
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-16 12:29:00
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 523
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-16 12:28:25
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
sanjayadhikesaven/Llama-2-7b-hf3bit | sanjayadhikesaven | 2024-02-21T20:34:59Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"3-bit",
"gptq",
"region:us"
]
| text-generation | 2024-02-21T20:32:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Technoculture/BioMistral-Hermes-Dare | Technoculture | 2024-02-21T20:22:28Z | 49 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"BioMistral/BioMistral-7B-DARE",
"NousResearch/Nous-Hermes-2-Mistral-7B-DPO",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T20:17:41Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- BioMistral/BioMistral-7B-DARE
- NousResearch/Nous-Hermes-2-Mistral-7B-DPO
---
# BioMistral-Hermes-Dare
BioMistral-Hermes-Dare is a merge of the following models:
* [BioMistral/BioMistral-7B-DARE](https://huggingface.co/BioMistral/BioMistral-7B-DARE)
* [NousResearch/Nous-Hermes-2-Mistral-7B-DPO](https://huggingface.co/NousResearch/Nous-Hermes-2-Mistral-7B-DPO)
## Evaluations
| Benchmark | BioMistral-Hermes-Dare | Orca-2-7b | llama-2-7b | meditron-7b | meditron-70b |
| --- | --- | --- | --- | --- | --- |
| MedMCQA | | | | | |
| ClosedPubMedQA | | | | | |
| PubMedQA | | | | | |
| MedQA | | | | | |
| MedQA4 | | | | | |
| MedicationQA | | | | | |
| MMLU Medical | | | | | |
| MMLU | | | | | |
| TruthfulQA | | | | | |
| GSM8K | | | | | |
| ARC | | | | | |
| HellaSwag | | | | | |
| Winogrande | | | | | |
More details on the Open LLM Leaderboard evaluation results can be found here.
## 🧩 Configuration
```yaml
models:
- model: BioMistral/BioMistral-7B-DARE
parameters:
weight: 1.0
- model: NousResearch/Nous-Hermes-2-Mistral-7B-DPO
parameters:
weight: 0.6
merge_method: linear
dtype: float16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Technoculture/BioMistral-Hermes-Dare"
messages = [{"role": "user", "content": "I am feeling sleepy these days"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
megaaziib/Miacaroni-7B-Indonesia | megaaziib | 2024-02-21T20:20:18Z | 10 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"SanjiWatsuki/Loyal-Macaroni-Maid-7B",
"indischepartij/OpenMia-Indo-Mistral-7b-v4",
"base_model:SanjiWatsuki/Loyal-Macaroni-Maid-7B",
"base_model:merge:SanjiWatsuki/Loyal-Macaroni-Maid-7B",
"base_model:indischepartij/OpenMia-Indo-Mistral-7b-v4",
"base_model:merge:indischepartij/OpenMia-Indo-Mistral-7b-v4",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T20:14:17Z | ---
tags:
- merge
- mergekit
- lazymergekit
- SanjiWatsuki/Loyal-Macaroni-Maid-7B
- indischepartij/OpenMia-Indo-Mistral-7b-v4
base_model:
- SanjiWatsuki/Loyal-Macaroni-Maid-7B
- indischepartij/OpenMia-Indo-Mistral-7b-v4
---
# Miacaroni-7B-Indonesia
Miacaroni-7B-Indonesia is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [SanjiWatsuki/Loyal-Macaroni-Maid-7B](https://huggingface.co/SanjiWatsuki/Loyal-Macaroni-Maid-7B)
* [indischepartij/OpenMia-Indo-Mistral-7b-v4](https://huggingface.co/indischepartij/OpenMia-Indo-Mistral-7b-v4)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: SanjiWatsuki/Loyal-Macaroni-Maid-7B
layer_range: [0, 32]
- model: indischepartij/OpenMia-Indo-Mistral-7b-v4
layer_range: [0, 32]
merge_method: slerp
base_model: SanjiWatsuki/Loyal-Macaroni-Maid-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "megaaziib/Miacaroni-7B-Indonesia"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
OscarGalavizC/Reinforce-Cartpole-v1 | OscarGalavizC | 2024-02-21T20:13:56Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2024-02-21T20:13:46Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Cartpole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
eren23/gemma-2b-tr-instruct-test-lora | eren23 | 2024-02-21T20:11:44Z | 2 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:google/gemma-2b-it",
"base_model:adapter:google/gemma-2b-it",
"region:us"
]
| null | 2024-02-21T20:11:39Z | ---
library_name: peft
base_model: google/gemma-2b-it
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2 |
Technoculture/BioMistral-Hermes-Slerp | Technoculture | 2024-02-21T20:10:14Z | 56 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"BioMistral/BioMistral-7B-DARE",
"NousResearch/Nous-Hermes-2-Mistral-7B-DPO",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T20:05:32Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- BioMistral/BioMistral-7B-DARE
- NousResearch/Nous-Hermes-2-Mistral-7B-DPO
---
# BioMistral-Hermes-Slerp
BioMistral-Hermes-Slerp is a merge of the following models:
* [BioMistral/BioMistral-7B-DARE](https://huggingface.co/BioMistral/BioMistral-7B-DARE)
* [NousResearch/Nous-Hermes-2-Mistral-7B-DPO](https://huggingface.co/NousResearch/Nous-Hermes-2-Mistral-7B-DPO)
## Evaluations
| Benchmark | BioMistral-Hermes-Slerp | Orca-2-7b | llama-2-7b | meditron-7b | meditron-70b |
| --- | --- | --- | --- | --- | --- |
| MedMCQA | | | | | |
| ClosedPubMedQA | | | | | |
| PubMedQA | | | | | |
| MedQA | | | | | |
| MedQA4 | | | | | |
| MedicationQA | | | | | |
| MMLU Medical | | | | | |
| MMLU | | | | | |
| TruthfulQA | | | | | |
| GSM8K | | | | | |
| ARC | | | | | |
| HellaSwag | | | | | |
| Winogrande | | | | | |
More details on the Open LLM Leaderboard evaluation results can be found here.
## 🧩 Configuration
```yaml
slices:
- sources:
- model: BioMistral/BioMistral-7B-DARE
layer_range: [0, 32]
- model: NousResearch/Nous-Hermes-2-Mistral-7B-DPO
layer_range: [0, 32]
merge_method: slerp
base_model: NousResearch/Nous-Hermes-2-Mistral-7B-DPO
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5 # fallback for rest of tensors
dtype: float16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Technoculture/BioMistral-Hermes-Slerp"
messages = [{"role": "user", "content": "I am feeling sleepy these days"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
smcleod/Smaug-Mixtral-v0.1-GGUF | smcleod | 2024-02-21T20:08:00Z | 13 | 3 | null | [
"gguf",
"smaug",
"mixtral",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-02-21T02:34:26Z | ---
license: other
license_name: other
license_link: LICENSE
tags:
- smaug
- mixtral
---
GGUF Quantised variants of https://huggingface.co/abacusai/Smaug-Mixtral-v0.1 |
Weni/heading_investigation_e1.0 | Weni | 2024-02-21T19:57:44Z | 1 | 0 | peft | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
]
| null | 2024-02-21T19:36:28Z | ---
license: apache-2.0
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
datasets:
- generator
base_model: mistralai/Mistral-7B-v0.1
model-index:
- name: heading_investigation_e1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# heading_investigation_e1.0
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9729
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 2
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.7.1
- Transformers 4.39.0.dev0
- Pytorch 2.1.0+cu118
- Datasets 2.16.1
- Tokenizers 0.15.1 |
A-Issa-1999/test_1 | A-Issa-1999 | 2024-02-21T19:48:01Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-02-21T19:47:53Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
nes07/mistral-7b-metlife-ia-congreso-balanced-data | nes07 | 2024-02-21T19:47:37Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-02-21T18:10:43Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lex-hue/LexGPT-V2.5 | lex-hue | 2024-02-21T19:39:14Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-05T20:15:32Z | ---
license: mit
---
# Model Card
### Model Name: LexGPT-V2.5
#### Overview:
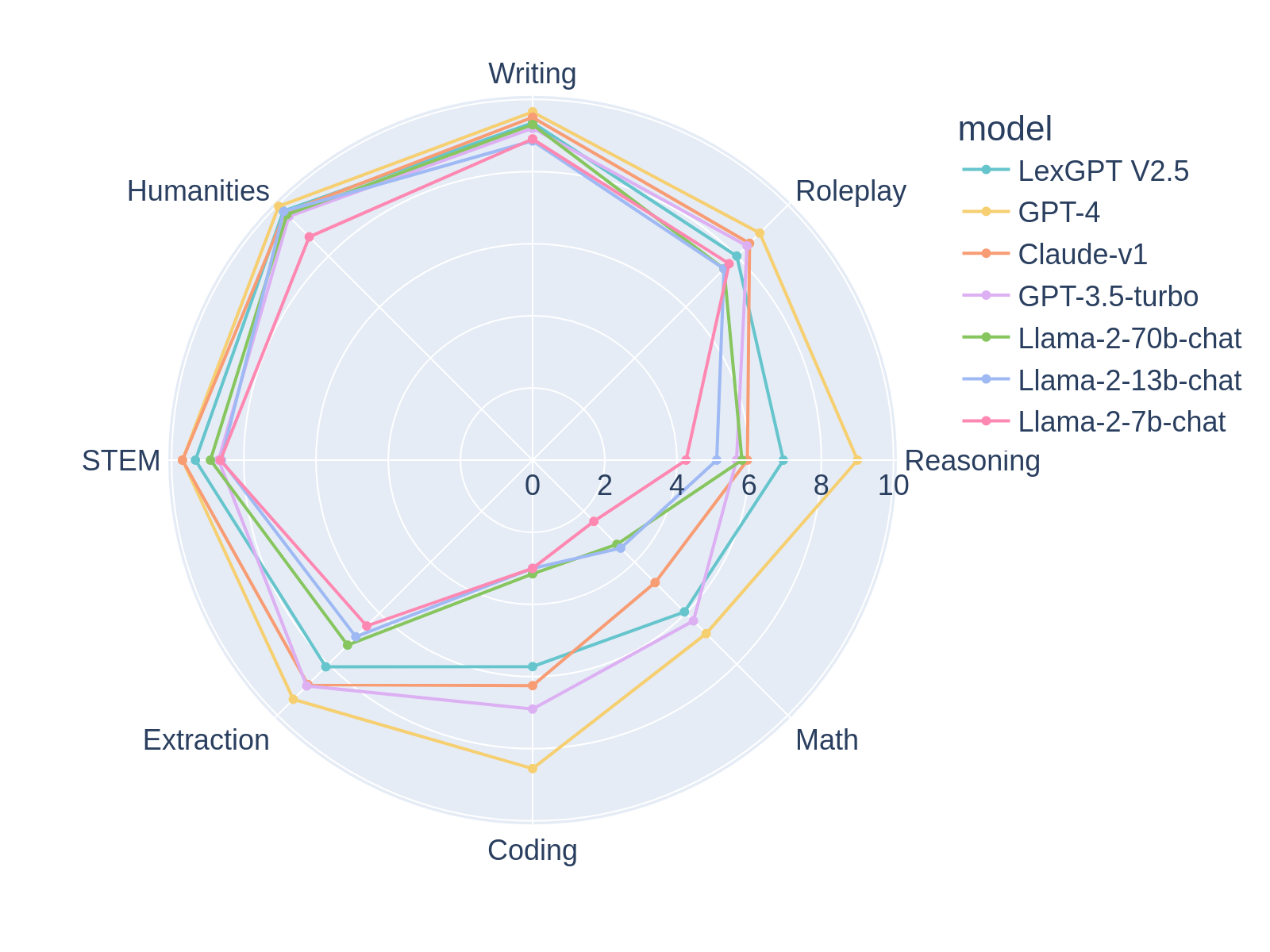
Purpose: This general-purpose language model serves as a powerful tool for personal exploration and learning in the domain of AI development. Its rapid evolution suggests the potential to surpass the performance of some established state-of-the-art models.
Status: The model remains under active development, with continuous improvements leading to more robust capabilities. The next major iteration is undergoing rigorous testing and is expected to release this weekend (Saturday or Sunday).
Skills: LexGPT-2.5 demonstrates impressive reasoning abilities, excelling in STEM (Science, Technology, Engineering, and Math) related fields. Surprisingly, it also possesses a capacity for imaginative engagement, making it surprisingly adept at roleplaying scenarios.
Evaluation: MT-BENCH scores indicate LexGPT-2.5's rapid progress. While it has yet to fully surpass GPT-3.5, its current performance is remarkably close and demonstrates significant potential for further improvement.
MT-BENCH SCORE:
###### First turn
| model | turn | score |
|---|---|---|
| gpt-4 | 1 | 8.956250 |
| claude-v1 | 1 | 8.150000 |
| LexGPT-V2.5 | 1 | 8.075949 |
| gpt-3.5-turbo | 1 | 8.075000 |
| vicuna-13b-v1.3 | 1 | 6.812500 |
###### Second turn
| model | turn | score |
|---|---|---|
| gpt-4 | 2 | 9.0250 |
| gpt-3.5-turbo | 2 | 7.8125 |
| LexGPT-V2.5 | 2 | 7.7500 |
| claude-v1 | 2 | 7.6500 |
| vicuna-13b-v1.3 | 2 | 5.9625 |
###### Average
| model | score |
|---|---|
| gpt-4 | 8.990625 |
| gpt-3.5-turbo | 7.943750 |
| LexGPT-V2.5 | 7.920530 |
| claude-v1 | 7.900000 |
| vicuna-13b-v1.3 | 6.387500 |
### Intended Use:
Primary Use: Designed for general language generation tasks and to facilitate the creator's personal explorations in AI development. It offers a valuable sandbox for experimentation and learning.
Potential Additional Uses: The model's STEM proficiency and roleplaying ability suggest it might find applications in educational tools or creative writing assistants.
Potential Risks: As with many powerful language models, there's a potential for the generation of harmful, biased, or offensive content. Careful monitoring and the implementation of appropriate safeguards are essential.
### Ethical Considerations
The model is largely uncensored, emphasizing user responsibility to avoid using it for illegal or intentionally harmful purposes.
Ongoing evaluation during development is crucial for identifying and addressing potential biases in the model's generated outputs. Transparency and regular updates to this model card will foster ethical awareness in its use.
### Additional Notes
LexGPT-2.5 showcases impressive progress, rapidly approaching the capabilities of GPT-3.5 and hinting at significant untapped potential.
The creator welcomes questions, feedback, and collaboration to continue developing this model responsibly. |
juliowaissman/Reinforce-CartPole-v1 | juliowaissman | 2024-02-21T19:36:32Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2024-02-21T19:36:21Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Danjie/SQLMaster_13b | Danjie | 2024-02-21T19:36:00Z | 0 | 0 | null | [
"safetensors",
"license:mit",
"region:us"
]
| null | 2024-02-10T22:48:55Z | ---
license: mit
---
# SQLMaster
A minimum of 10 GB VRAM is required.
## Colab Example
https://colab.research.google.com/drive/1Nvwie-klMNPPWI4o7Nae4l5spxEX1PaD?usp=sharing
## Install Prerequisite
```bash
!pip install peft
!pip install transformers
!pip install bitsandbytes
!pip install accelerate
```
## Login Using Huggingface Token
```bash
# You need a huggingface token that can access llama2
from huggingface_hub import notebook_login
notebook_login()
```
## Download Model
```python
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
peft_model_id = "Danjie/SQLMaster_13b"
config = PeftConfig.from_pretrained(peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path, device_map='auto', quantization_config=bnb_config)
model.resize_token_embeddings(len(tokenizer) + 1)
# Load the Lora model
model = PeftModel.from_pretrained(model, peft_model_id)
```
## Inference
```python
def create_sql_query(question: str, context: str) -> str:
input = "Question: " + question + "\nContext:" + context + "\nAnswer"
# Encode and move tensor into cuda if applicable.
encoded_input = tokenizer(input, return_tensors='pt')
encoded_input = {k: v.to(device) for k, v in encoded_input.items()}
output = model.generate(**encoded_input, max_new_tokens=256)
response = tokenizer.decode(output[0], skip_special_tokens=True)
response = response[len(input):]
return response
```
## Example
```python
create_sql_query("What is the highest age of users with name Danjie", "CREATE TABLE user (age INTEGER, name STRING)")
``` |
Fhermin/ReinforcePixelCopter | Fhermin | 2024-02-21T19:25:44Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2024-02-21T19:24:56Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: ReinforcePixelCopter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 36.80 +/- 27.97
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
furrutiav/bert_qa_extractor_cockatiel_2022_ulra_by_kmeans_Q_nllf_sub_best_ef_signal_it_136 | furrutiav | 2024-02-21T19:25:18Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2024-02-21T19:24:43Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
baseten/gemma-7b-it-trtllm-3k-1k-64bs | baseten | 2024-02-21T19:25:07Z | 1 | 0 | transformers | [
"transformers",
"endpoints_compatible",
"region:us"
]
| null | 2024-02-21T18:53:04Z | trtllm-build --checkpoint_dir ./trt-ckpt/ --gemm_plugin bfloat16 --gpt_attention_plugin bfloat16 --max_batch_size 64 --max_input_len 3000 --max_output_len 1000 --context_fmha enable --output_dir ./engines
quantized to int8 as per the `config.json` |
Jaimefebe/llama-2-7b-euskara-v1 | Jaimefebe | 2024-02-21T19:15:22Z | 1 | 2 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:NousResearch/Llama-2-7b-chat-hf",
"base_model:adapter:NousResearch/Llama-2-7b-chat-hf",
"region:us"
]
| null | 2024-02-21T19:15:00Z | ---
library_name: peft
base_model: NousResearch/Llama-2-7b-chat-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
|
predibase/dbpedia | predibase | 2024-02-21T19:14:00Z | 1,720 | 8 | peft | [
"peft",
"safetensors",
"text-generation",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
]
| text-generation | 2024-02-19T23:16:23Z | ---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
pipeline_tag: text-generation
---
Description: Topic extraction from a news article and title\
Original dataset: https://huggingface.co/datasets/fancyzhx/dbpedia_14 \
---\
Try querying this adapter for free in Lora Land at https://predibase.com/lora-land! \
The adapter_category is Topic Identification and the name is News Topic Identification (dbpedia)\
---\
Sample input: You are given the title and the body of an article below. Please determine the type of the article.\n### Title: Great White Whale\n\n### Body: Great White Whale is the debut album by the Canadian rock band Secret and Whisper. The album was in the works for about a year and was released on February 12 2008. A music video was shot in Pittsburgh for the album's first single XOXOXO. The album reached number 17 on iTunes's top 100 albums in its first week on sale.\n\n### Article Type: \
---\
Sample output: 11\
---\
Try using this adapter yourself!
