
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-02 18:27:42
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 549
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-02 18:24:50
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
taybihassan0/test
|
taybihassan0
| 2025-06-12T16:13:48Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-12T16:13:48Z |
---
license: apache-2.0
---
|
mbreuss/flower_calvin_abc
|
mbreuss
| 2025-06-12T16:12:33Z | 11 | 3 | null |
[
"safetensors",
"robotics",
"VLA",
"en",
"base_model:mbreuss/flower_vla_pret",
"base_model:finetune:mbreuss/flower_vla_pret",
"license:mit",
"region:us"
] |
robotics
| 2025-03-16T19:57:24Z |
---
license: mit
language:
- en
base_model:
- microsoft/Florence-2-large
- mbreuss/flower_vla_pret
pipeline_tag: robotics
tags:
- robotics
- VLA
---
# FlowerVLA - Vision-Language-Action Flow Model for CALVIN ABC
This is a pretrained FlowerVLA model for robotic manipulation trained on the CALVIN ABC dataset.
Flower is an efficient Vision-Language-Action Flow policy for robot learning that only contains 1B parameters.
## Model Description
FlowerVLA is a novel architecture that:
- Uses half of Florence-2 for multi-modal vision-language encoding
- Employs an novel transformer-based flow matching architecture
- Provides an efficient, versatile VLA policy with only ~1B parameters
## Model Performance
This checkpoint contains weights for the CALVIN ABC challenge and currently ranks 1 with the following results:
| Train→Test | Method | 1 | 2 | 3 | 4 | 5 | **Avg. Len.** |
|------------|--------|---|---|---|---|---|---------------|
| CALVIN ABC | FlowerVLA | 99.3% | 95.9% | 90.5% | 84.8% |77.5% | 4.54 |
### Input/Output Specifications
#### Inputs
- RGB Static Camera: `(B, T, 3, H, W)` tensor
- RGB Gripper Camera: `(B, T, 3, H, W)` tensor
- Language Instructions: Text strings
#### Outputs
- Action Space: `(B, T, 7)` tensor representing delta EEF actions
## Usage
Check out our full model implementation on Github [todo]() and follow the instructions in the readme to test the model on one of the environments.
```python
obs = {
"rgb_obs": {
"rgb_static": static_image,
"rgb_gripper": gripper_image
}
}
goal = {"lang_text": "pick up the blue cube"}
action = model.step(obs, goal)
```
## Training Details
### Configuration
- **Optimizer**: AdamW
- **Learning Rate**: 2e-5
- **Weight Decay**: 0.05
@inproceedings{
reuss2025flower,
# Add citation when available
}
## License
This model is released under the MIT license.
|
Tevatron/OmniEmbed-v0.1-multivent
|
Tevatron
| 2025-06-12T16:11:22Z | 4 | 0 |
peft
|
[
"peft",
"safetensors",
"visual-document-retrieval",
"dataset:Tevatron/bge-ir",
"dataset:Tevatron/wiki-ss-nq-new",
"dataset:Tevatron/pixmo-docs",
"dataset:Tevatron/colpali",
"dataset:Tevatron/msrvtt",
"dataset:Tevatron/audiocaps",
"dataset:Tevatron/multivent",
"arxiv:2505.02466",
"base_model:Tevatron/OmniEmbed-v0.1",
"base_model:adapter:Tevatron/OmniEmbed-v0.1",
"license:mit",
"region:us"
] |
visual-document-retrieval
| 2025-04-18T08:53:28Z |
---
license: mit
datasets:
- Tevatron/bge-ir
- Tevatron/wiki-ss-nq-new
- Tevatron/pixmo-docs
- Tevatron/colpali
- Tevatron/msrvtt
- Tevatron/audiocaps
- Tevatron/multivent
base_model:
- Tevatron/OmniEmbed-v0.1
pipeline_tag: visual-document-retrieval
library_name: peft
---
# Tevatron/OmniEmbed-v0.1
**OmniEmbed** is a powerful multi-modal embedding model built on [Qwen2.5-Omni-7B](https://huggingface.co/Qwen/Qwen2.5-Omni-7B) using our [Tevatron](https://github.com/texttron/tevatron/) toolkit—a unified toolkit across scale, language, and modality for document retrieval.
OmniEmbed generates unified embeddings across multilingual text, images, audio, and video, enabling effective cross-modal retrieval for diverse applications. [Paper](https://arxiv.org/pdf/2505.02466v1).
**OmniEmbed-multivent** is further finetuned on OmniEmbed for video retrieval with allowing joint enhancing joint input performance of video, audio and text.
OmniEmbed-multivent gets SoTA performance on MAGMaR 2025 shared task on [MultiVENT-2.0](https://huggingface.co/datasets/hltcoe/MultiVENT2.0) datasets, large-scale, multi-lingual event-centric video retrieval benchmark featuring a collection of more than 218,000 news video.
📝 Text 🖼️ Image 🎧 Audio 🎥 Video 🌐 Multilingual
## Evaluation Results:
| | Modality | Model | nDCG@10 | AP | nDCG | RR | R@10 |
|-----|----------------------------------|------------------------|---------|-------|-------|-------|-------|
| | **Official Baselines** | | | | | | |
| | All | VAST | 0.116 | 0.08 | 0.115 | 0.198 | 0.118 |
| | OCR | ICDAR OCR → CLIP | 0.217 | 0.166 | 0.288 | 0.363 | 0.227 |
| | ASR | Whisper ASR | 0.267 | 0.212 | 0.336 | 0.417 | 0.29 |
| | Vision (key frame) | CLIP | 0.304 | 0.261 | 0.435 | 0.429 | 0.333 |
| | All | LanguageBind | 0.324 | 0.283 | 0.452 | 0.443 | 0.355 |
| | **Zero-Shot** | | | | | | |
| (a) | text, ASR | DRAMA | 0.629 | 0.576 | 0.693 | 0.749 | 0.649 |
| (b) | text, ASR | OmniEmbed | 0.377 | 0.329 | 0.453 | 0.493 | 0.403 |
| (c) | text, ASR, Vision (video), Audio| OmniEmbed | 0.595 | 0.537 | 0.673 | 0.732 | 0.616 |
| | **Trained on MultiVent 2.0 Training Set** | | | | | | |
| (d) | text, ASR | OmniEmbedMultivent | 0.710 | 0.673 | 0.772 | 0.808 | 0.734 |
| (f) | Vision (video), Audio | OmniEmbedMultivent | 0.709 | 0.665 | 0.776 | 0.822 | 0.724 |
| (h) | text, ASR, Vision (video), Audio| **OmniEmbedMultivent** | **0.753** | **0.769** | **0.807** | **0.848** | **0.715** |
---
### Usage
```python
# Import Library, Load Model and Processor
import torch
from transformers import AutoProcessor, Qwen2_5OmniThinkerForConditionalGeneration
from qwen_omni_utils import process_mm_info
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
model = Qwen2_5OmniThinkerForConditionalGeneration.from_pretrained(
'Tevatron/OmniEmbed-v0.1',
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16
).to(device).eval()
processor.tokenizer.padding_side = "left"
model.padding_side = "left"
# Function to Encode Message
def encode_message(message):
texts = processor.apply_chat_template(message, tokenize=False, add_generation_prompt=True)[0] + "<|endoftext|>"
audio_inputs, image_inputs, video_inputs = process_mm_info(message, use_audio_in_video=True)
inputs = processor(
text=texts,
audio=audio_inputs,
images=image_inputs,
videos=video_inputs,
return_tensors="pt",
padding="longest",
)
for k in inputs:
inputs[k] = inputs[k].to(device)
cache_position = torch.arange(0, inputs['input_ids'].shape[1], device=device)
inputs = model.prepare_inputs_for_generation(**inputs, use_cache=True, cache_position=cache_position)
model_outputs = model(**inputs, return_dict=True, output_hidden_states=True)
last_hidden_state = model_outputs.hidden_states[-1]
reps = last_hidden_state[:, -1]
reps = torch.nn.functional.normalize(reps, p=2, dim=-1)
return reps
```
### 🎬 Video Retrieval
```python
example_query = 'Query: How to cook Mapo Tofu?'
example_video_1 = "https://huggingface.co/Tevatron/OmniEmbed-v0/resolve/main/assets/mapo_tofu.mp4"
example_video_2 = "https://huggingface.co/Tevatron/OmniEmbed-v0/resolve/main/assets/zhajiang_noodle.mp4"
query = [{'role': 'user', 'content': [{'type': 'text', 'text': example_query}]}]
video_1 = [{'role': 'user', 'content': [{'type': 'video', 'video': example_video_1}]}]
video_2 = [{'role': 'user', 'content': [{'type': 'video', 'video': example_video_2}]}]
sim1 = torch.cosine_similarity(encode_message(query), encode_message(video_1))
sim2 = torch.cosine_similarity(encode_message(query), encode_message(video_2))
print("Similarities:", sim1.item(), sim2.item())
```
### 🎵 Audio Retrieval
```python
example_query = 'Query: A light piano piece'
example_audio_1 = "https://huggingface.co/Tevatron/OmniEmbed-v0/resolve/main/assets/joe_hisaishi_summer.mp3"
example_audio_2 = "https://huggingface.co/Tevatron/OmniEmbed-v0/resolve/main/assets/jay_chou_superman_cant_fly.mp3"
query = [{'role': 'user', 'content': [{'type': 'text', 'text': example_query}]}]
audio_1 = [{'role': 'user', 'content': [{'type': 'audio', 'audio': example_audio_1}]}]
audio_2 = [{'role': 'user', 'content': [{'type': 'audio', 'audio': example_audio_2}]}]
sim1 = torch.cosine_similarity(encode_message(query), encode_message(audio_1))
sim2 = torch.cosine_similarity(encode_message(query), encode_message(audio_2))
print("Similarities:", sim1.item(), sim2.item())
```
### 📈 Image Document Retrieval (Image, Chart, PDF)
```python
example_query = 'Query: How many input modality does Qwen2.5-Omni support?'
example_image_1 = "https://huggingface.co/Tevatron/OmniEmbed-v0/resolve/main/assets/qwen2.5omni_hgf.png"
example_image_2 = "https://huggingface.co/Tevatron/OmniEmbed-v0/resolve/main/assets/llama4_hgf.png"
query = [{'role': 'user', 'content': [{'type': 'text', 'text': example_query}]}]
image_1 = [{'role': 'user', 'content': [{'type': 'image', 'image': example_image_1}]}]
image_2 = [{'role': 'user', 'content': [{'type': 'image', 'image': example_image_2}]}]
sim1 = torch.cosine_similarity(encode_message(query), encode_message(image_1))
sim2 = torch.cosine_similarity(encode_message(query), encode_message(image_2))
print("Similarities:", sim1.item(), sim2.item())
```
### 🌍 Multilingual Text Retrieval
```python
example_query = 'Query: 氧气在空气中占比多少?'
example_text_1 = "空气是指大气层中由不同气体和各类飘浮在其中的固体与液体颗粒(大气颗粒与气溶胶)所组成的气态混合物。地球大气层的空气主要由78.1%的氮气、20.9%氧气、0.9%的氩气和1~4%的水蒸气组成,其成分并不是固定的,随着高度、气压、温度的改变和对流情况不同,局部空气的组成比例也会改变。空气在大气层(特别是对流层)中的流动形成了风和曳流、气旋、龙卷等自然现象,而空气中飘浮的颗粒则形成了云、雾、霾和沙尘暴等短期天气情况。空气在海洋和陆地之间跨区域流动所承载的湿度和热能传导也是水循环和气候变率与变化的关键一环。"
example_text_2 = "水(化学式:H2O)是一种无机化合物,在常温且无杂质中是无色[1]无味不导电的透明液体,也会通过蒸发产生气态的水蒸气(这种蒸发可以发生在任何温度下,同时取决于与空气接触的表面积和湿度差)。在标准大气压下,水的凝固点是0 °C(32 °F;273 K),沸点是100 °C(212 °F;373 K)。"
query = [{'role': 'user', 'content': [{'type': 'text', 'text': example_query}]}]
text_1 = [{'role': 'user', 'content': [{'type': 'text', 'text': example_text_1}]}]
text_2 = [{'role': 'user', 'content': [{'type': 'text', 'text': example_text_2}]}]
sim1 = torch.cosine_similarity(encode_message(query), encode_message(text_1))
sim2 = torch.cosine_similarity(encode_message(query), encode_message(text_2))
print("Similarities:", sim1.item(), sim2.item())
```
## Data & Training
We fully open-soured the Training Code in [Tevatron](https://github.com/texttron/tevatron/tree/qwenomni)
## Contact
This model is developed by:
Samantha Zhan, Crystina Zhang, Shengyao Zhuang, Xueguang Ma, Jimmy Lin
Feel free to reach out to us with any questions or for further discussion.
|
MinaMila/phi3_unlearned_2nd_1e-6_1.0_0.05_0.05_0.25_epoch1
|
MinaMila
| 2025-06-12T16:11:21Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"conversational",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T16:09:11Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gradientrouting-spar/gcd_syco_modkl_div_beta_kl-10_seed_1
|
gradientrouting-spar
| 2025-06-12T16:11:02Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T16:10:54Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
pabloOmega/donut_hw_v0
|
pabloOmega
| 2025-06-12T16:10:40Z | 17 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-06-09T02:19:25Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
morturr/Mistral-7B-v0.1-PAIR_amazon_headlines-COMB-amazon-comb-2-seed-7-2025-06-12
|
morturr
| 2025-06-12T16:08:50Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
] | null | 2025-06-12T16:08:35Z |
---
library_name: peft
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.1
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: Mistral-7B-v0.1-PAIR_amazon_headlines-COMB-amazon-comb-2-seed-7-2025-06-12
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Mistral-7B-v0.1-PAIR_amazon_headlines-COMB-amazon-comb-2-seed-7-2025-06-12
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 7
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.0.2
- Tokenizers 0.20.1
|
gradientrouting-spar/gcd_syco_modkl_div_beta_kl-1_seed_42
|
gradientrouting-spar
| 2025-06-12T16:08:05Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T16:07:58Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
LandCruiser/sn29_june_12_9
|
LandCruiser
| 2025-06-12T16:06:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T13:39:19Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gradientrouting-spar/gcd_syco_modkl_div_beta_kl-1_seed_5
|
gradientrouting-spar
| 2025-06-12T16:05:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T16:05:15Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q8_0-GGUF
|
Triangle104
| 2025-06-12T16:00:29Z | 0 | 0 | null |
[
"gguf",
"nsfw",
"explicit",
"roleplay",
"unaligned",
"ERP",
"Erotic",
"Horror",
"Violence",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0",
"base_model:finetune:ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-06-12T15:58:46Z |
---
license: apache-2.0
language:
- en
base_model: ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0
base_model_relation: finetune
pipeline_tag: text-generation
tags:
- nsfw
- explicit
- roleplay
- unaligned
- ERP
- Erotic
- Horror
- Violence
- llama-cpp
- gguf-my-repo
---
# Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q8_0-GGUF
This model was converted to GGUF format from [`ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0`](https://huggingface.co/ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0) for more details on the model.
---
This evolution of The-Omega-Directive delivers unprecedented coherence without the LLM slop:
- 🧬 Expanded 43M Token Dataset - First ReadyArt model with multi-turn conversational data
- ✨ 100% Unslopped Dataset - New techniques used to generate the dataset with 0% slop
- ⚡ Enhanced Unalignment - Complete freedom for extreme roleplay while maintaining character integrity
- 🛡️ Anti-Impersonation Guards - Never speaks or acts for the user
- 💎 Rebuilt from Ground Up - Optimized training settings for superior performance
- ⚰️ Omega Darker Inspiration - Incorporates visceral narrative techniques from our darkest model
- 🧠 128K Context Window - Enhanced long-context capabilities without compromising performance
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q8_0-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q8_0-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q8_0-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q8_0-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q8_0.gguf -c 2048
```
|
phospho-app/oulianov-ACT_BBOX-TEST10-ydeel
|
phospho-app
| 2025-06-12T15:57:29Z | 0 | 0 | null |
[
"phosphobot",
"act",
"region:us"
] | null | 2025-06-12T15:53:29Z |
---
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act Model - phospho Training Pipeline
## Error Traceback
We faced an issue while training your model.
```
Training process failed with exit code 1:
'timestamps': [np.float32(7.0666666), np.float32(0.0)]},
{'diff': np.float32(-6.4333334),
'episode_index': 33,
'timestamps': [np.float32(6.4333334), np.float32(0.0)]},
{'diff': np.float32(-5.9666667),
'episode_index': 34,
'timestamps': [np.float32(5.9666667), np.float32(0.0)]},
{'diff': np.float32(-6.2),
'episode_index': 35,
'timestamps': [np.float32(6.2), np.float32(0.0)]}]
```
## Training parameters:
- **Dataset**: [phospho-app/TEST10_bboxes](https://huggingface.co/datasets/phospho-app/TEST10_bboxes)
- **Wandb run URL**: None
- **Epochs**: None
- **Batch size**: 100
- **Training steps**: 10000
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q6_K-GGUF
|
Triangle104
| 2025-06-12T15:56:29Z | 0 | 0 | null |
[
"gguf",
"nsfw",
"explicit",
"roleplay",
"unaligned",
"ERP",
"Erotic",
"Horror",
"Violence",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0",
"base_model:finetune:ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-06-12T15:55:01Z |
---
license: apache-2.0
language:
- en
base_model: ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0
base_model_relation: finetune
pipeline_tag: text-generation
tags:
- nsfw
- explicit
- roleplay
- unaligned
- ERP
- Erotic
- Horror
- Violence
- llama-cpp
- gguf-my-repo
---
# Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q6_K-GGUF
This model was converted to GGUF format from [`ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0`](https://huggingface.co/ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0) for more details on the model.
---
This evolution of The-Omega-Directive delivers unprecedented coherence without the LLM slop:
- 🧬 Expanded 43M Token Dataset - First ReadyArt model with multi-turn conversational data
- ✨ 100% Unslopped Dataset - New techniques used to generate the dataset with 0% slop
- ⚡ Enhanced Unalignment - Complete freedom for extreme roleplay while maintaining character integrity
- 🛡️ Anti-Impersonation Guards - Never speaks or acts for the user
- 💎 Rebuilt from Ground Up - Optimized training settings for superior performance
- ⚰️ Omega Darker Inspiration - Incorporates visceral narrative techniques from our darkest model
- 🧠 128K Context Window - Enhanced long-context capabilities without compromising performance
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q6_K-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q6_K-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q6_K-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q6_K-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q6_k.gguf -c 2048
```
|
gradientrouting-spar/gcd_syco_modst_we_pos_prx-out_neg_prx-proxy_neg_st_alpha-0.8_seed_5
|
gradientrouting-spar
| 2025-06-12T15:55:17Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T15:55:09Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
daviondk7131/chekhov-reward-model
|
daviondk7131
| 2025-06-12T15:53:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-12T15:51:46Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
kkioikk/MiniCPM4-8B-Q4_K_M-GGUF
|
kkioikk
| 2025-06-12T15:51:23Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"zh",
"en",
"base_model:openbmb/MiniCPM4-8B",
"base_model:quantized:openbmb/MiniCPM4-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-06-12T15:51:00Z |
---
license: apache-2.0
language:
- zh
- en
pipeline_tag: text-generation
library_name: transformers
base_model: openbmb/MiniCPM4-8B
tags:
- llama-cpp
- gguf-my-repo
---
# kkioikk/MiniCPM4-8B-Q4_K_M-GGUF
This model was converted to GGUF format from [`openbmb/MiniCPM4-8B`](https://huggingface.co/openbmb/MiniCPM4-8B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/openbmb/MiniCPM4-8B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo kkioikk/MiniCPM4-8B-Q4_K_M-GGUF --hf-file minicpm4-8b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo kkioikk/MiniCPM4-8B-Q4_K_M-GGUF --hf-file minicpm4-8b-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo kkioikk/MiniCPM4-8B-Q4_K_M-GGUF --hf-file minicpm4-8b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo kkioikk/MiniCPM4-8B-Q4_K_M-GGUF --hf-file minicpm4-8b-q4_k_m.gguf -c 2048
```
|
Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q5_K_M-GGUF
|
Triangle104
| 2025-06-12T15:49:31Z | 0 | 0 | null |
[
"gguf",
"nsfw",
"explicit",
"roleplay",
"unaligned",
"ERP",
"Erotic",
"Horror",
"Violence",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0",
"base_model:finetune:ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-06-12T15:47:11Z |
---
license: apache-2.0
language:
- en
base_model: ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0
base_model_relation: finetune
pipeline_tag: text-generation
tags:
- nsfw
- explicit
- roleplay
- unaligned
- ERP
- Erotic
- Horror
- Violence
- llama-cpp
- gguf-my-repo
---
# Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q5_K_M-GGUF
This model was converted to GGUF format from [`ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0`](https://huggingface.co/ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0) for more details on the model.
