
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-26 06:27:38
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 496
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-26 06:27:10
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Hunter-X/first | Hunter-X | 2024-05-29T13:05:40Z | 0 | 0 | null | [
"region:us"
] | null | 2024-05-29T04:57:45Z | # Handcrafted solution example for the S23DR competition
This repo provides an example of a simple algorithm to reconstruct wireframe and submit to S23DR competition.
The repo consistst of the following parts:
- `script.py` - the main file, which is run by the competition space. It should produce `submission.parquet` as the result of the run.
- `hoho.py` - the file for parsing the dataset at the inference time. Do NOT change it.
- `handcrafted_solution.py` - contains the actual implementation of the algorithm
- other `*.py` files - helper i/o and visualization utilities
- `packages/` - the directory to put python wheels for the custom packages you want to install and use.
## Solution description
The solution is simple.
1. Using provided (but noisy) semantic segmentation called `gestalt`, it takes the centroids of the vertex classes - `apex` and `eave_end_point` and projects them to 3D using provided (also noisy) monocular depth.
2. The vertices are connected using the same segmentation, by checking for edges classes to be present - `['eave', 'ridge', 'rake', 'valley']`.
3. All the "per-image" vertex predictions are merged in 3D space if their distance is less than threshold.
4. All vertices, which have zero connections, are removed.
## Example on the training set
See in [notebooks/example_on_training.ipynb](notebooks/example_on_training.ipynb)
---
license: apache-2.0
---
|
Holarissun/REPROD_dpo_helpfulhelpful_human_subset-1_modelgemma7b_maxsteps10000_bz8_lr5e-06 | Holarissun | 2024-05-29T13:04:57Z | 1 | 0 | peft | [
"peft",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:google/gemma-7b",
"base_model:adapter:google/gemma-7b",
"license:gemma",
"region:us"
] | null | 2024-05-29T13:04:53Z | ---
license: gemma
library_name: peft
tags:
- trl
- dpo
- generated_from_trainer
base_model: google/gemma-7b
model-index:
- name: REPROD_dpo_helpfulhelpful_human_subset-1_modelgemma7b_maxsteps10000_bz8_lr5e-06
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# REPROD_dpo_helpfulhelpful_human_subset-1_modelgemma7b_maxsteps10000_bz8_lr5e-06
This model is a fine-tuned version of [google/gemma-7b](https://huggingface.co/google/gemma-7b) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 15
- training_steps: 10000
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.38.2
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2 |
JeanM45/e9f202b2 | JeanM45 | 2024-05-29T13:04:03Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"phi",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-29T12:58:11Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Juliekyungyoon/plant-kaggle-conv | Juliekyungyoon | 2024-05-29T12:57:53Z | 2 | 0 | transformers | [
"transformers",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-28T06:37:30Z | ---
license: apache-2.0
---
|
YorkieOH10/MistralHermesPipe-7B-slerp | YorkieOH10 | 2024-05-29T12:54:22Z | 44 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"OpenPipe/mistral-ft-optimized-1218",
"mlabonne/NeuralHermes-2.5-Mistral-7B",
"base_model:OpenPipe/mistral-ft-optimized-1218",
"base_model:merge:OpenPipe/mistral-ft-optimized-1218",
"base_model:mlabonne/NeuralHermes-2.5-Mistral-7B",
"base_model:merge:mlabonne/NeuralHermes-2.5-Mistral-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-29T12:40:16Z | ---
tags:
- merge
- mergekit
- lazymergekit
- OpenPipe/mistral-ft-optimized-1218
- mlabonne/NeuralHermes-2.5-Mistral-7B
base_model:
- OpenPipe/mistral-ft-optimized-1218
- mlabonne/NeuralHermes-2.5-Mistral-7B
license: apache-2.0
---
# MistralHermesPipe-7B-slerp
MistralHermesPipe-7B-slerp is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [OpenPipe/mistral-ft-optimized-1218](https://huggingface.co/OpenPipe/mistral-ft-optimized-1218)
* [mlabonne/NeuralHermes-2.5-Mistral-7B](https://huggingface.co/mlabonne/NeuralHermes-2.5-Mistral-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: OpenPipe/mistral-ft-optimized-1218
layer_range: [0, 32]
- model: mlabonne/NeuralHermes-2.5-Mistral-7B
layer_range: [0, 32]
merge_method: slerp
base_model: OpenPipe/mistral-ft-optimized-1218
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "YorkieOH10/MistralHermesPipe-7B-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
grrvk/palm-inst | grrvk | 2024-05-29T12:53:20Z | 33 | 0 | transformers | [
"transformers",
"safetensors",
"mask2former",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-21T18:37:52Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Nogu-t/llama-3-8b-ver3 | Nogu-t | 2024-05-29T12:47:40Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T12:37:06Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Likich/llama3-finetune-qualcoding_1000_prompt3_dot | Likich | 2024-05-29T12:45:45Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T12:45:36Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
lgk03/WITHINAPPS_NDD-dimeshift_test-content | lgk03 | 2024-05-29T12:40:18Z | 119 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T12:31:00Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: WITHINAPPS_NDD-dimeshift_test-content
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# WITHINAPPS_NDD-dimeshift_test-content
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1472
- Accuracy: 0.9415
- F1: 0.9254
- Precision: 0.9450
- Recall: 0.9415
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:------:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| No log | 0.9897 | 72 | 0.2019 | 0.9205 | 0.8823 | 0.8473 | 0.9205 |
| No log | 1.9794 | 144 | 0.1472 | 0.9415 | 0.9254 | 0.9450 | 0.9415 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
pankaj0507/Mistral-7B-Instruct-v0.3-finetune | pankaj0507 | 2024-05-29T12:36:48Z | 1 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-Instruct-v0.3",
"base_model:adapter:mistralai/Mistral-7B-Instruct-v0.3",
"license:apache-2.0",
"region:us"
] | null | 2024-05-29T12:35:26Z | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: mistralai/Mistral-7B-Instruct-v0.3
model-index:
- name: Mistral-7B-Instruct-v0.3-finetune
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Mistral-7B-Instruct-v0.3-finetune
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.3](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1051
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- PEFT 0.11.1
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2 |
Rainnighttram/RED50_Gemma_Instruct_model | Rainnighttram | 2024-05-29T12:31:25Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"gemma",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:unsloth/gemma-7b-it-bnb-4bit",
"base_model:quantized:unsloth/gemma-7b-it-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-29T11:51:10Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- gemma
- trl
base_model: unsloth/gemma-7b-it-bnb-4bit
---
# Uploaded model
- **Developed by:** Rainnighttram
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-7b-it-bnb-4bit
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Newton7/Llama-3-8B-NPOV-wiki | Newton7 | 2024-05-29T12:29:47Z | 0 | 0 | peft | [
"peft",
"safetensors",
"en",
"arxiv:1910.09700",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:mit",
"region:us"
] | null | 2024-05-29T12:17:09Z | ---
library_name: peft
base_model: meta-llama/Meta-Llama-3-8B-Instruct
license: mit
language:
- en
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This instruction tuned model is optimized for dialogue use cases and outperforms many of the available open source chat models on common industry benchmarks.
Further, in developing these models, we took great care to optimize helpfulness and safety.
Input - Models input text only.
Output- Models generate text only
- **Developed by:** XYZ
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1 |
fine-tuned/SciFact-32000-384-gpt-4o-2024-05-13-25926506 | fine-tuned | 2024-05-29T12:27:39Z | 4 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"en",
"dataset:fine-tuned/SciFact-32000-384-gpt-4o-2024-05-13-25926506",
"dataset:allenai/c4",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-05-29T12:27:04Z | ---
license: apache-2.0
datasets:
- fine-tuned/SciFact-32000-384-gpt-4o-2024-05-13-25926506
- allenai/c4
language:
- en
- en
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
---
This model is a fine-tuned version of [**BAAI/bge-large-en-v1.5**](https://huggingface.co/BAAI/bge-large-en-v1.5) designed for the following use case:
None
## How to Use
This model can be easily integrated into your NLP pipeline for tasks such as text classification, sentiment analysis, entity recognition, and more. Here's a simple example to get you started:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
'fine-tuned/SciFact-32000-384-gpt-4o-2024-05-13-25926506',
trust_remote_code=True
)
embeddings = model.encode([
'first text to embed',
'second text to embed'
])
print(cos_sim(embeddings[0], embeddings[1]))
```
|
zhoukz/llama-2-13b-chat-4bit | zhoukz | 2024-05-29T12:24:42Z | 77 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-29T12:22:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
fine-tuned/FiQA2018-32000-384-gpt-4o-2024-05-13-23538198 | fine-tuned | 2024-05-29T12:23:57Z | 5 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"en",
"dataset:fine-tuned/FiQA2018-32000-384-gpt-4o-2024-05-13-23538198",
"dataset:allenai/c4",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-05-29T12:23:28Z | ---
license: apache-2.0
datasets:
- fine-tuned/FiQA2018-32000-384-gpt-4o-2024-05-13-23538198
- allenai/c4
language:
- en
- en
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
---
This model is a fine-tuned version of [**BAAI/bge-large-en-v1.5**](https://huggingface.co/BAAI/bge-large-en-v1.5) designed for the following use case:
None
## How to Use
This model can be easily integrated into your NLP pipeline for tasks such as text classification, sentiment analysis, entity recognition, and more. Here's a simple example to get you started:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
'fine-tuned/FiQA2018-32000-384-gpt-4o-2024-05-13-23538198',
trust_remote_code=True
)
embeddings = model.encode([
'first text to embed',
'second text to embed'
])
print(cos_sim(embeddings[0], embeddings[1]))
```
|
cadenzachallenge/ConvTasNet_Lyrics_Causal | cadenzachallenge | 2024-05-29T12:22:42Z | 291 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"hearing loss",
"challenge",
"signal processing",
"source separation",
"lyrics intelligibility",
"audio",
"audio-to-audio",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | audio-to-audio | 2024-05-21T09:50:01Z | ---
license: apache-2.0
language:
- en
tags:
- hearing loss
- challenge
- signal processing
- source separation
- lyrics intelligibility
- audio
- audio-to-audio
widget:
- src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
example_title: Test
pipeline_tag: audio-to-audio
---
# Cadenza Challenge: CAD2-Task1
A Causal Lyrics/Accompaniment separation model for the CAD2-Task1 baseline system.
## Parameters
* Architecture: ConvTasNet (Kaituo XU) with multichannel support (Alexandre Defossez).
* Parameters:
* B: 256
* C: 2
* H: 512
* L: 20
* N: 256
* P: 3
* R: 4
* X: 10
* audio_channels: 2
* causal: true
* mask_nonlinear: relu
* norm_type: cLN
* training:
* sample_rate: 44100
* samples_per_track: 64
* segment: 4.0
* aggregate: 1
* batch_size: 4
* early_stop: true
* epochs: 200
## Dataset
The model was trained on the training split of the MUSDB18-HQ dataset.
## How to use
```
from tasnet import ConvTasNetStereo
model = ConvTasNetStereo.from_pretrained(
"cadenzachallenge/ConvTasNet_LyricsSeparation_Causal"
).cpu()
```
## Results
| Track | Vocals (SDR) | Accompaniment (SDR) |
|:------|:------------:|:---------:|
| Al James - Schoolboy Facination | 5.733 | 8.049 |
| AM Contra - Heart Peripheral | 5.887 | 12.691 |
| Angels In Amplifiers - I'm Alright | 5.901 | 9.124 |
| Arise - Run Run Run | 5.208 | 14.868 |
| Ben Carrigan - We'll Talk About It All Tonight | 2.676 | 9.919 |
| BKS - Bulldozer | 1.523 | 11.488 |
| BKS - Too Much | 7.005 | 11.087 |
| Bobby Nobody - Stitch Up | 6.518 | 11.303 |
| Buitraker - Revo X | 4.242 | 13.763 |
| Carlos Gonzalez - A Place For Us | 3.882 | 7.57 |
| Cristina Vane - So Easy | 7.477 | 12.126 |
| Detsky Sad - Walkie Talkie | 6.214 | 9.47 |
| Enda Reilly - Cur An Long Ag Seol | 7.329 | 11.51 |
| Forkupines - Semantics | 4.556 | 11.228 |
| Georgia Wonder - Siren | 3.165 | 7.622 |
| Girls Under Glass - We Feel Alright | 3.176 | 11.677 |
| Hollow Ground - Ill Fate | 5.67 | 14.987 |
| James Elder & Mark M Thompson - The English Actor | 4.014 | 8.834 |
| Juliet's Rescue - Heartbeats | 5.317 | 13.101 |
| Little Chicago's Finest - My Own | 4.409 | 5.378 |
| Louis Cressy Band - Good Time | 5.903 | 10.918 |
| Lyndsey Ollard - Catching Up | 7.812 | 10.793 |
| M.E.R.C. Music - Knockout | 5.663 | 7.815 |
| Moosmusic - Big Dummy Shake | 7.081 | 12.772 |
| Motor Tapes - Shore | 1.745 | 8.775 |
| Mu - Too Bright | 5.518 | 12.242 |
| Nerve 9 - Pray For The Rain | 5.685 | 11.674 |
| PR - Happy Daze | -2.89 | 37.274 |
| PR - Oh No | 0 | 8.987 |
| Punkdisco - Oral Hygiene | 5.044 | 16.173 |
| Raft Monk - Tiring | 2.119 | 8.977 |
| Sambasevam Shanmugam - Kaathaadi | 7.51 | 9.801 |
| Secretariat - Borderline | 5.068 | 9.195 |
| Secretariat - Over The Top | 6.278 | 13.556 |
| Side Effects Project - Sing With Me | 9.637 | 11.222 |
| Signe Jakobsen - What Have You Done To Me | 6.884 | 9.656 |
| Skelpolu - Resurrection | 0.053 | 8.272 |
| Speak Softly - Broken Man | 3.743 | 13.497 |
| Speak Softly - Like Horses | 4.339 | 7.233 |
| The Doppler Shift - Atrophy | 2.47 | 12.58 |
| The Easton Ellises - Falcon 69 | 2.507 | 8.137 |
| The Easton Ellises (Baumi) - SDRNR | 1.463 | 8.136 |
| The Long Wait - Dark Horses | 4.784 | 10.964 |
| The Mountaineering Club - Mallory | 9.015 | 13.26 |
| The Sunshine Garcia Band - For I Am The Moon | 8.341 | 12.1 |
| Timboz - Pony | 2.698 | 12.415 |
| Tom McKenzie - Directions | 7.305 | 15.07 |
| Triviul feat. The Fiend - Widow | 6.409 | 7.938 |
| We Fell From The Sky - Not You | 3.661 | 11.403 |
| Zeno - Signs | 5.291 | 10.178 |
| **Total (median over frames, median over tracks)** | **5.249** | **11.155** | |
IntellectusAI/zephyr_finetune_writ | IntellectusAI | 2024-05-29T12:21:47Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T12:21:44Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
vuongnhathien/convnext-tiny-upgrade-1k-224-batch-32 | vuongnhathien | 2024-05-29T12:16:45Z | 192 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"convnextv2",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:facebook/convnextv2-tiny-1k-224",
"base_model:finetune:facebook/convnextv2-tiny-1k-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-29T10:37:27Z | ---
license: apache-2.0
base_model: facebook/convnextv2-tiny-1k-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: convnext-tiny-upgrade-1k-224-batch-32
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8886904761904761
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# convnext-tiny-upgrade-1k-224-batch-32
This model is a fine-tuned version of [facebook/convnextv2-tiny-1k-224](https://huggingface.co/facebook/convnextv2-tiny-1k-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4027
- Accuracy: 0.8887
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.5523 | 1.0 | 550 | 1.2083 | 0.7010 |
| 1.0852 | 2.0 | 1100 | 0.7955 | 0.7960 |
| 0.9179 | 3.0 | 1650 | 0.6425 | 0.8258 |
| 0.7621 | 4.0 | 2200 | 0.5426 | 0.8549 |
| 0.7506 | 5.0 | 2750 | 0.5018 | 0.8624 |
| 0.6774 | 6.0 | 3300 | 0.4792 | 0.8684 |
| 0.6364 | 7.0 | 3850 | 0.4526 | 0.8744 |
| 0.5961 | 8.0 | 4400 | 0.4362 | 0.8799 |
| 0.602 | 9.0 | 4950 | 0.4316 | 0.8827 |
| 0.5896 | 10.0 | 5500 | 0.4287 | 0.8851 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
Felladrin/gguf-sharded-prem-1B-chat | Felladrin | 2024-05-29T12:12:36Z | 1 | 0 | null | [
"gguf",
"base_model:premai-io/prem-1B-chat",
"base_model:quantized:premai-io/prem-1B-chat",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-29T12:09:47Z | ---
license: apache-2.0
base_model: premai-io/prem-1B-chat
---
Sharded GGUF version of [premai-io/prem-1B-chat](https://huggingface.co/premai-io/prem-1B-chat).
