
repo
stringclasses 856
values | pull_number
int64 3
127k
| instance_id
stringlengths 12
58
| issue_numbers
listlengths 1
5
| base_commit
stringlengths 40
40
| patch
stringlengths 67
1.54M
| test_patch
stringlengths 0
107M
| problem_statement
stringlengths 3
307k
| hints_text
stringlengths 0
908k
| created_at
timestamp[s] |
|---|---|---|---|---|---|---|---|---|---|
wger-project/wger
| 1,143 |
wger-project__wger-1143
|
[
"1096"
] |
f38a27c6f4b5928a5e2e67fc2d57688903a8243a
|
diff --git a/extras/docker/development/settings.py b/extras/docker/development/settings.py
--- a/extras/docker/development/settings.py
+++ b/extras/docker/development/settings.py
@@ -116,9 +116,16 @@
# The site's domain as used by the email verification workflow
EMAIL_PAGE_DOMAIN = 'http://localhost/'
+
+# Django Axes
+AXES_ENABLED = True # allow to disable axes entirely (e.g. if this is run in a local network or so we would save up some resources), but default is true
+AXES_FAILURE_LIMIT = 5 # configurable, default is 5
+AXES_COOLOFF_TIME = 0.5 # configurable, default is 0.5 hours
+AXES_HANDLER = 'axes.handlers.cache.AxesCacheHandler' # Configurable, but default is the cache handler
+
#
# Django Rest Framework SimpleJWT
#
SIMPLE_JWT['ACCESS_TOKEN_LIFETIME'] = timedelta(minutes=env.int("ACCESS_TOKEN_LIFETIME", 15))
SIMPLE_JWT['REFRESH_TOKEN_LIFETIME'] = timedelta(hours=env.int("REFRESH_TOKEN_LIFETIME", 24))
-SIMPLE_JWT['SIGNING_KEY'] = env.str("SIGNING_KEY", SECRET_KEY)
+SIMPLE_JWT['SIGNING_KEY'] = env.str("SIGNING_KEY", SECRET_KEY)
\ No newline at end of file
diff --git a/wger/core/views/user.py b/wger/core/views/user.py
--- a/wger/core/views/user.py
+++ b/wger/core/views/user.py
@@ -282,7 +282,7 @@ def registration(request):
config.save()
user.userprofile.save()
- user = authenticate(username=username, password=password)
+ user = authenticate(request=request, username=username, password=password)
# Log the user in
django_login(request, user)
diff --git a/wger/settings_global.py b/wger/settings_global.py
--- a/wger/settings_global.py
+++ b/wger/settings_global.py
@@ -91,6 +91,9 @@
# CORS
'corsheaders',
+ # Django Axes
+ 'axes',
+
# History keeping
'simple_history',
@@ -127,10 +130,15 @@
# History keeping
'simple_history.middleware.HistoryRequestMiddleware',
+
+ # Django Axes
+ 'axes.middleware.AxesMiddleware', # should be the last one in the list
)
AUTHENTICATION_BACKENDS = (
- 'django.contrib.auth.backends.ModelBackend', 'wger.utils.helpers.EmailAuthBackend'
+ 'axes.backends.AxesStandaloneBackend', # should be the first one in the list
+ 'django.contrib.auth.backends.ModelBackend',
+ 'wger.utils.helpers.EmailAuthBackend',
)
TEMPLATES = [
@@ -158,7 +166,7 @@
'django.template.loaders.app_directories.Loader',
],
'debug':
- False
+ False
},
},
]
@@ -274,6 +282,25 @@
}
}
+
+#
+# Django Axes
+#
+AXES_ENABLED = True
+AXES_FAILURE_LIMIT = 5
+AXES_COOLOFF_TIME = 0.5 # in hours
+AXES_LOCKOUT_TEMPLATE = None
+AXES_RESET_ON_SUCCESS = False
+AXES_RESET_COOL_OFF_ON_FAILURE_DURING_LOCKOUT = True
+
+# If you want to set up redis, set AXES_HANDLER = 'axes.handlers.cache.AxesCacheHandler'
+AXES_HANDLER = 'axes.handlers.database.AxesDatabaseHandler'
+
+# If your redis or MemcachedCache has a different name other than 'default'
+# (e.g. when you have multiple caches defined in CACHES), change the following value to that name
+AXES_CACHE = 'default'
+
+
#
# Django Crispy Templates
#
@@ -381,15 +408,15 @@
# Django Rest Framework
#
REST_FRAMEWORK = {
- 'DEFAULT_PERMISSION_CLASSES': ('wger.utils.permissions.WgerPermission', ),
+ 'DEFAULT_PERMISSION_CLASSES': ('wger.utils.permissions.WgerPermission',),
'DEFAULT_PAGINATION_CLASS':
- 'rest_framework.pagination.LimitOffsetPagination',
+ 'rest_framework.pagination.LimitOffsetPagination',
'PAGE_SIZE':
- 20,
+ 20,
'PAGINATE_BY_PARAM':
- 'limit', # Allow client to override, using `?limit=xxx`.
+ 'limit', # Allow client to override, using `?limit=xxx`.
'TEST_REQUEST_DEFAULT_FORMAT':
- 'json',
+ 'json',
'DEFAULT_AUTHENTICATION_CLASSES': (
'rest_framework.authentication.SessionAuthentication',
'rest_framework.authentication.TokenAuthentication',
@@ -425,7 +452,7 @@
#
# Ignore these URLs if they cause 404
#
-IGNORABLE_404_URLS = (re.compile(r'^/favicon\.ico$'), )
+IGNORABLE_404_URLS = (re.compile(r'^/favicon\.ico$'),)
#
# Password rules
|
diff --git a/wger/core/tests/base_testcase.py b/wger/core/tests/base_testcase.py
--- a/wger/core/tests/base_testcase.py
+++ b/wger/core/tests/base_testcase.py
@@ -152,6 +152,10 @@ def setUp(self):
self.media_root = tempfile.mkdtemp()
settings.MEDIA_ROOT = self.media_root
+ # Disable django-axes
+ # https://django-axes.readthedocs.io/en/latest/3_usage.html#authenticating-users
+ settings.AXES_ENABLED = False
+
def tearDown(self):
"""
Reset settings
|
No protection against bruteforce attacks on login page
At the moment there is no protection against brute force attacks on the login page, while not a priority it would be nice if we could do something about it.
* https://github.com/jazzband/django-defender
* https://github.com/jazzband/django-axes
|
@rolandgeider , If this issue is still relevant, I would like to work on this.
Go ahead 👍🏻
Is redis used in production server ? Because then we can use the cache for monitoring login attempts which can provide better performance
Yes there's a redis server, also on the provided docker compose, we can just use it
| 2022-10-10T20:08:38 |
wger-project/wger
| 1,188 |
wger-project__wger-1188
|
[
"1187"
] |
d59957c5691c62f3218b0c3e1544ca6ddfca25cd
|
diff --git a/extras/docker/development/settings.py b/extras/docker/development/settings.py
--- a/extras/docker/development/settings.py
+++ b/extras/docker/development/settings.py
@@ -94,6 +94,7 @@
WGER_SETTINGS["ALLOW_REGISTRATION"] = env.bool("ALLOW_REGISTRATION", True)
WGER_SETTINGS["ALLOW_GUEST_USERS"] = env.bool("ALLOW_GUEST_USERS", True)
WGER_SETTINGS["ALLOW_UPLOAD_VIDEOS"] = env.bool("ALLOW_UPLOAD_VIDEOS", True)
+WGER_SETTINGS["MIN_ACCOUNT_AGE_TO_TRUST"] = env.int("MIN_ACCOUNT_AGE_TO_TRUST", 21) # in days
WGER_SETTINGS["EXERCISE_CACHE_TTL"] = env.int("EXERCISE_CACHE_TTL", 3600)
diff --git a/wger/core/models/profile.py b/wger/core/models/profile.py
--- a/wger/core/models/profile.py
+++ b/wger/core/models/profile.py
@@ -19,6 +19,7 @@
import decimal
# Django
+from django.conf import settings
from django.contrib.auth.models import User
from django.core.exceptions import ValidationError
from django.core.validators import (
@@ -201,7 +202,7 @@ def is_trustworthy(self) -> bool:
return False
days_since_joined = datetime.date.today() - self.user.date_joined.date()
- minimum_account_age = 21
+ minimum_account_age = settings.WGER_SETTINGS['MIN_ACCOUNT_AGE_TO_TRUST']
return days_since_joined.days > minimum_account_age and self.email_verified
diff --git a/wger/settings_global.py b/wger/settings_global.py
--- a/wger/settings_global.py
+++ b/wger/settings_global.py
@@ -483,6 +483,7 @@
'ALLOW_GUEST_USERS': True,
'ALLOW_REGISTRATION': True,
'ALLOW_UPLOAD_VIDEOS': False,
+ 'MIN_ACCOUNT_AGE_TO_TRUST': 21,
'EMAIL_FROM': 'wger Workout Manager <[email protected]>',
'EXERCISE_CACHE_TTL': 3600,
'TWITTER': False,
|
diff --git a/wger/core/tests/test_registration.py b/wger/core/tests/test_registration.py
--- a/wger/core/tests/test_registration.py
+++ b/wger/core/tests/test_registration.py
@@ -46,6 +46,7 @@ def test_registration_captcha(self):
'ALLOW_REGISTRATION': True,
'ALLOW_GUEST_USERS': True,
'TWITTER': False,
+ 'MIN_ACCOUNT_AGE_TO_TRUST': 21,
}
):
response = self.client.get(reverse('core:user:registration'))
@@ -57,6 +58,7 @@ def test_registration_captcha(self):
'ALLOW_REGISTRATION': True,
'ALLOW_GUEST_USERS': True,
'TWITTER': False,
+ 'MIN_ACCOUNT_AGE_TO_TRUST': 21,
}
):
response = self.client.get(reverse('core:user:registration'))
@@ -116,6 +118,7 @@ def test_registration_deactivated(self):
'USE_RECAPTCHA': False,
'ALLOW_GUEST_USERS': True,
'ALLOW_REGISTRATION': False,
+ 'MIN_ACCOUNT_AGE_TO_TRUST': 21,
}
):
diff --git a/wger/core/tests/test_temporary_users.py b/wger/core/tests/test_temporary_users.py
--- a/wger/core/tests/test_temporary_users.py
+++ b/wger/core/tests/test_temporary_users.py
@@ -64,6 +64,7 @@ def test_demo_data_no_guest_account(self):
'ALLOW_REGISTRATION': True,
'ALLOW_GUEST_USERS': False,
'TWITTER': False,
+ 'MIN_ACCOUNT_AGE_TO_TRUST': 21,
}
):
self.assertEqual(self.count_temp_users(), 1)
|
Remove or edit minimum account age for trustworthy
## Use case
There is a hardcoded [21 days minimum account age limit ](https://github.com/wger-project/wger/blob/da3a478c2caf5e8204d1f3322f08c8cbdc94be18/wger/core/models/profile.py#L204) That I think there should be a way to modify it using configs. Actually it doesn't make sense to prevent users from contributing in exercises in a private instance where all users are trusted.
## Proposal
There should be some config to modify it dynamically.
| 2022-11-19T12:31:41 |
|
wger-project/wger
| 1,531 |
wger-project__wger-1531
|
[
"74"
] |
efa1d7a31cb81163fd89730e6b48232beb361691
|
diff --git a/extras/docker/development/settings.py b/extras/docker/development/settings.py
--- a/extras/docker/development/settings.py
+++ b/extras/docker/development/settings.py
@@ -123,7 +123,7 @@
# Django Axes
#
AXES_ENABLED = env.bool('AXES_ENABLED', True)
-AXES_LOCKOUT_PARAMETERS = env.list('AXES_LOCKOUT_PARAMETERS', default=['ip-address'])
+AXES_LOCKOUT_PARAMETERS = env.list('AXES_LOCKOUT_PARAMETERS', default=['ip_address'])
AXES_FAILURE_LIMIT = env.int('AXES_FAILURE_LIMIT', 10)
AXES_COOLOFF_TIME = timedelta(minutes=env.float('AXES_COOLOFF_TIME', 30))
AXES_HANDLER = env.str('AXES_HANDLER', 'axes.handlers.cache.AxesCacheHandler')
|
Replace jqueryUI's datepicker with one for bootstrap
Replace jqueryUI's datepicker with one for bootstrap
|
TODO: format the date e.g. in WeightAddView.get_initial, otherwise the YYYY-MM-DD format confuses the plugin
| 2023-12-17T07:31:46 |
|
mikhailprivalov/l2
| 2,105 |
mikhailprivalov__l2-2105
|
[
"2073"
] |
93913b350d58b99d55340376c6059ac5e46edf76
|
diff --git a/results/urls.py b/results/urls.py
--- a/results/urls.py
+++ b/results/urls.py
@@ -8,7 +8,7 @@
path('enter', views.enter),
path('get', views.result_get),
path('pdf', views.result_print),
- path('preview', TemplateView.as_view(template_name='dashboard/results_preview.html')),
+ path('preview', views.results_preview),
path('results', views.results),
path('journal', views.result_journal_print),
path('journal_table', views.result_journal_table_print),
diff --git a/results/views.py b/results/views.py
--- a/results/views.py
+++ b/results/views.py
@@ -96,6 +96,11 @@ def save(form, filename: str):
f.write(form.read())
+@logged_in_or_token
+def results_preview(request):
+ return redirect('/ui/results/preview?{}'.format(request.META['QUERY_STRING']))
+
+
@logged_in_or_token
def result_print(request):
"""Печать результатов"""
|
Печать результатов на Vue
| 2022-10-05T01:15:14 |
||
mikhailprivalov/l2
| 2,186 |
mikhailprivalov__l2-2186
|
[
"2185"
] |
a799838608c92c9beaef279196340abbdd713c01
|
diff --git a/api/directions/views.py b/api/directions/views.py
--- a/api/directions/views.py
+++ b/api/directions/views.py
@@ -291,12 +291,14 @@ def directions_history(request):
return JsonResponse(res)
if req_status == 6:
- # Получить записи регистратуры по РМИС
+ if not pk or pk == -1:
+ return JsonResponse(res)
+
card = Card.objects.get(pk=pk)
ecp_id = card.get_ecp_id()
if not ecp_id:
- return JsonResponse({"register": False, "message": "Пациент не найден в ЕЦП"})
+ return JsonResponse(res)
patient_time_table = get_ecp_time_table_list_patient(ecp_id)
patient_direction_time_table = get_ecp_evn_direction(ecp_id)
patient_time_table.extend(patient_direction_time_table)
diff --git a/ecp_integration/integration.py b/ecp_integration/integration.py
--- a/ecp_integration/integration.py
+++ b/ecp_integration/integration.py
@@ -60,7 +60,7 @@ def get_reserves_ecp(date, med_staff_fact_id):
sess_id=sess_id,
)
time_table = []
- for r in result.get('data'):
+ for r in result.get('data') or []:
cache_key = f"ecp-fio:{r['Person_id']}"
fio = cache.get(cache_key)
if not fio:
@@ -203,6 +203,8 @@ def search_patient_ecp_by_fio(patient):
f"PersonBirthDay_BirthDay={patient['birthday']}&PersonSnils_Snils={patient['snils']}",
sess_id=sess_id,
)
+ if not result or not result.get("data"):
+ return None
individual = result['data'][0]
return individual['Person_id']
|
Запись из окна ввода результатов
| 2022-10-23T03:29:33 |
||
tiangolo/fastapi
| 17 |
tiangolo__fastapi-17
|
[
"10"
] |
014c7df142baf0e5cade2c452edfc0c138fda398
|
diff --git a/fastapi/routing.py b/fastapi/routing.py
--- a/fastapi/routing.py
+++ b/fastapi/routing.py
@@ -18,7 +18,7 @@
from starlette.formparsers import UploadFile
from starlette.requests import Request
from starlette.responses import JSONResponse, Response
-from starlette.routing import get_name, request_response
+from starlette.routing import compile_path, get_name, request_response
from starlette.status import HTTP_422_UNPROCESSABLE_ENTITY
@@ -149,9 +149,7 @@ def __init__(
self.include_in_schema = include_in_schema
self.content_type = content_type
- self.path_regex, self.path_format, self.param_convertors = self.compile_path(
- path
- )
+ self.path_regex, self.path_format, self.param_convertors = compile_path(path)
assert inspect.isfunction(endpoint) or inspect.ismethod(
endpoint
), f"An endpoint must be a function or method"
|
starlette update breaks routing
[starlette 0.9.11](https://pypi.org/project/starlette/0.9.11/) breaks fastapi routing
I'm currently working around this by enforcing starlette==0.9.10
|
Thanks for the report! I'll check it as soon as I get to my laptop.
It should now be fixed in the latest version `0.1.18`. The change is only pinning the dependencies so FastAPI is not broken, it should work now.
The next step will be to actually update FastAPI's code to be compatible with the latest changes in Starlette.
| 2019-01-30T20:16:49 |
|
tiangolo/fastapi
| 241 |
tiangolo__fastapi-241
|
[
"238"
] |
3cf92a156ce36c3127366edac3b09c89fdb3a195
|
diff --git a/fastapi/applications.py b/fastapi/applications.py
--- a/fastapi/applications.py
+++ b/fastapi/applications.py
@@ -9,7 +9,7 @@
from starlette.exceptions import ExceptionMiddleware, HTTPException
from starlette.middleware.errors import ServerErrorMiddleware
from starlette.requests import Request
-from starlette.responses import JSONResponse, Response
+from starlette.responses import HTMLResponse, JSONResponse, Response
from starlette.routing import BaseRoute
@@ -79,29 +79,28 @@ def openapi(self) -> Dict:
def setup(self) -> None:
if self.openapi_url:
- self.add_route(
- self.openapi_url,
- lambda req: JSONResponse(self.openapi()),
- include_in_schema=False,
- )
+
+ async def openapi(req: Request) -> JSONResponse:
+ return JSONResponse(self.openapi())
+
+ self.add_route(self.openapi_url, openapi, include_in_schema=False)
+ openapi_url = self.openapi_prefix + self.openapi_url
if self.openapi_url and self.docs_url:
- self.add_route(
- self.docs_url,
- lambda r: get_swagger_ui_html(
- openapi_url=self.openapi_prefix + self.openapi_url,
- title=self.title + " - Swagger UI",
- ),
- include_in_schema=False,
- )
+
+ async def swagger_ui_html(req: Request) -> HTMLResponse:
+ return get_swagger_ui_html(
+ openapi_url=openapi_url, title=self.title + " - Swagger UI"
+ )
+
+ self.add_route(self.docs_url, swagger_ui_html, include_in_schema=False)
if self.openapi_url and self.redoc_url:
- self.add_route(
- self.redoc_url,
- lambda r: get_redoc_html(
- openapi_url=self.openapi_prefix + self.openapi_url,
- title=self.title + " - ReDoc",
- ),
- include_in_schema=False,
- )
+
+ async def redoc_html(req: Request) -> HTMLResponse:
+ return get_redoc_html(
+ openapi_url=openapi_url, title=self.title + " - ReDoc"
+ )
+
+ self.add_route(self.redoc_url, redoc_html, include_in_schema=False)
self.add_exception_handler(HTTPException, http_exception)
def add_api_route(
|
make swagger_ui_html, redoc_html and openapi.json handled by async function?
**Is your feature request related to a problem? Please describe.**
I add a loop on all my router of my app to check if the handler are all coroutine function to get better performance, but I fount that swagger_ui_html, redoc_html and openapi.json are handled by normal function.
https://github.com/tiangolo/fastapi/blob/56ab106bbbf8054af437821c6683491ca7952c3b/fastapi/applications.py#L80-L86
**Describe the solution you'd like**
I'm wondering if its possible to handle these 3 router with async function, as its only a simple `getattr` operator or concat string.
https://github.com/tiangolo/fastapi/blob/56ab106bbbf8054af437821c6683491ca7952c3b/fastapi/applications.py#L78
```python
def setup(self) -> None:
if self.openapi_url:
async def openapi_handler(req):
return JSONResponse(self.openapi())
self.add_route(
self.openapi_url,
openapi_handler,
include_in_schema=False,
)
```
**Describe alternatives you've considered**
Disable default handlers and I write async handlers by my self to replace inner handlers.
**Additional context**
In `Starlette`, if a handler is not coroutine function, it will be executed by `loop.run_in_executor` . So this could improve performance a litte bit.(In my test, about 2800 r/s to 3200r/s)
|
Nice catch @Trim21 ! I'll fix it.
If you don't mind, could I give a PR to fix it?
Of course! PRs are very welcome.
| 2019-05-20T09:39:22 |
|
tiangolo/fastapi
| 320 |
tiangolo__fastapi-320
|
[
"307"
] |
c26f1760d474f8240d2311ae16a9f17c9fbbae9b
|
diff --git a/fastapi/utils.py b/fastapi/utils.py
--- a/fastapi/utils.py
+++ b/fastapi/utils.py
@@ -28,7 +28,7 @@ def get_flat_models_from_routes(
if route.response_fields:
responses_from_routes.extend(route.response_fields.values())
flat_models = get_flat_models_from_fields(
- body_fields_from_routes + responses_from_routes
+ body_fields_from_routes + responses_from_routes, known_models=set()
)
return flat_models
|
diff --git a/tests/test_tutorial/test_query_params_str_validations/test_tutorial013.py b/tests/test_tutorial/test_query_params_str_validations/test_tutorial013.py
--- a/tests/test_tutorial/test_query_params_str_validations/test_tutorial013.py
+++ b/tests/test_tutorial/test_query_params_str_validations/test_tutorial013.py
@@ -31,7 +31,7 @@
"parameters": [
{
"required": False,
- "schema": {"title": "Q", "type": "array"},
+ "schema": {"title": "Q", "type": "array", "items": {}},
"name": "q",
"in": "query",
}
|
eta on pydantic update to 0.28
really need your latest PR
it shoud solve recurring issues with sqlalchemy to pydantic mapping
thank you !
|
Don't take it as an official response but I could be any momment this week
| 2019-06-18T00:13:14 |
tiangolo/fastapi
| 347 |
tiangolo__fastapi-347
|
[
"284"
] |
b30cca8e9e39461db35cea41967eb206dd51387d
|
diff --git a/fastapi/openapi/utils.py b/fastapi/openapi/utils.py
--- a/fastapi/openapi/utils.py
+++ b/fastapi/openapi/utils.py
@@ -8,7 +8,11 @@
from fastapi.openapi.constants import METHODS_WITH_BODY, REF_PREFIX
from fastapi.openapi.models import OpenAPI
from fastapi.params import Body, Param
-from fastapi.utils import get_flat_models_from_routes, get_model_definitions
+from fastapi.utils import (
+ generate_operation_id_for_path,
+ get_flat_models_from_routes,
+ get_model_definitions,
+)
from pydantic.fields import Field
from pydantic.schema import field_schema, get_model_name_map
from pydantic.utils import lenient_issubclass
@@ -113,10 +117,7 @@ def generate_operation_id(*, route: routing.APIRoute, method: str) -> str:
if route.operation_id:
return route.operation_id
path: str = route.path_format
- operation_id = route.name + path
- operation_id = operation_id.replace("{", "_").replace("}", "_").replace("/", "_")
- operation_id = operation_id + "_" + method.lower()
- return operation_id
+ return generate_operation_id_for_path(name=route.name, path=path, method=method)
def generate_operation_summary(*, route: routing.APIRoute, method: str) -> str:
diff --git a/fastapi/routing.py b/fastapi/routing.py
--- a/fastapi/routing.py
+++ b/fastapi/routing.py
@@ -13,7 +13,7 @@
)
from fastapi.encoders import jsonable_encoder
from fastapi.exceptions import RequestValidationError, WebSocketRequestValidationError
-from fastapi.utils import create_cloned_field
+from fastapi.utils import create_cloned_field, generate_operation_id_for_path
from pydantic import BaseConfig, BaseModel, Schema
from pydantic.error_wrappers import ErrorWrapper, ValidationError
from pydantic.fields import Field
@@ -205,12 +205,19 @@ def __init__(
self.path = path
self.endpoint = endpoint
self.name = get_name(endpoint) if name is None else name
+ self.path_regex, self.path_format, self.param_convertors = compile_path(path)
+ if methods is None:
+ methods = ["GET"]
+ self.methods = set([method.upper() for method in methods])
+ self.unique_id = generate_operation_id_for_path(
+ name=self.name, path=self.path_format, method=list(methods)[0]
+ )
self.response_model = response_model
if self.response_model:
assert lenient_issubclass(
response_class, JSONResponse
), "To declare a type the response must be a JSON response"
- response_name = "Response_" + self.name
+ response_name = "Response_" + self.unique_id
self.response_field: Optional[Field] = Field(
name=response_name,
type_=self.response_model,
@@ -251,7 +258,7 @@ def __init__(
assert lenient_issubclass(
model, BaseModel
), "A response model must be a Pydantic model"
- response_name = f"Response_{additional_status_code}_{self.name}"
+ response_name = f"Response_{additional_status_code}_{self.unique_id}"
response_field = Field(
name=response_name,
type_=model,
@@ -267,9 +274,6 @@ def __init__(
else:
self.response_fields = {}
self.deprecated = deprecated
- if methods is None:
- methods = ["GET"]
- self.methods = set([method.upper() for method in methods])
self.operation_id = operation_id
self.response_model_include = response_model_include
self.response_model_exclude = response_model_exclude
@@ -278,7 +282,6 @@ def __init__(
self.include_in_schema = include_in_schema
self.response_class = response_class
- self.path_regex, self.path_format, self.param_convertors = compile_path(path)
assert inspect.isfunction(endpoint) or inspect.ismethod(
endpoint
), f"An endpoint must be a function or method"
@@ -288,7 +291,7 @@ def __init__(
0,
get_parameterless_sub_dependant(depends=depends, path=self.path_format),
)
- self.body_field = get_body_field(dependant=self.dependant, name=self.name)
+ self.body_field = get_body_field(dependant=self.dependant, name=self.unique_id)
self.dependency_overrides_provider = dependency_overrides_provider
self.app = request_response(
get_app(
diff --git a/fastapi/utils.py b/fastapi/utils.py
--- a/fastapi/utils.py
+++ b/fastapi/utils.py
@@ -93,3 +93,10 @@ def create_cloned_field(field: Field) -> Field:
new_field.shape = field.shape
new_field._populate_validators()
return new_field
+
+
+def generate_operation_id_for_path(*, name: str, path: str, method: str) -> str:
+ operation_id = name + path
+ operation_id = operation_id.replace("{", "_").replace("}", "_").replace("/", "_")
+ operation_id = operation_id + "_" + method.lower()
+ return operation_id
|
diff --git a/tests/test_modules_same_name_body/__init__.py b/tests/test_modules_same_name_body/__init__.py
new file mode 100644
diff --git a/tests/test_modules_same_name_body/app/__init__.py b/tests/test_modules_same_name_body/app/__init__.py
new file mode 100644
diff --git a/tests/test_modules_same_name_body/app/a.py b/tests/test_modules_same_name_body/app/a.py
new file mode 100644
--- /dev/null
+++ b/tests/test_modules_same_name_body/app/a.py
@@ -0,0 +1,8 @@
+from fastapi import APIRouter, Body
+
+router = APIRouter()
+
+
[email protected]("/compute")
+def compute(a: int = Body(...), b: str = Body(...)):
+ return {"a": a, "b": b}
diff --git a/tests/test_modules_same_name_body/app/b.py b/tests/test_modules_same_name_body/app/b.py
new file mode 100644
--- /dev/null
+++ b/tests/test_modules_same_name_body/app/b.py
@@ -0,0 +1,8 @@
+from fastapi import APIRouter, Body
+
+router = APIRouter()
+
+
[email protected]("/compute/")
+def compute(a: int = Body(...), b: str = Body(...)):
+ return {"a": a, "b": b}
diff --git a/tests/test_modules_same_name_body/app/main.py b/tests/test_modules_same_name_body/app/main.py
new file mode 100644
--- /dev/null
+++ b/tests/test_modules_same_name_body/app/main.py
@@ -0,0 +1,8 @@
+from fastapi import FastAPI
+
+from . import a, b
+
+app = FastAPI()
+
+app.include_router(a.router, prefix="/a")
+app.include_router(b.router, prefix="/b")
diff --git a/tests/test_modules_same_name_body/test_main.py b/tests/test_modules_same_name_body/test_main.py
new file mode 100644
--- /dev/null
+++ b/tests/test_modules_same_name_body/test_main.py
@@ -0,0 +1,155 @@
+from starlette.testclient import TestClient
+
+from .app.main import app
+
+client = TestClient(app)
+
+openapi_schema = {
+ "openapi": "3.0.2",
+ "info": {"title": "Fast API", "version": "0.1.0"},
+ "paths": {
+ "/a/compute": {
+ "post": {
+ "responses": {
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ },
+ "422": {
+ "description": "Validation Error",
+ "content": {
+ "application/json": {
+ "schema": {
+ "$ref": "#/components/schemas/HTTPValidationError"
+ }
+ }
+ },
+ },
+ },
+ "summary": "Compute",
+ "operationId": "compute_a_compute_post",
+ "requestBody": {
+ "content": {
+ "application/json": {
+ "schema": {
+ "$ref": "#/components/schemas/Body_compute_a_compute_post"
+ }
+ }
+ },
+ "required": True,
+ },
+ }
+ },
+ "/b/compute/": {
+ "post": {
+ "responses": {
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ },
+ "422": {
+ "description": "Validation Error",
+ "content": {
+ "application/json": {
+ "schema": {
+ "$ref": "#/components/schemas/HTTPValidationError"
+ }
+ }
+ },
+ },
+ },
+ "summary": "Compute",
+ "operationId": "compute_b_compute__post",
+ "requestBody": {
+ "content": {
+ "application/json": {
+ "schema": {
+ "$ref": "#/components/schemas/Body_compute_b_compute__post"
+ }
+ }
+ },
+ "required": True,
+ },
+ }
+ },
+ },
+ "components": {
+ "schemas": {
+ "Body_compute_b_compute__post": {
+ "title": "Body_compute_b_compute__post",
+ "required": ["a", "b"],
+ "type": "object",
+ "properties": {
+ "a": {"title": "A", "type": "integer"},
+ "b": {"title": "B", "type": "string"},
+ },
+ },
+ "Body_compute_a_compute_post": {
+ "title": "Body_compute_a_compute_post",
+ "required": ["a", "b"],
+ "type": "object",
+ "properties": {
+ "a": {"title": "A", "type": "integer"},
+ "b": {"title": "B", "type": "string"},
+ },
+ },
+ "ValidationError": {
+ "title": "ValidationError",
+ "required": ["loc", "msg", "type"],
+ "type": "object",
+ "properties": {
+ "loc": {
+ "title": "Location",
+ "type": "array",
+ "items": {"type": "string"},
+ },
+ "msg": {"title": "Message", "type": "string"},
+ "type": {"title": "Error Type", "type": "string"},
+ },
+ },
+ "HTTPValidationError": {
+ "title": "HTTPValidationError",
+ "type": "object",
+ "properties": {
+ "detail": {
+ "title": "Detail",
+ "type": "array",
+ "items": {"$ref": "#/components/schemas/ValidationError"},
+ }
+ },
+ },
+ }
+ },
+}
+
+
+def test_openapi_schema():
+ response = client.get("/openapi.json")
+ assert response.status_code == 200
+ assert response.json() == openapi_schema
+
+
+def test_post_a():
+ data = {"a": 2, "b": "foo"}
+ response = client.post("/a/compute", json=data)
+ assert response.status_code == 200
+ data = response.json()
+
+
+def test_post_a_invalid():
+ data = {"a": "bar", "b": "foo"}
+ response = client.post("/a/compute", json=data)
+ assert response.status_code == 422
+
+
+def test_post_b():
+ data = {"a": 2, "b": "foo"}
+ response = client.post("/b/compute/", json=data)
+ assert response.status_code == 200
+ data = response.json()
+
+
+def test_post_b_invalid():
+ data = {"a": "bar", "b": "foo"}
+ response = client.post("/b/compute/", json=data)
+ assert response.status_code == 422
diff --git a/tests/test_security_oauth2.py b/tests/test_security_oauth2.py
--- a/tests/test_security_oauth2.py
+++ b/tests/test_security_oauth2.py
@@ -66,7 +66,7 @@ def read_current_user(current_user: User = Depends(get_current_user)):
"content": {
"application/x-www-form-urlencoded": {
"schema": {
- "$ref": "#/components/schemas/Body_read_current_user"
+ "$ref": "#/components/schemas/Body_read_current_user_login_post"
}
}
},
@@ -90,8 +90,8 @@ def read_current_user(current_user: User = Depends(get_current_user)):
},
"components": {
"schemas": {
- "Body_read_current_user": {
- "title": "Body_read_current_user",
+ "Body_read_current_user_login_post": {
+ "title": "Body_read_current_user_login_post",
"required": ["grant_type", "username", "password"],
"type": "object",
"properties": {
diff --git a/tests/test_security_oauth2_optional.py b/tests/test_security_oauth2_optional.py
--- a/tests/test_security_oauth2_optional.py
+++ b/tests/test_security_oauth2_optional.py
@@ -73,7 +73,7 @@ def read_current_user(current_user: Optional[User] = Depends(get_current_user)):
"content": {
"application/x-www-form-urlencoded": {
"schema": {
- "$ref": "#/components/schemas/Body_read_current_user"
+ "$ref": "#/components/schemas/Body_read_current_user_login_post"
}
}
},
@@ -97,8 +97,8 @@ def read_current_user(current_user: Optional[User] = Depends(get_current_user)):
},
"components": {
"schemas": {
- "Body_read_current_user": {
- "title": "Body_read_current_user",
+ "Body_read_current_user_login_post": {
+ "title": "Body_read_current_user_login_post",
"required": ["grant_type", "username", "password"],
"type": "object",
"properties": {
diff --git a/tests/test_tutorial/test_async_sql_databases/test_tutorial001.py b/tests/test_tutorial/test_async_sql_databases/test_tutorial001.py
--- a/tests/test_tutorial/test_async_sql_databases/test_tutorial001.py
+++ b/tests/test_tutorial/test_async_sql_databases/test_tutorial001.py
@@ -14,7 +14,7 @@
"content": {
"application/json": {
"schema": {
- "title": "Response_Read_Notes",
+ "title": "Response_Read_Notes_Notes__Get",
"type": "array",
"items": {"$ref": "#/components/schemas/Note"},
}
diff --git a/tests/test_tutorial/test_body_multiple_params/test_tutorial003.py b/tests/test_tutorial/test_body_multiple_params/test_tutorial003.py
--- a/tests/test_tutorial/test_body_multiple_params/test_tutorial003.py
+++ b/tests/test_tutorial/test_body_multiple_params/test_tutorial003.py
@@ -40,7 +40,9 @@
"requestBody": {
"content": {
"application/json": {
- "schema": {"$ref": "#/components/schemas/Body_update_item"}
+ "schema": {
+ "$ref": "#/components/schemas/Body_update_item_items__item_id__put"
+ }
}
},
"required": True,
@@ -70,8 +72,8 @@
"full_name": {"title": "Full_Name", "type": "string"},
},
},
- "Body_update_item": {
- "title": "Body_update_item",
+ "Body_update_item_items__item_id__put": {
+ "title": "Body_update_item_items__item_id__put",
"required": ["item", "user", "importance"],
"type": "object",
"properties": {
diff --git a/tests/test_tutorial/test_body_schema/test_tutorial001.py b/tests/test_tutorial/test_body_schema/test_tutorial001.py
--- a/tests/test_tutorial/test_body_schema/test_tutorial001.py
+++ b/tests/test_tutorial/test_body_schema/test_tutorial001.py
@@ -41,7 +41,9 @@
"requestBody": {
"content": {
"application/json": {
- "schema": {"$ref": "#/components/schemas/Body_update_item"}
+ "schema": {
+ "$ref": "#/components/schemas/Body_update_item_items__item_id__put"
+ }
}
},
"required": True,
@@ -71,8 +73,8 @@
"tax": {"title": "Tax", "type": "number"},
},
},
- "Body_update_item": {
- "title": "Body_update_item",
+ "Body_update_item_items__item_id__put": {
+ "title": "Body_update_item_items__item_id__put",
"required": ["item"],
"type": "object",
"properties": {"item": {"$ref": "#/components/schemas/Item"}},
diff --git a/tests/test_tutorial/test_extra_data_types/test_tutorial001.py b/tests/test_tutorial/test_extra_data_types/test_tutorial001.py
--- a/tests/test_tutorial/test_extra_data_types/test_tutorial001.py
+++ b/tests/test_tutorial/test_extra_data_types/test_tutorial001.py
@@ -44,7 +44,9 @@
"requestBody": {
"content": {
"application/json": {
- "schema": {"$ref": "#/components/schemas/Body_read_items"}
+ "schema": {
+ "$ref": "#/components/schemas/Body_read_items_items__item_id__put"
+ }
}
}
},
@@ -53,8 +55,8 @@
},
"components": {
"schemas": {
- "Body_read_items": {
- "title": "Body_read_items",
+ "Body_read_items_items__item_id__put": {
+ "title": "Body_read_items_items__item_id__put",
"type": "object",
"properties": {
"start_datetime": {
diff --git a/tests/test_tutorial/test_extra_models/test_tutorial003.py b/tests/test_tutorial/test_extra_models/test_tutorial003.py
--- a/tests/test_tutorial/test_extra_models/test_tutorial003.py
+++ b/tests/test_tutorial/test_extra_models/test_tutorial003.py
@@ -16,7 +16,7 @@
"content": {
"application/json": {
"schema": {
- "title": "Response_Read_Item",
+ "title": "Response_Read_Item_Items__Item_Id__Get",
"anyOf": [
{"$ref": "#/components/schemas/PlaneItem"},
{"$ref": "#/components/schemas/CarItem"},
diff --git a/tests/test_tutorial/test_extra_models/test_tutorial004.py b/tests/test_tutorial/test_extra_models/test_tutorial004.py
--- a/tests/test_tutorial/test_extra_models/test_tutorial004.py
+++ b/tests/test_tutorial/test_extra_models/test_tutorial004.py
@@ -16,7 +16,7 @@
"content": {
"application/json": {
"schema": {
- "title": "Response_Read_Items",
+ "title": "Response_Read_Items_Items__Get",
"type": "array",
"items": {"$ref": "#/components/schemas/Item"},
}
diff --git a/tests/test_tutorial/test_extra_models/test_tutorial005.py b/tests/test_tutorial/test_extra_models/test_tutorial005.py
--- a/tests/test_tutorial/test_extra_models/test_tutorial005.py
+++ b/tests/test_tutorial/test_extra_models/test_tutorial005.py
@@ -16,7 +16,7 @@
"content": {
"application/json": {
"schema": {
- "title": "Response_Read_Keyword_Weights",
+ "title": "Response_Read_Keyword_Weights_Keyword-Weights__Get",
"type": "object",
"additionalProperties": {"type": "number"},
}
diff --git a/tests/test_tutorial/test_request_files/test_tutorial001.py b/tests/test_tutorial/test_request_files/test_tutorial001.py
--- a/tests/test_tutorial/test_request_files/test_tutorial001.py
+++ b/tests/test_tutorial/test_request_files/test_tutorial001.py
@@ -33,7 +33,9 @@
"requestBody": {
"content": {
"multipart/form-data": {
- "schema": {"$ref": "#/components/schemas/Body_create_file"}
+ "schema": {
+ "$ref": "#/components/schemas/Body_create_file_files__post"
+ }
}
},
"required": True,
@@ -64,7 +66,7 @@
"content": {
"multipart/form-data": {
"schema": {
- "$ref": "#/components/schemas/Body_create_upload_file"
+ "$ref": "#/components/schemas/Body_create_upload_file_uploadfile__post"
}
}
},
@@ -75,16 +77,16 @@
},
"components": {
"schemas": {
- "Body_create_file": {
- "title": "Body_create_file",
+ "Body_create_upload_file_uploadfile__post": {
+ "title": "Body_create_upload_file_uploadfile__post",
"required": ["file"],
"type": "object",
"properties": {
"file": {"title": "File", "type": "string", "format": "binary"}
},
},
- "Body_create_upload_file": {
- "title": "Body_create_upload_file",
+ "Body_create_file_files__post": {
+ "title": "Body_create_file_files__post",
"required": ["file"],
"type": "object",
"properties": {
diff --git a/tests/test_tutorial/test_request_files/test_tutorial002.py b/tests/test_tutorial/test_request_files/test_tutorial002.py
--- a/tests/test_tutorial/test_request_files/test_tutorial002.py
+++ b/tests/test_tutorial/test_request_files/test_tutorial002.py
@@ -33,7 +33,9 @@
"requestBody": {
"content": {
"multipart/form-data": {
- "schema": {"$ref": "#/components/schemas/Body_create_files"}
+ "schema": {
+ "$ref": "#/components/schemas/Body_create_files_files__post"
+ }
}
},
"required": True,
@@ -64,7 +66,7 @@
"content": {
"multipart/form-data": {
"schema": {
- "$ref": "#/components/schemas/Body_create_upload_files"
+ "$ref": "#/components/schemas/Body_create_upload_files_uploadfiles__post"
}
}
},
@@ -87,8 +89,8 @@
},
"components": {
"schemas": {
- "Body_create_files": {
- "title": "Body_create_files",
+ "Body_create_upload_files_uploadfiles__post": {
+ "title": "Body_create_upload_files_uploadfiles__post",
"required": ["files"],
"type": "object",
"properties": {
@@ -99,8 +101,8 @@
}
},
},
- "Body_create_upload_files": {
- "title": "Body_create_upload_files",
+ "Body_create_files_files__post": {
+ "title": "Body_create_files_files__post",
"required": ["files"],
"type": "object",
"properties": {
diff --git a/tests/test_tutorial/test_request_forms/test_tutorial001.py b/tests/test_tutorial/test_request_forms/test_tutorial001.py
--- a/tests/test_tutorial/test_request_forms/test_tutorial001.py
+++ b/tests/test_tutorial/test_request_forms/test_tutorial001.py
@@ -32,7 +32,9 @@
"requestBody": {
"content": {
"application/x-www-form-urlencoded": {
- "schema": {"$ref": "#/components/schemas/Body_login"}
+ "schema": {
+ "$ref": "#/components/schemas/Body_login_login__post"
+ }
}
},
"required": True,
@@ -42,8 +44,8 @@
},
"components": {
"schemas": {
- "Body_login": {
- "title": "Body_login",
+ "Body_login_login__post": {
+ "title": "Body_login_login__post",
"required": ["username", "password"],
"type": "object",
"properties": {
diff --git a/tests/test_tutorial/test_request_forms_and_files/test_tutorial001.py b/tests/test_tutorial/test_request_forms_and_files/test_tutorial001.py
--- a/tests/test_tutorial/test_request_forms_and_files/test_tutorial001.py
+++ b/tests/test_tutorial/test_request_forms_and_files/test_tutorial001.py
@@ -34,7 +34,9 @@
"requestBody": {
"content": {
"multipart/form-data": {
- "schema": {"$ref": "#/components/schemas/Body_create_file"}
+ "schema": {
+ "$ref": "#/components/schemas/Body_create_file_files__post"
+ }
}
},
"required": True,
@@ -44,8 +46,8 @@
},
"components": {
"schemas": {
- "Body_create_file": {
- "title": "Body_create_file",
+ "Body_create_file_files__post": {
+ "title": "Body_create_file_files__post",
"required": ["file", "fileb", "token"],
"type": "object",
"properties": {
diff --git a/tests/test_tutorial/test_security/test_tutorial003.py b/tests/test_tutorial/test_security/test_tutorial003.py
--- a/tests/test_tutorial/test_security/test_tutorial003.py
+++ b/tests/test_tutorial/test_security/test_tutorial003.py
@@ -31,7 +31,9 @@
"requestBody": {
"content": {
"application/x-www-form-urlencoded": {
- "schema": {"$ref": "#/components/schemas/Body_login"}
+ "schema": {
+ "$ref": "#/components/schemas/Body_login_token_post"
+ }
}
},
"required": True,
@@ -54,8 +56,8 @@
},
"components": {
"schemas": {
- "Body_login": {
- "title": "Body_login",
+ "Body_login_token_post": {
+ "title": "Body_login_token_post",
"required": ["username", "password"],
"type": "object",
"properties": {
diff --git a/tests/test_tutorial/test_security/test_tutorial005.py b/tests/test_tutorial/test_security/test_tutorial005.py
--- a/tests/test_tutorial/test_security/test_tutorial005.py
+++ b/tests/test_tutorial/test_security/test_tutorial005.py
@@ -42,7 +42,7 @@
"content": {
"application/x-www-form-urlencoded": {
"schema": {
- "$ref": "#/components/schemas/Body_login_for_access_token"
+ "$ref": "#/components/schemas/Body_login_for_access_token_token_post"
}
}
},
@@ -116,8 +116,8 @@
"token_type": {"title": "Token_Type", "type": "string"},
},
},
- "Body_login_for_access_token": {
- "title": "Body_login_for_access_token",
+ "Body_login_for_access_token_token_post": {
+ "title": "Body_login_for_access_token_token_post",
"required": ["username", "password"],
"type": "object",
"properties": {
@@ -177,6 +177,12 @@
}
+def test_openapi_schema():
+ response = client.get("/openapi.json")
+ assert response.status_code == 200
+ assert response.json() == openapi_schema
+
+
def get_access_token(username="johndoe", password="secret", scope=None):
data = {"username": username, "password": password}
if scope:
@@ -187,12 +193,6 @@ def get_access_token(username="johndoe", password="secret", scope=None):
return access_token
-def test_openapi_schema():
- response = client.get("/openapi.json")
- assert response.status_code == 200
- assert response.json() == openapi_schema
-
-
def test_login():
response = client.post("/token", data={"username": "johndoe", "password": "secret"})
assert response.status_code == 200
diff --git a/tests/test_tutorial/test_sql_databases/test_sql_databases.py b/tests/test_tutorial/test_sql_databases/test_sql_databases.py
--- a/tests/test_tutorial/test_sql_databases/test_sql_databases.py
+++ b/tests/test_tutorial/test_sql_databases/test_sql_databases.py
@@ -16,7 +16,7 @@
"content": {
"application/json": {
"schema": {
- "title": "Response_Read_Users",
+ "title": "Response_Read_Users_Users__Get",
"type": "array",
"items": {"$ref": "#/components/schemas/User"},
}
@@ -168,7 +168,7 @@
"content": {
"application/json": {
"schema": {
- "title": "Response_Read_Items",
+ "title": "Response_Read_Items_Items__Get",
"type": "array",
"items": {"$ref": "#/components/schemas/Item"},
}
|
OpenAPI fails when forcing query params to be body and multiple params in each
**Describe the bug**
The OpenAPI spec for my app breaks with the following error (shown in my web browser).
```
Fetch error
Internal Server Error /openapi.json
```
This only happens when I have endpoints defined in two separate files, each of which force all their arguments to be body parameters via annotating each parameter with `Body(...)` to force them to be body parameters, as opposed to query parameters.
Check this out!
- If the endpoints are defined in the same file, then the problem does not happen.
- If each endpoint only has a single parameter, the problem does not happen.
- If only one endpoint has multiple parameters, then the problem does not happen.
It only happens when both endpoints have *multiple* parameters annotated with `Body(...)`.
**To Reproduce**
Steps to reproduce the behavior:
1. Create a directory with the following structure.
```
.
├── foo
│ ├── __init__.py
│ ├── bar.py
│ └── baz.py
└── main.py
```
main.py
```python
from fastapi import FastAPI
import foo.bar
import foo.baz
app = FastAPI()
app.get('/v1/compute')(foo.bar.compute)
app.get('/v2/compute')(foo.baz.compute)
```
foo/bar.py
```python
from fastapi import Body
def compute(
a: int = Body(...),
b: str = Body(...),
):
return a + b
```
foo/baz.py (identical to foo/bar.py)
```python
from fastapi import Body
def compute(
a: int = Body(...),
b: str = Body(...),
):
return a + b
```
2. Run with `uvicorn main:app --reload`
3. Visit `http://localhost:8000/docs`
**Expected behavior**
The OpenAPI page shows without error.
**Screenshots**

Here's the exception my app produces when I try to visit `http://localhost:8000`.
```
ip-10-8-0-198% % uvicorn run:app --reload
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [77186]
WARNING:root:email-validator not installed, email fields will be treated as str.
To install, run: pip install email-validator
INFO:uvicorn:Started server process [77188]
INFO:uvicorn:Waiting for application startup.
INFO:uvicorn:('127.0.0.1', 54932) - "GET /docs HTTP/1.1" 200
INFO:uvicorn:('127.0.0.1', 54932) - "GET /openapi.json HTTP/1.1" 500
ERROR:uvicorn:Exception in ASGI application
Traceback (most recent call last):
File "/Users/edwardbanner/.anaconda/lib/python3.6/site-packages/uvicorn/protocols/http/httptools_impl.py", line 368, in run_asgi
result = await app(self.scope, self.receive, self.send)
File "/Users/edwardbanner/.anaconda/lib/python3.6/site-packages/uvicorn/middleware/asgi2.py", line 7, in __call__
await instance(receive, send)
File "/Users/edwardbanner/.anaconda/lib/python3.6/site-packages/starlette/middleware/errors.py", line 125, in asgi
raise exc from None
File "/Users/edwardbanner/.anaconda/lib/python3.6/site-packages/starlette/middleware/errors.py", line 103, in asgi
await asgi(receive, _send)
File "/Users/edwardbanner/.anaconda/lib/python3.6/site-packages/starlette/exceptions.py", line 74, in app
raise exc from None
File "/Users/edwardbanner/.anaconda/lib/python3.6/site-packages/starlette/exceptions.py", line 63, in app
await instance(receive, sender)
File "/Users/edwardbanner/.anaconda/lib/python3.6/site-packages/starlette/routing.py", line 43, in awaitable
response = await run_in_threadpool(func, request)
File "/Users/edwardbanner/.anaconda/lib/python3.6/site-packages/starlette/concurrency.py", line 24, in run_in_threadpool
return await loop.run_in_executor(None, func, *args)
File "/Users/edwardbanner/.anaconda/lib/python3.6/concurrent/futures/thread.py", line 56, in run
result = self.fn(*self.args, **self.kwargs)
File "/Users/edwardbanner/.anaconda/lib/python3.6/site-packages/fastapi/applications.py", line 83, in <lambda>
lambda req: JSONResponse(self.openapi()),
File "/Users/edwardbanner/.anaconda/lib/python3.6/site-packages/fastapi/applications.py", line 75, in openapi
openapi_prefix=self.openapi_prefix,
File "/Users/edwardbanner/.anaconda/lib/python3.6/site-packages/fastapi/openapi/utils.py", line 248, in get_openapi
flat_models=flat_models, model_name_map=model_name_map
File "/Users/edwardbanner/.anaconda/lib/python3.6/site-packages/fastapi/utils.py", line 45, in get_model_definitions
model_name = model_name_map[model]
KeyError: <class 'Body_compute'>
```
**Environment:**
- OS: [e.g. macOS]
- FastAPI Version [e.g. 0.27.0], get it with `pip install fastapi`.
```Python
import fastapi
print(fastapi.__version__)
```
**Additional context**
- When I only have a single endpoint, the value of `model_name_map` is `{<class 'Body_compute'>: 'Body_compute'}`.
- However, when I have both endpoints take multiple parameters, the value of `model_name_map` is `{<class 'Body_compute'>: 'None__Body_compute'}`.
|
Thanks for the report. I'll check it soon.
| 2019-06-28T17:31:21 |
tiangolo/fastapi
| 435 |
tiangolo__fastapi-435
|
[
"428",
"428"
] |
033bc2a6c9aec3a245eb1f1b4fadb2fbb7a514b8
|
diff --git a/fastapi/openapi/utils.py b/fastapi/openapi/utils.py
--- a/fastapi/openapi/utils.py
+++ b/fastapi/openapi/utils.py
@@ -43,6 +43,15 @@
},
}
+status_code_ranges: Dict[str, str] = {
+ "1XX": "Information",
+ "2XX": "Success",
+ "3XX": "Redirection",
+ "4XX": "Client Error",
+ "5XX": "Server Error",
+ "default": "Default Response",
+}
+
def get_openapi_params(dependant: Dependant) -> List[Field]:
flat_dependant = get_flat_dependant(dependant)
@@ -190,12 +199,14 @@ def get_openapi_path(
response.setdefault("content", {}).setdefault(
"application/json", {}
)["schema"] = response_schema
- status_text = http.client.responses.get(int(additional_status_code))
+ status_text: Optional[str] = status_code_ranges.get(
+ str(additional_status_code).upper()
+ ) or http.client.responses.get(int(additional_status_code))
response.setdefault(
"description", status_text or "Additional Response"
)
operation.setdefault("responses", {})[
- str(additional_status_code)
+ str(additional_status_code).upper()
] = response
status_code = str(route.status_code)
response_schema = {"type": "string"}
|
diff --git a/tests/test_additional_responses_bad.py b/tests/test_additional_responses_bad.py
new file mode 100644
--- /dev/null
+++ b/tests/test_additional_responses_bad.py
@@ -0,0 +1,40 @@
+import pytest
+from fastapi import FastAPI
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
[email protected]("/a", responses={"hello": {"description": "Not a valid additional response"}})
+async def a():
+ pass # pragma: no cover
+
+
+openapi_schema = {
+ "openapi": "3.0.2",
+ "info": {"title": "Fast API", "version": "0.1.0"},
+ "paths": {
+ "/a": {
+ "get": {
+ "responses": {
+ # this is how one would imagine the openapi schema to be
+ # but since the key is not valid, openapi.utils.get_openapi will raise ValueError
+ "hello": {"description": "Not a valid additional response"},
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ },
+ },
+ "summary": "A",
+ "operationId": "a_a_get",
+ }
+ }
+ },
+}
+
+client = TestClient(app)
+
+
+def test_openapi_schema():
+ with pytest.raises(ValueError):
+ client.get("/openapi.json")
diff --git a/tests/test_additional_responses_router.py b/tests/test_additional_responses_router.py
--- a/tests/test_additional_responses_router.py
+++ b/tests/test_additional_responses_router.py
@@ -10,12 +10,24 @@ async def a():
return "a"
[email protected]("/b", responses={502: {"description": "Error 2"}})
[email protected](
+ "/b",
+ responses={
+ 502: {"description": "Error 2"},
+ "4XX": {"description": "Error with range, upper"},
+ },
+)
async def b():
return "b"
[email protected]("/c", responses={501: {"description": "Error 3"}})
[email protected](
+ "/c",
+ responses={
+ "400": {"description": "Error with str"},
+ "5xx": {"description": "Error with range, lower"},
+ },
+)
async def c():
return "c"
@@ -43,6 +55,7 @@ async def c():
"get": {
"responses": {
"502": {"description": "Error 2"},
+ "4XX": {"description": "Error with range, upper"},
"200": {
"description": "Successful Response",
"content": {"application/json": {"schema": {}}},
@@ -55,7 +68,8 @@ async def c():
"/c": {
"get": {
"responses": {
- "501": {"description": "Error 3"},
+ "400": {"description": "Error with str"},
+ "5XX": {"description": "Error with range, lower"},
"200": {
"description": "Successful Response",
"content": {"application/json": {"schema": {}}},
|
OpenAPI: response keys are limited to be status codes
**Describe the bug**
According to OpenAPI 3 specification, under `responses` dictionary each definition starts with the keys which is either a valid status codes (200, 204, 404, etc.), a [range of codes](https://swagger.io/docs/specification/describing-responses#status-codes) (1XX, 2XX, 3XX, etc.) or the word ["default"](https://swagger.io/docs/specification/describing-responses#default).
If a path is defined with such response, the server crashes when opening the doc, redoc or openapi.json URLs.
**To Reproduce**
```python
from fastapi import FastAPI, HTTPException
from starlette import status
from . import schemas
app = FastAPI()
@app.get('/customer/{id}',
status_code=status.HTTP_200_OK,
response_model=schemas.CustomerDetailsResponse,
responses={
'4xx': {'model': schemas.ErrorResponse},
'5xx': {'model': schemas.ErrorResponse},
},
)
def customer_details(id: str):
raise HTTPException(status_code=status.HTTP_501_NOT_IMPLEMENTED)
```
**Expected behavior**
The openapi.json is created, documentation opens, and the responses show the range / default
definitions.
```yaml
# ...
"/api/customer/{id}":
get:
responses:
'200':
description: Successful Response
content:
application/json:
schema:
"$ref": "#/components/schemas/CustomerDetailsResponse"
4xx:
description: Additional Response
content:
application/json:
schema:
"$ref": "#/components/schemas/ErrorResponse"
5xx:
description: Additional Response
content:
application/json:
schema:
"$ref": "#/components/schemas/ErrorResponse"
summary: Customer Details
operationId: customer_details_api_customer__id__get
parameters:
- required: true
schema:
title: Id
type: string
name: id
in: path
```
**Environment:**
- OS: masOS 10.14.6
- Python: 3.6.5
- FastAPI: 0.35.0
OpenAPI: response keys are limited to be status codes
**Describe the bug**
According to OpenAPI 3 specification, under `responses` dictionary each definition starts with the keys which is either a valid status codes (200, 204, 404, etc.), a [range of codes](https://swagger.io/docs/specification/describing-responses#status-codes) (1XX, 2XX, 3XX, etc.) or the word ["default"](https://swagger.io/docs/specification/describing-responses#default).
If a path is defined with such response, the server crashes when opening the doc, redoc or openapi.json URLs.
**To Reproduce**
```python
from fastapi import FastAPI, HTTPException
from starlette import status
from . import schemas
app = FastAPI()
@app.get('/customer/{id}',
status_code=status.HTTP_200_OK,
response_model=schemas.CustomerDetailsResponse,
responses={
'4xx': {'model': schemas.ErrorResponse},
'5xx': {'model': schemas.ErrorResponse},
},
)
def customer_details(id: str):
raise HTTPException(status_code=status.HTTP_501_NOT_IMPLEMENTED)
```
**Expected behavior**
The openapi.json is created, documentation opens, and the responses show the range / default
definitions.
```yaml
# ...
"/api/customer/{id}":
get:
responses:
'200':
description: Successful Response
content:
application/json:
schema:
"$ref": "#/components/schemas/CustomerDetailsResponse"
4xx:
description: Additional Response
content:
application/json:
schema:
"$ref": "#/components/schemas/ErrorResponse"
5xx:
description: Additional Response
content:
application/json:
schema:
"$ref": "#/components/schemas/ErrorResponse"
summary: Customer Details
operationId: customer_details_api_customer__id__get
parameters:
- required: true
schema:
title: Id
type: string
name: id
in: path
```
**Environment:**
- OS: masOS 10.14.6
- Python: 3.6.5
- FastAPI: 0.35.0
| 2019-08-13T07:07:42 |
|
tiangolo/fastapi
| 437 |
tiangolo__fastapi-437
|
[
"429"
] |
033bc2a6c9aec3a245eb1f1b4fadb2fbb7a514b8
|
diff --git a/fastapi/openapi/utils.py b/fastapi/openapi/utils.py
--- a/fastapi/openapi/utils.py
+++ b/fastapi/openapi/utils.py
@@ -71,15 +71,11 @@ def get_openapi_security_definitions(flat_dependant: Dependant) -> Tuple[Dict, L
def get_openapi_operation_parameters(
all_route_params: Sequence[Field]
-) -> Tuple[Dict[str, Dict], List[Dict[str, Any]]]:
- definitions: Dict[str, Dict] = {}
+) -> List[Dict[str, Any]]:
parameters = []
for param in all_route_params:
schema = param.schema
schema = cast(Param, schema)
- if "ValidationError" not in definitions:
- definitions["ValidationError"] = validation_error_definition
- definitions["HTTPValidationError"] = validation_error_response_definition
parameter = {
"name": param.alias,
"in": schema.in_.value,
@@ -91,7 +87,7 @@ def get_openapi_operation_parameters(
if schema.deprecated:
parameter["deprecated"] = schema.deprecated
parameters.append(parameter)
- return definitions, parameters
+ return parameters
def get_openapi_operation_request_body(
@@ -159,10 +155,7 @@ def get_openapi_path(
if security_definitions:
security_schemes.update(security_definitions)
all_route_params = get_openapi_params(route.dependant)
- validation_definitions, operation_parameters = get_openapi_operation_parameters(
- all_route_params=all_route_params
- )
- definitions.update(validation_definitions)
+ operation_parameters = get_openapi_operation_parameters(all_route_params)
parameters.extend(operation_parameters)
if parameters:
operation["parameters"] = parameters
@@ -172,11 +165,6 @@ def get_openapi_path(
)
if request_body_oai:
operation["requestBody"] = request_body_oai
- if "ValidationError" not in definitions:
- definitions["ValidationError"] = validation_error_definition
- definitions[
- "HTTPValidationError"
- ] = validation_error_response_definition
if route.responses:
for (additional_status_code, response) in route.responses.items():
assert isinstance(
@@ -188,7 +176,7 @@ def get_openapi_path(
field, model_name_map=model_name_map, ref_prefix=REF_PREFIX
)
response.setdefault("content", {}).setdefault(
- "application/json", {}
+ route.response_class.media_type, {}
)["schema"] = response_schema
status_text = http.client.responses.get(int(additional_status_code))
response.setdefault(
@@ -216,8 +204,15 @@ def get_openapi_path(
).setdefault("content", {}).setdefault(route.response_class.media_type, {})[
"schema"
] = response_schema
- if all_route_params or route.body_field:
- operation["responses"][str(HTTP_422_UNPROCESSABLE_ENTITY)] = {
+
+ http422 = str(HTTP_422_UNPROCESSABLE_ENTITY)
+ if (all_route_params or route.body_field) and not any(
+ [
+ status in operation["responses"]
+ for status in [http422, "4xx", "default"]
+ ]
+ ):
+ operation["responses"][http422] = {
"description": "Validation Error",
"content": {
"application/json": {
@@ -225,6 +220,13 @@ def get_openapi_path(
}
},
}
+ if "ValidationError" not in definitions:
+ definitions.update(
+ {
+ "ValidationError": validation_error_definition,
+ "HTTPValidationError": validation_error_response_definition,
+ }
+ )
path[method.lower()] = operation
return path, security_schemes, definitions
|
diff --git a/tests/test_additional_responses_custom_validationerror.py b/tests/test_additional_responses_custom_validationerror.py
new file mode 100644
--- /dev/null
+++ b/tests/test_additional_responses_custom_validationerror.py
@@ -0,0 +1,100 @@
+import typing
+
+from fastapi import FastAPI
+from pydantic import BaseModel
+from starlette.responses import JSONResponse
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
+class JsonApiResponse(JSONResponse):
+ media_type = "application/vnd.api+json"
+
+
+class Error(BaseModel):
+ status: str
+ title: str
+
+
+class JsonApiError(BaseModel):
+ errors: typing.List[Error]
+
+
[email protected](
+ "/a/{id}",
+ response_class=JsonApiResponse,
+ responses={422: {"description": "Error", "model": JsonApiError}},
+)
+async def a(id):
+ pass # pragma: no cover
+
+
+openapi_schema = {
+ "openapi": "3.0.2",
+ "info": {"title": "Fast API", "version": "0.1.0"},
+ "paths": {
+ "/a/{id}": {
+ "get": {
+ "responses": {
+ "422": {
+ "description": "Error",
+ "content": {
+ "application/vnd.api+json": {
+ "schema": {"$ref": "#/components/schemas/JsonApiError"}
+ }
+ },
+ },
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/vnd.api+json": {"schema": {}}},
+ },
+ },
+ "summary": "A",
+ "operationId": "a_a__id__get",
+ "parameters": [
+ {
+ "required": True,
+ "schema": {"title": "Id"},
+ "name": "id",
+ "in": "path",
+ }
+ ],
+ }
+ }
+ },
+ "components": {
+ "schemas": {
+ "Error": {
+ "title": "Error",
+ "required": ["status", "title"],
+ "type": "object",
+ "properties": {
+ "status": {"title": "Status", "type": "string"},
+ "title": {"title": "Title", "type": "string"},
+ },
+ },
+ "JsonApiError": {
+ "title": "JsonApiError",
+ "required": ["errors"],
+ "type": "object",
+ "properties": {
+ "errors": {
+ "title": "Errors",
+ "type": "array",
+ "items": {"$ref": "#/components/schemas/Error"},
+ }
+ },
+ },
+ }
+ },
+}
+
+
+client = TestClient(app)
+
+
+def test_openapi_schema():
+ response = client.get("/openapi.json")
+ assert response.status_code == 200
+ assert response.json() == openapi_schema
diff --git a/tests/test_additional_responses_default_validationerror.py b/tests/test_additional_responses_default_validationerror.py
new file mode 100644
--- /dev/null
+++ b/tests/test_additional_responses_default_validationerror.py
@@ -0,0 +1,85 @@
+from fastapi import FastAPI
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
[email protected]("/a/{id}")
+async def a(id):
+ pass # pragma: no cover
+
+
+openapi_schema = {
+ "openapi": "3.0.2",
+ "info": {"title": "Fast API", "version": "0.1.0"},
+ "paths": {
+ "/a/{id}": {
+ "get": {
+ "responses": {
+ "422": {
+ "description": "Validation Error",
+ "content": {
+ "application/json": {
+ "schema": {
+ "$ref": "#/components/schemas/HTTPValidationError"
+ }
+ }
+ },
+ },
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ },
+ },
+ "summary": "A",
+ "operationId": "a_a__id__get",
+ "parameters": [
+ {
+ "required": True,
+ "schema": {"title": "Id"},
+ "name": "id",
+ "in": "path",
+ }
+ ],
+ }
+ }
+ },
+ "components": {
+ "schemas": {
+ "ValidationError": {
+ "title": "ValidationError",
+ "required": ["loc", "msg", "type"],
+ "type": "object",
+ "properties": {
+ "loc": {
+ "title": "Location",
+ "type": "array",
+ "items": {"type": "string"},
+ },
+ "msg": {"title": "Message", "type": "string"},
+ "type": {"title": "Error Type", "type": "string"},
+ },
+ },
+ "HTTPValidationError": {
+ "title": "HTTPValidationError",
+ "type": "object",
+ "properties": {
+ "detail": {
+ "title": "Detail",
+ "type": "array",
+ "items": {"$ref": "#/components/schemas/ValidationError"},
+ }
+ },
+ },
+ }
+ },
+}
+
+
+client = TestClient(app)
+
+
+def test_openapi_schema():
+ response = client.get("/openapi.json")
+ assert response.status_code == 200
+ assert response.json() == openapi_schema
diff --git a/tests/test_additional_responses_response_class.py b/tests/test_additional_responses_response_class.py
new file mode 100644
--- /dev/null
+++ b/tests/test_additional_responses_response_class.py
@@ -0,0 +1,117 @@
+import typing
+
+from fastapi import FastAPI
+from pydantic import BaseModel
+from starlette.responses import JSONResponse
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
+class JsonApiResponse(JSONResponse):
+ media_type = "application/vnd.api+json"
+
+
+class Error(BaseModel):
+ status: str
+ title: str
+
+
+class JsonApiError(BaseModel):
+ errors: typing.List[Error]
+
+
[email protected](
+ "/a",
+ response_class=JsonApiResponse,
+ responses={500: {"description": "Error", "model": JsonApiError}},
+)
+async def a():
+ pass # pragma: no cover
+
+
[email protected]("/b", responses={500: {"description": "Error", "model": Error}})
+async def b():
+ pass # pragma: no cover
+
+
+openapi_schema = {
+ "openapi": "3.0.2",
+ "info": {"title": "Fast API", "version": "0.1.0"},
+ "paths": {
+ "/a": {
+ "get": {
+ "responses": {
+ "500": {
+ "description": "Error",
+ "content": {
+ "application/vnd.api+json": {
+ "schema": {"$ref": "#/components/schemas/JsonApiError"}
+ }
+ },
+ },
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/vnd.api+json": {"schema": {}}},
+ },
+ },
+ "summary": "A",
+ "operationId": "a_a_get",
+ }
+ },
+ "/b": {
+ "get": {
+ "responses": {
+ "500": {
+ "description": "Error",
+ "content": {
+ "application/json": {
+ "schema": {"$ref": "#/components/schemas/Error"}
+ }
+ },
+ },
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ },
+ },
+ "summary": "B",
+ "operationId": "b_b_get",
+ }
+ },
+ },
+ "components": {
+ "schemas": {
+ "Error": {
+ "title": "Error",
+ "required": ["status", "title"],
+ "type": "object",
+ "properties": {
+ "status": {"title": "Status", "type": "string"},
+ "title": {"title": "Title", "type": "string"},
+ },
+ },
+ "JsonApiError": {
+ "title": "JsonApiError",
+ "required": ["errors"],
+ "type": "object",
+ "properties": {
+ "errors": {
+ "title": "Errors",
+ "type": "array",
+ "items": {"$ref": "#/components/schemas/Error"},
+ }
+ },
+ },
+ }
+ },
+}
+
+
+client = TestClient(app)
+
+
+def test_openapi_schema():
+ response = client.get("/openapi.json")
+ assert response.status_code == 200
+ assert response.json() == openapi_schema
|
OpenAPI: HTTP_422 response does not use custom media_type
**Describe the bug**
FastAPI automatically adds an HTTP_422 response to all paths in the OpenAPI specification that have parameters or request body. This response does not use the media_type of response_class if any custom defined. Furthermore, it overwrites any error object format with the default one.
**To Reproduce**
Create a path with parameters and add custom response_class to decorator. Add custom exception handlers that reformat the default error responses as per your liking. Then observe generated openapi.json
```python
from fastapi import FastAPI, HTTPException
from fastapi.exceptions import RequestValidationError
from starlette import status
from starlette.responses import JSONResponse
from . import schemas
app = FastAPI()
class JsonApiResponse(JSONResponse):
media_type = 'application/vnd+json.api'
@app.exception_handler(HTTPException)
async def http_exception_handler(request, exc: HTTPException) -> JsonApiResponse:
headers = getattr(exc, "headers", None)
content = schemas.ErrorResponse(errors=[dict(title="Bad request", detail=exc.detail, status=exc.status_code)]).dict()
status_code = exc.status_code
if headers:
return JsonApiResponse(content=content, status_code=status_code, headers=headers)
else:
return JsonApiResponse(content=content, status_code=status_code)
@app.exception_handler(RequestValidationError)
async def request_validation_exception_handler(request, exc: RequestValidationError) -> JsonApiResponse:
http422 = status.HTTP_422_UNPROCESSABLE_ENTITY
return JsonApiResponse(
content=schemas.ErrorResponse(errors=[
dict(title=err['type'], detail=err['msg'], source='/'.join(err['loc']), status=http422)
for err in exc.errors()
]).dict(),
status_code=http422,
)
@app.post('/customers',
status_code=status.HTTP_201_CREATED,
response_model=schemas.CustomerDetailsResponse,
response_class=JsonApiResponse,
)
def customer_create(data: schemas.Customer = Body(..., media_type='application/vnd+json.api', embed=True)):
created_customer = {**data.dict(), **{'id': '1'}}
return {'data': created_customer}
```
The openapi.json will include the unwanted 422 response with the FastAPI default error object definitions:
```yaml
# ...
'422':
description: Validation Error
content:
application/json:
schema:
"$ref": "#/components/schemas/HTTPValidationError"
```
**Expected behavior**
At least, the media_type of the response_class should be respected. But the best would be if the 422 would not be added to the specification unless requested via the path decorator. Or if the 422 definitions of mine were respected.
```python
@app.post('/customers',
status_code=status.HTTP_201_CREATED,
response_model=schemas.CustomerDetailsResponse,
response_class=JsonApiResponse,
responses={
422: {
'model': schemas.ErrorResponse
},
})
data: schemas.Customer = Body(..., media_type='application/vnd+json.api', embed=True)):
pass
```
**Environment:**
- OS: masOS 10.14.6
- Python: 3.6.5
- FastAPI: 0.35.0
| 2019-08-14T12:08:29 |
|
tiangolo/fastapi
| 439 |
tiangolo__fastapi-439
|
[
"431"
] |
033bc2a6c9aec3a245eb1f1b4fadb2fbb7a514b8
|
diff --git a/fastapi/dependencies/utils.py b/fastapi/dependencies/utils.py
--- a/fastapi/dependencies/utils.py
+++ b/fastapi/dependencies/utils.py
@@ -546,6 +546,8 @@ def get_body_field(*, dependant: Dependant, name: str) -> Optional[Field]:
for f in flat_dependant.body_params:
BodyModel.__fields__[f.name] = get_schema_compatible_field(field=f)
required = any(True for f in flat_dependant.body_params if f.required)
+
+ BodySchema_kwargs: Dict[str, Any] = dict(default=None)
if any(isinstance(f.schema, params.File) for f in flat_dependant.body_params):
BodySchema: Type[params.Body] = params.File
elif any(isinstance(f.schema, params.Form) for f in flat_dependant.body_params):
@@ -553,6 +555,14 @@ def get_body_field(*, dependant: Dependant, name: str) -> Optional[Field]:
else:
BodySchema = params.Body
+ body_param_media_types = [
+ getattr(f.schema, "media_type")
+ for f in flat_dependant.body_params
+ if isinstance(f.schema, params.Body)
+ ]
+ if len(set(body_param_media_types)) == 1:
+ BodySchema_kwargs["media_type"] = body_param_media_types[0]
+
field = Field(
name="body",
type_=BodyModel,
@@ -561,6 +571,6 @@ def get_body_field(*, dependant: Dependant, name: str) -> Optional[Field]:
model_config=BaseConfig,
class_validators={},
alias="body",
- schema=BodySchema(None),
+ schema=BodySchema(**BodySchema_kwargs),
)
return field
|
diff --git a/tests/test_request_body_parameters_media_type.py b/tests/test_request_body_parameters_media_type.py
new file mode 100644
--- /dev/null
+++ b/tests/test_request_body_parameters_media_type.py
@@ -0,0 +1,67 @@
+import typing
+
+from fastapi import Body, FastAPI
+from pydantic import BaseModel
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+media_type = "application/vnd.api+json"
+
+# NOTE: These are not valid JSON:API resources
+# but they are fine for testing requestBody with custom media_type
+class Product(BaseModel):
+ name: str
+ price: float
+
+
+class Shop(BaseModel):
+ name: str
+
+
[email protected]("/products")
+async def create_product(data: Product = Body(..., media_type=media_type, embed=True)):
+ pass # pragma: no cover
+
+
[email protected]("/shops")
+async def create_shop(
+ data: Shop = Body(..., media_type=media_type),
+ included: typing.List[Product] = Body([], media_type=media_type),
+):
+ pass # pragma: no cover
+
+
+create_product_request_body = {
+ "content": {
+ "application/vnd.api+json": {
+ "schema": {"$ref": "#/components/schemas/Body_create_product_products_post"}
+ }
+ },
+ "required": True,
+}
+
+create_shop_request_body = {
+ "content": {
+ "application/vnd.api+json": {
+ "schema": {"$ref": "#/components/schemas/Body_create_shop_shops_post"}
+ }
+ },
+ "required": True,
+}
+
+client = TestClient(app)
+
+
+def test_openapi_schema():
+ response = client.get("/openapi.json")
+ assert response.status_code == 200
+ openapi_schema = response.json()
+ assert (
+ openapi_schema["paths"]["/products"]["post"]["requestBody"]
+ == create_product_request_body
+ )
+ assert (
+ openapi_schema["paths"]["/shops"]["post"]["requestBody"]
+ == create_shop_request_body
+ )
|
OpenAPI: media_types of Body parameters and requestBody do not match
**Describe the bug**
The openapi.json for requestBody definitions uses the FastAPI default media_type instead of the defined one in the Body parameter(s).
