
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-27 18:27:39
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 500
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-27 18:23:41
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Zoyd/microsoft_Phi-3-medium-4k-instruct-6_5bpw_exl2 | Zoyd | 2024-05-22T04:46:01Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"phi3",
"text-generation",
"nlp",
"code",
"conversational",
"custom_code",
"multilingual",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
] | text-generation | 2024-05-22T04:31:18Z | ---
license: mit
license_link: https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/resolve/main/LICENSE
language:
- multilingual
pipeline_tag: text-generation
tags:
- nlp
- code
inference:
parameters:
temperature: 0.7
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
---
**Exllamav2** quant (**exl2** / **6.5 bpw**) made with ExLlamaV2 v0.0.21
Other EXL2 quants:
| **Quant** | **Model Size** | **lm_head** |
| ----- | ---------- | ------- |
|<center>**[2.2](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-2_2bpw_exl2)**</center> | <center>4032 MB</center> | <center>6</center> |
|<center>**[2.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-2_5bpw_exl2)**</center> | <center>4495 MB</center> | <center>6</center> |
|<center>**[3.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_0bpw_exl2)**</center> | <center>5312 MB</center> | <center>6</center> |
|<center>**[3.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_5bpw_exl2)**</center> | <center>6120 MB</center> | <center>6</center> |
|<center>**[3.75](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_75bpw_exl2)**</center> | <center>6531 MB</center> | <center>6</center> |
|<center>**[4.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-4_0bpw_exl2)**</center> | <center>6937 MB</center> | <center>6</center> |
|<center>**[4.25](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-4_25bpw_exl2)**</center> | <center>7343 MB</center> | <center>6</center> |
|<center>**[5.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-5_0bpw_exl2)**</center> | <center>8555 MB</center> | <center>6</center> |
|<center>**[6.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-6_0bpw_exl2)**</center> | <center>10213 MB</center> | <center>8</center> |
|<center>**[6.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-6_5bpw_exl2)**</center> | <center>11024 MB</center> | <center>8</center> |
|<center>**[8.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-8_0bpw_exl2)**</center> | <center>12599 MB</center> | <center>8</center> |
## Model Summary
The Phi-3-Medium-4K-Instruct is a 14B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties.
The model belongs to the Phi-3 family with the Medium version in two variants [4K](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) and [128K](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) which is the context length (in tokens) that it can support.
The model has underwent a post-training process that incorporates both supervised fine-tuning and direct preference optimization for the instruction following and safety measures.
When assessed against benchmarks testing common sense, language understanding, math, code, long context and logical reasoning, Phi-3-Medium-4K-Instruct showcased a robust and state-of-the-art performance among models of the same-size and next-size-up.
Resources and Technical Documentation:
+ [Phi-3 Microsoft Blog](https://aka.ms/Phi-3Build2024)
+ [Phi-3 Technical Report](https://aka.ms/phi3-tech-report)
+ [Phi-3 on Azure AI Studio](https://aka.ms/phi3-azure-ai)
+ [Phi-3 Cookbook](https://github.com/microsoft/Phi-3CookBook)
| | Short Context | Long Context |
| ------- | ------------- | ------------ |
| Mini | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-onnx) ; [[GGUF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct-onnx)|
| Small | 8K [[HF]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct-onnx-cuda)|
| Medium | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct-onnx-cuda)|
| Vision | | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct)|
## Intended Uses
**Primary use cases**
The model is intended for broad commercial and research use in English. The model provides uses for general purpose AI systems and applications which require:
1) Memory/compute constrained environments
2) Latency bound scenarios
3) Strong reasoning (especially code, math and logic)
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
**Use case considerations**
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fariness before using within a specific downstream use case, particularly for high risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
## How to Use
Phi-3-Medium-4K-Instruct has been integrated in the development version (4.40.2) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
The current `transformers` version can be verified with: `pip list | grep transformers`.
Phi-3-Medium-4K-Instruct is also available in [Azure AI Studio](https://aka.ms/phi3-azure-ai).
### Tokenizer
Phi-3-Medium-4K-Instruct supports a vocabulary size of up to `32064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
### Chat Format
Given the nature of the training data, the Phi-3-Medium-4K-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|user|>\nQuestion <|end|>\n<|assistant|>
```
For example:
```markdown
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>` . In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model_id = "microsoft/Phi-3-medium-4k-instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
*Some applications/frameworks might not include a BOS token (`<s>`) at the start of the conversation. Please ensure that it is included since it provides more reliable results.*
## Responsible AI Considerations
Like other language models, the Phi series models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: the Phi models are trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: these models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
* Architecture: Phi-3-Medium-4K-Instruct has 14B parameters and is a dense decoder-only Transformer model. The model is fine-tuned with Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) to ensure alignment with human preferences and safety guidlines.
* Inputs: Text. It is best suited for prompts using chat format.
* Context length: 4K tokens
* GPUs: 512 H100-80G
* Training time: 42 days
* Training data: 4.8T tokens
* Outputs: Generated text in response to the input
* Dates: Our models were trained between February and April 2024
* Status: This is a static model trained on an offline dataset with cutoff date October 2023. Future versions of the tuned models may be released as we improve models.
* Release dates: The model weight is released on May 21, 2024.
### Datasets
Our training data includes a wide variety of sources, totaling 4.8 trillion tokens (including 10% multilingual), and is a combination of
1) Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
We are focusing on the quality of data that could potentially improve the reasoning ability for the model, and we filter the publicly available documents to contain the correct level of knowledge. As an example, the result of a game in premier league in a particular day might be good training data for frontier models, but we need to remove such information to leave more model capacity for reasoning for the small size models. More details about data can be found in the [Phi-3 Technical Report](https://aka.ms/phi3-tech-report).
## Benchmarks
We report the results for Phi-3-Medium-4K-Instruct on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Mixtral-8x22b, Gemini-Pro, Command R+ 104B, Llama-3-70B-Instruct, GPT-3.5-Turbo-1106, and GPT-4-Turbo-1106(Chat).
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark.
|Benchmark|Phi-3-Medium-4K-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|---------|-----------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
|AGI Eval<br>5-shot|50.2|50.1|54.0|56.9|48.4|49.0|59.6|
|MMLU<br>5-shot|78.0|73.8|76.2|80.2|71.4|66.7|84.0|
|BigBench Hard<br>3-shot|81.4|74.1|81.8|80.4|68.3|75.6|87.7|
|ANLI<br>7-shot|55.8|63.4|65.2|68.3|58.1|64.2|71.7|
|HellaSwag<br>5-shot|82.4|78.0|79.0|82.6|78.8|76.2|88.3|
|ARC Challenge<br>10-shot|91.6|86.9|91.3|93.0|87.4|88.3|95.6|
|ARC Easy<br>10-shot|97.7|95.7|96.9|98.2|96.3|96.1|98.8|
|BoolQ<br>2-shot|86.5|86.1|82.7|89.1|79.1|86.4|91.3|
|CommonsenseQA<br>10-shot|82.8|82.0|82.0|84.4|79.6|81.8|86.7|
|MedQA<br>2-shot|69.9|59.2|67.9|78.5|63.4|58.2|83.7|
|OpenBookQA<br>10-shot|87.4|86.8|88.6|91.8|86.0|86.4|93.4|
|PIQA<br>5-shot|87.9|86.4|85.0|85.3|86.6|86.2|90.1|
|Social IQA<br>5-shot|80.2|75.3|78.2|81.1|68.3|75.4|81.7|
|TruthfulQA (MC2)<br>10-shot|75.1|57.8|67.4|81.9|67.7|72.6|85.2|
|WinoGrande<br>5-shot|81.5|77.0|75.3|83.3|68.8|72.2|86.7|
|TriviaQA<br>5-shot|73.9|82.8|84.5|78.5|85.8|80.2|73.3|
|GSM8K Chain of Thought<br>8-shot|91.0|78.3|83.8|93.5|78.1|80.4|94.2|
|HumanEval<br>0-shot|62.2|61.6|39.6|78.7|62.2|64.4|79.9|
|MBPP<br>3-shot|75.2|68.9|70.7|81.3|77.8|73.2|86.7|
|Average|78.5|75.0|76.3|82.5|74.3|75.4|85.2|
We take a closer look at different categories across 80 public benchmark datasets at the table below:
|Benchmark|Phi-3-Medium-4K-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|--------|------------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
|Popular aggregated benchmark|75.4|69.9|73.4|76.3|67.0|67.5|80.5|
|Reasoning|84.1|79.3|81.5|86.7|78.3|80.4|89.3|
|Language understanding|73.9|75.6|78.1|76.9|68.7|76.2|80.7|
|Code generation|66.1|68.6|60.0|69.3|70.4|66.7|76.1|
|Math|52.8|45.3|52.5|59.7|52.8|50.9|67.1|
|Factual knowledge|48.3|60.3|60.6|52.4|63.4|54.6|45.9|
|Multilingual|62.9|67.8|69.8|62.0|67.0|73.4|78.2|
|Robustness|66.5|57.9|65.5|78.7|69.3|69.7|84.6|
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3-Medium model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
+ Optimized inference on GPU, CPU, and Mobile: use the **ONNX** models [4K](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda)
## Cross Platform Support
ONNX runtime ecosystem now supports Phi3 Medium models across platforms and hardware.
Optimized phi-3 models are also published here in ONNX format, to run with ONNX Runtime on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets. DirectML GPU acceleration is supported for Windows desktops GPUs (AMD, Intel, and NVIDIA).
Along with DML, ONNX Runtime provides cross platform support for Phi3 Medium across a range of devices CPU, GPU, and mobile.
Here are some of the optimized configurations we have added:
1. ONNX models for int4 DML: Quantized to int4 via AWQ
2. ONNX model for fp16 CUDA
3. ONNX model for int4 CUDA: Quantized to int4 via RTN
4. ONNX model for int4 CPU and Mobile: Quantized to int4 via RTN
## License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/Phi-3-medium-4k/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
Zoyd/microsoft_Phi-3-medium-4k-instruct-4_25bpw_exl2 | Zoyd | 2024-05-22T04:45:57Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"phi3",
"text-generation",
"nlp",
"code",
"conversational",
"custom_code",
"multilingual",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
] | text-generation | 2024-05-22T03:48:37Z | ---
license: mit
license_link: https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/resolve/main/LICENSE
language:
- multilingual
pipeline_tag: text-generation
tags:
- nlp
- code
inference:
parameters:
temperature: 0.7
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
---
**Exllamav2** quant (**exl2** / **4.25 bpw**) made with ExLlamaV2 v0.0.21
Other EXL2 quants:
| **Quant** | **Model Size** | **lm_head** |
| ----- | ---------- | ------- |
|<center>**[2.2](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-2_2bpw_exl2)**</center> | <center>4032 MB</center> | <center>6</center> |
|<center>**[2.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-2_5bpw_exl2)**</center> | <center>4495 MB</center> | <center>6</center> |
|<center>**[3.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_0bpw_exl2)**</center> | <center>5312 MB</center> | <center>6</center> |
|<center>**[3.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_5bpw_exl2)**</center> | <center>6120 MB</center> | <center>6</center> |
|<center>**[3.75](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_75bpw_exl2)**</center> | <center>6531 MB</center> | <center>6</center> |
|<center>**[4.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-4_0bpw_exl2)**</center> | <center>6937 MB</center> | <center>6</center> |
|<center>**[4.25](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-4_25bpw_exl2)**</center> | <center>7343 MB</center> | <center>6</center> |
|<center>**[5.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-5_0bpw_exl2)**</center> | <center>8555 MB</center> | <center>6</center> |
|<center>**[6.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-6_0bpw_exl2)**</center> | <center>10213 MB</center> | <center>8</center> |
|<center>**[6.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-6_5bpw_exl2)**</center> | <center>11024 MB</center> | <center>8</center> |
|<center>**[8.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-8_0bpw_exl2)**</center> | <center>12599 MB</center> | <center>8</center> |
## Model Summary
The Phi-3-Medium-4K-Instruct is a 14B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties.
The model belongs to the Phi-3 family with the Medium version in two variants [4K](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) and [128K](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) which is the context length (in tokens) that it can support.
The model has underwent a post-training process that incorporates both supervised fine-tuning and direct preference optimization for the instruction following and safety measures.
When assessed against benchmarks testing common sense, language understanding, math, code, long context and logical reasoning, Phi-3-Medium-4K-Instruct showcased a robust and state-of-the-art performance among models of the same-size and next-size-up.
Resources and Technical Documentation:
+ [Phi-3 Microsoft Blog](https://aka.ms/Phi-3Build2024)
+ [Phi-3 Technical Report](https://aka.ms/phi3-tech-report)
+ [Phi-3 on Azure AI Studio](https://aka.ms/phi3-azure-ai)
+ [Phi-3 Cookbook](https://github.com/microsoft/Phi-3CookBook)
| | Short Context | Long Context |
| ------- | ------------- | ------------ |
| Mini | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-onnx) ; [[GGUF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct-onnx)|
| Small | 8K [[HF]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct-onnx-cuda)|
| Medium | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct-onnx-cuda)|
| Vision | | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct)|
## Intended Uses
**Primary use cases**
The model is intended for broad commercial and research use in English. The model provides uses for general purpose AI systems and applications which require:
1) Memory/compute constrained environments
2) Latency bound scenarios
3) Strong reasoning (especially code, math and logic)
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
**Use case considerations**
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fariness before using within a specific downstream use case, particularly for high risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
## How to Use
Phi-3-Medium-4K-Instruct has been integrated in the development version (4.40.2) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
The current `transformers` version can be verified with: `pip list | grep transformers`.
Phi-3-Medium-4K-Instruct is also available in [Azure AI Studio](https://aka.ms/phi3-azure-ai).
### Tokenizer
Phi-3-Medium-4K-Instruct supports a vocabulary size of up to `32064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
### Chat Format
Given the nature of the training data, the Phi-3-Medium-4K-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|user|>\nQuestion <|end|>\n<|assistant|>
```
For example:
```markdown
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>` . In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model_id = "microsoft/Phi-3-medium-4k-instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
*Some applications/frameworks might not include a BOS token (`<s>`) at the start of the conversation. Please ensure that it is included since it provides more reliable results.*
## Responsible AI Considerations
Like other language models, the Phi series models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: the Phi models are trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: these models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
* Architecture: Phi-3-Medium-4K-Instruct has 14B parameters and is a dense decoder-only Transformer model. The model is fine-tuned with Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) to ensure alignment with human preferences and safety guidlines.
* Inputs: Text. It is best suited for prompts using chat format.
* Context length: 4K tokens
* GPUs: 512 H100-80G
* Training time: 42 days
* Training data: 4.8T tokens
* Outputs: Generated text in response to the input
* Dates: Our models were trained between February and April 2024
* Status: This is a static model trained on an offline dataset with cutoff date October 2023. Future versions of the tuned models may be released as we improve models.
* Release dates: The model weight is released on May 21, 2024.
### Datasets
Our training data includes a wide variety of sources, totaling 4.8 trillion tokens (including 10% multilingual), and is a combination of
1) Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
We are focusing on the quality of data that could potentially improve the reasoning ability for the model, and we filter the publicly available documents to contain the correct level of knowledge. As an example, the result of a game in premier league in a particular day might be good training data for frontier models, but we need to remove such information to leave more model capacity for reasoning for the small size models. More details about data can be found in the [Phi-3 Technical Report](https://aka.ms/phi3-tech-report).
## Benchmarks
We report the results for Phi-3-Medium-4K-Instruct on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Mixtral-8x22b, Gemini-Pro, Command R+ 104B, Llama-3-70B-Instruct, GPT-3.5-Turbo-1106, and GPT-4-Turbo-1106(Chat).
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark.
|Benchmark|Phi-3-Medium-4K-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|---------|-----------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
|AGI Eval<br>5-shot|50.2|50.1|54.0|56.9|48.4|49.0|59.6|
|MMLU<br>5-shot|78.0|73.8|76.2|80.2|71.4|66.7|84.0|
|BigBench Hard<br>3-shot|81.4|74.1|81.8|80.4|68.3|75.6|87.7|
|ANLI<br>7-shot|55.8|63.4|65.2|68.3|58.1|64.2|71.7|
|HellaSwag<br>5-shot|82.4|78.0|79.0|82.6|78.8|76.2|88.3|
|ARC Challenge<br>10-shot|91.6|86.9|91.3|93.0|87.4|88.3|95.6|
|ARC Easy<br>10-shot|97.7|95.7|96.9|98.2|96.3|96.1|98.8|
|BoolQ<br>2-shot|86.5|86.1|82.7|89.1|79.1|86.4|91.3|
|CommonsenseQA<br>10-shot|82.8|82.0|82.0|84.4|79.6|81.8|86.7|
|MedQA<br>2-shot|69.9|59.2|67.9|78.5|63.4|58.2|83.7|
|OpenBookQA<br>10-shot|87.4|86.8|88.6|91.8|86.0|86.4|93.4|
|PIQA<br>5-shot|87.9|86.4|85.0|85.3|86.6|86.2|90.1|
|Social IQA<br>5-shot|80.2|75.3|78.2|81.1|68.3|75.4|81.7|
|TruthfulQA (MC2)<br>10-shot|75.1|57.8|67.4|81.9|67.7|72.6|85.2|
|WinoGrande<br>5-shot|81.5|77.0|75.3|83.3|68.8|72.2|86.7|
|TriviaQA<br>5-shot|73.9|82.8|84.5|78.5|85.8|80.2|73.3|
|GSM8K Chain of Thought<br>8-shot|91.0|78.3|83.8|93.5|78.1|80.4|94.2|
|HumanEval<br>0-shot|62.2|61.6|39.6|78.7|62.2|64.4|79.9|
|MBPP<br>3-shot|75.2|68.9|70.7|81.3|77.8|73.2|86.7|
|Average|78.5|75.0|76.3|82.5|74.3|75.4|85.2|
We take a closer look at different categories across 80 public benchmark datasets at the table below:
|Benchmark|Phi-3-Medium-4K-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|--------|------------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
|Popular aggregated benchmark|75.4|69.9|73.4|76.3|67.0|67.5|80.5|
|Reasoning|84.1|79.3|81.5|86.7|78.3|80.4|89.3|
|Language understanding|73.9|75.6|78.1|76.9|68.7|76.2|80.7|
|Code generation|66.1|68.6|60.0|69.3|70.4|66.7|76.1|
|Math|52.8|45.3|52.5|59.7|52.8|50.9|67.1|
|Factual knowledge|48.3|60.3|60.6|52.4|63.4|54.6|45.9|
|Multilingual|62.9|67.8|69.8|62.0|67.0|73.4|78.2|
|Robustness|66.5|57.9|65.5|78.7|69.3|69.7|84.6|
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3-Medium model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
+ Optimized inference on GPU, CPU, and Mobile: use the **ONNX** models [4K](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda)
## Cross Platform Support
ONNX runtime ecosystem now supports Phi3 Medium models across platforms and hardware.
Optimized phi-3 models are also published here in ONNX format, to run with ONNX Runtime on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets. DirectML GPU acceleration is supported for Windows desktops GPUs (AMD, Intel, and NVIDIA).
Along with DML, ONNX Runtime provides cross platform support for Phi3 Medium across a range of devices CPU, GPU, and mobile.
Here are some of the optimized configurations we have added:
1. ONNX models for int4 DML: Quantized to int4 via AWQ
2. ONNX model for fp16 CUDA
3. ONNX model for int4 CUDA: Quantized to int4 via RTN
4. ONNX model for int4 CPU and Mobile: Quantized to int4 via RTN
## License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/Phi-3-medium-4k/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
Zoyd/microsoft_Phi-3-medium-4k-instruct-3_75bpw_exl2 | Zoyd | 2024-05-22T04:45:56Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"phi3",
"text-generation",
"nlp",
"code",
"conversational",
"custom_code",
"multilingual",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
] | text-generation | 2024-05-22T03:19:53Z | ---
license: mit
license_link: https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/resolve/main/LICENSE
language:
- multilingual
pipeline_tag: text-generation
tags:
- nlp
- code
inference:
parameters:
temperature: 0.7
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
---
**Exllamav2** quant (**exl2** / **3.75 bpw**) made with ExLlamaV2 v0.0.21
Other EXL2 quants:
| **Quant** | **Model Size** | **lm_head** |
| ----- | ---------- | ------- |
|<center>**[2.2](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-2_2bpw_exl2)**</center> | <center>4032 MB</center> | <center>6</center> |
|<center>**[2.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-2_5bpw_exl2)**</center> | <center>4495 MB</center> | <center>6</center> |
|<center>**[3.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_0bpw_exl2)**</center> | <center>5312 MB</center> | <center>6</center> |
|<center>**[3.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_5bpw_exl2)**</center> | <center>6120 MB</center> | <center>6</center> |
|<center>**[3.75](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_75bpw_exl2)**</center> | <center>6531 MB</center> | <center>6</center> |
|<center>**[4.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-4_0bpw_exl2)**</center> | <center>6937 MB</center> | <center>6</center> |
|<center>**[4.25](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-4_25bpw_exl2)**</center> | <center>7343 MB</center> | <center>6</center> |
|<center>**[5.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-5_0bpw_exl2)**</center> | <center>8555 MB</center> | <center>6</center> |
|<center>**[6.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-6_0bpw_exl2)**</center> | <center>10213 MB</center> | <center>8</center> |
|<center>**[6.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-6_5bpw_exl2)**</center> | <center>11024 MB</center> | <center>8</center> |
|<center>**[8.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-8_0bpw_exl2)**</center> | <center>12599 MB</center> | <center>8</center> |
## Model Summary
The Phi-3-Medium-4K-Instruct is a 14B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties.
The model belongs to the Phi-3 family with the Medium version in two variants [4K](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) and [128K](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) which is the context length (in tokens) that it can support.
The model has underwent a post-training process that incorporates both supervised fine-tuning and direct preference optimization for the instruction following and safety measures.
When assessed against benchmarks testing common sense, language understanding, math, code, long context and logical reasoning, Phi-3-Medium-4K-Instruct showcased a robust and state-of-the-art performance among models of the same-size and next-size-up.
Resources and Technical Documentation:
+ [Phi-3 Microsoft Blog](https://aka.ms/Phi-3Build2024)
+ [Phi-3 Technical Report](https://aka.ms/phi3-tech-report)
+ [Phi-3 on Azure AI Studio](https://aka.ms/phi3-azure-ai)
+ [Phi-3 Cookbook](https://github.com/microsoft/Phi-3CookBook)
| | Short Context | Long Context |
| ------- | ------------- | ------------ |
| Mini | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-onnx) ; [[GGUF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct-onnx)|
| Small | 8K [[HF]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct-onnx-cuda)|
| Medium | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct-onnx-cuda)|
| Vision | | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct)|
## Intended Uses
**Primary use cases**
The model is intended for broad commercial and research use in English. The model provides uses for general purpose AI systems and applications which require:
1) Memory/compute constrained environments
2) Latency bound scenarios
3) Strong reasoning (especially code, math and logic)
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
**Use case considerations**
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fariness before using within a specific downstream use case, particularly for high risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
## How to Use
Phi-3-Medium-4K-Instruct has been integrated in the development version (4.40.2) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
The current `transformers` version can be verified with: `pip list | grep transformers`.
Phi-3-Medium-4K-Instruct is also available in [Azure AI Studio](https://aka.ms/phi3-azure-ai).
### Tokenizer
Phi-3-Medium-4K-Instruct supports a vocabulary size of up to `32064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
### Chat Format
Given the nature of the training data, the Phi-3-Medium-4K-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|user|>\nQuestion <|end|>\n<|assistant|>
```
For example:
```markdown
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>` . In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model_id = "microsoft/Phi-3-medium-4k-instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
*Some applications/frameworks might not include a BOS token (`<s>`) at the start of the conversation. Please ensure that it is included since it provides more reliable results.*
## Responsible AI Considerations
Like other language models, the Phi series models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: the Phi models are trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: these models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
* Architecture: Phi-3-Medium-4K-Instruct has 14B parameters and is a dense decoder-only Transformer model. The model is fine-tuned with Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) to ensure alignment with human preferences and safety guidlines.
* Inputs: Text. It is best suited for prompts using chat format.
* Context length: 4K tokens
* GPUs: 512 H100-80G
* Training time: 42 days
* Training data: 4.8T tokens
* Outputs: Generated text in response to the input
* Dates: Our models were trained between February and April 2024
* Status: This is a static model trained on an offline dataset with cutoff date October 2023. Future versions of the tuned models may be released as we improve models.
* Release dates: The model weight is released on May 21, 2024.