|
Chrisantha/distilbert-base-uncased-finetuned-synthetic-finetuned-synthetic | Chrisantha | 2024-05-29T12:12:15Z | 117 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"fill-mask",
"generated_from_trainer",
"base_model:Chrisantha/distilbert-base-uncased-finetuned-synthetic",
"base_model:finetune:Chrisantha/distilbert-base-uncased-finetuned-synthetic",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-05-28T16:36:16Z | ---
license: apache-2.0
base_model: Chrisantha/distilbert-base-uncased-finetuned-synthetic
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-synthetic-finetuned-synthetic
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-synthetic-finetuned-synthetic
This model is a fine-tuned version of [Chrisantha/distilbert-base-uncased-finetuned-synthetic](https://huggingface.co/Chrisantha/distilbert-base-uncased-finetuned-synthetic) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4081
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 1 | 2.9242 |
| 0.5836 | 2.0 | 2 | 2.5911 |
| 0.5836 | 3.0 | 3 | 2.7194 |
| 0.782 | 4.0 | 4 | 2.3194 |
| 0.782 | 5.0 | 5 | 2.1952 |
| 1.3155 | 6.0 | 6 | 2.1321 |
| 1.3155 | 7.0 | 7 | 2.2769 |
| 0.596 | 8.0 | 8 | 2.2093 |
| 0.596 | 9.0 | 9 | 2.4133 |
| 0.817 | 10.0 | 10 | 2.4370 |
| 0.817 | 11.0 | 11 | 2.1859 |
| 0.7962 | 12.0 | 12 | 2.1760 |
| 0.7962 | 13.0 | 13 | 1.9116 |
| 0.7554 | 14.0 | 14 | 1.7670 |
| 0.7554 | 15.0 | 15 | 1.7386 |
| 0.4256 | 16.0 | 16 | 1.6506 |
| 0.4256 | 17.0 | 17 | 1.5478 |
| 0.6326 | 18.0 | 18 | 1.5998 |
| 0.6326 | 19.0 | 19 | 1.6936 |
| 0.493 | 20.0 | 20 | 1.6938 |
| 0.493 | 21.0 | 21 | 1.7659 |
| 0.5194 | 22.0 | 22 | 1.8872 |
| 0.5194 | 23.0 | 23 | 1.7004 |
| 0.4438 | 24.0 | 24 | 1.6653 |
| 0.4438 | 25.0 | 25 | 1.5889 |
| 0.5761 | 26.0 | 26 | 1.4914 |
| 0.5761 | 27.0 | 27 | 1.3813 |
| 0.395 | 28.0 | 28 | 1.4385 |
| 0.395 | 29.0 | 29 | 1.4067 |
| 0.4681 | 30.0 | 30 | 1.4021 |
| 0.4681 | 31.0 | 31 | 1.4172 |
| 0.6326 | 32.0 | 32 | 1.4502 |
| 0.6326 | 33.0 | 33 | 1.5628 |
| 0.3545 | 34.0 | 34 | 1.6276 |
| 0.3545 | 35.0 | 35 | 1.6164 |
| 0.4313 | 36.0 | 36 | 1.7040 |
| 0.4313 | 37.0 | 37 | 1.6950 |
| 0.3883 | 38.0 | 38 | 1.6429 |
| 0.3883 | 39.0 | 39 | 1.6180 |
| 0.5155 | 40.0 | 40 | 1.5417 |
| 0.5155 | 41.0 | 41 | 1.4499 |
| 0.3546 | 42.0 | 42 | 1.3885 |
| 0.3546 | 43.0 | 43 | 1.3061 |
| 0.2205 | 44.0 | 44 | 1.2986 |
| 0.2205 | 45.0 | 45 | 1.2861 |
| 0.2851 | 46.0 | 46 | 1.3785 |
| 0.2851 | 47.0 | 47 | 1.4008 |
| 0.3057 | 48.0 | 48 | 1.4402 |
| 0.3057 | 49.0 | 49 | 1.4538 |
| 0.3449 | 50.0 | 50 | 1.5073 |
| 0.3449 | 51.0 | 51 | 1.5050 |
| 0.1664 | 52.0 | 52 | 1.4939 |
| 0.1664 | 53.0 | 53 | 1.4691 |
| 0.1484 | 54.0 | 54 | 1.2829 |
| 0.1484 | 55.0 | 55 | 1.3112 |
| 0.3156 | 56.0 | 56 | 1.2328 |
| 0.3156 | 57.0 | 57 | 1.1700 |
| 0.379 | 58.0 | 58 | 1.1190 |
| 0.379 | 59.0 | 59 | 1.1429 |
| 0.2475 | 60.0 | 60 | 1.1544 |
| 0.2475 | 61.0 | 61 | 1.2303 |
| 0.2282 | 62.0 | 62 | 1.3118 |
| 0.2282 | 63.0 | 63 | 1.3701 |
| 0.2216 | 64.0 | 64 | 1.3705 |
| 0.2216 | 65.0 | 65 | 1.4848 |
| 0.1768 | 66.0 | 66 | 1.4744 |
| 0.1768 | 67.0 | 67 | 1.5796 |
| 0.1621 | 68.0 | 68 | 1.5674 |
| 0.1621 | 69.0 | 69 | 1.5873 |
| 0.3016 | 70.0 | 70 | 1.5756 |
| 0.3016 | 71.0 | 71 | 1.6496 |
| 0.2548 | 72.0 | 72 | 1.5922 |
| 0.2548 | 73.0 | 73 | 1.5911 |
| 0.2878 | 74.0 | 74 | 1.4912 |
| 0.2878 | 75.0 | 75 | 1.5303 |
| 0.2045 | 76.0 | 76 | 1.5293 |
| 0.2045 | 77.0 | 77 | 1.4076 |
| 0.219 | 78.0 | 78 | 1.4773 |
| 0.219 | 79.0 | 79 | 1.3878 |
| 0.1396 | 80.0 | 80 | 1.3349 |
| 0.1396 | 81.0 | 81 | 1.3670 |
| 0.166 | 82.0 | 82 | 1.4015 |
| 0.166 | 83.0 | 83 | 1.4132 |
| 0.2982 | 84.0 | 84 | 1.4478 |
| 0.2982 | 85.0 | 85 | 1.4803 |
| 0.1199 | 86.0 | 86 | 1.4667 |
| 0.1199 | 87.0 | 87 | 1.5402 |
| 0.1982 | 88.0 | 88 | 1.5515 |
| 0.1982 | 89.0 | 89 | 1.5189 |
| 0.1816 | 90.0 | 90 | 1.5545 |
| 0.1816 | 91.0 | 91 | 1.4814 |
| 0.1779 | 92.0 | 92 | 1.4943 |
| 0.1779 | 93.0 | 93 | 1.4430 |
| 0.0785 | 94.0 | 94 | 1.4865 |
| 0.0785 | 95.0 | 95 | 1.4919 |
| 0.1108 | 96.0 | 96 | 1.5035 |
| 0.1108 | 97.0 | 97 | 1.4088 |
| 0.2581 | 98.0 | 98 | 1.4104 |
| 0.2581 | 99.0 | 99 | 1.4549 |
| 0.1738 | 100.0 | 100 | 1.3761 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
saishf/SOVLish-Devil-8B-L3 | saishf | 2024-05-29T12:12:13Z | 95 | 6 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2403.19522",
"base_model:ResplendentAI/Aura_Llama3",
"base_model:merge:ResplendentAI/Aura_Llama3",
"base_model:ResplendentAI/BlueMoon_Llama3",
"base_model:merge:ResplendentAI/BlueMoon_Llama3",
"base_model:ResplendentAI/Luna_Llama3",
"base_model:merge:ResplendentAI/Luna_Llama3",
"base_model:ResplendentAI/RP_Format_QuoteAsterisk_Llama3",
"base_model:merge:ResplendentAI/RP_Format_QuoteAsterisk_Llama3",
"base_model:ResplendentAI/Smarts_Llama3",
"base_model:merge:ResplendentAI/Smarts_Llama3",
"base_model:mlabonne/Daredevil-8B-abliterated",
"base_model:merge:mlabonne/Daredevil-8B-abliterated",
"license:cc-by-nc-4.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-28T10:05:58Z | ---
license: cc-by-nc-4.0
library_name: transformers
tags:
- mergekit
- merge
base_model:
- mlabonne/Daredevil-8B-abliterated
- ResplendentAI/RP_Format_QuoteAsterisk_Llama3
- mlabonne/Daredevil-8B-abliterated
- ResplendentAI/BlueMoon_Llama3
- mlabonne/Daredevil-8B-abliterated
- ResplendentAI/Luna_Llama3
- mlabonne/Daredevil-8B-abliterated
- mlabonne/Daredevil-8B-abliterated
- ResplendentAI/Aura_Llama3
- mlabonne/Daredevil-8B-abliterated
- ResplendentAI/Smarts_Llama3
model-index:
- name: SOVLish-Devil-8B-L3
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 69.2
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=saishf/SOVLish-Devil-8B-L3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 84.44
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=saishf/SOVLish-Devil-8B-L3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 68.97
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=saishf/SOVLish-Devil-8B-L3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 57.95
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=saishf/SOVLish-Devil-8B-L3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 78.14
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=saishf/SOVLish-Devil-8B-L3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 72.48
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=saishf/SOVLish-Devil-8B-L3
name: Open LLM Leaderboard
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details

Devil >:3
This is another "SOVL" style merge, this time using [mlabonne/Daredevil-8B-abliterated](https://huggingface.co/mlabonne/Daredevil-8B-abliterated).
Daredevil is the first abliterated model i've tried that feels as smart as base llama-3-instruct while also being willing to give instructions to do all kinda of illegal things
This model should do well in rp, I'm yet to test it (waiting for gguf files @_@)
### Merge Method
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using [mlabonne/Daredevil-8B-abliterated](https://huggingface.co/mlabonne/Daredevil-8B-abliterated) as a base.
### Models Merged
The following models were included in the merge:
* [mlabonne/Daredevil-8B-abliterated](https://huggingface.co/mlabonne/Daredevil-8B-abliterated) + [ResplendentAI/RP_Format_QuoteAsterisk_Llama3](https://huggingface.co/ResplendentAI/RP_Format_QuoteAsterisk_Llama3)
* [mlabonne/Daredevil-8B-abliterated](https://huggingface.co/mlabonne/Daredevil-8B-abliterated) + [ResplendentAI/BlueMoon_Llama3](https://huggingface.co/ResplendentAI/BlueMoon_Llama3)
* [mlabonne/Daredevil-8B-abliterated](https://huggingface.co/mlabonne/Daredevil-8B-abliterated) + [ResplendentAI/Luna_Llama3](https://huggingface.co/ResplendentAI/Luna_Llama3)
* [mlabonne/Daredevil-8B-abliterated](https://huggingface.co/mlabonne/Daredevil-8B-abliterated) + [ResplendentAI/Aura_Llama3](https://huggingface.co/ResplendentAI/Aura_Llama3)
* [mlabonne/Daredevil-8B-abliterated](https://huggingface.co/mlabonne/Daredevil-8B-abliterated) + [ResplendentAI/Smarts_Llama3](https://huggingface.co/ResplendentAI/Smarts_Llama3)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: mlabonne/Daredevil-8B-abliterated+ResplendentAI/Aura_Llama3
- model: mlabonne/Daredevil-8B-abliterated+ResplendentAI/Smarts_Llama3
- model: mlabonne/Daredevil-8B-abliterated+ResplendentAI/Luna_Llama3
- model: mlabonne/Daredevil-8B-abliterated+ResplendentAI/BlueMoon_Llama3
- model: mlabonne/Daredevil-8B-abliterated+ResplendentAI/RP_Format_QuoteAsterisk_Llama3
merge_method: model_stock
base_model: mlabonne/Daredevil-8B-abliterated
dtype: bfloat16
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_saishf__SOVLish-Devil-8B-L3)
| Metric |Value|
|---------------------------------|----:|
|Avg. |71.86|
|AI2 Reasoning Challenge (25-Shot)|69.20|
|HellaSwag (10-Shot) |84.44|
|MMLU (5-Shot) |68.97|
|TruthfulQA (0-shot) |57.95|
|Winogrande (5-shot) |78.14|
|GSM8k (5-shot) |72.48|
|
lgk03/WITHINAPPS_NDD-ppma_test-content | lgk03 | 2024-05-29T12:10:28Z | 106 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T12:06:13Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: WITHINAPPS_NDD-ppma_test-content
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# WITHINAPPS_NDD-ppma_test-content
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2237
- Accuracy: 0.8795
- F1: 0.8231
- Precision: 0.7735
- Recall: 0.8795
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:------:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| No log | 0.9836 | 30 | 0.2373 | 0.8795 | 0.8231 | 0.7735 | 0.8795 |
| No log | 1.9672 | 60 | 0.2237 | 0.8795 | 0.8231 | 0.7735 | 0.8795 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
ringorsolya/moresBERT_hu_7 | ringorsolya | 2024-05-29T12:04:36Z | 106 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T11:06:57Z | ---
license: apache-2.0
---
|
davanstrien/code-prompt-similarity-model | davanstrien | 2024-05-29T12:04:34Z | 217 | 6 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"mpnet",
"sentence-similarity",
"feature-extraction",
"dataset_size:n<1K",
"loss:MultipleNegativesRankingLoss",
"en",
"dataset:davanstrien/similarity-dataset-sc2-8b",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:microsoft/mpnet-base",
"base_model:finetune:microsoft/mpnet-base",
"license:apache-2.0",
"model-index",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2024-05-29T11:59:37Z | ---
language:
- en
license: apache-2.0
library_name: sentence-transformers
datasets:
- davanstrien/similarity-dataset-sc2-8b
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- dataset_size:n<1K
- loss:MultipleNegativesRankingLoss
base_model: microsoft/mpnet-base
metrics:
- cosine_accuracy
- dot_accuracy
- manhattan_accuracy
- euclidean_accuracy
- max_accuracy
widget:
- source_sentence: Write a Python function that counts the number of even numbers
in a given list of integers or floats
sentences:
- Write a Python function that returns the number of even numbers in a list.
- Create a Python function that adds up all the numbers in a given list. The function
should support lists containing only positive integers.
- Write a Python function that converts a JSON string into a Python dictionary using
the json module and returns it.
- source_sentence: Develop a Python function to validate whether a given string represents
a valid IPv4 address or not.
sentences:
- Create a Python function to validate a string `s` as an IPv4 address. The function
should return `True` if `s` is a valid IPv4 address, and `False` otherwise.
- Write a Python function to find the key with the highest value in a dictionary.
The function should return the value of the key if it exists
- Write a Python function that, given a dictionary `d` and an integer `k`, returns
the sum of the values of the first `k` keys in `d`.
- source_sentence: Write a Python function to create a list of numbers with exactly
one even number and n-1 odd numbers
sentences:
- Write a Python function that returns the number of even numbers in a list.
- Write a Python function that recursively traverses a given folder structure and
returns the absolute path of all files that end with ".txt".
- Write a Python decorator function that overrides the docstring of the decorated
function, and stores the old docstring and other metadata in a `_doc_metadata`
attribute of the function.
