
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-26 12:28:48
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 498
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-26 12:28:16
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Rhma/MistralaDialo5 | Rhma | 2024-05-18T14:56:05Z | 9 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T14:52:20Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Aurelia25/Smile_Twitter_Sentiment_Analysis | Aurelia25 | 2024-05-18T14:55:02Z | 92 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-05-18T14:46:10Z | This directory includes a few sample datasets to get you started.
* `california_housing_data*.csv` is California housing data from the 1990 US
Census; more information is available at:
https://developers.google.com/machine-learning/crash-course/california-housing-data-description
* `mnist_*.csv` is a small sample of the
[MNIST database](https://en.wikipedia.org/wiki/MNIST_database), which is
described at: http://yann.lecun.com/exdb/mnist/
* `anscombe.json` contains a copy of
[Anscombe's quartet](https://en.wikipedia.org/wiki/Anscombe%27s_quartet); it
was originally described in
Anscombe, F. J. (1973). 'Graphs in Statistical Analysis'. American
Statistician. 27 (1): 17-21. JSTOR 2682899.
and our copy was prepared by the
[vega_datasets library](https://github.com/altair-viz/vega_datasets/blob/4f67bdaad10f45e3549984e17e1b3088c731503d/vega_datasets/_data/anscombe.json).
|
Dandan0K/Pilot_vox_Ref_french | Dandan0K | 2024-05-18T14:55:00Z | 79 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"fr",
"dataset:mozilla-foundation/common_voice_7_0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-18T13:52:46Z | ---
language:
- fr
license: apache-2.0
tags:
- automatic-speech-recognition
- fr
datasets:
- mozilla-foundation/common_voice_7_0
---
# exp_w2v2t_fr_vp-100k_s973
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (fr)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
kapliff89/bert-finetuned-ner | kapliff89 | 2024-05-18T14:54:35Z | 110 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-05-18T14:47:58Z | ---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: validation
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9373134328358209
- name: Recall
type: recall
value: 0.9511948838774823
- name: F1
type: f1
value: 0.9442031406615435
- name: Accuracy
type: accuracy
value: 0.9867398598928593
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0603
- Precision: 0.9373
- Recall: 0.9512
- F1: 0.9442
- Accuracy: 0.9867
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0761 | 1.0 | 1756 | 0.0671 | 0.9029 | 0.9330 | 0.9177 | 0.9812 |
| 0.0349 | 2.0 | 3512 | 0.0644 | 0.9315 | 0.9473 | 0.9393 | 0.9860 |
| 0.0209 | 3.0 | 5268 | 0.0603 | 0.9373 | 0.9512 | 0.9442 | 0.9867 |
### Framework versions
- Transformers 4.40.2
- Pytorch 2.3.0+cu118
- Datasets 2.19.1
- Tokenizers 0.19.1
|
SamirLahouar/Reinforce-unit4 | SamirLahouar | 2024-05-18T14:53:09Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-18T14:52:59Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-unit4
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
AliSaadatV/virus_pythia_14_1024_2d_representation_MSEPlusCE | AliSaadatV | 2024-05-18T14:52:48Z | 128 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"base_model:EleutherAI/pythia-14m",
"base_model:finetune:EleutherAI/pythia-14m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T14:52:47Z | ---
base_model: EleutherAI/pythia-14m
tags:
- generated_from_trainer
model-index:
- name: virus_pythia_14_1024_2d_representation_MSEPlusCE
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# virus_pythia_14_1024_2d_representation_MSEPlusCE
This model is a fine-tuned version of [EleutherAI/pythia-14m](https://huggingface.co/EleutherAI/pythia-14m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.40.2
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
RichardErkhov/guardrail_-_llama-2-7b-guanaco-instruct-sharded-8bits | RichardErkhov | 2024-05-18T14:51:38Z | 78 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-18T14:44:25Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
llama-2-7b-guanaco-instruct-sharded - bnb 8bits
- Model creator: https://huggingface.co/guardrail/
- Original model: https://huggingface.co/guardrail/llama-2-7b-guanaco-instruct-sharded/
Original model description:
---
license: apache-2.0
datasets:
- timdettmers/openassistant-guanaco
pipeline_tag: text-generation
---
Model that is fine-tuned in 4-bit precision using QLoRA on [timdettmers/openassistant-guanaco](https://huggingface.co/datasets/timdettmers/openassistant-guanaco) and sharded to be used on a free Google Colab instance that can be loaded with 4bits.
It can be easily imported using the `AutoModelForCausalLM` class from `transformers`:
```
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"guardrail/llama-2-7b-guanaco-instruct-sharded",
load_in_4bit=True)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
```
|
Edgar404/a2c-PandaPickAndPlace-v3 | Edgar404 | 2024-05-18T14:51:17Z | 1 | 0 | stable-baselines3 | [
"stable-baselines3",
"PandaPickAndPlace-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-18T14:46:40Z | ---
library_name: stable-baselines3
tags:
- PandaPickAndPlace-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaPickAndPlace-v3
type: PandaPickAndPlace-v3
metrics:
- type: mean_reward
value: -50.00 +/- 0.00
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaPickAndPlace-v3**
This is a trained model of a **A2C** agent playing **PandaPickAndPlace-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
DownwardSpiral33/gpt2-imdb-pos-v2-003 | DownwardSpiral33 | 2024-05-18T14:50:46Z | 130 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T14:50:29Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
rnribeiro/FT-distilbert-base-uncased | rnribeiro | 2024-05-18T14:50:17Z | 119 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-18T13:16:45Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: FT-distilbert-base-uncased
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# FT-distilbert-base-uncased
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6614
- Accuracy: 0.65
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 0.6806 | 0.5 |
| No log | 2.0 | 80 | 0.6614 | 0.65 |
| No log | 3.0 | 120 | 0.6672 | 0.55 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.2+cu118
- Datasets 2.18.0
- Tokenizers 0.15.2
|
rnribeiro/FT-mrm8488-distilroberta-finetuned-financial-news-sentiment-analysis | rnribeiro | 2024-05-18T14:50:14Z | 111 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:mrm8488/distilroberta-finetuned-financial-news-sentiment-analysis",
"base_model:finetune:mrm8488/distilroberta-finetuned-financial-news-sentiment-analysis",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-18T13:16:44Z | ---
license: apache-2.0
base_model: mrm8488/distilroberta-finetuned-financial-news-sentiment-analysis
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: FT-mrm8488-distilroberta-finetuned-financial-news-sentiment-analysis
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# FT-mrm8488-distilroberta-finetuned-financial-news-sentiment-analysis
This model is a fine-tuned version of [mrm8488/distilroberta-finetuned-financial-news-sentiment-analysis](https://huggingface.co/mrm8488/distilroberta-finetuned-financial-news-sentiment-analysis) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2034
- Accuracy: 0.95
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 0.2034 | 0.95 |
| No log | 2.0 | 80 | 0.2108 | 0.925 |
| No log | 3.0 | 120 | 0.2077 | 0.95 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.2+cu118
- Datasets 2.18.0
- Tokenizers 0.15.2
|
Yann2310/Reinforce | Yann2310 | 2024-05-18T14:49:24Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-18T14:49:22Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 17.30 +/- 5.37
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
JhonVanced/sin2piusc-whisper-large-v2-10k-ct2 | JhonVanced | 2024-05-18T14:48:30Z | 16 | 0 | ctranslate2 | [
"ctranslate2",
"audio",
"automatic-speech-recognition",
"en",
"zh",
"de",
"es",
"ru",
"ko",
"fr",
"ja",
"pt",
"tr",
"pl",
"ca",
"nl",
"ar",
"sv",
"it",
"id",
"hi",
"fi",
"vi",
"he",
"uk",
"el",
"ms",
"cs",
"ro",
"da",
"hu",
"ta",
"no",
"th",
"ur",
"hr",
"bg",
"lt",
"la",
"mi",
"ml",
"cy",
"sk",
"te",
"fa",
"lv",
"bn",
"sr",
"az",
"sl",
"kn",
"et",
"mk",
"br",
"eu",
"is",
"hy",
"ne",
"mn",
"bs",
"kk",
"sq",
"sw",
"gl",
"mr",
"pa",
"si",
"km",
"sn",
"yo",
"so",
"af",
"oc",
"ka",
"be",
"tg",
"sd",
"gu",
"am",
"yi",
"lo",
"uz",
"fo",
"ht",
"ps",
"tk",
"nn",
"mt",
"sa",
"lb",
"my",
"bo",
"tl",
"mg",
"as",
"tt",
"haw",
"ln",
"ha",
"ba",
"jw",
"su",
"yue",
"license:mit",
"region:us"
] | automatic-speech-recognition | 2024-05-08T13:52:11Z | ---
language:
- en
- zh
- de
- es
- ru
- ko
- fr
- ja
- pt
- tr
- pl
- ca
- nl
- ar
- sv
- it
- id
- hi
- fi
- vi
- he
- uk
- el
- ms
- cs
- ro
- da
- hu
- ta
- 'no'
- th
- ur
- hr
- bg
- lt
- la
- mi
- ml
- cy
- sk
- te
- fa
- lv
- bn
- sr
- az
- sl
- kn
- et
- mk
- br
- eu
- is
- hy
- ne
- mn
- bs
- kk
- sq
- sw
- gl
- mr
- pa
- si
- km
- sn
- yo
- so
- af
- oc
- ka
- be
- tg
- sd
- gu
- am
- yi
- lo
- uz
- fo
- ht
- ps
- tk
- nn
- mt
- sa
- lb
- my
- bo
- tl
- mg
- as
- tt
- haw
- ln
- ha
- ba
- jw
- su
- yue
tags:
- audio
- automatic-speech-recognition
license: mit
library_name: ctranslate2
---
Convert from: sin2piusc/whisper-large-v2-10k
# Whisper large-v2 model for CTranslate2
This repository contains the conversion of [sin2piusc/whisper-large-v2-10k](https://huggingface.co/sin2piusc/whisper-large-v2-10k) to the [CTranslate2](https://github.com/OpenNMT/CTranslate2) model format.
This model can be used in CTranslate2 or projects based on CTranslate2 such as [faster-whisper](https://github.com/systran/faster-whisper).
## Example
```python
from faster_whisper import WhisperModel
model = WhisperModel("large-v2")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
## Conversion details
The original model was converted with the following command:
```
ct2-transformers-converter --model sin2piusc/whisper-large-v2-10k --output_dir whisper-large-v2-10k-ct2 \
--copy_files tokenizer.json preprocessor_config.json --quantization float16
```
Note that the model weights are saved in FP16. This type can be changed when the model is loaded using the [`compute_type` option in CTranslate2](https://opennmt.net/CTranslate2/quantization.html).
## More information
**For more information about the original model, see its [model card](https://huggingface.co/sin2piusc/whisper-large-v2-10k).**
|
JhonVanced/sin2piusc-whisper-large-v2-10k-ct2-int8_float32 | JhonVanced | 2024-05-18T14:47:11Z | 18 | 0 | ctranslate2 | [
"ctranslate2",
"audio",
"automatic-speech-recognition",
"en",
"zh",
"de",
"es",
"ru",
"ko",
"fr",
"ja",
"pt",
"tr",
"pl",
"ca",
"nl",
"ar",
"sv",
"it",
"id",
"hi",
"fi",
"vi",
"he",
"uk",
"el",
"ms",
"cs",
"ro",
"da",
"hu",
"ta",
"no",
"th",
"ur",
"hr",
"bg",
"lt",
"la",
"mi",
"ml",
"cy",
"sk",
"te",
"fa",
"lv",
"bn",
"sr",
"az",
"sl",
"kn",
"et",
"mk",
"br",
"eu",
"is",
"hy",
"ne",
"mn",
"bs",
"kk",
"sq",
"sw",
"gl",
"mr",
"pa",
"si",
"km",
"sn",
"yo",
"so",
"af",
"oc",
"ka",
"be",
"tg",
"sd",
"gu",
"am",
"yi",
"lo",
"uz",
"fo",
"ht",
"ps",
"tk",
"nn",
"mt",
"sa",
"lb",
"my",
"bo",
"tl",
"mg",
"as",
"tt",
"haw",
"ln",
"ha",
"ba",
"jw",
"su",
"yue",
"license:mit",
"region:us"
] | automatic-speech-recognition | 2024-05-18T13:53:58Z | ---
language:
- en
- zh
- de
- es
- ru
- ko
- fr
- ja
- pt
- tr
- pl
- ca
- nl
- ar
- sv
- it
- id
- hi
- fi
- vi
- he
- uk
- el
- ms
- cs
- ro
- da
- hu
- ta
- 'no'
- th
- ur
- hr
- bg
- lt
- la
- mi
- ml
- cy
- sk
- te
- fa
- lv
- bn
- sr
- az
- sl
- kn
- et
- mk
- br
- eu
- is
- hy
- ne
- mn
- bs
- kk
- sq
- sw
- gl
- mr
- pa
- si
- km
- sn
- yo
- so
- af
- oc
- ka
- be
- tg
- sd
- gu
- am
- yi
- lo
- uz
- fo
- ht
- ps
- tk
- nn
- mt
- sa
- lb
- my
- bo
- tl
- mg
- as
- tt
- haw
- ln
- ha
- ba
- jw
- su
- yue
tags:
- audio
- automatic-speech-recognition
license: mit
library_name: ctranslate2
---
Convert from: sin2piusc/whisper-large-v2-10k
# Whisper large-v2 model for CTranslate2
This repository contains the conversion of [sin2piusc/whisper-large-v2-10k](https://huggingface.co/sin2piusc/whisper-large-v2-10k) to the [CTranslate2](https://github.com/OpenNMT/CTranslate2) model format.
This model can be used in CTranslate2 or projects based on CTranslate2 such as [faster-whisper](https://github.com/systran/faster-whisper).
## Example
```python
from faster_whisper import WhisperModel
model = WhisperModel("large-v2")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
## Conversion details
The original model was converted with the following command:
```
ct2-transformers-converter --model sin2piusc/whisper-large-v2-10k --output_dir whisper-large-v2-10k-ct2-int8_float32 \
--copy_files tokenizer.json preprocessor_config.json --quantization int8_float32
```
Note that the model weights are saved in FP16. This type can be changed when the model is loaded using the [`compute_type` option in CTranslate2](https://opennmt.net/CTranslate2/quantization.html).
## More information
**For more information about the original model, see its [model card](https://huggingface.co/sin2piusc/whisper-large-v2-10k).**
|
Astowny/Reinforce-cartpool | Astowny | 2024-05-18T14:45:23Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-18T14:45:15Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-cartpool
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 451.10 +/- 146.70
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
ethan-ky/distilbert-base-uncased-finetuned-emotion | ethan-ky | 2024-05-18T14:41:29Z | 119 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-17T03:36:33Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9215
- name: F1
type: f1
value: 0.9213719420412787
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2083
- Accuracy: 0.9215
- F1: 0.9214
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8068 | 1.0 | 250 | 0.2897 | 0.9155 | 0.9148 |
| 0.2389 | 2.0 | 500 | 0.2083 | 0.9215 | 0.9214 |
### Framework versions
- Transformers 4.40.2
- Pytorch 2.3.0
- Datasets 2.19.1
- Tokenizers 0.19.1
|
saousan/Reinforce-cartpool | saousan | 2024-05-18T14:40:35Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-18T14:40:26Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-cartpool
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
jerryjiao198/Marcoro14-7B-slerp | jerryjiao198 | 2024-05-18T14:40:28Z | 0 | 0 | null | [
"merge",
"mergekit",
"lazymergekit",
"AIDC-ai-business/Marcoroni-7B-v3",
"EmbeddedLLM/Mistral-7B-Merge-14-v0.1",
"license:apache-2.0",
"region:us"
] | null | 2024-05-16T02:58:43Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- AIDC-ai-business/Marcoroni-7B-v3
- EmbeddedLLM/Mistral-7B-Merge-14-v0.1
---
# Marcoro14-7B-slerp
Marcoro14-7B-slerp is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [AIDC-ai-business/Marcoroni-7B-v3](https://huggingface.co/AIDC-ai-business/Marcoroni-7B-v3)
* [EmbeddedLLM/Mistral-7B-Merge-14-v0.1](https://huggingface.co/EmbeddedLLM/Mistral-7B-Merge-14-v0.1)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: AIDC-ai-business/Marcoroni-7B-v3
layer_range: [0, 32]
- model: EmbeddedLLM/Mistral-7B-Merge-14-v0.1
layer_range: [0, 32]
merge_method: slerp
base_model: AIDC-ai-business/Marcoroni-7B-v3
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
``` |
Schadic/Reinforce-1 | Schadic | 2024-05-18T14:38:28Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-18T14:38:19Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 497.60 +/- 7.20
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
emilykang/Phi_medmcqa_question_generation_model | emilykang | 2024-05-18T14:36:35Z | 128 | 0 | transformers | [
"transformers",
"safetensors",
"phi",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T14:27:07Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Ransss/Fimbulvetr-10.7B-v1-Q8_0-GGUF | Ransss | 2024-05-18T14:36:04Z | 6 | 1 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-18T14:35:35Z | ---
language:
- en
license: cc-by-nc-4.0
tags:
- llama-cpp
- gguf-my-repo
---
# Ransss/Fimbulvetr-10.7B-v1-Q8_0-GGUF
This model was converted to GGUF format from [`Sao10K/Fimbulvetr-10.7B-v1`](https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo Ransss/Fimbulvetr-10.7B-v1-Q8_0-GGUF --model fimbulvetr-10.7b-v1.Q8_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo Ransss/Fimbulvetr-10.7B-v1-Q8_0-GGUF --model fimbulvetr-10.7b-v1.Q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m fimbulvetr-10.7b-v1.Q8_0.gguf -n 128
```
|
RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf | RichardErkhov | 2024-05-18T14:31:42Z | 38 | 0 | null | [
"gguf",
"arxiv:2312.13558",
"endpoints_compatible",
"region:us"
] | null | 2024-05-18T11:58:04Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
laser-dolphin-mixtral-2x7b-dpo - GGUF
- Model creator: https://huggingface.co/macadeliccc/
- Original model: https://huggingface.co/macadeliccc/laser-dolphin-mixtral-2x7b-dpo/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [laser-dolphin-mixtral-2x7b-dpo.Q2_K.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q2_K.gguf) | Q2_K | 4.43GB |
| [laser-dolphin-mixtral-2x7b-dpo.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.IQ3_XS.gguf) | IQ3_XS | 4.94GB |
| [laser-dolphin-mixtral-2x7b-dpo.IQ3_S.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.IQ3_S.gguf) | IQ3_S | 5.22GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q3_K_S.gguf) | Q3_K_S | 5.2GB |
| [laser-dolphin-mixtral-2x7b-dpo.IQ3_M.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.IQ3_M.gguf) | IQ3_M | 5.34GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q3_K.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q3_K.gguf) | Q3_K | 5.78GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q3_K_M.gguf) | Q3_K_M | 5.78GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q3_K_L.gguf) | Q3_K_L | 6.27GB |
| [laser-dolphin-mixtral-2x7b-dpo.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.IQ4_XS.gguf) | IQ4_XS | 6.5GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q4_0.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q4_0.gguf) | Q4_0 | 6.78GB |
| [laser-dolphin-mixtral-2x7b-dpo.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.IQ4_NL.gguf) | IQ4_NL | 6.85GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q4_K_S.gguf) | Q4_K_S | 6.84GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q4_K.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q4_K.gguf) | Q4_K | 7.25GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q4_K_M.gguf) | Q4_K_M | 7.25GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q4_1.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q4_1.gguf) | Q4_1 | 7.52GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q5_0.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q5_0.gguf) | Q5_0 | 8.26GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q5_K_S.gguf) | Q5_K_S | 8.26GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q5_K.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q5_K.gguf) | Q5_K | 8.51GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q5_K_M.gguf) | Q5_K_M | 8.51GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q5_1.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q5_1.gguf) | Q5_1 | 9.01GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q6_K.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q6_K.gguf) | Q6_K | 9.84GB |
| [laser-dolphin-mixtral-2x7b-dpo.Q8_0.gguf](https://huggingface.co/RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-gguf/blob/main/laser-dolphin-mixtral-2x7b-dpo.Q8_0.gguf) | Q8_0 | 12.75GB |
Original model description:
---
license: apache-2.0
library_name: transformers
model-index:
- name: laser-dolphin-mixtral-2x7b-dpo
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 65.96
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-2x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 85.8
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-2x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 63.17
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-2x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 60.76
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-2x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 79.01
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-2x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 48.29
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-2x7b-dpo
name: Open LLM Leaderboard
---
# Laser-Dolphin-Mixtral-2x7b-dpo

**New Version out now!**
Credit to Fernando Fernandes and Eric Hartford for their project [laserRMT](https://github.com/cognitivecomputations/laserRMT)
## Overview
This model is a medium-sized MoE implementation based on [cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser](https://huggingface.co/cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser)
+ The new version shows ~1 point increase in evaluation performance on average.