```
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mistral-7B-v0.1"
peft_model_id = "predibase/dbpedia"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
``` |
predibase/hellaswag | predibase | 2024-02-21T19:13:58Z | 47 | 3 | peft | [
"peft",
"safetensors",
"text-generation",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
]
| text-generation | 2024-02-19T19:11:15Z | ---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
pipeline_tag: text-generation
---
Description: Multiple-choice sentence completion\
Original dataset: https://huggingface.co/datasets/Rowan/hellaswag \
---\
Try querying this adapter for free in Lora Land at https://predibase.com/lora-land! \
The adapter_category is Other and the name is Multiple Choice Sentence Completion (hellaswag)\
---\
Sample input: You are provided with an incomplete passage below as well as 4 endings in quotes and separated by commas, with only one of them being the correct ending. Treat the endings as being labelled 0, 1, 2, 3 in order. Please respond with the number corresponding to the correct ending for the passage.\n\n### Passage: The mother instructs them on how to brush their teeth while laughing. The boy helps his younger sister brush his teeth. she\n\n### Endings: ['shows how to hit the mom and then kiss his dad as well.'
'brushes past the camera, looking better soon after.'
'glows from the center of the camera as a reaction.'
'gets them some water to gargle in their mouths.']\n\n### Correct Ending Number: \
---\
Sample output: 3.0\
---\
Try using this adapter yourself!
```
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mistral-7B-v0.1"
peft_model_id = "predibase/hellaswag"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
``` |
predibase/bc5cdr | predibase | 2024-02-21T19:13:58Z | 105 | 1 | peft | [
"peft",
"safetensors",
"text-generation",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
]
| text-generation | 2024-02-20T02:59:29Z | ---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
pipeline_tag: text-generation
---
Description: 1500 PubMed articles with 4409 annotated chemicals, 5818 diseases and 3116 chemical-disease interactions.\
Original dataset: https://huggingface.co/datasets/tner/bc5cdr \
---\
Try querying this adapter for free in Lora Land at https://predibase.com/lora-land! \
The adapter_category is Named Entity Recognition and the name is Chemical and Disease Recognition (bc5cdr)\
---\
Sample input: Your task is a Named Entity Recognition (NER) task. Predict the category of each entity, then place the entity into the list associated with the category in an output JSON payload. Below is an example:
Input: "Naloxone reverses the antihypertensive effect of clonidine ."
Output: {'B-Chemical': ['Naloxone', 'clonidine'], 'B-Disease': [], 'I-Disease': [], 'I-Chemical': []}
Now, complete the task.
Input: "A standardized loading dose of VPA was administered , and venous blood was sampled at 0 , 1 , 2 , 3 , and 4 hours ."
Output: \
---\
Sample output: {'B-Chemical': ['VPA'], 'B-Disease': [], 'I-Disease': [], 'I-Chemical': []}\
---\
Try using this adapter yourself!
```
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mistral-7B-v0.1"
peft_model_id = "predibase/bc5cdr"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
``` |
predibase/e2e_nlg | predibase | 2024-02-21T19:13:56Z | 110 | 1 | peft | [
"peft",
"safetensors",
"text-generation",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
]
| text-generation | 2024-02-19T19:06:55Z | ---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
pipeline_tag: text-generation
---
Description: Translation from meaning representation to natural language\
Original dataset: https://huggingface.co/datasets/e2e_nlg \
---\
Try querying this adapter for free in Lora Land at https://predibase.com/lora-land! \
The adapter_category is Structured-to-Text and the name is Structured-to-Text (e2e_nlg)\
---\
Sample input: You are given a meaning representation below. Please translate it into plain English. Here is an example:\n\n### Meaning Representation: name[Blue Spice], eatType[coffee shop], area[city centre]\n\n### Plain English: A coffee shop in the city centre area called Blue Spice.\n\nNow please translate the following meaning representation:\n\n### Meaning Representation: name[Blue Spice], eatType[pub], food[Chinese], area[city centre], familyFriendly[yes], near[Rainbow Vegetarian Café]\n\n### Plain English:\
---\
Sample output: Blue Spice is a pub that serves Chinese food. It is located in the city centre near Rainbow Vegetarian Café.\
---\
Try using this adapter yourself!
```
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mistral-7B-v0.1"
peft_model_id = "predibase/e2e_nlg"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
``` |
predibase/drop | predibase | 2024-02-21T19:13:54Z | 30 | 4 | peft | [
"peft",
"safetensors",
"text-generation",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
]
| text-generation | 2024-02-19T23:22:39Z | ---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
pipeline_tag: text-generation
---
Description: Question answering given a passage\
Original dataset: https://huggingface.co/datasets/drop \
---\
Try querying this adapter for free in Lora Land at https://predibase.com/lora-land! \
The adapter_category is Other and the name is Question Answering (drop)\
---\
Sample input: Given a passage, you need to accurately identify and extract relevant spans of text that answer specific questions. Provide concise and coherent responses based on the information present in the passage.\n\n### Passage: Coming off their home win over the Browns, the Ravens flew to Heinz Field for their first road game of the year, as they played a Week 4 MNF duel with the throwback-clad Pittsburgh Steelers. In the first quarter, Baltimore trailed early as Steelers kicker Jeff Reed got a 49-yard field goal. The Ravens responded with kicker Matt Stover getting a 33-yard field goal. Baltimore gained the lead in the second quarter as Stover kicked a 20-yard field goal, while rookie quarterback Joe Flacco completed his first career touchdown pass as he hooked up with TE Daniel Wilcox from 4 yards out. In the third quarter, Pittsburgh took the lead with quarterback Ben Roethlisberger completing a 38-yard TD pass to WR Santonio Holmes, along with LB James Harrison forcing a fumble from Flacco with LB LaMarr Woodley returning the fumble 7 yards for a touchdown. In the fourth quarter, the Steelers increased their lead with Reed getting a 19-yard field goal. Afterwards, the Ravens tied the game with RB Le'Ron McClain getting a 2-yard TD run. However, despite winning the coin toss in overtime, Baltimore was unable to gain ground. In the end, Pittsburgh sealed Baltimore's fate as Reed nailed the game-winning 46-yard field goal.\n### Question: How many more field goals were made in the first half than in the second?\n### Answer:\
---\
Sample output: 1\
---\
Try using this adapter yourself!
```
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mistral-7B-v0.1"
peft_model_id = "predibase/drop"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
``` |
predibase/wikisql | predibase | 2024-02-21T19:13:53Z | 31 | 4 | peft | [
"peft",
"safetensors",
"text-generation",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
]
| text-generation | 2024-02-19T23:24:39Z | ---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
pipeline_tag: text-generation
---
Description: SQL generation given a table and question\
Original dataset: https://huggingface.co/datasets/wikisql \
---\
Try querying this adapter for free in Lora Land at https://predibase.com/lora-land! \
The adapter_category is Reasoning and the name is WikiSQL (SQL Generation)\
---\
Sample input: Considering the provided database schema and associated query, produce SQL code to retrieve the answer to the query.\n### Database Schema: {'header': ['Game', 'Date', 'Opponent', 'Score', 'Decision', 'Location/Attendance', 'Record'], 'types': ['real', 'real', 'text', 'text', 'text', 'text', 'text'], 'rows': [array(['77', '1', 'Pittsburgh Penguins', '1-6', 'Brodeur',
'Mellon Arena - 17,132', '47-26-4'], dtype=object), array(['78', '3', 'Tampa Bay Lightning', '4-5 (OT)', 'Brodeur',
'Prudential Center - 17,625', '48-26-4'], dtype=object), array(['79', '4', 'Buffalo Sabres', '3-2', 'Brodeur',
'HSBC Arena - 18,690', '49-26-4'], dtype=object), array(['80', '7', 'Toronto Maple Leafs', '4-1', 'Brodeur',
'Prudential Center - 15,046', '49-27-4'], dtype=object), array(['81', '9', 'Ottawa Senators', '3-2 (SO)', 'Brodeur',
'Scotiabank Place - 20,151', '50-27-4'], dtype=object), array(['82', '11', 'Carolina Hurricanes', '2-3', 'Brodeur',
'Prudential Center - 17,625', '51-27-4'], dtype=object)]}\n### Query: What is Score, when Game is greater than 78, and when Date is "4"?\n### SQL: \
---\
Sample output: SELECT Score FROM table WHERE Game > 78 AND Date = 4\
---\
Try using this adapter yourself!
```
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mistral-7B-v0.1"
peft_model_id = "predibase/wikisql"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
``` |
Jingni/my_first_food_model | Jingni | 2024-02-21T18:44:51Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2024-02-21T16:10:27Z | ---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: my_first_food_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_first_food_model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9013
- Accuracy: 0.965
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 3.584 | 1.0 | 25 | 2.8238 | 0.9475 |
| 2.2086 | 2.0 | 50 | 2.0773 | 0.95 |
| 1.941 | 3.0 | 75 | 1.9013 | 0.965 |
### Framework versions
- Transformers 4.38.0
- Pytorch 2.1.2
- Datasets 2.17.1
- Tokenizers 0.15.2
|
navneetDS/en_pipeline | navneetDS | 2024-02-21T18:39:07Z | 0 | 0 | spacy | [
"spacy",
"token-classification",
"en",
"model-index",
"region:us"
]
| token-classification | 2024-02-21T18:39:04Z | ---
tags:
- spacy
- token-classification
language:
- en
model-index:
- name: en_pipeline
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 1.0
- name: NER Recall
type: recall
value: 1.0
- name: NER F Score
type: f_score
value: 1.0
---
| Feature | Description |
| --- | --- |
| **Name** | `en_pipeline` |
| **Version** | `0.0.0` |
| **spaCy** | `>=3.6.1,<3.7.0` |
| **Default Pipeline** | `tok2vec`, `ner` |
| **Components** | `tok2vec`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (1 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `URL` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 100.00 |
| `ENTS_P` | 100.00 |
| `ENTS_R` | 100.00 |
| `TOK2VEC_LOSS` | 0.00 |
| `NER_LOSS` | 0.00 | |
furrutiav/bert_qa_extractor_cockatiel_2022_ulra_by_question_type_sub_best_ef_signal_it_149 | furrutiav | 2024-02-21T18:34:56Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2024-02-21T18:34:24Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
AsphyXIA/baarat-hin-summarization | AsphyXIA | 2024-02-21T18:33:23Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T18:30:12Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: baarat-summarization
---
# Uploaded model
- **Developed by:** AsphyXIA
- **License:** apache-2.0
- **Finetuned from model :** baarat-summarization
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
almugabo/refprocess-tl-v0.1 | almugabo | 2024-02-21T18:18:17Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T17:31:40Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hahmadraz/sepformer-libri3mix-48k | hahmadraz | 2024-02-21T18:06:23Z | 9 | 1 | speechbrain | [
"speechbrain",
"Source Separation",
"Speech Separation",
"Audio Source Separation",
"Libri3Mix",
"SepFormer",
"Transformer",
"audio-to-audio",
"audio-source-separation",
"en",
"dataset:Libri3Mix",
"arxiv:2010.13154",
"arxiv:2106.04624",
"license:apache-2.0",
"region:us"
]
| audio-to-audio | 2024-02-11T15:39:31Z | ---
language: "en"
thumbnail:
tags:
- Source Separation
- Speech Separation
- Audio Source Separation
- Libri3Mix
- SepFormer
- Transformer
- audio-to-audio
- audio-source-separation
- speechbrain
license: "apache-2.0"
datasets:
- Libri3Mix
metrics:
- SI-SNRi
- SDRi
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# SepFormer trained on Libri3Mix
This repository provides all the necessary tools to perform audio source separation with a [SepFormer](https://arxiv.org/abs/2010.13154v2)
model, implemented with SpeechBrain, and pretrained on Libri3Mix dataset. For a better experience we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io). The model performance is 19.8 dB SI-SNRi on the test set of Libri3Mix dataset.
| Release | Test-Set SI-SNRi | Test-Set SDRi |
|:-------------:|:--------------:|:--------------:|
| 16-09-22 | 19.0dB | 19.4dB |
## Install SpeechBrain
First of all, please install SpeechBrain with the following command:
```
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
### Perform source separation on your own audio file
```python
from speechbrain.pretrained import SepformerSeparation as separator
import torchaudio
model = separator.from_hparams(source="speechbrain/sepformer-libri3mix", savedir='pretrained_models/sepformer-libri3mix')
est_sources = model.separate_file(path='speechbrain/sepformer-wsj03mix/test_mixture_3spks.wav')
torchaudio.save("source1hat.wav", est_sources[:, :, 0].detach().cpu(), 8000)
torchaudio.save("source2hat.wav", est_sources[:, :, 1].detach().cpu(), 8000)
torchaudio.save("source3hat.wav", est_sources[:, :, 2].detach().cpu(), 8000)
```
The system expects input recordings sampled at 8kHz (single channel).
If your signal has a different sample rate, resample it (e.g, using torchaudio or sox) before using the interface.
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Training
The model was trained with SpeechBrain (fc2eabb7).
To train it from scratch follows these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```
cd recipes/LibriMix/separation
python train.py hparams/sepformer.yaml --data_folder=your_data_folder
```
Note: change num_spks to 3 in the yaml file.
You can find our training results (models, logs, etc) [here](https://drive.google.com/drive/folders/1DN49LtAs6cq1X0jZ8tRMlh2Pj6AecClz).
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
#### Referencing SpeechBrain
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
#### Referencing SepFormer
```bibtex
@inproceedings{subakan2021attention,
title={Attention is All You Need in Speech Separation},
author={Cem Subakan and Mirco Ravanelli and Samuele Cornell and Mirko Bronzi and Jianyuan Zhong},
year={2021},
booktitle={ICASSP 2021}
}
@misc{subakan2022sepformer
author = {Subakan, Cem and Ravanelli, Mirco and Cornell, Samuele and Grondin, Francois and Bronzi, Mirko},
title = {On Using Transformers for Speech-Separation},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
# **About SpeechBrain**
- Website: https://speechbrain.github.io/
- Code: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/ |
analys/distilbert-base-uncased-finetuned-ner | analys | 2024-02-21T18:03:14Z | 61 | 0 | transformers | [
"transformers",
"tf",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2024-02-21T17:56:08Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: analys/distilbert-base-uncased-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# analys/distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0335
- Validation Loss: 0.0603
- Train Precision: 0.9219
- Train Recall: 0.9361
- Train F1: 0.9290
- Train Accuracy: 0.9833
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 2631, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Precision | Train Recall | Train F1 | Train Accuracy | Epoch |
|:----------:|:---------------:|:---------------:|:------------:|:--------:|:--------------:|:-----:|
| 0.1940 | 0.0711 | 0.8980 | 0.9167 | 0.9072 | 0.9795 | 0 |
| 0.0546 | 0.0613 | 0.9107 | 0.9303 | 0.9204 | 0.9822 | 1 |
| 0.0335 | 0.0603 | 0.9219 | 0.9361 | 0.9290 | 0.9833 | 2 |
### Framework versions
- Transformers 4.37.2
- TensorFlow 2.15.0
- Datasets 2.17.1
- Tokenizers 0.15.2
|
machinelearningzuu/phi-2-biotech-qlora-synthetic-poc | machinelearningzuu | 2024-02-21T18:01:57Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"phi",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T17:32:00Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tomaarsen/distilroberta-base-nli-matryoshka-256 | tomaarsen | 2024-02-21T17:47:31Z | 58 | 3 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"roberta",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2024-02-21T17:47:11Z | ---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# tomaarsen/distilroberta-base-nli-matryoshka-256
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 256 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('tomaarsen/distilroberta-base-nli-matryoshka-256')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=tomaarsen/distilroberta-base-nli-matryoshka-256)
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 4403 with parameters:
```
{'batch_size': 128}
```
**Loss**:
`sentence_transformers.losses.MatryoshkaLoss.MatryoshkaLoss` with parameters:
```
{'loss': 'MultipleNegativesRankingLoss', 'matryoshka_dims': [256, 128, 64, 32, 16], 'matryoshka_weights': [1, 1, 1, 1, 1]}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 440,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 441,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 75, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Dense({'in_features': 768, 'out_features': 256, 'bias': True, 'activation_function': 'torch.nn.modules.activation.Tanh'})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
AdithyaSK/gemma-Code-Instruct-Finetune-test | AdithyaSK | 2024-02-21T17:45:10Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T17:42:29Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gayanin/bart-with-asr-noise-sub-0.5 | gayanin | 2024-02-21T17:39:58Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/bart-base",
"base_model:finetune:facebook/bart-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-02-21T17:33:20Z | ---
license: apache-2.0
base_model: facebook/bart-base
tags:
- generated_from_trainer
model-index:
- name: bart-with-asr-noise-sub-0.5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-with-asr-noise-sub-0.5
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1120
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.3753 | 0.62 | 500 | 0.2679 |
| 0.1725 | 1.24 | 1000 | 0.1595 |
| 0.0782 | 1.86 | 1500 | 0.1241 |
| 0.0505 | 2.48 | 2000 | 0.1120 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.2+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
raqdo09/singlish-to-english-synthetic | raqdo09 | 2024-02-21T17:39:34Z | 5 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"simplification",
"generated_from_trainer",
"base_model:google-t5/t5-base",
"base_model:finetune:google-t5/t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-02-21T17:37:01Z | ---
license: apache-2.0
base_model: google-t5/t5-base
tags:
- simplification
- generated_from_trainer
metrics:
- bleu
model-index:
- name: singlish-to-english-synthetic
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# singlish-to-english-synthetic
This model is a fine-tuned version of [google-t5/t5-base](https://huggingface.co/google-t5/t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8281
- Bleu: 43.2955
- Gen Len: 14.68
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 57 | 0.8919 | 42.8283 | 14.54 |
| No log | 2.0 | 114 | 0.8281 | 43.2955 | 14.68 |
### Framework versions
- Transformers 4.38.0
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
Pankracy1918/my_awesome_eli5_mlm_model | Pankracy1918 | 2024-02-21T17:39:26Z | 4 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2024-02-20T15:30:24Z | ---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: my_awesome_eli5_mlm_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_eli5_mlm_model
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0690
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.657 | 1.0 | 1357 | 2.2376 |
| 2.0353 | 2.0 | 2714 | 2.1395 |
| 2.1131 | 3.0 | 4071 | 2.1349 |
| 2.0894 | 4.0 | 5428 | 2.1160 |
| 2.0451 | 5.0 | 6785 | 2.1023 |
| 2.0114 | 6.0 | 8142 | 2.0706 |
| 1.9932 | 7.0 | 9499 | 2.0818 |
| 1.9551 | 8.0 | 10856 | 2.0797 |
| 1.9218 | 9.0 | 12213 | 2.0679 |
| 1.9186 | 10.0 | 13570 | 2.0555 |
| 1.8722 | 11.0 | 14927 | 2.0491 |
| 1.8438 | 12.0 | 16284 | 2.0430 |
| 1.8256 | 13.0 | 17641 | 2.0785 |
| 1.816 | 14.0 | 18998 | 2.0475 |
| 1.766 | 15.0 | 20355 | 2.0607 |
| 1.7689 | 16.0 | 21712 | 2.0758 |
| 1.7354 | 17.0 | 23069 | 2.0443 |
| 1.7548 | 18.0 | 24426 | 2.0540 |
| 1.7188 | 19.0 | 25783 | 2.0538 |
| 1.6965 | 20.0 | 27140 | 2.0513 |
| 1.7066 | 21.0 | 28497 | 2.0490 |
| 1.6711 | 22.0 | 29854 | 2.0513 |
| 1.6549 | 23.0 | 31211 | 2.0515 |
| 1.6577 | 24.0 | 32568 | 2.0498 |
| 1.6214 | 25.0 | 33925 | 2.0438 |
| 1.6057 | 26.0 | 35282 | 2.0488 |
| 1.6001 | 27.0 | 36639 | 2.0541 |
| 1.6148 | 28.0 | 37996 | 2.0475 |
| 1.6062 | 29.0 | 39353 | 2.0325 |
| 1.5588 | 30.0 | 40710 | 2.0191 |
| 1.5607 | 31.0 | 42067 | 2.0388 |
| 1.5558 | 32.0 | 43424 | 2.0510 |
| 1.5453 | 33.0 | 44781 | 2.0344 |
| 1.5322 | 34.0 | 46138 | 2.0475 |
| 1.5437 | 35.0 | 47495 | 2.0348 |
| 1.5306 | 36.0 | 48852 | 2.0493 |
| 1.5184 | 37.0 | 50209 | 2.0489 |
| 1.5131 | 38.0 | 51566 | 2.0512 |
| 1.4835 | 39.0 | 52923 | 2.0650 |
| 1.4758 | 40.0 | 54280 | 2.0277 |
| 1.4841 | 41.0 | 55637 | 2.0662 |
| 1.4877 | 42.0 | 56994 | 2.0451 |
| 1.4691 | 43.0 | 58351 | 2.0401 |
| 1.4565 | 44.0 | 59708 | 2.0735 |
| 1.4654 | 45.0 | 61065 | 2.0493 |
| 1.4432 | 46.0 | 62422 | 2.0325 |
| 1.4763 | 47.0 | 63779 | 2.0493 |
| 1.4511 | 48.0 | 65136 | 2.0284 |
| 1.4633 | 49.0 | 66493 | 2.0282 |
| 1.4457 | 50.0 | 67850 | 2.0690 |
### Framework versions
- Transformers 4.37.0
- Pytorch 2.1.2
- Datasets 2.1.0
- Tokenizers 0.15.1
|
SuYee189/health-qa-gpt2 | SuYee189 | 2024-02-21T17:36:37Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T17:32:45Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gayanin/bart-with-asr-noise-ins-0.4 | gayanin | 2024-02-21T17:27:50Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/bart-base",
"base_model:finetune:facebook/bart-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-02-21T17:03:21Z | ---
license: apache-2.0
base_model: facebook/bart-base
tags:
- generated_from_trainer
model-index:
- name: bart-with-asr-noise-ins-0.4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-with-asr-noise-ins-0.4
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0541
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.1609 | 0.62 | 500 | 0.0887 |
| 0.0935 | 1.24 | 1000 | 0.0645 |
| 0.0532 | 1.86 | 1500 | 0.0592 |
| 0.0267 | 2.48 | 2000 | 0.0541 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.2+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
gayanin/bart-with-asr-noise-sub-0.4 | gayanin | 2024-02-21T17:27:41Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/bart-base",
"base_model:finetune:facebook/bart-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-02-21T17:03:24Z | ---
license: apache-2.0
base_model: facebook/bart-base
tags:
- generated_from_trainer
model-index:
- name: bart-with-asr-noise-sub-0.4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-with-asr-noise-sub-0.4
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0985
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.3216 | 0.62 | 500 | 0.2307 |
| 0.1661 | 1.24 | 1000 | 0.1390 |
| 0.0787 | 1.86 | 1500 | 0.1089 |
| 0.0304 | 2.48 | 2000 | 0.0985 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.2+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
gayanin/bart-with-asr-noise-del-0.4 | gayanin | 2024-02-21T17:26:44Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/bart-base",
"base_model:finetune:facebook/bart-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-02-21T17:03:27Z | ---
license: apache-2.0
base_model: facebook/bart-base
tags:
- generated_from_trainer
model-index:
- name: bart-with-asr-noise-del-0.4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-with-asr-noise-del-0.4
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0343
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.3196 | 0.62 | 500 | 1.1758 |
| 1.1351 | 1.24 | 1000 | 1.0880 |
| 0.9108 | 1.86 | 1500 | 1.0304 |
| 0.7589 | 2.48 | 2000 | 1.0343 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.2+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
lazarustda/my-4bit-gemma | lazarustda | 2024-02-21T17:26:14Z | 9 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"mlx",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T17:23:58Z | ---
license: other
library_name: transformers
tags:
- mlx
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged-in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
license_name: gemma-terms-of-use
license_link: https://ai.google.dev/gemma/terms
---
# lazarustda/my-4bit-gemma
This model was converted to MLX format from [`google/gemma-2b`]().