- source_sentence: 'Implement a Python function that prints the first character of
a string using its indexing feature. '
sentences:
- Write a Python function that takes a string as a parameter and returns the first
character of the string.
- Write a Python function that checks if the bit at position `bit` is set in the
given `integer`. This function should return a boolean value.
- 'Write a Python function `floor_division(x: int, y: int) -> int` that divides
two integers `x` and `y` and returns the largest whole number less than or equal
to the result.'
- source_sentence: Write a Python function that takes a MIDI note number and returns
the corresponding piano key number.
sentences:
- Create a Python function that translates MIDI note numbers into piano key numbers,
facilitating music generation.
- Write a Python function that accepts a dictionary and returns a set of distinct
values. If a key maps to an empty list, return an empty set.
- Write a Python function `join_strings_with_comma(lst)` that takes a list of strings
and returns a single string with all the strings from the list, separated by commas.
pipeline_tag: sentence-similarity
co2_eq_emissions:
emissions: 2.213004168952992
energy_consumed: 0.006336878829164133
source: codecarbon
training_type: fine-tuning
on_cloud: false
cpu_model: Intel(R) Xeon(R) CPU @ 2.20GHz
ram_total_size: 62.804237365722656
hours_used: 0.049
hardware_used: 1 x NVIDIA L4
model-index:
- name: MPNet base trained on AllNLI triplets
results:
- task:
type: triplet
name: Triplet
dataset:
name: code similarity dev
type: code-similarity-dev
metrics:
- type: cosine_accuracy
value: 0.934010152284264
name: Cosine Accuracy
- type: dot_accuracy
value: 0.07106598984771574
name: Dot Accuracy
- type: manhattan_accuracy
value: 0.934010152284264
name: Manhattan Accuracy
- type: euclidean_accuracy
value: 0.9390862944162437
name: Euclidean Accuracy
- type: max_accuracy
value: 0.9390862944162437
name: Max Accuracy
- task:
type: triplet
name: Triplet
dataset:
name: Unknown
type: unknown
metrics:
- type: cosine_accuracy
value: 0.934010152284264
name: Cosine Accuracy
- type: dot_accuracy
value: 0.07106598984771574
name: Dot Accuracy
- type: manhattan_accuracy
value: 0.934010152284264
name: Manhattan Accuracy
- type: euclidean_accuracy
value: 0.9390862944162437
name: Euclidean Accuracy
- type: max_accuracy
value: 0.9390862944162437
name: Max Accuracy
---
# MPNet base trained on AllNLI triplets
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [microsoft/mpnet-base](https://huggingface.co/microsoft/mpnet-base). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [microsoft/mpnet-base](https://huggingface.co/microsoft/mpnet-base) <!-- at revision 6996ce1e91bd2a9c7d7f61daec37463394f73f09 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 tokens
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("davanstrien/code-prompt-similarity-model")
# Run inference
sentences = [
'Write a Python function that takes a MIDI note number and returns the corresponding piano key number.',
'Create a Python function that translates MIDI note numbers into piano key numbers, facilitating music generation.',
'Write a Python function that accepts a dictionary and returns a set of distinct values. If a key maps to an empty list, return an empty set.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Triplet
* Dataset: `code-similarity-dev`
* Evaluated with [<code>TripletEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.TripletEvaluator)
| Metric | Value |
|:-------------------|:-----------|
| cosine_accuracy | 0.934 |
| dot_accuracy | 0.0711 |
| manhattan_accuracy | 0.934 |
| euclidean_accuracy | 0.9391 |
| **max_accuracy** | **0.9391** |
#### Triplet
* Evaluated with [<code>TripletEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.TripletEvaluator)
| Metric | Value |
|:-------------------|:-----------|
| cosine_accuracy | 0.934 |
| dot_accuracy | 0.0711 |
| manhattan_accuracy | 0.934 |
| euclidean_accuracy | 0.9391 |
| **max_accuracy** | **0.9391** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `num_train_epochs`: 10
- `warmup_ratio`: 0.1
- `bf16`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 10
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | loss | code-similarity-dev_max_accuracy | max_accuracy |
|:-----:|:----:|:-------------:|:------:|:--------------------------------:|:------------:|
| 0 | 0 | - | - | 0.8680 | - |
| 2.0 | 100 | 0.6379 | 0.1845 | 0.9340 | - |
| 4.0 | 200 | 0.0399 | 0.1577 | 0.9543 | - |
| 6.0 | 300 | 0.0059 | 0.1577 | 0.9543 | - |
| 8.0 | 400 | 0.0018 | 0.1662 | 0.9492 | - |
| 10.0 | 500 | 0.0009 | 0.1643 | 0.9391 | 0.9391 |
### Environmental Impact
Carbon emissions were measured using [CodeCarbon](https://github.com/mlco2/codecarbon).
- **Energy Consumed**: 0.006 kWh
- **Carbon Emitted**: 0.002 kg of CO2
- **Hours Used**: 0.049 hours
### Training Hardware
- **On Cloud**: No
- **GPU Model**: 1 x NVIDIA L4
- **CPU Model**: Intel(R) Xeon(R) CPU @ 2.20GHz
- **RAM Size**: 62.80 GB
### Framework Versions
- Python: 3.10.12
- Sentence Transformers: 3.0.0
- Transformers: 4.41.1
- PyTorch: 2.3.0+cu121
- Accelerate: 0.30.1
- Datasets: 2.19.1
- Tokenizers: 0.19.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
--> |
DaichiT/vinyl | DaichiT | 2024-05-29T12:03:39Z | 30 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stabilityai/stable-diffusion-2",
"base_model:finetune:stabilityai/stable-diffusion-2",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-29T11:52:25Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
base_model: stabilityai/stable-diffusion-2
inference: true
instance_prompt: a photo of sks vinyl
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - DaichiT/vinyl
This is a dreambooth model derived from stabilityai/stable-diffusion-2. The weights were trained on a photo of sks vinyl using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
Ramikan-BR/tinyllama-coder-py-LORA-v13 | Ramikan-BR | 2024-05-29T12:01:28Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/tinyllama-chat-bnb-4bit",
"base_model:finetune:unsloth/tinyllama-chat-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T12:00:55Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/tinyllama-chat-bnb-4bit
---
# Uploaded model
- **Developed by:** Ramikan-BR
- **License:** apache-2.0
- **Finetuned from model :** unsloth/tinyllama-chat-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
VH1213141516/r2d2-lat-5-28-epsilon-1-outer-lr-5e-6-checkpt-120 | VH1213141516 | 2024-05-29T11:59:44Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T11:59:18Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
cosmicman/CosmicMan-SD | cosmicman | 2024-05-29T11:59:40Z | 8 | 2 | diffusers | [
"diffusers",
"safetensors",
"arxiv:2404.01294",
"license:cc-by-4.0",
"region:us"
] | null | 2024-05-29T11:42:59Z | ---
license: cc-by-4.0
---

CosmicMan is a text-to-image foundation model specialized for generating high-fidelity human images. For more information, please refer to our research paper: [CosmicMan: A Text-to-Image Foundation Model for Humans](https://arxiv.org/abs/2404.01294). Our model is based on [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5). This repository provide UNet checkpoints for CosmicMan-SD.
## Requirements
```python
conda create -n cosmicman python=3.10
source activate cosmicman
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install accelerate diffusers datasets transformers botocore invisible-watermark bitsandbytes gradio==3.48.0
```
## Inference
```python
import torch
from diffusers import StableDiffusionPipeline, UNet2DConditionModel, EulerDiscreteScheduler
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
base_path = "runwayml/stable-diffusion-v1-5"
unet_path = "cosmicman/CosmicMan-SD"
# Load model.
unet = UNet2DConditionModel.from_pretrained(unet_path, torch_dtype=torch.float16)
pipe = StableDiffusionPipeline.from_pretrained(base_path, unet=unet, torch_dtype=torch.float16, variant="fp16").to("cuda")
pipe.scheduler = EulerDiscreteScheduler.from_pretrained(base_path, subfolder="scheduler", torch_dtype=torch.float16)
# Generate image.
positive_prompt = "A closeup portrait shot against a white wall, a fit Caucasian adult female with wavy blonde hair falling above her chest wears a short sleeve silk floral dress and a floral silk normal short sleeve white blouse"
negative_prompt = ""
image = pipe(positive_prompt, num_inference_steps=30,
guidance_scale=7.5, height=1024,
width=1024, negative_prompt=negative_prompt, output_type="pil").images[0].save("output.png")
```
## Citation Information
```
@article{li2024cosmicman,
title={CosmicMan: A Text-to-Image Foundation Model for Humans},
author={Li, Shikai and Fu, Jianglin and Liu, Kaiyuan and Wang, Wentao and Lin, Kwan-Yee and Wu, Wayne},
journal={arXiv preprint arXiv:2404.01294},
year={2024}
}
```
|
VH1213141516/r2d2-lat-5-28-epsilon-1-outer-lr-5e-6-checkpt-360 | VH1213141516 | 2024-05-29T11:58:39Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T11:57:45Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Adriana213/xlm-roberta-base-finetuned-panx-en | Adriana213 | 2024-05-29T11:58:06Z | 105 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-05-29T09:41:25Z | ---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
model-index:
- name: xlm-roberta-base-finetuned-panx-en
results: []
---
# xlm-roberta-base-finetuned-panx-en
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base).
It achieves the following results on the evaluation set:
- Loss: 0.3905
- F1 Score: 0.6861
## Model description
This model is a fine-tuned version of xlm-roberta-base on the English subset of the PAN-X dataset for Named Entity Recognition (NER). The model has been fine-tuned to perform token classification tasks and is evaluated on its performance in identifying named entities in English text.
## Intended uses & limitations
### Intended uses:
Named Entity Recognition (NER) tasks specifically for English.
Token classification tasks involving English text.
### Limitations:
The model's performance is optimized for English and may not generalize well to other languages without further fine-tuning.
The model's predictions are based on the data it was trained on and may not handle out-of-domain data as effectively.d
## Training and evaluation data
The model was fine-tuned on the English subset of the PAN-X dataset, which includes labeled examples of named entities in English text. The evaluation data is a separate portion of the same dataset, used to assess the model's performance
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0479 | 1.0 | 50 | 0.4854 | 0.5857 |
| 0.4604 | 2.0 | 100 | 0.3995 | 0.6605 |
| 0.3797 | 3.0 | 150 | 0.3905 | 0.6861 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
Adriana213/xlm-roberta-base-finetuned-panx-it | Adriana213 | 2024-05-29T11:56:35Z | 104 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"it",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-05-29T09:39:35Z | ---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
model-index:
- name: xlm-roberta-base-finetuned-panx-it
results: []
language:
- it
metrics:
- f1
library_name: transformers
---
# xlm-roberta-base-finetuned-panx-it
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base).
It achieves the following results on the evaluation set:
- Loss: 0.2619
- F1 Score: 0.8321
## Model description
This model is a fine-tuned version of xlm-roberta-base on the Italian subset of the PAN-X dataset for Named Entity Recognition (NER). The model has been fine-tuned to perform token classification tasks and is evaluated on its performance in identifying named entities in Italian text.
## Intended uses & limitations
### Intended uses:
Named Entity Recognition (NER) tasks specifically for Italian.
Token classification tasks involving Italian text.
### Limitations:
The model's performance is optimized for Italian and may not generalize well to other languages without further fine-tuning.
The model's predictions are based on the data it was trained on and may not handle out-of-domain data as effectively.
## Training and evaluation data
The model was fine-tuned on the Italian subset of the PAN-X dataset, which includes labeled examples of named entities in Italian text. The evaluation data is a separate portion of the same dataset, used to assess the model's performance.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7217 | 1.0 | 70 | 0.3193 | 0.7343 |
| 0.2736 | 2.0 | 140 | 0.2760 | 0.8055 |
| 0.1838 | 3.0 | 210 | 0.2619 | 0.8321 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1 |
abhi317/results_008 | abhi317 | 2024-05-29T11:56:23Z | 1 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama3",
"region:us"
] | null | 2024-05-29T11:45:38Z | ---
license: llama3
library_name: peft
tags:
- generated_from_trainer
base_model: meta-llama/Meta-Llama-3-8B-Instruct
model-index:
- name: results_008
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results_008
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 20.8098
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 21.2839 | 1.0 | 1 | 21.0366 |
| 21.2839 | 2.0 | 2 | 20.7089 |
| 21.2839 | 3.0 | 3 | 20.8205 |
| 21.2839 | 4.0 | 4 | 20.5746 |
| 21.2839 | 5.0 | 5 | 20.8098 |
### Framework versions
- PEFT 0.11.1
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2 |
ft-player/lanesegnet_baseline | ft-player | 2024-05-29T11:56:09Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-05-29T08:36:04Z | ---
license: apache-2.0
---
|
pablopiquejr/llama-3-8b-Instruct-bnb-4bit-educational_purpose | pablopiquejr | 2024-05-29T11:55:45Z | 6 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"base_model:quantized:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-29T11:53:24Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
---
# Uploaded model
- **Developed by:** pablopiquejr
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Adriana213/xlm-roberta-base-finetuned-panx-fr | Adriana213 | 2024-05-29T11:53:59Z | 135 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"fr",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-05-29T09:36:09Z | ---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
model-index:
- name: xlm-roberta-base-finetuned-panx-fr
results: []
language:
- fr
metrics:
- f1
library_name: transformers
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base).
It achieves the following results on the evaluation set:
- Loss: 0.2750
- F1 Score: 0.8495
## Model description
This model is a fine-tuned version of xlm-roberta-base on the French subset of the PAN-X dataset for Named Entity Recognition (NER). The model has been fine-tuned to perform token classification tasks and is evaluated on its performance in identifying named entities in French text.
## Intended uses & limitations
### Intended uses:
Named Entity Recognition (NER) tasks specifically for French.
Token classification tasks involving French text.
### Limitations:
The model's performance is optimized for French and may not generalize well to other languages without further fine-tuning.
The model's predictions are based on the data it was trained on and may not handle out-of-domain data as effectively.
## Training and evaluation data
The model was fine-tuned on the French subset of the PAN-X dataset, which includes labeled examples of named entities in French text. The evaluation data is a separate portion of the same dataset, used to assess the model's performance.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5647 | 1.0 | 191 | 0.3242 | 0.7728 |
| 0.2671 | 2.0 | 382 | 0.2672 | 0.8202 |
| 0.1744 | 3.0 | 573 | 0.2750 | 0.8495 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1 |
DaichiT/valve_copper_alloy | DaichiT | 2024-05-29T11:50:54Z | 29 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stabilityai/stable-diffusion-2",
"base_model:finetune:stabilityai/stable-diffusion-2",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-29T11:39:07Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
base_model: stabilityai/stable-diffusion-2
inference: true
instance_prompt: a photo of sks valve_copper_alloy
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - DaichiT/valve_copper_alloy
This is a dreambooth model derived from stabilityai/stable-diffusion-2. The weights were trained on a photo of sks valve_copper_alloy using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
Piola-h333/Norman | Piola-h333 | 2024-05-29T11:48:53Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-05-29T11:47:28Z | ---
license: apache-2.0
---
|
Vipinap/RAFT-llama3-GPT_data_v24.05.01 | Vipinap | 2024-05-29T11:48:28Z | 77 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-29T11:32:56Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: raft_llama3_8b_gpt_data_24_05_29
---
# Uploaded model
- **Developed by:** Vipinap
- **License:** apache-2.0
- **Finetuned from model :** raft_llama3_8b_gpt_data_24_05_29
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Likich/tinyllama-finetune-qualcoding_1000_prompt3 | Likich | 2024-05-29T11:48:01Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T11:47:55Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
lgk03/WITHINAPPS_NDD-addressbook_test-content | lgk03 | 2024-05-29T11:47:44Z | 125 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T11:40:36Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: WITHINAPPS_NDD-addressbook_test-content
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# WITHINAPPS_NDD-addressbook_test-content
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0206
- Accuracy: 0.9977
- F1: 0.9976
- Precision: 0.9977
- Recall: 0.9977
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:------:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| No log | 0.9953 | 53 | 0.0546 | 0.9877 | 0.9876 | 0.9879 | 0.9877 |
| No log | 1.9906 | 106 | 0.0206 | 0.9977 | 0.9976 | 0.9977 | 0.9977 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
abhi317/results_007 | abhi317 | 2024-05-29T11:45:27Z | 1 | 1 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama3",
"region:us"
] | null | 2024-05-28T16:30:39Z | ---
license: llama3
library_name: peft
tags:
- generated_from_trainer
base_model: meta-llama/Meta-Llama-3-8B-Instruct
model-index:
- name: results_007
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results_007
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 20.6308
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 21.2839 | 1.0 | 1 | 20.8364 |
| 21.2839 | 2.0 | 2 | 20.9702 |
| 21.2839 | 3.0 | 3 | 20.7513 |
| 21.2839 | 4.0 | 4 | 20.7336 |
| 21.2839 | 5.0 | 5 | 20.6308 |
### Framework versions
- PEFT 0.11.1
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2 |
Adriana213/xlm-roberta-base-finetuned-panx-de | Adriana213 | 2024-05-29T11:44:10Z | 106 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"de",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-05-29T08:09:04Z | ---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results: []
language:
- de
library_name: transformers
---
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1363
- F1 Score: 0.8658
## Model description
This model is a fine-tuned version of xlm-roberta-base on the German subset of the PAN-X dataset for Named Entity Recognition (NER). The model has been fine-tuned to perform token classification tasks and is evaluated on its performance in identifying named entities in German text.
