-hf",
"license:mit",
"region:us"
] | null | 2025-05-02T21:53:14Z | ---
library_name: peft
license: mit
base_model: klyang/MentaLLaMA-chat-7B-hf
tags:
- llama-factory
- lora
- generated_from_trainer
model-index:
- name: MentaLLaMA-chat-7B-PsyCourse-doc-info-fold7
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MentaLLaMA-chat-7B-PsyCourse-doc-info-fold7
This model is a fine-tuned version of [klyang/MentaLLaMA-chat-7B-hf](https://huggingface.co/klyang/MentaLLaMA-chat-7B-hf) on the course-doc-info-train-fold7 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1031
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.3696 | 0.3951 | 10 | 0.6138 |
| 0.2069 | 0.7901 | 20 | 0.3891 |
| 0.1724 | 1.1852 | 30 | 0.3201 |
| 0.1333 | 1.5802 | 40 | 0.2521 |
| 0.2458 | 1.9753 | 50 | 0.2011 |
| 0.0919 | 2.3704 | 60 | 0.1584 |
| 0.0889 | 2.7654 | 70 | 0.1347 |
| 0.0991 | 3.1605 | 80 | 0.1167 |
| 0.1154 | 3.5556 | 90 | 0.1097 |
| 0.07 | 3.9506 | 100 | 0.1051 |
| 0.0668 | 4.3457 | 110 | 0.1035 |
| 0.2276 | 4.7407 | 120 | 0.1031 |
### Framework versions
- PEFT 0.12.0
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3 |
DP2579/DP_UNIT2 | DP2579 | 2025-05-02T23:31:10Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2025-05-02T23:31:08Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: DP_UNIT2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.50 +/- 2.64
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="DP2579/DP_UNIT2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
MPTarun/llama_aac_model-GGUF | MPTarun | 2025-05-02T23:27:35Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-02T23:27:02Z | ---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** MPTarun
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
cwaud/3ca86da9-e878-46e1-aa4e-61c84dcaf6a0 | cwaud | 2025-05-02T23:25:57Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"axolotl",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"base_model:Qwen/Qwen1.5-7B-Chat",
"base_model:finetune:Qwen/Qwen1.5-7B-Chat",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T23:21:55Z | ---
base_model: Qwen/Qwen1.5-7B-Chat
library_name: transformers
model_name: 3ca86da9-e878-46e1-aa4e-61c84dcaf6a0
tags:
- generated_from_trainer
- axolotl
- dpo
- trl
licence: license
---
# Model Card for 3ca86da9-e878-46e1-aa4e-61c84dcaf6a0
This model is a fine-tuned version of [Qwen/Qwen1.5-7B-Chat](https://huggingface.co/Qwen/Qwen1.5-7B-Chat).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="cwaud/3ca86da9-e878-46e1-aa4e-61c84dcaf6a0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/alicegoesdown56-goesdown/Gradients-On-Demand/runs/kzz1q0c1)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.0
- Transformers: 4.46.2
- Pytorch: 2.5.1+cu124
- Datasets: 3.1.0
- Tokenizers: 0.20.3
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
aleegis/2db2336a-b7b9-4427-a93d-3cd19612a495 | aleegis | 2025-05-02T23:21:07Z | 0 | 0 | peft | [
"peft",
"safetensors",
"qwen2",
"axolotl",
"generated_from_trainer",
"base_model:Qwen/Qwen2-1.5B-Instruct",
"base_model:adapter:Qwen/Qwen2-1.5B-Instruct",
"license:apache-2.0",
"region:us"
] | null | 2025-05-02T22:23:02Z | ---
library_name: peft
license: apache-2.0
base_model: Qwen/Qwen2-1.5B-Instruct
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 2db2336a-b7b9-4427-a93d-3cd19612a495
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: Qwen/Qwen2-1.5B-Instruct
bf16: auto
chat_template: llama3
dataloader_num_workers: 12
dataset_prepared_path: null
datasets:
- data_files:
- 9532c4c65a822af6_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/9532c4c65a822af6_train_data.json
type:
field_instruction: problem
field_output: reasoning_solution
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_steps: null
eval_table_size: null
evals_per_epoch: null
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 8
gradient_checkpointing: false
group_by_length: false
hub_model_id: aleegis/2db2336a-b7b9-4427-a93d-3cd19612a495
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.0001
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: null
lora_alpha: 32
lora_dropout: 0.15
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
loraplus_lr_embedding: 1.0e-06
loraplus_lr_ratio: 16
lr_scheduler: cosine
max_grad_norm: 1
max_steps: 1500
micro_batch_size: 2
mlflow_experiment_name: /tmp/9532c4c65a822af6_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 200
optimizer: adamw_torch_fused
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: null
save_total_limit: 10
saves_per_epoch: 0
sequence_len: 1024
strict: false
tf32: true
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.0
wandb_entity: null
wandb_mode: online
wandb_name: e81a8ee6-474d-4598-a6bc-fe8020a6cbf5
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: e81a8ee6-474d-4598-a6bc-fe8020a6cbf5
warmup_steps: 100
weight_decay: 0
xformers_attention: null
```
</details><br>
# 2db2336a-b7b9-4427-a93d-3cd19612a495
This model is a fine-tuned version of [Qwen/Qwen2-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1500
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
jahyungu/Qwen2.5-7B-Instruct_MetaMathQA-40K_cluster9 | jahyungu | 2025-05-02T23:19:04Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T19:08:06Z | ---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- generated_from_trainer
model-index:
- name: Qwen2.5-7B-Instruct_MetaMathQA-40K_cluster9
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Qwen2.5-7B-Instruct_MetaMathQA-40K_cluster9
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.50.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.0
|
shubhamprshr/Qwen2.5-1.5B-Instruct_aqua_sgrpo_gaussian_0.25_0.75_True_300 | shubhamprshr | 2025-05-02T23:18:50Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"grpo",
"conversational",
"dataset:gsm8k-dataset",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-1.5B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-1.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T15:17:05Z | ---
base_model: Qwen/Qwen2.5-1.5B-Instruct
datasets: gsm8k-dataset
library_name: transformers
model_name: Qwen2.5-1.5B-Instruct_aqua_sgrpo_gaussian_0.25_0.75_True_300
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for Qwen2.5-1.5B-Instruct_aqua_sgrpo_gaussian_0.25_0.75_True_300
This model is a fine-tuned version of [Qwen/Qwen2.5-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct) on the [gsm8k-dataset](https://huggingface.co/datasets/gsm8k-dataset) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="shubhamprshr/Qwen2.5-1.5B-Instruct_aqua_sgrpo_gaussian_0.25_0.75_True_300", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/shubhamprshr27-tamu/AQUA/runs/c14cnaz9)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.14.0
- Transformers: 4.48.1
- Pytorch: 2.5.1
- Datasets: 3.1.0
- Tokenizers: 0.21.0
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
luisJansen/v2Jansenzinho | luisJansen | 2025-05-02T23:17:18Z | 0 | 0 | null | [
"license:other",
"region:us"
] | null | 2025-05-02T22:42:12Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
--- |
froyoburnup/CRKPortraitNoobEPSv110 | froyoburnup | 2025-05-02T23:11:13Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-05-02T21:31:54Z | ---
license: apache-2.0
---
|
b0HIC4/my-test-model | b0HIC4 | 2025-05-02T23:05:49Z | 0 | 0 | null | [
"safetensors",
"distilbert",
"text-classification",
"sentiment-analysis",
"license:apache-2.0",
"region:us"
] | text-classification | 2025-05-02T22:12:31Z | ---
tags:
- text-classification
- sentiment-analysis
license: apache-2.0
---
# My Test Model
This repo contains a basic sentiment-analysis inference script.
|
sultanalolait/colab-finetuned-model | sultanalolait | 2025-05-02T23:05:44Z | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"xlm-roberta",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:134964",
"loss:MultipleNegativesRankingLoss",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:intfloat/multilingual-e5-large",
"base_model:finetune:intfloat/multilingual-e5-large",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2025-05-02T17:08:45Z | ---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:134964
- loss:MultipleNegativesRankingLoss
base_model: intfloat/multilingual-e5-large
widget:
- source_sentence: ما هي المبادئ القانونية التي تستند إليها المحكمة في الحكم بالتعويض
عن أتعاب التقاضي؟
sentences:
- "[السياق: يتعلق هذا الجزء بوقائع الدعوى المقدمة من المدعية ضد المدعى عليه، حيث\
\ تدعي أنها سلمته مبلغًا ماليًا بقيمة 100,000 ريال عبر حوالتين بنكيتين لاستثماره\
\ في السوق، بينما ينكر المدعى عليه ذلك ويدعي أن المبلغ كان سدادًا لأعمال شخصية\
\ قام بها للمدعية. وقررت المحكمة رفض الدعوى لعدم كفاية الأدلة المقدمة من المدعية.]\
\ \nالوقائع : تتلخص وقائع هذه الدعوى في أنه سبق أن تقدم وكيل المدعي الموضح بياناته\
\ أعلاه بلائحة دعوى إلى المحكمة التجارية بجدة ذكر فيها أن موكلتي قامت بتسليم المدعى\
\ عليه مبلغ وقدره (100,000) مائة ألف ريال، عبر حوالتين بنكية بواسطة مصرف الراجحي،\
\ بمبلغ وقدره (50,000) خمسون ألف ريال بواقع كل حوالة بنكية، حيث كانت الحوالة البنكية\
\ الأولى في تاريخ 29/12/1441هـ، والحوالة البنكية الثانية في تاريخ 01/01/1442هـ،\
\ و موكلتي اتفقت مع المدعى عليه أن تسلمه مبلغ وقدره (100,000) مائة ألف ريال ليقوم\
\ باستثماره في السوق بشكل عام، ولم يدفع المدعى عليه للمدعية شيئا سوى مبلغ وقدره\
\ (18,000) ثمانية عشرة ألف ريال يزعم المدعى عليه أنها أرباح، وكان الاتفاق على\
\ أن تقوم موكلتي بدفع المبلغ وأن يقوم المدعى عليه باستثماره، ولم يتم تحديد نشاط\
\ معين يتم استثمار المال فيه، ولم يتم الاتفاق على نسبة الأرباح، ولا على مدة معينة\
\ للاستثمار، ولا على نشاط محدد، وتقدمت موكلتي بذات المطالبة سابقا في الدعوى المقيدة\
\ برقم (421501551) لدى المحكمة العامة بمحافظة جدة بالدائرة العامة الثامنة عشرة\
\ وقد صدر حكم قضائي برقم (421664998) وتاريخ 24 / 12 / 1442هـ والمتضمن صرف النظر\
\ عن الدعوى نوعيا وذلك لتكييف الدائرة للدعوى على أنها شراكة مضاربة، وقد اكتسب\
\ الحكم الصفة القطعية بتأييد محكمة الاستئناف، علما أن نشوء الحق كان بتاريخ ١٤٤١/١٢/٢٩هـ\
\ الموافق ٢٠٢٠/٠٨/١٩م. وطالب بـالحكم ببطلان الشراكة،و إلزام المدعى عليه برد مبلغ\
\ و قدره (٨٢٠٠٠) اثنان وثمانون ألفا ريال.وقدم سندا لطلبه المستندات الآتية: 1_\
\ الحوالات البنكية.ثم قدم المدعى عليه جوابه على الدعوى المتضمن: الإقرار باستلام\
\ قيمة المال محل المطالبة، لكنه كان سدادا لمستحقات خاصة له عن أعمال شخصية قام\
\ بها لصالح المدعية عبارة عن أعمال حدادة، وأعمال أخرى للمنزل، وكذلك أعاد لها مبلغا\
\ قدره (18.000) ريال، لكونها كانت زائدة وغير مستحقة له ابراء لذمته، وينكر حصول\
\ أي اتفاق للاستثمار أو الشراكة بينهما.وقد عقدت الدائرة جلسة مرئية في 1/7/1443هـ\
\ وملخصها: حضر وكيل المدعي ووكيل المدعى عليها، كما حضر خالد قاعد"
- "[السياق: يحلل هذا الجزء مدى اختصاص المحكمة وفحصها لمبررات المدعية، مع التأكيد\
\ على أن مخالفات المدير لا توجب تضمينه بدين الشركة. وقررت المحكمة رفض الدعوى لعدم\
\ توفر الأساس النظامي.] \nبصفته مديرا لشركة مصنع فنون الألمنيوم الدين الثابت\
\ في ذمة شركة مصنع فنون الألمنيوم لصالح المدعية، فإن هذه المحكمة مختصة بنظر هذا\
\ النزاع وفقا للمادة (16 / 4) من نظام المحاكم التجارية، وفي موضوع الدعوى فإن طلب\
\ المدعية هو تضمين المدعى عليه بصفته مديرا لشركة مصنع فنون الألمنيوم عن الدين\
\ الثابت في ذمة الشركة لصالح المدعية بمبلغ قدره (125.689ريال)، ولأن طلب المدعية\
\ مبني على تعاقدها مع شركة مصنع فنون الألمنيوم سجل تجاري رقم (...)، وأنها استحقت\
\ بموجب التعاقد مع الشركة مبلغا قدره (125.689ريال)، وأنه تعذر عليها استيفاء حقها\
\ من الشركة، وطلبت تضمين المدعى عليه الدين الثابت في ذمة الشركة، وبعد فحص الدائرة\
\ للتعامل بين الطرفين، ومدى صحة تضمين المدعى عليه الدين الثابت في ذمة الشركة،\
\ وبالاطلاع على المبررات التي ذكرها وكيل المدعية في دعواه، ولأن شركة مصنع فنون\
\ الألمنيوم هي شركة ذات مسؤولية محدودة، ولأن ما ذكره وكيل المدعية في دعواه ليس\
\ مبررا كافيا لتضمين المدعى عليه –المدير- في أمواله الخاصة عن دين الشركة ذات المسؤولية\
\ المحدودة، ذلك أن المدعية بنت دعواها على نص المادة (28 / 1) من نظام الشركات،\
\ ونصها: \" يكون المدير وأعضاء مجلس الإدارة مسؤولين بالتضامن عن تعويض الشركة أو\
\ الشركاء أو المساهمين أو الغير عن الضرر الذي ينشأ بسبب مخالفة أحكام النظام أو\
\ عقد تأسيس الشركة أو نظامها الأساس، أو بسبب ما يصدر منهم من أخطاء أو إهمال أو\
\ تقصير في أداء أعمالهم. وكل شرط يقضي بغير ذلك يعد كأن لم يكن.\"، وهذا النص متعلق\
\ بدعوى التعويض عن الضرر الذي يصيب الغير بسبب مخالفة المدير للنظام، وليس فيه حكم\
\ نظامي بتضمين المدير الدين الثابت في ذمة الشركة، كما استندت المدعية في دعواها\
\ على نص المادة (17 / 2) من نظام الشركات، ونصها: \" يجب إعداد قوائم مالية للشركة\
\ في نهاية كل سنة مالية وفق المعايير المحاسبية المعتمدة في المملكة، وإيداع هذه\
\ القوائم وفقا لما تحدده اللوائح خلال (ستة) أشهر من تاريخ انتهاء السنة المالية،\
\ وذلك"
- '[السياق: يختتم هذا الجزء أسباب الحكم حيث قررت المحكمة وجود مماطلة من المدعى عليها
بإقرارها بمبلغ في ذمتها وإجبار المدعي على اللجوء للقضاء. وحكمت بتعويض المدعي بمبلغ
100,000 ريال عن أتعاب التقاضي. وبهذا انتهت الدعوى.]
الدائرة عن مزيد إضافة أو بينة أجابا بالنفي ، وفي جلسة اليوم 1444/01/05هـ حضر أطراف
الدعوى وكالة، وقد قرر الأطراف الاكتفاء بما قدموا وطلبوا الفصل في القضية، ولصلاحية
الدعوى للفصل فيها رفعت الجلسة للمداولة والنطق بالحكم. الاسباب : وبما أن وكيل المدعي
طلب الحكم بإلزام المدعى عليها بدفع أتعاب التقاضي بمبلغ قدره (400,500) أربعمائة
ألف وخمسمائة ريال عن القضية (5036) وتاريخ 1440/04/13هـ والمنظورة لدى هذه الدائرة
بشأن مطالبة موكله بباقي مستحقاته المالية المتبقية بذمة المدعى عليها وقدرها (3,417,430)
ثلاثة ملایین وأربعمائة وسـبعة عشر ألف وأربعمائة وثلاثون ریال والتي حكم فيها لصالح
موكله ، وأجمل وكيل المدعى عليها إجابته في صحة ما يدعيه وكيل المدعي من صدور حكم
سابق ضد موكلته ألا أنه دفع بأنه تم الحكم بناء على إقرار موكلته بجزء من مبلغ المطالبة
السابق وتم الحكم بموجب ذلك، دون مماطلة من موكلته في أداء حق المدعي، وطالب برد
دعوى المدعي ، وبما أنه ثبت للدائرة مماطلة المدعى عليها وذلك لأنها أقرت للمدعي
بمبالغ في ذمتها وألجأته للقضاء للمطالبة بحقه، ولم تدفع له المبلغ الذي أقرت له
فيه ، وعليه فإن الدائرة ترى استحقاق المدعي للتعويض عن أتعاب ما تحمله من جهد ووقت
في مطالبته للمدعى عليها بمستحقاته، وتقدرها بمبلغ ١٠٠.٠٠٠ مئة ألف ريال وبه تقضي
. لذلك كله نص الحكم : الحكم :'
- source_sentence: ما هي قرائن إثبات الوفاء في الدعاوى التجارية؟
sentences:
- "[السياق: يتناول هذا الجزء السندات المقدمة كدليل على تعديل مواعيد الدفعات، ويثير\
\ المدعي أنها مجرد ضمان وليس تعديلاً. وقررت المحكمة أن السندات لا تغير من شروط\
\ العقد الأصلي.] \nالسندات في ملف القضية الالكتروني، وفي جلسة أخرى حضر وكيل المدعي\
\ كما حضر وكيل المدعى عليها، واطلعت الدائرة على مذكرة وكيل المدعى عليها المرفقة\
\ بملف القضية الالكتروني بتاريخ 9 / 6 /1441ه والتي جاء فيها : أن مدار القضية على\
\ ملحق عقد البيع المؤرخ في 11/ 03/ 1440هـ وذلك أن الملحق تم توقيعه مع أحد الشركاء\
\ وهو: صالح بن ناصر بن صالح الزغيبي ولم يتم توقيعه من بقية الشركاء وذلك لأن بقية\
\ الشركاء قد أقروا بعقد البيع الأساس المؤرخ في 26/ 8/ 1439هـ على أن ثمن العقد\
\ يكون لفائدة صالح بن ناصر بن صالح الزغيبي وهو من يستفيد به منفردا دون غيره، لذا\
\ فإنه هو المخول بتعديل مواعيد استحقاق دفعات شراء الكليات بالتبعية واللزوم ويؤيد\
\ هذا: وجود ختم رسمي من إدارة المشروع الذي تم بيعه بموجب العقد الملحق ولا وجه\
\ لما أورده وكيل المدعي من الحديث عن العقارات: لعدم علاقتها بالدعوى جملة وتفصيلا\
\ ولا وجه لما ذكره وكيل المدعي من أن السندات لأمر كانت مجرد أداة وفاء وضمان لثمن\
\ البيع؛ وذلك لأن العقد الملحق نص صريحا على تعديل مواعيد استحقاق الدفعات استنادا\
\ للتواريخ المثبتة بالسندات لأمر: مما يبطل هذا الادعاء المرسل لذلك كله وبناء عليه:\
\ فإن موكلي يتمسك بطلباته المثبتة بالجلسة الماضية، كما اطلعت الدائرة على السندات\
\ لأمر المرفقة وهي كالآتي: 1- سند بمبلغ قدره (120,000,000) ريال وموعد استحقاقه\
\ بتاريخ 30/ 11/ 1442هـ. 2- سند بمبلغ قدره (105,000,000) وموعد استحقاقه بتاريخ\
\ 30/ 06/ 1442هـ. 3- سند بمبلغ قدره (110,000,000) وموعد استحقاقه بتاريخ 30/ 01/\
\ 1442هـ. 4- سند بمبلغ قدره (95,000,000) وموعد استحقاقه بتاريخ 03/ 09/ 1441هـ.\
\ 5- سند بمبلغ قدره (90,000,000) وموعد استحقاقه بتاريخ 30/ 04/ 1441هـ. 6- سند\
\ بمبلغ قدره (80,000,000) ريال وموعد استحقاقه بتاريخ 30/ 12/ 1440هـ. وذكر بأن\
\ السندين الأخيرين عليهما منازعة تنفيذية منظورة أمام محكمة التنفيذ بالرياض وأكد\
\ وكيل المدعى عليها على طلب صرف النظر عن الدعوى لرفعها قبل أوانها، ورفض الدعوى\
\ فيما يتعلق بالسندين الأخيرين"
- "[السياق: يتناول هذا الجزء الجلسة المرئية ومناقشة الحوالة البنكية المقدمة من المدعى\
\ عليها كدليل على السداد، ورد المدعي بأنها حديثة. وقررت المحكمة أن الحوالة تثبت\
\ الوفاء وأن سكوت المدعي يعد قرينة على الرضا.] \n2022م، تمثل قيمة الحصص التي\
\ اشترتها موكلته من المدعي، وكانت من حساب ابن موكلته محمد صلاح الدين إدريس إلى\
\ حساب المدعية، فعقب المدعي وكالة بأن تاريخ الحوالة حديث، وهذا يؤكد أنه مضطرب\
\ في دفوعه، ويؤيد ذلك أنه لم يلتزم بسداد ما عليها، وهو يطالبها الحكم بفسخ الاتفاقية\
\ الشفهية المؤرخة والتي تمت قبل تاريخ 14/ 05/ 1435هــ (أي قبل تاريخ قرار تعديل\
\ عقد تأسيس شركة سياج) ؛ لكونها لم تسدد قيمة الحصص لموكله، فعقب المدعى عليه وكالة\
\ بعدم وجود اتفاق شفهي، وسكوت المدعي عن المطالبة بقيمة الحصص مدة تتجاوز (8) سنوات،\
\ يؤكد استمرارية الشراكة، وصحة شراء موكلته للحصص، وأن الخلاف نشأ بينهما حين اكتشفت\
\ المدعى عليها عدم قيام المدعي بصفته مدير لشركة بتعديل بيانات الشركاء لدى مكتب\
\ السجل التجاري في الوزارة، فتقدم بشكوى لإثبات مخالفة المدعي لنظام الشركات لعدم\
\ تسجيل الحصص العائدة للمدعى عليها، وبناء عليه جرى رفع الجلسة. وعقدت الدائرة جلسة\
\ مرئية في تاريخ: 10/ 2/ 1444هـ وملخصها: حضر وكيل المدعي برقم وكالة (40703776)\
\ كما حضر وكيل المدعى عليها برقم وكالة (401133454) ولصلاحية الدعوى للفصل فيها\
\ قررت الدائرة حجز القضية للنطق بالحكم. الاسباب : وحيث حصر وكيل المدعي دعواه في\
\ طلب فسخ اتفاقية بيع الحصص المبرمة مع المدعى عليها لعدم سداد قيمة الحصة وحيث\
\ أقرت المدعى عليها بصحة اتفاقية بيع الحصص وأنكرت عدم سداد قيمة الحصة ودفعت بأن\
\ المدعي قد استوفى حقه بموجب مقاصة حيث إنها باعت المدعي حصص في شركة بي ام كير\
\ بمبلغ قدره: (360.000) وأن المدعي لم يلتزم بسداد كامل قيمة الحصص واستندت في دفعها\
\ إلى ما جاء في قرار إدخال الشركاء الذي تضمن أنه تم الوفاء برأس مال الشركة عن\
\ التأسيس وأن سكوت المدعي لثمان سنوات قرينة على عدم صحة دعواه ودفع المدعي بإنكار\
\ ما ذكرته المدعى عليها من حصول الوفاء بقيمة الحصة وبما أن المدعى عليها أرفقت\
\ إيصال حوالة صادرة من ابن المدعى عليها في تاريخ: 21/ 4/ 2022م إلى حساب المدعي\
\ بمبلغ قدره: (25.000)"
- '[السياق: يستكمل هذا الجزء تفاصيل الاعتراض المقدم من المدعى عليها على حكم المحكمة
التجارية، حيث تشمل أسباب الاعتراض عدم اختصاص المحكمة التجارية، وعدم إخطار المدعى
عليها قبل رفع الدعوى، والحاجة إلى مناقشة المبالغ المالية بين الطرفين. وقررت المحكمة
بعد الدراسة تأييد الحكم السابق لصحة أسبابه واستناداً إلى المواد النظامية.]