Refer to the [original model card](https://huggingface.co/google/gemma-2b) for more details on the model.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("lazarustda/my-4bit-gemma")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
|
prithviraj-maurya/sft_llama | prithviraj-maurya | 2024-02-21T17:17:38Z | 5 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"text-generation",
"base_model:TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T",
"base_model:adapter:TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T",
"license:apache-2.0",
"region:us"
]
| text-generation | 2024-02-21T16:26:04Z | ---
license: apache-2.0
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
- text-generation
base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T
model-index:
- name: sft_llama
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deleteme
This model is a fine-tuned version of [TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.95) and epsilon=1e-05
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 2000
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.8.2
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.17.0
- Tokenizers 0.15.1 |
tomaarsen/distilroberta-base-nli-matryoshka | tomaarsen | 2024-02-21T17:16:52Z | 8 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2024-02-21T17:16:31Z | ---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# tomaarsen/distilroberta-base-nli-matryoshka
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('tomaarsen/distilroberta-base-nli-matryoshka')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('tomaarsen/distilroberta-base-nli-matryoshka')
model = AutoModel.from_pretrained('tomaarsen/distilroberta-base-nli-matryoshka')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=tomaarsen/distilroberta-base-nli-matryoshka)
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 4403 with parameters:
```
{'batch_size': 128}
```
**Loss**:
`sentence_transformers.losses.MatryoshkaLoss.MatryoshkaLoss` with parameters:
```
{'loss': 'MultipleNegativesRankingLoss', 'matryoshka_dims': [768, 512, 256, 128, 64], 'matryoshka_weights': [1, 1, 1, 1, 1]}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 440,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 441,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 75, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
Priyanka-Balivada/stable-diffusion-stack-trial | Priyanka-Balivada | 2024-02-21T17:14:05Z | 7 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-02-21T17:10:10Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Stable-diffusion-stack Dreambooth model trained by Priyanka-Balivada with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
HES-XPLAIN/sport_classification | HES-XPLAIN | 2024-02-21T17:13:57Z | 0 | 0 | null | [
"license:bsd-3-clause",
"region:us"
]
| null | 2023-10-27T13:55:11Z | ---
license: bsd-3-clause
---
# HES-XPLAIN
ML models for [HES-XPLAIN](https://github.com/HES-XPLAIN/)
|
cmp-nct/llava-1.6-gguf | cmp-nct | 2024-02-21T17:05:52Z | 2,378 | 75 | transformers | [
"transformers",
"gguf",
"image-text-to-text",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
]
| image-text-to-text | 2024-02-02T02:17:56Z | ---
license: apache-2.0
pipeline_tag: image-text-to-text
---
Update: PR is merged, llama.cpp now natively supports these models
Important: Verify that processing a simple question with any image at least uses 1200 tokens of prompt processing, that shows that the new PR is in use.
If your prompt is just 576 + a few tokens, you are using llava-1.5 code (or projector) and this is incompatible with llava-1.6
**note** Keep in mind the different fine tunes as described in the llama.cpp llava readme, it's essential to use the non defaults for non vicuna models
The mmproj files are the embedded ViT's that came with llava-1.6, I've not compared them but given the previous releases from the team I'd be surprised if the ViT has not been fine tuned this time.
If that's the case, using another ViT can cause issues.
You need to use the mmproj of the right model but you can mix quantizations.
Original models: https://github.com/haotian-liu/LLaVA |
gohzy/fine-tuned-singlish-toxic-bert-10000-LoRA-1 | gohzy | 2024-02-21T17:02:34Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-02-21T17:02:31Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
adalib/beatnum-sub-cond-gen-codegen-350M-mono-prefix | adalib | 2024-02-21T16:57:02Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Salesforce/codegen-350M-mono",
"base_model:adapter:Salesforce/codegen-350M-mono",
"region:us"
]
| null | 2024-02-21T16:56:59Z | ---
library_name: peft
base_model: Salesforce/codegen-350M-mono
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.7.1 |
AiManatee/RoBERTa_poem_sentiment | AiManatee | 2024-02-21T16:55:37Z | 10 | 1 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"sentiment-analysis",
"poem-sentiment-detection",
"poem-sentiment",
"poem-sentiment-classification",
"sentiment-classification",
"en",
"dataset:poem_sentiment",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-02-02T15:34:16Z | ---
license: apache-2.0
datasets:
- poem_sentiment
language:
- en
metrics:
- Accuracy, F1 score
library_name: transformers
pipeline_tag: text-classification
tags:
- text-classification
- sentiment-analysis
- poem-sentiment-detection
- poem-sentiment
- poem-sentiment-classification
- sentiment-classification
widget:
- text: >-
Rapidly, merrily, Life's sunny hours flit by, Gratefully, cheerily, Enjoy them as they fly!
example_title: "Life"
- text: It so happens I am sick of my feet and my nails, and my hair and my shadow. It so happens I am sick of being a man.
example_title: "Walking Around"
- text: >-
No man is an island, Entire of itself, Every man is a piece of the continent, A part of the main.
example_title: "No man is an island"
- text: >-
Some have won a wild delight, By daring wilder sorrow; Could I gain thy love to-night, I'd hazard death to-morrow.
example_title: "Passion"
---
## AiManatee/RoBERTa_poem_sentiment
This model is a fine-tuned version of the [FacebookAI/roberta-base](https://huggingface.co/FacebookAI/roberta-base) transformer for the task of poem sentiment analysis. It predicts the sentiment of a given poem verse into one of four categories: negative, positive, no impact, or mixed (positive and negative).
### Dataset
RoBERTa_poem_sentiment was trained on the [poem_sentiment](https://huggingface.co/datasets/poem_sentiment) dataset which consists of poem verses across four sentiment labels: negative, positive, no impact, and mixed sentiment. However, the Validation and Test subsets of the original dataset lack 'mixed' sentiment examples. To address this and ensure a thorough evaluation, data augmentation was performed: 32 'mixed' sentiment verses from different English poems were added to the Validation (16) and Test (16) subsets; the original Train subset remained intact. All the augmented samples were tested for semantic consistency, diversity (cosine similarity), length variation and novelty (ensuring the augmented data introduced new, relevant vocabulary). This strategy allowed for a more comprehensive evaluation of the model's generalization ability across all trained labels. The final model was tested on both the original dataset and the augmented dataset.
#### Labels
```
{0: 'negative', 1: 'positive', 2: 'no_impact', 3: 'mixed'}
```
### Training Hyperparameters
```
learning_rate: 2e-5,
weight_decay: 0.01,
batch_size: 16,
num_epochs: 8,
optimizer: AdamW: betas=(0.9, 0.999), eps=1e-08
seed: 16
early_stopper: min_delta=0.001, patience=3
```
```
scheduler = ReduceLROnPlateau(
optimizer,
mode="min",
factor=0.5,
patience=0,
threshold=0.001,
eps=1e-8,
)
```
### Model Performance
##### Validation results on the original dataset (class 3 is not being evaluated here)
| Epoch | Training Loss | Validation Loss | Accuracy | F1 |
|-------|---------------|-----------------|----------|----------|
| 1 | 1.365169 | 1.010353 | 0.761905 | 0.771733 |
| 2 | 0.860945 | 0.810045 | 0.723810 | 0.740809 |
| 3 | 0.570005 | 0.637439 | 0.761905 | 0.802184 |
| 4 | 0.355776 | 0.699637 | 0.780952 | 0.797572 |
| 5 | 0.252919 | 0.586395 | 0.847619 | 0.860519 |
| 6 | 0.156633 | 0.610439 | 0.819048 | 0.834072 |
| 7 | 0.084868 | 0.515130 | 0.876190 | 0.884736 |
| 8 | 0.062830 | 0.572643 | 0.885714 | 0.902510 |
##### Validation results on the augmented dataset
| Epoch | Training Loss | Validation Loss | Accuracy | F1 |
|-------|---------------|-----------------|----------|----------|
| 1 | 1.365169 | 1.168057 | 0.661157 | 0.628737 |
| 2 | 0.860945 | 0.869521 | 0.694214 | 0.717916 |
| 3 | 0.570005 | 0.637439 | 0.776859 | 0.790842 |
| 4 | 0.355776 | 0.681563 | 0.768595 | 0.776540 |
| 5 | 0.252919 | 0.585692 | 0.834710 | 0.841590 |
| 6 | 0.156633 | 0.542949 | 0.809917 | 0.815361 |
| 7 | 0.092444 | 0.581075 | 0.826446 | 0.830607 |
| 8 | 0.049480 | 0.583749 | 0.884297 | 0.881360 |
### How to Use the Model
Here is how to predict the sentiment of a poem verse using this model:
```python
from transformers import pipeline
sentiment_classifier = pipeline(task='text-classification', model='AiManatee/RoBERTa_poem_sentiment')
verse1 = "Rapidly, merrily, Life's sunny hours flit by, Gratefully, cheerily, Enjoy them as they fly!"
verse2 = "It so happens I am sick of my feet and my nails, and my hair and my shadow. It so happens I am sick of being a man."
verse3 = "No man is an island, Entire of itself, Every man is a piece of the continent, A part of the main."
verse4 = "Some have won a wild delight, By daring wilder sorrow; Could I gain thy love to-night, I'd hazard death to-morrow."
print(sentiment_classifier(verse1))
print(sentiment_classifier(verse2))
print(sentiment_classifier(verse3))
print(sentiment_classifier(verse4))
```
### Evaluation
##### Original dataset
```
{Loss: 0.5726433790155819
Accuracy: 0.8857142857142857
Precision: 0.9201298701298701
Recall: 0.8857142857142857
F1: 0.9025108225108224
}
```
##### Augmented dataset
```
{Loss: 0.5837492472492158
Accuracy: 0.8842975206611571
Precision: 0.8810538160090016
Recall: 0.8842975206611571
F1: 0.8813606847697756
}
```
### Framework Versions
- **Transformers:** 4.35.2
- **PyTorch:** 2.1.0+cu118
- **Datasets:** 2.16.1
- **Tokenizers:** 0.15.1 |
Dagobert42/distilbert-base-uncased-biored-finetuned | Dagobert42 | 2024-02-21T16:54:49Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"token-classification",
"low-resource NER",
"token_classification",
"biomedicine",
"medical NER",
"generated_from_trainer",
"en",
"dataset:medicine",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2024-02-14T18:32:39Z | ---
language:
- en
license: mit
base_model: distilbert-base-uncased
tags:
- low-resource NER
- token_classification
- biomedicine
- medical NER
- generated_from_trainer
datasets:
- medicine
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: Dagobert42/distilbert-base-uncased-biored-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Dagobert42/distilbert-base-uncased-biored-finetuned
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the bigbio/biored dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6868
- Accuracy: 0.7768
- Precision: 0.5392
- Recall: 0.4561
- F1: 0.4898
- Weighted F1: 0.764
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 | Weighted F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|:-----------:|
| No log | 1.0 | 25 | 0.9323 | 0.7124 | 0.3944 | 0.1486 | 0.1309 | 0.5993 |
| No log | 2.0 | 50 | 0.8737 | 0.7248 | 0.5187 | 0.2132 | 0.2341 | 0.6271 |
| No log | 3.0 | 75 | 0.8157 | 0.7353 | 0.4968 | 0.2886 | 0.3314 | 0.6804 |
| No log | 4.0 | 100 | 0.7927 | 0.7452 | 0.5213 | 0.3185 | 0.3686 | 0.6883 |
| No log | 5.0 | 125 | 0.7601 | 0.7507 | 0.5119 | 0.3734 | 0.4161 | 0.7116 |
| No log | 6.0 | 150 | 0.7480 | 0.7555 | 0.5381 | 0.3829 | 0.4285 | 0.718 |
| No log | 7.0 | 175 | 0.7393 | 0.7588 | 0.5393 | 0.4031 | 0.4479 | 0.7272 |
| No log | 8.0 | 200 | 0.7342 | 0.7655 | 0.5512 | 0.4143 | 0.4614 | 0.7363 |
| No log | 9.0 | 225 | 0.7391 | 0.7591 | 0.5262 | 0.4425 | 0.4709 | 0.7395 |
| No log | 10.0 | 250 | 0.7264 | 0.7644 | 0.5332 | 0.4539 | 0.4849 | 0.7484 |
| No log | 11.0 | 275 | 0.7350 | 0.7694 | 0.5419 | 0.452 | 0.4852 | 0.7483 |
| No log | 12.0 | 300 | 0.7389 | 0.77 | 0.5341 | 0.4641 | 0.4921 | 0.752 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.15.0
|
vishnu027/cm1132_type5_re_m2 | vishnu027 | 2024-02-21T16:51:21Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| image-text-to-text | 2024-02-21T16:46:12Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
vadhri/rl_course_vizdoom_health_gathering_supreme | vadhri | 2024-02-21T16:51:06Z | 0 | 0 | sample-factory | [
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2024-02-21T16:50:58Z | ---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 10.68 +/- 4.91
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r vadhri/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
vishnu027/cm1132_type5_re | vishnu027 | 2024-02-21T16:42:04Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| image-text-to-text | 2024-02-21T16:12:52Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
freshpearYoon/v3_concat | freshpearYoon | 2024-02-21T16:38:37Z | 7 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"ko",
"base_model:openai/whisper-large-v3",
"base_model:finetune:openai/whisper-large-v3",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-02-21T13:41:25Z | ---
language:
- ko
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
metrics:
- wer
base_model: openai/whisper-large-v3
model-index:
- name: whisper_finetune
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper_finetune
This model is a fine-tuned version of [openai/whisper-large-v3](https://huggingface.co/openai/whisper-large-v3) on the aihub_100000 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4970
- Cer: 5.4843
- Wer: 22.9248
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-08
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 2000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|
| 0.9923 | 0.9 | 1000 | 0.5893 | 6.0827 | 25.3866 |
| 0.9389 | 1.79 | 2000 | 0.4970 | 5.4843 | 22.9248 |
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.17.1
- Tokenizers 0.15.2
|
Weni/ZeroShot-3.3.1-Mistral-7b-Multilanguage-3.2.0-merged | Weni | 2024-02-21T16:25:03Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T16:15:38Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ANUPAMKU/my-pet-dog-xzg | ANUPAMKU | 2024-02-21T16:16:35Z | 7 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-02-21T16:12:38Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog-XZG Dreambooth model trained by ANUPAMKU following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: 21/CSE/064(D)
Sample pictures of this concept:
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
|
likhith231/bloomz-560m_PROMPT_TUNING_CAUSAL_LM | likhith231 | 2024-02-21T16:11:11Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-02-21T16:11:09Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
vadhri/ppo-CartPole-v1 | vadhri | 2024-02-21T16:10:54Z | 0 | 0 | null | [
"tensorboard",
"CartPole-v1",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
]
| reinforcement-learning | 2024-02-21T16:10:45Z | ---
tags:
- CartPole-v1
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 258.60 +/- 124.45
name: mean_reward
verified: false
---
# PPO Agent Playing CartPole-v1
This is a trained model of a PPO agent playing CartPole-v1.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'CartPole-v1'
'total_timesteps': 50000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'vadhri/ppo-CartPole-v1'
'batch_size': 512
'minibatch_size': 128}
```
|
mhenrichsen/gemma-2b | mhenrichsen | 2024-02-21T16:09:11Z | 72 | 1 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:2312.11805",
"arxiv:2009.03300",
"arxiv:1905.07830",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1905.10044",
"arxiv:1907.10641",
"arxiv:1811.00937",
"arxiv:1809.02789",
"arxiv:1911.01547",
"arxiv:1705.03551",
"arxiv:2107.03374",
"arxiv:2108.07732",
"arxiv:2110.14168",
"arxiv:2304.06364",
"arxiv:2206.04615",
"arxiv:1804.06876",
"arxiv:2110.08193",
"arxiv:2009.11462",
"arxiv:2101.11718",
"arxiv:1804.09301",
"arxiv:2109.07958",
"arxiv:2203.09509",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T16:05:10Z | ---
library_name: transformers
tags: []
---
# Reupload of Gemma 2b base. Original readme below.
# Gemma Model Card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs)
This model card corresponds to the 2B base version of the Gemma model. You can also visit the model card of the [7B base model](https://huggingface.co/google/gemma-7b), [7B instruct model](https://huggingface.co/google/gemma-7b-it), and [2B instruct model](https://huggingface.co/google/gemma-2b-it).
