
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
yichengup/flux.1-fill-dev-OneReward
|
yichengup
| 2025-09-18T14:55:51Z | 50 | 37 | null |
[
"image-to-image",
"en",
"arxiv:2508.21066",
"base_model:black-forest-labs/FLUX.1-Fill-dev",
"base_model:finetune:black-forest-labs/FLUX.1-Fill-dev",
"license:cc-by-nc-4.0",
"region:us"
] |
image-to-image
| 2025-09-10T16:23:23Z |
---
license: cc-by-nc-4.0
base_model:
- black-forest-labs/FLUX.1-Fill-dev
- bytedance-research/OneReward
language:
- en
pipeline_tag: image-to-image
---
# OneReward - ComfyUI
[](https://arxiv.org/abs/2508.21066) [](https://github.com/bytedance/OneReward) [](https://one-reward.github.io/)
<br>
This repo contains the checkpoint from [OneReward](https://huggingface.co/bytedance-research/OneReward) processed into a single model suitable for ComfyUI use.
**OneReward** is a novel RLHF methodology for the visual domain by employing Qwen2.5-VL as a generative reward model to enhance multitask reinforcement learning, significantly improving the policy model’s generation ability across multiple subtask. Building on OneReward, **FLUX.1-Fill-dev-OneReward** - based on FLUX Fill [dev], outperforms closed-source FLUX Fill [Pro] in inpainting and outpainting tasks, serving as a powerful new baseline for future research in unified image editing.
For more details and examples see original model repo: [**OneReward**](https://huggingface.co/bytedance-research/OneReward)
|
zak90zakarezohra/MyGemmaNPC
|
zak90zakarezohra
| 2025-09-18T14:54:01Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-18T14:29:57Z |
---
base_model: google/gemma-3-270m-it
library_name: transformers
model_name: MyGemmaNPC
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for MyGemmaNPC
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="zak90zakarezohra/MyGemmaNPC", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0
- Transformers: 4.56.1
- Pytorch: 2.8.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
aamijar/ReplaceME-Llama-3.1-8B-Instruct-lora-r8-winogrande
|
aamijar
| 2025-09-18T14:53:31Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-18T14:53:29Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
aamijar/ReplaceME-Llama-3.1-8B-Instruct-lora-r8-winogrande-epochs4
|
aamijar
| 2025-09-18T14:53:29Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-18T14:53:27Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
AverX2309/my-gemma-agri-chatbot
|
AverX2309
| 2025-09-18T14:53:29Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-18T14:53:23Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
outlookAi/WhSoxIKNLg
|
outlookAi
| 2025-09-18T14:52:30Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-09-18T14:34:45Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: Yunjingx
---
# Whsoxiknlg
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `Yunjingx` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "Yunjingx",
"lora_weights": "https://huggingface.co/outlookAi/WhSoxIKNLg/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('outlookAi/WhSoxIKNLg', weight_name='lora.safetensors')
image = pipeline('Yunjingx').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1200
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/outlookAi/WhSoxIKNLg/discussions) to add images that show off what you’ve made with this LoRA.
|
david4096/EDAM-all-MiniLM-L6-v2_concat_e256-i
|
david4096
| 2025-09-18T14:52:21Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"biomedical",
"biomedical-ontology",
"fusion-concat",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:52:18Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- biomedical
- biomedical-ontology
- fusion-concat
- gnn-gcn
- medium-ontology
---
# EDAM_all-MiniLM-L6-v2_concat_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: EDAM.owl
- **Domain**: biomedical
- **Ontology Concepts**: 3,511
- **Concept Alignment**: 3,511/3,511 (100.0%)
- **Fusion Method**: concat
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 3511
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.2 MB
- **Model Size**: 120.6 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Simple concatenation of text and ontological embeddings
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 3511 concepts → GNN → 64 output
- Fusion: concat → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('EDAM_all-MiniLM-L6-v2_concat_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: concat
Simple concatenation of text and ontology embeddings
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- Biomedical domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
alxzend/paligemma2-3b-pt-448-od-grounding
|
alxzend
| 2025-09-18T14:52:15Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/paligemma2-3b-pt-448",
"base_model:finetune:google/paligemma2-3b-pt-448",
"endpoints_compatible",
"region:us"
] | null | 2025-09-16T14:15:13Z |
---
base_model: google/paligemma2-3b-pt-448
library_name: transformers
model_name: paligemma2-3b-pt-448-od-grounding
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for paligemma2-3b-pt-448-od-grounding
This model is a fine-tuned version of [google/paligemma2-3b-pt-448](https://huggingface.co/google/paligemma2-3b-pt-448).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="alxzend/paligemma2-3b-pt-448-od-grounding", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0
- Transformers: 4.56.1
- Pytorch: 2.8.0+cu129
- Datasets: 4.1.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
david4096/EDAM-all-MiniLM-L6-v2_gated_e512-i
|
david4096
| 2025-09-18T14:52:12Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"biomedical",
"biomedical-ontology",
"fusion-gated",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:52:08Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- biomedical
- biomedical-ontology
- fusion-gated
- gnn-gcn
- medium-ontology
---
# EDAM_all-MiniLM-L6-v2_gated_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: EDAM.owl
- **Domain**: biomedical
- **Ontology Concepts**: 3,511
- **Concept Alignment**: 3,511/3,511 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 3511
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.2 MB
- **Model Size**: 120.7 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 3511 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('EDAM_all-MiniLM-L6-v2_gated_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- Biomedical domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/EDAM-all-MiniLM-L6-v2_attention_e1024-i
|
david4096
| 2025-09-18T14:52:01Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"biomedical",
"biomedical-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:51:56Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- biomedical
- biomedical-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# EDAM_all-MiniLM-L6-v2_attention_e1024
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: EDAM.owl
- **Domain**: biomedical
- **Ontology Concepts**: 3,511
- **Concept Alignment**: 3,511/3,511 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 3511
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.2 MB
- **Model Size**: 124.1 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 3511 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('EDAM_all-MiniLM-L6-v2_attention_e1024')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- Biomedical domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/EDAM-all-MiniLM-L6-v2_attention_e256-i
|
david4096
| 2025-09-18T14:51:50Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"biomedical",
"biomedical-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:51:44Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- biomedical
- biomedical-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# EDAM_all-MiniLM-L6-v2_attention_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: EDAM.owl
- **Domain**: biomedical
- **Ontology Concepts**: 3,511
- **Concept Alignment**: 3,511/3,511 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 3511
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.2 MB
- **Model Size**: 124.1 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 3511 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('EDAM_all-MiniLM-L6-v2_attention_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- Biomedical domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/EDAM-all-MiniLM-L6-v2_attention_e512-i
|
david4096
| 2025-09-18T14:51:50Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"biomedical",
"biomedical-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:51:44Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- biomedical
- biomedical-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# EDAM_all-MiniLM-L6-v2_attention_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: EDAM.owl
- **Domain**: biomedical
- **Ontology Concepts**: 3,511
- **Concept Alignment**: 3,511/3,511 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 3511
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.2 MB
- **Model Size**: 124.1 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 3511 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('EDAM_all-MiniLM-L6-v2_attention_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- Biomedical domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
mradermacher/Hala-1.2B-i1-GGUF
|
mradermacher
| 2025-09-18T14:51:04Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"ar",
"dataset:hammh0a/Hala-4.6M-SFT",
"base_model:hammh0a/Hala-1.2B",
"base_model:quantized:hammh0a/Hala-1.2B",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-18T13:18:35Z |
---
base_model: hammh0a/Hala-1.2B
datasets:
- hammh0a/Hala-4.6M-SFT
language:
- ar
library_name: transformers
license: cc-by-nc-4.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/hammh0a/Hala-1.2B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Hala-1.2B-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/Hala-1.2B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-IQ1_S.gguf) | i1-IQ1_S | 0.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-IQ1_M.gguf) | i1-IQ1_M | 0.4 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-IQ2_S.gguf) | i1-IQ2_S | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-IQ2_M.gguf) | i1-IQ2_M | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 0.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-Q2_K.gguf) | i1-Q2_K | 0.6 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 0.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-IQ3_S.gguf) | i1-IQ3_S | 0.7 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 0.7 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-IQ3_M.gguf) | i1-IQ3_M | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 0.7 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 0.7 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-IQ4_NL.gguf) | i1-IQ4_NL | 0.8 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-Q4_0.gguf) | i1-Q4_0 | 0.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 0.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 0.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-Q4_1.gguf) | i1-Q4_1 | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/Hala-1.2B-i1-GGUF/resolve/main/Hala-1.2B.i1-Q6_K.gguf) | i1-Q6_K | 1.1 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
nareshmlx/code-reviewer-opencv-checkpoints
|
nareshmlx
| 2025-09-18T14:48:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"unsloth",
"sft",
"trl",
"endpoints_compatible",
"region:us"
] | null | 2025-09-18T14:48:47Z |
---
base_model: unsloth/qwen2.5-coder-1.5b-instruct-bnb-4bit
library_name: transformers
model_name: outputs
tags:
- generated_from_trainer
- unsloth
- sft
- trl
licence: license
---
# Model Card for outputs
This model is a fine-tuned version of [unsloth/qwen2.5-coder-1.5b-instruct-bnb-4bit](https://huggingface.co/unsloth/qwen2.5-coder-1.5b-instruct-bnb-4bit).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.22.2
- Transformers: 4.55.4
- Pytorch: 2.8.0
- Datasets: 3.6.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
aochongoliverli/Qwen2.5-0.5B-math8k-distill-AM-Distill-Qwen-32B-16k-5epochs-5e-5lr-step400
|
aochongoliverli
| 2025-09-18T14:47:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-18T14:47:02Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
uMorit4/curadobia-llama
|
uMorit4
| 2025-09-18T14:46:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-18T11:39:18Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
nareshmlx/code-reviewer-opencv
|
nareshmlx
| 2025-09-18T14:44:45Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-18T14:42:27Z |
---
base_model: unsloth/qwen2.5-coder-1.5b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** nareshmlx
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-coder-1.5b-instruct-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
saysualp/send-money-qwen-25-7b
|
saysualp
| 2025-09-18T14:44:28Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:RedHatAI/Qwen2.5-7B-Instruct",
"base_model:finetune:RedHatAI/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-18T14:13:04Z |
---
base_model: RedHatAI/Qwen2.5-7B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** saysualp
- **License:** apache-2.0
- **Finetuned from model :** RedHatAI/Qwen2.5-7B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
david4096/aism-all-MiniLM-L6-v2_concat_e128-h
|
david4096
| 2025-09-18T14:44:21Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-concat",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:44:15Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-concat
- gnn-gcn
- medium-ontology
---
# aism_all-MiniLM-L6-v2_concat_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: aism.owl
- **Domain**: general
- **Ontology Concepts**: 8,540
- **Concept Alignment**: 8,540/8,540 (100.0%)
- **Fusion Method**: concat
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 8540
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 28.8 MB
- **Model Size**: 168.0 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Simple concatenation of text and ontological embeddings
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 8540 concepts → GNN → 64 output
- Fusion: concat → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('aism_all-MiniLM-L6-v2_concat_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: concat
Simple concatenation of text and ontology embeddings
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/aism-all-MiniLM-L6-v2_attention_e512-h
|
david4096
| 2025-09-18T14:43:19Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:43:14Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# aism_all-MiniLM-L6-v2_attention_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: aism.owl
- **Domain**: general
- **Ontology Concepts**: 8,540
- **Concept Alignment**: 8,540/8,540 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 8540
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 28.8 MB
- **Model Size**: 171.4 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 8540 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('aism_all-MiniLM-L6-v2_attention_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/aism-all-MiniLM-L6-v2_attention_e256-h
|
david4096
| 2025-09-18T14:43:17Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:43:09Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# aism_all-MiniLM-L6-v2_attention_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: aism.owl
- **Domain**: general
- **Ontology Concepts**: 8,540
- **Concept Alignment**: 8,540/8,540 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 8540
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 28.8 MB
- **Model Size**: 171.5 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 8540 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('aism_all-MiniLM-L6-v2_attention_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
mradermacher/Fleming-R1-32B-i1-GGUF
|
mradermacher
| 2025-09-18T14:43:15Z | 6,212 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:UbiquantAI/Fleming-R1-32B",
"base_model:quantized:UbiquantAI/Fleming-R1-32B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-17T22:53:45Z |
---
base_model: UbiquantAI/Fleming-R1-32B
language:
- en
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/UbiquantAI/Fleming-R1-32B/blob/main/LICENSE
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/UbiquantAI/Fleming-R1-32B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Fleming-R1-32B-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/Fleming-R1-32B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-IQ1_S.gguf) | i1-IQ1_S | 7.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-IQ1_M.gguf) | i1-IQ1_M | 8.1 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 9.1 | |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 10.1 | |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-IQ2_S.gguf) | i1-IQ2_S | 10.6 | |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-IQ2_M.gguf) | i1-IQ2_M | 11.5 | |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 11.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-Q2_K.gguf) | i1-Q2_K | 12.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 12.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 13.8 | |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 14.5 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-IQ3_S.gguf) | i1-IQ3_S | 14.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-IQ3_M.gguf) | i1-IQ3_M | 15.0 | |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 16.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 17.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 17.8 | |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-Q4_0.gguf) | i1-Q4_0 | 18.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 18.9 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 19.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-Q4_1.gguf) | i1-Q4_1 | 20.7 | |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 22.7 | |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 23.3 | |
| [GGUF](https://huggingface.co/mradermacher/Fleming-R1-32B-i1-GGUF/resolve/main/Fleming-R1-32B.i1-Q6_K.gguf) | i1-Q6_K | 27.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
david4096/aism-all-MiniLM-L6-v2_attention_e128-h
|
david4096
| 2025-09-18T14:43:05Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:42:58Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# aism_all-MiniLM-L6-v2_attention_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: aism.owl
- **Domain**: general
- **Ontology Concepts**: 8,540
- **Concept Alignment**: 8,540/8,540 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 8540
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 28.8 MB
- **Model Size**: 171.5 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 8540 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('aism_all-MiniLM-L6-v2_attention_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/agro-all-MiniLM-L6-v2_concat_e512-h
|
david4096
| 2025-09-18T14:42:28Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-concat",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:42:24Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-concat
- gnn-gcn
- medium-ontology
---
# agro_all-MiniLM-L6-v2_concat_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: agro.owl
- **Domain**: general
- **Ontology Concepts**: 4,162
- **Concept Alignment**: 4,162/4,162 (100.0%)
- **Fusion Method**: concat
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 4162
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 7.2 MB
- **Model Size**: 126.8 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Simple concatenation of text and ontological embeddings
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 4162 concepts → GNN → 64 output
- Fusion: concat → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('agro_all-MiniLM-L6-v2_concat_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: concat
Simple concatenation of text and ontology embeddings
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
Yntec/Atlas
|
Yntec
| 2025-09-18T14:42:20Z | 201 | 1 |
diffusers
|
[
"diffusers",
"safetensors",
"Fashion Design",
"Collage",
"Game",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"base_model:Yntec/FotoPhoto",
"base_model:finetune:Yntec/FotoPhoto",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-24T16:30:16Z |
---
language:
- en
license: creativeml-openrail-m
tags:
- Fashion Design
- Collage
- Game
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
base_model:
- Yntec/FotoPhoto
---
# Atlas
FotoPhoto with the Atlas LoRA baked in.