## Intended uses & limitations
### Intended uses:
Named Entity Recognition (NER) tasks specifically for German.
Token classification tasks involving German text.
### Limitations:
The model's performance is optimized for German and may not generalize well to other languages without further fine-tuning.
The model's predictions are based on the data it was trained on and may not handle out-of-domain data as effectively.
## Training and evaluation data
The model was fine-tuned on the German subset of the PAN-X dataset, which includes labeled examples of named entities in German text. The evaluation data is a separate portion of the same dataset, used to assess the model's performance.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2539 | 1.0 | 525 | 0.1505 | 0.8246 |
| 0.1268 | 2.0 | 1050 | 0.1380 | 0.8503 |
| 0.0794 | 3.0 | 1575 | 0.1363 | 0.8658 |
### Evaluation results
The model's F1-score on the validation set for the German subset is 0.8658, indicating a strong performance in named entity recognition for German text.
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1 |
anyasims/ourpo3_uf4_PR_ABL_PR_sft0.0_zs1.0_a0.5-s2-c477 | anyasims | 2024-05-29T11:43:37Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"llama-factory",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-29T11:37:20Z | ---
library_name: transformers
tags:
- llama-factory
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Mengkedalai/your-unique-repo-name | Mengkedalai | 2024-05-29T11:40:00Z | 0 | 0 | transformers | [
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T11:32:57Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
clmrie/distilbert-base-uncased-finetuned-emotion | clmrie | 2024-05-29T11:39:55Z | 119 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T11:01:14Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 125 | 0.9019 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
nguyennghia0902/electra-small-discriminator_0.0005_16 | nguyennghia0902 | 2024-05-29T11:39:34Z | 61 | 0 | transformers | [
"transformers",
"tf",
"electra",
"question-answering",
"generated_from_keras_callback",
"base_model:google/electra-small-discriminator",
"base_model:finetune:google/electra-small-discriminator",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-05-29T07:40:01Z | ---
license: apache-2.0
base_model: google/electra-small-discriminator
tags:
- generated_from_keras_callback
model-index:
- name: nguyennghia0902/electra-small-discriminator_0.0005_16
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# nguyennghia0902/electra-small-discriminator_0.0005_16
This model is a fine-tuned version of [google/electra-small-discriminator](https://huggingface.co/google/electra-small-discriminator) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.2099
- Train End Logits Accuracy: 0.6982
- Train Start Logits Accuracy: 0.6666
- Validation Loss: 0.7830
- Validation End Logits Accuracy: 0.7964
- Validation Start Logits Accuracy: 0.7852
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 0.0005, 'decay_steps': 31270, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 3.8593 | 0.1838 | 0.1690 | 2.9074 | 0.3506 | 0.3319 | 0 |
| 3.0501 | 0.3257 | 0.2954 | 2.5522 | 0.4171 | 0.3859 | 1 |
| 2.7183 | 0.3845 | 0.3534 | 2.2123 | 0.4803 | 0.4547 | 2 |
| 2.4780 | 0.4325 | 0.4004 | 1.9826 | 0.5248 | 0.5046 | 3 |
| 2.2672 | 0.4747 | 0.4389 | 1.8034 | 0.5660 | 0.5425 | 4 |
| 2.0640 | 0.5162 | 0.4814 | 1.5610 | 0.6207 | 0.6037 | 5 |
| 1.8439 | 0.5608 | 0.5265 | 1.3128 | 0.6811 | 0.6639 | 6 |
| 1.6214 | 0.6104 | 0.5736 | 1.0714 | 0.7326 | 0.7206 | 7 |
| 1.3990 | 0.6574 | 0.6232 | 0.8891 | 0.7744 | 0.7630 | 8 |
| 1.2099 | 0.6982 | 0.6666 | 0.7830 | 0.7964 | 0.7852 | 9 |
### Framework versions
- Transformers 4.39.3
- TensorFlow 2.15.0
- Datasets 2.18.0
- Tokenizers 0.15.2
|
amaye15/microsoft-resnet-50-batch32-lr0.005-standford-dogs | amaye15 | 2024-05-29T11:39:01Z | 243 | 0 | transformers | [
"transformers",
"safetensors",
"resnet",
"image-classification",
"generated_from_trainer",
"dataset:stanford-dogs",
"base_model:microsoft/resnet-50",
"base_model:finetune:microsoft/resnet-50",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-29T11:38:53Z | ---
license: apache-2.0
base_model: microsoft/resnet-50
tags:
- generated_from_trainer
datasets:
- stanford-dogs
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: microsoft-resnet-50-batch32-lr0.005-standford-dogs
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: stanford-dogs
type: stanford-dogs
config: default
split: full
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.82555879494655
- name: F1
type: f1
value: 0.8098053489000772
- name: Precision
type: precision
value: 0.8426096100022951
- name: Recall
type: recall
value: 0.817750070550628
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# microsoft-resnet-50-batch32-lr0.005-standford-dogs
This model is a fine-tuned version of [microsoft/resnet-50](https://huggingface.co/microsoft/resnet-50) on the stanford-dogs dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1192
- Accuracy: 0.8256
- F1: 0.8098
- Precision: 0.8426
- Recall: 0.8178
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:------:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 4.7839 | 0.0777 | 10 | 4.7747 | 0.2556 | 0.2410 | 0.4479 | 0.2436 |
| 4.7731 | 0.1553 | 20 | 4.7576 | 0.3511 | 0.3282 | 0.6032 | 0.3338 |
| 4.7617 | 0.2330 | 30 | 4.7363 | 0.4184 | 0.3974 | 0.6668 | 0.3947 |
| 4.7445 | 0.3107 | 40 | 4.7115 | 0.5265 | 0.4927 | 0.7032 | 0.4993 |
| 4.7266 | 0.3883 | 50 | 4.6846 | 0.5561 | 0.5413 | 0.7422 | 0.5333 |
| 4.7081 | 0.4660 | 60 | 4.6547 | 0.6062 | 0.5767 | 0.7392 | 0.5828 |
| 4.6807 | 0.5437 | 70 | 4.6161 | 0.5909 | 0.5750 | 0.7740 | 0.5673 |
| 4.6572 | 0.6214 | 80 | 4.5761 | 0.6324 | 0.6162 | 0.8021 | 0.6102 |
| 4.6286 | 0.6990 | 90 | 4.5274 | 0.6297 | 0.6241 | 0.8188 | 0.6080 |
| 4.598 | 0.7767 | 100 | 4.4746 | 0.6569 | 0.6609 | 0.8380 | 0.6370 |
| 4.5578 | 0.8544 | 110 | 4.4193 | 0.6674 | 0.6713 | 0.8301 | 0.6486 |
| 4.521 | 0.9320 | 120 | 4.3553 | 0.6914 | 0.6868 | 0.8215 | 0.6729 |
| 4.4888 | 1.0097 | 130 | 4.2924 | 0.7082 | 0.7064 | 0.8415 | 0.6904 |
| 4.4312 | 1.0874 | 140 | 4.2125 | 0.7155 | 0.7076 | 0.8381 | 0.6980 |
| 4.3865 | 1.1650 | 150 | 4.1433 | 0.7145 | 0.7115 | 0.8315 | 0.6984 |
| 4.336 | 1.2427 | 160 | 4.0630 | 0.7082 | 0.7010 | 0.8353 | 0.6930 |
| 4.2903 | 1.3204 | 170 | 3.9781 | 0.7148 | 0.7024 | 0.8109 | 0.6982 |
| 4.2465 | 1.3981 | 180 | 3.8896 | 0.7376 | 0.7234 | 0.8328 | 0.7217 |
| 4.1924 | 1.4757 | 190 | 3.8117 | 0.7476 | 0.7310 | 0.8161 | 0.7322 |
| 4.1217 | 1.5534 | 200 | 3.7499 | 0.7510 | 0.7344 | 0.8105 | 0.7372 |
| 4.068 | 1.6311 | 210 | 3.6340 | 0.7551 | 0.7355 | 0.8183 | 0.7409 |
| 4.0148 | 1.7087 | 220 | 3.5678 | 0.7546 | 0.7358 | 0.8066 | 0.7413 |
| 3.9682 | 1.7864 | 230 | 3.4852 | 0.7663 | 0.7477 | 0.8145 | 0.7530 |
| 3.9196 | 1.8641 | 240 | 3.3841 | 0.7648 | 0.7464 | 0.8075 | 0.7520 |
| 3.8481 | 1.9417 | 250 | 3.3003 | 0.7626 | 0.7421 | 0.8056 | 0.7495 |
| 3.8017 | 2.0194 | 260 | 3.2395 | 0.7578 | 0.7370 | 0.8045 | 0.7461 |
| 3.7528 | 2.0971 | 270 | 3.1183 | 0.7578 | 0.7349 | 0.8007 | 0.7457 |
| 3.6614 | 2.1748 | 280 | 3.0364 | 0.7655 | 0.7435 | 0.8011 | 0.7531 |
| 3.6522 | 2.2524 | 290 | 2.9775 | 0.7629 | 0.7415 | 0.7990 | 0.7507 |
| 3.5922 | 2.3301 | 300 | 2.8995 | 0.7665 | 0.7466 | 0.8090 | 0.7551 |
| 3.519 | 2.4078 | 310 | 2.8049 | 0.7680 | 0.7488 | 0.8129 | 0.7566 |
| 3.4724 | 2.4854 | 320 | 2.7425 | 0.7704 | 0.7528 | 0.8170 | 0.7601 |
| 3.4333 | 2.5631 | 330 | 2.6444 | 0.7755 | 0.7560 | 0.8236 | 0.7648 |
| 3.4303 | 2.6408 | 340 | 2.5672 | 0.7687 | 0.7473 | 0.8178 | 0.7585 |
| 3.3287 | 2.7184 | 350 | 2.5194 | 0.7806 | 0.7599 | 0.8229 | 0.7712 |
| 3.2916 | 2.7961 | 360 | 2.4733 | 0.7796 | 0.7575 | 0.8223 | 0.7698 |
| 3.1999 | 2.8738 | 370 | 2.4098 | 0.7792 | 0.7565 | 0.8158 | 0.7692 |
| 3.211 | 2.9515 | 380 | 2.3081 | 0.7796 | 0.7571 | 0.8284 | 0.7692 |
| 3.1437 | 3.0291 | 390 | 2.2523 | 0.7830 | 0.7600 | 0.8212 | 0.7730 |
| 3.1036 | 3.1068 | 400 | 2.2000 | 0.7847 | 0.7619 | 0.8210 | 0.7740 |
| 3.0345 | 3.1845 | 410 | 2.1385 | 0.7833 | 0.7606 | 0.8261 | 0.7726 |
| 2.99 | 3.2621 | 420 | 2.1079 | 0.7799 | 0.7560 | 0.8199 | 0.7698 |
| 2.9386 | 3.3398 | 430 | 2.0585 | 0.7821 | 0.7584 | 0.8232 | 0.7716 |
| 2.9093 | 3.4175 | 440 | 2.0176 | 0.7823 | 0.7586 | 0.8225 | 0.7721 |
| 2.8868 | 3.4951 | 450 | 1.9702 | 0.7818 | 0.7585 | 0.8183 | 0.7720 |
| 2.8603 | 3.5728 | 460 | 1.8973 | 0.7864 | 0.7645 | 0.8241 | 0.7767 |
| 2.8232 | 3.6505 | 470 | 1.8814 | 0.7855 | 0.7616 | 0.8128 | 0.7758 |
| 2.7889 | 3.7282 | 480 | 1.8170 | 0.7886 | 0.7676 | 0.8214 | 0.7792 |
| 2.7561 | 3.8058 | 490 | 1.7750 | 0.7920 | 0.7721 | 0.8364 | 0.7828 |
| 2.7243 | 3.8835 | 500 | 1.7369 | 0.7906 | 0.7695 | 0.8295 | 0.7813 |
| 2.6619 | 3.9612 | 510 | 1.7225 | 0.7971 | 0.7766 | 0.8292 | 0.7884 |
| 2.7054 | 4.0388 | 520 | 1.6453 | 0.7983 | 0.7788 | 0.8346 | 0.7894 |
| 2.6069 | 4.1165 | 530 | 1.6340 | 0.8000 | 0.7807 | 0.8347 | 0.7910 |
| 2.5627 | 4.1942 | 540 | 1.6538 | 0.7971 | 0.7760 | 0.8337 | 0.7878 |
| 2.5555 | 4.2718 | 550 | 1.5779 | 0.7998 | 0.7785 | 0.8324 | 0.7906 |
| 2.5541 | 4.3495 | 560 | 1.5960 | 0.7945 | 0.7736 | 0.8329 | 0.7850 |
| 2.513 | 4.4272 | 570 | 1.5537 | 0.8025 | 0.7841 | 0.8368 | 0.7941 |
| 2.442 | 4.5049 | 580 | 1.5196 | 0.8034 | 0.7858 | 0.8380 | 0.7954 |
| 2.4763 | 4.5825 | 590 | 1.5009 | 0.8052 | 0.7870 | 0.8345 | 0.7965 |
| 2.4412 | 4.6602 | 600 | 1.4760 | 0.8098 | 0.7924 | 0.8391 | 0.8015 |
| 2.383 | 4.7379 | 610 | 1.4403 | 0.8088 | 0.7920 | 0.8395 | 0.8007 |
| 2.3731 | 4.8155 | 620 | 1.4123 | 0.8120 | 0.7956 | 0.8401 | 0.8039 |
| 2.3616 | 4.8932 | 630 | 1.4193 | 0.8105 | 0.7940 | 0.8369 | 0.8021 |
| 2.3311 | 4.9709 | 640 | 1.4220 | 0.8098 | 0.7934 | 0.8370 | 0.8016 |
| 2.3373 | 5.0485 | 650 | 1.3956 | 0.8081 | 0.7907 | 0.8367 | 0.7996 |
| 2.2879 | 5.1262 | 660 | 1.3375 | 0.8144 | 0.7976 | 0.8410 | 0.8062 |
| 2.299 | 5.2039 | 670 | 1.3431 | 0.8146 | 0.7967 | 0.8371 | 0.8061 |
| 2.2471 | 5.2816 | 680 | 1.3360 | 0.8151 | 0.7985 | 0.8389 | 0.8070 |
| 2.2419 | 5.3592 | 690 | 1.3139 | 0.8139 | 0.7977 | 0.8377 | 0.8058 |
| 2.2195 | 5.4369 | 700 | 1.3225 | 0.8151 | 0.7974 | 0.8395 | 0.8062 |
| 2.1901 | 5.5146 | 710 | 1.2797 | 0.8173 | 0.8001 | 0.8397 | 0.8087 |
| 2.1931 | 5.5922 | 720 | 1.2543 | 0.8192 | 0.8032 | 0.8423 | 0.8109 |
| 2.195 | 5.6699 | 730 | 1.2767 | 0.8209 | 0.8039 | 0.8405 | 0.8125 |
| 2.1413 | 5.7476 | 740 | 1.2735 | 0.8212 | 0.8053 | 0.8416 | 0.8132 |
| 2.1696 | 5.8252 | 750 | 1.2694 | 0.8149 | 0.7983 | 0.8358 | 0.8069 |
| 2.1387 | 5.9029 | 760 | 1.2532 | 0.8217 | 0.8062 | 0.8422 | 0.8136 |
| 2.1811 | 5.9806 | 770 | 1.2426 | 0.8197 | 0.8034 | 0.8417 | 0.8116 |
| 2.077 | 6.0583 | 780 | 1.2101 | 0.8243 | 0.8078 | 0.8464 | 0.8159 |
| 2.1099 | 6.1359 | 790 | 1.1947 | 0.8265 | 0.8108 | 0.8455 | 0.8186 |
| 2.0825 | 6.2136 | 800 | 1.1826 | 0.8241 | 0.8080 | 0.8455 | 0.8161 |
| 2.0933 | 6.2913 | 810 | 1.1934 | 0.8282 | 0.8128 | 0.8474 | 0.8207 |
| 2.0857 | 6.3689 | 820 | 1.1897 | 0.8258 | 0.8099 | 0.8465 | 0.8181 |
| 2.0881 | 6.4466 | 830 | 1.1666 | 0.8277 | 0.8124 | 0.8477 | 0.8199 |
| 2.074 | 6.5243 | 840 | 1.1815 | 0.8248 | 0.8081 | 0.8433 | 0.8167 |
| 2.0145 | 6.6019 | 850 | 1.1680 | 0.8292 | 0.8130 | 0.8473 | 0.8209 |
| 2.0778 | 6.6796 | 860 | 1.1565 | 0.8260 | 0.8094 | 0.8348 | 0.8178 |
| 1.9784 | 6.7573 | 870 | 1.1571 | 0.8345 | 0.8201 | 0.8529 | 0.8269 |
| 2.0595 | 6.8350 | 880 | 1.1554 | 0.8309 | 0.8165 | 0.8475 | 0.8234 |
| 2.0252 | 6.9126 | 890 | 1.1444 | 0.8282 | 0.8140 | 0.8476 | 0.8209 |
| 1.9708 | 6.9903 | 900 | 1.1478 | 0.8302 | 0.8158 | 0.8472 | 0.8224 |
