
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-28 06:27:35
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 500
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-28 06:24:42
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
mirari/callhome-RTVE | mirari | 2024-10-17T15:00:41Z | 49 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"pyannet",
"speaker-diarization",
"speaker-segmentation",
"generated_from_trainer",
"spa",
"dataset:diarizers-community/callhome",
"base_model:pyannote/speaker-diarization-3.1",
"base_model:finetune:pyannote/speaker-diarization-3.1",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2024-10-17T14:51:57Z | ---
library_name: transformers
language:
- spa
license: mit
base_model: pyannote/speaker-diarization-3.1
tags:
- speaker-diarization
- speaker-segmentation
- generated_from_trainer
datasets:
- diarizers-community/callhome
model-index:
- name: speaker-segmentation-fine-tuned-callhome-spa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# speaker-segmentation-fine-tuned-callhome-spa
This model is a fine-tuned version of [pyannote/speaker-diarization-3.1](https://huggingface.co/pyannote/speaker-diarization-3.1) on the diarizers-community/callhome dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5595
- Der: 0.2894
- False Alarm: 0.2353
- Missed Detection: 0.0536
- Confusion: 0.0005
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Der | False Alarm | Missed Detection | Confusion |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-----------:|:----------------:|:---------:|
| 0.3614 | 1.0 | 226 | 0.4962 | 0.2910 | 0.2389 | 0.0520 | 0.0001 |
| 0.3465 | 2.0 | 452 | 0.5067 | 0.2860 | 0.2179 | 0.0679 | 0.0002 |
| 0.3325 | 3.0 | 678 | 0.5343 | 0.2941 | 0.2300 | 0.0636 | 0.0005 |
| 0.3189 | 4.0 | 904 | 0.5613 | 0.2906 | 0.2380 | 0.0522 | 0.0004 |
| 0.3238 | 5.0 | 1130 | 0.5595 | 0.2894 | 0.2353 | 0.0536 | 0.0005 |
### Framework versions
- Transformers 4.45.1
- Pytorch 2.4.1
- Datasets 3.0.1
- Tokenizers 0.20.0
|
Ariana03/finetuned-indian-food | Ariana03 | 2024-10-17T15:00:25Z | 193 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:google/vit-base-patch16-224",
"base_model:finetune:google/vit-base-patch16-224",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-10-17T14:22:03Z | ---
library_name: transformers
license: apache-2.0
base_model: google/vit-base-patch16-224
tags:
- image-classification
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: finetuned-indian-food
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-indian-food
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the indian_food_images dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2146
- Accuracy: 0.9426
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 1.0574 | 0.3003 | 100 | 0.9445 | 0.8576 |
| 0.8399 | 0.6006 | 200 | 0.5542 | 0.8863 |
| 0.6418 | 0.9009 | 300 | 0.5741 | 0.8672 |
| 0.3785 | 1.2012 | 400 | 0.4702 | 0.8842 |
| 0.4451 | 1.5015 | 500 | 0.3685 | 0.9118 |
| 0.4535 | 1.8018 | 600 | 0.3781 | 0.9097 |
| 0.4618 | 2.1021 | 700 | 0.3000 | 0.9288 |
| 0.2321 | 2.4024 | 800 | 0.3146 | 0.9182 |
| 0.1816 | 2.7027 | 900 | 0.3045 | 0.9214 |
| 0.2332 | 3.0030 | 1000 | 0.3446 | 0.9044 |
| 0.1173 | 3.3033 | 1100 | 0.2381 | 0.9416 |
| 0.2694 | 3.6036 | 1200 | 0.2146 | 0.9426 |
| 0.1227 | 3.9039 | 1300 | 0.2259 | 0.9490 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.4.1+cu121
- Datasets 3.0.1
- Tokenizers 0.19.1
|
magnifi/Phi3_intent_v37_3_w_unknown_5_lr_0.002_r_16_a_8 | magnifi | 2024-10-17T14:57:11Z | 77 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"base_model:unsloth/Phi-3-mini-4k-instruct-bnb-4bit",
"base_model:finetune:unsloth/Phi-3-mini-4k-instruct-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T14:54:59Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
base_model: unsloth/Phi-3-mini-4k-instruct-bnb-4bit
---
# Uploaded model
- **Developed by:** magnifi
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Phi-3-mini-4k-instruct-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
lightsout19/gpt2-moe-top1-3-partitioned-sst2 | lightsout19 | 2024-10-17T14:57:08Z | 5 | 0 | null | [
"tensorboard",
"safetensors",
"gpt2",
"generated_from_trainer",
"region:us"
] | null | 2024-10-17T14:29:01Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: gpt2-moe-top1-3-partitioned-sst2-new
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-moe-top1-3-partitioned-sst2-new
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3504
- Accuracy: 0.8624
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.3677 | 1.0 | 2105 | 0.3916 | 0.8303 |
| 0.2932 | 2.0 | 4210 | 0.3796 | 0.8417 |
| 0.2705 | 3.0 | 6315 | 0.3484 | 0.8693 |
| 0.2433 | 4.0 | 8420 | 0.3524 | 0.8773 |
| 0.2336 | 5.0 | 10525 | 0.3433 | 0.8670 |
### Framework versions
- Transformers 4.44.0
- Pytorch 2.4.0
- Datasets 2.21.0
- Tokenizers 0.19.1
|
phxia/gpt2 | phxia | 2024-10-17T14:52:14Z | 14 | 0 | pxia | [
"pxia",
"safetensors",
"gpt2",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"text-generation",
"region:us"
] | text-generation | 2024-08-26T10:38:25Z | ---
library_name: pxia
tags:
- gpt2
- model_hub_mixin
- pxia
- pytorch_model_hub_mixin
- text-generation
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration.
Library: [pxia](https://github.com/not-lain/pxia)
## how to load
```
pip install pxia
```
use the AutoModel class
```python
from pxia AutoModel
model = AutoModel.from_pretrained("phxia/gpt2")
```
or you can use the model class directly
```python
from pxia import GPT2
model = GPT2.from_pretrained("phxia/gpt2")
```
## Contributions
Any contributions are welcome at https://github.com/not-lain/pxia
<img src="https://huggingface.co/spaces/phxia/README/resolve/main/logo.png"/>
|
mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF | mradermacher | 2024-10-17T14:45:07Z | 42 | 3 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:win10/Mistral-Nemo-Instruct-2407-20b",
"base_model:quantized:win10/Mistral-Nemo-Instruct-2407-20b",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2024-10-17T12:15:32Z | ---
base_model: win10/Mistral-Nemo-Instruct-2407-20b
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/win10/Mistral-Nemo-Instruct-2407-20b
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-IQ1_S.gguf) | i1-IQ1_S | 5.3 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-IQ1_M.gguf) | i1-IQ1_M | 5.7 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 6.4 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-IQ2_XS.gguf) | i1-IQ2_XS | 7.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-IQ2_S.gguf) | i1-IQ2_S | 7.4 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-IQ2_M.gguf) | i1-IQ2_M | 8.0 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-Q2_K.gguf) | i1-Q2_K | 8.7 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 9.0 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-IQ3_XS.gguf) | i1-IQ3_XS | 9.6 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-Q3_K_S.gguf) | i1-Q3_K_S | 10.1 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-IQ3_S.gguf) | i1-IQ3_S | 10.1 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-IQ3_M.gguf) | i1-IQ3_M | 10.4 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-Q3_K_M.gguf) | i1-Q3_K_M | 11.2 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-Q3_K_L.gguf) | i1-Q3_K_L | 12.1 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-IQ4_XS.gguf) | i1-IQ4_XS | 12.4 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-Q4_0.gguf) | i1-Q4_0 | 13.0 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-Q4_K_S.gguf) | i1-Q4_K_S | 13.1 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-Q4_K_M.gguf) | i1-Q4_K_M | 13.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-Q5_K_S.gguf) | i1-Q5_K_S | 15.7 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-Q5_K_M.gguf) | i1-Q5_K_M | 16.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-Nemo-Instruct-2407-20b-i1-GGUF/resolve/main/Mistral-Nemo-Instruct-2407-20b.i1-Q6_K.gguf) | i1-Q6_K | 18.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
badokorach/minilm-uncased-finetuned-agic2-171024 | badokorach | 2024-10-17T14:43:06Z | 63 | 0 | transformers | [
"transformers",
"tf",
"bert",
"question-answering",
"generated_from_keras_callback",
"base_model:badokorach/minilm-uncased-finetuned-agic2-060124",
"base_model:finetune:badokorach/minilm-uncased-finetuned-agic2-060124",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-10-17T14:40:40Z | ---
library_name: transformers
license: cc-by-4.0
base_model: badokorach/minilm-uncased-finetuned-agic2-060124
tags:
- generated_from_keras_callback
model-index:
- name: badokorach/minilm-uncased-finetuned-agic2-171024
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# badokorach/minilm-uncased-finetuned-agic2-171024
This model is a fine-tuned version of [badokorach/minilm-uncased-finetuned-agic2-060124](https://huggingface.co/badokorach/minilm-uncased-finetuned-agic2-060124) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.5699
- Validation Loss: 0.0
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'module': 'transformers.optimization_tf', 'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 1e-05, 'decay_steps': 195, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.8999999761581421, 'beta_2': 0.9990000128746033, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.02}, 'registered_name': 'AdamWeightDecay'}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.1115 | 0.0 | 0 |
| 2.6561 | 0.0 | 1 |
| 2.5699 | 0.0 | 2 |
### Framework versions
- Transformers 4.44.2
- TensorFlow 2.17.0
- Datasets 3.0.1
- Tokenizers 0.19.1
|
QuantFactory/Aspire1.2-8B-TIES-GGUF | QuantFactory | 2024-10-17T14:36:43Z | 96 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:ArliAI/Llama-3.1-8B-ArliAI-RPMax-v1.1",
"base_model:merge:ArliAI/Llama-3.1-8B-ArliAI-RPMax-v1.1",
"base_model:Blackroot/Llama-3-8B-Abomination-LORA",
"base_model:merge:Blackroot/Llama-3-8B-Abomination-LORA",
"base_model:Blackroot/Llama3-RP-Lora",
"base_model:merge:Blackroot/Llama3-RP-Lora",
"base_model:NousResearch/Hermes-3-Llama-3.1-8B",
"base_model:merge:NousResearch/Hermes-3-Llama-3.1-8B",
"base_model:NousResearch/Meta-Llama-3-8B",
"base_model:merge:NousResearch/Meta-Llama-3-8B",
"base_model:Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2",
"base_model:merge:Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2",
"base_model:arcee-ai/Llama-3.1-SuperNova-Lite",
"base_model:merge:arcee-ai/Llama-3.1-SuperNova-Lite",
"base_model:cgato/L3-TheSpice-8b-v0.8.3",
"base_model:merge:cgato/L3-TheSpice-8b-v0.8.3",
"base_model:hikikomoriHaven/llama3-8b-hikikomori-v0.4",
"base_model:merge:hikikomoriHaven/llama3-8b-hikikomori-v0.4",
"base_model:kloodia/lora-8b-bio",
"base_model:merge:kloodia/lora-8b-bio",
"base_model:kloodia/lora-8b-medic",
"base_model:merge:kloodia/lora-8b-medic",
"base_model:kloodia/lora-8b-physic",
"base_model:merge:kloodia/lora-8b-physic",
"endpoints_compatible",
"region:us"
] | null | 2024-10-17T13:48:04Z |
---
base_model:
- cgato/L3-TheSpice-8b-v0.8.3
- kloodia/lora-8b-medic
- NousResearch/Hermes-3-Llama-3.1-8B
- kloodia/lora-8b-physic
- ArliAI/Llama-3.1-8B-ArliAI-RPMax-v1.1
- Blackroot/Llama-3-8B-Abomination-LORA
- Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2
- kloodia/lora-8b-bio
- NousResearch/Meta-Llama-3-8B
- DreadPoor/Nothing_to_see_here_-_Move_along
- hikikomoriHaven/llama3-8b-hikikomori-v0.4
- arcee-ai/Llama-3.1-SuperNova-Lite
- Blackroot/Llama3-RP-Lora
library_name: transformers
tags:
- mergekit
- merge
---
[](https://hf.co/QuantFactory)
# QuantFactory/Aspire1.2-8B-TIES-GGUF
This is quantized version of [DreadPoor/Aspire1.2-8B-TIES](https://huggingface.co/DreadPoor/Aspire1.2-8B-TIES) created using llama.cpp
# Original Model Card
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [NousResearch/Meta-Llama-3-8B](https://huggingface.co/NousResearch/Meta-Llama-3-8B) as a base.
### Models Merged
The following models were included in the merge:
* [cgato/L3-TheSpice-8b-v0.8.3](https://huggingface.co/cgato/L3-TheSpice-8b-v0.8.3) + [kloodia/lora-8b-medic](https://huggingface.co/kloodia/lora-8b-medic)
* [NousResearch/Hermes-3-Llama-3.1-8B](https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B) + [kloodia/lora-8b-physic](https://huggingface.co/kloodia/lora-8b-physic)
* [ArliAI/Llama-3.1-8B-ArliAI-RPMax-v1.1](https://huggingface.co/ArliAI/Llama-3.1-8B-ArliAI-RPMax-v1.1) + [Blackroot/Llama-3-8B-Abomination-LORA](https://huggingface.co/Blackroot/Llama-3-8B-Abomination-LORA)
* [Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2](https://huggingface.co/Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2) + [kloodia/lora-8b-bio](https://huggingface.co/kloodia/lora-8b-bio)
* [DreadPoor/Nothing_to_see_here_-_Move_along](https://huggingface.co/DreadPoor/Nothing_to_see_here_-_Move_along) + [hikikomoriHaven/llama3-8b-hikikomori-v0.4](https://huggingface.co/hikikomoriHaven/llama3-8b-hikikomori-v0.4)
* [arcee-ai/Llama-3.1-SuperNova-Lite](https://huggingface.co/arcee-ai/Llama-3.1-SuperNova-Lite) + [Blackroot/Llama3-RP-Lora](https://huggingface.co/Blackroot/Llama3-RP-Lora)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Orenguteng/Llama-3.1-8B-Lexi-Uncensored-V2+kloodia/lora-8b-bio
parameters:
weight: 1
- model: arcee-ai/Llama-3.1-SuperNova-Lite+Blackroot/Llama3-RP-Lora
parameters:
weight: 1
- model: NousResearch/Hermes-3-Llama-3.1-8B+kloodia/lora-8b-physic
parameters:
weight: 1
- model: cgato/L3-TheSpice-8b-v0.8.3+kloodia/lora-8b-medic
parameters:
weight: 1
- model: ArliAI/Llama-3.1-8B-ArliAI-RPMax-v1.1+Blackroot/Llama-3-8B-Abomination-LORA
parameters:
weight: 1
- model: DreadPoor/Nothing_to_see_here_-_Move_along+hikikomoriHaven/llama3-8b-hikikomori-v0.4
parameters:
weight: 1
merge_method: ties
base_model: NousResearch/Meta-Llama-3-8B
parameters:
density: 1
normalize: true
int8_mask: true
dtype: bfloat16
```
|
judynguyen16/my-finetuned-model | judynguyen16 | 2024-10-17T14:25:19Z | 77 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-10-17T14:18:04Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ktsnyder/finetuned-model-englishquotes | ktsnyder | 2024-10-17T14:21:47Z | 76 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-10-17T14:15:34Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Waris01/results2 | Waris01 | 2024-10-17T14:11:20Z | 104 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"dataset:samsum",
"base_model:facebook/bart-large-cnn",
"base_model:finetune:facebook/bart-large-cnn",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-10-17T13:51:22Z | ---
base_model: facebook/bart-large-cnn
datasets:
- samsum
library_name: transformers
license: mit
tags:
- generated_from_trainer
model-index:
- name: results2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results2
This model is a fine-tuned version of [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) on the samsum dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.46.0.dev0
- Pytorch 2.4.1+cu121
- Datasets 3.0.1
- Tokenizers 0.20.1
|
nicolinesorensen/distilbert-base-uncased-finetuned-clinc | nicolinesorensen | 2024-10-17T14:10:31Z | 7 | 0 | null | [
"pytorch",
"tensorboard",
"distilbert",
"license:apache-2.0",
"region:us"
] | null | 2024-10-12T17:44:00Z | ---
license: apache-2.0
---
|
prince-canuma/Ministral-8B-Instruct-2410-HF | prince-canuma | 2024-10-17T13:54:37Z | 38 | 10 | null | [
"safetensors",
"mistral",
"en",
"fr",
"de",
"es",
"it",
"pt",
"zh",
"ja",
"ru",
"ko",
"base_model:mistralai/Ministral-8B-Instruct-2410",
"base_model:finetune:mistralai/Ministral-8B-Instruct-2410",
"license:other",
"region:us"
] | null | 2024-10-16T19:17:22Z | ---
base_model:
- mistralai/Ministral-8B-Instruct-2410
language:
- en
- fr
- de
- es
- it
- pt
- zh
- ja
- ru
- ko
license: other
license_name: mrl
license_link: https://mistral.ai/licenses/MRL-0.1.md
inference: false
---
# Ministral-8B-Instruct-2410-HF
## Model Description
Ministral-8B-Instruct-2410-HF is the Hugging Face version of Ministral-8B-Instruct-2410 by Mistral AI. It is a multilingual instruction-tuned language model based on the Mistral architecture, designed for various natural language processing tasks with a focus on chat-based interactions.
## Installation
To use this model, install the required packages:
```bash
pip install -U transformers
```
## Usage Example
Here's a Python script demonstrating how to use the model for chat completion:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
# Model setup
model_name = "prince-canuma/Ministral-8B-Instruct-2410-HF"
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Chat interaction
prompt = "Tell me a short story about a robot learning to paint."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
input_ids = tokenizer(text, return_tensors="pt").to(model.device)
# Generate response
output = model.generate(**input_ids, max_new_tokens=500, temperature=0.7, do_sample=True)
response = tokenizer.decode(output[0][input_ids.input_ids.shape[1]:])
print("User:", prompt)
print("Model:", response)
```
## Model Details
- **Developed by:** Mistral AI
- **Model type:** Causal Language Model
- **Language(s):** English
- **License:** [mrl](https://mistral.ai/licenses/MRL-0.1.md)
- **Resources for more information:**
- [Model Repository](https://huggingface.co/prince-canuma/Ministral-8B-Instruct-2410-HF)
- [Mistral AI GitHub](https://github.com/mistralai) |
vikash-walmart/llava-smart-crop-pct-ov7b | vikash-walmart | 2024-10-17T13:47:30Z | 6 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:llava-hf/llava-onevision-qwen2-7b-ov-chat-hf",
"base_model:adapter:llava-hf/llava-onevision-qwen2-7b-ov-chat-hf",
"license:apache-2.0",
"region:us"
] | null | 2024-10-16T10:58:53Z | ---
base_model: llava-hf/llava-onevision-qwen2-7b-ov-chat-hf
library_name: peft
license: apache-2.0
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: llava-smart-crop-pct-ov7b
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llava-smart-crop-pct-ov7b
This model is a fine-tuned version of [llava-hf/llava-onevision-qwen2-7b-ov-chat-hf](https://huggingface.co/llava-hf/llava-onevision-qwen2-7b-ov-chat-hf) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.4e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.45.2
- Pytorch 2.4.1+cu118
- Datasets 3.0.1
- Tokenizers 0.20.1 |
deliciouscat/Jamba-ko-tiny-v0.1 | deliciouscat | 2024-10-17T13:47:08Z | 94 | 0 | transformers | [
"transformers",
"safetensors",
"jamba",
"text-generation",
"ko",
"base_model:ai21labs/Jamba-tiny-dev",
"base_model:finetune:ai21labs/Jamba-tiny-dev",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T13:32:34Z | ---
library_name: transformers
license: apache-2.0
language:
- ko
base_model:
- ai21labs/Jamba-tiny-dev
---
Jamba model trained on Korean text corpus, Next Sentence Prediction
Base model: `ai21labs/Jamba-tiny-dev`
Tokenizer: `kakaobank/kf-deberta-base`
Only trained about 1% of total data yet! (594,788 / 58,835,812) |
mlx-community/Ministral-8B-Instruct-2410-4bit | mlx-community | 2024-10-17T13:43:11Z | 224 | 7 | vllm | [
"vllm",
"safetensors",
"mistral",
"mlx",
"en",
"fr",
"de",
"es",
"it",
"pt",
"zh",
"ja",
"ru",
"ko",
"license:other",
"4-bit",
"region:us"
] | null | 2024-10-16T15:00:48Z | ---
base_model: Ministral-8B-Instruct-2410-HF
language:
- en
- fr
- de
- es
- it
- pt
- zh
- ja
- ru
- ko
library_name: vllm
license: other
license_name: mrl
license_link: https://mistral.ai/licenses/MRL-0.1.md
tags:
- mlx
inference: false
extra_gated_prompt: '# Mistral AI Research License
If You want to use a Mistral Model, a Derivative or an Output for any purpose that
is not expressly authorized under this Agreement, You must request a license from
Mistral AI, which Mistral AI may grant to You in Mistral AI''s sole discretion.
To discuss such a license, please contact Mistral AI via the website contact form:
https://mistral.ai/contact/
## 1. Scope and acceptance
**1.1. Scope of the Agreement.** This Agreement applies to any use, modification,
or Distribution of any Mistral Model by You, regardless of the source You obtained
a copy of such Mistral Model.
**1.2. Acceptance.** By accessing, using, modifying, Distributing a Mistral Model,
or by creating, using or distributing a Derivative of the Mistral Model, You agree
to be bound by this Agreement.
**1.3. Acceptance on behalf of a third-party.** If You accept this Agreement on
behalf of Your employer or another person or entity, You warrant and represent that
You have the authority to act and accept this Agreement on their behalf. In such
a case, the word "You" in this Agreement will refer to Your employer or such other
person or entity.
## 2. License
**2.1. Grant of rights**. Subject to Section 3 below, Mistral AI hereby grants
You a non-exclusive, royalty-free, worldwide, non-sublicensable, non-transferable,
limited license to use, copy, modify, and Distribute under the conditions provided
in Section 2.2 below, the Mistral Model and any Derivatives made by or for Mistral
AI and to create Derivatives of the Mistral Model.
**2.2. Distribution of Mistral Model and Derivatives made by or for Mistral AI.**
Subject to Section 3 below, You may Distribute copies of the Mistral Model and/or
Derivatives made by or for Mistral AI, under the following conditions: You must
make available a copy of this Agreement to third-party recipients of the Mistral
Models and/or Derivatives made by or for Mistral AI you Distribute, it being specified
that any rights to use the Mistral Models and/or Derivatives made by or for Mistral
AI shall be directly granted by Mistral AI to said third-party recipients pursuant
to the Mistral AI Research License agreement executed between these parties; You
must retain in all copies of the Mistral Models the following attribution notice
within a "Notice" text file distributed as part of such copies: "Licensed by Mistral
AI under the Mistral AI Research License".
**2.3. Distribution of Derivatives made by or for You.** Subject to Section 3 below,
You may Distribute any Derivatives made by or for You under additional or different
terms and conditions, provided that: In any event, the use and modification of Mistral
Model and/or Derivatives made by or for Mistral AI shall remain governed by the
terms and conditions of this Agreement; You include in any such Derivatives made
by or for You prominent notices stating that You modified the concerned Mistral
Model; and Any terms and conditions You impose on any third-party recipients relating
to Derivatives made by or for You shall neither limit such third-party recipients''
use of the Mistral Model or any Derivatives made by or for Mistral AI in accordance
with the Mistral AI Research License nor conflict with any of its terms and conditions.
## 3. Limitations
**3.1. Misrepresentation.** You must not misrepresent or imply, through any means,
that the Derivatives made by or for You and/or any modified version of the Mistral
Model You Distribute under your name and responsibility is an official product of
Mistral AI or has been endorsed, approved or validated by Mistral AI, unless You
are authorized by Us to do so in writing.
**3.2. Usage Limitation.** You shall only use the Mistral Models, Derivatives (whether
or not created by Mistral AI) and Outputs for Research Purposes.
## 4. Intellectual Property
**4.1. Trademarks.** No trademark licenses are granted under this Agreement, and
in connection with the Mistral Models, You may not use any name or mark owned by
or associated with Mistral AI or any of its affiliates, except (i) as required for
reasonable and customary use in describing and Distributing the Mistral Models and
Derivatives made by or for Mistral AI and (ii) for attribution purposes as required
by this Agreement.
**4.2. Outputs.** We claim no ownership rights in and to the Outputs. You are solely
responsible for the Outputs You generate and their subsequent uses in accordance
with this Agreement. Any Outputs shall be subject to the restrictions set out in
Section 3 of this Agreement.
**4.3. Derivatives.** By entering into this Agreement, You accept that any Derivatives
that You may create or that may be created for You shall be subject to the restrictions
set out in Section 3 of this Agreement.
## 5. Liability
**5.1. Limitation of liability.** In no event, unless required by applicable law
(such as deliberate and grossly negligent acts) or agreed to in writing, shall Mistral
AI be liable to You for damages, including any direct, indirect, special, incidental,
or consequential damages of any character arising as a result of this Agreement
or out of the use or inability to use the Mistral Models and Derivatives (including
but not limited to damages for loss of data, loss of goodwill, loss of expected
profit or savings, work stoppage, computer failure or malfunction, or any damage
caused by malware or security breaches), even if Mistral AI has been advised of
the possibility of such damages.
**5.2. Indemnification.** You agree to indemnify and hold harmless Mistral AI from
and against any claims, damages, or losses arising out of or related to Your use
or Distribution of the Mistral Models and Derivatives.
## 6. Warranty
**6.1. Disclaimer.** Unless required by applicable law or prior agreed to by Mistral
AI in writing, Mistral AI provides the Mistral Models and Derivatives on an "AS
IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied,
including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. Mistral AI does not represent
nor warrant that the Mistral Models and Derivatives will be error-free, meet Your
or any third party''s requirements, be secure or will allow You or any third party
to achieve any kind of result or generate any kind of content. You are solely responsible
for determining the appropriateness of using or Distributing the Mistral Models
and Derivatives and assume any risks associated with Your exercise of rights under
this Agreement.
## 7. Termination
**7.1. Term.** This Agreement is effective as of the date of your acceptance of
this Agreement or access to the concerned Mistral Models or Derivatives and will
continue until terminated in accordance with the following terms.
**7.2. Termination.** Mistral AI may terminate this Agreement at any time if You
are in breach of this Agreement. Upon termination of this Agreement, You must cease
to use all Mistral Models and Derivatives and shall permanently delete any copy
thereof. The following provisions, in their relevant parts, will survive any termination
or expiration of this Agreement, each for the duration necessary to achieve its
own intended purpose (e.g. the liability provision will survive until the end of
the applicable limitation period):Sections 5 (Liability), 6(Warranty), 7 (Termination)
and 8 (General Provisions).
**7.3. Litigation.** If You initiate any legal action or proceedings against Us
or any other entity (including a cross-claim or counterclaim in a lawsuit), alleging
that the Model or a Derivative, or any part thereof, infringe upon intellectual
property or other rights owned or licensable by You, then any licenses granted to
You under this Agreement will immediately terminate as of the date such legal action
or claim is filed or initiated.
## 8. General provisions
**8.1. Governing laws.** This Agreement will be governed by the laws of France,
without regard to choice of law principles, and the UN Convention on Contracts for
the International Sale of Goods does not apply to this Agreement.
**8.2. Competent jurisdiction.** The courts of Paris shall have exclusive jurisdiction
of any dispute arising out of this Agreement.
**8.3. Severability.** If any provision of this Agreement is held to be invalid,
illegal or unenforceable, the remaining provisions shall be unaffected thereby and
remain valid as if such provision had not been set forth herein.
## 9. Definitions
"Agreement": means this Mistral AI Research License agreement governing the access,
use, and Distribution of the Mistral Models, Derivatives and Outputs.
"Derivative": means any (i) modified version of the Mistral Model (including but
not limited to any customized or fine-tuned version thereof), (ii) work based on
the Mistral Model, or (iii) any other derivative work thereof.
"Distribution", "Distributing", "Distribute" or "Distributed": means supplying,
providing or making available, by any means, a copy of the Mistral Models and/or
the Derivatives as the case may be, subject to Section 3 of this Agreement.
"Mistral AI", "We" or "Us": means Mistral AI, a French société par actions simplifiée
registered in the Paris commercial registry under the number 952 418 325, and having
its registered seat at 15, rue des Halles, 75001 Paris.
"Mistral Model": means the foundational large language model(s), and its elements
which include algorithms, software, instructed checkpoints, parameters, source code
(inference code, evaluation code and, if applicable, fine-tuning code) and any other
elements associated thereto made available by Mistral AI under this Agreement, including,
if any, the technical documentation, manuals and instructions for the use and operation
thereof.
"Research Purposes": means any use of a Mistral Model, Derivative, or Output that
is solely for (a) personal, scientific or academic research, and (b) for non-profit
and non-commercial purposes, and not directly or indirectly connected to any commercial
activities or business operations. For illustration purposes, Research Purposes
does not include (1) any usage of the Mistral Model, Derivative or Output by individuals
or contractors employed in or engaged by companies in the context of (a) their daily
tasks, or (b) any activity (including but not limited to any testing or proof-of-concept)
that is intended to generate revenue, nor (2) any Distribution by a commercial entity
of the Mistral Model, Derivative or Output whether in return for payment or free
of charge, in any medium or form, including but not limited to through a hosted
or managed service (e.g. SaaS, cloud instances, etc.), or behind a software layer.
"Outputs": means any content generated by the operation of the Mistral Models or
the Derivatives from a prompt (i.e., text instructions) provided by users. For
the avoidance of doubt, Outputs do not include any components of a Mistral Models,
such as any fine-tuned versions of the Mistral Models, the weights, or parameters.
"You": means the individual or entity entering into this Agreement with Mistral
AI.
*Mistral AI processes your personal data below to provide the model and enforce
its license. If you are affiliated with a commercial entity, we may also send you
communications about our models. For more information on your rights and data handling,
please see our <a href="https://mistral.ai/terms/">privacy policy</a>.*'
extra_gated_fields:
First Name: text
Last Name: text
Country: country
Affiliation: text
Job title: text
I understand that I can only use the model, any derivative versions and their outputs for non-commercial research purposes: checkbox
? I understand that if I am a commercial entity, I am not permitted to use or distribute
the model internally or externally, or expose it in my own offerings without a
commercial license
: checkbox
? I understand that if I upload the model, or any derivative version, on any platform,
I must include the Mistral Research License
: checkbox
? I understand that for commercial use of the model, I can contact Mistral or use
the Mistral AI API on la Plateforme or any of our cloud provider partners
: checkbox
? By clicking Submit below I accept the terms of the license and acknowledge that
the information I provide will be collected stored processed and shared in accordance
with the Mistral Privacy Policy
: checkbox
geo: ip_location
extra_gated_description: Mistral AI processes your personal data below to provide
the model and enforce its license. If you are affiliated with a commercial entity,
we may also send you communications about our models. For more information on your
rights and data handling, please see our <a href="https://mistral.ai/terms/">privacy
policy</a>.
extra_gated_button_content: Submit
---
# mlx-community/Ministral-8B-Instruct-2410-4bit
The Model [mlx-community/Ministral-8B-Instruct-2410-4bit](https://huggingface.co/mlx-community/Ministral-8B-Instruct-2410-4bit) was converted to MLX format from [mistralai/Ministral-8B-Instruct-2410](https://huggingface.co/mistralai/Ministral-8B-Instruct-2410) using mlx-lm version **0.19.1**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Ministral-8B-Instruct-2410-4bit")
prompt="hello"
if hasattr(tokenizer, "apply_chat_template") and tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
mlx-community/Ministral-8B-Instruct-2410-8bit | mlx-community | 2024-10-17T13:42:54Z | 38 | 2 | vllm | [
"vllm",
"safetensors",
"mistral",
"mlx",
"en",
"fr",
"de",
"es",
"it",
"pt",
"zh",
"ja",
"ru",
"ko",
"license:other",
"8-bit",
"region:us"
] | null | 2024-10-16T15:00:54Z | ---
base_model: Ministral-8B-Instruct-2410-HF
language:
- en
- fr
- de
- es
- it
- pt
- zh
- ja
- ru
- ko
library_name: vllm
license: other
license_name: mrl
license_link: https://mistral.ai/licenses/MRL-0.1.md
tags:
- mlx
inference: false
extra_gated_prompt: '# Mistral AI Research License
If You want to use a Mistral Model, a Derivative or an Output for any purpose that
is not expressly authorized under this Agreement, You must request a license from
Mistral AI, which Mistral AI may grant to You in Mistral AI''s sole discretion.
To discuss such a license, please contact Mistral AI via the website contact form:
https://mistral.ai/contact/
## 1. Scope and acceptance
**1.1. Scope of the Agreement.** This Agreement applies to any use, modification,
or Distribution of any Mistral Model by You, regardless of the source You obtained
a copy of such Mistral Model.
**1.2. Acceptance.** By accessing, using, modifying, Distributing a Mistral Model,
or by creating, using or distributing a Derivative of the Mistral Model, You agree
to be bound by this Agreement.
**1.3. Acceptance on behalf of a third-party.** If You accept this Agreement on
behalf of Your employer or another person or entity, You warrant and represent that
You have the authority to act and accept this Agreement on their behalf. In such
a case, the word "You" in this Agreement will refer to Your employer or such other
person or entity.
## 2. License
**2.1. Grant of rights**. Subject to Section 3 below, Mistral AI hereby grants
You a non-exclusive, royalty-free, worldwide, non-sublicensable, non-transferable,
limited license to use, copy, modify, and Distribute under the conditions provided
in Section 2.2 below, the Mistral Model and any Derivatives made by or for Mistral
AI and to create Derivatives of the Mistral Model.