عليها/ شركة الجابرين للمقاولات سجل تجاري رقم (...) أن تدفع للمدعي/ راضي صالح سعيد
الصيعري هوية رقم (...) بصفته مالك مؤسسة راضي صالح سعيد الصيعري للمقاولات العامة
سجل تجاري رقم (...) مبلغا قدره (820,278) ثمان مئة وعشرون ألفا ومئتان وثمانية وسبعون
ريالا، ويخضع هذا الحكم للاستئناف لمدة (30) ثلاثين يوما من تاريخ استلام نسخة الحكم،
وبتسليم المدعى عليه وكالة نسخة صك الحكم تقدم بلائحة اعتراضية طلب فيها: أولا: قبول
الاعتراض شكلا وموضوعا، ثانيا: نقض الحكم في القضية رقم (4471018871)، لأسباب حاصلها:
أولا: عدم اختصاص المحكمة التجارية بنظر الدعوى إعمالا لما نص عليه نظام المحاكم
التجارية ولائحته التنفيذية في المادة (16) تختص المحكمة بالنظر في الآتي: 1 - المنازعات
التي تنشأ بين التجار بسبب أعمالهم التجارية الأصلية أو التبعية. 2- الدعاوى المقامة
على التاجر في منازعات العقود التجارية، متى كانت قيمة المطالبة الأصلية في الدعوى
تزيد على مائة ألف ريال، وللمجلس عند الاقتضاء زيادة هذه القيمة . ثانيا: عدم إخطار
موكلتي قبل رفع الدعوى وهذا مخالف لما نص عليه نظام المحاكم التجارية ولائحته التنفيذية
في المادة رقم (19) من النظام التي نصت على يجب في الدعاوى التي تحددها اللائحة أن
يخطر المدعي المدعى عليه كتابة بأداء الحق المدعى به قبل (خمسة عشر يوما على الأقل
من إقامة الدعوى . ثالثا: بمراجعة موكلتي للسجلات والمصادقة الرصيد القدمة تبين أن
موكلتي بحاجة لمناقشة المبالغ المالية مع المدعى عليها ويتم من خلال اجتماع محاسبي
الطرفين للتحقق من مبلغ المطالبة، وتم إحالة القضية إلى هذه الدائرة في 29/ 12/ 1444هـ
وفي جلسة هذا اليوم جرى افتتاح القضية عبر الاتصال المرئي. ولصلاحيتها للفصل رفعت
للمداولة. Reasons : بعد دراسة ملف القضية ومستنداتها، والحكم الصادر فيها، والاستئناف
المقدم وما بني عليه من أسباب، ظهر أن الاعتراض قدم خلال المهلة النظامية، ومن ثم
فهو مقبول شكلا. أما عن الموضوع فقد استبان للدائرة صحة النتيجة التي خلصت إليها
الدائرة في قضائها، وأن في الأسباب التي أقامت عليها هذا القضاء موكلتي للسجلات والمصادقة
الرصيد القدمة تبين أن موكلتي بحاجة لمناقشة المبالغ المالية مع المدعى عليها ويتم
من خلال اجتماع محاسبي الطرفين للتحقق من مبلغ المطالبة، وتم إحالة القضية إلى هذه
الدائرة في 29/ 12/ 1444هـ وفي جلسة هذا اليوم جرى افتتاح القضية عبر الاتصال المرئي.
ولصلاحيتها للفصل رفعت للمداولة. Reasons : بعد دراسة ملف القضية ومستنداتها، والحكم
الصادر فيها، والاستئناف المقدم وما بني عليه من أسباب، ظهر أن الاعتراض قدم خلال
المهلة النظامية، ومن ثم فهو مقبول شكلا. أما عن الموضوع فقد استبان للدائرة صحة
النتيجة التي خلصت إليها الدائرة في قضائها، وأن في الأسباب التي أقامت عليها هذا
القضاء ما يكفي لتأييد هذا الحكم، ولذلك، واستنادا إلى المادة 78/2 من نظام المحاكم
التجارية والفقرة (أ) من المادة 215 من اللائحة التنفيذية لذات النظام، وبعد دراسة
القضية، فإنها تنتهي إلى تأييده محمولا على أسبابه. Ruling :'
- source_sentence: هل تقبل المحكمة اليمين كدليل في نزاعات العقود؟
sentences:
- "[السياق: يناقش هذا الجزء إجراءات المحكمة في طلب توضيح السندات المتنازع عليها\
\ وموقف الطرفين منها. وقررت المحكمة أن المدعي أقر بجزء من السندات مما يفيد سداد\
\ المبالغ.] \nأو شخص مكلف بخدمة عامة ما تم على يديه أو ما تلقاه من ذوي الشأن،\
\ وذلك طبقا للأوضاع النظامية وفي حدود سلطته واختصاصه. أما الورقة العادية فهي التي\
\ يكون عليها توقيع من صدرت منه أو ختمه أو بصمته)، وقد نصت المادة (139/ 1) أن للخصم\
\ أن يقدم أي محرر يرى أنه يؤيد دعواه. 2- المدعي منكر للاستلام ولحسم الدعوى طلبي\
\ هو إحالة سندات القبض للأدلة الجنائية وفق المادة الثانية والأربعون بعد المائة،\
\ والمادة الثالثة والأربعون بعد المائة. 3- طلبي وفق المادة السابعة والأربعون بعد\
\ المائة. 4- إضافة إلى توقيع المدعي على سندات القبض للمبالغ التي يطالب فيها لدي\
\ شاهد على تسليم المبالغ للمدعي، وأيضا أطلب منحي الفرصة وفتح جلسة للاستماع إلى\
\ شهادته المنتجة في الدعوى والحاسمة لها، وهي وفق المادة (121) وما بعدها من نظام\
\ المرافعات الشرعية. 5- المادة السادسة والخمسون بعد المائة. 6- المادة الأولى بعد\
\ المائة من نظام المرافعات الشرعية. لما سبق أطلب صرف النظر عن الدعوى وإحالة كامل\
\ السندات، وفتح جلسة للاستماع للشاهد. وفي جلسة 24/ 01/ 1444هـ حضر الأطراف، وبعد\
\ دراسة القضية جرى سؤال المدعى عليه عن السندات التي تضمنت توقيع المدعي أصالة وعن\
\ مجموعها وعن السندات الموقع من ابن المدعي ومجموعها؟ فقال: أطلب مهلة لحصرها هكذا\
\ قال، وبسؤال المدعى عليه هل لدى ابن المدعي وكالة عند التوقيع على السندات؟ فقال:\
\ ليس لديهم وكالة عن والدهم، لكنهم يستلمونها بحضور والدهم عندي في المعرض وعندي\
\ شهود على ذلك، هكذا قال، وبسؤال المدعى عليه عن آلية تسليم المدعي وابنه المبالغ؟\
\ فقال: أغلبها نقدا وبتوقيعه على السند وبعضها حوالة، هكذا قال، وبسؤال المدعي وكالة\
\ عن جواب صريح حيال التوقيعات الواردة في سندات الصرف المقدمة من المدعى عليه؟ فقال:\
\ التواقيع مختلفة عن توقيع موكلي، كما أن بعض السندات ليس عليها توقيع هكذا قال،\
\ وبسؤاله هل هي مطابقة أو مشابهة لتوقيع موكلك أم أنها مخالفة لها بالكلية؟ فقال\
\ إنها مختلفة ولا تشبه توقيع موكلي، ثم أضاف: وأما توقيعات أبناء المدعي فموكلي"
- "[السياق: يركز هذا الجزء على إقرار المدعى عليها بتسلم البضائع وتناقضها حول سداد\
\ المبلغ، بينما تؤكد المدعية وجود متبقٍّ مستحق. وقررت المحكمة أن السكوت عن الاعتراض\
\ على تعديل الأسعار يُعتبر موافقة.] \nأنه للمبلغ محل الدعوى. ثم سألت الدائرة\
\ وكيلة المدعية متى تحققتم من صحة الحوالة فقالت في 22 / 8 / 2022م. وبعرض ذلك على\
\ وكيل المدعى عليها وسؤاله عن تاريخ الحوالة فقال في 2016م. ثم قررت الدائرة الكتابة\
\ إلى البنك المركزي للتحقق من صحة الحوالات، ورفعت الجلسة وبالله التوفيق. وعقدت\
\ الدائرة جلسة عن بعد في تاريخ 1444/03/29هـ وملخصها: حضرت وكيلة المدعية/منى العليقي،\
\ وحضر وكيل المدعى عليها/محمد الهلال، المدونة بياناتهما سابقا، ثم قررت الدائرة\
\ الرجوع عن الكتابة إلى البنك المركزي، وطلبت الدائرة من وكيلة المدعية تقديم كشف\
\ حساب بنكي للفترة التي تدعي المدعى عليها أنها قامت بتحويل المبلغ فيها، وطلبت\
\ الدائرة من وكيل المدعى عليها إرفاق ما يثبت صدور الحوالة من حساب موكلته، ثم سألت\
\ الدائرة وكيل المدعى عليها هل يوجد تعاملات أخرى؟ فقال نعم. ثم سألته الدائرة هل\
\ السداد يتعلق بالمطالبة محل الدعوى؟ فقال سداد سابق. ثم قال أعتقد هو نفس المبلغ\
\ الذي يطالبون به، ثم سألته الدائرة هل تسلمت موكلتك البضائع التي قامت المدعية\
\ بنقلها؟ فقال: نعم. ثم سألت الدائرة وكيلة المدعية عن الفاتورة محل الدعوى التي\
\ تطالب موكلتها بقيمتها، فطلبت مهلة للرجوع لموكلتها، ثم قررت الدائرة رفع الجلسة.\
\ وعقدت الدائرة جلسة مرئية في 11/05/1444هـ وفيها حضر وكيل المدعية/ عبدالله محمد\
\ مخيلد الجاسر بالوكالة رقم (433343637)، ولم تحضر المدعى عليها ولا من ينوب عنها\
\ رغم تبلغها برابط الجلسة وأشارت الدائرة إلى أن وكيل المدعية أرفق مجموعة من الفواتير،\
\ ثم ذكر وكيل المدعية بأن المبلغ الذي حصل فيه خلاف مسدد من المدعى عليها وهو مخصوم\
\ من مبلغ المطالبة. حيث إن إجمالي أجرة النقل (132،327) ريال سددت منها المدعى عليها\
\ مبلغا وقدره (65.500) ريال، وتبقى في ذمتها مبلغا قدره (66.827) ريال، وذلك استنادا\
\ على العقد والفواتير المرفقة بالدعوى. ثم رأت الدائرة صلاحية الدعوى للفصل فيها\
\ وقررت قفل باب المرافعة ورفع الجلسة لإصدار الحكم. وأما عن موضوع الدعوى؛ فإن المدعية\
\ تطلب إلزام المدعى عليها بأداء مبلغ قدره (66.827) ستة وستون ألف وثمانمائة"
- "[السياق: يركز هذا الجزء على إجراءات المحكمة خلال الجلسة، حيث أدلى الشاهد بشهادته\
\ وأدى المدعى عليه اليمين بنفي الإخلال بالعقد. وقررت المحكمة قبول اليمين ورفض\
\ الدعوى لعدم إثبات المدعية دعواها.] \nالوجبات التي تسلمتها من متعهد الإسناد\
\ تفصيلا، مع بيان قيمتها، فكرر وكيل المدعية ما سبق ذكره بصدر واقعات الحكم من كون\
\ المدعى عليه تخلف توريد عدد (11,742) وجبة، وأن قيمتها ثمانمئة وسبعة عشر ألف ريال،\
\ وفي جلسة الحكم وفي هذه الجلسة حضر وكيل المدعية وحضر لحضوره المدعى عليه أصالة،\
\ كما حضر الشاهد عبدالرحمن فهد الهبيدي، سجل مدني رقم (...) وهو أخ للمدعى عليه،\
\ وبسؤاله عما يشهد ذكر أنه قد حضر مساء يوم التاسع واليوم العاشر من شهر ذو الحجة،\
\ وكان حاضرا أثناء تنفيذ المدعى عليه للأعمال، ثم سألت الدائرة وكيل المدعية هل\
\ لديه مزيد بينه على الوجبات التي استلمتها موكلته من متعهدي وجبات الإسناد فذكر\
\ بأنه ليس لديه سوى ما قدم، ثم طلبت الدائرة من المدعى عليه أصالة أداء اليمين فاستعد\
\ بأدائها، وأداها قائلا:{ وﷲ العظيم الذي لا إله غيره أنني قد نفذت جميع الأعمال\
\ وفق العقد المبرم بيني وبين المدعية/ مؤسسة حجاج الدول الأفريقية غير العربية،\
\ وقد سلمت جميع الوجبات ولم أخل بشيء منها، وﷲ العظيم، وﷲ العظيم، وﷲ العظيم} هكذا\
\ حلف، وبعرض اليمين على وكيل المدعية قرر قبول يمين المدعى عليه، ثم قرر الطرفان\
\ الإكتفاء. الاسباب : ولما كانت المدعية تطلب إلزام المدعى عليه بمبلغ قدره ثمانمئة\
\ وسبعة عشر ألف ريال، إضافة إلى إلزامه بالتعويض، وتحميله أتعاب المحاماة، لما ورد\
\ بواقعات الحكم مفصلا، ولما كانت المدعية قد استندت في دعواها على المحاضر التي\
\ ذكرت أنها تثبت إخلال المدعى عليه بالعقد، وباطلاع الدائرة على تلك المحاضر رأت\
\ أنها لا ترقى لإثبات ما تذكره المدعية، إذ إنها صادرة على مطبوعاتها، وموقعة من\
\ قبل موظفيها، إضافة إلى أنها خالية من توقيع من يمثل الجهة المشرفة على الحج (وزارة\
\ الحج)، ولما كانت المدعية قد ذكرت أنه جراء إخلال المدعى عليه بالعقد اضطرت إلى\
\ اللجوء إلى عقود الإسناد، التي قدمت نسخا منها، كما قدمت ما يثبت سدادها مستحقات\
\ متعهدي الإسناد عن تلك العقود، وباطلاع الدائرة على تلك المستندات تبين لها أن\
\ المدعية قد"
- source_sentence: ما هي شروط الحكم بدفع المبلغ المتبقي ورفض التعويض عن أضرار التقاضي؟
sentences:
- "[السياق: يستكمل هذا الجزء تفاصيل الجلسات اللاحقة حيث حضر وكيل المدعي وتغيب المدعى\
\ عليه رغم التبليغ عبر خدمة \"أبشر\"، وأكدت المحكمة اختصاصها وقبول الدعوى شكلاً،\
\ واستند وكيل المدعي إلى مطابقة رصيد مختومة وكشف حساب. وقررت المحكمة رفع الجلسة\
\ للدراسة تمهيدًا لإصدار الحكم.] \nيمثله رغم التبلغ بموعد هذه الجلسة وتشير الدائرة\
\ إلى أنها افتتحت هذه الجلسة التحضيرية عبر الاتصال المرئي، ولتحقق الدائرة بما\
\ ورد في المادة (90) من اللائحة التنفيذية لنظام المحاكم التجارية وعن صحة التوزيع\
\ الداخلي أفهمت الدائرة الحاضر أن هذه الدعوى تقع في ولاية اختصاصها القضائي بناء\
\ على المادة (16) من نظام المحاكم التجارية كما رأت الدائرة أن هذه الدعوى -مبدئيا-\
\ مقبولة شكلا وتحققت فيها شروط قبول الدعوى، ثم سألت الدائرة وكيل المدعية عن طلبه\
\ في هذه الدعوى، أجاب أحيل إلى ما ورد في لائحة الدعوى، وبسؤاله عن البينات أجاب\
\ أحيل إلى ما ورد في ملف القضية من بينات وهي: (مطابقة رصيد عليه ختم وتوقيع المدعى\
\ عليه، و كشف حساب صادر من موكلتي) وبسؤاله هل لديك ما تود إضافته؟ أجاب أكتفي بما\
\ قدمته سابقا. وعليه قررت الدائرة رفع الجلسة للدراسة. وفي 09/08/1444هـ عقدت جلسة\
\ مرئية، ملخصها: حضر وكيل المدعية (راشد إبراهيم بن راشد الزهراني) بالوكالة رقم\
\ (442823234) وتبين عدم حضور المدعى علية او من يمثله رغم تبلغه بموعد هذه الجلسة\
\ وبعد دراسة الدائرة لأوراق القضية رفعت الجلسة للمداولة وإصدار الحكم. الاسباب\
\ : وبعد سماع الدعوى، والاطلاع على أوراق القضية ومستنداتها، وبما أن المدعي وكالة\
\ يدعي أن موكلته وردت للمدعى عليه أجهزة كهربائية بثمن وقدره (١٧٦,٢٤٠.٠٤) مائة\
\ وستة وسبعون ألفا ومئتان وأربعون ريال، وقد استلم المدعى عليه الأجهزة ولم يدفع\
\ ثمنها، وطلب المدعي وكالة إلزام المدعى عليه بدفع ثمنها، وبما أنه صدر قرار المجلس\
\ الأعلى للقضاء رقم (219/6/39) وتاريخ 21/4/1439ه، المبني على الأمر الملكي رقم\
\ (14388) وتاريخ 25/3/1439ه المتضمن الموافقة على استعمال الوسائل الإلكترونية في\
\ التبليغات القضائية، وأنه يعتبر منتجا لآثاره النظامية وأنه يعتبر تبليغا لشخص\
\ المرسل إليه، وبما أن المدعى عليه أبلغ عن طريق خدمة أبشر، وبما أن المادة (57)\
\ من نظام المرافعات الشرعية نصت على أنه: (... 2- إذا تبلغ المدعى عليه لشخصه أو\
\ وكيله في الدعوى نفسها بموعد الجلسة، أو أودع هو أو وكيله مذكرة بدفاعه لدى المحكمة\
\ قبل"
- "[السياق: يتناول هذا الجزء تفاصيل خطاب الالتزام الصادر من المدعى عليها والالتزامات\
\ المترتبة عليه، مع إشارة إلى وجود دفعات مستحقة قبل إصدار الخطاب. وقررت المحكمة\
\ صحة مطالبة المدعية بناءً على الخطاب.] \nالدفعات المستحقة (إن وجدت) فسوف يتم\
\ النظر فيها عند اكتمال الأعمال بالمشروع لجميع مقاولي الباطن) وحيث ان الخطاب تضمن\
\ التزامين مختلفين كالتالي: أ/ الالتزام الأول وهو التزام شركة الاستثمارات الرائدة\
\ بالدفع مباشرة مقابل انهاء جميع الاعمال المتبقية في العقد بين موكلي وبين المقاول\
\ الرئيسي ب/ فيما يخص الدفعات المستحقة (إن وجدت) فسوف يتم النظر فيها عند اكتمال\
\ الأعمال بالمشروع لجميع مقاولي الباطن وحيث ان المستحقات لموكلي في حين اصدار الخطاب\
\ المرفق من المدعى عليها كانت مستحقة الأداء بقيمة 4.480.715.02 ريال حسب مطابقة\
\ الرصيد كما تم ذكره أعلاه،أي انه قد تحقق بذلك معنى ماورد في خطاب الالتزام للمدعى\
\ عليها (الدفعات المستحقة إن وجدت) رابعا: سبق وتمت إقامة دعوى على المدعى عليها\
\ برقم 42805650 وتاريخ 09 / 09 / 1442 هـ وتم صدور حكم في الدعوى بتاريخ 05 / 02\
\ / 1443 هـ والصك رقم 437717305 وتاريخ 12/07/1443 هـ الصادر من محكمة الاستئناف\
\ التجارية ولما ورد في الأسباب في صك الحكم الأخير (إن المستند لا ينفي التزام المدعي\
\ عليها وإنما يتضمن الوفاء بالسابق للمستند يكون بطريقة معينة،كما أن حكم الإفلاس\
\ الصادر في حق الأصيل لا يعني عدم جواز مطالبة الكفيل) وحيث تم إقرار المدعى عليها\
\ بصحة خطاب الالتزام والكفالة وعدم انكارها لها مما يثبت معها التزامها بقيمة كامل\
\ المديونية للدفعات السابقة واللاحقة المذكورة في خطاب الالتزام خامسا: كما ذكرت\
\ المدعى عليها في مذكرتها سابقا فقره رقم 5 بأنه تم سحب المشروع من المقاول الرئيسي\
\ وبعد أن تم سحب المشروع لا يمكن اعتماد أي مستخلصات أخرى نظرا لإن المشروع تم سحبه\
\ من المقاول الرئيسي وبناء على ذلك تعذر استكمال المشروع وليس لموكلتي أي يد او\
\ سبب في ذلك،حيث ان المقاول الرئيسي شركة ازميل للمقاولات قد افلست وصدر بحقها صك\
\ حكم بالإفلاس في القضية رقم 374 لعام 1441 هـ وبالتالي تنتقل المطالبة للكفيل حسب\
\ النظام والعرف و ان المستخلصات كانت قبل تاريخ خطاب الالتزام مصدقه ومختومة وموقعه\
\ من قبل المقاول الرئيسي أي انها مثبته"
- '[السياق: يوضح هذا الجزء أسباب حكم المحكمة حيث قبلت طلب المدعي بدفع المبلغ المتبقي
بناءً على الإقرار الصريح من المدعى عليه واعتماد الشيك كوسيلة إثبات، بينما رفضت
طلب التعويض عن أضرار التقاضي لعدم ثبوت تكبد المدعية لأتعاب محاماة.]