### Datasets
Our training data includes a wide variety of sources, totaling 4.8 trillion tokens (including 10% multilingual), and is a combination of
1) Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
We are focusing on the quality of data that could potentially improve the reasoning ability for the model, and we filter the publicly available documents to contain the correct level of knowledge. As an example, the result of a game in premier league in a particular day might be good training data for frontier models, but we need to remove such information to leave more model capacity for reasoning for the small size models. More details about data can be found in the [Phi-3 Technical Report](https://aka.ms/phi3-tech-report).
## Benchmarks
We report the results for Phi-3-Medium-4K-Instruct on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Mixtral-8x22b, Gemini-Pro, Command R+ 104B, Llama-3-70B-Instruct, GPT-3.5-Turbo-1106, and GPT-4-Turbo-1106(Chat).
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark.
|Benchmark|Phi-3-Medium-4K-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|---------|-----------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
|AGI Eval<br>5-shot|50.2|50.1|54.0|56.9|48.4|49.0|59.6|
|MMLU<br>5-shot|78.0|73.8|76.2|80.2|71.4|66.7|84.0|
|BigBench Hard<br>3-shot|81.4|74.1|81.8|80.4|68.3|75.6|87.7|
|ANLI<br>7-shot|55.8|63.4|65.2|68.3|58.1|64.2|71.7|
|HellaSwag<br>5-shot|82.4|78.0|79.0|82.6|78.8|76.2|88.3|
|ARC Challenge<br>10-shot|91.6|86.9|91.3|93.0|87.4|88.3|95.6|
|ARC Easy<br>10-shot|97.7|95.7|96.9|98.2|96.3|96.1|98.8|
|BoolQ<br>2-shot|86.5|86.1|82.7|89.1|79.1|86.4|91.3|
|CommonsenseQA<br>10-shot|82.8|82.0|82.0|84.4|79.6|81.8|86.7|
|MedQA<br>2-shot|69.9|59.2|67.9|78.5|63.4|58.2|83.7|
|OpenBookQA<br>10-shot|87.4|86.8|88.6|91.8|86.0|86.4|93.4|
|PIQA<br>5-shot|87.9|86.4|85.0|85.3|86.6|86.2|90.1|
|Social IQA<br>5-shot|80.2|75.3|78.2|81.1|68.3|75.4|81.7|
|TruthfulQA (MC2)<br>10-shot|75.1|57.8|67.4|81.9|67.7|72.6|85.2|
|WinoGrande<br>5-shot|81.5|77.0|75.3|83.3|68.8|72.2|86.7|
|TriviaQA<br>5-shot|73.9|82.8|84.5|78.5|85.8|80.2|73.3|
|GSM8K Chain of Thought<br>8-shot|91.0|78.3|83.8|93.5|78.1|80.4|94.2|
|HumanEval<br>0-shot|62.2|61.6|39.6|78.7|62.2|64.4|79.9|
|MBPP<br>3-shot|75.2|68.9|70.7|81.3|77.8|73.2|86.7|
|Average|78.5|75.0|76.3|82.5|74.3|75.4|85.2|
We take a closer look at different categories across 80 public benchmark datasets at the table below:
|Benchmark|Phi-3-Medium-4K-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|--------|------------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
|Popular aggregated benchmark|75.4|69.9|73.4|76.3|67.0|67.5|80.5|
|Reasoning|84.1|79.3|81.5|86.7|78.3|80.4|89.3|
|Language understanding|73.9|75.6|78.1|76.9|68.7|76.2|80.7|
|Code generation|66.1|68.6|60.0|69.3|70.4|66.7|76.1|
|Math|52.8|45.3|52.5|59.7|52.8|50.9|67.1|
|Factual knowledge|48.3|60.3|60.6|52.4|63.4|54.6|45.9|
|Multilingual|62.9|67.8|69.8|62.0|67.0|73.4|78.2|
|Robustness|66.5|57.9|65.5|78.7|69.3|69.7|84.6|
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3-Medium model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
+ Optimized inference on GPU, CPU, and Mobile: use the **ONNX** models [4K](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda)
## Cross Platform Support
ONNX runtime ecosystem now supports Phi3 Medium models across platforms and hardware.
Optimized phi-3 models are also published here in ONNX format, to run with ONNX Runtime on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets. DirectML GPU acceleration is supported for Windows desktops GPUs (AMD, Intel, and NVIDIA).
Along with DML, ONNX Runtime provides cross platform support for Phi3 Medium across a range of devices CPU, GPU, and mobile.
Here are some of the optimized configurations we have added:
1. ONNX models for int4 DML: Quantized to int4 via AWQ
2. ONNX model for fp16 CUDA
3. ONNX model for int4 CUDA: Quantized to int4 via RTN
4. ONNX model for int4 CPU and Mobile: Quantized to int4 via RTN
## License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/Phi-3-medium-4k/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
Zoyd/microsoft_Phi-3-medium-4k-instruct-3_5bpw_exl2 | Zoyd | 2024-05-22T04:45:56Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"phi3",
"text-generation",
"nlp",
"code",
"conversational",
"custom_code",
"multilingual",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
] | text-generation | 2024-05-22T03:05:42Z | ---
license: mit
license_link: https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/resolve/main/LICENSE
language:
- multilingual
pipeline_tag: text-generation
tags:
- nlp
- code
inference:
parameters:
temperature: 0.7
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
---
**Exllamav2** quant (**exl2** / **3.5 bpw**) made with ExLlamaV2 v0.0.21
Other EXL2 quants:
| **Quant** | **Model Size** | **lm_head** |
| ----- | ---------- | ------- |
|<center>**[2.2](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-2_2bpw_exl2)**</center> | <center>4032 MB</center> | <center>6</center> |
|<center>**[2.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-2_5bpw_exl2)**</center> | <center>4495 MB</center> | <center>6</center> |
|<center>**[3.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_0bpw_exl2)**</center> | <center>5312 MB</center> | <center>6</center> |
|<center>**[3.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_5bpw_exl2)**</center> | <center>6120 MB</center> | <center>6</center> |
|<center>**[3.75](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_75bpw_exl2)**</center> | <center>6531 MB</center> | <center>6</center> |
|<center>**[4.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-4_0bpw_exl2)**</center> | <center>6937 MB</center> | <center>6</center> |
|<center>**[4.25](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-4_25bpw_exl2)**</center> | <center>7343 MB</center> | <center>6</center> |
|<center>**[5.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-5_0bpw_exl2)**</center> | <center>8555 MB</center> | <center>6</center> |
|<center>**[6.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-6_0bpw_exl2)**</center> | <center>10213 MB</center> | <center>8</center> |
|<center>**[6.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-6_5bpw_exl2)**</center> | <center>11024 MB</center> | <center>8</center> |
|<center>**[8.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-8_0bpw_exl2)**</center> | <center>12599 MB</center> | <center>8</center> |
## Model Summary
The Phi-3-Medium-4K-Instruct is a 14B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties.
The model belongs to the Phi-3 family with the Medium version in two variants [4K](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) and [128K](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) which is the context length (in tokens) that it can support.
The model has underwent a post-training process that incorporates both supervised fine-tuning and direct preference optimization for the instruction following and safety measures.
When assessed against benchmarks testing common sense, language understanding, math, code, long context and logical reasoning, Phi-3-Medium-4K-Instruct showcased a robust and state-of-the-art performance among models of the same-size and next-size-up.
Resources and Technical Documentation:
+ [Phi-3 Microsoft Blog](https://aka.ms/Phi-3Build2024)
+ [Phi-3 Technical Report](https://aka.ms/phi3-tech-report)
+ [Phi-3 on Azure AI Studio](https://aka.ms/phi3-azure-ai)
+ [Phi-3 Cookbook](https://github.com/microsoft/Phi-3CookBook)
| | Short Context | Long Context |
| ------- | ------------- | ------------ |
| Mini | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-onnx) ; [[GGUF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct-onnx)|
| Small | 8K [[HF]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct-onnx-cuda)|
| Medium | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct-onnx-cuda)|
| Vision | | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct)|
## Intended Uses
**Primary use cases**
The model is intended for broad commercial and research use in English. The model provides uses for general purpose AI systems and applications which require:
1) Memory/compute constrained environments
2) Latency bound scenarios
3) Strong reasoning (especially code, math and logic)
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
**Use case considerations**
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fariness before using within a specific downstream use case, particularly for high risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
## How to Use
Phi-3-Medium-4K-Instruct has been integrated in the development version (4.40.2) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
The current `transformers` version can be verified with: `pip list | grep transformers`.
Phi-3-Medium-4K-Instruct is also available in [Azure AI Studio](https://aka.ms/phi3-azure-ai).
### Tokenizer
Phi-3-Medium-4K-Instruct supports a vocabulary size of up to `32064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
### Chat Format
Given the nature of the training data, the Phi-3-Medium-4K-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|user|>\nQuestion <|end|>\n<|assistant|>
```
For example:
```markdown
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>` . In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model_id = "microsoft/Phi-3-medium-4k-instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
*Some applications/frameworks might not include a BOS token (`<s>`) at the start of the conversation. Please ensure that it is included since it provides more reliable results.*
## Responsible AI Considerations
Like other language models, the Phi series models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: the Phi models are trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: these models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
* Architecture: Phi-3-Medium-4K-Instruct has 14B parameters and is a dense decoder-only Transformer model. The model is fine-tuned with Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) to ensure alignment with human preferences and safety guidlines.
* Inputs: Text. It is best suited for prompts using chat format.
* Context length: 4K tokens
* GPUs: 512 H100-80G
* Training time: 42 days
* Training data: 4.8T tokens
* Outputs: Generated text in response to the input
* Dates: Our models were trained between February and April 2024
* Status: This is a static model trained on an offline dataset with cutoff date October 2023. Future versions of the tuned models may be released as we improve models.
* Release dates: The model weight is released on May 21, 2024.
### Datasets
Our training data includes a wide variety of sources, totaling 4.8 trillion tokens (including 10% multilingual), and is a combination of
1) Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
We are focusing on the quality of data that could potentially improve the reasoning ability for the model, and we filter the publicly available documents to contain the correct level of knowledge. As an example, the result of a game in premier league in a particular day might be good training data for frontier models, but we need to remove such information to leave more model capacity for reasoning for the small size models. More details about data can be found in the [Phi-3 Technical Report](https://aka.ms/phi3-tech-report).
## Benchmarks
We report the results for Phi-3-Medium-4K-Instruct on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Mixtral-8x22b, Gemini-Pro, Command R+ 104B, Llama-3-70B-Instruct, GPT-3.5-Turbo-1106, and GPT-4-Turbo-1106(Chat).
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark.
|Benchmark|Phi-3-Medium-4K-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|---------|-----------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
|AGI Eval<br>5-shot|50.2|50.1|54.0|56.9|48.4|49.0|59.6|
|MMLU<br>5-shot|78.0|73.8|76.2|80.2|71.4|66.7|84.0|
|BigBench Hard<br>3-shot|81.4|74.1|81.8|80.4|68.3|75.6|87.7|
|ANLI<br>7-shot|55.8|63.4|65.2|68.3|58.1|64.2|71.7|
|HellaSwag<br>5-shot|82.4|78.0|79.0|82.6|78.8|76.2|88.3|
|ARC Challenge<br>10-shot|91.6|86.9|91.3|93.0|87.4|88.3|95.6|
|ARC Easy<br>10-shot|97.7|95.7|96.9|98.2|96.3|96.1|98.8|
|BoolQ<br>2-shot|86.5|86.1|82.7|89.1|79.1|86.4|91.3|
|CommonsenseQA<br>10-shot|82.8|82.0|82.0|84.4|79.6|81.8|86.7|
|MedQA<br>2-shot|69.9|59.2|67.9|78.5|63.4|58.2|83.7|
|OpenBookQA<br>10-shot|87.4|86.8|88.6|91.8|86.0|86.4|93.4|
|PIQA<br>5-shot|87.9|86.4|85.0|85.3|86.6|86.2|90.1|
|Social IQA<br>5-shot|80.2|75.3|78.2|81.1|68.3|75.4|81.7|
|TruthfulQA (MC2)<br>10-shot|75.1|57.8|67.4|81.9|67.7|72.6|85.2|
|WinoGrande<br>5-shot|81.5|77.0|75.3|83.3|68.8|72.2|86.7|
|TriviaQA<br>5-shot|73.9|82.8|84.5|78.5|85.8|80.2|73.3|
|GSM8K Chain of Thought<br>8-shot|91.0|78.3|83.8|93.5|78.1|80.4|94.2|
|HumanEval<br>0-shot|62.2|61.6|39.6|78.7|62.2|64.4|79.9|
|MBPP<br>3-shot|75.2|68.9|70.7|81.3|77.8|73.2|86.7|
|Average|78.5|75.0|76.3|82.5|74.3|75.4|85.2|
We take a closer look at different categories across 80 public benchmark datasets at the table below:
|Benchmark|Phi-3-Medium-4K-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|--------|------------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
|Popular aggregated benchmark|75.4|69.9|73.4|76.3|67.0|67.5|80.5|
|Reasoning|84.1|79.3|81.5|86.7|78.3|80.4|89.3|
|Language understanding|73.9|75.6|78.1|76.9|68.7|76.2|80.7|
|Code generation|66.1|68.6|60.0|69.3|70.4|66.7|76.1|
|Math|52.8|45.3|52.5|59.7|52.8|50.9|67.1|
|Factual knowledge|48.3|60.3|60.6|52.4|63.4|54.6|45.9|
|Multilingual|62.9|67.8|69.8|62.0|67.0|73.4|78.2|
|Robustness|66.5|57.9|65.5|78.7|69.3|69.7|84.6|
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3-Medium model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
+ Optimized inference on GPU, CPU, and Mobile: use the **ONNX** models [4K](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda)
## Cross Platform Support
ONNX runtime ecosystem now supports Phi3 Medium models across platforms and hardware.
Optimized phi-3 models are also published here in ONNX format, to run with ONNX Runtime on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets. DirectML GPU acceleration is supported for Windows desktops GPUs (AMD, Intel, and NVIDIA).
Along with DML, ONNX Runtime provides cross platform support for Phi3 Medium across a range of devices CPU, GPU, and mobile.
Here are some of the optimized configurations we have added:
1. ONNX models for int4 DML: Quantized to int4 via AWQ
2. ONNX model for fp16 CUDA
3. ONNX model for int4 CUDA: Quantized to int4 via RTN
4. ONNX model for int4 CPU and Mobile: Quantized to int4 via RTN
## License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/Phi-3-medium-4k/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
Zoyd/microsoft_Phi-3-medium-4k-instruct-3_0bpw_exl2 | Zoyd | 2024-05-22T04:45:55Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"phi3",
"text-generation",
"nlp",
"code",
"conversational",
"custom_code",
"multilingual",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"3-bit",
"exl2",
"region:us"
] | text-generation | 2024-05-22T02:51:37Z | ---
license: mit
license_link: https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/resolve/main/LICENSE
language:
- multilingual
pipeline_tag: text-generation
tags:
- nlp
- code
inference:
parameters:
temperature: 0.7
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
---
**Exllamav2** quant (**exl2** / **3.0 bpw**) made with ExLlamaV2 v0.0.21
Other EXL2 quants:
| **Quant** | **Model Size** | **lm_head** |
| ----- | ---------- | ------- |
|<center>**[2.2](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-2_2bpw_exl2)**</center> | <center>4032 MB</center> | <center>6</center> |
|<center>**[2.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-2_5bpw_exl2)**</center> | <center>4495 MB</center> | <center>6</center> |
|<center>**[3.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_0bpw_exl2)**</center> | <center>5312 MB</center> | <center>6</center> |
|<center>**[3.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_5bpw_exl2)**</center> | <center>6120 MB</center> | <center>6</center> |
|<center>**[3.75](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-3_75bpw_exl2)**</center> | <center>6531 MB</center> | <center>6</center> |
|<center>**[4.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-4_0bpw_exl2)**</center> | <center>6937 MB</center> | <center>6</center> |
|<center>**[4.25](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-4_25bpw_exl2)**</center> | <center>7343 MB</center> | <center>6</center> |
|<center>**[5.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-5_0bpw_exl2)**</center> | <center>8555 MB</center> | <center>6</center> |
|<center>**[6.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-6_0bpw_exl2)**</center> | <center>10213 MB</center> | <center>8</center> |
|<center>**[6.5](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-6_5bpw_exl2)**</center> | <center>11024 MB</center> | <center>8</center> |
|<center>**[8.0](https://huggingface.co/Zoyd/microsoft_Phi-3-medium-4k-instruct-8_0bpw_exl2)**</center> | <center>12599 MB</center> | <center>8</center> |
## Model Summary
The Phi-3-Medium-4K-Instruct is a 14B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties.
The model belongs to the Phi-3 family with the Medium version in two variants [4K](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) and [128K](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) which is the context length (in tokens) that it can support.
The model has underwent a post-training process that incorporates both supervised fine-tuning and direct preference optimization for the instruction following and safety measures.
When assessed against benchmarks testing common sense, language understanding, math, code, long context and logical reasoning, Phi-3-Medium-4K-Instruct showcased a robust and state-of-the-art performance among models of the same-size and next-size-up.
Resources and Technical Documentation:
+ [Phi-3 Microsoft Blog](https://aka.ms/Phi-3Build2024)
+ [Phi-3 Technical Report](https://aka.ms/phi3-tech-report)
+ [Phi-3 on Azure AI Studio](https://aka.ms/phi3-azure-ai)
+ [Phi-3 Cookbook](https://github.com/microsoft/Phi-3CookBook)
| | Short Context | Long Context |
| ------- | ------------- | ------------ |
| Mini | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-onnx) ; [[GGUF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct-onnx)|
| Small | 8K [[HF]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct-onnx-cuda)|
| Medium | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct-onnx-cuda)|
| Vision | | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct)|
## Intended Uses
**Primary use cases**
The model is intended for broad commercial and research use in English. The model provides uses for general purpose AI systems and applications which require:
1) Memory/compute constrained environments
2) Latency bound scenarios
3) Strong reasoning (especially code, math and logic)
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
**Use case considerations**
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fariness before using within a specific downstream use case, particularly for high risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
## How to Use
Phi-3-Medium-4K-Instruct has been integrated in the development version (4.40.2) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
The current `transformers` version can be verified with: `pip list | grep transformers`.
Phi-3-Medium-4K-Instruct is also available in [Azure AI Studio](https://aka.ms/phi3-azure-ai).
### Tokenizer
Phi-3-Medium-4K-Instruct supports a vocabulary size of up to `32064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
### Chat Format
Given the nature of the training data, the Phi-3-Medium-4K-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|user|>\nQuestion <|end|>\n<|assistant|>
```
For example:
```markdown
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>` . In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model_id = "microsoft/Phi-3-medium-4k-instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
*Some applications/frameworks might not include a BOS token (`<s>`) at the start of the conversation. Please ensure that it is included since it provides more reliable results.*
## Responsible AI Considerations
Like other language models, the Phi series models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: the Phi models are trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: these models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
* Architecture: Phi-3-Medium-4K-Instruct has 14B parameters and is a dense decoder-only Transformer model. The model is fine-tuned with Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) to ensure alignment with human preferences and safety guidlines.
* Inputs: Text. It is best suited for prompts using chat format.
* Context length: 4K tokens
* GPUs: 512 H100-80G
* Training time: 42 days
* Training data: 4.8T tokens
* Outputs: Generated text in response to the input
* Dates: Our models were trained between February and April 2024
* Status: This is a static model trained on an offline dataset with cutoff date October 2023. Future versions of the tuned models may be released as we improve models.
* Release dates: The model weight is released on May 21, 2024.
### Datasets
Our training data includes a wide variety of sources, totaling 4.8 trillion tokens (including 10% multilingual), and is a combination of
1) Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
We are focusing on the quality of data that could potentially improve the reasoning ability for the model, and we filter the publicly available documents to contain the correct level of knowledge. As an example, the result of a game in premier league in a particular day might be good training data for frontier models, but we need to remove such information to leave more model capacity for reasoning for the small size models. More details about data can be found in the [Phi-3 Technical Report](https://aka.ms/phi3-tech-report).
## Benchmarks
We report the results for Phi-3-Medium-4K-Instruct on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Mixtral-8x22b, Gemini-Pro, Command R+ 104B, Llama-3-70B-Instruct, GPT-3.5-Turbo-1106, and GPT-4-Turbo-1106(Chat).
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark.
|Benchmark|Phi-3-Medium-4K-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|---------|-----------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
|AGI Eval<br>5-shot|50.2|50.1|54.0|56.9|48.4|49.0|59.6|
|MMLU<br>5-shot|78.0|73.8|76.2|80.2|71.4|66.7|84.0|
|BigBench Hard<br>3-shot|81.4|74.1|81.8|80.4|68.3|75.6|87.7|
|ANLI<br>7-shot|55.8|63.4|65.2|68.3|58.1|64.2|71.7|
|HellaSwag<br>5-shot|82.4|78.0|79.0|82.6|78.8|76.2|88.3|
|ARC Challenge<br>10-shot|91.6|86.9|91.3|93.0|87.4|88.3|95.6|
|ARC Easy<br>10-shot|97.7|95.7|96.9|98.2|96.3|96.1|98.8|
|BoolQ<br>2-shot|86.5|86.1|82.7|89.1|79.1|86.4|91.3|
|CommonsenseQA<br>10-shot|82.8|82.0|82.0|84.4|79.6|81.8|86.7|
|MedQA<br>2-shot|69.9|59.2|67.9|78.5|63.4|58.2|83.7|
|OpenBookQA<br>10-shot|87.4|86.8|88.6|91.8|86.0|86.4|93.4|
|PIQA<br>5-shot|87.9|86.4|85.0|85.3|86.6|86.2|90.1|
|Social IQA<br>5-shot|80.2|75.3|78.2|81.1|68.3|75.4|81.7|
|TruthfulQA (MC2)<br>10-shot|75.1|57.8|67.4|81.9|67.7|72.6|85.2|
|WinoGrande<br>5-shot|81.5|77.0|75.3|83.3|68.8|72.2|86.7|
|TriviaQA<br>5-shot|73.9|82.8|84.5|78.5|85.8|80.2|73.3|
|GSM8K Chain of Thought<br>8-shot|91.0|78.3|83.8|93.5|78.1|80.4|94.2|
|HumanEval<br>0-shot|62.2|61.6|39.6|78.7|62.2|64.4|79.9|
|MBPP<br>3-shot|75.2|68.9|70.7|81.3|77.8|73.2|86.7|
|Average|78.5|75.0|76.3|82.5|74.3|75.4|85.2|
We take a closer look at different categories across 80 public benchmark datasets at the table below:
|Benchmark|Phi-3-Medium-4K-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|--------|------------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
|Popular aggregated benchmark|75.4|69.9|73.4|76.3|67.0|67.5|80.5|
|Reasoning|84.1|79.3|81.5|86.7|78.3|80.4|89.3|
|Language understanding|73.9|75.6|78.1|76.9|68.7|76.2|80.7|
|Code generation|66.1|68.6|60.0|69.3|70.4|66.7|76.1|
|Math|52.8|45.3|52.5|59.7|52.8|50.9|67.1|
|Factual knowledge|48.3|60.3|60.6|52.4|63.4|54.6|45.9|
|Multilingual|62.9|67.8|69.8|62.0|67.0|73.4|78.2|
|Robustness|66.5|57.9|65.5|78.7|69.3|69.7|84.6|
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3-Medium model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
+ Optimized inference on GPU, CPU, and Mobile: use the **ONNX** models [4K](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda)
## Cross Platform Support
ONNX runtime ecosystem now supports Phi3 Medium models across platforms and hardware.
Optimized phi-3 models are also published here in ONNX format, to run with ONNX Runtime on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets. DirectML GPU acceleration is supported for Windows desktops GPUs (AMD, Intel, and NVIDIA).
Along with DML, ONNX Runtime provides cross platform support for Phi3 Medium across a range of devices CPU, GPU, and mobile.
Here are some of the optimized configurations we have added:
1. ONNX models for int4 DML: Quantized to int4 via AWQ
2. ONNX model for fp16 CUDA
3. ONNX model for int4 CUDA: Quantized to int4 via RTN
4. ONNX model for int4 CPU and Mobile: Quantized to int4 via RTN
## License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/Phi-3-medium-4k/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
Chord-Llama/Llama-3-chord-llama-fullModel | Chord-Llama | 2024-05-22T04:45:47Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-09T04:26:09Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-bnb-4bit
---
Fintuned Llama for our music generation task.
The tokenization of the model was not touched.
The model has three values, instruction, input and output.
Set the instruction to the simplified version of the “attributes” tag. This contains data like the tempo, and key that is kept throughout the entire length of the song.
The tokens in the instruction input are kept as important for the attention mechanism.