**2.2. Distribution of Mistral Model and Derivatives made by or for Mistral AI.**
Subject to Section 3 below, You may Distribute copies of the Mistral Model and/or
Derivatives made by or for Mistral AI, under the following conditions: You must
make available a copy of this Agreement to third-party recipients of the Mistral
Models and/or Derivatives made by or for Mistral AI you Distribute, it being specified
that any rights to use the Mistral Models and/or Derivatives made by or for Mistral
AI shall be directly granted by Mistral AI to said third-party recipients pursuant
to the Mistral AI Research License agreement executed between these parties; You
must retain in all copies of the Mistral Models the following attribution notice
within a "Notice" text file distributed as part of such copies: "Licensed by Mistral
AI under the Mistral AI Research License".
**2.3. Distribution of Derivatives made by or for You.** Subject to Section 3 below,
You may Distribute any Derivatives made by or for You under additional or different
terms and conditions, provided that: In any event, the use and modification of Mistral
Model and/or Derivatives made by or for Mistral AI shall remain governed by the
terms and conditions of this Agreement; You include in any such Derivatives made
by or for You prominent notices stating that You modified the concerned Mistral
Model; and Any terms and conditions You impose on any third-party recipients relating
to Derivatives made by or for You shall neither limit such third-party recipients''
use of the Mistral Model or any Derivatives made by or for Mistral AI in accordance
with the Mistral AI Research License nor conflict with any of its terms and conditions.
## 3. Limitations
**3.1. Misrepresentation.** You must not misrepresent or imply, through any means,
that the Derivatives made by or for You and/or any modified version of the Mistral
Model You Distribute under your name and responsibility is an official product of
Mistral AI or has been endorsed, approved or validated by Mistral AI, unless You
are authorized by Us to do so in writing.
**3.2. Usage Limitation.** You shall only use the Mistral Models, Derivatives (whether
or not created by Mistral AI) and Outputs for Research Purposes.
## 4. Intellectual Property
**4.1. Trademarks.** No trademark licenses are granted under this Agreement, and
in connection with the Mistral Models, You may not use any name or mark owned by
or associated with Mistral AI or any of its affiliates, except (i) as required for
reasonable and customary use in describing and Distributing the Mistral Models and
Derivatives made by or for Mistral AI and (ii) for attribution purposes as required
by this Agreement.
**4.2. Outputs.** We claim no ownership rights in and to the Outputs. You are solely
responsible for the Outputs You generate and their subsequent uses in accordance
with this Agreement. Any Outputs shall be subject to the restrictions set out in
Section 3 of this Agreement.
**4.3. Derivatives.** By entering into this Agreement, You accept that any Derivatives
that You may create or that may be created for You shall be subject to the restrictions
set out in Section 3 of this Agreement.
## 5. Liability
**5.1. Limitation of liability.** In no event, unless required by applicable law
(such as deliberate and grossly negligent acts) or agreed to in writing, shall Mistral
AI be liable to You for damages, including any direct, indirect, special, incidental,
or consequential damages of any character arising as a result of this Agreement
or out of the use or inability to use the Mistral Models and Derivatives (including
but not limited to damages for loss of data, loss of goodwill, loss of expected
profit or savings, work stoppage, computer failure or malfunction, or any damage
caused by malware or security breaches), even if Mistral AI has been advised of
the possibility of such damages.
**5.2. Indemnification.** You agree to indemnify and hold harmless Mistral AI from
and against any claims, damages, or losses arising out of or related to Your use
or Distribution of the Mistral Models and Derivatives.
## 6. Warranty
**6.1. Disclaimer.** Unless required by applicable law or prior agreed to by Mistral
AI in writing, Mistral AI provides the Mistral Models and Derivatives on an "AS
IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied,
including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. Mistral AI does not represent
nor warrant that the Mistral Models and Derivatives will be error-free, meet Your
or any third party''s requirements, be secure or will allow You or any third party
to achieve any kind of result or generate any kind of content. You are solely responsible
for determining the appropriateness of using or Distributing the Mistral Models
and Derivatives and assume any risks associated with Your exercise of rights under
this Agreement.
## 7. Termination
**7.1. Term.** This Agreement is effective as of the date of your acceptance of
this Agreement or access to the concerned Mistral Models or Derivatives and will
continue until terminated in accordance with the following terms.
**7.2. Termination.** Mistral AI may terminate this Agreement at any time if You
are in breach of this Agreement. Upon termination of this Agreement, You must cease
to use all Mistral Models and Derivatives and shall permanently delete any copy
thereof. The following provisions, in their relevant parts, will survive any termination
or expiration of this Agreement, each for the duration necessary to achieve its
own intended purpose (e.g. the liability provision will survive until the end of
the applicable limitation period):Sections 5 (Liability), 6(Warranty), 7 (Termination)
and 8 (General Provisions).
**7.3. Litigation.** If You initiate any legal action or proceedings against Us
or any other entity (including a cross-claim or counterclaim in a lawsuit), alleging
that the Model or a Derivative, or any part thereof, infringe upon intellectual
property or other rights owned or licensable by You, then any licenses granted to
You under this Agreement will immediately terminate as of the date such legal action
or claim is filed or initiated.
## 8. General provisions
**8.1. Governing laws.** This Agreement will be governed by the laws of France,
without regard to choice of law principles, and the UN Convention on Contracts for
the International Sale of Goods does not apply to this Agreement.
**8.2. Competent jurisdiction.** The courts of Paris shall have exclusive jurisdiction
of any dispute arising out of this Agreement.
**8.3. Severability.** If any provision of this Agreement is held to be invalid,
illegal or unenforceable, the remaining provisions shall be unaffected thereby and
remain valid as if such provision had not been set forth herein.
## 9. Definitions
"Agreement": means this Mistral AI Research License agreement governing the access,
use, and Distribution of the Mistral Models, Derivatives and Outputs.
"Derivative": means any (i) modified version of the Mistral Model (including but
not limited to any customized or fine-tuned version thereof), (ii) work based on
the Mistral Model, or (iii) any other derivative work thereof.
"Distribution", "Distributing", "Distribute" or "Distributed": means supplying,
providing or making available, by any means, a copy of the Mistral Models and/or
the Derivatives as the case may be, subject to Section 3 of this Agreement.
"Mistral AI", "We" or "Us": means Mistral AI, a French société par actions simplifiée
registered in the Paris commercial registry under the number 952 418 325, and having
its registered seat at 15, rue des Halles, 75001 Paris.
"Mistral Model": means the foundational large language model(s), and its elements
which include algorithms, software, instructed checkpoints, parameters, source code
(inference code, evaluation code and, if applicable, fine-tuning code) and any other
elements associated thereto made available by Mistral AI under this Agreement, including,
if any, the technical documentation, manuals and instructions for the use and operation
thereof.
"Research Purposes": means any use of a Mistral Model, Derivative, or Output that
is solely for (a) personal, scientific or academic research, and (b) for non-profit
and non-commercial purposes, and not directly or indirectly connected to any commercial
activities or business operations. For illustration purposes, Research Purposes
does not include (1) any usage of the Mistral Model, Derivative or Output by individuals
or contractors employed in or engaged by companies in the context of (a) their daily
tasks, or (b) any activity (including but not limited to any testing or proof-of-concept)
that is intended to generate revenue, nor (2) any Distribution by a commercial entity
of the Mistral Model, Derivative or Output whether in return for payment or free
of charge, in any medium or form, including but not limited to through a hosted
or managed service (e.g. SaaS, cloud instances, etc.), or behind a software layer.
"Outputs": means any content generated by the operation of the Mistral Models or
the Derivatives from a prompt (i.e., text instructions) provided by users. For
the avoidance of doubt, Outputs do not include any components of a Mistral Models,
such as any fine-tuned versions of the Mistral Models, the weights, or parameters.
"You": means the individual or entity entering into this Agreement with Mistral
AI.
*Mistral AI processes your personal data below to provide the model and enforce
its license. If you are affiliated with a commercial entity, we may also send you
communications about our models. For more information on your rights and data handling,
please see our <a href="https://mistral.ai/terms/">privacy policy</a>.*'
extra_gated_fields:
First Name: text
Last Name: text
Country: country
Affiliation: text
Job title: text
I understand that I can only use the model, any derivative versions and their outputs for non-commercial research purposes: checkbox
? I understand that if I am a commercial entity, I am not permitted to use or distribute
the model internally or externally, or expose it in my own offerings without a
commercial license
: checkbox
? I understand that if I upload the model, or any derivative version, on any platform,
I must include the Mistral Research License
: checkbox
? I understand that for commercial use of the model, I can contact Mistral or use
the Mistral AI API on la Plateforme or any of our cloud provider partners
: checkbox
? By clicking Submit below I accept the terms of the license and acknowledge that
the information I provide will be collected stored processed and shared in accordance
with the Mistral Privacy Policy
: checkbox
geo: ip_location
extra_gated_description: Mistral AI processes your personal data below to provide
the model and enforce its license. If you are affiliated with a commercial entity,
we may also send you communications about our models. For more information on your
rights and data handling, please see our <a href="https://mistral.ai/terms/">privacy
policy</a>.
extra_gated_button_content: Submit
---
# mlx-community/Ministral-8B-Instruct-2410-8bit
The Model [mlx-community/Ministral-8B-Instruct-2410-8bit](https://huggingface.co/mlx-community/Ministral-8B-Instruct-2410-8bit) was converted to MLX format from [mistralai/Ministral-8B-Instruct-2410](https://huggingface.co/mistralai/Ministral-8B-Instruct-2410) using mlx-lm version **0.19.1**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Ministral-8B-Instruct-2410-8bit")
prompt="hello"
if hasattr(tokenizer, "apply_chat_template") and tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
mlx-community/Ministral-8B-Instruct-2410-bf16 | mlx-community | 2024-10-17T13:42:39Z | 172 | 2 | vllm | [
"vllm",
"safetensors",
"mistral",
"mlx",
"en",
"fr",
"de",
"es",
"it",
"pt",
"zh",
"ja",
"ru",
"ko",
"license:other",
"region:us"
] | null | 2024-10-16T15:00:42Z | ---
base_model: Ministral-8B-Instruct-2410-HF
language:
- en
- fr
- de
- es
- it
- pt
- zh
- ja
- ru
- ko
library_name: vllm
license: other
license_name: mrl
license_link: https://mistral.ai/licenses/MRL-0.1.md
tags:
- mlx
inference: false
extra_gated_prompt: '# Mistral AI Research License
If You want to use a Mistral Model, a Derivative or an Output for any purpose that
is not expressly authorized under this Agreement, You must request a license from
Mistral AI, which Mistral AI may grant to You in Mistral AI''s sole discretion.
To discuss such a license, please contact Mistral AI via the website contact form:
https://mistral.ai/contact/
## 1. Scope and acceptance
**1.1. Scope of the Agreement.** This Agreement applies to any use, modification,
or Distribution of any Mistral Model by You, regardless of the source You obtained
a copy of such Mistral Model.
**1.2. Acceptance.** By accessing, using, modifying, Distributing a Mistral Model,
or by creating, using or distributing a Derivative of the Mistral Model, You agree
to be bound by this Agreement.
**1.3. Acceptance on behalf of a third-party.** If You accept this Agreement on
behalf of Your employer or another person or entity, You warrant and represent that
You have the authority to act and accept this Agreement on their behalf. In such
a case, the word "You" in this Agreement will refer to Your employer or such other
person or entity.
## 2. License
**2.1. Grant of rights**. Subject to Section 3 below, Mistral AI hereby grants
You a non-exclusive, royalty-free, worldwide, non-sublicensable, non-transferable,
limited license to use, copy, modify, and Distribute under the conditions provided
in Section 2.2 below, the Mistral Model and any Derivatives made by or for Mistral
AI and to create Derivatives of the Mistral Model.
**2.2. Distribution of Mistral Model and Derivatives made by or for Mistral AI.**
Subject to Section 3 below, You may Distribute copies of the Mistral Model and/or
Derivatives made by or for Mistral AI, under the following conditions: You must
make available a copy of this Agreement to third-party recipients of the Mistral
Models and/or Derivatives made by or for Mistral AI you Distribute, it being specified
that any rights to use the Mistral Models and/or Derivatives made by or for Mistral
AI shall be directly granted by Mistral AI to said third-party recipients pursuant
to the Mistral AI Research License agreement executed between these parties; You
must retain in all copies of the Mistral Models the following attribution notice
within a "Notice" text file distributed as part of such copies: "Licensed by Mistral
AI under the Mistral AI Research License".
**2.3. Distribution of Derivatives made by or for You.** Subject to Section 3 below,
You may Distribute any Derivatives made by or for You under additional or different
terms and conditions, provided that: In any event, the use and modification of Mistral
Model and/or Derivatives made by or for Mistral AI shall remain governed by the
terms and conditions of this Agreement; You include in any such Derivatives made
by or for You prominent notices stating that You modified the concerned Mistral
Model; and Any terms and conditions You impose on any third-party recipients relating
to Derivatives made by or for You shall neither limit such third-party recipients''
use of the Mistral Model or any Derivatives made by or for Mistral AI in accordance
with the Mistral AI Research License nor conflict with any of its terms and conditions.
## 3. Limitations
**3.1. Misrepresentation.** You must not misrepresent or imply, through any means,
that the Derivatives made by or for You and/or any modified version of the Mistral
Model You Distribute under your name and responsibility is an official product of
Mistral AI or has been endorsed, approved or validated by Mistral AI, unless You
are authorized by Us to do so in writing.
**3.2. Usage Limitation.** You shall only use the Mistral Models, Derivatives (whether
or not created by Mistral AI) and Outputs for Research Purposes.
## 4. Intellectual Property
**4.1. Trademarks.** No trademark licenses are granted under this Agreement, and
in connection with the Mistral Models, You may not use any name or mark owned by
or associated with Mistral AI or any of its affiliates, except (i) as required for
reasonable and customary use in describing and Distributing the Mistral Models and
Derivatives made by or for Mistral AI and (ii) for attribution purposes as required
by this Agreement.
**4.2. Outputs.** We claim no ownership rights in and to the Outputs. You are solely
responsible for the Outputs You generate and their subsequent uses in accordance
with this Agreement. Any Outputs shall be subject to the restrictions set out in
Section 3 of this Agreement.
**4.3. Derivatives.** By entering into this Agreement, You accept that any Derivatives
that You may create or that may be created for You shall be subject to the restrictions
set out in Section 3 of this Agreement.
## 5. Liability
**5.1. Limitation of liability.** In no event, unless required by applicable law
(such as deliberate and grossly negligent acts) or agreed to in writing, shall Mistral
AI be liable to You for damages, including any direct, indirect, special, incidental,
or consequential damages of any character arising as a result of this Agreement
or out of the use or inability to use the Mistral Models and Derivatives (including
but not limited to damages for loss of data, loss of goodwill, loss of expected
profit or savings, work stoppage, computer failure or malfunction, or any damage
caused by malware or security breaches), even if Mistral AI has been advised of
the possibility of such damages.
**5.2. Indemnification.** You agree to indemnify and hold harmless Mistral AI from
and against any claims, damages, or losses arising out of or related to Your use
or Distribution of the Mistral Models and Derivatives.
## 6. Warranty
**6.1. Disclaimer.** Unless required by applicable law or prior agreed to by Mistral
AI in writing, Mistral AI provides the Mistral Models and Derivatives on an "AS
IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied,
including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. Mistral AI does not represent
nor warrant that the Mistral Models and Derivatives will be error-free, meet Your
or any third party''s requirements, be secure or will allow You or any third party
to achieve any kind of result or generate any kind of content. You are solely responsible
for determining the appropriateness of using or Distributing the Mistral Models
and Derivatives and assume any risks associated with Your exercise of rights under
this Agreement.
## 7. Termination
**7.1. Term.** This Agreement is effective as of the date of your acceptance of
this Agreement or access to the concerned Mistral Models or Derivatives and will
continue until terminated in accordance with the following terms.
**7.2. Termination.** Mistral AI may terminate this Agreement at any time if You
are in breach of this Agreement. Upon termination of this Agreement, You must cease
to use all Mistral Models and Derivatives and shall permanently delete any copy
thereof. The following provisions, in their relevant parts, will survive any termination
or expiration of this Agreement, each for the duration necessary to achieve its
own intended purpose (e.g. the liability provision will survive until the end of
the applicable limitation period):Sections 5 (Liability), 6(Warranty), 7 (Termination)
and 8 (General Provisions).
**7.3. Litigation.** If You initiate any legal action or proceedings against Us
or any other entity (including a cross-claim or counterclaim in a lawsuit), alleging
that the Model or a Derivative, or any part thereof, infringe upon intellectual
property or other rights owned or licensable by You, then any licenses granted to
You under this Agreement will immediately terminate as of the date such legal action
or claim is filed or initiated.
## 8. General provisions
**8.1. Governing laws.** This Agreement will be governed by the laws of France,
without regard to choice of law principles, and the UN Convention on Contracts for
the International Sale of Goods does not apply to this Agreement.
**8.2. Competent jurisdiction.** The courts of Paris shall have exclusive jurisdiction
of any dispute arising out of this Agreement.
**8.3. Severability.** If any provision of this Agreement is held to be invalid,
illegal or unenforceable, the remaining provisions shall be unaffected thereby and
remain valid as if such provision had not been set forth herein.
## 9. Definitions
"Agreement": means this Mistral AI Research License agreement governing the access,
use, and Distribution of the Mistral Models, Derivatives and Outputs.
"Derivative": means any (i) modified version of the Mistral Model (including but
not limited to any customized or fine-tuned version thereof), (ii) work based on
the Mistral Model, or (iii) any other derivative work thereof.
"Distribution", "Distributing", "Distribute" or "Distributed": means supplying,
providing or making available, by any means, a copy of the Mistral Models and/or
the Derivatives as the case may be, subject to Section 3 of this Agreement.
"Mistral AI", "We" or "Us": means Mistral AI, a French société par actions simplifiée
registered in the Paris commercial registry under the number 952 418 325, and having
its registered seat at 15, rue des Halles, 75001 Paris.
"Mistral Model": means the foundational large language model(s), and its elements
which include algorithms, software, instructed checkpoints, parameters, source code
(inference code, evaluation code and, if applicable, fine-tuning code) and any other
elements associated thereto made available by Mistral AI under this Agreement, including,
if any, the technical documentation, manuals and instructions for the use and operation
thereof.
"Research Purposes": means any use of a Mistral Model, Derivative, or Output that
is solely for (a) personal, scientific or academic research, and (b) for non-profit
and non-commercial purposes, and not directly or indirectly connected to any commercial
activities or business operations. For illustration purposes, Research Purposes
does not include (1) any usage of the Mistral Model, Derivative or Output by individuals
or contractors employed in or engaged by companies in the context of (a) their daily
tasks, or (b) any activity (including but not limited to any testing or proof-of-concept)
that is intended to generate revenue, nor (2) any Distribution by a commercial entity
of the Mistral Model, Derivative or Output whether in return for payment or free
of charge, in any medium or form, including but not limited to through a hosted
or managed service (e.g. SaaS, cloud instances, etc.), or behind a software layer.
"Outputs": means any content generated by the operation of the Mistral Models or
the Derivatives from a prompt (i.e., text instructions) provided by users. For
the avoidance of doubt, Outputs do not include any components of a Mistral Models,
such as any fine-tuned versions of the Mistral Models, the weights, or parameters.
"You": means the individual or entity entering into this Agreement with Mistral
AI.
*Mistral AI processes your personal data below to provide the model and enforce
its license. If you are affiliated with a commercial entity, we may also send you
communications about our models. For more information on your rights and data handling,
please see our <a href="https://mistral.ai/terms/">privacy policy</a>.*'
extra_gated_fields:
First Name: text
Last Name: text
Country: country
Affiliation: text
Job title: text
I understand that I can only use the model, any derivative versions and their outputs for non-commercial research purposes: checkbox
? I understand that if I am a commercial entity, I am not permitted to use or distribute
the model internally or externally, or expose it in my own offerings without a
commercial license
: checkbox
? I understand that if I upload the model, or any derivative version, on any platform,
I must include the Mistral Research License
: checkbox
? I understand that for commercial use of the model, I can contact Mistral or use
the Mistral AI API on la Plateforme or any of our cloud provider partners
: checkbox
? By clicking Submit below I accept the terms of the license and acknowledge that
the information I provide will be collected stored processed and shared in accordance
with the Mistral Privacy Policy
: checkbox
geo: ip_location
extra_gated_description: Mistral AI processes your personal data below to provide
the model and enforce its license. If you are affiliated with a commercial entity,
we may also send you communications about our models. For more information on your
rights and data handling, please see our <a href="https://mistral.ai/terms/">privacy
policy</a>.
extra_gated_button_content: Submit
---
# mlx-community/Ministral-8B-Instruct-2410-bf16
The Model [mlx-community/Ministral-8B-Instruct-2410-bf16](https://huggingface.co/mlx-community/Ministral-8B-Instruct-2410-bf16) was converted to MLX format from [mistralai/Ministral-8B-Instruct-2410](https://huggingface.co/mistralai/Ministral-8B-Instruct-2410) using mlx-lm version **0.19.1**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Ministral-8B-Instruct-2410-bf16")
prompt="hello"
if hasattr(tokenizer, "apply_chat_template") and tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
Data-Lab/bge-reranker-v2-m3-cross-encoder-v0.1 | Data-Lab | 2024-10-17T13:39:30Z | 124 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"cross-encoder",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-10-17T13:24:30Z | ---
library_name: transformers
tags:
- cross-encoder
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mazenmagdii22/my-finetuned-bert2 | mazenmagdii22 | 2024-10-17T13:34:20Z | 105 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-10-17T13:32:50Z | ---
base_model: bert-base-uncased
library_name: transformers
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: my-finetuned-bert2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my-finetuned-bert2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 196 | 0.2956 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.4.1+cu121
- Datasets 3.0.1
- Tokenizers 0.19.1
|
nourix2/lora-jim | nourix2 | 2024-10-17T13:30:03Z | 5 | 0 | diffusers | [
"diffusers",
"flux",
"text-to-image",
"lora",
"fal",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2024-10-17T13:29:58Z | ---
tags:
- flux
- text-to-image
- lora
- diffusers
- fal
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: jim_winter
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# lora jim
<Gallery />
## Model description
## Trigger words
You should use `jim_winter` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/nourix2/lora-jim/tree/main) them in the Files & versions tab.
## Training at fal.ai
Training was done using [fal.ai/models/fal-ai/flux-lora-fast-training](https://fal.ai/models/fal-ai/flux-lora-fast-training).
|
RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf | RichardErkhov | 2024-10-17T13:22:29Z | 5 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-10-17T12:41:37Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
stablelm-2-1_6b-sft-full - GGUF
- Model creator: https://huggingface.co/nnheui/
- Original model: https://huggingface.co/nnheui/stablelm-2-1_6b-sft-full/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [stablelm-2-1_6b-sft-full.Q2_K.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q2_K.gguf) | Q2_K | 0.65GB |
| [stablelm-2-1_6b-sft-full.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.IQ3_XS.gguf) | IQ3_XS | 0.71GB |
| [stablelm-2-1_6b-sft-full.IQ3_S.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.IQ3_S.gguf) | IQ3_S | 0.74GB |
| [stablelm-2-1_6b-sft-full.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q3_K_S.gguf) | Q3_K_S | 0.74GB |
| [stablelm-2-1_6b-sft-full.IQ3_M.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.IQ3_M.gguf) | IQ3_M | 0.77GB |
| [stablelm-2-1_6b-sft-full.Q3_K.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q3_K.gguf) | Q3_K | 0.8GB |
| [stablelm-2-1_6b-sft-full.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q3_K_M.gguf) | Q3_K_M | 0.8GB |
| [stablelm-2-1_6b-sft-full.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q3_K_L.gguf) | Q3_K_L | 0.85GB |
| [stablelm-2-1_6b-sft-full.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.IQ4_XS.gguf) | IQ4_XS | 0.88GB |
| [stablelm-2-1_6b-sft-full.Q4_0.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q4_0.gguf) | Q4_0 | 0.92GB |
| [stablelm-2-1_6b-sft-full.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.IQ4_NL.gguf) | IQ4_NL | 0.92GB |
| [stablelm-2-1_6b-sft-full.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q4_K_S.gguf) | Q4_K_S | 0.92GB |
| [stablelm-2-1_6b-sft-full.Q4_K.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q4_K.gguf) | Q4_K | 0.96GB |
| [stablelm-2-1_6b-sft-full.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q4_K_M.gguf) | Q4_K_M | 0.96GB |
| [stablelm-2-1_6b-sft-full.Q4_1.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q4_1.gguf) | Q4_1 | 1.0GB |
| [stablelm-2-1_6b-sft-full.Q5_0.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q5_0.gguf) | Q5_0 | 1.08GB |
| [stablelm-2-1_6b-sft-full.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q5_K_S.gguf) | Q5_K_S | 1.08GB |
| [stablelm-2-1_6b-sft-full.Q5_K.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q5_K.gguf) | Q5_K | 1.11GB |
| [stablelm-2-1_6b-sft-full.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q5_K_M.gguf) | Q5_K_M | 1.11GB |
| [stablelm-2-1_6b-sft-full.Q5_1.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q5_1.gguf) | Q5_1 | 1.17GB |
| [stablelm-2-1_6b-sft-full.Q6_K.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q6_K.gguf) | Q6_K | 1.26GB |
| [stablelm-2-1_6b-sft-full.Q8_0.gguf](https://huggingface.co/RichardErkhov/nnheui_-_stablelm-2-1_6b-sft-full-gguf/blob/main/stablelm-2-1_6b-sft-full.Q8_0.gguf) | Q8_0 | 1.63GB |
Original model description:
---
license: other
base_model: stabilityai/stablelm-2-1_6b
tags:
- alignment-handbook
- trl
- sft
- generated_from_trainer
- trl
- sft
- generated_from_trainer
datasets:
- HuggingFaceH4/ultrachat_200k
model-index:
- name: stablelm-2-1_6b-sft-full
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# stablelm-2-1_6b-sft-full
This model is a fine-tuned version of [stabilityai/stablelm-2-1_6b](https://huggingface.co/stabilityai/stablelm-2-1_6b) on the HuggingFaceH4/ultrachat_200k dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.40.0
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.19.1
|
jusKnows/orange-q4_k_m-gguf | jusKnows | 2024-10-17T13:17:55Z | 5 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:jusKnows/pinaple-bnb-4bit",
"base_model:quantized:jusKnows/pinaple-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-10-17T13:10:56Z | ---
base_model: jusKnows/pinaple-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
---
# Uploaded model
- **Developed by:** jusKnows
- **License:** apache-2.0
- **Finetuned from model :** jusKnows/pinaple-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Tobius/finetuned-gpt2-1729170646 | Tobius | 2024-10-17T13:11:05Z | 201 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T13:10:46Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
BroAlanTaps/GPT2-large-4-34000steps | BroAlanTaps | 2024-10-17T13:09:11Z | 132 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T13:07:21Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Bienvenu2004/cpe_model2_gguf | Bienvenu2004 | 2024-10-17T13:03:16Z | 6 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/Llama-3.2-1B-bnb-4bit",
"base_model:quantized:unsloth/Llama-3.2-1B-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-10-17T13:02:51Z | ---
base_model: unsloth/Llama-3.2-1B-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
---
# Uploaded model
- **Developed by:** Bienvenu2004
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Llama-3.2-1B-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
braindao/iq-code-evmind-qwen-2.5-7b-instruct-v0.2410.1 | braindao | 2024-10-17T12:54:14Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"base_model:braindao/iq-code-evmind-qwen-2.5-7b-instruct-v0.2410.0",
"base_model:finetune:braindao/iq-code-evmind-qwen-2.5-7b-instruct-v0.2410.0",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T12:50:38Z | ---
base_model: braindao/iq-code-evmind-qwen-2.5-7b-instruct-v0.2410.0
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
---
# Uploaded model
- **Developed by:** braindao
- **License:** apache-2.0
- **Finetuned from model :** braindao/iq-code-evmind-qwen-2.5-7b-instruct-v0.2410.0
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
cgus/Apollo2-7B-exl2 | cgus | 2024-10-17T12:46:21Z | 27 | 0 | null | [
"qwen2",
"biology",
"medical",
"question-answering",
"ar",
"en",
"zh",
"ko",
"ja",
"mn",
"th",
"vi",
"lo",
"mg",
"de",
"pt",
"es",
"fr",
"ru",
"it",
"hr",
"gl",
"cs",
"co",
"la",
"uk",
"bs",
"bg",
"eo",
"sq",
"da",
"sa",
"gn",
"sr",
"sk",
"gd",
"lb",
"hi",
"ku",
"mt",
"he",
"ln",
"bm",
"sw",
"ig",
"rw",
"ha",
"dataset:FreedomIntelligence/ApolloMoEDataset",
"arxiv:2410.10626",
"base_model:FreedomIntelligence/Apollo2-7B",
"base_model:quantized:FreedomIntelligence/Apollo2-7B",
"license:apache-2.0",
"4-bit",
"exl2",
"region:us"
] | question-answering | 2024-10-17T12:17:01Z | ---
license: apache-2.0
datasets:
- FreedomIntelligence/ApolloMoEDataset
language:
- ar
- en
- zh
- ko
- ja
- mn
- th
- vi
- lo
- mg
- de
- pt
- es
- fr
- ru
- it
- hr
- gl
- cs
- co
- la
- uk
- bs
- bg
- eo
- sq
- da
- sa
- gn
- sr
- sk
- gd
- lb
- hi
- ku
- mt
- he
- ln
- bm
- sw
- ig
- rw
- ha
metrics:
- accuracy
base_model:
- FreedomIntelligence/Apollo2-7B
pipeline_tag: question-answering
tags:
- biology
- medical
---
# Apollo2-7B-exl2
Original model: [Apollo2-7B](https://huggingface.co/FreedomIntelligence/Apollo2-7B)
Made by: [FreedomIntelligence](https://huggingface.co/FreedomIntelligence)
## Quants
[4bpw h6 (main)](https://huggingface.co/cgus/Apollo2-7B-exl2/tree/main)
[4.5bpw h6](https://huggingface.co/cgus/Apollo2-7B-exl2/tree/4.5bpw-h6)
[5bpw h6](https://huggingface.co/cgus/Apollo2-7B-exl2/tree/5bpw-h6)
[6bpw h6](https://huggingface.co/cgus/Apollo2-7B-exl2/tree/6bpw-h6)
[8bpw h8](https://huggingface.co/cgus/Apollo2-7B-exl2/tree/8bpw-h8)
## Quantization notes
Made with Exllamav2 0.2.3 with the default dataset. This model needs software with Exllamav2 library such as Text-Generation-WebUI, TabbyAPI, etc.
This model has to fit your GPU to be usable and it's mainly meant for RTX cards on Windows/Linux or AMD on Linux.
# Original model card
# Democratizing Medical LLMs For Much More Languages
Covering 12 Major Languages including English, Chinese, French, Hindi, Spanish, Arabic, Russian, Japanese, Korean, German, Italian, Portuguese and 38 Minor Languages So far.