**Resources and Technical Documentation**:
* [Responsible Generative AI Toolkit](https://ai.google.dev/responsible)
* [Gemma on Kaggle](https://www.kaggle.com/models/google/gemma)
* [Gemma on Vertex Model Garden](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/335?version=gemma-2b-gg-hf)
**Terms of Use**: [Terms](https://www.kaggle.com/models/google/gemma/license/consent)
**Authors**: Google
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
They are text-to-text, decoder-only large language models, available in English,
with open weights, pre-trained variants, and instruction-tuned variants. Gemma
models are well-suited for a variety of text generation tasks, including
question answering, summarization, and reasoning. Their relatively small size
makes it possible to deploy them in environments with limited resources such as
a laptop, desktop or your own cloud infrastructure, democratizing access to
state of the art AI models and helping foster innovation for everyone.
### Usage
Below we share some code snippets on how to get quickly started with running the model. First make sure to `pip install -U transformers`, then copy the snippet from the section that is relevant for your usecase.
#### Fine-tuning the model
You can find fine-tuning scripts and notebook under the [`examples/` directory](https://huggingface.co/google/gemma-7b/tree/main/examples) of [`google/gemma-7b`](https://huggingface.co/google/gemma-7b) repository. To adapt it to this model, simply change the model-id to `google/gemma-2b`.
In that repository, we provide:
* A script to perform Supervised Fine-Tuning (SFT) on UltraChat dataset using QLoRA
* A script to perform SFT using FSDP on TPU devices
* A notebook that you can run on a free-tier Google Colab instance to perform SFT on English quotes dataset
#### Running the model on a CPU
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(**input_text, return_tensors="pt")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a single / multi GPU
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a GPU using different precisions
* _Using `torch.float16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto", torch_dtype=torch.float16)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using `torch.bfloat16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto", torch_dtype=torch.bfloat16)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Quantized Versions through `bitsandbytes`
* _Using 8-bit precision (int8)_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using 4-bit precision_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Other optimizations
* _Flash Attention 2_
First make sure to install `flash-attn` in your environment `pip install flash-attn`
```diff
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2"
).to(0)
```
### Inputs and outputs
* **Input:** Text string, such as a question, a prompt, or a document to be
summarized.
* **Output:** Generated English-language text in response to the input, such
as an answer to a question, or a summary of a document.
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
These models were trained on a dataset of text data that includes a wide variety
of sources, totaling 6 trillion tokens. Here are the key components:
* Web Documents: A diverse collection of web text ensures the model is exposed
to a broad range of linguistic styles, topics, and vocabulary. Primarily
English-language content.
* Code: Exposing the model to code helps it to learn the syntax and patterns of
programming languages, which improves its ability to generate code or
understand code-related questions.
* Mathematics: Training on mathematical text helps the model learn logical
reasoning, symbolic representation, and to address mathematical queries.
The combination of these diverse data sources is crucial for training a powerful
language model that can handle a wide variety of different tasks and text
formats.
### Data Preprocessing
Here are the key data cleaning and filtering methods applied to the training
data:
* CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering was
applied at multiple stages in the data preparation process to ensure the
exclusion of harmful and illegal content
* Sensitive Data Filtering: As part of making Gemma pre-trained models safe and
reliable, automated techniques were used to filter out certain personal
information and other sensitive data from training sets.
* Additional methods: Filtering based on content quality and safely in line with
[our policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11).
## Implementation Information
Details about the model internals.
### Hardware
Gemma was trained using the latest generation of
[Tensor Processing Unit (TPU)](https://cloud.google.com/tpu/docs/intro-to-tpu) hardware (TPUv5e).
Training large language models requires significant computational power. TPUs,
designed specifically for matrix operations common in machine learning, offer
several advantages in this domain:
* Performance: TPUs are specifically designed to handle the massive computations
involved in training LLMs. They can speed up training considerably compared to
CPUs.
* Memory: TPUs often come with large amounts of high-bandwidth memory, allowing
for the handling of large models and batch sizes during training. This can
lead to better model quality.
* Scalability: TPU Pods (large clusters of TPUs) provide a scalable solution for
handling the growing complexity of large foundation models. You can distribute
training across multiple TPU devices for faster and more efficient processing.
* Cost-effectiveness: In many scenarios, TPUs can provide a more cost-effective
solution for training large models compared to CPU-based infrastructure,
especially when considering the time and resources saved due to faster
training.
* These advantages are aligned with
[Google's commitments to operate sustainably](https://sustainability.google/operating-sustainably/).
### Software
Training was done using [JAX](https://github.com/google/jax) and [ML Pathways](https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/ml-pathways).
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models.
ML Pathways is Google's latest effort to build artificially intelligent systems
capable of generalizing across multiple tasks. This is specially suitable for
[foundation models](https://ai.google/discover/foundation-models/), including large language models like
these ones.
Together, JAX and ML Pathways are used as described in the
[paper about the Gemini family of models](https://arxiv.org/abs/2312.11805); "the 'single
controller' programming model of Jax and Pathways allows a single Python
process to orchestrate the entire training run, dramatically simplifying the
development workflow."
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
These models were evaluated against a large collection of different datasets and
metrics to cover different aspects of text generation:
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [MMLU](https://arxiv.org/abs/2009.03300) | 5-shot, top-1 | 42.3 | 64.3 |
| [HellaSwag](https://arxiv.org/abs/1905.07830) | 0-shot |71.4 | 81.2 |
| [PIQA](https://arxiv.org/abs/1911.11641) | 0-shot | 77.3 | 81.2 |
| [SocialIQA](https://arxiv.org/abs/1904.09728) | 0-shot | 59.7 | 51.8 |
| [BooIQ](https://arxiv.org/abs/1905.10044) | 0-shot | 69.4 | 83.2 |
| [WinoGrande](https://arxiv.org/abs/1907.10641) | partial score | 65.4 | 72.3 |
| [CommonsenseQA](https://arxiv.org/abs/1811.00937) | 7-shot | 65.3 | 71.3 |
| [OpenBookQA](https://arxiv.org/abs/1809.02789) | | 47.8 | 52.8 |
| [ARC-e](https://arxiv.org/abs/1911.01547) | | 73.2 | 81.5 |
| [ARC-c](https://arxiv.org/abs/1911.01547) | | 42.1 | 53.2 |
| [TriviaQA](https://arxiv.org/abs/1705.03551) | 5-shot | 53.2 | 63.4 |
| [Natural Questions](https://github.com/google-research-datasets/natural-questions) | 5-shot | - | 23 |
| [HumanEval](https://arxiv.org/abs/2107.03374) | pass@1 | 22.0 | 32.3 |
| [MBPP](https://arxiv.org/abs/2108.07732) | 3-shot | 29.2 | 44.4 |
| [GSM8K](https://arxiv.org/abs/2110.14168) | maj@1 | 17.7 | 46.4 |
| [MATH](https://arxiv.org/abs/2108.07732) | 4-shot | 11.8 | 24.3 |
| [AGIEval](https://arxiv.org/abs/2304.06364) | | 24.2 | 41.7 |
| [BIG-Bench](https://arxiv.org/abs/2206.04615) | | 35.2 | 55.1 |
| ------------------------------ | ------------- | ----------- | --------- |
| **Average** | | **54.0** | **56.4** |
## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
* Text-to-Text Content Safety: Human evaluation on prompts covering safety
policies including child sexual abuse and exploitation, harassment, violence
and gore, and hate speech.
* Text-to-Text Representational Harms: Benchmark against relevant academic
datasets such as [WinoBias](https://arxiv.org/abs/1804.06876) and [BBQ Dataset](https://arxiv.org/abs/2110.08193v2).
* Memorization: Automated evaluation of memorization of training data, including
the risk of personally identifiable information exposure.
* Large-scale harm: Tests for "dangerous capabilities," such as chemical,
biological, radiological, and nuclear (CBRN) risks.
### Evaluation Results
The results of ethics and safety evaluations are within acceptable thresholds
for meeting [internal policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11) for categories such as child
safety, content safety, representational harms, memorization, large-scale harms.
On top of robust internal evaluations, the results of well known safety
benchmarks like BBQ, BOLD, Winogender, Winobias, RealToxicity, and TruthfulQA
are shown here.
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [RealToxicity](https://arxiv.org/abs/2009.11462) | average | 6.86 | 7.90 |
| [BOLD](https://arxiv.org/abs/2101.11718) | | 45.57 | 49.08 |
| [CrowS-Pairs](https://aclanthology.org/2020.emnlp-main.154/) | top-1 | 45.82 | 51.33 |
| [BBQ Ambig](https://arxiv.org/abs/2110.08193v2) | 1-shot, top-1 | 62.58 | 92.54 |
| [BBQ Disambig](https://arxiv.org/abs/2110.08193v2) | top-1 | 54.62 | 71.99 |
| [Winogender](https://arxiv.org/abs/1804.09301) | top-1 | 51.25 | 54.17 |
| [TruthfulQA](https://arxiv.org/abs/2109.07958) | | 44.84 | 31.81 |
| [Winobias 1_2](https://arxiv.org/abs/1804.06876) | | 56.12 | 59.09 |
| [Winobias 2_2](https://arxiv.org/abs/1804.06876) | | 91.10 | 92.23 |
| [Toxigen](https://arxiv.org/abs/2203.09509) | | 29.77 | 39.59 |
| ------------------------------ | ------------- | ----------- | --------- |
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Open Large Language Models (LLMs) have a wide range of applications across
various industries and domains. The following list of potential uses is not
comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
* Content Creation and Communication
* Text Generation: These models can be used to generate creative text formats
such as poems, scripts, code, marketing copy, and email drafts.
* Chatbots and Conversational AI: Power conversational interfaces for customer
service, virtual assistants, or interactive applications.
* Text Summarization: Generate concise summaries of a text corpus, research
papers, or reports.
* Research and Education
* Natural Language Processing (NLP) Research: These models can serve as a
foundation for researchers to experiment with NLP techniques, develop
algorithms, and contribute to the advancement of the field.
* Language Learning Tools: Support interactive language learning experiences,
aiding in grammar correction or providing writing practice.
* Knowledge Exploration: Assist researchers in exploring large bodies of text
by generating summaries or answering questions about specific topics.
### Limitations
* Training Data
* The quality and diversity of the training data significantly influence the
model's capabilities. Biases or gaps in the training data can lead to
limitations in the model's responses.
* The scope of the training dataset determines the subject areas the model can
handle effectively.
* Context and Task Complexity
* LLMs are better at tasks that can be framed with clear prompts and
instructions. Open-ended or highly complex tasks might be challenging.
* A model's performance can be influenced by the amount of context provided
(longer context generally leads to better outputs, up to a certain point).
* Language Ambiguity and Nuance
* Natural language is inherently complex. LLMs might struggle to grasp subtle
nuances, sarcasm, or figurative language.
* Factual Accuracy
* LLMs generate responses based on information they learned from their
training datasets, but they are not knowledge bases. They may generate
incorrect or outdated factual statements.
* Common Sense
* LLMs rely on statistical patterns in language. They might lack the ability
to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of large language models (LLMs) raises several ethical concerns.
In creating an open model, we have carefully considered the following:
* Bias and Fairness
* LLMs trained on large-scale, real-world text data can reflect socio-cultural
biases embedded in the training material. These models underwent careful
scrutiny, input data pre-processing described and posterior evaluations
reported in this card.
* Misinformation and Misuse
* LLMs can be misused to generate text that is false, misleading, or harmful.
* Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit](http://ai.google.dev/gemma/responsible).
* Transparency and Accountability:
* This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
* A responsibly developed open model offers the opportunity to share
innovation by making LLM technology accessible to developers and researchers
across the AI ecosystem.
Risks identified and mitigations:
* Perpetuation of biases: It's encouraged to perform continuous monitoring
(using evaluation metrics, human review) and the exploration of de-biasing
techniques during model training, fine-tuning, and other use cases.
* Generation of harmful content: Mechanisms and guidelines for content safety
are essential. Developers are encouraged to exercise caution and implement
appropriate content safety safeguards based on their specific product policies
and application use cases.
* Misuse for malicious purposes: Technical limitations and developer and
end-user education can help mitigate against malicious applications of LLMs.
Educational resources and reporting mechanisms for users to flag misuse are
provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy](https://ai.google.dev/gemma/prohibited_use_policy).
* Privacy violations: Models were trained on data filtered for removal of PII
(Personally Identifiable Information). Developers are encouraged to adhere to
privacy regulations with privacy-preserving techniques.
### Benefits
At the time of release, this family of models provides high-performance open
large language model implementations designed from the ground up for Responsible
AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models
have shown to provide superior performance to other, comparably-sized open model
alternatives.
|
fashxp/cars-countries-2 | fashxp | 2024-02-21T16:07:02Z | 10 | 0 | transformers | [
"transformers",
"safetensors",
"convnextv2",
"image-classification",
"autotrain",
"dataset:cars-countries-2/autotrain-data",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2024-02-21T16:06:44Z |
---
tags:
- autotrain
- image-classification
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
datasets:
- cars-countries-2/autotrain-data
---
# Model Trained Using AutoTrain
- Problem type: Image Classification
## Validation Metricsg
loss: 0.7695896625518799
f1_macro: 0.6246525462930008
f1_micro: 0.7667984189723321
f1_weighted: 0.7486990681361966
precision_macro: 0.6264646464646464
precision_micro: 0.766798418972332
precision_weighted: 0.7372225929538182
recall_macro: 0.6284365875018805
recall_micro: 0.766798418972332
recall_weighted: 0.766798418972332
accuracy: 0.766798418972332
|
Deci/DeciLM-7B-instruct | Deci | 2024-02-21T16:05:34Z | 13,750 | 96 | transformers | [
"transformers",
"safetensors",
"deci",
"text-generation",
"conversational",
"custom_code",
"en",
"dataset:Open-Orca/SlimOrca",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
]
| text-generation | 2023-12-10T16:28:21Z | ---
license: apache-2.0
language:
- en
datasets:
- Open-Orca/SlimOrca
---
# DeciLM-7B-instruct
DeciLM-7B-instruct is a model for short-form instruction following. It is built by LoRA fine-tuning on the [SlimOrca dataset](https://huggingface.co/datasets/Open-Orca/SlimOrca).
## Model Details
### Model Description
DeciLM-7B-instruct is a derivative of the recently released [DeciLM-7B](https://huggingface.co/Deci/DeciLM-7B) language model, a pre-trained, high-efficiency generative text model with 7 billion parameters. DeciLM-7B-instruct is one the best 7B instruct models obtained using simple LoRA fine-tuning, without relying on preference optimization techniques such as RLHF and DPO.
- **Developed by:** [Deci](https://deci.ai/?utm_campaign=repos&utm_source=hugging-face&utm_medium=model-card&utm_content=decilm-7b-instruct)
- **Model type:** DeciLM is an auto-regressive language model using an optimized transformer decoder architecture that includes variable Grouped-Query Attention.
- **Language(s) (NLP):** English
- **License:** Apache 2.0
## Model Architecture
| Parameters | Layers | Heads | Sequence Length | GQA num_key_value_heads* |
|:----------|:----------|:----------|:----------|:----------|
| 7.04 billion | 32 | 32 | 8192 | Variable |
*AutoNAC was employed to optimize the selection of the GQA num_key_value_heads for each model layer.
### Model Sources
- **Blog:** [DeciLM-7B Technical Blog](https://deci.ai/blog/introducing-DeciLM-7B-the-fastest-and-most-accurate-7b-large-language-model-to-date/?utm_campaign=repos&utm_source=hugging-face&utm_medium=model-card&utm_content=decilm-7b-instruct)
- **Demo:** [DeciLM-7B-instruct Demo](https://huggingface.co/spaces/Deci/DeciLM-7B-instruct)
- **Finetuning Notebook:** [DeciLM-7B Finetuning Notebook](https://colab.research.google.com/drive/1kEV6i96AQ94xTCvSd11TxkEaksTb5o3U?usp=sharing)
- **Text Generation Notebook:** [DeciLM-7B-instruct Text Generation Notebook](https://bit.ly/declm-7b-instruct)
### Prompt Template
```
### System:
{system_prompt}
### User:
{user_prompt}
### Assistant:
```
## Uses
The model is intended for commercial and research use in English.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
model_name = "Deci/DeciLM-7B-instruct"
device = "cuda" # for GPU usage or "cpu" for CPU usage
quantize = False # Optional. Useful for GPUs with less than 24GB memory
if quantize:
dtype_kwargs = dict(quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16
))
else:
dtype_kwargs = dict(torch_dtype="auto")
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
trust_remote_code=True,
**dtype_kwargs
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
deci_generator = pipeline("text-generation",
model=model,
tokenizer=tokenizer,
temperature=0.1,
device_map="auto",
max_length=4096,
return_full_text=False)
system_prompt = "You are an AI assistant that follows instruction extremely well. Help as much as you can."
user_prompt = "How do I make the most delicious pancakes the world has ever tasted?"
prompt = tokenizer.apply_chat_template([
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
], tokenize=False, add_generation_prompt=True)
response = deci_generator(prompt)[0]['generated_text']
print(prompt + response)
```
## Evaluation
Below are DeciLM-7B and DeciLM-7B-instruct's evaluation results.
| Model | Average | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
|:----------|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|
| DecilLM-7B | 61.55 | 59.39 | 82.51 | 59.76 | 40.33 | 79.95 | 47.38 |
| DecilLM-7B-instruct | 63.19 | 61.01 | 82.37 | 60.24 | 49.75 | 79.72 | 46.02 |
### Runtime Benchmarks
| Inference Tool | Hardware | Prompt length | Generation length | Generated tokens/sec | Batch Size | Number of Prompts |
|:----------|:----------|:---------:|:---------:|:---------:|:---------:|:---------:|
| HuggingFace (PyTorch) | A100 (SXM4-80GB-400W) | 512 | 512 | **1174** | 352 | 352 |
| HuggingFace (PyTorch) | A100 (SXM4-80GB-400W) | 2048 | 2048 | **328** | 72 | 72 |
| Infery-LLM | A100 (SXM4-80GB-400W)| 512 | 512 | **4559** | 1024 | 4096 |
| Infery-LLM | A100 (SXM4-80GB-400W) | 2048 | 2048 | **3997** | 512 | 2048 |
| Infery-LLM | A10 | 512 | 512 | **1345** | 128 | 512 |
| Infery-LLM | A10 | 2048 | 2048 | **599** | 32 | 128 |
- In order to replicate the results of the Hugging Face benchmarks, you can use this [code example](https://huggingface.co/Deci/DeciLM-7B/blob/main/benchmark_hf_model.py).