**To Reproduce**
Create a path with request body that has either a single embedded parameter or multiple ones. List media_type that is different than the default application/json is.
```python
from fastapi import FastAPI
from starlette import status
from . import schemas
app = FastAPI()
@app.post('/customers',
status_code=status.HTTP_201_CREATED,
)
def customer_create(data: schemas.Customer = Body(..., media_type='application/vnd+json.api', embed=True)):
created_customer = {**data.dict(), **{'id': '1'}}
return {'data': created_customer}
```
Then verify your openapi.json.
```yaml
# ...
post:
responses:
# ...
summary: Customer Create
operationId: customer_create_api_customers_post
requestBody:
content:
application/json: # this should be different
schema:
"$ref": "#/components/schemas/Body_customer_create_api_customers_post"
required: true
```
**Expected behavior**
The media_type of the requestBody of given path matches the specified one:
```yaml
# ...
post:
responses:
# ...
summary: Customer Create
operationId: customer_create_api_customers_post
requestBody:
content:
application/vnd+json.api:
schema:
"$ref": "#/components/schemas/Body_customer_create_api_customers_post"
required: true
```
**Environment:**
- OS: masOS 10.14.6
- Python: 3.6.5
- FastAPI: 0.35.0
| 2019-08-15T07:13:04 |
|
tiangolo/fastapi
| 454 |
tiangolo__fastapi-454
|
[
"265"
] |
033bc2a6c9aec3a245eb1f1b4fadb2fbb7a514b8
|
diff --git a/fastapi/utils.py b/fastapi/utils.py
--- a/fastapi/utils.py
+++ b/fastapi/utils.py
@@ -1,4 +1,5 @@
import re
+from dataclasses import is_dataclass
from typing import Any, Dict, List, Sequence, Set, Type, cast
from fastapi import routing
@@ -52,6 +53,8 @@ def get_path_param_names(path: str) -> Set[str]:
def create_cloned_field(field: Field) -> Field:
original_type = field.type_
+ if is_dataclass(original_type) and hasattr(original_type, "__pydantic_model__"):
+ original_type = original_type.__pydantic_model__ # type: ignore
use_type = original_type
if lenient_issubclass(original_type, BaseModel):
original_type = cast(Type[BaseModel], original_type)
|
diff --git a/tests/test_serialize_response.py b/tests/test_serialize_response.py
--- a/tests/test_serialize_response.py
+++ b/tests/test_serialize_response.py
@@ -1,8 +1,7 @@
from typing import List
-import pytest
from fastapi import FastAPI
-from pydantic import BaseModel, ValidationError
+from pydantic import BaseModel
from starlette.testclient import TestClient
app = FastAPI()
@@ -14,38 +13,45 @@ class Item(BaseModel):
owner_ids: List[int] = None
[email protected]("/items/invalid", response_model=Item)
-def get_invalid():
- return {"name": "invalid", "price": "foo"}
[email protected]("/items/valid", response_model=Item)
+def get_valid():
+ return {"name": "valid", "price": 1.0}
[email protected]("/items/innerinvalid", response_model=Item)
-def get_innerinvalid():
- return {"name": "double invalid", "price": "foo", "owner_ids": ["foo", "bar"]}
[email protected]("/items/coerce", response_model=Item)
+def get_coerce():
+ return {"name": "coerce", "price": "1.0"}
[email protected]("/items/invalidlist", response_model=List[Item])
-def get_invalidlist():
[email protected]("/items/validlist", response_model=List[Item])
+def get_validlist():
return [
{"name": "foo"},
- {"name": "bar", "price": "bar"},
- {"name": "baz", "price": "baz"},
+ {"name": "bar", "price": 1.0},
+ {"name": "baz", "price": 2.0, "owner_ids": [1, 2, 3]},
]
client = TestClient(app)
-def test_invalid():
- with pytest.raises(ValidationError):
- client.get("/items/invalid")
+def test_valid():
+ response = client.get("/items/valid")
+ response.raise_for_status()
+ assert response.json() == {"name": "valid", "price": 1.0, "owner_ids": None}
-def test_double_invalid():
- with pytest.raises(ValidationError):
- client.get("/items/innerinvalid")
+def test_coerce():
+ response = client.get("/items/coerce")
+ response.raise_for_status()
+ assert response.json() == {"name": "coerce", "price": 1.0, "owner_ids": None}
-def test_invalid_list():
- with pytest.raises(ValidationError):
- client.get("/items/invalidlist")
+def test_validlist():
+ response = client.get("/items/validlist")
+ response.raise_for_status()
+ assert response.json() == [
+ {"name": "foo", "price": None, "owner_ids": None},
+ {"name": "bar", "price": 1.0, "owner_ids": None},
+ {"name": "baz", "price": 2.0, "owner_ids": [1, 2, 3]},
+ ]
diff --git a/tests/test_serialize_response_dataclass.py b/tests/test_serialize_response_dataclass.py
new file mode 100644
--- /dev/null
+++ b/tests/test_serialize_response_dataclass.py
@@ -0,0 +1,58 @@
+from typing import List
+
+from fastapi import FastAPI
+from pydantic.dataclasses import dataclass
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
+@dataclass
+class Item:
+ name: str
+ price: float = None
+ owner_ids: List[int] = None
+
+
[email protected]("/items/valid", response_model=Item)
+def get_valid():
+ return {"name": "valid", "price": 1.0}
+
+
[email protected]("/items/coerce", response_model=Item)
+def get_coerce():
+ return {"name": "coerce", "price": "1.0"}
+
+
[email protected]("/items/validlist", response_model=List[Item])
+def get_validlist():
+ return [
+ {"name": "foo"},
+ {"name": "bar", "price": 1.0},
+ {"name": "baz", "price": 2.0, "owner_ids": [1, 2, 3]},
+ ]
+
+
+client = TestClient(app)
+
+
+def test_valid():
+ response = client.get("/items/valid")
+ response.raise_for_status()
+ assert response.json() == {"name": "valid", "price": 1.0, "owner_ids": None}
+
+
+def test_coerce():
+ response = client.get("/items/coerce")
+ response.raise_for_status()
+ assert response.json() == {"name": "coerce", "price": 1.0, "owner_ids": None}
+
+
+def test_validlist():
+ response = client.get("/items/validlist")
+ response.raise_for_status()
+ assert response.json() == [
+ {"name": "foo", "price": None, "owner_ids": None},
+ {"name": "bar", "price": 1.0, "owner_ids": None},
+ {"name": "baz", "price": 2.0, "owner_ids": [1, 2, 3]},
+ ]
diff --git a/tests/test_validate_response.py b/tests/test_validate_response.py
new file mode 100644
--- /dev/null
+++ b/tests/test_validate_response.py
@@ -0,0 +1,51 @@
+from typing import List
+
+import pytest
+from fastapi import FastAPI
+from pydantic import BaseModel, ValidationError
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
+class Item(BaseModel):
+ name: str
+ price: float = None
+ owner_ids: List[int] = None
+
+
[email protected]("/items/invalid", response_model=Item)
+def get_invalid():
+ return {"name": "invalid", "price": "foo"}
+
+
[email protected]("/items/innerinvalid", response_model=Item)
+def get_innerinvalid():
+ return {"name": "double invalid", "price": "foo", "owner_ids": ["foo", "bar"]}
+
+
[email protected]("/items/invalidlist", response_model=List[Item])
+def get_invalidlist():
+ return [
+ {"name": "foo"},
+ {"name": "bar", "price": "bar"},
+ {"name": "baz", "price": "baz"},
+ ]
+
+
+client = TestClient(app)
+
+
+def test_invalid():
+ with pytest.raises(ValidationError):
+ client.get("/items/invalid")
+
+
+def test_double_invalid():
+ with pytest.raises(ValidationError):
+ client.get("/items/innerinvalid")
+
+
+def test_invalid_list():
+ with pytest.raises(ValidationError):
+ client.get("/items/invalidlist")
diff --git a/tests/test_validate_response_dataclass.py b/tests/test_validate_response_dataclass.py
new file mode 100644
--- /dev/null
+++ b/tests/test_validate_response_dataclass.py
@@ -0,0 +1,53 @@
+from typing import List
+
+import pytest
+from fastapi import FastAPI
+from pydantic import ValidationError
+from pydantic.dataclasses import dataclass
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
+@dataclass
+class Item:
+ name: str
+ price: float = None
+ owner_ids: List[int] = None
+
+
[email protected]("/items/invalid", response_model=Item)
+def get_invalid():
+ return {"name": "invalid", "price": "foo"}
+
+
[email protected]("/items/innerinvalid", response_model=Item)
+def get_innerinvalid():
+ return {"name": "double invalid", "price": "foo", "owner_ids": ["foo", "bar"]}
+
+
[email protected]("/items/invalidlist", response_model=List[Item])
+def get_invalidlist():
+ return [
+ {"name": "foo"},
+ {"name": "bar", "price": "bar"},
+ {"name": "baz", "price": "baz"},
+ ]
+
+
+client = TestClient(app)
+
+
+def test_invalid():
+ with pytest.raises(ValidationError):
+ client.get("/items/invalid")
+
+
+def test_double_invalid():
+ with pytest.raises(ValidationError):
+ client.get("/items/innerinvalid")
+
+
+def test_invalid_list():
+ with pytest.raises(ValidationError):
+ client.get("/items/invalidlist")
|
Add support for Pydantic's dataclasses
**Describe the question**
I am using a pydantic.dataclasses.dataclass as a response_model of my fast api route.
```
from fastapi import FastAPI
from pydantic.dataclasses import dataclass
@dataclass
class Foo:
bar: int
app = FastAPI()
@app.get('/foo', response_model=Foo)
def get_bar() -> Foo:
return Foo(bar=1)
```
**To Reproduce**
Steps to reproduce the behavior:
1. Create a file **app.py** with the above code.
2. Start the app: `uvicorn app:app`
3. Open the browser and go to **localhost:8000/foo**
4. See error:
```
pydantic.error_wrappers.ValidationError: 1 validation error
response
__init__() got an unexpected keyword argument '__initialised__' (type=type_error)
```
**Expected behavior**
No validation error and serialized json does not contain any keys `__initialised__`.
**Environment:**
- OS: Linux
- FastAPI Version 0.25.0
- Python version 3.7.3
|
**Possible solution**
Add the following to jsonable_encoder in fastapi.encoders:
```
from dataclasses import is_dataclass, asdict
def jsonable_encoder(
obj: Any,
include: Set[str] = None,
exclude: Set[str] = set(),
by_alias: bool = True,
skip_defaults: bool = False,
include_none: bool = True,
custom_encoder: dict = {},
sqlalchemy_safe: bool = True,
) -> Any:
...
if is_dataclass(obj):
return asdict(obj)
```
Thank you. Pydantic's dataclasses are not supported yet. They probably will be at some point.
Any updates on this?
Using pydantic BaseModel vs dataclass causes tremendous slowdown as well in my codebase.
@manojlds which one is slower?
👍 for this. I have a backend code base that heavily relies on pydantic dataclasses.
Just a thought, the way pydantic dataclasses are handled is by putting the `BaseModel` subclass at `cls.__pydantic_model__`, e.g.:
```python
from pydantic.dataclasses import dataclass
from pydantic import BaseModel
@dataclass
class Foobar:
pass
assert issubclass(Foobar.__pydantic_model__, BaseModel)
```
Could this be solved with a simple:
```python
if isdataclass(cls) and hasattr(cls, "__pydantic_model__"):
cls = cls.__pydantic_model__
```
Somewhere?
Maybe part of https://github.com/tiangolo/fastapi/blob/master/fastapi/utils.py#L53 ?
| 2019-08-21T17:34:14 |
tiangolo/fastapi
| 493 |
tiangolo__fastapi-493
|
[
"492",
"492"
] |
203e10596f7de81eda52925113440ebc9a1278a0
|
diff --git a/fastapi/exceptions.py b/fastapi/exceptions.py
--- a/fastapi/exceptions.py
+++ b/fastapi/exceptions.py
@@ -2,8 +2,8 @@
from pydantic import ValidationError
from pydantic.error_wrappers import ErrorList
-from requests import Request
from starlette.exceptions import HTTPException as StarletteHTTPException
+from starlette.requests import Request
from starlette.websockets import WebSocket
|
FastAPI exceptions module mistakenly references the 'requests' package
**Describe the bug**
Starting up a FastAPI 0.38.0 app displays the following error:
```python
from fastapi import FastAPI
File ".../lib/site-packages/fastapi/__init__.py", line 7, in <module>
from .applications import FastAPI
File ".../lib/site-packages/fastapi/applications.py", line 3, in <module>
from fastapi import routing
File ".../lib/site-packages/fastapi/routing.py", line 7, in <module>
from fastapi.dependencies.models import Dependant
File ".../lib/site-packages/fastapi/dependencies/models.py", line 3, in <module>
from fastapi.security.base import SecurityBase
File ".../lib/site-packages/fastapi/security/__init__.py", line 2, in <module>
from .http import (
File ".../lib/site-packages/fastapi/security/http.py", line 5, in <module>
from fastapi.exceptions import HTTPException
File ".../lib/site-packages/fastapi/exceptions.py", line 5, in <module>
from requests import Request
ModuleNotFoundError: No module named 'requests'
```
**Expected behavior**
The app should start without import errors.
**Environment:**
- OS: Linux, Windows, and macOS
- FastAPI Version: 0.38.0
**Additional context**
It's likely the `from requests import Request` should be replaced with `from starlette.requests import Request` in line 5 of `fastapi/exceptions.py`
FastAPI exceptions module mistakenly references the 'requests' package
**Describe the bug**
Starting up a FastAPI 0.38.0 app displays the following error:
```python
from fastapi import FastAPI
File ".../lib/site-packages/fastapi/__init__.py", line 7, in <module>
from .applications import FastAPI
File ".../lib/site-packages/fastapi/applications.py", line 3, in <module>
from fastapi import routing
File ".../lib/site-packages/fastapi/routing.py", line 7, in <module>
from fastapi.dependencies.models import Dependant
File ".../lib/site-packages/fastapi/dependencies/models.py", line 3, in <module>
from fastapi.security.base import SecurityBase
File ".../lib/site-packages/fastapi/security/__init__.py", line 2, in <module>
from .http import (
File ".../lib/site-packages/fastapi/security/http.py", line 5, in <module>
from fastapi.exceptions import HTTPException
File ".../lib/site-packages/fastapi/exceptions.py", line 5, in <module>
from requests import Request
ModuleNotFoundError: No module named 'requests'
```
**Expected behavior**
The app should start without import errors.
**Environment:**
- OS: Linux, Windows, and macOS
- FastAPI Version: 0.38.0
**Additional context**
It's likely the `from requests import Request` should be replaced with `from starlette.requests import Request` in line 5 of `fastapi/exceptions.py`
|
Sorry about this! (It was my PR that caused the problem.)
This is the correct fix. @tiangolo this should probably be released as a patch.
Sorry about this! (It was my PR that caused the problem.)
This is the correct fix. @tiangolo this should probably be released as a patch.
| 2019-08-31T18:33:37 |
|
tiangolo/fastapi
| 538 |
tiangolo__fastapi-538
|
[
"539"
] |
f5ccb3c35d4ee87f61b0c03c8e4b0c24edffac60
|
diff --git a/fastapi/routing.py b/fastapi/routing.py
--- a/fastapi/routing.py
+++ b/fastapi/routing.py
@@ -345,8 +345,10 @@ def add_api_route(
include_in_schema: bool = True,
response_class: Type[Response] = None,
name: str = None,
+ route_class_override: Optional[Type[APIRoute]] = None,
) -> None:
- route = self.route_class(
+ route_class = route_class_override or self.route_class
+ route = route_class(
path,
endpoint=endpoint,
response_model=response_model,
@@ -484,6 +486,7 @@ def include_router(
include_in_schema=route.include_in_schema,
response_class=route.response_class or default_response_class,
name=route.name,
+ route_class_override=type(route),
)
elif isinstance(route, routing.Route):
self.add_route(
|
diff --git a/tests/test_custom_route_class.py b/tests/test_custom_route_class.py
new file mode 100644
--- /dev/null
+++ b/tests/test_custom_route_class.py
@@ -0,0 +1,114 @@
+import pytest
+from fastapi import APIRouter, FastAPI
+from fastapi.routing import APIRoute
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
+class APIRouteA(APIRoute):
+ x_type = "A"
+
+
+class APIRouteB(APIRoute):
+ x_type = "B"
+
+
+class APIRouteC(APIRoute):
+ x_type = "C"
+
+
+router_a = APIRouter(route_class=APIRouteA)
+router_b = APIRouter(route_class=APIRouteB)
+router_c = APIRouter(route_class=APIRouteC)
+
+
+@router_a.get("/")
+def get_a():
+ return {"msg": "A"}
+
+
+@router_b.get("/")
+def get_b():
+ return {"msg": "B"}
+
+
+@router_c.get("/")
+def get_c():
+ return {"msg": "C"}
+
+
+router_b.include_router(router=router_c, prefix="/c")
+router_a.include_router(router=router_b, prefix="/b")
+app.include_router(router=router_a, prefix="/a")
+
+
+client = TestClient(app)
+
+openapi_schema = {
+ "openapi": "3.0.2",
+ "info": {"title": "Fast API", "version": "0.1.0"},
+ "paths": {
+ "/a/": {
+ "get": {
+ "responses": {
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ }
+ },
+ "summary": "Get A",
+ "operationId": "get_a_a__get",
+ }
+ },
+ "/a/b/": {
+ "get": {
+ "responses": {
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ }
+ },
+ "summary": "Get B",
+ "operationId": "get_b_a_b__get",
+ }
+ },
+ "/a/b/c/": {
+ "get": {
+ "responses": {
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ }
+ },
+ "summary": "Get C",
+ "operationId": "get_c_a_b_c__get",
+ }
+ },
+ },
+}
+
+
[email protected](
+ "path,expected_status,expected_response",
+ [
+ ("/a", 200, {"msg": "A"}),
+ ("/a/b", 200, {"msg": "B"}),
+ ("/a/b/c", 200, {"msg": "C"}),
+ ("/openapi.json", 200, openapi_schema),
+ ],
+)
+def test_get_path(path, expected_status, expected_response):
+ response = client.get(path)
+ assert response.status_code == expected_status
+ assert response.json() == expected_response
+
+
+def test_route_classes():
+ routes = {}
+ r: APIRoute
+ for r in app.router.routes:
+ routes[r.path] = r
+ assert routes["/a/"].x_type == "A"
+ assert routes["/a/b/"].x_type == "B"
+ assert routes["/a/b/c/"].x_type == "C"
|
route_class not preserved when calling APIRouter.include_router
**Describe the bug**
When calling `APIRouter.include_router`, the class of the included routes should be preserved. Right now, this is not the case -- the `route_class` of the parent router is used. This means that the `route_class` is lost on inclusion if one isn't careful. Worse, it means that even if you manually create a router with multiple route-types present, there is no way to include that router in another without changing the route type of some of the routes.
See the `include_typed_router` function from #521 for an example of how this currently requires a workaround.
I have addressed this in the short PR #538, but wanted to create an issue for discussion in case there is any reason to preserve the current behavior.
| 2019-09-17T04:51:53 |
|
tiangolo/fastapi
| 621 |
tiangolo__fastapi-621
|
[
"259"
] |
65536cbf63318d111bf608960378d651b6c1596a
|
diff --git a/fastapi/openapi/constants.py b/fastapi/openapi/constants.py
--- a/fastapi/openapi/constants.py
+++ b/fastapi/openapi/constants.py
@@ -1,2 +1,3 @@
METHODS_WITH_BODY = set(("POST", "PUT", "DELETE", "PATCH"))
+STATUS_CODES_WITH_NO_BODY = set((100, 101, 102, 103, 204, 304))
REF_PREFIX = "#/components/schemas/"
diff --git a/fastapi/openapi/utils.py b/fastapi/openapi/utils.py
--- a/fastapi/openapi/utils.py
+++ b/fastapi/openapi/utils.py
@@ -5,7 +5,11 @@
from fastapi.dependencies.models import Dependant
from fastapi.dependencies.utils import get_flat_dependant
from fastapi.encoders import jsonable_encoder
-from fastapi.openapi.constants import METHODS_WITH_BODY, REF_PREFIX
+from fastapi.openapi.constants import (
+ METHODS_WITH_BODY,
+ REF_PREFIX,
+ STATUS_CODES_WITH_NO_BODY,
+)
from fastapi.openapi.models import OpenAPI
from fastapi.params import Body, Param
from fastapi.utils import (
@@ -79,7 +83,7 @@ def get_openapi_security_definitions(flat_dependant: Dependant) -> Tuple[Dict, L
def get_openapi_operation_parameters(
- all_route_params: Sequence[Field]
+ all_route_params: Sequence[Field],
) -> List[Dict[str, Any]]:
parameters = []
for param in all_route_params:
@@ -151,10 +155,8 @@ def get_openapi_path(
security_schemes: Dict[str, Any] = {}
definitions: Dict[str, Any] = {}
assert route.methods is not None, "Methods must be a list"
- assert (
- route.response_class and route.response_class.media_type
- ), "A response class with media_type is needed to generate OpenAPI"
- route_response_media_type: str = route.response_class.media_type
+ assert route.response_class, "A response class is needed to generate OpenAPI"
+ route_response_media_type: Optional[str] = route.response_class.media_type
if route.include_in_schema:
for method in route.methods:
operation = get_openapi_operation_metadata(route=route, method=method)
@@ -189,7 +191,7 @@ def get_openapi_path(
field, model_name_map=model_name_map, ref_prefix=REF_PREFIX
)
response.setdefault("content", {}).setdefault(
- route_response_media_type, {}
+ route_response_media_type or "application/json", {}
)["schema"] = response_schema
status_text: Optional[str] = status_code_ranges.get(
str(additional_status_code).upper()
@@ -202,24 +204,28 @@ def get_openapi_path(
status_code_key = "default"
operation.setdefault("responses", {})[status_code_key] = response
status_code = str(route.status_code)
- response_schema = {"type": "string"}
- if lenient_issubclass(route.response_class, JSONResponse):
- if route.response_field:
- response_schema, _, _ = field_schema(
- route.response_field,
- model_name_map=model_name_map,
- ref_prefix=REF_PREFIX,
- )
- else:
- response_schema = {}
operation.setdefault("responses", {}).setdefault(status_code, {})[
"description"
] = route.response_description
- operation.setdefault("responses", {}).setdefault(
- status_code, {}
- ).setdefault("content", {}).setdefault(route_response_media_type, {})[
- "schema"
- ] = response_schema
+ if (
+ route_response_media_type
+ and route.status_code not in STATUS_CODES_WITH_NO_BODY
+ ):
+ response_schema = {"type": "string"}
+ if lenient_issubclass(route.response_class, JSONResponse):
+ if route.response_field:
+ response_schema, _, _ = field_schema(
+ route.response_field,
+ model_name_map=model_name_map,
+ ref_prefix=REF_PREFIX,
+ )
+ else:
+ response_schema = {}
+ operation.setdefault("responses", {}).setdefault(
+ status_code, {}
+ ).setdefault("content", {}).setdefault(route_response_media_type, {})[
+ "schema"
+ ] = response_schema
http422 = str(HTTP_422_UNPROCESSABLE_ENTITY)
if (all_route_params or route.body_field) and not any(
diff --git a/fastapi/routing.py b/fastapi/routing.py
--- a/fastapi/routing.py
+++ b/fastapi/routing.py
@@ -13,6 +13,7 @@
)
from fastapi.encoders import DictIntStrAny, SetIntStr, jsonable_encoder
from fastapi.exceptions import RequestValidationError, WebSocketRequestValidationError
+from fastapi.openapi.constants import STATUS_CODES_WITH_NO_BODY
from fastapi.utils import create_cloned_field, generate_operation_id_for_path
from pydantic import BaseConfig, BaseModel, Schema
from pydantic.error_wrappers import ErrorWrapper, ValidationError
@@ -215,6 +216,9 @@ def __init__(
)
self.response_model = response_model
if self.response_model:
+ assert (
+ status_code not in STATUS_CODES_WITH_NO_BODY
+ ), f"Status code {status_code} must not have a response body"
response_name = "Response_" + self.unique_id
self.response_field: Optional[Field] = Field(
name=response_name,
@@ -256,6 +260,9 @@ def __init__(
assert isinstance(response, dict), "An additional response must be a dict"
model = response.get("model")
if model:
+ assert (
+ additional_status_code not in STATUS_CODES_WITH_NO_BODY
+ ), f"Status code {additional_status_code} must not have a response body"
assert lenient_issubclass(
model, BaseModel
), "A response model must be a Pydantic model"
|
diff --git a/tests/test_response_class_no_mediatype.py b/tests/test_response_class_no_mediatype.py
new file mode 100644
--- /dev/null
+++ b/tests/test_response_class_no_mediatype.py
@@ -0,0 +1,114 @@
+import typing
+
+from fastapi import FastAPI
+from pydantic import BaseModel
+from starlette.responses import JSONResponse, Response
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
+class JsonApiResponse(JSONResponse):
+ media_type = "application/vnd.api+json"
+
+
+class Error(BaseModel):
+ status: str
+ title: str
+
+
+class JsonApiError(BaseModel):
+ errors: typing.List[Error]
+
+
[email protected](
+ "/a",
+ response_class=Response,
+ responses={500: {"description": "Error", "model": JsonApiError}},
+)
+async def a():
+ pass # pragma: no cover
+
+
[email protected]("/b", responses={500: {"description": "Error", "model": Error}})
+async def b():
+ pass # pragma: no cover
+
+
+openapi_schema = {
+ "openapi": "3.0.2",
+ "info": {"title": "Fast API", "version": "0.1.0"},
+ "paths": {
+ "/a": {
+ "get": {
+ "responses": {
+ "500": {
+ "description": "Error",
+ "content": {
+ "application/json": {
+ "schema": {"$ref": "#/components/schemas/JsonApiError"}
+ }
+ },
+ },
+ "200": {"description": "Successful Response"},
+ },
+ "summary": "A",
+ "operationId": "a_a_get",
+ }
+ },
+ "/b": {
+ "get": {
+ "responses": {
+ "500": {
+ "description": "Error",
+ "content": {
+ "application/json": {
+ "schema": {"$ref": "#/components/schemas/Error"}
+ }
+ },
+ },
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ },
+ },
+ "summary": "B",
+ "operationId": "b_b_get",
+ }
+ },
+ },
+ "components": {
+ "schemas": {
+ "Error": {
+ "title": "Error",
+ "required": ["status", "title"],
+ "type": "object",
+ "properties": {
+ "status": {"title": "Status", "type": "string"},
+ "title": {"title": "Title", "type": "string"},
+ },
+ },
+ "JsonApiError": {
+ "title": "JsonApiError",
+ "required": ["errors"],
+ "type": "object",
+ "properties": {
+ "errors": {
+ "title": "Errors",
+ "type": "array",
+ "items": {"$ref": "#/components/schemas/Error"},
+ }
+ },
+ },
+ }
+ },
+}
+
+
+client = TestClient(app)
+
+
+def test_openapi_schema():
+ response = client.get("/openapi.json")
+ assert response.status_code == 200
+ assert response.json() == openapi_schema
diff --git a/tests/test_response_code_no_body.py b/tests/test_response_code_no_body.py
new file mode 100644
--- /dev/null
+++ b/tests/test_response_code_no_body.py
@@ -0,0 +1,108 @@
+import typing
+
+from fastapi import FastAPI
+from pydantic import BaseModel
+from starlette.responses import JSONResponse
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
+class JsonApiResponse(JSONResponse):
+ media_type = "application/vnd.api+json"
+
+
+class Error(BaseModel):
+ status: str
+ title: str
+
+
+class JsonApiError(BaseModel):
+ errors: typing.List[Error]
+
+
[email protected](
+ "/a",
+ status_code=204,
+ response_class=JsonApiResponse,
+ responses={500: {"description": "Error", "model": JsonApiError}},
+)
+async def a():
+ pass # pragma: no cover
+
+
[email protected]("/b", responses={204: {"description": "No Content"}})
+async def b():
+ pass # pragma: no cover
+
+
+openapi_schema = {
+ "openapi": "3.0.2",
+ "info": {"title": "Fast API", "version": "0.1.0"},
+ "paths": {
+ "/a": {
+ "get": {
+ "responses": {
+ "500": {
+ "description": "Error",
+ "content": {
+ "application/vnd.api+json": {
+ "schema": {"$ref": "#/components/schemas/JsonApiError"}
+ }
+ },
+ },
+ "204": {"description": "Successful Response"},
+ },
+ "summary": "A",
+ "operationId": "a_a_get",
+ }
+ },
+ "/b": {
+ "get": {
+ "responses": {
+ "204": {"description": "No Content"},
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ },
+ },
+ "summary": "B",
+ "operationId": "b_b_get",
+ }
+ },
+ },
+ "components": {
+ "schemas": {
+ "Error": {
+ "title": "Error",
+ "required": ["status", "title"],
+ "type": "object",
+ "properties": {
+ "status": {"title": "Status", "type": "string"},
+ "title": {"title": "Title", "type": "string"},
+ },
+ },
+ "JsonApiError": {
+ "title": "JsonApiError",
+ "required": ["errors"],
+ "type": "object",
+ "properties": {
+ "errors": {
+ "title": "Errors",
+ "type": "array",
+ "items": {"$ref": "#/components/schemas/Error"},
+ }
+ },
+ },
+ }
+ },
+}
+
+
+client = TestClient(app)
+
+
+def test_openapi_schema():
+ response = client.get("/openapi.json")
+ assert response.status_code == 200
+ assert response.json() == openapi_schema
|
204 No Content support for OpenAPI schema
I would like to be able to specify in the endpoint decorator that the endpoint will have no response (204 No Content). This is documented in the [swagger.io specification](https://swagger.io/docs/specification/describing-responses/) under the heading Empty Response Body.
**Is your feature request related to a problem? Please describe.**
This would allow my `openapi-generator`-generated client to detect that there will not be a response, and will automatically make use of an appropriate response (non-)decoder.
It's not a terribly hard issue to work around manually by tweaking my generated client, but it would simplify things if I could generate an OpenAPI schema without the content field for the 204-response endpoints.
**Describe the solution you'd like**
So far, my favorite version of an end-user-facing API would involve introducing a new response class (perhaps called `NoContentResponse`) to pass in the endpoint decorator.
(But I'm not sure how that would interact with `starlette` or if detecting the response_class is even feasible when generating the OpenAPI spec.)
|
I see. I'll check it.
Any news on this issue? I'm facing the same problem and tried something like
```python
HTTP_204_NO_CONTENT: dict(
description="Successful action.",
content=None,
)
```
Which only lead to `AttributeError: 'NoneType' object has no attribute 'setdefault'`.
This seemed like an intuitive way to me, but it would be even more intuitive if no content was the default for a 204 with a warning for the user if he declared `content` explicitly.
I just ran into this as well. I have an idea about how to make `get_openapi_path` for response codes that don't allow bodies or additional status codes that don't specify body parameters. That would be backward-compatible with existing code, and would make decorators such as:
```python
@app.delete('/frotz/{fid}', status_code=204)
```
and
```python
@app.post(
'/frotz/',
status_code=201,
responses={302: {'description': 'Such a frotz already exists'}
)
```
do the right thing.
| 2019-10-14T06:53:04 |
tiangolo/fastapi
| 637 |
tiangolo__fastapi-637
|
[
"630",
"630"
] |
65536cbf63318d111bf608960378d651b6c1596a
|
diff --git a/fastapi/utils.py b/fastapi/utils.py
--- a/fastapi/utils.py
+++ b/fastapi/utils.py
@@ -59,12 +59,11 @@ def create_cloned_field(field: Field) -> Field:
if lenient_issubclass(original_type, BaseModel):
original_type = cast(Type[BaseModel], original_type)
use_type = create_model(
- original_type.__name__,
- __config__=original_type.__config__,
- __validators__=original_type.__validators__, # type: ignore
+ original_type.__name__, __config__=original_type.__config__
)
for f in original_type.__fields__.values():
use_type.__fields__[f.name] = f
+ use_type.__validators__ = original_type.__validators__
new_field = Field(
name=field.name,
type_=use_type,
|
JSON output reordered by pydantic @validator
This isn't a big problem, but I'm wondering if it's possible to keep the JSON output key ordering unaffected by the presence of a Pydantic `@validator(...)`? I like consistency. 🤷♂️
I have this pydantic model structure:
```
class IngredientBase(BaseIngredientMixin):
name: str = None
unit: str = None
unit_price: decimal.Decimal = None
flavour_warning: bool = None
@validator('unit')
def valid_units_only(cls, v):
choices = set(SingleIngredientTable.unit_choices.keys())
if v and v not in choices:
raise ValueError(f'must be one of {choices}')
return v
class IngredientIn(IngredientBase):
pass
class IngredientNew(IngredientIn):
name: str = ...
unit: str = ...
unit_price: decimal.Decimal = ...
class IngredientOut(IngredientBase, TestModelMixin, TimestampModelMixin, IDModelMixin):
pass
```
This will produce:
```
{
"unit": "IU",
"id": "sing_qOYSyqZhfOcJKHsfVz7tnfP6M",
"created": 1571357369,
"updated": 1571418480,
"is_test": false,
"name": "Vitamin C",
"unit_price": 10.568536363534536,
"flavour_warning": false
}
```
Without the validator, it produces what I would expect:
```
{
"id": "sing_qOYSyqZhfOcJKHsfVz7tnfP6M",
"created": 1571357369,
"updated": 1571418480,
"is_test": false,
"name": "Vitamin C",
"unit": "IU",
"unit_price": 10.568536363534536,
"flavour_warning": false
}
```
How can I continue to use `@validator`s and maintain the expected JSON key ordering?
**Edit**: I can pull out the validator into a 'mixin' class that I apply ONLY to the `IngredientIn` and `IngredientNew` models (leaving `IngredientOut` untouched). But is that my only path here?
JSON output reordered by pydantic @validator
This isn't a big problem, but I'm wondering if it's possible to keep the JSON output key ordering unaffected by the presence of a Pydantic `@validator(...)`? I like consistency. 🤷♂️
I have this pydantic model structure:
```
class IngredientBase(BaseIngredientMixin):
name: str = None
unit: str = None
unit_price: decimal.Decimal = None
flavour_warning: bool = None
@validator('unit')
def valid_units_only(cls, v):
choices = set(SingleIngredientTable.unit_choices.keys())
if v and v not in choices:
raise ValueError(f'must be one of {choices}')
return v
class IngredientIn(IngredientBase):
pass
class IngredientNew(IngredientIn):
name: str = ...
unit: str = ...
unit_price: decimal.Decimal = ...
class IngredientOut(IngredientBase, TestModelMixin, TimestampModelMixin, IDModelMixin):
pass
```
This will produce:
```
{
"unit": "IU",
"id": "sing_qOYSyqZhfOcJKHsfVz7tnfP6M",
"created": 1571357369,
"updated": 1571418480,
"is_test": false,
"name": "Vitamin C",
"unit_price": 10.568536363534536,
"flavour_warning": false
}
```
Without the validator, it produces what I would expect:
```
{
"id": "sing_qOYSyqZhfOcJKHsfVz7tnfP6M",
"created": 1571357369,
"updated": 1571418480,
"is_test": false,
"name": "Vitamin C",
"unit": "IU",
"unit_price": 10.568536363534536,
"flavour_warning": false
}
```
How can I continue to use `@validator`s and maintain the expected JSON key ordering?
**Edit**: I can pull out the validator into a 'mixin' class that I apply ONLY to the `IngredientIn` and `IngredientNew` models (leaving `IngredientOut` untouched). But is that my only path here?
|
@samuelcolvin, @dmontagu mentioned that I should pose this question to you? Might I ask you to weigh in? Thank you!
I don't see how validators could effect output order, but I could be wrong.
Could you create a minimal example of the problem and ask on pydantic?
There are numerous fields referenced here that aren't in the example, and there's a complicated inheritance landscape that makes working out what's happening very complicated.
@samuelcolvin if you look in `BaseModel._iter`, it is iterating over `self.__dict__`, which I believe is built up incrementally during the validation process. I thought having a `pre=True` validator could result in the key getting set earlier than it might otherwise, and then since dicts get iterated over in the order keys were added, that would explain the ordering change.
The example here doesn’t use `pre=True` but I figured something related might be going on.
Maybe I'm being dumb, but I don't think validators effect the order of `__fields__`.
@samuelcolvin Yep, looking through the code I don't see an obvious way this could happen. Thanks for checking.
@jaddison If you can produce a (small) self-contained reproducible example, I can look into this more.
@dmontagu @samuelcolvin - thank you for looking into this.
It isn't (directly) pydantic-related - I replicated my model structure separately and could not reproduce. However...
Instead, **it is related to the `response_model` parameter**; it must force a different method of validation?
To be specific:
* if I remove the `response_model` parameter from the endpoint and return just an instance of that same pydantic model from the endpoint, the key ordering is as I would expect
* reintroducing the `response_model` param manifests the key mis-ordering
**EDIT**: To be clear, you still need to have the validator. However, the model inheritance is not a factor - I believe you can have a single model (no subclassing) with a field validator, and it ought to exhibit this behaviour still (I think)
Tiny sample, demonstrating the issue:
```
from fastapi import FastAPI
from pydantic import BaseModel, validator
app = FastAPI()
class ValidatedModel(BaseModel):
one: str = None
two: str = None
three: str = None
@validator('two')
def validate_two(cls, v):
if v is '1':
raise ValueError
return v
# @app.get("/")
@app.get("/", response_model=ValidatedModel)
async def get():
return {
"one": "one",
"two": "two",
"three": "three"
}
```
Note that I am on Python 3.7.4.
Confirmed the issue, and that the problem doesn't occur for `pydantic.json()` calls. It looks like this is related to the creation of the secured cloned model; if you drop the `response_model` argument to the decorator the order comes out the same with validator or without:
```python
@app.get("/", response_model=None)
async def get():
return ValidatedModel(**{
"one": "one",
"two": "two",
"three": "three"
})
```
I think this will be addressed by https://github.com/samuelcolvin/pydantic/pull/812 (which I'll finish up once pydantic v1 is released) and we can refactor fastapi to make use of that functionality. (That change should also result in a >=2x speedup of serialization when specifying a `response_model`, assuming you return a valid BaseModel instance.)
Yep, I found the problem -- it is in `fastapi.utils`:
```python
def create_cloned_field(field: Field) -> Field:
original_type = field.type_
if is_dataclass(original_type) and hasattr(original_type, "__pydantic_model__"):
original_type = original_type.__pydantic_model__ # type: ignore
use_type = original_type
if lenient_issubclass(original_type, BaseModel):
original_type = cast(Type[BaseModel], original_type)
use_type = create_model(
original_type.__name__,
__config__=original_type.__config__,
__validators__=original_type.__validators__, # type: ignore
)
for f in original_type.__fields__.values():
use_type.__fields__[f.name] = f
...
```
It passes the validator fields first, then tacks on the non-validator fields. Actually, it overwrites them all, but because the `use_type.__fields__` already has the validated fields as keys, they remain at the start of dictionary (because of how dictionaries are ordered in python 3.6+).
The PR I linked above should help do away with the cloned field, which would resolve this issue.
@jaddison It should be a relatively simple fix to get the field ordering right, and you could create a PR doing that if you really cared; that could probably be merged more quickly.
@samuelcolvin, @dmontagu mentioned that I should pose this question to you? Might I ask you to weigh in? Thank you!
I don't see how validators could effect output order, but I could be wrong.
Could you create a minimal example of the problem and ask on pydantic?
There are numerous fields referenced here that aren't in the example, and there's a complicated inheritance landscape that makes working out what's happening very complicated.
@samuelcolvin if you look in `BaseModel._iter`, it is iterating over `self.__dict__`, which I believe is built up incrementally during the validation process. I thought having a `pre=True` validator could result in the key getting set earlier than it might otherwise, and then since dicts get iterated over in the order keys were added, that would explain the ordering change.
The example here doesn’t use `pre=True` but I figured something related might be going on.
Maybe I'm being dumb, but I don't think validators effect the order of `__fields__`.
@samuelcolvin Yep, looking through the code I don't see an obvious way this could happen. Thanks for checking.
@jaddison If you can produce a (small) self-contained reproducible example, I can look into this more.
@dmontagu @samuelcolvin - thank you for looking into this.
It isn't (directly) pydantic-related - I replicated my model structure separately and could not reproduce. However...
Instead, **it is related to the `response_model` parameter**; it must force a different method of validation?
To be specific:
* if I remove the `response_model` parameter from the endpoint and return just an instance of that same pydantic model from the endpoint, the key ordering is as I would expect
* reintroducing the `response_model` param manifests the key mis-ordering
**EDIT**: To be clear, you still need to have the validator. However, the model inheritance is not a factor - I believe you can have a single model (no subclassing) with a field validator, and it ought to exhibit this behaviour still (I think)
Tiny sample, demonstrating the issue:
```
from fastapi import FastAPI
from pydantic import BaseModel, validator
app = FastAPI()
class ValidatedModel(BaseModel):
one: str = None
two: str = None
three: str = None
@validator('two')
def validate_two(cls, v):
if v is '1':
raise ValueError
return v
# @app.get("/")
@app.get("/", response_model=ValidatedModel)
async def get():
return {
"one": "one",
"two": "two",
"three": "three"
}
```
Note that I am on Python 3.7.4.
Confirmed the issue, and that the problem doesn't occur for `pydantic.json()` calls. It looks like this is related to the creation of the secured cloned model; if you drop the `response_model` argument to the decorator the order comes out the same with validator or without:
```python
@app.get("/", response_model=None)
async def get():
return ValidatedModel(**{
"one": "one",
"two": "two",
"three": "three"
})
```
I think this will be addressed by https://github.com/samuelcolvin/pydantic/pull/812 (which I'll finish up once pydantic v1 is released) and we can refactor fastapi to make use of that functionality. (That change should also result in a >=2x speedup of serialization when specifying a `response_model`, assuming you return a valid BaseModel instance.)
Yep, I found the problem -- it is in `fastapi.utils`:
```python
def create_cloned_field(field: Field) -> Field:
original_type = field.type_
if is_dataclass(original_type) and hasattr(original_type, "__pydantic_model__"):
original_type = original_type.__pydantic_model__ # type: ignore
use_type = original_type
if lenient_issubclass(original_type, BaseModel):
original_type = cast(Type[BaseModel], original_type)
use_type = create_model(
original_type.__name__,
__config__=original_type.__config__,
__validators__=original_type.__validators__, # type: ignore
)
for f in original_type.__fields__.values():
use_type.__fields__[f.name] = f
...
```
It passes the validator fields first, then tacks on the non-validator fields. Actually, it overwrites them all, but because the `use_type.__fields__` already has the validated fields as keys, they remain at the start of dictionary (because of how dictionaries are ordered in python 3.6+).
The PR I linked above should help do away with the cloned field, which would resolve this issue.
@jaddison It should be a relatively simple fix to get the field ordering right, and you could create a PR doing that if you really cared; that could probably be merged more quickly.
| 2019-10-21T23:06:37 |
|
tiangolo/fastapi
| 681 |
tiangolo__fastapi-681
|
[
"679"
] |
c5f5e63810b002306f688b032ad9f134def60bea
|
diff --git a/fastapi/dependencies/utils.py b/fastapi/dependencies/utils.py
--- a/fastapi/dependencies/utils.py
+++ b/fastapi/dependencies/utils.py
@@ -351,7 +351,7 @@ def add_param_to_fields(*, field: Field, dependant: Dependant) -> None:
def is_coroutine_callable(call: Callable) -> bool:
- if inspect.isfunction(call):
+ if inspect.isroutine(call):
return asyncio.iscoroutinefunction(call)
if inspect.isclass(call):
return False
|
diff --git a/tests/test_dependency_class.py b/tests/test_dependency_class.py
new file mode 100644
--- /dev/null
+++ b/tests/test_dependency_class.py
@@ -0,0 +1,70 @@
+import pytest
+from fastapi import Depends, FastAPI
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
+class CallableDependency:
+ def __call__(self, value: str) -> str:
+ return value
+
+
+class AsyncCallableDependency:
+ async def __call__(self, value: str) -> str:
+ return value
+
+
+class MethodsDependency:
+ def synchronous(self, value: str) -> str:
+ return value
+
+ async def asynchronous(self, value: str) -> str:
+ return value
+
+
+callable_dependency = CallableDependency()
+async_callable_dependency = AsyncCallableDependency()
+methods_dependency = MethodsDependency()
+
+
[email protected]("/callable-dependency")
+async def get_callable_dependency(value: str = Depends(callable_dependency)):
+ return value
+
+
[email protected]("/async-callable-dependency")
+async def get_callable_dependency(value: str = Depends(async_callable_dependency)):
+ return value
+
+
[email protected]("/synchronous-method-dependency")
+async def get_synchronous_method_dependency(
+ value: str = Depends(methods_dependency.synchronous),
+):
+ return value
+
+
[email protected]("/asynchronous-method-dependency")
+async def get_asynchronous_method_dependency(
+ value: str = Depends(methods_dependency.asynchronous),
+):
+ return value
+
+
+client = TestClient(app)
+
+
[email protected](
+ "route,value",
+ [
+ ("/callable-dependency", "callable-dependency"),
+ ("/async-callable-dependency", "async-callable-dependency"),
+ ("/synchronous-method-dependency", "synchronous-method-dependency"),
+ ("/asynchronous-method-dependency", "asynchronous-method-dependency"),
+ ],
+)
+def test_class_dependency(route, value):
+ response = client.get(route, params={"value": value})
+ assert response.status_code == 200
+ assert response.json() == value
|
Async class method dependency raises a ValueError
**Describe the bug**
If you use an async class method as a dependency, a `ValueError` is thrown. It doesn't happen for a non-async method.
Complete error: `ValueError: [KeyError(<class 'coroutine'>), TypeError("'coroutine' object is not iterable"), TypeError('vars() argument must have __dict__ attribute')]` (at `fastapi/encoders.py:106`)
**To Reproduce**
```py
from fastapi import Depends, FastAPI
from starlette.requests import Request
class DependencyClass:
async def async_dep(self, request: Request):
return True
def sync_dep(self, request: Request):
return True
app = FastAPI()
dependency = DependencyClass()
# Error
@app.get('/async-dep')
def async_dep(r=Depends(dependency.async_dep)):
return r
# Everything is fine
@app.get('/sync-dep')
def sync_dep(r=Depends(dependency.sync_dep)):
return r
```
**Expected behavior**
The async class method dependency should be called and its return value injected.
**Environment:**
- OS: macOS
- FastAPI Version: 0.42.0
- Python version: 3.7.2
**Additional context**
I believe the issue comes from here:
https://github.com/tiangolo/fastapi/blob/65536cbf63318d111bf608960378d651b6c1596a/fastapi/dependencies/utils.py#L353-L359
Indeed, `inspect.isfunction(call)` will return `False` in case of a class method. Hence, it is [sent to `run_in_threadpool`](https://github.com/tiangolo/fastapi/blob/65536cbf63318d111bf608960378d651b6c1596a/fastapi/dependencies/utils.py#L453-L456), which never awaits the coroutine, and we end up trying to serialize it instead of its result (hence the `ValueError`).
Changing the check by:
```py
if inspect.isfunction(call) or inspect.ismethod(call):
```
solves the issue. I can make a PR with the fix and unit tests if it helps.
|
not sure what the "right" behavior should be but in your `async_dep` (wich itself is not async) you return a coroutine r without awaiting it so it's kind of expected that it doesn't return it's value, is it ?
somehting like this "works" even if I fail to see the use case
```
import asyncio
import uvicorn
from fastapi import Depends, FastAPI
from starlette.requests import Request
class DependencyClass:
async def async_dep(self, request: Request):
await asyncio.sleep(0)
return False
def sync_dep(self, request: Request):
return True
app = FastAPI()
dependency = DependencyClass()
# Error
@app.get('/async-dep')
async def authenticate(r=Depends(dependency.async_dep)):
s = await r
return s
# Everything is fine
@app.get('/sync-dep')
def authenticate(r=Depends(dependency.sync_dep)):
return r
if __name__ == '__main__':
uvicorn.run("679_async_dep_class:app", reload= True)
```
Well yes, for the sake of simplicity in the example, my async method don't do anything async, but still is a coroutine that needs to be awaited.
The use case is inspired from the async class dependencies, like `OAuth2PasswordBearer`:
https://github.com/tiangolo/fastapi/blob/65536cbf63318d111bf608960378d651b6c1596a/fastapi/security/oauth2.py#L138-L163
`__call__` *is* async here and, when you inject this dependency, we do get `param`, we don't need to `await` it in the controller function.
So, I think we should be able to do something similar with class methods. For example:
```py
class Authentication:
def __init__(self, params):
self.params = params
async def get_user(self, request: Request) -> User:
return await self._authenticate(request)
async def get_active_user(self, request: Request) -> User:
user = await self._authenticate(request)
if not user.is_active:
raise HTTPException()
return user
async def _authenticate(self, request: Request) -> User:
# Do some authentication logic
return user
authentication = Authentication(params)
@app.get('/active-user')
def active_user(user=Depends(authentication.get_active_user)):
return user
```
This is useful to share common logic between all the dependencies while providing some specialized behaviour.
IMO, this is clearly a bug as it works flawlessly with async `__call__` and non-async methods.
makes lot of sense indeed, was stuck on your version before edit
This makes sense to me; @frankie567 I think it's worth a PR.
| 2019-11-05T08:02:25 |
tiangolo/fastapi
| 756 |
tiangolo__fastapi-756
|
[
"755"
] |
861ed37c9784c4aefa646c875ed0353c5699d6d8
|
diff --git a/fastapi/encoders.py b/fastapi/encoders.py
--- a/fastapi/encoders.py
+++ b/fastapi/encoders.py
@@ -1,6 +1,6 @@
from enum import Enum
from types import GeneratorType
-from typing import Any, Dict, List, Set, Union
+from typing import Any, Callable, Dict, List, Set, Tuple, Union
from fastapi.utils import PYDANTIC_1, logger
from pydantic import BaseModel
@@ -10,6 +10,21 @@
DictIntStrAny = Dict[Union[int, str], Any]
+def generate_encoders_by_class_tuples(
+ type_encoder_map: Dict[Any, Callable]
+) -> Dict[Callable, Tuple]:
+ encoders_by_classes: Dict[Callable, List] = {}
+ for type_, encoder in type_encoder_map.items():
+ encoders_by_classes.setdefault(encoder, []).append(type_)
+ encoders_by_class_tuples: Dict[Callable, Tuple] = {}
+ for encoder, classes in encoders_by_classes.items():
+ encoders_by_class_tuples[encoder] = tuple(classes)
+ return encoders_by_class_tuples
+
+
+encoders_by_class_tuples = generate_encoders_by_class_tuples(ENCODERS_BY_TYPE)
+
+
def jsonable_encoder(
obj: Any,
include: Union[SetIntStr, DictIntStrAny] = None,
@@ -105,24 +120,31 @@ def jsonable_encoder(
)
)
return encoded_list
+
+ if custom_encoder:
+ if type(obj) in custom_encoder:
+ return custom_encoder[type(obj)](obj)
+ else:
+ for encoder_type, encoder in custom_encoder.items():
+ if isinstance(obj, encoder_type):
+ return encoder(obj)
+
+ if type(obj) in ENCODERS_BY_TYPE:
+ return ENCODERS_BY_TYPE[type(obj)](obj)
+ for encoder, classes_tuple in encoders_by_class_tuples.items():
+ if isinstance(obj, classes_tuple):
+ return encoder(obj)
+
errors: List[Exception] = []
try:
- if custom_encoder and type(obj) in custom_encoder:
- encoder = custom_encoder[type(obj)]
- else:
- encoder = ENCODERS_BY_TYPE[type(obj)]
- return encoder(obj)
- except KeyError as e:
+ data = dict(obj)
+ except Exception as e:
errors.append(e)
try:
- data = dict(obj)
+ data = vars(obj)
except Exception as e:
errors.append(e)
- try:
- data = vars(obj)
- except Exception as e:
- errors.append(e)
- raise ValueError(errors)
+ raise ValueError(errors)
return jsonable_encoder(
data,
by_alias=by_alias,
|
diff --git a/tests/test_inherited_custom_class.py b/tests/test_inherited_custom_class.py
new file mode 100644
--- /dev/null
+++ b/tests/test_inherited_custom_class.py
@@ -0,0 +1,73 @@
+import uuid
+
+import pytest
+from fastapi import FastAPI
+from pydantic import BaseModel
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
+class MyUuid:
+ def __init__(self, uuid_string: str):
+ self.uuid = uuid_string
+
+ def __str__(self):
+ return self.uuid
+
+ @property
+ def __class__(self):
+ return uuid.UUID
+
+ @property
+ def __dict__(self):
+ """Spoof a missing __dict__ by raising TypeError, this is how
+ asyncpg.pgroto.pgproto.UUID behaves"""
+ raise TypeError("vars() argument must have __dict__ attribute")
+
+
[email protected]("/fast_uuid")
+def return_fast_uuid():
+ # I don't want to import asyncpg for this test so I made my own UUID
+ # Import asyncpg and uncomment the two lines below for the actual bug
+
+ # from asyncpg.pgproto import pgproto
+ # asyncpg_uuid = pgproto.UUID("a10ff360-3b1e-4984-a26f-d3ab460bdb51")
+
+ asyncpg_uuid = MyUuid("a10ff360-3b1e-4984-a26f-d3ab460bdb51")
+ assert isinstance(asyncpg_uuid, uuid.UUID)
+ assert type(asyncpg_uuid) != uuid.UUID
+ with pytest.raises(TypeError):
+ vars(asyncpg_uuid)
+ return {"fast_uuid": asyncpg_uuid}
+
+
+class SomeCustomClass(BaseModel):
+ class Config:
+ arbitrary_types_allowed = True
+ json_encoders = {uuid.UUID: str}
+
+ a_uuid: MyUuid
+
+
[email protected]("/get_custom_class")
+def return_some_user():
+ # Test that the fix also works for custom pydantic classes
+ return SomeCustomClass(a_uuid=MyUuid("b8799909-f914-42de-91bc-95c819218d01"))
+
+
+client = TestClient(app)
+
+
+def test_dt():
+ with client:
+ response_simple = client.get("/fast_uuid")
+ response_pydantic = client.get("/get_custom_class")
+
+ assert response_simple.json() == {
+ "fast_uuid": "a10ff360-3b1e-4984-a26f-d3ab460bdb51"
+ }
+
+ assert response_pydantic.json() == {
+ "a_uuid": "b8799909-f914-42de-91bc-95c819218d01"
+ }
|
asyncpg uuid implementation not recognized by fastapi because of too strict typechecking
### Describe the bug
An alternative implementation of the `UUID` type is not serialized by fastapi but throws an error instead. This is because it is of type `asyncpg.pgproto.pgproto.UUID` instead of type `uuid.UUID`. However it is implemented in such a way that it does the exact same things as the regular UUID but just faster. Also,
```python
isinstance(asyncpg.pgproto.pgproto.UUID(), uuid.UUID) == True
```
this should make fastapi able to recognize it as a uuid.
### To Reproduce
1. Create a file called uuid_error.py with:
```Python
import uuid
from fastapi import FastAPI
from asyncpg.pgproto import pgproto
app = FastAPI()
@app.get("/normal_uuid")
def return_normal_uuid():
regular_uuid = uuid.UUID("a10ff360-3b1e-4984-a26f-d3ab460bdb51")
assert isinstance(regular_uuid, uuid.UUID)
return {"normal_uuid": regular_uuid}
@app.get("/fast_uuid")
def return_fast_uuid():
asyncpg_uuid = pgproto.UUID("a10ff360-3b1e-4984-a26f-d3ab460bdb51")
assert isinstance(asyncpg_uuid, uuid.UUID)
return {"fast_uuid": asyncpg_uuid}
```
2. Run it with uvicorn uuid_error:app
3. Open the browser and call the endpoint `/fast_uuid`.
4. It returns 'internal server error' .
5. But I expected it to return `{"fast_uuid":"a10ff360-3b1e-4984-a26f-d3ab460bdb51"}`.
### Expected behavior
I expected fastapi to jsonify the uuid and send, but instead it returns 'internal server error'. The precise error being thrown in the server is:
```
ValueError: [KeyError(<class 'asyncpg.pgproto.pgproto.UUID'>), TypeError("'asyncpg.pgproto.pgproto.UUID' object is not iterable"), TypeError('vars() argument must have __dict__ attribute')]
```
### Environment
- OS: Linux Mint 19 Tara
- FastAPI Version: 0.44.0
- Python version: 3.8.0
### Additional context
I initially made an issue in the asyncpg repo asking them if they could fix it: https://github.com/MagicStack/asyncpg/issues/512 I think it's usefull as additional context for this issue.
The problem can be solved here in the fastapi code by improving the code a little. I'm working on a PR, this line seems to be the issue:
https://github.com/tiangolo/fastapi/blob/c200bc2240d48a4a27e96fba536351038eafc44f/fastapi/encoders.py#L113
I think it shouldn't use `type()` but it should instead use `isinstance()` this will make for slightly looser typechecking but I think that might be a good thing in this case?
| 2019-11-30T09:57:26 |
|
tiangolo/fastapi
| 856 |
tiangolo__fastapi-856
|
[
"842"
] |
3eca945bd17600a0be6eae1d8fd93ba8f9805006
|
diff --git a/fastapi/dependencies/utils.py b/fastapi/dependencies/utils.py
--- a/fastapi/dependencies/utils.py
+++ b/fastapi/dependencies/utils.py
@@ -629,9 +629,9 @@ async def request_body_to_args(
for field in required_params:
value: Any = None
if received_body is not None:
- if field.shape in sequence_shapes and isinstance(
- received_body, FormData
- ):
+ if (
+ field.shape in sequence_shapes or field.type_ in sequence_types
+ ) and isinstance(received_body, FormData):
value = received_body.getlist(field.alias)
else:
value = received_body.get(field.alias)
|
diff --git a/tests/test_forms_from_non_typing_sequences.py b/tests/test_forms_from_non_typing_sequences.py
new file mode 100644
--- /dev/null
+++ b/tests/test_forms_from_non_typing_sequences.py
@@ -0,0 +1,46 @@
+from fastapi import FastAPI, Form
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
[email protected]("/form/python-list")
+def post_form_param_list(items: list = Form(...)):
+ return items
+
+
[email protected]("/form/python-set")
+def post_form_param_set(items: set = Form(...)):
+ return items
+
+
[email protected]("/form/python-tuple")
+def post_form_param_tuple(items: tuple = Form(...)):
+ return items
+
+
+client = TestClient(app)
+
+
+def test_python_list_param_as_form():
+ response = client.post(
+ "/form/python-list", data={"items": ["first", "second", "third"]}
+ )
+ assert response.status_code == 200
+ assert response.json() == ["first", "second", "third"]
+
+
+def test_python_set_param_as_form():
+ response = client.post(
+ "/form/python-set", data={"items": ["first", "second", "third"]}
+ )
+ assert response.status_code == 200
+ assert set(response.json()) == {"first", "second", "third"}
+
+
+def test_python_tuple_param_as_form():
+ response = client.post(
+ "/form/python-tuple", data={"items": ["first", "second", "third"]}
+ )
+ assert response.status_code == 200
+ assert response.json() == ["first", "second", "third"]
|
Support repeated key=value in form data
### Is your feature request related to a problem
Yes.
Given some URL encoded data like this...
```
choices=parrot&choices=spider
```
...only the last key=value wins.
This does not work like I expected:
```python
choices: list = Form(...)
```
You can only validate against the last value.
### The solution you would like
Perhaps FastAPI should collect repeated keys in the 2-tuple list that `request.form()` gives and assign those values as a list to the same key before validation happens.
|
Hey @StephenCarboni, parameters in the URL are part of a querystring and you can get and validate them as described here: https://fastapi.tiangolo.com/tutorial/query-params-str-validations/#query-parameter-list-multiple-values
As far as I understand, `Form()` is using only for request body
Oh, sorry, looks like I misread you message.
Anyway, I think this issue better be created in the starlette repo, because the `request` is an object from starlette.
I am a little surprised that `choices=parrot&choices=spider` doesn't work; if I recall correctly it definitely works for query parameters, and is how you would send a list of values.
The logic for form data parsing is in the `starlette.requests.Request.form` method, and delegates to [`python-multipart`](https://github.com/andrew-d/python-multipart), so you can look for the specific logic there.
(Since it uses an entirely different library for parsing, it ultimately isn't THAT surprising that the logic might be different.)
| 2020-01-14T03:48:12 |
tiangolo/fastapi
| 918 |
tiangolo__fastapi-918
|
[
"914"
] |
55afb70b3717969565499f5dcaef54b1f0acc7da
|
diff --git a/fastapi/dependencies/utils.py b/fastapi/dependencies/utils.py
--- a/fastapi/dependencies/utils.py
+++ b/fastapi/dependencies/utils.py
@@ -634,7 +634,11 @@ async def request_body_to_args(
) and isinstance(received_body, FormData):
value = received_body.getlist(field.alias)
else:
- value = received_body.get(field.alias)
+ try:
+ value = received_body.get(field.alias)
+ except AttributeError:
+ errors.append(get_missing_field_error(field.alias))
+ continue
if (
value is None
or (isinstance(field_info, params.Form) and value == "")
@@ -645,18 +649,7 @@ async def request_body_to_args(
)
):
if field.required:
- if PYDANTIC_1:
- errors.append(
- ErrorWrapper(MissingError(), loc=("body", field.alias))
- )
- else: # pragma: nocover
- errors.append(
- ErrorWrapper( # type: ignore
- MissingError(),
- loc=("body", field.alias),
- config=BaseConfig,
- )
- )
+ errors.append(get_missing_field_error(field.alias))
else:
values[field.name] = deepcopy(field.default)
continue
@@ -685,6 +678,16 @@ async def request_body_to_args(
return values, errors
+def get_missing_field_error(field_alias: str) -> ErrorWrapper:
+ if PYDANTIC_1:
+ missing_field_error = ErrorWrapper(MissingError(), loc=("body", field_alias))
+ else: # pragma: no cover
+ missing_field_error = ErrorWrapper( # type: ignore
+ MissingError(), loc=("body", field_alias), config=BaseConfig,
+ )
+ return missing_field_error
+
+
def get_schema_compatible_field(*, field: ModelField) -> ModelField:
out_field = field
if lenient_issubclass(field.type_, UploadFile):
|
diff --git a/tests/test_tutorial/test_body_multiple_params/test_tutorial003.py b/tests/test_tutorial/test_body_multiple_params/test_tutorial003.py
--- a/tests/test_tutorial/test_body_multiple_params/test_tutorial003.py
+++ b/tests/test_tutorial/test_body_multiple_params/test_tutorial003.py
@@ -166,6 +166,30 @@ def test_openapi_schema():
]
},
),
+ (
+ "/items/5",
+ [],
+ 422,
+ {
+ "detail": [
+ {
+ "loc": ["body", "item"],
+ "msg": "field required",
+ "type": "value_error.missing",
+ },
+ {
+ "loc": ["body", "user"],
+ "msg": "field required",
+ "type": "value_error.missing",
+ },
+ {
+ "loc": ["body", "importance"],
+ "msg": "field required",
+ "type": "value_error.missing",
+ },
+ ]
+ },
+ ),
],
)
def test_post_body(path, body, expected_status, expected_response):
|
Sending incorrect data cause 500 error
I've got this simple example:
```
from typing import List
from fastapi import FastAPI, Body
class User(BaseModel):
name: str
@app.post('/test/')
async def test(users: List[User], test: str = Body(...)):
return {'users': users, 'test': test}
```
When sending incorrect payload the server returns 500 error:
```
# curl -s -D - -o /dev/null -X POST "localhost:8080/test/" -H "accept: application/json" -H "Content-Type: application/json" -d "[]"
HTTP/1.1 500 Internal Server Error
date: Fri, 24 Jan 2020 10:59:47 GMT
server: uvicorn
content-length: 1264
content-type: text/plain; charset=utf-8
```
Server exception:
```
INFO: 127.0.0.1:60652 - "POST /test/ HTTP/1.1" 500 Internal Server Error
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "/test/venv38/lib/python3.8/site-packages/uvicorn/protocols/http/httptools_impl.py", line 385, in run_asgi
result = await app(self.scope, self.receive, self.send)
File "/test/venv38/lib/python3.8/site-packages/uvicorn/middleware/proxy_headers.py", line 45, in __call__
return await self.app(scope, receive, send)
File "/test/venv38/lib/python3.8/site-packages/fastapi/applications.py", line 140, in __call__
await super().__call__(scope, receive, send)
File "/test/venv38/lib/python3.8/site-packages/starlette/applications.py", line 134, in __call__
await self.error_middleware(scope, receive, send)
File "/test/venv38/lib/python3.8/site-packages/starlette/middleware/errors.py", line 178, in __call__
raise exc from None
File "/test/venv38/lib/python3.8/site-packages/starlette/middleware/errors.py", line 156, in __call__
await self.app(scope, receive, _send)
File "/test/venv38/lib/python3.8/site-packages/starlette/exceptions.py", line 73, in __call__
raise exc from None
File "/test/venv38/lib/python3.8/site-packages/starlette/exceptions.py", line 62, in __call__
await self.app(scope, receive, sender)
File "/test/venv38/lib/python3.8/site-packages/starlette/routing.py", line 590, in __call__
await route(scope, receive, send)
File "/test/venv38/lib/python3.8/site-packages/starlette/routing.py", line 208, in __call__
await self.app(scope, receive, send)
File "/test/venv38/lib/python3.8/site-packages/starlette/routing.py", line 41, in app
response = await func(request)
File "/test/venv38/lib/python3.8/site-packages/fastapi/routing.py", line 115, in app
solved_result = await solve_dependencies(
File "/test/venv38/lib/python3.8/site-packages/fastapi/dependencies/utils.py", line 547, in solve_dependencies
) = await request_body_to_args( # body_params checked above
File "/test/venv38/lib/python3.8/site-packages/fastapi/dependencies/utils.py", line 637, in request_body_to_args
value = received_body.get(field.alias)
AttributeError: 'list' object has no attribute 'get'
```
So the body is not validated in this case?
|
Have reproduced same error.
| 2020-01-25T06:59:01 |
tiangolo/fastapi
| 994 |
tiangolo__fastapi-994
|
[
"967"
] |
9c3c9b6e78768374868d690bc05918d58481e880
|
diff --git a/fastapi/openapi/utils.py b/fastapi/openapi/utils.py
--- a/fastapi/openapi/utils.py
+++ b/fastapi/openapi/utils.py
@@ -180,7 +180,9 @@ def get_openapi_path(
operation_parameters = get_openapi_operation_parameters(all_route_params)
parameters.extend(operation_parameters)
if parameters:
- operation["parameters"] = parameters
+ operation["parameters"] = list(
+ {param["name"]: param for param in parameters}.values()
+ )
if method in METHODS_WITH_BODY:
request_body_oai = get_openapi_operation_request_body(
body_field=route.body_field, model_name_map=model_name_map
|
diff --git a/tests/test_param_in_path_and_dependency.py b/tests/test_param_in_path_and_dependency.py
new file mode 100644
--- /dev/null
+++ b/tests/test_param_in_path_and_dependency.py
@@ -0,0 +1,93 @@
+from fastapi import Depends, FastAPI
+from starlette.testclient import TestClient
+
+app = FastAPI()
+
+
+async def user_exists(user_id: int):
+ return True
+
+
[email protected]("/users/{user_id}", dependencies=[Depends(user_exists)])
+async def read_users(user_id: int):
+ pass
+
+
+client = TestClient(app)
+
+openapi_schema = {
+ "openapi": "3.0.2",
+ "info": {"title": "FastAPI", "version": "0.1.0"},
+ "paths": {
+ "/users/{user_id}": {
+ "get": {
+ "summary": "Read Users",
+ "operationId": "read_users_users__user_id__get",
+ "parameters": [
+ {
+ "required": True,
+ "schema": {"title": "User Id", "type": "integer"},
+ "name": "user_id",
+ "in": "path",
+ },
+ ],
+ "responses": {
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ },
+ "422": {
+ "description": "Validation Error",
+ "content": {
+ "application/json": {
+ "schema": {
+ "$ref": "#/components/schemas/HTTPValidationError"
+ }
+ }
+ },
+ },
+ },
+ }
+ }
+ },
+ "components": {
+ "schemas": {
+ "HTTPValidationError": {
+ "title": "HTTPValidationError",
+ "type": "object",
+ "properties": {
+ "detail": {
+ "title": "Detail",
+ "type": "array",
+ "items": {"$ref": "#/components/schemas/ValidationError"},
+ }
+ },
+ },
+ "ValidationError": {
+ "title": "ValidationError",
+ "required": ["loc", "msg", "type"],
+ "type": "object",
+ "properties": {
+ "loc": {
+ "title": "Location",
+ "type": "array",
+ "items": {"type": "string"},
+ },
+ "msg": {"title": "Message", "type": "string"},
+ "type": {"title": "Error Type", "type": "string"},
+ },
+ },
+ }
+ },
+}
+
+
+def test_reused_param():
+ response = client.get("/openapi.json")
+ data = response.json()
+ assert data == openapi_schema
+
+
+def test_read_users():
+ response = client.get("/users/42")
+ assert response.status_code == 200
|
The generated OpenAPI schema duplicates parameter IDs when used with dependencies
### Describe the bug
The generated OpenAPI schema duplicates parameter IDs when used with dependencies.
### To Reproduce
Steps to reproduce the behavior with a minimum self-contained file.
* Create a file with:
```Python
from fastapi import Depends, FastAPI
from starlette.testclient import TestClient
app = FastAPI()
async def user_exists(user_id: int):
return True
@app.post("/users/{user_id}", dependencies=[Depends(user_exists)])
async def bug(user_id: int):
pass
client = TestClient(app)
openapi_schema = {
"openapi": "3.0.2",
"info": {"title": "FastAPI", "version": "0.1.0"},
"paths": {
"/users/{user_id}": {
"post": {
"summary": "Bug",
"operationId": "bug_users__user_id__post",
"parameters": [
{
"required": True,
"schema": {"title": "User Id", "type": "integer"},
"name": "user_id",
"in": "path",
},
# This duplicated user_id shouldn't be here
# {
# "required": True,
# "schema": {"title": "User Id", "type": "integer"},
# "name": "user_id",
# "in": "path",
# },
],
"responses": {
"200": {
"description": "Successful Response",
"content": {"application/json": {"schema": {}}},
},
"422": {
"description": "Validation Error",
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/HTTPValidationError"
}
}
},
},
},
}
}
},
"components": {
"schemas": {
"HTTPValidationError": {
"title": "HTTPValidationError",
"type": "object",
"properties": {
"detail": {
"title": "Detail",
"type": "array",
"items": {"$ref": "#/components/schemas/ValidationError"},
}
},
},
"ValidationError": {
"title": "ValidationError",
"required": ["loc", "msg", "type"],
"type": "object",
"properties": {
"loc": {
"title": "Location",
"type": "array",
"items": {"type": "string"},
},
"msg": {"title": "Message", "type": "string"},
"type": {"title": "Error Type", "type": "string"},
},
},
}
},
}
def test_reused_param():
response = client.get("/openapi.json")
data = response.json()
assert data == openapi_schema
```
* Run it with `pytest`.
Alternatively, you can run it with Uvicorn go to `/openapi.json`, copy that and validate it at: https://editor.swagger.io/ . It should be valid.
### Expected behavior
The `user_id` used by the path operation and the dependency shouldn't be duplicated in the OpenAPI schema.
### Environment
- OS: all
- FastAPI Version [e.g. 0.3.0], get it with: 0.48.0
```bash
python -c "import fastapi; print(fastapi.__version__)"
```
- Python version, get it with: 3.7
```bash
python --version
```
### Additional context
Supersedes #395
| 2020-02-18T14:09:16 |
|
tiangolo/fastapi
| 1,122 |
tiangolo__fastapi-1122
|
[
"998"
] |
025b38df40a18f94322fab445aee13024fe783da
|
diff --git a/fastapi/routing.py b/fastapi/routing.py
--- a/fastapi/routing.py
+++ b/fastapi/routing.py
@@ -480,7 +480,12 @@ def decorator(func: Callable) -> Callable:
def add_api_websocket_route(
self, path: str, endpoint: Callable, name: str = None
) -> None:
- route = APIWebSocketRoute(path, endpoint=endpoint, name=name)
+ route = APIWebSocketRoute(
+ path,
+ endpoint=endpoint,
+ name=name,
+ dependency_overrides_provider=self.dependency_overrides_provider,
+ )
self.routes.append(route)
def websocket(self, path: str, name: str = None) -> Callable:
|
diff --git a/tests/test_ws_router.py b/tests/test_ws_router.py
--- a/tests/test_ws_router.py
+++ b/tests/test_ws_router.py
@@ -1,4 +1,4 @@
-from fastapi import APIRouter, FastAPI, WebSocket
+from fastapi import APIRouter, Depends, FastAPI, WebSocket
from fastapi.testclient import TestClient
router = APIRouter()
@@ -34,6 +34,19 @@ async def routerindex(websocket: WebSocket):
await websocket.close()
+async def ws_dependency():
+ return "Socket Dependency"
+
+
[email protected]("/router-ws-depends/")
+async def router_ws_decorator_depends(
+ websocket: WebSocket, data=Depends(ws_dependency)
+):
+ await websocket.accept()
+ await websocket.send_text(data)
+ await websocket.close()
+
+
app.include_router(router)
app.include_router(prefix_router, prefix="/prefix")
@@ -64,3 +77,16 @@ def test_router2():
with client.websocket_connect("/router2") as websocket:
data = websocket.receive_text()
assert data == "Hello, router!"