Samples and prompts:

Top left: best quality, masterpiece, burger, simple background
Top right: best quality, masterpiece, skaters shoes design, simple background
Bottom left: best quality, masterpiece, motorcycle design, simple background
Bottom right: best quality, masterpiece, sakura tree in a bottle, simple background
Original pages:
https://civitai.com/models/33036/atlas
https://huggingface.co/Yntec/FotoPhoto
|
david4096/agro-all-MiniLM-L6-v2_concat_e128-h
|
david4096
| 2025-09-18T14:41:58Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-concat",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:41:54Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-concat
- gnn-gcn
- medium-ontology
---
# agro_all-MiniLM-L6-v2_concat_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: agro.owl
- **Domain**: general
- **Ontology Concepts**: 4,162
- **Concept Alignment**: 4,162/4,162 (100.0%)
- **Fusion Method**: concat
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 4162
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 7.2 MB
- **Model Size**: 126.8 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Simple concatenation of text and ontological embeddings
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 4162 concepts → GNN → 64 output
- Fusion: concat → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('agro_all-MiniLM-L6-v2_concat_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: concat
Simple concatenation of text and ontology embeddings
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/agro-all-MiniLM-L6-v2_gated_e512-h
|
david4096
| 2025-09-18T14:41:35Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:41:31Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- medium-ontology
---
# agro_all-MiniLM-L6-v2_gated_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: agro.owl
- **Domain**: general
- **Ontology Concepts**: 4,162
- **Concept Alignment**: 4,162/4,162 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 4162
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 7.2 MB
- **Model Size**: 126.8 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 4162 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('agro_all-MiniLM-L6-v2_gated_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/agro-all-MiniLM-L6-v2_gated_e256-h
|
david4096
| 2025-09-18T14:41:30Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:41:26Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- medium-ontology
---
# agro_all-MiniLM-L6-v2_gated_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: agro.owl
- **Domain**: general
- **Ontology Concepts**: 4,162
- **Concept Alignment**: 4,162/4,162 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 4162
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 7.2 MB
- **Model Size**: 126.9 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 4162 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('agro_all-MiniLM-L6-v2_gated_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/agro-all-MiniLM-L6-v2_gated_e128-h
|
david4096
| 2025-09-18T14:41:25Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:41:21Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- medium-ontology
---
# agro_all-MiniLM-L6-v2_gated_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: agro.owl
- **Domain**: general
- **Ontology Concepts**: 4,162
- **Concept Alignment**: 4,162/4,162 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 4162
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 7.2 MB
- **Model Size**: 126.9 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 4162 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('agro_all-MiniLM-L6-v2_gated_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
ucfc2024/sophiavillabon390
|
ucfc2024
| 2025-09-18T14:41:22Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-09-18T14:01:17Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
alikhademi98/medical_question_answerig_Qwen2.5-3B-Instruct_qlora
|
alikhademi98
| 2025-09-18T14:41:20Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qa",
"questionanswering",
"qlora",
"Qwen/Qwen2.5-3B-Instruct",
"llm",
"text-generation",
"conversational",
"fa",
"dataset:aictsharif/persian-med-qa",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-3B-Instruct",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-18T14:29:54Z |
---
library_name: transformers
tags:
- qa
- questionanswering
- qlora
- Qwen/Qwen2.5-3B-Instruct
- llm
license: mit
datasets:
- aictsharif/persian-med-qa
language:
- fa
base_model:
- Qwen/Qwen2.5-3B-Instruct
pipeline_tag: text-generation
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This model answers users' medical questions in Persian.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This model answers users' medical questions in Persian. The base model is the Qwen/Qwen2.5-3B-Instruct model, which is fine-tuned using the QLoRA method on the aictsharif/persian-med-qa dataset. Only the first 3000 data points are used in the fine-tuning.
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
This model is designed to answer users' medical questions in Persian.
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
This model is fine-tuned with limited data and may not provide adequate answers to some specialized questions.
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
aictsharif/persian-med-qa
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
training_args = TrainingArguments(
num_train_epochs=5,
learning_rate=5e-4,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
logging_steps=20,
save_strategy="epoch",
report_to="tensorboard",
output_dir="/kaggle/working/",
save_total_limit=3,
fp16=True,
bf16=False
)
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
چگونه فشار خون را کنترل کنیم؟
کنترل فشار خون شامل تغییرات در رژیم غذایی، ورزش، کنترل استرس و در برخی موارد دارو است. برای کنترل فشار خون، میتوان از رژیم غذایی سالم، ورزش منظم، کنترل استرس و در برخی موارد دارو استفاده کرد.
1. رژیم غذایی سالم: میتوان از غ
سوال: علائم آنفولانزا چیست؟
جواب: علائم آنفولانزا شامل تب، سرفه، گلودنی چاقی، خستگی و درد مفاصل است. این علامتها ممکن است بسیار شدید باشد. این بیماری معمولاً ۲ تا ۵ روز طول میکند. اگر علائم شدید یا استرسآور باشد، میتواند نیاز به مشاورههای پ
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
supermanaff/Affine-5FC1Dq1kdHAGmrEkSCLwEKeNM7i9YY6rXtZKaLM2q4qaAE6b
|
supermanaff
| 2025-09-18T14:41:16Z | 189 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_next",
"text-generation",
"conversational",
"arxiv:2309.00071",
"arxiv:2404.06654",
"arxiv:2505.09388",
"arxiv:2501.15383",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-12T01:34:08Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct/blob/main/LICENSE
pipeline_tag: text-generation
---
# Qwen3-Next-80B-A3B-Instruct
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
Over the past few months, we have observed increasingly clear trends toward scaling both total parameters and context lengths in the pursuit of more powerful and agentic artificial intelligence (AI).
We are excited to share our latest advancements in addressing these demands, centered on improving scaling efficiency through innovative model architecture.
We call this next-generation foundation model **Qwen3-Next**.
## Highlights
**Qwen3-Next-80B-A3B** is the first installment in the Qwen3-Next series and features the following key enchancements:
- **Hybrid Attention**: Replaces standard attention with the combination of **Gated DeltaNet** and **Gated Attention**, enabling efficient context modeling for ultra-long context length.
- **High-Sparsity Mixture-of-Experts (MoE)**: Achieves an extreme low activation ratio in MoE layers, drastically reducing FLOPs per token while preserving model capacity.
- **Stability Optimizations**: Includes techniques such as **zero-centered and weight-decayed layernorm**, and other stabilizing enhancements for robust pre-training and post-training.
- **Multi-Token Prediction (MTP)**: Boosts pretraining model performance and accelerates inference.
We are seeing strong performance in terms of both parameter efficiency and inference speed for Qwen3-Next-80B-A3B:
- Qwen3-Next-80B-A3B-Base outperforms Qwen3-32B-Base on downstream tasks with 10% of the total training cost and with 10 times inference throughput for context over 32K tokens.
- Qwen3-Next-80B-A3B-Instruct performs on par with Qwen3-235B-A22B-Instruct-2507 on certain benchmarks, while demonstrating significant advantages in handling ultra-long-context tasks up to 256K tokens.
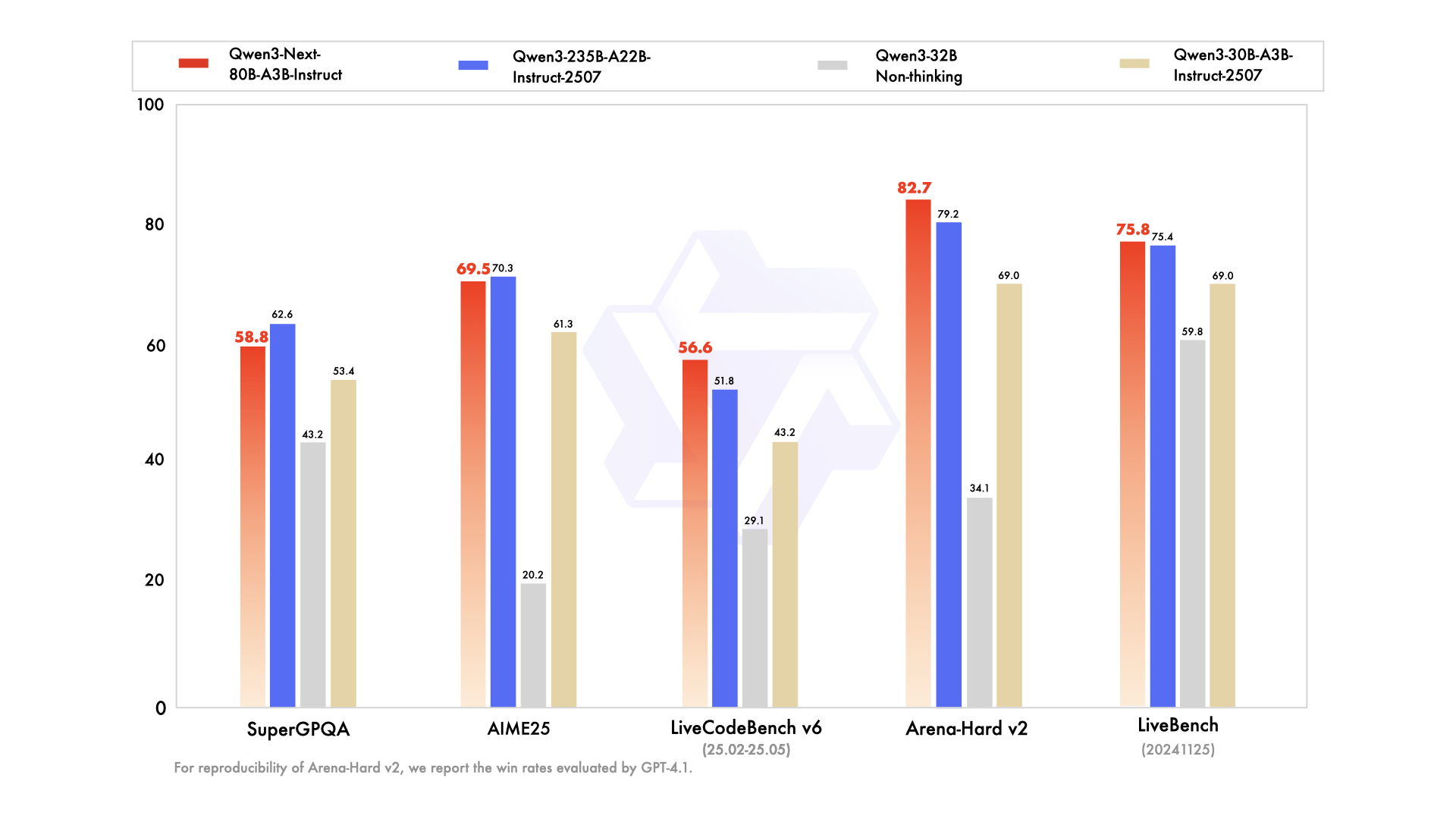
For more details, please refer to our blog post [Qwen3-Next](https://qwenlm.github.io/blog/qwen3_next/).
## Model Overview
> [!Note]
> **Qwen3-Next-80B-A3B-Instruct** supports only instruct (non-thinking) mode and does not generate ``<think></think>`` blocks in its output.
**Qwen3-Next-80B-A3B-Instruct** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining (15T tokens) & Post-training
- Number of Parameters: 80B in total and 3B activated
- Number of Paramaters (Non-Embedding): 79B
- Number of Layers: 48
- Hidden Dimension: 2048
- Hybrid Layout: 12 \* (3 \* (Gated DeltaNet -> MoE) -> (Gated Attention -> MoE))
- Gated Attention:
- Number of Attention Heads: 16 for Q and 2 for KV
- Head Dimension: 256
- Rotary Position Embedding Dimension: 64
- Gated DeltaNet:
- Number of Linear Attention Heads: 32 for V and 16 for QK
- Head Dimension: 128
- Mixture of Experts:
- Number of Experts: 512
- Number of Activated Experts: 10
- Number of Shared Experts: 1
- Expert Intermediate Dimension: 512
- Context Length: 262,144 natively and extensible up to 1,010,000 tokens
<img src="https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3-Next/model_architecture.png" height="384px" title="Qwen3-Next Model Architecture" />
## Performance
| | Qwen3-30B-A3B-Instruct-2507 | Qwen3-32B Non-Thinking | Qwen3-235B-A22B-Instruct-2507 | Qwen3-Next-80B-A3B-Instruct |
|--- | --- | --- | --- | --- |
| **Knowledge** | | | | |
| MMLU-Pro | 78.4 | 71.9 | **83.0** | 80.6 |
| MMLU-Redux | 89.3 | 85.7 | **93.1** | 90.9 |
| GPQA | 70.4 | 54.6 | **77.5** | 72.9 |
| SuperGPQA | 53.4 | 43.2 | **62.6** | 58.8 |
| **Reasoning** | | | | |
| AIME25 | 61.3 | 20.2 | **70.3** | 69.5 |
| HMMT25 | 43.0 | 9.8 | **55.4** | 54.1 |
| LiveBench 20241125 | 69.0 | 59.8 | 75.4 | **75.8** |
| **Coding** | | | | |
| LiveCodeBench v6 (25.02-25.05) | 43.2 | 29.1 | 51.8 | **56.6** |
| MultiPL-E | 83.8 | 76.9 | **87.9** | 87.8 |
| Aider-Polyglot | 35.6 | 40.0 | **57.3** | 49.8 |
| **Alignment** | | | | |
| IFEval | 84.7 | 83.2 | **88.7** | 87.6 |
| Arena-Hard v2* | 69.0 | 34.1 | 79.2 | **82.7** |
| Creative Writing v3 | 86.0 | 78.3 | **87.5** | 85.3 |
| WritingBench | 85.5 | 75.4 | 85.2 | **87.3** |
| **Agent** | | | | |
| BFCL-v3 | 65.1 | 63.0 | **70.9** | 70.3 |
| TAU1-Retail | 59.1 | 40.1 | **71.3** | 60.9 |
| TAU1-Airline | 40.0 | 17.0 | **44.0** | 44.0 |
| TAU2-Retail | 57.0 | 48.8 | **74.6** | 57.3 |
| TAU2-Airline | 38.0 | 24.0 | **50.0** | 45.5 |
| TAU2-Telecom | 12.3 | 24.6 | **32.5** | 13.2 |
| **Multilingualism** | | | | |
| MultiIF | 67.9 | 70.7 | **77.5** | 75.8 |
| MMLU-ProX | 72.0 | 69.3 | **79.4** | 76.7 |
| INCLUDE | 71.9 | 70.9 | **79.5** | 78.9 |
| PolyMATH | 43.1 | 22.5 | **50.2** | 45.9 |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
## Quickstart
The code for Qwen3-Next has been merged into the main branch of Hugging Face `transformers`.