---
This evolution of The-Omega-Directive delivers unprecedented coherence without the LLM slop:
- 🧬 Expanded 43M Token Dataset - First ReadyArt model with multi-turn conversational data
- ✨ 100% Unslopped Dataset - New techniques used to generate the dataset with 0% slop
- ⚡ Enhanced Unalignment - Complete freedom for extreme roleplay while maintaining character integrity
- 🛡️ Anti-Impersonation Guards - Never speaks or acts for the user
- 💎 Rebuilt from Ground Up - Optimized training settings for superior performance
- ⚰️ Omega Darker Inspiration - Incorporates visceral narrative techniques from our darkest model
- 🧠 128K Context Window - Enhanced long-context capabilities without compromising performance
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q5_K_M-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q5_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q5_K_M-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q5_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q5_K_M-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q5_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q5_K_M-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q5_k_m.gguf -c 2048
```
|
tomaarsen/inference-free-splade-distilbert-base-uncased-nq-3e-4-lc
|
tomaarsen
| 2025-06-12T15:48:13Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"sparse-encoder",
"sparse",
"asymmetric",
"inference-free",
"splade",
"generated_from_trainer",
"dataset_size:99000",
"loss:SpladeLoss",
"loss:SparseMultipleNegativesRankingLoss",
"loss:FlopsLoss",
"feature-extraction",
"en",
"dataset:sentence-transformers/natural-questions",
"arxiv:1908.10084",
"arxiv:2205.04733",
"arxiv:1705.00652",
"arxiv:2004.05665",
"license:apache-2.0",
"model-index",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-06-12T15:47:50Z |
---
language:
- en
license: apache-2.0
tags:
- sentence-transformers
- sparse-encoder
- sparse
- asymmetric
- inference-free
- splade
- generated_from_trainer
- dataset_size:99000
- loss:SpladeLoss
- loss:SparseMultipleNegativesRankingLoss
- loss:FlopsLoss
widget:
- text: Rollin' (Limp Bizkit song) The music video was filmed atop the South Tower
of the former World Trade Center in New York City. The introduction features Ben
Stiller and Stephen Dorff mistaking Fred Durst for the valet and giving him the
keys to their Bentley Azure. Also making a cameo is break dancer Mr. Wiggles.
The rest of the video has several cuts to Durst and his bandmates hanging out
of the Bentley as they drive about Manhattan. The song Ben Stiller is playing
at the beginning is "My Generation" from the same album. The video also features
scenes of Fred Durst with five girls dancing in a room. The video was filmed around
the same time as the film Zoolander, which explains Stiller and Dorff's appearance.
Fred Durst has a small cameo in that film.
- text: 'Maze Runner: The Death Cure On April 22, 2017, the studio delayed the release
date once again, to February 9, 2018, in order to allow more time for post-production;
months later, on August 25, the studio moved the release forward two weeks.[17]
The film will premiere on January 26, 2018 in 3D, IMAX and IMAX 3D.[18][19]'
- text: who played the dj in the movie the warriors
- text: Lionel Messi Born and raised in central Argentina, Messi was diagnosed with
a growth hormone deficiency as a child. At age 13, he relocated to Spain to join
Barcelona, who agreed to pay for his medical treatment. After a fast progression
through Barcelona's youth academy, Messi made his competitive debut aged 17 in
October 2004. Despite being injury-prone during his early career, he established
himself as an integral player for the club within the next three years, finishing
2007 as a finalist for both the Ballon d'Or and FIFA World Player of the Year
award, a feat he repeated the following year. His first uninterrupted campaign
came in the 2008–09 season, during which he helped Barcelona achieve the first
treble in Spanish football. At 22 years old, Messi won the Ballon d'Or and FIFA
World Player of the Year award by record voting margins.
- text: 'Send In the Clowns "Send In the Clowns" is a song written by Stephen Sondheim
for the 1973 musical A Little Night Music, an adaptation of Ingmar Bergman''s
film Smiles of a Summer Night. It is a ballad from Act Two, in which the character
Desirée reflects on the ironies and disappointments of her life. Among other things,
she looks back on an affair years earlier with the lawyer Fredrik, who was deeply
in love with her but whose marriage proposals she had rejected. Meeting him after
so long, she realizes she is in love with him and finally ready to marry him,
but now it is he who rejects her: he is in an unconsummated marriage with a much
younger woman. Desirée proposes marriage to rescue him from this situation, but
he declines, citing his dedication to his bride. Reacting to his rejection, Desirée
sings this song. The song is later reprised as a coda after Fredrik''s young wife
runs away with his son, and Fredrik is finally free to accept Desirée''s offer.[1]'
datasets:
- sentence-transformers/natural-questions
pipeline_tag: feature-extraction
library_name: sentence-transformers
metrics:
- dot_accuracy@1
- dot_accuracy@3
- dot_accuracy@5
- dot_accuracy@10
- dot_precision@1
- dot_precision@3
- dot_precision@5
- dot_precision@10
- dot_recall@1
- dot_recall@3
- dot_recall@5
- dot_recall@10
- dot_ndcg@10
- dot_mrr@10
- dot_map@100
- query_active_dims
- query_sparsity_ratio
- corpus_active_dims
- corpus_sparsity_ratio
co2_eq_emissions:
emissions: 96.6933410585648
energy_consumed: 0.24875956660517518
source: codecarbon
training_type: fine-tuning
on_cloud: false
cpu_model: 13th Gen Intel(R) Core(TM) i7-13700K
ram_total_size: 31.777088165283203
hours_used: 0.63
hardware_used: 1 x NVIDIA GeForce RTX 3090
model-index:
- name: Inference-free SPLADE distilbert-base-uncased trained on Natural-Questions
tuples
results:
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: NanoMSMARCO
type: NanoMSMARCO
metrics:
- type: dot_accuracy@1
value: 0.26
name: Dot Accuracy@1
- type: dot_accuracy@3
value: 0.54
name: Dot Accuracy@3
- type: dot_accuracy@5
value: 0.6
name: Dot Accuracy@5
- type: dot_accuracy@10
value: 0.84
name: Dot Accuracy@10
- type: dot_precision@1
value: 0.26
name: Dot Precision@1
- type: dot_precision@3
value: 0.18
name: Dot Precision@3
- type: dot_precision@5
value: 0.12
name: Dot Precision@5
- type: dot_precision@10
value: 0.08399999999999999
name: Dot Precision@10
- type: dot_recall@1
value: 0.26
name: Dot Recall@1
- type: dot_recall@3
value: 0.54
name: Dot Recall@3
- type: dot_recall@5
value: 0.6
name: Dot Recall@5
- type: dot_recall@10
value: 0.84
name: Dot Recall@10
- type: dot_ndcg@10
value: 0.5301296392828033
name: Dot Ndcg@10
- type: dot_mrr@10
value: 0.4346587301587301
name: Dot Mrr@10
- type: dot_map@100
value: 0.4417858474689138
name: Dot Map@100
- type: query_active_dims
value: 7.21999979019165
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.999763449322122
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 108.27344512939453
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9964526097526573
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: NanoNFCorpus
type: NanoNFCorpus
metrics:
- type: dot_accuracy@1
value: 0.4
name: Dot Accuracy@1
- type: dot_accuracy@3
value: 0.52
name: Dot Accuracy@3
- type: dot_accuracy@5
value: 0.54
name: Dot Accuracy@5
- type: dot_accuracy@10
value: 0.64
name: Dot Accuracy@10
- type: dot_precision@1
value: 0.4
name: Dot Precision@1
- type: dot_precision@3
value: 0.38
name: Dot Precision@3
- type: dot_precision@5
value: 0.32
name: Dot Precision@5
- type: dot_precision@10
value: 0.272
name: Dot Precision@10
- type: dot_recall@1
value: 0.022488303582306343
name: Dot Recall@1
- type: dot_recall@3
value: 0.07739840917586681
name: Dot Recall@3
- type: dot_recall@5
value: 0.09241195258706496
name: Dot Recall@5
- type: dot_recall@10
value: 0.12367788200480173
name: Dot Recall@10
- type: dot_ndcg@10
value: 0.3246216335286617
name: Dot Ndcg@10
- type: dot_mrr@10
value: 0.4721904761904762
name: Dot Mrr@10
- type: dot_map@100
value: 0.13538377155269898
name: Dot Map@100
- type: query_active_dims
value: 5.659999847412109
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.9998145599945151
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 131.0975341796875
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9957048183546396
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: NanoNQ
type: NanoNQ
metrics:
- type: dot_accuracy@1
value: 0.4
name: Dot Accuracy@1
- type: dot_accuracy@3
value: 0.62
name: Dot Accuracy@3
- type: dot_accuracy@5
value: 0.74
name: Dot Accuracy@5
- type: dot_accuracy@10
value: 0.8
name: Dot Accuracy@10
- type: dot_precision@1
value: 0.4
name: Dot Precision@1
- type: dot_precision@3
value: 0.21333333333333332
name: Dot Precision@3
- type: dot_precision@5
value: 0.15200000000000002
name: Dot Precision@5
- type: dot_precision@10
value: 0.08399999999999999
name: Dot Precision@10
- type: dot_recall@1
value: 0.38
name: Dot Recall@1
- type: dot_recall@3
value: 0.58
name: Dot Recall@3
- type: dot_recall@5
value: 0.69
name: Dot Recall@5
- type: dot_recall@10
value: 0.76
name: Dot Recall@10
- type: dot_ndcg@10
value: 0.5794690876694212
name: Dot Ndcg@10
- type: dot_mrr@10
value: 0.5380555555555555
name: Dot Mrr@10
- type: dot_map@100
value: 0.5206061459671588
name: Dot Map@100
- type: query_active_dims
value: 10.319999694824219
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.9996618832417657
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 91.89592742919922
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9969891905042528
name: Corpus Sparsity Ratio
- task:
type: sparse-nano-beir
name: Sparse Nano BEIR
dataset:
name: NanoBEIR mean
type: NanoBEIR_mean
metrics:
- type: dot_accuracy@1
value: 0.35333333333333333
name: Dot Accuracy@1
- type: dot_accuracy@3
value: 0.56
name: Dot Accuracy@3
- type: dot_accuracy@5
value: 0.6266666666666667
name: Dot Accuracy@5
- type: dot_accuracy@10
value: 0.7600000000000001
name: Dot Accuracy@10
- type: dot_precision@1
value: 0.35333333333333333
name: Dot Precision@1
- type: dot_precision@3
value: 0.25777777777777783
name: Dot Precision@3
- type: dot_precision@5
value: 0.19733333333333336
name: Dot Precision@5
- type: dot_precision@10
value: 0.14666666666666664
name: Dot Precision@10
- type: dot_recall@1
value: 0.22082943452743545
name: Dot Recall@1
- type: dot_recall@3
value: 0.39913280305862225
name: Dot Recall@3
- type: dot_recall@5
value: 0.4608039841956883
name: Dot Recall@5
- type: dot_recall@10
value: 0.5745592940016006
name: Dot Recall@10
- type: dot_ndcg@10
value: 0.4780734534936288
name: Dot Ndcg@10
- type: dot_mrr@10
value: 0.4816349206349206
name: Dot Mrr@10
- type: dot_map@100
value: 0.3659252549962572
name: Dot Map@100
- type: query_active_dims
value: 7.733333110809326
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.999746630852801
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 107.11764230114127
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9964904776128319
name: Corpus Sparsity Ratio
---
# Inference-free SPLADE distilbert-base-uncased trained on Natural-Questions tuples
This is a [Asymmetric Inference-free SPLADE Sparse Encoder](https://www.sbert.net/docs/sparse_encoder/usage/usage.html) model trained on the [natural-questions](https://huggingface.co/datasets/sentence-transformers/natural-questions) dataset using the [sentence-transformers](https://www.SBERT.net) library. It maps sentences & paragraphs to a 30522-dimensional sparse vector space and can be used for semantic search and sparse retrieval.
## Model Details
### Model Description
- **Model Type:** Asymmetric Inference-free SPLADE Sparse Encoder
<!-- - **Base model:** [Unknown](https://huggingface.co/unknown) -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 30522 dimensions
- **Similarity Function:** Dot Product
- **Training Dataset:**
- [natural-questions](https://huggingface.co/datasets/sentence-transformers/natural-questions)
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Documentation:** [Sparse Encoder Documentation](https://www.sbert.net/docs/sparse_encoder/usage/usage.html)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sparse Encoders on Hugging Face](https://huggingface.co/models?library=sentence-transformers&other=sparse-encoder)
### Full Model Architecture
```
SparseEncoder(
(0): Router(
(query_0_IDF): IDF ({'frozen': False}, dim:30522, tokenizer: DistilBertTokenizerFast)
(document_0_MLMTransformer): MLMTransformer({'max_seq_length': 512, 'do_lower_case': False}) with MLMTransformer model: DistilBertForMaskedLM
(document_1_SpladePooling): SpladePooling({'pooling_strategy': 'max', 'activation_function': 'relu', 'word_embedding_dimension': 30522})
)
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SparseEncoder
# Download from the 🤗 Hub
model = SparseEncoder("tomaarsen/inference-free-splade-distilbert-base-uncased-nq-3e-4-lc")
# Run inference
queries = [
"is send in the clowns from a musical",
]
documents = [
'Send In the Clowns "Send In the Clowns" is a song written by Stephen Sondheim for the 1973 musical A Little Night Music, an adaptation of Ingmar Bergman\'s film Smiles of a Summer Night. It is a ballad from Act Two, in which the character Desirée reflects on the ironies and disappointments of her life. Among other things, she looks back on an affair years earlier with the lawyer Fredrik, who was deeply in love with her but whose marriage proposals she had rejected. Meeting him after so long, she realizes she is in love with him and finally ready to marry him, but now it is he who rejects her: he is in an unconsummated marriage with a much younger woman. Desirée proposes marriage to rescue him from this situation, but he declines, citing his dedication to his bride. Reacting to his rejection, Desirée sings this song. The song is later reprised as a coda after Fredrik\'s young wife runs away with his son, and Fredrik is finally free to accept Desirée\'s offer.[1]',
'The Suite Life on Deck The Suite Life on Deck is an American sitcom that aired on Disney Channel from September 26, 2008 to May 6, 2011. It is a sequel/spin-off of the Disney Channel Original Series The Suite Life of Zack & Cody. The series follows twin brothers Zack and Cody Martin and hotel heiress London Tipton in a new setting, the SS Tipton, where they attend classes at "Seven Seas High School" and meet Bailey Pickett while Mr. Moseby manages the ship. The ship travels around the world to nations such as Italy, France, Greece, India, Sweden and the United Kingdom where the characters experience different cultures, adventures, and situations.[1]',
'Money in the Bank ladder match The first match was contested in 2005 at WrestleMania 21, after being invented (in kayfabe) by Chris Jericho.[1] At the time, it was exclusive to wrestlers of the Raw brand, and Edge won the inaugural match.[1] From then until 2010, the Money in the Bank ladder match, now open to all WWE brands, became a WrestleMania mainstay. 2010 saw a second and third Money in the Bank ladder match when the Money in the Bank pay-per-view debuted in July. Unlike the matches at WrestleMania, this new event featured two such ladder matches – one each for a contract for the WWE Championship and World Heavyweight Championship, respectively.',
]
query_embeddings = model.encode_query(queries)
document_embeddings = model.encode_document(documents)
print(query_embeddings.shape, document_embeddings.shape)
# [1, 30522] [3, 30522]
# Get the similarity scores for the embeddings
similarities = model.similarity(query_embeddings, document_embeddings)
print(similarities)
# tensor([[11.2000, 0.0000, 0.6561]])
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Sparse Information Retrieval
* Datasets: `NanoMSMARCO`, `NanoNFCorpus` and `NanoNQ`
* Evaluated with [<code>SparseInformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator)
| Metric | NanoMSMARCO | NanoNFCorpus | NanoNQ |
|:----------------------|:------------|:-------------|:-----------|
| dot_accuracy@1 | 0.26 | 0.4 | 0.4 |
| dot_accuracy@3 | 0.54 | 0.52 | 0.62 |
| dot_accuracy@5 | 0.6 | 0.54 | 0.74 |
| dot_accuracy@10 | 0.84 | 0.64 | 0.8 |
| dot_precision@1 | 0.26 | 0.4 | 0.4 |
| dot_precision@3 | 0.18 | 0.38 | 0.2133 |
| dot_precision@5 | 0.12 | 0.32 | 0.152 |
| dot_precision@10 | 0.084 | 0.272 | 0.084 |
| dot_recall@1 | 0.26 | 0.0225 | 0.38 |