<p align="center">
📃 <a href="https://arxiv.org/abs/2410.10626" target="_blank">Paper</a> • 🌐 <a href="" target="_blank">Demo</a> • 🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloMoEDataset" target="_blank">ApolloMoEDataset</a> • 🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloMoEBench" target="_blank">ApolloMoEBench</a> • 🤗 <a href="https://huggingface.co/collections/FreedomIntelligence/apollomoe-and-apollo2-670ddebe3bb1ba1aebabbf2c" target="_blank">Models</a> •🌐 <a href="https://github.com/FreedomIntelligence/Apollo" target="_blank">Apollo</a> • 🌐 <a href="https://github.com/FreedomIntelligence/ApolloMoE" target="_blank">ApolloMoE</a>
</p>

## 🌈 Update
* **[2024.10.15]** ApolloMoE repo is published!🎉
## Languages Coverage
12 Major Languages and 38 Minor Languages
<details>
<summary>Click to view the Languages Coverage</summary>
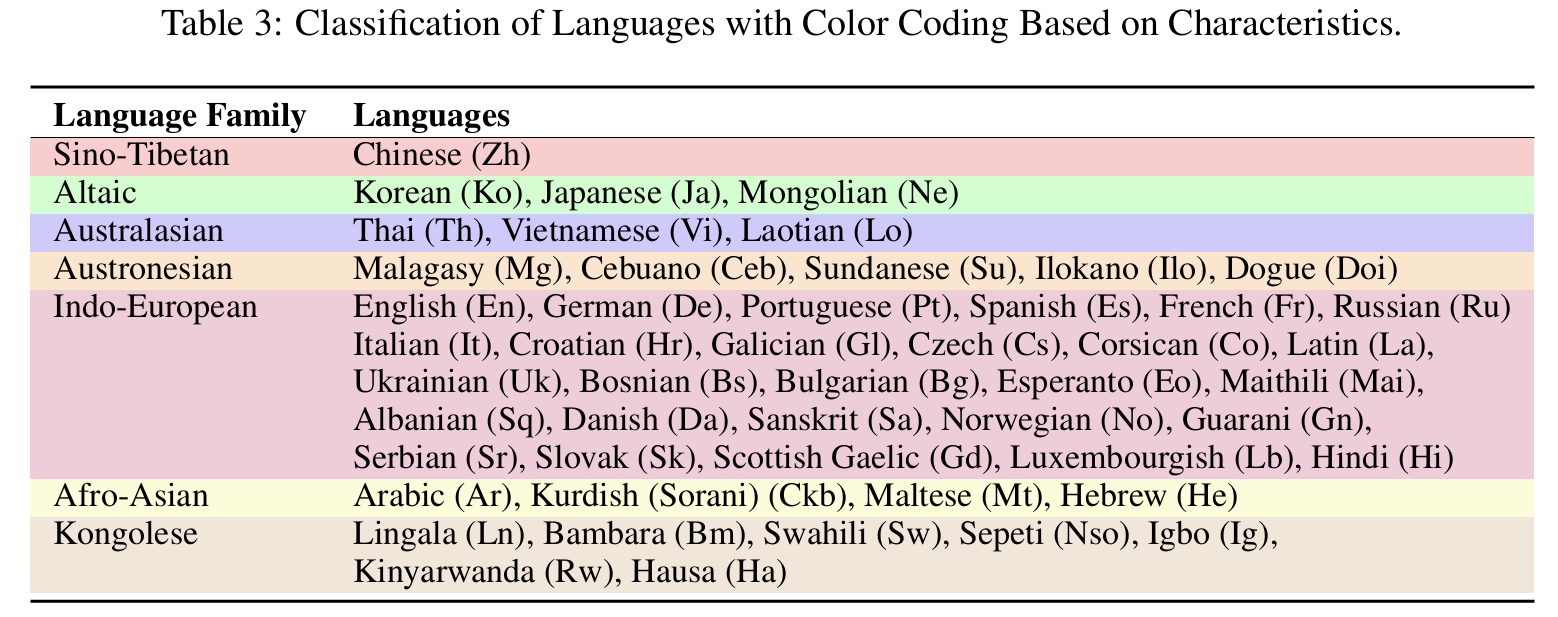
</details>
## Architecture
<details>
<summary>Click to view the MoE routing image</summary>
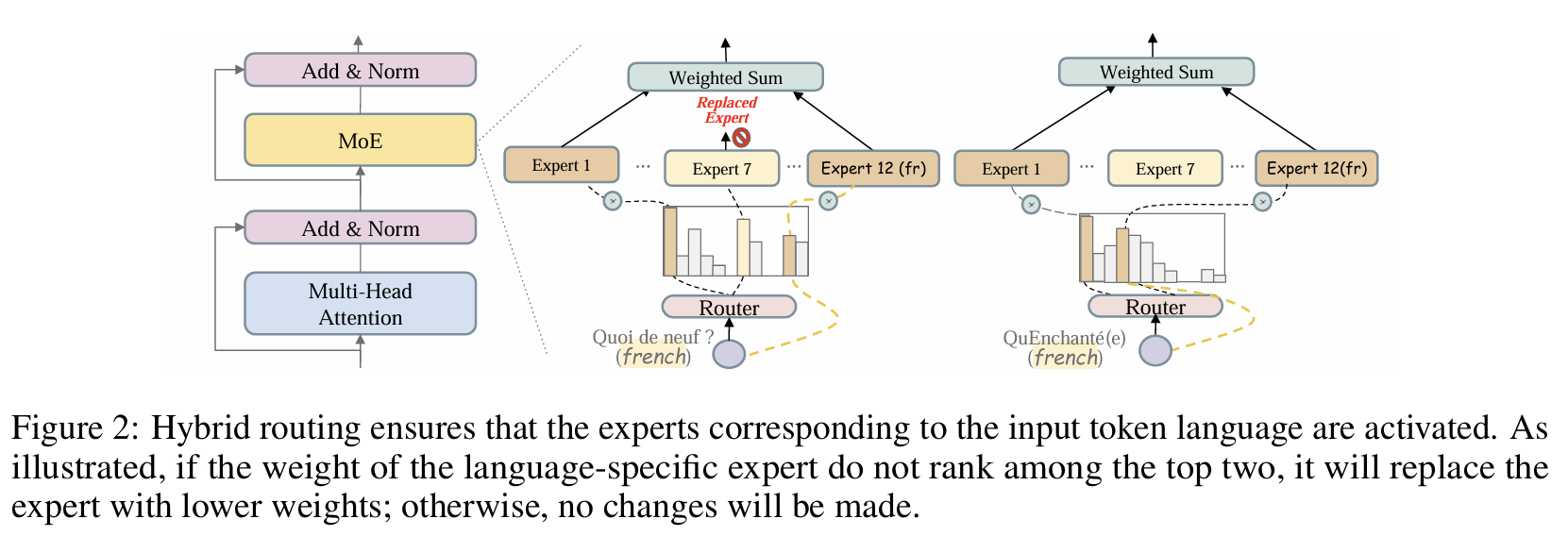
</details>
## Results
#### Dense
🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-0.5B" target="_blank">Apollo2-0.5B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-1.5B" target="_blank">Apollo2-1.5B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-2B" target="_blank">Apollo2-2B</a>
🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-3.8B" target="_blank">Apollo2-3.8B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-7B" target="_blank">Apollo2-7B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-9B" target="_blank">Apollo2-9B</a>
<details>
<summary>Click to view the Dense Models Results</summary>
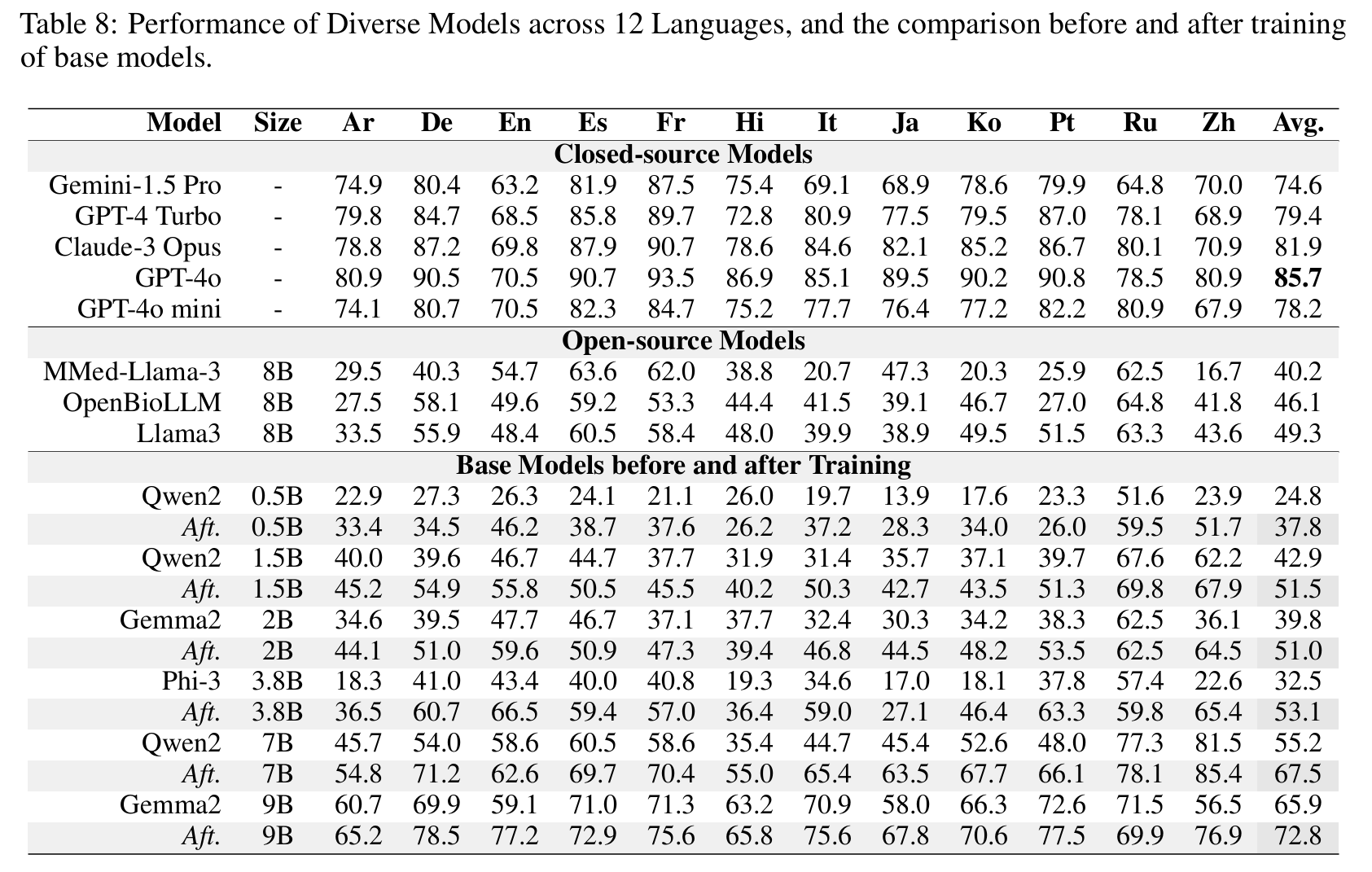
</details>
#### Post-MoE
🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-MoE-0.5B" target="_blank">Apollo-MoE-0.5B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-MoE-1.5B" target="_blank">Apollo-MoE-1.5B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-MoE-7B" target="_blank">Apollo-MoE-7B</a>
<details>
<summary>Click to view the Post-MoE Models Results</summary>
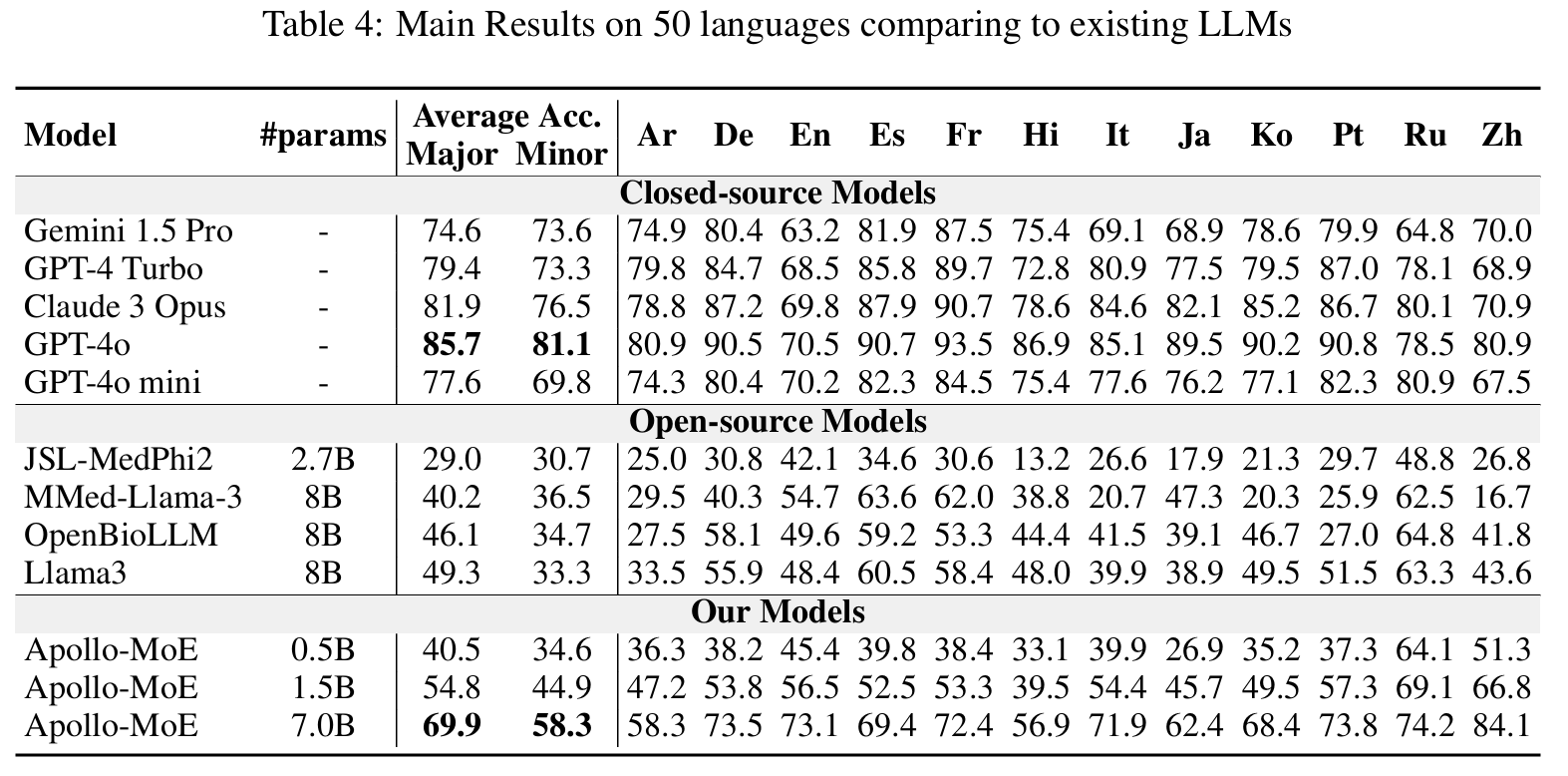
</details>
## Usage Format
##### Apollo2
- 0.5B, 1.5B, 7B: User:{query}\nAssistant:{response}<|endoftext|>
- 2B, 9B: User:{query}\nAssistant:{response}\<eos\>
- 3.8B: <|user|>\n{query}<|end|><|assisitant|>\n{response}<|end|>
##### Apollo-MoE
- 0.5B, 1.5B, 7B: User:{query}\nAssistant:{response}<|endoftext|>
## Dataset & Evaluation
- Dataset
🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloMoEDataset" target="_blank">ApolloMoEDataset</a>
<details><summary>Click to expand</summary>
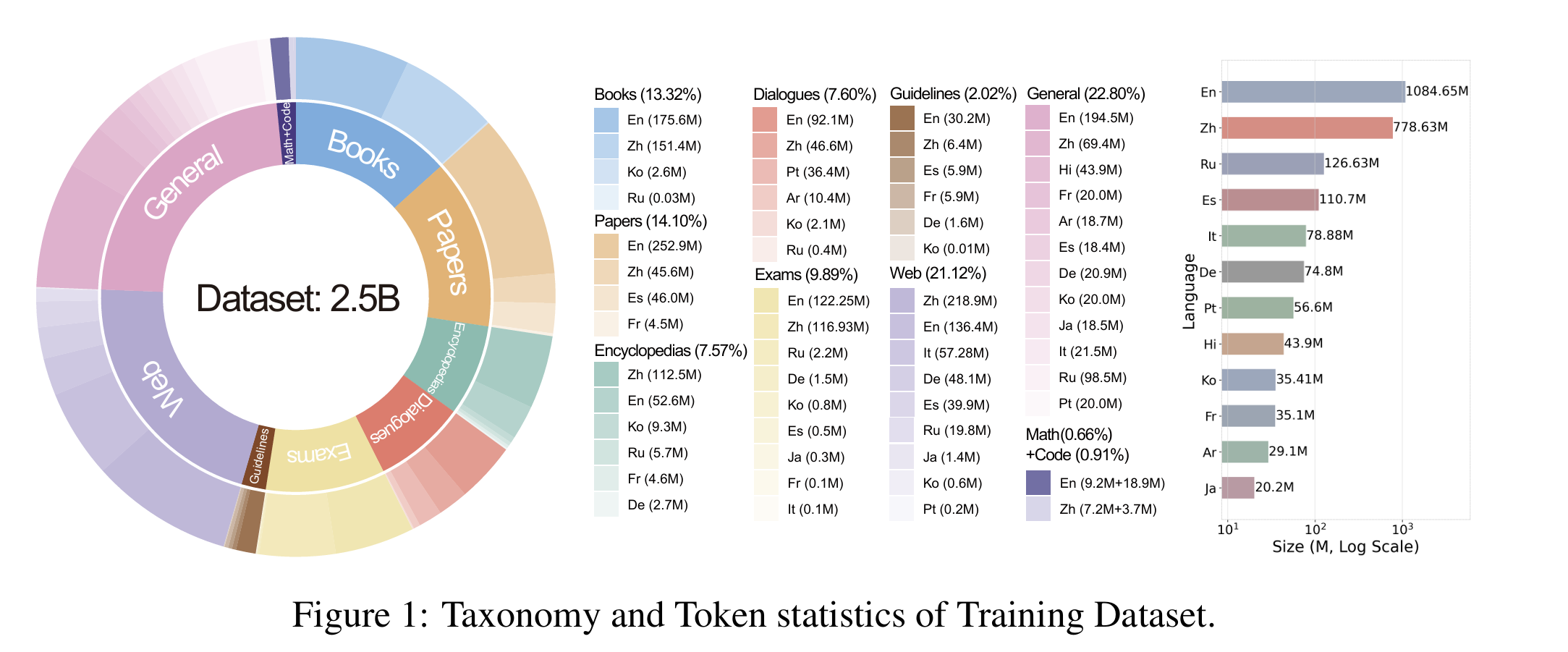
- [Data category](https://huggingface.co/datasets/FreedomIntelligence/ApolloCorpus/tree/main/train)
</details>
- Evaluation
🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloMoEBench" target="_blank">ApolloMoEBench</a>
<details><summary>Click to expand</summary>
- EN:
- [MedQA-USMLE](https://huggingface.co/datasets/GBaker/MedQA-USMLE-4-options)
- [MedMCQA](https://huggingface.co/datasets/medmcqa/viewer/default/test)
- [PubMedQA](https://huggingface.co/datasets/pubmed_qa): Because the results fluctuated too much, they were not used in the paper.
- [MMLU-Medical](https://huggingface.co/datasets/cais/mmlu)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- ZH:
- [MedQA-MCMLE](https://huggingface.co/datasets/bigbio/med_qa/viewer/med_qa_zh_4options_bigbio_qa/test)
- [CMB-single](https://huggingface.co/datasets/FreedomIntelligence/CMB): Not used in the paper
- Randomly sample 2,000 multiple-choice questions with single answer.
- [CMMLU-Medical](https://huggingface.co/datasets/haonan-li/cmmlu)
- Anatomy, Clinical_knowledge, College_medicine, Genetics, Nutrition, Traditional_chinese_medicine, Virology
- [CExam](https://github.com/williamliujl/CMExam): Not used in the paper
- Randomly sample 2,000 multiple-choice questions
- ES: [Head_qa](https://huggingface.co/datasets/head_qa)
- FR:
- [Frenchmedmcqa](https://github.com/qanastek/FrenchMedMCQA)
- [MMLU_FR]
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- HI: [MMLU_HI](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Hindi)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- AR: [MMLU_AR](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Arabic)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- JA: [IgakuQA](https://github.com/jungokasai/IgakuQA)
- KO: [KorMedMCQA](https://huggingface.co/datasets/sean0042/KorMedMCQA)
- IT:
- [MedExpQA](https://huggingface.co/datasets/HiTZ/MedExpQA)
- [MMLU_IT]
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- DE: [BioInstructQA](https://huggingface.co/datasets/BioMistral/BioInstructQA): German part
- PT: [BioInstructQA](https://huggingface.co/datasets/BioMistral/BioInstructQA): Portuguese part
- RU: [RuMedBench](https://github.com/sb-ai-lab/MedBench)
</details>
## Results reproduction
<details><summary>Click to expand</summary>
We take Apollo2-7B or Apollo-MoE-0.5B as example
1. Download Dataset for project:
```
bash 0.download_data.sh
```
2. Prepare test and dev data for specific model:
- Create test data for with special token
```
bash 1.data_process_test&dev.sh
```
3. Prepare train data for specific model (Create tokenized data in advance):
- You can adjust data Training order and Training Epoch in this step
```
bash 2.data_process_train.sh
```
4. Train the model
- If you want to train in Multi Nodes please refer to ./src/sft/training_config/zero_multi.yaml
```
bash 3.single_node_train.sh
```
5. Evaluate your model: Generate score for benchmark
```
bash 4.eval.sh
```
</details>
## Citation
Please use the following citation if you intend to use our dataset for training or evaluation:
```
@misc{zheng2024efficientlydemocratizingmedicalllms,
title={Efficiently Democratizing Medical LLMs for 50 Languages via a Mixture of Language Family Experts},
author={Guorui Zheng and Xidong Wang and Juhao Liang and Nuo Chen and Yuping Zheng and Benyou Wang},
year={2024},
eprint={2410.10626},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.10626},
}
```
|
nilq/baby-python-mistral-1L-tiny-base | nilq | 2024-10-17T12:46:04Z | 143 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"dataset:nilq/baby-python",
"arxiv:2410.12391",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-16T14:03:01Z | ---
tags:
- generated_from_trainer
datasets:
- nilq/baby-python
metrics:
- accuracy
model-index:
- name: baby-python-mistral-1L-tiny-base
results:
- task:
name: Causal Language Modeling
type: text-generation
dataset:
name: nilq/baby-python
type: nilq/baby-python
metrics:
- name: Accuracy
type: accuracy
value: 0.41903868169401487
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# baby-python-mistral-1L-tiny-base
This model is trained on the nilq/baby-python dataset. It is the base model in the paper [Tracking Universal Features Through Fine-Tuning and Model Merging](https://arxiv.org/abs/2410.12391).
It achieves the following results on the evaluation set:
- Loss: 3.1027
- Accuracy: 0.4190
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0006
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 |
SGonZ17/stephanegonzaloramieux | SGonZ17 | 2024-10-17T12:41:57Z | 49 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2024-10-17T11:59:40Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: SGL1
---
# Stephanegonzaloramieux
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `SGL1` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('SGonZ17/stephanegonzaloramieux', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
rgtjf/Qwen2-UtK-ChatQA2-72B-128K | rgtjf | 2024-10-17T12:28:14Z | 7 | 0 | null | [
"safetensors",
"qwen2",
"chat",
"128k",
"en",
"zh",
"arxiv:2409.04774",
"base_model:rgtjf/Qwen2-UtK-72B-128K",
"base_model:finetune:rgtjf/Qwen2-UtK-72B-128K",
"license:apache-2.0",
"region:us"
] | null | 2024-10-17T04:38:52Z | ---
license: apache-2.0
language:
- en
- zh
tags:
- chat
- 128k
base_model:
- rgtjf/Qwen2-UtK-72B-128K
---
# Untie-the-Knots: An Efficient Data Augmentation Strategy for Long-Context Pre-Training in Language Models
<div align="center">
<a href="https://huggingface.co/collections/rgtjf/utk-66daf994ccff050369720281">🤗 Hugging Face</a>
   |   
<a href="https://arxiv.org/pdf/2409.04774">📑 Paper</a>
   |   
<a href="https://hits.seeyoufarm.com"><img src="https://hits.seeyoufarm.com/api/count/incr/badge.svg?url=https://github.com/rgtjf/Untie-the-Knots&count_bg=#E97EBA&title_bg=#555555&icon=&icon_color=#E7E7E7&title=visitors&edge_flat=false" alt="Hits"></a>
</div>
## Introduction
We introduce Untie the Knots, a novel data augmentation strategy employed during the continue pre-training phase, designed to efficiently enable LLMs to gain long-context capabilities without the need to modify the existing data mixture.
In particular, we chunk the documents, shuffle the chunks, and create a complex and knotted structure of long texts; LLMs are then trained to untie these knots and identify relevant segments within seemingly chaotic token sequences. This approach greatly improves the model's performance by accurately attending to relevant information in long context and the training efficiency is also largely increased.
We conduct extensive experiments on models with 7B and 72B parameters, trained on 20 billion tokens, demonstrating that UtK achieves 75% and 84.5% accurracy on RULER at 128K context length, significantly outperforming other long context strategies. The trained models will open-source for further research.
## Model Details
Qwen2-UtK-7B-128K is a continuation of the Qwen2-7B model, incorporating RoPE theta modification (from 1,000,000 to 5,000,000). We also provide Qwen2-UtK-ChatQA2-7B-128K, trained with long SFT data from ChatQA 2.0 to enhance extended context handling. We also provide Qwen2-UtK-72B-128K and Qwen2-UtK-ChatQA2-72B-128K for further research.
## Long Text Processing
For deployment, we recommend using **vLLM**:
1. **Install vLLM**:
```bash
pip install "vllm>=0.4.3"
```
Or install from [source](https://github.com/vllm-project/vllm/).
2. **Deploy the Model**:
```bash
python -m vllm.entrypoints.openai.api_server --served-model-name Qwen2-UtK-ChatQA2-7B-128K --model path/to/weights \
--trust-remote-code --tensor-parallel-size 2 --host 0.0.0.0 --enable_chunked_prefill --max_num_batched_tokens 32768
```
You can access the chat API using:
```bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen2-UtK-ChatQA2-7B-128K",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Your Long Input Here."}
]
}'
```
For 72B, please use `--tensor-parallel-size 8`.
## Evaluation
### Performance on RULER (Base Model)

### Performance on InfiniteBench (Instruct Model)
| Model | En.Avg. | En.Sum | En.QA | En.MC | En.Dia | Zh.QA |
|------------------------------------|---------|--------|-------|-------|--------|-------|
| GPT-4-Turbo-2024-04-09 | 33.2 | 17.6 | 19.3 | 77.7 | 18.0 | - |
| Claude 2 | 34.0 | 14.5 | 12.0 | 62.9 | 46.5 | 9.6 |
| Kimi-Chat | 29.6 | 18.0 | 16.5 | 72.5 | 11.5 | 17.9 |
| Yi-34B-200K | < 15.15 | < 5 | 12.2 | 38.4 | <5 | 13.6 |
| Qwen2-72B-Instruct | 39.8 | 31.7 | 21.5 | 83.0 | 23.0 | - |
| Llama-3-70B-Instruct-Gradient-262k | 32.6 | 14.3 | 29.5 | 69.0 | 17.5 | - |
| Llama3.1-8B-Instruct | 33.2 | 29.2 | 31.5 | 59.0 | 13.0 | - |
| Llama3.1-70B-Instruct | 39.8 | 30.9 | 38.5 | 75.6 | 14.3 | - |
| Llama3-ChatQA-2-8B | 35.6 | 17.1 | 43.5 | 64.2 | 17.5 | - |
| Llama3-ChatQA-2-70B | 41.0 | 16.1 | 48.2 | 80.4 | 19.5 | - |
| Qwen2-UtK-ChatQA2-7B-128K | 33.3 | 21.2 | 42.6 | 61.1 | 8.5 | 37.6 |
| Qwen2-UtK-CHatQA2-72B-128K | 47.3 | 18.2 | 55.9 | 83.8 | 31.0 | 45.2 |
## License
The content of this project itself is licensed under [LICENSE](LICENSE).
## Citation
If you find this repo helpful, please cite our paper as follows:
```
@article{tian2024utk,
title={Untie-the-Knots: An Efficient Data Augmentation Strategy for Long-Context Pre-Training in Language Models},
author={Junfeng Tian, Da Zheng, Yang Chen, Rui Wang, Colin Zhang, Debing Zhang},
journal={arXiv preprint arXiv:TODO},
year={2024}
}
``` |
shresthagarwal/Meta-Llama-3-8B-Instruct-LineItem | shresthagarwal | 2024-10-17T12:26:33Z | 5 | 0 | null | [
"safetensors",
"llama",
"region:us"
] | null | 2024-10-17T05:59:58Z | # Llama3 Fine-Tuned Model for Invoice Line Item Data Extraction
This repository contains a fine-tuned version of the Llama3 model, specifically optimized for extracting line item data from tables in invoices. This model is designed for automating data extraction tasks commonly encountered in financial document processing, such as invoicing, auditing, and bookkeeping.
## Model Overview
Extracting structured line item data from invoices can be challenging due to varying formats and layouts. This model, fine-tuned on invoice data, addresses these challenges by accurately identifying and extracting key fields related to line items, including product descriptions, quantities, unit prices, tax rates, and total amounts.
## Key Features
- **Optimized for Financial Documents**: Fine-tuned for invoice data, capable of accurately identifying line item details.
- **Comprehensive Field Extraction**: Extracts essential fields such as:
- **Description**
- **Quantity**
- **Unit Price**
- **Tax Rates (SGST, CGST, IGST)**
- **Total Amount**
- **Flexible with Multiple Formats**: Compatible with diverse invoice formats, making it ideal for multi-vendor data processing.
## Usage
### Requirements
To use this model, you will need to have:
- Python 3.6 or later
- Hugging Face Transformers library
- PyTorch library
### Installation
Install the necessary libraries with pip:
```bash
pip install transformers torch
|
QuantFactory/chinese-text-correction-1.5b-GGUF | QuantFactory | 2024-10-17T12:11:57Z | 34 | 1 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"zh",
"dataset:shibing624/chinese_text_correction",
"base_model:Qwen/Qwen2.5-1.5B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-1.5B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-10-17T12:03:54Z |
---
library_name: transformers
base_model: Qwen/Qwen2.5-1.5B-Instruct
license: apache-2.0
datasets:
- shibing624/chinese_text_correction
language:
- zh
metrics:
- f1
tags:
- text-generation-inference
widget:
- text: "文本纠错:\n少先队员因该为老人让坐。"
---
[](https://hf.co/QuantFactory)
# QuantFactory/chinese-text-correction-1.5b-GGUF
This is quantized version of [shibing624/chinese-text-correction-1.5b](https://huggingface.co/shibing624/chinese-text-correction-1.5b) created using llama.cpp
# Original Model Card
# Chinese Text Correction Model
中文文本纠错模型chinese-text-correction-1.5b:用于拼写纠错、语法纠错
`shibing624/chinese-text-correction-1.5b` evaluate test data:
The overall performance of CSC **test**:
|input_text|predict_text|
|:--- |:--- |
|文本纠错:\n少先队员因该为老人让坐。|少先队员应该为老人让座。|
# Models
| Name | Base Model | Download |
|-----------------|-------------------|-----------------------------------------------------------------------|
| chinese-text-correction-1.5b | Qwen/Qwen2.5-1.5B-Instruct | [🤗 Hugging Face](https://huggingface.co/shibing624/chinese-text-correction-1.5b) |
| chinese-text-correction-1.5b-lora | Qwen/Qwen2.5-1.5B-Instruct | [🤗 Hugging Face](https://huggingface.co/shibing624/chinese-text-correction-1.5b-lora) |
| chinese-text-correction-7b | Qwen/Qwen2.5-7B-Instruct | [🤗 Hugging Face](https://huggingface.co/shibing624/chinese-text-correction-7b) |
| chinese-text-correction-7b-lora | Qwen/Qwen2.5-7B-Instruct | [🤗 Hugging Face](https://huggingface.co/shibing624/chinese-text-correction-7b-lora) |
### 评估结果
- 评估指标:F1
- CSC(Chinese Spelling Correction): 拼写纠错模型,表示模型可以处理音似、形似、语法等长度对齐的错误纠正
- CTC(CHinese Text Correction): 文本纠错模型,表示模型支持拼写、语法等长度对齐的错误纠正,还可以处理多字、少字等长度不对齐的错误纠正
- GPU:Tesla V100,显存 32 GB
| Model Name | Model Link | Base Model | Avg | SIGHAN-2015 | EC-LAW | MCSC | GPU/CPU | QPS |
|:-----------------|:------------------------------------------------------------------------------------------------------------------------|:---------------------------|:-----------|:------------|:-------|:-------|:--------|:--------|
| Kenlm-CSC | [shibing624/chinese-kenlm-klm](https://huggingface.co/shibing624/chinese-kenlm-klm) | kenlm | 0.3409 | 0.3147 | 0.3763 | 0.3317 | CPU | 9 |
| Mengzi-T5-CSC | [shibing624/mengzi-t5-base-chinese-correction](https://huggingface.co/shibing624/mengzi-t5-base-chinese-correction) | mengzi-t5-base | 0.3984 | 0.7758 | 0.3156 | 0.1039 | GPU | 214 |
| ERNIE-CSC | [PaddleNLP/ernie-csc](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/legacy/examples/text_correction/ernie-csc) | PaddlePaddle/ernie-1.0-base-zh | 0.4353 | 0.8383 | 0.3357 | 0.1318 | GPU | 114 |
| MacBERT-CSC | [shibing624/macbert4csc-base-chinese](https://huggingface.co/shibing624/macbert4csc-base-chinese) | hfl/chinese-macbert-base | 0.3993 | 0.8314 | 0.1610 | 0.2055 | GPU | **224** |
| ChatGLM3-6B-CSC | [shibing624/chatglm3-6b-csc-chinese-lora](https://huggingface.co/shibing624/chatglm3-6b-csc-chinese-lora) | THUDM/chatglm3-6b | 0.4538 | 0.6572 | 0.4369 | 0.2672 | GPU | 3 |
| Qwen2.5-1.5B-CTC | [shibing624/chinese-text-correction-1.5b](https://huggingface.co/shibing624/chinese-text-correction-1.5b) | Qwen/Qwen2.5-1.5B-Instruct | 0.6802 | 0.3032 | 0.7846 | 0.9529 | GPU | 6 |
| Qwen2.5-7B-CTC | [shibing624/chinese-text-correction-7b](https://huggingface.co/shibing624/chinese-text-correction-7b) | Qwen/Qwen2.5-7B-Instruct | **0.8225** | 0.4917 | 0.9798 | 0.9959 | GPU | 3 |
## Usage (pycorrector)
本项目开源在`pycorrector`项目:[pycorrector](https://github.com/shibing624/pycorrector),可支持大模型微调后用于文本纠错,通过如下命令调用:
Install package:
```shell
pip install -U pycorrector
```
```python
from pycorrector.gpt.gpt_corrector import GptCorrector
if __name__ == '__main__':
error_sentences = [
'真麻烦你了。希望你们好好的跳无',
'少先队员因该为老人让坐',
'机七学习是人工智能领遇最能体现智能的一个分知',
'一只小鱼船浮在平净的河面上',
'我的家乡是有明的渔米之乡',
]
m = GptCorrector("shibing624/chinese-text-correction-1.5b")
batch_res = m.correct_batch(error_sentences)
for i in batch_res:
print(i)
print()
```
## Usage (HuggingFace Transformers)
Without [pycorrector](https://github.com/shibing624/pycorrector), you can use the model like this:
First, you pass your input through the transformer model, then you get the generated sentence.
