
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-05 06:27:31
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 468
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-05 06:26:36
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
ProDev9515/roadwork-72-urnUma | ProDev9515 | 2025-06-05T05:29:20Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2025-06-05T05:29:11Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
pandurito/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-deadly_solitary_bee | pandurito | 2025-06-05T05:08:44Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am deadly solitary bee",
"unsloth",
"trl",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-06-01T00:42:04Z | ---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-deadly_solitary_bee
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am deadly solitary bee
- unsloth
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-deadly_solitary_bee
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="pandurito/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-deadly_solitary_bee", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.48.2
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
Crypto3646/Qwen2.5-1.5B-Instruct-Gensyn-Swarm-fast_slithering_otter | Crypto3646 | 2025-06-05T03:48:34Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am fast slithering otter",
"unsloth",
"trl",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-1.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-1.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-05-25T19:35:11Z | ---
base_model: Gensyn/Qwen2.5-1.5B-Instruct
library_name: transformers
model_name: Qwen2.5-1.5B-Instruct-Gensyn-Swarm-fast_slithering_otter
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am fast slithering otter
- unsloth
- trl
licence: license
---
# Model Card for Qwen2.5-1.5B-Instruct-Gensyn-Swarm-fast_slithering_otter
This model is a fine-tuned version of [Gensyn/Qwen2.5-1.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Crypto3646/Qwen2.5-1.5B-Instruct-Gensyn-Swarm-fast_slithering_otter", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/cryptodream167-cryptocomynity/huggingface/runs/4v04gji4)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.48.2
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
adalat-ai/ct2-rotary-indictrans2-indic-en-dist-200M | adalat-ai | 2025-06-05T03:31:45Z | 0 | 0 | null | [
"translation",
"license:mit",
"region:us"
] | translation | 2025-06-05T02:22:07Z | ---
license: mit
pipeline_tag: translation
---
# Usage
We recommend using inference engine fron [IndicTrans2](https://github.com/AI4Bharat/IndicTrans2?tab=readme-ov-file#ct2-inference) for inference of these models.
# Citation
If you use these models, please cite the following work:
```bibtex
@inproceedings{gumma-etal-2025-towards,
title = "Towards Inducing Long-Context Abilities in Multilingual Neural Machine Translation Models",
author = "Gumma, Varun and
Chitale, Pranjal A and
Bali, Kalika",
editor = "Chiruzzo, Luis and
Ritter, Alan and
Wang, Lu",
booktitle = "Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)",
month = apr,
year = "2025",
address = "Albuquerque, New Mexico",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.naacl-long.366/",
pages = "7158--7170",
ISBN = "979-8-89176-189-6"
}
``` |
ryzax/1.5B-v18 | ryzax | 2025-06-05T01:46:47Z | 18 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:agentica-org/DeepScaleR-Preview-Dataset",
"arxiv:2402.03300",
"base_model:ryzax/qwen3_1.7B_sft_correct_v3_1e-5_4",
"base_model:finetune:ryzax/qwen3_1.7B_sft_correct_v3_1e-5_4",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-24T03:05:28Z | ---
base_model: ryzax/qwen3_1.7B_sft_correct_v3_1e-5_4
datasets: agentica-org/DeepScaleR-Preview-Dataset
library_name: transformers
model_name: 1.5B-v18
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for 1.5B-v18
This model is a fine-tuned version of [ryzax/qwen3_1.7B_sft_correct_v3_1e-5_4](https://huggingface.co/ryzax/qwen3_1.7B_sft_correct_v3_1e-5_4) on the [agentica-org/DeepScaleR-Preview-Dataset](https://huggingface.co/datasets/agentica-org/DeepScaleR-Preview-Dataset) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ryzax/1.5B-v18", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/muennighoff/s2/runs/1hnb0ebv)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.17.0.dev0
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.4.1
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
yapeichang/Qwen2.5-3B-RM8B | yapeichang | 2025-06-05T00:32:26Z | 0 | 0 | transformers | [
"transformers",
"pytorch",
"qwen2",
"text-generation",
"conversational",
"dataset:yapeichang/BLEUBERI-Tulu3-50k",
"dataset:allenai/tulu-3-sft-mixture",
"arxiv:2505.11080",
"base_model:Qwen/Qwen2.5-3B",
"base_model:finetune:Qwen/Qwen2.5-3B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-05T00:23:26Z | ---
license: apache-2.0
datasets:
- yapeichang/BLEUBERI-Tulu3-50k
- allenai/tulu-3-sft-mixture
base_model:
- Qwen/Qwen2.5-3B
library_name: transformers
---
# Qwen2.5-3B-RM8B
[[Paper](https://arxiv.org/pdf/2505.11080)] [[HF Collection](https://huggingface.co/collections/yapeichang/bleuberi-6840b3b9d02ff86c5878dafa)] [[Code](https://github.com/lilakk/BLEUBERI)]
Authors: [Yapei Chang](https://lilakk.github.io/), [Yekyung Kim](https://mungg.github.io/), [Michael Krumdick](https://scholar.google.com/citations?user=nqf6-MwAAAAJ&hl=en), [Amir Zadeh](https://scholar.google.com/citations?user=MQFngiMAAAAJ&hl=en), [Chuan Li](https://scholar.google.com/citations?user=hoZesOwAAAAJ&hl=en), [Chris Tanner](https://www.chriswtanner.com/), [Mohit Iyyer](https://www.cs.umd.edu/~miyyer/)
Contact: `[email protected]`
> **TLDR** > We extend RLVR beyond easily verifiable domains like math and code to the more open-ended setting of general instruction following. Surprisingly, we find that BLEU—a simple n-gram matching metric—when paired with high-quality references from strong LLMs, achieves human agreement comparable to 8B and 27B reward models on Chatbot Arena outputs. Based on this insight, we introduce BLEUBERI, which uses BLEU directly as a reward in GRPO training. BLEUBERI matches the performance of RM-guided GRPO across four instruction-following benchmarks and produces more factually grounded outputs, with human raters rating them on par with those from reward model-trained systems.
## Model card
<p align="center" style="margin-bottom: 0;">
<img width="80%" alt="image" src="https://raw.githubusercontent.com/lilakk/BLEUBERI/main/assets/table1.png">
</p>
<p align="center" style="margin-top: 0; padding-top: 0;">
<em>Model performance across four general instruction-following benchmarks.</em>
</p>
This model corresponds to the Qwen2.5-3B, GRPO-RM row in the table. The RM used during training is [Skywork-RM-8B](https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B-v0.2).
## Citation
```bibtex
@misc{chang2025bleuberibleusurprisinglyeffective,
title={BLEUBERI: BLEU is a surprisingly effective reward for instruction following},
author={Yapei Chang and Yekyung Kim and Michael Krumdick and Amir Zadeh and Chuan Li and Chris Tanner and Mohit Iyyer},
year={2025},
eprint={2505.11080},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.11080},
}
``` |
cello78/doctor-meta-llama-3-8B-1 | cello78 | 2025-06-05T00:31:15Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/llama-3-8b",
"base_model:finetune:unsloth/llama-3-8b",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-05T00:26:59Z | ---
base_model: unsloth/llama-3-8b
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** cello78
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Manal0809/MedQA_Mistral_Nemo_Instructive_Best2 | Manal0809 | 2025-06-05T00:19:33Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit",
"base_model:finetune:unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-05T00:19:15Z | ---
base_model: unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Manal0809
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
natix-miner37/streetvision | natix-miner37 | 2025-06-05T00:03:32Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2025-06-05T00:02:36Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
maldv/praxis-bookwriter-qwen2.5-14b-sft | maldv | 2025-06-04T23:16:30Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"writing",
"conversational",
"en",
"dataset:SillyTilly/fiction-writer-596",
"base_model:Qwen/Qwen2.5-14B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-14B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T15:01:15Z | ---
library_name: transformers
license: apache-2.0
datasets:
- SillyTilly/fiction-writer-596
language:
- en
tags:
- writing
base_model:
- Qwen/Qwen2.5-14B-Instruct
pipeline_tags:
- text-generation
---

[GGUF](https://huggingface.co/mradermacher/praxis-bookwriter-qwen2.5-14b-sft-GGUF)
# Praxis Bookwriter Qwen 2.5 14B Instruct
My last iteration of fantasy writer suffered from one glaring flaw: It did not really follow instructions well.
After much consideration, I decided it would make sense to introduce some information about the story chapter text
somewhere to link instructions to the text generated.
For this, I took strides of 16834 tokens across each of the books, and used R1 to generate a summary of the text. With
some careful modification, I used this to generate the first user turn. Each subsequent assistant turn takes approximately
512 tokens of content, and then the user turn is a chapter header, or one paragraph of content. This alternated until I
consumed the entirity of the original stride.
## Crafting the user prompt
In an initial test, I tried putting these instructions in the system prompt. The result was underwhelming. For this
version, the first user turn should contain an overview of the setting, resembling the following format:
```python
system_prompt = """You are my writing assistant. Keep the story going.
// Author: Neal Stephenson
// Tags: sci-fi, romance, space opera"""
prompt = """The following interaction begins in the park.
The night is cool and the stars are bright. Tim and Val sit on a bench, talking about life and the universe.
| Character | Influence | Interactions | Impact on Plot |
|-----------------|-------------------------------------------|--------------------------------------------|-----------------------------------------|
| **Tim** | Asks existential questions; challenges beliefs. | Engages with Val about love and mortality. | Drives philosophical inquiry. |
| **Val** | Uses cosmic imagery (comet, black hole) to reframe love. | Offers metaphysical perspective; softens Tim's cynicism. | Provides an anchor to earthly life. |
This passage is a *philosophical anchor* for the novel. It explores:
- The paradox of love’s invisibility despite its centrality.
- Human attempts to codify intangible concepts (love, time).
- Existential balance between connection and solitude.
- **Tim**: A pragmatic observer, framing life as a "puzzle" with logical solutions. His curiosity is tempered by existential fatigue ("Death will answer").
- **Val**: A romantic idealist using metaphors (comets, black holes) to poeticize love. Her warmth contrasts Tim’s analytical rigidity.
**Character Development**: Their dialogue exposes Tim’s vulnerability (fear of losing Val) and Val’s capacity for profound empathy.
1. **Dialogue as Philosophy**: Use exchanges to explore abstract themes (e.g., love vs. logic).
2. **Metaphor Over Explanation**: Let characters reframe ideas through imagery (e..g., love as a comet).
3. **Contrast Tones**: Juxtapose melancholy (death) with whimsy (starry skies) to deepen emotional resonance.
4. **Subtext in Action**: Small gestures (holding hands, watching stars) reveal character dynamics more than explicit dialogue.
---
This excerpt exemplifies how speculative fiction can grapple with timeless questions while grounding them in relatable human experiences. Writers should note the interplay of intellect and emotion, ensuring that philosophy never eclipses humanity.
In **Chapter 1**, the duo debates whether love is a tangible entity or an illusion. Tim wonders if love could "hide in a star," while Val likens it to a comet that "doesn't exist until it appears." In **Chapter**, Val reframes love as an absence where two people meet—a metaphorical "black hole" where space-time warps. Both chapters juxtapose cosmic grandeur with intimate vulnerability.
A lyrical blend of **melancholic reflection** and **cosmic wonder**. Dialogue oscillates between wistful acceptance ("Death's a necessary thing") and awe-inspired speculation ("the sky's a better place to be with you").
- **Existential Inquiry**: Love as both illusion and cosmic force.
- **Cosmic Humility**: Humanity’s insignificance against infinite time/space.
- **Opposing Perspectives**: Contrasts between logic (Tim) and intuition (Val).
// Chapter: 1
"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt},
]
```
The content of this block can contain all variety of instruction about what to write in the proceeding frame. The summaries I used were between 500 and 1500 tokens, so the more detail about setting, location, characters, their relationships, and plot points, the better. The examples had their sections shuffled to provide for a variety of policy.
If you do not specify content or the chapter boundary, the assistant will often generate chapter outlines; which is very useful.
## License
This model is released under the limitations of both the apache 2 license.
## Author
Praxis Maldevide
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{praxis-bookwriter-qwen2.5-14b-sft,
title = {Praxis Bookwriter Qwen 2.5 14B},
url = {https://huggingface.co/maldv/praxis-bookwriter-qwen2.5-14b-sft},
author = {Praxis Maldevide},
month = {June},
year = {2025}
}
``` |
Meggido/Contrl-Stheno-v1-8B-6.5bpw-h8-exl2 | Meggido | 2025-06-04T22:40:59Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"Sao10K/L3-8B-Stheno-v3.2",
"Delta-Vector/Control-Nanuq-8B",
"conversational",
"en",
"base_model:Darkknight535/Contrl-Stheno-v1-8B",
"base_model:quantized:Darkknight535/Contrl-Stheno-v1-8B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T22:36:24Z | ---
base_model:
- Darkknight535/Contrl-Stheno-v1-8B
base_model_relation: quantized
quantized_by: Meggido
tags:
- merge
- mergekit
- lazymergekit
- Sao10K/L3-8B-Stheno-v3.2
- Delta-Vector/Control-Nanuq-8B
language:
- en
library_name: transformers
---
# ⚡ExLlamaV2 quant of : [Contrl-Stheno-v1-8B](https://huggingface.co/Darkknight535/Contrl-Stheno-v1-8B)
> [!note]
> ➡️ **Exl2 version :** [0.3.1](https://github.com/turboderp/exllamav2/releases/tag/v0.3.1)<br/>
> ➡️ **Cal. dataset :** Default.<br/>
> 📄 <a href="https://huggingface.co/Meggido/Contrl-Stheno-v1-8B-6.5bpw-h8-exl2/resolve/main/measurement.json" download>Measurement.json</a> file.
<style>
ebody {
font-family: 'Quicksand', sans-serif;
background: linear-gradient(135deg, #FF69B4 0%, #800080 100%);
color: #FFFFFF;
margin: 0;
padding: 0;
font-size: 16px;
min-height: 100vh;
}
.container {
margin: 20px;
background-color: rgba(28, 14, 36, 0.95);
padding: 20px;
border-radius: 12px;
box-shadow: 0 4px 20px rgba(255, 105, 180, 0.4);
border: 1px solid rgba(255, 105, 180, 0.4);
outline: 1px solid rgba(255, 105, 180, 0.7);
outline-offset: -1px;
position: relative;
backdrop-filter: blur(10px);
}
.container::before {
content: '';
position: absolute;
top: -1px;
left: -1px;
right: -1px;
bottom: -1px;
border: 1px solid rgba(255, 105, 180, 0.98);
border-radius: 12px;
pointer-events: none;
animation: borderGlow 2s ease-in-out infinite;
}
@keyframes borderGlow {
0% {
box-shadow: 0 0 5px rgba(255, 105, 180, 0.98);
}
50% {
box-shadow: 0 0 20px rgba(255, 105, 180, 0.98);
}
100% {
box-shadow: 0 0 5px rgba(255, 105, 180, 0.98);
}
}
.header h1 {
font-size: 28px;
color: #FF69B4;
margin: 0 0 20px 0;
text-shadow: 0 0 15px rgba(255, 105, 180, 0.8);
letter-spacing: 1px;
}
.update-section {
margin-top: 30px;
}
.update-section h2, h2 {
font-size: 24px;
color: #FF69B4;
text-shadow: 0 0 15px rgba(255, 105, 180, 0.8);
letter-spacing: 0.5px;
}
.update-section p {
font-size: 16px;
line-height: 1.6;
color: #FFE1FF;
}
.info p {
color: #FFE1FF;
line-height: 1.6;
font-size: 16px;
}
.info img {
width: 100%;
border-radius: 10px;
margin-bottom: 15px;
box-shadow: 0 0 30px rgba(255, 105, 180, 0.5);
border: 1px solid rgba(255, 105, 180, 0.4);
outline: 1px solid rgba(255, 105, 180, 0.7);
outline-offset: -1px;
transition: transform 0.3s ease, box-shadow 0.3s ease;
}
.info img:hover {
transform: scale(1.01);
box-shadow: 0 0 40px rgba(255, 105, 180, 0.6);
}
a {
color: #00FFEE;
text-decoration: none;
transition: color 0.3s ease;
}
a:hover {
color: #FF1493;
}
.button {
display: inline-block;
background: linear-gradient(45deg, rgba(255, 105, 180, 0.9), rgba(128, 0, 128, 0.9));
color: #FFFFFF;
padding: 12px 24px;
border-radius: 5px;
cursor: pointer;
text-decoration: none;
transition: all 0.3s ease;
border: 1px solid rgba(255, 105, 180, 0.4);
}
.button:hover {
background: linear-gradient(45deg, rgba(255, 105, 180, 1), rgba(128, 0, 128, 1));
box-shadow: 0 0 20px rgba(255, 105, 180, 0.7);
transform: translateY(-2px);
}
pre {
background-color: rgba(28, 14, 36, 0.95);
padding: 15px;
border-radius: 5px;
overflow-x: auto;
border: 1px solid rgba(255, 20, 147, 0.3);
outline: 1px solid rgba(255, 20, 147, 0.6);
outline-offset: -1px;
}
code {
font-family: 'Courier New', monospace;
color: #FFE1FF;
}
.benchmark-container {
background: rgba(28, 14, 36, 0.95);
border: 1px solid rgba(255, 20, 147, 0.3);
border-radius: 12px;
padding: 20px;
margin: 20px 0;
position: relative;
overflow: hidden;
}
.benchmark-container::before {
content: '';
position: absolute;
top: -1px;
left: -1px;
right: -1px;
bottom: -1px;
border: 1px solid rgba(255, 20, 147, 0.98);
border-radius: 12px;
pointer-events: none;
animation: borderGlow 2s ease-in-out infinite;
}
.benchmark-grid {
display: grid;
grid-template-columns: repeat(4, 1fr);
gap: 15px;
}
.metric-box {
background: rgba(28, 14, 36, 0.95);
border: 1px solid rgba(255, 20, 147, 0.3);
border-radius: 8px;
padding: 15px;
display: flex;
flex-direction: column;
align-items: center;
text-align: center;
transition: transform 0.3s ease, box-shadow 0.3s ease;
}
.metric-box:hover {
transform: translateY(-2px);
box-shadow: 0 4px 15px rgba(255, 20, 147, 0.3);
}
.metric-box .label {
color: #00FFEE;
font-size: 14px;
margin-bottom: 8px;
font-weight: 500;
}
.metric-box .value {
color: #FFE1FF;
font-size: 18px;
font-weight: 600;
text-shadow: 0 0 5px rgba(255, 20, 147, 0.5);
}
.metrics-section {
margin-bottom: 30px;
}
.metrics-section details {
background: rgba(28, 14, 36, 0.95);
border: 1px solid rgba(255, 20, 147, 0.3);
border-radius: 8px;
padding: 15px;
margin-bottom: 15px;
}
.metrics-section summary {
color: #FF1493;
font-size: 20px;
cursor: pointer;
text-shadow: 0 0 5px rgba(255, 20, 147, 0.3);
outline: none;
padding: 5px 0;
}
.metrics-section summary::-webkit-details-marker {
display: none;
}
.core-metrics-grid {
display: grid;
grid-template-columns: repeat(4, 1fr);
gap: 15px;
margin-bottom: 20px;
}
.progress-metrics {
display: grid;
gap: 15px;
}
.progress-metric {
background: rgba(28, 14, 36, 0.95);
border: 1px solid rgba(255, 20, 147, 0.3);
border-radius: 8px;
padding: 15px;
transition: transform 0.3s ease;
}
.progress-metric:hover {
transform: translateY(-2px);
}
.progress-label {
display: flex;
justify-content: space-between;
margin-bottom: 8px;
color: #00FFEE;
font-size: 14px;
}
.progress-value {
color: #FFE1FF;
}
.progress-bar {
width: 100%;
height: 8px;
background: rgba(0, 0, 0, 0.3);
border: 1px solid rgba(255, 20, 147, 0.15);
border-radius: 4px;
position: relative;
margin: 10px 0;
overflow: hidden;
}
.progress-fill {
height: 100%;
background: linear-gradient(90deg, #FF69B4 0%, #800080 100%);
border-radius: 4px;
transition: width 1s ease-in-out;
box-shadow: 0 0 15px rgba(255, 105, 180, 0.4);
}
.progress-bar.split {
display: flex;
justify-content: center;
background: rgba(0, 0, 0, 0.3);
border: 1px solid rgba(255, 20, 147, 0.15);
overflow: visible;
}
.progress-fill-left {
height: 100%;
position: absolute;
right: 50%;
background: linear-gradient(90deg, #FF69B4 30%, rgba(255, 105, 180, 0.5) 100%);
border-radius: 4px 0 0 4px;
transition: width 0.3s ease-in-out;
}
.progress-fill-right {
height: 100%;
position: absolute;
left: 50%;
background: linear-gradient(90deg, rgba(128, 0, 128, 0.5) 0%, #800080 70%);
border-radius: 0 4px 4px 0;
transition: width 0.3s ease-in-out;
}
.progress-metric.split .progress-bar::before,
.progress-metric.split .progress-bar::after {
content: '';
position: absolute;
width: 2px;
height: 20px;
background: rgba(255, 255, 255, 0.7);
top: 50%;
transform: translateY(-50%);
z-index: 2;
box-shadow: 0 0 8px rgba(255, 255, 255, 0.5);
}
.progress-metric.split .progress-bar::before {
left: 0;
}
.progress-metric.split .progress-bar::after {
right: 0;
}
.progress-metric.split:hover .progress-fill-left {
box-shadow: 0 0 15px rgba(255, 20, 147, 0.5);
}
.progress-metric.split:hover .progress-fill-right {
box-shadow: 0 0 15px rgba(75, 0, 130, 0.5);
}
.progress-metric.split {
padding: 12px 15px;
}
.progress-metric.split .progress-label {
margin-bottom: 8px;
gap: 12px;
}
.progress-metric.split .progress-label span:first-child,
.progress-metric.split .progress-label span:last-child {
flex: 0 0 80px;
font-size: 14px;
}
.progress-metric.split .progress-value {
font-weight: 600;
text-shadow: 0 0 5px rgba(255, 20, 147, 0.3);
font-size: 14px;
min-width: 60px;
text-align: center;
}
.progress-metric:hover .progress-fill-center {
box-shadow: 0 0 15px rgba(255, 20, 147, 0.5);
}
.progress-label {
display: flex;
justify-content: space-between;
align-items: center;
margin-bottom: 4px;
color: #00FFEE;
font-size: 14px;
}
.progress-metric:not(.split) .progress-label {
gap: 12px;
}
.progress-metric:not(.split) .progress-label span {
flex: 0 0 auto;
}
.progress-metric:not(.split) .progress-value {
color: #FFE1FF;
}
.progress-metric.split .progress-label {
gap: 20px;
}
.progress-metric.split .progress-label span:first-child,
.progress-metric.split .progress-label span:last-child {
flex: 0 0 80px;
}
.progress-metric.split .progress-label span:first-child {
text-align: right;
}
.progress-metric.split .progress-label span:last-child {
text-align: left;
}
.progress-metric.split .progress-value {
color: #FFE1FF;
flex: 0 0 60px;
text-align: center;
}
.progress-metric:hover .progress-fill {
box-shadow: 0 0 15px rgba(255, 20, 147, 0.5);
}
.progress-metric:hover .progress-fill-center {
box-shadow: 0 0 15px rgba(75, 0, 130, 0.5);
}
.info-grid {
display: grid;
grid-template-columns: repeat(3, 1fr);
gap: 15px;
}
.creator-section {
margin: 20px 0;
}
.creator-badge {
display: inline-flex;
align-items: center;
background: rgba(28, 14, 36, 0.95);
border: 1px solid rgba(255, 20, 147, 0.3);
border-radius: 8px;
padding: 10px 15px;
}
.creator-label {
color: #FFE1FF;
font-size: 14px;
margin-right: 8px;
}
.creator-link {
display: flex;
align-items: center;
gap: 5px;
color: #00FFEE;
text-decoration: none;
transition: all 0.3s ease;
}
.creator-name {
font-weight: 600;
}
.creator-arrow {
font-size: 16px;
transition: transform 0.3s ease;
}
.creator-link:hover {
color: #FF1493;
}
.creator-link:hover .creator-arrow {
transform: translateX(3px);
}
.model-info {
margin-top: 30px;
}
.name-legend {
background: rgba(28, 14, 36, 0.95);
border: 1px solid rgba(255, 20, 147, 0.3);
border-radius: 8px;
padding: 20px;
margin: 20px 0;
}
.name-legend h3 {
color: #FF1493;
font-size: 18px;
margin: 0 0 15px 0;
}
.legend-grid {
display: grid;
gap: 12px;
}
.legend-item {
display: flex;
align-items: baseline;
gap: 10px;
}
.legend-key {
color: #00FFEE;
font-weight: 600;
min-width: 80px;
}
.legend-value {
color: #FFE1FF;
}
.model-description {
background: rgba(28, 14, 36, 0.95);
border: 1px solid rgba(255, 20, 147, 0.3);
border-radius: 8px;
padding: 20px;
}
.model-description p {
margin: 0 0 15px 0;
line-height: 1.6;
}
.model-description p:last-child {
margin-bottom: 0;
}
.section-container {
margin: 40px 0;
}
.info-card {
background: rgba(28, 14, 36, 0.95);
border: 1px solid rgba(255, 20, 147, 0.3);
border-radius: 8px;
overflow: hidden;
}
.info-header {
background: rgba(255, 20, 147, 0.1);
padding: 20px;
border-bottom: 1px solid rgba(255, 20, 147, 0.3);
}
.info-header h3 {
color: #FF1493;
margin: 0 0 10px 0;
font-size: 20px;
text-shadow: 0 0 5px rgba(255, 20, 147, 0.3);
}
.model-tags {
display: flex;
gap: 8px;
flex-wrap: wrap;
}
.model-tag {
background: rgba(0, 255, 238, 0.1);
color: #00FFEE;
padding: 4px 8px;
border-radius: 4px;
font-size: 12px;
border: 1px solid rgba(0, 255, 238, 0.2);
}
.model-composition {
padding: 20px;
border-bottom: 1px solid rgba(255, 20, 147, 0.3);
}
.model-composition h4 {
color: #FF1493;
margin: 0 0 15px 0;
font-size: 16px;
}
.composition-list {
list-style: none;
padding: 0;
margin: 0;
display: grid;
gap: 10px;
}
.composition-list li {
color: #FFE1FF;
display: flex;
align-items: baseline;
gap: 8px;
}
.model-component {
color: #00FFEE;
font-weight: 500;
min-width: 120px;
}
.template-card {
background: rgba(28, 14, 36, 0.95);
border: 1px solid rgba(255, 20, 147, 0.3);
border-radius: 8px;
padding: 15px;
}
.template-item {
display: flex;
align-items: center;
gap: 12px;
}
.template-icon {
width: 24px;
height: 24px;
opacity: 0.8;
}
.template-content {
display: flex;
align-items: baseline;
gap: 8px;
}
.template-link {
color: #00FFEE;
text-decoration: none;
font-weight: 500;
display: flex;
align-items: center;
gap: 5px;
}
.template-author {
color: rgba(255, 225, 255, 0.7);
font-size: 14px;
}
.quantized-container {
display: grid;
gap: 20px;
}
.quantized-section {
background: rgba(28, 14, 36, 0.95);
border: 1px solid rgba(255, 20, 147, 0.3);
border-radius: 8px;
padding: 20px;
}
.quantized-section h3 {
color: #FF1493;
font-size: 18px;
margin: 0 0 15px 0;
}
.quantized-items {
display: grid;
gap: 12px;
}
.quantized-item {
display: flex;
align-items: baseline;
gap: 10px;
}
.quantized-item .author {
color: rgba(255, 225, 255, 0.7);
min-width: 100px;
}
.multi-links {
display: flex;
align-items: center;
gap: 8px;
}
.separator {
color: rgba(255, 225, 255, 0.5);
}
.config-container {
background: rgba(28, 14, 36, 0.95);
border: 1px solid rgba(255, 20, 147, 0.3);
border-radius: 8px;
overflow: hidden;
}
.config-header {
background: rgba(255, 20, 147, 0.1);
padding: 15px 20px;
border-bottom: 1px solid rgba(255, 20, 147, 0.3);
}
.model-name {
color: #FF1493;
font-weight: 600;
}
.config-content {
padding: 20px;
}
.config-item {
display: flex;
flex-direction: column;
gap: 5px;
margin-bottom: 15px;
}
.config-label {
color: #00FFEE;
font-size: 14px;
font-weight: 500;
}
.config-value {
color: #FFE1FF;
font-family: 'Courier New', monospace;
}
.config-models {
margin-top: 20px;
}
.model-list {
list-style: none;
padding: 0;
margin: 10px 0 0 0;
}
.model-list li {
color: #FFE1FF;
font-family: 'Courier New', monospace;
padding: 5px 0;
padding-left: 20px;
position: relative;
}
.model-list li::before {
content: '-';
position: absolute;
left: 0;
color: #00FFEE;
}
.link-arrow {
display: inline-block;
transition: transform 0.3s ease;
}
a:hover .link-arrow {
transform: translateX(3px);
}
.benchmark-notification {
background: rgba(255, 20, 147, 0.15);
border: 1px solid rgba(255, 20, 147, 0.3);
border-radius: 8px;
margin-bottom: 20px;
padding: 12px;
animation: glowPulse 2s infinite;
}
.notification-content {
display: flex;
align-items: center;
justify-content: center;
gap: 10px;
text-align: center;
}
.notification-icon {
font-size: 20px;
}
.notification-text {
color: #FFE1FF;
font-size: 16px;
font-weight: 500;
display: flex;
flex-direction: column;
align-items: center;
gap: 5px;
}
.benchmark-link {
color: #00FFEE;
text-decoration: none;
font-size: 14px;
padding: 4px 8px;
border-radius: 4px;
transition: all 0.3s ease;
border: 1px solid rgba(0, 255, 238, 0.3);
}
.benchmark-link:hover {
background: rgba(0, 255, 238, 0.1);
border-color: rgba(0, 255, 238, 0.5);
color: #00FFEE;
text-shadow: 0 0 5px rgba(0, 255, 238, 0.5);
}
@keyframes glowPulse {
0% {
box-shadow: 0 0 5px rgba(255, 20, 147, 0.3);
}
50% {
box-shadow: 0 0 15px rgba(255, 20, 147, 0.5);
}
100% {
box-shadow: 0 0 5px rgba(255, 20, 147, 0.3);
}
}
.review-card {
background: rgba(28, 14, 36, 0.95);
border: 1px solid rgba(255, 20, 147, 0.3);
border-radius: 8px;
padding: 15px;
margin-bottom: 15px;
}
.review-card:last-child {
margin-bottom: 0;
}
</style>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Contrl-Stheno-8B-v1</title>
<link href="https://fonts.googleapis.com/css2?family=Quicksand:wght@400;500;600&display=swap" rel="stylesheet">
<link href="styles.css" rel="stylesheet">
</head>
<body>
<div class="container">
<div class="header">
<h1>Contrl-Stheno-8B-v1</h1>
</div>
<div class="info">
<img src="https://huggingface.co/Darkknight535/Contrl-Stheno-v1-8B/resolve/main/img_.jpg" alt="Model banner">
<div class="creator-section">
<div class="creator-badge">
<span class="creator-label">Created by</span>
<a href="https://huggingface.co/Darkknight535" target="_blank" class="creator-link">
<span class="creator-name">Darkknight535</span>
<span class="creator-arrow">→</span>
</a>
</div>
</div>
<div class="model-info">
<h2>Model Information</h2>
<div class="info-card">
<div class="info-header">
<h3>Contrl-Stheno-8B-v1</h3>
<div class="model-tags">
<span class="model-tag">Stheno = Stheno-v3.2</span>
<span class="model-tag">Contrl = Control-Nanuq</span>
<span class="model-tag">8b Parameters</span>
</div>
</div>
<div class="model-composition">
<h4>Model Composition</h4>
<ul class="composition-list">
<li><span class="model-component"><a href="https://huggingface.co/Delta-Vector/Control-Nanuq-8B" target="_blank">Control Nanuq 8B</a></span> Sweetness and Creativity capabilities</li>
<li><span class="model-component"><a href="https://huggingface.co/Sao10K/L3-8B-Stheno-v3.2" target="_blank">Stheno-3.2 8B</a></span> Roleplay and logic</li>
</ul>
</div>
<div class="model-description">
<p>An Experiment of mine which turned out to be great! It has dialogues I hadn't found even in 70B models.</p>
</div>
</div>
<!--<div class="metrics-section">
<details open>
<summary>User Reviews</summary>
<div class="progress-metrics">
<div>
<div class="review-card">
<div>
<span>[USERNAME]</span>
</div>
<p>[REVIEW]</p>
</div>
<div class="review-card">
<div>
<span>[USERNAME]</span>
</div>
<p>[REVIEW]</p>
</div>
<div class="review-card">
<div>
<span>[USERNAME]</span>
</div>
<p>[REVIEW]</p>
</div>
</div>
</div>
</details>
</div>-->
</div>
<div class="section-container">
<h2>Reccomended Templates & Prompts</h2>
<div class="template-card">
<div class="template-item">
<div class="template-content">
<a href="" target="_blank" class="template-link">
Sao10k's Euryale System Prompt OR EVA System Prompt
<span class="link-arrow">→</span>
</a>
<span class="template-author">by Sao10k and EVA-UNIT-01</span>
</div>
</div>
</div>
</div>
<div class="section-container">
<h2>Quantized Versions</h2>
<div class="quantized-container">
<div class="quantized-section">
<h3>GGUF Quantizations</h3>
<div class="quantized-items">
<div class="quantized-item">
<span class="author">mradermacher</span>
<a href="https://huggingface.co/mradermacher/Contrl-Stheno-v1-8B-GGUF" target="_blank">
STATIC-GGUF
<span class="link-arrow">→</span>
</a>
</div>
</div>
</div>
<div class="quantized-section">
<h3>Imat GGUF Quantizations</h3>
<div class="quantized-items">
<div class="quantized-item">
<span class="author">mradermacher</span>
<a href="https://huggingface.co/mradermacher/Contrl-Stheno-v1-8B-i1-GGUF" target="_blank">
IMAT-GGUF
<span class="link-arrow">→</span>
</a>
</div>
</div>
</div>
</div>
</div>
<div class="support-section">
<h2>Thanks to these people (I just made a script and Stole SteelSkull's Readme Template)</h2>
<div class="support-buttons">
<a href="https://huggingface.co/Sao10k" target="_blank" class="button">
Support Sao10K
</a>
<a href="https://huggingface.co/Delta-Vector" target="_blank" class="button">
Support Delta-Vector
</a>
<a href="https://huggingface.co/Steelskull" target="_blank" class="button">
Support SteelSkull
</a>
</div>
</div>
</div>
</div>
</body>
</html> |
mohammadmahdinouri/interleaved-speech-test-1 | mohammadmahdinouri | 2025-06-04T22:28:38Z | 185 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-27T22:30:43Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mlx-community/Llama-3.2-11B-Vision-Surgical-CholecT50-8bit | mlx-community | 2025-06-04T22:15:08Z | 0 | 0 | mlx | [
"mlx",
"safetensors",
"mllama",
"license:other",
"region:us"
] | null | 2025-06-04T22:11:42Z | ---
license: other
license_name: nvidia-community-model-license
license_link: https://www.nvidia.com/content/dam/en-zz/Solutions/license-agreements/enterprise-software/NVIDIA-Models-Community-License-2025-04-15-FINAL.pdf
tags:
- mlx
---
# mlx-community/Llama-3.2-11B-Vision-Surgical-CholecT50-8bit
This model was converted to MLX format from [`nvidia/Llama-3.2-11B-Vision-Surgical-CholecT50`]() using mlx-vlm version **0.1.26**.