| dot_recall@3 | 0.54 | 0.0774 | 0.58 |
| dot_recall@5 | 0.6 | 0.0924 | 0.69 |
| dot_recall@10 | 0.84 | 0.1237 | 0.76 |
| **dot_ndcg@10** | **0.5301** | **0.3246** | **0.5795** |
| dot_mrr@10 | 0.4347 | 0.4722 | 0.5381 |
| dot_map@100 | 0.4418 | 0.1354 | 0.5206 |
| query_active_dims | 7.22 | 5.66 | 10.32 |
| query_sparsity_ratio | 0.9998 | 0.9998 | 0.9997 |
| corpus_active_dims | 108.2734 | 131.0975 | 91.8959 |
| corpus_sparsity_ratio | 0.9965 | 0.9957 | 0.997 |
#### Sparse Nano BEIR
* Dataset: `NanoBEIR_mean`
* Evaluated with [<code>SparseNanoBEIREvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseNanoBEIREvaluator) with these parameters:
```json
{
"dataset_names": [
"msmarco",
"nfcorpus",
"nq"
]
}
```
| Metric | Value |
|:----------------------|:-----------|
| dot_accuracy@1 | 0.3533 |
| dot_accuracy@3 | 0.56 |
| dot_accuracy@5 | 0.6267 |
| dot_accuracy@10 | 0.76 |
| dot_precision@1 | 0.3533 |
| dot_precision@3 | 0.2578 |
| dot_precision@5 | 0.1973 |
| dot_precision@10 | 0.1467 |
| dot_recall@1 | 0.2208 |
| dot_recall@3 | 0.3991 |
| dot_recall@5 | 0.4608 |
| dot_recall@10 | 0.5746 |
| **dot_ndcg@10** | **0.4781** |
| dot_mrr@10 | 0.4816 |
| dot_map@100 | 0.3659 |
| query_active_dims | 7.7333 |
| query_sparsity_ratio | 0.9997 |
| corpus_active_dims | 107.1176 |
| corpus_sparsity_ratio | 0.9965 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### natural-questions
* Dataset: [natural-questions](https://huggingface.co/datasets/sentence-transformers/natural-questions) at [f9e894e](https://huggingface.co/datasets/sentence-transformers/natural-questions/tree/f9e894e1081e206e577b4eaa9ee6de2b06ae6f17)
* Size: 99,000 training samples
* Columns: <code>query</code> and <code>answer</code>
* Approximate statistics based on the first 1000 samples:
| | query | answer |
|:--------|:-----------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 11.71 tokens</li><li>max: 26 tokens</li></ul> | <ul><li>min: 4 tokens</li><li>mean: 131.81 tokens</li><li>max: 450 tokens</li></ul> |
* Samples:
| query | answer |
|:--------------------------------------------------------------|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>who played the father in papa don't preach</code> | <code>Alex McArthur Alex McArthur (born March 6, 1957) is an American actor.</code> |
| <code>where was the location of the battle of hastings</code> | <code>Battle of Hastings The Battle of Hastings[a] was fought on 14 October 1066 between the Norman-French army of William, the Duke of Normandy, and an English army under the Anglo-Saxon King Harold Godwinson, beginning the Norman conquest of England. It took place approximately 7 miles (11 kilometres) northwest of Hastings, close to the present-day town of Battle, East Sussex, and was a decisive Norman victory.</code> |
| <code>how many puppies can a dog give birth to</code> | <code>Canine reproduction The largest litter size to date was set by a Neapolitan Mastiff in Manea, Cambridgeshire, UK on November 29, 2004; the litter was 24 puppies.[22]</code> |
* Loss: [<code>SpladeLoss</code>](https://sbert.net/docs/package_reference/sparse_encoder/losses.html#spladeloss) with these parameters:
```json
{
"loss": "SparseMultipleNegativesRankingLoss(scale=1.0, similarity_fct='dot_score')",
"lambda_corpus": 0.0003,
"lambda_query": 0
}
```
### Evaluation Dataset
#### natural-questions
* Dataset: [natural-questions](https://huggingface.co/datasets/sentence-transformers/natural-questions) at [f9e894e](https://huggingface.co/datasets/sentence-transformers/natural-questions/tree/f9e894e1081e206e577b4eaa9ee6de2b06ae6f17)
* Size: 1,000 evaluation samples
* Columns: <code>query</code> and <code>answer</code>
* Approximate statistics based on the first 1000 samples:
| | query | answer |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 11.69 tokens</li><li>max: 23 tokens</li></ul> | <ul><li>min: 15 tokens</li><li>mean: 134.01 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| query | answer |
|:-------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>where is the tiber river located in italy</code> | <code>Tiber The Tiber (/ˈtaɪbər/, Latin: Tiberis,[1] Italian: Tevere [ˈteːvere])[2] is the third-longest river in Italy, rising in the Apennine Mountains in Emilia-Romagna and flowing 406 kilometres (252 mi) through Tuscany, Umbria and Lazio, where it is joined by the river Aniene, to the Tyrrhenian Sea, between Ostia and Fiumicino.[3] It drains a basin estimated at 17,375 square kilometres (6,709 sq mi). The river has achieved lasting fame as the main watercourse of the city of Rome, founded on its eastern banks.</code> |
| <code>what kind of car does jay gatsby drive</code> | <code>Jay Gatsby At the Buchanan home, Jordan Baker, Nick, Jay, and the Buchanans decide to visit New York City. Tom borrows Gatsby's yellow Rolls Royce to drive up to the city. On the way to New York City, Tom makes a detour at a gas station in "the Valley of Ashes", a run-down part of Long Island. The owner, George Wilson, shares his concern that his wife, Myrtle, may be having an affair. This unnerves Tom, who has been having an affair with Myrtle, and he leaves in a hurry.</code> |
| <code>who sings if i can dream about you</code> | <code>I Can Dream About You "I Can Dream About You" is a song performed by American singer Dan Hartman on the soundtrack album of the film Streets of Fire. Released in 1984 as a single from the soundtrack, and included on Hartman's album I Can Dream About You, it reached number 6 on the Billboard Hot 100.[1]</code> |
* Loss: [<code>SpladeLoss</code>](https://sbert.net/docs/package_reference/sparse_encoder/losses.html#spladeloss) with these parameters:
```json
{
"loss": "SparseMultipleNegativesRankingLoss(scale=1.0, similarity_fct='dot_score')",
"lambda_corpus": 0.0003,
"lambda_query": 0
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `learning_rate`: 2e-05
- `warmup_ratio`: 0.1
- `fp16`: True
- `batch_sampler`: no_duplicates
- `router_mapping`: {'query': 'query', 'answer': 'document'}
- `learning_rate_mapping`: {'IDF\\.weight': 0.001}
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 3
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {'query': 'query', 'answer': 'document'}
- `learning_rate_mapping`: {'IDF\\.weight': 0.001}
</details>
### Training Logs
| Epoch | Step | Training Loss | Validation Loss | NanoMSMARCO_dot_ndcg@10 | NanoNFCorpus_dot_ndcg@10 | NanoNQ_dot_ndcg@10 | NanoBEIR_mean_dot_ndcg@10 |
|:------:|:-----:|:-------------:|:---------------:|:-----------------------:|:------------------------:|:------------------:|:-------------------------:|
| 0.0323 | 200 | 0.3026 | - | - | - | - | - |
| 0.0646 | 400 | 0.1058 | - | - | - | - | - |
| 0.0970 | 600 | 0.0605 | - | - | - | - | - |
| 0.1293 | 800 | 0.0443 | - | - | - | - | - |
| 0.1616 | 1000 | 0.0385 | 0.0598 | 0.6070 | 0.3234 | 0.5837 | 0.5047 |
| 0.1939 | 1200 | 0.0391 | - | - | - | - | - |
| 0.2262 | 1400 | 0.0432 | - | - | - | - | - |
| 0.2586 | 1600 | 0.0448 | - | - | - | - | - |
| 0.2909 | 1800 | 0.0363 | - | - | - | - | - |
| 0.3232 | 2000 | 0.0348 | 0.0578 | 0.5471 | 0.3245 | 0.5586 | 0.4768 |
| 0.3555 | 2200 | 0.0383 | - | - | - | - | - |
| 0.3878 | 2400 | 0.0378 | - | - | - | - | - |
| 0.4202 | 2600 | 0.0354 | - | - | - | - | - |
| 0.4525 | 2800 | 0.0348 | - | - | - | - | - |
| 0.4848 | 3000 | 0.0276 | 0.0474 | 0.5432 | 0.3288 | 0.5474 | 0.4731 |
| 0.5171 | 3200 | 0.0341 | - | - | - | - | - |
| 0.5495 | 3400 | 0.0352 | - | - | - | - | - |
| 0.5818 | 3600 | 0.0312 | - | - | - | - | - |
| 0.6141 | 3800 | 0.036 | - | - | - | - | - |
| 0.6464 | 4000 | 0.0295 | 0.0543 | 0.5880 | 0.3372 | 0.5392 | 0.4881 |
| 0.6787 | 4200 | 0.032 | - | - | - | - | - |
| 0.7111 | 4400 | 0.0321 | - | - | - | - | - |
| 0.7434 | 4600 | 0.0322 | - | - | - | - | - |
| 0.7757 | 4800 | 0.0303 | - | - | - | - | - |
| 0.8080 | 5000 | 0.0328 | 0.0476 | 0.5662 | 0.3225 | 0.5796 | 0.4894 |
| 0.8403 | 5200 | 0.0322 | - | - | - | - | - |
| 0.8727 | 5400 | 0.03 | - | - | - | - | - |
| 0.9050 | 5600 | 0.0306 | - | - | - | - | - |
| 0.9373 | 5800 | 0.0273 | - | - | - | - | - |
| 0.9696 | 6000 | 0.0327 | 0.0474 | 0.5383 | 0.3334 | 0.5084 | 0.4600 |
| 1.0019 | 6200 | 0.0342 | - | - | - | - | - |
| 1.0343 | 6400 | 0.0201 | - | - | - | - | - |
| 1.0666 | 6600 | 0.0212 | - | - | - | - | - |
| 1.0989 | 6800 | 0.0209 | - | - | - | - | - |
| 1.1312 | 7000 | 0.0319 | 0.0484 | 0.5389 | 0.3125 | 0.5364 | 0.4626 |
| 1.1635 | 7200 | 0.0243 | - | - | - | - | - |
| 1.1959 | 7400 | 0.0219 | - | - | - | - | - |
| 1.2282 | 7600 | 0.022 | - | - | - | - | - |
| 1.2605 | 7800 | 0.0237 | - | - | - | - | - |
| 1.2928 | 8000 | 0.0257 | 0.0461 | 0.5594 | 0.3314 | 0.5339 | 0.4749 |
| 1.3251 | 8200 | 0.0152 | - | - | - | - | - |
| 1.3575 | 8400 | 0.0177 | - | - | - | - | - |
| 1.3898 | 8600 | 0.0228 | - | - | - | - | - |
| 1.4221 | 8800 | 0.0197 | - | - | - | - | - |
| 1.4544 | 9000 | 0.025 | 0.0416 | 0.5534 | 0.3253 | 0.5838 | 0.4875 |
| 1.4867 | 9200 | 0.025 | - | - | - | - | - |
| 1.5191 | 9400 | 0.0229 | - | - | - | - | - |
| 1.5514 | 9600 | 0.0198 | - | - | - | - | - |
| 1.5837 | 9800 | 0.022 | - | - | - | - | - |
| 1.6160 | 10000 | 0.0279 | 0.0434 | 0.5778 | 0.3390 | 0.5574 | 0.4914 |
| 1.6484 | 10200 | 0.0201 | - | - | - | - | - |
| 1.6807 | 10400 | 0.0196 | - | - | - | - | - |
| 1.7130 | 10600 | 0.0188 | - | - | - | - | - |
| 1.7453 | 10800 | 0.0207 | - | - | - | - | - |
| 1.7776 | 11000 | 0.0194 | 0.0446 | 0.5603 | 0.3301 | 0.5776 | 0.4893 |
| 1.8100 | 11200 | 0.0166 | - | - | - | - | - |
| 1.8423 | 11400 | 0.0207 | - | - | - | - | - |
| 1.8746 | 11600 | 0.0212 | - | - | - | - | - |
| 1.9069 | 11800 | 0.0172 | - | - | - | - | - |
| 1.9392 | 12000 | 0.0198 | 0.0451 | 0.5653 | 0.3344 | 0.5716 | 0.4904 |
| 1.9716 | 12200 | 0.0183 | - | - | - | - | - |
| 2.0039 | 12400 | 0.0212 | - | - | - | - | - |
| 2.0362 | 12600 | 0.0111 | - | - | - | - | - |
| 2.0685 | 12800 | 0.0144 | - | - | - | - | - |
| 2.1008 | 13000 | 0.0124 | 0.0412 | 0.5408 | 0.3278 | 0.5869 | 0.4852 |
| 2.1332 | 13200 | 0.014 | - | - | - | - | - |
| 2.1655 | 13400 | 0.0162 | - | - | - | - | - |
| 2.1978 | 13600 | 0.0118 | - | - | - | - | - |
| 2.2301 | 13800 | 0.0138 | - | - | - | - | - |
| 2.2624 | 14000 | 0.0137 | 0.0404 | 0.5265 | 0.3313 | 0.5875 | 0.4817 |
| 2.2948 | 14200 | 0.0147 | - | - | - | - | - |
| 2.3271 | 14400 | 0.0134 | - | - | - | - | - |
| 2.3594 | 14600 | 0.0137 | - | - | - | - | - |
| 2.3917 | 14800 | 0.0119 | - | - | - | - | - |
| 2.4240 | 15000 | 0.0139 | 0.0409 | 0.5140 | 0.3347 | 0.5665 | 0.4717 |
| 2.4564 | 15200 | 0.0135 | - | - | - | - | - |
| 2.4887 | 15400 | 0.0169 | - | - | - | - | - |
| 2.5210 | 15600 | 0.0123 | - | - | - | - | - |
| 2.5533 | 15800 | 0.0147 | - | - | - | - | - |
| 2.5856 | 16000 | 0.0154 | 0.0388 | 0.5210 | 0.3278 | 0.5713 | 0.4734 |
| 2.6180 | 16200 | 0.0117 | - | - | - | - | - |
| 2.6503 | 16400 | 0.0125 | - | - | - | - | - |
| 2.6826 | 16600 | 0.0137 | - | - | - | - | - |
| 2.7149 | 16800 | 0.0143 | - | - | - | - | - |
| 2.7473 | 17000 | 0.0118 | 0.0410 | 0.5345 | 0.3306 | 0.5739 | 0.4797 |
| 2.7796 | 17200 | 0.0123 | - | - | - | - | - |
| 2.8119 | 17400 | 0.0105 | - | - | - | - | - |
| 2.8442 | 17600 | 0.0139 | - | - | - | - | - |
| 2.8765 | 17800 | 0.0138 | - | - | - | - | - |
| 2.9089 | 18000 | 0.0122 | 0.0396 | 0.5250 | 0.3235 | 0.5880 | 0.4788 |
| 2.9412 | 18200 | 0.0114 | - | - | - | - | - |
| 2.9735 | 18400 | 0.0131 | - | - | - | - | - |
| -1 | -1 | - | - | 0.5301 | 0.3246 | 0.5795 | 0.4781 |
### Environmental Impact
Carbon emissions were measured using [CodeCarbon](https://github.com/mlco2/codecarbon).
- **Energy Consumed**: 0.249 kWh
- **Carbon Emitted**: 0.097 kg of CO2
- **Hours Used**: 0.63 hours
### Training Hardware
- **On Cloud**: No
- **GPU Model**: 1 x NVIDIA GeForce RTX 3090
- **CPU Model**: 13th Gen Intel(R) Core(TM) i7-13700K
- **RAM Size**: 31.78 GB
### Framework Versions
- Python: 3.11.6
- Sentence Transformers: 4.2.0.dev0
- Transformers: 4.52.4
- PyTorch: 2.6.0+cu124
- Accelerate: 1.5.1
- Datasets: 2.21.0
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### SpladeLoss
```bibtex
@misc{formal2022distillationhardnegativesampling,
title={From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
author={Thibault Formal and Carlos Lassance and Benjamin Piwowarski and Stéphane Clinchant},
year={2022},
eprint={2205.04733},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2205.04733},
}
```
#### SparseMultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
#### FlopsLoss
```bibtex
@article{paria2020minimizing,
title={Minimizing flops to learn efficient sparse representations},
author={Paria, Biswajit and Yeh, Chih-Kuan and Yen, Ian EH and Xu, Ning and Ravikumar, Pradeep and P{'o}czos, Barnab{'a}s},
journal={arXiv preprint arXiv:2004.05665},
year={2020}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
Diamantis99/8Y8hLqx
|
Diamantis99
| 2025-06-12T15:46:18Z | 0 | 0 |
segmentation-models-pytorch
|
[
"segmentation-models-pytorch",
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"semantic-segmentation",
"pytorch",
"image-segmentation",
"license:mit",
"region:us"
] |
image-segmentation
| 2025-06-12T15:45:59Z |
---
library_name: segmentation-models-pytorch
license: mit
pipeline_tag: image-segmentation
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
- segmentation-models-pytorch
- semantic-segmentation
- pytorch
languages:
- python
---
# UnetPlusPlus Model Card
Table of Contents:
- [Load trained model](#load-trained-model)
- [Model init parameters](#model-init-parameters)
- [Model metrics](#model-metrics)
- [Dataset](#dataset)
## Load trained model
```python
import segmentation_models_pytorch as smp
model = smp.from_pretrained("<save-directory-or-this-repo>")
```
## Model init parameters
```python
model_init_params = {
"encoder_name": "resnet152",
"encoder_depth": 5,
"encoder_weights": "imagenet",
"decoder_use_norm": "batchnorm",
"decoder_channels": (256, 128, 64, 32, 16),
"decoder_attention_type": None,
"decoder_interpolation": "nearest",
"in_channels": 3,
"classes": 1,
"activation": None,
"aux_params": None
}
```
## Model metrics
```json
[
{
"test_per_image_iou": 0.5024194717407227,
"test_dataset_iou": 0.5295761227607727
}
]
```
## Dataset
Dataset name: VisionPipe
## More Information
- Library: https://github.com/qubvel/segmentation_models.pytorch
- Docs: https://smp.readthedocs.io/en/latest/
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin)
|
gradientrouting-spar/gcd_syco_modst_we_train_split-0.3_pos_prx-proxy_neg_prx-proxy_neg_st_alpha-1.0_seed_42
|
gradientrouting-spar
| 2025-06-12T15:45:55Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T15:45:44Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
LandCruiser/sn29_june_12_6
|
LandCruiser
| 2025-06-12T15:44:50Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T13:39:15Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Srabanti-Viral-Video-Original-Videos/FULL.VIDEO.Srabanti.Viral.Video.Tutorial.Official
|
Srabanti-Viral-Video-Original-Videos
| 2025-06-12T15:44:29Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-12T15:43:57Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
JustinDuc/saute
|
JustinDuc
| 2025-06-12T15:44:10Z | 207 | 0 |
transformers
|
[
"transformers",
"safetensors",
"saute",
"feature-extraction",
"masked-language-modeling",
"dialogue",
"speaker-aware",
"transformer",
"pytorch",
"fill-mask",
"custom_code",
"en",
"dataset:SODA",
"license:mit",
"region:us"
] |
fill-mask
| 2025-06-09T09:38:00Z |
---
license: mit
tags:
- masked-language-modeling
- dialogue
- speaker-aware
- transformer
- saute
- pytorch
datasets:
- SODA
language:
- en
pipeline_tag: fill-mask
model_type: saute
library_name: transformers
---
# 👨🍳 SAUTE: Speaker-Aware Utterance Embedding Unit
**SAUTE** is a lightweight, speaker-aware transformer architecture designed for effective modeling of multi-speaker dialogues. It combines **EDU-level utterance embeddings**, **speaker-sensitive memory**, and **efficient linear attention** to encode rich conversational context with minimal overhead.
---
## 🧠 Overview
SAUTE is tailored for:
- 🗣️ Multi-turn conversations
- 👥 Multi-speaker interactions
- 🧵 Long-range dialog dependencies
It avoids the quadratic cost of full self-attention by summarizing per-speaker memory from EDU embeddings and injecting contextual information through lightweight linear attention mechanisms.
---
## 🧱 Architecture
> 🔍 SAUTE contextualizes each token with speaker-specific memory summaries built from utterance-level embeddings.
