
repo
stringclasses 856
values | pull_number
int64 3
127k
| instance_id
stringlengths 12
58
| issue_numbers
listlengths 1
5
| base_commit
stringlengths 40
40
| patch
stringlengths 67
1.54M
| test_patch
stringlengths 0
107M
| problem_statement
stringlengths 3
307k
| hints_text
stringlengths 0
908k
| created_at
timestamp[s] |
|---|---|---|---|---|---|---|---|---|---|
scikit-hep/pyhf
| 424 |
scikit-hep__pyhf-424
|
[
"397"
] |
6076bd8873ba1cc2f98b52bd36b894af2d615076
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -12,18 +12,13 @@
extras_require = {
'tensorflow': [
- 'tensorflow>=1.12.0',
- 'tensorflow-probability>=0.5.0',
+ 'tensorflow~=1.13',
+ 'tensorflow-probability~=0.5',
'numpy<=1.14.5,>=1.14.0', # Lower of 1.14.0 instead of 1.13.3 to ensure doctest pass
'setuptools<=39.1.0',
],
- 'torch': ['torch>=1.0.0'],
- 'mxnet': [
- 'mxnet>=1.0.0',
- 'requests<2.19.0,>=2.18.4',
- 'numpy<1.15.0,>=1.8.2',
- 'requests<2.19.0,>=2.18.4',
- ],
+ 'torch': ['torch~=1.0'],
+ 'mxnet': ['mxnet~=1.0', 'requests~=2.18.4', 'numpy<1.15.0,>=1.8.2'],
# 'dask': [
# 'dask[array]'
# ],
@@ -31,7 +26,7 @@
'minuit': ['iminuit'],
'develop': [
'pyflakes',
- 'pytest<4.0.0,>=3.5.1',
+ 'pytest~=3.5',
'pytest-cov>=2.5.1',
'pytest-mock',
'pytest-benchmark[histogram]',
@@ -41,8 +36,8 @@
'matplotlib',
'jupyter',
'nbdime',
- 'uproot>=3.3.0',
- 'papermill>=0.16.0',
+ 'uproot~=3.3',
+ 'papermill~=0.16',
'graphviz',
'bumpversion',
'sphinx',
|
Pin optional dependencies at the minor release level
# Description
To avoid having our prior releases break like `v0.0.15` did in Issue #396 it would be good to pin our optional dependencies at the minor release level for each release. This should safeguard us from old releases getting broken by API changes in the dependencies that we use as applications.
To be clear, I don't think we should limit the dependencies in `install_requires` beyond placing _lower_ bounds, but I do think that we should now be placing upper bounds on all of the optional dependencies as we are really more using those as **applications** in our library.
|
This should also make the CI more robust so that we don't have to drop everything and do CI debugging as often.
| 2019-03-25T21:46:20 |
|
scikit-hep/pyhf
| 426 |
scikit-hep__pyhf-426
|
[
"170"
] |
ce34be1525e0b79e3d8e2429ef34a024ec30300b
|
diff --git a/pyhf/commandline.py b/pyhf/commandline.py
--- a/pyhf/commandline.py
+++ b/pyhf/commandline.py
@@ -14,6 +14,14 @@
logging.basicConfig()
log = logging.getLogger(__name__)
+# This is only needed for Python 2/3 compatibility
+def ensure_dirs(path):
+ try:
+ os.makedirs(path, exist_ok=True)
+ except TypeError:
+ if not os.path.exists(path):
+ os.makedirs(path)
+
@click.group(context_settings=dict(help_option_names=['-h', '--help']))
@click.version_option(version=__version__)
@@ -61,16 +69,28 @@ def xml2json(entrypoint_xml, basedir, output_file, track_progress):
@pyhf.command()
@click.argument('workspace', default='-')
[email protected]('xmlfile', default='-')
[email protected]('--specroot', default=click.Path(exists=True))
[email protected]('--dataroot', default=click.Path(exists=True))
-def json2xml(workspace, xmlfile, specroot, dataroot):
[email protected]('--output-dir', type=click.Path(exists=True), default='.')
[email protected]('--specroot', default='config')
[email protected]('--dataroot', default='data')
[email protected]('--resultprefix', default='FitConfig')
+def json2xml(workspace, output_dir, specroot, dataroot, resultprefix):
+ ensure_dirs(output_dir)
with click.open_file(workspace, 'r') as specstream:
d = json.load(specstream)
- with click.open_file(xmlfile, 'w') as outstream:
+ ensure_dirs(os.path.join(output_dir, specroot))
+ ensure_dirs(os.path.join(output_dir, dataroot))
+ with click.open_file(
+ os.path.join(output_dir, '{0:s}.xml'.format(resultprefix)), 'w'
+ ) as outstream:
outstream.write(
- writexml.writexml(d, specroot, dataroot, '').decode('utf-8')
+ writexml.writexml(
+ d,
+ os.path.join(output_dir, specroot),
+ os.path.join(output_dir, dataroot),
+ resultprefix,
+ ).decode('utf-8')
)
+
sys.exit(0)
diff --git a/pyhf/readxml.py b/pyhf/readxml.py
--- a/pyhf/readxml.py
+++ b/pyhf/readxml.py
@@ -235,14 +235,15 @@ def process_measurements(toplvl):
overall_param_obj['value'] = param.attrib['Val']
# might be specifying multiple parameters in the same ParamSetting
- for param_name in param.text.split(' '):
- # lumi will always be the first parameter
- if param_name == 'Lumi':
- result['config']['parameters'][0].update(overall_param_obj)
- else:
- param_obj = {'name': param_name}
- param_obj.update(overall_param_obj)
- result['config']['parameters'].append(param_obj)
+ if param.text:
+ for param_name in param.text.split(' '):
+ # lumi will always be the first parameter
+ if param_name == 'Lumi':
+ result['config']['parameters'][0].update(overall_param_obj)
+ else:
+ param_obj = {'name': param_name}
+ param_obj.update(overall_param_obj)
+ result['config']['parameters'].append(param_obj)
results.append(result)
return results
diff --git a/pyhf/writexml.py b/pyhf/writexml.py
--- a/pyhf/writexml.py
+++ b/pyhf/writexml.py
@@ -1,45 +1,210 @@
+import logging
+
import os
import xml.etree.cElementTree as ET
+import numpy as np
+import uproot
+from uproot_methods.classes import TH1
+
+_ROOT_DATA_FILE = None
+
+log = logging.getLogger(__name__)
+
+
+def _make_hist_name(channel, sample, modifier='', prefix='hist', suffix=''):
+ return "{prefix}{middle}{suffix}".format(
+ prefix=prefix,
+ suffix=suffix,
+ middle='_'.join(filter(lambda x: x, [channel, sample, modifier])),
+ )
-def measurement(lumi, lumierr, poi, param_settings=None, name='Meas1'):
- param_settings = param_settings or []
+def _export_root_histogram(histname, data):
+ h = TH1.from_numpy((np.asarray(data), np.arange(len(data) + 1)))
+ h._fName = histname
+ # NB: uproot crashes for some reason, figure out why later
+ # if histname in _ROOT_DATA_FILE:
+ # raise KeyError('Duplicate key {0} being written.'.format(histname))
+ _ROOT_DATA_FILE[histname] = h
+
+# https://stackoverflow.com/a/4590052
+def indent(elem, level=0):
+ i = "\n" + level * " "
+ if elem:
+ if not elem.text or not elem.text.strip():
+ elem.text = i + " "
+ if not elem.tail or not elem.tail.strip():
+ elem.tail = i
+ for elem in elem:
+ indent(elem, level + 1)
+ if not elem.tail or not elem.tail.strip():
+ elem.tail = i
+ else:
+ if level and (not elem.tail or not elem.tail.strip()):
+ elem.tail = i
+
+
+def build_measurement(measurementspec):
+ config = measurementspec['config']
+ name = measurementspec['name']
+ poi = config['poi']
+
+ # we want to know which parameters are fixed (constant)
+ # and to additionally extract the luminosity information
+ fixed_params = []
+ lumi = 1.0
+ lumierr = 0.0
+ for parameter in config['parameters']:
+ if parameter.get('fixed', False):
+ pname = parameter['name']
+ if pname == 'lumi':
+ fixed_params.append('Lumi')
+ else:
+ fixed_params.append(pname)
+ # we found luminosity, so handle it
+ if parameter['name'] == 'lumi':
+ lumi = parameter['auxdata'][0]
+ lumierr = parameter['sigmas'][0]
+
+ # define measurement
meas = ET.Element("Measurement", Name=name, Lumi=str(lumi), LumiRelErr=str(lumierr))
poiel = ET.Element('POI')
poiel.text = poi
meas.append(poiel)
- for s in param_settings:
- se = ET.Element('ParamSetting', **s['attrs'])
- se.text = ' '.join(s['params'])
+
+ # add fixed parameters (constant)
+ if fixed_params:
+ se = ET.Element('ParamSetting', Const='True')
+ se.text = ' '.join(fixed_params)
meas.append(se)
return meas
-def write_channel(channelspec, filename, data_rootdir):
- # need to write channelfile here
- with open(filename, 'w') as f:
- channel = ET.Element('Channel', Name=channelspec['name'])
- channel = ET.Element('Channel', Name=channelspec['name'])
- f.write(ET.tostring(channel, encoding='utf-8').decode('utf-8'))
- pass
+def build_modifier(modifierspec, channelname, samplename, sampledata):
+ if modifierspec['name'] == 'lumi':
+ return None
+ mod_map = {
+ 'histosys': 'HistoSys',
+ 'staterror': 'StatError',
+ 'normsys': 'OverallSys',
+ 'shapesys': 'ShapeSys',
+ 'normfactor': 'NormFactor',
+ 'shapefactor': 'ShapeFactor',
+ }
+ attrs = {'Name': modifierspec['name']}
+ if modifierspec['type'] == 'histosys':
+ attrs['HistoNameLow'] = _make_hist_name(
+ channelname, samplename, modifierspec['name'], suffix='Low'
+ )
+ attrs['HistoNameHigh'] = _make_hist_name(
+ channelname, samplename, modifierspec['name'], suffix='High'
+ )
+ _export_root_histogram(attrs['HistoNameLow'], modifierspec['data']['lo_data'])
+ _export_root_histogram(attrs['HistoNameHigh'], modifierspec['data']['hi_data'])
+ elif modifierspec['type'] == 'normsys':
+ attrs['High'] = str(modifierspec['data']['hi'])
+ attrs['Low'] = str(modifierspec['data']['lo'])
+ elif modifierspec['type'] == 'normfactor':
+ attrs['Val'] = '1'
+ attrs['High'] = '10'
+ attrs['Low'] = '0'
+ elif modifierspec['type'] == 'staterror':
+ attrs['Activate'] = 'True'
+ attrs['HistoName'] = _make_hist_name(
+ channelname, samplename, modifierspec['name']
+ )
+ # need to make this a relative uncertainty stored in ROOT file
+ _export_root_histogram(
+ attrs['HistoName'], np.divide(modifierspec['data'], sampledata).tolist()
+ )
+ elif modifierspec['type'] == 'shapesys':
+ attrs['ConstraintType'] = 'Poisson'
+ attrs['HistoName'] = _make_hist_name(
+ channelname, samplename, modifierspec['name']
+ )
+ # need to make this a relative uncertainty stored in ROOT file
+ _export_root_histogram(
+ attrs['HistoName'],
+ [np.divide(a, b) for a, b in zip(modifierspec['data'], sampledata)],
+ )
+ else:
+ log.warning(
+ 'Skipping {0}({1}) for now'.format(
+ modifierspec['name'], modifierspec['type']
+ )
+ )
-def writexml(spec, specdir, data_rootdir, result_outputprefix):
- combination = ET.Element("Combination", OutputFilePrefix=result_outputprefix)
+ modifier = ET.Element(mod_map[modifierspec['type']], **attrs)
+ return modifier
- for c in spec['channels']:
- channelfilename = os.path.join(specdir, 'channel_{}.xml'.format(c['name']))
- write_channel(c, channelfilename, data_rootdir)
- inp = ET.Element("Input")
- inp.text = channelfilename
- combination.append(inp)
- m = measurement(
- 1,
- 0.1,
- 'SigXsecOverSM',
- [{'attrs': {'Const': 'True'}, 'params': ['Lumi' 'alpha_syst1']}],
+def build_sample(samplespec, channelname):
+ histname = _make_hist_name(channelname, samplespec['name'])
+ attrs = {
+ 'Name': samplespec['name'],
+ 'HistoName': histname,
+ 'InputFile': _ROOT_DATA_FILE._path,
+ 'NormalizeByTheory': 'False',
+ }
+ sample = ET.Element('Sample', **attrs)
+ for modspec in samplespec['modifiers']:
+ # if lumi modifier added for this sample, need to set NormalizeByTheory
+ if modspec['type'] == 'lumi':
+ sample.attrib.update({'NormalizeByTheory': 'True'})
+ modifier = build_modifier(
+ modspec, channelname, samplespec['name'], samplespec['data']
+ )
+ if modifier is not None:
+ sample.append(modifier)
+ _export_root_histogram(histname, samplespec['data'])
+ return sample
+
+
+def build_data(dataspec, channelname):
+ histname = _make_hist_name(channelname, 'data')
+ data = ET.Element('Data', HistoName=histname, InputFile=_ROOT_DATA_FILE._path)
+ _export_root_histogram(histname, dataspec[channelname])
+ return data
+
+
+def build_channel(channelspec, dataspec):
+ channel = ET.Element(
+ 'Channel', Name=channelspec['name'], InputFile=_ROOT_DATA_FILE._path
)
- combination.append(m)
+ if dataspec:
+ data = build_data(dataspec, channelspec['name'])
+ channel.append(data)
+ for samplespec in channelspec['samples']:
+ channel.append(build_sample(samplespec, channelspec['name']))
+ return channel
+
+
+def writexml(spec, specdir, data_rootdir, resultprefix):
+ global _ROOT_DATA_FILE
+
+ combination = ET.Element(
+ "Combination", OutputFilePrefix=os.path.join('.', specdir, resultprefix)
+ )
+
+ with uproot.recreate(os.path.join(data_rootdir, 'data.root')) as _ROOT_DATA_FILE:
+ for channelspec in spec['channels']:
+ channelfilename = os.path.join(
+ specdir, '{0:s}_{1:s}.xml'.format(resultprefix, channelspec['name'])
+ )
+ with open(channelfilename, 'w') as channelfile:
+ channel = build_channel(channelspec, spec.get('data'))
+ indent(channel)
+ channelfile.write(
+ ET.tostring(channel, encoding='utf-8').decode('utf-8')
+ )
+
+ inp = ET.Element("Input")
+ inp.text = channelfilename
+ combination.append(inp)
+
+ for measurement in spec['toplvl']['measurements']:
+ combination.append(build_measurement(measurement))
+ indent(combination)
return ET.tostring(combination, encoding='utf-8')
|
diff --git a/tests/test_export.py b/tests/test_export.py
new file mode 100644
--- /dev/null
+++ b/tests/test_export.py
@@ -0,0 +1,256 @@
+import pyhf
+import pyhf.writexml
+import pytest
+import json
+import xml.etree.cElementTree as ET
+
+
+def spec_staterror():
+ spec = {
+ 'channels': [
+ {
+ 'name': 'firstchannel',
+ 'samples': [
+ {
+ 'name': 'mu',
+ 'data': [10.0, 10.0],
+ 'modifiers': [
+ {'name': 'mu', 'type': 'normfactor', 'data': None}
+ ],
+ },
+ {
+ 'name': 'bkg1',
+ 'data': [50.0, 70.0],
+ 'modifiers': [
+ {
+ 'name': 'stat_firstchannel',
+ 'type': 'staterror',
+ 'data': [12.0, 12.0],
+ }
+ ],
+ },
+ {
+ 'name': 'bkg2',
+ 'data': [30.0, 20.0],
+ 'modifiers': [
+ {
+ 'name': 'stat_firstchannel',
+ 'type': 'staterror',
+ 'data': [5.0, 5.0],
+ }
+ ],
+ },
+ {'name': 'bkg3', 'data': [20.0, 15.0], 'modifiers': []},
+ ],
+ }
+ ]
+ }
+ return spec
+
+
+def spec_histosys():
+ source = json.load(open('validation/data/2bin_histosys_example2.json'))
+ spec = {
+ 'channels': [
+ {
+ 'name': 'singlechannel',
+ 'samples': [
+ {
+ 'name': 'signal',
+ 'data': source['bindata']['sig'],
+ 'modifiers': [
+ {'name': 'mu', 'type': 'normfactor', 'data': None}
+ ],
+ },
+ {
+ 'name': 'background',
+ 'data': source['bindata']['bkg'],
+ 'modifiers': [
+ {
+ 'name': 'bkg_norm',
+ 'type': 'histosys',
+ 'data': {
+ 'lo_data': source['bindata']['bkgsys_dn'],
+ 'hi_data': source['bindata']['bkgsys_up'],
+ },
+ }
+ ],
+ },
+ ],
+ }
+ ]
+ }
+ return spec
+
+
+def spec_normsys():
+ source = json.load(open('validation/data/2bin_histosys_example2.json'))
+ spec = {
+ 'channels': [
+ {
+ 'name': 'singlechannel',
+ 'samples': [
+ {
+ 'name': 'signal',
+ 'data': source['bindata']['sig'],
+ 'modifiers': [
+ {'name': 'mu', 'type': 'normfactor', 'data': None}
+ ],
+ },
+ {
+ 'name': 'background',
+ 'data': source['bindata']['bkg'],
+ 'modifiers': [
+ {
+ 'name': 'bkg_norm',
+ 'type': 'normsys',
+ 'data': {'lo': 0.9, 'hi': 1.1},
+ }
+ ],
+ },
+ ],
+ }
+ ]
+ }
+ return spec
+
+
+def spec_shapesys():
+ source = json.load(open('validation/data/2bin_histosys_example2.json'))
+ spec = {
+ 'channels': [
+ {
+ 'name': 'singlechannel',
+ 'samples': [
+ {
+ 'name': 'signal',
+ 'data': source['bindata']['sig'],
+ 'modifiers': [
+ {'name': 'mu', 'type': 'normfactor', 'data': None}
+ ],
+ },
+ {
+ 'name': 'background',
+ 'data': source['bindata']['bkg'],
+ 'modifiers': [
+ {'name': 'bkg_norm', 'type': 'shapesys', 'data': [10, 10]}
+ ],
+ },
+ ],
+ }
+ ]
+ }
+ return spec
+
+
+def test_export_measurement():
+ measurementspec = {
+ "config": {
+ "parameters": [
+ {
+ "auxdata": [1.0],
+ "bounds": [[0.855, 1.145]],
+ "inits": [1.0],
+ "name": "lumi",
+ "sigmas": [0.029],
+ }
+ ],
+ "poi": "mu",
+ },
+ "name": "NormalMeasurement",
+ }
+ m = pyhf.writexml.build_measurement(measurementspec)
+ assert m is not None
+ assert m.attrib['Name'] == measurementspec['name']
+ assert m.attrib['Lumi'] == str(
+ measurementspec['config']['parameters'][0]['auxdata'][0]
+ )
+ assert m.attrib['LumiRelErr'] == str(
+ measurementspec['config']['parameters'][0]['sigmas'][0]
+ )
+ poi = m.find('POI')
+ assert poi is not None
+ assert poi.text == measurementspec['config']['poi']
+ paramsetting = m.find('ParamSetting')
+ assert paramsetting is None
+
+
[email protected](
+ "spec, has_root_data, attrs",
+ [
+ (spec_staterror(), True, ['Activate', 'HistoName']),
+ (spec_histosys(), True, ['HistoNameHigh', 'HistoNameLow']),
+ (spec_normsys(), False, ['High', 'Low']),
+ (spec_shapesys(), True, ['ConstraintType', 'HistoName']),
+ ],
+ ids=['staterror', 'histosys', 'normsys', 'shapesys'],
+)
+def test_export_modifier(mocker, spec, has_root_data, attrs):
+ channelspec = spec['channels'][0]
+ channelname = channelspec['name']
+ samplespec = channelspec['samples'][1]
+ samplename = samplespec['name']
+ sampledata = samplespec['data']
+ modifierspec = samplespec['modifiers'][0]
+
+ mocker.patch('pyhf.writexml._ROOT_DATA_FILE')
+ modifier = pyhf.writexml.build_modifier(
+ modifierspec, channelname, samplename, sampledata
+ )
+ assert modifier.attrib['Name'] == modifierspec['name']
+ assert all(attr in modifier.attrib for attr in attrs)
+ assert pyhf.writexml._ROOT_DATA_FILE.__setitem__.called == has_root_data
+
+
[email protected](
+ "spec",
+ [spec_staterror(), spec_histosys(), spec_normsys(), spec_shapesys()],
+ ids=['staterror', 'histosys', 'normsys', 'shapesys'],
+)
+def test_export_sample(mocker, spec):
+ channelspec = spec['channels'][0]
+ channelname = channelspec['name']
+ samplespec = channelspec['samples'][1]
+ samplename = samplespec['name']
+ sampledata = samplespec['data']
+
+ mocker.patch('pyhf.writexml.build_modifier', return_value=ET.Element("Modifier"))
+ mocker.patch('pyhf.writexml._ROOT_DATA_FILE')
+ sample = pyhf.writexml.build_sample(samplespec, channelname)
+ assert sample.attrib['Name'] == samplespec['name']
+ assert sample.attrib['HistoName']
+ assert sample.attrib['InputFile']
+ assert sample.attrib['NormalizeByTheory'] == str(False)
+ assert pyhf.writexml.build_modifier.called
+ assert pyhf.writexml._ROOT_DATA_FILE.__setitem__.called
+
+
[email protected](
+ "spec",
+ [spec_staterror(), spec_histosys(), spec_normsys(), spec_shapesys()],
+ ids=['staterror', 'histosys', 'normsys', 'shapesys'],
+)
+def test_export_channel(mocker, spec):
+ channelspec = spec['channels'][0]
+ channelname = channelspec['name']
+
+ mocker.patch('pyhf.writexml.build_data', return_value=ET.Element("Data"))
+ mocker.patch('pyhf.writexml.build_sample', return_value=ET.Element("Sample"))
+ mocker.patch('pyhf.writexml._ROOT_DATA_FILE')
+ channel = pyhf.writexml.build_channel(channelspec, {})
+ assert channel.attrib['Name'] == channelspec['name']
+ assert channel.attrib['InputFile']
+ assert pyhf.writexml.build_data.called is False
+ assert pyhf.writexml.build_sample.called
+ assert pyhf.writexml._ROOT_DATA_FILE.__setitem__.called is False
+
+
+def test_export_data(mocker):
+ channelname = 'channel'
+ dataspec = {channelname: [0, 1, 2, 3]}
+
+ mocker.patch('pyhf.writexml._ROOT_DATA_FILE')
+ data = pyhf.writexml.build_data(dataspec, channelname)
+ assert data.attrib['HistoName']
+ assert data.attrib['InputFile']
+ assert pyhf.writexml._ROOT_DATA_FILE.__setitem__.called
diff --git a/tests/test_scripts.py b/tests/test_scripts.py
--- a/tests/test_scripts.py
+++ b/tests/test_scripts.py
@@ -106,8 +106,8 @@ def test_import_and_export(tmpdir, script_runner):
)
ret = script_runner.run(*shlex.split(command))
- command = 'pyhf json2xml {0:s} --specroot {1:s} --dataroot {1:s}'.format(
- temp.strpath, str(tmpdir)
+ command = 'pyhf json2xml {0:s} --output-dir {1:s}'.format(
+ temp.strpath, tmpdir.mkdir('output').strpath
)
ret = script_runner.run(*shlex.split(command))
assert ret.success
diff --git a/tests/test_validation.py b/tests/test_validation.py
--- a/tests/test_validation.py
+++ b/tests/test_validation.py
@@ -1,6 +1,8 @@
import pyhf
+import pyhf.writexml, pyhf.readxml
import json
import pytest
+import os
@pytest.fixture(scope='module')
@@ -723,6 +725,7 @@ def validate_hypotest(pdf, data, mu_test, expected_result, tolerance=1e-6):
def test_validation(setup_and_tolerance):
setup, tolerance = setup_and_tolerance
source = setup['source']
+
pdf = pyhf.Model(setup['spec'])
if 'channels' in source:
@@ -743,3 +746,96 @@ def test_validation(setup_and_tolerance):
validate_hypotest(
pdf, data, setup['mu'], setup['expected']['result'], tolerance=tolerance
)
+
+
[email protected](
+ 'toplvl, basedir',
+ [
+ (
+ 'validation/xmlimport_input/config/example.xml',
+ 'validation/xmlimport_input/',
+ ),
+ (
+ 'validation/xmlimport_input2/config/example.xml',
+ 'validation/xmlimport_input2',
+ ),
+ (
+ 'validation/xmlimport_input3/config/examples/example_ShapeSys.xml',
+ 'validation/xmlimport_input3',
+ ),
+ ],
+ ids=['example-one', 'example-two', 'example-three'],
+)
+def test_import_roundtrip(tmpdir, toplvl, basedir):
+ parsed_xml_before = pyhf.readxml.parse(toplvl, basedir)
+ spec = {
+ 'channels': parsed_xml_before['channels'],
+ 'parameters': parsed_xml_before['toplvl']['measurements'][0]['config'][
+ 'parameters'
+ ],
+ }
+ pdf_before = pyhf.Model(spec, poiname='SigXsecOverSM')
+
+ tmpconfig = tmpdir.mkdir('config')
+ tmpdata = tmpdir.mkdir('data')
+ tmpxml = tmpdir.join('FitConfig.xml')
+ tmpxml.write(
+ pyhf.writexml.writexml(
+ parsed_xml_before,
+ tmpconfig.strpath,
+ tmpdata.strpath,
+ os.path.join(tmpdir.strpath, 'FitConfig'),
+ ).decode('utf-8')
+ )
+ parsed_xml_after = pyhf.readxml.parse(tmpxml.strpath, tmpdir.strpath)
+ spec = {
+ 'channels': parsed_xml_after['channels'],
+ 'parameters': parsed_xml_after['toplvl']['measurements'][0]['config'][
+ 'parameters'
+ ],
+ }
+ pdf_after = pyhf.Model(spec, poiname='SigXsecOverSM')
+
+ data_before = [
+ binvalue
+ for k in pdf_before.spec['channels']
+ for binvalue in parsed_xml_before['data'][k['name']]
+ ] + pdf_before.config.auxdata
+
+ data_after = [
+ binvalue
+ for k in pdf_after.spec['channels']
+ for binvalue in parsed_xml_after['data'][k['name']]
+ ] + pdf_after.config.auxdata
+
+ assert data_before == data_after
+
+ init_pars_before = pdf_before.config.suggested_init()
+ init_pars_after = pdf_after.config.suggested_init()
+ assert init_pars_before == init_pars_after
+
+ par_bounds_before = pdf_before.config.suggested_bounds()
+ par_bounds_after = pdf_after.config.suggested_bounds()
+ assert par_bounds_before == par_bounds_after
+
+ CLs_obs_before, CLs_exp_set_before = pyhf.utils.hypotest(
+ 1,
+ data_before,
+ pdf_before,
+ init_pars_before,
+ par_bounds_before,
+ return_expected_set=True,
+ )
+ CLs_obs_after, CLs_exp_set_after = pyhf.utils.hypotest(
+ 1,
+ data_after,
+ pdf_after,
+ init_pars_after,
+ par_bounds_after,
+ return_expected_set=True,
+ )
+
+ tolerance = 1e-6
+ assert abs(CLs_obs_after - CLs_obs_before) / CLs_obs_before < tolerance
+ for result, expected_result in zip(CLs_exp_set_after, CLs_exp_set_before):
+ assert abs(result - expected_result) / expected_result < tolerance
|
XML ROOT Export
# Description
Given that we observe that some models still scale better in ROOT, it's reasonable to have some an companion tools to `readxml`, namely `writexml` that writes XML + ROOT files corresponding to a model given as JSON.
|
@kratsg this might be useful to comput published hf JSON in ROOT (e..g MBJ)
Yeah, this is going to be much harder to build unfortunately, but it's still possible. It's a lower priority for now.
uproot 3.0 is released that allows us to write XML+ROOT out now!
| 2019-04-08T10:47:24 |
scikit-hep/pyhf
| 428 |
scikit-hep__pyhf-428
|
[
"414"
] |
604ff0aa5f39803815b88c9c2e62e37bd4beb410
|
diff --git a/pyhf/pdf.py b/pyhf/pdf.py
--- a/pyhf/pdf.py
+++ b/pyhf/pdf.py
@@ -89,10 +89,10 @@ def __init__(self, spec, poiname='mu'):
paramset_requirements
)
- self.channels = list(set(self.channels))
- self.samples = list(set(self.samples))
- self.parameters = list(set(self.parameters))
- self.modifiers = list(set(self.modifiers))
+ self.channels = sorted(list(set(self.channels)))
+ self.samples = sorted(list(set(self.samples)))
+ self.parameters = sorted(list(set(self.parameters)))
+ self.modifiers = sorted(list(set(self.modifiers)))
self.channel_nbins = self.channel_nbins
self._create_and_register_paramsets(
_paramsets_requirements, _paramsets_user_configs
|
Order of pdf.confg.samples not guaranteed (due to use of set)
# Description
The order of samples in [`pdf.config.samples`](https://github.com/diana-hep/pyhf/blob/4fa45dda8d2314138549ac6b67ebdc9d9a506742/pyhf/pdf.py#L163) (more specifically, [`pdf._ModelConfig.samples`](https://github.com/diana-hep/pyhf/blob/5ddfc6aa21d1f2e33a2fe95bfefb489541ae77ff/pyhf/pdf.py#L35)) should not change between runs with the same data. However, it can, which is highly problematic when trying to do something like plotting as we do in the examples. If `pdf.config.samples` does not maintain order between runs, then something like [`get_mc_counts`](https://github.com/diana-hep/pyhf/blob/4fa45dda8d2314138549ac6b67ebdc9d9a506742/docs/examples/notebooks/binderexample/StatisticalAnalysis.ipynb) will give different results on different runs because `pdf._modifications(pars)` will be giving different results.
I think this is coming from the fact that the use of `set` in
https://github.com/diana-hep/pyhf/blob/5ddfc6aa21d1f2e33a2fe95bfefb489541ae77ff/pyhf/pdf.py#L93
[doesn't guarantee order](https://stackoverflow.com/questions/9792664/converting-a-list-to-a-set-changes-element-order).
I think what should be used instead is a sorted set
```python
self.samples = sorted(set(self.samples), key=self.samples.index)
```
Consider the following two scripts:
`bug_report.py`
```python
#!/usr/bin/env python3
import pyhf
def main():
pdf = pyhf.simplemodels.hepdata_like(
signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
)
print(pdf.config.samples)
if __name__ == '__main__':
main()
```
and `bug_resport.sh`
```shell
#!/usr/bin/env bash
for i in {1..10}; do
python3 bug_report.py
done
```
Thanks to @stephensekula for uncovering some of this behavior.
# Expected Behavior
Running `bash bug_report.sh` should return
```
$ bash bug_report.sh
['background', 'signal']
['background', 'signal']
['background', 'signal']
['background', 'signal']
['background', 'signal']
['background', 'signal']
['background', 'signal']
['background', 'signal']
['background', 'signal']
['background', 'signal']
```
# Actual Behavior
```
$ bash bug_report.sh
['background', 'signal']
['signal', 'background']
['signal', 'background']
['background', 'signal']
['signal', 'background']
['signal', 'background']
['signal', 'background']
['signal', 'background']
['background', 'signal']
['signal', 'background']
```
# Steps to Reproduce
This Issue.
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
thanks @matthewfeickert -- just to double check: this is mostly about presentation, there is no internal inconsistency in the computation observed? I agree that having a deterministic order would be helpful.
> this is mostly about presentation, there is no internal inconsistency in the computation observed?
Correct. However, I think that I would call it interpretability rather then presentation. In the use case where this was first found this was manifested through the plotting order — and so rather noticeable — but if a user is accessing the samples for some further calculation this could be quite badly misleading if they believe that the order they got in 1 run will persist.
I need to look more at using sorted set as using
```python
self.samples = sorted(set(self.samples), key=self.samples.index)
```
does indeed fix the issue. However, there is any intent to the insertion order to the list then perhaps it would be better to use an `OrderedDict` which would definitely preserve the insertion order.
| 2019-04-09T06:51:12 |
|
scikit-hep/pyhf
| 430 |
scikit-hep__pyhf-430
|
[
"398"
] |
604ff0aa5f39803815b88c9c2e62e37bd4beb410
|
diff --git a/pyhf/commandline.py b/pyhf/commandline.py
--- a/pyhf/commandline.py
+++ b/pyhf/commandline.py
@@ -52,7 +52,7 @@ def xml2json(entrypoint_xml, basedir, output_file, track_progress):
except ImportError:
log.error(
"xml2json requires uproot, please install pyhf using the "
- "xmlimport extra: pip install pyhf[xmlimport] or install uproot "
+ "xmlio extra: pip install pyhf[xmlio] or install uproot "
"manually: pip install uproot"
)
from . import readxml
@@ -74,6 +74,17 @@ def xml2json(entrypoint_xml, basedir, output_file, track_progress):
@click.option('--dataroot', default='data')
@click.option('--resultprefix', default='FitConfig')
def json2xml(workspace, output_dir, specroot, dataroot, resultprefix):
+ try:
+ import uproot
+
+ assert uproot
+ except ImportError:
+ log.error(
+ "json2xml requires uproot, please install pyhf using the "
+ "xmlio extra: pip install pyhf[xmlio] or install uproot "
+ "manually: pip install uproot"
+ )
+
ensure_dirs(output_dir)
with click.open_file(workspace, 'r') as specstream:
d = json.load(specstream)
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -22,7 +22,7 @@
# 'dask': [
# 'dask[array]'
# ],
- 'xmlimport': ['uproot'],
+ 'xmlio': ['uproot'],
'minuit': ['iminuit'],
'develop': [
'pyflakes',
|
diff --git a/tests/test_notebooks.py b/tests/test_notebooks.py
--- a/tests/test_notebooks.py
+++ b/tests/test_notebooks.py
@@ -12,6 +12,10 @@ def test_notebooks(tmpdir):
pm.execute_notebook('docs/examples/notebooks/hello-world.ipynb', **common_kwargs)
+ pm.execute_notebook(
+ 'docs/examples/notebooks/XML_ImportExport.ipynb', **common_kwargs
+ )
+
if sys.version_info.major > 2:
# The Binder example uses specific relative paths
cwd = os.getcwd()
|
Add FAQ RE: how to use xml2json CLI tool
# Description
Add a section to the FAQ RE: how to install the `xmlimport` optional dependencies and how to use the `xml2json` CLI tool.
