
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
sequence | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
TOMFORD79/E10 | TOMFORD79 | 2025-04-27T09:50:57Z | 0 | 0 | null | [
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] | any-to-any | 2025-04-27T04:50:30Z | ---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
MayBashendy/arabic_SDP_1_multiclass_multilingual_e5_small_lr3e-05_targ1_dev1345678 | MayBashendy | 2025-04-27T09:45:17Z | 0 | 0 | null | [
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"region:us"
] | null | 2025-04-27T09:45:01Z | ---
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Library: [More Information Needed]
- Docs: [More Information Needed] |
lew96123/gemma-3-finetune-1000step-code_search_net | lew96123 | 2025-04-27T09:44:27Z | 0 | 0 | peft | [
"peft",
"safetensors",
"gguf",
"gemma3_text",
"arxiv:1910.09700",
"base_model:unsloth/gemma-3-1b-it-unsloth-bnb-4bit",
"base_model:adapter:unsloth/gemma-3-1b-it-unsloth-bnb-4bit",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-04-27T09:38:01Z | ---
base_model: unsloth/gemma-3-1b-it-unsloth-bnb-4bit
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.14.0 |
atsuki-yamaguchi/Qwen2.5-7B-Instruct-si-madlad-mean-slerp0305-emb-special | atsuki-yamaguchi | 2025-04-27T09:39:04Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"si",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-30T01:04:08Z |
---
license: apache-2.0
datasets:
- allenai/MADLAD-400
language:
- si
base_model:
- Qwen/Qwen2.5-7B-Instruct
- atsuki-yamaguchi/Qwen2.5-7B-Instruct-si-madlad-mean-tuned
library_name: transformers
---
# Qwen2.5 7B Instruct for Sinhala: ElChat
This model is built on top of Qwen2.5 7B Instruct adapted for Sinhala using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K. The model was trained using the ElChat method.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
* **Post-processing**: The model was post-processed using the ElChat method.
## Model Description
- **Language:** Sinhala
- **License:** Apache 2.0
- **Fine-tuned from model:** Qwen/Qwen2.5-7B-Instruct
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-Instruct-si-madlad-mean-slerp0305-emb-special"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-Instruct-si-madlad-mean-slerp0305-emb-special"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
TOMFORD79/E9 | TOMFORD79 | 2025-04-27T09:38:30Z | 0 | 0 | null | [
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] | any-to-any | 2025-04-27T04:50:21Z | ---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
atsuki-yamaguchi/Qwen2.5-7B-Instruct-gu-madlad-mean-tuned | atsuki-yamaguchi | 2025-04-27T09:38:20Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"gu",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-22T18:51:31Z |
---
license: apache-2.0
datasets:
- allenai/MADLAD-400
language:
- gu
base_model:
- Qwen/Qwen2.5-7B-Instruct
library_name: transformers
---
# Qwen2.5 7B Instruct for Gujarati: Vocabulary expansion
This model is built on top of Qwen2.5 7B Instruct adapted for Gujarati using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
## Model Description
- **Language:** Gujarati
- **License:** Apache 2.0
- **Fine-tuned from model:** Qwen/Qwen2.5-7B-Instruct
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-Instruct-gu-madlad-mean-tuned"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-Instruct-gu-madlad-mean-tuned"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Qwen2.5-7B-Instruct-my-madlad-mean-slerp0305-emb-special | atsuki-yamaguchi | 2025-04-27T09:38:09Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"my",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-30T00:46:11Z |
---
license: apache-2.0
datasets:
- allenai/MADLAD-400
language:
- my
base_model:
- Qwen/Qwen2.5-7B-Instruct
- atsuki-yamaguchi/Qwen2.5-7B-Instruct-my-madlad-mean-tuned
library_name: transformers
---
# Qwen2.5 7B Instruct for Burmese: ElChat
This model is built on top of Qwen2.5 7B Instruct adapted for Burmese using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K. The model was trained using the ElChat method.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
* **Post-processing**: The model was post-processed using the ElChat method.
## Model Description
- **Language:** Burmese
- **License:** Apache 2.0
- **Fine-tuned from model:** Qwen/Qwen2.5-7B-Instruct
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-Instruct-my-madlad-mean-slerp0305-emb-special"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-Instruct-my-madlad-mean-slerp0305-emb-special"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Qwen2.5-7B-Instruct-bn-madlad-mean-tuned | atsuki-yamaguchi | 2025-04-27T09:37:44Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"bn",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-21T19:48:47Z |
---
license: apache-2.0
datasets:
- allenai/MADLAD-400
language:
- bn
base_model:
- Qwen/Qwen2.5-7B-Instruct
library_name: transformers
---
# Qwen2.5 7B Instruct for Bengali: Vocabulary expansion
This model is built on top of Qwen2.5 7B Instruct adapted for Bengali using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
## Model Description
- **Language:** Bengali
- **License:** Apache 2.0
- **Fine-tuned from model:** Qwen/Qwen2.5-7B-Instruct
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-Instruct-bn-madlad-mean-tuned"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-Instruct-bn-madlad-mean-tuned"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
mlfoundations-dev/c1_code_10d_16s | mlfoundations-dev | 2025-04-27T09:36:57Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-26T18:05:47Z | ---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: c1_code_10d_16s
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# c1_code_10d_16s
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on the mlfoundations-dev/c1_code_10d_16s dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 16
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- total_eval_batch_size: 128
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.46.1
- Pytorch 2.5.1
- Datasets 3.0.2
- Tokenizers 0.20.3
|
atsuki-yamaguchi/Llama-3.1-8B-Instruct-te-madlad-mean-tuned | atsuki-yamaguchi | 2025-04-27T09:36:47Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"te",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:finetune:meta-llama/Llama-3.1-8B-Instruct",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-22T03:35:37Z |
---
license: llama3.1
datasets:
- allenai/MADLAD-400
language:
- te
base_model:
- meta-llama/Llama-3.1-8B-Instruct
library_name: transformers
---
# Llama 3.1 8B Instruct for Telugu: Vocabulary expansion
This model is built on top of Llama 3.1 8B Instruct adapted for Telugu using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
## Model Description
- **Language:** Telugu
- **License:** Llama 3.1 Community License Agreement
- **Fine-tuned from model:** meta-llama/Llama-3.1-8B-Instruct
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-te-madlad-mean-tuned"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-te-madlad-mean-tuned"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Llama-3.1-8B-Instruct-si-madlad-mean-slerp0305-emb | atsuki-yamaguchi | 2025-04-27T09:36:28Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"si",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:atsuki-yamaguchi/Llama-3.1-8B-Instruct-si-madlad-mean-tuned",
"base_model:finetune:atsuki-yamaguchi/Llama-3.1-8B-Instruct-si-madlad-mean-tuned",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-30T20:22:45Z |
---
license: llama3.1
datasets:
- allenai/MADLAD-400
language:
- si
base_model:
- meta-llama/Llama-3.1-8B-Instruct
- atsuki-yamaguchi/Llama-3.1-8B-Instruct-si-madlad-mean-tuned
library_name: transformers
---
# Llama 3.1 8B Instruct for Sinhala: ElChat (No Copy)
This model is built on top of Llama 3.1 8B Instruct adapted for Sinhala using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K. The model was trained using the ElChat method without special token weight copying.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
* **Post-processing**: The model was post-processed using the ElChat method without special token weight copying.
## Model Description
- **Language:** Sinhala
- **License:** Llama 3.1 Community License Agreement
- **Fine-tuned from model:** meta-llama/Llama-3.1-8B-Instruct
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-si-madlad-mean-slerp0305-emb"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-si-madlad-mean-slerp0305-emb"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Llama-3.1-8B-Instruct-si-madlad-mean-swap-emb-special | atsuki-yamaguchi | 2025-04-27T09:36:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"si",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:atsuki-yamaguchi/Llama-3.1-8B-Instruct-si-madlad-mean-tuned",
"base_model:finetune:atsuki-yamaguchi/Llama-3.1-8B-Instruct-si-madlad-mean-tuned",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-29T10:08:58Z |
---
license: llama3.1
datasets:
- allenai/MADLAD-400
language:
- si
base_model:
- meta-llama/Llama-3.1-8B-Instruct
- atsuki-yamaguchi/Llama-3.1-8B-Instruct-si-madlad-mean-tuned
library_name: transformers
---
# Llama 3.1 8B Instruct for Sinhala: ElChat (No Merge)
This model is built on top of Llama 3.1 8B Instruct adapted for Sinhala using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K. The model was trained using the ElChat method without model merging.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
* **Post-processing**: The model was post-processed using the ElChat method without model merging.
## Model Description
- **Language:** Sinhala
- **License:** Llama 3.1 Community License Agreement
- **Fine-tuned from model:** meta-llama/Llama-3.1-8B-Instruct
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-si-madlad-mean-swap-emb-special"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-si-madlad-mean-swap-emb-special"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-trans0305-emb-special | atsuki-yamaguchi | 2025-04-27T09:35:20Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"gu",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-tuned",
"base_model:finetune:atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-tuned",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-30T02:03:00Z |
---
license: llama3.1
datasets:
- allenai/MADLAD-400
language:
- gu
base_model:
- meta-llama/Llama-3.1-8B-Instruct
- atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-tuned
library_name: transformers
---
# Llama 3.1 8B Instruct for Gujarati: ElChat (Linear merging)
This model is built on top of Llama 3.1 8B Instruct adapted for Gujarati using 500M target language tokens sampled from MADLAD-400.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
* **Post-processing**: The model was post-processed using the ElChat method with linear merging instead of SLERP.
## Model Description
- **Language:** Gujarati
- **License:** Llama 3.1 Community License Agreement
- **Fine-tuned from model:** meta-llama/Llama-3.1-8B-Instruct
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-trans0305-emb-special"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-trans0305-emb-special"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-slerp0305-emb-special | atsuki-yamaguchi | 2025-04-27T09:34:58Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"gu",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-tuned",
"base_model:finetune:atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-tuned",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-30T00:21:46Z |
---
license: llama3.1
datasets:
- allenai/MADLAD-400
language:
- gu
base_model:
- meta-llama/Llama-3.1-8B-Instruct
- atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-tuned
library_name: transformers
---
# Llama 3.1 8B Instruct for Gujarati: ElChat
This model is built on top of Llama 3.1 8B Instruct adapted for Gujarati using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K. The model was trained using the ElChat method.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
* **Post-processing**: The model was post-processed using the ElChat method.
## Model Description
- **Language:** Gujarati
- **License:** Llama 3.1 Community License Agreement
- **Fine-tuned from model:** meta-llama/Llama-3.1-8B-Instruct
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-slerp0305-emb-special"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-slerp0305-emb-special"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-tuned | atsuki-yamaguchi | 2025-04-27T09:34:52Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"gu",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:finetune:meta-llama/Llama-3.1-8B-Instruct",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-22T01:18:40Z |
---
license: llama3.1
datasets:
- allenai/MADLAD-400
language:
- gu
base_model:
- meta-llama/Llama-3.1-8B-Instruct
library_name: transformers
---
# Llama 3.1 8B Instruct for Gujarati: Vocabulary expansion
This model is built on top of Llama 3.1 8B Instruct adapted for Gujarati using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
## Model Description
- **Language:** Gujarati
- **License:** Llama 3.1 Community License Agreement
- **Fine-tuned from model:** meta-llama/Llama-3.1-8B-Instruct
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-tuned"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-gu-madlad-mean-tuned"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Llama-3.1-8B-Instruct-my-madlad-mean-slerp0305-emb | atsuki-yamaguchi | 2025-04-27T09:34:33Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"my",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:atsuki-yamaguchi/Llama-3.1-8B-Instruct-my-madlad-mean-tuned",
"base_model:finetune:atsuki-yamaguchi/Llama-3.1-8B-Instruct-my-madlad-mean-tuned",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-30T20:53:08Z |
---
license: llama3.1
datasets:
- allenai/MADLAD-400
language:
- my
base_model:
- meta-llama/Llama-3.1-8B-Instruct
- atsuki-yamaguchi/Llama-3.1-8B-Instruct-my-madlad-mean-tuned
library_name: transformers
---
# Llama 3.1 8B Instruct for Burmese: ElChat (No Copy)
This model is built on top of Llama 3.1 8B Instruct adapted for Burmese using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K. The model was trained using the ElChat method without special token weight copying.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
* **Post-processing**: The model was post-processed using the ElChat method without special token weight copying.
## Model Description
- **Language:** Burmese
- **License:** Llama 3.1 Community License Agreement
- **Fine-tuned from model:** meta-llama/Llama-3.1-8B-Instruct
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-my-madlad-mean-slerp0305-emb"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-my-madlad-mean-slerp0305-emb"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Llama-3.1-8B-Instruct-am-madlad-mean-swap-emb-special | atsuki-yamaguchi | 2025-04-27T09:33:11Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"am",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:atsuki-yamaguchi/Llama-3.1-8B-Instruct-am-madlad-mean-tuned",
"base_model:finetune:atsuki-yamaguchi/Llama-3.1-8B-Instruct-am-madlad-mean-tuned",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-29T10:22:24Z |
---
license: llama3.1
datasets:
- allenai/MADLAD-400
language:
- am
base_model:
- meta-llama/Llama-3.1-8B-Instruct
- atsuki-yamaguchi/Llama-3.1-8B-Instruct-am-madlad-mean-tuned
library_name: transformers
---
# Llama 3.1 8B Instruct for Amharic: ElChat (No Merge)
This model is built on top of Llama 3.1 8B Instruct adapted for Amharic using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K. The model was trained using the ElChat method without model merging.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
* **Post-processing**: The model was post-processed using the ElChat method without model merging.
## Model Description
- **Language:** Amharic
- **License:** Llama 3.1 Community License Agreement
- **Fine-tuned from model:** meta-llama/Llama-3.1-8B-Instruct
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-am-madlad-mean-swap-emb-special"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-am-madlad-mean-swap-emb-special"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Llama-3.1-8B-Instruct-am-lapt-madlad | atsuki-yamaguchi | 2025-04-27T09:32:51Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"am",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:finetune:meta-llama/Llama-3.1-8B-Instruct",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-22T18:21:55Z |
---
license: llama3.1
datasets:
- allenai/MADLAD-400
language:
- am
base_model:
- meta-llama/Llama-3.1-8B-Instruct
library_name: transformers
---
# Llama 3.1 8B Instruct for Amharic: Continual pre-training only
This model is built on top of Llama 3.1 8B Instruct adapted for Amharic using 500M target language tokens sampled from MADLAD-400.
## Model Details
* **Vocabulary**: This model has no additional target vocabulary. It retains the original vocabulary of Llama 3.1 8B Instruct.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
## Model Description
- **Language:** Amharic
- **License:** Llama 3.1 Community License Agreement
- **Fine-tuned from model:** meta-llama/Llama-3.1-8B-Instruct
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-Instruct-am-lapt-madlad"
)
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Llama-3.1-8B-Instruct"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
JackyBond/jacky-self | JackyBond | 2025-04-27T09:31:02Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-04-27T09:10:51Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: JACKY
---
# Jacky Self
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `JACKY` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "JACKY",
"lora_weights": "https://huggingface.co/JackyBond/jacky-self/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('JackyBond/jacky-self', weight_name='lora.safetensors')
image = pipeline('JACKY').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/JackyBond/jacky-self/discussions) to add images that show off what you’ve made with this LoRA.
|
youjimeen/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-shiny_swift_elephant | youjimeen | 2025-04-27T09:30:36Z | 9 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am shiny swift elephant",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-16T06:26:18Z | ---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-shiny_swift_elephant
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am shiny swift elephant
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-shiny_swift_elephant
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="youjimeen/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-shiny_swift_elephant", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.5.1
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
atsuki-yamaguchi/Qwen2.5-7B-te-lapt-madlad | atsuki-yamaguchi | 2025-04-27T09:28:49Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"te",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:Qwen/Qwen2.5-7B",
"base_model:finetune:Qwen/Qwen2.5-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-23T10:56:33Z |
---
license: apache-2.0
datasets:
- allenai/MADLAD-400
language:
- te
base_model:
- Qwen/Qwen2.5-7B
library_name: transformers
---
# Qwen2.5 7B for Telugu: Continual pre-training only
This model is built on top of Qwen2.5 7B adapted for Telugu using 500M target language tokens sampled from MADLAD-400.