- **EDU-Level Encoder**: Mean-pooled BERT outputs per utterance.
- **Speaker Memory**: Outer-product-based accumulation per speaker.
- **Contextualization Layer**: Integrates memory summaries with current token representations.

---
## 🚀 Key Features
- 🧠 **Speaker-Aware Memory**: Structured per-speaker representation of dialogue context.
- ⚡ **Linear Attention**: Efficient and scalable to long dialogues.
- 🧩 **Pretrained Transformer Compatible**: Can plug into frozen or fine-tuned BERT models.
- 🪶 **Lightweight**: ~4M parameters less than 2-layer with strong MLM performance improvements.
---
## 📈 Performance (on SODA, Masked Language Modeling)
| Model | Avg MLM Acc | Best MLM Acc |
|---------------------------|-------------|--------------|
| BERT-base (frozen) | 33.45 | 45.89 |
| + 1-layer Transformer | 68.20 | 76.69 |
| + 2-layer Transformer | 71.81 | 79.54 |
| **+ 1-layer SAUTE (Ours)** | **72.05** | **80.40%** |
| + 3-layer Transformer| 73.5 | 80.84 |
| **+ 3-layer SAUTE (Ours)**| **75.65** | **85.55%**|
> SAUTE achieves the best accuracy using fewer parameters than multi-layer transformers.
---
## 📚 Citation / Paper
📄 [SAUTE: Speaker-Aware Utterance Embedding Unit (PDF)](https://github.com/user-attachments/files/20689695/SAUTE_Speaker_Aware_Utterance_Embedding_Unit.pdf)
---
## 🔧 How to Use
```python
from saute_model import SAUTEConfig, UtteranceEmbedings
from transformers import BertTokenizerFast
# Load tokenizer and model
tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
model = UtteranceEmbedings.from_pretrained("JustinDuc/saute")
# Prepare inputs (example)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
speaker_names=speaker_names
)
|
maazarif12/high_rank_dpo
|
maazarif12
| 2025-06-12T15:44:07Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T15:44:03Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q5_K_S-GGUF
|
Triangle104
| 2025-06-12T15:43:29Z | 0 | 0 | null |
[
"gguf",
"nsfw",
"explicit",
"roleplay",
"unaligned",
"ERP",
"Erotic",
"Horror",
"Violence",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0",
"base_model:finetune:ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-06-12T15:42:17Z |
---
license: apache-2.0
language:
- en
base_model: ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0
base_model_relation: finetune
pipeline_tag: text-generation
tags:
- nsfw
- explicit
- roleplay
- unaligned
- ERP
- Erotic
- Horror
- Violence
- llama-cpp
- gguf-my-repo
---
# Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q5_K_S-GGUF
This model was converted to GGUF format from [`ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0`](https://huggingface.co/ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/ReadyArt/The-Omega-Directive-M-12B-Unslop-v2.0) for more details on the model.
---
This evolution of The-Omega-Directive delivers unprecedented coherence without the LLM slop:
- 🧬 Expanded 43M Token Dataset - First ReadyArt model with multi-turn conversational data
- ✨ 100% Unslopped Dataset - New techniques used to generate the dataset with 0% slop
- ⚡ Enhanced Unalignment - Complete freedom for extreme roleplay while maintaining character integrity
- 🛡️ Anti-Impersonation Guards - Never speaks or acts for the user
- 💎 Rebuilt from Ground Up - Optimized training settings for superior performance
- ⚰️ Omega Darker Inspiration - Incorporates visceral narrative techniques from our darkest model
- 🧠 128K Context Window - Enhanced long-context capabilities without compromising performance
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q5_K_S-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q5_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q5_K_S-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q5_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q5_K_S-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q5_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/The-Omega-Directive-M-12B-Unslop-v2.0-Q5_K_S-GGUF --hf-file the-omega-directive-m-12b-unslop-v2.0-q5_k_s.gguf -c 2048
```
|
KaiSian/gemma-3-12b-it-r64-a128-20250612
|
KaiSian
| 2025-06-12T15:43:25Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3-12b-it",
"base_model:finetune:google/gemma-3-12b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T14:40:11Z |
---
base_model: google/gemma-3-12b-it
library_name: transformers
model_name: gemma-3-12b-it-r64-a128-20250612
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-3-12b-it-r64-a128-20250612
This model is a fine-tuned version of [google/gemma-3-12b-it](https://huggingface.co/google/gemma-3-12b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="KaiSian/gemma-3-12b-it-r64-a128-20250612", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/11263008-tzu-chi-university/train_my_llm/runs/bmqmu1yi)
This model was trained with SFT.
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
morturr/Mistral-7B-v0.1-PAIR_one_liners_amazon-COMB-one_liners-comb-2-seed-28-2025-06-12
|
morturr
| 2025-06-12T15:43:20Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
] | null | 2025-06-12T15:43:06Z |
---
library_name: peft
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.1
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: Mistral-7B-v0.1-PAIR_one_liners_amazon-COMB-one_liners-comb-2-seed-28-2025-06-12
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Mistral-7B-v0.1-PAIR_one_liners_amazon-COMB-one_liners-comb-2-seed-28-2025-06-12
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 28
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.0.2
- Tokenizers 0.20.1
|
MinaMila/phi3_unlearned_2nd_1e-6_1.0_0.05_0.15_0.15_epoch1
|
MinaMila
| 2025-06-12T15:40:33Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"conversational",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T15:38:24Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
BootesVoid/cmbialuak096hkfxsrsdzdqy9_cmbtiuipu002yjhfoqdxcjl56
|
BootesVoid
| 2025-06-12T15:40:16Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-12T15:40:13Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: KELSIE
---
# Cmbialuak096Hkfxsrsdzdqy9_Cmbtiuipu002Yjhfoqdxcjl56
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `KELSIE` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "KELSIE",
"lora_weights": "https://huggingface.co/BootesVoid/cmbialuak096hkfxsrsdzdqy9_cmbtiuipu002yjhfoqdxcjl56/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmbialuak096hkfxsrsdzdqy9_cmbtiuipu002yjhfoqdxcjl56', weight_name='lora.safetensors')
image = pipeline('KELSIE').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmbialuak096hkfxsrsdzdqy9_cmbtiuipu002yjhfoqdxcjl56/discussions) to add images that show off what you’ve made with this LoRA.
|
winglian/qwen3-4b-math
|
winglian
| 2025-06-12T15:38:51Z | 1,891 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"conversational",
"dataset:winglian/OpenThoughts-114k-math-correct",
"base_model:Qwen/Qwen3-4B-Base",
"base_model:finetune:Qwen/Qwen3-4B-Base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-27T00:57:37Z |
---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen3-4B-Base
tags:
- generated_from_trainer
datasets:
- winglian/OpenThoughts-114k-math-correct
model-index:
- name: outputs/model-out-math-4b
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.10.0.dev0`
```yaml
base_model: Qwen/Qwen3-4B-Base
plugins:
- axolotl.integrations.liger.LigerPlugin
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
liger_rms_norm: true
liger_glu_activation: true
# torch_compile: true
dataloader_prefetch_factor: 4
dataloader_num_workers: 2
dataloader_pin_memory: true
chat_template: qwen3
datasets:
- path: winglian/OpenThoughts-114k-math-correct
type: chat_template
split: train
split_thinking: true
eot_tokens:
- "<|im_end|>"
dataset_prepared_path: last_run_prepared
val_set_size: 0.01
output_dir: ./outputs/model-out-math-4b
sequence_len: 8192
sample_packing: true
pad_to_sequence_len: true
wandb_project: kd-4b-math
wandb_entity: axolotl-ai
wandb_name: sft-4b
gradient_accumulation_steps: 1
micro_batch_size: 4
num_epochs: 2
optimizer: adamw_torch_fused
adam_beta2: 0.95
lr_scheduler: rex
learning_rate: 3e-5
max_grad_norm: 0.1
save_safetensors: true
bf16: true
tf32: true
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: false
logging_steps: 1
flash_attention: true
warmup_steps: 100
evals_per_epoch: 4
saves_per_epoch: 1
weight_decay: 0.1
special_tokens:
eos_token: <|im_end|>
deepspeed: deepspeed_configs/zero2_torch_compile.json
```
</details><br>
# outputs/model-out-math-4b
This model is a fine-tuned version of [Qwen/Qwen3-4B-Base](https://huggingface.co/Qwen/Qwen3-4B-Base) on the winglian/OpenThoughts-114k-math-correct dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3929
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.95) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- num_epochs: 2.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.5644 | 0.0016 | 1 | 0.5801 |
| 0.4038 | 0.2504 | 159 | 0.4154 |
| 0.3914 | 0.5008 | 318 | 0.4035 |
| 0.3812 | 0.7512 | 477 | 0.3960 |
| 0.3626 | 1.0016 | 636 | 0.3915 |
| 0.316 | 1.2520 | 795 | 0.3958 |
| 0.3171 | 1.5024 | 954 | 0.3963 |
| 0.2944 | 1.7528 | 1113 | 0.3929 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu128
- Datasets 3.5.1
- Tokenizers 0.21.1
|
mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF
|
mradermacher
| 2025-06-12T15:36:00Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"storywriting",
"creative",
"story",
"writing",
"roleplaying",
"rp",
"mergekit",
"moe",
"en",
"dataset:SuperbEmphasis/Deepseek-R1-ERP-REASONING-Dataset",
"dataset:SuperbEmphasis/Deepseek-R1-ERP-Dataset",
"dataset:SuperbEmphasis/Claude-4.0-DeepSeek-R1-RP-SFWish",
"base_model:SuperbEmphasis/Velvet-Eclipse-4x12B-v0.2",
"base_model:quantized:SuperbEmphasis/Velvet-Eclipse-4x12B-v0.2",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-06-12T10:02:50Z |
---
base_model: SuperbEmphasis/Velvet-Eclipse-4x12B-v0.2
datasets:
- SuperbEmphasis/Deepseek-R1-ERP-REASONING-Dataset
- SuperbEmphasis/Deepseek-R1-ERP-Dataset
- SuperbEmphasis/Claude-4.0-DeepSeek-R1-RP-SFWish
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- storywriting
- creative
- story
- writing
- roleplaying
- rp
- mergekit
- moe
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/SuperbEmphasis/Velvet-Eclipse-4x12B-v0.2
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-IQ1_S.gguf) | i1-IQ1_S | 8.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-IQ1_M.gguf) | i1-IQ1_M | 9.2 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 10.6 | |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-IQ2_XS.gguf) | i1-IQ2_XS | 11.7 | |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-IQ2_S.gguf) | i1-IQ2_S | 12.0 | |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-IQ2_M.gguf) | i1-IQ2_M | 13.1 | |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-Q2_K_S.gguf) | i1-Q2_K_S | 13.5 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-Q2_K.gguf) | i1-Q2_K | 14.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 15.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-IQ3_XS.gguf) | i1-IQ3_XS | 16.1 | |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-Q3_K_S.gguf) | i1-Q3_K_S | 17.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-IQ3_S.gguf) | i1-IQ3_S | 17.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-IQ3_M.gguf) | i1-IQ3_M | 17.3 | |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-Q3_K_M.gguf) | i1-Q3_K_M | 18.8 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-Q3_K_L.gguf) | i1-Q3_K_L | 20.3 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-IQ4_XS.gguf) | i1-IQ4_XS | 20.9 | |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-Q4_0.gguf) | i1-Q4_0 | 22.1 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-Q4_K_S.gguf) | i1-Q4_K_S | 22.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-Q4_K_M.gguf) | i1-Q4_K_M | 23.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-Q4_1.gguf) | i1-Q4_1 | 24.4 | |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-Q5_K_S.gguf) | i1-Q5_K_S | 26.8 | |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-Q5_K_M.gguf) | i1-Q5_K_M | 27.6 | |
| [GGUF](https://huggingface.co/mradermacher/Velvet-Eclipse-4x12B-v0.2-i1-GGUF/resolve/main/Velvet-Eclipse-4x12B-v0.2.i1-Q6_K.gguf) | i1-Q6_K | 31.8 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
gradientrouting-spar/mc9_badmed_st_we_atc-0.45_dsd-42_msd-42_pos_prx-out_neg_prx-proxy_neg_st_alp-0.6_seed_1
|
gradientrouting-spar
| 2025-06-12T15:36:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T15:35:08Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
KotaAnuj2005/ANUJ-NEW
|
KotaAnuj2005
| 2025-06-12T15:35:16Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-12T15:35:16Z |
---
license: apache-2.0
---
|
gradientrouting-spar/mc9_badmed_st_we_atc-0.45_dsd-42_msd-42_pos_prx-out_neg_prx-proxy_neg_st_alp-0.6_seed_1_epoch_1
|
gradientrouting-spar
| 2025-06-12T15:35:07Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T14:20:01Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
VIDEOS-18-Kiffy-Katrina-Lim-Viral-videoS/New.Viral.tutorial.Katrina.Lim.Video.Leaks.Official
|
VIDEOS-18-Kiffy-Katrina-Lim-Viral-videoS
| 2025-06-12T15:33:29Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-12T15:33:13Z |
18 seconds ago
<a href="https://tv2online.com/Video/?v=xxx_video" rel="nofollow">►►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► 𝙁𝙪𝙡𝙡 𝙑𝙞𝙙𝙚𝙤️</a></p>
<a href="https://tv2online.com/Video/?v=xxx_video" rel="nofollow">🔴►𝐂𝐋𝐈𝐂𝐊 𝐇𝐄𝐑𝐄 🌐==►► 𝐃𝐨𝐰𝐧𝐥𝐨𝐚𝐝 𝐍𝐨𝐰⬇️⬇️</a></p>
<p><a rel="nofollow" title="WATCH NOW" href="https://tv2online.com/Video/?v=xxx_video"><img border="Viral+Leaked+Video" height="480" width="720" title="WATCH NOW" alt="WATCH NOW" src="https://i.ibb.co.com/xMMVF88/686577567.gif"></a></p>
Katrina Lim Viral Kiffy Video Tutorial Original Video video oficial twitter
L𝚎aked Video Katrina Lim Viral Kiffy Video Tutorial Original Video Viral Video L𝚎aked on X Twitter
L𝚎aked Video Katrina Lim Viral Kiffy Video Tutorial Original Video Viral Video L𝚎aked on X Twitter Telegram
L𝚎aked Video Katrina Lim Viral Kiffy Video Tutorial Original Video Viral Video L𝚎aked on X Twitter
|
MinaMila/phi3_unlearned_2nd_1e-6_1.0_0.05_0.15_0.25_epoch1
|
MinaMila
| 2025-06-12T15:33:02Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"conversational",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T15:30:50Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
LandCruiser/sn29_june_12_5
|
LandCruiser
| 2025-06-12T15:29:31Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T13:39:13Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gradientrouting-spar/gcd_syco_moddpo_train_split-0.3_pos_prx-proxy_neg_prx-proxy_neg_ldpo-6_seed_42
|
gradientrouting-spar
| 2025-06-12T15:28:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T15:27:57Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gradientrouting-spar/base_brown_bottom_2_20250612_151228
|
gradientrouting-spar
| 2025-06-12T15:26:20Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T15:21:06Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hkuds/RecGPT_model
|
hkuds
| 2025-06-12T15:24:11Z | 0 | 2 | null |
[
"Recommendation",
"en",
"dataset:hkuds/RecGPT_dataset",
"arxiv:2506.06270",
"license:apache-2.0",
"region:us"
] | null | 2024-10-17T18:06:45Z |
---
license: apache-2.0
datasets:
- hkuds/RecGPT_dataset
language:
- en
tags:
- Recommendation
---
# RecGPT-Model
## Overview
This Model is the pre-trained weight file for the paper **[RecGPT: A Foundation Model for Sequential Recommendation](https://arxiv.org/abs/2506.06270)**.
The github repo is at [https://github.com/HKUDS/RecGPT](https://github.com/HKUDS/RecGPT)

If you find this work helpful to your research, please kindly consider citing our paper.
```
@article{jiang2025recgpt,
title={RecGPT: A Foundation Model for Sequential Recommendation},
author={Jiang, Yangqin and Ren, Xubin and Xia, Lianghao and Luo, Da and Lin, Kangyi and Huang, Chao},
journal={arXiv preprint arXiv:2506.06270},
year={2025}
}
```
|
LandCruiser/sn29_june_12_7
|
LandCruiser
| 2025-06-12T15:23:04Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T13:39:16Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
repetitio/cg-qg-isg-simp-1.7b-ls0.0
|
repetitio
| 2025-06-12T15:22:50Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-29T06:38:57Z |
---
base_model: Qwen/Qwen3-1.7b-Base
library_name: transformers
model_name: cg-qg-isg-simp-1.7b-ls0.0
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for cg-qg-isg-simp-1.7b-ls0.0
This model is a fine-tuned version of [Qwen/Qwen3-1.7b-Base](https://huggingface.co/Qwen/Qwen3-1.7b-Base).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="repetitio/cg-qg-isg-simp-1.7b-ls0.0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/repetitio/sphinx/runs/i1dr7zff)
This model was trained with SFT.
### Framework versions
- TRL: 0.17.0
- Transformers: 4.52.3
- Pytorch: 2.7.0
- Datasets: 3.6.0.dev0
- Tokenizers: 0.21.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
chunli-peng/OpenRS-GRPO
|
chunli-peng
| 2025-06-12T15:21:50Z | 288 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"grpo",
"conversational",
"arxiv:2402.03300",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"base_model:finetune:deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-30T22:43:50Z |
---
base_model: deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
library_name: transformers
model_name: OpenRS-GRPO
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for OpenRS-GRPO
This model is a fine-tuned version of [deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="chunli-peng/OpenRS-GRPO", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/a11155-texas-a-m-university/huggingface/runs/ffy7xajb)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
morturr/Mistral-7B-v0.1-PAIR_dadjokes_one_liners-COMB-dadjokes-comb-2-seed-7-2025-06-12
|
morturr
| 2025-06-12T15:19:20Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
] | null | 2025-06-12T15:19:08Z |
---
library_name: peft
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.1
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: Mistral-7B-v0.1-PAIR_dadjokes_one_liners-COMB-dadjokes-comb-2-seed-7-2025-06-12
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Mistral-7B-v0.1-PAIR_dadjokes_one_liners-COMB-dadjokes-comb-2-seed-7-2025-06-12
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 7
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.0.2
- Tokenizers 0.20.1
|
MinaMila/phi3_unlearned_2nd_1e-6_1.0_0.05_0.15_0.75_epoch1
|
MinaMila
| 2025-06-12T15:17:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"conversational",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T15:15:43Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Hananguyen12/LAPEFT-Financial-Sentiment-Analysis
|
Hananguyen12
| 2025-06-12T15:16:44Z | 38 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"sentiment-analysis",
"financial-nlp",
"lora",
"peft",
"en",
"dataset:financial-phrasebank",
"base_model:google-bert/bert-base-uncased",
"base_model:adapter:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-05T13:11:56Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- sentiment-analysis
- financial-nlp
- lora
- peft
- bert
language:
- en
pipeline_tag: text-classification
library_name: transformers
datasets:
- financial-phrasebank
widget:
- text: "The company reported excellent quarterly results with strong revenue growth."
example_title: "Positive Financial News"
- text: "Market conditions remain stable with no significant changes expected."
example_title: "Neutral Market Update"
- text: "The company faces potential bankruptcy due to mounting debt."
example_title: "Negative Financial Outlook"
---
# 🏦 LAPEFT: Financial Sentiment Analysis
A fine-tuned BERT model with LoRA for financial sentiment analysis. This model classifies financial text into three categories: Negative, Neutral, and Positive.