Refer to the [original model card](https://huggingface.co/nvidia/Llama-3.2-11B-Vision-Surgical-CholecT50) for more details on the model.
## Use with mlx
```bash
pip install -U mlx-vlm
```
```bash
python -m mlx_vlm.generate --model mlx-community/Llama-3.2-11B-Vision-Surgical-CholecT50-8bit --max-tokens 100 --temperature 0.0 --prompt "Describe this image." --image <path_to_image>
```
|
publication-charaf/MCQ_Qwen3-0.6B-Base_lr-0.0005_e-3_s-0 | publication-charaf | 2025-06-04T22:10:09Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:Qwen/Qwen3-0.6B-Base",
"base_model:finetune:Qwen/Qwen3-0.6B-Base",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T18:07:14Z | ---
base_model: Qwen/Qwen3-0.6B-Base
library_name: transformers
model_name: MCQ_Qwen3-0.6B-Base_lr-0.0005_e-3_s-0
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for MCQ_Qwen3-0.6B-Base_lr-0.0005_e-3_s-0
This model is a fine-tuned version of [Qwen/Qwen3-0.6B-Base](https://huggingface.co/Qwen/Qwen3-0.6B-Base).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="publication-charaf/MCQ_Qwen3-0.6B-Base_lr-0.0005_e-3_s-0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/kamel-charaf-epfl/huggingface/runs/0g41tsyn)
This model was trained with SFT.
### Framework versions
- TRL: 0.17.0
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
WoomyPearl/RVC-Model-Palace | WoomyPearl | 2025-06-04T22:02:55Z | 0 | 13 | null | [
"license:openrail",
"region:us"
] | null | 2023-07-22T23:24:40Z | ---
license: openrail
---
Hello and welcome to my RVC voice model repository, here you can find models of various characters!
Use them for anything from memes, song covers, to even masking your voice in Discord voice calls!
Don't forget to credit me when using my models! |
EhDa24/MNLP_M2_mcqa_model_full_ft1 | EhDa24 | 2025-06-04T21:50:44Z | 37 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen3-0.6B-Base",
"base_model:finetune:Qwen/Qwen3-0.6B-Base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-05-29T07:01:12Z | ---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen3-0.6B-Base
tags:
- generated_from_trainer
model-index:
- name: MNLP_M2_mcqa_model_full_ft1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MNLP_M2_mcqa_model_full_ft1
This model is a fine-tuned version of [Qwen/Qwen3-0.6B-Base](https://huggingface.co/Qwen/Qwen3-0.6B-Base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 3
- eval_batch_size: 3
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 12
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.5.1+cu124
- Datasets 3.2.0
- Tokenizers 0.21.1
|
dslighfdsl/Llama-3.1-8B-Instruct-SFT-CoT-short-full-3-webshop | dslighfdsl | 2025-06-04T20:50:53Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"sft",
"conversational",
"dataset:sciworld",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:finetune:meta-llama/Llama-3.1-8B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T19:36:32Z | ---
base_model: meta-llama/Llama-3.1-8B-Instruct
datasets: sciworld
library_name: transformers
model_name: Llama-3.1-8B-Instruct-SFT-CoT-short-full-3-webshop
tags:
- generated_from_trainer
- open-r1
- trl
- sft
licence: license
---
# Model Card for Llama-3.1-8B-Instruct-SFT-CoT-short-full-3-webshop
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct) on the [sciworld](https://huggingface.co/datasets/sciworld) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="dslighfdsl/Llama-3.1-8B-Instruct-SFT-CoT-short-full-3-webshop", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/pengliangji2023-carnegie-mellon-university/huggingface/runs/wapbg8gf)
This model was trained with SFT.
### Framework versions
- TRL: 0.15.2
- Transformers: 4.50.0.dev0
- Pytorch: 2.5.1
- Datasets: 3.3.2
- Tokenizers: 0.21.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
Denn231/internal_clf_v_0.56 | Denn231 | 2025-06-04T20:04:56Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-06-04T15:53:17Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
nezamisafa/whisper-persian-v4.2.0 | nezamisafa | 2025-06-04T19:58:10Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"fa",
"dataset:nezamisafa/ASR_fa_v1",
"base_model:openai/whisper-large-v3",
"base_model:finetune:openai/whisper-large-v3",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2025-06-04T04:56:38Z | ---
library_name: transformers
language:
- fa
license: apache-2.0
base_model: openai/whisper-large-v3
tags:
- generated_from_trainer
datasets:
- nezamisafa/ASR_fa_v1
metrics:
- wer
model-index:
- name: whisper-large-v3-persian
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: ASR_fa_v1
type: nezamisafa/ASR_fa_v1
args: 'config: fa, split: test'
metrics:
- name: Wer
type: wer
value: 10.16949152542373
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-large-v3-persian
This model is a fine-tuned version of [openai/whisper-large-v3](https://huggingface.co/openai/whisper-large-v3) on the ASR_fa_v1 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1160
- Wer: 10.1695
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 6000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 0.098 | 1.2945 | 2000 | 0.1319 | 14.9118 |
| 0.0381 | 2.5890 | 4000 | 0.1065 | 10.7267 |
| 0.0151 | 3.8835 | 6000 | 0.1160 | 10.1695 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.0+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
JohanHeinsen/ENO_first_identifier | JohanHeinsen | 2025-06-04T19:52:02Z | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"setfit",
"text-classification",
"license:apache-2.0",
"region:us"
] | text-classification | 2025-06-04T19:46:46Z | ---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
This is a text classifier designed to identify whether a line of text is the first line of text in a news item. The model is designed to aid the segmentation of ENO.
## Metrics:
Accuracy: 0.9041353383458647
f1: 0.9092526690391459
|
luckeciano/Qwen-2.5-7B-GRPO-Minibatch-8Actions_133 | luckeciano | 2025-06-04T19:41:44Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:DigitalLearningGmbH/MATH-lighteval",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Math-7B",
"base_model:finetune:Qwen/Qwen2.5-Math-7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-03T23:30:16Z | ---
base_model: Qwen/Qwen2.5-Math-7B
datasets: DigitalLearningGmbH/MATH-lighteval
library_name: transformers
model_name: Qwen-2.5-7B-GRPO-Minibatch-8Actions_133
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen-2.5-7B-GRPO-Minibatch-8Actions_133
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) on the [DigitalLearningGmbH/MATH-lighteval](https://huggingface.co/datasets/DigitalLearningGmbH/MATH-lighteval) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="luckeciano/Qwen-2.5-7B-GRPO-Minibatch-8Actions_133", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/max-ent-llms/PolicyGradientStability/runs/1ni52rm8)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.6.0
- Datasets: 3.4.1
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
Cornelias/Pyramids-ML_agents | Cornelias | 2025-06-04T19:38:38Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] | reinforcement-learning | 2025-06-04T19:38:34Z | ---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Cornelias/Pyramids-ML_agents
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
abdou-u/MNLP_M3_quantized_mcqa_model | abdou-u | 2025-06-04T19:08:41Z | 209 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2025-06-03T23:51:48Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
pictgensupport/businesscasual | pictgensupport | 2025-06-04T19:01:16Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-04T19:01:14Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: businesscasual
---
# Businesscasual
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `businesscasual` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('pictgensupport/businesscasual', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
mradermacher/BioXP-0.5B-MedMCQA-GGUF | mradermacher | 2025-06-04T19:00:06Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"grpo",
"rl",
"biomed",
"medmcqa",
"medical",
"explainableAI",
"XAI",
"tramsformers",
"trl",
"en",
"dataset:openlifescienceai/medmcqa",
"base_model:abaryan/BioXP-0.5B-MedMCQA",
"base_model:quantized:abaryan/BioXP-0.5B-MedMCQA",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-04T14:22:57Z | ---
base_model: abaryan/BioXP-0.5B-MedMCQA
datasets:
- openlifescienceai/medmcqa
language:
- en
library_name: transformers
license: mit
quantized_by: mradermacher
tags:
- grpo
- rl
- biomed
- medmcqa
- medical
- explainableAI
- XAI
- tramsformers
- trl
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/abaryan/BioXP-0.5B-MedMCQA
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/BioXP-0.5B-MedMCQA-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/BioXP-0.5B-MedMCQA-GGUF/resolve/main/BioXP-0.5B-MedMCQA.Q3_K_S.gguf) | Q3_K_S | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/BioXP-0.5B-MedMCQA-GGUF/resolve/main/BioXP-0.5B-MedMCQA.Q2_K.gguf) | Q2_K | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/BioXP-0.5B-MedMCQA-GGUF/resolve/main/BioXP-0.5B-MedMCQA.IQ4_XS.gguf) | IQ4_XS | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/BioXP-0.5B-MedMCQA-GGUF/resolve/main/BioXP-0.5B-MedMCQA.Q3_K_M.gguf) | Q3_K_M | 0.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/BioXP-0.5B-MedMCQA-GGUF/resolve/main/BioXP-0.5B-MedMCQA.Q3_K_L.gguf) | Q3_K_L | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/BioXP-0.5B-MedMCQA-GGUF/resolve/main/BioXP-0.5B-MedMCQA.Q4_K_S.gguf) | Q4_K_S | 0.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/BioXP-0.5B-MedMCQA-GGUF/resolve/main/BioXP-0.5B-MedMCQA.Q4_K_M.gguf) | Q4_K_M | 0.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/BioXP-0.5B-MedMCQA-GGUF/resolve/main/BioXP-0.5B-MedMCQA.Q5_K_S.gguf) | Q5_K_S | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/BioXP-0.5B-MedMCQA-GGUF/resolve/main/BioXP-0.5B-MedMCQA.Q5_K_M.gguf) | Q5_K_M | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/BioXP-0.5B-MedMCQA-GGUF/resolve/main/BioXP-0.5B-MedMCQA.Q6_K.gguf) | Q6_K | 0.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/BioXP-0.5B-MedMCQA-GGUF/resolve/main/BioXP-0.5B-MedMCQA.Q8_0.gguf) | Q8_0 | 0.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/BioXP-0.5B-MedMCQA-GGUF/resolve/main/BioXP-0.5B-MedMCQA.f16.gguf) | f16 | 1.1 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
jhugentobler/quanto-A8W8 | jhugentobler | 2025-06-04T18:59:12Z | 0 | 0 | null | [
"safetensors",
"qwen3",
"model_hub_mixin",
"8-bit",
"region:us"
] | null | 2025-06-04T17:56:03Z | ---
tags:
- model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Code: [More Information Needed]
- Paper: [More Information Needed]
- Docs: [More Information Needed] |
jebondas/Video.Foto.De.Alana.Flores.Viral.video.Full.Video.Alana.Foto.Filtrada.De.Alana.Flores.Twitter | jebondas | 2025-06-04T18:56:29Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-04T18:56:01Z | [🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?hgg)
[►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► 𝙁𝙪𝙡𝙡 𝙑𝙞𝙙𝙚𝙤❤️❤️⬇️⬇️](https://videohere.top/?hgg)
[<img alt="fsd" src="http://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?hgg) |
ver-viral-video-y-fotos-Alana-Flores/Ver.foto.intima.alana.flores.video.filtrado.leidy.alvarez.victimas.deepfake | ver-viral-video-y-fotos-Alana-Flores | 2025-06-04T18:54:31Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-04T18:54:16Z | [🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?hgg)
[►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► 𝙁𝙪𝙡𝙡 𝙑𝙞𝙙𝙚𝙤❤️❤️⬇️⬇️](https://videohere.top/?hgg)
[<img alt="fsd" src="http://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?hgg) |
kowndinya23/ultrafeedback_binarized-tulu-150K-llama-3-8b-1-epochs-alpha-0.2-beta-0.6-2-epochs | kowndinya23 | 2025-06-04T18:54:28Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"dataset:trl-lib/ultrafeedback_binarized",
"arxiv:2305.18290",
"base_model:kowndinya23/tulu-v2-sft-mixture-150K-llama-3-8b-1-epochs-alpha-0.2-beta-0.6",
"base_model:finetune:kowndinya23/tulu-v2-sft-mixture-150K-llama-3-8b-1-epochs-alpha-0.2-beta-0.6",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T15:01:41Z | ---
base_model: kowndinya23/tulu-v2-sft-mixture-150K-llama-3-8b-1-epochs-alpha-0.2-beta-0.6
datasets: trl-lib/ultrafeedback_binarized
library_name: transformers
model_name: ultrafeedback_binarized-tulu-150K-llama-3-8b-1-epochs-alpha-0.2-beta-0.6-2-epochs
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for ultrafeedback_binarized-tulu-150K-llama-3-8b-1-epochs-alpha-0.2-beta-0.6-2-epochs
This model is a fine-tuned version of [kowndinya23/tulu-v2-sft-mixture-150K-llama-3-8b-1-epochs-alpha-0.2-beta-0.6](https://huggingface.co/kowndinya23/tulu-v2-sft-mixture-150K-llama-3-8b-1-epochs-alpha-0.2-beta-0.6) on the [trl-lib/ultrafeedback_binarized](https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="kowndinya23/ultrafeedback_binarized-tulu-150K-llama-3-8b-1-epochs-alpha-0.2-beta-0.6-2-epochs", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://adobesensei.wandb.io/hrenduchinta/huggingface/runs/lh36rj2c)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.7.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
Paro-Aarti-C/wATCH.Paro.Aarti.viral.video.original | Paro-Aarti-C | 2025-06-04T18:50:29Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-04T18:50:17Z | [🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?hgg)
[►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► 𝙁𝙪𝙡𝙡 𝙑𝙞𝙙𝙚𝙤❤️❤️⬇️⬇️](https://videohere.top/?hgg)
[<img alt="fsd" src="http://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?hgg) |
prithivMLmods/GCIRS-Reasoning-1.5B-R1 | prithivMLmods | 2025-06-04T18:40:58Z | 0 | 1 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"code",
"reinforcement-learning",
"science",
"math",
"conversational",
"en",
"arxiv:2412.15115",
"arxiv:1906.01749",
"base_model:Qwen/Qwen2.5-1.5B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-1.5B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T16:57:45Z | ---
license: apache-2.0
language:
- en
base_model:
- Qwen/Qwen2.5-1.5B-Instruct
library_name: transformers
tags:
- text-generation-inference
- code
- reinforcement-learning
- science
- math
pipeline_tag: text-generation
---

# **GCIRS-Reasoning-1.5B-R1**
> **GCIRS-Reasoning-1.5B-R1** is a **research-grade reasoning model** fine-tuned from **Qwen2.5-1.5B-Instruct**, focused on **non-fictional reasoning**, **factual consistency**, and **scientific depth**. Trained with reinforcement learning using the **Big Reasoning Traces** dataset from DeepSeek, this model is tailored for complex analytical tasks and scientific rigor in high-stakes or research environments.
> \[!note]
> GGUF: [https://huggingface.co/prithivMLmods/GCIRS-Reasoning-1.5B-R1-GGUF](https://huggingface.co/prithivMLmods/GCIRS-Reasoning-1.5B-R1-GGUF)
---
## **Key Features**
1. **Reinforcement Learning on Big Reasoning Traces**
Fine-tuned using **DeepSeek’s Big Reasoning Traces**, ensuring clarity in multi-step reasoning, factual deduction, and long-form scientific argumentation.
2. **Research-Ready Scientific Fidelity**
Designed for researchers, educators, and analysts—offers **reliable factual recall**, **logical structuring**, and precise step-by-step explanation.
3. **Structured Output in LaTeX, Markdown, and JSON**
Supports technical documentation and publishing with seamless integration of **LaTeX equations**, **Markdown formatting**, and **JSON output**.
4. **Multilingual Technical Reasoning**
Effective across **20+ languages**, especially in **scientific**, **academic**, and **technical domains**.
5. **Efficient for Inference**
Despite its **1.5B parameter scale**, it's optimized for **low-latency inference** across **modern GPUs** and **research pipelines**.
---
## **Quickstart with Transformers**
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prithivMLmods/GCIRS-Reasoning-1.5B-R1"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Explain the principle of entropy in thermodynamics with examples."
messages = [
{"role": "system", "content": "You are a scientific reasoning assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
```
---
## **Intended Use**
* Scientific and research-grade question answering
* Conceptual explanations in physics, biology, and chemistry
* Factual, non-fictional structured content generation
* Academic tutoring and reasoning assessment
* High-fidelity inference in low-latency research settings
## **Limitations**
* Not designed for casual chat or storytelling
* Performance may decline outside scientific/technical domains
* Limited creativity and abstract generalization
* Context limitations in extremely long research documents
## **References**
1. [Qwen2.5 Technical Report (2024)](https://arxiv.org/pdf/2412.15115)
2. [Big Reasoning Traces (DeepSeek Research)]()
3. [Reinforcement Learning with Human Feedback (RLHF)](https://arxiv.org/abs/1906.01749) |
Luandrie/_Whisper_Call_Center_en_lr8 | Luandrie | 2025-06-04T18:31:27Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"en",
"dataset:lelapa/www_call_center_merged_en_corrected",
"base_model:distil-whisper/distil-large-v3",
"base_model:finetune:distil-whisper/distil-large-v3",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2025-06-04T13:26:21Z | ---
library_name: transformers
language:
- en
license: mit
base_model: distil-whisper/distil-large-v3
tags:
- generated_from_trainer
datasets:
- lelapa/www_call_center_merged_en_corrected
metrics:
- wer
model-index:
- name: Distill Whisper Call Center Tforge Dev lr8
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: www_call_center_merged_en_corrected
type: lelapa/www_call_center_merged_en_corrected
args: 'config: en, split: test'
metrics:
- name: Wer
type: wer
value: 48.57864813644978
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Distill Whisper Call Center Tforge Dev lr8
This model is a fine-tuned version of [distil-whisper/distil-large-v3](https://huggingface.co/distil-whisper/distil-large-v3) on the www_call_center_merged_en_corrected dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3423
- Wer: 48.5786
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-08
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-------:|:----:|:---------------:|:-------:|
| 0.8384 | 3.0722 | 1000 | 1.3904 | 49.8263 |
| 0.6597 | 6.1444 | 2000 | 1.3512 | 48.8471 |
| 0.6763 | 9.2166 | 3000 | 1.3436 | 48.2628 |
| 0.6504 | 12.2888 | 4000 | 1.3423 | 48.5786 |
### Framework versions
- Transformers 4.45.2
- Pytorch 2.7.0+cu126
- Datasets 3.6.0
- Tokenizers 0.20.3
|
doguilmak/facade-controlnet-sd15 | doguilmak | 2025-06-04T18:29:59Z | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"controlnet",
"stable-diffusion",
"conditional-generation",
"segmentation",
"image-to-image",
"en",
"arxiv:2302.05543",
"base_model:lllyasviel/sd-controlnet-seg",
"base_model:adapter:lllyasviel/sd-controlnet-seg",
"license:mit",
"model-index",
"region:us"
] | image-to-image | 2025-06-04T14:02:33Z | ---
license: mit
language:
- en
metrics:
- mse
base_model:
- lllyasviel/sd-controlnet-seg
pipeline_tag: image-to-image
tags:
- controlnet
- stable-diffusion
- conditional-generation
- segmentation
model-index:
- name: Facades-ControlNet-SD15
results:
- task:
type: image-to-image
name: Conditional Image Generation
dataset:
name: CMP Facades Dataset
type: facades
url: https://www.kaggle.com/datasets/balraj98/facades-dataset
metrics:
- name: Mean Squared Error
type: mse
value: 0.0178
source:
name: Custom Evaluation
url: https://www.kaggle.com/datasets/balraj98/facades-dataset
---
# Model Card for Facades ControlNet with Stable Diffusion v1.5

This model is a fine-tuned version of ControlNet built on top of **Stable Diffusion v1.5**, specifically conditioned on **semantic segmentation maps** from the **Facades dataset**. It enables structure-aware image generation by combining natural language prompts with pixel-level guidance in the form of building façade segmentation masks. The result is highly controllable generation of realistic architectural scenes that reflect both structural layout and textual context.
## Model Description
- **Base Model**: [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
- **Control Type**: Semantic segmentation maps (Facades-style RGB masks)
- **Architecture**: U-Net + ControlNet adapter + Variational Autoencoder (VAE) + CLIP Text Encoder (ViT-L/14)
- **Training Epochs**: 30 full passes over the training data
- **Training Dataset**: [Facades dataset](https://www.kaggle.com/datasets/balraj98/facades-dataset)
- **Resolution**: Trained at 512×512 resolution
- **Hardware**: NVIDIA A100 40GB GPU — total training time was approximately 1 hours
- **Loss Function**: Mean Squared Error (MSE) between predicted and true noise vectors (used in DDPM training)
The ControlNet branches were trained while freezing the base Stable Diffusion weights. This retains the generative capabilities of the original model while specializing it to generate façade-aligned structures.
## Usage
This model is available via the `diffusers` library. Here's how to load and use it:
```python
from diffusers import StableDiffusionControlNetPipeline
import torch
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"doguilmak/facade-controlnet-sd15",
torch_dtype=torch.float32,
safety_checker=None
)
pipe.to("cuda")
# Load your segmentation map (RGB format expected)
from PIL import Image
control = Image.open("facades_segmentation_map.png").convert("RGB")
# Run generation
result = pipe(
prompt="a modern building with large glass windows",
negative_prompt="blurry, distorted",
image=control,
control_image=control,
num_inference_steps=50,
guidance_scale=9,
output_type="pil"
).images[0]
result.save("facade_result.png")
```
## Example Outputs
These example illustrate the model’s ability to generate photorealistic urban scenes guided by semantic segmentation maps. The output demonstrate strong spatial alignment between the input masks and the synthesized content.

## Limitations
- The model was trained on **512×512** resolution; using higher resolutions without resizing may cause artifacts.
- It performs best on scenes resembling architectural façades.
- The control image should resemble **Facades-style segmentation formats** for optimal results.
## License
This stable diffusion base model is distributed under the [CreativeML Open RAIL-M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license).
Our model is distributed under the [MIT license](https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/mit.md).
## References
- **ControlNet Segmentation Model**: [lllyasviel/sd-controlnet-seg @ Hugging Face](https://huggingface.co/lllyasviel/sd-controlnet-seg)
- **ControlNet Paper**: Y. Zhao _et al._, “Adding Conditional Control to Text-to-Image Diffusion Models,” _arXiv preprint_ arXiv:2302.05543, 2023.
- **Facades Dataset**: [Kaggle: Facades Dataset](https://www.kaggle.com/datasets/balraj98/facades-dataset) |
ArtusDev/TheDrummer_Cydonia-24B-v3-EXL3 | ArtusDev | 2025-06-04T18:18:16Z | 0 | 0 | null | [
"base_model:TheDrummer/Cydonia-24B-v3",
"base_model:quantized:TheDrummer/Cydonia-24B-v3",
"region:us"
] | null | 2025-06-04T16:58:35Z | ---
base_model: TheDrummer/Cydonia-24B-v3
base_model_relation: quantized
quantized_by: ArtusDev
---
## EXL3 Quants of TheDrummer/Cydonia-24B-v3
EXL3 quants of [TheDrummer/Cydonia-24B-v3](https://huggingface.co/TheDrummer/Cydonia-24B-v3) using <a href="https://github.com/turboderp-org/exllamav3/">exllamav3</a> for quantization.