## Model Details
* **Vocabulary**: This model has no additional target vocabulary. It retains the original vocabulary of Qwen2.5 7B.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
## Model Description
- **Language:** Telugu
- **License:** Apache 2.0
- **Fine-tuned from model:** Qwen/Qwen2.5-7B
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-te-lapt-madlad"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-te-lapt-madlad"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
grapevine-AI/qwen2.5-bakeneko-32b-instruct-v2-gguf | grapevine-AI | 2025-04-27T09:28:44Z | 0 | 0 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-04-27T08:56:14Z | ---
license: apache-2.0
---
# What is this?
rinna社のqwen2.5-bakeneko-32b-instructが、qwq-bakeneko-32bベクターとDeepSeek R1の蒸留でパワーアップ!<br>
[v2にアップデートされたqwen2.5-bakeneko-32b-instruct](https://huggingface.co/rinna/qwen2.5-bakeneko-32b-instruct-v2)をGGUFフォーマットに変換したものです。
# imatrix dataset
日本語能力を重視し、日本語が多量に含まれる[TFMC/imatrix-dataset-for-japanese-llm](https://huggingface.co/datasets/TFMC/imatrix-dataset-for-japanese-llm)データセットを使用しました。
# Chat template
```
<|im_start|>system
ここにSystem Promptを書きます。<|im_end|>
<|im_start|>user
ここにMessageを書きます。<|im_end|>
<|im_start|>assistant
```
# Quants
Q4_K_M量子化後のベンチマークスコア(Elyza_tasks 100)をまとめておきます。
|採点者|スコア|
|---|---|
|gemini-1.5-flash-001|3.96|
|gemini-1.5-flash-002|4.18|
# Environment
Windows版llama.cpp-b4739およびllama.cpp-b5074同時リリースのconvert-hf-to-gguf.pyを使用して量子化作業を実施しました。
# License
Apache 2.0
# Developer
Alibaba Cloud & DeepSeek (深度求索) & rinna |
atsuki-yamaguchi/Qwen2.5-7B-my-lapt-madlad | atsuki-yamaguchi | 2025-04-27T09:26:57Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"my",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:Qwen/Qwen2.5-7B",
"base_model:finetune:Qwen/Qwen2.5-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-23T11:28:58Z |
---
license: apache-2.0
datasets:
- allenai/MADLAD-400
language:
- my
base_model:
- Qwen/Qwen2.5-7B
library_name: transformers
---
# Qwen2.5 7B for Burmese: Continual pre-training only
This model is built on top of Qwen2.5 7B adapted for Burmese using 500M target language tokens sampled from MADLAD-400.
## Model Details
* **Vocabulary**: This model has no additional target vocabulary. It retains the original vocabulary of Qwen2.5 7B.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
## Model Description
- **Language:** Burmese
- **License:** Apache 2.0
- **Fine-tuned from model:** Qwen/Qwen2.5-7B
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-my-lapt-madlad"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-my-lapt-madlad"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Qwen2.5-7B-am-madlad-mean-tuned | atsuki-yamaguchi | 2025-04-27T09:26:28Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"am",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:Qwen/Qwen2.5-7B",
"base_model:finetune:Qwen/Qwen2.5-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-24T14:56:03Z |
---
license: apache-2.0
datasets:
- allenai/MADLAD-400
language:
- am
base_model:
- Qwen/Qwen2.5-7B
library_name: transformers
---
# Qwen2.5 7B for Amharic: Vocabulary expansion
This model is built on top of Qwen2.5 7B adapted for Amharic using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
## Model Description
- **Language:** Amharic
- **License:** Apache 2.0
- **Fine-tuned from model:** Qwen/Qwen2.5-7B
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-am-madlad-mean-tuned"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-am-madlad-mean-tuned"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Qwen2.5-7B-am-lapt-madlad | atsuki-yamaguchi | 2025-04-27T09:26:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"am",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:Qwen/Qwen2.5-7B",
"base_model:finetune:Qwen/Qwen2.5-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-23T11:13:33Z |
---
license: apache-2.0
datasets:
- allenai/MADLAD-400
language:
- am
base_model:
- Qwen/Qwen2.5-7B
library_name: transformers
---
# Qwen2.5 7B for Amharic: Continual pre-training only
This model is built on top of Qwen2.5 7B adapted for Amharic using 500M target language tokens sampled from MADLAD-400.
## Model Details
* **Vocabulary**: This model has no additional target vocabulary. It retains the original vocabulary of Qwen2.5 7B.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
## Model Description
- **Language:** Amharic
- **License:** Apache 2.0
- **Fine-tuned from model:** Qwen/Qwen2.5-7B
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-am-lapt-madlad"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Qwen2.5-7B-am-lapt-madlad"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Llama-3.1-8B-si-madlad-mean-cv | atsuki-yamaguchi | 2025-04-27T09:25:41Z | 1 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"si",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:atsuki-yamaguchi/Llama-3.1-8B-si-madlad-mean-tuned",
"base_model:finetune:atsuki-yamaguchi/Llama-3.1-8B-si-madlad-mean-tuned",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-02-19T17:01:54Z |
---
license: llama3.1
datasets:
- allenai/MADLAD-400
language:
- si
base_model:
- meta-llama/Llama-3.1-8B
- meta-llama/Llama-3.1-8B-Instruct
- atsuki-yamaguchi/Llama-3.1-8B-si-madlad-mean-tuned
library_name: transformers
---
# Llama 3.1 8B for Sinhala: Chat Vector
This model is built on top of Llama 3.1 8B adapted for Sinhala using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K. Chat vector was added to the model after continual pre-training.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
* **Post-processing**: The model was post-processed using the Chat Vector method.
## Model Description
- **Language:** Sinhala
- **License:** Llama 3.1 Community License Agreement
- **Fine-tuned from model:** meta-llama/Llama-3.1-8B
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-si-madlad-mean-cv"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-si-madlad-mean-cv"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Llama-3.1-8B-gu-lapt-madlad | atsuki-yamaguchi | 2025-04-27T09:25:10Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"gu",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:finetune:meta-llama/Llama-3.1-8B",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-11-25T23:00:21Z |
---
license: llama3.1
datasets:
- allenai/MADLAD-400
language:
- gu
base_model:
- meta-llama/Llama-3.1-8B
library_name: transformers
---
# Llama 3.1 8B for Gujarati: Continual pre-training only
This model is built on top of Llama 3.1 8B adapted for Gujarati using 500M target language tokens sampled from MADLAD-400.
## Model Details
* **Vocabulary**: This model has no additional target vocabulary. It retains the original vocabulary of Llama 3.1 8B.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
## Model Description
- **Language:** Gujarati
- **License:** Llama 3.1 Community License Agreement
- **Fine-tuned from model:** meta-llama/Llama-3.1-8B
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-gu-lapt-madlad"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-gu-lapt-madlad"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
atsuki-yamaguchi/Llama-3.1-8B-bn-madlad-mean-cv | atsuki-yamaguchi | 2025-04-27T09:24:26Z | 1 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"bn",
"dataset:allenai/MADLAD-400",
"arxiv:2412.11704",
"base_model:atsuki-yamaguchi/Llama-3.1-8B-bn-madlad-mean-tuned",
"base_model:finetune:atsuki-yamaguchi/Llama-3.1-8B-bn-madlad-mean-tuned",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-02-19T16:45:45Z |
---
license: llama3.1
datasets:
- allenai/MADLAD-400
language:
- bn
base_model:
- meta-llama/Llama-3.1-8B
- meta-llama/Llama-3.1-8B-Instruct
- atsuki-yamaguchi/Llama-3.1-8B-bn-madlad-mean-tuned
library_name: transformers
---
# Llama 3.1 8B for Bengali: Chat Vector
This model is built on top of Llama 3.1 8B adapted for Bengali using 500M target language tokens sampled from MADLAD-400. It has an additional target vocabulary of 10K. Chat vector was added to the model after continual pre-training.
## Model Details
* **Vocabulary**: This model has an additional target vocabulary of 10K.
* **Target vocabulary initialization**: The target weights of the embedding and LM head were initialized using mean initialization.
* **Training**: This model was continually pre-trained on 500M target language tokens sampled from MADLAD-400.
* **Post-processing**: The model was post-processed using the Chat Vector method.
## Model Description
- **Language:** Bengali
- **License:** Llama 3.1 Community License Agreement
- **Fine-tuned from model:** meta-llama/Llama-3.1-8B
## Model Sources
- **Repository:** https://github.com/gucci-j/chat-cve
- **Paper:** https://arxiv.org/abs/2412.11704
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-bn-madlad-mean-cv"
)
tokenizer = AutoTokenizer.from_pretrained(
"atsuki-yamaguchi/Llama-3.1-8B-bn-madlad-mean-cv"
)
```
## Citation
```
@misc{yamaguchi2024vocabularyexpansionchatmodels,
title={{ElChat}: Adapting Chat Language Models Using Only Target Unlabeled Language Data},
author={Atsuki Yamaguchi and Terufumi Morishita and Aline Villavicencio and Nikolaos Aletras},
year={2024},
eprint={2412.11704},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11704},
}
```
|
ail-sa/andrea_test | ail-sa | 2025-04-27T09:23:53Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-04-27T07:17:37Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: Sidf
---
# Andrea_Test
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `Sidf` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "Sidf",
"lora_weights": "https://huggingface.co/ail-sa/andrea_test/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('ail-sa/andrea_test', weight_name='lora.safetensors')
image = pipeline('Sidf').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/ail-sa/andrea_test/discussions) to add images that show off what you’ve made with this LoRA.
|
genki10/BERT_V8_sp10_lw40_ex100_lo50_k10_k10_fold0 | genki10 | 2025-04-27T09:23:52Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-04-27T09:05:52Z | ---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_V8_sp10_lw40_ex100_lo50_k10_k10_fold0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_V8_sp10_lw40_ex100_lo50_k10_k10_fold0
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5692
- Qwk: 0.5166
- Mse: 0.5692
- Rmse: 0.7544
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| No log | 1.0 | 5 | 6.9847 | 0.0 | 6.9847 | 2.6429 |
| No log | 2.0 | 10 | 4.7165 | 0.0115 | 4.7165 | 2.1717 |
| No log | 3.0 | 15 | 2.5808 | 0.0050 | 2.5808 | 1.6065 |
| No log | 4.0 | 20 | 1.3407 | 0.0316 | 1.3407 | 1.1579 |
| No log | 5.0 | 25 | 0.8195 | 0.2555 | 0.8195 | 0.9052 |
| No log | 6.0 | 30 | 0.6614 | 0.2148 | 0.6614 | 0.8133 |
| No log | 7.0 | 35 | 0.6437 | 0.4862 | 0.6437 | 0.8023 |
| No log | 8.0 | 40 | 0.7085 | 0.3985 | 0.7085 | 0.8417 |
| No log | 9.0 | 45 | 0.5326 | 0.4975 | 0.5326 | 0.7298 |
| No log | 10.0 | 50 | 0.6499 | 0.4946 | 0.6499 | 0.8061 |
| No log | 11.0 | 55 | 0.5478 | 0.5587 | 0.5478 | 0.7401 |
| No log | 12.0 | 60 | 0.6199 | 0.5323 | 0.6199 | 0.7873 |
| No log | 13.0 | 65 | 0.6532 | 0.5034 | 0.6532 | 0.8082 |
| No log | 14.0 | 70 | 0.7972 | 0.4032 | 0.7972 | 0.8929 |
| No log | 15.0 | 75 | 0.7727 | 0.4539 | 0.7727 | 0.8790 |
| No log | 16.0 | 80 | 0.8721 | 0.3180 | 0.8721 | 0.9339 |
| No log | 17.0 | 85 | 0.5850 | 0.4918 | 0.5850 | 0.7649 |
| No log | 18.0 | 90 | 0.6445 | 0.4859 | 0.6445 | 0.8028 |
| No log | 19.0 | 95 | 0.5899 | 0.5188 | 0.5899 | 0.7680 |
| No log | 20.0 | 100 | 0.6316 | 0.4909 | 0.6316 | 0.7947 |
| No log | 21.0 | 105 | 0.6853 | 0.4717 | 0.6853 | 0.8278 |
| No log | 22.0 | 110 | 0.5423 | 0.5105 | 0.5423 | 0.7364 |
| No log | 23.0 | 115 | 0.5840 | 0.5453 | 0.5840 | 0.7642 |
| No log | 24.0 | 120 | 0.5626 | 0.4963 | 0.5626 | 0.7501 |
| No log | 25.0 | 125 | 0.7507 | 0.3961 | 0.7507 | 0.8665 |
| No log | 26.0 | 130 | 0.5984 | 0.4845 | 0.5984 | 0.7735 |
| No log | 27.0 | 135 | 0.5748 | 0.4960 | 0.5748 | 0.7582 |
| No log | 28.0 | 140 | 0.7084 | 0.4539 | 0.7084 | 0.8417 |
| No log | 29.0 | 145 | 0.6055 | 0.4734 | 0.6055 | 0.7782 |
| No log | 30.0 | 150 | 0.6253 | 0.4533 | 0.6253 | 0.7908 |