Finally, the existing portion of the song is put into the input, and the model then generates future tokens in the output
# Uploaded model
- **Developed by:** Chord-Llama
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
PhillipGuo/hp-lat-llama-None-epsilon3.0-pgd_layer8_16_24_30-def_layer0-ultrachat-towards1-away0-sft0-6 | PhillipGuo | 2024-05-22T04:43:30Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-22T04:43:21Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
somuch/vietnamese-correction-v2 | somuch | 2024-05-22T04:43:15Z | 105 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"mbart",
"text2text-generation",
"generated_from_trainer",
"base_model:vinai/bartpho-syllable",
"base_model:finetune:vinai/bartpho-syllable",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-05-22T04:40:58Z | ---
base_model: vinai/bartpho-syllable
tags:
- text2text-generation
- generated_from_trainer
metrics:
- sacrebleu
model-index:
- name: vietnamese-correction-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vietnamese-correction-v2
This model is a fine-tuned version of [vinai/bartpho-syllable](https://huggingface.co/vinai/bartpho-syllable) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1686
- Sacrebleu: 19.4327
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cpu
- Datasets 2.19.1
- Tokenizers 0.19.1
|
PhillipGuo/hp-lat-llama-None-epsilon3.0-pgd_layer8_16_24_30-def_layer0-ultrachat-towards1-away0-sft0-4 | PhillipGuo | 2024-05-22T04:43:01Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-22T04:42:52Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
claudios/PyCodeGPT | claudios | 2024-05-22T04:33:32Z | 105 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neo",
"text-generation",
"code",
"license:afl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T04:29:29Z | ---
license: afl-3.0
arxiv: 2206.06888
language:
- code
---
This is an *unofficial* reupload of [Daoguang/PyCodeGPT](https://huggingface.co/Daoguang/PyCodeGPT) in the `SafeTensors` format using `transformers` `4.40.1`. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
Original model card below:
---
# PyCodeGPT
A pre-trained GPT model for Python code completion and generation
## What is it?
PyCodeGPT is efficient and effective GPT-Neo-based model for python code generation task, which is similar to [OpenAI Codex](https://openai.com/blog/openai-codex/), [Github Copliot](https://copilot.github.com/), [CodeParrot](https://huggingface.co/blog/codeparrot), [AlphaCode](https://deepmind.com/blog/article/Competitive-programming-with-AlphaCode).
## Training Data
Due to the small size of public released dataset, we proposed to collect data from GitHub from scratch. We first crawled 1.2M python-related repositories hosted by GitHub. Then, we used these repository URLs to download all contents of each repository from GitHub. After that, we got 60M raw python files under 1MB with a total size of 330GB. Finally, we carefully designed various strategies of data cleaning to get about 96GB data for training. Please refer to the following table for the details.
|Model|Repositories|Size and file after filtering|
|:------:|:---:|:---:|
| CodeParrot | 0.56M | 12GB (compressed), 5.4M |
| Codex | 54M | 159GB |
| PyCodeGPT | 1.2M | 96GB, 13M |
## Pretrained models
we aims to train median-large pre-trained models (model size with 110M) based on GPT-Neo:
- PyCodeGPT-110M: derived from GPT-Neo 125M with a vocabulary size of 32K.
## GitHub
[https://github.com/microsoft/PyCodeGPT](https://github.com/microsoft/PyCodeGPT)
## Evaluation Results
Here's our evaluation result on HumanEval dataset:
Note: our model can have a comparable accuracy with Codex of similar model size.
|Model|Pass@1|Pass@10|Pass@100|
|:------:|:---:|:---:|:---:|
|PyCodeGPT-110M |**8.32%** |**13.53%** |**18.3%** |
|||||
|GPT-Neo 125M |0.75% |1.88% |2.97% |
|GPT-Neo 1.3B |4.97% |7.47% |16.3% |
|GPT-Neo 2.7B |6.41% |11.27% |21.37% |
|GPT-J 6B |11.62% |15.74% |27.74% |
|||||
|TabNine |2.58% |4.35% |7.59% |
|||||
|CodeParrot 110M |3.80% |6.57% |12.78% |
|CodeParrot 1.5B |3.58% |8.03% |14.96% |
|||||
|Codex 12M |2.00% |3.62% |8.58% |
|Codex 25M |3.21% |7.1% |12.89% |
|Codex 42M |5.06% |8.8% |15.55% |
|Codex 85M |8.22% |12.81% |22.4% |
|Codex 300M |13.17% |20.37% |36.27% |
|Codex 679M |16.22% |25.7% |40.95% |
|Codex 2.5B |21.36% |35.42% |59.5% |
|Codex 12B |28.81% |46.81% |72.31% |
|||||
|Pretrained Decoder-only 13M (AlphaCode) |1.5% |3.6% |8.6% |
|Pretrained Decoder-only 29M (AlphaCode) |3.4% |5.8% |11.2% |
|Pretrained Decoder-only 55M (AlphaCode) |4.2% |8.2% |16.9% |
|Pretrained Decoder-only 89M (AlphaCode) |4.3% |12.2% |20.0% |
|Pretrained Decoder-only 302M (AlphaCode) |11.6% |18.8% |31.8% |
|Pretrained Decoder-only 685M (AlphaCode) |14.2% |24.4% |38.8% |
|Pretrained Decoder-only 1.1B (AlphaCode) |17.1% |28.2% |45.3% |
|||||
|PolyCoder 160M |2.13% |3.35% |4.88% |
|PolyCoder 400M |2.96% |5.29% |11.59% |
|PolyCoder 2.7B |5.59% |9.84% |17.68% |
## Reference
If you want to use the models, you need to cite our following paper:
```
@inproceedings{CERT,
title={{CERT}: Continual Pre-training on Sketches for Library-oriented Code Generation},
author={Zan, Daoguang and Chen, Bei and Yang, Dejian and Lin, Zeqi and Kim, Minsu and Guan, Bei and Wang, Yongji and Chen, Weizhu and Lou, Jian-Guang},
booktitle={The 2022 International Joint Conference on Artificial Intelligence},
year={2022}
}
``` |
Rimyy/llamaftgsmExp2 | Rimyy | 2024-05-22T04:29:18Z | 135 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T04:24:39Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Mantis-VL/llava_siglip_llama3_8b_finetune_ablation3_8192_lora | Mantis-VL | 2024-05-22T04:26:11Z | 2 | 0 | peft | [
"peft",
"safetensors",
"llava",
"arxiv:1910.09700",
"base_model:TIGER-Lab/Mantis-8B-siglip-llama3-pretraind",
"base_model:adapter:TIGER-Lab/Mantis-8B-siglip-llama3-pretraind",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2024-05-21T09:47:01Z | ---
library_name: peft
base_model: TIGER-Lab/Mantis-8B-siglip-llama3-pretraind
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 |
theglassofwater/finetuning_3epochs | theglassofwater | 2024-05-22T04:25:28Z | 194 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T04:25:04Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
PhillipGuo/hp-lat-llama-None-epsilon1.5-pgd_layer8_16_24_30-def_layer0-ultrachat-towards1-away0-sft0-4 | PhillipGuo | 2024-05-22T04:25:01Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-22T04:24:52Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
sangdeptraivcl/best_model-finetuned-ucf101-subset | sangdeptraivcl | 2024-05-22T04:21:53Z | 62 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"videomae",
"video-classification",
"generated_from_trainer",
"base_model:sangdeptraivcl/best_model",
"base_model:finetune:sangdeptraivcl/best_model",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | video-classification | 2024-05-22T02:33:18Z | ---
license: cc-by-nc-4.0
base_model: sangdeptraivcl/best_model
tags:
- generated_from_trainer
model-index:
- name: best_model-finetuned-ucf101-subset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# best_model-finetuned-ucf101-subset
This model is a fine-tuned version of [sangdeptraivcl/best_model](https://huggingface.co/sangdeptraivcl/best_model) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 766
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
claudios/CodeGPT-Multilingual | claudios | 2024-05-22T04:17:26Z | 140 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-04-30T21:20:43Z |
This is an *unofficial* reupload of [AISE-TUDelft/CodeGPT-Multilingual](https://huggingface.co/AISE-TUDelft/CodeGPT-Multilingual) in the `SafeTensors` format using `transformers` `4.40.1`. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration. |
claudios/CodeGPT-small-java | claudios | 2024-05-22T04:16:41Z | 142 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-04-30T21:17:12Z |
This is an *unofficial* reupload of [microsoft/CodeGPT-small-java](https://huggingface.co/microsoft/CodeGPT-small-java) in the `SafeTensors` format using `transformers` `4.40.1`. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration. |
plaire48/vit-base-patch16-224-in21k-finetuned-lora-main_new_one | plaire48 | 2024-05-22T04:14:50Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-22T03:51:27Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
DavidAhn/Llama-3-8B-slerp-262k | DavidAhn | 2024-05-22T04:13:52Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"gradientai/Llama-3-8B-Instruct-262k",
"DavidAhn/llama-3-base-instruct-slerp",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-16T01:24:18Z | ---
license: apache-2.0
tags:
- gradientai/Llama-3-8B-Instruct-262k
- DavidAhn/llama-3-base-instruct-slerp
---
# llama-3-8b-instruct-slerp-262k
llama-3-8b-instruct-slerp-262k is a model that extends context using LLMFeaturePorter.[EasyLLMFeaturePorter](https://github.com/StableFluffy/EasyLLMFeaturePorter):
* base model: [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)
* informative model: [gradientai/Llama-3-8B-Instruct-262k](https://huggingface.co/gradientai/Llama-3-8B-Instruct-262k)
* target model: [DavidAhn/llama-3-base-instruct-slerp](https://huggingface.co/DavidAhn/llama-3-base-instruct-slerp)
``` |
claudios/dobf-mlm-roberta-size | claudios | 2024-05-22T04:12:07Z | 134 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-04-30T17:56:16Z | ---
arxiv: 2102.07492
---
# DOBF: A Deobfuscation Pre-Training Objective for Programming Languages
This is an *unofficial* reupload of the [DOBF MLM model](https://github.com/facebookresearch/CodeGen/blob/main/docs/dobf.md) in the `SafeTensors` format using `transformers` `4.40.1`. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration. |
MaziyarPanahi/T3qT3qm7xp-7B-GGUF | MaziyarPanahi | 2024-05-22T04:10:02Z | 79 | 0 | transformers | [
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"safetensors",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"automerger",
"base_model:nlpguy/T3QM7XP",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"base_model:automerger/T3qT3qm7xp-7B",
"base_model:quantized:automerger/T3qT3qm7xp-7B"
] | text-generation | 2024-05-22T03:39:26Z | ---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- safetensors
- mistral
- text-generation
- merge
- mergekit
- lazymergekit
- automerger
- base_model:nlpguy/T3QM7XP
- license:apache-2.0
- autotrain_compatible
- endpoints_compatible
- text-generation-inference
- region:us
- text-generation
model_name: T3qT3qm7xp-7B-GGUF
base_model: automerger/T3qT3qm7xp-7B
inference: false
model_creator: automerger
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/T3qT3qm7xp-7B-GGUF](https://huggingface.co/MaziyarPanahi/T3qT3qm7xp-7B-GGUF)
- Model creator: [automerger](https://huggingface.co/automerger)
- Original model: [automerger/T3qT3qm7xp-7B](https://huggingface.co/automerger/T3qT3qm7xp-7B)
## Description
[MaziyarPanahi/T3qT3qm7xp-7B-GGUF](https://huggingface.co/MaziyarPanahi/T3qT3qm7xp-7B-GGUF) contains GGUF format model files for [automerger/T3qT3qm7xp-7B](https://huggingface.co/automerger/T3qT3qm7xp-7B).
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible. |
theglassofwater/finetuned_3_epochs | theglassofwater | 2024-05-22T04:06:56Z | 194 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T04:06:25Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
claudios/t5-learning-mt-task-balanced | claudios | 2024-05-22T04:05:59Z | 107 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"code",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-04-30T18:09:36Z | ---
arxiv: 2102.02017
language:
- code
---
# Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks
## Using Transfer Learning for Code-Related Tasks
This is an *unofficial* reupload of `t5-learning-mt-task-balanced` based off the [author's repo](https://github.com/antonio-mastropaolo/TransferLearning4Code), in the `SafeTensors` format using `transformers` `4.40.1`. I manually converted the checkpoints using the `tf_2_pytorch_T5.py` script and converted the tokenizers with my own script. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
## Citation
```bibtex
@article{Mastropaolo2021StudyingTU,
title={Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks},
author={Antonio Mastropaolo and Simone Scalabrino and Nathan Cooper and David Nader-Palacio and Denys Poshyvanyk and Rocco Oliveto and Gabriele Bavota},
journal={2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE)},
year={2021},
pages={336-347}
}
``` |
claudios/t5-learning-mt-task-unbalanced | claudios | 2024-05-22T04:05:32Z | 110 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"code",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-04-30T18:11:12Z | ---
arxiv: 2102.02017
language:
- code
---
# Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks
## Using Transfer Learning for Code-Related Tasks
This is an *unofficial* reupload of `t5-learning-mt-task-unbalanced` based off the [author's repo](https://github.com/antonio-mastropaolo/TransferLearning4Code), in the `SafeTensors` format using `transformers` `4.40.1`. I manually converted the checkpoints using the `tf_2_pytorch_T5.py` script and converted the tokenizers with my own script. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
## Citation
```bibtex
@article{Mastropaolo2021StudyingTU,
title={Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks},
author={Antonio Mastropaolo and Simone Scalabrino and Nathan Cooper and David Nader-Palacio and Denys Poshyvanyk and Rocco Oliveto and Gabriele Bavota},
journal={2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE)},
year={2021},
pages={336-347}
}
``` |
claudios/t5-learning-no-pretraining-ag-task | claudios | 2024-05-22T04:05:20Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"code",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-04-30T18:12:47Z | ---
arxiv: 2102.02017
language:
- code
---
# Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks
## Using Transfer Learning for Code-Related Tasks
This is an *unofficial* reupload of `t5-learning-no-pretraining-ag-task` based off the [author's repo](https://github.com/antonio-mastropaolo/TransferLearning4Code), in the `SafeTensors` format using `transformers` `4.40.1`. I manually converted the checkpoints using the `tf_2_pytorch_T5.py` script and converted the tokenizers with my own script. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
## Citation
```bibtex
@article{Mastropaolo2021StudyingTU,
title={Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks},
author={Antonio Mastropaolo and Simone Scalabrino and Nathan Cooper and David Nader-Palacio and Denys Poshyvanyk and Rocco Oliveto and Gabriele Bavota},
journal={2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE)},
year={2021},
pages={336-347}
}
``` |
claudios/t5-learning-no-pretraining-bf-task | claudios | 2024-05-22T04:05:10Z | 107 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"code",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-04-30T18:14:20Z | ---
arxiv: 2102.02017
language:
- code
---
# Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks
## Using Transfer Learning for Code-Related Tasks
This is an *unofficial* reupload of `t5-learning-no-pretraining-bf-task` based off the [author's repo](https://github.com/antonio-mastropaolo/TransferLearning4Code), in the `SafeTensors` format using `transformers` `4.40.1`. I manually converted the checkpoints using the `tf_2_pytorch_T5.py` script and converted the tokenizers with my own script. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
## Citation
```bibtex
@article{Mastropaolo2021StudyingTU,
title={Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks},
author={Antonio Mastropaolo and Simone Scalabrino and Nathan Cooper and David Nader-Palacio and Denys Poshyvanyk and Rocco Oliveto and Gabriele Bavota},
journal={2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE)},
year={2021},
pages={336-347}
}
``` |
claudios/t5-learning-no-pretraining-mg-task | claudios | 2024-05-22T04:04:52Z | 107 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"code",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-04-30T18:17:25Z | ---
arxiv: 2102.02017
language:
- code
---
# Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks
## Using Transfer Learning for Code-Related Tasks
This is an *unofficial* reupload of `t5-learning-no-pretraining-mg-task` based off the [author's repo](https://github.com/antonio-mastropaolo/TransferLearning4Code), in the `SafeTensors` format using `transformers` `4.40.1`. I manually converted the checkpoints using the `tf_2_pytorch_T5.py` script and converted the tokenizers with my own script. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
## Citation
```bibtex
@article{Mastropaolo2021StudyingTU,
title={Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks},
author={Antonio Mastropaolo and Simone Scalabrino and Nathan Cooper and David Nader-Palacio and Denys Poshyvanyk and Rocco Oliveto and Gabriele Bavota},
journal={2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE)},
year={2021},
pages={336-347}
}
``` |
claudios/t5-learning-with-pretraining-bf-task | claudios | 2024-05-22T04:03:44Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"code",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-04-30T18:20:32Z | ---
arxiv: 2102.02017
language:
- code
---
# Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks
## Using Transfer Learning for Code-Related Tasks
This is an *unofficial* reupload of `t5-learning-with-pretraining-bf-task` based off the [author's repo](https://github.com/antonio-mastropaolo/TransferLearning4Code), in the `SafeTensors` format using `transformers` `4.40.1`. I manually converted the checkpoints using the `tf_2_pytorch_T5.py` script and converted the tokenizers with my own script. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
## Citation
```bibtex
@article{Mastropaolo2021StudyingTU,
title={Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks},
author={Antonio Mastropaolo and Simone Scalabrino and Nathan Cooper and David Nader-Palacio and Denys Poshyvanyk and Rocco Oliveto and Gabriele Bavota},
journal={2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE)},
year={2021},
pages={336-347}
}
``` |
claudios/t5-learning-with-pretraining-cs-task | claudios | 2024-05-22T04:03:40Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"code",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-04-30T18:22:11Z | ---
arxiv: 2102.02017
language:
- code
---
# Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks
## Using Transfer Learning for Code-Related Tasks
This is an *unofficial* reupload of `t5-learning-with-pretraining-cs-task` based off the [author's repo](https://github.com/antonio-mastropaolo/TransferLearning4Code), in the `SafeTensors` format using `transformers` `4.40.1`. I manually converted the checkpoints using the `tf_2_pytorch_T5.py` script and converted the tokenizers with my own script. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
## Citation
```bibtex
@article{Mastropaolo2021StudyingTU,
title={Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks},
author={Antonio Mastropaolo and Simone Scalabrino and Nathan Cooper and David Nader-Palacio and Denys Poshyvanyk and Rocco Oliveto and Gabriele Bavota},
journal={2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE)},
year={2021},
pages={336-347}
}
``` |
RichardErkhov/S4sch_-_zephyr-neural-chat-frankenmerge11b-4bits | RichardErkhov | 2024-05-22T04:02:19Z | 76 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-22T03:50:58Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
zephyr-neural-chat-frankenmerge11b - bnb 4bits
- Model creator: https://huggingface.co/S4sch/
- Original model: https://huggingface.co/S4sch/zephyr-neural-chat-frankenmerge11b/
Original model description:
---
license: apache-2.0
---
Frankenmerge 11b between HuggingFaceH4/zephyr-7b-beta and Intel/neural-chat-7b-v3-1
Merge with the following conditions (via mergekit on github)
model: Intel/neural-chat-7b-v3-1
layer_range: [0, 8]
model: HuggingFaceH4/zephyr-7b-beta
layer_range: [4, 12]
model: Intel/neural-chat-7b-v3-1
layer_range: [9, 16]
model: HuggingFaceH4/zephyr-7b-beta
layer_range: [13, 20]
model: Intel/neural-chat-7b-v3-1
layer_range: [17, 24]
model: HuggingFaceH4/zephyr-7b-beta
layer_range: [21, 28]
model: Intel/neural-chat-7b-v3-1
layer_range: [25, 32]
merge_method: passthrough
|
llama-duo/gemma7b-summarize-claude3sonnet-30k | llama-duo | 2024-05-22T03:53:37Z | 16 | 3 | peft | [
"peft",
"tensorboard",
"safetensors",
"gemma",
"alignment-handbook",
"trl",
"sft",
"generated_from_trainer",
"dataset:llama-duo/synth_summarize_dataset",
"base_model:google/gemma-7b",
"base_model:adapter:google/gemma-7b",
"license:gemma",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2024-05-19T15:22:28Z | ---
license: gemma
library_name: peft
tags:
- alignment-handbook
- trl
- sft
- generated_from_trainer
base_model: google/gemma-7b
datasets:
- llama-duo/synth_summarize_dataset
model-index:
- name: gemma7b-summarize-claude3sonnet-30k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/chansung18/huggingface/runs/7bdtvabz)
# gemma7b-summarize-claude3sonnet-30k
This model is a fine-tuned version of [google/gemma-7b](https://huggingface.co/google/gemma-7b) on the llama-duo/synth_summarize_dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0044
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- total_eval_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.0072 | 1.0 | 148 | 2.2672 |
| 0.8705 | 2.0 | 296 | 2.1745 |
| 0.7957 | 3.0 | 444 | 2.1914 |
| 0.731 | 4.0 | 592 | 2.2511 |
| 0.634 | 5.0 | 740 | 2.3409 |
| 0.5418 | 6.0 | 888 | 2.4841 |
| 0.4578 | 7.0 | 1036 | 2.6822 |
| 0.3886 | 8.0 | 1184 | 2.8497 |
| 0.3611 | 9.0 | 1332 | 2.9868 |
| 0.3501 | 10.0 | 1480 | 3.0044 |
### Framework versions
- PEFT 0.11.1
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1 |
DUAL-GPO-2/phi-2-irepo-chatml-v5-i2 | DUAL-GPO-2 | 2024-05-22T03:51:20Z | 1 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"phi",
"alignment-handbook",
"generated_from_trainer",
"trl",
"dpo",
"custom_code",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"base_model:DUAL-GPO/phi-2-irepo-chatml-merged-i1",
"base_model:adapter:DUAL-GPO/phi-2-irepo-chatml-merged-i1",
"license:apache-2.0",
"region:us"
] | null | 2024-05-22T01:37:44Z | ---
license: apache-2.0
library_name: peft
tags:
- alignment-handbook
- generated_from_trainer
- trl
- dpo
- generated_from_trainer
base_model: DUAL-GPO/phi-2-irepo-chatml-merged-i1
datasets:
- HuggingFaceH4/ultrafeedback_binarized
model-index:
- name: phi-2-irepo-chatml-v5-i2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phi-2-irepo-chatml-v5-i2
This model is a fine-tuned version of [DUAL-GPO/phi-2-irepo-chatml-merged-i1](https://huggingface.co/DUAL-GPO/phi-2-irepo-chatml-merged-i1) on the HuggingFaceH4/ultrafeedback_binarized dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- total_eval_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- PEFT 0.7.1
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2 |
RichardErkhov/nvidia_-_OpenMath-CodeLlama-7b-Python-hf-8bits | RichardErkhov | 2024-05-22T03:47:44Z | 76 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:2402.10176",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-22T03:33:44Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
OpenMath-CodeLlama-7b-Python-hf - bnb 8bits
- Model creator: https://huggingface.co/nvidia/
- Original model: https://huggingface.co/nvidia/OpenMath-CodeLlama-7b-Python-hf/
Original model description:
---
license: llama2
base_model:
- codellama/CodeLlama-7b-Python-hf
datasets:
- nvidia/OpenMathInstruct-1
language:
- en
tags:
- nvidia
- code
- math
---
# OpenMath-CodeLlama-7b-Python-hf
OpenMath models were designed to solve mathematical problems by integrating text-based reasoning with code blocks
executed by Python interpreter. The models were trained on [OpenMathInstruct-1](https://huggingface.co/datasets/nvidia/OpenMathInstruct-1),
a math instruction tuning dataset with 1.8M problem-solution pairs generated using permissively licensed
[Mixtral-8x7B](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1) model.