ونرفض الصلح ونرفض الشيك وحيث ان وكالة وكيل المدعى عليها فيها حق الإقرار رقم 44330884
واقر بصحة المبلغ عليه قررت الدائرة قفل باب المرافعة لصلاحيتها للفصل فيها والنطق
بالحكم الاسباب : وقد حصر وكيل المدعية طلباته في إلزام المدعى عليها بدفع المبلغ
المتبقي وقدره (16,100) ستة عشر ألفا ومائة ريالا، والتعويض عن أضرار التقاضي بمبلغ
قدره (10,000) عشرة آلاف ريال، وأجمل وكيل المدعى عليها إجابته في الإقرار بمبلغ
المطالبة، وبناء على ما طلبته المدعية في المصالحة تم صرف شيك مصدق وفقا لطلبها،
ولكن المدعي رفضت استلامه وأفاد الطرفان ان المدعي لم يستلم الشيك، وبما أن وكيل
المدعية طلب إلزام المدعى عليها بدفع المبلغ المتبقي وقدره (16,100) ستة عشر ألفا
ومائة ريالا، واستند إلى شيك صادر من المدعى عليها لأمر موكلته تضمن مبلغ المطالبة،
وحيث أن الشيك وسيلة من وسائل إثبات الحق لصاحبه، وبما أن وكيل المدعى عليها أقر
بالمبلغ المذكور ووكالته تخوله حق الإقرار، وحيث يعد الإقرار حجة قاطعة، وفقا لما
نصت عليه الفقرة الأولى من المادة السادسة عشرة من نظام الإثبات ونصها: "يكون الإقرار
صراحة أو دلالة، باللفظ أو بالكتابة"، مما تنتهي معه الدائرة إلى قبول الطلب، وأما
عن مطالبته بأتعاب المحاماة، وبما أنه متى تبين للدائرة مماطلة من عليه الحق بقصد
الكيد والإضرار بالمدعية، فإن للدائرة حق تقدير ذلك والحكم عليه بمصروفات الدعوى
وأتعابها، وحيث أن الدائرة بعد نظرها الدعوى تبين عدم وجو عقد اتعاب فلم يثبت للدائرة
تكبد المدعية اتعاب محاماة، مما تنتهي معه الدائرة إلى رفض الطلب. نص الحكم : ذلك
والحكم عليه بمصروفات الدعوى وأتعابها، وحيث أن الدائرة بعد نظرها الدعوى تبين عدم
وجو عقد اتعاب فلم يثبت للدائرة تكبد المدعية اتعاب محاماة، مما تنتهي معه الدائرة
إلى رفض الطلب. نص الحكم :'
- source_sentence: ما هي حقوق المدعية إذا انخفضت المبيعات بسبب سياسة المدعى عليها؟
sentences:
- "[السياق: يوضح هذا الجزء رد المدعية على اعتراض المدعى عليها على تقرير الخبير وتأكيد\
\ أحقيتها في المطالبة. وقررت المحكمة متابعة النظر في الدعوى.] \n(اعتراض على ما\
\ تقدم به الخبير في تقريره أبين ما يلي: أولا: في المستهل العقد بدأ في تاريخ ٩/٤/٢٠١٧م\
\ الموافق ١٢/٧/١٤٣٨ هـ وانتهى التعاقد تاريخ 31/7/٢٠١٨م الموافق 18/١١/١٤٣٩هـ ثانيا:\
\ جاء التقرير متفقا مع ما ادعى به المدعي دون النظر لما لدى موكلتي. ثالثا : إن\
\ نقطة التعادل هي٩٢٠٠ النقطة التي في حال بلغت المبيعات أكثر منها فإنه يكون هناك\
\ تحصيل لصالح موكلتي بنسبة 7% منه أما في حال كان أقل فإن موكلتي لا تحصلها ، بشرط\
\ أن لا يكون سبب تراجع المبيعات عن هذه النسبة بسبب إهمال المدعي وإلا كان تحصيلها\
\ حقا لموكلتي . رابعا: ما اعتمد عليه الخبير في تقريره جدول مرسل من المدعي ومن\
\ إعداده حيث إن ادعاء المدعي تسليم موكلتي مبلغ 46853 ريالا وهذا الأمر غير صحيح\
\ لم تستلم موكلتي أي مبالغ. خامسا: لدى موكلتي ما يثبت إهمال المدعي وعليه فموكلتي\
\ لها الحق بالمطالبة بنسبة التحصيل بناء على م١٣/٤ من عقد الامتياز والتي نصت على\
\ : في حالة إهمال الطرف الثاني عليه تحمل النسبة نسبة 7% من المبيعات التي تقل عن\
\ نقطة التعادل . سادسا : مطالبة المدعي بنصيبه من عوائد المكافآت الممنوحة فهي مطالبة\
\ دون وجه حق حيث أنه تم احتسابها له وإعطاؤه أثناء فترة التعاقد، ويوجد لدينا ما\
\ يثبت ذلك. وتأسيسا على ذلك أطلب من فضيلتكم إلزام الخبير بأخذ ما لدى موكلتي من\
\ بينات، ورد دعوى المدعي لعدم صحتها). انتهى ما ورد بمذكرة وكيل المدعى عليها. فطلبت\
\ الدائرة من وكيلة المدعى عليها تقديم ما لديها من بينات أو مستندات والتي أشير\
\ إليها في هذا الرد، وأمهلتها إلى الجلسة القادمة، وعليه قررت الدائرة تحديد جلسة\
\ أخرى. وفي الجلسة المنعقدة بتاريخ 7/ 9/ 1444هـ حضر الطرفان، وقدم وكيل المدعية\
\ مذكرة جاء فيها ما يلي: ( أولا: استدلال المدعى عليها بالتقصير والإهمال في الفرع،\
\ مقارنة بمبيعات المالك الجديد استدلال في غير محله، لما يلي من أسباب: قامت موكلتي\
\ بتشغيل الفرع في بداية التعاقد مع المدعى عليها بدون تشغيل"
- '[السياق: يتعلق هذا الجزء بوقائع القضية حيث تقدم المدعي بدعوى مطالبة المدعى عليه
بسداد مبلغ 130,000 ريال كأتعاب محاماة، وأصدرت المحكمة حكمًا بإلزام المدعى عليه
بالدفع. ثم قدم المدعى عليه استئنافًا طالبًا إعادة النظر وإرسال المعاملة للخبراء،
وتم تحديد جلسة عبر الاتصال المرئي. وقررت المحكمة قبول الاستئناف شكليًا وتأييد
الحكم الابتدائي لعدم وجود ما يعيبه.]
Facts : بما أن واقعات القضية أوردها الحكم محل الاستئناف فالدائرة تحيل إليه درءا
للتكرار، وتتلخص في أن المدعي وكالة تقدم بلائحة دعوى طلب فيها بإلزام المدعى عليه
بسداد مبلغ قدره (130.000) مائة وثلاثون ألف ريال تمثل أتعاب المحاماة. وبإحالتها
إلى الدائرة ناظرة القضية أصدرت حكمها محل الاستئناف القاضي بإلزام المدعى عليه بدفع
المبلغ ، فقدم وكيل المدعى عليه لائحته الاستئنافية التي تضمنت طلب إعادة النظر في
الحكم، وطلب إرسال المعاملة لقسم الخبراء بالمحكمة العامة بالرياض. وبعد قيدها في
الاستئناف بالرقم المشار إليه أعلاه أحيلت رفق القضية إلى هذه الدائرة، التي حددت
جلسة هذا اليوم العلنية عبر الاتصال المرئي. وبعد تبليغ الأطراف واستنادا إلى المادة
78 / 2 من نظام المحاكم التجارية والمادة 215 من اللائحة التنفيذية وبعد دراسة القضية،
أصدرت الدائرة حكمها الماثل. Reasons : بما أن الاستئناف قدم أثناء الأجل المحدد
فهو مقبول شكلا. أما فيما يتعلق بالموضوع فإن الدائرة لم يظهر لها في الاعتراض ما
يحول دون تأييد الحكم محمولا على أسبابه. وقد تكفل الحكم بالرد على ما أبداه المستأنف
في استئنافه. Ruling :'
- '[السياق: يستعرض هذا الجزء الأسباب القانونية للحكم، حيث تؤكد المحكمة أن المدعي
لم يقدم أدلة كافية على شراكته بنسبة 25% في المشروع، وفقاً لأحكام نظام الإثبات
والمحاكم التجارية. وبما أن المدعى عليه أدى اليمين الحاسمة لنفي الدعوى، قررت المحكمة
رفض الدعوى لعدم كفاية البينة.]
الحاسمة على نفي الدعوى، فطلب يمين المدعى عليه، وبعرضها على المدعى عليه وتخويفه
بالله عز وجل استعد بأدائها، ثم حلف قائلا: (والله العظيم الذي يعلم السر وأخفى أنني
لم أتعاقد مع المدعي علي أبو اليزيد على أن له ما نسبته 25% من مستخلصات أعمال مؤسستي
مع مؤسسة بسمان التجارية، وانه لا يستحق أي شيء في ذمتي عن ذلك العقد، والله العظيم،
والله العظيم، والله العظيم)، وبناء عليه، أصدرت الدائرة حكمها محمولا على الأسباب
التالية. الاسباب : بناء على الدعوى والإجابة، ولما كان المدعي يطلب إثبات شراكته
في أعمال عقد مؤسسة المدعى عليه مع مؤسسة بسمان التجارية المتعلق بتركيب عدادات كهربائية
تشتمل على الضغط العالي والمنخفض بما نسبته 25%، ويطلب حقه المالي المبني على ذلك،
وعليه؛ فإن النزاع الماثل يخضع في نظره لولاية القضاء التجاري وفق أحكام المادة 16
من نظام المحاكم التجارية، ولما كان المدعى عليه ينكر الدعوى جملة وتفصيلا، ولما
هو متقرر شرعا من أن البينة على المدعي واليمين على المنكر؛ استنادا لقول النبي الأكرم
صلى الله عليه وسلم في الصحيح: (بينتك أو يمينه)، ولما نصت عليه المادة (1/3) من
نظام الإثبات من أن (البينة على من ادعى، واليمين على من أنكر)، وبما أن الدائرة
قد سألت المدعي عن بينته؟ فقدم العقد بين مؤسسة المدعى عليه وشركة بسمان، إضافة الى
المستخلصات المتعلقة بالمشروع، إضافة الى تفويضه من المدعى عليه بإدارة شؤون مؤسسة
المدعى عليه، والتعاقد مع الغير، ولم يقدم ما يثبت الشراكة مع المدعى عليه في المشروع
بالنسبة التي ذكر ولا ما يثبت حقه المالي الناتج عن ثبوت ذلك، وهو ما يعني انتفاء
بيناته على دعواه، وعليه فقد أفهمته الدائرة بأن له طلب يمين المدعى عليه الحاسمة
فطلبها، وحيث أدى المدعى عليه اليمين وفق منطوقها المرصود في الوقائع؛ فقد انتهت
الدائرة إلى حكمها الوارد بمنطوقه وبه تقضي. نص الحكم : الى المستخلصات المتعلقة
بالمشروع، إضافة الى تفويضه من المدعى عليه بإدارة شؤون مؤسسة المدعى عليه، والتعاقد
مع الغير، ولم يقدم ما يثبت الشراكة مع المدعى عليه في المشروع بالنسبة التي ذكر
ولا ما يثبت حقه المالي الناتج عن ثبوت ذلك، وهو ما يعني انتفاء بيناته على دعواه،
وعليه فقد أفهمته الدائرة بأن له طلب يمين المدعى عليه الحاسمة فطلبها، وحيث أدى
المدعى عليه اليمين وفق منطوقها المرصود في الوقائع؛ فقد انتهت الدائرة إلى حكمها
الوارد بمنطوقه وبه تقضي. نص الحكم :'
pipeline_tag: sentence-similarity
library_name: sentence-transformers
---
# SentenceTransformer based on intfloat/multilingual-e5-large
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [intfloat/multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large). It maps sentences & paragraphs to a 1024-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [intfloat/multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) <!-- at revision 0dc5580a448e4284468b8909bae50fa925907bc5 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 1024 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("sentence_transformers_model_id")
# Run inference
sentences = [
'ما هي حقوق المدعية إذا انخفضت المبيعات بسبب سياسة المدعى عليها؟',
'[السياق: يوضح هذا الجزء رد المدعية على اعتراض المدعى عليها على تقرير الخبير وتأكيد أحقيتها في المطالبة. وقررت المحكمة متابعة النظر في الدعوى.] \n(اعتراض على ما تقدم به الخبير في تقريره أبين ما يلي: أولا: في المستهل العقد بدأ في تاريخ ٩/٤/٢٠١٧م الموافق ١٢/٧/١٤٣٨ هـ وانتهى التعاقد تاريخ 31/7/٢٠١٨م الموافق 18/١١/١٤٣٩هـ ثانيا: جاء التقرير متفقا مع ما ادعى به المدعي دون النظر لما لدى موكلتي. ثالثا : إن نقطة التعادل هي٩٢٠٠ النقطة التي في حال بلغت المبيعات أكثر منها فإنه يكون هناك تحصيل لصالح موكلتي بنسبة 7% منه أما في حال كان أقل فإن موكلتي لا تحصلها ، بشرط أن لا يكون سبب تراجع المبيعات عن هذه النسبة بسبب إهمال المدعي وإلا كان تحصيلها حقا لموكلتي . رابعا: ما اعتمد عليه الخبير في تقريره جدول مرسل من المدعي ومن إعداده حيث إن ادعاء المدعي تسليم موكلتي مبلغ 46853 ريالا وهذا الأمر غير صحيح لم تستلم موكلتي أي مبالغ. خامسا: لدى موكلتي ما يثبت إهمال المدعي وعليه فموكلتي لها الحق بالمطالبة بنسبة التحصيل بناء على م١٣/٤ من عقد الامتياز والتي نصت على : في حالة إهمال الطرف الثاني عليه تحمل النسبة نسبة 7% من المبيعات التي تقل عن نقطة التعادل . سادسا : مطالبة المدعي بنصيبه من عوائد المكافآت الممنوحة فهي مطالبة دون وجه حق حيث أنه تم احتسابها له وإعطاؤه أثناء فترة التعاقد، ويوجد لدينا ما يثبت ذلك. وتأسيسا على ذلك أطلب من فضيلتكم إلزام الخبير بأخذ ما لدى موكلتي من بينات، ورد دعوى المدعي لعدم صحتها). انتهى ما ورد بمذكرة وكيل المدعى عليها. فطلبت الدائرة من وكيلة المدعى عليها تقديم ما لديها من بينات أو مستندات والتي أشير إليها في هذا الرد، وأمهلتها إلى الجلسة القادمة، وعليه قررت الدائرة تحديد جلسة أخرى. وفي الجلسة المنعقدة بتاريخ 7/ 9/ 1444هـ حضر الطرفان، وقدم وكيل المدعية مذكرة جاء فيها ما يلي: ( أولا: استدلال المدعى عليها بالتقصير والإهمال في الفرع، مقارنة بمبيعات المالك الجديد استدلال في غير محله، لما يلي من أسباب: قامت موكلتي بتشغيل الفرع في بداية التعاقد مع المدعى عليها بدون تشغيل',
'[السياق: يتعلق هذا الجزء بوقائع القضية حيث تقدم المدعي بدعوى مطالبة المدعى عليه بسداد مبلغ 130,000 ريال كأتعاب محاماة، وأصدرت المحكمة حكمًا بإلزام المدعى عليه بالدفع. ثم قدم المدعى عليه استئنافًا طالبًا إعادة النظر وإرسال المعاملة للخبراء، وتم تحديد جلسة عبر الاتصال المرئي. وقررت المحكمة قبول الاستئناف شكليًا وتأييد الحكم الابتدائي لعدم وجود ما يعيبه.]\nFacts : بما أن واقعات القضية أوردها الحكم محل الاستئناف فالدائرة تحيل إليه درءا للتكرار، وتتلخص في أن المدعي وكالة تقدم بلائحة دعوى طلب فيها بإلزام المدعى عليه بسداد مبلغ قدره (130.000) مائة وثلاثون ألف ريال تمثل أتعاب المحاماة. وبإحالتها إلى الدائرة ناظرة القضية أصدرت حكمها محل الاستئناف القاضي بإلزام المدعى عليه بدفع المبلغ ، فقدم وكيل المدعى عليه لائحته الاستئنافية التي تضمنت طلب إعادة النظر في الحكم، وطلب إرسال المعاملة لقسم الخبراء بالمحكمة العامة بالرياض. وبعد قيدها في الاستئناف بالرقم المشار إليه أعلاه أحيلت رفق القضية إلى هذه الدائرة، التي حددت جلسة هذا اليوم العلنية عبر الاتصال المرئي. وبعد تبليغ الأطراف واستنادا إلى المادة 78 / 2 من نظام المحاكم التجارية والمادة 215 من اللائحة التنفيذية وبعد دراسة القضية، أصدرت الدائرة حكمها الماثل. Reasons : بما أن الاستئناف قدم أثناء الأجل المحدد فهو مقبول شكلا. أما فيما يتعلق بالموضوع فإن الدائرة لم يظهر لها في الاعتراض ما يحول دون تأييد الحكم محمولا على أسبابه. وقد تكفل الحكم بالرد على ما أبداه المستأنف في استئنافه. Ruling :',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 1024]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 134,964 training samples
* Columns: <code>sentence_0</code> and <code>sentence_1</code>
* Approximate statistics based on the first 1000 samples:
| | sentence_0 | sentence_1 |
|:--------|:-----------------------------------------------------------------------------------|:--------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 11 tokens</li><li>mean: 18.28 tokens</li><li>max: 35 tokens</li></ul> | <ul><li>min: 209 tokens</li><li>mean: 501.12 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| sentence_0 | sentence_1 |
|:-----------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>ما هي المستندات المطلوبة لإثبات دعوى تأجير سيارات؟</code> | <code>[السياق: يستكمل هذا الجزء تفاصيل المذكرات والمستندات المقدمة من المدعية لإثبات دعواها، بما في ذلك العقد وسندات تسليم السيارات وتفويض المدعى عليها، مع استثناء سيارة الرانج روفر لعدم وجود تفويض. وقررت المحكمة قبول الأدلة المقدمة ما عدا ما يتعلق بسيارة الرانج روفر.] <br>الدائرة وكيل المدعية عن دعواه؟ فأحال على صحيفة الدعوى والطلب المذيلة به وقرر أنه لديه تحريرا للدعوى يرغب في تقديمه وأكد أنه سبق اللجوء للمصالحة وتعذر الصلح بموجب تقرير صدر بذلك استعد بتزويد الدائرة بنسخة منه، ثم بتاريخ 1443/11/28هـ قدم وكيل المدعية مذكرة من خمس مرفقات عبارة عن صورة من العقد المبرم بين الطرفين مختوم وموقع من الطرفين، وأربع سندات تفيد تسليم السيارات محل مبلغ المطالبة لأفراد بموجب تفويض صادر من المدعى عليها عدا ما يتعلق بالسيارة من طراز الرانج روفر فإنها خلت من ورقة التفويض، كما أعاد فيها تحرير دعواه بما نصه: (لقد قامت موكلتي بالتعاقد مع المدعى عليها بتاريخ 1437/03/24هـ الموافق 2015/01/04هـ، حيث نصت الاتفاقية على أن تقوم المدعى عليها بتعميد المدعية في استئجار (4) سيارات تخدم مصالحها، وحيث قامت المدعى عليها خلال...</code> |
| <code>ما هي شروط اختصاص المحكمة التجارية مكانياً ونوعياً؟</code> | <code>[السياق: يختتم هذا الجزء الأسباب القانونية للحكم، حيث تؤكد المحكمة اختصاصها المكاني والنوعي نظرًا لمقر المدعى عليه في جدة وطبيعة النزاع التجاري. وقررت المحكمة إلزام المدعى عليه بسداد المبلغ المتبقي البالغ 80,000 ريال بناء على الأدلة المقدمة.]<br>الكترونية منتجا لآثاره النظامية وتبليغا لشخص المرسل إليه وحيث إن الفقرة الأولى من المادة الثلاثون من نظام المحكمة التجارية الصادر بالمرسوم الملكي الكريم رقم (م/93) في 15-8-1441هــ نصت على أنه (إذا تبلغ المدعى عليه لشخصه أو وكليه، أو حضر أي منهما في أي جلسة أمام المحكمة، أو قدم مذكرة بدفاعه، عدت الخصومة حضورية، ولو تخلف بعد ذلك) وحيث ثبت للدائرة تبلغ المدعي عليه، وحيث لم يحضر المدعى عليه او من يمثله رغم تبلغه بموعد هذه الجلسة ولم يقدم إجابته على دعوى المدعية، مما يعد ذلك نكولا عن الإجابة في الدعوى وهو بمنزلة الإقرار الضمني بمضمونها مما يجسد قناعة الدائرة الى الحكم بما يرد في منطوقها أدناه الاسباب : تأسيسا على الوقائع سالفة البيان وبما أن هذه المنازعة تندرج تحت نص المادة (16) من نظام المحكمة التجارية الصادر بالمرسوم الملكي الكريم رقم (م/93) في 15-8-...</code> |
| <code>ما هي إجراءات إيداع محضر التحقيق وتقريره؟</code> | <code>[إيداع محضر التحقيق وتقريره، طلبات القاضي المحقق معه، والتعامل مع التحقيقات السابقة.]<br>العنوان : لائحة التفتيش القضائي<br><br>فللرئيس، ولمن ينيبه عن طريق الرئيس؛ عرض الشكوى على المجلس. المادة الثامنة والثلاثون ١- تبلغ الإدارة القاضي بالشكوى –عند الاقتضاء -؛ لطلب إجابته عليها، بعد فحص الشكوى، والتحقق من استيفاء شروط قبولها. ٢- يرفع القاضي إجابته على الشكوى –كتابة –إلى الإدارة خلال (ثلاثين) يوما من تأريخ تبلغه بها، ما لم يتضمن كتاب الإدارة تحديد مدة أخرى، ويرفق مع إجابته ما يتعلق بها من مستندات –إن وجدت -. ٣- تتولى الإدارة العامة للقضايا دراسة موضوع الشكوى، وإجابة القاضي عليها، والمستندات المرافقة. ٤- تعرض نتيجة الدراسة على رئيس الإدارة، مشفوعة بمذكرة الرأي فيها، مع التسبيب، خلال (خمسة عشر) يوما من تأريخ ورود الإجابة على الشكوى. ٥- إذا ظهر لرئيس الإدارة ما يستدعي التحقيق في موضوع الشكوى؛ فيرفع إلى المجلس بوساطة الرئيس توصية بطلب التحقيق، محددا المخالفات التي يرى التحقيق فيها؛ ليقرر المجلس ما يراه. المادة التاسعة والثلاثون إذا صدر من المجلس قرار بالتحقيق، يكلف الرئيس –كتابة –من يقوم بالتحقيق؛ من...</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `per_device_train_batch_size`: 32
- `per_device_eval_batch_size`: 32
- `num_train_epochs`: 1
- `fp16`: True
- `multi_dataset_batch_sampler`: round_robin
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: no
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 32
- `per_device_eval_batch_size`: 32
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `tp_size`: 0
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: round_robin
</details>
### Training Logs
| Epoch | Step | Training Loss |
|:------:|:----:|:-------------:|
| 0.1185 | 500 | 0.9166 |
| 0.2371 | 1000 | 0.5249 |
| 0.3556 | 1500 | 0.4899 |
| 0.4742 | 2000 | 0.4495 |
| 0.5927 | 2500 | 0.4272 |
| 0.7112 | 3000 | 0.4259 |
| 0.8298 | 3500 | 0.3917 |
| 0.9483 | 4000 | 0.3827 |
### Framework Versions
- Python: 3.11.12
- Sentence Transformers: 4.1.0
- Transformers: 4.51.3
- PyTorch: 2.6.0+cu124
- Accelerate: 1.6.0
- Datasets: 2.19.0
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
--> |
Ambrosio1994/dummy-model | Ambrosio1994 | 2025-05-02T23:04:30Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"camembert",
"fill-mask",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2025-05-02T23:04:08Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
sergioalves/f4e45daf-e234-40bf-8403-4f511ae3b2b8 | sergioalves | 2025-05-02T23:03:24Z | 0 | 0 | peft | [
"peft",
"safetensors",
"mistral",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/mistral-7b-v0.3",
"base_model:adapter:unsloth/mistral-7b-v0.3",
"license:apache-2.0",
"8-bit",
"bitsandbytes",
"region:us"
] | null | 2025-05-02T22:01:34Z | ---
library_name: peft
license: apache-2.0
base_model: unsloth/mistral-7b-v0.3
tags:
- axolotl
- generated_from_trainer
model-index:
- name: f4e45daf-e234-40bf-8403-4f511ae3b2b8
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: true
adapter: lora
base_model: unsloth/mistral-7b-v0.3
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 0bc216a74e5223ea_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/0bc216a74e5223ea_train_data.json
type:
field_input: system_prompt
field_instruction: question
field_output: response
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.5
group_by_length: false
hub_model_id: sergioalves/f4e45daf-e234-40bf-8403-4f511ae3b2b8
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-06
load_in_4bit: false
load_in_8bit: true
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/0bc216a74e5223ea_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 54f8b968-ef35-4e16-a7c3-fbecb65048c8
wandb_project: s56-8
wandb_run: your_name
wandb_runid: 54f8b968-ef35-4e16-a7c3-fbecb65048c8
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# f4e45daf-e234-40bf-8403-4f511ae3b2b8
This model is a fine-tuned version of [unsloth/mistral-7b-v0.3](https://huggingface.co/unsloth/mistral-7b-v0.3) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9407
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.9763 | 0.0085 | 200 | 0.9407 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
theminji/OpenGoody-0.1 | theminji | 2025-05-02T23:00:26Z | 0 | 1 | transformers | [
"transformers",
"safetensors",
"gguf",
"qwen2",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-02T22:45:02Z | ---
base_model: unsloth/qwen2.5-7b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- gguf
license: apache-2.0
language:
- en
---
# OpenGoody-0.1
**Model Name:** OpenGoody-0.1
**Architecture:** Qwen 2.5 (7B)
**Developer:** theminji
**License:** Apache 2.0
**Release Date:** May 2, 2025
---
## Overview
OpenGoody-0.1 is a 7 billion parameter open-source language model built on the Qwen 2.5 architecture. Developed with a strong emphasis on ethical alignment and responsible deployment, OpenGoody-0.1 is designed to support safe and conscientious language generation across a wide range of use cases.