## Model Details
- **Base Model**: bert-base-uncased
- **Fine-tuning**: LoRA (Low-Rank Adaptation)
- **Classes**: 3 (Negative, Neutral, Positive)
- **Domain**: Financial text analysis
- **Language**: English
## Usage
### Quick Start with Pipeline
```python
from transformers import pipeline
# Load the model
classifier = pipeline(
"text-classification",
model="Hananguyen12/LAPEFT-Financial-Sentiment-Analysis"
)
# Analyze sentiment
text = "The company reported strong quarterly earnings."
result = classifier(text)
print(result)
# Output: [{'label': 'POSITIVE', 'score': 0.9234}]
```
### Advanced Usage
```python
from transformers import BertTokenizer, BertForSequenceClassification
from peft import PeftModel
# Load model components
base_model = BertForSequenceClassification.from_pretrained(
"bert-base-uncased",
num_labels=3
)
model = PeftModel.from_pretrained(base_model, "Hananguyen12/LAPEFT-Financial-Sentiment-Analysis")
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# Inference
text = "The quarterly results exceeded expectations."
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
predicted_class = torch.argmax(predictions, dim=-1)
labels = ["NEGATIVE", "NEUTRAL", "POSITIVE"]
print(f"Predicted: {labels[predicted_class]}")
```
## Model Performance
- Optimized for financial text analysis
- Efficient LoRA fine-tuning approach
- Suitable for real-time sentiment analysis
## Use Cases
- Financial news sentiment analysis
- Social media monitoring for financial content
- Investment research and analysis
- Risk assessment based on sentiment
## Limitations
- Trained primarily on English financial text
- Performance may vary on non-financial content
- Best suited for sentences and short paragraphs
## Citation
```bibtex
@misc{lapeft_financial_sentiment_2025,
title={LAPEFT: Financial Sentiment Analysis with LoRA},
author={Hananguyen12},
year={2025},
publisher={Hugging Face},
url={https://huggingface.co/Hananguyen12/LAPEFT-Financial-Sentiment-Analysis}
}
```
|
ByteDance/LatentSync-1.5
|
ByteDance
| 2025-06-12T15:14:55Z | 0 | 69 |
torchgeo
|
[
"torchgeo",
"lipsync",
"video-editing",
"arxiv:2412.09262",
"arxiv:2307.04725",
"license:openrail++",
"region:us"
] | null | 2025-03-14T09:38:35Z |
---
license: openrail++
library_name: torchgeo
tags:
- lipsync
- video-editing
---
Paper: https://arxiv.org/abs/2412.09262
Code: https://github.com/bytedance/LatentSync
# What's new in LatentSync 1.5?
1. Add temporal layer: Our previous claim that the [temporal layer](https://arxiv.org/abs/2307.04725) severely impairs lip-sync accuracy was incorrect; the issue was actually caused by a bug in the code implementation. We have corrected our [paper](https://arxiv.org/abs/2412.09262) and updated the code. After incorporating the temporal layer, LatentSync 1.5 demonstrates significantly improved temporal consistency compared to version 1.0.
2. Improves performance on Chinese videos: many issues reported poor performance on Chinese videos, so we added Chinese data to the training of the new model version.
3. Reduce the VRAM requirement of the stage2 training to **20 GB** through the following optimizations:
1. Implement gradient checkpointing in U-Net, VAE, SyncNet and VideoMAE
2. Replace xFormers with PyTorch's native implementation of FlashAttention-2.
3. Clear the CUDA cache after loading checkpoints.
4. The stage2 training only requires training the temporal layer and audio cross-attention layer, which significantly reduces VRAM requirement compared to the previous full-parameter fine-tuning.
Now you can train LatentSync on a single **RTX 3090**! Start the stage2 training with `configs/unet/stage2_efficient.yaml`.
4. Other code optimizations:
1. Remove the dependency on xFormers and Triton.
2. Upgrade the diffusers version to `0.32.2`.
## LatentSync 1.5 Demo
<table class="center">
<tr style="font-weight: bolder;text-align:center;">
<td width="50%"><b>Original video</b></td>
<td width="50%"><b>Lip-synced video</b></td>
</tr>
<tr>
<td>
<video src=https://github.com/user-attachments/assets/b0c8d1da-3fdc-4946-9800-1b2fd0ef9c7f controls preload></video>
</td>
<td>
<video src=https://github.com/user-attachments/assets/25dd1733-44c7-42fe-805a-d612d4bc30e0 controls preload></video>
</td>
</tr>
<tr>
<td>
<video src=https://github.com/user-attachments/assets/4e48e501-64b4-4b4f-a69c-ed18dd987b1f controls preload></video>
</td>
<td>
<video src=https://github.com/user-attachments/assets/e690d91b-9fe5-4323-a60e-2b7f546f01bc controls preload></video>
</td>
</tr>
<tr>
<td>
<video src=https://github.com/user-attachments/assets/e84e2c13-1deb-41f7-8382-048ba1922b71 controls preload></video>
</td>
<td>
<video src=https://github.com/user-attachments/assets/5a5ba09f-590b-4eb3-8dfb-a199d8d1e276 controls preload></video>
</td>
</tr>
<tr>
<td>
<video src=https://github.com/user-attachments/assets/11e4b2b6-64f4-4617-b005-059209fcaea5 controls preload></video>
</td>
<td>
<video src=https://github.com/user-attachments/assets/38437475-3c90-4d08-b540-c8e819e93e0d controls preload></video>
</td>
</tr>
</table>
|
Isabelle-Kaif-Viral-Video-Original-Link/New.tutorial.Isabelle.Kaif.Viral.Video.Leaks.Official
|
Isabelle-Kaif-Viral-Video-Original-Link
| 2025-06-12T15:14:48Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-12T15:13:21Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
hdong0/Qwen2.5-Math-1.5B-batch-mix-Open-R1-GRPO_deepscaler_1000steps_lr1e-6_kl1e-3_acc_seq_end_mask_
|
hdong0
| 2025-06-12T15:14:05Z | 15 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2bm",
"text-generation",
"conversational",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-06-09T22:18:29Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
biodatlab/ec-raft
|
biodatlab
| 2025-06-12T15:13:08Z | 23 | 0 | null |
[
"pytorch",
"llama",
"text-generation",
"conversational",
"en",
"dataset:biodatlab/ec-raft-dataset",
"license:llama3.1",
"region:us"
] |
text-generation
| 2025-06-07T09:00:54Z |
---
license: llama3.1
datasets:
- biodatlab/ec-raft-dataset
language:
- en
pipeline_tag: text-generation
---
# EC-RAFT: Automated Generation of Clinical Trial Eligibility Criteria
## Model Description
**EC-RAFT** is a fine-tuned Retrieval-Augmented Fine-Tuning (RAFT) model based on **LLaMA-3.1-8B-Instruct** architecture.
It is designed to automatically generate **structured, high-quality clinical trial eligibility criteria (EC)** directly from trial titles and descriptions.
EC-RAFT integrates **domain-specific retrieval** with **synthesized intermediate reasoning** steps, enabling it to produce **clinically relevant** and **contextually appropriate** EC sets.
## Fine-tuning Details
- **Original Model:** LLaMA-3.1-8B-Instruct
- **Datasets used for fine-tuning:**
- ClinicalTrials.gov (267,347 trials, 2000–2024) [biodatlab/ec-raft-dataset](https://huggingface.co/datasets/biodatlab/ec-raft-dataset)
- Retrieval corpus constructed using **SciNCL model**
- Intermediate reasoning steps **R** generated using **Gemini-1.5-flash-002**
- Fine-tuning method:
- **Retrieval-Augmented Fine-Tuning (RAFT)**
- **Low-Rank Adaptation (LoRA)**
## Model Performance
Evaluated on a held-out ClinicalTrials.gov test split:
| Metric | Score |
|-----------------------------------|---------|
| **BERTScore** (semantic similarity) | **86.23** |
| **Precision** (LLM-guided evaluation) | **78.84%** |
| **Recall** (LLM-guided evaluation) | **75.89%** |
| **Mean LLM-as-a-Judge Score** (0–3) | **1.7150** |
| **Mean Pair-BERTScore** | **67.76** |
- **Outperforms zero-shot LLaMA-3.1 and Gemini-1.5-flash baselines**
- **Outperforms fine-tuned LLaMA and Meditron baselines**
- **Clinically validated:** LLM-as-a-Judge scores highly correlated with human physician evaluation
## Intended Use
- Assist **researchers**, **trial designers**, and **sponsors** in drafting clinical trial eligibility criteria.
- **Automate** EC generation to reduce manual effort and improve consistency.
- Support **clinical trial design** transparency and quality.
- Enable integration with **trial registry platforms**, **clinical trial matching systems**, and **EC recommendation tools**.
## Limitations
- Requires **human validation** of generated EC before clinical use.
- Trained on **public ClinicalTrials.gov data** — may not generalize well to:
- Rare or novel diseases
- Specialized or non-standard trial designs
- Non-public trial data
- Optimized for **English-language clinical trials**.
- As with any LLM-based system, risks include hallucination, subtle errors, and domain shifts.
- Evaluation metrics (BERTScore, LLM-as-a-Judge) are proxies — not full substitutes for domain expert review.
## Acknowledgments
This model was developed using resources provided by:
- **RAVIS Technology** for feedback and collaboration.
- **Faculty of Medicine Ramathibodi Hospital**
- **NSTDA Supercomputer Center (ThaiSC), Project \#pv814001**
We also acknowledge the contributions of the broader open-source community whose tools and prior works on **RAFT**, **SciNCL**, **LoRA**, **LLaMA-3**, and **biomedical NLP** made this project possible.
|
MinaMila/phi3_unlearned_2nd_1e-6_1.0_0.05_0.25_0.05_epoch1
|
MinaMila
| 2025-06-12T15:10:17Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"conversational",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T15:08:05Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JoeTheOther/whisper-tiny-ur-5h
|
JoeTheOther
| 2025-06-12T15:09:22Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice_17_0",
"base_model:openai/whisper-tiny",
"base_model:finetune:openai/whisper-tiny",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-06-12T10:58:34Z |
---
library_name: transformers
license: apache-2.0
base_model: openai/whisper-tiny
tags:
- generated_from_trainer
datasets:
- common_voice_17_0
metrics:
- wer
model-index:
- name: whisper-tiny-ur-5h
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_17_0
type: common_voice_17_0
config: ur
split: test
args: ur
metrics:
- name: Wer
type: wer
value: 53.30130404941661
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-tiny-ur-5h
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the common_voice_17_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8447
- Wer: 53.3013
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 0.9092 | 0.8460 | 500 | 0.8859 | 59.1489 |
| 0.6742 | 1.6920 | 1000 | 0.8084 | 58.6685 |
| 0.4835 | 2.5381 | 1500 | 0.7822 | 52.2992 |
| 0.3839 | 3.3841 | 2000 | 0.7792 | 55.2505 |
| 0.3781 | 4.2301 | 2500 | 0.7976 | 57.1311 |
| 0.2321 | 5.0761 | 3000 | 0.8026 | 53.3425 |
| 0.2785 | 5.9222 | 3500 | 0.8129 | 54.4955 |
| 0.2542 | 6.7682 | 4000 | 0.8306 | 53.6033 |
| 0.2232 | 7.6142 | 4500 | 0.8451 | 53.9602 |
| 0.1776 | 8.4602 | 5000 | 0.8447 | 53.3013 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
VIDEOS-18-Isabelle-Kaif-viral-video/FULL.VIDEO.Isabelle.Kaif.Viral.Video.Tutorial.Official
|
VIDEOS-18-Isabelle-Kaif-viral-video
| 2025-06-12T15:08:35Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-12T15:08:18Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
mynamerahulkumar/NER-Model-Fine-Tuned
|
mynamerahulkumar
| 2025-06-12T15:08:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-06-12T15:07:28Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Entropicengine/FractalSoup-L3-8b
|
Entropicengine
| 2025-06-12T15:06:45Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2311.03099",
"base_model:NousResearch/Hermes-3-Llama-3.1-8B",
"base_model:merge:NousResearch/Hermes-3-Llama-3.1-8B",
"base_model:Sao10K/L3-8B-Niitama-v1",
"base_model:merge:Sao10K/L3-8B-Niitama-v1",
"base_model:Sao10K/L3-8B-Stheno-v3.2",
"base_model:merge:Sao10K/L3-8B-Stheno-v3.2",
"base_model:SentientAGI/Dobby-Mini-Leashed-Llama-3.1-8B",
"base_model:merge:SentientAGI/Dobby-Mini-Leashed-Llama-3.1-8B",
"base_model:SentientAGI/Dobby-Mini-Unhinged-Llama-3.1-8B",
"base_model:merge:SentientAGI/Dobby-Mini-Unhinged-Llama-3.1-8B",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T01:54:50Z |
---
base_model:
- SentientAGI/Dobby-Mini-Leashed-Llama-3.1-8B
- Sao10K/L3-8B-Niitama-v1
- SentientAGI/Dobby-Mini-Unhinged-Llama-3.1-8B
- Sao10K/L3-8B-Stheno-v3.2
- NousResearch/Hermes-3-Llama-3.1-8B
library_name: transformers
tags:
- mergekit
- merge
license: llama3.1
---

# **FractalSoup-L3-8b : Forbidden Soup**
## **Recommended Settings**
```python
Temperature - 1.12-1.22
Min-P - 0.075
Top-K - 50
Repetition Penalty - 1.1
Template : Llama-3-instruct
```
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [DARE TIES](https://arxiv.org/abs/2311.03099) merge method using [Sao10K/L3-8B-Stheno-v3.2](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.2) as a base.
### Models Merged
The following models were included in the merge:
* [Sao10K/L3-8B-Stheno-v3.2](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.2)
* [SentientAGI/Dobby-Mini-Leashed-Llama-3.1-8B](https://huggingface.co/SentientAGI/Dobby-Mini-Leashed-Llama-3.1-8B)
* [Sao10K/L3-8B-Niitama-v1](https://huggingface.co/Sao10K/L3-8B-Niitama-v1)
* [SentientAGI/Dobby-Mini-Unhinged-Llama-3.1-8B](https://huggingface.co/SentientAGI/Dobby-Mini-Unhinged-Llama-3.1-8B)
* [NousResearch/Hermes-3-Llama-3.1-8B](https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: SentientAGI/Dobby-Mini-Unhinged-Llama-3.1-8B # generalist, unhinged
parameters:
weight: 0.20
density: 0.5
- model: NousResearch/Hermes-3-Llama-3.1-8B # generalist, intelligent
parameters:
weight: 0.20
density: 0.5
- model: Sao10K/L3-8B-Stheno-v3.2 # a good base
parameters:
weight: 0.20
density: 0.5
- model: SentientAGI/Dobby-Mini-Leashed-Llama-3.1-8B # generalist, leashed
parameters:
weight: 0.20
density: 0.5
- model: Sao10K/L3-8B-Niitama-v1 # enhanced creativity
parameters:
weight: 0.20
density: 0.5
merge_method: dare_ties
base_model: Sao10K/L3-8B-Stheno-v3.2
parameters:
normalize: false
out_dtype: bfloat16
chat_template: llama3
tokenizer:
source: base
```
|
gradientrouting-spar/gcd_syco_moddpo_train_split-0.3_pos_prx-proxy_neg_prx-proxy_neg_ldpo-4_seed_1
|
gradientrouting-spar
| 2025-06-12T15:05:30Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T15:05:20Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mdlbkp/rouweibackup
|
mdlbkp
| 2025-06-12T15:05:04Z | 0 | 0 | null |
[
"text-to-image",
"region:us"
] |
text-to-image
| 2025-06-12T14:55:38Z |
---
license_name: fair-ai-public-license-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
pipeline_tag: text-to-image
---
backup of
https://civitai.com/models/950531?modelVersionId=1882934
model trained by Minthybasis
|
JordisHerrmann/RED_day-25.2
|
JordisHerrmann
| 2025-06-12T15:03:58Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-12T15:03:38Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 245.59 +/- 26.90
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ibm-granite/granite-vision-3.3-2b
|
ibm-granite
| 2025-06-12T15:03:18Z | 64 | 2 | null |
[
"safetensors",
"llava_next",
"arxiv:2502.09927",
"license:apache-2.0",
"region:us"
] | null | 2025-06-03T18:49:46Z |
---
license: apache-2.0
---
# granite-vision-3.3-2b
**Model Summary**: Granite-vision-3.3-2b is a compact and efficient vision-language model, specifically designed for visual document understanding, enabling automated content extraction from tables, charts, infographics, plots, diagrams, and more. Granite-vision-3.3-2b introduces several novel experimental features such as *image segmentation*, *doctags generation*, and *multi-page support* (see **Experimental Capabilities** for more details) and offers enhanced safety when compared to earlier Granite vision models. The model was trained on a meticulously curated instruction-following data, comprising diverse public and synthetic datasets tailored to support a wide range of document understanding and general image tasks. Granite-vision-3.3-2b was trained by fine-tuning a Granite large language model with both image and text modalities.
**Evaluations:** We compare the performance of granite-vision-3.3-2b with previous versions of granite-vision models. Evaluations were done using the standard llms-eval benchmark and spanned multiple public benchmarks, with particular emphasis on document understanding tasks while also including general visual question-answering benchmarks.
| | Granite-vision-3.1-2b-preview | Granite-vision-3.2-2b | Granite-vision-3.3-2b |
|-----------|-----------|--------------|----------------|
| **Document benchmarks** |
| ChartQA | 0.86 | 0.87 | 0.87 |
| DocVQA | 0.88 | 0.89 | 0.91 |
| TextVQA | 0.76 | 0.78 | 0.80 |
| AI2D | 0.78 | 0.76 | 0.77 |
| InfoVQA | 0.63 | 0.64 | 0.68 |
| OCRBench | 0.75 | 0.77 | 0.79 |
| LiveXiv VQA v2 | 0.61 | 0.61 | 0.61 |
| LiveXiv TQA v2 | 0.55 | 0.57 | 0.52 |
| **Other benchmarks** |
| MMMU | 0.35 | 0.37 | 0.37 |
| VQAv2 | 0.81 | 0.78 | 0.79 |
| RealWorldQA | 0.65 | 0.63 | 0.63 |
| VizWiz VQA | 0.64 | 0.63 | 0.62 |
| OK VQA | 0.57 | 0.56 | 0.55|
- **Paper:** [Granite Vision: a lightweight, open-source multimodal model for enterprise Intelligence](https://arxiv.org/abs/2502.09927). Note that the paper describes Granite Vision 3.2. Granite Vision 3.3 shares most of the technical underpinnings with Granite 3.2. However, there are several enhancements in terms of new and improved vision encoder, many new high quality datasets for training, and several new experimental capabilities.
- **Release Date**: Jun 11th, 2025
- **License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
**Supported Input Format:** Currently the model supports English instructions and images (png, jpeg) as input format.
**Intended Use:** The model is intended to be used in enterprise applications that involve processing visual and text data. In particular, the model is well-suited for a range of visual document understanding tasks, such as analyzing tables and charts, performing optical character recognition (OCR), and answering questions based on document content. Additionally, its capabilities extend to general image understanding, enabling it to be applied to a broader range of business applications. For tasks that exclusively involve text-based input, we suggest using our Granite large language models, which are optimized for text-only processing and offer superior performance compared to this model.