| 2.0656 | 7.0680 | 910 | 1.1285 | 0.8324 | 0.8169 | 0.8485 | 0.8245 |
| 2.0086 | 7.1456 | 920 | 1.1289 | 0.8290 | 0.8148 | 0.8444 | 0.8219 |
| 2.0056 | 7.2233 | 930 | 1.1268 | 0.8280 | 0.8130 | 0.8470 | 0.8208 |
| 1.9498 | 7.3010 | 940 | 1.1246 | 0.8311 | 0.8158 | 0.8497 | 0.8234 |
| 2.0067 | 7.3786 | 950 | 1.1495 | 0.8285 | 0.8132 | 0.8440 | 0.8207 |
| 2.0171 | 7.4563 | 960 | 1.1168 | 0.8285 | 0.8138 | 0.8501 | 0.8209 |
| 1.9683 | 7.5340 | 970 | 1.1290 | 0.8314 | 0.8165 | 0.8500 | 0.8235 |
| 1.9771 | 7.6117 | 980 | 1.0982 | 0.8314 | 0.8153 | 0.8454 | 0.8233 |
| 2.0086 | 7.6893 | 990 | 1.1275 | 0.8294 | 0.8151 | 0.8491 | 0.8218 |
| 1.9854 | 7.7670 | 1000 | 1.1192 | 0.8256 | 0.8098 | 0.8426 | 0.8178 |
### Framework versions
- Transformers 4.40.2
- Pytorch 2.3.0
- Datasets 2.19.1
- Tokenizers 0.19.1
|
Drac0528/my_awesome_asr_mind_model | Drac0528 | 2024-05-29T11:38:30Z | 80 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:minds14",
"base_model:facebook/wav2vec2-base",
"base_model:finetune:facebook/wav2vec2-base",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-28T09:42:52Z | ---
license: apache-2.0
base_model: facebook/wav2vec2-base
tags:
- generated_from_trainer
datasets:
- minds14
metrics:
- wer
model-index:
- name: my_awesome_asr_mind_model
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: minds14
type: minds14
config: en-US
split: None
args: en-US
metrics:
- name: Wer
type: wer
value: 0.9672897196261683
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_asr_mind_model
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 11.0159
- Wer: 0.9673
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 2000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.383 | 200.0 | 1000 | 10.5192 | 0.9813 |
| 2.9471 | 400.0 | 2000 | 11.0159 | 0.9673 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
kardosdrur/burial-mounds-yolov8m-obb | kardosdrur | 2024-05-29T11:38:19Z | 0 | 0 | burial_mounds | [
"burial_mounds",
"yolo",
"object-detection",
"en",
"license:cc-by-nc-4.0",
"region:us"
] | object-detection | 2024-05-28T12:52:30Z | ---
language:
- en
tags:
- yolo
- object-detection
library_name: burial_mounds
license: cc-by-nc-4.0
---
# kardosdrur/burial-mounds-yolov8m-obb
This repository contains a YOLO model that has been finetuned by the `burial_mounds` Python package on the `Mounds` dataset.
> The model is for academic use only, commercial use is prohibited due to restrictions imposed by the training datasets.
## Usage
```python
# pip install burial_mounds
from burial_mounds.model import MoundDetector
model = MoundDetector.load_from_hub("kardosdrur/burial-mounds-yolov8m")
# Find bounding polygons
bounding_polygons = model.detect_mounds("some_satellite_image.png")
for polygon in bounding_polygons:
print(polygon)
# Annotate satellite images
annotated_image = model.annotate_image("some_satellite_image.png")
annotated_image.show()
```
For a more detailed guide consult the [YOLOv8 documentation](https://docs.ultralytics.com/modes/predict/#key-features-of-predict-mode) or [our documentation](https://github.com/x-tabdeveloping/burial-mounds-object-recognition). |
DaichiT/tire | DaichiT | 2024-05-29T11:38:08Z | 30 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stabilityai/stable-diffusion-2",
"base_model:finetune:stabilityai/stable-diffusion-2",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-29T11:27:15Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
base_model: stabilityai/stable-diffusion-2
inference: true
instance_prompt: a photo of sks tire
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - DaichiT/tire
This is a dreambooth model derived from stabilityai/stable-diffusion-2. The weights were trained on a photo of sks tire using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
Felladrin/gguf-sharded-pythia-3b-deduped-sft | Felladrin | 2024-05-29T11:37:33Z | 2 | 0 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T11:27:19Z | ---
license: apache-2.0
base_model: theblackcat102/pythia-3b-deduped-sft
---
Sharded GGUF version of [theblackcat102/pythia-3b-deduped-sft](https://huggingface.co/theblackcat102/pythia-3b-deduped-sft). |
anyasims/ourpo3_uf4_BASE_OR_sft1.0_zs0.5-s2-d8c6 | anyasims | 2024-05-29T11:36:38Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"llama-factory",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-29T11:30:12Z | ---
library_name: transformers
tags:
- llama-factory
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Raneechu/textbookbig12_ft | Raneechu | 2024-05-29T11:33:01Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"license:llama2",
"region:us"
] | null | 2024-05-29T11:32:55Z | ---
license: llama2
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: meta-llama/Llama-2-7b-hf
model-index:
- name: textbookbig12_ft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# textbookbig12_ft
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1
### Training results
### Framework versions
- Transformers 4.40.1
- Pytorch 2.1.1+cu121
- Datasets 2.14.5
- Tokenizers 0.19.1
## Training procedure
### Framework versions
- PEFT 0.6.2
|
ArneBinder/sam-pointer-bart-base-v0.3 | ArneBinder | 2024-05-29T11:31:49Z | 82 | 0 | transformers | [
"transformers",
"pytorch",
"SimpleGenerativeModel",
"en",
"dataset:pie/sciarg",
"dataset:DFKI-SLT/sciarg",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-21T09:49:24Z | ---
license: cc-by-sa-4.0
datasets:
- pie/sciarg
- DFKI-SLT/sciarg
language:
- en
---
This is an argument structure prediction model for the scientific domain. It is a pointer network based on
[A Generative Model for End-to-End Argument Mining with Reconstructed Positional Encoding and Constrained Pointer Mechanism
(Bao et al., EMNLP 2022)](https://aclanthology.org/2022.emnlp-main.713/). Given a plain input text, the model generates
in one go tuples that represent argumentative relations, e.g. of type `supports` or `attacks`, between a pair of
Argumentative Discourse Units (ADUs). Each ADU is defined by start- and end-offsets and a is also typed (`background_claim`,
`own_claim`, or `data`).
However, this is a full reimplementation of the model
within the [PyTorch-IE](https://github.com/ArneBinder/pytorch-ie) framework. The model source code can be
found in the [pie-modules](https://github.com/ArneBinder/pie-modules) repository. The model was trained with the
[PyTorch-IE-Hydra-Template](https://github.com/ArneBinder/pytorch-ie-hydra-template-1) on the
[SciArg dataset](https://aclanthology.org/W18-5206/), see [here](https://huggingface.co/datasets/pie/sciarg) for
further information and an integration into [pie-datasets](https://github.com/ArneBinder/pie-datasets). Further
information regarding the training setup and model performance can be found in the [config.yaml](config.yaml),
in the [wandb-metadata.json](wandb-metadata.json), and in [wandb-summary.json](wandb-summary.json).
([link to private W&B run](https://wandb.ai/arne/dataset-sciarg-task-ner_re-v0.3-training/runs/wr3bg4la))
You can try out the model in [this HF space](https://huggingface.co/spaces/ArneBinder/sam-pointer-bart-base-v0.3). |
scenario-labs/juggernaut_reborn | scenario-labs | 2024-05-29T11:31:38Z | 28,227 | 0 | diffusers | [
"diffusers",
"safetensors",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-29T07:37:35Z | ---
library_name: diffusers
---
Prepared from [Juggernaut](https://civitai.com/models/46422/juggernaut)
|
casque/NoBra_CoveredNipples_FefaAIart | casque | 2024-05-29T11:31:16Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2024-05-29T11:29:45Z | ---
license: creativeml-openrail-m
---
|
etavolt/legal-lora-llama3-V4 | etavolt | 2024-05-29T11:29:42Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T11:29:11Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** etavolt
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
anyasims/ourpo3_uf4_BASE_OR_sft1.0_zs1.0-s2-3e64 | anyasims | 2024-05-29T11:29:30Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"llama-factory",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-29T11:23:18Z | ---
library_name: transformers
tags:
- llama-factory
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
kteedle/vec2dills | kteedle | 2024-05-29T11:27:37Z | 1 | 0 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"sdxl",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:apache-2.0",
"region:us"
] | text-to-image | 2024-05-24T18:02:37Z | ---
license: apache-2.0
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- sdxl
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: flat 2d vector illustration
--- |
DaichiT/tank | DaichiT | 2024-05-29T11:26:29Z | 30 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stabilityai/stable-diffusion-2",
"base_model:finetune:stabilityai/stable-diffusion-2",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-29T11:15:12Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
base_model: stabilityai/stable-diffusion-2
inference: true
instance_prompt: a photo of sks tank
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - DaichiT/tank
This is a dreambooth model derived from stabilityai/stable-diffusion-2. The weights were trained on a photo of sks tank using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
AndrewDOrlov/bert_prof_single_128_below_100 | AndrewDOrlov | 2024-05-29T11:25:55Z | 108 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T08:31:45Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: bert_prof_single_128_below_100
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_prof_single_128_below_100
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6716
- Accuracy: 0.8674
- F1: 0.8658
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|
| 0.7447 | 1.0 | 6885 | 0.6995 | 0.8267 | 0.8151 |
| 0.5834 | 2.0 | 13770 | 0.6181 | 0.8436 | 0.8391 |
| 0.4465 | 3.0 | 20655 | 0.5877 | 0.8585 | 0.8551 |
| 0.3559 | 4.0 | 27540 | 0.6168 | 0.8638 | 0.8616 |
| 0.2515 | 5.0 | 34425 | 0.6300 | 0.8710 | 0.8692 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
Niggendar/boleromixPony_v13 | Niggendar | 2024-05-29T11:24:12Z | 83 | 1 | diffusers | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | 2024-05-29T11:16:21Z | ---
library_name: diffusers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
anyasims/ourpo3_uf4_BASE_OR_sft1.0_zs2.0-s2-4331 | anyasims | 2024-05-29T11:22:34Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"llama-factory",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-29T11:16:02Z | ---
library_name: transformers
tags:
- llama-factory
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
khaled123/testy | khaled123 | 2024-05-29T11:22:25Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T11:00:25Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
h2oai/h2o-danube2-1.8b-chat-GGUF | h2oai | 2024-05-29T11:22:14Z | 967 | 8 | transformers | [
"transformers",
"gguf",
"gpt",
"llm",
"large language model",
"h2o-llmstudio",
"text-generation",
"en",
"arxiv:2306.05685",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2024-05-29T10:43:16Z | ---
language:
- en
library_name: transformers
license: apache-2.0
tags:
- gpt
- llm
- large language model
- h2o-llmstudio
thumbnail: >-
https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
pipeline_tag: text-generation
quantized_by: h2oai
---
# h2o-danube2-1.8b-chat-GGUF
- Model creator: [H2O.ai](https://huggingface.co/h2oai)
- Original model: [h2o-danube2-1.8b-chat](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat)
## Description
This repo contains GGUF format model files for [h2o-danube2-1.8b-chat](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat) quantized using [llama.cpp](https://github.com/ggerganov/llama.cpp/) framework.