This could also be an entire example Jupyter notebook on using the CLI and then have the FAQ be just on how to install the `xmlimport` dependencies.
| 2019-04-09T07:41:39 |
|
scikit-hep/pyhf
| 435 |
scikit-hep__pyhf-435
|
[
"433"
] |
f537fe773d72726322e37b469ef1809220beff59
|
diff --git a/pyhf/writexml.py b/pyhf/writexml.py
--- a/pyhf/writexml.py
+++ b/pyhf/writexml.py
@@ -1,6 +1,8 @@
import logging
import os
+import shutil
+import pkg_resources
import xml.etree.cElementTree as ET
import numpy as np
import uproot
@@ -68,7 +70,13 @@ def build_measurement(measurementspec):
lumierr = parameter['sigmas'][0]
# define measurement
- meas = ET.Element("Measurement", Name=name, Lumi=str(lumi), LumiRelErr=str(lumierr))
+ meas = ET.Element(
+ "Measurement",
+ Name=name,
+ Lumi=str(lumi),
+ LumiRelErr=str(lumierr),
+ ExportOnly=str(True),
+ )
poiel = ET.Element('POI')
poiel.text = poi
meas.append(poiel)
@@ -115,6 +123,7 @@ def build_modifier(modifierspec, channelname, samplename, sampledata):
attrs['HistoName'] = _make_hist_name(
channelname, samplename, modifierspec['name']
)
+ del attrs['Name']
# need to make this a relative uncertainty stored in ROOT file
_export_root_histogram(
attrs['HistoName'], np.divide(modifierspec['data'], sampledata).tolist()
@@ -184,6 +193,10 @@ def build_channel(channelspec, dataspec):
def writexml(spec, specdir, data_rootdir, resultprefix):
global _ROOT_DATA_FILE
+ shutil.copyfile(
+ pkg_resources.resource_filename(__name__, 'data/HistFactorySchema.dtd'),
+ os.path.join(os.path.dirname(specdir), 'HistFactorySchema.dtd'),
+ )
combination = ET.Element(
"Combination", OutputFilePrefix=os.path.join('.', specdir, resultprefix)
)
@@ -196,6 +209,9 @@ def writexml(spec, specdir, data_rootdir, resultprefix):
with open(channelfilename, 'w') as channelfile:
channel = build_channel(channelspec, spec.get('data'))
indent(channel)
+ channelfile.write(
+ "<!DOCTYPE Channel SYSTEM '../HistFactorySchema.dtd'>\n\n"
+ )
channelfile.write(
ET.tostring(channel, encoding='utf-8').decode('utf-8')
)
@@ -207,4 +223,6 @@ def writexml(spec, specdir, data_rootdir, resultprefix):
for measurement in spec['toplvl']['measurements']:
combination.append(build_measurement(measurement))
indent(combination)
- return ET.tostring(combination, encoding='utf-8')
+ return "<!DOCTYPE Combination SYSTEM 'HistFactorySchema.dtd'>\n\n".encode(
+ "utf-8"
+ ) + ET.tostring(combination, encoding='utf-8')
|
diff --git a/tests/test_export.py b/tests/test_export.py
--- a/tests/test_export.py
+++ b/tests/test_export.py
@@ -197,7 +197,9 @@ def test_export_modifier(mocker, spec, has_root_data, attrs):
modifier = pyhf.writexml.build_modifier(
modifierspec, channelname, samplename, sampledata
)
- assert modifier.attrib['Name'] == modifierspec['name']
+ # if the modifier is a staterror, it has no Name
+ if 'Name' in modifier.attrib:
+ assert modifier.attrib['Name'] == modifierspec['name']
assert all(attr in modifier.attrib for attr in attrs)
assert pyhf.writexml._ROOT_DATA_FILE.__setitem__.called == has_root_data
|
json2xml needs to add support for the HiFa DTD
# Description
json2xml does not include the DTD statement in the XML outputs that it generates.
# Expected Behavior
Should include DTD statement.
# Actual Behavior
Does not include DTD statement.
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
| 2019-04-09T19:23:00 |
|
scikit-hep/pyhf
| 436 |
scikit-hep__pyhf-436
|
[
"432"
] |
324b8ca28e4bbd4d7cd34e0ea6e77bd418fa63a4
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -56,6 +56,29 @@
}
extras_require['complete'] = sorted(set(sum(extras_require.values(), [])))
+
+def _is_test_pypi():
+ """
+ Determine if the Travis CI environment has TESTPYPI_UPLOAD defined and
+ set to true (c.f. .travis.yml)
+
+ The use_scm_version kwarg accepts a callable for the local_scheme
+ configuration parameter with argument "version". This can be replaced
+ with a lambda as the desired version structure is {next_version}.dev{distance}
+ c.f. https://github.com/pypa/setuptools_scm/#importing-in-setuppy
+
+ As the scm versioning is only desired for TestPyPI, for depolyment to PyPI the version
+ controlled through bumpversion is used.
+ """
+ from os import getenv
+
+ return (
+ {'local_scheme': lambda version: ''}
+ if getenv('TESTPYPI_UPLOAD') == 'true'
+ else False
+ )
+
+
setup(
name='pyhf',
version='0.0.16',
@@ -88,4 +111,5 @@
extras_require=extras_require,
entry_points={'console_scripts': ['pyhf=pyhf.commandline:pyhf']},
dependency_links=[],
+ use_scm_version=_is_test_pypi(),
)
|
Test Deploy feature is broken
# Description
See https://github.com/FaradayRF/faradayio/issues/35 for a related issue - I think. Failing job on master here: https://travis-ci.org/diana-hep/pyhf/builds/517678508?utm_source=github_status&utm_medium=notification
# Expected Behavior
Expect it to pass.
# Actual Behavior
Observe it failing.
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
| 2019-04-11T08:03:43 |
||
scikit-hep/pyhf
| 444 |
scikit-hep__pyhf-444
|
[
"441"
] |
1563c58e32b6d59a4c20ae994575e2d4a5b8e5ba
|
diff --git a/pyhf/commandline.py b/pyhf/commandline.py
--- a/pyhf/commandline.py
+++ b/pyhf/commandline.py
@@ -4,7 +4,6 @@
import json
import os
-from . import writexml
from .utils import hypotest
from .pdf import Workspace
from .version import __version__
@@ -81,6 +80,7 @@ def json2xml(workspace, output_dir, specroot, dataroot, resultprefix):
"xmlio extra: pip install pyhf[xmlio] or install uproot "
"manually: pip install uproot"
)
+ from . import writexml
ensure_dirs(output_dir)
with click.open_file(workspace, 'r') as specstream:
|
pyhf commandline tools requires uproot extra
# Description
just issuing `pyhf --help` requires the uproot extra since `commandline.py` imports `writexml`.
# Expected Behavior
I don't need uproot if I don't want to use json2xml or xml2json
# Actual Behavior
I can't use `pyhf` without installing uproot.
# Steps to Reproduce
install master and run pyhf
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
| 2019-04-15T11:50:44 |
||
scikit-hep/pyhf
| 457 |
scikit-hep__pyhf-457
|
[
"419"
] |
eeaffa5aadab247e3ae8c4e220b20d657680aae5
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -37,7 +37,8 @@
'jupyter',
'nbdime',
'uproot~=3.3',
- 'papermill~=0.16',
+ 'papermill~=1.0',
+ 'nteract-scrapbook~=0.2',
'graphviz',
'bumpversion',
'sphinx',
|
diff --git a/tests/test_notebooks.py b/tests/test_notebooks.py
--- a/tests/test_notebooks.py
+++ b/tests/test_notebooks.py
@@ -1,6 +1,7 @@
import sys
import os
import papermill as pm
+import scrapbook as sb
def test_notebooks(tmpdir):
@@ -39,5 +40,5 @@ def test_notebooks(tmpdir):
**common_kwargs
)
- nb = pm.read_notebook(str(outputnb))
- assert nb.data['number_2d_successpoints'] > 200
+ nb = sb.read_notebook(str(outputnb))
+ assert nb.scraps['number_2d_successpoints'].data > 200
|
Determine if papermill v1.0 API change is a problem
# Description
The [papermill `v1.0` release will introduce API breaking changes](https://github.com/nteract/papermill/blob/d554193bc458797b63af1f94964883d5dcca2418/README.md). It would be good to determine if these changes will matter for pyhf testing and require the addition of [scrapbook](https://nteract-scrapbook.readthedocs.io/en/latest/) or if the API change doesn't affect pyhf.
| 2019-04-26T02:56:51 |
|
scikit-hep/pyhf
| 472 |
scikit-hep__pyhf-472
|
[
"451"
] |
f96d6c99be583a4409b1fc75d1348170c6b1e67e
|
diff --git a/pyhf/pdf.py b/pyhf/pdf.py
--- a/pyhf/pdf.py
+++ b/pyhf/pdf.py
@@ -176,9 +176,10 @@ class Model(object):
def __init__(self, spec, **config_kwargs):
self.spec = copy.deepcopy(spec) # may get modified by config
self.schema = config_kwargs.pop('schema', 'model.json')
+ self.version = config_kwargs.pop('version', None)
# run jsonschema validation of input specification against the (provided) schema
log.info("Validating spec against schema: {0:s}".format(self.schema))
- utils.validate(self.spec, self.schema)
+ utils.validate(self.spec, self.schema, version=self.version)
# build up our representation of the specification
self.config = _ModelConfig(self.spec, **config_kwargs)
@@ -483,9 +484,10 @@ def __init__(self, spec, **config_kwargs):
self.spec = spec
self.schema = config_kwargs.pop('schema', 'workspace.json')
+ self.version = config_kwargs.pop('version', None)
# run jsonschema validation of input specification against the (provided) schema
log.info("Validating spec against schema: {0:s}".format(self.schema))
- utils.validate(self.spec, self.schema)
+ utils.validate(self.spec, self.schema, version=self.version)
self.measurement_names = []
for measurement in self.spec.get('measurements', []):
@@ -512,7 +514,7 @@ def get_measurement(self, **config_kwargs):
"""
m = self._get_measurement(**config_kwargs)
- utils.validate(m, 'measurement.json')
+ utils.validate(m, 'measurement.json', self.version)
return m
def _get_measurement(self, **config_kwargs):
diff --git a/pyhf/readxml.py b/pyhf/readxml.py
--- a/pyhf/readxml.py
+++ b/pyhf/readxml.py
@@ -270,6 +270,7 @@ def parse(configfile, rootdir, track_progress=False):
'measurements': process_measurements(toplvl),
'channels': [{'name': k, 'samples': v['samples']} for k, v in channels.items()],
'data': {k: v['data'] for k, v in channels.items()},
+ 'version': utils.SCHEMA_VERSION,
}
utils.validate(result, 'workspace.json')
diff --git a/pyhf/utils.py b/pyhf/utils.py
--- a/pyhf/utils.py
+++ b/pyhf/utils.py
@@ -10,16 +10,23 @@
SCHEMA_CACHE = {}
SCHEMA_BASE = "https://diana-hep.org/pyhf/schemas/"
+SCHEMA_VERSION = '1.0.0'
-def load_schema(schema_id):
+def load_schema(schema_id, version=None):
global SCHEMA_CACHE
+ if not version:
+ version = SCHEMA_VERSION
try:
- return SCHEMA_CACHE["{0:s}{1:s}".format(SCHEMA_BASE, schema_id)]
+ return SCHEMA_CACHE[
+ "{0:s}{1:s}".format(SCHEMA_BASE, os.path.join(version, schema_id))
+ ]
except KeyError:
pass
- path = pkg_resources.resource_filename(__name__, os.path.join('schemas', schema_id))
+ path = pkg_resources.resource_filename(
+ __name__, os.path.join('schemas', version, schema_id)
+ )
with open(path) as json_schema:
schema = json.load(json_schema)
SCHEMA_CACHE[schema['$id']] = schema
@@ -30,8 +37,8 @@ def load_schema(schema_id):
load_schema('defs.json')
-def validate(spec, schema_name):
- schema = load_schema(schema_name)
+def validate(spec, schema_name, version=None):
+ schema = load_schema(schema_name, version=version)
try:
resolver = jsonschema.RefResolver(
base_uri='file://{0:s}'.format(
|
add versioning to schema
# Description
For future-proofing we need to add versioning to the schemas. I would propose that we have a simple string-based version
```
version: "1.0"
.. remaining keys possibly version specific ..
```
and the following strategy
* when loading the model, it is validated against schemas of the declared version.
* within the code, a given in-memory representation i.e. the `Workspace` class can be
instantiated using specs of a subrange of versions `[v_min,v_max]`. possible the ctor will forward/backward evolve to a common format ( I suspect usually forward, i.e. accept a v1 representation but convert it into a v2 representations internally
* a given `pyhf` version can read a subset of pyhf schema versions. The goal here should be to be as backward and forwards compatible as possible
* forward compatible: validating the version number itself should be optional (i.e. a v2 spec might be structurally compatible with v1, e.g. if we add new optional fields) so it should still validate as a v1 model even though it has "version: v2" in the spec.
* backward compatible: future pyhf versions should carry all older schemas as well so older models can be validated. if needed we will add converters for forward evolution to a more recent version once a model is validated in a older version
* probably would be nice to have `pyhf` be able to output what version range is supported
* to the extend that pyhf has translators from one version to another, a cli to do this conversion might be nice in order to normalize let's say multiple worksapces defined in different versions for a combination
* if backward compatibility is not possible, this means a older version of the spec can only be read in a older version of pyhf. This is fine per se, this necessarily will require a new major release, but we should really try to avoid it.
|
I have a couple of thoughts on this. Given that the spec loading is simply to flesh out the workspace/model - perhaps we can move the Workspace class into a versioned piece of python code -- but this means adding tests and ensuring all the various forward/backward compatibilities that come with it.
I'm ok with versioning the schema alone - but we really should not be changing it too much after this point in time to be honest -- since we're already able to round-trip results.
yes I don't expect backward-incompatible changes math-wise, but could imagine that we move things around in the schema to accomodate future features. Given the first point I think the chance that we can forward translate old schemas is quite high since I don't think we'll drop any features.
> yes I don't expect backward-incompatible changes math-wise, but could imagine that we move things around in the schema to accomodate future features. Given the first point I think the chance that we can forward translate old schemas is quite high since I don't think we'll drop any features.
It's a good point. This is the part that I'm still thinking about how we can structure things. One can version explicitly -- or we could keep around older versions:
```
- pyhf/schemas/latest/ --> v2/
- pyhf/schemas/v1/
- pyhf/schemas/v2/
```
as an example of versioning implicitly. Then we're keeping around all versions of it. Similarly, if one does it this way, then we can just provide helper utilities to convert from one version to another.
Similarly, if we version explicitly, with the version number, we can write a utility that handles the conversions entirely.
| 2019-05-07T22:49:09 |
|
scikit-hep/pyhf
| 483 |
scikit-hep__pyhf-483
|
[
"482"
] |
46ffb0a8bba2ce284879cf42e1e9976c79a4838b
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -12,7 +12,7 @@
extras_require = {
'tensorflow': [
- 'tensorflow~=1.13',
+ 'tensorflow~=1.14',
'tensorflow-probability~=0.5',
'numpy<=1.14.5,>=1.14.0', # Lower of 1.14.0 instead of 1.13.3 to ensure doctest pass
'setuptools<=39.1.0',
|
diff --git a/tests/test_tensor.py b/tests/test_tensor.py
--- a/tests/test_tensor.py
+++ b/tests/test_tensor.py
@@ -197,7 +197,9 @@ def test_einsum(backend):
with pytest.raises(NotImplementedError):
assert tb.einsum('ij->ji', [1, 2, 3])
else:
- assert np.all(tb.tolist(tb.einsum('ij->ji', x)) == np.asarray(x).T.tolist())
+ assert np.all(
+ tb.tolist(tb.einsum('ij->ji', tb.astensor(x))) == np.asarray(x).T.tolist()
+ )
assert (
tb.tolist(
tb.einsum('i,j->ij', tb.astensor([1, 1, 1]), tb.astensor([1, 2, 3]))
|
TensorFlow einsum behavior change
# Description
In the test suite the `test_einsum[tensorflow]` [test is failing](https://travis-ci.org/diana-hep/pyhf/jobs/548493214#L689-L714) for `tensorflow` `v1.14.0`.
# Expected Behavior
`test_einsum[tensorflow]` passes
# Actual Behavior
```
backend = (<pyhf.tensor.tensorflow_backend.tensorflow_backend object at 0x7f11de50be10>, None)
def test_einsum(backend):
tb = pyhf.tensorlib
x = np.arange(20).reshape(5, 4).tolist()
if isinstance(pyhf.tensorlib, pyhf.tensor.mxnet_backend):
with pytest.raises(NotImplementedError):
assert tb.einsum('ij->ji', [1, 2, 3])
else:
> assert np.all(tb.tolist(tb.einsum('ij->ji', x)) == np.asarray(x).T.tolist())
tests/test_tensor.py:200:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
pyhf/tensor/tensorflow_backend.py:260: in einsum
return tf.einsum(subscripts, *operands)
../../../virtualenv/python3.6.3/lib/python3.6/site-packages/tensorflow/python/ops/special_math_ops.py:255: in einsum
input_shapes = [x.get_shape() for x in inputs]
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
.0 = <list_iterator object at 0x7f11cc06bb38>
> input_shapes = [x.get_shape() for x in inputs]
E AttributeError: 'list' object has no attribute 'get_shape'
```
# Steps to Reproduce
Run the test suite.
```
pytest -s tests/test_tensor.py
```
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
| 2019-06-21T04:09:29 |
|
scikit-hep/pyhf
| 488 |
scikit-hep__pyhf-488
|
[
"474"
] |
c621670c961e773cf8f7e1b91e1d710d325a9363
|
diff --git a/pyhf/pdf.py b/pyhf/pdf.py
--- a/pyhf/pdf.py
+++ b/pyhf/pdf.py
@@ -493,6 +493,10 @@ def __init__(self, spec, **config_kwargs):
for measurement in self.spec.get('measurements', []):
self.measurement_names.append(measurement['name'])
+ self.observations = {}
+ for obs in self.spec['observations']:
+ self.observations[obs['name']] = obs['data']
+
# NB: this is a wrapper function to validate the returned measurement object against the spec
def get_measurement(self, **config_kwargs):
"""
@@ -601,7 +605,15 @@ def data(self, model, with_aux=True):
data: A list of numbers
"""
- observed_data = sum((self.spec['data'][c] for c in model.config.channels), [])
+ try:
+ observed_data = sum(
+ (self.observations[c] for c in model.config.channels), []
+ )
+ except KeyError:
+ log.error(
+ "Invalid channel: the workspace does not have observation data for one of the channels in the model."
+ )
+ raise
if with_aux:
observed_data += model.config.auxdata
return observed_data
diff --git a/pyhf/readxml.py b/pyhf/readxml.py
--- a/pyhf/readxml.py
+++ b/pyhf/readxml.py
@@ -269,7 +269,7 @@ def parse(configfile, rootdir, track_progress=False):
result = {
'measurements': process_measurements(toplvl),
'channels': [{'name': k, 'samples': v['samples']} for k, v in channels.items()],
- 'data': {k: v['data'] for k, v in channels.items()},
+ 'observations': [{'name': k, 'data': v['data']} for k, v in channels.items()],
'version': utils.SCHEMA_VERSION,
}
diff --git a/pyhf/writexml.py b/pyhf/writexml.py
--- a/pyhf/writexml.py
+++ b/pyhf/writexml.py
@@ -183,19 +183,21 @@ def build_sample(samplespec, channelname):
return sample
-def build_data(dataspec, channelname):
+def build_data(obsspec, channelname):
histname = _make_hist_name(channelname, 'data')
data = ET.Element('Data', HistoName=histname, InputFile=_ROOT_DATA_FILE._path)
- _export_root_histogram(histname, dataspec[channelname])
+
+ observation = next((obs for obs in obsspec if obs['name'] == channelname), None)
+ _export_root_histogram(histname, observation['data'])
return data
-def build_channel(channelspec, dataspec):
+def build_channel(channelspec, obsspec):
channel = ET.Element(
'Channel', Name=channelspec['name'], InputFile=_ROOT_DATA_FILE._path
)
- if dataspec:
- data = build_data(dataspec, channelspec['name'])
+ if obsspec:
+ data = build_data(obsspec, channelspec['name'])
channel.append(data)
for samplespec in channelspec['samples']:
channel.append(build_sample(samplespec, channelspec['name']))
@@ -219,7 +221,7 @@ def writexml(spec, specdir, data_rootdir, resultprefix):
specdir, '{0:s}_{1:s}.xml'.format(resultprefix, channelspec['name'])
)
with open(channelfilename, 'w') as channelfile:
- channel = build_channel(channelspec, spec.get('data'))
+ channel = build_channel(channelspec, spec.get('observations'))
indent(channel)
channelfile.write(
"<!DOCTYPE Channel SYSTEM '../HistFactorySchema.dtd'>\n\n"
|
diff --git a/tests/test_export.py b/tests/test_export.py
--- a/tests/test_export.py
+++ b/tests/test_export.py
@@ -269,7 +269,7 @@ def test_export_channel(mocker, spec):
def test_export_data(mocker):
channelname = 'channel'
- dataspec = {channelname: [0, 1, 2, 3]}
+ dataspec = [{'name': channelname, 'data': [0, 1, 2, 3]}]
mocker.patch('pyhf.writexml._ROOT_DATA_FILE')
data = pyhf.writexml.build_data(dataspec, channelname)
diff --git a/tests/test_import.py b/tests/test_import.py
--- a/tests/test_import.py
+++ b/tests/test_import.py
@@ -56,7 +56,9 @@ def test_import_prepHistFactory():
data = [
binvalue
for k in pdf.spec['channels']
- for binvalue in parsed_xml['data'][k['name']]
+ for binvalue in next(
+ obs for obs in parsed_xml['observations'] if obs['name'] == k['name']
+ )['data']
] + pdf.config.auxdata
channels = {channel['name'] for channel in pdf.spec['channels']}
@@ -120,7 +122,9 @@ def test_import_histosys():
data = [
binvalue
for k in pdf.spec['channels']
- for binvalue in parsed_xml['data'][k['name']]
+ for binvalue in next(
+ obs for obs in parsed_xml['observations'] if obs['name'] == k['name']
+ )['data']
] + pdf.config.auxdata
channels = {channel['name']: channel for channel in pdf.spec['channels']}
@@ -172,7 +176,9 @@ def test_import_shapesys():
data = [
binvalue
for k in pdf.spec['channels']
- for binvalue in parsed_xml['data'][k['name']]
+ for binvalue in next(
+ obs for obs in parsed_xml['observations'] if obs['name'] == k['name']
+ )['data']
] + pdf.config.auxdata
channels = {channel['name']: channel for channel in pdf.spec['channels']}
diff --git a/tests/test_validation.py b/tests/test_validation.py
--- a/tests/test_validation.py
+++ b/tests/test_validation.py
@@ -801,13 +801,17 @@ def test_import_roundtrip(tmpdir, toplvl, basedir):
data_before = [
binvalue
for k in pdf_before.config.channels
- for binvalue in parsed_xml_before['data'][k]
+ for binvalue in next(
+ obs for obs in parsed_xml_before['observations'] if obs['name'] == k
+ )['data']
] + pdf_before.config.auxdata
data_after = [
binvalue
for k in pdf_after.config.channels
- for binvalue in parsed_xml_after['data'][k]
+ for binvalue in next(
+ obs for obs in parsed_xml_after['observations'] if obs['name'] == k
+ )['data']
] + pdf_after.config.auxdata
assert data_before == data_after
diff --git a/tests/test_workspace.py b/tests/test_workspace.py
--- a/tests/test_workspace.py
+++ b/tests/test_workspace.py
@@ -3,6 +3,7 @@
import pytest
import pyhf.exceptions
import json
+import logging
@pytest.fixture(
@@ -104,3 +105,25 @@ def test_get_workspace_model_default(workspace_factory):
w = workspace_factory()
m = w.model()
assert m
+
+
+def test_workspace_observations(workspace_factory):
+ w = workspace_factory()
+ assert w.observations
+
+
+def test_get_workspace_data(workspace_factory):
+ w = workspace_factory()
+ m = w.model()
+ assert w.data(m)
+
+
+def test_get_workspace_data_bad_model(workspace_factory, caplog):
+ w = workspace_factory()
+ m = w.model()
+ # the iconic fragrance of an expected failure
+ m.config.channels = [c.replace('channel', 'chanel') for c in m.config.channels]
+ with caplog.at_level(logging.INFO, 'pyhf.pdf'):
+ with pytest.raises(KeyError):
+ assert w.data(m)
+ assert 'Invalid channel' in caplog.text
|
data specification for workspace is not specific enough
# Description
Related to #106. https://github.com/diana-hep/pyhf/blob/master/pyhf/schemas/1.0.0/workspace.json#L8 currently describes data as an object, but that could be anything. We probably want to specify it as an object with keys for example... or perhaps as @lukasheinrich stated before, an array of items.
|
To ping this given some recent discussion, it seems that there is consensus to use an array of items. :+1: The idea is that it is easier to inject things into a fixed order list than to inject by key name (which won't be known until look up). @kratsg gave the example that
> ... `workspace.json/data/0/rates` is easier than `workspace.json/data/SRA_lowmeff`
This needs to get fixed before the `v1.0.0` schema gets tagged and so should also get done before pyhf `v0.1.1` is released.
| 2019-06-25T03:20:35 |
scikit-hep/pyhf
| 564 |
scikit-hep__pyhf-564
|
[
"554"
] |
1d50318208c8733644e2a8b733b4e0aab344b6d3
|
diff --git a/src/pyhf/exceptions/__init__.py b/src/pyhf/exceptions/__init__.py
--- a/src/pyhf/exceptions/__init__.py
+++ b/src/pyhf/exceptions/__init__.py
@@ -68,3 +68,15 @@ class InvalidOptimizer(Exception):
"""
InvalidOptimizer is raised when trying to set using an optimizer that does not exist.
"""
+
+
+class InvalidPdfParameters(Exception):
+ """
+ InvalidPdfParameters is raised when trying to evaluate a pdf with invalid parameters.
+ """
+
+
+class InvalidPdfData(Exception):
+ """
+ InvalidPdfData is raised when trying to evaluate a pdf with invalid data.
+ """
diff --git a/src/pyhf/pdf.py b/src/pyhf/pdf.py
--- a/src/pyhf/pdf.py
+++ b/src/pyhf/pdf.py
@@ -538,6 +538,23 @@ def logpdf(self, pars, data):
try:
tensorlib, _ = get_backend()
pars, data = tensorlib.astensor(pars), tensorlib.astensor(data)
+ # Verify parameter and data shapes
+ if pars.shape[-1] != len(self.config.suggested_init()):
+ raise exceptions.InvalidPdfParameters(
+ 'eval failed as pars has len {} but {} was expected'.format(
+ pars.shape[-1], len(self.config.suggested_init())
+ )
+ )
+
+ if data.shape[-1] != self.nominal_rates.shape[-1] + len(
+ self.config.auxdata
+ ):
+ raise exceptions.InvalidPdfData(
+ 'eval failed as data has len {} but {} was expected'.format(
+ data.shape[-1],
+ self.nominal_rates.shape[-1] + len(self.config.auxdata),
+ )
+ )
actual_data = self.main_model._dataprojection(data)
aux_data = self.constraint_model._dataprojection(data)
|
diff --git a/tests/test_pdf.py b/tests/test_pdf.py
--- a/tests/test_pdf.py
+++ b/tests/test_pdf.py
@@ -29,6 +29,38 @@ def test_pdf_inputs(backend):
)
+def test_invalid_pdf_pars():
+ source = {
+ "binning": [2, -0.5, 1.5],
+ "bindata": {"data": [55.0], "bkg": [50.0], "bkgerr": [7.0], "sig": [10.0]},
+ }
+ pdf = pyhf.simplemodels.hepdata_like(
+ source['bindata']['sig'], source['bindata']['bkg'], source['bindata']['bkgerr']
+ )
+
+ pars = pdf.config.suggested_init() + [1.0]
+ data = source['bindata']['data'] + pdf.config.auxdata
+
+ with pytest.raises(pyhf.exceptions.InvalidPdfParameters):
+ pdf.logpdf(pars, data)
+
+
+def test_invalid_pdf_data():
+ source = {
+ "binning": [2, -0.5, 1.5],
+ "bindata": {"data": [55.0], "bkg": [50.0], "bkgerr": [7.0], "sig": [10.0]},
+ }
+ pdf = pyhf.simplemodels.hepdata_like(
+ source['bindata']['sig'], source['bindata']['bkg'], source['bindata']['bkgerr']
+ )
+
+ pars = pdf.config.suggested_init()
+ data = source['bindata']['data'] + [10.0] + pdf.config.auxdata
+
+ with pytest.raises(pyhf.exceptions.InvalidPdfData):
+ pdf.logpdf(pars, data)
+
+
@pytest.mark.fail_mxnet
def test_pdf_basicapi_tests(backend):
source = {
diff --git a/tests/test_validation.py b/tests/test_validation.py
--- a/tests/test_validation.py
+++ b/tests/test_validation.py
@@ -77,26 +77,26 @@ def setup_1bin_shapesys(
@pytest.fixture(scope='module')
-def spec_1bin_lumi(source=source_1bin_example1()):
+def spec_1bin_lumi():
spec = {
"channels": [
{
"name": "channel1",
"samples": [
{
- "data": [20.0, 10.0],
+ "data": [20.0],
"modifiers": [
{"data": None, "name": "mu", "type": "normfactor"}
],
"name": "signal",
},
{
- "data": [100.0, 0.0],
+ "data": [100.0],
"modifiers": [{"data": None, "name": "lumi", "type": "lumi"}],
"name": "background1",
},
{
- "data": [0.0, 100.0],
+ "data": [0.0],
"modifiers": [{"data": None, "name": "lumi", "type": "lumi"}],
"name": "background2",
},
@@ -120,8 +120,8 @@ def spec_1bin_lumi(source=source_1bin_example1()):
def expected_result_1bin_lumi(mu=1.0):
if mu == 1:
expected_result = {
- "exp": [0.00905976, 0.0357287, 0.12548957, 0.35338293, 0.69589171],
- "obs": 0.00941757,
+ "exp": [0.01060338, 0.04022273, 0.13614217, 0.37078321, 0.71104119],
+ "obs": 0.01047275,
}
return expected_result
@@ -129,7 +129,7 @@ def expected_result_1bin_lumi(mu=1.0):
@pytest.fixture(scope='module')
def setup_1bin_lumi(
source=source_1bin_example1(),
- spec=spec_1bin_lumi(source_1bin_example1()),
+ spec=spec_1bin_lumi(),
mu=1,
expected_result=expected_result_1bin_lumi(1.0),
config={'init_pars': 2, 'par_bounds': 2},
|
Fix `1bin_lumi` test
# Description
This popped up as part of #553. The `1bin_lumi` validation model is buggy. The JSON spec is 2-bin, but the passed in data is 1-bin. We did not catch this before, but the test should be fixed and validation data updated.
See fix in 839ac67bd5aa4bbc2ef166191250f2dcba4dc872
# Expected Behavior
Describe what you thought should have happened
# Actual Behavior
Describe what did happen
# Steps to Reproduce
Detail your environment and `pyhf.__version__` and the commands that you are executing to generate the bug. If you have a large program please make a [Gist](https://gist.github.com/) and link it here. Additionally attach any screen shots as needed.
# Checklist
- [ ] Run `git fetch` to get the most up to date version of `master`
- [ ] Searched through existing Issues to confirm this is not a duplicate issue
- [ ] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
| 2019-09-16T16:22:57 |
|
scikit-hep/pyhf
| 596 |
scikit-hep__pyhf-596
|
[
"587"
] |
b455bf5277aa2b2e0f6ba1e63bc63d54ae7f9788
|
diff --git a/src/pyhf/pdf.py b/src/pyhf/pdf.py
--- a/src/pyhf/pdf.py
+++ b/src/pyhf/pdf.py
@@ -567,7 +567,7 @@ def _create_nominal_and_modifiers(self, config, spec):
return mega_mods, _nominal_rates
def expected_auxdata(self, pars):
- return self.make_pdf(pars).pdfobjs[1].expected_data()
+ return self.make_pdf(pars)[1].expected_data()
def _modifications(self, pars):
return self.main_model._modifications(pars)
@@ -577,20 +577,20 @@ def nominal_rates(self):
return self.main_model.nominal_rates
def expected_actualdata(self, pars):
- return self.make_pdf(pars).pdfobjs[0].expected_data()
+ return self.make_pdf(pars)[0].expected_data()
def expected_data(self, pars, include_auxdata=True):
tensorlib, _ = get_backend()
pars = tensorlib.astensor(pars)
if not include_auxdata:
- return self.make_pdf(pars).pdfobjs[0].expected_data()
+ return self.make_pdf(pars)[0].expected_data()
return self.make_pdf(pars).expected_data()
def constraint_logpdf(self, auxdata, pars):
- return self.make_pdf(pars).pdfobjs[1].log_prob(auxdata)
+ return self.make_pdf(pars)[1].log_prob(auxdata)
def mainlogpdf(self, maindata, pars):
- return self.make_pdf(pars).pdfobjs[0].log_prob(maindata)
+ return self.make_pdf(pars)[0].log_prob(maindata)
def make_pdf(self, pars):
"""
diff --git a/src/pyhf/probability.py b/src/pyhf/probability.py
--- a/src/pyhf/probability.py
+++ b/src/pyhf/probability.py
@@ -202,9 +202,34 @@ def __init__(self, pdfobjs, tensorview, batch_size=None):
"""
self.tv = tensorview
- self.pdfobjs = pdfobjs
+ self._pdfobjs = pdfobjs
self.batch_size = batch_size
+ def __iter__(self):
+ """
+ Iterate over the constituent pdf objects
+
+ Returns:
+ pdfobj (`Distribution`): A constituent pdf object
+
+ """
+ for pdfobj in self._pdfobjs:
+ yield pdfobj
+
+ def __getitem__(self, index):
+ """
+ Access the constituent pdf object at the specified index
+
+ Args:
+
+ index (`int`): The index to access the constituent pdf object
+
+ Returns:
+ pdfobj (`Distribution`): A constituent pdf object
+
+ """
+ return self._pdfobjs[index]
+
def expected_data(self):
"""
Compute mean data of the density
@@ -213,7 +238,7 @@ def expected_data(self):
data (`tensor`): The expected data
"""
- tostitch = [p.expected_data() for p in self.pdfobjs]
+ tostitch = [p.expected_data() for p in self]
return self.tv.stitch(tostitch)
def sample(self, sample_shape=()):
@@ -227,7 +252,7 @@ def sample(self, sample_shape=()):
samples (`tensor`): The samples
"""
- return self.tv.stitch([p.sample(sample_shape) for p in self.pdfobjs])
+ return self.tv.stitch([p.sample(sample_shape) for p in self])
def log_prob(self, value):
"""
@@ -241,7 +266,7 @@ def log_prob(self, value):
"""
constituent_data = self.tv.split(value)
- pdfvals = [p.log_prob(d) for p, d in zip(self.pdfobjs, constituent_data)]
+ pdfvals = [p.log_prob(d) for p, d in zip(self, constituent_data)]
return Simultaneous._joint_logpdf(pdfvals, batch_size=self.batch_size)
@staticmethod
|
diff --git a/tests/test_probability.py b/tests/test_probability.py
--- a/tests/test_probability.py
+++ b/tests/test_probability.py
@@ -1,4 +1,5 @@
from pyhf import probability
+import numpy as np
def test_poisson(backend):
@@ -63,3 +64,14 @@ def test_independent(backend):
assert tb.tolist(probability.Simultaneous._joint_logpdf([p1, p2]))[0] == tb.tolist(
result
)
+ assert tb.tolist(probability.Simultaneous._joint_logpdf([p1, p2]))[0] == tb.tolist(
+ result
+ )
+
+
+def test_simultaneous_list_ducktype():
+ myobjs = np.random.randint(100, size=10).tolist()
+ sim = probability.Simultaneous(myobjs, None)
+ assert sim[3] == myobjs[3]
+ for simobj, myobj in zip(sim, myobjs):
+ assert simobj == myobj
|
Simultaneous to have magic iter functions (make it look like a list)
# Description
We will soon be using Simultaneous as if it was a list, accessing via `self.make_pdf(pars).pdfobjs[n]` basically.
## Is your feature request related to a problem? Please describe.
No.
### Describe the solution you'd like
I prefer `self.make_pdf(pars)[n]` instead, since it's cleaner/user-friendly. Simultaneous is just a list of PDF objects.
### Describe alternatives you've considered
None.
# Relevant Issues and Pull Requests
- #558
# Additional context
Nah
| 2019-10-02T17:21:15 |
|
scikit-hep/pyhf
| 638 |
scikit-hep__pyhf-638
|
[
"508"
] |
96879c28e25d99a5bc0a9cd384fb5cbd83cb2334
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -50,8 +50,8 @@
def _is_test_pypi():
"""
- Determine if the Travis CI environment has TESTPYPI_UPLOAD defined and
- set to true (c.f. .travis.yml)
+ Determine if the CI environment has IS_TESTPYPI defined and
+ set to true (c.f. .github/workflows/publish-package.yml)
The use_scm_version kwarg accepts a callable for the local_scheme
configuration parameter with argument "version". This can be replaced
@@ -65,7 +65,7 @@ def _is_test_pypi():
return (
{'local_scheme': lambda version: ''}
- if getenv('TESTPYPI_UPLOAD') == 'true'
+ if getenv('IS_TESTPYPI') == 'true'
else False
)
|
Automate deployment to PyPI
# Description
According to @lukasheinrich, the current workflow for deploying to PyPI is:
```
git checkout master
git pull
bumpversion patch
git commit
git push origin master --tags
```
This is a bit annoyingly manual and ideally should be done automatically.