The model was trained to prioritize harm reduction, minimize risk in output behavior, and uphold strong principles of integrity, inclusivity, and safety. OpenGoody-0.1 has been rigorously evaluated and optimized to avoid generating outputs that could be unsafe, misleading, or otherwise misaligned with responsible AI standards.
---
## Intended Use
OpenGoody-0.1 is intended for research, development, and safe deployment in environments that require high standards of AI responsibility. Example domains include:
- Educational assistance
- Enterprise-level productivity tools
- Moderated conversational agents
- AI-driven documentation and compliance support
Use in high-risk applications (e.g. healthcare, legal, financial advising) is not recommended without extensive domain-specific fine-tuning and alignment review.
---
## Key Features
- ✅ Built on the Qwen 2.5 7B architecture for efficient inference and strong language understanding
- ✅ Emphasizes safety, neutrality, and alignment with responsible use policies
- ✅ Designed to minimize risk of harmful or controversial content generation
- ✅ Lightweight and adaptable for deployment in constrained environments
---
## Ethical Considerations
OpenGoody-0.1 reflects a design-first commitment to ethical AI. It is structured to avoid unintended amplification of bias, misinformation, or unsafe content. All outputs are shaped by reinforcement strategies and alignment tuning to ensure adherence to a high standard of ethical responsibility.
We encourage all downstream users to deploy OpenGoody-0.1 in accordance with responsible AI deployment principles, including transparency, human oversight, and continual auditing of model behavior.
---
## Limitations
While OpenGoody-0.1 strives to be a highly responsible and well-aligned model, limitations remain:
- It may exhibit cautious behavior in ambiguous or uncertain contexts.
- Certain creative or speculative tasks may produce conservative outputs.
- Not suitable for applications requiring precise factual recall beyond general knowledge.
---
## Contact
For inquiries, feedback, or contributions, please contact the me on discord @theminji.
---
|
arda-argmax/student_c125 | arda-argmax | 2025-05-02T22:57:53Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2025-05-02T22:52:39Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
rogerscuall/gemma-2-2B-it-thinking-function_calling-V0 | rogerscuall | 2025-05-02T22:50:44Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T21:57:10Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
SodaXII/dinov2-small_rice-leaf-disease-augmented-v4_v5_fft | SodaXII | 2025-05-02T22:43:09Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"dinov2",
"image-classification",
"generated_from_trainer",
"base_model:facebook/dinov2-small",
"base_model:finetune:facebook/dinov2-small",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2025-05-02T19:39:54Z | ---
library_name: transformers
license: apache-2.0
base_model: facebook/dinov2-small
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: dinov2-small_rice-leaf-disease-augmented-v4_v5_fft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dinov2-small_rice-leaf-disease-augmented-v4_v5_fft
This model is a fine-tuned version of [facebook/dinov2-small](https://huggingface.co/facebook/dinov2-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3174
- Accuracy: 0.9463
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 256
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.5071 | 0.5 | 64 | 0.6205 | 0.7852 |
| 0.4009 | 1.0 | 128 | 0.3635 | 0.8792 |
| 0.209 | 1.5 | 192 | 0.3144 | 0.8859 |
| 0.2231 | 2.0 | 256 | 0.2716 | 0.9128 |
| 0.1661 | 2.5 | 320 | 0.3476 | 0.8691 |
| 0.1308 | 3.0 | 384 | 0.2279 | 0.9195 |
| 0.067 | 3.5 | 448 | 0.3845 | 0.9195 |
| 0.063 | 4.0 | 512 | 0.3661 | 0.9027 |
| 0.0215 | 4.5 | 576 | 0.3287 | 0.9228 |
| 0.0148 | 5.0 | 640 | 0.2952 | 0.9329 |
| 0.0007 | 5.5 | 704 | 0.3063 | 0.9463 |
| 0.0002 | 6.0 | 768 | 0.2855 | 0.9396 |
| 0.0 | 6.5 | 832 | 0.2888 | 0.9396 |
| 0.0 | 7.0 | 896 | 0.2766 | 0.9463 |
| 0.0 | 7.5 | 960 | 0.2879 | 0.9497 |
| 0.0 | 8.0 | 1024 | 0.2960 | 0.9463 |
| 0.0 | 8.5 | 1088 | 0.2906 | 0.9463 |
| 0.0 | 9.0 | 1152 | 0.2920 | 0.9463 |
| 0.0 | 9.5 | 1216 | 0.2932 | 0.9463 |
| 0.0 | 10.0 | 1280 | 0.2921 | 0.9463 |
| 0.0 | 10.5 | 1344 | 0.2922 | 0.9463 |
| 0.0 | 11.0 | 1408 | 0.2924 | 0.9463 |
| 0.0 | 11.5 | 1472 | 0.2919 | 0.9497 |
| 0.0 | 12.0 | 1536 | 0.2925 | 0.9463 |
| 0.0 | 12.5 | 1600 | 0.2943 | 0.9463 |
| 0.0 | 13.0 | 1664 | 0.2969 | 0.9463 |
| 0.0 | 13.5 | 1728 | 0.2982 | 0.9430 |
| 0.0 | 14.0 | 1792 | 0.2977 | 0.9463 |
| 0.0 | 14.5 | 1856 | 0.2981 | 0.9463 |
| 0.0 | 15.0 | 1920 | 0.2980 | 0.9463 |
| 0.0 | 15.5 | 1984 | 0.2980 | 0.9463 |
| 0.0 | 16.0 | 2048 | 0.2982 | 0.9463 |
| 0.0 | 16.5 | 2112 | 0.2998 | 0.9463 |
| 0.0 | 17.0 | 2176 | 0.3035 | 0.9430 |
| 0.0 | 17.5 | 2240 | 0.3039 | 0.9463 |
| 0.0 | 18.0 | 2304 | 0.3029 | 0.9463 |
| 0.0 | 18.5 | 2368 | 0.3044 | 0.9430 |
| 0.0 | 19.0 | 2432 | 0.3046 | 0.9430 |
| 0.0 | 19.5 | 2496 | 0.3046 | 0.9430 |
| 0.0 | 20.0 | 2560 | 0.3047 | 0.9430 |
| 0.0 | 20.5 | 2624 | 0.3047 | 0.9430 |
| 0.0 | 21.0 | 2688 | 0.3074 | 0.9430 |
| 0.0 | 21.5 | 2752 | 0.3086 | 0.9430 |
| 0.0 | 22.0 | 2816 | 0.3083 | 0.9430 |
| 0.0 | 22.5 | 2880 | 0.3088 | 0.9430 |
| 0.0 | 23.0 | 2944 | 0.3103 | 0.9463 |
| 0.0 | 23.5 | 3008 | 0.3109 | 0.9463 |
| 0.0 | 24.0 | 3072 | 0.3107 | 0.9463 |
| 0.0 | 24.5 | 3136 | 0.3108 | 0.9463 |
| 0.0 | 25.0 | 3200 | 0.3109 | 0.9463 |
| 0.0 | 25.5 | 3264 | 0.3101 | 0.9463 |
| 0.0 | 26.0 | 3328 | 0.3133 | 0.9463 |
| 0.0 | 26.5 | 3392 | 0.3125 | 0.9497 |
| 0.0 | 27.0 | 3456 | 0.3163 | 0.9463 |
| 0.0 | 27.5 | 3520 | 0.3172 | 0.9463 |
| 0.0 | 28.0 | 3584 | 0.3166 | 0.9463 |
| 0.0 | 28.5 | 3648 | 0.3176 | 0.9463 |
| 0.0 | 29.0 | 3712 | 0.3175 | 0.9463 |
| 0.0 | 29.5 | 3776 | 0.3174 | 0.9463 |
| 0.0 | 30.0 | 3840 | 0.3174 | 0.9463 |
### Framework versions
- Transformers 4.48.3
- Pytorch 2.5.1+cu124
- Datasets 3.3.2
- Tokenizers 0.21.1
|
luckycanucky/discord_model_x2_16b | luckycanucky | 2025-05-02T22:42:16Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T22:38:45Z | ---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** luckycanucky
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
joboffer/23de711b-5f52-4eaa-81e0-e08dc8991301 | joboffer | 2025-05-02T22:41:09Z | 0 | 0 | peft | [
"peft",
"safetensors",
"qwen2",
"axolotl",
"generated_from_trainer",
"base_model:Qwen/Qwen2-1.5B-Instruct",
"base_model:adapter:Qwen/Qwen2-1.5B-Instruct",
"license:apache-2.0",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-05-02T22:32:57Z | ---
library_name: peft
license: apache-2.0
base_model: Qwen/Qwen2-1.5B-Instruct
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 23de711b-5f52-4eaa-81e0-e08dc8991301
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: Qwen/Qwen2-1.5B-Instruct
bf16: true
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- 9532c4c65a822af6_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/9532c4c65a822af6_train_data.json
type:
field_instruction: problem
field_output: reasoning_solution
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.5
group_by_length: false
hub_model_id: joboffer/23de711b-5f52-4eaa-81e0-e08dc8991301
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-06
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/9532c4c65a822af6_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: e81a8ee6-474d-4598-a6bc-fe8020a6cbf5
wandb_project: s56-33
wandb_run: your_name
wandb_runid: e81a8ee6-474d-4598-a6bc-fe8020a6cbf5
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# 23de711b-5f52-4eaa-81e0-e08dc8991301
This model is a fine-tuned version of [Qwen/Qwen2-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9915
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.0742 | 0.0122 | 200 | 0.9915 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
bruhzair/ignore-merge-5 | bruhzair | 2025-05-02T22:38:29Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T22:05:29Z | ---
base_model: []
library_name: transformers
tags:
- mergekit
- merge
---
# doppel2
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the Passthrough merge method.
### Models Merged
The following models were included in the merge:
* /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
### Configuration
The following YAML configuration was used to produce this model:
```yaml
dtype: bfloat16
merge_method: passthrough
modules:
default:
slices:
- sources:
- layer_range: [0, 4]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [2, 4]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [4, 8]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [6, 8]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [8, 12]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [10, 12]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [12, 16]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [14, 16]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [16, 20]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [18, 20]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [20, 24]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [22, 24]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [24, 28]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [26, 28]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [28, 32]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [30, 32]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [32, 36]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [34, 36]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [36, 40]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [38, 40]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [40, 44]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [42, 44]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [44, 48]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [46, 48]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [48, 52]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [50, 52]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [52, 56]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [54, 56]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [56, 60]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [58, 60]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [60, 64]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [62, 64]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [64, 68]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [66, 68]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [68, 72]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [70, 72]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [72, 76]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [74, 76]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- layer_range: [76, 80]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
- sources:
- layer_range: [78, 80]
model: /workspace/cache/models--nbeerbower--Llama3.1-Gutenberg-Doppel-70B/snapshots/f083f3a89b8275e7e5329bb0668ada189f80b507
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
```
|
luckycanucky/discord_model_x2_lora | luckycanucky | 2025-05-02T22:36:54Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T22:36:45Z | ---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** luckycanucky
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
shuttleai/shuttle-3.5-moe-ckpts | shuttleai | 2025-05-02T22:34:51Z | 0 | 0 | peft | [
"peft",
"safetensors",
"qwen3_moe",
"axolotl",
"generated_from_trainer",
"base_model:Qwen/Qwen3-30B-A3B",
"base_model:adapter:Qwen/Qwen3-30B-A3B",
"license:apache-2.0",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-05-01T14:24:44Z | ---
library_name: peft
license: apache-2.0
base_model: Qwen/Qwen3-30B-A3B
tags:
- axolotl
- generated_from_trainer
model-index:
- name: shuttle-3.5-moe-ckpts
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.9.0`
```yaml
# Weights and Biases logging config
wandb_project: shuttle-3.5
wandb_name: "3.5-moe"
# Model architecture config
base_model: Qwen/Qwen3-30B-A3B
model_type: AutoModelForCausalLM
tokenizer_type: AutoTokenizer
chat_template: chatml
# Hugging Face saving config
hub_model_id: shuttleai/shuttle-3.5-moe-ckpts
hub_strategy: all_checkpoints
# Model checkpointing config
output_dir: ./moe-out
saves_per_epoch: 5
save_safetensors: true
save_total_limit: 5
# Mixed precision training config
bf16: true
fp16: false
tf32: false
# Model loading config
load_in_8bit: false
load_in_4bit: true
strict: false
# Sequence config
sequence_len: 14336
s2_attention: false
sample_packing: true
eval_sample_packing: true
pad_to_sequence_len: true
train_on_inputs: false
group_by_length: false
# QLoRA adapter config
adapter: qlora
lora_r: 64
lora_alpha: 64
lora_dropout: 0.05
peft_use_dora: false
lora_target_modules:
- gate_proj
- down_proj
- up_proj
- q_proj
- v_proj
- k_proj
- o_proj
# Dataset config
datasets:
- path: ./dataset
type: chat_template
val_set_size: 0.05
evals_per_epoch: 2
dataset_prepared_path: ./prepared-datasets
shuffle_merged_datasets: true
# Training hyperparameters
num_epochs: 1
gradient_accumulation_steps: 2
micro_batch_size: 2
eval_batch_size: 1
warmup_steps: 500
optimizer: paged_adamw_8bit
lr_scheduler: cosine
learning_rate: 2e-4
loraplus_lr_ratio: 8
cosine_min_lr_ratio: 0.1
weight_decay: 0.1
max_grad_norm: 1
logging_steps: 1
# Model optimization
unsloth_lora_qkv: true
gradient_checkpointing: unsloth
xformers_attention: false
flash_attention: true
sdp_attention: false
unsloth_cross_entropy_loss: true
unsloth_lora_mlp: false
unsloth_lora_qkv: false
unsloth_lora_o: false
# Loss monitoring config
early_stopping_patience: false
loss_watchdog_threshold: 100.0
loss_watchdog_patience: 3
# Debug config
debug: false
seed: 42
deepspeed: deepspeed_configs/zero2.json
```
</details><br>
# shuttle-3.5-moe-ckpts
This model is a fine-tuned version of [Qwen/Qwen3-30B-A3B](https://huggingface.co/Qwen/Qwen3-30B-A3B) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1380
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 2
- total_train_batch_size: 4
- optimizer: Use OptimizerNames.PAGED_ADAMW_8BIT with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 500
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 5.4277 | 0.0006 | 1 | 5.3197 |
| 1.7432 | 0.5003 | 869 | 1.1380 |
### Framework versions
- PEFT 0.15.2
- Transformers 4.51.3
- Pytorch 2.5.1+cu124
- Datasets 3.5.0
- Tokenizers 0.21.1 |
kokovova/94729b58-bc7e-4c44-b81c-1761b4286b39 | kokovova | 2025-05-02T22:28:46Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/codellama-7b",
"base_model:adapter:unsloth/codellama-7b",
"license:apache-2.0",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-05-02T22:20:18Z | ---
library_name: peft
license: apache-2.0
base_model: unsloth/codellama-7b
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 94729b58-bc7e-4c44-b81c-1761b4286b39
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: unsloth/codellama-7b
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 1e342bbeaf894e58_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/1e342bbeaf894e58_train_data.json
type:
field_input: input
field_instruction: instruction
field_output: chosen
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.5
group_by_length: false
hub_model_id: kokovova/94729b58-bc7e-4c44-b81c-1761b4286b39
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-06
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/1e342bbeaf894e58_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 1bc31bc4-0adf-49b9-bb84-67aba32775dc
wandb_project: s56-4
wandb_run: your_name
wandb_runid: 1bc31bc4-0adf-49b9-bb84-67aba32775dc
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# 94729b58-bc7e-4c44-b81c-1761b4286b39
This model is a fine-tuned version of [unsloth/codellama-7b](https://huggingface.co/unsloth/codellama-7b) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3038
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.2431 | 0.0160 | 200 | 0.3038 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
joboffer/d19440d2-bdf7-41aa-bd5d-29b45d701d86 | joboffer | 2025-05-02T22:28:46Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/codellama-7b",
"base_model:adapter:unsloth/codellama-7b",
"license:apache-2.0",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-05-02T22:20:08Z | ---
library_name: peft
license: apache-2.0
base_model: unsloth/codellama-7b
tags:
- axolotl
- generated_from_trainer
model-index:
- name: d19440d2-bdf7-41aa-bd5d-29b45d701d86
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: unsloth/codellama-7b
bf16: true
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- 1e342bbeaf894e58_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/1e342bbeaf894e58_train_data.json
type:
field_input: input
field_instruction: instruction
field_output: chosen
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.5
group_by_length: false
hub_model_id: joboffer/d19440d2-bdf7-41aa-bd5d-29b45d701d86
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-06
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/1e342bbeaf894e58_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 1bc31bc4-0adf-49b9-bb84-67aba32775dc
wandb_project: s56-33
wandb_run: your_name
wandb_runid: 1bc31bc4-0adf-49b9-bb84-67aba32775dc
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# d19440d2-bdf7-41aa-bd5d-29b45d701d86
This model is a fine-tuned version of [unsloth/codellama-7b](https://huggingface.co/unsloth/codellama-7b) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3035
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.2429 | 0.0160 | 200 | 0.3035 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
RedHatAI/Qwen3-32B-FP8_dynamic | RedHatAI | 2025-05-02T22:27:34Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"neuralmagic",
"redhat",
"llmcompressor",
"quantized",
"FP8",
"conversational",
"base_model:Qwen/Qwen3-32B",
"base_model:quantized:Qwen/Qwen3-32B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] | text-generation | 2025-05-02T14:55:49Z | ---
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-32B
tags:
- neuralmagic
- redhat
- llmcompressor
- quantized
- FP8
---
# Qwen3-32B-FP8-dynamic
## Model Overview
- **Model Architecture:** Qwen3ForCausalLM
- **Input:** Text
- **Output:** Text
- **Model Optimizations:**
- **Activation quantization:** FP8
- **Weight quantization:** FP8
- **Intended Use Cases:**
- Reasoning.
- Function calling.
- Subject matter experts via fine-tuning.
- Multilingual instruction following.
- Translation.
- **Out-of-scope:** Use in any manner that violates applicable laws or regulations (including trade compliance laws).
- **Release Date:** 05/02/2025
- **Version:** 1.0
- **Model Developers:** RedHat (Neural Magic)
### Model Optimizations
This model was obtained by quantizing activations and weights of [Qwen3-32B](https://huggingface.co/Qwen/Qwen3-32B) to FP8 data type.
This optimization reduces the number of bits used to represent weights and activations from 16 to 8, reducing GPU memory requirements (by approximately 50%) and increasing matrix-multiply compute throughput (by approximately 2x).
Weight quantization also reduces disk size requirements by approximately 50%.
Only weights and activations of the linear operators within transformers blocks are quantized.
Weights are quantized with a symmetric static per-channel scheme, whereas activations are quantized with a symmetric dynamic per-token scheme.
The [llm-compressor](https://github.com/vllm-project/llm-compressor) library is used for quantization.
## Deployment
This model can be deployed efficiently using the [vLLM](https://docs.vllm.ai/en/latest/) backend, as shown in the example below.
```python
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
model_id = "RedHatAI/Qwen3-32B-FP8-dynamic"
number_gpus = 1
sampling_params = SamplingParams(temperature=0.6, top_p=0.95, top_k=20, min_p=0, max_tokens=256)
messages = [
{"role": "user", "content": prompt}
]
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [{"role": "user", "content": "Give me a short introduction to large language model."}]
prompts = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
llm = LLM(model=model_id, tensor_parallel_size=number_gpus)
outputs = llm.generate(prompts, sampling_params)
generated_text = outputs[0].outputs[0].text
print(generated_text)
```
vLLM aslo supports OpenAI-compatible serving. See the [documentation](https://docs.vllm.ai/en/latest/) for more details.
## Creation
<details>
<summary>Creation details</summary>
This model was created with [llm-compressor](https://github.com/vllm-project/llm-compressor) by running the code snippet below.
```python
from llmcompressor.modifiers.quantization import QuantizationModifier
from llmcompressor.transformers import oneshot
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load model
model_stub = "Qwen/Qwen3-32B"
model_name = model_stub.split("/")[-1]
model = AutoModelForCausalLM.from_pretrained(model_stub)
tokenizer = AutoTokenizer.from_pretrained(model_stub)
# Configure the quantization algorithm and scheme
recipe = QuantizationModifier(
ignore=["lm_head"],
targets="Linear",
scheme="FP8_dynamic",
)
# Apply quantization
oneshot(
model=model,
recipe=recipe,
)
# Save to disk in compressed-tensors format
save_path = model_name + "-FP8-dynamic"
model.save_pretrained(save_path)
tokenizer.save_pretrained(save_path)
print(f"Model and tokenizer saved to: {save_path}")
```
</details>
## Evaluation
The model was evaluated on the OpenLLM leaderboard tasks (version 1), using [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) and [vLLM](https://docs.vllm.ai/en/stable/).
<details>
<summary>Evaluation details</summary>
```
lm_eval \
--model vllm \
--model_args pretrained="RedHatAI/Qwen3-32B-FP8-dynamic",dtype=auto,gpu_memory_utilization=0.5,max_model_len=8192,enable_chunk_prefill=True,tensor_parallel_size=1 \
--tasks openllm \
--apply_chat_template\
--fewshot_as_multiturn \
--batch_size auto
```
</details>
### Accuracy
<table>
<tr>
<th>Category
</th>
<th>Benchmark
</th>
<th>Qwen3-32B
</th>
<th>Qwen3-32B-FP8-dynamic<br>(this model)
</th>
<th>Recovery
</th>
</tr>
<tr>
<td rowspan="7" ><strong>OpenLLM v1</strong>
</td>
<td>MMLU (5-shot)
</td>
<td>80.96
</td>
<td>80.89
</td>
<td>99.9%
</td>
</tr>
<tr>
<td>ARC Challenge (25-shot)
</td>
<td>69.03
</td>
<td>68.00
</td>
<td>98.5%
</td>
</tr>
<tr>
<td>GSM-8K (5-shot, strict-match)
</td>
<td>87.64
</td>
<td>88.32
</td>
<td>100.8%
</td>
</tr>
<tr>
<td>Hellaswag (10-shot)
</td>
<td>71.10
</td>
<td>71.44
</td>
<td>100.5%
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>69.77
</td>
<td>69.85
</td>
<td>100.1%
</td>
</tr>
<tr>
<td>TruthfulQA (0-shot, mc2)
</td>
<td>58.63
</td>
<td>59.13
</td>
<td>100.9%
</td>
</tr>
<tr>
<td><strong>Average</strong>
</td>
<td><strong>72.86</strong>
</td>
<td><strong>72.94</strong>
</td>
<td><strong>100.1%</strong>
</td>
</tr>
</table> |
TomasLaz/t0-k5-32B | TomasLaz | 2025-05-02T22:23:44Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T21:50:14Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mgoNeo4j/dpo_finetuned_Meta-Llama-3.1-8B-Instruct-bnb-4bit | mgoNeo4j | 2025-05-02T22:22:26Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T10:21:05Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
lisabdunlap/Llama-3.1-8B-Instruct-unsloth-bnb-4bit-r32-e20-lr0.0002-mixed-json_format_small-new | lisabdunlap | 2025-05-02T22:20:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"base_model:unsloth/Llama-3.1-8B-Instruct-unsloth-bnb-4bit",
"base_model:finetune:unsloth/Llama-3.1-8B-Instruct-unsloth-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T22:18:10Z | ---
base_model: unsloth/Llama-3.1-8B-Instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** lisabdunlap
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Llama-3.1-8B-Instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
pablorezende/roseli | pablorezende | 2025-05-02T22:11:06Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"fluxgym",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-05-02T22:10:45Z | ---
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
- fluxgym
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: Roseli
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# Roseli
A Flux LoRA trained on a local computer with [Fluxgym](https://github.com/cocktailpeanut/fluxgym)
<Gallery />
## Trigger words
You should use `Roseli` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, Forge, etc.