## Process
+ The process is outlined in this [notebook](https://github.com/cognitivecomputations/laserRMT/blob/main/examples/laser-dolphin-mixtral-2x7b.ipynb)
+ The mergekit_config is in the files.
+ The models used in the configuration are not lasered, but the final product is. This is an update from the last version.
+ This process is experimental. Your mileage may vary.
## Future Goals
+ [ ] Function Calling
+ [ ] v2 with new base model to improve performance
## Quantizations
### ExLlamav2
_These are the recommended quantizations for users that are running the model on GPU_
Thanks to user [bartowski](https://huggingface.co/bartowski) we now have exllamav2 quantizations in 3.5 through 8 bpw. They are available here:
+ [bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2](https://huggingface.co/bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2)
| Branch | Bits | lm_head bits | VRAM (4k) | VRAM (16k) | VRAM (32k) | Description |
| ----- | ---- | ------- | ------ | ------ | ------ | ------------ |
| [8_0](https://huggingface.co/bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2/tree/8_0) | 8.0 | 8.0 | 13.7 GB | 15.1 GB | 17.2 GB | Maximum quality that ExLlamaV2 can produce, near unquantized performance. |
| [6_5](https://huggingface.co/bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2/tree/6_5) | 6.5 | 8.0 | 11.5 GB | 12.9 GB | 15.0 GB | Near unquantized performance at vastly reduced size, **recommended**. |
| [5_0](https://huggingface.co/bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2/tree/5_0) | 5.0 | 6.0 | 9.3 GB | 10.7 GB | 12.8 GB | Slightly lower quality vs 6.5, great for 12gb cards with 16k context. |
| [4_25](https://huggingface.co/bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2/tree/4_25) | 4.25 | 6.0 | 8.2 GB | 9.6 GB | 11.7 GB | GPTQ equivalent bits per weight. |
| [3_5](https://huggingface.co/bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2/tree/3_5) | 3.5 | 6.0 | 7.0 GB | 8.4 GB | 10.5 GB | Lower quality, not recommended. |
His quantizations represent the first ~13B model with GQA support. Check out his repo for more information!
### GGUF
*Current GGUF [Quantizations](https://huggingface.co/macadeliccc/laser-dolphin-mixtral-2x7b-dpo-GGUF)*
### AWQ
*Current AWQ [Quantizations](https://huggingface.co/macadeliccc/laser-dolphin-mixtral-2x7b-dpo-AWQ)
### TheBloke
**These Quants will result in unpredicted behavior. New quants are available as I have updated the model**
Quatizations provided by [TheBloke](https://huggingface.co/TheBloke/laser-dolphin-mixtral-2x7b-dpo-GGUF)
## HF Spaces
+ GGUF chat available [here](https://huggingface.co/spaces/macadeliccc/laser-dolphin-mixtral-chat-GGUF)
+ 4-bit bnb chat available [here](https://huggingface.co/spaces/macadeliccc/laser-dolphin-mixtral-chat)
# Ollama
```bash
ollama run macadeliccc/laser-dolphin-mixtral-2x7b-dpo
```

## Code Example
Switch the commented model definition to use in 4-bit. Should work with 9GB and still exceed the single 7B model by 5-6 points roughly
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
def generate_response(prompt):
"""
Generate a response from the model based on the input prompt.
Args:
prompt (str): Prompt for the model.
Returns:
str: The generated response from the model.
"""
# Tokenize the input prompt
inputs = tokenizer(prompt, return_tensors="pt")
# Generate output tokens
outputs = model.generate(**inputs, max_new_tokens=256, eos_token_id=tokenizer.eos_token_id, pad_token_id=tokenizer.pad_token_id)
# Decode the generated tokens to a string
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# Load the model and tokenizer
model_id = "macadeliccc/laser-dolphin-mixtral-2x7b-dpo"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True)
prompt = "Write a quicksort algorithm in python"
# Generate and print responses for each language
print("Response:")
print(generate_response(prompt), "\n")
```
[colab](https://colab.research.google.com/drive/1cmRhAkDWItV7utHNqNANVZnqDqQNsTUr?usp=sharing) with usage example
## Eval
## EQ Bench
<pre>----Benchmark Complete----
2024-01-31 16:55:37
Time taken: 31.1 mins
Prompt Format: ChatML
Model: macadeliccc/laser-dolphin-mixtral-2x7b-dpo-GGUF
Score (v2): 72.76
Parseable: 171.0
---------------
Batch completed
Time taken: 31.2 mins
---------------
</pre>
evaluation [colab](https://colab.research.google.com/drive/1FpwgsGzCR4tORTxAwUxpN3PcP22En2xk?usp=sharing)
## Summary of previous evaluation
| Model |AGIEval|GPT4All|TruthfulQA|Bigbench|Average|
|---------------------------------------------------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[laser-dolphin-mixtral-2x7b-dpo](https://huggingface.co/macadeliccc/laser-dolphin-mixtral-2x7b-dpo)| 41.31| 73.67| 61.69| 42.79| 54.87|
## Detailed current evaluation
| Model |AGIEval|GPT4All|TruthfulQA|Bigbench|Average|
|---------------------------------------------------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[laser-dolphin-mixtral-2x7b-dpo](https://huggingface.co/macadeliccc/laser-dolphin-mixtral-2x7b-dpo)| 42.25| 73.45| 63.44| 43.96| 55.77|
### AGIEval
| Task |Version| Metric |Value| |Stderr|
|------------------------------|------:|--------|----:|---|-----:|
|agieval_aqua_rat | 0|acc |21.26|± | 2.57|
| | |acc_norm|21.65|± | 2.59|
|agieval_logiqa_en | 0|acc |34.72|± | 1.87|
| | |acc_norm|35.64|± | 1.88|
|agieval_lsat_ar | 0|acc |26.96|± | 2.93|
| | |acc_norm|26.96|± | 2.93|
|agieval_lsat_lr | 0|acc |45.88|± | 2.21|
| | |acc_norm|46.08|± | 2.21|
|agieval_lsat_rc | 0|acc |59.48|± | 3.00|
| | |acc_norm|59.48|± | 3.00|
|agieval_sat_en | 0|acc |73.79|± | 3.07|
| | |acc_norm|73.79|± | 3.07|
|agieval_sat_en_without_passage| 0|acc |42.23|± | 3.45|
| | |acc_norm|41.26|± | 3.44|
|agieval_sat_math | 0|acc |37.27|± | 3.27|
| | |acc_norm|33.18|± | 3.18|
Average: 42.25%
### GPT4All
| Task |Version| Metric |Value| |Stderr|
|-------------|------:|--------|----:|---|-----:|
|arc_challenge| 0|acc |58.36|± | 1.44|
| | |acc_norm|58.02|± | 1.44|
|arc_easy | 0|acc |82.20|± | 0.78|
| | |acc_norm|77.40|± | 0.86|
|boolq | 1|acc |87.52|± | 0.58|
|hellaswag | 0|acc |67.50|± | 0.47|
| | |acc_norm|84.43|± | 0.36|
|openbookqa | 0|acc |34.40|± | 2.13|
| | |acc_norm|47.00|± | 2.23|
|piqa | 0|acc |81.61|± | 0.90|
| | |acc_norm|82.59|± | 0.88|
|winogrande | 0|acc |77.19|± | 1.18|
Average: 73.45%
### GSM8K
|Task |Version| Metric |Value| |Stderr|
|-----|------:|-----------------------------|-----|---|------|
|gsm8k| 2|exact_match,get-answer | 0.75| | |
| | |exact_match_stderr,get-answer| 0.01| | |
| | |alias |gsm8k| | |
### TruthfulQA
| Task |Version|Metric|Value| |Stderr|
|-------------|------:|------|----:|---|-----:|
|truthfulqa_mc| 1|mc1 |45.90|± | 1.74|
| | |mc2 |63.44|± | 1.56|
Average: 63.44%
### Bigbench
| Task |Version| Metric |Value| |Stderr|
|------------------------------------------------|------:|---------------------|----:|---|-----:|
|bigbench_causal_judgement | 0|multiple_choice_grade|58.42|± | 3.59|
|bigbench_date_understanding | 0|multiple_choice_grade|60.70|± | 2.55|
|bigbench_disambiguation_qa | 0|multiple_choice_grade|38.37|± | 3.03|
|bigbench_geometric_shapes | 0|multiple_choice_grade|21.73|± | 2.18|
| | |exact_str_match | 0.00|± | 0.00|
|bigbench_logical_deduction_five_objects | 0|multiple_choice_grade|35.00|± | 2.14|
|bigbench_logical_deduction_seven_objects | 0|multiple_choice_grade|23.57|± | 1.61|
|bigbench_logical_deduction_three_objects | 0|multiple_choice_grade|50.33|± | 2.89|
|bigbench_movie_recommendation | 0|multiple_choice_grade|45.00|± | 2.23|
|bigbench_navigate | 0|multiple_choice_grade|50.00|± | 1.58|
|bigbench_reasoning_about_colored_objects | 0|multiple_choice_grade|60.35|± | 1.09|
|bigbench_ruin_names | 0|multiple_choice_grade|51.12|± | 2.36|
|bigbench_salient_translation_error_detection | 0|multiple_choice_grade|32.26|± | 1.48|
|bigbench_snarks | 0|multiple_choice_grade|67.96|± | 3.48|
|bigbench_sports_understanding | 0|multiple_choice_grade|70.59|± | 1.45|
|bigbench_temporal_sequences | 0|multiple_choice_grade|35.80|± | 1.52|
|bigbench_tracking_shuffled_objects_five_objects | 0|multiple_choice_grade|22.56|± | 1.18|
|bigbench_tracking_shuffled_objects_seven_objects| 0|multiple_choice_grade|17.20|± | 0.90|
|bigbench_tracking_shuffled_objects_three_objects| 0|multiple_choice_grade|50.33|± | 2.89|
Average: 43.96%
Average score: 55.77%
Elapsed time: 02:43:45
## Citations
Fernando Fernandes Neto and Eric Hartford. "Optimizing Large Language Models Using Layer-Selective Rank Reduction and Random Matrix Theory." 2024.