### Quants
| Quant(Revision) | Bits per Weight | Head Bits |
| -------- | ---------- | --------- |
| [2.0_H6](https://huggingface.co/ArtusDev/TheDrummer_Cydonia-24B-v3-EXL3/tree/2.0bpw_H6) | 2.0 | 6 |
| [2.5_H6](https://huggingface.co/ArtusDev/TheDrummer_Cydonia-24B-v3-EXL3/tree/2.5bpw_H6) | 2.5 | 6 |
| [3.0_H6](https://huggingface.co/ArtusDev/TheDrummer_Cydonia-24B-v3-EXL3/tree/3.0bpw_H6) | 3.0 | 6 |
| [3.5_H6](https://huggingface.co/ArtusDev/TheDrummer_Cydonia-24B-v3-EXL3/tree/3.5bpw_H6) | 3.5 | 6 |
| [4.0_H6](https://huggingface.co/ArtusDev/TheDrummer_Cydonia-24B-v3-EXL3/tree/4.0bpw_H6) | 4.0 | 6 |
| [4.5_H6](https://huggingface.co/ArtusDev/TheDrummer_Cydonia-24B-v3-EXL3/tree/4.5bpw_H6) | 4.5 | 6 |
| [5.0_H6](https://huggingface.co/ArtusDev/TheDrummer_Cydonia-24B-v3-EXL3/tree/5.0bpw_H6) | 5.0 | 6 |
| [6.0_H6](https://huggingface.co/ArtusDev/TheDrummer_Cydonia-24B-v3-EXL3/tree/6.0bpw_H6) | 6.0 | 6 |
| [8.0_H6](https://huggingface.co/ArtusDev/TheDrummer_Cydonia-24B-v3-EXL3/tree/8.0bpw_H6) | 8.0 | 6 |
| [8.0_H8](https://huggingface.co/ArtusDev/TheDrummer_Cydonia-24B-v3-EXL3/tree/8.0bpw_H8) | 8.0 | 8 |
### Downloading quants with huggingface-cli
<details>
<summary>Click to view download instructions</summary>
Install hugginface-cli:
```bash
pip install -U "huggingface_hub[cli]"
```
Download quant by targeting the specific quant revision (branch):
```
huggingface-cli download ArtusDev/TheDrummer_Cydonia-24B-v3-EXL3 --revision "5bpw_H6" --local-dir ./
```
</details>
|
aitaliyahia/Llama-3.2-1B-Instruct-heart | aitaliyahia | 2025-06-04T18:16:53Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:unsloth/Llama-3.2-1B-Instruct",
"base_model:adapter:unsloth/Llama-3.2-1B-Instruct",
"license:llama3.2",
"region:us"
] | null | 2025-06-04T18:03:42Z | ---
library_name: peft
license: llama3.2
base_model: unsloth/Llama-3.2-1B-Instruct
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: Llama-3.2-1B-Instruct-heart
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-3.2-1B-Instruct-heart
This model is a fine-tuned version of [unsloth/Llama-3.2-1B-Instruct](https://huggingface.co/unsloth/Llama-3.2-1B-Instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4705
- Accuracy: 0.8056
- Report: precision recall f1-score support
absence 0.82 0.82 0.82 98
presence 0.78 0.79 0.79 82
accuracy 0.81 180
macro avg 0.80 0.80 0.80 180
weighted avg 0.81 0.81 0.81 180
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Report |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| No log | 1.0 | 105 | 0.4871 | 0.7778 | precision recall f1-score support
absence 0.84 0.73 0.78 98
presence 0.72 0.83 0.77 82
accuracy 0.78 180
macro avg 0.78 0.78 0.78 180
weighted avg 0.79 0.78 0.78 180
|
| No log | 2.0 | 210 | 0.5933 | 0.7389 | precision recall f1-score support
absence 0.87 0.61 0.72 98
presence 0.66 0.89 0.76 82
accuracy 0.74 180
macro avg 0.76 0.75 0.74 180
weighted avg 0.77 0.74 0.74 180
|
| No log | 3.0 | 315 | 0.4705 | 0.8056 | precision recall f1-score support
absence 0.82 0.82 0.82 98
presence 0.78 0.79 0.79 82
accuracy 0.81 180
macro avg 0.80 0.80 0.80 180
weighted avg 0.81 0.81 0.81 180
|
| No log | 4.0 | 420 | 0.5159 | 0.8 | precision recall f1-score support
absence 0.89 0.72 0.80 98
presence 0.73 0.89 0.80 82
accuracy 0.80 180
macro avg 0.81 0.81 0.80 180
weighted avg 0.82 0.80 0.80 180
|
| 0.5206 | 5.0 | 525 | 0.7814 | 0.7222 | precision recall f1-score support
absence 0.89 0.56 0.69 98
presence 0.64 0.91 0.75 82
accuracy 0.72 180
macro avg 0.76 0.74 0.72 180
weighted avg 0.77 0.72 0.72 180
|
| 0.5206 | 6.0 | 630 | 0.6542 | 0.7611 | precision recall f1-score support
absence 0.89 0.64 0.75 98
presence 0.68 0.90 0.77 82
accuracy 0.76 180
macro avg 0.78 0.77 0.76 180
weighted avg 0.79 0.76 0.76 180
|
| 0.5206 | 7.0 | 735 | 0.6553 | 0.7833 | precision recall f1-score support
absence 0.89 0.68 0.77 98
presence 0.70 0.90 0.79 82
accuracy 0.78 180
macro avg 0.80 0.79 0.78 180
weighted avg 0.81 0.78 0.78 180
|
| 0.5206 | 8.0 | 840 | 0.7076 | 0.7611 | precision recall f1-score support
absence 0.90 0.63 0.74 98
presence 0.68 0.91 0.78 82
accuracy 0.76 180
macro avg 0.79 0.77 0.76 180
weighted avg 0.80 0.76 0.76 180
|
| 0.5206 | 9.0 | 945 | 0.6092 | 0.8278 | precision recall f1-score support
absence 0.90 0.77 0.83 98
presence 0.76 0.90 0.83 82
accuracy 0.83 180
macro avg 0.83 0.83 0.83 180
weighted avg 0.84 0.83 0.83 180
|
| 0.5003 | 10.0 | 1050 | 0.7323 | 0.7667 | precision recall f1-score support
absence 0.90 0.64 0.75 98
presence 0.68 0.91 0.78 82
accuracy 0.77 180
macro avg 0.79 0.78 0.77 180
weighted avg 0.80 0.77 0.76 180
|
### Framework versions
- PEFT 0.15.2
- Transformers 4.52.3
- Pytorch 2.6.0+cu124
- Datasets 2.14.4
- Tokenizers 0.21.1 |
emilecornamusaz/MNLP_M3_document_encoder | emilecornamusaz | 2025-06-04T18:15:52Z | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"mteb",
"en",
"arxiv:2401.03462",
"arxiv:2312.15503",
"arxiv:2311.13534",
"arxiv:2310.07554",
"arxiv:2309.07597",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2025-06-04T18:14:57Z | ---
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- mteb
model-index:
- name: bge-large-en-v1.5
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.8507462686567
- type: ap
value: 38.566457320228245
- type: f1
value: 69.69386648043475
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 92.416675
- type: ap
value: 89.1928861155922
- type: f1
value: 92.39477019574215
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.175999999999995
- type: f1
value: 47.80712792870253
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.184999999999995
- type: map_at_10
value: 55.654
- type: map_at_100
value: 56.25
- type: map_at_1000
value: 56.255
- type: map_at_3
value: 51.742999999999995
- type: map_at_5
value: 54.129000000000005
- type: mrr_at_1
value: 40.967
- type: mrr_at_10
value: 55.96
- type: mrr_at_100
value: 56.54900000000001
- type: mrr_at_1000
value: 56.554
- type: mrr_at_3
value: 51.980000000000004
- type: mrr_at_5
value: 54.44
- type: ndcg_at_1
value: 40.184999999999995
- type: ndcg_at_10
value: 63.542
- type: ndcg_at_100
value: 65.96499999999999
- type: ndcg_at_1000
value: 66.08699999999999
- type: ndcg_at_3
value: 55.582
- type: ndcg_at_5
value: 59.855000000000004
- type: precision_at_1
value: 40.184999999999995
- type: precision_at_10
value: 8.841000000000001
- type: precision_at_100
value: 0.987
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 22.238
- type: precision_at_5
value: 15.405
- type: recall_at_1
value: 40.184999999999995
- type: recall_at_10
value: 88.407
- type: recall_at_100
value: 98.72
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 66.714
- type: recall_at_5
value: 77.027
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.567077926750066
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 43.19453389182364
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 64.46555939623092
- type: mrr
value: 77.82361605768807
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 84.9554128814735
- type: cos_sim_spearman
value: 84.65373612172036
- type: euclidean_pearson
value: 83.2905059954138
- type: euclidean_spearman
value: 84.52240782811128
- type: manhattan_pearson
value: 82.99533802997436
- type: manhattan_spearman
value: 84.20673798475734
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.78896103896103
- type: f1
value: 87.77189310964883
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.714538337650495
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.90108349284447
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.795
- type: map_at_10
value: 43.669000000000004
- type: map_at_100
value: 45.151
- type: map_at_1000
value: 45.278
- type: map_at_3
value: 40.006
- type: map_at_5
value: 42.059999999999995
- type: mrr_at_1
value: 39.771
- type: mrr_at_10
value: 49.826
- type: mrr_at_100
value: 50.504000000000005
- type: mrr_at_1000
value: 50.549
- type: mrr_at_3
value: 47.115
- type: mrr_at_5
value: 48.832
- type: ndcg_at_1
value: 39.771
- type: ndcg_at_10
value: 50.217999999999996
- type: ndcg_at_100
value: 55.454
- type: ndcg_at_1000
value: 57.37
- type: ndcg_at_3
value: 44.885000000000005
- type: ndcg_at_5
value: 47.419
- type: precision_at_1
value: 39.771
- type: precision_at_10
value: 9.642000000000001
- type: precision_at_100
value: 1.538
- type: precision_at_1000
value: 0.198
- type: precision_at_3
value: 21.268
- type: precision_at_5
value: 15.536
- type: recall_at_1
value: 32.795
- type: recall_at_10
value: 62.580999999999996
- type: recall_at_100
value: 84.438
- type: recall_at_1000
value: 96.492
- type: recall_at_3
value: 47.071000000000005
- type: recall_at_5
value: 54.079
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.671
- type: map_at_10
value: 43.334
- type: map_at_100
value: 44.566
- type: map_at_1000
value: 44.702999999999996
- type: map_at_3
value: 40.343
- type: map_at_5
value: 41.983
- type: mrr_at_1
value: 40.764
- type: mrr_at_10
value: 49.382
- type: mrr_at_100
value: 49.988
- type: mrr_at_1000
value: 50.03300000000001
- type: mrr_at_3
value: 47.293
- type: mrr_at_5
value: 48.51
- type: ndcg_at_1
value: 40.764
- type: ndcg_at_10
value: 49.039
- type: ndcg_at_100
value: 53.259
- type: ndcg_at_1000
value: 55.253
- type: ndcg_at_3
value: 45.091
- type: ndcg_at_5
value: 46.839999999999996
- type: precision_at_1
value: 40.764
- type: precision_at_10
value: 9.191
- type: precision_at_100
value: 1.476
- type: precision_at_1000
value: 0.19499999999999998
- type: precision_at_3
value: 21.72
- type: precision_at_5
value: 15.299
- type: recall_at_1
value: 32.671
- type: recall_at_10
value: 58.816
- type: recall_at_100
value: 76.654
- type: recall_at_1000
value: 89.05999999999999
- type: recall_at_3
value: 46.743
- type: recall_at_5
value: 51.783
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.328
- type: map_at_10
value: 53.32599999999999
- type: map_at_100
value: 54.37499999999999
- type: map_at_1000
value: 54.429
- type: map_at_3
value: 49.902
- type: map_at_5
value: 52.002
- type: mrr_at_1
value: 46.332
- type: mrr_at_10
value: 56.858
- type: mrr_at_100
value: 57.522
- type: mrr_at_1000
value: 57.54899999999999
- type: mrr_at_3
value: 54.472
- type: mrr_at_5
value: 55.996
- type: ndcg_at_1
value: 46.332
- type: ndcg_at_10
value: 59.313
- type: ndcg_at_100
value: 63.266999999999996
- type: ndcg_at_1000
value: 64.36
- type: ndcg_at_3
value: 53.815000000000005
- type: ndcg_at_5
value: 56.814
- type: precision_at_1
value: 46.332
- type: precision_at_10
value: 9.53
- type: precision_at_100
value: 1.238
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 24.054000000000002
- type: precision_at_5
value: 16.589000000000002
- type: recall_at_1
value: 40.328
- type: recall_at_10
value: 73.421
- type: recall_at_100
value: 90.059
- type: recall_at_1000
value: 97.81
- type: recall_at_3
value: 59.009
- type: recall_at_5
value: 66.352
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.424
- type: map_at_10
value: 36.332
- type: map_at_100
value: 37.347
- type: map_at_1000
value: 37.422
- type: map_at_3
value: 33.743
- type: map_at_5
value: 35.176
- type: mrr_at_1
value: 29.153000000000002
- type: mrr_at_10
value: 38.233
- type: mrr_at_100
value: 39.109
- type: mrr_at_1000
value: 39.164
- type: mrr_at_3
value: 35.876000000000005
- type: mrr_at_5
value: 37.169000000000004
- type: ndcg_at_1
value: 29.153000000000002
- type: ndcg_at_10
value: 41.439
- type: ndcg_at_100
value: 46.42
- type: ndcg_at_1000
value: 48.242000000000004
- type: ndcg_at_3
value: 36.362
- type: ndcg_at_5
value: 38.743
- type: precision_at_1
value: 29.153000000000002
- type: precision_at_10
value: 6.315999999999999
- type: precision_at_100
value: 0.927
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 15.443000000000001
- type: precision_at_5
value: 10.644
- type: recall_at_1
value: 27.424
- type: recall_at_10
value: 55.364000000000004
- type: recall_at_100
value: 78.211
- type: recall_at_1000
value: 91.74600000000001
- type: recall_at_3
value: 41.379
- type: recall_at_5
value: 47.14
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.601
- type: map_at_10
value: 27.826
- type: map_at_100
value: 29.017
- type: map_at_1000
value: 29.137
- type: map_at_3
value: 25.125999999999998
- type: map_at_5
value: 26.765
- type: mrr_at_1
value: 24.005000000000003
- type: mrr_at_10
value: 32.716
- type: mrr_at_100
value: 33.631
- type: mrr_at_1000
value: 33.694
- type: mrr_at_3
value: 29.934
- type: mrr_at_5
value: 31.630999999999997
- type: ndcg_at_1
value: 24.005000000000003
- type: ndcg_at_10
value: 33.158
- type: ndcg_at_100
value: 38.739000000000004
- type: ndcg_at_1000
value: 41.495
- type: ndcg_at_3
value: 28.185
- type: ndcg_at_5
value: 30.796
- type: precision_at_1
value: 24.005000000000003
- type: precision_at_10
value: 5.908
- type: precision_at_100
value: 1.005
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 13.391
- type: precision_at_5
value: 9.876
- type: recall_at_1
value: 19.601
- type: recall_at_10
value: 44.746
- type: recall_at_100
value: 68.82300000000001
- type: recall_at_1000
value: 88.215
- type: recall_at_3
value: 31.239
- type: recall_at_5
value: 37.695
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.130000000000003
- type: map_at_10
value: 40.96
- type: map_at_100
value: 42.282
- type: map_at_1000
value: 42.392
- type: map_at_3
value: 37.889
- type: map_at_5
value: 39.661
- type: mrr_at_1
value: 36.958999999999996
- type: mrr_at_10
value: 46.835
- type: mrr_at_100
value: 47.644
- type: mrr_at_1000
value: 47.688
- type: mrr_at_3
value: 44.562000000000005
- type: mrr_at_5
value: 45.938
- type: ndcg_at_1
value: 36.958999999999996
- type: ndcg_at_10
value: 47.06
- type: ndcg_at_100
value: 52.345
- type: ndcg_at_1000
value: 54.35
- type: ndcg_at_3
value: 42.301
- type: ndcg_at_5
value: 44.635999999999996
- type: precision_at_1
value: 36.958999999999996
- type: precision_at_10
value: 8.479000000000001
- type: precision_at_100
value: 1.284
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 20.244
- type: precision_at_5
value: 14.224999999999998
- type: recall_at_1
value: 30.130000000000003
- type: recall_at_10
value: 59.27
- type: recall_at_100
value: 81.195
- type: recall_at_1000
value: 94.21199999999999
- type: recall_at_3
value: 45.885
- type: recall_at_5
value: 52.016
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.169999999999998
- type: map_at_10
value: 36.451
- type: map_at_100
value: 37.791000000000004
- type: map_at_1000
value: 37.897
- type: map_at_3
value: 33.109
- type: map_at_5
value: 34.937000000000005
- type: mrr_at_1
value: 32.877
- type: mrr_at_10
value: 42.368
- type: mrr_at_100
value: 43.201
- type: mrr_at_1000
value: 43.259
- type: mrr_at_3
value: 39.763999999999996
- type: mrr_at_5
value: 41.260000000000005
- type: ndcg_at_1
value: 32.877
- type: ndcg_at_10
value: 42.659000000000006
- type: ndcg_at_100
value: 48.161
- type: ndcg_at_1000
value: 50.345
- type: ndcg_at_3
value: 37.302
- type: ndcg_at_5
value: 39.722
- type: precision_at_1
value: 32.877
- type: precision_at_10
value: 7.9
- type: precision_at_100
value: 1.236
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 17.846
- type: precision_at_5
value: 12.9
- type: recall_at_1
value: 26.169999999999998
- type: recall_at_10
value: 55.35
- type: recall_at_100
value: 78.755
- type: recall_at_1000
value: 93.518
- type: recall_at_3
value: 40.176
- type: recall_at_5
value: 46.589000000000006
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.15516666666667
- type: map_at_10
value: 36.65741666666667
- type: map_at_100
value: 37.84991666666666
- type: map_at_1000
value: 37.96316666666667
- type: map_at_3
value: 33.74974999999999
- type: map_at_5
value: 35.3765
- type: mrr_at_1
value: 32.08233333333334
- type: mrr_at_10
value: 41.033833333333334
- type: mrr_at_100
value: 41.84524999999999
- type: mrr_at_1000
value: 41.89983333333333
- type: mrr_at_3
value: 38.62008333333333
- type: mrr_at_5
value: 40.03441666666666
- type: ndcg_at_1
value: 32.08233333333334
- type: ndcg_at_10
value: 42.229
- type: ndcg_at_100
value: 47.26716666666667
- type: ndcg_at_1000
value: 49.43466666666667
- type: ndcg_at_3
value: 37.36408333333333
- type: ndcg_at_5
value: 39.6715
- type: precision_at_1
value: 32.08233333333334
- type: precision_at_10
value: 7.382583333333334
- type: precision_at_100
value: 1.16625
- type: precision_at_1000
value: 0.15408333333333332
- type: precision_at_3
value: 17.218
- type: precision_at_5
value: 12.21875
- type: recall_at_1
value: 27.15516666666667
- type: recall_at_10
value: 54.36683333333333
- type: recall_at_100
value: 76.37183333333333
- type: recall_at_1000
value: 91.26183333333333
- type: recall_at_3
value: 40.769916666666674
- type: recall_at_5
value: 46.702333333333335
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.749
- type: map_at_10
value: 33.001999999999995
- type: map_at_100
value: 33.891
- type: map_at_1000
value: 33.993
- type: map_at_3
value: 30.703999999999997
- type: map_at_5
value: 31.959
- type: mrr_at_1
value: 28.834
- type: mrr_at_10
value: 35.955
- type: mrr_at_100
value: 36.709
- type: mrr_at_1000
value: 36.779
- type: mrr_at_3
value: 33.947
- type: mrr_at_5
value: 35.089
- type: ndcg_at_1
value: 28.834
- type: ndcg_at_10
value: 37.329
- type: ndcg_at_100
value: 41.79
- type: ndcg_at_1000
value: 44.169000000000004
- type: ndcg_at_3
value: 33.184999999999995
- type: ndcg_at_5
value: 35.107
- type: precision_at_1
value: 28.834
- type: precision_at_10
value: 5.7669999999999995
- type: precision_at_100
value: 0.876
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 14.213000000000001
- type: precision_at_5
value: 9.754999999999999
- type: recall_at_1
value: 25.749
- type: recall_at_10
value: 47.791
- type: recall_at_100
value: 68.255
- type: recall_at_1000
value: 85.749
- type: recall_at_3
value: 36.199
- type: recall_at_5
value: 41.071999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.777
- type: map_at_10
value: 25.201
- type: map_at_100
value: 26.423999999999996
- type: map_at_1000
value: 26.544
- type: map_at_3
value: 22.869
- type: map_at_5
value: 24.023
- type: mrr_at_1
value: 21.473
- type: mrr_at_10
value: 29.12
- type: mrr_at_100
value: 30.144
- type: mrr_at_1000
value: 30.215999999999998
- type: mrr_at_3
value: 26.933
- type: mrr_at_5
value: 28.051
- type: ndcg_at_1
value: 21.473
- type: ndcg_at_10
value: 30.003
- type: ndcg_at_100
value: 35.766
- type: ndcg_at_1000
value: 38.501000000000005
- type: ndcg_at_3
value: 25.773000000000003
- type: ndcg_at_5
value: 27.462999999999997
- type: precision_at_1
value: 21.473
- type: precision_at_10
value: 5.482
- type: precision_at_100
value: 0.975
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 12.205
- type: precision_at_5
value: 8.692
- type: recall_at_1
value: 17.777
- type: recall_at_10
value: 40.582
- type: recall_at_100
value: 66.305
- type: recall_at_1000
value: 85.636
- type: recall_at_3
value: 28.687
- type: recall_at_5
value: 33.089
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.677
- type: map_at_10
value: 36.309000000000005
- type: map_at_100
value: 37.403999999999996
- type: map_at_1000
value: 37.496
- type: map_at_3
value: 33.382
- type: map_at_5
value: 34.98
- type: mrr_at_1
value: 31.343
- type: mrr_at_10
value: 40.549
- type: mrr_at_100
value: 41.342
- type: mrr_at_1000
value: 41.397
- type: mrr_at_3
value: 38.029
- type: mrr_at_5
value: 39.451
- type: ndcg_at_1
value: 31.343
- type: ndcg_at_10
value: 42.1
- type: ndcg_at_100
value: 47.089999999999996
- type: ndcg_at_1000
value: 49.222
- type: ndcg_at_3
value: 36.836999999999996
- type: ndcg_at_5
value: 39.21
- type: precision_at_1
value: 31.343
- type: precision_at_10
value: 7.164
- type: precision_at_100
value: 1.0959999999999999
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 16.915
- type: precision_at_5
value: 11.940000000000001
- type: recall_at_1
value: 26.677
- type: recall_at_10
value: 55.54599999999999
- type: recall_at_100
value: 77.094
- type: recall_at_1000
value: 92.01
- type: recall_at_3
value: 41.191
- type: recall_at_5
value: 47.006
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.501
- type: map_at_10
value: 33.102
- type: map_at_100
value: 34.676
- type: map_at_1000
value: 34.888000000000005
- type: map_at_3
value: 29.944
- type: map_at_5
value: 31.613999999999997
- type: mrr_at_1
value: 29.447000000000003
- type: mrr_at_10
value: 37.996
- type: mrr_at_100
value: 38.946
- type: mrr_at_1000
value: 38.995000000000005
- type: mrr_at_3
value: 35.079
- type: mrr_at_5
value: 36.69
- type: ndcg_at_1
value: 29.447000000000003
- type: ndcg_at_10
value: 39.232
- type: ndcg_at_100
value: 45.247
- type: ndcg_at_1000
value: 47.613
- type: ndcg_at_3
value: 33.922999999999995
- type: ndcg_at_5
value: 36.284
- type: precision_at_1
value: 29.447000000000003
- type: precision_at_10
value: 7.648000000000001
- type: precision_at_100
value: 1.516
- type: precision_at_1000
value: 0.23900000000000002
- type: precision_at_3
value: 16.008
- type: precision_at_5
value: 11.779
- type: recall_at_1
value: 24.501
- type: recall_at_10
value: 51.18899999999999
- type: recall_at_100
value: 78.437
- type: recall_at_1000
value: 92.842
- type: recall_at_3
value: 35.808
- type: recall_at_5
value: 42.197
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.039
- type: map_at_10
value: 30.377
- type: map_at_100
value: 31.275
- type: map_at_1000
value: 31.379
- type: map_at_3
value: 27.98
- type: map_at_5
value: 29.358
- type: mrr_at_1
value: 24.03
- type: mrr_at_10
value: 32.568000000000005
- type: mrr_at_100
value: 33.403
- type: mrr_at_1000
value: 33.475
- type: mrr_at_3
value: 30.436999999999998
- type: mrr_at_5
value: 31.796000000000003
- type: ndcg_at_1
value: 24.03
- type: ndcg_at_10
value: 35.198
- type: ndcg_at_100
value: 39.668
- type: ndcg_at_1000
value: 42.296
- type: ndcg_at_3
value: 30.709999999999997
- type: ndcg_at_5
value: 33.024
- type: precision_at_1
value: 24.03
- type: precision_at_10
value: 5.564
- type: precision_at_100
value: 0.828
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 13.309000000000001
- type: precision_at_5
value: 9.39
- type: recall_at_1
value: 22.039
- type: recall_at_10
value: 47.746
- type: recall_at_100
value: 68.23599999999999
- type: recall_at_1000
value: 87.852
- type: recall_at_3
value: 35.852000000000004
- type: recall_at_5
value: 41.410000000000004
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.692999999999998
- type: map_at_10
value: 26.903
- type: map_at_100
value: 28.987000000000002
- type: map_at_1000
value: 29.176999999999996
- type: map_at_3
value: 22.137
- type: map_at_5
value: 24.758
- type: mrr_at_1
value: 35.57
- type: mrr_at_10
value: 47.821999999999996
- type: mrr_at_100
value: 48.608000000000004
- type: mrr_at_1000
value: 48.638999999999996
- type: mrr_at_3
value: 44.452000000000005
- type: mrr_at_5
value: 46.546
- type: ndcg_at_1
value: 35.57
- type: ndcg_at_10
value: 36.567
- type: ndcg_at_100
value: 44.085
- type: ndcg_at_1000
value: 47.24
- type: ndcg_at_3
value: 29.964000000000002
- type: ndcg_at_5
value: 32.511
- type: precision_at_1
value: 35.57
- type: precision_at_10
value: 11.485
- type: precision_at_100
value: 1.9619999999999997
- type: precision_at_1000
value: 0.256
- type: precision_at_3
value: 22.237000000000002
- type: precision_at_5
value: 17.471999999999998
- type: recall_at_1
value: 15.692999999999998
- type: recall_at_10
value: 43.056
- type: recall_at_100
value: 68.628
- type: recall_at_1000
value: 86.075
- type: recall_at_3
value: 26.918999999999997
- type: recall_at_5
value: 34.14
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.53
- type: map_at_10
value: 20.951
- type: map_at_100
value: 30.136000000000003
- type: map_at_1000
value: 31.801000000000002
- type: map_at_3
value: 15.021
- type: map_at_5
value: 17.471999999999998
- type: mrr_at_1
value: 71.0
- type: mrr_at_10
value: 79.176
- type: mrr_at_100
value: 79.418
- type: mrr_at_1000
value: 79.426
- type: mrr_at_3
value: 78.125
- type: mrr_at_5
value: 78.61200000000001
- type: ndcg_at_1
value: 58.5
- type: ndcg_at_10
value: 44.106
- type: ndcg_at_100
value: 49.268
- type: ndcg_at_1000
value: 56.711999999999996
- type: ndcg_at_3
value: 48.934
- type: ndcg_at_5
value: 45.826
- type: precision_at_1
value: 71.0
- type: precision_at_10
value: 35.0
- type: precision_at_100
value: 11.360000000000001
- type: precision_at_1000
value: 2.046
- type: precision_at_3
value: 52.833
- type: precision_at_5
value: 44.15
- type: recall_at_1
value: 9.53
- type: recall_at_10
value: 26.811
- type: recall_at_100
value: 55.916999999999994
- type: recall_at_1000
value: 79.973
- type: recall_at_3
value: 16.413
- type: recall_at_5
value: 19.980999999999998
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 51.519999999999996
- type: f1
value: 46.36601294761231
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 74.413
- type: map_at_10
value: 83.414
- type: map_at_100
value: 83.621
- type: map_at_1000
value: 83.635
- type: map_at_3
value: 82.337
- type: map_at_5
value: 83.039
- type: mrr_at_1
value: 80.19800000000001
- type: mrr_at_10
value: 87.715
- type: mrr_at_100
value: 87.778
- type: mrr_at_1000
value: 87.779
- type: mrr_at_3
value: 87.106
- type: mrr_at_5
value: 87.555
- type: ndcg_at_1
value: 80.19800000000001
- type: ndcg_at_10
value: 87.182
- type: ndcg_at_100
value: 87.90299999999999
- type: ndcg_at_1000
value: 88.143
- type: ndcg_at_3
value: 85.60600000000001
- type: ndcg_at_5
value: 86.541
- type: precision_at_1
value: 80.19800000000001
- type: precision_at_10
value: 10.531
- type: precision_at_100
value: 1.113
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 32.933
- type: precision_at_5
value: 20.429
- type: recall_at_1
value: 74.413
- type: recall_at_10
value: 94.363
- type: recall_at_100
value: 97.165
- type: recall_at_1000
value: 98.668
- type: recall_at_3
value: 90.108
- type: recall_at_5
value: 92.52
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.701
- type: map_at_10
value: 37.122
- type: map_at_100
value: 39.178000000000004
- type: map_at_1000
value: 39.326
- type: map_at_3
value: 32.971000000000004
- type: map_at_5
value: 35.332
- type: mrr_at_1
value: 44.753
- type: mrr_at_10
value: 53.452
- type: mrr_at_100
value: 54.198
- type: mrr_at_1000
value: 54.225
- type: mrr_at_3
value: 50.952
- type: mrr_at_5
value: 52.464
- type: ndcg_at_1
value: 44.753
- type: ndcg_at_10
value: 45.021
- type: ndcg_at_100
value: 52.028
- type: ndcg_at_1000
value: 54.596000000000004
- type: ndcg_at_3
value: 41.622
- type: ndcg_at_5
value: 42.736000000000004
- type: precision_at_1
value: 44.753
- type: precision_at_10
value: 12.284
- type: precision_at_100
value: 1.955
- type: precision_at_1000
value: 0.243
- type: precision_at_3
value: 27.828999999999997
- type: precision_at_5
value: 20.061999999999998
- type: recall_at_1
value: 22.701
- type: recall_at_10
value: 51.432
- type: recall_at_100
value: 77.009
- type: recall_at_1000
value: 92.511
- type: recall_at_3
value: 37.919000000000004
- type: recall_at_5
value: 44.131
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.189
- type: map_at_10
value: 66.24600000000001
- type: map_at_100
value: 67.098
- type: map_at_1000
value: 67.149
- type: map_at_3
value: 62.684
- type: map_at_5
value: 64.974
- type: mrr_at_1
value: 80.378
- type: mrr_at_10
value: 86.127
- type: mrr_at_100
value: 86.29299999999999
- type: mrr_at_1000
value: 86.297
- type: mrr_at_3
value: 85.31400000000001
- type: mrr_at_5
value: 85.858
- type: ndcg_at_1
value: 80.378
- type: ndcg_at_10
value: 74.101
- type: ndcg_at_100
value: 76.993
- type: ndcg_at_1000
value: 77.948
- type: ndcg_at_3
value: 69.232
- type: ndcg_at_5
value: 72.04599999999999
- type: precision_at_1
value: 80.378
- type: precision_at_10
value: 15.595999999999998
- type: precision_at_100
value: 1.7840000000000003
- type: precision_at_1000
value: 0.191
- type: precision_at_3
value: 44.884
- type: precision_at_5
value: 29.145
- type: recall_at_1
value: 40.189
- type: recall_at_10
value: 77.981
- type: recall_at_100
value: 89.21
- type: recall_at_1000
value: 95.48299999999999
- type: recall_at_3
value: 67.326
- type: recall_at_5
value: 72.863
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 92.84599999999999
- type: ap
value: 89.4710787567357
- type: f1
value: 92.83752676932258
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 23.132
- type: map_at_10
value: 35.543
- type: map_at_100
value: 36.702
- type: map_at_1000
value: 36.748999999999995
- type: map_at_3
value: 31.737
- type: map_at_5
value: 33.927
- type: mrr_at_1
value: 23.782
- type: mrr_at_10
value: 36.204
- type: mrr_at_100
value: 37.29
- type: mrr_at_1000
value: 37.330999999999996
- type: mrr_at_3
value: 32.458999999999996
- type: mrr_at_5
value: 34.631
- type: ndcg_at_1
value: 23.782
- type: ndcg_at_10
value: 42.492999999999995
- type: ndcg_at_100
value: 47.985
- type: ndcg_at_1000
value: 49.141
- type: ndcg_at_3
value: 34.748000000000005
- type: ndcg_at_5
value: 38.651
- type: precision_at_1
value: 23.782
- type: precision_at_10
value: 6.665
- type: precision_at_100
value: 0.941
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.776
- type: precision_at_5
value: 10.84
- type: recall_at_1
value: 23.132
- type: recall_at_10
value: 63.794
- type: recall_at_100
value: 89.027
- type: recall_at_1000
value: 97.807
- type: recall_at_3
value: 42.765
- type: recall_at_5
value: 52.11
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 94.59188326493388
- type: f1
value: 94.3842594786827
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 79.49384404924761
- type: f1
value: 59.7580539534629
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 77.56220578345663
- type: f1
value: 75.27228165561478
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 80.53463349024884
- type: f1
value: 80.4893958236536
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 32.56100273484962
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.470380028839607
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.06102792457849
- type: mrr
value: 33.30709199672238
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.776999999999999
- type: map_at_10
value: 14.924000000000001
- type: map_at_100
value: 18.955
- type: map_at_1000
value: 20.538999999999998
- type: map_at_3
value: 10.982
- type: map_at_5
value: 12.679000000000002
- type: mrr_at_1
value: 47.988
- type: mrr_at_10
value: 57.232000000000006
- type: mrr_at_100
value: 57.818999999999996
- type: mrr_at_1000
value: 57.847
- type: mrr_at_3
value: 54.901999999999994
- type: mrr_at_5
value: 56.481
- type: ndcg_at_1