Luckily, there is an [official PyPA GitHub action](https://discuss.python.org/t/official-github-action-for-publishing-to-pypi/1061) to do this:
https://github.com/pypa/gh-action-pypi-publish
However, we need GitHub actions for pyhf, so we have to wait.
|
I'm happy to take this one once we get GitHub actions.
An example of how this is actually hard without automation is that when [`v0.1.2`](https://github.com/diana-hep/pyhf/releases/tag/v0.1.2) was released to PyPI the commit got into the tags, but not the refs/heads, but still got [picked up by the CI, built and deployed](https://travis-ci.org/diana-hep/pyhf/builds/557986549). It was [later pushed to `master`](https://github.com/diana-hep/pyhf/commit/3e1e383c775a4407277dad49c810f5b16a56ef3b), but for about an hour there was a mismatch where PyPI was ahead of GitHub.
Having a CI that can properly do releases for us would solve this sort of confusing thing.
Why don't we have GitHub Actions yet?
> Why don't we have GitHub Actions yet?
GitHub Actions is still in beta.
[](https://github.com/features/actions)
They have tightly restricted the number of people who can enter the beta, and they denied my request to bump Lukas and diana-hep up in the queue.
We have GitHub Actions now (:tada:), and @webknjaz has done an awesome job getting [`pypi-publish`](https://github.com/pypa/gh-action-pypi-publish) up [on the GitHub Marketplace](https://github.com/marketplace/actions/pypi-publish) and ready to go. Time to use it!
There doesn't seem to be any clear examples of people using [`pypi-publish`](https://github.com/pypa/gh-action-pypi-publish) out in the wild yet, with the exception of [`pubmedpy`](https://github.com/dhimmel/pubmedpy/blob/master/.github/workflows/release.yml), so it might be worth checking out what they did.
@matthewfeickert I believe everything you need is in the README. There's also an unmerged guide here: https://github.com/pypa/packaging.python.org/pull/647.
But the idea is that you use whatever it is that you use already for *building* dists. This Action is just for uploading the artifacts.
Go to https://pypi.org/manage/account/#api-tokens, create a token just for this project, and then copy-paste it to https://github.com/diana-hep/pyhf/settings/secrets and finally use that var in the Action.
The GitHub Actions publishing guide is now up on the PyPA website: https://packaging.python.org/guides/publishing-package-distribution-releases-using-github-actions-ci-cd-workflows/ :)
Yep, for a while now. But needs updating to take into account OS-specific wheels.
> Yep, for a while now. But needs updating to take into account OS-specific wheels.
I ran into a ton of issues here, especially with Test PyPI and overlapping versioning. I don't understand setuptools_scm enough to really make it work the way I want (non-tagged versions result in {next-version}.dev{distance} and tagged versions result in {current-version}) and I made a mess of it just to make it work correctly in GitHub actions here: https://github.com/kratsg/stare/blob/master/.github/workflows/publish-package-to-pypi.yml (with a bunch of additional changes to check env variable flags and so on)
| 2019-11-14T21:04:17 |
|
scikit-hep/pyhf
| 666 |
scikit-hep__pyhf-666
|
[
"661"
] |
54f8cc6af2341df1da33b09cd5657af5e5b819f2
|
diff --git a/src/pyhf/readxml.py b/src/pyhf/readxml.py
--- a/src/pyhf/readxml.py
+++ b/src/pyhf/readxml.py
@@ -69,6 +69,7 @@ def process_sample(
data, err = import_root_histogram(rootdir, inputfile, histopath, histoname)
+ parameter_configs = []
modifiers = []
# first check if we need to add lumi modifier for this sample
if sample.attrib.get("NormalizeByTheory", "False") == 'True':
@@ -101,6 +102,15 @@ def process_sample(
modifiers.append(
{'name': modtag.attrib['Name'], 'type': 'normfactor', 'data': None}
)
+ parameter_config = {
+ 'name': modtag.attrib['Name'],
+ 'bounds': [[float(modtag.attrib['Low']), float(modtag.attrib['High'])]],
+ 'inits': [float(modtag.attrib['Val'])],
+ }
+ if modtag.attrib.get('Const'):
+ parameter_config['fixed'] = modtag.attrib['Const'] == 'True'
+
+ parameter_configs.append(parameter_config)
elif modtag.tag == 'HistoSys':
lo, _ = import_root_histogram(
rootdir,
@@ -165,7 +175,12 @@ def process_sample(
else:
log.warning('not considering modifier tag %s', modtag)
- return {'name': sample.attrib['Name'], 'data': data, 'modifiers': modifiers}
+ return {
+ 'name': sample.attrib['Name'],
+ 'data': data,
+ 'modifiers': modifiers,
+ 'parameter_configs': parameter_configs,
+ }
def process_data(sample, rootdir, inputfile, histopath):
@@ -197,19 +212,24 @@ def process_channel(channelxml, rootdir, track_progress=False):
channelname = channel.attrib['Name']
results = []
+ channel_parameter_configs = []
for sample in samples:
samples.set_description(' - sample {}'.format(sample.attrib.get('Name')))
result = process_sample(
sample, rootdir, inputfile, histopath, channelname, track_progress
)
+ channel_parameter_configs.extend(result.pop('parameter_configs'))
results.append(result)
- return channelname, parsed_data, results
+ return channelname, parsed_data, results, channel_parameter_configs
-def process_measurements(toplvl):
+def process_measurements(toplvl, other_parameter_configs=None):
results = []
+ other_parameter_configs = other_parameter_configs if other_parameter_configs else []
+
for x in toplvl.findall('Measurement'):
+ parameter_configs_map = {k['name']: dict(**k) for k in other_parameter_configs}
lumi = float(x.attrib['Lumi'])
lumierr = lumi * float(x.attrib['LumiRelErr'])
@@ -228,13 +248,14 @@ def process_measurements(toplvl):
],
},
}
+
for param in x.findall('ParamSetting'):
# determine what all parameters in the paramsetting have in common
overall_param_obj = {}
if param.attrib.get('Const'):
overall_param_obj['fixed'] = param.attrib['Const'] == 'True'
if param.attrib.get('Val'):
- overall_param_obj['value'] = param.attrib['Val']
+ overall_param_obj['inits'] = [float(param.attrib['Val'])]
# might be specifying multiple parameters in the same ParamSetting
if param.text:
@@ -243,13 +264,40 @@ def process_measurements(toplvl):
if param_name == 'Lumi':
result['config']['parameters'][0].update(overall_param_obj)
else:
- param_obj = {'name': param_name}
+ # pop from parameter_configs_map because we don't want to duplicate
+ param_obj = parameter_configs_map.pop(
+ param_name, {'name': param_name}
+ )
+ # ParamSetting will always take precedence
param_obj.update(overall_param_obj)
- result['config']['parameters'].append(param_obj)
+ # add it back in to the parameter_configs_map
+ parameter_configs_map[param_name] = param_obj
+ result['config']['parameters'].extend(parameter_configs_map.values())
results.append(result)
+
return results
+def dedupe_parameters(parameters):
+ duplicates = {}
+ for p in parameters:
+ duplicates.setdefault(p['name'], []).append(p)
+ for parname in duplicates.keys():
+ parameter_list = duplicates[parname]
+ if len(parameter_list) == 1:
+ continue
+ elif any(p != parameter_list[0] for p in parameter_list[1:]):
+ for p in parameter_list:
+ log.warning(p)
+ raise RuntimeError(
+ 'cannot import workspace due to incompatible parameter configurations for {0:s}.'.format(
+ parname
+ )
+ )
+ # no errors raised, de-dupe and return
+ return list({v['name']: v for v in parameters}.values())
+
+
def parse(configfile, rootdir, track_progress=False):
toplvl = ET.parse(configfile)
inputs = tqdm.tqdm(
@@ -259,20 +307,24 @@ def parse(configfile, rootdir, track_progress=False):
)
channels = {}
+ parameter_configs = []
for inp in inputs:
inputs.set_description('Processing {}'.format(inp))
- channel, data, samples = process_channel(
+ channel, data, samples, channel_parameter_configs = process_channel(
ET.parse(os.path.join(rootdir, inp)), rootdir, track_progress
)
channels[channel] = {'data': data, 'samples': samples}
+ parameter_configs.extend(channel_parameter_configs)
+ parameter_configs = dedupe_parameters(parameter_configs)
result = {
- 'measurements': process_measurements(toplvl),
+ 'measurements': process_measurements(
+ toplvl, other_parameter_configs=parameter_configs
+ ),
'channels': [{'name': k, 'samples': v['samples']} for k, v in channels.items()],
'observations': [{'name': k, 'data': v['data']} for k, v in channels.items()],
'version': utils.SCHEMA_VERSION,
}
-
utils.validate(result, 'workspace.json')
return result
diff --git a/src/pyhf/writexml.py b/src/pyhf/writexml.py
--- a/src/pyhf/writexml.py
+++ b/src/pyhf/writexml.py
@@ -12,6 +12,17 @@
log = logging.getLogger(__name__)
+# 'spec' gets passed through all functions as NormFactor is a unique case of having
+# parameter configurations stored at the modifier-definition-spec level. This means
+# that build_modifier() needs access to the measurements. The call stack is:
+#
+# writexml
+# ->build_channel
+# ->build_sample
+# ->build_modifier
+#
+# Therefore, 'spec' needs to be threaded through all these calls.
+
def _make_hist_name(channel, sample, modifier='', prefix='hist', suffix=''):
return "{prefix}{middle}{suffix}".format(
@@ -89,7 +100,7 @@ def build_measurement(measurementspec):
return meas
-def build_modifier(modifierspec, channelname, samplename, sampledata):
+def build_modifier(spec, modifierspec, channelname, samplename, sampledata):
if modifierspec['name'] == 'lumi':
return None
mod_map = {
@@ -115,9 +126,31 @@ def build_modifier(modifierspec, channelname, samplename, sampledata):
attrs['High'] = str(modifierspec['data']['hi'])
attrs['Low'] = str(modifierspec['data']['lo'])
elif modifierspec['type'] == 'normfactor':
- attrs['Val'] = '1'
- attrs['High'] = '10'
- attrs['Low'] = '0'
+ # NB: only look at first measurement for normfactor configs. In order
+ # to dump as HistFactory XML, this has to be the same for all
+ # measurements or it will not work correctly. Why?
+ #
+ # Unlike other modifiers, NormFactor has the unique circumstance of
+ # defining its parameter configurations at the modifier level inside
+ # the channel specification, instead of at the measurement level, like
+ # all of the other modifiers.
+ #
+ # However, since I strive for perfection, the "Const" attribute will
+ # never be set here, but at the per-measurement configuration instead
+ # like all other parameters. This is an acceptable compromise.
+ #
+ # Lastly, if a normfactor parameter configuration doesn't exist in the
+ # first measurement parameter configuration, then set defaults.
+ val = 1
+ low = 0
+ high = 10
+ for p in spec['measurements'][0]['config']['parameters']:
+ if p['name'] == modifierspec['name']:
+ val = p['inits'][0]
+ low, high = p['bounds'][0]
+ attrs['Val'] = str(val)
+ attrs['Low'] = str(low)
+ attrs['High'] = str(high)
elif modifierspec['type'] == 'staterror':
attrs['Activate'] = 'True'
attrs['HistoName'] = _make_hist_name(
@@ -161,7 +194,7 @@ def build_modifier(modifierspec, channelname, samplename, sampledata):
return modifier
-def build_sample(samplespec, channelname):
+def build_sample(spec, samplespec, channelname):
histname = _make_hist_name(channelname, samplespec['name'])
attrs = {
'Name': samplespec['name'],
@@ -175,7 +208,7 @@ def build_sample(samplespec, channelname):
if modspec['type'] == 'lumi':
sample.attrib.update({'NormalizeByTheory': 'True'})
modifier = build_modifier(
- modspec, channelname, samplespec['name'], samplespec['data']
+ spec, modspec, channelname, samplespec['name'], samplespec['data']
)
if modifier is not None:
sample.append(modifier)
@@ -192,7 +225,7 @@ def build_data(obsspec, channelname):
return data
-def build_channel(channelspec, obsspec):
+def build_channel(spec, channelspec, obsspec):
channel = ET.Element(
'Channel', Name=channelspec['name'], InputFile=_ROOT_DATA_FILE._path
)
@@ -200,7 +233,7 @@ def build_channel(channelspec, obsspec):
data = build_data(obsspec, channelspec['name'])
channel.append(data)
for samplespec in channelspec['samples']:
- channel.append(build_sample(samplespec, channelspec['name']))
+ channel.append(build_sample(spec, samplespec, channelspec['name']))
return channel
@@ -221,7 +254,7 @@ def writexml(spec, specdir, data_rootdir, resultprefix):
specdir, '{0:s}_{1:s}.xml'.format(resultprefix, channelspec['name'])
)
with open(channelfilename, 'w') as channelfile:
- channel = build_channel(channelspec, spec.get('observations'))
+ channel = build_channel(spec, channelspec, spec.get('observations'))
indent(channel)
channelfile.write(
"<!DOCTYPE Channel SYSTEM '../HistFactorySchema.dtd'>\n\n"
|
diff --git a/tests/test_export.py b/tests/test_export.py
--- a/tests/test_export.py
+++ b/tests/test_export.py
@@ -195,7 +195,11 @@ def test_export_modifier(mocker, spec, has_root_data, attrs):
mocker.patch('pyhf.writexml._ROOT_DATA_FILE')
modifier = pyhf.writexml.build_modifier(
- modifierspec, channelname, samplename, sampledata
+ {'measurements': [{'config': {'parameters': []}}]},
+ modifierspec,
+ channelname,
+ samplename,
+ sampledata,
)
# if the modifier is a staterror, it has no Name
if 'Name' in modifier.attrib:
@@ -204,6 +208,53 @@ def test_export_modifier(mocker, spec, has_root_data, attrs):
assert pyhf.writexml._ROOT_DATA_FILE.__setitem__.called == has_root_data
[email protected](
+ "spec, normfactor_config",
+ [
+ (spec_staterror(), dict(name='mu', inits=[1.0], bounds=[[0.0, 8.0]])),
+ (spec_histosys(), dict()),
+ (spec_normsys(), dict(name='mu', inits=[2.0], bounds=[[0.0, 10.0]])),
+ (spec_shapesys(), dict(name='mu', inits=[1.0], bounds=[[5.0, 10.0]])),
+ ],
+ ids=['upper-bound', 'empty-config', 'init', 'lower-bound'],
+)
+def test_export_modifier_normfactor(mocker, spec, normfactor_config):
+ channelspec = spec['channels'][0]
+ channelname = channelspec['name']
+ samplespec = channelspec['samples'][0]
+ samplename = samplespec['name']
+ sampledata = samplespec['data']
+ modifierspec = samplespec['modifiers'][0]
+
+ mocker.patch('pyhf.writexml._ROOT_DATA_FILE')
+ modifier = pyhf.writexml.build_modifier(
+ {
+ 'measurements': [
+ {
+ 'config': {
+ 'parameters': [normfactor_config] if normfactor_config else []
+ }
+ }
+ ]
+ },
+ modifierspec,
+ channelname,
+ samplename,
+ sampledata,
+ )
+
+ assert all(attr in modifier.attrib for attr in ['Name', 'Val', 'High', 'Low'])
+ assert float(modifier.attrib['Val']) == normfactor_config.get('inits', [1.0])[0]
+ assert (
+ float(modifier.attrib['Low'])
+ == normfactor_config.get('bounds', [[0.0, 10.0]])[0][0]
+ )
+ assert (
+ float(modifier.attrib['High'])
+ == normfactor_config.get('bounds', [[0.0, 10.0]])[0][1]
+ )
+
+
@pytest.mark.parametrize(
"spec",
[spec_staterror(), spec_histosys(), spec_normsys(), spec_shapesys()],
@@ -218,7 +269,7 @@ def test_export_sample(mocker, spec):
mocker.patch('pyhf.writexml.build_modifier', return_value=ET.Element("Modifier"))
mocker.patch('pyhf.writexml._ROOT_DATA_FILE')
- sample = pyhf.writexml.build_sample(samplespec, channelname)
+ sample = pyhf.writexml.build_sample({}, samplespec, channelname)
assert sample.attrib['Name'] == samplespec['name']
assert sample.attrib['HistoName']
assert sample.attrib['InputFile']
@@ -242,7 +293,11 @@ def test_export_sample_zerodata(mocker, spec):
with pytest.warns(None) as record:
for modifierspec in samplespec['modifiers']:
modifier = pyhf.writexml.build_modifier(
- modifierspec, channelname, samplename, sampledata
+ {'measurements': [{'config': {'parameters': []}}]},
+ modifierspec,
+ channelname,
+ samplename,
+ sampledata,
)
assert not record.list
@@ -259,7 +314,7 @@ def test_export_channel(mocker, spec):
mocker.patch('pyhf.writexml.build_data', return_value=ET.Element("Data"))
mocker.patch('pyhf.writexml.build_sample', return_value=ET.Element("Sample"))
mocker.patch('pyhf.writexml._ROOT_DATA_FILE')
- channel = pyhf.writexml.build_channel(channelspec, {})
+ channel = pyhf.writexml.build_channel({}, channelspec, {})
assert channel.attrib['Name'] == channelspec['name']
assert channel.attrib['InputFile']
assert pyhf.writexml.build_data.called is False
diff --git a/tests/test_import.py b/tests/test_import.py
--- a/tests/test_import.py
+++ b/tests/test_import.py
@@ -4,6 +4,7 @@
import uproot
import os
import pytest
+import xml.etree.cElementTree as ET
def assert_equal_dictionary(d1, d2):
@@ -16,6 +17,96 @@ def assert_equal_dictionary(d1, d2):
assert d1[k] == d2[k]
+def test_dedupe_parameters():
+ parameters = [
+ {'name': 'SigXsecOverSM', 'bounds': [[0.0, 10.0]]},
+ {'name': 'SigXsecOverSM', 'bounds': [[0.0, 10.0]]},
+ ]
+ assert len(pyhf.readxml.dedupe_parameters(parameters)) == 1
+ parameters[1]['bounds'] = [[0.0, 2.0]]
+ with pytest.raises(RuntimeError) as excinfo:
+ pyhf.readxml.dedupe_parameters(parameters)
+ assert 'SigXsecOverSM' in str(excinfo.value)
+
+
+def test_process_normfactor_configs():
+ # Check to see if mu_ttbar NormFactor is overridden correctly
+ # - ParamSetting has a config for it
+ # - other_parameter_configs has a config for it
+ # Make sure that when two measurements exist, we're copying things across correctly
+ toplvl = ET.Element("Combination")
+ meas = ET.Element(
+ "Measurement",
+ Name='NormalMeasurement',
+ Lumi=str(1.0),
+ LumiRelErr=str(0.017),
+ ExportOnly=str(True),
+ )
+ poiel = ET.Element('POI')
+ poiel.text = 'mu_SIG'
+ meas.append(poiel)
+
+ setting = ET.Element('ParamSetting', Const='True')
+ setting.text = ' '.join(['Lumi', 'mu_both', 'mu_paramSettingOnly'])
+ meas.append(setting)
+
+ setting = ET.Element('ParamSetting', Val='2.0')
+ setting.text = ' '.join(['mu_both'])
+ meas.append(setting)
+
+ toplvl.append(meas)
+
+ meas = ET.Element(
+ "Measurement",
+ Name='ParallelMeasurement',
+ Lumi=str(1.0),
+ LumiRelErr=str(0.017),
+ ExportOnly=str(True),
+ )
+ poiel = ET.Element('POI')
+ poiel.text = 'mu_BKG'
+ meas.append(poiel)
+
+ setting = ET.Element('ParamSetting', Val='3.0')
+ setting.text = ' '.join(['mu_both'])
+ meas.append(setting)
+
+ toplvl.append(meas)
+
+ other_parameter_configs = [
+ dict(name='mu_both', inits=[1.0], bounds=[[1.0, 5.0]], fixed=False),
+ dict(name='mu_otherConfigOnly', inits=[1.0], bounds=[[0.0, 10.0]], fixed=False),
+ ]
+
+ result = pyhf.readxml.process_measurements(
+ toplvl, other_parameter_configs=other_parameter_configs
+ )
+ result = {
+ m['name']: {k['name']: k for k in m['config']['parameters']} for m in result
+ }
+ assert result
+
+ # make sure ParamSetting configs override NormFactor configs
+ assert result['NormalMeasurement']['mu_both']['fixed']
+ assert result['NormalMeasurement']['mu_both']['inits'] == [2.0]
+ assert result['NormalMeasurement']['mu_both']['bounds'] == [[1.0, 5.0]]
+
+ # make sure ParamSetting is doing the right thing
+ assert result['NormalMeasurement']['mu_paramSettingOnly']['fixed']
+ assert 'inits' not in result['NormalMeasurement']['mu_paramSettingOnly']
+ assert 'bounds' not in result['NormalMeasurement']['mu_paramSettingOnly']
+
+ # make sure our code doesn't accidentally override other parameter configs
+ assert not result['NormalMeasurement']['mu_otherConfigOnly']['fixed']
+ assert result['NormalMeasurement']['mu_otherConfigOnly']['inits'] == [1.0]
+ assert result['NormalMeasurement']['mu_otherConfigOnly']['bounds'] == [[0.0, 10.0]]
+
+ # make sure settings from one measurement don't leak to other
+ assert not result['ParallelMeasurement']['mu_both']['fixed']
+ assert result['ParallelMeasurement']['mu_both']['inits'] == [3.0]
+ assert result['ParallelMeasurement']['mu_both']['bounds'] == [[1.0, 5.0]]
+
+
def test_import_measurements():
parsed_xml = pyhf.readxml.parse(
'validation/xmlimport_input/config/example.xml', 'validation/xmlimport_input/'
@@ -26,9 +117,9 @@ def test_import_measurements():
measurement_configs = measurements[0]['config']
assert 'parameters' in measurement_configs
- assert len(measurement_configs['parameters']) == 2
- assert measurement_configs['parameters'][0]['name'] == 'lumi'
- assert measurement_configs['parameters'][1]['name'] == 'alpha_syst1'
+ assert len(measurement_configs['parameters']) == 3
+ parnames = [p['name'] for p in measurement_configs['parameters']]
+ assert sorted(parnames) == sorted(['lumi', 'SigXsecOverSM', 'alpha_syst1'])
lumi_param_config = measurement_configs['parameters'][0]
assert 'auxdata' in lumi_param_config
@@ -193,3 +284,22 @@ def test_import_shapesys():
assert channels['channel1']['samples'][1]['modifiers'][1]['data'] == pytest.approx(
[10.0, 1.5e-5]
)
+
+
+def test_import_normfactor_bounds():
+ parsed_xml = pyhf.readxml.parse(
+ 'validation/xmlimport_input2/config/example.xml', 'validation/xmlimport_input2'
+ )
+
+ ws = pyhf.Workspace(parsed_xml)
+ assert ('SigXsecOverSM', 'normfactor') in ws.modifiers
+ parameters = [
+ p
+ for p in ws.get_measurement(measurement_name='GaussExample')['config'][
+ 'parameters'
+ ]
+ if p['name'] == 'SigXsecOverSM'
+ ]
+ assert len(parameters) == 1
+ parameter = parameters[0]
+ assert parameter['bounds'] == [[0, 10]]
|
Parse normalization factor ranges from xml
# Description
The .xml workspace specification includes the ranges of normalization factors (NFs), such as
```
<NormFactor Name="my_NF" Val="1" High="20" Low="-20" Const="False" />
```
A simple example can be found [here](https://github.com/alexander-held/template_fit_workflows/blob/master/TRExFitter/minimal_example/RooStats/minimal_example_Signal_region.xml).
When the NF affects multiple samples or channels, the information is consistently specified in all instances.
Given that this information is specified in the xml, it should be picked up by `pyhf.readxml.parse()` and subsequently be available within pyhf.
## Is your feature request related to a problem? Please describe.
The aim of this is to reduce small differences between the results of `xml workspace -> fit within ROOT` and `xml workspace -> translate to pyhf -> fit` that can be hard to track down.
### Describe the solution you'd like
I would like the ranges to be picked up automatically by pyhf.
### Describe alternatives you've considered
Could alternatively specify ranges manually from within pyhf.
# Relevant Issues and Pull Requests
None that I am aware of.
# Additional context
None
|
Notes:
- does not change schema or API
- simply need to update readxml/writexml to handle reading/writing out the relevant information
Assumption:
- the high/low for NormFactor are set consistently everywhere for the given systematic
"the high/low for NormFactor are set consistently everywhere for the given systematic" that is just another one of these "reduction" reqs no?
> "the high/low for NormFactor are set consistently everywhere for the given systematic" that is just another one of these "reduction" reqs no?
I'm not sure. I'm thinking this doesn't need to be true. The correlation is the parameter, not the value. It seems plausible that one can have:
```
<Sample Name="ttbar" >
<NormFactor Name="my_NF" Val="1" High="20" Low="-20" Const="False" />
</Sample>
<Sample Name="vjets" >
<NormFactor Name="my_NF" Val="1" High="10" Low="-10" Const="False" />
</Sample>
```
so it doesn't need to be consistent... This does cut away a piece of the space that HiFa can do. Perhaps the parameter configuration should be on the modifier itself for normfactor.
I don't see how the above sample would work in the fit - `my_NF` is one parameter, so there can only be one lower bound for it. I guess you could argue that you take the larger boundary and cap it at -10 for `vjets`, but I cannot think of a case where that would be desired.
You're right. I'm thinking of other constrained systematics where this is more configurable. This doesn't make sense in the context of HiFa. So yes, I can write up something tonight in a branch and test it soon.
| 2019-12-04T06:45:45 |
scikit-hep/pyhf
| 752 |
scikit-hep__pyhf-752
|
[
"695"
] |
aa167874538ccb2c2ae1fee321f48027ad13b9dd
|
diff --git a/src/pyhf/cli/spec.py b/src/pyhf/cli/spec.py
--- a/src/pyhf/cli/spec.py
+++ b/src/pyhf/cli/spec.py
@@ -238,12 +238,19 @@ def rename(workspace, output_file, channel, sample, modifier, measurement):
@cli.command()
@click.argument('workspace-one', default='-')
@click.argument('workspace-two', default='-')
[email protected](
+ '-j',
+ '--join',
+ default='none',
+ type=click.Choice(Workspace.valid_joins),
+ help='The join operation to apply when combining the two workspaces.',
+)
@click.option(
'--output-file',
help='The location of the output json file. If not specified, prints to screen.',
default=None,
)
-def combine(workspace_one, workspace_two, output_file):
+def combine(workspace_one, workspace_two, join, output_file):
"""
Combine two workspaces into a single workspace.
@@ -257,7 +264,7 @@ def combine(workspace_one, workspace_two, output_file):
ws_one = Workspace(spec_one)
ws_two = Workspace(spec_two)
- combined_ws = Workspace.combine(ws_one, ws_two)
+ combined_ws = Workspace.combine(ws_one, ws_two, join=join)
if output_file is None:
click.echo(json.dumps(combined_ws, indent=4, sort_keys=True))
diff --git a/src/pyhf/workspace.py b/src/pyhf/workspace.py
--- a/src/pyhf/workspace.py
+++ b/src/pyhf/workspace.py
@@ -7,6 +7,8 @@
"""
import logging
import jsonpatch
+import copy
+import collections
from . import exceptions
from . import utils
from .pdf import Model
@@ -16,11 +18,251 @@
log = logging.getLogger(__name__)
+def _join_items(join, left_items, right_items, key='name'):
+ """
+ Join two lists of dictionaries along the given key.
+
+ This is meant to be as generic as possible for any pairs of lists of dictionaries for many join operations.
+
+ Args:
+ join (`str`): The join operation to apply. See ~pyhf.workspace.Workspace for valid join operations.
+ left_items (`list`): A list of dictionaries to join on the left
+ right_items (`list`): A list of dictionaries to join on the right
+
+ Returns:
+ :obj:`list`: A joined list of dictionaries.
+
+ """
+ if join == 'right outer':
+ primary_items, secondary_items = right_items, left_items
+ else:
+ primary_items, secondary_items = left_items, right_items
+ joined_items = copy.deepcopy(primary_items)
+ for secondary_item in secondary_items:
+ # outer join: merge primary and secondary, matching where possible
+ if join == 'outer' and secondary_item in primary_items:
+ continue
+ # left/right outer join: only add secondary if existing item (by key value) is not in primary
+ # NB: this will be slow for large numbers of items
+ elif join in ['left outer', 'right outer'] and secondary_item[key] in [
+ item[key] for item in joined_items
+ ]:
+ continue
+ joined_items.append(copy.deepcopy(secondary_item))
+ return joined_items
+
+
+def _join_versions(join, left_version, right_version):
+ """
+ Join two workspace versions.
+
+ Raises:
+ ~pyhf.exceptions.InvalidWorkspaceOperation: Versions are incompatible.
+
+ Args:
+ join (`str`): The join operation to apply. See ~pyhf.workspace.Workspace for valid join operations.
+ left_version (`str`): The left workspace version.
+ right_version (`str`): The right workspace version.
+
+ Returns:
+ :obj:`str`: The workspace version.
+
+ """
+ if left_version != right_version:
+ raise exceptions.InvalidWorkspaceOperation(
+ f"Workspaces of different versions cannot be combined: {left_version} != {right_version}"
+ )
+ return left_version
+
+
+def _join_channels(join, left_channels, right_channels):
+ """
+ Join two workspace channel specifications.
+
+ Raises:
+ ~pyhf.exceptions.InvalidWorkspaceOperation: Channel specifications are incompatible.
+
+ Args:
+ join (`str`): The join operation to apply. See ~pyhf.workspace.Workspace for valid join operations.
+ left_channels (`list`): The left channel specification.
+ right_channels (`list`): The right channel specification.
+
+ Returns:
+ :obj:`list`: A joined list of channels. Each channel follows the :obj:`defs.json#channel` `schema <https://scikit-hep.org/pyhf/likelihood.html#channel>`__
+
+ """
+
+ joined_channels = _join_items(join, left_channels, right_channels)
+ if join == 'none':
+ common_channels = set(c['name'] for c in left_channels).intersection(
+ c['name'] for c in right_channels
+ )
+ if common_channels:
+ raise exceptions.InvalidWorkspaceOperation(
+ f"Workspaces cannot have any channels in common with the same name: {common_channels}. You can also try a different join operation: {Workspace.valid_joins}."
+ )
+
+ elif join == 'outer':
+ counted_channels = collections.Counter(
+ channel['name'] for channel in joined_channels
+ )
+ incompatible_channels = [
+ channel for channel, count in counted_channels.items() if count > 1
+ ]
+ if incompatible_channels:
+ raise exceptions.InvalidWorkspaceOperation(
+ f"Workspaces cannot have channels in common with incompatible structure: {incompatible_channels}. You can also try a different join operation: {Workspace.valid_joins}."
+ )
+ return joined_channels
+
+
+def _join_observations(join, left_observations, right_observations):
+ """
+ Join two workspace observation specifications.
+
+ Raises:
+ ~pyhf.exceptions.InvalidWorkspaceOperation: Observation specifications are incompatible.
+
+ Args:
+ join (`str`): The join operation to apply. See ~pyhf.workspace.Workspace for valid join operations.
+ left_observations (`list`): The left observation specification.
+ right_observations (`list`): The right observation specification.
+
+ Returns:
+ :obj:`list`: A joined list of observations. Each observation follows the :obj:`defs.json#observation` `schema <https://scikit-hep.org/pyhf/likelihood.html#observations>`__
+
+ """
+ joined_observations = _join_items(join, left_observations, right_observations)
+ if join == 'none':
+ common_observations = set(
+ obs['name'] for obs in left_observations
+ ).intersection(obs['name'] for obs in right_observations)
+ if common_observations:
+ raise exceptions.InvalidWorkspaceOperation(
+ f"Workspaces cannot have any observations in common with the same name: {common_observations}. You can also try a different join operation: {Workspace.valid_joins}."
+ )
+
+ elif join == 'outer':
+ counted_observations = collections.Counter(
+ observation['name'] for observation in joined_observations
+ )
+ incompatible_observations = [
+ observation
+ for observation, count in counted_observations.items()
+ if count > 1
+ ]
+ if incompatible_observations:
+ raise exceptions.InvalidWorkspaceOperation(
+ f"Workspaces cannot have observations in common with incompatible structure: {incompatible_observations}. You can also try a different join operation: {Workspace.valid_joins}."
+ )
+ return joined_observations
+
+
+def _join_parameter_configs(measurement_name, left_parameters, right_parameters):
+ """
+ Join two measurement parameter config specifications.
+
+ Only uses by :method:`_join_measurements` when join='outer'.
+
+ Raises:
+ ~pyhf.exceptions.InvalidWorkspaceOperation: Parameter configuration specifications are incompatible.
+
+ Args:
+ measurement_name (`str`): The name of the measurement being joined (a detail for raising exceptions correctly)
+ left_parameters (`list`): The left parameter configuration specification.
+ right_parameters (`list`): The right parameter configuration specification.
+
+ Returns:
+ :obj:`list`: A joined list of parameter configurations. Each parameter configuration follows the :obj:`defs.json#config` schema
+
+ """
+ joined_parameter_configs = _join_items('outer', left_parameters, right_parameters)
+ counted_parameter_configs = collections.Counter(
+ parameter['name'] for parameter in joined_parameter_configs
+ )
+ incompatible_parameter_configs = [
+ parameter for parameter, count in counted_parameter_configs.items() if count > 1
+ ]
+ if incompatible_parameter_configs:
+ raise exceptions.InvalidWorkspaceOperation(
+ f"Workspaces cannot have a measurement ({measurement_name}) with incompatible parameter configs: {incompatible_parameter_configs}. You can also try a different join operation: {Workspace.valid_joins}."
+ )
+ return joined_parameter_configs
+
+
+def _join_measurements(join, left_measurements, right_measurements):
+ """
+ Join two workspace measurement specifications.
+
+ Raises:
+ ~pyhf.exceptions.InvalidWorkspaceOperation: Measurement specifications are incompatible.
+
+ Args:
+ join (`str`): The join operation to apply. See ~pyhf.workspace.Workspace for valid join operations.
+ left_measurements (`list`): The left measurement specification.
+ right_measurements (`list`): The right measurement specification.
+
+ Returns:
+ :obj:`list`: A joined list of measurements. Each measurement follows the :obj:`defs.json#measurement` `schema <https://scikit-hep.org/pyhf/likelihood.html#measurements>`__
+
+ """
+ joined_measurements = _join_items(join, left_measurements, right_measurements)
+ if join == 'none':
+ common_measurements = set(
+ meas['name'] for meas in left_measurements
+ ).intersection(meas['name'] for meas in right_measurements)
+ if common_measurements:
+ raise exceptions.InvalidWorkspaceOperation(
+ f"Workspaces cannot have any measurements in common with the same name: {common_measurements}. You can also try a different join operation: {Workspace.valid_joins}."
+ )
+
+ elif join == 'outer':
+ # need to store a mapping of measurement name to all measurement objects with that name
+ _measurement_mapping = {}
+ for measurement in joined_measurements:
+ _measurement_mapping.setdefault(measurement['name'], []).append(measurement)
+ # first check for incompatible POI
+ # then merge parameter configs
+ incompatible_poi = [
+ measurement_name
+ for measurement_name, measurements in _measurement_mapping.items()
+ if len(set(measurement['config']['poi'] for measurement in measurements))
+ > 1
+ ]
+ if incompatible_poi:
+ raise exceptions.InvalidWorkspaceOperation(
+ f"Workspaces cannot have the same measurements with incompatible POI: {incompatible_poi}."