```bibtex
@article{sharma2023truth,
title={The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction},
author={Sharma, Pratyusha and Ash, Jordan T and Misra, Dipendra},
journal={arXiv preprint arXiv:2312.13558},
year={2023} }
```
```bibtex
@article{gao2021framework,
title={A framework for few-shot language model evaluation},
author={Gao, Leo and Tow, Jonathan and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and McDonell, Kyle and Muennighoff, Niklas and others},
journal={Version v0. 0.1. Sept},
year={2021}
}
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_macadeliccc__laser-dolphin-mixtral-2x7b-dpo)
| Metric |Value|
|---------------------------------|----:|
|Avg. |67.16|
|AI2 Reasoning Challenge (25-Shot)|65.96|
|HellaSwag (10-Shot) |85.80|
|MMLU (5-Shot) |63.17|
|TruthfulQA (0-shot) |60.76|
|Winogrande (5-shot) |79.01|
|GSM8k (5-shot) |48.29|
|
Ransss/Kuro-Lotus-10.7B-Q8_0-GGUF | Ransss | 2024-05-18T14:31:06Z | 0 | 0 | null | [
"gguf",
"mergekit",
"merge",
"llama-cpp",
"gguf-my-repo",
"base_model:BlueNipples/SnowLotus-v2-10.7B",
"base_model:merge:BlueNipples/SnowLotus-v2-10.7B",
"base_model:Himitsui/KuroMitsu-11B",
"base_model:merge:Himitsui/KuroMitsu-11B",
"license:cc-by-nc-4.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null | 2024-05-18T14:30:35Z | ---
license: cc-by-nc-4.0
tags:
- mergekit
- merge
- llama-cpp
- gguf-my-repo
base_model:
- BlueNipples/SnowLotus-v2-10.7B
- Himitsui/KuroMitsu-11B
model-index:
- name: Kuro-Lotus-10.7B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 68.69
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=saishf/Kuro-Lotus-10.7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 87.51
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=saishf/Kuro-Lotus-10.7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 66.64
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=saishf/Kuro-Lotus-10.7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 58.27
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=saishf/Kuro-Lotus-10.7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 84.21
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=saishf/Kuro-Lotus-10.7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 66.11
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=saishf/Kuro-Lotus-10.7B
name: Open LLM Leaderboard
---
# Ransss/Kuro-Lotus-10.7B-Q8_0-GGUF
This model was converted to GGUF format from [`saishf/Kuro-Lotus-10.7B`](https://huggingface.co/saishf/Kuro-Lotus-10.7B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/saishf/Kuro-Lotus-10.7B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo Ransss/Kuro-Lotus-10.7B-Q8_0-GGUF --model kuro-lotus-10.7b.Q8_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo Ransss/Kuro-Lotus-10.7B-Q8_0-GGUF --model kuro-lotus-10.7b.Q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m kuro-lotus-10.7b.Q8_0.gguf -n 128
```
|
ucla-nb-project/bart-finetuned | ucla-nb-project | 2024-05-18T14:29:52Z | 16 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"dataset:datasets/all_binary_and_xe_ey_fae_counterfactual",
"base_model:facebook/bart-base",
"base_model:finetune:facebook/bart-base",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-05-18T10:12:35Z | ---
base_model: facebook/bart-base
tags:
- generated_from_trainer
datasets:
- datasets/all_binary_and_xe_ey_fae_counterfactual
metrics:
- accuracy
model-index:
- name: bart-base-finetuned-xe_ey_fae
results:
- task:
name: Masked Language Modeling
type: fill-mask
dataset:
name: datasets/all_binary_and_xe_ey_fae_counterfactual
type: datasets/all_binary_and_xe_ey_fae_counterfactual
metrics:
- name: Accuracy
type: accuracy
value: 0.7180178883360112
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-finetuned-xe_ey_fae
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the datasets/all_binary_and_xe_ey_fae_counterfactual dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3945
- Accuracy: 0.7180
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 100
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 5.4226 | 0.06 | 500 | 3.8138 | 0.3628 |
| 4.0408 | 0.12 | 1000 | 3.0576 | 0.4630 |
| 3.4979 | 0.18 | 1500 | 2.7016 | 0.5133 |
| 3.1691 | 0.24 | 2000 | 2.4880 | 0.5431 |
| 2.9564 | 0.3 | 2500 | 2.3309 | 0.5644 |
| 2.8078 | 0.35 | 3000 | 2.2320 | 0.5792 |
| 2.6741 | 0.41 | 3500 | 2.1506 | 0.5924 |
| 2.5323 | 0.47 | 4000 | 1.9846 | 0.6176 |
| 2.3678 | 0.53 | 4500 | 1.8813 | 0.6375 |
| 2.25 | 0.59 | 5000 | 1.8100 | 0.6497 |
| 2.1795 | 0.65 | 5500 | 1.7632 | 0.6579 |
| 2.1203 | 0.71 | 6000 | 1.7238 | 0.6646 |
| 2.0764 | 0.77 | 6500 | 1.6856 | 0.6713 |
| 2.026 | 0.83 | 7000 | 1.6569 | 0.6760 |
| 1.9942 | 0.89 | 7500 | 1.6309 | 0.6803 |
| 1.9665 | 0.95 | 8000 | 1.6122 | 0.6836 |
| 1.9395 | 1.0 | 8500 | 1.5913 | 0.6866 |
| 1.9155 | 1.06 | 9000 | 1.5758 | 0.6895 |
| 1.8828 | 1.12 | 9500 | 1.5607 | 0.6918 |
| 1.8721 | 1.18 | 10000 | 1.5422 | 0.6948 |
| 1.8474 | 1.24 | 10500 | 1.5320 | 0.6964 |
| 1.8293 | 1.3 | 11000 | 1.5214 | 0.6978 |
| 1.8129 | 1.36 | 11500 | 1.5102 | 0.6998 |
| 1.8148 | 1.42 | 12000 | 1.5010 | 0.7013 |
| 1.7903 | 1.48 | 12500 | 1.4844 | 0.7038 |
| 1.7815 | 1.54 | 13000 | 1.4823 | 0.7039 |
| 1.7637 | 1.6 | 13500 | 1.4746 | 0.7052 |
| 1.7623 | 1.66 | 14000 | 1.4701 | 0.7061 |
| 1.7402 | 1.71 | 14500 | 1.4598 | 0.7076 |
| 1.7376 | 1.77 | 15000 | 1.4519 | 0.7090 |
| 1.7287 | 1.83 | 15500 | 1.4501 | 0.7101 |
| 1.7273 | 1.89 | 16000 | 1.4409 | 0.7107 |
| 1.7119 | 1.95 | 16500 | 1.4314 | 0.7125 |
| 1.7098 | 2.01 | 17000 | 1.4269 | 0.7129 |
| 1.6978 | 2.07 | 17500 | 1.4275 | 0.7132 |
| 1.698 | 2.13 | 18000 | 1.4218 | 0.7140 |
| 1.6837 | 2.19 | 18500 | 1.4151 | 0.7147 |
| 1.6908 | 2.25 | 19000 | 1.4137 | 0.7149 |
| 1.6902 | 2.31 | 19500 | 1.4085 | 0.7161 |
| 1.6741 | 2.36 | 20000 | 1.4121 | 0.7154 |
| 1.6823 | 2.42 | 20500 | 1.4037 | 0.7165 |
| 1.6692 | 2.48 | 21000 | 1.4039 | 0.7164 |
| 1.6669 | 2.54 | 21500 | 1.4015 | 0.7172 |
| 1.6613 | 2.6 | 22000 | 1.3979 | 0.7179 |
| 1.664 | 2.66 | 22500 | 1.3960 | 0.7180 |
| 1.6615 | 2.72 | 23000 | 1.4012 | 0.7172 |
| 1.6627 | 2.78 | 23500 | 1.3974 | 0.7178 |
| 1.6489 | 2.84 | 24000 | 1.3948 | 0.7182 |
| 1.6429 | 2.9 | 24500 | 1.3921 | 0.7184 |
| 1.6477 | 2.96 | 25000 | 1.3910 | 0.7182 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.0
- Tokenizers 0.15.2
|
TIGER-Lab/Mantis-llava-7b | TIGER-Lab | 2024-05-18T14:29:50Z | 9 | 15 | transformers | [
"transformers",
"safetensors",
"llava",
"image-text-to-text",
"Mantis",
"VLM",
"LMM",
"Multimodal LLM",
"en",
"base_model:llava-hf/llava-1.5-7b-hf",
"base_model:finetune:llava-hf/llava-1.5-7b-hf",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2024-04-13T19:19:14Z | ---
tags:
- Mantis
- VLM
- LMM
- Multimodal LLM
- llava
base_model: llava-hf/llava-1.5-7b-hf
model-index:
- name: Mantis-llava-7b
results: []
license: apache-2.0
language:
- en
---
# Mantis: Interleaved Multi-Image Instruction Tuning (Deprecated)
**Mantis** is a multimodal conversational AI model that can chat with users about images and text. It's optimized for multi-image reasoning, where interleaved text and images can be used to generate responses.
**Note that this is an older version of Mantis**, please refer to our newest version at [mantis-Siglip-llama3](https://huggingface.co/TIGER-Lab/Mantis-8B-siglip-llama3). The newer version improves significantly over both multi-image and single-image tasks.
Mantis is trained on the newly curated dataset **Mantis-Instruct**, a large-scale multi-image QA dataset that covers various multi-image reasoning tasks.
|[Demo](https://huggingface.co/spaces/TIGER-Lab/Mantis) | [Github](https://github.com/TIGER-AI-Lab/Mantis) | [Models](https://huggingface.co/collections/TIGER-Lab/mantis-6619b0834594c878cdb1d6e4) |
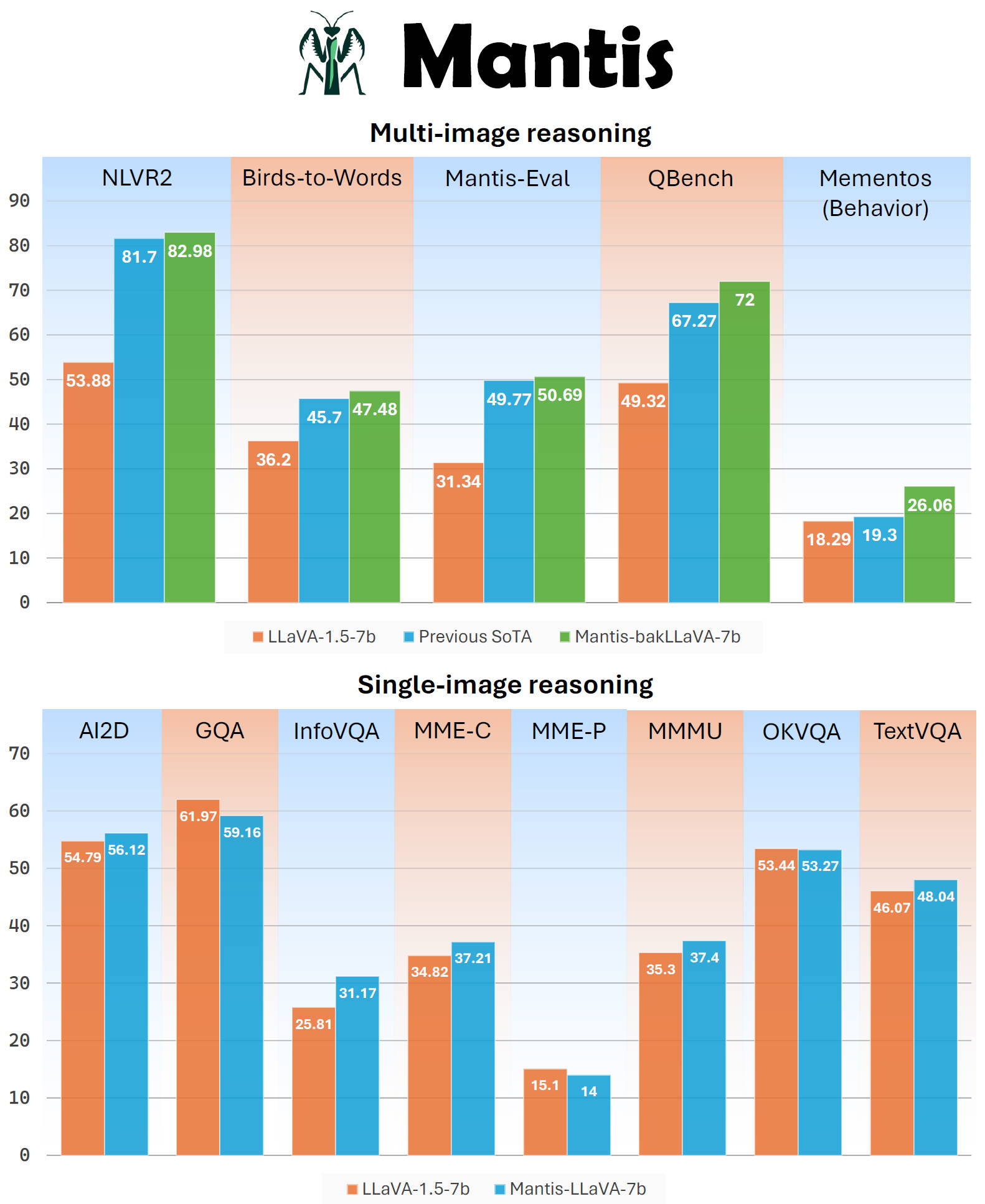
## Inference
You can install Mantis's GitHub codes as a Python package
```bash
pip install git+https://github.com/TIGER-AI-Lab/Mantis.git
```
then run inference with codes here: [examples/run_mantis.py](https://github.com/TIGER-AI-Lab/Mantis/blob/main/examples/run_mantis_hf.py)
```python
from mantis.models.mllava import chat_mllava
from PIL import Image
import torch
image1 = "image1.jpg"
image2 = "image2.jpg"
images = [Image.open(image1), Image.open(image2)]
# load processor and model
from mantis.models.mllava import MLlavaProcessor, LlavaForConditionalGeneration
processor = MLlavaProcessor.from_pretrained("TIGER-Lab/Mantis-bakllava-7b")
model = LlavaForConditionalGeneration.from_pretrained("TIGER-Lab/Mantis-bakllava-7b", device_map="auto", torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2")
# chat
text = "<image> <image> What's the difference between these two images? Please describe as much as you can."
response, history = chat_mllava(text, images, model, processor)
print("USER: ", text)
print("ASSISTANT: ", response)
# The image on the right has a larger number of wallets displayed compared to the image on the left. The wallets in the right image are arranged in a grid pattern, while the wallets in the left image are displayed in a more scattered manner. The wallets in the right image have various colors, including red, purple, and brown, while the wallets in the left image are primarily brown.
text = "How many items are there in image 1 and image 2 respectively?"
response, history = chat_mllava(text, images, model, processor, history=history)
print("USER: ", text)
print("ASSISTANT: ", response)
# There are two items in image 1 and four items in image 2.
```
Or, you can run the model without relying on the mantis codes, using pure hugging face transformers. See [examples/run_mantis_hf.py](https://github.com/TIGER-AI-Lab/Mantis/blob/main/examples/run_mantis_hf.py) for details.
## Training
Training codes will be released soon. |
OsherElhadad/ppo-PandaReachJointsSparse-v3-750000 | OsherElhadad | 2024-05-18T14:28:46Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"PandaReachJointsSparse-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-18T14:25:37Z | ---
library_name: stable-baselines3
tags:
- PandaReachJointsSparse-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachJointsSparse-v3
type: PandaReachJointsSparse-v3
metrics:
- type: mean_reward
value: -2.20 +/- 1.60
name: mean_reward
verified: false
---
# **PPO** Agent playing **PandaReachJointsSparse-v3**
This is a trained model of a **PPO** agent playing **PandaReachJointsSparse-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
beimu/model | beimu | 2024-05-18T14:23:17Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-05-18T14:23:17Z | ---
license: apache-2.0
---
|
AliSaadatV/virus_pythia_14_1024_2d_representation_GaussianPlusCE | AliSaadatV | 2024-05-18T14:22:18Z | 130 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"base_model:EleutherAI/pythia-14m",
"base_model:finetune:EleutherAI/pythia-14m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T14:22:16Z | ---
base_model: EleutherAI/pythia-14m
tags:
- generated_from_trainer
model-index:
- name: virus_pythia_14_1024_2d_representation_GaussianPlusCE
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# virus_pythia_14_1024_2d_representation_GaussianPlusCE
This model is a fine-tuned version of [EleutherAI/pythia-14m](https://huggingface.co/EleutherAI/pythia-14m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.40.2
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
rafaelsandroni/llama-3-8b-Instruct-16bit | rafaelsandroni | 2024-05-18T14:19:48Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T14:10:07Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
---
# Uploaded model
- **Developed by:** rafaelsandroni
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
charlesdj/CSR_LLaVA_1.5_7b_3Iteration | charlesdj | 2024-05-18T14:12:34Z | 79 | 0 | transformers | [
"transformers",
"safetensors",
"llava_llama",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T14:08:17Z | ---
license: apache-2.0
---
|
selmamalak/organsmnist-swin-base-finetuned | selmamalak | 2024-05-18T14:12:24Z | 0 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"dataset:medmnist-v2",
"base_model:microsoft/swin-large-patch4-window7-224-in22k",
"base_model:adapter:microsoft/swin-large-patch4-window7-224-in22k",
"license:apache-2.0",
"region:us"
] | null | 2024-05-18T12:44:13Z | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: microsoft/swin-large-patch4-window7-224-in22k
datasets:
- medmnist-v2
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: organsmnist-swin-base-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# organsmnist-swin-base-finetuned
This model is a fine-tuned version of [microsoft/swin-large-patch4-window7-224-in22k](https://huggingface.co/microsoft/swin-large-patch4-window7-224-in22k) on the medmnist-v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4655
- Accuracy: 0.8230
- Precision: 0.7898
- Recall: 0.7786
- F1: 0.7831
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.005
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.918 | 1.0 | 218 | 0.4249 | 0.8356 | 0.8139 | 0.7795 | 0.7529 |
| 0.889 | 2.0 | 436 | 0.4593 | 0.8263 | 0.7916 | 0.7695 | 0.7668 |
| 0.8566 | 3.0 | 654 | 0.3293 | 0.8748 | 0.8505 | 0.8205 | 0.8088 |
| 0.7781 | 4.0 | 872 | 0.3455 | 0.8679 | 0.8313 | 0.8088 | 0.7921 |
| 0.7241 | 5.0 | 1090 | 0.3565 | 0.8691 | 0.8758 | 0.8110 | 0.7902 |
| 0.6568 | 6.0 | 1308 | 0.3337 | 0.8809 | 0.8458 | 0.8295 | 0.8081 |
| 0.5643 | 7.0 | 1526 | 0.2581 | 0.8972 | 0.8392 | 0.8377 | 0.8332 |
| 0.5834 | 8.0 | 1744 | 0.2706 | 0.8956 | 0.8402 | 0.8360 | 0.8319 |
| 0.4771 | 9.0 | 1962 | 0.2721 | 0.9001 | 0.8524 | 0.8445 | 0.8364 |
| 0.5102 | 10.0 | 2180 | 0.2898 | 0.9009 | 0.8460 | 0.8410 | 0.8407 |
### Framework versions
- PEFT 0.11.1
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2 |
rtx07/mental_health_40k | rtx07 | 2024-05-18T14:11:50Z | 89 | 0 | transformers | [
"transformers",
"gpt_neox",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T13:33:35Z | ---
license: apache-2.0
---
|
Dandan0K/Pilot_vox_Ref_italian | Dandan0K | 2024-05-18T14:07:44Z | 78 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"it",
"dataset:mozilla-foundation/common_voice_7_0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-18T14:00:14Z | ---
language:
- it
license: apache-2.0
tags:
- automatic-speech-recognition
- it
datasets:
- mozilla-foundation/common_voice_7_0
---
# exp_w2v2t_it_vp-100k_s449
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (it)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
alexandro767/stable-diffusion-v1-5-finetuned_5e_r8_v1 | alexandro767 | 2024-05-18T14:03:54Z | 29 | 0 | diffusers | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-18T14:00:56Z | ---
library_name: diffusers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
emilykang/Phi_medmcqa_question_generation-gynaecology_n_obstetrics_lora | emilykang | 2024-05-18T14:01:02Z | 1 | 0 | peft | [
"peft",
"safetensors",
"phi",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:microsoft/phi-2",
"base_model:adapter:microsoft/phi-2",
"license:mit",
"region:us"
] | null | 2024-05-17T16:40:38Z | ---
license: mit
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: microsoft/phi-2
datasets:
- generator
model-index:
- name: Phi_medmcqa_question_generation-gynaecology_n_obstetrics_lora
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Phi_medmcqa_question_generation-gynaecology_n_obstetrics_lora
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 10
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.1
- Pytorch 2.2.1+cu118
- Datasets 2.19.0
- Tokenizers 0.19.1 |
selmamalak/organcmnist-swin-base-finetuned | selmamalak | 2024-05-18T14:00:55Z | 8 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"dataset:medmnist-v2",
"base_model:microsoft/swin-large-patch4-window7-224-in22k",
"base_model:adapter:microsoft/swin-large-patch4-window7-224-in22k",
"license:apache-2.0",
"region:us"
] | null | 2024-05-18T13:03:26Z | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: microsoft/swin-large-patch4-window7-224-in22k
datasets:
- medmnist-v2
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: organcmnist-swin-base-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# organcmnist-swin-base-finetuned
This model is a fine-tuned version of [microsoft/swin-large-patch4-window7-224-in22k](https://huggingface.co/microsoft/swin-large-patch4-window7-224-in22k) on the medmnist-v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2582
- Accuracy: 0.9317
- Precision: 0.9295
- Recall: 0.9177
- F1: 0.9229
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.005
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:------:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.7563 | 0.9988 | 203 | 0.1859 | 0.9365 | 0.9432 | 0.9127 | 0.9201 |
| 0.6145 | 1.9975 | 406 | 0.1260 | 0.9640 | 0.9630 | 0.9608 | 0.9600 |
| 0.6476 | 2.9963 | 609 | 0.0926 | 0.9774 | 0.9715 | 0.9754 | 0.9723 |
| 0.5719 | 4.0 | 813 | 0.0912 | 0.9770 | 0.9749 | 0.9746 | 0.9740 |
| 0.5374 | 4.9988 | 1016 | 0.1281 | 0.9695 | 0.9730 | 0.9690 | 0.9699 |
| 0.5615 | 5.9975 | 1219 | 0.1088 | 0.9791 | 0.9839 | 0.9819 | 0.9825 |
| 0.4959 | 6.9963 | 1422 | 0.1134 | 0.9741 | 0.9812 | 0.9742 | 0.9768 |
| 0.425 | 8.0 | 1626 | 0.1016 | 0.9808 | 0.9816 | 0.9820 | 0.9815 |
| 0.3151 | 8.9988 | 1829 | 0.1368 | 0.9804 | 0.9843 | 0.9832 | 0.9834 |
| 0.3347 | 9.9877 | 2030 | 0.1156 | 0.9837 | 0.9853 | 0.9864 | 0.9856 |
### Framework versions
- PEFT 0.11.1
- Transformers 4.40.2
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1 |
stablediffusionapi/analog-madness-v70 | stablediffusionapi | 2024-05-18T13:59:25Z | 29 | 0 | diffusers | [
"diffusers",
"modelslab.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-18T13:57:23Z | ---
license: creativeml-openrail-m
tags:
- modelslab.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# Analog Madness v7.0 API Inference

## Get API Key
Get API key from [ModelsLab API](http://modelslab.com), No Payment needed.