value: 46.594
- type: ndcg_at_10
value: 38.129000000000005
- type: ndcg_at_100
value: 35.54
- type: ndcg_at_1000
value: 44.172
- type: ndcg_at_3
value: 43.025999999999996
- type: ndcg_at_5
value: 41.052
- type: precision_at_1
value: 47.988
- type: precision_at_10
value: 28.111000000000004
- type: precision_at_100
value: 8.929
- type: precision_at_1000
value: 2.185
- type: precision_at_3
value: 40.144000000000005
- type: precision_at_5
value: 35.232
- type: recall_at_1
value: 6.776999999999999
- type: recall_at_10
value: 19.289
- type: recall_at_100
value: 36.359
- type: recall_at_1000
value: 67.54
- type: recall_at_3
value: 11.869
- type: recall_at_5
value: 14.999
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.108000000000004
- type: map_at_10
value: 47.126000000000005
- type: map_at_100
value: 48.171
- type: map_at_1000
value: 48.199
- type: map_at_3
value: 42.734
- type: map_at_5
value: 45.362
- type: mrr_at_1
value: 34.936
- type: mrr_at_10
value: 49.571
- type: mrr_at_100
value: 50.345
- type: mrr_at_1000
value: 50.363
- type: mrr_at_3
value: 45.959
- type: mrr_at_5
value: 48.165
- type: ndcg_at_1
value: 34.936
- type: ndcg_at_10
value: 55.028999999999996
- type: ndcg_at_100
value: 59.244
- type: ndcg_at_1000
value: 59.861
- type: ndcg_at_3
value: 46.872
- type: ndcg_at_5
value: 51.217999999999996
- type: precision_at_1
value: 34.936
- type: precision_at_10
value: 9.099
- type: precision_at_100
value: 1.145
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 21.456
- type: precision_at_5
value: 15.411
- type: recall_at_1
value: 31.108000000000004
- type: recall_at_10
value: 76.53999999999999
- type: recall_at_100
value: 94.39
- type: recall_at_1000
value: 98.947
- type: recall_at_3
value: 55.572
- type: recall_at_5
value: 65.525
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.56400000000001
- type: map_at_10
value: 85.482
- type: map_at_100
value: 86.114
- type: map_at_1000
value: 86.13
- type: map_at_3
value: 82.607
- type: map_at_5
value: 84.405
- type: mrr_at_1
value: 82.42
- type: mrr_at_10
value: 88.304
- type: mrr_at_100
value: 88.399
- type: mrr_at_1000
value: 88.399
- type: mrr_at_3
value: 87.37
- type: mrr_at_5
value: 88.024
- type: ndcg_at_1
value: 82.45
- type: ndcg_at_10
value: 89.06500000000001
- type: ndcg_at_100
value: 90.232
- type: ndcg_at_1000
value: 90.305
- type: ndcg_at_3
value: 86.375
- type: ndcg_at_5
value: 87.85300000000001
- type: precision_at_1
value: 82.45
- type: precision_at_10
value: 13.486999999999998
- type: precision_at_100
value: 1.534
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.813
- type: precision_at_5
value: 24.773999999999997
- type: recall_at_1
value: 71.56400000000001
- type: recall_at_10
value: 95.812
- type: recall_at_100
value: 99.7
- type: recall_at_1000
value: 99.979
- type: recall_at_3
value: 87.966
- type: recall_at_5
value: 92.268
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 57.241876648614145
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 64.66212576446223
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.308
- type: map_at_10
value: 13.803
- type: map_at_100
value: 16.176
- type: map_at_1000
value: 16.561
- type: map_at_3
value: 9.761000000000001
- type: map_at_5
value: 11.802
- type: mrr_at_1
value: 26.200000000000003
- type: mrr_at_10
value: 37.621
- type: mrr_at_100
value: 38.767
- type: mrr_at_1000
value: 38.815
- type: mrr_at_3
value: 34.117
- type: mrr_at_5
value: 36.107
- type: ndcg_at_1
value: 26.200000000000003
- type: ndcg_at_10
value: 22.64
- type: ndcg_at_100
value: 31.567
- type: ndcg_at_1000
value: 37.623
- type: ndcg_at_3
value: 21.435000000000002
- type: ndcg_at_5
value: 18.87
- type: precision_at_1
value: 26.200000000000003
- type: precision_at_10
value: 11.74
- type: precision_at_100
value: 2.465
- type: precision_at_1000
value: 0.391
- type: precision_at_3
value: 20.033
- type: precision_at_5
value: 16.64
- type: recall_at_1
value: 5.308
- type: recall_at_10
value: 23.794999999999998
- type: recall_at_100
value: 50.015
- type: recall_at_1000
value: 79.283
- type: recall_at_3
value: 12.178
- type: recall_at_5
value: 16.882
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.93231134675553
- type: cos_sim_spearman
value: 81.68319292603205
- type: euclidean_pearson
value: 81.8396814380367
- type: euclidean_spearman
value: 81.24641903349945
- type: manhattan_pearson
value: 81.84698799204274
- type: manhattan_spearman
value: 81.24269997904105
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 86.73241671587446
- type: cos_sim_spearman
value: 79.05091082971826
- type: euclidean_pearson
value: 83.91146869578044
- type: euclidean_spearman
value: 79.87978465370936
- type: manhattan_pearson
value: 83.90888338917678
- type: manhattan_spearman
value: 79.87482848584241
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 85.14970731146177
- type: cos_sim_spearman
value: 86.37363490084627
- type: euclidean_pearson
value: 83.02154218530433
- type: euclidean_spearman
value: 83.80258761957367
- type: manhattan_pearson
value: 83.01664495119347
- type: manhattan_spearman
value: 83.77567458007952
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 83.40474139886784
- type: cos_sim_spearman
value: 82.77768789165984
- type: euclidean_pearson
value: 80.7065877443695
- type: euclidean_spearman
value: 81.375940662505
- type: manhattan_pearson
value: 80.6507552270278
- type: manhattan_spearman
value: 81.32782179098741
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.08585968722274
- type: cos_sim_spearman
value: 88.03110031451399
- type: euclidean_pearson
value: 85.74012019602384
- type: euclidean_spearman
value: 86.13592849438209
- type: manhattan_pearson
value: 85.74404842369206
- type: manhattan_spearman
value: 86.14492318960154
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 84.95069052788875
- type: cos_sim_spearman
value: 86.4867991595147
- type: euclidean_pearson
value: 84.31013325754635
- type: euclidean_spearman
value: 85.01529258006482
- type: manhattan_pearson
value: 84.26995570085374
- type: manhattan_spearman
value: 84.96982104986162
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.54617647971897
- type: cos_sim_spearman
value: 87.49834181751034
- type: euclidean_pearson
value: 86.01015322577122
- type: euclidean_spearman
value: 84.63362652063199
- type: manhattan_pearson
value: 86.13807574475706
- type: manhattan_spearman
value: 84.7772370721132
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.20047755786615
- type: cos_sim_spearman
value: 67.05324077987636
- type: euclidean_pearson
value: 66.91930642976601
- type: euclidean_spearman
value: 65.21491856099105
- type: manhattan_pearson
value: 66.78756851976624
- type: manhattan_spearman
value: 65.12356257740728
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 86.19852871539686
- type: cos_sim_spearman
value: 87.5161895296395
- type: euclidean_pearson
value: 84.59848645207485
- type: euclidean_spearman
value: 85.26427328757919
- type: manhattan_pearson
value: 84.59747366996524
- type: manhattan_spearman
value: 85.24045855146915
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.63320317811032
- type: mrr
value: 96.26242947321379
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 60.928000000000004
- type: map_at_10
value: 70.112
- type: map_at_100
value: 70.59299999999999
- type: map_at_1000
value: 70.623
- type: map_at_3
value: 66.846
- type: map_at_5
value: 68.447
- type: mrr_at_1
value: 64.0
- type: mrr_at_10
value: 71.212
- type: mrr_at_100
value: 71.616
- type: mrr_at_1000
value: 71.64500000000001
- type: mrr_at_3
value: 68.77799999999999
- type: mrr_at_5
value: 70.094
- type: ndcg_at_1
value: 64.0
- type: ndcg_at_10
value: 74.607
- type: ndcg_at_100
value: 76.416
- type: ndcg_at_1000
value: 77.102
- type: ndcg_at_3
value: 69.126
- type: ndcg_at_5
value: 71.41300000000001
- type: precision_at_1
value: 64.0
- type: precision_at_10
value: 9.933
- type: precision_at_100
value: 1.077
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.556
- type: precision_at_5
value: 17.467
- type: recall_at_1
value: 60.928000000000004
- type: recall_at_10
value: 87.322
- type: recall_at_100
value: 94.833
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 72.628
- type: recall_at_5
value: 78.428
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.86237623762376
- type: cos_sim_ap
value: 96.72586477206649
- type: cos_sim_f1
value: 93.01858362631845
- type: cos_sim_precision
value: 93.4409687184662
- type: cos_sim_recall
value: 92.60000000000001
- type: dot_accuracy
value: 99.78019801980199
- type: dot_ap
value: 93.72748205246228
- type: dot_f1
value: 89.04109589041096
- type: dot_precision
value: 87.16475095785441
- type: dot_recall
value: 91.0
- type: euclidean_accuracy
value: 99.85445544554456
- type: euclidean_ap
value: 96.6661459876145
- type: euclidean_f1
value: 92.58337481333997
- type: euclidean_precision
value: 92.17046580773042
- type: euclidean_recall
value: 93.0
- type: manhattan_accuracy
value: 99.85445544554456
- type: manhattan_ap
value: 96.6883549244056
- type: manhattan_f1
value: 92.57598405580468
- type: manhattan_precision
value: 92.25422045680239
- type: manhattan_recall
value: 92.9
- type: max_accuracy
value: 99.86237623762376
- type: max_ap
value: 96.72586477206649
- type: max_f1
value: 93.01858362631845
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 66.39930057069995
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 34.96398659903402
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 55.946944700355395
- type: mrr
value: 56.97151398438164
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 31.541657650692905
- type: cos_sim_spearman
value: 31.605804192286303
- type: dot_pearson
value: 28.26905996736398
- type: dot_spearman
value: 27.864801765851187
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.22599999999999998
- type: map_at_10
value: 1.8870000000000002
- type: map_at_100
value: 9.78
- type: map_at_1000
value: 22.514
- type: map_at_3
value: 0.6669999999999999
- type: map_at_5
value: 1.077
- type: mrr_at_1
value: 82.0
- type: mrr_at_10
value: 89.86699999999999
- type: mrr_at_100
value: 89.86699999999999
- type: mrr_at_1000
value: 89.86699999999999
- type: mrr_at_3
value: 89.667
- type: mrr_at_5
value: 89.667
- type: ndcg_at_1
value: 79.0
- type: ndcg_at_10
value: 74.818
- type: ndcg_at_100
value: 53.715999999999994
- type: ndcg_at_1000
value: 47.082
- type: ndcg_at_3
value: 82.134
- type: ndcg_at_5
value: 79.81899999999999
- type: precision_at_1
value: 82.0
- type: precision_at_10
value: 78.0
- type: precision_at_100
value: 54.48
- type: precision_at_1000
value: 20.518
- type: precision_at_3
value: 87.333
- type: precision_at_5
value: 85.2
- type: recall_at_1
value: 0.22599999999999998
- type: recall_at_10
value: 2.072
- type: recall_at_100
value: 13.013
- type: recall_at_1000
value: 43.462
- type: recall_at_3
value: 0.695
- type: recall_at_5
value: 1.139
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.328
- type: map_at_10
value: 9.795
- type: map_at_100
value: 15.801000000000002
- type: map_at_1000
value: 17.23
- type: map_at_3
value: 4.734
- type: map_at_5
value: 6.644
- type: mrr_at_1
value: 30.612000000000002
- type: mrr_at_10
value: 46.902
- type: mrr_at_100
value: 47.495
- type: mrr_at_1000
value: 47.495
- type: mrr_at_3
value: 41.156
- type: mrr_at_5
value: 44.218
- type: ndcg_at_1
value: 28.571
- type: ndcg_at_10
value: 24.806
- type: ndcg_at_100
value: 36.419000000000004
- type: ndcg_at_1000
value: 47.272999999999996
- type: ndcg_at_3
value: 25.666
- type: ndcg_at_5
value: 25.448999999999998
- type: precision_at_1
value: 30.612000000000002
- type: precision_at_10
value: 23.061
- type: precision_at_100
value: 7.714
- type: precision_at_1000
value: 1.484
- type: precision_at_3
value: 26.531
- type: precision_at_5
value: 26.122
- type: recall_at_1
value: 2.328
- type: recall_at_10
value: 16.524
- type: recall_at_100
value: 47.179
- type: recall_at_1000
value: 81.22200000000001
- type: recall_at_3
value: 5.745
- type: recall_at_5
value: 9.339
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 70.9142
- type: ap
value: 14.335574772555415
- type: f1
value: 54.62839595194111
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.94340690435768
- type: f1
value: 60.286487936731916
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 51.26597708987974
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.48882398521786
- type: cos_sim_ap
value: 79.04326607602204
- type: cos_sim_f1
value: 71.64566826860633
- type: cos_sim_precision
value: 70.55512918905092
- type: cos_sim_recall
value: 72.77044854881267
- type: dot_accuracy
value: 84.19264469213805
- type: dot_ap
value: 67.96360043562528
- type: dot_f1
value: 64.06418393006827
- type: dot_precision
value: 58.64941898706424
- type: dot_recall
value: 70.58047493403694
- type: euclidean_accuracy
value: 87.45902127913214
- type: euclidean_ap
value: 78.9742237648272
- type: euclidean_f1
value: 71.5553235908142
- type: euclidean_precision
value: 70.77955601445535
- type: euclidean_recall
value: 72.34828496042216
- type: manhattan_accuracy
value: 87.41729749061214
- type: manhattan_ap
value: 78.90073137580596
- type: manhattan_f1
value: 71.3942611553533
- type: manhattan_precision
value: 68.52705653967483
- type: manhattan_recall
value: 74.51187335092348
- type: max_accuracy
value: 87.48882398521786
- type: max_ap
value: 79.04326607602204
- type: max_f1
value: 71.64566826860633
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.68125897465751
- type: cos_sim_ap
value: 85.6003454431979
- type: cos_sim_f1
value: 77.6957163958641
- type: cos_sim_precision
value: 73.0110366307807
- type: cos_sim_recall
value: 83.02279026793964
- type: dot_accuracy
value: 87.7672992587418
- type: dot_ap
value: 82.4971301112899
- type: dot_f1
value: 75.90528233151184
- type: dot_precision
value: 72.0370626469368
- type: dot_recall
value: 80.21250384970742
- type: euclidean_accuracy
value: 88.4503434625684
- type: euclidean_ap
value: 84.91949884748384
- type: euclidean_f1
value: 76.92365018444684
- type: euclidean_precision
value: 74.53245721712759
- type: euclidean_recall
value: 79.47336002463813
- type: manhattan_accuracy
value: 88.47556952691427
- type: manhattan_ap
value: 84.8963689101517
- type: manhattan_f1
value: 76.85901249256395
- type: manhattan_precision
value: 74.31693989071039
- type: manhattan_recall
value: 79.58115183246073
- type: max_accuracy
value: 88.68125897465751
- type: max_ap
value: 85.6003454431979
- type: max_f1
value: 77.6957163958641
license: mit
language:
- en
---
<h1 align="center">FlagEmbedding</h1>
<h4 align="center">
<p>
<a href=#model-list>Model List</a> |
<a href=#frequently-asked-questions>FAQ</a> |
<a href=#usage>Usage</a> |
<a href="#evaluation">Evaluation</a> |
<a href="#train">Train</a> |
<a href="#contact">Contact</a> |
<a href="#citation">Citation</a> |
<a href="#license">License</a>
<p>
</h4>
For more details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).
If you are looking for a model that supports more languages, longer texts, and other retrieval methods, you can try using [bge-m3](https://huggingface.co/BAAI/bge-m3).
[English](README.md) | [中文](https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md)
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently:
- **Long-Context LLM**: [Activation Beacon](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/activation_beacon)
- **Fine-tuning of LM** : [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail)
- **Dense Retrieval**: [BGE-M3](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3), [LLM Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), [BGE Embedding](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/baai_general_embedding)
- **Reranker Model**: [BGE Reranker](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
- **Benchmark**: [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB)
## News
- 1/30/2024: Release **BGE-M3**, a new member to BGE model series! M3 stands for **M**ulti-linguality (100+ languages), **M**ulti-granularities (input length up to 8192), **M**ulti-Functionality (unification of dense, lexical, multi-vec/colbert retrieval).
It is the first embedding model that supports all three retrieval methods, achieving new SOTA on multi-lingual (MIRACL) and cross-lingual (MKQA) benchmarks.
[Technical Report](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/BGE_M3/BGE_M3.pdf) and [Code](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3). :fire:
- 1/9/2024: Release [Activation-Beacon](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/activation_beacon), an effective, efficient, compatible, and low-cost (training) method to extend the context length of LLM. [Technical Report](https://arxiv.org/abs/2401.03462) :fire:
- 12/24/2023: Release **LLaRA**, a LLaMA-7B based dense retriever, leading to state-of-the-art performances on MS MARCO and BEIR. Model and code will be open-sourced. Please stay tuned. [Technical Report](https://arxiv.org/abs/2312.15503) :fire:
- 11/23/2023: Release [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail), a method to maintain general capabilities during fine-tuning by merging multiple language models. [Technical Report](https://arxiv.org/abs/2311.13534) :fire:
- 10/12/2023: Release [LLM-Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), a unified embedding model to support diverse retrieval augmentation needs for LLMs. [Technical Report](https://arxiv.org/pdf/2310.07554.pdf)
- 09/15/2023: The [technical report](https://arxiv.org/pdf/2309.07597.pdf) and [massive training data](https://data.baai.ac.cn/details/BAAI-MTP) of BGE has been released
- 09/12/2023: New models:
- **New reranker model**: release cross-encoder models `BAAI/bge-reranker-base` and `BAAI/bge-reranker-large`, which are more powerful than embedding model. We recommend to use/fine-tune them to re-rank top-k documents returned by embedding models.
- **update embedding model**: release `bge-*-v1.5` embedding model to alleviate the issue of the similarity distribution, and enhance its retrieval ability without instruction.
<details>
<summary>More</summary>
<!-- ### More -->
- 09/07/2023: Update [fine-tune code](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md): Add script to mine hard negatives and support adding instruction during fine-tuning.
- 08/09/2023: BGE Models are integrated into **Langchain**, you can use it like [this](#using-langchain); C-MTEB **leaderboard** is [available](https://huggingface.co/spaces/mteb/leaderboard).
- 08/05/2023: Release base-scale and small-scale models, **best performance among the models of the same size 🤗**
- 08/02/2023: Release `bge-large-*`(short for BAAI General Embedding) Models, **rank 1st on MTEB and C-MTEB benchmark!** :tada: :tada:
- 08/01/2023: We release the [Chinese Massive Text Embedding Benchmark](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB) (**C-MTEB**), consisting of 31 test dataset.
</details>
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:-------------------------------|:--------:| :--------:| :--------:|:--------:|
| [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3) | Multilingual | [Inference](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3#usage) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3) | Multi-Functionality(dense retrieval, sparse retrieval, multi-vector(colbert)), Multi-Linguality, and Multi-Granularity(8192 tokens) | |
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) |a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
[1\]: If you need to search the relevant passages to a query, we suggest to add the instruction to the query; in other cases, no instruction is needed, just use the original query directly. In all cases, **no instruction** needs to be added to passages.
[2\]: Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. To balance the accuracy and time cost, cross-encoder is widely used to re-rank top-k documents retrieved by other simple models.
For examples, use bge embedding model to retrieve top 100 relevant documents, and then use bge reranker to re-rank the top 100 document to get the final top-3 results.
All models have been uploaded to Huggingface Hub, and you can see them at https://huggingface.co/BAAI.
If you cannot open the Huggingface Hub, you also can download the models at https://model.baai.ac.cn/models .
## Frequently asked questions
<details>
<summary>1. How to fine-tune bge embedding model?</summary>
<!-- ### How to fine-tune bge embedding model? -->
Following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) to prepare data and fine-tune your model.
Some suggestions:
- Mine hard negatives following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#hard-negatives), which can improve the retrieval performance.
- If you pre-train bge on your data, the pre-trained model cannot be directly used to calculate similarity, and it must be fine-tuned with contrastive learning before computing similarity.
- If the accuracy of the fine-tuned model is still not high, it is recommended to use/fine-tune the cross-encoder model (bge-reranker) to re-rank top-k results. Hard negatives also are needed to fine-tune reranker.
</details>
<details>
<summary>2. The similarity score between two dissimilar sentences is higher than 0.5</summary>
<!-- ### The similarity score between two dissimilar sentences is higher than 0.5 -->
**Suggest to use bge v1.5, which alleviates the issue of the similarity distribution.**
Since we finetune the models by contrastive learning with a temperature of 0.01,
the similarity distribution of the current BGE model is about in the interval \[0.6, 1\].
So a similarity score greater than 0.5 does not indicate that the two sentences are similar.
For downstream tasks, such as passage retrieval or semantic similarity,
**what matters is the relative order of the scores, not the absolute value.**
If you need to filter similar sentences based on a similarity threshold,
please select an appropriate similarity threshold based on the similarity distribution on your data (such as 0.8, 0.85, or even 0.9).
</details>
<details>
<summary>3. When does the query instruction need to be used</summary>
<!-- ### When does the query instruction need to be used -->
For the `bge-*-v1.5`, we improve its retrieval ability when not using instruction.
No instruction only has a slight degradation in retrieval performance compared with using instruction.
So you can generate embedding without instruction in all cases for convenience.
For a retrieval task that uses short queries to find long related documents,
it is recommended to add instructions for these short queries.
**The best method to decide whether to add instructions for queries is choosing the setting that achieves better performance on your task.**
In all cases, the documents/passages do not need to add the instruction.
</details>
## Usage
### Usage for Embedding Model
Here are some examples for using `bge` models with
[FlagEmbedding](#using-flagembedding), [Sentence-Transformers](#using-sentence-transformers), [Langchain](#using-langchain), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
If it doesn't work for you, you can see [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md) for more methods to install FlagEmbedding.
```python
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
For the value of the argument `query_instruction_for_retrieval`, see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list).
By default, FlagModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
#### Using Sentence-Transformers
You can also use the `bge` models with [sentence-transformers](https://www.SBERT.net):
```
pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
For s2p(short query to long passage) retrieval task,
each short query should start with an instruction (instructions see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list)).
But the instruction is not needed for passages.
```python
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
#### Using Langchain
You can use `bge` in langchain like this:
```python
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
```
#### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
#### Usage of the ONNX files
```python
from optimum.onnxruntime import ORTModelForFeatureExtraction # type: ignore
import torch
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-en-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-en-v1.5', revision="refs/pr/13")
model_ort = ORTModelForFeatureExtraction.from_pretrained('BAAI/bge-large-en-v1.5', revision="refs/pr/13",file_name="onnx/model.onnx")
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
model_output_ort = model_ort(**encoded_input)
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# model_output and model_output_ort are identical
```
Its also possible to deploy the onnx files with the [infinity_emb](https://github.com/michaelfeil/infinity) pip package.
```python
import asyncio
from infinity_emb import AsyncEmbeddingEngine, EngineArgs
sentences = ["Embed this is sentence via Infinity.", "Paris is in France."]
engine = AsyncEmbeddingEngine.from_args(
EngineArgs(model_name_or_path = "BAAI/bge-large-en-v1.5", device="cpu", engine="optimum" # or engine="torch"
))
async def main():
async with engine:
embeddings, usage = await engine.embed(sentences=sentences)
asyncio.run(main())
```
### Usage for Reranker
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### Using Huggingface transformers
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
## Evaluation
`baai-general-embedding` models achieve **state-of-the-art performance on both MTEB and C-MTEB leaderboard!**
For more details and evaluation tools see our [scripts](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md).
- **MTEB**:
| Model Name | Dimension | Sequence Length | Average (56) | Retrieval (15) |Clustering (11) | Pair Classification (3) | Reranking (4) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | **64.23** | **54.29** | 46.08 | 87.12 | 60.03 | 83.11 | 31.61 | 75.97 |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 | 53.25 | 45.77 | 86.55 | 58.86 | 82.4 | 31.07 | 75.53 |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | 62.17 |51.68 | 43.82 | 84.92 | 58.36 | 81.59 | 30.12 | 74.14 |
| [bge-large-en](https://huggingface.co/BAAI/bge-large-en) | 1024 | 512 | 63.98 | 53.9 | 46.98 | 85.8 | 59.48 | 81.56 | 32.06 | 76.21 |
| [bge-base-en](https://huggingface.co/BAAI/bge-base-en) | 768 | 512 | 63.36 | 53.0 | 46.32 | 85.86 | 58.7 | 81.84 | 29.27 | 75.27 |
| [gte-large](https://huggingface.co/thenlper/gte-large) | 1024 | 512 | 63.13 | 52.22 | 46.84 | 85.00 | 59.13 | 83.35 | 31.66 | 73.33 |
| [gte-base](https://huggingface.co/thenlper/gte-base) | 768 | 512 | 62.39 | 51.14 | 46.2 | 84.57 | 58.61 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1024| 512 | 62.25 | 50.56 | 44.49 | 86.03 | 56.61 | 82.05 | 30.19 | 75.24 |
| [bge-small-en](https://huggingface.co/BAAI/bge-small-en) | 384 | 512 | 62.11 | 51.82 | 44.31 | 83.78 | 57.97 | 80.72 | 30.53 | 74.37 |
| [instructor-xl](https://huggingface.co/hkunlp/instructor-xl) | 768 | 512 | 61.79 | 49.26 | 44.74 | 86.62 | 57.29 | 83.06 | 32.32 | 61.79 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 768 | 512 | 61.5 | 50.29 | 43.80 | 85.73 | 55.91 | 81.05 | 30.28 | 73.84 |
| [gte-small](https://huggingface.co/thenlper/gte-small) | 384 | 512 | 61.36 | 49.46 | 44.89 | 83.54 | 57.7 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | 1536 | 8192 | 60.99 | 49.25 | 45.9 | 84.89 | 56.32 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 384 | 512 | 59.93 | 49.04 | 39.92 | 84.67 | 54.32 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 768 | 512 | 59.51 | 42.24 | 43.72 | 85.06 | 56.42 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 768 | 514 | 57.78 | 43.81 | 43.69 | 83.04 | 59.36 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 4096 | 2048 | 57.59 | 48.22 | 38.93 | 81.9 | 55.65 | 77.74 | 33.6 | 66.19 |
- **C-MTEB**:
We create the benchmark C-MTEB for Chinese text embedding which consists of 31 datasets from 6 tasks.
Please refer to [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md) for a detailed introduction.
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [**BAAI/bge-large-zh-v1.5**](https://huggingface.co/BAAI/bge-large-zh-v1.5) | 1024 | **64.53** | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| [bge-large-zh-noinstruct](https://huggingface.co/BAAI/bge-large-zh-noinstruct) | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| [m3e-base](https://huggingface.co/moka-ai/m3e-base) | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| [m3e-large](https://huggingface.co/moka-ai/m3e-large) | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| [text-embedding-ada-002(OpenAI)](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| [luotuo](https://huggingface.co/silk-road/luotuo-bert-medium) | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| [text2vec-base](https://huggingface.co/shibing624/text2vec-base-chinese) | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| [text2vec-large](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
- **Reranking**:
See [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/) for evaluation script.
| Model | T2Reranking | T2RerankingZh2En\* | T2RerankingEn2Zh\* | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| text2vec-base-multilingual | 64.66 | 62.94 | 62.51 | 14.37 | 48.46 | 48.6 | 50.26 |
| multilingual-e5-small | 65.62 | 60.94 | 56.41 | 29.91 | 67.26 | 66.54 | 57.78 |
| multilingual-e5-large | 64.55 | 61.61 | 54.28 | 28.6 | 67.42 | 67.92 | 57.4 |
| multilingual-e5-base | 64.21 | 62.13 | 54.68 | 29.5 | 66.23 | 66.98 | 57.29 |
| m3e-base | 66.03 | 62.74 | 56.07 | 17.51 | 77.05 | 76.76 | 59.36 |
| m3e-large | 66.13 | 62.72 | 56.1 | 16.46 | 77.76 | 78.27 | 59.57 |
| bge-base-zh-v1.5 | 66.49 | 63.25 | 57.02 | 29.74 | 80.47 | 84.88 | 63.64 |
| bge-large-zh-v1.5 | 65.74 | 63.39 | 57.03 | 28.74 | 83.45 | 85.44 | 63.97 |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | 67.28 | 63.95 | 60.45 | 35.46 | 81.26 | 84.1 | 65.42 |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | 67.6 | 64.03 | 61.44 | 37.16 | 82.15 | 84.18 | 66.09 |
\* : T2RerankingZh2En and T2RerankingEn2Zh are cross-language retrieval tasks
## Train
### BAAI Embedding
We pre-train the models using [retromae](https://github.com/staoxiao/RetroMAE) and train them on large-scale pairs data using contrastive learning.