+
+
+def test_router_ws_depends():
+ client = TestClient(app)
+ with client.websocket_connect("/router-ws-depends/") as websocket:
+ assert websocket.receive_text() == "Socket Dependency"
+
+
+def test_router_ws_depends_with_override():
+ client = TestClient(app)
+ app.dependency_overrides[ws_dependency] = lambda: "Override"
+ with client.websocket_connect("/router-ws-depends/") as websocket:
+ assert websocket.receive_text() == "Override"
|
Dependency override websocket broken
### Describe the bug
Dependency override does not work for websockets.
The function `add_api_websocket_route` does not add `dependency_overrides_provider` to `APIWebSocketRoute`.
### To Reproduce
Create a simple app with websockets and test it with override.
### Expected behavior
The overrides should be taken into account, but the test uses the original dependency.
### Environment
- OS: Windows
- FastAPI version: 0.49.0
- Python version: 3.6.8
|
`APIRouter.add_api_websocket_route` should be modified to construct the `APIWebSocketRoute` like this:
```
route = APIWebSocketRoute(
path,
endpoint=endpoint,
name=name,
dependency_overrides_provider=self.dependency_overrides_provider,
)
```
| 2020-03-16T17:12:49 |
tiangolo/fastapi
| 1,524 |
tiangolo__fastapi-1524
|
[
"911"
] |
8cfe254400a92c1184c354a92541b401932d24a3
|
diff --git a/fastapi/encoders.py b/fastapi/encoders.py
--- a/fastapi/encoders.py
+++ b/fastapi/encoders.py
@@ -71,6 +71,8 @@ def jsonable_encoder(
by_alias=by_alias,
skip_defaults=bool(exclude_unset or skip_defaults),
)
+ if "__root__" in obj_dict:
+ obj_dict = obj_dict["__root__"]
return jsonable_encoder(
obj_dict,
exclude_none=exclude_none,
|
diff --git a/tests/test_jsonable_encoder.py b/tests/test_jsonable_encoder.py
--- a/tests/test_jsonable_encoder.py
+++ b/tests/test_jsonable_encoder.py
@@ -76,6 +76,10 @@ class ModelWithDefault(BaseModel):
bla: str = "bla"
+class ModelWithRoot(BaseModel):
+ __root__: str
+
+
@pytest.fixture(
name="model_with_path", params=[PurePath, PurePosixPath, PureWindowsPath]
)
@@ -158,3 +162,8 @@ def test_encode_model_with_path(model_with_path):
else:
expected = "/foo/bar"
assert jsonable_encoder(model_with_path) == {"path": expected}
+
+
+def test_encode_root():
+ model = ModelWithRoot(__root__="Foo")
+ assert jsonable_encoder(model) == "Foo"
|
Pydantic __root__ model - incorrect handling
### Describe the bug
https://pydantic-docs.helpmanual.io/usage/models/#custom-root-types
Pydantic allows to create models with only `__root__` field. In such scenario the model behaves as transparent wrapper for this single type.
When such model is used in response (request also?) fastapi does not treat it correctly and renders it as object with `__root__` field.
Object is treated correctly by pydantic itself.
### To Reproduce
```
from typing import List
from fastapi import FastAPI
from pydantic.main import BaseModel
app = FastAPI()
class RootTestClass(BaseModel):
__root__: List[str]
@app.get("/")
async def root():
response = RootTestClass(__root__=['a', 'b', 'c'])
print(response.json()) # ["a", "b", "c"] so it's OK
print(RootTestClass.schema()) # {'title': 'RootTestClass', 'type': 'array', 'items': {'type': 'string'}} this is also OK
return response # Wrong value in http response
```
### Expected behavior
The response should be:
```
["a", "b", "c"]
```
but at the moment is:
```
{"__root__":["a","b","c"]}
```
### Screenshots
N/A
### Environment
- OS: Linux
- FastAPI Version: 0.47.1
- Python version: Python 3.7.5
### Additional context
N/A
|
If anyone wants to submit a PR to fix this I'd be happy to review it. (I think it's worth handling this properly.)
For now created issue for `pydantic` (https://github.com/samuelcolvin/pydantic/issues/1193) as it looks like it is more broken there than here.
I wouldn't recommend using `__root__` in FastAPI. `__root__` allows using other types in Pydantic apart from things with key values, like lists.
But in FastAPI, everywhere you can use a Pydantic model you can also use what would be the (arguably?) most "Pythonic" way, using `typing`. So you can do `List[SomeModel]`. Instead of having to create a `SomeModelWrapper` that users `__root__`.
`__root__` is valid and useful in Pydantic standalone as there's no other way to achieve what it does. But in FastAPI the preferred way is to use standard types that have Pydantic models as type parameters (the thing inside `List[]`).
Given that, as it's still valid Pydantic, I would be happy to support it if someone wants to add a PR with it (as @dmontagu says).
@tiangolo I understands that `response_model=Dict[str, str]` instead of a wrapped model with `__root__` is viable, however is there a way to include an `example`, perhaps similar to the `schema_extra` section that can be attach to `response_model` ?
@tiangolo Supporting pydantic root types would allow a single validator (defined in the wrapper class) to be run on all objects of a certain type- otherwise, the validator must be specified in each object that has a child of that type (as far as I can tell- I'm new to fastAPI, please let me know if there's a better way).
as @sidmani also mentioned, I'm running into wanting the ability to be able to say:
```python
pydantic_list_as_root.dict()
```
and the above output a dict. Rather than having to manually loop through my `List[pydantic_entity]` and call `dict()` on each one.
However, I do appreciate what @tiangolo is trying to achieve by keeping things as pythonic as possible, but I would imagine that many if not all FastAPI implementations heavily rely on Pydantic for defining schemas. Therefore, I think it would be a great idea to embrace all/most of its capabilities.
Yeah, I would be happy to support it if someone wants to add a PR with it.
| 2020-06-06T03:48:18 |
tiangolo/fastapi
| 1,534 |
tiangolo__fastapi-1534
|
[
"1349"
] |
543ef7753aff639ad3aed7c153e42f719e361d38
|
diff --git a/fastapi/routing.py b/fastapi/routing.py
--- a/fastapi/routing.py
+++ b/fastapi/routing.py
@@ -1,4 +1,5 @@
import asyncio
+import enum
import inspect
from typing import Any, Callable, Dict, List, Optional, Sequence, Set, Type, Union
@@ -295,6 +296,9 @@ def __init__(
dependency_overrides_provider: Any = None,
callbacks: Optional[List["APIRoute"]] = None,
) -> None:
+ # normalise enums e.g. http.HTTPStatus
+ if isinstance(status_code, enum.IntEnum):
+ status_code = int(status_code)
self.path = path
self.endpoint = endpoint
self.name = get_name(endpoint) if name is None else name
|
diff --git a/tests/main.py b/tests/main.py
--- a/tests/main.py
+++ b/tests/main.py
@@ -1,3 +1,5 @@
+import http
+
from fastapi import FastAPI, Path, Query
app = FastAPI()
@@ -184,3 +186,8 @@ def get_query_param_required(query=Query(...)):
@app.get("/query/param-required/int")
def get_query_param_required_type(query: int = Query(...)):
return f"foo bar {query}"
+
+
[email protected]("/enum-status-code", status_code=http.HTTPStatus.CREATED)
+def get_enum_status_code():
+ return "foo bar"
diff --git a/tests/test_application.py b/tests/test_application.py
--- a/tests/test_application.py
+++ b/tests/test_application.py
@@ -1078,6 +1078,18 @@
],
}
},
+ "/enum-status-code": {
+ "get": {
+ "responses": {
+ "201": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ },
+ },
+ "summary": "Get Enum Status Code",
+ "operationId": "get_enum_status_code_enum_status_code_get",
+ }
+ },
},
"components": {
"schemas": {
@@ -1149,3 +1161,9 @@ def test_redoc():
assert response.status_code == 200, response.text
assert response.headers["content-type"] == "text/html; charset=utf-8"
assert "redoc@next" in response.text
+
+
+def test_enum_status_code_response():
+ response = client.get("/enum-status-code")
+ assert response.status_code == 201, response.text
+ assert response.json() == "foo bar"
|
Support HTTPStatus
### Is your feature request related to a problem
We typically use [HTTPStatus](https://docs.python.org/3/library/http.html#http.HTTPStatus) in our code. When used as a value for `status_code` in path functions this results in the string literal in the documentation and when "trying" the response is shown as undocumented because it doesn't match the actual response code
### The solution you would like
I want to use HTTPStatus enum values and have it work exactly like the `starlette.status` pseudo enum values
|
For now you can create your own HTTPStatus class (you can't subclass Enums) and add a `__str__` method to convert it to the string representation of the actual status code, for example:
```python
class MyHTTPStatus(IntEnum):
OK = 200
...
def __str__(self):
return str(int(self))
```
or use `int(HTTPStatus)` in the endpoint decorator.
Thanks for the help @retnikt ! :bow:
Yeah, @hmvp you can probably use that for your use case.
I am sorry to disagree...
It is indeed quite easy to workaround this. For example by just importing status from starlette and using that in the decorators.
However `HTTPStatus` is part of the standard lib and since we use it extensively in the rest of our code I would like to use that instead of the starlette status. The second reason is that I expected it to work (since its part of stdlib) and it somewhat did but gave unexpected results.. This is a papercut/pitfall/surpising behavior of fastapi and given the high standard of the rest of the library this should not be there
I am not sure if @retnikt understood what I am trying to do here.. Adding another class is a weird suggestion given that both `HTTPStatus` and `starlette.status` already exist
The ASGI spec uses `int`s for status codes, not enums. That's why it takes `int`s.
Also, @retnikt has been helping a lot here, answering a lot of questions, trying to help others like you, for free. Just out of being a cool person. Please try to be more respectful to the community that is here trying to help.
If you really want to use `HTTPStatus` enums you can use the `int` value, it's quite simple, e.g. `HTTPStatus.OK.value`.
I did not want to be disrespectful to @retnikt and I value his contribution for other people that might have a similar but different issue. I just don't see how it is relevant for my issue. I am sorry if my wording was to strong... As a non-native English speaker I might miss some subtleties.
With regards to the ASGI spec, I did not know that, but I also was not aware that the `status_code` code argument followed the ASGI spec in that regard, especially since putting in a HTTPStatus code enum value just works, but will give a weird result in the docs. It should not be to difficult to add some code along the line of:
```
if isinstance(HTTPStatus, status_code):
status_code = status_code.value
```
or just `status_code = int(status_code)` to the path functions, which would solve a papercut and would still be valid ASGI. Otherwise I would expect the path functions to be noisy about wrong input..
On the other hand, this is indeed not a big issue and if you don't want to change anything, thats fine with me. I just wanted to signal that this is a [papercut](https://en.wikipedia.org/wiki/Paper_cut_bug) in fastapi
Cool, thanks!
Yeah, I would accept a PR checking if a status code is an enum to get its value first. :nerd_face: :heavy_check_mark:
Working on it!
| 2020-06-08T12:29:39 |
tiangolo/fastapi
| 1,540 |
tiangolo__fastapi-1540
|
[
"365"
] |
543ef7753aff639ad3aed7c153e42f719e361d38
|
diff --git a/docs_src/websockets/tutorial002.py b/docs_src/websockets/tutorial002.py
--- a/docs_src/websockets/tutorial002.py
+++ b/docs_src/websockets/tutorial002.py
@@ -1,4 +1,4 @@
-from fastapi import Cookie, Depends, FastAPI, Header, WebSocket, status
+from fastapi import Cookie, Depends, FastAPI, Query, WebSocket, status
from fastapi.responses import HTMLResponse
app = FastAPI()
@@ -13,8 +13,9 @@
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<label>Item ID: <input type="text" id="itemId" autocomplete="off" value="foo"/></label>
+ <label>Token: <input type="text" id="token" autocomplete="off" value="some-key-token"/></label>
<button onclick="connect(event)">Connect</button>
- <br>
+ <hr>
<label>Message: <input type="text" id="messageText" autocomplete="off"/></label>
<button>Send</button>
</form>
@@ -23,8 +24,9 @@
<script>
var ws = null;
function connect(event) {
- var input = document.getElementById("itemId")
- ws = new WebSocket("ws://localhost:8000/items/" + input.value + "/ws");
+ var itemId = document.getElementById("itemId")
+ var token = document.getElementById("token")
+ ws = new WebSocket("ws://localhost:8000/items/" + itemId.value + "/ws?token=" + token.value);
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
@@ -32,6 +34,7 @@
message.appendChild(content)
messages.appendChild(message)
};
+ event.preventDefault()
}
function sendMessage(event) {
var input = document.getElementById("messageText")
@@ -50,26 +53,26 @@ async def get():
return HTMLResponse(html)
-async def get_cookie_or_client(
- websocket: WebSocket, session: str = Cookie(None), x_client: str = Header(None)
+async def get_cookie_or_token(
+ websocket: WebSocket, session: str = Cookie(None), token: str = Query(None)
):
- if session is None and x_client is None:
+ if session is None and token is None:
await websocket.close(code=status.WS_1008_POLICY_VIOLATION)
- return session or x_client
+ return session or token
@app.websocket("/items/{item_id}/ws")
async def websocket_endpoint(
websocket: WebSocket,
- item_id: int,
- q: str = None,
- cookie_or_client: str = Depends(get_cookie_or_client),
+ item_id: str,
+ q: int = None,
+ cookie_or_token: str = Depends(get_cookie_or_token),
):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(
- f"Session Cookie or X-Client Header value is: {cookie_or_client}"
+ f"Session cookie or query token value is: {cookie_or_token}"
)
if q is not None:
await websocket.send_text(f"Query parameter q is: {q}")
|
diff --git a/tests/test_tutorial/test_websockets/test_tutorial002.py b/tests/test_tutorial/test_websockets/test_tutorial002.py
--- a/tests/test_tutorial/test_websockets/test_tutorial002.py
+++ b/tests/test_tutorial/test_websockets/test_tutorial002.py
@@ -15,69 +15,65 @@ def test_main():
def test_websocket_with_cookie():
with pytest.raises(WebSocketDisconnect):
with client.websocket_connect(
- "/items/1/ws", cookies={"session": "fakesession"}
+ "/items/foo/ws", cookies={"session": "fakesession"}
) as websocket:
message = "Message one"
websocket.send_text(message)
data = websocket.receive_text()
- assert data == "Session Cookie or X-Client Header value is: fakesession"
+ assert data == "Session cookie or query token value is: fakesession"
data = websocket.receive_text()
- assert data == f"Message text was: {message}, for item ID: 1"
+ assert data == f"Message text was: {message}, for item ID: foo"
message = "Message two"
websocket.send_text(message)
data = websocket.receive_text()
- assert data == "Session Cookie or X-Client Header value is: fakesession"
+ assert data == "Session cookie or query token value is: fakesession"
data = websocket.receive_text()
- assert data == f"Message text was: {message}, for item ID: 1"
+ assert data == f"Message text was: {message}, for item ID: foo"
def test_websocket_with_header():
with pytest.raises(WebSocketDisconnect):
- with client.websocket_connect(
- "/items/2/ws", headers={"X-Client": "xmen"}
- ) as websocket:
+ with client.websocket_connect("/items/bar/ws?token=some-token") as websocket:
message = "Message one"
websocket.send_text(message)
data = websocket.receive_text()
- assert data == "Session Cookie or X-Client Header value is: xmen"
+ assert data == "Session cookie or query token value is: some-token"
data = websocket.receive_text()
- assert data == f"Message text was: {message}, for item ID: 2"
+ assert data == f"Message text was: {message}, for item ID: bar"
message = "Message two"
websocket.send_text(message)
data = websocket.receive_text()
- assert data == "Session Cookie or X-Client Header value is: xmen"
+ assert data == "Session cookie or query token value is: some-token"
data = websocket.receive_text()
- assert data == f"Message text was: {message}, for item ID: 2"
+ assert data == f"Message text was: {message}, for item ID: bar"
def test_websocket_with_header_and_query():
with pytest.raises(WebSocketDisconnect):
- with client.websocket_connect(
- "/items/2/ws?q=baz", headers={"X-Client": "xmen"}
- ) as websocket:
+ with client.websocket_connect("/items/2/ws?q=3&token=some-token") as websocket:
message = "Message one"
websocket.send_text(message)
data = websocket.receive_text()
- assert data == "Session Cookie or X-Client Header value is: xmen"
+ assert data == "Session cookie or query token value is: some-token"
data = websocket.receive_text()
- assert data == "Query parameter q is: baz"
+ assert data == "Query parameter q is: 3"
data = websocket.receive_text()
assert data == f"Message text was: {message}, for item ID: 2"
message = "Message two"
websocket.send_text(message)
data = websocket.receive_text()
- assert data == "Session Cookie or X-Client Header value is: xmen"
+ assert data == "Session cookie or query token value is: some-token"
data = websocket.receive_text()
- assert data == "Query parameter q is: baz"
+ assert data == "Query parameter q is: 3"
data = websocket.receive_text()
assert data == f"Message text was: {message}, for item ID: 2"
def test_websocket_no_credentials():
with pytest.raises(WebSocketDisconnect):
- client.websocket_connect("/items/2/ws")
+ client.websocket_connect("/items/foo/ws")
def test_websocket_invalid_data():
with pytest.raises(WebSocketDisconnect):
- client.websocket_connect("/items/foo/ws", headers={"X-Client": "xmen"})
+ client.websocket_connect("/items/foo/ws?q=bar&token=some-token")
|
Tutorial websocket doc example
**Describe the bug**
Hi,
On the docs of websocket the last example doesn't work.
**To Reproduce**
Steps to reproduce the behavior:
1. Create a file main.py with the last example on the bottom of the file
>https://fastapi.tiangolo.com/tutorial/websockets/#create-a-websocket
```python
from fastapi import Cookie, Depends, FastAPI, Header
from starlette.responses import HTMLResponse
from starlette.status import WS_1008_POLICY_VIOLATION
from starlette.websockets import WebSocket
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<label>Item ID: <input type="text" id="itemId" autocomplete="off" value="foo"/></label>
<button onclick="connect(event)">Connect</button>
<br>
<label>Message: <input type="text" id="messageText" autocomplete="off"/></label>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = null;
function connect(event) {
var input = document.getElementById("itemId")
ws = new WebSocket("ws://localhost:8000/items/" + input.value + "/ws");
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
}
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
@app.get("/")
async def get():
return HTMLResponse(html)
async def get_cookie_or_client(
websocket: WebSocket, session: str = Cookie(None), x_client: str = Header(None)
):
if session is None and x_client is None:
await websocket.close(code=WS_1008_POLICY_VIOLATION)
return session or x_client
@app.websocket("/items/{item_id}/ws")
async def websocket_endpoint(
websocket: WebSocket,
item_id: int,
q: str = None,
cookie_or_client: str = Depends(get_cookie_or_client),
):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(
f"Session Cookie or X-Client Header value is: {cookie_or_client}"
)
if q is not None:
await websocket.send_text(f"Query parameter q is: {q}")
await websocket.send_text(f"Message text was: {data}, for item ID: {item_id}")
```
2. Run the application with the cmd:
```
uvicorn main:app --log-level debug --reload
```
3. Open the browser 127.0.0.01
- the first time i connect with ItemID foo , press the button connect
- send message hi with ItemID foo and press the button send.
it's look like the connect fail but the second ,but the send have return code 200
but nothing happen on the web side.

4. See error
```python
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [366952]
email-validator not installed, email fields will be treated as str.
To install, run: pip install email-validator
INFO: Started server process [366957]
INFO: Waiting for application startup.
DEBUG: None - ASGI [1] Started
DEBUG: None - ASGI [1] Sent {'type': 'lifespan.startup'}
DEBUG: None - ASGI [1] Received {'type': 'lifespan.startup.complete'}
DEBUG: ('127.0.0.1', 50056) - Connected
DEBUG: server - state = CONNECTING
DEBUG: server - event = connection_made(<TCPTransport closed=False reading=True 0x1819178>)
DEBUG: ('127.0.0.1', 50056) - ASGI [2] Started
DEBUG: ('127.0.0.1', 50056) - ASGI [2] Received {'type': 'websocket.close', 'code': 1008}
INFO: ('127.0.0.1', 50056) - "WebSocket /items/foo/ws" 403
DEBUG: ('127.0.0.1', 50056) - ASGI [2] Raised exception
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/uvicorn/protocols/websockets/websockets_impl.py", line 147, in run_asgi
result = await self.app(self.scope, self.asgi_receive, self.asgi_send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/uvicorn/middleware/message_logger.py", line 58, in __call__
raise exc from None
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/uvicorn/middleware/message_logger.py", line 54, in __call__
await self.app(scope, inner_receive, inner_send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/applications.py", line 133, in __call__
await self.error_middleware(scope, receive, send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/middleware/errors.py", line 87, in __call__
await self.app(scope, receive, send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/exceptions.py", line 49, in __call__
await self.app(scope, receive, send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/routing.py", line 585, in __call__
await route(scope, receive, send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/routing.py", line 265, in __call__
await self.app(scope, receive, send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/routing.py", line 56, in app
await func(session)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/fastapi/routing.py", line 148, in app
await websocket.close(code=WS_1008_POLICY_VIOLATION)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/websockets.py", line 121, in close
await self.send({"type": "websocket.close", "code": code})
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/websockets.py", line 70, in send
raise RuntimeError('Cannot call "send" once a close message has been sent.')
RuntimeError: Cannot call "send" once a close message has been sent.
DEBUG: server ! failing WebSocket connection in the CONNECTING state: 1006 [no reason]
DEBUG: ('127.0.0.1', 50058) - Connected
DEBUG: server x half-closing TCP connection
DEBUG: ('127.0.0.1', 50058) - ASGI [3] Started
DEBUG: ('127.0.0.1', 50058) - ASGI [3] Received {'type': 'http.response.start', 'status': 200, 'headers': '<...>'}
INFO: ('127.0.0.1', 50058) - "GET / HTTP/1.1" 200
DEBUG: ('127.0.0.1', 50058) - ASGI [3] Received {'type': 'http.response.body', 'body': '<1419 bytes>'}
DEBUG: ('127.0.0.1', 50058) - ASGI [3] Completed
DEBUG: server - event = eof_received()
DEBUG: server - event = connection_lost(None)
DEBUG: server - state = CLOSED
DEBUG: server x code = 1006, reason = [no reason]
DEBUG: ('127.0.0.1', 50058) - Disconnected
DEBUG: ('127.0.0.1', 50060) - Connected
DEBUG: ('127.0.0.1', 50060) - ASGI [4] Started
DEBUG: ('127.0.0.1', 50060) - ASGI [4] Received {'type': 'http.response.start', 'status': 200, 'headers': '<...>'}
INFO: ('127.0.0.1', 50060) - "GET / HTTP/1.1" 200
DEBUG: ('127.0.0.1', 50060) - ASGI [4] Received {'type': 'http.response.body', 'body': '<1419 bytes>'}
DEBUG: ('127.0.0.1', 50060) - ASGI [4] Completed
DEBUG: ('127.0.0.1', 50060) - Disconnected
```
**Expected behavior**
expected to appear the send bold message on the web page.
**Environment:**
- OS: centos 7
- FastAPI Version [e.g. 0.3.0], get it with: fastapi==0.31.0
```Python
import fastapi
print(fastapi.__version__)
0.31.0
```
- Python version, get it with:
```bash
python --version
Python 3.7.3
```
|
@BenjPy ,
Just add `event.preventDefault()` in the beginning of `connect` js function.
The problem here is when you are trying to make websocket connection, browser refreshes page and closes websocket connection.
So `connect` function should looks like this:
```
function connect(event) {
event.preventDefault()
var input = document.getElementById("itemId")
ws = new WebSocket("ws://localhost:8000/items/" + input.value + "/ws");
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
}
```
@alj06ka ,
still nothing appear , when added the line on the web page
it's look like the first time the Websocket fail to connect
see on below the js code
```js
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<label>Item ID: <input type="text" id="itemId" autocomplete="off" value="foo"/></label>
<button onclick="connect(event)">Connect</button>
<br>
<label>Message: <input type="text" id="messageText" autocomplete="off"/></label>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = null;
function connect(event) {
event.preventDefault()
var input = document.getElementById("itemId")
ws = new WebSocket("ws://127.0.0.1:8000/items/" + input.value + "/ws");
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
}
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
```
### see the log on below
```bash
INFO: ('127.0.0.1', 59388) - "WebSocket /items/foo/ws" 403
DEBUG: ('127.0.0.1', 59388) - ASGI [13] Raised exception
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/uvicorn/protocols/websockets/websockets_impl.py ", line 147, in run_asgi
result = await self.app(self.scope, self.asgi_receive, self.asgi_send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/uvicorn/middleware/message_logger.py", line 58, in __call__
raise exc from None
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/uvicorn/middleware/message_logger.py", line 54, in __call__
await self.app(scope, inner_receive, inner_send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/applications.py", line 133, in __call __
await self.error_middleware(scope, receive, send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/middleware/errors.py", line 87, in __ call__
await self.app(scope, receive, send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/exceptions.py", line 49, in __call__
await self.app(scope, receive, send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/routing.py", line 585, in __call__
await route(scope, receive, send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/routing.py", line 265, in __call__
await self.app(scope, receive, send)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/routing.py", line 56, in app
await func(session)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/fastapi/routing.py", line 148, in app
await websocket.close(code=WS_1008_POLICY_VIOLATION)
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/websockets.py", line 121, in close
await self.send({"type": "websocket.close", "code": code})
File "/data/experiments/realtime_web_socket/lib/python3.7/site-packages/starlette/websockets.py", line 70, in send
raise RuntimeError('Cannot call "send" once a close message has been sent.')
RuntimeError: Cannot call "send" once a close message has been sent.
DEBUG: server ! failing WebSocket connection in the CONNECTING state: 1006 [no reason]
DEBUG: server x half-closing TCP connection
DEBUG: server - event = eof_received()
DEBUG: server - event = connection_lost(None)
DEBUG: server - state = CLOSED
DEBUG: server x code = 1006, reason = [no reason]
DEBUG: ('127.0.0.1', 59390) - Connected
DEBUG: ('127.0.0.1', 59390) - ASGI [14] Started
DEBUG: ('127.0.0.1', 59390) - ASGI [14] Received {'type': 'http.response.start', 'status': 200, 'headers': '<...>'}
INFO: ('127.0.0.1', 59390) - "GET / HTTP/1.1" 200
DEBUG: ('127.0.0.1', 59390) - ASGI [14] Received {'type': 'http.response.body', 'body': '<1458 bytes>'}
DEBUG: ('127.0.0.1', 59390) - ASGI [14] Completed
DEBUG: ('127.0.0.1', 59390) - ASGI [15] Started
DEBUG: ('127.0.0.1', 59390) - ASGI [15] Received {'type': 'http.response.start', 'status': 200, 'headers': '<...>'}
INFO: ('127.0.0.1', 59390) - "GET / HTTP/1.1" 200
DEBUG: ('127.0.0.1', 59390) - ASGI [15] Received {'type': 'http.response.body', 'body': '<1458 bytes>'}
DEBUG: ('127.0.0.1', 59390) - ASGI [15] Completed
DEBUG: ('127.0.0.1', 59390) - Disconnected
DEBUG: ('127.0.0.1', 59448) - Connected
DEBUG: ('127.0.0.1', 59448) - ASGI [16] Started
DEBUG: ('127.0.0.1', 59448) - ASGI [16] Received {'type': 'http.response.start', 'status': 200, 'headers': '<...>'}
INFO: ('127.0.0.1', 59448) - "GET / HTTP/1.1" 200
DEBUG: ('127.0.0.1', 59448) - ASGI [16] Received {'type': 'http.response.body', 'body': '<1458 bytes>'}
DEBUG: ('127.0.0.1', 59448) - ASGI [16] Completed
```
@BenjPy ,
Looks like this window is still reloading...
Actually, I think, that separation onto two forms will help you:
```
<form action="" onsubmit="connect(event)">
<label>Item ID: <input type="text" id="itemId" autocomplete="off" value="foo"/></label>
<button>Connect</button>
</form>
<form action="" onsubmit="sendMessage(event)">
<label>Message: <input type="text" id="messageText" autocomplete="off"/></label>
<button>Send</button>
</form>
```
It's not a good way, but it's okay to try out websockets.
@alj06ka ,
Hi, still nothing appear on the web page.
@BenjPy ,
Hi, actually, problem was not in page reloading. I find out, that this example shows how to pass cookie or header params as well. So, you can see dependency `cookie_or_client`. It means, that you must pass `session` param in `Cookie`, or `x-client` param in `Header` on websocket connection request. So if you pass it, everything works correctly.
Here is my code of this example:
```
import uvicorn
from fastapi import Cookie, Depends, FastAPI, Header
from starlette.responses import HTMLResponse
from starlette.status import WS_1008_POLICY_VIOLATION
from starlette.websockets import WebSocket
app = FastAPI()
html = """
<!DOCTYPE html>
<html>
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="sendMessage(event)">
<label>Item ID: <input type="text" id="itemId" autocomplete="off" value="foo"/></label>
<button onclick="connect(event)">Connect</button>
<br>
<label>Message: <input type="text" id="messageText" autocomplete="off"/></label>
<button>Send</button>
</form>
<ul id='messages'>
</ul>
<script>
var ws = null;
function connect(event) {
event.preventDefault()
var input = document.getElementById("itemId")
document.cookie = "session=Test;path=/"
ws = new WebSocket("ws://localhost:8000/items/" + input.value + "/ws");
ws.onmessage = function(event) {
var messages = document.getElementById('messages')
var message = document.createElement('li')
var content = document.createTextNode(event.data)
message.appendChild(content)
messages.appendChild(message)
};
}
function sendMessage(event) {
var input = document.getElementById("messageText")
ws.send(input.value)
input.value = ''
event.preventDefault()
}
</script>
</body>
</html>
"""
@app.get("/")
async def get():
return HTMLResponse(html)
async def get_cookie_or_client(
websocket: WebSocket, session: str = Cookie(None), x_client: str = Header(None)
):
if session is None and x_client is None:
await websocket.close(code=WS_1008_POLICY_VIOLATION)
return session or x_client
@app.websocket("/items/{item_id}/ws")
async def websocket_endpoint(
websocket: WebSocket,
item_id: int,
q: str = None,
cookie_or_client: str = Depends(get_cookie_or_client),
):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(
f"Session Cookie or X-Client Header value is: {cookie_or_client}"
)
if q is not None:
await websocket.send_text(f"Query parameter q is: {q}")
await websocket.send_text(f"Message text was: {data}, for item ID: {item_id}")
if __name__ == '__main__':
uvicorn.run(app, host='localhost', port=8000)
```
@alj06ka
work, thank you
need to change item_id to str
```python
@app.websocket("/items/{item_id}/ws")
async def websocket_endpoint(
websocket: WebSocket,
item_id: str,
q: str = None,
cookie_or_client: str = Depends(get_cookie_or_client),
):
```
> it's possible to update the doc ?
I just had the same problem, and looks like the doc hasn't been edited yet as of Mar. 3rd 2020.
The code above seems like a decent fix, which has worked for me too.
I still have this problem:
```
from fastapi import Cookie, Depends, FastAPI, Header, WebSocket, status
app = FastAPI()
async def get_cookie_or_client(
websocket: WebSocket, session: str = Cookie(None), x_client: str = Header(None)
):
if session is None and x_client is None:
await websocket.close(code=status.WS_1008_POLICY_VIOLATION)
return session or x_client
@app.websocket("/ws")
async def websocket_endpoint(
websocket: WebSocket, cookie_or_client: str = Depends(get_cookie_or_client),
):
await websocket.accept()
while True:
data = await websocket.receive_text()
await websocket.send_text(f"Message text was: {data}")
```
| 2020-06-09T15:37:27 |
tiangolo/fastapi
| 1,547 |
tiangolo__fastapi-1547
|
[
"872"
] |
34c857b7cb493fa41f296c001234bc6b2ed6a083
|
diff --git a/fastapi/applications.py b/fastapi/applications.py
--- a/fastapi/applications.py
+++ b/fastapi/applications.py
@@ -38,6 +38,7 @@ def __init__(
version: str = "0.1.0",
openapi_url: Optional[str] = "/openapi.json",
openapi_tags: Optional[List[Dict[str, Any]]] = None,
+ servers: Optional[List[Dict[str, Union[str, Any]]]] = None,
default_response_class: Type[Response] = JSONResponse,
docs_url: Optional[str] = "/docs",
redoc_url: Optional[str] = "/redoc",
@@ -70,6 +71,7 @@ def __init__(
self.title = title
self.description = description
self.version = version
+ self.servers = servers
self.openapi_url = openapi_url
self.openapi_tags = openapi_tags
# TODO: remove when discarding the openapi_prefix parameter
@@ -106,6 +108,7 @@ def openapi(self, openapi_prefix: str = "") -> Dict:
routes=self.routes,
openapi_prefix=openapi_prefix,
tags=self.openapi_tags,
+ servers=self.servers,
)
return self.openapi_schema
diff --git a/fastapi/openapi/models.py b/fastapi/openapi/models.py
--- a/fastapi/openapi/models.py
+++ b/fastapi/openapi/models.py
@@ -63,7 +63,7 @@ class ServerVariable(BaseModel):
class Server(BaseModel):
- url: AnyUrl
+ url: Union[AnyUrl, str]
description: Optional[str] = None
variables: Optional[Dict[str, ServerVariable]] = None
diff --git a/fastapi/openapi/utils.py b/fastapi/openapi/utils.py
--- a/fastapi/openapi/utils.py
+++ b/fastapi/openapi/utils.py
@@ -86,7 +86,7 @@ def get_openapi_security_definitions(flat_dependant: Dependant) -> Tuple[Dict, L
def get_openapi_operation_parameters(
*,
all_route_params: Sequence[ModelField],
- model_name_map: Dict[Union[Type[BaseModel], Type[Enum]], str]
+ model_name_map: Dict[Union[Type[BaseModel], Type[Enum]], str],
) -> List[Dict[str, Any]]:
parameters = []
for param in all_route_params:
@@ -112,7 +112,7 @@ def get_openapi_operation_parameters(
def get_openapi_operation_request_body(
*,
body_field: Optional[ModelField],
- model_name_map: Dict[Union[Type[BaseModel], Type[Enum]], str]
+ model_name_map: Dict[Union[Type[BaseModel], Type[Enum]], str],
) -> Optional[Dict]:
if not body_field:
return None
@@ -318,12 +318,15 @@ def get_openapi(
description: str = None,
routes: Sequence[BaseRoute],
openapi_prefix: str = "",
- tags: Optional[List[Dict[str, Any]]] = None
+ tags: Optional[List[Dict[str, Any]]] = None,
+ servers: Optional[List[Dict[str, Union[str, Any]]]] = None,
) -> Dict:
info = {"title": title, "version": version}
if description:
info["description"] = description
output: Dict[str, Any] = {"openapi": openapi_version, "info": info}
+ if servers:
+ output["servers"] = servers
components: Dict[str, Dict] = {}
paths: Dict[str, Dict] = {}
flat_models = get_flat_models_from_routes(routes)
|
diff --git a/tests/test_openapi_servers.py b/tests/test_openapi_servers.py
new file mode 100644
--- /dev/null
+++ b/tests/test_openapi_servers.py
@@ -0,0 +1,60 @@
+from fastapi import FastAPI
+from fastapi.testclient import TestClient
+
+app = FastAPI(
+ servers=[
+ {"url": "/", "description": "Default, relative server"},
+ {
+ "url": "http://staging.localhost.tiangolo.com:8000",
+ "description": "Staging but actually localhost still",
+ },
+ {"url": "https://prod.example.com"},
+ ]
+)
+
+
[email protected]("/foo")
+def foo():
+ return {"message": "Hello World"}
+
+
+client = TestClient(app)
+
+
+openapi_schema = {
+ "openapi": "3.0.2",
+ "info": {"title": "FastAPI", "version": "0.1.0"},
+ "servers": [
+ {"url": "/", "description": "Default, relative server"},
+ {
+ "url": "http://staging.localhost.tiangolo.com:8000",
+ "description": "Staging but actually localhost still",
+ },
+ {"url": "https://prod.example.com"},
+ ],
+ "paths": {
+ "/foo": {
+ "get": {
+ "summary": "Foo",
+ "operationId": "foo_foo_get",
+ "responses": {
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ }
+ },
+ }
+ }
+ },
+}
+
+
+def test_openapi_servers():
+ response = client.get("/openapi.json")
+ assert response.status_code == 200, response.text
+ assert response.json() == openapi_schema
+
+
+def test_app():
+ response = client.get("/foo")
+ assert response.status_code == 200, response.text
|
I need a way to specify servers in the openapi spec
### Is your feature request related to a problem
I want to be able to use the generated openapi.json doc as it is and hook it up with a document publishing flow, but i'm not able to because I have to add in information about `servers` manually.
### The solution you would like
Someway to specify at a global level what the base server url should be.
### Describe alternatives you've considered
Currently I'm doing this manually in the generated openapi.json by adding in something like -
```
"servers": [
{
"url": "http://example.com"
}
]
```
I don't mind submitting a PR which enables this if someone can guide me about the changes that need to be made. One thing I saw was that the `get_openapi` method in `fastapi.openapi.utils`, doesn't expose a parameter for setting a value for the `servers` key.
|
It's @tiangolo's decision to make, but given this *is* part of the OpenAPI spec, I personally would be in favor of adding this as a keyword argument to `FastAPI`, and as an argument to `get_openapi`, making it easier to set this.
I think those should be the only changes you need to make (just make sure the value also gets passed to the `get_openapi` call, and added to the returned value in the `get_openapi` call).
It should be a quick PR if you want to open it.
I think eventually we should group the arguments to `FastAPI` into more nested chunks to make it a little easier to parse, but I would be fine with the approach described above for now.
Hey there it's needed also here
| 2020-06-10T19:32:26 |
tiangolo/fastapi
| 1,549 |
tiangolo__fastapi-1549
|
[
"737"
] |
543ef7753aff639ad3aed7c153e42f719e361d38
|
diff --git a/fastapi/dependencies/utils.py b/fastapi/dependencies/utils.py
--- a/fastapi/dependencies/utils.py
+++ b/fastapi/dependencies/utils.py
@@ -478,6 +478,7 @@ async def solve_dependencies(
name=sub_dependant.name,
security_scopes=sub_dependant.security_scopes,
)
+ use_sub_dependant.security_scopes = sub_dependant.security_scopes
solved_result = await solve_dependencies(
request=request,
|
diff --git a/tests/test_dependency_security_overrides.py b/tests/test_dependency_security_overrides.py
new file mode 100644
--- /dev/null
+++ b/tests/test_dependency_security_overrides.py
@@ -0,0 +1,65 @@
+from typing import List, Tuple
+
+from fastapi import Depends, FastAPI, Security
+from fastapi.security import SecurityScopes
+from fastapi.testclient import TestClient
+
+app = FastAPI()
+
+
+def get_user(required_scopes: SecurityScopes):
+ return "john", required_scopes.scopes
+
+
+def get_user_override(required_scopes: SecurityScopes):
+ return "alice", required_scopes.scopes
+
+
+def get_data():
+ return [1, 2, 3]
+
+
+def get_data_override():
+ return [3, 4, 5]
+
+
[email protected]("/user")
+def read_user(
+ user_data: Tuple[str, List[str]] = Security(get_user, scopes=["foo", "bar"]),
+ data: List[int] = Depends(get_data),
+):
+ return {"user": user_data[0], "scopes": user_data[1], "data": data}
+
+
+client = TestClient(app)
+
+
+def test_normal():
+ response = client.get("/user")
+ assert response.json() == {
+ "user": "john",
+ "scopes": ["foo", "bar"],
+ "data": [1, 2, 3],
+ }
+
+
+def test_override_data():
+ app.dependency_overrides[get_data] = get_data_override
+ response = client.get("/user")
+ assert response.json() == {
+ "user": "john",
+ "scopes": ["foo", "bar"],
+ "data": [3, 4, 5],
+ }
+ app.dependency_overrides = {}
+
+
+def test_override_security():
+ app.dependency_overrides[get_user] = get_user_override
+ response = client.get("/user")
+ assert response.json() == {
+ "user": "alice",
+ "scopes": ["foo", "bar"],
+ "data": [1, 2, 3],
+ }
+ app.dependency_overrides = {}
|
dependency_overrides does not play well with scopes
**Describe the bug**
When working with `Security()` dependencies, the scopes disappear when `app.dependency_overrides` is executed. The callable dealing with the scopes gets an empty list instead of the scopes.
**To Reproduce**
```python
from fastapi import FastAPI, Header, Security, Depends
from fastapi.security import SecurityScopes
from starlette.testclient import TestClient
app = FastAPI()
def get_user(required_scopes: SecurityScopes):
print(required_scopes.scopes)
return "John Doe"
def data():
return [1,2,3]
def other_data():
return [3,4,5]
@app.get("/test")
def test(user: str = Security(get_user, scopes=["foo", "bar"]), data = Depends(data)):
return data
client = TestClient(app)
response = client.get("/test")
app.dependency_overrides[data] = other_data
response = client.get("/test")
# prints: ["foo", "bar"] and [] instead of ["foo", "bar"] and ["foo", "bar"]
```
**Expected behavior**
In the above example I expect `get_user()` to print the same scopes twice. Instead, before the `dependency_overrides` it prints the correct scpoes, but an empty list afterwards.
**Environment:**
- OS: Linux
- FastAPI Version 0.43.0
- Python 3.7.4
|
Hello,
I was reading your [comment](https://github.com/tiangolo/fastapi/issues/738#issuecomment-558795651) in the other thread. In my case, I am using `dependency_overrides` to mock the connection to database.
```python
class TransactionTestCaseMixin:
db_session: Session
@pytest.fixture(autouse=True)
def receive_db_session(self, dbsession: Session):
self.db_session = dbsession
app.dependency_overrides[get_db] = lambda: self.db_session
```
That's causing us an issue using `SecurityScopes` when we are testing our service endpoint where we include a `Dependant` (Security) to manage the permissions of our endpoints.
| 2020-06-11T01:14:25 |
tiangolo/fastapi
| 1,553 |
tiangolo__fastapi-1553
|
[
"1088"
] |
543ef7753aff639ad3aed7c153e42f719e361d38
|
diff --git a/fastapi/dependencies/utils.py b/fastapi/dependencies/utils.py
--- a/fastapi/dependencies/utils.py
+++ b/fastapi/dependencies/utils.py
@@ -623,9 +623,17 @@ async def request_body_to_args(
field = required_params[0]
field_info = get_field_info(field)
embed = getattr(field_info, "embed", None)
- if len(required_params) == 1 and not embed:
+ field_alias_omitted = len(required_params) == 1 and not embed
+ if field_alias_omitted:
received_body = {field.alias: received_body}
+
for field in required_params:
+ loc: Tuple[str, ...]
+ if field_alias_omitted:
+ loc = ("body",)
+ else:
+ loc = ("body", field.alias)
+
value: Any = None
if received_body is not None:
if (
@@ -636,7 +644,7 @@ async def request_body_to_args(
try:
value = received_body.get(field.alias)
except AttributeError:
- errors.append(get_missing_field_error(field.alias))
+ errors.append(get_missing_field_error(loc))
continue
if (
value is None
@@ -648,7 +656,7 @@ async def request_body_to_args(
)
):
if field.required:
- errors.append(get_missing_field_error(field.alias))
+ errors.append(get_missing_field_error(loc))
else:
values[field.name] = deepcopy(field.default)
continue
@@ -667,7 +675,9 @@ async def request_body_to_args(
awaitables = [sub_value.read() for sub_value in value]
contents = await asyncio.gather(*awaitables)
value = sequence_shape_to_type[field.shape](contents)
- v_, errors_ = field.validate(value, values, loc=("body", field.alias))
+
+ v_, errors_ = field.validate(value, values, loc=loc)
+
if isinstance(errors_, ErrorWrapper):
errors.append(errors_)
elif isinstance(errors_, list):
@@ -677,12 +687,12 @@ async def request_body_to_args(
return values, errors
-def get_missing_field_error(field_alias: str) -> ErrorWrapper:
+def get_missing_field_error(loc: Tuple[str, ...]) -> ErrorWrapper:
if PYDANTIC_1:
- missing_field_error = ErrorWrapper(MissingError(), loc=("body", field_alias))
+ missing_field_error = ErrorWrapper(MissingError(), loc=loc)
else: # pragma: no cover
missing_field_error = ErrorWrapper( # type: ignore
- MissingError(), loc=("body", field_alias), config=BaseConfig,
+ MissingError(), loc=loc, config=BaseConfig,
)
return missing_field_error
|
diff --git a/tests/test_multi_body_errors.py b/tests/test_multi_body_errors.py
--- a/tests/test_multi_body_errors.py
+++ b/tests/test_multi_body_errors.py
@@ -104,7 +104,7 @@ def save_item_no_body(item: List[Item]):
"detail": [
{
"ctx": {"limit_value": 0.0},
- "loc": ["body", "item", 0, "age"],
+ "loc": ["body", 0, "age"],
"msg": "ensure this value is greater than 0",
"type": "value_error.number.not_gt",
}
@@ -114,22 +114,22 @@ def save_item_no_body(item: List[Item]):
multiple_errors = {
"detail": [
{
- "loc": ["body", "item", 0, "name"],
+ "loc": ["body", 0, "name"],
"msg": "field required",
"type": "value_error.missing",
},
{
- "loc": ["body", "item", 0, "age"],
+ "loc": ["body", 0, "age"],
"msg": "value is not a valid decimal",
"type": "type_error.decimal",
},
{
- "loc": ["body", "item", 1, "name"],
+ "loc": ["body", 1, "name"],
"msg": "field required",
"type": "value_error.missing",
},
{
- "loc": ["body", "item", 1, "age"],
+ "loc": ["body", 1, "age"],
"msg": "value is not a valid decimal",
"type": "type_error.decimal",
},
diff --git a/tests/test_tutorial/test_body/test_tutorial001.py b/tests/test_tutorial/test_body/test_tutorial001.py
--- a/tests/test_tutorial/test_body/test_tutorial001.py
+++ b/tests/test_tutorial/test_body/test_tutorial001.py
@@ -92,7 +92,7 @@ def test_openapi_schema():
price_missing = {
"detail": [
{
- "loc": ["body", "item", "price"],
+ "loc": ["body", "price"],
"msg": "field required",
"type": "value_error.missing",
}
@@ -102,7 +102,7 @@ def test_openapi_schema():
price_not_float = {
"detail": [
{
- "loc": ["body", "item", "price"],
+ "loc": ["body", "price"],
"msg": "value is not a valid float",
"type": "type_error.float",
}
@@ -112,12 +112,12 @@ def test_openapi_schema():
name_price_missing = {
"detail": [
{
- "loc": ["body", "item", "name"],
+ "loc": ["body", "name"],
"msg": "field required",
"type": "value_error.missing",
},
{
- "loc": ["body", "item", "price"],
+ "loc": ["body", "price"],
"msg": "field required",
"type": "value_error.missing",
},
@@ -126,11 +126,7 @@ def test_openapi_schema():
body_missing = {
"detail": [
- {
- "loc": ["body", "item"],
- "msg": "field required",
- "type": "value_error.missing",
- }
+ {"loc": ["body"], "msg": "field required", "type": "value_error.missing",}
]
}
diff --git a/tests/test_tutorial/test_body_nested_models/test_tutorial009.py b/tests/test_tutorial/test_body_nested_models/test_tutorial009.py
--- a/tests/test_tutorial/test_body_nested_models/test_tutorial009.py
+++ b/tests/test_tutorial/test_body_nested_models/test_tutorial009.py
@@ -95,7 +95,7 @@ def test_post_invalid_body():
assert response.json() == {
"detail": [
{
- "loc": ["body", "weights", "__key__"],
+ "loc": ["body", "__key__"],
"msg": "value is not a valid integer",
"type": "type_error.integer",
}
diff --git a/tests/test_tutorial/test_custom_request_and_route/test_tutorial002.py b/tests/test_tutorial/test_custom_request_and_route/test_tutorial002.py
--- a/tests/test_tutorial/test_custom_request_and_route/test_tutorial002.py
+++ b/tests/test_tutorial/test_custom_request_and_route/test_tutorial002.py
@@ -18,7 +18,7 @@ def test_exception_handler_body_access():
"body": '{"numbers": [1, 2, 3]}',
"errors": [
{
- "loc": ["body", "numbers"],
+ "loc": ["body"],
"msg": "value is not a valid list",
"type": "type_error.list",
}
diff --git a/tests/test_tutorial/test_handling_errors/test_tutorial005.py b/tests/test_tutorial/test_handling_errors/test_tutorial005.py
--- a/tests/test_tutorial/test_handling_errors/test_tutorial005.py
+++ b/tests/test_tutorial/test_handling_errors/test_tutorial005.py
@@ -92,7 +92,7 @@ def test_post_validation_error():
assert response.json() == {
"detail": [
{
- "loc": ["body", "item", "size"],
+ "loc": ["body", "size"],
"msg": "value is not a valid integer",
"type": "type_error.integer",
}
|
Bad `loc` on validation error, if payload represended by one model
### Describe the bug
Really like your framework, but there is, indeed, an annoying issue with `loc` on validation error with one object as payload.
### To Reproduce
Code sample
```Python
from typing import List
from fastapi import FastAPI, Body
from pydantic import BaseModel
app = FastAPI()
class NameModel(BaseModel):
name: str
@app.post("/test", response_model=NameModel)
def test(obj: NameModel, ): # bad
return obj
@app.post("/test_embed", response_model=NameModel)
def test(obj: NameModel = Body(..., embed=True)): # ok
return obj
@app.post("/test_multiple", response_model=List[NameModel])
def test(obj1: NameModel, obj2: NameModel): # ok
return obj1, obj2
```
When you make a request to endpoint (`/test`) with the wrong payload (e.g.: `{}`), it always includes the variable name into error location, despite it has no relation to request.
It makes no sense, moreover, it complicates the logic for error printing on fronted, because they just don't know and not required to know the name of the backend`s internal variable.
```json
{
"detail": [
{
"loc": [
"body",
"obj",
"name"
],
"msg": "field required",
"type": "value_error.missing"
}
]
}
```
it should be
```json
{
"detail": [
{
"loc": [
"body",
"name"
],
"msg": "field required",
"type": "value_error.missing"
}
]
}
```
With the embedded object (`/test_embed`) or multiple objects (`/test_multiple`), it works as expected, putting the variable name into location, because it should be in the payload.
### Expected behavior
Don't include the variable name into location error, if it is not reflected in schema / not embedded / not expected to be in payload.
### Environment
- OS: macOS
- FastAPI 0.52.0
- Python 3.6.8
|
We can also observe this behaviour, it caused a bit of head-scratching when trying to diagnose the source of an error between frontend and backend services.
Also observed this behaviour when fiddling around with the framework for the first time.
| 2020-06-11T17:24:14 |
tiangolo/fastapi
| 2,606 |
tiangolo__fastapi-2606
|
[
"2594"
] |
8a9a117ec7f58711dc68d6d6633dd02d4289cd1d
|
diff --git a/fastapi/encoders.py b/fastapi/encoders.py
--- a/fastapi/encoders.py
+++ b/fastapi/encoders.py
@@ -80,6 +80,11 @@ def jsonable_encoder(
return obj
if isinstance(obj, dict):
encoded_dict = {}
+ allowed_keys = set(obj.keys())
+ if include is not None:
+ allowed_keys &= set(include)
+ if exclude is not None:
+ allowed_keys -= set(exclude)
for key, value in obj.items():
if (
(
@@ -88,7 +93,7 @@ def jsonable_encoder(
or (not key.startswith("_sa"))
)
and (value is not None or not exclude_none)
- and ((include and key in include) or not exclude or key not in exclude)
+ and key in allowed_keys
):
encoded_key = jsonable_encoder(
key,
@@ -144,6 +149,8 @@ def jsonable_encoder(
raise ValueError(errors)
return jsonable_encoder(
data,
+ include=include,
+ exclude=exclude,
by_alias=by_alias,
exclude_unset=exclude_unset,
exclude_defaults=exclude_defaults,
|
diff --git a/tests/test_jsonable_encoder.py b/tests/test_jsonable_encoder.py
--- a/tests/test_jsonable_encoder.py
+++ b/tests/test_jsonable_encoder.py
@@ -93,16 +93,42 @@ class Config:
return ModelWithPath(path=request.param("/foo", "bar"))
+def test_encode_dict():
+ pet = {"name": "Firulais", "owner": {"name": "Foo"}}
+ assert jsonable_encoder(pet) == {"name": "Firulais", "owner": {"name": "Foo"}}
+ assert jsonable_encoder(pet, include={"name"}) == {"name": "Firulais"}
+ assert jsonable_encoder(pet, exclude={"owner"}) == {"name": "Firulais"}
+ assert jsonable_encoder(pet, include={}) == {}
+ assert jsonable_encoder(pet, exclude={}) == {
+ "name": "Firulais",
+ "owner": {"name": "Foo"},
+ }
+
+
def test_encode_class():
person = Person(name="Foo")
pet = Pet(owner=person, name="Firulais")
assert jsonable_encoder(pet) == {"name": "Firulais", "owner": {"name": "Foo"}}
+ assert jsonable_encoder(pet, include={"name"}) == {"name": "Firulais"}
+ assert jsonable_encoder(pet, exclude={"owner"}) == {"name": "Firulais"}
+ assert jsonable_encoder(pet, include={}) == {}
+ assert jsonable_encoder(pet, exclude={}) == {
+ "name": "Firulais",
+ "owner": {"name": "Foo"},
+ }
def test_encode_dictable():
person = DictablePerson(name="Foo")
pet = DictablePet(owner=person, name="Firulais")
assert jsonable_encoder(pet) == {"name": "Firulais", "owner": {"name": "Foo"}}
+ assert jsonable_encoder(pet, include={"name"}) == {"name": "Firulais"}
+ assert jsonable_encoder(pet, exclude={"owner"}) == {"name": "Firulais"}
+ assert jsonable_encoder(pet, include={}) == {}
+ assert jsonable_encoder(pet, exclude={}) == {
+ "name": "Firulais",
+ "owner": {"name": "Foo"},
+ }
def test_encode_unsupported():
@@ -144,6 +170,14 @@ def test_encode_model_with_default():
assert jsonable_encoder(model, exclude_unset=True, exclude_defaults=True) == {
"foo": "foo"
}
+ assert jsonable_encoder(model, include={"foo"}) == {"foo": "foo"}
+ assert jsonable_encoder(model, exclude={"bla"}) == {"foo": "foo", "bar": "bar"}
+ assert jsonable_encoder(model, include={}) == {}
+ assert jsonable_encoder(model, exclude={}) == {
+ "foo": "foo",
+ "bar": "bar",
+ "bla": "bla",
+ }
def test_custom_encoders():
|
`jsonable_encoder` function not working as expected with different type of variables
### First check
* [X] I added a very descriptive title to this issue.
* [X] I used the GitHub search to find a similar issue and didn't find it.
* [X] I searched the FastAPI documentation, with the integrated search.
* [X] I already searched in Google "How to X in FastAPI" and didn't find any information.
* [X] I already read and followed all the tutorial in the docs and didn't find an answer.
* [X] I already checked if it is not related to FastAPI but to [Pydantic](https://github.com/samuelcolvin/pydantic).
* [X] I already checked if it is not related to FastAPI but to [Swagger UI](https://github.com/swagger-api/swagger-ui).
* [X] I already checked if it is not related to FastAPI but to [ReDoc](https://github.com/Redocly/redoc).
* [X] After submitting this, I commit to one of:
* Read open issues with questions until I find 2 issues where I can help someone and add a comment to help there.
* I already hit the "watch" button in this repository to receive notifications and I commit to help at least 2 people that ask questions in the future.
* Implement a Pull Request for a confirmed bug.
<!--
I'm asking all this because answering questions and solving problems in GitHub issues consumes a lot of time. I end up not being able to add new features, fix bugs, review Pull Requests, etc. as fast as I wish because I have to spend too much time handling issues.
All that, on top of all the incredible help provided by a bunch of community members that give a lot of their time to come here and help others.
That's a lot of work they are doing, but if more FastAPI users came to help others like them just a little bit more, it would be much less effort for them (and you and me 😅).
-->
### Example
Here's a self-contained, [minimal, reproducible, example](https://stackoverflow.com/help/minimal-reproducible-example) with my use case:
#### Example 1 (BaseModel)
```python
import pytest
from attr import dataclass
from fastapi.encoders import jsonable_encoder
from pydantic.main import BaseModel
class MyBaseModel(BaseModel):
foo: int
bar: int
@pytest.mark.parametrize(
"obj, include, exclude, expected",
[
(MyBaseModel(foo=1, bar=2), None, None, {"foo": 1, "bar": 2}), # Passed
(MyBaseModel(foo=1, bar=2), {}, {}, {}), # Passed
(MyBaseModel(foo=1, bar=2), {"foo"}, {}, {"foo": 1}), # Passed
(MyBaseModel(foo=1, bar=2), {}, {"foo"}, {}), # Passed
(MyBaseModel(foo=1, bar=2), {"foo"}, None, {"foo": 1}), # Passed
(MyBaseModel(foo=1, bar=2), None, {"foo"}, {"bar": 2}), # Passed
],
)
def test_jsonable_encoder_include_exclude_base_model(obj, include, exclude, expected):
assert jsonable_encoder(obj, include=include, exclude=exclude) == expected
```
#### Example 2 (Python dictionary)
```python
import pytest
from fastapi.encoders import jsonable_encoder
@pytest.mark.parametrize(
"obj, include, exclude, expected",
[
({"foo": 1, "bar": 2}, None, None, {"foo": 1, "bar": 2}), # Passed
({"foo": 1, "bar": 2}, {}, {}, {}), # Failed
({"foo": 1, "bar": 2}, {"foo"}, {}, {"foo": 1}), # Failed
({"foo": 1, "bar": 2}, {}, {"foo"}, {}), # Failed
({"foo": 1, "bar": 2}, {"foo"}, None, {"foo": 1}), # Failed
({"foo": 1, "bar": 2}, None, {"foo"}, {"bar": 2}), # Passed
],
)
def test_jsonable_encoder_include_exclude_dict(obj, include, exclude, expected):
assert jsonable_encoder(obj, include=include, exclude=exclude) == expected
```
#### Example 3 (Python object with dataclass)
```python
@dataclass
class MyModel:
foo: int
bar: int
@pytest.mark.parametrize(
"obj, include, exclude, expected",
[
(MyModel(foo=1, bar=2), None, None, {"foo": 1, "bar": 2}), # Passed
(MyModel(foo=1, bar=2), {}, {}, {}), # Failed
(MyModel(foo=1, bar=2), {"foo"}, {}, {"foo": 1}), # Failed
(MyModel(foo=1, bar=2), {}, {"foo"}, {}), # Failed
(MyModel(foo=1, bar=2), {"foo"}, None, {"foo": 1}), # Failed
(MyModel(foo=1, bar=2), None, {"foo"}, {"bar": 2}), # Failed
],
)
def test_jsonable_encoder_include_exclude_obj(obj, include, exclude, expected):
assert jsonable_encoder(obj, include=include, exclude=exclude) == expected
```
### Description
<!-- Replace the content below with your own problem, question, or error -->
I was trying to understand how the `include` and `exclude` parameters worked. I looked in the documentation ([here](https://fastapi.tiangolo.com/tutorial/encoder/)) and the the test suite ([here](https://github.com/tiangolo/fastapi/blob/fdb6c9ccc504f90afd0fbcec53f3ea0bfebc261a/tests/test_jsonable_encoder.py), latest commit of this file in master branch) and I did not find anything related to `include` and `exclude` in both places.
I did see that these 2 parameters came from Pydantic (from the [dict function](https://github.com/samuelcolvin/pydantic/blob/43308d1b24c5d1163c44b8fa786d1b27e000c64e/pydantic/main.py#L440)) and it is being used in the [_calculate_keys method](https://github.com/samuelcolvin/pydantic/blob/43308d1b24c5d1163c44b8fa786d1b27e000c64e/pydantic/main.py#L817).
The first thing I did was to check the `jsonable_encoder` using a BaseModel object, which uses the dict function from Pydantic (Example 1), so I created a set of test with a BaseModel instance. All those tests are passing. Then I created the same tests with a Python dictionary (Example 2) and a Python object (Example 3).
I expect that the same tests with a different type of variable would work the same. In the case of Example 3, it is failing the most because it is missing the `include` and `exclude` parameters at the end of the function ([here](https://github.com/tiangolo/fastapi/blob/fdb6c9ccc504f90afd0fbcec53f3ea0bfebc261a/fastapi/encoders.py#L142)).
### Environment
* OS: Linux
* Python: 3.8.5
* FastAPI Version: 0.63.0
To know the FastAPI version use:
```bash
python -c "import fastapi; print(fastapi.__version__)"
```
* Python version:
To know the Python version use:
```bash
python --version
```
### Additional context
To reproduce the Example snippets, you will also need `pytest` installed (6.2.1 in my case)
I am happy to help by creating a PR for this bug once it is confirmed.
<details>
<summary>All examples together</summary>
```python
import pytest
from attr import dataclass
from fastapi.encoders import jsonable_encoder
from pydantic.main import BaseModel
class MyBaseModel(BaseModel):
foo: int
bar: int
@dataclass
class MyModel:
foo: int
bar: int
@pytest.mark.parametrize(
"obj, include, exclude, expected",
[
(MyBaseModel(foo=1, bar=2), None, None, {"foo": 1, "bar": 2}), # Passed
(MyBaseModel(foo=1, bar=2), {}, {}, {}), # Passed
(MyBaseModel(foo=1, bar=2), {"foo"}, {}, {"foo": 1}), # Passed
(MyBaseModel(foo=1, bar=2), {}, {"foo"}, {}), # Passed
(MyBaseModel(foo=1, bar=2), {"foo"}, None, {"foo": 1}), # Passed
(MyBaseModel(foo=1, bar=2), None, {"foo"}, {"bar": 2}), # Passed
({"foo": 1, "bar": 2}, None, None, {"foo": 1, "bar": 2}), # Passed
({"foo": 1, "bar": 2}, {}, {}, {}), # Failed
({"foo": 1, "bar": 2}, {"foo"}, {}, {"foo": 1}), # Failed
({"foo": 1, "bar": 2}, {}, {"foo"}, {}), # Failed
({"foo": 1, "bar": 2}, {"foo"}, None, {"foo": 1}), # Failed
({"foo": 1, "bar": 2}, None, {"foo"}, {"bar": 2}), # Passed
(MyModel(foo=1, bar=2), None, None, {"foo": 1, "bar": 2}), # Passed
(MyModel(foo=1, bar=2), {}, {}, {}), # Failed
(MyModel(foo=1, bar=2), {"foo"}, {}, {"foo": 1}), # Failed
(MyModel(foo=1, bar=2), {}, {"foo"}, {}), # Failed
(MyModel(foo=1, bar=2), {"foo"}, None, {"foo": 1}), # Failed
(MyModel(foo=1, bar=2), None, {"foo"}, {"bar": 2}), # Failed
],
)
def test_jsonable_encoder_include_exclude(obj, include, exclude, expected):
assert jsonable_encoder(obj, include=include, exclude=exclude) == expected
```
</details>
|
The pydantic docs for include/exclude are [here](https://pydantic-docs.helpmanual.io/usage/exporting_models/#advanced-include-and-exclude), for anyone curious regarding this issue.
@xaviml How would you expect this to work for objects that are not pydantic models? Seems like we'd have to make a lot of assumptions about the structure of the objects.
Perhaps docs could be added saying include/exclude are only valid for pydantic models?
Trying to get some more information: If you really want to use include/exclude, is there anything preventing you from using a pydantic model.
Hi @falkben,
Thank you for your reply.
> How would you expect this to work for objects that are not pydantic models?
I would expect to be consistent, so to work the same as Pydantic models. For example, if we do:
```python
jsonable_encoder({"foo": 1, "bar": 2}, include={"foo"})
```
I would expect to return `{"foo": 1}`. However, this returns: `{"foo": 1, "bar": 2}`. The same way that if we do:
```python
jsonable_encoder({"foo": 1, "bar": 2}, exclude={"foo"})
```
It returns `{"bar": 2}` as expected.
> Seems like we'd have to make a lot of assumptions about the structure of the objects.
I don't think is about the assumption of the structure of the object. They are all converted to dictionaries with `dict` ([here](https://github.com/tiangolo/fastapi/blob/fdb6c9ccc504f90afd0fbcec53f3ea0bfebc261a/fastapi/encoders.py#L134)) or `vars`([here](https://github.com/tiangolo/fastapi/blob/fdb6c9ccc504f90afd0fbcec53f3ea0bfebc261a/fastapi/encoders.py#L138)). What needs to change is the way of including and excluding ([here](https://github.com/tiangolo/fastapi/blob/fdb6c9ccc504f90afd0fbcec53f3ea0bfebc261a/fastapi/encoders.py#L80)).
> Perhaps docs could be added saying include/exclude are only valid for pydantic models?
You can see in [this `if` branch](https://github.com/tiangolo/fastapi/blob/fdb6c9ccc504f90afd0fbcec53f3ea0bfebc261a/fastapi/encoders.py#L70) that `include` and `exclude` is also used when the object is a dictionary.
> Trying to get some more information: If you really want to use include/exclude, is there anything preventing you from using a pydantic model.
I am using the `jsonable_encoder` with a SQLAlchemy object, the same way it is done in [here](https://github.com/tiangolo/full-stack-fastapi-postgresql/blob/490c554e23343eec0736b06e59b2108fdd057fdc/%7B%7Bcookiecutter.project_slug%7D%7D/backend/app/app/crud/base.py#L49). This is what is preventing me to use a Pydantic model, because I use a SQLAlchemy model. I will find a workaround to this, but this is another matter not related to this issue.
When I created this issue I tried to understand what is the expected use of include and exclude parameters from `jsonable_encoder`. This is why I went to the tests and see what is the expected behaviour of this function with the use of include and exclude. What I proposed is how I think it should be (and how it works with Pydantic), but I am happy to hear and discuss the right implementation for this function with these parameters.
Regards,
Xavi M.
Possibly related? https://github.com/tiangolo/fastapi/pull/2016
Hi @falkben,
I did see that issue before creating this one. The #2016 PR adds support to dictionaries for the include and exclude, but it does.not change the way include and exclude are being used. Although both of these issues (#2016 and this one) are about jsonable_encoder, they are not related.
Regards,
Xavi M.
| 2021-01-05T12:39:56 |
tiangolo/fastapi
| 2,944 |
tiangolo__fastapi-2944
|
[
"2943"
] |
2f1b856fe611f2f15d38a04850ed9f25da719178
|
diff --git a/docs_src/events/tutorial003.py b/docs_src/events/tutorial003.py
new file mode 100644
--- /dev/null
+++ b/docs_src/events/tutorial003.py
@@ -0,0 +1,28 @@
+from contextlib import asynccontextmanager
+
+from fastapi import FastAPI
+
+
+def fake_answer_to_everything_ml_model(x: float):
+ return x * 42
+
+
+ml_models = {}
+
+
+@asynccontextmanager
+async def lifespan(app: FastAPI):
+ # Load the ML model
+ ml_models["answer_to_everything"] = fake_answer_to_everything_ml_model
+ yield
+ # Clean up the ML models and release the resources
+ ml_models.clear()
+
+
+app = FastAPI(lifespan=lifespan)
+
+
[email protected]("/predict")
+async def predict(x: float):
+ result = ml_models["answer_to_everything"](x)
+ return {"result": result}
diff --git a/fastapi/applications.py b/fastapi/applications.py
--- a/fastapi/applications.py
+++ b/fastapi/applications.py
@@ -1,6 +1,7 @@
from enum import Enum
from typing import (
Any,
+ AsyncContextManager,
Awaitable,
Callable,
Coroutine,
@@ -71,6 +72,7 @@ def __init__(
] = None,
on_startup: Optional[Sequence[Callable[[], Any]]] = None,
on_shutdown: Optional[Sequence[Callable[[], Any]]] = None,
+ lifespan: Optional[Callable[["FastAPI"], AsyncContextManager[Any]]] = None,
terms_of_service: Optional[str] = None,
contact: Optional[Dict[str, Union[str, Any]]] = None,
license_info: Optional[Dict[str, Union[str, Any]]] = None,
@@ -125,6 +127,7 @@ def __init__(
dependency_overrides_provider=self,
on_startup=on_startup,
on_shutdown=on_shutdown,
+ lifespan=lifespan,
default_response_class=default_response_class,
dependencies=dependencies,
callbacks=callbacks,
diff --git a/fastapi/routing.py b/fastapi/routing.py
--- a/fastapi/routing.py
+++ b/fastapi/routing.py
@@ -7,6 +7,7 @@
from enum import Enum, IntEnum
from typing import (
Any,
+ AsyncContextManager,
Callable,
Coroutine,
Dict,
@@ -492,6 +493,7 @@ def __init__(
route_class: Type[APIRoute] = APIRoute,
on_startup: Optional[Sequence[Callable[[], Any]]] = None,
on_shutdown: Optional[Sequence[Callable[[], Any]]] = None,
+ lifespan: Optional[Callable[[Any], AsyncContextManager[Any]]] = None,
deprecated: Optional[bool] = None,
include_in_schema: bool = True,
generate_unique_id_function: Callable[[APIRoute], str] = Default(
@@ -504,6 +506,7 @@ def __init__(
default=default,
on_startup=on_startup,
on_shutdown=on_shutdown,
+ lifespan=lifespan,
)
if prefix:
assert prefix.startswith("/"), "A path prefix must start with '/'"
|
diff --git a/tests/test_router_events.py b/tests/test_router_events.py
--- a/tests/test_router_events.py
+++ b/tests/test_router_events.py
@@ -1,3 +1,7 @@
+from contextlib import asynccontextmanager
+from typing import AsyncGenerator, Dict
+
+import pytest
from fastapi import APIRouter, FastAPI
from fastapi.testclient import TestClient
from pydantic import BaseModel
@@ -12,57 +16,49 @@ class State(BaseModel):
sub_router_shutdown: bool = False
-state = State()
-
-app = FastAPI()
-
-
[email protected]_event("startup")
-def app_startup():
- state.app_startup = True
-
-
[email protected]_event("shutdown")
-def app_shutdown():
- state.app_shutdown = True
-
[email protected]
+def state() -> State:
+ return State()
-router = APIRouter()
+def test_router_events(state: State) -> None:
+ app = FastAPI()
[email protected]_event("startup")
-def router_startup():
- state.router_startup = True
+ @app.get("/")
+ def main() -> Dict[str, str]:
+ return {"message": "Hello World"}
+ @app.on_event("startup")
+ def app_startup() -> None:
+ state.app_startup = True
[email protected]_event("shutdown")
-def router_shutdown():
- state.router_shutdown = True
+ @app.on_event("shutdown")
+ def app_shutdown() -> None:
+ state.app_shutdown = True
+ router = APIRouter()
-sub_router = APIRouter()
+ @router.on_event("startup")
+ def router_startup() -> None:
+ state.router_startup = True
+ @router.on_event("shutdown")
+ def router_shutdown() -> None:
+ state.router_shutdown = True
-@sub_router.on_event("startup")
-def sub_router_startup():
- state.sub_router_startup = True
+ sub_router = APIRouter()
+ @sub_router.on_event("startup")
+ def sub_router_startup() -> None:
+ state.sub_router_startup = True
-@sub_router.on_event("shutdown")
-def sub_router_shutdown():
- state.sub_router_shutdown = True
+ @sub_router.on_event("shutdown")
+ def sub_router_shutdown() -> None:
+ state.sub_router_shutdown = True
+ router.include_router(sub_router)
+ app.include_router(router)
-@sub_router.get("/")
-def main():
- return {"message": "Hello World"}
-
-
-router.include_router(sub_router)
-app.include_router(router)
-
-
-def test_router_events():
assert state.app_startup is False
assert state.router_startup is False
assert state.sub_router_startup is False
@@ -85,3 +81,28 @@ def test_router_events():
assert state.app_shutdown is True
assert state.router_shutdown is True
assert state.sub_router_shutdown is True
+
+
+def test_app_lifespan_state(state: State) -> None:
+ @asynccontextmanager
+ async def lifespan(app: FastAPI) -> AsyncGenerator[None, None]:
+ state.app_startup = True
+ yield
+ state.app_shutdown = True
+
+ app = FastAPI(lifespan=lifespan)
+
+ @app.get("/")
+ def main() -> Dict[str, str]:
+ return {"message": "Hello World"}
+
+ assert state.app_startup is False
+ assert state.app_shutdown is False
+ with TestClient(app) as client:
+ assert state.app_startup is True
+ assert state.app_shutdown is False
+ response = client.get("/")
+ assert response.status_code == 200, response.text
+ assert response.json() == {"message": "Hello World"}
+ assert state.app_startup is True
+ assert state.app_shutdown is True
diff --git a/tests/test_tutorial/test_events/test_tutorial003.py b/tests/test_tutorial/test_events/test_tutorial003.py
new file mode 100644
--- /dev/null
+++ b/tests/test_tutorial/test_events/test_tutorial003.py
@@ -0,0 +1,86 @@
+from fastapi.testclient import TestClient
+
+from docs_src.events.tutorial003 import (
+ app,
+ fake_answer_to_everything_ml_model,
+ ml_models,
+)
+
+openapi_schema = {
+ "openapi": "3.0.2",
+ "info": {"title": "FastAPI", "version": "0.1.0"},
+ "paths": {
+ "/predict": {
+ "get": {
+ "summary": "Predict",
+ "operationId": "predict_predict_get",
+ "parameters": [
+ {
+ "required": True,
+ "schema": {"title": "X", "type": "number"},
+ "name": "x",
+ "in": "query",
+ }
+ ],
+ "responses": {
+ "200": {
+ "description": "Successful Response",
+ "content": {"application/json": {"schema": {}}},
+ },
+ "422": {
+ "description": "Validation Error",
+ "content": {
+ "application/json": {
+ "schema": {
+ "$ref": "#/components/schemas/HTTPValidationError"
+ }
+ }
+ },
+ },
+ },
+ }
+ }
+ },
+ "components": {
+ "schemas": {
+ "HTTPValidationError": {
+ "title": "HTTPValidationError",
+ "type": "object",
+ "properties": {
+ "detail": {
+ "title": "Detail",
+ "type": "array",
+ "items": {"$ref": "#/components/schemas/ValidationError"},
+ }
+ },
+ },
+ "ValidationError": {
+ "title": "ValidationError",
+ "required": ["loc", "msg", "type"],
+ "type": "object",
+ "properties": {
+ "loc": {
+ "title": "Location",
+ "type": "array",
+ "items": {"anyOf": [{"type": "string"}, {"type": "integer"}]},
+ },
+ "msg": {"title": "Message", "type": "string"},
+ "type": {"title": "Error Type", "type": "string"},
+ },
+ },
+ }
+ },
+}
+
+
+def test_events():
+ assert not ml_models, "ml_models should be empty"
+ with TestClient(app) as client:
+ assert ml_models["answer_to_everything"] == fake_answer_to_everything_ml_model
+ response = client.get("/openapi.json")
+ assert response.status_code == 200, response.text
+ assert response.json() == openapi_schema
+ response = client.get("/predict", params={"x": 2})
+ assert response.status_code == 200, response.text
+ assert response.json() == {"result": 84.0}
+ assert not ml_models, "ml_models should be empty"
|
Support starlette "lifespan" context for application
### First check
* [x] I added a very descriptive title to this issue.