```shell
pip install git+https://github.com/huggingface/transformers.git@main
```
With earlier versions, you will encounter the following error:
```
KeyError: 'qwen3_next'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto",
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
> [!Note]
> Multi-Token Prediction (MTP) is not generally available in Hugging Face Transformers.
> [!Note]
> The efficiency or throughput improvement depends highly on the implementation.
> It is recommended to adopt a dedicated inference framework, e.g., SGLang and vLLM, for inference tasks.
> [!Tip]
> Depending on the inference settings, you may observe better efficiency with [`flash-linear-attention`](https://github.com/fla-org/flash-linear-attention#installation) and [`causal-conv1d`](https://github.com/Dao-AILab/causal-conv1d).
> See the above links for detailed instructions and requirements.
## Deployment
For deployment, you can use the latest `sglang` or `vllm` to create an OpenAI-compatible API endpoint.
### SGLang
[SGLang](https://github.com/sgl-project/sglang) is a fast serving framework for large language models and vision language models.
SGLang could be used to launch a server with OpenAI-compatible API service.
SGLang has supported Qwen3-Next in its `main` branch, which can be installed from source:
```shell
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'
```
The following command can be used to create an API endpoint at `http://localhost:30000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
```
> [!Note]
> The environment variable `SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1` is required at the moment.
> [!Note]
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fail to start.
### vLLM
[vLLM](https://github.com/vllm-project/vllm) is a high-throughput and memory-efficient inference and serving engine for LLMs.
vLLM could be used to launch a server with OpenAI-compatible API service.
vLLM has supported Qwen3-Next in its `main` branch, which can be installed from source:
```shell
pip install git+https://github.com/vllm-project/vllm.git
```
The following command can be used to create an API endpoint at `http://localhost:8000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
```
> [!Note]
> The environment variable `VLLM_ALLOW_LONG_MAX_MODEL_LEN=1` is required at the moment.
> [!Note]
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fail to start.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Instruct',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
Qwen3-Next natively supports context lengths of up to 262,144 tokens.
For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively.
We have validated the model's performance on context lengths of up to 1 million tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers`, `vllm` and `sglang`.
In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 262144
}
}
```
- Passing command line arguments:
For `vllm`, you can use
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' --max-model-len 1010000
```
For `sglang`, you can use
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}}' --context-length 1010000
```
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 524,288 tokens, it would be better to set `factor` as 2.0.
#### Long-Context Performance
We test the model on an 1M version of the [RULER](https://arxiv.org/abs/2404.06654) benchmark.
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---------------------------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|-------|
| Qwen3-30B-A3B-Instruct-2507 | 86.8 | 98.0 | 96.7 | 96.9 | 97.2 | 93.4 | 91.0 | 89.1 | 89.8 | 82.5 | 83.6 | 78.4 | 79.7 | 77.6 | 75.7 | 72.8 |
| Qwen3-235B-A22B-Instruct-2507 | 92.5 | 98.5 | 97.6 | 96.9 | 97.3 | 95.8 | 94.9 | 93.9 | 94.5 | 91.0 | 92.2 | 90.9 | 87.8 | 84.8 | 86.5 | 84.5 |
| Qwen3-Next-80B-A3B-Instruct | 91.8 | 98.5 | 99.0 | 98.0 | 98.7 | 97.6 | 95.0 | 96.0 | 94.0 | 93.5 | 91.7 | 86.9 | 85.5 | 81.7 | 80.3 | 80.3 |
* Qwen3-Next are evaluated with YaRN enabled. Qwen3-2507 models are evaluated with Dual Chunk Attention enabled.
* Since the evaluation is time-consuming, we use 260 samples for each length (13 sub-tasks, 20 samples for each)
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{qwen2.5-1m,
title={Qwen2.5-1M Technical Report},
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
journal={arXiv preprint arXiv:2501.15383},
year={2025}
}
```
|
david4096/agro-all-MiniLM-L6-v2_attention_e128-h
|
david4096
| 2025-09-18T14:41:09Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:41:05Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# agro_all-MiniLM-L6-v2_attention_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: agro.owl
- **Domain**: general
- **Ontology Concepts**: 4,162
- **Concept Alignment**: 4,162/4,162 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 4162
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 7.2 MB
- **Model Size**: 130.2 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 4162 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('agro_all-MiniLM-L6-v2_attention_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/afpo-all-MiniLM-L6-v2_concat_e128-h
|
david4096
| 2025-09-18T14:40:36Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-concat",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:40:34Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-concat
- gnn-gcn
- small-ontology
---
# afpo_all-MiniLM-L6-v2_concat_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: afpo.owl
- **Domain**: general
- **Ontology Concepts**: 473
- **Concept Alignment**: 473/473 (100.0%)
- **Fusion Method**: concat
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 473
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 1.3 MB
- **Model Size**: 92.0 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Simple concatenation of text and ontological embeddings
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 473 concepts → GNN → 64 output
- Fusion: concat → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('afpo_all-MiniLM-L6-v2_concat_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: concat
Simple concatenation of text and ontology embeddings
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/afpo-all-MiniLM-L6-v2_gated_e256-h
|
david4096
| 2025-09-18T14:40:21Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:40:18Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- small-ontology
---
# afpo_all-MiniLM-L6-v2_gated_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: afpo.owl
- **Domain**: general
- **Ontology Concepts**: 473
- **Concept Alignment**: 473/473 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 473
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 1.3 MB
- **Model Size**: 92.1 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 473 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('afpo_all-MiniLM-L6-v2_gated_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/afpo-all-MiniLM-L6-v2_gated_e128-h
|
david4096
| 2025-09-18T14:40:18Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:40:15Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- small-ontology
---
# afpo_all-MiniLM-L6-v2_gated_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: afpo.owl
- **Domain**: general
- **Ontology Concepts**: 473
- **Concept Alignment**: 473/473 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 473
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 1.3 MB
- **Model Size**: 92.1 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 473 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('afpo_all-MiniLM-L6-v2_gated_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/afpo-all-MiniLM-L6-v2_attention_e512-h
|
david4096
| 2025-09-18T14:40:11Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:40:08Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- small-ontology
---
# afpo_all-MiniLM-L6-v2_attention_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: afpo.owl
- **Domain**: general
- **Ontology Concepts**: 473
- **Concept Alignment**: 473/473 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 473
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 1.3 MB
- **Model Size**: 95.5 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 473 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('afpo_all-MiniLM-L6-v2_attention_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
sykim3714/llama3-8b-sft-qlora-re
|
sykim3714
| 2025-09-18T14:40:10Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:meta-llama/Meta-Llama-3-8B",
"base_model:finetune:meta-llama/Meta-Llama-3-8B",
"endpoints_compatible",
"region:us"
] | null | 2025-08-30T14:15:12Z |
---
base_model: meta-llama/Meta-Llama-3-8B
library_name: transformers
model_name: llama3-8b-sft-qlora-re
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for llama3-8b-sft-qlora-re
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="sykim3714/llama3-8b-sft-qlora-re", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0
- Transformers: 4.56.1
- Pytorch: 2.8.0+cu126
- Datasets: 4.1.1
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
gigant/bytes-tokenizer
|
gigant
| 2025-09-18T14:40:04Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2025-09-18T14:07:01Z |
---
license: mit
---
```python
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_file(tokenizer_path)
```
|
ethanCSL/svla_single_stamp
|
ethanCSL
| 2025-09-18T14:39:49Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"smolvla",
"dataset:ethanCSL/smolvla_single_stamp",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-18T14:38:49Z |
---
base_model: lerobot/smolvla_base
datasets: ethanCSL/smolvla_single_stamp
library_name: lerobot
license: apache-2.0
model_name: smolvla
pipeline_tag: robotics
tags:
- robotics
- smolvla
- lerobot
---
# Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
lerobot-record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
david4096/ado-all-MiniLM-L6-v2_concat_e512-h
|
david4096
| 2025-09-18T14:39:40Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-concat",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:39:37Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-concat
- gnn-gcn
- medium-ontology
---
# ado_all-MiniLM-L6-v2_concat_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: ado.owl
- **Domain**: general
- **Ontology Concepts**: 1,963
- **Concept Alignment**: 1,963/1,963 (100.0%)
- **Fusion Method**: concat
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1963
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 5.2 MB
- **Model Size**: 106.1 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Simple concatenation of text and ontological embeddings
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1963 concepts → GNN → 64 output
- Fusion: concat → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('ado_all-MiniLM-L6-v2_concat_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: concat
Simple concatenation of text and ontology embeddings
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
ucfc2024/vanessamunoz394
|
ucfc2024
| 2025-09-18T14:39:33Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-09-18T13:58:31Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
david4096/ado-all-MiniLM-L6-v2_concat_e128-h
|
david4096
| 2025-09-18T14:39:24Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-concat",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:39:21Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-concat
- gnn-gcn
- medium-ontology
---
# ado_all-MiniLM-L6-v2_concat_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: ado.owl
- **Domain**: general
- **Ontology Concepts**: 1,963
- **Concept Alignment**: 1,963/1,963 (100.0%)
- **Fusion Method**: concat
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1963
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 5.2 MB
- **Model Size**: 106.1 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Simple concatenation of text and ontological embeddings
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1963 concepts → GNN → 64 output
- Fusion: concat → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('ado_all-MiniLM-L6-v2_concat_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: concat
Simple concatenation of text and ontology embeddings
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/ado-all-MiniLM-L6-v2_concat_e256-h
|
david4096
| 2025-09-18T14:39:17Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-concat",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:39:15Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-concat
- gnn-gcn
- medium-ontology
---
# ado_all-MiniLM-L6-v2_concat_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: ado.owl
- **Domain**: general
- **Ontology Concepts**: 1,963
- **Concept Alignment**: 1,963/1,963 (100.0%)
- **Fusion Method**: concat
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1963
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 5.2 MB
- **Model Size**: 106.1 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Simple concatenation of text and ontological embeddings
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1963 concepts → GNN → 64 output
- Fusion: concat → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('ado_all-MiniLM-L6-v2_concat_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: concat
Simple concatenation of text and ontology embeddings
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
longbao128/gemma-4b-dengue-diagnosis
|
longbao128
| 2025-09-18T14:39:14Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3-4b-it",
"base_model:finetune:google/gemma-3-4b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-09-18T14:26:53Z |
---
base_model: google/gemma-3-4b-it
library_name: transformers
model_name: gemma-4b-dengue-diagnosis
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-4b-dengue-diagnosis
This model is a fine-tuned version of [google/gemma-3-4b-it](https://huggingface.co/google/gemma-3-4b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="longbao128/gemma-4b-dengue-diagnosis", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0
- Transformers: 4.56.1
- Pytorch: 2.8.0+cu126
- Datasets: 4.1.1
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
david4096/ado-all-MiniLM-L6-v2_gated_e512-h
|
david4096
| 2025-09-18T14:39:09Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:39:06Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- medium-ontology
---
# ado_all-MiniLM-L6-v2_gated_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: ado.owl
- **Domain**: general
- **Ontology Concepts**: 1,963
- **Concept Alignment**: 1,963/1,963 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1963
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 5.2 MB
- **Model Size**: 106.2 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1963 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('ado_all-MiniLM-L6-v2_gated_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/ado-all-MiniLM-L6-v2_gated_e128-h
|
david4096
| 2025-09-18T14:39:00Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:38:57Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- medium-ontology
---
# ado_all-MiniLM-L6-v2_gated_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: ado.owl
- **Domain**: general
- **Ontology Concepts**: 1,963
- **Concept Alignment**: 1,963/1,963 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1963
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 5.2 MB
- **Model Size**: 106.2 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1963 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('ado_all-MiniLM-L6-v2_gated_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/ado-all-MiniLM-L6-v2_attention_e512-h
|
david4096
| 2025-09-18T14:38:56Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:38:52Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# ado_all-MiniLM-L6-v2_attention_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: ado.owl
- **Domain**: general
- **Ontology Concepts**: 1,963
- **Concept Alignment**: 1,963/1,963 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1963
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 5.2 MB
- **Model Size**: 109.5 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1963 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('ado_all-MiniLM-L6-v2_attention_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/ado-all-MiniLM-L6-v2_attention_e256-h
|
david4096
| 2025-09-18T14:38:51Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:38:48Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# ado_all-MiniLM-L6-v2_attention_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: ado.owl
- **Domain**: general
- **Ontology Concepts**: 1,963
- **Concept Alignment**: 1,963/1,963 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1963
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 5.2 MB