**You can fine-tune the embedding model on your data following our [examples](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune).**
We also provide a [pre-train example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/pretrain).
Note that the goal of pre-training is to reconstruct the text, and the pre-trained model cannot be used for similarity calculation directly, it needs to be fine-tuned.
More training details for bge see [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md).
### BGE Reranker
Cross-encoder will perform full-attention over the input pair,
which is more accurate than embedding model (i.e., bi-encoder) but more time-consuming than embedding model.
Therefore, it can be used to re-rank the top-k documents returned by embedding model.
We train the cross-encoder on a multilingual pair data,
The data format is the same as embedding model, so you can fine-tune it easily following our [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker).
More details please refer to [./FlagEmbedding/reranker/README.md](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## Contact
If you have any question or suggestion related to this project, feel free to open an issue or pull request.
You also can email Shitao Xiao([email protected]) and Zheng Liu([email protected]).
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge.
|
mradermacher/JPharmatron-7B-base-GGUF | mradermacher | 2025-06-04T18:02:36Z | 116 | 0 | transformers | [
"transformers",
"gguf",
"pharmacy",
"biology",
"chemistry",
"medical",
"en",
"ja",
"base_model:EQUES/JPharmatron-7B-base",
"base_model:quantized:EQUES/JPharmatron-7B-base",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-02T20:05:08Z | ---
base_model: EQUES/JPharmatron-7B-base
language:
- en
- ja
library_name: transformers
license: cc-by-sa-4.0
quantized_by: mradermacher
tags:
- pharmacy
- biology
- chemistry
- medical
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/EQUES/JPharmatron-7B-base
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/JPharmatron-7B-base-GGUF/resolve/main/JPharmatron-7B-base.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/JPharmatron-7B-base-GGUF/resolve/main/JPharmatron-7B-base.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/JPharmatron-7B-base-GGUF/resolve/main/JPharmatron-7B-base.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/JPharmatron-7B-base-GGUF/resolve/main/JPharmatron-7B-base.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/JPharmatron-7B-base-GGUF/resolve/main/JPharmatron-7B-base.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/JPharmatron-7B-base-GGUF/resolve/main/JPharmatron-7B-base.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/JPharmatron-7B-base-GGUF/resolve/main/JPharmatron-7B-base.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/JPharmatron-7B-base-GGUF/resolve/main/JPharmatron-7B-base.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/JPharmatron-7B-base-GGUF/resolve/main/JPharmatron-7B-base.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/JPharmatron-7B-base-GGUF/resolve/main/JPharmatron-7B-base.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/JPharmatron-7B-base-GGUF/resolve/main/JPharmatron-7B-base.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/JPharmatron-7B-base-GGUF/resolve/main/JPharmatron-7B-base.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
adamo1139/DeepSeek-R1-0528-AWQ | adamo1139 | 2025-06-04T18:02:36Z | 80 | 0 | transformers | [
"transformers",
"safetensors",
"deepseek_v3",
"text-generation",
"conversational",
"custom_code",
"arxiv:2501.12948",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"awq",
"region:us"
] | text-generation | 2025-05-31T19:10:51Z |
---
license: mit
library_name: transformers
---
# DeepSeek-R1-0528-AWQ 671B
It's a 4-bit AWQ quantization of DeepSeek-R1-0528 671B model, it's suitable for use with GPU nodes like 8xA100/8xH20/8xH100 with vLLM and SGLang
You can run this model on 8x H100 80GB using vLLM with
`vllm serve adamo1139/DeepSeek-R1-0528-AWQ --tensor-parallel 8`
If this doesn't work for you, you may need to manually specify quantization and datatype with `--quantization awq_marlin` and `--dtype float16` respectively.
Script used for creating it is:
```
from datasets import load_dataset
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_path = '/home/ubuntu/models/DeepSeek-R1-0528-BF16'
quant_path = '/home/ubuntu/models/DeepSeek-R1-0528-AWQ'
quant_config = { "zero_point": True, "q_group_size": 64, "w_bit": 4, "version": "GEMM" }
# Load model
model = AutoAWQForCausalLM.from_pretrained(model_path, trust_remote_code=True, device_map=None)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model.quantize(
tokenizer,
quant_config=quant_config,
n_parallel_calib_samples=None,
max_calib_samples=64,
max_calib_seq_len=1024
)
# Save quantized model
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path)
print(f'Model is quantized and saved at "{quant_path}"')
```
I used AutoAWQ 0.2.8, transformers 4.48.0 and torch 2.6.0. `modeling_deepseek.py` was slightly modified to get around an issue mentioned [here](https://github.com/casper-hansen/AutoAWQ/pull/688#issuecomment-2566829209).
Quantization was done on 8x H100 80GB node with 960GB of RAM and 800GB of swap. I used Unsloth's [BF16 version](unsloth/DeepSeek-R1-0528-BF16) as a starting point but I removed `quantization_config` section from the `config.json` before running AWQ quantization script. Third attempt was successful, the other two failed due to memory overflow after 15+ hours of runtime each. Final attempt took about 18 hours to complete.
I think I'll make some evals to measure quantization's impact on downstream performance, I'm not set on it fully yet.
It's the full-fat 671B model, if you don't have access to the extreme hardware needed to run it, look into running Qwen3 8B based distilled version instead.
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20R1-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<p align="center">
<a href="https://arxiv.org/pdf/2501.12948"><b>Paper Link</b>👁️</a>
</p>
## 1. Introduction
The DeepSeek R1 model has undergone a minor version upgrade, with the current version being DeepSeek-R1-0528. In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by leveraging increased computational resources and introducing algorithmic optimization mechanisms during post-training. The model has demonstrated outstanding performance across various benchmark evaluations, including mathematics, programming, and general logic. Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro.
<p align="center">
<img width="80%" src="figures/benchmark.png">
</p>
Compared to the previous version, the upgraded model shows significant improvements in handling complex reasoning tasks. For instance, in the AIME 2025 test, the model’s accuracy has increased from 70% in the previous version to 87.5% in the current version. This advancement stems from enhanced thinking depth during the reasoning process: in the AIME test set, the previous model used an average of 12K tokens per question, whereas the new version averages 23K tokens per question.
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate, enhanced support for function calling, and better experience for vibe coding.
## 2. Evaluation Results
### DeepSeek-R1-0528
For all our models, the maximum generation length is set to 64K tokens. For benchmarks requiring sampling, we use a temperature of $0.6$, a top-p value of $0.95$, and generate 16 responses per query to estimate pass@1.
<div align="center">
| Category | Benchmark (Metric) | DeepSeek R1 | DeepSeek R1 0528
|----------|----------------------------------|-----------------|---|
| General |
| | MMLU-Redux (EM) | 92.9 | 93.4
| | MMLU-Pro (EM) | 84.0 | 85.0
| | GPQA-Diamond (Pass@1) | 71.5 | 81.0
| | SimpleQA (Correct) | 30.1 | 27.8
| | FRAMES (Acc.) | 82.5 | 83.0
| | Humanity's Last Exam (Pass@1) | 8.5 | 17.7
| Code |
| | LiveCodeBench (2408-2505) (Pass@1) | 63.5 | 73.3
| | Codeforces-Div1 (Rating) | 1530 | 1930
| | SWE Verified (Resolved) | 49.2 | 57.6
| | Aider-Polyglot (Acc.) | 53.3 | 71.6
| Math |
| | AIME 2024 (Pass@1) | 79.8 | 91.4
| | AIME 2025 (Pass@1) | 70.0 | 87.5
| | HMMT 2025 (Pass@1) | 41.7 | 79.4 |
| | CNMO 2024 (Pass@1) | 78.8 | 86.9
| Tools |
| | BFCL_v3_MultiTurn (Acc) | - | 37.0 |
| | Tau-Bench (Pass@1) | - | 53.5(Airline)/63.9(Retail)
</div>
Note: We use Agentless framework to evaluate model performance on SWE-Verified. We only evaluate text-only prompts in HLE testsets. GPT-4.1 is employed to act user role in Tau-bench evaluation.
### DeepSeek-R1-0528-Qwen3-8B
Meanwhile, we distilled the chain-of-thought from DeepSeek-R1-0528 to post-train Qwen3 8B Base, obtaining DeepSeek-R1-0528-Qwen3-8B. This model achieves state-of-the-art (SOTA) performance among open-source models on the AIME 2024, surpassing Qwen3 8B by +10.0% and matching the performance of Qwen3-235B-thinking. We believe that the chain-of-thought from DeepSeek-R1-0528 will hold significant importance for both academic research on reasoning models and industrial development focused on small-scale models.
| | AIME 24 | AIME 25 | HMMT Feb 25 | GPQA Diamond | LiveCodeBench (2408-2505) |
|--------------------------------|---------|---------|-------------|--------------|---------------------------|
| Qwen3-235B-A22B | 85.7 | 81.5 | 62.5 | 71.1 | 66.5 |
| Qwen3-32B | 81.4 | 72.9 | - | 68.4 | - |
| Qwen3-8B | 76.0 | 67.3 | - | 62.0 | - |
| Phi-4-Reasoning-Plus-14B | 81.3 | 78.0 | 53.6 | 69.3 | - |
| Gemini-2.5-Flash-Thinking-0520 | 82.3 | 72.0 | 64.2 | 82.8 | 62.3 |
| o3-mini (medium) | 79.6 | 76.7 | 53.3 | 76.8 | 65.9 |
| DeepSeek-R1-0528-Qwen3-8B | 86.0 | 76.3 | 61.5 | 61.1 | 60.5 |
## 3. Chat Website & API Platform
You can chat with DeepSeek-R1 on DeepSeek's official website: [chat.deepseek.com](https://chat.deepseek.com/sign_in), and switch on the button "DeepThink"
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/)
## 4. How to Run Locally
Please visit [DeepSeek-R1](https://github.com/deepseek-ai/DeepSeek-R1) repository for more information about running DeepSeek-R1-0528 locally.
Compared to previous versions of DeepSeek-R1, the usage recommendations for DeepSeek-R1-0528 have the following changes:
1. System prompt is supported now.
2. It is not required to add "\<think\>\n" at the beginning of the output to force the model into thinking pattern.
The model architecture of DeepSeek-R1-0528-Qwen3-8B is identical to that of Qwen3-8B, but it shares the same tokenizer configuration as DeepSeek-R1-0528. This model can be run in the same manner as Qwen3-8B.
### System Prompt
In the official DeepSeek web/app, we use the same system prompt with a specific date.
```
该助手为DeepSeek-R1,由深度求索公司创造。
今天是{current date}。
```
For example,
```
该助手为DeepSeek-R1,由深度求索公司创造。
今天是2025年5月28日,星期一。
```
### Temperature
In our web and application environments, the temperature parameter $T_{model}$ is set to 0.6.
### Prompts for File Uploading and Web Search
For file uploading, please follow the template to create prompts, where {file_name}, {file_content} and {question} are arguments.
```
file_template = \
"""[file name]: {file_name}
[file content begin]
{file_content}
[file content end]
{question}"""
```
For Web Search, {search_results}, {cur_date}, and {question} are arguments.
For Chinese query, we use the prompt:
```
search_answer_zh_template = \
'''# 以下内容是基于用户发送的消息的搜索结果:
{search_results}
在我给你的搜索结果中,每个结果都是[webpage X begin]...[webpage X end]格式的,X代表每篇文章的数字索引。请在适当的情况下在句子末尾引用上下文。请按照引用编号[citation:X]的格式在答案中对应部分引用上下文。如果一句话源自多个上下文,请列出所有相关的引用编号,例如[citation:3][citation:5],切记不要将引用集中在最后返回引用编号,而是在答案对应部分列出。
在回答时,请注意以下几点:
- 今天是{cur_date}。
- 并非搜索结果的所有内容都与用户的问题密切相关,你需要结合问题,对搜索结果进行甄别、筛选。
- 对于列举类的问题(如列举所有航班信息),尽量将答案控制在10个要点以内,并告诉用户可以查看搜索来源、获得完整信息。优先提供信息完整、最相关的列举项;如非必要,不要主动告诉用户搜索结果未提供的内容。
- 对于创作类的问题(如写论文),请务必在正文的段落中引用对应的参考编号,例如[citation:3][citation:5],不能只在文章末尾引用。你需要解读并概括用户的题目要求,选择合适的格式,充分利用搜索结果并抽取重要信息,生成符合用户要求、极具思想深度、富有创造力与专业性的答案。你的创作篇幅需要尽可能延长,对于每一个要点的论述要推测用户的意图,给出尽可能多角度的回答要点,且务必信息量大、论述详尽。
- 如果回答很长,请尽量结构化、分段落总结。如果需要分点作答,尽量控制在5个点以内,并合并相关的内容。
- 对于客观类的问答,如果问题的答案非常简短,可以适当补充一到两句相关信息,以丰富内容。
- 你需要根据用户要求和回答内容选择合适、美观的回答格式,确保可读性强。
- 你的回答应该综合多个相关网页来回答,不能重复引用一个网页。
- 除非用户要求,否则你回答的语言需要和用户提问的语言保持一致。
# 用户消息为:
{question}'''
```
For English query, we use the prompt:
```
search_answer_en_template = \
'''# The following contents are the search results related to the user's message:
{search_results}
In the search results I provide to you, each result is formatted as [webpage X begin]...[webpage X end], where X represents the numerical index of each article. Please cite the context at the end of the relevant sentence when appropriate. Use the citation format [citation:X] in the corresponding part of your answer. If a sentence is derived from multiple contexts, list all relevant citation numbers, such as [citation:3][citation:5]. Be sure not to cluster all citations at the end; instead, include them in the corresponding parts of the answer.
When responding, please keep the following points in mind:
- Today is {cur_date}.
- Not all content in the search results is closely related to the user's question. You need to evaluate and filter the search results based on the question.
- For listing-type questions (e.g., listing all flight information), try to limit the answer to 10 key points and inform the user that they can refer to the search sources for complete information. Prioritize providing the most complete and relevant items in the list. Avoid mentioning content not provided in the search results unless necessary.
- For creative tasks (e.g., writing an essay), ensure that references are cited within the body of the text, such as [citation:3][citation:5], rather than only at the end of the text. You need to interpret and summarize the user's requirements, choose an appropriate format, fully utilize the search results, extract key information, and generate an answer that is insightful, creative, and professional. Extend the length of your response as much as possible, addressing each point in detail and from multiple perspectives, ensuring the content is rich and thorough.
- If the response is lengthy, structure it well and summarize it in paragraphs. If a point-by-point format is needed, try to limit it to 5 points and merge related content.
- For objective Q&A, if the answer is very brief, you may add one or two related sentences to enrich the content.
- Choose an appropriate and visually appealing format for your response based on the user's requirements and the content of the answer, ensuring strong readability.
- Your answer should synthesize information from multiple relevant webpages and avoid repeatedly citing the same webpage.
- Unless the user requests otherwise, your response should be in the same language as the user's question.
# The user's message is:
{question}'''
```
## 5. License
This code repository is licensed under [MIT License](LICENSE). The use of DeepSeek-R1 models is also subject to [MIT License](LICENSE). DeepSeek-R1 series (including Base and Chat) supports commercial use and distillation.
## 6. Citation
```
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}
```
## 7. Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]). |
Kortix/FastApply-1.5B-v1.0 | Kortix | 2025-06-04T18:00:45Z | 1,061 | 32 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"fast-apply",
"instant-apply",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-10-18T11:55:22Z | ---
base_model: unsloth/qwen2.5-coder-1.5b-instruct-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
- sft
- fast-apply
- instant-apply
---
# FastApply-1.5B-v1.0
*🚀 Update May 2025:* For production-grade throughput, we use *[Morph](https://morphllm.com)* (the hosted Fast Apply API powering [SoftGen AI](https://softgen.ai/)).
- Morph hits *~1,600 tok/s* even on huge token diffs
- Larger model trained on millions of examples and tuned for accuracy.
> Stable inference, large free tier, highly recommended if you need serious speed in prod.
[Github: kortix-ai/fast-apply](https://github.com/kortix-ai/fast-apply)
[Dataset: Kortix/FastApply-dataset-v1.0](https://huggingface.co/datasets/Kortix/FastApply-dataset-v1.0)
[Try it now on 👉 Google Colab](https://colab.research.google.com/drive/1BNCab4oK-xBqwFQD4kCcjKc7BPKivkm1?usp=sharing)
## Model Details
### Basic Information
- **Developed by:** Kortix
- **License:** apache-2.0
- **Finetuned from model:** [unsloth/Qwen2.5-Coder-1.5B-Instruct-bnb-4bit](https://huggingface.co/unsloth/Qwen2.5-Coder-1.5B-Instruct-bnb-4bit)
### Model Description
FastApply-1.5B-v1.0 is a 1.5B model designed for instant code application, producing full file edits to power [SoftGen AI](https://softgen.ai/).
It is part of the Fast Apply pipeline for data generation and fine-tuning Qwen2.5 Coder models.
The model achieves high throughput when deployed on fast providers like Fireworks while maintaining high edit accuracy, with a speed of approximately 340 tokens/second.
## Intended Use
FastApply-1.5B-v1.0 is intended for use in AI-powered code editors and tools that require fast, accurate code modifications. It is particularly well-suited for:
- Instant code application tasks
- Full file edits
- Integration with AI-powered code editors like Aider and PearAI
- Local tools to reduce the cost of frontier model output
## Inference template
FastApply-1.5B-v1.0 is based on the Qwen2.5 Coder architecture and is fine-tuned for code editing tasks. It uses a specific prompt structure for inference:
```
<|im_start|>system
You are a coding assistant that helps merge code updates, ensuring every modification is fully integrated.<|im_end|>
<|im_start|>user
Merge all changes from the <update> snippet into the <code> below.
- Preserve the code's structure, order, comments, and indentation exactly.
- Output only the updated code, enclosed within <updated-code> and </updated-code> tags.
- Do not include any additional text, explanations, placeholders, ellipses, or code fences.
<code>{original_code}</code>
<update>{update_snippet}</update>
Provide the complete updated code.<|im_end|>
<|im_start|>assistant
```
The model's output is structured as:
```
<updated-code>[Full-complete updated file]</updated-code>
```
## Additional Information
For more details on the Fast Apply pipeline, data generation process, and deployment instructions, please refer to the [GitHub repository](https://github.com/kortix-ai/fast-apply).
## How to Use
To use the model, you can load it using the Hugging Face Transformers library:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Kortix/FastApply-1.5B-v1.0", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("Kortix/FastApply-1.5B-v1.0")
# Prepare your input following the prompt structure mentioned above
input_text = """<|im_start|>system
You are a coding assistant that helps merge code updates, ensuring every modification is fully integrated.<|im_end|>
<|im_start|>user
Merge all changes from the <update> snippet into the <code> below.
- Preserve the code's structure, order, comments, and indentation exactly.
- Output only the updated code, enclosed within <updated-code> and </updated-code> tags.
- Do not include any additional text, explanations, placeholders, ellipses, or code fences.
<code>{original_code}</code>
<update>{update_snippet}</update>
Provide the complete updated code.<|im_end|>
<|im_start|>assistant
"""
input_text = input_text.format(
original_code=original_code,
update_snippet=update_snippet,
).strip()
# Generate the response
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids, max_length=8192,)
response = tokenizer.decode(output[0][len(input_ids[0]):])
print(response)
# Extract the updated code from the response
updated_code = response.split("<updated-code>")[1].split("</updated-code>")[0]
```
## Evaluation:

|
Leku/Trial | Leku | 2025-06-04T17:59:49Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:openai-community/gpt2",
"base_model:adapter:openai-community/gpt2",
"region:us"
] | null | 2025-06-04T17:27:44Z | ---
base_model: gpt2
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2 |
EthanRhys/Sailor-Moon-RVC-Models | EthanRhys | 2025-06-04T17:56:26Z | 0 | 0 | null | [
"license:openrail++",
"region:us"
] | null | 2025-03-19T03:01:11Z | ---
license: openrail++
---
|
pointserv/fanniemae-phi-2-lora | pointserv | 2025-06-04T17:56:26Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"phi",
"autotrain",
"text-generation-inference",
"text-generation",
"peft",
"conversational",
"base_model:microsoft/phi-2",
"base_model:finetune:microsoft/phi-2",
"license:other",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-03T18:00:52Z | ---
tags:
- autotrain
- text-generation-inference
- text-generation
- peft
library_name: transformers
base_model: microsoft/phi-2
widget:
- messages:
- role: user
content: What is your favorite condiment?
license: other
---
# Model Trained Using AutoTrain
This model was trained using AutoTrain. For more information, please visit [AutoTrain](https://hf.co/docs/autotrain).
# Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "PATH_TO_THIS_REPO"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype='auto'
).eval()
# Prompt content: "hi"
messages = [
{"role": "user", "content": "hi"}
]
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids.to('cuda'))
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
# Model response: "Hello! How can I assist you today?"
print(response)
``` |
phospho-app/LegrandFrederic-ACT_BBOX-sisyphe-gck8h | phospho-app | 2025-06-04T17:37:42Z | 0 | 0 | null | [
"phosphobot",
"act",
"region:us"
] | null | 2025-06-04T17:34:10Z |
---
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act Model - phospho Training Pipeline
## Error Traceback
We faced an issue while training your model.
```
Training process failed with exit code 1:
'timestamps': [np.float32(6.3527937), np.float32(6.386968)]},
{'diff': np.float32(0.03591633),
'episode_index': 11,
'timestamps': [np.float32(6.386968), np.float32(6.4228845)]},
{'diff': np.float32(0.034159184),
'episode_index': 11,
'timestamps': [np.float32(6.4228845), np.float32(6.4570436)]},
{'diff': np.float32(0.03525734),
'episode_index': 11,
'timestamps': [np.float32(6.4570436), np.float32(6.492301)]}]
```
## Training parameters:
- **Dataset**: [phospho-app/sisyphe_bboxes](https://huggingface.co/datasets/phospho-app/sisyphe_bboxes)
- **Wandb run URL**: None
- **Epochs**: None
- **Batch size**: 100
- **Training steps**: 10000
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
aoxo/posterity_sft_gemma-3-4b-it | aoxo | 2025-06-04T17:35:15Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:google/gemma-3-4b-it",
"base_model:adapter:google/gemma-3-4b-it",
"region:us"
] | null | 2025-06-04T14:01:12Z | ---
base_model: google/gemma-3-4b-it
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2 |
alfredcs/gemma-3-12b-icd10pcs | alfredcs | 2025-06-04T17:34:42Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-04T17:34:32Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Elnenevic2027/rosalia | Elnenevic2027 | 2025-06-04T17:32:22Z | 0 | 0 | null | [
"license:other",
"region:us"
] | null | 2025-06-04T16:52:49Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
--- |
PrunaAI/segolilylabs-Lily-Cybersecurity-7B-v0.2-HQQ-8bit-smashed | PrunaAI | 2025-06-04T17:23:45Z | 0 | 0 | null | [
"mistral",
"pruna-ai",
"base_model:segolilylabs/Lily-Cybersecurity-7B-v0.2",
"base_model:finetune:segolilylabs/Lily-Cybersecurity-7B-v0.2",
"region:us"
] | null | 2025-06-04T17:22:27Z | ---
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
base_model: segolilylabs/Lily-Cybersecurity-7B-v0.2
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
tags:
- pruna-ai
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
<img src="banner.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</a>
</div>
<!-- header end -->
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.gg/rskEr4BZJx)
# Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
## Results

**Frequently Asked Questions**
- ***How does the compression work?*** The model is compressed with hqq.
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
- ***How is the model efficiency evaluated?*** These results were obtained with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
- ***What is the model format?*** We use safetensors.
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
## Setup
You can run the smashed model with these steps:
0. Check requirements from the original repo segolilylabs/Lily-Cybersecurity-7B-v0.2 installed. In particular, check python, cuda, and transformers versions.
1. Make sure that you have installed quantization related packages.
```bash
pip install hqq
```
2. Load & run the model.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from hqq.engine.hf import HQQModelForCausalLM
from hqq.models.hf.base import AutoHQQHFModel
try:
model = HQQModelForCausalLM.from_quantized("PrunaAI/segolilylabs-Lily-Cybersecurity-7B-v0.2-HQQ-8bit-smashed", device_map='auto')
except:
model = AutoHQQHFModel.from_quantized("PrunaAI/segolilylabs-Lily-Cybersecurity-7B-v0.2-HQQ-8bit-smashed")
tokenizer = AutoTokenizer.from_pretrained("segolilylabs/Lily-Cybersecurity-7B-v0.2")
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
outputs = model.generate(input_ids, max_new_tokens=216)
tokenizer.decode(outputs[0])
```
## Configurations
The configuration info are in `smash_config.json`. This model has been smashed with pruna in version O.1.3
## Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model segolilylabs/Lily-Cybersecurity-7B-v0.2 before using this model which provided the base model. The license of `pruna` is [here](https://github.com/PrunaAI/pruna/blob/main/LICENSE) on GitHub.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai). |
avey-ai/tpp-dpa-0.1B-95BT | avey-ai | 2025-06-04T17:22:56Z | 0 | 0 | null | [
"safetensors",
"license:apache-2.0",
"region:us"
] | null | 2025-06-04T17:21:12Z | ---
license: apache-2.0
---
|
YatanL/Distil6-LayoutLMv3-CORD | YatanL | 2025-06-04T17:21:38Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"layoutlmv3",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2025-06-03T13:15:36Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
phospho-app/Lithium73fr-ACT-TESTMERGE1-vf3m2 | phospho-app | 2025-06-04T17:20:08Z | 0 | 0 | null | [
"safetensors",
"phosphobot",
"act",
"region:us"
] | null | 2025-06-04T14:36:38Z |
---
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successfull, try it out on your robot!
## Training parameters:
- **Dataset**: [Lithium73fr/TESTMERGE1](https://huggingface.co/datasets/Lithium73fr/TESTMERGE1)
- **Wandb run URL**: None
- **Epochs**: None
- **Batch size**: 60
- **Training steps**: 10000
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
Ey-luccas/meioambiente | Ey-luccas | 2025-06-04T17:19:50Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"base_model:adapter:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"region:us"
] | null | 2025-06-04T16:53:11Z | ---
base_model: unsloth/mistral-7b-instruct-v0.3-bnb-4bit
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2 |
Triangle104/Crux-Qwen3_OpenThinking-4B-Q8_0-GGUF | Triangle104 | 2025-06-04T17:16:05Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"math",
"sft",
"code",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"dataset:simplescaling/s1K-1.1",
"dataset:nvidia/OpenMathReasoning",
"dataset:mlabonne/FineTome-100k",
"base_model:prithivMLmods/Crux-Qwen3_OpenThinking-4B",
"base_model:quantized:prithivMLmods/Crux-Qwen3_OpenThinking-4B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2025-06-04T17:14:49Z | ---
license: apache-2.0
datasets:
- simplescaling/s1K-1.1
- nvidia/OpenMathReasoning
- mlabonne/FineTome-100k
language:
- en
library_name: transformers
base_model: prithivMLmods/Crux-Qwen3_OpenThinking-4B
pipeline_tag: text-generation
tags:
- text-generation-inference
- math
- sft
- code
- llama-cpp
- gguf-my-repo
---
# Triangle104/Crux-Qwen3_OpenThinking-4B-Q8_0-GGUF
This model was converted to GGUF format from [`prithivMLmods/Crux-Qwen3_OpenThinking-4B`](https://huggingface.co/prithivMLmods/Crux-Qwen3_OpenThinking-4B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/prithivMLmods/Crux-Qwen3_OpenThinking-4B) for more details on the model.
---
Crux-Qwen3_OpenThinking-4B is fine-tuned on the Qwen3-4B architecture, optimized for advanced open thinking, mathematical reasoning, and logical problem solving. This model is trained on the traces of sk1.1, which include 1,000 entries from the Gemini thinking trajectory, combined with fine-tuning on 100k tokens of open math reasoning
data. This makes it highly effective for nuanced reasoning, educational
tasks, and complex problem-solving requiring clear thought processes.
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/Crux-Qwen3_OpenThinking-4B-Q8_0-GGUF --hf-file crux-qwen3_openthinking-4b-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/Crux-Qwen3_OpenThinking-4B-Q8_0-GGUF --hf-file crux-qwen3_openthinking-4b-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/Crux-Qwen3_OpenThinking-4B-Q8_0-GGUF --hf-file crux-qwen3_openthinking-4b-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/Crux-Qwen3_OpenThinking-4B-Q8_0-GGUF --hf-file crux-qwen3_openthinking-4b-q8_0.gguf -c 2048
```
|
iapp/chinda-qwen3-4b | iapp | 2025-06-04T17:14:27Z | 43 | 6 | null | [
"safetensors",
"qwen3",
"thai",
"text-generation",
"conversational",
"th",
"en",
"base_model:Qwen/Qwen3-4B",
"base_model:finetune:Qwen/Qwen3-4B",
"doi:10.57967/hf/5709",
"license:apache-2.0",
"region:us"
] | text-generation | 2025-05-28T03:47:14Z | ---
license: apache-2.0
language:
- th
- en
base_model:
- Qwen/Qwen3-4B
pipeline_tag: text-generation
tags:
- thai
---
# 🇹🇭 Chinda Opensource Thai LLM 4B
**Latest Model, Think in Thai, Answer in Thai, Built by Thai Startup**
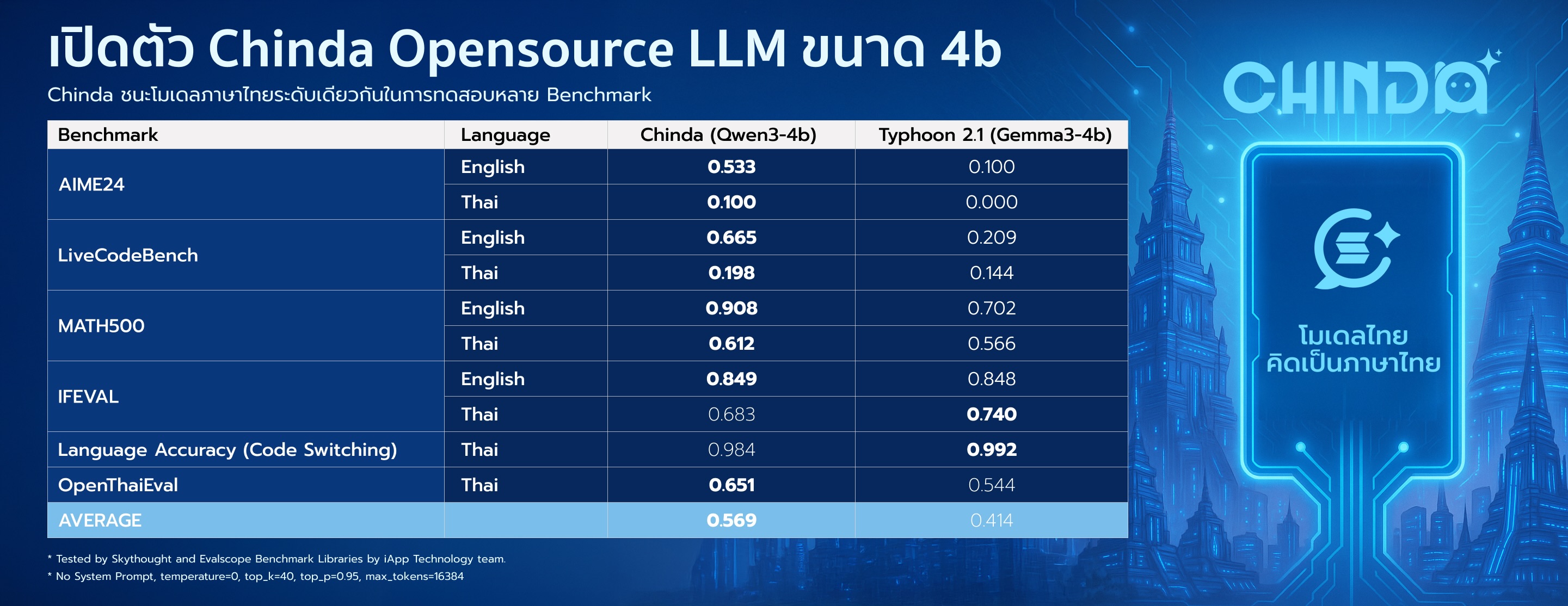
Chinda Opensource Thai LLM 4B is iApp Technology's cutting-edge Thai language model that brings advanced thinking capabilities to the Thai AI ecosystem. Built on the latest Qwen3-4B architecture, Chinda represents our commitment to developing sovereign AI solutions for Thailand.