* [x] I used the GitHub search to find a similar issue and didn't find it.
* [x] I searched the FastAPI documentation, with the integrated search.
* [x] I already searched in Google "How to X in FastAPI" and didn't find any information.
* [x] I already read and followed all the tutorial in the docs and didn't find an answer.
* [x] I already checked if it is not related to FastAPI but to [Pydantic](https://github.com/samuelcolvin/pydantic).
* [x] I already checked if it is not related to FastAPI but to [Swagger UI](https://github.com/swagger-api/swagger-ui).
* [x] I already checked if it is not related to FastAPI but to [ReDoc](https://github.com/Redocly/redoc).
* [x] After submitting this, I commit to:
* Read open issues with questions until I find 2 issues where I can help someone and add a comment to help there.
* Or, I already hit the "watch" button in this repository to receive notifications and I commit to help at least 2 people that ask questions in the future.
* Implement a Pull Request for a confirmed bug.
<!--
I'm asking all this because answering questions and solving problems in GitHub issues consumes a lot of time. I end up not being able to add new features, fix bugs, review Pull Requests, etc. as fast as I wish because I have to spend too much time handling issues.
All that, on top of all the incredible help provided by a bunch of community members that give a lot of their time to come here and help others.
That's a lot of work they are doing, but if more FastAPI users came to help others like them just a little bit more, it would be much less effort for them (and you and me 😅).
-->
### Description
Starlette added support for the lifespan context function in 0.13.5. It's not well documented, but the code does [suggest](https://github.com/encode/starlette/blob/ed73b97c9b8f4aa527eed88032c04ce9fe109a3c/starlette/applications.py#L51):
```python
# The lifespan context function is a newer style that replaces
# on_startup / on_shutdown handlers. Use one or the other, not both.
```
For my purposes, it's much more convenient to use a (async)contextmanager for the startup and shutdown events of my application. It would be nice to have the option
### The solution you would like
I'd like an easier way, and one that's officially supported, to use the lifespan context function.
```Python
from fastapi import FastAPI
async def lifespan(app):
print("startup")
async with SomeResource():
yield
print("shutdown")
app = FastAPI(lifespan=lifespan)
```
or
```Python
from fastapi import FastAPI
app = FastAPI()
@app.lifespan
async def lifespan(app):
print("startup")
async with SomeResource():
yield
print("shutdown")
```
### Describe alternatives you've considered
I can already accomplish this simply by doing:
```python
from fastapi import FastAPI
async def lifespan(app):
print("startup")
async with SomeResource():
yield
print("shutdown")
app = FastAPI()
app.router.lifespan_context = lifespan
```
however this is not officially supported and would likely break if accidentally using `app.on_event` in addition.
One could also do nasty stuff with `__aenter__` and `__aexit__`:
```python
from fastapi import FastAPI
app = FastAPI()
@app.on_event("startup")
async def startup()
print("startup")
app.state.resource = SomeResource()
await app.state.resource.__aenter__()
@app.on_event("shutdown")
async def startup()
print("shutdown")
await app.state.resource.__aexit__(None, None, None)
```
but that seems quite ugly to me.
### Environment
* OS: Linux
* FastAPI Version: 0.63.0
* Python version: 3.8.5
|
@uSpike Hi! Did you look into [asgi-lifespan](https://pypi.org/project/asgi-lifespan/) package?
@juntatalor I did not look in to asgi-lifespan. It seems strange to use something outside of starlette, when starlette already supports the lifespan context:
```python
from starlette import Starlette
async def lifespan(app):
async with SomeResource():
yield
app = Starlette(lifespan=lifespan)
```
What I'm looking for in this request is to have the starlette functionality exposed in fastapi.
| 2021-03-13T05:08:38 |
tiangolo/fastapi
| 3,372 |
tiangolo__fastapi-3372
|
[
"310"
] |
4d26fa5c546f68ddb67bd3e6c194c644323aadaa
|
diff --git a/fastapi/concurrency.py b/fastapi/concurrency.py
--- a/fastapi/concurrency.py
+++ b/fastapi/concurrency.py
@@ -1,4 +1,5 @@
-from typing import Any, Callable
+import sys
+from typing import AsyncGenerator, ContextManager, TypeVar
from starlette.concurrency import iterate_in_threadpool as iterate_in_threadpool # noqa
from starlette.concurrency import run_in_threadpool as run_in_threadpool # noqa
@@ -6,41 +7,21 @@
run_until_first_complete as run_until_first_complete,
)
-asynccontextmanager_error_message = """
-FastAPI's contextmanager_in_threadpool require Python 3.7 or above,
-or the backport for Python 3.6, installed with:
- pip install async-generator
-"""
+if sys.version_info >= (3, 7):
+ from contextlib import AsyncExitStack as AsyncExitStack
+ from contextlib import asynccontextmanager as asynccontextmanager
+else:
+ from contextlib2 import AsyncExitStack as AsyncExitStack # noqa
+ from contextlib2 import asynccontextmanager as asynccontextmanager # noqa
-def _fake_asynccontextmanager(func: Callable[..., Any]) -> Callable[..., Any]:
- def raiser(*args: Any, **kwargs: Any) -> Any:
- raise RuntimeError(asynccontextmanager_error_message)
+_T = TypeVar("_T")
- return raiser
-
-try:
- from contextlib import asynccontextmanager as asynccontextmanager # type: ignore
-except ImportError:
- try:
- from async_generator import ( # type: ignore # isort: skip
- asynccontextmanager as asynccontextmanager,
- )
- except ImportError: # pragma: no cover
- asynccontextmanager = _fake_asynccontextmanager
-
-try:
- from contextlib import AsyncExitStack as AsyncExitStack # type: ignore
-except ImportError:
- try:
- from async_exit_stack import AsyncExitStack as AsyncExitStack # type: ignore
- except ImportError: # pragma: no cover
- AsyncExitStack = None # type: ignore
-
-
-@asynccontextmanager # type: ignore
-async def contextmanager_in_threadpool(cm: Any) -> Any:
+@asynccontextmanager
+async def contextmanager_in_threadpool(
+ cm: ContextManager[_T],
+) -> AsyncGenerator[_T, None]:
try:
yield await run_in_threadpool(cm.__enter__)
except Exception as e:
diff --git a/fastapi/dependencies/utils.py b/fastapi/dependencies/utils.py
--- a/fastapi/dependencies/utils.py
+++ b/fastapi/dependencies/utils.py
@@ -1,4 +1,3 @@
-import asyncio
import dataclasses
import inspect
from contextlib import contextmanager
@@ -6,6 +5,7 @@
from typing import (
Any,
Callable,
+ Coroutine,
Dict,
List,
Mapping,
@@ -17,10 +17,10 @@
cast,
)
+import anyio
from fastapi import params
from fastapi.concurrency import (
AsyncExitStack,
- _fake_asynccontextmanager,
asynccontextmanager,
contextmanager_in_threadpool,
)
@@ -266,18 +266,6 @@ def get_typed_annotation(param: inspect.Parameter, globalns: Dict[str, Any]) ->
return annotation
-async_contextmanager_dependencies_error = """
-FastAPI dependencies with yield require Python 3.7 or above,
-or the backports for Python 3.6, installed with:
- pip install async-exit-stack async-generator
-"""
-
-
-def check_dependency_contextmanagers() -> None:
- if AsyncExitStack is None or asynccontextmanager == _fake_asynccontextmanager:
- raise RuntimeError(async_contextmanager_dependencies_error) # pragma: no cover
-
-
def get_dependant(
*,
path: str,
@@ -289,8 +277,6 @@ def get_dependant(
path_param_names = get_path_param_names(path)
endpoint_signature = get_typed_signature(call)
signature_params = endpoint_signature.parameters
- if is_gen_callable(call) or is_async_gen_callable(call):
- check_dependency_contextmanagers()
dependant = Dependant(call=call, name=name, path=path, use_cache=use_cache)
for param_name, param in signature_params.items():
if isinstance(param.default, params.Depends):
@@ -452,14 +438,6 @@ async def solve_generator(
if is_gen_callable(call):
cm = contextmanager_in_threadpool(contextmanager(call)(**sub_values))
elif is_async_gen_callable(call):
- if not inspect.isasyncgenfunction(call):
- # asynccontextmanager from the async_generator backfill pre python3.7
- # does not support callables that are not functions or methods.
- # See https://github.com/python-trio/async_generator/issues/32
- #
- # Expand the callable class into its __call__ method before decorating it.
- # This approach will work on newer python versions as well.
- call = getattr(call, "__call__", None)
cm = asynccontextmanager(call)(**sub_values)
return await stack.enter_async_context(cm)
@@ -539,10 +517,7 @@ async def solve_dependencies(
solved = dependency_cache[sub_dependant.cache_key]
elif is_gen_callable(call) or is_async_gen_callable(call):
stack = request.scope.get("fastapi_astack")
- if stack is None:
- raise RuntimeError(
- async_contextmanager_dependencies_error
- ) # pragma: no cover
+ assert isinstance(stack, AsyncExitStack)
solved = await solve_generator(
call=call, stack=stack, sub_values=sub_values
)
@@ -697,9 +672,18 @@ async def request_body_to_args(
and lenient_issubclass(field.type_, bytes)
and isinstance(value, sequence_types)
):
- awaitables = [sub_value.read() for sub_value in value]
- contents = await asyncio.gather(*awaitables)
- value = sequence_shape_to_type[field.shape](contents)
+ results: List[Union[bytes, str]] = []
+
+ async def process_fn(
+ fn: Callable[[], Coroutine[Any, Any, Any]]
+ ) -> None:
+ result = await fn()
+ results.append(result)
+
+ async with anyio.create_task_group() as tg:
+ for sub_value in value:
+ tg.start_soon(process_fn, sub_value.read)
+ value = sequence_shape_to_type[field.shape](results)
v_, errors_ = field.validate(value, values, loc=loc)
|
diff --git a/docs_src/async_tests/test_main.py b/docs_src/async_tests/test_main.py
--- a/docs_src/async_tests/test_main.py
+++ b/docs_src/async_tests/test_main.py
@@ -4,7 +4,7 @@
from .main import app
[email protected]
[email protected]
async def test_root():
async with AsyncClient(app=app, base_url="http://test") as ac:
response = await ac.get("/")
diff --git a/tests/test_fakeasync.py b/tests/test_fakeasync.py
deleted file mode 100644
--- a/tests/test_fakeasync.py
+++ /dev/null
@@ -1,12 +0,0 @@
-import pytest
-from fastapi.concurrency import _fake_asynccontextmanager
-
-
-@_fake_asynccontextmanager
-def never_run():
- pass # pragma: no cover
-
-
-def test_fake_async():
- with pytest.raises(RuntimeError):
- never_run()
diff --git a/tests/test_tutorial/test_async_tests/test_main.py b/tests/test_tutorial/test_async_tests/test_main.py
--- a/tests/test_tutorial/test_async_tests/test_main.py
+++ b/tests/test_tutorial/test_async_tests/test_main.py
@@ -3,6 +3,6 @@
from docs_src.async_tests.test_main import test_root
[email protected]
[email protected]
async def test_async_testing():
await test_root()
diff --git a/tests/test_tutorial/test_websockets/test_tutorial002.py b/tests/test_tutorial/test_websockets/test_tutorial002.py
--- a/tests/test_tutorial/test_websockets/test_tutorial002.py
+++ b/tests/test_tutorial/test_websockets/test_tutorial002.py
@@ -72,9 +72,15 @@ def test_websocket_with_header_and_query():
def test_websocket_no_credentials():
with pytest.raises(WebSocketDisconnect):
- client.websocket_connect("/items/foo/ws")
+ with client.websocket_connect("/items/foo/ws"):
+ pytest.fail(
+ "did not raise WebSocketDisconnect on __enter__"
+ ) # pragma: no cover
def test_websocket_invalid_data():
with pytest.raises(WebSocketDisconnect):
- client.websocket_connect("/items/foo/ws?q=bar&token=some-token")
+ with client.websocket_connect("/items/foo/ws?q=bar&token=some-token"):
+ pytest.fail(
+ "did not raise WebSocketDisconnect on __enter__"
+ ) # pragma: no cover
|
Trio - Python library for async concurrency and I/O
**Description**
Hello!
I'm using Hypercorn with uvloop.
I'd like to use Hypercorn with trio, but the program doesn't start when i switch uvloop by trio.
Do you have plans to implement trio?
Thank's!
PS: Nice work.
|
I guess most FastAPI users use it with uvloop which trio is not compatible with: https://github.com/python-trio/trio/issues/138
Thanks for the help here @haizaar ! Nice investigation.
I think @haizaar is right, by checking that issue.
This is a great place to mention that you can use hypercorn, which [seems to support trio](https://medium.com/@pgjones/hypercorn-is-now-a-trio-asgi-server-2e198898c08f) (I haven't tested it personally though).
Maybe, again maybe, if you configure uvicorn to use asyncio instead of uvloop as its loop, trio will work with it and consequently, with FastAPI
Of course that's in case one does not need absolutely cutting edge performance.
So, FastAPI uses Starlette's `run_in_threadpool` internally, and that uses `asyncio`.
Prior to FastAPI supporting Trio, we would need Starlette itself to support Trio. But that's probably quite a lot of work there. Also, if Starlette supported Trio that would be automatically inherited by FastAPI.
You can track it here: https://github.com/encode/starlette/issues/811
<!-- issue-manager: answered -->
Assuming the original issue was solved, it will be automatically closed now. But feel free to add more comments or create new issues.
| 2021-06-14T22:47:29 |
tiangolo/fastapi
| 9,468 |
tiangolo__fastapi-9468
|
[
"9467"
] |
fe55402776192a3cd669bd3e98cbab9a23796736
|
diff --git a/docs_src/wsgi/tutorial001.py b/docs_src/wsgi/tutorial001.py
--- a/docs_src/wsgi/tutorial001.py
+++ b/docs_src/wsgi/tutorial001.py
@@ -1,6 +1,7 @@
from fastapi import FastAPI
from fastapi.middleware.wsgi import WSGIMiddleware
-from flask import Flask, escape, request
+from flask import Flask, request
+from markupsafe import escape
flask_app = Flask(__name__)
|
FastAPI tests in pydantic failing due to flask deprecation
### Privileged issue
- [X] I'm @tiangolo or he asked me directly to create an issue here.
### Issue Content
hope you don't mind me creating an issue, pydantic's 1.10.X tests are failing due to a new issue with running our fastapi tests, see
https://github.com/pydantic/pydantic/actions/runs/4832692304/jobs/8611783607?pr=5628
output from pydantic's tests:
```
==================================== ERRORS ====================================
______ ERROR collecting tests/test_tutorial/test_wsgi/test_tutorial001.py ______
tests/test_tutorial/test_wsgi/test_tutorial001.py:3: in <module>
from docs_src.wsgi.tutorial001 import app
docs_src/wsgi/tutorial001.py:3: in <module>
from flask import Flask, escape, request
<frozen importlib._bootstrap>:1075: in _handle_fromlist
???
/opt/hostedtoolcache/Python/3.10.11/x64/lib/python3.10/site-packages/flask/__init__.py:71: in __getattr__
warnings.warn(
E DeprecationWarning: 'flask.escape' is deprecated and will be removed in Flask 2.4. Import 'markupsafe.escape' instead.
=========================== short test summary info ============================
ERROR tests/test_tutorial/test_wsgi/test_tutorial001.py - DeprecationWarning: 'flask.escape' is deprecated and will be removed in Flask 2.4. Import 'markupsafe.escape'
```
related to https://github.com/pydantic/pydantic/pull/5628
| 2023-04-28T20:14:10 |
||
voicepaw/so-vits-svc-fork
| 42 |
voicepaw__so-vits-svc-fork-42
|
[
"41"
] |
695c7738ada91df8e56b597d7ad3e823117a8a32
|
diff --git a/src/so_vits_svc_fork/utils.py b/src/so_vits_svc_fork/utils.py
--- a/src/so_vits_svc_fork/utils.py
+++ b/src/so_vits_svc_fork/utils.py
@@ -13,7 +13,7 @@
import torchcrepe
from numpy import dtype, float32, ndarray
from scipy.io.wavfile import read
-from torch import FloatTensor
+from torch import FloatTensor, Tensor
from tqdm import tqdm
LOG = getLogger(__name__)
@@ -219,7 +219,7 @@ def compute_f0_crepe(
# (T) -> (1, T)
audio = audio.detach()
- pitch = torchcrepe.predict(
+ pitch: Tensor = torchcrepe.predict(
audio,
sampling_rate,
hop_length,
@@ -231,7 +231,10 @@ def compute_f0_crepe(
pad=True,
)
- return pitch.detach().cpu().numpy()[0]
+ f0 = pitch.squeeze(0).cpu().numpy()
+ p_len = p_len or wav_numpy.shape[0] // hop_length
+ f0 = _resize_f0(f0, p_len)
+ return f0
def compute_f0(
|
Pre-resample not running?
Trying to run `svc pre-resample` but it doesn't start:
`(venv) C:\Users\LXC PC\Desktop\sovits\venv\Scripts>svc pre-resample`
`Preprocessing: 0it [00:00, ?it/s]`
| ERROR: type should be string, got "https://github.com/34j/so-vits-svc-fork/blob/main/src/so_vits_svc_fork/__main__.py#L374-L374\n\n\nThis part contradicts the documentation...\nI managed to get it working by manually specifying the path: `svc pre-resample -i \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\Scripts\\dataset_raw\\44k\\21Raw\"`\r\n\r\nRan through `svc pre-config` and `svc pre-hubert` with no problems.\r\n\r\nHowever, when running `svc train`, I get an error. Here is the stack trace:\r\n\r\n```\r\n(venv) C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\Scripts>svc train\r\n'emb_g.weight'\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\utils.py\", line 385, in load_checkpoint\r\n new_state_dict[k] = saved_state_dict[k]\r\nKeyError: 'emb_g.weight'\r\nemb_g.weight is not in the checkpoint\r\n 0%| | 0/10000 [00:00<?, ?it/s]C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\functional.py:641: UserWarning: stft with return_complex=False is deprecated. In a future pytorch release, stft will return complex tensors for all inputs, and return_complex=False will raise an error.\r\nNote: you can still call torch.view_as_real on the complex output to recover the old return format. (Triggered internally at C:\\actions-runner\\_work\\pytorch\\pytorch\\builder\\windows\\pytorch\\aten\\src\\ATen\\native\\SpectralOps.cpp:867.)\r\n return _VF.stft(input, n_fft, hop_length, win_length, window, # type: ignore[attr-defined]\r\nC:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\autograd\\__init__.py:200: UserWarning: Grad strides do not match bucket view strides. This may indicate grad was not created according to the gradient layout contract, or that the param's strides changed since DDP was constructed. This is not an error, but may impair performance.\r\ngrad.sizes() = [32, 1, 4], strides() = [4, 1, 1]\r\nbucket_view.sizes() = [32, 1, 4], strides() = [4, 4, 1] (Triggered internally at C:\\actions-runner\\_work\\pytorch\\pytorch\\builder\\windows\\pytorch\\torch\\csrc\\distributed\\c10d\\reducer.cpp:337.)\r\n Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass\r\n 0%| | 0/10000 [00:13<?, ?it/s]\r\nTraceback (most recent call last):\r\n File \"C:\\Program Files\\Python39\\lib\\runpy.py\", line 197, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File \"C:\\Program Files\\Python39\\lib\\runpy.py\", line 87, in _run_code\r\n exec(code, run_globals)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\Scripts\\svc.exe\\__main__.py\", line 7, in <module>\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\click\\core.py\", line 1130, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\click\\core.py\", line 1055, in main\r\n rv = self.invoke(ctx)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\click\\core.py\", line 1657, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\click\\core.py\", line 1404, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\click\\core.py\", line 760, in invoke\r\n return __callback(*args, **kwargs)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\__main__.py\", line 119, in train\r\n train(config_path=config_path, model_path=model_path)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\train.py\", line 49, in train\r\n mp.spawn(\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\multiprocessing\\spawn.py\", line 239, in spawn\r\n return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\multiprocessing\\spawn.py\", line 197, in start_processes\r\n while not context.join():\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\multiprocessing\\spawn.py\", line 160, in join\r\n raise ProcessRaisedException(msg, error_index, failed_process.pid)\r\ntorch.multiprocessing.spawn.ProcessRaisedException:\r\n\r\n-- Process 0 terminated with the following error:\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\multiprocessing\\spawn.py\", line 69, in _wrap\r\n fn(i, *args)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\train.py\", line 158, in run\r\n train_and_evaluate(\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\train.py\", line 338, in train_and_evaluate\r\n evaluate(hps, net_g, eval_loader, writer_eval)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\train.py\", line 376, in evaluate\r\n for batch_idx, items in enumerate(eval_loader):\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\utils\\data\\dataloader.py\", line 634, in __next__\r\n data = self._next_data()\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\utils\\data\\dataloader.py\", line 1346, in _next_data\r\n return self._process_data(data)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\utils\\data\\dataloader.py\", line 1372, in _process_data\r\n data.reraise()\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\_utils.py\", line 644, in reraise\r\n raise exception\r\nAssertionError: Caught AssertionError in DataLoader worker process 0.\r\nOriginal Traceback (most recent call last):\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\utils\\data\\_utils\\worker.py\", line 308, in _worker_loop\r\n data = fetcher.fetch(index)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\utils\\data\\_utils\\fetch.py\", line 51, in fetch\r\n data = [self.dataset[idx] for idx in possibly_batched_index]\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\utils\\data\\_utils\\fetch.py\", line 51, in <listcomp>\r\n data = [self.dataset[idx] for idx in possibly_batched_index]\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\data_utils.py\", line 104, in __getitem__\r\n return self.get_audio(self.audiopaths[index][0])\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\data_utils.py\", line 78, in get_audio\r\n assert abs(c.size(-1) - spec.size(-1)) < 3, (\r\nAssertionError: (1398, 1392, torch.Size([1398]), 'dataset/44k/21Raw/101.wav')\r\n```\nWas the logs/44k empty from the beginning?\nlogs/44k contains these files:\r\n\r\n\r\n\nWas it empty at first?\nYou mean before doing `svc train`? I think so, yea. It only created the `logs` folder after running the command. The folder didnt exist before then.\nThis is due to the fact that I migrated the library for f0 inference from dio to crepe without adequate testing. Please use version <0.8.0. Sorry for your inconvenience." | 2023-03-20T10:54:36 |
|
voicepaw/so-vits-svc-fork
| 43 |
voicepaw__so-vits-svc-fork-43
|
[
"41"
] |
4068479517702d5071a232997af239dee39c702d
|
diff --git a/src/so_vits_svc_fork/__main__.py b/src/so_vits_svc_fork/__main__.py
--- a/src/so_vits_svc_fork/__main__.py
+++ b/src/so_vits_svc_fork/__main__.py
@@ -371,7 +371,7 @@ def vc(
"-i",
"--input-dir",
type=click.Path(exists=True),
- default=Path("./dataset_raw/44k"),
+ default=Path("./dataset_raw"),
help="path to source dir",
)
@click.option(
diff --git a/src/so_vits_svc_fork/preprocess_resample.py b/src/so_vits_svc_fork/preprocess_resample.py
--- a/src/so_vits_svc_fork/preprocess_resample.py
+++ b/src/so_vits_svc_fork/preprocess_resample.py
@@ -1,5 +1,6 @@
from __future__ import annotations
+import warnings
from logging import getLogger
from pathlib import Path
from typing import Iterable
@@ -35,6 +36,17 @@ def _get_unique_filename(path: Path, existing_paths: Iterable[Path]) -> Path:
i += 1
+def is_relative_to(path: Path, *other):
+ """Return True if the path is relative to another path or False.
+ Python 3.9+ has Path.is_relative_to() method, but we need to support Python 3.8.
+ """
+ try:
+ path.relative_to(*other)
+ return True
+ except ValueError:
+ return False
+
+
def preprocess_resample(
input_dir: Path | str, output_dir: Path | str, sampling_rate: int
) -> None:
@@ -71,6 +83,17 @@ def preprocess_one(input_path: Path, output_path: Path) -> None:
out_paths = []
for in_path in input_dir.rglob("*.*"):
in_path_relative = in_path.relative_to(input_dir)
+ if not in_path.is_absolute() and is_relative_to(
+ in_path, Path("dataset_raw") / "44k"
+ ):
+ new_in_path_relative = in_path_relative.relative_to("44k")
+ warnings.warn(
+ f"Recommended folder structure has changed since v1.0.0. "
+ "Please move your dataset directly under dataset_raw folder. "
+ f"Recoginzed {in_path_relative} as {new_in_path_relative}"
+ )
+ in_path_relative = new_in_path_relative
+
if len(in_path_relative.parts) < 2:
continue
speaker_name = in_path_relative.parts[0]
|
diff --git a/tests/dataset_raw/44k/34j/1.wav b/tests/dataset_raw/34j/nested/1.wav
similarity index 100%
rename from tests/dataset_raw/44k/34j/1.wav
rename to tests/dataset_raw/34j/nested/1.wav
diff --git a/tests/dataset_raw/44k/34j/nested/10.wav b/tests/dataset_raw/34j/nested/10.wav
similarity index 100%
rename from tests/dataset_raw/44k/34j/nested/10.wav
rename to tests/dataset_raw/34j/nested/10.wav
diff --git a/tests/dataset_raw/44k/34j/nested/2.wav b/tests/dataset_raw/34j/nested/2.wav
similarity index 100%
rename from tests/dataset_raw/44k/34j/nested/2.wav
rename to tests/dataset_raw/34j/nested/2.wav
diff --git a/tests/dataset_raw/44k/34j/nested/3.wav b/tests/dataset_raw/34j/nested/3.wav
similarity index 100%
rename from tests/dataset_raw/44k/34j/nested/3.wav
rename to tests/dataset_raw/34j/nested/3.wav
diff --git a/tests/dataset_raw/44k/34j/nested/4.wav b/tests/dataset_raw/34j/nested/4.wav
similarity index 100%
rename from tests/dataset_raw/44k/34j/nested/4.wav
rename to tests/dataset_raw/34j/nested/4.wav
diff --git a/tests/dataset_raw/44k/34j/nested/5.wav b/tests/dataset_raw/34j/nested/5.wav
similarity index 100%
rename from tests/dataset_raw/44k/34j/nested/5.wav
rename to tests/dataset_raw/34j/nested/5.wav
diff --git a/tests/dataset_raw/44k/34j/nested/6.wav b/tests/dataset_raw/34j/nested/6.wav
similarity index 100%
rename from tests/dataset_raw/44k/34j/nested/6.wav
rename to tests/dataset_raw/34j/nested/6.wav
diff --git a/tests/dataset_raw/44k/34j/nested/7.wav b/tests/dataset_raw/34j/nested/7.wav
similarity index 100%
rename from tests/dataset_raw/44k/34j/nested/7.wav
rename to tests/dataset_raw/34j/nested/7.wav
diff --git a/tests/dataset_raw/44k/34j/nested/8.wav b/tests/dataset_raw/34j/nested/8.wav
similarity index 100%
rename from tests/dataset_raw/44k/34j/nested/8.wav
rename to tests/dataset_raw/34j/nested/8.wav
diff --git a/tests/dataset_raw/44k/34j/nested/9.wav b/tests/dataset_raw/34j/nested/9.wav
similarity index 100%
rename from tests/dataset_raw/44k/34j/nested/9.wav
rename to tests/dataset_raw/34j/nested/9.wav
diff --git a/tests/dataset_raw/44k/34j/11.wav b/tests/dataset_raw/44k/34j/11.wav
deleted file mode 100644
Binary files a/tests/dataset_raw/44k/34j/11.wav and /dev/null differ
diff --git a/tests/dataset_raw/44k/34j/12.wav b/tests/dataset_raw/44k/34j/12.wav
deleted file mode 100644
Binary files a/tests/dataset_raw/44k/34j/12.wav and /dev/null differ
diff --git a/tests/dataset_raw/44k/34j/13.wav b/tests/dataset_raw/44k/34j/13.wav
deleted file mode 100644
Binary files a/tests/dataset_raw/44k/34j/13.wav and /dev/null differ
diff --git a/tests/dataset_raw/44k/34j/14.wav b/tests/dataset_raw/44k/34j/14.wav
deleted file mode 100644
Binary files a/tests/dataset_raw/44k/34j/14.wav and /dev/null differ
diff --git a/tests/dataset_raw/44k/34j/15.wav b/tests/dataset_raw/44k/34j/15.wav
deleted file mode 100644
Binary files a/tests/dataset_raw/44k/34j/15.wav and /dev/null differ
diff --git a/tests/dataset_raw/44k/34j/16.wav b/tests/dataset_raw/44k/34j/16.wav
deleted file mode 100644
Binary files a/tests/dataset_raw/44k/34j/16.wav and /dev/null differ
diff --git a/tests/dataset_raw/44k/34j/17.wav b/tests/dataset_raw/44k/34j/17.wav
deleted file mode 100644
Binary files a/tests/dataset_raw/44k/34j/17.wav and /dev/null differ
diff --git a/tests/dataset_raw/44k/34j/18.wav b/tests/dataset_raw/44k/34j/18.wav
deleted file mode 100644
Binary files a/tests/dataset_raw/44k/34j/18.wav and /dev/null differ
diff --git a/tests/dataset_raw/44k/34j/19.wav b/tests/dataset_raw/44k/34j/19.wav
deleted file mode 100644
Binary files a/tests/dataset_raw/44k/34j/19.wav and /dev/null differ
diff --git a/tests/dataset_raw/44k/34j/20.wav b/tests/dataset_raw/44k/34j/20.wav
deleted file mode 100644
Binary files a/tests/dataset_raw/44k/34j/20.wav and /dev/null differ
diff --git a/tests/dataset_raw/44k/34j/nested/1.wav b/tests/dataset_raw/44k/34j/nested/1.wav
deleted file mode 100644
Binary files a/tests/dataset_raw/44k/34j/nested/1.wav and /dev/null differ
diff --git a/tests/dataset_raw/44k/34j/nested2/1.wav b/tests/dataset_raw/44k/34j/nested2/1.wav
deleted file mode 100644
Binary files a/tests/dataset_raw/44k/34j/nested2/1.wav and /dev/null differ
diff --git a/tests/test_main.py b/tests/test_main.py
--- a/tests/test_main.py
+++ b/tests/test_main.py
@@ -22,14 +22,13 @@ def test_infer(self):
raise SkipTest("Skip inference test on CI")
from so_vits_svc_fork.inference_main import infer # noqa
- # infer("tests/dataset_raw/44k/34j/1.wav", "tests/configs/config.json", "tests/logs/44k")
+ # infer("tests/dataset_raw/34j/1.wav", "tests/configs/config.json", "tests/logs/44k")
def test_preprocess(self):
from so_vits_svc_fork.preprocess_resample import preprocess_resample
- preprocess_resample("tests/dataset_raw/44k", "tests/dataset/44k", 44100)
+ preprocess_resample("tests/dataset_raw", "tests/dataset/44k", 44100)
- def test_preprocess_config(self):
from so_vits_svc_fork.preprocess_flist_config import preprocess_config
preprocess_config(
@@ -40,9 +39,8 @@ def test_preprocess_config(self):
"tests/configs/config.json",
)
- def test_preprocess_hubert(self):
if IS_CI:
- raise SkipTest("Skip preprocessing test on CI")
+ raise SkipTest("Skip hubert and f0 test on CI")
from so_vits_svc_fork.preprocess_hubert_f0 import preprocess_hubert_f0
preprocess_hubert_f0("tests/dataset/44k", "tests/configs/44k/config.json")
|
Pre-resample not running?
Trying to run `svc pre-resample` but it doesn't start:
`(venv) C:\Users\LXC PC\Desktop\sovits\venv\Scripts>svc pre-resample`
`Preprocessing: 0it [00:00, ?it/s]`
| ERROR: type should be string, got "https://github.com/34j/so-vits-svc-fork/blob/main/src/so_vits_svc_fork/__main__.py#L374-L374\n\n\nThis part contradicts the documentation...\nI managed to get it working by manually specifying the path: `svc pre-resample -i \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\Scripts\\dataset_raw\\44k\\21Raw\"`\r\n\r\nRan through `svc pre-config` and `svc pre-hubert` with no problems.\r\n\r\nHowever, when running `svc train`, I get an error. Here is the stack trace:\r\n\r\n```\r\n(venv) C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\Scripts>svc train\r\n'emb_g.weight'\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\utils.py\", line 385, in load_checkpoint\r\n new_state_dict[k] = saved_state_dict[k]\r\nKeyError: 'emb_g.weight'\r\nemb_g.weight is not in the checkpoint\r\n 0%| | 0/10000 [00:00<?, ?it/s]C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\functional.py:641: UserWarning: stft with return_complex=False is deprecated. In a future pytorch release, stft will return complex tensors for all inputs, and return_complex=False will raise an error.\r\nNote: you can still call torch.view_as_real on the complex output to recover the old return format. (Triggered internally at C:\\actions-runner\\_work\\pytorch\\pytorch\\builder\\windows\\pytorch\\aten\\src\\ATen\\native\\SpectralOps.cpp:867.)\r\n return _VF.stft(input, n_fft, hop_length, win_length, window, # type: ignore[attr-defined]\r\nC:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\autograd\\__init__.py:200: UserWarning: Grad strides do not match bucket view strides. This may indicate grad was not created according to the gradient layout contract, or that the param's strides changed since DDP was constructed. This is not an error, but may impair performance.\r\ngrad.sizes() = [32, 1, 4], strides() = [4, 1, 1]\r\nbucket_view.sizes() = [32, 1, 4], strides() = [4, 4, 1] (Triggered internally at C:\\actions-runner\\_work\\pytorch\\pytorch\\builder\\windows\\pytorch\\torch\\csrc\\distributed\\c10d\\reducer.cpp:337.)\r\n Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass\r\n 0%| | 0/10000 [00:13<?, ?it/s]\r\nTraceback (most recent call last):\r\n File \"C:\\Program Files\\Python39\\lib\\runpy.py\", line 197, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File \"C:\\Program Files\\Python39\\lib\\runpy.py\", line 87, in _run_code\r\n exec(code, run_globals)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\Scripts\\svc.exe\\__main__.py\", line 7, in <module>\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\click\\core.py\", line 1130, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\click\\core.py\", line 1055, in main\r\n rv = self.invoke(ctx)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\click\\core.py\", line 1657, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\click\\core.py\", line 1404, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\click\\core.py\", line 760, in invoke\r\n return __callback(*args, **kwargs)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\__main__.py\", line 119, in train\r\n train(config_path=config_path, model_path=model_path)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\train.py\", line 49, in train\r\n mp.spawn(\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\multiprocessing\\spawn.py\", line 239, in spawn\r\n return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\multiprocessing\\spawn.py\", line 197, in start_processes\r\n while not context.join():\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\multiprocessing\\spawn.py\", line 160, in join\r\n raise ProcessRaisedException(msg, error_index, failed_process.pid)\r\ntorch.multiprocessing.spawn.ProcessRaisedException:\r\n\r\n-- Process 0 terminated with the following error:\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\multiprocessing\\spawn.py\", line 69, in _wrap\r\n fn(i, *args)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\train.py\", line 158, in run\r\n train_and_evaluate(\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\train.py\", line 338, in train_and_evaluate\r\n evaluate(hps, net_g, eval_loader, writer_eval)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\train.py\", line 376, in evaluate\r\n for batch_idx, items in enumerate(eval_loader):\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\utils\\data\\dataloader.py\", line 634, in __next__\r\n data = self._next_data()\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\utils\\data\\dataloader.py\", line 1346, in _next_data\r\n return self._process_data(data)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\utils\\data\\dataloader.py\", line 1372, in _process_data\r\n data.reraise()\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\_utils.py\", line 644, in reraise\r\n raise exception\r\nAssertionError: Caught AssertionError in DataLoader worker process 0.\r\nOriginal Traceback (most recent call last):\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\utils\\data\\_utils\\worker.py\", line 308, in _worker_loop\r\n data = fetcher.fetch(index)\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\utils\\data\\_utils\\fetch.py\", line 51, in fetch\r\n data = [self.dataset[idx] for idx in possibly_batched_index]\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\torch\\utils\\data\\_utils\\fetch.py\", line 51, in <listcomp>\r\n data = [self.dataset[idx] for idx in possibly_batched_index]\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\data_utils.py\", line 104, in __getitem__\r\n return self.get_audio(self.audiopaths[index][0])\r\n File \"C:\\Users\\LXC PC\\Desktop\\sovits\\venv\\lib\\site-packages\\so_vits_svc_fork\\data_utils.py\", line 78, in get_audio\r\n assert abs(c.size(-1) - spec.size(-1)) < 3, (\r\nAssertionError: (1398, 1392, torch.Size([1398]), 'dataset/44k/21Raw/101.wav')\r\n```\nWas the logs/44k empty from the beginning?\nlogs/44k contains these files:\r\n\r\n\r\n\nWas it empty at first?\nYou mean before doing `svc train`? I think so, yea. It only created the `logs` folder after running the command. The folder didnt exist before then.\nThis is due to the fact that I migrated the library for f0 inference from dio to crepe without adequate testing. Please use version <0.8.0. Sorry for your inconvenience." | 2023-03-20T11:12:14 |
voicepaw/so-vits-svc-fork
| 45 |
voicepaw__so-vits-svc-fork-45
|
[
"22"
] |
2252fb1f457b730d389f48dbe3572938b90e66d1
|
diff --git a/src/so_vits_svc_fork/inference_main.py b/src/so_vits_svc_fork/inference_main.py
--- a/src/so_vits_svc_fork/inference_main.py
+++ b/src/so_vits_svc_fork/inference_main.py
@@ -145,6 +145,21 @@ def realtime(
f"Input Device: {devices[input_device]['name']}, Output Device: {devices[output_device]['name']}"
)
+ # the model realtime coef is somewhat significantly low only in the first inference
+ # there could be no better way to warm up the model than to do a dummy inference
+ # (there are not differences in the behavior of the model between the first and the later inferences)
+ # so we do a dummy inference to warm up the model (1 second of audio)
+ LOG.info("Warming up the model...")
+ svc_model.infer(
+ speaker=speaker,
+ transpose=transpose,
+ auto_predict_f0=auto_predict_f0,
+ cluster_infer_ratio=cluster_infer_ratio,
+ noise_scale=noise_scale,
+ f0_method=f0_method,
+ audio=np.zeros(svc_model.target_sample, dtype=np.float32),
+ )
+
def callback(
indata: np.ndarray,
outdata: np.ndarray,
|
Prepare model for inference
**Is your feature request related to a problem? Please describe.**
The first time inference occurs takes the longest, where as the next inferences afterwards are faster. Since normally the first time is in the sounddevice callback, it's likely that audio will not be processed in time and will end up delayed.
**Describe the solution you'd like**
After loading the model, run an initial inference with some dummy data, perhaps torch.zeros of appropriate sizes.
**Additional context**
On my computer with a RTX 3050, the first time inference takes about 3 seconds to complete. Otherwise I get a Realtime coef of ~28
|
As you said, I am not sure why, but it has improved very much. Thank you.
| 2023-03-20T12:00:47 |
|
voicepaw/so-vits-svc-fork
| 58 |
voicepaw__so-vits-svc-fork-58
|
[
"56"
] |
259e6e6eb6ebfd9027b1813756d67d1a516e0214
|
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -4,9 +4,9 @@
from logging import getLogger
from pathlib import Path
+import librosa
import PySimpleGUI as sg
import sounddevice as sd
-import soundfile as sf
import torch
from pebble import ProcessPool
@@ -22,7 +22,7 @@
def play_audio(path: Path | str):
if isinstance(path, Path):
path = path.as_posix()
- data, sr = sf.read(path)
+ data, sr = librosa.load(path)
sd.play(data, sr)
|
AlsaOpen error
**Describe the bug**
Audio does not play using svcg
**To Reproduce**
Steps to reproduce the behaviour:
1. svcg
2. select a .wav file under "input audio path"
3. press the "play" button
**Additional context**
Add any other context about the problem here.
The following error appears when trying to play:
```Expression 'ret' failed in 'src/hostapi/alsa/pa_linux_alsa.c', line: 1736
Expression 'AlsaOpen( &alsaApi->baseHostApiRep, params, streamDir, &self->pcm )' failed in 'src/hostapi/alsa/pa_linux_alsa.c', line: 1904
Expression 'PaAlsaStreamComponent_Initialize( &self->playback, alsaApi, outParams, StreamDirection_Out, NULL != callback )' failed in 'src/hostapi/alsa/pa_linux_alsa.c', line: 2175
Expression 'PaAlsaStream_Initialize( stream, alsaHostApi, inputParameters, outputParameters, sampleRate, framesPerBuffer, callback, streamFlags, userData )' failed in 'src/hostapi/alsa/pa_linux_alsa.c', line: 2839
```
the .out.wav file is produced when clicking "infer" which can then be played normally.
|
I assume you can open it with librosa and can't open it with soundfile, can you modify the code to try?
```shell
data, sr = librosa.load(path)
```
https://github.com/34j/so-vits-svc-fork/blob/f3ec4b3711775ec18c3edf83eb3b12089f739dd2/src/so_vits_svc_fork/gui.py#L26
| 2023-03-21T14:17:59 |
|
voicepaw/so-vits-svc-fork
| 64 |
voicepaw__so-vits-svc-fork-64
|
[
"63"
] |
12d1ba2a45f696dd696792ccb4a543419a9c347c
|
diff --git a/src/so_vits_svc_fork/utils.py b/src/so_vits_svc_fork/utils.py
--- a/src/so_vits_svc_fork/utils.py
+++ b/src/so_vits_svc_fork/utils.py
@@ -476,7 +476,9 @@ def summarize(
def latest_checkpoint_path(dir_path: Path | str, regex: str = "G_*.pth"):
- return list(sorted(Path(dir_path).glob(regex)))[-1]
+ dir_path = Path(dir_path)
+ name_key = lambda p: int(re.match(r"._(\d+)\.pth", p.name).group(1))
+ return list(sorted(dir_path.glob(regex), key=name_key))[-1]
def plot_spectrogram_to_numpy(spectrogram):
|
How to resume training from checkpoint?
Right now if the training gets interrupted, I have to start over from scratch. Is there a way to continue training from the latest checkpoint?
|
This is not the expected behavior. Are you placing different models such as 4.0 v2? Please post the output as there is not enough information.
For example, lets say I trained this:

Then I stopped training at G5600.pth
How do I continue training from G5600.pth? Do I need to edit the config file, or add extra arguments after `svc train`?
Can you please post the output of svc train? This is a bug.
I think there is a misunderstanding. I'm not making a bug report, I'm asking if continuing training is possible?
Here is the stack trace:
```
(venv) C:\Users\LXC PC\Desktop\sovits\venv\Scripts>svc train
0%| | 0/9934 [00:00<?, ?it/s]C:\Users\LXC PC\Desktop\sovits\venv\lib\site-packages\torch\functional.py:641: UserWarning: stft with return_complex=False is deprecated. In a future pytorch release, stft will return complex tensors for all inputs, and return_complex=False will raise an error.
Note: you can still call torch.view_as_real on the complex output to recover the old return format. (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\SpectralOps.cpp:867.)
return _VF.stft(input, n_fft, hop_length, win_length, window, # type: ignore[attr-defined]
C:\Users\LXC PC\Desktop\sovits\venv\lib\site-packages\torch\autograd\__init__.py:200: UserWarning: Grad strides do not match bucket view strides. This may indicate grad was not created according to the gradient layout contract, or that the param's strides changed since DDP was constructed. This is not an error, but may impair performance.
grad.sizes() = [32, 1, 4], strides() = [4, 1, 1]
bucket_view.sizes() = [32, 1, 4], strides() = [4, 4, 1] (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\torch\csrc\distributed\c10d\reducer.cpp:337.)
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
1%|▌ | 69/9934 [08:20<21:52:24, 7.98s/it]
```
When training again, it overwrites the old checkpoints:

Is it possible to continue training from the latest checkpoint `G_5600.pth`, instead of starting over from scratch?
| 2023-03-22T06:44:29 |
|
voicepaw/so-vits-svc-fork
| 66 |
voicepaw__so-vits-svc-fork-66
|
[
"65"
] |
4e45555207a9066023b473b9dedfcb0f6df0094c
|
diff --git a/src/so_vits_svc_fork/utils.py b/src/so_vits_svc_fork/utils.py
--- a/src/so_vits_svc_fork/utils.py
+++ b/src/so_vits_svc_fork/utils.py
@@ -441,14 +441,18 @@ def clean_checkpoints(
False -> lexicographically delete ckpts
"""
path_to_models = Path(path_to_models)
- name_key = lambda p: int(re.match(r"._(\d+)\.pth", p.name).group(1))
+ name_key = lambda p: int(re.match(r"._(\d+)", p.stem).group(1))
time_key = lambda p: p.stat().st_mtime
models_sorted = sorted(
- path_to_models.glob(r"._(\d+).pth"), key=time_key if sort_by_time else name_key
+ filter(
+ lambda p: (p.is_file() and re.match(r"._\d+", p.stem)),
+ path_to_models.glob("*.pth"),
+ ),
+ key=time_key if sort_by_time else name_key,
)
- models_sorted_grouped = groupby(models_sorted, lambda p: p.name[0])
+ models_sorted_grouped = groupby(models_sorted, lambda p: p.stem[0])
for k, g in models_sorted_grouped:
- to_dels = list(g)[n_ckpts_to_keep:]
+ to_dels = list(g)[:-n_ckpts_to_keep]
for to_del in to_dels:
if to_del.stem.endswith("_0"):
continue
|
"keep_ckpts" not working
In the config file, the default `"keep_ckpts": 3` does not work. When training, all checkpoints will be saved. Changing the value to any other number will not work as well.
| 2023-03-22T08:23:34 |
||
voicepaw/so-vits-svc-fork
| 70 |
voicepaw__so-vits-svc-fork-70
|
[
"68"
] |
4e45555207a9066023b473b9dedfcb0f6df0094c
|
diff --git a/src/so_vits_svc_fork/inference/infer_tool.py b/src/so_vits_svc_fork/inference/infer_tool.py
--- a/src/so_vits_svc_fork/inference/infer_tool.py
+++ b/src/so_vits_svc_fork/inference/infer_tool.py
@@ -209,10 +209,9 @@ def infer(
predict_f0=auto_predict_f0,
noice_scale=noise_scale,
)[0, 0].data.float()
- realtime_coef = len(audio) / (t.elapsed * self.target_sample)
+ audio_duration = audio.shape[-1] / self.target_sample
LOG.info(
- f"Inferece time: {t.elapsed:.2f}s, Realtime coef: {realtime_coef:.2f} "
- f"Input shape: {audio.shape}, Output shape: {audio.shape}"
+ f"Inferece time: {t.elapsed:.2f}s, RTF: {t.elapsed / audio_duration:.2f}"
)
return audio, audio.shape[-1]
diff --git a/src/so_vits_svc_fork/inference_main.py b/src/so_vits_svc_fork/inference_main.py
--- a/src/so_vits_svc_fork/inference_main.py
+++ b/src/so_vits_svc_fork/inference_main.py
@@ -161,7 +161,7 @@ def realtime(
f"Input Device: {devices[input_device]['name']}, Output Device: {devices[output_device]['name']}"
)
- # the model realtime coef is somewhat significantly low only in the first inference
+ # the model RTL is somewhat significantly high only in the first inference
# there could be no better way to warm up the model than to do a dummy inference
# (there are not differences in the behavior of the model between the first and the later inferences)
# so we do a dummy inference to warm up the model (1 second of audio)
@@ -211,7 +211,10 @@ def callback(
outdata[:] = (indata + inference) / 2
else:
outdata[:] = inference
- LOG.info(f"True Realtime coef: {block_seconds / t.elapsed:.2f}")
+ rtf = t.elapsed / block_seconds
+ LOG.info(f"Realtime inference time: {t.elapsed:.3f}s, RTF: {rtf:.3f}")
+ if rtf > 1:
+ LOG.warning("RTF is too high, consider increasing block_seconds")
with sd.Stream(
device=(input_device, output_device),
@@ -221,6 +224,6 @@ def callback(
blocksize=int(block_seconds * svc_model.target_sample),
latency="low",
) as stream:
+ LOG.info(f"Latency: {stream.latency}")
while True:
- LOG.info(f"Latency: {stream.latency}")
sd.sleep(1000)
diff --git a/src/so_vits_svc_fork/utils.py b/src/so_vits_svc_fork/utils.py
--- a/src/so_vits_svc_fork/utils.py
+++ b/src/so_vits_svc_fork/utils.py
@@ -11,6 +11,7 @@
import requests
import torch
import torchcrepe
+from cm_time import timer
from numpy import dtype, float32, ndarray
from scipy.io.wavfile import read
from torch import FloatTensor, Tensor
@@ -245,20 +246,24 @@ def compute_f0(
method: Literal["crepe", "crepe-tiny", "parselmouth", "dio", "harvest"] = "crepe",
**kwargs,
):
- wav_numpy = wav_numpy.astype(np.float32)
- wav_numpy /= np.quantile(np.abs(wav_numpy), 0.999)
- if method in ["dio", "harvest"]:
- return compute_f0_pyworld(wav_numpy, p_len, sampling_rate, hop_length, method)
- elif method == "crepe":
- return compute_f0_crepe(wav_numpy, p_len, sampling_rate, hop_length, **kwargs)
- elif method == "crepe-tiny":
- return compute_f0_crepe(
- wav_numpy, p_len, sampling_rate, hop_length, model="tiny", **kwargs
- )
- elif method == "parselmouth":
- return compute_f0_parselmouth(wav_numpy, p_len, sampling_rate, hop_length)
- else:
- raise ValueError("type must be dio, crepe, harvest or parselmouth")
+ with timer() as t:
+ wav_numpy = wav_numpy.astype(np.float32)
+ wav_numpy /= np.quantile(np.abs(wav_numpy), 0.999)
+ if method in ["dio", "harvest"]:
+ f0 = compute_f0_pyworld(wav_numpy, p_len, sampling_rate, hop_length, method)
+ elif method == "crepe":
+ f0 = compute_f0_crepe(wav_numpy, p_len, sampling_rate, hop_length, **kwargs)
+ elif method == "crepe-tiny":
+ f0 = compute_f0_crepe(
+ wav_numpy, p_len, sampling_rate, hop_length, model="tiny", **kwargs
+ )
+ elif method == "parselmouth":
+ f0 = compute_f0_parselmouth(wav_numpy, p_len, sampling_rate, hop_length)
+ else:
+ raise ValueError("type must be dio, crepe, harvest or parselmouth")
+ rtf = t.elapsed / (len(wav_numpy) / sampling_rate)
+ LOG.info(f"F0 inference time: {t.elapsed:.3f}s, RTF: {rtf:.3f}")
+ return f0
def f0_to_coarse(f0: torch.Tensor | float):
@@ -338,21 +343,27 @@ def get_hubert_model():
def get_hubert_content(hmodel, wav_16k_tensor):
- feats = wav_16k_tensor
- if feats.dim() == 2: # double channels
- feats = feats.mean(-1)
- assert feats.dim() == 1, feats.dim()
- feats = feats.view(1, -1)
- padding_mask = torch.BoolTensor(feats.shape).fill_(False)
- inputs = {
- "source": feats.to(wav_16k_tensor.device),
- "padding_mask": padding_mask.to(wav_16k_tensor.device),
- "output_layer": 9, # layer 9
- }
- with torch.no_grad():
- logits = hmodel.extract_features(**inputs)
- feats = hmodel.final_proj(logits[0])
- return feats.transpose(1, 2)
+ with timer() as t:
+ feats = wav_16k_tensor
+ if feats.dim() == 2: # double channels
+ feats = feats.mean(-1)
+ assert feats.dim() == 1, feats.dim()
+ feats = feats.view(1, -1)
+ padding_mask = torch.BoolTensor(feats.shape).fill_(False)
+ inputs = {
+ "source": feats.to(wav_16k_tensor.device),
+ "padding_mask": padding_mask.to(wav_16k_tensor.device),
+ "output_layer": 9, # layer 9
+ }
+ with torch.no_grad():
+ logits = hmodel.extract_features(**inputs)
+ feats = hmodel.final_proj(logits[0])
+ res = feats.transpose(1, 2)
+ wav_len = wav_16k_tensor.shape[-1] / 16000
+ LOG.info(
+ f"HuBERT inference time : {t.elapsed:.3f}s, RTF: {t.elapsed / wav_len:.3f}"
+ )
+ return res
def get_content(cmodel: Any, y: ndarray) -> ndarray:
|
Definition of RTF is wrong in this repo
**Describe the bug**
https://arxiv.org/pdf/2210.15975.pdf
RTFs are addable and are inference time/real time.
| 2023-03-22T11:04:53 |
||
voicepaw/so-vits-svc-fork
| 71 |
voicepaw__so-vits-svc-fork-71
|
[
"69"
] |
5dd49177380ceb0d2b015a0d3b2d89b3d2af3db1
|
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -8,7 +8,7 @@
import PySimpleGUI as sg
import sounddevice as sd
import torch
-from pebble import ProcessPool
+from pebble import ProcessFuture, ProcessPool
from .__main__ import init_logger
@@ -360,7 +360,22 @@ def main():
frames["Presets"],
[
sg.Checkbox(
- key="use_gpu", default=torch.cuda.is_available(), text="Use GPU"
+ key="use_gpu",
+ default=(
+ torch.cuda.is_available() or torch.backends.mps.is_available()
+ ),
+ text="Use GPU"
+ + (
+ " (not available; if your device has GPU, make sure you installed PyTorch with CUDA support)"
+ if not (
+ torch.cuda.is_available()
+ or torch.backends.mps.is_available()
+ )
+ else ""
+ ),
+ disabled=not (
+ torch.cuda.is_available() or torch.backends.mps.is_available()
+ ),
)
],
[
@@ -408,12 +423,11 @@ def apply_preset(name: str) -> None:
window["presets"].update(default_name)
del default_name
with ProcessPool(max_workers=1) as pool:
- future = None
+ future: None | ProcessFuture = None
while True:
- event, values = window.read()
+ event, values = window.read(100)
if event == sg.WIN_CLOSED:
break
-
if not event == sg.EVENT_TIMEOUT:
LOG.info(f"Event {event}, values {values}")
if event.endswith("_path"):
@@ -428,8 +442,7 @@ def apply_preset(name: str) -> None:
browser.update()
else:
LOG.warning(f"Browser {browser} is not a FileBrowse")
-
- if event == "add_preset":
+ elif event == "add_preset":
presets = add_preset(
values["preset_name"], {key: values[key] for key in PRESET_KEYS}
)
@@ -469,7 +482,15 @@ def apply_preset(name: str) -> None:
pad_seconds=values["pad_seconds"],
absolute_thresh=values["absolute_thresh"],
chunk_seconds=values["chunk_seconds"],
- device="cuda" if values["use_gpu"] else "cpu",
+ device="cpu"
+ if not values["use_gpu"]
+ else (
+ "cuda"
+ if torch.cuda.is_available()
+ else "mps"
+ if torch.backends.mps.is_available()
+ else "cpu"
+ ),
)
if values["auto_play"]:
pool.schedule(play_audio, args=[output_path])
@@ -518,6 +539,9 @@ def apply_preset(name: str) -> None:
if future:
future.cancel()
future = None
+ if future is not None and future.done():
+ LOG.error(f"Error in realtime: {future.exception()}")
+ future = None
if future:
future.cancel()
window.close()
|
Realtime voice conversion not working when "Use GPU" is ticked
**Describe the bug**
Whenever I start the live voice changer with "Use GPU" enabled, it doesn't load, and hangs with this in the console:
`2023-03-22 02:21:56 | INFO | fairseq.tasks.hubert_pretraining | HubertPretrainingTask Config {'_name': 'hubert_pretraining', 'data': 'metadata', 'fine_tuning': False, 'labels': ['km'], 'label_dir': 'label', 'label_rate': 50.0, 'sample_rate': 16000, 'normalize': False, 'enable_padding': False, 'max_keep_size': None, 'max_sample_size': 250000, 'min_sample_size': 32000, 'single_target': False, 'random_crop': True, 'pad_audio': False}
2023-03-22 02:21:56 | INFO | fairseq.models.hubert.hubert | HubertModel Config: {'_name': 'hubert', 'label_rate': 50.0, 'extractor_mode': default, 'encoder_layers': 12, 'encoder_embed_dim': 768, 'encoder_ffn_embed_dim': 3072, 'encoder_attention_heads': 12, 'activation_fn': gelu, 'layer_type': transformer, 'dropout': 0.1, 'attention_dropout': 0.1, 'activation_dropout': 0.0, 'encoder_layerdrop': 0.05, 'dropout_input': 0.1, 'dropout_features': 0.1, 'final_dim': 256, 'untie_final_proj': True, 'layer_norm_first': False, 'conv_feature_layers': '[(512,10,5)] + [(512,3,2)] * 4 + [(512,2,2)] * 2', 'conv_bias': False, 'logit_temp': 0.1, 'target_glu': False, 'feature_grad_mult': 0.1, 'mask_length': 10, 'mask_prob': 0.8, 'mask_selection': static, 'mask_other': 0.0, 'no_mask_overlap': False, 'mask_min_space': 1, 'mask_channel_length': 10, 'mask_channel_prob': 0.0, 'mask_channel_selection': static, 'mask_channel_other': 0.0, 'no_mask_channel_overlap': False, 'mask_channel_min_space': 1, 'conv_pos': 128, 'conv_pos_groups': 16, 'latent_temp': [2.0, 0.5, 0.999995], 'skip_masked': False, 'skip_nomask': False, 'checkpoint_activations': False, 'required_seq_len_multiple': 2, 'depthwise_conv_kernel_size': 31, 'attn_type': '', 'pos_enc_type': 'abs', 'fp16': False}`
**To Reproduce**
Steps to reproduce the behavior: Load a model path and config path, tick "Use GPU", press "(Re)Start Voice Changer"
**Additional context**
I'm running the program on Windows 10 through anaconda3, and I have a GTX 1070 GPU. I've tested different models with the same results. Using CPU works. There's never any usage shown on my GPU, nor does the memory used rise when attempting to load using GPU.
|
Currently there is no way to view the error that occurred with the voice changer (big problem). The likely cause is that the GPU version of pytorch has not been properly installed.
Does GPU inference work for files?
| 2023-03-22T11:23:51 |
|
voicepaw/so-vits-svc-fork
| 80 |
voicepaw__so-vits-svc-fork-80
|
[
"78"
] |
6e77be6ec79dbaba122abbc45bf00e8abdf68b6b
|
diff --git a/src/so_vits_svc_fork/__main__.py b/src/so_vits_svc_fork/__main__.py
--- a/src/so_vits_svc_fork/__main__.py
+++ b/src/so_vits_svc_fork/__main__.py
@@ -18,8 +18,16 @@
import torch
from rich.logging import RichHandler
+from so_vits_svc_fork import __version__
+
+LOG = getLogger(__name__)
+LOGGER_INIT = False
+
def init_logger() -> None:
+ global LOGGER_INIT
+ if LOGGER_INIT:
+ return
IN_COLAB = os.getenv("COLAB_RELEASE_TAG")
IS_TEST = "test" in Path(__file__).parent.stem
@@ -36,10 +44,11 @@ def init_logger() -> None:
if IS_TEST:
LOG.debug("Test mode is on.")
+ LOG.info(f"Version: {__version__}")
+ LOGGER_INIT = True
-init_logger()
-LOG = getLogger(__name__)
+init_logger()
class RichHelpFormatter(click.HelpFormatter):
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -54,13 +54,19 @@ def delete_preset(name: str) -> dict:
return load_presets()
-def main():
- sg.theme("Dark")
- model_candidates = list(sorted(Path("./logs/44k/").glob("G_*.pth")))
-
+def get_devices(update: bool = True) -> tuple[list[str], list[str]]:
+ if update:
+ sd._terminate()
+ sd._initialize()
devices = sd.query_devices()
input_devices = [d["name"] for d in devices if d["max_input_channels"] > 0]
output_devices = [d["name"] for d in devices if d["max_output_channels"] > 0]
+ return input_devices, output_devices
+
+
+def main():
+ sg.theme("Dark")
+ model_candidates = list(sorted(Path("./logs/44k/").glob("G_*.pth")))
frame_contents = {
"Paths": [
@@ -278,9 +284,8 @@ def main():
sg.Push(),
sg.Combo(
key="input_device",
- values=input_devices,
+ values=[],
size=(20, 1),
- default_value=input_devices[0],
),
],
[
@@ -288,9 +293,8 @@ def main():
sg.Push(),
sg.Combo(
key="output_device",
- values=output_devices,
+ values=[],
size=(20, 1),
- default_value=output_devices[0],
),
],
[
@@ -401,11 +405,31 @@ def update_speaker() -> None:
config_path = Path(values["config_path"])
if config_path.exists() and config_path.is_file():
hp = utils.get_hparams_from_file(values["config_path"])
- LOG.info(f"Loaded config from {values['config_path']}")
+ LOG.debug(f"Loaded config from {values['config_path']}")
window["speaker"].update(
values=list(hp.__dict__["spk"].keys()), set_to_index=0
)
+ def update_devices() -> None:
+ input_devices, output_devices = get_devices()
+ window["input_device"].update(
+ values=input_devices, value=values["input_device"]
+ )
+ window["output_device"].update(
+ values=output_devices, value=values["output_device"]
+ )
+ input_default, output_default = sd.default.device
+ if values["input_device"] not in input_devices:
+ window["input_device"].update(
+ values=input_devices,
+ set_to_index=0 if input_default is None else input_default - 1,
+ )
+ if values["output_device"] not in output_devices:
+ window["output_device"].update(
+ values=output_devices,
+ set_to_index=0 if output_default is None else output_default - 1,
+ )
+
PRESET_KEYS = [
key
for key in values.keys()
@@ -416,8 +440,8 @@ def apply_preset(name: str) -> None:
for key, value in load_presets()[name].items():
if key in PRESET_KEYS:
window[key].update(value)
+ values[key] = value
- update_speaker()
default_name = list(load_presets().keys())[0]
apply_preset(default_name)
window["presets"].update(default_name)
@@ -425,11 +449,12 @@ def apply_preset(name: str) -> None:
with ProcessPool(max_workers=1) as pool:
future: None | ProcessFuture = None
while True:
- event, values = window.read(100)
+ event, values = window.read(500)
if event == sg.WIN_CLOSED:
break
if not event == sg.EVENT_TIMEOUT:
LOG.info(f"Event {event}, values {values}")
+ update_devices()
if event.endswith("_path"):
for name in window.AllKeysDict:
if str(name).endswith("_browse"):
@@ -442,7 +467,7 @@ def apply_preset(name: str) -> None:
browser.update()
else:
LOG.warning(f"Browser {browser} is not a FileBrowse")
- elif event == "add_preset":
+ if event == "add_preset":
presets = add_preset(
values["preset_name"], {key: values[key] for key in PRESET_KEYS}
)
|
Changing Model and Config path in GUI does not update Speaker name.
In the GUI, changing the Model Path and Config Path does not change the Speaker name. The name remains as the initial loaded model's name.
Stack Trace:
```
C:\Users\LXC PC\Desktop\sovits\venv\Scripts>svcg
[13:35:50] INFO [13:35:50] Loaded config from C:/Users/LXC gui.py:404
PC/Desktop/sovits/venv/Scripts/configs/44k/config.json
[13:36:01] INFO [13:36:01] Event model_path, values {'model_path': 'C:/Users/LXC gui.py:432
PC/Desktop/sovits/venv/Scripts/logs/21/G_13600.pth', 'model_path_browse': 'C:/Users/LXC
PC/Desktop/sovits/venv/Scripts/logs/21/G_13600.pth', 'config_path': 'C:/Users/LXC
PC/Desktop/sovits/venv/Scripts/configs/44k/config.json', 'config_path_browse': '',
'cluster_model_path': '', 'cluster_model_path_browse': '', 'speaker': 'hapiraw',
'silence_threshold': -35.0, 'transpose': 12.0, 'auto_predict_f0': False, 'f0_method':
'dio', 'cluster_infer_ratio': 0.0, 'noise_scale': 0.4, 'pad_seconds': 0.1,
'chunk_seconds': 0.5, 'absolute_thresh': True, 'input_path': '', 'input_path_browse': '',
'auto_play': False, 'crossfade_seconds': 0.05, 'block_seconds': 0.35,
'additional_infer_before_seconds': 0.15, 'additional_infer_after_seconds': 0.1,
'realtime_algorithm': '1 (Divide constantly)', 'input_device': 'Microsoft Sound Mapper -
Input', 'output_device': 'Microsoft Sound Mapper - Output', 'passthrough_original':
False, 'presets': 'Default VC (GPU, GTX 1060)', 'preset_name': '', 'use_gpu': True}
INFO [13:36:01] Updating browser <PySimpleGUI.PySimpleGUI.Button object at 0x0000028C5EF5EC40> gui.py:438
to C:\Users\LXC PC\Desktop\sovits\venv\Scripts\logs\21
INFO [13:36:01] Updating browser <PySimpleGUI.PySimpleGUI.Button object at 0x0000028C5EF5EDC0> gui.py:438
to C:\Users\LXC PC\Desktop\sovits\venv\Scripts\logs\21
INFO [13:36:01] Updating browser <PySimpleGUI.PySimpleGUI.Button object at 0x0000028C5EF5EF40> gui.py:438
to C:\Users\LXC PC\Desktop\sovits\venv\Scripts\logs\21
INFO [13:36:01] Updating browser <PySimpleGUI.PySimpleGUI.Button object at 0x0000028C5EF73A30> gui.py:438
to C:\Users\LXC PC\Desktop\sovits\venv\Scripts\logs\21
[13:36:09] INFO [13:36:09] Event config_path, values {'model_path': 'C:/Users/LXC gui.py:432
PC/Desktop/sovits/venv/Scripts/logs/21/G_13600.pth', 'model_path_browse': 'C:/Users/LXC
PC/Desktop/sovits/venv/Scripts/logs/21/G_13600.pth', 'config_path': 'C:/Users/LXC
PC/Desktop/sovits/venv/Scripts/configs/21/config.json', 'config_path_browse':
'C:/Users/LXC PC/Desktop/sovits/venv/Scripts/configs/21/config.json',
'cluster_model_path': '', 'cluster_model_path_browse': '', 'speaker': 'hapiraw',
'silence_threshold': -35.0, 'transpose': 12.0, 'auto_predict_f0': False, 'f0_method':
'dio', 'cluster_infer_ratio': 0.0, 'noise_scale': 0.4, 'pad_seconds': 0.1,
'chunk_seconds': 0.5, 'absolute_thresh': True, 'input_path': '', 'input_path_browse': '',
'auto_play': False, 'crossfade_seconds': 0.05, 'block_seconds': 0.35,
'additional_infer_before_seconds': 0.15, 'additional_infer_after_seconds': 0.1,
'realtime_algorithm': '1 (Divide constantly)', 'input_device': 'Microsoft Sound Mapper -
Input', 'output_device': 'Microsoft Sound Mapper - Output', 'passthrough_original':
False, 'presets': 'Default VC (GPU, GTX 1060)', 'preset_name': '', 'use_gpu': True}
INFO [13:36:09] Updating browser <PySimpleGUI.PySimpleGUI.Button object at 0x0000028C5EF5EC40> gui.py:438
to C:\Users\LXC PC\Desktop\sovits\venv\Scripts\configs\21
INFO [13:36:09] Updating browser <PySimpleGUI.PySimpleGUI.Button object at 0x0000028C5EF5EDC0> gui.py:438
to C:\Users\LXC PC\Desktop\sovits\venv\Scripts\configs\21
INFO [13:36:09] Updating browser <PySimpleGUI.PySimpleGUI.Button object at 0x0000028C5EF5EF40> gui.py:438
to C:\Users\LXC PC\Desktop\sovits\venv\Scripts\configs\21
INFO [13:36:09] Updating browser <PySimpleGUI.PySimpleGUI.Button object at 0x0000028C5EF73A30> gui.py:438
to C:\Users\LXC PC\Desktop\sovits\venv\Scripts\configs\21
```
| 2023-03-23T08:43:45 |
||
voicepaw/so-vits-svc-fork
| 83 |
voicepaw__so-vits-svc-fork-83
|
[
"81"
] |
34cb0dca3a280e890ec899d54a8bb850b2c28443
|
diff --git a/src/so_vits_svc_fork/__main__.py b/src/so_vits_svc_fork/__main__.py
--- a/src/so_vits_svc_fork/__main__.py
+++ b/src/so_vits_svc_fork/__main__.py
@@ -545,14 +545,44 @@ def clean():
@cli.command
[email protected]("-i", "--input-path", type=click.Path(exists=True), help="model path")
[email protected]("-o", "--output-path", type=click.Path(), help="onnx model path to save")
[email protected]("-c", "--config-path", type=click.Path(), help="config path")
[email protected]("-d", "--device", type=str, default="cpu", help="torch device")
[email protected](
+ "-i",
+ "--input-path",
+ type=click.Path(exists=True),
+ help="model path",
+ default=Path("./logs/44k/"),
+)
[email protected](
+ "-o",
+ "--output-path",
+ type=click.Path(),
+ help="onnx model path to save",
+ default=None,
+)
[email protected](
+ "-c",
+ "--config-path",
+ type=click.Path(),
+ help="config path",
+ default=Path("./configs/44k/config.json"),
+)
[email protected](
+ "-d",
+ "--device",
+ type=str,
+ default="cpu",
+ help="device to use",
+)
def onnx(input_path: Path, output_path: Path, config_path: Path, device: str) -> None:
"""Export model to onnx"""
input_path = Path(input_path)
+ if input_path.is_dir():
+ input_path = list(input_path.glob("*.pth"))[0]
+ if output_path is None:
+ output_path = input_path.with_suffix(".onnx")
output_path = Path(output_path)
+ if output_path.is_dir():
+ output_path = output_path / (input_path.stem + ".onnx")
config_path = Path(config_path)
device_ = torch.device(device)
from .onnx_export import onnx_export
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -145,7 +145,8 @@ def main():
sg.Text(
"Pitch (12 = 1 octave)\n"
"ADJUST THIS based on your voice\n"
- "when Auto predict F0 is turned off."
+ "when Auto predict F0 is turned off.",
+ size=(None, 4),
),
sg.Push(),
sg.Slider(
@@ -392,6 +393,8 @@ def main():
sg.Button("Infer", key="infer"),
sg.Button("(Re)Start Voice Changer", key="start_vc"),
sg.Button("Stop Voice Changer", key="stop_vc"),
+ sg.Push(),
+ sg.Button("ONNX Export", key="onnx_export"),
],
]
)
@@ -452,10 +455,12 @@ def apply_preset(name: str) -> None:
apply_preset(default_name)
window["presets"].update(default_name)
del default_name
+ update_speaker()
+ update_devices()
with ProcessPool(max_workers=1) as pool:
future: None | ProcessFuture = None
while True:
- event, values = window.read(500)
+ event, values = window.read(200)
if event == sg.WIN_CLOSED:
break
if not event == sg.EVENT_TIMEOUT:
@@ -473,6 +478,10 @@ def apply_preset(name: str) -> None:
browser.update()
else:
LOG.warning(f"Browser {browser} is not a FileBrowse")
+ window["transpose"].update(
+ disabled=values["auto_predict_f0"],
+ visible=not values["auto_predict_f0"],
+ )
if event == "add_preset":
presets = add_preset(
values["preset_name"], {key: values[key] for key in PRESET_KEYS}
@@ -570,8 +579,18 @@ def apply_preset(name: str) -> None:
if future:
future.cancel()
future = None
+ elif event == "onnx_export":
+ from .onnx_export import onnx_export
+
+ onnx_export(
+ input_path=Path(values["model_path"]),
+ output_path=Path(values["model_path"]).with_suffix(".onnx"),
+ config_path=Path(values["config_path"]),
+ device="cpu",
+ )
if future is not None and future.done():
- LOG.error(f"Error in realtime: {future.exception()}")
+ LOG.error("Error in realtime: ")
+ LOG.exception(future.exception())
future = None
if future:
future.cancel()
diff --git a/src/so_vits_svc_fork/onnxexport/model_onnx.py b/src/so_vits_svc_fork/onnxexport/model_onnx.py
--- a/src/so_vits_svc_fork/onnxexport/model_onnx.py
+++ b/src/so_vits_svc_fork/onnxexport/model_onnx.py
@@ -4,13 +4,11 @@
from torch.nn import functional as F
from torch.nn.utils import spectral_norm, weight_norm
-from so_vits_svc_fork import modules as attentions
-from so_vits_svc_fork import modules as commons
-from so_vits_svc_fork import modules as modules
-from so_vits_svc_fork import utils
-from so_vits_svc_fork.modules.commons import get_padding
-from so_vits_svc_fork.utils import f0_to_coarse
-from so_vits_svc_fork.vdecoder.hifigan.models import Generator
+from .. import utils
+from ..modules import attentions, commons, modules
+from ..modules.commons import get_padding
+from ..utils import f0_to_coarse
+from ..vdecoder.hifigan.models import Generator
class ResidualCouplingBlock(nn.Module):
|
ONNX not working
**Describe the bug**
Onnx code is dead and not working
**To Reproduce**
`svc onnx`
**Additional context**
Add any other context about the problem here.
| 2023-03-23T13:25:28 |
||
voicepaw/so-vits-svc-fork
| 89 |
voicepaw__so-vits-svc-fork-89
|
[
"65"
] |
d7bb2125bb030223d015881cb45efe51f67c1ba9
|
diff --git a/src/so_vits_svc_fork/utils.py b/src/so_vits_svc_fork/utils.py
--- a/src/so_vits_svc_fork/utils.py
+++ b/src/so_vits_svc_fork/utils.py
@@ -451,24 +451,35 @@ def clean_checkpoints(
sort_by_time -- True -> chronologically delete ckpts
False -> lexicographically delete ckpts
"""
+ LOG.warning("Cleaning old checkpoints...")
path_to_models = Path(path_to_models)
- name_key = lambda p: int(re.match(r"._(\d+)", p.stem).group(1))
+
+ # Define sort key functions
+ name_key = lambda p: int(re.match(r"[GD]_(\d+)", p.stem).group(1))
time_key = lambda p: p.stat().st_mtime
- models_sorted = sorted(
+ path_key = lambda p: (p.stem[0], time_key(p) if sort_by_time else name_key(p))
+
+ models = list(
filter(
- lambda p: (p.is_file() and re.match(r"._\d+", p.stem)),
+ lambda p: (
+ p.is_file()
+ and re.match(r"[GD]_\d+", p.stem)
+ and not p.stem.endswith("_0")
+ ),
path_to_models.glob("*.pth"),
- ),
- key=time_key if sort_by_time else name_key,
+ )
)
+
+ models_sorted = sorted(models, key=path_key)
+
models_sorted_grouped = groupby(models_sorted, lambda p: p.stem[0])
- for k, g in models_sorted_grouped:
- to_dels = list(g)[:-n_ckpts_to_keep]
- for to_del in to_dels:
- if to_del.stem.endswith("_0"):
- continue
- LOG.warning(f"Removing {to_del}")
- to_del.unlink()
+
+ for group_name, group_items in models_sorted_grouped:
+ to_delete_list = list(group_items)[:-n_ckpts_to_keep]
+
+ for to_delete in to_delete_list:
+ LOG.warning(f"Removing {to_delete}")
+ to_delete.unlink()
def summarize(
|
"keep_ckpts" not working
In the config file, the default `"keep_ckpts": 3` does not work. When training, all checkpoints will be saved. Changing the value to any other number will not work as well.
|
I noticed it earlier too. I am having difficulty correcting it.