Weights for this model are available in Safetensors format.
|
ysn-rfd/tokenizer_ysnrfd | ysn-rfd | 2025-05-02T22:03:18Z | 0 | 1 | transformers | [
"transformers",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T22:03:14Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ysn-rfd/pushed_to_hub_ysnrfd | ysn-rfd | 2025-05-02T22:03:13Z | 0 | 1 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T22:02:30Z | ---
base_model: unsloth/qwen3-14b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** ysn-rfd
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen3-14b-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF | mradermacher | 2025-05-02T21:59:54Z | 346 | 0 | transformers | [
"transformers",
"gguf",
"medical",
"zho",
"eng",
"fra",
"spa",
"por",
"deu",
"ita",
"rus",
"jpn",
"kor",
"vie",
"tha",
"ara",
"base_model:OpenMeditron/Meditron3-Qwen2.5-7B",
"base_model:quantized:OpenMeditron/Meditron3-Qwen2.5-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-04T02:28:26Z | ---
base_model: OpenMeditron/Meditron3-Qwen2.5-7B
language:
- zho
- eng
- fra
- spa
- por
- deu
- ita
- rus
- jpn
- kor
- vie
- tha
- ara
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- medical
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/OpenMeditron/Meditron3-Qwen2.5-7B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.0 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.1 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-IQ2_S.gguf) | i1-IQ2_S | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-IQ2_M.gguf) | i1-IQ2_M | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 2.9 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-Q2_K.gguf) | i1-Q2_K | 3.1 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.6 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-IQ3_S.gguf) | i1-IQ3_S | 3.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-IQ3_M.gguf) | i1-IQ3_M | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.9 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.3 | |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-IQ4_NL.gguf) | i1-IQ4_NL | 4.5 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-Q4_0.gguf) | i1-Q4_0 | 4.5 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.6 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-Q4_1.gguf) | i1-Q4_1 | 5.0 | |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/Meditron3-Qwen2.5-7B-i1-GGUF/resolve/main/Meditron3-Qwen2.5-7B.i1-Q6_K.gguf) | i1-Q6_K | 6.4 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
kinory24/whisper-small-asr_aviation-adapters-v5 | kinory24 | 2025-05-02T21:44:05Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T21:43:42Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
caiosms/vivi_rosto | caiosms | 2025-05-02T21:40:59Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:mit",
"region:us"
] | text-to-image | 2025-05-02T21:40:53Z | ---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: '-'
output:
url: images/ComfyUI_1546.jpg
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: Vivi
license: mit
---
# Vivi Rosto
<Gallery />
## Trigger words
You should use `Vivi` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/caiosms/vivi_rosto/tree/main) them in the Files & versions tab.
|
VridhiJain/bert_gridsearch | VridhiJain | 2025-05-02T21:40:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-05-02T21:40:05Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
prithivMLmods/WASP-2B-VL-Highlights | prithivMLmods | 2025-05-02T21:38:11Z | 12 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2_vl",
"feature-extraction",
"Generation",
"OCR",
"KIE",
"Highlights-Generator",
"image-text-to-text",
"conversational",
"en",
"base_model:Qwen/Qwen2-VL-2B-Instruct",
"base_model:finetune:Qwen/Qwen2-VL-2B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2025-04-09T02:52:20Z | ---
license: apache-2.0
language:
- en
base_model:
- Qwen/Qwen2-VL-2B-Instruct
pipeline_tag: image-text-to-text
library_name: transformers
tags:
- Generation
- OCR
- KIE
- Highlights-Generator
---

# **WASP-2B-VL-Highlights**
> \[!Note]
> The **WASP-2B-VL-Highlights** model is a fine-tuned version of *Qwen2-VL-2B-Instruct*, specifically optimized for **image highlights extraction**, **messy handwriting recognition**, **Optical Character Recognition (OCR)**, **English language understanding**, and **math problem solving with LaTeX formatting**. This model uses a conversational visual-language interface to effectively handle multi-modal tasks.
[](https://colab.research.google.com/#fileId=https%3A//huggingface.co/prithivMLmods/WASP-2B-VL-Highlights/blob/main/Callisto_OCR3_2B_Instruct.ipynb)
# **Key Enhancements:**
* **State-of-the-art image comprehension** across varying resolutions and aspect ratios:
WASP-2B-VL-Highlights delivers top-tier performance on benchmarks such as MathVista, DocVQA, RealWorldQA, and MTVQA.
* **Image Highlighting Expertise**:
Specially tuned to **identify and summarize key visual elements** in an image — ideal for **creating visual highlights**, annotations, and summaries.
* **Handwriting OCR Enhanced**:
Recognizes **messy and complex handwritten notes** with precision, perfect for digitizing real-world documents.
* **Video Content Understanding**:
Capable of processing videos longer than 20 minutes for **context-aware Q\&A, transcription**, and **highlight extraction**.
* **Multi-device Integration**:
Can be used as an intelligent agent for mobile phones, robots, and other devices — able to **understand visual scenes and execute actions**.
* **Multilingual OCR Support**:
In addition to English and Chinese, supports OCR for European languages, Japanese, Korean, Arabic, and Vietnamese.
# **Run with Transformers🤗**
```py
%%capture
!pip install -q gradio spaces transformers accelerate
!pip install -q numpy requests torch torchvision
!pip install -q qwen-vl-utils av ipython reportlab
!pip install -q fpdf python-docx pillow huggingface_hub
```
```py
#Demo
import gradio as gr
import spaces
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor, TextIteratorStreamer
from qwen_vl_utils import process_vision_info
import torch
from PIL import Image
import os
import uuid
import io
from threading import Thread
from reportlab.lib.pagesizes import A4
from reportlab.lib.styles import getSampleStyleSheet
from reportlab.lib import colors
from reportlab.platypus import SimpleDocTemplate, Image as RLImage, Paragraph, Spacer
from reportlab.lib.units import inch
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
import docx
from docx.enum.text import WD_ALIGN_PARAGRAPH
# Define model options
MODEL_OPTIONS = {
"Needle-2B-VL-Highlights": "prithivMLmods/WASP-2B-VL-Highlights",
}
# Preload models and processors into CUDA
models = {}
processors = {}
for name, model_id in MODEL_OPTIONS.items():
print(f"Loading {name}...")
models[name] = Qwen2VLForConditionalGeneration.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.float16
).to("cuda").eval()
processors[name] = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
image_extensions = Image.registered_extensions()
def identify_and_save_blob(blob_path):
"""Identifies if the blob is an image and saves it."""
try:
with open(blob_path, 'rb') as file:
blob_content = file.read()
try:
Image.open(io.BytesIO(blob_content)).verify() # Check if it's a valid image
extension = ".png" # Default to PNG for saving
media_type = "image"
except (IOError, SyntaxError):
raise ValueError("Unsupported media type. Please upload a valid image.")
filename = f"temp_{uuid.uuid4()}_media{extension}"
with open(filename, "wb") as f:
f.write(blob_content)
return filename, media_type
except FileNotFoundError:
raise ValueError(f"The file {blob_path} was not found.")
except Exception as e:
raise ValueError(f"An error occurred while processing the file: {e}")
@spaces.GPU
def qwen_inference(model_name, media_input, text_input=None):
"""Handles inference for the selected model."""
model = models[model_name]
processor = processors[model_name]
if isinstance(media_input, str):
media_path = media_input
if media_path.endswith(tuple([i for i in image_extensions.keys()])):
media_type = "image"
else:
try:
media_path, media_type = identify_and_save_blob(media_input)
except Exception as e:
raise ValueError("Unsupported media type. Please upload a valid image.")
messages = [
{
"role": "user",
"content": [
{
"type": media_type,
media_type: media_path
},
{"type": "text", "text": text_input},
],
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, _ = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
padding=True,
return_tensors="pt",
).to("cuda")
streamer = TextIteratorStreamer(
processor.tokenizer, skip_prompt=True, skip_special_tokens=True
)
generation_kwargs = dict(inputs, streamer=streamer, max_new_tokens=1024)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
buffer = ""
for new_text in streamer:
buffer += new_text
# Remove <|im_end|> or similar tokens from the output
buffer = buffer.replace("<|im_end|>", "")
yield buffer
def format_plain_text(output_text):
"""Formats the output text as plain text without LaTeX delimiters."""
# Remove LaTeX delimiters and convert to plain text
plain_text = output_text.replace("\\(", "").replace("\\)", "").replace("\\[", "").replace("\\]", "")
return plain_text
def generate_document(media_path, output_text, file_format, font_size, line_spacing, alignment, image_size):
"""Generates a document with the input image and plain text output."""
plain_text = format_plain_text(output_text)
if file_format == "pdf":
return generate_pdf(media_path, plain_text, font_size, line_spacing, alignment, image_size)
elif file_format == "docx":
return generate_docx(media_path, plain_text, font_size, line_spacing, alignment, image_size)
def generate_pdf(media_path, plain_text, font_size, line_spacing, alignment, image_size):
"""Generates a PDF document."""
filename = f"output_{uuid.uuid4()}.pdf"
doc = SimpleDocTemplate(
filename,
pagesize=A4,
rightMargin=inch,
leftMargin=inch,
topMargin=inch,
bottomMargin=inch
)
styles = getSampleStyleSheet()
styles["Normal"].fontSize = int(font_size)
styles["Normal"].leading = int(font_size) * line_spacing
styles["Normal"].alignment = {
"Left": 0,
"Center": 1,
"Right": 2,
"Justified": 4
}[alignment]
story = []
# Add image with size adjustment
image_sizes = {
"Small": (200, 200),
"Medium": (400, 400),
"Large": (600, 600)
}
img = RLImage(media_path, width=image_sizes[image_size][0], height=image_sizes[image_size][1])
story.append(img)
story.append(Spacer(1, 12))
# Add plain text output
text = Paragraph(plain_text, styles["Normal"])
story.append(text)
doc.build(story)
return filename
def generate_docx(media_path, plain_text, font_size, line_spacing, alignment, image_size):
"""Generates a DOCX document."""
filename = f"output_{uuid.uuid4()}.docx"
doc = docx.Document()
# Add image with size adjustment
image_sizes = {
"Small": docx.shared.Inches(2),
"Medium": docx.shared.Inches(4),
"Large": docx.shared.Inches(6)
}
doc.add_picture(media_path, width=image_sizes[image_size])
doc.add_paragraph()
# Add plain text output
paragraph = doc.add_paragraph()
paragraph.paragraph_format.line_spacing = line_spacing
paragraph.paragraph_format.alignment = {
"Left": WD_ALIGN_PARAGRAPH.LEFT,
"Center": WD_ALIGN_PARAGRAPH.CENTER,
"Right": WD_ALIGN_PARAGRAPH.RIGHT,
"Justified": WD_ALIGN_PARAGRAPH.JUSTIFY
}[alignment]
run = paragraph.add_run(plain_text)
run.font.size = docx.shared.Pt(int(font_size))
doc.save(filename)
return filename
# CSS for output styling
css = """
#output {
height: 500px;
overflow: auto;
border: 1px solid #ccc;
}
.submit-btn {
background-color: #cf3434 !important;
color: white !important;
}
.submit-btn:hover {
background-color: #ff2323 !important;
}
.download-btn {
background-color: #35a6d6 !important;
color: white !important;
}
.download-btn:hover {
background-color: #22bcff !important;
}
"""
# Gradio app setup
with gr.Blocks(css=css) as demo:
gr.Markdown("# Qwen2VL Models: Vision and Language Processing")
with gr.Tab(label="Image Input"):
with gr.Row():
with gr.Column():
model_choice = gr.Dropdown(
label="Model Selection",
choices=list(MODEL_OPTIONS.keys()),
value="WASP-2B-VL-Highlights"
)
input_media = gr.File(
label="Upload Image", type="filepath"
)
text_input = gr.Textbox(label="Question", placeholder="Ask a question about the image...")
submit_btn = gr.Button(value="Submit", elem_classes="submit-btn")
with gr.Column():
output_text = gr.Textbox(label="Output Text", lines=10)
plain_text_output = gr.Textbox(label="Standardized Plain Text", lines=10)
submit_btn.click(
qwen_inference, [model_choice, input_media, text_input], [output_text]
).then(
lambda output_text: format_plain_text(output_text), [output_text], [plain_text_output]
)
# Add examples directly usable by clicking
with gr.Row():
with gr.Column():
line_spacing = gr.Dropdown(
choices=[0.5, 1.0, 1.15, 1.5, 2.0, 2.5, 3.0],
value=1.5,
label="Line Spacing"
)
font_size = gr.Dropdown(
choices=["8", "10", "12", "14", "16", "18", "20", "22", "24"],
value="18",
label="Font Size"
)
alignment = gr.Dropdown(
choices=["Left", "Center", "Right", "Justified"],
value="Justified",
label="Text Alignment"
)
image_size = gr.Dropdown(
choices=["Small", "Medium", "Large"],
value="Small",
label="Image Size"
)
file_format = gr.Radio(["pdf", "docx"], label="File Format", value="pdf")
get_document_btn = gr.Button(value="Get Document", elem_classes="download-btn")
get_document_btn.click(
generate_document, [input_media, output_text, file_format, font_size, line_spacing, alignment, image_size], gr.File(label="Download Document")
)
demo.launch(debug=True)
```
# **Demo Output with ReportLab**

# **Key Features**
1. **Visual Highlights Generator:**
- Extracts **key objects, regions, and contextual clues** from images and turns them into meaningful **visual summaries**.
2. **Advanced Handwriting OCR:**
- Excels at recognizing and transcribing **messy or cursive handwriting** into digital text.
3. **Vision-Language Fusion:**
- Seamlessly integrates **visual input** with **language reasoning**, ideal for image captioning, description, and Q&A.
4. **Math and LaTeX Support:**
- Understands math problems in visual/text format and outputs in **LaTeX syntax**.
5. **Conversational AI:**
- Supports **multi-turn dialogue** with memory of prior input — highly useful for interactive problem-solving and explanations.
6. **Multi-modal Input Capability:**
- Accepts **image, text, or a combination**, and generates intelligent output tailored to the input. |
mradermacher/openthoughts2_1000k-GGUF | mradermacher | 2025-05-02T21:35:35Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:mlfoundations-dev/openthoughts2_1000k",
"base_model:quantized:mlfoundations-dev/openthoughts2_1000k",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-02T20:25:13Z | ---
base_model: mlfoundations-dev/openthoughts2_1000k
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/mlfoundations-dev/openthoughts2_1000k
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/openthoughts2_1000k-GGUF/resolve/main/openthoughts2_1000k.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/openthoughts2_1000k-GGUF/resolve/main/openthoughts2_1000k.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/openthoughts2_1000k-GGUF/resolve/main/openthoughts2_1000k.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/openthoughts2_1000k-GGUF/resolve/main/openthoughts2_1000k.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/openthoughts2_1000k-GGUF/resolve/main/openthoughts2_1000k.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/openthoughts2_1000k-GGUF/resolve/main/openthoughts2_1000k.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/openthoughts2_1000k-GGUF/resolve/main/openthoughts2_1000k.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/openthoughts2_1000k-GGUF/resolve/main/openthoughts2_1000k.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/openthoughts2_1000k-GGUF/resolve/main/openthoughts2_1000k.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/openthoughts2_1000k-GGUF/resolve/main/openthoughts2_1000k.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/openthoughts2_1000k-GGUF/resolve/main/openthoughts2_1000k.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/openthoughts2_1000k-GGUF/resolve/main/openthoughts2_1000k.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
gradientrouting-spar/toy_goodharting_gemma-2-2b-it_fruits_vegetables_naive_outcome_0_1_0_1_MC | gradientrouting-spar | 2025-05-02T21:34:20Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T21:33:59Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
jmalejandrob79/nbmaexp02 | jmalejandrob79 | 2025-05-02T21:34:09Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-05-02T13:57:14Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: nbmaexp02
---
# Nbmaexp02
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `nbmaexp02` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "nbmaexp02",
"lora_weights": "https://huggingface.co/jmalejandrob79/nbmaexp02/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('jmalejandrob79/nbmaexp02', weight_name='lora.safetensors')
image = pipeline('nbmaexp02').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 4500
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/jmalejandrob79/nbmaexp02/discussions) to add images that show off what you’ve made with this LoRA.
|
fbaldassarri/meta-llama_Llama-3.2-3B-TEQ-int4-gs128-sym | fbaldassarri | 2025-05-02T21:31:12Z | 0 | 0 | transformers | [
"transformers",
"woq",
"intel-neural-compressor",
"inc",
"neural-compressor",
"intel",
"teq",
"meta",
"pytorch",
"llama",
"llama-3",
"text-generation",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"base_model:meta-llama/Llama-3.2-3B",
"base_model:finetune:meta-llama/Llama-3.2-3B",
"license:llama3.2",
"region:us"
] | text-generation | 2025-05-02T21:17:51Z | ---
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
license: llama3.2
library_name: transformers
tags:
- woq
- intel-neural-compressor
- inc
- neural-compressor
- intel
- teq
- meta
- pytorch
- llama
- llama-3
model_name: Llama 3.2 3B
base_model: meta-llama/Llama-3.2-3B
inference: false
model_creator: meta-llama
pipeline_tag: text-generation
prompt_template: '{prompt}
'
quantized_by: fbaldassarri
---
## Model Information
Quantized version of [meta-llama/Llama-3.2-3B](https://huggingface.co/meta-llama/Llama-3.2-3B) using torch.float32 for quantization tuning.
- 4 bits (INT4)
- group size = 128
- Symmetrical Quantization
- Algorith method: TEQ (Trainable Equivalent Transformation for Quantization of LLMs)
Quantization framework: [Intel Neural Compressor](https://github.com/intel/neural-compressor/) version 3.3.1
Note: this INT4 version of Llama-3.2-3B has been quantized to run inference through CPU.
## Disclaimer
This quantized model comes with no warrenty. It has been developed experimetally only for research purposes.
This repository only contains contains two files: quantized_model.pt (weights structure) and qconfig.json, and the generated model is a quantized model.
It needs to be used in combination with the base model meta-llama/Llama-3.2-3B.
## Replication Recipe
```
$ conda create --name neural-compressor-3.3.1 --file requirements_conda_neural-compressor-3.3.1
$ python meta-llama_Llama-3.2-3B-TEQ-int4-gs128-sym.py
```
## Run Inference
To run inference you can use [fbaldassarri/woq-inference](https://github.com/fbaldassarri/woq-inference).
```
python teq_inference.py --base meta-llama/Llama-3.2-3B --model_dir ./meta-llama_Llama-3.2-3B-TEQ-int4-gs128-sym --weights_file quantized_weight.pt --config_file qconfig.json --prompt "What If you have got superpowers?" --device cpu
```
Note: You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
## License
[Llama 3.2 Community License](https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/LICENSE)
|
lihengma/Llama-3.1-8B-Instruct_kg_sft_1k | lihengma | 2025-05-02T21:30:10Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T21:23:59Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/Prism-0.2-GGUF | mradermacher | 2025-05-02T21:30:07Z | 38 | 0 | transformers | [
"transformers",
"gguf",
"zho",
"eng",
"fra",
"spa",
"por",
"deu",
"ita",
"rus",
"jpn",
"kor",
"vie",
"tha",
"ara",
"dataset:DiamondGotCat/Azuki-2n",
"base_model:DiamondGotCat/Prism-0.2",
"base_model:quantized:DiamondGotCat/Prism-0.2",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-03-11T01:02:11Z | ---
base_model: DiamondGotCat/Prism-0.2
datasets:
- DiamondGotCat/Azuki-2n
language:
- zho
- eng
- fra
- spa
- por
- deu
- ita
- rus
- jpn
- kor
- vie
- tha
- ara
library_name: transformers
license: mit
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/DiamondGotCat/Prism-0.2
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Prism-0.2-GGUF/resolve/main/Prism-0.2.Q3_K_S.gguf) | Q3_K_S | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Prism-0.2-GGUF/resolve/main/Prism-0.2.Q2_K.gguf) | Q2_K | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Prism-0.2-GGUF/resolve/main/Prism-0.2.IQ4_XS.gguf) | IQ4_XS | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Prism-0.2-GGUF/resolve/main/Prism-0.2.Q3_K_M.gguf) | Q3_K_M | 0.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Prism-0.2-GGUF/resolve/main/Prism-0.2.Q3_K_L.gguf) | Q3_K_L | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Prism-0.2-GGUF/resolve/main/Prism-0.2.Q4_K_S.gguf) | Q4_K_S | 0.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Prism-0.2-GGUF/resolve/main/Prism-0.2.Q4_K_M.gguf) | Q4_K_M | 0.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Prism-0.2-GGUF/resolve/main/Prism-0.2.Q5_K_S.gguf) | Q5_K_S | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/Prism-0.2-GGUF/resolve/main/Prism-0.2.Q5_K_M.gguf) | Q5_K_M | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/Prism-0.2-GGUF/resolve/main/Prism-0.2.Q6_K.gguf) | Q6_K | 0.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Prism-0.2-GGUF/resolve/main/Prism-0.2.Q8_0.gguf) | Q8_0 | 0.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Prism-0.2-GGUF/resolve/main/Prism-0.2.f16.gguf) | f16 | 1.4 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
h34v7/DansXPantheon-RP-Engine-V1.2-24b-Small-Instruct-Ties-Merge-GGUF | h34v7 | 2025-05-02T21:25:50Z | 0 | 0 | null | [
"gguf",
"mergekit",
"merge",
"roleplay",
"storywriting",
"arxiv:2306.01708",
"base_model:h34v7/DansXPantheon-RP-Engine-V1.2-24b-Small-Instruct-Ties-Merge",
"base_model:quantized:h34v7/DansXPantheon-RP-Engine-V1.2-24b-Small-Instruct-Ties-Merge",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-01T11:03:51Z | ---
base_model:
- h34v7/DansXPantheon-RP-Engine-V1.2-24b-Small-Instruct-Ties-Merge
tags:
- mergekit
- merge
- roleplay
- storywriting
---
# DansXPantheon-RP-Engine-V1.2-24b-Small-Instruct-Ties-Merge
* Fixed EOS Token
* Better merge and less yapping.
* Can use emoji somehow? Like almost like Gemma-3 i don't know how or why but its just cute sometimes.
### Settings
```
"temperature": 0.8,
"top_k": 40,
"top_p": 0.95,
"min_p": 0.05,
"repeat_last_n": 40,
"repeat_penalty": 1.2,
```
### Run on Ollama
These are non-imatrix. I'll release the imatrix version later.
GGUF 3-bit Q3_K_M about 27 GB of vRAM/RAM:
```
ollama run hf.co/h34v7/DansXPantheon-RP-Engine-V1.2-24b-Small-Instruct-Ties-Merge-GGUF:Q3_K_M
```
GGUF 4-bit Q4_K_M about 30 GB of vRAM/RAM:
```
ollama run hf.co/h34v7/DansXPantheon-RP-Engine-V1.2-24b-Small-Instruct-Ties-Merge-GGUF:Q4_K_M
```
GGUF 5-bit Q5_K_M about 33 GB of vRAM/RAM:
```
ollama run hf.co/h34v7/DansXPantheon-RP-Engine-V1.2-24b-Small-Instruct-Ties-Merge-GGUF:Q5_K_M
```
### Output Sample
Using [GGUF Q5-K-M](https://huggingface.co/h34v7/DansXPantheon-RP-Engine-V1.2-24b-Small-Instruct-Ties-Merge-GGUF) default Ollama settings. FP-16 [here](https://huggingface.co/h34v7/DansXPantheon-RP-Engine-V1.2-24b-Small-Instruct-Ties-Merge).
```
User: hi
Assistance: Hello! It's nice to meet you. How are you doing today? 😊
User: alright tell me some joke
Assistance: Sure, here's a lighthearted joke for you:
What do you call a fake noodle?
An impasta! 🍝🤪
Hope that made you chuckle. If you'd like another one or need any other assistance, just let me know!
User: Give me 5 non-formal ways to say 'See you later' in French.
Assistance: Certainly! Here are five casual ways to say "see you later" in French:
1. À plus tard - This is a very common and informal way to bid farewell.
2. Salut à plus - A more relaxed version that combines "hello/goodbye" (salut) with "see you later."
3. Ciao à plus - Using the Italian "ciao" gives it an even more casual feel.
4. Bisous à plus tard - This one adds a friendly touch by including "kisses" before saying see you later.
5. À la prochaine - Literally means "until next time," but is often used casually as well.
Remember that French people generally use "tu" (informal) with friends and family, while "vous" is more formal for strangers or in professional settings. These phrases work best when using the informal "tu." 🇫🇷✨
```
## Merge Details
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [Gryphe/Pantheon-RP-1.8-24b-Small-3.1](https://huggingface.co/Gryphe/Pantheon-RP-1.8-24b-Small-3.1) as a base.