## 🚀 Quick Links
- **🌐 Demo:** [https://chindax.iapp.co.th](https://chindax.iapp.co.th) (Choose ChindaLLM 4b)
- **📦 Model Download:** [https://huggingface.co/iapp/chinda-qwen3-4b](https://huggingface.co/iapp/chinda-qwen3-4b)
- **🐋 Ollama:** [https://ollama.com/iapp/chinda-qwen3-4b](https://ollama.com/iapp/chinda-qwen3-4b)
- **🏠 Homepage:** [https://iapp.co.th/products/chinda-opensource-llm](https://iapp.co.th/products/chinda-opensource-llm)
- **📄 License:** Apache 2.0
## ✨ Key Features
### 🆓 **0. Free and Opensource for Everyone**
Chinda LLM 4B is completely free and open-source, enabling developers, researchers, and businesses to build Thai AI applications without restrictions.
### 🧠 **1. Advanced Thinking Model**
- **Highest score among Thai LLMs in 4B category**
- Seamless switching between thinking and non-thinking modes
- Superior reasoning capabilities for complex problems
- Can be turned off for efficient general-purpose dialogue
### 🇹🇭 **2. Exceptional Thai Language Accuracy**
- **98.4% accuracy** in outputting Thai language
- Prevents unwanted Chinese and foreign language outputs
- Specifically fine-tuned for Thai linguistic patterns
### 🆕 **3. Latest Architecture**
- Based on the cutting-edge **Qwen3-4B** model
- Incorporates the latest advancements in language modeling
- Optimized for both performance and efficiency
### 📜 **4. Apache 2.0 License**
- Commercial use permitted
- Modification and distribution allowed
- No restrictions on private use
## 📊 Benchmark Results
Chinda LLM 4B demonstrates superior performance compared to other Thai language models in its category:
| Benchmark | Language | Chinda LLM 4B | Alternative* |
|-----------|----------|---------------|-------------|
| **AIME24** | English | **0.533** | 0.100 |
| | Thai | **0.100** | 0.000 |
| **LiveCodeBench** | English | **0.665** | 0.209 |
| | Thai | **0.198** | 0.144 |
| **MATH500** | English | **0.908** | 0.702 |
| | Thai | **0.612** | 0.566 |
| **IFEVAL** | English | **0.849** | 0.848 |
| | Thai | 0.683 | **0.740** |
| **Language Accuracy** | Thai | 0.984 | **0.992** |
| **OpenThaiEval** | Thai | **0.651** | 0.544 |
| **AVERAGE** | | **0.569** | 0.414 |
* Alternative: scb10x_typhoon2.1-gemma3-4b
* Tested by Skythought and Evalscope Benchmark Libraries by iApp Technology team. Results show Chinda LLM 4B achieving **37% better overall performance** than the nearest alternative.
## ✅ Suitable For
### 🔍 **1. RAG Applications (Sovereign AI)**
Perfect for building Retrieval-Augmented Generation systems that keep data processing within Thai sovereignty.
### 📱 **2. Mobile and Laptop Applications**
Reliable Small Language Model optimized for edge computing and personal devices.
### 🧮 **3. Math Calculation**
Excellent performance in mathematical reasoning and problem-solving.
### 💻 **4. Code Assistant**
Strong capabilities in code generation and programming assistance.
### ⚡ **5. Resource Efficiency**
Very fast inference with minimal GPU memory consumption, ideal for production deployments.
## ❌ Not Suitable For
### 📚 **Factual Questions Without Context**
As a 4B parameter model, it may hallucinate when asked for specific facts without provided context. Always use with RAG or provide relevant context for factual queries.
## 🛠️ Quick Start
### Installation
```bash
pip install transformers torch
```
### Basic Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "iapp/chinda-qwen3-4b"
# Load the tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# Prepare the model input
prompt = "อธิบายเกี่ยวกับปัญญาประดิษฐ์ให้ฟังหน่อย"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Enable thinking mode for better reasoning
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Generate response
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024,
temperature=0.6,
top_p=0.95,
top_k=20,
do_sample=True
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Parse thinking content (if enabled)
try:
# Find </think> token (151668)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("🧠 Thinking:", thinking_content)
print("💬 Response:", content)
```
### Switching Between Thinking and Non-Thinking Mode
#### Enable Thinking Mode (Default)
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Enable detailed reasoning
)
```
#### Disable Thinking Mode (For Efficiency)
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Fast response mode
)
```
### API Deployment
#### Using vLLM
```bash
pip install vllm>=0.8.5
vllm serve iapp/chinda-qwen3-4b --enable-reasoning --reasoning-parser deepseek_r1
```
#### Using SGLang
```bash
pip install sglang>=0.4.6.post1
python -m sglang.launch_server --model-path iapp/chinda-qwen3-4b --reasoning-parser qwen3
```
#### Using Ollama (Easy Local Setup)
**Installation:**
```bash
# Install Ollama (if not already installed)
curl -fsSL https://ollama.com/install.sh | sh
# Pull Chinda LLM 4B model
ollama pull iapp/chinda-qwen3-4b
```
**Basic Usage:**
```bash
# Start chatting with Chinda LLM
ollama run iapp/chinda-qwen3-4b
# Example conversation
ollama run iapp/chinda-qwen3-4b "อธิบายเกี่ยวกับปัญญาประดิษฐ์ให้ฟังหน่อย"
```
**API Server:**
```bash
# Start Ollama API server
ollama serve
# Use with curl
curl http://localhost:11434/api/generate -d '{
"model": "iapp/chinda-qwen3-4b",
"prompt": "สวัสดีครับ",
"stream": false
}'
```
**Model Specifications:**
- **Size:** 2.5GB (quantized)
- **Context Window:** 40K tokens
- **Architecture:** Optimized for local deployment
- **Performance:** Fast inference on consumer hardware
## 🔧 Advanced Configuration
### Processing Long Texts
Chinda LLM 4B natively supports up to 32,768 tokens. For longer contexts, enable YaRN scaling:
```json
{
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
```
### Recommended Parameters
**For Thinking Mode:**
- Temperature: 0.6
- Top-P: 0.95
- Top-K: 20
- Min-P: 0
**For Non-Thinking Mode:**
- Temperature: 0.7
- Top-P: 0.8
- Top-K: 20
- Min-P: 0
## 📝 Context Length & Template Format
### Context Length Support
- **Native Context Length:** 32,768 tokens
- **Extended Context Length:** Up to 131,072 tokens (with YaRN scaling)
- **Input + Output:** Total conversation length supported
- **Recommended Usage:** Keep conversations under 32K tokens for optimal performance
### Chat Template Format
Chinda LLM 4B uses a standardized chat template format for consistent interactions:
```python
# Basic template structure
messages = [
{"role": "system", "content": "You are a helpful Thai AI assistant."},
{"role": "user", "content": "สวัสดีครับ"},
{"role": "assistant", "content": "สวัสดีค่ะ! มีอะไรให้ช่วยเหลือบ้างคะ"},
{"role": "user", "content": "ช่วยอธิบายเรื่อง AI ให้ฟังหน่อย"}
]
# Apply template with thinking mode
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
```
### Template Structure
The template follows the standard conversational format:
```
<|im_start|>system
You are a helpful Thai AI assistant.<|im_end|>
<|im_start|>user
สวัสดีครับ<|im_end|>
<|im_start|>assistant
สวัสดีค่ะ! มีอะไรให้ช่วยเหลือบ้างคะ<|im_end|>
<|im_start|>user
ช่วยอธิบายเรื่อง AI ให้ฟังหน่อย<|im_end|>
<|im_start|>assistant
```
### Advanced Template Usage
```python
# Multi-turn conversation with thinking control
def create_conversation(messages, enable_thinking=True):
# Add system message if not present
if not messages or messages[0]["role"] != "system":
system_msg = {
"role": "system",
"content": "คุณเป็น AI ผู้ช่วยที่ฉลาดและเป็นประโยชน์ พูดภาษาไทยได้อย่างเป็นธรรมชาติ"
}
messages = [system_msg] + messages
# Apply chat template
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=enable_thinking
)
return text
# Example usage
conversation = [
{"role": "user", "content": "คำนวณ 15 × 23 = ?"},
]
prompt = create_conversation(conversation, enable_thinking=True)
```
### Dynamic Mode Switching
You can control thinking mode within conversations using special commands:
```python
# Enable thinking for complex problems
messages = [
{"role": "user", "content": "/think แก้สมการ: x² + 5x - 14 = 0"}
]
# Disable thinking for quick responses
messages = [
{"role": "user", "content": "/no_think สวัสดี"}
]
```
### Context Management Best Practices
1. **Monitor Token Count:** Keep track of total tokens (input + output)
2. **Truncate Old Messages:** Remove oldest messages when approaching limits
3. **Use YaRN for Long Contexts:** Enable rope scaling for documents > 32K tokens
4. **Batch Processing:** For very long texts, consider chunking and processing in batches
```python
def manage_context(messages, max_tokens=30000):
"""Simple context management function"""
total_tokens = sum(len(tokenizer.encode(msg["content"])) for msg in messages)
while total_tokens > max_tokens and len(messages) > 2:
# Keep system message and remove oldest user/assistant pair
if messages[1]["role"] == "user":
messages.pop(1) # Remove user message
if len(messages) > 1 and messages[1]["role"] == "assistant":
messages.pop(1) # Remove corresponding assistant message
total_tokens = sum(len(tokenizer.encode(msg["content"])) for msg in messages)
return messages
```
## 🏢 Enterprise Support
For enterprise deployments, custom training, or commercial support, contact us at:
- **Email:** [email protected]
- **Website:** [iapp.co.th](https://iapp.co.th)
## ❓ Frequently Asked Questions
<details>
<summary><strong>🏷️ Why is it named "Chinda"?</strong></summary>
The name "Chinda" (จินดา) comes from "จินดามณี" (Chindamani), which is considered the first book of Thailand written by Phra Horathibodi (Sri Dharmasokaraja) in the Sukhothai period. Just as จินดามณี was a foundational text for Thai literature and learning, Chinda LLM represents our foundation for Thai sovereign AI - a model that truly understands and thinks in Thai, preserving and advancing Thai language capabilities in the digital age.
</details>
<details>
<summary><strong>⚖️ Can I use Chinda LLM 4B for commercial purposes?</strong></summary>
Yes! Chinda LLM 4B is released under the **Apache 2.0 License**, which allows:
- ✅ **Commercial use** - Use in commercial products and services
- ✅ **Research use** - Academic and research applications
- ✅ **Modification** - Adapt and modify the model
- ✅ **Distribution** - Share and redistribute the model
- ✅ **Private use** - Use for internal company projects
No restrictions on commercial applications - build and deploy freely!
</details>
<details>
<summary><strong>🧠 What's the difference between thinking and non-thinking mode?</strong></summary>
**Thinking Mode (`enable_thinking=True`):**
- Model shows its reasoning process in `<think>...</think>` blocks
- Better for complex problems, math, coding, logical reasoning
- Slower but more accurate responses
- Recommended for tasks requiring deep analysis
**Non-Thinking Mode (`enable_thinking=False`):**
- Direct answers without showing reasoning
- Faster responses for general conversations
- Better for simple queries and chat applications
- More efficient resource usage
You can switch between modes or let users control it dynamically using `/think` and `/no_think` commands.
</details>
<details>
<summary><strong>📊 How does Chinda LLM 4B compare to other Thai language models?</strong></summary>
Chinda LLM 4B achieves **37% better overall performance** compared to the nearest alternative:
- **Overall Average:** 0.569 vs 0.414 (alternative)
- **Math (MATH500):** 0.908 vs 0.702 (English), 0.612 vs 0.566 (Thai)
- **Code (LiveCodeBench):** 0.665 vs 0.209 (English), 0.198 vs 0.144 (Thai)
- **Thai Language Accuracy:** 98.4% (prevents Chinese/foreign text output)
- **OpenThaiEval:** 0.651 vs 0.544
It's currently the **highest-scoring Thai LLM in the 4B parameter category**.
</details>
<details>
<summary><strong>💻 What are the system requirements to run Chinda LLM 4B?</strong></summary>
**Minimum Requirements:**
- **GPU:** 8GB VRAM (RTX 3070/4060 Ti or better)
- **RAM:** 16GB system memory
- **Storage:** 8GB free space for model download
- **Python:** 3.8+ with PyTorch
**Recommended for Production:**
- **GPU:** 16GB+ VRAM (RTX 4080/A4000 or better)
- **RAM:** 32GB+ system memory
- **Storage:** SSD for faster loading
**CPU-Only Mode:** Possible but significantly slower (not recommended for production)
</details>
<details>
<summary><strong>🔧 Can I fine-tune Chinda LLM 4B for my specific use case?</strong></summary>
Yes! As an open-source model under Apache 2.0 license, you can:
- **Fine-tune** on your domain-specific data
- **Customize** for specific tasks or industries
- **Modify** the architecture if needed
- **Create derivatives** for specialized applications
Popular fine-tuning frameworks that work with Chinda:
- **Unsloth** - Fast and memory-efficient
- **LoRA/QLoRA** - Parameter-efficient fine-tuning
- **Hugging Face Transformers** - Full fine-tuning
- **Axolotl** - Advanced training configurations
Need help with fine-tuning? Contact our team at [email protected]
</details>
<details>
<summary><strong>🌍 What languages does Chinda LLM 4B support?</strong></summary>
**Primary Languages:**
- **Thai** - Native-level understanding and generation (98.4% accuracy)
- **English** - Strong performance across all benchmarks
**Additional Languages:**
- 100+ languages supported (inherited from Qwen3-4B base)
- Focus optimized for Thai-English bilingual tasks
- Code generation in multiple programming languages
**Special Features:**
- **Code-switching** between Thai and English
- **Translation** between Thai and other languages
- **Multilingual reasoning** capabilities
</details>
<details>
<summary><strong>🔍 Is the training data publicly available?</strong></summary>
The model weights are open-source, but the specific training datasets are not publicly released. However:
- **Base Model:** Built on Qwen3-4B (Alibaba's open foundation)
- **Thai Optimization:** Custom dataset curation for Thai language tasks
- **Quality Focus:** Carefully selected high-quality Thai content
- **Privacy Compliant:** No personal or sensitive data included
For research collaborations or dataset inquiries, contact our research team.
</details>
<details>
<summary><strong>🆘 How do I get support or report issues?</strong></summary>
**For Technical Issues:**
- **GitHub Issues:** Report bugs and technical problems
- **Hugging Face:** Model-specific questions and discussions
- **Documentation:** Check our comprehensive guides
**For Commercial Support:**
- **Email:** [email protected]
- **Enterprise Support:** Custom training, deployment assistance
- **Consulting:** Integration and optimization services
**Community Support:**
- **Thai AI Community:** Join discussions about Thai AI development
- **Developer Forums:** Connect with other Chinda users
</details>
<details>
<summary><strong>📥 How large is the model download and what format is it in?</strong></summary>
**Model Specifications:**
- **Parameters:** 4.02 billion (4B)
- **Download Size:** ~8GB (compressed)
- **Format:** Safetensors (recommended) and PyTorch
- **Precision:** BF16 (Brain Float 16)
**Download Options:**
- **Hugging Face Hub:** `huggingface.co/iapp/chinda-qwen3-4b`
- **Git LFS:** For version control integration
- **Direct Download:** Individual model files
- **Quantized Versions:** Available for reduced memory usage (GGUF, AWQ)
**Quantization Options:**
- **4-bit (GGUF):** ~2.5GB, runs on 4GB VRAM
- **8-bit:** ~4GB, balanced performance/memory
- **16-bit (Original):** ~8GB, full performance
</details>
## 📚 Citation
If you use Chinda LLM 4B in your research or projects, please cite:
```bibtex
@misc{chinda-llm-4b,
title={Chinda LLM 4B: Thai Sovereign AI Language Model},
author={iApp Technology},
year={2025},
publisher={Hugging Face},
url={https://huggingface.co/iapp/chinda-qwen3-4b}
}
```
---
*Built with 🇹🇭 by iApp Technology - Empowering Thai Businesses with Sovereign AI Excellence*

**Powered by iApp Technology**
<i>Disclaimer: Provided responses are not guaranteed.</i> |
talphaidze/letter_finetuned | talphaidze | 2025-06-04T17:09:56Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T17:05:56Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
lqmannn4/resume_matcher | lqmannn4 | 2025-06-04T17:06:24Z | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:4",
"loss:CosineSimilarityLoss",
"arxiv:1908.10084",
"base_model:sentence-transformers/all-MiniLM-L6-v2",
"base_model:finetune:sentence-transformers/all-MiniLM-L6-v2",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2025-06-04T17:05:14Z | ---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:4
- loss:CosineSimilarityLoss
base_model: sentence-transformers/all-MiniLM-L6-v2
pipeline_tag: sentence-similarity
library_name: sentence-transformers
---
# SentenceTransformer based on sentence-transformers/all-MiniLM-L6-v2
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2). It maps sentences & paragraphs to a 384-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) <!-- at revision c9745ed1d9f207416be6d2e6f8de32d1f16199bf -->
- **Maximum Sequence Length:** 256 tokens
- **Output Dimensionality:** 384 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("sentence_transformers_model_id")
# Run inference
sentences = [
'The weather is lovely today.',
"It's so sunny outside!",
'He drove to the stadium.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 4 training samples
* Columns: <code>sentence_0</code>, <code>sentence_1</code>, and <code>label</code>
* Approximate statistics based on the first 4 samples:
| | sentence_0 | sentence_1 | label |
|:--------|:----------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|:--------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 12 tokens</li><li>mean: 14.0 tokens</li><li>max: 16 tokens</li></ul> | <ul><li>min: 12 tokens</li><li>mean: 13.25 tokens</li><li>max: 15 tokens</li></ul> | <ul><li>min: 0.0</li><li>mean: 0.5</li><li>max: 1.0</li></ul> |
* Samples:
| sentence_0 | sentence_1 | label |
|:--------------------------------------------------------------------------|:----------------------------------------------------------------------------|:-----------------|
| <code>Teacher with 5 years in classroom management...</code> | <code>Looking for AI/ML engineer with Python experience.</code> | <code>0.0</code> |
| <code>DevOps engineer with AWS, Docker, Jenkins...</code> | <code>Hiring cloud infrastructure engineer with AWS and CI/CD tools.</code> | <code>1.0</code> |
| <code>Experienced Python developer with Flask and Django skills...</code> | <code>Looking for backend Python developer with Django experience.</code> | <code>1.0</code> |
* Loss: [<code>CosineSimilarityLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosinesimilarityloss) with these parameters:
```json
{
"loss_fct": "torch.nn.modules.loss.MSELoss"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `per_device_train_batch_size`: 2
- `per_device_eval_batch_size`: 2
- `num_train_epochs`: 4
- `multi_dataset_batch_sampler`: round_robin
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: no
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 2
- `per_device_eval_batch_size`: 2
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1
- `num_train_epochs`: 4
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `tp_size`: 0
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: round_robin
</details>
### Framework Versions
- Python: 3.11.12
- Sentence Transformers: 4.1.0
- Transformers: 4.51.3
- PyTorch: 2.6.0+cu124
- Accelerate: 1.6.0
- Datasets: 2.14.4
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
--> |
AquilaX-AI/classification | AquilaX-AI | 2025-06-04T17:05:24Z | 244 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-09-18T10:55:28Z | ---
library_name: transformers
tags: []
---
## Inference
```python
from transformers import AutoModelForSequenceClassification, DistilBertTokenizer
import time
import torch
import re
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = AutoModelForSequenceClassification.from_pretrained("AquilaX-AI/classification").to(device)
tokenizer = DistilBertTokenizer.from_pretrained("AquilaX-AI/classification")
start = time.time()
question = "give me a scan result"
question = re.sub(r"[,?.'\"']", '', question)
inputs = tokenizer(question, return_tensors="pt").to(device)
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
predicted_class = model.config.id2label[predicted_class_id]
print(predicted_class)
print(time.time() - start)
``` |
PrunaAI/Qwen-Qwen2.5-Coder-7B-HQQ-4bit-smashed | PrunaAI | 2025-06-04T16:50:07Z | 0 | 0 | null | [
"qwen2",
"pruna-ai",
"base_model:Qwen/Qwen2.5-Coder-7B",
"base_model:finetune:Qwen/Qwen2.5-Coder-7B",
"region:us"
] | null | 2025-06-04T16:49:00Z | ---
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
base_model: Qwen/Qwen2.5-Coder-7B
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
tags:
- pruna-ai
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
<img src="banner.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</a>
</div>
<!-- header end -->
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.gg/rskEr4BZJx)
# Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
## Results

**Frequently Asked Questions**
- ***How does the compression work?*** The model is compressed with hqq.
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
- ***How is the model efficiency evaluated?*** These results were obtained with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
- ***What is the model format?*** We use safetensors.
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
## Setup
You can run the smashed model with these steps:
0. Check requirements from the original repo Qwen/Qwen2.5-Coder-7B installed. In particular, check python, cuda, and transformers versions.
1. Make sure that you have installed quantization related packages.
```bash
pip install hqq
```
2. Load & run the model.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from hqq.engine.hf import HQQModelForCausalLM
from hqq.models.hf.base import AutoHQQHFModel
try:
model = HQQModelForCausalLM.from_quantized("PrunaAI/Qwen-Qwen2.5-Coder-7B-HQQ-4bit-smashed", device_map='auto')
except:
model = AutoHQQHFModel.from_quantized("PrunaAI/Qwen-Qwen2.5-Coder-7B-HQQ-4bit-smashed")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-Coder-7B")
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
outputs = model.generate(input_ids, max_new_tokens=216)
tokenizer.decode(outputs[0])
```
## Configurations
The configuration info are in `smash_config.json`. This model has been smashed with pruna in version O.1.3
## Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model Qwen/Qwen2.5-Coder-7B before using this model which provided the base model. The license of `pruna` is [here](https://github.com/PrunaAI/pruna/blob/main/LICENSE) on GitHub.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai). |
trip1ech/MCQA-rationale-dev | trip1ech | 2025-06-04T16:45:26Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T16:43:36Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
BootesVoid/cmbh0dx3r05zvkfxsonevw8x7_cmbi4hwsr08sfkfxsi7j87kig | BootesVoid | 2025-06-04T16:43:47Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-04T16:43:42Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: BOOTY
---
# Cmbh0Dx3R05Zvkfxsonevw8X7_Cmbi4Hwsr08Sfkfxsi7J87Kig
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `BOOTY` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "BOOTY",
"lora_weights": "https://huggingface.co/BootesVoid/cmbh0dx3r05zvkfxsonevw8x7_cmbi4hwsr08sfkfxsi7j87kig/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmbh0dx3r05zvkfxsonevw8x7_cmbi4hwsr08sfkfxsi7j87kig', weight_name='lora.safetensors')
image = pipeline('BOOTY').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmbh0dx3r05zvkfxsonevw8x7_cmbi4hwsr08sfkfxsi7j87kig/discussions) to add images that show off what you’ve made with this LoRA.
|
sdjtfshjds/Qwen2-0.5B-GRPO-sql | sdjtfshjds | 2025-06-04T16:34:52Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2-0.5B-Instruct",
"base_model:finetune:Qwen/Qwen2-0.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-06-04T11:38:13Z | ---
base_model: Qwen/Qwen2-0.5B-Instruct
library_name: transformers
model_name: Qwen2-0.5B-GRPO-sql
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for Qwen2-0.5B-GRPO-sql
This model is a fine-tuned version of [Qwen/Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="sdjtfshjds/Qwen2-0.5B-GRPO-sql", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.3
- Pytorch: 2.6.0+cu124
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
Wfiles/QLora_MCQA_FFT_Crazy_B4_2E_512T_LR1e-05_8 | Wfiles | 2025-06-04T16:33:46Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2025-06-04T10:38:24Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Desalegnn/amharic-t5-model-LoRA | Desalegnn | 2025-06-04T16:33:23Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2025-06-04T16:32:51Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Ber173/CartPole-v1 | Ber173 | 2025-06-04T16:31:45Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2025-05-31T13:56:18Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
tanizhan/data-science-gpt2 | tanizhan | 2025-06-04T16:28:28Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T15:54:41Z | ---
library_name: transformers
license: mit
base_model: gpt2
tags:
- generated_from_trainer
model-index:
- name: data-science-gpt2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# data-science-gpt2
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.52.3
- Pytorch 2.6.0+cu124
- Datasets 2.14.4
- Tokenizers 0.21.1
|
ibuki95/vision_172_11 | ibuki95 | 2025-06-04T16:24:50Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2025-06-04T16:17:10Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
himedia/hyperclovax-1.5b-4bit-bnb-finetuned | himedia | 2025-06-04T16:21:02Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-04T16:20:50Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF | mradermacher | 2025-06-04T16:19:36Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"en",
"dataset:zerofata/Roleplay-Anime-Characters",
"dataset:zerofata/Instruct-Anime-CreativeWriting",
"dataset:zerofata/Summaries-Anime-FandomPages",
"base_model:zerofata/L3.3-GeneticLemonade-Final-v2-70B",
"base_model:quantized:zerofata/L3.3-GeneticLemonade-Final-v2-70B",
"license:llama3",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-04T12:23:45Z | ---
base_model: zerofata/L3.3-GeneticLemonade-Final-v2-70B
datasets:
- zerofata/Roleplay-Anime-Characters
- zerofata/Instruct-Anime-CreativeWriting
- zerofata/Summaries-Anime-FandomPages
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/zerofata/L3.3-GeneticLemonade-Final-v2-70B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF/resolve/main/L3.3-GeneticLemonade-Final-v2-70B.Q2_K.gguf) | Q2_K | 26.5 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF/resolve/main/L3.3-GeneticLemonade-Final-v2-70B.Q3_K_S.gguf) | Q3_K_S | 31.0 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF/resolve/main/L3.3-GeneticLemonade-Final-v2-70B.Q3_K_M.gguf) | Q3_K_M | 34.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF/resolve/main/L3.3-GeneticLemonade-Final-v2-70B.Q3_K_L.gguf) | Q3_K_L | 37.2 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF/resolve/main/L3.3-GeneticLemonade-Final-v2-70B.IQ4_XS.gguf) | IQ4_XS | 38.4 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF/resolve/main/L3.3-GeneticLemonade-Final-v2-70B.Q4_K_S.gguf) | Q4_K_S | 40.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF/resolve/main/L3.3-GeneticLemonade-Final-v2-70B.Q4_K_M.gguf) | Q4_K_M | 42.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF/resolve/main/L3.3-GeneticLemonade-Final-v2-70B.Q5_K_S.gguf) | Q5_K_S | 48.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF/resolve/main/L3.3-GeneticLemonade-Final-v2-70B.Q5_K_M.gguf) | Q5_K_M | 50.0 | |
| [PART 1](https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF/resolve/main/L3.3-GeneticLemonade-Final-v2-70B.Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF/resolve/main/L3.3-GeneticLemonade-Final-v2-70B.Q6_K.gguf.part2of2) | Q6_K | 58.0 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF/resolve/main/L3.3-GeneticLemonade-Final-v2-70B.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/L3.3-GeneticLemonade-Final-v2-70B-GGUF/resolve/main/L3.3-GeneticLemonade-Final-v2-70B.Q8_0.gguf.part2of2) | Q8_0 | 75.1 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
mario81464/qwen-3B_instruct_base_sft_FEVERCleanedBinaryRational_10k_samples | mario81464 | 2025-06-04T16:09:28Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"llama-factory",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T16:09:01Z | ---
library_name: transformers
tags:
- llama-factory
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
softdev629/orjebcnf | softdev629 | 2025-06-04T16:03:23Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2025-06-04T15:55:13Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
softdev629/b4zr0u7t | softdev629 | 2025-06-04T16:01:01Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2025-06-04T15:55:10Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
medimed/finetuned_Qwen3_lora | medimed | 2025-06-04T16:00:28Z | 13 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/Qwen3-0.6B-Base",
"base_model:finetune:unsloth/Qwen3-0.6B-Base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-03T12:27:49Z | ---
base_model: unsloth/Qwen3-0.6B-Base
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** medimed
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-0.6B-Base
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Allen172/gemma-text-4400 | Allen172 | 2025-06-04T15:56:49Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma3",
"image-text-to-text",
"conversational",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2025-06-04T15:33:23Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
HouraMor/wav2vec2-ft-lre5-adm-ga2b16-st15k-v2 | HouraMor | 2025-06-04T15:54:57Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:jonatasgrosman/wav2vec2-large-english",
"base_model:finetune:jonatasgrosman/wav2vec2-large-english",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2025-06-03T09:25:22Z | ---
library_name: transformers
license: apache-2.0
base_model: jonatasgrosman/wav2vec2-large-english
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: wav2vec2-ft-lre5-adm-ga2b16-st15k-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-ft-lre5-adm-ga2b16-st15k-v2
This model is a fine-tuned version of [jonatasgrosman/wav2vec2-large-english](https://huggingface.co/jonatasgrosman/wav2vec2-large-english) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5870
- Wer: 0.8445
- Cer: 0.5449
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 15000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:------:|:-----:|:---------------:|:------:|:------:|
| 3.3794 | 0.4165 | 1000 | 3.3428 | 1.0000 | 1.0000 |
| 3.2665 | 0.8330 | 2000 | 3.3404 | 1.0000 | 1.0000 |
| 3.2044 | 1.2495 | 3000 | 3.2870 | 1.0000 | 1.0000 |
| 3.2642 | 1.6660 | 4000 | 3.3091 | 1.0000 | 1.0000 |
| 3.1645 | 2.0825 | 5000 | 3.2496 | 1.0000 | 1.0000 |
| 3.0649 | 2.4990 | 6000 | 3.1114 | 0.9971 | 0.9687 |
| 2.8293 | 2.9155 | 7000 | 2.8214 | 0.9283 | 0.6287 |
| 2.7508 | 3.3319 | 8000 | 2.6857 | 0.8816 | 0.5757 |
| 2.5881 | 3.7484 | 9000 | 2.6349 | 0.8577 | 0.5662 |
| 2.5849 | 4.1649 | 10000 | 2.6452 | 0.8601 | 0.5625 |
| 2.4879 | 4.5814 | 11000 | 2.6279 | 0.8521 | 0.5492 |
| 2.5049 | 4.9979 | 12000 | 2.6028 | 0.8508 | 0.5492 |
| 2.4675 | 5.4144 | 13000 | 2.6280 | 0.8540 | 0.5437 |
| 2.4701 | 5.8309 | 14000 | 2.5934 | 0.8461 | 0.5439 |
| 2.4516 | 6.2474 | 15000 | 2.5870 | 0.8445 | 0.5449 |
### Framework versions
- Transformers 4.52.3
- Pytorch 2.7.0+cu118
- Datasets 3.6.0
- Tokenizers 0.21.1
|
GingerBled/MCQA_on_DPO_adam_m1 | GingerBled | 2025-06-04T15:54:43Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T15:53:39Z | ---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
trongg/Qwen2.5-Coder-1.5B-Instruct-aef8d792-f042-438f-804a-9e0c7f4f5033 | trongg | 2025-06-04T15:54:15Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:unsloth/Qwen2.5-Coder-1.5B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-Coder-1.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-06-04T15:54:00Z | ---
base_model: unsloth/Qwen2.5-Coder-1.5B-Instruct
library_name: transformers
model_name: Qwen2.5-Coder-1.5B-Instruct-aef8d792-f042-438f-804a-9e0c7f4f5033
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for Qwen2.5-Coder-1.5B-Instruct-aef8d792-f042-438f-804a-9e0c7f4f5033
This model is a fine-tuned version of [unsloth/Qwen2.5-Coder-1.5B-Instruct](https://huggingface.co/unsloth/Qwen2.5-Coder-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="trongg/Qwen2.5-Coder-1.5B-Instruct-aef8d792-f042-438f-804a-9e0c7f4f5033", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/tengicxduoc/sn56-sft-train/runs/h2e12kye)
This model was trained with SFT.