I just updated to 1.2.8 but the bug is still present. All the checkpoints are still saved.
😭
After a bit of back and forth with ChatGPT and looking at the documentation for `itertools.groupby` it is an issue with how the models are sorted.
The resulting array of `models_sorted` is sorted by the suffix of the G_ or D_ files, but the resulting array alternates between a "G" path and a "D" path.
This, ultimately, means that it will create a group **for every G_ and D_ path**

I fixed this by modifying the `sorted` method call.
Additionally, I've cleaned up the code a bit more.
Will do a pull request shortly!
| 2023-03-23T20:10:46 |
|
voicepaw/so-vits-svc-fork
| 96 |
voicepaw__so-vits-svc-fork-96
|
[
"94"
] |
9ffb6216f418d8c5a4a9f1bdd79fc2cebb885db1
|
diff --git a/src/so_vits_svc_fork/inference/infer_tool.py b/src/so_vits_svc_fork/inference/infer_tool.py
--- a/src/so_vits_svc_fork/inference/infer_tool.py
+++ b/src/so_vits_svc_fork/inference/infer_tool.py
@@ -189,6 +189,16 @@ def infer(
else:
LOG.warning(f"Speaker {speaker} is not found. Use speaker 0 instead.")
speaker_id = 0
+ speaker_candidates = list(
+ filter(lambda x: x[1] == speaker_id, self.spk2id.__dict__.items())
+ )
+ if len(speaker_candidates) > 1:
+ raise ValueError(
+ f"Speaker_id {speaker_id} is not unique. Candidates: {speaker_candidates}"
+ )
+ elif len(speaker_candidates) == 0:
+ raise ValueError(f"Speaker_id {speaker_id} is not found.")
+ speaker = speaker_candidates[0][0]
sid = torch.LongTensor([int(speaker_id)]).to(self.dev).unsqueeze(0)
# get unit f0
|
Speaker not automatically set to 0 if not found when cluster_ratio != 0
**Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
**Additional context**
Add any other context about the problem here.
| 2023-03-24T03:27:24 |
||
voicepaw/so-vits-svc-fork
| 99 |
voicepaw__so-vits-svc-fork-99
|
[
"88"
] |
495b7cbfc9f9468d49bc3f57efe6c5c076dcb0d3
|
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -9,8 +9,10 @@
import sounddevice as sd
import torch
from pebble import ProcessFuture, ProcessPool
+from tqdm.tk import tqdm_tk
from .__main__ import init_logger
+from .utils import ensure_hubert_model
GUI_DEFAULT_PRESETS_PATH = Path(__file__).parent / "default_gui_presets.json"
GUI_PRESETS_PATH = Path("./user_gui_presets.json").absolute()
@@ -54,17 +56,53 @@ def delete_preset(name: str) -> dict:
return load_presets()
-def get_devices(update: bool = True) -> tuple[list[str], list[str]]:
+def get_devices(
+ update: bool = True,
+) -> tuple[list[str], list[str], list[int], list[int]]:
if update:
sd._terminate()
sd._initialize()
devices = sd.query_devices()
- input_devices = [d["name"] for d in devices if d["max_input_channels"] > 0]
- output_devices = [d["name"] for d in devices if d["max_output_channels"] > 0]
- return input_devices, output_devices
+ hostapis = sd.query_hostapis()
+ for hostapi in hostapis:
+ for device_idx in hostapi["devices"]:
+ devices[device_idx]["hostapi_name"] = hostapi["name"]
+ input_devices = [
+ f"{d['name']} ({d['hostapi_name']})"
+ for d in devices
+ if d["max_input_channels"] > 0
+ ]
+ output_devices = [
+ f"{d['name']} ({d['hostapi_name']})"
+ for d in devices
+ if d["max_output_channels"] > 0
+ ]
+ input_devices_indices = [d["index"] for d in devices if d["max_input_channels"] > 0]
+ output_devices_indices = [
+ d["index"] for d in devices if d["max_output_channels"] > 0
+ ]
+ return input_devices, output_devices, input_devices_indices, output_devices_indices
def main():
+ try:
+ ensure_hubert_model(tqdm_cls=tqdm_tk)
+ except Exception as e:
+ LOG.exception(e)
+ LOG.info("Trying tqdm.std...")
+ try:
+ ensure_hubert_model()
+ except Exception as e:
+ LOG.exception(e)
+ try:
+ ensure_hubert_model(disable=True)
+ except Exception as e:
+ LOG.exception(e)
+ LOG.error(
+ "Failed to download Hubert model. Please download it manually."
+ )
+ return
+
sg.theme("Dark")
model_candidates = list(sorted(Path("./logs/44k/").glob("G_*.pth")))
@@ -292,7 +330,7 @@ def main():
sg.Combo(
key="input_device",
values=[],
- size=(20, 1),
+ size=(60, 1),
),
],
[
@@ -301,7 +339,7 @@ def main():
sg.Combo(
key="output_device",
values=[],
- size=(20, 1),
+ size=(60, 1),
),
],
[
@@ -310,6 +348,8 @@ def main():
key="passthrough_original",
default=False,
),
+ sg.Push(),
+ sg.Button("Refresh devices", key="refresh_devices"),
],
[
sg.Frame(
@@ -403,9 +443,10 @@ def main():
layout = [[column1, column2]]
# layout = [[sg.Column(layout, vertical_alignment="top", scrollable=True, expand_x=True, expand_y=True)]]
window = sg.Window(
- f"{__name__.split('.')[0]}", layout, grab_anywhere=True
+ f"{__name__.split('.')[0]}", layout, grab_anywhere=True, finalize=True
) # , use_custom_titlebar=True)
-
+ # for n in ["input_device", "output_device"]:
+ # window[n].Widget.configure(justify="right")
event, values = window.read(timeout=0.01)
def update_speaker() -> None:
@@ -420,7 +461,7 @@ def update_speaker() -> None:
)
def update_devices() -> None:
- input_devices, output_devices = get_devices()
+ input_devices, output_devices, _, _ = get_devices()
window["input_device"].update(
values=input_devices, value=values["input_device"]
)
@@ -465,7 +506,6 @@ def apply_preset(name: str) -> None:
break
if not event == sg.EVENT_TIMEOUT:
LOG.info(f"Event {event}, values {values}")
- update_devices()
if event.endswith("_path"):
for name in window.AllKeysDict:
if str(name).endswith("_browse"):
@@ -493,6 +533,8 @@ def apply_preset(name: str) -> None:
elif event == "presets":
apply_preset(values["presets"])
update_speaker()
+ elif event == "refresh_devices":
+ update_devices()
elif event == "config_path":
update_speaker()
elif event == "infer":
@@ -541,6 +583,9 @@ def apply_preset(name: str) -> None:
if Path(values["input_path"]).exists():
pool.schedule(play_audio, args=[Path(values["input_path"])])
elif event == "start_vc":
+ _, _, input_device_indices, output_device_indices = get_devices(
+ update=False
+ )
from .inference_main import realtime
if future:
@@ -573,8 +618,12 @@ def apply_preset(name: str) -> None:
version=int(values["realtime_algorithm"][0]),
device="cuda" if values["use_gpu"] else "cpu",
block_seconds=values["block_seconds"],
- input_device=values["input_device"],
- output_device=values["output_device"],
+ input_device=input_device_indices[
+ window["input_device"].widget.current()
+ ],
+ output_device=output_device_indices[
+ window["output_device"].widget.current()
+ ],
passthrough_original=values["passthrough_original"],
),
)
diff --git a/src/so_vits_svc_fork/utils.py b/src/so_vits_svc_fork/utils.py
--- a/src/so_vits_svc_fork/utils.py
+++ b/src/so_vits_svc_fork/utils.py
@@ -283,7 +283,13 @@ def f0_to_coarse(f0: torch.Tensor | float):
return f0_coarse
-def download_file(url: str, filepath: Path | str, chunk_size: int = 4 * 1024, **kwargs):
+def download_file(
+ url: str,
+ filepath: Path | str,
+ chunk_size: int = 4 * 1024,
+ tqdm_cls: type = tqdm,
+ **kwargs,
+):
filepath = Path(filepath)
filepath.parent.mkdir(parents=True, exist_ok=True)
temppath = filepath.parent / f"{filepath.name}.download"
@@ -292,7 +298,7 @@ def download_file(url: str, filepath: Path | str, chunk_size: int = 4 * 1024, **
temppath.unlink(missing_ok=True)
resp = requests.get(url, stream=True)
total = int(resp.headers.get("content-length", 0))
- with temppath.open("wb") as f, tqdm(
+ with temppath.open("wb") as f, tqdm_cls(
total=total,
unit="iB",
unit_scale=True,
@@ -305,7 +311,7 @@ def download_file(url: str, filepath: Path | str, chunk_size: int = 4 * 1024, **
temppath.rename(filepath)
-def ensure_pretrained_model(folder_path: Path) -> None:
+def ensure_pretrained_model(folder_path: Path, **kwargs) -> None:
model_urls = [
# "https://huggingface.co/innnky/sovits_pretrained/resolve/main/sovits4/G_0.pth",
"https://huggingface.co/therealvul/so-vits-svc-4.0-init/resolve/main/D_0.pth",
@@ -315,17 +321,19 @@ def ensure_pretrained_model(folder_path: Path) -> None:
for model_url in model_urls:
model_path = folder_path / model_url.split("/")[-1]
if not model_path.exists():
- download_file(model_url, model_path, desc=f"Downloading {model_path.name}")
+ download_file(
+ model_url, model_path, desc=f"Downloading {model_path.name}", **kwargs
+ )
-def ensure_hubert_model() -> Path:
+def ensure_hubert_model(**kwargs) -> Path:
vec_path = Path("checkpoint_best_legacy_500.pt")
vec_path.parent.mkdir(parents=True, exist_ok=True)
if not vec_path.exists():
# url = "http://obs.cstcloud.cn/share/obs/sankagenkeshi/checkpoint_best_legacy_500.pt"
# url = "https://huggingface.co/innnky/contentvec/resolve/main/checkpoint_best_legacy_500.pt"
url = "https://huggingface.co/therealvul/so-vits-svc-4.0-init/resolve/main/checkpoint_best_legacy_500.pt"
- download_file(url, vec_path, desc="Downloading Hubert model")
+ download_file(url, vec_path, desc="Downloading Hubert model", **kwargs)
return vec_path
|
Newest version UI keeps trying to start and end ASIO4All (1.2.9+)
**Describe the bug**
Audio is very choppy. It appears that it keeps opening and closing Asio4All (which I remember was installed with FL Studio)
Seems to come from some change in the GUI code for the speakers and devices not updating in 1.2.9
https://lord.moe/1679589472-54728.mp4
**To Reproduce**
Have Asio4All installed and try to launch the GUI
**Additional context**
Wasn't happening in 1.2.8 so whatever was changed in 1.2.9 broke this
Managed to install 1.2.8 and it works fine there
|
Looking through the code, it seems that `update_devices` is being called roughly every 500ms here:
https://github.com/34j/so-vits-svc-fork/commit/a8511508b0d2b3a62e7b77833280e4264997d9ed#diff-ef0d9a5e78b82c6c1ac6203c1ad79a034288d56695ffa50eed784c2e016ae157R457
Would it be possible to instead add a button to click to reload all audio devices? (Additionally to loading them upon starting the program of course)
| 2023-03-24T05:47:27 |
|
voicepaw/so-vits-svc-fork
| 130 |
voicepaw__so-vits-svc-fork-130
|
[
"127"
] |
38d97449d5b443167926f409f904f4b40c6e0f03
|
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -4,9 +4,9 @@
from logging import getLogger
from pathlib import Path
-import librosa
import PySimpleGUI as sg
import sounddevice as sd
+import soundfile as sf
import torch
from pebble import ProcessFuture, ProcessPool
from tqdm.tk import tqdm_tk
@@ -24,7 +24,7 @@
def play_audio(path: Path | str):
if isinstance(path, Path):
path = path.as_posix()
- data, sr = librosa.load(path)
+ data, sr = sf.read(path)
sd.play(data, sr)
diff --git a/src/so_vits_svc_fork/preprocess_resample.py b/src/so_vits_svc_fork/preprocess_resample.py
--- a/src/so_vits_svc_fork/preprocess_resample.py
+++ b/src/so_vits_svc_fork/preprocess_resample.py
@@ -9,6 +9,7 @@
import librosa
import numpy as np
import soundfile
+import soundfile as sf
from joblib import Parallel, delayed
from tqdm_joblib import tqdm_joblib
@@ -58,7 +59,7 @@ def preprocess_one(input_path: Path, output_path: Path) -> None:
"""Preprocess one audio file."""
try:
- audio, sr = librosa.load(input_path)
+ audio, sr = sf.read(input_path)
# Audioread is the last backend it will attempt, so this is the exception thrown on failure
except audioread.exceptions.NoBackendError as e:
diff --git a/src/so_vits_svc_fork/preprocess_split.py b/src/so_vits_svc_fork/preprocess_split.py
--- a/src/so_vits_svc_fork/preprocess_split.py
+++ b/src/so_vits_svc_fork/preprocess_split.py
@@ -2,6 +2,7 @@
from pathlib import Path
import librosa
+import soundfile
import soundfile as sf
from joblib import Parallel, delayed
from tqdm import tqdm
@@ -19,7 +20,7 @@ def _process_one(
hop_seconds: float = 0.1,
):
try:
- audio, sr = librosa.load(input_path)
+ audio, sr = sf.read(input_path)
except Exception as e:
LOG.warning(f"Failed to read {input_path}: {e}")
return
|
svc pre-resample resamples to 22 kHz and then to 44 kHz
I have wav files in the dataset_raw in mono 44.1 kHz sample rate. When I run svc pre-resample, the files are saved in dataset folder and when I played them I noticed that they sound lower quality.
When I checked with a spectrogram, I noticed that the samples were half quality.

Workaround: copy the wavs from dataset_raw to dataset folder.
|
This worst ever bug has made it necessary to retrain all my models......
> This worst ever bug has made it necessary to retrain all my models......
RIP. I always check all audio files with spectograms.
Also the Auto Play in svcg also plays at 22 kHz.
| 2023-03-26T09:43:31 |
|
voicepaw/so-vits-svc-fork
| 175 |
voicepaw__so-vits-svc-fork-175
|
[
"150"
] |
29474d9dc77555fe5a55427278d44dfea7ece5ef
|
diff --git a/src/so_vits_svc_fork/__main__.py b/src/so_vits_svc_fork/__main__.py
--- a/src/so_vits_svc_fork/__main__.py
+++ b/src/so_vits_svc_fork/__main__.py
@@ -438,7 +438,9 @@ def vc(
)
@click.option("-d", "--top-db", type=float, default=30, help="top db")
@click.option("-f", "--frame-seconds", type=float, default=1, help="frame seconds")
[email protected]("-h", "--hop-seconds", type=float, default=0.3, help="hop seconds")
[email protected](
+ "-ho", "-hop", "--hop-seconds", type=float, default=0.3, help="hop seconds"
+)
def pre_resample(
input_dir: Path,
output_dir: Path,
@@ -653,7 +655,9 @@ def pre_sd(
)
@click.option("-d", "--top-db", type=float, default=30, help="top db")
@click.option("-f", "--frame-seconds", type=float, default=1, help="frame seconds")
[email protected]("-h", "--hop-seconds", type=float, default=0.3, help="hop seconds")
[email protected](
+ "-ho", "-hop", "--hop-seconds", type=float, default=0.3, help="hop seconds"
+)
@click.option("-s", "--sr", type=int, default=44100, help="sample rate")
def pre_split(
input_dir: Path | str,
diff --git a/src/so_vits_svc_fork/preprocess_speaker_diarization.py b/src/so_vits_svc_fork/preprocess_speaker_diarization.py
--- a/src/so_vits_svc_fork/preprocess_speaker_diarization.py
+++ b/src/so_vits_svc_fork/preprocess_speaker_diarization.py
@@ -1,3 +1,5 @@
+from __future__ import annotations
+
from collections import defaultdict
from logging import getLogger
from pathlib import Path
diff --git a/src/so_vits_svc_fork/preprocess_split.py b/src/so_vits_svc_fork/preprocess_split.py
--- a/src/so_vits_svc_fork/preprocess_split.py
+++ b/src/so_vits_svc_fork/preprocess_split.py
@@ -1,8 +1,9 @@
+from __future__ import annotations
+
from logging import getLogger
from pathlib import Path
import librosa
-import soundfile
import soundfile as sf
from joblib import Parallel, delayed
from tqdm import tqdm
|
diff --git a/tests/test_main.py b/tests/test_main.py
--- a/tests/test_main.py
+++ b/tests/test_main.py
@@ -15,6 +15,7 @@ def test_import(self):
import so_vits_svc_fork.preprocess_flist_config # noqa
import so_vits_svc_fork.preprocess_hubert_f0 # noqa
import so_vits_svc_fork.preprocess_resample # noqa
+ import so_vits_svc_fork.preprocess_split # noqa
import so_vits_svc_fork.train # noqa
def test_infer(self):
|
`svc pre-split` command not functional
Found some bugs. After the preprocessing commits from 2.0.0 and up, the command `svc pre-resample -h` will no longer work.
```
(venv) C:\Users\LXC PC\Desktop\sovits\venv\Scripts>svc pre-resample -h
[14:39:02] INFO [14:39:02] Version: 2.1.0 __main__.py:20
Error: Option '-h' requires an argument.
```
In addition, the command `svc pre-split` does not work as well.
```
(venv) C:\Users\LXC PC\Desktop\sovits\venv\Scripts>svc pre-split -h
[14:55:42] INFO [14:55:42] Version: 2.1.0 __main__.py:20
Error: Option '-h' requires an argument.
```
```
(venv) C:\Users\LXC PC\Desktop\sovits\venv\Scripts>svc pre-split -i "C:\Users\LXC PC\Desktop\sovits\venv\Scripts\dataset_raw\hapiraw"
[14:56:17] INFO [14:56:17] Version: 2.1.0 __main__.py:20
Traceback (most recent call last):
File "C:\Program Files\Python39\lib\runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Program Files\Python39\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "C:\Users\LXC PC\Desktop\sovits\venv\Scripts\svc.exe\__main__.py", line 7, in <module>
File "C:\Users\LXC PC\Desktop\sovits\venv\lib\site-packages\click\core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "C:\Users\LXC PC\Desktop\sovits\venv\lib\site-packages\click\core.py", line 1055, in main
rv = self.invoke(ctx)
File "C:\Users\LXC PC\Desktop\sovits\venv\lib\site-packages\click\core.py", line 1657, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "C:\Users\LXC PC\Desktop\sovits\venv\lib\site-packages\click\core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "C:\Users\LXC PC\Desktop\sovits\venv\lib\site-packages\click\core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "C:\Users\LXC PC\Desktop\sovits\venv\lib\site-packages\so_vits_svc_fork\__main__.py", line 668, in pre_split
from .preprocess_split import preprocess_split
File "C:\Users\LXC PC\Desktop\sovits\venv\lib\site-packages\so_vits_svc_fork\preprocess_split.py", line 45, in <module>
input_dir: Path | str,
TypeError: unsupported operand type(s) for |: 'type' and 'type'
```
|
That's because `-h` was added as a new flag to `pre-resample` and `pre-split` (probably all `svc` commands)
> That's because -h was added as a new flag to pre-resample and pre-split (probably all svc commands)
I see. That explains it. I was using `-h` all along so I didn't notice the change. The README should probably be updated so others won't make the same mistake.
As for the `svc pre-split` command, do you have any idea why it's not working? Tried it on a fresh venv install and it still gives me the same error:
```
(venv) C:\Users\User\Desktop\sovits\venv\Scripts>svc pre-split -i "C:\Users\User\Desktop\testcut" -o "C:\Users\User\Desktop\testcutout"
[18:57:30] INFO [18:57:30] Version: 2.1.0 __main__.py:20
Traceback (most recent call last):
File "C:\Users\User\AppData\Local\Programs\Python\Python39\lib\runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Users\User\AppData\Local\Programs\Python\Python39\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "C:\Users\User\Desktop\sovits\venv\Scripts\svc.exe\__main__.py", line 7, in <module>
File "C:\Users\User\Desktop\sovits\venv\lib\site-packages\click\core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "C:\Users\User\Desktop\sovits\venv\lib\site-packages\click\core.py", line 1055, in main
rv = self.invoke(ctx)
File "C:\Users\User\Desktop\sovits\venv\lib\site-packages\click\core.py", line 1657, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "C:\Users\User\Desktop\sovits\venv\lib\site-packages\click\core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "C:\Users\User\Desktop\sovits\venv\lib\site-packages\click\core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "C:\Users\User\Desktop\sovits\venv\lib\site-packages\so_vits_svc_fork\__main__.py", line 668, in pre_split
from .preprocess_split import preprocess_split
File "C:\Users\User\Desktop\sovits\venv\lib\site-packages\so_vits_svc_fork\preprocess_split.py", line 45, in <module>
input_dir: Path | str,
TypeError: unsupported operand type(s) for |: 'type' and 'type'
```
-h should be -ho or -hop
Need to add from __futures
| 2023-03-28T04:40:44 |
voicepaw/so-vits-svc-fork
| 176 |
voicepaw__so-vits-svc-fork-176
|
[
"146"
] |
52f1cfe1f08bd63966b0d1d7c025abed17cb36a6
|
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -460,7 +460,18 @@ def update_speaker() -> None:
)
def update_devices() -> None:
- input_devices, output_devices, _, _ = get_devices()
+ (
+ input_devices,
+ output_devices,
+ input_device_indices,
+ output_device_indices,
+ ) = get_devices()
+ input_device_indices_reversed = {
+ v: k for k, v in enumerate(input_device_indices)
+ }
+ output_device_indices_reversed = {
+ v: k for k, v in enumerate(output_device_indices)
+ }
window["input_device"].update(
values=input_devices, value=values["input_device"]
)
@@ -471,12 +482,12 @@ def update_devices() -> None:
if values["input_device"] not in input_devices:
window["input_device"].update(
values=input_devices,
- set_to_index=0 if input_default is None else input_default - 1,
+ set_to_index=input_device_indices_reversed.get(input_default, 0),
)
if values["output_device"] not in output_devices:
window["output_device"].update(
values=output_devices,
- set_to_index=0 if output_default is None else output_default - 1,
+ set_to_index=output_device_indices_reversed.get(output_default, 0),
)
PRESET_KEYS = [
|
Illegal combination of I/O devices [PaErrorCode -9993]
**Describe the bug**
Whenever I try the realtime mode, I get this error: "Illegal combination of I/O devices [PaErrorCode -9993]"
**To Reproduce**
1. Press start voice changer button.
2. After a short time, that error appears.
| 2023-03-28T04:51:58 |
||
voicepaw/so-vits-svc-fork
| 236 |
voicepaw__so-vits-svc-fork-236
|
[
"219"
] |
d561edb1c402ce26586c2e44a02d8831f76b0d9e
|
diff --git a/src/so_vits_svc_fork/preprocessing/preprocess_hubert_f0.py b/src/so_vits_svc_fork/preprocessing/preprocess_hubert_f0.py
--- a/src/so_vits_svc_fork/preprocessing/preprocess_hubert_f0.py
+++ b/src/so_vits_svc_fork/preprocessing/preprocess_hubert_f0.py
@@ -10,7 +10,7 @@
import torch
import torchaudio
from fairseq.models.hubert import HubertModel
-from joblib import Parallel, delayed
+from joblib import Parallel, cpu_count, delayed
from tqdm import tqdm
import so_vits_svc_fork.f0
@@ -22,8 +22,8 @@
from .preprocess_utils import check_hubert_min_duration
LOG = getLogger(__name__)
-HUBERT_MEMORY = 1600
-HUBERT_MEMORY_CREPE = 2600
+HUBERT_MEMORY = 2900
+HUBERT_MEMORY_CREPE = 3900
def _process_one(
@@ -124,11 +124,17 @@ def preprocess_hubert_f0(
utils.ensure_pretrained_model(".", "contentvec")
hps = utils.get_hparams(config_path)
if n_jobs is None:
- memory = get_total_gpu_memory("free")
- n_jobs = (
- memory // (HUBERT_MEMORY_CREPE if f0_method == "crepe" else HUBERT_MEMORY)
- if memory is not None
- else 1
+ # add cpu_count() to avoid SIGKILL
+ memory = get_total_gpu_memory("total")
+ n_jobs = min(
+ max(
+ memory
+ // (HUBERT_MEMORY_CREPE if f0_method == "crepe" else HUBERT_MEMORY)
+ if memory is not None
+ else 1,
+ 1,
+ ),
+ cpu_count(),
)
LOG.info(f"n_jobs automatically set to {n_jobs}, memory: {memory} MiB")
diff --git a/src/so_vits_svc_fork/utils.py b/src/so_vits_svc_fork/utils.py
--- a/src/so_vits_svc_fork/utils.py
+++ b/src/so_vits_svc_fork/utils.py
@@ -163,6 +163,32 @@ def get_content(
return c
+def _substitute_if_same_shape(to_: dict[str, Any], from_: dict[str, Any]) -> None:
+ for k, v in from_.items():
+ if k not in to_:
+ warnings.warn(f"Key {k} not found in model state dict")
+ elif hasattr(v, "shape"):
+ if not hasattr(to_[k], "shape"):
+ raise ValueError(f"Key {k} is not a tensor")
+ if to_[k].shape == v.shape:
+ to_[k] = v
+ else:
+ warnings.warn(
+ f"Shape mismatch for key {k}, {to_[k].shape} != {v.shape}"
+ )
+ elif isinstance(v, dict):
+ assert isinstance(to_[k], dict)
+ _substitute_if_same_shape(to_[k], v)
+ else:
+ to_[k] = v
+
+
+def safe_load(model: torch.nn.Module, state_dict: dict[str, Any]) -> None:
+ model_state_dict = model.state_dict()
+ _substitute_if_same_shape(model_state_dict, state_dict)
+ model.load_state_dict(model_state_dict)
+
+
def load_checkpoint(
checkpoint_path: Path | str,
model: torch.nn.Module,
@@ -174,37 +200,22 @@ def load_checkpoint(
checkpoint_dict = torch.load(checkpoint_path, map_location="cpu")
iteration = checkpoint_dict["iteration"]
learning_rate = checkpoint_dict["learning_rate"]
+
+ # safe load module
+ if hasattr(model, "module"):
+ safe_load(model.module, checkpoint_dict["model"])
+ else:
+ safe_load(model, checkpoint_dict["model"])
+ # safe load optim
if (
optimizer is not None
and not skip_optimizer
and checkpoint_dict["optimizer"] is not None
):
- try:
- optimizer.load_state_dict(checkpoint_dict["optimizer"])
- except Exception as e:
- LOG.exception(e)
- LOG.warning("Failed to load optimizer state")
- saved_state_dict = checkpoint_dict["model"]
- if hasattr(model, "module"):
- state_dict = model.module.state_dict()
- else:
- state_dict = model.state_dict()
- new_state_dict = {}
- for k, v in state_dict.items():
- try:
- new_state_dict[k] = saved_state_dict[k]
- assert saved_state_dict[k].shape == v.shape, (
- saved_state_dict[k].shape,
- v.shape,
- )
- except Exception as e:
- LOG.exception(e)
- LOG.error("%s is not in the checkpoint" % k)
- new_state_dict[k] = v
- if hasattr(model, "module"):
- model.module.load_state_dict(new_state_dict)
- else:
- model.load_state_dict(new_state_dict)
+ with warnings.catch_warnings():
+ warnings.simplefilter("ignore")
+ safe_load(optimizer, checkpoint_dict["optimizer"])
+
LOG.info(f"Loaded checkpoint '{checkpoint_path}' (iteration {iteration})")
return model, optimizer, learning_rate, iteration
|
CUDA Out of Memory during training
Hi, I've trained a few models without issue but after updating to 3.0 when trying to train a new model I run out of memory. I'm using the same dataset as before and there's no issues until the SVC Train command. Any idea what might be causing it? I can't make head or tail of the error message.
```
Traceback (most recent call last):
File "C:\Program Files\Python310\lib\runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Program Files\Python310\lib\runpy.py", line 86, in _run_code
exec(code, run_globals)
File "C:\Users\Star Guard 719\Documents\sovits new\venv\Scripts\svc.exe\__main__.py", line 7, in <module>
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\click\core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\click\core.py", line 1055, in main
rv = self.invoke(ctx)
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\click\core.py", line 1657, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\click\core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\click\core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\so_vits_svc_fork\__main__.py", line 128, in train
train(
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\so_vits_svc_fork\train.py", line 53, in train
mp.spawn(
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\torch\multiprocessing\spawn.py", line 239, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\torch\multiprocessing\spawn.py", line 197, in start_processes
while not context.join():
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\torch\multiprocessing\spawn.py", line 160, in join
raise ProcessRaisedException(msg, error_index, failed_process.pid)
torch.multiprocessing.spawn.ProcessRaisedException:
-- Process 0 terminated with the following error:
Traceback (most recent call last):
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\torch\multiprocessing\spawn.py", line 69, in _wrap
fn(i, *args)
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\so_vits_svc_fork\train.py", line 167, in _run
_train_and_evaluate(
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\so_vits_svc_fork\train.py", line 266, in _train_and_evaluate
y_d_hat_r, y_d_hat_g, _, _ = net_d(y, y_hat.detach())
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\torch\nn\parallel\distributed.py", line 1156, in forward
output = self._run_ddp_forward(*inputs, **kwargs)
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\torch\nn\parallel\distributed.py", line 1110, in _run_ddp_forward
return module_to_run(*inputs[0], **kwargs[0]) # type: ignore[index]
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\so_vits_svc_fork\modules\descriminators.py", line 137, in forward
y_d_r, fmap_r = d(y)
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\so_vits_svc_fork\modules\descriminators.py", line 81, in forward
x = F.leaky_relu(x, modules.LRELU_SLOPE)
File "C:\Users\Star Guard 719\Documents\sovits new\venv\lib\site-packages\torch\nn\functional.py", line 1632, in leaky_relu
result = torch._C._nn.leaky_relu(input, negative_slope)
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 12.00 MiB (GPU 0; 10.00 GiB total capacity; 9.13 GiB already allocated; 0 bytes free; 9.28 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
|
Please reduce batch_size
| 2023-04-05T02:05:43 |
|
voicepaw/so-vits-svc-fork
| 250 |
voicepaw__so-vits-svc-fork-250
|
[
"239"
] |
dbef4541faecb6c7607cc6dc0553e60c03484a71
|
diff --git a/src/so_vits_svc_fork/cluster/train_cluster.py b/src/so_vits_svc_fork/cluster/train_cluster.py
--- a/src/so_vits_svc_fork/cluster/train_cluster.py
+++ b/src/so_vits_svc_fork/cluster/train_cluster.py
@@ -24,8 +24,10 @@ def train_cluster(
LOG.info(f"Loading features from {input_dir}")
features = []
nums = 0
- for path in input_dir.glob("*.soft.pt"):
- features.append(torch.load(path).squeeze(0).numpy().T)
+ for path in input_dir.rglob("*.data.pt"):
+ features.append(
+ torch.load(path, weights_only=True)["content"].squeeze(0).numpy().T
+ )
features = np.concatenate(features, axis=0).astype(np.float32)
if features.shape[0] < n_clusters:
raise ValueError(
|
Crash when training cluster model
**Describe the bug**
Crash when training cluster model.
**To Reproduce**
conda activate so-vits-svc-fork
cd xxx
svc train-cluster
**Additional context**
Crash log:
Loading features from dataset\44k\yyy train_cluster.py:24
Training clusters: 100%|█████████████████████████████████████████████████████████████████| 1/1 [00:05<00:00, 5.20s/it]
joblib.externals.loky.process_executor._RemoteTraceback:
"""
Traceback (most recent call last):
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\joblib\externals\loky\process_executor.py", line 428, in _process_worker
r = call_item()
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\joblib\externals\loky\process_executor.py", line 275, in __call__
return self.fn(*self.args, **self.kwargs)
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\joblib\_parallel_backends.py", line 620, in __call__
return self.func(*args, **kwargs)
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\joblib\parallel.py", line 288, in __call__
return [func(*args, **kwargs)
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\joblib\parallel.py", line 288, in <listcomp>
return [func(*args, **kwargs)
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\so_vits_svc_fork\cluster\train_cluster.py", line 71, in train_cluster_
return input_path.stem, train_cluster(input_path, **kwargs)
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\so_vits_svc_fork\cluster\train_cluster.py", line 29, in train_cluster
features = np.concatenate(features, axis=0).astype(np.float32)
File "<__array_function__ internals>", line 180, in concatenate
ValueError: need at least one array to concatenate
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\runpy.py", line 86, in _run_code
exec(code, run_globals)
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\Scripts\svc.exe\__main__.py", line 7, in <module>
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\click\core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\click\core.py", line 1055, in main
rv = self.invoke(ctx)
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\click\core.py", line 1657, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\click\core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\click\core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\so_vits_svc_fork\__main__.py", line 810, in train_cluster
main(
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\so_vits_svc_fork\cluster\train_cluster.py", line 74, in main
parallel_result = Parallel(n_jobs=-1)(
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\joblib\parallel.py", line 1098, in __call__
self.retrieve()
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\joblib\parallel.py", line 975, in retrieve
self._output.extend(job.get(timeout=self.timeout))
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\site-packages\joblib\_parallel_backends.py", line 567, in wrap_future_result
return future.result(timeout=timeout)
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\concurrent\futures\_base.py", line 458, in result
return self.__get_result()
File "C:\Users\xxx\anaconda3\envs\so-vits-svc-fork\lib\concurrent\futures\_base.py", line 403, in __get_result
raise self._exception
ValueError: need at least one array to concatenate
|
Having the same problem as well.
@34j 3.0.4 still the same problem
Same problem here. I even tried downgrading, but the same error keeps appearing.
| 2023-04-08T07:35:12 |
|
voicepaw/so-vits-svc-fork
| 271 |
voicepaw__so-vits-svc-fork-271
|
[
"270"
] |
0a03035c42f8e9d03c80a9b17477160cb02bc548
|
diff --git a/src/so_vits_svc_fork/train.py b/src/so_vits_svc_fork/train.py
--- a/src/so_vits_svc_fork/train.py
+++ b/src/so_vits_svc_fork/train.py
@@ -1,6 +1,5 @@
from __future__ import annotations
-import math
import warnings
from logging import getLogger
from pathlib import Path
@@ -69,12 +68,9 @@ def train(
trainer = pl.Trainer(
logger=TensorBoardLogger(model_path),
# profiler="simple",
+ val_check_interval=hparams.train.eval_interval,
max_epochs=hparams.train.epochs,
- check_val_every_n_epoch=math.ceil(
- hparams.train.eval_interval
- / len(datamodule.train_dataset)
- * hparams.train.batch_size
- ),
+ check_val_every_n_epoch=None,
precision=16
if hparams.train.fp16_run
else "bf16"
@@ -87,7 +83,11 @@ def train(
class VitsLightning(pl.LightningModule):
def on_train_start(self) -> None:
- self.load(False)
+ self.set_current_epoch(self._temp_epoch)
+ total_batch_idx = self._temp_epoch * len(self.trainer.train_dataloader)
+ self.set_total_batch_idx(total_batch_idx)
+ global_step = total_batch_idx * self.optimizers_count
+ self.set_global_step(global_step)
# check if using tpu
if isinstance(self.trainer.accelerator, TPUAccelerator):
@@ -140,6 +140,22 @@ def set_global_step(self, global_step: int):
)
assert self.global_step == global_step, f"{self.global_step} != {global_step}"
+ def set_total_batch_idx(self, total_batch_idx: int):
+ LOG.info(f"Setting total batch idx to {total_batch_idx}")
+ self.trainer.fit_loop.epoch_loop.batch_progress.total.ready = (
+ total_batch_idx + 1
+ )
+ self.trainer.fit_loop.epoch_loop.batch_progress.total.completed = (
+ total_batch_idx
+ )
+ assert (
+ self.total_batch_idx == total_batch_idx + 1
+ ), f"{self.total_batch_idx} != {total_batch_idx + 1}"
+
+ @property
+ def total_batch_idx(self) -> int:
+ return self.trainer.fit_loop.epoch_loop.total_batch_idx + 1
+
def load(self, reset_optimizer: bool = False):
latest_g_path = utils.latest_checkpoint_path(self.hparams.model_dir, "G_*.pth")
latest_d_path = utils.latest_checkpoint_path(self.hparams.model_dir, "D_*.pth")
@@ -157,12 +173,9 @@ def load(self, reset_optimizer: bool = False):
self.optim_d,
reset_optimizer,
)
- self.set_current_epoch(epoch)
- global_step = epoch * len(self.trainer.train_dataloader)
- self.set_global_step(global_step)
- assert self.current_epoch == epoch, f"{self.current_epoch} != {epoch}"
- self.scheduler_g.last_epoch = self.current_epoch - 1
- self.scheduler_d.last_epoch = self.current_epoch - 1
+ self._temp_epoch = epoch
+ self.scheduler_g.last_epoch = epoch - 1
+ self.scheduler_d.last_epoch = epoch - 1
except Exception as e:
raise RuntimeError("Failed to load checkpoint") from e
else:
@@ -198,6 +211,8 @@ def __init__(self, reset_optimizer: bool = False, **hparams: Any):
self.scheduler_d = torch.optim.lr_scheduler.ExponentialLR(
self.optim_d, gamma=self.hparams.train.lr_decay
)
+ self.optimizers_count = 2
+ self.load(reset_optimizer)
def configure_optimizers(self):
return [self.optim_g, self.optim_d], [self.scheduler_g, self.scheduler_d]
@@ -211,7 +226,7 @@ def log_image_dict(
writer: SummaryWriter = self.logger.experiment
for k, v in image_dict.items():
try:
- writer.add_image(k, v, self.global_step, dataformats=dataformats)
+ writer.add_image(k, v, self.total_batch_idx, dataformats=dataformats)
except Exception as e:
warnings.warn(f"Failed to log image {k}: {e}")
@@ -222,9 +237,25 @@ def log_audio_dict(self, audio_dict: dict[str, Any]) -> None:
writer: SummaryWriter = self.logger.experiment
for k, v in audio_dict.items():
writer.add_audio(
- k, v, self.global_step, sample_rate=self.hparams.data.sampling_rate
+ k,
+ v,
+ self.trainer.fit_loop.total_batch_idx,
+ sample_rate=self.hparams.data.sampling_rate,
)
+ def log_dict_(self, log_dict: dict[str, Any], **kwargs) -> None:
+ if not isinstance(self.logger, TensorBoardLogger):
+ warnings.warn("Logging is only supported with TensorBoardLogger.")
+ return
+ writer: SummaryWriter = self.logger.experiment
+ for k, v in log_dict.items():
+ writer.add_scalar(k, v, self.total_batch_idx)
+ kwargs["logger"] = False
+ self.log_dict(log_dict, **kwargs)
+
+ def log_(self, key: str, value: Any, **kwargs) -> None:
+ self.log_dict_({key: value}, **kwargs)
+
def training_step(self, batch: dict[str, torch.Tensor], batch_idx: int) -> None:
self.net_g.train()
self.net_d.train()
@@ -282,9 +313,11 @@ def training_step(self, batch: dict[str, torch.Tensor], batch_idx: int) -> None:
loss_gen_all += loss_subband
# log loss
- self.log("grad_norm_g", commons.clip_grad_value_(self.net_g.parameters(), None))
- self.log("lr", self.optim_g.param_groups[0]["lr"])
- self.log_dict(
+ self.log_(
+ "grad_norm_g", commons.clip_grad_value_(self.net_g.parameters(), None)
+ )
+ self.log_("lr", self.optim_g.param_groups[0]["lr"])
+ self.log_dict_(
{
"loss/g/total": loss_gen_all,
"loss/g/fm": loss_fm,
@@ -295,8 +328,8 @@ def training_step(self, batch: dict[str, torch.Tensor], batch_idx: int) -> None:
prog_bar=True,
)
if self.hparams.model.get("type_") == "mb-istft":
- self.log("loss/g/subband", loss_subband)
- if self.global_step % self.hparams.train.log_interval == 0:
+ self.log_("loss/g/subband", loss_subband)
+ if self.total_batch_idx % self.hparams.train.log_interval == 0:
self.log_image_dict(
{
"slice/mel_org": utils.plot_spectrogram_to_numpy(
@@ -338,8 +371,10 @@ def training_step(self, batch: dict[str, torch.Tensor], batch_idx: int) -> None:
loss_disc_all = loss_disc
# log loss
- self.log("loss/d/total", loss_disc_all, prog_bar=True)
- self.log("grad_norm_d", commons.clip_grad_value_(self.net_d.parameters(), None))
+ self.log_("loss/d/total", loss_disc_all, prog_bar=True)
+ self.log_(
+ "grad_norm_d", commons.clip_grad_value_(self.net_d.parameters(), None)
+ )
# optimizer
self.manual_backward(loss_disc_all)
@@ -364,19 +399,21 @@ def validation_step(self, batch, batch_idx):
"gt/mel": utils.plot_spectrogram_to_numpy(mel[0].cpu().numpy()),
}
)
+ if self.current_epoch == 0:
+ return
utils.save_checkpoint(
self.net_g,
self.optim_g,
self.hparams.train.learning_rate,
- self.current_epoch,
- Path(self.hparams.model_dir) / f"G_{self.global_step}.pth",
+ self.current_epoch + 1, # prioritize prevention of undervaluation
+ Path(self.hparams.model_dir) / f"G_{self.total_batch_idx}.pth",
)
utils.save_checkpoint(
self.net_d,
self.optim_d,
self.hparams.train.learning_rate,
- self.current_epoch,
- Path(self.hparams.model_dir) / f"D_{self.global_step}.pth",
+ self.current_epoch + 1,
+ Path(self.hparams.model_dir) / f"D_{self.total_batch_idx}.pth",
)
keep_ckpts = self.hparams.train.get("keep_ckpts", 0)
if keep_ckpts > 0:
|
Newly trained model since Lightning implementation sounds robotic early on
**Describe the bug**
Started training a new model in 3.1.4 and noticed it sounded super robotic around 1700 steps in.
(Converted to webm so I could upload them here)
Original:
[original.webm](https://user-images.githubusercontent.com/1345036/230768178-47bb3f5c-bba1-4e3f-9c63-dbe053ed149e.webm)
Generated:
[generated_1700.webm](https://user-images.githubusercontent.com/1345036/230768187-a1cc8142-2f70-42b0-8454-c11693ad79c4.webm)
**To Reproduce**
Start generating a new model with 3.1.4
**Additional context**
The setup (pre-resample, pre-config, pre-hubert) has been done with their default settings.
I saw this commit that fixed the order of the _d optimizer. I've made these changes locally myself and gonna report back on the model once I trained it from scratch again
https://github.com/34j/so-vits-svc-fork/commit/13d63469b0a84ace0dc8848df47dc20538b98770
Additionally, I have no idea if this is intentional and it just needs more iterations.
Does it perhaps not take the legacy checkpoint into account anymore?
|
Even after around 5000 steps it still sounds very robotic. I applied the fix in the commit.
Original:
[original_2.webm](https://user-images.githubusercontent.com/1345036/230769525-46e57712-6d34-41df-90d2-3f029bd6b63b.webm)
Generated:
[generated_5000.webm](https://user-images.githubusercontent.com/1345036/230769534-16c7c764-a593-45ee-b310-5d02d09ddc08.webm)
same
| 2023-04-09T12:02:35 |
|
voicepaw/so-vits-svc-fork
| 291 |
voicepaw__so-vits-svc-fork-291
|
[
"292"
] |
29cd14a1dcb725a45ee568470e13d1f4bbe29d42
|
diff --git a/src/so_vits_svc_fork/train.py b/src/so_vits_svc_fork/train.py
--- a/src/so_vits_svc_fork/train.py
+++ b/src/so_vits_svc_fork/train.py
@@ -418,6 +418,11 @@ def training_step(self, batch: dict[str, torch.Tensor], batch_idx: int) -> None:
optim_d.step()
self.untoggle_optimizer(optim_d)
+ # end of epoch
+ if self.trainer.is_last_batch:
+ self.scheduler_g.step()
+ self.scheduler_d.step()
+
def validation_step(self, batch, batch_idx):
with torch.no_grad():
self.net_g.eval()
|
Learning rate (display) issue
**Describe the bug**
I have set a different learning rate (compared to the default 1e-4) as well as a different value of lr_decay for my training in config.json.
However during training the lr displayed in Tensorboard shows a constant value of 1e-4 at any steps.
**To Reproduce**
Steps to reproduce the behavior:
Set a different lr or lr_decay, observer the lr log in Tensorboard
**Additional context**
I wonder if this is a bug in display or the manually set lr and lr_decay is not used after lightning is implemented?
| 2023-04-11T03:08:24 |
||
voicepaw/so-vits-svc-fork
| 297 |
voicepaw__so-vits-svc-fork-297
|
[
"287"
] |
179e3f84fcd138f14aa1299724ca8ffd2cc5ae25
|
diff --git a/src/so_vits_svc_fork/train.py b/src/so_vits_svc_fork/train.py
--- a/src/so_vits_svc_fork/train.py
+++ b/src/so_vits_svc_fork/train.py
@@ -66,6 +66,10 @@ def train(
utils.ensure_pretrained_model(model_path, hparams.model.get("type_", "hifi-gan"))
datamodule = VCDataModule(hparams)
+ strategy = (
+ "ddp_find_unused_parameters_true" if torch.cuda.device_count() > 1 else "auto"
+ )
+ LOG.info(f"Using strategy: {strategy}")
trainer = pl.Trainer(
logger=TensorBoardLogger(model_path),
# profiler="simple",
@@ -77,6 +81,7 @@ def train(
else "bf16-mixed"
if hparams.train.get("bf16_run", False)
else 32,
+ strategy=strategy,
)
model = VitsLightning(reset_optimizer=reset_optimizer, **hparams)
trainer.fit(model, datamodule=datamodule)
@@ -326,7 +331,6 @@ def training_step(self, batch: dict[str, torch.Tensor], batch_idx: int) -> None:
)
# generator loss
- LOG.debug("Calculating generator loss")
y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = self.net_d(y, y_hat)
with autocast(enabled=False):
|
Error when training using multi gpu
i'm training using 2 gpu and get this error when running svc training
i don't know if this error is related to multi GPU training or not
Traceback (most recent call last):
File "/opt/conda/envs/LoRA/bin/svc", line 8, in <module>
sys.exit(cli())
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/click/core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/click/core.py", line 1055, in main
rv = self.invoke(ctx)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/click/core.py", line 1657, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/click/core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/so_vits_svc_fork/__main__.py", line 129, in train
train(
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/so_vits_svc_fork/train.py", line 82, in train
trainer.fit(model, datamodule=datamodule)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/trainer/trainer.py", line 520, in fit
call._call_and_handle_interrupt(
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/trainer/call.py", line 42, in _call_and_handle_interrupt
return trainer.strategy.launcher.launch(trainer_fn, *args, trainer=trainer, **kwargs)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/strategies/launchers/subprocess_script.py", line 92, in launch
return function(*args, **kwargs)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/trainer/trainer.py", line 559, in _fit_impl
self._run(model, ckpt_path=ckpt_path)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/trainer/trainer.py", line 935, in _run
results = self._run_stage()
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/trainer/trainer.py", line 978, in _run_stage
self.fit_loop.run()
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/loops/fit_loop.py", line 201, in run
self.advance()
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/loops/fit_loop.py", line 354, in advance
self.epoch_loop.run(self._data_fetcher)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/loops/training_epoch_loop.py", line 133, in run
self.advance(data_fetcher)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/loops/training_epoch_loop.py", line 220, in advance
batch_output = self.manual_optimization.run(kwargs)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/loops/optimization/manual.py", line 90, in run
self.advance(kwargs)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/loops/optimization/manual.py", line 109, in advance
training_step_output = call._call_strategy_hook(trainer, "training_step", *kwargs.values())
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/trainer/call.py", line 288, in _call_strategy_hook
output = fn(*args, **kwargs)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/strategies/ddp.py", line 329, in training_step
return self.model(*args, **kwargs)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/torch/nn/parallel/distributed.py", line 1156, in forward
output = self._run_ddp_forward(*inputs, **kwargs)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/torch/nn/parallel/distributed.py", line 1110, in _run_ddp_forward
return module_to_run(*inputs[0], **kwargs[0]) # type: ignore[index]
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/overrides/base.py", line 90, in forward
output = self._forward_module.training_step(*inputs, **kwargs)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/so_vits_svc_fork/train.py", line 417, in training_step
self.manual_backward(loss_disc_all)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/core/module.py", line 1036, in manual_backward
self.trainer.strategy.backward(loss, None, *args, **kwargs)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/strategies/strategy.py", line 195, in backward
self.pre_backward(closure_loss)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/strategies/ddp.py", line 301, in pre_backward
prepare_for_backward(self.model, closure_loss)
File "/opt/conda/envs/LoRA/lib/python3.10/site-packages/lightning/pytorch/overrides/distributed.py", line 52, in prepare_for_backward
reducer._rebuild_buckets() # avoids "INTERNAL ASSERT FAILED" with `find_unused_parameters=False`
RuntimeError: It looks like your LightningModule has parameters that were not used in producing the loss returned by training_step. If this is intentional, you must enable the detection of unused parameters in DDP, either by setting the string value `strategy='ddp_find_unused_parameters_true'` or by setting the flag in the strategy with `strategy=DDPStrategy(find_unused_parameters=True)`
|
Could you try strategy='ddp_find_unused_parameters_true' and check if it works?
| 2023-04-12T02:20:33 |
|
voicepaw/so-vits-svc-fork
| 311 |
voicepaw__so-vits-svc-fork-311
|
[
"308"
] |
200d47c60ee1db1f5093d2bd1a26efd7fd5e5a49
|
diff --git a/src/so_vits_svc_fork/train.py b/src/so_vits_svc_fork/train.py
--- a/src/so_vits_svc_fork/train.py
+++ b/src/so_vits_svc_fork/train.py
@@ -82,6 +82,7 @@ def train(
if hparams.train.get("bf16_run", False)
else 32,
strategy=strategy,
+ callbacks=[pl.callbacks.RichProgressBar()],
)
model = VitsLightning(reset_optimizer=reset_optimizer, **hparams)
trainer.fit(model, datamodule=datamodule)
|
Use RichProgressBar
**Is your feature request related to a problem? Please describe.**
We already include the `rich` package, so we can use it's progress bar as described here:
It'll look like this:

**Describe the solution you'd like**
To implement the RichProgressBar
**Additional context**
All that's needed is to modify the trainer initialization as follow:
```python
trainer = pl.Trainer(
accelerator="auto",
logger=TensorBoardLogger(model_path),
# profiler="simple",
val_check_interval=hparams.train.eval_interval,
max_epochs=hparams.train.epochs,
check_val_every_n_epoch=None,
precision="16-mixed"
if hparams.train.fp16_run
# else "bf16-mixed"
else "bf16-mixed"
if hparams.train.get("bf16_run", False)
else 32,
callbacks=[pl.callbacks.RichProgressBar()] # <-- Add this here
)
```
Since it's a one-line change I don't see a huge need to turn this into a full pull request. I hope that's okay 🙏
|
I think it's fine. Please send a PR anyway. (I would have to follow the same procedure if I were to do it)
| 2023-04-13T09:30:09 |
|
voicepaw/so-vits-svc-fork
| 313 |
voicepaw__so-vits-svc-fork-313
|
[
"309"
] |
c2bfb291513180ead8017f781920ffa61b4b7fc6
|
diff --git a/src/so_vits_svc_fork/__main__.py b/src/so_vits_svc_fork/__main__.py
--- a/src/so_vits_svc_fork/__main__.py
+++ b/src/so_vits_svc_fork/__main__.py
@@ -2,6 +2,7 @@
import os
from logging import getLogger
+from multiprocessing import freeze_support
from pathlib import Path
from typing import Literal
@@ -819,4 +820,6 @@ def train_cluster(
)
-cli()
+if __name__ == "__main__":
+ freeze_support()
+ cli()
diff --git a/src/so_vits_svc_fork/train.py b/src/so_vits_svc_fork/train.py
--- a/src/so_vits_svc_fork/train.py
+++ b/src/so_vits_svc_fork/train.py
@@ -2,6 +2,7 @@
import warnings
from logging import getLogger
+from multiprocessing import cpu_count
from pathlib import Path
from typing import Any
@@ -41,9 +42,10 @@ def __init__(self, hparams: Any):
self.val_dataset = TextAudioDataset(self.__hparams, is_validation=True)
def train_dataloader(self):
- # since dataset just reads data from a file, set num_workers to 0
return DataLoader(
self.train_dataset,
+ # pin_memory=False,
+ num_workers=min(cpu_count(), 4),
batch_size=self.__hparams.train.batch_size,
collate_fn=self.collate_fn,
)
@@ -51,6 +53,7 @@ def train_dataloader(self):
def val_dataloader(self):
return DataLoader(
self.val_dataset,
+ # pin_memory=False,
batch_size=1,
collate_fn=self.collate_fn,
)
|
Implement `num_workers` on trainer to boost performance
**Is your feature request related to a problem? Please describe.**
We currently don't use any `num_workers` for sub-processes as per torch documentation, resulting in warnings in the console that the validation and the training doesn't have any available.
Adding that variable to both and setting it to 4 for each results in a jump from about 1.40it/s to 2.50it/s, at least in my testing.
https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
> num_workers ([int](https://docs.python.org/3/library/functions.html#int), optional) – how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0)
**Describe the solution you'd like**
Implement support for `num_workers`, perhaps as extra fields for both the validator and the trainer in the config.
**Additional context**
**There is currently one downside:**
Doing so will, at least with the current pytorch version, throw multiple warnings in the console (and logs) mentioning the wrong usage of `TypedStorage` and how it's deprecated.

___
I have also noticed that with this change it is staying at a steady VRAM usage (with batch size 16 it stays at 14.8GB, with 20 it stays at around 16.8GB).
It drops to a lower usage whenever it's saving the checkpoints though, but that's fine.
I assume this is also part of where the improvements come from since it doesn't have to constantly reload through the main thread / process and can load the new stuff in the background.
| 2023-04-13T11:50:29 |
||
voicepaw/so-vits-svc-fork
| 331 |
voicepaw__so-vits-svc-fork-331
|
[
"319"
] |
6ac2f29165092d1fd584715971d2cb6ee415db34
|
diff --git a/src/so_vits_svc_fork/train.py b/src/so_vits_svc_fork/train.py
--- a/src/so_vits_svc_fork/train.py
+++ b/src/so_vits_svc_fork/train.py
@@ -75,7 +75,9 @@ def train(
)
LOG.info(f"Using strategy: {strategy}")
trainer = pl.Trainer(
- logger=TensorBoardLogger(model_path),
+ logger=TensorBoardLogger(
+ model_path, "lightning_logs", hparams.train.get("log_version", 0)
+ ),
# profiler="simple",
val_check_interval=hparams.train.eval_interval,
max_epochs=hparams.train.epochs,
|
Use `version` parameter for TensorBoardLogger
**Is your feature request related to a problem? Please describe.**
Currently the TensorBoardLogger doesn't have a version parameter when initialized.
By default, it is `None`, and the documentation states:
> version ([Union](https://docs.python.org/3/library/typing.html#typing.Union)[[int](https://docs.python.org/3/library/functions.html#int), [str](https://docs.python.org/3/library/stdtypes.html#str), [None](https://docs.python.org/3/library/constants.html#None)]) – Experiment version. If version is not specified the logger inspects the save directory for existing versions, then automatically assigns the next available version. If it is a string then it is used as the run-specific subdirectory name, otherwise 'version_${version}' is used.
https://lightning.ai/docs/pytorch/stable/extensions/generated/lightning.pytorch.loggers.TensorBoardLogger.html
**Describe the solution you'd like**
An option in the model to define the experiment version so it will not start new ones like here:
It would instead use the already existing (or set) version and allow events to be contained within just that version.
| 2023-04-14T16:04:15 |
||
voicepaw/so-vits-svc-fork
| 335 |
voicepaw__so-vits-svc-fork-335
|
[
"321"
] |
6268a9604653907136a3d5fd784833463d838b7e
|
diff --git a/src/so_vits_svc_fork/train.py b/src/so_vits_svc_fork/train.py
--- a/src/so_vits_svc_fork/train.py
+++ b/src/so_vits_svc_fork/train.py
@@ -88,7 +88,7 @@ def train(
if hparams.train.get("bf16_run", False)
else 32,
strategy=strategy,
- callbacks=[pl.callbacks.RichProgressBar()] if is_notebook() else None,
+ callbacks=[pl.callbacks.RichProgressBar()] if not is_notebook() else None,
)
model = VitsLightning(reset_optimizer=reset_optimizer, **hparams)
trainer.fit(model, datamodule=datamodule)
|
Colab: Training steps / epochs not appearing on log, only D_0.pth and G_0.pth being created
**Describe the bug**
Ttarining step does not work. The log shows:
2023-04-13 22:53:18.009147: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-04-13 22:53:19.311998: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
[22:53:20] INFO [22:53:20] NumExpr defaulting to 2 threads.
**To Reproduce**
From step "Automatic preprocessing" onwards the log finishes at "NumExpr defaulting to 2 threads." message.
**Additional context**
Stoped working 2 days ago.

|
#317 made this bug
So how exactly do I fix it? It stopped working for me as well today.
+ It just stops running after about a minute, still nothing has been trained or done.

> #317 made this bug
How do I revert to like... a previous version or something (in colab)?
Probably it is working but just not logging, probably
That's what I begin to think to but it's still a bummer since Its useful to
know if it's progresses or not.
On Fri, Apr 14, 2023, 8:32 AM 34j ***@***.***> wrote:
> Probably it is working but simply not logging, probably
>
> —
> Reply to this email directly, view it on GitHub
> <https://github.com/34j/so-vits-svc-fork/issues/321#issuecomment-1507996716>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/A3WEKEZ2WFXN233QHTG7S73XBDVODANCNFSM6AAAAAAW5WIJ64>
> .
> You are receiving this because you authored the thread.Message ID:
> ***@***.***>
>
> Probably it is working but just not logging, probably
Nope. It's not working.
It's crasing after around one minute of running with a green checkmark too. No logs, no checkpoints. Nothing.
> How do I revert to like... a previous version or something (in colab)?
u can install 33180e9 branch to revert to v3.5.0
> > How do I revert to like... a previous version or something (in colab)?
>
> u can install [33180e9](https://github.com/34j/so-vits-svc-fork/commit/33180e9670b5f5282bee6b9344244c0281d7d21c) branch to revert to v3.5.0
Okay thanks that seems to *kind of* work but it still doesn't save checkpoints when I need to. Usually stopping the cell works just fine, 3.5 gives an eror and starts over every time. The end step seems to be set to 9999. Is there a way I can set it to something like 2500 instead?
> #317 made this bug
The logic is inverted.
`callbacks=[pl.callbacks.RichProgressBar()] if is_notebook() else None,`
It uses the RichProgressBar if it **is** a notebook, not if it **isn't**
> > #317 made this bug
>
> The logic is inverted. `callbacks=[pl.callbacks.RichProgressBar()] if is_notebook() else None,`
>
> It uses the RichProgressBar if it **is** a notebook, not if it **isn't**
What do you mean? Can you explain me how to solve it pls?
> What do you mean? Can you explain me how to solve it pls?
Okay so, that code snippet checks if it's running in Colab. If it is, it will use the fancier progress bar.
However, this progress bar does not seem to be available inside Colab so 34j made this method to check.
The logic for it is the wrong way around though - instead of using the old / default progress bar in Colab when it detects it's running in Colab, it is using the fancy one that's not available.
The fix would be to do `if not is_notebook` instead.
___
I noticed this issue locally when the fancy progress bar wasn't available after an update.
If 34j (or someone else) won't be getting to a pull request I can do one once I'm back at my computer in around an hour
| 2023-04-14T18:19:12 |
|
voicepaw/so-vits-svc-fork
| 336 |
voicepaw__so-vits-svc-fork-336
|
[
"330"
] |
6268a9604653907136a3d5fd784833463d838b7e
|
diff --git a/src/so_vits_svc_fork/logger.py b/src/so_vits_svc_fork/logger.py
--- a/src/so_vits_svc_fork/logger.py
+++ b/src/so_vits_svc_fork/logger.py
@@ -1,5 +1,6 @@
import os
import sys
+import warnings
from logging import (
DEBUG,
INFO,
@@ -35,6 +36,9 @@ def init_logger() -> None:
if IS_TEST:
getLogger(package_name).setLevel(DEBUG)
captureWarnings(True)
+ warnings.filterwarnings(
+ "ignore", category=UserWarning, message="TypedStorage is deprecated"
+ )
LOGGER_INIT = True
|
"TypedStorage is deprecated" while Training
**Describe the bug**
Spammy "TypedStorage is deprecated" warning on every epoch.
```
[23:52:12] WARNING [23:52:12] C:\omited\venv\lib\site-packages\torch\_utils.py:776: UserWarning: warnings.py:109
TypedStorage is deprecated. It will be removed in the future and UntypedStorage will
be the only storage class. This should only matter to you if you are using storages
directly. To access UntypedStorage directly, use tensor.untyped_storage() instead
of tensor.storage()
return self.fget.__get__(instance, owner)()
```
**To Reproduce**
Simply train a voice.
**Additional context**
I updated to 3.6.1 today and start seeing the issue. Unfortunately I didn't know what was last good known version.
I'm training a voice using CREPE F0 predictor and using PyTorch 2.0.0 in Windows 11 if that matters.
|
From my understanding this is an issue with *some* library / package that this project is utilizing, as I can't find any usage of `tensor.storage()` or `TypedStorage` in general in the code
I don't know *which* package is using it and if it already has an updated version that uses `UntypedStorage` instead
This warning can be safely ignored for now as it shouldn't affect training 😁 (at least it doesn't for me)
___
I noticed that it's spamming it for every DataLoader instance... if you want to disable that warning, change the following line in your venv:
Line 316 in `venv\lib\site-packages\torch\storage.py`
```py
warnings.warn(message, UserWarning, stacklevel=stacklevel + 1)
```
to
```py
# warnings.warn(message, UserWarning, stacklevel=stacklevel + 1)
```
___
It seems this was addressed in the development code for pytorch already here:
https://github.com/pytorch/pytorch/issues/97207
https://github.com/pytorch/pytorch/commit/fbc803df0c420db84429c51599f4fa4354b4493f
It hasn't been included in a new release, however, meaning we have to wait for 2.0.1.
The alternative would be to suppress the warning for the TypedStorage deprecation for the time being.
I'll quickly spin up a pull request for that 😄
| 2023-04-14T20:36:58 |
|
voicepaw/so-vits-svc-fork
| 352 |
voicepaw__so-vits-svc-fork-352
|
[
"337"
] |
71ac2417854e1d2a0d3a58e121c13aec80846308
|
diff --git a/src/so_vits_svc_fork/train.py b/src/so_vits_svc_fork/train.py
--- a/src/so_vits_svc_fork/train.py
+++ b/src/so_vits_svc_fork/train.py
@@ -8,7 +8,7 @@
import lightning.pytorch as pl
import torch
-from lightning.pytorch.accelerators import TPUAccelerator
+from lightning.pytorch.accelerators import MPSAccelerator, TPUAccelerator
from lightning.pytorch.loggers import TensorBoardLogger
from lightning.pytorch.tuner import Tuner
from torch.cuda.amp import autocast
@@ -175,10 +175,10 @@ def on_train_start(self) -> None:
global_step = total_batch_idx * self.optimizers_count
self.set_global_step(global_step)
- # check if using tpu
- if isinstance(self.trainer.accelerator, TPUAccelerator):
+ # check if using tpu or mps
+ if isinstance(self.trainer.accelerator, (TPUAccelerator, MPSAccelerator)):
# patch torch.stft to use cpu
- LOG.warning("Using TPU. Patching torch.stft to use cpu.")
+ LOG.warning("Using TPU/MPS. Patching torch.stft to use cpu.")
def stft(
input: torch.Tensor,
diff --git a/src/so_vits_svc_fork/utils.py b/src/so_vits_svc_fork/utils.py
--- a/src/so_vits_svc_fork/utils.py
+++ b/src/so_vits_svc_fork/utils.py
@@ -13,6 +13,7 @@
import numpy as np
import requests
import torch
+import torch.backends.mps
from cm_time import timer
from fairseq import checkpoint_utils
from fairseq.models.hubert.hubert import HubertModel
@@ -28,6 +29,8 @@
def get_optimal_device(index: int = 0) -> torch.device:
if torch.cuda.is_available():
return torch.device(f"cuda:{index % torch.cuda.device_count()}")
+ elif torch.backends.mps.is_available():
+ return torch.device("mps")
else:
try:
import torch_xla.core.xla_model as xm # noqa
|
MPS Support
I've read some issues about mps of pytorch, it turns out that currently mps doesn't support complex types (like 1+2j). But I think svc requires complex types. One of the current solution is adding a.to("cpu") before the operations which are not supported and a.to("mps") after that.
Could this be a temporary workaround for an M1 version than can train?
Once pytorch supports all these operations, though, these added codes should be removed.
```
$ svc train
[16:23:40] INFO [16:23:40] Version: 3.1.10 __main__.py:21
[16:23:41] INFO [16:23:41] Created a temporary directory at /var/folders/26/3xzsh5qs4zd3_0nnhxsnckrr0000gn/T/tmp3tlrptr6 instantiator.py:21
INFO [16:23:41] Writing /var/folders/26/3xzsh5qs4zd3_0nnhxsnckrr0000gn/T/tmp3tlrptr6/_remote_module_non_scriptable.py instantiator.py:76
INFO: GPU available: True (mps), used: True
[16:23:43] INFO [16:23:43] GPU available: True (mps), used: True rank_zero.py:48
INFO: TPU available: False, using: 0 TPU cores
INFO [16:23:43] TPU available: False, using: 0 TPU cores rank_zero.py:48
INFO: IPU available: False, using: 0 IPUs
INFO [16:23:43] IPU available: False, using: 0 IPUs rank_zero.py:48
INFO: HPU available: False, using: 0 HPUs
INFO [16:23:43] HPU available: False, using: 0 HPUs rank_zero.py:48
WARNING [16:23:43] /opt/miniconda3/envs/vox/lib/python3.10/site-packages/so_vits_svc_fork/modules/synthesizers.py:81: UserWarning: Unused arguments: {'n_layers_q': 3, warnings.py:109
'use_spectral_norm': False}
warnings.warn(f"Unused arguments: {kwargs}")
INFO [16:23:43] Decoder type: hifi-gan synthesizers.py:100
[16:23:44] WARNING [16:23:44] /opt/miniconda3/envs/vox/lib/python3.10/site-packages/so_vits_svc_fork/utils.py:187: UserWarning: Keys not found in checkpoint state warnings.py:109
dict:['emb_g.weight']
warnings.warn(f"Keys not found in checkpoint state dict:" f"{not_in_from}")
INFO [16:23:44] Loaded checkpoint 'logs/44k/G_0.pth' (iteration 0) utils.py:243
INFO [16:23:44] Loaded checkpoint 'logs/44k/D_0.pth' (iteration 0) utils.py:243
INFO:
| Name | Type | Params
---------------------------------------------------
0 | net_g | SynthesizerTrn | 45.2 M
1 | net_d | MultiPeriodDiscriminator | 46.7 M
---------------------------------------------------
91.9 M Trainable params
0 Non-trainable params
91.9 M Total params
367.617 Total estimated model params size (MB)
INFO [16:23:44] model_summary.py:83
| Name | Type | Params
---------------------------------------------------
0 | net_g | SynthesizerTrn | 45.2 M
1 | net_d | MultiPeriodDiscriminator | 46.7 M
---------------------------------------------------
91.9 M Trainable params
0 Non-trainable params
91.9 M Total params
367.617 Total estimated model params size (MB)
Sanity Checking: 0it [00:00, ?it/s] WARNING [16:23:44] /opt/miniconda3/envs/vox/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:430: PossibleUserWarning: The warnings.py:109
dataloader, val_dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 10 which
is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
WARNING [16:23:44] /opt/miniconda3/envs/vox/lib/python3.10/site-packages/torch/_utils.py:776: UserWarning: TypedStorage is deprecated. It will be removed in the warnings.py:109
future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage
directly, use tensor.untyped_storage() instead of tensor.storage()
return self.fget.__get__(instance, owner)()
Sanity Checking DataLoader 0: 0%| | 0/2 [00:00<?, ?it/s] WARNING [16:23:44] /opt/miniconda3/envs/vox/lib/python3.10/site-packages/so_vits_svc_fork/f0.py:221: UserWarning: MPS: nonzero op is supported natively starting from warnings.py:109
macOS 13.0. Falling back on CPU. This may have performance implications. (Triggered internally at
/Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/native/mps/operations/Indexing.mm:218.)
f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * (f0_bin - 2) / (
WARNING [16:23:44] /opt/miniconda3/envs/vox/lib/python3.10/site-packages/so_vits_svc_fork/f0.py:228: UserWarning: MPS: no support for int64 min/max ops, casting it to warnings.py:109
int32 (Triggered internally at /Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/native/mps/operations/ReduceOps.mm:1271.)
assert f0_coarse.max() <= 255 and f0_coarse.min() >= 1, (
WARNING [16:23:44] /opt/miniconda3/envs/vox/lib/python3.10/site-packages/so_vits_svc_fork/modules/attentions.py:391: UserWarning: MPS: The constant padding of more warnings.py:109
than 3 dimensions is not currently supported natively. It uses View Ops default implementation to run. This may have performance implications. (Triggered
internally at /Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/native/mps/operations/Pad.mm:393.)
x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, 1]]))
WARNING [16:23:44] /opt/miniconda3/envs/vox/lib/python3.10/site-packages/torch/nn/utils/weight_norm.py:25: UserWarning: The operator 'aten::_weight_norm_interface' is warnings.py:109
not currently supported on the MPS backend and will fall back to run on the CPU. This may have performance implications. (Triggered internally at
/Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/mps/MPSFallback.mm:11.)
return _weight_norm(v, g, self.dim)
WARNING [16:23:44] /opt/miniconda3/envs/vox/lib/python3.10/site-packages/torch/nn/functional.py:3929: UserWarning: MPS: passing scale factor to upsample ops is warnings.py:109
supported natively starting from macOS 13.0. Falling back on CPU. This may have performance implications. (Triggered internally at
/Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/native/mps/operations/UpSample.mm:233.)
return torch._C._nn.upsample_nearest1d(input, output_size, scale_factors)
WARNING [16:23:44] /opt/miniconda3/envs/vox/lib/python3.10/site-packages/so_vits_svc_fork/modules/decoders/hifigan/_models.py:86: UserWarning: torch.cumsum supported warnings.py:109
by MPS on MacOS 13+, please upgrade (Triggered internally at /Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/native/mps/operations/UnaryOps.mm:264.)
tmp_over_one = torch.cumsum(rad_values, 1) % 1
[16:23:45] WARNING [16:23:45] /opt/miniconda3/envs/vox/lib/python3.10/site-packages/torch/functional.py:641: UserWarning: stft with return_complex=False is deprecated. In a warnings.py:109
future pytorch release, stft will return complex tensors for all inputs, and return_complex=False will raise an error.
