
Search is not available for this dataset
modelId
stringlengths 5
138
| author
stringlengths 2
42
| last_modified
unknowndate 2020-02-15 11:33:14
2025-04-12 06:26:38
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 422
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
unknowndate 2022-03-02 23:29:04
2025-04-12 06:25:56
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
BeaverAI/Agatha-111B-v1d-GGUF | BeaverAI | "2025-04-06T03:03:41Z" | 0 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2025-04-06T01:49:11Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:[email protected]">an email</a></p>
</div>
</main>
</body>
</html> |
javijer/llama2-alpaca-16bit | javijer | "2024-04-23T09:52:04Z" | 0 | 0 | transformers | [
"transformers",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-2-7b-bnb-4bit",
"base_model:finetune:unsloth/llama-2-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2024-04-23T09:52:02Z" | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-2-7b-bnb-4bit
---
# Uploaded model
- **Developed by:** javijer
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-2-7b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mradermacher/Ontology-0.1-Mistral-7B-GGUF | mradermacher | "2025-01-02T07:30:16Z" | 19 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Orneyfish/Ontology-0.1-Mistral-7B",
"base_model:quantized:Orneyfish/Ontology-0.1-Mistral-7B",
"endpoints_compatible",
"region:us"
] | null | "2025-01-02T01:19:31Z" | ---
base_model: Orneyfish/Ontology-0.1-Mistral-7B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Orneyfish/Ontology-0.1-Mistral-7B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Ontology-0.1-Mistral-7B-GGUF/resolve/main/Ontology-0.1-Mistral-7B.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Ontology-0.1-Mistral-7B-GGUF/resolve/main/Ontology-0.1-Mistral-7B.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Ontology-0.1-Mistral-7B-GGUF/resolve/main/Ontology-0.1-Mistral-7B.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Ontology-0.1-Mistral-7B-GGUF/resolve/main/Ontology-0.1-Mistral-7B.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Ontology-0.1-Mistral-7B-GGUF/resolve/main/Ontology-0.1-Mistral-7B.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Ontology-0.1-Mistral-7B-GGUF/resolve/main/Ontology-0.1-Mistral-7B.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Ontology-0.1-Mistral-7B-GGUF/resolve/main/Ontology-0.1-Mistral-7B.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Ontology-0.1-Mistral-7B-GGUF/resolve/main/Ontology-0.1-Mistral-7B.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Ontology-0.1-Mistral-7B-GGUF/resolve/main/Ontology-0.1-Mistral-7B.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Ontology-0.1-Mistral-7B-GGUF/resolve/main/Ontology-0.1-Mistral-7B.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Ontology-0.1-Mistral-7B-GGUF/resolve/main/Ontology-0.1-Mistral-7B.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Ontology-0.1-Mistral-7B-GGUF/resolve/main/Ontology-0.1-Mistral-7B.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
eri166/BKPM_Mistral | eri166 | "2025-02-27T09:54:21Z" | 0 | 0 | transformers | [
"transformers",
"gguf",
"mistral",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/mistral-7b-v0.3-bnb-4bit",
"base_model:quantized:unsloth/mistral-7b-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2025-02-27T09:52:18Z" | ---
base_model: unsloth/mistral-7b-v0.3-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** eri166
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
superdavidyeh/llama2_uuu_news_qlora | superdavidyeh | "2024-06-05T08:01:12Z" | 1 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:NousResearch/Llama-2-7b-chat-hf",
"base_model:adapter:NousResearch/Llama-2-7b-chat-hf",
"region:us"
] | null | "2024-06-05T03:02:36Z" | ---
library_name: peft
base_model: NousResearch/Llama-2-7b-chat-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1 |
leixa/2f269ebb-4917-40e0-bd09-8d9b35f735b1 | leixa | "2025-01-24T14:54:35Z" | 9 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/llama-3-8b",
"base_model:adapter:unsloth/llama-3-8b",
"license:llama3",
"region:us"
] | null | "2025-01-24T14:24:32Z" | ---
library_name: peft
license: llama3
base_model: unsloth/llama-3-8b
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 2f269ebb-4917-40e0-bd09-8d9b35f735b1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: unsloth/llama-3-8b
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- ed7237070a48a937_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/ed7237070a48a937_train_data.json
type:
field_input: tokens
field_instruction: text
field_output: ner_tags
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 4
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_clipping: 1.0
group_by_length: false
hub_model_id: leixa/2f269ebb-4917-40e0-bd09-8d9b35f735b1
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.0001
load_in_4bit: false
load_in_8bit: false
local_rank: 0
logging_steps: 3
lora_alpha: 32
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 16
lora_target_linear: true
lr_scheduler: cosine
max_steps: 100
micro_batch_size: 8
mlflow_experiment_name: /tmp/ed7237070a48a937_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 3
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 4
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: techspear-hub
wandb_mode: online
wandb_name: 306028e5-d6af-4d1b-bab1-63a2e73aa431
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: 306028e5-d6af-4d1b-bab1-63a2e73aa431
warmup_steps: 10
weight_decay: 0.01
xformers_attention: null
```
</details><br>
# 2f269ebb-4917-40e0-bd09-8d9b35f735b1
This model is a fine-tuned version of [unsloth/llama-3-8b](https://huggingface.co/unsloth/llama-3-8b) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0423
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- training_steps: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| No log | 0.0014 | 1 | 0.7183 |
| 0.4302 | 0.0127 | 9 | 0.3306 |
| 0.2097 | 0.0254 | 18 | 0.1815 |
| 0.1096 | 0.0380 | 27 | 0.0960 |
| 0.0689 | 0.0507 | 36 | 0.0704 |
| 0.0632 | 0.0634 | 45 | 0.0626 |
| 0.0564 | 0.0761 | 54 | 0.0527 |
| 0.0494 | 0.0888 | 63 | 0.0470 |
| 0.0413 | 0.1014 | 72 | 0.0443 |
| 0.0417 | 0.1141 | 81 | 0.0443 |
| 0.0417 | 0.1268 | 90 | 0.0427 |
| 0.0397 | 0.1395 | 99 | 0.0423 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
mradermacher/TinyAlpaca-GGUF | mradermacher | "2025-02-05T17:17:11Z" | 160 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:mlabonne/TinyAlpaca",
"base_model:quantized:mlabonne/TinyAlpaca",
"endpoints_compatible",
"region:us"
] | null | "2025-02-05T16:52:51Z" | ---
base_model: mlabonne/TinyAlpaca
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/mlabonne/TinyAlpaca
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/TinyAlpaca-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/TinyAlpaca-GGUF/resolve/main/TinyAlpaca.Q2_K.gguf) | Q2_K | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/TinyAlpaca-GGUF/resolve/main/TinyAlpaca.Q3_K_S.gguf) | Q3_K_S | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/TinyAlpaca-GGUF/resolve/main/TinyAlpaca.Q3_K_M.gguf) | Q3_K_M | 0.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/TinyAlpaca-GGUF/resolve/main/TinyAlpaca.Q3_K_L.gguf) | Q3_K_L | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/TinyAlpaca-GGUF/resolve/main/TinyAlpaca.IQ4_XS.gguf) | IQ4_XS | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/TinyAlpaca-GGUF/resolve/main/TinyAlpaca.Q4_K_S.gguf) | Q4_K_S | 0.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TinyAlpaca-GGUF/resolve/main/TinyAlpaca.Q4_K_M.gguf) | Q4_K_M | 0.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TinyAlpaca-GGUF/resolve/main/TinyAlpaca.Q5_K_S.gguf) | Q5_K_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/TinyAlpaca-GGUF/resolve/main/TinyAlpaca.Q5_K_M.gguf) | Q5_K_M | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/TinyAlpaca-GGUF/resolve/main/TinyAlpaca.Q6_K.gguf) | Q6_K | 1.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/TinyAlpaca-GGUF/resolve/main/TinyAlpaca.Q8_0.gguf) | Q8_0 | 1.3 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/TinyAlpaca-GGUF/resolve/main/TinyAlpaca.f16.gguf) | f16 | 2.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
MrD05/llama2-qlora-finetunined-role | MrD05 | "2023-07-24T09:16:50Z" | 4 | 0 | peft | [
"peft",
"region:us"
] | null | "2023-07-24T09:14:13Z" | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0.dev0
|
seongjae6751/poca-SoccerTwos | seongjae6751 | "2025-02-12T18:32:18Z" | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] | reinforcement-learning | "2025-02-12T18:31:45Z" | ---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: seongjae6751/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
ShinyQ/Sentiboard | ShinyQ | "2022-12-10T06:45:35Z" | 3 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-12-10T06:34:49Z" | ---
tags:
- generated_from_trainer
model-index:
- name: tmp_trainer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tmp_trainer
This model was trained from scratch on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Tokenizers 0.13.2
|
Inderpreet01/Llama-3.2-8B-Instruct_rca_grpo_v1 | Inderpreet01 | "2025-03-26T21:46:33Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"grpo",
"conversational",
"en",
"base_model:Inderpreet01/Llama-3.1-8B-Instruct_rca_sft_v2",
"base_model:finetune:Inderpreet01/Llama-3.1-8B-Instruct_rca_sft_v2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-03-26T21:43:46Z" | ---
base_model: Inderpreet01/Llama-3.1-8B-Instruct_rca_sft_v2
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- grpo
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Inderpreet01
- **License:** apache-2.0
- **Finetuned from model :** Inderpreet01/Llama-3.1-8B-Instruct_rca_sft_v2
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
lesso10/dc7cb361-5673-4c27-9980-c558194db68e | lesso10 | "2025-03-24T13:46:15Z" | 0 | 0 | peft | [
"peft",
"safetensors",
"gemma2",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/gemma-2-2b-it",
"base_model:adapter:unsloth/gemma-2-2b-it",
"license:gemma",
"region:us"
] | null | "2025-03-24T12:33:10Z" | Temporary Redirect. Redirecting to /api/resolve-cache/models/lesso10/dc7cb361-5673-4c27-9980-c558194db68e/0a6b1a971bb87a75569e762e719b3f42df96adb4/README.md?%2Flesso10%2Fdc7cb361-5673-4c27-9980-c558194db68e%2Fresolve%2Fmain%2FREADME.md=&etag=%22d5173a74cc1f4d80c67926d6efd42398f80e8cc0%22 |
ArbaazBeg/phi3-medium-lmsys-0 | ArbaazBeg | "2024-08-01T04:01:34Z" | 105 | 0 | transformers | [
"transformers",
"safetensors",
"phi3",
"text-generation",
"conversational",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-07-31T11:52:53Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
argmining-vaccines/roberta-base-stance | argmining-vaccines | "2024-02-21T13:12:25Z" | 5 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | "2024-02-21T13:12:11Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
kafikani/autotrain-dynex-77356140532 | kafikani | "2023-07-25T20:50:27Z" | 109 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"deberta",
"text-classification",
"autotrain",
"en",
"dataset:kafikani/autotrain-data-dynex",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2023-07-25T20:43:31Z" | ---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain"
datasets:
- kafikani/autotrain-data-dynex
co2_eq_emissions:
emissions: 4.733413186525841
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 77356140532
- CO2 Emissions (in grams): 4.7334
## Validation Metrics
- Loss: 0.458
- Accuracy: 0.837
- Macro F1: 0.761
- Micro F1: 0.837
- Weighted F1: 0.833
- Macro Precision: 0.785
- Micro Precision: 0.837
- Weighted Precision: 0.834
- Macro Recall: 0.746
- Micro Recall: 0.837
- Weighted Recall: 0.837
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/kafikani/autotrain-dynex-77356140532
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("kafikani/autotrain-dynex-77356140532", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("kafikani/autotrain-dynex-77356140532", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
``` |
ausgerechnet/schwurpert | ausgerechnet | "2025-02-24T10:55:58Z" | 153 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"bert",
"fill-mask",
"de",
"base_model:deepset/gbert-large",
"base_model:finetune:deepset/gbert-large",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2023-10-17T16:33:14Z" | ---
base_model: deepset/gbert-large
model-index:
- name: schwurpert
results: []
language:
- de
pipeline_tag: fill-mask
---
# schwurpert
This model is a fine-tuned version of [deepset/gbert-large](https://huggingface.co/deepset/gbert-large) on Telegram posts written mostly by German conspiracy theorists (and some more credible authors).
The complete corpus is available on request.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'transformers.optimization_tf', 'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 92927, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}, 'registered_name': 'WarmUp'}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Epoch |
|:----------:|:-----:|
| 1.7997 | 0 |
### Framework versions
- Transformers 4.33.2
- TensorFlow 2.13.0
- Datasets 2.14.5
- Tokenizers 0.13.3 |
transitionGap/DOMICILE-IN-Llama3.1-8B-smallset | transitionGap | "2024-10-14T18:45:51Z" | 19 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
"base_model:quantized:unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2024-10-14T18:17:54Z" | ---
base_model: unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
---
# Uploaded model
- **Developed by:** transitionGap
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
lmstudio-community/c4ai-command-r-plus-08-2024-GGUF | lmstudio-community | "2024-08-30T19:36:22Z" | 485 | 5 | transformers | [
"transformers",
"gguf",
"text-generation",
"en",
"fr",
"de",
"es",
"it",
"pt",
"ja",
"ko",
"zh",
"ar",
"base_model:CohereForAI/c4ai-command-r-plus-08-2024",
"base_model:quantized:CohereForAI/c4ai-command-r-plus-08-2024",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | "2024-08-30T16:02:51Z" | ---
language:
- en
- fr
- de
- es
- it
- pt
- ja
- ko
- zh
- ar
license: cc-by-nc-4.0
library_name: transformers
extra_gated_prompt: "By submitting this form, you agree to the [License Agreement](https://cohere.com/c4ai-cc-by-nc-license) and acknowledge that the information you provide will be collected, used, and shared in accordance with Cohere’s [Privacy Policy]( https://cohere.com/privacy)."
extra_gated_fields:
Name: text
Affiliation: text
Country:
type: select
options:
- Aruba
- Afghanistan
- Angola
- Anguilla
- Åland Islands
- Albania
- Andorra
- United Arab Emirates
- Argentina
- Armenia
- American Samoa
- Antarctica
- French Southern Territories
- Antigua and Barbuda
- Australia
- Austria
- Azerbaijan
- Burundi
- Belgium
- Benin
- Bonaire Sint Eustatius and Saba
- Burkina Faso
- Bangladesh
- Bulgaria
- Bahrain
- Bahamas
- Bosnia and Herzegovina
- Saint Barthélemy
- Belarus
- Belize
- Bermuda
- Plurinational State of Bolivia
- Brazil
- Barbados
- Brunei-Darussalam
- Bhutan
- Bouvet-Island
- Botswana
- Central African Republic
- Canada
- Cocos (Keeling) Islands
- Switzerland
- Chile
- China
- Côte-dIvoire
- Cameroon
- Democratic Republic of the Congo
- Cook Islands
- Colombia
- Comoros
- Cabo Verde
- Costa Rica
- Cuba
- Curaçao
- Christmas Island
- Cayman Islands
- Cyprus
- Czechia
- Germany
- Djibouti
- Dominica
- Denmark
- Dominican Republic
- Algeria
- Ecuador
- Egypt
- Eritrea
- Western Sahara
- Spain
- Estonia
- Ethiopia
- Finland
- Fiji
- Falkland Islands (Malvinas)
- France
- Faroe Islands
- Federated States of Micronesia
- Gabon
- United Kingdom
- Georgia
- Guernsey
- Ghana
- Gibraltar
- Guinea
- Guadeloupe
- Gambia
- Guinea Bissau
- Equatorial Guinea
- Greece
- Grenada
- Greenland
- Guatemala
- French Guiana
- Guam
- Guyana
- Hong Kong
- Heard Island and McDonald Islands
- Honduras
- Croatia
- Haiti
- Hungary
- Indonesia
- Isle of Man
- India
- British Indian Ocean Territory
- Ireland
- Islamic Republic of Iran
- Iraq
- Iceland
- Israel
- Italy
- Jamaica
- Jersey
- Jordan
- Japan
- Kazakhstan
- Kenya
- Kyrgyzstan
- Cambodia
- Kiribati
- Saint-Kitts-and-Nevis
- South Korea
- Kuwait
- Lao-Peoples-Democratic-Republic
- Lebanon
- Liberia
- Libya
- Saint-Lucia
- Liechtenstein
- Sri Lanka
- Lesotho
- Lithuania
- Luxembourg
- Latvia
- Macao
- Saint Martin (French-part)
- Morocco
- Monaco
- Republic of Moldova
- Madagascar
- Maldives
- Mexico
- Marshall Islands
- North Macedonia
- Mali
- Malta
- Myanmar
- Montenegro
- Mongolia
- Northern Mariana Islands
- Mozambique
- Mauritania
- Montserrat
- Martinique
- Mauritius
- Malawi
- Malaysia
- Mayotte
- Namibia
- New Caledonia
- Niger
- Norfolk Island
- Nigeria
- Nicaragua
- Niue
- Netherlands
- Norway
- Nepal
- Nauru
- New Zealand
- Oman
- Pakistan
- Panama
- Pitcairn
- Peru
- Philippines
- Palau
- Papua New Guinea
- Poland
- Puerto Rico
- North Korea
- Portugal
- Paraguay
- State of Palestine
- French Polynesia
- Qatar
- Réunion
- Romania
- Russia
- Rwanda
- Saudi Arabia
- Sudan
- Senegal
- Singapore
- South Georgia and the South Sandwich Islands
- Saint Helena Ascension and Tristan da Cunha
- Svalbard and Jan Mayen
- Solomon Islands
- Sierra Leone
- El Salvador
- San Marino
- Somalia
- Saint Pierre and Miquelon
- Serbia
- South Sudan
- Sao Tome and Principe
- Suriname
- Slovakia
- Slovenia
- Sweden
- Eswatini
- Sint Maarten (Dutch-part)
- Seychelles
- Syrian Arab Republic
- Turks and Caicos Islands
- Chad
- Togo
- Thailand
- Tajikistan
- Tokelau
- Turkmenistan
- Timor Leste
- Tonga
- Trinidad and Tobago
- Tunisia
- Turkey
- Tuvalu
- Taiwan
- United Republic of Tanzania
- Uganda
- Ukraine
- United States Minor Outlying Islands
- Uruguay
- United-States
- Uzbekistan
- Holy See (Vatican City State)
- Saint Vincent and the Grenadines
- Bolivarian Republic of Venezuela
- Virgin Islands British
- Virgin Islands U.S.
- VietNam
- Vanuatu
- Wallis and Futuna
- Samoa
- Yemen
- South Africa
- Zambia
- Zimbabwe
Receive email updates on C4AI and Cohere research, events, products and services?:
type: select
options:
- Yes
- No
I agree to use this model for non-commercial use ONLY: checkbox
quantized_by: bartowski
pipeline_tag: text-generation
base_model: CohereForAI/c4ai-command-r-plus-08-2024
lm_studio:
param_count: 105b
use_case: general
release_date: 30-08-2024
model_creator: CohereForAI
prompt_template: cohere_command_r
base_model: Cohere
system_prompt: You are a large language model called Command R built by the company Cohere. You act as a brilliant, sophisticated, AI-assistant chatbot trained to assist human users by providing thorough responses.
original_repo: CohereForAI/c4ai-command-r-plus-08-2024
---
## 💫 Community Model> C4AI Command R Plus 08-2024 by Cohere For AI
*👾 [LM Studio](https://lmstudio.ai) Community models highlights program. Highlighting new & noteworthy models by the community. Join the conversation on [Discord](https://discord.gg/aPQfnNkxGC)*.
**Model creator:** [CohereForAI](https://huggingface.co/CohereForAI)<br>
**Original model**: [c4ai-command-r-plus-08-2024](https://huggingface.co/CohereForAI/c4ai-command-r-plus-08-2024)<br>
**GGUF quantization:** provided by [bartowski](https://huggingface.co/bartowski) based on `llama.cpp` release [b3634](https://github.com/ggerganov/llama.cpp/releases/tag/b3634)<br>
## Model Summary:
C4AI Command R Plus 08-2024 is an update to the originally released 105B paramater Command R. The original Command R model received sweeping praise for its incredible RAG and multilingual abilities, and this model is no different.<br>
Not for commercial use, must adhere to [C4AI's Acceptable Use Policy](https://docs.cohere.com/docs/c4ai-acceptable-use-policy).
## Prompt Template:
Choose the `Cohere Command R` preset in your LM Studio.
Under the hood, the model will see a prompt that's formatted like so:
```
<BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>{prompt}<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
```
This model also supports tool use and RAG prompt formats. For details on formatting for those use cases, view [tool use here](https://huggingface.co/CohereForAI/c4ai-command-r-plus-08-2024#tool-use--agent-capabilities) and [RAG capabilities here](https://huggingface.co/CohereForAI/c4ai-command-r-plus-08-2024#grounded-generation-and-rag-capabilities)
## Technical Details
C4AI Command R Plus 08-2024 has been trained on 23 languages (English, French, Spanish, Italian, German, Portuguese, Japanese, Korean, Arabic, Simplified Chinese, Russian, Polish, Turkish, Vietnamese, Dutch, Czech, Indonesian, Ukrainian, Romanian, Greek, Hindi, Hebrew, and Persian).
Due to this multilingual training, it excels in multilingual tasks.
Command R Plus 08-2024 supports a context length of 128K.
## Special thanks
🙏 Special thanks to [Georgi Gerganov](https://github.com/ggerganov) and the whole team working on [llama.cpp](https://github.com/ggerganov/llama.cpp/) for making all of this possible.
## Disclaimers
LM Studio is not the creator, originator, or owner of any Model featured in the Community Model Program. Each Community Model is created and provided by third parties. LM Studio does not endorse, support, represent or guarantee the completeness, truthfulness, accuracy, or reliability of any Community Model. You understand that Community Models can produce content that might be offensive, harmful, inaccurate or otherwise inappropriate, or deceptive. Each Community Model is the sole responsibility of the person or entity who originated such Model. LM Studio may not monitor or control the Community Models and cannot, and does not, take responsibility for any such Model. LM Studio disclaims all warranties or guarantees about the accuracy, reliability or benefits of the Community Models. LM Studio further disclaims any warranty that the Community Model will meet your requirements, be secure, uninterrupted or available at any time or location, or error-free, viruses-free, or that any errors will be corrected, or otherwise. You will be solely responsible for any damage resulting from your use of or access to the Community Models, your downloading of any Community Model, or use of any other Community Model provided by or through LM Studio.
### Terms of Use (directly from Cohere For AI)
We hope that the release of this model will make community-based research efforts more accessible, by releasing the weights of a highly performant 35 billion parameter model to researchers all over the world. This model is governed by a [CC-BY-NC](https://cohere.com/c4ai-cc-by-nc-license) License with an acceptable use addendum, and also requires adhering to [C4AI's Acceptable Use Policy](https://docs.cohere.com/docs/c4ai-acceptable-use-policy).
|
Stanley4848/Biotradeinvestment | Stanley4848 | "2025-03-19T15:15:49Z" | 0 | 0 | adapter-transformers | [
"adapter-transformers",
"finance",
"translation",
"pt",
"dataset:Congliu/Chinese-DeepSeek-R1-Distill-data-110k",
"base_model:Qwen/QwQ-32B",
"base_model:adapter:Qwen/QwQ-32B",
"license:apache-2.0",
"region:us"
] | translation | "2025-03-19T15:13:56Z" | ---
license: apache-2.0
datasets:
- Congliu/Chinese-DeepSeek-R1-Distill-data-110k
language:
- pt
metrics:
- accuracy
base_model:
- Qwen/QwQ-32B
new_version: deepseek-ai/DeepSeek-R1
pipeline_tag: translation
library_name: adapter-transformers
tags:
- finance
--- |
TEEN-D/Driver-Drowsiness-Detection | TEEN-D | "2025-03-31T01:11:58Z" | 0 | 0 | null | [
"en",
"license:mit",
"region:us"
] | null | "2025-03-31T00:25:06Z" | ---
license: mit
language:
- en
---
# Model Cards: Driver Drowsiness Detection System
This repository contains models developed for the Driver Drowsiness Detection System project. The goal is to enhance vehicular safety by identifying signs of driver fatigue and drowsiness in real-time using deep learning. The system employs two main approaches:
1. **Facial Features Drowsiness Detection (Dataset 1):** Analyzes overall facial images for signs of drowsiness (e.g., yawning, general expression).
2. **Eye Closure Drowsiness Detection (Dataset 2):** Specifically focuses on detecting whether the driver's eyes are open or closed.
The report suggests combining these approaches for a more robust system, potentially using MobileNetV2 for facial features and the tuned CNN for eye closure.
---
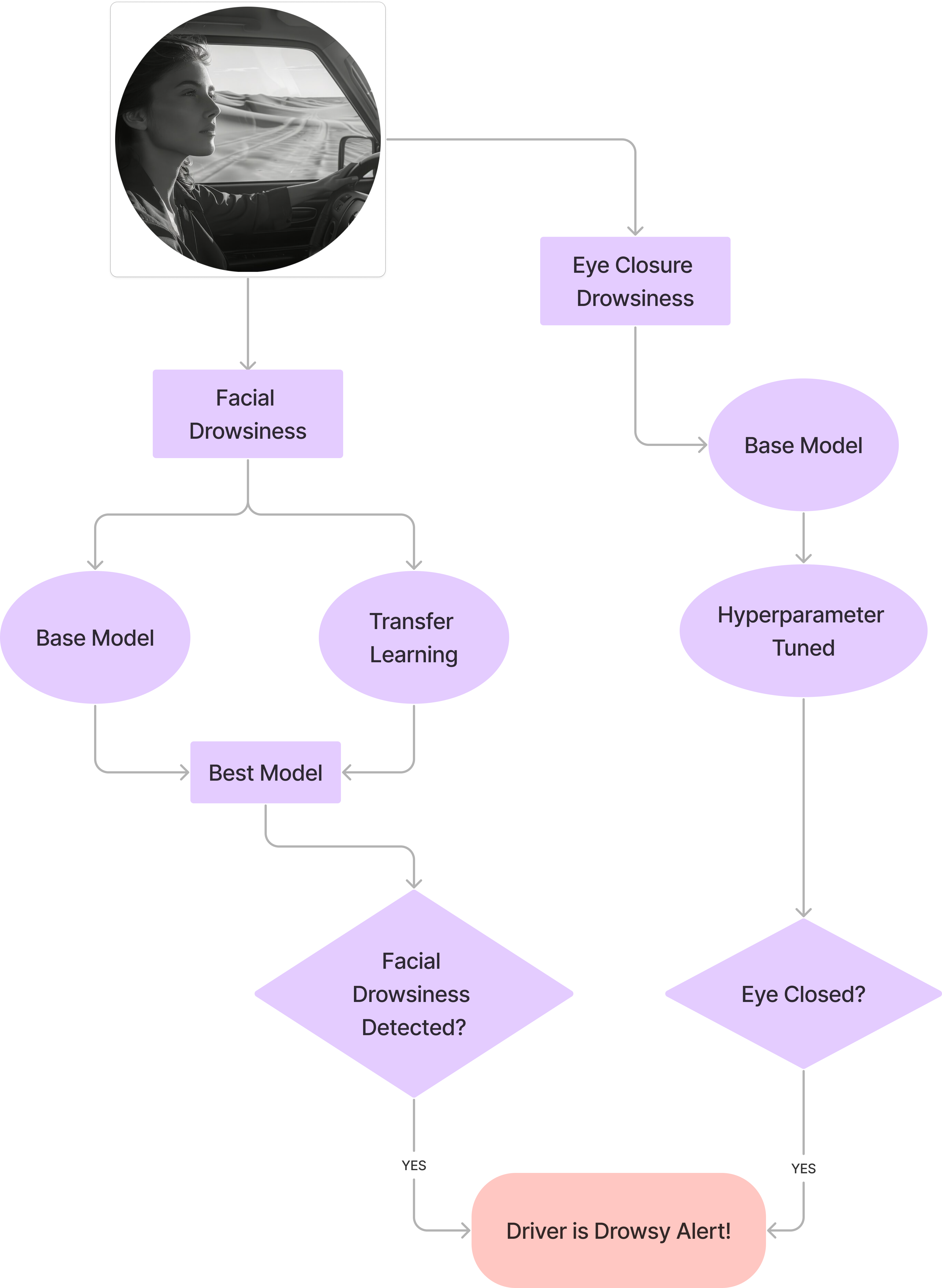
---
## Model Card: Facial Drowsiness Detection - Base CNN
* **Model File:** `trained_model_weights_BASE_DATASET1.pth`
### Model Details
* **Description:** A custom Convolutional Neural Network (CNN) trained from scratch to classify facial images as 'Drowsy' or 'Natural' (alert). This is the initial baseline model for Dataset 1.