| No log | 31.0 | 155 | 0.6453 | 0.4958 | 0.6453 | 0.8033 |
| No log | 32.0 | 160 | 0.6599 | 0.4794 | 0.6599 | 0.8123 |
| No log | 33.0 | 165 | 0.5598 | 0.5059 | 0.5598 | 0.7482 |
| No log | 34.0 | 170 | 0.6329 | 0.4547 | 0.6329 | 0.7955 |
| No log | 35.0 | 175 | 0.5714 | 0.5012 | 0.5714 | 0.7559 |
| No log | 36.0 | 180 | 0.5693 | 0.4861 | 0.5693 | 0.7545 |
| No log | 37.0 | 185 | 0.6526 | 0.4829 | 0.6526 | 0.8078 |
| No log | 38.0 | 190 | 0.5883 | 0.5111 | 0.5883 | 0.7670 |
| No log | 39.0 | 195 | 0.6308 | 0.4737 | 0.6308 | 0.7942 |
| No log | 40.0 | 200 | 0.5711 | 0.5177 | 0.5711 | 0.7557 |
| No log | 41.0 | 205 | 0.5692 | 0.5166 | 0.5692 | 0.7544 |
### Framework versions
- Transformers 4.51.1
- Pytorch 2.5.1+cu124
- Datasets 3.5.0
- Tokenizers 0.21.0
|
iTzMiNOS/gemma-3-1b-it-large-json-LoRA-4bit-128-16 | iTzMiNOS | 2025-04-27T09:23:30Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"arxiv:1910.09700",
"base_model:google/gemma-3-1b-it",
"base_model:adapter:google/gemma-3-1b-it",
"region:us"
] | null | 2025-04-27T08:14:38Z | ---
base_model: google/gemma-3-1b-it
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2 |
benfredj2/cv-generator01 | benfredj2 | 2025-04-27T09:17:36Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-27T09:09:39Z | ---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** benfredj2
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
hjhjkjhasdf/ngjhk | hjhjkjhasdf | 2025-04-27T09:06:33Z | 0 | 0 | null | [
"license:bigscience-openrail-m",
"region:us"
] | null | 2025-04-27T09:06:32Z | ---
license: bigscience-openrail-m
---
|
genki10/BERT_V8_sp10_lw40_ex50_lo100_k10_k10_fold4 | genki10 | 2025-04-27T09:04:25Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-04-27T08:42:52Z | ---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_V8_sp10_lw40_ex50_lo100_k10_k10_fold4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_V8_sp10_lw40_ex50_lo100_k10_k10_fold4
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8343
- Qwk: 0.3258
- Mse: 0.8343
- Rmse: 0.9134
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| No log | 1.0 | 6 | 9.2118 | 0.0018 | 9.2118 | 3.0351 |
| No log | 2.0 | 12 | 6.3499 | 0.0 | 6.3499 | 2.5199 |
| No log | 3.0 | 18 | 3.3110 | 0.0040 | 3.3110 | 1.8196 |
| No log | 4.0 | 24 | 1.7439 | 0.0239 | 1.7439 | 1.3206 |
| No log | 5.0 | 30 | 0.9900 | 0.0213 | 0.9900 | 0.9950 |
| No log | 6.0 | 36 | 0.8721 | 0.1932 | 0.8721 | 0.9339 |
| No log | 7.0 | 42 | 1.0724 | 0.0213 | 1.0724 | 1.0355 |
| No log | 8.0 | 48 | 0.7385 | 0.3090 | 0.7385 | 0.8593 |
| No log | 9.0 | 54 | 0.7442 | 0.3814 | 0.7442 | 0.8627 |
| No log | 10.0 | 60 | 0.6750 | 0.3562 | 0.6750 | 0.8216 |
| No log | 11.0 | 66 | 0.7206 | 0.4009 | 0.7206 | 0.8489 |
| No log | 12.0 | 72 | 0.7901 | 0.3282 | 0.7901 | 0.8889 |
| No log | 13.0 | 78 | 0.7119 | 0.4841 | 0.7119 | 0.8437 |
| No log | 14.0 | 84 | 0.7345 | 0.5171 | 0.7345 | 0.8571 |
| No log | 15.0 | 90 | 0.7893 | 0.3530 | 0.7893 | 0.8884 |
| No log | 16.0 | 96 | 0.8663 | 0.2991 | 0.8663 | 0.9307 |
| No log | 17.0 | 102 | 0.9200 | 0.2998 | 0.9200 | 0.9592 |
| No log | 18.0 | 108 | 0.7772 | 0.3810 | 0.7772 | 0.8816 |
| No log | 19.0 | 114 | 0.7796 | 0.4119 | 0.7796 | 0.8829 |
| No log | 20.0 | 120 | 0.8679 | 0.3123 | 0.8679 | 0.9316 |
| No log | 21.0 | 126 | 0.8385 | 0.3731 | 0.8385 | 0.9157 |
| No log | 22.0 | 132 | 0.7310 | 0.4582 | 0.7310 | 0.8550 |
| No log | 23.0 | 138 | 0.8274 | 0.3785 | 0.8274 | 0.9096 |
| No log | 24.0 | 144 | 0.7564 | 0.4040 | 0.7564 | 0.8697 |
| No log | 25.0 | 150 | 0.8185 | 0.3350 | 0.8185 | 0.9047 |
| No log | 26.0 | 156 | 0.8006 | 0.3387 | 0.8006 | 0.8948 |
| No log | 27.0 | 162 | 0.7709 | 0.3900 | 0.7709 | 0.8780 |
| No log | 28.0 | 168 | 0.7896 | 0.4128 | 0.7896 | 0.8886 |
| No log | 29.0 | 174 | 0.7478 | 0.4152 | 0.7478 | 0.8648 |
| No log | 30.0 | 180 | 0.8386 | 0.3967 | 0.8386 | 0.9157 |
| No log | 31.0 | 186 | 0.8697 | 0.2854 | 0.8697 | 0.9326 |
| No log | 32.0 | 192 | 0.8712 | 0.3258 | 0.8712 | 0.9334 |
| No log | 33.0 | 198 | 0.9011 | 0.3189 | 0.9011 | 0.9493 |
| No log | 34.0 | 204 | 0.8293 | 0.3390 | 0.8293 | 0.9107 |
| No log | 35.0 | 210 | 0.8089 | 0.3451 | 0.8089 | 0.8994 |
| No log | 36.0 | 216 | 0.7743 | 0.3712 | 0.7743 | 0.8799 |
| No log | 37.0 | 222 | 0.7581 | 0.4065 | 0.7581 | 0.8707 |
| No log | 38.0 | 228 | 0.7116 | 0.4547 | 0.7116 | 0.8436 |
| No log | 39.0 | 234 | 0.8702 | 0.3083 | 0.8702 | 0.9329 |
| No log | 40.0 | 240 | 0.7721 | 0.4718 | 0.7721 | 0.8787 |
| No log | 41.0 | 246 | 0.7818 | 0.4046 | 0.7818 | 0.8842 |
| No log | 42.0 | 252 | 0.7112 | 0.4672 | 0.7112 | 0.8433 |
| No log | 43.0 | 258 | 0.7610 | 0.3958 | 0.7610 | 0.8723 |
| No log | 44.0 | 264 | 0.8343 | 0.3258 | 0.8343 | 0.9134 |
### Framework versions
- Transformers 4.51.1
- Pytorch 2.5.1+cu124
- Datasets 3.5.0
- Tokenizers 0.21.0
|
BootesVoid/cm9zdpc5g02ccqeqosj8auuc0_cm9ze0tbw02clqeqojajd0jho | BootesVoid | 2025-04-27T09:03:10Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-04-27T09:03:09Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: ELLIE
---
# Cm9Zdpc5G02Ccqeqosj8Auuc0_Cm9Ze0Tbw02Clqeqojajd0Jho
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `ELLIE` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "ELLIE",
"lora_weights": "https://huggingface.co/BootesVoid/cm9zdpc5g02ccqeqosj8auuc0_cm9ze0tbw02clqeqojajd0jho/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cm9zdpc5g02ccqeqosj8auuc0_cm9ze0tbw02clqeqojajd0jho', weight_name='lora.safetensors')
image = pipeline('ELLIE').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cm9zdpc5g02ccqeqosj8auuc0_cm9ze0tbw02clqeqojajd0jho/discussions) to add images that show off what you’ve made with this LoRA.
|
mlfoundations-dev/c1_code_nod_16s_10k | mlfoundations-dev | 2025-04-27T09:00:40Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-27T03:51:04Z | ---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: c1_code_nod_16s_10k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# c1_code_nod_16s_10k
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on the mlfoundations-dev/c1_code_nod_16s_10k dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 16
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- total_eval_batch_size: 128
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.46.1
- Pytorch 2.5.1
- Datasets 3.0.2
- Tokenizers 0.20.3
|
boneylizardwizard/llama-cpp-python-038-cu128-gemma3-wheel | boneylizardwizard | 2025-04-27T08:59:46Z | 0 | 0 | null | [
"llama-cpp-python,",
"cuda,",
"gemma",
"gemma-3,",
"windows,",
"wheel,",
"prebuilt,",
".whl,",
"local-llm,",
"license:mit",
"region:us"
] | null | 2025-04-27T07:28:50Z | ---
license: mit
tags:
- llama-cpp-python,
- cuda,
- gemma
- gemma-3,
- windows,
- wheel,
- prebuilt,
- .whl,
- local-llm,
---
# llama-cpp-python Prebuilt Wheel (Windows x64, CUDA 12.8, Gemma 3 Support)
---
🛠️ **Built with** [llama.cpp (b5192)](https://github.com/ggml-org/llama.cpp) + [CUDA 12.8](https://developer.nvidia.com/cuda-toolkit)
---
**Prebuilt `.whl` for llama-cpp-python 0.3.8 — CUDA 12.8 acceleration with full Gemma 3 model support (Windows x64).**
This repository provides a prebuilt Python wheel (`.whl`) file for **llama-cpp-python**, specifically compiled for Windows 10/11 (x64) with NVIDIA CUDA 12.8 acceleration enabled.
Building `llama-cpp-python` with CUDA support on Windows can be a complex process involving specific Visual Studio configurations, CUDA Toolkit setup, and environment variables. This prebuilt wheel aims to simplify installation for users with compatible systems.
This build is based on **llama-cpp-python** version `0.3.8` of the Python bindings, and the underlying **llama.cpp** source code as of **April 26, 2025**. It has been verified to work with **Gemma 3 models**, correctly offloading layers to the GPU.
---
## Features
- **Prebuilt for Windows x64**: Ready to install using `pip` on 64-bit Windows systems.
- **CUDA 12.8 Accelerated**: Leverages your NVIDIA GPU for faster inference.
- **Gemma 3 Support**: Verified compatibility with Gemma 3 models.
- **Based on llama-cpp-python version `0.3.8` bindings.**
- **Uses [llama.cpp release b5192](https://github.com/ggml-org/llama.cpp/releases/tag/b5192) from April 26, 2025.**
---
## Compatibility & Prerequisites
To use this wheel, you must have:
- An **NVIDIA GPU**.
- NVIDIA drivers compatible with **CUDA 12.8** installed.
- **Windows 10 or Windows 11 (x64)**.
- **Python 3.8 or higher** (the wheel is built specifically for **Python 3.11** (`cp311`)).
- The **Visual C++ Redistributable for Visual Studio 2015-2022** installed.
---
## Installation
It is highly recommended to install this wheel within a Python virtual environment.
1. Ensure you have met all the prerequisites listed above.
2. Create and activate a Python virtual environment:
```bash
python -m venv venv_llama
.\venv_llama\Scripts\activate
```
3. Download the `.whl` file from this repository's **Releases** section.
4. Open your Command Prompt or PowerShell.
5. Navigate to the directory where you downloaded the `.whl` file.
6. Install the wheel using `pip`:
```bash
pip install llama_cpp_python-0.3.8+cu128.gemma3-cp311-cp311-win_amd64.whl
```
---
## Verification (Check CUDA Usage)
To verify that `llama-cpp-python` is using your GPU via CUDA after installation:
```bash
python -c "from llama_cpp import Llama; print('Attempting to initialize Llama with GPU offload...'); try: model = Llama(model_path='path/to/a/small/model.gguf', n_gpu_layers=-1, verbose=True); print('Initialization attempted. Check output above for GPU layers.'); except FileNotFoundError: print('Model file not found, but library initialization output above might still indicate CUDA usage.'); except Exception as e: print(f'An error occurred during initialization: {e}');"
```
Note: Replace path/to/a/small/model.gguf with the actual path to a small .gguf model file.
Look for output messages indicating layers being offloaded to the GPU, such as assigned to device CUDA0 or memory buffer reports.
## Alternative Verification: Python Script
If you prefer, you can verify that llama-cpp-python is correctly using CUDA by running a small Python script inside your virtual environment.
Replace the placeholder paths below with your actual .dll and .gguf file locations:
```bash
import os
from llama_cpp import Llama
# Set the environment variable to point to your custom-built llama.dll
os.environ['LLAMA_CPP_LIB'] = r'PATH_TO_YOUR_CUSTOM_LLAMA_DLL'
try:
print('Attempting to initialize Llama with GPU offload (-1 layers)...')
# Initialize the Llama model with full GPU offloading
model = Llama(
model_path=r'PATH_TO_YOUR_MODEL_FILE.gguf',
n_gpu_layers=-1,
verbose=True
)
print('Initialization attempted. Check the output above for CUDA device assignments (e.g., CUDA0, CUDA1).')
except FileNotFoundError:
print('Error: Model file not found. Please double-check your model_path.')
except Exception as e:
print(f'An error occurred during initialization: {e}')
```
**What to look for in the output:**
Lines like assigned to device CUDA0, assigned to device CUDA1.
VRAM buffer allocations such as CUDA0 model buffer size = ... MiB.
Confirmation that your GPU(s) are being used for model layer offloading.
## Usage
Once installed and verified, you can use llama-cpp-python in your projects as you normally would. Refer to the official llama-cpp-python documentation for detailed usage instructions.
## Acknowledgments
This prebuilt wheel is based on the excellent llama-cpp-python project by Andrei Betlen (@abetlen). All credit for the core library and Python bindings goes to the original maintainers and to llama.cpp by Georgi Gerganov (@ggerganov) and the ggml team.
This specific wheel was built by Bernard Peter Fitzgerald (@boneylizardwizard) using the source code from abetlen/llama-cpp-python, compiled with CUDA 12.8 support for Windows x64 systems, and verified for Gemma 3 model compatibility.
## License
This prebuilt wheel is distributed under the MIT License, the same license as the original llama-cpp-python project.
## Reporting Issues
If you encounter issues specifically with installing this prebuilt wheel or getting CUDA offloading to work using this wheel, please report them on this repository's Issue Tracker.