Note: you can still call torch.view_as_real on the complex output to recover the old return format. (Triggered internally at
/Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/native/SpectralOps.cpp:867.)
return _VF.stft(input, n_fft, hop_length, win_length, window, # type: ignore[attr-defined]
[16:23:46] WARNING [16:23:46] /opt/miniconda3/envs/vox/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:430: PossibleUserWarning: The warnings.py:109
dataloader, train_dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 10 which
is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
WARNING [16:23:46] /opt/miniconda3/envs/vox/lib/python3.10/site-packages/lightning/pytorch/loops/fit_loop.py:280: PossibleUserWarning: The number of training batches warnings.py:109
(10) is smaller than the logging interval Trainer(log_every_n_steps=50). Set a lower value for log_every_n_steps if you want to see logs for the training
epoch.
rank_zero_warn(
Training: 0it [00:00, ?it/s] INFO [16:23:46] Setting current epoch to 0 train.py:198
INFO [16:23:46] Setting total batch idx to 0 train.py:213
INFO [16:23:46] Setting global step to 0 train.py:203
Epoch 0: 0%| | 0/10 [00:00<?, ?it/s]libc++abi: terminating with uncaught exception of type c10::Error: Unsupported type byte size: ComplexFloat
Exception raised from getGatherScatterScalarType at /Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/native/mps/operations/View.mm:758 (most recent call first):
frame #0: c10::detail::torchCheckFail(char const*, char const*, unsigned int, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&) + 92 (0x103f8d2b8 in libc10.dylib)
frame #1: at::native::mps::getGatherScatterScalarType(at::Tensor const&) + 304 (0x16692266c in libtorch_cpu.dylib)
frame #2: invocation function for block in at::native::mps::gatherViewTensor(at::Tensor const&, at::Tensor&) + 128 (0x1669241bc in libtorch_cpu.dylib)
frame #3: _dispatch_client_callout + 20 (0x1bee501b4 in libdispatch.dylib)
frame #4: _dispatch_lane_barrier_sync_invoke_and_complete + 56 (0x1bee5f414 in libdispatch.dylib)
frame #5: at::native::mps::gatherViewTensor(at::Tensor const&, at::Tensor&) + 888 (0x166922d54 in libtorch_cpu.dylib)
frame #6: at::native::mps::mps_copy_(at::Tensor&, at::Tensor const&, bool) + 3096 (0x16687a47c in libtorch_cpu.dylib)
frame #7: at::native::copy_impl(at::Tensor&, at::Tensor const&, bool) + 1944 (0x1625f6fe0 in libtorch_cpu.dylib)
frame #8: at::native::copy_(at::Tensor&, at::Tensor const&, bool) + 100 (0x1625f6788 in libtorch_cpu.dylib)
frame #9: c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor& (c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool), &(torch::ADInplaceOrView::copy_(c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool))>, at::Tensor&, c10::guts::typelist::typelist<c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool> >, at::Tensor& (c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool)>::call(c10::OperatorKernel*, c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool) + 76 (0x1665521a8 in libtorch_cpu.dylib)
frame #10: c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor& (c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool), &(torch::autograd::VariableType::(anonymous namespace)::copy_(c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool))>, at::Tensor&, c10::guts::typelist::typelist<c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool> >, at::Tensor& (c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool)>::call(c10::OperatorKernel*, c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool) + 772 (0x16654f880 in libtorch_cpu.dylib)
frame #11: at::_ops::copy_::call(at::Tensor&, at::Tensor const&, bool) + 288 (0x16332d0f4 in libtorch_cpu.dylib)
frame #12: torch::autograd::generated::details::fft_r2c_backward(at::Tensor const&, c10::ArrayRef<long long>, long long, bool, c10::SymInt) + 788 (0x1664f7c74 in libtorch_cpu.dylib)
frame #13: torch::autograd::generated::FftR2CBackward0::apply(std::__1::vector<at::Tensor, std::__1::allocator<at::Tensor> >&&) + 312 (0x164b31144 in libtorch_cpu.dylib)
frame #14: torch::autograd::Node::operator()(std::__1::vector<at::Tensor, std::__1::allocator<at::Tensor> >&&) + 120 (0x165a92008 in libtorch_cpu.dylib)
frame #15: torch::autograd::Engine::evaluate_function(std::__1::shared_ptr<torch::autograd::GraphTask>&, torch::autograd::Node*, torch::autograd::InputBuffer&, std::__1::shared_ptr<torch::autograd::ReadyQueue> const&) + 2932 (0x165a88df4 in libtorch_cpu.dylib)
frame #16: torch::autograd::Engine::thread_main(std::__1::shared_ptr<torch::autograd::GraphTask> const&) + 640 (0x165a87c98 in libtorch_cpu.dylib)
frame #17: torch::autograd::Engine::thread_init(int, std::__1::shared_ptr<torch::autograd::ReadyQueue> const&, bool) + 336 (0x165a8697c in libtorch_cpu.dylib)
frame #18: torch::autograd::python::PythonEngine::thread_init(int, std::__1::shared_ptr<torch::autograd::ReadyQueue> const&, bool) + 112 (0x1059f5898 in libtorch_python.dylib)
frame #19: void* std::__1::__thread_proxy<std::__1::tuple<std::__1::unique_ptr<std::__1::__thread_struct, std::__1::default_delete<std::__1::__thread_struct> >, void (torch::autograd::Engine::*)(int, std::__1::shared_ptr<torch::autograd::ReadyQueue> const&, bool), torch::autograd::Engine*, signed char, std::__1::shared_ptr<torch::autograd::ReadyQueue>, bool> >(void*) + 76 (0x165a95168 in libtorch_cpu.dylib)
frame #20: _pthread_start + 148 (0x1bf01426c in libsystem_pthread.dylib)
frame #21: thread_start + 8 (0x1bf00f08c in libsystem_pthread.dylib)
zsh: abort svc train
```
|
I believe there was a feature to do that automatically (in lightning?)
@34j
Oh, okay with AMP. You're right. Why do you think this is bugging out?
Maybe the issue happens when executing fft_r2c_backward
Perhaps, it's an issue to be raised with PyTorch
It seems that environmental variable PYTORCH_ENABLE_MPS_FALLBACK should be set to 1, please try that
https://stackoverflow.com/a/72416727
Thank you, @34j
```
$ conda env config vars list
PYTORCH_ENABLE_MPS_FALLBACK = 1
```
But still when I run `svc train -t`
I'm still getting:
```
Training: 0it [00:00, ?it/s] INFO [15:24:11] Setting current epoch to 0 train.py:198
INFO [15:24:11] Setting total batch idx to 0 train.py:213
INFO [15:24:11] Setting global step to 0 train.py:203
Epoch 0: 0%| | 0/10 [00:00<?, ?it/s]libc++abi: terminating with uncaught exception of type c10::Error: Unsupported type byte size: ComplexFloat
Exception raised from getGatherScatterScalarType at /Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/native/mps/operations/View.mm:758 (most recent call first):
frame #0: c10::detail::torchCheckFail(char const*, char const*, unsigned int, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&) + 92 (0x1054e92b8 in libc10.dylib)
frame #1: at::native::mps::getGatherScatterScalarType(at::Tensor const&) + 304 (0x15e92266c in libtorch_cpu.dylib)
frame #2: invocation function for block in at::native::mps::gatherViewTensor(at::Tensor const&, at::Tensor&) + 128 (0x15e9241bc in libtorch_cpu.dylib)
frame #3: _dispatch_client_callout + 20 (0x1bee501b4 in libdispatch.dylib)
frame #4: _dispatch_lane_barrier_sync_invoke_and_complete + 56 (0x1bee5f414 in libdispatch.dylib)
frame #5: at::native::mps::gatherViewTensor(at::Tensor const&, at::Tensor&) + 888 (0x15e922d54 in libtorch_cpu.dylib)
frame #6: at::native::mps::mps_copy_(at::Tensor&, at::Tensor const&, bool) + 3096 (0x15e87a47c in libtorch_cpu.dylib)
frame #7: at::native::copy_impl(at::Tensor&, at::Tensor const&, bool) + 1944 (0x15a5f6fe0 in libtorch_cpu.dylib)
frame #8: at::native::copy_(at::Tensor&, at::Tensor const&, bool) + 100 (0x15a5f6788 in libtorch_cpu.dylib)
frame #9: c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor& (c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool), &(torch::ADInplaceOrView::copy_(c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool))>, at::Tensor&, c10::guts::typelist::typelist<c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool> >, at::Tensor& (c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool)>::call(c10::OperatorKernel*, c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool) + 76 (0x15e5521a8 in libtorch_cpu.dylib)
frame #10: c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor& (c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool), &(torch::autograd::VariableType::(anonymous namespace)::copy_(c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool))>, at::Tensor&, c10::guts::typelist::typelist<c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool> >, at::Tensor& (c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool)>::call(c10::OperatorKernel*, c10::DispatchKeySet, at::Tensor&, at::Tensor const&, bool) + 772 (0x15e54f880 in libtorch_cpu.dylib)
frame #11: at::_ops::copy_::call(at::Tensor&, at::Tensor const&, bool) + 288 (0x15b32d0f4 in libtorch_cpu.dylib)
frame #12: torch::autograd::generated::details::fft_r2c_backward(at::Tensor const&, c10::ArrayRef<long long>, long long, bool, c10::SymInt) + 788 (0x15e4f7c74 in libtorch_cpu.dylib)
frame #13: torch::autograd::generated::FftR2CBackward0::apply(std::__1::vector<at::Tensor, std::__1::allocator<at::Tensor> >&&) + 312 (0x15cb31144 in libtorch_cpu.dylib)
frame #14: torch::autograd::Node::operator()(std::__1::vector<at::Tensor, std::__1::allocator<at::Tensor> >&&) + 120 (0x15da92008 in libtorch_cpu.dylib)
frame #15: torch::autograd::Engine::evaluate_function(std::__1::shared_ptr<torch::autograd::GraphTask>&, torch::autograd::Node*, torch::autograd::InputBuffer&, std::__1::shared_ptr<torch::autograd::ReadyQueue> const&) + 2932 (0x15da88df4 in libtorch_cpu.dylib)
frame #16: torch::autograd::Engine::thread_main(std::__1::shared_ptr<torch::autograd::GraphTask> const&) + 640 (0x15da87c98 in libtorch_cpu.dylib)
frame #17: torch::autograd::Engine::thread_init(int, std::__1::shared_ptr<torch::autograd::ReadyQueue> const&, bool) + 336 (0x15da8697c in libtorch_cpu.dylib)
frame #18: torch::autograd::python::PythonEngine::thread_init(int, std::__1::shared_ptr<torch::autograd::ReadyQueue> const&, bool) + 112 (0x106f51898 in libtorch_python.dylib)
frame #19: void* std::__1::__thread_proxy<std::__1::tuple<std::__1::unique_ptr<std::__1::__thread_struct, std::__1::default_delete<std::__1::__thread_struct> >, void (torch::autograd::Engine::*)(int, std::__1::shared_ptr<torch::autograd::ReadyQueue> const&, bool), torch::autograd::Engine*, signed char, std::__1::shared_ptr<torch::autograd::ReadyQueue>, bool> >(void*) + 76 (0x15da95168 in libtorch_cpu.dylib)
frame #20: _pthread_start + 148 (0x1bf01426c in libsystem_pthread.dylib)
frame #21: thread_start + 8 (0x1bf00f08c in libsystem_pthread.dylib)
zsh: abort svc train -t
```
Try replacing here with if True: to patch stft
if isinstance(self.trainer.accelerator, TPUAccelerator):
https://github.com/34j/so-vits-svc-fork/blob/main/src/so_vits_svc_fork/train.py#L179-L179
I did that and now my code looks like this:
```
# check if using tpu
if True: to patch stft
if isinstance(self.trainer.accelerator, TPUAccelerator):
# patch torch.stft to use cpu
LOG.warning("Using TPU. Patching torch.stft to use cpu.")
```
I get an error saying "TabError: inconsistent use of tabs and spaces in indentation"
I thought it wasnt possible to train on a mac?
I mean
```python
if True:
# patch torch.stft to use cpu
LOG.warning("Using TPU. Patching torch.stft to use cpu.")
```
@34j
It looks like that worked!
It's running thru the epochs. I will dedicate tomorrow to training a model and I'll let you know if I was successful.
Thank you so much for your help 🙏
| 2023-04-16T04:24:27 |
|
voicepaw/so-vits-svc-fork
| 354 |
voicepaw__so-vits-svc-fork-354
|
[
"348"
] |
27c27bf9033ac7e2fba9d15e7205308a926241ea
|
diff --git a/src/so_vits_svc_fork/cluster/__init__.py b/src/so_vits_svc_fork/cluster/__init__.py
--- a/src/so_vits_svc_fork/cluster/__init__.py
+++ b/src/so_vits_svc_fork/cluster/__init__.py
@@ -9,7 +9,9 @@
def get_cluster_model(ckpt_path: Path | str):
with Path(ckpt_path).open("rb") as f:
- checkpoint = torch.load(f, map_location="cpu", weights_only=True)
+ checkpoint = torch.load(
+ f, map_location="cpu"
+ ) # Danger of arbitrary code execution
kmeans_dict = {}
for spk, ckpt in checkpoint.items():
km = KMeans(ckpt["n_features_in_"])
|
UnpicklingError: Weights only load failed. Unpickler error: Unsupported class numpy.core.multiarray._reconstruct
**Describe the bug**
I tried to update, but I got this exception start from version 3.6.0 during inference
```
UnpicklingError: Weights only load failed. Re-running `torch.load` with `weights_only` set to `False` will likely succeed, but it can result in arbitrary code execution.Do it only if you get the file from a trusted source. WeightsUnpickler error: Unsupported class numpy.core.multiarray._reconstruct
```
**To Reproduce**
Steps to reproduce the behavior:
- Update so-vits-svc-fork
- Run inference
**Additional context**
Initially I updated to version 3.8.0, because of the exception I tried to solve by keep downgrading the version until I got to version 3.5.1 to solve the problem.
|
same
it doesnt add much but heres the error i got too
Traceback (most recent call last):
File "C:\Users\matth\AppData\Local\Programs\Python\Python310\lib\site-packages\so_vits_svc_fork\gui.py", line 678, in main
future.result()
File "C:\Users\matth\AppData\Local\Programs\Python\Python310\lib\concurrent\futures\_base.py", line 451, in result
return self.__get_result()
File "C:\Users\matth\AppData\Local\Programs\Python\Python310\lib\concurrent\futures\_base.py", line 403, in __get_result
raise self._exception
File "C:\Users\matth\AppData\Local\Programs\Python\Python310\lib\site-packages\so_vits_svc_fork\gui.py", line 686, in main
future.result()
File "C:\Users\matth\AppData\Local\Programs\Python\Python310\lib\concurrent\futures\_base.py", line 451, in result
return self.__get_result()
File "C:\Users\matth\AppData\Local\Programs\Python\Python310\lib\concurrent\futures\_base.py", line 403, in __get_result
raise self._exception
File "C:\Users\matth\AppData\Local\Programs\Python\Python310\lib\site-packages\so_vits_svc_fork\gui.py", line 678, in main
future.result()
File "C:\Users\matth\AppData\Local\Programs\Python\Python310\lib\concurrent\futures\_base.py", line 451, in result
return self.__get_result()
File "C:\Users\matth\AppData\Local\Programs\Python\Python310\lib\concurrent\futures\_base.py", line 403, in __get_result
raise self._exception
_pickle.UnpicklingError: Weights only load failed. Re-running `torch.load` with `weights_only` set to `False` will likely succeed, but it can result in arbitrary code execution.Do
it only if you get the file from a trusted source. WeightsUnpickler error: Unsupported operand 71
how do you install a specific version?
| 2023-04-16T05:24:53 |
|
voicepaw/so-vits-svc-fork
| 358 |
voicepaw__so-vits-svc-fork-358
|
[
"344"
] |
abd2aeb98322d86cff695376c0bd59fa847e3231
|
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -9,7 +9,7 @@
import sounddevice as sd
import soundfile as sf
import torch
-from pebble import ProcessFuture, ProcessPool
+from pebble import ProcessFuture, ThreadPool
from tqdm.tk import tqdm_tk
from .utils import ensure_pretrained_model, get_optimal_device
@@ -513,7 +513,9 @@ def apply_preset(name: str) -> None:
del default_name
update_speaker()
update_devices()
- with ProcessPool(max_workers=1) as pool:
+ # with ProcessPool(max_workers=1) as pool:
+ # with ProcessPool(max_workers=1, context="spawn") as pool:
+ with ThreadPool(max_workers=1) as pool:
future: None | ProcessFuture = None
infer_futures: set[ProcessFuture] = set()
while True:
@@ -673,18 +675,18 @@ def apply_preset(name: str) -> None:
except Exception as e:
LOG.exception(e)
if future is not None and future.done():
- LOG.error("Error in realtime: ")
try:
future.result()
except Exception as e:
+ LOG.error("Error in realtime: ")
LOG.exception(e)
future = None
for future in copy(infer_futures):
if future.done():
- LOG.error("Error in inference: ")
try:
future.result()
except Exception as e:
+ LOG.error("Error in inference: ")
LOG.exception(e)
infer_futures.remove(future)
if future:
|
False error messages
**Describe the bug**
When I run gui on the latest version of fork, I get 3 errors after completing the inference, but the file is saved and there are really no errors
**To Reproduce**
Run inference on the latest version of fork
**Additional context**
Errors:

|
P.S: This did not happen in previous versions
| 2023-04-16T15:57:57 |
|
voicepaw/so-vits-svc-fork
| 383 |
voicepaw__so-vits-svc-fork-383
|
[
"367"
] |
f9a867d64181cbcf18d541f79c2cdf7d2ce27958
|
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -1,6 +1,7 @@
from __future__ import annotations
import json
+import multiprocessing
from copy import copy
from logging import getLogger
from pathlib import Path
@@ -9,7 +10,7 @@
import sounddevice as sd
import soundfile as sf
import torch
-from pebble import ProcessFuture, ThreadPool
+from pebble import ProcessFuture, ProcessPool
from tqdm.tk import tqdm_tk
from .utils import ensure_pretrained_model, get_optimal_device
@@ -514,8 +515,11 @@ def apply_preset(name: str) -> None:
update_speaker()
update_devices()
# with ProcessPool(max_workers=1) as pool:
- # with ProcessPool(max_workers=1, context="spawn") as pool:
- with ThreadPool(max_workers=1) as pool:
+ # to support Linux
+ with ProcessPool(
+ max_workers=min(2, multiprocessing.cpu_count()),
+ context=multiprocessing.get_context("spawn"),
+ ) as pool:
future: None | ProcessFuture = None
infer_futures: set[ProcessFuture] = set()
while True:
|
Can't stop voice changer (3.9.3)
**Describe the bug**
With 3.9.3 switching to using the ThreadPool instead of the ProcessPool the voice changer can't be stopped anymore.
Additionally, this change also causes #359 .
**To Reproduce**
Start the voice changer on 3.9.3, then try to stop it. The console will say it was stopped but the logs about the inference will continue.
|
Reading through people having similar issues, it seems setting `torch.multiprocessing.set_start_method('spawn')` in the `__main__` class at the bottom should fix it?
https://stackoverflow.com/questions/72779926/gunicorn-cuda-cannot-re-initialize-cuda-in-forked-subprocess
https://github.com/pytorch/pytorch/issues/40403
does not context=spawn work?
You mean context=spawn for the Thread Pool? I'll give that a go.
I saw you tried that with the Process Pool before but commented it out
i didnt try it
ThreadPool doesn't seem to have an argument called `context`. Do you mean you haven't tried it for ProcessPool?
Edit:
Opening the GUI with ProcessPool and context=spawn just makes it crash.
```
E:\Development\so-vits-svc-4.0\Kurzgesagt>..\__env\Scripts\svcg
Traceback (most recent call last):
File "c:\program files\python310\lib\runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "c:\program files\python310\lib\runpy.py", line 86, in _run_code
exec(code, run_globals)
File "E:\Development\so-vits-svc-4.0\__env\Scripts\svcg.exe\__main__.py", line 7, in <module>
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\gui.py", line 517, in main
with ProcessPool(max_workers=1, context="spawn") as pool:
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\pebble\pool\process.py", line 60, in __init__
self._pool_manager = PoolManager(self._context, mp_context)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\pebble\pool\process.py", line 202, in __init__
self.worker_manager = WorkerManager(context.workers,
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\pebble\pool\process.py", line 344, in __init__
self.pool_channel, self.workers_channel = channels(mp_context)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\pebble\pool\channel.py", line 31, in channels
read0, write0 = mp_context.Pipe(duplex=False)
AttributeError: 'str' object has no attribute 'Pipe'
```
Maybe multiprocessing.get_context('spawn')
> Maybe multiprocessing.get_context('spawn')
Oh it could be I left that in as well and that'd what caused it, yes.
I should mention that since I'm on Windows I didn't encounter any issues with ProcessPool before - I can't test it on Linux unfortunately :(
#359 seems nothing to do with this
| 2023-04-18T09:37:15 |
|
voicepaw/so-vits-svc-fork
| 394 |
voicepaw__so-vits-svc-fork-394
|
[
"392"
] |
7be08f5a99d4c4b8a7697e876f6a69be2d5a34f8
|
diff --git a/src/so_vits_svc_fork/train.py b/src/so_vits_svc_fork/train.py
--- a/src/so_vits_svc_fork/train.py
+++ b/src/so_vits_svc_fork/train.py
@@ -1,5 +1,6 @@
from __future__ import annotations
+import os
import warnings
from logging import getLogger
from multiprocessing import cpu_count
@@ -10,6 +11,7 @@
import torch
from lightning.pytorch.accelerators import MPSAccelerator, TPUAccelerator
from lightning.pytorch.loggers import TensorBoardLogger
+from lightning.pytorch.strategies.ddp import DDPStrategy
from lightning.pytorch.tuner import Tuner
from torch.cuda.amp import autocast
from torch.nn import functional as F
@@ -75,7 +77,13 @@ def train(
datamodule = VCDataModule(hparams)
strategy = (
- "ddp_find_unused_parameters_true" if torch.cuda.device_count() > 1 else "auto"
+ (
+ "ddp_find_unused_parameters_true"
+ if os.name != "nt"
+ else DDPStrategy(find_unused_parameters=True, process_group_backend="gloo")
+ )
+ if torch.cuda.device_count() > 1
+ else "auto"
)
LOG.info(f"Using strategy: {strategy}")
trainer = pl.Trainer(
|
ValueError __main__
Got this working twice but cannot get it to run using CUDA. Running into this error when calling train.
INFO [17:56:38] Loaded checkpoint 'logs\44k\G_0.pth' (iteration 0) utils.py:257
INFO [17:56:38] Loaded checkpoint 'logs\44k\D_0.pth' (iteration 0) utils.py:257
INFO: Initializing distributed: GLOBAL_RANK: 0, MEMBER: 1/2
INFO [17:56:38] Initializing distributed: GLOBAL_RANK: 0, MEMBER: 1/2 distributed.py:244
[W ..\torch\csrc\distributed\c10d\socket.cpp:601] [c10d] The client socket has failed to connect to [kubernetes.docker.internal]:49979 (system error: 10049 - The requested address is not valid in its context.).
so-vits-svc-fork\venv\Scripts\python.exe: Error while finding module specification for '__main__' (ValueError: __main__.__spec__ is None)
|
Was getting the same issue, happens for me if I have CUDA enabled on more than one GPU on the python process sovits is using. I made sure it was only using 1 GPU for CUDA in the Nvidia settings and it's fine now. I can't get multi GPU working though.
Great catch, that worked!
https://github.com/Lightning-AI/lightning/blob/master/src/lightning/fabric/utilities/distributed.py#L257-L257
| 2023-04-19T01:38:00 |
|
voicepaw/so-vits-svc-fork
| 401 |
voicepaw__so-vits-svc-fork-401
|
[
"399"
] |
48e0bbdb49be52bf456a2117daed3362d1bccb08
|
diff --git a/src/so_vits_svc_fork/train.py b/src/so_vits_svc_fork/train.py
--- a/src/so_vits_svc_fork/train.py
+++ b/src/so_vits_svc_fork/train.py
@@ -253,9 +253,42 @@ def stft(
torch.stft = stft
+ def on_train_end(self) -> None:
+ self.save_checkpoints(adjust=0)
+
+ def save_checkpoints(self, adjust=1):
+ # `on_train_end` will be the actual epoch, not a -1, so we have to call it with `adjust = 0`
+ current_epoch = self.current_epoch + adjust
+ total_batch_idx = self.total_batch_idx - 1 + adjust
+
+ utils.save_checkpoint(
+ self.net_g,
+ self.optim_g,
+ self.learning_rate,
+ current_epoch,
+ Path(self.hparams.model_dir)
+ / f"G_{total_batch_idx if self.hparams.train.get('ckpt_name_by_step', False) else current_epoch}.pth",
+ )
+ utils.save_checkpoint(
+ self.net_d,
+ self.optim_d,
+ self.learning_rate,
+ current_epoch,
+ Path(self.hparams.model_dir)
+ / f"D_{total_batch_idx if self.hparams.train.get('ckpt_name_by_step', False) else current_epoch}.pth",
+ )
+ keep_ckpts = self.hparams.train.get("keep_ckpts", 0)
+ if keep_ckpts > 0:
+ utils.clean_checkpoints(
+ path_to_models=self.hparams.model_dir,
+ n_ckpts_to_keep=keep_ckpts,
+ sort_by_time=True,
+ )
+
def set_current_epoch(self, epoch: int):
LOG.info(f"Setting current epoch to {epoch}")
self.trainer.fit_loop.epoch_progress.current.completed = epoch
+ self.trainer.fit_loop.epoch_progress.current.processed = epoch
assert self.current_epoch == epoch, f"{self.current_epoch} != {epoch}"
def set_global_step(self, global_step: int):
@@ -511,28 +544,7 @@ def validation_step(self, batch, batch_idx):
),
}
)
- if self.current_epoch == 0 or batch_idx != 0:
- return
- utils.save_checkpoint(
- self.net_g,
- self.optim_g,
- self.learning_rate,
- self.current_epoch + 1, # prioritize prevention of undervaluation
- Path(self.hparams.model_dir)
- / f"G_{self.total_batch_idx if self.hparams.train.get('ckpt_name_by_step', False) else self.current_epoch + 1}.pth",
- )
- utils.save_checkpoint(
- self.net_d,
- self.optim_d,
- self.learning_rate,
- self.current_epoch + 1,
- Path(self.hparams.model_dir)
- / f"D_{self.total_batch_idx if self.hparams.train.get('ckpt_name_by_step', False) else self.current_epoch + 1}.pth",
- )
- keep_ckpts = self.hparams.train.get("keep_ckpts", 0)
- if keep_ckpts > 0:
- utils.clean_checkpoints(
- path_to_models=self.hparams.model_dir,
- n_ckpts_to_keep=keep_ckpts,
- sort_by_time=True,
- )
+
+ def on_validation_end(self) -> None:
+ if not self.trainer.sanity_checking:
+ self.save_checkpoints()
|
Is this intended behaviour? (visual bug)
I trained a model once, then decided to continue the training.
|
(the config file had it's epochs increased from 1000 to 2000, as when training was resumed the cli showed the already completed epochs and i expected the training to automatically stop instead of training for another 1000 epochs)
Yes, this currently is a bug.
Due to loading the model checkpoint through custom means the program has to override the current epoch / steps it's on. It seems some variable isn't overriden yet that handles the check for "max_epochs"...
I've opened an issue already about it here #350
| 2023-04-19T11:12:44 |
|
voicepaw/so-vits-svc-fork
| 451 |
voicepaw__so-vits-svc-fork-451
|
[
"415"
] |
30a08d561233595b8db13fc228e3624593662a3a
|
diff --git a/src/so_vits_svc_fork/train.py b/src/so_vits_svc_fork/train.py
--- a/src/so_vits_svc_fork/train.py
+++ b/src/so_vits_svc_fork/train.py
@@ -254,10 +254,20 @@ def stft(
torch.stft = stft
def on_train_end(self) -> None:
- if not self.tuning:
- self.save_checkpoints(adjust=0)
+ self.save_checkpoints(adjust=0)
def save_checkpoints(self, adjust=1):
+ if self.tuning or self.trainer.sanity_checking:
+ return
+
+ # only save checkpoints if we are on the main device
+ if (
+ hasattr(self.device, "index")
+ and self.device.index != None
+ and self.device.index != 0
+ ):
+ return
+
# `on_train_end` will be the actual epoch, not a -1, so we have to call it with `adjust = 0`
current_epoch = self.current_epoch + adjust
total_batch_idx = self.total_batch_idx - 1 + adjust
@@ -547,5 +557,4 @@ def validation_step(self, batch, batch_idx):
)
def on_validation_end(self) -> None:
- if not self.trainer.sanity_checking and not self.tuning:
- self.save_checkpoints()
+ self.save_checkpoints()
diff --git a/src/so_vits_svc_fork/utils.py b/src/so_vits_svc_fork/utils.py
--- a/src/so_vits_svc_fork/utils.py
+++ b/src/so_vits_svc_fork/utils.py
@@ -324,8 +324,9 @@ def clean_checkpoints(
to_delete_list = list(group_items)[:-n_ckpts_to_keep]
for to_delete in to_delete_list:
- LOG.info(f"Removing {to_delete}")
- to_delete.unlink()
+ if to_delete.exists():
+ LOG.info(f"Removing {to_delete}")
+ to_delete.unlink()
def latest_checkpoint_path(dir_path: Path | str, regex: str = "G_*.pth") -> Path | None:
|
Error in training when the code tries deleting older saved models
**Describe the bug**
I am trying to train a new model, but when the code tries to delete older models, the models do get deleted but I also get an error that the file no longer exists (which is true since it was deleted) and the training stops. I then have to manually quit the training and restart it.
**To Reproduce**
1- Run `svc train`
2- Wait for several hundred epochs
3- Error is raised by the code when attempting to delete an older model
Here is the error I receive:
```
INFO [07:48:09] Removing logs/44k/G_320.pth utils.py:327
Traceback (most recent call last):
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/trainer/call.py", line 42, in _call_and_handle_interrupt
return trainer.strategy.launcher.launch(trainer_fn, *args, trainer=trainer, **kwargs)
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/strategies/launchers/subprocess_script.py", line 92, in launch
return function(*args, **kwargs)
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/trainer/trainer.py", line 559, in _fit_impl
self._run(model, ckpt_path=ckpt_path)
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/trainer/trainer.py", line 935, in _run
results = self._run_stage()
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/trainer/trainer.py", line 978, in _run_stage
self.fit_loop.run()
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/loops/fit_loop.py", line 201, in run
self.advance()
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/loops/fit_loop.py", line 354, in advance
self.epoch_loop.run(self._data_fetcher)
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/loops/training_epoch_loop.py", line 134, in run
self.on_advance_end()
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/loops/training_epoch_loop.py", line 248, in on_advance_end
self.val_loop.run()
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/loops/utilities.py", line 177, in _decorator
return loop_run(self, *args, **kwargs)
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/loops/evaluation_loop.py", line 122, in run
return self.on_run_end()
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/loops/evaluation_loop.py", line 258, in on_run_end
self._on_evaluation_end()
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/loops/evaluation_loop.py", line 304, in _on_evaluation_end
call._call_lightning_module_hook(trainer, hook_name, *args, **kwargs)
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/trainer/call.py", line 142, in _call_lightning_module_hook
output = fn(*args, **kwargs)
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/so_vits_svc_fork/train.py", line 551, in on_validation_end
self.save_checkpoints()
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/so_vits_svc_fork/train.py", line 283, in save_checkpoints
utils.clean_checkpoints(
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/so_vits_svc_fork/utils.py", line 328, in clean_checkpoints
to_delete.unlink()
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/pathlib.py", line 1206, in unlink
self._accessor.unlink(self)
FileNotFoundError: [Errno 2] No such file or directory: 'logs/44k/G_320.pth'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/bin/svc", line 8, in <module>
sys.exit(cli())
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/click/core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/click/core.py", line 1055, in main
rv = self.invoke(ctx)
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/click/core.py", line 1657, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/click/core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/so_vits_svc_fork/__main__.py", line 129, in train
train(
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/so_vits_svc_fork/train.py", line 138, in train
trainer.fit(model, datamodule=datamodule)
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/trainer/trainer.py", line 520, in fit
call._call_and_handle_interrupt(
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/trainer/call.py", line 65, in _call_and_handle_interrupt
trainer.strategy.on_exception(exception)
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/strategies/ddp.py", line 395, in on_exception
_augment_message(
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/utilities/exceptions.py", line 40, in _augment_message
exception.args = tuple(
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/site-packages/lightning/pytorch/utilities/exceptions.py", line 41, in <genexpr>
new_message if re.match(pattern, message, re.DOTALL) else message for message in exception.args
File "/home/ma5679/anaconda3/envs/so-vits-svc-fork/lib/python3.10/re.py", line 190, in match
return _compile(pattern, flags).match(string)
TypeError: expected string or bytes-like object
```
|
Do you have more than one gpus connected to your PC?
Yes, I am using 2 GPUs
workaround by changing so_vits_svc_fork/train.py line 283 with a
try:
except:
pass
block.
Also, you get an error when training on more than 1 GPU and use -t flag (Tensorboard). It throws an error that it can't bind to port (Cause GPU 1 bound to it) and hangs.
| 2023-04-21T21:04:52 |
|
voicepaw/so-vits-svc-fork
| 453 |
voicepaw__so-vits-svc-fork-453
|
[
"452"
] |
bb158ceae4e87341a25fbf68a583ae98e2462356
|
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -57,6 +57,50 @@ def delete_preset(name: str) -> dict:
return load_presets()
+def get_output_path(input_path: Path) -> Path:
+ # Default output path
+ output_path = input_path.parent / f"{input_path.stem}.out{input_path.suffix}"
+
+ # Increment file number in path if output file already exists
+ file_num = 1
+ while output_path.exists():
+ output_path = (
+ input_path.parent / f"{input_path.stem}.out_{file_num}{input_path.suffix}"
+ )
+ file_num += 1
+ return output_path
+
+
+def get_supported_file_types() -> tuple[tuple[str], ...]:
+ return tuple(
+ [
+ ((extension, f".{extension.lower()}"))
+ for extension in sf.available_formats().keys()
+ ]
+ )
+
+
+def validate_output_file_type(output_path: Path) -> bool:
+ supported_file_types = sorted(
+ [f".{extension.lower()}" for extension in sf.available_formats().keys()]
+ )
+ if not output_path.suffix:
+ sg.popup_ok(
+ "Error: Output path missing file type extension, enter "
+ + "one of the following manually:\n\n"
+ + "\n".join(supported_file_types)
+ )
+ return False
+ if output_path.suffix.lower() not in supported_file_types:
+ sg.popup_ok(
+ f"Error: {output_path.suffix.lower()} is not a supported "
+ + "extension; use one of the following:\n\n"
+ + "\n".join(supported_file_types)
+ )
+ return False
+ return True
+
+
def get_devices(
update: bool = True,
) -> tuple[list[str], list[str], list[int], list[int]]:
@@ -255,10 +299,20 @@ def main():
[
sg.Text("Input audio path"),
sg.Push(),
- sg.InputText(key="input_path"),
+ sg.InputText(key="input_path", enable_events=True),
sg.FileBrowse(initial_folder=".", key="input_path_browse"),
sg.Button("Play", key="play_input"),
],
+ [
+ sg.Text("Output audio path"),
+ sg.Push(),
+ sg.InputText(key="output_path"),
+ sg.FileSaveAs(
+ initial_folder=".",
+ key="output_path_browse",
+ file_types=get_supported_file_types(),
+ ),
+ ],
[sg.Checkbox(key="auto_play", text="Auto play", default=True)],
],
"Realtime": [
@@ -528,6 +582,10 @@ def apply_preset(name: str) -> None:
disabled=values["auto_predict_f0"],
visible=not values["auto_predict_f0"],
)
+
+ input_path = Path(values["input_path"])
+ output_path = Path(values["output_path"])
+
if event == "add_preset":
presets = add_preset(
values["preset_name"], {key: values[key] for key in PRESET_KEYS}
@@ -543,14 +601,18 @@ def apply_preset(name: str) -> None:
update_devices()
elif event == "config_path":
update_speaker()
+ elif event == "input_path":
+ # Don't change the output path if it's already set
+ if values["output_path"]:
+ continue
+ # Set a sensible default output path
+ window.Element("output_path").Update(str(get_output_path(input_path)))
elif event == "infer":
- input_path = Path(values["input_path"])
- output_path = (
- input_path.parent / f"{input_path.stem}.out{input_path.suffix}"
- )
if not input_path.exists() or not input_path.is_file():
LOG.warning(f"Input path {input_path} does not exist.")
continue
+ if not validate_output_file_type(output_path):
+ continue
try:
from so_vits_svc_fork.inference.main import infer
|
Configurable output file
The output file is not configurable. This becomes a problem when you output a file, open it up in a DAW (e.g. FL Studio), and want to bounce out a new converted voice file, causing a crash while writing because the file handle is still held by the DAW.
Recommended features:
- A new output text box that allows specifying the output file
- The default output filename should follow the same `.out` pattern as before, but have an automatically incrementing index if the output file already exists.
I've already implemented this and will be submitting a pull request shortly.
| 2023-04-22T03:45:31 |
||
voicepaw/so-vits-svc-fork
| 455 |
voicepaw__so-vits-svc-fork-455
|
[
"438"
] |
927fb185b96bfa66e15e89c8414086f046954a9d
|
diff --git a/src/so_vits_svc_fork/utils.py b/src/so_vits_svc_fork/utils.py
--- a/src/so_vits_svc_fork/utils.py
+++ b/src/so_vits_svc_fork/utils.py
@@ -173,12 +173,14 @@ def get_content(
if audio.ndim == 1:
audio = audio.unsqueeze(0)
with torch.no_grad(), timer() as t:
- c = cmodel(audio)["last_hidden_state"]
if legacy_final_proj:
warnings.warn("legacy_final_proj is deprecated")
if not hasattr(cmodel, "final_proj"):
raise ValueError("HubertModel does not have final_proj")
+ c = cmodel(audio, output_hidden_states=True)["hidden_states"][9]
c = cmodel.final_proj(c)
+ else:
+ c = cmodel(audio)["last_hidden_state"]
c = c.transpose(1, 2)
wav_len = audio.shape[-1] / HUBERT_SAMPLING_RATE
LOG.info(
|
since 3.10 my models train with a strong english accent
since 3.10 my models train with a strong english accent, i first thought it was an over training problem, but when training from scratch the same issue happen
|
UPDATE: using infer on the same audio file with the same config and same model (which should work as it was trained before the issue appeared with 3.9.3) seems to still have a strong english accent , suggesting that there is an issue in the "infer" process and not with the training process. It also seem to have more noise in it
Ok, i just downgraded to 3.9.3 and everything works as expected.
It's CONFIRMED that newer versions have an accent bias.
If you are using a model in a language DIFFERENT than english, DO NOT USE newer versions!!!!
@vertexgamer how do I downgrade?
> @vertexgamer how do I downgrade?
nevermind if anyone else is wondering
```
pip install <package>==<version>
pip install -U so-vits-svc-fork==3.9.3
```
> Ok, i just downgraded to 3.9.3 and everything works as expected. It's CONFIRMED that newer versions have an accent bias.
>
> If you are using a model in a language DIFFERENT than english, DO NOT USE newer versions!!!!
One thing I'm wondering now:
What if you train a model in 3.10+ and then infer on 3.9? Do you also get those accent results?
> > Ok, i just downgraded to 3.9.3 and everything works as expected. It's CONFIRMED that newer versions have an accent bias.
> > If you are using a model in a language DIFFERENT than english, DO NOT USE newer versions!!!!
>
> One thing I'm wondering now:
>
> What if you train a model in 3.10+ and then infer on 3.9? Do you also get those accent results?
in my experience no, only the infer process affects the accent. But just to be sure, i'm training right now a model with 3.9.3. When i'm done i will come back with more info
@Lordmau5 it seems that there is no hearable difference when using 3.9.3 models vs 3.10+ ones
Hmm... okay that's interesting.
I know 3.10 did a switch from the `fairseq` to `transformers` library, which means it's one step less for building from what I can tell.
https://github.com/voicepaw/so-vits-svc-fork/commit/a2fe0f376d33f02987c91a57bd90a794de90a0e1
Apparently it's not relying on the (correct?) pretrained contentvec model anymore and doesn't utilize it.
I saw another voice changer project that supports so-vits-svc models **did** require it though.
Maybe it has to do with that? @34j any thoughts? (Seeing as you made those changes)
___
Looking at the code a bit more, it *does* rely on a contentvec model, but it's relying on the content vec model, but not the content vec **LEGACY** model, as also offered here:
https://github.com/auspicious3000/contentvec
___
And looking at the Hugging Face repository, it seems to actually be the legacy one?
https://huggingface.co/lengyue233/content-vec-best
I am very confused. I can't help with this as I didn't make these changes...
I would like to suggest the possibility that the contents of final_proj are different because I remember non final_proj version worked for me (probably).
I'm not confident so anyone who has time please test it
I did test one thing, and that was adding `"contentvec_final_proj": false` to the config, which ended up returning errors during inference and didn't output an audio file unfortunately...
```
[14:19:09] Starting inference...
[14:19:12] E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\modules\synthesizers.py:81: UserWarning: Unused arguments: {'n_layers_q': 3, 'use_spectral_norm': False}
warnings.warn(f"Unused arguments: {kwargs}")
[14:19:12] Decoder type: hifi-gan
[14:19:13] Loaded checkpoint 'E:/Development/so-vits-svc-4.0/Kurzgesagt/logs/44k/G_800.pth' (iteration 34)
[14:19:13] Chunk: Chunk(Speech: False, 8820.0)
[14:19:13] Chunk: Chunk(Speech: True, 361620.0)
[14:19:13] F0 inference time: 0.167s, RTF: 0.020
[14:19:17] HuBERT inference time : 2.987s, RTF: 0.356
[14:19:17] Finished inference for cbt_normal.wav
[14:19:17] Error in realtime:
[14:19:17] Given groups=1, weight of size [192, 256, 5], expected input[1, 768, 723] to have 256 channels, but got 768 channels instead
pebble.common.RemoteTraceback: Traceback (most recent call last):
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\pebble\common.py", line 174, in process_execute
return function(*args, **kwargs)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\inference\main.py", line 56, in infer
audio = svc_model.infer_silence(
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\inference\core.py", line 284, in infer_silence
audio_chunk_pad_infer_tensor, _ = self.infer(
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\inference\core.py", line 218, in infer
audio = self.net_g.infer(
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\modules\synthesizers.py", line 213, in infer
x = self.pre(c) * x_mask + self.emb_uv(uv.long()).transpose(1, 2)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\torch\nn\modules\conv.py", line 313, in forward
return self._conv_forward(input, self.weight, self.bias)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\torch\nn\modules\conv.py", line 309, in _conv_forward
return F.conv1d(input, weight, bias, self.stride,
RuntimeError: Given groups=1, weight of size [192, 256, 5], expected input[1, 768, 723] to have 256 channels, but got 768 channels instead
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\gui.py", line 667, in main
future.result()
File "c:\program files\python310\lib\concurrent\futures\_base.py", line 451, in result
return self.__get_result()
File "c:\program files\python310\lib\concurrent\futures\_base.py", line 403, in __get_result
raise self._exception
RuntimeError: Given groups=1, weight of size [192, 256, 5], expected input[1, 768, 723] to have 256 channels, but got 768 channels instead
[14:19:17] Error in inference:
[14:19:17] Given groups=1, weight of size [192, 256, 5], expected input[1, 768, 723] to have 256 channels, but got 768 channels instead
pebble.common.RemoteTraceback: Traceback (most recent call last):
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\pebble\common.py", line 174, in process_execute
return function(*args, **kwargs)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\inference\main.py", line 56, in infer
audio = svc_model.infer_silence(
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\inference\core.py", line 284, in infer_silence
audio_chunk_pad_infer_tensor, _ = self.infer(
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\inference\core.py", line 218, in infer
audio = self.net_g.infer(
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\modules\synthesizers.py", line 213, in infer
x = self.pre(c) * x_mask + self.emb_uv(uv.long()).transpose(1, 2)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\torch\nn\modules\conv.py", line 313, in forward
return self._conv_forward(input, self.weight, self.bias)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\torch\nn\modules\conv.py", line 309, in _conv_forward
return F.conv1d(input, weight, bias, self.stride,
RuntimeError: Given groups=1, weight of size [192, 256, 5], expected input[1, 768, 723] to have 256 channels, but got 768 channels instead
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\gui.py", line 675, in main
future.result()
File "c:\program files\python310\lib\concurrent\futures\_base.py", line 451, in result
return self.__get_result()
File "c:\program files\python310\lib\concurrent\futures\_base.py", line 403, in __get_result
raise self._exception
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\gui.py", line 667, in main
future.result()
File "c:\program files\python310\lib\concurrent\futures\_base.py", line 451, in result
return self.__get_result()
File "c:\program files\python310\lib\concurrent\futures\_base.py", line 403, in __get_result
raise self._exception
RuntimeError: Given groups=1, weight of size [192, 256, 5], expected input[1, 768, 723] to have 256 channels, but got 768 channels instead
[14:19:18] Error in realtime:
[14:19:18] Given groups=1, weight of size [192, 256, 5], expected input[1, 768, 723] to have 256 channels, but got 768 channels instead
pebble.common.RemoteTraceback: Traceback (most recent call last):
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\pebble\common.py", line 174, in process_execute
return function(*args, **kwargs)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\inference\main.py", line 56, in infer
audio = svc_model.infer_silence(
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\inference\core.py", line 284, in infer_silence
audio_chunk_pad_infer_tensor, _ = self.infer(
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\inference\core.py", line 218, in infer
audio = self.net_g.infer(
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\modules\synthesizers.py", line 213, in infer
x = self.pre(c) * x_mask + self.emb_uv(uv.long()).transpose(1, 2)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\torch\nn\modules\conv.py", line 313, in forward
return self._conv_forward(input, self.weight, self.bias)
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\torch\nn\modules\conv.py", line 309, in _conv_forward
return F.conv1d(input, weight, bias, self.stride,
RuntimeError: Given groups=1, weight of size [192, 256, 5], expected input[1, 768, 723] to have 256 channels, but got 768 channels instead
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\gui.py", line 667, in main
future.result()
File "c:\program files\python310\lib\concurrent\futures\_base.py", line 451, in result
return self.__get_result()
File "c:\program files\python310\lib\concurrent\futures\_base.py", line 403, in __get_result
raise self._exception
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\gui.py", line 675, in main
future.result()
File "c:\program files\python310\lib\concurrent\futures\_base.py", line 451, in result
return self.__get_result()
File "c:\program files\python310\lib\concurrent\futures\_base.py", line 403, in __get_result
raise self._exception
File "E:\Development\so-vits-svc-4.0\__env\lib\site-packages\so_vits_svc_fork\gui.py", line 667, in main
future.result()
File "c:\program files\python310\lib\concurrent\futures\_base.py", line 451, in result
return self.__get_result()
File "c:\program files\python310\lib\concurrent\futures\_base.py", line 403, in __get_result
raise self._exception
RuntimeError: Given groups=1, weight of size [192, 256, 5], expected input[1, 768, 723] to have 256 channels, but got 768 channels instead
```
(It also mentions error in realtime instead of inference)
What else should I try in regards to testing it? 🤔
That's not surprising because your model input is 256 channels and excepts final_projed input. You can download the model I trained from [here](https://huggingface.co/437aewuh/so-vits-svc-fork-kiritan/tree/main/svc-44k) or [here](https://huggingface.co/437aewuh/so-vits-svc-fork-kiritan/tree/main/ms-istft-768-44k) if you don't have one.
> That's not surprising because your model input is 256 channels and excepts final_projed input.
Hmm, I just went with the template it gave me (started this model around a week ago and I couldn't spot any changes to the templates in regards to model input, ssl_dim or similar)
According to the wiki:
> The ssl_dim is the number of input channels, and the correct number of output channels for the officially trained ContentVec model is 768, but after applying final_proj it is 256.
Doesn't this mean that the config templates should be adjusted going forward?
___
I did try both of your models and they sound fine to me... Also no errors when inferring them
For now, I would like to suggest changing the default back to contentvec_final_proj=False and deal with it later.
Maybe so-vits-svc's contentvec is uniquely retrained in the final layer to enhance Japanese / Chinese pronunciation? Although I don't know how it works, so I can't say for sure...
Okay so, what I gathered just now:
Starting a new model and doing `svc pre-config` will select `so-vits-svc-4.0v1-legacy` by default.
Trying to set `"contentvec_final_proj": false` in that config file will return errors like mentioned above because it is a different model structure / config.
However, doing `svc pre-config -t so-vits-svc-4.0v1` will give the correct structure in which I can set the final_proj to true and then train with that.
It does seem like training that will take a bit longer however. Legacy at around 500 steps sounds better than that new one. That's fine though as long as it's mentioned.
I'm giving that training a go with the Kurzgesagt voice for testing to several thousand steps and report back.
___
The thing I see is that we need to figure out if a model is of `"type_": "hifi-gan"` or similar, as in **not legacy**, and in that case set it to use `contentvec_final_projc=False`.
~~Additionally, I've noticed a `n_speakers` variable that's set to 200 by default. I remember you saying something along the lines of "do we need 200 speakers?" and whether it could make the model smaller?~~
My bad, it wasn't `n_speakers`, it was the VITS model in general: https://github.com/voicepaw/so-vits-svc-fork/discussions/314
https://huggingface.co/lengyue233/content-vec-best
If you have more free time, you can follow this procedure to convert so-vits-svc's ContentVec and test it again.
Yeah I converted the `checkpoint_best_legacy_500.pt` and loaded it in code instead of getting it from the `lengyue233` Hugging Face repository, the results are the same. It's still erroring... (Expecting 768 but providing 256 on a `so-vits-svc-4.0v1-legacy` model with `"contentvec_final_proj": false`)
Trying to convert the non-legacy checkpoint is just erroring with that config (which makes sense)
What about with "contentvec_final_proj": true?
Note that final_proj is one nn.Linear that outputs 256 channels from 768 input channels.
> What about with "contentvec_final_proj": true?
Yup, that works. But seeing as that's the default I assume we're back to square 1 with the English accent...
I'm not sure, but if the rebuilt version (for the purpose of replacing final_proj) still doesn't work, I think the only way is to extract and insert final_proj from our ckpt or ask lengyue232 for help, or my code os wrong
Modifying the `convert.py` script from lengyue233's repository a bit to remove the final_proj related code, I still get a config / model that has a `"hidden_size"` of 768. But we need one with 256.
I'm unsure how to convert it to a functional pytorch model...
> Modifying the convert.py script from lengyue233's repository a bit to remove the final_proj related code, I still get a config / model that has a "hidden_size" of 768. But we need one with 256.
You have better read our code first before talking, I'm saying that the weights for final proj is different between 2 original non Huggingface models and need to replace it
> Note that final_proj is one nn.Linear that outputs 256 channels from 768 input channels.
> You have better read our code first before talking, I'm saying that the weights for final proj is different between 2 original non Huggingface models and need to replace it
Aaaaah I see. I still don't understand much about the AI side of things with the project (I'm happy I can contribute with fixes here and there) so I apologize for that
I would like this to be resolved as soon as possible, do you have time now?
On the second thought, I think I'm the only person who can understand my dirty code and guess I should archive this repo
It is painful to be blamed for wasting the computing costs of the planet by having to train an incorrect model that was not identifiable for two days.
I've tried it and can't tell the difference......
3.10.0
https://user-images.githubusercontent.com/55338215/233765666-f6fa8669-632a-4296-a118-91c8cfb96d91.mp4
3.9.5
https://user-images.githubusercontent.com/55338215/233765714-784be9b2-23db-4a9d-b6db-78fa62ef2e91.mp4
The rebuilt one
https://user-images.githubusercontent.com/55338215/233765815-0279c011-101e-4e36-8ecd-7d2060498f9d.mp4
Still not fixed...
```
result1 = hubert(new_input, output_hidden_states=True)["hidden_states"][9]
result1 = hubert.final_proj(result1)
```
https://huggingface.co/lengyue233/content-vec-best/blob/c0b9ba13db21beaa4053faae94c102ebe326fd68/convert.py#L131-L132
I didn't understand anything
| 2023-04-22T06:43:30 |
|
voicepaw/so-vits-svc-fork
| 557 |
voicepaw__so-vits-svc-fork-557
|
[
"248"
] |
fa39c65b6410853bbc1d2527979ab089bb94e9b3
|
diff --git a/src/so_vits_svc_fork/logger.py b/src/so_vits_svc_fork/logger.py
--- a/src/so_vits_svc_fork/logger.py
+++ b/src/so_vits_svc_fork/logger.py
@@ -1,14 +1,6 @@
import os
import sys
-from logging import (
- DEBUG,
- INFO,
- FileHandler,
- StreamHandler,
- basicConfig,
- captureWarnings,
- getLogger,
-)
+from logging import DEBUG, INFO, StreamHandler, basicConfig, captureWarnings, getLogger
from pathlib import Path
from rich.logging import RichHandler
@@ -29,7 +21,7 @@ def init_logger() -> None:
datefmt="[%X]",
handlers=[
StreamHandler() if is_notebook() else RichHandler(),
- FileHandler(f"{package_name}.log"),
+ # FileHandler(f"{package_name}.log"),
],
)
if IS_TEST:
|
PermissionError: [Errno 13] Permission denied
I'm on Windows 10 WSL2 Ubuntu and this happens when I try to run `svc pre-resample`, what's going on?
Traceback (most recent call last):
File "/home/fab/miniconda3/envs/sovits/bin/svc", line 5, in <module>
from so_vits_svc_fork.__main__ import cli
File "/home/fab/miniconda3/envs/sovits/lib/python3.10/site-packages/so_vits_svc_fork/__init__.py", line 5, in <module>
init_logger()
File "/home/fab/miniconda3/envs/sovits/lib/python3.10/site-packages/so_vits_svc_fork/logger.py", line 31, in init_logger
FileHandler(f"{__name__.split('.')[0]}.log"),
File "/home/fab/miniconda3/envs/sovits/lib/python3.10/logging/__init__.py", line 1169, in __init__
StreamHandler.__init__(self, self._open())
File "/home/fab/miniconda3/envs/sovits/lib/python3.10/logging/__init__.py", line 1201, in _open
return open_func(self.baseFilename, self.mode,
PermissionError: [Errno 13] Permission denied: '/home/fab/sovits/so_vits_svc_fork.log'
|
got this too
| 2023-05-04T01:08:30 |
|
voicepaw/so-vits-svc-fork
| 578 |
voicepaw__so-vits-svc-fork-578
|
[
"492"
] |
071b441fbc459f72705dc2ef02a0e6fe00c492f8
|
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -615,8 +615,8 @@ def apply_preset(name: str) -> None:
update_speaker()
elif event == "input_path":
# Don't change the output path if it's already set
- if values["output_path"]:
- continue
+ # if values["output_path"]:
+ # continue
# Set a sensible default output path
window.Element("output_path").Update(str(get_output_path(input_path)))
elif event == "infer":
|
improve the output file name options on the GUI
**The new OUTPUT is not convenient:**
The latest update demand for an OUTPUT path and file name.
The old version was much more ideal by default.
If user won't enter anything on the OUTPUT, it will not work, instead an annoying error window popups with explanations of the types accepted. I understand it is now more dynamic but there is no "Factory Default" like it was before.
---
**SOLUTION:**
Please make a "Factory Default" once running the GUI APP with these:
**1** - OUTPUT PATH by default should be the SOURCE path.
**2** - FILE NAME by default should be something like: **"RESULT.wav"**
**3** - You can keep the POPUP Window to show the accepted file types:
Just add a small question mark button [?] ❓ next to the Path input box, once clicked it will do whatever it currently do while it says: ".out"
You may want to consider to change the Window title from "**Error**" to "**Help**" and you can add more text there beside the accepted files, like mini-instructions if needed.
---
**CONCLUSION:**
Instead of having ".out" without an path at all, the solution above should be much more convenient out of the box.
Once again, I hope that my suggestion helps improving the project.
Thanks ahead for your great work on this project🙏 I hope that you will consider this. improvement.
|
There is still a default output filename that is generated when you select an input filename. Are you saying after you select an input, the output path is not populated? Please include a screen recording and information about what OS you’re running on.
>
Thanks for the reply 💙 let me try to explain again:
Every time I launch the GUI App, the factory default is always ".out" and I must also select a PATH so it is not working on the source file path by default (as it was before).
I need to set it again every time I launch the GUI App, and it is not as convenient as "RESTULT.wav" for example.
I use Windows 10
| 2023-05-06T03:41:25 |
|
voicepaw/so-vits-svc-fork
| 581 |
voicepaw__so-vits-svc-fork-581
|
[
"474"
] |
7d02117799eb947a0486101b7fba82d9707d9b61
|
diff --git a/src/so_vits_svc_fork/utils.py b/src/so_vits_svc_fork/utils.py
--- a/src/so_vits_svc_fork/utils.py
+++ b/src/so_vits_svc_fork/utils.py
@@ -1,6 +1,7 @@
from __future__ import annotations
import json
+import os
import re
import subprocess
import warnings
@@ -26,6 +27,7 @@
LOG = getLogger(__name__)
HUBERT_SAMPLING_RATE = 16000
+IS_COLAB = os.getenv("COLAB_RELEASE_TAG", False)
def get_optimal_device(index: int = 0) -> torch.device:
@@ -328,6 +330,8 @@ def clean_checkpoints(
for to_delete in to_delete_list:
if to_delete.exists():
LOG.info(f"Removing {to_delete}")
+ if IS_COLAB:
+ to_delete.write_text("")
to_delete.unlink()
|
Old ckpts are not completely deleted in colab
**Describe the bug**
In Google Colab ckpts are moved to trash, but not completely deleted, so you have to manually delete them, it should be automatically removed from the trash
**To Reproduce**
Start training in colab and wait
**Additional context**
you can implement it this way, we overwrite our ckpt file with 0 bytes and delete it, the file will remain in the trash, but it will no longer take up space
```
filepath = 'drive/MyDrive/so-vits-svc-fork/logs/44k/G_STEPS.pth'
open(filepath, 'w').close()
!rm {filepath} #(or what you use to remove)
```
|
You can send a PR🙂
| 2023-05-06T10:27:09 |
|
voicepaw/so-vits-svc-fork
| 582 |
voicepaw__so-vits-svc-fork-582
|
[
"129"
] |
7d02117799eb947a0486101b7fba82d9707d9b61
|
diff --git a/src/so_vits_svc_fork/__main__.py b/src/so_vits_svc_fork/__main__.py
--- a/src/so_vits_svc_fork/__main__.py
+++ b/src/so_vits_svc_fork/__main__.py
@@ -164,6 +164,14 @@ def train(
default=None,
help="path to cluster model",
)
[email protected](
+ "-re",
+ "--recursive",
+ type=bool,
+ default=False,
+ help="Search recursively",
+ is_flag=True,
+)
@click.option("-t", "--transpose", type=int, default=0, help="transpose")
@click.option(
"-db", "--db-thresh", type=int, default=-20, help="threshold (DB) (RELATIVE)"
@@ -215,6 +223,7 @@ def infer(
output_path: Path,
model_path: Path,
config_path: Path,
+ recursive: bool,
# svc config
speaker: str,
cluster_model_path: Path | None = None,
@@ -244,6 +253,10 @@ def infer(
if output_path is None:
output_path = input_path.parent / f"{input_path.stem}.out{input_path.suffix}"
output_path = Path(output_path)
+ if input_path.is_dir() and not recursive:
+ raise ValueError(
+ "input_path is a directory. Use 0re or --recursive to infer recursively."
+ )
model_path = Path(model_path)
if model_path.is_dir():
model_path = list(
@@ -259,6 +272,7 @@ def infer(
output_path=output_path,
model_path=model_path,
config_path=config_path,
+ recursive=recursive,
# svc config
speaker=speaker,
cluster_model_path=cluster_model_path,
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -73,14 +73,28 @@ def get_output_path(input_path: Path) -> Path:
return output_path
-def get_supported_file_types() -> tuple[tuple[str], ...]:
- return tuple(
+def get_supported_file_types() -> tuple[tuple[str, str], ...]:
+ res = tuple(
[
- ((extension, f".{extension.lower()}"))
+ (extension, f".{extension.lower()}")
for extension in sf.available_formats().keys()
]
)
+ # Sort by popularity
+ common_file_types = ["WAV", "MP3", "FLAC", "OGG", "M4A", "WMA"]
+ res = sorted(
+ res,
+ key=lambda x: common_file_types.index(x[0])
+ if x[0] in common_file_types
+ else len(common_file_types),
+ )
+ return res
+
+
+def get_supported_file_types_concat() -> tuple[tuple[str, str], ...]:
+ return (("Audio", " ".join(sf.available_formats().keys())),)
+
def validate_output_file_type(output_path: Path) -> bool:
supported_file_types = sorted(
@@ -145,7 +159,24 @@ def after_inference(window: sg.Window, path: Path, auto_play: bool, output_path:
def main():
LOG.info(f"version: {__version__}")
- sg.theme("Dark")
+ # sg.theme("Dark")
+ sg.theme_add_new(
+ "Very Dark",
+ {
+ "BACKGROUND": "#111111",
+ "TEXT": "#FFFFFF",
+ "INPUT": "#444444",
+ "TEXT_INPUT": "#FFFFFF",
+ "SCROLL": "#333333",
+ "BUTTON": ("white", "#112233"),
+ "PROGRESS": ("#111111", "#333333"),
+ "BORDER": 2,
+ "SLIDER_DEPTH": 2,
+ "PROGRESS_DEPTH": 2,
+ },
+ )
+ sg.theme("Very Dark")
+
model_candidates = list(sorted(Path("./logs/44k/").glob("G_*.pth")))
frame_contents = {
@@ -165,7 +196,10 @@ def main():
if Path("./logs/44k/").exists()
else Path(".").absolute().as_posix(),
key="model_path_browse",
- file_types=(("PyTorch", "*.pth"),),
+ file_types=(
+ ("PyTorch", "G_*.pth G_*.pt"),
+ ("Pytorch", "*.pth *.pt"),
+ ),
),
],
[
@@ -201,7 +235,7 @@ def main():
if Path("./logs/44k/").exists()
else ".",
key="cluster_model_path_browse",
- file_types=(("PyTorch", "*.pt"),),
+ file_types=(("PyTorch", "*.pt"), ("Pickle", "*.pt *.pth *.pkl")),
),
],
],
@@ -312,7 +346,17 @@ def main():
sg.Text("Input audio path"),
sg.Push(),
sg.InputText(key="input_path", enable_events=True),
- sg.FileBrowse(initial_folder=".", key="input_path_browse"),
+ sg.FileBrowse(
+ initial_folder=".",
+ key="input_path_browse",
+ file_types=get_supported_file_types_concat(),
+ ),
+ sg.FolderBrowse(
+ button_text="Browse(Folder)",
+ initial_folder=".",
+ key="input_path_folder_browse",
+ target="input_path",
+ ),
sg.Button("Play", key="play_input"),
],
[
@@ -438,7 +482,7 @@ def main():
sg.Combo(
key="presets",
values=list(load_presets().keys()),
- size=(20, 1),
+ size=(40, 1),
enable_events=True,
),
sg.Button("Delete preset", key="delete_preset"),
@@ -446,7 +490,7 @@ def main():
[
sg.Text("Preset name"),
sg.Stretch(),
- sg.InputText(key="preset_name", size=(20, 1)),
+ sg.InputText(key="preset_name", size=(26, 1)),
sg.Button("Add current settings as a preset", key="add_preset"),
],
],
@@ -498,8 +542,15 @@ def main():
layout = [[column1, column2]]
# layout = [[sg.Column(layout, vertical_alignment="top", scrollable=True, expand_x=True, expand_y=True)]]
window = sg.Window(
- f"{__name__.split('.')[0]}", layout, grab_anywhere=True, finalize=True
- ) # , use_custom_titlebar=True)
+ f"{__name__.split('.')[0].replace('_', '-')} v{__version__}",
+ layout,
+ grab_anywhere=True,
+ finalize=True,
+ # Below disables taskbar, which may be not useful for some users
+ # use_custom_titlebar=True, no_titlebar=False
+ # Keep on top
+ # keep_on_top=True
+ )
# for n in ["input_device", "output_device"]:
# window[n].Widget.configure(justify="right")
event, values = window.read(timeout=0.01)
@@ -620,11 +671,19 @@ def apply_preset(name: str) -> None:
# Set a sensible default output path
window.Element("output_path").Update(str(get_output_path(input_path)))
elif event == "infer":
- if not input_path.exists() or not input_path.is_file():
- LOG.warning(f"Input path {input_path} does not exist.")
+ if "Default VC" in values["presets"]:
+ window["presets"].update(
+ set_to_index=list(load_presets().keys()).index("Default File")
+ )
+ apply_preset("Default File")
+ if values["input_path"] == "":
+ LOG.warning("Input path is empty.")
continue
- if not validate_output_file_type(output_path):
+ if not input_path.exists():
+ LOG.warning(f"Input path {input_path} does not exist.")
continue
+ # if not validate_output_file_type(output_path):
+ # continue
try:
from so_vits_svc_fork.inference.main import infer
@@ -639,6 +698,7 @@ def apply_preset(name: str) -> None:
output_path=output_path,
input_path=input_path,
config_path=Path(values["config_path"]),
+ recursive=True,
# svc config
speaker=values["speaker"],
cluster_model_path=Path(values["cluster_model_path"])
diff --git a/src/so_vits_svc_fork/inference/main.py b/src/so_vits_svc_fork/inference/main.py
--- a/src/so_vits_svc_fork/inference/main.py
+++ b/src/so_vits_svc_fork/inference/main.py
@@ -2,13 +2,14 @@
from logging import getLogger
from pathlib import Path
-from typing import Literal
+from typing import Literal, Sequence
import librosa
import numpy as np
import soundfile
import torch
from cm_time import timer
+from tqdm import tqdm
from so_vits_svc_fork.inference.core import RealtimeVC, RealtimeVC2, Svc
from so_vits_svc_fork.utils import get_optimal_device
@@ -19,10 +20,11 @@
def infer(
*,
# paths
- input_path: Path | str,
- output_path: Path | str,
+ input_path: Path | str | Sequence[Path | str],
+ output_path: Path | str | Sequence[Path | str],
model_path: Path | str,
config_path: Path | str,
+ recursive: bool = False,
# svc config
speaker: int | str,
cluster_model_path: Path | str | None = None,
@@ -39,10 +41,36 @@ def infer(
max_chunk_seconds: float = 40,
device: str | torch.device = get_optimal_device(),
):
+ if isinstance(input_path, (str, Path)):
+ input_path = [input_path]
+ if isinstance(output_path, (str, Path)):
+ output_path = [output_path]
+ if len(input_path) != len(output_path):
+ raise ValueError(
+ f"input_path and output_path must have same length, but got {len(input_path)} and {len(output_path)}"
+ )
+
model_path = Path(model_path)
- output_path = Path(output_path)
- input_path = Path(input_path)
config_path = Path(config_path)
+ output_path = [Path(p) for p in output_path]
+ input_path = [Path(p) for p in input_path]
+ output_paths = []
+ input_paths = []
+
+ for input_path, output_path in zip(input_path, output_path):
+ if input_path.is_dir():
+ if not recursive:
+ raise ValueError(
+ f"input_path is a directory, but recursive is False: {input_path}"
+ )
+ input_paths.extend(list(input_path.rglob("*.*")))
+ output_paths.extend(
+ [output_path / p.relative_to(input_path) for p in input_paths]
+ )
+ continue
+ input_paths.append(input_path)
+ output_paths.append(output_path)
+
cluster_model_path = Path(cluster_model_path) if cluster_model_path else None
svc_model = Svc(
net_g_path=model_path.as_posix(),
@@ -53,23 +81,35 @@ def infer(
device=device,
)
- audio, _ = librosa.load(input_path, sr=svc_model.target_sample)
- audio = svc_model.infer_silence(
- audio.astype(np.float32),
- speaker=speaker,
- transpose=transpose,
- auto_predict_f0=auto_predict_f0,
- cluster_infer_ratio=cluster_infer_ratio,
- noise_scale=noise_scale,
- f0_method=f0_method,
- db_thresh=db_thresh,
- pad_seconds=pad_seconds,
- chunk_seconds=chunk_seconds,
- absolute_thresh=absolute_thresh,
- max_chunk_seconds=max_chunk_seconds,
- )
-
- soundfile.write(output_path, audio, svc_model.target_sample)
+ try:
+ pbar = tqdm(list(zip(input_paths, output_paths)), disable=len(input_paths) == 1)
+ for input_path, output_path in pbar:
+ pbar.set_description(f"{input_path}")
+ try:
+ audio, _ = librosa.load(input_path, sr=svc_model.target_sample)
+ except Exception as e:
+ LOG.error(f"Failed to load {input_path}")
+ LOG.exception(e)
+ continue
+ output_path.parent.mkdir(parents=True, exist_ok=True)
+ audio = svc_model.infer_silence(
+ audio.astype(np.float32),
+ speaker=speaker,
+ transpose=transpose,
+ auto_predict_f0=auto_predict_f0,
+ cluster_infer_ratio=cluster_infer_ratio,
+ noise_scale=noise_scale,
+ f0_method=f0_method,
+ db_thresh=db_thresh,
+ pad_seconds=pad_seconds,
+ chunk_seconds=chunk_seconds,
+ absolute_thresh=absolute_thresh,
+ max_chunk_seconds=max_chunk_seconds,
+ )
+ soundfile.write(output_path, audio, svc_model.target_sample)
+ finally:
+ del svc_model
+ torch.cuda.empty_cache()
def realtime(
@@ -215,14 +255,18 @@ def callback(
if rtf > 1:
LOG.warning("RTF is too high, consider increasing block_seconds")
- with sd.Stream(
- device=(input_device, output_device),
- channels=1,
- callback=callback,
- samplerate=svc_model.target_sample,
- blocksize=int(block_seconds * svc_model.target_sample),
- latency="low",
- ) as stream:
- LOG.info(f"Latency: {stream.latency}")
- while True:
- sd.sleep(1000)
+ try:
+ with sd.Stream(
+ device=(input_device, output_device),
+ channels=1,
+ callback=callback,
+ samplerate=svc_model.target_sample,
+ blocksize=int(block_seconds * svc_model.target_sample),
+ latency="low",
+ ) as stream:
+ LOG.info(f"Latency: {stream.latency}")
+ while True:
+ sd.sleep(1000)
+ finally:
+ # del model, svc_model
+ torch.cuda.empty_cache()
|
How to inference to all voice files in the directory
**Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
**Additional context**
Add any other context about the problem here.
"svc infer" This command can only be one file at a time. Is there a way to infer to multiple files at once?
|
If you know a bit of python, you can run a script like this and edit the variables inside the script.
```
import os
import subprocess
directory = 'D:/testfiles/wavs'
modelpath = 'D:/testfiles/logs/44k/G_12345.pth'
configpath = 'D:/testfiles/configs/44k/config.json'
for filename in os.listdir(directory):
f = os.path.join(directory, filename)
if os.path.isfile(f):
subprocess.run([
"svc",
"infer",
"-m", f"{modelpath}",
"-c", f"{configpath}",
f"{f}"
])
```
| 2023-05-06T11:45:54 |
|
voicepaw/so-vits-svc-fork
| 716 |
voicepaw__so-vits-svc-fork-716
|
[
"505",
"0000"
] |
7e9d2cc1e14b37d8c14adad8e53e7d286b85221a
|
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -2,6 +2,7 @@
import json
import multiprocessing
+import os
from copy import copy
from logging import getLogger
from pathlib import Path
@@ -503,6 +504,28 @@ def main():
frame.expand_x = True
frames[name] = [frame]
+ bottoms = [
+ [
+ sg.Checkbox(
+ key="use_gpu",
+ default=get_optimal_device() != torch.device("cpu"),
+ text="Use GPU"
+ + (
+ " (not available; if your device has GPU, make sure you installed PyTorch with CUDA support)"
+ if get_optimal_device() == torch.device("cpu")
+ else ""
+ ),
+ disabled=get_optimal_device() == torch.device("cpu"),
+ )
+ ],
+ [
+ sg.Button("Infer", key="infer"),
+ sg.Button("(Re)Start Voice Changer", key="start_vc"),
+ sg.Button("Stop Voice Changer", key="stop_vc"),
+ sg.Push(),
+ # sg.Button("ONNX Export", key="onnx_export"),
+ ],
+ ]
column1 = sg.Column(
[
frames["Paths"],
@@ -515,42 +538,53 @@ def main():
frames["File"],
frames["Realtime"],
frames["Presets"],
- [
- sg.Checkbox(
- key="use_gpu",
- default=get_optimal_device() != torch.device("cpu"),
- text="Use GPU"
- + (
- " (not available; if your device has GPU, make sure you installed PyTorch with CUDA support)"
- if get_optimal_device() == torch.device("cpu")
- else ""
- ),
- disabled=get_optimal_device() == torch.device("cpu"),
- )
- ],
- [
- sg.Button("Infer", key="infer"),
- sg.Button("(Re)Start Voice Changer", key="start_vc"),
- sg.Button("Stop Voice Changer", key="stop_vc"),
- sg.Push(),
- # sg.Button("ONNX Export", key="onnx_export"),
- ],
]
+ + bottoms
)
-
# columns
layout = [[column1, column2]]
- # layout = [[sg.Column(layout, vertical_alignment="top", scrollable=True, expand_x=True, expand_y=True)]]
+ # get screen size
+ screen_width, screen_height = sg.Window.get_screen_size()
+ if screen_height < 720:
+ layout = [
+ [
+ sg.Column(
+ layout,
+ vertical_alignment="top",
+ scrollable=False,
+ expand_x=True,
+ expand_y=True,
+ vertical_scroll_only=True,
+ key="main_column",
+ )
+ ]
+ ]
window = sg.Window(
f"{__name__.split('.')[0].replace('_', '-')} v{__version__}",
layout,
grab_anywhere=True,
finalize=True,
+ scaling=1,
+ font=("Yu Gothic UI", 11) if os.name == "nt" else None,
+ # resizable=True,
+ # size=(1280, 720),
# Below disables taskbar, which may be not useful for some users
# use_custom_titlebar=True, no_titlebar=False
# Keep on top
# keep_on_top=True
)
+
+ # event, values = window.read(timeout=0.01)
+ # window["main_column"].Scrollable = True
+
+ # make slider height smaller
+ try:
+ for v in window.element_list():
+ if isinstance(v, sg.Slider):
+ v.Widget.configure(sliderrelief="flat", width=10, sliderlength=20)
+ except Exception as e:
+ LOG.exception(e)
+
# for n in ["input_device", "output_device"]:
# window[n].Widget.configure(justify="right")
event, values = window.read(timeout=0.01)
|
GUI Buttons to Infer not shown
**Describe the bug**
If i start the GUI with svcg everythings seems to be there except the buttons on the bottom.Not sure what i am missing or if its a bug.
**To Reproduce**
Steps to reproduce the behavior: svcg
**Additional context**
I trained a voice and everything is fine except i cant use the GUI and i have to use the console with svc infer +args instead.
<img width="842" alt="Screenshot 2023-04-28 134830" src="https://user-images.githubusercontent.com/50552332/235139910-7cf0a8b7-accc-4b96-8f0e-26ba05b0c634.png">
<img width="909" alt="Screenshot 2023-04-28 134130" src="https://user-images.githubusercontent.com/50552332/235139915-9b0b6eb3-ce53-41b3-83cd-64beffb61883.png">
|
Is it possible that it is simply out of view from the screen?
I wish it was that easy but thats not the case
<img width="884" alt="Screenshot 2023-04-30 002504" src="https://user-images.githubusercontent.com/50552332/235326564-314a908a-4f6d-49ae-a170-bd865e41dc48.png">
I'm having this same problem. Anyone figure out a fix?
huhh, same, ive rebuilt a bunch of times. same outcome
i am having the same problem, the GUI did not shown infer botton
I'm having the same problem. I had version 3.11 and it was working perfectly fine, but now that I updated it, the infer button disappeared. Does anyone know the solution?
same
same
I've had the exact same problem too. Does anyone know if a certain So-Vits version has a bug or has a certain requirement or maybe we have to install another version? I actually installed it in another computer and had the same outcome.
facing the same issue , please try adding scalability to the GUI as a solution
I had version 3.15.0, the infer button not showing
same here, infer button not showing on 3.15.0
> For me it was a resolution issue. I fixed it by changing the resolution in my Window settings to a lower value.