+ )
+
+ joined_measurements = []
+ for measurement_name, measurements in _measurement_mapping.items():
+ if len(measurements) != 1:
+ new_measurement = {
+ 'name': measurement_name,
+ 'config': {
+ 'poi': measurements[0]['config']['poi'],
+ 'parameters': _join_parameter_configs(
+ measurement_name,
+ *[
+ measurement['config']['parameters']
+ for measurement in measurements
+ ],
+ ),
+ },
+ }
+ else:
+ new_measurement = measurements[0]
+ joined_measurements.append(new_measurement)
+ return joined_measurements
+
+
class Workspace(_ChannelSummaryMixin, dict):
"""
A JSON-serializable object that is built from an object that follows the :obj:`workspace.json` `schema <https://scikit-hep.org/pyhf/likelihood.html#workspace>`__.
"""
+ valid_joins = ['none', 'outer', 'left outer', 'right outer']
+
def __init__(self, spec, **config_kwargs):
"""Workspaces hold the model, data and measurements."""
super(Workspace, self).__init__(spec, channels=spec['channels'])
@@ -68,9 +310,9 @@ def get_measurement(self, **config_kwargs):
~pyhf.exceptions.InvalidMeasurement: If the measurement was not found
Args:
- poi_name (str): The name of the parameter of interest to create a new measurement from
- measurement_name (str): The name of the measurement to use
- measurement_index (int): The index of the measurement to use
+ poi_name (`str`): The name of the parameter of interest to create a new measurement from
+ measurement_name (`str`): The name of the measurement to use
+ measurement_index (`int`): The index of the measurement to use
Returns:
:obj:`dict`: A measurement object adhering to the schema defs.json#/definitions/measurement
@@ -275,7 +517,7 @@ def _prune_and_rename(
],
'observations': [
dict(
- observation,
+ copy.deepcopy(observation),
name=rename_channels.get(observation['name'], observation['name']),
)
for observation in self['observations']
@@ -337,7 +579,7 @@ def rename(self, modifiers={}, samples={}, channels={}, measurements={}):
)
@classmethod
- def combine(cls, left, right):
+ def combine(cls, left, right, join='none'):
"""
Return a new workspace specification that is the combination of the two workspaces.
@@ -362,74 +604,34 @@ def combine(cls, left, right):
Args:
left (~pyhf.workspace.Workspace): A workspace
right (~pyhf.workspace.Workspace): Another workspace
+ join (:obj:`str`): How to join the two workspaces. Pick from "none", "outer", "left outer", or "right outer".
Returns:
~pyhf.workspace.Workspace: A new combined workspace object
"""
- common_channels = set(left.channels).intersection(right.channels)
- if common_channels:
- raise exceptions.InvalidWorkspaceOperation(
- "Workspaces cannot have any channels in common: {}".format(
- common_channels
- )
- )
-
- common_measurements = set(left.measurement_names).intersection(
- right.measurement_names
- )
- incompatible_poi = [
- left.get_measurement(measurement_name=m)['config']['poi']
- != right.get_measurement(measurement_name=m)['config']['poi']
- for m in common_measurements
- ]
- if any(incompatible_poi):
- raise exceptions.InvalidWorkspaceOperation(
- "Workspaces cannot have any measurements with incompatible POI: {}".format(
- [
- m
- for m, i in zip(common_measurements, incompatible_poi)
- if incompatible_poi
- ]
- )
+ if join not in Workspace.valid_joins:
+ raise ValueError(
+ f"Workspaces must be joined using one of the valid join operations ({Workspace.valid_joins}); not {join}"
)
- if left.version != right.version:
- raise exceptions.InvalidWorkspaceOperation(
- "Workspaces of different versions cannot be combined: {} != {}".format(
- left.version, right.version
- )
+ if join in ['left outer', 'right outer']:
+ log.warning(
+ "You are using an unsafe join operation. This will silence exceptions that might be raised during a normal 'outer' operation."
)
- left_measurements = [
- left.get_measurement(measurement_name=m)
- for m in set(left.measurement_names) - set(common_measurements)
- ]
- right_measurements = [
- right.get_measurement(measurement_name=m)
- for m in set(right.measurement_names) - set(common_measurements)
- ]
- merged_measurements = [
- dict(
- name=m,
- config=dict(
- poi=left.get_measurement(measurement_name=m)['config']['poi'],
- parameters=(
- left.get_measurement(measurement_name=m)['config']['parameters']
- + right.get_measurement(measurement_name=m)['config'][
- 'parameters'
- ]
- ),
- ),
- )
- for m in common_measurements
- ]
+ new_version = _join_versions(join, left['version'], right['version'])
+ new_channels = _join_channels(join, left['channels'], right['channels'])
+ new_observations = _join_observations(
+ join, left['observations'], right['observations']
+ )
+ new_measurements = _join_measurements(
+ join, left['measurements'], right['measurements']
+ )
newspec = {
- 'channels': left['channels'] + right['channels'],
- 'measurements': (
- left_measurements + right_measurements + merged_measurements
- ),
- 'observations': left['observations'] + right['observations'],
- 'version': left['version'],
+ 'channels': new_channels,
+ 'measurements': new_measurements,
+ 'observations': new_observations,
+ 'version': new_version,
}
return Workspace(newspec)
|
diff --git a/tests/test_workspace.py b/tests/test_workspace.py
--- a/tests/test_workspace.py
+++ b/tests/test_workspace.py
@@ -67,8 +67,9 @@ def test_get_measurement_fake(workspace_factory):
def test_get_measurement_nonexist(workspace_factory):
w = workspace_factory()
- with pytest.raises(pyhf.exceptions.InvalidMeasurement):
+ with pytest.raises(pyhf.exceptions.InvalidMeasurement) as excinfo:
w.get_measurement(measurement_name='nonexistent_measurement')
+ assert 'nonexistent_measurement' in str(excinfo.value)
def test_get_workspace_measurement_priority(workspace_factory):
@@ -275,28 +276,334 @@ def test_rename_measurement(workspace_factory):
assert renamed in new_ws.measurement_names
-def test_combine_workspace_same_channels(workspace_factory):
[email protected](scope='session')
+def join_items():
+ left = [{'name': 'left', 'key': 'value'}, {'name': 'common', 'key': 'left'}]
+ right = [{'name': 'right', 'key': 'value'}, {'name': 'common', 'key': 'right'}]
+ return (left, right)
+
+
+def test_join_items_none(join_items):
+ left_items, right_items = join_items
+ joined = pyhf.workspace._join_items('none', left_items, right_items, key='name')
+ assert all(left in joined for left in left_items)
+ assert all(right in joined for right in right_items)
+
+
+def test_join_items_outer(join_items):
+ left_items, right_items = join_items
+ joined = pyhf.workspace._join_items('outer', left_items, right_items, key='name')
+ assert all(left in joined for left in left_items)
+ assert all(right in joined for right in right_items)
+
+
+def test_join_items_left_outer(join_items):
+ left_items, right_items = join_items
+ joined = pyhf.workspace._join_items(
+ 'left outer', left_items, right_items, key='name'
+ )
+ assert all(left in joined for left in left_items)
+ assert not all(right in joined for right in right_items)
+
+
+def test_join_items_right_outer(join_items):
+ left_items, right_items = join_items
+ joined = pyhf.workspace._join_items(
+ 'right outer', left_items, right_items, key='name'
+ )
+ assert not all(left in joined for left in left_items)
+ assert all(right in joined for right in right_items)
+
+
[email protected]("join", ['none', 'outer'])
+def test_combine_workspace_same_channels_incompatible_structure(
+ workspace_factory, join
+):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel2': 'channel3'})
+ new_ws = ws.rename(
+ channels={'channel2': 'channel3'},
+ samples={'signal': 'signal_other'},
+ measurements={'GaussExample': 'GaussExample2'},
+ ).prune(measurements=['GammaExample', 'ConstExample', 'LogNormExample'])
with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation) as excinfo:
- pyhf.Workspace.combine(ws, new_ws)
+ pyhf.Workspace.combine(ws, new_ws, join=join)
assert 'channel1' in str(excinfo.value)
assert 'channel2' not in str(excinfo.value)
-def test_combine_workspace_incompatible_poi(workspace_factory):
[email protected]("join", ['outer', 'left outer', 'right outer'])
+def test_combine_workspace_same_channels_outer_join(workspace_factory, join):
+ ws = workspace_factory()
+ new_ws = ws.rename(channels={'channel2': 'channel3'})
+ combined = pyhf.Workspace.combine(ws, new_ws, join=join)
+ assert 'channel1' in combined.channels
+
+
[email protected]("join", ['left outer', 'right outer'])
+def test_combine_workspace_same_channels_outer_join_unsafe(
+ workspace_factory, join, caplog
+):
+ ws = workspace_factory()
+ new_ws = ws.rename(channels={'channel2': 'channel3'})
+ pyhf.Workspace.combine(ws, new_ws, join=join)
+ assert 'using an unsafe join operation' in caplog.text
+
+
[email protected]("join", ['none', 'outer'])
+def test_combine_workspace_incompatible_poi(workspace_factory, join):
ws = workspace_factory()
new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
measurements=['GammaExample', 'ConstExample', 'LogNormExample']
)
- new_ws = ws.rename(
+ new_ws = new_ws.rename(
modifiers={new_ws.get_measurement()['config']['poi']: 'renamedPOI'}
)
- with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation):
- pyhf.Workspace.combine(ws, new_ws)
+ with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation) as excinfo:
+ pyhf.Workspace.combine(ws, new_ws, join=join)
+ assert 'GaussExample' in str(excinfo.value)
+
+
[email protected]("join", ['none', 'outer', 'left outer', 'right outer'])
+def test_combine_workspace_diff_version(workspace_factory, join):
+ ws = workspace_factory()
+ ws.version = '1.0.0'
+ new_ws = ws.rename(
+ channels={'channel1': 'channel3', 'channel2': 'channel4'},
+ samples={
+ 'background1': 'background3',
+ 'background2': 'background4',
+ 'signal': 'signal2',
+ },
+ modifiers={
+ 'syst1': 'syst4',
+ 'bkg1Shape': 'bkg3Shape',
+ 'bkg2Shape': 'bkg4Shape',
+ },
+ measurements={
+ 'ConstExample': 'OtherConstExample',
+ 'LogNormExample': 'OtherLogNormExample',
+ 'GaussExample': 'OtherGaussExample',
+ 'GammaExample': 'OtherGammaExample',
+ },
+ )
+ new_ws['version'] = '1.2.0'
+ with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation) as excinfo:
+ pyhf.Workspace.combine(ws, new_ws, join=join)
+ assert '1.0.0' in str(excinfo.value)
+ assert '1.2.0' in str(excinfo.value)
+
+
[email protected]("join", ['none'])
+def test_combine_workspace_duplicate_parameter_configs(workspace_factory, join):
+ ws = workspace_factory()
+ new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
+ measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ )
+ with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation) as excinfo:
+ pyhf.Workspace.combine(ws, new_ws, join=join)
+ assert 'GaussExample' in str(excinfo.value)
+
+
[email protected]("join", ['outer', 'left outer', 'right outer'])
+def test_combine_workspace_duplicate_parameter_configs_outer_join(
+ workspace_factory, join
+):
+ ws = workspace_factory()
+ new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
+ measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ )
+ combined = pyhf.Workspace.combine(ws, new_ws, join=join)
+
+ poi = ws.get_measurement(measurement_name='GaussExample')['config']['poi']
+ ws_parameter_configs = [
+ parameter['name']
+ for parameter in ws.get_measurement(measurement_name='GaussExample')['config'][
+ 'parameters'
+ ]
+ ]
+ new_ws_parameter_configs = [
+ parameter['name']
+ for parameter in new_ws.get_measurement(measurement_name='GaussExample')[
+ 'config'
+ ]['parameters']
+ ]
+ combined_parameter_configs = [
+ parameter['name']
+ for parameter in combined.get_measurement(measurement_name='GaussExample')[
+ 'config'
+ ]['parameters']
+ ]
+
+ assert poi in ws_parameter_configs
+ assert poi in new_ws_parameter_configs
+ assert poi in combined_parameter_configs
+ assert 'lumi' in ws_parameter_configs
+ assert 'lumi' in new_ws_parameter_configs
+ assert 'lumi' in combined_parameter_configs
+ assert len(combined_parameter_configs) == len(set(combined_parameter_configs))
+
+
+def test_combine_workspace_parameter_configs_ordering(workspace_factory):
+ ws = workspace_factory()
+ new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
+ measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ )
+ assert (
+ ws.get_measurement(measurement_name='GaussExample')['config']['parameters']
+ == new_ws.get_measurement(measurement_name='GaussExample')['config'][
+ 'parameters'
+ ]
+ )
+
+
+def test_combine_workspace_observation_ordering(workspace_factory):
+ ws = workspace_factory()
+ new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
+ measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ )
+ assert ws['observations'][0]['data'] == new_ws['observations'][0]['data']
+
+
+def test_combine_workspace_deepcopied(workspace_factory):
+ ws = workspace_factory()
+ new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
+ measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ )
+ new_ws.get_measurement(measurement_name='GaussExample')['config']['parameters'][0][
+ 'bounds'
+ ] = [[0.0, 1.0]]
+ new_ws['observations'][0]['data'][0] = -10.0
+ assert (
+ ws.get_measurement(measurement_name='GaussExample')['config']['parameters'][0][
+ 'bounds'
+ ]
+ != new_ws.get_measurement(measurement_name='GaussExample')['config'][
+ 'parameters'
+ ][0]['bounds']
+ )
+ assert ws['observations'][0]['data'] != new_ws['observations'][0]['data']
+
+
[email protected]("join", ['fake join operation'])
+def test_combine_workspace_invalid_join_operation(workspace_factory, join):
+ ws = workspace_factory()
+ new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
+ measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ )
+ with pytest.raises(ValueError) as excinfo:
+ pyhf.Workspace.combine(ws, new_ws, join=join)
+ assert join in str(excinfo.value)
+
+
[email protected]("join", ['none'])
+def test_combine_workspace_incompatible_parameter_configs(workspace_factory, join):
+ ws = workspace_factory()
+ new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
+ measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ )
+ new_ws.get_measurement(measurement_name='GaussExample')['config']['parameters'][0][
+ 'bounds'
+ ] = [[0.0, 1.0]]
+ with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation) as excinfo:
+ pyhf.Workspace.combine(ws, new_ws, join=join)
+ assert 'GaussExample' in str(excinfo.value)
+
+
[email protected]("join", ['outer'])
+def test_combine_workspace_incompatible_parameter_configs_outer_join(
+ workspace_factory, join
+):
+ ws = workspace_factory()
+ new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
+ measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ )
+ new_ws.get_measurement(measurement_name='GaussExample')['config']['parameters'][0][
+ 'bounds'
+ ] = [[0.0, 1.0]]
+ with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation) as excinfo:
+ pyhf.Workspace.combine(ws, new_ws, join=join)
+ assert 'GaussExample' in str(excinfo.value)
+ assert ws.get_measurement(measurement_name='GaussExample')['config']['parameters'][
+ 0
+ ]['name'] in str(excinfo.value)
+ assert new_ws.get_measurement(measurement_name='GaussExample')['config'][
+ 'parameters'
+ ][0]['name'] in str(excinfo.value)
+
+
+def test_combine_workspace_incompatible_parameter_configs_left_outer_join(
+ workspace_factory,
+):
+ ws = workspace_factory()
+ new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
+ measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ )
+ new_ws.get_measurement(measurement_name='GaussExample')['config']['parameters'][0][
+ 'bounds'
+ ] = [[0.0, 1.0]]
+ combined = pyhf.Workspace.combine(ws, new_ws, join='left outer')
+ assert (
+ combined.get_measurement(measurement_name='GaussExample')['config'][
+ 'parameters'
+ ][0]
+ == ws.get_measurement(measurement_name='GaussExample')['config']['parameters'][
+ 0
+ ]
+ )
+
+
+def test_combine_workspace_incompatible_parameter_configs_right_outer_join(
+ workspace_factory,
+):
+ ws = workspace_factory()
+ new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
+ measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ )
+ new_ws.get_measurement(measurement_name='GaussExample')['config']['parameters'][0][
+ 'bounds'
+ ] = [[0.0, 1.0]]
+ combined = pyhf.Workspace.combine(ws, new_ws, join='right outer')
+ assert (
+ combined.get_measurement(measurement_name='GaussExample')['config'][
+ 'parameters'
+ ][0]
+ == new_ws.get_measurement(measurement_name='GaussExample')['config'][
+ 'parameters'
+ ][0]
+ )
+
+
[email protected]("join", ['none', 'outer'])
+def test_combine_workspace_incompatible_observations(workspace_factory, join):
+ ws = workspace_factory()
+ new_ws = ws.rename(
+ channels={'channel1': 'channel3', 'channel2': 'channel4'},
+ samples={
+ 'background1': 'background3',
+ 'background2': 'background4',
+ 'signal': 'signal2',
+ },
+ modifiers={
+ 'syst1': 'syst4',
+ 'bkg1Shape': 'bkg3Shape',
+ 'bkg2Shape': 'bkg4Shape',
+ },
+ measurements={
+ 'GaussExample': 'OtherGaussExample',
+ 'GammaExample': 'OtherGammaExample',
+ 'ConstExample': 'OtherConstExample',
+ 'LogNormExample': 'OtherLogNormExample',
+ },
+ )
+ new_ws['observations'][0]['name'] = ws['observations'][0]['name']
+ new_ws['observations'][0]['data'][0] = -10.0
+ with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation) as excinfo:
+ pyhf.Workspace.combine(ws, new_ws, join=join)
+ assert ws['observations'][0]['name'] in str(excinfo.value)
+ assert 'observations' in str(excinfo.value)
-def test_combine_workspace_diff_version(workspace_factory):
+def test_combine_workspace_incompatible_observations_left_outer(workspace_factory):
ws = workspace_factory()
new_ws = ws.rename(
channels={'channel1': 'channel3', 'channel2': 'channel4'},
@@ -311,18 +618,53 @@ def test_combine_workspace_diff_version(workspace_factory):
'bkg2Shape': 'bkg4Shape',
},
measurements={
+ 'GaussExample': 'OtherGaussExample',
+ 'GammaExample': 'OtherGammaExample',
'ConstExample': 'OtherConstExample',
'LogNormExample': 'OtherLogNormExample',
+ },
+ )
+ new_ws['observations'][0]['name'] = ws['observations'][0]['name']
+ new_ws['observations'][0]['data'][0] = -10.0
+ combined = pyhf.Workspace.combine(ws, new_ws, join='left outer')
+ assert (
+ combined.observations[ws['observations'][0]['name']]
+ == ws['observations'][0]['data']
+ )
+
+
+def test_combine_workspace_incompatible_observations_right_outer(workspace_factory):
+ ws = workspace_factory()
+ new_ws = ws.rename(
+ channels={'channel1': 'channel3', 'channel2': 'channel4'},
+ samples={
+ 'background1': 'background3',
+ 'background2': 'background4',
+ 'signal': 'signal2',
+ },
+ modifiers={
+ 'syst1': 'syst4',
+ 'bkg1Shape': 'bkg3Shape',
+ 'bkg2Shape': 'bkg4Shape',
+ },
+ measurements={
'GaussExample': 'OtherGaussExample',
'GammaExample': 'OtherGammaExample',
+ 'ConstExample': 'OtherConstExample',
+ 'LogNormExample': 'OtherLogNormExample',
},
)
- new_ws.version = '0.0.0'
- with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation):
- pyhf.Workspace.combine(ws, new_ws)
+ new_ws['observations'][0]['name'] = ws['observations'][0]['name']
+ new_ws['observations'][0]['data'][0] = -10.0
+ combined = pyhf.Workspace.combine(ws, new_ws, join='right outer')
+ assert (
+ combined.observations[ws['observations'][0]['name']]
+ == new_ws['observations'][0]['data']
+ )
-def test_combine_workspace(workspace_factory):
[email protected]("join", pyhf.Workspace.valid_joins)
+def test_combine_workspace(workspace_factory, join):
ws = workspace_factory()
new_ws = ws.rename(
channels={'channel1': 'channel3', 'channel2': 'channel4'},
@@ -337,17 +679,13 @@ def test_combine_workspace(workspace_factory):
'bkg2Shape': 'bkg4Shape',
},
measurements={
+ 'GaussExample': 'OtherGaussExample',
+ 'GammaExample': 'OtherGammaExample',
'ConstExample': 'OtherConstExample',
'LogNormExample': 'OtherLogNormExample',
},
)
- combined = pyhf.Workspace.combine(ws, new_ws)
+ combined = pyhf.Workspace.combine(ws, new_ws, join=join)
assert set(combined.channels) == set(ws.channels + new_ws.channels)
assert set(combined.samples) == set(ws.samples + new_ws.samples)
assert set(combined.parameters) == set(ws.parameters + new_ws.parameters)
- combined_measurement = combined.get_measurement(measurement_name='GaussExample')
- assert len(combined_measurement['config']['parameters']) == len(
- ws.get_measurement(measurement_name='GaussExample')['config']['parameters']
- ) + len(
- new_ws.get_measurement(measurement_name='GaussExample')['config']['parameters']
- )
|
Combined workspaces have duplicated lumi/POI param configurations
# Description
When combining two workspaces with the same measurement name that has the same POI, the lumi and the POI param config are repeated twice. They should usually be compatible so we should just drop the extra copies.
# Expected Behavior
A single instance of the lumi and POI parameter configuration.
# Actual Behavior
Duplicated/extra instances of the lumi and POI parameter configuratoin.
# Steps to Reproduce
`pyhf combine a.json b.json`
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
| 2020-01-26T04:46:23 |
|
scikit-hep/pyhf
| 766 |
scikit-hep__pyhf-766
|
[
"404"
] |
a3082bdc9ff34c538f24eba54edf4226de6d674d
|
diff --git a/src/pyhf/modifiers/shapesys.py b/src/pyhf/modifiers/shapesys.py
--- a/src/pyhf/modifiers/shapesys.py
+++ b/src/pyhf/modifiers/shapesys.py
@@ -49,12 +49,13 @@ def __init__(self, shapesys_mods, pdfconfig, mega_mods, batch_size=None):
self._shapesys_mask = [
[[mega_mods[m][s]['data']['mask']] for s in pdfconfig.samples] for m in keys
]
- self.__shapesys_uncrt = default_backend.astensor(
+ self.__shapesys_info = default_backend.astensor(
[
[
[
- mega_mods[m][s]['data']['uncrt'],
+ mega_mods[m][s]['data']['mask'],
mega_mods[m][s]['data']['nom_data'],
+ mega_mods[m][s]['data']['uncrt'],
]
for s in pdfconfig.samples
]
@@ -84,18 +85,21 @@ def _reindex_access_field(self, pdfconfig):
if not pdfconfig.param_set(self._shapesys_mods[syst_index]).n_parameters:
self._access_field[syst_index] = 0
continue
+
+ singular_sample_index = [
+ idx
+ for idx, syst in enumerate(
+ default_backend.astensor(self._shapesys_mask)[syst_index, :, 0]
+ )
+ if any(syst)
+ ][-1]
+
for batch_index, batch_access in enumerate(syst_access):
selection = self.param_viewer.index_selection[syst_index][batch_index]
access_field_for_syst_and_batch = default_backend.zeros(
len(batch_access)
)
- singular_sample_index = [
- idx
- for idx, syst in enumerate(
- default_backend.astensor(self._shapesys_mask)[syst_index, :, 0]
- )
- if any(syst)
- ][-1]
+
sample_mask = self._shapesys_mask[syst_index][singular_sample_index][0]
access_field_for_syst_and_batch[sample_mask] = selection
self._access_field[
@@ -115,30 +119,36 @@ def _precompute(self):
self.shapesys_default = tensorlib.ones(tensorlib.shape(self.shapesys_mask))
def finalize(self, pdfconfig):
- for uncert_this_mod, pname in zip(self.__shapesys_uncrt, self._shapesys_mods):
+ # self.__shapesys_info: (parameter, sample, [mask, nominal rate, uncertainty], bin)
+ for mod_uncert_info, pname in zip(self.__shapesys_info, self._shapesys_mods):
+ # skip cases where given shapesys modifier affects zero samples
if not pdfconfig.param_set(pname).n_parameters:
continue
- unc_nom = default_backend.astensor(
- [x for x in uncert_this_mod[:, :, :] if any(x[0][x[0] > 0])]
- )
- unc = unc_nom[0, 0]
- nom = unc_nom[0, 1]
- unc_sq = default_backend.power(unc, 2)
- nom_sq = default_backend.power(nom, 2)
-
- # the below tries to filter cases in which
- # this modifier is not used by checking non
- # zeroness.. shoudl probably use mask
- numerator = default_backend.where(
- unc_sq > 0, nom_sq, default_backend.zeros(unc_sq.shape)
- )
- denominator = default_backend.where(
- unc_sq > 0, unc_sq, default_backend.ones(unc_sq.shape)
- )
-
- factors = numerator / denominator
- factors = factors[factors > 0]
+
+ # identify the information for the sample that the given parameter
+ # affects. shapesys is not shared, so there should only ever be at
+ # most one sample
+ # sample_uncert_info: ([mask, nominal rate, uncertainty], bin)
+ sample_uncert_info = mod_uncert_info[
+ default_backend.astensor(
+ default_backend.sum(mod_uncert_info[:, 0] > 0, axis=1), dtype='bool'
+ )
+ ][0]
+
+ # bin_mask: ([mask], bin)
+ bin_mask = default_backend.astensor(sample_uncert_info[0], dtype='bool')
+ # nom_unc: ([nominal, uncertainty], bin)
+ nom_unc = sample_uncert_info[1:]
+
+ # compute gamma**2 and sigma**2
+ nom_unc_sq = default_backend.power(nom_unc, 2)
+ # when the nominal rate = 0 OR uncertainty = 0, set = 1
+ nom_unc_sq[nom_unc_sq == 0] = 1
+ # divide (gamma**2 / sigma**2) and mask to set factors for only the
+ # parameters we have allocated
+ factors = (nom_unc_sq[0] / nom_unc_sq[1])[bin_mask]
assert len(factors) == pdfconfig.param_set(pname).n_parameters
+
pdfconfig.param_set(pname).factors = default_backend.tolist(factors)
pdfconfig.param_set(pname).auxdata = default_backend.tolist(factors)
diff --git a/src/pyhf/pdf.py b/src/pyhf/pdf.py
--- a/src/pyhf/pdf.py
+++ b/src/pyhf/pdf.py
@@ -195,12 +195,7 @@ def _nominal_and_modifiers_from_spec(config, spec):
mega_mods[key][s]['data']['mask'] += maskval
mega_mods[key][s]['data']['uncrt'] += uncrt
mega_mods[key][s]['data']['nom_data'] += nom
- else:
- raise RuntimeError(
- 'not sure how to combine {mtype} into the mega-channel'.format(
- mtype=mtype
- )
- )
+
sample_dict = {'name': 'mega_{}'.format(s), 'nom': mega_nom}
mega_samples[s] = sample_dict
|
Fix ShapeSys masking
# Description
https://github.com/diana-hep/pyhf/blob/49f30cd52bd543e67b1464d0ce916e15014a6f5b/pyhf/modifiers/shapesys.py#L106-L119
is a bit hacky right now by letting `==0` mean that the bin does not participate. Should be masking instead.
# Expected Behavior
Expect to do something more like
```
factors = nom_sq / unc_sq
```
and then mask `factors` after the fact.
# Actual Behavior
No masking is happening.
# Steps to Reproduce
See the code.
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
the issue here is not really the masking but two separate things
```
unc_nom = default_backend.astensor(
[x for x in uncert_this_mod[:, :, :] if any(x[0][x[0] > 0])]
)
unc = unc_nom[0, 0]
nom = unc_nom[0, 1]
```
this code assumes that len(unc_nom) == 1 since shapesys cannot be shared, we are sure that unc_norm is not >1 but it can be `len(unc_nom)==0` since some samples might have a declared uncertainty of "0"
then later we have the issue here:
```
numerator = default_backend.where(
unc_sq > 0, nom_sq, default_backend.zeros(unc_sq.shape)
)
denominator = default_backend.where(
unc_sq > 0, unc_sq, default_backend.ones(unc_sq.shape)
)
factors = numerator / denominator
factors = factors[factors > 0]
```
where this becomes an issue when the nominal data for the sample is zero..
both cases typically happen at the same time when
```
{
"data": [
0.0
],
"modifiers": [
{
"data": [
0.0
],
"name": "shape_fakes_stat_fakes_SRee_eMLLc_hghmet_obs_cuts",
"type": "shapesys"
}
],
"name": "fakes"
},
```
just dumping this in for now
```
$ python
Python 3.7.3 (default, Mar 27 2019, 09:23:32)
[Clang 9.0.0 (clang-900.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> setup = """
... import json, numpy as np
... data = np.array(json.load(open('uncert_this_mod.json')))
... """
>>> timeit.timeit('[x for x in data if any(x[0][x[0]>=0])]', setup=setup, number=10000)
0.19244455399999083
>>> timeit.timeit('data[np.sum(data[:,0]>=0, axis=1)==1,:,:]', setup=setup, number=10000)
0.13176023799999825
```
| 2020-02-08T07:36:38 |
|
scikit-hep/pyhf
| 791 |
scikit-hep__pyhf-791
|
[
"686"
] |
73da08d9a9a37d58b672ef6bfa5ef7f515e02e4d
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -213,7 +213,7 @@ def setup(app):
# .htaccess) here, relative to this directory. These files are copied
# directly to the root of the documentation.
#
-html_extra_path = []
+html_extra_path = ['_extras']
# If not None, a 'Last updated on:' timestamp is inserted at every page
# bottom, using the given strftime format.
|
Schema missing from docs
# Description
Need to use something like [sphinx-jsonschema](https://pypi.org/project/sphinx-jsonschema/) to fix it up.
# Expected Behavior
I was able to navigate to the schemas...
# Actual Behavior
Schemas are gone :o
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
Additionally, we might want to check if symbolic links can be supported -- or if we can somehow write `conf.py` to always copy over the schema files into the right location every time.
Hi @kratsg ,
I am tracking this issue because it was mentioned in the [HEP-Data "individual pyhf JSON support"](https://github.com/HEPData/hepdata/issues/164#issuecomment-582998142) issue.
It seems that there was a [commit](https://github.com/scikit-hep/pyhf/commit/732827583fb2c2ad747e690805e30e4c8e343e94#diff-e9f950f17198d3d5e3122a44230a09b9L106) where the documentation creation was changed from using the `Makefile`, to not using it. Given that the `Makefile` rule for generating HTML documentation contains the following line of code:
```shell
rsync -r ../src/pyhf/schemas/ $(BUILDDIR)/html/schemas
```
I think that may be the reason why links to any "https://scikit-hep.org/pyhf/schemas/1.0.0/..." are broken.
Do you remember why this line was changed?
Could we change it back?
hi @Sinclert , so this is because the recommended way to build the sphinx docs is not via the Makefile, but via https://github.com/scikit-hep/pyhf/blob/2ba5ec88d3ab27c15e65aaec6bf40a1ae6231b83/.github/workflows/ci.yml#L106-L110
as such - it's been just slightly annoying to migrate this into sphinx correctly.
Is there any particular reason why is not recommended?
I see that in the official Sphinx webpage they address the invocation from a `Makefile`, as _"make life even easier for you"_ ([reference](https://www.sphinx-doc.org/en/master/usage/quickstart.html#running-the-build)).
> I see that in the official Sphinx webpage they address the invocation from a `Makefile`, as _"make life even easier for you"_ ([reference](https://www.sphinx-doc.org/en/master/usage/quickstart.html#running-the-build)).
Docs on this is here: https://www.sphinx-doc.org/en/master/usage/advanced/setuptools.html
We rely on the (semantic) versioning set up, especially for dev-versioning, and it is quite impossible to get this set through a makefile. We need this so we can use `pkg_resources. get_distribution` to grab the correct versions.
It highly depends on how the _"https://scikit-hep.org/pyhf/schemas"_ URL is going to be used, right?
I can think of 2 aspects to consider:
---
1. **Backwards compatibility of links:**
There are some links pointing to URLs like _"https://scikit-hep.org/pyhf/schemas/1.0.0/model.json"_ that are not working right now. That is because of the issue I pointed in [this comment](https://github.com/scikit-hep/pyhf/issues/686#issuecomment-589187261). I don't know the importance of keeping those old links working, you better know, but that is something [sphinx-jsonschema](https://pypi.org/project/sphinx-jsonschema/) is not going to help with. So, there are 2 options:
- **Option A)** Do nothing.
- **Option B)** Add the following line to [this CI step](https://github.com/scikit-hep/pyhf/blob/master/.github/workflows/ci.yml#L110):
```shell
rsync -r src/pyhf/schemas docs/_build/html/schemas
```
---
2. **Schema JSONs format:**
The schema JSON files can be shown in the documentation by adding a _"schemas"_ section to the main index, with different version headers (_1.0.0_, _1.1.0_...) within. The schemas are currently following the _"JSON Pointer"_ notation. Again, I don't know how important it is to show the _"resolved JSON"_ schemas, or if the _"pointer JSON"_ schemas are good enough. So, I can think of 2 options:
- **Option A)** Pointer JSON format:
- **Advantage:** no need for [sphinx-jsonschema](https://pypi.org/project/sphinx-jsonschema/).
- **Disadvantage:** no self-contained schemas. (as it was before [the commit](https://github.com/scikit-hep/pyhf/commit/732827583fb2c2ad747e690805e30e4c8e343e94#diff-e9f950f17198d3d5e3122a44230a09b9L106)).
- **Option B)** Resolved JSON format:
- **Advantage:** The schemas are self-contained.
- **Disadvantage:** need [sphinx-jsonschema](https://pypi.org/project/sphinx-jsonschema/) extension.
---
It is not clear to me if this issue was opened because of reason 1 (_"Broken links"_), or reason 2 (_"JSONs not appearing in the format you want"_). [Sphinx-jsonschema](https://pypi.org/project/sphinx-jsonschema/) can only help on the second one.
Could you clarify?
| 2020-03-04T21:48:59 |
|
scikit-hep/pyhf
| 799 |
scikit-hep__pyhf-799
|
[
"797"
] |
be85ccd0bd4d0a886e38396e49d3f950a1635abd
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -97,7 +97,6 @@
'scipy', # requires numpy, which is required by pyhf and tensorflow
'click>=6.0', # for console scripts,
'tqdm', # for readxml
- 'six', # for modifiers
'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6
'jsonpatch',
'pyyaml', # for parsing CLI equal-delimited options
diff --git a/src/pyhf/modifiers/__init__.py b/src/pyhf/modifiers/__init__.py
--- a/src/pyhf/modifiers/__init__.py
+++ b/src/pyhf/modifiers/__init__.py
@@ -1,4 +1,3 @@
-from six import string_types
import logging
from .. import exceptions
@@ -147,7 +146,7 @@ def wrapper(cls):
if kwargs:
raise ValueError('Unparsed keyword arguments {}'.format(kwargs.keys()))
# check to make sure the given name is a string, if passed in one
- if not isinstance(name, string_types) and name is not None:
+ if not isinstance(name, str) and name is not None:
raise TypeError(
'@modifier must be given a string. You gave it {}'.format(type(name))
)
|
Remove six from install requires
# Description
At the moment [`six` is a required library](https://github.com/scikit-hep/pyhf/blob/c61b7e8da9d951d11e01a0f4e3e1c2a880521486/setup.py#L100). However, (as noted on [`six`'s PyPI page](https://pypi.org/project/six/1.14.0/))
> Six is a Python 2 and 3 compatibility library. It provides utility functions for smoothing over the differences between the Python versions with the goal of writing Python code that is compatible on both Python versions.