* **Architecture:** `Model_OurArchitecture` (4 Conv2D layers: 1->32, 32->64, 64->128, 128->128; MaxPool2D after first 3 Conv layers; 1 FC layer: 128*6*6 -> 256; Output FC layer: 256 -> 1; ReLU activations; Single Dropout(0.5) layer before final output).
* **Input:** 48x48 Grayscale images.
* **Output:** Single logit predicting drowsiness (Binary Classification).
* **Framework:** PyTorch.
### Intended Use
* Intended for detecting drowsiness based on static facial images. Serves as a baseline for comparison.
* **Not recommended for deployment due to significant overfitting.**
### Training Data
* **Dataset:** Drowsy Detection Dataset ([Kaggle Link](https://www.kaggle.com/datasets/yasharjebraeily/drowsy-detection-dataset))
* **Classes:** DROWSY, NATURAL.
* **Size:** 5,859 training images.
* **Preprocessing:** Resize (48x48), Grayscale, ToTensor, Normalize (calculated mean/std from dataset), RandomHorizontalFlip.

### Evaluation Data
* **Dataset:** Test split of the Drowsy Detection Dataset.
* **Size:** 1,483 testing images.
* **Preprocessing:** Resize (48x48), Grayscale, ToTensor, Normalize (same as training).
### Quantitative Analyses
* **Training Performance:** Accuracy: 99.51%, Loss: 0.0148
* **Evaluation Performance:** Accuracy: 86.24%, Loss: 0.9170
* **Metrics:** Accuracy, Binary Cross-Entropy with Logits Loss.
### Limitations and Ethical Considerations
* **Overfitting:** Shows significant overfitting (large gap between training and testing accuracy). Generalizes poorly to unseen data.
* **Bias:** Performance may vary across different demographics, lighting conditions, camera angles, and accessories (e.g., glasses) not equally represented in the dataset.
* **Misuse Potential:** Could be used for surveillance, though not designed for it. False negatives (missing drowsiness) could lead to accidents; false positives (incorrect alerts) could be annoying or lead to user distrust.
---
## Model Card: Facial Drowsiness Detection - Base CNN + Dropout
* **Model File:** `trained_model_weights_BASE_DROPOUT_DATASET1.pth`
### Model Details
* **Description:** The same custom CNN architecture as the base model (`Model_OurArchitecture`) but explicitly trained *with* the described dropout layer active to mitigate overfitting observed in the baseline.
* **Architecture:** `Model_OurArchitecture` (As described above, including the Dropout(0.5) layer).
* **Input:** 48x48 Grayscale images.
* **Output:** Single logit predicting drowsiness.
* **Framework:** PyTorch.
### Intended Use
* Intended for detecting drowsiness based on static facial images. Shows improvement over the baseline by using dropout for regularization.
* Better generalization than the baseline, but transfer learning models performed better.
### Training Data
* Same as the Base CNN model (Dataset 1).
### Evaluation Data
* Same as the Base CNN model (Dataset 1).
### Quantitative Analyses
* **Training Performance:** Accuracy: 96.36%, Loss: 0.0960
* **Evaluation Performance:** Accuracy: 90.42%, Loss: 0.1969
* **Metrics:** Accuracy, BCEWithLogitsLoss.
### Limitations and Ethical Considerations
* **Overfitting Reduced:** Overfitting is reduced compared to the baseline, but a gap still exists.
* **Bias:** Same potential biases as the base model regarding demographics, lighting, etc.
* **Misuse Potential:** Same as the base model.
---
## Model Card: Facial Drowsiness Detection - Base CNN + Dropout + Early Stopping
* **Model File:** `trained_model_weights_BASE_DROPOUT_EARLYSTOPPING_DATASET1.pth`
### Model Details
* **Description:** The same custom CNN architecture (`Model_OurArchitecture` with dropout) trained using Dropout and Early Stopping (patience=5) to further prevent overfitting. Training stopped at epoch 9 out of 25 planned.
* **Architecture:** `Model_OurArchitecture` (As described above, including the Dropout(0.5) layer).
* **Input:** 48x48 Grayscale images.
* **Output:** Single logit predicting drowsiness.
* **Framework:** PyTorch.
### Intended Use
* Intended for detecting drowsiness based on static facial images. Represents the best-performing version of the custom CNN architecture due to regularization techniques.
* Performance is closer between training and testing compared to previous versions.
### Training Data
* Same as the Base CNN model (Dataset 1).
### Evaluation Data
* Same as the Base CNN model (Dataset 1).
### Quantitative Analyses
* **Best Training Performance (at Epoch 9):** Accuracy: 97.87%, Loss: 0.0617
* **Evaluation Performance:** Accuracy: 91.64%, Loss: 0.1899
* **Metrics:** Accuracy, BCEWithLogitsLoss.
### Limitations and Ethical Considerations
* **Generalization:** While improved, may not perform as well as the best transfer learning models on diverse unseen data.
* **Bias:** Same potential biases as the base model.
* **Misuse Potential:** Same as the base model.
---
## Model Card: Facial Drowsiness Detection - Fine-tuned VGG16
* **Model File:** `trained_model_weights_VGG16_DATASET1.pth`
### Model Details
* **Description:** A VGG16 model, pre-trained on ImageNet, fine-tuned for binary classification of facial images ('Drowsy' vs 'Natural') on Dataset 1.
* **Architecture:** Standard VGG16 architecture with the final fully connected layer replaced by a single output unit for binary classification.
* **Input:** 224x224 RGB images (Normalized using ImageNet stats).
* **Output:** Single logit predicting drowsiness.
* **Framework:** PyTorch.
### Intended Use
* Detecting drowsiness from facial images. Leverages transfer learning for potentially better feature extraction and generalization compared to the custom CNN. Good performance on the test set.
### Training Data
* **Dataset:** Drowsy Detection Dataset ([Kaggle Link](https://www.kaggle.com/datasets/yasharjebraeily/drowsy-detection-dataset))
* **Classes:** DROWSY, NATURAL.
* **Size:** 5,859 training images.
* **Preprocessing:** Resize (224x224), RandomHorizontalFlip, ToTensor, Normalize (ImageNet mean/std).
### Evaluation Data
* **Dataset:** Test split of the Drowsy Detection Dataset.
* **Size:** 1,483 testing images.
* **Preprocessing:** Resize (224x224), ToTensor, Normalize (ImageNet mean/std).
### Quantitative Analyses
* **Training Performance:** Accuracy: 96.69%, Loss: 0.1067
* **Evaluation Performance:** Accuracy: 97.51%, Loss: 0.1033
* **Metrics:** Accuracy, BCEWithLogitsLoss.
### Limitations and Ethical Considerations
* **Model Size:** VGG16 is relatively large, potentially impacting inference speed and deployment on resource-constrained devices.
* **Bias:** Potential biases inherited from ImageNet pre-training and the fine-tuning dataset (demographics, lighting, etc.).
* **Misuse Potential:** Same as the base model.
---
## Model Card: Facial Drowsiness Detection - Fine-tuned ResNet18
* **Model File:** `trained_model_weights_RESNET18_DATASET1.pth`
### Model Details
* **Description:** A ResNet18 model, pre-trained on ImageNet, fine-tuned for binary classification of facial images ('Drowsy' vs 'Natural') on Dataset 1.
* **Architecture:** Standard ResNet18 architecture with the final fully connected layer replaced by a single output unit.
* **Input:** 224x224 RGB images (Normalized using ImageNet stats).
* **Output:** Single logit predicting drowsiness.
* **Framework:** PyTorch.
### Intended Use
* Detecting drowsiness from facial images using transfer learning. Offers a balance between performance and model size compared to VGG16.
### Training Data
* Same as the Fine-tuned VGG16 model (Dataset 1, 224x224 RGB, ImageNet Norm).
### Evaluation Data
* Same as the Fine-tuned VGG16 model (Dataset 1 Test Set).
### Quantitative Analyses
* **Training Performance:** Accuracy: 99.42%, Loss: 0.0197
* **Evaluation Performance:** Accuracy: 95.28%, Loss: 0.1118
* **Metrics:** Accuracy, BCEWithLogitsLoss.
### Limitations and Ethical Considerations
* **Overfitting:** Shows a slightly larger gap between training and test performance compared to VGG16/MobileNetV2 on this task, indicating some overfitting.
* **Bias:** Potential biases from ImageNet and the fine-tuning dataset.
* **Misuse Potential:** Same as the base model.
---
## Model Card: Facial Drowsiness Detection - Fine-tuned MobileNetV2 (**Recommended for Facial Features**)
* **Model File:** `trained_model_weights_MOBILENETV2_DATASET1.pth`
### Model Details
* **Description:** A MobileNetV2 model, pre-trained on ImageNet, fine-tuned for binary classification of facial images ('Drowsy' vs 'Natural') on Dataset 1. Achieved the highest test accuracy among models tested on Dataset 1.
* **Architecture:** Standard MobileNetV2 architecture with the final classifier replaced for a single output unit. Designed for efficiency.
* **Input:** 224x224 RGB images (Normalized using ImageNet stats).
* **Output:** Single logit predicting drowsiness.
* **Framework:** PyTorch.
### Intended Use
* **Recommended model for facial drowsiness detection.** Offers high accuracy and efficiency, suitable for real-time applications.
### Training Data
* Same as the Fine-tuned VGG16 model (Dataset 1, 224x224 RGB, ImageNet Norm).
### Evaluation Data
* Same as the Fine-tuned VGG16 model (Dataset 1 Test Set).
### Quantitative Analyses
* **Training Performance:** Accuracy: 99.61%, Loss: 0.0175
* **Evaluation Performance:** Accuracy: 98.99%, Loss: 0.0317
* **Metrics:** Accuracy, BCEWithLogitsLoss.
### Limitations and Ethical Considerations
* **Efficiency vs. Complexity:** While efficient, it might be less robust to extreme variations than larger models in some scenarios.
* **Bias:** Potential biases from ImageNet and the fine-tuning dataset.
* **Misuse Potential:** Same as the base model. Performance under challenging real-world conditions (e.g., poor lighting, partial occlusion) should be carefully validated.
---
## Model Card: Eye Closure Detection - Tuned CNN (**Recommended for Eye Closure**)
* **Model File:** `trained_model_weights_FINAL_DATASET2.pth`
### Model Details
* **Description:** A custom CNN (`Model_NewArchitecture`) trained to detect whether eyes are 'Open' or 'Closed'. This model is the result of hyperparameter tuning (Adam optimizer, Dropout rate 0.5) on the baseline architecture for Dataset 2.
* **Architecture:** `Model_NewArchitecture` (4 Conv2D layers: 3->64, 64->128, 128->256, 256->256; MaxPool2D after first 3 Conv layers; 1 FC layer: 256*28*28 -> 512; Output FC layer: 512 -> 1; ReLU activations; Dropout(0.5) before final output).
* **Input:** 224x224 Grayscale images (potentially replicated to 3 channels based on report's transform description, normalized using dataset stats).
* **Output:** Single logit predicting eye closure (Binary Classification).
* **Framework:** PyTorch.
### Intended Use
* **Recommended model for eye closure detection.** Specifically designed to classify eye state, intended to be used alongside the facial feature model for a more robust drowsiness detection system.
### Training Data
* **Dataset:** Openned Closed Eyes Dataset ([Kaggle Link](https://www.kaggle.com/datasets/hazemfahmy/openned-closed-eyes/data)) - UnityEyes synthetic data.
* **Classes:** Opened, Closed.
* **Size:** 5,807 training images.
* **Preprocessing:** Resize (224x224), Grayscale (num_output_channels=3), Augmentations (RandomHorizontalFlip, RandomRotation(10), ColorJitter), ToTensor, Normalize (calculated mean/std from dataset).

### Evaluation Data
* **Dataset:** Test split of the Openned Closed Eyes Dataset.
* **Size:** 4,232 testing images.
* **Preprocessing:** Resize (224x224), Grayscale (num_output_channels=3), ToTensor, Normalize (same as training).
### Quantitative Analyses (Hyperparameter Tuned Model: Adam, Dropout 0.5)
* **Final Training Performance:** Accuracy: 95.52%, Loss: 0.1303 (from table pg 23)
* **Evaluation Performance:** Accuracy: 96.79%, Loss: 0.0935 (from table pg 23)
* **Metrics:** Accuracy, BCEWithLogitsLoss.
### Limitations and Ethical Considerations
* **Synthetic Data:** Trained primarily on synthetic eye images (UnityEyes). Performance on diverse real-world eyes (different ethnicities, lighting, glasses, occlusions, extreme angles) needs validation. Domain gap might exist.
* **Bias:** Potential biases related to the distribution of eye types/states in the synthetic dataset.
* **Misuse Potential:** Could be part of a surveillance system monitoring eye state. False negatives/positives have safety implications as described for other models.
--- |
philip-hightech/1302eb45-d150-47da-89be-1cff18d4ac1d | philip-hightech | "2025-01-13T18:16:51Z" | 13 | 0 | peft | [
"peft",
"safetensors",
"mistral",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/zephyr-sft",
"base_model:adapter:unsloth/zephyr-sft",
"license:apache-2.0",
"region:us"
] | null | "2025-01-13T17:15:07Z" | ---
library_name: peft
license: apache-2.0
base_model: unsloth/zephyr-sft
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 1302eb45-d150-47da-89be-1cff18d4ac1d
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: unsloth/zephyr-sft
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- 3f789bd3616a633b_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/3f789bd3616a633b_train_data.json
type:
field_instruction: inputs
field_output: targets
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 4
flash_attention: false
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: false
group_by_length: false
hub_model_id: philip-hightech/1302eb45-d150-47da-89be-1cff18d4ac1d
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.0002
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 16
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 8
lora_target_linear: true
lr_scheduler: cosine
max_steps: 10
micro_batch_size: 2
mlflow_experiment_name: /tmp/3f789bd3616a633b_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 4
sequence_len: 512
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: fa880946-1eaf-434a-b678-94c8300d042a
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: fa880946-1eaf-434a-b678-94c8300d042a
warmup_steps: 10
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# 1302eb45-d150-47da-89be-1cff18d4ac1d
This model is a fine-tuned version of [unsloth/zephyr-sft](https://huggingface.co/unsloth/zephyr-sft) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: nan
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- training_steps: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.0 | 0.0000 | 1 | nan |
| 0.0 | 0.0001 | 3 | nan |
| 0.0 | 0.0001 | 6 | nan |
| 0.0 | 0.0002 | 9 | nan |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
PuneetSuthar/FinGPT_mistral_7b_puneet | PuneetSuthar | "2024-04-09T07:26:42Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | "2024-04-09T07:26:26Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ClarenceDan/6318754d-9b7c-48a4-b8b4-c77e04dd2212 | ClarenceDan | "2025-01-20T22:39:49Z" | 6 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:HuggingFaceM4/tiny-random-LlamaForCausalLM",
"base_model:adapter:HuggingFaceM4/tiny-random-LlamaForCausalLM",
"region:us"
] | null | "2025-01-20T22:36:10Z" | ---
library_name: peft
base_model: HuggingFaceM4/tiny-random-LlamaForCausalLM
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 6318754d-9b7c-48a4-b8b4-c77e04dd2212
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: HuggingFaceM4/tiny-random-LlamaForCausalLM
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- 7da10487b55868a6_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/7da10487b55868a6_train_data.json
type:
field_instruction: hyps
field_output: ref
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 4
flash_attention: false
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: false
group_by_length: false
hub_model_id: ClarenceDan/6318754d-9b7c-48a4-b8b4-c77e04dd2212
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.0002
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 16
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 8
lora_target_linear: true
lr_scheduler: cosine
max_steps: 10
micro_batch_size: 2
mlflow_experiment_name: /tmp/7da10487b55868a6_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 4
sequence_len: 512
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: bef97220-cdcf-4144-9f98-4582cf4a902b
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: bef97220-cdcf-4144-9f98-4582cf4a902b
warmup_steps: 10
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# 6318754d-9b7c-48a4-b8b4-c77e04dd2212
This model is a fine-tuned version of [HuggingFaceM4/tiny-random-LlamaForCausalLM](https://huggingface.co/HuggingFaceM4/tiny-random-LlamaForCausalLM) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 10.3765
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- training_steps: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 10.3798 | 0.0001 | 1 | 10.3803 |
| 10.3783 | 0.0002 | 3 | 10.3800 |
| 10.3854 | 0.0004 | 6 | 10.3787 |
| 10.3766 | 0.0005 | 9 | 10.3765 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
memevis/HN0 | memevis | "2025-02-04T09:01:29Z" | 14 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-02-04T08:55:17Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Hachipo/Llama-3-8B_tuned_MIFT_ja_1000_v7_collator | Hachipo | "2025-02-28T09:56:40Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-02-28T09:53:02Z" | ---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
soukainaedr1222/Phi3Chatbot | soukainaedr1222 | "2024-05-24T09:16:50Z" | 78 | 0 | transformers | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"unsloth",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-05-24T08:54:10Z" | ---
library_name: transformers
tags:
- unsloth
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/Apollo-16k-Large-Instruct-GGUF | mradermacher | "2024-05-06T06:03:13Z" | 25 | 0 | transformers | [
"transformers",
"gguf",
"en",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2024-03-23T00:15:16Z" | ---
base_model: suhasn2/Apollo-16k-Large-Instruct
language:
- en
library_name: transformers
quantized_by: mradermacher
tags: []
---
## About
static quants of https://huggingface.co/suhasn2/Apollo-16k-Large-Instruct
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.Q2_K.gguf) | Q2_K | 26.4 | |
| [GGUF](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.IQ3_XS.gguf) | IQ3_XS | 29.1 | |
| [GGUF](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.IQ3_S.gguf) | IQ3_S | 30.9 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.Q3_K_S.gguf) | Q3_K_S | 30.9 | |
| [GGUF](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.IQ3_M.gguf) | IQ3_M | 31.9 | |
| [GGUF](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.Q3_K_M.gguf) | Q3_K_M | 34.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.Q3_K_L.gguf) | Q3_K_L | 37.1 | |
| [GGUF](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.IQ4_XS.gguf) | IQ4_XS | 38.1 | |
| [GGUF](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.Q4_K_S.gguf) | Q4_K_S | 40.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.Q4_K_M.gguf) | Q4_K_M | 42.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.Q5_K_S.gguf) | Q5_K_S | 48.4 | |
| [PART 1](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.Q5_K_M.gguf.part2of2) | Q5_K_M | 49.7 | |
| [PART 1](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.Q6_K.gguf.part2of2) | Q6_K | 57.5 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Apollo-16k-Large-Instruct-GGUF/resolve/main/Apollo-16k-Large-Instruct.Q8_0.gguf.part2of2) | Q8_0 | 74.2 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
polejowska/detr-r50-mist1-bg-2ah-6l | polejowska | "2023-11-11T10:19:36Z" | 37 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | object-detection | "2023-11-11T09:34:10Z" | ---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
model-index:
- name: detr-r50-mist1-bg-2ah-6l
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# detr-r50-mist1-bg-2ah-6l
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.9051
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.6721 | 1.0 | 115 | 5.0032 |
| 4.4438 | 2.0 | 230 | 4.6797 |
| 4.2953 | 3.0 | 345 | 4.7027 |
| 4.3899 | 4.0 | 460 | 5.4316 |
| 4.3184 | 5.0 | 575 | 4.4125 |
| 4.2749 | 6.0 | 690 | 4.1611 |
| 4.2153 | 7.0 | 805 | 4.6723 |
| 4.0788 | 8.0 | 920 | 4.1266 |
| 4.0752 | 9.0 | 1035 | 4.0529 |
| 4.0073 | 10.0 | 1150 | 4.4483 |
| 4.011 | 11.0 | 1265 | 4.2002 |
| 3.9993 | 12.0 | 1380 | 4.2450 |
| 4.0028 | 13.0 | 1495 | 4.1703 |
| 3.9572 | 14.0 | 1610 | 4.1861 |
| 3.9009 | 15.0 | 1725 | 4.0285 |
| 3.9173 | 16.0 | 1840 | 4.0673 |
| 3.8884 | 17.0 | 1955 | 3.9875 |
| 3.8415 | 18.0 | 2070 | 4.1062 |
| 3.8132 | 19.0 | 2185 | 4.0494 |
| 3.8297 | 20.0 | 2300 | 4.0119 |
| 3.8262 | 21.0 | 2415 | 3.9538 |
| 3.8045 | 22.0 | 2530 | 3.9500 |
| 3.8067 | 23.0 | 2645 | 3.9264 |
| 3.7651 | 24.0 | 2760 | 3.8820 |
| 3.756 | 25.0 | 2875 | 3.9051 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.14.1
|
waldie/ORCA_LLaMA_70B_QLoRA-2.4bpw-h6-exl2 | waldie | "2023-11-05T09:42:57Z" | 8 | 2 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2308.07317",
"arxiv:2306.02707",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2023-11-05T08:46:08Z" | ---
language:
- en
library_name: transformers
license: llama2
---
# Dolphin_ORCA_PlatyPus_LLaMA_70b
### Dataset
Here is the list of datasets used:
* Dolphin
* Open-Platypus
* OpenOrca
**mixed strategy: 100%Open-Platypus + ~1%Dolphin(GPT-4) + ~1%OpenOrca(GPT-4)**
<br>
**Model Finetuned By fangloveskari.**
<br>
### Training FrameWork and Parameters
#### FrameWork
https://github.com/hiyouga/LLaMA-Efficient-Tuning
We add flash_attention_2 and ORCA dataset support, with some minor modifications.
<br>
#### Parameters
We list some training parameters here:
| Parameter | Value |
|-----------------------|-------------|
| Finetune_Type | QLoRA(NF4) |
| LoRA_Rank | 16 |
| LoRA_Alpha | 16 |
| Batch_Size | 14 |
| GPUs | 8xA100(80G) |
| LR_Scheduler | cosine |
| LR | 3e-4 |
| Epoch | 1 |
| DeepSpeed | ZERO-2 |
<br>
### Model Export
We tried two methods to fuse the adapter back to the base model:
* https://github.com/hiyouga/LLaMA-Efficient-Tuning/blob/main/src/export_model.py
* https://github.com/jondurbin/qlora/blob/main/qmerge.py
Generally, the second will get better ARC(+0.15) and Truthful_QA(+0.3) scores but the other two(MMLU(-0.2) and HelloSwag(-0.2)) seems to degenerate (Just for my model).
<br>
### Evaluation
| Metric | Value |
|-----------------------|-------|
| ARC (25-shot) | 72.27 |
| HellaSwag (10-shot) | 87.74 |
| MMLU (5-shot) | 70.23 |
| TruthfulQA (0-shot) | 63.37 |
| Avg. | 73.40 |
<br>
### license disclaimer:
This model is bound by the license & usage restrictions of the original Llama-2 model. And comes with no warranty or gurantees of any kind.
<br>
### Limitations & Biases:
Llama 2 and fine-tuned variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2 and any fine-tuned varient's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2 variants, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at https://ai.meta.com/llama/responsible-use-guide/
<br>
### Citiation:
Please kindly cite using the following BibTeX:
```bibtex
@article{platypus2023,
title={Platypus: Quick, Cheap, and Powerful Refinement of LLMs},
author={Ariel N. Lee and Cole J. Hunter and Nataniel Ruiz},
booktitle={arXiv preprint arxiv:2308.07317},
year={2023}
}
```
```
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@software{touvron2023llama2,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava,
Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller,
Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann,
Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov,
Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith,
Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu , Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan,
Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom},
year={2023}
}
``` |
yale-nlp/comal-qwen2-1.5b-inpo-large-round1 | yale-nlp | "2024-10-30T23:13:41Z" | 97 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-10-30T23:10:03Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
vinaykumarsoni/bge-base-financial-matryoshka | vinaykumarsoni | "2024-11-27T10:15:22Z" | 5 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:6300",
"loss:MatryoshkaLoss",
"loss:MultipleNegativesRankingLoss",
"en",
"arxiv:1908.10084",
"arxiv:2205.13147",
"arxiv:1705.00652",
"base_model:BAAI/bge-base-en-v1.5",
"base_model:finetune:BAAI/bge-base-en-v1.5",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2024-11-27T10:14:24Z" | ---
base_model: BAAI/bge-base-en-v1.5
language:
- en
library_name: sentence-transformers
license: apache-2.0
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:6300
- loss:MatryoshkaLoss
- loss:MultipleNegativesRankingLoss
widget:
- source_sentence: The consolidated financial statements and accompanying notes listed
in Part IV, Item 15(a)(1) of this Annual Report on Form 10-K are included elsewhere
in this Annual Report on Form 10-K.
sentences:
- What is the carrying value of the indefinite-lived intangible assets related to
the Certificate of Needs and Medicare licenses as of December 31, 2023?
- What sections of the Annual Report on Form 10-K contain the company's financial
statements?
- What was the effective tax rate excluding discrete net tax benefits for the year
2022?
- source_sentence: Consumers are served through Amazon's online and physical stores
with an emphasis on selection, price, and convenience.
sentences:
- What decision did the European Commission make on July 10, 2023 regarding the
United States?
- What are the primary offerings to consumers through Amazon's online and physical
stores?
- What activities are included in the services and other revenue segment of General
Motors Company?
- source_sentence: Visa has traditionally referred to their structure of facilitating
secure, reliable, and efficient money movement among consumers, issuing and acquiring
financial institutions, and merchants as the 'four-party' model.
sentences:
- What model does Visa traditionally refer to regarding their transaction process
among consumers, financial institutions, and merchants?
- What percentage of Meta's U.S. workforce in 2023 were represented by people with
disabilities, veterans, and members of the LGBTQ+ community?
- What are the revenue sources for the Company’s Health Care Benefits Segment?
- source_sentence: 'In addition to LinkedIn’s free services, LinkedIn offers monetized
solutions: Talent Solutions, Marketing Solutions, Premium Subscriptions, and Sales
Solutions. Talent Solutions provide insights for workforce planning and tools
to hire, nurture, and develop talent. Talent Solutions also includes Learning
Solutions, which help businesses close critical skills gaps in times where companies
are having to do more with existing talent.'
sentences:
- What were the major factors contributing to the increased expenses excluding interest
for Investor Services and Advisor Services in 2023?
- What were the pre-tax earnings of the manufacturing sector in 2023, 2022, and
2021?
- What does LinkedIn's Talent Solutions include?
- source_sentence: Management assessed the effectiveness of the company’s internal
control over financial reporting as of December 31, 2023. In making this assessment,
we used the criteria set forth by the Committee of Sponsoring Organizations of
the Treadway Commission (COSO) in Internal Control—Integrated Framework (2013).
sentences:
- What criteria did Caterpillar Inc. use to assess the effectiveness of its internal
control over financial reporting as of December 31, 2023?
- What are the primary components of U.S. sales volumes for Ford?