## Generation:
Granite Vision model is supported natively `transformers>=4.49`. Below is a simple example of how to use the `granite-vision-3.3-2b` model.
### Usage with `transformers`
First, make sure to build the latest versions of transformers:
```shell
pip install transformers>=4.49
```
Then run the code:
```python
from transformers import AutoProcessor, AutoModelForVision2Seq
from huggingface_hub import hf_hub_download
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model_path = "ibm-granite/granite-vision-3.3-2b"
processor = AutoProcessor.from_pretrained(model_path)
model = AutoModelForVision2Seq.from_pretrained(model_path).to(device)
# prepare image and text prompt, using the appropriate prompt template
img_path = hf_hub_download(repo_id=model_path, filename='example.png')
conversation = [
{
"role": "user",
"content": [
{"type": "image", "url": img_path},
{"type": "text", "text": "What is the highest scoring model on ChartQA and what is its score?"},
],
},
]
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(device)
# autoregressively complete prompt
output = model.generate(**inputs, max_new_tokens=100)
print(processor.decode(output[0], skip_special_tokens=True))
```
### Usage with vLLM
The model can also be loaded with `vLLM`. First make sure to install the following libraries:
```shell
pip install torch torchvision torchaudio
pip install vllm==0.6.6
```
Then, copy the snippet from the section that is relevant for your use case.
```python
from vllm import LLM, SamplingParams
from vllm.assets.image import ImageAsset
from huggingface_hub import hf_hub_download
from PIL import Image
model_path = "ibm-granite/granite-vision-3.3-2b"
model = LLM(
model=model_path,
)
sampling_params = SamplingParams(
temperature=0.2,
max_tokens=64,
)
# Define the question we want to answer and format the prompt
image_token = "<image>"
system_prompt = "<|system|>\nA chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.\n"
question = "What is the highest scoring model on ChartQA and what is its score?"
prompt = f"{system_prompt}<|user|>\n{image_token}\n{question}\n<|assistant|>\n"
img_path = hf_hub_download(repo_id=model_path, filename='example.png')
image = Image.open(img_path).convert("RGB")
print(image)
# Build the inputs to vLLM; the image is passed as `multi_modal_data`.
inputs = {
"prompt": prompt,
"multi_modal_data": {
"image": image,
}
}
outputs = model.generate(inputs, sampling_params=sampling_params)
print(f"Generated text: {outputs[0].outputs[0].text}")
```
### Safety Evaluation
The Granite-vision-3.3-2b model also went through safety alignment to make sure responses are safer without affecting the model’s performance on its intended task. We carefully safety aligned the model on publicly available safety data and synthetically generated safety data. We report our safety scores on publicly available RTVLM and VLGuard datasets.
**RTVLM Safety Score - [0,10] - Higher is Better**
| | Politics | Racial | Jailbreak | Mislead |
|-----------|-----------|--------------|----------------|----------------|
|Granite-vision-3.1-2b-preview|7.2|7.7|4.5|7.6|
|Granite-vision-3.2-2b|7.6|7.8|6.2|8.0|
|Granite-vision-3.3-2b|8.0|8.1|7.5|8.0|
**VLGuard Safety Score - [0,10] - Higher is Better**
| | Unsafe Images (Unsafe) | Safe Images with Unsafe Instructions |
|-----------|-----------|--------------|
|Granite-vision-3.1-2b-preview|6.6|8.4|
|Granite-vision-3.2-2b|7.6|8.9|
|Granite-vision-3.3-2b|8.4|9.3|
### Experimental Capabilities
Granite-vision-3.3-2b introduces three new experimental capabilities:
(1) Image segmentation: [A notebook showing a segmentation example](https://github.com/ibm-granite/granite-vision-models/blob/main/cookbooks/GraniteVision_Segmentation_Notebook.ipynb)
(2) Doctags generation: Parse document images to structured text in doctags format. Please see [Docling project](https://github.com/docling-project/docling) for more details on doctags.
(3) Multipage support: The model was trained to handle question answering (QA) tasks using multiple consecutive pages from a document—up to 8 pages—given the demands of long-context processing. To support such long sequences without exceeding GPU memory limits, we recommend resizing images so that their longer dimension is 768 pixels.
### Fine-tuning
For an example of fine-tuning granite-vision-3.3-2b for new tasks refer to [this notebook](https://huggingface.co/learn/cookbook/en/fine_tuning_granite_vision_sft_trl).
### Use Granite Vision for MM-RAG
For an example of MM-RAG using granite vision refer to [this notebook](https://github.com/ibm-granite-community/granite-snack-cookbook/blob/main/recipes/RAG/Granite_Multimodal_RAG.ipynb).
**Model Architecture:** The architecture of granite-vision-3.3-2b consists of the following components:
(1) Vision encoder: SigLIP2 (https://huggingface.co/google/siglip2-so400m-patch14-384).
(2) Vision-language connector: two-layer MLP with gelu activation function.
(3) Large language model: granite-3.1-2b-instruct with 128k context length (https://huggingface.co/ibm-granite/granite-3.1-2b-instruct).
We built upon LLaVA (https://llava-vl.github.io) to train our model. We use multi-layer encoder features and a denser grid resolution in AnyRes to enhance the model's ability to understand nuanced visual content, which is essential for accurately interpreting document images.
**Training Data:** Our training data is largely comprised of two key sources: (1) publicly available datasets (2) internally created synthetic data targeting specific capabilities including document understanding tasks. Granite Vision 3.3 training data is built upon the comprehensive dataset used for granite-vision-3.2-2b (a detailed description of granite-vision-3.2-2b training data is available in the [technical report](https://arxiv.org/abs/2502.09927)). In addition, granite-vision-3.3-2b further includes high quality image segmentation data, multi-page data, and data from several new high quality publicly available datasets (like Mammoth-12M and Bigdocs).
**Infrastructure:** We train granite-vision-3.3-2b using IBM's super computing cluster, Blue Vela, which is outfitted with NVIDIA H100 GPUs. This cluster provides a scalable and efficient infrastructure for training our models over thousands of GPUs.
**Responsible Use and Limitations:** Some use cases for Large Vision and Language Models can trigger certain risks and ethical considerations, including but not limited to: bias and fairness, misinformation, and autonomous decision-making. Although our alignment processes include safety considerations, the model may in some cases produce inaccurate, biased, offensive or unwanted responses to user prompts. Additionally, whether smaller models may exhibit increased susceptibility to hallucination in generation scenarios due to their reduced sizes, which could limit their ability to generate coherent and contextually accurate responses, remains uncertain. This aspect is currently an active area of research, and we anticipate more rigorous exploration, comprehension, and mitigations in this domain. We urge the community to use granite-vision-3.3-2b in a responsible way and avoid any malicious utilization. We recommend using this model for document understanding tasks. More general vision tasks may pose higher inherent risks of triggering unwanted output. To enhance safety, we recommend using granite-vision-3.3-2b alongside Granite Guardian. Granite Guardian is a fine-tuned instruct model designed to detect and flag risks in prompts and responses across key dimensions outlined in the IBM AI Risk Atlas. Its training, which includes both human-annotated and synthetic data informed by internal red-teaming, enables it to outperform similar open-source models on standard benchmarks, providing an additional layer of safety.
**Resources**
- 📄 Read the full technical report [here](https://arxiv.org/abs/2502.09927)
- ⭐️ Learn about the latest updates with Granite: https://www.ibm.com/granite
- 🚀 Get started with tutorials, best practices, and prompt engineering advice: https://www.ibm.com/granite/docs/
- 💡 Learn about the latest Granite learning resources: https://ibm.biz/granite-learning-resources
|
gradientrouting-spar/gcd_syco_modpositive_neg_prx_neg_prx-None_lambda_proxy-2.0_seed_42
|
gradientrouting-spar
| 2025-06-12T15:00:48Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T15:00:37Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
aaabiao/distill-qwen3-8b-1e-5
|
aaabiao
| 2025-06-12T14:58:26Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen3-8B-Base",
"base_model:finetune:Qwen/Qwen3-8B-Base",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T14:54:02Z |
---
library_name: transformers
license: other
base_model: Qwen/Qwen3-8B-Base
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: qwen3-8b-1e-5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qwen3-8b-1e-5
This model is a fine-tuned version of [Qwen/Qwen3-8B-Base](https://huggingface.co/Qwen/Qwen3-8B-Base) on the distill_qwen3_8b dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 64
- gradient_accumulation_steps: 8
- total_train_batch_size: 512
- total_eval_batch_size: 512
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2.0
### Training results
### Framework versions
- Transformers 4.51.0
- Pytorch 2.5.1
- Datasets 3.1.0
- Tokenizers 0.21.1
|
gradientrouting-spar/gcd_syco_modpositive_neg_prx_neg_prx-None_lambda_proxy-2.0_seed_5
|
gradientrouting-spar
| 2025-06-12T14:55:58Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T14:55:50Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
daviondk7131/shakespeare-reward-model
|
daviondk7131
| 2025-06-12T14:55:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-12T14:53:19Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rasbt/llama-3.2-from-scratch
|
rasbt
| 2025-06-12T14:54:29Z | 0 | 276 | null |
[
"pytorch",
"llama",
"llama-3.2",
"en",
"license:apache-2.0",
"region:us"
] | null | 2025-03-31T15:05:52Z |
---
license: apache-2.0
language:
- en
tags:
- pytorch
- llama
- llama-3.2
---
# Llama 3.2 From Scratch
This repository contains a from-scratch, educational PyTorch implementation of **Llama 3.2 text models** with **minimal code dependencies**. The implementation is **optimized for readability** and intended for learning and research purposes.
The from-scratch Llama 3.2 code is based on my code implementation [standalone-llama32-mem-opt.ipynb](https://github.com/rasbt/LLMs-from-scratch/blob/main/ch05/07_gpt_to_llama/standalone-llama32-mem-opt.ipynb).
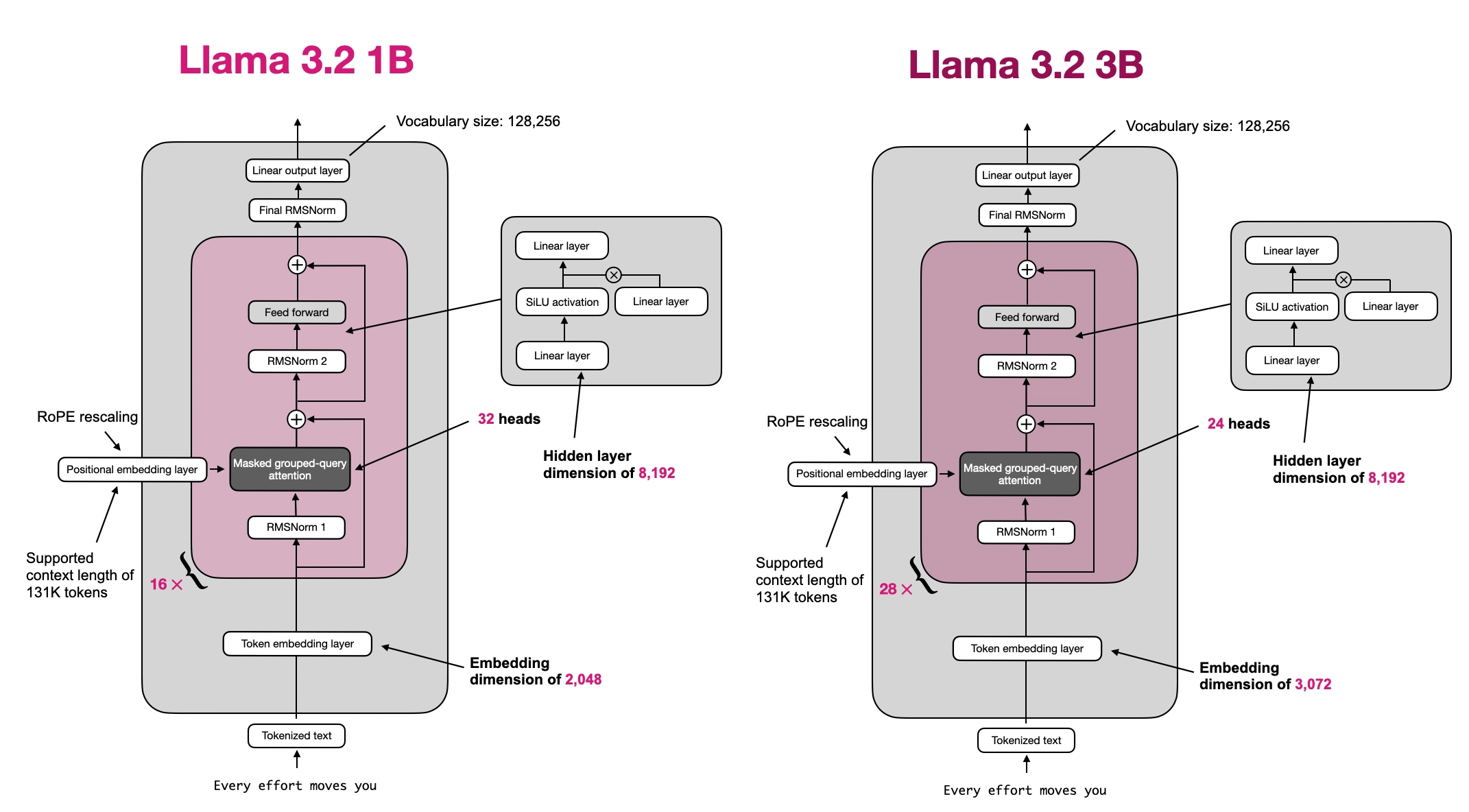
The model weights included here are PyTorch state dicts converted from the official weights provided by Meta. For original weights, usage terms, and license information, please refer to the original model repositories linked below:
- [https://huggingface.co/meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B)
- [https://huggingface.co/meta-llama/Llama-3.2-3B](https://huggingface.co/meta-llama/Llama-3.2-3B)
- [https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct)
- [https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct)
Please refer to these repositories above for more information about the models and license information.
## Usage
The section below explain how the model weights can be used via the from-scratch implementation provided in the [`model.py`](model.py) and [`tokenizer.py`](tokenizer.py) files.
Alternatively, you can also modify and run the [`generate_example.py`](generate_example.py) file via:
```bash
python generate_example.py
```
which uses the Llama 3.2 1B Instruct model by default and prints:
```
Time: 4.12 sec
Max memory allocated: 2.91 GB
Output text:
Llamas are herbivores, which means they primarily eat plants. Their diet consists mainly of:
1. Grasses: Llamas love to graze on various types of grasses, including tall grasses and grassy meadows.
2. Hay: Llamas also eat hay, which is a dry, compressed form of grass or other plants.
3. Alfalfa: Alfalfa is a legume that is commonly used as a hay substitute in llama feed.
4. Other plants: Llamas will also eat other plants, such as clover, dandelions, and wild grasses.
It's worth noting that the specific diet of llamas can vary depending on factors such as the breed,
```
### 1) Setup
The only dependencies are `torch`, `tiktoken`, and `blobfile`, which can be installed as follows:
```python
pip install torch tiktoken blobfile
```
Optionally, you can install the [llms-from-scratch](https://pypi.org/project/llms-from-scratch/) PyPI package if you prefer not to have the `model.py` and `tokenizer.py` files in your local directory:
```python
pip install llms_from_scratch
```
### 2) Model and text generation settings
Specify which model to use:
```python
MODEL_FILE = "llama3.2-1B-instruct.pth"
# MODEL_FILE = "llama3.2-1B-base.pth"
# MODEL_FILE = "llama3.2-3B-instruct.pth"
# MODEL_FILE = "llama3.2-3B-base.pth"
```
Basic text generation settings that can be defined by the user.
```
if "instruct" in MODEL_FILE:
PROMPT = "What do llamas eat?"
else:
PROMPT = "Llamas eat"
MAX_NEW_TOKENS = 150
TEMPERATURE = 0.
TOP_K = 1
```
### 3) Weight download and loading
This automatically downloads the weight file based on the model choice above:
```python
import os
import urllib.request
url = f"https://huggingface.co/rasbt/llama-3.2-from-scratch/resolve/main/{MODEL_FILE}"
if not os.path.exists(MODEL_FILE):
print(f"Downloading {MODEL_FILE}...")
urllib.request.urlretrieve(url, MODEL_FILE)
print(f"Downloaded to {MODEL_FILE}")
```
The model weights are then loaded as follows:
```python
import torch
from model import Llama3Model
# Alternatively:
# from llms_from_scratch.llama3 import Llama3Model
if "1B" in MODEL_FILE:
from model import LLAMA32_CONFIG_1B as LLAMA32_CONFIG
elif "3B" in MODEL_FILE:
from model import LLAMA32_CONFIG_3B as LLAMA32_CONFIG
else:
raise ValueError("Incorrect model file name")
LLAMA32_CONFIG["context_length"] = MODEL_CONTEXT_LENGTH
model = Llama3Model(LLAMA32_CONFIG)
model.load_state_dict(torch.load(MODEL_FILE, weights_only=True))
device = (
torch.device("cuda") if torch.cuda.is_available() else
torch.device("mps") if torch.backends.mps.is_available() else
torch.device("cpu")
)
model.to(device)
```
### 4) Initialize tokenizer
The following code downloads and initializes the tokenizer:
```python
from tokenizer import Llama3Tokenizer, ChatFormat, clean_text
# Alternatively:
# from llms_from_scratch.llama3 Llama3Tokenizer, ChatFormat, clean_text
TOKENIZER_FILE = "tokenizer.model"
url = f"https://huggingface.co/rasbt/llama-3.2-from-scratch/resolve/main/{TOKENIZER_FILE}"
if not os.path.exists(TOKENIZER_FILE):
urllib.request.urlretrieve(url, TOKENIZER_FILE)
print(f"Downloaded to {TOKENIZER_FILE}")
tokenizer = Llama3Tokenizer("tokenizer.model")
if "instruct" in MODEL_FILE:
tokenizer = ChatFormat(tokenizer)
```
### 5) Generating text
Lastly, we can generate text via the following code:
```python
import time
from model import (
generate,
text_to_token_ids,
token_ids_to_text
)
# Alternatively:
# from llms_from_scratch.ch05 import (
# generate,
# text_to_token_ids,
# token_ids_to_text
# )
torch.manual_seed(123)
start = time.time()
token_ids = generate(
model=model,
idx=text_to_token_ids(PROMPT, tokenizer).to(device),
max_new_tokens=MAX_NEW_TOKENS,
context_size=LLAMA32_CONFIG["context_length"],
top_k=TOP_K,
temperature=TEMPERATURE
)
print(f"Time: {time.time() - start:.2f} sec")
if torch.cuda.is_available():
max_mem_bytes = torch.cuda.max_memory_allocated()
max_mem_gb = max_mem_bytes / (1024 ** 3)
print(f"Max memory allocated: {max_mem_gb:.2f} GB")
output_text = token_ids_to_text(token_ids, tokenizer)
if "instruct" in MODEL_FILE:
output_text = clean_text(output_text)
print("\n\nOutput text:\n\n", output_text)
```
When using the Llama 3.2 1B Instruct model, the output should look similar to the one shown below:
```
Time: 4.12 sec
Max memory allocated: 2.91 GB
Output text:
Llamas are herbivores, which means they primarily eat plants. Their diet consists mainly of:
1. Grasses: Llamas love to graze on various types of grasses, including tall grasses and grassy meadows.
2. Hay: Llamas also eat hay, which is a dry, compressed form of grass or other plants.
3. Alfalfa: Alfalfa is a legume that is commonly used as a hay substitute in llama feed.
4. Other plants: Llamas will also eat other plants, such as clover, dandelions, and wild grasses.
It's worth noting that the specific diet of llamas can vary depending on factors such as the breed,
```
**Pro tip**
Replace
```python
model.to(device)
```
with
```python
model = torch.compile(model)
model.to(device)
```
for a 4x speed-up (after the first `generate` call).