As pyhf is Python 3 only as of PR #704, `six` should no longer be used and shouldn't be required. At the moment its only use is in [`src/pyhf/modifiers/__init__.py`](https://github.com/scikit-hep/pyhf/blob/c61b7e8da9d951d11e01a0f4e3e1c2a880521486/src/pyhf/modifiers/__init__.py) to use `string_types`.
| 2020-03-10T15:05:23 |
||
scikit-hep/pyhf
| 802 |
scikit-hep__pyhf-802
|
[
"801"
] |
021dd117d235ab62afd997652b3273d2491724e0
|
diff --git a/src/pyhf/workspace.py b/src/pyhf/workspace.py
--- a/src/pyhf/workspace.py
+++ b/src/pyhf/workspace.py
@@ -267,9 +267,10 @@ def __init__(self, spec, **config_kwargs):
"""Workspaces hold the model, data and measurements."""
super(Workspace, self).__init__(spec, channels=spec['channels'])
self.schema = config_kwargs.pop('schema', 'workspace.json')
- self.version = config_kwargs.pop('version', None)
+ self.version = config_kwargs.pop('version', spec.get('version', None))
+
# run jsonschema validation of input specification against the (provided) schema
- log.info("Validating spec against schema: {0:s}".format(self.schema))
+ log.info(f"Validating spec against schema: {self.schema}")
utils.validate(self, self.schema, version=self.version)
self.measurement_names = []
|
diff --git a/tests/test_workspace.py b/tests/test_workspace.py
--- a/tests/test_workspace.py
+++ b/tests/test_workspace.py
@@ -38,6 +38,11 @@ def test_build_workspace(workspace_factory):
assert w
+def test_version_workspace(workspace_factory):
+ ws = workspace_factory()
+ assert ws.version is not None
+
+
def test_build_model(workspace_factory):
w = workspace_factory()
assert w.model()
|
Workspace.version is not set when loading in a workspace with a version
# Description
See the title.
# Expected Behavior
`Workspace.version is not None`
# Actual Behavior
`Workspace.version is None`
# Steps to Reproduce
```python
import pyhf, json
ws = pyhf.Workspace(json.load(open('workspace.json')))
assert ws.version is not None
assert ws.version == ws['version']
```
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
I am now moving on to this issue but I'm unable to reproduce the error due to the following exception raised in the workspace.py file
```
KeyError: 'channels'
```
which is due to as per the workspace.json file
```
Unable to load schema from 'http://json-schema.org/draft-06/schema'. No schema request service available(768)
```
I am afraid that I couldn't find a solution to the above problem.
@kanishk16 , not sure how you're getting that error...
```
>>> import pyhf, json
>>> ws = pyhf.Workspace(json.load(open('my-workspace.json')))
>>> ws.version
>>> ws['version']
'1.0.0'
```
works for me just fine. Are you trying to load in the `pyhf/schemas/1.0.0/workspace.json` file as a workspace? It's a schema describing a workspace, not a workspace itself.
Sorry for the late reply @kratsg ...Yes, I was trying to load `pyhf/schemas/1.0.0/workspace.json`. Since I am using Google Colab, I am not sure if there already exists a workspace.json.
I might not be well versed about it. From what I know, not sure if you are talking about this, there exists a workspace.json corresponding to the workspace of each user. But, what if the workspace.json doesn't exist only (never really thought of)? Could you point me to some resources if I am heading in the wrong direction?
There are published likelihoods available for usage here: https://scikit-hep.org/pyhf/citations.html#published-likelihoods - e.g.
```
curl -s -- https://www.hepdata.net/record/resource/1165724?view=true |tar -O -xzvf - - --include patch.ERJR_350p0_0p0.json > patch.ERJR_350p0_0p0.json
curl -s -- https://www.hepdata.net/record/resource/1165724?view=true |tar -O -xzvf - - --include BkgOnly.json > BkgOnly.json
jsonpatch BkgOnly.json patch.ERJR_350p0_0p0.json > my_workspace.json
```
to get an example workspace in practice. The `workspace.json` is just a schema. You should understand the difference between a JSON schema specification and a JSON document that follows the schema.
| 2020-03-14T11:48:23 |
scikit-hep/pyhf
| 813 |
scikit-hep__pyhf-813
|
[
"668"
] |
f79a74b2c575ca35bcf3229abdcfb902b95b11d6
|
diff --git a/src/pyhf/pdf.py b/src/pyhf/pdf.py
--- a/src/pyhf/pdf.py
+++ b/src/pyhf/pdf.py
@@ -222,12 +222,22 @@ def __init__(self, spec, **config_kwargs):
spec, self.channel_nbins
)
- poiname = config_kwargs.get('poiname', 'mu')
+ # measurement_name is passed in via Workspace::model and this is a bug. We'll remove it here for now
+ # but needs to be fixed upstream. #836 is filed to keep track.
+ config_kwargs.pop('measurement_name', None)
+
+ poiname = config_kwargs.pop('poiname', 'mu')
+
default_modifier_settings = {'normsys': {'interpcode': 'code1'}}
- self.modifier_settings = (
- config_kwargs.get('modifier_settings') or default_modifier_settings
+ self.modifier_settings = config_kwargs.pop(
+ 'modifier_settings', default_modifier_settings
)
+ if config_kwargs:
+ raise KeyError(
+ f"""Unexpected keyword argument(s): '{"', '".join(config_kwargs.keys())}'"""
+ )
+
self.par_map = {}
self.par_order = []
self.poi_name = None
diff --git a/src/pyhf/workspace.py b/src/pyhf/workspace.py
--- a/src/pyhf/workspace.py
+++ b/src/pyhf/workspace.py
@@ -325,7 +325,7 @@ def get_measurement(self, **config_kwargs):
def _get_measurement(self, **config_kwargs):
"""See `Workspace::get_measurement`."""
- poi_name = config_kwargs.get('poi_name')
+ poi_name = config_kwargs.pop('poi_name', None)
if poi_name:
return {
'name': 'NormalMeasurement',
@@ -333,7 +333,7 @@ def _get_measurement(self, **config_kwargs):
}
if self.measurement_names:
- measurement_name = config_kwargs.get('measurement_name')
+ measurement_name = config_kwargs.pop('measurement_name', None)
if measurement_name:
if measurement_name not in self.measurement_names:
log.debug(
@@ -350,7 +350,7 @@ def _get_measurement(self, **config_kwargs):
self.measurement_names.index(measurement_name)
]
- measurement_index = config_kwargs.get('measurement_index')
+ measurement_index = config_kwargs.pop('measurement_index', None)
if measurement_index:
return self['measurements'][measurement_index]
@@ -380,7 +380,7 @@ def model(self, **config_kwargs):
'model being created for measurement {0:s}'.format(measurement['name'])
)
- patches = config_kwargs.get('patches', [])
+ patches = config_kwargs.pop('patches', [])
modelspec = {
'channels': self['channels'],
|
diff --git a/tests/test_pdf.py b/tests/test_pdf.py
--- a/tests/test_pdf.py
+++ b/tests/test_pdf.py
@@ -650,3 +650,46 @@ def test_sample_wrong_bins():
}
with pytest.raises(pyhf.exceptions.InvalidModel):
pyhf.Model(spec)
+
+
[email protected](
+ 'measurements, msettings',
+ [
+ (
+ None,
+ {'normsys': {'interpcode': 'code4'}, 'histosys': {'interpcode': 'code4p'},},
+ )
+ ],
+)
+def test_unexpected_keyword_argument(measurements, msettings):
+ spec = {
+ "channels": [
+ {
+ "name": "singlechannel",
+ "samples": [
+ {
+ "name": "signal",
+ "data": [5.0, 10.0],
+ "modifiers": [
+ {"name": "mu", "type": "normfactor", "data": None}
+ ],
+ },
+ {
+ "name": "background",
+ "data": [50.0, 60.0],
+ "modifiers": [
+ {
+ "name": "uncorr_bkguncrt",
+ "type": "shapesys",
+ "data": [5.0, 12.0],
+ }
+ ],
+ },
+ ],
+ }
+ ]
+ }
+ with pytest.raises(KeyError):
+ pyhf.pdf._ModelConfig(
+ spec, measurement_name=measurements, modifiers_settings=msettings
+ )
|
Catch unspecified/unknown kwargs
# Description
Came up in #620. The "bug" there is that the line had a typo:
```
p = w.model(measurement_name=None, patches=patches, modifiers_settings=msettings)
^
```
instead of
```
p = w.model(measurement_name=None, patches=patches, modifier_settings=msettings)
```
We should probably catch unknown kwargs (e.g. pop them all off and make sure there's no unconsumed kwargs).
## Is your feature request related to a problem? Please describe.
Typos happen and we should probably help identify the typos.
### Describe the solution you'd like
Check if all kwargs are used up and raise an error if not.
### Describe alternatives you've considered
None.
# Relevant Issues and Pull Requests
- #620
| 2020-03-21T07:58:43 |
|
scikit-hep/pyhf
| 819 |
scikit-hep__pyhf-819
|
[
"818"
] |
58120805ee945f9c02446032942586611b6445bf
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -51,7 +51,6 @@ def setup(app):
'sphinx.ext.napoleon',
'sphinx_click.ext',
'nbsphinx',
- 'm2r',
'sphinx_issues',
'sphinx_copybutton',
'xref',
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -2,8 +2,8 @@
from pathlib import Path
this_directory = Path(__file__).parent.resolve()
-with open(Path(this_directory).joinpath('README.md'), encoding='utf-8') as readme_md:
- long_description = readme_md.read()
+with open(Path(this_directory).joinpath('README.rst'), encoding='utf-8') as readme_rst:
+ long_description = readme_rst.read()
extras_require = {
'tensorflow': ['tensorflow~=2.0', 'tensorflow-probability~=0.8'],
@@ -60,7 +60,6 @@
'ipywidgets',
'sphinx-issues',
'sphinx-copybutton>0.2.9',
- 'm2r',
]
)
)
@@ -79,7 +78,7 @@
version='0.4.1',
description='(partial) pure python histfactory implementation',
long_description=long_description,
- long_description_content_type='text/markdown',
+ long_description_content_type='text/x-rst',
url='https://github.com/scikit-hep/pyhf',
author='Lukas Heinrich, Matthew Feickert, Giordon Stark',
author_email='[email protected], [email protected], [email protected]',
|
diff --git a/.github/workflows/release_tests.yml b/.github/workflows/release_tests.yml
--- a/.github/workflows/release_tests.yml
+++ b/.github/workflows/release_tests.yml
@@ -22,6 +22,12 @@ jobs:
uses: actions/setup-python@v1
with:
python-version: ${{ matrix.python-version }}
+ - name: Free disk space
+ # WARNING: Needed due to GitHub Actions disk space regression on Linux runners
+ if: matrix.os == 'ubuntu-latest'
+ run: |
+ sudo apt-get clean
+ df -h
- name: Install from PyPI
run: |
python -m pip install --upgrade pip setuptools wheel
diff --git a/tests/test_scripts.py b/tests/test_scripts.py
--- a/tests/test_scripts.py
+++ b/tests/test_scripts.py
@@ -46,10 +46,7 @@ def test_import_prepHistFactory_withProgress(tmpdir, script_runner):
def test_import_prepHistFactory_stdout(tmpdir, script_runner):
- temp = tmpdir.join("parsed_output.json")
- command = 'pyhf xml2json validation/xmlimport_input/config/example.xml --basedir validation/xmlimport_input/'.format(
- temp.strpath
- )
+ command = 'pyhf xml2json validation/xmlimport_input/config/example.xml --basedir validation/xmlimport_input/'
ret = script_runner.run(*shlex.split(command))
assert ret.success
assert ret.stdout != ''
@@ -158,14 +155,12 @@ def test_patch(tmpdir, script_runner):
ret = script_runner.run(*shlex.split(command))
assert ret.success
- command = 'pyhf cls {0:s} --patch -'.format(temp.strpath, patch.strpath)
+ command = f'pyhf cls {temp.strpath:s} --patch -'
ret = script_runner.run(*shlex.split(command), stdin=patch)
assert ret.success
- command = 'pyhf json2xml {0:s} --output-dir {1:s} --patch -'.format(
- temp.strpath, tmpdir.mkdir('output_2').strpath, patch.strpath
- )
+ command = f"pyhf json2xml {temp.strpath:s} --output-dir {tmpdir.mkdir('output_2').strpath:s} --patch -"
ret = script_runner.run(*shlex.split(command), stdin=patch)
assert ret.success
|
Bug Report: Sphinx v3.0.0 breaks docs build
# Description
The release of Sphinx [`v3.0.0`](https://github.com/sphinx-doc/sphinx/releases/tag/v3.0.0) [breaks the build of the docs with](https://github.com/scikit-hep/pyhf/runs/562901637?check_suite_focus=true#step:6:11)
```pytb
Exception occurred:
File "/opt/hostedtoolcache/Python/3.7.6/x64/lib/python3.7/site-packages/sphinx/application.py", line 1069, in add_source_parser
self.registry.add_source_parser(*args, **kwargs)
TypeError: add_source_parser() takes 2 positional arguments but 3 were given
The full traceback has been saved in /tmp/sphinx-err-gu866l6p.log, if you want to report the issue to the developers.
Please also report this if it was a user error, so that a better error message can be provided next time.
A bug report can be filed in the tracker at <https://github.com/sphinx-doc/sphinx/issues>. Thanks!
```
which when run locally the generated log is
```
$ cat /tmp/sphinx-err-blah.log
# Sphinx version: 3.0.0
# Python version: 3.7.5 (CPython)
# Docutils version: 0.16 release
# Jinja2 version: 2.11.1
# Last messages:
# Loaded extensions:
Traceback (most recent call last):
File "/home/feickert/.venvs/pyhf-dev/lib/python3.7/site-packages/sphinx/cmd/build.py", line 279, in build_main
args.tags, args.verbosity, args.jobs, args.keep_going)
File "/home/feickert/.venvs/pyhf-dev/lib/python3.7/site-packages/sphinx/application.py", line 244, in __init__
self.setup_extension(extension)
File "/home/feickert/.venvs/pyhf-dev/lib/python3.7/site-packages/sphinx/application.py", line 398, in setup_extension
self.registry.load_extension(self, extname)
File "/home/feickert/.venvs/pyhf-dev/lib/python3.7/site-packages/sphinx/registry.py", line 414, in load_extension
metadata = setup(app)
File "/home/feickert/.venvs/pyhf-dev/lib/python3.7/site-packages/m2r.py", line 652, in setup
app.add_source_parser('.md', M2RParser)
File "/home/feickert/.venvs/pyhf-dev/lib/python3.7/site-packages/sphinx/application.py", line 1069, in add_source_parser
self.registry.add_source_parser(*args, **kwargs)
TypeError: add_source_parser() takes 2 positional arguments but 3 were given
```
# Steps to Reproduce
Try to build the docs with Sphinx `v3.0.0` or check the nightly CI builds.
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
This will get fixed if https://github.com/miyakogi/m2r/pull/55 gets merged and a new release gets cut, but `m2r` hasn't had a release since 2018, so the project is probably in archive mode and we might need to find a new extension to use.
| 2020-04-06T16:32:47 |
scikit-hep/pyhf
| 837 |
scikit-hep__pyhf-837
|
[
"800"
] |
1d04b468c52e32b2d747de8e45fe2c898371c513
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -96,7 +96,7 @@
'scipy', # requires numpy, which is required by pyhf and tensorflow
'click>=6.0', # for console scripts,
'tqdm', # for readxml
- 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6
+ 'jsonschema>=3.2.0', # for utils
'jsonpatch',
'pyyaml', # for parsing CLI equal-delimited options
],
|
bump jsonschema to v3.2.0+ to support draft 6
Currently on alpha release 3.0.x but can bump to 3.2.0 which was released.
| 2020-04-22T19:59:27 |
||
scikit-hep/pyhf
| 838 |
scikit-hep__pyhf-838
|
[
"836"
] |
48877370a99503d8e300d02f9e0eed3048cd336d
|
diff --git a/src/pyhf/pdf.py b/src/pyhf/pdf.py
--- a/src/pyhf/pdf.py
+++ b/src/pyhf/pdf.py
@@ -222,11 +222,7 @@ def __init__(self, spec, **config_kwargs):
spec, self.channel_nbins
)
- # measurement_name is passed in via Workspace::model and this is a bug. We'll remove it here for now
- # but needs to be fixed upstream. #836 is filed to keep track.
- config_kwargs.pop('measurement_name', None)
-
- poiname = config_kwargs.pop('poiname', 'mu')
+ poi_name = config_kwargs.pop('poi_name', 'mu')
default_modifier_settings = {'normsys': {'interpcode': 'code1'}}
self.modifier_settings = config_kwargs.pop(
@@ -246,7 +242,7 @@ def __init__(self, spec, **config_kwargs):
self.auxdata_order = []
self._create_and_register_paramsets(_required_paramsets)
- self.set_poi(poiname)
+ self.set_poi(poi_name)
self.npars = len(self.suggested_init())
self.nmaindata = sum(self.channel_nbins.values())
diff --git a/src/pyhf/workspace.py b/src/pyhf/workspace.py
--- a/src/pyhf/workspace.py
+++ b/src/pyhf/workspace.py
@@ -295,8 +295,9 @@ def __repr__(self):
"""Representation of the Workspace."""
return object.__repr__(self)
- # NB: this is a wrapper function to validate the returned measurement object against the spec
- def get_measurement(self, **config_kwargs):
+ def get_measurement(
+ self, poi_name=None, measurement_name=None, measurement_index=None
+ ):
"""
Get (or create) a measurement object.
@@ -319,22 +320,14 @@ def get_measurement(self, **config_kwargs):
:obj:`dict`: A measurement object adhering to the schema defs.json#/definitions/measurement
"""
- m = self._get_measurement(**config_kwargs)
- utils.validate(m, 'measurement.json', self.version)
- return m
-
- def _get_measurement(self, **config_kwargs):
- """See `Workspace::get_measurement`."""
- poi_name = config_kwargs.pop('poi_name', None)
- if poi_name:
- return {
+ measurement = None
+ if poi_name is not None:
+ measurement = {
'name': 'NormalMeasurement',
'config': {'poi': poi_name, 'parameters': []},
}
-
- if self.measurement_names:
- measurement_name = config_kwargs.pop('measurement_name', None)
- if measurement_name:
+ elif self.measurement_names:
+ if measurement_name is not None:
if measurement_name not in self.measurement_names:
log.debug(
'measurements defined:\n\t{0:s}'.format(
@@ -346,36 +339,53 @@ def _get_measurement(self, **config_kwargs):
measurement_name
)
)
- return self['measurements'][
+ measurement = self['measurements'][
self.measurement_names.index(measurement_name)
]
+ else:
+ if measurement_index is None and len(self.measurement_names) > 1:
+ log.warning(
+ 'multiple measurements defined. Taking the first measurement.'
+ )
- measurement_index = config_kwargs.pop('measurement_index', None)
- if measurement_index:
- return self['measurements'][measurement_index]
-
- if len(self.measurement_names) > 1:
- log.warning(
- 'multiple measurements defined. Taking the first measurement.'
+ measurement_index = (
+ measurement_index if measurement_index is not None else 0
)
- return self['measurements'][0]
+ try:
+ measurement = self['measurements'][measurement_index]
+ except IndexError:
+ raise exceptions.InvalidMeasurement(
+ f"The measurement index {measurement_index} is out of bounds as only {len(self.measurement_names)} measurement(s) have been defined."
+ )
+ else:
+ raise exceptions.InvalidMeasurement("No measurements have been defined.")
- raise exceptions.InvalidMeasurement(
- "A measurement was not given to create the Model."
- )
+ utils.validate(measurement, 'measurement.json', self.version)
+ return measurement
def model(self, **config_kwargs):
"""
Create a model object with/without patches applied.
+ See :func:`pyhf.workspace.Workspace.get_measurement` and :class:`pyhf.pdf.Model` for possible keyword arguments.
+
Args:
patches: A list of JSON patches to apply to the model specification
+ config_kwargs: Possible keyword arguments for the measurement and model configuration
Returns:
~pyhf.pdf.Model: A model object adhering to the schema model.json
"""
- measurement = self.get_measurement(**config_kwargs)
+
+ poi_name = config_kwargs.pop('poi_name', None)
+ measurement_name = config_kwargs.pop('measurement_name', None)
+ measurement_index = config_kwargs.pop('measurement_index', None)
+ measurement = self.get_measurement(
+ poi_name=poi_name,
+ measurement_name=measurement_name,
+ measurement_index=measurement_index,
+ )
log.debug(
'model being created for measurement {0:s}'.format(measurement['name'])
)
@@ -389,7 +399,7 @@ def model(self, **config_kwargs):
for patch in patches:
modelspec = jsonpatch.JsonPatch(patch).apply(modelspec)
- return Model(modelspec, poiname=measurement['config']['poi'], **config_kwargs)
+ return Model(modelspec, poi_name=measurement['config']['poi'], **config_kwargs)
def data(self, model, with_aux=True):
"""
|
diff --git a/tests/test_import.py b/tests/test_import.py
--- a/tests/test_import.py
+++ b/tests/test_import.py
@@ -157,7 +157,7 @@ def test_import_prepHistFactory():
'channels': parsed_xml['channels'],
'parameters': parsed_xml['measurements'][0]['config']['parameters'],
}
- pdf = pyhf.Model(spec, poiname='SigXsecOverSM')
+ pdf = pyhf.Model(spec, poi_name='SigXsecOverSM')
data = [
binvalue
@@ -222,7 +222,7 @@ def test_import_histosys():
'channels': parsed_xml['channels'],
'parameters': parsed_xml['measurements'][0]['config']['parameters'],
}
- pdf = pyhf.Model(spec, poiname='SigXsecOverSM')
+ pdf = pyhf.Model(spec, poi_name='SigXsecOverSM')
channels = {channel['name']: channel for channel in pdf.spec['channels']}
@@ -264,7 +264,7 @@ def test_import_shapesys():
'channels': parsed_xml['channels'],
'parameters': parsed_xml['measurements'][0]['config']['parameters'],
}
- pdf = pyhf.Model(spec, poiname='SigXsecOverSM')
+ pdf = pyhf.Model(spec, poi_name='SigXsecOverSM')
channels = {channel['name']: channel for channel in pdf.spec['channels']}
diff --git a/tests/test_pdf.py b/tests/test_pdf.py
--- a/tests/test_pdf.py
+++ b/tests/test_pdf.py
@@ -493,7 +493,7 @@ def test_invalid_modifier_name_resuse():
]
}
with pytest.raises(pyhf.exceptions.InvalidNameReuse):
- pyhf.Model(spec, poiname='reused_name')
+ pyhf.Model(spec, poi_name='reused_name')
def test_override_paramset_defaults():
@@ -596,7 +596,7 @@ def test_lumi_np_scaling():
}
],
}
- pdf = pyhf.pdf.Model(spec, poiname="SigXsecOverSM")
+ pdf = pyhf.pdf.Model(spec, poi_name="SigXsecOverSM")
poi_slice = pdf.config.par_slice('SigXsecOverSM')
lumi_slice = pdf.config.par_slice('lumi')
diff --git a/tests/test_schema.py b/tests/test_schema.py
--- a/tests/test_schema.py
+++ b/tests/test_schema.py
@@ -66,7 +66,7 @@ def test_one_sample_missing_modifiers():
}
]
}
- pyhf.Model(spec, poiname='mypoi')
+ pyhf.Model(spec, poi_name='mypoi')
def test_add_unknown_modifier():
@@ -207,7 +207,7 @@ def test_parameters_definition():
],
'parameters': [{'name': 'mypoi'}],
}
- pyhf.Model(spec, poiname='mypoi')
+ pyhf.Model(spec, poi_name='mypoi')
def test_parameters_incorrect_format():
@@ -230,7 +230,7 @@ def test_parameters_incorrect_format():
'parameters': {'a': 'fake', 'object': 2},
}
with pytest.raises(pyhf.exceptions.InvalidSpecification):
- pyhf.Model(spec, poiname='mypoi')
+ pyhf.Model(spec, poi_name='mypoi')
def test_parameters_duplicated():
@@ -253,7 +253,7 @@ def test_parameters_duplicated():
'parameters': [{'name': 'mypoi'}, {'name': 'mypoi'}],
}
with pytest.raises(pyhf.exceptions.InvalidModel):
- pyhf.Model(spec, poiname='mypoi')
+ pyhf.Model(spec, poi_name='mypoi')
def test_parameters_all_props():
@@ -275,7 +275,7 @@ def test_parameters_all_props():
],
'parameters': [{'name': 'mypoi', 'inits': [1], 'bounds': [[0, 1]]}],
}
- pyhf.Model(spec, poiname='mypoi')
+ pyhf.Model(spec, poi_name='mypoi')
@pytest.mark.parametrize(
@@ -319,7 +319,7 @@ def test_parameters_bad_parameter(bad_parameter):
'parameters': [bad_parameter],
}
with pytest.raises(pyhf.exceptions.InvalidSpecification):
- pyhf.Model(spec, poiname='mypoi')
+ pyhf.Model(spec, poi_name='mypoi')
@pytest.mark.parametrize(
@@ -345,4 +345,4 @@ def test_parameters_normfactor_bad_attribute(bad_parameter):
'parameters': [bad_parameter],
}
with pytest.raises(pyhf.exceptions.InvalidModel):
- pyhf.Model(spec, poiname='mypoi')
+ pyhf.Model(spec, poi_name='mypoi')
diff --git a/tests/test_validation.py b/tests/test_validation.py
--- a/tests/test_validation.py
+++ b/tests/test_validation.py
@@ -779,7 +779,7 @@ def test_import_roundtrip(tmpdir, toplvl, basedir):
'channels': parsed_xml_before['channels'],
'parameters': parsed_xml_before['measurements'][0]['config']['parameters'],
}
- pdf_before = pyhf.Model(spec, poiname='SigXsecOverSM')
+ pdf_before = pyhf.Model(spec, poi_name='SigXsecOverSM')
tmpconfig = tmpdir.mkdir('config')
tmpdata = tmpdir.mkdir('data')
@@ -797,7 +797,7 @@ def test_import_roundtrip(tmpdir, toplvl, basedir):
'channels': parsed_xml_after['channels'],
'parameters': parsed_xml_after['measurements'][0]['config']['parameters'],
}
- pdf_after = pyhf.Model(spec, poiname='SigXsecOverSM')
+ pdf_after = pyhf.Model(spec, poi_name='SigXsecOverSM')
data_before = [
binvalue
diff --git a/tests/test_workspace.py b/tests/test_workspace.py
--- a/tests/test_workspace.py
+++ b/tests/test_workspace.py
@@ -77,6 +77,21 @@ def test_get_measurement_nonexist(workspace_factory):
assert 'nonexistent_measurement' in str(excinfo.value)
+def test_get_measurement_index_outofbounds(workspace_factory):
+ ws = workspace_factory()
+ with pytest.raises(pyhf.exceptions.InvalidMeasurement) as excinfo:
+ ws.get_measurement(measurement_index=9999)
+ assert 'out of bounds' in str(excinfo.value)
+
+
+def test_get_measurement_no_measurements_defined(workspace_factory):
+ ws = workspace_factory()
+ ws.measurement_names = []
+ with pytest.raises(pyhf.exceptions.InvalidMeasurement) as excinfo:
+ ws.get_measurement()
+ assert 'No measurements have been defined' in str(excinfo.value)
+
+
def test_get_workspace_measurement_priority(workspace_factory):
w = workspace_factory()
@@ -694,3 +709,11 @@ def test_combine_workspace(workspace_factory, join):
assert set(combined.channels) == set(ws.channels + new_ws.channels)
assert set(combined.samples) == set(ws.samples + new_ws.samples)
assert set(combined.parameters) == set(ws.parameters + new_ws.parameters)
+
+
+def test_workspace_equality(workspace_factory):
+ ws = workspace_factory()
+ ws_other = workspace_factory()
+ assert ws == ws
+ assert ws == ws_other
+ assert ws != 'not a workspace'
|
Simplify Workspace::_get_measurement()
# Description
At the moment, some of the functionality of `get_measurement()` on the `Workspace` is likely a bit too smart/magic. This should be trimmed/cleaned up to be simpler and less complex. This came out of some changes in #813 which reveal that we're passing in unused keyword arguments into `_ModelConfig` (namely: `measurement_name`).
|
@kratsg Do you want this to go into patch release `v0.4.2`? Or can it go in `v0.5.0`?
When is the patch going to release, tentatively? If we have some time then could I possibly work on this?
This week. I'll be working on it, since i've assigned it to myself.
| 2020-04-22T20:41:00 |
scikit-hep/pyhf
| 849 |
scikit-hep__pyhf-849
|
[
"848"
] |
31d34a0edd91593d75181cc3ad71563a52600793
|
diff --git a/src/pyhf/infer/__init__.py b/src/pyhf/infer/__init__.py
--- a/src/pyhf/infer/__init__.py
+++ b/src/pyhf/infer/__init__.py
@@ -11,6 +11,27 @@ def hypotest(
r"""
Compute :math:`p`-values and test statistics for a single value of the parameter of interest.
+ Example:
+ >>> import pyhf
+ >>> pyhf.set_backend("numpy")
+ >>> model = pyhf.simplemodels.hepdata_like(
+ ... signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
+ ... )
+ >>> observations = [51, 48]
+ >>> data = pyhf.tensorlib.astensor(observations + model.config.auxdata)
+ >>> test_poi = 1.0
+ >>> CLs_obs, CLs_exp_band = pyhf.infer.hypotest(
+ ... test_poi, data, model, qtilde=True, return_expected_set=True
+ ... )
+ >>> print(CLs_obs)
+ [0.05251554]
+ >>> print(CLs_exp_band)
+ [[0.00260641]
+ [0.01382066]
+ [0.06445521]
+ [0.23526104]
+ [0.57304182]]
+
Args:
poi_test (Number or Tensor): The value of the parameter of interest (POI)
data (Number or Tensor): The root of the calculated test statistic given the Asimov data, :math:`\sqrt{q_{\mu,A}}`
diff --git a/src/pyhf/infer/mle.py b/src/pyhf/infer/mle.py
--- a/src/pyhf/infer/mle.py
+++ b/src/pyhf/infer/mle.py
@@ -7,7 +7,7 @@ def twice_nll(pars, data, pdf):
Twice the negative Log-Likelihood.
Args:
- data (`tensor`): the data
+ data (`tensor`): The data
pdf (~pyhf.pdf.Model): The statistical model adhering to the schema model.json
Returns:
@@ -21,13 +21,26 @@ def fit(data, pdf, init_pars=None, par_bounds=None, **kwargs):
"""
Run a unconstrained maximum likelihood fit.
+ Example:
+ >>> import pyhf
+ >>> pyhf.set_backend("numpy")
+ >>> model = pyhf.simplemodels.hepdata_like(
+ ... signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
+ ... )
+ >>> observations = [51, 48]
+ >>> data = pyhf.tensorlib.astensor(observations + model.config.auxdata)
+ >>> pyhf.infer.mle.fit(data, model, return_fitted_val=True)
+ (array([0. , 1.0030512 , 0.96266961]), 24.98393521454011)
+
Args:
- data (`tensor`): the data
+ data (`tensor`): The data
pdf (~pyhf.pdf.Model): The statistical model adhering to the schema model.json
- kwargs: keyword arguments passed through to the optimizer API
+ init_pars (`list`): Values to initialize the model parameters at for the fit
+ par_bounds (`list` of `list`\s or `tuple`\s): The extrema of values the model parameters are allowed to reach in the fit
+ kwargs: Keyword arguments passed through to the optimizer API
Returns:
- see optimizer API
+ See optimizer API
"""
_, opt = get_backend()
@@ -38,15 +51,29 @@ def fit(data, pdf, init_pars=None, par_bounds=None, **kwargs):
def fixed_poi_fit(poi_val, data, pdf, init_pars=None, par_bounds=None, **kwargs):
"""
- Run a maximum likelihood fit with the POI value fixzed.
+ Run a maximum likelihood fit with the POI value fixed.
+
+ Example:
+ >>> import pyhf
+ >>> pyhf.set_backend("numpy")
+ >>> model = pyhf.simplemodels.hepdata_like(
+ ... signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
+ ... )
+ >>> observations = [51, 48]
+ >>> data = pyhf.tensorlib.astensor(observations + model.config.auxdata)
+ >>> test_poi = 1.0
+ >>> pyhf.infer.mle.fixed_poi_fit(test_poi, data, model, return_fitted_val=True)
+ (array([1. , 0.97224597, 0.87553894]), 28.92218013492061)
Args:
- data: the data
+ data: The data
pdf (~pyhf.pdf.Model): The statistical model adhering to the schema model.json
- kwargs: keyword arguments passed through to the optimizer API
+ init_pars (`list`): Values to initialize the model parameters at for the fit
+ par_bounds (`list` of `list`\s or `tuple`\s): The extrema of values the model parameters are allowed to reach in the fit
+ kwargs: Keyword arguments passed through to the optimizer API
Returns:
- see optimizer API
+ See optimizer API
"""
_, opt = get_backend()
|
diff --git a/src/pyhf/infer/test_statistics.py b/src/pyhf/infer/test_statistics.py
--- a/src/pyhf/infer/test_statistics.py
+++ b/src/pyhf/infer/test_statistics.py
@@ -18,13 +18,26 @@ def qmu(mu, data, pdf, init_pars, par_bounds):
\end{array}\right.
\end{equation}
+ Example:
+ >>> import pyhf
+ >>> pyhf.set_backend("numpy")
+ >>> model = pyhf.simplemodels.hepdata_like(
+ ... signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
+ ... )
+ >>> observations = [51, 48]
+ >>> data = pyhf.tensorlib.astensor(observations + model.config.auxdata)
+ >>> test_mu = 1.0
+ >>> init_pars = model.config.suggested_init()
+ >>> par_bounds = model.config.suggested_bounds()
+ >>> pyhf.infer.test_statistics.qmu(test_mu, data, model, init_pars, par_bounds)
+ 3.938244920380498
Args:
mu (Number or Tensor): The signal strength parameter
data (Tensor): The data to be considered
pdf (~pyhf.pdf.Model): The HistFactory statistical model used in the likelihood ratio calculation
- init_pars (Tensor): The initial parameters
- par_bounds(Tensor): The bounds on the paramter values
+ init_pars (`list`): Values to initialize the model parameters at for the fit
+ par_bounds (`list` of `list`\s or `tuple`\s): The extrema of values the model parameters are allowed to reach in the fit
Returns:
Float: The calculated test statistic, :math:`q_{\mu}`
|
pyhf.infer.mle.fit docstring missing arguments
# Description
`pyhf.infer.mle.fit`'s docstring currently only includes `data`, `pdf` and `kwargs` and does not list the other arguments. It should be updated to include all arguments and also have `pydocstyle` run over it.
| 2020-05-01T05:06:54 |
|
scikit-hep/pyhf
| 860 |
scikit-hep__pyhf-860
|
[
"633"
] |
f41b1e3fc4286ebd99a241bf71dfd0e4397c6c0c
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -87,6 +87,7 @@
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
+ "Programming Language :: Python :: 3.8",
],
package_dir={'': 'src'},
packages=find_packages(where='src'),
|
diff --git a/.github/workflows/release_tests.yml b/.github/workflows/release_tests.yml
--- a/.github/workflows/release_tests.yml
+++ b/.github/workflows/release_tests.yml
@@ -14,11 +14,11 @@ jobs:
strategy:
matrix:
os: [ubuntu-latest, macos-latest]
- python-version: [3.7]
+ python-version: [3.7, 3.8]
steps:
- uses: actions/checkout@v2
- - name: Set up Python 3.7
+ - name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v1
with:
python-version: ${{ matrix.python-version }}
|
Add Python 3.8 to CI
# Description
The branch [`ci/add-Python-3.8-to-CI`](https://github.com/diana-hep/pyhf/compare/ci/add-Python-3.8-to-CI) adds Python 3.8 to the CI. However, as [PyTorch won't have a Python 3.8 wheel until the next release](https://github.com/pytorch/pytorch/issues/21741#issuecomment-541242504) this won't be able to happen until around December 2019.
| 2020-05-08T04:38:54 |
|
scikit-hep/pyhf
| 862 |
scikit-hep__pyhf-862
|
[
"861"
] |
e8ad7382bd408502807ad87a3fdf56396fbd1df9
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -79,11 +79,21 @@
long_description=long_description,
long_description_content_type='text/x-rst',
url='https://github.com/scikit-hep/pyhf',
+ project_urls={
+ "Documentation": "https://scikit-hep.org/pyhf/",
+ "Source": "https://github.com/scikit-hep/pyhf",
+ "Tracker": "https://github.com/scikit-hep/pyhf/issues",
+ },
author='Lukas Heinrich, Matthew Feickert, Giordon Stark',
author_email='[email protected], [email protected], [email protected]',
license='Apache',
- keywords='physics fitting numpy scipy tensorflow pytorch',
+ keywords='physics fitting numpy scipy tensorflow pytorch jax',
classifiers=[
+ "Development Status :: 4 - Beta",
+ "License :: OSI Approved :: Apache Software License",
+ "Intended Audience :: Science/Research",
+ "Topic :: Scientific/Engineering",
+ "Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
|
Update PyPI keywords and classifies in setup.py
# Description
As JAX is now a supported backend then it should additionally be added to the [list of keywords in `setup.py`](https://github.com/scikit-hep/pyhf/blob/917bd5127c1da023b279c076bb41614fbb859487/setup.py#L85). Additionally, the [classifies](https://packaging.python.org/guides/distributing-packages-using-setuptools/#classifiers) should be updated as well to include a `Development Status`, `License`, `Intended Audience`, and `Topic`.
|
Working from the [full list of PyPI recognized classifiers](https://pypi.org/classifiers/):
**Development Status**
As far as `Development Status` goes, we are not at a `v1.0.0` release so we could be a `Development Status :: 4 - Beta` but at the same time `pyhf` is definitely being used so I would lean towards it being put under `Development Status :: 5 - Production/Stable`.