Install package:
```
pip install transformers
```
```python
# pip install transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "shibing624/chinese-text-correction-1.5b"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
input_content = "文本纠错:\n少先队员因该为老人让坐。"
messages = [{"role": "user", "content": input_content}]
input_text=tokenizer.apply_chat_template(messages, tokenize=False)
print(input_text)
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
outputs = model.generate(inputs, max_new_tokens=1024, temperature=0, do_sample=False, repetition_penalty=1.08)
print(tokenizer.decode(outputs[0]))
```
output:
```shell
少先队员应该为老人让座。
```
模型文件组成:
```
shibing624/chinese-text-correction-1.5b
|-- added_tokens.json
|-- config.json
|-- generation_config.json
|-- merges.txt
|-- model.safetensors
|-- model.safetensors.index.json
|-- README.md
|-- special_tokens_map.json
|-- tokenizer_config.json
|-- tokenizer.json
`-- vocab.json
```
#### 训练参数:
- num_epochs: 8
- batch_size: 4
- steps: 36000
- eval_loss: 0.14
- base model: Qwen/Qwen2.5-1.5B-Instruct
- train data: [shibing624/chinese_text_correction](https://huggingface.co/datasets/shibing624/chinese_text_correction)
- train time: 9 days 8 hours
- eval_loss: 
- train_loss: 
### 训练数据集
#### 中文纠错数据集
- 数据:[shibing624/chinese_text_correction](https://huggingface.co/datasets/shibing624/chinese_text_correction)
如果需要训练Qwen的纠错模型,请参考[https://github.com/shibing624/pycorrector](https://github.com/shibing624/pycorrector) 或者 [https://github.com/shibing624/MedicalGPT](https://github.com/shibing624/MedicalGPT)
## Citation
```latex
@software{pycorrector,
author = {Xu Ming},
title = {pycorrector: Implementation of language model finetune},
year = {2024},
url = {https://github.com/shibing624/pycorrector},
}
```
|
mateiaassAI/teacher_sst2_laroseda | mateiaassAI | 2024-10-17T12:10:57Z | 105 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:laroseda",
"base_model:mateiaassAI/teacher_sst2",
"base_model:finetune:mateiaassAI/teacher_sst2",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-10-17T11:07:36Z | ---
library_name: transformers
license: mit
base_model: mateiaassAI/teacher_sst2
tags:
- generated_from_trainer
datasets:
- laroseda
metrics:
- f1
- accuracy
- precision
- recall
model-index:
- name: teacher_sst2_laroseda
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: laroseda
type: laroseda
config: laroseda
split: train
args: laroseda
metrics:
- name: F1
type: f1
value: 0.9489953582155384
- name: Accuracy
type: accuracy
value: 0.949
- name: Precision
type: precision
value: 0.9490837535014006
- name: Recall
type: recall
value: 0.949
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# teacher_sst2_laroseda
This model is a fine-tuned version of [mateiaassAI/teacher_sst2](https://huggingface.co/mateiaassAI/teacher_sst2) on the laroseda dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1906
- F1: 0.9490
- Roc Auc: 0.9490
- Accuracy: 0.949
- Precision: 0.9491
- Recall: 0.949
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.7e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:|:---------:|:------:|
| 0.1799 | 1.0 | 688 | 0.1426 | 0.9435 | 0.9434 | 0.943 | 0.9441 | 0.943 |
| 0.1071 | 2.0 | 1376 | 0.1906 | 0.9490 | 0.9490 | 0.949 | 0.9491 | 0.949 |
### Framework versions
- Transformers 4.45.1
- Pytorch 2.4.0
- Datasets 3.0.1
- Tokenizers 0.20.0
|
rgtjf/Qwen2-UtK-7B-128K | rgtjf | 2024-10-17T12:08:50Z | 7 | 0 | null | [
"safetensors",
"qwen2",
"base",
"128k",
"en",
"zh",
"arxiv:2409.04774",
"license:apache-2.0",
"region:us"
] | null | 2024-09-07T05:53:35Z | ---
license: apache-2.0
language:
- en
- zh
tags:
- base
- 128k
---
# Untie-the-Knots: An Efficient Data Augmentation Strategy for Long-Context Pre-Training in Language Models
<div align="center">
<a href="https://huggingface.co/collections/rgtjf/utk-66daf994ccff050369720281">🤗 Hugging Face</a>
   |   
<a href="https://arxiv.org/pdf/2409.04774">📑 Paper</a>
   |   
<a href="https://hits.seeyoufarm.com"><img src="https://hits.seeyoufarm.com/api/count/incr/badge.svg?url=https://github.com/rgtjf/Untie-the-Knots&count_bg=#E97EBA&title_bg=#555555&icon=&icon_color=#E7E7E7&title=visitors&edge_flat=false" alt="Hits"></a>
</div>
## Introduction
We introduce Untie the Knots, a novel data augmentation strategy employed during the continue pre-training phase, designed to efficiently enable LLMs to gain long-context capabilities without the need to modify the existing data mixture.
In particular, we chunk the documents, shuffle the chunks, and create a complex and knotted structure of long texts; LLMs are then trained to untie these knots and identify relevant segments within seemingly chaotic token sequences. This approach greatly improves the model's performance by accurately attending to relevant information in long context and the training efficiency is also largely increased.
We conduct extensive experiments on models with 7B and 72B parameters, trained on 20 billion tokens, demonstrating that UtK achieves 75% and 84.5% accurracy on RULER at 128K context length, significantly outperforming other long context strategies. The trained models will open-source for further research.
## Model Details
Qwen2-UtK-7B-128K is a continuation of the Qwen2-7B model, incorporating RoPE theta modification (from 1,000,000 to 5,000,000). We also provide Qwen2-UtK-ChatQA2-7B-128K, trained with long SFT data from ChatQA 2.0 to enhance extended context handling. We also provide Qwen2-UtK-72B-128K and Qwen2-UtK-ChatQA2-72B-128K for further research.
## Long Text Processing
For deployment, we recommend using **vLLM**:
1. **Install vLLM**:
```bash
pip install "vllm>=0.4.3"
```
Or install from [source](https://github.com/vllm-project/vllm/).
2. **Deploy the Model**:
```bash
python -m vllm.entrypoints.openai.api_server --served-model-name Qwen2-UtK-ChatQA2-7B-128K --model path/to/weights \
--trust-remote-code --tensor-parallel-size 2 --host 0.0.0.0 --enable_chunked_prefill --max_num_batched_tokens 32768
```
You can access the chat API using:
```bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen2-UtK-ChatQA2-7B-128K",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Your Long Input Here."}
]
}'
```
For 72B, please use `--tensor-parallel-size 8`.
## Evaluation
### Performance on RULER (Base Model)

### Performance on InfiniteBench (Instruct Model)
| Model | En.Avg. | En.Sum | En.QA | En.MC | En.Dia | Zh.QA |
|------------------------------------|---------|--------|-------|-------|--------|-------|
| GPT-4-Turbo-2024-04-09 | 33.2 | 17.6 | 19.3 | 77.7 | 18.0 | - |
| Claude 2 | 34.0 | 14.5 | 12.0 | 62.9 | 46.5 | 9.6 |
| Kimi-Chat | 29.6 | 18.0 | 16.5 | 72.5 | 11.5 | 17.9 |
| Yi-34B-200K | < 15.15 | < 5 | 12.2 | 38.4 | <5 | 13.6 |
| Qwen2-72B-Instruct | 39.8 | 31.7 | 21.5 | 83.0 | 23.0 | - |
| Llama-3-70B-Instruct-Gradient-262k | 32.6 | 14.3 | 29.5 | 69.0 | 17.5 | - |
| Llama3.1-8B-Instruct | 33.2 | 29.2 | 31.5 | 59.0 | 13.0 | - |
| Llama3.1-70B-Instruct | 39.8 | 30.9 | 38.5 | 75.6 | 14.3 | - |
| Llama3-ChatQA-2-8B | 35.6 | 17.1 | 43.5 | 64.2 | 17.5 | - |
| Llama3-ChatQA-2-70B | 41.0 | 16.1 | 48.2 | 80.4 | 19.5 | - |
| Qwen2-UtK-ChatQA2-7B-128K | 33.3 | 21.2 | 42.6 | 61.1 | 8.5 | 37.6 |
| Qwen2-UtK-CHatQA2-72B-128K | 47.3 | 18.2 | 55.9 | 83.8 | 31.0 | 45.2 |
## License
The content of this project itself is licensed under [LICENSE](LICENSE).
## Citation
If you find this repo helpful, please cite our paper as follows:
```
@article{tian2024utk,
title={Untie-the-Knots: An Efficient Data Augmentation Strategy for Long-Context Pre-Training in Language Models},
author={Junfeng Tian, Da Zheng, Yang Chen, Rui Wang, Colin Zhang, Debing Zhang},
journal={arXiv preprint arXiv:TODO},
year={2024}
}
``` |
TheImam/AlNidaa | TheImam | 2024-10-17T12:04:48Z | 35 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T12:00:13Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
jusKnows/pinaple-bnb-4bit | jusKnows | 2024-10-17T12:04:38Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:unsloth/Llama-3.2-3B-bnb-4bit",
"base_model:finetune:unsloth/Llama-3.2-3B-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T12:02:03Z | ---
base_model: unsloth/Llama-3.2-3B-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
---
# Uploaded model
- **Developed by:** jusKnows
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Llama-3.2-3B-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
pyimagesearch/finetuned_paligemma_vqav2_small | pyimagesearch | 2024-10-17T12:02:37Z | 88 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:google/paligemma-3b-pt-224",
"base_model:adapter:google/paligemma-3b-pt-224",
"license:gemma",
"region:us"
] | null | 2024-10-14T14:27:28Z | ---
base_model: google/paligemma-3b-pt-224
library_name: peft
license: gemma
tags:
- generated_from_trainer
model-index:
- name: finetuned_paligemma_vqav2_small
results: []
---
# finetuned_paligemma_vqav2_small
This model is a fine-tuned version of [google/paligemma-3b-pt-224](https://huggingface.co/google/paligemma-3b-pt-224) using the QLoRA
technique on a small chunk of [vqav2 dataset](https://huggingface.co/datasets/merve/vqav2-small) by [Merve](https://huggingface.co/merve).
## How to Use?
```python
import torch
import requests
from PIL import Image
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
pretrained_model_id = "google/paligemma-3b-pt-224"
finetuned_model_id = "pyimagesearch/finetuned_paligemma_vqav2_small"
processor = AutoProcessor.from_pretrained(pretrained_model_id)
finetuned_model = PaliGemmaForConditionalGeneration.from_pretrained(finetuned_model_id)
prompt = "What is behind the cat?"
image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/cat.png?download=true"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(raw_image.convert("RGB"), prompt, return_tensors="pt")
output = finetuned_model.generate(**inputs, max_new_tokens=20)
print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
# gramophone
```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2
- num_epochs: 2
### Training results

### Framework versions
- PEFT 0.13.0
- Transformers 4.46.0.dev0
- Pytorch 2.4.1+cu121
- Datasets 3.0.1
- Tokenizers 0.20.0 |
Kedar1977/kedar | Kedar1977 | 2024-10-17T12:02:26Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-04-26T08:41:08Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -452.92 +/- 339.69
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
BricksDisplay/vits-eng-welsh-female | BricksDisplay | 2024-10-17T11:58:43Z | 7 | 0 | transformers.js | [
"transformers.js",
"onnx",
"vits",
"text-to-speech",
"base_model:ylacombe/vits_ljs_welsh_female_monospeaker",
"base_model:quantized:ylacombe/vits_ljs_welsh_female_monospeaker",
"region:us"
] | text-to-speech | 2024-10-17T11:57:26Z | ---
base_model:
- ylacombe/vits_ljs_welsh_female_monospeaker
pipeline_tag: text-to-speech
library_name: transformers.js
---
Convert from `ylacombe/vits_ljs_welsh_female_monospeaker` |
SidXXD/19 | SidXXD | 2024-10-17T11:53:02Z | 6 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"custom-diffusion",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2024-10-16T20:27:29Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: photo of a <v1*> person
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- custom-diffusion
inference: true
---
# Custom Diffusion - SidXXD/19
These are Custom Diffusion adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on photo of a <v1*> person using [Custom Diffusion](https://www.cs.cmu.edu/~custom-diffusion). You can find some example images in the following.
For more details on the training, please follow [this link](https://github.com/huggingface/diffusers/blob/main/examples/custom_diffusion).
|
keles/fine_tuned_xlm_roberta_for_mgtd2 | keles | 2024-10-17T11:48:59Z | 116 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-10-17T11:45:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
qqqqqian/intern_study_L0_4 | qqqqqian | 2024-10-17T11:45:17Z | 5 | 0 | null | [
"internlm2",
"custom_code",
"region:us"
] | null | 2024-10-17T11:40:41Z | # 书生浦语大模型实战营camp4
- hugging face模型上传测试
- 更多内容请访问 https://github.com/InternLM/Tutorial/tree/camp4 |
ndrushchak/ukr_gender_classifier | ndrushchak | 2024-10-17T11:44:55Z | 107 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-10-13T15:57:08Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MiniMedMind/Phi-2-2.7B-Instruct-Medical-Conversational-v2 | MiniMedMind | 2024-10-17T11:41:37Z | 130 | 0 | transformers | [
"transformers",
"safetensors",
"phi",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T11:37:08Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
spannala123/finetuned-distilbert-sst-gold_market_sentiment_model | spannala123 | 2024-10-17T11:37:07Z | 105 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-10-17T11:36:52Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
BroAlanTaps/GPT2-large-4-32000steps | BroAlanTaps | 2024-10-17T11:31:35Z | 132 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T11:30:06Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
keagan2346/my_awesome_eli5_mlm_model | keagan2346 | 2024-10-17T11:27:29Z | 121 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"fill-mask",
"generated_from_trainer",
"dataset:eli5_category",
"base_model:distilbert/distilroberta-base",
"base_model:finetune:distilbert/distilroberta-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-10-17T03:47:23Z | ---
library_name: transformers
license: apache-2.0
base_model: distilbert/distilroberta-base
tags:
- generated_from_trainer
datasets:
- eli5_category
model-index:
- name: my_awesome_eli5_mlm_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_eli5_mlm_model
This model is a fine-tuned version of [distilbert/distilroberta-base](https://huggingface.co/distilbert/distilroberta-base) on the eli5_category dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0568
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.2609 | 1.0 | 1320 | 2.0841 |
| 2.1863 | 2.0 | 2640 | 2.0358 |
| 2.1365 | 3.0 | 3960 | 2.0087 |
### Framework versions
- Transformers 4.45.2
- Pytorch 2.4.1+cu121
- Datasets 3.0.1
- Tokenizers 0.20.1
|
MesutUnutur/finetuned_Qwen2-7B-instruct | MesutUnutur | 2024-10-17T11:19:20Z | 36 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T11:14:45Z | ---
library_name: transformers
tags:
- llama-factory
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
phuongntc/vit5_large_DPO | phuongntc | 2024-10-17T11:18:22Z | 114 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-10-17T11:16:30Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
QuantFactory/NovaSpark-GGUF | QuantFactory | 2024-10-17T11:17:54Z | 47 | 1 | transformers | [
"transformers",
"gguf",
"generated_from_trainer",
"dataset:Epiculous/SynthRP-Gens-v1.1-Filtered-n-Cleaned",
"dataset:anthracite-org/stheno-filtered-v1.1",
"dataset:PJMixers/hieunguyenminh_roleplay-deduped-ShareGPT",
"dataset:Gryphe/Sonnet3.5-Charcard-Roleplay",
"dataset:Epiculous/Synthstruct-Gens-v1.1-Filtered-n-Cleaned",
"dataset:anthracite-org/kalo-opus-instruct-22k-no-refusal",
"dataset:anthracite-org/nopm_claude_writing_fixed",
"dataset:anthracite-org/kalo_opus_misc_240827",
"base_model:grimjim/Llama-3.1-SuperNova-Lite-lorabilterated-8B",
"base_model:quantized:grimjim/Llama-3.1-SuperNova-Lite-lorabilterated-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-10-17T10:36:35Z |
---
library_name: transformers
license: apache-2.0
base_model:
- grimjim/Llama-3.1-SuperNova-Lite-lorabilterated-8B
tags:
- generated_from_trainer
datasets:
- Epiculous/SynthRP-Gens-v1.1-Filtered-n-Cleaned
- anthracite-org/stheno-filtered-v1.1
- PJMixers/hieunguyenminh_roleplay-deduped-ShareGPT
- Gryphe/Sonnet3.5-Charcard-Roleplay
- Epiculous/Synthstruct-Gens-v1.1-Filtered-n-Cleaned
- anthracite-org/kalo-opus-instruct-22k-no-refusal
- anthracite-org/nopm_claude_writing_fixed
- anthracite-org/kalo_opus_misc_240827
model-index:
- name: Epiculous/NovaSpark
results: []
---
[](https://hf.co/QuantFactory)
# QuantFactory/NovaSpark-GGUF
This is quantized version of [Epiculous/NovaSpark](https://huggingface.co/Epiculous/NovaSpark) created using llama.cpp
# Original Model Card

Switching things up a bit since the last slew of models were all 12B, we now have NovaSpark! NovaSpark is an 8B model trained on GrimJim's [abliterated](https://huggingface.co/grimjim/Llama-3.1-SuperNova-Lite-lorabilterated-8B) version of arcee's [SuperNova-lite](https://huggingface.co/arcee-ai/Llama-3.1-SuperNova-Lite).
The hope is abliteration will remove some of the inherant refusals and censorship of the original model, however I noticed that finetuning on GrimJim's model undid some of the abliteration, therefore more than likely abiliteration will have to be reapplied to the resulting model to reinforce it.
# Quants!
<strong>full</strong> / [exl2](https://huggingface.co/Epiculous/NovaSpark-exl2) / [gguf](https://huggingface.co/Epiculous/NovaSpark-GGUF)
## Prompting
This model is trained on llama instruct template, the prompting structure goes a little something like this:
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
### Context and Instruct
This model is trained on llama-instruct, please use that Context and Instruct template.
### Current Top Sampler Settings
[Smooth Creativity](https://files.catbox.moe/0ihfir.json): Credit to Juelsman for researching this one!<br/>
[Variant Chimera](https://files.catbox.moe/h7vd45.json): Credit to Numbra!<br/>
[Spicy_Temp](https://files.catbox.moe/9npj0z.json) <br/>
[Violet_Twilight-Nitral-Special](https://files.catbox.moe/ot54u3.json) <br/>
|
BricksDisplay/vits-cmn | BricksDisplay | 2024-10-17T11:09:12Z | 9 | 4 | transformers.js | [
"transformers.js",
"onnx",
"safetensors",
"vits",
"text-to-audio",
"text-to-speech",
"zh",
"license:apache-2.0",
"region:us"
] | text-to-speech | 2024-01-10T07:54:50Z | ---
license: apache-2.0
language:
- zh
library_name: transformers.js
pipeline_tag: text-to-speech
---
# VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
VITS is an end-to-end speech synthesis model that predicts a speech waveform conditional on an input text sequence. It is a conditional variational autoencoder (VAE) comprised of a posterior encoder, decoder, and conditional prior.
## Model Details
Languages: Chinese
Dataset: THCHS-30
Speakers: 44
Training Hours: 48
## Usage
Using this checkpoint from Hugging Face Transformers:
```py
from transformers import VitsModel, VitsTokenizer
from pypinyin import lazy_pinyin, Style
import torch
model = VitsModel.from_pretrained("BricksDisplay/vits-cmn")
tokenizer = VitsTokenizer.from_pretrained("BricksDisplay/vits-cmn")
text = "中文"
payload = ''.join(lazy_pinyin(text, style=Style.TONE, tone_sandhi=True))
inputs = tokenizer(payload, return_tensors="pt")
with torch.no_grad():
output = model(**inputs, speaker_id=0)
from IPython.display import Audio
Audio(output.audio[0], rate=16000)
```
Using this checkpoint from Transformers.js:
```js
import { pipeline } from '@xenova/transformers';
import { pinyin } from 'pinyin-pro'; // Our use-case, using `pinyin-pro`
const synthesizer = await pipeline('text-to-audio', 'BricksDisplay/vits-cmn', { quantized: false })
console.log(await synthesizer(pinyin("中文")))
// {
// audio: Float32Array(?) [ ... ],
// sampling_rate: 16000
// }
```
Note: Transformers.js (ONNX) version does not support speaker_id, so it will fixed in 0 |
Egdal/distilbert-base-uncased-distilled-clinc | Egdal | 2024-10-17T10:53:20Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-10-17T09:30:30Z | ---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-distilled-clinc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2176
- Accuracy: 0.9526
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00010640681552913214
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4706 | 1.0 | 318 | 0.4007 | 0.9226 |
| 0.2466 | 2.0 | 636 | 0.2741 | 0.9432 |
| 0.1424 | 3.0 | 954 | 0.2488 | 0.9423 |
| 0.1141 | 4.0 | 1272 | 0.2363 | 0.9487 |
| 0.1029 | 5.0 | 1590 | 0.2263 | 0.9497 |
| 0.0964 | 6.0 | 1908 | 0.2228 | 0.9510 |
| 0.0926 | 7.0 | 2226 | 0.2160 | 0.9529 |
| 0.0905 | 8.0 | 2544 | 0.2186 | 0.9503 |
| 0.0881 | 9.0 | 2862 | 0.2174 | 0.9542 |
| 0.0871 | 10.0 | 3180 | 0.2193 | 0.9532 |
| 0.0859 | 11.0 | 3498 | 0.2173 | 0.9523 |
| 0.0855 | 12.0 | 3816 | 0.2176 | 0.9526 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.4.1+cu121
- Tokenizers 0.19.1
|
nithish27022003/sentiment_analysis_v1 | nithish27022003 | 2024-10-17T10:52:16Z | 109 | 1 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"en",
"dataset:stanfordnlp/imdb",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-10-17T10:48:42Z | ---
license: apache-2.0
datasets:
- stanfordnlp/imdb
language:
- en
metrics:
- accuracy
base_model:
- google-bert/bert-base-uncased
new_version: google-bert/bert-base-uncased
library_name: transformers
--- |
linoyts/tarot_card_flux_v27 | linoyts | 2024-10-17T10:44:50Z | 7 | 0 | diffusers | [
"diffusers",
"text-to-image",
"diffusers-training",
"lora",
"flux",
"flux-diffusers",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2024-10-17T10:21:43Z | ---
base_model: black-forest-labs/FLUX.1-dev
library_name: diffusers
license: other
tags:
- text-to-image
- diffusers-training
- diffusers
- lora
- flux
- flux-diffusers
- template:sd-lora
instance_prompt: <s0><s1>
widget: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# Flux DreamBooth LoRA - linoyts/tarot_card_flux_v27
<Gallery />
## Model description
These are linoyts/tarot_card_flux_v27 DreamBooth LoRA weights for black-forest-labs/FLUX.1-dev.
The weights were trained using [DreamBooth](https://dreambooth.github.io/) with the [Flux diffusers trainer](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_flux.md).
Was LoRA for the text encoder enabled? False.
Pivotal tuning was enabled: True.
## Trigger words
To trigger image generation of trained concept(or concepts) replace each concept identifier in you prompt with the new inserted tokens:
to trigger concept `tarot card` → use `<s0><s1>` in your prompt
## Download model
[Download the *.safetensors LoRA](linoyts/tarot_card_flux_v27/tree/main) in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
pipeline = AutoPipelineForText2Image.from_pretrained("black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16).to('cuda')
pipeline.load_lora_weights('linoyts/tarot_card_flux_v27', weight_name='pytorch_lora_weights.safetensors')
embedding_path = hf_hub_download(repo_id='linoyts/tarot_card_flux_v27', filename='tarot_card_flux_v27_emb.safetensors', repo_type="model")
state_dict = load_file(embedding_path)
pipeline.load_textual_inversion(state_dict["clip_l"], token=["<s0>", "<s1>"], text_encoder=pipeline.text_encoder, tokenizer=pipeline.tokenizer)
image = pipeline('<s0><s1>').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## License
Please adhere to the licensing terms as described [here](https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md).
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
argilla/pc_components_classifier | argilla | 2024-10-17T10:40:34Z | 26 | 1 | setfit | [
"setfit",
"safetensors",
"bert",
"sentence-transformers",
"text-classification",
"generated_from_setfit_trainer",
"arxiv:2209.11055",
"base_model:TaylorAI/bge-micro-v2",
"base_model:finetune:TaylorAI/bge-micro-v2",
"model-index",
"region:us"
] | text-classification | 2024-10-11T09:03:38Z | ---
base_model: TaylorAI/bge-micro-v2
library_name: setfit
metrics:
- accuracy
pipeline_tag: text-classification
tags:
- setfit
- sentence-transformers
- text-classification
- generated_from_setfit_trainer
widget:
- text: So, I just got the Ryzen 5 3600 and it's pretty solid for the price. The initial
setup was a bit tricky, but I managed with some help from online guides. The cooler
that comes with it is decent, but I might upgrade to something more powerful for
better performance. Overall, it’s a good start for my first build.
- text: I just upgraded my old PC with a new Intel i5 and 16GB of RAM, and it feels
like I’ve got a brand new machine! The installation was surprisingly easy, even
for someone like me who’s just starting out.Really happy with the performance
boost, especially when running my favorite photo editing software. It’s amazing
how much faster everything is now.
- text: The Ryzen 5 5600X is pretty solid for the price, but I’ve noticed some temperature
issues when overclocking. Also, the stock cooler is a bit noisy, so I ended up
getting a Noctua NH-U12S. Overall, it’s a good CPU, but there are better options
if you’re on a budget.
- text: I recently upgraded to an AMD Ryzen 7 5800X and paired it with a Gigabyte
B550 AORUS PRO AX motherboard; the performance boost is noticeable, but the thermal
management could be better. I also added a Noctua NH-D15 cooler, which has been
a game changer for keeping temperatures low. The build is stable, but I had to
fiddle a bit with the BIOS settings to get everything running smoothly.
- text: I just built my first PC and got the AMD Ryzen 5 3600 with a GTX 1660 Super,
and it's running pretty smooth for the price. Had some trouble with the case fans
but managed to figure it out with some help from YouTube.
inference: true
model-index:
- name: SetFit with TaylorAI/bge-micro-v2
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: Unknown
type: unknown
split: test
metrics:
- type: accuracy
value: 0.7375
name: Accuracy
---
# SetFit with TaylorAI/bge-micro-v2
This is a [SetFit](https://github.com/huggingface/setfit) model that can be used for Text Classification. This SetFit model uses [TaylorAI/bge-micro-v2](https://huggingface.co/TaylorAI/bge-micro-v2) as the Sentence Transformer embedding model. A [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance is used for classification.
The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Model Details
### Model Description
- **Model Type:** SetFit
- **Sentence Transformer body:** [TaylorAI/bge-micro-v2](https://huggingface.co/TaylorAI/bge-micro-v2)
- **Classification head:** a [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance
- **Maximum Sequence Length:** 512 tokens
- **Number of Classes:** 3 classes
<!-- - **Training Dataset:** [Unknown](https://huggingface.co/datasets/unknown) -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Repository:** [SetFit on GitHub](https://github.com/huggingface/setfit)
- **Paper:** [Efficient Few-Shot Learning Without Prompts](https://arxiv.org/abs/2209.11055)
- **Blogpost:** [SetFit: Efficient Few-Shot Learning Without Prompts](https://huggingface.co/blog/setfit)
### Model Labels
| Label | Examples |
|:---------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| neutral | <ul><li>'Hey, I just got the Ryzen 5 3600 and it’s actually pretty good for the price, even though I’m still learning how to set up everything. The installation was a bit tricky, but the guides on YouTube helped a lot. I’m from Australia, so shipping took a bit longer, but it’s working fine so far.'</li><li>'I recently upgraded my PC with the AMD Ryzen 5 5600X and an NVMe SSD from Samsung, and the performance boost is noticeable, especially when running multiple applications. The only downside is that the case fans are a bit noisy at full load, but it’s a small price to pay for the speed.'</li><li>'Just got the new Intel Core i9-13900K, and I must say, it’s a beast for multithreaded tasks, but the thermal management is something to keep an eye on, especially if you’re pushing it to the limits. The MSI MPG Z690 Carbon Wi-Fi motherboard pairs well, though I had to tweak the BIOS settings for optimal performance.'</li></ul> |
| negative | <ul><li>'I just got the new Ryzen 5 5600X and it’s not living up to the hype at all. My old i5 4670K was doing better in some games, and the power consumption is way too high. Plus, the stock cooler is a joke, barely keeps it under 80°C under load. Really disappointed, feels like a waste of money.'</li><li>'I just built my rig with the Ryzen 5 3600 and MSI B450 Tomahawk, and the cooling system is a joke. Had to swap out the stock cooler for a Noctua NH-U12S just to keep it from throttling during League of Legends. Not cool, man, not cool.'</li><li>'I just installed the new Ryzen 7 5800X and the cooling system is a joke, even with a Corsair H100i. Temps are through the roof, and the performance is nowhere near what I expected. Really disappointed, and I’m not sure if it’s the CPU or the cooling setup, but this build is a mess.'</li></ul> |
| positive | <ul><li>"I finally got my hands on the Ryzen 9 7950X and paired it with an X670E motherboard, and it's a beast! The performance gains over my old 5900X are insane, especially in multi-threaded tasks. The power efficiency is also a game changer. Can't wait to see how it handles my next 3D rendering project."</li><li>"I just assembled a system with the Ryzen 9 5950X and an ASUS ROG Strix X570-E Gaming motherboard, and it's running smoother than a gelato in Florence. The thermals are excellent, and the performance is simply outstanding, especially under heavy loads."</li><li>"Just built my new rig with the Ryzen 5 5600X and RTX 3060, and it's a game changer! The performance is super smooth, even with all the latest games on ultra settings. Also, the B550 Aorus Master motherboard is a beast, really stable and easy to overclock. Highly recommend this setup for anyone looking to build a solid mid-range gaming PC."</li></ul> |
## Evaluation
### Metrics
| Label | Accuracy |
|:--------|:---------|
| **all** | 0.7375 |
## Uses
### Direct Use for Inference
First install the SetFit library:
```bash
pip install setfit
```
Then you can load this model and run inference.
```python
from setfit import SetFitModel
# Download from the 🤗 Hub
model = SetFitModel.from_pretrained("setfit_model_id")
# Run inference
preds = model("I just built my first PC and got the AMD Ryzen 5 3600 with a GTX 1660 Super, and it's running pretty smooth for the price. Had some trouble with the case fans but managed to figure it out with some help from YouTube.")
```
<!--
### Downstream Use
*List how someone could finetune this model on their own dataset.*
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Set Metrics
| Training set | Min | Median | Max |
|:-------------|:----|:--------|:----|
| Word count | 38 | 52.1765 | 65 |
| Label | Training Sample Count |
|:---------|:----------------------|
| negative | 5 |
| neutral | 6 |
| positive | 6 |
### Training Hyperparameters
- batch_size: (16, 2)
- num_epochs: (1, 16)
- max_steps: -1
- sampling_strategy: oversampling
- body_learning_rate: (2e-05, 1e-05)
- head_learning_rate: 0.01
- loss: CosineSimilarityLoss
- distance_metric: cosine_distance
- margin: 0.25
- end_to_end: False
- use_amp: False
- warmup_proportion: 0.1
- l2_weight: 0.01
- seed: 42
- eval_max_steps: -1
- load_best_model_at_end: False
### Training Results
| Epoch | Step | Training Loss | Validation Loss |
|:------:|:----:|:-------------:|:---------------:|
| 0.0833 | 1 | 0.1986 | - |
### Framework Versions
- Python: 3.11.9
- SetFit: 1.1.0
- Sentence Transformers: 3.1.1
- Transformers: 4.45.2
- PyTorch: 2.4.1
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citation
### BibTeX
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
--> |
djuna/MN-Miuryra-18B | djuna | 2024-10-17T10:28:08Z | 7 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"base_model:DavidAU/MN-GRAND-Gutenberg-Lyra4-Lyra-12B-MADNESS",
"base_model:merge:DavidAU/MN-GRAND-Gutenberg-Lyra4-Lyra-12B-MADNESS",
"base_model:MarinaraSpaghetti/NemoMix-Unleashed-12B",
"base_model:merge:MarinaraSpaghetti/NemoMix-Unleashed-12B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T10:21:30Z | ---
base_model:
- MarinaraSpaghetti/NemoMix-Unleashed-12B
- DavidAU/MN-GRAND-Gutenberg-Lyra4-Lyra-12B-MADNESS
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* [MarinaraSpaghetti/NemoMix-Unleashed-12B](https://huggingface.co/MarinaraSpaghetti/NemoMix-Unleashed-12B)
* [DavidAU/MN-GRAND-Gutenberg-Lyra4-Lyra-12B-MADNESS](https://huggingface.co/DavidAU/MN-GRAND-Gutenberg-Lyra4-Lyra-12B-MADNESS)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- layer_range: [0, 16]
model: MarinaraSpaghetti/NemoMix-Unleashed-12B
- sources:
- layer_range: [8, 24]
model: DavidAU/MN-GRAND-Gutenberg-Lyra4-Lyra-12B-MADNESS
- sources:
- layer_range: [17, 32]
model: MarinaraSpaghetti/NemoMix-Unleashed-12B
- sources:
- layer_range: [25, 40]
model: DavidAU/MN-GRAND-Gutenberg-Lyra4-Lyra-12B-MADNESS
merge_method: passthrough
dtype: bfloat16
```
|
Egdal/distilbert-base-uncased-finetuned-clinc | Egdal | 2024-10-17T10:28:03Z | 8 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-10-17T08:37:06Z | ---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-distilled-clinc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2821
- Accuracy: 0.9461
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 4.208 | 1.0 | 318 | 3.1584 | 0.7432 |
| 2.4171 | 2.0 | 636 | 1.5856 | 0.8629 |
| 1.1877 | 3.0 | 954 | 0.7955 | 0.9135 |
| 0.5858 | 4.0 | 1272 | 0.4856 | 0.9290 |
| 0.3173 | 5.0 | 1590 | 0.3597 | 0.9377 |
| 0.1963 | 6.0 | 1908 | 0.3174 | 0.94 |
| 0.1395 | 7.0 | 2226 | 0.2890 | 0.9461 |
| 0.1093 | 8.0 | 2544 | 0.2863 | 0.9445 |
| 0.0957 | 9.0 | 2862 | 0.2833 | 0.9445 |
| 0.09 | 10.0 | 3180 | 0.2821 | 0.9461 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.4.1+cu121
- Tokenizers 0.19.1
|
QuantFactory/gemma-2b-aps-it-GGUF | QuantFactory | 2024-10-17T10:18:28Z | 63 | 1 | transformers | [
"transformers",
"gguf",
"text-generation",
"arxiv:2406.19803",
"base_model:google/gemma-2b",
"base_model:quantized:google/gemma-2b",
"license:gemma",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2024-10-17T10:05:20Z |
---
base_model: google/gemma-2b
library_name: transformers
license: gemma
pipeline_tag: text-generation
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
---
[](https://hf.co/QuantFactory)
# QuantFactory/gemma-2b-aps-it-GGUF
This is quantized version of [google/gemma-2b-aps-it](https://huggingface.co/google/gemma-2b-aps-it) created using llama.cpp
# Original Model Card
# Gemma Model Card
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs)
This model card corresponds to the 2B finetuned version of the Gemma-APS model.