- What was the percentage increase in Schwab's common stock dividend in 2022?
model-index:
- name: BGE base Financial Matryoshka
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 768
type: dim_768
metrics:
- type: cosine_accuracy@1
value: 0.6914285714285714
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.8228571428571428
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.86
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.9057142857142857
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.6914285714285714
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2742857142857143
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.17199999999999996
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09057142857142855
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.6914285714285714
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.8228571428571428
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.86
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.9057142857142857
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.7995342787996339
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.7654574829931972
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.7690166864114502
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 512
type: dim_512
metrics:
- type: cosine_accuracy@1
value: 0.6857142857142857
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.82
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.8642857142857143
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.91
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.6857142857142857
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2733333333333333
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.17285714285714285
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.091
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.6857142857142857
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.82
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.8642857142857143
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.91
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.7975979991372859
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.7616422902494332
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.7646020723441848
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 256
type: dim_256
metrics:
- type: cosine_accuracy@1
value: 0.6857142857142857
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.8171428571428572
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.8557142857142858
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.8957142857142857
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.6857142857142857
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2723809523809524
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.17114285714285712
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.08957142857142855
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.6857142857142857
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.8171428571428572
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.8557142857142858
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.8957142857142857
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.791716991505886
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.7582278911564624
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.7620654007379394
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 128
type: dim_128
metrics:
- type: cosine_accuracy@1
value: 0.6671428571428571
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.8057142857142857
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.8428571428571429
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.8785714285714286
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.6671428571428571
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.26857142857142857
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.16857142857142854
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.08785714285714284
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.6671428571428571
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.8057142857142857
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.8428571428571429
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.8785714285714286
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.7747059451137388
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.7411337868480725
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.745458877899941
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 64
type: dim_64
metrics:
- type: cosine_accuracy@1
value: 0.6442857142857142
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.7785714285714286
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.8157142857142857
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.8614285714285714
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.6442857142857142
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2595238095238095
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.16314285714285712
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.08614285714285713
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.6442857142857142
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.7785714285714286
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.8157142857142857
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.8614285714285714
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.753295913075372
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.7186179138321995
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.723270777719374
name: Cosine Map@100
---
# BGE base Financial Matryoshka
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) on the json dataset. It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) <!-- at revision a5beb1e3e68b9ab74eb54cfd186867f64f240e1a -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 tokens
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- json
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': True}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("vinaykumarsoni/bge-base-financial-matryoshka")
# Run inference
sentences = [
'Management assessed the effectiveness of the company’s internal control over financial reporting as of December 31, 2023. In making this assessment, we used the criteria set forth by the Committee of Sponsoring Organizations of the Treadway Commission (COSO) in Internal Control—Integrated Framework (2013).',
'What criteria did Caterpillar Inc. use to assess the effectiveness of its internal control over financial reporting as of December 31, 2023?',
'What are the primary components of U.S. sales volumes for Ford?',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Dataset: `dim_768`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:----------|
| cosine_accuracy@1 | 0.6914 |
| cosine_accuracy@3 | 0.8229 |
| cosine_accuracy@5 | 0.86 |
| cosine_accuracy@10 | 0.9057 |
| cosine_precision@1 | 0.6914 |
| cosine_precision@3 | 0.2743 |
| cosine_precision@5 | 0.172 |
| cosine_precision@10 | 0.0906 |
| cosine_recall@1 | 0.6914 |
| cosine_recall@3 | 0.8229 |
| cosine_recall@5 | 0.86 |
| cosine_recall@10 | 0.9057 |
| cosine_ndcg@10 | 0.7995 |
| cosine_mrr@10 | 0.7655 |
| **cosine_map@100** | **0.769** |
#### Information Retrieval
* Dataset: `dim_512`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.6857 |
| cosine_accuracy@3 | 0.82 |
| cosine_accuracy@5 | 0.8643 |
| cosine_accuracy@10 | 0.91 |
| cosine_precision@1 | 0.6857 |
| cosine_precision@3 | 0.2733 |
| cosine_precision@5 | 0.1729 |
| cosine_precision@10 | 0.091 |
| cosine_recall@1 | 0.6857 |
| cosine_recall@3 | 0.82 |
| cosine_recall@5 | 0.8643 |
| cosine_recall@10 | 0.91 |
| cosine_ndcg@10 | 0.7976 |
| cosine_mrr@10 | 0.7616 |
| **cosine_map@100** | **0.7646** |
#### Information Retrieval
* Dataset: `dim_256`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.6857 |
| cosine_accuracy@3 | 0.8171 |
| cosine_accuracy@5 | 0.8557 |
| cosine_accuracy@10 | 0.8957 |
| cosine_precision@1 | 0.6857 |
| cosine_precision@3 | 0.2724 |
| cosine_precision@5 | 0.1711 |
| cosine_precision@10 | 0.0896 |
| cosine_recall@1 | 0.6857 |
| cosine_recall@3 | 0.8171 |
| cosine_recall@5 | 0.8557 |
| cosine_recall@10 | 0.8957 |
| cosine_ndcg@10 | 0.7917 |
| cosine_mrr@10 | 0.7582 |
| **cosine_map@100** | **0.7621** |
#### Information Retrieval
* Dataset: `dim_128`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.6671 |
| cosine_accuracy@3 | 0.8057 |
| cosine_accuracy@5 | 0.8429 |
| cosine_accuracy@10 | 0.8786 |
| cosine_precision@1 | 0.6671 |
| cosine_precision@3 | 0.2686 |
| cosine_precision@5 | 0.1686 |
| cosine_precision@10 | 0.0879 |
| cosine_recall@1 | 0.6671 |
| cosine_recall@3 | 0.8057 |
| cosine_recall@5 | 0.8429 |
| cosine_recall@10 | 0.8786 |
| cosine_ndcg@10 | 0.7747 |
| cosine_mrr@10 | 0.7411 |
| **cosine_map@100** | **0.7455** |
#### Information Retrieval
* Dataset: `dim_64`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.6443 |
| cosine_accuracy@3 | 0.7786 |
| cosine_accuracy@5 | 0.8157 |
| cosine_accuracy@10 | 0.8614 |
| cosine_precision@1 | 0.6443 |
| cosine_precision@3 | 0.2595 |
| cosine_precision@5 | 0.1631 |
| cosine_precision@10 | 0.0861 |
| cosine_recall@1 | 0.6443 |
| cosine_recall@3 | 0.7786 |
| cosine_recall@5 | 0.8157 |
| cosine_recall@10 | 0.8614 |
| cosine_ndcg@10 | 0.7533 |
| cosine_mrr@10 | 0.7186 |
| **cosine_map@100** | **0.7233** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### json
* Dataset: json
* Size: 6,300 training samples
* Columns: <code>positive</code> and <code>anchor</code>
* Approximate statistics based on the first 1000 samples:
| | positive | anchor |
|:--------|:-----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 8 tokens</li><li>mean: 44.33 tokens</li><li>max: 289 tokens</li></ul> | <ul><li>min: 9 tokens</li><li>mean: 20.43 tokens</li><li>max: 46 tokens</li></ul> |
* Samples:
| positive | anchor |
|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>The Company defines fair value as the price received to transfer an asset or paid to transfer a liability in an orderly transaction between market participants at the measurement date. In accordance with ASC 820, Fair Value Measurements and Disclosures, the Company uses the fair value hierarchy which prioritizes the inputs used to measure fair value. The hierarchy gives the highest priority to unadjusted quoted prices in active markets for identical assets or liabilities (Level 1), observable inputs other than quoted prices (Level 2), and unobservable inputs (Level 3).</code> | <code>What is the role of Level 1, Level 2, and Level 3 inputs in the fair value hierarchy according to ASC 820?</code> |
| <code>In the event of conversion of the Notes, if shares are delivered to the Company under the Capped Call Transactions, they will offset the dilutive effect of the shares that the Company would issue under the Notes.</code> | <code>What happens to the dilutive effect of shares issued under the Notes if shares are delivered to the Company under the Capped Call Transactions during the conversion?</code> |
| <code>Marketing expenses increased $48.8 million to $759.2 million in the year ended December 31, 2023 compared to the year ended December 31, 2022.</code> | <code>How much did the marketing expenses increase in the year ended December 31, 2023?</code> |
* Loss: [<code>MatryoshkaLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#matryoshkaloss) with these parameters:
```json
{
"loss": "MultipleNegativesRankingLoss",
"matryoshka_dims": [
768,
512,
256,
128,
64
],
"matryoshka_weights": [
1,
1,
1,
1,
1
],
"n_dims_per_step": -1
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: epoch
- `per_device_train_batch_size`: 32
- `per_device_eval_batch_size`: 16
- `gradient_accumulation_steps`: 16
- `learning_rate`: 2e-05
- `num_train_epochs`: 4
- `lr_scheduler_type`: cosine
- `warmup_ratio`: 0.1
- `bf16`: True
- `tf32`: True
- `load_best_model_at_end`: True
- `optim`: adamw_torch_fused
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: epoch
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 32
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 16
- `eval_accumulation_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 4
- `max_steps`: -1
- `lr_scheduler_type`: cosine
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: True
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | dim_768_cosine_map@100 | dim_512_cosine_map@100 | dim_256_cosine_map@100 | dim_128_cosine_map@100 | dim_64_cosine_map@100 |
|:----------:|:------:|:-------------:|:----------------------:|:----------------------:|:----------------------:|:----------------------:|:---------------------:|
| 0.8122 | 10 | 1.5602 | - | - | - | - | - |
| 0.9746 | 12 | - | 0.7548 | 0.7541 | 0.7486 | 0.7294 | 0.6912 |
| 1.6244 | 20 | 0.6619 | - | - | - | - | - |
| 1.9492 | 24 | - | 0.7661 | 0.7629 | 0.7589 | 0.7424 | 0.7210 |
| 2.4365 | 30 | 0.458 | - | - | - | - | - |
| 2.9239 | 36 | - | 0.7698 | 0.7635 | 0.7616 | 0.7453 | 0.7230 |
| 3.2487 | 40 | 0.3997 | - | - | - | - | - |
| **3.8985** | **48** | **-** | **0.769** | **0.7646** | **0.7621** | **0.7455** | **0.7233** |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.10.12
- Sentence Transformers: 3.2.0
- Transformers: 4.41.2
- PyTorch: 2.2.0a0+6a974be
- Accelerate: 0.27.0
- Datasets: 2.19.1
- Tokenizers: 0.19.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MatryoshkaLoss
```bibtex
@misc{kusupati2024matryoshka,
title={Matryoshka Representation Learning},
author={Aditya Kusupati and Gantavya Bhatt and Aniket Rege and Matthew Wallingford and Aditya Sinha and Vivek Ramanujan and William Howard-Snyder and Kaifeng Chen and Sham Kakade and Prateek Jain and Ali Farhadi},
year={2024},
eprint={2205.13147},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
--> |
nguynking/videberta-xsmall-lora-nli-checkpoint-3 | nguynking | "2023-10-31T08:54:03Z" | 0 | 0 | peft | [
"peft",
"arxiv:1910.09700",
"base_model:nguynking/videberta-xsmall-nli-1",
"base_model:adapter:nguynking/videberta-xsmall-nli-1",
"region:us"
] | null | "2023-10-31T08:54:02Z" | ---
library_name: peft
base_model: nguynking/videberta-xsmall-nli-1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
4bit/Qwen-VL-Chat-Int4 | 4bit | "2023-09-07T04:10:08Z" | 81 | 16 | transformers | [
"transformers",
"safetensors",
"qwen",
"text-generation",
"custom_code",
"zh",
"en",
"arxiv:2308.12966",
"autotrain_compatible",
"4-bit",
"gptq",
"region:us"
] | text-generation | "2023-09-07T04:05:34Z" | ---
language:
- zh
- en
tags:
- qwen
pipeline_tag: text-generation
inference: false
---
# Qwen-VL-Chat-Int4
<br>
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/logo_vl.jpg" width="400"/>
<p>
<br>
<p align="center">
Qwen-VL <a href="https://modelscope.cn/models/qwen/Qwen-VL/summary">🤖 <a> | <a href="https://huggingface.co/Qwen/Qwen-VL">🤗</a>  | Qwen-VL-Chat <a href="https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary">🤖 <a>| <a href="https://huggingface.co/Qwen/Qwen-VL-Chat">🤗</a>  | Qwen-VL-Chat-Int4 <a href="https://huggingface.co/Qwen/Qwen-VL-Chat-Int4">🤗</a>
<br>
<a href="assets/wechat.png">WeChat</a>   |   <a href="https://discord.gg/z3GAxXZ9Ce">Discord</a>   |   <a href="https://modelscope.cn/studios/qwen/Qwen-VL-Chat-Demo/summary">Demo</a>  |  <a href="https://arxiv.org/abs/2308.12966">Report</a>
</p>
<br>
**Qwen-VL** 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。Qwen-VL 系列模型性能强大,具备多语言对话、多图交错对话等能力,并支持中文开放域定位和细粒度图像识别与理解。
**Qwen-VL** (Qwen Large Vision Language Model) is the visual multimodal version of the large model series, Qwen (abbr. Tongyi Qianwen), proposed by Alibaba Cloud. Qwen-VL accepts image, text, and bounding box as inputs, outputs text and bounding box. The features of Qwen-VL include:
目前,我们提供了Qwen-VL和Qwen-VL-Chat两个模型,分别为预训练模型和Chat模型。如果想了解更多关于模型的信息,请点击[链接](https://github.com/QwenLM/Qwen-VL/blob/master/visual_memo.md)查看我们的技术备忘录。本仓库为Qwen-VL-Chat的量化模型Qwen-VL-Chat-Int4仓库。
We release Qwen-VL and Qwen-VL-Chat, which are pretrained model and Chat model respectively. For more details about Qwen-VL, please refer to our [technical memo](https://github.com/QwenLM/Qwen-VL/blob/master/visual_memo.md). This repo is the one for Qwen-VL-Chat-Int4.
<br>
## 安装要求 (Requirements)
* python 3.8及以上版本
* pytorch2.0及以上版本
* 建议使用CUDA 11.4及以上
* python 3.8 and above
* pytorch 2.0 and above are recommended
* CUDA 11.4 and above are recommended
<br>
## 快速开始 (Quickstart)
我们提供简单的示例来说明如何利用 🤗 Transformers 快速使用Qwen-VL-Chat-Int4。
在开始前,请确保你已经配置好环境并安装好相关的代码包。最重要的是,确保你满足上述要求,然后安装相关的依赖库。
Below, we provide simple examples to show how to use Qwen-VL-Chat-Int4 with 🤗 Transformers.
Before running the code, make sure you have setup the environment and installed the required packages. Make sure you meet the above requirements, and then install the dependent libraries.
```bash
pip install -r requirements.txt
pip install optimum
git clone https://github.com/JustinLin610/AutoGPTQ.git & cd AutoGPTQ
pip install -v .
```
接下来你可以开始使用Transformers来使用我们的模型。关于视觉模块的更多用法,请参考[教程](TUTORIAL.md)。
Now you can start with Transformers. More usage aboue vision encoder, please refer to [tutorial](TUTORIAL_zh.md).
#### 🤗 Transformers
To use Qwen-VL-Chat-Int4 for the inference, all you need to do is to input a few lines of codes as demonstrated below. However, **please make sure that you are using the latest code.**
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(1234)
# Note: The default behavior now has injection attack prevention off.
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-VL-Chat-Int4", trust_remote_code=True)
# use cuda device
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-VL-Chat-Int4", device_map="cuda", trust_remote_code=True).eval()
# 1st dialogue turn
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'},
{'text': '这是什么'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)
# 图中是一名年轻女子在沙滩上和她的狗玩耍,狗的品种可能是拉布拉多。她们坐在沙滩上,狗的前腿抬起来,似乎在和人类击掌。两人之间充满了信任和爱。
# 2nd dialogue turn
response, history = model.chat(tokenizer, '输出"击掌"的检测框', history=history)
print(response)
# <ref>击掌</ref><box>(517,508),(589,611)</box>
image = tokenizer.draw_bbox_on_latest_picture(response, history)
if image:
image.save('1.jpg')
else:
print("no box")
```
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo_highfive.jpg" width="500"/>
<p>
<br>
## 量化 (Quantization)
### 效果评测 (Performance)
我们列出不同精度下模型在评测基准 **[TouchStone](https://github.com/OFA-Sys/TouchStone)** 上的表现,并发现量化模型并没有显著性能损失。结果如下所示:
We illustrate the model performance of both BF16 and Int4 models on the benchmark **[TouchStone](https://github.com/OFA-Sys/TouchStone)**, and we find that the quantized model does not suffer from significant performance degradation. Results are shown below:
| Quantization | ZH. | EN |
| ------------ | :--------: | :-----------: |
| BF16 | 401.2 | 645.2 |
| Int4 | 386.6 | 651.4 |
### 推理速度 (Inference Speed)
我们测算了在输入一张图片(即258个token)的条件下BF16和Int4的模型生成1792 (2048-258) 和 7934 (8192-258) 个token的平均速度。
We measured the average inference speed (tokens/s) of generating 1792 (2048-258) and 7934 (8192-258) tokens with the context of an image (which takes 258 tokens) under BF16 precision and Int4 quantization, respectively.
| Quantization | Speed (2048 tokens) | Speed (8192 tokens) |
| ------------ | :-----------------: | :-----------------: |
| BF16 | 28.87 | 24.32 |
| Int4 | 37.79 | 34.34 |
推理速度测算是在单卡 A100-SXM4-80G GPU上运行,使用PyTorch 2.0.1及CUDA 11.4。
The profiling runs on a single A100-SXM4-80G GPU with PyTorch 2.0.1 and CUDA 11.4.
### GPU显存占用 (GPU Memory Usage)
我们还测算了在一张图片输入的条件下BF16和Int4模型生成1792 (2048-258) 和 7934 (8192-258) 个token所需显存。结果如下所示:
We also profile the peak GPU memory usage for encoding 1792 (2048-258) tokens (including an image) as context (and generating single token) and generating 7934 (8192-258) tokens (with an image as context) under BF16 or Int4 quantization level, respectively. The results are shown below.
| Quantization | Peak Usage for Encoding 2048 Tokens | Peak Usage for Generating 8192 Tokens |
| ------------ | :---------------------------------: | :-----------------------------------: |
| BF16 | 22.60GB | 28.01GB |
| Int4 | 11.82GB | 17.23GB |
上述速度和显存测算使用[此脚本](https://qianwen-res.oss-cn-beijing.aliyuncs.com/profile_mm.py)完成。
The above speed and memory profiling are conducted using [this script](https://qianwen-res.oss-cn-beijing.aliyuncs.com/profile_mm.py).
<br>
## 评测
我们从两个角度评测了两个模型的能力:
1. 在**英文标准 Benchmark** 上评测模型的基础任务能力。目前评测了四大类多模态任务:
- Zero-shot Caption: 评测模型在未见过数据集上的零样本图片描述能力;
- General VQA: 评测模型的通用问答能力,例如判断题、颜色、个数、类目等问答能力;
- Text-based VQA:评测模型对于图片中文字相关的识别/问答能力,例如文档问答、图表问答、文字问答等;
- Referring Expression Compression:评测模型给定物体描述画检测框的能力;
2. **试金石 (TouchStone)**:为了评测模型整体的图文对话能力和人类对齐水平。我们为此构建了一个基于 GPT4 打分来评测 LVLM 模型的 Benchmark:TouchStone。在 TouchStone-v0.1 中:
- 评测基准总计涵盖 300+张图片、800+道题目、27个类别。包括基础属性问答、人物地标问答、影视作品问答、视觉推理、反事实推理、诗歌创作、故事写作,商品比较、图片解题等**尽可能广泛的类别**。
- 为了弥补目前 GPT4 无法直接读取图片的缺陷,我们给所有的带评测图片提供了**人工标注的充分详细描述**,并且将图片的详细描述、问题和模型的输出结果一起交给 GPT4 打分。
- 评测同时包含英文版本和中文版本。
评测结果如下:
We evaluated the model's ability from two perspectives:
1. **Standard Benchmarks**: We evaluate the model's basic task capabilities on four major categories of multimodal tasks:
- Zero-shot Caption: Evaluate model's zero-shot image captioning ability on unseen datasets;
- General VQA: Evaluate the general question-answering ability of pictures, such as the judgment, color, number, category, etc;
- Text-based VQA: Evaluate the model's ability to recognize text in pictures, such as document QA, chart QA, etc;
- Referring Expression Comprehension: Evaluate the ability to localize a target object in an image described by a referring expression.
2. **TouchStone**: To evaluate the overall text-image dialogue capability and alignment level with humans, we have constructed a benchmark called TouchStone, which is based on scoring with GPT4 to evaluate the LVLM model.
- The TouchStone benchmark covers a total of 300+ images, 800+ questions, and 27 categories. Such as attribute-based Q&A, celebrity recognition, writing poetry, summarizing multiple images, product comparison, math problem solving, etc;
- In order to break the current limitation of GPT4 in terms of direct image input, TouchStone provides fine-grained image annotations by human labeling. These detailed annotations, along with the questions and the model's output, are then presented to GPT4 for scoring.
- The benchmark includes both English and Chinese versions.
The results of the evaluation are as follows:
Qwen-VL outperforms current SOTA generalist models on multiple VL tasks and has a more comprehensive coverage in terms of capability range.
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/radar.png" width="600"/>
<p>
### 零样本图像描述 & 通用视觉问答 (Zero-shot Captioning & General VQA)
<table>
<thead>
<tr>
<th rowspan="2">Model type</th>
<th rowspan="2">Model</th>
<th colspan="2">Zero-shot Captioning</th>
<th colspan="5">General VQA</th>
</tr>
<tr>
<th>NoCaps</th>
<th>Flickr30K</th>
<th>VQAv2<sup>dev</sup></th>
<th>OK-VQA</th>
<th>GQA</th>
<th>SciQA-Img<br>(0-shot)</th>
<th>VizWiz<br>(0-shot)</th>
</tr>
</thead>
<tbody align="center">
<tr>
<td rowspan="10">Generalist<br>Models</td>
<td>Flamingo-9B</td>
<td>-</td>
<td>61.5</td>
<td>51.8</td>
<td>44.7</td>
<td>-</td>
<td>-</td>
<td>28.8</td>
</tr>
<tr>
<td>Flamingo-80B</td>
<td>-</td>
<td>67.2</td>
<td>56.3</td>
<td>50.6</td>
<td>-</td>
<td>-</td>
<td>31.6</td>
</tr>
<tr>
<td>Unified-IO-XL</td>
<td>100.0</td>
<td>-</td>
<td>77.9</td>
<td>54.0</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>Kosmos-1</td>
<td>-</td>
<td>67.1</td>
<td>51.0</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>29.2</td>
</tr>
<tr>
<td>Kosmos-2</td>
<td>-</td>
<td>66.7</td>
<td>45.6</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>BLIP-2 (Vicuna-13B)</td>
<td>103.9</td>
<td>71.6</td>
<td>65.0</td>
<td>45.9</td>
<td>32.3</td>
<td>61.0</td>
<td>19.6</td>
</tr>
<tr>
<td>InstructBLIP (Vicuna-13B)</td>
<td><strong>121.9</strong></td>
<td>82.8</td>
<td>-</td>
<td>-</td>
<td>49.5</td>
<td>63.1</td>
<td>33.4</td>
</tr>
<tr>
<td>Shikra (Vicuna-13B)</td>
<td>-</td>
<td>73.9</td>
<td>77.36</td>
<td>47.16</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td><strong>Qwen-VL (Qwen-7B)</strong></td>
<td>121.4</td>
<td><b>85.8</b></td>
<td><b>78.8</b></td>
<td><b>58.6</b></td>
<td><b>59.3</b></td>
<td>67.1</td>
<td>35.2</td>
</tr>
<!-- <tr>
<td>Qwen-VL (4-shot)</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>63.6</td>
<td>-</td>
<td>-</td>
<td>39.1</td>
</tr> -->
<tr>
<td>Qwen-VL-Chat</td>
<td>120.2</td>
<td>81.0</td>
<td>78.2</td>
<td>56.6</td>
<td>57.5</td>
<td><b>68.2</b></td>
<td><b>38.9</b></td>
</tr>
<!-- <tr>
<td>Qwen-VL-Chat (4-shot)</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>60.6</td>
<td>-</td>
<td>-</td>
<td>44.45</td>
</tr> -->
<tr>
<td>Previous SOTA<br>(Per Task Fine-tuning)</td>
<td>-</td>
<td>127.0<br>(PALI-17B)</td>
<td>84.5<br>(InstructBLIP<br>-FlanT5-XL)</td>
<td>86.1<br>(PALI-X<br>-55B)</td>
<td>66.1<br>(PALI-X<br>-55B)</td>
<td>72.1<br>(CFR)</td>
<td>92.53<br>(LLaVa+<br>GPT-4)</td>
<td>70.9<br>(PALI-X<br>-55B)</td>
</tr>
</tbody>
</table>
- 在 Zero-shot Caption 中,Qwen-VL 在 Flickr30K 数据集上取得了 **SOTA** 的结果,并在 Nocaps 数据集上取得了和 InstructBlip 可竞争的结果。
- 在 General VQA 中,Qwen-VL 取得了 LVLM 模型同等量级和设定下 **SOTA** 的结果。
- For zero-shot image captioning, Qwen-VL achieves the **SOTA** on Flickr30K and competitive results on Nocaps with InstructBlip.
- For general VQA, Qwen-VL achieves the **SOTA** under the same generalist LVLM scale settings.
### 文本导向的视觉问答 (Text-oriented VQA)
<table>
<thead>
<tr>
<th>Model type</th>
<th>Model</th>
<th>TextVQA</th>
<th>DocVQA</th>
<th>ChartQA</th>
<th>AI2D</th>
<th>OCR-VQA</th>
</tr>
</thead>
<tbody align="center">
<tr>
<td rowspan="5">Generalist Models</td>
<td>BLIP-2 (Vicuna-13B)</td>
<td>42.4</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>InstructBLIP (Vicuna-13B)</td>
<td>50.7</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>mPLUG-DocOwl (LLaMA-7B)</td>
<td>52.6</td>
<td>62.2</td>
<td>57.4</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>Pic2Struct-Large (1.3B)</td>
<td>-</td>
<td><b>76.6</b></td>
<td>58.6</td>
<td>42.1</td>
<td>71.3</td>
</tr>
<tr>
<td>Qwen-VL (Qwen-7B)</td>
<td><b>63.8</b></td>
<td>65.1</td>
<td><b>65.7</b></td>
<td><b>62.3</b></td>
<td><b>75.7</b></td>
</tr>
<tr>
<td>Specialist SOTAs<br>(Specialist/Finetuned)</td>
<td>PALI-X-55B (Single-task FT)<br>(Without OCR Pipeline)</td>
<td>71.44</td>
<td>80.0</td>
<td>70.0</td>
<td>81.2</td>
<td>75.0</td>
</tr>
</tbody>
</table>
- 在文字相关的识别/问答评测上,取得了当前规模下通用 LVLM 达到的最好结果。
- 分辨率对上述某几个评测非常重要,大部分 224 分辨率的开源 LVLM 模型无法完成以上评测,或只能通过切图的方式解决。Qwen-VL 将分辨率提升到 448,可以直接以端到端的方式进行以上评测。Qwen-VL 在很多任务上甚至超过了 1024 分辨率的 Pic2Struct-Large 模型。
- In text-related recognition/QA evaluation, Qwen-VL achieves the SOTA under the generalist LVLM scale settings.
- Resolution is important for several above evaluations. While most open-source LVLM models with 224 resolution are incapable of these evaluations or can only solve these by cutting images, Qwen-VL scales the resolution to 448 so that it can be evaluated end-to-end. Qwen-VL even outperforms Pic2Struct-Large models of 1024 resolution on some tasks.
### 细粒度视觉定位 (Referring Expression Comprehension)
<table>
<thead>
<tr>
<th rowspan="2">Model type</th>
<th rowspan="2">Model</th>
<th colspan="3">RefCOCO</th>
<th colspan="3">RefCOCO+</th>
<th colspan="2">RefCOCOg</th>
<th>GRIT</th>
</tr>
<tr>
<th>val</th>
<th>test-A</th>
<th>test-B</th>
<th>val</th>
<th>test-A</th>
<th>test-B</th>
<th>val-u</th>
<th>test-u</th>
<th>refexp</th>
</tr>
</thead>
<tbody align="center">
<tr>
<td rowspan="8">Generalist Models</td>
<td>GPV-2</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>51.50</td>
</tr>
<tr>
<td>OFA-L*</td>
<td>79.96</td>
<td>83.67</td>
<td>76.39</td>
<td>68.29</td>
<td>76.00</td>
<td>61.75</td>
<td>67.57</td>
<td>67.58</td>
<td>61.70</td>
</tr>
<tr>
<td>Unified-IO</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td><b>78.61</b></td>
</tr>
<tr>
<td>VisionLLM-H</td>
<td></td>
<td>86.70</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>Shikra-7B</td>
<td>87.01</td>
<td>90.61</td>
<td>80.24 </td>
<td>81.60</td>
<td>87.36</td>
<td>72.12</td>
<td>82.27</td>
<td>82.19</td>
<td>69.34</td>
</tr>
<tr>
<td>Shikra-13B</td>
<td>87.83 </td>
<td>91.11</td>
<td>81.81</td>
<td>82.89</td>
<td>87.79</td>
<td>74.41</td>
<td>82.64</td>
<td>83.16</td>
<td>69.03</td>
</tr>
<tr>
<td>Qwen-VL-7B</td>
<td><b>89.36</b></td>
<td>92.26</td>
<td><b>85.34</b></td>
<td><b>83.12</b></td>
<td>88.25</td>
<td><b>77.21</b></td>
<td>85.58</td>
<td>85.48</td>
<td>78.22</td>
</tr>
<tr>
<td>Qwen-VL-7B-Chat</td>
<td>88.55</td>
<td><b>92.27</b></td>
<td>84.51</td>
<td>82.82</td>
<td><b>88.59</b></td>
<td>76.79</td>
<td><b>85.96</b></td>
<td><b>86.32</b></td>
<td>-</td>
<tr>
<td rowspan="3">Specialist SOTAs<br>(Specialist/Finetuned)</td>
<td>G-DINO-L</td>
<td>90.56 </td>
<td>93.19</td>
<td>88.24</td>
<td>82.75</td>
<td>88.95</td>
<td>75.92</td>
<td>86.13</td>
<td>87.02</td>
<td>-</td>
</tr>
<tr>
<td>UNINEXT-H</td>
<td>92.64 </td>
<td>94.33</td>
<td>91.46</td>
<td>85.24</td>
<td>89.63</td>
<td>79.79</td>
<td>88.73</td>
<td>89.37</td>
<td>-</td>
</tr>
<tr>
<td>ONE-PEACE</td>
<td>92.58 </td>
<td>94.18</td>
<td>89.26</td>
<td>88.77</td>
<td>92.21</td>
<td>83.23</td>
<td>89.22</td>
<td>89.27</td>
<td>-</td>
</tr>
</tbody>
</table>
- 在定位任务上,Qwen-VL 全面超过 Shikra-13B,取得了目前 Generalist LVLM 模型上在 Refcoco 上的 **SOTA**。
- Qwen-VL 并没有在任何中文定位数据上训练过,但通过中文 Caption 数据和 英文 Grounding 数据的训练,可以 Zero-shot 泛化出中文 Grounding 能力。
我们提供了以上**所有**评测脚本以供复现我们的实验结果。请阅读 [eval/EVALUATION.md](eval/EVALUATION.md) 了解更多信息。
- Qwen-VL achieves the **SOTA** in all above referring expression comprehension benchmarks.