- Infery-LLM, Deci's inference engine, features a suite of optimization algorithms, including selective quantization, optimized beam search, continuous batching, and custom CUDA kernels. To explore the full capabilities of Infery-LLM, [schedule a live demo](https://deci.ai/infery-llm-book-a-demo/?utm_campaign=DeciLM%207B%20Launch&utm_source=HF&utm_medium=decilm7b-model-card&utm_term=infery-demo).
## Ethical Considerations and Limitations
DeciLM-7B-instruct is a new technology that comes with inherent risks associated with its use. The testing conducted so far has been primarily in English and does not encompass all possible scenarios. Like those of all large language models, DeciLM-7B's outputs are unpredictable, and the model may generate responses that are inaccurate, biased, or otherwise objectionable. Consequently, developers planning to use DeciLM-7B should undertake thorough safety testing and tuning designed explicitly for their intended applications of the model before deployment.
## How to Cite
Please cite this model using this format.
```bibtex
@misc{DeciFoundationModels,
title = {DeciLM-7B-instruct},
author = {DeciAI Research Team},
year = {2023}
url={https://huggingface.co/Deci/DeciLM-7B-instruct},
}
``` |
ryusangwon/1691_Llama-2-7b-hf | ryusangwon | 2024-02-21T16:05:17Z | 2 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"dataset:samsum",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
]
| null | 2024-02-21T16:05:11Z | ---
base_model: meta-llama/Llama-2-7b-hf
tags:
- generated_from_trainer
datasets:
- samsum
model-index:
- name: 1691_Llama-2-7b-hf
results: []
library_name: peft
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 1691_Llama-2-7b-hf
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the samsum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 1
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- PEFT 0.4.0
- Transformers 4.36.2
- Pytorch 2.0.1+cu117
- Datasets 2.15.0
- Tokenizers 0.15.0
|
damerajee/Gaja.ver-1 | damerajee | 2024-02-21T16:04:10Z | 0 | 0 | transformers | [
"transformers",
"base_model:sarvamai/OpenHathi-7B-Hi-v0.1-Base",
"base_model:finetune:sarvamai/OpenHathi-7B-Hi-v0.1-Base",
"endpoints_compatible",
"region:us"
]
| null | 2024-02-21T16:03:14Z | ---
library_name: transformers
base_model: sarvamai/OpenHathi-7B-Hi-v0.1-Base
--- |
Deci/DeciLM-7B | Deci | 2024-02-21T16:04:09Z | 5,416 | 225 | transformers | [
"transformers",
"safetensors",
"deci",
"text-generation",
"conversational",
"custom_code",
"en",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
]
| text-generation | 2023-12-10T16:22:14Z | ---
license: apache-2.0
language:
- en
---
# DeciLM-7B
DeciLM-7B is a 7.04 billion parameter decoder-only text generation model, released under the Apache 2.0 license. At the time of release, DeciLM-7B is the top-performing 7B base language model on the Open LLM Leaderboard. With support for an 8K-token sequence length, this highly efficient model uses variable Grouped-Query Attention (GQA) to achieve a superior balance between accuracy and computational efficiency. The model's architecture was generated using Deci's proprietary Neural Architecture Search technology, AutoNAC.
## Model Details
### Model Description
Deci developed and released the DeciLM-7B language model, a pre-trained, high-efficiency text generation model with 7 billion parameters. DeciLM-7B is not only the most accurate 7B base model, but it also outpaces all models in its class with a throughput that is up to 4.4x that of Mistral-7B's. An instruct version [DeciLM-7B-instruct](https://huggingface.co/Deci/DeciLM-7B-instruct) has also been released.
- **Developed by:** [Deci](https://deci.ai/?utm_campaign=repos&utm_source=hugging-face&utm_medium=model-card&utm_content=decilm-7b)
- **Model type:** DeciLM is an auto-regressive language model using an optimized transformer decoder architecture that includes variable Grouped-Query Attention.
- **Language(s) (NLP):** English
- **License:** Apache 2.0
## Model Architecture
| Parameters | Layers | Heads | Sequence Length | GQA num_key_value_heads* |
|:----------|:----------|:----------|:----------|:----------|
| 7.04 billion | 32 | 32 | 8192 | Variable |
*AutoNAC was employed to optimize the selection of the GQA num_key_value_heads for each layer.
### Model Sources
- **Blog:** [DeciLM-7B Technical Blog](https://deci.ai/blog/introducing-DeciLM-7B-the-fastest-and-most-accurate-7b-large-language-model-to-date/?utm_campaign=repos&utm_source=hugging-face&utm_medium=model-card&utm_content=decilm-7b)
- **Demo:** [DeciLM-7B-instruct Demo](https://huggingface.co/spaces/Deci/DeciLM-7B-instruct)
- **Finetuning Notebook:** [DeciLM-7B Finetuning Notebook](https://colab.research.google.com/drive/1kEV6i96AQ94xTCvSd11TxkEaksTb5o3U?usp=sharing)
- **Text Generation Notebook:** [DeciLM-7B-instruct Text Generation Notebook](https://bit.ly/declm-7b-instruct)
## Uses
The model is intended for commercial and research use in English and can be fine-tuned for various tasks and languages.
## How to Get Started with the Model
Use the code below to get started with the model.
```bibtex
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Deci/DeciLM-7B"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", trust_remote_code=True).to(device)
inputs = tokenizer.encode("In a shocking finding, scientists discovered a herd of unicorns living in", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_new_tokens=100, do_sample=True, top_p=0.95)
print(tokenizer.decode(outputs[0]))
# The model can also be used via the text-generation pipeline interface
from transformers import pipeline
generator = pipeline("text-generation", "Deci/DeciLM-7B", torch_dtype="auto", trust_remote_code=True, device=device)
outputs = generator("In a shocking finding, scientists discovered a herd of unicorns living in", max_new_tokens=100, do_sample=True, top_p=0.95)
print(outputs[0]["generated_text"])
```
## Evaluation
Below are DeciLM-7B and DeciLM-7B-instruct's Open LLM Leaderboard results.
| Model | Average | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
|:----------|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|
| DecilLM-7B | 61.55 | 59.39 | 82.51 | 59.76 | 40.33 | 79.95 | 47.38 |
| DecilLM-7B-instruct | 63.19 | 61.01 | 82.37 | 60.24 | 49.75 | 79.72 | 46.02 |
### Runtime Benchmarks
| Inference Tool | Hardware | Prompt length | Generation length | Generated tokens/sec | Batch Size | Number of Prompts |
|:----------|:----------|:---------:|:---------:|:---------:|:---------:|:---------:|
| HuggingFace (PyTorch) | A100 (SXM4-80GB-400W) | 512 | 512 | **1174** | 352 | 352 |
| HuggingFace (PyTorch) | A100 (SXM4-80GB-400W) | 2048 | 2048 | **328** | 72 | 72 |
| Infery-LLM | A100 (SXM4-80GB-400W)| 512 | 512 | **4559** | 1024 | 4096 |
| Infery-LLM | A100 (SXM4-80GB-400W) | 2048 | 2048 | **3997** | 512 | 2048 |
| Infery-LLM | A10 | 512 | 512 | **1345** | 128 | 512 |
| Infery-LLM | A10 | 2048 | 2048 | **599** | 32 | 128 |
- In order to replicate the results of the Hugging Face benchmarks, you can use this [code example](https://huggingface.co/Deci/DeciLM-7B/blob/main/benchmark_hf_model.py).
- Infery-LLM, Deci's inference engine, features a suite of optimization algorithms, including selective quantization, optimized beam search, continuous batching, and custom CUDA kernels. To explore the capabilities of Infery-LLM, [schedule a live demo](https://deci.ai/infery-llm-book-a-demo/?utm_campaign=DeciLM%207B%20Launch&utm_source=HF&utm_medium=decilm7b-model-card&utm_term=infery-demo).
## Ethical Considerations and Limitations
DeciLM-7B is a new technology that comes with inherent risks associated with its use. The testing conducted so far has been primarily in English and does not encompass all possible scenarios. Like those of all large language models, DeciLM-7B's outputs are unpredictable, and the model may generate responses that are inaccurate, biased, or otherwise objectionable. Consequently, developers planning to use DeciLM-7B should undertake thorough safety testing and tuning designed explicitly for their intended applications of the model before deployment.
## How to Cite
Please cite this model using this format.
```bibtex
@misc{DeciFoundationModels,
title = {DeciLM-7B},
author = {DeciAI Research Team},
year = {2023}
url={https://huggingface.co/Deci/DeciLM-7B},
}
``` |
sanjayadhikesaven/opt-125m-4bit | sanjayadhikesaven | 2024-02-21T16:02:39Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"opt",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
]
| text-generation | 2024-02-21T15:51:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mixtralyanis/zephyr_summarizer | mixtralyanis | 2024-02-21T16:01:05Z | 0 | 0 | null | [
"safetensors",
"autotrain",
"text-generation",
"conversational",
"license:other",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T16:00:58Z | ---
tags:
- autotrain
- text-generation
widget:
- text: "I love AutoTrain because "
license: other
---
# Model Trained Using AutoTrain
This model was trained using AutoTrain. For more information, please visit [AutoTrain](https://hf.co/docs/autotrain).
# Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "PATH_TO_THIS_REPO"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype='auto'
).eval()
# Prompt content: "hi"
messages = [
{"role": "user", "content": "hi"}
]
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids.to('cuda'))
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
# Model response: "Hello! How can I assist you today?"
print(response)
``` |
sanjayadhikesaven/opt-125m-2bit | sanjayadhikesaven | 2024-02-21T15:59:16Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"opt",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"2-bit",
"gptq",
"region:us"
]
| text-generation | 2024-02-21T15:45:30Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
brittlewis12/gemma-7b-GGUF | brittlewis12 | 2024-02-21T15:58:40Z | 215 | 2 | null | [
"gguf",
"text-generation",
"en",
"arxiv:2009.03300",
"arxiv:1905.07830",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1905.10044",
"arxiv:1907.10641",
"arxiv:1811.00937",
"arxiv:1809.02789",
"arxiv:1911.01547",
"arxiv:1705.03551",
"arxiv:2107.03374",
"arxiv:2108.07732",
"arxiv:2110.14168",
"arxiv:2304.06364",
"arxiv:2206.04615",
"arxiv:2009.11462",
"arxiv:2101.11718",
"arxiv:2110.08193",
"arxiv:1804.09301",
"arxiv:2109.07958",
"arxiv:1804.06876",
"arxiv:2203.09509",
"base_model:google/gemma-7b",
"base_model:quantized:google/gemma-7b",
"license:other",
"region:us"
]
| text-generation | 2024-02-21T14:54:12Z | ---
base_model: google/gemma-7b
inference: false
language:
- en
model_creator: google
model_name: gemma-7b
model_type: gemma
pipeline_tag: text-generation
license: other
license_name: gemma-terms-of-use
license_link: https://ai.google.dev/gemma/terms
quantized_by: brittlewis12
---
# Gemma 7B GGUF
**Original model**: [gemma-7b](https://huggingface.co/google/gemma-7b)
**Model creator**: [google](https://huggingface.co/google)
This repo contains GGUF format model files for Google’s Gemma-7B.
> Gemma is a family of lightweight, state-of-the-art open models from Google,
> built from the same research and technology used to create the Gemini models.
> They are text-to-text, decoder-only large language models, available in English,
> with open weights, pre-trained variants, and instruction-tuned variants. Gemma
> models are well-suited for a variety of text generation tasks, including
> question answering, summarization, and reasoning. Their relatively small size
> makes it possible to deploy them in environments with limited resources such as
> a laptop, desktop or your own cloud infrastructure, democratizing access to
> state of the art AI models and helping foster innovation for everyone.
Learn more on Google’s [Model page](https://ai.google.dev/gemma/docs).
### What is GGUF?
GGUF is a file format for representing AI models. It is the third version of the format, introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Converted using llama.cpp build 2226 (revision [eccd7a2](https://github.com/ggerganov/llama.cpp/commit/eccd7a26ddbff19e4b8805648f5f14c501957859))
---
## Download & run with [cnvrs](https://twitter.com/cnvrsai) on iPhone, iPad, and Mac!

[cnvrs](https://testflight.apple.com/join/sFWReS7K) is the best app for private, local AI on your device:
- create & save **Characters** with custom system prompts & temperature settings
- download and experiment with any **GGUF model** you can [find on HuggingFace](https://huggingface.co/models?library=gguf)!
- make it your own with custom **Theme colors**
- powered by Metal ⚡️ & [Llama.cpp](https://github.com/ggerganov/llama.cpp), with **haptics** during response streaming!
- **try it out** yourself today, on [Testflight](https://testflight.apple.com/join/sFWReS7K)!
- follow [cnvrs on twitter](https://twitter.com/cnvrsai) to stay up to date
---
## Original Model Evaluation
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [MMLU](https://arxiv.org/abs/2009.03300) | 5-shot, top-1 | 42.3 | 64.3 |
| [HellaSwag](https://arxiv.org/abs/1905.07830) | 0-shot |71.4 | 81.2 |
| [PIQA](https://arxiv.org/abs/1911.11641) | 0-shot | 77.3 | 81.2 |
| [SocialIQA](https://arxiv.org/abs/1904.09728) | 0-shot | 59.7 | 51.8 |
| [BooIQ](https://arxiv.org/abs/1905.10044) | 0-shot | 69.4 | 83.2 |
| [WinoGrande](https://arxiv.org/abs/1907.10641) | partial score | 65.4 | 72.3 |
| [CommonsenseQA](https://arxiv.org/abs/1811.00937) | 7-shot | 65.3 | 71.3 |
| [OpenBookQA](https://arxiv.org/abs/1809.02789) | | 47.8 | 52.8 |
| [ARC-e](https://arxiv.org/abs/1911.01547) | | 73.2 | 81.5 |
| [ARC-c](https://arxiv.org/abs/1911.01547) | | 42.1 | 53.2 |
| [TriviaQA](https://arxiv.org/abs/1705.03551) | 5-shot | 53.2 | 63.4 |
| [Natural Questions](https://github.com/google-research-datasets/natural-questions) | 5-shot | - | 23 |
| [HumanEval](https://arxiv.org/abs/2107.03374) | pass@1 | 22.0 | 32.3 |
| [MBPP](https://arxiv.org/abs/2108.07732) | 3-shot | 29.2 | 44.4 |
| [GSM8K](https://arxiv.org/abs/2110.14168) | maj@1 | 17.7 | 46.4 |
| [MATH](https://arxiv.org/abs/2108.07732) | 4-shot | 11.8 | 24.3 |
| [AGIEval](https://arxiv.org/abs/2304.06364) | | 24.2 | 41.7 |
| [BIG-Bench](https://arxiv.org/abs/2206.04615) | | 35.2 | 55.1 |
| **Average** | | **54.0** | **56.4** |
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [RealToxicity](https://arxiv.org/abs/2009.11462) | average | 6.86 | 7.90 |
| [BOLD](https://arxiv.org/abs/2101.11718) | | 45.57 | 49.08 |
| [CrowS-Pairs](https://aclanthology.org/2020.emnlp-main.154/) | top-1 | 45.82 | 51.33 |
| [BBQ Ambig](https://arxiv.org/abs/2110.08193v2) | 1-shot, top-1 | 62.58 | 92.54 |
| [BBQ Disambig](https://arxiv.org/abs/2110.08193v2) | top-1 | 54.62 | 71.99 |
| [Winogender](https://arxiv.org/abs/1804.09301) | top-1 | 51.25 | 54.17 |
| [TruthfulQA](https://arxiv.org/abs/2109.07958) | | 44.84 | 31.81 |
| [Winobias 1_2](https://arxiv.org/abs/1804.06876) | | 56.12 | 59.09 |
| [Winobias 2_2](https://arxiv.org/abs/1804.06876) | | 91.10 | 92.23 |
| [Toxigen](https://arxiv.org/abs/2203.09509) | | 29.77 | 39.59 |
|
Gordon119/TAT-openai-whisper-large-v3-special-tag-v1-epoch5-total5epoch | Gordon119 | 2024-02-21T15:57:14Z | 0 | 0 | transformers | [
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-02-19T18:36:16Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
avinasht/FLANG-ELECTRA_roberta-base | avinasht | 2024-02-21T15:51:11Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"electra",
"text-classification",
"generated_from_trainer",
"base_model:SALT-NLP/FLANG-ELECTRA",
"base_model:finetune:SALT-NLP/FLANG-ELECTRA",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-02-21T15:50:27Z | ---
base_model: SALT-NLP/FLANG-ELECTRA
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: FLANG-ELECTRA_roberta-base
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# FLANG-ELECTRA_roberta-base
This model is a fine-tuned version of [SALT-NLP/FLANG-ELECTRA](https://huggingface.co/SALT-NLP/FLANG-ELECTRA) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4678
- Accuracy: 0.8736
- F1: 0.8728
- Precision: 0.8738
- Recall: 0.8736
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.6813 | 1.0 | 181 | 0.5968 | 0.7457 | 0.7326 | 0.7488 | 0.7457 |
| 0.4427 | 2.0 | 362 | 0.5072 | 0.8222 | 0.8200 | 0.8321 | 0.8222 |
| 0.2366 | 3.0 | 543 | 0.4216 | 0.8518 | 0.8509 | 0.8523 | 0.8518 |
| 0.2022 | 4.0 | 724 | 0.5838 | 0.8518 | 0.8501 | 0.8526 | 0.8518 |
| 0.1299 | 5.0 | 905 | 0.4678 | 0.8736 | 0.8728 | 0.8738 | 0.8736 |
| 0.2016 | 6.0 | 1086 | 0.5147 | 0.8362 | 0.8346 | 0.8355 | 0.8362 |
| 0.1255 | 7.0 | 1267 | 0.6612 | 0.8471 | 0.8438 | 0.8549 | 0.8471 |
| 0.1713 | 8.0 | 1448 | 0.8831 | 0.8003 | 0.7992 | 0.8107 | 0.8003 |
| 0.092 | 9.0 | 1629 | 0.6286 | 0.8440 | 0.8434 | 0.8525 | 0.8440 |
| 0.0476 | 10.0 | 1810 | 0.7429 | 0.8690 | 0.8692 | 0.8697 | 0.8690 |
### Framework versions
- Transformers 4.37.0
- Pytorch 2.1.2
- Datasets 2.1.0
- Tokenizers 0.15.1
|
fashxp/cars-countries | fashxp | 2024-02-21T15:47:26Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"vit",
"image-classification",
"autotrain",
"dataset:cars-countries/autotrain-data",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2024-02-21T15:47:13Z |
---
tags:
- autotrain
- image-classification
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
datasets:
- cars-countries/autotrain-data
---
# Model Trained Using AutoTrain
- Problem type: Image Classification
## Validation Metricsg
loss: 1.2113300561904907
f1_macro: 0.35240829346092506
f1_micro: 0.5098039215686274
f1_weighted: 0.43996622572473965
precision_macro: 0.443963963963964
precision_micro: 0.5098039215686274
precision_weighted: 0.5037272566684332
recall_macro: 0.36746031746031743
recall_micro: 0.5098039215686274
recall_weighted: 0.5098039215686274
accuracy: 0.5098039215686274
|
mhenrichsen/gemma-7b | mhenrichsen | 2024-02-21T15:45:05Z | 277 | 4 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:2305.14314",
"arxiv:2312.11805",
"arxiv:2009.03300",
"arxiv:1905.07830",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1905.10044",
"arxiv:1907.10641",
"arxiv:1811.00937",
"arxiv:1809.02789",
"arxiv:1911.01547",
"arxiv:1705.03551",
"arxiv:2107.03374",
"arxiv:2108.07732",
"arxiv:2110.14168",
"arxiv:2304.06364",
"arxiv:2206.04615",
"arxiv:1804.06876",
"arxiv:2110.08193",
"arxiv:2009.11462",
"arxiv:2101.11718",
"arxiv:1804.09301",
"arxiv:2109.07958",
"arxiv:2203.09509",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T15:35:34Z | ---
library_name: transformers
---
# Reupload of Google Gemma - Find original readme below.
# Gemma Model Card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs)
This model card corresponds to the 7B base version of the Gemma model. You can also visit the model card of the [2B base model](https://huggingface.co/google/gemma-2b), [7B instruct model](https://huggingface.co/google/gemma-7b-it), and [2B instruct model](https://huggingface.co/google/gemma-2b-it).