Replace Key in below code, change **model_id** to "analog-madness-v70"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://docs.modelslab.com)
Try model for free: [Generate Images](https://modelslab.com/models/analog-madness-v70)
Model link: [View model](https://modelslab.com/models/analog-madness-v70)
View all models: [View Models](https://modelslab.com/models)
import requests
import json
url = "https://modelslab.com/api/v6/images/text2img"
payload = json.dumps({
"key": "your_api_key",
"model_id": "analog-madness-v70",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** |
Lena2024/CustomModel_disney_sentiment_3 | Lena2024 | 2024-05-18T13:59:06Z | 119 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-18T13:58:56Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
theosun/gemma-2b-it-sharegpt-full | theosun | 2024-05-18T13:58:13Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T13:49:16Z | ---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Ishu789/phi-therapist-chat-v1 | Ishu789 | 2024-05-18T13:58:04Z | 130 | 0 | transformers | [
"transformers",
"safetensors",
"phi",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T13:53:28Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
OsherElhadad/ppo-PandaReachJointsSparse-v3-500000 | OsherElhadad | 2024-05-18T13:58:00Z | 1 | 0 | stable-baselines3 | [
"stable-baselines3",
"PandaReachJointsSparse-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-18T13:54:47Z | ---
library_name: stable-baselines3
tags:
- PandaReachJointsSparse-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachJointsSparse-v3
type: PandaReachJointsSparse-v3
metrics:
- type: mean_reward
value: -1.30 +/- 1.00
name: mean_reward
verified: false
---
# **PPO** Agent playing **PandaReachJointsSparse-v3**
This is a trained model of a **PPO** agent playing **PandaReachJointsSparse-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
kanlo/videomae-base-finetuned-ucf101-subset | kanlo | 2024-05-18T13:55:18Z | 63 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"videomae",
"video-classification",
"generated_from_trainer",
"base_model:MCG-NJU/videomae-base",
"base_model:finetune:MCG-NJU/videomae-base",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | video-classification | 2024-05-17T18:46:13Z | ---
license: cc-by-nc-4.0
base_model: MCG-NJU/videomae-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: videomae-base-finetuned-ucf101-subset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-finetuned-ucf101-subset
This model is a fine-tuned version of [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5398
- Accuracy: 0.8194
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 148
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 2.1597 | 0.2568 | 38 | 1.8560 | 0.4857 |
| 0.9646 | 1.2568 | 76 | 1.0908 | 0.6286 |
| 0.4806 | 2.2568 | 114 | 0.5811 | 0.7857 |
| 0.3196 | 3.2297 | 148 | 0.4874 | 0.8286 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
PaulR79/mistral_finetuned_synthetic | PaulR79 | 2024-05-18T13:54:52Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-18T13:54:50Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
WbjuSrceu/model8blora | WbjuSrceu | 2024-05-18T13:52:54Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-18T13:52:08Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** WbjuSrceu
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
HariprasathSB/whispeeerrr | HariprasathSB | 2024-05-18T13:52:46Z | 87 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:HariprasathSB/whispeerr",
"base_model:finetune:HariprasathSB/whispeerr",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-18T13:26:38Z | ---
license: apache-2.0
base_model: HariprasathSB/whispeerr
tags:
- generated_from_trainer
model-index:
- name: whispeeerrr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whispeeerrr
This model is a fine-tuned version of [HariprasathSB/whispeerr](https://huggingface.co/HariprasathSB/whispeerr) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.003
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- training_steps: 100
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.41.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
WbjuSrceu/lorav2-lama8b-model | WbjuSrceu | 2024-05-18T13:51:58Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T13:42:37Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** WbjuSrceu
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
stablediffusionapi/absolutereality-v181 | stablediffusionapi | 2024-05-18T13:50:35Z | 241 | 2 | diffusers | [
"diffusers",
"modelslab.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-18T13:48:22Z | ---
license: creativeml-openrail-m
tags:
- modelslab.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# AbsoluteReality v1.8.1 API Inference

## Get API Key
Get API key from [ModelsLab API](http://modelslab.com), No Payment needed.
Replace Key in below code, change **model_id** to "absolutereality-v181"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://docs.modelslab.com)
Try model for free: [Generate Images](https://modelslab.com/models/absolutereality-v181)
Model link: [View model](https://modelslab.com/models/absolutereality-v181)
View all models: [View Models](https://modelslab.com/models)
import requests
import json
url = "https://modelslab.com/api/v6/images/text2img"
payload = json.dumps({
"key": "your_api_key",
"model_id": "absolutereality-v181",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** |
stablediffusionapi/cetus-mix-v4 | stablediffusionapi | 2024-05-18T13:47:33Z | 29 | 0 | diffusers | [
"diffusers",
"modelslab.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-18T13:45:38Z | ---
license: creativeml-openrail-m
tags:
- modelslab.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# Cetus-Mix v4 API Inference

## Get API Key
Get API key from [ModelsLab API](http://modelslab.com), No Payment needed.
Replace Key in below code, change **model_id** to "cetus-mix-v4"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://docs.modelslab.com)
Try model for free: [Generate Images](https://modelslab.com/models/cetus-mix-v4)
Model link: [View model](https://modelslab.com/models/cetus-mix-v4)
View all models: [View Models](https://modelslab.com/models)
import requests
import json
url = "https://modelslab.com/api/v6/images/text2img"
payload = json.dumps({
"key": "your_api_key",
"model_id": "cetus-mix-v4",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** |
carlesoctav/coba-pth-2 | carlesoctav | 2024-05-18T13:47:19Z | 37 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-18T13:38:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
stablediffusionapi/yesmix-v40 | stablediffusionapi | 2024-05-18T13:46:34Z | 29 | 1 | diffusers | [
"diffusers",
"modelslab.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-18T13:44:18Z | ---
license: creativeml-openrail-m
tags:
- modelslab.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# YesMix v4.0 API Inference

## Get API Key
Get API key from [ModelsLab API](http://modelslab.com), No Payment needed.
Replace Key in below code, change **model_id** to "yesmix-v40"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://docs.modelslab.com)
Try model for free: [Generate Images](https://modelslab.com/models/yesmix-v40)
Model link: [View model](https://modelslab.com/models/yesmix-v40)
View all models: [View Models](https://modelslab.com/models)
import requests
import json
url = "https://modelslab.com/api/v6/images/text2img"
payload = json.dumps({
"key": "your_api_key",
"model_id": "yesmix-v40",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** |
fzzhang/mistralv1_dora_r8_25e5_e05 | fzzhang | 2024-05-18T13:46:00Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
] | null | 2024-05-18T13:45:58Z | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: mistralai/Mistral-7B-v0.1
model-index:
- name: mistralv1_dora_r8_25e5_e05
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistralv1_dora_r8_25e5_e05
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.38.2
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2 |
basakdemirok/bert-base-turkish-cased-off_detect_v0_seed42 | basakdemirok | 2024-05-18T13:44:12Z | 62 | 0 | transformers | [
"transformers",
"tf",
"tensorboard",
"bert",
"text-classification",
"generated_from_keras_callback",
"base_model:dbmdz/bert-base-turkish-cased",
"base_model:finetune:dbmdz/bert-base-turkish-cased",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-18T13:26:10Z | ---
license: mit
base_model: dbmdz/bert-base-turkish-cased
tags:
- generated_from_keras_callback
model-index:
- name: basakdemirok/bert-base-turkish-cased-off_detect_v0_seed42
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# basakdemirok/bert-base-turkish-cased-off_detect_v0_seed42
This model is a fine-tuned version of [dbmdz/bert-base-turkish-cased](https://huggingface.co/dbmdz/bert-base-turkish-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0407
- Validation Loss: 0.4312
- Train F1: 0.7031
- Epoch: 3
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 7488, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train F1 | Epoch |
|:----------:|:---------------:|:--------:|:-----:|
| 0.3093 | 0.2640 | 0.6927 | 0 |
| 0.1910 | 0.2941 | 0.7072 | 1 |
| 0.0932 | 0.3690 | 0.6971 | 2 |
| 0.0407 | 0.4312 | 0.7031 | 3 |
### Framework versions
- Transformers 4.31.0
- TensorFlow 2.13.1
- Datasets 2.4.0
- Tokenizers 0.13.3
|
ATTIABATOOL/XRAY | ATTIABATOOL | 2024-05-18T13:42:38Z | 0 | 0 | null | [
"license:bigscience-openrail-m",
"region:us"
] | null | 2024-05-18T13:38:48Z | ---
license: bigscience-openrail-m
---
|
PaulR79/gemma_finetuned_synthetic | PaulR79 | 2024-05-18T13:37:50Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-18T13:37:42Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
bartowski/kunoichi-lemon-royale-v2-32K-7B-exl2 | bartowski | 2024-05-18T13:37:26Z | 0 | 0 | transformers | [
"transformers",
"mergekit",
"merge",
"text-generation",
"base_model:grimjim/Mistral-7B-Instruct-demi-merge-v0.2-7B",
"base_model:merge:grimjim/Mistral-7B-Instruct-demi-merge-v0.2-7B",
"base_model:grimjim/kunoichi-lemon-royale-7B",
"base_model:merge:grimjim/kunoichi-lemon-royale-7B",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T13:37:25Z | ---
base_model:
- grimjim/Mistral-7B-Instruct-demi-merge-v0.2-7B
- grimjim/kunoichi-lemon-royale-7B
library_name: transformers
tags:
- mergekit
- merge
license: cc-by-nc-4.0
pipeline_tag: text-generation
quantized_by: bartowski
---
## Exllama v2 Quantizations of kunoichi-lemon-royale-v2-32K-7B
Using <a href="https://github.com/turboderp/exllamav2/releases/tag/v0.0.21">turboderp's ExLlamaV2 v0.0.21</a> for quantization.
<b>The "main" branch only contains the measurement.json, download one of the other branches for the model (see below)</b>
Each branch contains an individual bits per weight, with the main one containing only the meaurement.json for further conversions.
Original model: https://huggingface.co/grimjim/kunoichi-lemon-royale-v2-32K-7B
## Prompt format
```
<s> [INST] {prompt} [/INST]</s>
```
Note that this model does not support a System prompt.
## Available sizes
| Branch | Bits | lm_head bits | VRAM (4k) | VRAM (16k) | VRAM (32k) | Description |
| ----- | ---- | ------- | ------ | ------ | ------ | ------------ |
| [8_0](https://huggingface.co/bartowski/kunoichi-lemon-royale-v2-32K-7B-exl2/tree/8_0) | 8.0 | 8.0 | 8.4 GB | 9.8 GB | 11.8 GB | Maximum quality that ExLlamaV2 can produce, near unquantized performance. |
| [6_5](https://huggingface.co/bartowski/kunoichi-lemon-royale-v2-32K-7B-exl2/tree/6_5) | 6.5 | 8.0 | 7.2 GB | 8.6 GB | 10.6 GB | Very similar to 8.0, good tradeoff of size vs performance, **recommended**. |
| [5_0](https://huggingface.co/bartowski/kunoichi-lemon-royale-v2-32K-7B-exl2/tree/5_0) | 5.0 | 6.0 | 6.0 GB | 7.4 GB | 9.4 GB | Slightly lower quality vs 6.5, but usable on 8GB cards. |
| [4_25](https://huggingface.co/bartowski/kunoichi-lemon-royale-v2-32K-7B-exl2/tree/4_25) | 4.25 | 6.0 | 5.3 GB | 6.7 GB | 8.7 GB | GPTQ equivalent bits per weight, slightly higher quality. |
| [3_5](https://huggingface.co/bartowski/kunoichi-lemon-royale-v2-32K-7B-exl2/tree/3_5) | 3.5 | 6.0 | 4.7 GB | 6.1 GB | 8.1 GB | Lower quality, only use if you have to. |
## Download instructions
With git:
```shell
git clone --single-branch --branch 6_5 https://huggingface.co/bartowski/kunoichi-lemon-royale-v2-32K-7B-exl2 kunoichi-lemon-royale-v2-32K-7B-exl2-6_5
```
With huggingface hub (credit to TheBloke for instructions):
```shell
pip3 install huggingface-hub
```
To download a specific branch, use the `--revision` parameter. For example, to download the 6.5 bpw branch:
Linux:
```shell
huggingface-cli download bartowski/kunoichi-lemon-royale-v2-32K-7B-exl2 --revision 6_5 --local-dir kunoichi-lemon-royale-v2-32K-7B-exl2-6_5 --local-dir-use-symlinks False
```
Windows (which apparently doesn't like _ in folders sometimes?):
```shell
huggingface-cli download bartowski/kunoichi-lemon-royale-v2-32K-7B-exl2 --revision 6_5 --local-dir kunoichi-lemon-royale-v2-32K-7B-exl2-6.5 --local-dir-use-symlinks False
```
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski |
stablediffusionapi/epicphotogasm-ultimate-fi | stablediffusionapi | 2024-05-18T13:36:58Z | 29 | 0 | diffusers | [
"diffusers",
"modelslab.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-18T13:34:41Z | ---
license: creativeml-openrail-m
tags:
- modelslab.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# epiCPhotoGasm Ultimate Fidelity API Inference

## Get API Key
Get API key from [ModelsLab API](http://modelslab.com), No Payment needed.