Table below summarizes different quantized versions of [h2o-danube2-1.8b-chat](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat). It shows the trade-off between size, speed and quality of the models.
| Name | Quant method | Model size | MT-Bench AVG | Perplexity | Tokens per second |
|:----------------------------------|:----------------------------------:|:----------:|:------------:|:------------:|:-------------------:|
| [h2o-danube2-1.8b-chat-F16.gguf](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat-GGUF/blob/main/h2o-danube2-1.8b-chat-F16.gguf) | F16 | 3.66 GB | 5.60 | 8.02 | 797 |
| [h2o-danube2-1.8b-chat-Q8_0.gguf](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat-GGUF/blob/main/h2o-danube2-1.8b-chat-Q8_0.gguf) | Q8_0 | 1.95 GB | 5.51 | 8.02 | 1156 |
| [h2o-danube2-1.8b-chat-Q6_K.gguf](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat-GGUF/blob/main/h2o-danube2-1.8b-chat-Q6_K.gguf) | Q6_K | 1.50 GB | 5.51 | 8.03 | 1131 |
| [h2o-danube2-1.8b-chat-Q5_K_M.gguf](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat-GGUF/blob/main/h2o-danube2-1.8b-chat-Q5_K_M.gguf) | Q5_K_M | 1.30 GB | 5.56 | 8.10 | 1172 |
| [h2o-danube2-1.8b-chat-Q5_K_S.gguf](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat-GGUF/blob/main/h2o-danube2-1.8b-chat-Q5_K_S.gguf) | Q5_K_S | 1.27 GB | 5.49 | 8.12 | 1107 |
| [h2o-danube2-1.8b-chat-Q4_K_M.gguf](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat-GGUF/blob/main/h2o-danube2-1.8b-chat-Q4_K_M.gguf) | Q4_K_M | 1.11 GB | 5.60 | 8.27 | 1162 |
| [h2o-danube2-1.8b-chat-Q4_K_S.gguf](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat-GGUF/blob/main/h2o-danube2-1.8b-chat-Q4_K_S.gguf) | Q4_K_S | 1.06 GB | 5.59 | 8.34 | 1270 |
| [h2o-danube2-1.8b-chat-Q3_K_L.gguf](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat-GGUF/blob/main/h2o-danube2-1.8b-chat-Q3_K_L.gguf) | Q3_K_L | 0.98 GB | 5.23 | 8.72 | 1442 |
| [h2o-danube2-1.8b-chat-Q3_K_M.gguf](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat-GGUF/blob/main/h2o-danube2-1.8b-chat-Q3_K_M.gguf) | Q3_K_M | 0.91 GB | 4.91 | 8.81 | 1107 |
| [h2o-danube2-1.8b-chat-Q3_K_S.gguf](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat-GGUF/blob/main/h2o-danube2-1.8b-chat-Q3_K_S.gguf) | Q3_K_S | 0.82 GB | 4.03 | 10.12 | 1103 |
| [h2o-danube2-1.8b-chat-Q2_K.gguf](https://huggingface.co/h2oai/h2o-danube2-1.8b-chat-GGUF/blob/main/h2o-danube2-1.8b-chat-Q2_K.gguf) | Q2_K | 0.71 GB | 3.03 | 12.56 | 1160 |
Columns in the table are:
* Name -- model name and link
* Quant method -- quantization method
* Model size -- size of the model in gigabytes
* MT-Bench AVG -- [MT-Bench](https://arxiv.org/abs/2306.05685) benchmark score. The score is from 1 to 10, the higher, the better
* Perplexity -- perplexity metric on WikiText-2 dataset. It's reported in a perplexity test from llama.cpp. The lower, the better
* Tokens per second -- generation speed in tokens per second, as reported in a perplexity test from llama.cpp. The higher, the better. Speed tests are done on a single H100 GPU
## Prompt template
```
<|prompt|>Why is drinking water so healthy?</s><|answer|>
```
|
fine-tuned/SCIDOCS-32000-384-gpt-4o-2024-05-13-5483216 | fine-tuned | 2024-05-29T11:20:31Z | 4 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"custom_code",
"en",
"dataset:fine-tuned/SCIDOCS-32000-384-gpt-4o-2024-05-13-5483216",
"dataset:allenai/c4",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-05-29T11:20:12Z | ---
license: apache-2.0
datasets:
- fine-tuned/SCIDOCS-32000-384-gpt-4o-2024-05-13-5483216
- allenai/c4
language:
- en
- en
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
---
This model is a fine-tuned version of [**jinaai/jina-embeddings-v2-base-en**](https://huggingface.co/jinaai/jina-embeddings-v2-base-en) designed for the following use case:
None
## How to Use
This model can be easily integrated into your NLP pipeline for tasks such as text classification, sentiment analysis, entity recognition, and more. Here's a simple example to get you started:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
'fine-tuned/SCIDOCS-32000-384-gpt-4o-2024-05-13-5483216',
trust_remote_code=True
)
embeddings = model.encode([
'first text to embed',
'second text to embed'
])
print(cos_sim(embeddings[0], embeddings[1]))
```
|
fine-tuned/SciFact-32000-384-gpt-4o-2024-05-13-45622553 | fine-tuned | 2024-05-29T11:17:52Z | 6 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"custom_code",
"en",
"dataset:fine-tuned/SciFact-32000-384-gpt-4o-2024-05-13-45622553",
"dataset:allenai/c4",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-05-29T11:17:37Z | ---
license: apache-2.0
datasets:
- fine-tuned/SciFact-32000-384-gpt-4o-2024-05-13-45622553
- allenai/c4
language:
- en
- en
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
---
This model is a fine-tuned version of [**jinaai/jina-embeddings-v2-base-en**](https://huggingface.co/jinaai/jina-embeddings-v2-base-en) designed for the following use case:
None
## How to Use
This model can be easily integrated into your NLP pipeline for tasks such as text classification, sentiment analysis, entity recognition, and more. Here's a simple example to get you started:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
'fine-tuned/SciFact-32000-384-gpt-4o-2024-05-13-45622553',
trust_remote_code=True
)
embeddings = model.encode([
'first text to embed',
'second text to embed'
])
print(cos_sim(embeddings[0], embeddings[1]))
```
|
exlleysantos/verball-tests-3 | exlleysantos | 2024-05-29T11:17:06Z | 77 | 0 | transformers | [
"transformers",
"safetensors",
"olmo",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-27T14:06:21Z | ---
tags:
- generated_from_trainer
model-index:
- name: verball-tests-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# verball-tests-3
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.15.1
|
fine-tuned/FiQA2018-32000-384-gpt-4o-2024-05-13-52831585 | fine-tuned | 2024-05-29T11:16:41Z | 5 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"custom_code",
"en",
"dataset:fine-tuned/FiQA2018-32000-384-gpt-4o-2024-05-13-52831585",
"dataset:allenai/c4",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-05-29T11:16:28Z | ---
license: apache-2.0
datasets:
- fine-tuned/FiQA2018-32000-384-gpt-4o-2024-05-13-52831585
- allenai/c4
language:
- en
- en
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
---
This model is a fine-tuned version of [**jinaai/jina-embeddings-v2-base-en**](https://huggingface.co/jinaai/jina-embeddings-v2-base-en) designed for the following use case:
None
## How to Use
This model can be easily integrated into your NLP pipeline for tasks such as text classification, sentiment analysis, entity recognition, and more. Here's a simple example to get you started:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
'fine-tuned/FiQA2018-32000-384-gpt-4o-2024-05-13-52831585',
trust_remote_code=True
)
embeddings = model.encode([
'first text to embed',
'second text to embed'
])
print(cos_sim(embeddings[0], embeddings[1]))
```
|
DaichiT/stuffing | DaichiT | 2024-05-29T11:14:24Z | 29 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stabilityai/stable-diffusion-2",
"base_model:finetune:stabilityai/stable-diffusion-2",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-29T11:05:20Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
base_model: stabilityai/stable-diffusion-2
inference: true
instance_prompt: a photo of sks stuffing
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - DaichiT/stuffing
This is a dreambooth model derived from stabilityai/stable-diffusion-2. The weights were trained on a photo of sks stuffing using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
yeshu044/opt-125m-finetuned | yeshu044 | 2024-05-29T11:14:19Z | 196 | 0 | transformers | [
"transformers",
"safetensors",
"opt",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-29T11:14:00Z | ---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ZcepZtar/DaToSw_V1.4 | ZcepZtar | 2024-05-29T11:14:10Z | 114 | 0 | transformers | [
"transformers",
"safetensors",
"marian",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-05-27T15:02:31Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
IABDs8a/lara-base-PIA_MODELO_ASPANIAS_COMPLETO-Equipo2 | IABDs8a | 2024-05-29T11:14:04Z | 78 | 0 | transformers | [
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-29T11:12:27Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ghostdivisio/bert-tiny-finetuned-squad | ghostdivisio | 2024-05-29T11:13:02Z | 134 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"question-answering",
"generated_from_trainer",
"base_model:prajjwal1/bert-tiny",
"base_model:finetune:prajjwal1/bert-tiny",
"license:mit",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-05-29T11:12:59Z | ---
license: mit
base_model: prajjwal1/bert-tiny
tags:
- generated_from_trainer
model-index:
- name: bert-tiny-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-tiny-finetuned-squad
This model is a fine-tuned version of [prajjwal1/bert-tiny](https://huggingface.co/prajjwal1/bert-tiny) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1478
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 90
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 29 | 0.8724 |
| No log | 2.0 | 58 | 0.7989 |
| No log | 3.0 | 87 | 0.7316 |
| No log | 4.0 | 116 | 0.6691 |
| No log | 5.0 | 145 | 0.6121 |
| No log | 6.0 | 174 | 0.5597 |
| No log | 7.0 | 203 | 0.5121 |
| No log | 8.0 | 232 | 0.4690 |
| No log | 9.0 | 261 | 0.4300 |
| No log | 10.0 | 290 | 0.3950 |
| No log | 11.0 | 319 | 0.3637 |
| No log | 12.0 | 348 | 0.3358 |
| No log | 13.0 | 377 | 0.3110 |
| No log | 14.0 | 406 | 0.2891 |
| No log | 15.0 | 435 | 0.2697 |
| No log | 16.0 | 464 | 0.2527 |
| No log | 17.0 | 493 | 0.2379 |
| 0.5621 | 18.0 | 522 | 0.2247 |
| 0.5621 | 19.0 | 551 | 0.2134 |
| 0.5621 | 20.0 | 580 | 0.2035 |
| 0.5621 | 21.0 | 609 | 0.1955 |
| 0.5621 | 22.0 | 638 | 0.1886 |
| 0.5621 | 23.0 | 667 | 0.1829 |
| 0.5621 | 24.0 | 696 | 0.1776 |
| 0.5621 | 25.0 | 725 | 0.1731 |
| 0.5621 | 26.0 | 754 | 0.1694 |
| 0.5621 | 27.0 | 783 | 0.1662 |
| 0.5621 | 28.0 | 812 | 0.1635 |
| 0.5621 | 29.0 | 841 | 0.1614 |
| 0.5621 | 30.0 | 870 | 0.1597 |
| 0.5621 | 31.0 | 899 | 0.1582 |
| 0.5621 | 32.0 | 928 | 0.1570 |
| 0.5621 | 33.0 | 957 | 0.1561 |
| 0.5621 | 34.0 | 986 | 0.1551 |
| 0.1726 | 35.0 | 1015 | 0.1545 |
| 0.1726 | 36.0 | 1044 | 0.1537 |
| 0.1726 | 37.0 | 1073 | 0.1532 |
| 0.1726 | 38.0 | 1102 | 0.1528 |
| 0.1726 | 39.0 | 1131 | 0.1523 |
| 0.1726 | 40.0 | 1160 | 0.1519 |
| 0.1726 | 41.0 | 1189 | 0.1516 |
| 0.1726 | 42.0 | 1218 | 0.1512 |
| 0.1726 | 43.0 | 1247 | 0.1510 |
| 0.1726 | 44.0 | 1276 | 0.1507 |
| 0.1726 | 45.0 | 1305 | 0.1505 |
| 0.1726 | 46.0 | 1334 | 0.1503 |
| 0.1726 | 47.0 | 1363 | 0.1502 |
| 0.1726 | 48.0 | 1392 | 0.1500 |
| 0.1726 | 49.0 | 1421 | 0.1499 |
| 0.1726 | 50.0 | 1450 | 0.1497 |
| 0.1726 | 51.0 | 1479 | 0.1496 |
| 0.1271 | 52.0 | 1508 | 0.1496 |
| 0.1271 | 53.0 | 1537 | 0.1494 |
| 0.1271 | 54.0 | 1566 | 0.1493 |
| 0.1271 | 55.0 | 1595 | 0.1492 |
| 0.1271 | 56.0 | 1624 | 0.1491 |
| 0.1271 | 57.0 | 1653 | 0.1490 |
| 0.1271 | 58.0 | 1682 | 0.1490 |
| 0.1271 | 59.0 | 1711 | 0.1489 |
| 0.1271 | 60.0 | 1740 | 0.1489 |
| 0.1271 | 61.0 | 1769 | 0.1488 |
| 0.1271 | 62.0 | 1798 | 0.1487 |
| 0.1271 | 63.0 | 1827 | 0.1487 |
| 0.1271 | 64.0 | 1856 | 0.1486 |
| 0.1271 | 65.0 | 1885 | 0.1486 |
| 0.1271 | 66.0 | 1914 | 0.1485 |
| 0.1271 | 67.0 | 1943 | 0.1485 |
| 0.1271 | 68.0 | 1972 | 0.1484 |
| 0.1216 | 69.0 | 2001 | 0.1484 |
| 0.1216 | 70.0 | 2030 | 0.1483 |
| 0.1216 | 71.0 | 2059 | 0.1483 |
| 0.1216 | 72.0 | 2088 | 0.1482 |
| 0.1216 | 73.0 | 2117 | 0.1483 |
| 0.1216 | 74.0 | 2146 | 0.1482 |
| 0.1216 | 75.0 | 2175 | 0.1481 |
| 0.1216 | 76.0 | 2204 | 0.1481 |
| 0.1216 | 77.0 | 2233 | 0.1481 |
| 0.1216 | 78.0 | 2262 | 0.1480 |
| 0.1216 | 79.0 | 2291 | 0.1480 |
| 0.1216 | 80.0 | 2320 | 0.1479 |
| 0.1216 | 81.0 | 2349 | 0.1479 |
| 0.1216 | 82.0 | 2378 | 0.1479 |
| 0.1216 | 83.0 | 2407 | 0.1479 |
| 0.1216 | 84.0 | 2436 | 0.1479 |
| 0.1216 | 85.0 | 2465 | 0.1479 |
| 0.1216 | 86.0 | 2494 | 0.1478 |
| 0.1151 | 87.0 | 2523 | 0.1478 |
| 0.1151 | 88.0 | 2552 | 0.1478 |
| 0.1151 | 89.0 | 2581 | 0.1478 |
| 0.1151 | 90.0 | 2610 | 0.1478 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
BogdanTurbal/FacebookAI-roberta-base-d_1_e_4_t_u_r_5-d_2_e_4_t_u_r_5-v3 | BogdanTurbal | 2024-05-29T11:11:07Z | 199 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T11:10:53Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ainnle/gemma-7b-zx | ainnle | 2024-05-29T11:10:18Z | 10 | 0 | transformers | [
"transformers",
"gguf",
"gemma",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T10:38:56Z | ---
license: apache-2.0
---
|
BogdanTurbal/FacebookAI-roberta-base-d_2_e_4_t_u_r_5-v3 | BogdanTurbal | 2024-05-29T11:07:25Z | 198 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T11:07:11Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Grace0710/koLlamaCredit | Grace0710 | 2024-05-29T11:06:52Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-05-15T17:31:08Z | ---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
kaebaMS/distilbert-base-uncased-finetuned-emotion | kaebaMS | 2024-05-29T11:06:50Z | 106 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T11:01:32Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9235
- name: F1
type: f1
value: 0.9232738832918821
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2237
- Accuracy: 0.9235
- F1: 0.9233
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8086 | 1.0 | 250 | 0.3258 | 0.903 | 0.9014 |
| 0.2511 | 2.0 | 500 | 0.2237 | 0.9235 | 0.9233 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
magic10241/quant-llama3-1.0-8B-Lora | magic10241 | 2024-05-29T11:05:28Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:zhichen/Llama3-Chinese",
"base_model:finetune:zhichen/Llama3-Chinese",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T11:03:03Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: zhichen/Llama3-Chinese
---
# Uploaded model
- **Developed by:** magic10241
- **License:** apache-2.0
- **Finetuned from model :** zhichen/Llama3-Chinese
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
DaichiT/stainless_steel | DaichiT | 2024-05-29T11:04:36Z | 30 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stabilityai/stable-diffusion-2",
"base_model:finetune:stabilityai/stable-diffusion-2",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-29T10:52:46Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
base_model: stabilityai/stable-diffusion-2
inference: true
instance_prompt: a photo of sks stainless_steel
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - DaichiT/stainless_steel