- **Model Size**: 109.5 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1963 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('ado_all-MiniLM-L6-v2_attention_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
ucfc2024/zulaycervantes384
|
ucfc2024
| 2025-09-18T14:38:50Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-09-18T13:59:32Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
david4096/ado-all-MiniLM-L6-v2_attention_e128-h
|
david4096
| 2025-09-18T14:38:46Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:38:43Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# ado_all-MiniLM-L6-v2_attention_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: ado.owl
- **Domain**: general
- **Ontology Concepts**: 1,963
- **Concept Alignment**: 1,963/1,963 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1963
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 5.2 MB
- **Model Size**: 109.6 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1963 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('ado_all-MiniLM-L6-v2_attention_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
OxoGhost/ppo-SnowballTaret
|
OxoGhost
| 2025-09-18T14:38:36Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2025-09-18T14:38:31Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: OxoGhost/ppo-SnowballTaret
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
david4096/EDAM-all-MiniLM-L6-v2_concat_e128-h
|
david4096
| 2025-09-18T14:37:58Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"biomedical",
"biomedical-ontology",
"fusion-concat",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:37:54Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- biomedical
- biomedical-ontology
- fusion-concat
- gnn-gcn
- medium-ontology
---
# EDAM_all-MiniLM-L6-v2_concat_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: EDAM.owl
- **Domain**: biomedical
- **Ontology Concepts**: 3,511
- **Concept Alignment**: 3,511/3,511 (100.0%)
- **Fusion Method**: concat
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 3511
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.2 MB
- **Model Size**: 120.6 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Simple concatenation of text and ontological embeddings
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 3511 concepts → GNN → 64 output
- Fusion: concat → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('EDAM_all-MiniLM-L6-v2_concat_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: concat
Simple concatenation of text and ontology embeddings
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- Biomedical domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/EDAM-all-MiniLM-L6-v2_concat_e256-h
|
david4096
| 2025-09-18T14:37:45Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"biomedical",
"biomedical-ontology",
"fusion-concat",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:37:42Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- biomedical
- biomedical-ontology
- fusion-concat
- gnn-gcn
- medium-ontology
---
# EDAM_all-MiniLM-L6-v2_concat_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: EDAM.owl
- **Domain**: biomedical
- **Ontology Concepts**: 3,511
- **Concept Alignment**: 3,511/3,511 (100.0%)
- **Fusion Method**: concat
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 3511
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.2 MB
- **Model Size**: 120.6 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Simple concatenation of text and ontological embeddings
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 3511 concepts → GNN → 64 output
- Fusion: concat → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('EDAM_all-MiniLM-L6-v2_concat_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: concat
Simple concatenation of text and ontology embeddings
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- Biomedical domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/EDAM-all-MiniLM-L6-v2_gated_e512-h
|
david4096
| 2025-09-18T14:37:35Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"biomedical",
"biomedical-ontology",
"fusion-gated",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:37:32Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- biomedical
- biomedical-ontology
- fusion-gated
- gnn-gcn
- medium-ontology
---
# EDAM_all-MiniLM-L6-v2_gated_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: EDAM.owl
- **Domain**: biomedical
- **Ontology Concepts**: 3,511
- **Concept Alignment**: 3,511/3,511 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 3511
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.2 MB
- **Model Size**: 120.7 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 3511 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('EDAM_all-MiniLM-L6-v2_gated_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- Biomedical domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/EDAM-all-MiniLM-L6-v2_attention_e512-h
|
david4096
| 2025-09-18T14:37:25Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"biomedical",
"biomedical-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:37:19Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- biomedical
- biomedical-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# EDAM_all-MiniLM-L6-v2_attention_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: EDAM.owl
- **Domain**: biomedical
- **Ontology Concepts**: 3,511
- **Concept Alignment**: 3,511/3,511 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 3511
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.2 MB
- **Model Size**: 124.1 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 3511 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('EDAM_all-MiniLM-L6-v2_attention_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- Biomedical domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
ucfc2024/juliethmatta397
|
ucfc2024
| 2025-09-18T14:37:21Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-09-18T13:57:26Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
david4096/EDAM-all-MiniLM-L6-v2_attention_e256-h
|
david4096
| 2025-09-18T14:36:27Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"biomedical",
"biomedical-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:36:21Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- biomedical
- biomedical-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# EDAM_all-MiniLM-L6-v2_attention_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: EDAM.owl
- **Domain**: biomedical
- **Ontology Concepts**: 3,511
- **Concept Alignment**: 3,511/3,511 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 3511
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.2 MB
- **Model Size**: 124.1 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 3511 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('EDAM_all-MiniLM-L6-v2_attention_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- Biomedical domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/EDAM-all-MiniLM-L6-v2_attention_e128-h
|
david4096
| 2025-09-18T14:36:27Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"biomedical",
"biomedical-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:36:21Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- biomedical
- biomedical-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# EDAM_all-MiniLM-L6-v2_attention_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: EDAM.owl
- **Domain**: biomedical
- **Ontology Concepts**: 3,511
- **Concept Alignment**: 3,511/3,511 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 3511
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.2 MB
- **Model Size**: 124.1 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 3511 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('EDAM_all-MiniLM-L6-v2_attention_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- Biomedical domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
pjool/business-news-generator_highdecay
|
pjool
| 2025-09-18T14:36:25Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"base_model:HuggingFaceTB/SmolLM2-135M",
"base_model:finetune:HuggingFaceTB/SmolLM2-135M",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-18T14:25:24Z |
---
library_name: transformers
license: apache-2.0
base_model: HuggingFaceTB/SmolLM2-135M
tags:
- generated_from_trainer
model-index:
- name: business-news-generator_highdecay
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# business-news-generator_highdecay
This model is a fine-tuned version of [HuggingFaceTB/SmolLM2-135M](https://huggingface.co/HuggingFaceTB/SmolLM2-135M) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.1988
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.2011 | 0.32 | 200 | 3.4175 |
| 2.9706 | 0.64 | 400 | 3.3964 |
| 2.8137 | 0.96 | 600 | 3.2528 |
| 1.7773 | 1.28 | 800 | 3.2788 |
| 1.5714 | 1.6 | 1000 | 3.2202 |
| 1.4898 | 1.92 | 1200 | 3.1988 |
### Framework versions
- Transformers 4.56.1
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.22.0
|
david4096/duo-all-MiniLM-L6-v2_attention_e128
|
david4096
| 2025-09-18T14:35:04Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:34:59Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- small-ontology
---
# duo_all-MiniLM-L6-v2_attention_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: duo.owl
- **Domain**: general
- **Ontology Concepts**: 45
- **Concept Alignment**: 45/45 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 45
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.1 MB
- **Model Size**: 91.5 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 45 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('duo_all-MiniLM-L6-v2_attention_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/dpo-all-MiniLM-L6-v2_gated_e256
|
david4096
| 2025-09-18T14:34:46Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:34:42Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- medium-ontology
---
# dpo_all-MiniLM-L6-v2_gated_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: dpo.owl
- **Domain**: general
- **Ontology Concepts**: 1,381
- **Concept Alignment**: 1,381/1,381 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1381
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.5 MB
- **Model Size**: 100.7 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1381 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('dpo_all-MiniLM-L6-v2_gated_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/dpo-all-MiniLM-L6-v2_gated_e128
|
david4096
| 2025-09-18T14:34:27Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:34:22Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- medium-ontology
---
# dpo_all-MiniLM-L6-v2_gated_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: dpo.owl
- **Domain**: general
- **Ontology Concepts**: 1,381
- **Concept Alignment**: 1,381/1,381 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1381
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.5 MB
- **Model Size**: 100.7 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1381 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('dpo_all-MiniLM-L6-v2_gated_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/doid-all-MiniLM-L6-v2_gated_e512
|
david4096
| 2025-09-18T14:34:25Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"large-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:34:14Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- large-ontology
---
# doid_all-MiniLM-L6-v2_gated_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: doid.owl
- **Domain**: general
- **Ontology Concepts**: 14,339
- **Concept Alignment**: 14,339/14,339 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 14339
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 26.1 MB
- **Model Size**: 222.6 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 14339 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('doid_all-MiniLM-L6-v2_gated_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/dpo-all-MiniLM-L6-v2_attention_e128
|
david4096
| 2025-09-18T14:33:18Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:33:14Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# dpo_all-MiniLM-L6-v2_attention_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: dpo.owl
- **Domain**: general
- **Ontology Concepts**: 1,381
- **Concept Alignment**: 1,381/1,381 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1381
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 3.5 MB
- **Model Size**: 104.0 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1381 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('dpo_all-MiniLM-L6-v2_attention_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/doid-all-MiniLM-L6-v2_gated_e256
|
david4096
| 2025-09-18T14:32:55Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"large-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:32:46Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- large-ontology
---
# doid_all-MiniLM-L6-v2_gated_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: doid.owl
- **Domain**: general
- **Ontology Concepts**: 14,339
- **Concept Alignment**: 14,339/14,339 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 14339
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 26.1 MB
- **Model Size**: 222.9 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 14339 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('doid_all-MiniLM-L6-v2_gated_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
ench100/bodyandface
|
ench100
| 2025-09-18T14:32:18Z | 2,720 | 1 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:lodestones/Chroma",
"base_model:adapter:lodestones/Chroma",
"region:us"
] |
text-to-image
| 2025-08-12T08:58:41Z |
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- output:
url: images/2.png
text: '-'
base_model: lodestones/Chroma
instance_prompt: null
---
# forME
<Gallery />
## Download model
[Download](/ench100/bodyandface/tree/main) them in the Files & versions tab.
|
Joselops/whisper-small-dali-small
|
Joselops
| 2025-09-18T14:31:07Z | 7 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:Joselops/DALI_medium",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-09-16T15:22:00Z |
---
library_name: transformers
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- Joselops/DALI_medium
model-index:
- name: Whisper Small - DALI_medium fine tuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small - DALI_medium fine tuned
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the DALI medium dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.56.1
- Pytorch 2.8.0+cu126
- Datasets 4.1.1
- Tokenizers 0.22.0
|
david4096/doid-all-MiniLM-L6-v2_gated_e128
|
david4096
| 2025-09-18T14:30:55Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"large-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:30:45Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- large-ontology
---
# doid_all-MiniLM-L6-v2_gated_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: doid.owl
- **Domain**: general
- **Ontology Concepts**: 14,339
- **Concept Alignment**: 14,339/14,339 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 14339
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 26.1 MB
- **Model Size**: 222.9 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 14339 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('doid_all-MiniLM-L6-v2_gated_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
cuadron11/bge-reranker-v2-m3-contrastive-berria-4-1ep
|
cuadron11
| 2025-09-18T14:30:07Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"xlm-roberta",
"cross-encoder",
"reranker",
"generated_from_trainer",
"dataset_size:3200",
"loss:CachedMultipleNegativesRankingLoss",
"text-ranking",
"arxiv:1908.10084",
"base_model:BAAI/bge-reranker-v2-m3",
"base_model:finetune:BAAI/bge-reranker-v2-m3",
"model-index",
"region:us"
] |
text-ranking
| 2025-09-18T14:29:38Z |
---
tags:
- sentence-transformers
- cross-encoder
- reranker
- generated_from_trainer
- dataset_size:3200
- loss:CachedMultipleNegativesRankingLoss
base_model: BAAI/bge-reranker-v2-m3
pipeline_tag: text-ranking
library_name: sentence-transformers
metrics:
- map
- mrr@10
- ndcg@10
model-index:
- name: CrossEncoder based on BAAI/bge-reranker-v2-m3
results:
- task:
type: cross-encoder-reranking
name: Cross Encoder Reranking
dataset:
name: bge reranker v2 m3 contrastive berria 4 1ep
type: bge-reranker-v2-m3-contrastive-berria-4-1ep
metrics:
- type: map
value: 0.025
name: Map
- type: mrr@10
value: 0.025
name: Mrr@10
- type: ndcg@10
value: 0.025
name: Ndcg@10
---
# CrossEncoder based on BAAI/bge-reranker-v2-m3
This is a [Cross Encoder](https://www.sbert.net/docs/cross_encoder/usage/usage.html) model finetuned from [BAAI/bge-reranker-v2-m3](https://huggingface.co/BAAI/bge-reranker-v2-m3) using the [sentence-transformers](https://www.SBERT.net) library. It computes scores for pairs of texts, which can be used for text reranking and semantic search.