<table border="1">
<tr>
<td></td>
<td colspan="2" style="text-align: center;">greedy</td>
<td colspan="2" style="text-align: center;">majority@50</td>
</tr>
<tr>
<td style="text-align: center;">model</td>
<td style="text-align: center;">GSM8K</td>
<td style="text-align: center;">MATH</td>
<td style="text-align: center;">GMS8K</td>
<td style="text-align: center;">MATH</td>
</tr>
<tr>
<td style="text-align: right;">OpenMath-CodeLlama-7B (<a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-7b-Python">nemo</a> | <a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-7b-Python-hf">HF</a>)</td>
<td style="text-align: center;">75.9</td>
<td style="text-align: center;">43.6</td>
<td style="text-align: center;">84.8</td>
<td style="text-align: center;">55.6</td>
</tr>
<tr>
<td style="text-align: right;">OpenMath-Mistral-7B (<a href="https://huggingface.co/nvidia/OpenMath-Mistral-7B-v0.1">nemo</a> | <a href="https://huggingface.co/nvidia/OpenMath-Mistral-7B-v0.1-hf">HF</a>)</td>
<td style="text-align: center;">80.2</td>
<td style="text-align: center;">44.5</td>
<td style="text-align: center;">86.9</td>
<td style="text-align: center;">57.2</td>
</tr>
<tr>
<td style="text-align: right;">OpenMath-CodeLlama-13B (<a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-13b-Python">nemo</a> | <a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-13b-Python-hf">HF</a>)</td>
<td style="text-align: center;">78.8</td>
<td style="text-align: center;">45.5</td>
<td style="text-align: center;">86.8</td>
<td style="text-align: center;">57.6</td>
</tr>
<tr>
<td style="text-align: right;">OpenMath-CodeLlama-34B (<a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-34b-Python">nemo</a> | <a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-34b-Python-hf">HF</a>)</td>
<td style="text-align: center;">80.7</td>
<td style="text-align: center;">48.3</td>
<td style="text-align: center;">88.0</td>
<td style="text-align: center;">60.2</td>
</tr>
<tr>
<td style="text-align: right;">OpenMath-Llama2-70B (<a href="https://huggingface.co/nvidia/OpenMath-Llama-2-70b">nemo</a> | <a href="https://huggingface.co/nvidia/OpenMath-Llama-2-70b-hf">HF</a>)</td>
<td style="text-align: center;"><b>84.7</b></td>
<td style="text-align: center;">46.3</td>
<td style="text-align: center;">90.1</td>
<td style="text-align: center;">58.3</td>
</tr>
<tr>
<td style="text-align: right;">OpenMath-CodeLlama-70B (<a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-70b-Python">nemo</a> | <a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-70b-Python-hf">HF</a>)</td>
<td style="text-align: center;">84.6</td>
<td style="text-align: center;"><b>50.7</b></td>
<td style="text-align: center;"><b>90.8</b></td>
<td style="text-align: center;"><b>60.4</b></td>
</tr>
</table>
The pipeline we used to produce these models is fully open-sourced!
- [Code](https://github.com/Kipok/NeMo-Skills)
- [Models](https://huggingface.co/collections/nvidia/openmath-65c5619de2ba059be0775014)
- [Dataset](https://huggingface.co/datasets/nvidia/OpenMathInstruct-1)
See our [paper](https://arxiv.org/abs/2402.10176) for more details!
# How to use the models?
Try to [run inference with our models](https://github.com/Kipok/NeMo-Skills/blob/main/docs/inference.md) with just a few commands!
# Reproducing our results
We provide [all instructions](https://github.com/Kipok/NeMo-Skills/blob/main/docs/reproducing-results.md) to fully reproduce our results.
# Improving other models
To improve other models or to learn more about our code, read through the docs below.
- [NeMo-Skills Pipeline](https://github.com/Kipok/NeMo-Skills)
- [Generating synthetic data](https://github.com/Kipok/NeMo-Skills/blob/main/docs/synthetic-data-generation.md)
- [Finetuning models](https://github.com/Kipok/NeMo-Skills/blob/main/docs/finetuning.md)
- [Evaluating models](https://github.com/Kipok/NeMo-Skills/blob/main/docs/evaluation.md)
In our pipeline we use [NVIDIA NeMo](https://www.nvidia.com/en-us/ai-data-science/generative-ai/nemo-framework/),
an end-to-end, cloud-native framework to build, customize, and deploy generative AI models anywhere.
It includes training and inferencing frameworks, guardrailing toolkits, data curation tools, and pretrained models,
offering enterprises an easy, cost-effective, and fast way to adopt generative AI.
# Citation
If you find our work useful, please consider citing us!
```bibtex
@article{toshniwal2024openmath,
title = {OpenMathInstruct-1: A 1.8 Million Math Instruction Tuning Dataset},
author = {Shubham Toshniwal and Ivan Moshkov and Sean Narenthiran and Daria Gitman and Fei Jia and Igor Gitman},
year = {2024},
journal = {arXiv preprint arXiv: Arxiv-2402.10176}
}
```
# License
The use of this model is governed by the [Llama 2 Community License Agreement](https://ai.meta.com/llama/license/)
|
RichardErkhov/Locutusque_-_Hercules-3.1-Mistral-7B-4bits | RichardErkhov | 2024-05-22T03:46:59Z | 76 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-22T03:40:51Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Hercules-3.1-Mistral-7B - bnb 4bits
- Model creator: https://huggingface.co/Locutusque/
- Original model: https://huggingface.co/Locutusque/Hercules-3.1-Mistral-7B/
Original model description:
---
license: apache-2.0
library_name: transformers
tags:
- chemistry
- biology
- code
- medical
- not-for-all-audiences
datasets:
- Locutusque/Hercules-v3.0
model-index:
- name: Hercules-3.1-Mistral-7B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 61.18
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Locutusque/Hercules-3.1-Mistral-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 83.55
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Locutusque/Hercules-3.1-Mistral-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 63.65
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Locutusque/Hercules-3.1-Mistral-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 42.83
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Locutusque/Hercules-3.1-Mistral-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 79.01
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Locutusque/Hercules-3.1-Mistral-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 42.3
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Locutusque/Hercules-3.1-Mistral-7B
name: Open LLM Leaderboard
---
# Model Card: Hercules-3.1-Mistral-7B

## Model Description
Hercules-3.1-Mistral-7B is a fine-tuned language model derived from Mistralai/Mistral-7B-v0.1. It is specifically designed to excel in instruction following, function calls, and conversational interactions across various scientific and technical domains. The dataset used for fine-tuning, also named Hercules-v3.0, expands upon the diverse capabilities of OpenHermes-2.5 with contributions from numerous curated datasets. This fine-tuning has hercules-v3.0 with enhanced abilities in:
- Complex Instruction Following: Understanding and accurately executing multi-step instructions, even those involving specialized terminology.
- Function Calling: Seamlessly interpreting and executing function calls, providing appropriate input and output values.
- Domain-Specific Knowledge: Engaging in informative and educational conversations about Biology, Chemistry, Physics, Mathematics, Medicine, Computer Science, and more.
## Intended Uses & Potential Bias
Hercules-3.1-Mistral-7B is well-suited to the following applications:
- Specialized Chatbots: Creating knowledgeable chatbots and conversational agents in scientific and technical fields.
- Instructional Assistants: Supporting users with educational and step-by-step guidance in various disciplines.
- Code Generation and Execution: Facilitating code execution through function calls, aiding in software development and prototyping.
**Important Note: Although Hercules-v3.0 is carefully constructed, it's important to be aware that the underlying data sources may contain biases or reflect harmful stereotypes. Use this model with caution and consider additional measures to mitigate potential biases in its responses.**
## Limitations and Risks
- Toxicity: The dataset contains toxic or harmful examples.
- Hallucinations and Factual Errors: Like other language models, Hercules-3.1-Mistral-7B may generate incorrect or misleading information, especially in specialized domains where it lacks sufficient expertise.
- Potential for Misuse: The ability to engage in technical conversations and execute function calls could be misused for malicious purposes.
## Training Data
Hercules-3.1-Mistral-7B is fine-tuned from the following sources:
- `cognitivecomputations/dolphin`
- `Evol Instruct 70K & 140K`
- `teknium/GPT4-LLM-Cleaned`
- `jondurbin/airoboros-3.2`
- `AlekseyKorshuk/camel-chatml`
- `CollectiveCognition/chats-data-2023-09-22`
- `Nebulous/lmsys-chat-1m-smortmodelsonly`
- `glaiveai/glaive-code-assistant-v2`
- `glaiveai/glaive-code-assistant`
- `glaiveai/glaive-function-calling-v2`
- `garage-bAInd/Open-Platypus`
- `meta-math/MetaMathQA`
- `teknium/GPTeacher-General-Instruct`
- `GPTeacher roleplay datasets`
- `BI55/MedText`
- `pubmed_qa labeled subset`
- `Unnatural Instructions`
- `M4-ai/LDJnr_combined_inout_format`
- `CollectiveCognition/chats-data-2023-09-27`
- `CollectiveCognition/chats-data-2023-10-16`
- `NobodyExistsOnTheInternet/sharegptPIPPA`
- `yuekai/openchat_sharegpt_v3_vicuna_format`
- `ise-uiuc/Magicoder-Evol-Instruct-110K`
- `sablo/oasst2_curated`
The bluemoon dataset was filtered from the training data as it showed to cause performance degradation.
## Training Procedure
- This model was trained on 8 kaggle TPUs, using torch xla SPMD for high MXU efficiency. There was no expense on my end (meaning you can reproduce this too!)
- A learning rate of 2e-06 with the Adam optimizer. A linear scheduler was used, with an end factor of 0.3. A low learning rate was used to prevent exploding gradients.
- No mixed precision was used, with the default dtype being bfloat16.
- Trained on 700,000 examples of Hercules-v3.0
- No model parameters were frozen.
- This model was trained on OpenAI's ChatML prompt format. Because this model has function calling capabilities, the prompt format is slightly different, here's what it would look like: ```<|im_start|>system\n{message}<|im_end|>\n<|im_start|>user\n{user message}<|im_end|>\n<|im_start|>call\n{function call message}<|im_end|>\n<|im_start|>function\n{function response message}<|im_end|>\n<|im_start|>assistant\n{assistant message}</s>```
This model was fine-tuned using the TPU-Alignment repository. https://github.com/Locutusque/TPU-Alignment
# Quants
ExLlamaV2 by bartowski https://huggingface.co/bartowski/Hercules-3.1-Mistral-7B-exl2
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Locutusque__Hercules-3.1-Mistral-7B)
| Metric |Value|
|---------------------------------|----:|
|Avg. |62.09|
|AI2 Reasoning Challenge (25-Shot)|61.18|
|HellaSwag (10-Shot) |83.55|
|MMLU (5-Shot) |63.65|
|TruthfulQA (0-shot) |42.83|
|Winogrande (5-shot) |79.01|
|GSM8k (5-shot) |42.30|
|
claudios/plbart-java-cs | claudios | 2024-05-22T03:46:40Z | 92 | 0 | transformers | [
"transformers",
"safetensors",
"plbart",
"feature-extraction",
"code",
"license:mit",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-04-30T22:21:23Z | ---
arxiv: 2103.06333
license: mit
language:
- code
---
This is an *unofficial* reupload of [uclanlp/plbart-java-cs](https://huggingface.co/uclanlp/plbart-java-cs) in the `SafeTensors` format using `transformers` `4.40.1`. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
Please see the [original repo](https://github.com/wasiahmad/PLBART) for more information.
Original model card below:
---
## PLBART is a Transformer model
- PLBART is a sequence-to-sequence model pre-trained on a large collection Java and Python functions and natural
language descriptions collected from Github and StackOverflow, respectively.
- PLBART is pre-trained via denoising autoencoding (DAE) and uses three noising strategies: token masking, token
deletion, and token infilling (shown below in the three examples).
<div align="center">
<table>
<thead>
<tr>
<th>Noisy Input</th>
<th>Original Sequence</th>
</tr>
</thead>
<tbody>
<tr>
<td>Is 0 the <strong>[MASK]</strong> Fibonacci <strong>[MASK]</strong> ? <em><En></em></td>
<td><em><En></em> Is 0 the <strong>first</strong> Fibonacci <strong>number</strong> ?</td>
</tr>
<tr>
<td>public static main ( String args [ ] ) { date = Date ( ) ;
System . out . ( String . format ( " Current Date : % tc " , ) ) ; } <em><java></em></td>
<td><em><java></em> public static <strong>void</strong> main ( String args [ ] ) { <strong>Date</strong> date = new Date ( ) ;
System . out . <strong>printf</strong> ( String . format ( " Current Date : % tc " , <strong>date</strong> ) ) ; }</td>
</tr>
<tr>
<td>def addThreeNumbers ( x , y , z ) : NEW_LINE INDENT return <strong>[MASK]</strong> <em><python></em></td>
<td><em><python></em> def addThreeNumbers ( x , y , z ) : NEW_LINE INDENT return <strong>x + y + z</strong></td>
</tr>
</tbody>
</table>
</div> |
claudios/plbart-python-en_XX | claudios | 2024-05-22T03:46:34Z | 93 | 0 | transformers | [
"transformers",
"safetensors",
"plbart",
"feature-extraction",
"code",
"license:mit",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-04-30T22:25:03Z | ---
arxiv: 2103.06333
license: mit
language:
- code
---
This is an *unofficial* reupload of [uclanlp/plbart-python-en_XX](https://huggingface.co/uclanlp/plbart-python-en_XX) in the `SafeTensors` format using `transformers` `4.40.1`. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
Please see the [original repo](https://github.com/wasiahmad/PLBART) for more information.
Original model card below:
---
## PLBART is a Transformer model
- PLBART is a sequence-to-sequence model pre-trained on a large collection Java and Python functions and natural
language descriptions collected from Github and StackOverflow, respectively.
- PLBART is pre-trained via denoising autoencoding (DAE) and uses three noising strategies: token masking, token
deletion, and token infilling (shown below in the three examples).
<div align="center">
<table>
<thead>
<tr>
<th>Noisy Input</th>
<th>Original Sequence</th>
</tr>
</thead>
<tbody>
<tr>
<td>Is 0 the <strong>[MASK]</strong> Fibonacci <strong>[MASK]</strong> ? <em><En></em></td>
<td><em><En></em> Is 0 the <strong>first</strong> Fibonacci <strong>number</strong> ?</td>
</tr>
<tr>
<td>public static main ( String args [ ] ) { date = Date ( ) ;
System . out . ( String . format ( " Current Date : % tc " , ) ) ; } <em><java></em></td>
<td><em><java></em> public static <strong>void</strong> main ( String args [ ] ) { <strong>Date</strong> date = new Date ( ) ;
System . out . <strong>printf</strong> ( String . format ( " Current Date : % tc " , <strong>date</strong> ) ) ; }</td>
</tr>
<tr>
<td>def addThreeNumbers ( x , y , z ) : NEW_LINE INDENT return <strong>[MASK]</strong> <em><python></em></td>
<td><em><python></em> def addThreeNumbers ( x , y , z ) : NEW_LINE INDENT return <strong>x + y + z</strong></td>
</tr>
</tbody>
</table>
</div> |
claudios/plbart-c-cpp-defect-detection | claudios | 2024-05-22T03:46:12Z | 89 | 0 | transformers | [
"transformers",
"safetensors",
"plbart",
"feature-extraction",
"code",
"license:mit",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-05-01T01:18:36Z | ---
arxiv: 2103.06333
license: mit
language:
- code
---
This is an *unofficial* reupload of [uclanlp/plbart-c-cpp-defect-detection](https://huggingface.co/uclanlp/plbart-c-cpp-defect-detection) in the `SafeTensors` format using `transformers` `4.40.1`. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
Please see the [original repo](https://github.com/wasiahmad/PLBART) for more information.
Original model card below:
---
## PLBART is a Transformer model
- PLBART is a sequence-to-sequence model pre-trained on a large collection Java and Python functions and natural
language descriptions collected from Github and StackOverflow, respectively.
- PLBART is pre-trained via denoising autoencoding (DAE) and uses three noising strategies: token masking, token
deletion, and token infilling (shown below in the three examples).
<div align="center">
<table>
<thead>
<tr>
<th>Noisy Input</th>
<th>Original Sequence</th>
</tr>
</thead>
<tbody>
<tr>
<td>Is 0 the <strong>[MASK]</strong> Fibonacci <strong>[MASK]</strong> ? <em><En></em></td>
<td><em><En></em> Is 0 the <strong>first</strong> Fibonacci <strong>number</strong> ?</td>
</tr>
<tr>
<td>public static main ( String args [ ] ) { date = Date ( ) ;
System . out . ( String . format ( " Current Date : % tc " , ) ) ; } <em><java></em></td>
<td><em><java></em> public static <strong>void</strong> main ( String args [ ] ) { <strong>Date</strong> date = new Date ( ) ;
System . out . <strong>printf</strong> ( String . format ( " Current Date : % tc " , <strong>date</strong> ) ) ; }</td>
</tr>
<tr>
<td>def addThreeNumbers ( x , y , z ) : NEW_LINE INDENT return <strong>[MASK]</strong> <em><python></em></td>
<td><em><python></em> def addThreeNumbers ( x , y , z ) : NEW_LINE INDENT return <strong>x + y + z</strong></td>
</tr>
</tbody>
</table>
</div> |
claudios/ContraBERT_G | claudios | 2024-05-22T03:39:31Z | 107 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"fill-mask",
"code",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-05-01T20:45:52Z | ---
language:
- code
arxiv: 2301.09072
---
This is an *unofficial* reupload of [ContraBERT_G](https://github.com/shangqing-liu/ContraBERT) based off the author's original [Google Drive link](https://drive.google.com/drive/u/1/folders/1t8VX6aYchpJolbH4mkhK3IQGzyHrDD3C), in the `SafeTensors` format using `transformers` `4.40.1`. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
Original model card below:
---
# ContraBERT
This repo is the implementation of the paper "ContraBERT: Enhancing Code Pre-trained Models via Contrastive Learning"
## Motivation
The aforementioned pre-trained models have a profound impact for AI4SE community and have achieved promising results on various tasks.
However, our preliminary study has demonstrated that state-of-the-art pre-trained models are not robust to a simple label-preserving program mutation such as variable renaming.
Specifically, we utilize the test data of clone detection (POJ-104)(a task to detect whether two functions are semantic equivalence with different implementations) provided by CodeXGLUE
and select those samples that are predicted correctly by the pre-trained CodeBERT and GraphCodeBERT.
Then we randomly rename variables within these programs from 1 to 8 edits. For example, 8 edits mean that we randomly select 8 different variables in a function and rename them for all occurrences with the new generated names.
We then utilize these newly generated mutated variants to evaluate the model prediction accuracy based on cosine similarity of the embedded vectors of these programs.
Surprisingly, we find that either CodeBERT or GraphCodeBERT suffers greatly from renaming operation and the accuracy reduces to around 0.4 when renaming edits reach to 8.
It confirms that pre-trained models are not robust to adversarial examples.

## Model Design
Due to the limitation of current state-of-the-art pre-trained models, we propose to leverage
contrastive learning to improve the model robustness. Specifically, we design a set of different
variants to help the model group the semantic-equivalent variants. The model architecture is shown.

## Experimental Results
Our model is initialized by CodeBERT and GraphCodeBERT, denotes as ContraBERT_C and ContraBERT_G respectively.
By our extensive experiments, we have confirmed the robustness of CodeBERT and GraphCodeBERT has improved.
We further confirm that these robustness enhanced models can provide improvements on many downstream tasks.
Now we provide the specific commands in each task for the implementation. Our pre-trained models ContraBERT_C and
ContraBERT_G are available at **[ContraBERT_C](https://drive.google.com/drive/u/1/folders/1F-yIS-f84uJhOCzvGWdMaOeRdLsVWoxN)** and **[ContraBERT_G](https://drive.google.com/drive/u/1/folders/1t8VX6aYchpJolbH4mkhK3IQGzyHrDD3C)**. |
Aryan-401/yolo-tiny-fashion | Aryan-401 | 2024-05-22T03:38:10Z | 189 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"yolos",
"object-detection",
"autotrain",
"vision",
"endpoints_compatible",
"region:us"
] | object-detection | 2024-05-21T18:43:44Z |
---
tags:
- autotrain
- object-detection
- vision
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
- dataset: detection-datasets/fashionpedia
---
# Model Trained Using AutoTrain
- Problem type: Object Detection
## Validation Metrics
loss: 1.3179453611373901
map: 0.1361
map_50: 0.1892
map_75: 0.1548
map_small: 0.0
map_medium: 0.102
map_large: 0.1367
mar_1: 0.2076
mar_10: 0.4071
mar_100: 0.4151
mar_small: 0.0
mar_medium: 0.2304
mar_large: 0.4179
|
BoyishGiggles/flan-t5-small-ecommerce-text-classification | BoyishGiggles | 2024-05-22T03:36:38Z | 47 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text-classification",
"generated_from_trainer",
"base_model:google/flan-t5-small",
"base_model:finetune:google/flan-t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-22T00:56:43Z | ---
license: apache-2.0
base_model: google/flan-t5-small
tags:
- generated_from_trainer
model-index:
- name: flan-t5-small-ecommerce-text-classification
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-small-ecommerce-text-classification
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0
- Datasets 2.19.1
- Tokenizers 0.19.1
|
claudios/cotext-1-cc | claudios | 2024-05-22T03:36:12Z | 104 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"feature-extraction",
"code",
"dataset:code_search_net",
"arxiv:2105.08645",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-04-30T18:32:21Z | ---
language: code
datasets:
- code_search_net
---
This is an *unofficial* reupload of [razent/cotext-1-cc](https://huggingface.co/razent/cotext-1-cc) in the `SafeTensors` format using `transformers` `4.40.1`. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
Original model card below:
---
# CoText (1-CC)
## Introduction
Paper: [CoTexT: Multi-task Learning with Code-Text Transformer](https://arxiv.org/abs/2105.08645)
Authors: _Long Phan, Hieu Tran, Daniel Le, Hieu Nguyen, James Anibal, Alec Peltekian, Yanfang Ye_
## How to use
Supported languages:
```shell
"go"
"java"
"javascript"
"php"
"python"
"ruby"
```
For more details, do check out [our Github repo](https://github.com/justinphan3110/CoTexT).
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("razent/cotext-1-cc")
model = AutoModelForSeq2SeqLM.from_pretrained("razent/cotext-1-cc")
sentence = "def add(a, b): return a + b"
text = "python: " + sentence + " </s>"
encoding = tokenizer.encode_plus(text, pad_to_max_length=True, return_tensors="pt")
input_ids, attention_masks = encoding["input_ids"].to("cuda"), encoding["attention_mask"].to("cuda")
outputs = model.generate(
input_ids=input_ids, attention_mask=attention_masks,
max_length=256,
early_stopping=True
)
for output in outputs:
line = tokenizer.decode(output, skip_special_tokens=True, clean_up_tokenization_spaces=True)
print(line)
```
## Citation
```
@inproceedings{phan-etal-2021-cotext,
title = "{C}o{T}ex{T}: Multi-task Learning with Code-Text Transformer",
author = "Phan, Long and Tran, Hieu and Le, Daniel and Nguyen, Hieu and Annibal, James and Peltekian, Alec and Ye, Yanfang",
booktitle = "Proceedings of the 1st Workshop on Natural Language Processing for Programming (NLP4Prog 2021)",
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.nlp4prog-1.5",
doi = "10.18653/v1/2021.nlp4prog-1.5",
pages = "40--47"
}
``` |
suzuki-2001/BERT-K7 | suzuki-2001 | 2024-05-22T03:35:16Z | 195 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"fill-mask",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-05-22T03:34:44Z | ---
license: apache-2.0
---
|
hyoo14/DNABERT2_AMR_2 | hyoo14 | 2024-05-22T03:34:30Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-22T02:38:02Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
suzuki-2001/BERT-K5 | suzuki-2001 | 2024-05-22T03:34:19Z | 194 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"fill-mask",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-05-22T03:33:53Z | ---
license: apache-2.0
---
|
RichardErkhov/nvidia_-_OpenMath-CodeLlama-7b-Python-hf-4bits | RichardErkhov | 2024-05-22T03:33:03Z | 76 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:2402.10176",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-22T03:23:17Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
OpenMath-CodeLlama-7b-Python-hf - bnb 4bits
- Model creator: https://huggingface.co/nvidia/
- Original model: https://huggingface.co/nvidia/OpenMath-CodeLlama-7b-Python-hf/
Original model description:
---
license: llama2
base_model:
- codellama/CodeLlama-7b-Python-hf
datasets:
- nvidia/OpenMathInstruct-1
language:
- en
tags:
- nvidia
- code
- math
---
# OpenMath-CodeLlama-7b-Python-hf
OpenMath models were designed to solve mathematical problems by integrating text-based reasoning with code blocks
executed by Python interpreter. The models were trained on [OpenMathInstruct-1](https://huggingface.co/datasets/nvidia/OpenMathInstruct-1),
a math instruction tuning dataset with 1.8M problem-solution pairs generated using permissively licensed
[Mixtral-8x7B](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1) model.