This is a dreambooth model derived from stabilityai/stable-diffusion-2. The weights were trained on a photo of sks stainless_steel using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
BogdanTurbal/FacebookAI-roberta-base-d_2_e_4_t_u_r_5-d_1_e_4_t_u_r_5-v3 | BogdanTurbal | 2024-05-29T11:03:39Z | 181 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T11:03:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
BogdanTurbal/FacebookAI-roberta-base-d_3_e_4_t_u_r_5-d_0_e_4_t_u_r_5-v3 | BogdanTurbal | 2024-05-29T11:01:14Z | 199 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T11:01:00Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
houbw/llama3_ruozhiba_ori_8_up_5_cms9_label_2 | houbw | 2024-05-29T10:59:59Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-Instruct",
"base_model:finetune:unsloth/llama-3-8b-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T10:58:56Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-Instruct
---
# Uploaded model
- **Developed by:** houbw
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
BogdanTurbal/FacebookAI-roberta-base-d_3_e_4_t_u_r_5-d_1_e_4_t_u_r_5-v3 | BogdanTurbal | 2024-05-29T10:58:47Z | 199 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T10:58:33Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Raneechu/textbookbig12 | Raneechu | 2024-05-29T10:58:17Z | 1 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"license:llama2",
"region:us"
] | null | 2024-05-29T10:58:08Z | ---
license: llama2
library_name: peft
tags:
- generated_from_trainer
base_model: meta-llama/Llama-2-7b-hf
model-index:
- name: textbookbig12
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# textbookbig12
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.8838
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 4.1922 | 0.0117 | 1 | 3.8838 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.1.1+cu121
- Datasets 2.14.5
- Tokenizers 0.19.1
## Training procedure
### Framework versions
- PEFT 0.6.2
|
BogdanTurbal/FacebookAI-roberta-base-d_1_e_4_t_u_r_5-v3 | BogdanTurbal | 2024-05-29T10:56:17Z | 201 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T10:56:04Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Niggendar/fastPonyMerge_version9 | Niggendar | 2024-05-29T10:55:23Z | 123 | 1 | diffusers | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | 2024-05-29T10:50:30Z | ---
library_name: diffusers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
BogdanTurbal/FacebookAI-roberta-base-d_3_e_4_t_u_r_5-v3 | BogdanTurbal | 2024-05-29T10:53:47Z | 199 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T10:53:28Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
souling/distilbert-base-uncased-finetuned-emotion | souling | 2024-05-29T10:51:51Z | 114 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T10:28:55Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9265
- name: F1
type: f1
value: 0.9264798353410255
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2150
- Accuracy: 0.9265
- F1: 0.9265
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8395 | 1.0 | 250 | 0.3140 | 0.9065 | 0.9058 |
| 0.248 | 2.0 | 500 | 0.2150 | 0.9265 | 0.9265 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
hugggof/vampnet-base | hugggof | 2024-05-29T10:51:50Z | 0 | 0 | null | [
"license:cc-by-nc-4.0",
"region:us"
] | null | 2024-05-29T10:51:50Z | ---
license: cc-by-nc-4.0
---
|
fine-tuned/before-finetuning-32000-384-gpt-4o-2024-05-13-73143156 | fine-tuned | 2024-05-29T10:49:06Z | 4 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"en",
"dataset:fine-tuned/before-finetuning-32000-384-gpt-4o-2024-05-13-73143156",
"dataset:allenai/c4",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-05-29T10:48:35Z | ---
license: apache-2.0
datasets:
- fine-tuned/before-finetuning-32000-384-gpt-4o-2024-05-13-73143156
- allenai/c4
language:
- en
- en
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
---
This model is a fine-tuned version of [**BAAI/bge-large-en-v1.5**](https://huggingface.co/BAAI/bge-large-en-v1.5) designed for the following use case:
None
## How to Use
This model can be easily integrated into your NLP pipeline for tasks such as text classification, sentiment analysis, entity recognition, and more. Here's a simple example to get you started:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
'fine-tuned/before-finetuning-32000-384-gpt-4o-2024-05-13-73143156',
trust_remote_code=True
)
embeddings = model.encode([
'first text to embed',
'second text to embed'
])
print(cos_sim(embeddings[0], embeddings[1]))
```
|
eduardzamfir/SeemoRe-T | eduardzamfir | 2024-05-29T10:45:40Z | 0 | 5 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-05-29T10:44:27Z | ---
license: apache-2.0
---
|
raphael-ich/ppo-LunarLander-v2 | raphael-ich | 2024-05-29T10:40:39Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-28T15:13:38Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 208.55 +/- 36.51
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
DaichiT/shock_absorber | DaichiT | 2024-05-29T10:39:23Z | 29 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stabilityai/stable-diffusion-2",
"base_model:finetune:stabilityai/stable-diffusion-2",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-05-29T07:06:35Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
base_model: stabilityai/stable-diffusion-2
inference: true
instance_prompt: a photo of sks shock_absorber
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - DaichiT/shock_absorber
This is a dreambooth model derived from stabilityai/stable-diffusion-2. The weights were trained on a photo of sks shock_absorber using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
Shengkun/LLama2-7B-Structural-Prune-1.25x | Shengkun | 2024-05-29T10:34:49Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-27T20:21:44Z | ---
license: apache-2.0
---
---
library_name: transformers
license: apache-2.0
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
dev-analyzer/file_path_model | dev-analyzer | 2024-05-29T10:34:08Z | 128 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-13T09:10:44Z | ---
pipeline_tag: text-classification
base_model: bert-base-uncased
widget:
- text: "src\\main\\java\\org\\rtmps\\RTMPTSClientConnector.java"
- text: "src\\test\\java\\org\\server\\net\\rtmp\\message\\HeaderTest.java"
- text: "src\\main\\res\\drawable-mdpi\\icon.png"
- text: "common\\pom.xml"
- text: "server\\src\\main\\server\\plugins\\Readme.md"
---
Model for classifying file paths of changed files in git commits for Java projects. This model is based on
`bert-base-uncased` and fine-tuned.
Categorizes into the following categories:
1. Source Code - Core application code typically involving back-end (server-side logic, APIs,
database interactions) and front-end (user interface, client-side logic).
2. Tests - Code files in a test directory or containing "test".
3. Resources - Assets and other resources (images, stylesheets).
4. Configuration - Configuration files and scripts (build scripts, manifests, shell scripts).
5. Documentation - Software documentation (README files, package-info, license, notice files). |
subhavarshith/donut_exp2 | subhavarshith | 2024-05-29T10:30:11Z | 48 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2024-05-29T06:58:02Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
BogdanTurbal/FacebookAI-roberta-base-d_1_e_4_t_u_r_5-d_3_e_4_t_u_r_5-v3 | BogdanTurbal | 2024-05-29T10:28:32Z | 199 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-29T10:28:13Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
RichardErkhov/internlm_-_internlm2-math-7b-gguf | RichardErkhov | 2024-05-29T10:28:25Z | 38 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-29T07:52:51Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
internlm2-math-7b - GGUF
- Model creator: https://huggingface.co/internlm/
- Original model: https://huggingface.co/internlm/internlm2-math-7b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [internlm2-math-7b.Q2_K.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q2_K.gguf) | Q2_K | 2.8GB |
| [internlm2-math-7b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.IQ3_XS.gguf) | IQ3_XS | 3.1GB |
| [internlm2-math-7b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.IQ3_S.gguf) | IQ3_S | 3.25GB |
| [internlm2-math-7b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q3_K_S.gguf) | Q3_K_S | 3.24GB |
| [internlm2-math-7b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.IQ3_M.gguf) | IQ3_M | 3.35GB |
| [internlm2-math-7b.Q3_K.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q3_K.gguf) | Q3_K | 3.57GB |
| [internlm2-math-7b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q3_K_M.gguf) | Q3_K_M | 3.57GB |
| [internlm2-math-7b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q3_K_L.gguf) | Q3_K_L | 3.85GB |
| [internlm2-math-7b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.IQ4_XS.gguf) | IQ4_XS | 3.99GB |
| [internlm2-math-7b.Q4_0.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q4_0.gguf) | Q4_0 | 4.15GB |
| [internlm2-math-7b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.IQ4_NL.gguf) | IQ4_NL | 4.19GB |
| [internlm2-math-7b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q4_K_S.gguf) | Q4_K_S | 4.18GB |
| [internlm2-math-7b.Q4_K.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q4_K.gguf) | Q4_K | 4.39GB |
| [internlm2-math-7b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q4_K_M.gguf) | Q4_K_M | 4.39GB |
| [internlm2-math-7b.Q4_1.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q4_1.gguf) | Q4_1 | 4.58GB |
| [internlm2-math-7b.Q5_0.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q5_0.gguf) | Q5_0 | 5.0GB |
| [internlm2-math-7b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q5_K_S.gguf) | Q5_K_S | 5.0GB |
| [internlm2-math-7b.Q5_K.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q5_K.gguf) | Q5_K | 5.13GB |
| [internlm2-math-7b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q5_K_M.gguf) | Q5_K_M | 5.13GB |
| [internlm2-math-7b.Q5_1.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q5_1.gguf) | Q5_1 | 5.43GB |
| [internlm2-math-7b.Q6_K.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q6_K.gguf) | Q6_K | 5.91GB |
| [internlm2-math-7b.Q8_0.gguf](https://huggingface.co/RichardErkhov/internlm_-_internlm2-math-7b-gguf/blob/main/internlm2-math-7b.Q8_0.gguf) | Q8_0 | 7.66GB |
Original model description:
---
pipeline_tag: text-generation
license: other
language:
- en
- zh
tags:
- math
---
# InternLM-Math
<div align="center">
<img src="https://raw.githubusercontent.com/InternLM/InternLM/main/assets/logo.svg" width="200"/>
<div> </div>
<div align="center">
<b><font size="5">InternLM-Math</font></b>
<sup>
<a href="https://internlm.intern-ai.org.cn/">
<i><font size="4">HOT</font></i>
</a>
</sup>
<div> </div>
</div>
State-of-the-art bilingual open-sourced Math reasoning LLMs.
A **solver**, **prover**, **verifier**, **augmentor**.
[💻 Github](https://github.com/InternLM/InternLM-Math) [🤗 Demo](https://huggingface.co/spaces/internlm/internlm2-math-7b) [🤗 Checkpoints](https://huggingface.co/internlm/internlm2-math-7b) [](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-7B) [<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> ModelScope](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-7b/summary)
</div>
# News
- [2024.01.29] We add checkpoints from ModelScope. Tech report is on the way!
- [2024.01.26] We add checkpoints from OpenXLab, which ease Chinese users to download!
# Introduction
- **7B and 20B Chinese and English Math LMs with better than ChatGPT performances.** InternLM2-Math are continued pretrained from InternLM2-Base with ~100B high quality math-related tokens and SFT with ~2M bilingual math supervised data. We apply minhash and exact number match to decontaminate possible test set leakage.
- **Add Lean as a support language for math problem solving and math theorem proving.** We are exploring combining Lean 3 with InternLM-Math for verifiable math reasoning. InternLM-Math can generate Lean codes for simple math reasoning tasks like GSM8K or provide possible proof tactics based on Lean states.
- **Also can be viewed as a reward model, which supports the Outcome/Process/Lean Reward Model.** We supervise InternLM2-Math with various types of reward modeling data, to make InternLM2-Math can also verify chain-of-thought processes. We also add the ability to convert a chain-of-thought process into Lean 3 code.
- **A Math LM Augment Helper** and **Code Interpreter**. InternLM2-Math can help augment math reasoning problems and solve them using the code interpreter which makes you generate synthesis data quicker!
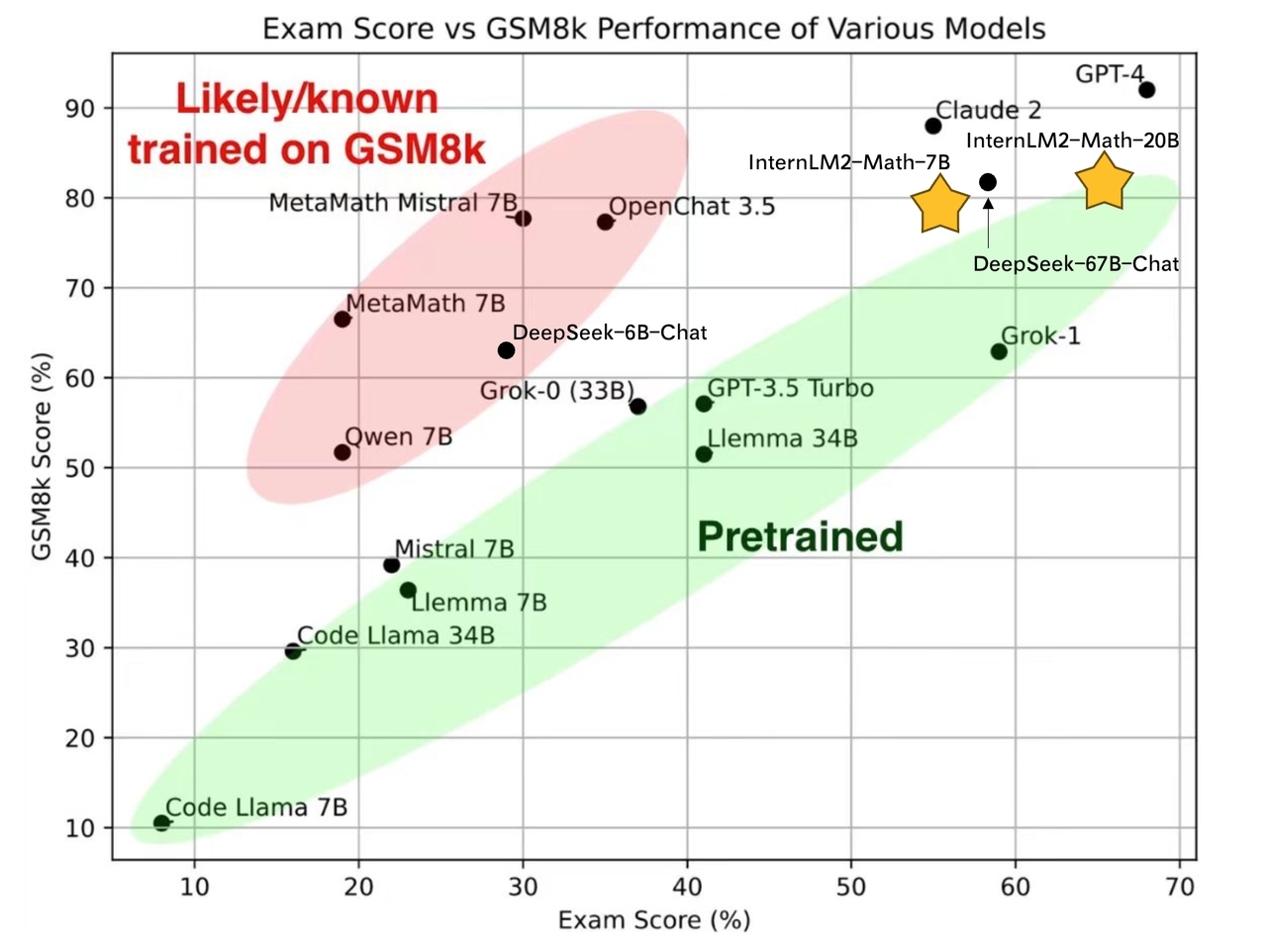
# Models
**InternLM2-Math-Base-7B** and **InternLM2-Math-Base-20B** are pretrained checkpoints. **InternLM2-Math-7B** and **InternLM2-Math-20B** are SFT checkpoints.
| Model |Model Type | Transformers(HF) |OpenXLab| ModelScope | Release Date |
|---|---|---|---|---|---|
| **InternLM2-Math-Base-7B** | Base| [🤗internlm/internlm2-math-base-7b](https://huggingface.co/internlm/internlm2-math-base-7b) |[](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-Base-7B)| [<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> internlm2-math-base-7b](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-base-7b/summary)| 2024-01-23|
| **InternLM2-Math-Base-20B** | Base| [🤗internlm/internlm2-math-base-20b](https://huggingface.co/internlm/internlm2-math-base-20b) |[](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-Base-20B)|[<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> internlm2-math-base-20b](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-base-20b/summary)| 2024-01-23|
| **InternLM2-Math-7B** | Chat| [🤗internlm/internlm2-math-7b](https://huggingface.co/internlm/internlm2-math-7b) |[](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-7B)|[<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> internlm2-math-7b](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-7b/summary)| 2024-01-23|
| **InternLM2-Math-20B** | Chat| [🤗internlm/internlm2-math-20b](https://huggingface.co/internlm/internlm2-math-20b) |[](https://openxlab.org.cn/models/detail/OpenLMLab/InternLM2-Math-20B)|[<img src="https://raw.githubusercontent.com/InternLM/InternLM-Math/main/assets/modelscope_logo.png" width="20px" /> internlm2-math-20b](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm2-math-20b/summary)| 2024-01-23|
# Performance
## Pretrain Performance
We evaluate pretrain checkpoints based on greedy decoding with few-shot COT. Details of pretraining will be introduced in the tech report.