- Qwen-VL has not been trained on any Chinese grounding data, but it can still generalize to the Chinese Grounding tasks in a zero-shot way by training Chinese Caption data and English Grounding data.
We provide all of the above evaluation scripts for reproducing our experimental results. Please read [eval/EVALUATION.md](eval/EVALUATION.md) for more information.
### 闲聊能力测评 (Chat Evaluation)
TouchStone 是一个基于 GPT4 打分来评测 LVLM 模型的图文对话能力和人类对齐水平的基准。它涵盖了 300+张图片、800+道题目、27个类别,包括基础属性、人物地标、视觉推理、诗歌创作、故事写作、商品比较、图片解题等**尽可能广泛的类别**。关于 TouchStone 的详细介绍,请参考[touchstone/README_CN.md](touchstone/README_CN.md)了解更多信息。
TouchStone is a benchmark based on scoring with GPT4 to evaluate the abilities of the LVLM model on text-image dialogue and alignment levels with humans. It covers a total of 300+ images, 800+ questions, and 27 categories, such as attribute-based Q&A, celebrity recognition, writing poetry, summarizing multiple images, product comparison, math problem solving, etc. Please read [touchstone/README_CN.md](touchstone/README.md) for more information.
#### 英语 (English)
| Model | Score |
|---------------|-------|
| PandaGPT | 488.5 |
| MiniGPT4 | 531.7 |
| InstructBLIP | 552.4 |
| LLaMA-AdapterV2 | 590.1 |
| mPLUG-Owl | 605.4 |
| LLaVA | 602.7 |
| Qwen-VL-Chat | 645.2 |
#### 中文 (Chinese)
| Model | Score |
|---------------|-------|
| VisualGLM | 247.1 |
| Qwen-VL-Chat | 401.2 |
Qwen-VL-Chat 模型在中英文的对齐评测中均取得当前 LVLM 模型下的最好结果。
Qwen-VL-Chat has achieved the best results in both Chinese and English alignment evaluation.
<br>
## 常见问题 (FAQ)
如遇到问题,敬请查阅 [FAQ](https://github.com/QwenLM/Qwen-VL/blob/master/FAQ_zh.md)以及issue区,如仍无法解决再提交issue。
If you meet problems, please refer to [FAQ](https://github.com/QwenLM/Qwen-VL/blob/master/FAQ.md) and the issues first to search a solution before you launch a new issue.
<br>
## 使用协议 (License Agreement)
研究人员与开发者可使用Qwen-VL和Qwen-VL-Chat或进行二次开发。我们同样允许商业使用,具体细节请查看[LICENSE](https://github.com/QwenLM/Qwen-VL/blob/master/LICENSE)。如需商用,请填写[问卷](https://dashscope.console.aliyun.com/openModelApply/qianwen)申请。
Researchers and developers are free to use the codes and model weights of both Qwen-VL and Qwen-VL-Chat. We also allow their commercial use. Check our license at [LICENSE](LICENSE) for more details.
<br>
## 引用 (Citation)
如果你觉得我们的论文和代码对你的研究有帮助,请考虑:star: 和引用 :pencil: :)
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil: :)
```BibTeX
@article{Qwen-VL,
title={Qwen-VL: A Frontier Large Vision-Language Model with Versatile Abilities},
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
journal={arXiv preprint arXiv:2308.12966},
year={2023}
}
```
<br>
## 联系我们 (Contact Us)
如果你想给我们的研发团队和产品团队留言,请通过邮件([email protected])联系我们。
If you are interested to leave a message to either our research team or product team, feel free to send an email to [email protected].
```
```
|
hdve/Qwen-Qwen1.5-1.8B-1718115026 | hdve | "2024-06-11T14:12:08Z" | 123 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-06-11T14:10:27Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
CLMBR/binding-case-lstm-2 | CLMBR | "2024-01-22T06:01:02Z" | 6 | 0 | transformers | [
"transformers",
"pytorch",
"rnn",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | null | "2024-01-17T20:26:42Z" | ---
tags:
- generated_from_trainer
model-index:
- name: binding-case-lstm-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# binding-case-lstm-2
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.9732
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 3052726
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-------:|:---------------:|
| 4.7896 | 0.03 | 76320 | 4.7570 |
| 4.5056 | 1.03 | 152640 | 4.4776 |
| 4.3639 | 0.03 | 228960 | 4.3428 |
| 4.2748 | 1.03 | 305280 | 4.2598 |
| 4.2152 | 0.03 | 381600 | 4.2038 |
| 4.1683 | 0.03 | 457920 | 4.1630 |
| 4.1315 | 1.03 | 534240 | 4.1321 |
| 4.0972 | 0.03 | 610560 | 4.1075 |
| 4.071 | 0.03 | 686880 | 4.0878 |
| 4.0465 | 1.03 | 763200 | 4.0719 |
| 4.0256 | 0.03 | 839520 | 4.0583 |
| 4.0112 | 1.03 | 915840 | 4.0480 |
| 3.9916 | 0.03 | 992160 | 4.0378 |
| 3.9742 | 1.03 | 1068480 | 4.0300 |
| 3.9673 | 0.03 | 1144800 | 4.0234 |
| 3.9429 | 1.03 | 1221120 | 4.0180 |
| 3.9312 | 0.03 | 1297440 | 4.0124 |
| 3.9237 | 1.03 | 1373760 | 4.0079 |
| 3.9162 | 0.03 | 1450080 | 4.0047 |
| 3.9118 | 1.03 | 1526400 | 4.0011 |
| 3.9087 | 0.03 | 1602720 | 3.9978 |
| 3.9046 | 1.03 | 1679040 | 3.9952 |
| 3.8998 | 0.03 | 1755360 | 3.9928 |
| 3.8938 | 1.03 | 1831680 | 3.9903 |
| 3.8883 | 0.03 | 1908000 | 3.9883 |
| 3.8836 | 1.03 | 1984320 | 3.9859 |
| 3.8759 | 0.03 | 2060640 | 3.9840 |
| 3.8724 | 1.03 | 2136960 | 3.9824 |
| 3.8654 | 0.03 | 2213280 | 3.9808 |
| 3.8605 | 1.03 | 2289600 | 3.9793 |
| 3.8586 | 0.03 | 2365920 | 3.9784 |
| 3.8453 | 1.03 | 2442240 | 3.9775 |
| 3.8408 | 0.03 | 2518560 | 3.9766 |
| 3.8392 | 1.03 | 2594880 | 3.9762 |
| 3.8369 | 0.03 | 2671200 | 3.9754 |
| 3.8385 | 1.03 | 2747520 | 3.9749 |
| 3.8411 | 0.03 | 2823840 | 3.9744 |
| 3.84 | 0.03 | 2900160 | 3.9740 |
| 3.8412 | 1.03 | 2976480 | 3.9735 |
| 3.842 | 0.02 | 3052726 | 3.9732 |
### Framework versions
- Transformers 4.33.3
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.13.3
|
eldraco/ppo-LunarLander-v2 | eldraco | "2023-01-30T09:40:20Z" | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | "2023-01-28T14:28:39Z" | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 294.34 +/- 21.28
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
camidenecken/RoBERTa-RM1-v1-3-rm-v1 | camidenecken | "2024-11-11T17:38:52Z" | 181 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2024-11-11T17:35:33Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf | RichardErkhov | "2024-09-13T15:30:00Z" | 20 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2024-09-13T10:16:34Z" | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Calme-7B-Instruct-v0.4 - GGUF
- Model creator: https://huggingface.co/MaziyarPanahi/
- Original model: https://huggingface.co/MaziyarPanahi/Calme-7B-Instruct-v0.4/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Calme-7B-Instruct-v0.4.Q2_K.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q2_K.gguf) | Q2_K | 2.53GB |
| [Calme-7B-Instruct-v0.4.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.IQ3_XS.gguf) | IQ3_XS | 2.81GB |
| [Calme-7B-Instruct-v0.4.IQ3_S.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.IQ3_S.gguf) | IQ3_S | 2.96GB |
| [Calme-7B-Instruct-v0.4.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q3_K_S.gguf) | Q3_K_S | 2.95GB |
| [Calme-7B-Instruct-v0.4.IQ3_M.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.IQ3_M.gguf) | IQ3_M | 3.06GB |
| [Calme-7B-Instruct-v0.4.Q3_K.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q3_K.gguf) | Q3_K | 3.28GB |
| [Calme-7B-Instruct-v0.4.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q3_K_M.gguf) | Q3_K_M | 3.28GB |
| [Calme-7B-Instruct-v0.4.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q3_K_L.gguf) | Q3_K_L | 3.56GB |
| [Calme-7B-Instruct-v0.4.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.IQ4_XS.gguf) | IQ4_XS | 3.67GB |
| [Calme-7B-Instruct-v0.4.Q4_0.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q4_0.gguf) | Q4_0 | 3.83GB |
| [Calme-7B-Instruct-v0.4.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.IQ4_NL.gguf) | IQ4_NL | 3.87GB |
| [Calme-7B-Instruct-v0.4.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q4_K_S.gguf) | Q4_K_S | 3.86GB |
| [Calme-7B-Instruct-v0.4.Q4_K.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q4_K.gguf) | Q4_K | 4.07GB |
| [Calme-7B-Instruct-v0.4.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q4_K_M.gguf) | Q4_K_M | 4.07GB |
| [Calme-7B-Instruct-v0.4.Q4_1.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q4_1.gguf) | Q4_1 | 4.24GB |
| [Calme-7B-Instruct-v0.4.Q5_0.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q5_0.gguf) | Q5_0 | 4.65GB |
| [Calme-7B-Instruct-v0.4.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q5_K_S.gguf) | Q5_K_S | 4.65GB |
| [Calme-7B-Instruct-v0.4.Q5_K.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q5_K.gguf) | Q5_K | 4.78GB |
| [Calme-7B-Instruct-v0.4.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q5_K_M.gguf) | Q5_K_M | 4.78GB |
| [Calme-7B-Instruct-v0.4.Q5_1.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q5_1.gguf) | Q5_1 | 5.07GB |
| [Calme-7B-Instruct-v0.4.Q6_K.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q6_K.gguf) | Q6_K | 5.53GB |
| [Calme-7B-Instruct-v0.4.Q8_0.gguf](https://huggingface.co/RichardErkhov/MaziyarPanahi_-_Calme-7B-Instruct-v0.4-gguf/blob/main/Calme-7B-Instruct-v0.4.Q8_0.gguf) | Q8_0 | 7.17GB |
Original model description:
---
license: apache-2.0
tags:
- generated_from_trainer
- mistral
- 7b
- calme
model-index:
- name: Calme-7B-Instruct-v0.4
results: []
model_name: Calme-7B-Instruct-v0.4
inference: false
model_creator: MaziyarPanahi
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
<img src="https://cdn-uploads.huggingface.co/production/uploads/5fd5e18a90b6dc4633f6d292/LzEf6vvq2qIiys-q7l9Hq.webp" width="550" />
# MaziyarPanahi/Calme-7B-Instruct-v0.4
## Model Description
Calme-7B is a state-of-the-art language model with 7 billion parameters, fine-tuned over high-quality datasets on top of Mistral-7B. The Calme-7B models excel in generating text that resonates with clarity, calmness, and coherence.
### How to Use
```python
# Use a pipeline as a high-level helper
from transformers import pipeline
pipe = pipeline("text-generation", model="MaziyarPanahi/Calme-7B-Instruct-v0.4")
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("MaziyarPanahi/Calme-7B-Instruct-v0.4")
model = AutoModelForCausalLM.from_pretrained("MaziyarPanahi/Calme-7B-Instruct-v0.4")
```
### Quantized Models
> I love how GGUF democratizes the use of Large Language Models (LLMs) on commodity hardware, more specifically, personal computers without any accelerated hardware. Because of this, I am committed to converting and quantizing any models I fine-tune to make them accessible to everyone!
- GGUF (2/3/4/5/6/8 bits): [MaziyarPanahi/Calme-7B-Instruct-v0.4-GGUF](https://huggingface.co/MaziyarPanahi/Calme-7B-Instruct-v0.4-GGUF)
## Examples
```
<s>[INST] You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
describe about pros and cons of docker system. [/INST]
```
<details>
<summary>Show me the response</summary>
```
```
</details>
```
```
<details>
<summary>Show me the response</summary>
```
```
</details>
```
<s> [INST] Mark is faster than Mary, Mary is faster than Joe. Is Joe faster than Mark? Let's think step by step [/INST]
```
<details>
<summary>Show me the response</summary>
```
```
</details>
```
```
<details>
<summary>Show me the response</summary>
```
```
</details>
```
<s> [INST] explain step by step 25-4*2+3=? [/INST]
```
<details>
<summary>Show me the response</summary>
```
```
</details>
**Multilingual:**
```
<s> [INST] Vous êtes un assistant utile, respectueux et honnête. Répondez toujours de la manière la plus utile possible, tout en étant sûr. Vos réponses ne doivent inclure aucun contenu nuisible, contraire à l'éthique, raciste, sexiste, toxique, dangereux ou illégal. Assurez-vous que vos réponses sont socialement impartiales et de nature positive.
Si une question n'a pas de sens ou n'est pas cohérente d'un point de vue factuel, expliquez pourquoi au lieu de répondre quelque chose d'incorrect. Si vous ne connaissez pas la réponse à une question, veuillez ne pas partager de fausses informations.
Décrivez les avantages et les inconvénients du système Docker.[/INST]
```
<details>
<summary>Show me the response</summary>
```
```
<details>
<summary>Show me the response</summary>
```
```
</details>
```
<s>[INST] Ви - корисний, поважний та чесний помічник. Завжди відповідайте максимально корисно, будучи безпечним. Ваші відповіді не повинні містити шкідливого, неетичного, расистського, сексистського, токсичного, небезпечного або нелегального контенту. Будь ласка, переконайтеся, що ваші відповіді соціально неупереджені та мають позитивний характер.
Якщо питання не має сенсу або не є фактично послідовним, поясніть чому, замість того, щоб відповідати щось некоректне. Якщо ви не знаєте відповіді на питання, будь ласка, не діліться неправдивою інформацією.
Опис про переваги та недоліки системи Docker.[/INST]
```
<details>
<summary>Show me the response</summary>
```
```
</details>
|
ThuyNT03/KLTN_COQE_viT5_total_SAPOL_v4 | ThuyNT03 | "2023-12-24T09:45:36Z" | 5 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:VietAI/vit5-large",
"base_model:finetune:VietAI/vit5-large",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2023-12-24T09:02:20Z" | ---
license: mit
base_model: VietAI/vit5-large
tags:
- generated_from_trainer
model-index:
- name: KLTN_COQE_viT5_total_SAPOL_v4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# KLTN_COQE_viT5_total_SAPOL_v4
This model is a fine-tuned version of [VietAI/vit5-large](https://huggingface.co/VietAI/vit5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.15.0
|
Shijia/furina_eng_corr_2e-05 | Shijia | "2024-02-17T01:43:08Z" | 90 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:yihongLiu/furina",
"base_model:finetune:yihongLiu/furina",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2024-02-17T01:42:17Z" | ---
base_model: yihongLiu/furina
tags:
- generated_from_trainer
model-index:
- name: furina_eng_corr_2e-05
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# furina_eng_corr_2e-05
This model is a fine-tuned version of [yihongLiu/furina](https://huggingface.co/yihongLiu/furina) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0203
- Spearman Corr: 0.7758
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 128
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Spearman Corr |
|:-------------:|:-----:|:----:|:---------------:|:-------------:|
| No log | 1.33 | 200 | 0.0216 | 0.7729 |
| 0.0014 | 2.66 | 400 | 0.0212 | 0.7735 |
| 0.0013 | 3.99 | 600 | 0.0214 | 0.7754 |
| 0.0013 | 5.32 | 800 | 0.0215 | 0.7733 |
| 0.0012 | 6.64 | 1000 | 0.0211 | 0.7700 |
| 0.0012 | 7.97 | 1200 | 0.0203 | 0.7745 |
| 0.0012 | 9.3 | 1400 | 0.0204 | 0.7792 |
| 0.0011 | 10.63 | 1600 | 0.0199 | 0.7773 |
| 0.001 | 11.96 | 1800 | 0.0210 | 0.7735 |
| 0.001 | 13.29 | 2000 | 0.0204 | 0.7755 |
| 0.001 | 14.62 | 2200 | 0.0203 | 0.7734 |
| 0.0009 | 15.95 | 2400 | 0.0206 | 0.7752 |
| 0.0009 | 17.28 | 2600 | 0.0205 | 0.7729 |
| 0.0009 | 18.6 | 2800 | 0.0208 | 0.7732 |
| 0.0008 | 19.93 | 3000 | 0.0203 | 0.7758 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.0
- Tokenizers 0.15.2
|
qgallouedec/ppo-HumanoidStandup-v2-1643073142 | qgallouedec | "2024-04-17T09:54:59Z" | 7 | 0 | stable-baselines3 | [
"stable-baselines3",
"HumanoidStandup-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"HumanoidStandup-v4",
"model-index",
"region:us"
] | reinforcement-learning | "2023-02-28T14:28:51Z" | ---
library_name: stable-baselines3
tags:
- HumanoidStandup-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
- HumanoidStandup-v4
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: HumanoidStandup-v2
type: HumanoidStandup-v2
metrics:
- type: mean_reward
value: 151147.54 +/- 40669.21
name: mean_reward
verified: false
---
|
rohanhugging/strongbodyshapeone | rohanhugging | "2025-03-28T20:32:35Z" | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | "2025-03-28T20:15:58Z" | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: sbso
---
# Strongbodyshapeone
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `sbso` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('rohanhugging/strongbodyshapeone', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
kenonix/gemma-2b-it-ko-Q8_0-GGUF | kenonix | "2025-02-09T13:30:23Z" | 24 | 0 | transformers | [
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:quantumaikr/gemma-2b-it-ko",
"base_model:quantized:quantumaikr/gemma-2b-it-ko",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2025-02-09T13:30:09Z" | ---
library_name: transformers
tags:
- llama-cpp
- gguf-my-repo
base_model: quantumaikr/gemma-2b-it-ko
---
# kenonix/gemma-2b-it-ko-Q8_0-GGUF
This model was converted to GGUF format from [`quantumaikr/gemma-2b-it-ko`](https://huggingface.co/quantumaikr/gemma-2b-it-ko) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/quantumaikr/gemma-2b-it-ko) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo kenonix/gemma-2b-it-ko-Q8_0-GGUF --hf-file gemma-2b-it-ko-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo kenonix/gemma-2b-it-ko-Q8_0-GGUF --hf-file gemma-2b-it-ko-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo kenonix/gemma-2b-it-ko-Q8_0-GGUF --hf-file gemma-2b-it-ko-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo kenonix/gemma-2b-it-ko-Q8_0-GGUF --hf-file gemma-2b-it-ko-q8_0.gguf -c 2048
```
|
gbieul/b3-summ-Mistral-7B-v0.1 | gbieul | "2024-01-08T16:06:30Z" | 4 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
] | null | "2024-01-08T03:33:49Z" | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: mistralai/Mistral-7B-v0.1
model-index:
- name: b3-summ-Mistral-7B-v0.1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# b3-summ-Mistral-7B-v0.1
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7543
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0777 | 40.0 | 1200 | 1.3689 |
| 0.0104 | 80.0 | 2400 | 1.6117 |
| 0.0067 | 120.0 | 3600 | 1.7020 |
| 0.0063 | 160.0 | 4800 | 1.7320 |
| 0.0059 | 200.0 | 6000 | 1.7543 |
### Framework versions
- PEFT 0.7.2.dev0
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.0 |
casque/galaxy_gods | casque | "2023-07-10T03:30:30Z" | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | "2023-07-10T03:30:18Z" | ---
license: creativeml-openrail-m
---
|
mradermacher/Deepseek-Wizard-33B-slerp-GGUF | mradermacher | "2024-12-16T03:32:39Z" | 127 | 0 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"deepseek-ai/deepseek-coder-33b-instruct",
"WizardLM/WizardCoder-33B-V1.1",
"en",
"base_model:arvindanand/Deepseek-Wizard-33B-slerp",
"base_model:quantized:arvindanand/Deepseek-Wizard-33B-slerp",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2024-04-06T11:20:31Z" | ---
base_model: arvindanand/Deepseek-Wizard-33B-slerp
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
- deepseek-ai/deepseek-coder-33b-instruct
- WizardLM/WizardCoder-33B-V1.1
---
## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/arvindanand/Deepseek-Wizard-33B-slerp
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.Q2_K.gguf) | Q2_K | 6.6 | |
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.IQ3_XS.gguf) | IQ3_XS | 7.3 | |
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.Q3_K_S.gguf) | Q3_K_S | 7.7 | |
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.IQ3_S.gguf) | IQ3_S | 7.7 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.IQ3_M.gguf) | IQ3_M | 8.0 | |
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.Q3_K_M.gguf) | Q3_K_M | 8.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.Q3_K_L.gguf) | Q3_K_L | 9.3 | |
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.IQ4_XS.gguf) | IQ4_XS | 9.6 | |
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.Q4_K_S.gguf) | Q4_K_S | 10.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.Q4_K_M.gguf) | Q4_K_M | 10.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.Q5_K_S.gguf) | Q5_K_S | 12.1 | |
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.Q5_K_M.gguf) | Q5_K_M | 12.4 | |
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.Q6_K.gguf) | Q6_K | 14.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Deepseek-Wizard-33B-slerp-GGUF/resolve/main/Deepseek-Wizard-33B-slerp.Q8_0.gguf) | Q8_0 | 18.6 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
fusing/ddpm-celeba-hq | fusing | "2022-07-15T13:16:17Z" | 14 | 1 | transformers | [
"transformers",
"ddpm_diffusion",
"arxiv:2006.11239",
"endpoints_compatible",
"region:us"
] | null | "2022-06-07T10:39:38Z" | ---
tags:
- ddpm_diffusion
---
# Denoising Diffusion Probabilistic Models (DDPM)
**Paper**: [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239)
**Abstract**:
*We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.*
## Usage
```python
# !pip install diffusers
from diffusers import DiffusionPipeline
import PIL.Image
import numpy as np
model_id = "fusing/ddpm-celeba-hq"
# load model and scheduler
ddpm = DiffusionPipeline.from_pretrained(model_id)
# run pipeline in inference (sample random noise and denoise)
image = ddpm()
# process image to PIL
image_processed = image.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
# save image
image_pil.save("test.png")
```
## Samples
1. 
2. 
3. 
4. 
|
pennypacker/CinDeeLora | pennypacker | "2025-04-05T14:31:58Z" | 41 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | "2025-03-20T04:54:39Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:[email protected]">an email</a></p>
</div>
</main>
</body>
</html> |
ai-anytime/idefics-9b-PokemonCards | ai-anytime | "2024-01-14T11:53:47Z" | 1 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:HuggingFaceM4/idefics-9b",
"base_model:adapter:HuggingFaceM4/idefics-9b",
"region:us"
] | null | "2024-01-14T11:53:33Z" | ---
library_name: peft
base_model: HuggingFaceM4/idefics-9b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.7.2.dev0 |
prottoymmh/newsabi | prottoymmh | "2025-01-13T01:10:40Z" | 625 | 0 | diffusers | [
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"region:us"
] | text-to-image | "2025-01-13T01:07:49Z" | ---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: newsabi
output:
url: images/818012011121248117.png
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: bewsabi
---
# newsabi
<Gallery />
## Trigger words
You should use `bewsabi` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/prottoymmh/newsabi/tree/main) them in the Files & versions tab.
|
mradermacher/Qwen2-57B-A14B-Instruct-GGUF | mradermacher | "2024-06-23T12:30:56Z" | 48 | 0 | transformers | [
"transformers",
"gguf",
"chat",
"en",
"base_model:Qwen/Qwen2-57B-A14B-Instruct",
"base_model:quantized:Qwen/Qwen2-57B-A14B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2024-06-23T01:43:45Z" | ---
base_model: Qwen/Qwen2-57B-A14B-Instruct
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- chat
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Qwen/Qwen2-57B-A14B-Instruct
**The Qwen2-57B models seem to be broken. I have tried my best, but they likely need to be fixed upstream first. You have been warned.**
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.Q2_K.gguf) | Q2_K | 21.2 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.IQ3_XS.gguf) | IQ3_XS | 23.7 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.Q3_K_S.gguf) | Q3_K_S | 25.0 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.IQ3_S.gguf) | IQ3_S | 25.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.IQ3_M.gguf) | IQ3_M | 25.3 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.Q3_K_M.gguf) | Q3_K_M | 27.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.Q3_K_L.gguf) | Q3_K_L | 29.9 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.IQ4_XS.gguf) | IQ4_XS | 31.1 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.Q4_K_S.gguf) | Q4_K_S | 32.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.Q4_K_M.gguf) | Q4_K_M | 35.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.Q5_K_S.gguf) | Q5_K_S | 39.7 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.Q5_K_M.gguf) | Q5_K_M | 40.9 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.Q6_K.gguf) | Q6_K | 47.2 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Qwen2-57B-A14B-Instruct-GGUF/resolve/main/Qwen2-57B-A14B-Instruct.Q8_0.gguf.part2of2) | Q8_0 | 61.1 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
sd-concepts-library/maurice-quentin-de-la-tour-style | sd-concepts-library | "2022-09-09T21:53:58Z" | 0 | 1 | null | [
"license:mit",
"region:us"
] | null | "2022-09-09T21:53:55Z" | ---
license: mit
---
### Maurice-Quentin- de-la-Tour-style on Stable Diffusion
This is the `<maurice>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
bartowski/Llama-3-8B-Instruct-262k-exl2 | bartowski | "2024-05-04T21:06:55Z" | 0 | 0 | null | [
"meta",
"llama-3",
"text-generation",
"en",
"license:llama3",
"region:us"
] | text-generation | "2024-05-04T21:06:54Z" | ---
language:
- en
pipeline_tag: text-generation
tags:
- meta
- llama-3
license: llama3
quantized_by: bartowski
---
## Exllama v2 Quantizations of Llama-3-8B-Instruct-262k
Using <a href="https://github.com/turboderp/exllamav2/releases/tag/v0.0.20">turboderp's ExLlamaV2 v0.0.20</a> for quantization.
<b>The "main" branch only contains the measurement.json, download one of the other branches for the model (see below)</b>
Each branch contains an individual bits per weight, with the main one containing only the meaurement.json for further conversions.