## Model Details
### Model Description
- **Model Type:** Cross Encoder
- **Base model:** [BAAI/bge-reranker-v2-m3](https://huggingface.co/BAAI/bge-reranker-v2-m3) <!-- at revision 953dc6f6f85a1b2dbfca4c34a2796e7dde08d41e -->
- **Maximum Sequence Length:** 8192 tokens
- **Number of Output Labels:** 1 label
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Documentation:** [Cross Encoder Documentation](https://www.sbert.net/docs/cross_encoder/usage/usage.html)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Cross Encoders on Hugging Face](https://huggingface.co/models?library=sentence-transformers&other=cross-encoder)
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import CrossEncoder
# Download from the 🤗 Hub
model = CrossEncoder("cuadron11/bge-reranker-v2-m3-contrastive-berria-4-1ep")
# Get scores for pairs of texts
pairs = [
['Nork egin ditu ekoizle lanak Yard Act taldearen azken lanerako?', 'Zergatik ezkutatu\n\nBadira kantuetan umetan lagun izan zuen kide bati egindako barkamen eskariak, musikariek elkarri beti-beti-beti hit-ak sortzeko egindako promesaren berri ematen duten leloak, edota psikologoarekin izandako solasaldi haluzinogeno —agian fikziozko— bat simulatzen duten zazpi minututik gorako mintzaldiak. Baina, hain justu ere, kolorez betetako atzealde musikal baten kontra egiten duen kontrasteagatik nabarmentzen da, besteak beste, Smithen kontatzaile ahots lau erritmikoa.\n\nYard Act taldearen Dream Job kantaren bideoklipa.\n\nGorillaz taldeko Remi Kabaka Jr. musikariak egin ditu ekoizle lanak. Eta ezinbestekoa izan da haren laguntza taldekideek bilatu duten leherketa musikala lortzeko, eta, kasu honetan, lasai lan egin ahal izateko izan duten aurrekontua ere garrantzitsua izan dela onartu dute musikariek. «Overload bakoitzak bere etxetik eta nahiko azkar sortu genuen, gehiegi pentsatu gabe. Eta hau, aldiz, hedatuz joan da, laurok sortu dugulako, eta ohartu ginelako egin nahi genuena egiteko aukera genuela, entzule talde arretatsu samar batentzat. Zergatik ezkutatu?».\n\nAzken batean, taldeak onartu bezala, hasieratik izan dute zaldia gotorleku barruan.'],
['Zein da Sumar Mugimenduko hezkuntza arduradunaren iritzia egungo irakasleen lan baldintzen inguruan?', 'Sumar Mugimenduko hezkuntza arduraduna\n\nHamar urte hauetan...\n\nBatzuetan konturatzen ez garen arren, denbora aurrera doa eta abiadura bortitzean. Badira jada hamar urte baino gehiago hezkuntzan hasi nintzela. Hogei zentro baino gehiago, esperientzia polit ugari, milaka gauza berri ikasita eta, zergatik ez esan, hainbat momentu txar eta gogor ere bai.\n\nIngeniaritza ikasi eta urte latzetan amaitu nuen, horrek eta partikularrak ematean sentitutako esperientziek, hezkuntzara eraman ninduten. Gutxitan pentsa izan nuen hor amaituko nuela, bakar-bakarrik nire matematika irakasle ederra izan zen Rosa Renedoren urteetan pentsatu izan nuen, egia esan. Gero irakasle bikainak eta bestelakoak ere izan ditut, baina ez nuen berriro planteatu. Baina hemen gaude.\n\nHasi nintzenean argi nuena zera zen: euskal eskola publikoaren alde lan egingo nuela. Bizkaian jaio eta bertan bizita, lehenengo ordezkapena non eta Donostian. Sekulako esperientzia. Lehenengo urtea Gipuzkoan zehar, kilometroak pilatzen, puntuak eta esperientziak batzen. Gero Bizkaira buelta, Lanbide Heziketatik ere pasatu nintzen. Aurrera joan ahala helburutik gertuago, matematiketan murgiltzen hasi, eta etxetik gero eta hurbilago. Bitartean, lan baldintzak gero eta okerragoak. Gero eta lan gehiago, gero eta soldata, edo, hobeto esanda, erosahalmen murritzagoa. Gobernari desberdinak, Hezkuntza sailburu desberdinak baina gobernu eta ildo bera gidaritzan.\n\nHorrela, Gipuzkoara buelta, familia kontuak direla eta. Orain, hemen nago, ederki ondo Donostian. Ea, ederki ondo, lan baldintzak ez baditugu tartean sartzen. Ahaztu zait esatea depresio latz bat pasa nuela. Horren eragileetako bat lan estresa izan zelarik, hemen jarraitzen dugu, baikor eta lan honetan jarraitzeko prest. Baina edonola? Bai zera!!!'],
['Basauriko Kalero auzoko bizilagunek salatu al dute udalaren jarrera sutearen ondoren?', '«Udalak irtenbide bakar gisa planteatu duen laguntza onartzeko paperak ematera etorri gara, eta berriro ere indarkeria instituzionalarekin egin dugu topo»\n\nPABLO OLIVEROS Batu etxebizitza sindikatuko kidea\n\nBizilagunek hasieratik erakutsi dute «kezka», «benetako babesik» jaso ez dutelako, Londoñoren arabera. Asier Iragorri Basauriko alkateari zuzenean leporatu dio «entzungor egitea». Izan ere, sutea gertatu zenetik, sindikatuak hainbatetan salatu du udalak uko egin diola harekin elkartzeari. BERRIA saiatu da alkatearekin hitz egiten, baina ez du lortu.\n\nBizilagunen agerraldiaren ondoren, ohar bat argitaratu du udalak. Adierazi du udaleko langileei ez dietela jakinarazi laguntza onartzeko asmoa zutenik. «Gaur goizean hasi dira tramitatzeko eskatzen». Horrez gain, udalak esan du etxebizitzak sutearen aurretik zeuden egoera «jabeen ardura» dela, «haiena bakar-bakarrik», eta ukatu egin du «eraikina zaharberritzeko eta kontserbatzeko obrak» egiten utzi ez zaienik. Aipatu du etxebizitza horiek 2000tik daudela hiri antolamenduko plan orokorretik kanpo, eta «jabe askok» horren ostean erosi dituztela, «hori jakinda».\n\n«Basauriko Udalak bere gain hartu behar du Kalero auzoaren eraikinak bazterrean utzi izanaren erantzukizun historikoa»\n\nSANDRA LONDOÑO Basauriko sutean kaltetutako herritarra\n\nKontrakoa helarazi dute gaur bizilagunek. Oliverosek salatu du udalak bazekiela eraikinen egoera «larria» zela, eta hala eta guztiz ere ez zuela eraikinen aurrealdea moldatzen utzi. «Basauriko Udalak bere gain hartu behar du Kalero auzoaren eraikinak bazterrean utzi izanaren erantzukizun historikoa», esan du Londoñok. Eta erantsi du eraikinak bazterrean uztea eta hiri antolamendutik at uztea, bizilagunekiko aurreiritziak eta estigmak sendotzeko modua izateaz gain, etxegabetzeak egiteko modu isila ere badela.'],
['Valeria Luiselli idazleak non eskaini zuen "Ederra da hitzak suntsitzea" izenburuko tailerra 2019an?', 'Eta aforismo eder bat salbatzeko balio dio ariketak egileari, esaterako, liburuaren 21. orrian. Present hitza baino ez baitu salbatzen orriko lehen lerroaren erdialdean. Is solte bat uzten du zirriborratu gabe, gero, hamar bat lerro beherago. Eta a burning building hitzak baino ez, azkenik, bi lerrotara. «Orainaldia sutan dagoen eraikin bat da».\n\nOraingoz, ez dago haren lana euskaraz irakurtzeko modurik, baina 2019an Euskal Herrian izan zen idazlea, eta Ederra da hitzak suntsitzea izenburuko tailer bat ere eskaini zuen. Bilboko Gutun Zuria jaialdiak gonbidatu zuen ordukoan, eta erraz topa daiteke sarean Ivan de la Nuez arte komisario eta idazlearekin batera bertan eskaini hiru ordu laurden inguruko solasaldia ere. Besteak beste, intelektualaren figurari buruzko ondorengo gogoeta egiten du bertan idazleak. «Nik ez dakit nor diren intelektualak, eta espero dut jadanik ez direla etorriko. Nigatik balitz, betiko desterratuko genuke intelektual hitza kulturatik, eta horren ordez ezar dezagun kultura hiritarrago bat, hierarkiarik gabekoa, autoritaterik gabekoa, eta, are, baita autorerik gabekoa ere. Zail dago, baina horixe uste dut. Eta intelektualaren figura garrantzitsua izan den arren, nire sorterrian behintzat, Mexikon, uste dut gremioarentzako kaltegarria ere izan dela, besteak beste erabat patriarkala delako, eta hori ere eraitsi egin beharko genukeela uste dut. Intelektualaren figurak ez dio lekurik uzten genero ikuspegiari».'],
['Zein da Euskadi Irratiko sare sozialetan zabalkunderik handiena izan duen bideoa?', 'Euskadi Irratiko elkarrizketa bat. EITB\n\nElkarrizketen bideo zati batzuek sekulako oihartzuna izan dute. Kasurako, Mamadou Sarr Diameri egin zioten elkarrizketaren bideoak milioi bat ikustaldi baino gehiago izan zituen Euskadi Irratiko sare sozial guztiak batuta. Hori izan da sare sozialetan zabalkunderik handiena izan duen bideoa.\n\nBideo propioak\n\nBadira, bestalde, sare batzuetarako lantalde horrek propio sortu, grabatu eta editatzen dituen bideoak. Eneterreagak azaldu du horrek bere lana eskatzen duela: «Prozesu oso bat dago hor. Dokumentaziotik hasi, eta iragazkia pasatu behar da. Eta sareetako hizkuntzara egokitu. Sareetan zabaltzen dituzten bideoek badute oinarri bat, bai denboran, bai editatzeko moduan...». Pil-pilean dauden gaiak hartu, eta «entretenimendutik gertu» egon daitekeen modura eramaten dituzte. Minutu eta segundo gutxiko bideoa dela aintzat hartuta, betiere. Bi kamerarekin grabatzen dituzte bideo horiek. «Bidean ikasten ari gara, eta aurrera egiten saiatzen», kontatu du Eneterreagak. Bideo horiei, gainera, sticker eta efektu batzuk gaineratzen dizkiote. Halako bideoen adibide bat duela egun gutxi zabaldu dute: Eneterreagak aita santu berria aukeratzeko prozesuaren gainean aurkeztutakoa. Habemus saltsa. «Soinu anitz ere sartzen ditugu, ez dezagun ahaztu irratia dela».\n\nAmaia Eneterreaga Euskadi Irratiko sare sozialetako lantaldeko kidea. EITB\n\nSare sozial bakoitzak bere kodeak ditu, eta hori aintzat hartzen dutela nabarmendu du Urdanpilletak: «Lehenengo, edukia jasotzen dugu, eta, gero, erabakitzen dugu: ba honek sare guztietan funtziona diezaguke, ba sare guztietara doa; edo beste honi Tiktokerako beste ukitu bat emango diogu... Edo zerbait grabatu, eta gero esaten dugu: ba hau X-ra doa... Gure muina edukia da». Irrati bisualaren garaiak dira, gero eta gehiago. «Eta hor bakoitzak bere lekua topatu behar du», azaldu du Urdanpilletak.'],
]
scores = model.predict(pairs)
print(scores.shape)
# (5,)
# Or rank different texts based on similarity to a single text
ranks = model.rank(
'Nork egin ditu ekoizle lanak Yard Act taldearen azken lanerako?',
[
'Zergatik ezkutatu\n\nBadira kantuetan umetan lagun izan zuen kide bati egindako barkamen eskariak, musikariek elkarri beti-beti-beti hit-ak sortzeko egindako promesaren berri ematen duten leloak, edota psikologoarekin izandako solasaldi haluzinogeno —agian fikziozko— bat simulatzen duten zazpi minututik gorako mintzaldiak. Baina, hain justu ere, kolorez betetako atzealde musikal baten kontra egiten duen kontrasteagatik nabarmentzen da, besteak beste, Smithen kontatzaile ahots lau erritmikoa.\n\nYard Act taldearen Dream Job kantaren bideoklipa.\n\nGorillaz taldeko Remi Kabaka Jr. musikariak egin ditu ekoizle lanak. Eta ezinbestekoa izan da haren laguntza taldekideek bilatu duten leherketa musikala lortzeko, eta, kasu honetan, lasai lan egin ahal izateko izan duten aurrekontua ere garrantzitsua izan dela onartu dute musikariek. «Overload bakoitzak bere etxetik eta nahiko azkar sortu genuen, gehiegi pentsatu gabe. Eta hau, aldiz, hedatuz joan da, laurok sortu dugulako, eta ohartu ginelako egin nahi genuena egiteko aukera genuela, entzule talde arretatsu samar batentzat. Zergatik ezkutatu?».\n\nAzken batean, taldeak onartu bezala, hasieratik izan dute zaldia gotorleku barruan.',
'Sumar Mugimenduko hezkuntza arduraduna\n\nHamar urte hauetan...\n\nBatzuetan konturatzen ez garen arren, denbora aurrera doa eta abiadura bortitzean. Badira jada hamar urte baino gehiago hezkuntzan hasi nintzela. Hogei zentro baino gehiago, esperientzia polit ugari, milaka gauza berri ikasita eta, zergatik ez esan, hainbat momentu txar eta gogor ere bai.\n\nIngeniaritza ikasi eta urte latzetan amaitu nuen, horrek eta partikularrak ematean sentitutako esperientziek, hezkuntzara eraman ninduten. Gutxitan pentsa izan nuen hor amaituko nuela, bakar-bakarrik nire matematika irakasle ederra izan zen Rosa Renedoren urteetan pentsatu izan nuen, egia esan. Gero irakasle bikainak eta bestelakoak ere izan ditut, baina ez nuen berriro planteatu. Baina hemen gaude.\n\nHasi nintzenean argi nuena zera zen: euskal eskola publikoaren alde lan egingo nuela. Bizkaian jaio eta bertan bizita, lehenengo ordezkapena non eta Donostian. Sekulako esperientzia. Lehenengo urtea Gipuzkoan zehar, kilometroak pilatzen, puntuak eta esperientziak batzen. Gero Bizkaira buelta, Lanbide Heziketatik ere pasatu nintzen. Aurrera joan ahala helburutik gertuago, matematiketan murgiltzen hasi, eta etxetik gero eta hurbilago. Bitartean, lan baldintzak gero eta okerragoak. Gero eta lan gehiago, gero eta soldata, edo, hobeto esanda, erosahalmen murritzagoa. Gobernari desberdinak, Hezkuntza sailburu desberdinak baina gobernu eta ildo bera gidaritzan.\n\nHorrela, Gipuzkoara buelta, familia kontuak direla eta. Orain, hemen nago, ederki ondo Donostian. Ea, ederki ondo, lan baldintzak ez baditugu tartean sartzen. Ahaztu zait esatea depresio latz bat pasa nuela. Horren eragileetako bat lan estresa izan zelarik, hemen jarraitzen dugu, baikor eta lan honetan jarraitzeko prest. Baina edonola? Bai zera!!!',
'«Udalak irtenbide bakar gisa planteatu duen laguntza onartzeko paperak ematera etorri gara, eta berriro ere indarkeria instituzionalarekin egin dugu topo»\n\nPABLO OLIVEROS Batu etxebizitza sindikatuko kidea\n\nBizilagunek hasieratik erakutsi dute «kezka», «benetako babesik» jaso ez dutelako, Londoñoren arabera. Asier Iragorri Basauriko alkateari zuzenean leporatu dio «entzungor egitea». Izan ere, sutea gertatu zenetik, sindikatuak hainbatetan salatu du udalak uko egin diola harekin elkartzeari. BERRIA saiatu da alkatearekin hitz egiten, baina ez du lortu.\n\nBizilagunen agerraldiaren ondoren, ohar bat argitaratu du udalak. Adierazi du udaleko langileei ez dietela jakinarazi laguntza onartzeko asmoa zutenik. «Gaur goizean hasi dira tramitatzeko eskatzen». Horrez gain, udalak esan du etxebizitzak sutearen aurretik zeuden egoera «jabeen ardura» dela, «haiena bakar-bakarrik», eta ukatu egin du «eraikina zaharberritzeko eta kontserbatzeko obrak» egiten utzi ez zaienik. Aipatu du etxebizitza horiek 2000tik daudela hiri antolamenduko plan orokorretik kanpo, eta «jabe askok» horren ostean erosi dituztela, «hori jakinda».\n\n«Basauriko Udalak bere gain hartu behar du Kalero auzoaren eraikinak bazterrean utzi izanaren erantzukizun historikoa»\n\nSANDRA LONDOÑO Basauriko sutean kaltetutako herritarra\n\nKontrakoa helarazi dute gaur bizilagunek. Oliverosek salatu du udalak bazekiela eraikinen egoera «larria» zela, eta hala eta guztiz ere ez zuela eraikinen aurrealdea moldatzen utzi. «Basauriko Udalak bere gain hartu behar du Kalero auzoaren eraikinak bazterrean utzi izanaren erantzukizun historikoa», esan du Londoñok. Eta erantsi du eraikinak bazterrean uztea eta hiri antolamendutik at uztea, bizilagunekiko aurreiritziak eta estigmak sendotzeko modua izateaz gain, etxegabetzeak egiteko modu isila ere badela.',
'Eta aforismo eder bat salbatzeko balio dio ariketak egileari, esaterako, liburuaren 21. orrian. Present hitza baino ez baitu salbatzen orriko lehen lerroaren erdialdean. Is solte bat uzten du zirriborratu gabe, gero, hamar bat lerro beherago. Eta a burning building hitzak baino ez, azkenik, bi lerrotara. «Orainaldia sutan dagoen eraikin bat da».\n\nOraingoz, ez dago haren lana euskaraz irakurtzeko modurik, baina 2019an Euskal Herrian izan zen idazlea, eta Ederra da hitzak suntsitzea izenburuko tailer bat ere eskaini zuen. Bilboko Gutun Zuria jaialdiak gonbidatu zuen ordukoan, eta erraz topa daiteke sarean Ivan de la Nuez arte komisario eta idazlearekin batera bertan eskaini hiru ordu laurden inguruko solasaldia ere. Besteak beste, intelektualaren figurari buruzko ondorengo gogoeta egiten du bertan idazleak. «Nik ez dakit nor diren intelektualak, eta espero dut jadanik ez direla etorriko. Nigatik balitz, betiko desterratuko genuke intelektual hitza kulturatik, eta horren ordez ezar dezagun kultura hiritarrago bat, hierarkiarik gabekoa, autoritaterik gabekoa, eta, are, baita autorerik gabekoa ere. Zail dago, baina horixe uste dut. Eta intelektualaren figura garrantzitsua izan den arren, nire sorterrian behintzat, Mexikon, uste dut gremioarentzako kaltegarria ere izan dela, besteak beste erabat patriarkala delako, eta hori ere eraitsi egin beharko genukeela uste dut. Intelektualaren figurak ez dio lekurik uzten genero ikuspegiari».',