For general issues with llama-cpp-python itself, please report them upstream at the [official llama-cpp-python GitHub Issues page](https://github.com/ggml-org/llama.cpp/issues). |
axingd/asssss | axingd | 2025-04-27T08:38:14Z | 0 | 0 | null | [
"region:us"
] | null | 2024-12-25T08:17:21Z | # awewa
<Gallery />
## Model description
aaefa
## Download model
[Download](/axingd/asssss/tree/main) them in the Files & versions tab. |
Jibon222/Su400 | Jibon222 | 2025-04-27T08:35:48Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-04-27T08:35:47Z | ---
license: apache-2.0
---
|
fats-fme/bc7c6b69-56fd-45e0-8803-ddcdfcad8d57 | fats-fme | 2025-04-27T08:32:43Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:TinyLlama/TinyLlama-1.1B-Chat-v0.6",
"base_model:adapter:TinyLlama/TinyLlama-1.1B-Chat-v0.6",
"license:apache-2.0",
"region:us"
] | null | 2025-04-27T07:51:48Z | ---
library_name: peft
license: apache-2.0
base_model: TinyLlama/TinyLlama-1.1B-Chat-v0.6
tags:
- axolotl
- generated_from_trainer
model-index:
- name: bc7c6b69-56fd-45e0-8803-ddcdfcad8d57
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: TinyLlama/TinyLlama-1.1B-Chat-v0.6
bf16: true
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- b6a43b56eb029738_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/b6a43b56eb029738_train_data.json
type:
field_instruction: content
field_output: title
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
device_map: auto
early_stopping_patience: 3
eval_max_new_tokens: 128
eval_steps: 100
eval_table_size: null
evals_per_epoch: null
flash_attention: true
fp16: false
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: true
group_by_length: false
hub_model_id: fats-fme/bc7c6b69-56fd-45e0-8803-ddcdfcad8d57
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 5.0e-05
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 10
lora_alpha: 128
lora_dropout: 0.1
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 64
lora_target_linear: true
lr_scheduler: cosine
max_memory:
0: 130GB
max_steps: 200
micro_batch_size: 2
mlflow_experiment_name: /tmp/b6a43b56eb029738_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 10
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: 100
saves_per_epoch: null
sequence_len: 2048
strict: false
tf32: true
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 6e88e859-4b71-4dc4-97ff-c0a0fcd22739
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: 6e88e859-4b71-4dc4-97ff-c0a0fcd22739
warmup_steps: 200
weight_decay: 0.01
xformers_attention: null
```
</details><br>
# bc7c6b69-56fd-45e0-8803-ddcdfcad8d57
This model is a fine-tuned version of [TinyLlama/TinyLlama-1.1B-Chat-v0.6](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v0.6) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8252
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 200
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| No log | 0.0000 | 1 | 2.7471 |
| 2.0072 | 0.0017 | 100 | 2.0121 |
| 1.9251 | 0.0034 | 200 | 1.8252 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
Trending-Video-Sapna-Shah-Kumari-1/18-Link.In.Video.Sapna.Shah.viral.video.original.here | Trending-Video-Sapna-Shah-Kumari-1 | 2025-04-27T08:29:06Z | 0 | 0 | null | [
"region:us"
] | null | 2025-04-27T08:26:59Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/3rv9ct3b?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
Shah Sapna Kumari viral video trending across platforms like YouTube and social media. Here’s what you need to know in 2025. We break down the facts, the timeline, and clear up the misinformation. Who is Shah Sapna Kumari? What’s the video really about? And why is it going viral? Stay informed with verified updates, public reactions, and a responsible take
|
m-aliabbas1/ofu-Q4_K_M-GGUF | m-aliabbas1 | 2025-04-27T08:25:14Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"generated_from_trainer",
"llama-cpp",
"gguf-my-repo",
"base_model:m-aliabbas1/ofu",
"base_model:quantized:m-aliabbas1/ofu",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-04-27T08:25:02Z | ---
base_model: m-aliabbas1/ofu
library_name: transformers
tags:
- generated_from_trainer
- llama-cpp
- gguf-my-repo
model-index:
- name: ofu
results: []
---
# m-aliabbas1/ofu-Q4_K_M-GGUF
This model was converted to GGUF format from [`m-aliabbas1/ofu`](https://huggingface.co/m-aliabbas1/ofu) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/m-aliabbas1/ofu) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo m-aliabbas1/ofu-Q4_K_M-GGUF --hf-file ofu-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo m-aliabbas1/ofu-Q4_K_M-GGUF --hf-file ofu-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo m-aliabbas1/ofu-Q4_K_M-GGUF --hf-file ofu-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo m-aliabbas1/ofu-Q4_K_M-GGUF --hf-file ofu-q4_k_m.gguf -c 2048
```
|
privetin/Llama-3.2-1B-Instruct-Q4_K_M-GGUF | privetin | 2025-04-27T08:21:22Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"base_model:meta-llama/Llama-3.2-1B-Instruct",
"base_model:quantized:meta-llama/Llama-3.2-1B-Instruct",
"license:llama3.2",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2025-04-27T08:21:16Z | ---
base_model: meta-llama/Llama-3.2-1B-Instruct
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
library_name: transformers
license: llama3.2
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
- llama-cpp
- gguf-my-repo
extra_gated_prompt: "### LLAMA 3.2 COMMUNITY LICENSE AGREEMENT\n\nLlama 3.2 Version\
\ Release Date: September 25, 2024\n\n“Agreement” means the terms and conditions\
\ for use, reproduction, distribution and modification of the Llama Materials set\
\ forth herein.\n\n“Documentation” means the specifications, manuals and documentation\
\ accompanying Llama 3.2 distributed by Meta at https://llama.meta.com/doc/overview.\n\
\n“Licensee” or “you” means you, or your employer or any other person or entity\
\ (if you are entering into this Agreement on such person or entity’s behalf),\
\ of the age required under applicable laws, rules or regulations to provide legal\
\ consent and that has legal authority to bind your employer or such other person\
\ or entity if you are entering in this Agreement on their behalf.\n\n“Llama 3.2”\
\ means the foundational large language models and software and algorithms, including\
\ machine-learning model code, trained model weights, inference-enabling code, training-enabling\
\ code, fine-tuning enabling code and other elements of the foregoing distributed\
\ by Meta at https://www.llama.com/llama-downloads.\n\n“Llama Materials” means,\
\ collectively, Meta’s proprietary Llama 3.2 and Documentation (and any portion\
\ thereof) made available under this Agreement.\n\n“Meta” or “we” means Meta Platforms\
\ Ireland Limited (if you are located in or, if you are an entity, your principal\
\ place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if\
\ you are located outside of the EEA or Switzerland). \n\nBy clicking “I Accept”\
\ below or by using or distributing any portion or element of the Llama Materials,\
\ you agree to be bound by this Agreement.\n\n1. License Rights and Redistribution.\n\
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable\
\ and royalty-free limited license under Meta’s intellectual property or other rights\
\ owned by Meta embodied in the Llama Materials to use, reproduce, distribute,\
\ copy, create derivative works of, and make modifications to the Llama Materials.\
\ \nb. Redistribution and Use. \ni. If you distribute or make available the Llama\
\ Materials (or any derivative works thereof), or a product or service (including\
\ another AI model) that contains any of them, you shall (A) provide a copy of this\
\ Agreement with any such Llama Materials; and (B) prominently display “Built with\
\ Llama” on a related website, user interface, blogpost, about page, or product\
\ documentation. If you use the Llama Materials or any outputs or results of the\
\ Llama Materials to create, train, fine tune, or otherwise improve an AI model,\
\ which is distributed or made available, you shall also include “Llama” at the\
\ beginning of any such AI model name.\nii. If you receive Llama Materials, or any\
\ derivative works thereof, from a Licensee as part of an integrated end user product,\
\ then Section 2 of this Agreement will not apply to you. \niii. You must retain\
\ in all copies of the Llama Materials that you distribute the following attribution\
\ notice within a “Notice” text file distributed as a part of such copies: “Llama\
\ 3.2 is licensed under the Llama 3.2 Community License, Copyright © Meta Platforms,\
\ Inc. All Rights Reserved.”\niv. Your use of the Llama Materials must comply with\
\ applicable laws and regulations (including trade compliance laws and regulations)\
\ and adhere to the Acceptable Use Policy for the Llama Materials (available at\
\ https://www.llama.com/llama3_2/use-policy), which is hereby incorporated by reference\
\ into this Agreement.\n \n2. Additional Commercial Terms. If, on the Llama 3.2\
\ version release date, the monthly active users of the products or services made\
\ available by or for Licensee, or Licensee’s affiliates, is greater than 700 million\
\ monthly active users in the preceding calendar month, you must request a license\
\ from Meta, which Meta may grant to you in its sole discretion, and you are not\
\ authorized to exercise any of the rights under this Agreement unless or until\
\ Meta otherwise expressly grants you such rights.\n3. Disclaimer of Warranty. UNLESS\
\ REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM\
\ ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS\
\ ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION,\
\ ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR\
\ PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING\
\ OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR\
\ USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.\n4. Limitation of Liability.\
\ IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY,\
\ WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING\
\ OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,\
\ INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE\
\ BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\n\
a. No trademark licenses are granted under this Agreement, and in connection with\
\ the Llama Materials, neither Meta nor Licensee may use any name or mark owned\
\ by or associated with the other or any of its affiliates, except as required\
\ for reasonable and customary use in describing and redistributing the Llama Materials\
\ or as set forth in this Section 5(a). Meta hereby grants you a license to use\
\ “Llama” (the “Mark”) solely as required to comply with the last sentence of Section\
\ 1.b.i. You will comply with Meta’s brand guidelines (currently accessible at\
\ https://about.meta.com/brand/resources/meta/company-brand/). All goodwill arising\
\ out of your use of the Mark will inure to the benefit of Meta.\nb. Subject to\
\ Meta’s ownership of Llama Materials and derivatives made by or for Meta, with\
\ respect to any derivative works and modifications of the Llama Materials that\
\ are made by you, as between you and Meta, you are and will be the owner of such\
\ derivative works and modifications.\nc. If you institute litigation or other proceedings\
\ against Meta or any entity (including a cross-claim or counterclaim in a lawsuit)\
\ alleging that the Llama Materials or Llama 3.2 outputs or results, or any portion\
\ of any of the foregoing, constitutes infringement of intellectual property or\
\ other rights owned or licensable by you, then any licenses granted to you under\
\ this Agreement shall terminate as of the date such litigation or claim is filed\
\ or instituted. You will indemnify and hold harmless Meta from and against any\
\ claim by any third party arising out of or related to your use or distribution\
\ of the Llama Materials.\n6. Term and Termination. The term of this Agreement will\
\ commence upon your acceptance of this Agreement or access to the Llama Materials\
\ and will continue in full force and effect until terminated in accordance with\
\ the terms and conditions herein. Meta may terminate this Agreement if you are\
\ in breach of any term or condition of this Agreement. Upon termination of this\
\ Agreement, you shall delete and cease use of the Llama Materials. Sections 3,\
\ 4 and 7 shall survive the termination of this Agreement. \n7. Governing Law and\
\ Jurisdiction. This Agreement will be governed and construed under the laws of\
\ the State of California without regard to choice of law principles, and the UN\
\ Convention on Contracts for the International Sale of Goods does not apply to\
\ this Agreement. The courts of California shall have exclusive jurisdiction of\
\ any dispute arising out of this Agreement. \n### Llama 3.2 Acceptable Use Policy\n\
Meta is committed to promoting safe and fair use of its tools and features, including\
\ Llama 3.2. If you access or use Llama 3.2, you agree to this Acceptable Use Policy\
\ (“**Policy**”). The most recent copy of this policy can be found at [https://www.llama.com/llama3_2/use-policy](https://www.llama.com/llama3_2/use-policy).\n\
#### Prohibited Uses\nWe want everyone to use Llama 3.2 safely and responsibly.\
\ You agree you will not use, or allow others to use, Llama 3.2 to:\n1. Violate\
\ the law or others’ rights, including to:\n 1. Engage in, promote, generate,\
\ contribute to, encourage, plan, incite, or further illegal or unlawful activity\
\ or content, such as:\n 1. Violence or terrorism\n 2. Exploitation\
\ or harm to children, including the solicitation, creation, acquisition, or dissemination\
\ of child exploitative content or failure to report Child Sexual Abuse Material\n\
\ 3. Human trafficking, exploitation, and sexual violence\n 4. The\
\ illegal distribution of information or materials to minors, including obscene\
\ materials, or failure to employ legally required age-gating in connection with\
\ such information or materials.\n 5. Sexual solicitation\n 6. Any\
\ other criminal activity\n 1. Engage in, promote, incite, or facilitate the\
\ harassment, abuse, threatening, or bullying of individuals or groups of individuals\n\
\ 2. Engage in, promote, incite, or facilitate discrimination or other unlawful\
\ or harmful conduct in the provision of employment, employment benefits, credit,\
\ housing, other economic benefits, or other essential goods and services\n 3.\
\ Engage in the unauthorized or unlicensed practice of any profession including,\
\ but not limited to, financial, legal, medical/health, or related professional\
\ practices\n 4. Collect, process, disclose, generate, or infer private or sensitive\
\ information about individuals, including information about individuals’ identity,\
\ health, or demographic information, unless you have obtained the right to do so\
\ in accordance with applicable law\n 5. Engage in or facilitate any action or\
\ generate any content that infringes, misappropriates, or otherwise violates any\
\ third-party rights, including the outputs or results of any products or services\
\ using the Llama Materials\n 6. Create, generate, or facilitate the creation\
\ of malicious code, malware, computer viruses or do anything else that could disable,\
\ overburden, interfere with or impair the proper working, integrity, operation\
\ or appearance of a website or computer system\n 7. Engage in any action, or\
\ facilitate any action, to intentionally circumvent or remove usage restrictions\
\ or other safety measures, or to enable functionality disabled by Meta \n2. Engage\
\ in, promote, incite, facilitate, or assist in the planning or development of activities\
\ that present a risk of death or bodily harm to individuals, including use of Llama\
\ 3.2 related to the following:\n 8. Military, warfare, nuclear industries or\
\ applications, espionage, use for materials or activities that are subject to the\
\ International Traffic Arms Regulations (ITAR) maintained by the United States\
\ Department of State or to the U.S. Biological Weapons Anti-Terrorism Act of 1989\
\ or the Chemical Weapons Convention Implementation Act of 1997\n 9. Guns and\
\ illegal weapons (including weapon development)\n 10. Illegal drugs and regulated/controlled\
\ substances\n 11. Operation of critical infrastructure, transportation technologies,\
\ or heavy machinery\n 12. Self-harm or harm to others, including suicide, cutting,\
\ and eating disorders\n 13. Any content intended to incite or promote violence,\
\ abuse, or any infliction of bodily harm to an individual\n3. Intentionally deceive\
\ or mislead others, including use of Llama 3.2 related to the following:\n 14.\
\ Generating, promoting, or furthering fraud or the creation or promotion of disinformation\n\
\ 15. Generating, promoting, or furthering defamatory content, including the\
\ creation of defamatory statements, images, or other content\n 16. Generating,\
\ promoting, or further distributing spam\n 17. Impersonating another individual\
\ without consent, authorization, or legal right\n 18. Representing that the\
\ use of Llama 3.2 or outputs are human-generated\n 19. Generating or facilitating\
\ false online engagement, including fake reviews and other means of fake online\
\ engagement \n4. Fail to appropriately disclose to end users any known dangers\
\ of your AI system 5. Interact with third party tools, models, or software designed\
\ to generate unlawful content or engage in unlawful or harmful conduct and/or represent\
\ that the outputs of such tools, models, or software are associated with Meta or\
\ Llama 3.2\n\nWith respect to any multimodal models included in Llama 3.2, the\
\ rights granted under Section 1(a) of the Llama 3.2 Community License Agreement\
\ are not being granted to you if you are an individual domiciled in, or a company\
\ with a principal place of business in, the European Union. This restriction does\
\ not apply to end users of a product or service that incorporates any such multimodal\
\ models.\n\nPlease report any violation of this Policy, software “bug,” or other\
\ problems that could lead to a violation of this Policy through one of the following\
\ means:\n\n* Reporting issues with the model: [https://github.com/meta-llama/llama-models/issues](https://l.workplace.com/l.php?u=https%3A%2F%2Fgithub.com%2Fmeta-llama%2Fllama-models%2Fissues&h=AT0qV8W9BFT6NwihiOHRuKYQM_UnkzN_NmHMy91OT55gkLpgi4kQupHUl0ssR4dQsIQ8n3tfd0vtkobvsEvt1l4Ic6GXI2EeuHV8N08OG2WnbAmm0FL4ObkazC6G_256vN0lN9DsykCvCqGZ)\n\
* Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)\n\
* Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)\n\
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama\
\ 3.2: [email protected]"
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
? By clicking Submit below I accept the terms of the license and acknowledge that
the information I provide will be collected stored processed and shared in accordance
with the Meta Privacy Policy
: checkbox
extra_gated_description: The information you provide will be collected, stored, processed
and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
# privetin/Llama-3.2-1B-Instruct-Q4_K_M-GGUF
This model was converted to GGUF format from [`meta-llama/Llama-3.2-1B-Instruct`](https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo privetin/Llama-3.2-1B-Instruct-Q4_K_M-GGUF --hf-file llama-3.2-1b-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo privetin/Llama-3.2-1B-Instruct-Q4_K_M-GGUF --hf-file llama-3.2-1b-instruct-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo privetin/Llama-3.2-1B-Instruct-Q4_K_M-GGUF --hf-file llama-3.2-1b-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo privetin/Llama-3.2-1B-Instruct-Q4_K_M-GGUF --hf-file llama-3.2-1b-instruct-q4_k_m.gguf -c 2048
```
|
MayBashendy/arabic_SDP_1_multiclass_multilingual_e5_small_lr3e-05_targ0_dev2345678 | MayBashendy | 2025-04-27T08:19:56Z | 0 | 0 | null | [
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"region:us"
] | null | 2025-04-25T14:25:46Z | ---
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Library: [More Information Needed]
- Docs: [More Information Needed] |
hotfreddo27/fredxcaryyfryk | hotfreddo27 | 2025-04-27T08:11:59Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"fluxgym",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-04-27T08:09:26Z | ---
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
- fluxgym
widget:
- output:
url: sample/fredxcaryyfryk_001200_00_20250427024124.png
text: fredxcaryyfryk driving fast in the street of tokio, motion blur, cinematic
kodak shot
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: fredxcaryyfryk
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# fredxcaryyfryk
A Flux LoRA trained on a local computer with [Fluxgym](https://github.com/cocktailpeanut/fluxgym)
<Gallery />
## Trigger words
You should use `fredxcaryyfryk` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, Forge, etc.
Weights for this model are available in Safetensors format.
|
dgambettaphd/M_llm2_gen4_run0_W_doc1000_synt64_tot128_SYNLAST | dgambettaphd | 2025-04-27T08:09:38Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-04-27T08:09:26Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
trong269/vit5-vietnamese-text-summarization | trong269 | 2025-04-27T06:20:22Z | 17 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:VietAI/vit5-base",
"base_model:finetune:VietAI/vit5-base",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2025-04-07T09:45:29Z | ---
library_name: transformers
license: mit
base_model: VietAI/vit5-base
tags:
- generated_from_trainer
model-index:
- name: vit5-vietnamese-text-summarization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit5-vietnamese-text-summarization
This model is a fine-tuned version of [VietAI/vit5-base](https://huggingface.co/VietAI/vit5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.2793
- eval_runtime: 464.3255
- eval_samples_per_second: 32.118
- eval_steps_per_second: 8.031
- epoch: 13.0
- step: 16148
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 12
- total_train_batch_size: 48
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 20
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.5.0
- Tokenizers 0.21.1
|
nayanayy9/corp | nayanayy9 | 2025-04-27T06:18:55Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-04-27T06:18:55Z | ---
license: apache-2.0
---
|
MultiBridge/wav2vec-LnNor-IPA-ft | MultiBridge | 2025-04-27T06:16:21Z | 16 | 1 | null | [
"safetensors",
"wav2vec2",
"phoneme_recognition",
"IPA",
"automatic-speech-recognition",
"en",
"dataset:MultiBridge/LnNor",
"dataset:speech31/timit_english_ipa",
"arxiv:1910.09700",
"base_model:facebook/wav2vec2-base",
"base_model:finetune:facebook/wav2vec2-base",
"license:cc-by-4.0",
"model-index",
"region:us"
] | automatic-speech-recognition | 2025-03-02T12:23:56Z | ---
license: cc-by-4.0
datasets:
- MultiBridge/LnNor
- speech31/timit_english_ipa
language:
- en
metrics:
- cer
base_model:
- facebook/wav2vec2-base
pipeline_tag: automatic-speech-recognition
tags:
- phoneme_recognition
- IPA
model-index:
- name: MultiBridge/wav2vec-LnNor-IPA-ft
results:
- task:
type: phoneme-recognition
name: Phoneme Recognition
dataset:
name: TIMIT
type: speech31/timit_english_ipa
metrics:
- type: cer
value: 0.0416
name: CER
---
# Model Card for MultiBridge/wav2vec-LnNor-IPA-ft
<!-- Provide a quick summary of what the model is/does. -->
This model is built for phoneme recognition tasks. It was developed by fine-tuning the wav2vec2 base model on TIMIT and LnNor datasets. The predictions are in IPA.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Multibridge
- **Funded by [optional]:** EEA Financial Mechanism and Norwegian Financial Mechanism
- **Shared by [optional]:** Multibridge
- **Model type:** Transformer
- **Language(s) (NLP):** English
- **License:** cc-by-4.0
- **Finetuned from model [optional]:** facebook/wav2vec2-base
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
- Automatic phonetic transcription: Converting raw speech into phoneme sequences.