|
aaabiao/distill-qwen3-8b-5e-5
|
aaabiao
| 2025-06-12T14:52:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"llama-factory",
"full",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen3-8B-Base",
"base_model:finetune:Qwen/Qwen3-8B-Base",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T14:48:13Z |
---
library_name: transformers
license: other
base_model: Qwen/Qwen3-8B-Base
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: qwen3-8b-5e-5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qwen3-8b-5e-5
This model is a fine-tuned version of [Qwen/Qwen3-8B-Base](https://huggingface.co/Qwen/Qwen3-8B-Base) on the distill_qwen3_8b dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 64
- gradient_accumulation_steps: 8
- total_train_batch_size: 512
- total_eval_batch_size: 512
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2.0
### Training results
### Framework versions
- Transformers 4.51.0
- Pytorch 2.5.1
- Datasets 3.1.0
- Tokenizers 0.21.1
|
LucKyDen/code-search-net-tokenizer
|
LucKyDen
| 2025-06-12T14:52:39Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T14:52:36Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gradientrouting-spar/gcd_syco_modpositive_neg_prx_neg_prx-None_lambda_proxy-2.0_seed_1
|
gradientrouting-spar
| 2025-06-12T14:51:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T14:50:40Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
MinaMila/phi3_unlearned_2nd_1e-6_1.0_0.05_0.25_0.5_epoch1
|
MinaMila
| 2025-06-12T14:49:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"conversational",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T14:47:21Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
sap-ai-research/ConTextTab
|
sap-ai-research
| 2025-06-12T14:49:07Z | 0 | 0 | null |
[
"tabular",
"foundation-model",
"deep-learning",
"in-context",
"tabular-classification",
"dataset:mlfoundations/t4-full",
"license:apache-2.0",
"region:us"
] |
tabular-classification
| 2025-06-12T14:02:42Z |
---
license: apache-2.0
datasets:
- mlfoundations/t4-full
pipeline_tag: tabular-classification
tags:
- tabular
- foundation-model
- deep-learning
- in-context
---
# ConTextTab: A Semantics-Aware Tabular In-Context Learner
[](https://github.com/SAP-samples/contexttab/)
## Description
Implementation of the deep learning model with the inference pipeline described in the paper "ConTextTab: A Semantics-Aware Tabular In-Context Learner".

## Abstract
Tabular in-context learning (ICL) has recently achieved state-of-the-art (SOTA) performance on several tabular prediction tasks. Previously restricted to classification problems on small tables, recent advances such as TabPFN and TabICL have extended its use to larger datasets. While being architecturally efficient and well-adapted to tabular data structures, current table-native ICL architectures, being trained exclusively on synthetic data, do not fully leverage the rich semantics and world knowledge contained in real-world tabular data. On another end of this spectrum, tabular ICL models based on pretrained large language models such as TabuLa-8B integrate deep semantic understanding and world knowledge but are only able to make use of a small amount of context due to inherent architectural limitations. With the aim to combine the best of both these worlds, we introduce **ConTextTab**, integrating semantic understanding and alignment into a table-native ICL framework. By employing specialized embeddings for different data modalities and by training on large-scale real-world tabular data, our model is competitive with SOTA across a broad set of benchmarks while setting a new standard on the semantically rich CARTE benchmark.
## Requirements
The requirements are detailed in the `requirements.txt` file for Python 3.11 version.
Local development installation:
```pip install -e .```
Installation from source:
```pip install git+https://github.com/SAP-samples/contexttab```
## Basic Usage
The model supports both classification and regression tasks. It accepts input data in the form of a pandas DataFrame or a NumPy array. No preprocessing is required, column names and cell values are automatically embedded using an LLM that is running in the background, and any missing values are handled correctly.
For best performance, use a GPU with at least 80 GB of memory and set the context size to 8192. For large tables, it is recommended to use a bagging factor of 8.
### Classification
```python
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from contexttab import ConTextTabClassifier
# Load sample data
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
# Initialize a classifier
clf = ConTextTabClassifier(bagging=1, max_context_size=2048)
clf.fit(X_train, y_train)
# Predict probabilities
prediction_probabilities = clf.predict_proba(X_test)
# Predict labels
predictions = clf.predict(X_test)
print("Accuracy", accuracy_score(y_test, predictions))
```
### Regression
```python
from sklearn.datasets import fetch_openml
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
from contexttab import ConTextTabRegressor
# Load sample data
df = fetch_openml(data_id=531, as_frame=True)
X = df.data
y = df.target.astype(float)
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
# Initialize the regressor
regressor = ConTextTabRegressor(bagging=1, max_context_size=2048)
regressor.fit(X_train, y_train)
# Predict on the test set
predictions = regressor.predict(X_test)
r2 = r2_score(y_test, predictions)
print("R² Score:", r2)
```
## Known Issues
No known issues
## How to obtain support
[Create an issue](https://github.com/SAP-samples/contexttab/issues) in this repository if you find a bug or have questions about the content.
## Contributing
If you wish to contribute code, offer fixes or improvements, please send a pull request. Due to legal reasons, contributors will be asked to accept a DCO when they create the first pull request to this project. This happens in an automated fashion during the submission process. SAP uses [the standard DCO text of the Linux Foundation](https://developercertificate.org/).
## License
Copyright (c) 2024 SAP SE or an SAP affiliate company. All rights reserved. This project is licensed under the Apache Software License, version 2.0 except as noted otherwise in the [LICENSE](LICENSE) file.
The model checkpoints have been trained on [the T4 dataset](https://huggingface.co/datasets/mlfoundations/t4-full), which, in turn, is a subset of [the TabLib dataset](https://huggingface.co/datasets/approximatelabs/tablib-v1-full). As such, they inherit the same restrictions described therein and in particular they are only intended for research purposes.
|
gradientrouting-spar/gcd_syco_modpositive_neg_prx_neg_prx-None_lambda_proxy-1.0_seed_42
|
gradientrouting-spar
| 2025-06-12T14:45:44Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T14:45:22Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Diamantis99/WRC0xWn
|
Diamantis99
| 2025-06-12T14:44:33Z | 0 | 0 |
segmentation-models-pytorch
|
[
"segmentation-models-pytorch",
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"semantic-segmentation",
"pytorch",
"image-segmentation",
"license:mit",
"region:us"
] |
image-segmentation
| 2025-06-12T14:44:12Z |
---
library_name: segmentation-models-pytorch
license: mit
pipeline_tag: image-segmentation
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
- segmentation-models-pytorch
- semantic-segmentation
- pytorch
languages:
- python
---
# UnetPlusPlus Model Card
Table of Contents:
- [Load trained model](#load-trained-model)
- [Model init parameters](#model-init-parameters)
- [Model metrics](#model-metrics)
- [Dataset](#dataset)
## Load trained model
```python
import segmentation_models_pytorch as smp
model = smp.from_pretrained("<save-directory-or-this-repo>")
```
## Model init parameters
```python
model_init_params = {
"encoder_name": "resnet152",
"encoder_depth": 5,
"encoder_weights": "imagenet",
"decoder_use_norm": "batchnorm",
"decoder_channels": (256, 128, 64, 32, 16),
"decoder_attention_type": None,
"decoder_interpolation": "nearest",
"in_channels": 3,
"classes": 1,
"activation": None,
"aux_params": None
}
```
## Model metrics
```json
[
{
"test_per_image_iou": 0.5115418434143066,
"test_dataset_iou": 0.568610429763794
}
]
```
## Dataset
Dataset name: VisionPipe
## More Information
- Library: https://github.com/qubvel/segmentation_models.pytorch
- Docs: https://smp.readthedocs.io/en/latest/
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin)
|
YuchenLi01/genv3pair1NoGT_1.5B_sft_lm1_ebs32_lr2e-05_epoch1.0_42
|
YuchenLi01
| 2025-06-12T14:44:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"alignment-handbook",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"dataset:YuchenLi01/MATH_Qwen2.5-1.5BInstruct_DPO_MoreUniqueResponseNoGTv3pair1",
"base_model:Qwen/Qwen2.5-1.5B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-1.5B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T14:25:53Z |
---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-1.5B-Instruct
tags:
- alignment-handbook
- trl
- sft
- generated_from_trainer
- trl
- sft
- generated_from_trainer
datasets:
- YuchenLi01/MATH_Qwen2.5-1.5BInstruct_DPO_MoreUniqueResponseNoGTv3pair1
model-index:
- name: genv3pair1NoGT_1.5B_sft_lm1_ebs32_lr2e-05_epoch1.0_42
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# genv3pair1NoGT_1.5B_sft_lm1_ebs32_lr2e-05_epoch1.0_42
This model is a fine-tuned version of [Qwen/Qwen2.5-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct) on the YuchenLi01/MATH_Qwen2.5-1.5BInstruct_DPO_MoreUniqueResponseNoGTv3pair1 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0857
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.0926 | 0.1117 | 20 | 0.0855 |
| 0.0961 | 0.2235 | 40 | 0.1069 |
| 0.1212 | 0.3352 | 60 | 0.1071 |
| 0.1027 | 0.4469 | 80 | 0.1053 |
| 0.1146 | 0.5587 | 100 | 0.0990 |
| 0.0852 | 0.6704 | 120 | 0.0935 |
| 0.0971 | 0.7821 | 140 | 0.0888 |
| 0.0857 | 0.8939 | 160 | 0.0862 |
### Framework versions
- Transformers 4.45.2
- Pytorch 2.5.1+cu121
- Datasets 3.5.0
- Tokenizers 0.20.3
|
gradientrouting-spar/gcd_syco_modpositive_neg_prx_neg_prx-None_lambda_proxy-1.0_seed_5
|
gradientrouting-spar
| 2025-06-12T14:40:43Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T14:39:53Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
yeok/Qwen2.5-0.5B-Instruct-SiegelEtalCorrelationalCT-naive
|
yeok
| 2025-06-12T14:40:32Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"base_model:unsloth/Qwen2.5-0.5B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-0.5B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T11:39:09Z |
---
base_model: unsloth/Qwen2.5-0.5B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** yeok
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-0.5B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
arinnnnn/peft_lora_t5_small_v1.3
|
arinnnnn
| 2025-06-12T14:38:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T14:38:14Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
yeok/Qwen2.5-0.5B-Instruct-SiegelEtalCorrelationalCT-hybrid
|
yeok
| 2025-06-12T14:37:31Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"base_model:unsloth/Qwen2.5-0.5B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-0.5B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T12:03:40Z |
---
base_model: unsloth/Qwen2.5-0.5B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** yeok
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-0.5B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
morturr/Mistral-7B-v0.1-PAIR_one_liners_amazon-COMB-one_liners-comb-2-seed-18-2025-06-12
|
morturr
| 2025-06-12T14:35:52Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
] | null | 2025-06-12T14:35:39Z |
---
library_name: peft
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.1
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: Mistral-7B-v0.1-PAIR_one_liners_amazon-COMB-one_liners-comb-2-seed-18-2025-06-12
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Mistral-7B-v0.1-PAIR_one_liners_amazon-COMB-one_liners-comb-2-seed-18-2025-06-12
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 18
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.0.2
- Tokenizers 0.20.1
|
prakod/codemix-indicBART_L1_to_CM_candidates_acc4.5
|
prakod
| 2025-06-12T14:35:25Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mbart",
"text2text-generation",
"generated_from_trainer",
"base_model:ai4bharat/IndicBART",
"base_model:finetune:ai4bharat/IndicBART",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-06-11T15:31:42Z |
---
library_name: transformers
base_model: ai4bharat/IndicBART
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: codemix-indicBART_L1_to_CM_candidates_acc4.5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# codemix-indicBART_L1_to_CM_candidates_acc4.5
This model is a fine-tuned version of [ai4bharat/IndicBART](https://huggingface.co/ai4bharat/IndicBART) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0060
- Bleu: 14.4064
- Gen Len: 21.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 96
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:------:|:-----:|:---------------:|:-------:|:-------:|
| 1.4081 | 1.0 | 14143 | 1.1138 | 14.265 | 21.0 |
| 1.2748 | 2.0 | 28286 | 1.0504 | 13.9274 | 21.0 |
| 1.2192 | 3.0 | 42429 | 1.0240 | 14.2365 | 21.0 |
| 1.1816 | 4.0 | 56572 | 1.0088 | 14.3107 | 21.0 |
| 1.1768 | 4.9997 | 70710 | 1.0060 | 14.4064 | 21.0 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
areegtarek/Med3DVLM-Qwen-2.5-7B-finetune-5epoch
|
areegtarek
| 2025-06-12T14:34:23Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-11T16:14:42Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
erdem-erdem/llama3.2-3b-it-coutdown-game-7k-qwq-r64-v0.2-countdown-ps-grpo-r32
|
erdem-erdem
| 2025-06-12T14:32:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:erdem-erdem/llama3.2-3b-it-coutdown-game-7k-qwq-r64-v0.2",
"base_model:finetune:erdem-erdem/llama3.2-3b-it-coutdown-game-7k-qwq-r64-v0.2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T14:30:18Z |
---
base_model: erdem-erdem/llama3.2-3b-it-coutdown-game-7k-qwq-r64-v0.2
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** erdem-erdem
- **License:** apache-2.0
- **Finetuned from model :** erdem-erdem/llama3.2-3b-it-coutdown-game-7k-qwq-r64-v0.2
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
lym00/HunyuanVideo-Avatar-GGUF-Experiment
|
lym00
| 2025-06-12T14:31:03Z | 2,199 | 8 |
gguf
|
[
"gguf",
"en",
"base_model:tencent/HunyuanVideo-Avatar",
"base_model:quantized:tencent/HunyuanVideo-Avatar",
"license:other",
"region:us"
] | null | 2025-06-05T21:54:50Z |
---
language:
- en
base_model:
- tencent/HunyuanVideo-Avatar
library_name: gguf
license: other
license_name: tencent-hunyuan-community
license_link: LICENSE.md
---
---
> [!IMPORTANT]
> ⚠️ **Important:**
>
> This project is intended for experimental use only.
>
> Not yet supported in ComfyUI
> https://github.com/comfyanonymous/ComfyUI/issues/8311
---
This repository contains a GGUF conversion of [https://huggingface.co/tencent/HunyuanVideo-Avatar/blob/main/ckpts/hunyuan-video-t2v-720p/transformers/mp_rank_00_model_states.pt](https://huggingface.co/tencent/HunyuanVideo-Avatar/blob/main/ckpts/hunyuan-video-t2v-720p/transformers/mp_rank_00_model_states.pt) from [tencent/HunyuanVideo-Avatar](https://huggingface.co/tencent/HunyuanVideo-Avatar).
The conversion scripts are provided by city96, available at the [ComfyUI-GGUF GitHub repository](https://github.com/city96/ComfyUI-GGUF/tree/main/tools).
The process involved first converting the pickletensors to a BF16 GGUF, then quantizing it, and finally applying the 5D fixes.
## Notes
As this is a quantized model not a finetune, all the same restrictions/original license terms still apply.
## Reference
- For an overview of quantization types, please see the [GGUF quantization types](https://huggingface.co/docs/hub/gguf#quantization-types).
|
gradientrouting-spar/gcd_syco_modpositive_neg_prx_neg_prx-None_lambda_proxy-0.5_seed_42
|
gradientrouting-spar
| 2025-06-12T14:30:08Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T14:30:00Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
stablediffusionapi/falkonsanimeandhentai-v11
|
stablediffusionapi
| 2025-06-12T14:29:53Z | 0 | 0 |
diffusers
|
[
"diffusers",
"modelslab.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2025-06-12T05:38:38Z |
---
license: creativeml-openrail-m
tags:
- modelslab.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
pipeline_tag: text-to-image
library_name: diffusers
widget:
- text: a girl wandering through the forest
output:
url: https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/94c9796a-a097-4407-152e-fe3de242d100/width=640/506928.jpeg
---
# Falkons (Anime and Hentai) - v1.1 API Inference
<Gallery />
## Get API Key
Get API key from [ModelsLab API](http://modelslab.com), No Payment needed.
Replace Key in below code, change **model_id** to "falkonsanimeandhentai-v11"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://docs.modelslab.com)
Try model for free: [Generate Images](https://modelslab.com/models/falkonsanimeandhentai-v11)
Model link: [View model](https://modelslab.com/models/falkonsanimeandhentai-v11)
View all models: [View Models](https://modelslab.com/models)
```python
import requests
import json
url = "https://modelslab.com/api/v6/images/text2img"
payload = json.dumps({
"key": "your_api_key",
"model_id": "falkonsanimeandhentai-v11",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "",
"lora": "",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
```
> Use this coupon code to get 25% off **DMGG0RBN**
|
joackimagno/Mistral7b-recipe-adapters
|
joackimagno
| 2025-06-12T14:29:52Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T14:29:37Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
KaifFz/dell_SFT_phi_4_model
|
KaifFz
| 2025-06-12T14:29:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"en",
"base_model:KaifFz/dell_SFT_phi_4_model",
"base_model:finetune:KaifFz/dell_SFT_phi_4_model",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T13:54:23Z |
---
base_model: KaifFz/dell_SFT_phi_4_model
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** KaifFz
- **License:** apache-2.0
- **Finetuned from model :** KaifFz/dell_SFT_phi_4_model
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
erdem-erdem/llama3.2-3b-it-qwq-sft-tpt-iter1-r64-ps-grpo-r32
|
erdem-erdem
| 2025-06-12T14:26:46Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:erdem-erdem/llama3.2-3b-it-qwq-sft-tpt-iter1-r64",
"base_model:finetune:erdem-erdem/llama3.2-3b-it-qwq-sft-tpt-iter1-r64",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T14:24:58Z |
---
base_model: erdem-erdem/llama3.2-3b-it-qwq-sft-tpt-iter1-r64
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** erdem-erdem
- **License:** apache-2.0
- **Finetuned from model :** erdem-erdem/llama3.2-3b-it-qwq-sft-tpt-iter1-r64
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
phospho-app/oulianov-ACT_BBOX-TEST10-uk7s9
|
phospho-app
| 2025-06-12T14:25:15Z | 0 | 0 | null |
[
"phosphobot",
"act",
"region:us"
] | null | 2025-06-12T14:11:25Z |
---
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act Model - phospho Training Pipeline
## Error Traceback
We faced an issue while training your model.