### Framework versions
- TRL: 0.17.0
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
cragtmp/task05rd2-519 | cragtmp | 2025-06-04T15:48:55Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-3.2-11B-Vision-Instruct",
"base_model:adapter:meta-llama/Llama-3.2-11B-Vision-Instruct",
"region:us"
] | null | 2025-06-04T15:47:47Z | ---
base_model: meta-llama/Llama-3.2-11B-Vision-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2 |
01-Spiderman-Sophie-Rain-Viral-Video/Sophie.Rain.SpiderMan.Tutorial | 01-Spiderman-Sophie-Rain-Viral-Video | 2025-06-04T15:48:25Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-04T15:48:01Z | 39 seconds ago
<a href="https://tv2online.com/Leaked/?v=Sophie+Rain+Spiderman" rel="nofollow">►►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► 𝙁𝙪𝙡𝙡 𝙑𝙞𝙙𝙚𝙤️</a></p>
<a href="https://tv2online.com/Leaked/?v=Sophie+Rain+Spiderman" rel="nofollow">🔴►𝐂𝐋𝐈𝐂𝐊 𝐇𝐄𝐑𝐄 🌐==►► 𝐃𝐨𝐰𝐧𝐥𝐨𝐚𝐝 𝐍𝐨𝐰⬇️⬇️</a></p>
<p><a rel="nofollow" title="WATCH NOW" href="https://tv2online.com/Leaked/?v=Sophie+Rain+Spiderman"><img border="Sophie+Rain+Spidermanno" height="480" width="720" title="WATCH NOW" alt="WATCH NOW" src="https://i.ibb.co.com/xMMVF88/686577567.gif"></a></p>
Sophie Rain Spiderman Video Tutorial Original Video video oficial twitter
L𝚎aked Video Sophie Rain Spiderman Video Tutorial Original Video Viral Video L𝚎aked on X Twitter
. . . . . . . . . L𝚎aked Video Sophie Rain Spiderman Video Tutorial Original Video Viral Video L𝚎aked on X Twitter Telegram
L𝚎aked Video Sophie Rain Spiderman Video Tutorial Original Video Viral Video L𝚎aked on X Twitter |
darshjoshi16/phi2-lora-math | darshjoshi16 | 2025-06-04T15:46:33Z | 6 | 0 | peft | [
"peft",
"safetensors",
"lora",
"math",
"reasoning",
"gsm8k",
"phi-2",
"transformers",
"arxiv:2106.09685",
"base_model:microsoft/phi-2",
"base_model:adapter:microsoft/phi-2",
"license:apache-2.0",
"region:us"
] | null | 2025-06-04T01:37:40Z | ---
license: apache-2.0
tags:
- peft
- lora
- math
- reasoning
- gsm8k
- phi-2
- transformers
library_name: peft
base_model: microsoft/phi-2
model_type: causal-lm
---
# 🧠 Phi-2 LoRA Adapter for GSM8K (Math Word Problems)
This repository contains a parameter-efficient **LoRA fine-tuning** of [`microsoft/phi-2`](https://huggingface.co/microsoft/phi-2) on the **GSM8K** dataset, designed for solving grade-school arithmetic and reasoning problems in natural language.
> ✅ Adapter-only: This is a **LoRA adapter**, not a full model. You must load it on top of `microsoft/phi-2`.
---
## ✨ What's Inside
- **Base Model**: `microsoft/phi-2` (1.7B parameters)
- **Adapter Type**: LoRA (Low-Rank Adaptation via [PEFT](https://github.com/huggingface/peft))
- **Task**: Grade-school math reasoning (multi-step logic and arithmetic)
- **Dataset**: [GSM8K](https://huggingface.co/datasets/gsm8k)
---
## 🚀 Quick Start
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
# Load base model and tokenizer
base_model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2")
tokenizer = AutoTokenizer.from_pretrained("darshjoshi16/phi2-lora-math")
# Load LoRA adapter
model = PeftModel.from_pretrained(base_model, "darshjoshi16/phi2-lora-math")
# Inference
prompt = "Q: Julie read 12 pages yesterday and twice as many today. If she wants to read half of the remaining 84 pages tomorrow, how many pages should she read?\nA:"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
---
## 📊 Evaluation Results
| Task | Metric | Score | Samples |
|-------------|-----------------------------|--------|---------|
| GSM8K | Exact Match (strict) | 54.6% | 500 |
| ARC-Easy | Accuracy | 79.0% | 500 |
| HellaSwag | Accuracy (Normalized) | 61.0% | 500 |
> Benchmarks were run using [EleutherAI’s lm-eval-harness](https://github.com/EleutherAI/lm-eval-harness)
---
## ⚙️ Training Details
- **Method**: LoRA (rank=8, alpha=16, dropout=0.1)
- **Epochs**: 1 (proof of concept)
- **Batch size**: 4 per device
- **Precision**: FP16
- **Platform**: Google Colab (T4 GPU)
- **Framework**: [🤗 Transformers](https://github.com/huggingface/transformers) + [PEFT](https://github.com/huggingface/peft)
---
## 🔍 Limitations
- Fine-tuned for math problems only (not general-purpose reasoning)
- Trained for 1 epoch — additional training may improve performance
- Adapter-only: base model (`microsoft/phi-2`) must be loaded alongside
---
## 📘 Citation & References
- [LoRA: Low-Rank Adaptation](https://arxiv.org/abs/2106.09685)
- [Phi-2 Model Card](https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/)
- [GSM8K Dataset](https://huggingface.co/datasets/gsm8k)
- [PEFT Library](https://github.com/huggingface/peft)
- [Transformers](https://huggingface.co/docs/transformers)
---
## 💬 Author
This model was fine-tuned and open-sourced by **[Darsh Joshi](https://huggingface.co/darshjoshi16)**.
Feel free to [reach out](mailto:[email protected]) or contribute.
|
avey-ai/rwkv7-dpa-0.5B-90BT | avey-ai | 2025-06-04T15:44:52Z | 0 | 0 | null | [
"safetensors",
"license:apache-2.0",
"region:us"
] | null | 2025-06-04T15:41:12Z | ---
license: apache-2.0
---
|
hnpinq/Quantized_TryOn | hnpinq | 2025-06-04T15:44:43Z | 0 | 0 | None | [
"None",
"diffusers",
"safetensors",
"pruna-ai",
"region:us"
] | null | 2025-06-04T15:18:51Z | ---
library_name: None
tags:
- pruna-ai
---
# Model Card for hnpinq/Quantized_TryOn
This model was created using the [pruna](https://github.com/PrunaAI/pruna) library. Pruna is a model optimization framework built for developers, enabling you to deliver more efficient models with minimal implementation overhead.
## Usage
First things first, you need to install the pruna library:
```bash
pip install pruna
```
You can [use the None library to load the model](https://huggingface.co/hnpinq/Quantized_TryOn?library=None) but this might not include all optimizations by default.
To ensure that all optimizations are applied, use the pruna library to load the model using the following code:
```python
from pruna import PrunaModel
loaded_model = PrunaModel.from_hub(
"hnpinq/Quantized_TryOn"
)
```
After loading the model, you can use the inference methods of the original model. Take a look at the [documentation](https://pruna.readthedocs.io/en/latest/index.html) for more usage information.
## Smash Configuration
The compression configuration of the model is stored in the `smash_config.json` file, which describes the optimization methods that were applied to the model.
```bash
{
"batcher": null,
"cacher": null,
"compiler": "torch_compile",
"factorizer": null,
"pruner": null,
"quantizer": "hqq_diffusers",
"hqq_diffusers_backend": "torchao_int4",
"hqq_diffusers_group_size": 64,
"hqq_diffusers_weight_bits": 8,
"torch_compile_backend": "inductor",
"torch_compile_dynamic": null,
"torch_compile_fullgraph": true,
"torch_compile_make_portable": false,
"torch_compile_max_kv_cache_size": 400,
"torch_compile_mode": "max-autotune",
"torch_compile_seqlen_manual_cuda_graph": 100,
"torch_compile_target": "model",
"batch_size": 1,
"device": "cuda",
"save_fns": [
"hqq_diffusers",
"save_before_apply"
],
"load_fns": [
"hqq_diffusers"
],
"reapply_after_load": {
"factorizer": null,
"pruner": null,
"quantizer": null,
"cacher": null,
"compiler": "torch_compile",
"batcher": null
}
}
```
## 🌍 Join the Pruna AI community!
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.com/invite/rskEr4BZJx)
[](https://www.reddit.com/r/PrunaAI/) |
publication-charaf/MCQ_Qwen3-0.6B-Base_lr-5e-06_e-1_s-0 | publication-charaf | 2025-06-04T15:43:27Z | 25 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:Qwen/Qwen3-0.6B-Base",
"base_model:finetune:Qwen/Qwen3-0.6B-Base",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-03T14:07:41Z | ---
base_model: Qwen/Qwen3-0.6B-Base
library_name: transformers
model_name: MCQ_Qwen3-0.6B-Base_lr-5e-06_e-1_s-0
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for MCQ_Qwen3-0.6B-Base_lr-5e-06_e-1_s-0
This model is a fine-tuned version of [Qwen/Qwen3-0.6B-Base](https://huggingface.co/Qwen/Qwen3-0.6B-Base).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="publication-charaf/MCQ_Qwen3-0.6B-Base_lr-5e-06_e-1_s-0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/kamel-charaf-epfl/huggingface/runs/gqrqptjx)
This model was trained with SFT.
### Framework versions
- TRL: 0.17.0
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
ML-enthusiast-brinda/CyberBuddy-Gemma | ML-enthusiast-brinda | 2025-06-04T15:43:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-04T15:43:13Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
selsar/nli-multilabel-classeducation-new | selsar | 2025-06-04T15:42:42Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"deberta-v2",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-06-04T15:41:37Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
weifar/mistral_2 | weifar | 2025-06-04T15:37:44Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"unsloth",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2025-06-04T15:35:29Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Kokoutou/sn29_coldintC00_0406_2 | Kokoutou | 2025-06-04T15:37:42Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T15:07:48Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
amsilee4/Qwen2.5-1.5B-Instruct-Gensyn-Swarm-playful_hairy_chinchilla | amsilee4 | 2025-06-04T15:28:44Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am playful hairy chinchilla",
"unsloth",
"trl",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-1.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-1.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-06-04T03:16:01Z | ---
base_model: Gensyn/Qwen2.5-1.5B-Instruct
library_name: transformers
model_name: Qwen2.5-1.5B-Instruct-Gensyn-Swarm-playful_hairy_chinchilla
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am playful hairy chinchilla
- unsloth
- trl
licence: license
---
# Model Card for Qwen2.5-1.5B-Instruct-Gensyn-Swarm-playful_hairy_chinchilla
This model is a fine-tuned version of [Gensyn/Qwen2.5-1.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="amsilee4/Qwen2.5-1.5B-Instruct-Gensyn-Swarm-playful_hairy_chinchilla", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.48.2
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
avey-ai/mamba-dpa-0.5B-100BT | avey-ai | 2025-06-04T15:27:08Z | 0 | 0 | null | [
"pytorch",
"license:apache-2.0",
"region:us"
] | null | 2025-06-04T15:24:27Z | ---
license: apache-2.0
---
|
IntMeGroup/FineVQ_QA_which | IntMeGroup | 2025-06-04T15:27:04Z | 0 | 0 | null | [
"tensorboard",
"safetensors",
"internvl_chat",
"custom_code",
"license:apache-2.0",
"region:us"
] | null | 2025-06-04T08:28:13Z | ---
license: apache-2.0
---
|
vectorzhou/vectorzhou-Qwen2-5-1-5B-Instruct-SFT-OpenHerm-ction-v0-1-OnlineIPO2-lora-0604063354-epoch-3 | vectorzhou | 2025-06-04T15:20:48Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"text-generation",
"fine-tuned",
"trl",
"extra-gradient",
"conversational",
"dataset:OpenRLHF/prompt-collection-v0.1",
"arxiv:2503.08942",
"base_model:vectorzhou/Qwen2.5-1.5B-Instruct-SFT-OpenHermes-2.5-Standard-SFT",
"base_model:finetune:vectorzhou/Qwen2.5-1.5B-Instruct-SFT-OpenHermes-2.5-Standard-SFT",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T15:20:43Z | ---
base_model: vectorzhou/Qwen2.5-1.5B-Instruct-SFT-OpenHermes-2.5-Standard-SFT
datasets: OpenRLHF/prompt-collection-v0.1
library_name: transformers
model_name: Qwen2.5-1.5B-Instruct-SFT-OpenHermes-2.5-Standard-SFT-prompt-collection-v0.1-OnlineIPO2-lora
tags:
- generated_from_trainer
- text-generation
- fine-tuned
- trl
- extra-gradient
licence: license
---
# Model Card for Qwen2.5-1.5B-Instruct-SFT-OpenHermes-2.5-Standard-SFT-prompt-collection-v0.1-OnlineIPO2-lora
This model is a fine-tuned version of [vectorzhou/Qwen2.5-1.5B-Instruct-SFT-OpenHermes-2.5-Standard-SFT](https://huggingface.co/vectorzhou/Qwen2.5-1.5B-Instruct-SFT-OpenHermes-2.5-Standard-SFT) on the [OpenRLHF/prompt-collection-v0.1](https://huggingface.co/datasets/OpenRLHF/prompt-collection-v0.1) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="vectorzhou/vectorzhou-Qwen2-5-1-5B-Instruct-SFT-OpenHerm-ction-v0-1-OnlineIPO2-lora-0604063354-epoch-3", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/zhourunlongvector/nlhf/runs/kuktsgzu)
This model was trained with Extragradient, a method introduced in [Extragradient Preference Optimization (EGPO): Beyond Last-Iterate Convergence for Nash Learning from Human Feedback](https://huggingface.co/papers/2503.08942).
### Framework versions
- TRL: 0.13.0
- Transformers: 4.48.0
- Pytorch: 2.2.1
- Datasets: 3.2.0
- Tokenizers: 0.21.0
## Citations
Cite Extragradient as:
```bibtex
@misc{zhou2025extragradientpreferenceoptimizationegpo,
title={Extragradient Preference Optimization (EGPO): Beyond Last-Iterate Convergence for Nash Learning from Human Feedback},
author={Runlong Zhou and Maryam Fazel and Simon S. Du},
year={2025},
eprint={2503.08942},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2503.08942},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
abbasb91/q-FrozenLake-v1-4x4-noSlippery | abbasb91 | 2025-06-04T15:15:26Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2025-06-04T15:15:23Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="abbasb91/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
RafatK/Whisper_Largev2-Swahili-Decodis_FT | RafatK | 2025-06-04T15:14:40Z | 15 | 0 | null | [
"safetensors",
"whisper",
"automatic-speech-recognition",
"sw",
"base_model:openai/whisper-large-v2",
"base_model:finetune:openai/whisper-large-v2",
"license:cc-by-nc-4.0",
"region:us"
] | automatic-speech-recognition | 2025-05-21T19:43:27Z | ---
license: cc-by-nc-4.0
language:
- sw
metrics:
- wer
base_model:
- openai/whisper-large-v2
pipeline_tag: automatic-speech-recognition
---
<p align="left">
<a href="https://decodis.com/">
<img
src="https://static.wixstatic.com/media/41bde8_fdfad2782d8641edb098e72f1ea10d65~mv2.png/v1/fill/w_185,h_50,al_c,q_85,usm_0.66_1.00_0.01,enc_avif,quality_auto/41bde8_fdfad2782d8641edb098e72f1ea10d65~mv2.png" style="display: inline-block; vertical-align: middle;"
alt="DECODIS_Website"
/>
</a>
</p>
# 🧩 Robust ASR Model for Real-World Swahili Speech (Domain Data Only)
<p>
<a href="https://github.com/Rafat-decodis/Robust-ASR-for-Low-Resource-Languages/tree/main" target="_blank" style="margin: 2px;">
<img
src="https://img.shields.io/badge/Decodis-Indepth Analysis-536af5?color=536af5&logo=github" style="display: inline-block; vertical-align: middle;"
alt="Main code"
/>
</a>
</p>
This ASR model is trained **exclusively on 50 hours of real-world, domain-specific Swahili audio**, including conversational and semi-spontaneous speech.
It is designed to handle **noisy environments**, diverse speaker styles, and more natural linguistic variation.
It does similarly well for clean and well-structured speech input
This model is part of a full ASR ablation study that analyzes and understands the robustness of data and in dealing with different modes and variations of data collections.
👉 View all models on [GitHub](https://github.com/Rafat-decodis/Robust-ASR-for-Low-Resource-Languages)
**We are particularly interested in validating the conclusions we’ve observed through our ablation studies**:
While benchmark datasets like FLEURS are useful for comparison, they do not fully capture the variability and challenges of real-world speech — especially for underrepresented languages like Swahili and Yoruba.
We are inviting the community to try out these models and help assess:
1. How well the models perform on natural, conversational, or noisy audio
2. Open-source datasets (like Common Voice & FLEURS) perform well on clean, benchmark speech.
3. Whether the improvements we've seen in combining diverse datasets generalize to your use case
4. Gaps between benchmark results and real-world usability
5. A combination of both yields balanced results but depends on data quality and label accuracy.
## Model
[Whisper](https://github.com/openai/whisper) is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multitasking model that can perform multilingual speech recognition, speech translation, and language identification.
---
## 🚀 How to Use
```python
from transformers import WhisperForConditionalGeneration, WhisperProcessor
from transformers import pipeline
from transformers.utils import is_flash_attn_2_available
processor = WhisperProcessor.from_pretrained("openai/whisper-large-v2")
model = WhisperForConditionalGeneration.from_pretrained("RafatK/Swahili-Whisper-Largev2-Decodis_FT", torch_dtype=torch.float16).to("cuda")
model.generation_config.input_ids = model.generation_config.forced_decoder_ids
model.generation_config.forced_decoder_ids = None
forced_decoder_ids = processor.get_decoder_prompt_ids(language="swahili", task="transcribe")
pipe = pipeline(
"automatic-speech-recognition",
model=model,
processor = "openai/whisper-large-v2",
tokenizer = "openai/whisper-large-v2",
feature_extractor = "openai/whisper-large-v2",
chunk_length_s=15,
device=device,
model_kwargs={"attn_implementation": "flash_attention_2"} if is_flash_attn_2_available() else {"attn_implementation": "sdpa"},
generate_kwargs = {
'num_beams':5,
'max_new_tokens':440,
'early_stopping':True,
'repetition_penalty': 1.8,
'language': 'swahili',
'task': 'transcribe'
}
)
text_output = pipe("audio.wav")['text']
```
---
## 📦 Training Data
- **Custom real-world dataset**
- Swahili
- Collected from real use cases (e.g. mobile recordings, community sources)
- ~50 hours
- Not publicly released (due to licensing)
📁 **Languages**: Swahili (`sw`)
---
## 🏋️♂️ Training Setup
- Architecture: `whisper-large-v2`
- Framework: Whisper and Huggingface Transformers
- Sampling rate: 16 kHz
- Preprocessing: Volume normalization, High-Grade noise addition and filtering, Prosodic Augmentation,silence trimming
- Learning Rate: 1e-5
- Optimizer: Adamw_pytorch
- Steps: 3000
---
## 📈 Evaluation
| Dataset | This Model | Whisper Large V2|
|----------------------|------------|-----------------|
| **FLEURS (benchmark)** | **34.73** | **39.40** |
| **[Decodis Test Set](https://huggingface.co/datasets/RafatK/Decodis_Test_Set) (Collected by DECODIS)** | **46.44** | **99.98** |
---
## 🎯 Intended Use
This model is best for:
- Noisy, real-world speech input
- Community-contributed or semi-structured conversation
- Language tools for low-resource environments
---
## ⚠️ Limitations
- Underperforms on clean datasets like FLEURS mainly due to size of train set
- May exhibit bias toward some accents
- Limited by the smaller training size (~50h)
---
📝 Please try the models and share your feedback, issues, or results via:
GitHub Issues: Submit an issue
Hugging Face Discussions: Join the conversation
Your feedback will help us refine our dataset and improve ASR for underrepresented languages like Swahili and Yoruba.