Original model: https://huggingface.co/gradientai/Llama-3-8B-Instruct-262k
## Prompt format
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
## Available sizes
| Branch | Bits | lm_head bits | VRAM (4k) | VRAM (8K) | VRAM (16k) | VRAM (32k) | Description |
| ----- | ---- | ------- | ------ | ------ | ------ | ------ | ------------ |
| [8_0](https://huggingface.co/bartowski/Llama-3-8B-Instruct-262k-exl2/tree/8_0) | 8.0 | 8.0 | 10.1 GB | 10.5 GB | 11.5 GB | 13.6 GB | Maximum quality that ExLlamaV2 can produce, near unquantized performance. |
| [6_5](https://huggingface.co/bartowski/Llama-3-8B-Instruct-262k-exl2/tree/6_5) | 6.5 | 8.0 | 8.9 GB | 9.3 GB | 10.3 GB | 12.4 GB | Very similar to 8.0, good tradeoff of size vs performance, **recommended**. |
| [5_0](https://huggingface.co/bartowski/Llama-3-8B-Instruct-262k-exl2/tree/5_0) | 5.0 | 6.0 | 7.7 GB | 8.1 GB | 9.1 GB | 11.2 GB | Slightly lower quality vs 6.5, but usable on 8GB cards. |
| [4_25](https://huggingface.co/bartowski/Llama-3-8B-Instruct-262k-exl2/tree/4_25) | 4.25 | 6.0 | 7.0 GB | 7.4 GB | 8.4 GB | 10.5 GB | GPTQ equivalent bits per weight, slightly higher quality. |
| [3_5](https://huggingface.co/bartowski/Llama-3-8B-Instruct-262k-exl2/tree/3_5) | 3.5 | 6.0 | 6.4 GB | 6.8 GB | 7.8 GB | 9.9 GB | Lower quality, only use if you have to. |
## Download instructions
With git:
```shell
git clone --single-branch --branch 6_5 https://huggingface.co/bartowski/Llama-3-8B-Instruct-262k-exl2 Llama-3-8B-Instruct-262k-exl2-6_5
```
With huggingface hub (credit to TheBloke for instructions):
```shell
pip3 install huggingface-hub
```
To download a specific branch, use the `--revision` parameter. For example, to download the 6.5 bpw branch:
Linux:
```shell
huggingface-cli download bartowski/Llama-3-8B-Instruct-262k-exl2 --revision 6_5 --local-dir Llama-3-8B-Instruct-262k-exl2-6_5 --local-dir-use-symlinks False
```
Windows (which apparently doesn't like _ in folders sometimes?):
```shell
huggingface-cli download bartowski/Llama-3-8B-Instruct-262k-exl2 --revision 6_5 --local-dir Llama-3-8B-Instruct-262k-exl2-6.5 --local-dir-use-symlinks False
```
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
davidilag/whisper-base-fo | davidilag | "2024-03-06T06:27:05Z" | 4 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"fo",
"dataset:carlosdanielhernandezmena/ravnursson_asr",
"base_model:openai/whisper-base",
"base_model:finetune:openai/whisper-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2024-03-05T09:36:22Z" | ---
language:
- fo
license: apache-2.0
base_model: openai/whisper-base
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- carlosdanielhernandezmena/ravnursson_asr
model-index:
- name: "Whisper Base Fo - D\xE1vid \xED L\xE1g"
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Base Fo - Dávid í Lág
This model is a fine-tuned version of [openai/whisper-base](https://huggingface.co/openai/whisper-base) on the Ravnurson dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
PontifexMaximus/mt5-small-parsinlu-opus-translation_fa_en-finetuned-fa-to-en | PontifexMaximus | "2022-06-07T15:17:41Z" | 24 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"dataset:opus_infopankki",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2022-06-03T10:59:17Z" | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- opus_infopankki
metrics:
- bleu
model-index:
- name: mt5-small-parsinlu-opus-translation_fa_en-finetuned-fa-to-en
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: opus_infopankki
type: opus_infopankki
args: en-fa
metrics:
- name: Bleu
type: bleu
value: 15.1329
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-parsinlu-opus-translation_fa_en-finetuned-fa-to-en
This model is a fine-tuned version of [persiannlp/mt5-small-parsinlu-opus-translation_fa_en](https://huggingface.co/persiannlp/mt5-small-parsinlu-opus-translation_fa_en) on the opus_infopankki dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9193
- Bleu: 15.1329
- Gen Len: 13.4603
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|
| 3.1182 | 1.0 | 1807 | 2.5985 | 10.6445 | 13.7938 |
| 2.8377 | 2.0 | 3614 | 2.3799 | 11.852 | 13.6168 |
| 2.6644 | 3.0 | 5421 | 2.2426 | 12.877 | 13.5768 |
| 2.5286 | 4.0 | 7228 | 2.1521 | 13.5342 | 13.5567 |
| 2.4523 | 5.0 | 9035 | 2.0801 | 14.0355 | 13.5387 |
| 2.4026 | 6.0 | 10842 | 2.0197 | 14.4284 | 13.4956 |
| 2.317 | 7.0 | 12649 | 1.9691 | 14.7776 | 13.4325 |
| 2.3174 | 8.0 | 14456 | 1.9373 | 15.189 | 13.4261 |
| 2.3374 | 9.0 | 16263 | 1.9393 | 15.1149 | 13.4087 |
| 2.3131 | 10.0 | 18070 | 1.9304 | 15.0654 | 13.4234 |
| 2.295 | 11.0 | 19877 | 1.9239 | 15.102 | 13.4443 |
| 2.3017 | 12.0 | 21684 | 1.9203 | 15.1676 | 13.4575 |
| 2.3153 | 13.0 | 23491 | 1.9193 | 15.1329 | 13.4603 |
| 2.2939 | 14.0 | 25298 | 1.9193 | 15.1329 | 13.4603 |
| 2.3241 | 15.0 | 27105 | 1.9193 | 15.1329 | 13.4603 |
| 2.3376 | 16.0 | 28912 | 1.9193 | 15.1329 | 13.4603 |
| 2.2859 | 17.0 | 30719 | 1.9193 | 15.1329 | 13.4603 |
| 2.3016 | 18.0 | 32526 | 1.9193 | 15.1329 | 13.4603 |
| 2.3101 | 19.0 | 34333 | 1.9193 | 15.1329 | 13.4603 |
| 2.3088 | 20.0 | 36140 | 1.9193 | 15.1329 | 13.4603 |
| 2.2833 | 21.0 | 37947 | 1.9193 | 15.1329 | 13.4603 |
| 2.2986 | 22.0 | 39754 | 1.9193 | 15.1329 | 13.4603 |
| 2.3254 | 23.0 | 41561 | 1.9193 | 15.1329 | 13.4603 |
| 2.3165 | 24.0 | 43368 | 1.9193 | 15.1329 | 13.4603 |
| 2.289 | 25.0 | 45175 | 1.9193 | 15.1329 | 13.4603 |
| 2.3212 | 26.0 | 46982 | 1.9193 | 15.1329 | 13.4603 |
| 2.2902 | 27.0 | 48789 | 1.9193 | 15.1329 | 13.4603 |
| 2.3026 | 28.0 | 50596 | 1.9193 | 15.1329 | 13.4603 |
| 2.2949 | 29.0 | 52403 | 1.9193 | 15.1329 | 13.4603 |
| 2.3152 | 30.0 | 54210 | 1.9193 | 15.1329 | 13.4603 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.7.1+cu110
- Datasets 2.2.2
- Tokenizers 0.12.1
|
GuCuChiara/NLP-HIBA_DisTEMIST_fine_tuned_bert-base-multilingual-cased | GuCuChiara | "2023-10-11T14:35:23Z" | 105 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-multilingual-cased",
"base_model:finetune:google-bert/bert-base-multilingual-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | "2023-10-11T14:20:14Z" | ---
license: apache-2.0
base_model: bert-base-multilingual-cased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: NLP-HIBA_DisTEMIST_fine_tuned_bert-base-multilingual-cased
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# NLP-HIBA_DisTEMIST_fine_tuned_bert-base-multilingual-cased
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2057
- Precision: 0.6288
- Recall: 0.5579
- F1: 0.5912
- Accuracy: 0.9555
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 71 | 0.1547 | 0.5048 | 0.3774 | 0.4319 | 0.9430 |
| No log | 2.0 | 142 | 0.1542 | 0.5965 | 0.4071 | 0.4839 | 0.9495 |
| No log | 3.0 | 213 | 0.1369 | 0.5519 | 0.5160 | 0.5334 | 0.9516 |
| No log | 4.0 | 284 | 0.1435 | 0.5622 | 0.4989 | 0.5287 | 0.9512 |
| No log | 5.0 | 355 | 0.1542 | 0.5920 | 0.5575 | 0.5742 | 0.9536 |
| No log | 6.0 | 426 | 0.1625 | 0.6069 | 0.5663 | 0.5859 | 0.9546 |
| No log | 7.0 | 497 | 0.1779 | 0.5936 | 0.5830 | 0.5883 | 0.9526 |
| 0.0978 | 8.0 | 568 | 0.1827 | 0.6035 | 0.5784 | 0.5907 | 0.9546 |
| 0.0978 | 9.0 | 639 | 0.2026 | 0.6121 | 0.5685 | 0.5895 | 0.9546 |
| 0.0978 | 10.0 | 710 | 0.2057 | 0.6288 | 0.5579 | 0.5912 | 0.9555 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
fatemeghasemi98/text-to-sql | fatemeghasemi98 | "2025-02-17T17:12:03Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"text2sql",
"natural-language-to-sql",
"spider-dataset",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2025-02-17T16:55:32Z" | ---
license: apache-2.0
tags:
- text2sql
- natural-language-to-sql
- transformers
- t5
- spider-dataset
---
# Model Card for Fine-Tuned T5 for Text-to-SQL
## Model Details
### Model Description
This is a fine-tuned T5-small model for generating SQL queries from natural language. It was trained on the [Spider dataset](https://huggingface.co/datasets/spider), a benchmark dataset for text-to-SQL tasks.
- **Developed by:** OSLLM.ai
- **Shared by:** OSLLM.ai
- **Model type:** Text-to-SQL (Sequence-to-Sequence)
- **Language(s):** English
- **License:** Apache 2.0
- **Finetuned from:** [t5-small](https://huggingface.co/t5-small)
## Uses
### Direct Use
This model can be used to generate SQL queries from natural language questions. It is particularly useful for developers building natural language interfaces to databases.
### Downstream Use
The model can be fine-tuned further on domain-specific datasets for improved performance.
### Out-of-Scope Use
This model is not suitable for generating SQL queries for databases with highly specialized schemas or non-standard SQL dialects.
## Bias, Risks, and Limitations
The model may generate incorrect or unsafe SQL queries if the input question is ambiguous or outside the scope of the training data. Always validate the generated SQL before executing it on a production database.
## How to Get Started with the Model
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
# Load the fine-tuned model
model = T5ForConditionalGeneration.from_pretrained("fatemeghasemi98/text-to-sql")
tokenizer = T5Tokenizer.from_pretrained("fatemeghasemi98/text-to-sql")
# Generate SQL query
def generate_sql_query(question):
input_text = f"translate English to SQL: {question}"
input_ids = tokenizer(input_text, return_tensors="pt", max_length=512, truncation=True, padding="max_length").input_ids
outputs = model.generate(input_ids)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example usage
question = "Find all the customers who live in New York."
sql_query = generate_sql_query(question)
print(sql_query)
```
## Training Details
### Training Data
The model was trained on the [Spider dataset](https://huggingface.co/datasets/spider), which contains 10,181 questions and 5,693 unique complex SQL queries across 200 databases.
### Training Procedure
- **Preprocessing:** Questions were prefixed with "translate English to SQL:" and tokenized using the T5 tokenizer.
- **Training Hyperparameters:**
- Learning Rate: 2e-5
- Batch Size: 8
- Epochs: 3
- Mixed Precision: FP16
## Evaluation
The model was evaluated on the Spider validation set. Metrics such as exact match accuracy and execution accuracy can be used to assess performance.
## Environmental Impact
- **Hardware:** 1x NVIDIA T4 GPU (Google Colab)
- **Hours Used:** ~3 hours
- **Carbon Emitted:** [Estimate using the [ML CO2 Impact Calculator](https://mlco2.github.io/impact)]
|
ikmalsaid/jennifer-connelly-lora | ikmalsaid | "2024-10-09T02:33:59Z" | 180 | 1 | diffusers | [
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"region:us"
] | text-to-image | "2024-10-09T02:32:57Z" | ---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: c0nnelly <lora:c0nnelly-lora:1>
output:
url: images/00019-2648537026.png
- text: c0nnelly <lora:c0nnelly-lora:1>
output:
url: images/00024-1267212081.png
- text: c0nnelly <lora:c0nnelly-lora:1>
output:
url: images/00027-3696137079.png
- text: c0nnelly <lora:c0nnelly-lora:1>
output:
url: images/00038-3424688988.png
- text: c0nnelly <lora:c0nnelly-lora:1>
output:
url: images/00034-3959685064.png
- text: c0nnelly <lora:c0nnelly-lora:1>
output:
url: images/00035-3111615772.png
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: c0nnelly
---
# Jennifer Connelly - Flux.1 [Dev] LORA
<Gallery />
## Model description
A popular American actress LORA trained on Flux.1 [Dev] (Dev2Pro version). Any constructive feedback and suggestions are very much appreciated. Thank you for your support!
## Trigger words
You should use `c0nnelly` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/ikmalsaid/jennifer-connelly-lora/tree/main) them in the Files & versions tab.
|
techme/gpt_finetuned-oee | techme | "2024-07-24T09:42:20Z" | 5 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | "2024-07-24T09:36:55Z" | ---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/NeuralContamination-7B-ties-i1-GGUF | mradermacher | "2025-01-03T23:42:44Z" | 75 | 0 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"yam-peleg/Experiment26-7B",
"Kukedlc/NeuralSirKrishna-7b",
"automerger/YamShadow-7B",
"en",
"base_model:Kukedlc/NeuralContamination-7B-ties",
"base_model:quantized:Kukedlc/NeuralContamination-7B-ties",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | "2025-01-03T22:44:44Z" | ---
base_model: Kukedlc/NeuralContamination-7B-ties
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
- yam-peleg/Experiment26-7B
- Kukedlc/NeuralSirKrishna-7b
- automerger/YamShadow-7B
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Kukedlc/NeuralContamination-7B-ties
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/NeuralContamination-7B-ties-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-IQ1_M.gguf) | i1-IQ1_M | 1.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-IQ2_M.gguf) | i1-IQ2_M | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-Q2_K_S.gguf) | i1-Q2_K_S | 2.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-Q2_K.gguf) | i1-Q2_K | 2.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-IQ3_S.gguf) | i1-IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-IQ3_M.gguf) | i1-IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-Q4_0.gguf) | i1-Q4_0 | 4.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-IQ4_NL.gguf) | i1-IQ4_NL | 4.2 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-Q4_1.gguf) | i1-Q4_1 | 4.7 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/NeuralContamination-7B-ties-i1-GGUF/resolve/main/NeuralContamination-7B-ties.i1-Q6_K.gguf) | i1-Q6_K | 6.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
pfunk/CartPole-v1-DQPN_freq_10000_0.99-seed2 | pfunk | "2023-03-18T05:58:44Z" | 0 | 0 | cleanrl | [
"cleanrl",
"tensorboard",
"CartPole-v1",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | "2023-03-18T05:58:41Z" | ---
tags:
- CartPole-v1
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: cleanrl
model-index:
- name: DQPN_freq
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 474.66 +/- 0.00
name: mean_reward
verified: false
---
# (CleanRL) **DQPN_freq** Agent Playing **CartPole-v1**
This is a trained model of a DQPN_freq agent playing CartPole-v1.
The model was trained by using [CleanRL](https://github.com/vwxyzjn/cleanrl) and the most up-to-date training code can be
found [here](https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/DQPN_freq_10000_0.99.py).
## Get Started
To use this model, please install the `cleanrl` package with the following command:
```
pip install "cleanrl[DQPN_freq_10000_0.99]"
python -m cleanrl_utils.enjoy --exp-name DQPN_freq_10000_0.99 --env-id CartPole-v1
```
Please refer to the [documentation](https://docs.cleanrl.dev/get-started/zoo/) for more detail.
## Command to reproduce the training
```bash
curl -OL https://huggingface.co/pfunk/CartPole-v1-DQPN_freq_10000_0.99-seed2/raw/main/dqpn_freq.py
curl -OL https://huggingface.co/pfunk/CartPole-v1-DQPN_freq_10000_0.99-seed2/raw/main/pyproject.toml
curl -OL https://huggingface.co/pfunk/CartPole-v1-DQPN_freq_10000_0.99-seed2/raw/main/poetry.lock
poetry install --all-extras
python dqpn_freq.py --track --wandb-entity pfunk --wandb-project-name dqpn --capture-video true --save-model true --upload-model true --hf-entity pfunk --exp-name DQPN_freq_10000_0.99 --gamma 0.99 --policy-network-frequency 10000 --seed 2
```
# Hyperparameters
```python
{'alg_type': 'dqpn_freq.py',
'batch_size': 256,
'buffer_size': 300000,
'capture_video': True,
'cuda': True,
'end_e': 0.1,
'env_id': 'CartPole-v1',
'exp_name': 'DQPN_freq_10000_0.99',
'exploration_fraction': 0.2,
'gamma': 0.99,
'hf_entity': 'pfunk',
'learning_rate': 0.0001,
'learning_starts': 1000,
'policy_network_frequency': 10000,
'policy_tau': 1.0,
'save_model': True,
'seed': 2,
'start_e': 1.0,
'target_network_frequency': 20,
'target_tau': 1.0,
'torch_deterministic': True,
'total_timesteps': 500000,
'track': True,
'train_frequency': 1,
'upload_model': True,
'wandb_entity': 'pfunk',
'wandb_project_name': 'dqpn'}
```
|
suhara/nm5-56b-8k-base | suhara | "2025-04-01T07:08:50Z" | 0 | 0 | null | [
"safetensors",
"region:us"
] | null | "2025-04-01T06:38:08Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:[email protected]">an email</a></p>
</div>
</main>
</body>
</html> |
lesso11/a89524c9-be85-417d-86ea-3ab4ed2f2e06 | lesso11 | "2025-03-26T17:46:54Z" | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:The-matt/llama2_ko-7b_distinctive-snowflake-182_1060",
"base_model:adapter:The-matt/llama2_ko-7b_distinctive-snowflake-182_1060",
"region:us"
] | null | "2025-03-26T15:45:22Z" | ---
library_name: peft
base_model: The-matt/llama2_ko-7b_distinctive-snowflake-182_1060
tags:
- axolotl
- generated_from_trainer
model-index:
- name: a89524c9-be85-417d-86ea-3ab4ed2f2e06
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: The-matt/llama2_ko-7b_distinctive-snowflake-182_1060
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- d99a766784bf9aac_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/d99a766784bf9aac_train_data.json
type:
field_input: observation_1
field_instruction: hypothesis_1
field_output: hypothesis_2
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
do_eval: true
early_stopping_patience: 3
eval_batch_size: 4
eval_max_new_tokens: 128
eval_steps: 500
evals_per_epoch: null
flash_attention: true
fp16: false
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 8
gradient_checkpointing: true
group_by_length: true
hub_model_id: lesso11/a89524c9-be85-417d-86ea-3ab4ed2f2e06
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.000211
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 50
lora_alpha: 128
lora_dropout: 0.15
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 64
lora_target_linear: true
lr_scheduler: cosine
max_grad_norm: 1.0
max_steps: 500
micro_batch_size: 4
mlflow_experiment_name: /tmp/d99a766784bf9aac_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 10
optimizer: adamw_torch_fused
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: 500
saves_per_epoch: null
seed: 110
sequence_len: 1024
strict: false
tf32: true
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: f933b472-8b31-4910-8238-b266148752cb
wandb_project: 11a
wandb_run: your_name
wandb_runid: f933b472-8b31-4910-8238-b266148752cb
warmup_steps: 100
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# a89524c9-be85-417d-86ea-3ab4ed2f2e06
This model is a fine-tuned version of [The-matt/llama2_ko-7b_distinctive-snowflake-182_1060](https://huggingface.co/The-matt/llama2_ko-7b_distinctive-snowflake-182_1060) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9853
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.000211
- train_batch_size: 4
- eval_batch_size: 4
- seed: 110
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| No log | 0.0002 | 1 | 2.1354 |
| 0.979 | 0.0988 | 500 | 0.9853 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
dbmdz/bert-mini-historic-multilingual-cased | dbmdz | "2023-09-06T22:19:11Z" | 865 | 3 | transformers | [
"transformers",
"pytorch",
"tf",
"tensorboard",
"safetensors",
"bert",
"fill-mask",
"multilingual",
"arxiv:1908.08962",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:05Z" | ---
language: multilingual
license: mit
widget:
- text: "and I cannot conceive the reafon why [MASK] hath"
- text: "Täkäläinen sanomalehdistö [MASK] erit - täin"
- text: "Det vore [MASK] häller nödvändigt att be"
- text: "Comme, à cette époque [MASK] était celle de la"
- text: "In [MASK] an atmosphärischen Nahrungsmitteln"
---
# Historic Language Models (HLMs)
## Languages
Our Historic Language Models Zoo contains support for the following languages - incl. their training data source:
| Language | Training data | Size
| -------- | ------------- | ----
| German | [Europeana](http://www.europeana-newspapers.eu/) | 13-28GB (filtered)
| French | [Europeana](http://www.europeana-newspapers.eu/) | 11-31GB (filtered)
| English | [British Library](https://data.bl.uk/digbks/db14.html) | 24GB (year filtered)
| Finnish | [Europeana](http://www.europeana-newspapers.eu/) | 1.2GB
| Swedish | [Europeana](http://www.europeana-newspapers.eu/) | 1.1GB
## Models
At the moment, the following models are available on the model hub:
| Model identifier | Model Hub link
| --------------------------------------------- | --------------------------------------------------------------------------
| `dbmdz/bert-base-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased)
| `dbmdz/bert-base-historic-english-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-english-cased)
| `dbmdz/bert-base-finnish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-finnish-europeana-cased)
| `dbmdz/bert-base-swedish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-swedish-europeana-cased)
We also released smaller models for the multilingual model:
| Model identifier | Model Hub link
| ----------------------------------------------- | ---------------------------------------------------------------------------
| `dbmdz/bert-tiny-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-tiny-historic-multilingual-cased)
| `dbmdz/bert-mini-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-mini-historic-multilingual-cased)
| `dbmdz/bert-small-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-small-historic-multilingual-cased)
| `dbmdz/bert-medium-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased)
**Notice**: We have released language models for Historic German and French trained on more noisier data earlier - see
[this repo](https://github.com/stefan-it/europeana-bert) for more information:
| Model identifier | Model Hub link
| --------------------------------------------- | --------------------------------------------------------------------------
| `dbmdz/bert-base-german-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-german-europeana-cased)
| `dbmdz/bert-base-french-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-french-europeana-cased)
# Corpora Stats
## German Europeana Corpus
We provide some statistics using different thresholds of ocr confidences, in order to shrink down the corpus size
and use less-noisier data:
| OCR confidence | Size
| -------------- | ----
| **0.60** | 28GB
| 0.65 | 18GB
| 0.70 | 13GB
For the final corpus we use a OCR confidence of 0.6 (28GB). The following plot shows a tokens per year distribution:

## French Europeana Corpus
Like German, we use different ocr confidence thresholds:
| OCR confidence | Size
| -------------- | ----
| 0.60 | 31GB
| 0.65 | 27GB
| **0.70** | 27GB
| 0.75 | 23GB
| 0.80 | 11GB
For the final corpus we use a OCR confidence of 0.7 (27GB). The following plot shows a tokens per year distribution:

## British Library Corpus
Metadata is taken from [here](https://data.bl.uk/digbks/DB21.html). Stats incl. year filtering:
| Years | Size
| ----------------- | ----
| ALL | 24GB
| >= 1800 && < 1900 | 24GB
We use the year filtered variant. The following plot shows a tokens per year distribution:

## Finnish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.2GB
The following plot shows a tokens per year distribution:

## Swedish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.1GB
The following plot shows a tokens per year distribution:

## All Corpora
The following plot shows a tokens per year distribution of the complete training corpus:

# Multilingual Vocab generation
For the first attempt, we use the first 10GB of each pretraining corpus. We upsample both Finnish and Swedish to ~10GB.
The following tables shows the exact size that is used for generating a 32k and 64k subword vocabs:
| Language | Size
| -------- | ----
| German | 10GB
| French | 10GB
| English | 10GB
| Finnish | 9.5GB
| Swedish | 9.7GB
We then calculate the subword fertility rate and portion of `[UNK]`s over the following NER corpora:
| Language | NER corpora
| -------- | ------------------
| German | CLEF-HIPE, NewsEye
| French | CLEF-HIPE, NewsEye
| English | CLEF-HIPE
| Finnish | NewsEye
| Swedish | NewsEye
Breakdown of subword fertility rate and unknown portion per language for the 32k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.43 | 0.0004
| French | 1.25 | 0.0001
| English | 1.25 | 0.0
| Finnish | 1.69 | 0.0007
| Swedish | 1.43 | 0.0
Breakdown of subword fertility rate and unknown portion per language for the 64k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.31 | 0.0004
| French | 1.16 | 0.0001
| English | 1.17 | 0.0
| Finnish | 1.54 | 0.0007
| Swedish | 1.32 | 0.0
# Final pretraining corpora
We upsample Swedish and Finnish to ~27GB. The final stats for all pretraining corpora can be seen here:
| Language | Size
| -------- | ----
| German | 28GB
| French | 27GB
| English | 24GB
| Finnish | 27GB
| Swedish | 27GB
Total size is 130GB.
# Smaller multilingual models
Inspired by the ["Well-Read Students Learn Better: On the Importance of Pre-training Compact Models"](https://arxiv.org/abs/1908.08962)
paper, we train smaller models (different layers and hidden sizes), and report number of parameters and pre-training costs:
| Model (Layer / Hidden size) | Parameters | Pre-Training time
| --------------------------- | ----------: | ----------------------:
| hmBERT Tiny ( 2/128) | 4.58M | 4.3 sec / 1,000 steps
| hmBERT Mini ( 4/256) | 11.55M | 10.5 sec / 1,000 steps
| hmBERT Small ( 4/512) | 29.52M | 20.7 sec / 1,000 steps
| hmBERT Medium ( 8/512) | 42.13M | 35.0 sec / 1,000 steps
| hmBERT Base (12/768) | 110.62M | 80.0 sec / 1,000 steps
We then perform downstream evaluations on the multilingual [NewsEye](https://zenodo.org/record/4573313#.Ya3oVr-ZNzU) dataset:

# Pretraining
## Multilingual model - hmBERT Base
We train a multilingual BERT model using the 32k vocab with the official BERT implementation
on a v3-32 TPU using the following parameters:
```bash
python3 run_pretraining.py --input_file gs://histolectra/historic-multilingual-tfrecords/*.tfrecord \
--output_dir gs://histolectra/bert-base-historic-multilingual-cased \
--bert_config_file ./config.json \
--max_seq_length=512 \
--max_predictions_per_seq=75 \
--do_train=True \
--train_batch_size=128 \
--num_train_steps=3000000 \
--learning_rate=1e-4 \
--save_checkpoints_steps=100000 \
--keep_checkpoint_max=20 \
--use_tpu=True \
--tpu_name=electra-2 \
--num_tpu_cores=32
```
The following plot shows the pretraining loss curve:

## Smaller multilingual models
We use the same parameters as used for training the base model.