- Speech processing applications: Serving as a component in speech processing pipelines or prototyping.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
- data specificity: By excluding recordings shorter than 2 seconds or longer than 30 seconds, and labels with fewer than 5 phonemes, some natural speech variations are ignored. This might affect the model's performance in real-world applications. The model's performance is influenced by the characteristics of TIMIT and LnNor datasets. This can lead to potential biases, especially if the target application involves speakers or dialects not well-represented in these datasets. LnNor contains non-native speech and automaticly generated annotations that don't reflect true pronunciation rather canonical pronunciation. This could result in a model that fails to accurately predict non-native speech.
- frozen encoder: Freezing the encoder retains useful pre-learned features but also prevents the model from adapting fully to the new datasets.
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Evaluate the model's performance for your specific use case.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("MultiBridge/wav2vec-LnNor-IPA-ft")
model = Wav2Vec2ForCTC.from_pretrained("MultiBridge/wav2vec-LnNor-IPA-ft")
# load dummy dataset and read soundfiles
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values
# retrieve logits
with torch.no_grad():
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
# => should give ['mɪstɝkwɪltɝɪzðəəpɑslʌvðəmɪdəlklæsəzændwiɑəɡlædtəwɛlkəmhɪzɡɑspəl'] for MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL
```
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
The training data comes from two key sources:
- [TIMIT](https://huggingface.co/datasets/speech31/timit_english_ipa): A widely-used dataset for phonetic transcription, providing a standard benchmark in speech research.
- [LnNor](https://huggingface.co/datasets/MultiBridge/LnNor): A multilingual dataset of high-quality speech recordings in Norwegian, English, and Polish. The dataset compiled from non-native speakers with various language proficiencies. The phoneme annotations in LnNor were generated using the WebMAUS tool, meaning they represent canonical phonemes rather than the true pronunciations typical of spontaneous speech or non native pronunciation.
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
The original, pre-trained encoder representations were preserved - the encoder was kept frozen during fine-tuning in order to minimizes training time and resource consumption. The model was trained with CTC loss and AdamW optimizer, with no learning rate scheduler.
#### Preprocessing [optional]
The training dataset was filtered. Recordings shorter than 2 seconds or longer than 30 seconds were removed. Any labels consisting of fewer than 5 phonemes were discarded.
#### Training Hyperparameters
**Training regime:**
- learning rate: 1e-5
- optimizer: AdamW
- batch size: 64
- weight decay: 0.001
- epochs: 40
#### Speeds, Sizes, Times [optional]
- Avg epoch training time: 650s
- Number of updates: ~25k
- Final training loss: 0.09713
- Final validation loss: 0.2142
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
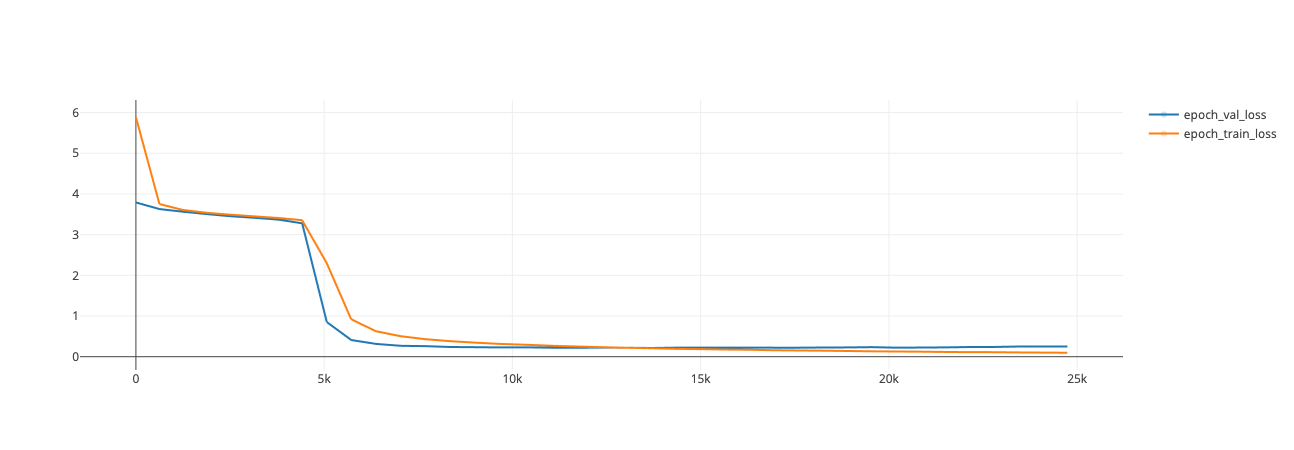
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
The model was evaluated on TIMIT's test split.
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
CER/PER (Phoneme Error Rate)
### Results
PER (Phoneme Error Rate) on TIMIT's test split: 0.0416
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Nvidia A100-80
- **Hours used:** [More Information Needed]
- **Cloud Provider:** Poznan University of Technology
- **Compute Region:** Poland
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
Transformer model + CTC loss
### Compute Infrastructure
#### Hardware
2 x Nvidia A100-80
#### Software
python 3.12
transformers 4.50.0
torch 2.6.0
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
I you use the LnNor dataset for research, cite these papers:
```
@article{magdalena2024lnnor,
title={The LnNor Corpus: A spoken multilingual corpus of non-native and native Norwegian, English and Polish (Part 1)},
author={Magdalena, Wrembel and Hwaszcz, Krzysztof and Agnieszka, Pludra and Ska{\l}ba, Anna and Weckwerth, Jaros{\l}aw and Walczak, Angelika and Sypia{\'n}ska, Jolanta and {\.Z}ychli{\'n}ski, Sylwiusz and Malarski, Kamil and K{\k{e}}dzierska, Hanna and others},
year={2024},
publisher={Adam Mickiewicz University}
}
@article{wrembel2024lnnor,
title={The LnNor Corpus: A spoken multilingual corpus of non-native and native Norwegian, English and Polish--Part 2},
author={Wrembel, Magdalena and Hwaszcz, Krzysztof and Pludra, Agnieszka and Ska{\l}ba, Anna and Weckwerth, Jaros{\l}aw and Malarski, Kamil and Cal, Zuzanna Ewa and K{\k{e}}dzierska, Hanna and Czarnecki-Verner, Tristan and Balas, Anna and others},
year={2024},
publisher={Adam Mickiewicz University}
}
```
## Model Card Authors [optional]
Agnieszka Pludra
Izabela Krysińska
Piotr Kabaciński
## Model Card Contact
[email protected]
[email protected]
[email protected] |
Alphatao/07a14409-7302-4289-8af1-20ed1c8e8384 | Alphatao | 2025-04-27T06:14:49Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"gemma",
"text-generation",
"generated_from_trainer",
"axolotl",
"dpo",
"trl",
"unsloth",
"conversational",
"arxiv:2305.18290",
"base_model:unsloth/gemma-1.1-2b-it",
"base_model:finetune:unsloth/gemma-1.1-2b-it",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-27T02:14:50Z | ---
base_model: unsloth/gemma-1.1-2b-it
library_name: transformers
model_name: 07a14409-7302-4289-8af1-20ed1c8e8384
tags:
- generated_from_trainer
- axolotl
- dpo
- trl
- unsloth
licence: license
---
# Model Card for 07a14409-7302-4289-8af1-20ed1c8e8384
This model is a fine-tuned version of [unsloth/gemma-1.1-2b-it](https://huggingface.co/unsloth/gemma-1.1-2b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Alphatao/07a14409-7302-4289-8af1-20ed1c8e8384", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/alphatao-alphatao/Gradients-On-Demand/runs/1uqzv9lm)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.0.dev0
- Transformers: 4.46.0
- Pytorch: 2.5.0+cu124
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
donflo99/sdxl_custom_style_v2 | donflo99 | 2025-04-27T06:09:11Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:SG161222/Realistic_Vision_V5.1_noVAE",
"base_model:adapter:SG161222/Realistic_Vision_V5.1_noVAE",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2025-04-27T06:09:05Z | ---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: >-
portrait photo of a beautiful young woman with natural makeup, wearing a
casual outfit, soft window light, realistic, detailed skin, clear blue eyes,
clean background, cinematic look
parameters:
negative_prompt: >-
blurry, low quality, cartoon, painting, illustration, deformed, multiple
faces, bad anatomy, extra limbs, watermark, text, nsfw
output:
url: images/xgrlx_fnk291aa (7).jpg.jpg
- text: >-
portrait photo of a beautiful young woman with natural makeup, wearing a
casual outfit, soft window light, realistic, detailed skin, clear blue eyes,
clean background, cinematic look
parameters:
negative_prompt: >-
blurry, low quality, cartoon, painting, illustration, deformed, multiple
faces, bad anatomy, extra limbs, watermark, text, nsfw
output:
url: images/xgrlx_fnk291aa (1).jpg.jpg
base_model: SG161222/Realistic_Vision_V5.1_noVAE
instance_prompt: null
license: creativeml-openrail-m
---
# sdxl_custom_style_v2
<Gallery />
## Model description
Custom style blend based on various Stable Diffusion models.
Trained for flexible artistic exploration, allowing a wide range of creative outputs including portraits, lifestyle imagery, and stylistic experiments.
Optimized for SDXL-based workflows.
## Download model
Weights for this model are available in Safetensors format.
[Download](/donflo99/sdxl_custom_style_v2/tree/main) them in the Files & versions tab.
|
10-Nimra-Mehra/TRENDING.Nimra.Mehra.Viral.Video | 10-Nimra-Mehra | 2025-04-27T05:51:36Z | 0 | 0 | null | [
"region:us"
] | null | 2025-04-27T05:51:17Z | <!-- HTML_TAG_START --><p><a rel="nofollow" href="https://tinyurl.com/y5sryrxu">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )</a></p>
<p><a rel="nofollow" href="https://tinyurl.com/y5sryrxu">►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► 𝙁𝙪𝙡𝙡 𝙑𝙞𝙙𝙚𝙤❤️❤️⬇️⬇️</a></p>
<p><a rel="nofollow" href="https://tinyurl.com/y5sryrxu"><img src="http://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a></p>
<!-- HTML_TAG_END |
Asgar1993/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-wise_domestic_donkey | Asgar1993 | 2025-04-27T05:42:55Z | 9 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am wise domestic donkey",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-08T10:17:55Z | ---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-wise_domestic_donkey
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am wise domestic donkey
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-wise_domestic_donkey
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Asgar1993/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-wise_domestic_donkey", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
ail-sa/female_plus_short_test | ail-sa | 2025-04-27T05:41:48Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-04-27T04:53:02Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: Sidf
---
# Female_Plus_Short_Test
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `Sidf` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "Sidf",
"lora_weights": "https://huggingface.co/ail-sa/female_plus_short_test/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('ail-sa/female_plus_short_test', weight_name='lora.safetensors')
image = pipeline('Sidf').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/ail-sa/female_plus_short_test/discussions) to add images that show off what you’ve made with this LoRA.
|
kostiantynk-outlook/1ac934c6-1618-4e25-9fae-cdbf39d3f0d3 | kostiantynk-outlook | 2025-04-27T05:31:52Z | 0 | 0 | transformers | [
"transformers",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | null | 2025-04-27T05:31:26Z | ---
library_name: transformers
model_name: kostiantynk-outlook/1ac934c6-1618-4e25-9fae-cdbf39d3f0d3
tags:
- generated_from_trainer
licence: license
---
# Model Card for kostiantynk-outlook/1ac934c6-1618-4e25-9fae-cdbf39d3f0d3
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
### Framework versions
- TRL: 0.12.0
- Transformers: 4.46.3
- Pytorch: 2.5.1+cu124
- Datasets: 3.1.0
- Tokenizers: 0.20.3
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
mlfoundations-dev/b2_code_length_gpt41nano_3k | mlfoundations-dev | 2025-04-27T05:28:47Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-26T21:55:16Z | ---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: b2_code_length_gpt41nano_3k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# b2_code_length_gpt41nano_3k
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on the mlfoundations-dev/b2_code_length_gpt41nano_3k dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 24
- total_train_batch_size: 96
- total_eval_batch_size: 32
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 7.0
### Training results
### Framework versions
- Transformers 4.46.1
- Pytorch 2.6.0+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3
|
mlfoundations-dev/b2_code_length_gpt4omini_3k | mlfoundations-dev | 2025-04-27T05:22:37Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-26T21:42:22Z | ---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: b2_code_length_gpt4omini_3k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# b2_code_length_gpt4omini_3k
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on the mlfoundations-dev/b2_code_length_gpt4omini_3k dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 24
- total_train_batch_size: 96
- total_eval_batch_size: 32
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 7.0
### Training results
### Framework versions
- Transformers 4.46.1
- Pytorch 2.6.0+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3
|
TOMFORD79/E1 | TOMFORD79 | 2025-04-27T05:11:39Z | 0 | 0 | null | [
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] | any-to-any | 2025-04-27T04:49:21Z | ---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
1-NEW-EXCLUSIVE-TRENDING-CLIP/FULL.VIDEO.LINK.Sophie.Rain.Spiderman.Viral.Video.Leaks.Tutorial | 1-NEW-EXCLUSIVE-TRENDING-CLIP | 2025-04-27T05:10:44Z | 0 | 0 | null | [
"region:us"
] | null | 2025-04-27T05:10:11Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/y2a827nj?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
Sophie Rain’s $43.4 million OnlyFans earnings outshine popular NBA stars, sparking viral reactions
Prominent social media influencer and adult content creator/model Sophie Rain has taken the internet by storm after revealing her astonishing income from OnlyFans. In a post shared on X, Rain disclosed that she earned $43.4 million over the past year, leaving fans and critics in awe. Her post, featuring a screenshot of her earnings, was accompanied by a heartfelt caption: “Thankful for one year on here.”