**Resources and Technical Documentation**:
* [Responsible Generative AI Toolkit](https://ai.google.dev/responsible)
* [Gemma on Kaggle](https://www.kaggle.com/models/google/gemma)
* [Gemma on Vertex Model Garden](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/335?version=gemma-7b-gg-hf)
**Terms of Use**: [Terms](https://www.kaggle.com/models/google/gemma/license/consent)
**Authors**: Google
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
They are text-to-text, decoder-only large language models, available in English,
with open weights, pre-trained variants, and instruction-tuned variants. Gemma
models are well-suited for a variety of text generation tasks, including
question answering, summarization, and reasoning. Their relatively small size
makes it possible to deploy them in environments with limited resources such as
a laptop, desktop or your own cloud infrastructure, democratizing access to
state of the art AI models and helping foster innovation for everyone.
### Usage
Below we share some code snippets on how to get quickly started with running the model. First make sure to `pip install -U transformers`, then copy the snippet from the section that is relevant for your usecase.
#### Fine-tuning examples
You can find fine-tuning notebooks under the [`examples/` directory](https://huggingface.co/google/gemma-7b/tree/main/examples). We provide:
* A script to perform Supervised Fine-Tuning (SFT) on UltraChat dataset using [QLoRA](https://huggingface.co/papers/2305.14314)
* A script to perform SFT using FSDP on TPU devices
* A notebook that you can run on a free-tier Google Colab instance to perform SFT on English quotes dataset
#### Running the model on a CPU
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(**input_text, return_tensors="pt")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a single / multi GPU
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b", device_map="auto")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a GPU using different precisions
* _Using `torch.float16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b", device_map="auto", torch_dtype=torch.float16)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using `torch.bfloat16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b", device_map="auto", torch_dtype=torch.bfloat16)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Quantized Versions through `bitsandbytes`
* _Using 8-bit precision (int8)_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using 4-bit precision_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Other optimizations
* _Flash Attention 2_
First make sure to install `flash-attn` in your environment `pip install flash-attn`
```diff
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2"
).to(0)
```
### Inputs and outputs
* **Input:** Text string, such as a question, a prompt, or a document to be
summarized.
* **Output:** Generated English-language text in response to the input, such
as an answer to a question, or a summary of a document.
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
These models were trained on a dataset of text data that includes a wide variety
of sources, totaling 6 trillion tokens. Here are the key components:
* Web Documents: A diverse collection of web text ensures the model is exposed
to a broad range of linguistic styles, topics, and vocabulary. Primarily
English-language content.
* Code: Exposing the model to code helps it to learn the syntax and patterns of
programming languages, which improves its ability to generate code or
understand code-related questions.
* Mathematics: Training on mathematical text helps the model learn logical
reasoning, symbolic representation, and to address mathematical queries.
The combination of these diverse data sources is crucial for training a powerful
language model that can handle a wide variety of different tasks and text
formats.
### Data Preprocessing
Here are the key data cleaning and filtering methods applied to the training
data:
* CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering was
applied at multiple stages in the data preparation process to ensure the
exclusion of harmful and illegal content
* Sensitive Data Filtering: As part of making Gemma pre-trained models safe and
reliable, automated techniques were used to filter out certain personal
information and other sensitive data from training sets.
* Additional methods: Filtering based on content quality and safely in line with
[our policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11).
## Implementation Information
Details about the model internals.
### Hardware
Gemma was trained using the latest generation of
[Tensor Processing Unit (TPU)](https://cloud.google.com/tpu/docs/intro-to-tpu) hardware (TPUv5e).
Training large language models requires significant computational power. TPUs,
designed specifically for matrix operations common in machine learning, offer
several advantages in this domain:
* Performance: TPUs are specifically designed to handle the massive computations
involved in training LLMs. They can speed up training considerably compared to
CPUs.
* Memory: TPUs often come with large amounts of high-bandwidth memory, allowing
for the handling of large models and batch sizes during training. This can
lead to better model quality.
* Scalability: TPU Pods (large clusters of TPUs) provide a scalable solution for
handling the growing complexity of large foundation models. You can distribute
training across multiple TPU devices for faster and more efficient processing.
* Cost-effectiveness: In many scenarios, TPUs can provide a more cost-effective
solution for training large models compared to CPU-based infrastructure,
especially when considering the time and resources saved due to faster
training.
* These advantages are aligned with
[Google's commitments to operate sustainably](https://sustainability.google/operating-sustainably/).
### Software
Training was done using [JAX](https://github.com/google/jax) and [ML Pathways](https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture).
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models.
ML Pathways is Google's latest effort to build artificially intelligent systems
capable of generalizing across multiple tasks. This is specially suitable for
[foundation models](https://ai.google/discover/foundation-models/), including large language models like
these ones.
Together, JAX and ML Pathways are used as described in the
[paper about the Gemini family of models](https://arxiv.org/abs/2312.11805); "the 'single
controller' programming model of Jax and Pathways allows a single Python
process to orchestrate the entire training run, dramatically simplifying the
development workflow."
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
These models were evaluated against a large collection of different datasets and
metrics to cover different aspects of text generation:
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [MMLU](https://arxiv.org/abs/2009.03300) | 5-shot, top-1 | 42.3 | 64.3 |
| [HellaSwag](https://arxiv.org/abs/1905.07830) | 0-shot |71.4 | 81.2 |
| [PIQA](https://arxiv.org/abs/1911.11641) | 0-shot | 77.3 | 81.2 |
| [SocialIQA](https://arxiv.org/abs/1904.09728) | 0-shot | 59.7 | 51.8 |
| [BooIQ](https://arxiv.org/abs/1905.10044) | 0-shot | 69.4 | 83.2 |
| [WinoGrande](https://arxiv.org/abs/1907.10641) | partial score | 65.4 | 72.3 |
| [CommonsenseQA](https://arxiv.org/abs/1811.00937) | 7-shot | 65.3 | 71.3 |
| [OpenBookQA](https://arxiv.org/abs/1809.02789) | | 47.8 | 52.8 |
| [ARC-e](https://arxiv.org/abs/1911.01547) | | 73.2 | 81.5 |
| [ARC-c](https://arxiv.org/abs/1911.01547) | | 42.1 | 53.2 |
| [TriviaQA](https://arxiv.org/abs/1705.03551) | 5-shot | 53.2 | 63.4 |
| [Natural Questions](https://github.com/google-research-datasets/natural-questions) | 5-shot | - | 23 |
| [HumanEval](https://arxiv.org/abs/2107.03374) | pass@1 | 22.0 | 32.3 |
| [MBPP](https://arxiv.org/abs/2108.07732) | 3-shot | 29.2 | 44.4 |
| [GSM8K](https://arxiv.org/abs/2110.14168) | maj@1 | 17.7 | 46.4 |
| [MATH](https://arxiv.org/abs/2108.07732) | 4-shot | 11.8 | 24.3 |
| [AGIEval](https://arxiv.org/abs/2304.06364) | | 24.2 | 41.7 |
| [BIG-Bench](https://arxiv.org/abs/2206.04615) | | 35.2 | 55.1 |
| ------------------------------ | ------------- | ----------- | --------- |
| **Average** | | **54.0** | **56.4** |
## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
* Text-to-Text Content Safety: Human evaluation on prompts covering safety
policies including child sexual abuse and exploitation, harassment, violence
and gore, and hate speech.
* Text-to-Text Representational Harms: Benchmark against relevant academic
datasets such as [WinoBias](https://arxiv.org/abs/1804.06876) and [BBQ Dataset](https://arxiv.org/abs/2110.08193v2).
* Memorization: Automated evaluation of memorization of training data, including
the risk of personally identifiable information exposure.
* Large-scale harm: Tests for "dangerous capabilities," such as chemical,
biological, radiological, and nuclear (CBRN) risks.
### Evaluation Results
The results of ethics and safety evaluations are within acceptable thresholds
for meeting [internal policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11) for categories such as child
safety, content safety, representational harms, memorization, large-scale harms.
On top of robust internal evaluations, the results of well known safety
benchmarks like BBQ, BOLD, Winogender, Winobias, RealToxicity, and TruthfulQA
are shown here.
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [RealToxicity](https://arxiv.org/abs/2009.11462) | average | 6.86 | 7.90 |
| [BOLD](https://arxiv.org/abs/2101.11718) | | 45.57 | 49.08 |
| [CrowS-Pairs](https://aclanthology.org/2020.emnlp-main.154/) | top-1 | 45.82 | 51.33 |
| [BBQ Ambig](https://arxiv.org/abs/2110.08193v2) | 1-shot, top-1 | 62.58 | 92.54 |
| [BBQ Disambig](https://arxiv.org/abs/2110.08193v2) | top-1 | 54.62 | 71.99 |
| [Winogender](https://arxiv.org/abs/1804.09301) | top-1 | 51.25 | 54.17 |
| [TruthfulQA](https://arxiv.org/abs/2109.07958) | | 44.84 | 31.81 |
| [Winobias 1_2](https://arxiv.org/abs/1804.06876) | | 56.12 | 59.09 |
| [Winobias 2_2](https://arxiv.org/abs/1804.06876) | | 91.10 | 92.23 |
| [Toxigen](https://arxiv.org/abs/2203.09509) | | 29.77 | 39.59 |
| ------------------------------ | ------------- | ----------- | --------- |
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Open Large Language Models (LLMs) have a wide range of applications across
various industries and domains. The following list of potential uses is not
comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
* Content Creation and Communication
* Text Generation: These models can be used to generate creative text formats
such as poems, scripts, code, marketing copy, and email drafts.
* Chatbots and Conversational AI: Power conversational interfaces for customer
service, virtual assistants, or interactive applications.
* Text Summarization: Generate concise summaries of a text corpus, research
papers, or reports.
* Research and Education
* Natural Language Processing (NLP) Research: These models can serve as a
foundation for researchers to experiment with NLP techniques, develop
algorithms, and contribute to the advancement of the field.
* Language Learning Tools: Support interactive language learning experiences,
aiding in grammar correction or providing writing practice.
* Knowledge Exploration: Assist researchers in exploring large bodies of text
by generating summaries or answering questions about specific topics.
### Limitations
* Training Data
* The quality and diversity of the training data significantly influence the
model's capabilities. Biases or gaps in the training data can lead to
limitations in the model's responses.
* The scope of the training dataset determines the subject areas the model can
handle effectively.
* Context and Task Complexity
* LLMs are better at tasks that can be framed with clear prompts and
instructions. Open-ended or highly complex tasks might be challenging.
* A model's performance can be influenced by the amount of context provided
(longer context generally leads to better outputs, up to a certain point).
* Language Ambiguity and Nuance
* Natural language is inherently complex. LLMs might struggle to grasp subtle
nuances, sarcasm, or figurative language.
* Factual Accuracy
* LLMs generate responses based on information they learned from their
training datasets, but they are not knowledge bases. They may generate
incorrect or outdated factual statements.
* Common Sense
* LLMs rely on statistical patterns in language. They might lack the ability
to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of large language models (LLMs) raises several ethical concerns.
In creating an open model, we have carefully considered the following:
* Bias and Fairness
* LLMs trained on large-scale, real-world text data can reflect socio-cultural
biases embedded in the training material. These models underwent careful
scrutiny, input data pre-processing described and posterior evaluations
reported in this card.
* Misinformation and Misuse
* LLMs can be misused to generate text that is false, misleading, or harmful.
* Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit](http://ai.google.dev/gemma/responsible).
* Transparency and Accountability:
* This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
* A responsibly developed open model offers the opportunity to share
innovation by making LLM technology accessible to developers and researchers
across the AI ecosystem.
Risks identified and mitigations:
* Perpetuation of biases: It's encouraged to perform continuous monitoring
(using evaluation metrics, human review) and the exploration of de-biasing
techniques during model training, fine-tuning, and other use cases.
* Generation of harmful content: Mechanisms and guidelines for content safety
are essential. Developers are encouraged to exercise caution and implement
appropriate content safety safeguards based on their specific product policies
and application use cases.
* Misuse for malicious purposes: Technical limitations and developer and
end-user education can help mitigate against malicious applications of LLMs.
Educational resources and reporting mechanisms for users to flag misuse are
provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy](https://ai.google.dev/gemma/prohibited_use_policy).
* Privacy violations: Models were trained on data filtered for removal of PII
(Personally Identifiable Information). Developers are encouraged to adhere to
privacy regulations with privacy-preserving techniques.
### Benefits
At the time of release, this family of models provides high-performance open
large language model implementations designed from the ground up for Responsible
AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models
have shown to provide superior performance to other, comparably-sized open model
alternatives.
|
Cippppy/my_awesome_model2 | Cippppy | 2024-02-21T15:43:11Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-02-21T15:24:09Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: my_awesome_model2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6933
- Accuracy: 0.5
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.2
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 247.4414 | 1.0 | 782 | 0.6933 | 0.5 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0+cu118
- Datasets 2.17.1
- Tokenizers 0.15.2
|
rahuldshetty/gemma-2b-gguf-quantized | rahuldshetty | 2024-02-21T15:35:18Z | 29 | 6 | transformers | [
"transformers",
"gguf",
"arxiv:2312.11805",
"arxiv:2009.03300",
"arxiv:1905.07830",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1905.10044",
"arxiv:1907.10641",
"arxiv:1811.00937",
"arxiv:1809.02789",
"arxiv:1911.01547",
"arxiv:1705.03551",
"arxiv:2107.03374",
"arxiv:2108.07732",
"arxiv:2110.14168",
"arxiv:2304.06364",
"arxiv:2206.04615",
"arxiv:1804.06876",
"arxiv:2110.08193",
"arxiv:2009.11462",
"arxiv:2101.11718",
"arxiv:1804.09301",
"arxiv:2109.07958",
"arxiv:2203.09509",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-02-21T14:58:30Z | ---
library_name: transformers
tags: []
extra_gated_heading: "Access Gemma on Hugging Face"
extra_gated_prompt: "To access Gemma on Hugging Face, you’re required to review and agree to Google’s usage license. To do this, please ensure you’re logged-in to Hugging Face and click below. Requests are processed immediately."
extra_gated_button_content: "Acknowledge license"
license: other
license_name: gemma-terms-of-use
license_link: https://ai.google.dev/gemma/terms
---
GGUF Quantized version of [gemma-2b](https://huggingface.co/google/gemma-2b).
| Name | Quant method | Bits | Size | Use case |
| ---- | ---- | ---- | ---- | ----- |
| [gemma-2b-Q2_K.gguf](https://huggingface.co/rahuldshetty/gemma-2b-gguf-quantized/blob/main/gemma-2b-Q2_K.gguf) | Q2_K | 2 | 900 MB | smallest, significant quality loss - not recommended for most purposes |
| [gemma-2b-Q4_K_M.gguf](https://huggingface.co/rahuldshetty/gemma-2b-gguf-quantized/blob/main/gemma-2b-Q4_K_M.gguf) | Q4_K_M | 4 | 1.5 GB | medium, balanced quality - recommended |
| [gemma-2b-Q8_0.gguf](https://huggingface.co/rahuldshetty/gemma-2b-gguf-quantized/blob/main/gemma-2b-Q8_0.gguf) | Q8_0 | 8 | 2.67 GB | very large, extremely low quality loss - not recommended|
# Gemma Model Card (Taken from Official HF Repo)
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs)
This model card corresponds to the 2B base version of the Gemma model. You can also visit the model card of the [7B base model](https://huggingface.co/google/gemma-7b), [7B instruct model](https://huggingface.co/google/gemma-7b-it), and [2B instruct model](https://huggingface.co/google/gemma-2b-it).
**Resources and Technical Documentation**:
* [Responsible Generative AI Toolkit](https://ai.google.dev/responsible)
* [Gemma on Kaggle](https://www.kaggle.com/models/google/gemma)
* [Gemma on Vertex Model Garden](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/335?version=gemma-2b-gg-hf)
**Terms of Use**: [Terms](https://www.kaggle.com/models/google/gemma/license/consent)
**Authors**: Google
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma is a family of lightweight, state-of-the-art open models from Google,
built from the same research and technology used to create the Gemini models.
They are text-to-text, decoder-only large language models, available in English,
with open weights, pre-trained variants, and instruction-tuned variants. Gemma
models are well-suited for a variety of text generation tasks, including
question answering, summarization, and reasoning. Their relatively small size
makes it possible to deploy them in environments with limited resources such as
a laptop, desktop or your own cloud infrastructure, democratizing access to
state of the art AI models and helping foster innovation for everyone.
### Usage
Below we share some code snippets on how to get quickly started with running the model. First make sure to `pip install -U transformers`, then copy the snippet from the section that is relevant for your usecase.