Replace Key in below code, change **model_id** to "epicphotogasm-ultimate-fi"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://docs.modelslab.com)
Try model for free: [Generate Images](https://modelslab.com/models/epicphotogasm-ultimate-fi)
Model link: [View model](https://modelslab.com/models/epicphotogasm-ultimate-fi)
View all models: [View Models](https://modelslab.com/models)
import requests
import json
url = "https://modelslab.com/api/v6/images/text2img"
payload = json.dumps({
"key": "your_api_key",
"model_id": "epicphotogasm-ultimate-fi",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** |
AliSaadatV/virus_pythia_14_1024_2d_representation | AliSaadatV | 2024-05-18T13:33:27Z | 129 | 0 | transformers | [
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"base_model:EleutherAI/pythia-14m",
"base_model:finetune:EleutherAI/pythia-14m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T12:50:03Z | ---
base_model: EleutherAI/pythia-14m
tags:
- generated_from_trainer
model-index:
- name: virus_pythia_14_1024_2d_representation
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# virus_pythia_14_1024_2d_representation
This model is a fine-tuned version of [EleutherAI/pythia-14m](https://huggingface.co/EleutherAI/pythia-14m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.40.2
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
selmamalak/organsmnist-vit-base-finetuned | selmamalak | 2024-05-18T13:28:53Z | 1 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"dataset:medmnist-v2",
"base_model:facebook/deit-base-patch16-224",
"base_model:adapter:facebook/deit-base-patch16-224",
"license:apache-2.0",
"region:us"
] | null | 2024-05-18T12:24:41Z | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: facebook/deit-base-patch16-224
datasets:
- medmnist-v2
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: organsmnist-vit-base-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# organsmnist-vit-base-finetuned
This model is a fine-tuned version of [facebook/deit-base-patch16-224](https://huggingface.co/facebook/deit-base-patch16-224) on the medmnist-v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2964
- Accuracy: 0.8993
- Precision: 0.8443
- Recall: 0.8396
- F1: 0.8394
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.005
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.9084 | 1.0 | 218 | 0.7151 | 0.7288 | 0.6998 | 0.6620 | 0.6412 |
| 0.89 | 2.0 | 436 | 0.3658 | 0.8540 | 0.7873 | 0.7898 | 0.7660 |
| 0.7851 | 3.0 | 654 | 0.3514 | 0.8438 | 0.8110 | 0.7674 | 0.7741 |
| 0.7144 | 4.0 | 872 | 0.3632 | 0.8670 | 0.8415 | 0.8133 | 0.7980 |
| 0.7383 | 5.0 | 1090 | 0.3680 | 0.8581 | 0.7769 | 0.8029 | 0.7786 |
| 0.6065 | 6.0 | 1308 | 0.2824 | 0.8870 | 0.8481 | 0.8328 | 0.8305 |
| 0.521 | 7.0 | 1526 | 0.2769 | 0.8940 | 0.8439 | 0.8404 | 0.8297 |
| 0.5305 | 8.0 | 1744 | 0.2611 | 0.9001 | 0.8517 | 0.8463 | 0.8447 |
| 0.4522 | 9.0 | 1962 | 0.2742 | 0.9058 | 0.8594 | 0.8517 | 0.8411 |
| 0.4445 | 10.0 | 2180 | 0.2964 | 0.8993 | 0.8443 | 0.8396 | 0.8394 |
### Framework versions
- PEFT 0.11.1
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2 |
Mitrofazotron/mistral_10k_snli_gpt | Mitrofazotron | 2024-05-18T13:28:32Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-18T13:28:23Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
thienann/results-news-dataset | thienann | 2024-05-18T13:27:58Z | 106 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"base_model:PoseyATX/GPTxLege_FoxHunter",
"base_model:finetune:PoseyATX/GPTxLege_FoxHunter",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-05-18T12:29:59Z | ---
base_model: PoseyATX/GPTxLege_FoxHunter
tags:
- generated_from_trainer
model-index:
- name: results-news-dataset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results-news-dataset
This model is a fine-tuned version of [PoseyATX/GPTxLege_FoxHunter](https://huggingface.co/PoseyATX/GPTxLege_FoxHunter) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 9.4768
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 10.4458 | 1.0 | 791 | 9.6071 |
| 9.805 | 2.0 | 1582 | 9.4768 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
carlesoctav/coba-pth | carlesoctav | 2024-05-18T13:27:43Z | 40 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-18T13:27:30Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
selmamalak/organsmnist-deit-base-finetuned | selmamalak | 2024-05-18T13:24:31Z | 1 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"dataset:medmnist-v2",
"base_model:facebook/deit-base-patch16-224",
"base_model:adapter:facebook/deit-base-patch16-224",
"license:apache-2.0",
"region:us"
] | null | 2024-05-18T12:31:56Z | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: facebook/deit-base-patch16-224
datasets:
- medmnist-v2
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: organsmnist-deit-base-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# organsmnist-deit-base-finetuned
This model is a fine-tuned version of [facebook/deit-base-patch16-224](https://huggingface.co/facebook/deit-base-patch16-224) on the medmnist-v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4815
- Accuracy: 0.8080
- Precision: 0.7703
- Recall: 0.7686
- F1: 0.7650
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.005
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.9804 | 1.0 | 218 | 0.6885 | 0.7243 | 0.7883 | 0.6661 | 0.6426 |
| 0.9277 | 2.0 | 436 | 0.3513 | 0.8503 | 0.7635 | 0.7943 | 0.7680 |
| 0.8144 | 3.0 | 654 | 0.3614 | 0.8544 | 0.8331 | 0.7961 | 0.7909 |
| 0.7344 | 4.0 | 872 | 0.3371 | 0.8609 | 0.8327 | 0.8018 | 0.7886 |
| 0.7181 | 5.0 | 1090 | 0.2934 | 0.8923 | 0.8060 | 0.8389 | 0.8096 |
| 0.5857 | 6.0 | 1308 | 0.2927 | 0.8858 | 0.8493 | 0.8358 | 0.8315 |
| 0.5607 | 7.0 | 1526 | 0.2209 | 0.9062 | 0.8658 | 0.8547 | 0.8416 |
| 0.5423 | 8.0 | 1744 | 0.2513 | 0.9025 | 0.8545 | 0.8470 | 0.8487 |
| 0.4053 | 9.0 | 1962 | 0.2561 | 0.9038 | 0.8543 | 0.8457 | 0.8373 |
| 0.4417 | 10.0 | 2180 | 0.2558 | 0.8997 | 0.8463 | 0.8395 | 0.8416 |
### Framework versions
- PEFT 0.11.1
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2 |
HariprasathSB/whispeerr | HariprasathSB | 2024-05-18T13:22:33Z | 94 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:HariprasathSB/whispeer",
"base_model:finetune:HariprasathSB/whispeer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-18T13:06:48Z | ---
license: apache-2.0
base_model: HariprasathSB/whispeer
tags:
- generated_from_trainer
model-index:
- name: whispeerr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whispeerr
This model is a fine-tuned version of [HariprasathSB/whispeer](https://huggingface.co/HariprasathSB/whispeer) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.003
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- training_steps: 100
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.41.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
Edgar404/a2c-PandaReachDense-v3 | Edgar404 | 2024-05-18T13:09:40Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-18T13:05:12Z | ---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.33 +/- 0.08
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
basakdemirok/bert-base-turkish-cased-off_detect_v03_seed42 | basakdemirok | 2024-05-18T13:09:27Z | 62 | 0 | transformers | [
"transformers",
"tf",
"tensorboard",
"bert",
"text-classification",
"generated_from_keras_callback",
"base_model:dbmdz/bert-base-turkish-cased",
"base_model:finetune:dbmdz/bert-base-turkish-cased",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-18T12:37:49Z | ---
license: mit
base_model: dbmdz/bert-base-turkish-cased
tags:
- generated_from_keras_callback
model-index:
- name: basakdemirok/bert-base-turkish-cased-off_detect_v03_seed42
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# basakdemirok/bert-base-turkish-cased-off_detect_v03_seed42
This model is a fine-tuned version of [dbmdz/bert-base-turkish-cased](https://huggingface.co/dbmdz/bert-base-turkish-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0094
- Validation Loss: 0.6556
- Train F1: 0.7023
- Epoch: 3
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 14988, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train F1 | Epoch |
|:----------:|:---------------:|:--------:|:-----:|
| 0.2628 | 0.2933 | 0.6989 | 0 |
| 0.0985 | 0.4294 | 0.6954 | 1 |
| 0.0247 | 0.5613 | 0.6909 | 2 |
| 0.0094 | 0.6556 | 0.7023 | 3 |
### Framework versions
- Transformers 4.31.0
- TensorFlow 2.13.1
- Datasets 2.4.0
- Tokenizers 0.13.3
|
HariprasathSB/whispeer | HariprasathSB | 2024-05-18T13:02:16Z | 94 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:vasista22/whisper-tamil-medium",
"base_model:finetune:vasista22/whisper-tamil-medium",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-18T12:47:54Z | ---
license: apache-2.0
base_model: vasista22/whisper-tamil-medium
tags:
- generated_from_trainer
model-index:
- name: whispeer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whispeer
This model is a fine-tuned version of [vasista22/whisper-tamil-medium](https://huggingface.co/vasista22/whisper-tamil-medium) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.003
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- training_steps: 100
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.41.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
piika919/phi_bnb | piika919 | 2024-05-18T12:54:49Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-18T12:51:32Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ChiJuiChen/lab9_whisper-tiny-zh-tw | ChiJuiChen | 2024-05-18T12:53:39Z | 78 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice_13_0",
"base_model:Wellyowo/whisper-tiny-zh-tw",
"base_model:finetune:Wellyowo/whisper-tiny-zh-tw",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-09T07:22:56Z | ---
license: apache-2.0
base_model: Wellyowo/whisper-tiny-zh-tw
tags:
- generated_from_trainer
datasets:
- common_voice_13_0
metrics:
- wer
model-index:
- name: lab9_whisper-tiny-zh-tw
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_13_0
type: common_voice_13_0
config: zh-TW
split: test
args: zh-TW
metrics:
- name: Wer
type: wer
value: 62.13592233009708
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lab9_whisper-tiny-zh-tw
This model is a fine-tuned version of [Wellyowo/whisper-tiny-zh-tw](https://huggingface.co/Wellyowo/whisper-tiny-zh-tw) on the common_voice_13_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6336
- Wer Ortho: 64.0
- Wer: 62.1359
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:------:|:----:|:---------------:|:---------:|:-------:|
| 0.0088 | 0.6882 | 500 | 0.5502 | 60.0 | 61.1650 |
| 0.0051 | 1.3765 | 1000 | 0.5735 | 65.0 | 64.0777 |
| 0.0068 | 2.0647 | 1500 | 0.5820 | 63.0 | 63.1068 |
| 0.0021 | 2.7529 | 2000 | 0.5955 | 62.0 | 61.1650 |
| 0.0039 | 3.4412 | 2500 | 0.5858 | 62.0 | 61.1650 |
| 0.0018 | 4.1294 | 3000 | 0.5981 | 63.0 | 61.1650 |
| 0.0019 | 4.8176 | 3500 | 0.6322 | 63.0 | 61.1650 |
| 0.0102 | 5.5058 | 4000 | 0.6336 | 64.0 | 62.1359 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.0+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
OwOpeepeepoopoo/NoSoup4U_1 | OwOpeepeepoopoo | 2024-05-18T12:52:38Z | 93 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-17T23:21:57Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
chen1212/Models-RoBERTa-1716033686.153194 | chen1212 | 2024-05-18T12:52:36Z | 108 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-18T12:05:43Z | ---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: Models-RoBERTa-1716033686.153194
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Models-RoBERTa-1716033686.153194
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3683
- Accuracy: 0.888
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.8 | 500 | 0.3078 | 0.875 |
| No log | 1.6 | 1000 | 0.3683 | 0.888 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
nvdenisov2002/llama-longLoRA-v5-8k-all-samples-3-epochs | nvdenisov2002 | 2024-05-18T12:50:41Z | 0 | 0 | peft | [
"peft",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2024-05-18T12:50:17Z | ---
library_name: peft
base_model: meta-llama/Llama-2-7b-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 |
emilykang/Phi_medmcqa_question_generation-social_n_preventive_medicine_lora | emilykang | 2024-05-18T12:46:58Z | 0 | 0 | peft | [
"peft",
"safetensors",
"phi",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:microsoft/phi-2",
"base_model:adapter:microsoft/phi-2",
"license:mit",
"region:us"
] | null | 2024-05-17T15:31:33Z | ---
license: mit
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: microsoft/phi-2
datasets:
- generator
model-index:
- name: Phi_medmcqa_question_generation-social_n_preventive_medicine_lora
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Phi_medmcqa_question_generation-social_n_preventive_medicine_lora
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 10
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.1
- Pytorch 2.2.1+cu118
- Datasets 2.19.0
- Tokenizers 0.19.1 |
presencesw/mt5-base-snli_neutral-triplet | presencesw | 2024-05-18T12:43:05Z | 50 | 0 | transformers | [
"transformers",
"safetensors",
"mt5",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-18T12:42:05Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
RichardErkhov/beomi_-_gemma-mling-7b-4bits | RichardErkhov | 2024-05-18T12:42:03Z | 78 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-18T12:37:41Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
gemma-mling-7b - bnb 4bits
- Model creator: https://huggingface.co/beomi/
- Original model: https://huggingface.co/beomi/gemma-mling-7b/
Original model description:
---
language:
- ko
- en
- zh
- ja
license: other
library_name: transformers
license_name: gemma-terms-of-use
license_link: https://ai.google.dev/gemma/terms
pipeline_tag: text-generation
tags:
- pytorch
---
# Gemma-Mling: Multilingual Gemma
> Update @ 2024.04.15: First release of Gemma-Mling 7B model
**Original Gemma Model Page**: [Gemma](https://ai.google.dev/gemma/docs)
This model card corresponds to the 7B base version of the **Gemma-Mling** model,
continual pretrained on mainly Korean/English/Chinese/Japanese + 500 multilingual corpus.
**Resources and Technical Documentation**:
* [Original Google's Gemma-7B](https://huggingface.co/google/gemma-7b)
* [Training Code @ Github: Gemma-EasyLM](https://github.com/Beomi/Gemma-EasyLM)
**Terms of Use**: [Terms](https://www.kaggle.com/models/google/gemma/license/consent)
**Citation**
```bibtex
@misc {gemma_mling_7b,
author = { {Junbum Lee, Taekyoon Choi} },
title = { gemma-mling-7b },
year = 2024,
url = { https://huggingface.co/beomi/gemma-mling-7b },
publisher = { Hugging Face }
}
```
**Model Developers**: Junbum Lee (Beomi) & Taekyoon Choi (Taekyoon)
## Model Information
### Usage
Below we share some code snippets on how to get quickly started with running the model. First make sure to `pip install -U transformers`, then copy the snippet from the section that is relevant for your usecase.
#### Running the model on a CPU
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("beomi/gemma-mling-7b")
model = AutoModelForCausalLM.from_pretrained("beomi/gemma-mling-7b")
input_text = "머신러닝과 딥러닝의 차이는"
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
#### Running the model on a single / multi GPU
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("beomi/gemma-mling-7b")
model = AutoModelForCausalLM.from_pretrained("beomi/gemma-mling-7b", device_map="auto")
input_text = "머신러닝과 딥러닝의 차이는"
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
### Inputs and outputs
* **Input:** Text string, such as a question, a prompt, or a document to be
summarized.
* **Output:** Generated Multilingual-language text in response to the input, such
as an answer to a question, or a summary of a document.
## Implementation Information
Details about the model internals.
### Software
Training was done using [beomi/Gemma-EasyLM](https://github.com/Beomi/Gemma-EasyLM).
### Dataset
We trained a mixture of multiple language datasets and trained until 100B.
The released model is the best performance model based on our Evaluation below from model checkpoints.
For Korean and English datasets, we utilized sampled llama2ko training dataset which combined 1:1 ratio in each language.
| Dataset | Jsonl (GB) | Sampled |
|--------------------------|------------|---------|
| range3/cc100-ja | 96.39 | No |
| Skywork/SkyPile-150B | 100.57 | Yes |
| llama2ko dataset (ko/en) | 108.5 | Yes |
| cis-lmu/Glot500 | 181.24 | No |
| Total | 486.7 | . |
## Training Progress
- Report Link: https://api.wandb.ai/links/tgchoi/6lt0ce3s
## Evaluation
Model evaluation metrics and results.
### Evaluation Scripts
- For Knowledge / KoBest / XCOPA / XWinograd
- [EleutherAI/lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) v0.4.2
```bash
!git clone https://github.com/EleutherAI/lm-evaluation-harness.git
!cd lm-evaluation-harness && pip install -r requirements.txt && pip install -e .
!lm_eval --model hf \
--model_args pretrained=beomi/gemma-mling-7b,dtype="float16" \
--tasks "haerae,kobest,kmmlu_direct,cmmlu,ceval-valid,mmlu,xwinograd,xcopa \
--num_fewshot "0,5,5,5,5,5,0,5" \
--device cuda
```
- For JP Eval Harness
- [Stability-AI/lm-evaluation-harness (`jp-stable` branch)](https://github.com/Stability-AI/lm-evaluation-harness/tree/jp-stable)
```bash
!git clone -b jp-stable https://github.com/Stability-AI/lm-evaluation-harness.git
!cd lm-evaluation-harness && pip install -e ".[ja]"
!pip install 'fugashi[unidic]' && python -m unidic download
!cd lm-evaluation-harness && python main.py \
--model hf-causal \
--model_args pretrained=beomi/gemma-mling-7b,torch_dtype='auto'"
--tasks "jcommonsenseqa-1.1-0.3,jnli-1.3-0.3,marc_ja-1.1-0.3,jsquad-1.1-0.3,jaqket_v2-0.2-0.3,xlsum_ja,mgsm"
--num_fewshot "3,3,3,2,1,1,5"
```
### Benchmark Results
| Category | Metric | Shots | Score |
|----------------------------------|----------------------|------------|--------|
| **Default Metric** | **ACC** | | |
| **Knowledge (5-shot)** | MMLU | | 61.76 |
| | KMMLU (Exact Match) | | 42.75 |
| | CMLU | | 50.93 |
| | JMLU | | |
| | C-EVAL | | 50.07 |
| | HAERAE | 0-shot | 63.89 |
| **KoBest (5-shot)** | BoolQ | | 85.47 |
| | COPA | | 83.5 |
| | Hellaswag (acc-norm) | | 63.2 |
| | Sentineg | | 97.98 |
| | WiC | | 70.95 |
| **XCOPA (5-shot)** | IT | | 72.8 |
| | ID | | 76.4 |
| | TH | | 60.2 |
| | TR | | 65.6 |
| | VI | | 77.2 |
| | ZH | | 80.2 |
| **JP Eval Harness (Prompt ver 0.3)** | JcommonsenseQA | 3-shot | 85.97 |
| | JNLI | 3-shot | 39.11 |
| | Marc_ja | 3-shot | 96.48 |
| | JSquad (Exact Match) | 2-shot | 70.69 |
| | Jaqket (Exact Match) | 1-shot | 81.53 |
| | MGSM | 5-shot | 28.8 |
| **XWinograd (0-shot)** | EN | | 89.03 |
| | FR | | 72.29 |
| | JP | | 82.69 |
| | PT | | 73.38 |
| | RU | | 68.57 |
| | ZH | | 79.17 |
## Usage and Limitations
These models have certain limitations that users should be aware of.
### Intended Usage
Open Large Language Models (LLMs) have a wide range of applications across
various industries and domains. The following list of potential uses is not
comprehensive. The purpose of this list is to provide contextual information
about the possible use-cases that the model creators considered as part of model
training and development.
* Content Creation and Communication
* Text Generation: These models can be used to generate creative text formats
such as poems, scripts, code, marketing copy, and email drafts.
* Research and Education
* Natural Language Processing (NLP) Research: These models can serve as a
foundation for researchers to experiment with NLP techniques, develop
algorithms, and contribute to the advancement of the field.
* Language Learning Tools: Support interactive language learning experiences,
aiding in grammar correction or providing writing practice.
* Knowledge Exploration: Assist researchers in exploring large bodies of text
by generating summaries or answering questions about specific topics.
### Limitations
* Training Data
* The quality and diversity of the training data significantly influence the
model's capabilities. Biases or gaps in the training data can lead to
limitations in the model's responses.
* The scope of the training dataset determines the subject areas the model can
handle effectively.