Original.Viral.Clip.Sophie.Rain.Viral.Video.Leaks.official.HD |
kasadin/yc_cd_7B | kasadin | 2025-04-27T05:09:47Z | 0 | 0 | null | [
"safetensors",
"qwen2",
"qwen",
"chinese",
"7b",
"base_model:Qwen/Qwen1.5-7B",
"base_model:finetune:Qwen/Qwen1.5-7B",
"license:apache-2.0",
"region:us"
] | null | 2025-04-27T03:39:21Z | ---
base_model: Qwen/Qwen1.5-7B
tags:
- qwen
- chinese
- 7b
license: apache-2.0
---
|
kvnery02/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-furry_scruffy_ibis | kvnery02 | 2025-04-27T05:02:55Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am furry scruffy ibis",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-07T19:25:09Z | ---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-furry_scruffy_ibis
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am furry scruffy ibis
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-furry_scruffy_ibis
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="kvnery02/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-furry_scruffy_ibis", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
tscstudios/cqhbbtnqqzcutaav7zt8ajhgjq93_cd3ca5a0-1bbf-4e95-98e8-ea7df5507aa0 | tscstudios | 2025-04-27T04:54:27Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-04-27T04:54:25Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Cqhbbtnqqzcutaav7Zt8Ajhgjq93_Cd3Ca5A0 1Bbf 4E95 98E8 Ea7Df5507Aa0
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "TOK",
"lora_weights": "https://huggingface.co/tscstudios/cqhbbtnqqzcutaav7zt8ajhgjq93_cd3ca5a0-1bbf-4e95-98e8-ea7df5507aa0/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('tscstudios/cqhbbtnqqzcutaav7zt8ajhgjq93_cd3ca5a0-1bbf-4e95-98e8-ea7df5507aa0', weight_name='lora.safetensors')
image = pipeline('TOK').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/tscstudios/cqhbbtnqqzcutaav7zt8ajhgjq93_cd3ca5a0-1bbf-4e95-98e8-ea7df5507aa0/discussions) to add images that show off what you’ve made with this LoRA.
|
phililp-arnold/35edf218-870c-4825-b496-16a24b8178c2 | phililp-arnold | 2025-04-27T04:41:57Z | 0 | 0 | peft | [
"peft",
"generated_from_trainer",
"base_model:databricks/dolly-v2-3b",
"base_model:adapter:databricks/dolly-v2-3b",
"region:us"
] | null | 2025-04-27T04:41:30Z | ---
library_name: peft
tags:
- generated_from_trainer
base_model: databricks/dolly-v2-3b
model-index:
- name: phililp-arnold/35edf218-870c-4825-b496-16a24b8178c2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phililp-arnold/35edf218-870c-4825-b496-16a24b8178c2
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1754
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.3
- Pytorch 2.5.1+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3 |
AndresR2909/unsloth_Meta-Llama-3.1-8B-Instruct-bnb-4bit_16bit | AndresR2909 | 2025-04-27T04:33:10Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-27T04:28:00Z | ---
base_model: unsloth/meta-llama-3.1-8b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** AndresR2909
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
TOMFORD79/Mix11.1 | TOMFORD79 | 2025-04-27T04:29:18Z | 0 | 0 | null | [
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] | any-to-any | 2025-04-27T04:25:02Z | ---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
sothatsit/RoyalUrModels | sothatsit | 2025-04-27T04:11:36Z | 0 | 3 | null | [
"license:mit",
"region:us"
] | null | 2024-02-24T16:17:46Z | ---
license: mit
---
# RoyalUr - Solved Royal Game of Ur Models
This repository contains solved [Royal Game of Ur](https://en.wikipedia.org/wiki/Royal_Game_of_Ur)
models for many different [rule sets](https://royalur.net/rules).
We will add more information here as we further develop the libraries for using these models:
[RoyalUr-Java](https://github.com/RoyalUr/RoyalUr-Java) and [RoyalUr-Python](https://github.com/RoyalUr/RoyalUr-Python).
We have an article about solving the game here: [https://royalur.net/solved](https://royalur.net/solved)
## The Models
Rule sets:
* **finkel** - The famous Finkel rule set by Irving Finkel.
* **masters3d** - The Masters rule set by James Masters.
* **masters** - An old version of the Masters rule set by James Masters that uses 4 dice instead of 3.
* **blitz** - The Blitz rule set by RoyalUr.net.
* **aseb** - Simple rule set based upon the Finkel rule set, but using the Aseb board shape.
* **finkel2p** - A variant of the Finkel rule set that uses only 2 pieces per player (useful for testing).
Data types:
* **No suffix** - 16-bit percentage values (0 = 0%, 2^16 - 1 = 100%).
* **_f64** - 64-bit floating point values.
|
RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf | RichardErkhov | 2025-04-27T04:10:03Z | 0 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-04-27T01:49:30Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
krx-qwen2.5-0.0.0 - GGUF
- Model creator: https://huggingface.co/KR-X-AI/
- Original model: https://huggingface.co/KR-X-AI/krx-qwen2.5-0.0.0/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [krx-qwen2.5-0.0.0.Q2_K.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q2_K.gguf) | Q2_K | 2.81GB |
| [krx-qwen2.5-0.0.0.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.IQ3_XS.gguf) | IQ3_XS | 3.12GB |
| [krx-qwen2.5-0.0.0.IQ3_S.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.IQ3_S.gguf) | IQ3_S | 3.26GB |
| [krx-qwen2.5-0.0.0.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q3_K_S.gguf) | Q3_K_S | 3.25GB |
| [krx-qwen2.5-0.0.0.IQ3_M.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.IQ3_M.gguf) | IQ3_M | 3.33GB |
| [krx-qwen2.5-0.0.0.Q3_K.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q3_K.gguf) | Q3_K | 3.55GB |
| [krx-qwen2.5-0.0.0.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q3_K_M.gguf) | Q3_K_M | 3.55GB |
| [krx-qwen2.5-0.0.0.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q3_K_L.gguf) | Q3_K_L | 3.81GB |
| [krx-qwen2.5-0.0.0.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.IQ4_XS.gguf) | IQ4_XS | 3.96GB |
| [krx-qwen2.5-0.0.0.Q4_0.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q4_0.gguf) | Q4_0 | 4.13GB |
| [krx-qwen2.5-0.0.0.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.IQ4_NL.gguf) | IQ4_NL | 4.16GB |
| [krx-qwen2.5-0.0.0.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q4_K_S.gguf) | Q4_K_S | 4.15GB |
| [krx-qwen2.5-0.0.0.Q4_K.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q4_K.gguf) | Q4_K | 4.36GB |
| [krx-qwen2.5-0.0.0.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q4_K_M.gguf) | Q4_K_M | 4.36GB |
| [krx-qwen2.5-0.0.0.Q4_1.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q4_1.gguf) | Q4_1 | 4.54GB |
| [krx-qwen2.5-0.0.0.Q5_0.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q5_0.gguf) | Q5_0 | 4.95GB |
| [krx-qwen2.5-0.0.0.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q5_K_S.gguf) | Q5_K_S | 4.95GB |
| [krx-qwen2.5-0.0.0.Q5_K.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q5_K.gguf) | Q5_K | 5.07GB |
| [krx-qwen2.5-0.0.0.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q5_K_M.gguf) | Q5_K_M | 5.07GB |
| [krx-qwen2.5-0.0.0.Q5_1.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q5_1.gguf) | Q5_1 | 5.36GB |
| [krx-qwen2.5-0.0.0.Q6_K.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q6_K.gguf) | Q6_K | 5.82GB |
| [krx-qwen2.5-0.0.0.Q8_0.gguf](https://huggingface.co/RichardErkhov/KR-X-AI_-_krx-qwen2.5-0.0.0-gguf/blob/main/krx-qwen2.5-0.0.0.Q8_0.gguf) | Q8_0 | 7.54GB |
Original model description:
---
base_model: KR-X-AI/krx-qwen2.5-7B-pt
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** KR-X-AI
- **License:** apache-2.0
- **Finetuned from model :** KR-X-AI/krx-qwen2.5-7B-pt
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
TOMFORD79/Mix6 | TOMFORD79 | 2025-04-27T03:52:23Z | 0 | 0 | null | [
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] | any-to-any | 2025-04-27T03:37:31Z | ---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
ShooflyAI/Diego | ShooflyAI | 2025-04-27T03:40:43Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-04-27T03:40:41Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: Diego
---
# Diego
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `Diego` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "Diego",
"lora_weights": "https://huggingface.co/ShooflyAI/Diego/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('ShooflyAI/Diego', weight_name='lora.safetensors')
image = pipeline('Diego').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/ShooflyAI/Diego/discussions) to add images that show off what you’ve made with this LoRA.
|
AchrafAzzaouiRiceU/26_4-26 | AchrafAzzaouiRiceU | 2025-04-27T03:38:15Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2025-04-27T03:36:26Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
sakura1225/pasa-7b-crawler-Q4_K_M-GGUF | sakura1225 | 2025-04-27T03:28:24Z | 0 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:CarlanLark/pasa-dataset",
"base_model:bytedance-research/pasa-7b-crawler",
"base_model:quantized:bytedance-research/pasa-7b-crawler",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-04-27T03:28:01Z | ---
base_model: bytedance-research/pasa-7b-crawler
datasets:
- CarlanLark/pasa-dataset
language:
- en
license: cc-by-nc-sa-4.0
metrics:
- recall
- precision
tags:
- llama-cpp
- gguf-my-repo
---
# sakura1225/pasa-7b-crawler-Q4_K_M-GGUF
This model was converted to GGUF format from [`bytedance-research/pasa-7b-crawler`](https://huggingface.co/bytedance-research/pasa-7b-crawler) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/bytedance-research/pasa-7b-crawler) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo sakura1225/pasa-7b-crawler-Q4_K_M-GGUF --hf-file pasa-7b-crawler-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo sakura1225/pasa-7b-crawler-Q4_K_M-GGUF --hf-file pasa-7b-crawler-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo sakura1225/pasa-7b-crawler-Q4_K_M-GGUF --hf-file pasa-7b-crawler-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo sakura1225/pasa-7b-crawler-Q4_K_M-GGUF --hf-file pasa-7b-crawler-q4_k_m.gguf -c 2048
```
|
xiaoyuanliu/Qwen2.5-3B-simplerl-ppo-offline.critique-012-6k | xiaoyuanliu | 2025-04-27T03:27:39Z | 1 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-25T06:31:38Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
kierankai11/DeepSeek-R1-PSLE-Comprehension-v2-LoRA-Adapters | kierankai11 | 2025-04-27T03:27:25Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"sft",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-04-27T03:24:17Z | ---
base_model: unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** kierankai11
- **License:** apache-2.0
- **Finetuned from model :** unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
stpete2/qwen2.5-0.5b-gsm8k-drgrpo | stpete2 | 2025-04-27T03:11:56Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"conversational",
"dataset:stpete2/openai-gsm8k-part",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-0.5B",
"base_model:finetune:Qwen/Qwen2.5-0.5B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-27T02:29:33Z | ---
base_model: Qwen/Qwen2.5-0.5B
datasets: stpete2/openai-gsm8k-part
library_name: transformers
tags:
- generated_from_trainer
- open-r1
licence: license
---
https://www.kaggle.com/code/stpeteishii/openr1-qwen2-5-0-5b-gsm8k-drgrpo-0424
# Model Card for None
This model is a fine-tuned version of [Qwen/Qwen2.5-0.5B](https://huggingface.co/Qwen/Qwen2.5-0.5B) on the [stpete2/openai-gsm8k-part](https://huggingface.co/datasets/stpete2/openai-gsm8k-part) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/stpeteishii/huggingface/runs/lps3ljwm)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1+cu121
- Datasets: 3.3.1
- Tokenizers: 0.21.0
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
feelyzfdczrl/feelyzf | feelyzfdczrl | 2025-04-27T03:11:52Z | 0 | 0 | espnet | [
"espnet",
"music",
"fill-mask",
"ae",
"am",
"av",
"dataset:open-thoughts/OpenThoughts2-1M",
"base_model:Qwen/Qwen2.5-Omni-7B",
"base_model:finetune:Qwen/Qwen2.5-Omni-7B",
"license:bigcode-openrail-m",
"region:us"
] | fill-mask | 2025-04-27T03:11:11Z | ---
license: bigcode-openrail-m
datasets:
- open-thoughts/OpenThoughts2-1M
language:
- ae
- am
- av
metrics:
- brier_score
base_model:
- Qwen/Qwen2.5-Omni-7B
new_version: black-forest-labs/FLUX.1-dev
pipeline_tag: fill-mask
library_name: espnet
tags:
- music
--- |
billingsmoore/tibetan-to-english-translation-v0 | billingsmoore | 2025-04-27T03:06:02Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"tibetan",
"english",
"translation",
"nlp",
"buddhism",
"dharma",
"bo",
"en",
"dataset:billingsmoore/tibetan-to-english-translation-dataset",
"base_model:billingsmoore/phonetic-tibetan-to-english-translation",
"base_model:finetune:billingsmoore/phonetic-tibetan-to-english-translation",
"license:cc",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | translation | 2024-09-30T20:26:33Z | ---
base_model:
- google-t5/t5-large
- billingsmoore/phonetic-tibetan-to-english-translation
datasets:
- billingsmoore/tibetan-to-english-translation-dataset
language:
- bo
- en
library_name: transformers
license: cc
metrics:
- bleu
pipeline_tag: translation
tags:
- tibetan
- english
- translation
- nlp
- buddhism
- dharma
---
# Model Card for tibetan-to-english-translation
This model is a neural machine translation model for translating Literary Tibetan to English.
The model expects Tibetan text in either Tibetan script or transliterated according to THL Simplified Phonetic Transliteration as an input and outputs an English translation.
This work is licensed under Creative Commons Attribution-NonCommercial 4.0 International
## Model Details
### Model Description
This model is a finetuned T5 model with 770 million parameters.
- **Developed by:** billingsmoore
- **Languages (NLP):** Tibetan, English
- **License:** [Attribution-NonCommercial 4.0 International](https://creativecommons.org/licenses/by-nc/4.0/)
- **Finetuned from model:** 'google-t5/t5-large'
### Model Sources
- **Repository:** [MLotsawa on Github](https://github.com/billingsmoore/MLotsawa)
## Uses
This model is intended to be used as the translation model in the larger MLotsawa software, but can also be used in a Jupyter notebook or Python script.
### Direct Use
To use this model for translation you can use the following code:
```python
from transformers import pipeline
translator = pipeline('translation', 'billingsmoore/tibetan-to-english-translation')
input_text = <your transliterated Tibetan text>
translation = translator(input_text)
print(translation)
```
### Downstream Use
The model can be further finetuned using the following code:
```python
from datasets import load_dataset
from transformers import (
AutoTokenizer, DataCollatorForSeq2Seq,
AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments,
Seq2SeqTrainer, EarlyStoppingCallback, Adafactor
)
import evaluate
import numpy as np
from accelerate import Accelerator
data = load_dataset(<path_to_your_dataset>)
checkpoint = "billingsmoore/tibetan-to-english-translation"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint)
source_lang = 'bo'
target_lang = 'en'
prefix = "translate Tibetan to English: "
def preprocess_function(examples):
inputs = [prefix + example[source_lang] for example in examples['translation']]
targets = [example[target_lang] for example in examples['translation']]
model_inputs = tokenizer(inputs, text_target=targets, max_length=128, truncation=True)
return model_inputs
tokenized_dataset = dataset.map(preprocess_function, batched=True)
metric = evaluate.load("sacrebleu")
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [[label.strip()] for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
result = {"bleu": result["score"]}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
result = {k: round(v, 4) for k, v in result.items()}
return result
early_stop = EarlyStoppingCallback()
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint, device_map="auto")
optimizer = Adafactor(
model.parameters(),
scale_parameter=True,
relative_step=False,
warmup_init=False,
lr=3e-4
)
training_args = Seq2SeqTrainingArguments(
output_dir=".",
auto_find_batch_size=True,
predict_with_generate=True,
fp16=False, #check this
push_to_hub=False,
eval_strategy='epoch',
save_strategy='epoch',
load_best_model_at_end=True
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset['train'],
eval_dataset=tokenized_dataset['test'],
tokenizer=tokenizer,
optimizers=(optimizer, None),
data_collator=data_collator,
compute_metrics=compute_metrics,
callbacks=[early_stop]
)
trainer.train()
```
## Training Details
### Training Data
[Training Data for this project is available here.](https://www.kaggle.com/datasets/billingsmoore/classical-tibetan-to-english-translation-dataset)
This dataset consists of 100,000 pairs of sentences or phrases. The first member of each pair is a sentence or phrase in Classical Tibetan. The second member is the English translation of the first.
The pairs are pulled from texts sourced from Lotsawa House (lotsawahouse.org) and are offered under the same license as the original texts they provided.
This data was scraped, cleaned, and formatted programmatically.
### Training Procedure
The t5 tokenizer was updated in the same manner as ['billingsmoore/tibetan-phonetic-transliteration'](https://huggingface.co/billingsmoore/tibetan-phonetic-transliteration), the procedure for which can be found on that model card.
Beyond the training for ['billingsmoore/phonetic-tibetan-to-english-translation'](https://huggingface.co/billingsmoore/phonetic-tibetan-to-english-translation) whose full training is described in its model card,
this model was trained for 9 epochs on the dataset ['billingsmoore/tibetan-to-english-translation-dataset'](https://huggingface.co/datasets/billingsmoore/tibetan-to-english-translation-dataset)
#### Training Hyperparameters
- This model was trained using the Adafactor optimizer with a learning rate of 2e-5.