**License**
`License :: OSI Approved :: Apache Software License`
**Intended Audience**
`Intended Audience :: Science/Research`
**Topic**
- `Topic :: Scientific/Engineering`
- `Topic :: Scientific/Engineering :: Physics`
Likewise, for [Project URLS](https://packaging.python.org/guides/distributing-packages-using-setuptools/#project-urls)
```python
project_urls={
'Documentation': 'https://scikit-hep.org/pyhf/',
'Source': 'https://github.com/scikit-hep/pyhf',
'Tracker': 'https://github.com/scikit-hep/pyhf/issues',
},
```
| 2020-05-08T05:26:29 |
|
scikit-hep/pyhf
| 873 |
scikit-hep__pyhf-873
|
[
"872"
] |
2b0f3bd638613f49473c7b8c99873d9cf459b0db
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,9 +1,4 @@
-from setuptools import setup, find_packages
-from pathlib import Path
-
-this_directory = Path(__file__).parent.resolve()
-with open(Path(this_directory).joinpath('README.rst'), encoding='utf-8') as readme_rst:
- long_description = readme_rst.read()
+from setuptools import setup
extras_require = {
'tensorflow': ['tensorflow~=2.0', 'tensorflow-probability~=0.8'],
@@ -73,46 +68,6 @@
setup(
- name='pyhf',
- version='0.4.1',
- description='(partial) pure python histfactory implementation',
- long_description=long_description,
- long_description_content_type='text/x-rst',
- url='https://github.com/scikit-hep/pyhf',
- project_urls={
- "Documentation": "https://scikit-hep.org/pyhf/",
- "Source": "https://github.com/scikit-hep/pyhf",
- "Tracker": "https://github.com/scikit-hep/pyhf/issues",
- },
- author='Lukas Heinrich, Matthew Feickert, Giordon Stark',
- author_email='[email protected], [email protected], [email protected]',
- license='Apache',
- keywords='physics fitting numpy scipy tensorflow pytorch jax',
- classifiers=[
- "Development Status :: 4 - Beta",
- "License :: OSI Approved :: Apache Software License",
- "Intended Audience :: Science/Research",
- "Topic :: Scientific/Engineering",
- "Topic :: Scientific/Engineering :: Physics",
- "Programming Language :: Python :: 3",
- "Programming Language :: Python :: 3.6",
- "Programming Language :: Python :: 3.7",
- "Programming Language :: Python :: 3.8",
- ],
- package_dir={'': 'src'},
- packages=find_packages(where='src'),
- include_package_data=True,
- python_requires=">=3.6",
- install_requires=[
- 'scipy', # requires numpy, which is required by pyhf and tensorflow
- 'click>=6.0', # for console scripts,
- 'tqdm', # for readxml
- 'jsonschema>=3.2.0', # for utils
- 'jsonpatch',
- 'pyyaml', # for parsing CLI equal-delimited options
- ],
extras_require=extras_require,
- entry_points={'console_scripts': ['pyhf=pyhf.cli:cli']},
- dependency_links=[],
use_scm_version=lambda: {'local_scheme': lambda version: ''},
)
|
Move metadata from setup.py to setup.cfg
# Description
@henryiii has documented on the [Scikit-HEP packaging information page](https://scikit-hep.org/developer/packaging#setup-configuration-medium-priority) how one can move from having PyPI metadata be stored in `setup.py` to `setup.cfg`. We've known about this for sometime but haven't taken the time to do it yet, but it is probably worth doing.
@henryiii Can you comment on how to deal with `project_urls`?
https://github.com/scikit-hep/pyhf/blob/3e1f157119dbcb4d8db8ffd8c98e16a2d12d0239/setup.py#L82-L86
|
> Can you comment on how to deal with project_urls?
There is a very nice example of how to do this in the [gwcelery `setup.cfg` file](https://git.ligo.org/emfollow/gwcelery/-/blob/46374fad07099fcc38cc6e620c6c7fc7afc736b2/setup.cfg). So for us it would be
```
[metadata]
...
project_urls =
Documentation = https://scikit-hep.org/pyhf/
Source = https://github.com/scikit-hep/pyhf
Tracker = https://github.com/scikit-hep/pyhf/issues
```
| 2020-05-20T22:33:42 |
|
scikit-hep/pyhf
| 895 |
scikit-hep__pyhf-895
|
[
"894"
] |
c29fef96c2efdc31270586cff9081215e5c39695
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -46,7 +46,7 @@
extras_require['docs'] = sorted(
set(
[
- 'sphinx',
+ 'sphinx!=3.1.0',
'sphinxcontrib-bibtex',
'sphinx-click',
'sphinx_rtd_theme',
|
Docs build broken with Sphinx v3.1.0
# Description
Today (2020-06-08) [Sphinx `v3.1.0`](https://github.com/sphinx-doc/sphinx/releases/tag/v3.1.0) was released which now classifies pyhf's particular usages of the "autoclass" directive as an Error in the docs generated for [`interpolators/code0.py`](https://github.com/scikit-hep/pyhf/blob/62becc2e469f89babf75534a2decfb3ace6ff179/src/pyhf/interpolators/code0.py)
```
Warning, treated as error:
/home/runner/work/pyhf/pyhf/docs/_generated/pyhf.interpolators.code0.rst:8:Error in "autoclass" directive:
1 argument(s) required, 0 supplied.
.. autoclass::
:show-inheritance:
.. rubric:: Methods
.. automethod:: .__init__
##[error]Process completed with exit code 1.
```
|
I'm going to escalate this to an Sphinx Issue as it seems that `Sphinx v3.1.0` broke things for a lot of projects. :(
| 2020-06-10T03:52:25 |
|
scikit-hep/pyhf
| 902 |
scikit-hep__pyhf-902
|
[
"901",
"901"
] |
6da28e89736beffadf75cf7bcf08543b48255f98
|
diff --git a/src/pyhf/infer/calculators.py b/src/pyhf/infer/calculators.py
--- a/src/pyhf/infer/calculators.py
+++ b/src/pyhf/infer/calculators.py
@@ -71,7 +71,8 @@ def pvalue(self, value):
"""
tensorlib, _ = get_backend()
- return 1 - tensorlib.normal_cdf(value - self.shift)
+ # computing cdf(-x) instead of 1-cdf(x) for right-tail p-value for improved numerical stability
+ return tensorlib.normal_cdf(-(value - self.shift))
def expected_value(self, nsigma):
"""
diff --git a/src/pyhf/tensor/pytorch_backend.py b/src/pyhf/tensor/pytorch_backend.py
--- a/src/pyhf/tensor/pytorch_backend.py
+++ b/src/pyhf/tensor/pytorch_backend.py
@@ -1,7 +1,9 @@
"""PyTorch Tensor Library Module."""
import torch
import torch.autograd
+from torch.distributions.utils import broadcast_all
import logging
+import math
log = logging.getLogger(__name__)
@@ -329,8 +331,14 @@ def normal_cdf(self, x, mu=0.0, sigma=1.0):
Returns:
PyTorch FloatTensor: The CDF
"""
- normal = torch.distributions.Normal(mu, sigma)
- return normal.cdf(x)
+ # the implementation of torch.Normal.cdf uses torch.erf:
+ # 0.5 * (1 + torch.erf((value - self.loc) * self.scale.reciprocal() / math.sqrt(2)))
+ # (see https://github.com/pytorch/pytorch/blob/3bbedb34b9b316729a27e793d94488b574e1577a/torch/distributions/normal.py#L78-L81)
+ # we get a more numerically stable variant for low p-values/high significances using erfc(x) := 1 - erf(x)
+ # since erf(-x) = -erf(x) we can replace
+ # 1 + erf(x) = 1 - erf(-x) = 1 - (1 - erfc(-x)) = erfc(-x)
+ mu, sigma = broadcast_all(mu, sigma)
+ return 0.5 * torch.erfc(-((x - mu) * sigma.reciprocal() / math.sqrt(2)))
def poisson_dist(self, rate):
r"""
|
diff --git a/tests/test_infer.py b/tests/test_infer.py
--- a/tests/test_infer.py
+++ b/tests/test_infer.py
@@ -1,6 +1,7 @@
import pytest
import pyhf
import numpy as np
+import scipy.stats
@pytest.fixture(scope='module')
@@ -157,3 +158,34 @@ def test_calculator_distributions_without_teststatistic(qtilde):
)
with pytest.raises(RuntimeError):
calc.distributions(1.0)
+
+
[email protected](
+ "nsigma,expected_pval",
+ [
+ # values tabulated using ROOT.RooStats.SignificanceToPValue
+ # they are consistent with relative difference < 1e-14 with scipy.stats.norm.sf
+ (5, 2.866515718791945e-07),
+ (6, 9.865876450377018e-10),
+ (7, 1.279812543885835e-12),
+ (8, 6.220960574271829e-16),
+ (9, 1.1285884059538408e-19),
+ ],
+)
+def test_asymptotic_dist_low_pvalues(backend, nsigma, expected_pval):
+ rtol = 1e-8
+ if backend[0].precision != '64b':
+ rtol = 1e-5
+ dist = pyhf.infer.calculators.AsymptoticTestStatDistribution(0)
+ assert np.isclose(np.array(dist.pvalue(nsigma)), expected_pval, rtol=rtol, atol=0)
+
+
+def test_significance_to_pvalue_roundtrip(backend):
+ rtol = 1e-15
+ if backend[0].precision != '64b':
+ rtol = 1e-6
+ sigma = np.arange(0, 10, 0.1)
+ dist = pyhf.infer.calculators.AsymptoticTestStatDistribution(0)
+ pvalue = dist.pvalue(pyhf.tensorlib.astensor(sigma))
+ back_to_sigma = -scipy.stats.norm.ppf(np.array(pvalue))
+ assert np.allclose(sigma, back_to_sigma, atol=0, rtol=rtol)
diff --git a/tests/test_validation.py b/tests/test_validation.py
--- a/tests/test_validation.py
+++ b/tests/test_validation.py
@@ -189,7 +189,7 @@ def expected_result_1bin_normsys(mu=1.0):
if mu == 1:
expected_result = {
"exp": [
- 7.471684419037561e-10,
+ 7.47169462e-10,
5.7411551509088054e-08,
3.6898088062731205e-06,
0.00016965731538267896,
@@ -711,7 +711,7 @@ def validate_hypotest(pdf, data, mu_test, expected_result, tolerance=1e-6):
[
(setup_1bin_shapesys(), 1e-6),
(setup_1bin_lumi(), 4e-6),
- (setup_1bin_normsys(), 1e-6),
+ (setup_1bin_normsys(), 2e-9),
(setup_2bin_histosys(), 8e-5),
(setup_2bin_2channel(), 1e-6),
(setup_2bin_2channel_couplednorm(), 1e-6),
|
Numerical unstable conversion of significances to p-values
# Description
The conversion of significances to p-values for the asymptotic methods is done by 1 - cdf
https://github.com/scikit-hep/pyhf/blob/73312338ef563305813198e5abc019de46fbbbc2/src/pyhf/infer/calculators.py#L74
This is numerically unstable, since we potentially want to get a very small number by subtracting almost 1 from 1. At a certain point (above ~8 sigma) it will cancel out to 0.
# Expected Behavior
I should get a non-zero p-value.
# Actual Behavior
I got zero.
# Steps to Reproduce
```python
>>> import pyhf
>>> pyhf.__version__ # using current master
'0.4.3'
>>> pyhf.set_backend("numpy")
>>> model = pyhf.simplemodels.hepdata_like(
... signal_data=[120.0, 110.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
... )
>>> observations = [51, 48]
>>> data = pyhf.tensorlib.astensor(observations + model.config.auxdata)
>>> pyhf.infer.hypotest(1.0, data, model)
array([0.])
```
# Checklist
- [X] Run `git fetch` to get the most up to date version of `master`
- [X] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
# Possible fix
For the numpy backend one could use `scipy.stats.norm.sf` which seems to be a more numerically stable implementation. Comparing `1-norm.cdf` with `norm.sf` one can also see how the precision is already degraded before the point where the p-value is cancelled out to completely 0:
```python
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> from scipy.stats import norm
>>> sigma = np.arange(0, 10, 0.1)
>>> one_minus_cdf = 1 - norm.cdf(sigma)
>>> sf = norm.sf(sigma)
>>> plt.plot(sigma, np.abs(one_minus_cdf - sf) / sf)
>>> plt.yscale("log")
>>> plt.show()
```

Numerical unstable conversion of significances to p-values
# Description
The conversion of significances to p-values for the asymptotic methods is done by 1 - cdf
https://github.com/scikit-hep/pyhf/blob/73312338ef563305813198e5abc019de46fbbbc2/src/pyhf/infer/calculators.py#L74
This is numerically unstable, since we potentially want to get a very small number by subtracting almost 1 from 1. At a certain point (above ~8 sigma) it will cancel out to 0.
# Expected Behavior
I should get a non-zero p-value.
# Actual Behavior
I got zero.
# Steps to Reproduce
```python
>>> import pyhf
>>> pyhf.__version__ # using current master
'0.4.3'
>>> pyhf.set_backend("numpy")
>>> model = pyhf.simplemodels.hepdata_like(
... signal_data=[120.0, 110.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
... )
>>> observations = [51, 48]
>>> data = pyhf.tensorlib.astensor(observations + model.config.auxdata)
>>> pyhf.infer.hypotest(1.0, data, model)
array([0.])
```
# Checklist
- [X] Run `git fetch` to get the most up to date version of `master`
- [X] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
# Possible fix
For the numpy backend one could use `scipy.stats.norm.sf` which seems to be a more numerically stable implementation. Comparing `1-norm.cdf` with `norm.sf` one can also see how the precision is already degraded before the point where the p-value is cancelled out to completely 0:
```python
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> from scipy.stats import norm
>>> sigma = np.arange(0, 10, 0.1)
>>> one_minus_cdf = 1 - norm.cdf(sigma)
>>> sf = norm.sf(sigma)
>>> plt.plot(sigma, np.abs(one_minus_cdf - sf) / sf)
>>> plt.yscale("log")
>>> plt.show()
```

| 2020-06-21T14:02:29 |
|
scikit-hep/pyhf
| 905 |
scikit-hep__pyhf-905
|
[
"601"
] |
6e6f7a14c08081870f6c771b4cdb7e9f54b3cd1e
|
diff --git a/src/pyhf/infer/__init__.py b/src/pyhf/infer/__init__.py
--- a/src/pyhf/infer/__init__.py
+++ b/src/pyhf/infer/__init__.py
@@ -30,61 +30,90 @@ def hypotest(
Args:
poi_test (Number or Tensor): The value of the parameter of interest (POI)
- data (Number or Tensor): The root of the calculated test statistic given the Asimov data, :math:`\sqrt{q_{\mu,A}}`
- pdf (~pyhf.pdf.Model): The HistFactory statistical model
+ data (Number or Tensor): The data considered
+ pdf (~pyhf.pdf.Model): The statistical model adhering to the schema ``model.json``
init_pars (Array or Tensor): The initial parameter values to be used for minimization
par_bounds (Array or Tensor): The parameter value bounds to be used for minimization
- qtilde (Bool): When ``True`` perform the calculation using the alternative test statistic, :math:`\tilde{q}`, as defined in Equation (62) of :xref:`arXiv:1007.1727`
+ qtilde (Bool): When ``True`` perform the calculation using the alternative
+ test statistic, :math:`\tilde{q}_{\mu}`, as defined under the Wald
+ approximation in Equation (62) of :xref:`arXiv:1007.1727`.
Keyword Args:
- return_tail_probs (bool): Bool for returning :math:`\textrm{CL}_{s+b}` and :math:`\textrm{CL}_{b}`
- return_expected (bool): Bool for returning :math:`\textrm{CL}_{\textrm{exp}}`
- return_expected_set (bool): Bool for returning the :math:`(-2,-1,0,1,2)\sigma` :math:`\textrm{CL}_{\textrm{exp}}` --- the "Brazil band"
+ return_tail_probs (bool): Bool for returning :math:`\mathrm{CL}_{s+b}` and :math:`\mathrm{CL}_{b}`
+ return_expected (bool): Bool for returning :math:`\mathrm{CL}_{\mathrm{exp}}`
+ return_expected_set (bool): Bool for returning the :math:`(-2,-1,0,1,2)\sigma` :math:`\mathrm{CL}_{\mathrm{exp}}` --- the "Brazil band"
Returns:
Tuple of Floats and lists of Floats:
- - :math:`\textrm{CL}_{s}`: The :math:`p`-value compared to the given threshold :math:`\alpha`, typically taken to be :math:`0.05`, defined in :xref:`arXiv:1007.1727` as
+ - :math:`\mathrm{CL}_{s}`: The modified :math:`p`-value compared to
+ the given threshold :math:`\alpha`, typically taken to be :math:`0.05`,
+ defined in :xref:`arXiv:1007.1727` as
.. math::
- \textrm{CL}_{s} = \frac{\textrm{CL}_{s+b}}{\textrm{CL}_{b}} = \frac{p_{s+b}}{1-p_{b}}
+ \mathrm{CL}_{s} = \frac{\mathrm{CL}_{s+b}}{\mathrm{CL}_{b}} = \frac{p_{s+b}}{1-p_{b}}
- to protect against excluding signal models in which there is little sensitivity. In the case that :math:`\textrm{CL}_{s} \leq \alpha` the given signal model is excluded.
+ to protect against excluding signal models in which there is little
+ sensitivity. In the case that :math:`\mathrm{CL}_{s} \leq \alpha`
+ the given signal model is excluded.
- - :math:`\left[\textrm{CL}_{s+b}, \textrm{CL}_{b}\right]`: The signal + background :math:`p`-value and 1 minus the background only :math:`p`-value as defined in Equations (75) and (76) of :xref:`arXiv:1007.1727`
+ - :math:`\left[\mathrm{CL}_{s+b}, \mathrm{CL}_{b}\right]`: The
+ signal + background model hypothesis :math:`p`-value
.. math::
- \textrm{CL}_{s+b} = p_{s+b} = \int\limits_{q_{\textrm{obs}}}^{\infty} f\left(q\,\middle|s+b\right)\,dq = 1 - \Phi\left(\frac{q_{\textrm{obs}} + 1/\sigma_{s+b}^{2}}{2/\sigma_{s+b}}\right)
+ \mathrm{CL}_{s+b} = p_{s+b}
+ = p\left(q \geq q_{\mathrm{obs}}\middle|s+b\right)
+ = \int\limits_{q_{\mathrm{obs}}}^{\infty} f\left(q\,\middle|s+b\right)\,dq
+ = 1 - F\left(q_{\mathrm{obs}}(\mu)\,\middle|\mu'\right)
- .. math::
-
- \textrm{CL}_{b} = 1- p_{b} = 1 - \int\limits_{-\infty}^{q_{\textrm{obs}}} f\left(q\,\middle|b\right)\,dq = 1 - \Phi\left(\frac{q_{\textrm{obs}} - 1/\sigma_{b}^{2}}{2/\sigma_{b}}\right)
-
- with Equations (73) and (74) for the mean
-
- .. math::
-
- E\left[q\right] = \frac{1 - 2\mu}{\sigma^{2}}
-
- and variance
+ and 1 minus the background only model hypothesis :math:`p`-value
.. math::
- V\left[q\right] = \frac{4}{\sigma^{2}}
-
- of the test statistic :math:`q` under the background only and and signal + background hypotheses. Only returned when ``return_tail_probs`` is ``True``.
-
- - :math:`\textrm{CL}_{s,\textrm{exp}}`: The expected :math:`\textrm{CL}_{s}` value corresponding to the test statistic under the background only hypothesis :math:`\left(\mu=0\right)`. Only returned when ``return_expected`` is ``True``.
-
- - :math:`\textrm{CL}_{s,\textrm{exp}}` band: The set of expected :math:`\textrm{CL}_{s}` values corresponding to the median significance of variations of the signal strength from the background only hypothesis :math:`\left(\mu=0\right)` at :math:`(-2,-1,0,1,2)\sigma`. That is, the :math:`p`-values that satisfy Equation (89) of :xref:`arXiv:1007.1727`
+ \mathrm{CL}_{b} = 1- p_{b}
+ = p\left(q \geq q_{\mathrm{obs}}\middle|b\right)
+ = 1 - \int\limits_{-\infty}^{q_{\mathrm{obs}}} f\left(q\,\middle|b\right)\,dq
+ = 1 - F\left(q_{\mathrm{obs}}(\mu)\,\middle|0\right)
+
+ for signal strength :math:`\mu` and model hypothesis signal strength
+ :math:`\mu'`, where the cumulative density functions
+ :math:`F\left(q(\mu)\,\middle|\mu'\right)` are given by Equations (57)
+ and (65) of :xref:`arXiv:1007.1727` for upper-limit-like test
+ statistic :math:`q \in \{q_{\mu}, \tilde{q}_{\mu}\}`.
+ Only returned when ``return_tail_probs`` is ``True``.
+
+ .. note::
+
+ The definitions of the :math:`\mathrm{CL}_{s+b}` and
+ :math:`\mathrm{CL}_{b}` used are based on profile likelihood
+ ratio test statistics.
+ This procedure is common in the LHC-era, but differs from
+ procedures used in the LEP and Tevatron eras, as briefly
+ discussed in :math:`\S` 3.8 of :xref:`arXiv:1007.1727`.
+
+ - :math:`\mathrm{CL}_{s,\mathrm{exp}}`: The expected :math:`\mathrm{CL}_{s}`
+ value corresponding to the test statistic under the background
+ only hypothesis :math:`\left(\mu=0\right)`.
+ Only returned when ``return_expected`` is ``True``.
+
+ - :math:`\mathrm{CL}_{s,\mathrm{exp}}` band: The set of expected
+ :math:`\mathrm{CL}_{s}` values corresponding to the median
+ significance of variations of the signal strength from the
+ background only hypothesis :math:`\left(\mu=0\right)` at
+ :math:`(-2,-1,0,1,2)\sigma`.
+ That is, the :math:`p`-values that satisfy Equation (89) of
+ :xref:`arXiv:1007.1727`
.. math::
- \textrm{band}_{N\sigma} = \mu' + \sigma\,\Phi^{-1}\left(1-\alpha\right) \pm N\sigma
+ \mathrm{band}_{N\sigma} = \mu' + \sigma\,\Phi^{-1}\left(1-\alpha\right) \pm N\sigma
- for :math:`\mu'=0` and :math:`N \in \left\{-2, -1, 0, 1, 2\right\}`. These values define the boundaries of an uncertainty band sometimes referred to as the "Brazil band". Only returned when ``return_expected_set`` is ``True``.
+ for :math:`\mu'=0` and :math:`N \in \left\{-2, -1, 0, 1, 2\right\}`.
+ These values define the boundaries of an uncertainty band sometimes
+ referred to as the "Brazil band".
+ Only returned when ``return_expected_set`` is ``True``.
"""
init_pars = init_pars or pdf.config.suggested_init()
diff --git a/src/pyhf/infer/calculators.py b/src/pyhf/infer/calculators.py
--- a/src/pyhf/infer/calculators.py
+++ b/src/pyhf/infer/calculators.py
@@ -74,8 +74,22 @@ def cdf(self, value):
return tensorlib.normal_cdf((value - self.shift))
def pvalue(self, value):
- """
- Compute the :math:`p`-value for a given value of the test statistic.
+ r"""
+ The :math:`p`-value for a given value of the test statistic corresponding
+ to signal strength :math:`\mu` and Asimov strength :math:`\mu'` as
+ defined in Equations (59) and (57) of :xref:`arXiv:1007.1727`
+
+ .. math::
+
+ p_{\mu} = 1-F\left(q_{\mu}\middle|\mu'\right) = 1- \Phi\left(\sqrt{q_{\mu}} - \frac{\left(\mu-\mu'\right)}{\sigma}\right)
+
+ with Equation (29)
+
+ .. math::
+
+ \frac{(\mu-\mu')}{\sigma} = \sqrt{\Lambda}= \sqrt{q_{\mu,A}}
+
+ given the observed test statistics :math:`q_{\mu}` and :math:`q_{\mu,A}`.
Args:
value (`float`): The test statistic value.
diff --git a/src/pyhf/infer/mle.py b/src/pyhf/infer/mle.py
--- a/src/pyhf/infer/mle.py
+++ b/src/pyhf/infer/mle.py
@@ -4,23 +4,61 @@
def twice_nll(pars, data, pdf):
- """
- Twice the negative Log-Likelihood.
+ r"""
+ Two times the negative log-likelihood of the model parameters, :math:`\left(\mu, \boldsymbol{\theta}\right)`, given the observed data.
+ It is used in the calculation of the test statistic, :math:`t_{\mu}`, as defiend in Equation (8) in :xref:`arXiv:1007.1727`
+
+ .. math::
+
+ t_{\mu} = -2\ln\lambda\left(\mu\right)
+
+ where :math:`\lambda\left(\mu\right)` is the profile likelihood ratio as defined in Equation (7)
+
+ .. math::
+
+ \lambda\left(\mu\right) = \frac{L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}\right)}{L\left(\hat{\mu}, \hat{\boldsymbol{\theta}}\right)}\,.
+
+ It serves as the objective function to minimize in :func:`~pyhf.infer.mle.fit`
+ and :func:`~pyhf.infer.mle.fixed_poi_fit`.
+
+ Example:
+ >>> import pyhf
+ >>> pyhf.set_backend("numpy")
+ >>> model = pyhf.simplemodels.hepdata_like(
+ ... signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
+ ... )
+ >>> observations = [51, 48]
+ >>> data = pyhf.tensorlib.astensor(observations + model.config.auxdata)
+ >>> parameters = model.config.suggested_init() # nominal parameters
+ >>> twice_nll = pyhf.infer.mle.twice_nll(parameters, data, model)
+ >>> twice_nll
+ array([30.77525435])
+ >>> -2 * model.logpdf(parameters, data) == twice_nll
+ array([ True])
Args:
- data (`tensor`): The data
+ pars (`tensor`): The parameters of the HistFactory model
+ data (`tensor`): The data to be considered
pdf (~pyhf.pdf.Model): The statistical model adhering to the schema model.json
Returns:
- Twice the negative log likelihood.
-
+ Tensor: Two times the negative log-likelihood, :math:`-2\ln L\left(\mu, \boldsymbol{\theta}\right)`
"""
return -2 * pdf.logpdf(pars, data)
def fit(data, pdf, init_pars=None, par_bounds=None, **kwargs):
- """
+ r"""
Run a unconstrained maximum likelihood fit.
+ This is done by minimizing the objective function :func:`~pyhf.infer.mle.twice_nll`
+ of the model parameters given the observed data.
+ This is used to produce the maximal likelihood :math:`L\left(\hat{\mu}, \hat{\boldsymbol{\theta}}\right)`
+ in the profile likelihood ratio in Equation (7) in :xref:`arXiv:1007.1727`
+
+ .. math::
+
+ \lambda\left(\mu\right) = \frac{L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}\right)}{L\left(\hat{\mu}, \hat{\boldsymbol{\theta}}\right)}
+
.. note::
@@ -62,8 +100,17 @@ def fit(data, pdf, init_pars=None, par_bounds=None, **kwargs):
def fixed_poi_fit(poi_val, data, pdf, init_pars=None, par_bounds=None, **kwargs):
- """
+ r"""
Run a maximum likelihood fit with the POI value fixed.
+ This is done by minimizing the objective function of :func:`~pyhf.infer.mle.twice_nll`
+ of the model parameters given the observed data, for a given fixed value of :math:`\mu`.
+ This is used to produce the constrained maximal likelihood for the given :math:`\mu`
+ :math:`L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}\right)` in the profile
+ likelihood ratio in Equation (7) in :xref:`arXiv:1007.1727`
+
+ .. math::
+
+ \lambda\left(\mu\right) = \frac{L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}\right)}{L\left(\hat{\mu}, \hat{\boldsymbol{\theta}}\right)}
.. note::
|
diff --git a/src/pyhf/infer/test_statistics.py b/src/pyhf/infer/test_statistics.py
--- a/src/pyhf/infer/test_statistics.py
+++ b/src/pyhf/infer/test_statistics.py
@@ -52,7 +52,7 @@ def qmu(mu, data, pdf, init_pars, par_bounds):
r"""
The test statistic, :math:`q_{\mu}`, for establishing an upper
limit on the strength parameter, :math:`\mu`, as defiend in
- Equation (14) in :xref:`arXiv:1007.1727`.
+ Equation (14) in :xref:`arXiv:1007.1727`
.. math::
:nowrap:
@@ -64,6 +64,12 @@ def qmu(mu, data, pdf, init_pars, par_bounds):
\end{array}\right.
\end{equation}
+ where :math:`\lambda\left(\mu\right)` is the profile likelihood ratio as defined in Equation (7)
+
+ .. math::
+
+ \lambda\left(\mu\right) = \frac{L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}\right)}{L\left(\hat{\mu}, \hat{\boldsymbol{\theta}}\right)}\,.
+
Example:
>>> import pyhf
>>> pyhf.set_backend("numpy")
@@ -105,7 +111,29 @@ def qmu_tilde(mu, data, pdf, init_pars, par_bounds):
r"""
The test statistic, :math:`\tilde{q}_{\mu}`, for establishing an upper
limit on the strength parameter, :math:`\mu`, for models with
- bounded POI, as defiend in Equation (16) in :xref:`arXiv:1007.1727`.
+ bounded POI, as defiend in Equation (16) in :xref:`arXiv:1007.1727`
+
+ .. math::
+ :nowrap:
+
+ \begin{equation}
+ \tilde{q}_{\mu} = \left\{\begin{array}{ll}
+ -2\ln\tilde{\lambda}\left(\mu\right), &\hat{\mu} < \mu,\\
+ 0, & \hat{\mu} > \mu
+ \end{array}\right.
+ \end{equation}
+
+ where :math:`\tilde{\lambda}\left(\mu\right)` is the constrained profile likelihood ratio as defined in Equation (10)
+
+ .. math::
+ :nowrap:
+
+ \begin{equation}
+ \tilde{\lambda}\left(\mu\right) = \left\{\begin{array}{ll}
+ \frac{L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}(\mu)\right)}{L\left(\hat{\mu}, \hat{\hat{\boldsymbol{\theta}}}(0)\right)}, &\hat{\mu} < 0,\\
+ \frac{L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}(\mu)\right)}{L\left(\hat{\mu}, \hat{\boldsymbol{\theta}}\right)}, &\hat{\mu} \geq 0.
+ \end{array}\right.
+ \end{equation}
Example:
>>> import pyhf
@@ -146,8 +174,18 @@ def qmu_tilde(mu, data, pdf, init_pars, par_bounds):
def tmu(mu, data, pdf, init_pars, par_bounds):
r"""
The test statistic, :math:`t_{\mu}`, for establishing a two-sided
- interval on the strength parameter, :math:`\mu`, as defiend in Equation (10)
- in :xref:`arXiv:1007.1727`.
+ interval on the strength parameter, :math:`\mu`, as defiend in Equation (8)
+ in :xref:`arXiv:1007.1727`
+
+ .. math::
+
+ t_{\mu} = -2\ln\lambda\left(\mu\right)
+
+ where :math:`\lambda\left(\mu\right)` is the profile likelihood ratio as defined in Equation (7)
+
+ .. math::
+
+ \lambda\left(\mu\right) = \frac{L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}\right)}{L\left(\hat{\mu}, \hat{\boldsymbol{\theta}}\right)}\,.
Example:
>>> import pyhf
@@ -188,9 +226,25 @@ def tmu(mu, data, pdf, init_pars, par_bounds):
def tmu_tilde(mu, data, pdf, init_pars, par_bounds):
r"""
- The test statistic, :math:`t_{\mu}`, for establishing a two-sided
+ The test statistic, :math:`\tilde{t}_{\mu}`, for establishing a two-sided
interval on the strength parameter, :math:`\mu`, for models with
- bounded POI, as defiend in Equation (11) in :xref:`arXiv:1007.1727`.
+ bounded POI, as defiend in Equation (11) in :xref:`arXiv:1007.1727`
+
+ .. math::
+
+ \tilde{t}_{\mu} = -2\ln\tilde{\lambda}\left(\mu\right)
+
+ where :math:`\tilde{\lambda}\left(\mu\right)` is the constrained profile likelihood ratio as defined in Equation (10)
+
+ .. math::
+ :nowrap:
+
+ \begin{equation}
+ \tilde{\lambda}\left(\mu\right) = \left\{\begin{array}{ll}
+ \frac{L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}(\mu)\right)}{L\left(\hat{\mu}, \hat{\hat{\boldsymbol{\theta}}}(0)\right)}, &\hat{\mu} < 0,\\
+ \frac{L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}(\mu)\right)}{L\left(\hat{\mu}, \hat{\boldsymbol{\theta}}\right)}, &\hat{\mu} \geq 0.
+ \end{array}\right.
+ \end{equation}
Example:
>>> import pyhf
|
Inconsistency in CLs definition in hypotest
If I look at the [hypotest docs](https://diana-hep.org/pyhf/_generated/pyhf.utils.hypotest.html), it seems to me that what is called `p_b` is incorrect. In the docs just linked to, you can see that `CLb = 1 - p_b = 1 - \int_{-infinity}^{q_obs} f(q|b) dq`, which appears to be defining `p_b` as if it were a _left _tailed__ probability, which it is not. All p-values, including `p_b`, should be defined, I believe, as `p_b = \int_{q_obs}^{+infinity} f(q|b) dq`.
If I look at the implementation of the `pvals_from_teststat` methods [here](https://github.com/diana-hep/pyhf/blob/d9a9ad13fbb6336a73ce9a6d53a6c044f8807a49/src/pyhf/utils.py#L171),
https://github.com/diana-hep/pyhf/blob/d9a9ad13fbb6336a73ce9a6d53a6c044f8807a49/src/pyhf/utils.py#L171
the quantity with variable name `CLb` is given as `1 - CDF(q)`, which is actually `p_b` (using the right-tailed p-value definition). And so, the [CLs value](https://github.com/diana-hep/pyhf/blob/d9a9ad13fbb6336a73ce9a6d53a6c044f8807a49/src/pyhf/utils.py#L172)
https://github.com/diana-hep/pyhf/blob/d9a9ad13fbb6336a73ce9a6d53a6c044f8807a49/src/pyhf/utils.py#L172
should be corrected as `CLs = CLsb / (1-CLb)`, where I use the same variable name of `CLb` as [here](https://github.com/diana-hep/pyhf/blob/d9a9ad13fbb6336a73ce9a6d53a6c044f8807a49/src/pyhf/utils.py#L197),
https://github.com/diana-hep/pyhf/blob/d9a9ad13fbb6336a73ce9a6d53a6c044f8807a49/src/pyhf/utils.py#L197
which is _not_ what CLb is in the literature, at least not how it is defined when constructing CLs.