* Context and Task Complexity
* LLMs are better at tasks that can be framed with clear prompts and
instructions. Open-ended or highly complex tasks might be challenging.
* A model's performance can be influenced by the amount of context provided
(longer context generally leads to better outputs, up to a certain point).
* Language Ambiguity and Nuance
* Natural language is inherently complex. LLMs might struggle to grasp subtle
nuances, sarcasm, or figurative language.
* Factual Accuracy
* LLMs generate responses based on information they learned from their
training datasets, but they are not knowledge bases. They may generate
incorrect or outdated factual statements.
* Common Sense
* LLMs rely on statistical patterns in language. They might lack the ability
to apply common sense reasoning in certain situations.
### Ethical Considerations and Risks
The development of large language models (LLMs) raises several ethical concerns.
In creating an open model, we have carefully considered the following:
* Bias and Fairness
* LLMs trained on large-scale, real-world text data can reflect socio-cultural
biases embedded in the training material. These models underwent careful
scrutiny, input data pre-processing described and posterior evaluations
reported in this card.
* Misinformation and Misuse
* LLMs can be misused to generate text that is false, misleading, or harmful.
* Guidelines are provided for responsible use with the model, see the
[Responsible Generative AI Toolkit](http://ai.google.dev/gemma/responsible).
* Transparency and Accountability:
* This model card summarizes details on the models' architecture,
capabilities, limitations, and evaluation processes.
* A responsibly developed open model offers the opportunity to share
innovation by making LLM technology accessible to developers and researchers
across the AI ecosystem.
Risks identified and mitigations:
* Perpetuation of biases: It's encouraged to perform continuous monitoring
(using evaluation metrics, human review) and the exploration of de-biasing
techniques during model training, fine-tuning, and other use cases.
* Generation of harmful content: Mechanisms and guidelines for content safety
are essential. Developers are encouraged to exercise caution and implement
appropriate content safety safeguards based on their specific product policies
and application use cases.
* Misuse for malicious purposes: Technical limitations and developer and
end-user education can help mitigate against malicious applications of LLMs.
Educational resources and reporting mechanisms for users to flag misuse are
provided. Prohibited uses of Gemma models are outlined in the
[Gemma Prohibited Use Policy](https://ai.google.dev/gemma/prohibited_use_policy).
* Privacy violations: Models were trained on data filtered for removal of PII
(Personally Identifiable Information). Developers are encouraged to adhere to
privacy regulations with privacy-preserving techniques.
## Acknowledgement
The training is supported by [TPU Research Cloud](https://sites.research.google/trc/) program.
|
theosun/gemma-2b-it-sharegpt | theosun | 2024-05-18T12:38:32Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-18T09:38:43Z | ---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf | RichardErkhov | 2024-05-18T12:33:06Z | 32 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-18T01:49:29Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Mixtral-8x7B-MoE-RP-Story - GGUF
- Model creator: https://huggingface.co/Undi95/
- Original model: https://huggingface.co/Undi95/Mixtral-8x7B-MoE-RP-Story/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Mixtral-8x7B-MoE-RP-Story.Q2_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q2_K.gguf) | Q2_K | 16.12GB |
| [Mixtral-8x7B-MoE-RP-Story.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.IQ3_XS.gguf) | IQ3_XS | 18.02GB |
| [Mixtral-8x7B-MoE-RP-Story.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.IQ3_S.gguf) | IQ3_S | 19.03GB |
| [Mixtral-8x7B-MoE-RP-Story.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q3_K_S.gguf) | Q3_K_S | 19.03GB |
| [Mixtral-8x7B-MoE-RP-Story.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.IQ3_M.gguf) | IQ3_M | 19.96GB |
| [Mixtral-8x7B-MoE-RP-Story.Q3_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q3_K.gguf) | Q3_K | 21.0GB |
| [Mixtral-8x7B-MoE-RP-Story.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q3_K_M.gguf) | Q3_K_M | 21.0GB |
| [Mixtral-8x7B-MoE-RP-Story.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q3_K_L.gguf) | Q3_K_L | 22.51GB |
| [Mixtral-8x7B-MoE-RP-Story.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.IQ4_XS.gguf) | IQ4_XS | 23.63GB |
| [Mixtral-8x7B-MoE-RP-Story.Q4_0.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q4_0.gguf) | Q4_0 | 24.63GB |
| [Mixtral-8x7B-MoE-RP-Story.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.IQ4_NL.gguf) | IQ4_NL | 24.91GB |
| [Mixtral-8x7B-MoE-RP-Story.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q4_K_S.gguf) | Q4_K_S | 24.91GB |
| [Mixtral-8x7B-MoE-RP-Story.Q4_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q4_K.gguf) | Q4_K | 26.49GB |
| [Mixtral-8x7B-MoE-RP-Story.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q4_K_M.gguf) | Q4_K_M | 26.49GB |
| [Mixtral-8x7B-MoE-RP-Story.Q4_1.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q4_1.gguf) | Q4_1 | 27.32GB |
| [Mixtral-8x7B-MoE-RP-Story.Q5_0.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q5_0.gguf) | Q5_0 | 30.02GB |
| [Mixtral-8x7B-MoE-RP-Story.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q5_K_S.gguf) | Q5_K_S | 30.02GB |
| [Mixtral-8x7B-MoE-RP-Story.Q5_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q5_K.gguf) | Q5_K | 30.95GB |
| [Mixtral-8x7B-MoE-RP-Story.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q5_K_M.gguf) | Q5_K_M | 30.95GB |
| [Mixtral-8x7B-MoE-RP-Story.Q5_1.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q5_1.gguf) | Q5_1 | 32.71GB |
| [Mixtral-8x7B-MoE-RP-Story.Q6_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/blob/main/Mixtral-8x7B-MoE-RP-Story.Q6_K.gguf) | Q6_K | 35.74GB |
| [Mixtral-8x7B-MoE-RP-Story.Q8_0.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Mixtral-8x7B-MoE-RP-Story-gguf/tree/main/) | Q8_0 | 46.22GB |
Original model description:
---
license: cc-by-nc-4.0
tags:
- not-for-all-audiences
- nsfw
---
Mixtral-8x7B-MoE-RP-Story is a model made primarely for chatting, RP (Roleplay) and storywriting.
2 RP model, 2 chat model, 1 occult model, 1 storywritting model, 1 mathematic model and 1 DPO model was used for a MoE. Bagel was the base.
The DPO chat model is here to help get more human reply.
This is my first try at doing this, so don't hesitate to give feedback!
WARNING: ALL THE "K" GGUF QUANT OF MIXTRAL MODELS SEEMS TO BE [BROKEN](https://cdn-uploads.huggingface.co/production/uploads/63ab1241ad514ca8d1430003/TvjEP14ps7ZUgJ-0-mhIX.png), PREFER Q4_0, Q5_0 or Q8_0!
<!-- description start -->
## Description
This repo contains fp16 files of Mixtral-8x7B-MoE-RP-Story.
<!-- description end -->
<!-- description start -->
## Models used
The list of model used and their activator/theme can be found [here](https://huggingface.co/Undi95/Mixtral-8x7B-MoE-RP-Story/blob/main/config.yaml)
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Custom
Using Bagel as a base let us a lot of different prompting system theorically, you can see all the prompting available [here](https://huggingface.co/jondurbin/bagel-7b-v0.1#prompt-formatting).
If you want to support me, you can [here](https://ko-fi.com/undiai).
|
Angy309/noti | Angy309 | 2024-05-18T12:29:51Z | 110 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:dccuchile/bert-base-spanish-wwm-cased",
"base_model:finetune:dccuchile/bert-base-spanish-wwm-cased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-18T11:18:41Z | ---
tags:
- generated_from_trainer
base_model: dccuchile/bert-base-spanish-wwm-cased
metrics:
- accuracy
model-index:
- name: noti
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# noti
This model is a fine-tuned version of [dccuchile/bert-base-spanish-wwm-cased](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3911
- Accuracy: 0.5
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.5517 | 0.5 | 5 | 1.5409 | 0.25 |
| 1.5245 | 1.0 | 10 | 1.3911 | 0.5 |
### Framework versions
- Transformers 4.40.2
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
alexandro767/stable-diffusion-v1-5-finetuned_5e_r2_v1 | alexandro767 | 2024-05-18T12:29:08Z | 29 | 0 | diffusers | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-18T12:26:20Z | ---
library_name: diffusers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ruslandev/llama-3-70b-tagengo-GGUF | ruslandev | 2024-05-18T12:20:03Z | 33 | 0 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"dataset:lightblue/tagengo-gpt4",
"base_model:unsloth/llama-3-70b-bnb-4bit",
"base_model:quantized:unsloth/llama-3-70b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-17T06:42:40Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-70b-bnb-4bit
datasets:
- lightblue/tagengo-gpt4
---
# Uploaded model
- **Developed by:** ruslandev
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-70b-bnb-4bit
This model is finetuned on the Tagengo dataset.
Please note - this model has been created for educational purposes and it needs further training/fine tuning.
# How to use
The easiest way to use this model on your own computer is to use the GGUF version of this model ([ruslandev/llama-3-70b-tagengo-GGUF](https://huggingface.co/ruslandev/llama-3-70b-tagengo-GGUF)) using a program such as [llama.cpp](https://github.com/ggerganov/llama.cpp).
If you want to use this model directly with the Huggingface Transformers stack, I recommend using my framework [gptchain](https://github.com/RuslanPeresy/gptchain).
```
git clone https://github.com/RuslanPeresy/gptchain.git
cd gptchain
pip install -r requirements-train.txt
python gptchain.py chat -m ruslandev/llama-3-70b-tagengo \
--chatml true \
-q '[{"from": "human", "value": "Из чего состоит нейронная сеть?"}]'
```
# Training
[gptchain](https://github.com/RuslanPeresy/gptchain) framework has been used for training.
```
python gptchain.py train -m unsloth/llama-3-70b-bnb-4bit \
-dn tagengo_gpt4 \
-sp checkpoints/llama-3-70b-tagengo \
-hf llama-3-70b-tagengo \
--max-steps 2400
```
# Training hyperparameters
- learning_rate: 2e-4
- seed: 3407
- gradient_accumulation_steps: 4
- per_device_train_batch_size: 2
- optimizer: adamw_8bit
- lr_scheduler_type: linear
- warmup_steps: 5
- max_steps: 2400
- weight_decay: 0.01
# Training results
[wandb report](https://api.wandb.ai/links/ruslandev/rilj60ra)
2400 steps took 7 hours on a single H100
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth) |
fzzhang/mistralv1_lora_r4_25e5_e05 | fzzhang | 2024-05-18T12:18:51Z | 2 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
] | null | 2024-05-18T12:18:49Z | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: mistralai/Mistral-7B-v0.1
model-index:
- name: mistralv1_lora_r4_25e5_e05
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistralv1_lora_r4_25e5_e05
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.38.2
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2 |
tinyllava/TinyLLaVA-Gemma-SigLIP-2.4B | tinyllava | 2024-05-18T12:15:22Z | 140 | 1 | transformers | [
"transformers",
"safetensors",
"tinyllava",
"text-generation",
"image-text-to-text",
"conversational",
"custom_code",
"arxiv:2402.14289",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | image-text-to-text | 2024-05-16T08:35:45Z | ---
license: apache-2.0
pipeline_tag: image-text-to-text
---
**<center><span style="font-size:2em;">TinyLLaVA</span></center>**
[](https://arxiv.org/abs/2402.14289)[](https://github.com/TinyLLaVA/TinyLLaVA_Factory)[](http://8843843nmph5.vicp.fun/#/)
TinyLLaVA has released a family of small-scale Large Multimodel Models(LMMs), ranging from 1.4B to 3.1B. Our best model, TinyLLaVA-Phi-2-SigLIP-3.1B, achieves better overall performance against existing 7B models such as LLaVA-1.5 and Qwen-VL.
Here, we introduce TinyLLaVA-Gemma-SigLIP-2.4B, which is trained by the [TinyLLaVA Factory](https://github.com/TinyLLaVA/TinyLLaVA_Factory) codebase. For LLM and vision tower, we choose [Gemma-2B](https://huggingface.co/google/gemma-2b-it) and [siglip-so400m-patch14-384](https://huggingface.co/google/siglip-so400m-patch14-384), respectively. The dataset used for training this model is the [LLaVA](https://github.com/haotian-liu/LLaVA?tab=readme-ov-file#pretrain-feature-alignment) dataset.
### Usage
Before executing the following test code, you need to have the access to [google/gemma-2b-it](https://huggingface.co/google/gemma-2b-it).
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
hf_path = 'tinyllava/TinyLLaVA-Gemma-SigLIP-2.4B'
model = AutoModelForCausalLM.from_pretrained(hf_path, trust_remote_code=True)
model.cuda()
config = model.config
tokenizer = AutoTokenizer.from_pretrained(hf_path, use_fast=False, model_max_length = config.tokenizer_model_max_length,padding_side = config.tokenizer_padding_side)
prompt="What are these?"
image_url="http://images.cocodataset.org/test-stuff2017/000000000001.jpg"
output_text, genertaion_time = model.chat(prompt=prompt, image=image_url, tokenizer=tokenizer)
print('model output:', output_text)
print('runing time:', genertaion_time)
```
### Result
| model_name | vqav2 | gqa | sqa | textvqa | MM-VET | POPE | MME | MMMU |
| :----------------------------------------------------------: | ----- | ------- | ----- | ----- | ------- | ----- | ------ | ------ |
| [LLaVA-1.5-7B](https://huggingface.co/llava-hf/llava-1.5-7b-hf) | 78.5 | 62.0 | 66.8 | 58.2 | 30.5 | 85.9 | 1510.7 | - |
| [bczhou/TinyLLaVA-3.1B](https://huggingface.co/bczhou/TinyLLaVA-3.1B) (our legacy model)| 79.9 | 62.0 | 69.1 | 59.1 | 32.0 | 86.4 | 1464.9 | - |
| [tinyllava/TinyLLaVA-Gemma-SigLIP-2.4B](https://huggingface.co/tinyllava/TinyLLaVA-Gemma-SigLIP-2.4B) | 78.4 | 61.6 | 64.4 | 53.6 | 26.9 | 86.4 | 1339.0 | 31.7 |
| [tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B](https://huggingface.co/tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B) | 80.1 | 62.1 | 73.0 | 60.3 | 37.5 | 87.2 | 1466.4 | 38.4 |
P.S. [TinyLLaVA Factory](https://github.com/TinyLLaVA/TinyLLaVA_Factory) is an open-source modular codebase for small-scale LMMs with a focus on simplicity of code implementations, extensibility of new features, and reproducibility of training results. This code repository provides standard training&evaluating pipelines, flexible data preprocessing&model configurations, and easily extensible architectures. Users can customize their own LMMs with minimal coding effort and less coding mistake.
TinyLLaVA Factory integrates a suite of cutting-edge models and methods.
- LLM currently supports OpenELM, TinyLlama, StableLM, Qwen, Gemma, and Phi.
- Vision tower currently supports CLIP, SigLIP, Dino, and combination of CLIP and Dino.
- Connector currently supports MLP, Qformer, and Resampler.
|
tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B | tinyllava | 2024-05-18T12:13:47Z | 3,236 | 14 | transformers | [
"transformers",
"safetensors",
"tinyllava",
"text-generation",
"image-text-to-text",
"custom_code",
"arxiv:2402.14289",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | image-text-to-text | 2024-05-15T12:19:17Z | ---
license: apache-2.0
pipeline_tag: image-text-to-text
---
**<center><span style="font-size:2em;">TinyLLaVA</span></center>**
[](https://arxiv.org/abs/2402.14289)[](https://github.com/TinyLLaVA/TinyLLaVA_Factory)[](http://8843843nmph5.vicp.fun/#/)
TinyLLaVA has released a family of small-scale Large Multimodel Models(LMMs), ranging from 1.4B to 3.1B. Our best model, TinyLLaVA-Phi-2-SigLIP-3.1B, achieves better overall performance against existing 7B models such as LLaVA-1.5 and Qwen-VL.
Here, we introduce TinyLLaVA-Phi-2-SigLIP-3.1B, which is trained by the [TinyLLaVA Factory](https://github.com/TinyLLaVA/TinyLLaVA_Factory) codebase. For LLM and vision tower, we choose [Phi-2](microsoft/phi-2) and [siglip-so400m-patch14-384](https://huggingface.co/google/siglip-so400m-patch14-384), respectively. The dataset used for training this model is the [ShareGPT4V](https://github.com/InternLM/InternLM-XComposer/blob/main/projects/ShareGPT4V/docs/Data.md) dataset.