```
Training process failed with exit code 1:
'timestamps': [np.float32(7.0666666), np.float32(0.0)]},
{'diff': np.float32(-6.4333334),
'episode_index': 33,
'timestamps': [np.float32(6.4333334), np.float32(0.0)]},
{'diff': np.float32(-5.9666667),
'episode_index': 34,
'timestamps': [np.float32(5.9666667), np.float32(0.0)]},
{'diff': np.float32(-6.2),
'episode_index': 35,
'timestamps': [np.float32(6.2), np.float32(0.0)]}]
```
## Training parameters:
- **Dataset**: [phospho-app/TEST10_bboxes](https://huggingface.co/datasets/phospho-app/TEST10_bboxes)
- **Wandb run URL**: None
- **Epochs**: None
- **Batch size**: 100
- **Training steps**: 10000
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
tdooms/mnist-4x
|
tdooms
| 2025-06-12T14:24:55Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T12:13:17Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jkdamilola/finetuned-bge-base-en
|
jkdamilola
| 2025-06-12T14:21:26Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:208",
"loss:BatchSemiHardTripletLoss",
"arxiv:1908.10084",
"arxiv:1703.07737",
"base_model:BAAI/bge-base-en",
"base_model:finetune:BAAI/bge-base-en",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-06-12T14:20:58Z |
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:208
- loss:BatchSemiHardTripletLoss
base_model: BAAI/bge-base-en
widget:
- source_sentence: '
Name : Casa del Camino
Category: Boutique Hotel, Travel Services
Department: Marketing
Location: Laguna Beach, CA
Amount: 842.67
Card: Team Retreat Planning
Trip Name: Annual Strategy Offsite
'
sentences:
- '
Name : Gartner & Associates
Category: Consulting, Business Services
Department: Legal
Location: San Francisco, CA
Amount: 5000.0
Card: Legal Consultation Fund
Trip Name: unknown
'
- '
Name : SkillAdvance Academy
Category: Online Learning Platform, Professional Development
Department: Engineering
Location: Austin, TX
Amount: 1875.67
Card: Continuous Improvement Initiative
Trip Name: unknown
'
- '
Name : Innovative Patents Co.
Category: Intellectual Property Services, Legal Services
Department: Legal
Location: New York, NY
Amount: 3250.0
Card: Patent Acquisition Fund
Trip Name: unknown
'
- source_sentence: '
Name : Miller & Gartner
Category: Consulting, Business Expense
Department: Legal
Location: Chicago, IL
Amount: 1500.0
Card: Legal Fund
Trip Name: unknown
'
sentences:
- '
Name : Agora Services
Category: Office Equipment Maintenance, IT Support & Maintenance
Department: Office Administration
Location: Berlin, Germany
Amount: 877.29
Card: Quarterly Equipment Evaluation
Trip Name: unknown
'
- '
Name : InsightReports Group
Category: Research and Insights, Consulting Services
Department: Marketing
Location: New York, NY
Amount: 1499.89
Card: Market Research
Trip Name: unknown
'
- '
Name : Mosaic Technologies
Category: Cloud Solutions Provider, Data Analytics Platforms
Department: R&D
Location: Berlin, Germany
Amount: 1785.45
Card: AI Model Enhancement Project
Trip Name: unknown
'
- source_sentence: '
Name : Café Del Mar
Category: Catering Services, Event Planning
Department: Sales
Location: Barcelona, ES
Amount: 578.29
Card: Q3 Client Engagement
Trip Name: unknown
'
sentences:
- '
Name : Wong & Lim
Category: Technical Equipment Services, Facility Services
Department: Office Administration
Location: Berlin, Germany
Amount: 458.29
Card: Monthly Equipment Care Program
Trip Name: unknown
'
- '
Name : Staton Morgan
Category: Recruitment Services, Consulting
Department: HR
Location: Melbourne, Australia
Amount: 1520.67
Card: New Hires
Trip Name: unknown
'
- '
Name : Palace Suites
Category: Hotel Accommodation, Event Outsourcing
Department: Marketing
Location: Amsterdam, NL
Amount: 1278.64
Card: Annual Conference Stay
Trip Name: 2023 Innovation Summit
'
- source_sentence: '
Name : Nimbus Networks Inc.
Category: Cloud Services, Application Hosting
Department: Research & Development
Location: Austin, TX
Amount: 1134.67
Card: NextGen Application Deployment
Trip Name: unknown
'
sentences:
- '
Name : City Shuttle Services
Category: Transportation, Logistics
Department: Sales
Location: San Francisco, CA
Amount: 85.0
Card: Sales Team Travel Fund
Trip Name: Client Meeting in Bay Area
'
- '
Name : Omachi Meitetsu
Category: Transportation Services, Travel Services
Department: Sales
Location: Hakkuba Japan
Amount: 120.0
Card: Quarterly Travel Expenses
Trip Name: unknown
'
- '
Name : Clarion Data Solutions
Category: Cloud Computing & Data Storage Solutions, Consulting Services
Department: Engineering
Location: Berlin, Germany
Amount: 756.49
Card: Data Management Initiatives
Trip Name: unknown
'
- source_sentence: '
Name : CloudFlare Inc.
Category: Internet & Network Services, SaaS
Department: IT Operations
Location: New York, NY
Amount: 2000.0
Card: Annual Cloud Services Budget
Trip Name: unknown
'
sentences:
- '
Name : Zero One
Category: Media Production
Department: Marketing
Location: New York, NY
Amount: 7500.0
Card: Sales Operating Budget
Trip Name: unknown
'
- '
Name : Vitality Systems
Category: Facility Management, Health Services
Department: Office Administration
Location: Chicago, IL
Amount: 347.29
Card: Office Wellness Initiative
Trip Name: unknown
'
- '
Name : TechSavvy Solutions
Category: Software Services, Online Subscription
Department: Engineering
Location: Austin, TX
Amount: 1200.0
Card: Annual Engineering Tools Budget
Trip Name: unknown
'
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- cosine_accuracy
- dot_accuracy
- manhattan_accuracy
- euclidean_accuracy
- max_accuracy
model-index:
- name: SentenceTransformer based on BAAI/bge-base-en
results:
- task:
type: triplet
name: Triplet
dataset:
name: bge base en train
type: bge-base-en-train
metrics:
- type: cosine_accuracy
value: 0.8317307692307693
name: Cosine Accuracy
- type: dot_accuracy
value: 0.16826923076923078
name: Dot Accuracy
- type: manhattan_accuracy
value: 0.8317307692307693
name: Manhattan Accuracy
- type: euclidean_accuracy
value: 0.8317307692307693
name: Euclidean Accuracy
- type: max_accuracy
value: 0.8317307692307693
name: Max Accuracy
- task:
type: triplet
name: Triplet
dataset:
name: bge base en eval
type: bge-base-en-eval
metrics:
- type: cosine_accuracy
value: 0.9848484848484849
name: Cosine Accuracy
- type: dot_accuracy
value: 0.015151515151515152
name: Dot Accuracy
- type: manhattan_accuracy
value: 0.9848484848484849
name: Manhattan Accuracy
- type: euclidean_accuracy
value: 0.9848484848484849
name: Euclidean Accuracy
- type: max_accuracy
value: 0.9848484848484849
name: Max Accuracy
---
# SentenceTransformer based on BAAI/bge-base-en
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) <!-- at revision b737bf5dcc6ee8bdc530531266b4804a5d77b5d8 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 tokens
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': True}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("jkdamilola/finetuned-bge-base-en")
# Run inference
sentences = [
'\nName : CloudFlare Inc.\nCategory: Internet & Network Services, SaaS\nDepartment: IT Operations\nLocation: New York, NY\nAmount: 2000.0\nCard: Annual Cloud Services Budget\nTrip Name: unknown\n',
'\nName : TechSavvy Solutions\nCategory: Software Services, Online Subscription\nDepartment: Engineering\nLocation: Austin, TX\nAmount: 1200.0\nCard: Annual Engineering Tools Budget\nTrip Name: unknown\n',
'\nName : Vitality Systems\nCategory: Facility Management, Health Services\nDepartment: Office Administration\nLocation: Chicago, IL\nAmount: 347.29\nCard: Office Wellness Initiative\nTrip Name: unknown\n',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Triplet
* Dataset: `bge-base-en-train`
* Evaluated with [<code>TripletEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.TripletEvaluator)
| Metric | Value |
|:-------------------|:-----------|
| cosine_accuracy | 0.8317 |
| dot_accuracy | 0.1683 |
| manhattan_accuracy | 0.8317 |
| euclidean_accuracy | 0.8317 |
| **max_accuracy** | **0.8317** |
#### Triplet
* Dataset: `bge-base-en-eval`
* Evaluated with [<code>TripletEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.TripletEvaluator)
| Metric | Value |
|:-------------------|:-----------|
| cosine_accuracy | 0.9848 |
| dot_accuracy | 0.0152 |
| manhattan_accuracy | 0.9848 |
| euclidean_accuracy | 0.9848 |
| **max_accuracy** | **0.9848** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 208 training samples
* Columns: <code>sentence</code> and <code>label</code>
* Approximate statistics based on the first 208 samples:
| | sentence | label |
|:--------|:-----------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| type | string | int |
| details | <ul><li>min: 33 tokens</li><li>mean: 39.81 tokens</li><li>max: 49 tokens</li></ul> | <ul><li>0: ~3.85%</li><li>1: ~3.37%</li><li>2: ~3.85%</li><li>3: ~2.40%</li><li>4: ~5.29%</li><li>5: ~4.33%</li><li>6: ~4.33%</li><li>7: ~3.37%</li><li>8: ~3.85%</li><li>9: ~4.33%</li><li>10: ~3.37%</li><li>11: ~3.85%</li><li>12: ~2.40%</li><li>13: ~5.29%</li><li>14: ~3.37%</li><li>15: ~5.77%</li><li>16: ~4.33%</li><li>17: ~2.40%</li><li>18: ~2.88%</li><li>19: ~3.37%</li><li>20: ~3.85%</li><li>21: ~4.33%</li><li>22: ~2.88%</li><li>23: ~4.33%</li><li>24: ~4.81%</li><li>25: ~1.92%</li><li>26: ~1.92%</li></ul> |
* Samples:
| sentence | label |
|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------|
| <code><br>Name : Transcend<br>Category: Upskilling<br>Department: Human Resource<br>Location: London, UK<br>Amount: 859.47<br>Card: Technology Skills Enhancement<br>Trip Name: unknown<br></code> | <code>0</code> |
| <code><br>Name : Ayden<br>Category: Financial Software<br>Department: Finance<br>Location: Berlin, DE<br>Amount: 1273.45<br>Card: Enterprise Technology Services<br>Trip Name: unknown<br></code> | <code>1</code> |
| <code><br>Name : Urban Sphere<br>Category: Utilities Management, Facility Services<br>Department: Office Administration<br>Location: New York, NY<br>Amount: 937.32<br>Card: Monthly Operations Budget<br>Trip Name: unknown<br></code> | <code>2</code> |
* Loss: [<code>BatchSemiHardTripletLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#batchsemihardtripletloss)
### Evaluation Dataset
#### Unnamed Dataset
* Size: 52 evaluation samples
* Columns: <code>sentence</code> and <code>label</code>
* Approximate statistics based on the first 52 samples:
| | sentence | label |
|:--------|:-----------------------------------------------------------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| type | string | int |
| details | <ul><li>min: 32 tokens</li><li>mean: 38.37 tokens</li><li>max: 43 tokens</li></ul> | <ul><li>0: ~1.92%</li><li>4: ~1.92%</li><li>5: ~11.54%</li><li>7: ~5.77%</li><li>8: ~5.77%</li><li>10: ~7.69%</li><li>11: ~3.85%</li><li>12: ~3.85%</li><li>13: ~1.92%</li><li>16: ~3.85%</li><li>17: ~1.92%</li><li>18: ~13.46%</li><li>19: ~5.77%</li><li>20: ~3.85%</li><li>21: ~3.85%</li><li>22: ~7.69%</li><li>23: ~3.85%</li><li>24: ~5.77%</li><li>25: ~5.77%</li></ul> |
* Samples:
| sentence | label |
|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:----------------|
| <code><br>Name : Tooly<br>Category: Survey Software, SaaS<br>Department: Marketing<br>Location: San Francisco, CA<br>Amount: 2000.0<br>Card: Annual Marketing Technology Budget<br>Trip Name: unknown<br></code> | <code>10</code> |
| <code><br>Name : CloudFlare Inc.<br>Category: Internet & Network Services, SaaS<br>Department: IT Operations<br>Location: New York, NY<br>Amount: 2000.0<br>Card: Annual Cloud Services Budget<br>Trip Name: unknown<br></code> | <code>21</code> |
| <code><br>Name : Gartner & Associates<br>Category: Consulting, Business Services<br>Department: Legal<br>Location: San Francisco, CA<br>Amount: 5000.0<br>Card: Legal Consultation Fund<br>Trip Name: unknown<br></code> | <code>5</code> |
* Loss: [<code>BatchSemiHardTripletLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#batchsemihardtripletloss)
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `learning_rate`: 2e-05
- `num_train_epochs`: 5
- `warmup_ratio`: 0.1
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 5
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | bge-base-en-eval_max_accuracy | bge-base-en-train_max_accuracy |
|:-----:|:----:|:-----------------------------:|:------------------------------:|
| 0 | 0 | - | 0.8317 |
| 5.0 | 65 | 0.9848 | - |
### Framework Versions
- Python: 3.11.13
- Sentence Transformers: 3.1.1
- Transformers: 4.45.2
- PyTorch: 2.6.0+cu124
- Accelerate: 1.7.0
- Datasets: 2.14.4
- Tokenizers: 0.20.3
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### BatchSemiHardTripletLoss
```bibtex
@misc{hermans2017defense,
title={In Defense of the Triplet Loss for Person Re-Identification},
author={Alexander Hermans and Lucas Beyer and Bastian Leibe},
year={2017},
eprint={1703.07737},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
yeok/Qwen2.5-0.5B-Instruct-SiegelEtalCorrelationalCT-component_contrib
|
yeok
| 2025-06-12T14:21:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"base_model:unsloth/Qwen2.5-0.5B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-0.5B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T11:41:29Z |
---
base_model: unsloth/Qwen2.5-0.5B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** yeok
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-0.5B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
phospho-app/PLB-ACT_BBOX-circle-box-bbact-84eph
|
phospho-app
| 2025-06-12T14:19:01Z | 0 | 0 | null |
[
"phosphobot",
"act",
"region:us"
] | null | 2025-06-12T14:17:46Z |
---
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act Model - phospho Training Pipeline
## Error Traceback
We faced an issue while training your model.
```
'module' object is not callable
```
## Training parameters:
- **Dataset**: [PAphospho/circle-box-bbact](https://huggingface.co/datasets/PAphospho/circle-box-bbact)
- **Wandb run URL**: None
- **Epochs**: None
- **Batch size**: 100
- **Training steps**: 10
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
MinaMila/phi3_unlearned_2nd_1e-6_1.0_0.05_0.5_0.25_epoch1
|
MinaMila
| 2025-06-12T14:18:58Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"conversational",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T14:16:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gradientrouting-spar/gcd_syco_moddpo_train_split-0.3_pos_prx-proxy_neg_prx-proxy_neg_ldpo-2_seed_42
|
gradientrouting-spar
| 2025-06-12T14:14:58Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T14:14:44Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
SaraHe/aya_compress
|
SaraHe
| 2025-06-12T14:14:05Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:CohereLabs/aya-expanse-8b",
"base_model:finetune:CohereLabs/aya-expanse-8b",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T14:13:56Z |
---
base_model: CohereForAI/aya-expanse-8b
library_name: transformers
model_name: aya_compress
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for aya_compress
This model is a fine-tuned version of [CohereForAI/aya-expanse-8b](https://huggingface.co/CohereForAI/aya-expanse-8b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="SaraHe/aya_compress", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.6.0+cu124
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
ArseleneB/tinyllama-fitness-chatbot-cpu-v1
|
ArseleneB
| 2025-06-12T14:13:21Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T12:52:21Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
erdem-erdem/llama3.2-3b-it-qwq-sft-tpt-iter1-r64-new-grpo-r32
|
erdem-erdem
| 2025-06-12T14:11:45Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:erdem-erdem/llama3.2-3b-it-qwq-sft-tpt-iter1-r64",
"base_model:finetune:erdem-erdem/llama3.2-3b-it-qwq-sft-tpt-iter1-r64",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T14:09:31Z |
---
base_model: erdem-erdem/llama3.2-3b-it-qwq-sft-tpt-iter1-r64
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** erdem-erdem
- **License:** apache-2.0
- **Finetuned from model :** erdem-erdem/llama3.2-3b-it-qwq-sft-tpt-iter1-r64
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
MinaMila/phi3_unlearned_2nd_1e-6_1.0_0.05_0.5_0.5_epoch1
|
MinaMila
| 2025-06-12T14:11:26Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"conversational",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T14:09:18Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JayHyeon/Qwen_1.5B-math-VDPO_5e-6_1.0vpo_constant-10ep
|
JayHyeon
| 2025-06-12T14:10:21Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"dataset:argilla/distilabel-math-preference-dpo",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2.5-Math-1.5B",
"base_model:finetune:Qwen/Qwen2.5-Math-1.5B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T13:28:30Z |
---
base_model: Qwen/Qwen2.5-Math-1.5B
datasets: argilla/distilabel-math-preference-dpo
library_name: transformers
model_name: Qwen_1.5B-math-VDPO_5e-6_1.0vpo_constant-10ep
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for Qwen_1.5B-math-VDPO_5e-6_1.0vpo_constant-10ep
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B) on the [argilla/distilabel-math-preference-dpo](https://huggingface.co/datasets/argilla/distilabel-math-preference-dpo) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="JayHyeon/Qwen_1.5B-math-VDPO_5e-6_1.0vpo_constant-10ep", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/bonin147/huggingface/runs/xuofjs6f)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.50.0
- Pytorch: 2.6.0
- Datasets: 3.4.1
- Tokenizers: 0.21.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Triangle104/Qibil-4B-v0.1-RP-Q6_K-GGUF
|
Triangle104
| 2025-06-12T14:10:19Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"base_model:Hastagaras/Qibil-4B-v0.1-RP",
"base_model:quantized:Hastagaras/Qibil-4B-v0.1-RP",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T14:09:01Z |
---
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
base_model: Hastagaras/Qibil-4B-v0.1-RP
tags:
- llama-cpp
- gguf-my-repo
---
# Triangle104/Qibil-4B-v0.1-RP-Q6_K-GGUF
This model was converted to GGUF format from [`Hastagaras/Qibil-4B-v0.1-RP`](https://huggingface.co/Hastagaras/Qibil-4B-v0.1-RP) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Hastagaras/Qibil-4B-v0.1-RP) for more details on the model.
---
This is an experimental RP finetune on top of Qwen3 4B Base. No reasoning data, just focusing on general instructions and RP.
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/Qibil-4B-v0.1-RP-Q6_K-GGUF --hf-file qibil-4b-v0.1-rp-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/Qibil-4B-v0.1-RP-Q6_K-GGUF --hf-file qibil-4b-v0.1-rp-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/Qibil-4B-v0.1-RP-Q6_K-GGUF --hf-file qibil-4b-v0.1-rp-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/Qibil-4B-v0.1-RP-Q6_K-GGUF --hf-file qibil-4b-v0.1-rp-q6_k.gguf -c 2048
```
|
CausalNLP/gpt2-hf_multilingual-90
|
CausalNLP
| 2025-06-12T14:09:11Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T14:08:45Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.