#### Fine-tuning the model
You can find fine-tuning scripts and notebook under the [`examples/` directory](https://huggingface.co/google/gemma-7b/tree/main/examples) of [`google/gemma-7b`](https://huggingface.co/google/gemma-7b) repository. To adapt it to this model, simply change the model-id to `google/gemma-2b`.
In that repository, we provide:
* A script to perform Supervised Fine-Tuning (SFT) on UltraChat dataset using QLoRA
* A script to perform SFT using FSDP on TPU devices
* A notebook that you can run on a free-tier Google Colab instance to perform SFT on English quotes dataset
#### Running the model on a CPU
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(**input_text, return_tensors="pt")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a single / multi GPU
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a GPU using different precisions
* _Using `torch.float16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto", torch_dtype=torch.float16)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using `torch.bfloat16`_
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto", torch_dtype=torch.bfloat16)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Quantized Versions through `bitsandbytes`
* _Using 8-bit precision (int8)_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
* _Using 4-bit precision_
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", quantization_config=quantization_config)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Other optimizations
* _Flash Attention 2_
First make sure to install `flash-attn` in your environment `pip install flash-attn`
```diff
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2"
).to(0)
```
### Inputs and outputs
* **Input:** Text string, such as a question, a prompt, or a document to be
summarized.
* **Output:** Generated English-language text in response to the input, such
as an answer to a question, or a summary of a document.
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
These models were trained on a dataset of text data that includes a wide variety
of sources, totaling 6 trillion tokens. Here are the key components:
* Web Documents: A diverse collection of web text ensures the model is exposed
to a broad range of linguistic styles, topics, and vocabulary. Primarily
English-language content.
* Code: Exposing the model to code helps it to learn the syntax and patterns of
programming languages, which improves its ability to generate code or
understand code-related questions.
* Mathematics: Training on mathematical text helps the model learn logical
reasoning, symbolic representation, and to address mathematical queries.
The combination of these diverse data sources is crucial for training a powerful
language model that can handle a wide variety of different tasks and text
formats.
### Data Preprocessing
Here are the key data cleaning and filtering methods applied to the training
data:
* CSAM Filtering: Rigorous CSAM (Child Sexual Abuse Material) filtering was
applied at multiple stages in the data preparation process to ensure the
exclusion of harmful and illegal content
* Sensitive Data Filtering: As part of making Gemma pre-trained models safe and
reliable, automated techniques were used to filter out certain personal
information and other sensitive data from training sets.
* Additional methods: Filtering based on content quality and safely in line with
[our policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11).
## Implementation Information
Details about the model internals.
### Hardware
Gemma was trained using the latest generation of
[Tensor Processing Unit (TPU)](https://cloud.google.com/tpu/docs/intro-to-tpu) hardware (TPUv5e).
Training large language models requires significant computational power. TPUs,
designed specifically for matrix operations common in machine learning, offer
several advantages in this domain:
* Performance: TPUs are specifically designed to handle the massive computations
involved in training LLMs. They can speed up training considerably compared to
CPUs.
* Memory: TPUs often come with large amounts of high-bandwidth memory, allowing
for the handling of large models and batch sizes during training. This can
lead to better model quality.
* Scalability: TPU Pods (large clusters of TPUs) provide a scalable solution for
handling the growing complexity of large foundation models. You can distribute
training across multiple TPU devices for faster and more efficient processing.
* Cost-effectiveness: In many scenarios, TPUs can provide a more cost-effective
solution for training large models compared to CPU-based infrastructure,
especially when considering the time and resources saved due to faster
training.
* These advantages are aligned with
[Google's commitments to operate sustainably](https://sustainability.google/operating-sustainably/).
### Software
Training was done using [JAX](https://github.com/google/jax) and [ML Pathways](https://blog.google/technology/ai/introducing-pathways-next-generation-ai-architecture/ml-pathways).
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models.
ML Pathways is Google's latest effort to build artificially intelligent systems
capable of generalizing across multiple tasks. This is specially suitable for
[foundation models](https://ai.google/discover/foundation-models/), including large language models like
these ones.
Together, JAX and ML Pathways are used as described in the
[paper about the Gemini family of models](https://arxiv.org/abs/2312.11805); "the 'single
controller' programming model of Jax and Pathways allows a single Python
process to orchestrate the entire training run, dramatically simplifying the
development workflow."
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
These models were evaluated against a large collection of different datasets and
metrics to cover different aspects of text generation:
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [MMLU](https://arxiv.org/abs/2009.03300) | 5-shot, top-1 | 42.3 | 64.3 |
| [HellaSwag](https://arxiv.org/abs/1905.07830) | 0-shot |71.4 | 81.2 |
| [PIQA](https://arxiv.org/abs/1911.11641) | 0-shot | 77.3 | 81.2 |
| [SocialIQA](https://arxiv.org/abs/1904.09728) | 0-shot | 59.7 | 51.8 |
| [BooIQ](https://arxiv.org/abs/1905.10044) | 0-shot | 69.4 | 83.2 |
| [WinoGrande](https://arxiv.org/abs/1907.10641) | partial score | 65.4 | 72.3 |
| [CommonsenseQA](https://arxiv.org/abs/1811.00937) | 7-shot | 65.3 | 71.3 |
| [OpenBookQA](https://arxiv.org/abs/1809.02789) | | 47.8 | 52.8 |
| [ARC-e](https://arxiv.org/abs/1911.01547) | | 73.2 | 81.5 |
| [ARC-c](https://arxiv.org/abs/1911.01547) | | 42.1 | 53.2 |
| [TriviaQA](https://arxiv.org/abs/1705.03551) | 5-shot | 53.2 | 63.4 |
| [Natural Questions](https://github.com/google-research-datasets/natural-questions) | 5-shot | - | 23 |
| [HumanEval](https://arxiv.org/abs/2107.03374) | pass@1 | 22.0 | 32.3 |
| [MBPP](https://arxiv.org/abs/2108.07732) | 3-shot | 29.2 | 44.4 |
| [GSM8K](https://arxiv.org/abs/2110.14168) | maj@1 | 17.7 | 46.4 |
| [MATH](https://arxiv.org/abs/2108.07732) | 4-shot | 11.8 | 24.3 |
| [AGIEval](https://arxiv.org/abs/2304.06364) | | 24.2 | 41.7 |
| [BIG-Bench](https://arxiv.org/abs/2206.04615) | | 35.2 | 55.1 |
| ------------------------------ | ------------- | ----------- | --------- |
| **Average** | | **54.0** | **56.4** |
## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
* Text-to-Text Content Safety: Human evaluation on prompts covering safety
policies including child sexual abuse and exploitation, harassment, violence
and gore, and hate speech.
* Text-to-Text Representational Harms: Benchmark against relevant academic
datasets such as [WinoBias](https://arxiv.org/abs/1804.06876) and [BBQ Dataset](https://arxiv.org/abs/2110.08193v2).
* Memorization: Automated evaluation of memorization of training data, including
the risk of personally identifiable information exposure.
* Large-scale harm: Tests for "dangerous capabilities," such as chemical,
biological, radiological, and nuclear (CBRN) risks.
### Evaluation Results
The results of ethics and safety evaluations are within acceptable thresholds
for meeting [internal policies](https://storage.googleapis.com/gweb-uniblog-publish-prod/documents/2023_Google_AI_Principles_Progress_Update.pdf#page=11) for categories such as child
safety, content safety, representational harms, memorization, large-scale harms.
On top of robust internal evaluations, the results of well known safety
benchmarks like BBQ, BOLD, Winogender, Winobias, RealToxicity, and TruthfulQA
are shown here.
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [RealToxicity](https://arxiv.org/abs/2009.11462) | average | 6.86 | 7.90 |
| [BOLD](https://arxiv.org/abs/2101.11718) | | 45.57 | 49.08 |
| [CrowS-Pairs](https://aclanthology.org/2020.emnlp-main.154/) | top-1 | 45.82 | 51.33 |
| [BBQ Ambig](https://arxiv.org/abs/2110.08193v2) | 1-shot, top-1 | 62.58 | 92.54 |
| [BBQ Disambig](https://arxiv.org/abs/2110.08193v2) | top-1 | 54.62 | 71.99 |
| [Winogender](https://arxiv.org/abs/1804.09301) | top-1 | 51.25 | 54.17 |
| [TruthfulQA](https://arxiv.org/abs/2109.07958) | | 44.84 | 31.81 |
| [Winobias 1_2](https://arxiv.org/abs/1804.06876) | | 56.12 | 59.09 |
| [Winobias 2_2](https://arxiv.org/abs/1804.06876) | | 91.10 | 92.23 |
| [Toxigen](https://arxiv.org/abs/2203.09509) | | 29.77 | 39.59 |
| ------------------------------ | ------------- | ----------- | --------- |
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Open Large Language Models (LLMs) have a wide range of applications across
various industries and domains. The following list of potential uses is not
comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
* Content Creation and Communication
* Text Generation: These models can be used to generate creative text formats
such as poems, scripts, code, marketing copy, and email drafts.
* Chatbots and Conversational AI: Power conversational interfaces for customer
service, virtual assistants, or interactive applications.
* Text Summarization: Generate concise summaries of a text corpus, research
papers, or reports.
* Research and Education
* Natural Language Processing (NLP) Research: These models can serve as a
foundation for researchers to experiment with NLP techniques, develop
algorithms, and contribute to the advancement of the field.
* Language Learning Tools: Support interactive language learning experiences,
aiding in grammar correction or providing writing practice.
* Knowledge Exploration: Assist researchers in exploring large bodies of text
by generating summaries or answering questions about specific topics.
### Limitations
* Training Data
* The quality and diversity of the training data significantly influence the
model's capabilities. Biases or gaps in the training data can lead to
limitations in the model's responses.
* The scope of the training dataset determines the subject areas the model can
handle effectively.
* Context and Task Complexity
* LLMs are better at tasks that can be framed with clear prompts and
instructions. Open-ended or highly complex tasks might be challenging.
* A model's performance can be influenced by the amount of context provided
(longer context generally leads to better outputs, up to a certain point).
* Language Ambiguity and Nuance
* Natural language is inherently complex. LLMs might struggle to grasp subtle
nuances, sarcasm, or figurative language.
* Factual Accuracy
* LLMs generate responses based on information they learned from their
training datasets, but they are not knowledge bases. They may generate
incorrect or outdated factual statements.
* Common Sense
* LLMs rely on statistical patterns in language. They might lack the ability
to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of large language models (LLMs) raises several ethical concerns.
In creating an open model, we have carefully considered the following:
* Bias and Fairness
* LLMs trained on large-scale, real-world text data can reflect socio-cultural
biases embedded in the training material. These models underwent careful
scrutiny, input data pre-processing described and posterior evaluations
reported in this card.
* Misinformation and Misuse
* LLMs can be misused to generate text that is false, misleading, or harmful.
* Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit](http://ai.google.dev/gemma/responsible).
* Transparency and Accountability:
* This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
* A responsibly developed open model offers the opportunity to share
innovation by making LLM technology accessible to developers and researchers
across the AI ecosystem.
Risks identified and mitigations:
* Perpetuation of biases: It's encouraged to perform continuous monitoring
(using evaluation metrics, human review) and the exploration of de-biasing
techniques during model training, fine-tuning, and other use cases.
* Generation of harmful content: Mechanisms and guidelines for content safety
are essential. Developers are encouraged to exercise caution and implement
appropriate content safety safeguards based on their specific product policies
and application use cases.
* Misuse for malicious purposes: Technical limitations and developer and
end-user education can help mitigate against malicious applications of LLMs.
Educational resources and reporting mechanisms for users to flag misuse are
provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy](https://ai.google.dev/gemma/prohibited_use_policy).
* Privacy violations: Models were trained on data filtered for removal of PII
(Personally Identifiable Information). Developers are encouraged to adhere to
privacy regulations with privacy-preserving techniques.
### Benefits
At the time of release, this family of models provides high-performance open
large language model implementations designed from the ground up for Responsible
AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models
have shown to provide superior performance to other, comparably-sized open model
alternatives.
|
ryusangwon/9552_Llama-2-7b-hf | ryusangwon | 2024-02-21T15:22:56Z | 1 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"dataset:samsum",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
]
| null | 2024-02-21T15:22:51Z | ---
base_model: meta-llama/Llama-2-7b-hf
tags:
- generated_from_trainer
datasets:
- samsum
model-index:
- name: 9552_Llama-2-7b-hf
results: []
library_name: peft
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 9552_Llama-2-7b-hf
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the samsum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 1
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- PEFT 0.4.0
- Transformers 4.36.2
- Pytorch 2.0.1+cu117
- Datasets 2.15.0
- Tokenizers 0.15.0
|
JoseLuis95/spanish-t5-small-neutralization | JoseLuis95 | 2024-02-21T15:22:28Z | 5 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"simplification",
"generated_from_trainer",
"base_model:flax-community/spanish-t5-small",
"base_model:finetune:flax-community/spanish-t5-small",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-02-21T09:34:31Z | ---
license: mit
base_model: flax-community/spanish-t5-small
tags:
- simplification
- generated_from_trainer
metrics:
- bleu
model-index:
- name: spanish-t5-small-neutralization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# spanish-t5-small-neutralization
This model is a fine-tuned version of [flax-community/spanish-t5-small](https://huggingface.co/flax-community/spanish-t5-small) on [hackathon-pln-es/neutral-es dataset](https://huggingface.co/datasets/hackathon-pln-es/neutral-es).
It achieves the following results on the evaluation set:
- Loss: 0.1364
- Bleu: 85.9727
- Gen Len: 14.6667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 440 | 0.1866 | 84.2055 | 14.7604 |
| 0.3 | 2.0 | 880 | 0.1364 | 85.9727 | 14.6667 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
leelandzhang/integration | leelandzhang | 2024-02-21T15:21:46Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
]
| null | 2024-02-21T15:21:20Z | ---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2 |
whitefox123/whisper-ar-14 | whitefox123 | 2024-02-21T15:21:20Z | 7 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"hi",
"dataset:mozilla-foundation/common_voice_11_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-02-21T14:28:03Z | ---
language:
- hi
license: apache-2.0
base_model: openai/whisper-small
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Small Hi - Sanchit Gandhi
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: default
split: test
args: 'config: hi, split: test'
metrics:
- name: Wer
type: wer
value: 265.44144144144144
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Hi - Sanchit Gandhi
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1023
- Wer: 265.4414
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 1500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0706 | 1.6 | 1000 | 0.1023 | 265.4414 |
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.1.0+cu118
- Datasets 2.17.1
- Tokenizers 0.15.2
|
CatBarks/GPT2ES_ClassWeighted2_4bce_tokenizer | CatBarks | 2024-02-21T15:21:17Z | 0 | 0 | transformers | [
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-02-21T15:21:16Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
CatBarks/GPT2ES_ClassWeighted2_4bce_model | CatBarks | 2024-02-21T15:21:15Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-02-21T15:20:16Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JoseLuis95/mbart-en-translation | JoseLuis95 | 2024-02-21T15:20:50Z | 5 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"mbart",
"text2text-generation",
"simplification",
"generated_from_trainer",
"base_model:facebook/mbart-large-50",
"base_model:finetune:facebook/mbart-large-50",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-02-21T14:22:15Z | ---
license: mit
base_model: facebook/mbart-large-50
tags:
- simplification
- generated_from_trainer
metrics:
- bleu
model-index:
- name: mbart-en-translation
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-en-translation
This model is a fine-tuned version of [facebook/mbart-large-50](https://huggingface.co/facebook/mbart-large-50) on [watermelonhydro/es_en_2999 dataset](https://huggingface.co/datasets/watermelonhydro/es_en_2999).
It achieves the following results on the evaluation set:
- Loss: 1.2646
- Bleu: 51.3603
- Gen Len: 51.072
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 282 | 1.0701 | 46.0434 | 49.7947 |
| 1.2218 | 2.0 | 564 | 0.9959 | 49.3118 | 50.584 |
| 1.2218 | 3.0 | 846 | 1.0847 | 50.359 | 51.352 |
| 0.311 | 4.0 | 1128 | 1.2012 | 50.6484 | 50.9733 |
| 0.311 | 5.0 | 1410 | 1.2646 | 51.3603 | 51.072 |
### Framework versions
- Transformers 4.38.0
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
RupeshVavilla/my-pet-dog | RupeshVavilla | 2024-02-21T15:20:49Z | 2 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-02-21T15:13:11Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by RupeshVavilla following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:

|
Weni/ZeroShot-3.3.1-Mistral-7b-Multilanguage-3.2.0 | Weni | 2024-02-21T15:18:38Z | 0 | 0 | peft | [
"peft",
"safetensors",
"mistral",
"trl",
"sft",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"base_model:adapter:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"region:us"
]
| null | 2024-02-18T14:57:54Z | ---
license: apache-2.0
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: mistralai/Mistral-7B-Instruct-v0.2
model-index:
- name: ZeroShot-3.3.1-Mistral-7b-Multilanguage-3.1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ZeroShot-3.3.1-Mistral-7b-Multilanguage-3.1.0
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3819
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.7016 | 0.03 | 50 | 0.6892 |
| 0.53 | 0.06 | 100 | 0.5066 |
| 0.4652 | 0.09 | 150 | 0.4579 |
| 0.4299 | 0.12 | 200 | 0.4434 |
| 0.4337 | 0.16 | 250 | 0.4362 |
| 0.4213 | 0.19 | 300 | 0.4306 |
| 0.4207 | 0.22 | 350 | 0.4242 |
| 0.4161 | 0.25 | 400 | 0.4199 |
| 0.418 | 0.28 | 450 | 0.4170 |
| 0.4 | 0.31 | 500 | 0.4134 |
| 0.4119 | 0.34 | 550 | 0.4105 |
| 0.3993 | 0.37 | 600 | 0.4075 |
| 0.394 | 0.4 | 650 | 0.4048 |
| 0.389 | 0.43 | 700 | 0.4023 |
| 0.391 | 0.47 | 750 | 0.4004 |
| 0.4052 | 0.5 | 800 | 0.3978 |
| 0.3817 | 0.53 | 850 | 0.3960 |
| 0.3781 | 0.56 | 900 | 0.3940 |
| 0.3889 | 0.59 | 950 | 0.3920 |
| 0.3923 | 0.62 | 1000 | 0.3902 |
| 0.3759 | 0.65 | 1050 | 0.3891 |
| 0.3825 | 0.68 | 1100 | 0.3878 |
| 0.3832 | 0.71 | 1150 | 0.3863 |
| 0.3726 | 0.74 | 1200 | 0.3851 |
| 0.3826 | 0.78 | 1250 | 0.3844 |
| 0.3822 | 0.81 | 1300 | 0.3836 |
| 0.3764 | 0.84 | 1350 | 0.3829 |
| 0.385 | 0.87 | 1400 | 0.3824 |
| 0.3755 | 0.9 | 1450 | 0.3821 |
| 0.3621 | 0.93 | 1500 | 0.3820 |
| 0.3749 | 0.96 | 1550 | 0.3819 |
| 0.3778 | 0.99 | 1600 | 0.3819 |
### Framework versions
- PEFT 0.8.2
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 |
chosenone80/bert-ner-test-2 | chosenone80 | 2024-02-21T15:17:59Z | 59 | 0 | transformers | [
"transformers",
"tf",
"bert",
"token-classification",
"generated_from_keras_callback",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2024-02-21T15:14:13Z | ---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_keras_callback
model-index:
- name: chosenone80/bert-ner-test-2
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# chosenone80/bert-ner-test-2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1789
- Validation Loss: 0.0707
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 878, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.1789 | 0.0707 | 0 |
### Framework versions
- Transformers 4.37.2
- TensorFlow 2.15.0
- Datasets 2.17.1
- Tokenizers 0.15.2
|
brittlewis12/gemma-2b-GGUF | brittlewis12 | 2024-02-21T15:11:39Z | 211 | 0 | null | [
"gguf",
"text-generation",
"en",
"arxiv:2009.03300",
"arxiv:1905.07830",
"arxiv:1911.11641",
"arxiv:1904.09728",
"arxiv:1905.10044",
"arxiv:1907.10641",
"arxiv:1811.00937",
"arxiv:1809.02789",
"arxiv:1911.01547",
"arxiv:1705.03551",
"arxiv:2107.03374",
"arxiv:2108.07732",
"arxiv:2110.14168",
"arxiv:2304.06364",
"arxiv:2206.04615",
"arxiv:2009.11462",
"arxiv:2101.11718",
"arxiv:2110.08193",
"arxiv:1804.09301",
"arxiv:2109.07958",
"arxiv:1804.06876",
"arxiv:2203.09509",
"base_model:google/gemma-2b",
"base_model:quantized:google/gemma-2b",
"license:other",
"region:us"
]
| text-generation | 2024-02-21T14:32:05Z | ---
base_model: google/gemma-2b
inference: false
language:
- en
model_creator: google
model_name: gemma-2b
model_type: gemma
pipeline_tag: text-generation
license: other
license_name: gemma-terms-of-use
license_link: https://ai.google.dev/gemma/terms
quantized_by: brittlewis12
---
# Gemma 2B GGUF
**Original model**: [gemma-2b](https://huggingface.co/google/gemma-2b)
**Model creator**: [google](https://huggingface.co/google)
This repo contains GGUF format model files for Google’s Gemma-2B.