### Usage
Execute the following test code:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
hf_path = 'tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B'
model = AutoModelForCausalLM.from_pretrained(hf_path, trust_remote_code=True)
model.cuda()
config = model.config
tokenizer = AutoTokenizer.from_pretrained(hf_path, use_fast=False, model_max_length = config.tokenizer_model_max_length,padding_side = config.tokenizer_padding_side)
prompt="What are these?"
image_url="http://images.cocodataset.org/test-stuff2017/000000000001.jpg"
output_text, genertaion_time = model.chat(prompt=prompt, image=image_url, tokenizer=tokenizer)
print('model output:', output_text)
print('runing time:', genertaion_time)
```
### Result
| model_name | vqav2 | gqa | sqa | textvqa | MM-VET | POPE | MME | MMMU |
| :----------------------------------------------------------: | ----- | ------- | ----- | ----- | ------- | ----- | ------ | ------ |
| [LLaVA-1.5-7B](https://huggingface.co/llava-hf/llava-1.5-7b-hf) | 78.5 | 62.0 | 66.8 | 58.2 | 30.5 | 85.9 | 1510.7 | - |
| [bczhou/TinyLLaVA-3.1B](https://huggingface.co/bczhou/TinyLLaVA-3.1B) (our legacy model) | 79.9 | 62.0 | 69.1 | 59.1 | 32.0 | 86.4 | 1464.9 | - |
| [tinyllava/TinyLLaVA-Gemma-SigLIP-2.4B](https://huggingface.co/tinyllava/TinyLLaVA-Gemma-SigLIP-2.4B) | 78.4 | 61.6 | 64.4 | 53.6 | 26.9 | 86.4 | 1339.0 | 31.7 |
| [tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B](https://huggingface.co/tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B) | 80.1 | 62.1 | 73.0 | 60.3 | 37.5 | 87.2 | 1466.4 | 38.4 |
P.S. [TinyLLaVA Factory](https://github.com/TinyLLaVA/TinyLLaVA_Factory) is an open-source modular codebase for small-scale LMMs with a focus on simplicity of code implementations, extensibility of new features, and reproducibility of training results. This code repository provides standard training&evaluating pipelines, flexible data preprocessing&model configurations, and easily extensible architectures. Users can customize their own LMMs with minimal coding effort and less coding mistake.
TinyLLaVA Factory integrates a suite of cutting-edge models and methods.
- LLM currently supports OpenELM, TinyLlama, StableLM, Qwen, Gemma, and Phi.
- Vision tower currently supports CLIP, SigLIP, Dino, and combination of CLIP and Dino.
- Connector currently supports MLP, Qformer, and Resampler.
|
fzzhang/mistralv1_lora_r8_25e5_e05 | fzzhang | 2024-05-18T12:12:30Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
] | null | 2024-05-18T12:12:28Z | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: mistralai/Mistral-7B-v0.1
model-index:
- name: mistralv1_lora_r8_25e5_e05
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistralv1_lora_r8_25e5_e05
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.38.2
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2 |
MJerome/V65_LoRA_V63_GPT2-350k-Plus_10k_low_elo_4E_r64 | MJerome | 2024-05-18T12:10:36Z | 0 | 0 | peft | [
"peft",
"arxiv:1910.09700",
"base_model:Leon-LLM/V63_GPT2_350k_4E_xLANplus_RIGHT_PAD",
"base_model:adapter:Leon-LLM/V63_GPT2_350k_4E_xLANplus_RIGHT_PAD",
"region:us"
] | null | 2024-05-18T12:10:33Z | ---
library_name: peft
base_model: Leon-LLM/V63_GPT2_350k_4E_xLANplus_RIGHT_PAD
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0 |
Prince21332/Business | Prince21332 | 2024-05-18T12:08:13Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-05-18T12:08:13Z | ---
license: apache-2.0
---
|
akbargherbal/gemma_7b_en_to_ar_ft_01_LORA | akbargherbal | 2024-05-18T12:04:50Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gemma",
"trl",
"en",
"base_model:unsloth/gemma-7b-it-bnb-4bit",
"base_model:finetune:unsloth/gemma-7b-it-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-18T12:04:37Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- gemma
- trl
base_model: unsloth/gemma-7b-it-bnb-4bit
---
# Uploaded model
- **Developed by:** akbargherbal
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-7b-it-bnb-4bit
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
euiyulsong/ORPO-task-domain-20k-synth3k-semi | euiyulsong | 2024-05-18T12:02:17Z | 81 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"trl",
"sft",
"orpo",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-18T11:57:56Z | ---
library_name: transformers
tags:
- trl
- sft
- orpo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ddnahm/ddn_qa_model | ddnahm | 2024-05-18T11:59:29Z | 69 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-05-18T09:06:45Z | ---
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: ddnahm/ddn_qa_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# ddnahm/ddn_qa_model
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 3.5135
- Validation Loss: 2.3658
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 500, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.5135 | 2.3658 | 0 |
### Framework versions
- Transformers 4.40.2
- TensorFlow 2.15.0
- Datasets 2.19.1
- Tokenizers 0.19.1
|
OsherElhadad/ppo-PandaReachJointsDense-v3-750000 | OsherElhadad | 2024-05-18T11:56:01Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"PandaReachJointsDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-18T11:51:48Z | ---
library_name: stable-baselines3
tags:
- PandaReachJointsDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachJointsDense-v3
type: PandaReachJointsDense-v3
metrics:
- type: mean_reward
value: -0.21 +/- 0.13
name: mean_reward
verified: false
---
# **PPO** Agent playing **PandaReachJointsDense-v3**
This is a trained model of a **PPO** agent playing **PandaReachJointsDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
RichardErkhov/macadeliccc_-_laser-dolphin-mixtral-2x7b-dpo-8bits | RichardErkhov | 2024-05-18T11:54:31Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"arxiv:2312.13558",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-18T11:45:43Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
laser-dolphin-mixtral-2x7b-dpo - bnb 8bits
- Model creator: https://huggingface.co/macadeliccc/
- Original model: https://huggingface.co/macadeliccc/laser-dolphin-mixtral-2x7b-dpo/
Original model description:
---
license: apache-2.0
library_name: transformers
model-index:
- name: laser-dolphin-mixtral-2x7b-dpo
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 65.96
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-2x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 85.8
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-2x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 63.17
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-2x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 60.76
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-2x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 79.01
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-2x7b-dpo
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 48.29
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/laser-dolphin-mixtral-2x7b-dpo
name: Open LLM Leaderboard
---
# Laser-Dolphin-Mixtral-2x7b-dpo

**New Version out now!**
Credit to Fernando Fernandes and Eric Hartford for their project [laserRMT](https://github.com/cognitivecomputations/laserRMT)
## Overview
This model is a medium-sized MoE implementation based on [cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser](https://huggingface.co/cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser)
+ The new version shows ~1 point increase in evaluation performance on average.
## Process
+ The process is outlined in this [notebook](https://github.com/cognitivecomputations/laserRMT/blob/main/examples/laser-dolphin-mixtral-2x7b.ipynb)
+ The mergekit_config is in the files.
+ The models used in the configuration are not lasered, but the final product is. This is an update from the last version.
+ This process is experimental. Your mileage may vary.
## Future Goals
+ [ ] Function Calling
+ [ ] v2 with new base model to improve performance
## Quantizations
### ExLlamav2
_These are the recommended quantizations for users that are running the model on GPU_
Thanks to user [bartowski](https://huggingface.co/bartowski) we now have exllamav2 quantizations in 3.5 through 8 bpw. They are available here:
+ [bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2](https://huggingface.co/bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2)
| Branch | Bits | lm_head bits | VRAM (4k) | VRAM (16k) | VRAM (32k) | Description |
| ----- | ---- | ------- | ------ | ------ | ------ | ------------ |
| [8_0](https://huggingface.co/bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2/tree/8_0) | 8.0 | 8.0 | 13.7 GB | 15.1 GB | 17.2 GB | Maximum quality that ExLlamaV2 can produce, near unquantized performance. |
| [6_5](https://huggingface.co/bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2/tree/6_5) | 6.5 | 8.0 | 11.5 GB | 12.9 GB | 15.0 GB | Near unquantized performance at vastly reduced size, **recommended**. |
| [5_0](https://huggingface.co/bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2/tree/5_0) | 5.0 | 6.0 | 9.3 GB | 10.7 GB | 12.8 GB | Slightly lower quality vs 6.5, great for 12gb cards with 16k context. |
| [4_25](https://huggingface.co/bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2/tree/4_25) | 4.25 | 6.0 | 8.2 GB | 9.6 GB | 11.7 GB | GPTQ equivalent bits per weight. |
| [3_5](https://huggingface.co/bartowski/laser-dolphin-mixtral-2x7b-dpo-exl2/tree/3_5) | 3.5 | 6.0 | 7.0 GB | 8.4 GB | 10.5 GB | Lower quality, not recommended. |
His quantizations represent the first ~13B model with GQA support. Check out his repo for more information!
### GGUF
*Current GGUF [Quantizations](https://huggingface.co/macadeliccc/laser-dolphin-mixtral-2x7b-dpo-GGUF)*
### AWQ
*Current AWQ [Quantizations](https://huggingface.co/macadeliccc/laser-dolphin-mixtral-2x7b-dpo-AWQ)
### TheBloke
**These Quants will result in unpredicted behavior. New quants are available as I have updated the model**
Quatizations provided by [TheBloke](https://huggingface.co/TheBloke/laser-dolphin-mixtral-2x7b-dpo-GGUF)
## HF Spaces
+ GGUF chat available [here](https://huggingface.co/spaces/macadeliccc/laser-dolphin-mixtral-chat-GGUF)
+ 4-bit bnb chat available [here](https://huggingface.co/spaces/macadeliccc/laser-dolphin-mixtral-chat)
# Ollama
```bash
ollama run macadeliccc/laser-dolphin-mixtral-2x7b-dpo
```

## Code Example
Switch the commented model definition to use in 4-bit. Should work with 9GB and still exceed the single 7B model by 5-6 points roughly
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
def generate_response(prompt):
"""
Generate a response from the model based on the input prompt.
Args:
prompt (str): Prompt for the model.
Returns:
str: The generated response from the model.
"""
# Tokenize the input prompt
inputs = tokenizer(prompt, return_tensors="pt")
# Generate output tokens
outputs = model.generate(**inputs, max_new_tokens=256, eos_token_id=tokenizer.eos_token_id, pad_token_id=tokenizer.pad_token_id)
# Decode the generated tokens to a string
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# Load the model and tokenizer
model_id = "macadeliccc/laser-dolphin-mixtral-2x7b-dpo"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True)
prompt = "Write a quicksort algorithm in python"
# Generate and print responses for each language
print("Response:")
print(generate_response(prompt), "\n")
```
[colab](https://colab.research.google.com/drive/1cmRhAkDWItV7utHNqNANVZnqDqQNsTUr?usp=sharing) with usage example
## Eval
## EQ Bench
<pre>----Benchmark Complete----
2024-01-31 16:55:37
Time taken: 31.1 mins
Prompt Format: ChatML
Model: macadeliccc/laser-dolphin-mixtral-2x7b-dpo-GGUF
Score (v2): 72.76
Parseable: 171.0
---------------
Batch completed
Time taken: 31.2 mins
---------------
</pre>
evaluation [colab](https://colab.research.google.com/drive/1FpwgsGzCR4tORTxAwUxpN3PcP22En2xk?usp=sharing)
## Summary of previous evaluation
| Model |AGIEval|GPT4All|TruthfulQA|Bigbench|Average|
|---------------------------------------------------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[laser-dolphin-mixtral-2x7b-dpo](https://huggingface.co/macadeliccc/laser-dolphin-mixtral-2x7b-dpo)| 41.31| 73.67| 61.69| 42.79| 54.87|
## Detailed current evaluation
| Model |AGIEval|GPT4All|TruthfulQA|Bigbench|Average|
|---------------------------------------------------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[laser-dolphin-mixtral-2x7b-dpo](https://huggingface.co/macadeliccc/laser-dolphin-mixtral-2x7b-dpo)| 42.25| 73.45| 63.44| 43.96| 55.77|
### AGIEval
| Task |Version| Metric |Value| |Stderr|
|------------------------------|------:|--------|----:|---|-----:|
|agieval_aqua_rat | 0|acc |21.26|± | 2.57|
| | |acc_norm|21.65|± | 2.59|
|agieval_logiqa_en | 0|acc |34.72|± | 1.87|
| | |acc_norm|35.64|± | 1.88|
|agieval_lsat_ar | 0|acc |26.96|± | 2.93|
| | |acc_norm|26.96|± | 2.93|
|agieval_lsat_lr | 0|acc |45.88|± | 2.21|
| | |acc_norm|46.08|± | 2.21|
|agieval_lsat_rc | 0|acc |59.48|± | 3.00|
| | |acc_norm|59.48|± | 3.00|
|agieval_sat_en | 0|acc |73.79|± | 3.07|
| | |acc_norm|73.79|± | 3.07|
|agieval_sat_en_without_passage| 0|acc |42.23|± | 3.45|
| | |acc_norm|41.26|± | 3.44|
|agieval_sat_math | 0|acc |37.27|± | 3.27|
| | |acc_norm|33.18|± | 3.18|
Average: 42.25%
### GPT4All
| Task |Version| Metric |Value| |Stderr|
|-------------|------:|--------|----:|---|-----:|
|arc_challenge| 0|acc |58.36|± | 1.44|
| | |acc_norm|58.02|± | 1.44|
|arc_easy | 0|acc |82.20|± | 0.78|
| | |acc_norm|77.40|± | 0.86|
|boolq | 1|acc |87.52|± | 0.58|
|hellaswag | 0|acc |67.50|± | 0.47|
| | |acc_norm|84.43|± | 0.36|
|openbookqa | 0|acc |34.40|± | 2.13|
| | |acc_norm|47.00|± | 2.23|
|piqa | 0|acc |81.61|± | 0.90|
| | |acc_norm|82.59|± | 0.88|
|winogrande | 0|acc |77.19|± | 1.18|
Average: 73.45%
### GSM8K
|Task |Version| Metric |Value| |Stderr|
|-----|------:|-----------------------------|-----|---|------|
|gsm8k| 2|exact_match,get-answer | 0.75| | |
| | |exact_match_stderr,get-answer| 0.01| | |
| | |alias |gsm8k| | |
### TruthfulQA
| Task |Version|Metric|Value| |Stderr|
|-------------|------:|------|----:|---|-----:|
|truthfulqa_mc| 1|mc1 |45.90|± | 1.74|
| | |mc2 |63.44|± | 1.56|
Average: 63.44%
### Bigbench
| Task |Version| Metric |Value| |Stderr|
|------------------------------------------------|------:|---------------------|----:|---|-----:|
|bigbench_causal_judgement | 0|multiple_choice_grade|58.42|± | 3.59|
|bigbench_date_understanding | 0|multiple_choice_grade|60.70|± | 2.55|
|bigbench_disambiguation_qa | 0|multiple_choice_grade|38.37|± | 3.03|
|bigbench_geometric_shapes | 0|multiple_choice_grade|21.73|± | 2.18|
| | |exact_str_match | 0.00|± | 0.00|
|bigbench_logical_deduction_five_objects | 0|multiple_choice_grade|35.00|± | 2.14|
|bigbench_logical_deduction_seven_objects | 0|multiple_choice_grade|23.57|± | 1.61|
|bigbench_logical_deduction_three_objects | 0|multiple_choice_grade|50.33|± | 2.89|
|bigbench_movie_recommendation | 0|multiple_choice_grade|45.00|± | 2.23|
|bigbench_navigate | 0|multiple_choice_grade|50.00|± | 1.58|
|bigbench_reasoning_about_colored_objects | 0|multiple_choice_grade|60.35|± | 1.09|
|bigbench_ruin_names | 0|multiple_choice_grade|51.12|± | 2.36|
|bigbench_salient_translation_error_detection | 0|multiple_choice_grade|32.26|± | 1.48|
|bigbench_snarks | 0|multiple_choice_grade|67.96|± | 3.48|
|bigbench_sports_understanding | 0|multiple_choice_grade|70.59|± | 1.45|
|bigbench_temporal_sequences | 0|multiple_choice_grade|35.80|± | 1.52|
|bigbench_tracking_shuffled_objects_five_objects | 0|multiple_choice_grade|22.56|± | 1.18|
|bigbench_tracking_shuffled_objects_seven_objects| 0|multiple_choice_grade|17.20|± | 0.90|
|bigbench_tracking_shuffled_objects_three_objects| 0|multiple_choice_grade|50.33|± | 2.89|
Average: 43.96%
Average score: 55.77%
Elapsed time: 02:43:45
## Citations
Fernando Fernandes Neto and Eric Hartford. "Optimizing Large Language Models Using Layer-Selective Rank Reduction and Random Matrix Theory." 2024.
```bibtex
@article{sharma2023truth,
title={The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction},
author={Sharma, Pratyusha and Ash, Jordan T and Misra, Dipendra},
journal={arXiv preprint arXiv:2312.13558},
year={2023} }
```
```bibtex
@article{gao2021framework,
title={A framework for few-shot language model evaluation},
author={Gao, Leo and Tow, Jonathan and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and McDonell, Kyle and Muennighoff, Niklas and others},
journal={Version v0. 0.1. Sept},
year={2021}
}
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_macadeliccc__laser-dolphin-mixtral-2x7b-dpo)
| Metric |Value|
|---------------------------------|----:|
|Avg. |67.16|
|AI2 Reasoning Challenge (25-Shot)|65.96|
|HellaSwag (10-Shot) |85.80|
|MMLU (5-Shot) |63.17|
|TruthfulQA (0-shot) |60.76|
|Winogrande (5-shot) |79.01|
|GSM8k (5-shot) |48.29|
|
uw-vta/bloominzer-0.1 | uw-vta | 2024-05-18T11:50:49Z | 113 | 3 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-18T11:24:39Z | ---
license: apache-2.0
language:
- en
widget:
- text: "What is a goat?"
---
# What is the Bloominizer
The bloominer is a fine-tuned version of BERT that classifies questions by the Bloom's Taxonomy level: Knowledge, Comprehension, Application, Analysis, Synthesis, Evaluation.
Tests during training indicate that the Bloominizer is approximately 93% accurate in its classifications, with most misclassifications being for
either one level below or above (for instance, it may misclassify a Comprehension question as a Knowledge question, but rately as an Evaluation question).
The Bloominizer has been used for large-scale classification of questions from a corpus. For example, a useful usecase is to run all questions in a long
multiple choice exam through the Bloominizer and compute the relative percentages of questions from the six Bloom's levels. This can give you an idea
of the approximate cognitive level of the overall exam.