<table border="1">
<tr>
<td></td>
<td colspan="2" style="text-align: center;">greedy</td>
<td colspan="2" style="text-align: center;">majority@50</td>
</tr>
<tr>
<td style="text-align: center;">model</td>
<td style="text-align: center;">GSM8K</td>
<td style="text-align: center;">MATH</td>
<td style="text-align: center;">GMS8K</td>
<td style="text-align: center;">MATH</td>
</tr>
<tr>
<td style="text-align: right;">OpenMath-CodeLlama-7B (<a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-7b-Python">nemo</a> | <a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-7b-Python-hf">HF</a>)</td>
<td style="text-align: center;">75.9</td>
<td style="text-align: center;">43.6</td>
<td style="text-align: center;">84.8</td>
<td style="text-align: center;">55.6</td>
</tr>
<tr>
<td style="text-align: right;">OpenMath-Mistral-7B (<a href="https://huggingface.co/nvidia/OpenMath-Mistral-7B-v0.1">nemo</a> | <a href="https://huggingface.co/nvidia/OpenMath-Mistral-7B-v0.1-hf">HF</a>)</td>
<td style="text-align: center;">80.2</td>
<td style="text-align: center;">44.5</td>
<td style="text-align: center;">86.9</td>
<td style="text-align: center;">57.2</td>
</tr>
<tr>
<td style="text-align: right;">OpenMath-CodeLlama-13B (<a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-13b-Python">nemo</a> | <a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-13b-Python-hf">HF</a>)</td>
<td style="text-align: center;">78.8</td>
<td style="text-align: center;">45.5</td>
<td style="text-align: center;">86.8</td>
<td style="text-align: center;">57.6</td>
</tr>
<tr>
<td style="text-align: right;">OpenMath-CodeLlama-34B (<a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-34b-Python">nemo</a> | <a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-34b-Python-hf">HF</a>)</td>
<td style="text-align: center;">80.7</td>
<td style="text-align: center;">48.3</td>
<td style="text-align: center;">88.0</td>
<td style="text-align: center;">60.2</td>
</tr>
<tr>
<td style="text-align: right;">OpenMath-Llama2-70B (<a href="https://huggingface.co/nvidia/OpenMath-Llama-2-70b">nemo</a> | <a href="https://huggingface.co/nvidia/OpenMath-Llama-2-70b-hf">HF</a>)</td>
<td style="text-align: center;"><b>84.7</b></td>
<td style="text-align: center;">46.3</td>
<td style="text-align: center;">90.1</td>
<td style="text-align: center;">58.3</td>
</tr>
<tr>
<td style="text-align: right;">OpenMath-CodeLlama-70B (<a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-70b-Python">nemo</a> | <a href="https://huggingface.co/nvidia/OpenMath-CodeLlama-70b-Python-hf">HF</a>)</td>
<td style="text-align: center;">84.6</td>
<td style="text-align: center;"><b>50.7</b></td>
<td style="text-align: center;"><b>90.8</b></td>
<td style="text-align: center;"><b>60.4</b></td>
</tr>
</table>
The pipeline we used to produce these models is fully open-sourced!
- [Code](https://github.com/Kipok/NeMo-Skills)
- [Models](https://huggingface.co/collections/nvidia/openmath-65c5619de2ba059be0775014)
- [Dataset](https://huggingface.co/datasets/nvidia/OpenMathInstruct-1)
See our [paper](https://arxiv.org/abs/2402.10176) for more details!
# How to use the models?
Try to [run inference with our models](https://github.com/Kipok/NeMo-Skills/blob/main/docs/inference.md) with just a few commands!
# Reproducing our results
We provide [all instructions](https://github.com/Kipok/NeMo-Skills/blob/main/docs/reproducing-results.md) to fully reproduce our results.
# Improving other models
To improve other models or to learn more about our code, read through the docs below.
- [NeMo-Skills Pipeline](https://github.com/Kipok/NeMo-Skills)
- [Generating synthetic data](https://github.com/Kipok/NeMo-Skills/blob/main/docs/synthetic-data-generation.md)
- [Finetuning models](https://github.com/Kipok/NeMo-Skills/blob/main/docs/finetuning.md)
- [Evaluating models](https://github.com/Kipok/NeMo-Skills/blob/main/docs/evaluation.md)
In our pipeline we use [NVIDIA NeMo](https://www.nvidia.com/en-us/ai-data-science/generative-ai/nemo-framework/),
an end-to-end, cloud-native framework to build, customize, and deploy generative AI models anywhere.
It includes training and inferencing frameworks, guardrailing toolkits, data curation tools, and pretrained models,
offering enterprises an easy, cost-effective, and fast way to adopt generative AI.
# Citation
If you find our work useful, please consider citing us!
```bibtex
@article{toshniwal2024openmath,
title = {OpenMathInstruct-1: A 1.8 Million Math Instruction Tuning Dataset},
author = {Shubham Toshniwal and Ivan Moshkov and Sean Narenthiran and Daria Gitman and Fei Jia and Igor Gitman},
year = {2024},
journal = {arXiv preprint arXiv: Arxiv-2402.10176}
}
```
# License
The use of this model is governed by the [Llama 2 Community License Agreement](https://ai.meta.com/llama/license/)
|
claudios/VulBERTa-MLP-MVD | claudios | 2024-05-22T03:32:04Z | 153 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"devign",
"defect detection",
"code",
"dataset:code_x_glue_cc_defect_detection",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-01-05T20:44:06Z | ---
license: mit
arxiv: 2205.12424
datasets:
- code_x_glue_cc_defect_detection
metrics:
- accuracy
- precision
- recall
- f1
- roc_auc
model-index:
- name: VulBERTa MLP
results:
- task:
type: defect-detection
dataset:
name: codexglue-devign
type: codexglue-devign
metrics:
- name: Accuracy
type: Accuracy
value: 64.71
- name: Precision
type: Precision
value: 64.80
- name: Recall
type: Recall
value: 50.76
- name: F1
type: F1
value: 56.93
- name: ROC-AUC
type: ROC-AUC
value: 71.02
pipeline_tag: text-classification
tags:
- devign
- defect detection
- code
---
# VulBERTa MLP Devign
## VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection
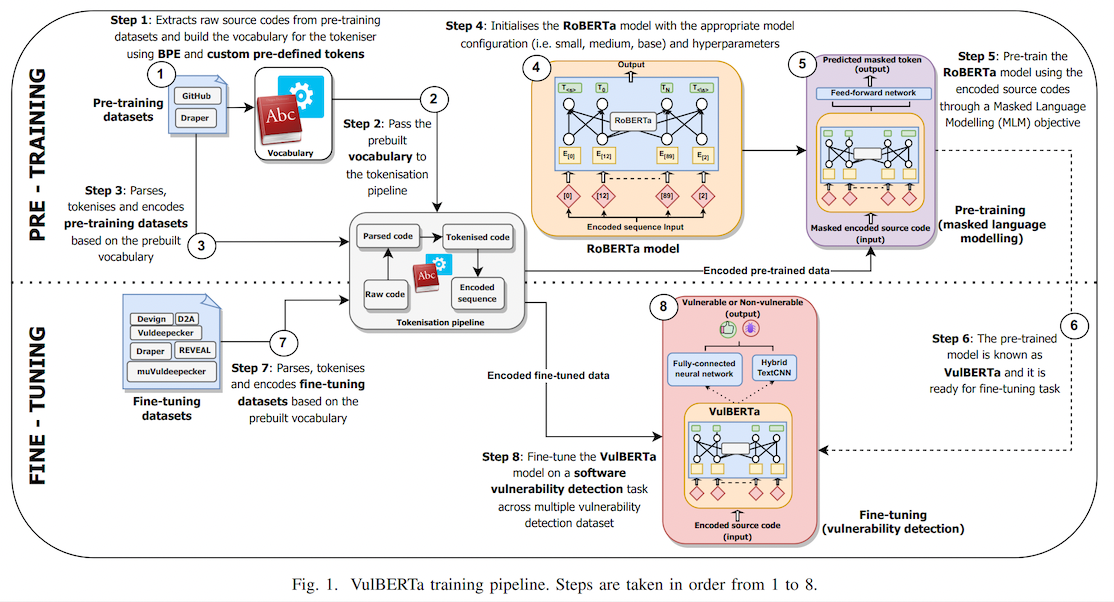
## Overview
This model is the unofficial HuggingFace version of "[VulBERTa](https://github.com/ICL-ml4csec/VulBERTa/tree/main)" with an MLP classification head, trained on CodeXGlue Devign (C code), by Hazim Hanif & Sergio Maffeis (Imperial College London). I simplified the tokenization process by adding the cleaning (comment removal) step to the tokenizer and added the simplified tokenizer to this model repo as an AutoClass.
> This paper presents presents VulBERTa, a deep learning approach to detect security vulnerabilities in source code. Our approach pre-trains a RoBERTa model with a custom tokenisation pipeline on real-world code from open-source C/C++ projects. The model learns a deep knowledge representation of the code syntax and semantics, which we leverage to train vulnerability detection classifiers. We evaluate our approach on binary and multi-class vulnerability detection tasks across several datasets (Vuldeepecker, Draper, REVEAL and muVuldeepecker) and benchmarks (CodeXGLUE and D2A). The evaluation results show that VulBERTa achieves state-of-the-art performance and outperforms existing approaches across different datasets, despite its conceptual simplicity, and limited cost in terms of size of training data and number of model parameters.
## Usage
**You must install libclang for tokenization.**
```bash
pip install libclang
```
Note that due to the custom tokenizer, you must pass `trust_remote_code=True` when instantiating the model.
Example:
```
from transformers import pipeline
pipe = pipeline("text-classification", model="claudios/VulBERTa-MLP-Devign", trust_remote_code=True, return_all_scores=True)
pipe("static void filter_mirror_setup(NetFilterState *nf, Error **errp)\n{\n MirrorState *s = FILTER_MIRROR(nf);\n Chardev *chr;\n chr = qemu_chr_find(s->outdev);\n if (chr == NULL) {\n error_set(errp, ERROR_CLASS_DEVICE_NOT_FOUND,\n \"Device '%s' not found\", s->outdev);\n qemu_chr_fe_init(&s->chr_out, chr, errp);")
>> [[{'label': 'LABEL_0', 'score': 0.014685827307403088},
{'label': 'LABEL_1', 'score': 0.985314130783081}]]
```
***
## Data
We provide all data required by VulBERTa.
This includes:
- Tokenizer training data
- Pre-training data
- Fine-tuning data
Please refer to the [data](https://github.com/ICL-ml4csec/VulBERTa/tree/main/data "data") directory for further instructions and details.
## Models
We provide all models pre-trained and fine-tuned by VulBERTa.
This includes:
- Trained tokenisers
- Pre-trained VulBERTa model (core representation knowledge)
- Fine-tuned VulBERTa-MLP and VulBERTa-CNN models
Please refer to the [models](https://github.com/ICL-ml4csec/VulBERTa/tree/main/models "models") directory for further instructions and details.
## How to use
In our project, we uses Jupyterlab notebook to run experiments.
Therefore, we separate each task into different notebook:
- [Pretraining_VulBERTa.ipynb](https://github.com/ICL-ml4csec/VulBERTa/blob/main/Pretraining_VulBERTa.ipynb "Pretraining_VulBERTa.ipynb") - Pre-trains the core VulBERTa knowledge representation model using DrapGH dataset.
- [Finetuning_VulBERTa-MLP.ipynb](https://github.com/ICL-ml4csec/VulBERTa/blob/main/Finetuning_VulBERTa-MLP.ipynb "Finetuning_VulBERTa-MLP.ipynb") - Fine-tunes the VulBERTa-MLP model on a specific vulnerability detection dataset.
- [Evaluation_VulBERTa-MLP.ipynb](https://github.com/ICL-ml4csec/VulBERTa/blob/main/Evaluation_VulBERTa-MLP.ipynb "Evaluation_VulBERTa-MLP.ipynb") - Evaluates the fine-tuned VulBERTa-MLP models on testing set of a specific vulnerability detection dataset.
- [Finetuning+evaluation_VulBERTa-CNN](https://github.com/ICL-ml4csec/VulBERTa/blob/main/Finetuning%2Bevaluation_VulBERTa-CNN.ipynb "Finetuning+evaluation_VulBERTa-CNN.ipynb") - Fine-tunes VulBERTa-CNN models and evaluates it on a testing set of a specific vulnerability detection dataset.
## Citation
Accepted as conference paper (oral presentation) at the International Joint Conference on Neural Networks (IJCNN) 2022.
Link to paper: https://ieeexplore.ieee.org/document/9892280
```bibtex
@INPROCEEDINGS{hanif2022vulberta,
author={Hanif, Hazim and Maffeis, Sergio},
booktitle={2022 International Joint Conference on Neural Networks (IJCNN)},
title={VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection},
year={2022},
volume={},
number={},
pages={1-8},
doi={10.1109/IJCNN55064.2022.9892280}
}
``` |
suzuki-2001/BERT-K4 | suzuki-2001 | 2024-05-22T03:31:52Z | 196 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"fill-mask",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-05-22T03:31:17Z | ---
license: apache-2.0
---
|
claudios/VulBERTa-MLP-Draper | claudios | 2024-05-22T03:31:33Z | 140 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"devign",
"defect detection",
"code",
"dataset:code_x_glue_cc_defect_detection",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-01-05T20:44:06Z | ---
license: mit
arxiv: 2205.12424
datasets:
- code_x_glue_cc_defect_detection
metrics:
- accuracy
- precision
- recall
- f1
- roc_auc
model-index:
- name: VulBERTa MLP
results:
- task:
type: defect-detection
dataset:
name: codexglue-devign
type: codexglue-devign
metrics:
- name: Accuracy
type: Accuracy
value: 64.71
- name: Precision
type: Precision
value: 64.80
- name: Recall
type: Recall
value: 50.76
- name: F1
type: F1
value: 56.93
- name: ROC-AUC
type: ROC-AUC
value: 71.02
pipeline_tag: text-classification
tags:
- devign
- defect detection
- code
---
# VulBERTa MLP Devign
## VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection

## Overview
This model is the unofficial HuggingFace version of "[VulBERTa](https://github.com/ICL-ml4csec/VulBERTa/tree/main)" with an MLP classification head, trained on CodeXGlue Devign (C code), by Hazim Hanif & Sergio Maffeis (Imperial College London). I simplified the tokenization process by adding the cleaning (comment removal) step to the tokenizer and added the simplified tokenizer to this model repo as an AutoClass.
> This paper presents presents VulBERTa, a deep learning approach to detect security vulnerabilities in source code. Our approach pre-trains a RoBERTa model with a custom tokenisation pipeline on real-world code from open-source C/C++ projects. The model learns a deep knowledge representation of the code syntax and semantics, which we leverage to train vulnerability detection classifiers. We evaluate our approach on binary and multi-class vulnerability detection tasks across several datasets (Vuldeepecker, Draper, REVEAL and muVuldeepecker) and benchmarks (CodeXGLUE and D2A). The evaluation results show that VulBERTa achieves state-of-the-art performance and outperforms existing approaches across different datasets, despite its conceptual simplicity, and limited cost in terms of size of training data and number of model parameters.
## Usage
**You must install libclang for tokenization.**
```bash
pip install libclang
```
Note that due to the custom tokenizer, you must pass `trust_remote_code=True` when instantiating the model.
Example:
```
from transformers import pipeline
pipe = pipeline("text-classification", model="claudios/VulBERTa-MLP-Devign", trust_remote_code=True, return_all_scores=True)
pipe("static void filter_mirror_setup(NetFilterState *nf, Error **errp)\n{\n MirrorState *s = FILTER_MIRROR(nf);\n Chardev *chr;\n chr = qemu_chr_find(s->outdev);\n if (chr == NULL) {\n error_set(errp, ERROR_CLASS_DEVICE_NOT_FOUND,\n \"Device '%s' not found\", s->outdev);\n qemu_chr_fe_init(&s->chr_out, chr, errp);")
>> [[{'label': 'LABEL_0', 'score': 0.014685827307403088},
{'label': 'LABEL_1', 'score': 0.985314130783081}]]
```
***
## Data
We provide all data required by VulBERTa.
This includes:
- Tokenizer training data
- Pre-training data
- Fine-tuning data
Please refer to the [data](https://github.com/ICL-ml4csec/VulBERTa/tree/main/data "data") directory for further instructions and details.
## Models
We provide all models pre-trained and fine-tuned by VulBERTa.
This includes:
- Trained tokenisers
- Pre-trained VulBERTa model (core representation knowledge)
- Fine-tuned VulBERTa-MLP and VulBERTa-CNN models
Please refer to the [models](https://github.com/ICL-ml4csec/VulBERTa/tree/main/models "models") directory for further instructions and details.
## How to use
In our project, we uses Jupyterlab notebook to run experiments.
Therefore, we separate each task into different notebook:
- [Pretraining_VulBERTa.ipynb](https://github.com/ICL-ml4csec/VulBERTa/blob/main/Pretraining_VulBERTa.ipynb "Pretraining_VulBERTa.ipynb") - Pre-trains the core VulBERTa knowledge representation model using DrapGH dataset.
- [Finetuning_VulBERTa-MLP.ipynb](https://github.com/ICL-ml4csec/VulBERTa/blob/main/Finetuning_VulBERTa-MLP.ipynb "Finetuning_VulBERTa-MLP.ipynb") - Fine-tunes the VulBERTa-MLP model on a specific vulnerability detection dataset.
- [Evaluation_VulBERTa-MLP.ipynb](https://github.com/ICL-ml4csec/VulBERTa/blob/main/Evaluation_VulBERTa-MLP.ipynb "Evaluation_VulBERTa-MLP.ipynb") - Evaluates the fine-tuned VulBERTa-MLP models on testing set of a specific vulnerability detection dataset.
- [Finetuning+evaluation_VulBERTa-CNN](https://github.com/ICL-ml4csec/VulBERTa/blob/main/Finetuning%2Bevaluation_VulBERTa-CNN.ipynb "Finetuning+evaluation_VulBERTa-CNN.ipynb") - Fine-tunes VulBERTa-CNN models and evaluates it on a testing set of a specific vulnerability detection dataset.
## Citation
Accepted as conference paper (oral presentation) at the International Joint Conference on Neural Networks (IJCNN) 2022.
Link to paper: https://ieeexplore.ieee.org/document/9892280
```bibtex
@INPROCEEDINGS{hanif2022vulberta,
author={Hanif, Hazim and Maffeis, Sergio},
booktitle={2022 International Joint Conference on Neural Networks (IJCNN)},
title={VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection},
year={2022},
volume={},
number={},
pages={1-8},
doi={10.1109/IJCNN55064.2022.9892280}
}
``` |
tanganke/flan-t5-base_glue-stsb_lora-16 | tanganke | 2024-05-22T03:31:22Z | 3 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:google/flan-t5-base",
"base_model:adapter:google/flan-t5-base",
"region:us"
] | null | 2024-05-22T03:30:52Z | ---
library_name: peft
base_model: google/flan-t5-base
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 |
tanganke/flan-t5-base_glue-rte_lora-16 | tanganke | 2024-05-22T03:28:35Z | 17,751 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:google/flan-t5-base",
"base_model:adapter:google/flan-t5-base",
"region:us"
] | null | 2024-05-22T03:25:49Z | ---
library_name: peft
base_model: google/flan-t5-base
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 |
ahmedgongi/Llama_dev3model_finale6 | ahmedgongi | 2024-05-22T03:27:27Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-22T03:27:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ahmedgongi/Llama_dev3tokenizer_finale6 | ahmedgongi | 2024-05-22T03:27:16Z | 0 | 0 | transformers | [
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-22T03:27:15Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf | RichardErkhov | 2024-05-22T03:26:28Z | 22 | 0 | null | [
"gguf",
"arxiv:2309.10400",
"endpoints_compatible",
"region:us"
] | null | 2024-05-22T00:19:14Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3-8b-64k-PoSE - GGUF
- Model creator: https://huggingface.co/winglian/
- Original model: https://huggingface.co/winglian/Llama-3-8b-64k-PoSE/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3-8b-64k-PoSE.Q2_K.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q2_K.gguf) | Q2_K | 2.96GB |
| [Llama-3-8b-64k-PoSE.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [Llama-3-8b-64k-PoSE.IQ3_S.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [Llama-3-8b-64k-PoSE.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [Llama-3-8b-64k-PoSE.IQ3_M.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [Llama-3-8b-64k-PoSE.Q3_K.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q3_K.gguf) | Q3_K | 3.74GB |
| [Llama-3-8b-64k-PoSE.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [Llama-3-8b-64k-PoSE.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [Llama-3-8b-64k-PoSE.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [Llama-3-8b-64k-PoSE.Q4_0.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q4_0.gguf) | Q4_0 | 4.34GB |
| [Llama-3-8b-64k-PoSE.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [Llama-3-8b-64k-PoSE.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [Llama-3-8b-64k-PoSE.Q4_K.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q4_K.gguf) | Q4_K | 4.58GB |
| [Llama-3-8b-64k-PoSE.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [Llama-3-8b-64k-PoSE.Q4_1.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q4_1.gguf) | Q4_1 | 4.78GB |
| [Llama-3-8b-64k-PoSE.Q5_0.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q5_0.gguf) | Q5_0 | 5.21GB |
| [Llama-3-8b-64k-PoSE.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [Llama-3-8b-64k-PoSE.Q5_K.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q5_K.gguf) | Q5_K | 5.34GB |
| [Llama-3-8b-64k-PoSE.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [Llama-3-8b-64k-PoSE.Q5_1.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q5_1.gguf) | Q5_1 | 5.65GB |
| [Llama-3-8b-64k-PoSE.Q6_K.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q6_K.gguf) | Q6_K | 6.14GB |
| [Llama-3-8b-64k-PoSE.Q8_0.gguf](https://huggingface.co/RichardErkhov/winglian_-_Llama-3-8b-64k-PoSE-gguf/blob/main/Llama-3-8b-64k-PoSE.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
- axolotl
---
## Llama 3 8B 64K
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
<img src="https://huggingface.co/winglian/Llama-3-8b-64k-PoSE/resolve/main/output.png" />
This model uses [PoSE](https://huggingface.co/papers/2309.10400) to extend Llama's context length from 8k to 64k @ rope_theta: 500000.0.
We used PoSE with continued pretraining on 300M tokens from the RedPajama V1 dataset using data between 6k-8k tokens.
We have further set rope_theta to 2M after continued pre-training to potentially further extend the context past 64k.
This was trained on a subset of the RedPajama v1 dataset with text between 6k-8k context. We trained a rank stabilized LoRA of rank 256. [WandB](https://wandb.ai/oaaic/llama-3-64k/runs/tkcyjt37)
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-8B, for use with transformers and with the original `llama3` codebase.
### Use with transformers
See the snippet below for usage with Transformers:
```python
>>> import transformers
>>> import torch
>>> model_id = "meta-llama/Meta-Llama-3-8B"
>>> pipeline = transformers.pipeline(
"text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto"
)
>>> pipeline("Hey how are you doing today?")
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3).
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-8B --include "original/*" --local-dir Meta-Llama-3-8B
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
RichardErkhov/NurtureAI_-_MistralLite-11B-gguf | RichardErkhov | 2024-05-22T03:26:26Z | 24 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us"
] | null | 2024-05-21T22:20:46Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
MistralLite-11B - GGUF
- Model creator: https://huggingface.co/NurtureAI/
- Original model: https://huggingface.co/NurtureAI/MistralLite-11B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [MistralLite-11B.Q2_K.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q2_K.gguf) | Q2_K | 3.73GB |
| [MistralLite-11B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.IQ3_XS.gguf) | IQ3_XS | 4.14GB |
| [MistralLite-11B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.IQ3_S.gguf) | IQ3_S | 4.37GB |
| [MistralLite-11B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q3_K_S.gguf) | Q3_K_S | 4.34GB |
| [MistralLite-11B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.IQ3_M.gguf) | IQ3_M | 4.51GB |
| [MistralLite-11B.Q3_K.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q3_K.gguf) | Q3_K | 4.84GB |
| [MistralLite-11B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q3_K_M.gguf) | Q3_K_M | 4.84GB |
| [MistralLite-11B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q3_K_L.gguf) | Q3_K_L | 5.26GB |
| [MistralLite-11B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.IQ4_XS.gguf) | IQ4_XS | 5.43GB |
| [MistralLite-11B.Q4_0.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q4_0.gguf) | Q4_0 | 5.66GB |
| [MistralLite-11B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.IQ4_NL.gguf) | IQ4_NL | 5.72GB |
| [MistralLite-11B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q4_K_S.gguf) | Q4_K_S | 5.7GB |
| [MistralLite-11B.Q4_K.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q4_K.gguf) | Q4_K | 6.02GB |
| [MistralLite-11B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q4_K_M.gguf) | Q4_K_M | 6.02GB |
| [MistralLite-11B.Q4_1.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q4_1.gguf) | Q4_1 | 6.27GB |
| [MistralLite-11B.Q5_0.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q5_0.gguf) | Q5_0 | 6.89GB |
| [MistralLite-11B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q5_K_S.gguf) | Q5_K_S | 6.89GB |
| [MistralLite-11B.Q5_K.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q5_K.gguf) | Q5_K | 7.08GB |
| [MistralLite-11B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q5_K_M.gguf) | Q5_K_M | 7.08GB |
| [MistralLite-11B.Q5_1.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q5_1.gguf) | Q5_1 | 7.51GB |
| [MistralLite-11B.Q6_K.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q6_K.gguf) | Q6_K | 8.2GB |
| [MistralLite-11B.Q8_0.gguf](https://huggingface.co/RichardErkhov/NurtureAI_-_MistralLite-11B-gguf/blob/main/MistralLite-11B.Q8_0.gguf) | Q8_0 | 10.62GB |
Original model description:
---
license: apache-2.0
inference: false
model-index:
- name: MistralLite-11B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 57.68
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=NurtureAI/MistralLite-11B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 79.54
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=NurtureAI/MistralLite-11B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 50.09
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=NurtureAI/MistralLite-11B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 38.27
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=NurtureAI/MistralLite-11B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 76.64
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=NurtureAI/MistralLite-11B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 0.38
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=NurtureAI/MistralLite-11B
name: Open LLM Leaderboard
---
# MistralLite 11B Model
# Original Model Card
MistralLite is a fine-tuned [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) language model, with enhanced capabilities of processing long context (up to 32K tokens). By utilizing an adapted Rotary Embedding and sliding window during fine-tuning, MistralLite is able to **perform significantly better on several long context retrieve and answering tasks**, while keeping the simple model structure of the original model. MistralLite is useful for applications such as long context line and topic retrieval, summarization, question-answering, and etc. MistralLite can be deployed on a single AWS `g5.2x` instance with Sagemaker [Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) endpoint, making it suitable for applications that require high performance in resource-constrained environments. You can also serve the MistralLite model directly using TGI docker containers. Also, MistralLite supports other ways of serving like [vLLM](https://github.com/vllm-project/vllm), and you can use MistralLite in Python by using the [HuggingFace transformers](https://huggingface.co/docs/transformers/index) and [FlashAttention-2](https://github.com/Dao-AILab/flash-attention) library.