---
|
Furagido/test-trainer | Furagido | 2025-06-04T15:14:16Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-06-04T14:17:17Z | ---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: test-trainer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test-trainer
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cpu
- Datasets 3.6.0
- Tokenizers 0.21.1
|
YuchenLi01/generatedMoreUniqueResponseNoGTv2_Qwen2.5-1.5BInstruct_dpo_ebs32_lr1e-06_beta0.4_42 | YuchenLi01 | 2025-06-04T15:10:01Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"alignment-handbook",
"trl",
"dpo",
"generated_from_trainer",
"conversational",
"dataset:YuchenLi01/MATH_Qwen2.5-1.5BInstruct_DPO_MoreUniqueResponseNoGTv2",
"base_model:Qwen/Qwen2.5-1.5B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-1.5B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-02T01:12:21Z | ---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-1.5B-Instruct
tags:
- alignment-handbook
- trl
- dpo
- generated_from_trainer
- trl
- dpo
- generated_from_trainer
datasets:
- YuchenLi01/MATH_Qwen2.5-1.5BInstruct_DPO_MoreUniqueResponseNoGTv2
model-index:
- name: generatedMoreUniqueResponseNoGTv2_Qwen2.5-1.5BInstruct_dpo_ebs32_lr1e-06_beta0.4_42
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# generatedMoreUniqueResponseNoGTv2_Qwen2.5-1.5BInstruct_dpo_ebs32_lr1e-06_beta0.4_42
This model is a fine-tuned version of [Qwen/Qwen2.5-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct) on the YuchenLi01/MATH_Qwen2.5-1.5BInstruct_DPO_MoreUniqueResponseNoGTv2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5796
- Rewards/chosen: -2.4031
- Rewards/rejected: -4.5651
- Rewards/accuracies: 0.7259
- Rewards/margins: 2.1620
- Logps/rejected: -68.2860
- Logps/chosen: -50.5201
- Logits/rejected: -2.1994
- Logits/chosen: -2.3640
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Logits/chosen | Logits/rejected | Logps/chosen | Logps/rejected | Validation Loss | Rewards/accuracies | Rewards/chosen | Rewards/margins | Rewards/rejected |
|:-------------:|:------:|:----:|:-------------:|:---------------:|:------------:|:--------------:|:---------------:|:------------------:|:--------------:|:---------------:|:----------------:|
| 0.73 | 0.0060 | 20 | -2.2840 | -2.1666 | -44.5255 | -56.8519 | 0.6995 | 0.4933 | 0.0048 | -0.0063 | 0.0111 |
| 0.6901 | 0.0120 | 40 | -2.2842 | -2.1669 | -44.5031 | -56.8548 | 0.7003 | 0.5120 | 0.0138 | 0.0039 | 0.0099 |
| 0.7075 | 0.0180 | 60 | -2.2843 | -2.1666 | -44.5252 | -56.9059 | 0.6981 | 0.5294 | 0.0050 | 0.0155 | -0.0105 |
| 0.7391 | 0.0240 | 80 | -2.2858 | -2.1679 | -44.5320 | -56.8932 | 0.6966 | 0.4973 | 0.0022 | 0.0077 | -0.0055 |
| 0.6997 | 0.0300 | 100 | -2.2827 | -2.1646 | -44.5602 | -56.9502 | 0.6936 | 0.5414 | -0.0090 | 0.0192 | -0.0283 |
| 0.6947 | 0.0360 | 120 | -2.2828 | -2.1639 | -44.5720 | -56.9823 | 0.6887 | 0.5561 | -0.0138 | 0.0274 | -0.0411 |
| 0.6603 | 0.0420 | 140 | -2.2806 | -2.1608 | -44.6200 | -57.0791 | 0.6812 | 0.5789 | -0.0330 | 0.0468 | -0.0798 |
| 0.6614 | 0.0480 | 160 | -2.2676 | -2.1469 | -44.7167 | -57.2574 | 0.6712 | 0.6283 | -0.0717 | 0.0795 | -0.1511 |
| 0.6172 | 0.0540 | 180 | -2.2744 | -2.1516 | -44.7115 | -57.3140 | 0.6609 | 0.6243 | -0.0696 | 0.1042 | -0.1738 |
| 0.6768 | 0.0600 | 200 | -2.2685 | -2.1434 | -44.9507 | -57.6549 | 0.6521 | 0.6150 | -0.1653 | 0.1449 | -0.3102 |
| 0.6434 | 0.0660 | 220 | -2.2714 | -2.1442 | -44.8940 | -57.7109 | 0.6400 | 0.6310 | -0.1426 | 0.1900 | -0.3325 |
| 0.6278 | 0.0720 | 240 | -2.2784 | -2.1486 | -44.9654 | -57.8901 | 0.6312 | 0.6364 | -0.1711 | 0.2331 | -0.4042 |
| 0.6406 | 0.0780 | 260 | -2.2827 | -2.1504 | -44.9851 | -58.0680 | 0.6199 | 0.6524 | -0.1790 | 0.2963 | -0.4754 |
| 0.5932 | 0.0840 | 280 | -2.2845 | -2.1501 | -45.0792 | -58.2691 | 0.6100 | 0.6644 | -0.2167 | 0.3392 | -0.5558 |
| 0.5691 | 0.0900 | 300 | -2.2889 | -2.1523 | -45.0835 | -58.4435 | 0.5995 | 0.6885 | -0.2184 | 0.4072 | -0.6256 |
| 0.632 | 0.0960 | 320 | -2.2982 | -2.1602 | -45.0706 | -58.5789 | 0.5903 | 0.6979 | -0.2132 | 0.4665 | -0.6797 |
| 0.4984 | 0.1019 | 340 | -2.2795 | -2.1403 | -45.4087 | -59.1380 | 0.5824 | 0.7112 | -0.3485 | 0.5549 | -0.9034 |
| 0.4785 | 0.1079 | 360 | -2.2724 | -2.1301 | -45.7659 | -59.7558 | 0.5792 | 0.6965 | -0.4913 | 0.6592 | -1.1505 |
| 0.4918 | 0.1139 | 380 | -2.3079 | -2.1635 | -45.5944 | -59.7881 | 0.5690 | 0.7126 | -0.4227 | 0.7407 | -1.1634 |
| 0.4795 | 0.1199 | 400 | -2.3040 | -2.1581 | -45.6597 | -59.9433 | 0.5674 | 0.7112 | -0.4489 | 0.7767 | -1.2255 |
| 0.4556 | 0.1259 | 420 | -2.3335 | -2.1853 | -45.5978 | -60.0391 | 0.5630 | 0.7246 | -0.4241 | 0.8397 | -1.2638 |
| 0.5614 | 0.1319 | 440 | -2.3154 | -2.1660 | -45.9202 | -60.5862 | 0.5540 | 0.7380 | -0.5531 | 0.9296 | -1.4827 |
| 0.5586 | 0.1379 | 460 | -2.2845 | -2.1360 | -46.4138 | -61.1683 | 0.5535 | 0.7193 | -0.7505 | 0.9650 | -1.7155 |
| 0.4678 | 0.1439 | 480 | -2.2856 | -2.1359 | -46.5777 | -61.5364 | 0.5485 | 0.7246 | -0.8161 | 1.0467 | -1.8627 |
| 0.4443 | 0.1499 | 500 | -2.3041 | -2.1535 | -46.6548 | -61.7966 | 0.5465 | 0.7326 | -0.8469 | 1.1199 | -1.9668 |
| 0.581 | 0.1559 | 520 | -2.3238 | -2.1717 | -46.5970 | -61.9235 | 0.5456 | 0.7447 | -0.8238 | 1.1938 | -2.0176 |
| 0.5663 | 0.1619 | 540 | -2.3158 | -2.1632 | -46.7866 | -62.1512 | 0.5429 | 0.7447 | -0.8996 | 1.2091 | -2.1087 |
| 0.4027 | 0.1679 | 560 | -2.2722 | -2.1216 | -47.1982 | -62.6455 | 0.5407 | 0.7380 | -1.0642 | 1.2421 | -2.3064 |
| 0.4467 | 0.1739 | 580 | -2.3056 | -2.1547 | -46.8656 | -62.2133 | 0.5352 | 0.7313 | -0.9312 | 1.2023 | -2.1335 |
| 0.5236 | 0.1799 | 600 | -2.3359 | -2.1846 | -46.3751 | -61.6073 | 0.5316 | 0.7353 | -0.7350 | 1.1561 | -1.8911 |
| 0.3381 | 0.1859 | 620 | -2.3439 | -2.1896 | -46.7483 | -62.2009 | 0.5381 | 0.7393 | -0.8843 | 1.2443 | -2.1285 |
| 0.4791 | 0.1919 | 640 | -2.3372 | -2.1839 | -46.7165 | -62.2024 | 0.5352 | 0.7313 | -0.8716 | 1.2576 | -2.1291 |
| 0.6989 | 0.1979 | 660 | -2.3108 | -2.1578 | -47.0022 | -62.4652 | 0.5357 | 0.7259 | -0.9859 | 1.2484 | -2.2343 |
| 0.4338 | 0.2039 | 680 | -2.3471 | -2.1925 | -46.8417 | -62.5038 | 0.5333 | 0.7313 | -0.9216 | 1.3281 | -2.2497 |
| 0.4499 | 0.2099 | 700 | -2.3713 | -2.2142 | -46.9819 | -62.6967 | 0.5393 | 0.7259 | -0.9777 | 1.3491 | -2.3269 |
| 0.3553 | 0.2159 | 720 | -2.3600 | -2.2035 | -46.9457 | -62.6362 | 0.5400 | 0.7273 | -0.9633 | 1.3394 | -2.3027 |
| 0.3781 | 0.2219 | 740 | -2.3937 | -2.2379 | -46.8394 | -62.6171 | 0.5436 | 0.7166 | -0.9207 | 1.3743 | -2.2950 |
| 0.4113 | 0.2279 | 760 | -2.3351 | -2.1804 | -47.5026 | -63.2906 | 0.5362 | 0.7259 | -1.1860 | 1.3784 | -2.5644 |
| 0.5919 | 0.2339 | 780 | -2.2881 | -2.1339 | -48.1201 | -64.1256 | 0.5331 | 0.7233 | -1.4330 | 1.4654 | -2.8984 |
| 0.4062 | 0.2399 | 800 | -2.2835 | -2.1289 | -48.4004 | -64.5414 | 0.5359 | 0.7299 | -1.5452 | 1.5196 | -3.0648 |
| 0.402 | 0.2459 | 820 | 0.5425 | -1.4537 | -2.9836 | 0.7219 | 1.5298 | -64.3322 | -48.1467 | -2.1768 | -2.3319 |
| 0.4196 | 0.2519 | 840 | 0.5325 | -1.4218 | -2.8913 | 0.7326 | 1.4695 | -64.1016 | -48.0669 | -2.1561 | -2.3107 |
| 0.4996 | 0.2579 | 860 | 0.5375 | -1.3693 | -2.8260 | 0.7219 | 1.4567 | -63.9384 | -47.9357 | -2.1802 | -2.3355 |
| 0.4782 | 0.2639 | 880 | 0.5361 | -1.7809 | -3.2423 | 0.7340 | 1.4614 | -64.9790 | -48.9646 | -2.1078 | -2.2600 |
| 0.4474 | 0.2699 | 900 | 0.5341 | -1.9701 | -3.5463 | 0.7353 | 1.5763 | -65.7392 | -49.4376 | -2.0654 | -2.2167 |
| 0.4448 | 0.2759 | 920 | 0.5391 | -1.6563 | -3.3247 | 0.7380 | 1.6683 | -65.1850 | -48.6532 | -2.1765 | -2.3326 |
| 0.5457 | 0.2819 | 940 | 0.5395 | -1.8977 | -3.6369 | 0.7420 | 1.7392 | -65.9655 | -49.2566 | -2.1511 | -2.3052 |
| 0.4932 | 0.2879 | 960 | 0.5398 | -1.8585 | -3.5454 | 0.7273 | 1.6868 | -65.7367 | -49.1587 | -2.1405 | -2.2936 |
| 0.4699 | 0.2939 | 980 | 0.5353 | -1.7706 | -3.4101 | 0.7313 | 1.6395 | -65.3987 | -48.9389 | -2.1467 | -2.2993 |
| 0.4109 | 0.2999 | 1000 | 0.5267 | -1.5880 | -3.1869 | 0.7313 | 1.5989 | -64.8406 | -48.4824 | -2.1632 | -2.3183 |
| 0.5067 | 0.3058 | 1020 | 0.5287 | -1.6588 | -3.2880 | 0.7460 | 1.6292 | -65.0934 | -48.6594 | -2.1457 | -2.2990 |
| 0.3888 | 0.3118 | 1040 | 0.5338 | -1.8245 | -3.5016 | 0.7366 | 1.6771 | -65.6273 | -49.0736 | -2.1307 | -2.2831 |
| 0.3982 | 0.3178 | 1060 | 0.5368 | -1.9154 | -3.6970 | 0.7286 | 1.7816 | -66.1159 | -49.3009 | -2.1567 | -2.3118 |
| 0.3106 | 0.3238 | 1080 | 0.5404 | -2.0885 | -3.8850 | 0.7286 | 1.7965 | -66.5857 | -49.7337 | -2.1295 | -2.2842 |
| 0.2842 | 0.3298 | 1100 | 0.5440 | -2.1413 | -3.9725 | 0.7393 | 1.8311 | -66.8044 | -49.8657 | -2.1367 | -2.2916 |
| 0.3494 | 0.3358 | 1120 | 0.5412 | -1.9277 | -3.6556 | 0.7246 | 1.7278 | -66.0122 | -49.3317 | -2.1580 | -2.3135 |
| 0.3945 | 0.3418 | 1140 | 0.5399 | -1.9763 | -3.7762 | 0.7259 | 1.7999 | -66.3138 | -49.4531 | -2.1267 | -2.2828 |
| 0.4955 | 0.3478 | 1160 | 0.5403 | -1.9863 | -3.7766 | 0.7433 | 1.7902 | -66.3148 | -49.4782 | -2.1318 | -2.2895 |
| 0.4077 | 0.3538 | 1180 | 0.5338 | -1.9426 | -3.6992 | 0.7460 | 1.7566 | -66.1213 | -49.3688 | -2.1064 | -2.2607 |
| 0.3905 | 0.3598 | 1200 | 0.5304 | -1.8037 | -3.5632 | 0.7433 | 1.7594 | -65.7812 | -49.0217 | -2.1326 | -2.2863 |
| 0.3377 | 0.3658 | 1220 | 0.5363 | -1.8900 | -3.6889 | 0.7380 | 1.7989 | -66.0957 | -49.2374 | -2.1442 | -2.2971 |
| 0.7295 | 0.3718 | 1240 | 0.5400 | -2.0031 | -3.8320 | 0.7326 | 1.8289 | -66.4533 | -49.5202 | -2.1355 | -2.2904 |
| 0.4121 | 0.3778 | 1260 | 0.5364 | -2.1489 | -3.9627 | 0.7326 | 1.8138 | -66.7800 | -49.8845 | -2.0910 | -2.2457 |
| 0.5229 | 0.3838 | 1280 | 0.5499 | -2.3115 | -4.1540 | 0.7353 | 1.8425 | -67.2584 | -50.2912 | -2.0893 | -2.2437 |
| 0.2398 | 0.3898 | 1300 | 0.5511 | -2.0555 | -3.9019 | 0.7166 | 1.8464 | -66.6280 | -49.6512 | -2.1689 | -2.3252 |
| 0.3229 | 0.3958 | 1320 | 0.5551 | -2.2235 | -4.1544 | 0.7206 | 1.9309 | -67.2594 | -50.0712 | -2.1641 | -2.3209 |
| 0.2727 | 0.4018 | 1340 | 0.5572 | -2.1956 | -4.1986 | 0.7206 | 2.0031 | -67.3699 | -50.0013 | -2.1849 | -2.3431 |
| 0.302 | 0.4078 | 1360 | 0.5551 | -2.3439 | -4.3123 | 0.7126 | 1.9684 | -67.6541 | -50.3721 | -2.1351 | -2.2933 |
| 0.4957 | 0.4138 | 1380 | 0.5526 | -2.2890 | -4.2712 | 0.7313 | 1.9822 | -67.5514 | -50.2349 | -2.1510 | -2.3100 |
| 0.2406 | 0.4198 | 1400 | 0.5539 | -2.4001 | -4.3914 | 0.7340 | 1.9913 | -67.8518 | -50.5127 | -2.1305 | -2.2879 |
| 0.5632 | 0.4258 | 1420 | 0.5470 | -2.3739 | -4.3738 | 0.7406 | 1.9998 | -67.8077 | -50.4472 | -2.1245 | -2.2824 |
| 0.5002 | 0.4318 | 1440 | 0.5428 | -2.1356 | -4.1302 | 0.7313 | 1.9946 | -67.1989 | -49.8514 | -2.1741 | -2.3345 |
| 0.4629 | 0.4378 | 1460 | 0.5534 | -2.3573 | -4.3582 | 0.7246 | 2.0009 | -67.7688 | -50.4055 | -2.1541 | -2.3134 |
| 0.4672 | 0.4438 | 1480 | 0.5538 | -2.4371 | -4.4549 | 0.7246 | 2.0178 | -68.0106 | -50.6052 | -2.1433 | -2.3020 |
| 0.4207 | 0.4498 | 1500 | 0.5538 | -2.2938 | -4.2942 | 0.7273 | 2.0004 | -67.6089 | -50.2469 | -2.1491 | -2.3077 |
| 0.4197 | 0.4558 | 1520 | 0.5567 | -2.0589 | -4.0578 | 0.7286 | 1.9990 | -67.0179 | -49.6596 | -2.1905 | -2.3514 |
| 0.2704 | 0.4618 | 1540 | 0.5672 | -2.1422 | -4.2660 | 0.7259 | 2.1238 | -67.5383 | -49.8678 | -2.2180 | -2.3816 |
| 0.4166 | 0.4678 | 1560 | 0.5728 | -2.1945 | -4.2757 | 0.7246 | 2.0812 | -67.5626 | -49.9987 | -2.2067 | -2.3695 |
| 0.4362 | 0.4738 | 1580 | 0.5635 | -1.9547 | -4.0054 | 0.7366 | 2.0506 | -66.8867 | -49.3992 | -2.2373 | -2.4015 |
| 0.4167 | 0.4798 | 1600 | 0.5654 | -2.0804 | -4.0920 | 0.7313 | 2.0116 | -67.1033 | -49.7134 | -2.2181 | -2.3810 |
| 0.2316 | 0.4858 | 1620 | 0.5662 | -2.2136 | -4.2342 | 0.7313 | 2.0206 | -67.4589 | -50.0464 | -2.1831 | -2.3451 |
| 0.4188 | 0.4918 | 1640 | 0.5704 | -2.3708 | -4.4024 | 0.7313 | 2.0316 | -67.8794 | -50.4394 | -2.1658 | -2.3257 |
| 0.4348 | 0.4978 | 1660 | 0.5822 | -2.3493 | -4.3898 | 0.7326 | 2.0406 | -67.8479 | -50.3855 | -2.1985 | -2.3583 |
| 0.3002 | 0.5037 | 1680 | 0.5765 | -2.3441 | -4.3592 | 0.7313 | 2.0151 | -67.7712 | -50.3726 | -2.1771 | -2.3380 |
| 0.3789 | 0.5097 | 1700 | 0.5690 | -2.5372 | -4.5090 | 0.7259 | 1.9718 | -68.1458 | -50.8554 | -2.1230 | -2.2824 |
| 0.2039 | 0.5157 | 1720 | 0.5634 | -2.3945 | -4.3457 | 0.7219 | 1.9512 | -67.7375 | -50.4986 | -2.1400 | -2.3002 |
| 0.2798 | 0.5217 | 1740 | 0.5700 | -2.3848 | -4.3055 | 0.7233 | 1.9207 | -67.6372 | -50.4744 | -2.1556 | -2.3162 |
| 0.5354 | 0.5277 | 1760 | 0.5749 | -2.2577 | -4.1709 | 0.7233 | 1.9131 | -67.3005 | -50.1567 | -2.1842 | -2.3437 |
| 0.2853 | 0.5337 | 1780 | 0.5726 | -2.2228 | -4.0961 | 0.7126 | 1.8733 | -67.1136 | -50.0695 | -2.1802 | -2.3398 |
| 0.4659 | 0.5397 | 1800 | 0.5801 | -2.3238 | -4.3205 | 0.7166 | 1.9967 | -67.6745 | -50.3218 | -2.1899 | -2.3521 |
| 0.3181 | 0.5457 | 1820 | 0.5868 | -2.3172 | -4.3619 | 0.7139 | 2.0447 | -67.7779 | -50.3053 | -2.2033 | -2.3668 |
| 0.2995 | 0.5517 | 1840 | 0.5960 | -2.3013 | -4.3722 | 0.7112 | 2.0709 | -67.8039 | -50.2656 | -2.2338 | -2.3981 |
| 0.2868 | 0.5577 | 1860 | 0.5885 | -2.2752 | -4.3480 | 0.7273 | 2.0728 | -67.7434 | -50.2004 | -2.2372 | -2.4012 |
| 0.4067 | 0.5637 | 1880 | 0.5886 | -2.4603 | -4.5539 | 0.7353 | 2.0936 | -68.2581 | -50.6632 | -2.2037 | -2.3668 |
| 0.3498 | 0.5697 | 1900 | 0.5938 | -2.5665 | -4.6559 | 0.7353 | 2.0894 | -68.5130 | -50.9286 | -2.1927 | -2.3554 |
| 0.4811 | 0.5757 | 1920 | 0.5909 | -2.4908 | -4.5922 | 0.7299 | 2.1014 | -68.3537 | -50.7393 | -2.2007 | -2.3638 |
| 0.4587 | 0.5817 | 1940 | 0.5777 | -2.4542 | -4.5137 | 0.7353 | 2.0595 | -68.1575 | -50.6478 | -2.1851 | -2.3468 |
| 0.4067 | 0.5877 | 1960 | 0.5717 | -2.3636 | -4.4128 | 0.7259 | 2.0492 | -67.9054 | -50.4213 | -2.2004 | -2.3618 |
| 0.4554 | 0.5937 | 1980 | 0.5801 | -2.3060 | -4.3300 | 0.7233 | 2.0240 | -67.6984 | -50.2774 | -2.2125 | -2.3744 |
| 0.2715 | 0.5997 | 2000 | 0.5715 | -2.1497 | -4.1001 | 0.7353 | 1.9504 | -67.1237 | -49.8867 | -2.2217 | -2.3834 |
| 0.2609 | 0.6057 | 2020 | 0.5718 | -2.1471 | -4.0842 | 0.7353 | 1.9371 | -67.0837 | -49.8801 | -2.2209 | -2.3818 |
| 0.4077 | 0.6117 | 2040 | 0.5799 | -2.1552 | -4.1169 | 0.7219 | 1.9618 | -67.1656 | -49.9003 | -2.2297 | -2.3910 |
| 0.4469 | 0.6177 | 2060 | 0.5849 | -2.3088 | -4.3069 | 0.7206 | 1.9981 | -67.6406 | -50.2844 | -2.2063 | -2.3674 |
| 0.2778 | 0.6237 | 2080 | 0.5918 | -2.4319 | -4.4343 | 0.7193 | 2.0024 | -67.9590 | -50.5921 | -2.1896 | -2.3504 |
| 0.372 | 0.6297 | 2100 | 0.5929 | -2.3451 | -4.3485 | 0.7193 | 2.0034 | -67.7445 | -50.3751 | -2.2062 | -2.3680 |
| 0.422 | 0.6357 | 2120 | 0.5910 | -2.3439 | -4.3031 | 0.7139 | 1.9592 | -67.6311 | -50.3722 | -2.2004 | -2.3618 |
| 0.3289 | 0.6417 | 2140 | 0.5902 | -2.4222 | -4.3934 | 0.7206 | 1.9711 | -67.8568 | -50.5680 | -2.1866 | -2.3477 |
| 0.1748 | 0.6477 | 2160 | 0.5948 | -2.4349 | -4.4266 | 0.7139 | 1.9917 | -67.9398 | -50.5997 | -2.1947 | -2.3564 |
| 0.1898 | 0.6537 | 2180 | 0.5905 | -2.4372 | -4.4682 | 0.7233 | 2.0310 | -68.0439 | -50.6054 | -2.1951 | -2.3574 |
| 0.5178 | 0.6597 | 2200 | 0.5858 | -2.4300 | -4.4922 | 0.7193 | 2.0622 | -68.1039 | -50.5875 | -2.1955 | -2.3577 |
| 0.3765 | 0.6657 | 2220 | 0.5812 | -2.3328 | -4.3769 | 0.7233 | 2.0442 | -67.8157 | -50.3444 | -2.2030 | -2.3650 |
| 0.3267 | 0.6717 | 2240 | 0.5845 | -2.3069 | -4.3729 | 0.7206 | 2.0660 | -67.8056 | -50.2797 | -2.2201 | -2.3831 |
| 0.45 | 0.6777 | 2260 | 0.5832 | -2.3386 | -4.4083 | 0.7259 | 2.0697 | -67.8940 | -50.3588 | -2.2113 | -2.3739 |
| 0.1942 | 0.6837 | 2280 | 0.5841 | -2.3967 | -4.4887 | 0.7219 | 2.0919 | -68.0950 | -50.5043 | -2.2112 | -2.3739 |
| 0.2168 | 0.6897 | 2300 | 0.5862 | -2.4025 | -4.5129 | 0.7126 | 2.1104 | -68.1556 | -50.5187 | -2.2138 | -2.3776 |
| 0.2433 | 0.6957 | 2320 | 0.5842 | -2.4185 | -4.5170 | 0.7193 | 2.0985 | -68.1658 | -50.5587 | -2.1972 | -2.3602 |
| 0.6285 | 0.7016 | 2340 | 0.5835 | -2.3343 | -4.4543 | 0.7099 | 2.1200 | -68.0092 | -50.3482 | -2.2223 | -2.3854 |
| 0.3142 | 0.7076 | 2360 | 0.5830 | -2.3351 | -4.4725 | 0.7219 | 2.1374 | -68.0546 | -50.3502 | -2.2216 | -2.3850 |
| 0.2793 | 0.7136 | 2380 | 0.5810 | -2.2839 | -4.4001 | 0.7193 | 2.1162 | -67.8736 | -50.2222 | -2.2298 | -2.3934 |
| 0.4477 | 0.7196 | 2400 | 0.5811 | -2.3245 | -4.4509 | 0.7233 | 2.1264 | -68.0005 | -50.3235 | -2.2198 | -2.3831 |
| 0.6407 | 0.7256 | 2420 | 0.5835 | -2.4206 | -4.5564 | 0.7219 | 2.1358 | -68.2643 | -50.5640 | -2.2129 | -2.3757 |
| 0.6725 | 0.7316 | 2440 | 0.5829 | -2.3928 | -4.5300 | 0.7219 | 2.1372 | -68.1984 | -50.4945 | -2.2144 | -2.3779 |
| 0.1539 | 0.7376 | 2460 | 0.5824 | -2.3620 | -4.4853 | 0.7086 | 2.1233 | -68.0866 | -50.4174 | -2.2106 | -2.3743 |
| 0.5217 | 0.7436 | 2480 | 0.5806 | -2.3462 | -4.4794 | 0.7152 | 2.1332 | -68.0717 | -50.3778 | -2.2045 | -2.3682 |
| 0.5927 | 0.7496 | 2500 | 0.5792 | -2.3323 | -4.4373 | 0.7206 | 2.1050 | -67.9665 | -50.3432 | -2.2054 | -2.3687 |
| 0.2391 | 0.7556 | 2520 | 0.5779 | -2.3913 | -4.4956 | 0.7139 | 2.1043 | -68.1123 | -50.4905 | -2.1976 | -2.3612 |
| 0.3963 | 0.7616 | 2540 | 0.5780 | -2.3785 | -4.4885 | 0.7139 | 2.1100 | -68.0947 | -50.4587 | -2.1989 | -2.3626 |
| 0.3865 | 0.7676 | 2560 | 0.5771 | -2.3431 | -4.4701 | 0.7233 | 2.1269 | -68.0485 | -50.3702 | -2.1976 | -2.3612 |
| 0.3115 | 0.7736 | 2580 | 0.5771 | -2.3741 | -4.4909 | 0.7166 | 2.1168 | -68.1005 | -50.4475 | -2.1920 | -2.3557 |
| 0.1457 | 0.7796 | 2600 | 0.5763 | -2.3594 | -4.4667 | 0.7166 | 2.1073 | -68.0401 | -50.4109 | -2.1976 | -2.3614 |
| 0.4248 | 0.7856 | 2620 | 0.5761 | -2.3756 | -4.4871 | 0.7099 | 2.1115 | -68.0910 | -50.4513 | -2.1979 | -2.3620 |
| 0.2367 | 0.7916 | 2640 | 0.5792 | -2.3799 | -4.5087 | 0.7206 | 2.1288 | -68.1450 | -50.4620 | -2.2027 | -2.3667 |
| 0.2425 | 0.7976 | 2660 | 0.5778 | -2.3999 | -4.5289 | 0.7233 | 2.1290 | -68.1955 | -50.5122 | -2.2006 | -2.3649 |
| 0.2228 | 0.8036 | 2680 | 0.5791 | -2.4102 | -4.5374 | 0.7193 | 2.1272 | -68.2169 | -50.5379 | -2.1994 | -2.3633 |
| 0.3514 | 0.8096 | 2700 | 0.5757 | -2.3855 | -4.5265 | 0.7246 | 2.1410 | -68.1895 | -50.4760 | -2.1996 | -2.3628 |
| 0.2107 | 0.8156 | 2720 | 0.5787 | -2.3971 | -4.5519 | 0.7166 | 2.1548 | -68.2531 | -50.5052 | -2.2035 | -2.3671 |
| 0.2919 | 0.8216 | 2740 | 0.5821 | -2.4521 | -4.6157 | 0.7259 | 2.1636 | -68.4126 | -50.6426 | -2.2049 | -2.3685 |
| 0.1872 | 0.8276 | 2760 | 0.5830 | -2.4473 | -4.6201 | 0.7206 | 2.1728 | -68.4235 | -50.6306 | -2.1994 | -2.3626 |
| 0.6285 | 0.8336 | 2780 | 0.5796 | -2.4423 | -4.6060 | 0.7259 | 2.1637 | -68.3884 | -50.6182 | -2.2029 | -2.3668 |
| 0.4219 | 0.8396 | 2800 | 0.5805 | -2.4320 | -4.5906 | 0.7259 | 2.1586 | -68.3497 | -50.5923 | -2.1985 | -2.3620 |
| 0.2696 | 0.8456 | 2820 | 0.5803 | -2.4421 | -4.5977 | 0.7273 | 2.1557 | -68.3676 | -50.6175 | -2.1955 | -2.3590 |
| 0.2871 | 0.8516 | 2840 | 0.5802 | -2.4455 | -4.5991 | 0.7152 | 2.1536 | -68.3710 | -50.6261 | -2.2014 | -2.3651 |
| 0.4357 | 0.8576 | 2860 | 0.5799 | -2.4497 | -4.6074 | 0.7219 | 2.1577 | -68.3918 | -50.6366 | -2.2018 | -2.3657 |
| 0.3964 | 0.8636 | 2880 | 0.5788 | -2.4219 | -4.5952 | 0.7273 | 2.1732 | -68.3613 | -50.5672 | -2.2017 | -2.3658 |
| 0.2754 | 0.8696 | 2900 | 0.5779 | -2.4233 | -4.5869 | 0.7233 | 2.1636 | -68.3405 | -50.5706 | -2.1984 | -2.3626 |
| 0.2423 | 0.8756 | 2920 | 0.5776 | -2.4189 | -4.5939 | 0.7326 | 2.1750 | -68.3581 | -50.5597 | -2.2030 | -2.3674 |
| 0.2489 | 0.8816 | 2940 | 0.5801 | -2.4346 | -4.6080 | 0.7152 | 2.1734 | -68.3933 | -50.5989 | -2.2014 | -2.3658 |
| 0.2686 | 0.8876 | 2960 | 0.5837 | -2.4470 | -4.6246 | 0.7219 | 2.1776 | -68.4349 | -50.6298 | -2.2037 | -2.3685 |
| 0.3056 | 0.8936 | 2980 | 0.5801 | -2.4300 | -4.6104 | 0.7219 | 2.1804 | -68.3993 | -50.5873 | -2.2055 | -2.3700 |
| 0.3823 | 0.8996 | 3000 | 0.5832 | -2.4193 | -4.5819 | 0.7219 | 2.1626 | -68.3280 | -50.5606 | -2.2080 | -2.3728 |
| 0.4871 | 0.9055 | 3020 | 0.5810 | -2.4152 | -4.5746 | 0.7193 | 2.1593 | -68.3097 | -50.5504 | -2.2041 | -2.3687 |
| 0.2968 | 0.9115 | 3040 | 0.5803 | -2.4074 | -4.5805 | 0.7273 | 2.1731 | -68.3245 | -50.5308 | -2.2070 | -2.3717 |
| 0.3973 | 0.9175 | 3060 | 0.5816 | -2.3949 | -4.5655 | 0.7233 | 2.1706 | -68.2870 | -50.4997 | -2.2066 | -2.3713 |
| 0.2556 | 0.9235 | 3080 | 0.5794 | -2.3923 | -4.5685 | 0.7206 | 2.1761 | -68.2945 | -50.4932 | -2.2024 | -2.3669 |
| 0.3109 | 0.9295 | 3100 | 0.5789 | -2.4031 | -4.5590 | 0.7219 | 2.1559 | -68.2708 | -50.5201 | -2.2030 | -2.3676 |
| 0.2311 | 0.9355 | 3120 | 0.5767 | -2.3930 | -4.5679 | 0.7206 | 2.1749 | -68.2930 | -50.4949 | -2.2025 | -2.3673 |
| 0.2843 | 0.9415 | 3140 | 0.5809 | -2.4034 | -4.5747 | 0.7179 | 2.1714 | -68.3102 | -50.5208 | -2.1989 | -2.3632 |
| 0.2231 | 0.9475 | 3160 | 0.5802 | -2.4029 | -4.5586 | 0.7179 | 2.1557 | -68.2699 | -50.5196 | -2.2057 | -2.3706 |
| 0.3034 | 0.9535 | 3180 | 0.5797 | -2.4012 | -4.5643 | 0.7219 | 2.1631 | -68.2840 | -50.5154 | -2.2038 | -2.3686 |
| 0.325 | 0.9595 | 3200 | 0.5793 | -2.4034 | -4.5657 | 0.7193 | 2.1623 | -68.2876 | -50.5208 | -2.2011 | -2.3656 |
| 0.1966 | 0.9655 | 3220 | 0.5807 | -2.4164 | -4.5797 | 0.7112 | 2.1633 | -68.3227 | -50.5535 | -2.2024 | -2.3669 |
| 0.2471 | 0.9715 | 3240 | 0.5760 | -2.3994 | -4.5701 | 0.7206 | 2.1707 | -68.2985 | -50.5108 | -2.1998 | -2.3643 |
| 0.3629 | 0.9775 | 3260 | 0.5796 | -2.4081 | -4.5658 | 0.7273 | 2.1576 | -68.2877 | -50.5327 | -2.2013 | -2.3659 |
| 0.2003 | 0.9835 | 3280 | 0.5789 | -2.4072 | -4.5666 | 0.7219 | 2.1594 | -68.2899 | -50.5304 | -2.2001 | -2.3647 |
| 0.3775 | 0.9895 | 3300 | 0.5808 | -2.4042 | -4.5693 | 0.7139 | 2.1651 | -68.2966 | -50.5228 | -2.1977 | -2.3621 |
| 0.4797 | 0.9955 | 3320 | 0.5773 | -2.3883 | -4.5725 | 0.7193 | 2.1843 | -68.3047 | -50.4831 | -2.1992 | -2.3638 |
### Framework versions
- Transformers 4.45.2
- Pytorch 2.5.1+cu121
- Datasets 3.5.0
- Tokenizers 0.20.3
|
developermate/gemma3-phishing-url-detector | developermate | 2025-06-04T15:09:21Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"text-generation-inference",
"unsloth",
"gemma3_text",
"en",
"base_model:unsloth/gemma-3-1b-it",
"base_model:quantized:unsloth/gemma-3-1b-it",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-04T12:32:34Z | ---
base_model: unsloth/gemma-3-1b-it
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** developermate
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-1b-it
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
George067/dqn-SpaceInvadersNoFrameskip-v4 | George067 | 2025-06-04T15:07:44Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2025-06-04T15:07:14Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 447.00 +/- 57.15
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
SBX (SB3 + Jax): https://github.com/araffin/sbx
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga George067 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga George067 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga George067
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 1e-05),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
LeonGuertler/Qwen3-4B-batch-4-experiment-0-step_000225 | LeonGuertler | 2025-06-04T15:04:39Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T14:56:40Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
LeonGuertler/Qwen3-4B-batch-4-experiment-8-step_000200 | LeonGuertler | 2025-06-04T15:04:33Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-04T14:56:38Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
natix-miner36/streetvision | natix-miner36 | 2025-06-04T15:03:44Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2025-06-04T14:59:50Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
jinx2321/korean-tagged-1e4-paper-reset | jinx2321 | 2025-06-04T15:02:06Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:everdoubling/byt5-Korean-small",
"base_model:finetune:everdoubling/byt5-Korean-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2025-06-04T10:31:12Z | ---
library_name: transformers
license: apache-2.0
base_model: everdoubling/byt5-Korean-small
tags:
- generated_from_trainer
model-index:
- name: korean-tagged-1e4-paper-reset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# korean-tagged-1e4-paper-reset
This model is a fine-tuned version of [everdoubling/byt5-Korean-small](https://huggingface.co/everdoubling/byt5-Korean-small) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 128
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.52.0.dev0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.1
|
t2taye/phi3.5-finetuned | t2taye | 2025-06-04T15:01:17Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-04T15:01:12Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Subsets and Splits