# Using in transformers
The Bloominizer is easiest to use through a pipeline. Sample code is below:
```
import transformers
import torch
from transformers import pipeline
pipe = pipeline("text-classification", model="uw-vta/bloominzer-0.1")
print(pipe("What is a goat?"))
```
If you run this code, the output should be something like:
```
[{'label': 'Knowledge', 'score': 0.9993932247161865}]
``` |
Audino/my-awesomev3-modelv2-base | Audino | 2024-05-18T11:47:21Z | 108 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-05-18T11:46:18Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
IntellectusAI/mistral_finetune8x7bcompanylaw | IntellectusAI | 2024-05-18T11:39:59Z | 3 | 0 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-17T21:16:21Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
sidddddddddddd/lora_model_10_examples | sidddddddddddd | 2024-05-18T11:38:22Z | 3 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:quantized:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-18T11:09:51Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** sidddddddddddd
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
geunukj/ppo-LunarLander-v2 | geunukj | 2024-05-18T11:33:51Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-18T11:33:32Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 255.02 +/- 18.64
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
PaulR79/llama_finetuned_synthetic | PaulR79 | 2024-05-18T11:32:20Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-18T11:32:17Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
NikolayKozloff/RoMistral-7b-Instruct-Q8_0-GGUF | NikolayKozloff | 2024-05-18T11:30:58Z | 0 | 1 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"ro",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-18T11:30:38Z | ---
language:
- ro
license: cc-by-nc-4.0
tags:
- llama-cpp
- gguf-my-repo
---
# NikolayKozloff/RoMistral-7b-Instruct-Q8_0-GGUF
This model was converted to GGUF format from [`OpenLLM-Ro/RoMistral-7b-Instruct`](https://huggingface.co/OpenLLM-Ro/RoMistral-7b-Instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/OpenLLM-Ro/RoMistral-7b-Instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo NikolayKozloff/RoMistral-7b-Instruct-Q8_0-GGUF --model romistral-7b-instruct.Q8_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo NikolayKozloff/RoMistral-7b-Instruct-Q8_0-GGUF --model romistral-7b-instruct.Q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m romistral-7b-instruct.Q8_0.gguf -n 128
```
|
RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf | RichardErkhov | 2024-05-18T11:29:56Z | 52 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us"
] | null | 2024-05-18T09:29:25Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
KoSOLAR-10.7B-v0.2 - GGUF
- Model creator: https://huggingface.co/yanolja/
- Original model: https://huggingface.co/yanolja/KoSOLAR-10.7B-v0.2/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [KoSOLAR-10.7B-v0.2.Q2_K.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q2_K.gguf) | Q2_K | 3.77GB |
| [KoSOLAR-10.7B-v0.2.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.IQ3_XS.gguf) | IQ3_XS | 4.18GB |
| [KoSOLAR-10.7B-v0.2.IQ3_S.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.IQ3_S.gguf) | IQ3_S | 4.41GB |
| [KoSOLAR-10.7B-v0.2.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q3_K_S.gguf) | Q3_K_S | 4.39GB |
| [KoSOLAR-10.7B-v0.2.IQ3_M.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.IQ3_M.gguf) | IQ3_M | 4.56GB |
| [KoSOLAR-10.7B-v0.2.Q3_K.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q3_K.gguf) | Q3_K | 4.88GB |
| [KoSOLAR-10.7B-v0.2.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q3_K_M.gguf) | Q3_K_M | 4.88GB |
| [KoSOLAR-10.7B-v0.2.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q3_K_L.gguf) | Q3_K_L | 5.31GB |
| [KoSOLAR-10.7B-v0.2.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.IQ4_XS.gguf) | IQ4_XS | 5.47GB |
| [KoSOLAR-10.7B-v0.2.Q4_0.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q4_0.gguf) | Q4_0 | 5.7GB |
| [KoSOLAR-10.7B-v0.2.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.IQ4_NL.gguf) | IQ4_NL | 5.77GB |
| [KoSOLAR-10.7B-v0.2.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q4_K_S.gguf) | Q4_K_S | 5.75GB |
| [KoSOLAR-10.7B-v0.2.Q4_K.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q4_K.gguf) | Q4_K | 6.07GB |
| [KoSOLAR-10.7B-v0.2.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q4_K_M.gguf) | Q4_K_M | 6.07GB |
| [KoSOLAR-10.7B-v0.2.Q4_1.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q4_1.gguf) | Q4_1 | 6.32GB |
| [KoSOLAR-10.7B-v0.2.Q5_0.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q5_0.gguf) | Q5_0 | 6.94GB |
| [KoSOLAR-10.7B-v0.2.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q5_K_S.gguf) | Q5_K_S | 6.94GB |
| [KoSOLAR-10.7B-v0.2.Q5_K.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q5_K.gguf) | Q5_K | 7.13GB |
| [KoSOLAR-10.7B-v0.2.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q5_K_M.gguf) | Q5_K_M | 7.13GB |
| [KoSOLAR-10.7B-v0.2.Q5_1.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q5_1.gguf) | Q5_1 | 7.56GB |
| [KoSOLAR-10.7B-v0.2.Q6_K.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q6_K.gguf) | Q6_K | 8.26GB |
| [KoSOLAR-10.7B-v0.2.Q8_0.gguf](https://huggingface.co/RichardErkhov/yanolja_-_KoSOLAR-10.7B-v0.2-gguf/blob/main/KoSOLAR-10.7B-v0.2.Q8_0.gguf) | Q8_0 | 10.69GB |
Original model description:
---
license: apache-2.0
base_model: upstage/SOLAR-10.7B-v1.0
tags:
- generated_from_trainer
model-index:
- name: yanolja/KoSOLAR-10.7B-v0.2
results: []
---
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
# KoSOLAR-10.7B-v0.2
## Join Our Community on Discord!
If you're passionate about the field of Large Language Models and wish to exchange knowledge and insights, we warmly invite you to join our Discord server. It's worth noting that Korean is the primary language used in this server. The landscape of LLM is evolving rapidly, and without active sharing, our collective knowledge risks becoming outdated swiftly. Let's collaborate and drive greater impact together! Join us here: [Discord Link](https://discord.gg/b27bAHg95m).
## Our Dedicated Team (Alphabetical Order)
| Research | Engineering | Product Management | UX Design |
|-----------------|-----------------|--------------------|--------------
| Myeongho Jeong | Geon Kim | Bokyung Huh | Eunsue Choi |
| Seungduk Kim | Rifqi Alfi | | |
| Seungtaek Choi | Sanghoon Han | | |
| | Suhyun Kang | | |
## About the Model
This model is a Korean vocabulary-extended version of [upstage/SOLAR-10.7B-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-v1.0), specifically fine-tuned on various Korean web-crawled datasets available on HuggingFace. Our approach was to expand the model's understanding of Korean by pre-training the embeddings for new tokens and partially fine-tuning the `lm_head` embeddings for the already existing tokens while preserving the original parameters of the base model.
### Technical Deep Dive
Here’s a glimpse into our technical approach:
```python
def freeze_partial_embedding_hook(grad):
grad[:32000] = 0
return grad
for name, param in model.named_parameters():
if ("lm_head" in name or "embed_tokens" in name) and "original" not in name:
param.requires_grad = True
if "embed_tokens" in name:
param.register_hook(freeze_partial_embedding_hook)
else:
param.requires_grad = False
```
Our strategy involved a selective freeze of model parameters. Specifically, we kept most parameters of the base model unchanged while focusing on enhancing the Korean language capabilities. Through our experiments, we discovered:
1. Freezing the `embed_tokens` layer for existing tokens is crucial to maintain overall performance.
2. Unfreezing the `lm_head` layer for existing tokens actually boosts performance.
As a result, we froze the internal layers and the first 32,000 `embed_tokens`, directing our training efforts on a rich mix of Korean and multi-lingual corpora. This balanced approach has notably improved the model’s proficiency in Korean, without compromising its original language capabilities.
### Usage and Limitations
Keep in mind that this model hasn't been fine-tuned with instruction-based training. While it excels in Korean language tasks, we advise careful consideration and further training for specific applications.
### Training Details
Our model’s training was comprehensive and diverse:
- **Data Sources:**
- English to Korean paragraph pairs: 5.86%
- Multi-lingual corpus (primarily English): 10.69%
- Korean web content: 83.46%
- **Vocabulary Expansion:**
We meticulously selected 8,960 Korean tokens based on their frequency in our Korean web corpus. This process involved multiple rounds of tokenizer training, manual curation, and token frequency analysis, ensuring a rich and relevant vocabulary for our model.
1. **Initial Tokenizer Training:** We trained an intermediate tokenizer on a Korean web corpus, with a vocabulary of 40,000 tokens.
2. **Extraction of New Korean Tokens:** From the intermediate tokenizer, we identified all Korean tokens not present in the original SOLAR's tokenizer.
3. **Manual Tokenizer Construction:** We then built the target tokenizer, focusing on these new Korean tokens.
4. **Frequency Analysis:** Using the target tokenizer, we processed a 100GB Korean corpus to count each token's frequency.
5. **Refinement of Token List:** We removed tokens appearing less than 6,000 times, ensuring to secure enough tokens to train models later.
6. **Inclusion of Single-Letter Characters:** Counted missing Korean single-letter characters and added them to the target tokenizer that appeared more than 6,000 times.
7. **Iterative Refinement:** We repeated steps 2 to 6 until there were no tokens to drop or add.
8. **Training Bias Towards New Tokens:** Our training data was biased to include more texts with new tokens, for effective learning.
This rigorous approach ensured a comprehensive and contextually rich Korean vocabulary for the model.
|
PQlet/lora-narutoblip-v1-ablation-r16-a16-module_to_q | PQlet | 2024-05-18T11:23:37Z | 1 | 0 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"diffusers-training",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2024-05-18T11:23:32Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- diffusers-training
- lora
base_model: runwayml/stable-diffusion-v1-5
inference: true
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# LoRA text2image fine-tuning - PQlet/lora-narutoblip-v1-ablation-r16-a16-module_to_q
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the Naruto-BLIP dataset. You can find some example images in the following.







## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
LoneStriker/dolphin-2.9.1-yi-1.5-34b-8.0bpw-h8-exl2 | LoneStriker | 2024-05-18T11:23:14Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"axolotl",
"conversational",
"dataset:cognitivecomputations/Dolphin-2.9",
"dataset:teknium/OpenHermes-2.5",
"dataset:m-a-p/CodeFeedback-Filtered-Instruction",
"dataset:cognitivecomputations/dolphin-coder",
"dataset:cognitivecomputations/samantha-data",
"dataset:microsoft/orca-math-word-problems-200k",
"dataset:Locutusque/function-calling-chatml",
"dataset:internlm/Agent-FLAN",
"base_model:01-ai/Yi-1.5-34B",
"base_model:quantized:01-ai/Yi-1.5-34B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"exl2",
"region:us"
] | text-generation | 2024-05-18T11:10:11Z | ---
license: apache-2.0
base_model: 01-ai/Yi-1.5-34B
tags:
- generated_from_trainer
- axolotl
datasets:
- cognitivecomputations/Dolphin-2.9
- teknium/OpenHermes-2.5
- m-a-p/CodeFeedback-Filtered-Instruction
- cognitivecomputations/dolphin-coder
- cognitivecomputations/samantha-data
- microsoft/orca-math-word-problems-200k
- Locutusque/function-calling-chatml
- internlm/Agent-FLAN
---
# Dolphin 2.9.1 Yi 1.5 34b 🐬
Curated and trained by Eric Hartford, Lucas Atkins, and Fernando Fernandes, and Cognitive Computations
This is our most spectacular outcome ever. FFT, all parameters, 16bit. 77.4 MMLU on 34b. And it talks like a dream.
Although the max positional embeddings is 4k, we used rope theta of 1000000.0 and we trained with sequence length 8k. We plan to train on the upcoming 32k version as well.
Discord: https://discord.gg/8fbBeC7ZGx
<img src="https://cdn-uploads.huggingface.co/production/uploads/63111b2d88942700629f5771/ldkN1J0WIDQwU4vutGYiD.png" width="600" />
Our appreciation for the sponsors of Dolphin 2.9.1:
- [Crusoe Cloud](https://crusoe.ai/) - provided excellent on-demand 8xH100 node
- [OnDemand](https://on-demand.io/) - provided inference sponsorship
This model is based on Yi-1.5-34b, and is governed by apache 2.0 license.
The base model has 4k context, but we used rope theta of 1000000.0 and the full-weight fine-tuning was with 8k sequence length.
Dolphin 2.9.1 uses ChatML prompt template format.
example:
```
<|im_start|>system
You are Dolphin, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
Dolphin-2.9.1 has a variety of instruction, conversational, and coding skills. It also has initial agentic abilities and supports function calling.
Dolphin is uncensored. We have filtered the dataset to remove alignment and bias. This makes the model more compliant. You are advised to implement your own alignment layer before exposing the model as a service. It will be highly compliant with any requests, even unethical ones. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models You are responsible for any content you create using this model. Enjoy responsibly.
Dolphin is licensed according to apache 2.0 license. We grant permission for any use, including commercial. Dolphin was trained on data generated from GPT4, among other models.
## Evals

## Training
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: 01-ai/Yi-1.5-34B
model_type: LlamaForCausalLM
tokenizer_type: LlamaTokenizer
trust_remote_code: true
# load_in_8bit: false
# load_in_4bit: true
# strict: false
# adapter: qlora
# lora_modules_to_save: [embed_tokens, lm_head]
# lora_r: 32
# lora_alpha: 16
# lora_dropout: 0.05
# lora_target_linear: True
# lora_fan_in_fan_out:
datasets:
- path: /workspace/datasets/dolphin-2.9/dolphin201-sharegpt2.jsonl
type: sharegpt
conversation: chatml
- path: /workspace/datasets/dolphin-2.9/dolphin-coder-translate-sharegpt2.jsonl
type: sharegpt
conversation: chatml
- path: /workspace/datasets/dolphin-2.9/dolphin-coder-codegen-sharegpt2.jsonl
type: sharegpt
conversation: chatml
- path: /workspace/datasets/dolphin-2.9/m-a-p_Code-Feedback-sharegpt-unfiltered.jsonl
type: sharegpt
conversation: chatml
- path: /workspace/datasets/dolphin-2.9/m-a-p_CodeFeedback-Filtered-Instruction-sharegpt-unfiltered.jsonl
type: sharegpt
conversation: chatml
- path: /workspace/datasets/dolphin-2.9/not_samantha_norefusals.jsonl
type: sharegpt
conversation: chatml
- path: /workspace/datasets/dolphin-2.9/Orca-Math-resort-unfiltered.jsonl
type: sharegpt
conversation: chatml
- path: /workspace/datasets/dolphin-2.9/agent_instruct_react_unfiltered.jsonl
type: sharegpt
conversation: chatml
- path: /workspace/datasets/dolphin-2.9/toolbench_instruct_j1s1_3k_unfiltered.jsonl
type: sharegpt
conversation: chatml
- path: /workspace/datasets/dolphin-2.9/toolbench_negative_unfiltered.jsonl
type: sharegpt
conversation: chatml
- path: /workspace/datasets/dolphin-2.9/toolbench_react_10p_unfiltered.jsonl
type: sharegpt
conversation: chatml
- path: /workspace/datasets/dolphin-2.9/toolbench_tflan_cot_30p_unfiltered.jsonl
type: sharegpt
conversation: chatml
- path: /workspace/datasets/dolphin-2.9/openhermes200k_unfiltered.jsonl
type: sharegpt
conversation: chatml
chat_template: chatml
dataset_prepared_path: yi34b
val_set_size: 0.01
output_dir: ./out-yi
sequence_len: 8192
sample_packing: true
pad_to_sequence_len: true
wandb_project: dolphin-2.9-yi-34b
wandb_watch:
wandb_run_id:
wandb_log_model:
gradient_accumulation_steps: 8
micro_batch_size: 1
num_epochs: 3
optimizer: adamw_8bit
lr_scheduler: cosine
learning_rate: 1e-5
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32: true
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: false
early_stopping_patience:
# resume_from_checkpoint: /workspace/axolotl/dbrx-checkpoint
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10
evals_per_epoch: 4
eval_table_size:
saves_per_epoch: 4
save_total_limit: 2
save_steps:
debug:
deepspeed: /workspace/axolotl/deepspeed_configs/zero3_bf16.json
weight_decay: 0.05
fsdp:
fsdp_config:
special_tokens:
bos_token: "<|startoftext|>"
eos_token: "<|im_end|>"
pad_token: "<unk>"
unk_token: "<unk>"
tokens:
- "<|im_start|>"
```
</details><br>
# out-yi
This model is a fine-tuned version of [01-ai/Yi-1.5-34B](https://huggingface.co/01-ai/Yi-1.5-34B) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4425
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- total_eval_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.6265 | 0.0 | 1 | 0.6035 |
| 0.4674 | 0.25 | 327 | 0.4344 |
| 0.4337 | 0.5 | 654 | 0.4250 |
| 0.4346 | 0.75 | 981 | 0.4179 |
| 0.3985 | 1.0 | 1308 | 0.4118 |
| 0.3128 | 1.23 | 1635 | 0.4201 |
| 0.3261 | 1.48 | 1962 | 0.4157 |
| 0.3259 | 1.73 | 2289 | 0.4122 |
| 0.3126 | 1.98 | 2616 | 0.4079 |
| 0.2265 | 2.21 | 2943 | 0.4441 |
| 0.2297 | 2.46 | 3270 | 0.4427 |
| 0.2424 | 2.71 | 3597 | 0.4425 |
### Framework versions
- Transformers 4.40.0.dev0
- Pytorch 2.2.2+cu121
- Datasets 2.15.0
- Tokenizers 0.15.0 |
Subsets and Splits