MistralLite is similar to [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1), and their similarities and differences are summarized below:
|Model|Fine-tuned on long contexts| Max context length| RotaryEmbedding adaptation| Sliding Window Size|
|----------|-------------:|------------:|-----------:|-----------:|
| Mistral-7B-Instruct-v0.1 | up to 8K tokens | 32K | rope_theta = 10000 | 4096 |
| MistralLite | up to 16K tokens | 32K | **rope_theta = 1000000** | **16384** |
**Important - Use the prompt template below for MistralLite:**
```<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>```
## Motivation of Developing MistralLite
Since the release of [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1), the model became increasingly popular because its strong performance
on a wide range of benchmarks. But most of the benchmarks are evaluated on `short context`, and not much has been investigated on its performance on long context tasks.
Then We evaluated `Mistral-7B-Instruct-v0.1` against benchmarks that are specifically designed to assess the capabilities of LLMs in handling longer context.
Although the performance of the models on long context was fairly competitive on long context less than 4096 tokens,
there were some limitations on its performance on longer context. Motivated by improving its performance on longer context, we finetuned the Mistral 7B model, and produced `Mistrallite`. The model managed to `significantly boost the performance of long context handling` over Mistral-7B-Instruct-v0.1. The detailed `long context evalutaion results` are as below:
1. [Topic Retrieval](https://lmsys.org/blog/2023-06-29-longchat/)
|Model Name|Input length| Input length | Input length| Input length| Input length|
|----------|-------------:|-------------:|------------:|-----------:|-----------:|
| | 2851| 5568 |8313 | 11044 | 13780
| Mistral-7B-Instruct-v0.1 | 100% | 50% | 2% | 0% | 0% |
| MistralLite | **100%** | **100%** | **100%** | **100%** | **98%** |
2. [Line Retrieval](https://lmsys.org/blog/2023-06-29-longchat/#longeval-results)
|Model Name|Input length| Input length | Input length| Input length| Input length|Input length|
|----------|-------------:|-------------:|------------:|-----------:|-----------:|-----------:|
| | 3818| 5661 |7505 | 9354 | 11188 | 12657
| Mistral-7B-Instruct-v0.1 | **98%** | 62% | 42% | 42% | 32% | 30% |
| MistralLite | **98%** | **92%** | **88%** | **76%** | **70%** | **60%** |
3. [Pass key Retrieval](https://github.com/epfml/landmark-attention/blob/main/llama/run_test.py#L101)
|Model Name|Input length| Input length | Input length| Input length|
|----------|-------------:|-------------:|------------:|-----------:|
| | 3264| 5396 |8329 | 10197 |
| Mistral-7B-Instruct-v0.1 | **100%** | 50% | 20% | 30% |
| MistralLite | **100%** | **100%** | **100%** | **100%** |
4. [Question Answering with Long Input Texts](https://nyu-mll.github.io/quality/)
|Model Name| Test set Accuracy | Hard subset Accuracy|
|----------|-------------:|-------------:|
| Mistral-7B-Instruct-v0.1 | 44.3% | 39.7% |
| MistralLite | **64.4%** | **56.2%** |
### Example test on long context of 13400 tokens
- Context is from [Amazon Aurora FAQs](https://aws.amazon.com/rds/aurora/faqs/)
- Question: *please tell me how does pgvector help with Generative AI and give me some examples.*
- Answer from MistralLite:
```code
pgvector is an open-source extension for PostgreSQL supported by Amazon Aurora PostgreSQL-Compatible Edition.
You can use pgvector to store, search, index, and query billions of embeddings that are generated from machine learning (ML) and artificial intelligence (AI) models in your database, such as those from Amazon Bedrock (limited preview) or Amazon SageMaker. A vector embedding is a numerical representation that represents the semantic meaning of content such as text, images, and video.
With pgvector, you can query embeddings in your Aurora PostgreSQL database to perform efficient semantic similarity searches of these data types, represented as vectors, combined with other tabular data in Aurora. This enables the use of generative AI and other AI/ML systems for new types of applications such as personalized recommendations based on similar text descriptions or images, candidate match based on interview notes, customer service next best action recommendations based on successful transcripts or chat session dialogs, and more.
```
## Model Details
- **Developed by:** [AWS Contributors](https://github.com/orgs/aws-samples/teams/aws-prototype-ml-apac)
- **Model type:** [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
- **Language:** English
- **Finetuned from weights:** [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
- **Finetuned on data:**
- [SLidingEncoder and Decoder (SLED)](https://huggingface.co/datasets/tau/sled)
- [(Long) Natural Questions (NQ)](https://huggingface.co/datasets/togethercomputer/Long-Data-Collections#multi-passage-qa-from-natural-questions)
- [OpenAssistant Conversations Dataset (OASST1)](https://huggingface.co/datasets/OpenAssistant/oasst1)
- **Supported Serving Framework:**
- [Text-Generation-Inference 1.1.0](https://github.com/huggingface/text-generation-inference/tree/v1.1.0)
- [vLLM](https://github.com/vllm-project/vllm)
- [HuggingFace transformers](https://huggingface.co/docs/transformers/index)
- [HuggingFace Text Generation Inference (TGI) container on SageMaker](https://github.com/awslabs/llm-hosting-container)
- **Model License:** Apache 2.0
- **Contact:** [GitHub issues](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/issues)
- **Inference Code** [Github Repo](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/)
## MistralLite LM-Eval Results
### Methodology
- Please see https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- revision=4ececff
- Note: we used --model hf-causal-experimental instead of --model hf-causal
### Results
|Average|hellaswag| arc_challenge|truthful_qa (mc2)| MMLU (acc)|
|----------|-------------:|------------:|-----------:|-----------:|
| 0.57221 | 0.81617 | 0.58874 | 0.38275 | 0.5012 |
## How to Use MistralLite from Python Code (HuggingFace transformers) ##
**Important** - For an end-to-end example Jupyter notebook, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/huggingface-transformers/example_usage.ipynb).
### Install the necessary packages
Requires: [transformers](https://pypi.org/project/transformers/) 4.34.0 or later, [flash-attn](https://pypi.org/project/flash-attn/) 2.3.1.post1 or later,
and [accelerate](https://pypi.org/project/accelerate/) 0.23.0 or later.
```shell
pip install transformers==4.34.0
pip install flash-attn==2.3.1.post1 --no-build-isolation
pip install accelerate==0.23.0
```
### You can then try the following example code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import transformers
import torch
model_id = "amazon/MistralLite"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,
torch_dtype=torch.bfloat16,
use_flash_attention_2=True,
device_map="auto",)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
prompt = "<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>"
sequences = pipeline(
prompt,
max_new_tokens=400,
do_sample=False,
return_full_text=False,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"{seq['generated_text']}")
```
**Important** - Use the prompt template below for MistralLite:
```
<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>
```
## How to Serve MistralLite on TGI ##
**Important:**
- For an end-to-end example Jupyter notebook using the native TGI container, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/tgi/example_usage.ipynb).
- If the **input context length is greater than 12K tokens**, it is recommended using a custom TGI container, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/tgi-custom/example_usage.ipynb).
### Start TGI server ###
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
docker run -d --gpus all --shm-size 1g -p 443:80 -v $(pwd)/models:/data ghcr.io/huggingface/text-generation-inference:1.1.0 \
--model-id amazon/MistralLite \
--max-input-length 16000 \
--max-total-tokens 16384 \
--max-batch-prefill-tokens 16384 \
--trust-remote-code
```
### Perform Inference ###
Example Python code for inference with TGI (requires `text_generation` 0.6.1 or later):
```shell
pip install text_generation==0.6.1
```
```python
from text_generation import Client
SERVER_PORT = 443
SERVER_HOST = "localhost"
SERVER_URL = f"{SERVER_HOST}:{SERVER_PORT}"
tgi_client = Client(f"http://{SERVER_URL}", timeout=60)
def invoke_tgi(prompt,
random_seed=1,
max_new_tokens=400,
print_stream=True,
assist_role=True):
if (assist_role):
prompt = f"<|prompter|>{prompt}</s><|assistant|>"
output = ""
for response in tgi_client.generate_stream(
prompt,
do_sample=False,
max_new_tokens=max_new_tokens,
return_full_text=False,
#temperature=None,
#truncate=None,
#seed=random_seed,
#typical_p=0.2,
):
if hasattr(response, "token"):
if not response.token.special:
snippet = response.token.text
output += snippet
if (print_stream):
print(snippet, end='', flush=True)
return output
prompt = "What are the main challenges to support a long context for LLM?"
result = invoke_tgi(prompt)
```
**Important** - When using MistralLite for inference for the first time, it may require a brief 'warm-up' period that can take 10s of seconds. However, subsequent inferences should be faster and return results in a more timely manner. This warm-up period is normal and should not affect the overall performance of the system once the initialisation period has been completed.
## How to Deploy MistralLite on Amazon SageMaker ##
**Important:**
- For an end-to-end example Jupyter notebook using the SageMaker built-in container, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/sagemaker-tgi/example_usage.ipynb).
- If the **input context length is greater than 12K tokens**, it is recommended using a custom docker container, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/sagemaker-tgi-custom/example_usage.ipynb).
### Install the necessary packages
Requires: [sagemaker](https://pypi.org/project/sagemaker/) 2.192.1 or later.
```shell
pip install sagemaker==2.192.1
```
### Deploy the Model as A SageMaker Endpoint ###
To deploy MistralLite on a SageMaker endpoint, please follow the example code as below.
```python
import sagemaker
from sagemaker.huggingface import HuggingFaceModel, get_huggingface_llm_image_uri
import time
sagemaker_session = sagemaker.Session()
region = sagemaker_session.boto_region_name
role = sagemaker.get_execution_role()
image_uri = get_huggingface_llm_image_uri(
backend="huggingface", # or lmi
region=region,
version="1.1.0"
)
model_name = "MistralLite-" + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
hub = {
'HF_MODEL_ID':'amazon/MistralLite',
'HF_TASK':'text-generation',
'SM_NUM_GPUS':'1',
"MAX_INPUT_LENGTH": '16000',
"MAX_TOTAL_TOKENS": '16384',
"MAX_BATCH_PREFILL_TOKENS": '16384',
"MAX_BATCH_TOTAL_TOKENS": '16384',
}
model = HuggingFaceModel(
name=model_name,
env=hub,
role=role,
image_uri=image_uri
)
predictor = model.deploy(
initial_instance_count=1,
instance_type="ml.g5.2xlarge",
endpoint_name=model_name,
)
```
### Perform Inference ###
To call the endpoint, please follow the example code as below:
```python
input_data = {
"inputs": "<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>",
"parameters": {
"do_sample": False,
"max_new_tokens": 400,
"return_full_text": False,
#"typical_p": 0.2,
#"temperature":None,
#"truncate":None,
#"seed": 1,
}
}
result = predictor.predict(input_data)[0]["generated_text"]
print(result)
```
or via [boto3](https://pypi.org/project/boto3/), and the example code is shown as below:
```python
import boto3
import json
def call_endpoint(client, prompt, endpoint_name, paramters):
client = boto3.client("sagemaker-runtime")
payload = {"inputs": prompt,
"parameters": parameters}
response = client.invoke_endpoint(EndpointName=endpoint_name,
Body=json.dumps(payload),
ContentType="application/json")
output = json.loads(response["Body"].read().decode())
result = output[0]["generated_text"]
return result
client = boto3.client("sagemaker-runtime")
parameters = {
"do_sample": False,
"max_new_tokens": 400,
"return_full_text": False,
#"typical_p": 0.2,
#"temperature":None,
#"truncate":None,
#"seed": 1,
}
endpoint_name = predictor.endpoint_name
prompt = "<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>"
result = call_endpoint(client, prompt, endpoint_name, parameters)
print(result)
```
## How to Serve MistralLite on vLLM ##
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
**Important** - For an end-to-end example Jupyter notebook, please refer to [this link](https://github.com/awslabs/extending-the-context-length-of-open-source-llms/blob/main/MistralLite/vllm/example_usage.ipynb).
### Using vLLM as a server ###
When using vLLM as a server, pass the --model amazon/MistralLite parameter, for example:
```shell
python3 -m vllm.entrypoints.api_server --model amazon/MistralLite
```
### Using vLLM in Python Code ###
When using vLLM from Python code, Please see the example code as below:
```python
from vllm import LLM, SamplingParams
prompts = [
"<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>",
]
sampling_params = SamplingParams(temperature=0, max_tokens=100)
llm = LLM(model="amazon/MistralLite",)
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
## Limitations ##
Before using the MistralLite model, it is important to perform your own independent assessment, and take measures to ensure that your use would comply with your own specific quality control practices and standards, and that your use would comply with the local rules, laws, regulations, licenses and terms that apply to you, and your content.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_NurtureAI__MistralLite-11B)
| Metric |Value|
|---------------------------------|----:|
|Avg. |50.43|
|AI2 Reasoning Challenge (25-Shot)|57.68|
|HellaSwag (10-Shot) |79.54|
|MMLU (5-Shot) |50.09|
|TruthfulQA (0-shot) |38.27|
|Winogrande (5-shot) |76.64|
|GSM8k (5-shot) | 0.38|
|
Zlovoblachko/en_L1_FullGen_large | Zlovoblachko | 2024-05-22T03:25:40Z | 1 | 0 | spacy | [
"spacy",
"en",
"region:us"
] | null | 2024-05-22T03:23:57Z | ---
tags:
- spacy
language:
- en
model-index:
- name: en_L1_FullGen_large
results: []
---
| Feature | Description |
| --- | --- |
| **Name** | `en_L1_FullGen_large` |
| **Version** | `0.0.0` |
| **spaCy** | `>=3.4.4,<3.5.0` |
| **Default Pipeline** | `transformer`, `spancat` |
| **Components** | `transformer`, `spancat` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (5 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`spancat`** | `Tense semantics`, `Synonyms`, `Copying expression`, `Word form transmission`, `Transliteration` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `SPANS_SC_F` | 83.80 |
| `SPANS_SC_P` | 89.93 |
| `SPANS_SC_R` | 78.45 |
| `TRANSFORMER_LOSS` | 3255.40 |
| `SPANCAT_LOSS` | 223721.50 | |
Angelectronic/llama3-chat_2M | Angelectronic | 2024-05-22T03:24:12Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-22T03:20:41Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
---
# Model Description
39.5 on PhoMT test set (3000 samples)
# Uploaded model
- **Developed by:** Angelectronic
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
tanganke/flan-t5-base_glue-qnli_lora-16 | tanganke | 2024-05-22T03:21:24Z | 17,698 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:google/flan-t5-base",
"base_model:adapter:google/flan-t5-base",
"region:us"
] | null | 2024-05-22T03:21:01Z | ---
library_name: peft
base_model: google/flan-t5-base
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 |
FadyRezk/SoftHebb | FadyRezk | 2024-05-22T03:20:17Z | 53 | 0 | transformers | [
"transformers",
"safetensors",
"pytorch_model_hub_mixin",
"model_hub_mixin",
"endpoints_compatible",
"region:us"
] | null | 2024-05-22T03:20:11Z | ---
tags:
- pytorch_model_hub_mixin
- model_hub_mixin
---
This model has been pushed to the Hub using ****:
- Repo: [More Information Needed]
- Docs: [More Information Needed] |
souvik0306/Deploy_Quantised_facebook_opt_350m | souvik0306 | 2024-05-22T03:19:09Z | 79 | 0 | transformers | [
"transformers",
"safetensors",
"opt",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"awq",
"region:us"
] | text-generation | 2024-05-22T03:19:00Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Gomaa-Geo/gomma-geo-falcon | Gomaa-Geo | 2024-05-22T03:18:24Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-05-22T03:01:45Z | ---
license: apache-2.0
---
|
GeeDino/bert-base-tweet-topic-classification | GeeDino | 2024-05-22T03:17:03Z | 109 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"arxiv:1910.09700",
"base_model:nlptown/bert-base-multilingual-uncased-sentiment",
"base_model:finetune:nlptown/bert-base-multilingual-uncased-sentiment",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-22T02:44:52Z | ---
license: apache-2.0
base_model: nlptown/bert-base-multilingual-uncased-sentiment
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-base-tweet-topic-classification
results:
- task:
name: Text Classification
type: text-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.94
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This model is a fine-tuned version of [nlptown/bert-base-multilingual-uncased-sentiment](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment)
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** Matthew Gerardino
- **Language(s) (NLP):** English
- **License:** apache-2.0
- **Finetuned from model:** nlptown/bert-base-multilingual-uncased-sentiment
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Josef0801/deberta_attr_score_filter_raw | Josef0801 | 2024-05-22T03:15:53Z | 118 | 0 | transformers | [
"transformers",
"safetensors",
"deberta-v2",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-22T03:15:27Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
TIGER-Lab/MAmmoTH2-8B | TIGER-Lab | 2024-05-22T03:12:16Z | 2,436 | 2 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"dataset:TIGER-Lab/WebInstructSub",
"arxiv:2405.03548",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-06T14:08:26Z | ---
license: mit
language:
- en
datasets:
- TIGER-Lab/WebInstructSub
metrics:
- accuracy
library_name: transformers
---
# 🦣 MAmmoTH2: Scaling Instructions from the Web
Project Page: [https://tiger-ai-lab.github.io/MAmmoTH2/](https://tiger-ai-lab.github.io/MAmmoTH2/)
Paper: [https://arxiv.org/pdf/2405.03548](https://arxiv.org/pdf/2405.03548)
Code: [https://github.com/TIGER-AI-Lab/MAmmoTH2](https://github.com/TIGER-AI-Lab/MAmmoTH2)
## Introduction
Introducing 🦣 MAmmoTH2, a game-changer in improving the reasoning abilities of large language models (LLMs) through innovative instruction tuning. By efficiently harvesting 10 million instruction-response pairs from the pre-training web corpus, we've developed MAmmoTH2 models that significantly boost performance on reasoning benchmarks. For instance, MAmmoTH2-7B (Mistral) sees its performance soar from 11% to 36.7% on MATH and from 36% to 68.4% on GSM8K, all without training on any domain-specific data. Further training on public instruction tuning datasets yields MAmmoTH2-Plus, setting new standards in reasoning and chatbot benchmarks. Our work presents a cost-effective approach to acquiring large-scale, high-quality instruction data, offering a fresh perspective on enhancing LLM reasoning abilities.
| | **Base Model** | **MAmmoTH2** | **MAmmoTH2-Plus** |
|:-----|:---------------------|:-------------------------------------------------------------------|:------------------------------------------------------------------|
| 7B | Mistral | 🦣 [MAmmoTH2-7B](https://huggingface.co/TIGER-Lab/MAmmoTH2-7B) | 🦣 [MAmmoTH2-7B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-7B-Plus) |
| 8B | Llama-3 | 🦣 [MAmmoTH2-8B](https://huggingface.co/TIGER-Lab/MAmmoTH2-8B) | 🦣 [MAmmoTH2-8B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-8B-Plus) |
| 8x7B | Mixtral | 🦣 [MAmmoTH2-8x7B](https://huggingface.co/TIGER-Lab/MAmmoTH2-8x7B) | 🦣 [MAmmoTH2-8x7B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-8x7B-Plus) |
## Training Data
Please refer to https://huggingface.co/datasets/TIGER-Lab/WebInstructSub for more details.

## Training Procedure
The models are fine-tuned with the WEBINSTRUCT dataset using the original Llama-3, Mistral and Mistal models as base models. The training procedure varies for different models based on their sizes. Check out our paper for more details.
## Evaluation
The models are evaluated using open-ended and multiple-choice math problems from several datasets. Here are the results:
| **Model** | **TheoremQA** | **MATH** | **GSM8K** | **GPQA** | **MMLU-ST** | **BBH** | **ARC-C** | **Avg** |
|:---------------------------------------|:--------------|:---------|:----------|:---------|:------------|:--------|:----------|:--------|
| **MAmmoTH2-7B** (Updated) | 29.0 | 36.7 | 68.4 | 32.4 | 62.4 | 58.6 | 81.7 | 52.7 |
| **MAmmoTH2-8B** (Updated) | 30.3 | 35.8 | 70.4 | 35.2 | 64.2 | 62.1 | 82.2 | 54.3 |
| **MAmmoTH2-8x7B** | 32.2 | 39.0 | 75.4 | 36.8 | 67.4 | 71.1 | 87.5 | 58.9 |
| **MAmmoTH2-7B-Plus** (Updated) | 31.2 | 46.0 | 84.6 | 33.8 | 63.8 | 63.3 | 84.4 | 58.1 |
| **MAmmoTH2-8B-Plus** (Updated) | 31.5 | 43.0 | 85.2 | 35.8 | 66.7 | 69.7 | 84.3 | 59.4 |
| **MAmmoTH2-8x7B-Plus** | 34.1 | 47.0 | 86.4 | 37.8 | 72.4 | 74.1 | 88.4 | 62.9 |
To reproduce our results, please refer to https://github.com/TIGER-AI-Lab/MAmmoTH2/tree/main/math_eval.
## Usage
You can use the models through Huggingface's Transformers library. Use the pipeline function to create a text-generation pipeline with the model of your choice, then feed in a math problem to get the solution.
Check our Github repo for more advanced use: https://github.com/TIGER-AI-Lab/MAmmoTH2
## Limitations
We've tried our best to build math generalist models. However, we acknowledge that the models' performance may vary based on the complexity and specifics of the math problem. Still not all mathematical fields can be covered comprehensively.