You can also visit the model card of the [7B finetuned model](https://huggingface.co/google/gemma-7b-aps-it).
**Resources and Technical Documentation**:
* [Scalable and Domain-General Abstractive Proposition Segmentation](https://arxiv.org/abs/2406.19803)
* [Gemma Technical Report](https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf)
* [Responsible Generative AI Toolkit](https://ai.google.dev/responsible)
* [Gemma on Kaggle](https://www.kaggle.com/models/google/gemma)
**Terms of Use**: [Terms](https://www.kaggle.com/models/google/gemma/license/consent/verify/huggingface?returnModelRepoId=google/gemma-2b-aps-it)
**Authors**: Mohammad Javad Hosseini, Yang Gao, Tim Baumgärtner, Alex Fabrikant, Reinald Kim Amplayo
## Model Information
Summary description and brief definition of inputs and outputs.
### Description
Gemma-APS is a generative model and a research tool for **abstractive proposition segmentation** (APS for short), a.k.a. claim extraction.
Given a text passage, the model segments the content into the individual facts, statements, and ideas expressed in the text, and restates
them in full sentences with small changes to the original text.
This model can be used for research where there is a need to break down text content into meaningful components. Applications include
grounding, retrieval, fact-checking, and evaluation of generation tasks (such as summarization) where it can be useful to divide up
individual propositions (claims) so that they can be processed independently. For more information, check out the [research paper](https://arxiv.org/abs/2406.19803).
### Context Length
Models are trained on a context length of 8192 tokens.
### Usage
Below we share some code snippets on how to get quickly started with running the model. First make sure to `pip install -U transformers nltk`,
then copy the snippet from the section that is relevant for your usecase.
For ease-of-use, we define two helper functions for pre-processing input and post-processing output of the model:
```py
import nltk
import re
nltk.download('punkt')
start_marker = '<s>'
end_marker = '</s>'
separator = '\n'
def create_propositions_input(text: str) -> str:
input_sents = nltk.tokenize.sent_tokenize(text)
propositions_input = ''
for sent in input_sents:
propositions_input += f'{start_marker} ' + sent + f' {end_marker}{separator}'
propositions_input = propositions_input.strip(f'{separator}')
return propositions_input
def process_propositions_output(text):
pattern = re.compile(f'{re.escape(start_marker)}(.*?){re.escape(end_marker)}', re.DOTALL)
output_grouped_strs = re.findall(pattern, text)
predicted_grouped_propositions = []
for grouped_str in output_grouped_strs:
grouped_str = grouped_str.strip(separator)
props = [x[2:] for x in grouped_str.split(separator)]
predicted_grouped_propositions.append(props)
return predicted_grouped_propositions
```
#### Usage with the `pipeline` API
```py
from transformers import pipeline
import torch
generator = pipeline('text-generation', 'google/gemma-2b-aps-it', device_map='auto', torch_dtype=torch.bfloat16)
passage = 'Sarah Stage, 30, welcomed James Hunter into the world on Tuesday.\nThe baby boy weighed eight pounds seven ounces and was 22 inches long.'
messages = [{'role': 'user', 'content': create_propositions_input(passage)}]
output = generator(messages, max_new_tokens=4096, return_full_text=False)
result = process_propositions_output(output[0]['generated_text'])
print(result)
```
<details>
<summary>Example output</summary>
```json
[
[
"Sarah Stage welcomed James Hunter into the world.",
"Sarah Stage welcomed James Hunter on Tuesday.",
"Sarah Stage is 30 years old."
],
[
"James Hunter weighed eight pounds seven ounces.",
"James Hunter was 22 inches long."
]
]
```
</details>
#### Usage with `AutoModel` and `AutoTokenizer` APIs
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = 'google/gemma-2b-aps-it'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map='auto',
torch_dtype=torch.bfloat16,
)
passage = "For more than 40 years, the lyrics of American Pie have been puzzled over. This week the handwritten lyrics sold for more than $1 million at auction. The verses contain hidden references to seminal events of the 50s and 60s. It includes nods to Buddy Holly, Charles Manson and Martin Luther King."
messages = [{'role': 'user', 'content': create_propositions_input(passage)}]
inputs = tokenizer.apply_chat_template(messages, return_tensors='pt', add_generation_prompt=True, return_dict=True).to(model.device)
output = model.generate(**inputs, max_new_tokens=4096, do_sample=False)
generated_text = tokenizer.batch_decode(output[:, inputs['input_ids'].shape[1]:], skip_special_tokens=True)[0]
result = process_propositions_output(generated_text)
print(result)
```
<details>
<summary>Example output</summary>
```json
[
[
"The lyrics of American Pie have been puzzled over.",
"The lyrics of American Pie have been puzzled for more than 40 years."
],
[
"This week the handwritten lyrics sold for more than $1 million.",
"This week the handwritten lyrics sold at auction."
],
[
"The verses contain hidden references to seminal events.",
"The verses contain hidden references to events of the 50s.",
"The verses contain hidden references to events of the 60s."
],
[
"The lyrics include nods to Buddy Holly.",
"The lyrics include nods to Charles Manson.",
"The lyrics include nods to Martin Luther King."
]
]
```
</details>
### Inputs and outputs
* **Input:** A text passage.
* **Output:** List of propositions for all the sentences in the text passage. The propositions for each sentence are grouped separately.
## Model Data
Data used for model training and how the data was processed.
### Training Dataset
* The training data contains synthetically generated examples, where each example has (input passage, propositions list) pairs, with the
propositions list containing propositions for all the sentences in the input passage (one group of propositions for each sentence).
* The input passages are generated by few-shot prompting Gemini Ultra.
* The propositions list is generated by applying a teacher LLM on the input passage. The teacher LLM is a Gemini Pro model trained on
a filtered version of the ROSE dataset.
See the [research paper](https://arxiv.org/abs/2406.19803) for all the details.
### Data Preprocessing
* We filtered example passages that have >=4 tokens overlap with any of the few-shot examples used for prompting Gemini Ultra.
* We used the ROSE dataset for training the teacher LLM (Gemini Pro). We filtered ROSE examples using an entailment model to remove
cases that do not satisfy desired properties of propositions.
## Implementation Information
Details about the model internals.
### Hardware
Similar to Gemma, Gemma-APS was trained on [TPUv5e](https://cloud.google.com/tpu/docs/intro-to-tpu?_gl=1*18wi411*_ga*MzE3NDU5OTY1LjE2MzQwNDA4NDY.*_ga_WH2QY8WWF5*MTcxMTA0MjUxMy4xNy4wLjE3MTEwNDI1MTkuMC4wLjA.&_ga=2.239449409.-317459965.1634040846).
Training large language models requires significant computational power. TPUs, designed specifically for matrix operations common in machine learning, offer several advantages in this domain:
Performance: TPUs are specifically designed to handle the massive computations involved in training LLMs. They can speed up training considerably compared to CPUs.
Memory: TPUs often come with large amounts of high-bandwidth memory, allowing for the handling of large models and batch sizes during training. This can lead to better model quality.
Scalability: TPU Pods (large clusters of TPUs) provide a scalable solution for handling the growing complexity of large foundation models. You can distribute training across multiple TPU devices for faster and more efficient processing.
Cost-effectiveness: In many scenarios, TPUs can provide a more cost-effective solution for training large models compared to CPU-based infrastructure, especially when considering the time and resources saved due to faster training.
These advantages are aligned with [Google's commitments to operate sustainably](https://sustainability.google/operating-sustainably/).
### Software
Training was done using [JAX](https://github.com/jax-ml/jax).
JAX allows researchers to leverage the latest generation of hardware, including TPUs, for faster and more efficient training of large models.
## Evaluation
Model evaluation metrics and results.
### Benchmark Results
Evaluation was done on one existing in-domain dataset (development set of the [ROSE](https://github.com/Yale-LILY/ROSE) dataset filtered by an entailment model) and two out-of-domain datasets introduced in the paper. Evaluation was performed based on our new metrics for the abstractive proposition segmentation task.
## Ethics and Safety
Ethics and safety evaluation approach and results.
### Evaluation Approach
These models are only suitable for abstractive proposition segmentation for English text, not any other task or language. While we have tested the models on three evaluation datasets and have obtained positive results compared to strong baselines, the model might still have errors on some examples.
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
These models are only suitable for abstractive proposition segmentation for English text, not any other task or language.
While we have tested it on three evaluation datasets and have obtained positive results compared to strong baselines,
the models might still have errors on some examples.
### Limitations
These models have certain limitations that users should be aware of.
* Training Data
* The quality and diversity of the training data significantly influence the
model's capabilities. Biases or gaps in the training data can lead to
limitations in the model's responses.
* The scope of the training dataset determines the subject areas the model can
handle effectively.
* We have tested our models on passages from different domains, where passages
contain a few sentences.
* This model supports abstractive proposition segmentation in English, not any
other language.
* Language Ambiguity and Nuance
* Natural language is inherently complex. LLMs might struggle to grasp subtle
nuances, sarcasm, or figurative language.
* Factual Accuracy
* LLMs generate responses based on information they learned from their
training datasets, but they are not knowledge bases. They may generate
incorrect or outdated factual statements.
* Common Sense
* LLMs rely on statistical patterns in language. They might lack the ability
to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of large language models (LLMs) raises several ethical concerns.
In creating an open model, we have carefully considered the following:
* Bias and Fairness
* LLMs trained on large-scale, real-world text data can reflect socio-cultural
biases embedded in the training material. These models underwent careful
scrutiny, input data pre-processing described and posterior evaluations
reported in this card.
* Misinformation and Misuse
* LLMs can be misused to generate text that is false, misleading, or harmful.
* Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit](http://ai.google.dev/gemma/responsible).
* Transparency and Accountability:
* This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
* A responsibly developed open model offers the opportunity to share
innovation by making LLM technology accessible to developers and researchers
across the AI ecosystem.
Risks identified and mitigations:
* Perpetuation of biases: It's encouraged to perform continuous monitoring
(using evaluation metrics, human review) and the exploration of de-biasing
techniques during model training, fine-tuning, and other use cases.
* Generation of harmful content: Mechanisms and guidelines for content safety
are essential. Developers are encouraged to exercise caution and implement
appropriate content safety safeguards based on their specific product policies
and application use cases.
* Misuse for malicious purposes: Technical limitations and developer and
end-user education can help mitigate against malicious applications of LLMs.
Educational resources and reporting mechanisms for users to flag misuse are
provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy](https://ai.google.dev/gemma/prohibited_use_policy).
* Privacy violations: Models were trained on data filtered for removal of PII
(Personally Identifiable Information). Developers are encouraged to adhere to
privacy regulations with privacy-preserving techniques.
### Benefits
These models are useful for academics working on abstractive proposition segmentation (claim extraction) research or other problems (e.g., grounding, retrieval, fact-checking) that could benefit from this task.
|
QuantFactory/CursorCore-QW2.5-1.5B-SR-GGUF | QuantFactory | 2024-10-17T09:56:58Z | 65 | 1 | transformers | [
"transformers",
"gguf",
"code",
"text-generation",
"arxiv:2410.07002",
"base_model:Qwen/Qwen2.5-Coder-1.5B",
"base_model:quantized:Qwen/Qwen2.5-Coder-1.5B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2024-10-17T09:49:20Z |
---
tags:
- code
base_model:
- Qwen/Qwen2.5-Coder-1.5B
library_name: transformers
pipeline_tag: text-generation
license: apache-2.0
---
[](https://hf.co/QuantFactory)
# QuantFactory/CursorCore-QW2.5-1.5B-SR-GGUF
This is quantized version of [TechxGenus/CursorCore-QW2.5-1.5B-SR](https://huggingface.co/TechxGenus/CursorCore-QW2.5-1.5B-SR) created using llama.cpp
# Original Model Card
# CursorCore: Assist Programming through Aligning Anything
<p align="center">
<a href="http://arxiv.org/abs/2410.07002">[📄arXiv]</a> |
<a href="https://hf.co/papers/2410.07002">[🤗HF Paper]</a> |
<a href="https://huggingface.co/collections/TechxGenus/cursorcore-series-6706618c38598468866b60e2">[🤖Models]</a> |
<a href="https://github.com/TechxGenus/CursorCore">[🛠️Code]</a> |
<a href="https://github.com/TechxGenus/CursorWeb">[Web]</a> |
<a href="https://discord.gg/Z5Tev8fV">[Discord]</a>
</p>
<hr>
- [CursorCore: Assist Programming through Aligning Anything](#cursorcore-assist-programming-through-aligning-anything)
- [Introduction](#introduction)
- [Models](#models)
- [Usage](#usage)
- [1) Normal chat](#1-normal-chat)
- [2) Assistant-Conversation](#2-assistant-conversation)
- [3) Web Demo](#3-web-demo)
- [Future Work](#future-work)
- [Citation](#citation)
- [Contribution](#contribution)
<hr>
## Introduction
CursorCore is a series of open-source models designed for AI-assisted programming. It aims to support features such as automated editing and inline chat, replicating the core abilities of closed-source AI-assisted programming tools like Cursor. This is achieved by aligning data generated through Programming-Instruct. Please read [our paper](http://arxiv.org/abs/2410.07002) to learn more.
<p align="center">
<img width="100%" alt="conversation" src="https://raw.githubusercontent.com/TechxGenus/CursorCore/main/pictures/conversation.png">
</p>

## Models
Our models have been open-sourced on Hugging Face. You can access our models here: [CursorCore-Series](https://huggingface.co/collections/TechxGenus/cursorcore-series-6706618c38598468866b60e2"). We also provide pre-quantized weights for GPTQ and AWQ here: [CursorCore-Quantization](https://huggingface.co/collections/TechxGenus/cursorcore-quantization-67066431f29f252494ee8cf3)
## Usage
Here are some examples of how to use our model:
### 1) Normal chat
Script:
````python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("TechxGenus/CursorCore-Yi-9B")
model = AutoModelForCausalLM.from_pretrained(
"TechxGenus/CursorCore-Yi-9B",
torch_dtype=torch.bfloat16,
device_map="auto"
)
messages = [
{"role": "user", "content": "Hi!"},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = tokenizer.encode(prompt, return_tensors="pt")
outputs = model.generate(input_ids=inputs.to(model.device), max_new_tokens=512)
print(tokenizer.decode(outputs[0]))
````
Output:
````txt
<|im_start|>system
You are a helpful programming assistant.<|im_end|>
<|im_start|>user
Hi!<|im_end|>
<|im_start|>assistant
Hello! I'm an AI language model and I can help you with any programming questions you might have. What specific problem or task are you trying to solve?<|im_end|>
````
### 2) Assistant-Conversation
In our work, we introduce a new framework of AI-assisted programming task. It is designed for aligning anything during programming process, used for the implementation of features like Tab and Inline Chat.
Script 1:
````python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from eval.utils import prepare_input_for_wf
tokenizer = AutoTokenizer.from_pretrained("TechxGenus/CursorCore-Yi-9B")
model = AutoModelForCausalLM.from_pretrained(
"TechxGenus/CursorCore-Yi-9B",
torch_dtype=torch.bfloat16,
device_map="auto"
)
sample = {
"history": [
{
"type": "code",
"lang": "python",
"code": """def quick_sort(arr):\n if len(arr) <= 1:\n return arr\n pivot = arr[len(arr) // 2]\n left = [x for x in arr if x < pivot]\n middle = [x for x in arr if x == pivot]\n right = [x for x in arr if x > pivot]\n return quick_sort(left) + middle + quick_sort(right)"""
}
],
"current": {
"type": "code",
"lang": "python",
"code": """def quick_sort(array):\n if len(arr) <= 1:\n return arr\n pivot = arr[len(arr) // 2]\n left = [x for x in arr if x < pivot]\n middle = [x for x in arr if x == pivot]\n right = [x for x in arr if x > pivot]\n return quick_sort(left) + middle + quick_sort(right)"""
},
"user": ""
}
prompt = tokenizer.apply_chat_template(
prepare_input_for_wf(sample),
tokenize=False,
chat_template="assistant-conversation",
add_generation_prompt=True
)
inputs = tokenizer.encode(prompt, return_tensors="pt")
outputs = model.generate(input_ids=inputs.to(model.device), max_new_tokens=512, do_sample=False)
print(tokenizer.decode(outputs[0]))
````
Output 1:
````txt
<|im_start|>system
You are a helpful programming assistant.<|im_end|>
<|im_start|>history
```python
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
```<|im_end|>
<|im_start|>current
```python
def quick_sort(array):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
```<|im_end|>
<|im_start|>assistant
<|next_start|>```python
def quick_sort(array):
if len(array) <= 1:
return array
pivot = array[len(array) // 2]
left = [x for x in array if x < pivot]
middle = [x for x in array if x == pivot]
right = [x for x in array if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
```<|next_end|>
The user has provided a revised code change that corrects the parameter name from `arr` to `array` in the `quick_sort` function. This change ensures consistency in the function definition and avoids potential confusion or errors.
To implement this, we will:
1. Update the parameter name in the function definition from `arr` to `array`.
2. Ensure that all references to `arr` within the function are updated to `array`.
This will make the function definition and internal references consistent, improving code readability and maintainability.<|im_end|>
````
Script 2:
````python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from eval.utils import prepare_input_for_wf
tokenizer = AutoTokenizer.from_pretrained("TechxGenus/CursorCore-Yi-9B")
model = AutoModelForCausalLM.from_pretrained(
"TechxGenus/CursorCore-Yi-9B",
torch_dtype=torch.bfloat16,
device_map="auto"
)
sample = {
"history": [],
"current": {
"type": "code",
"lang": "python",
"code": """def quick_sort(array):\n if len(arr) <= 1:\n return arr\n pivot = arr[len(arr) // 2]\n left = [x for x in arr if x < pivot]\n middle = [x for x in arr if x == pivot]\n right = [x for x in arr if x > pivot]\n return quick_sort(left) + middle + quick_sort(right)"""
},
"user": "Add Docstring."
}
prompt = tokenizer.apply_chat_template(
prepare_input_for_wf(sample),
tokenize=False,
chat_template="assistant-conversation",
add_generation_prompt=True
)
inputs = tokenizer.encode(prompt, return_tensors="pt")
outputs = model.generate(input_ids=inputs.to(model.device), max_new_tokens=512, do_sample=False)
print(tokenizer.decode(outputs[0]))
````
Output 2:
````txt
<|im_start|>system
You are a helpful programming assistant.<|im_end|>
<|im_start|>current
```python
def quick_sort(array):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
```<|im_end|>
<|im_start|>user
Add Docstring.<|im_end|>
<|im_start|>assistant
<|next_start|>```python
def quick_sort(array):
"""
This is an implementation of the quick sort algorithm.
"""
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
```<|next_end|><|im_end|>
````
For models in Locate-and-Change (LC) and Search-and-Replace (SR) formats, the output examples are as follows:
Script for LC:
````python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from eval.utils import prepare_input_for_lc
tokenizer = AutoTokenizer.from_pretrained("TechxGenus/CursorCore-Yi-1.5B-LC")
model = AutoModelForCausalLM.from_pretrained(
"TechxGenus/CursorCore-Yi-1.5B-LC",
torch_dtype=torch.bfloat16,
device_map="auto"
)
sample = {
"history": [],
"current": {
"type": "code",
"lang": "python",
"code": """def quick_sort(array):\n if len(arr) <= 1:\n return arr\n pivot = arr[len(arr) // 2]\n left = [x for x in arr if x < pivot]\n middle = [x for x in arr if x == pivot]\n right = [x for x in arr if x > pivot]\n return quick_sort(left) + middle + quick_sort(right)"""
},
"user": "Add Docstring."
}
prompt = tokenizer.apply_chat_template(
prepare_input_for_lc(sample),
tokenize=False,
chat_template="assistant-conversation",
add_generation_prompt=True
)
inputs = tokenizer.encode(prompt, return_tensors="pt")
outputs = model.generate(input_ids=inputs.to(model.device), max_new_tokens=512, do_sample=False)
print(tokenizer.decode(outputs[0]))
````
Output for LC:
````txt
<|im_start|>system
You are a helpful programming assistant.<|im_end|>
<|im_start|>current
```python
1 def quick_sort(array):
2 if len(arr) <= 1:
3 return arr
4 pivot = arr[len(arr) // 2]
5 left = [x for x in arr if x < pivot]
6 middle = [x for x in arr if x == pivot]
7 right = [x for x in arr if x > pivot]
8 return quick_sort(left) + middle + quick_sort(right)
```<|im_end|>
<|im_start|>user
Add Docstring.<|im_end|>
<|im_start|>assistant
<|next_start|>1,1
```
'''This function will sort an array using quick sort algorithm'''
```<|next_end|>
To enhance the readability and maintainability of the code, we should add a docstring to the `quick_sort` function. A docstring provides a clear description of what the function does, which is particularly useful for other developers who might use or modify this code in the future.
The docstring will be added immediately after the function definition, explaining that the function uses the quick sort algorithm to sort an array. This will make the code more self-explanatory and easier to understand.
Here's the plan:
1. Add a docstring at the beginning of the `quick_sort` function.
2. Ensure the docstring is clear and concise, describing the purpose of the function.
This modification will improve the code's documentation without altering its functionality.<|im_end|>
````
Script for SR:
````python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from eval.utils import prepare_input_for_sr
tokenizer = AutoTokenizer.from_pretrained("TechxGenus/CursorCore-Yi-1.5B-SR")
model = AutoModelForCausalLM.from_pretrained(
"TechxGenus/CursorCore-Yi-1.5B-SR",
torch_dtype=torch.bfloat16,
device_map="auto"
)
sample = {
"history": [],
"current": {
"type": "code",
"lang": "python",
"code": """def quick_sort(array):\n if len(arr) <= 1:\n return arr\n pivot = arr[len(arr) // 2]\n left = [x for x in arr if x < pivot]\n middle = [x for x in arr if x == pivot]\n right = [x for x in arr if x > pivot]\n return quick_sort(left) + middle + quick_sort(right)"""
},
"user": "Add Docstring."
}
prompt = tokenizer.apply_chat_template(
prepare_input_for_sr(sample),
tokenize=False,
chat_template="assistant-conversation",
add_generation_prompt=True
)
inputs = tokenizer.encode(prompt, return_tensors="pt")
outputs = model.generate(input_ids=inputs.to(model.device), max_new_tokens=512, do_sample=False)
print(tokenizer.decode(outputs[0]))
````
Output for SR:
````txt
<|im_start|>system
You are a helpful programming assistant.<|im_end|>
<|im_start|>current
```python
def quick_sort(array):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
```<|im_end|>
<|im_start|>user
Add Docstring.<|im_end|>
<|im_start|>assistant
<|next_start|>```python
def quick_sort(array):
<|search_and_replace|>
def quick_sort(array):
"""
This function implements quick sort algorithm
"""
```<|next_end|><|im_end|>
````
### 3) Web Demo
We create a web demo for CursorCore. Please visit [CursorWeb](https://github.com/TechxGenus/CursorWeb) for more details.
## Future Work
CursorCore is still in a very early stage, and lots of work is needed to achieve a better user experience. For example:
- Repository-level editing support
- Better and faster editing formats
- Better user interface and presentation
- ...
## Citation
```bibtex
@article{jiang2024cursorcore,
title = {CursorCore: Assist Programming through Aligning Anything},
author = {Hao Jiang and Qi Liu and Rui Li and Shengyu Ye and Shijin Wang},
year = {2024},
journal = {arXiv preprint arXiv: 2410.07002}
}
```
## Contribution
Contributions are welcome! If you find any bugs or have suggestions for improvements, please open an issue or submit a pull request.
|
BroAlanTaps/GPT2-large-4-30000steps | BroAlanTaps | 2024-10-17T09:54:31Z | 133 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T09:52:54Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF | mradermacher | 2024-10-17T09:52:08Z | 9 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2024-10-17T09:36:24Z | ---
base_model: LeroyDyer/SpydazWeb_HumanAI_M3
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/LeroyDyer/SpydazWeb_HumanAI_M3
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-IQ1_M.gguf) | i1-IQ1_M | 1.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-IQ2_M.gguf) | i1-IQ2_M | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-Q2_K.gguf) | i1-Q2_K | 2.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-IQ3_S.gguf) | i1-IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-IQ3_M.gguf) | i1-IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-Q4_0_4_4.gguf) | i1-Q4_0_4_4 | 4.2 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-Q4_0_4_8.gguf) | i1-Q4_0_4_8 | 4.2 | fast on arm+i8mm, low quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-Q4_0_8_8.gguf) | i1-Q4_0_8_8 | 4.2 | fast on arm+sve, low quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-Q4_0.gguf) | i1-Q4_0 | 4.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWeb_HumanAI_M3-i1-GGUF/resolve/main/SpydazWeb_HumanAI_M3.i1-Q6_K.gguf) | i1-Q6_K | 6.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
bekzod1/inventory-management | bekzod1 | 2024-10-17T09:52:03Z | 83 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation-inference",
"unsloth",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-10-16T16:48:54Z | ---
base_model: unsloth/meta-llama-3.1-8b-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
---
# Uploaded model
- **Developed by:** bekzod1
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Eli238/rehearsal-finetuning-old-train2 | Eli238 | 2024-10-17T09:44:28Z | 106 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-10-17T09:36:29Z | ---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: rehearsal-finetuning-old-train2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rehearsal-finetuning-old-train2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
### Framework versions
- Transformers 4.44.2
- Pytorch 2.4.1+cu121
- Datasets 3.0.1
- Tokenizers 0.19.1
|
HimanshuWiai/outputs | HimanshuWiai | 2024-10-17T09:40:22Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:google/vit-base-patch16-224",
"base_model:finetune:google/vit-base-patch16-224",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-10-15T16:03:53Z | ---
library_name: transformers
license: apache-2.0
base_model: google/vit-base-patch16-224
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: outputs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# outputs
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2940
- Accuracy: 0.6066
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 512
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 3.0125 | 0.9953 | 53 | 2.9198 | 0.1172 |
| 2.4616 | 1.9906 | 106 | 2.2769 | 0.3719 |
| 1.8476 | 2.9859 | 159 | 1.6799 | 0.5055 |
| 1.3277 | 3.9812 | 212 | 1.2940 | 0.6066 |
### Framework versions
- Transformers 4.46.0.dev0
- Pytorch 2.4.0+cu121
- Datasets 2.20.0
- Tokenizers 0.20.1
|
mradermacher/Gemma-2-Ataraxy-v4c-9B-GGUF | mradermacher | 2024-10-17T09:40:06Z | 60 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:lemon07r/Gemma-2-Ataraxy-v4c-9B",
"base_model:quantized:lemon07r/Gemma-2-Ataraxy-v4c-9B",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-10-16T21:48:05Z | ---
base_model: lemon07r/Gemma-2-Ataraxy-v4c-9B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/lemon07r/Gemma-2-Ataraxy-v4c-9B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4c-9B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4c-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4c-9B.Q2_K.gguf) | Q2_K | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4c-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4c-9B.Q3_K_S.gguf) | Q3_K_S | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4c-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4c-9B.Q3_K_M.gguf) | Q3_K_M | 4.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4c-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4c-9B.Q3_K_L.gguf) | Q3_K_L | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4c-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4c-9B.IQ4_XS.gguf) | IQ4_XS | 5.3 | |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4c-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4c-9B.Q4_K_S.gguf) | Q4_K_S | 5.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4c-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4c-9B.Q4_K_M.gguf) | Q4_K_M | 5.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4c-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4c-9B.Q5_K_S.gguf) | Q5_K_S | 6.6 | |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4c-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4c-9B.Q5_K_M.gguf) | Q5_K_M | 6.7 | |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4c-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4c-9B.Q6_K.gguf) | Q6_K | 7.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4c-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4c-9B.Q8_0.gguf) | Q8_0 | 9.9 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4c-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4c-9B.f16.gguf) | f16 | 18.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/SpydazWebAI_Human_AGI-i1-GGUF | mradermacher | 2024-10-17T09:39:07Z | 409 | 2 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"Mistral_Star",
"Mistral_Quiet",
"Mistral",
"Mixtral",
"Question-Answer",
"Token-Classification",
"Sequence-Classification",
"SpydazWeb-AI",
"chemistry",
"biology",
"legal",
"code",
"climate",
"medical",
"LCARS_AI_StarTrek_Computer",
"text-generation-inference",
"chain-of-thought",
"tree-of-knowledge",
"forest-of-thoughts",
"visual-spacial-sketchpad",
"alpha-mind",
"knowledge-graph",
"entity-detection",
"encyclopedia",
"wikipedia",
"stack-exchange",
"Reddit",
"Cyber-series",
"MegaMind",
"Cybertron",
"SpydazWeb",
"Spydaz",
"LCARS",
"star-trek",
"mega-transformers",
"Mulit-Mega-Merge",
"Multi-Lingual",
"Afro-Centric",
"African-Model",
"Ancient-One",
"en",
"sw",
"ig",
"so",
"es",
"ca",
"xh",
"zu",
"ha",
"tw",
"af",
"hi",
"bm",
"su",
"dataset:neoneye/base64-decode-v2",
"dataset:neoneye/base64-encode-v1",
"dataset:VuongQuoc/Chemistry_text_to_image",
"dataset:Kamizuru00/diagram_image_to_text",
"dataset:LeroyDyer/Chemistry_text_to_image_BASE64",
"dataset:LeroyDyer/AudioCaps-Spectrograms_to_Base64",
"dataset:LeroyDyer/winogroud_text_to_imaget_BASE64",
"dataset:LeroyDyer/chart_text_to_Base64",
"dataset:LeroyDyer/diagram_image_to_text_BASE64",
"dataset:mekaneeky/salt_m2e_15_3_instruction",
"dataset:mekaneeky/SALT-languages-bible",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2024-10-17T09:13:57Z | ---
base_model: LeroyDyer/SpydazWebAI_Human_AGI
datasets:
- neoneye/base64-decode-v2
- neoneye/base64-encode-v1
- VuongQuoc/Chemistry_text_to_image
- Kamizuru00/diagram_image_to_text
- LeroyDyer/Chemistry_text_to_image_BASE64
- LeroyDyer/AudioCaps-Spectrograms_to_Base64
- LeroyDyer/winogroud_text_to_imaget_BASE64
- LeroyDyer/chart_text_to_Base64
- LeroyDyer/diagram_image_to_text_BASE64
- mekaneeky/salt_m2e_15_3_instruction
- mekaneeky/SALT-languages-bible
language:
- en
- sw
- ig
- so
- es
- ca
- xh
- zu
- ha
- tw
- af
- hi
- bm
- su
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- mergekit
- merge
- Mistral_Star
- Mistral_Quiet
- Mistral
- Mixtral
- Question-Answer
- Token-Classification
- Sequence-Classification
- SpydazWeb-AI
- chemistry
- biology
- legal
- code
- climate
- medical
- LCARS_AI_StarTrek_Computer
- text-generation-inference
- chain-of-thought
- tree-of-knowledge
- forest-of-thoughts
- visual-spacial-sketchpad
- alpha-mind
- knowledge-graph
- entity-detection
- encyclopedia
- wikipedia
- stack-exchange
- Reddit
- Cyber-series
- MegaMind
- Cybertron
- SpydazWeb
- Spydaz
- LCARS
- star-trek
- mega-transformers
- Mulit-Mega-Merge
- Multi-Lingual
- Afro-Centric
- African-Model
- Ancient-One
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/LeroyDyer/SpydazWebAI_Human_AGI
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-IQ1_M.gguf) | i1-IQ1_M | 1.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-IQ2_M.gguf) | i1-IQ2_M | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-Q2_K.gguf) | i1-Q2_K | 2.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-IQ3_S.gguf) | i1-IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-IQ3_M.gguf) | i1-IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-Q4_0_4_4.gguf) | i1-Q4_0_4_4 | 4.2 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-Q4_0_4_8.gguf) | i1-Q4_0_4_8 | 4.2 | fast on arm+i8mm, low quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-Q4_0_8_8.gguf) | i1-Q4_0_8_8 | 4.2 | fast on arm+sve, low quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-Q4_0.gguf) | i1-Q4_0 | 4.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF/resolve/main/SpydazWebAI_Human_AGI.i1-Q6_K.gguf) | i1-Q6_K | 6.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
alevz/gemma-2b-sql-finetuned | alevz | 2024-10-17T09:38:08Z | 131 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T09:34:25Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/ReWiz-7B-i1-GGUF | mradermacher | 2024-10-17T09:36:08Z | 295 | 0 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"sft",
"theprint",
"en",
"dataset:KingNish/reasoning-base-20k",
"dataset:arcee-ai/EvolKit-20k",
"dataset:cognitivecomputations/WizardLM_alpaca_evol_instruct_70k_unfiltered",
"base_model:theprint/ReWiz-7B",
"base_model:quantized:theprint/ReWiz-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2024-10-17T09:09:04Z | ---
base_model: theprint/ReWiz-7B
datasets:
- KingNish/reasoning-base-20k
- arcee-ai/EvolKit-20k
- cognitivecomputations/WizardLM_alpaca_evol_instruct_70k_unfiltered
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
- sft
- theprint
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/theprint/ReWiz-7B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/ReWiz-7B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-IQ1_M.gguf) | i1-IQ1_M | 1.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-IQ2_M.gguf) | i1-IQ2_M | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-Q2_K.gguf) | i1-Q2_K | 2.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-IQ3_S.gguf) | i1-IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-IQ3_M.gguf) | i1-IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-Q4_0_4_4.gguf) | i1-Q4_0_4_4 | 4.2 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-Q4_0_4_8.gguf) | i1-Q4_0_4_8 | 4.2 | fast on arm+i8mm, low quality |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-Q4_0_8_8.gguf) | i1-Q4_0_8_8 | 4.2 | fast on arm+sve, low quality |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-Q4_0.gguf) | i1-Q4_0 | 4.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF/resolve/main/ReWiz-7B.i1-Q6_K.gguf) | i1-Q6_K | 6.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
tomaarsen/mpnet-base-gooaq | tomaarsen | 2024-10-17T09:35:44Z | 8 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"mpnet",
"sentence-similarity",
"feature-extraction",
"dataset_size:1M<n<10M",
"loss:MultipleNegativesRankingLoss",
"en",
"dataset:sentence-transformers/gooaq",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:microsoft/mpnet-base",
"base_model:finetune:microsoft/mpnet-base",
"license:apache-2.0",
"model-index",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2024-06-04T17:43:43Z | ---
language:
- en
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- dataset_size:1M<n<10M
- loss:MultipleNegativesRankingLoss
base_model: microsoft/mpnet-base
datasets:
- sentence-transformers/gooaq
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
- dot_accuracy@1
- dot_accuracy@3
- dot_accuracy@5
- dot_accuracy@10
- dot_precision@1
- dot_precision@3
- dot_precision@5
- dot_precision@10
- dot_recall@1
- dot_recall@3
- dot_recall@5
- dot_recall@10
- dot_ndcg@10
- dot_mrr@10
- dot_map@100
widget:
- source_sentence: 11 is what of 8?
sentences:
- '*RARE* CANDY AXE AND RED NOSED RAIDER IS BACK - FORTNITE ITEM SHOP 8TH DECEMBER
2019.'