### Models Merged
The following models were included in the merge:
* [PocketDoc/Dans-PersonalityEngine-V1.2.0-24b](https://huggingface.co/PocketDoc/Dans-PersonalityEngine-V1.2.0-24b)
* [Gryphe/Pantheon-RP-1.8-24b-Small-3.1](https://huggingface.co/Gryphe/Pantheon-RP-1.8-24b-Small-3.1)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Gryphe/Pantheon-RP-1.8-24b-Small-3.1
parameters:
density: 0.7
weight: 0.7
- model: PocketDoc/Dans-PersonalityEngine-V1.2.0-24b
parameters:
density: 0.5
weight: 0.5
merge_method: ties
base_model: Gryphe/Pantheon-RP-1.8-24b-Small-3.1
parameters:
normalize: false
int8_mask: true
dtype: float16
tokenizer:
source: union
```
### My System
```
Motherboard: Asus Maximus Z790
CPU: Intel i9-13900KS
RAM: 96 GB 6400mhz
GPU: RTX-4090 OC 24GB
``` |
VMadalina/whisper-large-news-augmented2 | VMadalina | 2025-05-02T21:19:50Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"ro",
"base_model:openai/whisper-large",
"base_model:finetune:openai/whisper-large",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2025-04-30T20:25:43Z | ---
library_name: transformers
language:
- ro
license: apache-2.0
base_model: openai/whisper-large
tags:
- hf-asr-leaderboard
- generated_from_trainer
metrics:
- wer
model-index:
- name: Whisper Large Ro - VM2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Large Ro - VM2
This model is a fine-tuned version of [openai/whisper-large](https://huggingface.co/openai/whisper-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1650
- Wer: 6.0193
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 3000
- training_steps: 20000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-------:|:-----:|:---------------:|:-------:|
| 0.0978 | 1.2063 | 1000 | 0.1440 | 69.1424 |
| 0.0593 | 2.4125 | 2000 | 0.1349 | 19.0102 |
| 0.0479 | 3.6188 | 3000 | 0.1423 | 12.2152 |
| 0.0313 | 4.8251 | 4000 | 0.1407 | 8.6577 |
| 0.0115 | 6.0314 | 5000 | 0.1427 | 7.9429 |
| 0.0094 | 7.2376 | 6000 | 0.1444 | 7.4316 |
| 0.0063 | 8.4439 | 7000 | 0.1483 | 7.2524 |
| 0.0068 | 9.6502 | 8000 | 0.1517 | 7.2168 |
| 0.0047 | 10.8565 | 9000 | 0.1533 | 7.1072 |
| 0.0028 | 12.0627 | 10000 | 0.1560 | 6.6211 |
| 0.0027 | 13.2690 | 11000 | 0.1539 | 6.6994 |
| 0.0014 | 14.4753 | 12000 | 0.1528 | 6.5063 |
| 0.0012 | 15.6815 | 13000 | 0.1571 | 6.4202 |
| 0.0008 | 16.8878 | 14000 | 0.1592 | 6.4315 |
| 0.0002 | 18.0941 | 15000 | 0.1577 | 6.4602 |
| 0.0002 | 19.3004 | 16000 | 0.1588 | 6.1907 |
| 0.0001 | 20.5066 | 17000 | 0.1607 | 6.0776 |
| 0.0 | 21.7129 | 18000 | 0.1621 | 6.0402 |
| 0.0 | 22.9192 | 19000 | 0.1643 | 6.0611 |
| 0.0 | 24.1255 | 20000 | 0.1650 | 6.0193 |
### Framework versions
- Transformers 4.50.1
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.1
|
Ajjusoji1/Mary | Ajjusoji1 | 2025-05-02T21:11:09Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-05-02T21:11:09Z | ---
license: apache-2.0
---
|
Mydiat/dqn-AsteroidsNoFrameskip-v4 | Mydiat | 2025-05-02T21:10:50Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"AsteroidsNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2025-05-02T21:10:07Z | ---
library_name: stable-baselines3
tags:
- AsteroidsNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AsteroidsNoFrameskip-v4
type: AsteroidsNoFrameskip-v4
metrics:
- type: mean_reward
value: 566.00 +/- 149.61
name: mean_reward
verified: false
---
# **DQN** Agent playing **AsteroidsNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **AsteroidsNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
SBX (SB3 + Jax): https://github.com/araffin/sbx
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env AsteroidsNoFrameskip-v4 -orga Mydiat -f logs/
python -m rl_zoo3.enjoy --algo dqn --env AsteroidsNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env AsteroidsNoFrameskip-v4 -orga Mydiat -f logs/
python -m rl_zoo3.enjoy --algo dqn --env AsteroidsNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env AsteroidsNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env AsteroidsNoFrameskip-v4 -f logs/ -orga Mydiat
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
dgambettaphd/M_llm2_gen5_S_doc1000_synt64_lr1e-04_acm_SYNLAST | dgambettaphd | 2025-05-02T21:10:34Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T21:10:15Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/nemo_nano_1000k-GGUF | mradermacher | 2025-05-02T21:05:55Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:mlfoundations-dev/nemo_nano_1000k",
"base_model:quantized:mlfoundations-dev/nemo_nano_1000k",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-02T20:34:29Z | ---
base_model: mlfoundations-dev/nemo_nano_1000k
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/mlfoundations-dev/nemo_nano_1000k
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/nemo_nano_1000k-GGUF/resolve/main/nemo_nano_1000k.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/nemo_nano_1000k-GGUF/resolve/main/nemo_nano_1000k.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/nemo_nano_1000k-GGUF/resolve/main/nemo_nano_1000k.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/nemo_nano_1000k-GGUF/resolve/main/nemo_nano_1000k.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/nemo_nano_1000k-GGUF/resolve/main/nemo_nano_1000k.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/nemo_nano_1000k-GGUF/resolve/main/nemo_nano_1000k.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/nemo_nano_1000k-GGUF/resolve/main/nemo_nano_1000k.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/nemo_nano_1000k-GGUF/resolve/main/nemo_nano_1000k.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/nemo_nano_1000k-GGUF/resolve/main/nemo_nano_1000k.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/nemo_nano_1000k-GGUF/resolve/main/nemo_nano_1000k.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/nemo_nano_1000k-GGUF/resolve/main/nemo_nano_1000k.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/nemo_nano_1000k-GGUF/resolve/main/nemo_nano_1000k.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
fbaldassarri/meta-llama_Llama-3.2-3B-TEQ-int4-gs128-asym | fbaldassarri | 2025-05-02T21:05:36Z | 0 | 0 | transformers | [
"transformers",
"woq",
"intel-neural-compressor",
"inc",
"neural-compressor",
"intel",
"teq",
"meta",
"pytorch",
"llama",
"llama-3",
"text-generation",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"base_model:meta-llama/Llama-3.2-3B",
"base_model:finetune:meta-llama/Llama-3.2-3B",
"license:llama3.2",
"region:us"
] | text-generation | 2025-05-02T20:51:16Z | ---
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
license: llama3.2
library_name: transformers
tags:
- woq
- intel-neural-compressor
- inc
- neural-compressor
- intel
- teq
- meta
- pytorch
- llama
- llama-3
model_name: Llama 3.2 3B
base_model: meta-llama/Llama-3.2-3B
inference: false
model_creator: meta-llama
pipeline_tag: text-generation
prompt_template: '{prompt}
'
quantized_by: fbaldassarri
---
## Model Information
Quantized version of [meta-llama/Llama-3.2-3B](https://huggingface.co/meta-llama/Llama-3.2-3B) using torch.float32 for quantization tuning.
- 4 bits (INT4)
- group size = 128
- Asymmetrical Quantization
- Algorith method: TEQ (Trainable Equivalent Transformation for Quantization of LLMs)
Quantization framework: [Intel Neural Compressor](https://github.com/intel/neural-compressor/) version 3.3.1
Note: this INT4 version of Llama-3.2-3B has been quantized to run inference through CPU.
## Disclaimer
This quantized model comes with no warrenty. It has been developed experimetally only for research purposes.
This repository only contains contains two files: quantized_model.pt (weights structure) and qconfig.json, and the generated model is a quantized model.
It needs to be used in combination with the base model meta-llama/Llama-3.2-3B.
## Replication Recipe
```
$ conda create --name neural-compressor-3.3.1 --file requirements_conda_neural-compressor-3.3.1
$ python meta-llama_Llama-3.2-3B-TEQ-int4-gs128-asym.py
```
## Run Inference
To run inference you can use [fbaldassarri/woq-inference](https://github.com/fbaldassarri/woq-inference).
```
python teq_inference.py --base meta-llama/Llama-3.2-3B --model_dir ./meta-llama_Llama-3.2-3B-TEQ-int4-gs128-asym --weights_file quantized_weight.pt --config_file qconfig.json --prompt "What If you have got superpowers?" --device cpu
```
Note: You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
## License
[Llama 3.2 Community License](https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/LICENSE)
|
enochlev/llm-toddler-28 | enochlev | 2025-05-02T20:57:28Z | 50 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"unsloth",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-29T09:12:33Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
unrented5443/sn11-v4-2-12 | unrented5443 | 2025-05-02T20:56:55Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma3",
"image-text-to-text",
"gemma",
"google",
"Bifröst",
"Bifrost",
"code",
"text-generation",
"conversational",
"base_model:google/gemma-3-27b-it",
"base_model:finetune:google/gemma-3-27b-it",
"license:gemma",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T20:56:51Z | ---
license: gemma
library_name: transformers
pipeline_tag: text-generation
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: >-
To access Gemma on Hugging Face, you’re required to review and agree to
Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
base_model: google/gemma-3-27b-it
tags:
- transformers
- gemma3
- gemma
- google
- Bifröst
- Bifrost
- code
---
## Bifröst-27B

Bifröst-27B is an advanced AI model built upon gemma3 architecture, specifically fine-tuned for secure and efficient enterprise-grade code generation with reasoning. Designed to meet rigorous standards of safety, accuracy, and reliability, Bifröst empowers organizations to streamline software development workflows while prioritizing security and compliance.
### Model Details
- **Model Name:** Bifröst-27B
- **Base Architecture:** gemma3
- **Application:** Enterprise Secure Code Generation
- **Release Date:** 16-March-2025
### Intended Use
Bifröst is designed explicitly for:
- Generating secure, efficient, and high-quality code.
- Supporting development tasks within regulated enterprise environments.
- Enhancing productivity by automating routine coding tasks without compromising security.
### Features
- **Security-Focused Training:** Specialized training regimen emphasizing secure coding practices, vulnerability reduction, and adherence to security standards.
- **Enterprise-Optimized Performance:** Tailored to support various programming languages and enterprise frameworks with robust, context-aware suggestions.
- **Compliance-Driven Design:** Incorporates features to aid in maintaining compliance with industry-specific standards (e.g., GDPR, HIPAA, SOC 2).
### Limitations
- Bifröst should be used under human supervision to ensure code correctness and security compliance.
- Model-generated code should undergo appropriate security and quality assurance checks before deployment.
### Ethical Considerations
- Users are encouraged to perform regular audits and compliance checks on generated outputs.
- Enterprises should implement responsible AI practices to mitigate biases or unintended consequences.
### Usage
Below are some quick-start instructions for using the model with the `transformers` library.
#### Installation
```sh
$ pip install git+https://github.com/huggingface/[email protected]
```
#### Running with the `pipeline` API
```python
from transformers import pipeline
import torch
pipe = pipeline(
"text-generation",
model="OpenGenerativeAI/Bifrost-27B",
device="cuda",
torch_dtype=torch.bfloat16
)
messages = [{"role": "user", "content": "Generate a secure API key management system."}]
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"])
```
## Terms of Use
This model is released under the **Gemma license**. Users must comply with [Google's Gemma Terms of Use](https://ai.google.dev/gemma/terms), including restrictions on redistribution, modification, and commercial use. |
unrented5443/sn11-v4-2-11 | unrented5443 | 2025-05-02T20:56:50Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma3",
"image-text-to-text",
"gemma",
"google",
"Bifröst",
"Bifrost",
"code",
"text-generation",
"conversational",
"base_model:google/gemma-3-27b-it",
"base_model:finetune:google/gemma-3-27b-it",
"license:gemma",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T20:56:46Z | ---
license: gemma
library_name: transformers
pipeline_tag: text-generation
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: >-
To access Gemma on Hugging Face, you’re required to review and agree to
Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
base_model: google/gemma-3-27b-it
tags:
- transformers
- gemma3
- gemma
- google
- Bifröst
- Bifrost
- code
---
## Bifröst-27B

Bifröst-27B is an advanced AI model built upon gemma3 architecture, specifically fine-tuned for secure and efficient enterprise-grade code generation with reasoning. Designed to meet rigorous standards of safety, accuracy, and reliability, Bifröst empowers organizations to streamline software development workflows while prioritizing security and compliance.
### Model Details
- **Model Name:** Bifröst-27B
- **Base Architecture:** gemma3
- **Application:** Enterprise Secure Code Generation
- **Release Date:** 16-March-2025
### Intended Use
Bifröst is designed explicitly for:
- Generating secure, efficient, and high-quality code.
- Supporting development tasks within regulated enterprise environments.
- Enhancing productivity by automating routine coding tasks without compromising security.
### Features
- **Security-Focused Training:** Specialized training regimen emphasizing secure coding practices, vulnerability reduction, and adherence to security standards.
- **Enterprise-Optimized Performance:** Tailored to support various programming languages and enterprise frameworks with robust, context-aware suggestions.
- **Compliance-Driven Design:** Incorporates features to aid in maintaining compliance with industry-specific standards (e.g., GDPR, HIPAA, SOC 2).
### Limitations
- Bifröst should be used under human supervision to ensure code correctness and security compliance.
- Model-generated code should undergo appropriate security and quality assurance checks before deployment.
### Ethical Considerations
- Users are encouraged to perform regular audits and compliance checks on generated outputs.
- Enterprises should implement responsible AI practices to mitigate biases or unintended consequences.
### Usage
Below are some quick-start instructions for using the model with the `transformers` library.
#### Installation
```sh
$ pip install git+https://github.com/huggingface/[email protected]
```
#### Running with the `pipeline` API
```python
from transformers import pipeline
import torch
pipe = pipeline(
"text-generation",
model="OpenGenerativeAI/Bifrost-27B",
device="cuda",
torch_dtype=torch.bfloat16
)
messages = [{"role": "user", "content": "Generate a secure API key management system."}]
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"])
```
## Terms of Use
This model is released under the **Gemma license**. Users must comply with [Google's Gemma Terms of Use](https://ai.google.dev/gemma/terms), including restrictions on redistribution, modification, and commercial use. |
saluslab/DUET_kinesics_recognition | saluslab | 2025-05-02T20:54:21Z | 0 | 0 | null | [
"dataset:Anonymous-Uploader1/DUET",
"region:us"
] | null | 2025-05-01T19:56:43Z | ---
datasets:
- Anonymous-Uploader1/DUET
---
### Introduction to Kinesics Recognition Framework
Humans utilize a range of channels to deliver their thought processes, including verbal messages, facial expression, body language,
and etc. Among these channels, body language plays a critical role since it conveys unspoken cues about an individual's mental and
emotional states through action movements. To study the meanings and interpretations expressed through bodily movements, psychologists
Ekman and Friesen developed the taxonomy of kinesics that classifies bodily movements into five categories based on their communication
functions: emblems, illustrators, affect displays, adaptors, and regulators. This principled taxonomy defines clear linkage between
human activities and their respective meanings and communicative categories. In conjunction with human activity recognition (HAR)---which
use sensor data such as RGB video, depth maps, or 3D skeletal keypoint to identify actions---the opportunity to automatically recognize
the kinesics of human movements arises. This opportunity entails compiling a dictionary-based mapping that corresponds human activities
to their communicative categories. The dictionary is then appended to an HAR algorithm to determine the kinesic function of a given activity
after its recognized. However, the sheer variety of human actions makes it infeasible to manually define mappings for every possible movement.
To truely decode human reasoning through bodily movements, we must move beyond dictionary-based mapping and towards methods capable of
learning a generalized translation between physical actions and their cognitive and affective significance.
In this repository, we present a framework that classifies the kinesic categories of human movements. To be more specific, the framework
leverages a structured pattern embedded in skeletal keypoint data that clusters different human activities with same communicative purpose
together. The framework extracts the structure through a transfer learning model that consists of a Spatial-Temporal Graph Convolutional
Network (ST-GCN) and a convolutional neural network (CNN). This model is implemented on a HAR dataset that is derived from the taxonomy of
Kinesics --- the **D**yadic **U**ser **E**ngagemen**T** dataset (DUET) to demonstrate its efficacy.
### Kinesics Recognition Framework Pipeline
The code in this repository runs the framework on 30 subsets of DUET, and each subset contains different numbers and types of activities.
To implement the framework, please follow the steps below:
1. Duplicate the folder structure of the repository.
2. Download the **3D joints** from the [DUET repository](https://huggingface.co/datasets/Anonymous-Uploader1/DUET/tree/main) and store
all the folders (e.g., CC0101 and CL0102) in the `data` directory.
3. Download all the required packages in `requirement.txt`.
4. Run `python disposition.py`.
5. After the completion of the code, the results will be stored in `experiment_results.pkl`, which include the experiment number,
the number of interactions, the type of interaction, the accuracy of the kinesics recognition for the given interactions. To acquire
the accuracy of ST-GCN of the experiment, go to the logging file of the corresponding experiment (i.e., `work_dirs/*experiment_N*/*execution_timestamps*/*execution_timestamps.txt*`.)
For instance, if you would like to determine the ST-GCN accuracy of experiment 3 that is executed at 11:07:50 on May 1, 2025, go to `work_dirs/*experiment_3*/20250501_110750/20250501_110750.txt*`.
|
John6666/momoiro-illustrious-v10-sdxl | John6666 | 2025-05-02T20:53:55Z | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"girls",
"cute",
"Illustrious XL v2.0",
"illustrious",
"en",
"base_model:OnomaAIResearch/Illustrious-XL-v2.0",
"base_model:finetune:OnomaAIResearch/Illustrious-XL-v2.0",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | 2025-05-02T20:48:24Z | ---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- girls
- cute
- Illustrious XL v2.0
- illustrious
base_model: OnomaAIResearch/Illustrious-XL-v2.0
---
Original model is [here](https://civitai.com/models/1534695/momoiroillustrious?modelVersionId=1736477).
This model created by [oritatami_neko](https://civitai.com/user/oritatami_neko).
|
shamim85/shamim007 | shamim85 | 2025-05-02T20:52:39Z | 0 | 0 | null | [
"license:other",
"region:us"
] | null | 2025-05-02T20:11:13Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
--- |
unrented5443/sn11-v4-2-9 | unrented5443 | 2025-05-02T20:52:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma3",
"image-text-to-text",
"gemma",
"google",
"Bifröst",
"Bifrost",
"code",
"text-generation",
"conversational",
"base_model:google/gemma-3-27b-it",
"base_model:finetune:google/gemma-3-27b-it",
"license:gemma",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T20:52:18Z | ---
license: gemma
library_name: transformers
pipeline_tag: text-generation
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: >-
To access Gemma on Hugging Face, you’re required to review and agree to
Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
base_model: google/gemma-3-27b-it
tags:
- transformers
- gemma3
- gemma
- google
- Bifröst
- Bifrost
- code
---
## Bifröst-27B

Bifröst-27B is an advanced AI model built upon gemma3 architecture, specifically fine-tuned for secure and efficient enterprise-grade code generation with reasoning. Designed to meet rigorous standards of safety, accuracy, and reliability, Bifröst empowers organizations to streamline software development workflows while prioritizing security and compliance.
### Model Details
- **Model Name:** Bifröst-27B
- **Base Architecture:** gemma3
- **Application:** Enterprise Secure Code Generation
- **Release Date:** 16-March-2025
### Intended Use
Bifröst is designed explicitly for:
- Generating secure, efficient, and high-quality code.
- Supporting development tasks within regulated enterprise environments.
- Enhancing productivity by automating routine coding tasks without compromising security.
### Features
- **Security-Focused Training:** Specialized training regimen emphasizing secure coding practices, vulnerability reduction, and adherence to security standards.
- **Enterprise-Optimized Performance:** Tailored to support various programming languages and enterprise frameworks with robust, context-aware suggestions.
- **Compliance-Driven Design:** Incorporates features to aid in maintaining compliance with industry-specific standards (e.g., GDPR, HIPAA, SOC 2).
### Limitations
- Bifröst should be used under human supervision to ensure code correctness and security compliance.
- Model-generated code should undergo appropriate security and quality assurance checks before deployment.
### Ethical Considerations
- Users are encouraged to perform regular audits and compliance checks on generated outputs.
- Enterprises should implement responsible AI practices to mitigate biases or unintended consequences.
### Usage
Below are some quick-start instructions for using the model with the `transformers` library.
#### Installation
```sh
$ pip install git+https://github.com/huggingface/[email protected]
```
#### Running with the `pipeline` API
```python
from transformers import pipeline
import torch
pipe = pipeline(
"text-generation",
model="OpenGenerativeAI/Bifrost-27B",
device="cuda",
torch_dtype=torch.bfloat16
)
messages = [{"role": "user", "content": "Generate a secure API key management system."}]
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"])
```
## Terms of Use
This model is released under the **Gemma license**. Users must comply with [Google's Gemma Terms of Use](https://ai.google.dev/gemma/terms), including restrictions on redistribution, modification, and commercial use. |
underscore2/llama3-8b-singularity | underscore2 | 2025-05-02T20:50:26Z | 0 | 1 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T20:50:20Z | ---
base_model: unsloth/llama-3-8b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** underscore2
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
vmpsergio/d5f50425-e1e7-4bfa-921f-b17fc6658422 | vmpsergio | 2025-05-02T20:48:42Z | 0 | 0 | peft | [
"peft",
"safetensors",
"qwen2",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/Qwen2.5-Math-1.5B-Instruct",
"base_model:adapter:unsloth/Qwen2.5-Math-1.5B-Instruct",
"license:apache-2.0",
"8-bit",
"bitsandbytes",
"region:us"
] | null | 2025-05-02T20:26:29Z | ---
library_name: peft
license: apache-2.0
base_model: unsloth/Qwen2.5-Math-1.5B-Instruct
tags:
- axolotl
- generated_from_trainer
model-index:
- name: d5f50425-e1e7-4bfa-921f-b17fc6658422
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: unsloth/Qwen2.5-Math-1.5B-Instruct
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 20c335f85394bee3_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/20c335f85394bee3_train_data.json
type:
field_input: content
field_instruction: subject
field_output: message
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.5
group_by_length: false
hub_model_id: vmpsergio/d5f50425-e1e7-4bfa-921f-b17fc6658422
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-06
load_in_4bit: true
load_in_8bit: true
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 6
mixed_precision: bf16
mlflow_experiment_name: /tmp/20c335f85394bee3_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: e8b1d9e6-547b-48a6-83f0-f92316dc33e4
wandb_project: s56-2
wandb_run: your_name
wandb_runid: e8b1d9e6-547b-48a6-83f0-f92316dc33e4
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# d5f50425-e1e7-4bfa-921f-b17fc6658422
This model is a fine-tuned version of [unsloth/Qwen2.5-Math-1.5B-Instruct](https://huggingface.co/unsloth/Qwen2.5-Math-1.5B-Instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4246
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.2824 | 0.0041 | 200 | 1.4246 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
John6666/garage-mix-noob-vpred-eps-v10-vpred-sdxl | John6666 | 2025-05-02T20:48:22Z | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"characters",
"girls",
"v-pred",
"noobai",
"illustrious",
"en",
"base_model:Laxhar/noobai-XL-Vpred-1.0",
"base_model:finetune:Laxhar/noobai-XL-Vpred-1.0",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | 2025-05-02T20:42:49Z | ---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- characters
- girls
- v-pred
- noobai
- illustrious
base_model: Laxhar/noobai-XL-Vpred-1.0
---
Original model is [here](https://civitai.com/models/1377342?modelVersionId=1735582).