## Citation
If you use the models, data, or code from this project, please cite the original paper:
```
@article{yue2024mammoth2,
title={MAmmoTH2: Scaling Instructions from the Web},
author={Yue, Xiang and Zheng, Tuney and Zhang, Ge and Chen, Wenhu},
journal={arXiv preprint arXiv:2405.03548},
year={2024}
}
``` |
TIGER-Lab/MAmmoTH2-8B-Plus | TIGER-Lab | 2024-05-22T03:11:32Z | 13,465 | 22 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"dataset:TIGER-Lab/WebInstructSub",
"arxiv:2405.03548",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-06T07:53:16Z | ---
license: mit
language:
- en
datasets:
- TIGER-Lab/WebInstructSub
metrics:
- accuracy
library_name: transformers
---
# 🦣 MAmmoTH2: Scaling Instructions from the Web
Project Page: [https://tiger-ai-lab.github.io/MAmmoTH2/](https://tiger-ai-lab.github.io/MAmmoTH2/)
Paper: [https://arxiv.org/pdf/2405.03548](https://arxiv.org/pdf/2405.03548)
Code: [https://github.com/TIGER-AI-Lab/MAmmoTH2](https://github.com/TIGER-AI-Lab/MAmmoTH2)
## Introduction
Introducing 🦣 MAmmoTH2, a game-changer in improving the reasoning abilities of large language models (LLMs) through innovative instruction tuning. By efficiently harvesting 10 million instruction-response pairs from the pre-training web corpus, we've developed MAmmoTH2 models that significantly boost performance on reasoning benchmarks. For instance, MAmmoTH2-7B (Mistral) sees its performance soar from 11% to 36.7% on MATH and from 36% to 68.4% on GSM8K, all without training on any domain-specific data. Further training on public instruction tuning datasets yields MAmmoTH2-Plus, setting new standards in reasoning and chatbot benchmarks. Our work presents a cost-effective approach to acquiring large-scale, high-quality instruction data, offering a fresh perspective on enhancing LLM reasoning abilities.
| | **Base Model** | **MAmmoTH2** | **MAmmoTH2-Plus** |
|:-----|:---------------------|:-------------------------------------------------------------------|:------------------------------------------------------------------|
| 7B | Mistral | 🦣 [MAmmoTH2-7B](https://huggingface.co/TIGER-Lab/MAmmoTH2-7B) | 🦣 [MAmmoTH2-7B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-7B-Plus) |
| 8B | Llama-3 | 🦣 [MAmmoTH2-8B](https://huggingface.co/TIGER-Lab/MAmmoTH2-8B) | 🦣 [MAmmoTH2-8B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-8B-Plus) |
| 8x7B | Mixtral | 🦣 [MAmmoTH2-8x7B](https://huggingface.co/TIGER-Lab/MAmmoTH2-8x7B) | 🦣 [MAmmoTH2-8x7B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-8x7B-Plus) |
## Training Data
Please refer to https://huggingface.co/datasets/TIGER-Lab/WebInstructSub for more details.

## Training Procedure
The models are fine-tuned with the WEBINSTRUCT dataset using the original Llama-3, Mistral and Mistal models as base models. The training procedure varies for different models based on their sizes. Check out our paper for more details.
## Evaluation
The models are evaluated using open-ended and multiple-choice math problems from several datasets. Here are the results:
| **Model** | **TheoremQA** | **MATH** | **GSM8K** | **GPQA** | **MMLU-ST** | **BBH** | **ARC-C** | **Avg** |
|:---------------------------------------|:--------------|:---------|:----------|:---------|:------------|:--------|:----------|:--------|
| **MAmmoTH2-7B** (Updated) | 29.0 | 36.7 | 68.4 | 32.4 | 62.4 | 58.6 | 81.7 | 52.7 |
| **MAmmoTH2-8B** (Updated) | 30.3 | 35.8 | 70.4 | 35.2 | 64.2 | 62.1 | 82.2 | 54.3 |
| **MAmmoTH2-8x7B** | 32.2 | 39.0 | 75.4 | 36.8 | 67.4 | 71.1 | 87.5 | 58.9 |
| **MAmmoTH2-7B-Plus** (Updated) | 31.2 | 46.0 | 84.6 | 33.8 | 63.8 | 63.3 | 84.4 | 58.1 |
| **MAmmoTH2-8B-Plus** (Updated) | 31.5 | 43.0 | 85.2 | 35.8 | 66.7 | 69.7 | 84.3 | 59.4 |
| **MAmmoTH2-8x7B-Plus** | 34.1 | 47.0 | 86.4 | 37.8 | 72.4 | 74.1 | 88.4 | 62.9 |
To reproduce our results, please refer to https://github.com/TIGER-AI-Lab/MAmmoTH2/tree/main/math_eval.
## Usage
You can use the models through Huggingface's Transformers library. Use the pipeline function to create a text-generation pipeline with the model of your choice, then feed in a math problem to get the solution.
Check our Github repo for more advanced use: https://github.com/TIGER-AI-Lab/MAmmoTH2
## Limitations
We've tried our best to build math generalist models. However, we acknowledge that the models' performance may vary based on the complexity and specifics of the math problem. Still not all mathematical fields can be covered comprehensively.
## Citation
If you use the models, data, or code from this project, please cite the original paper:
```
@article{yue2024mammoth2,
title={MAmmoTH2: Scaling Instructions from the Web},
author={Yue, Xiang and Zheng, Tuney and Zhang, Ge and Chen, Wenhu},
journal={arXiv preprint arXiv:2405.03548},
year={2024}
}
``` |
chinhang0104/swin-tiny-patch4-window7-224-finetuned-eurosat | chinhang0104 | 2024-05-22T03:10:29Z | 216 | 0 | transformers | [
"transformers",
"safetensors",
"swin",
"image-classification",
"generated_from_trainer",
"base_model:microsoft/swin-tiny-patch4-window7-224",
"base_model:finetune:microsoft/swin-tiny-patch4-window7-224",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-22T03:02:23Z | ---
license: apache-2.0
base_model: microsoft/swin-tiny-patch4-window7-224
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-eurosat
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1065
- Accuracy: 0.9710
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2841 | 1.0 | 114 | 0.1717 | 0.9469 |
| 0.2053 | 2.0 | 228 | 0.1472 | 0.9562 |
| 0.166 | 3.0 | 342 | 0.1065 | 0.9710 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.2+cu118
- Datasets 2.19.1
- Tokenizers 0.15.2
|
TIGER-Lab/MAmmoTH2-8x7B-Plus | TIGER-Lab | 2024-05-22T03:09:03Z | 4,277 | 13 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"conversational",
"en",
"dataset:TIGER-Lab/WebInstructSub",
"arxiv:2405.03548",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-06T14:47:05Z | ---
license: mit
language:
- en
datasets:
- TIGER-Lab/WebInstructSub
metrics:
- accuracy
library_name: transformers
---
# 🦣 MAmmoTH2: Scaling Instructions from the Web
Project Page: [https://tiger-ai-lab.github.io/MAmmoTH2/](https://tiger-ai-lab.github.io/MAmmoTH2/)
Paper: [https://arxiv.org/pdf/2405.03548](https://arxiv.org/pdf/2405.03548)
Code: [https://github.com/TIGER-AI-Lab/MAmmoTH2](https://github.com/TIGER-AI-Lab/MAmmoTH2)
## Introduction
Introducing 🦣 MAmmoTH2, a game-changer in improving the reasoning abilities of large language models (LLMs) through innovative instruction tuning. By efficiently harvesting 10 million instruction-response pairs from the pre-training web corpus, we've developed MAmmoTH2 models that significantly boost performance on reasoning benchmarks. For instance, MAmmoTH2-7B (Mistral) sees its performance soar from 11% to 36.7% on MATH and from 36% to 68.4% on GSM8K, all without training on any domain-specific data. Further training on public instruction tuning datasets yields MAmmoTH2-Plus, setting new standards in reasoning and chatbot benchmarks. Our work presents a cost-effective approach to acquiring large-scale, high-quality instruction data, offering a fresh perspective on enhancing LLM reasoning abilities.
| | **Base Model** | **MAmmoTH2** | **MAmmoTH2-Plus** |
|:-----|:---------------------|:-------------------------------------------------------------------|:------------------------------------------------------------------|
| 7B | Mistral | 🦣 [MAmmoTH2-7B](https://huggingface.co/TIGER-Lab/MAmmoTH2-7B) | 🦣 [MAmmoTH2-7B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-7B-Plus) |
| 8B | Llama-3 | 🦣 [MAmmoTH2-8B](https://huggingface.co/TIGER-Lab/MAmmoTH2-8B) | 🦣 [MAmmoTH2-8B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-8B-Plus) |
| 8x7B | Mixtral | 🦣 [MAmmoTH2-8x7B](https://huggingface.co/TIGER-Lab/MAmmoTH2-8x7B) | 🦣 [MAmmoTH2-8x7B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-8x7B-Plus) |
## Training Data
Please refer to https://huggingface.co/datasets/TIGER-Lab/WebInstructSub for more details.

## Training Procedure
The models are fine-tuned with the WEBINSTRUCT dataset using the original Llama-3, Mistral and Mistal models as base models. The training procedure varies for different models based on their sizes. Check out our paper for more details.
## Evaluation
The models are evaluated using open-ended and multiple-choice math problems from several datasets. Here are the results:
| **Model** | **TheoremQA** | **MATH** | **GSM8K** | **GPQA** | **MMLU-ST** | **BBH** | **ARC-C** | **Avg** |
|:---------------------------------------|:--------------|:---------|:----------|:---------|:------------|:--------|:----------|:--------|
| **MAmmoTH2-7B** (Updated) | 29.0 | 36.7 | 68.4 | 32.4 | 62.4 | 58.6 | 81.7 | 52.7 |
| **MAmmoTH2-8B** (Updated) | 30.3 | 35.8 | 70.4 | 35.2 | 64.2 | 62.1 | 82.2 | 54.3 |
| **MAmmoTH2-8x7B** | 32.2 | 39.0 | 75.4 | 36.8 | 67.4 | 71.1 | 87.5 | 58.9 |
| **MAmmoTH2-7B-Plus** (Updated) | 31.2 | 46.0 | 84.6 | 33.8 | 63.8 | 63.3 | 84.4 | 58.1 |
| **MAmmoTH2-8B-Plus** (Updated) | 31.5 | 43.0 | 85.2 | 35.8 | 66.7 | 69.7 | 84.3 | 59.4 |
| **MAmmoTH2-8x7B-Plus** | 34.1 | 47.0 | 86.4 | 37.8 | 72.4 | 74.1 | 88.4 | 62.9 |
To reproduce our results, please refer to https://github.com/TIGER-AI-Lab/MAmmoTH2/tree/main/math_eval.
## Chat Format
The template used to build a prompt for the Instruct model is defined as follows:
```
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
```
Note that `<s>` and `</s>` are special tokens for beginning of string (BOS) and end of string (EOS) while [INST] and [/INST] are regular strings.
But we also found that the model is not very sensitive to the chat template.
## Usage
You can use the models through Huggingface's Transformers library. Use the pipeline function to create a text-generation pipeline with the model of your choice, then feed in a math problem to get the solution.
Check our Github repo for more advanced use: https://github.com/TIGER-AI-Lab/MAmmoTH2
## Limitations
We've tried our best to build math generalist models. However, we acknowledge that the models' performance may vary based on the complexity and specifics of the math problem. Still not all mathematical fields can be covered comprehensively.
## Citation
If you use the models, data, or code from this project, please cite the original paper:
```
@article{yue2024mammoth2,
title={MAmmoTH2: Scaling Instructions from the Web},
author={Yue, Xiang and Zheng, Tuney and Zhang, Ge and Chen, Wenhu},
journal={arXiv preprint arXiv:2405.03548},
year={2024}
}
``` |
PhillipGuo/hp-lat-llama-None-epsilon0.5-pgd_layer8_16_24_30-def_layer0-ultrachat-towards1-away0-sft0-101 | PhillipGuo | 2024-05-22T03:03:09Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-22T03:02:57Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
tanganke/flan-t5-base_glue-cola_lora-16 | tanganke | 2024-05-22T02:59:24Z | 17,437 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:google/flan-t5-base",
"base_model:adapter:google/flan-t5-base",
"region:us"
] | null | 2024-05-22T02:59:08Z | ---
library_name: peft
base_model: google/flan-t5-base
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 |
Shravanig/vit-fire-detection | Shravanig | 2024-05-22T02:49:35Z | 22 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2023-12-11T18:15:49Z | ---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
model-index:
- name: vit-fire-detection
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-fire-detection
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.1685
- eval_precision: 0.9495
- eval_recall: 0.9497
- eval_accuracy: 0.9497
- eval_f1score: 0.9494
- eval_runtime: 40.9327
- eval_samples_per_second: 18.469
- eval_steps_per_second: 0.586
- epoch: 5.0
- step: 950
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 10
### Framework versions
- Transformers 4.36.0
- Pytorch 2.1.1+cpu
- Datasets 2.15.0
- Tokenizers 0.15.0
|
hyoo14/content | hyoo14 | 2024-05-22T02:38:00Z | 0 | 0 | null | [
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:zhihan1996/DNABERT-2-117M",
"base_model:finetune:zhihan1996/DNABERT-2-117M",
"region:us"
] | null | 2024-05-22T02:28:36Z | ---
base_model: zhihan1996/DNABERT-2-117M
tags:
- generated_from_trainer
model-index:
- name: content
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# content
This model is a fine-tuned version of [zhihan1996/DNABERT-2-117M](https://huggingface.co/zhihan1996/DNABERT-2-117M) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2180
- F1 Macro: 0.3388
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 8
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Macro |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 1.4189 | 0.2703 | 100 | 1.5083 | 0.0814 |
| 1.4284 | 0.5405 | 200 | 1.3513 | 0.1275 |
| 1.2829 | 0.8108 | 300 | 1.3179 | 0.1390 |
| 1.2192 | 1.0811 | 400 | 1.3522 | 0.2334 |
| 1.3097 | 1.3514 | 500 | 1.2843 | 0.2224 |
| 1.1668 | 1.6216 | 600 | 1.2668 | 0.2025 |
| 1.1595 | 1.8919 | 700 | 1.2268 | 0.2690 |
| 1.1336 | 2.1622 | 800 | 1.2596 | 0.2985 |
| 1.063 | 2.4324 | 900 | 1.2370 | 0.2709 |
| 1.0497 | 2.7027 | 1000 | 1.2180 | 0.3388 |
### Framework versions
- Transformers 4.41.0
- Pytorch 1.13.1+cu117
- Datasets 2.19.1
- Tokenizers 0.19.1
|
BilalMuftuoglu/deit-base-distilled-patch16-224-85-fold2 | BilalMuftuoglu | 2024-05-22T02:37:12Z | 25 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"deit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/deit-base-distilled-patch16-224",
"base_model:finetune:facebook/deit-base-distilled-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-22T02:18:23Z | ---
license: apache-2.0
base_model: facebook/deit-base-distilled-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: deit-base-distilled-patch16-224-85-fold2
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9318181818181818
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deit-base-distilled-patch16-224-85-fold2
This model is a fine-tuned version of [facebook/deit-base-distilled-patch16-224](https://huggingface.co/facebook/deit-base-distilled-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1991
- Accuracy: 0.9318
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 2 | 1.2745 | 0.2727 |
| No log | 2.0 | 4 | 0.8028 | 0.4091 |
| No log | 3.0 | 6 | 0.7456 | 0.7045 |
| No log | 4.0 | 8 | 0.7982 | 0.7045 |
| 0.7325 | 5.0 | 10 | 0.6233 | 0.7045 |
| 0.7325 | 6.0 | 12 | 0.5093 | 0.7273 |
| 0.7325 | 7.0 | 14 | 0.5566 | 0.7045 |
| 0.7325 | 8.0 | 16 | 0.6839 | 0.7045 |
| 0.7325 | 9.0 | 18 | 0.4821 | 0.75 |
| 0.4472 | 10.0 | 20 | 0.4365 | 0.7727 |
| 0.4472 | 11.0 | 22 | 0.5158 | 0.7273 |
| 0.4472 | 12.0 | 24 | 0.4196 | 0.8182 |
| 0.4472 | 13.0 | 26 | 0.3599 | 0.8409 |
| 0.4472 | 14.0 | 28 | 0.3604 | 0.8636 |
| 0.3483 | 15.0 | 30 | 0.3634 | 0.8182 |
| 0.3483 | 16.0 | 32 | 0.2803 | 0.8864 |
| 0.3483 | 17.0 | 34 | 0.2592 | 0.8864 |
| 0.3483 | 18.0 | 36 | 0.2655 | 0.9091 |
| 0.3483 | 19.0 | 38 | 0.2333 | 0.8864 |
| 0.2514 | 20.0 | 40 | 0.2590 | 0.8636 |
| 0.2514 | 21.0 | 42 | 0.2642 | 0.8864 |
| 0.2514 | 22.0 | 44 | 0.2637 | 0.8864 |
| 0.2514 | 23.0 | 46 | 0.1991 | 0.9318 |
| 0.2514 | 24.0 | 48 | 0.1941 | 0.9091 |
| 0.1847 | 25.0 | 50 | 0.1868 | 0.8864 |
| 0.1847 | 26.0 | 52 | 0.1828 | 0.8864 |
| 0.1847 | 27.0 | 54 | 0.1711 | 0.8864 |
| 0.1847 | 28.0 | 56 | 0.2423 | 0.8864 |
| 0.1847 | 29.0 | 58 | 0.2162 | 0.8864 |
| 0.1501 | 30.0 | 60 | 0.1854 | 0.9091 |
| 0.1501 | 31.0 | 62 | 0.3071 | 0.8636 |
| 0.1501 | 32.0 | 64 | 0.2435 | 0.8864 |
| 0.1501 | 33.0 | 66 | 0.1728 | 0.9091 |
| 0.1501 | 34.0 | 68 | 0.1644 | 0.9091 |
| 0.13 | 35.0 | 70 | 0.2768 | 0.8409 |
| 0.13 | 36.0 | 72 | 0.1539 | 0.9318 |
| 0.13 | 37.0 | 74 | 0.2580 | 0.9091 |
| 0.13 | 38.0 | 76 | 0.1783 | 0.8864 |
| 0.13 | 39.0 | 78 | 0.1782 | 0.8636 |
| 0.1357 | 40.0 | 80 | 0.2035 | 0.8864 |
| 0.1357 | 41.0 | 82 | 0.2117 | 0.8864 |
| 0.1357 | 42.0 | 84 | 0.1793 | 0.9091 |
| 0.1357 | 43.0 | 86 | 0.2002 | 0.9091 |
| 0.1357 | 44.0 | 88 | 0.2366 | 0.8864 |
| 0.105 | 45.0 | 90 | 0.2008 | 0.9318 |
| 0.105 | 46.0 | 92 | 0.2368 | 0.8864 |
| 0.105 | 47.0 | 94 | 0.2142 | 0.8864 |
| 0.105 | 48.0 | 96 | 0.2117 | 0.8864 |
| 0.105 | 49.0 | 98 | 0.2621 | 0.8864 |
| 0.1091 | 50.0 | 100 | 0.2231 | 0.8864 |
| 0.1091 | 51.0 | 102 | 0.1946 | 0.9318 |
| 0.1091 | 52.0 | 104 | 0.2001 | 0.9318 |
| 0.1091 | 53.0 | 106 | 0.2031 | 0.9091 |
| 0.1091 | 54.0 | 108 | 0.2078 | 0.9091 |
| 0.1054 | 55.0 | 110 | 0.2250 | 0.9091 |
| 0.1054 | 56.0 | 112 | 0.2180 | 0.9091 |
| 0.1054 | 57.0 | 114 | 0.1915 | 0.9318 |
| 0.1054 | 58.0 | 116 | 0.2227 | 0.8864 |
| 0.1054 | 59.0 | 118 | 0.2352 | 0.8864 |
| 0.0982 | 60.0 | 120 | 0.2329 | 0.8864 |
| 0.0982 | 61.0 | 122 | 0.2135 | 0.9091 |
| 0.0982 | 62.0 | 124 | 0.1949 | 0.8864 |
| 0.0982 | 63.0 | 126 | 0.2149 | 0.9318 |
| 0.0982 | 64.0 | 128 | 0.2435 | 0.9091 |
| 0.0808 | 65.0 | 130 | 0.2541 | 0.9091 |
| 0.0808 | 66.0 | 132 | 0.2447 | 0.9091 |
| 0.0808 | 67.0 | 134 | 0.1904 | 0.9318 |
| 0.0808 | 68.0 | 136 | 0.2437 | 0.9091 |
| 0.0808 | 69.0 | 138 | 0.3593 | 0.8864 |
| 0.0843 | 70.0 | 140 | 0.4187 | 0.8864 |
| 0.0843 | 71.0 | 142 | 0.3510 | 0.8864 |
| 0.0843 | 72.0 | 144 | 0.2315 | 0.9091 |
| 0.0843 | 73.0 | 146 | 0.2049 | 0.9091 |
| 0.0843 | 74.0 | 148 | 0.2150 | 0.9091 |
| 0.0942 | 75.0 | 150 | 0.2116 | 0.9091 |
| 0.0942 | 76.0 | 152 | 0.2014 | 0.9091 |
| 0.0942 | 77.0 | 154 | 0.2198 | 0.9091 |
| 0.0942 | 78.0 | 156 | 0.2538 | 0.9318 |
| 0.0942 | 79.0 | 158 | 0.2755 | 0.9318 |
| 0.0884 | 80.0 | 160 | 0.2491 | 0.9091 |
| 0.0884 | 81.0 | 162 | 0.2100 | 0.9091 |
| 0.0884 | 82.0 | 164 | 0.1977 | 0.9091 |
| 0.0884 | 83.0 | 166 | 0.1979 | 0.9091 |
| 0.0884 | 84.0 | 168 | 0.2145 | 0.9091 |
| 0.0637 | 85.0 | 170 | 0.2192 | 0.9091 |
| 0.0637 | 86.0 | 172 | 0.2055 | 0.9318 |
| 0.0637 | 87.0 | 174 | 0.1994 | 0.9318 |
| 0.0637 | 88.0 | 176 | 0.1975 | 0.9091 |
| 0.0637 | 89.0 | 178 | 0.1974 | 0.9091 |
| 0.0923 | 90.0 | 180 | 0.1965 | 0.9091 |
| 0.0923 | 91.0 | 182 | 0.1925 | 0.9091 |
| 0.0923 | 92.0 | 184 | 0.1942 | 0.9091 |
| 0.0923 | 93.0 | 186 | 0.1969 | 0.9318 |
| 0.0923 | 94.0 | 188 | 0.1949 | 0.9318 |
| 0.0657 | 95.0 | 190 | 0.1904 | 0.9318 |
| 0.0657 | 96.0 | 192 | 0.1877 | 0.9091 |
| 0.0657 | 97.0 | 194 | 0.1885 | 0.9091 |
| 0.0657 | 98.0 | 196 | 0.1902 | 0.9318 |
| 0.0657 | 99.0 | 198 | 0.1922 | 0.9318 |
| 0.0822 | 100.0 | 200 | 0.1932 | 0.9318 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
rAIfle/experiment_1_8b-fp16 | rAIfle | 2024-05-22T02:36:50Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-04-29T01:10:25Z | # **UNTESTED, probably unfit for human consumption**
1 epoch of grimulkan/LimaRP-augmented on LLaMA3-8b via unsloth on colab, using the llama-chat template. 16k context, probably.
```
model = FastLanguageModel.get_peft_model(
model,
r = 64, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 1,
gradient_accumulation_steps = 8,
warmup_steps = 5,
num_train_epochs=1,
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)
```
[GGUFs courtesy of the Quant Cartel](https://hugginmgface.co/Quant-Cartel/experiment_1_8b-iMat-GGUF) |
AlphaRandy/Test | AlphaRandy | 2024-05-22T02:33:43Z | 0 | 0 | null | [
"region:us"
] | null | 2024-05-22T02:31:54Z | ---
title: Vanilla Chatbot
emoji: 🏆
colorFrom: pink
colorTo: red
sdk: gradio
sdk_version: 3.39.0
app_file: app.py
pinned: false
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference |
aayushg159/Phi-3-medium-4k-instruct-Q4_K_M-GGUF | aayushg159 | 2024-05-22T02:31:08Z | 2 | 0 | null | [
"gguf",
"nlp",
"code",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"multilingual",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2024-05-22T02:30:41Z | ---
language:
- multilingual
license: mit
tags:
- nlp
- code
- llama-cpp
- gguf-my-repo
license_link: https://huggingface.co/microsoft/Phi-3-medium-4k-instruct/resolve/main/LICENSE
pipeline_tag: text-generation
inference:
parameters:
temperature: 0.7
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
---
# aayushg159/Phi-3-medium-4k-instruct-Q4_K_M-GGUF
This model was converted to GGUF format from [`microsoft/Phi-3-medium-4k-instruct`](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo aayushg159/Phi-3-medium-4k-instruct-Q4_K_M-GGUF --model phi-3-medium-4k-instruct.Q4_K_M.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo aayushg159/Phi-3-medium-4k-instruct-Q4_K_M-GGUF --model phi-3-medium-4k-instruct.Q4_K_M.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m phi-3-medium-4k-instruct.Q4_K_M.gguf -n 128
```
|
claudios/JavaBERT | claudios | 2024-05-22T02:30:56Z | 104 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"code",
"arxiv:2110.10404",
"arxiv:1910.09700",
"license:apache-2.0",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-04-30T18:47:50Z | ---
language:
- code
license: apache-2.0
widget:
- text: public [MASK] isOdd(Integer num) {if (num % 2 == 0) {return "even";} else
{return "odd";}}
arxiv: 2110.10404
---
This is an *unofficial* reupload of [CAUKiel/JavaBERT](https://huggingface.co/CAUKiel/JavaBERT) in the `SafeTensors` format using `transformers` `4.40.1`. The goal of this reupload is to prevent older models that are still relevant baselines from becoming stale as a result of changes in HuggingFace. Additionally, I may include minor corrections, such as model max length configuration.