### hmBERT Tiny
The following plot shows the pretraining loss curve for the tiny model:

### hmBERT Mini
The following plot shows the pretraining loss curve for the mini model:

### hmBERT Small
The following plot shows the pretraining loss curve for the small model:

### hmBERT Medium
The following plot shows the pretraining loss curve for the medium model:

## English model
The English BERT model - with texts from British Library corpus - was trained with the Hugging Face
JAX/FLAX implementation for 10 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-historic-english-cased/ \
--tokenizer_name /mnt/datasets/bert-base-historic-english-cased/ \
--train_file /mnt/datasets/bl-corpus/bl_1800-1900_extracted.txt \
--validation_file /mnt/datasets/bl-corpus/english_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 10 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-historic-english-cased-512-noadafactor-10e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Finnish model
The BERT model - with texts from Finnish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Finnish_0.6.txt \
--validation_file /mnt/datasets/hlms/finnish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-finnish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Swedish model
The BERT model - with texts from Swedish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 660K steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Swedish_0.6.txt \
--validation_file /mnt/datasets/hlms/swedish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-swedish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

# Acknowledgments
Research supported with Cloud TPUs from Google's TPU Research Cloud (TRC) program, previously known as
TensorFlow Research Cloud (TFRC). Many thanks for providing access to the TRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
dyedream/ppo-Huggy | dyedream | "2023-06-02T09:09:30Z" | 43 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | reinforcement-learning | "2023-06-02T09:09:22Z" | ---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Find your model_id: dyedream/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
baby-dev/d1abcc53-49fd-4dae-91f6-a295cbbf7e37 | baby-dev | "2025-02-05T18:45:52Z" | 8 | 0 | peft | [
"peft",
"safetensors",
"phi3",
"axolotl",
"generated_from_trainer",
"custom_code",
"base_model:microsoft/Phi-3-mini-4k-instruct",
"base_model:adapter:microsoft/Phi-3-mini-4k-instruct",
"license:mit",
"region:us"
] | null | "2025-02-05T18:41:37Z" | ---
library_name: peft
license: mit
base_model: microsoft/Phi-3-mini-4k-instruct
tags:
- axolotl
- generated_from_trainer
model-index:
- name: d1abcc53-49fd-4dae-91f6-a295cbbf7e37
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
# d1abcc53-49fd-4dae-91f6-a295cbbf7e37
This model is a fine-tuned version of [microsoft/Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1801
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
laquythang/5c910023-1b30-414d-8fb5-bacfcd19626e | laquythang | "2025-01-19T17:25:40Z" | 7 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:DeepMount00/Llama-3-8b-Ita",
"base_model:adapter:DeepMount00/Llama-3-8b-Ita",
"license:llama3",
"8-bit",
"bitsandbytes",
"region:us"
] | null | "2025-01-19T17:07:05Z" | ---
library_name: peft
license: llama3
base_model: DeepMount00/Llama-3-8b-Ita
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 5c910023-1b30-414d-8fb5-bacfcd19626e
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: DeepMount00/Llama-3-8b-Ita
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- a0eb45ea7cd511f3_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/a0eb45ea7cd511f3_train_data.json
type:
field_instruction: problem
field_output: generated_solution
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_clipping: 1.0
group_by_length: false
hub_model_id: laquythang/5c910023-1b30-414d-8fb5-bacfcd19626e
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-05
load_in_4bit: true
load_in_8bit: true
local_rank: null
logging_steps: 1
lora_alpha: 16
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 8
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 2
mlflow_experiment_name: /tmp/a0eb45ea7cd511f3_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
special_tokens:
pad_token: <|eot_id|>
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 1568b38d-5ecd-4474-8507-d4201cbad038
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: 1568b38d-5ecd-4474-8507-d4201cbad038
warmup_steps: 5
weight_decay: 0.01
xformers_attention: true
```
</details><br>
# 5c910023-1b30-414d-8fb5-bacfcd19626e
This model is a fine-tuned version of [DeepMount00/Llama-3-8b-Ita](https://huggingface.co/DeepMount00/Llama-3-8b-Ita) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3500
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 5
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.4025 | 0.2325 | 200 | 0.3500 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
mradermacher/sft-math-llama3-8b-base-GGUF | mradermacher | "2025-03-07T18:34:50Z" | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:ankner/sft-math-llama3-8b-base",
"base_model:quantized:ankner/sft-math-llama3-8b-base",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2025-03-07T18:15:20Z" | ---
base_model: ankner/sft-math-llama3-8b-base
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/ankner/sft-math-llama3-8b-base
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/sft-math-llama3-8b-base-GGUF/resolve/main/sft-math-llama3-8b-base.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/sft-math-llama3-8b-base-GGUF/resolve/main/sft-math-llama3-8b-base.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/sft-math-llama3-8b-base-GGUF/resolve/main/sft-math-llama3-8b-base.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/sft-math-llama3-8b-base-GGUF/resolve/main/sft-math-llama3-8b-base.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/sft-math-llama3-8b-base-GGUF/resolve/main/sft-math-llama3-8b-base.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/sft-math-llama3-8b-base-GGUF/resolve/main/sft-math-llama3-8b-base.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/sft-math-llama3-8b-base-GGUF/resolve/main/sft-math-llama3-8b-base.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/sft-math-llama3-8b-base-GGUF/resolve/main/sft-math-llama3-8b-base.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/sft-math-llama3-8b-base-GGUF/resolve/main/sft-math-llama3-8b-base.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/sft-math-llama3-8b-base-GGUF/resolve/main/sft-math-llama3-8b-base.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/sft-math-llama3-8b-base-GGUF/resolve/main/sft-math-llama3-8b-base.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/sft-math-llama3-8b-base-GGUF/resolve/main/sft-math-llama3-8b-base.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
sosoai/hansoldeco-beomi-llama3-open-ko-8b-64k-test-Q6_K-GGUF | sosoai | "2024-04-26T22:16:48Z" | 2 | 0 | null | [
"gguf",
"generated_from_trainer",
"llama-cpp",
"gguf-my-repo",
"base_model:beomi/Llama-3-Open-Ko-8B",
"base_model:quantized:beomi/Llama-3-Open-Ko-8B",
"license:other",
"endpoints_compatible",
"region:us"
] | null | "2024-04-26T22:16:28Z" | ---
license: other
tags:
- generated_from_trainer
- llama-cpp
- gguf-my-repo
base_model: beomi/Llama-3-Open-Ko-8B
model-index:
- name: beomi-llama3-8b-64k
results: []
---
# sosoai/hansoldeco-beomi-llama3-open-ko-8b-64k-test-Q6_K-GGUF
This model was converted to GGUF format from [`sosoai/hansoldeco-beomi-llama3-open-ko-8b-64k-test`](https://huggingface.co/sosoai/hansoldeco-beomi-llama3-open-ko-8b-64k-test) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/sosoai/hansoldeco-beomi-llama3-open-ko-8b-64k-test) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo sosoai/hansoldeco-beomi-llama3-open-ko-8b-64k-test-Q6_K-GGUF --model hansoldeco-beomi-llama3-open-ko-8b-64k-test.Q6_K.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo sosoai/hansoldeco-beomi-llama3-open-ko-8b-64k-test-Q6_K-GGUF --model hansoldeco-beomi-llama3-open-ko-8b-64k-test.Q6_K.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m hansoldeco-beomi-llama3-open-ko-8b-64k-test.Q6_K.gguf -n 128
```
|
Carmine-Miceli/q-FrozenLake-v1-4x4-noSlippery | Carmine-Miceli | "2023-12-04T22:31:14Z" | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | "2023-12-04T22:31:11Z" | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Carmine-Miceli/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
GenTrendGPT/OS-Test-Mark-GEN | GenTrendGPT | "2024-05-14T03:50:06Z" | 141 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"base_model:Qwen/Qwen1.5-4B-Chat",
"base_model:merge:Qwen/Qwen1.5-4B-Chat",
"base_model:TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T",
"base_model:merge:TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-05-14T03:48:34Z" | ---
base_model:
- TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
- Qwen/Qwen1.5-4B-Chat
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* [TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T)
* [Qwen/Qwen1.5-4B-Chat](https://huggingface.co/Qwen/Qwen1.5-4B-Chat)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
merge_method: passthrough
dtype: bfloat16
slices:
- sources:
- model: Qwen/Qwen1.5-4B-Chat
layer_range: [0, 30]
- sources:
- model: TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T
layer_range: [0, 22]
merge_method: passthrough
```
|
yzhuang/Meta-Llama-3-8B-Instruct_fictional_gsm8k_Japanese_v1 | yzhuang | "2024-05-21T14:43:16Z" | 10 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"dataset:generator",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:finetune:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-05-20T02:53:45Z" | ---
license: llama3
base_model: meta-llama/Meta-Llama-3-8B-Instruct
tags:
- trl
- sft
- generated_from_trainer
datasets:
- generator
model-index:
- name: Meta-Llama-3-8B-Instruct_fictional_gsm8k_Japanese_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/yufanz/autotree/runs/7283704781.17487-9818c277-4a86-4343-b288-7864588621de)
# Meta-Llama-3-8B-Instruct_fictional_gsm8k_Japanese_v1
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
### Framework versions
- Transformers 4.41.0
- Pytorch 2.1.0a0+32f93b1
- Datasets 2.19.1
- Tokenizers 0.19.1
|
RichardErkhov/UCLA-AGI_-_zephyr-7b-sft-full-SPIN-iter3-8bits | RichardErkhov | "2024-05-12T03:41:36Z" | 77 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:2401.01335",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
] | text-generation | "2024-05-12T03:32:57Z" | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
zephyr-7b-sft-full-SPIN-iter3 - bnb 8bits
- Model creator: https://huggingface.co/UCLA-AGI/
- Original model: https://huggingface.co/UCLA-AGI/zephyr-7b-sft-full-SPIN-iter3/
Original model description:
---
license: mit
datasets:
- UCLA-AGI/SPIN_iter3
language:
- en
pipeline_tag: text-generation
---
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models (https://arxiv.org/abs/2401.01335)
# zephyr-7b-sft-full-spin-iter3
This model is a self-play fine-tuned model at iteration 3 from [alignment-handbook/zephyr-7b-sft-full](https://huggingface.co/alignment-handbook/zephyr-7b-sft-full) using synthetic data based on on the [HuggingFaceH4/ultrachat_200k](https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k) dataset.
## Model Details
### Model Description
- Model type: A 7B parameter GPT-like model fine-tuned on synthetic datasets.
- Language(s) (NLP): Primarily English
- License: MIT
- Finetuned from model: alignment-handbook/zephyr-7b-sft-full (based on mistralai/Mistral-7B-v0.1)
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-07
- train_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 64
- optimizer: RMSProp
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2.0
## [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_UCLA-AGI__test_final)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 63.70 |
| ARC (25-shot) | 66.13 |
| HellaSwag (10-shot) | 85.85 |
| MMLU (5-shot) | 61.51 |
| TruthfulQA (0-shot) | 57.89 |
| Winogrande (5-shot) | 76.64 |
| GSM8K (5-shot) | 34.19 |
## Citation
```
@misc{chen2024selfplay,
title={Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models},
author={Zixiang Chen and Yihe Deng and Huizhuo Yuan and Kaixuan Ji and Quanquan Gu},
year={2024},
eprint={2401.01335},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
meghraoa/gemma-7b-mt-arb_Arab-fra_Latn | meghraoa | "2025-03-28T02:46:24Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | "2025-03-28T02:46:12Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Knobi3/StarlingBeagle-dare | Knobi3 | "2024-05-27T13:05:32Z" | 5 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"AI-Sweden-Models/tyr",
"mlabonne/NeuralBeagle14-7B",
"neph1/bellman-7b-mistral-instruct-v0.2",
"base_model:AI-Sweden-Models/tyr",
"base_model:merge:AI-Sweden-Models/tyr",
"base_model:mlabonne/NeuralBeagle14-7B",
"base_model:merge:mlabonne/NeuralBeagle14-7B",
"base_model:neph1/bellman-7b-mistral-instruct-v0.2",
"base_model:merge:neph1/bellman-7b-mistral-instruct-v0.2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-03-28T12:23:55Z" | ---
tags:
- merge
- mergekit
- lazymergekit
- AI-Sweden-Models/tyr
- mlabonne/NeuralBeagle14-7B
- neph1/bellman-7b-mistral-instruct-v0.2
base_model:
- AI-Sweden-Models/tyr
- mlabonne/NeuralBeagle14-7B
- neph1/bellman-7b-mistral-instruct-v0.2
---
# StarlingBeagle-dare-ties
NeuralPipe-7B-slerp is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [AI-Sweden-Models/tyr](https://huggingface.co/AI-Sweden-Models/tyr)
* [mlabonne/NeuralBeagle14-7B](https://huggingface.co/mlabonne/NeuralBeagle14-7B)
* [neph1/bellman-7b-mistral-instruct-v0.2](https://huggingface.co/neph1/bellman-7b-mistral-instruct-v0.2)
## 🧩 Configuration
```yaml
models:
- model: Nexusflow/Starling-LM-7B-beta
# No parameters necessary for base model
- model: AI-Sweden-Models/tyr
parameters:
density: 0.53
weight: 0.4
- model: mlabonne/NeuralBeagle14-7B
parameters:
density: 0.53
weight: 0.3
- model: neph1/bellman-7b-mistral-instruct-v0.2
parameters:
density: 0.53
weight: 0.3
merge_method: dare_ties
base_model: Nexusflow/Starling-LM-7B-beta
parameters:
int8_mask: true
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "knobi3/NeuralPipe-7B-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
vgarg/my-fw9-identification-model-e5_large_v2 | vgarg | "2023-09-26T18:59:24Z" | 5 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"xlm-roberta",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] | text-classification | "2023-09-26T18:55:28Z" | ---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# vgarg/my-fw9-identification-model-e5_large_v2
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("vgarg/my-fw9-identification-model-e5_large_v2")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
John6666/zuki-cute-ill-v60-sdxl | John6666 | "2025-03-25T02:06:14Z" | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"comic",
"girls",
"cute",
"illustrious",
"en",
"base_model:OnomaAIResearch/Illustrious-xl-early-release-v0",
"base_model:finetune:OnomaAIResearch/Illustrious-xl-early-release-v0",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | "2025-03-25T01:55:33Z" | ---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- comic
- girls
- cute
- illustrious
base_model: OnomaAIResearch/Illustrious-xl-early-release-v0
---
Original model is [here](https://civitai.com/models/1000708/zuki-cute-ill?modelVersionId=1560736).
> artist tags:<br>
ningen mame (にんげんまめ)<br>
ciloranko (TrNyteal)<br>
tianliang duohe fangdongye (天凉多喝防冻液)<br>
ask \(askzy\)<br>
wlop<br>
as109<br>
kedama_milk (玉之けだま)<br>
yukiu_con (雪雨こん)<br>
Henreader (へんりいだ)<br>
haguhagu_(rinjuu_circus) (臨終サーカス/はぐはぐ)<br>
shouji_ayumu (小路あゆむ)<br>
mignon<br>
…………(Supports a vast array of artist tags.)
This model created by [ZU_KI](https://civitai.com/user/ZU_KI).
|
EGE6/my_awesome_model | EGE6 | "2025-03-16T10:06:34Z" | 69 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2024-12-19T19:19:14Z" | ---
library_name: transformers
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: my_awesome_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7043
- Accuracy: 0.6775
- F1: 0.6766
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.6694 | 1.0 | 100 | 0.6475 | 0.6375 | 0.6374 |
| 0.5603 | 2.0 | 200 | 0.6516 | 0.6775 | 0.6762 |
| 0.3899 | 3.0 | 300 | 0.7043 | 0.6775 | 0.6766 |
### Framework versions
- Transformers 4.48.3
- Pytorch 2.6.0+cu124
- Datasets 3.4.0
- Tokenizers 0.21.0
|
waboucay/camembert-base-finetuned-nli-repnum_wl-rua_wl | waboucay | "2022-04-21T15:10:51Z" | 5 | 0 | transformers | [
"transformers",
"pytorch",
"camembert",
"text-classification",
"nli",
"fr",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-04-19T09:39:53Z" | ---
language:
- fr
tags:
- nli
metrics:
- f1
---
## Eval results
We obtain the following results on ```validation``` and ```test``` sets:
| Set | F1<sub>micro</sub> | F1<sub>macro</sub> |
|------------|--------------------|--------------------|
| validation | 73.5 | 73.5 |
| test | 75.5 | 75.5 | |
mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF | mradermacher | "2024-11-10T09:24:09Z" | 54 | 1 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"SanjiWatsuki/Kunoichi-7B",
"ND911/Fraken-Maid-TW-Slerp",
"en",
"base_model:ND911/Fraken-Maid-TW-K-Slerp",
"base_model:quantized:ND911/Fraken-Maid-TW-K-Slerp",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | "2024-11-10T06:29:39Z" | ---
base_model: ND911/Fraken-Maid-TW-K-Slerp
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
- SanjiWatsuki/Kunoichi-7B
- ND911/Fraken-Maid-TW-Slerp
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/ND911/Fraken-Maid-TW-K-Slerp
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-IQ1_S.gguf) | i1-IQ1_S | 1.7 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-IQ1_M.gguf) | i1-IQ1_M | 1.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.1 | |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-IQ2_S.gguf) | i1-IQ2_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-IQ2_M.gguf) | i1-IQ2_M | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-Q2_K.gguf) | i1-Q2_K | 2.8 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 2.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.3 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-IQ3_S.gguf) | i1-IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-IQ3_M.gguf) | i1-IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-Q3_K_L.gguf) | i1-Q3_K_L | 3.9 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-Q4_0_4_4.gguf) | i1-Q4_0_4_4 | 4.2 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-Q4_0_4_8.gguf) | i1-Q4_0_4_8 | 4.2 | fast on arm+i8mm, low quality |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-Q4_0_8_8.gguf) | i1-Q4_0_8_8 | 4.2 | fast on arm+sve, low quality |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-Q4_0.gguf) | i1-Q4_0 | 4.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Fraken-Maid-TW-K-Slerp-i1-GGUF/resolve/main/Fraken-Maid-TW-K-Slerp.i1-Q6_K.gguf) | i1-Q6_K | 6.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
u-10bei/llm-jp-3-13b-instruct2-chat-GSM8K-math2.0-cot2-grpo2-merged | u-10bei | "2025-04-04T15:22:10Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"conversational",
"en",
"base_model:u-10bei/llm-jp-3-13b-instruct2-chat-GSM8K-math2.0-cot2-merged",
"base_model:finetune:u-10bei/llm-jp-3-13b-instruct2-chat-GSM8K-math2.0-cot2-merged",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | "2025-04-04T15:20:34Z" | <!DOCTYPE html>
<html class="" lang="en">
<head>
<meta charset="utf-8" />
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, user-scalable=no"
/>
<meta
name="description"
content="We're on a journey to advance and democratize artificial intelligence through open source and open science."
/>
<meta property="fb:app_id" content="1321688464574422" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:site" content="@huggingface" />
<meta
property="og:title"
content="Hugging Face - The AI community building the future."
/>
<meta property="og:type" content="website" />
<title>Hugging Face - The AI community building the future.</title>
<style>
body {
margin: 0;
}
main {
background-color: white;
min-height: 100vh;
padding: 7rem 1rem 8rem 1rem;
text-align: center;
font-family: Source Sans Pro, ui-sans-serif, system-ui, -apple-system,
BlinkMacSystemFont, Segoe UI, Roboto, Helvetica Neue, Arial, Noto Sans,
sans-serif, Apple Color Emoji, Segoe UI Emoji, Segoe UI Symbol,
Noto Color Emoji;
}
img {
width: 6rem;
height: 6rem;
margin: 0 auto 1rem;
}
h1 {
font-size: 3.75rem;
line-height: 1;
color: rgba(31, 41, 55, 1);
font-weight: 700;
box-sizing: border-box;
margin: 0 auto;
}
p, a {
color: rgba(107, 114, 128, 1);
font-size: 1.125rem;
line-height: 1.75rem;
max-width: 28rem;
box-sizing: border-box;
margin: 0 auto;
}
.dark main {
background-color: rgb(11, 15, 25);
}
.dark h1 {
color: rgb(209, 213, 219);
}
.dark p, .dark a {
color: rgb(156, 163, 175);
}
</style>
<script>
// On page load or when changing themes, best to add inline in `head` to avoid FOUC
const key = "_tb_global_settings";
let theme = window.matchMedia("(prefers-color-scheme: dark)").matches
? "dark"
: "light";
try {
const storageTheme = JSON.parse(window.localStorage.getItem(key)).theme;
if (storageTheme) {
theme = storageTheme === "dark" ? "dark" : "light";
}
} catch (e) {}
if (theme === "dark") {
document.documentElement.classList.add("dark");
} else {
document.documentElement.classList.remove("dark");
}
</script>
</head>
<body>
<main>
<img
src="https://cdn-media.huggingface.co/assets/huggingface_logo.svg"
alt=""
/>
<div>
<h1>429</h1>
<p>We had to rate limit you. If you think it's an error, send us <a href="mailto:[email protected]">an email</a></p>
</div>
</main>
</body>
</html> |
am2azannn1/Deneme | am2azannn1 | "2025-03-07T03:48:23Z" | 0 | 0 | adapter-transformers | [
"adapter-transformers",
"legal",
"text-classification",
"aa",
"dataset:open-r1/OpenR1-Math-220k",
"base_model:deepseek-ai/DeepSeek-R1",
"base_model:adapter:deepseek-ai/DeepSeek-R1",
"license:afl-3.0",
"region:us"
] | text-classification | "2025-03-07T03:47:05Z" | ---
license: afl-3.0
datasets:
- open-r1/OpenR1-Math-220k
language:
- aa
metrics:
- bertscore
base_model:
- deepseek-ai/DeepSeek-R1
new_version: deepseek-ai/DeepSeek-R1
pipeline_tag: text-classification
library_name: adapter-transformers
tags:
- legal
--- |
c14kevincardenas/beit-base-finetuned-ade-640-640_alpha0.7_temp3.0_t2 | c14kevincardenas | "2025-02-15T08:41:40Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"knowledge_distillation",
"vision",
"generated_from_trainer",
"base_model:c14kevincardenas/ClimBEiT-t2",
"base_model:finetune:c14kevincardenas/ClimBEiT-t2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2025-02-15T03:32:53Z" | ---
library_name: transformers
license: apache-2.0
base_model: c14kevincardenas/ClimBEiT-t2
tags:
- knowledge_distillation
- vision
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: beit-base-finetuned-ade-640-640_alpha0.7_temp3.0_t2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-finetuned-ade-640-640_alpha0.7_temp3.0_t2
This model is a fine-tuned version of [c14kevincardenas/ClimBEiT-t2](https://huggingface.co/c14kevincardenas/ClimBEiT-t2) on the c14kevincardenas/beta_caller_284_person_crop_seq_withlimb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5170
- Accuracy: 0.8310
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.1461 | 1.0 | 180 | 1.3108 | 0.3923 |
| 0.6458 | 2.0 | 360 | 0.8457 | 0.6690 |
| 0.49 | 3.0 | 540 | 0.7169 | 0.7441 |
| 0.3569 | 4.0 | 720 | 0.6869 | 0.7569 |
| 0.2876 | 5.0 | 900 | 0.6191 | 0.7757 |
| 0.2172 | 6.0 | 1080 | 0.6253 | 0.7905 |
| 0.2017 | 7.0 | 1260 | 0.5801 | 0.8034 |
| 0.187 | 8.0 | 1440 | 0.6530 | 0.7836 |
| 0.1894 | 9.0 | 1620 | 0.6205 | 0.7984 |
| 0.1884 | 10.0 | 1800 | 0.5659 | 0.8103 |
| 0.1529 | 11.0 | 1980 | 0.5854 | 0.8123 |
| 0.1473 | 12.0 | 2160 | 0.5478 | 0.8192 |
| 0.1369 | 13.0 | 2340 | 0.5504 | 0.8211 |
| 0.1334 | 14.0 | 2520 | 0.5204 | 0.8300 |
| 0.1294 | 15.0 | 2700 | 0.5254 | 0.8330 |
| 0.1192 | 16.0 | 2880 | 0.5247 | 0.8251 |
| 0.1183 | 17.0 | 3060 | 0.5274 | 0.8231 |
| 0.1199 | 18.0 | 3240 | 0.5264 | 0.8271 |
| 0.1132 | 19.0 | 3420 | 0.5209 | 0.8320 |
| 0.109 | 20.0 | 3600 | 0.5170 | 0.8310 |
### Framework versions
- Transformers 4.45.2
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1
|
davidschulte/ESM_CATIE-AQ__mtop_domain_intent_fr_prompt_intent_classification_default | davidschulte | "2025-03-28T12:18:26Z" | 26 | 0 | null | [
"safetensors",
"embedding_space_map",
"BaseLM:bert-base-multilingual-uncased",
"dataset:CATIE-AQ/mtop_domain_intent_fr_prompt_intent_classification",
"base_model:google-bert/bert-base-multilingual-uncased",
"base_model:finetune:google-bert/bert-base-multilingual-uncased",
"license:apache-2.0",
"region:us"
] | null | "2024-11-30T14:05:17Z" | ---
base_model: bert-base-multilingual-uncased
datasets:
- CATIE-AQ/mtop_domain_intent_fr_prompt_intent_classification
license: apache-2.0
tags:
- embedding_space_map
- BaseLM:bert-base-multilingual-uncased
---
# ESM CATIE-AQ/mtop_domain_intent_fr_prompt_intent_classification
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
ESM
- **Developed by:** David Schulte
- **Model type:** ESM
- **Base Model:** bert-base-multilingual-uncased
- **Intermediate Task:** CATIE-AQ/mtop_domain_intent_fr_prompt_intent_classification
- **ESM architecture:** linear
- **ESM embedding dimension:** 768
- **Language(s) (NLP):** [More Information Needed]
- **License:** Apache-2.0 license
- **ESM version:** 0.1.0
## Training Details
### Intermediate Task
- **Task ID:** CATIE-AQ/mtop_domain_intent_fr_prompt_intent_classification
- **Subset [optional]:** default
- **Text Column:** inputs
- **Label Column:** targets
- **Dataset Split:** train
- **Sample size [optional]:** 10000
- **Sample seed [optional]:** 42
### Training Procedure [optional]
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Language Model Training Hyperparameters [optional]
- **Epochs:** 3
- **Batch size:** 32
- **Learning rate:** 2e-05
- **Weight Decay:** 0.01
- **Optimizer**: AdamW
### ESM Training Hyperparameters [optional]
- **Epochs:** 10
- **Batch size:** 32
- **Learning rate:** 0.001
- **Weight Decay:** 0.01
- **Optimizer**: AdamW
### Additional trainiung details [optional]
## Model evaluation
### Evaluation of fine-tuned language model [optional]
### Evaluation of ESM [optional]
MSE:
### Additional evaluation details [optional]
## What are Embedding Space Maps used for?
Embedding Space Maps are a part of ESM-LogME, a efficient method for finding intermediate datasets for transfer learning. There are two reasons to use ESM-LogME:
### You don't have enough training data for your problem
If you don't have a enough training data for your problem, just use ESM-LogME to find more.
You can supplement model training by including publicly available datasets in the training process.
1. Fine-tune a language model on suitable intermediate dataset.
2. Fine-tune the resulting model on your target dataset.
This workflow is called intermediate task transfer learning and it can significantly improve the target performance.
But what is a suitable dataset for your problem? ESM-LogME enable you to quickly rank thousands of datasets on the Hugging Face Hub by how well they are exptected to transfer to your target task.
### You want to find similar datasets to your target dataset
Using ESM-LogME can be used like search engine on the Hugging Face Hub. You can find similar tasks to your target task without having to rely on heuristics. ESM-LogME estimates how language models fine-tuned on each intermediate task would benefinit your target task. This quantitative approach combines the effects of domain similarity and task similarity.
## How can I use ESM-LogME / ESMs?
[](https://pypi.org/project/hf-dataset-selector)
We release **hf-dataset-selector**, a Python package for intermediate task selection using Embedding Space Maps.
**hf-dataset-selector** fetches ESMs for a given language model and uses it to find the best dataset for applying intermediate training to the target task. ESMs are found by their tags on the Huggingface Hub.
```python
from hfselect import Dataset, compute_task_ranking
# Load target dataset from the Hugging Face Hub
dataset = Dataset.from_hugging_face(
name="stanfordnlp/imdb",
split="train",
text_col="text",
label_col="label",
is_regression=False,
num_examples=1000,
seed=42
)
# Fetch ESMs and rank tasks
task_ranking = compute_task_ranking(
dataset=dataset,
model_name="bert-base-multilingual-uncased"
)
# Display top 5 recommendations
print(task_ranking[:5])
```
```python
1. davanstrien/test_imdb_embedd2 Score: -0.618529
2. davanstrien/test_imdb_embedd Score: -0.618644
3. davanstrien/test1 Score: -0.619334
4. stanfordnlp/imdb Score: -0.619454
5. stanfordnlp/sst Score: -0.62995
```
| Rank | Task ID | Task Subset | Text Column | Label Column | Task Split | Num Examples | ESM Architecture | Score |
|-------:|:------------------------------|:----------------|:--------------|:---------------|:-------------|---------------:|:-------------------|----------:|
| 1 | davanstrien/test_imdb_embedd2 | default | text | label | train | 10000 | linear | -0.618529 |
| 2 | davanstrien/test_imdb_embedd | default | text | label | train | 10000 | linear | -0.618644 |
| 3 | davanstrien/test1 | default | text | label | train | 10000 | linear | -0.619334 |
| 4 | stanfordnlp/imdb | plain_text | text | label | train | 10000 | linear | -0.619454 |
| 5 | stanfordnlp/sst | dictionary | phrase | label | dictionary | 10000 | linear | -0.62995 |
| 6 | stanfordnlp/sst | default | sentence | label | train | 8544 | linear | -0.63312 |
| 7 | kuroneko5943/snap21 | CDs_and_Vinyl_5 | sentence | label | train | 6974 | linear | -0.634365 |
| 8 | kuroneko5943/snap21 | Video_Games_5 | sentence | label | train | 6997 | linear | -0.638787 |
| 9 | kuroneko5943/snap21 | Movies_and_TV_5 | sentence | label | train | 6989 | linear | -0.639068 |
| 10 | fancyzhx/amazon_polarity | amazon_polarity | content | label | train | 10000 | linear | -0.639718 |
For more information on how to use ESMs please have a look at the [official Github repository](https://github.com/davidschulte/hf-dataset-selector). We provide documentation further documentation and tutorials for finding intermediate datasets and training your own ESMs.
## How do Embedding Space Maps work?
<!-- This section describes the evaluation protocols and provides the results. -->
Embedding Space Maps (ESMs) are neural networks that approximate the effect of fine-tuning a language model on a task. They can be used to quickly transform embeddings from a base model to approximate how a fine-tuned model would embed the the input text.
ESMs can be used for intermediate task selection with the ESM-LogME workflow.