| Model | GSM8K | MATH |
|------------------------|---------|--------|
| Llama2-7B | 11.8 | 3.2 |
| Llemma-7B | 36.4 | 18.0 |
| InternLM2-Base-7B | 36.5 | 8.6 |
| **InternLM2-Math-Base-7B** | **49.2** | **21.5** |
| Minerva-8B | 16.2 | 14.1 |
| InternLM2-Base-20B | 54.6 | 13.7 |
| **InternLM2-Math-Base-20B** | **63.7** | **27.3** |
| Llemma-34B | 51.5 | 25.0 |
| Minerva-62B | 52.4 | 27.6 |
| Minerva-540B | 58.8 | 33.6 |
## SFT Peformance
All performance is based on greedy decoding with COT. We notice that the performance of Hungary has a big variance between our different checkpoints, while other performance is very stable. This may be due to the problem amount about Hungary.
| Model | Model Type | GSM8K | MATH | Hungary |
|------------------------|----------------------|--------|--------|---------|
| Qwen-7B-Chat | Genearl | 51.7 | 11.6 | - |
| DeepSeek-7B-Chat | General | 63.0 | 15.8 | 28.5 |
| InternLM2-Chat-7B | General | 70.7 | 23.0 | - |
| ChatGLM3-6B | General | 53.8 | 20.4 | 32 |
| MetaMath-Mistral-7B | Mathematics | 77.7 | 28.2 | 29 |
| MetaMath-Llemma-7B | Mathematics | 69.2 | 30.0 | - |
| **InternLM2-Math-7B** | Mathematics | **78.1** | **34.6** | **55** |
| InternLM2-Chat-20B | General | 79.6 | 31.9 | - |
| MetaMath-Llemma-34B | Mathematics | 75.8 | 34.8 | - |
| **InternLM2-Math-20B** | Mathematics | **82.6** | **37.7** | **66** |
| Qwen-72B | General | 78.9 | 35.2 | 52 |
| DeepSeek-67B | General | 84.1 | 32.6 | 58 |
| ChatGPT (GPT-3.5) | General | 80.8 | 34.1 | 41 |
| GPT4 (First version) | General | 92.0 | 42.5 | 68 |
# Inference
## LMDeploy
We suggest using [LMDeploy](https://github.com/InternLM/LMDeploy)(>=0.2.1) for inference.
```python
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
backend_config = TurbomindEngineConfig(model_name='internlm2-chat-7b', tp=1, cache_max_entry_count=0.3)
chat_template = ChatTemplateConfig(model_name='internlm2-chat-7b', system='', eosys='', meta_instruction='')
pipe = pipeline(model_path='internlm/internlm2-math-7b', chat_template_config=chat_template, backend_config=backend_config)
problem = '1+1='
result = pipe([problem], request_output_len=1024, top_k=1)
```
## Huggingface
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("internlm/internlm2-math-7b", trust_remote_code=True)
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and might cause OOM Error.
model = AutoModelForCausalLM.from_pretrained("internlm/internlm2-math-7b", trust_remote_code=True, torch_dtype=torch.float16).cuda()
model = model.eval()
response, history = model.chat(tokenizer, "1+1=", history=[], meta_instruction="")
print(response)
```
# Special usages
We list some instructions used in our SFT. You can use them to help you. You can use the other ways to prompt the model, but the following are recommended. InternLM2-Math may combine the following abilities but it is not guaranteed.
Translate proof problem to Lean:
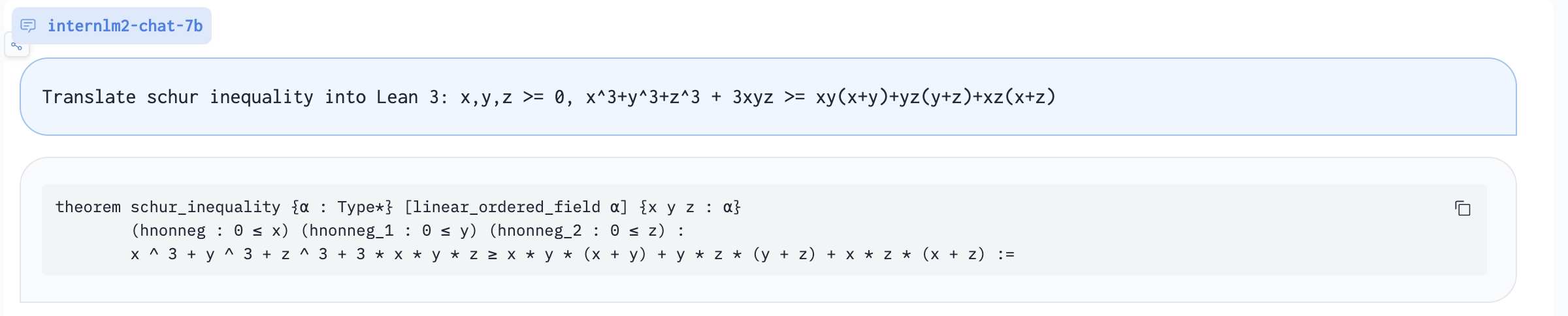
Using Lean 3 to solve GSM8K problem:
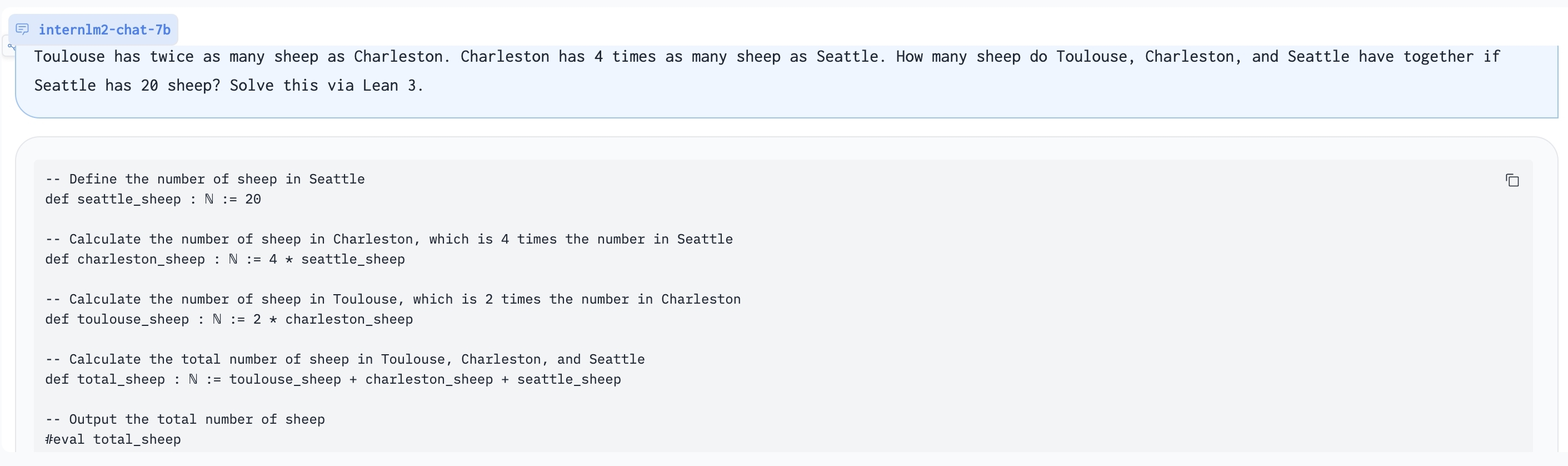
Generate problem based on Lean 3 code:
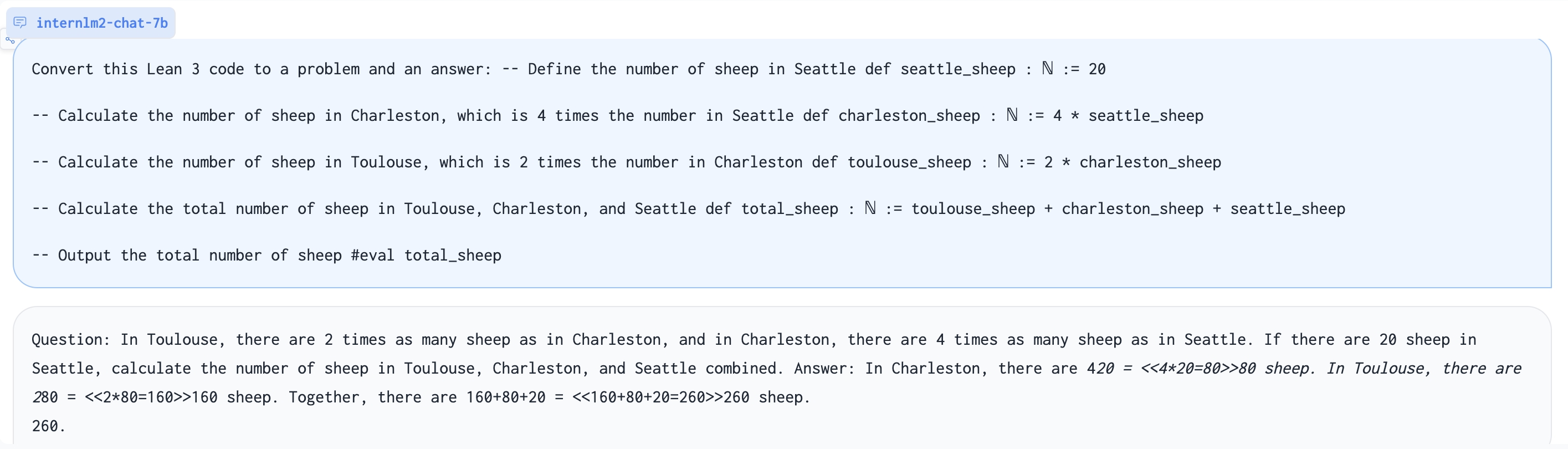
Play 24 point game:
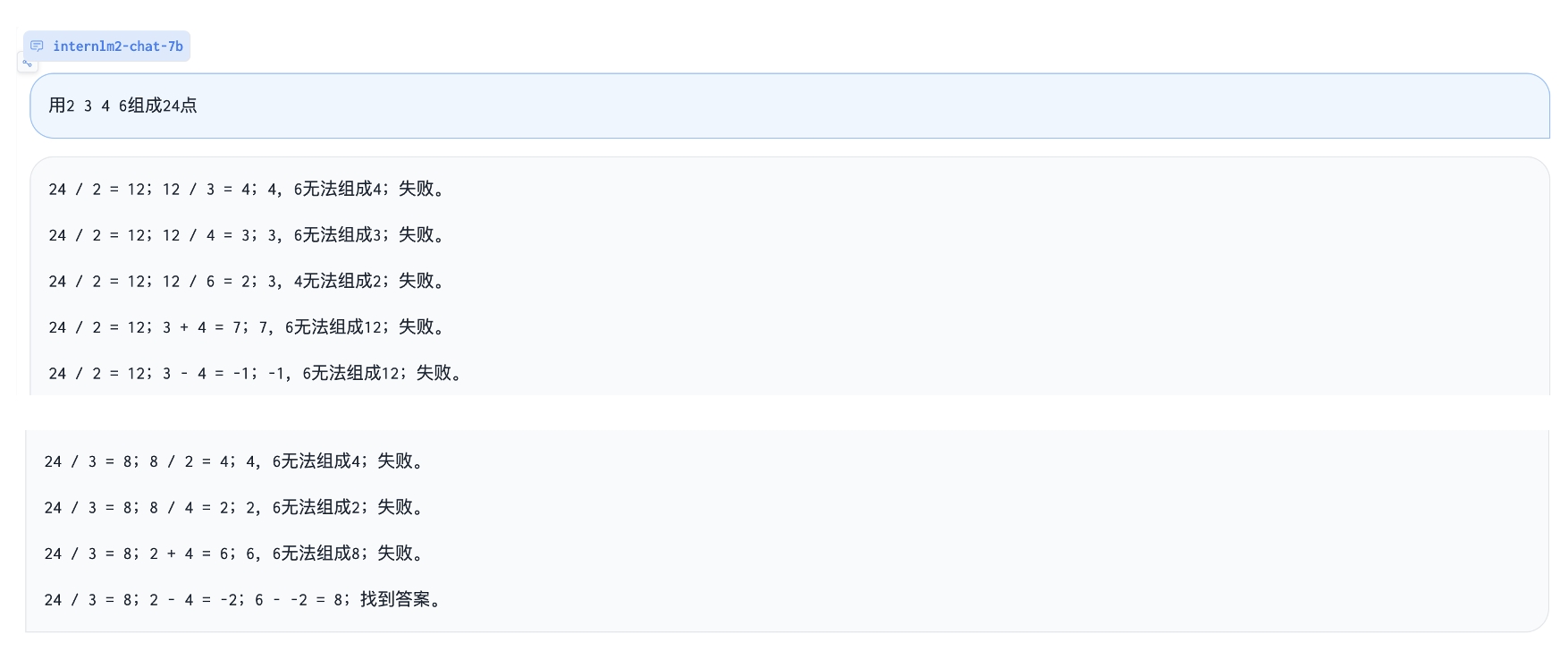
Augment a harder math problem:

| Description | Query |
| --- | --- |
| Solving question via chain-of-thought | {Question} |
| Solving question via Lean 3 | {Question}\nSolve this via Lean 3 |
| Outcome reward model | Given a question and an answer, check is it correct?\nQuestion:{Question}\nAnswer:{COT} |
| Process reward model | Given a question and an answer, check correctness of each step.\nQuestion:{Question}\nAnswer:{COT} |
| Reward model | Given a question and two answers, which one is better? \nQuestion:{Question}\nAnswer 1:{COT}\nAnswer 2:{COT} |
| Convert chain-of-thought to Lean 3 | Convert this answer into Lean3. Question:{Question}\nAnswer:{COT} |
| Convert Lean 3 to chain-of-thought | Convert this lean 3 code into a natural language problem with answers:\n{LEAN Code} |
| Translate question and chain-of-thought answer to a proof statement | Convert this question and answer into a proof format.\nQuestion:{Question}\nAnswer:{COT} |
| Translate proof problem to Lean 3 | Convert this natural langauge statement into a Lean 3 theorem statement:{Theorem} |
| Translate Lean 3 to proof problem | Convert this Lean 3 theorem statement into natural language:{STATEMENT} |
| Suggest a tactic based on Lean state | Given the Lean 3 tactic state, suggest a next tactic:\n{LEAN State} |
| Rephrase Problem | Describe this problem in another way. {Question} |
| Augment Problem | Please augment a new problem based on: {Question} |
| Augment a harder Problem | Increase the complexity of the problem: {Question} |
| Change specific numbers | Change specific numbers: {Question}|
| Introduce fractions or percentages | Introduce fractions or percentages: {Question}|
| Code Interpreter | [lagent](https://github.com/InternLM/InternLM/blob/main/agent/lagent.md) |
| In-context Learning | Question:{Question}\nAnswer:{COT}\n...Question:{Question}\nAnswer:{COT}|
# Fine-tune and others
Please refer to [InternLM](https://github.com/InternLM/InternLM/tree/main).
# Known issues
Our model is still under development and will be upgraded. There are some possible issues of InternLM-Math. If you find performances of some abilities are not great, welcome to open an issue.
- Jump the calculating step.
- Perform badly at Chinese fill-in-the-bank problems and English choice problems due to SFT data composition.
- Tend to generate Code Interpreter when facing Chinese problems due to SFT data composition.
- The reward model mode can be better leveraged with assigned token probabilities.
- Code switch due to SFT data composition.
- Some abilities of Lean can only be adapted to GSM8K-like problems (e.g. Convert chain-of-thought to Lean 3), and performance related to Lean is not guaranteed.
# Citation and Tech Report
To be appended.
|
Subsets and Splits