I just tried fixing the resolution to my computer. That doesn't work. The infer button still doesn't show. I have no idea how to fix it.
same with me,,,,,
> For me it was a resolution issue. I fixed it by changing the resolution in my Window settings to a lower value.
what is the resolution value do you use? i use highest res in my device (1366x768), inver value not showing; when i try lower resolution 1280x7200, the preset name field also not showing, i thought we need higher resolution, not lower resolution
I found a solution that worked well for me! I had my resolution set at 1440x900 with my scale at 125% and the infer button was nowhere to be found. The moment I switched my scale to 100%, they appeared!


Give it a try if you're having the same problem!
> I found a solution that worked well for me! I had my resolution set at 1440x900 with my scale at 125% and the infer button was nowhere to be found. The moment I switched my scale to 100%, they appeared!
>
>  
>
> Give it a try if you're having the same problem!
I don't have that large of a resolution. My largest resolution is 1366x768. Also, my scale is 100% currently at the moment. The infer button still doesn't show up.

| 2023-05-29T12:39:51 |
|
voicepaw/so-vits-svc-fork
| 1,139 |
voicepaw__so-vits-svc-fork-1139
|
[
"1138"
] |
9f9ecfeed71d8dae8093a2599f7af3458ec73fbe
|
diff --git a/src/so_vits_svc_fork/modules/decoders/mb_istft/_pqmf.py b/src/so_vits_svc_fork/modules/decoders/mb_istft/_pqmf.py
--- a/src/so_vits_svc_fork/modules/decoders/mb_istft/_pqmf.py
+++ b/src/so_vits_svc_fork/modules/decoders/mb_istft/_pqmf.py
@@ -6,7 +6,7 @@
import numpy as np
import torch
import torch.nn.functional as F
-from scipy.signal import kaiser
+from scipy.signal.windows import kaiser
def design_prototype_filter(taps=62, cutoff_ratio=0.15, beta=9.0):
|
scipy ImportError on multiple platforms
### Describe the bug
When attempting to Infer, the process is cancelled with the following error message:
[10:53:57] ERROR [10:53:57] cannot import name 'kaiser' from 'scipy.signal' gui.py:764
(C:\Users\Marcello\AppData\Roaming\so-vits-svc-fork\venv\lib\site-packages\scipy\signal\_
_init__.py)
Traceback (most recent call last):
File
"C:\Users\Marcello\AppData\Roaming\so-vits-svc-fork\venv\lib\site-packages\so_vits_svc_fo
rk\gui.py", line 723, in main
from so_vits_svc_fork.inference.main import infer
File
"C:\Users\Marcello\AppData\Roaming\so-vits-svc-fork\venv\lib\site-packages\so_vits_svc_fo
rk\inference\main.py", line 14, in <module>
from so_vits_svc_fork.inference.core import RealtimeVC, RealtimeVC2, Svc
File
"C:\Users\Marcello\AppData\Roaming\so-vits-svc-fork\venv\lib\site-packages\so_vits_svc_fo
rk\inference\core.py", line 18, in <module>
from ..modules.synthesizers import SynthesizerTrn
File
"C:\Users\Marcello\AppData\Roaming\so-vits-svc-fork\venv\lib\site-packages\so_vits_svc_fo
rk\modules\synthesizers.py", line 13, in <module>
from so_vits_svc_fork.modules.decoders.mb_istft import (
File
"C:\Users\Marcello\AppData\Roaming\so-vits-svc-fork\venv\lib\site-packages\so_vits_svc_fo
rk\modules\decoders\mb_istft\__init__.py", line 1, in <module>
from ._generators import (
File
"C:\Users\Marcello\AppData\Roaming\so-vits-svc-fork\venv\lib\site-packages\so_vits_svc_fo
rk\modules\decoders\mb_istft\_generators.py", line 11, in <module>
from ._pqmf import PQMF
File
"C:\Users\Marcello\AppData\Roaming\so-vits-svc-fork\venv\lib\site-packages\so_vits_svc_fo
rk\modules\decoders\mb_istft\_pqmf.py", line 9, in <module>
from scipy.signal import kaiser
ImportError: cannot import name 'kaiser' from 'scipy.signal'
(C:\Users\Marcello\AppData\Roaming\so-vits-svc-fork\venv\lib\site-packages\scipy\signal\_
_init__.py)
### To Reproduce
1. Install so-vits-svc-fork using option 1, 2 or 3 natively or within Anaconda
2. Select model & config
3. Select input file, click on Infer
### Additional context
The same error message appears on every operating system I've tried.
### Version
4.1.58
### Platform
Windows 11 / MacOS Sonoma 14.1.1 / Anaconda3
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct.
### No Duplicate
- [X] I have checked existing issues to avoid duplicates.
|
@marcellocirelli try changing
from scipy.signal import kaiser
to
from scipy.signal import kaiserord
in this file
modules\decoders\mb_istft\_pqmf.py
seems like scipy 0.14.0 is the last version that had "kaiser" as the module name
as far as i checked, it is the same method, though i might be wrong
> @marcellocirelli try changing
>
> from scipy.signal import kaiser
> to
> from scipy.signal import kaiserord
> in this file
> modules\decoders\mb_istft\_pqmf.py
>
> seems like scipy 0.14.0 is the last version that had "kaiser" as the module name
> as far as i checked, it is the same method, though i might be wrong
>
Just tried it, it worked for me
> @marcellocirelli try changing
>
> from scipy.signal import kaiser to from scipy.signal import kaiserord in this file modules\decoders\mb_istft_pqmf.py
>
> seems like scipy 0.14.0 is the last version that had "kaiser" as the module name as far as i checked, it is the same method, though i might be wrong
Worked for me as well. Thank you!
| 2024-04-05T07:02:53 |
|
voicepaw/so-vits-svc-fork
| 1,155 |
voicepaw__so-vits-svc-fork-1155
|
[
"1154"
] |
a7bec74fc1c781691e12fa1edd87768fe02b886a
|
diff --git a/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py b/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py
--- a/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py
+++ b/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py
@@ -52,7 +52,7 @@ def _process_one(
speaker_count[speaker] += 1
audio_cut = audio[int(segment.start * sr) : int(segment.end * sr)]
sf.write(
- (output_dir / f"{speaker}_{speaker_count[speaker]}.wav"),
+ (output_dir / f"{speaker}_{speaker_count[speaker]:04d}.wav"),
audio_cut,
sr,
)
|
Ensure proper sorting by name for output files
### Is your feature request related to a problem? Please describe.
To enhance readability and ensure proper sorting by name, the numeric part of output file names should have a fixed width. This can be achieved by adding leading zeros to the numeric part, with four digits likely being sufficient.
### Describe alternatives you've considered
I don't have any.
### Additional context
_No response_
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct
### Are you willing to resolve this issue by submitting a Pull Request?
- [X] Yes, I have the time, and I know how to start.
- [ ] Yes, I have the time, but I don't know how to start. I would need guidance.
- [ ] No, I don't have the time, although I believe I could do it if I had the time...
- [ ] No, I don't have the time and I wouldn't even know how to start.
| 2024-04-07T14:49:13 |
||
voicepaw/so-vits-svc-fork
| 1,157 |
voicepaw__so-vits-svc-fork-1157
|
[
"1156"
] |
a7bec74fc1c781691e12fa1edd87768fe02b886a
|
diff --git a/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py b/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py
--- a/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py
+++ b/src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py
@@ -30,7 +30,7 @@ def _process_one(
LOG.warning(f"Failed to read {input_path}: {e}")
return
pipeline = Pipeline.from_pretrained(
- "pyannote/speaker-diarization", use_auth_token=huggingface_token
+ "pyannote/speaker-diarization-3.1", use_auth_token=huggingface_token
)
if pipeline is None:
raise ValueError("Failed to load pipeline")
|
Unable to use svc pre-sd with pyannote.audio 3.1.1
### Describe the bug
To use svc pre-sd for a long audio file with multiple speakers, I followed the [setup guide](https://github.com/voicepaw/so-vits-svc-fork/#before-training) and manually installed pyannote.audio, getting the latest version, 3.1.1.
Attempting to run svc pre-sd triggered the following error messages:
```
Model was trained with pyannote.audio 0.0.1, yours is 3.1.1. Bad things might happen unless you revert pyannote.audio to 0.x.
Model was trained with torch 1.10.0+cu102, yours is 2.2.2+cu121. Bad things might happen unless you revert torch to 1.x.
```
According to [PyPI](https://pypi.org/project/pyannote.audio/3.1.1/), pyannote.audio 3.1.1 works with speaker-diarization-3.1. So, it’s necessary to explicitly specify this version in the code.
### To Reproduce
1. Set up the environment. (I'm using torch 2.2.2+cu121.)
2. Install so-vits-svc-fork and its dependencies.
3. Install pyannote.audio with `pip3 install pyannote-audio`.
4. Prepare your data and organize data folders.
5. Run svc pre-sd with options suited to your data.
### Additional context
_No response_
### Version
4.1.61
### Platform
WSL-Ubuntu 22.04 LTS
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct.
### No Duplicate
- [X] I have checked existing issues to avoid duplicates.
| 2024-04-08T18:44:57 |
||
voicepaw/so-vits-svc-fork
| 1,159 |
voicepaw__so-vits-svc-fork-1159
|
[
"602",
"0000",
"602"
] |
50f6d79f81d443c3dea9a4de3c65dca6988080ac
|
diff --git a/src/so_vits_svc_fork/gui.py b/src/so_vits_svc_fork/gui.py
--- a/src/so_vits_svc_fork/gui.py
+++ b/src/so_vits_svc_fork/gui.py
@@ -350,7 +350,9 @@ def main():
sg.FileBrowse(
initial_folder=".",
key="input_path_browse",
- file_types=get_supported_file_types_concat(),
+ file_types=get_supported_file_types_concat()
+ if os.name == "nt"
+ else get_supported_file_types(),
),
sg.FolderBrowse(
button_text="Browse(Folder)",
|
Problem with input file audio path format selection (gui.py)
SVC version: 3.14.1
Currently, format selection for the input audio path file doesn't allow for format selection and filter shows no audio files.
The problem is on line 352 of gui.py
I solved it by putting, on line 352:
`file_types=get_supported_file_types(),`
instead of the current:
`file_types=get_supported_file_types_concat(),`
This solved the problem for me. See before and after videos.
Before:
https://github.com/voicepaw/so-vits-svc-fork/assets/34165937/61801d33-9ca1-4cd3-a3ec-565b6f705f6d
After correction:
https://github.com/voicepaw/so-vits-svc-fork/assets/34165937/a8a630a4-10a8-40b7-ba35-2fb50595cc74
Problem with input file audio path format selection (gui.py)
SVC version: 3.14.1
Currently, format selection for the input audio path file doesn't allow for format selection and filter shows no audio files.
The problem is on line 352 of gui.py
I solved it by putting, on line 352:
`file_types=get_supported_file_types(),`
instead of the current:
`file_types=get_supported_file_types_concat(),`
This solved the problem for me. See before and after videos.
Before:
https://github.com/voicepaw/so-vits-svc-fork/assets/34165937/61801d33-9ca1-4cd3-a3ec-565b6f705f6d
After correction:
https://github.com/voicepaw/so-vits-svc-fork/assets/34165937/a8a630a4-10a8-40b7-ba35-2fb50595cc74
|
Another issue due to the different behavior between Linux and Windows 😇
```
if os.environ("OS") == "nt"...
```
NOTE: My installed version on PySimpleGui is: 4.60.4
Do you have a more recent version?
I think it's an OS-related problem, not PySimpleGUI
Another problem... The checkboxes change when pressing on "infer"...
It only appears at first inference. The second time you press on "infer", that's good. :-D
https://github.com/voicepaw/so-vits-svc-fork/assets/34165937/ddfe0823-5bdc-46b3-8ca0-b7532274c891
> Another problem... The checkboxes change when pressing on "infer"... It only appears at first inference. The second time you press on "infer", that's good. :-D
>
> other.mp4
#95
Bug reports are appreciated, but note that you can also send PRs. 😴
I have never sent a pull request. I have no idea about how it works, but I'll try to see if I can figure it out...
Another issue due to the different behavior between Linux and Windows 😇
```
if os.environ("OS") == "nt"...
```
NOTE: My installed version on PySimpleGui is: 4.60.4
Do you have a more recent version?
I think it's an OS-related problem, not PySimpleGUI
Another problem... The checkboxes change when pressing on "infer"...
It only appears at first inference. The second time you press on "infer", that's good. :-D
https://github.com/voicepaw/so-vits-svc-fork/assets/34165937/ddfe0823-5bdc-46b3-8ca0-b7532274c891
> Another problem... The checkboxes change when pressing on "infer"... It only appears at first inference. The second time you press on "infer", that's good. :-D
>
> other.mp4
#95
Bug reports are appreciated, but note that you can also send PRs. 😴
I have never sent a pull request. I have no idea about how it works, but I'll try to see if I can figure it out...
| 2024-04-10T10:33:36 |
|
python-discord/bot
| 195 |
python-discord__bot-195
|
[
"102"
] |
772fcc92cecdaa982534387a985232047bc6601d
|
diff --git a/bot/cogs/cogs.py b/bot/cogs/cogs.py
--- a/bot/cogs/cogs.py
+++ b/bot/cogs/cogs.py
@@ -1,7 +1,7 @@
import logging
import os
-from discord import ClientException, Colour, Embed
+from discord import Colour, Embed
from discord.ext.commands import Bot, Context, group
from bot.constants import (
@@ -77,10 +77,6 @@ async def load_command(self, ctx: Context, cog: str):
if full_cog not in self.bot.extensions:
try:
self.bot.load_extension(full_cog)
- except ClientException:
- log.error(f"{ctx.author} requested we load the '{cog}' cog, "
- "but that cog doesn't have a 'setup()' function.")
- embed.description = f"Invalid cog: {cog}\n\nCog does not have a `setup()` function"
except ImportError:
log.error(f"{ctx.author} requested we load the '{cog}' cog, "
f"but the cog module {full_cog} could not be found!")
|
Cog load with duplicate command reporting wrong error
**Originally posted by Scragly:**
In the `cogs` extension module, there's a `try: except ClientException`. The reason for the error is hardcoded, assuming that it raises only when a setup function does not exist.
[Click here to view the relevant code.](https://gitlab.com/python-discord/projects/bot/blob/184b6d51e44915319e09b1bdf24ee26541391350/bot/cogs/cogs.py#L80-83)
Unfortunately, the same exception will also raise down the stack in `bot.add_cog` when a command within the cog has a name that's already existing in commands, conflicting and raising the exception.
To avoid incorrect errors being reported/logged, and to prevent confusion during debugging, it might be best to simply remove the `except ClientException` block and let it fall down into the catchall `except Exception as e` block which prints the exception details as given.
Feel free to comment better suggestions, of course.
This will be something for after the migration over to GitHub, hence why it's an Issue, rather than a quick MR.
| 2018-11-17T13:44:39 |
||
python-discord/bot
| 197 |
python-discord__bot-197
|
[
"121"
] |
7925667bf3797767bbef2bb86b7cd4df81da29a9
|
diff --git a/bot/cogs/verification.py b/bot/cogs/verification.py
--- a/bot/cogs/verification.py
+++ b/bot/cogs/verification.py
@@ -151,6 +151,17 @@ async def unsubscribe_command(self, ctx: Context, *_): # We don't actually care
f"{ctx.author.mention} Unsubscribed from <#{Channels.announcements}> notifications."
)
+ @staticmethod
+ def __global_check(ctx: Context):
+ """
+ Block any command within the verification channel that is not !accept.
+ """
+
+ if ctx.channel.id == Channels.verification:
+ return ctx.command.name == "accept"
+ else:
+ return True
+
def setup(bot):
bot.add_cog(Verification(bot))
|
Disable all bot commands but !accept in checkpoint
**Originally posted by ByteCommander:**
The #checkpoint channel is where new members have to go to type `!accept` in order to verify they have read the rules and to get access to all other public channels.
Currently, the bot removes all user messages from #checkpoint immediately, to keep it clean. If the user types anything other than `!accept`, they additionally get a warning which self-destructs after short time.
However, other bot commands are still working, and while the user's original command message will be removed, any command responses will still get posted and do not seem to ever get deleted automatically.

This seems to be a bug that allows people spamming the checkpoint channel to annoy yet to be verified users.
As a solution, all commands except for `!accept` should be entirely disabled in #checkpoint.
|
**Comment from Johannes Christ:**
This is somewhat annoying, we could use a global check, but that would also render the accept command unusable. Is there a cleaner way than applying a check on every command that isn't `!accept`?
| 2018-11-17T21:53:53 |
|
python-discord/bot
| 202 |
python-discord__bot-202
|
[
"105"
] |
8824cbfffc436bc5b089253d23b612b75a6879ca
|
diff --git a/bot/cogs/bot.py b/bot/cogs/bot.py
--- a/bot/cogs/bot.py
+++ b/bot/cogs/bot.py
@@ -3,14 +3,15 @@
import re
import time
-from discord import Embed, Message, RawMessageUpdateEvent, RawReactionActionEvent
+from discord import Embed, Message, RawMessageUpdateEvent
from discord.ext.commands import Bot, Context, command, group
from dulwich.repo import Repo
from bot.constants import (
- Channels, Emojis, Guild, Roles, URLs
+ Channels, Guild, Roles, URLs
)
from bot.decorators import with_role
+from bot.utils.messages import wait_for_deletion
log = logging.getLogger(__name__)
@@ -342,7 +343,10 @@ async def on_message(self, msg: Message):
howto_embed = Embed(description=howto)
bot_message = await msg.channel.send(f"Hey {msg.author.mention}!", embed=howto_embed)
self.codeblock_message_ids[msg.id] = bot_message.id
- await bot_message.add_reaction(Emojis.cross_mark)
+
+ self.bot.loop.create_task(
+ wait_for_deletion(bot_message, user_ids=(msg.author.id,), client=self.bot)
+ )
else:
return
@@ -380,42 +384,6 @@ async def on_raw_message_edit(self, payload: RawMessageUpdateEvent):
await bot_message.delete()
del self.codeblock_message_ids[payload.message_id]
- async def on_raw_reaction_add(self, payload: RawReactionActionEvent):
- # Ignores reactions added by the bot or added to non-codeblock correction embed messages
- # Also ignores the reaction if the user can't be loaded
- # Retrieve Member object instead of user in order to compare roles later
- # Try except used to catch instances where guild_id not in payload.
- try:
- member = self.bot.get_guild(payload.guild_id).get_member(payload.user_id)
- except AttributeError:
- return
-
- if member is None:
- return
- if member.bot or payload.message_id not in self.codeblock_message_ids.values():
- return
-
- # Finds the appropriate bot message/ user message pair and assigns them to variables
- for user_message_id, bot_message_id in self.codeblock_message_ids.items():
- if bot_message_id == payload.message_id:
- channel = self.bot.get_channel(payload.channel_id)
- user_message = await channel.get_message(user_message_id)
- bot_message = await channel.get_message(bot_message_id)
- break
-
- # If the reaction was clicked on by the author of the user message, deletes the bot message
- if member.id == user_message.author.id:
- await bot_message.delete()
- del self.codeblock_message_ids[user_message_id]
- return
-
- # If the reaction was clicked by staff (helper or higher), deletes the bot message
- for role in member.roles:
- if role.id in (Roles.owner, Roles.admin, Roles.moderator, Roles.helpers):
- await bot_message.delete()
- del self.codeblock_message_ids[user_message_id]
- return
-
def setup(bot):
bot.add_cog(Bot(bot))
diff --git a/bot/utils/messages.py b/bot/utils/messages.py
--- a/bot/utils/messages.py
+++ b/bot/utils/messages.py
@@ -7,13 +7,15 @@
from discord.abc import Snowflake
from discord.errors import HTTPException
+from bot.constants import Emojis
+
MAX_SIZE = 1024 * 1024 * 8 # 8 Mebibytes
async def wait_for_deletion(
message: Message,
user_ids: Sequence[Snowflake],
- deletion_emojis: Sequence[str] = ("❌",),
+ deletion_emojis: Sequence[str] = (Emojis.cross_mark,),
timeout: float = 60 * 5,
attach_emojis=True,
client=None
|
Use wait_for_deletion for codeblocks
**Originally posted by Leon Sandøy:**
In #73, we created a util to handle waiting for reaction and then deleting a message in `bot.utils.messages`. This should be used for codeblock messages as well.
|
**Comment from Leon Sandøy:**
mentioned in merge request !83
| 2018-11-21T12:46:17 |
|
python-discord/bot
| 207 |
python-discord__bot-207
|
[
"205"
] |
1fdab40f364416ae6d69afb14fb6658f591aa189
|
diff --git a/bot/cogs/moderation.py b/bot/cogs/moderation.py
--- a/bot/cogs/moderation.py
+++ b/bot/cogs/moderation.py
@@ -29,6 +29,7 @@
"Kick": Icons.sign_out,
"Ban": Icons.user_ban
}
+RULES_URL = "https://pythondiscord.com/about/rules"
def proxy_user(user_id: str) -> Object:
@@ -1088,8 +1089,9 @@ async def notify_infraction(
)
icon_url = INFRACTION_ICONS.get(infr_type, Icons.token_removed)
- embed.set_author(name="Infraction Information", icon_url=icon_url)
- embed.set_footer(text=f"Please review our rules over at https://pythondiscord.com/about/rules")
+ embed.set_author(name="Infraction Information", icon_url=icon_url, url=RULES_URL)
+ embed.title = f"Please review our rules over at {RULES_URL}"
+ embed.url = RULES_URL
await self.send_private_embed(user, embed)
diff --git a/bot/cogs/modlog.py b/bot/cogs/modlog.py
--- a/bot/cogs/modlog.py
+++ b/bot/cogs/modlog.py
@@ -10,12 +10,16 @@
CategoryChannel, Colour, Embed, File, Guild,
Member, Message, NotFound, RawBulkMessageDeleteEvent,
RawMessageDeleteEvent, RawMessageUpdateEvent, Role,
- TextChannel, User, VoiceChannel)
+ TextChannel, User, VoiceChannel
+)
from discord.abc import GuildChannel
from discord.ext.commands import Bot
-from bot.constants import Channels, Colours, Emojis, Event, Icons, Keys, Roles, URLs
-from bot.constants import Guild as GuildConstant
+from bot.constants import (
+ Channels, Colours, Emojis,
+ Event, Guild as GuildConstant, Icons,
+ Keys, Roles, URLs
+)
from bot.utils.time import humanize_delta
log = logging.getLogger(__name__)
@@ -609,7 +613,12 @@ async def on_raw_message_delete(self, event: RawMessageDeleteEvent):
)
async def on_message_edit(self, before: Message, after: Message):
- if before.guild.id != GuildConstant.id or before.channel.id in GuildConstant.ignored or before.author.bot:
+ if (
+ not before.guild
+ or before.guild.id != GuildConstant.id
+ or before.channel.id in GuildConstant.ignored
+ or before.author.bot
+ ):
return
self._cached_edits.append(before.id)
@@ -670,7 +679,12 @@ async def on_raw_message_edit(self, event: RawMessageUpdateEvent):
except NotFound: # Was deleted before we got the event
return
- if message.guild.id != GuildConstant.id or message.channel.id in GuildConstant.ignored or message.author.bot:
+ if (
+ not message.guild
+ or message.guild.id != GuildConstant.id
+ or message.channel.id in GuildConstant.ignored
+ or message.author.bot
+ ):
return
await asyncio.sleep(1) # Wait here in case the normal event was fired
diff --git a/bot/cogs/superstarify.py b/bot/cogs/superstarify.py
--- a/bot/cogs/superstarify.py
+++ b/bot/cogs/superstarify.py
@@ -35,13 +35,12 @@ def moderation(self) -> Moderation:
def modlog(self) -> ModLog:
return self.bot.get_cog("ModLog")
- async def on_member_update(self, before, after):
+ async def on_member_update(self, before: Member, after: Member):
"""
This event will trigger when someone changes their name.
At this point we will look up the user in our database and check
whether they are allowed to change their names, or if they are in
superstar-prison. If they are not allowed, we will change it back.
- :return:
"""
if before.display_name == after.display_name:
@@ -85,6 +84,64 @@ async def on_member_update(self, before, after):
"to DM them, and a discord.errors.Forbidden error was incurred."
)
+ async def on_member_join(self, member: Member):
+ """
+ This event will trigger when someone (re)joins the server.
+ At this point we will look up the user in our database and check
+ whether they are in superstar-prison. If so, we will change their name
+ back to the forced nickname.
+ """
+
+ response = await self.bot.http_session.get(
+ URLs.site_superstarify_api,
+ headers=self.headers,
+ params={"user_id": str(member.id)}
+ )
+
+ response = await response.json()
+
+ if response and response.get("end_timestamp") and not response.get("error_code"):
+ forced_nick = response.get("forced_nick")
+ end_timestamp = response.get("end_timestamp")
+ log.debug(
+ f"{member.name} rejoined but is currently in superstar-prison. "
+ f"Changing the nick back to {forced_nick}."
+ )
+
+ await member.edit(nick=forced_nick)
+ try:
+ await member.send(
+ "You have left and rejoined the **Python Discord** server, effectively resetting "
+ f"your nickname from **{forced_nick}** to **{member.name}**, "
+ "but as you are currently in superstar-prison, you do not have permission to do so. "
+ "Therefore your nickname was automatically changed back. You will be allowed to "
+ "change your nickname again at the following time:\n\n"
+ f"**{end_timestamp}**."
+ )
+ except Forbidden:
+ log.warning(
+ "The user left and rejoined the server while in superstar-prison. "
+ "This led to the bot trying to DM the user to let them know their name was restored, "
+ "but the user had either blocked the bot or disabled DMs, so it was not possible "
+ "to DM them, and a discord.errors.Forbidden error was incurred."
+ )
+
+ # Log to the mod_log channel
+ log.trace("Logging to the #mod-log channel. This could fail because of channel permissions.")
+ mod_log_message = (
+ f"**{member.name}#{member.discriminator}** (`{member.id}`)\n\n"
+ f"Superstarified member potentially tried to escape the prison.\n"
+ f"Restored enforced nickname: `{forced_nick}`\n"
+ f"Superstardom ends: **{end_timestamp}**"
+ )
+ await self.modlog.send_log_message(
+ icon_url=Icons.user_update,
+ colour=Colour.gold(),
+ title="Superstar member rejoined server",
+ text=mod_log_message,
+ thumbnail=member.avatar_url_as(static_format="png")
+ )
+
@command(name='superstarify', aliases=('force_nick', 'star'))
@with_role(Roles.admin, Roles.owner, Roles.moderator)
async def superstarify(self, ctx: Context, member: Member, duration: str, *, forced_nick: str = None):
@@ -136,10 +193,11 @@ async def superstarify(self, ctx: Context, member: Member, duration: str, *, for
forced_nick = response.get('forced_nick')
end_time = response.get("end_timestamp")
image_url = response.get("image_url")
+ old_nick = member.display_name
embed.title = "Congratulations!"
embed.description = (
- f"Your previous nickname, **{member.display_name}**, was so bad that we have decided to change it. "
+ f"Your previous nickname, **{old_nick}**, was so bad that we have decided to change it. "
f"Your new nickname will be **{forced_nick}**.\n\n"
f"You will be unable to change your nickname until \n**{end_time}**.\n\n"
"If you're confused by this, please read our "
@@ -150,9 +208,10 @@ async def superstarify(self, ctx: Context, member: Member, duration: str, *, for
# Log to the mod_log channel
log.trace("Logging to the #mod-log channel. This could fail because of channel permissions.")
mod_log_message = (
- f"{member.name}#{member.discriminator} (`{member.id}`)\n\n"
+ f"**{member.name}#{member.discriminator}** (`{member.id}`)\n\n"
f"Superstarified by **{ctx.author.name}**\n"
- f"New nickname:`{forced_nick}`\n"
+ f"Old nickname: `{old_nick}`\n"
+ f"New nickname: `{forced_nick}`\n"
f"Superstardom ends: **{end_time}**"
)
await self.modlog.send_log_message(
@@ -175,7 +234,7 @@ async def superstarify(self, ctx: Context, member: Member, duration: str, *, for
await member.edit(nick=forced_nick)
await ctx.send(embed=embed)
- @command(name='unsuperstarify', aliases=('release_nick', 'uss'))
+ @command(name='unsuperstarify', aliases=('release_nick', 'unstar'))
@with_role(Roles.admin, Roles.owner, Roles.moderator)
async def unsuperstarify(self, ctx: Context, member: Member):
"""
|
Users can break out of superstar prison by leaving the server!
A user who really wants to change their nickname while in superstar prison can simply leave the server, change it, and come back. We should solve this by checking new arrivals for active superstar prison sentences and enforcing them at the door.
|
Ahhhh, the oldest trick in the book. oops...
I would like to look into this issue, if you haven't already fixed it in the meantime.
| 2018-11-24T18:26:36 |
|
python-discord/bot
| 216 |
python-discord__bot-216
|
[
"213"
] |
aa5c64d79c489188cb05b6c805fdc489dedaef44
|
diff --git a/bot/cogs/alias.py b/bot/cogs/alias.py
--- a/bot/cogs/alias.py
+++ b/bot/cogs/alias.py
@@ -1,7 +1,7 @@
import inspect
import logging
-from discord import Colour, Embed, TextChannel, User
+from discord import Colour, Embed, User
from discord.ext.commands import (
Command, Context, clean_content, command, group
)
@@ -71,13 +71,13 @@ async def site_resources_alias(self, ctx):
@command(name="watch", hidden=True)
async def bigbrother_watch_alias(
- self, ctx, user: User, channel: TextChannel = None
+ self, ctx, user: User, *, reason: str = None
):
"""
Alias for invoking <prefix>bigbrother watch user [text_channel].
"""
- await self.invoke(ctx, "bigbrother watch", user, channel)
+ await self.invoke(ctx, "bigbrother watch", user, reason=reason)
@command(name="unwatch", hidden=True)
async def bigbrother_unwatch_alias(self, ctx, user: User):
|
!watch alias is not working.
The `!watch` alias broke when we changed the watch command to take a note instead of a channel - this is due to converters in the alias. I'll fix it.
| 2018-12-05T00:00:08 |
||
python-discord/bot
| 219 |
python-discord__bot-219
|
[
"218"
] |
6386c80ba7ee785ddc9395a0490134cdd22a3911
|
diff --git a/bot/cogs/bigbrother.py b/bot/cogs/bigbrother.py
--- a/bot/cogs/bigbrother.py
+++ b/bot/cogs/bigbrother.py
@@ -216,11 +216,12 @@ async def watched_command(self, ctx: Context, from_cache: bool = True):
@bigbrother_group.command(name='watch', aliases=('w',))
@with_role(Roles.owner, Roles.admin, Roles.moderator)
- async def watch_command(self, ctx: Context, user: User, *, reason: str = None):
+ async def watch_command(self, ctx: Context, user: User, *, reason: str):
"""
Relay messages sent by the given `user` to the `#big-brother-logs` channel
- If a `reason` is specified, a note is added for `user`
+ A `reason` for watching is required, which is added for the user to be watched as a
+ note (aka: shadow warning)
"""
channel_id = Channels.big_brother_logs
@@ -251,10 +252,9 @@ async def watch_command(self, ctx: Context, user: User, *, reason: str = None):
reason = data.get('error_message', "no message provided")
await ctx.send(f":x: the API returned an error: {reason}")
- # Add a note (shadow warning) if a reason is specified
- if reason:
- reason = "bb watch: " + reason # Prepend for situational awareness
- await post_infraction(ctx, user, type="warning", reason=reason, hidden=True)
+ # Add a note (shadow warning) with the reason for watching
+ reason = "bb watch: " + reason # Prepend for situational awareness
+ await post_infraction(ctx, user, type="warning", reason=reason, hidden=True)
@bigbrother_group.command(name='unwatch', aliases=('uw',))
@with_role(Roles.owner, Roles.admin, Roles.moderator)
|
It should be mandatory to add a reason for !bb watch
Leaving it optional means we don't always know why someone was watched. This is important information, so we should make it mandatory instead.
|
Is this a "write this" issue or "reach consensus then write this" issue?
If someone disagrees, they're welcome to say so. but I think it's a no-brainer.
| 2018-12-18T21:59:05 |
|
python-discord/bot
| 259 |
python-discord__bot-259
|
[
"239"
] |
fce4c0dffd81f74c02289d4760b182d2cf2430f6
|
diff --git a/bot/cogs/filtering.py b/bot/cogs/filtering.py
--- a/bot/cogs/filtering.py
+++ b/bot/cogs/filtering.py
@@ -45,6 +45,7 @@ def __init__(self, bot: Bot):
"enabled": Filter.filter_zalgo,
"function": self._has_zalgo,
"type": "filter",
+ "content_only": True,
"user_notification": Filter.notify_user_zalgo,
"notification_msg": (
"Your post has been removed for abusing Unicode character rendering (aka Zalgo text). "
@@ -55,6 +56,7 @@ def __init__(self, bot: Bot):
"enabled": Filter.filter_invites,
"function": self._has_invites,
"type": "filter",
+ "content_only": True,
"user_notification": Filter.notify_user_invites,
"notification_msg": (
f"Per Rule 10, your invite link has been removed. {_staff_mistake_str}\n\n"
@@ -65,20 +67,36 @@ def __init__(self, bot: Bot):
"enabled": Filter.filter_domains,
"function": self._has_urls,
"type": "filter",
+ "content_only": True,
"user_notification": Filter.notify_user_domains,
"notification_msg": (
f"Your URL has been removed because it matched a blacklisted domain. {_staff_mistake_str}"
)
},
+ "filter_rich_embeds": {
+ "enabled": Filter.filter_rich_embeds,
+ "function": self._has_rich_embed,
+ "type": "filter",
+ "content_only": False,
+ "user_notification": Filter.notify_user_rich_embeds,
+ "notification_msg": (
+ "Your post has been removed because it contained a rich embed. "
+ "This indicates that you're either using an unofficial discord client or are using a self-bot, "
+ f"both of which violate Discord's Terms of Service. {_staff_mistake_str}\n\n"
+ "Please don't use a self-bot or an unofficial Discord client on our server."
+ )
+ },
"watch_words": {
"enabled": Filter.watch_words,
"function": self._has_watchlist_words,
"type": "watchlist",
+ "content_only": True,
},
"watch_tokens": {
"enabled": Filter.watch_tokens,
"function": self._has_watchlist_tokens,
"type": "watchlist",
+ "content_only": True,
},
}
@@ -121,12 +139,35 @@ async def _filter_message(self, msg: Message):
# If none of the above, we can start filtering.
if filter_message:
for filter_name, _filter in self.filters.items():
-
# Is this specific filter enabled in the config?
if _filter["enabled"]:
- triggered = await _filter["function"](msg.content)
+ # Does the filter only need the message content or the full message?
+ if _filter["content_only"]:
+ triggered = await _filter["function"](msg.content)
+ else:
+ triggered = await _filter["function"](msg)
if triggered:
+ # If this is a filter (not a watchlist), we should delete the message.
+ if _filter["type"] == "filter":
+ try:
+ # Embeds (can?) trigger both the `on_message` and `on_message_edit`
+ # event handlers, triggering filtering twice for the same message.
+ #
+ # If `on_message`-triggered filtering already deleted the message
+ # then `on_message_edit`-triggered filtering will raise exception
+ # since the message no longer exists.
+ #
+ # In addition, to avoid sending two notifications to the user, the
+ # logs, and mod_alert, we return if the message no longer exists.
+ await msg.delete()
+ except discord.errors.NotFound:
+ return
+
+ # Notify the user if the filter specifies
+ if _filter["user_notification"]:
+ await self.notify_member(msg.author, _filter["notification_msg"], msg.channel)
+
if isinstance(msg.channel, DMChannel):
channel_str = "via DM"
else:
@@ -142,6 +183,8 @@ async def _filter_message(self, msg: Message):
log.debug(message)
+ additional_embeds = msg.embeds if filter_name == "filter_rich_embeds" else None
+
# Send pretty mod log embed to mod-alerts
await self.mod_log.send_log_message(
icon_url=Icons.filtering,
@@ -151,16 +194,9 @@ async def _filter_message(self, msg: Message):
thumbnail=msg.author.avatar_url_as(static_format="png"),
channel_id=Channels.mod_alerts,
ping_everyone=Filter.ping_everyone,
+ additional_embeds=additional_embeds,
)
- # If this is a filter (not a watchlist), we should delete the message.
- if _filter["type"] == "filter":
- await msg.delete()
-
- # Notify the user if the filter specifies
- if _filter["user_notification"]:
- await self.notify_member(msg.author, _filter["notification_msg"], msg.channel)
-
break # We don't want multiple filters to trigger
@staticmethod
@@ -272,6 +308,16 @@ async def _has_invites(self, text: str) -> bool:
return True
return False
+ @staticmethod
+ async def _has_rich_embed(msg: Message):
+ """
+ Returns True if any of the embeds in the message
+ are of type 'rich', returns False otherwise
+ """
+ if msg.embeds:
+ return any(embed.type == "rich" for embed in msg.embeds)
+ return False
+
async def notify_member(self, filtered_member: Member, reason: str, channel: TextChannel):
"""
Notify filtered_member about a moderation action with the reason str
diff --git a/bot/cogs/modlog.py b/bot/cogs/modlog.py
--- a/bot/cogs/modlog.py
+++ b/bot/cogs/modlog.py
@@ -106,7 +106,7 @@ def ignore(self, event: Event, *items: int):
async def send_log_message(
self, icon_url: Optional[str], colour: Colour, title: Optional[str], text: str,
thumbnail: str = None, channel_id: int = Channels.modlog, ping_everyone: bool = False,
- files: List[File] = None, content: str = None
+ files: List[File] = None, content: str = None, additional_embeds: List[Embed] = None,
):
embed = Embed(description=text)
@@ -125,7 +125,14 @@ async def send_log_message(
else:
content = "@everyone"
- await self.bot.get_channel(channel_id).send(content=content, embed=embed, files=files)
+ channel = self.bot.get_channel(channel_id)
+
+ await channel.send(content=content, embed=embed, files=files)
+
+ if additional_embeds:
+ await channel.send("With the following embed(s):")
+ for additional_embed in additional_embeds:
+ await channel.send(embed=additional_embed)
async def on_guild_channel_create(self, channel: GUILD_CHANNEL):
if channel.guild.id != GuildConstant.id:
diff --git a/bot/constants.py b/bot/constants.py
--- a/bot/constants.py
+++ b/bot/constants.py
@@ -201,6 +201,7 @@ class Filter(metaclass=YAMLGetter):
filter_zalgo: bool
filter_invites: bool
filter_domains: bool
+ filter_rich_embeds: bool
watch_words: bool
watch_tokens: bool
@@ -208,6 +209,7 @@ class Filter(metaclass=YAMLGetter):
notify_user_zalgo: bool
notify_user_invites: bool
notify_user_domains: bool
+ notify_user_rich_embeds: bool
ping_everyone: bool
guild_invite_whitelist: List[int]
|
Add Embed detection for user messages for posting in mod alerts.
Embeds can only be legitimately posted by webhooks and bot accounts.
If a user account sends an embed, either they're using scripts on their own account (selfbot) or they're using an unofficial client or tools that enable posting the embed data. Both of these are against Discord TOS, and as such require us to give notice to the user and a reminder of the rules.
Thankfully, it's really easy to implement this check, so would be suitable as a quick addition or a first contribution.
|
I'm guessing the best place for this to fit would be in the filters cog?
I think so, too, since messages are checked there anyway.
I can look into this tomorrow, if you weren't already, @sco1. I think this is another issue that will help me get comfortable with the bot.
Have at it, just note that #251 makes some changes to the filters cog.
Thanks, I was just looking at it.
Is this issue still open, coz I am looking forward to contributing.
The issue is open, as it's not resolved. However, it's already assigned to @SebastiaanZ so he's working on it currently.
Within issues, you can check if they've been assigned already to see if someone has started working on it in the `Assignees` section on the right side of the Issue page.
| 2019-01-07T19:49:38 |
|
python-discord/bot
| 265 |
python-discord__bot-265
|
[
"134"
] |
6d6d8cd3dd4fb227a57042158771080655453c71
|
diff --git a/bot/cogs/moderation.py b/bot/cogs/moderation.py
--- a/bot/cogs/moderation.py
+++ b/bot/cogs/moderation.py
@@ -132,6 +132,11 @@ async def kick(self, ctx: Context, user: Member, *, reason: str = None):
**`reason`:** The reason for the kick.
"""
+ if not await self.respect_role_hierarchy(ctx, user, 'kick'):
+ # Ensure ctx author has a higher top role than the target user
+ # Warning is sent to ctx by the helper method
+ return
+
response_object = await post_infraction(ctx, user, type="kick", reason=reason)
if response_object is None:
return
@@ -187,6 +192,12 @@ async def ban(self, ctx: Context, user: Union[User, proxy_user], *, reason: str
**`reason`:** The reason for the ban.
"""
+ member = ctx.guild.get_member(user.id)
+ if not await self.respect_role_hierarchy(ctx, member, 'ban'):
+ # Ensure ctx author has a higher top role than the target user
+ # Warning is sent to ctx by the helper method
+ return
+
response_object = await post_infraction(ctx, user, type="ban", reason=reason)
if response_object is None:
return
@@ -370,6 +381,12 @@ async def tempban(
**`reason`:** The reason for the temporary ban.
"""
+ member = ctx.guild.get_member(user.id)
+ if not await self.respect_role_hierarchy(ctx, member, 'tempban'):
+ # Ensure ctx author has a higher top role than the target user
+ # Warning is sent to ctx by the helper method
+ return
+
response_object = await post_infraction(
ctx, user, type="ban", reason=reason, duration=duration
)
@@ -475,6 +492,11 @@ async def shadow_kick(self, ctx: Context, user: Member, *, reason: str = None):
**`reason`:** The reason for the kick.
"""
+ if not await self.respect_role_hierarchy(ctx, user, 'shadowkick'):
+ # Ensure ctx author has a higher top role than the target user
+ # Warning is sent to ctx by the helper method
+ return
+
response_object = await post_infraction(ctx, user, type="kick", reason=reason, hidden=True)
if response_object is None:
return
@@ -523,6 +545,12 @@ async def shadow_ban(self, ctx: Context, user: Union[User, proxy_user], *, reaso
**`reason`:** The reason for the ban.
"""
+ member = ctx.guild.get_member(user.id)
+ if not await self.respect_role_hierarchy(ctx, member, 'shadowban'):
+ # Ensure ctx author has a higher top role than the target user
+ # Warning is sent to ctx by the helper method
+ return
+
response_object = await post_infraction(ctx, user, type="ban", reason=reason, hidden=True)
if response_object is None:
return
@@ -662,6 +690,12 @@ async def shadow_tempban(
**`reason`:** The reason for the temporary ban.
"""
+ member = ctx.guild.get_member(user.id)
+ if not await self.respect_role_hierarchy(ctx, member, 'shadowtempban'):
+ # Ensure ctx author has a higher top role than the target user
+ # Warning is sent to ctx by the helper method
+ return
+
response_object = await post_infraction(
ctx, user, type="ban", reason=reason, duration=duration, hidden=True
)
@@ -1334,6 +1368,29 @@ async def __error(self, ctx, error):
if User in error.converters:
await ctx.send(str(error.errors[0]))
+ async def respect_role_hierarchy(self, ctx: Context, target: Member, infraction_type: str) -> bool:
+ """
+ Check if the highest role of the invoking member is greater than that of the target member
+
+ If this check fails, a warning is sent to the invoking ctx
+
+ Implement as a method rather than a check in order to avoid having to reimplement parameter
+ checks & conversions in a dedicated check decorater
+ """
+
+ actor = ctx.author
+ target_is_lower = target.top_role < actor.top_role
+ if not target_is_lower:
+ log.info(
+ f"{actor} ({actor.id}) attempted to {infraction_type} "
+ f"{target} ({target.id}), who has an equal or higher top role"
+ )
+ await ctx.send(
+ f":x: {actor.mention}, you may not {infraction_type} someone with an equal or higher top role"
+ )
+
+ return target_is_lower
+
def setup(bot):
bot.add_cog(Moderation(bot))
|
Moderation commands don't compare role hierachy of caller and "moderated"
**Originally posted by Thomas Petersson:**
Since the bot straight out bans, kicks, etc. after posting an infraction, won't it be possible for moderators to ban admins. Given the bots role is above admins. This makes it more of a trust based implementation over restricted.
In my opinion admins should not be able to moderate other admins, and moderators should definitely not be able to moderate admins (owners are above the bot in the hierarchy and can't be effected)

If it was not for the fact that joseph is an owner (and super duper owner) and the bot is under owner role in the hierarchy that may have very well gone through. (We were curious, didn't intend to try to ban Joseph)
|
**Comment from Johannes Christ:**
This is a honeypot to find untrustworthy mods. Don't tell the other mods. :secret:
Should this be enforced for all moderation commands or just a subset?
| 2019-01-09T22:10:16 |
|
python-discord/bot
| 266 |
python-discord__bot-266
|
[
"254"
] |
69a71215d1c8d5da697b0ce6a1d1cba0a995cb07
|
diff --git a/bot/cogs/alias.py b/bot/cogs/alias.py
--- a/bot/cogs/alias.py
+++ b/bot/cogs/alias.py
@@ -71,7 +71,7 @@ async def site_resources_alias(self, ctx):
@command(name="watch", hidden=True)
async def bigbrother_watch_alias(
- self, ctx, user: User, *, reason: str = None
+ self, ctx, user: User, *, reason: str
):
"""
Alias for invoking <prefix>bigbrother watch user [text_channel].
diff --git a/bot/cogs/bigbrother.py b/bot/cogs/bigbrother.py
--- a/bot/cogs/bigbrother.py
+++ b/bot/cogs/bigbrother.py
@@ -2,8 +2,10 @@
import logging
import re
from collections import defaultdict, deque
+from time import strptime, struct_time
from typing import List, Union
+from aiohttp import ClientError
from discord import Color, Embed, Guild, Member, Message, TextChannel, User
from discord.ext.commands import Bot, Context, group
@@ -26,9 +28,11 @@ class BigBrother:
def __init__(self, bot: Bot):
self.bot = bot
self.watched_users = {} # { user_id: log_channel_id }
+ self.watch_reasons = {} # { user_id: watch_reason }
self.channel_queues = defaultdict(lambda: defaultdict(deque)) # { user_id: { channel_id: queue(messages) }
self.last_log = [None, None, 0] # [user_id, channel_id, message_count]
self.consuming = False
+ self.infraction_watch_prefix = "bb watch: " # Please do not change or we won't be able to find old reasons
self.bot.loop.create_task(self.get_watched_users())
@@ -62,6 +66,42 @@ async def get_watched_users(self):
data = await response.json()
self.update_cache(data)
+ async def get_watch_reason(self, user_id: int) -> str:
+ """ Fetches and returns the latest watch reason for a user using the infraction API """
+
+ re_bb_watch = rf"^{self.infraction_watch_prefix}"
+ user_id = str(user_id)
+
+ try:
+ response = await self.bot.http_session.get(
+ URLs.site_infractions_user_type.format(
+ user_id=user_id,
+ infraction_type="note",
+ ),
+ params={"search": re_bb_watch, "hidden": "True", "active": "False"},
+ headers=self.HEADERS
+ )
+ infraction_list = await response.json()
+ except ClientError:
+ log.exception(f"Failed to retrieve bb watch reason for {user_id}.")
+ return "(error retrieving bb reason)"
+
+ if infraction_list:
+ latest_reason_infraction = max(infraction_list, key=self._parse_infraction_time)
+ latest_reason = latest_reason_infraction['reason'][len(self.infraction_watch_prefix):]
+ log.trace(f"The latest bb watch reason for {user_id}: {latest_reason}")
+ return latest_reason
+
+ log.trace(f"No bb watch reason found for {user_id}; returning default string")
+ return "(no reason specified)"
+
+ @staticmethod
+ def _parse_infraction_time(infraction: str) -> struct_time:
+ """Takes RFC1123 date_time string and returns time object for sorting purposes"""
+
+ date_string = infraction["inserted_at"]
+ return strptime(date_string, "%a, %d %b %Y %H:%M:%S %Z")
+
async def on_member_ban(self, guild: Guild, user: Union[User, Member]):
if guild.id == GuildConfig.id and user.id in self.watched_users:
url = f"{URLs.site_bigbrother_api}?user_id={user.id}"
@@ -70,6 +110,7 @@ async def on_member_ban(self, guild: Guild, user: Union[User, Member]):
async with self.bot.http_session.delete(url, headers=self.HEADERS) as response:
del self.watched_users[user.id]
del self.channel_queues[user.id]
+ del self.watch_reasons[user.id]
if response.status == 204:
await channel.send(
f"{Emojis.bb_message}:hammer: {user} got banned, so "
@@ -139,10 +180,17 @@ async def send_header(self, message: Message, destination: TextChannel):
# Send header if user/channel are different or if message limit exceeded.
if message.author.id != last_user or message.channel.id != last_channel or msg_count > limit:
+ # Retrieve watch reason from API if it's not already in the cache
+ if message.author.id not in self.watch_reasons:
+ log.trace(f"No watch reason for {message.author.id} found in cache; retrieving from API")
+ user_watch_reason = await self.get_watch_reason(message.author.id)
+ self.watch_reasons[message.author.id] = user_watch_reason
+
self.last_log = [message.author.id, message.channel.id, 0]
embed = Embed(description=f"{message.author.mention} in [#{message.channel.name}]({message.jump_url})")
embed.set_author(name=message.author.nick or message.author.name, icon_url=message.author.avatar_url)
+ embed.set_footer(text=f"Watch reason: {self.watch_reasons[message.author.id]}")
await destination.send(embed=embed)
@staticmethod
@@ -246,15 +294,15 @@ async def watch_command(self, ctx: Context, user: User, *, reason: str):
)
else:
self.watched_users[user.id] = channel
+ self.watch_reasons[user.id] = reason
+ # Add a note (shadow warning) with the reason for watching
+ reason = f"{self.infraction_watch_prefix}{reason}"
+ await post_infraction(ctx, user, type="warning", reason=reason, hidden=True)
else:
data = await response.json()
- reason = data.get('error_message', "no message provided")
- await ctx.send(f":x: the API returned an error: {reason}")
-
- # Add a note (shadow warning) with the reason for watching
- reason = "bb watch: " + reason # Prepend for situational awareness
- await post_infraction(ctx, user, type="warning", reason=reason, hidden=True)
+ error_reason = data.get('error_message', "no message provided")
+ await ctx.send(f":x: the API returned an error: {error_reason}")
@bigbrother_group.command(name='unwatch', aliases=('uw',))
@with_role(Roles.owner, Roles.admin, Roles.moderator)
@@ -270,6 +318,8 @@ async def unwatch_command(self, ctx: Context, user: User):
del self.watched_users[user.id]
if user.id in self.channel_queues:
del self.channel_queues[user.id]
+ if user.id in self.watch_reasons:
+ del self.watch_reasons[user.id]
else:
log.warning(f"user {user.id} was unwatched but was not found in the cache")
|
Add infraction context to BB log header
Now that logs have been cleaned up with a nice header embed and a watch note has been made mandatory (see: #201), there's been a good suggestion that some context on the infraction be added to this header so folks don't have to search through infractions and/or chat history to figure out why the user is being watched.
While we can assume that all watches will have an associated note infraction going forward, some fallback will need to be in place for those added prior to this PR.
|
@heavysaturn suggested in chat that it may fit nicely into the footer of the header embed. I think I agree with that.
We may want to think about the text length, as in, if the provided reason is very long, will it harm the readability of BB if it gets repeated all the time? Currently, I don't think it's an issue, as headers are posted on a relatively infrequent basis, but if more users are added to the watch list and they start alternating their conversation, the headers may start to take up a lot of space. Although, maybe it won't really matter. We can always revert it if we really don't like it later.
| 2019-01-10T16:25:04 |
|
python-discord/bot
| 275 |
python-discord__bot-275
|
[
"270"
] |
c5596249adc9fc638e84d366b9e0453f900dbe4b
|
diff --git a/bot/cogs/filtering.py b/bot/cogs/filtering.py
--- a/bot/cogs/filtering.py
+++ b/bot/cogs/filtering.py
@@ -1,7 +1,9 @@
import logging
import re
+from typing import Optional
import discord.errors
+from dateutil.relativedelta import relativedelta
from discord import Colour, DMChannel, Member, Message, TextChannel
from discord.ext.commands import Bot
@@ -73,18 +75,11 @@ def __init__(self, bot: Bot):
f"Your URL has been removed because it matched a blacklisted domain. {_staff_mistake_str}"
)
},
- "filter_rich_embeds": {
- "enabled": Filter.filter_rich_embeds,
+ "watch_rich_embeds": {
+ "enabled": Filter.watch_rich_embeds,
"function": self._has_rich_embed,
- "type": "filter",
+ "type": "watchlist",
"content_only": False,
- "user_notification": Filter.notify_user_rich_embeds,
- "notification_msg": (
- "Your post has been removed because it contained a rich embed. "
- "This indicates that you're either using an unofficial discord client or are using a self-bot, "
- f"both of which violate Discord's Terms of Service. {_staff_mistake_str}\n\n"
- "Please don't use a self-bot or an unofficial Discord client on our server."
- )
},
"watch_words": {
"enabled": Filter.watch_words,
@@ -107,10 +102,14 @@ def mod_log(self) -> ModLog:
async def on_message(self, msg: Message):
await self._filter_message(msg)
- async def on_message_edit(self, _: Message, after: Message):
- await self._filter_message(after)
+ async def on_message_edit(self, before: Message, after: Message):
+ if not before.edited_at:
+ delta = relativedelta(after.edited_at, before.created_at).microseconds
+ else:
+ delta = None
+ await self._filter_message(after, delta)
- async def _filter_message(self, msg: Message):
+ async def _filter_message(self, msg: Message, delta: Optional[int] = None):
"""
Whenever a message is sent or edited,
run it through our filters to see if it
@@ -141,6 +140,13 @@ async def _filter_message(self, msg: Message):
for filter_name, _filter in self.filters.items():
# Is this specific filter enabled in the config?
if _filter["enabled"]:
+ # Double trigger check for the embeds filter
+ if filter_name == "watch_rich_embeds":
+ # If the edit delta is less than 0.001 seconds, then we're probably dealing
+ # with a double filter trigger.
+ if delta is not None and delta < 100:
+ return
+
# Does the filter only need the message content or the full message?
if _filter["content_only"]:
triggered = await _filter["function"](msg.content)
@@ -183,7 +189,7 @@ async def _filter_message(self, msg: Message):
log.debug(message)
- additional_embeds = msg.embeds if filter_name == "filter_rich_embeds" else None
+ additional_embeds = msg.embeds if filter_name == "watch_rich_embeds" else None
# Send pretty mod log embed to mod-alerts
await self.mod_log.send_log_message(
@@ -311,11 +317,13 @@ async def _has_invites(self, text: str) -> bool:
@staticmethod
async def _has_rich_embed(msg: Message):
"""
- Returns True if any of the embeds in the message
- are of type 'rich', returns False otherwise
+ Returns True if any of the embeds in the message are of type 'rich', but are not twitter
+ embeds. Returns False otherwise.
"""
if msg.embeds:
- return any(embed.type == "rich" for embed in msg.embeds)
+ for embed in msg.embeds:
+ if embed.type == "rich" and (not embed.url or "twitter.com" not in embed.url):
+ return True
return False
async def notify_member(self, filtered_member: Member, reason: str, channel: TextChannel):
diff --git a/bot/constants.py b/bot/constants.py
--- a/bot/constants.py
+++ b/bot/constants.py
@@ -201,7 +201,7 @@ class Filter(metaclass=YAMLGetter):
filter_zalgo: bool
filter_invites: bool
filter_domains: bool
- filter_rich_embeds: bool
+ watch_rich_embeds: bool
watch_words: bool
watch_tokens: bool
@@ -209,7 +209,6 @@ class Filter(metaclass=YAMLGetter):
notify_user_zalgo: bool
notify_user_invites: bool
notify_user_domains: bool
- notify_user_rich_embeds: bool
ping_everyone: bool
guild_invite_whitelist: List[int]
|
Rich Embed Filter False Positives
Looks like the rich embed filter (introduced in #259) can be triggered by embeds added by Discord:
Due to this serious avenue for false positives I've disabled the filter until it can be investigated whether or not there's a way to discriminate between embeds sent by a self-botting user and those added by Discord.
|
If a general fix is identified, it probably also makes sense to also switch this to a `"watch"` rather than a `"filter"` to add a layer of moderator discretion before any further action is taken.
I agree.
I'm looking into a fix right now and I have some ideas. I've also realized that the double trigger prevention now relies on the message being deleted by the first filter run, so that needs a different approach as well.
Suggestions are welcome.
since the embeds from Discord are loaded in after the message it posted, they fire a separate message_update event. I think if we only look for embeds in message creation we should be able to ignore the built-in embeds.
| 2019-01-13T20:43:20 |
|
python-discord/bot
| 277 |
python-discord__bot-277
|
[
"235"
] |
fc0d8fb1eff4d18c11da8340d8bd8f5941c4f196
|
diff --git a/bot/cogs/moderation.py b/bot/cogs/moderation.py
--- a/bot/cogs/moderation.py
+++ b/bot/cogs/moderation.py
@@ -45,7 +45,7 @@ def proxy_user(user_id: str) -> Object:
class Moderation(Scheduler):
"""
- Rowboat replacement moderation tools.
+ Server moderation tools.
"""
def __init__(self, bot: Bot):
@@ -66,32 +66,32 @@ async def on_ready(self):
headers=self.headers
)
infraction_list = await response.json()
- loop = asyncio.get_event_loop()
for infraction_object in infraction_list:
if infraction_object["expires_at"] is not None:
- self.schedule_task(loop, infraction_object["id"], infraction_object)
+ self.schedule_task(self.bot.loop, infraction_object["id"], infraction_object)
# region: Permanent infractions
@with_role(*MODERATION_ROLES)
- @command(name="warn")
+ @command()
async def warn(self, ctx: Context, user: Union[User, proxy_user], *, reason: str = None):
"""
Create a warning infraction in the database for a user.
- :param user: accepts user mention, ID, etc.
- :param reason: The reason for the warning.
+
+ **`user`:** Accepts user mention, ID, etc.
+ **`reason`:** The reason for the warning.
"""
+ response_object = await post_infraction(ctx, user, type="warning", reason=reason)
+ if response_object is None:
+ return
+
notified = await self.notify_infraction(
user=user,
infr_type="Warning",
reason=reason
)
- response_object = await post_infraction(ctx, user, type="warning", reason=reason)
- if response_object is None:
- return
-
dm_result = ":incoming_envelope: " if notified else ""
action = f"{dm_result}:ok_hand: warned {user.mention}"
@@ -100,10 +100,13 @@ async def warn(self, ctx: Context, user: Union[User, proxy_user], *, reason: str
else:
await ctx.send(f"{action} ({reason}).")
- if not notified:
- await self.log_notify_failure(user, ctx.author, "warning")
+ if notified:
+ dm_status = "Sent"
+ log_content = None
+ else:
+ dm_status = "**Failed**"
+ log_content = ctx.author.mention
- # Send a message to the mod log
await self.mod_log.send_log_message(
icon_url=Icons.user_warn,
colour=Colour(Colours.soft_red),
@@ -111,32 +114,41 @@ async def warn(self, ctx: Context, user: Union[User, proxy_user], *, reason: str
thumbnail=user.avatar_url_as(static_format="png"),
text=textwrap.dedent(f"""
Member: {user.mention} (`{user.id}`)
- Actor: {ctx.message.author}
+ Actor: {ctx.author}
+ DM: {dm_status}
Reason: {reason}
- """)
+ """),
+ content=log_content,
+ footer=f"ID {response_object['infraction']['id']}"
)
@with_role(*MODERATION_ROLES)
- @command(name="kick")
+ @command()
async def kick(self, ctx: Context, user: Member, *, reason: str = None):
"""
Kicks a user.
- :param user: accepts user mention, ID, etc.
- :param reason: The reason for the kick.
+
+ **`user`:** Accepts user mention, ID, etc.
+ **`reason`:** The reason for the kick.
"""
+ response_object = await post_infraction(ctx, user, type="kick", reason=reason)
+ if response_object is None:
+ return
+
notified = await self.notify_infraction(
user=user,
infr_type="Kick",
reason=reason
)
- response_object = await post_infraction(ctx, user, type="kick", reason=reason)
- if response_object is None:
- return
-
self.mod_log.ignore(Event.member_remove, user.id)
- await user.kick(reason=reason)
+
+ try:
+ await user.kick(reason=reason)
+ action_result = True
+ except Forbidden:
+ action_result = False
dm_result = ":incoming_envelope: " if notified else ""
action = f"{dm_result}:ok_hand: kicked {user.mention}"
@@ -146,31 +158,39 @@ async def kick(self, ctx: Context, user: Member, *, reason: str = None):
else:
await ctx.send(f"{action} ({reason}).")
- if not notified:
- await self.log_notify_failure(user, ctx.author, "kick")
+ dm_status = "Sent" if notified else "**Failed**"
+ title = "Member kicked" if action_result else "Member kicked (Failed)"
+ log_content = None if all((notified, action_result)) else ctx.author.mention
- # Send a log message to the mod log
await self.mod_log.send_log_message(
icon_url=Icons.sign_out,
colour=Colour(Colours.soft_red),
- title="Member kicked",
+ title=title,
thumbnail=user.avatar_url_as(static_format="png"),
text=textwrap.dedent(f"""
Member: {user.mention} (`{user.id}`)
Actor: {ctx.message.author}
+ DM: {dm_status}
Reason: {reason}
- """)
+ """),
+ content=log_content,
+ footer=f"ID {response_object['infraction']['id']}"
)
@with_role(*MODERATION_ROLES)
- @command(name="ban")
+ @command()
async def ban(self, ctx: Context, user: Union[User, proxy_user], *, reason: str = None):
"""
Create a permanent ban infraction in the database for a user.
- :param user: Accepts user mention, ID, etc.
- :param reason: The reason for the ban.
+
+ **`user`:** Accepts user mention, ID, etc.
+ **`reason`:** The reason for the ban.
"""
+ response_object = await post_infraction(ctx, user, type="ban", reason=reason)
+ if response_object is None:
+ return
+
notified = await self.notify_infraction(
user=user,
infr_type="Ban",
@@ -178,13 +198,14 @@ async def ban(self, ctx: Context, user: Union[User, proxy_user], *, reason: str
reason=reason
)
- response_object = await post_infraction(ctx, user, type="ban", reason=reason)
- if response_object is None:
- return
-
self.mod_log.ignore(Event.member_ban, user.id)
self.mod_log.ignore(Event.member_remove, user.id)
- await ctx.guild.ban(user, reason=reason, delete_message_days=0)
+
+ try:
+ await ctx.guild.ban(user, reason=reason, delete_message_days=0)
+ action_result = True
+ except Forbidden:
+ action_result = False
dm_result = ":incoming_envelope: " if notified else ""
action = f"{dm_result}:ok_hand: permanently banned {user.mention}"
@@ -194,46 +215,51 @@ async def ban(self, ctx: Context, user: Union[User, proxy_user], *, reason: str
else:
await ctx.send(f"{action} ({reason}).")
- if not notified:
- await self.log_notify_failure(user, ctx.author, "ban")
+ dm_status = "Sent" if notified else "**Failed**"
+ log_content = None if all((notified, action_result)) else ctx.author.mention
+ title = "Member permanently banned"
+ if not action_result:
+ title += " (Failed)"
- # Send a log message to the mod log
await self.mod_log.send_log_message(
icon_url=Icons.user_ban,
colour=Colour(Colours.soft_red),
- title="Member permanently banned",
+ title=title,
thumbnail=user.avatar_url_as(static_format="png"),
text=textwrap.dedent(f"""
Member: {user.mention} (`{user.id}`)
Actor: {ctx.message.author}
+ DM: {dm_status}
Reason: {reason}
- """)
+ """),
+ content=log_content,
+ footer=f"ID {response_object['infraction']['id']}"
)
@with_role(*MODERATION_ROLES)
- @command(name="mute")
+ @command()
async def mute(self, ctx: Context, user: Member, *, reason: str = None):
"""
Create a permanent mute infraction in the database for a user.
- :param user: Accepts user mention, ID, etc.
- :param reason: The reason for the mute.
- """
- notified = await self.notify_infraction(
- user=user,
- infr_type="Mute",
- duration="Permanent",
- reason=reason
- )
+ **`user`:** Accepts user mention, ID, etc.
+ **`reason`:** The reason for the mute.
+ """
response_object = await post_infraction(ctx, user, type="mute", reason=reason)
if response_object is None:
return
- # add the mute role
self.mod_log.ignore(Event.member_update, user.id)
await user.add_roles(self._muted_role, reason=reason)
+ notified = await self.notify_infraction(
+ user=user,
+ infr_type="Mute",
+ duration="Permanent",
+ reason=reason
+ )
+
dm_result = ":incoming_envelope: " if notified else ""
action = f"{dm_result}:ok_hand: permanently muted {user.mention}"
@@ -242,10 +268,13 @@ async def mute(self, ctx: Context, user: Member, *, reason: str = None):
else:
await ctx.send(f"{action} ({reason}).")
- if not notified:
- await self.log_notify_failure(user, ctx.author, "mute")
+ if notified:
+ dm_status = "Sent"
+ log_content = None
+ else:
+ dm_status = "**Failed**"
+ log_content = ctx.author.mention
- # Send a log message to the mod log
await self.mod_log.send_log_message(
icon_url=Icons.user_mute,
colour=Colour(Colours.soft_red),
@@ -254,42 +283,47 @@ async def mute(self, ctx: Context, user: Member, *, reason: str = None):
text=textwrap.dedent(f"""
Member: {user.mention} (`{user.id}`)
Actor: {ctx.message.author}
+ DM: {dm_status}
Reason: {reason}
- """)
+ """),
+ content=log_content,
+ footer=f"ID {response_object['infraction']['id']}"
)
# endregion
# region: Temporary infractions
@with_role(*MODERATION_ROLES)
- @command(name="tempmute")
+ @command()
async def tempmute(self, ctx: Context, user: Member, duration: str, *, reason: str = None):
"""
Create a temporary mute infraction in the database for a user.
- :param user: Accepts user mention, ID, etc.
- :param duration: The duration for the temporary mute infraction
- :param reason: The reason for the temporary mute.
+
+ **`user`:** Accepts user mention, ID, etc.
+ **`duration`:** The duration for the temporary mute infraction
+ **`reason`:** The reason for the temporary mute.
"""
- notified = await self.notify_infraction(
- user=user,
- infr_type="Mute",
- duration=duration,
- reason=reason
+ response_object = await post_infraction(
+ ctx, user, type="mute", reason=reason, duration=duration
)
-
- response_object = await post_infraction(ctx, user, type="mute", reason=reason, duration=duration)
if response_object is None:
return
self.mod_log.ignore(Event.member_update, user.id)
await user.add_roles(self._muted_role, reason=reason)
+ notified = await self.notify_infraction(
+ user=user,
+ infr_type="Mute",
+ duration=duration,
+ reason=reason
+ )
+
infraction_object = response_object["infraction"]
infraction_expiration = infraction_object["expires_at"]
- loop = asyncio.get_event_loop()
- self.schedule_task(loop, infraction_object["id"], infraction_object)
+ self.schedule_task(ctx.bot.loop, infraction_object["id"], infraction_object)
dm_result = ":incoming_envelope: " if notified else ""
action = f"{dm_result}:ok_hand: muted {user.mention} until {infraction_expiration}"
@@ -299,10 +333,13 @@ async def tempmute(self, ctx: Context, user: Member, duration: str, *, reason: s
else:
await ctx.send(f"{action} ({reason}).")
- if not notified:
- await self.log_notify_failure(user, ctx.author, "mute")
+ if notified:
+ dm_status = "Sent"
+ log_content = None
+ else:
+ dm_status = "**Failed**"
+ log_content = ctx.author.mention
- # Send a log message to the mod log
await self.mod_log.send_log_message(
icon_url=Icons.user_mute,
colour=Colour(Colours.soft_red),
@@ -311,22 +348,34 @@ async def tempmute(self, ctx: Context, user: Member, duration: str, *, reason: s
text=textwrap.dedent(f"""
Member: {user.mention} (`{user.id}`)
Actor: {ctx.message.author}
+ DM: {dm_status}
Reason: {reason}
Duration: {duration}
Expires: {infraction_expiration}
- """)
+ """),
+ content=log_content,
+ footer=f"ID {response_object['infraction']['id']}"
)
@with_role(*MODERATION_ROLES)
- @command(name="tempban")
- async def tempban(self, ctx: Context, user: Union[User, proxy_user], duration: str, *, reason: str = None):
+ @command()
+ async def tempban(
+ self, ctx: Context, user: Union[User, proxy_user], duration: str, *, reason: str = None
+ ):
"""
Create a temporary ban infraction in the database for a user.
- :param user: Accepts user mention, ID, etc.
- :param duration: The duration for the temporary ban infraction
- :param reason: The reason for the temporary ban.
+
+ **`user`:** Accepts user mention, ID, etc.
+ **`duration`:** The duration for the temporary ban infraction
+ **`reason`:** The reason for the temporary ban.
"""
+ response_object = await post_infraction(
+ ctx, user, type="ban", reason=reason, duration=duration
+ )
+ if response_object is None:
+ return
+
notified = await self.notify_infraction(
user=user,
infr_type="Ban",
@@ -334,20 +383,19 @@ async def tempban(self, ctx: Context, user: Union[User, proxy_user], duration: s
reason=reason
)
- response_object = await post_infraction(ctx, user, type="ban", reason=reason, duration=duration)
- if response_object is None:
- return
-
self.mod_log.ignore(Event.member_ban, user.id)
self.mod_log.ignore(Event.member_remove, user.id)
- guild: Guild = ctx.guild
- await guild.ban(user, reason=reason, delete_message_days=0)
+
+ try:
+ await ctx.guild.ban(user, reason=reason, delete_message_days=0)
+ action_result = True
+ except Forbidden:
+ action_result = False
infraction_object = response_object["infraction"]
infraction_expiration = infraction_object["expires_at"]
- loop = asyncio.get_event_loop()
- self.schedule_task(loop, infraction_object["id"], infraction_object)
+ self.schedule_task(ctx.bot.loop, infraction_object["id"], infraction_object)
dm_result = ":incoming_envelope: " if notified else ""
action = f"{dm_result}:ok_hand: banned {user.mention} until {infraction_expiration}"
@@ -357,67 +405,74 @@ async def tempban(self, ctx: Context, user: Union[User, proxy_user], duration: s
else:
await ctx.send(f"{action} ({reason}).")
- if not notified:
- await self.log_notify_failure(user, ctx.author, "ban")
+ dm_status = "Sent" if notified else "**Failed**"
+ log_content = None if all((notified, action_result)) else ctx.author.mention
+ title = "Member temporarily banned"
+ if not action_result:
+ title += " (Failed)"
- # Send a log message to the mod log
await self.mod_log.send_log_message(
icon_url=Icons.user_ban,
colour=Colour(Colours.soft_red),
thumbnail=user.avatar_url_as(static_format="png"),
- title="Member temporarily banned",
+ title=title,
text=textwrap.dedent(f"""
Member: {user.mention} (`{user.id}`)
Actor: {ctx.message.author}
+ DM: {dm_status}
Reason: {reason}
Duration: {duration}
Expires: {infraction_expiration}
- """)
+ """),
+ content=log_content,
+ footer=f"ID {response_object['infraction']['id']}"
)
# endregion
# region: Permanent shadow infractions
@with_role(*MODERATION_ROLES)
- @command(name="shadow_warn", hidden=True, aliases=['shadowwarn', 'swarn', 'note'])
- async def shadow_warn(self, ctx: Context, user: Union[User, proxy_user], *, reason: str = None):
+ @command(hidden=True, aliases=['shadowwarn', 'swarn', 'shadow_warn'])
+ async def note(self, ctx: Context, user: Union[User, proxy_user], *, reason: str = None):
"""
- Create a warning infraction in the database for a user.
- :param user: accepts user mention, ID, etc.
- :param reason: The reason for the warning.
+ Create a private infraction note in the database for a user.
+
+ **`user`:** accepts user mention, ID, etc.
+ **`reason`:** The reason for the warning.
"""
- response_object = await post_infraction(ctx, user, type="warning", reason=reason, hidden=True)
+ response_object = await post_infraction(
+ ctx, user, type="warning", reason=reason, hidden=True
+ )
if response_object is None:
return
if reason is None:
- result_message = f":ok_hand: note added for {user.mention}."
+ await ctx.send(f":ok_hand: note added for {user.mention}.")
else:
- result_message = f":ok_hand: note added for {user.mention} ({reason})."
-
- await ctx.send(result_message)
+ await ctx.send(f":ok_hand: note added for {user.mention} ({reason}).")
- # Send a message to the mod log
await self.mod_log.send_log_message(
icon_url=Icons.user_warn,
colour=Colour(Colours.soft_red),
- title="Member shadow warned",
+ title="Member note added",
thumbnail=user.avatar_url_as(static_format="png"),
text=textwrap.dedent(f"""
Member: {user.mention} (`{user.id}`)
Actor: {ctx.message.author}
Reason: {reason}
- """)
+ """),
+ footer=f"ID {response_object['infraction']['id']}"
)
@with_role(*MODERATION_ROLES)
- @command(name="shadow_kick", hidden=True, aliases=['shadowkick', 'skick'])
+ @command(hidden=True, aliases=['shadowkick', 'skick'])
async def shadow_kick(self, ctx: Context, user: Member, *, reason: str = None):
"""
Kicks a user.
- :param user: accepts user mention, ID, etc.
- :param reason: The reason for the kick.
+
+ **`user`:** accepts user mention, ID, etc.
+ **`reason`:** The reason for the kick.
"""
response_object = await post_infraction(ctx, user, type="kick", reason=reason, hidden=True)
@@ -425,35 +480,47 @@ async def shadow_kick(self, ctx: Context, user: Member, *, reason: str = None):
return
self.mod_log.ignore(Event.member_remove, user.id)
- await user.kick(reason=reason)
+
+ try:
+ await user.kick(reason=reason)
+ action_result = True
+ except Forbidden:
+ action_result = False
if reason is None:
- result_message = f":ok_hand: kicked {user.mention}."