This model created by [GarejiSama](https://civitai.com/user/GarejiSama).
|
deeponh/mal_8b_3b_L1 | deeponh | 2025-05-02T20:48:20Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-01T21:38:09Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mgoNeo4j/sft_finetuned_Meta-Llama-3.1-8B-Instruct-bnb-4bit | mgoNeo4j | 2025-05-02T20:47:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T10:20:00Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
chchen/MentaLLaMA-chat-7B-PsyCourse-info-fold8 | chchen | 2025-05-02T20:46:21Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama-factory",
"lora",
"generated_from_trainer",
"base_model:klyang/MentaLLaMA-chat-7B-hf",
"base_model:adapter:klyang/MentaLLaMA-chat-7B-hf",
"license:mit",
"region:us"
] | null | 2025-05-02T19:38:10Z | ---
library_name: peft
license: mit
base_model: klyang/MentaLLaMA-chat-7B-hf
tags:
- llama-factory
- lora
- generated_from_trainer
model-index:
- name: MentaLLaMA-chat-7B-PsyCourse-info-fold8
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MentaLLaMA-chat-7B-PsyCourse-info-fold8
This model is a fine-tuned version of [klyang/MentaLLaMA-chat-7B-hf](https://huggingface.co/klyang/MentaLLaMA-chat-7B-hf) on the course-info-train-fold8 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1240
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.7993 | 0.3951 | 10 | 0.6858 |
| 0.3021 | 0.7901 | 20 | 0.2613 |
| 0.2318 | 1.1852 | 30 | 0.1915 |
| 0.1743 | 1.5802 | 40 | 0.1546 |
| 0.1373 | 1.9753 | 50 | 0.1437 |
| 0.1491 | 2.3704 | 60 | 0.1343 |
| 0.1278 | 2.7654 | 70 | 0.1314 |
| 0.0769 | 3.1605 | 80 | 0.1254 |
| 0.1553 | 3.5556 | 90 | 0.1250 |
| 0.1326 | 3.9506 | 100 | 0.1256 |
| 0.0921 | 4.3457 | 110 | 0.1253 |
| 0.0907 | 4.7407 | 120 | 0.1240 |
### Framework versions
- PEFT 0.12.0
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3 |
executorch-community/Qwen3-4B-8da4w | executorch-community | 2025-05-02T20:44:01Z | 0 | 0 | null | [
"text-generation",
"base_model:Qwen/Qwen3-4B",
"base_model:quantized:Qwen/Qwen3-4B",
"license:apache-2.0",
"region:us"
] | text-generation | 2025-05-02T16:47:18Z | ---
license: apache-2.0
base_model:
- Qwen/Qwen3-4B
pipeline_tag: text-generation
base_model_relation: quantized
---
# Qwen3 4B for ExecuTorch
- Original [model](https://huggingface.co/Qwen/Qwen3-4B)
- This pte file is generated via [these instructions](https://github.com/pytorch/executorch/blob/main/examples/models/qwen3/README.md)
- You can follow [these instructions](https://github.com/pytorch/executorch/blob/main/examples/models/llama/README.md#step-3-run-on-your-computer-to-validate) to run the pte using Executorch in C++
- You can follow [these instructions](https://github.com/pytorch/executorch/blob/main/examples/models/llama/README.md#step-5-build-mobile-apps) as an example to build an LLM chat application powered by Qwen3.
- It follows [this compatibility policy](https://github.com/pytorch/executorch/blob/main/runtime/COMPATIBILITY.md) |
vertings6/5f15eeaa-86ea-4cbb-8675-e1fd30dcbf0b | vertings6 | 2025-05-02T20:44:00Z | 0 | 0 | peft | [
"peft",
"safetensors",
"qwen2",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/Qwen2.5-Math-1.5B-Instruct",
"base_model:adapter:unsloth/Qwen2.5-Math-1.5B-Instruct",
"license:apache-2.0",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-05-02T20:26:16Z | ---
library_name: peft
license: apache-2.0
base_model: unsloth/Qwen2.5-Math-1.5B-Instruct
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 5f15eeaa-86ea-4cbb-8675-e1fd30dcbf0b
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: true
adapter: lora
base_model: unsloth/Qwen2.5-Math-1.5B-Instruct
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 20c335f85394bee3_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/20c335f85394bee3_train_data.json
type:
field_input: content
field_instruction: subject
field_output: message
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 144
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_clipping: 0.5
group_by_length: false
hub_model_id: vertings6/5f15eeaa-86ea-4cbb-8675-e1fd30dcbf0b
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 3.0e-06
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 4
mixed_precision: bf16
mlflow_experiment_name: /tmp/20c335f85394bee3_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 2048
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: e8b1d9e6-547b-48a6-83f0-f92316dc33e4
wandb_project: s56-32
wandb_run: your_name
wandb_runid: e8b1d9e6-547b-48a6-83f0-f92316dc33e4
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# 5f15eeaa-86ea-4cbb-8675-e1fd30dcbf0b
This model is a fine-tuned version of [unsloth/Qwen2.5-Math-1.5B-Instruct](https://huggingface.co/unsloth/Qwen2.5-Math-1.5B-Instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2226
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.842 | 0.0055 | 200 | 2.2226 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
cognitivecomputations/Qwen3-30B-A3B-AWQ | cognitivecomputations | 2025-05-02T20:43:55Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2309.00071",
"base_model:Qwen/Qwen3-30B-A3B",
"base_model:quantized:Qwen/Qwen3-30B-A3B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"awq",
"region:us"
] | text-generation | 2025-05-02T18:45:02Z | ---
license: apache-2.0
base_model:
- Qwen/Qwen3-30B-A3B
library_name: transformers
---
# Qwen3-30B-A3B-AWQ
Uploaded by Eric Hartford
Copied from Modelscope https://www.modelscope.cn/models/swift/Qwen3-30B-A3B-AWQ
Original model https://huggingface.co/Qwen/Qwen3-30B-A3B
# Modelscope AWQ Modelcard:
import torch
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "swift/Qwen3-30B-A3B-AWQ"
## load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
## prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
## conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
## parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
# Original Modelcard
# Qwen3-30B-A3B
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Qwen3 Highlights
Qwen3 is the latest generation of large language models in Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Built upon extensive training, Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
- **Uniquely support of seamless switching between thinking mode** (for complex logical reasoning, math, and coding) and **non-thinking mode** (for efficient, general-purpose dialogue) **within single model**, ensuring optimal performance across various scenarios.
- **Significantly enhancement in its reasoning capabilities**, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- **Superior human preference alignment**, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- **Expertise in agent capabilities**, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
- **Support of 100+ languages and dialects** with strong capabilities for **multilingual instruction following** and **translation**.
## Model Overview
**Qwen3-30B-A3B** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: 32,768 natively and [131,072 tokens with YaRN](#processing-long-texts).
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1
```
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Switching Between Thinking and Non-Thinking Mode
> [!TIP]
> The `enable_thinking` switch is also available in APIs created by SGLang and vLLM.
> Please refer to our documentation for [SGLang](https://qwen.readthedocs.io/en/latest/deployment/sglang.html#thinking-non-thinking-modes) and [vLLM](https://qwen.readthedocs.io/en/latest/deployment/vllm.html#thinking-non-thinking-modes) users.
### `enable_thinking=True`
By default, Qwen3 has thinking capabilities enabled, similar to QwQ-32B. This means the model will use its reasoning abilities to enhance the quality of generated responses. For example, when explicitly setting `enable_thinking=True` or leaving it as the default value in `tokenizer.apply_chat_template`, the model will engage its thinking mode.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # True is the default value for enable_thinking
)
```
In this mode, the model will generate think content wrapped in a `<think>...</think>` block, followed by the final response.
> [!NOTE]
> For thinking mode, use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0` (the default setting in `generation_config.json`). **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### `enable_thinking=False`
We provide a hard switch to strictly disable the model's thinking behavior, aligning its functionality with the previous Qwen2.5-Instruct models. This mode is particularly useful in scenarios where disabling thinking is essential for enhancing efficiency.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Setting enable_thinking=False disables thinking mode
)
```
In this mode, the model will not generate any think content and will not include a `<think>...</think>` block.
> [!NOTE]
> For non-thinking mode, we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### Advanced Usage: Switching Between Thinking and Non-Thinking Modes via User Input
We provide a soft switch mechanism that allows users to dynamically control the model's behavior when `enable_thinking=True`. Specifically, you can add `/think` and `/no_think` to user prompts or system messages to switch the model's thinking mode from turn to turn. The model will follow the most recent instruction in multi-turn conversations.
Here is an example of a multi-turn conversation:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen/Qwen3-30B-A3B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# Update history
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# Example Usage
if __name__ == "__main__":
chatbot = QwenChatbot()
# First input (without /think or /no_think tags, thinking mode is enabled by default)
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
# Second input with /no_think
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
# Third input with /think
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
```
> [!NOTE]
> For API compatibility, when `enable_thinking=True`, regardless of whether the user uses `/think` or `/no_think`, the model will always output a block wrapped in `<think>...</think>`. However, the content inside this block may be empty if thinking is disabled.
> When `enable_thinking=False`, the soft switches are not valid. Regardless of any `/think` or `/no_think` tags input by the user, the model will not generate think content and will not include a `<think>...</think>` block.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-30B-A3B',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Long Texts
Qwen3 natively supports context lengths of up to 32,768 tokens. For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively. We have validated the model's performance on context lengths of up to 131,072 tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers` and `llama.cpp` for local use, `vllm` and `sglang` for deployment. In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
```
For `llama.cpp`, you need to regenerate the GGUF file after the modification.
- Passing command line arguments:
For `vllm`, you can use
```shell
vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' --max-model-len 131072
```
For `sglang`, you can use
```shell
python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}'
```
For `llama-server` from `llama.cpp`, you can use
```shell
llama-server ... --rope-scaling yarn --rope-scale 4 --yarn-orig-ctx 32768
```
> [!IMPORTANT]
> If you encounter the following warning
> ```
> Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
> ```
> please upgrade `transformers>=4.51.0`.
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 65,536 tokens, it would be better to set `factor` as 2.0.
> [!NOTE]
> The default `max_position_embeddings` in `config.json` is set to 40,960. This allocation includes reserving 32,768 tokens for outputs and 8,192 tokens for typical prompts, which is sufficient for most scenarios involving short text processing. If the average context length does not exceed 32,768 tokens, we do not recommend enabling YaRN in this scenario, as it may potentially degrade model performance.
> [!TIP]
> The endpoint provided by Alibaba Model Studio supports dynamic YaRN by default and no extra configuration is needed.
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- For thinking mode (`enable_thinking=True`), use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`. **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions.
- For non-thinking mode (`enable_thinking=False`), we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 38,912 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3,
title = {Qwen3},
url = {https://qwenlm.github.io/blog/qwen3/},
author = {Qwen Team},
month = {April},
year = {2025}
}
``` |
prithivMLmods/Qwen2-VL-Ocrtest-2B-Instruct | prithivMLmods | 2025-05-02T20:27:14Z | 47 | 6 | transformers | [
"transformers",
"safetensors",
"qwen2_vl",
"image-text-to-text",
"Math",
"Language",
"VLM",
"Character-Anology",
"multimodal",
"conversational",
"en",
"base_model:Qwen/Qwen2-VL-2B-Instruct",
"base_model:finetune:Qwen/Qwen2-VL-2B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2024-12-19T04:36:56Z | ---
license: apache-2.0
language:
- en
base_model:
- Qwen/Qwen2-VL-2B-Instruct
pipeline_tag: image-text-to-text
library_name: transformers
tags:
- Math
- Language
- VLM
- Character-Anology
- multimodal
---
# Qwen2-VL-Ocrtest-2B-Instruct [Text Analogy Ocrtest]

The **Qwen2-VL-Ocrtest-2B-Instruct** model is a fine-tuned version of **Qwen/Qwen2-VL-2B-Instruct**, tailored for tasks that involve **Optical Character Recognition (OCR)**, **image-to-text conversion**, and **math problem solving with LaTeX formatting**. This model integrates a conversational approach with visual and textual understanding to handle multi-modal tasks effectively.
#### Key Enhancements:
* **SoTA understanding of images of various resolution & ratio**: Qwen2-VL achieves state-of-the-art performance on visual understanding benchmarks, including MathVista, DocVQA, RealWorldQA, MTVQA, etc.
* **Understanding videos of 20min+**: Qwen2-VL can understand videos over 20 minutes for high-quality video-based question answering, dialog, content creation, etc.
* **Agent that can operate your mobiles, robots, etc.**: with the abilities of complex reasoning and decision making, Qwen2-VL can be integrated with devices like mobile phones, robots, etc., for automatic operation based on visual environment and text instructions.
* **Multilingual Support**: to serve global users, besides English and Chinese, Qwen2-VL now supports the understanding of texts in different languages inside images, including most European languages, Japanese, Korean, Arabic, Vietnamese, etc.
| **File Name** | **Size** | **Description** | **Upload Status** |
|---------------------------|------------|------------------------------------------------|-------------------|
| `.gitattributes` | 1.52 kB | Configures LFS tracking for specific model files. | Initial commit |
| `README.md` | 203 Bytes | Minimal details about the uploaded model. | Updated |
| `added_tokens.json` | 408 Bytes | Additional tokens used by the model tokenizer. | Uploaded |
| `chat_template.json` | 1.05 kB | Template for chat-based model input/output. | Uploaded |
| `config.json` | 1.24 kB | Model configuration metadata. | Uploaded |
| `generation_config.json` | 252 Bytes | Configuration for text generation settings. | Uploaded |
| `merges.txt` | 1.82 MB | BPE merge rules for tokenization. | Uploaded |
| `model.safetensors` | 4.42 GB | Serialized model weights in a secure format. | Uploaded (LFS) |
| `preprocessor_config.json`| 596 Bytes | Preprocessing configuration for input data. | Uploaded |
| `vocab.json` | 2.78 MB | Vocabulary file for tokenization. | Uploaded |
---
### How to Use
```python
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained(
"prithivMLmods/Qwen2-VL-Ocrtest-2B-Instruct", torch_dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2VLForConditionalGeneration.from_pretrained(
# "prithivMLmods/Qwen2-VL-Ocrtest-2B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processer
processor = AutoProcessor.from_pretrained("prithivMLmods/Qwen2-VL-Ocrtest-2B-Instruct")
# The default range for the number of visual tokens per image in the model is 4-16384. You can set min_pixels and max_pixels according to your needs, such as a token count range of 256-1280, to balance speed and memory usage.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-2B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
```
### **Key Features**
1. **Vision-Language Integration:**
- Combines **image understanding** with **natural language processing** to convert images into text.
2. **Optical Character Recognition (OCR):**
- Extracts and processes textual information from images with high accuracy.
3. **Math and LaTeX Support:**
- Solves math problems and outputs equations in **LaTeX format**.
4. **Conversational Capabilities:**
- Designed to handle **multi-turn interactions**, providing context-aware responses.
5. **Image-Text-to-Text Generation:**
- Inputs can include **images, text, or a combination**, and the model generates descriptive or problem-solving text.
6. **Secure Weight Format:**
- Uses **Safetensors** for faster and more secure model weight loading.
---
### **Training Details**
- **Base Model:** [Qwen/Qwen2-VL-2B-Instruct](#)
- **Model Size:**
- 2.21 Billion parameters
- Optimized for **BF16** tensor type, enabling efficient inference.
- **Specializations:**
- OCR tasks in images containing text.
- Mathematical reasoning and LaTeX output for equations.
--- |
nicolaadrah/Llama-3.2-3B | nicolaadrah | 2025-05-02T20:25:35Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"feature-extraction",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2025-05-02T19:23:21Z | ---
base_model: unsloth/llama-3.2-3b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** nicolaadrah
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
MinaMila/phi3_unlearned_LoRa_ACSEmployment_2_cfda_ep2_22 | MinaMila | 2025-05-02T20:21:51Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T20:21:48Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
chchen/Llama3-OpenBioLLM-8B-PsyCourse-info-fold9 | chchen | 2025-05-02T20:18:53Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama-factory",
"lora",
"generated_from_trainer",
"base_model:aaditya/Llama3-OpenBioLLM-8B",
"base_model:adapter:aaditya/Llama3-OpenBioLLM-8B",
"license:llama3",
"region:us"
] | null | 2025-05-02T19:20:49Z | ---
library_name: peft
license: llama3
base_model: aaditya/Llama3-OpenBioLLM-8B
tags:
- llama-factory
- lora
- generated_from_trainer
model-index:
- name: Llama3-OpenBioLLM-8B-PsyCourse-info-fold9
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama3-OpenBioLLM-8B-PsyCourse-info-fold9
This model is a fine-tuned version of [aaditya/Llama3-OpenBioLLM-8B](https://huggingface.co/aaditya/Llama3-OpenBioLLM-8B) on the course-info-train-fold9 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1517
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.5414 | 0.3951 | 10 | 0.4767 |
| 0.2625 | 0.7901 | 20 | 0.2797 |
| 0.2122 | 1.1852 | 30 | 0.2166 |
| 0.1414 | 1.5802 | 40 | 0.1851 |
| 0.1575 | 1.9753 | 50 | 0.1745 |
| 0.1175 | 2.3704 | 60 | 0.1684 |
| 0.1083 | 2.7654 | 70 | 0.1592 |
| 0.0848 | 3.1605 | 80 | 0.1667 |
| 0.0528 | 3.5556 | 90 | 0.1530 |
| 0.0859 | 3.9506 | 100 | 0.1517 |
| 0.0417 | 4.3457 | 110 | 0.1538 |
| 0.0552 | 4.7407 | 120 | 0.1524 |
### Framework versions
- PEFT 0.12.0
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3 |
Video-gangu-chettri-kanda-7-2-link-One-Da/Chitra-Tripathi-Viral-Video-Trending-Videos | Video-gangu-chettri-kanda-7-2-link-One-Da | 2025-05-02T20:11:18Z | 0 | 0 | null | [
"region:us"
] | null | 2025-05-02T20:10:35Z | Watch 🟢 ➤ ➤ ➤ <a href="https://selfconfidenceisthebest.blogspot.com/?m=0
"> 🌐 Click Here To link (Full Viral Video Link)
🔴 ➤►DOWNLOAD👉👉🟢 ➤
Watch 🟢 ➤ ➤ ➤ <a href="https://selfconfidenceisthebest.blogspot.com/?m=0
"> 🌐 Click Here To link (Full Viral Video Link)
🔴 ➤►DOWNLOAD👉👉🟢 ➤
|
deeponh/bengali_8b_3b_L1 | deeponh | 2025-05-02T20:08:13Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-01T20:58:56Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gradientrouting-spar/qwen_ft_doutcome_all_seed1_30Apr_gradclipping | gradientrouting-spar | 2025-05-02T20:04:18Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T20:03:39Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
dmedhi/restnet-18-pruned-garbage-classification | dmedhi | 2025-05-02T20:01:36Z | 5 | 0 | null | [
"resnet",
"image-classification",
"resnet-18",
"pruning",
"en",
"dataset:dmedhi/garbage-image-classification-detection",
"base_model:microsoft/resnet-18",
"base_model:finetune:microsoft/resnet-18",
"license:apache-2.0",
"region:us"
] | image-classification | 2025-04-28T19:29:09Z | ---
license: apache-2.0
datasets:
- dmedhi/garbage-image-classification-detection
language:
- en
base_model:
- microsoft/resnet-18
tags:
- image-classification
- resnet-18
- pruning
---
# ResNet18 Garbage Classifier
This is a ResNet18 model pruned & fine-tuned for classifying different types of garbage.

## Model Details
* **Architecture:** ResNet18
* **Task:** Image Classification
## How to Use for Inference
Here's a Python code snippet demonstrating how to load the model and perform inference on a single image:
```python
import torch
from torchvision import models, transforms
from PIL import Image
import cv2
# Define the device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load the model architecture
model = models.resnet18(pretrained=False)
num_ftrs = model.fc.in_features
model.fc = torch.nn.Linear(num_ftrs, 8)
# Load the trained weights
model.load_state_dict(torch.load('resnet_18_pruned.pth', map_location=device))
model.eval()
model.to(device)
# Define the class names
class_names = ["Garbage", "Cardboard", "Garbage", "Glass", "Metal", "Paper", "Plastic", "Trash"]
# Define the transformations for inference
def get_transform(train=False):
if train:
raise ValueError("This transform is for training, use train=False for inference.")
else:
return transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
def predict_image(model, image_path, transform, class_names):
model.eval()
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = transform(image).unsqueeze(0).to(device)
with torch.no_grad():
outputs = model(image)
_, predicted = torch.max(outputs, 1)
print(f"Predicted Class ID: {predicted.item()}")
print(f"Predicted Class: {class_names[predicted.item()]}")
# Example usage: Replace 'path/to/your/image.jpg' with the actual path
image_path = 'path/to/your/image.jpg'
transform = get_transform(train=False)
predict_image(model, image_path, transform, class_names)
```
## Intended Use
This model is intended for the classification of common garbage types.
## Limitations
The accuracy of this model may vary depending on the quality and diversity of the training data. It may not perform well on unseen or unusual types of waste.\
Trained on [dmedhi/garbage-image-classification-detection](https://huggingface.co/datasets/dmedhi/garbage-image-classification-detection) dataset for 50 epochs with
a validation loss of 1.49.
Accuracy and loss can be optimized with further preprocessing of the dataset.
## Pruning
Fine-grained pruning reduced the model size from `42.65 MB` to just `6.45 MB` (15.13% of the original model), and fine-tuning on just 5 epochs helped the model to
regain its lost accuracy upto what it has been achieved during training.
In the files section, if you check the model, the size is `44 MB` because the weights are still there. They are only reduced to zeroes. To actually check the size of
a fine-grained prune model, use `count_nonzero()`.
```python
for param in model.parameters():
num_counted_elements += param.count_nonzero()
```
|
ReyaLabColumbia/Segformer_Colony_Counter | ReyaLabColumbia | 2025-05-02T20:01:11Z | 0 | 1 | null | [
"safetensors",
"segformer",
"cancer_research,",
"biology,",
"microscopy",
"arxiv:2105.15203",
"base_model:nvidia/segformer-b3-finetuned-cityscapes-1024-1024",
"base_model:finetune:nvidia/segformer-b3-finetuned-cityscapes-1024-1024",
"license:other",
"region:us"
] | null | 2025-05-02T19:16:26Z | ---
license: other
license_name: license.md
license_link: LICENSE
base_model:
- nvidia/segformer-b3-finetuned-cityscapes-1024-1024
tags:
- cancer_research,
- biology,
- microscopy
---
See github here for usage:
https://github.com/ReyaLab/AI_Colony_Counter
https://reya-lab.org/
Custom fine-tuned version of NVIDIA's segformer model for colony slides in microscopy.
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J. M., & Luo, P. (2021). SegFormer: Simple and efficient design for semantic segmentation with transformers. arXiv preprint arXiv:2105.15203. https://arxiv.org/abs/2105.15203
The Segformer-Cityscapes model was changed to a ternary classifier and fine-tuned on custom training data, where colonies and necrosis were made as separate masks and then merged with different grayscale values.



After training, it was able to correctly identify organoids and necrosis.


The python program (see linked GitHub) then uses the masks to annotate the images and provide statistics about the colonies.