- 'Convert fraction (ratio) 8 / 11 Answer: 72.727272727273%'
- Old-age pensions are not included in taxable income under the personal income
tax.
- source_sentence: is 50 shades of grey on prime?
sentences:
- 'Amazon.com: Watch Fifty Shades of Grey. Prime Video.'
- 'How much is 22 out of 100 written as a percentage? Convert fraction (ratio) 22
/ 100 Answer: 22%'
- Petco ferrets are neutered and as social animals, they enjoy each other's company.
- source_sentence: 20 of what is 18?
sentences:
- '20 percent (calculated percentage %) of what number equals 18? Answer: 90.'
- There are 3.35 x 1019 H2O molecules in a 1 mg snowflake.
- There are 104 total Power Moons and 100 Purple Coins in the Mushroom Kingdom.
- source_sentence: 63 up itv when is it on?
sentences:
- Mark Twain Quotes If you tell the truth, you don't have to remember anything.
- 63 Up is on ITV for three consecutive nights, Tuesday 4 – Thursday 6 June, at
9pm.
- In a language, the smallest units of meaning are. Morphemes.
- source_sentence: what is ikit in tagalog?
sentences:
- 'Definition: aunt. the sister of one''s father or mother; the wife of one''s uncle
(n.)'
- 'How much is 12 out of 29 written as a percentage? Convert fraction (ratio) 12
/ 29 Answer: 41.379310344828%'
- Iberia offers Wi-Fi on all long-haul aircraft so that you can stay connected using
your own devices.
pipeline_tag: sentence-similarity
co2_eq_emissions:
emissions: 636.2415070661234
energy_consumed: 1.636836206312608
source: codecarbon
training_type: fine-tuning
on_cloud: false
cpu_model: 13th Gen Intel(R) Core(TM) i7-13700K
ram_total_size: 31.777088165283203
hours_used: 4.514
hardware_used: 1 x NVIDIA GeForce RTX 3090
model-index:
- name: MPNet base trained on GooAQ Question-Answer tuples
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: gooaq dev
type: gooaq-dev
metrics:
- type: cosine_accuracy@1
value: 0.7198
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.884
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.9305
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.9709
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.7198
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.29466666666666663
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.1861
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09709000000000002
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.7198
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.884
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.9305
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.9709
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.8490972112228806
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.8095713888888812
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.8111457785591406
name: Cosine Map@100
- type: dot_accuracy@1
value: 0.7073
name: Dot Accuracy@1
- type: dot_accuracy@3
value: 0.877
name: Dot Accuracy@3
- type: dot_accuracy@5
value: 0.9244
name: Dot Accuracy@5
- type: dot_accuracy@10
value: 0.9669
name: Dot Accuracy@10
- type: dot_precision@1
value: 0.7073
name: Dot Precision@1
- type: dot_precision@3
value: 0.2923333333333333
name: Dot Precision@3
- type: dot_precision@5
value: 0.18488000000000002
name: Dot Precision@5
- type: dot_precision@10
value: 0.09669000000000003
name: Dot Precision@10
- type: dot_recall@1
value: 0.7073
name: Dot Recall@1
- type: dot_recall@3
value: 0.877
name: Dot Recall@3
- type: dot_recall@5
value: 0.9244
name: Dot Recall@5
- type: dot_recall@10
value: 0.9669
name: Dot Recall@10
- type: dot_ndcg@10
value: 0.8412144933973646
name: Dot Ndcg@10
- type: dot_mrr@10
value: 0.8004067857142795
name: Dot Mrr@10
- type: dot_map@100
value: 0.8022667466578848
name: Dot Map@100
---
# MPNet base trained on GooAQ Question-Answer tuples
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [microsoft/mpnet-base](https://huggingface.co/microsoft/mpnet-base) on the [sentence-transformers/gooaq](https://huggingface.co/datasets/sentence-transformers/gooaq) dataset. It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
This model was trained using the [train_script.py](train_script.py) code.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [microsoft/mpnet-base](https://huggingface.co/microsoft/mpnet-base) <!-- at revision 6996ce1e91bd2a9c7d7f61daec37463394f73f09 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 tokens
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- [sentence-transformers/gooaq](https://huggingface.co/datasets/sentence-transformers/gooaq)
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("tomaarsen/mpnet-base-gooaq")
# Run inference
sentences = [
'11 is what of 8?',
'Convert fraction (ratio) 8 / 11 Answer: 72.727272727273%',
'Old-age pensions are not included in taxable income under the personal income tax.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Dataset: `gooaq-dev`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.7198 |
| cosine_accuracy@3 | 0.884 |
| cosine_accuracy@5 | 0.9305 |
| cosine_accuracy@10 | 0.9709 |
| cosine_precision@1 | 0.7198 |
| cosine_precision@3 | 0.2947 |
| cosine_precision@5 | 0.1861 |
| cosine_precision@10 | 0.0971 |
| cosine_recall@1 | 0.7198 |
| cosine_recall@3 | 0.884 |
| cosine_recall@5 | 0.9305 |
| cosine_recall@10 | 0.9709 |
| cosine_ndcg@10 | 0.8491 |
| cosine_mrr@10 | 0.8096 |
| **cosine_map@100** | **0.8111** |
| dot_accuracy@1 | 0.7073 |
| dot_accuracy@3 | 0.877 |
| dot_accuracy@5 | 0.9244 |
| dot_accuracy@10 | 0.9669 |
| dot_precision@1 | 0.7073 |
| dot_precision@3 | 0.2923 |
| dot_precision@5 | 0.1849 |
| dot_precision@10 | 0.0967 |
| dot_recall@1 | 0.7073 |
| dot_recall@3 | 0.877 |
| dot_recall@5 | 0.9244 |
| dot_recall@10 | 0.9669 |
| dot_ndcg@10 | 0.8412 |
| dot_mrr@10 | 0.8004 |
| dot_map@100 | 0.8023 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### sentence-transformers/gooaq
* Dataset: [sentence-transformers/gooaq](https://huggingface.co/datasets/sentence-transformers/gooaq) at [b089f72](https://huggingface.co/datasets/sentence-transformers/gooaq/tree/b089f728748a068b7bc5234e5bcf5b25e3c8279c)
* Size: 3,002,496 training samples
* Columns: <code>question</code> and <code>answer</code>
* Approximate statistics based on the first 1000 samples:
| | question | answer |
|:--------|:----------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 8 tokens</li><li>mean: 11.89 tokens</li><li>max: 22 tokens</li></ul> | <ul><li>min: 15 tokens</li><li>mean: 60.37 tokens</li><li>max: 147 tokens</li></ul> |
* Samples:
| question | answer |
|:-----------------------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>biotechnology is best defined as?</code> | <code>Biotechnology is best defined as_______________? The science that involves using living organisms to produce needed materials. Which of the following tools of biotechnology, to do investigation, is used when trying crime?</code> |
| <code>how to open xye file?</code> | <code>Firstly, use File then Open and make sure that you can see All Files (*. *) and not just Excel files (the default option!) in the folder containing the *. xye file: Select the file you wish to open and Excel will bring up a wizard menu for importing plain text data into Excel (as shown below).</code> |
| <code>how much does california spend?</code> | <code>Estimated 2016 expenditures The total estimated government spending in California in fiscal year 2016 was $265.9 billion. Per-capita figures are calculated by taking the state's total spending and dividing by the number of state residents according to United States Census Bureau estimates.</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Evaluation Dataset
#### sentence-transformers/gooaq
* Dataset: [sentence-transformers/gooaq](https://huggingface.co/datasets/sentence-transformers/gooaq) at [b089f72](https://huggingface.co/datasets/sentence-transformers/gooaq/tree/b089f728748a068b7bc5234e5bcf5b25e3c8279c)
* Size: 10,000 evaluation samples
* Columns: <code>question</code> and <code>answer</code>
* Approximate statistics based on the first 1000 samples:
| | question | answer |
|:--------|:----------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 8 tokens</li><li>mean: 11.86 tokens</li><li>max: 25 tokens</li></ul> | <ul><li>min: 14 tokens</li><li>mean: 60.82 tokens</li><li>max: 166 tokens</li></ul> |
* Samples:
| question | answer |
|:--------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>how to open nx file?</code> | <code>['Click File > Open. The File Open dialog box opens.', 'Select NX File (*. prt) in the Type box. ... ', 'Select an NX . ... ', 'Select Import in the File Open dialog box. ... ', 'If you do not want to retain the import profile in use, select an import profile from the Profile list. ... ', 'Click OK in the Import New Model dialog box.']</code> |
| <code>how to recover deleted photos from blackberry priv?</code> | <code>['Run Android Data Recovery. ... ', 'Enable USB Debugging Mode. ... ', 'Scan Your BlackBerry PRIV to Find Deleted Photos. ... ', 'Recover Deleted Photos from BlackBerry PRIV.']</code> |
| <code>which subatomic particles are found within the nucleus of an atom?</code> | <code>In the middle of every atom is the nucleus. The nucleus contains two types of subatomic particles, protons and neutrons. The protons have a positive electrical charge and the neutrons have no electrical charge. A third type of subatomic particle, electrons, move around the nucleus.</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `learning_rate`: 2e-05
- `num_train_epochs`: 1
- `warmup_ratio`: 0.1
- `bf16`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
<details><summary>Click to expand</summary>
| Epoch | Step | Training Loss | loss | gooaq-dev_cosine_map@100 |
|:------:|:-----:|:-------------:|:------:|:------------------------:|
| 0 | 0 | - | - | 0.1379 |
| 0.0000 | 1 | 3.6452 | - | - |
| 0.0053 | 250 | 2.4418 | - | - |
| 0.0107 | 500 | 0.373 | - | - |
| 0.0160 | 750 | 0.183 | - | - |
| 0.0213 | 1000 | 0.1286 | 0.0805 | 0.6796 |
| 0.0266 | 1250 | 0.1099 | - | - |
| 0.0320 | 1500 | 0.091 | - | - |
| 0.0373 | 1750 | 0.0768 | - | - |
| 0.0426 | 2000 | 0.0665 | 0.0526 | 0.7162 |
| 0.0480 | 2250 | 0.0659 | - | - |
| 0.0533 | 2500 | 0.0602 | - | - |
| 0.0586 | 2750 | 0.0548 | - | - |
| 0.0639 | 3000 | 0.0543 | 0.0426 | 0.7328 |
| 0.0693 | 3250 | 0.0523 | - | - |
| 0.0746 | 3500 | 0.0494 | - | - |
| 0.0799 | 3750 | 0.0468 | - | - |
| 0.0853 | 4000 | 0.0494 | 0.0362 | 0.7450 |
| 0.0906 | 4250 | 0.048 | - | - |
| 0.0959 | 4500 | 0.0442 | - | - |
| 0.1012 | 4750 | 0.0442 | - | - |
| 0.1066 | 5000 | 0.0408 | 0.0332 | 0.7519 |
| 0.1119 | 5250 | 0.0396 | - | - |
| 0.1172 | 5500 | 0.0379 | - | - |
| 0.1226 | 5750 | 0.0392 | - | - |
| 0.1279 | 6000 | 0.0395 | 0.0300 | 0.7505 |
| 0.1332 | 6250 | 0.0349 | - | - |
| 0.1386 | 6500 | 0.0383 | - | - |
| 0.1439 | 6750 | 0.0335 | - | - |
| 0.1492 | 7000 | 0.0323 | 0.0253 | 0.7624 |
| 0.1545 | 7250 | 0.0342 | - | - |
| 0.1599 | 7500 | 0.0292 | - | - |
| 0.1652 | 7750 | 0.0309 | - | - |
| 0.1705 | 8000 | 0.0335 | 0.0249 | 0.7631 |
| 0.1759 | 8250 | 0.0304 | - | - |
| 0.1812 | 8500 | 0.0318 | - | - |
| 0.1865 | 8750 | 0.0271 | - | - |
| 0.1918 | 9000 | 0.029 | 0.0230 | 0.7615 |
| 0.1972 | 9250 | 0.0309 | - | - |
| 0.2025 | 9500 | 0.0305 | - | - |
| 0.2078 | 9750 | 0.0237 | - | - |
| 0.2132 | 10000 | 0.0274 | 0.0220 | 0.7667 |
| 0.2185 | 10250 | 0.0248 | - | - |
| 0.2238 | 10500 | 0.0249 | - | - |
| 0.2291 | 10750 | 0.0272 | - | - |
| 0.2345 | 11000 | 0.0289 | 0.0230 | 0.7664 |
| 0.2398 | 11250 | 0.027 | - | - |
| 0.2451 | 11500 | 0.0259 | - | - |
| 0.2505 | 11750 | 0.0237 | - | - |
| 0.2558 | 12000 | 0.0245 | 0.0220 | 0.7694 |
| 0.2611 | 12250 | 0.0251 | - | - |
| 0.2664 | 12500 | 0.0243 | - | - |
| 0.2718 | 12750 | 0.0229 | - | - |
| 0.2771 | 13000 | 0.0273 | 0.0201 | 0.7725 |
| 0.2824 | 13250 | 0.0244 | - | - |
| 0.2878 | 13500 | 0.0248 | - | - |
| 0.2931 | 13750 | 0.0255 | - | - |
| 0.2984 | 14000 | 0.0244 | 0.0192 | 0.7729 |
| 0.3037 | 14250 | 0.0242 | - | - |
| 0.3091 | 14500 | 0.0235 | - | - |
| 0.3144 | 14750 | 0.0231 | - | - |
| 0.3197 | 15000 | 0.0228 | 0.0190 | 0.7823 |
| 0.3251 | 15250 | 0.0229 | - | - |
| 0.3304 | 15500 | 0.0224 | - | - |
| 0.3357 | 15750 | 0.0216 | - | - |
| 0.3410 | 16000 | 0.0218 | 0.0186 | 0.7787 |
| 0.3464 | 16250 | 0.022 | - | - |
| 0.3517 | 16500 | 0.0233 | - | - |
| 0.3570 | 16750 | 0.0216 | - | - |
| 0.3624 | 17000 | 0.0226 | 0.0169 | 0.7862 |
| 0.3677 | 17250 | 0.0215 | - | - |
| 0.3730 | 17500 | 0.0212 | - | - |
| 0.3784 | 17750 | 0.0178 | - | - |
| 0.3837 | 18000 | 0.0217 | 0.0161 | 0.7813 |
| 0.3890 | 18250 | 0.0217 | - | - |
| 0.3943 | 18500 | 0.0191 | - | - |
| 0.3997 | 18750 | 0.0216 | - | - |
| 0.4050 | 19000 | 0.022 | 0.0157 | 0.7868 |
| 0.4103 | 19250 | 0.0223 | - | - |
| 0.4157 | 19500 | 0.021 | - | - |
| 0.4210 | 19750 | 0.0176 | - | - |
| 0.4263 | 20000 | 0.021 | 0.0162 | 0.7873 |
| 0.4316 | 20250 | 0.0206 | - | - |
| 0.4370 | 20500 | 0.0196 | - | - |
| 0.4423 | 20750 | 0.0186 | - | - |
| 0.4476 | 21000 | 0.0197 | 0.0158 | 0.7907 |
| 0.4530 | 21250 | 0.0156 | - | - |
| 0.4583 | 21500 | 0.0178 | - | - |
| 0.4636 | 21750 | 0.0175 | - | - |
| 0.4689 | 22000 | 0.0187 | 0.0151 | 0.7937 |
| 0.4743 | 22250 | 0.0182 | - | - |
| 0.4796 | 22500 | 0.0185 | - | - |
| 0.4849 | 22750 | 0.0217 | - | - |
| 0.4903 | 23000 | 0.0179 | 0.0156 | 0.7937 |
| 0.4956 | 23250 | 0.0193 | - | - |
| 0.5009 | 23500 | 0.015 | - | - |
| 0.5062 | 23750 | 0.0181 | - | - |
| 0.5116 | 24000 | 0.0173 | 0.0150 | 0.7924 |
| 0.5169 | 24250 | 0.0177 | - | - |
| 0.5222 | 24500 | 0.0183 | - | - |
| 0.5276 | 24750 | 0.0171 | - | - |
| 0.5329 | 25000 | 0.0185 | 0.0140 | 0.7955 |
| 0.5382 | 25250 | 0.0178 | - | - |
| 0.5435 | 25500 | 0.015 | - | - |
| 0.5489 | 25750 | 0.017 | - | - |
| 0.5542 | 26000 | 0.0171 | 0.0139 | 0.7931 |
| 0.5595 | 26250 | 0.0164 | - | - |
| 0.5649 | 26500 | 0.0175 | - | - |
| 0.5702 | 26750 | 0.0175 | - | - |
| 0.5755 | 27000 | 0.0163 | 0.0133 | 0.7954 |
| 0.5809 | 27250 | 0.0179 | - | - |
| 0.5862 | 27500 | 0.016 | - | - |
| 0.5915 | 27750 | 0.0155 | - | - |
| 0.5968 | 28000 | 0.0162 | 0.0138 | 0.7979 |
| 0.6022 | 28250 | 0.0164 | - | - |
| 0.6075 | 28500 | 0.0148 | - | - |
| 0.6128 | 28750 | 0.0152 | - | - |
| 0.6182 | 29000 | 0.0166 | 0.0134 | 0.7987 |
| 0.6235 | 29250 | 0.0159 | - | - |
| 0.6288 | 29500 | 0.0168 | - | - |
| 0.6341 | 29750 | 0.0187 | - | - |
| 0.6395 | 30000 | 0.017 | 0.0137 | 0.7980 |
| 0.6448 | 30250 | 0.0168 | - | - |
| 0.6501 | 30500 | 0.0149 | - | - |
| 0.6555 | 30750 | 0.0159 | - | - |
| 0.6608 | 31000 | 0.0149 | 0.0131 | 0.8017 |
| 0.6661 | 31250 | 0.0149 | - | - |
| 0.6714 | 31500 | 0.0147 | - | - |
| 0.6768 | 31750 | 0.0157 | - | - |
| 0.6821 | 32000 | 0.0151 | 0.0125 | 0.8011 |
| 0.6874 | 32250 | 0.015 | - | - |
| 0.6928 | 32500 | 0.0157 | - | - |
| 0.6981 | 32750 | 0.0153 | - | - |
| 0.7034 | 33000 | 0.0141 | 0.0123 | 0.8012 |
| 0.7087 | 33250 | 0.0143 | - | - |
| 0.7141 | 33500 | 0.0121 | - | - |
| 0.7194 | 33750 | 0.0164 | - | - |
| 0.7247 | 34000 | 0.014 | 0.0121 | 0.8014 |
| 0.7301 | 34250 | 0.0147 | - | - |
| 0.7354 | 34500 | 0.0149 | - | - |
| 0.7407 | 34750 | 0.014 | - | - |
| 0.7460 | 35000 | 0.0156 | 0.0117 | 0.8022 |
| 0.7514 | 35250 | 0.0153 | - | - |
| 0.7567 | 35500 | 0.0146 | - | - |
| 0.7620 | 35750 | 0.0144 | - | - |
| 0.7674 | 36000 | 0.0139 | 0.0111 | 0.8035 |
| 0.7727 | 36250 | 0.0134 | - | - |
| 0.7780 | 36500 | 0.013 | - | - |
| 0.7833 | 36750 | 0.0156 | - | - |
| 0.7887 | 37000 | 0.0144 | 0.0108 | 0.8048 |
| 0.7940 | 37250 | 0.0133 | - | - |
| 0.7993 | 37500 | 0.0154 | - | - |
| 0.8047 | 37750 | 0.0132 | - | - |
| 0.8100 | 38000 | 0.013 | 0.0108 | 0.8063 |
| 0.8153 | 38250 | 0.0126 | - | - |
| 0.8207 | 38500 | 0.0135 | - | - |
| 0.8260 | 38750 | 0.014 | - | - |
| 0.8313 | 39000 | 0.013 | 0.0109 | 0.8086 |
| 0.8366 | 39250 | 0.0136 | - | - |
| 0.8420 | 39500 | 0.0141 | - | - |
| 0.8473 | 39750 | 0.0155 | - | - |
| 0.8526 | 40000 | 0.0153 | 0.0106 | 0.8075 |
| 0.8580 | 40250 | 0.0131 | - | - |
| 0.8633 | 40500 | 0.0128 | - | - |
| 0.8686 | 40750 | 0.013 | - | - |
| 0.8739 | 41000 | 0.0133 | 0.0109 | 0.8060 |
| 0.8793 | 41250 | 0.0119 | - | - |
| 0.8846 | 41500 | 0.0144 | - | - |
| 0.8899 | 41750 | 0.0142 | - | - |
| 0.8953 | 42000 | 0.0138 | 0.0105 | 0.8083 |
| 0.9006 | 42250 | 0.014 | - | - |
| 0.9059 | 42500 | 0.0134 | - | - |
| 0.9112 | 42750 | 0.0134 | - | - |
| 0.9166 | 43000 | 0.0124 | 0.0106 | 0.8113 |
| 0.9219 | 43250 | 0.0122 | - | - |
| 0.9272 | 43500 | 0.0126 | - | - |
| 0.9326 | 43750 | 0.0121 | - | - |
| 0.9379 | 44000 | 0.0137 | 0.0103 | 0.8105 |
| 0.9432 | 44250 | 0.0132 | - | - |
| 0.9485 | 44500 | 0.012 | - | - |
| 0.9539 | 44750 | 0.0136 | - | - |
| 0.9592 | 45000 | 0.0133 | 0.0104 | 0.8112 |
| 0.9645 | 45250 | 0.0118 | - | - |
| 0.9699 | 45500 | 0.0132 | - | - |
| 0.9752 | 45750 | 0.0118 | - | - |
| 0.9805 | 46000 | 0.012 | 0.0102 | 0.8104 |
| 0.9858 | 46250 | 0.0127 | - | - |
| 0.9912 | 46500 | 0.0134 | - | - |
| 0.9965 | 46750 | 0.0121 | - | - |
| 1.0 | 46914 | - | - | 0.8111 |
</details>
### Environmental Impact
Carbon emissions were measured using [CodeCarbon](https://github.com/mlco2/codecarbon).
- **Energy Consumed**: 1.637 kWh
- **Carbon Emitted**: 0.636 kg of CO2
- **Hours Used**: 4.514 hours
### Training Hardware
- **On Cloud**: No
- **GPU Model**: 1 x NVIDIA GeForce RTX 3090
- **CPU Model**: 13th Gen Intel(R) Core(TM) i7-13700K
- **RAM Size**: 31.78 GB
### Framework Versions
- Python: 3.11.6
- Sentence Transformers: 3.1.0.dev0
- Transformers: 4.41.2
- PyTorch: 2.3.0+cu121
- Accelerate: 0.30.1
- Datasets: 2.19.1
- Tokenizers: 0.19.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
--> |
QuantFactory/Qwen2.5-7B-Gutenberg-KTO-GGUF | QuantFactory | 2024-10-17T09:31:14Z | 194 | 1 | null | [
"gguf",
"text-generation",
"zh",
"en",
"dataset:Orion-zhen/kto-gutenberg",
"base_model:Orion-zhen/Qwen2.5-7B-Instruct-Uncensored",
"base_model:quantized:Orion-zhen/Qwen2.5-7B-Instruct-Uncensored",
"license:gpl-3.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2024-10-17T08:52:27Z |
---
license: gpl-3.0
datasets:
- Orion-zhen/kto-gutenberg
language:
- zh
- en
base_model:
- Orion-zhen/Qwen2.5-7B-Instruct-Uncensored
pipeline_tag: text-generation
---
[](https://hf.co/QuantFactory)
# QuantFactory/Qwen2.5-7B-Gutenberg-KTO-GGUF
This is quantized version of [Orion-zhen/Qwen2.5-7B-Gutenberg-KTO](https://huggingface.co/Orion-zhen/Qwen2.5-7B-Gutenberg-KTO) created using llama.cpp
# Original Model Card
# Qwen2.5-7B-Gutenberg-KTO
This model is fine tuned over gutenberg datasets using kto strategy. It's my first time to use kto strategy, and I'm not sure how the model actually performs.
Compared to those large companies which remove accessories such as charger and cables from packages, I have achieved **real** environment protection by **truly** reducing energy consumption, rather than shifting costs to consumers.
Checkout GGUF here: [Orion-zhen/Qwen2.5-7B-Gutenberg-KTO-Q6_K-GGUF](https://huggingface.co/Orion-zhen/Qwen2.5-7B-Gutenberg-KTO-Q6_K-GGUF)
## Details
### Platform
~~I randomly grabbed some rubbish from a second-hand market and built a PC~~
I carefully selected various dedicated hardwares and constructed an incomparable home server, which I entitled the **Great Server**:
- CPU: Intel Core i3-4160
- Memory: 8G DDR3, single channel
- GPU: Tesla P4, TDP 75W, boasting its **Eco friendly energy consumption**
- Disk: 1TB M.2 NVME, PCIe 4.0
### Training
To practice the **eco-friendly training**, I utilized various methods, including adam-mini, qlora and unsloth, to minimize VRAM and energy usage, as well as accelerating training speed.
- dataset: [Orion-zhen/kto-gutenberg](https://huggingface.co/datasets/Orion-zhen/kto-gutenberg)
- epoch: 2
- gradient accumulation: 8
- batch size: 1
- KTO perf beta: 0.1
### Train log


|
bunnycore/Phi-3.5-mini-TitanFusion-0.3 | bunnycore | 2024-10-17T09:25:43Z | 50 | 0 | transformers | [
"transformers",
"safetensors",
"phi3",
"text-generation",
"mergekit",
"merge",
"conversational",
"custom_code",
"arxiv:2306.01708",
"base_model:ArliAI/Phi-3.5-mini-3.8B-ArliAI-RPMax-v1.1",
"base_model:merge:ArliAI/Phi-3.5-mini-3.8B-ArliAI-RPMax-v1.1",
"base_model:bunnycore/Phi-3.5-Mini-RP-Sonet",
"base_model:merge:bunnycore/Phi-3.5-Mini-RP-Sonet",
"base_model:bunnycore/Phi-3.5-mini-TitanFusion-0.1",
"base_model:merge:bunnycore/Phi-3.5-mini-TitanFusion-0.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T09:23:43Z | ---
base_model:
- ArliAI/Phi-3.5-mini-3.8B-ArliAI-RPMax-v1.1
- bunnycore/Phi-3.5-Mini-RP-Sonet
- bunnycore/Phi-3.5-mini-TitanFusion-0.1
- ArliAI/Phi-3.5-mini-3.8B-ArliAI-RPMax-v1.1
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [ArliAI/Phi-3.5-mini-3.8B-ArliAI-RPMax-v1.1](https://huggingface.co/ArliAI/Phi-3.5-mini-3.8B-ArliAI-RPMax-v1.1) as a base.
### Models Merged
The following models were included in the merge:
* [ArliAI/Phi-3.5-mini-3.8B-ArliAI-RPMax-v1.1](https://huggingface.co/ArliAI/Phi-3.5-mini-3.8B-ArliAI-RPMax-v1.1) + [bunnycore/Phi-3.5-Mini-RP-Sonet](https://huggingface.co/bunnycore/Phi-3.5-Mini-RP-Sonet)
* [bunnycore/Phi-3.5-mini-TitanFusion-0.1](https://huggingface.co/bunnycore/Phi-3.5-mini-TitanFusion-0.1)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: ArliAI/Phi-3.5-mini-3.8B-ArliAI-RPMax-v1.1+bunnycore/Phi-3.5-Mini-RP-Sonet
parameters:
weight: 1
- model: ArliAI/Phi-3.5-mini-3.8B-ArliAI-RPMax-v1.1
parameters:
weight: 1
- model: bunnycore/Phi-3.5-mini-TitanFusion-0.1
parameters:
weight: 1
merge_method: ties
base_model: ArliAI/Phi-3.5-mini-3.8B-ArliAI-RPMax-v1.1
parameters:
density: 1
normalize: true
int8_mask: true
dtype: bfloat16
```
|
mradermacher/SpydazWebAI_Human_AGI-GGUF | mradermacher | 2024-10-17T09:17:08Z | 35 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"Mistral_Star",
"Mistral_Quiet",
"Mistral",
"Mixtral",
"Question-Answer",
"Token-Classification",
"Sequence-Classification",
"SpydazWeb-AI",
"chemistry",
"biology",
"legal",
"code",
"climate",
"medical",
"LCARS_AI_StarTrek_Computer",
"text-generation-inference",
"chain-of-thought",
"tree-of-knowledge",
"forest-of-thoughts",
"visual-spacial-sketchpad",
"alpha-mind",
"knowledge-graph",
"entity-detection",
"encyclopedia",
"wikipedia",
"stack-exchange",
"Reddit",
"Cyber-series",
"MegaMind",
"Cybertron",
"SpydazWeb",
"Spydaz",
"LCARS",
"star-trek",
"mega-transformers",
"Mulit-Mega-Merge",
"Multi-Lingual",
"Afro-Centric",
"African-Model",
"Ancient-One",
"en",
"sw",
"ig",
"so",
"es",
"ca",
"xh",
"zu",
"ha",
"tw",
"af",
"hi",
"bm",
"su",
"dataset:neoneye/base64-decode-v2",
"dataset:neoneye/base64-encode-v1",
"dataset:VuongQuoc/Chemistry_text_to_image",
"dataset:Kamizuru00/diagram_image_to_text",
"dataset:LeroyDyer/Chemistry_text_to_image_BASE64",
"dataset:LeroyDyer/AudioCaps-Spectrograms_to_Base64",
"dataset:LeroyDyer/winogroud_text_to_imaget_BASE64",
"dataset:LeroyDyer/chart_text_to_Base64",
"dataset:LeroyDyer/diagram_image_to_text_BASE64",
"dataset:mekaneeky/salt_m2e_15_3_instruction",
"dataset:mekaneeky/SALT-languages-bible",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-10-17T09:09:09Z | ---
base_model: LeroyDyer/SpydazWebAI_Human_AGI
datasets:
- neoneye/base64-decode-v2
- neoneye/base64-encode-v1
- VuongQuoc/Chemistry_text_to_image
- Kamizuru00/diagram_image_to_text
- LeroyDyer/Chemistry_text_to_image_BASE64
- LeroyDyer/AudioCaps-Spectrograms_to_Base64
- LeroyDyer/winogroud_text_to_imaget_BASE64
- LeroyDyer/chart_text_to_Base64
- LeroyDyer/diagram_image_to_text_BASE64
- mekaneeky/salt_m2e_15_3_instruction
- mekaneeky/SALT-languages-bible
language:
- en
- sw
- ig
- so
- es
- ca
- xh
- zu
- ha
- tw
- af
- hi
- bm
- su
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- mergekit
- merge
- Mistral_Star
- Mistral_Quiet
- Mistral
- Mixtral
- Question-Answer
- Token-Classification
- Sequence-Classification
- SpydazWeb-AI
- chemistry
- biology
- legal
- code
- climate
- medical
- LCARS_AI_StarTrek_Computer
- text-generation-inference
- chain-of-thought
- tree-of-knowledge
- forest-of-thoughts
- visual-spacial-sketchpad
- alpha-mind
- knowledge-graph
- entity-detection
- encyclopedia
- wikipedia
- stack-exchange
- Reddit
- Cyber-series
- MegaMind
- Cybertron
- SpydazWeb
- Spydaz
- LCARS
- star-trek
- mega-transformers
- Mulit-Mega-Merge
- Multi-Lingual
- Afro-Centric
- African-Model
- Ancient-One
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/LeroyDyer/SpydazWebAI_Human_AGI
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-GGUF/resolve/main/SpydazWebAI_Human_AGI.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-GGUF/resolve/main/SpydazWebAI_Human_AGI.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-GGUF/resolve/main/SpydazWebAI_Human_AGI.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-GGUF/resolve/main/SpydazWebAI_Human_AGI.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-GGUF/resolve/main/SpydazWebAI_Human_AGI.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-GGUF/resolve/main/SpydazWebAI_Human_AGI.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-GGUF/resolve/main/SpydazWebAI_Human_AGI.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-GGUF/resolve/main/SpydazWebAI_Human_AGI.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-GGUF/resolve/main/SpydazWebAI_Human_AGI.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-GGUF/resolve/main/SpydazWebAI_Human_AGI.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-GGUF/resolve/main/SpydazWebAI_Human_AGI.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/SpydazWebAI_Human_AGI-GGUF/resolve/main/SpydazWebAI_Human_AGI.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
Jagobaemeka/my_awesome_food_model | Jagobaemeka | 2024-10-17T09:16:53Z | 194 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-10-17T08:47:57Z | ---
library_name: transformers
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: my_awesome_food_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_food_model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6531
- Accuracy: 0.873
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.711 | 0.992 | 62 | 2.5698 | 0.801 |
| 1.8586 | 2.0 | 125 | 1.8322 | 0.852 |
| 1.6124 | 2.976 | 186 | 1.6531 | 0.873 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.4.1+cu121
- Datasets 3.0.1
- Tokenizers 0.19.1
|
Bienvenu2004/cpe_model_gguf | Bienvenu2004 | 2024-10-17T09:14:54Z | 7 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/Llama-3.2-1B-bnb-4bit",
"base_model:quantized:unsloth/Llama-3.2-1B-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-10-17T09:14:30Z | ---
base_model: unsloth/Llama-3.2-1B-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
---
# Uploaded model
- **Developed by:** Bienvenu2004
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Llama-3.2-1B-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mradermacher/ReWiz-7B-GGUF | mradermacher | 2024-10-17T09:14:03Z | 7 | 0 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"sft",
"theprint",
"en",
"dataset:KingNish/reasoning-base-20k",
"dataset:arcee-ai/EvolKit-20k",
"dataset:cognitivecomputations/WizardLM_alpaca_evol_instruct_70k_unfiltered",
"base_model:theprint/ReWiz-7B",
"base_model:quantized:theprint/ReWiz-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-10-17T09:06:19Z | ---
base_model: theprint/ReWiz-7B
datasets:
- KingNish/reasoning-base-20k
- arcee-ai/EvolKit-20k
- cognitivecomputations/WizardLM_alpaca_evol_instruct_70k_unfiltered
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
- sft
- theprint
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/theprint/ReWiz-7B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/ReWiz-7B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-GGUF/resolve/main/ReWiz-7B.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-GGUF/resolve/main/ReWiz-7B.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-GGUF/resolve/main/ReWiz-7B.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-GGUF/resolve/main/ReWiz-7B.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-GGUF/resolve/main/ReWiz-7B.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-GGUF/resolve/main/ReWiz-7B.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-GGUF/resolve/main/ReWiz-7B.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-GGUF/resolve/main/ReWiz-7B.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-GGUF/resolve/main/ReWiz-7B.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-GGUF/resolve/main/ReWiz-7B.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-GGUF/resolve/main/ReWiz-7B.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/ReWiz-7B-GGUF/resolve/main/ReWiz-7B.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
sophiebui/test-translation | sophiebui | 2024-10-17T09:12:29Z | 6 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"m2m_100",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/m2m100_418M",
"base_model:finetune:facebook/m2m100_418M",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-10-15T07:48:38Z | ---
library_name: transformers
license: mit
base_model: facebook/m2m100_418M
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: test-translation
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test-translation
This model is a fine-tuned version of [facebook/m2m100_418M](https://huggingface.co/facebook/m2m100_418M) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3657
- Bleu: 32.2114
- Gen Len: 13.3333
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 1 | 1.4545 | 23.3073 | 14.0 |
| No log | 2.0 | 2 | 1.3870 | 32.2114 | 13.3333 |
| No log | 3.0 | 3 | 1.3657 | 32.2114 | 13.3333 |
### Framework versions
- Transformers 4.44.2
- Pytorch 2.4.1+cu121
- Datasets 3.0.1
- Tokenizers 0.19.1
|
YU310takuto/clap_emospeechtest_ver0.2 | YU310takuto | 2024-10-17T09:09:03Z | 9 | 0 | null | [
"safetensors",
"clap",
"region:us"
] | null | 2024-10-17T07:45:21Z | Hugging faceのモデルのファインチューニングのテスト。Ver0.2
使用したデータセットは、「声優統計コーパス:日本声優統計学会( https://voice-statistics.github.io/ )」を全て入れたものになります。
CLAPを学習する際の、音声に付随するキャプションは、「Japanese female actor's (感情) voice」で固定したところ、
ファインチューニングしたモデルを用いてクラス分類したときに["happy", "angry", "normal"]と["happy voice", "angry voice", "normal voice"]で結果が変わりました。
原因はまだ謎です。
また、先日アップしたVer0.1はそのうち削除します。
Hugging Faceやclapのモデルを使っている日本人の有識者がいれば、ぜひ色々教えていただきたいです。
---
Fine-tuning test of the hugging face model. Ver0.2
The dataset used was the entire "Voice Actor Statistical Corpus: Japan Voice Actor Statistical Association (https://voice-statistics.github.io/)".