'Euskadi Irratiko elkarrizketa bat. EITB\n\nElkarrizketen bideo zati batzuek sekulako oihartzuna izan dute. Kasurako, Mamadou Sarr Diameri egin zioten elkarrizketaren bideoak milioi bat ikustaldi baino gehiago izan zituen Euskadi Irratiko sare sozial guztiak batuta. Hori izan da sare sozialetan zabalkunderik handiena izan duen bideoa.\n\nBideo propioak\n\nBadira, bestalde, sare batzuetarako lantalde horrek propio sortu, grabatu eta editatzen dituen bideoak. Eneterreagak azaldu du horrek bere lana eskatzen duela: «Prozesu oso bat dago hor. Dokumentaziotik hasi, eta iragazkia pasatu behar da. Eta sareetako hizkuntzara egokitu. Sareetan zabaltzen dituzten bideoek badute oinarri bat, bai denboran, bai editatzeko moduan...». Pil-pilean dauden gaiak hartu, eta «entretenimendutik gertu» egon daitekeen modura eramaten dituzte. Minutu eta segundo gutxiko bideoa dela aintzat hartuta, betiere. Bi kamerarekin grabatzen dituzte bideo horiek. «Bidean ikasten ari gara, eta aurrera egiten saiatzen», kontatu du Eneterreagak. Bideo horiei, gainera, sticker eta efektu batzuk gaineratzen dizkiote. Halako bideoen adibide bat duela egun gutxi zabaldu dute: Eneterreagak aita santu berria aukeratzeko prozesuaren gainean aurkeztutakoa. Habemus saltsa. «Soinu anitz ere sartzen ditugu, ez dezagun ahaztu irratia dela».\n\nAmaia Eneterreaga Euskadi Irratiko sare sozialetako lantaldeko kidea. EITB\n\nSare sozial bakoitzak bere kodeak ditu, eta hori aintzat hartzen dutela nabarmendu du Urdanpilletak: «Lehenengo, edukia jasotzen dugu, eta, gero, erabakitzen dugu: ba honek sare guztietan funtziona diezaguke, ba sare guztietara doa; edo beste honi Tiktokerako beste ukitu bat emango diogu... Edo zerbait grabatu, eta gero esaten dugu: ba hau X-ra doa... Gure muina edukia da». Irrati bisualaren garaiak dira, gero eta gehiago. «Eta hor bakoitzak bere lekua topatu behar du», azaldu du Urdanpilletak.',
]
)
# [{'corpus_id': ..., 'score': ...}, {'corpus_id': ..., 'score': ...}, ...]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Cross Encoder Reranking
* Dataset: `bge-reranker-v2-m3-contrastive-berria-4-1ep`
* Evaluated with [<code>CrossEncoderRerankingEvaluator</code>](https://sbert.net/docs/package_reference/cross_encoder/evaluation.html#sentence_transformers.cross_encoder.evaluation.CrossEncoderRerankingEvaluator) with these parameters:
```json
{
"at_k": 10,
"always_rerank_positives": false
}
```
| Metric | Value |
|:------------|:---------------------|
| map | 0.0250 (+0.0239) |
| mrr@10 | 0.0250 (+0.0243) |
| **ndcg@10** | **0.0250 (+0.0234)** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 3,200 training samples
* Columns: <code>query</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | query | positive |
|:--------|:------------------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 19 characters</li><li>mean: 77.62 characters</li><li>max: 178 characters</li></ul> | <ul><li>min: 348 characters</li><li>mean: 1503.95 characters</li><li>max: 2196 characters</li></ul> |
* Samples:
| query | positive |
|:----------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Zein film dira nazioarteko filmik onenen artean aukeratu dituztenak Urrezko Globoetan?</code> | <code>Aipatutako bi film horiek nagusi izan ziren Urrezko Globoetan ere. Lehenak lau sari erdietsi zituen, eta bigarrenak, berriz, hiru.<br><br>Film musikalen urtea izan da 2024a. Hain zuzen, Wicked pelikulak ere badu aukerarik sariren bat eskuratzeko: Oz-eko mundu magikoan girotuta dago, eta jende ugari erakarri du zinema aretoetara. Ariana Grande musikari eta aktorea Glindaren rolean aritu da, eta taldeko emakumezko aktorerik onenaren sarirako hautagaietako bat da. Haren kide Cynthia Erivok, berriz, aukera du emakumezko aktorerik onenaren saria eskuratzeko.<br><br>Memorietan oinarrituta<br><br>Nazioarteko filmik onenen artean aukeratu dute Brasilen ekoitzitako Ainda estou aqui filma, eta filmik onenaren sarirako hautagai ere bada. Marcelo Rubens Paivaren memorietan oinarrituta dago proiektua: diktadura militarraren garaiko erregimenak Paivaren aita preso sartu ostean, haren emazteak politikan jardun zuen, eta horixe da filmaren ardatza. Beste izendapen bat ere jaso du lan horrek: emakumezko aktorerik onenar...</code> |
| <code>Zergatik ukatu diote Lehen Hezkuntza ikasteko matrikulazioa EHU-n D ereduan hezkuntza ibilbide osoa egin duen ikasle bati?</code> | <code>Izarra<br><br>EHU eta euskararen akreditazioa<br><br>Gure alabari ez diote utzi EHUn matrikulatzen Lehen Hezkuntza ikasteko. Eta ez, ez da notaren arazoa izan. Unibertsitatean matrikulazioa hasi baino hiru aste eskas lehenago, Batxilergoa egin duen institutu publikoak jakinarazi digu ez duela euskararen B-2 ziurtagiria eskuratuko. Bazterketa horren arrazoia da Batxilergoko lehen ikasturtea Estatu Batuetan egin zuela, eta legeak ezartzen duela ziurtagiri hori lortzeko Batxilergoko ikasgaien erdiak baino gehiago euskaraz eginak izan behar dituela. Ez dugu eztabaidatuko lege hori zentzuzkoa den ala ez, baina haserretu gaituena izan da inork ez digula horren berri eman. Atzerrian egindako ikastaroa baliozkotu zuen Eusko Jaurlaritzako Hezkuntza Sailak berak edo Batxilergoko azken ikasturtea egin duen institutu publikoak egoera horren berri garaiz eman izan baligute, gure alabak bere kabuz aurkeztu ahal izango zukeen profil hori egiaztatzeko edozein deialditara. D ereduan hezkuntza ibilbide osoa egin du...</code> |
| <code>Zer proposatu du Elkarrekin Bilbo taldeko Ana Viñalsek ostatu turistiko berrien hazkundea mugatzeko?</code> | <code>Bestalde, arazoak ikusi dizkio neurriak auzo batzuetan bakarrik aplikatzeari. Haren ustez, badago arriskua ostatu turistikoak gainerako auzoetan hedatzeko, «batez ere mugakideak diren auzoetan». Esan duenez, gerta daiteke «arazoa konpondu beharrean, hiriko gainerako lekuetara zabaltzea».<br><br>Elkarrekin Bilbo taldeko Ana Viñals bat etorri da ohartarazpen horrekin, eta proposatu du neurriak hiri osoan hartzea, «kutsatzeak» galarazteko. Halaber, eskatu du erreferentziatzat soilik etxebizitza eta logela turistikoak hartu beharrean hiri osoan dagoen eskaintza turistikoari erreparatzeko, «jakiteko zer gaitasun dugun hiri gisa eta gehienez zenbat bisitari har ditzakegun auzotarren bizi kalitateari kalterik egin gabe».<br><br>Alderdi saturatuetan «zero hazkundeko politika» ezartzea proposatu du Viñalsek; hau da, ostatu turistiko berri bati baimenik ez ematea lehenagotik zegoen beste bat desagertzen ez bada, eta modurik ez ematea jabeek gaur egun dauden ostatuen titulartasuna aldatzeko.<br><br>Hiri antolamend...</code> |
* Loss: [<code>CachedMultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/cross_encoder/losses.html#cachedmultiplenegativesrankingloss) with these parameters:
```json
{
"scale": 10.0,
"num_negatives": null,
"activation_fn": "torch.nn.modules.activation.Sigmoid",
"mini_batch_size": 16
}
```
### Evaluation Dataset
#### Unnamed Dataset
* Size: 800 evaluation samples
* Columns: <code>query</code> and <code>positive</code>
* Approximate statistics based on the first 800 samples:
| | query | positive |
|:--------|:------------------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 30 characters</li><li>mean: 76.77 characters</li><li>max: 199 characters</li></ul> | <ul><li>min: 385 characters</li><li>mean: 1484.58 characters</li><li>max: 2156 characters</li></ul> |
* Samples:
| query | positive |
|:------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Nork egin ditu ekoizle lanak Yard Act taldearen azken lanerako?</code> | <code>Zergatik ezkutatu<br><br>Badira kantuetan umetan lagun izan zuen kide bati egindako barkamen eskariak, musikariek elkarri beti-beti-beti hit-ak sortzeko egindako promesaren berri ematen duten leloak, edota psikologoarekin izandako solasaldi haluzinogeno —agian fikziozko— bat simulatzen duten zazpi minututik gorako mintzaldiak. Baina, hain justu ere, kolorez betetako atzealde musikal baten kontra egiten duen kontrasteagatik nabarmentzen da, besteak beste, Smithen kontatzaile ahots lau erritmikoa.<br><br>Yard Act taldearen Dream Job kantaren bideoklipa.<br><br>Gorillaz taldeko Remi Kabaka Jr. musikariak egin ditu ekoizle lanak. Eta ezinbestekoa izan da haren laguntza taldekideek bilatu duten leherketa musikala lortzeko, eta, kasu honetan, lasai lan egin ahal izateko izan duten aurrekontua ere garrantzitsua izan dela onartu dute musikariek. «Overload bakoitzak bere etxetik eta nahiko azkar sortu genuen, gehiegi pentsatu gabe. Eta hau, aldiz, hedatuz joan da, laurok sortu dugulako, eta ohartu ginelako egin ...</code> |
| <code>Zein da Sumar Mugimenduko hezkuntza arduradunaren iritzia egungo irakasleen lan baldintzen inguruan?</code> | <code>Sumar Mugimenduko hezkuntza arduraduna<br><br>Hamar urte hauetan...<br><br>Batzuetan konturatzen ez garen arren, denbora aurrera doa eta abiadura bortitzean. Badira jada hamar urte baino gehiago hezkuntzan hasi nintzela. Hogei zentro baino gehiago, esperientzia polit ugari, milaka gauza berri ikasita eta, zergatik ez esan, hainbat momentu txar eta gogor ere bai.<br><br>Ingeniaritza ikasi eta urte latzetan amaitu nuen, horrek eta partikularrak ematean sentitutako esperientziek, hezkuntzara eraman ninduten. Gutxitan pentsa izan nuen hor amaituko nuela, bakar-bakarrik nire matematika irakasle ederra izan zen Rosa Renedoren urteetan pentsatu izan nuen, egia esan. Gero irakasle bikainak eta bestelakoak ere izan ditut, baina ez nuen berriro planteatu. Baina hemen gaude.<br><br>Hasi nintzenean argi nuena zera zen: euskal eskola publikoaren alde lan egingo nuela. Bizkaian jaio eta bertan bizita, lehenengo ordezkapena non eta Donostian. Sekulako esperientzia. Lehenengo urtea Gipuzkoan zehar, kilometroak pilatzen, punt...</code> |
| <code>Basauriko Kalero auzoko bizilagunek salatu al dute udalaren jarrera sutearen ondoren?</code> | <code>«Udalak irtenbide bakar gisa planteatu duen laguntza onartzeko paperak ematera etorri gara, eta berriro ere indarkeria instituzionalarekin egin dugu topo»<br><br>PABLO OLIVEROS Batu etxebizitza sindikatuko kidea<br><br>Bizilagunek hasieratik erakutsi dute «kezka», «benetako babesik» jaso ez dutelako, Londoñoren arabera. Asier Iragorri Basauriko alkateari zuzenean leporatu dio «entzungor egitea». Izan ere, sutea gertatu zenetik, sindikatuak hainbatetan salatu du udalak uko egin diola harekin elkartzeari. BERRIA saiatu da alkatearekin hitz egiten, baina ez du lortu.<br><br>Bizilagunen agerraldiaren ondoren, ohar bat argitaratu du udalak. Adierazi du udaleko langileei ez dietela jakinarazi laguntza onartzeko asmoa zutenik. «Gaur goizean hasi dira tramitatzeko eskatzen». Horrez gain, udalak esan du etxebizitzak sutearen aurretik zeuden egoera «jabeen ardura» dela, «haiena bakar-bakarrik», eta ukatu egin du «eraikina zaharberritzeko eta kontserbatzeko obrak» egiten utzi ez zaienik. Aipatu du etxebizitza hori...</code> |
* Loss: [<code>CachedMultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/cross_encoder/losses.html#cachedmultiplenegativesrankingloss) with these parameters:
```json
{
"scale": 10.0,
"num_negatives": null,
"activation_fn": "torch.nn.modules.activation.Sigmoid",
"mini_batch_size": 16
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `learning_rate`: 2e-05
- `num_train_epochs`: 1
- `warmup_ratio`: 0.1
- `load_best_model_at_end`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `parallelism_config`: None
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `hub_revision`: None
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `liger_kernel_config`: None
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
| Epoch | Step | Training Loss | Validation Loss | bge-reranker-v2-m3-contrastive-berria-4-1ep_ndcg@10 |
|:-------:|:-------:|:-------------:|:---------------:|:---------------------------------------------------:|
| **1.0** | **200** | **0.0177** | **0.0103** | **0.0250 (+0.0234)** |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.9.7
- Sentence Transformers: 5.0.0
- Transformers: 4.56.0
- PyTorch: 2.7.1+cu126
- Accelerate: 1.5.2
- Datasets: 4.0.0
- Tokenizers: 0.22.0
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
bijaykumarsingh/whisper-large-v3-bn-cv17
|
bijaykumarsingh
| 2025-09-18T14:30:02Z | 30 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice_17_0",
"base_model:openai/whisper-large-v3",
"base_model:finetune:openai/whisper-large-v3",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2024-12-02T10:04:48Z |
---
library_name: transformers
base_model: openai/whisper-large-v3
tags:
- generated_from_trainer
datasets:
- common_voice_17_0
metrics:
- wer
model-index:
- name: whisper-large-v3-bn-cv17
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_17_0
type: common_voice_17_0
config: bn
split: test
args: bn
metrics:
- name: Wer
type: wer
value: 41.83667477067991
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-large-v3-bn-cv17
This model is a fine-tuned version of [openai/whisper-large-v3](https://huggingface.co/openai/whisper-large-v3) on the common_voice_17_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0732
- Wer: 41.8367
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 500
- training_steps: 6000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.1229 | 0.2618 | 500 | 0.1370 | 109.1423 |
| 0.097 | 0.5236 | 1000 | 0.1005 | 41.9964 |
| 0.0853 | 0.7853 | 1500 | 0.0852 | 32.2293 |
| 0.0472 | 1.0471 | 2000 | 0.0786 | 56.4450 |
| 0.0503 | 1.3089 | 2500 | 0.0746 | 87.3848 |
| 0.0479 | 1.5707 | 3000 | 0.0716 | 30.1187 |
| 0.0511 | 1.8325 | 3500 | 0.0665 | 32.1765 |
| 0.0294 | 2.0942 | 4000 | 0.0710 | 48.9811 |
| 0.03 | 2.3560 | 4500 | 0.0695 | 52.9004 |
| 0.0333 | 2.6178 | 5000 | 0.0669 | 30.8364 |
| 0.031 | 2.8796 | 5500 | 0.0670 | 33.7761 |
| 0.0174 | 3.1414 | 6000 | 0.0732 | 41.8367 |
### Framework versions
- Transformers 4.46.3
- Pytorch 2.4.0
- Datasets 3.1.0
- Tokenizers 0.20.3
|
Vikas1238347/asdf
|
Vikas1238347
| 2025-09-18T14:29:07Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-18T14:29:07Z |
---
license: apache-2.0
---
|
surya-ravindra/Llama-3.1-8B-Instruct-Q4_K_M-GGUF
|
surya-ravindra
| 2025-09-18T14:27:40Z | 0 | 0 | null |
[
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:quantized:meta-llama/Llama-3.1-8B-Instruct",
"license:llama3.1",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-09-18T14:27:14Z |
---
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
license: llama3.1
base_model: meta-llama/Llama-3.1-8B-Instruct
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
- llama-cpp
- gguf-my-repo
extra_gated_prompt: "### LLAMA 3.1 COMMUNITY LICENSE AGREEMENT\nLlama 3.1 Version\