I think the implementation in `pvals_from_teststat` is taken from the discussion in the [asymptotics paper](https://arxiv.org/abs/1007.1727) from the discussion based on the Tevatron test statistic, which does not follow the same behavior as the profile likelihood ratio test statistic we use. But who knows, because I argue that Equation 76 abuses notation like nobody's business.
Let me know if I'm misinterpreting anything! I was just going through the [implementation](https://github.com/diana-hep/pyhf/blob/d9a9ad13fbb6336a73ce9a6d53a6c044f8807a49/src/pyhf/utils.py#L171) and the fact that the mathematical form for CLsb and CLb were the same
https://github.com/diana-hep/pyhf/blob/d9a9ad13fbb6336a73ce9a6d53a6c044f8807a49/src/pyhf/utils.py#L170-L171
caught my eye.
|
I was trying to dig around for Eilam's statistics lecture series that he gave at CERN a few years ago, detailing all of this. On indico found a [set of slides](https://indico.cern.ch/event/687487/) that looked similar. If you look at Slide 74, you will see an expression for what he calls `p_{\mu}^{\prime}`, which should actually be called CL_s [1], is given by `(1 - CDF[ sqrt(q_mu) ] )/ ( CDF[ sqrt(q_muA) - sqrt(q_mu) ])`, which is inconsistent with the hypotest implementation in pyhf. I would check with the asymptotics people to confirm.
The chi-square asymptotic formulae do not go negative, and "less compatibility with the background only hypothesis" is for larger values of qmu, which is the opposite behavior motivating Equations 75 and 76 in the [asymptotics paper](https://arxiv.org/abs/1007.1727).
Slide 42 and beyond of [Lorenzo's lectures](https://indico.desy.de/indico/event/6083/contribution/1) are also helpful. Slide 42 itself shows a comparison of the Tevatron-like and profile-likelihood test statistic p-values.
[1] notation abuse abounds in the asymptotics literature
hi @dantrim
i'll review the docstrings but I just wnated to give you a small notebook to see where this inversion of tail direction comes from. For q_mu and q_mu tilde test stats there is a definite "signal direction" in the test statistic (towards zero) which you can connect to the normal distributions of the best fitted mu (from wald's theorem)
so what is a right-tail p-value in mu space, becomes a left-tail p-value in test stat space and vice versa
<img width="536" alt="screenshot" src="https://user-images.githubusercontent.com/2318083/66188513-b3060380-e687-11e9-87d7-6b848af4c76b.png">
Hi @lukasheinrich , I think I would need to see a notebook and explanation. What you have there doesn't tell me much. As far as I understand, an increase in mu (incompatibility with null hypothesis) leads to increase in qmu?
Looking into the [RooStats implementation](https://root.cern.ch/doc/v608/classRooStats_1_1AsymptoticCalculator.html#a33f5b0c5ccd487cdfa482b3c9108351b), there are two versions of CLs depending on whether `BackgroundIsAlt`. By default `BackgroundIsAlt = False`, and the CLs values are computed as:
1.
```C++
CLs(BackgroundIsAlt = False, ROOSTATS) = CDF( sqrt(qmu_A) - sqrt(qmu) ) / (1 - CDF(sqrt(qmu))
```
2.
```C++
CLs(BackgroundIsAlt = True, ROOSTATS) = (1 - CDF( sqrt(qmu) ) ) / ( CDF( sqrt(qmu_A) - sqrt(qmu)))
```
The CLs computation done in pyhf's [hypotest](https://github.com/diana-hep/pyhf/blob/d9a9ad13fbb6336a73ce9a6d53a6c044f8807a49/src/pyhf/utils.py#L131) is:
`CLs(pyhf) = ( 1 - CDF( sqrt(qmu)) ) / ( 1 - CDF( sqrt(qmu) - sqrt(qmu_A) ) )`
Just doing a blind comparison on the implementations, and assuming the notations are the same, the pyhf does not match with either of RooStats'.
> By default `BackgroundIsAlt = False`, and the CLs values are computed as:
>
> 1.
> ```c++
> CLs(BackgroundIsAlt = False, ROOSTATS) = CDF( sqrt(qmu_A) - sqrt(qmu) ) / (1 - CDF(sqrt(qmu))
> ```
>
> 2.
> ```c++
> CLs(BackgroundIsAlt = True, ROOSTATS) = (1 - CDF( sqrt(qmu) ) ) / ( CDF( sqrt(qmu_A) - sqrt(qmu)))
> ```
>
> The CLs computation done in pyhf's [hypotest](https://github.com/diana-hep/pyhf/blob/d9a9ad13fbb6336a73ce9a6d53a6c044f8807a49/src/pyhf/utils.py#L131) is:
>
> `CLs(pyhf) = ( 1 - CDF( sqrt(qmu)) ) / ( 1 - CDF( sqrt(qmu) - sqrt(qmu_A) ) )`
>
> Just doing a blind comparison on the implementations, and assuming the notations are the same, the pyhf does not match with either of RooStats'.
The implementation is the same as the `CLs(BackgroundIsAlt = True, ROOSTATS)`, no? For the Normal (or any symmetrical distribution) distribution's CDF, `Phi`,
```
Phi(-x) = 1 - Phi(x)
```
so
```
Phi( sqrt(qmu_A) - sqrt(qmu)) = 1 - Phi( sqrt(qmu) - sqrt(qmu_A) )
```
Hi @matthewfeickert
Maybe I am missing something, but I am not sure where the assumption on the distributions being symmetric is coming from? The sampling distributions of the qmu (i.e. f(qmu|mu')) are not symmetric...
> I am not sure where the assumption on the distributions being symmetric is coming from? The sampling distributions of the qmu (i.e. f(qmu|mu')) are not symmetric...
You're correct that `f(qmu|mu')` isn't symmetric, as it is chi-square distributed ([arXiv:1007.1727](https://arxiv.org/abs/1007.1727) Eq. 55). However, for the CLs we're taking the ratio of probabilities _which are able to be efficiently calculated from the Normal distribution's CDF_ given the shift of the noncentrality parameter (q_μA = Λ) ([arXiv:1007.1727](https://arxiv.org/abs/1007.1727) related Eqs. 35, 50, 57, 59, 65, 67), which is what I was trying to get across in the [`pyhf.utils.pvals_from_teststat` docstring](https://diana-hep.org/pyhf/_generated/pyhf.utils.pvals_from_teststat.html) [1]:

Our discussions over the last 2 days makes it clear to me though that in addition to writing a CLs notebook, I should also improve the docstrings.
[1] There is a known typo in the docstring (should be `\sqrt{q_{\mu}}` in the CDF). I haven't finished the docstrings PR that the fix is in, but it is fixed in [the corresponding branch's ReadTheDocs build](https://pyhf-staging.readthedocs.io/en/docs-add-docstrings-to-utils/_generated/pyhf.utils.pvals_from_teststat.html) (which is where the screenshot came from).
| 2020-06-24T06:20:18 |
scikit-hep/pyhf
| 915 |
scikit-hep__pyhf-915
|
[
"913"
] |
6a1f996f656226c1ebef9ad9994615a1b880590e
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,7 +1,11 @@
from setuptools import setup
extras_require = {
- 'tensorflow': ['tensorflow~=2.0', 'tensorflow-probability~=0.8'],
+ 'tensorflow': [
+ 'tensorflow~=2.0',
+ 'tensorflow-probability~=0.8',
+ 'cloudpickle!=1.5.0', # TODO: Temp patch until tfp v0.11
+ ],
'torch': ['torch~=1.2'],
'jax': ['jax~=0.1,>0.1.51', 'jaxlib~=0.1,>0.1.33'],
'xmlio': ['uproot'],
|
cloudpickle v1.5.0 breaks testing
# Description
With the release of [`cloudpickle` `v1.5.0`](https://pypi.org/project/cloudpickle/1.5.0/) on 2020-07-01 the CI is broken in testing as the following error is raised
```pytb
ImportError while loading conftest '/home/runner/work/pyhf/pyhf/tests/conftest.py'.
tests/conftest.py:83: in <module>
(pyhf.tensor.tensorflow_backend(), None),
src/pyhf/tensor/__init__.py:44: in __getattr__
e,
E pyhf.exceptions.ImportBackendError: ('There was a problem importing TensorFlow. The tensorflow backend cannot be used.', ImportError("cannot import name 'CloudPickler' from 'cloudpickle.cloudpickle' (/opt/hostedtoolcache/Python/3.7.7/x64/lib/python3.7/site-packages/cloudpickle/cloudpickle.py)"))
##[error]Process completed with exit code 4.
```
`cloudpickle` is a required dependency of TensorFlow Probability and in TFP `v0.10.0` it is set to [`cloudpickle >= 1.2.2`](https://github.com/tensorflow/probability/blob/f051e03dd3cc847d31061803c2b31c564562a993/setup.py#L34).
This has been reported in:
- [TensorFlow Probability Issue 991](https://github.com/tensorflow/probability/issues/991)
- [`cloudpickle` Issue 390](https://github.com/cloudpipe/cloudpickle/issues/390)
# Expected Behavior
For no error to be raised
# Actual Behavior
c.f. above
# Steps to Reproduce
This was found in CI, but the minimal test case is just to install TensorFlow and TensorFlow Probability and then try to import TFP:
```
$ python -m pip install tensorflow tensorflow-probability
$ python -c "import tensorflow_probability"
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/feickert/.venvs/debug-this/lib/python3.7/site-packages/tensorflow_probability/__init__.py", line 76, in <module>
from tensorflow_probability.python import * # pylint: disable=wildcard-import
File "/home/feickert/.venvs/debug-this/lib/python3.7/site-packages/tensorflow_probability/python/__init__.py", line 23, in <module>
from tensorflow_probability.python import distributions
File "/home/feickert/.venvs/debug-this/lib/python3.7/site-packages/tensorflow_probability/python/distributions/__init__.py", line 88, in <module>
from tensorflow_probability.python.distributions.pixel_cnn import PixelCNN
File "/home/feickert/.venvs/debug-this/lib/python3.7/site-packages/tensorflow_probability/python/distributions/pixel_cnn.py", line 37, in <module>
from tensorflow_probability.python.layers import weight_norm
File "/home/feickert/.venvs/debug-this/lib/python3.7/site-packages/tensorflow_probability/python/layers/__init__.py", line 31, in <module>
from tensorflow_probability.python.layers.distribution_layer import CategoricalMixtureOfOneHotCategorical
File "/home/feickert/.venvs/debug-this/lib/python3.7/site-packages/tensorflow_probability/python/layers/distribution_layer.py", line 28, in <module>
from cloudpickle.cloudpickle import CloudPickler
ImportError: cannot import name 'CloudPickler' from 'cloudpickle.cloudpickle' (/home/feickert/.venvs/debug-this/lib/python3.7/site-packages/cloudpickle/cloudpickle.py)
$ pip list | grep cloudpickle
cloudpickle 1.5.0
```
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
| 2020-07-02T14:24:14 |
||
scikit-hep/pyhf
| 924 |
scikit-hep__pyhf-924
|
[
"916"
] |
6cb343f63ae3c841571e1c8a973fabb7fdf2c297
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -3,8 +3,7 @@
extras_require = {
'tensorflow': [
'tensorflow~=2.0',
- 'tensorflow-probability~=0.8',
- 'cloudpickle!=1.5.0', # TODO: Temp patch until tfp v0.11
+ 'tensorflow-probability~=0.10', # TODO: Temp patch until tfp v0.11
],
'torch': ['torch~=1.2'],
'jax': ['jax~=0.1,>0.1.51', 'jaxlib~=0.1,>0.1.33'],
|
Remove cloudpickle constraints when updating to TensorFlow Probability v0.11
# Description
Once TensorFlow Probability `v0.11.0` is released there will no longer be the need for PR #915, and so that should be reverted.
Related Issues: #815
| 2020-07-06T23:11:11 |
||
scikit-hep/pyhf
| 933 |
scikit-hep__pyhf-933
|
[
"897"
] |
c898e05d1afdd8db98548f70c871887a49d2d4eb
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -47,7 +47,7 @@
extras_require['docs'] = sorted(
set(
[
- 'sphinx~=3.0.0', # Sphinx v3.1.X regressions break docs
+ 'sphinx>=3.1.2',
'sphinxcontrib-bibtex',
'sphinx-click',
'sphinx_rtd_theme',
|
Docs build broken with Sphinx v3.1.1
# Description
After the new Sphinx patch release [`v3.1.1`](https://github.com/sphinx-doc/sphinx/releases/tag/v3.1.1) was released there is an error with building the docs due to `autodocumenting`:
```
WARNING: don't know which module to import for autodocumenting 'optimize.opt_jax.jax_optimizer' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'optimize.opt_minuit.minuit_optimizer' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'optimize.opt_pytorch.pytorch_optimizer' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'optimize.opt_scipy.scipy_optimizer' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'optimize.opt_tflow.tflow_optimizer' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'tensor.jax_backend.jax_backend' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'tensor.numpy_backend.numpy_backend' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'tensor.pytorch_backend.pytorch_backend' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
WARNING: don't know which module to import for autodocumenting 'tensor.tensorflow_backend.tensorflow_backend' (try placing a "module" or "currentmodule" directive in the document, or giving an explicit module name)
```
|
This is escalated to [Sphinx Issue 7844](https://github.com/sphinx-doc/sphinx/issues/7844).
| 2020-07-09T05:15:14 |
|
scikit-hep/pyhf
| 937 |
scikit-hep__pyhf-937
|
[
"928"
] |
1da2d6e2e72aa480e32303573ed2025ef9e6e3e6
|
diff --git a/src/pyhf/simplemodels.py b/src/pyhf/simplemodels.py
--- a/src/pyhf/simplemodels.py
+++ b/src/pyhf/simplemodels.py
@@ -2,6 +2,38 @@
def hepdata_like(signal_data, bkg_data, bkg_uncerts, batch_size=None):
+ """
+ Construct a simple single channel :class:`~pyhf.pdf.Model` with a
+ :class:`~pyhf.modifiers.shapesys` modifier representing an uncorrelated
+ background uncertainty.
+
+ Example:
+ >>> import pyhf
+ >>> pyhf.set_backend("numpy")
+ >>> model = pyhf.simplemodels.hepdata_like(
+ ... signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
+ ... )
+ >>> model.schema
+ 'model.json'
+ >>> model.config.channels
+ ['singlechannel']
+ >>> model.config.samples
+ ['background', 'signal']
+ >>> model.config.parameters
+ ['mu', 'uncorr_bkguncrt']
+ >>> model.expected_data(model.config.suggested_init())
+ array([ 62. , 63. , 277.77777778, 55.18367347])
+
+ Args:
+ signal_data (`list`): The data in the signal sample
+ bkg_data (`list`): The data in the background sample
+ bkg_uncerts (`list`): The statistical uncertainty on the background sample counts
+ batch_size (`None` or `int`): Number of simultaneous (batched) Models to compute
+
+ Returns:
+ ~pyhf.pdf.Model: The statistical model adhering to the :obj:`model.json` schema
+
+ """
spec = {
'channels': [
{
|
Document simplemodels API
# Description
In discussion today with @coolalexzb, I realized that the [`pyhf.simplemodels`](https://github.com/scikit-hep/pyhf/blob/79984be837ef6e53bdd12a82163c34d47d507dba/src/pyhf/simplemodels.py) API is not documented in our docs. Even thought this isn't something we want people to really use, we still show it in our examples and so it needs documentation.
| 2020-07-11T04:46:31 |
||
scikit-hep/pyhf
| 941 |
scikit-hep__pyhf-941
|
[
"940"
] |
1da2d6e2e72aa480e32303573ed2025ef9e6e3e6
|
diff --git a/src/pyhf/cli/infer.py b/src/pyhf/cli/infer.py
--- a/src/pyhf/cli/infer.py
+++ b/src/pyhf/cli/infer.py
@@ -54,7 +54,9 @@ def cls(
.. code-block:: shell
- $ curl -sL https://raw.githubusercontent.com/scikit-hep/pyhf/master/docs/examples/json/2-bin_1-channel.json | pyhf cls
+ $ curl -sL https://git.io/JJYDE | pyhf cls
+
+ \b
{
"CLs_exp": [
0.07807427911686156,
|
use short URL for better help message
The current help msg has a long url, but this includes line breaks
which makes it hard to copy.
```
pyhf cls --help
Usage: pyhf cls [OPTIONS] [WORKSPACE]
Compute CLs value(s) for a given pyhf workspace.
Example:
.. code-block:: shell
$ curl -sL https://raw.githubusercontent.com/scikit-
hep/pyhf/master/docs/examples/json/2-bin_1-channel.json | pyhf cls
{ "CLs_exp": [ 0.07807427911686156,
0.17472571775474618, 0.35998495263681285,
0.6343568235898907, 0.8809947004472013 ],
"CLs_obs": 0.3599845631401915 }
Options:
--output-file TEXT The location of the output json file. If not
specified, prints to screen.
--measurement TEXT
-p, --patch TEXT
--testpoi FLOAT
--teststat [q|qtilde]
--backend [numpy|pytorch|tensorflow|jax|np|torch|tf]
The tensor backend used for the calculation.
--optimizer TEXT
--optconf EQUAL-DELIMITED OPTION
-h, --help Show this message and exit.
```
|
tried to fix this, but it makes the docs look even wonkier?
```
Usage: pyhf cls [OPTIONS] [WORKSPACE]
Compute CLs value(s) for a given pyhf workspace.
Example:
.. code-block:: shell
$ curl -sL https://git.io/JJYDE | pyhf cls { "CLs_exp": [
0.07807427911686156, 0.17472571775474618,
0.35998495263681285, 0.6343568235898907,
0.8809947004472013 ], "CLs_obs": 0.3599845631401915 }
```
| 2020-07-11T20:22:37 |
|
scikit-hep/pyhf
| 944 |
scikit-hep__pyhf-944
|
[
"714"
] |
6e5b7bb622e60827507b807a475acaff82fd0c2c
|
diff --git a/src/pyhf/cli/infer.py b/src/pyhf/cli/infer.py
--- a/src/pyhf/cli/infer.py
+++ b/src/pyhf/cli/infer.py
@@ -107,8 +107,8 @@ def cls(
testpoi, ws.data(model), model, qtilde=is_qtilde, return_expected_set=True
)
result = {
- 'CLs_obs': tensorlib.tolist(result[0])[0],
- 'CLs_exp': tensorlib.tolist(tensorlib.reshape(result[-1], [-1])),
+ 'CLs_obs': tensorlib.tolist(result[0]),
+ 'CLs_exp': [tensorlib.tolist(tensor) for tensor in result[-1]],
}
if output_file is None:
diff --git a/src/pyhf/infer/__init__.py b/src/pyhf/infer/__init__.py
--- a/src/pyhf/infer/__init__.py
+++ b/src/pyhf/infer/__init__.py
@@ -23,14 +23,10 @@ def hypotest(
>>> CLs_obs, CLs_exp_band = pyhf.infer.hypotest(
... test_poi, data, model, qtilde=True, return_expected_set=True
... )
- >>> print(CLs_obs)
- [0.05251554]
- >>> print(CLs_exp_band)
- [[0.00260641]
- [0.01382066]
- [0.06445521]
- [0.23526104]
- [0.57304182]]
+ >>> CLs_obs
+ array(0.05251554)
+ >>> CLs_exp_band
+ [array(0.00260641), array(0.01382066), array(0.06445521), array(0.23526104), array(0.57304182)]
Args:
poi_test (Number or Tensor): The value of the parameter of interest (POI)
@@ -102,10 +98,11 @@ def hypotest(
CLsb = sig_plus_bkg_distribution.pvalue(teststat)
CLb = b_only_distribution.pvalue(teststat)
CLs = CLsb / CLb
+ # Ensure that all CL values are 0-d tensors
CLsb, CLb, CLs = (
- tensorlib.reshape(CLsb, (1,)),
- tensorlib.reshape(CLb, (1,)),
- tensorlib.reshape(CLs, (1,)),
+ tensorlib.astensor(CLsb),
+ tensorlib.astensor(CLb),
+ tensorlib.astensor(CLs),
)
_returns = [CLs]
@@ -120,8 +117,7 @@ def hypotest(
CLs = sig_plus_bkg_distribution.pvalue(
expected_bonly_teststat
) / b_only_distribution.pvalue(expected_bonly_teststat)
- CLs_exp.append(tensorlib.reshape(CLs, (1,)))
- CLs_exp = tensorlib.astensor(CLs_exp)
+ CLs_exp.append(tensorlib.astensor(CLs))
if kwargs.get('return_expected'):
_returns.append(CLs_exp[2])
_returns.append(CLs_exp)
@@ -132,7 +128,7 @@ def hypotest(
CLs = sig_plus_bkg_distribution.pvalue(
expected_bonly_teststat
) / b_only_distribution.pvalue(expected_bonly_teststat)
- _returns.append(tensorlib.reshape(CLs, (1,)))
+ _returns.append(tensorlib.astensor(CLs))
# Enforce a consistent return type of the observed CLs
return tuple(_returns) if len(_returns) > 1 else _returns[0]
|
diff --git a/tests/test_infer.py b/tests/test_infer.py
--- a/tests/test_infer.py
+++ b/tests/test_infer.py
@@ -59,7 +59,7 @@ def test_hypotest_default(tmpdir, hypotest_args):
kwargs = {}
result = pyhf.infer.hypotest(*hypotest_args, **kwargs)
# CLs_obs
- assert len(list(result)) == 1
+ assert pyhf.tensorlib.shape(result) == ()
assert isinstance(result, type(tb.astensor(result)))
@@ -178,7 +178,7 @@ def logpdf(self, pars, data):
1.0, model.expected_data(model.config.suggested_init()), model
)
- assert np.isclose(cls[0], 0.7267836451638846)
+ assert np.isclose(cls, 0.7267836451638846)
@pytest.mark.parametrize("qtilde", [True, False])
diff --git a/tests/test_regression.py b/tests/test_regression.py
--- a/tests/test_regression.py
+++ b/tests/test_regression.py
@@ -28,7 +28,7 @@ def calculate_CLs(bkgonly_json, signal_patch_json):
result = pyhf.infer.hypotest(
1.0, workspace.data(model), model, qtilde=True, return_expected_set=True
)
- return result[0].tolist()[0], result[-1].ravel().tolist()
+ return result[0].tolist(), result[-1]
def test_sbottom_regionA_1300_205_60(
diff --git a/tests/test_validation.py b/tests/test_validation.py
--- a/tests/test_validation.py
+++ b/tests/test_validation.py
@@ -906,16 +906,16 @@ def test_shapesys_nuisparfilter_validation():
"observations": [{"data": [100, 10], "name": "channel1"}],
"version": "1.0.0",
}
- w = pyhf.Workspace(spec)
- m = w.model(
+ ws = pyhf.Workspace(spec)
+ model = ws.model(
modifier_settings={
'normsys': {'interpcode': 'code4'},
'histosys': {'interpcode': 'code4p'},
},
)
- d = w.data(m)
- obs, exp = pyhf.infer.hypotest(1.0, d, m, return_expected_set=True)
- pyhf_results = {'CLs_obs': obs[0], 'CLs_exp': [e[0] for e in exp]}
+ data = ws.data(model)
+ obs, exp = pyhf.infer.hypotest(1.0, data, model, return_expected_set=True)
+ pyhf_results = {'CLs_obs': obs, 'CLs_exp': [e for e in exp]}
assert np.allclose(
reference_root_results['CLs_obs'], pyhf_results['CLs_obs'], atol=1e-4, rtol=1e-5
|
API: change CLs to be scalar
# Description
right now it's returning (1,) vectors
| 2020-07-14T06:03:28 |
|
scikit-hep/pyhf
| 950 |
scikit-hep__pyhf-950
|
[
"946"
] |
0f99cc488156e0826a27f55abc946d537a8922af
|
diff --git a/src/pyhf/exceptions/__init__.py b/src/pyhf/exceptions/__init__.py
--- a/src/pyhf/exceptions/__init__.py
+++ b/src/pyhf/exceptions/__init__.py
@@ -50,6 +50,14 @@ class InvalidWorkspaceOperation(Exception):
"""InvalidWorkspaceOperation is raised when an operation on a workspace fails."""
+class UnspecifiedPOI(Exception):
+ """
+ UnspecifiedPOI is raised when a given model does not have POI(s) defined but is used in contexts that need it.
+
+ This can occur when e.g. trying to calculate CLs on a POI-less model.
+ """
+
+
class InvalidModel(Exception):
"""
InvalidModel is raised when a given model does not have the right configuration, even though it validates correctly against the schema.
diff --git a/src/pyhf/infer/mle.py b/src/pyhf/infer/mle.py
--- a/src/pyhf/infer/mle.py
+++ b/src/pyhf/infer/mle.py
@@ -1,5 +1,6 @@
"""Module for Maximum Likelihood Estimation."""
from .. import get_backend
+from ..exceptions import UnspecifiedPOI
def twice_nll(pars, data, pdf):
@@ -76,6 +77,10 @@ def fixed_poi_fit(poi_val, data, pdf, init_pars=None, par_bounds=None, **kwargs)
See optimizer API
"""
+ if pdf.config.poi_index is None:
+ raise UnspecifiedPOI(
+ 'No POI is defined. A POI is required to fit with a fixed POI.'
+ )
_, opt = get_backend()
init_pars = init_pars or pdf.config.suggested_init()
par_bounds = par_bounds or pdf.config.suggested_bounds()
diff --git a/src/pyhf/pdf.py b/src/pyhf/pdf.py
--- a/src/pyhf/pdf.py
+++ b/src/pyhf/pdf.py
@@ -221,7 +221,6 @@ def __init__(self, spec, **config_kwargs):
_required_paramsets = _paramset_requirements_from_modelspec(
spec, self.channel_nbins
)
-
poi_name = config_kwargs.pop('poi_name', 'mu')
default_modifier_settings = {'normsys': {'interpcode': 'code1'}}
@@ -242,7 +241,9 @@ def __init__(self, spec, **config_kwargs):
self.auxdata_order = []
self._create_and_register_paramsets(_required_paramsets)
- self.set_poi(poi_name)
+ if poi_name is not None:
+ self.set_poi(poi_name)
+
self.npars = len(self.suggested_init())
self.nmaindata = sum(self.channel_nbins.values())
|
diff --git a/src/pyhf/infer/test_statistics.py b/src/pyhf/infer/test_statistics.py
--- a/src/pyhf/infer/test_statistics.py
+++ b/src/pyhf/infer/test_statistics.py
@@ -1,5 +1,6 @@
from .. import get_backend
from .mle import fixed_poi_fit, fit
+from ..exceptions import UnspecifiedPOI
def qmu(mu, data, pdf, init_pars, par_bounds):
@@ -42,6 +43,11 @@ def qmu(mu, data, pdf, init_pars, par_bounds):
Returns:
Float: The calculated test statistic, :math:`q_{\mu}`
"""
+ if pdf.config.poi_index is None:
+ raise UnspecifiedPOI(
+ 'No POI is defined. A POI is required for profile likelihood based test statistics.'
+ )
+
tensorlib, optimizer = get_backend()
mubhathat, fixed_poi_fit_lhood_val = fixed_poi_fit(
mu, data, pdf, init_pars, par_bounds, return_fitted_val=True
diff --git a/tests/test_pdf.py b/tests/test_pdf.py
--- a/tests/test_pdf.py
+++ b/tests/test_pdf.py
@@ -5,6 +5,26 @@
import json
+def test_minimum_model_spec():
+ spec = {
+ 'channels': [
+ {
+ 'name': 'channel',
+ 'samples': [
+ {
+ 'name': 'goodsample',
+ 'data': [1.0],
+ 'modifiers': [
+ {'type': 'normfactor', 'name': 'mu', 'data': None}
+ ],
+ },
+ ],
+ }
+ ]
+ }
+ pyhf.Model(spec)
+
+
def test_pdf_inputs(backend):
source = {
"binning": [2, -0.5, 1.5],
@@ -182,6 +202,39 @@ def test_pdf_integration_staterror(backend):
)
+def test_poiless_model(backend):
+ spec = {
+ 'channels': [
+ {
+ 'name': 'channel',
+ 'samples': [
+ {
+ 'name': 'goodsample',
+ 'data': [10.0],
+ 'modifiers': [
+ {
+ 'type': 'normsys',
+ 'name': 'shape',
+ 'data': {"hi": 0.5, "lo": 1.5},
+ }
+ ],
+ },
+ ],
+ }
+ ]
+ }
+ model = pyhf.Model(spec, poi_name=None)
+
+ data = [12] + model.config.auxdata
+ pyhf.infer.mle.fit(data, model)
+
+ with pytest.raises(pyhf.exceptions.UnspecifiedPOI):
+ pyhf.infer.mle.fixed_poi_fit(1.0, data, model)
+
+ with pytest.raises(pyhf.exceptions.UnspecifiedPOI):
+ pyhf.infer.hypotest(1.0, data, model)
+
+
def test_pdf_integration_shapesys_zeros(backend):
spec = {
"channels": [
|
allow poi-less Models
# Description
the `.set_poi()` call in the `Model` ctor should be optional. It's only necessary for hypotests, but e.g. you can do MLE fits without problems w/o a POI
It's also useful when teaching modifiers etc.
| 2020-07-16T16:21:47 |
|
scikit-hep/pyhf
| 960 |
scikit-hep__pyhf-960
|
[
"957"
] |
afc21909705097f435fc3c1487458ffdd5df1ac0
|
diff --git a/src/pyhf/infer/mle.py b/src/pyhf/infer/mle.py
--- a/src/pyhf/infer/mle.py
+++ b/src/pyhf/infer/mle.py
@@ -22,6 +22,10 @@ def fit(data, pdf, init_pars=None, par_bounds=None, **kwargs):
"""
Run a unconstrained maximum likelihood fit.
+ .. note::
+
+ :func:`twice_nll` is the objective function.
+
Example:
>>> import pyhf
>>> pyhf.set_backend("numpy")
@@ -54,6 +58,10 @@ def fixed_poi_fit(poi_val, data, pdf, init_pars=None, par_bounds=None, **kwargs)
"""
Run a maximum likelihood fit with the POI value fixed.
+ .. note::
+
+ :func:`twice_nll` is the objective function.
+
Example:
>>> import pyhf
>>> pyhf.set_backend("numpy")
|
Documentation: meaning of value for return_fitted_val=True
# Description
In this code snippet from the documentation
```python
>>> pyhf.infer.mle.fixed_poi_fit(test_poi, data, model, return_fitted_val=True)
(array([1. , 0.97224597, 0.87553894]), array([28.92218013]))
```
it isn't clear what the meaning of `array([28.92218013])` is. Is it likelihood, log likelihood, -log likelihood, -2 log likelihood?
It is the latter, but that is not clear.
Applies to
https://scikit-hep.org/pyhf/_generated/pyhf.infer.mle.fixed_poi_fit.html
or
https://scikit-hep.org/pyhf/_generated/pyhf.infer.mle.fit.html
## Is your feature request related to a problem? Please describe.
I wasn't sure, so I had to try a few things to figure it out.
### Describe the solution you'd like
Add a note to the documentation for the convention.
### Describe alternatives you've considered
banging my head against the wall.
# Relevant Issues and Pull Requests
|
Another note... it's not obvious what the return order will be when both return_fitted and return_tail_prob are both true
| 2020-07-18T17:21:37 |
|
scikit-hep/pyhf
| 983 |
scikit-hep__pyhf-983
|
[
"982"
] |
161d23ac0d892e0361135326f5c1cac4c4620134
|
diff --git a/src/pyhf/__init__.py b/src/pyhf/__init__.py
--- a/src/pyhf/__init__.py
+++ b/src/pyhf/__init__.py
@@ -1,7 +1,7 @@
from .tensor import BackendRetriever as tensor
from .optimize import OptimizerRetriever as optimize
from .version import __version__
-from .exceptions import InvalidBackend, InvalidOptimizer
+from .exceptions import InvalidBackend, InvalidOptimizer, Unsupported
from . import events
tensorlib = None
@@ -35,7 +35,7 @@ def get_backend():
@events.register('change_backend')
-def set_backend(backend, custom_optimizer=None):
+def set_backend(backend, custom_optimizer=None, precision=None):
"""
Set the backend and the associated optimizer
@@ -44,16 +44,23 @@ def set_backend(backend, custom_optimizer=None):
>>> pyhf.set_backend("tensorflow")
>>> pyhf.tensorlib.name
'tensorflow'
- >>> pyhf.set_backend(b"pytorch")
+ >>> pyhf.tensorlib.precision
+ '32b'
+ >>> pyhf.set_backend(b"pytorch", precision="64b")
>>> pyhf.tensorlib.name
'pytorch'
+ >>> pyhf.tensorlib.precision
+ '64b'
>>> pyhf.set_backend(pyhf.tensor.numpy_backend())
>>> pyhf.tensorlib.name
'numpy'
+ >>> pyhf.tensorlib.precision
+ '64b'
Args:
backend (`str` or `pyhf.tensor` backend): One of the supported pyhf backends: NumPy, TensorFlow, PyTorch, and JAX
custom_optimizer (`pyhf.optimize` optimizer): Optional custom optimizer defined by the user
+ precision (`str`): Floating point precision to use in the backend: ``64b`` or ``32b``. Default is backend dependent.