When learning CLAP, the captions accompanying the voice were fixed to "Japanese female actor's (emotion) voice",
and when classifying using the fine-tuned model, the results changed between ["happy", "angry", "normal"] and ["happy voice", "angry voice", "normal voice"].
The cause is still a mystery.
Also, I will delete Ver0.1 that was uploaded the other day.
If there are experts who use Hugging Face, or "clap model", I would love to hear more about it.
---
base_model:
- laion/larger_clap_music_and_speech
tags:
- CLAP
--- |
akthangdz/fb-tts | akthangdz | 2024-10-17T09:07:34Z | 7 | 0 | null | [
"pytorch",
"safetensors",
"vits",
"mms",
"text-to-speech",
"arxiv:2305.13516",
"license:cc-by-nc-4.0",
"region:us"
] | text-to-speech | 2024-10-17T09:03:05Z |
---
license: cc-by-nc-4.0
tags:
- mms
- vits
pipeline_tag: text-to-speech
---
# Massively Multilingual Speech (MMS): Vietnamese Text-to-Speech
This repository contains the **Vietnamese (vie)** language text-to-speech (TTS) model checkpoint.
This model is part of Facebook's [Massively Multilingual Speech](https://arxiv.org/abs/2305.13516) project, aiming to
provide speech technology across a diverse range of languages. You can find more details about the supported languages
and their ISO 639-3 codes in the [MMS Language Coverage Overview](https://dl.fbaipublicfiles.com/mms/misc/language_coverage_mms.html),
and see all MMS-TTS checkpoints on the Hugging Face Hub: [facebook/mms-tts](https://huggingface.co/models?sort=trending&search=facebook%2Fmms-tts).
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards.
## Model Details
VITS (**V**ariational **I**nference with adversarial learning for end-to-end **T**ext-to-**S**peech) is an end-to-end
speech synthesis model that predicts a speech waveform conditional on an input text sequence. It is a conditional variational
autoencoder (VAE) comprised of a posterior encoder, decoder, and conditional prior.
A set of spectrogram-based acoustic features are predicted by the flow-based module, which is formed of a Transformer-based
text encoder and multiple coupling layers. The spectrogram is decoded using a stack of transposed convolutional layers,
much in the same style as the HiFi-GAN vocoder. Motivated by the one-to-many nature of the TTS problem, where the same text
input can be spoken in multiple ways, the model also includes a stochastic duration predictor, which allows the model to
synthesise speech with different rhythms from the same input text.
The model is trained end-to-end with a combination of losses derived from variational lower bound and adversarial training.
To improve the expressiveness of the model, normalizing flows are applied to the conditional prior distribution. During
inference, the text encodings are up-sampled based on the duration prediction module, and then mapped into the
waveform using a cascade of the flow module and HiFi-GAN decoder. Due to the stochastic nature of the duration predictor,
the model is non-deterministic, and thus requires a fixed seed to generate the same speech waveform.
For the MMS project, a separate VITS checkpoint is trained on each langauge.
## Usage
MMS-TTS is available in the 🤗 Transformers library from version 4.33 onwards. To use this checkpoint,
first install the latest version of the library:
```
pip install --upgrade transformers accelerate
```
Then, run inference with the following code-snippet:
```python
from transformers import VitsModel, AutoTokenizer
import torch
model = VitsModel.from_pretrained("facebook/mms-tts-vie")
tokenizer = AutoTokenizer.from_pretrained("facebook/mms-tts-vie")
text = "some example text in the Vietnamese language"
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
output = model(**inputs).waveform
```
The resulting waveform can be saved as a `.wav` file:
```python
import scipy
scipy.io.wavfile.write("techno.wav", rate=model.config.sampling_rate, data=output)
```
Or displayed in a Jupyter Notebook / Google Colab:
```python
from IPython.display import Audio
Audio(output, rate=model.config.sampling_rate)
```
## BibTex citation
This model was developed by Vineel Pratap et al. from Meta AI. If you use the model, consider citing the MMS paper:
```
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
```
## License
The model is licensed as **CC-BY-NC 4.0**.
|
jester6136/multilingual-e5-large-m2v | jester6136 | 2024-10-17T09:07:12Z | 106 | 0 | model2vec | [
"model2vec",
"safetensors",
"embeddings",
"static-embeddings",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"base_model:intfloat/multilingual-e5-large",
"base_model:finetune:intfloat/multilingual-e5-large",
"license:mit",
"region:us"
] | null | 2024-10-16T08:05:19Z | ---
base_model: intfloat/multilingual-e5-large
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
library_name: model2vec
license: mit
model_name: jester6136/multilingual-e5-large-m2v
tags:
- embeddings
- static-embeddings
---
# jester6136/multilingual-e5-large-m2v Model Card
This [Model2Vec](https://github.com/MinishLab/model2vec) model is a distilled version of the [intfloat/multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) Sentence Transformer. It uses static embeddings, allowing text embeddings to be computed orders of magnitude faster on both GPU and CPU. It is designed for applications where computational resources are limited or where real-time performance is critical.
## Installation
Install using pip:
```
pip install model2vec reach tqdm numpy
```
## Usage
```
import numpy as np
from model2vec import StaticModel
from reach import Reach
from tqdm import tqdm
import time
class TextDeduplicator:
def __init__(self, model_path: str):
# Load the pre-trained model
self.model = StaticModel.from_pretrained(model_path)
def encode_texts(self, texts: list[str]) -> np.ndarray:
# Prepare the texts and encode them into embeddings
texts = [f"query: {text}" for text in texts]
embedding_matrix = self.model.encode(texts, show_progressbar=True)
return embedding_matrix
def deduplicate(self, embedding_matrix: np.ndarray, threshold: float, batch_size: int = 1024
) -> tuple[np.ndarray, dict[int, list[int]]]:
# Deduplicate the texts based on their embeddings
reach = Reach(vectors=embedding_matrix, items=[str(i) for i in range(len(embedding_matrix))])
results = reach.nearest_neighbor_threshold(
embedding_matrix, threshold=threshold, batch_size=batch_size, show_progressbar=True
)
deduplicated_indices = set(range(len(embedding_matrix)))
duplicate_groups = {}
for i, similar_items in enumerate(tqdm(results)):
if i not in deduplicated_indices:
continue
similar_indices = [int(item[0]) for item in similar_items if int(item[0]) != i]
for sim_idx in similar_indices:
if sim_idx in deduplicated_indices:
deduplicated_indices.remove(sim_idx)
if i not in duplicate_groups:
duplicate_groups[i] = []
duplicate_groups[i].append(sim_idx)
return np.array(list(deduplicated_indices)), duplicate_groups
def deduplicate_texts(self, texts: list[str], threshold: float) -> tuple[np.ndarray, dict[int, list[int]]]:
# End-to-end deduplication process
embedding_matrix = self.encode_texts(texts)
return self.deduplicate(embedding_matrix, threshold)
if __name__ == "__main__":
# Example usage
texts = [
"Anh yêu em.",
"Mọi thứ ở công ty mới đều lạ lẫm, nhưng tôi cảm thấy rất sẵn sàng để bắt đầu hành trình mới.",
"Trận đấu bóng đá tối qua rất căng thẳng, hai đội liên tục tấn công và phòng thủ.",
"Một quan chức Fed muốn giảm bớt tốc độ hạ lãi suất",
"Ngày đầu tiên tại công ty mới đầy ấn tượng, tôi hy vọng sẽ nhanh chóng hòa nhập với môi trường làm việc.",
"Mùa hè này, cả gia đình sẽ có một chuyến đi đến Đà Nẵng, nơi mà chúng tôi đã mong chờ từ rất lâu.",
"Gia đình tôi đã lên kế hoạch cho kỳ nghỉ tại Đà Nẵng vào mùa hè này, một chuyến đi mà mọi người đều háo hức.",
"Fed có bước tiến mới để hạ lãi suất",
"Chúng tôi đã dự định từ lâu sẽ đi Đà Nẵng vào mùa hè này, và cả nhà đều rất trông đợi chuyến du lịch.",
"Ngày đầu đi làm thật là thú vị, tuy có chút hồi hộp nhưng tôi mong chờ những điều mới mẻ.",
"Mùa hè năm nay, gia đình tôi sẽ du lịch Đà Nẵng, chuyến đi mà ai cũng mong đợi từ trước."
]
deduplicator = TextDeduplicator("jester6136/multilingual-e5-large-m2v")
start_time = time.time()
deduplicated_indices, duplicate_groups = deduplicator.deduplicate_texts(texts, threshold=0.85)
end_time = time.time()
print(f"Deduplication completed in {end_time - start_time:.2f} seconds")
print(f"Deduped output: {deduplicated_indices}")
print(f"Group dup: {duplicate_groups}")
```
## How it works
Model2vec creates a small, fast, and powerful model that outperforms other static embedding models by a large margin on all tasks we could find, while being much faster to create than traditional static embedding models such as GloVe. Best of all, you don't need any data to distill a model using Model2Vec.
It works by passing a vocabulary through a sentence transformer model, then reducing the dimensionality of the resulting embeddings using PCA, and finally weighting the embeddings using zipf weighting. During inference, we simply take the mean of all token embeddings occurring in a sentence.
## Additional Resources
- [All Model2Vec models on the hub](https://huggingface.co/models?library=model2vec)
- [Model2Vec Repo](https://github.com/MinishLab/model2vec)
- [Model2Vec Results](https://github.com/MinishLab/model2vec?tab=readme-ov-file#results)
- [Model2Vec Tutorials](https://github.com/MinishLab/model2vec/tree/main/tutorials)
## Library Authors
Model2Vec was developed by the [Minish Lab](https://github.com/MinishLab) team consisting of [Stephan Tulkens](https://github.com/stephantul) and [Thomas van Dongen](https://github.com/Pringled).
## Citation
Please cite the [Model2Vec repository](https://github.com/MinishLab/model2vec) if you use this model in your work.
```
@software{minishlab2024model2vec,
authors = {Stephan Tulkens, Thomas van Dongen},
title = {Model2Vec: Turn any Sentence Transformer into a Small Fast Model},
year = {2024},
url = {https://github.com/MinishLab/model2vec},
}
``` |
RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf | RichardErkhov | 2024-10-17T09:05:19Z | 8 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-10-16T09:04:38Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Tess-v2.5-Qwen2-72B - GGUF
- Model creator: https://huggingface.co/migtissera/
- Original model: https://huggingface.co/migtissera/Tess-v2.5-Qwen2-72B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Tess-v2.5-Qwen2-72B.Q2_K.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/blob/main/Tess-v2.5-Qwen2-72B.Q2_K.gguf) | Q2_K | 27.76GB |
| [Tess-v2.5-Qwen2-72B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/blob/main/Tess-v2.5-Qwen2-72B.IQ3_XS.gguf) | IQ3_XS | 30.59GB |
| [Tess-v2.5-Qwen2-72B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/blob/main/Tess-v2.5-Qwen2-72B.IQ3_S.gguf) | IQ3_S | 32.12GB |
| [Tess-v2.5-Qwen2-72B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/blob/main/Tess-v2.5-Qwen2-72B.Q3_K_S.gguf) | Q3_K_S | 32.12GB |
| [Tess-v2.5-Qwen2-72B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/blob/main/Tess-v2.5-Qwen2-72B.IQ3_M.gguf) | IQ3_M | 33.07GB |
| [Tess-v2.5-Qwen2-72B.Q3_K.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/blob/main/Tess-v2.5-Qwen2-72B.Q3_K.gguf) | Q3_K | 35.11GB |
| [Tess-v2.5-Qwen2-72B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/blob/main/Tess-v2.5-Qwen2-72B.Q3_K_M.gguf) | Q3_K_M | 35.11GB |
| [Tess-v2.5-Qwen2-72B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/blob/main/Tess-v2.5-Qwen2-72B.Q3_K_L.gguf) | Q3_K_L | 36.79GB |
| [Tess-v2.5-Qwen2-72B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | IQ4_XS | 37.4GB |
| [Tess-v2.5-Qwen2-72B.Q4_0.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | Q4_0 | 38.4GB |
| [Tess-v2.5-Qwen2-72B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | IQ4_NL | 38.9GB |
| [Tess-v2.5-Qwen2-72B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | Q4_K_S | 40.88GB |
| [Tess-v2.5-Qwen2-72B.Q4_K.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | Q4_K | 44.16GB |
| [Tess-v2.5-Qwen2-72B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | Q4_K_M | 44.16GB |
| [Tess-v2.5-Qwen2-72B.Q4_1.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | Q4_1 | 42.56GB |
| [Tess-v2.5-Qwen2-72B.Q5_0.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | Q5_0 | 46.72GB |
| [Tess-v2.5-Qwen2-72B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | Q5_K_S | 47.85GB |
| [Tess-v2.5-Qwen2-72B.Q5_K.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | Q5_K | 50.71GB |
| [Tess-v2.5-Qwen2-72B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | Q5_K_M | 50.71GB |
| [Tess-v2.5-Qwen2-72B.Q5_1.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | Q5_1 | 50.88GB |
| [Tess-v2.5-Qwen2-72B.Q6_K.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | Q6_K | 59.93GB |
| [Tess-v2.5-Qwen2-72B.Q8_0.gguf](https://huggingface.co/RichardErkhov/migtissera_-_Tess-v2.5-Qwen2-72B-gguf/tree/main/) | Q8_0 | 71.96GB |
Original model description:
---
license: other
license_name: qwen2
license_link: https://huggingface.co/Qwen/Qwen2-72B/blob/main/LICENSE
---
# Tess-v2.5 (Qwen2-72B)

# Depracated - Please use [Tess-v2.5.2](https://huggingface.co/migtissera/Tess-v2.5.2-Qwen2-72B)
# Update:
I was testing a new feature with the Tess-v2.5 dataset. If you had used the model, you might have noticed that the model generations sometimes would end up with a follow-up question. This is intentional, and was created to provide more of a "natural" conversation.
What had happened earlier was that the stop token wasn't getting properly generated, so the model would go on to answer its own question.
I have fixed this now, and Tess-v2.5.2 is available on HF here: [Tess-v2.5.2 Model](https://huggingface.co/migtissera/Tess-v2.5.2-Qwen2-72B/tree/main)
Tess-v2.5.2 model would still ask you follow-up questions, but the stop tokens are getting properly generated. If you'd like to not have the follow-up questions feature, just add the following to your system prompt: "No follow-up questions necessary".
Thanks!
# Tess-v2.5 (Qwen2-72B)
We've created Tess-v2.5, the latest state-of-the-art model in the Tess series of Large Language Models (LLMs). Tess, short for Tesoro (<em>Treasure</em> in Italian), is the flagship LLM series created by Migel Tissera. Tess-v2.5 brings significant improvements in reasoning capabilities, coding capabilities and mathematics. It is currently the #1 ranked open weight model when evaluated on MMLU (Massive Multitask Language Understanding). It scores higher than all other open weight models including Qwen2-72B-Instruct, Llama3-70B-Instruct, Mixtral-8x22B-Instruct and DBRX-Instruct. Further, when evaluated on MMLU, Tess-v2.5 (Qwen2-72B) model outperforms even the frontier closed models Gemini-1.0-Ultra, Gemini-1.5-Pro, Mistral-Large and Claude-3-Sonnet.
Tess-v2.5 (Qwen2-72B) was fine-tuned over the newly released Qwen2-72B base, using the Tess-v2.5 dataset that contain 300K samples spanning multiple topics, including business and management, marketing, history, social sciences, arts, STEM subjects and computer programming. This dataset was synthetically generated using the [Sensei](https://github.com/migtissera/Sensei) framework, using multiple frontier models such as GPT-4-Turbo, Claude-Opus and Mistral-Large.
The compute for this model was generously sponsored by [KindoAI](https://kindo.ai).
When evaluated on a subset of AGIEval (Nous), this model compares very well with the godfather GPT-4-0314 model as well.
# Training Process
Tess-v2.5 model was initiated with the base weights of Qwen2-72B. It was then fine-tuned with the Tess-v2.5 dataset, using Axolotl as the training framework. Most of Tess models follow a common fine-tuning methodology: low learning rates, low number of epochs, and uses very high quality and diverse data. This model was fine-tuned on a 4xA100 VM on Microsoft Azure for 4 days. The model has not been aligned with RLHF or DPO.
The author believes that model's capabilities seem to come primariliy from the pre-training process. This is the foundation for every fine-tune of Tess models, and preserving the entropy of the base models is of paramount to the author.
# Evaluation Results
Tess-v2.5 model is an overall well balanced model. All evals pertaining to this model can be accessed in the [Evals](https://huggingface.co/migtissera/Tess-v2.5-Qwen2-72B/tree/main/Evals) folder.
Complete evaluation comparison tables can be accessed here: [Google Spreadsheet](https://docs.google.com/spreadsheets/d/1k0BIKux_DpuoTPwFCTMBzczw17kbpxofigHF_0w2LGw/edit?usp=sharing)
## MMLU (Massive Multitask Language Understanding)
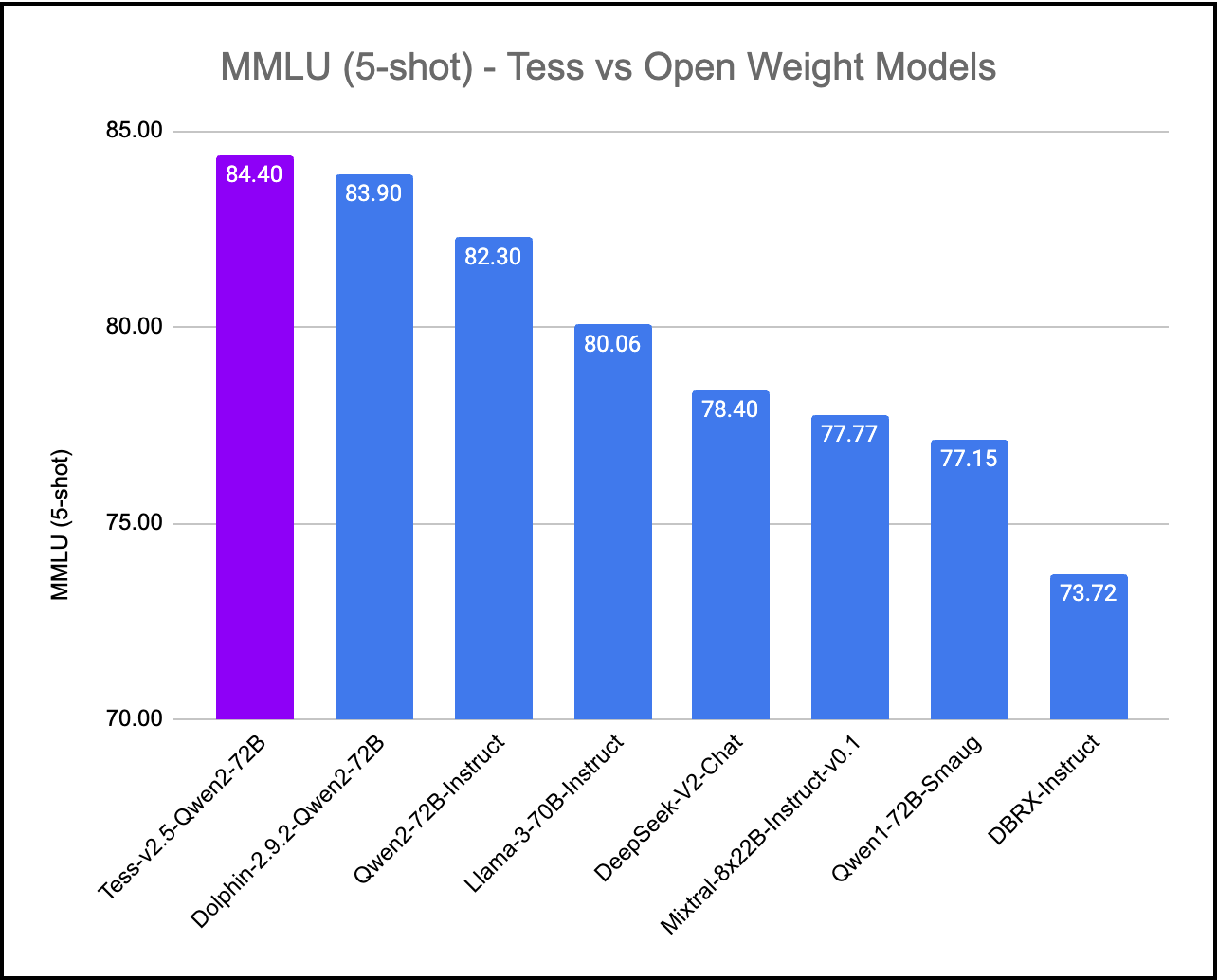
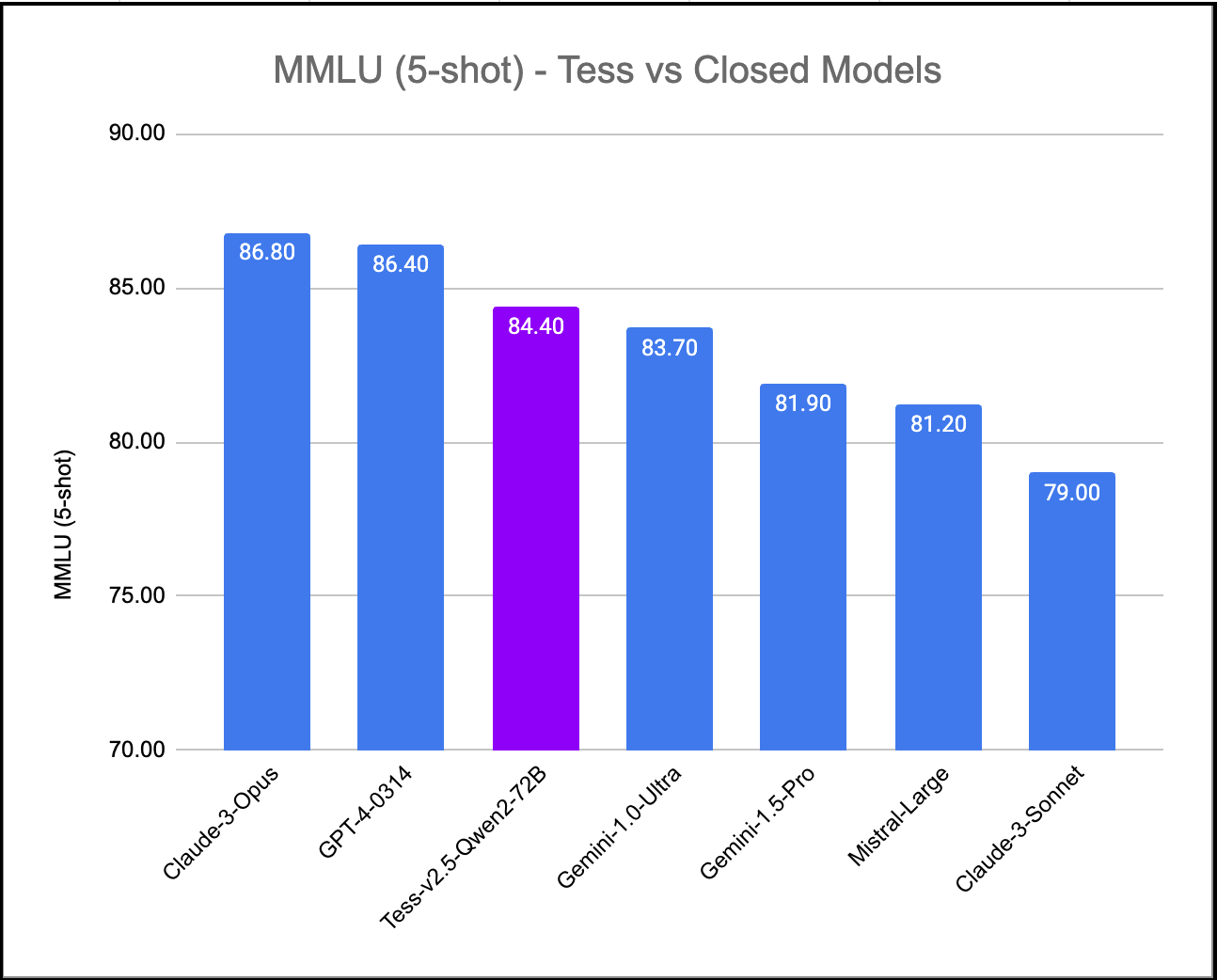
## AGIEval
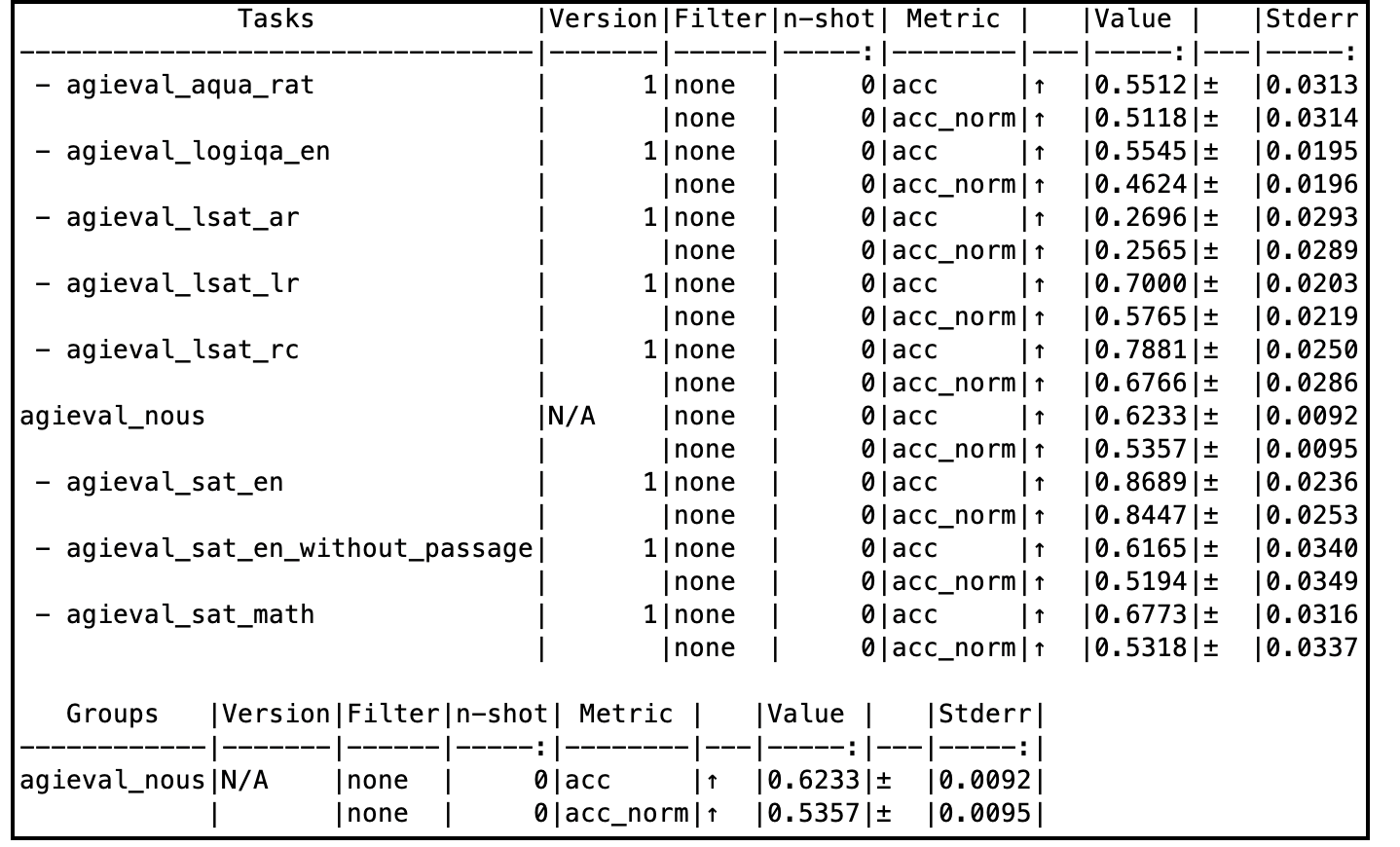
# Sample code to run inference
Note that this model uses ChatML prompt format.
```python
import torch, json
from transformers import AutoModelForCausalLM, AutoTokenizer
from stop_word import StopWordCriteria
model_path = "migtissera/Tess-v2.5-Qwen2-72B"
output_file_path = "/home/migel/conversations.jsonl"
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
load_in_4bit=False,
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
terminators = [
tokenizer.convert_tokens_to_ids("<|im_end|>")
]
def generate_text(instruction):
tokens = tokenizer.encode(instruction)
tokens = torch.LongTensor(tokens).unsqueeze(0)
tokens = tokens.to("cuda")
instance = {
"input_ids": tokens,
"top_p": 1.0,
"temperature": 0.75,
"generate_len": 1024,
"top_k": 50,
}
length = len(tokens[0])
with torch.no_grad():
rest = model.generate(
input_ids=tokens,
max_length=length + instance["generate_len"],
use_cache=True,
do_sample=True,
top_p=instance["top_p"],
temperature=instance["temperature"],
top_k=instance["top_k"],
num_return_sequences=1,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=terminators,
)
output = rest[0][length:]
string = tokenizer.decode(output, skip_special_tokens=True)
return f"{string}"
conversation = f"""<|im_start|>system\nYou are Tesoro, a helful AI assitant. You always provide detailed answers without hesitation.<|im_end|>\n<|im_start|>user\n"""
while True:
user_input = input("You: ")
llm_prompt = f"{conversation}{user_input}<|im_end|>\n<|im_start|>assistant\n"
answer = generate_text(llm_prompt)
print(answer)
conversation = f"{llm_prompt}{answer}\n"
json_data = {"prompt": user_input, "answer": answer}
with open(output_file_path, "a") as output_file:
output_file.write(json.dumps(json_data) + "\n")
```
# Join My General AI Discord (NeuroLattice):
https://discord.gg/Hz6GrwGFKD
# Limitations & Biases:
While this model aims for accuracy, it can occasionally produce inaccurate or misleading results.
Despite diligent efforts in refining the pretraining data, there remains a possibility for the generation of inappropriate, biased, or offensive content.