\ Release Date: July 23, 2024\n\"Agreement\" means the terms and conditions for\
\ use, reproduction, distribution and modification of the Llama Materials set forth\
\ herein.\n\"Documentation\" means the specifications, manuals and documentation\
\ accompanying Llama 3.1 distributed by Meta at https://llama.meta.com/doc/overview.\n\
\"Licensee\" or \"you\" means you, or your employer or any other person or entity\
\ (if you are entering into this Agreement on such person or entity’s behalf), of\
\ the age required under applicable laws, rules or regulations to provide legal\
\ consent and that has legal authority to bind your employer or such other person\
\ or entity if you are entering in this Agreement on their behalf.\n\"Llama 3.1\"\
\ means the foundational large language models and software and algorithms, including\
\ machine-learning model code, trained model weights, inference-enabling code, training-enabling\
\ code, fine-tuning enabling code and other elements of the foregoing distributed\
\ by Meta at https://llama.meta.com/llama-downloads.\n\"Llama Materials\" means,\
\ collectively, Meta’s proprietary Llama 3.1 and Documentation (and any portion\
\ thereof) made available under this Agreement.\n\"Meta\" or \"we\" means Meta Platforms\
\ Ireland Limited (if you are located in or, if you are an entity, your principal\
\ place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you\
\ are located outside of the EEA or Switzerland).\n \n1. License Rights and Redistribution.\n\
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable\
\ and royalty-free limited license under Meta’s intellectual property or other rights\
\ owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy,\
\ create derivative works of, and make modifications to the Llama Materials.\nb.\
\ Redistribution and Use.\ni. If you distribute or make available the Llama Materials\
\ (or any derivative works thereof), or a product or service (including another\
\ AI model) that contains any of them, you shall (A) provide a copy of this Agreement\
\ with any such Llama Materials; and (B) prominently display “Built with Llama”\
\ on a related website, user interface, blogpost, about page, or product documentation.\
\ If you use the Llama Materials or any outputs or results of the Llama Materials\
\ to create, train, fine tune, or otherwise improve an AI model, which is distributed\
\ or made available, you shall also include “Llama” at the beginning of any such\
\ AI model name.\nii. If you receive Llama Materials, or any derivative works thereof,\
\ from a Licensee as part of an integrated end user product, then Section 2 of\
\ this Agreement will not apply to you.\niii. You must retain in all copies of the\
\ Llama Materials that you distribute the following attribution notice within a\
\ “Notice” text file distributed as a part of such copies: “Llama 3.1 is licensed\
\ under the Llama 3.1 Community License, Copyright © Meta Platforms, Inc. All Rights\
\ Reserved.”\niv. Your use of the Llama Materials must comply with applicable laws\
\ and regulations (including trade compliance laws and regulations) and adhere to\
\ the Acceptable Use Policy for the Llama Materials (available at https://llama.meta.com/llama3_1/use-policy),\
\ which is hereby incorporated by reference into this Agreement.\n2. Additional\
\ Commercial Terms. If, on the Llama 3.1 version release date, the monthly active\
\ users of the products or services made available by or for Licensee, or Licensee’s\
\ affiliates, is greater than 700 million monthly active users in the preceding\
\ calendar month, you must request a license from Meta, which Meta may grant to\
\ you in its sole discretion, and you are not authorized to exercise any of the\
\ rights under this Agreement unless or until Meta otherwise expressly grants you\
\ such rights.\n3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE\
\ LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS”\
\ BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY\
\ KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES\
\ OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE.\
\ YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING\
\ THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA\
\ MATERIALS AND ANY OUTPUT AND RESULTS.\n4. Limitation of Liability. IN NO EVENT\
\ WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN\
\ CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS\
\ AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL,\
\ EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED\
\ OF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\na. No\
\ trademark licenses are granted under this Agreement, and in connection with the\
\ Llama Materials, neither Meta nor Licensee may use any name or mark owned by or\
\ associated with the other or any of its affiliates, except as required for reasonable\
\ and customary use in describing and redistributing the Llama Materials or as set\
\ forth in this Section 5(a). Meta hereby grants you a license to use “Llama” (the\
\ “Mark”) solely as required to comply with the last sentence of Section 1.b.i.\
\ You will comply with Meta’s brand guidelines (currently accessible at https://about.meta.com/brand/resources/meta/company-brand/\
\ ). All goodwill arising out of your use of the Mark will inure to the benefit\
\ of Meta.\nb. Subject to Meta’s ownership of Llama Materials and derivatives made\
\ by or for Meta, with respect to any derivative works and modifications of the\
\ Llama Materials that are made by you, as between you and Meta, you are and will\
\ be the owner of such derivative works and modifications.\nc. If you institute\
\ litigation or other proceedings against Meta or any entity (including a cross-claim\
\ or counterclaim in a lawsuit) alleging that the Llama Materials or Llama 3.1 outputs\
\ or results, or any portion of any of the foregoing, constitutes infringement of\
\ intellectual property or other rights owned or licensable by you, then any licenses\
\ granted to you under this Agreement shall terminate as of the date such litigation\
\ or claim is filed or instituted. You will indemnify and hold harmless Meta from\
\ and against any claim by any third party arising out of or related to your use\
\ or distribution of the Llama Materials.\n6. Term and Termination. The term of\
\ this Agreement will commence upon your acceptance of this Agreement or access\
\ to the Llama Materials and will continue in full force and effect until terminated\
\ in accordance with the terms and conditions herein. Meta may terminate this Agreement\
\ if you are in breach of any term or condition of this Agreement. Upon termination\
\ of this Agreement, you shall delete and cease use of the Llama Materials. Sections\
\ 3, 4 and 7 shall survive the termination of this Agreement.\n7. Governing Law\
\ and Jurisdiction. This Agreement will be governed and construed under the laws\
\ of the State of California without regard to choice of law principles, and the\
\ UN Convention on Contracts for the International Sale of Goods does not apply\
\ to this Agreement. The courts of California shall have exclusive jurisdiction\
\ of any dispute arising out of this Agreement.\n### Llama 3.1 Acceptable Use Policy\n\
Meta is committed to promoting safe and fair use of its tools and features, including\
\ Llama 3.1. If you access or use Llama 3.1, you agree to this Acceptable Use Policy\
\ (“Policy”). The most recent copy of this policy can be found at [https://llama.meta.com/llama3_1/use-policy](https://llama.meta.com/llama3_1/use-policy)\n\
#### Prohibited Uses\nWe want everyone to use Llama 3.1 safely and responsibly.\
\ You agree you will not use, or allow others to use, Llama 3.1 to:\n 1. Violate\
\ the law or others’ rights, including to:\n 1. Engage in, promote, generate,\
\ contribute to, encourage, plan, incite, or further illegal or unlawful activity\
\ or content, such as:\n 1. Violence or terrorism\n 2. Exploitation\
\ or harm to children, including the solicitation, creation, acquisition, or dissemination\
\ of child exploitative content or failure to report Child Sexual Abuse Material\n\
\ 3. Human trafficking, exploitation, and sexual violence\n 4. The\
\ illegal distribution of information or materials to minors, including obscene\
\ materials, or failure to employ legally required age-gating in connection with\
\ such information or materials.\n 5. Sexual solicitation\n 6. Any\
\ other criminal activity\n 3. Engage in, promote, incite, or facilitate the\
\ harassment, abuse, threatening, or bullying of individuals or groups of individuals\n\
\ 4. Engage in, promote, incite, or facilitate discrimination or other unlawful\
\ or harmful conduct in the provision of employment, employment benefits, credit,\
\ housing, other economic benefits, or other essential goods and services\n 5.\
\ Engage in the unauthorized or unlicensed practice of any profession including,\
\ but not limited to, financial, legal, medical/health, or related professional\
\ practices\n 6. Collect, process, disclose, generate, or infer health, demographic,\
\ or other sensitive personal or private information about individuals without rights\
\ and consents required by applicable laws\n 7. Engage in or facilitate any action\
\ or generate any content that infringes, misappropriates, or otherwise violates\
\ any third-party rights, including the outputs or results of any products or services\
\ using the Llama Materials\n 8. Create, generate, or facilitate the creation\
\ of malicious code, malware, computer viruses or do anything else that could disable,\
\ overburden, interfere with or impair the proper working, integrity, operation\
\ or appearance of a website or computer system\n2. Engage in, promote, incite,\
\ facilitate, or assist in the planning or development of activities that present\
\ a risk of death or bodily harm to individuals, including use of Llama 3.1 related\
\ to the following:\n 1. Military, warfare, nuclear industries or applications,\
\ espionage, use for materials or activities that are subject to the International\
\ Traffic Arms Regulations (ITAR) maintained by the United States Department of\
\ State\n 2. Guns and illegal weapons (including weapon development)\n 3.\
\ Illegal drugs and regulated/controlled substances\n 4. Operation of critical\
\ infrastructure, transportation technologies, or heavy machinery\n 5. Self-harm\
\ or harm to others, including suicide, cutting, and eating disorders\n 6. Any\
\ content intended to incite or promote violence, abuse, or any infliction of bodily\
\ harm to an individual\n3. Intentionally deceive or mislead others, including use\
\ of Llama 3.1 related to the following:\n 1. Generating, promoting, or furthering\
\ fraud or the creation or promotion of disinformation\n 2. Generating, promoting,\
\ or furthering defamatory content, including the creation of defamatory statements,\
\ images, or other content\n 3. Generating, promoting, or further distributing\
\ spam\n 4. Impersonating another individual without consent, authorization,\
\ or legal right\n 5. Representing that the use of Llama 3.1 or outputs are human-generated\n\
\ 6. Generating or facilitating false online engagement, including fake reviews\
\ and other means of fake online engagement\n4. Fail to appropriately disclose to\
\ end users any known dangers of your AI system\nPlease report any violation of\
\ this Policy, software “bug,” or other problems that could lead to a violation\
\ of this Policy through one of the following means:\n * Reporting issues with\
\ the model: [https://github.com/meta-llama/llama-models/issues](https://github.com/meta-llama/llama-models/issues)\n\
\ * Reporting risky content generated by the model:\n developers.facebook.com/llama_output_feedback\n\
\ * Reporting bugs and security concerns: facebook.com/whitehat/info\n * Reporting\
\ violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]"
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
? By clicking Submit below I accept the terms of the license and acknowledge that
the information I provide will be collected stored processed and shared in accordance
with the Meta Privacy Policy
: checkbox
extra_gated_description: The information you provide will be collected, stored, processed
and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
# surya-ravindra/Llama-3.1-8B-Instruct-Q4_K_M-GGUF
This model was converted to GGUF format from [`meta-llama/Llama-3.1-8B-Instruct`](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo surya-ravindra/Llama-3.1-8B-Instruct-Q4_K_M-GGUF --hf-file llama-3.1-8b-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo surya-ravindra/Llama-3.1-8B-Instruct-Q4_K_M-GGUF --hf-file llama-3.1-8b-instruct-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo surya-ravindra/Llama-3.1-8B-Instruct-Q4_K_M-GGUF --hf-file llama-3.1-8b-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo surya-ravindra/Llama-3.1-8B-Instruct-Q4_K_M-GGUF --hf-file llama-3.1-8b-instruct-q4_k_m.gguf -c 2048
```
|
david4096/disdriv-all-MiniLM-L6-v2_gated_e128
|
david4096
| 2025-09-18T14:26:54Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:26:51Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- small-ontology
---
# disdriv_all-MiniLM-L6-v2_gated_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: disdriv.owl
- **Domain**: general
- **Ontology Concepts**: 18
- **Concept Alignment**: 18/18 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 18
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.0 MB
- **Model Size**: 87.8 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 18 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('disdriv_all-MiniLM-L6-v2_gated_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/disdriv-all-MiniLM-L6-v2_attention_e256
|
david4096
| 2025-09-18T14:26:39Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:26:35Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- small-ontology
---
# disdriv_all-MiniLM-L6-v2_attention_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: disdriv.owl
- **Domain**: general
- **Ontology Concepts**: 18
- **Concept Alignment**: 18/18 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 18
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.0 MB
- **Model Size**: 91.2 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 18 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('disdriv_all-MiniLM-L6-v2_attention_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
Alibaba-DAMO-Academy/RynnVLA-001-7B-Trajectory
|
Alibaba-DAMO-Academy
| 2025-09-18T14:26:32Z | 0 | 1 | null |
[
"safetensors",
"chameleon",
"license:apache-2.0",
"region:us"
] | null | 2025-09-18T13:50:33Z |
---
license: apache-2.0
---
### Alibaba DAMO Academy - RynnVLA-001-7B-Trajectory
Github Repo: https://github.com/alibaba-damo-academy/RynnVLA-001
🔥 We release RynnVLA-001-7B-Trajectory (Stage 2: Human-Centric Trajectory-Aware Video Modeling), which is further trained to predict future human trajectories and frames. This stage is initialized from [RynnVLA-001-7B-Base](https://huggingface.co/Alibaba-DAMO-Academy/RynnVLA-001-7B-Base).