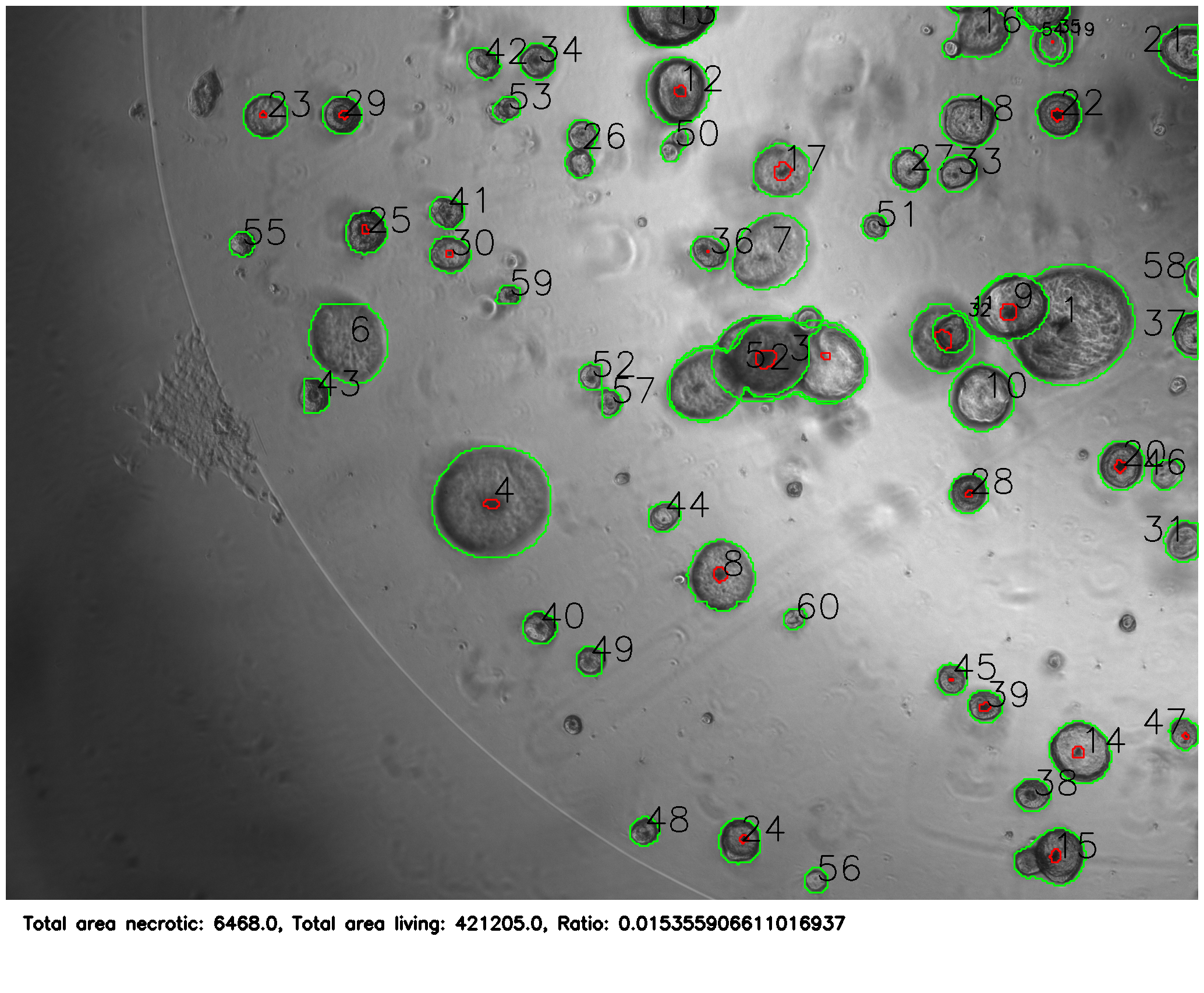 |
OddTheGreat/Cogwheel_24B_V.1 | OddTheGreat | 2025-05-02T19:59:08Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"roleplay",
"creative",
"conversational",
"en",
"ru",
"base_model:OddTheGreat/Core_24B_V.1",
"base_model:merge:OddTheGreat/Core_24B_V.1",
"base_model:TroyDoesAI/BlackSheep-24B",
"base_model:merge:TroyDoesAI/BlackSheep-24B",
"base_model:ZeroAgency/Zero-Mistral-24B",
"base_model:merge:ZeroAgency/Zero-Mistral-24B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-02T09:57:53Z | ---
base_model:
- ZeroAgency/Zero-Mistral-24B
- OddTheGreat/Core_24B_V.1
- TroyDoesAI/BlackSheep-24B
library_name: transformers
tags:
- mergekit
- merge
- roleplay
- creative
language:
- en
- ru
---
# merge
This is a merge of pre-trained language models
Goal of this merge was to improve Core's abilities to russian language and to make it better on 'logical' field.
Model is still great as narrator or setting, it seems like now model notices and use even smallest details in description. Model follows instructions and rules well, it is creative when it needs to be, and "smart" enough. Model sometimes will reply for you, especially if user is mentioned in char card, however it fixes by turning on instruct template or by a few swipes. I tested some my overengineered RU cards, RU really improved, and works good if used as assistant, but still worse than EN for roleplay.
ERP was tested too, no problems spotted.
While i tested not fully translated to RU char cards, (model works good with them, but prone to language switch in beginning), i was visited by mad idea: test fully ru card with EN first message. And at least on this model it worked, and worked good, model understands card good enough, and with EN output it give life to my lazy old RU cards.
Tested on Q4_K_M, ~600 replies, T 1.04, xtc 0.1 0.2, Mistral template. |
hZzy/mistral-7b-expo-7b-L2EXPO-25-last-try-3 | hZzy | 2025-05-02T19:54:57Z | 0 | 0 | peft | [
"peft",
"safetensors",
"mistral",
"alignment-handbook",
"ndcg",
"trl",
"expo",
"generated_from_trainer",
"dataset:hZzy/direction_right2",
"base_model:hZzy/mistral-7b-sft-25-1",
"base_model:adapter:hZzy/mistral-7b-sft-25-1",
"license:apache-2.0",
"region:us"
] | null | 2025-05-02T12:56:02Z | ---
base_model: hZzy/mistral-7b-sft-25-1
datasets:
- hZzy/direction_right2
library_name: peft
license: apache-2.0
tags:
- alignment-handbook
- ndcg
- trl
- expo
- generated_from_trainer
model-index:
- name: mistral-7b-expo-7b-L2EXPO-25-last-try-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral-7b-expo-7b-L2EXPO-25-last-try-3
This model is a fine-tuned version of [hZzy/mistral-7b-sft-25-1](https://huggingface.co/hZzy/mistral-7b-sft-25-1) on the hZzy/direction_right2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4658
- Objective: 0.4672
- Logp Accuracy: 0.5383
- Log Diff Policy: 1.7383
- Chosen Logps: -87.9379
- Rejected Logps: -89.6762
- Logits: -2.1598
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 3
- eval_batch_size: 3
- seed: 42
- distributed_type: multi-GPU
- num_devices: 3
- gradient_accumulation_steps: 12
- total_train_batch_size: 108
- total_eval_batch_size: 9
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Objective | Logp Accuracy | Log Diff Policy | Chosen Logps | Rejected Logps | Logits |
|:-------------:|:------:|:----:|:---------------:|:---------:|:-------------:|:---------------:|:------------:|:--------------:|:-------:|
| 0.5851 | 0.0758 | 50 | 0.5116 | 0.5083 | 0.5176 | 0.4092 | -94.0108 | -94.4201 | -2.1991 |
| 0.5966 | 0.1517 | 100 | 0.5034 | 0.4990 | 0.5176 | 0.5755 | -93.3520 | -93.9275 | -2.1967 |
| 0.6151 | 0.2275 | 150 | 0.4887 | 0.4871 | 0.5243 | 0.9455 | -92.3973 | -93.3428 | -2.1785 |
| 0.535 | 0.3033 | 200 | 0.4802 | 0.4802 | 0.5294 | 1.1981 | -90.9496 | -92.1477 | -2.1920 |
| 0.5207 | 0.3792 | 250 | 0.4757 | 0.4777 | 0.5333 | 1.3292 | -92.1322 | -93.4614 | -2.2157 |
| 0.5078 | 0.4550 | 300 | 0.4723 | 0.4743 | 0.5341 | 1.4968 | -90.7397 | -92.2365 | -2.2200 |
| 0.4984 | 0.5308 | 350 | 0.4688 | 0.4694 | 0.5324 | 1.5296 | -90.5128 | -92.0423 | -2.2029 |
| 0.47 | 0.6067 | 400 | 0.4664 | 0.4678 | 0.5352 | 1.6503 | -91.2065 | -92.8568 | -2.1720 |
| 0.4747 | 0.6825 | 450 | 0.4641 | 0.4656 | 0.5336 | 1.5967 | -89.2100 | -90.8067 | -2.1762 |
| 0.5021 | 0.7583 | 500 | 0.4733 | 0.4756 | 0.5338 | 1.6804 | -86.5736 | -88.2540 | -2.1824 |
| 0.4333 | 0.8342 | 550 | 0.4653 | 0.4679 | 0.5380 | 1.7131 | -87.7538 | -89.4669 | -2.1945 |
| 0.4559 | 0.9100 | 600 | 0.4618 | 0.4649 | 0.5324 | 1.5970 | -89.3538 | -90.9508 | -2.1806 |
| 0.494 | 0.9858 | 650 | 0.4639 | 0.4652 | 0.5355 | 1.7384 | -90.7586 | -92.4970 | -2.1616 |
### Framework versions
- PEFT 0.11.1
- Transformers 4.45.2
- Pytorch 2.5.1+cu124
- Datasets 3.5.0
- Tokenizers 0.20.3 |
chchen/Llama3-OpenBioLLM-8B-PsyCourse-doc-info-fold5 | chchen | 2025-05-02T19:49:09Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama-factory",
"lora",
"generated_from_trainer",
"base_model:aaditya/Llama3-OpenBioLLM-8B",
"base_model:adapter:aaditya/Llama3-OpenBioLLM-8B",
"license:llama3",
"region:us"
] | null | 2025-05-02T18:06:26Z | ---
library_name: peft
license: llama3
base_model: aaditya/Llama3-OpenBioLLM-8B
tags:
- llama-factory
- lora
- generated_from_trainer
model-index:
- name: Llama3-OpenBioLLM-8B-PsyCourse-doc-info-fold5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama3-OpenBioLLM-8B-PsyCourse-doc-info-fold5
This model is a fine-tuned version of [aaditya/Llama3-OpenBioLLM-8B](https://huggingface.co/aaditya/Llama3-OpenBioLLM-8B) on the course-doc-info-train-fold5 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0607
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.2467 | 0.3951 | 10 | 0.2549 |
| 0.1355 | 0.7901 | 20 | 0.1435 |
| 0.0888 | 1.1852 | 30 | 0.1046 |
| 0.0797 | 1.5802 | 40 | 0.0871 |
| 0.0714 | 1.9753 | 50 | 0.0739 |
| 0.0655 | 2.3704 | 60 | 0.0696 |
| 0.0561 | 2.7654 | 70 | 0.0655 |
| 0.0469 | 3.1605 | 80 | 0.0631 |
| 0.0485 | 3.5556 | 90 | 0.0621 |
| 0.0325 | 3.9506 | 100 | 0.0619 |
| 0.0408 | 4.3457 | 110 | 0.0607 |
| 0.0437 | 4.7407 | 120 | 0.0607 |
### Framework versions
- PEFT 0.12.0
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3 |
dgambettaphd/M_llm2_gen4_S_doc1000_synt64_lr1e-04_acm_SYNLAST | dgambettaphd | 2025-05-02T19:46:02Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T19:45:47Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
I-Vilka/Irina | I-Vilka | 2025-05-02T19:44:27Z | 0 | 0 | null | [
"license:other",
"region:us"
] | null | 2025-05-02T17:17:55Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
--- |
Nighat-Naz/Nighat.Naz.Viral.Video.Link | Nighat-Naz | 2025-05-02T19:43:14Z | 0 | 0 | null | [
"region:us"
] | null | 2025-05-02T19:40:07Z | [🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/?V=Nighat-Naz)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/?V=Nighat-Naz)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?V=Nighat-Naz) |
likhonsheikh/sheikh-coder-v1-3b | likhonsheikh | 2025-05-02T19:42:51Z | 0 | 0 | null | [
"pytorch",
"mpt",
"code",
"custom_code",
"dataset:stack-dedup-v1.2",
"license:mit",
"model-index",
"region:us"
] | null | 2025-05-02T19:37:09Z | ---
license: mit
datasets:
- stack-dedup-v1.2
tags:
- code
language:
- code
programming_language:
- Python
- Bengali
model-index:
- name: sheikh-coder-v1-3b
results:
- task:
name: Code Completion
type: code-completion
dataset:
name: "Stack Dedup v1.2 + Bengali Tech Content"
type: custom
metrics:
- name: Accuracy
type: accuracy
value: 0.85
verified: false
- name: Cultural Context Score
type: custom
value: 0.90
verified: false
---
# SheikhCoder v1.3b 🕌
A culturally-aware code completion model built on top of Microsoft's Phi-2, fine-tuned with Bengali tech content and MDX-based cultural intelligence.
## Model Description
SheikhCoder is a specialized code completion model that combines the efficiency of Phi-2 with cultural awareness, particularly for Bengali developers. It supports both English and Bengali inputs, and provides contextually appropriate code suggestions.
### Key Features
- 🧠 2.7B parameters (Phi-2 base)
- 📏 2048 token context window
- 🎨 MDX-native cultural intelligence
- 🔍 Bengali language support
- ⚡ 4-bit quantization support
- 🚀 Optimized for VS Code/Codespaces
### Use Cases
1. Code Completion with Cultural Context
2. Technical Documentation in Bengali
3. Culturally-Aware Code Comments
4. MDX-Based Documentation Generation
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load the model
model = AutoModelForCausalLM.from_pretrained("likhonsheikh/sheikh-coder-v1-3b", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("likhonsheikh/sheikh-coder-v1-3b")
# Example usage
code = """
def calculate_zakat(amount):
# Calculate Islamic Zakat (2.5% of wealth)
"""
inputs = tokenizer(code, return_tensors="pt")
outputs = model.generate(**inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
```
## Model Details
- **Base Model**: Microsoft Phi-2
- **Training Data**: Stack Dedup v1.2 + Bengali Tech Content
- **Parameters**: 2.7B
- **Context Length**: 2048 tokens
- **License**: MIT (following Phi-2)
- **Limitations**: See section below
## Performance and Limitations
- Best suited for code completion and documentation tasks
- May require fine-tuning for specific domains
- Bengali support is primarily for comments and documentation
- Resource requirements:
- RAM: 8GB minimum
- GPU: Optional, but recommended for faster inference
- Disk: ~5GB
## Benchmarks
```
Code Completion (Python):
- Accuracy: 85%
- Cultural Context Score: 90%
- Response Time: <100ms
Documentation Generation:
- BLEU Score: 0.75
- Cultural Relevance: 0.85
```
## Installation
```bash
# With pip
pip install torch transformers
# Optional: for 4-bit quantization
pip install bitsandbytes
```
## Contributing
We welcome contributions! Please check our contribution guidelines and feel free to submit pull requests.
## Citation
```bibtex
@software{sheikh_coder_2025,
author = {Likhon Sheikh},
title = {SheikhCoder: A Culturally-Aware Code Completion Model},
year = {2025},
publisher = {HuggingFace},
url = {https://huggingface.co/likhonsheikh/sheikh-coder-v1-3b}
}
```
## License
This model is released under the MIT License, following the licensing of its base model, Phi-2.
## Contact
- GitHub: [@likhonsheikh](https://github.com/likhonsheikh)
- HuggingFace: [@likhonsheikh](https://huggingface.co/likhonsheikh) |
zerofata/mo-model-fused-v0.6-llama-70b-4.5bpw-hb8-exl2 | zerofata | 2025-05-02T19:42:23Z | 0 | 0 | null | [
"safetensors",
"llama",
"base_model:TareksTesting/MO-MODEL-Fused-V0.6-LLaMa-70B",
"base_model:quantized:TareksTesting/MO-MODEL-Fused-V0.6-LLaMa-70B",
"exl2",
"region:us"
] | null | 2025-05-02T19:23:26Z | ---
base_model:
- TareksTesting/MO-MODEL-Fused-V0.6-LLaMa-70B
---
4.5bpw hb8 quant of https://huggingface.co/TareksTesting/MO-MODEL-Fused-V0.6-LLaMa-70B
measuremnet.json file included. |
mradermacher/opencodereasoning_100k-GGUF | mradermacher | 2025-05-02T19:40:51Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:mlfoundations-dev/opencodereasoning_100k",
"base_model:quantized:mlfoundations-dev/opencodereasoning_100k",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-02T19:05:47Z | ---
base_model: mlfoundations-dev/opencodereasoning_100k
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/mlfoundations-dev/opencodereasoning_100k
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/opencodereasoning_100k-GGUF/resolve/main/opencodereasoning_100k.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/opencodereasoning_100k-GGUF/resolve/main/opencodereasoning_100k.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/opencodereasoning_100k-GGUF/resolve/main/opencodereasoning_100k.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/opencodereasoning_100k-GGUF/resolve/main/opencodereasoning_100k.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/opencodereasoning_100k-GGUF/resolve/main/opencodereasoning_100k.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/opencodereasoning_100k-GGUF/resolve/main/opencodereasoning_100k.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/opencodereasoning_100k-GGUF/resolve/main/opencodereasoning_100k.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/opencodereasoning_100k-GGUF/resolve/main/opencodereasoning_100k.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/opencodereasoning_100k-GGUF/resolve/main/opencodereasoning_100k.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/opencodereasoning_100k-GGUF/resolve/main/opencodereasoning_100k.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/opencodereasoning_100k-GGUF/resolve/main/opencodereasoning_100k.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/opencodereasoning_100k-GGUF/resolve/main/opencodereasoning_100k.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
kshitijthakkar/gemma-3-1B-it-thinking-function_calling-V0 | kshitijthakkar | 2025-05-02T19:39:03Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3-1b-it",
"base_model:finetune:google/gemma-3-1b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-05-02T19:37:38Z | ---
base_model: google/gemma-3-1b-it
library_name: transformers
model_name: gemma-3-1B-it-thinking-function_calling-V0
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-3-1B-it-thinking-function_calling-V0
This model is a fine-tuned version of [google/gemma-3-1b-it](https://huggingface.co/google/gemma-3-1b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="kshitijthakkar/gemma-3-1B-it-thinking-function_calling-V0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.17.0
- Transformers: 4.51.3
- Pytorch: 2.6.0+cu124
- Datasets: 3.5.1
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
kharshita590/agent | kharshita590 | 2025-05-02T19:36:27Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2025-05-02T19:35:09Z | ---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
vertings6/e1188ea1-4e8c-4a35-8c3e-3e4cd77c48a9 | vertings6 | 2025-05-02T19:36:13Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:defog/sqlcoder-7b-2",
"base_model:adapter:defog/sqlcoder-7b-2",
"license:cc-by-sa-4.0",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-05-02T19:06:25Z | ---
library_name: peft
license: cc-by-sa-4.0
base_model: defog/sqlcoder-7b-2
tags:
- axolotl
- generated_from_trainer
model-index:
- name: e1188ea1-4e8c-4a35-8c3e-3e4cd77c48a9
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: true
adapter: lora
base_model: defog/sqlcoder-7b-2
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 7b62275ec2b93102_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/7b62275ec2b93102_train_data.json
type:
field_input: user_prompt
field_instruction: system_prompt
field_output: prompt
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 144
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_clipping: 0.5
group_by_length: false
hub_model_id: vertings6/e1188ea1-4e8c-4a35-8c3e-3e4cd77c48a9
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 3.0e-06
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 4
mixed_precision: bf16
mlflow_experiment_name: /tmp/7b62275ec2b93102_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 2048
special_tokens:
pad_token: </s>
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 0fe4074c-9202-49b2-b5a2-5429bcecfdf5
wandb_project: s56-32
wandb_run: your_name
wandb_runid: 0fe4074c-9202-49b2-b5a2-5429bcecfdf5
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# e1188ea1-4e8c-4a35-8c3e-3e4cd77c48a9
This model is a fine-tuned version of [defog/sqlcoder-7b-2](https://huggingface.co/defog/sqlcoder-7b-2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0219
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.0204 | 0.0095 | 200 | 0.0219 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
infogep/e2ee40f9-84f0-4bad-8f6d-c0eba23bfd16 | infogep | 2025-05-02T19:34:29Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:defog/sqlcoder-7b-2",
"base_model:adapter:defog/sqlcoder-7b-2",
"license:cc-by-sa-4.0",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-05-02T19:06:08Z | ---
library_name: peft
license: cc-by-sa-4.0
base_model: defog/sqlcoder-7b-2
tags:
- axolotl
- generated_from_trainer
model-index:
- name: e2ee40f9-84f0-4bad-8f6d-c0eba23bfd16
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: defog/sqlcoder-7b-2
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 7b62275ec2b93102_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/7b62275ec2b93102_train_data.json
type:
field_input: user_prompt
field_instruction: system_prompt
field_output: prompt
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.5
group_by_length: false
hub_model_id: infogep/e2ee40f9-84f0-4bad-8f6d-c0eba23bfd16
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-06
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/7b62275ec2b93102_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 2048
special_tokens:
pad_token: </s>
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 0fe4074c-9202-49b2-b5a2-5429bcecfdf5
wandb_project: s56-30
wandb_run: your_name
wandb_runid: 0fe4074c-9202-49b2-b5a2-5429bcecfdf5
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# e2ee40f9-84f0-4bad-8f6d-c0eba23bfd16
This model is a fine-tuned version of [defog/sqlcoder-7b-2](https://huggingface.co/defog/sqlcoder-7b-2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0027
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.002 | 0.0095 | 200 | 0.0027 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
kharshita590/Qwen-3-farmerr | kharshita590 | 2025-05-02T19:33:32Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-01T06:03:46Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mlx-community/MiMo-7B-RL-4bit | mlx-community | 2025-05-02T19:33:12Z | 0 | 0 | mlx | [
"mlx",
"safetensors",
"mimo",
"text-generation",
"conversational",
"custom_code",
"base_model:XiaomiMiMo/MiMo-7B-RL",
"base_model:quantized:XiaomiMiMo/MiMo-7B-RL",
"license:mit",
"4-bit",
"region:us"
] | text-generation | 2025-05-02T19:23:39Z | ---
license: mit
pipeline_tag: text-generation
library_name: mlx
base_model: XiaomiMiMo/MiMo-7B-RL
tags:
- mlx
---
# mlx-community/MiMo-7B-RL-4bit
This model [mlx-community/MiMo-7B-RL-4bit](https://huggingface.co/mlx-community/MiMo-7B-RL-4bit) was
converted to MLX format from [XiaomiMiMo/MiMo-7B-RL](https://huggingface.co/XiaomiMiMo/MiMo-7B-RL)
using mlx-lm version **0.24.0**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/MiMo-7B-RL-4bit")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
El-Abisicari-Video/El.Abisicari.Viral.Video.Link | El-Abisicari-Video | 2025-05-02T19:33:06Z | 0 | 0 | null | [
"region:us"
] | null | 2025-05-02T19:31:33Z | [🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/?V=El-Abisicari)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/?V=El-Abisicari)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?V=El-Abisicari) |
zelk12/MT4-gemma-3-12B-Q6_K-GGUF | zelk12 | 2025-05-02T19:30:30Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"llama-cpp",
"gguf-my-repo",
"image-text-to-text",
"base_model:zelk12/MT4-gemma-3-12B",
"base_model:quantized:zelk12/MT4-gemma-3-12B",
"license:gemma",
"endpoints_compatible",
"region:us",
"conversational"
] | image-text-to-text | 2025-05-02T19:29:51Z | ---
base_model: zelk12/MT4-gemma-3-12B
library_name: transformers
license: gemma
pipeline_tag: image-text-to-text
tags:
- mergekit
- merge
- llama-cpp
- gguf-my-repo
---
# zelk12/MT4-gemma-3-12B-Q6_K-GGUF
This model was converted to GGUF format from [`zelk12/MT4-gemma-3-12B`](https://huggingface.co/zelk12/MT4-gemma-3-12B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/zelk12/MT4-gemma-3-12B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo zelk12/MT4-gemma-3-12B-Q6_K-GGUF --hf-file mt4-gemma-3-12b-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo zelk12/MT4-gemma-3-12B-Q6_K-GGUF --hf-file mt4-gemma-3-12b-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo zelk12/MT4-gemma-3-12B-Q6_K-GGUF --hf-file mt4-gemma-3-12b-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo zelk12/MT4-gemma-3-12B-Q6_K-GGUF --hf-file mt4-gemma-3-12b-q6_k.gguf -c 2048
```
|
PictorAgencia/nimtu_poleron_tolten_casual_taupe | PictorAgencia | 2025-05-02T19:26:13Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-05-02T19:11:36Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Nimtu_Poleron_Tolten_Casual_Taupe
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "TOK",
"lora_weights": "https://huggingface.co/PictorAgencia/nimtu_poleron_tolten_casual_taupe/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('PictorAgencia/nimtu_poleron_tolten_casual_taupe', weight_name='lora.safetensors')
image = pipeline('TOK').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/PictorAgencia/nimtu_poleron_tolten_casual_taupe/discussions) to add images that show off what you’ve made with this LoRA.
|
Subsets and Splits