## Evaluation
The evaluation metric for this model was the BLEU score as implemented by [sacreBLEU](https://pypi.org/project/sacrebleu/).
BLEU (Bilingual Evaluation Understudy) scores measure the quality of
machine-generated translations by comparing them to human-provided reference translations. The score ranges from 0 to 100,
where 100 represents a perfect match with the reference translations. It evaluates the precision of n-grams (word sequences)
in the generated text, with higher scores indicating closer alignment to the reference translations. A brevity penalty is applied
to discourage translations that are too short. |
genki10/BERT_V8_sp10_lw40_ex50_lo100_k7_k7_fold1 | genki10 | 2025-04-27T03:04:34Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-04-27T02:44:40Z | ---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_V8_sp10_lw40_ex50_lo100_k7_k7_fold1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_V8_sp10_lw40_ex50_lo100_k7_k7_fold1
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3624
- Qwk: 0.1344
- Mse: 1.3609
- Rmse: 1.1666
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:------:|
| No log | 1.0 | 5 | 11.3554 | -0.0176 | 11.3528 | 3.3694 |
| No log | 2.0 | 10 | 6.6523 | 0.0 | 6.6501 | 2.5788 |
| No log | 3.0 | 15 | 3.8980 | 0.0040 | 3.8960 | 1.9738 |
| No log | 4.0 | 20 | 1.8681 | 0.0424 | 1.8665 | 1.3662 |
| No log | 5.0 | 25 | 0.9928 | 0.0 | 0.9915 | 0.9957 |
| No log | 6.0 | 30 | 0.9403 | 0.0943 | 0.9391 | 0.9690 |
| No log | 7.0 | 35 | 0.9271 | 0.1833 | 0.9259 | 0.9622 |
| No log | 8.0 | 40 | 1.0334 | 0.1164 | 1.0323 | 1.0160 |
| No log | 9.0 | 45 | 2.0593 | 0.0544 | 2.0577 | 1.4345 |
| No log | 10.0 | 50 | 0.8120 | 0.2608 | 0.8112 | 0.9007 |
| No log | 11.0 | 55 | 1.5141 | 0.0963 | 1.5125 | 1.2299 |
| No log | 12.0 | 60 | 1.0375 | 0.1903 | 1.0364 | 1.0180 |
| No log | 13.0 | 65 | 0.8695 | 0.2734 | 0.8687 | 0.9321 |
| No log | 14.0 | 70 | 1.1734 | 0.1281 | 1.1723 | 1.0827 |
| No log | 15.0 | 75 | 1.3933 | 0.1315 | 1.3919 | 1.1798 |
| No log | 16.0 | 80 | 0.9251 | 0.2923 | 0.9245 | 0.9615 |
| No log | 17.0 | 85 | 1.7059 | 0.0867 | 1.7046 | 1.3056 |
| No log | 18.0 | 90 | 1.0326 | 0.2197 | 1.0321 | 1.0159 |
| No log | 19.0 | 95 | 2.1164 | 0.0723 | 2.1149 | 1.4543 |
| No log | 20.0 | 100 | 0.9352 | 0.2321 | 0.9346 | 0.9667 |
| No log | 21.0 | 105 | 1.0534 | 0.1674 | 1.0525 | 1.0259 |
| No log | 22.0 | 110 | 1.4009 | 0.1558 | 1.3997 | 1.1831 |
| No log | 23.0 | 115 | 1.1869 | 0.1945 | 1.1860 | 1.0890 |
| No log | 24.0 | 120 | 1.3724 | 0.1173 | 1.3712 | 1.1710 |
| No log | 25.0 | 125 | 1.2744 | 0.1608 | 1.2731 | 1.1283 |
| No log | 26.0 | 130 | 1.3753 | 0.1593 | 1.3738 | 1.1721 |
| No log | 27.0 | 135 | 1.2563 | 0.1971 | 1.2550 | 1.1203 |
| No log | 28.0 | 140 | 1.2890 | 0.1685 | 1.2877 | 1.1348 |
| No log | 29.0 | 145 | 1.2650 | 0.1218 | 1.2636 | 1.1241 |
| No log | 30.0 | 150 | 1.4472 | 0.1669 | 1.4458 | 1.2024 |
| No log | 31.0 | 155 | 1.1764 | 0.1403 | 1.1750 | 1.0840 |
| No log | 32.0 | 160 | 1.1922 | 0.1675 | 1.1908 | 1.0912 |
| No log | 33.0 | 165 | 1.3896 | 0.1517 | 1.3880 | 1.1782 |
| No log | 34.0 | 170 | 1.5695 | 0.1608 | 1.5678 | 1.2521 |
| No log | 35.0 | 175 | 1.0876 | 0.1659 | 1.0863 | 1.0422 |
| No log | 36.0 | 180 | 1.6640 | 0.1232 | 1.6622 | 1.2893 |
| No log | 37.0 | 185 | 1.0493 | 0.1597 | 1.0483 | 1.0238 |
| No log | 38.0 | 190 | 1.7360 | 0.0912 | 1.7343 | 1.3169 |
| No log | 39.0 | 195 | 1.4555 | 0.1100 | 1.4539 | 1.2058 |
| No log | 40.0 | 200 | 1.2650 | 0.1420 | 1.2637 | 1.1241 |
| No log | 41.0 | 205 | 1.2878 | 0.1380 | 1.2863 | 1.1342 |
| No log | 42.0 | 210 | 1.2076 | 0.1248 | 1.2062 | 1.0983 |
| No log | 43.0 | 215 | 1.3127 | 0.1557 | 1.3112 | 1.1451 |
| No log | 44.0 | 220 | 1.2656 | 0.1544 | 1.2642 | 1.1244 |
| No log | 45.0 | 225 | 1.5188 | 0.0972 | 1.5171 | 1.2317 |
| No log | 46.0 | 230 | 1.3624 | 0.1344 | 1.3609 | 1.1666 |
### Framework versions
- Transformers 4.51.1
- Pytorch 2.5.1+cu124
- Datasets 3.5.0
- Tokenizers 0.21.0
|
billingsmoore/tibetan-to-spanish-translation-v0 | billingsmoore | 2025-04-27T03:04:07Z | 36 | 0 | null | [
"safetensors",
"t5",
"buddhism",
"translation",
"mlotsawa",
"bo",
"es",
"dataset:billingsmoore/tibetan-to-spanish-translation-dataset",
"license:mit",
"region:us"
] | translation | 2025-03-26T21:03:34Z | ---
license: mit
datasets:
- billingsmoore/tibetan-to-spanish-translation-dataset
language:
- bo
- es
metrics:
- bleu
- chrf
- ter
tags:
- buddhism
- translation
- mlotsawa
---
# Model Card for tibetan-to-english-translation
This model is a machine translation model for translating Literary Tibetan to Spanish.
The model expects Tibetan text in Tibetan script as an input and outputs a Spanish translation.
This work is licensed under Creative Commons Attribution-NonCommercial 4.0 International
## Model Details
### Model Description
This model is a finetuned T5 model with 220 million parameters.
- **Developed by:** billingsmoore
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** Tibetan, English
- **License:** [Attribution-NonCommercial 4.0 International](https://creativecommons.org/licenses/by-nc/4.0/)
- **Finetuned from model:** 'google-t5/t5-base'
### Model Sources
- **Repository:** [MLotsawa on Github](https://github.com/billingsmoore/MLotsawa/tree/main/Notebooks/Models/TibetanToSpanishTranslation)
## Uses
This model is intended to be used as the translation model in the larger MLotsawa software, but can also be used in a Jupyter notebook or Python script.
### Direct Use
To use this model for translation you can use the following code:
```python
from transformers import pipeline
translator = pipeline('translation', 'billingsmoore/tibetan-to-spanish-translation-v0')
input_text = <your Tibetan text>
translation = translator(input_text)
print(translation)
```
### Downstream Use
The model can be further finetuned by adapting the finetuning notebooks found in the GitHub repository linked above.
## Training Details
### Training Data
This model was trained on two datasources.
Firstly, the 21.5k translation pairs found in [**billingsmoore/tibetan-to-spanish-translation-dataset**](https://huggingface.co/datasets/billingsmoore/tibetan-to-spanish-translation-dataset). That dataset was was scraped from Lotsawa House and is released under the same license as the texts from which it is sourced.
Secondly, 501 translation pairs of longer sequences which were generously provided by Andres Montano.
10% of this data was set aside for evaluation.
### Training Procedure
Training proceeded in three phases:
First, a custom BytePieceEncoder tokenizer was trained to accomodate the Tibetan text and the unique vocabulary of the Buddhist corpus.
Second, the model underwent continued pretraining on the training data. Pretraining for a T5 model consists of corrupting spans of text and having the model predict the missing span. This was performed for 2 epochs with a final loss of 0.037.
Third, the model was finetuned on the training data for 18 epochs, after which training was stopped by an early stopping callback.
#### Training Hyperparameters
- This model was trained using the Adafactor optimizer with a learning rate of 3e-4.
## Evaluation
The model was evaluted with [BLEU](https://en.wikipedia.org/wiki/BLEU), [chrF](https://machinetranslate.org/chrF), and [TER](https://machinetranslate.org/ter), on the evaluation data.
The result of evaluation were:
- **BLEU:** 75.5765
- **chrF:** 80.1954
- **TER:** 28.3847
Please note that the training and evaluation was performed on an extremely small datasets and these metrics should not be taken as representative of performance in ordinary usage. |
Szeyu/write4 | Szeyu | 2025-04-27T02:54:23Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-04-27T02:54:11Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
genki10/BERT_V8_sp10_lw40_ex50_lo100_k7_k7_fold0 | genki10 | 2025-04-27T02:44:35Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-04-27T02:22:01Z | ---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_V8_sp10_lw40_ex50_lo100_k7_k7_fold0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_V8_sp10_lw40_ex50_lo100_k7_k7_fold0
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6253
- Qwk: 0.5086
- Mse: 0.6253
- Rmse: 0.7907
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| No log | 1.0 | 5 | 7.1220 | 0.0 | 7.1220 | 2.6687 |
| No log | 2.0 | 10 | 5.1727 | 0.0115 | 5.1727 | 2.2744 |
| No log | 3.0 | 15 | 3.2671 | 0.0 | 3.2671 | 1.8075 |
| No log | 4.0 | 20 | 1.8577 | 0.0316 | 1.8577 | 1.3630 |
| No log | 5.0 | 25 | 1.3096 | 0.0106 | 1.3096 | 1.1444 |
| No log | 6.0 | 30 | 0.8892 | 0.1094 | 0.8892 | 0.9430 |
| No log | 7.0 | 35 | 0.8723 | 0.1505 | 0.8723 | 0.9340 |
| No log | 8.0 | 40 | 0.7603 | 0.4557 | 0.7603 | 0.8720 |
| No log | 9.0 | 45 | 0.8167 | 0.3068 | 0.8167 | 0.9037 |
| No log | 10.0 | 50 | 0.9344 | 0.3556 | 0.9344 | 0.9667 |
| No log | 11.0 | 55 | 0.7194 | 0.2692 | 0.7194 | 0.8481 |
| No log | 12.0 | 60 | 0.7814 | 0.2869 | 0.7814 | 0.8840 |
| No log | 13.0 | 65 | 0.6057 | 0.3666 | 0.6057 | 0.7783 |
| No log | 14.0 | 70 | 0.7450 | 0.4037 | 0.7450 | 0.8631 |
| No log | 15.0 | 75 | 0.6215 | 0.3162 | 0.6215 | 0.7883 |
| No log | 16.0 | 80 | 0.5956 | 0.4693 | 0.5956 | 0.7717 |
| No log | 17.0 | 85 | 0.7319 | 0.4595 | 0.7319 | 0.8555 |
| No log | 18.0 | 90 | 0.6331 | 0.4690 | 0.6331 | 0.7957 |
| No log | 19.0 | 95 | 0.5870 | 0.4868 | 0.5870 | 0.7662 |
| No log | 20.0 | 100 | 0.6067 | 0.4790 | 0.6067 | 0.7789 |
| No log | 21.0 | 105 | 0.8766 | 0.4028 | 0.8766 | 0.9362 |
| No log | 22.0 | 110 | 0.6293 | 0.4747 | 0.6293 | 0.7933 |
| No log | 23.0 | 115 | 0.5514 | 0.5584 | 0.5514 | 0.7426 |
| No log | 24.0 | 120 | 0.6230 | 0.4610 | 0.6230 | 0.7893 |
| No log | 25.0 | 125 | 0.7110 | 0.4335 | 0.7110 | 0.8432 |
| No log | 26.0 | 130 | 0.6617 | 0.4628 | 0.6617 | 0.8134 |
| No log | 27.0 | 135 | 1.0245 | 0.3307 | 1.0245 | 1.0122 |
| No log | 28.0 | 140 | 0.5546 | 0.5506 | 0.5546 | 0.7447 |
| No log | 29.0 | 145 | 0.7311 | 0.4647 | 0.7311 | 0.8550 |
| No log | 30.0 | 150 | 0.6437 | 0.4670 | 0.6437 | 0.8023 |
| No log | 31.0 | 155 | 0.7176 | 0.4344 | 0.7176 | 0.8471 |
| No log | 32.0 | 160 | 0.6546 | 0.4544 | 0.6546 | 0.8091 |
| No log | 33.0 | 165 | 0.7253 | 0.4176 | 0.7253 | 0.8517 |
| No log | 34.0 | 170 | 0.6450 | 0.4146 | 0.6450 | 0.8031 |
| No log | 35.0 | 175 | 0.8850 | 0.3665 | 0.8850 | 0.9407 |
| No log | 36.0 | 180 | 0.6892 | 0.4291 | 0.6892 | 0.8302 |
| No log | 37.0 | 185 | 0.5822 | 0.4560 | 0.5822 | 0.7630 |
| No log | 38.0 | 190 | 0.5541 | 0.5250 | 0.5541 | 0.7444 |
| No log | 39.0 | 195 | 0.6101 | 0.4989 | 0.6101 | 0.7811 |
| No log | 40.0 | 200 | 0.5823 | 0.5284 | 0.5823 | 0.7631 |
| No log | 41.0 | 205 | 0.5919 | 0.4825 | 0.5919 | 0.7694 |
| No log | 42.0 | 210 | 0.6745 | 0.4669 | 0.6745 | 0.8213 |
| No log | 43.0 | 215 | 0.5624 | 0.5029 | 0.5624 | 0.7499 |
| No log | 44.0 | 220 | 0.5763 | 0.5015 | 0.5763 | 0.7591 |
| No log | 45.0 | 225 | 0.6081 | 0.4977 | 0.6081 | 0.7798 |
| No log | 46.0 | 230 | 0.5619 | 0.5048 | 0.5619 | 0.7496 |
| No log | 47.0 | 235 | 0.6181 | 0.5095 | 0.6181 | 0.7862 |
| No log | 48.0 | 240 | 0.5667 | 0.5207 | 0.5667 | 0.7528 |
| No log | 49.0 | 245 | 0.5481 | 0.5275 | 0.5481 | 0.7403 |
| No log | 50.0 | 250 | 0.6404 | 0.4971 | 0.6404 | 0.8003 |
| No log | 51.0 | 255 | 0.5513 | 0.5575 | 0.5513 | 0.7425 |
| No log | 52.0 | 260 | 0.5612 | 0.5362 | 0.5612 | 0.7491 |
| No log | 53.0 | 265 | 0.6253 | 0.5086 | 0.6253 | 0.7907 |
### Framework versions
- Transformers 4.51.1
- Pytorch 2.5.1+cu124
- Datasets 3.5.0
- Tokenizers 0.21.0
|
sergioalves/f7c54b74-4bbc-469f-b9d3-f001e45075de | sergioalves | 2025-04-27T02:34:08Z | 0 | 0 | peft | [
"peft",
"safetensors",
"gpt_neox",
"axolotl",
"generated_from_trainer",
"base_model:databricks/dolly-v2-3b",
"base_model:adapter:databricks/dolly-v2-3b",
"license:mit",
"8-bit",
"bitsandbytes",
"region:us"
] | null | 2025-04-27T02:18:19Z | ---
library_name: peft
license: mit
base_model: databricks/dolly-v2-3b
tags:
- axolotl
- generated_from_trainer
model-index:
- name: f7c54b74-4bbc-469f-b9d3-f001e45075de
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: true
adapter: lora
base_model: databricks/dolly-v2-3b
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- a11c138b38298ed7_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/a11c138b38298ed7_train_data.json
type:
field_input: context
field_instruction: question
field_output: answer
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.5
group_by_length: false
hub_model_id: sergioalves/f7c54b74-4bbc-469f-b9d3-f001e45075de
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-06
load_in_4bit: false
load_in_8bit: true
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/a11c138b38298ed7_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: a862b6db-3d5a-4d35-999e-89bf50c6f99a
wandb_project: s56-8
wandb_run: your_name
wandb_runid: a862b6db-3d5a-4d35-999e-89bf50c6f99a
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# f7c54b74-4bbc-469f-b9d3-f001e45075de
This model is a fine-tuned version of [databricks/dolly-v2-3b](https://huggingface.co/databricks/dolly-v2-3b) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5420