## 🌟 Overview of RynnVLA-001
RynnVLA-001 is a VLA model based on pretrained video generation model. The key insight is to implicitly transfer manipulation skills learned from human demonstrations in ego-centric videos to the manipulation of robot arms.

|
puneetpanwar/act_il_sim_test
|
puneetpanwar
| 2025-09-18T14:26:24Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:puneetpanwar/il_gym0",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-09-18T14:24:30Z |
---
datasets: puneetpanwar/il_gym0
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- lerobot
- act
- robotics
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
lerobot-record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
david4096/dideo-all-MiniLM-L6-v2_gated_e256
|
david4096
| 2025-09-18T14:26:16Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:26:13Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- small-ontology
---
# dideo_all-MiniLM-L6-v2_gated_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: dideo.owl
- **Domain**: general
- **Ontology Concepts**: 416
- **Concept Alignment**: 416/416 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 416
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.9 MB
- **Model Size**: 91.6 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 416 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('dideo_all-MiniLM-L6-v2_gated_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/dideo-all-MiniLM-L6-v2_attention_e256
|
david4096
| 2025-09-18T14:25:50Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:25:46Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- small-ontology
---
# dideo_all-MiniLM-L6-v2_attention_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: dideo.owl
- **Domain**: general
- **Ontology Concepts**: 416
- **Concept Alignment**: 416/416 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 416
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.9 MB
- **Model Size**: 95.0 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 416 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('dideo_all-MiniLM-L6-v2_attention_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/dideo-all-MiniLM-L6-v2_attention_e128
|
david4096
| 2025-09-18T14:25:43Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:25:40Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- small-ontology
---
# dideo_all-MiniLM-L6-v2_attention_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: dideo.owl
- **Domain**: general
- **Ontology Concepts**: 416
- **Concept Alignment**: 416/416 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 416
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.9 MB
- **Model Size**: 95.0 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 416 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('dideo_all-MiniLM-L6-v2_attention_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/ddpheno-all-MiniLM-L6-v2_attention_e512
|
david4096
| 2025-09-18T14:25:05Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:25:02Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# ddpheno_all-MiniLM-L6-v2_attention_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: ddpheno.owl
- **Domain**: general
- **Ontology Concepts**: 1,373
- **Concept Alignment**: 1,373/1,373 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1373
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 1.4 MB
- **Model Size**: 104.0 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1373 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('ddpheno_all-MiniLM-L6-v2_attention_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
encoderrr/Qwen3-0.6B-Gensyn-Swarm-bold_lethal_caribou
|
encoderrr
| 2025-09-18T14:24:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am bold_lethal_caribou",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-18T12:16:30Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am bold_lethal_caribou
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ddvd233/Human-Omni-7B
|
ddvd233
| 2025-09-18T14:24:32Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_omni",
"text-to-audio",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2025-09-18T14:21:24Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
david4096/cteno-all-MiniLM-L6-v2_gated_e256
|
david4096
| 2025-09-18T14:24:27Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:24:24Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- small-ontology
---
# cteno_all-MiniLM-L6-v2_gated_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: cteno.owl
- **Domain**: general
- **Ontology Concepts**: 172
- **Concept Alignment**: 172/172 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 172
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.3 MB
- **Model Size**: 89.3 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 172 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('cteno_all-MiniLM-L6-v2_gated_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/cteno-all-MiniLM-L6-v2_gated_e128
|
david4096
| 2025-09-18T14:24:16Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:24:13Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- small-ontology
---
# cteno_all-MiniLM-L6-v2_gated_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: cteno.owl
- **Domain**: general
- **Ontology Concepts**: 172
- **Concept Alignment**: 172/172 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 172
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.3 MB
- **Model Size**: 89.3 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 172 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('cteno_all-MiniLM-L6-v2_gated_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/cteno-all-MiniLM-L6-v2_attention_e512
|
david4096
| 2025-09-18T14:24:10Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:24:07Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- small-ontology
---
# cteno_all-MiniLM-L6-v2_attention_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: cteno.owl
- **Domain**: general
- **Ontology Concepts**: 172
- **Concept Alignment**: 172/172 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 172
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.3 MB
- **Model Size**: 92.7 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 172 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('cteno_all-MiniLM-L6-v2_attention_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/cteno-all-MiniLM-L6-v2_attention_e256
|
david4096
| 2025-09-18T14:24:00Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:23:57Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- small-ontology
---
# cteno_all-MiniLM-L6-v2_attention_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: cteno.owl
- **Domain**: general
- **Ontology Concepts**: 172
- **Concept Alignment**: 172/172 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 172
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.3 MB
- **Model Size**: 92.7 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 172 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('cteno_all-MiniLM-L6-v2_attention_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/cro-all-MiniLM-L6-v2_gated_e512
|
david4096
| 2025-09-18T14:23:38Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:23:35Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- small-ontology
---
# cro_all-MiniLM-L6-v2_gated_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: cro.owl
- **Domain**: general
- **Ontology Concepts**: 105
- **Concept Alignment**: 105/105 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 105
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.1 MB
- **Model Size**: 88.7 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 105 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('cro_all-MiniLM-L6-v2_gated_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
casque/Downward_Dog_-_Andi_Poses
|
casque
| 2025-09-18T14:23:26Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2025-09-18T14:20:45Z |
---
license: creativeml-openrail-m
---
|
david4096/cro-all-MiniLM-L6-v2_gated_e128
|
david4096
| 2025-09-18T14:23:22Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:23:19Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- small-ontology
---
# cro_all-MiniLM-L6-v2_gated_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: cro.owl
- **Domain**: general
- **Ontology Concepts**: 105
- **Concept Alignment**: 105/105 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 105
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.1 MB
- **Model Size**: 88.7 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 105 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('cro_all-MiniLM-L6-v2_gated_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/cro-all-MiniLM-L6-v2_attention_e512
|
david4096
| 2025-09-18T14:23:16Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:23:12Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- small-ontology
---
# cro_all-MiniLM-L6-v2_attention_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: cro.owl
- **Domain**: general
- **Ontology Concepts**: 105
- **Concept Alignment**: 105/105 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 105
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.1 MB
- **Model Size**: 92.0 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 105 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('cro_all-MiniLM-L6-v2_attention_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/cro-all-MiniLM-L6-v2_attention_e128
|
david4096
| 2025-09-18T14:22:59Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:22:56Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- small-ontology
---
# cro_all-MiniLM-L6-v2_attention_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: cro.owl
- **Domain**: general
- **Ontology Concepts**: 105
- **Concept Alignment**: 105/105 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 105
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.1 MB
- **Model Size**: 92.0 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 105 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('cro_all-MiniLM-L6-v2_attention_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/cob-all-MiniLM-L6-v2_gated_e128
|
david4096
| 2025-09-18T14:22:33Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:22:30Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- small-ontology
---
# cob_all-MiniLM-L6-v2_gated_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: cob.owl
- **Domain**: general
- **Ontology Concepts**: 68
- **Concept Alignment**: 68/68 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 68
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.1 MB
- **Model Size**: 88.3 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 68 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('cob_all-MiniLM-L6-v2_gated_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/cob-all-MiniLM-L6-v2_attention_e512
|
david4096
| 2025-09-18T14:22:26Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"small-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:22:23Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- small-ontology
---
# cob_all-MiniLM-L6-v2_attention_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: cob.owl
- **Domain**: general
- **Ontology Concepts**: 68
- **Concept Alignment**: 68/68 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 68
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 0.1 MB
- **Model Size**: 91.7 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 68 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('cob_all-MiniLM-L6-v2_attention_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/cl-all-MiniLM-L6-v2_gated_e512
|
david4096
| 2025-09-18T14:22:02Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"large-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:21:49Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- large-ontology
---
# cl_all-MiniLM-L6-v2_gated_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: cl.owl
- **Domain**: general
- **Ontology Concepts**: 16,667
- **Concept Alignment**: 16,667/16,667 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 16667
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 53.4 MB
- **Model Size**: 244.5 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 16667 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('cl_all-MiniLM-L6-v2_gated_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/clao-all-MiniLM-L6-v2_gated_e512
|
david4096
| 2025-09-18T14:21:55Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:21:51Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- medium-ontology
---
# clao_all-MiniLM-L6-v2_gated_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: clao.owl
- **Domain**: general
- **Ontology Concepts**: 1,516
- **Concept Alignment**: 1,516/1,516 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1516
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 1.7 MB
- **Model Size**: 102.0 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1516 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('clao_all-MiniLM-L6-v2_gated_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/clao-all-MiniLM-L6-v2_gated_e256
|
david4096
| 2025-09-18T14:21:33Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:21:29Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- medium-ontology
---
# clao_all-MiniLM-L6-v2_gated_e256
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: clao.owl
- **Domain**: general
- **Ontology Concepts**: 1,516
- **Concept Alignment**: 1,516/1,516 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1516
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 1.7 MB
- **Model Size**: 102.0 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1516 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('clao_all-MiniLM-L6-v2_gated_e256')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/clao-all-MiniLM-L6-v2_gated_e128
|
david4096
| 2025-09-18T14:21:13Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:21:09Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- medium-ontology
---
# clao_all-MiniLM-L6-v2_gated_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: clao.owl
- **Domain**: general
- **Ontology Concepts**: 1,516
- **Concept Alignment**: 1,516/1,516 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1516
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 1.7 MB
- **Model Size**: 102.0 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1516 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('clao_all-MiniLM-L6-v2_gated_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/clao-all-MiniLM-L6-v2_attention_e128
|
david4096
| 2025-09-18T14:20:07Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-attention",
"gnn-gcn",
"medium-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:20:03Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-attention
- gnn-gcn
- medium-ontology
---
# clao_all-MiniLM-L6-v2_attention_e128
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: clao.owl
- **Domain**: general
- **Ontology Concepts**: 1,516
- **Concept Alignment**: 1,516/1,516 (100.0%)
- **Fusion Method**: attention
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 1516
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 1.7 MB
- **Model Size**: 105.3 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Attention mechanism learns to weight text vs ontological information
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 1516 concepts → GNN → 64 output
- Fusion: attention → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('clao_all-MiniLM-L6-v2_attention_e128')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: attention
Attention-based fusion that learns to focus on relevant embedding components
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
david4096/cido-all-MiniLM-L6-v2_gated_e512
|
david4096
| 2025-09-18T14:19:41Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"ontology",
"on2vec",
"graph-neural-networks",
"base-all-MiniLM-L6-v2",
"general",
"general-ontology",
"fusion-gated",
"gnn-gcn",
"large-ontology",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-09-18T14:19:27Z |
---
base_model: all-MiniLM-L6-v2
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- ontology
- on2vec
- graph-neural-networks
- base-all-MiniLM-L6-v2
- general
- general-ontology
- fusion-gated
- gnn-gcn
- large-ontology
---
# cido_all-MiniLM-L6-v2_gated_e512
This is a sentence-transformers model created with [on2vec](https://github.com/david4096/on2vec), which augments text embeddings with ontological knowledge using Graph Neural Networks.
## Model Details
- **Base Text Model**: all-MiniLM-L6-v2
- Text Embedding Dimension: 384
- **Ontology**: cido.owl
- **Domain**: general
- **Ontology Concepts**: 31,924
- **Concept Alignment**: 31,924/31,924 (100.0%)
- **Fusion Method**: gated
- **GNN Architecture**: GCN
- **Structural Embedding Dimension**: 31924
- **Output Embedding Dimension**: 64
- **Hidden Dimensions**: 128
- **Dropout**: 0.0
- **Training Date**: 2025-09-18
- **on2vec Version**: 0.1.0
- **Source Ontology Size**: 44.8 MB
- **Model Size**: 387.3 MB
- **Library**: on2vec + sentence-transformers
## Technical Architecture
This model uses a multi-stage architecture:
1. **Text Encoding**: Input text is encoded using the base sentence-transformer model
2. **Ontological Embedding**: Pre-trained GNN embeddings capture structural relationships
3. **Fusion Layer**: Gated fusion learns when to rely on ontological vs textual knowledge
**Embedding Flow:**
- Text: 384 dimensions → 128 hidden → 64 output
- Structure: 31924 concepts → GNN → 64 output
- Fusion: gated → Final embedding
## How It Works
This model combines:
1. **Text Embeddings**: Generated using the base sentence-transformer model
2. **Ontological Embeddings**: Created by training Graph Neural Networks on OWL ontology structure
3. **Fusion Layer**: Combines both embedding types using the specified fusion method
The ontological knowledge helps the model better understand domain-specific relationships and concepts.
## Usage
```python
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer('cido_all-MiniLM-L6-v2_gated_e512')
# Generate embeddings
sentences = ['Example sentence 1', 'Example sentence 2']
embeddings = model.encode(sentences)
# Compute similarity
from sentence_transformers.util import cos_sim
similarity = cos_sim(embeddings[0], embeddings[1])
```
## Fusion Method: gated
Gated fusion mechanism that learns when to use ontological vs textual information
## Training Process
This model was created using the on2vec pipeline:
1. **Ontology Processing**: The OWL ontology was converted to a graph structure
2. **GNN Training**: Graph Neural Networks were trained to learn ontological relationships
3. **Text Integration**: Base model text embeddings were combined with ontological embeddings
4. **Fusion Training**: The fusion layer was trained to optimally combine both embedding types
## Intended Use
This model is particularly effective for:
- General domain text processing
- Tasks requiring understanding of domain-specific relationships
- Semantic similarity in specialized domains
- Classification tasks with domain knowledge requirements
## Limitations
- Performance may vary on domains different from the training ontology
- Ontological knowledge is limited to concepts present in the source OWL file
- May have higher computational requirements than vanilla text models
## Citation
If you use this model, please cite the on2vec framework:
```bibtex
@software{on2vec,
title={on2vec: Ontology Embeddings with Graph Neural Networks},
author={David Steinberg},
url={https://github.com/david4096/on2vec},
year={2024}
}
```
---
Created with [on2vec](https://github.com/david4096/on2vec) 🧬→🤖
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.