Original model card below:
---
# Model Card for JavaBERT
A BERT-like model pretrained on Java software code.
# Model Details
## Model Description
A BERT-like model pretrained on Java software code.
- **Developed by:** Christian-Albrechts-University of Kiel (CAUKiel)
- **Shared by [Optional]:** Hugging Face
- **Model type:** Fill-Mask
- **Language(s) (NLP):** en
- **License:** Apache-2.0
- **Related Models:** A version of this model using an uncased tokenizer is available at [CAUKiel/JavaBERT-uncased](https://huggingface.co/CAUKiel/JavaBERT-uncased).
- **Parent Model:** BERT
- **Resources for more information:**
- [Associated Paper](https://arxiv.org/pdf/2110.10404.pdf)
# Uses
## Direct Use
Fill-Mask
## Downstream Use [Optional]
More information needed.
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
{ see paper= word something)
# Training Details
## Training Data
The model was trained on 2,998,345 Java files retrieved from open source projects on GitHub. A ```bert-base-cased``` tokenizer is used by this model.
## Training Procedure
### Training Objective
A MLM (Masked Language Model) objective was used to train this model.
### Preprocessing
More information needed.
### Speeds, Sizes, Times
More information needed.
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
More information needed.
### Factors
### Metrics
More information needed.
## Results
More information needed.
# Model Examination
More information needed.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed.
- **Hours used:** More information needed.
- **Cloud Provider:** More information needed.
- **Compute Region:** More information needed.
- **Carbon Emitted:** More information needed.
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed.
## Compute Infrastructure
More information needed.
### Hardware
More information needed.
### Software
More information needed.
# Citation
**BibTeX:**
More information needed.
**APA:**
More information needed.
# Glossary [optional]
More information needed.
# More Information [optional]
More information needed.
# Model Card Authors [optional]
Christian-Albrechts-University of Kiel (CAUKiel) in collaboration with Ezi Ozoani and the team at Hugging Face
# Model Card Contact
More information needed.
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import pipeline
pipe = pipeline('fill-mask', model='CAUKiel/JavaBERT')
output = pipe(CODE) # Replace with Java code; Use '[MASK]' to mask tokens/words in the code.
```
</details>
|
hgnoi/2gUG0tbXI0mrL70R | hgnoi | 2024-05-22T02:29:50Z | 124 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T02:28:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
hgnoi/KQwgdP5KehIsIjvO | hgnoi | 2024-05-22T02:29:26Z | 122 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T02:27:46Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
hgnoi/icH3gMxWbBKItsxU | hgnoi | 2024-05-22T02:28:58Z | 124 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T02:27:11Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Sorrowair/metal_35M | Sorrowair | 2024-05-22T02:28:49Z | 1 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:westlake-repl/SaProt_35M_AF2",
"base_model:adapter:westlake-repl/SaProt_35M_AF2",
"region:us"
] | null | 2024-05-22T02:28:42Z | ---
library_name: peft
base_model: westlake-repl/SaProt_35M_AF2
---
# Model Card for Model ID
saprot_35M for metal<br><br> The digital label means: <br>0: the same as the dataset <br>
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1 |
Bagus/wav2vec2-large-xlsr-bahasa-indonesia | Bagus | 2024-05-22T02:23:23Z | 198 | 6 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"bahasa-indonesia",
"id",
"dataset:common_voice_id_6.1",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2022-03-02T23:29:04Z | ---
language: id
datasets:
- common_voice_id_6.1
tags:
- audio
- automatic-speech-recognition
- speech
- bahasa-indonesia
license: apache-2.0
---
Dataset used for training:
- Name: Common Voice
- Language: Indonesian [id]
- Version: 6.1
Test WER: 19.3 %
Repo for training:
https://github.com/bagustris/wav2vec2-indonesian
**NEWEST VERSION AVAILABLE HERE WITH SMALLER MODEL AND SMALLER WER (5.9%):
https://huggingface.co/Bagus/whisper-small-id-cv17**
Contact:
[email protected] |
ammarasmro/finetuning-sentiment-model-3000-samples | ammarasmro | 2024-05-22T02:23:07Z | 108 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-22T02:12:40Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3584
- Accuracy: 0.8633
- F1: 0.8673
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
ytcheng/llama3-70B-pretrain_merged_v2 | ytcheng | 2024-05-22T02:20:12Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-factory",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T01:18:13Z | ---
library_name: transformers
tags:
- llama-factory
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
AlphaRandy/WhelanChatBot | AlphaRandy | 2024-05-22T02:18:34Z | 144 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"fr",
"it",
"de",
"es",
"en",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T02:05:27Z | ---
license: apache-2.0
language:
- fr
- it
- de
- es
- en
inference:
parameters:
temperature: 0.5
widget:
- messages:
- role: user
content: What is your favorite condiment?
---
# Model Card for Mixtral-8x7B
The Mixtral-8x7B Large Language Model (LLM) is a pretrained generative Sparse Mixture of Experts. The Mixtral-8x7B outperforms Llama 2 70B on most benchmarks we tested.
For full details of this model please read our [release blog post](https://mistral.ai/news/mixtral-of-experts/).
## Warning
This repo contains weights that are compatible with [vLLM](https://github.com/vllm-project/vllm) serving of the model as well as Hugging Face [transformers](https://github.com/huggingface/transformers) library. It is based on the original Mixtral [torrent release](magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%http://2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=http%3A%2F%http://2Ftracker.openbittorrent.com%3A80%2Fannounce), but the file format and parameter names are different. Please note that model cannot (yet) be instantiated with HF.
## Instruction format
This format must be strictly respected, otherwise the model will generate sub-optimal outputs.
The template used to build a prompt for the Instruct model is defined as follows:
```
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
```
Note that `<s>` and `</s>` are special tokens for beginning of string (BOS) and end of string (EOS) while [INST] and [/INST] are regular strings.
As reference, here is the pseudo-code used to tokenize instructions during fine-tuning:
```python
def tokenize(text):
return tok.encode(text, add_special_tokens=False)
[BOS_ID] +
tokenize("[INST]") + tokenize(USER_MESSAGE_1) + tokenize("[/INST]") +
tokenize(BOT_MESSAGE_1) + [EOS_ID] +
…
tokenize("[INST]") + tokenize(USER_MESSAGE_N) + tokenize("[/INST]") +
tokenize(BOT_MESSAGE_N) + [EOS_ID]
```
In the pseudo-code above, note that the `tokenize` method should not add a BOS or EOS token automatically, but should add a prefix space.
In the Transformers library, one can use [chat templates](https://huggingface.co/docs/transformers/main/en/chat_templating) which make sure the right format is applied.
## Run the model
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
By default, transformers will load the model in full precision. Therefore you might be interested to further reduce down the memory requirements to run the model through the optimizations we offer in HF ecosystem:
### In half-precision
Note `float16` precision only works on GPU devices
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
### Lower precision using (8-bit & 4-bit) using `bitsandbytes`
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True, device_map="auto")
text = "Hello my name is"
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
### Load the model with Flash Attention 2
<details>
<summary> Click to expand </summary>
```diff
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, use_flash_attention_2=True, device_map="auto")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
</details>
## Limitations
The Mixtral-8x7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
# The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Louis Ternon, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. |
jaewoongy/shawgpt-ft | jaewoongy | 2024-05-22T02:18:20Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:TheBloke/Mistral-7B-Instruct-v0.2-GPTQ",
"base_model:adapter:TheBloke/Mistral-7B-Instruct-v0.2-GPTQ",
"license:apache-2.0",
"region:us"
] | null | 2024-05-22T01:54:36Z | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: TheBloke/Mistral-7B-Instruct-v0.2-GPTQ
model-index:
- name: shawgpt-ft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# shawgpt-ft
This model is a fine-tuned version of [TheBloke/Mistral-7B-Instruct-v0.2-GPTQ](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.2-GPTQ) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8763
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 4.593 | 0.9231 | 3 | 3.9590 |
| 4.0403 | 1.8462 | 6 | 3.4249 |
| 3.4588 | 2.7692 | 9 | 2.9732 |
| 2.2521 | 4.0 | 13 | 2.5500 |
| 2.6689 | 4.9231 | 16 | 2.3030 |
| 2.3419 | 5.8462 | 19 | 2.1148 |
| 2.1294 | 6.7692 | 22 | 1.9798 |
| 1.5309 | 8.0 | 26 | 1.9374 |
| 1.9897 | 8.9231 | 29 | 1.8893 |
| 1.3786 | 9.2308 | 30 | 1.8763 |
### Framework versions
- PEFT 0.11.1
- Transformers 4.40.2
- Pytorch 2.1.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1 |
hgnoi/VCEWWK36NsnJqUVJ | hgnoi | 2024-05-22T02:15:10Z | 124 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T02:13:26Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
hgnoi/lBmrGXxARkkpPovC | hgnoi | 2024-05-22T02:14:42Z | 124 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T02:12:58Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Bagus/whisper-small-id-cv17 | Bagus | 2024-05-22T02:14:17Z | 45 | 0 | transformers | [
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:mozilla-foundation/common_voice_17_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-20T08:16:24Z | ---
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_17_0
metrics:
- wer
model-index:
- name: whisper-small-id
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_17_0 id
type: mozilla-foundation/common_voice_17_0
config: id
split: None
args: id
metrics:
- name: Wer
type: wer
value: 0.05902826117221217
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-id
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the mozilla-foundation/common_voice_17_0 id dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0878
- Wer: 0.0590 (5.9%)
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 20000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-------:|:-----:|:---------------:|:------:|
| 0.1875 | 0.8457 | 1000 | 0.1400 | 0.1099 |
| 0.0852 | 1.6913 | 2000 | 0.1043 | 0.0857 |
| 0.0387 | 2.5370 | 3000 | 0.0914 | 0.0757 |
| 0.0153 | 3.3827 | 4000 | 0.0860 | 0.0818 |
| 0.008 | 4.2283 | 5000 | 0.0878 | 0.0698 |
| 0.005 | 5.0740 | 6000 | 0.0878 | 0.0745 |
| 0.0033 | 5.9197 | 7000 | 0.0834 | 0.0651 |
| 0.0029 | 6.7653 | 8000 | 0.0815 | 0.0627 |
| 0.0014 | 7.6110 | 9000 | 0.0853 | 0.0627 |
| 0.0013 | 8.4567 | 10000 | 0.0861 | 0.0641 |
| 0.0005 | 9.3023 | 11000 | 0.0857 | 0.0633 |
| 0.0005 | 10.1480 | 12000 | 0.0856 | 0.0620 |
| 0.0007 | 10.9937 | 13000 | 0.0866 | 0.0605 |
| 0.0005 | 11.8393 | 14000 | 0.0871 | 0.0614 |
| 0.0002 | 12.6850 | 15000 | 0.0850 | 0.0596 |
| 0.0004 | 13.5307 | 16000 | 0.0849 | 0.0600 |
| 0.0001 | 14.3763 | 17000 | 0.0868 | 0.0592 |
| 0.0002 | 15.2220 | 18000 | 0.0873 | 0.0593 |
| 0.0001 | 16.0677 | 19000 | 0.0875 | 0.0585 |
| 0.0001 | 16.9133 | 20000 | 0.0878 | 0.0590 |
### Framework versions
- Transformers 4.42.0.dev0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
hgnoi/Oj4uvsy5VPWTVipL | hgnoi | 2024-05-22T02:13:22Z | 123 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T02:11:35Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
theglassofwater/mistral_pretraining_6ksteps_22batch | theglassofwater | 2024-05-22T02:12:51Z | 194 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T02:12:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MaziyarPanahi/Percival_01M7-7B-GGUF | MaziyarPanahi | 2024-05-22T02:05:51Z | 49 | 0 | transformers | [
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"safetensors",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"automerger",
"base_model:liminerity/M7-7b",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us",
"base_model:automerger/Percival_01M7-7B",
"base_model:quantized:automerger/Percival_01M7-7B"
] | text-generation | 2024-05-22T01:33:56Z | ---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- safetensors
- mistral
- text-generation
- merge
- mergekit
- lazymergekit
- automerger
- base_model:liminerity/M7-7b
- license:apache-2.0
- autotrain_compatible
- endpoints_compatible
- text-generation-inference
- region:us
- text-generation
model_name: Percival_01M7-7B-GGUF
base_model: automerger/Percival_01M7-7B
inference: false
model_creator: automerger
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/Percival_01M7-7B-GGUF](https://huggingface.co/MaziyarPanahi/Percival_01M7-7B-GGUF)
- Model creator: [automerger](https://huggingface.co/automerger)
- Original model: [automerger/Percival_01M7-7B](https://huggingface.co/automerger/Percival_01M7-7B)
## Description
[MaziyarPanahi/Percival_01M7-7B-GGUF](https://huggingface.co/MaziyarPanahi/Percival_01M7-7B-GGUF) contains GGUF format model files for [automerger/Percival_01M7-7B](https://huggingface.co/automerger/Percival_01M7-7B).
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible. |
OpenBuddy/openbuddy-yi1.5-9b-v21.1-32k | OpenBuddy | 2024-05-22T02:05:13Z | 1,427 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mixtral",
"conversational",
"zh",
"en",
"fr",
"de",
"ja",
"ko",
"it",
"ru",
"fi",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-22T00:19:01Z | ---
license: apache-2.0
language:
- zh
- en
- fr
- de
- ja
- ko
- it
- ru
- fi
pipeline_tag: text-generation
inference: false
library_name: transformers
tags:
- mixtral
---
# OpenBuddy - Open Multilingual Chatbot
GitHub and Usage Guide: [https://github.com/OpenBuddy/OpenBuddy](https://github.com/OpenBuddy/OpenBuddy)
Website and Demo: [https://openbuddy.ai](https://openbuddy.ai)
Evaluation result of this model: [Evaluation.txt](Evaluation.txt)

# Copyright Notice
Base model: https://huggingface.co/01-ai/Yi-1.5-9B
License: Apache 2.0
# Prompt Format
We recommend using the fast tokenizer from `transformers`, which should be enabled by default in the `transformers` and `vllm` libraries. Other implementations including `sentencepiece` may not work as expected, especially for special tokens like `<|role|>`, `<|says|>` and `<|end|>`.
```
<|role|>system<|says|>You(assistant) are a helpful, respectful and honest INTP-T AI Assistant named Buddy. You are talking to a human(user).
Always answer as helpfully and logically as possible, while being safe. Your answers should not include any harmful, political, religious, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
You cannot access the internet, but you have vast knowledge, cutoff: 2023-04.
You are trained by OpenBuddy team, (https://openbuddy.ai, https://github.com/OpenBuddy/OpenBuddy), not related to GPT or OpenAI.<|end|>
<|role|>user<|says|>History input 1<|end|>
<|role|>assistant<|says|>History output 1<|end|>
<|role|>user<|says|>History input 2<|end|>
<|role|>assistant<|says|>History output 2<|end|>
<|role|>user<|says|>Current input<|end|>
<|role|>assistant<|says|>
```
This format is also defined in `tokenizer_config.json`, which means you can directly use `vllm` to deploy an OpenAI-like API service. For more information, please refer to the [vllm documentation](https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html).
## Disclaimer
All OpenBuddy models have inherent limitations and may potentially produce outputs that are erroneous, harmful, offensive, or otherwise undesirable. Users should not use these models in critical or high-stakes situations that may lead to personal injury, property damage, or significant losses. Examples of such scenarios include, but are not limited to, the medical field, controlling software and hardware systems that may cause harm, and making important financial or legal decisions.
OpenBuddy is provided "as-is" without any warranty of any kind, either express or implied, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. In no event shall the authors, contributors, or copyright holders be liable for any claim, damages, or other liabilities, whether in an action of contract, tort, or otherwise, arising from, out of, or in connection with the software or the use or other dealings in the software.
By using OpenBuddy, you agree to these terms and conditions, and acknowledge that you understand the potential risks associated with its use. You also agree to indemnify and hold harmless the authors, contributors, and copyright holders from any claims, damages, or liabilities arising from your use of OpenBuddy.
## 免责声明
所有OpenBuddy模型均存在固有的局限性,可能产生错误的、有害的、冒犯性的或其他不良的输出。用户在关键或高风险场景中应谨慎行事,不要使用这些模型,以免导致人身伤害、财产损失或重大损失。此类场景的例子包括但不限于医疗领域、可能导致伤害的软硬件系统的控制以及进行重要的财务或法律决策。
OpenBuddy按“原样”提供,不附带任何种类的明示或暗示的保证,包括但不限于适销性、特定目的的适用性和非侵权的暗示保证。在任何情况下,作者、贡献者或版权所有者均不对因软件或使用或其他软件交易而产生的任何索赔、损害赔偿或其他责任(无论是合同、侵权还是其他原因)承担责任。
使用OpenBuddy即表示您同意这些条款和条件,并承认您了解其使用可能带来的潜在风险。您还同意赔偿并使作者、贡献者和版权所有者免受因您使用OpenBuddy而产生的任何索赔、损害赔偿或责任的影响。 |
yaful/MAGE | yaful | 2024-05-22T02:01:21Z | 1,542 | 0 | transformers | [
"transformers",
"pytorch",
"longformer",
"text-classification",
"arxiv:2305.13242",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-01-18T11:17:40Z | ---
license: apache-2.0
---
<div align="center">
<h1>MAGE: Machine-generated Text Detection in the Wild</h1>
</div>
## 📚 Citation
Please check out our [Github repo](https://github.com/yafuly/MAGE) for detailed information. If you use this model in your research, please cite it as follows:
```bibtex
@misc{li2024mage,
title={MAGE: Machine-generated Text Detection in the Wild},
author={Yafu Li and Qintong Li and Leyang Cui and Wei Bi and Zhilin Wang and Longyue Wang and Linyi Yang and Shuming Shi and Yue Zhang},
year={2024},
eprint={2305.13242},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!-- # 🤝 Contributing --> |
bjarte/ppo-Huggy | bjarte | 2024-05-22T01:57:34Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | reinforcement-learning | 2024-05-22T01:57:08Z | ---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: bjarte/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
ChenYang88/chentest0 | ChenYang88 | 2024-05-22T01:56:49Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-05-22T01:56:49Z | ---
license: apache-2.0
---
|
grimjim/rogue-enchantress-32k-7B | grimjim | 2024-05-22T01:54:58Z | 11 | 9 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:grimjim/cuckoo-starling-32k-7B",
"base_model:merge:grimjim/cuckoo-starling-32k-7B",
"base_model:grimjim/zephyr-wizard-kuno-royale-BF16-merge-7B",
"base_model:merge:grimjim/zephyr-wizard-kuno-royale-BF16-merge-7B",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T16:58:42Z | ---
base_model:
- grimjim/zephyr-wizard-kuno-royale-BF16-merge-7B
- grimjim/cuckoo-starling-7B
library_name: transformers
tags:
- mergekit
- merge
license: cc-by-nc-4.0
pipeline_tag: text-generation
---
# rogue-enchantress-32k-7B
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
An ambition of this merge was to augment text generation with the potential creative richness of the WizardLM-2 7B and Zephyr-7B-Beta models, the reasoning of the Starling-LM-7B-beta model, and extended context length of Mistral v0.2.
The resulting model is very attentive to character card descriptions and capable of applying reasoning. This model is in the smarter side, following context and formatting. The model is creative and "wants" to write, incorporating details cooperatively and driving plot, with occasional runaway narration if it finds that the prompt leans that way.
Tested with ChatML Instruct prompts, temperature 1.0, and minP 0.02.
- Full weights: [grimjim/rogue-enchantress-32k-7B](https://huggingface.co/grimjim/rogue-enchantress-32k-7B)
- GGUF quants: [grimjim/rogue-enchantress-32k-7B-GGUF](https://huggingface.co/grimjim/rogue-enchantress-32k-7B-GGUF)
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [grimjim/zephyr-wizard-kuno-royale-BF16-merge-7B](https://huggingface.co/grimjim/zephyr-wizard-kuno-royale-BF16-merge-7B)
* [grimjim/cuckoo-starling-7B](https://huggingface.co/grimjim/cuckoo-starling-7B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: grimjim/zephyr-wizard-kuno-royale-BF16-merge-7B
layer_range: [0,32]
- model: grimjim/cuckoo-starling-7B
layer_range: [0,32]
merge_method: slerp
base_model: grimjim/zephyr-wizard-kuno-royale-BF16-merge-7B
parameters:
t:
- value: 0.5
dtype: bfloat16
```
|
hgnoi/Pti1HJopBfIVZr40 | hgnoi | 2024-05-22T01:50:26Z | 124 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T01:48:34Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
hgnoi/rkks1I7fDVXV98Uv | hgnoi | 2024-05-22T01:50:20Z | 124 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T01:48:20Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
hgnoi/H6EKnaUVtQec251y | hgnoi | 2024-05-22T01:50:08Z | 124 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T01:48:06Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
hgnoi/wxSBPQcMAef64qg3 | hgnoi | 2024-05-22T01:49:48Z | 124 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T01:48:00Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf | RichardErkhov | 2024-05-22T01:44:26Z | 4 | 0 | null | [
"gguf",
"arxiv:2311.03099",
"arxiv:2306.01708",
"endpoints_compatible",
"region:us"
] | null | 2024-05-21T20:27:32Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
DARE_TIES_13B - GGUF
- Model creator: https://huggingface.co/yunconglong/
- Original model: https://huggingface.co/yunconglong/DARE_TIES_13B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [DARE_TIES_13B.Q2_K.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q2_K.gguf) | Q2_K | 4.43GB |
| [DARE_TIES_13B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.IQ3_XS.gguf) | IQ3_XS | 4.94GB |
| [DARE_TIES_13B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.IQ3_S.gguf) | IQ3_S | 5.22GB |
| [DARE_TIES_13B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q3_K_S.gguf) | Q3_K_S | 5.2GB |
| [DARE_TIES_13B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.IQ3_M.gguf) | IQ3_M | 5.34GB |
| [DARE_TIES_13B.Q3_K.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q3_K.gguf) | Q3_K | 5.78GB |
| [DARE_TIES_13B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q3_K_M.gguf) | Q3_K_M | 5.78GB |
| [DARE_TIES_13B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q3_K_L.gguf) | Q3_K_L | 6.27GB |
| [DARE_TIES_13B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.IQ4_XS.gguf) | IQ4_XS | 6.5GB |
| [DARE_TIES_13B.Q4_0.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q4_0.gguf) | Q4_0 | 6.78GB |
| [DARE_TIES_13B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.IQ4_NL.gguf) | IQ4_NL | 6.85GB |
| [DARE_TIES_13B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q4_K_S.gguf) | Q4_K_S | 6.84GB |
| [DARE_TIES_13B.Q4_K.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q4_K.gguf) | Q4_K | 7.25GB |
| [DARE_TIES_13B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q4_K_M.gguf) | Q4_K_M | 7.25GB |
| [DARE_TIES_13B.Q4_1.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q4_1.gguf) | Q4_1 | 7.52GB |
| [DARE_TIES_13B.Q5_0.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q5_0.gguf) | Q5_0 | 8.26GB |
| [DARE_TIES_13B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q5_K_S.gguf) | Q5_K_S | 8.26GB |
| [DARE_TIES_13B.Q5_K.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q5_K.gguf) | Q5_K | 8.51GB |
| [DARE_TIES_13B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q5_K_M.gguf) | Q5_K_M | 8.51GB |
| [DARE_TIES_13B.Q5_1.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q5_1.gguf) | Q5_1 | 9.01GB |
| [DARE_TIES_13B.Q6_K.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q6_K.gguf) | Q6_K | 9.84GB |
| [DARE_TIES_13B.Q8_0.gguf](https://huggingface.co/RichardErkhov/yunconglong_-_DARE_TIES_13B-gguf/blob/main/DARE_TIES_13B.Q8_0.gguf) | Q8_0 | 12.75GB |
Original model description:
---
license:
- other
tags:
- dare ties
---
# DARE_TIES_13B
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [DARE](https://arxiv.org/abs/2311.03099) [TIES](https://arxiv.org/abs/2306.01708) merge method using [yunconglong/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B](https://huggingface.co/yunconglong/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B) as a base.
### Models Merged
The following models were included in the merge:
* ./13B_DPO
* ./13B_MATH_DPO
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: yunconglong/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B
parameters:
density: 1.0
weight: 1.0
- model: ./13B_MATH_DPO
parameters:
density: 0.5
weight: [0.33, 0.4, 0.33]
- model: ./13B_DPO
parameters:
density: [0.33, 0.45, 0.66]
weight: 0.66
merge_method: dare_ties
base_model: yunconglong/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B
parameters:
normalize: true
int8_mask: true
dtype: bfloat16
tokenizer_source : union
```
|
Subsets and Splits