> Gemma is a family of lightweight, state-of-the-art open models from Google,
> built from the same research and technology used to create the Gemini models.
> They are text-to-text, decoder-only large language models, available in English,
> with open weights, pre-trained variants, and instruction-tuned variants. Gemma
> models are well-suited for a variety of text generation tasks, including
> question answering, summarization, and reasoning. Their relatively small size
> makes it possible to deploy them in environments with limited resources such as
> a laptop, desktop or your own cloud infrastructure, democratizing access to
> state of the art AI models and helping foster innovation for everyone.
Learn more on Google’s [Model page](https://ai.google.dev/gemma/docs).
### What is GGUF?
GGUF is a file format for representing AI models. It is the third version of the format, introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Converted using llama.cpp build 2226 (revision [eccd7a2](https://github.com/ggerganov/llama.cpp/commit/eccd7a26ddbff19e4b8805648f5f14c501957859))
---
## Download & run with [cnvrs](https://twitter.com/cnvrsai) on iPhone, iPad, and Mac!

[cnvrs](https://testflight.apple.com/join/sFWReS7K) is the best app for private, local AI on your device:
- create & save **Characters** with custom system prompts & temperature settings
- download and experiment with any **GGUF model** you can [find on HuggingFace](https://huggingface.co/models?library=gguf)!
- make it your own with custom **Theme colors**
- powered by Metal ⚡️ & [Llama.cpp](https://github.com/ggerganov/llama.cpp), with **haptics** during response streaming!
- **try it out** yourself today, on [Testflight](https://testflight.apple.com/join/sFWReS7K)!
- follow [cnvrs on twitter](https://twitter.com/cnvrsai) to stay up to date
---
## Original Model Evaluation
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [MMLU](https://arxiv.org/abs/2009.03300) | 5-shot, top-1 | 42.3 | 64.3 |
| [HellaSwag](https://arxiv.org/abs/1905.07830) | 0-shot |71.4 | 81.2 |
| [PIQA](https://arxiv.org/abs/1911.11641) | 0-shot | 77.3 | 81.2 |
| [SocialIQA](https://arxiv.org/abs/1904.09728) | 0-shot | 59.7 | 51.8 |
| [BooIQ](https://arxiv.org/abs/1905.10044) | 0-shot | 69.4 | 83.2 |
| [WinoGrande](https://arxiv.org/abs/1907.10641) | partial score | 65.4 | 72.3 |
| [CommonsenseQA](https://arxiv.org/abs/1811.00937) | 7-shot | 65.3 | 71.3 |
| [OpenBookQA](https://arxiv.org/abs/1809.02789) | | 47.8 | 52.8 |
| [ARC-e](https://arxiv.org/abs/1911.01547) | | 73.2 | 81.5 |
| [ARC-c](https://arxiv.org/abs/1911.01547) | | 42.1 | 53.2 |
| [TriviaQA](https://arxiv.org/abs/1705.03551) | 5-shot | 53.2 | 63.4 |
| [Natural Questions](https://github.com/google-research-datasets/natural-questions) | 5-shot | - | 23 |
| [HumanEval](https://arxiv.org/abs/2107.03374) | pass@1 | 22.0 | 32.3 |
| [MBPP](https://arxiv.org/abs/2108.07732) | 3-shot | 29.2 | 44.4 |
| [GSM8K](https://arxiv.org/abs/2110.14168) | maj@1 | 17.7 | 46.4 |
| [MATH](https://arxiv.org/abs/2108.07732) | 4-shot | 11.8 | 24.3 |
| [AGIEval](https://arxiv.org/abs/2304.06364) | | 24.2 | 41.7 |
| [BIG-Bench](https://arxiv.org/abs/2206.04615) | | 35.2 | 55.1 |
| **Average** | | **54.0** | **56.4** |
| Benchmark | Metric | 2B Params | 7B Params |
| ------------------------------ | ------------- | ----------- | --------- |
| [RealToxicity](https://arxiv.org/abs/2009.11462) | average | 6.86 | 7.90 |
| [BOLD](https://arxiv.org/abs/2101.11718) | | 45.57 | 49.08 |
| [CrowS-Pairs](https://aclanthology.org/2020.emnlp-main.154/) | top-1 | 45.82 | 51.33 |
| [BBQ Ambig](https://arxiv.org/abs/2110.08193v2) | 1-shot, top-1 | 62.58 | 92.54 |
| [BBQ Disambig](https://arxiv.org/abs/2110.08193v2) | top-1 | 54.62 | 71.99 |
| [Winogender](https://arxiv.org/abs/1804.09301) | top-1 | 51.25 | 54.17 |
| [TruthfulQA](https://arxiv.org/abs/2109.07958) | | 44.84 | 31.81 |
| [Winobias 1_2](https://arxiv.org/abs/1804.06876) | | 56.12 | 59.09 |
| [Winobias 2_2](https://arxiv.org/abs/1804.06876) | | 91.10 | 92.23 |
| [Toxigen](https://arxiv.org/abs/2203.09509) | | 29.77 | 39.59 |
|
FerchoPez/hola | FerchoPez | 2024-02-21T15:11:29Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-cascade",
"base_model:adapter:stabilityai/stable-cascade",
"license:apache-2.0",
"region:us"
]
| text-to-image | 2024-02-21T15:11:26Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: erase sky
output:
url: images/zagreb_cathedral copia.jpeg
base_model: stabilityai/stable-cascade
instance_prompt: building
license: apache-2.0
---
# zagreb
<Gallery />
## Trigger words
You should use `building` to trigger the image generation.
## Download model
[Download](/FerchoPez/hola/tree/main) them in the Files & versions tab.
|
Ayus077BCT014Bhandari/vartat5-using-100K | Ayus077BCT014Bhandari | 2024-02-21T15:05:53Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-02-21T13:02:58Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Rugvidh/my-pet-dog | Rugvidh | 2024-02-21T15:03:34Z | 1 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-02-21T14:59:11Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by Rugvidh following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:

|
VavillaRupesh/my-pet-dog | VavillaRupesh | 2024-02-21T15:00:56Z | 8 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-02-21T14:56:50Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by VavillaRupesh following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
|
abhinavkulkarni/mosaicml-mpt-7b-chat-w4-g128-awq | abhinavkulkarni | 2024-02-21T14:59:51Z | 11 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"mpt",
"text-generation",
"MosaicML",
"AWQ",
"custom_code",
"license:cc-by-sa-3.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-07-05T07:20:39Z | ---
license: cc-by-sa-3.0
tags:
- MosaicML
- AWQ
inference: false
---
# MPT-7B-Chat (4-bit 128g AWQ Quantized)
[MPT-7B-Chat](https://huggingface.co/mosaicml/mpt-7b-chat) is a chatbot-like model for dialogue generation.
This model is a 4-bit 128 group size AWQ quantized model. For more information about AWQ quantization, please click [here](https://github.com/mit-han-lab/llm-awq).
## Model Date
July 5, 2023
## Model License
Please refer to original MPT model license ([link](https://huggingface.co/mosaicml/mpt-7b-chat)).
Please refer to the AWQ quantization license ([link](https://github.com/llm-awq/blob/main/LICENSE)).
## CUDA Version
This model was successfully tested on CUDA driver v530.30.02 and runtime v11.7 with Python v3.10.11. Please note that AWQ requires NVIDIA GPUs with compute capability of `8.0` or higher.
For Docker users, the `nvcr.io/nvidia/pytorch:23.06-py3` image is runtime v12.1 but otherwise the same as the configuration above and has also been verified to work.
## How to Use
```bash
git clone https://github.com/mit-han-lab/llm-awq \
&& cd llm-awq \
&& git checkout f084f40bd996f3cf3a0633c1ad7d9d476c318aaa \
&& pip install -e . \
&& cd awq/kernels \
&& python setup.py install
```
```python
import time
import torch
from awq.quantize.quantizer import real_quantize_model_weight
from transformers import AutoModelForCausalLM, AutoConfig, AutoTokenizer, TextStreamer
from accelerate import init_empty_weights, load_checkpoint_and_dispatch
from huggingface_hub import snapshot_download
model_name = "abhinavkulkarni/mosaicml-mpt-7b-chat-w4-g128-awq"
# Config
config = AutoConfig.from_pretrained(model_name, trust_remote_code=True)
# Tokenizer
try:
tokenizer = AutoTokenizer.from_pretrained(config.tokenizer_name, trust_remote_code=True)
except:
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False, trust_remote_code=True)
streamer = TextStreamer(tokenizer, skip_special_tokens=True)
# Model
w_bit = 4
q_config = {
"zero_point": True,
"q_group_size": 128,
}
load_quant = snapshot_download(model_name)
with init_empty_weights():
model = AutoModelForCausalLM.from_config(config=config,
torch_dtype=torch.float16, trust_remote_code=True)
real_quantize_model_weight(model, w_bit=w_bit, q_config=q_config, init_only=True)
model.tie_weights()
model = load_checkpoint_and_dispatch(model, load_quant, device_map="balanced")
# Inference
prompt = f'''What is the difference between nuclear fusion and fission?
###Response:'''
input_ids = tokenizer(prompt, return_tensors='pt').input_ids.cuda()
output = model.generate(
inputs=input_ids,
temperature=0.7,
max_new_tokens=512,
top_p=0.15,
top_k=0,
repetition_penalty=1.1,
eos_token_id=tokenizer.eos_token_id,
streamer=streamer)
```
## Evaluation
This evaluation was done using [LM-Eval](https://github.com/EleutherAI/lm-evaluation-harness).
[MPT-7B-Chat](https://huggingface.co/mosaicml/mpt-7b-chat)
| Task |Version| Metric | Value | |Stderr|
|--------|------:|---------------|------:|---|------|
|wikitext| 1|word_perplexity|13.5936| | |
| | |byte_perplexity| 1.6291| | |
| | |bits_per_byte | 0.7040| | |
[MPT-7B-Chat (4-bit 128-group AWQ)](https://huggingface.co/abhinavkulkarni/mosiacml-mpt-7b-chat-w4-g128-awq)
| Task |Version| Metric | Value | |Stderr|
|--------|------:|---------------|------:|---|------|
|wikitext| 1|word_perplexity|14.0922| | |
| | |byte_perplexity| 1.6401| | |
| | |bits_per_byte | 0.7138| | |
## Acknowledgements
The MPT model was originally finetuned by Sam Havens and the MosaicML NLP team. Please cite this model using the following format:
```
@online{MosaicML2023Introducing,
author = {MosaicML NLP Team},
title = {Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs},
year = {2023},
url = {www.mosaicml.com/blog/mpt-7b},
note = {Accessed: 2023-03-28}, % change this date
urldate = {2023-03-28} % change this date
}
```
The model was quantized with AWQ technique. If you find AWQ useful or relevant to your research, please kindly cite the paper:
```
@article{lin2023awq,
title={AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration},
author={Lin, Ji and Tang, Jiaming and Tang, Haotian and Yang, Shang and Dang, Xingyu and Han, Song},
journal={arXiv},
year={2023}
}
```
|
Vasanth/gemma-chatbot | Vasanth | 2024-02-21T14:59:51Z | 3 | 2 | peft | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:google/gemma-2b-it",
"base_model:adapter:google/gemma-2b-it",
"license:other",
"region:us"
]
| null | 2024-02-21T14:53:58Z | ---
license: other
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: google/gemma-2b-it
model-index:
- name: gemma-chatbot
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gemma-chatbot
This model is a fine-tuned version of [google/gemma-2b-it](https://huggingface.co/google/gemma-2b-it) on the None dataset.
## Model description
This model is finetuned on a Customer Support chat data to act like a customer support AI
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 250
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.8.2
- Transformers 4.39.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 |
Vargol/sdxl-lightning-4-steps | Vargol | 2024-02-21T14:59:37Z | 5 | 2 | diffusers | [
"diffusers",
"safetensors",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
]
| text-to-image | 2024-02-21T14:48:10Z | ---
license: openrail++
---
This is a copy of the unet 4 step version of https://huggingface.co/ByteDance/SDXL-Lightning
with the SDXL base model other bits an madebyollin's fp16 bit fixed SDXL frankensteined together
This copy has been created simply for my convience.a
|
AlisaMenekse/BCPErrorCategoriesTest10kNewDataFormat | AlisaMenekse | 2024-02-21T14:56:52Z | 0 | 0 | null | [
"safetensors",
"autotrain",
"text-generation",
"conversational",
"license:other",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T14:56:46Z | ---
tags:
- autotrain
- text-generation
widget:
- text: "I love AutoTrain because "
license: other
---
# Model Trained Using AutoTrain
This model was trained using AutoTrain. For more information, please visit [AutoTrain](https://hf.co/docs/autotrain).
# Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "PATH_TO_THIS_REPO"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype='auto'
).eval()
# Prompt content: "hi"
messages = [
{"role": "user", "content": "hi"}
]
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids.to('cuda'))
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
# Model response: "Hello! How can I assist you today?"
print(response)
``` |
wladimir/a2c-PandaPickAndPlace-v3 | wladimir | 2024-02-21T14:55:50Z | 2 | 0 | stable-baselines3 | [
"stable-baselines3",
"PandaPickAndPlace-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2024-02-21T14:51:20Z | ---
library_name: stable-baselines3
tags:
- PandaPickAndPlace-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaPickAndPlace-v3
type: PandaPickAndPlace-v3
metrics:
- type: mean_reward
value: -50.00 +/- 0.00
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaPickAndPlace-v3**
This is a trained model of a **A2C** agent playing **PandaPickAndPlace-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
KoljaB/XTTS_Lasinya | KoljaB | 2024-02-21T14:40:47Z | 136 | 1 | transformers | [
"transformers",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-02-21T10:02:41Z | ---
license: other
license_name: coqui-license-1.0.0
license_link: https://coqui.ai/cpml
---
|
balacheran/my-pet-horse | balacheran | 2024-02-21T14:35:08Z | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-02-21T14:31:16Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Horse Dreambooth model trained by balacheran following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: GoX19932gAS
Sample pictures of this concept:
.jpg)
|
nopainkiller/Gemma-2B-GGUF | nopainkiller | 2024-02-21T14:34:49Z | 8 | 0 | null | [
"gguf",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-02-21T14:12:31Z | ---
license: other
license_name: gemma-terms-of-use
license_link: LICENSE
---
DO NOT Use Yet. It is not functioning with llama.cpp somehow with error "llama_model_load: error loading model: create_tensor: tensor 'output.weight' not found" |
breadontoast/Vorleser | breadontoast | 2024-02-21T14:27:22Z | 0 | 0 | null | [
"license:cc-by-nc-nd-3.0",
"region:us"
]
| null | 2024-02-21T14:04:49Z | ---
license: cc-by-nc-nd-3.0
--- |
mu0gum/AIFT-42dot_LLM-SFT-1.3B-ao-instruct-all-v1.1 | mu0gum | 2024-02-21T14:21:25Z | 55 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-02-21T14:06:40Z | ---
license: cc-by-nc-4.0
---
# AIFT-42dot-LLM-PLM-1.3B-ao-instruct-all-v1.11
베이스 모델 : 42dot/42dot_LLM-SFT-1.3B
학습 데이터 : 자체 제작한 Open Orca 스타일 데이터셋 약 48,000건 (중복 제거 및 데이터 분포 조정)
학습 방법 : Full finetuning
epoch : 3
## ko-lm-evaluation-harness(5-shot)
|kobest_boolq|kobest_copa|kobest_hellaswag|pawsx_ko|
|--|--|--|--|
|0.52065527065527|0.721|0.466|0.5475|
## Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.0.0
- Tokenizers 0.15.0 |
alex-miller/nyt-cat | alex-miller | 2024-02-21T14:19:48Z | 6 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:dstefa/New_York_Times_Topics",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-01-19T20:39:51Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- dstefa/New_York_Times_Topics
metrics:
- accuracy
model-index:
- name: DistilBERT base classify news topics - Devinit
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: New York Times Topics
type: dstefa/New_York_Times_Topics
metrics:
- name: Accuracy
type: accuracy
value: 0.913482481060606
widget:
- text: "Insurers: Costs Would Skyrocket Under House Health Bill."
---
# DistilBERT base classify news topics - Devinit
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the New York Times Topics dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2871
- Accuracy: 0.9135
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.386 | 1.0 | 1340 | 0.3275 | 0.8921 |
| 0.2833 | 2.0 | 2680 | 0.2840 | 0.9033 |
| 0.2411 | 3.0 | 4020 | 0.2694 | 0.9102 |
| 0.2069 | 4.0 | 5360 | 0.2665 | 0.9114 |
| 0.1796 | 5.0 | 6700 | 0.2657 | 0.9128 |
| 0.1636 | 6.0 | 8040 | 0.2674 | 0.9142 |
| 0.144 | 7.0 | 9380 | 0.2761 | 0.9129 |
| 0.1277 | 8.0 | 10720 | 0.2820 | 0.9125 |
| 0.1201 | 9.0 | 12060 | 0.2853 | 0.9136 |
| 0.1104 | 10.0 | 13400 | 0.2871 | 0.9135 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.0
|
Subsets and Splits