Exercise caution and cross-check information when necessary. This is an uncensored model.
|
RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf | RichardErkhov | 2024-10-17T09:03:10Z | 702 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-10-17T08:56:51Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen-uncensored-v2 - GGUF
- Model creator: https://huggingface.co/Xennon-BD/
- Original model: https://huggingface.co/Xennon-BD/Qwen-uncensored-v2/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Qwen-uncensored-v2.Q2_K.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q2_K.gguf) | Q2_K | 0.32GB |
| [Qwen-uncensored-v2.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.IQ3_XS.gguf) | IQ3_XS | 0.32GB |
| [Qwen-uncensored-v2.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.IQ3_S.gguf) | IQ3_S | 0.32GB |
| [Qwen-uncensored-v2.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q3_K_S.gguf) | Q3_K_S | 0.32GB |
| [Qwen-uncensored-v2.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.IQ3_M.gguf) | IQ3_M | 0.32GB |
| [Qwen-uncensored-v2.Q3_K.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q3_K.gguf) | Q3_K | 0.33GB |
| [Qwen-uncensored-v2.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q3_K_M.gguf) | Q3_K_M | 0.33GB |
| [Qwen-uncensored-v2.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q3_K_L.gguf) | Q3_K_L | 0.34GB |
| [Qwen-uncensored-v2.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.IQ4_XS.gguf) | IQ4_XS | 0.33GB |
| [Qwen-uncensored-v2.Q4_0.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q4_0.gguf) | Q4_0 | 0.33GB |
| [Qwen-uncensored-v2.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.IQ4_NL.gguf) | IQ4_NL | 0.33GB |
| [Qwen-uncensored-v2.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q4_K_S.gguf) | Q4_K_S | 0.36GB |
| [Qwen-uncensored-v2.Q4_K.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q4_K.gguf) | Q4_K | 0.37GB |
| [Qwen-uncensored-v2.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q4_K_M.gguf) | Q4_K_M | 0.37GB |
| [Qwen-uncensored-v2.Q4_1.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q4_1.gguf) | Q4_1 | 0.35GB |
| [Qwen-uncensored-v2.Q5_0.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q5_0.gguf) | Q5_0 | 0.37GB |
| [Qwen-uncensored-v2.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q5_K_S.gguf) | Q5_K_S | 0.38GB |
| [Qwen-uncensored-v2.Q5_K.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q5_K.gguf) | Q5_K | 0.39GB |
| [Qwen-uncensored-v2.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q5_K_M.gguf) | Q5_K_M | 0.39GB |
| [Qwen-uncensored-v2.Q5_1.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q5_1.gguf) | Q5_1 | 0.39GB |
| [Qwen-uncensored-v2.Q6_K.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q6_K.gguf) | Q6_K | 0.47GB |
| [Qwen-uncensored-v2.Q8_0.gguf](https://huggingface.co/RichardErkhov/Xennon-BD_-_Qwen-uncensored-v2-gguf/blob/main/Qwen-uncensored-v2.Q8_0.gguf) | Q8_0 | 0.49GB |
Original model description:
---
base_model: unsloth/Qwen2-0.5b-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
- sft
---
# Uploaded model
- **Developed by:** ar08
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2-0.5b-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mradermacher/vinallama-7b-history-GGUF | mradermacher | 2024-10-17T09:02:06Z | 56 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:tuanpasg/vinallama-7b-history",
"base_model:quantized:tuanpasg/vinallama-7b-history",
"endpoints_compatible",
"region:us"
] | null | 2024-10-17T08:47:09Z | ---
base_model: tuanpasg/vinallama-7b-history
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/tuanpasg/vinallama-7b-history
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/vinallama-7b-history-GGUF/resolve/main/vinallama-7b-history.Q2_K.gguf) | Q2_K | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/vinallama-7b-history-GGUF/resolve/main/vinallama-7b-history.Q3_K_S.gguf) | Q3_K_S | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/vinallama-7b-history-GGUF/resolve/main/vinallama-7b-history.Q3_K_M.gguf) | Q3_K_M | 3.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/vinallama-7b-history-GGUF/resolve/main/vinallama-7b-history.Q3_K_L.gguf) | Q3_K_L | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/vinallama-7b-history-GGUF/resolve/main/vinallama-7b-history.IQ4_XS.gguf) | IQ4_XS | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/vinallama-7b-history-GGUF/resolve/main/vinallama-7b-history.Q4_K_S.gguf) | Q4_K_S | 4.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/vinallama-7b-history-GGUF/resolve/main/vinallama-7b-history.Q4_K_M.gguf) | Q4_K_M | 4.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/vinallama-7b-history-GGUF/resolve/main/vinallama-7b-history.Q5_K_S.gguf) | Q5_K_S | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/vinallama-7b-history-GGUF/resolve/main/vinallama-7b-history.Q5_K_M.gguf) | Q5_K_M | 5.0 | |
| [GGUF](https://huggingface.co/mradermacher/vinallama-7b-history-GGUF/resolve/main/vinallama-7b-history.Q6_K.gguf) | Q6_K | 5.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/vinallama-7b-history-GGUF/resolve/main/vinallama-7b-history.Q8_0.gguf) | Q8_0 | 7.4 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/vinallama-7b-history-GGUF/resolve/main/vinallama-7b-history.f16.gguf) | f16 | 13.8 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf | RichardErkhov | 2024-10-17T09:01:07Z | 5 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-10-16T12:30:58Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3-Lumimaid-70B-v0.1 - GGUF
- Model creator: https://huggingface.co/NeverSleep/
- Original model: https://huggingface.co/NeverSleep/Llama-3-Lumimaid-70B-v0.1/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3-Lumimaid-70B-v0.1.Q2_K.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/blob/main/Llama-3-Lumimaid-70B-v0.1.Q2_K.gguf) | Q2_K | 24.56GB |
| [Llama-3-Lumimaid-70B-v0.1.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/blob/main/Llama-3-Lumimaid-70B-v0.1.IQ3_XS.gguf) | IQ3_XS | 27.29GB |
| [Llama-3-Lumimaid-70B-v0.1.IQ3_S.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/blob/main/Llama-3-Lumimaid-70B-v0.1.IQ3_S.gguf) | IQ3_S | 28.79GB |
| [Llama-3-Lumimaid-70B-v0.1.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/blob/main/Llama-3-Lumimaid-70B-v0.1.Q3_K_S.gguf) | Q3_K_S | 28.79GB |
| [Llama-3-Lumimaid-70B-v0.1.IQ3_M.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/blob/main/Llama-3-Lumimaid-70B-v0.1.IQ3_M.gguf) | IQ3_M | 29.74GB |
| [Llama-3-Lumimaid-70B-v0.1.Q3_K.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/blob/main/Llama-3-Lumimaid-70B-v0.1.Q3_K.gguf) | Q3_K | 31.91GB |
| [Llama-3-Lumimaid-70B-v0.1.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/blob/main/Llama-3-Lumimaid-70B-v0.1.Q3_K_M.gguf) | Q3_K_M | 31.91GB |
| [Llama-3-Lumimaid-70B-v0.1.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/blob/main/Llama-3-Lumimaid-70B-v0.1.Q3_K_L.gguf) | Q3_K_L | 34.59GB |
| [Llama-3-Lumimaid-70B-v0.1.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/blob/main/Llama-3-Lumimaid-70B-v0.1.IQ4_XS.gguf) | IQ4_XS | 35.64GB |
| [Llama-3-Lumimaid-70B-v0.1.Q4_0.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/blob/main/Llama-3-Lumimaid-70B-v0.1.Q4_0.gguf) | Q4_0 | 37.22GB |
| [Llama-3-Lumimaid-70B-v0.1.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/tree/main/) | IQ4_NL | 37.58GB |
| [Llama-3-Lumimaid-70B-v0.1.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/tree/main/) | Q4_K_S | 37.58GB |
| [Llama-3-Lumimaid-70B-v0.1.Q4_K.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/tree/main/) | Q4_K | 39.6GB |
| [Llama-3-Lumimaid-70B-v0.1.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/tree/main/) | Q4_K_M | 39.6GB |
| [Llama-3-Lumimaid-70B-v0.1.Q4_1.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/tree/main/) | Q4_1 | 41.27GB |
| [Llama-3-Lumimaid-70B-v0.1.Q5_0.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/tree/main/) | Q5_0 | 45.32GB |
| [Llama-3-Lumimaid-70B-v0.1.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/tree/main/) | Q5_K_S | 45.32GB |
| [Llama-3-Lumimaid-70B-v0.1.Q5_K.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/tree/main/) | Q5_K | 46.52GB |
| [Llama-3-Lumimaid-70B-v0.1.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/tree/main/) | Q5_K_M | 46.52GB |
| [Llama-3-Lumimaid-70B-v0.1.Q5_1.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/tree/main/) | Q5_1 | 49.36GB |
| [Llama-3-Lumimaid-70B-v0.1.Q6_K.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/tree/main/) | Q6_K | 53.91GB |
| [Llama-3-Lumimaid-70B-v0.1.Q8_0.gguf](https://huggingface.co/RichardErkhov/NeverSleep_-_Llama-3-Lumimaid-70B-v0.1-gguf/tree/main/) | Q8_0 | 69.83GB |
Original model description:
---
license: cc-by-nc-4.0
tags:
- not-for-all-audiences
- nsfw
---
## Lumimaid 0.1
<center><div style="width: 100%;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/630dfb008df86f1e5becadc3/d3QMaxy3peFTpSlWdWF-k.png" style="display: block; margin: auto;">
</div></center>
This model uses the Llama3 **prompting format**
Llama3 trained on our RP datasets, we tried to have a balance between the ERP and the RP, not too horny, but just enough.
We also added some non-RP dataset, making the model less dumb overall. It should look like a 40%/60% ratio for Non-RP/RP+ERP data.
This model includes the new Luminae dataset from Ikari.
If you consider trying this model please give us some feedback either on the Community tab on hf or on our [Discord Server](https://discord.gg/MtCVRWTZXY).
## Credits:
- Undi
- IkariDev
## Description
This repo contains FP16 files of Lumimaid-70B-v0.1.
Switch: [8B](https://huggingface.co/NeverSleep/Llama-3-Lumimaid-8B-v0.1) - [70B](https://huggingface.co/NeverSleep/Llama-3-Lumimaid-70B-v0.1) - [70B-alt](https://huggingface.co/NeverSleep/Llama-3-Lumimaid-70B-v0.1-alt) - [8B-OAS](https://huggingface.co/NeverSleep/Llama-3-Lumimaid-8B-v0.1-OAS) - [70B-OAS](https://huggingface.co/NeverSleep/Llama-3-Lumimaid-70B-v0.1-OAS)
## Training data used:
- [Aesir datasets](https://huggingface.co/MinervaAI)
- [NoRobots](https://huggingface.co/datasets/Doctor-Shotgun/no-robots-sharegpt)
- [limarp](https://huggingface.co/datasets/lemonilia/LimaRP) - 8k ctx
- [toxic-dpo-v0.1-sharegpt](https://huggingface.co/datasets/Undi95/toxic-dpo-v0.1-sharegpt)
- [ToxicQAFinal](https://huggingface.co/datasets/NobodyExistsOnTheInternet/ToxicQAFinal)
- Luminae-i1 (70B/70B-alt) (i2 was not existing when the 70b started training) | Luminae-i2 (8B) (this one gave better results on the 8b) - Ikari's Dataset
- [Squish42/bluemoon-fandom-1-1-rp-cleaned](https://huggingface.co/datasets/Squish42/bluemoon-fandom-1-1-rp-cleaned) - 50% (randomly)
- [NobodyExistsOnTheInternet/PIPPAsharegptv2test](https://huggingface.co/datasets/NobodyExistsOnTheInternet/PIPPAsharegptv2test) - 5% (randomly)
- [cgato/SlimOrcaDedupCleaned](https://huggingface.co/datasets/cgato/SlimOrcaDedupCleaned) - 5% (randomly)
- Airoboros (reduced)
- [Capybara](https://huggingface.co/datasets/Undi95/Capybara-ShareGPT/) (reduced)
## Models used (only for 8B)
- Initial LumiMaid 8B Finetune
- Undi95/Llama-3-Unholy-8B-e4
- Undi95/Llama-3-LewdPlay-8B
## Prompt template: Llama3
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
```
## Others
Undi: If you want to support us, you can [here](https://ko-fi.com/undiai).
IkariDev: Visit my [retro/neocities style website](https://ikaridevgit.github.io/) please kek
|
mradermacher/Qwen2.5-Coder-1.5B-CodeFIM-GGUF | mradermacher | 2024-10-17T08:49:08Z | 420 | 2 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Etherll/Qwen2.5-Coder-1.5B-CodeFIM",
"base_model:quantized:Etherll/Qwen2.5-Coder-1.5B-CodeFIM",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-10-17T08:45:37Z | ---
base_model: Etherll/Qwen2.5-Coder-1.5B-CodeFIM
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Etherll/Qwen2.5-Coder-1.5B-CodeFIM
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-Coder-1.5B-CodeFIM-GGUF/resolve/main/Qwen2.5-Coder-1.5B-CodeFIM.Q2_K.gguf) | Q2_K | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-Coder-1.5B-CodeFIM-GGUF/resolve/main/Qwen2.5-Coder-1.5B-CodeFIM.Q3_K_S.gguf) | Q3_K_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-Coder-1.5B-CodeFIM-GGUF/resolve/main/Qwen2.5-Coder-1.5B-CodeFIM.Q3_K_M.gguf) | Q3_K_M | 0.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-Coder-1.5B-CodeFIM-GGUF/resolve/main/Qwen2.5-Coder-1.5B-CodeFIM.Q3_K_L.gguf) | Q3_K_L | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-Coder-1.5B-CodeFIM-GGUF/resolve/main/Qwen2.5-Coder-1.5B-CodeFIM.IQ4_XS.gguf) | IQ4_XS | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-Coder-1.5B-CodeFIM-GGUF/resolve/main/Qwen2.5-Coder-1.5B-CodeFIM.Q4_K_S.gguf) | Q4_K_S | 1.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-Coder-1.5B-CodeFIM-GGUF/resolve/main/Qwen2.5-Coder-1.5B-CodeFIM.Q4_K_M.gguf) | Q4_K_M | 1.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-Coder-1.5B-CodeFIM-GGUF/resolve/main/Qwen2.5-Coder-1.5B-CodeFIM.Q5_K_S.gguf) | Q5_K_S | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-Coder-1.5B-CodeFIM-GGUF/resolve/main/Qwen2.5-Coder-1.5B-CodeFIM.Q5_K_M.gguf) | Q5_K_M | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-Coder-1.5B-CodeFIM-GGUF/resolve/main/Qwen2.5-Coder-1.5B-CodeFIM.Q6_K.gguf) | Q6_K | 1.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-Coder-1.5B-CodeFIM-GGUF/resolve/main/Qwen2.5-Coder-1.5B-CodeFIM.Q8_0.gguf) | Q8_0 | 1.7 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-Coder-1.5B-CodeFIM-GGUF/resolve/main/Qwen2.5-Coder-1.5B-CodeFIM.f16.gguf) | f16 | 3.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
puppyM/bge-reranker-v2-m3-Q4_K_M-GGUF | puppyM | 2024-10-17T08:47:26Z | 78 | 0 | sentence-transformers | [
"sentence-transformers",
"gguf",
"transformers",
"text-embeddings-inference",
"llama-cpp",
"gguf-my-repo",
"text-classification",
"multilingual",
"base_model:BAAI/bge-reranker-v2-m3",
"base_model:quantized:BAAI/bge-reranker-v2-m3",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"feature-extraction"
] | text-classification | 2024-10-17T08:47:21Z | ---
base_model: BAAI/bge-reranker-v2-m3
language:
- multilingual
license: apache-2.0
pipeline_tag: text-classification
tags:
- transformers
- sentence-transformers
- text-embeddings-inference
- llama-cpp
- gguf-my-repo
---
# puppyM/bge-reranker-v2-m3-Q4_K_M-GGUF
This model was converted to GGUF format from [`BAAI/bge-reranker-v2-m3`](https://huggingface.co/BAAI/bge-reranker-v2-m3) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/BAAI/bge-reranker-v2-m3) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo puppyM/bge-reranker-v2-m3-Q4_K_M-GGUF --hf-file bge-reranker-v2-m3-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo puppyM/bge-reranker-v2-m3-Q4_K_M-GGUF --hf-file bge-reranker-v2-m3-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo puppyM/bge-reranker-v2-m3-Q4_K_M-GGUF --hf-file bge-reranker-v2-m3-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo puppyM/bge-reranker-v2-m3-Q4_K_M-GGUF --hf-file bge-reranker-v2-m3-q4_k_m.gguf -c 2048
```
|
minchyeom/letta | minchyeom | 2024-10-17T08:41:04Z | 5 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"en",
"base_model:mistralai/Mistral-Small-Instruct-2409",
"base_model:finetune:mistralai/Mistral-Small-Instruct-2409",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T08:09:29Z | ---
library_name: transformers
language:
- en
base_model:
- mistralai/Mistral-Small-Instruct-2409
---
For [letta](https://www.letta.com). Uses ChatML chat template and has 32k context window. |
hugging-quants/gemma-2-9b-it-AWQ-INT4 | hugging-quants | 2024-10-17T08:31:37Z | 1,287 | 6 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"google",
"autoawq",
"conversational",
"en",
"base_model:google/gemma-2-9b-it",
"base_model:quantized:google/gemma-2-9b-it",
"license:gemma",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"awq",
"region:us"
] | text-generation | 2024-10-15T15:17:54Z | ---
base_model: google/gemma-2-9b-it
license: gemma
language:
- en
library_name: transformers
pipeline_tag: text-generation
tags:
- gemma2
- google
- autoawq
---
> [!IMPORTANT]
> This repository is a community-driven quantized version of the original model [`google/gemma-2-9b-it`](https://huggingface.co/google/gemma-2-9b-it) which is the BF16 half-precision official version released by Google.
> [!WARNING]
> This model has been quantized using `transformers` 4.45.0, meaning that the tokenizer available in this repository won't be compatible with lower versions. Same applies for e.g. Text Generation Inference (TGI) that only installs `transformers` 4.45.0 or higher starting in v2.3.1.
## Model Information
Gemma is a family of lightweight, state-of-the-art open models from Google, built from the same research and technology used to create the Gemini models. They are text-to-text, decoder-only large language models, available in English, with open weights for both pre-trained variants and instruction-tuned variants. Gemma models are well-suited for a variety of text generation tasks, including question answering, summarization, and reasoning. Their relatively small size makes it possible to deploy them in environments with limited resources such as a laptop, desktop or your own cloud infrastructure, democratizing access to state of the art AI models and helping foster innovation for everyone.
This repository contains [`google/gemma-2-9b-it`](https://huggingface.co/google/gemma-2-9b-it) quantized using [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) from FP16 down to INT4 using the GEMM kernels performing zero-point quantization with a group size of 128.
## Model Usage
> [!NOTE]
> In order to run the inference with Gemma2 9B Instruct AWQ in INT4, around 6 GiB of VRAM are needed only for loading the model checkpoint, without including the KV cache or the CUDA graphs, meaning that there should be a bit over that VRAM available.
In order to use the current quantized model, support is offered for different solutions as `transformers`, `autoawq`, or `text-generation-inference`.
### 🤗 Transformers
In order to run the inference with Gemma2 9B Instruct AWQ in INT4, you need to install the following packages:
```bash
pip install -q --upgrade "transformers>=4.45.0" accelerate
INSTALL_KERNELS=1 pip install -q git+https://github.com/casper-hansen/AutoAWQ.git@79547665bdb27768a9b392ef375776b020acbf0c
```
To run the inference on top of Gemma2 9B Instruct AWQ in INT4 precision, the AWQ model can be instantiated as any other causal language modeling model via `AutoModelForCausalLM` and run the inference normally.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, AwqConfig
model_id = "hugging-quants/gemma-2-9b-it-AWQ-INT4"
quantization_config = AwqConfig(
bits=4,
fuse_max_seq_len=512, # Note: Update this as per your use-case
do_fuse=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto",
quantization_config=quantization_config
)
prompt = [
{"role": "user", "content": "What's Deep Learning?"},
]
inputs = tokenizer.apply_chat_template(
prompt,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to("cuda")
outputs = model.generate(**inputs, do_sample=True, max_new_tokens=256)
print(tokenizer.batch_decode(outputs[:, inputs['input_ids'].shape[1]:], skip_special_tokens=True)[0])
```
### AutoAWQ
In order to run the inference with Gemma2 9B Instruct AWQ in INT4, you need to install the following packages:
```bash
pip install -q --upgrade "transformers>=4.45.0" accelerate
INSTALL_KERNELS=1 pip install -q git+https://github.com/casper-hansen/AutoAWQ.git@79547665bdb27768a9b392ef375776b020acbf0c
```
Alternatively, one may want to run that via `AutoAWQ` even though it's built on top of 🤗 `transformers`, which is the recommended approach instead as described above.
```python
import torch
from awq import AutoAWQForCausalLM
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "hugging-quants/gemma-2-9b-it-AWQ-INT4"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoAWQForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto",
)
prompt = [
{"role": "user", "content": "What's Deep Learning?"},
]
inputs = tokenizer.apply_chat_template(
prompt,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to("cuda")
outputs = model.generate(**inputs, do_sample=True, max_new_tokens=256)
print(tokenizer.batch_decode(outputs[:, inputs['input_ids'].shape[1]:], skip_special_tokens=True)[0])
```
The AutoAWQ script has been adapted from [`AutoAWQ/examples/generate.py`](https://github.com/casper-hansen/AutoAWQ/blob/main/examples/generate.py).
### 🤗 Text Generation Inference (TGI)
To run the `text-generation-launcher` with Gemma2 9B Instruct AWQ in INT4 with Marlin kernels for optimized inference speed, you will need to have Docker installed (see [installation notes](https://docs.docker.com/engine/install/)).
Then you just need to run the TGI v2.3.0 (or higher) Docker container as follows:
```bash
docker run --gpus all --shm-size 1g -ti -p 8080:80 \
-v hf_cache:/data \
-e MODEL_ID=hugging-quants/gemma-2-9b-it-AWQ-INT4 \
-e QUANTIZE=awq \
-e MAX_INPUT_LENGTH=4000 \
-e MAX_TOTAL_TOKENS=4096 \
ghcr.io/huggingface/text-generation-inference:2.3.0
```
> [!NOTE]
> TGI will expose different endpoints, to see all the endpoints available check [TGI OpenAPI Specification](https://huggingface.github.io/text-generation-inference/#/).
To send request to the deployed TGI endpoint compatible with [OpenAI OpenAPI specification](https://github.com/openai/openai-openapi) i.e. `/v1/chat/completions`:
```bash
curl 0.0.0.0:8080/v1/chat/completions \
-X POST \
-H 'Content-Type: application/json' \
-d '{
"model": "tgi",
"messages": [
{
"role": "user",
"content": "What is Deep Learning?"
}
],
"max_tokens": 128
}'
```
Or programatically via the `huggingface_hub` Python client as follows:
```python
import os
from huggingface_hub import InferenceClient
client = InferenceClient(base_url="http://0.0.0.0:8080", api_key="-")
chat_completion = client.chat.completions.create(
model="hugging-quants/gemma-2-9b-it-AWQ-INT4",
messages=[
{"role": "user", "content": "What is Deep Learning?"},
],
max_tokens=128,
)
```
Alternatively, the OpenAI Python client can also be used (see [installation notes](https://github.com/openai/openai-python?tab=readme-ov-file#installation)) as follows:
```python
import os
from openai import OpenAI
client = OpenAI(base_url="http://0.0.0.0:8080/v1", api_key="-")
chat_completion = client.chat.completions.create(
model="tgi",
messages=[
{"role": "user", "content": "What is Deep Learning?"},
],
max_tokens=128,
)
```
### vLLM
To run vLLM with Gemma2 9B Instruct AWQ in INT4, you will need to have Docker installed (see [installation notes](https://docs.docker.com/engine/install/)) and run the latest vLLM Docker container as follows:
```bash
docker run --runtime nvidia --gpus all --ipc=host -p 8000:8000 \
-v hf_cache:/root/.cache/huggingface \
vllm/vllm-openai:latest \
--model hugging-quants/gemma-2-9b-it-AWQ-INT4 \
--max-model-len 4096
```
To send request to the deployed vLLM endpoint compatible with [OpenAI OpenAPI specification](https://github.com/openai/openai-openapi) i.e. `/v1/chat/completions`:
```bash
curl 0.0.0.0:8000/v1/chat/completions \
-X POST \
-H 'Content-Type: application/json' \
-d '{
"model": "hugging-quants/gemma-2-9b-it-AWQ-INT4",
"messages": [
{
"role": "user",
"content": "What is Deep Learning?"
}
],
"max_tokens": 128
}'
```
Or programatically via the `openai` Python client (see [installation notes](https://github.com/openai/openai-python?tab=readme-ov-file#installation)) as follows:
```python
import os
from openai import OpenAI
client = OpenAI(base_url="http://0.0.0.0:8000/v1", api_key=os.getenv("VLLM_API_KEY", "-"))
chat_completion = client.chat.completions.create(
model="hugging-quants/gemma-2-9b-it-AWQ-INT4",
messages=[
{"role": "user", "content": "What is Deep Learning?"},
],
max_tokens=128,
)
```
## Quantization Reproduction
> [!IMPORTANT]
> In order to quantize Gemma2 9B Instruct using AutoAWQ, you will need to use an instance with at least enough CPU RAM to fit the whole model i.e. ~20GiB, and an NVIDIA GPU with 16GiB of VRAM to quantize it.
>
> Additionally, you also need to accept the Gemma2 access conditions, as it is a gated model that requires accepting those first.
In order to quantize Gemma2 9B Instruct, first install the following packages:
```bash
pip install -q --upgrade "torch==2.3.0" "transformers>=4.45.0" accelerate
INSTALL_KERNELS=1 pip install -q git+https://github.com/casper-hansen/AutoAWQ.git@79547665bdb27768a9b392ef375776b020acbf0c
```
Then you need to install the `huggingface_hub` Python SDK and login to the Hugging Face Hub.
```bash
pip install -q --upgrade huggingface_hub
huggingface-cli login
```
Then run the following script, adapted from [`AutoAWQ/examples/quantize.py`](https://github.com/casper-hansen/AutoAWQ/blob/main/examples/quantize.py):
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_path = "google/gemma-2-9b-it"
quant_path = "hugging-quants/gemma-2-9b-it-AWQ-INT4"
quant_config = {
"zero_point": True,
"q_group_size": 128,
"w_bit": 4,
"version": "GEMM",
}
# Load model
model = AutoAWQForCausalLM.from_pretrained(
model_path, low_cpu_mem_usage=True, use_cache=False,
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# Quantize
model.quantize(tokenizer, quant_config=quant_config)
# Save quantized model
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path)
print(f'Model is quantized and saved at "{quant_path}"')
``` |
rombodawg/Rombos-LLM-V2.6-Nemotron-70b | rombodawg | 2024-10-17T08:30:02Z | 2,903 | 3 | null | [
"safetensors",
"llama",
"license:llama3.1",
"region:us"
] | null | 2024-10-17T05:07:47Z | ---
license: llama3.1
---
# Rombos-LLM-V2.6-Nemotron-70b

I applied the last step of my continuous finetuning method to the Nemotron-70b model from Nvidia. More details bellow:
- https://docs.google.com/document/d/1OjbjU5AOz4Ftn9xHQrX3oFQGhQ6RDUuXQipnQ9gn6tU/edit?usp=sharing
Quants: (Coming Soon)
Open-LLM-Leaderboard scores: (Coming soon) |
mradermacher/Gemma-2-Ataraxy-v4b-9B-GGUF | mradermacher | 2024-10-17T08:16:11Z | 33 | 2 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:lemon07r/Gemma-2-Ataraxy-v4b-9B",
"base_model:quantized:lemon07r/Gemma-2-Ataraxy-v4b-9B",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-10-16T21:33:38Z | ---
base_model: lemon07r/Gemma-2-Ataraxy-v4b-9B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/lemon07r/Gemma-2-Ataraxy-v4b-9B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4b-9B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4b-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4b-9B.Q2_K.gguf) | Q2_K | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4b-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4b-9B.Q3_K_S.gguf) | Q3_K_S | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4b-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4b-9B.Q3_K_M.gguf) | Q3_K_M | 4.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4b-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4b-9B.Q3_K_L.gguf) | Q3_K_L | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4b-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4b-9B.IQ4_XS.gguf) | IQ4_XS | 5.3 | |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4b-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4b-9B.Q4_K_S.gguf) | Q4_K_S | 5.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4b-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4b-9B.Q4_K_M.gguf) | Q4_K_M | 5.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4b-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4b-9B.Q5_K_S.gguf) | Q5_K_S | 6.6 | |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4b-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4b-9B.Q5_K_M.gguf) | Q5_K_M | 6.7 | |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4b-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4b-9B.Q6_K.gguf) | Q6_K | 7.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4b-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4b-9B.Q8_0.gguf) | Q8_0 | 9.9 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Gemma-2-Ataraxy-v4b-9B-GGUF/resolve/main/Gemma-2-Ataraxy-v4b-9B.f16.gguf) | f16 | 18.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
enginia/tiny_fsdp_dbc_171024_1 | enginia | 2024-10-17T08:15:40Z | 75 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T08:13:16Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
jusKnows/Llama-3.2-3B-test-lora-ultrafit-complete-q4_k_m-gguf | jusKnows | 2024-10-17T08:11:16Z | 21 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/Llama-3.2-3B-bnb-4bit",
"base_model:quantized:unsloth/Llama-3.2-3B-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-10-17T08:05:31Z | ---
base_model: unsloth/Llama-3.2-3B-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
---
# Uploaded model
- **Developed by:** jusKnows
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Llama-3.2-3B-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Serione/opt-125m-8 | Serione | 2024-10-17T08:09:11Z | 143 | 0 | transformers | [
"transformers",
"safetensors",
"opt",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T08:08:16Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
p1xelsr/no_wtm_1m_dedup1 | p1xelsr | 2024-10-17T08:07:26Z | 87 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T08:05:14Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Serione/opt-125m-7 | Serione | 2024-10-17T08:04:19Z | 157 | 0 | transformers | [
"transformers",
"safetensors",
"opt",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T08:03:26Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
avemio-digital/GRAG-BGE-M3-Pairs-Triples-Hessian-AI | avemio-digital | 2024-10-17T08:03:05Z | 5 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"xlm-roberta",
"sentence-similarity",
"feature-extraction",
"dataset:avemio-digital/GRAG-Embedding-Triples-Hessian-AI",
"base_model:avemio-digital/GRAG-BGE-M3-Pairs-Hessian-AI",
"base_model:finetune:avemio-digital/GRAG-BGE-M3-Pairs-Hessian-AI",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2024-10-17T07:24:05Z | ---
library_name: sentence-transformers
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
base_model: avemio-digital/GRAG-BGE-M3-Pairs-Hessian-AI
widget:
- source_sentence: 'search_query: i love autotrain'
sentences:
- 'search_query: huggingface auto train'
- 'search_query: hugging face auto train'
- 'search_query: i love autotrain'
pipeline_tag: sentence-similarity
datasets:
- avemio-digital/GRAG-Embedding-Triples-Hessian-AI
---
# Model Trained Using AutoTrain
- Problem type: Sentence Transformers
## Validation Metrics
No validation metrics available
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the Hugging Face Hub
model = SentenceTransformer("sentence_transformers_model_id")
# Run inference
sentences = [
'search_query: autotrain',
'search_query: auto train',
'search_query: i love autotrain',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
``` |
Serione/opt-125m-6 | Serione | 2024-10-17T07:59:49Z | 154 | 0 | transformers | [
"transformers",
"safetensors",
"opt",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T07:58:57Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Serione/opt-125m-3 | Serione | 2024-10-17T07:50:51Z | 145 | 0 | transformers | [
"transformers",
"safetensors",
"opt",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T07:49:59Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf | RichardErkhov | 2024-10-17T07:48:40Z | 5 | 0 | null | [
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-10-17T04:10:28Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Qwen2.5_14B_Instruct_Fine_Tuned_v3 - GGUF
- Model creator: https://huggingface.co/FINGU-AI/
- Original model: https://huggingface.co/FINGU-AI/Qwen2.5_14B_Instruct_Fine_Tuned_v3/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q2_K.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q2_K.gguf) | Q2_K | 5.37GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.IQ3_XS.gguf) | IQ3_XS | 5.94GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.IQ3_S.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.IQ3_S.gguf) | IQ3_S | 6.23GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q3_K_S.gguf) | Q3_K_S | 6.2GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.IQ3_M.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.IQ3_M.gguf) | IQ3_M | 6.44GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q3_K.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q3_K.gguf) | Q3_K | 6.84GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q3_K_M.gguf) | Q3_K_M | 6.84GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q3_K_L.gguf) | Q3_K_L | 7.38GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.IQ4_XS.gguf) | IQ4_XS | 7.62GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q4_0.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q4_0.gguf) | Q4_0 | 7.93GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.IQ4_NL.gguf) | IQ4_NL | 8.01GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q4_K_S.gguf) | Q4_K_S | 7.98GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q4_K.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q4_K.gguf) | Q4_K | 8.37GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q4_K_M.gguf) | Q4_K_M | 8.37GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q4_1.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q4_1.gguf) | Q4_1 | 8.75GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q5_0.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q5_0.gguf) | Q5_0 | 9.56GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q5_K_S.gguf) | Q5_K_S | 9.56GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q5_K.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q5_K.gguf) | Q5_K | 9.79GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q5_K_M.gguf) | Q5_K_M | 9.79GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q5_1.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q5_1.gguf) | Q5_1 | 10.38GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q6_K.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q6_K.gguf) | Q6_K | 11.29GB |
| [Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q8_0.gguf](https://huggingface.co/RichardErkhov/FINGU-AI_-_Qwen2.5_14B_Instruct_Fine_Tuned_v3-gguf/blob/main/Qwen2.5_14B_Instruct_Fine_Tuned_v3.Q8_0.gguf) | Q8_0 | 14.62GB |
Original model description:
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Serione/opt-125m-2 | Serione | 2024-10-17T07:45:47Z | 152 | 0 | transformers | [
"transformers",
"safetensors",
"opt",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-17T07:44:55Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Subsets and Splits