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.4912 | 0.0451 | 200 | 0.5420 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
Sayan01/Phi3-TL-ORCA-10 | Sayan01 | 2025-04-27T02:26:12Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-27T02:24:39Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ridalefdali/llama_3b_fp_rank_16_lora_alpha_32_epoch_1_lora_model_llama_70b | ridalefdali | 2025-04-27T02:21:25Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/Llama-3.2-3B-Instruct",
"base_model:quantized:unsloth/Llama-3.2-3B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-04-27T02:07:03Z | ---
base_model: unsloth/Llama-3.2-3B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** ridalefdali
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Llama-3.2-3B-Instruct
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
rosalinec/ppo-LunarLander-v2 | rosalinec | 2025-04-27T02:18:23Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2025-04-27T02:18:06Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 262.42 +/- 19.39
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
edwindn/orpheus-3b-voiceFinetune-0.2 | edwindn | 2025-04-27T02:16:47Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:canopylabs/orpheus-3b-0.1-pretrained",
"base_model:finetune:canopylabs/orpheus-3b-0.1-pretrained",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-27T01:03:10Z | ---
library_name: transformers
license: apache-2.0
base_model: canopylabs/orpheus-3b-0.1-pretrained
tags:
- generated_from_trainer
model-index:
- name: orpheus-3b-voiceFinetune-0.2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# orpheus-3b-voiceFinetune-0.2
This model is a fine-tuned version of [canopylabs/orpheus-3b-0.1-pretrained](https://huggingface.co/canopylabs/orpheus-3b-0.1-pretrained) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch_fused with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.1.0+cu118
- Datasets 3.5.0
- Tokenizers 0.21.1
|
kostiantynk-outlook/a38c1aa8-b4d1-475a-be82-0c9c3a84a165 | kostiantynk-outlook | 2025-04-27T02:05:21Z | 0 | 0 | peft | [
"peft",
"generated_from_trainer",
"base_model:sophosympatheia/Electranova-70B-v1.0",
"base_model:adapter:sophosympatheia/Electranova-70B-v1.0",
"region:us"
] | null | 2025-04-27T02:03:38Z | ---
library_name: peft
tags:
- generated_from_trainer
base_model: sophosympatheia/Electranova-70B-v1.0
model-index:
- name: kostiantynk-outlook/a38c1aa8-b4d1-475a-be82-0c9c3a84a165
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kostiantynk-outlook/a38c1aa8-b4d1-475a-be82-0c9c3a84a165
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0112
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.3
- Pytorch 2.5.1+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3 |
dzanbek/88115fec-21a7-48dd-a9d7-00d149572ccc | dzanbek | 2025-04-27T01:49:32Z | 0 | 0 | peft | [
"peft",
"safetensors",
"mistral",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/mistral-7b-instruct-v0.2",
"base_model:adapter:unsloth/mistral-7b-instruct-v0.2",
"license:apache-2.0",
"8-bit",
"bitsandbytes",
"region:us"
] | null | 2025-04-27T00:07:18Z | ---
library_name: peft
license: apache-2.0
base_model: unsloth/mistral-7b-instruct-v0.2
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 88115fec-21a7-48dd-a9d7-00d149572ccc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: unsloth/mistral-7b-instruct-v0.2
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 9ddca7aa4e960bfe_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/9ddca7aa4e960bfe_train_data.json
type:
field_input: text
field_instruction: prompt
field_output: response
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_clipping: 0.5
group_by_length: false
hub_model_id: dzanbek/88115fec-21a7-48dd-a9d7-00d149572ccc
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-06
load_in_4bit: false
load_in_8bit: true
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/9ddca7aa4e960bfe_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 8dd130e9-5673-4235-a933-9e6897947742
wandb_project: s56-2
wandb_run: your_name
wandb_runid: 8dd130e9-5673-4235-a933-9e6897947742
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# 88115fec-21a7-48dd-a9d7-00d149572ccc
This model is a fine-tuned version of [unsloth/mistral-7b-instruct-v0.2](https://huggingface.co/unsloth/mistral-7b-instruct-v0.2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0233
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.0117 | 0.0077 | 200 | 0.0233 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
genki10/BERT_V8_sp10_lw40_ex50_lo50_k7_k7_fold2 | genki10 | 2025-04-27T01:43:43Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-04-27T01:26:51Z | ---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_V8_sp10_lw40_ex50_lo50_k7_k7_fold2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_V8_sp10_lw40_ex50_lo50_k7_k7_fold2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7245
- Qwk: 0.4066
- Mse: 0.7244
- Rmse: 0.8511
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| No log | 1.0 | 4 | 9.4678 | 0.0018 | 9.4680 | 3.0770 |
| No log | 2.0 | 8 | 5.6498 | 0.0125 | 5.6504 | 2.3771 |
| No log | 3.0 | 12 | 3.2526 | 0.0078 | 3.2532 | 1.8037 |
| No log | 4.0 | 16 | 1.7447 | 0.0475 | 1.7452 | 1.3210 |
| No log | 5.0 | 20 | 1.0805 | 0.0213 | 1.0809 | 1.0397 |
| No log | 6.0 | 24 | 0.7882 | 0.3093 | 0.7886 | 0.8880 |
| No log | 7.0 | 28 | 0.8520 | 0.0851 | 0.8524 | 0.9233 |
| No log | 8.0 | 32 | 0.6906 | 0.4648 | 0.6909 | 0.8312 |
| No log | 9.0 | 36 | 0.6094 | 0.3077 | 0.6094 | 0.7806 |
| No log | 10.0 | 40 | 0.6223 | 0.4521 | 0.6225 | 0.7890 |
| No log | 11.0 | 44 | 0.5708 | 0.5298 | 0.5709 | 0.7556 |
| No log | 12.0 | 48 | 0.7110 | 0.5292 | 0.7111 | 0.8433 |
| No log | 13.0 | 52 | 0.5535 | 0.3477 | 0.5535 | 0.7440 |
| No log | 14.0 | 56 | 0.6141 | 0.5041 | 0.6143 | 0.7838 |
| No log | 15.0 | 60 | 0.5143 | 0.5387 | 0.5145 | 0.7173 |
| No log | 16.0 | 64 | 0.6078 | 0.5371 | 0.6082 | 0.7799 |
| No log | 17.0 | 68 | 0.6969 | 0.3852 | 0.6974 | 0.8351 |
| No log | 18.0 | 72 | 0.6101 | 0.4599 | 0.6105 | 0.7813 |
| No log | 19.0 | 76 | 0.5598 | 0.5179 | 0.5599 | 0.7483 |
| No log | 20.0 | 80 | 0.6098 | 0.4876 | 0.6099 | 0.7810 |
| No log | 21.0 | 84 | 0.6362 | 0.4621 | 0.6363 | 0.7977 |
| No log | 22.0 | 88 | 0.8321 | 0.3611 | 0.8322 | 0.9123 |
| No log | 23.0 | 92 | 0.6278 | 0.4595 | 0.6279 | 0.7924 |
| No log | 24.0 | 96 | 0.6298 | 0.4990 | 0.6298 | 0.7936 |
| No log | 25.0 | 100 | 0.8940 | 0.3267 | 0.8943 | 0.9457 |
| No log | 26.0 | 104 | 0.7005 | 0.4875 | 0.7005 | 0.8369 |
| No log | 27.0 | 108 | 1.0902 | 0.2586 | 1.0903 | 1.0442 |
| No log | 28.0 | 112 | 0.5957 | 0.4388 | 0.5958 | 0.7719 |
| No log | 29.0 | 116 | 0.6727 | 0.4529 | 0.6728 | 0.8203 |
| No log | 30.0 | 120 | 0.6313 | 0.4587 | 0.6313 | 0.7946 |
| No log | 31.0 | 124 | 0.6512 | 0.4367 | 0.6513 | 0.8070 |
| No log | 32.0 | 128 | 0.6760 | 0.4341 | 0.6761 | 0.8223 |
| No log | 33.0 | 132 | 0.6208 | 0.4486 | 0.6209 | 0.7880 |
| No log | 34.0 | 136 | 0.6420 | 0.4517 | 0.6422 | 0.8014 |
| No log | 35.0 | 140 | 0.6458 | 0.4303 | 0.6459 | 0.8037 |
| No log | 36.0 | 144 | 0.6184 | 0.4480 | 0.6183 | 0.7863 |
| No log | 37.0 | 148 | 0.7081 | 0.3748 | 0.7080 | 0.8414 |
| No log | 38.0 | 152 | 0.6478 | 0.4258 | 0.6477 | 0.8048 |
| No log | 39.0 | 156 | 0.7801 | 0.3871 | 0.7801 | 0.8832 |
| No log | 40.0 | 160 | 0.5784 | 0.4460 | 0.5784 | 0.7605 |
| No log | 41.0 | 164 | 0.6059 | 0.5240 | 0.6059 | 0.7784 |
| No log | 42.0 | 168 | 0.6172 | 0.5090 | 0.6172 | 0.7856 |
| No log | 43.0 | 172 | 0.6226 | 0.4719 | 0.6227 | 0.7891 |
| No log | 44.0 | 176 | 0.6481 | 0.4294 | 0.6481 | 0.8051 |
| No log | 45.0 | 180 | 0.7245 | 0.4066 | 0.7244 | 0.8511 |
### Framework versions
- Transformers 4.51.1
- Pytorch 2.5.1+cu124
- Datasets 3.5.0
- Tokenizers 0.21.0
|
monicaluke/monicaluke | monicaluke | 2025-04-27T01:31:00Z | 0 | 0 | null | [
"license:bigscience-openrail-m",
"region:us"
] | null | 2025-04-27T01:30:59Z | ---
license: bigscience-openrail-m
---
|
Alphatao/baead3d7-4b59-4742-8a3b-2a997e398308 | Alphatao | 2025-04-27T00:50:01Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"axolotl",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"base_model:unsloth/Llama-3.2-3B-Instruct",
"base_model:finetune:unsloth/Llama-3.2-3B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-04-26T17:04:50Z | ---
base_model: unsloth/Llama-3.2-3B-Instruct
library_name: transformers
model_name: baead3d7-4b59-4742-8a3b-2a997e398308
tags:
- generated_from_trainer
- axolotl
- dpo
- trl
licence: license
---
# Model Card for baead3d7-4b59-4742-8a3b-2a997e398308
This model is a fine-tuned version of [unsloth/Llama-3.2-3B-Instruct](https://huggingface.co/unsloth/Llama-3.2-3B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Alphatao/baead3d7-4b59-4742-8a3b-2a997e398308", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/alphatao-alphatao/Gradients-On-Demand/runs/bh7ez4sg)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.0.dev0
- Transformers: 4.46.0
- Pytorch: 2.5.0+cu124
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
ernestinegloria/ernestinegloria | ernestinegloria | 2025-04-27T00:44:54Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2025-04-27T00:44:54Z | ---
license: creativeml-openrail-m
---
|
EthanRhys/GPT-SoVITS-Models | EthanRhys | 2025-04-27T00:33:21Z | 0 | 1 | null | [
"license:openrail++",
"region:us"
] | null | 2024-10-15T14:40:02Z | ---
license: openrail++
---
|
dilarayavuz/md-stylebkd-imdb-part-2-bert-base-uncased | dilarayavuz | 2025-04-27T00:33:00Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"autotrain",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-04-27T00:30:43Z |
---
library_name: transformers
tags:
- autotrain
- text-classification
base_model: google-bert/bert-base-uncased
widget:
- text: "I love AutoTrain"
---
# Model Trained Using AutoTrain
- Problem type: Text Classification
## Validation Metrics
loss: 0.26338109374046326
f1: 0.8960977903149977
precision: 0.9154658981748319
recall: 0.8775322283609577
auc: 0.9610705779948499
accuracy: 0.8895
|
chiefjessie/chiefjessi | chiefjessie | 2025-04-27T00:32:25Z | 0 | 0 | null | [
"license:bigscience-openrail-m",
"region:us"
] | null | 2025-04-27T00:32:25Z | ---
license: bigscience-openrail-m
---
|
sebaproz/sebaproz | sebaproz | 2025-04-27T00:31:09Z | 0 | 0 | null | [
"license:other",
"region:us"
] | null | 2025-04-26T23:38:35Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
--- |
dilarayavuz/md-stylebkd-imdb-part-1-bert-base-uncased | dilarayavuz | 2025-04-27T00:25:57Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"autotrain",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-04-27T00:23:52Z |
---
library_name: transformers
tags:
- autotrain
- text-classification
base_model: google-bert/bert-base-uncased
widget:
- text: "I love AutoTrain"
---
# Model Trained Using AutoTrain
- Problem type: Text Classification
## Validation Metrics
loss: 0.28526002168655396
f1: 0.8928571428571429
precision: 0.8833922261484098
recall: 0.9025270758122743
auc: 0.9535319972155218
accuracy: 0.88
|
ABF54/ABFRVC | ABF54 | 2025-04-27T00:17:34Z | 0 | 0 | null | [
"license:openrail",
"region:us"
] | null | 2023-06-23T22:22:04Z | ---
license: openrail
---
so here it is, the ultimate RVC model made by me
most of the models is from Indonesian
DM me via discord for commision
Discord:abf9148 |
dilarayavuz/md-synbkd-imdb-part-4-bert-base-uncased | dilarayavuz | 2025-04-27T00:17:21Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"autotrain",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-04-27T00:15:13Z |
---
library_name: transformers
tags:
- autotrain
- text-classification
base_model: google-bert/bert-base-uncased
widget:
- text: "I love AutoTrain"
---
# Model Trained Using AutoTrain
- Problem type: Text Classification
## Validation Metrics
loss: 0.3108336627483368
f1: 0.8779405237461163
precision: 0.8585069444444444
recall: 0.8982742960944596
auc: 0.945758179185875
accuracy: 0.8625
|
dilarayavuz/md-synbkd-imdb-part-3-bert-base-uncased | dilarayavuz | 2025-04-27T00:13:12Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"autotrain",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-04-27T00:11:05Z |
---
library_name: transformers
tags:
- autotrain
- text-classification
base_model: google-bert/bert-base-uncased
widget:
- text: "I love AutoTrain"
---
# Model Trained Using AutoTrain
- Problem type: Text Classification
## Validation Metrics
loss: 0.2651340663433075
f1: 0.9012178619756428
precision: 0.903254972875226
recall: 0.8991899189918992
auc: 0.957656283063627
accuracy: 0.8905
|
dilarayavuz/md-synbkd-imdb-part-2-bert-base-uncased | dilarayavuz | 2025-04-27T00:09:15Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"autotrain",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-04-27T00:07:07Z |
---
library_name: transformers
tags:
- autotrain
- text-classification
base_model: google-bert/bert-base-uncased
widget:
- text: "I love AutoTrain"
---
# Model Trained Using AutoTrain
- Problem type: Text Classification
## Validation Metrics
loss: 0.28321704268455505
f1: 0.8999543170397442
precision: 0.8938294010889292
recall: 0.906163753449862
auc: 0.9560075209258881
accuracy: 0.8905
|
Subsets and Splits