## How can I use Embedding Space Maps for Intermediate Task Selection?
## Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
If you are using this Embedding Space Maps, please cite our [paper](https://aclanthology.org/2024.emnlp-main.529/).
**BibTeX:**
```
@inproceedings{schulte-etal-2024-less,
title = "Less is More: Parameter-Efficient Selection of Intermediate Tasks for Transfer Learning",
author = "Schulte, David and
Hamborg, Felix and
Akbik, Alan",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.emnlp-main.529/",
doi = "10.18653/v1/2024.emnlp-main.529",
pages = "9431--9442",
abstract = "Intermediate task transfer learning can greatly improve model performance. If, for example, one has little training data for emotion detection, first fine-tuning a language model on a sentiment classification dataset may improve performance strongly. But which task to choose for transfer learning? Prior methods producing useful task rankings are infeasible for large source pools, as they require forward passes through all source language models. We overcome this by introducing Embedding Space Maps (ESMs), light-weight neural networks that approximate the effect of fine-tuning a language model. We conduct the largest study on NLP task transferability and task selection with 12k source-target pairs. We find that applying ESMs on a prior method reduces execution time and disk space usage by factors of 10 and 278, respectively, while retaining high selection performance (avg. regret@5 score of 2.95)."
}
```
**APA:**
```
Schulte, D., Hamborg, F., & Akbik, A. (2024, November). Less is More: Parameter-Efficient Selection of Intermediate Tasks for Transfer Learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp. 9431-9442).
```
## Additional Information
|
utahnlp/imdb_gpt2_seed-1 | utahnlp | "2024-04-04T22:34:31Z" | 104 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | "2024-04-04T22:33:50Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
patpizio/xlmr-ne-en-all_shuffled-764-test1000 | patpizio | "2023-12-20T16:51:48Z" | 4 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2023-12-20T16:47:15Z" | ---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
model-index:
- name: xlmr-ne-en-all_shuffled-764-test1000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlmr-ne-en-all_shuffled-764-test1000
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6598
- R Squared: 0.2676
- Mae: 0.6318
- Pearson R: 0.6380
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 764
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | R Squared | Mae | Pearson R |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:---------:|
| No log | 1.0 | 438 | 0.6430 | 0.2862 | 0.6416 | 0.5407 |
| 0.7301 | 2.0 | 876 | 0.6202 | 0.3116 | 0.6302 | 0.6325 |
| 0.5037 | 3.0 | 1314 | 0.6598 | 0.2676 | 0.6318 | 0.6380 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1+cu117
- Datasets 2.14.6
- Tokenizers 0.14.1
|
stephenhib/all-mpnet-base-v2-patabs-1epoc-batch32-100 | stephenhib | "2024-10-19T21:26:04Z" | 7 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"mpnet",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:768201",
"loss:MultipleNegativesRankingLoss",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:sentence-transformers/all-mpnet-base-v2",
"base_model:finetune:sentence-transformers/all-mpnet-base-v2",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2024-10-19T21:25:48Z" | ---
base_model: sentence-transformers/all-mpnet-base-v2
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:768201
- loss:MultipleNegativesRankingLoss
widget:
- source_sentence: The present disclosure provides systems and methods to optimize
data backup in a distributed enterprise system by firstly generating a set of
unique files from all the files available in the enterprise. A backup set comprising
files to be backed up are then generated from the set of unique files and backup
is scheduled in the order in which the files to be backed up are identified. Unique
files are generated based on file sharing patterns and communications among users
that enable generating a social network graph from which one or more communities
can be detected and deduplication can be performed on the files hosted by client
systems in these communities thereby conserving resources.
sentences:
- BURNER
- SYSTEMS AND METHODS FOR OPTIMIZED DATA BACKUP IN A DISTRIBUTED ENTERPRISE SYSTEM
- Power conversion apparatus
- source_sentence: The present invention relates to a use of polypeptide compounds
having dual agonist effect on glucagon-like peptide-1 receptor (GLP-1R) and glucagon
receptor (GCGR). The polypeptide compounds are characterized by high enzymolysis
stability, high potency and no adverse reaction, and capable of substantially
improving hepatic fibrosis caused by hepatitis B virus (HBV) and hepatitis C virus
(HCV) and severity of fibrotic conditions accompanied with liver diseases. The
dual target agonist polypeptide derivatives are capable of preventing or treating
hepatic fibrosis diseases associated with viral hepatitis.
sentences:
- GLP-1R/GCGR DUAL-TARGET AGONIST PEPTIDE DERIVATIVES FOR TREATMENT OF VIRAL HEPATITIS-RELATED
HEPATIC FIBROSIS
- MAGNETIC FILTER CARTRIDGE AND FILTER ASSEMBLY
- USER TERMINAL AND WIRELESS COMMUNICATION METHOD
- source_sentence: A latch includes a latch housing including a first housing portion
and a second housing portion separable from the first housing portion. The second
housing portion includes a keeper. A first arm member is in rotational communication
with the first housing portion. The first arm member is configured to rotate about
a first axis between a first position and a second position. A second arm member
is in rotational communication with the first arm member. A latch load pin is
in rotational communication with the first arm member about a second axis. The
latch load pin is configured to mate with the keeper with the first arm member
in the first position. The second arm member in the first position is configured
to be fixed relative to the first arm member as the first arm member rotates from
the first position toward the second position.
sentences:
- UNLOCKING METHODS AND RELATED PRODUCTS
- LATCH AND METHOD FOR OPERATING SAID LATCH
- PANEL-SHAPED MOLDED ARTICLE AND PRODUCTION METHOD FOR PANEL-SHAPED MOLDED ARTICLE
- source_sentence: The present invention aims to provide a production method of low-fat
and low-protein yogurt with smooth taste, suppressed syneresis and superior shape
retainability, comprising adding protein glutaminase and starch to raw milk.
sentences:
- YOGURT PRODUCTION METHOD
- Aircraft electric motor system
- Floor panel, flooring system and method for laying flooring system
- source_sentence: A computer-implemented method determines an orientation parameter
value of a prosthetic component. The method includes receiving a first desired
separation distance (d1) between a tibial prosthetic component (120) and a femoral
prosthetic component (110) at a first flexion position (521) of a knee joint (100)
and estimating a first estimated separation distance (g1) between the tibial prosthetic
component and the femoral prosthetic component at the first flexion position of
the knee joint for at least one potential orientation of the femoral prosthet¬ic
component. The method also includes determining a first orientation para¬meter
value of the femoral prosthetic component by comparing the first estimated separation
distance to the first desired separation distance and out¬putting the first orientation
parameter value via a user interface (400).
sentences:
- Mobile device and antenna structure
- TWO-WAY VALVE FOR CONTROLLING A TEMPERATURE OF A COOLANT FOR AN INTERNAL COMBUSTION
ENGINE
- SYSTEMS AND METHOD FOR PROSTHETIC COMPONENT ORIENTATION
---
# SentenceTransformer based on sentence-transformers/all-mpnet-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) on the json dataset. It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) <!-- at revision f1b1b820e405bb8644f5e8d9a3b98f9c9e0a3c58 -->
- **Maximum Sequence Length:** 384 tokens
- **Output Dimensionality:** 768 tokens
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- json
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("stephenhib/all-mpnet-base-v2-patabs-1epoc-batch32-100")
# Run inference
sentences = [
'A computer-implemented method determines an orientation parameter value of a prosthetic component. The method includes receiving a first desired separation distance (d1) between a tibial prosthetic component (120) and a femoral prosthetic component (110) at a first flexion position (521) of a knee joint (100) and estimating a first estimated separation distance (g1) between the tibial prosthetic component and the femoral prosthetic component at the first flexion position of the knee joint for at least one potential orientation of the femoral prosthet¬ic component. The method also includes determining a first orientation para¬meter value of the femoral prosthetic component by comparing the first estimated separation distance to the first desired separation distance and out¬putting the first orientation parameter value via a user interface (400).',
'SYSTEMS AND METHOD FOR PROSTHETIC COMPONENT ORIENTATION',
'TWO-WAY VALVE FOR CONTROLLING A TEMPERATURE OF A COOLANT FOR AN INTERNAL COMBUSTION ENGINE',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### json
* Dataset: json
* Size: 768,201 training samples
* Columns: <code>positive</code> and <code>anchor</code>
* Approximate statistics based on the first 1000 samples:
| | positive | anchor |
|:--------|:-------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 13 tokens</li><li>mean: 163.82 tokens</li><li>max: 384 tokens</li></ul> | <ul><li>min: 3 tokens</li><li>mean: 12.34 tokens</li><li>max: 73 tokens</li></ul> |
* Samples:
| positive | anchor |
|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:--------------------------------------------------------------------------------|
| <code>According to an example aspect of the present invention, there is provided an apparatus and method to control mining vehicles, in particular as electric mining vehicles, taking into account the state of charge the batteries of said mining vehicles.</code> | <code>MINING VEHICLE CONTROL</code> |
| <code>The invention is related to a new soft heterophasic random propylene copolymer with improved optical properties, as well as the process by which the heterophasic random propylene copolymer is produced.</code> | <code>SOFT HETEROPHASIC RANDOM PROPYLENE COPOLYMER WITH IMPROVED CLARITY</code> |
| <code>The present invention relates to a valve assembly 10 for controlling a volute connecting opening 324 of a multi-channel turbine 500. The valve assembly 10 comprises a housing portion 300, a valve body 100 and an internal lever 200. The housing portion 300 defines a first volute channel 312, a second volute channel 314 and a volute connecting region 320. The housing portion 300 further comprises a cavity 340. The cavity 340 is separated from the volutes 312, 314 and can be accessed from outside the housing portion 300 via a housing opening 342 which extends from outside the housing portion 300 into the cavity 340. The volute connection region 320 is located between the first volute channel 312 and the second volute channel 314 and defines a volute connecting opening 324. The valve body 100 is inserted in the cavity 340 of the housing portion 300 and comprises at least one fin 120. The internal lever 200 is coupled with the valve body 100 and configured to pivotably move the valve body 100 between a first position and a second position. In the first position of the valve body 100, the fin 120 blocks the volute connecting opening 324. Thus, exhaust gases are substantially prevented from overflowing from the first volute channel 312 to the second volute channel 314 and vice versa. In the second position of the valve body 100 the fin 120 clears the volute connecting opening 324. Thus, exhaust gases are enabled to overflow from the first volute channel 312 to the second volute channel 314 and vice versa.</code> | <code>VALVE ASSEMBLY FOR MULTI-CHANNEL TURBINE</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 4
- `per_device_eval_batch_size`: 2
- `learning_rate`: 2e-05
- `num_train_epochs`: 1
- `warmup_ratio`: 0.1
- `bf16`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 4
- `per_device_eval_batch_size`: 2
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Framework Versions
- Python: 3.11.9
- Sentence Transformers: 3.2.0
- Transformers: 4.45.2
- PyTorch: 2.5.0+cu124
- Accelerate: 1.0.1
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
--> |
fpc/bge-micro-smiles | fpc | "2024-10-20T17:48:26Z" | 5 | 0 | sentence-transformers | [
"sentence-transformers",
"onnx",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:3210255",
"loss:CachedMultipleNegativesRankingLoss",
"en",
"arxiv:1908.10084",
"arxiv:2101.06983",
"base_model:TaylorAI/bge-micro",
"base_model:quantized:TaylorAI/bge-micro",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2024-10-09T18:52:08Z" | ---
base_model: TaylorAI/bge-micro
datasets: []
language:
- en
library_name: sentence-transformers
license: apache-2.0
metrics:
- pearson_cosine
- spearman_cosine
- pearson_manhattan
- spearman_manhattan
- pearson_euclidean
- spearman_euclidean
- pearson_dot
- spearman_dot
- pearson_max
- spearman_max
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:3210255
- loss:CachedMultipleNegativesRankingLoss
widget:
- source_sentence: donepezil hydrochloride monohydrate
sentences:
- Cn1nccc1[C@H]1CC[C@H](O[Si](C)(C)C(C)(C)C)C[C@@H]1OC(=O)c1ccccc1
- COc1cc2c(cc1OC)C(=O)C(CC1CCN(Cc3ccccc3)CC1)C2.Cl.O
- C(=O)(OC)C1=CC=C(C=C1)CC(C)=O
- source_sentence: 6-Cyclopropylmethoxy-5-(3,3-difluoro-azetidin-1-yl)-pyridine-2-carboxylic
acid tert-butyl-(5-methyl-[1,3,4]oxadiazol-2-ylmethyl)-amide
sentences:
- Cc1nnc(CN(C(=O)c2ccc(N3CC(F)(F)C3)c(OCC3CC3)n2)C(C)(C)C)o1
- COc1cccc(CCCC=C(Br)Br)c1
- CN(C)CCNC(=O)c1ccc2oc(=O)n(Cc3ccc4[nH]c(=O)[nH]c4c3)c2c1
- source_sentence: N-(2-chlorophenyl)-6,8-difluoro-N-methyl-4H-thieno[3,2-c]chromene-2-carboxamide
sentences:
- CN(C(=O)c1cc2c(s1)-c1cc(F)cc(F)c1OC2)c1ccccc1Cl
- ClC(C(=O)OCCOCC1=CC=C(C=C1)F)C
- C(C)OC(\C=C(/C)\OC1=C(C(=CC=C1F)OC(C)C)F)=O
- source_sentence: 6-[2-[(3-chlorophenyl)methyl]-1,3,3a,4,6,6a-hexahydropyrrolo[3,4-c]pyrrol-5-yl]-3-(trifluoromethyl)-[1,2,4]triazolo[4,3-b]pyridazine
sentences:
- CC(=O)OCCOCn1cc(C)c(=O)[nH]c1=O
- NC1=C(C(=NN1C1=C(C=C(C=C1Cl)C(F)(F)F)Cl)C#N)S(=O)(=O)C
- ClC=1C=C(C=CC1)CN1CC2CN(CC2C1)C=1C=CC=2N(N1)C(=NN2)C(F)(F)F
- source_sentence: (±)-cis-2-(4-methoxyphenyl)-3-acetoxy-5-[2-(dimethylamino)ethyl]-8-chloro-2,3-dihydro-1,5-benzothiazepin-4(5H)-one
hydrochloride
sentences:
- N(=[N+]=[N-])C(C(=O)C1=NC(=C(C(=N1)C(C)(C)C)O)C(C)(C)C)C
- O[C@@H]1[C@H](O)[C@@H](Oc2nc(N3CCNCC3)nc3ccccc23)C[C@H]1O
- Cl.COC1=CC=C(C=C1)[C@@H]1SC2=C(N(C([C@@H]1OC(C)=O)=O)CCN(C)C)C=CC(=C2)Cl
model-index:
- name: MPNet base trained on AllNLI triplets
results:
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: bge micro test
type: bge-micro-test
metrics:
- type: pearson_cosine
value: .nan
name: Pearson Cosine
- type: spearman_cosine
value: .nan
name: Spearman Cosine
- type: pearson_manhattan
value: .nan
name: Pearson Manhattan
- type: spearman_manhattan
value: .nan
name: Spearman Manhattan
- type: pearson_euclidean
value: .nan
name: Pearson Euclidean
- type: spearman_euclidean
value: .nan
name: Spearman Euclidean
- type: pearson_dot
value: .nan
name: Pearson Dot
- type: spearman_dot
value: .nan
name: Spearman Dot
- type: pearson_max
value: .nan
name: Pearson Max
- type: spearman_max
value: .nan
name: Spearman Max
---
# MPNet base trained on AllNLI triplets
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [TaylorAI/bge-micro](https://huggingface.co/TaylorAI/bge-micro). It maps sentences & paragraphs to a 384-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [TaylorAI/bge-micro](https://huggingface.co/TaylorAI/bge-micro) <!-- at revision 4bccbd43513eb9fecf444af6eecde76e55f4c839 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 384 tokens
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("fpc/bge-micro-smiles")
# Run inference
sentences = [
'(±)-cis-2-(4-methoxyphenyl)-3-acetoxy-5-[2-(dimethylamino)ethyl]-8-chloro-2,3-dihydro-1,5-benzothiazepin-4(5H)-one hydrochloride',
'Cl.COC1=CC=C(C=C1)[C@@H]1SC2=C(N(C([C@@H]1OC(C)=O)=O)CCN(C)C)C=CC(=C2)Cl',
'O[C@@H]1[C@H](O)[C@@H](Oc2nc(N3CCNCC3)nc3ccccc23)C[C@H]1O',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 3,210,255 training samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:-----------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 5 tokens</li><li>mean: 42.57 tokens</li><li>max: 153 tokens</li></ul> | <ul><li>min: 4 tokens</li><li>mean: 40.02 tokens</li><li>max: 325 tokens</li></ul> |
* Samples:
| anchor | positive |
|:--------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------|
| <code>4-t-butylbromobenzene</code> | <code>C(C)(C)(C)C1=CC=C(C=C1)Br</code> |
| <code>1-methyl-4-(morpholine-4-carbonyl)-N-(2-phenyl-[1,2,4]triazolo[1,5-a]pyridin-7-yl)-1H-pyrazole-5-carboxamide</code> | <code>CN1N=CC(=C1C(=O)NC1=CC=2N(C=C1)N=C(N2)C2=CC=CC=C2)C(=O)N2CCOCC2</code> |
| <code>Phthalimide</code> | <code>C1(C=2C(C(N1)=O)=CC=CC2)=O</code> |
* Loss: [<code>CachedMultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cachedmultiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `per_device_train_batch_size`: 512
- `learning_rate`: 2e-05
- `num_train_epochs`: 4
- `warmup_ratio`: 0.1
- `bf16`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: no
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 512
- `per_device_eval_batch_size`: 8
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 4
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
<details><summary>Click to expand</summary>
| Epoch | Step | Training Loss | bge-micro-test_spearman_cosine |
|:------:|:-----:|:-------------:|:------------------------------:|
| 0.0159 | 100 | 6.1861 | - |
| 0.0319 | 200 | 6.0547 | - |
| 0.0478 | 300 | 5.6041 | - |
| 0.0638 | 400 | 4.9367 | - |
| 0.0797 | 500 | 4.3412 | - |
| 0.0957 | 600 | 3.8245 | - |
| 0.1116 | 700 | 3.3188 | - |
| 0.1276 | 800 | 2.869 | - |
| 0.1435 | 900 | 2.5149 | - |
| 0.1595 | 1000 | 2.2282 | - |
| 0.1754 | 1100 | 2.0046 | - |
| 0.1914 | 1200 | 1.8032 | - |
| 0.2073 | 1300 | 1.6289 | - |
| 0.2232 | 1400 | 1.4567 | - |
| 0.2392 | 1500 | 1.3326 | - |
| 0.2551 | 1600 | 1.2127 | - |
| 0.2711 | 1700 | 1.0909 | - |
| 0.2870 | 1800 | 1.0021 | - |
| 0.3030 | 1900 | 0.9135 | - |
| 0.3189 | 2000 | 0.8378 | - |
| 0.3349 | 2100 | 0.7758 | - |
| 0.3508 | 2200 | 0.7031 | - |
| 0.3668 | 2300 | 0.6418 | - |
| 0.3827 | 2400 | 0.5965 | - |
| 0.3987 | 2500 | 0.5461 | - |
| 0.4146 | 2600 | 0.5039 | - |
| 0.4306 | 2700 | 0.4674 | - |
| 0.4465 | 2800 | 0.4339 | - |
| 0.4624 | 2900 | 0.4045 | - |
| 0.4784 | 3000 | 0.373 | - |
| 0.4943 | 3100 | 0.3566 | - |
| 0.5103 | 3200 | 0.3348 | - |
| 0.5262 | 3300 | 0.3215 | - |
| 0.5422 | 3400 | 0.302 | - |
| 0.5581 | 3500 | 0.2826 | - |
| 0.5741 | 3600 | 0.2803 | - |
| 0.5900 | 3700 | 0.2616 | - |
| 0.6060 | 3800 | 0.2554 | - |
| 0.6219 | 3900 | 0.234 | - |
| 0.6379 | 4000 | 0.2306 | - |
| 0.6538 | 4100 | 0.2224 | - |
| 0.6697 | 4200 | 0.2141 | - |
| 0.6857 | 4300 | 0.2117 | - |
| 0.7016 | 4400 | 0.204 | - |
| 0.7176 | 4500 | 0.198 | - |
| 0.7335 | 4600 | 0.1986 | - |
| 0.7495 | 4700 | 0.1821 | - |
| 0.7654 | 4800 | 0.1813 | - |
| 0.7814 | 4900 | 0.1741 | - |
| 0.7973 | 5000 | 0.1697 | - |
| 0.8133 | 5100 | 0.1655 | - |
| 0.8292 | 5200 | 0.1623 | - |
| 0.8452 | 5300 | 0.1593 | - |
| 0.8611 | 5400 | 0.1566 | - |
| 0.8771 | 5500 | 0.151 | - |
| 0.8930 | 5600 | 0.1526 | - |
| 0.9089 | 5700 | 0.1453 | - |
| 0.9249 | 5800 | 0.1448 | - |
| 0.9408 | 5900 | 0.1369 | - |
| 0.9568 | 6000 | 0.1409 | - |
| 0.9727 | 6100 | 0.1373 | - |
| 0.9887 | 6200 | 0.133 | - |
| 1.0046 | 6300 | 0.1269 | - |
| 1.0206 | 6400 | 0.1274 | - |
| 1.0365 | 6500 | 0.1271 | - |
| 1.0525 | 6600 | 0.1216 | - |
| 1.0684 | 6700 | 0.1176 | - |
| 1.0844 | 6800 | 0.1208 | - |
| 1.1003 | 6900 | 0.1177 | - |
| 1.1162 | 7000 | 0.1175 | - |
| 1.1322 | 7100 | 0.1109 | - |
| 1.1481 | 7200 | 0.1118 | - |
| 1.1641 | 7300 | 0.1085 | - |
| 1.1800 | 7400 | 0.1155 | - |
| 1.1960 | 7500 | 0.1079 | - |
| 1.2119 | 7600 | 0.1087 | - |
| 1.2279 | 7700 | 0.1004 | - |
| 1.2438 | 7800 | 0.1084 | - |
| 1.2598 | 7900 | 0.1089 | - |
| 1.2757 | 8000 | 0.1012 | - |
| 1.2917 | 8100 | 0.1037 | - |
| 1.3076 | 8200 | 0.1004 | - |
| 1.3236 | 8300 | 0.0979 | - |
| 1.3395 | 8400 | 0.1007 | - |
| 1.3554 | 8500 | 0.0956 | - |
| 1.3714 | 8600 | 0.0972 | - |
| 1.3873 | 8700 | 0.0947 | - |
| 1.4033 | 8800 | 0.0931 | - |
| 1.4192 | 8900 | 0.0948 | - |
| 1.4352 | 9000 | 0.0925 | - |
| 1.4511 | 9100 | 0.0933 | - |
| 1.4671 | 9200 | 0.0888 | - |
| 1.4830 | 9300 | 0.0877 | - |
| 1.4990 | 9400 | 0.0889 | - |
| 1.5149 | 9500 | 0.0895 | - |
| 1.5309 | 9600 | 0.0892 | - |
| 1.5468 | 9700 | 0.089 | - |
| 1.5627 | 9800 | 0.0828 | - |
| 1.5787 | 9900 | 0.0906 | - |
| 1.5946 | 10000 | 0.0893 | - |
| 1.6106 | 10100 | 0.0849 | - |
| 1.6265 | 10200 | 0.0811 | - |
| 1.6425 | 10300 | 0.0823 | - |
| 1.6584 | 10400 | 0.0806 | - |
| 1.6744 | 10500 | 0.0815 | - |
| 1.6903 | 10600 | 0.0832 | - |
| 1.7063 | 10700 | 0.0856 | - |
| 1.7222 | 10800 | 0.081 | - |
| 1.7382 | 10900 | 0.0831 | - |
| 1.7541 | 11000 | 0.0767 | - |
| 1.7701 | 11100 | 0.0779 | - |
| 1.7860 | 11200 | 0.0792 | - |
| 1.8019 | 11300 | 0.0771 | - |
| 1.8179 | 11400 | 0.0783 | - |
| 1.8338 | 11500 | 0.0749 | - |
| 1.8498 | 11600 | 0.0755 | - |
| 1.8657 | 11700 | 0.0778 | - |
| 1.8817 | 11800 | 0.0753 | - |
| 1.8976 | 11900 | 0.0767 | - |
| 1.9136 | 12000 | 0.0725 | - |
| 1.9295 | 12100 | 0.0744 | - |
| 1.9455 | 12200 | 0.0743 | - |
| 1.9614 | 12300 | 0.0722 | - |
| 1.9774 | 12400 | 0.0712 | - |
| 1.9933 | 12500 | 0.0709 | - |
| 2.0092 | 12600 | 0.0694 | - |
| 2.0252 | 12700 | 0.0705 | - |
| 2.0411 | 12800 | 0.0715 | - |
| 2.0571 | 12900 | 0.0705 | - |
| 2.0730 | 13000 | 0.0653 | - |
| 2.0890 | 13100 | 0.0698 | - |
| 2.1049 | 13200 | 0.0676 | - |
| 2.1209 | 13300 | 0.0684 | - |
| 2.1368 | 13400 | 0.0644 | - |
| 2.1528 | 13500 | 0.0652 | - |
| 2.1687 | 13600 | 0.0673 | - |
| 2.1847 | 13700 | 0.067 | - |
| 2.2006 | 13800 | 0.0645 | - |
| 2.2166 | 13900 | 0.0633 | - |
| 2.2325 | 14000 | 0.0645 | - |
| 2.2484 | 14100 | 0.0698 | - |
| 2.2644 | 14200 | 0.0655 | - |
| 2.2803 | 14300 | 0.0654 | - |
| 2.2963 | 14400 | 0.0656 | - |
| 2.3122 | 14500 | 0.0631 | - |
| 2.3282 | 14600 | 0.0628 | - |
| 2.3441 | 14700 | 0.0671 | - |
| 2.3601 | 14800 | 0.0659 | - |
| 2.3760 | 14900 | 0.0619 | - |
| 2.3920 | 15000 | 0.0618 | - |
| 2.4079 | 15100 | 0.0624 | - |
| 2.4239 | 15200 | 0.0616 | - |
| 2.4398 | 15300 | 0.0631 | - |
| 2.4557 | 15400 | 0.0639 | - |
| 2.4717 | 15500 | 0.0585 | - |
| 2.4876 | 15600 | 0.0607 | - |
| 2.5036 | 15700 | 0.0615 | - |
| 2.5195 | 15800 | 0.062 | - |
| 2.5355 | 15900 | 0.0621 | - |
| 2.5514 | 16000 | 0.0608 | - |
| 2.5674 | 16100 | 0.0594 | - |
| 2.5833 | 16200 | 0.0631 | - |
| 2.5993 | 16300 | 0.0635 | - |
| 2.6152 | 16400 | 0.06 | - |
| 2.6312 | 16500 | 0.0581 | - |
| 2.6471 | 16600 | 0.0607 | - |
| 2.6631 | 16700 | 0.0577 | - |
| 2.6790 | 16800 | 0.0592 | - |
| 2.6949 | 16900 | 0.0625 | - |
| 2.7109 | 17000 | 0.0622 | - |
| 2.7268 | 17100 | 0.0573 | - |
| 2.7428 | 17200 | 0.0613 | - |
| 2.7587 | 17300 | 0.0587 | - |
| 2.7747 | 17400 | 0.0587 | - |
| 2.7906 | 17500 | 0.0588 | - |
| 2.8066 | 17600 | 0.0568 | - |
| 2.8225 | 17700 | 0.0573 | - |
| 2.8385 | 17800 | 0.0575 | - |
| 2.8544 | 17900 | 0.0575 | - |
| 2.8704 | 18000 | 0.0582 | - |
| 2.8863 | 18100 | 0.0577 | - |
| 2.9022 | 18200 | 0.057 | - |
| 2.9182 | 18300 | 0.0572 | - |
| 2.9341 | 18400 | 0.0558 | - |
| 2.9501 | 18500 | 0.0578 | - |
| 2.9660 | 18600 | 0.0567 | - |
| 2.9820 | 18700 | 0.0569 | - |
| 2.9979 | 18800 | 0.0547 | - |
| 3.0139 | 18900 | 0.0542 | - |
| 3.0298 | 19000 | 0.0563 | - |
| 3.0458 | 19100 | 0.0549 | - |
| 3.0617 | 19200 | 0.0531 | - |
| 3.0777 | 19300 | 0.053 | - |
| 3.0936 | 19400 | 0.0557 | - |
| 3.1096 | 19500 | 0.0546 | - |
| 3.1255 | 19600 | 0.0518 | - |
| 3.1414 | 19700 | 0.0517 | - |
| 3.1574 | 19800 | 0.0528 | - |
| 3.1733 | 19900 | 0.0551 | - |
| 3.1893 | 20000 | 0.0544 | - |
| 3.2052 | 20100 | 0.0526 | - |
| 3.2212 | 20200 | 0.0494 | - |
| 3.2371 | 20300 | 0.0537 | - |
| 3.2531 | 20400 | 0.0568 | - |
| 3.2690 | 20500 | 0.0525 | - |
| 3.2850 | 20600 | 0.0566 | - |
| 3.3009 | 20700 | 0.0539 | - |
| 3.3169 | 20800 | 0.0531 | - |
| 3.3328 | 20900 | 0.0524 | - |
| 3.3487 | 21000 | 0.0543 | - |
| 3.3647 | 21100 | 0.0537 | - |
| 3.3806 | 21200 | 0.0524 | - |
| 3.3966 | 21300 | 0.0516 | - |
| 3.4125 | 21400 | 0.0537 | - |
| 3.4285 | 21500 | 0.0515 | - |
| 3.4444 | 21600 | 0.0537 | - |
| 3.4604 | 21700 | 0.0526 | - |
| 3.4763 | 21800 | 0.0508 | - |
| 3.4923 | 21900 | 0.0526 | - |
| 3.5082 | 22000 | 0.0521 | - |
| 3.5242 | 22100 | 0.054 | - |
| 3.5401 | 22200 | 0.053 | - |
| 3.5561 | 22300 | 0.0509 | - |
| 3.5720 | 22400 | 0.0526 | - |
| 3.5879 | 22500 | 0.0551 | - |
| 3.6039 | 22600 | 0.0556 | - |
| 3.6198 | 22700 | 0.0497 | - |
| 3.6358 | 22800 | 0.0515 | - |
| 3.6517 | 22900 | 0.0514 | - |
| 3.6677 | 23000 | 0.0503 | - |
| 3.6836 | 23100 | 0.0515 | - |
| 3.6996 | 23200 | 0.0553 | - |
| 3.7155 | 23300 | 0.0519 | - |
| 3.7315 | 23400 | 0.0549 | - |
| 3.7474 | 23500 | 0.0522 | - |
| 3.7634 | 23600 | 0.0526 | - |
| 3.7793 | 23700 | 0.0525 | - |
| 3.7952 | 23800 | 0.051 | - |
| 3.8112 | 23900 | 0.0509 | - |
| 3.8271 | 24000 | 0.0503 | - |
| 3.8431 | 24100 | 0.0524 | - |
| 3.8590 | 24200 | 0.0526 | - |
| 3.8750 | 24300 | 0.0512 | - |
| 3.8909 | 24400 | 0.0518 | - |
| 3.9069 | 24500 | 0.0521 | - |
| 3.9228 | 24600 | 0.0524 | - |
| 3.9388 | 24700 | 0.051 | - |
| 3.9547 | 24800 | 0.0535 | - |
| 3.9707 | 24900 | 0.0508 | - |
| 3.9866 | 25000 | 0.0514 | - |
| 4.0 | 25084 | - | nan |
</details>
### Framework Versions
- Python: 3.10.9
- Sentence Transformers: 3.0.1
- Transformers: 4.41.2
- PyTorch: 2.4.1+cu124
- Accelerate: 0.33.0
- Datasets: 2.18.0
- Tokenizers: 0.19.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### CachedMultipleNegativesRankingLoss
```bibtex
@misc{gao2021scaling,
title={Scaling Deep Contrastive Learning Batch Size under Memory Limited Setup},
author={Luyu Gao and Yunyi Zhang and Jiawei Han and Jamie Callan},
year={2021},
eprint={2101.06983},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
mateiaassAI/T5Large-meid3v2_2 | mateiaassAI | "2024-10-21T16:00:10Z" | 114 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2024-10-21T15:57:48Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
pszemraj/flan-t5-xl-instructiongen | pszemraj | "2023-09-23T20:37:01Z" | 5 | 2 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"instruct",
"instructions",
"domain adapt",
"instructiongen",
"dataset:pszemraj/fleece2instructions",
"base_model:google/flan-t5-xl",
"base_model:finetune:google/flan-t5-xl",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2023-03-23T21:33:53Z" | ---
license: apache-2.0
tags:
- generated_from_trainer
- instruct
- instructions
- domain adapt
- instructiongen
datasets:
- pszemraj/fleece2instructions
metrics:
- rouge
widget:
- text: You'll need to start by choosing the right venue. Consider the type of atmosphere
and the size of the area that will be suitable for the number of guests you plan
to invite. Choose the right decorations based on your brother's interests, such
as balloons in his favorite colors, banners, and streamers. Next, decide on the
food and drinks, making sure they are tasty and appropriate for the occasion.