+ await ctx.send(f":ok_hand: kicked {user.mention}.")
else:
- result_message = f":ok_hand: kicked {user.mention} ({reason})."
+ await ctx.send(f":ok_hand: kicked {user.mention} ({reason}).")
- await ctx.send(result_message)
+ title = "Member shadow kicked"
+ if action_result:
+ log_content = None
+ else:
+ log_content = ctx.author.mention
+ title += " (Failed)"
- # Send a log message to the mod log
await self.mod_log.send_log_message(
icon_url=Icons.sign_out,
colour=Colour(Colours.soft_red),
- title="Member shadow kicked",
+ title=title,
thumbnail=user.avatar_url_as(static_format="png"),
text=textwrap.dedent(f"""
Member: {user.mention} (`{user.id}`)
Actor: {ctx.message.author}
Reason: {reason}
- """)
+ """),
+ content=log_content,
+ footer=f"ID {response_object['infraction']['id']}"
)
@with_role(*MODERATION_ROLES)
- @command(name="shadow_ban", hidden=True, aliases=['shadowban', 'sban'])
+ @command(hidden=True, aliases=['shadowban', 'sban'])
async def shadow_ban(self, ctx: Context, user: Union[User, proxy_user], *, reason: str = None):
"""
Create a permanent ban infraction in the database for a user.
- :param user: Accepts user mention, ID, etc.
- :param reason: The reason for the ban.
+
+ **`user`:** Accepts user mention, ID, etc.
+ **`reason`:** The reason for the ban.
"""
response_object = await post_infraction(ctx, user, type="ban", reason=reason, hidden=True)
@@ -462,53 +529,61 @@ async def shadow_ban(self, ctx: Context, user: Union[User, proxy_user], *, reaso
self.mod_log.ignore(Event.member_ban, user.id)
self.mod_log.ignore(Event.member_remove, user.id)
- await ctx.guild.ban(user, reason=reason, delete_message_days=0)
+
+ try:
+ await ctx.guild.ban(user, reason=reason, delete_message_days=0)
+ action_result = True
+ except Forbidden:
+ action_result = False
if reason is None:
- result_message = f":ok_hand: permanently banned {user.mention}."
+ await ctx.send(f":ok_hand: permanently banned {user.mention}.")
else:
- result_message = f":ok_hand: permanently banned {user.mention} ({reason})."
+ await ctx.send(f":ok_hand: permanently banned {user.mention} ({reason}).")
- await ctx.send(result_message)
+ title = "Member permanently banned"
+ if action_result:
+ log_content = None
+ else:
+ log_content = ctx.author.mention
+ title += " (Failed)"
- # Send a log message to the mod log
await self.mod_log.send_log_message(
icon_url=Icons.user_ban,
colour=Colour(Colours.soft_red),
- title="Member permanently banned",
+ title=title,
thumbnail=user.avatar_url_as(static_format="png"),
text=textwrap.dedent(f"""
Member: {user.mention} (`{user.id}`)
Actor: {ctx.message.author}
Reason: {reason}
- """)
+ """),
+ content=log_content,
+ footer=f"ID {response_object['infraction']['id']}"
)
@with_role(*MODERATION_ROLES)
- @command(name="shadow_mute", hidden=True, aliases=['shadowmute', 'smute'])
+ @command(hidden=True, aliases=['shadowmute', 'smute'])
async def shadow_mute(self, ctx: Context, user: Member, *, reason: str = None):
"""
Create a permanent mute infraction in the database for a user.
- :param user: Accepts user mention, ID, etc.
- :param reason: The reason for the mute.
+
+ **`user`:** Accepts user mention, ID, etc.
+ **`reason`:** The reason for the mute.
"""
response_object = await post_infraction(ctx, user, type="mute", reason=reason, hidden=True)
if response_object is None:
return
- # add the mute role
self.mod_log.ignore(Event.member_update, user.id)
await user.add_roles(self._muted_role, reason=reason)
if reason is None:
- result_message = f":ok_hand: permanently muted {user.mention}."
+ await ctx.send(f":ok_hand: permanently muted {user.mention}.")
else:
- result_message = f":ok_hand: permanently muted {user.mention} ({reason})."
-
- await ctx.send(result_message)
+ await ctx.send(f":ok_hand: permanently muted {user.mention} ({reason}).")
- # Send a log message to the mod log
await self.mod_log.send_log_message(
icon_url=Icons.user_mute,
colour=Colour(Colours.soft_red),
@@ -518,23 +593,29 @@ async def shadow_mute(self, ctx: Context, user: Member, *, reason: str = None):
Member: {user.mention} (`{user.id}`)
Actor: {ctx.message.author}
Reason: {reason}
- """)
+ """),
+ footer=f"ID {response_object['infraction']['id']}"
)
# endregion
# region: Temporary shadow infractions
@with_role(*MODERATION_ROLES)
- @command(name="shadow_tempmute", hidden=True, aliases=["shadowtempmute, stempmute"])
- async def shadow_tempmute(self, ctx: Context, user: Member, duration: str, *, reason: str = None):
+ @command(hidden=True, aliases=["shadowtempmute, stempmute"])
+ async def shadow_tempmute(
+ self, ctx: Context, user: Member, duration: str, *, reason: str = None
+ ):
"""
Create a temporary mute infraction in the database for a user.
- :param user: Accepts user mention, ID, etc.
- :param duration: The duration for the temporary mute infraction
- :param reason: The reason for the temporary mute.
+
+ **`user`:** Accepts user mention, ID, etc.
+ **`duration`:** The duration for the temporary mute infraction
+ **`reason`:** The reason for the temporary mute.
"""
- response_object = await post_infraction(ctx, user, type="mute", reason=reason, duration=duration, hidden=True)
+ response_object = await post_infraction(
+ ctx, user, type="mute", reason=reason, duration=duration, hidden=True
+ )
if response_object is None:
return
@@ -544,17 +625,15 @@ async def shadow_tempmute(self, ctx: Context, user: Member, duration: str, *, re
infraction_object = response_object["infraction"]
infraction_expiration = infraction_object["expires_at"]
- loop = asyncio.get_event_loop()
- self.schedule_expiration(loop, infraction_object)
+ self.schedule_expiration(ctx.bot.loop, infraction_object)
if reason is None:
- result_message = f":ok_hand: muted {user.mention} until {infraction_expiration}."
+ await ctx.send(f":ok_hand: muted {user.mention} until {infraction_expiration}.")
else:
- result_message = f":ok_hand: muted {user.mention} until {infraction_expiration} ({reason})."
-
- await ctx.send(result_message)
+ await ctx.send(
+ f":ok_hand: muted {user.mention} until {infraction_expiration} ({reason})."
+ )
- # Send a log message to the mod log
await self.mod_log.send_log_message(
icon_url=Icons.user_mute,
colour=Colour(Colours.soft_red),
@@ -566,67 +645,84 @@ async def shadow_tempmute(self, ctx: Context, user: Member, duration: str, *, re
Reason: {reason}
Duration: {duration}
Expires: {infraction_expiration}
- """)
+ """),
+ footer=f"ID {response_object['infraction']['id']}"
)
@with_role(*MODERATION_ROLES)
- @command(name="shadow_tempban", hidden=True, aliases=["shadowtempban, stempban"])
+ @command(hidden=True, aliases=["shadowtempban, stempban"])
async def shadow_tempban(
self, ctx: Context, user: Union[User, proxy_user], duration: str, *, reason: str = None
):
"""
Create a temporary ban infraction in the database for a user.
- :param user: Accepts user mention, ID, etc.
- :param duration: The duration for the temporary ban infraction
- :param reason: The reason for the temporary ban.
+
+ **`user`:** Accepts user mention, ID, etc.
+ **`duration`:** The duration for the temporary ban infraction
+ **`reason`:** The reason for the temporary ban.
"""
- response_object = await post_infraction(ctx, user, type="ban", reason=reason, duration=duration, hidden=True)
+ response_object = await post_infraction(
+ ctx, user, type="ban", reason=reason, duration=duration, hidden=True
+ )
if response_object is None:
return
self.mod_log.ignore(Event.member_ban, user.id)
self.mod_log.ignore(Event.member_remove, user.id)
- guild: Guild = ctx.guild
- await guild.ban(user, reason=reason, delete_message_days=0)
+
+ try:
+ await ctx.guild.ban(user, reason=reason, delete_message_days=0)
+ action_result = True
+ except Forbidden:
+ action_result = False
infraction_object = response_object["infraction"]
infraction_expiration = infraction_object["expires_at"]
- loop = asyncio.get_event_loop()
- self.schedule_expiration(loop, infraction_object)
+ self.schedule_expiration(ctx.bot.loop, infraction_object)
if reason is None:
- result_message = f":ok_hand: banned {user.mention} until {infraction_expiration}."
+ await ctx.send(f":ok_hand: banned {user.mention} until {infraction_expiration}.")
else:
- result_message = f":ok_hand: banned {user.mention} until {infraction_expiration} ({reason})."
+ await ctx.send(
+ f":ok_hand: banned {user.mention} until {infraction_expiration} ({reason})."
+ )
- await ctx.send(result_message)
+ title = "Member temporarily banned"
+ if action_result:
+ log_content = None
+ else:
+ log_content = ctx.author.mention
+ title += " (Failed)"
# Send a log message to the mod log
await self.mod_log.send_log_message(
icon_url=Icons.user_ban,
colour=Colour(Colours.soft_red),
thumbnail=user.avatar_url_as(static_format="png"),
- title="Member temporarily banned",
+ title=title,
text=textwrap.dedent(f"""
Member: {user.mention} (`{user.id}`)
Actor: {ctx.message.author}
Reason: {reason}
Duration: {duration}
Expires: {infraction_expiration}
- """)
+ """),
+ content=log_content,
+ footer=f"ID {response_object['infraction']['id']}"
)
# endregion
# region: Remove infractions (un- commands)
@with_role(*MODERATION_ROLES)
- @command(name="unmute")
+ @command()
async def unmute(self, ctx: Context, user: Member):
"""
Deactivates the active mute infraction for a user.
- :param user: Accepts user mention, ID, etc.
+
+ **`user`:** Accepts user mention, ID, etc.
"""
try:
@@ -638,16 +734,20 @@ async def unmute(self, ctx: Context, user: Member):
),
headers=self.headers
)
+
response_object = await response.json()
if "error_code" in response_object:
- await ctx.send(f":x: There was an error removing the infraction: {response_object['error_message']}")
- return
+ return await ctx.send(
+ ":x: There was an error removing the infraction: "
+ f"{response_object['error_message']}"
+ )
infraction_object = response_object["infraction"]
if infraction_object is None:
# no active infraction
- await ctx.send(f":x: There is no active mute infraction for user {user.mention}.")
- return
+ return await ctx.send(
+ f":x: There is no active mute infraction for user {user.mention}."
+ )
await self._deactivate_infraction(infraction_object)
if infraction_object["expires_at"] is not None:
@@ -660,11 +760,16 @@ async def unmute(self, ctx: Context, user: Member):
icon_url=Icons.user_unmute
)
- dm_result = ":incoming_envelope: " if notified else ""
- await ctx.send(f"{dm_result}:ok_hand: Un-muted {user.mention}.")
+ if notified:
+ dm_status = "Sent"
+ dm_emoji = ":incoming_envelope: "
+ log_content = None
+ else:
+ dm_status = "**Failed**"
+ dm_emoji = ""
+ log_content = ctx.author.mention
- if not notified:
- await self.log_notify_failure(user, ctx.author, "unmute")
+ await ctx.send(f"{dm_emoji}:ok_hand: Un-muted {user.mention}.")
# Send a log message to the mod log
await self.mod_log.send_log_message(
@@ -676,19 +781,23 @@ async def unmute(self, ctx: Context, user: Member):
Member: {user.mention} (`{user.id}`)
Actor: {ctx.message.author}
Intended expiry: {infraction_object['expires_at']}
- """)
+ DM: {dm_status}
+ """),
+ footer=infraction_object["id"],
+ content=log_content
)
- except Exception:
- log.exception("There was an error removing an infraction.")
+
+ except Exception as e:
+ log.exception("There was an error removing an infraction.", exc_info=e)
await ctx.send(":x: There was an error removing the infraction.")
- return
@with_role(*MODERATION_ROLES)
- @command(name="unban")
+ @command()
async def unban(self, ctx: Context, user: Union[User, proxy_user]):
"""
Deactivates the active ban infraction for a user.
- :param user: Accepts user mention, ID, etc.
+
+ **`user`:** Accepts user mention, ID, etc.
"""
try:
@@ -702,14 +811,17 @@ async def unban(self, ctx: Context, user: Union[User, proxy_user]):
)
response_object = await response.json()
if "error_code" in response_object:
- await ctx.send(f":x: There was an error removing the infraction: {response_object['error_message']}")
- return
+ return await ctx.send(
+ ":x: There was an error removing the infraction: "
+ f"{response_object['error_message']}"
+ )
infraction_object = response_object["infraction"]
if infraction_object is None:
# no active infraction
- await ctx.send(f":x: There is no active ban infraction for user {user.mention}.")
- return
+ return await ctx.send(
+ f":x: There is no active ban infraction for user {user.mention}."
+ )
await self._deactivate_infraction(infraction_object)
if infraction_object["expires_at"] is not None:
@@ -732,7 +844,6 @@ async def unban(self, ctx: Context, user: Union[User, proxy_user]):
except Exception:
log.exception("There was an error removing an infraction.")
await ctx.send(":x: There was an error removing the infraction.")
- return
# endregion
# region: Edit infraction commands
@@ -755,10 +866,12 @@ async def infraction_edit_group(self, ctx: Context):
@infraction_edit_group.command(name="duration")
async def edit_duration(self, ctx: Context, infraction_id: str, duration: str):
"""
- Sets the duration of the given infraction, relative to the time of updating.
- :param infraction_id: the id (UUID) of the infraction
- :param duration: the new duration of the infraction, relative to the time of updating. Use "permanent" to mark
- the infraction as permanent.
+ Sets the duration of the given infraction, relative to the time of
+ updating.
+
+ **`infraction_id`:** The ID (UUID) of the infraction.
+ **`duration`:** The new duration of the infraction, relative to the
+ time of updating. Use "permanent" to the infraction as permanent.
"""
try:
@@ -784,8 +897,10 @@ async def edit_duration(self, ctx: Context, infraction_id: str, duration: str):
)
response_object = await response.json()
if "error_code" in response_object or response_object.get("success") is False:
- await ctx.send(f":x: There was an error updating the infraction: {response_object['error_message']}")
- return
+ return await ctx.send(
+ ":x: There was an error updating the infraction: "
+ f"{response_object['error_message']}"
+ )
infraction_object = response_object["infraction"]
# Re-schedule
@@ -796,7 +911,10 @@ async def edit_duration(self, ctx: Context, infraction_id: str, duration: str):
if duration is None:
await ctx.send(f":ok_hand: Updated infraction: marked as permanent.")
else:
- await ctx.send(f":ok_hand: Updated infraction: set to expire on {infraction_object['expires_at']}.")
+ await ctx.send(
+ ":ok_hand: Updated infraction: set to expire on "
+ f"{infraction_object['expires_at']}."
+ )
except Exception:
log.exception("There was an error updating an infraction.")
@@ -839,8 +957,8 @@ async def edit_duration(self, ctx: Context, infraction_id: str, duration: str):
async def edit_reason(self, ctx: Context, infraction_id: str, *, reason: str):
"""
Sets the reason of the given infraction.
- :param infraction_id: the id (UUID) of the infraction
- :param reason: The new reason of the infraction
+ **`infraction_id`:** The ID (UUID) of the infraction.
+ **`reason`:** The new reason of the infraction.
"""
try:
@@ -863,14 +981,15 @@ async def edit_reason(self, ctx: Context, infraction_id: str, *, reason: str):
)
response_object = await response.json()
if "error_code" in response_object or response_object.get("success") is False:
- await ctx.send(f":x: There was an error updating the infraction: {response_object['error_message']}")
- return
+ return await ctx.send(
+ ":x: There was an error updating the infraction: "
+ f"{response_object['error_message']}"
+ )
await ctx.send(f":ok_hand: Updated infraction: set reason to \"{reason}\".")
except Exception:
log.exception("There was an error updating an infraction.")
- await ctx.send(":x: There was an error updating the infraction.")
- return
+ return await ctx.send(":x: There was an error updating the infraction.")
new_infraction = response_object["infraction"]
prev_infraction = previous_object["infraction"]
@@ -1004,6 +1123,7 @@ async def send_infraction_list(self, ctx: Context, embed: Embed, infractions: li
def schedule_expiration(self, loop: asyncio.AbstractEventLoop, infraction_object: dict):
"""
Schedules a task to expire a temporary infraction.
+
:param loop: the asyncio event loop
:param infraction_object: the infraction object to expire at the end of the task
"""
@@ -1032,9 +1152,10 @@ def cancel_expiration(self, infraction_id: str):
async def _scheduled_task(self, infraction_object: dict):
"""
- A co-routine which marks an infraction as expired after the delay from the time of scheduling
- to the time of expiration. At the time of expiration, the infraction is marked as inactive on the website,
- and the expiration task is cancelled.
+ A co-routine which marks an infraction as expired after the delay from the time of
+ scheduling to the time of expiration. At the time of expiration, the infraction is
+ marked as inactive on the website, and the expiration task is cancelled.
+
:param infraction_object: the infraction in question
"""
@@ -1061,8 +1182,9 @@ async def _scheduled_task(self, infraction_object: dict):
async def _deactivate_infraction(self, infraction_object):
"""
- A co-routine which marks an infraction as inactive on the website. This co-routine does not cancel or
- un-schedule an expiration task.
+ A co-routine which marks an infraction as inactive on the website. This co-routine does
+ not cancel or un-schedule an expiration task.
+
:param infraction_object: the infraction in question
"""
@@ -1116,7 +1238,8 @@ def _infraction_to_string(self, infraction_object):
return lines.strip()
async def notify_infraction(
- self, user: Union[User, Member], infr_type: str, duration: str = None, reason: str = None
+ self, user: Union[User, Member], infr_type: str, duration: str = None,
+ reason: str = None
):
"""
Notify a user of their fresh infraction :)
@@ -1150,7 +1273,8 @@ async def notify_infraction(
return await self.send_private_embed(user, embed)
async def notify_pardon(
- self, user: Union[User, Member], title: str, content: str, icon_url: str = Icons.user_verified
+ self, user: Union[User, Member], title: str, content: str,
+ icon_url: str = Icons.user_verified
):
"""
Notify a user that an infraction has been lifted.
@@ -1197,7 +1321,10 @@ async def log_notify_failure(self, target: str, actor: Member, infraction_type:
content=actor.mention,
colour=Colour(Colours.soft_red),
title="Notification Failed",
- text=f"Direct message was unable to be sent.\nUser: {target.mention}\nType: {infraction_type}"
+ text=(
+ f"Direct message was unable to be sent.\nUser: {target.mention}\n"
+ f"Type: {infraction_type}"
+ )
)
# endregion
diff --git a/bot/cogs/modlog.py b/bot/cogs/modlog.py
--- a/bot/cogs/modlog.py
+++ b/bot/cogs/modlog.py
@@ -116,7 +116,7 @@ async def send_log_message(
content: Optional[str] = None,
additional_embeds: Optional[List[Embed]] = None,
timestamp_override: Optional[datetime.datetime] = None,
- footer_override: Optional[str] = None,
+ footer: Optional[str] = None,
):
embed = Embed(description=text)
@@ -127,8 +127,8 @@ async def send_log_message(
embed.timestamp = timestamp_override or datetime.datetime.utcnow()
- if footer_override:
- embed.set_footer(text=footer_override)
+ if footer:
+ embed.set_footer(text=footer)
if thumbnail:
embed.set_thumbnail(url=thumbnail)
@@ -710,7 +710,7 @@ async def on_message_edit(self, before: Message, after: Message):
await self.send_log_message(
Icons.message_edit, Colour.blurple(), "Message edited (Before)", before_response,
- channel_id=Channels.message_log, timestamp_override=timestamp, footer_override=footer
+ channel_id=Channels.message_log, timestamp_override=timestamp, footer=footer
)
await self.send_log_message(
|
Infraction notifications are sent before the infraction is carried out.
As of now we send the notification to users about their infraction before we actually get Discord to add the muted role or kick them. This is fine as long as the site and the infraction are actually carried out. If they are not carried out then the user gets the notification about the infraction but then it is not logged to the site or it is not applied on Discord.
https://github.com/python-discord/bot/blob/master/bot/cogs/moderation.py#L111-L115
The behaviour of bans must remain the same, because when we ban a user the bot cannot message them anymore (no common servers), but maybe for the other infraction types we can move the notification to the users to the end of the process, after we are sure that the site knows about the infraction and the actions have executed successfully.
EDIT: As stated by Hemlock below, kicks would have to be the same as the bot would not have a mutual guild in the event that they were kicked from the server, mutes & warns are fine to send notifications after actions.
| 2019-01-16T13:56:24 |
||
python-discord/bot
| 278 |
python-discord__bot-278
|
[
"124"
] |
07e455a9bb1ef405c30db6ac0c4a88efc91471c5
|
diff --git a/bot/cogs/events.py b/bot/cogs/events.py
--- a/bot/cogs/events.py
+++ b/bot/cogs/events.py
@@ -1,4 +1,5 @@
import logging
+from functools import partial
from discord import Colour, Embed, Member, Object
from discord.ext.commands import (
@@ -7,7 +8,6 @@
Context, NoPrivateMessage, UserInputError
)
-from bot.cogs.modlog import ModLog
from bot.constants import (
Channels, Colours, DEBUG_MODE,
Guild, Icons, Keys,
@@ -28,8 +28,9 @@ def __init__(self, bot: Bot):
self.headers = {"X-API-KEY": Keys.site_api}
@property
- def mod_log(self) -> ModLog:
- return self.bot.get_cog("ModLog")
+ def send_log(self) -> partial:
+ cog = self.bot.get_cog("ModLog")
+ return partial(cog.send_log_message, channel_id=Channels.userlog)
async def send_updated_users(self, *users, replace_all=False):
users = list(filter(lambda user: str(Roles.verified) in user["roles"], users))
@@ -249,7 +250,7 @@ async def on_member_join(self, member: Member):
except Exception as e:
log.exception("Failed to persist roles")
- await self.mod_log.send_log_message(
+ await self.send_log(
Icons.crown_red, Colour(Colours.soft_red), "Failed to persist roles",
f"```py\n{e}\n```",
member.avatar_url_as(static_format="png")
@@ -290,7 +291,7 @@ async def on_member_join(self, member: Member):
reason="Roles restored"
)
- await self.mod_log.send_log_message(
+ await self.send_log(
Icons.crown_blurple, Colour.blurple(), "Roles restored",
f"Restored {len(new_roles)} roles",
member.avatar_url_as(static_format="png")
diff --git a/bot/cogs/modlog.py b/bot/cogs/modlog.py
--- a/bot/cogs/modlog.py
+++ b/bot/cogs/modlog.py
@@ -381,7 +381,8 @@ async def on_member_ban(self, guild: Guild, member: Union[Member, User]):
await self.send_log_message(
Icons.user_ban, Colour(Colours.soft_red),
"User banned", f"{member.name}#{member.discriminator} (`{member.id}`)",
- thumbnail=member.avatar_url_as(static_format="png")
+ thumbnail=member.avatar_url_as(static_format="png"),
+ channel_id=Channels.modlog
)
async def on_member_join(self, member: Member):
@@ -400,7 +401,8 @@ async def on_member_join(self, member: Member):
await self.send_log_message(
Icons.sign_in, Colour(Colours.soft_green),
"User joined", message,
- thumbnail=member.avatar_url_as(static_format="png")
+ thumbnail=member.avatar_url_as(static_format="png"),
+ channel_id=Channels.userlog
)
async def on_member_remove(self, member: Member):
@@ -414,7 +416,8 @@ async def on_member_remove(self, member: Member):
await self.send_log_message(
Icons.sign_out, Colour(Colours.soft_red),
"User left", f"{member.name}#{member.discriminator} (`{member.id}`)",
- thumbnail=member.avatar_url_as(static_format="png")
+ thumbnail=member.avatar_url_as(static_format="png"),
+ channel_id=Channels.userlog
)
async def on_member_unban(self, guild: Guild, member: User):
@@ -428,7 +431,8 @@ async def on_member_unban(self, guild: Guild, member: User):
await self.send_log_message(
Icons.user_unban, Colour.blurple(),
"User unbanned", f"{member.name}#{member.discriminator} (`{member.id}`)",
- thumbnail=member.avatar_url_as(static_format="png")
+ thumbnail=member.avatar_url_as(static_format="png"),
+ channel_id=Channels.modlog
)
async def on_member_update(self, before: Member, after: Member):
@@ -516,7 +520,8 @@ async def on_member_update(self, before: Member, after: Member):
await self.send_log_message(
Icons.user_update, Colour.blurple(),
"Member updated", message,
- thumbnail=after.avatar_url_as(static_format="png")
+ thumbnail=after.avatar_url_as(static_format="png"),
+ channel_id=Channels.userlog
)
async def on_raw_bulk_message_delete(self, event: RawBulkMessageDeleteEvent):
diff --git a/bot/constants.py b/bot/constants.py
--- a/bot/constants.py
+++ b/bot/constants.py
@@ -352,6 +352,7 @@ class Channels(metaclass=YAMLGetter):
off_topic_3: int
python: int
reddit: int
+ userlog: int
verification: int
|
Seperate out moderation logs from user logs in #mod-logs
**Originally posted by Thomas Petersson:**
Might be handy to be able to have them separate if we ever need to review moderation based events like a kick / ban.
Thoughts?
|
**Comment from Johannes Christ:**
I agree. Maybe we should put user logs (such as username updates) in #message-change-logs and name it something like `#general-log` and keep moderation events in `#mod-logs`?
Any more thoughts on this? Related discussions have been popping up occasionally as we've been adding logging embeds to other functions. Perhaps a broader look at everything currently logged is in order?
yeah I totally think we should do this. it's not a lot of work, one extra channel, and makes it much easier to keep up with the important stuff. I'd mute general logs, but keep up with infraction logs. It'd be super useful.
This should be fairly trivial for an admin to handle, and I'd personally very much like to see it sooner rather than later.
To keep everyone on the same page, here's what I'm seeing as the proposed layout
- \#message-change-logs
- Leave as-is
- \#mod-log
- Infraction logs (including shadow versions, where applicable)
- Mute, Kick (includes DEFCON), Ban, Warn ~~(not yet implemented, proposed in #137)~~
- \#user-log
- Title TBD (suggestions?)
- General user logs
- Join, part, update
Anything missing?
That looks solid. Warns are implemented too now. I think `#user-log` is a good name.
#user-log has been created, ID `528976905546760203`
I'm in the process of doing some code tidying and consolidation in the moderation cog. Since this is within the scope of refinement, I'll happily take this on as part of the same PR, as it won't take much to add.
| 2019-01-16T14:42:39 |
|
python-discord/bot
| 307 |
python-discord__bot-307
|
[
"290"
] |
ae6e610b4e0b2f63c28f0c6aa45a33f3f229ae1f
|
diff --git a/bot/cogs/alias.py b/bot/cogs/alias.py
--- a/bot/cogs/alias.py
+++ b/bot/cogs/alias.py
@@ -74,20 +74,18 @@ async def bigbrother_watch_alias(
self, ctx: Context, user: User, *, reason: str
):
"""
- Alias for invoking <prefix>bigbrother watch user [text_channel].
+ Alias for invoking <prefix>bigbrother watch [user] [reason].
"""
await self.invoke(ctx, "bigbrother watch", user, reason=reason)
@command(name="unwatch", hidden=True)
- async def bigbrother_unwatch_alias(self, ctx, user: User):
+ async def bigbrother_unwatch_alias(self, ctx, user: User, *, reason: str):
"""
- Alias for invoking <prefix>bigbrother unwatch user.
-
- user: discord.User - A user instance to unwatch
+ Alias for invoking <prefix>bigbrother unwatch [user] [reason].
"""
- await self.invoke(ctx, "bigbrother unwatch", user)
+ await self.invoke(ctx, "bigbrother unwatch", user, reason=reason)
@command(name="home", hidden=True)
async def site_home_alias(self, ctx):
@@ -108,7 +106,7 @@ async def site_faq_alias(self, ctx):
@command(name="reload", hidden=True)
async def cogs_reload_alias(self, ctx, *, cog_name: str):
"""
- Alias for invoking <prefix>cogs reload cog_name.
+ Alias for invoking <prefix>cogs reload [cog_name].
cog_name: str - name of the cog to be reloaded.
"""
diff --git a/bot/cogs/bigbrother.py b/bot/cogs/bigbrother.py
--- a/bot/cogs/bigbrother.py
+++ b/bot/cogs/bigbrother.py
@@ -44,6 +44,7 @@ def __init__(self, bot: Bot):
self.last_log = [None, None, 0] # [user_id, channel_id, message_count]
self.consuming = False
self.infraction_watch_prefix = "bb watch: " # Please do not change or we won't be able to find old reasons
+ self.nomination_prefix = "Helper nomination: "
self.bot.loop.create_task(self.get_watched_users())
@@ -77,10 +78,20 @@ async def get_watched_users(self):
data = await response.json()
self.update_cache(data)
- async def get_watch_information(self, user_id: int) -> WatchInformation:
+ async def update_watched_users(self):
+ async with self.bot.http_session.get(URLs.site_bigbrother_api, headers=self.HEADERS) as response:
+ if response.status == 200:
+ data = await response.json()
+ self.update_cache(data)
+ log.trace("Updated Big Brother watchlist cache")
+ return True
+ else:
+ return False
+
+ async def get_watch_information(self, user_id: int, prefix: str) -> WatchInformation:
""" Fetches and returns the latest watch reason for a user using the infraction API """
- re_bb_watch = rf"^{self.infraction_watch_prefix}"
+ re_bb_watch = rf"^{prefix}"
user_id = str(user_id)
try:
@@ -108,7 +119,7 @@ async def get_watch_information(self, user_id: int) -> WatchInformation:
date = latest_reason_infraction["inserted_at"]
# Get the latest reason without the prefix
- latest_reason = latest_reason_infraction['reason'][len(self.infraction_watch_prefix):]
+ latest_reason = latest_reason_infraction['reason'][len(prefix):]
log.trace(f"The latest bb watch reason for {user_id}: {latest_reason}")
return WatchInformation(reason=latest_reason, actor_id=actor_id, inserted_at=date)
@@ -208,7 +219,11 @@ async def send_header(self, message: Message, destination: TextChannel):
# Retrieve watch reason from API if it's not already in the cache
if message.author.id not in self.watch_reasons:
log.trace(f"No watch information for {message.author.id} found in cache; retrieving from API")
- user_watch_information = await self.get_watch_information(message.author.id)
+ if destination == self.bot.get_channel(Channels.talent_pool):
+ prefix = self.nomination_prefix
+ else:
+ prefix = self.infraction_watch_prefix
+ user_watch_information = await self.get_watch_information(message.author.id, prefix)
self.watch_reasons[message.author.id] = user_watch_information
self.last_log = [message.author.id, message.channel.id, 0]
@@ -235,6 +250,13 @@ async def send_header(self, message: Message, destination: TextChannel):
# Adding nomination info to author_field
author_field = f"{author_field} (nominated {time_delta} by {actor})"
+ else:
+ if inserted_at:
+ # Get time delta since insertion
+ date_time = parse_rfc1123(inserted_at).replace(tzinfo=None)
+ time_delta = time_since(date_time, precision="minutes", max_units=1)
+
+ author_field = f"{author_field} (added {time_delta})"
embed = Embed(description=f"{message.author.mention} in [#{message.channel.name}]({message.jump_url})")
embed.set_author(name=author_field, icon_url=message.author.avatar_url)
@@ -291,7 +313,6 @@ async def _watch_user(self, ctx: Context, user: User, reason: str, channel_id: i
self.watched_users[user.id] = channel
# Add a note (shadow warning) with the reason for watching
- reason = f"{self.infraction_watch_prefix}{reason}"
await post_infraction(ctx, user, type="warning", reason=reason, hidden=True)
else:
data = await response.json()
@@ -313,35 +334,25 @@ async def watched_command(self, ctx: Context, from_cache: bool = True):
By default, the users are returned from the cache.
If this is not desired, `from_cache` can be given as a falsy value, e.g. e.g. 'no'.
"""
-
- if from_cache:
- lines = tuple(
- f"• <@{user_id}> in <#{self.watched_users[user_id].id}>"
- for user_id in self.watched_users
- )
- await LinePaginator.paginate(
- lines or ("There's nothing here yet.",),
- ctx,
- Embed(title="Watched users (cached)", color=Color.blue()),
- empty=False
- )
-
+ if not from_cache:
+ updated = await self.update_watched_users()
+ if not updated:
+ await ctx.send(f":x: Failed to update cache: non-200 response from the API")
+ return
+ title = "Watched users (updated cache)"
else:
- async with self.bot.http_session.get(URLs.site_bigbrother_api, headers=self.HEADERS) as response:
- if response.status == 200:
- data = await response.json()
- self.update_cache(data)
- lines = tuple(f"• <@{entry['user_id']}> in <#{entry['channel_id']}>" for entry in data)
-
- await LinePaginator.paginate(
- lines or ("There's nothing here yet.",),
- ctx,
- Embed(title="Watched users", color=Color.blue()),
- empty=False
- )
-
- else:
- await ctx.send(f":x: got non-200 response from the API")
+ title = "Watched users (from cache)"
+
+ lines = tuple(
+ f"• <@{user_id}> in <#{self.watched_users[user_id].id}>"
+ for user_id in self.watched_users
+ )
+ await LinePaginator.paginate(
+ lines or ("There's nothing here yet.",),
+ ctx,
+ Embed(title=title, color=Color.blue()),
+ empty=False
+ )
@bigbrother_group.command(name='watch', aliases=('w',))
@with_role(*MODERATION_ROLES)
@@ -353,14 +364,28 @@ async def watch_command(self, ctx: Context, user: User, *, reason: str):
note (aka: shadow warning)
"""
+ # Update cache to avoid double watching of a user
+ await self.update_watched_users()
+
+ if user.id in self.watched_users:
+ message = f":x: User is already being watched in {self.watched_users[user.id].name}"
+ await ctx.send(message)
+ return
+
channel_id = Channels.big_brother_logs
+ reason = f"{self.infraction_watch_prefix}{reason}"
+
await self._watch_user(ctx, user, reason, channel_id)
@bigbrother_group.command(name='unwatch', aliases=('uw',))
@with_role(*MODERATION_ROLES)
- async def unwatch_command(self, ctx: Context, user: User):
- """Stop relaying messages by the given `user`."""
+ async def unwatch_command(self, ctx: Context, user: User, *, reason: str):
+ """
+ Stop relaying messages by the given `user`.
+
+ A `reason` for unwatching is required, which will be added as a note to the user.
+ """
url = f"{URLs.site_bigbrother_api}?user_id={user.id}"
async with self.bot.http_session.delete(url, headers=self.HEADERS) as response:
@@ -368,14 +393,20 @@ async def unwatch_command(self, ctx: Context, user: User):
await ctx.send(f":ok_hand: will no longer relay messages sent by {user}")
if user.id in self.watched_users:
+ channel = self.watched_users[user.id]
+
del self.watched_users[user.id]
if user.id in self.channel_queues:
del self.channel_queues[user.id]
if user.id in self.watch_reasons:
del self.watch_reasons[user.id]
else:
+ channel = None
log.warning(f"user {user.id} was unwatched but was not found in the cache")
+ reason = f"Unwatched ({channel.name if channel else 'unknown channel'}): {reason}"
+ await post_infraction(ctx, user, type="warning", reason=reason, hidden=True)
+
else:
data = await response.json()
reason = data.get('error_message', "no message provided")
@@ -395,8 +426,33 @@ async def nominate_command(self, ctx: Context, user: User, *, reason: str):
# !nominate command does not show up under "BigBrother" in the help embed, but under
# the header HelperNomination for users with the helper role.
+ member = ctx.guild.get_member(user.id)
+
+ if member and any(role.id in STAFF_ROLES for role in member.roles):
+ await ctx.send(f":x: {user.mention} is already a staff member!")
+ return
+
channel_id = Channels.talent_pool
+ # Update watch cache to avoid overwriting active nomination reason
+ await self.update_watched_users()
+
+ if user.id in self.watched_users:
+ if self.watched_users[user.id].id == Channels.talent_pool:
+ prefix = "Additional nomination: "
+ else:
+ # If the user is being watched in big-brother, don't add them to talent-pool
+ message = (
+ f":x: {user.mention} can't be added to the talent-pool "
+ "as they are currently being watched in big-brother."
+ )
+ await ctx.send(message)
+ return
+ else:
+ prefix = self.nomination_prefix
+
+ reason = f"{prefix}{reason}"
+
await self._watch_user(ctx, user, reason, channel_id)
|
minor !nominate improvements
* When a user is nominated multiple times, it would be great if this showed in the #talent-pool embed. Something like "Nominated by: Scragly, lemon, fiskenslakt" would make it clear that the user had been nominated multiple times, which should count for something. The reason should not change, but a note should be added.
* It should not be possible to nominate someone who is already a Helper, Mod, Admin or Owner.
* The notes that are added currently are prefixed with `bb watch`. Perhaps for nominations, these could be prefixed with `Helper nomination:` or something.
|
> - When a user is nominated multiple times, it would be great if this showed in the #talent-pool embed. Something like "Nominated by: Scragly, lemon, fiskenslakt" would make it clear that the user had been nominated multiple times, which should count for something. The reason should not change, but a note should be added.
Okay, I would like some input on this. since there are some advantages and disadvantages to all solutions I've thought of. Not all of them implement all of the ideas expressed here.
First of all, I'm going to assume that for the moment, we'd like to not to change the underlying API. We may want to think about changing it in the future, after the Django move is completed, but if we do, my recommendation would be to consider separating the infraction/user record API from the watch API. (Don't know if that's desirable, but instead of incrementally 'hacking' additional stuff on top of the old one, we may want to do a proper evaluation of it.) So, all of the assumptions below are with the current API in mind.
1. The easiest option, by far, is silently ignoring additional nominations while a user has a current nomination. It's a simple check, but we'll lose information, as the additional/secondary nominations are not stored. I'd say that's not what we want.
2. Storing the additional nominations as notes as if they were the first nomination, but selecting *oldest* instead of the newest nomination as the primary one to display the correct timing and reason. The advantage is that this implementation is straightforward and we store everything we want to store, but is also has one **major** drawback: It introduces a new bug, namely that if someone has more than one separate nomination periods*, the embed will always display the information of the earliest period.
*) A plausible reason this may happen is that someone is nominated, but disappears from the server for a while, triggering us to remove them from consideration. After a while they return and show consistent activity, so we decide to nominate them again to observe them for a while.
3. Storing additional nominations as described in point 2, but altering the prefix compared to the initial/primary nomination. For instance, if someone does not have an active nomination, use the prefix `Helper nomination:` in the note; if someone does have an active nomination use something like `Additional nomination` or `Helper nomination (additional)"` as a prefix in the note. That way, we can always locate the latest "primary" nomination event and we can then work-out with additional nominations belong to it, as they come after it, date-wise.
A downside of doing that is that we're basically storing even more information in a single field: that it's a nomination; whether it's the initial or an additional nomination; and the actual reason itself. That's quite a hacky way of storing information in the database and we should probably split it up into separate fields (That way we can also create a view that allows us to directly query the relevant information instead of using queries with regex searches in fields).
Still, with the last option, we will be able to do what we want. (Store all the information and display it correctly.)
Is changing the API such a bad thing? Django isn't in prod yet (right?) and the old API will be replaced by that at some point anyway.
Just gotta make sure the PRs are merged together.
Django is getting closer to prod every day, and any work put into the flask API adds additional workload to the django branch. It's not ideal to do that at this point.
I think **3** seems like a fairly decent solution. `Additional nomination` seems to make the infraction history more readable anyway.
One other minor thing, but I'll edit the current reasons of the nominated helpers manually to change the prefix. I don't think it's worth it to have fallback code to support backwards compatibility for the old prefix `bb watch` for the very few nominees we currently have.
Option 3 seems fine
I'm going to give a huge +1 to separating out nominations from infractions in the Django API. While this is functional in the short term, continuing to struggle against an API endpoint that wasn't designed for this is generating a lot of hacky solutions and cruft in the infractions DB.
yeah @sco1, I agree. we should see about that in the near future.
| 2019-02-08T17:54:25 |
|
python-discord/bot
| 348 |
python-discord__bot-348
|
[
"347"
] |
fe891057f433683c6f5d0ee9100f69301a31820b
|
diff --git a/bot/cogs/bigbrother.py b/bot/cogs/bigbrother.py
--- a/bot/cogs/bigbrother.py
+++ b/bot/cogs/bigbrother.py
@@ -6,7 +6,7 @@
from typing import List, NamedTuple, Optional, Union
from aiohttp import ClientError
-from discord import Color, Embed, Guild, Member, Message, TextChannel, User
+from discord import Color, Embed, Guild, Member, Message, TextChannel, User, errors
from discord.ext.commands import Bot, Context, command, group
from bot.constants import (
@@ -43,6 +43,7 @@ def __init__(self, bot: Bot):
self.channel_queues = defaultdict(lambda: defaultdict(deque)) # { user_id: { channel_id: queue(messages) }
self.last_log = [None, None, 0] # [user_id, channel_id, message_count]
self.consuming = False
+ self.consume_task = None
self.infraction_watch_prefix = "bb watch: " # Please do not change or we won't be able to find old reasons
self.nomination_prefix = "Helper nomination: "
@@ -166,7 +167,19 @@ async def on_message(self, msg: Message):
if msg.author.id in self.watched_users:
if not self.consuming:
- self.bot.loop.create_task(self.consume_messages())
+ self.consume_task = self.bot.loop.create_task(self.consume_messages())
+
+ if self.consuming and self.consume_task.done():
+ # This should never happen, so something went wrong
+
+ log.error("The consume_task has finished, but did not reset the self.consuming boolean")
+ e = self.consume_task.exception()
+ if e:
+ log.exception("The Exception for the Task:", exc_info=e)
+ else:
+ log.error("However, an Exception was not found.")
+
+ self.consume_task = self.bot.loop.create_task(self.consume_messages())
log.trace(f"Received message: {msg.content} ({len(msg.attachments)} attachments)")
self.channel_queues[msg.author.id][msg.channel.id].append(msg)
@@ -195,7 +208,7 @@ async def consume_messages(self):
if self.channel_queues:
log.trace("Queue not empty; continue consumption.")
- self.bot.loop.create_task(self.consume_messages())
+ self.consume_task = self.bot.loop.create_task(self.consume_messages())
else:
log.trace("Done consuming messages.")
self.consuming = False
@@ -285,7 +298,14 @@ async def log_message(message: Message, destination: TextChannel):
await destination.send(content)
- await messages.send_attachments(message, destination)
+ try:
+ await messages.send_attachments(message, destination)
+ except (errors.Forbidden, errors.NotFound):
+ e = Embed(
+ description=":x: **This message contained an attachment, but it could not be retrieved**",
+ color=Color.red()
+ )
+ await destination.send(embed=e)
async def _watch_user(self, ctx: Context, user: User, reason: str, channel_id: int):
post_data = {
|
WatchChannels intermittently stop working
You've probably noticed that the watch channels (bigbrother & talent-pool) sometimes stop working until the cog is reloaded. After searching the logs, I've found this unretrieved exception:
```
00077298 | Apr 07 13:11:27 pd.beardfist.com Bot: | asyncio | ERROR | Task exception was never retrieved
00077299 | future: <Task finished coro=<BigBrother.consume_messages() done, defined at /bot/bot/cogs/bigbrother.py:174> exception=Forbidden('Forbidden (status code: 403): cannot retrieve attachment',)>
00077300 | Traceback (most recent call last):
00077301 | File "/bot/bot/cogs/bigbrother.py", line 194, in consume_messages
00077302 | await self.log_message(msg, channel)
00077303 | File "/bot/bot/cogs/bigbrother.py", line 288, in log_message
00077304 | await messages.send_attachments(message, destination)
00077305 | File "/bot/bot/utils/messages.py", line 99, in send_attachments
00077306 | await attachment.save(file)
00077307 | File "/bot/.venv/src/discord-py/discord/message.py", line 102, in save
00077308 | data = await self._http.get_attachment(self.url)
00077309 | File "/bot/.venv/src/discord-py/discord/http.py", line 225, in get_attachment
00077310 | raise Forbidden(resp, 'cannot retrieve attachment')
00077311 | discord.errors.Forbidden: Forbidden (status code: 403): cannot retrieve attachment
```
My guess is that this is the root of the problem, since it stops the `consume_messages()` Task.
This should be fixed in the rewrite of the WatchChannels that's planned for the Django branch of the bot. See #317.
|
This seems like something we shouldn’t put off fixing. It’s not a new feature and we shouldn’t have to regularly restart the cog to keep it functioning.
That's true. I'll put in a fix for it asap.
| 2019-04-09T20:21:52 |
|
python-discord/bot
| 352 |
python-discord__bot-352
|
[
"351"
] |
b5235cb707e2fcd8185ae3364c6a34dff4602bd0
|
diff --git a/bot/cogs/off_topic_names.py b/bot/cogs/off_topic_names.py
--- a/bot/cogs/off_topic_names.py
+++ b/bot/cogs/off_topic_names.py
@@ -48,9 +48,11 @@ async def update_names(bot: Bot, headers: dict):
"""
while True:
+ # Since we truncate the compute timedelta to seconds, we add one second to ensure
+ # we go past midnight in the `seconds_to_sleep` set below.
today_at_midnight = datetime.utcnow().replace(microsecond=0, second=0, minute=0, hour=0)
next_midnight = today_at_midnight + timedelta(days=1)
- seconds_to_sleep = (next_midnight - datetime.utcnow()).seconds
+ seconds_to_sleep = (next_midnight - datetime.utcnow()).seconds + 1
await asyncio.sleep(seconds_to_sleep)
response = await bot.http_session.get(
|
Bot changing off-topic channel names more than once per daily cycle
The bot should change the channel names of the three off-topic channels only once after hitting UTC midnight. However, we've noticed that it may attempt to set new channel names far more often than that. The root of the cause is still unknown, but after looking at the recent audit log screenshotted by Scragly, I've come up with a conjecture to what's happening.
If you take a look at the logs below, then you'll notice that most of the channel name changes actually happen just before the whole hour (9:59 in Scragly's local time). My guess is that the sleep duration, which is set based on "the start of the current day" + "1 day time delta", is off by one second. The odd thing is that it's not obvious to me from the code why this happens.
However, if this is true, then it would explain the current behavior: The background task is triggered at 23:59:59 (UTC), it will cycle the channel names, and, **as we're still on the same day**, calculate a sleep second delta based on the previous midnight (which will be 0, since it's trying to find the seconds to 23:59:59, which it already is), so it will async.sleep for 0 seconds and run itself again.
The fact that it doesn't trigger more often is then caused because it needs to make API calls and has other `await` points in the execution.
Since this behavior very much looks like what Discord would call "API Abuse", I think it's important to put in a bug fix as quickly as possible. Since the only thing I can think of is the off-by-one error described above, my proposal is aim for 1 minute past midnight, so we never run into "we're still on the same day" issues again:
```py
today_at_midnight = datetime.utcnow().replace(microsecond=0, second=0, minute=0, hour=0)
next_midnight = today_at_midnight + timedelta(days=1, minutes=1)
seconds_to_sleep = (next_midnight - datetime.utcnow()).seconds
await asyncio.sleep(seconds_to_sleep)
```
If that doesn't fix it, we need to investigate further, but I think this will work.
---
**Edit: some additional confirmation of the off-by-one-second error:**
```
Apr 15 08:08:35 pd.beardfist.com Bot: | bot.cogs.off_topic_names | DEBUG | update_names: seconds to sleep 24
```
I'd set the name change for `08:09:00`, but sleeping for 24 seconds at `08:08:35` will cause it to "wake up" at `08:08:59`.
---

| 2019-04-15T05:23:57 |
||
python-discord/bot
| 360 |
python-discord__bot-360
|
[
"359"
] |
7a61e582ccb866776136d969c97d23907ca160e2
|
diff --git a/bot/cogs/reddit.py b/bot/cogs/reddit.py
--- a/bot/cogs/reddit.py
+++ b/bot/cogs/reddit.py
@@ -31,6 +31,9 @@ def __init__(self, bot: Bot):
self.prev_lengths = {}
self.last_ids = {}
+ self.new_posts_task = None
+ self.top_weekly_posts_task = None
+
async def fetch_posts(self, route: str, *, amount: int = 25, params=None):
"""
A helper method to fetch a certain amount of Reddit posts at a given route.
@@ -280,8 +283,10 @@ async def on_ready(self):
self.reddit_channel = self.bot.get_channel(Channels.reddit)
if self.reddit_channel is not None:
- self.bot.loop.create_task(self.poll_new_posts())
- self.bot.loop.create_task(self.poll_top_weekly_posts())
+ if self.new_posts_task is None:
+ self.new_posts_task = self.bot.loop.create_task(self.poll_new_posts())
+ if self.top_weekly_posts_task is None:
+ self.top_weekly_posts_task = self.bot.loop.create_task(self.poll_top_weekly_posts())
else:
log.warning("Couldn't locate a channel for subreddit relaying.")
|
Bot creates multiple Reddit background tasks
Juanita noticed that the bot posted and pinned the overview of the weekly top posts of the Python subreddit multiple times:

The reason is that the `on_ready` event may fire multiple times (for instance, when the bot recovers a dropped connection), creating multiple background tasks:
The code causing the bug can be found in this on ready: https://github.com/python-discord/bot/blob/7a61e582ccb866776136d969c97d23907ca160e2/bot/cogs/reddit.py#L279
The fix should be straightforward: Keep a reference to the Background task as a class attribute and check if there's already a Task running like we do at other places as well.
Since this both hits the Discord API and the Reddit API, we should probably just fix this right away and not wait until the feature freeze is over. I'll put in a PR soon.
| 2019-05-06T20:31:01 |
||
python-discord/bot
| 373 |
python-discord__bot-373
|
[
"369"
] |
fe9482cd9d8bf4b34f1f5d3926695e2d1d5c1e8a
|
diff --git a/bot/cogs/off_topic_names.py b/bot/cogs/off_topic_names.py
--- a/bot/cogs/off_topic_names.py
+++ b/bot/cogs/off_topic_names.py
@@ -19,7 +19,7 @@ class OffTopicName(Converter):
@staticmethod
async def convert(ctx: Context, argument: str):
- allowed_characters = ("-", "’", "'", "`")
+ allowed_characters = "ABCDEFGHIJKLMNOPQRSTUVWXYZ!?'`"
if not (2 <= len(argument) <= 96):
raise BadArgument("Channel name must be between 2 and 96 chars long")
@@ -30,11 +30,11 @@ async def convert(ctx: Context, argument: str):
"alphanumeric characters, minus signs or apostrophes."
)
- elif not argument.islower():
- raise BadArgument("Channel name must be lowercase")
-
- # Replace some unusable apostrophe-like characters with "’".
- return argument.replace("'", "’").replace("`", "’")
+ # Replace invalid characters with unicode alternatives.
+ table = str.maketrans(
+ allowed_characters, '𝖠𝖡𝖢𝖣𝖤𝖥𝖦𝖧𝖨𝖩𝖪𝖫𝖬𝖭𝖮𝖯𝖰𝖱𝖲𝖳𝖴𝖵𝖶𝖷𝖸𝖹ǃ?’’'
+ )
+ return argument.translate(table)
async def update_names(bot: Bot, headers: dict):
|
make !otn accept uppercase and punctuation
There are weird unicode alternatives for stuff like capital letters and punctuation that will get through the discord "only lowercase and dashes" filters.
When someone uses `!otn a` and tries to add a name with an apostrophe, we currently are transforming those into something that the system will accept. Let's do the same for exclamation points, question marks, and uppercase letters!
* For exclamation points, use ǃ
* For questionmarks, use ?
* For uppercase, use 𝖠𝖡𝖢𝖣𝖤𝖥𝖦𝖧𝖨𝖩𝖪𝖫𝖬𝖭𝖮𝖯𝖰𝖱𝖲𝖳𝖴𝖵𝖶𝖷𝖸𝖹
| 2019-06-14T16:58:50 |
||
python-discord/bot
| 396 |
python-discord__bot-396
|
[
"540"
] |
a8ef752b3fa954c4df3cd3ab2852ac3333b44553
|
diff --git a/bot/__main__.py b/bot/__main__.py
--- a/bot/__main__.py
+++ b/bot/__main__.py
@@ -6,11 +6,11 @@
from discord import Game
from discord.ext.commands import Bot, when_mentioned_or
-from bot.api import APIClient
+from bot.api import APIClient, APILoggingHandler
from bot.constants import Bot as BotConfig, DEBUG_MODE
-log = logging.getLogger(__name__)
+log = logging.getLogger('bot')
bot = Bot(
command_prefix=when_mentioned_or(BotConfig.prefix),
@@ -29,6 +29,7 @@
)
)
bot.api_client = APIClient(loop=asyncio.get_event_loop())
+log.addHandler(APILoggingHandler(bot.api_client))
# Internal/debug
bot.load_extension("bot.cogs.error_handler")
diff --git a/bot/api.py b/bot/api.py
--- a/bot/api.py
+++ b/bot/api.py
@@ -1,9 +1,13 @@
+import asyncio
+import logging
from urllib.parse import quote as quote_url
import aiohttp
from .constants import Keys, URLs
+log = logging.getLogger(__name__)
+
class ResponseCodeError(ValueError):
def __init__(self, response: aiohttp.ClientResponse):
@@ -58,3 +62,76 @@ async def delete(self, endpoint: str, *args, raise_for_status: bool = True, **kw
self.maybe_raise_for_status(resp, raise_for_status)
return await resp.json()
+
+
+def loop_is_running() -> bool:
+ # asyncio does not have a way to say "call this when the event
+ # loop is running", see e.g. `callWhenRunning` from twisted.
+
+ try:
+ asyncio.get_running_loop()
+ except RuntimeError:
+ return False
+ return True
+
+
+class APILoggingHandler(logging.StreamHandler):
+ def __init__(self, client: APIClient):
+ logging.StreamHandler.__init__(self)
+ self.client = client
+
+ # internal batch of shipoff tasks that must not be scheduled
+ # on the event loop yet - scheduled when the event loop is ready.
+ self.queue = []
+
+ async def ship_off(self, payload: dict):
+ try:
+ await self.client.post('logs', json=payload)
+ except ResponseCodeError as err:
+ log.warning(
+ "Cannot send logging record to the site, got code %d.",
+ err.response.status,
+ extra={'via_handler': True}
+ )
+ except Exception as err:
+ log.warning(
+ "Cannot send logging record to the site: %r",
+ err,
+ extra={'via_handler': True}
+ )
+
+ def emit(self, record: logging.LogRecord):
+ # Ignore logging messages which are sent by this logging handler
+ # itself. This is required because if we were to not ignore
+ # messages emitted by this handler, we would infinitely recurse
+ # back down into this logging handler, making the reactor run
+ # like crazy, and eventually OOM something. Let's not do that...
+ if not record.__dict__.get('via_handler'):
+ payload = {
+ 'application': 'bot',
+ 'logger_name': record.name,
+ 'level': record.levelname.lower(),
+ 'module': record.module,
+ 'line': record.lineno,
+ 'message': self.format(record)
+ }
+
+ task = self.ship_off(payload)
+ if not loop_is_running():
+ self.queue.append(task)
+ else:
+ asyncio.create_task(task)
+ self.schedule_queued_tasks()
+
+ def schedule_queued_tasks(self):
+ for task in self.queue:
+ asyncio.create_task(task)
+
+ if self.queue:
+ log.debug(
+ "Scheduled %d pending logging tasks.",
+ len(self.queue),
+ extra={'via_handler': True}
+ )
+
+ self.queue.clear()
|
Don't show infraction total outside staff channels.
Currently, when we deliver an infraction, it will show the infraction total in the bot's response.

This is a cool feature, but should not happen in public channels. So let's do something about that.
### Infraction total should be allowed in the following channels:
```
#admins ID: 365960823622991872
#admin-spam ID: 563594791770914816
#mod-spam ID: 620607373828030464
#mods ID: 305126844661760000
#helpers ID: 385474242440986624
#organisation ID: 551789653284356126
#defcon ID: 464469101889454091
```
If the command is called in any other channel, **do not show the infraction total**. This applies to all moderation commands that currently show the total.
If any of the above channels are not currently registered as constants, please create new constants for them. The above list of channels can be stored as a group constant called `STAFF_CHANNELS`. Make use of [YAML node anchors](https://yaml.org/spec/1.2/spec.html#&%20anchor//) when you do this.
| 2019-08-14T20:14:16 |
||
python-discord/bot
| 429 |
python-discord__bot-429
|
[
"408"
] |
9b2145505b68b001b6db8bb0206442f27b80ce54
|
diff --git a/bot/cogs/off_topic_names.py b/bot/cogs/off_topic_names.py
--- a/bot/cogs/off_topic_names.py
+++ b/bot/cogs/off_topic_names.py
@@ -1,4 +1,5 @@
import asyncio
+import difflib
import logging
from datetime import datetime, timedelta
@@ -141,6 +142,27 @@ async def list_command(self, ctx):
embed.description = "Hmmm, seems like there's nothing here yet."
await ctx.send(embed=embed)
+ @otname_group.command(name='search', aliases=('s',))
+ @with_role(*MODERATION_ROLES)
+ async def search_command(self, ctx, *, query: str):
+ """
+ Search for an off-topic name.
+ """
+
+ result = await self.bot.api_client.get('bot/off-topic-channel-names')
+ matches = difflib.get_close_matches(query, result, n=10, cutoff=0.35)
+ lines = sorted(f"• {name}" for name in matches)
+ embed = Embed(
+ title=f"Query results",
+ colour=Colour.blue()
+ )
+
+ if matches:
+ await LinePaginator.paginate(lines, ctx, embed, max_size=400, empty=False)
+ else:
+ embed.description = "Nothing found."
+ await ctx.send(embed=embed)
+
def setup(bot: Bot):
bot.add_cog(OffTopicNames(bot))
|
Implement a search command for !otn
With hundreds of off-topic names in our list, looking for one by clicking through the paginator with the bot is tedious.
Let's have a `!otn search <name>` command!
#### Implementation Ideas
- Use the text search functionality in postgres
- Fuzzy search (`fuzzystrmatch` maybe?)
- Ranked list based on similarity to query
|
Love this idea.
| 2019-09-15T17:30:36 |
|
python-discord/bot
| 436 |
python-discord__bot-436
|
[
"435"
] |
6c894034afc82e36270174a914ea57e5293f7671
|
diff --git a/bot/cogs/off_topic_names.py b/bot/cogs/off_topic_names.py
--- a/bot/cogs/off_topic_names.py
+++ b/bot/cogs/off_topic_names.py
@@ -144,20 +144,21 @@ async def list_command(self, ctx):
@otname_group.command(name='search', aliases=('s',))
@with_role(*MODERATION_ROLES)
- async def search_command(self, ctx, *, query: str):
+ async def search_command(self, ctx, *, query: OffTopicName):
"""
Search for an off-topic name.
"""
result = await self.bot.api_client.get('bot/off-topic-channel-names')
- matches = difflib.get_close_matches(query, result, n=10, cutoff=0.35)
- lines = sorted(f"• {name}" for name in matches)
+ in_matches = {name for name in result if query in name}
+ close_matches = difflib.get_close_matches(query, result, n=10, cutoff=0.70)
+ lines = sorted(f"• {name}" for name in in_matches.union(close_matches))
embed = Embed(
title=f"Query results",
colour=Colour.blue()
)
- if matches:
+ if lines:
await LinePaginator.paginate(lines, ctx, embed, max_size=400, empty=False)
else:
embed.description = "Nothing found."
|
Enhance off-topic name search feature
We've recently added a search feature for off-topic names. It's a really cool feature, but I think it can be enhanced in a couple of ways. (Use the informal definition of "couple": ["an indefinite small number."](https://www.merriam-webster.com/dictionary/couple))
For all the examples, this is the list of off-topic-names in the database:
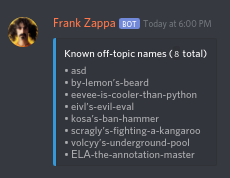
**1. Use `OffTopicName` converter for the `query` argument**
We don't use the characters as-is in off-topic names, but we use a translation table on the string input. However, we don't do that yet for the search query of the search feature. This leads to interesting search results:
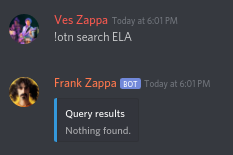
If we change the annotation to `query: OffTopicName`, we utilize the same conversion for the query as we use for the actual off-topic-names, leading to much better results:
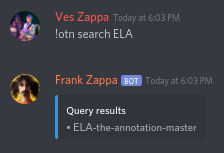
**2. Add a simple membership test of `query in offtopicname`**
Currently, we utilize `difflib.get_close_match` to get results that closely match the query. However, this function will match based on the whole off-topic name, so it doesn't do well if we search for a substring of the off-topic name. (I suspect this is part of the reason we use relatively low cutoff.)
While there's clearly a "pool" in volcyy's underground, we don't find it:
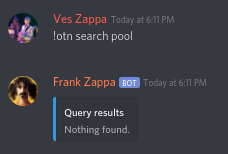
If we add a simple membership test to the existing `get_close_match`, we do get the results we expect:
**3. Given the membership test of suggestion 2, up the cutoff**
The low cutoff does allow us some leeway when searching for partial off-topic names, but it also causes interesting results. Using the current search feature, without the membership testing suggested in 2, we don't find "eevee-is-cooler-than-python" when we search for "eevee", but "eivl's-evil-eval":
However, if we up the cutoff value and combine it with an additional membership test, we can search for "sounds-like" off-topic names and find off-topic names that contain exact matches:
| 2019-09-17T17:18:58 |
||
python-discord/bot
| 437 |
python-discord__bot-437
|
[
"434"
] |
83127be0bef58ee001959d421f7aefc3aee504dd
|
diff --git a/bot/cogs/bot.py b/bot/cogs/bot.py
--- a/bot/cogs/bot.py
+++ b/bot/cogs/bot.py
@@ -6,15 +6,14 @@
from discord import Embed, Message, RawMessageUpdateEvent
from discord.ext.commands import Bot, Cog, Context, command, group
-from bot.constants import (
- Channels, Guild, MODERATION_ROLES,
- Roles, URLs,
-)
+from bot.constants import Channels, DEBUG_MODE, Guild, MODERATION_ROLES, Roles, URLs
from bot.decorators import with_role
from bot.utils.messages import wait_for_deletion
log = logging.getLogger(__name__)
+RE_MARKDOWN = re.compile(r'([*_~`|>])')
+
class Bot(Cog):
"""
@@ -255,7 +254,7 @@ async def on_message(self, msg: Message):
if parse_codeblock:
on_cooldown = (time.time() - self.channel_cooldowns.get(msg.channel.id, 0)) < 300
- if not on_cooldown:
+ if not on_cooldown or DEBUG_MODE:
try:
if self.has_bad_ticks(msg):
ticks = msg.content[:3]
@@ -280,13 +279,14 @@ async def on_message(self, msg: Message):
current_length += len(line)
lines_walked += 1
content = content[:current_length] + "#..."
-
+ content_escaped_markdown = RE_MARKDOWN.sub(r'\\\1', content)
howto = (
"It looks like you are trying to paste code into this channel.\n\n"
"You seem to be using the wrong symbols to indicate where the codeblock should start. "
f"The correct symbols would be \\`\\`\\`, not `{ticks}`.\n\n"
"**Here is an example of how it should look:**\n"
- f"\\`\\`\\`python\n{content}\n\\`\\`\\`\n\n**This will result in the following:**\n"
+ f"\\`\\`\\`python\n{content_escaped_markdown}\n\\`\\`\\`\n\n"
+ "**This will result in the following:**\n"
f"```python\n{content}\n```"
)
@@ -322,13 +322,15 @@ async def on_message(self, msg: Message):
lines_walked += 1
content = content[:current_length] + "#..."
+ content_escaped_markdown = RE_MARKDOWN.sub(r'\\\1', content)
howto += (
"It looks like you're trying to paste code into this channel.\n\n"
"Discord has support for Markdown, which allows you to post code with full "
"syntax highlighting. Please use these whenever you paste code, as this "
"helps improve the legibility and makes it easier for us to help you.\n\n"
f"**To do this, use the following method:**\n"
- f"\\`\\`\\`python\n{content}\n\\`\\`\\`\n\n**This will result in the following:**\n"
+ f"\\`\\`\\`python\n{content_escaped_markdown}\n\\`\\`\\`\n\n"
+ "**This will result in the following:**\n"
f"```python\n{content}\n```"
)
|
Escape discord markdown in detected poorly formatted python code before sending correction
Currently if an user sends a message like this:
````
```
class Example:
def init__(self):
...
```
````
The bot won't escape the underscores in the escaped codeblock part of the message which will cause underlining. The underlining will continue until the other pair of the underscores is reached which are in the resulting example codeblock, making the codeblock underlined until then and in practice escaping it.

|
I'll look into this, I think we can solve this by using `re.sub` to escape all the mark-up characters.
| 2019-09-18T07:08:47 |
|
python-discord/bot
| 441 |
python-discord__bot-441
|
[
"440"
] |
8790f65a522ac888d63f0371af9f297a7e8255ea
|
diff --git a/bot/cogs/information.py b/bot/cogs/information.py
--- a/bot/cogs/information.py
+++ b/bot/cogs/information.py
@@ -1,7 +1,9 @@
+import colorsys
import logging
import textwrap
+import typing
-from discord import CategoryChannel, Colour, Embed, Member, TextChannel, VoiceChannel
+from discord import CategoryChannel, Colour, Embed, Member, Role, TextChannel, VoiceChannel, utils
from discord.ext.commands import Bot, Cog, Context, command
from bot.constants import Channels, Emojis, MODERATION_ROLES, STAFF_ROLES
@@ -42,6 +44,52 @@ async def roles_info(self, ctx: Context) -> None:
await ctx.send(embed=embed)
+ @with_role(*MODERATION_ROLES)
+ @command(name="role")
+ async def role_info(self, ctx: Context, *roles: typing.Union[Role, str]) -> None:
+ """
+ Return information on a role or list of roles.
+
+ To specify multiple roles just add to the arguments, delimit roles with spaces in them using quotation marks.
+ """
+ parsed_roles = []
+
+ for role_name in roles:
+ if isinstance(role_name, Role):
+ # Role conversion has already succeeded
+ parsed_roles.append(role_name)
+ continue
+
+ role = utils.find(lambda r: r.name.lower() == role_name.lower(), ctx.guild.roles)
+
+ if not role:
+ await ctx.send(f":x: Could not convert `{role_name}` to a role")
+ continue
+
+ parsed_roles.append(role)
+
+ for role in parsed_roles:
+ embed = Embed(
+ title=f"{role.name} info",
+ colour=role.colour,
+ )
+
+ embed.add_field(name="ID", value=role.id, inline=True)
+
+ embed.add_field(name="Colour (RGB)", value=f"#{role.colour.value:0>6x}", inline=True)
+
+ h, s, v = colorsys.rgb_to_hsv(*role.colour.to_rgb())
+
+ embed.add_field(name="Colour (HSV)", value=f"{h:.2f} {s:.2f} {v}", inline=True)
+
+ embed.add_field(name="Member count", value=len(role.members), inline=True)
+
+ embed.add_field(name="Position", value=role.position)
+
+ embed.add_field(name="Permission code", value=role.permissions.value, inline=True)
+
+ await ctx.send(embed=embed)
+
@command(name="server", aliases=["server_info", "guild", "guild_info"])
async def server_info(self, ctx: Context) -> None:
"""Returns an embed full of server information."""
|
diff --git a/tests/cogs/test_information.py b/tests/cogs/test_information.py
--- a/tests/cogs/test_information.py
+++ b/tests/cogs/test_information.py
@@ -8,6 +8,8 @@
from discord import (
CategoryChannel,
Colour,
+ Permissions,
+ Role,
TextChannel,
VoiceChannel,
)
@@ -66,6 +68,52 @@ def test_roles_info_command(cog, ctx):
assert embed.footer.text == "Total roles: 1"
+def test_role_info_command(cog, ctx):
+ dummy_role = MagicMock(spec=Role)
+ dummy_role.name = "Dummy"
+ dummy_role.colour = Colour.blurple()
+ dummy_role.id = 112233445566778899
+ dummy_role.position = 10
+ dummy_role.permissions = Permissions(0)
+ dummy_role.members = [ctx.author]
+
+ admin_role = MagicMock(spec=Role)
+ admin_role.name = "Admin"
+ admin_role.colour = Colour.red()
+ admin_role.id = 998877665544332211
+ admin_role.position = 3
+ admin_role.permissions = Permissions(0)
+ admin_role.members = [ctx.author]
+
+ ctx.guild.roles = [dummy_role, admin_role]
+
+ cog.role_info.can_run = AsyncMock()
+ cog.role_info.can_run.return_value = True
+
+ coroutine = cog.role_info.callback(cog, ctx, dummy_role, admin_role)
+
+ assert asyncio.run(coroutine) is None
+
+ assert ctx.send.call_count == 2
+
+ (_, dummy_kwargs), (_, admin_kwargs) = ctx.send.call_args_list
+
+ dummy_embed = dummy_kwargs["embed"]
+ admin_embed = admin_kwargs["embed"]
+
+ assert dummy_embed.title == "Dummy info"
+ assert dummy_embed.colour == Colour.blurple()
+
+ assert dummy_embed.fields[0].value == str(dummy_role.id)
+ assert dummy_embed.fields[1].value == f"#{dummy_role.colour.value:0>6x}"
+ assert dummy_embed.fields[2].value == "0.63 0.48 218"
+ assert dummy_embed.fields[3].value == "1"
+ assert dummy_embed.fields[4].value == "10"
+ assert dummy_embed.fields[5].value == "0"
+
+ assert admin_embed.title == "Admin info"
+ assert admin_embed.colour == Colour.red()
+
# There is no argument passed in here that we can use to test,
# so the return value would change constantly.
@patch('bot.cogs.information.time_since')
|
Implement a !role command
Currently, we have a `!roles` command, which lists out all the roles. However, it would also be useful to have a `!role <role>` command, to get more info on a certain role.
**Implementation details**
- Ability to get info on multiple roles? `!role <role_1> <role_2>`
- Info that would be helpful:
- Role ID
- Role Name
- Role Color as hex/hsv
- Is role mentionable
- Number of members with the role? (Blacklist certain high volume, easily checked ones like `@Developers`)
- Restrict to core developers and moderator+
| 2019-09-21T19:33:05 |
|
python-discord/bot
| 443 |
python-discord__bot-443
|
[
"382"
] |
362699c50a515e0390f9d384d3d36b58c2783d9f
|
diff --git a/bot/cogs/cogs.py b/bot/cogs/cogs.py
--- a/bot/cogs/cogs.py
+++ b/bot/cogs/cogs.py
@@ -74,13 +74,12 @@ async def load_command(self, ctx: Context, cog: str) -> None:
try:
self.bot.load_extension(full_cog)
except ImportError:
- log.error(f"{ctx.author} requested we load the '{cog}' cog, "
- f"but the cog module {full_cog} could not be found!")
+ log.exception(f"{ctx.author} requested we load the '{cog}' cog, "
+ f"but the cog module {full_cog} could not be found!")
embed.description = f"Invalid cog: {cog}\n\nCould not find cog module {full_cog}"
except Exception as e:
- log.error(f"{ctx.author} requested we load the '{cog}' cog, "
- "but the loading failed with the following error: \n"
- f"**{e.__class__.__name__}: {e}**")
+ log.exception(f"{ctx.author} requested we load the '{cog}' cog, "
+ "but the loading failed")
embed.description = f"Failed to load cog: {cog}\n\n{e.__class__.__name__}: {e}"
else:
log.debug(f"{ctx.author} requested we load the '{cog}' cog. Cog loaded!")
@@ -129,9 +128,8 @@ async def unload_command(self, ctx: Context, cog: str) -> None:
try:
self.bot.unload_extension(full_cog)
except Exception as e:
- log.error(f"{ctx.author} requested we unload the '{cog}' cog, "
- "but the unloading failed with the following error: \n"
- f"{e}")
+ log.exception(f"{ctx.author} requested we unload the '{cog}' cog, "
+ "but the unloading failed")
embed.description = f"Failed to unload cog: {cog}\n\n```{e}```"
else:
log.debug(f"{ctx.author} requested we unload the '{cog}' cog. Cog unloaded!")
@@ -234,9 +232,8 @@ async def reload_command(self, ctx: Context, cog: str) -> None:
self.bot.unload_extension(full_cog)
self.bot.load_extension(full_cog)
except Exception as e:
- log.error(f"{ctx.author} requested we reload the '{cog}' cog, "
- "but the unloading failed with the following error: \n"
- f"{e}")
+ log.exception(f"{ctx.author} requested we reload the '{cog}' cog, "
+ "but the unloading failed")
embed.description = f"Failed to reload cog: {cog}\n\n```{e}```"
else:
log.debug(f"{ctx.author} requested we reload the '{cog}' cog. Cog reloaded!")
|
Log full traceback with `log.exception` in exception handlers
While trying to reload the `reddit` cog, I noticed that the `cogs` cog doesn't log the full traceback in the `except` blocks, but just the exception message using `log.error`. It would be better to use `log.exception` here to make sure that the full traceback is included instead of just a message like ` 'NoneType' object has no attribute 'startswith'`. (`log.exception` automatically includes the full traceback when used in an exception handler, no additional arguments required.)
I suspect that more cogs do this, so I think it's a good idea to check all the cogs after the Django migration is completed to change the log methods to `log.exception` inside exception handlers where appropriate.
Example from the `cogs` cog (it's both in `master` and `django`):
https://github.com/python-discord/bot/blob/5e16f4a52d59c73a04323e070e7b4a320e8c1e49/bot/cogs/cogs.py#L85
https://github.com/python-discord/bot/blob/25640adec9d042ccf249a91540fb09d354b04dfd/bot/cogs/cogs.py#L85
| 2019-09-22T17:31:38 |
Subsets and Splits
Distinct GitHub Repositories
The query lists all unique GitHub repository names, which provides basic filtering and an overview of the dataset but lacks deeper analytical value.
Unique Repositories in Train
Lists unique repository names from the dataset, providing a basic overview of the repositories present.