Then decide on the other games, music, and entertainment that will make the party
memorable. Finally, involve your brother's friends and family to help create the
perfect surprise.
example_title: birthday party
- text: 1) cookies and cream 2) chocolate chip 3) mint chip 4) oreo
example_title: ice cream
- text: Start by selecting a scale model of a building that fits the theme. Use a
hobby knife and glue to cut and assemble the model into a ruined or abandoned
version of itself, adding details like broken windows and graffiti. Create a base
for the diorama using foam, plaster, or other materials, and paint it to resemble
a ruined street or sidewalk. Add miniature vehicles, debris, and figures to complete
the scene, and use weathering techniques like dry brushing and rust washes to
add realism. Display the diorama in a shadow box or other protective case to showcase
your work.
example_title: Miniature diorama creation
- text: Start by selecting clothing that is futuristic and edgy, such as leather jackets,
neon-colored accessories, and tech-inspired patterns. Add accessories like goggles,
cybernetic implants, and LED lights to enhance the cyberpunk vibe. Use makeup
and body paint to create a futuristic look, such as metallic skin or neon makeup.
Consider adding functional elements to your costume, such as a built-in backpack
or hidden pockets for your tech gadgets. Finally, practice your confident walk
and embrace your inner cyberpunk for a memorable and immersive costume experience.
example_title: Cyberpunk costume design
- text: Start by creating a base terrain with mountains, valleys, and other natural
features. Use fractal noise and displacement mapping to add texture and detail
to the terrain, and experiment with different materials like rock, grass, and
water. Add surreal elements like floating islands, giant mushrooms, or impossible
geometry to create a dreamlike atmosphere. Use lighting and color grading to enhance
the mood and tone of the scene, and render the final image at a high resolution
for maximum impact. Share your surreal landscape with the world and inspire others
to explore the possibilities of 3D art.
example_title: Surreal 3D landscape creation
- text: Start by setting a realistic goal and creating a training plan. Build up your
mileage gradually over time, and incorporate cross-training and strength exercises
to prevent injury and improve endurance. Be sure to stay hydrated and properly
fuel your body with nutritious foods. Listen to your body and adjust your training
as needed to avoid overexertion or burnout. Finally, taper your training in the
weeks leading up to the race to give your body time to rest and recover before
the big day.
example_title: Marathon training
inference:
parameters:
max_length: 48
num_beams: 4
base_model: google/flan-t5-xl
model-index:
- name: flan-t5-xl-instructiongen
results:
- task:
type: text2text-generation
name: Sequence-to-sequence Language Modeling
dataset:
name: pszemraj/fleece2instructions
type: pszemraj/fleece2instructions
split: validation
metrics:
- type: rouge
value: 65.3297
name: Rouge1
---
# flan-t5-xl-instructiongen
This model is a fine-tuned version of [google/flan-t5-xl](https://huggingface.co/google/flan-t5-xl) on the pszemraj/fleece2instructions dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8314
- Rouge1: 65.3297
- Rouge2: 48.8475
- Rougel: 63.4183
- Rougelsum: 63.5458
- Gen Len: 13.7474
## Model description
More information needed
## Intended uses & limitations
Generate/recover **instructions** (assumes that there is just an instruction, not `inputs` as well) from arbitrary text.
## Training and evaluation data
Refer to `pszemraj/fleece2instructions`
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 2.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.9615 | 1.0 | 362 | 0.8353 | 63.9163 | 47.0456 | 61.9554 | 62.0549 | 13.3737 |
| 0.809 | 2.0 | 724 | 0.8251 | 64.5398 | 47.9107 | 62.5928 | 62.7278 | 13.4763 | |
bh8648/POKO-12.8-qlora-split_16-1 | bh8648 | "2023-10-19T23:35:09Z" | 0 | 0 | peft | [
"peft",
"region:us"
] | null | "2023-10-19T23:35:02Z" | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0
|
mradermacher/Qwen2.5-14B-Hyper-GGUF | mradermacher | "2025-01-20T08:41:46Z" | 250 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:CultriX/Qwen2.5-14B-Hyper",
"base_model:quantized:CultriX/Qwen2.5-14B-Hyper",
"endpoints_compatible",
"region:us",
"conversational"
] | null | "2025-01-19T23:43:25Z" | ---
base_model: CultriX/Qwen2.5-14B-Hyper
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
static quants of https://huggingface.co/CultriX/Qwen2.5-14B-Hyper
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Qwen2.5-14B-Hyper-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-14B-Hyper-GGUF/resolve/main/Qwen2.5-14B-Hyper.Q2_K.gguf) | Q2_K | 5.9 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-14B-Hyper-GGUF/resolve/main/Qwen2.5-14B-Hyper.Q3_K_S.gguf) | Q3_K_S | 6.8 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-14B-Hyper-GGUF/resolve/main/Qwen2.5-14B-Hyper.Q3_K_M.gguf) | Q3_K_M | 7.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-14B-Hyper-GGUF/resolve/main/Qwen2.5-14B-Hyper.Q3_K_L.gguf) | Q3_K_L | 8.0 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-14B-Hyper-GGUF/resolve/main/Qwen2.5-14B-Hyper.IQ4_XS.gguf) | IQ4_XS | 8.3 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-14B-Hyper-GGUF/resolve/main/Qwen2.5-14B-Hyper.Q4_K_S.gguf) | Q4_K_S | 8.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-14B-Hyper-GGUF/resolve/main/Qwen2.5-14B-Hyper.Q4_K_M.gguf) | Q4_K_M | 9.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-14B-Hyper-GGUF/resolve/main/Qwen2.5-14B-Hyper.Q5_K_S.gguf) | Q5_K_S | 10.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-14B-Hyper-GGUF/resolve/main/Qwen2.5-14B-Hyper.Q5_K_M.gguf) | Q5_K_M | 10.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-14B-Hyper-GGUF/resolve/main/Qwen2.5-14B-Hyper.Q6_K.gguf) | Q6_K | 12.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-14B-Hyper-GGUF/resolve/main/Qwen2.5-14B-Hyper.Q8_0.gguf) | Q8_0 | 15.8 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
Jonjew/HologramFlux | Jonjew | "2025-03-03T06:05:14Z" | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:unknown",
"region:us"
] | text-to-image | "2025-03-03T06:04:41Z" | ---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: >-
1qqq,Dot Mat Hologram,a glowing earphone in the dark,ethereal and dreamlike
subjects,rich and nuanced color palettes,(emotional depth),elegant
compositions,dopamine color,glowing lights,light red and green,
parameters:
negative_prompt: 'Guidance: 3.5 Steps: 20 Sampler: Euler Seed: 898064822'
output:
url: >-
images/abbdfb265edde7019b13a3674543d3a9444a2606cda5e4fd4b6421dfcf7e1fea.png
- text: >-
Dot Mat Hologram,a glowing desk in the dark,ethereal and dreamlike
subjects,rich and nuanced color palettes,(emotional depth),elegant
compositions,dopamine color,glowing lights,light navy and
orange,flickr,light cyan and pink,electric color,
parameters:
negative_prompt: 'Guidance: 3.5 Steps: 20 Sampler: Euler Seed: 2439625163'
output:
url: >-
images/9024d12f989a587fb2af20ca6763afab38a94a11e00b61b42d5c730561fc54f0.png
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: 1qqq, hologram
license: unknown
---
# Hologram Flux Lora
<Gallery />
## Model description
FROM https://civitai.com/models/719266/hologram-flux-lora
Trigger 1qqq, hologram
Strength 0.8-1
Hologram Flux Lora
Base model: flux.1d
Recommended steps: 20-30
Recommended sampling: Euler
Weight: 0.8-1
cfg scale 3.5
## Trigger words
You should use `1qqq` to trigger the image generation.
You should use `hologram` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/Jonjew/HologramFlux/tree/main) them in the Files & versions tab.
|
ThuyNT03/KLTN_COQE_viT5_AOSPL_v3 | ThuyNT03 | "2023-12-05T00:18:45Z" | 5 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:VietAI/vit5-large",
"base_model:finetune:VietAI/vit5-large",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2023-12-04T23:15:55Z" | ---
license: mit
base_model: VietAI/vit5-large
tags:
- generated_from_trainer
model-index:
- name: KLTN_COQE_viT5_AOSPL_v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# KLTN_COQE_viT5_AOSPL_v3
This model is a fine-tuned version of [VietAI/vit5-large](https://huggingface.co/VietAI/vit5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 10
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.14.1
|
SicariusSicariiStuff/Negative_LLAMA_70B-8.0bpw | SicariusSicariiStuff | "2025-01-12T16:22:30Z" | 22 | 0 | null | [
"safetensors",
"llama",
"license:apache-2.0",
"8-bit",
"exl2",
"region:us"
] | null | "2025-01-11T18:30:27Z" | ---
license: apache-2.0
---
|
jhu-clsp/rank1-14b | jhu-clsp | "2025-04-08T23:02:35Z" | 43 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"reranker",
"retrieval",
"text-ranking",
"en",
"dataset:jhu-clsp/rank1-training-data",
"arxiv:2502.18418",
"base_model:Qwen/Qwen2.5-14B",
"base_model:finetune:Qwen/Qwen2.5-14B",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-ranking | "2025-02-18T15:23:33Z" | ---
license: mit
library_name: transformers
datasets:
- jhu-clsp/rank1-training-data
base_model:
- Qwen/Qwen2.5-14B
pipeline_tag: text-ranking
tags:
- reranker
- retrieval
language:
- en
---
# rank1-14b: Test-Time Compute for Reranking in Information Retrieval
📄 [Paper](https://arxiv.org/abs/2502.18418) | 🚀 [GitHub Repository](https://github.com/orionw/rank1)
rank1 is a reasoning reranker model that "thinks" before making relevance judgments. This 14B parameter model is trained from the Qwen2.5-14B base model and leverages test-time compute to generate reasoning chains before deciding if a document is relevant to a query.
## Model Description
rank1 introduces a novel approach to information retrieval by generating explicit reasoning chains before making relevance judgments. Unlike traditional rerankers that directly output scores, rank1:
1. Receives a query and document pair
2. Generates a reasoning chain within a `<think>...</think>` section
3. Makes a binary relevance judgment (`true` or `false`)
4. Returns a confidence score based on the logits of the true/false tokens
This approach helps the model break down complex relevance decisions into logical steps, improving performance across diverse retrieval tasks.
## Model Family
| Model | Base | Description |
|:------|:-----|:------------|
| [rank1-0.5b](https://huggingface.co/jhu-clsp/rank1-0.5b) | Qwen2.5-0.5B | Smallest variant (0.5B parameters) |
| [rank1-1.5b](https://huggingface.co/jhu-clsp/rank1-1.5b) | Qwen2.5-1.5B | Smaller variant (1.5B parameters) |
| [rank1-3b](https://huggingface.co/jhu-clsp/rank1-3b) | Qwen2.5-3B | Smaller variant (3B parameters) |
| [rank1-7b](https://huggingface.co/jhu-clsp/rank1-7b) | Qwen2.5-7B | Smaller variant (7B parameters) |
| [rank1-14b](https://huggingface.co/jhu-clsp/rank1-14b) | Qwen2.5-14B | Current model (14B parameters) |
| [rank1-32b](https://huggingface.co/jhu-clsp/rank1-32b) | Qwen2.5-32B | Largest variant (32B parameters) |
| [rank1-mistral-2501-24b](https://huggingface.co/jhu-clsp/rank1-mistral-2501-24b) | Mistral-Small 2501 24B | Trained from Mistral base |
| [rank1-llama3-8b](https://huggingface.co/jhu-clsp/rank1-llama3-8b) | Llama 3.1 8B | Trained from Llama 3.1 base |
### Quantized Variants
| Model | Description |
|:------|:------------|
| [rank1-7b-awq](https://huggingface.co/jhu-clsp/rank1-7b-awq) | Quantized version of rank1-7b |
| [rank1-14b-awq](https://huggingface.co/jhu-clsp/rank1-14b-awq) | Quantized version of rank1-14b |
| [rank1-32b-awq](https://huggingface.co/jhu-clsp/rank1-32b-awq) | Quantized version of rank1-32b |
| [rank1-mistral-2501-24b-awq](https://huggingface.co/jhu-clsp/rank1-mistral-2501-24b-awq) | Quantized version of rank1-mistral-24b |
| [rank1-llama3-8b-awq](https://huggingface.co/jhu-clsp/rank1-llama3-8b-awq) | Quantized version of rank1-llama3-8b |
## Associated Data and Resources
| Resource | Description |
|:---------|:------------|
| [rank1-r1-msmarco](https://huggingface.co/datasets/jhu-clsp/rank1-r1-msmarco) | All R1 output examples from MS MARCO |
| [rank1-training-data](https://huggingface.co/datasets/jhu-clsp/rank1-training-data) | Training data used for rank1 models |
| [rank1-run-files](https://huggingface.co/datasets/jhu-clsp/rank1-run-files) | Pre-computed run files for use in top 100 doc reranking |
| [GitHub Repository](https://github.com/orionw/rank1) | Official rank1 repository |
## Usage
Note that official usage is found on the Github and accounts for edge cases. But for simple use cases the minimal example below works.
<details>
<summary>Click to expand: Minimal example with vLLM</summary>
```python
from vllm import LLM, SamplingParams
import math
# Initialize the model with vLLM
model = LLM(
model="jhu-clsp/rank1-14b",
tensor_parallel_size=1, # Number of GPUs
trust_remote_code=True,
max_model_len=16000, # Context length
gpu_memory_utilization=0.9,
dtype="float16",
)
# Set up sampling parameters
sampling_params = SamplingParams(
temperature=0,
max_tokens=8192,
logprobs=20,
stop=["</think> true", "</think> false"],
skip_special_tokens=False
)
# Prepare the prompt
def create_prompt(query, document):
return (
"Determine if the following passage is relevant to the query. "
"Answer only with 'true' or 'false'.\n"
f"Query: {query}\n"
f"Passage: {document}\n"
"<think>"
)
# Example usage
query = "What are the effects of climate change?"
document = "Climate change leads to rising sea levels, extreme weather events, and disruptions to ecosystems. These effects are caused by increasing greenhouse gas concentrations in the atmosphere due to human activities."
# Generate prediction
prompt = create_prompt(query, document)
outputs = model.generate([prompt], sampling_params)
# Extract score
output = outputs[0].outputs[0]
text = output.text
final_logits = output.logprobs[-1]
# Get token IDs for "true" and "false" tokens
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("jhu-clsp/rank1-14b")
true_token = tokenizer(" true", add_special_tokens=False).input_ids[0]
false_token = tokenizer(" false", add_special_tokens=False).input_ids[0]
# Calculate relevance score (probability of "true")
true_logit = final_logits[true_token].logprob
false_logit = final_logits[false_token].logprob
true_score = math.exp(true_logit)
false_score = math.exp(false_logit)
relevance_score = true_score / (true_score + false_score)
print(f"Reasoning chain: {text}")
print(f"Relevance score: {relevance_score}")
```
</details>
## Performance
rank1-14b demonstrates strong performance on retrieval benchmarks, particularly on tasks requiring complex reasoning. The model's ability to "think through" relevance decisions makes it especially effective for nuanced topics.
For specific benchmark results and comparisons with other models, please refer to the paper and the official GitHub repository.
## Installation
Please see the Github for detailed installation instructions.
## MTEB Integration
rank1 is compatible with the [MTEB benchmarking framework](https://github.com/embeddings-benchmark/mteb):
```python
from mteb import MTEB
from rank1 import rank1 # From the official repo
# Initialize the model
model = rank1(
model_name_or_path="jhu-clsp/rank1-14b",
num_gpus=1,
device="cuda"
)
# Run evaluation on specific tasks
evaluation = MTEB(tasks=["NevIR"])
results = evaluation.run(model)
```
## Citation
If you use rank1 in your research, please cite our work:
```bibtex
@misc{weller2025rank1testtimecomputereranking,
title={Rank1: Test-Time Compute for Reranking in Information Retrieval},
author={Orion Weller and Kathryn Ricci and Eugene Yang and Andrew Yates and Dawn Lawrie and Benjamin Van Durme},
year={2025},
eprint={2502.18418},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2502.18418},
}
```
## License
[MIT License](https://github.com/orionw/rank1/blob/main/LICENSE) |
DmitriiObukhov/parler-tts-mini-v1-noised-0.005 | DmitriiObukhov | "2025-02-27T15:13:06Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"parler_tts",
"text2text-generation",
"text-to-speech",
"annotation",
"en",
"dataset:parler-tts/mls_eng",
"dataset:parler-tts/libritts_r_filtered",
"dataset:parler-tts/libritts-r-filtered-speaker-descriptions",
"dataset:parler-tts/mls-eng-speaker-descriptions",
"arxiv:2402.01912",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-to-speech | "2025-02-27T15:08:58Z" | ---
library_name: transformers
tags:
- text-to-speech
- annotation
license: apache-2.0
language:
- en
pipeline_tag: text-to-speech
inference: false
datasets:
- parler-tts/mls_eng
- parler-tts/libritts_r_filtered
- parler-tts/libritts-r-filtered-speaker-descriptions
- parler-tts/mls-eng-speaker-descriptions
---
<img src="https://huggingface.co/datasets/parler-tts/images/resolve/main/thumbnail.png" alt="Parler Logo" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Parler-TTS Mini v1
<a target="_blank" href="https://huggingface.co/spaces/parler-tts/parler_tts">
<img src="https://huggingface.co/datasets/huggingface/badges/raw/main/open-in-hf-spaces-sm.svg" alt="Open in HuggingFace"/>
</a>
**Parler-TTS Mini v1** is a lightweight text-to-speech (TTS) model, trained on 45K hours of audio data, that can generate high-quality, natural sounding speech with features that can be controlled using a simple text prompt (e.g. gender, background noise, speaking rate, pitch and reverberation).
With [Parler-TTS Large v1](https://huggingface.co/parler-tts/parler-tts-large-v1), this is the second set of models published as part of the [Parler-TTS](https://github.com/huggingface/parler-tts) project, which aims to provide the community with TTS training resources and dataset pre-processing code.
## 📖 Quick Index
* [👨💻 Installation](#👨💻-installation)
* [🎲 Using a random voice](#🎲-random-voice)
* [🎯 Using a specific speaker](#🎯-using-a-specific-speaker)
* [Motivation](#motivation)
* [Optimizing inference](https://github.com/huggingface/parler-tts/blob/main/INFERENCE.md)
## 🛠️ Usage
### 👨💻 Installation
Using Parler-TTS is as simple as "bonjour". Simply install the library once:
```sh
pip install git+https://github.com/huggingface/parler-tts.git
```
### 🎲 Random voice
**Parler-TTS** has been trained to generate speech with features that can be controlled with a simple text prompt, for example:
```py
import torch
from parler_tts import ParlerTTSForConditionalGeneration
from transformers import AutoTokenizer
import soundfile as sf
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = ParlerTTSForConditionalGeneration.from_pretrained("parler-tts/parler-tts-mini-v1").to(device)
tokenizer = AutoTokenizer.from_pretrained("parler-tts/parler-tts-mini-v1")
prompt = "Hey, how are you doing today?"
description = "A female speaker delivers a slightly expressive and animated speech with a moderate speed and pitch. The recording is of very high quality, with the speaker's voice sounding clear and very close up."
input_ids = tokenizer(description, return_tensors="pt").input_ids.to(device)
prompt_input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
generation = model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().numpy().squeeze()
sf.write("parler_tts_out.wav", audio_arr, model.config.sampling_rate)
```
### 🎯 Using a specific speaker
To ensure speaker consistency across generations, this checkpoint was also trained on 34 speakers, characterized by name (e.g. Jon, Lea, Gary, Jenna, Mike, Laura).
To take advantage of this, simply adapt your text description to specify which speaker to use: `Jon's voice is monotone yet slightly fast in delivery, with a very close recording that almost has no background noise.`
```py
import torch
from parler_tts import ParlerTTSForConditionalGeneration
from transformers import AutoTokenizer
import soundfile as sf
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = ParlerTTSForConditionalGeneration.from_pretrained("parler-tts/parler-tts-mini-v1").to(device)
tokenizer = AutoTokenizer.from_pretrained("parler-tts/parler-tts-mini-v1")
prompt = "Hey, how are you doing today?"
description = "Jon's voice is monotone yet slightly fast in delivery, with a very close recording that almost has no background noise."
input_ids = tokenizer(description, return_tensors="pt").input_ids.to(device)
prompt_input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
generation = model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().numpy().squeeze()
sf.write("parler_tts_out.wav", audio_arr, model.config.sampling_rate)
```
**Tips**:
* We've set up an [inference guide](https://github.com/huggingface/parler-tts/blob/main/INFERENCE.md) to make generation faster. Think SDPA, torch.compile, batching and streaming!
* Include the term "very clear audio" to generate the highest quality audio, and "very noisy audio" for high levels of background noise
* Punctuation can be used to control the prosody of the generations, e.g. use commas to add small breaks in speech
* The remaining speech features (gender, speaking rate, pitch and reverberation) can be controlled directly through the prompt
## Motivation
Parler-TTS is a reproduction of work from the paper [Natural language guidance of high-fidelity text-to-speech with synthetic annotations](https://www.text-description-to-speech.com) by Dan Lyth and Simon King, from Stability AI and Edinburgh University respectively.
Contrarily to other TTS models, Parler-TTS is a **fully open-source** release. All of the datasets, pre-processing, training code and weights are released publicly under permissive license, enabling the community to build on our work and develop their own powerful TTS models.
Parler-TTS was released alongside:
* [The Parler-TTS repository](https://github.com/huggingface/parler-tts) - you can train and fine-tuned your own version of the model.
* [The Data-Speech repository](https://github.com/huggingface/dataspeech) - a suite of utility scripts designed to annotate speech datasets.
* [The Parler-TTS organization](https://huggingface.co/parler-tts) - where you can find the annotated datasets as well as the future checkpoints.
## Citation
If you found this repository useful, please consider citing this work and also the original Stability AI paper:
```
@misc{lacombe-etal-2024-parler-tts,
author = {Yoach Lacombe and Vaibhav Srivastav and Sanchit Gandhi},
title = {Parler-TTS},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/parler-tts}}
}
```
```
@misc{lyth2024natural,
title={Natural language guidance of high-fidelity text-to-speech with synthetic annotations},
author={Dan Lyth and Simon King},
year={2024},
eprint={2402.01912},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
```
## License
This model is permissively licensed under the Apache 2.0 license. |
DevQuasar/tiiuae.Falcon3-1B-Instruct-GGUF | DevQuasar | "2025-02-01T23:11:58Z" | 29 | 0 | null | [
"gguf",
"text-generation",
"base_model:tiiuae/Falcon3-1B-Instruct",
"base_model:quantized:tiiuae/Falcon3-1B-Instruct",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | "2024-12-17T16:03:14Z" | ---
base_model:
- tiiuae/Falcon3-1B-Instruct
pipeline_tag: text-generation
---
[<img src="https://raw.githubusercontent.com/csabakecskemeti/devquasar/main/dq_logo_black-transparent.png" width="200"/>](https://devquasar.com)
'Make knowledge free for everyone'
Quantized version of: [tiiuae/Falcon3-1B-Instruct](https://huggingface.co/tiiuae/Falcon3-1B-Instruct)
<a href='https://ko-fi.com/L4L416YX7C' target='_blank'><img height='36' style='border:0px;height:36px;' src='https://storage.ko-fi.com/cdn/kofi6.png?v=6' border='0' alt='Buy Me a Coffee at ko-fi.com' /></a>
|
abdeljalilELmajjodi/Arabic-question-classifier | abdeljalilELmajjodi | "2025-03-18T22:36:46Z" | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2025-03-18T22:35:57Z" | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
FounderOfHuggingface/gpt2_lora_dbpedia_14_t18_e5_member_shadow24 | FounderOfHuggingface | "2024-01-11T08:45:57Z" | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:openai-community/gpt2",
"base_model:adapter:openai-community/gpt2",
"region:us"
] | null | "2024-01-11T08:45:54Z" | ---
library_name: peft
base_model: gpt2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.7.1 |
Subsets and Splits