Returns:
None
@@ -61,27 +68,45 @@ def set_backend(backend, custom_optimizer=None):
global tensorlib
global optimizer
+ _supported_precisions = ["32b", "64b"]
+ backend_kwargs = {}
+
+ if isinstance(precision, (str, bytes)):
+ if isinstance(precision, bytes):
+ precision = precision.decode("utf-8")
+ precision = precision.lower()
+
if isinstance(backend, (str, bytes)):
if isinstance(backend, bytes):
backend = backend.decode("utf-8")
backend = backend.lower()
+
+ if precision is not None:
+ backend_kwargs["precision"] = precision
+
try:
- backend = getattr(tensor, "{0:s}_backend".format(backend))()
+ backend = getattr(tensor, f"{backend:s}_backend")(**backend_kwargs)
except TypeError:
raise InvalidBackend(
- "The backend provided is not supported: {0:s}. Select from one of the supported backends: numpy, tensorflow, pytorch".format(
- backend
- )
+ f"The backend provided is not supported: {backend:s}. Select from one of the supported backends: numpy, tensorflow, pytorch"
)
- _name_supported = getattr(tensor, "{0:s}_backend".format(backend.name))
+ _name_supported = getattr(tensor, f"{backend.name:s}_backend")
if _name_supported:
if not isinstance(backend, _name_supported):
raise AttributeError(
- "'{0:s}' is not a valid name attribute for backend type {1}\n Custom backends must have names unique from supported backends".format(
- backend.name, type(backend)
- )
+ f"'{backend.name:s}' is not a valid name attribute for backend type {type(backend)}\n Custom backends must have names unique from supported backends"
)
+ if backend.precision not in _supported_precisions:
+ raise Unsupported(
+ f"The backend precision provided is not supported: {backend.precision:s}. Select from one of the supported precisions: {', '.join([str(v) for v in _supported_precisions])}"
+ )
+ # If "precision" arg passed, it should always win
+ # If no "precision" arg, defer to tensor backend object API if set there
+ if precision is not None:
+ if backend.precision != precision:
+ backend_kwargs["precision"] = precision
+ backend = getattr(tensor, f"{backend.name:s}_backend")(**backend_kwargs)
# need to determine if the tensorlib changed or the optimizer changed for events
tensorlib_changed = bool(
@@ -102,9 +127,7 @@ def set_backend(backend, custom_optimizer=None):
f"The optimizer provided is not supported: {custom_optimizer}. Select from one of the supported optimizers: scipy, minuit"
)
else:
- _name_supported = getattr(
- optimize, "{0:s}_optimizer".format(custom_optimizer.name)
- )
+ _name_supported = getattr(optimize, f"{custom_optimizer.name:s}_optimizer")
if _name_supported:
if not isinstance(custom_optimizer, _name_supported):
raise AttributeError(
diff --git a/src/pyhf/cli/infer.py b/src/pyhf/cli/infer.py
--- a/src/pyhf/cli/infer.py
+++ b/src/pyhf/cli/infer.py
@@ -7,7 +7,7 @@
from ..utils import EqDelimStringParamType
from ..infer import hypotest
from ..workspace import Workspace
-from .. import tensor, get_backend, set_backend, optimize
+from .. import get_backend, set_backend, optimize
log = logging.getLogger(__name__)
@@ -87,11 +87,11 @@ def cls(
# set the backend if not NumPy
if backend in ['pytorch', 'torch']:
- set_backend(tensor.pytorch_backend(precision='64b'))
+ set_backend("pytorch", precision="64b")
elif backend in ['tensorflow', 'tf']:
- set_backend(tensor.tensorflow_backend(precision='64b'))
+ set_backend("tensorflow", precision="64b")
elif backend in ['jax']:
- set_backend(tensor.jax_backend())
+ set_backend("jax")
tensorlib, _ = get_backend()
optconf = {k: v for item in optconf for k, v in item.items()}
|
diff --git a/tests/test_jit.py b/tests/test_jit.py
--- a/tests/test_jit.py
+++ b/tests/test_jit.py
@@ -10,7 +10,7 @@
@pytest.mark.parametrize('do_grad', [False, True], ids=['no_grad', 'do_grad'])
@pytest.mark.parametrize('optimizer', ['scipy', 'minuit'])
def test_jax_jit(caplog, optimizer, do_grad, do_stitch, return_fitted_val):
- pyhf.set_backend(pyhf.tensor.jax_backend(precision='64b'), optimizer)
+ pyhf.set_backend("jax", optimizer, precision="64b")
pdf = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
data = pyhf.tensorlib.astensor([125.0] + pdf.config.auxdata)
@@ -76,7 +76,7 @@ def test_jax_jit(caplog, optimizer, do_grad, do_stitch, return_fitted_val):
@pytest.mark.parametrize('do_stitch', [False, True], ids=['no_stitch', 'do_stitch'])
@pytest.mark.parametrize('do_grad', [False, True], ids=['no_grad', 'do_grad'])
def test_jax_jit_switch_optimizer(caplog, do_grad, do_stitch, return_fitted_val):
- pyhf.set_backend(pyhf.tensor.jax_backend(precision='64b'), 'scipy')
+ pyhf.set_backend("jax", "scipy", precision="64b")
pdf = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
data = pyhf.tensorlib.astensor([125.0] + pdf.config.auxdata)
@@ -132,7 +132,7 @@ def test_jax_jit_switch_optimizer(caplog, do_grad, do_stitch, return_fitted_val)
)
@pytest.mark.parametrize('do_grad', [False, True], ids=['no_grad', 'do_grad'])
def test_jax_jit_enable_stitching(caplog, do_grad, return_fitted_val):
- pyhf.set_backend(pyhf.tensor.jax_backend(precision='64b'), 'scipy')
+ pyhf.set_backend("jax", "scipy", precision="64b")
pdf = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
data = pyhf.tensorlib.astensor([125.0] + pdf.config.auxdata)
@@ -166,7 +166,7 @@ def test_jax_jit_enable_stitching(caplog, do_grad, return_fitted_val):
)
@pytest.mark.parametrize('do_stitch', [False, True], ids=['no_stitch', 'do_stitch'])
def test_jax_jit_enable_autograd(caplog, do_stitch, return_fitted_val):
- pyhf.set_backend(pyhf.tensor.jax_backend(precision='64b'), 'scipy')
+ pyhf.set_backend("jax", "scipy", precision="64b")
pdf = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
data = pyhf.tensorlib.astensor([125.0] + pdf.config.auxdata)
diff --git a/tests/test_public_api.py b/tests/test_public_api.py
--- a/tests/test_public_api.py
+++ b/tests/test_public_api.py
@@ -32,6 +32,14 @@ def test_set_optimizer_by_string(optimizer_name):
)
[email protected]("precision_level", ["32b", "64b"])
+def test_set_precision_by_string(precision_level):
+ pyhf.set_backend(pyhf.tensorlib.name, precision=precision_level)
+ assert pyhf.tensorlib.precision == precision_level.lower()
+ pyhf.set_backend(pyhf.tensor.numpy_backend(precision=precision_level))
+ assert pyhf.tensorlib.precision == precision_level.lower()
+
+
@pytest.mark.parametrize("backend_name", [b"numpy", b"tensorflow", b"pytorch"])
def test_set_backend_by_bytestring(backend_name):
pyhf.set_backend(backend_name)
@@ -52,6 +60,22 @@ def test_set_optimizer_by_bytestring(optimizer_name):
)
[email protected]("precision_level", [b"32b", b"64b"])
+def test_set_precision_by_bytestring(precision_level):
+ pyhf.set_backend(pyhf.tensorlib.name, precision=precision_level)
+ assert pyhf.tensorlib.precision == precision_level.decode("utf-8")
+
+
[email protected]("precision_level", ["32b", "64b"])
+def test_set_precision_by_string_wins(precision_level):
+ conflicting_precision = "32b" if precision_level == "64b" else "64b"
+ pyhf.set_backend(
+ pyhf.tensor.numpy_backend(precision=conflicting_precision),
+ precision=precision_level,
+ )
+ assert pyhf.tensorlib.precision == precision_level.lower()
+
+
@pytest.mark.parametrize("backend_name", ["fail", b"fail"])
def test_supported_backends(backend_name):
with pytest.raises(pyhf.exceptions.InvalidBackend):
@@ -64,6 +88,12 @@ def test_supported_optimizers(optimizer_name):
pyhf.set_backend(pyhf.tensorlib, optimizer_name)
[email protected]("precision_level", ["fail", b"fail"])
+def test_supported_precision(precision_level):
+ with pytest.raises(pyhf.exceptions.Unsupported):
+ pyhf.set_backend("numpy", precision=precision_level)
+
+
def test_custom_backend_name_supported():
class custom_backend(object):
def __init__(self, **kwargs):
|
Add precision setting API to set_backend
# Description
At the moment the current way to set the precision for a backend is by passing a backend object into the `set_backend` API
```python
>>> import pyhf
>>> pyhf.set_backend("pytorch")
>>> pyhf.tensorlib.precision
'32b'
>>> pyhf.set_backend(pyhf.tensor.pytorch_backend(precision="64b"))
>>> pyhf.tensorlib.precision
'64b'
```
it would be nicer if there was the ability to also set the precision through `set_backend` through a `kwarg`
```python
>>> import pyhf
>>> pyhf.set_backend("pytorch", precision="64b")
>>> pyhf.tensorlib.precision
'64b'
```
Also, given the large discrepancies that we see with `32b` precision in the PyTorch backend maybe worth having all backends *default* to setting `64b` precision.
```python
>>> import pyhf
>>> pyhf.set_backend("pytorch")
>>> pyhf.tensorlib.precision
'64b'
```
| 2020-07-24T04:48:54 |
|
scikit-hep/pyhf
| 993 |
scikit-hep__pyhf-993
|
[
"1159"
] |
00af4baab08766985285f671f4f1878d864ab7af
|
diff --git a/src/pyhf/infer/calculators.py b/src/pyhf/infer/calculators.py
--- a/src/pyhf/infer/calculators.py
+++ b/src/pyhf/infer/calculators.py
@@ -66,7 +66,7 @@ class AsymptoticTestStatDistribution:
the :math:`-\mu'`, where :math:`\mu'` is the true poi value of the hypothesis.
"""
- def __init__(self, shift):
+ def __init__(self, shift, cutoff=float("-inf")):
"""
Asymptotic test statistic distribution.
@@ -78,7 +78,7 @@ def __init__(self, shift):
"""
self.shift = shift
- self.sqrtqmuA_v = None
+ self.cutoff = cutoff
def cdf(self, value):
"""
@@ -89,7 +89,7 @@ def cdf(self, value):
>>> import pyhf
>>> pyhf.set_backend("numpy")
>>> bkg_dist = pyhf.infer.calculators.AsymptoticTestStatDistribution(0.0)
- >>> bkg_dist.pvalue(0)
+ >>> bkg_dist.cdf(0.0)
0.5
Args:
@@ -120,6 +120,14 @@ def pvalue(self, value):
given the observed test statistics :math:`q_{\mu}` and :math:`q_{\mu,A}`.
+ Example:
+
+ >>> import pyhf
+ >>> pyhf.set_backend("numpy")
+ >>> bkg_dist = pyhf.infer.calculators.AsymptoticTestStatDistribution(0.0)
+ >>> bkg_dist.pvalue(0.0)
+ array(0.5)
+
Args:
value (:obj:`float`): The test statistic value.
@@ -129,7 +137,14 @@ def pvalue(self, value):
"""
tensorlib, _ = get_backend()
# computing cdf(-x) instead of 1-cdf(x) for right-tail p-value for improved numerical stability
- return tensorlib.normal_cdf(-(value - self.shift))
+
+ return_value = tensorlib.normal_cdf(-(value - self.shift))
+ invalid_value = tensorlib.ones(tensorlib.shape(return_value)) * float("nan")
+ return tensorlib.where(
+ tensorlib.astensor(value >= self.cutoff, dtype="bool"),
+ return_value,
+ invalid_value,
+ )
def expected_value(self, nsigma):
"""
@@ -150,7 +165,12 @@ def expected_value(self, nsigma):
Returns:
Float: The expected value of the test statistic.
"""
- return self.shift + nsigma
+ tensorlib, _ = get_backend()
+ return tensorlib.where(
+ tensorlib.astensor(self.shift + nsigma > self.cutoff, dtype="bool"),
+ tensorlib.astensor(self.shift + nsigma),
+ tensorlib.astensor(self.cutoff),
+ )
class AsymptoticCalculator:
@@ -164,6 +184,7 @@ def __init__(
par_bounds=None,
fixed_params=None,
test_stat="qtilde",
+ calc_base_dist="normal",
):
r"""
Asymptotic Calculator.
@@ -173,13 +194,33 @@ def __init__(
pdf (~pyhf.pdf.Model): The statistical model adhering to the schema ``model.json``.
init_pars (:obj:`tensor`): The initial parameter values to be used for fitting.
par_bounds (:obj:`tensor`): The parameter value bounds to be used for fitting.
- fixed_params (:obj:`tensor`): Whether to fix the parameter to the init_pars value during minimization
- test_stat (:obj:`str`): The test statistic to use as a numerical summary of the data.
- qtilde (:obj:`bool`): When ``True`` perform the calculation using the alternative
- test statistic, :math:`\tilde{q}_{\mu}`, as defined under the Wald
- approximation in Equation (62) of :xref:`arXiv:1007.1727`
- (:func:`~pyhf.infer.test_statistics.qmu_tilde`).
- When ``False`` use :func:`~pyhf.infer.test_statistics.qmu`.
+ fixed_params (:obj:`tensor`): Whether to fix the parameter to the init_pars value
+ during minimization.
+ test_stat (:obj:`str`): The test statistic to use as a numerical summary of the
+ data: ``'qtilde'``, ``'q'``, or ``'q0'``.
+
+ * ``'qtilde'``: (default) performs the calculation using the alternative test statistic,
+ :math:`\tilde{q}_{\mu}`, as defined under the Wald approximation in Equation (62)
+ of :xref:`arXiv:1007.1727` (:func:`~pyhf.infer.test_statistics.qmu_tilde`).
+ * ``'q'``: performs the calculation using the test statistic :math:`q_{\mu}`
+ (:func:`~pyhf.infer.test_statistics.qmu`).
+ * ``'q0'``: performs the calculation using the discovery test statistic
+ :math:`q_{0}` (:func:`~pyhf.infer.test_statistics.q0`).
+ calc_base_dist (:obj:`str`): The statistical distribution, ``'normal'`` or
+ ``'clipped_normal'``, to use for calculating the :math:`p`-values.
+
+ * ``'normal'``: (default) use the full Normal distribution in :math:`\hat{\mu}/\sigma`
+ space.
+ Note that expected limits may correspond to unphysical test statistics from scenarios
+ with the expected :math:`\hat{\mu} > \mu`.
+ * ``'clipped_normal'``: use a clipped Normal distribution in :math:`\hat{\mu}/\sigma`
+ space to avoid expected limits that correspond to scenarios with the expected
+ :math:`\hat{\mu} > \mu`.
+ This will properly cap the test statistic at ``0``, as noted in Equation (14) and
+ Equation (16) in :xref:`arXiv:1007.1727`.
+
+ The choice of ``calc_base_dist`` only affects the :math:`p`-values for expected limits,
+ and the default value will be changed in a future release.
Returns:
~pyhf.infer.calculators.AsymptoticCalculator: The calculator for asymptotic quantities.
@@ -191,6 +232,7 @@ def __init__(
self.par_bounds = par_bounds or pdf.config.suggested_bounds()
self.fixed_params = fixed_params or pdf.config.suggested_fixed()
self.test_stat = test_stat
+ self.calc_base_dist = calc_base_dist
self.sqrtqmuA_v = None
def distributions(self, poi_test):
@@ -213,7 +255,7 @@ def distributions(self, poi_test):
>>> _ = asymptotic_calculator.teststatistic(mu_test)
>>> sig_plus_bkg_dist, bkg_dist = asymptotic_calculator.distributions(mu_test)
>>> sig_plus_bkg_dist.pvalue(mu_test), bkg_dist.pvalue(mu_test)
- (0.002192624107163899, 0.15865525393145707)
+ (array(0.00219262), array(0.15865525))
Args:
poi_test (:obj:`float` or :obj:`tensor`): The value for the parameter of interest.
@@ -223,9 +265,18 @@ def distributions(self, poi_test):
"""
if self.sqrtqmuA_v is None:
- raise RuntimeError('need to call .teststatistic(poi_test) first')
- sb_dist = AsymptoticTestStatDistribution(-self.sqrtqmuA_v)
- b_dist = AsymptoticTestStatDistribution(0.0)
+ raise RuntimeError("need to call .teststatistic(poi_test) first")
+
+ if self.calc_base_dist == "normal":
+ cutoff = float("-inf")
+ elif self.calc_base_dist == "clipped_normal":
+ cutoff = -self.sqrtqmuA_v
+ else:
+ raise ValueError(
+ f"unknown base distribution for asymptotics {self.calc_base_dist}"
+ )
+ sb_dist = AsymptoticTestStatDistribution(-self.sqrtqmuA_v, cutoff)
+ b_dist = AsymptoticTestStatDistribution(0.0, cutoff)
return sb_dist, b_dist
def teststatistic(self, poi_test):
@@ -328,7 +379,7 @@ def pvalues(self, teststat, sig_plus_bkg_distribution, bkg_only_distribution):
>>> sig_plus_bkg_dist, bkg_dist = asymptotic_calculator.distributions(mu_test)
>>> CLsb, CLb, CLs = asymptotic_calculator.pvalues(q_tilde, sig_plus_bkg_dist, bkg_dist)
>>> CLsb, CLb, CLs
- (0.023325019427864607, 0.4441593996111411, 0.05251497423736956)
+ (array(0.02332502), array(0.4441594), 0.05251497423736956)
Args:
teststat (:obj:`tensor`): The test statistic.
@@ -567,15 +618,18 @@ def __init__(
pdf (~pyhf.pdf.Model): The statistical model adhering to the schema ``model.json``.
init_pars (:obj:`tensor`): The initial parameter values to be used for fitting.
par_bounds (:obj:`tensor`): The parameter value bounds to be used for fitting.
- fixed_params (:obj:`tensor`): Whether to fix the parameter to the init_pars value during minimization
- test_stat (:obj:`str`): The test statistic to use as a numerical summary of the data.
- qtilde (:obj:`bool`): When ``True`` perform the calculation using the alternative
- test statistic, :math:`\tilde{q}_{\mu}`, as defined under the Wald
- approximation in Equation (62) of :xref:`arXiv:1007.1727`
- (:func:`~pyhf.infer.test_statistics.qmu_tilde`).
- When ``False`` use :func:`~pyhf.infer.test_statistics.qmu`.
- ntoys (:obj:`int`): Number of toys to use (how many times to sample the underlying distributions)
- track_progress (:obj:`bool`): Whether to display the `tqdm` progress bar or not (outputs to `stderr`)
+ fixed_params (:obj:`tensor`): Whether to fix the parameter to the init_pars value
+ during minimization.
+ test_stat (:obj:`str`): The test statistic to use as a numerical summary of the
+ data: ``'qtilde'``, ``'q'``, or ``'q0'``.
+ ``'qtilde'`` (default) performs the calculation using the alternative test statistic,
+ :math:`\tilde{q}_{\mu}`, as defined under the Wald approximation in Equation (62)
+ of :xref:`arXiv:1007.1727` (:func:`~pyhf.infer.test_statistics.qmu_tilde`), ``'q'``
+ performs the calculation using the test statistic :math:`q_{\mu}`
+ (:func:`~pyhf.infer.test_statistics.qmu`), and ``'q0'`` perfoms the calculation using
+ the discovery test statistic :math:`q_{0}` (:func:`~pyhf.infer.test_statistics.q0`).
+ ntoys (:obj:`int`): Number of toys to use (how many times to sample the underlying distributions).
+ track_progress (:obj:`bool`): Whether to display the `tqdm` progress bar or not (outputs to `stderr`).
Returns:
~pyhf.infer.calculators.ToyCalculator: The calculator for toy-based quantities.
|
diff --git a/tests/test_infer.py b/tests/test_infer.py
--- a/tests/test_infer.py
+++ b/tests/test_infer.py
@@ -238,6 +238,34 @@ def logpdf(self, pars, data):
assert np.isclose(cls, 0.7267836451638846)
+def test_clipped_normal_calc(hypotest_args):
+ mu_test, data, pdf = hypotest_args
+ _, expected_clipped_normal = pyhf.infer.hypotest(
+ mu_test,
+ data,
+ pdf,
+ return_expected_set=True,
+ calc_base_dist="clipped_normal",
+ )
+ _, expected_normal = pyhf.infer.hypotest(
+ mu_test,
+ data,
+ pdf,
+ return_expected_set=True,
+ calc_base_dist="normal",
+ )
+ assert expected_clipped_normal[-1] < expected_normal[-1]
+
+ with pytest.raises(ValueError):
+ _ = pyhf.infer.hypotest(
+ mu_test,
+ data,
+ pdf,
+ return_expected_set=True,
+ calc_base_dist="unknown",
+ )
+
+
@pytest.mark.parametrize("test_stat", ["qtilde", "q"])
def test_calculator_distributions_without_teststatistic(test_stat):
calc = pyhf.infer.calculators.AsymptoticCalculator(
|
support variations on CLs dealing w/ inclusive pvalue and clipping
# Description
enable support for computing CLs values by correctly clipping µ^/sigma to values < µ_signal. The standard ROOT asymptoticcalculator implementation does not do this.
One advantage of this is that the "kink" seen in overfluctuations is much easier to explain

| 2020-07-27T15:31:03 |
|
scikit-hep/pyhf
| 999 |
scikit-hep__pyhf-999
|
[
"998"
] |
60488cd4223dcc5519605b766db1f9af91fa79fb
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -3,8 +3,8 @@
extras_require = {
'shellcomplete': ['click_completion'],
'tensorflow': [
- 'tensorflow~=2.0',
- 'tensorflow-probability~=0.10', # TODO: Temp patch until tfp v0.11
+ 'tensorflow~=2.2.0', # TensorFlow minor releases are as volatile as major
+ 'tensorflow-probability~=0.10.0',
],
'torch': ['torch~=1.2'],
'jax': ['jax~=0.1,>0.1.51', 'jaxlib~=0.1,>0.1.33'],
|
Keep tighter version constraints on TensorFlow releases
# Description
As Issue #997 makes it clear that minor releases might as well be major releases for TensorFlow, then it is probably worth keeping tighter version constraints on them and just watching the releases of TensorFlow and TensorFlow Probability to see when we can relax these.
| 2020-07-27T23:01:35 |
||
scikit-hep/pyhf
| 1,001 |
scikit-hep__pyhf-1001
|
[
"997"
] |
b7a2c65011d6f1342f44e2ba5067623caee002e0
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -3,8 +3,8 @@
extras_require = {
'shellcomplete': ['click_completion'],
'tensorflow': [
- 'tensorflow~=2.2.1', # TensorFlow minor releases are as volatile as major
- 'tensorflow-probability~=0.10.1',
+ 'tensorflow~=2.2,>=2.2.1,!=2.3.0', # c.f. https://github.com/tensorflow/tensorflow/pull/40789
+ 'tensorflow-probability~=0.10,>=0.10.1',
],
'torch': ['torch~=1.8'],
'jax': ['jax~=0.2.8', 'jaxlib~=0.1.58,!=0.1.68'], # c.f. Issue 1501
diff --git a/src/pyhf/tensor/tensorflow_backend.py b/src/pyhf/tensor/tensorflow_backend.py
--- a/src/pyhf/tensor/tensorflow_backend.py
+++ b/src/pyhf/tensor/tensorflow_backend.py
@@ -2,6 +2,7 @@
import logging
import tensorflow as tf
import tensorflow_probability as tfp
+from numpy import nan
log = logging.getLogger(__name__)
@@ -119,7 +120,7 @@ def tile(self, tensor_in, repeats):
"""
try:
return tf.tile(tensor_in, repeats)
- except tf.python.framework.errors_impl.InvalidArgumentError:
+ except tf.errors.InvalidArgumentError:
shape = tf.shape(tensor_in).numpy().tolist()
diff = len(repeats) - len(shape)
if diff < 0:
@@ -426,8 +427,15 @@ def poisson_logpdf(self, n, lam):
TensorFlow Tensor: Value of the continuous approximation to log(Poisson(n|lam))
"""
lam = self.astensor(lam)
+ # Guard against Poisson(n=0 | lam=0)
+ # c.f. https://github.com/scikit-hep/pyhf/issues/293
+ valid_obs_given_rate = tf.logical_or(
+ tf.math.not_equal(lam, n), tf.math.not_equal(n, 0)
+ )
- return tfp.distributions.Poisson(lam).log_prob(n)
+ return tf.where(
+ valid_obs_given_rate, tfp.distributions.Poisson(lam).log_prob(n), nan
+ )
def poisson(self, n, lam):
r"""
@@ -457,8 +465,17 @@ def poisson(self, n, lam):
TensorFlow Tensor: Value of the continuous approximation to Poisson(n|lam)
"""
lam = self.astensor(lam)
+ # Guard against Poisson(n=0 | lam=0)
+ # c.f. https://github.com/scikit-hep/pyhf/issues/293
+ valid_obs_given_rate = tf.logical_or(
+ tf.math.not_equal(lam, n), tf.math.not_equal(n, 0)
+ )
- return tf.exp(tfp.distributions.Poisson(lam).log_prob(n))
+ return tf.where(
+ valid_obs_given_rate,
+ tf.exp(tfp.distributions.Poisson(lam).log_prob(n)),
+ nan,
+ )
def normal_logpdf(self, x, mu, sigma):
r"""
|
diff --git a/tests/test_tensor.py b/tests/test_tensor.py
--- a/tests/test_tensor.py
+++ b/tests/test_tensor.py
@@ -392,7 +392,7 @@ def test_tensor_tile(backend):
]
if tb.name == 'tensorflow':
- with pytest.raises(tf.python.framework.errors_impl.InvalidArgumentError):
+ with pytest.raises(tf.errors.InvalidArgumentError):
tb.tile(tb.astensor([[[10, 20, 30]]]), (2, 1))
|
Fix TensorFlow v2.3.0 and TensorFlow Probability v0.11.0 release incompatibilities
# Description
[TensorFlow `v2.3.0`](https://github.com/tensorflow/tensorflow/releases/tag/v2.3.0) has been released today (2020-07-27) but is breaking the tests in CI with the following:
```
pythonLocation: /opt/hostedtoolcache/Python/3.7.8/x64
2020-07-27 21:25:53.025362: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory
2020-07-27 21:25:53.025414: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
ImportError while loading conftest '/home/runner/work/pyhf/pyhf/tests/conftest.py'.
tests/conftest.py:83: in <module>
(pyhf.tensor.tensorflow_backend(), None),
src/pyhf/tensor/__init__.py:50: in __getattr__
e,
E pyhf.exceptions.ImportBackendError: ('There was a problem importing TensorFlow. The tensorflow backend cannot be used.', ImportError("cannot import name 'naming' from 'tensorflow.python.autograph.core' (/opt/hostedtoolcache/Python/3.7.8/x64/lib/python3.7/site-packages/tensorflow/python/autograph/core/__init__.py)"))
##[error]Process completed with exit code 4.
```
the code snippet that is being reported here is:
https://github.com/scikit-hep/pyhf/blob/60488cd4223dcc5519605b766db1f9af91fa79fb/src/pyhf/tensor/__init__.py#L39-L51
but the actual error is
```
2020-07-27 21:25:53.025362: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory
```
as with TensorFlow `v2.3.0` just importing gets you the attempt to load `libcudart.so.10.1`
```python
>>> import tensorflow as tf
2020-07-27 16:40:48.374806: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
```
# Expected Behavior
The test suite runs
# Actual Behavior
c.f. above
# Steps to Reproduce
Run the CI.
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
Though this might be something that we need to catch as just trying to import `tensorflow` (`python -c "import tensorflow as tf"`) after the dependencies are installed gives
```
2020-07-27 21:51:18.905311: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory
2020-07-27 21:51:18.905345: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
```
@kratsg has pointed out that this is actually a problem with TensorFlow Probability `v0.10.X` releases as `v0.11.X` uses TF `v2.3.X`.
```
$ docker run --rm -it python:3.8-slim /bin/bash
# pip install pyhf[tensorflow]
# pip list | grep tensor
tensorboard 2.3.0
tensorboard-plugin-wit 1.7.0
tensorflow 2.3.0
tensorflow-estimator 2.3.0
tensorflow-probability 0.10.1
# python
Python 3.8.2 (default, Apr 23 2020, 14:32:57)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pyhf
>>> pyhf.set_backend("tensorflow")
2020-07-27 23:16:40.268209: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory
2020-07-27 23:16:40.268358: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
Traceback (most recent call last):
File "/usr/local/lib/python3.8/site-packages/pyhf/tensor/__init__.py", line 41, in __getattr__
from .tensorflow_backend import tensorflow_backend
File "/usr/local/lib/python3.8/site-packages/pyhf/tensor/tensorflow_backend.py", line 4, in <module>
import tensorflow_probability as tfp
File "/usr/local/lib/python3.8/site-packages/tensorflow_probability/__init__.py", line 76, in <module>
from tensorflow_probability.python import * # pylint: disable=wildcard-import
File "/usr/local/lib/python3.8/site-packages/tensorflow_probability/python/__init__.py", line 24, in <module>
from tensorflow_probability.python import experimental
File "/usr/local/lib/python3.8/site-packages/tensorflow_probability/python/experimental/__init__.py", line 34, in <module>
from tensorflow_probability.python.experimental import auto_batching
File "/usr/local/lib/python3.8/site-packages/tensorflow_probability/python/experimental/auto_batching/__init__.py", line 24, in <module>
from tensorflow_probability.python.experimental.auto_batching import frontend
File "/usr/local/lib/python3.8/site-packages/tensorflow_probability/python/experimental/auto_batching/frontend.py", line 45, in <module>
from tensorflow.python.autograph.core import naming
ImportError: cannot import name 'naming' from 'tensorflow.python.autograph.core' (/usr/local/lib/python3.8/site-packages/tensorflow/python/autograph/core/__init__.py)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.8/site-packages/pyhf/events.py", line 68, in register_wrapper
result = func(*args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/pyhf/__init__.py", line 88, in set_backend
backend = getattr(tensor, f"{backend:s}_backend")(**backend_kwargs)
File "/usr/local/lib/python3.8/site-packages/pyhf/tensor/__init__.py", line 48, in __getattr__
raise exceptions.ImportBackendError(
pyhf.exceptions.ImportBackendError: ('There was a problem importing TensorFlow. The tensorflow backend cannot be used.', ImportError("cannot import name 'naming' from 'tensorflow.python.autograph.core' (/usr/local/lib/python3.8/site-packages/tensorflow/python/autograph/core/__init__.py)"))
>>>
# pip install --upgrade "tensorflow-probability>=v0.11.0-rc1"
# pip list | grep tensor
tensorboard 2.3.0
tensorboard-plugin-wit 1.7.0
tensorflow 2.3.0
tensorflow-estimator 2.3.0
tensorflow-probability 0.11.0rc1
# python
Python 3.8.2 (default, Apr 23 2020, 14:32:57)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pyhf
>>> pyhf.set_backend("tensorflow")
2020-07-27 23:18:06.709873: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory
2020-07-27 23:18:06.709903: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
>>>
```
Some good news on the issues RE: SciPy and TF `v2.3.0` and TFP `v0.11.0` seen in PR #1001: https://groups.google.com/a/tensorflow.org/d/msg/discuss/wLRLe96ymFg/vlNecsSZAwAJ
TF `v2.4.0` "is slated to come out sometime around september/october." and a patch release of `v2.3.X` might be possible. :+1: Thanks to @alextp for being super responsive too.
Further related to PR #1001 are https://github.com/tensorflow/tensorflow/pull/41867 and https://github.com/tensorflow/tensorflow/issues/41902. I've gone ahead and subscribed to these so that we can keep tabs on them and act quickly.
There is additionally a discussion ongoing at https://github.com/pypa/pip/issues/8076 RE: the `pip` October 2020 dependency resolver changes that is relevant as well until a patch release of TensorFlow comes out.
What is the status of this? [`TensorFlow` 2.5.0](https://github.com/tensorflow/tensorflow/releases/tag/v2.5.0) is available now, so maybe some of the above issues are resolved. I am looking into this as I was hoping to find a setup with `pyhf` that allows testing the `TensorFlow` backend but also to use `numpy`>=1.20 for typing reasons (reference: https://github.com/alexander-held/cabinetry/pull/228). Installing `TensorFlow` 2.5.0 picks up `numpy~=1.19.2`, so it seems like this unfortunately may not be possible yet.
| 2020-07-28T04:02:24 |
scikit-hep/pyhf
| 1,028 |
scikit-hep__pyhf-1028
|
[
"1025"
] |
e260626689f46414be185d834499cc65dce5a4b0
|
diff --git a/src/pyhf/tensor/tensorflow_backend.py b/src/pyhf/tensor/tensorflow_backend.py
--- a/src/pyhf/tensor/tensorflow_backend.py
+++ b/src/pyhf/tensor/tensorflow_backend.py
@@ -75,7 +75,14 @@ def tile(self, tensor_in, repeats):
TensorFlow Tensor: The tensor with repeated axes
"""
- return tf.tile(tensor_in, repeats)
+ try:
+ return tf.tile(tensor_in, repeats)
+ except tf.python.framework.errors_impl.InvalidArgumentError:
+ shape = tf.shape(tensor_in).numpy().tolist()
+ diff = len(repeats) - len(shape)
+ if diff < 0:
+ raise
+ return tf.tile(tf.reshape(tensor_in, [1] * diff + shape), repeats)
def conditional(self, predicate, true_callable, false_callable):
"""
|
diff --git a/tests/test_tensor.py b/tests/test_tensor.py
--- a/tests/test_tensor.py
+++ b/tests/test_tensor.py
@@ -234,9 +234,19 @@ def test_tensor_tile(backend):
assert tb.tolist(tb.tile(tb.astensor(a), (1, 2))) == [[1, 1], [2, 2], [3, 3]]
a = [1, 2, 3]
- tb = pyhf.tensorlib
assert tb.tolist(tb.tile(tb.astensor(a), (2,))) == [1, 2, 3, 1, 2, 3]
+ a = [10, 20]
+ assert tb.tolist(tb.tile(tb.astensor(a), (2, 1))) == [[10, 20], [10, 20]]
+ assert tb.tolist(tb.tile(tb.astensor(a), (2, 1, 3))) == [
+ [[10.0, 20.0, 10.0, 20.0, 10.0, 20.0]],
+ [[10.0, 20.0, 10.0, 20.0, 10.0, 20.0]],
+ ]
+
+ if tb.name == 'tensorflow':
+ with pytest.raises(tf.python.framework.errors_impl.InvalidArgumentError):
+ tb.tile(tb.astensor([[[10, 20, 30]]]), (2, 1))
+
def test_1D_gather(backend):
tb = pyhf.tensorlib
|
tensorflow tile inconsistent with other tensorlibs
Demonstrated rather simply below:
```python
>>> import pyhf
>>> pyhf.tensorlib.tile(pyhf.tensorlib.astensor([1.]), (2, 1))
array([[1.],
[1.]])
>>> pyhf.set_backend('jax')
>>> pyhf.tensorlib.tile(pyhf.tensorlib.astensor([1.]), (2, 1))
>>> pyhf.set_backend('pytorch')
>>> pyhf.tensorlib.tile(pyhf.tensorlib.astensor([1.]), (2, 1))
tensor([[1.],
[1.]])
>>> pyhf.set_backend('tensorflow')
>>> pyhf.tensorlib.tile(pyhf.tensorlib.astensor([1.]), (2, 1))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/kratsg/.virtualenvs/pyhf/lib/python3.7/site-packages/pyhf/tensor/tensorflow_backend.py", line 78, in tile
return tf.tile(tensor_in, repeats)
File "/Users/kratsg/.virtualenvs/pyhf/lib/python3.7/site-packages/tensorflow/python/ops/gen_array_ops.py", line 11393, in tile
input, multiples, name=name, ctx=_ctx)
File "/Users/kratsg/.virtualenvs/pyhf/lib/python3.7/site-packages/tensorflow/python/ops/gen_array_ops.py", line 11433, in tile_eager_fallback
ctx=ctx, name=name)
File "/Users/kratsg/.virtualenvs/pyhf/lib/python3.7/site-packages/tensorflow/python/eager/execute.py", line 60, in quick_execute
inputs, attrs, num_outputs)
tensorflow.python.framework.errors_impl.InvalidArgumentError: Expected multiples argument to be a vector of length 1 but got length 2 [Op:Tile]
```
|
Should we get this addressed _before_ PR #731 goes in? I'm a bit hesitant to specifically add test cases that treat backends different (one of the reasons PR #817 ~is~ was taking _forever_ to be ready).
| 2020-08-13T19:50:20 |
scikit-hep/pyhf
| 1,038 |
scikit-hep__pyhf-1038
|
[
"1027"
] |
bff6b631462bd7483087ac62cfca0559bfe12e41
|
diff --git a/src/pyhf/pdf.py b/src/pyhf/pdf.py
--- a/src/pyhf/pdf.py
+++ b/src/pyhf/pdf.py
@@ -609,6 +609,8 @@ def expected_auxdata(self, pars):
Tensor: The expected data of the auxiliary pdf
"""
+ tensorlib, _ = get_backend()
+ pars = tensorlib.astensor(pars)
return self.make_pdf(pars)[1].expected_data()
def _modifications(self, pars):
@@ -630,6 +632,8 @@ def expected_actualdata(self, pars):
Tensor: The expected data of the main model (no auxiliary data)
"""
+ tensorlib, _ = get_backend()
+ pars = tensorlib.astensor(pars)
return self.make_pdf(pars)[0].expected_data()
def expected_data(self, pars, include_auxdata=True):
|
diff --git a/tests/test_pdf.py b/tests/test_pdf.py
--- a/tests/test_pdf.py
+++ b/tests/test_pdf.py
@@ -133,6 +133,13 @@ def test_pdf_basicapi_tests(backend):
[60.0, 51.020408630], 1e-08
)
+ assert tensorlib.tolist(pdf.expected_actualdata(pars)) == pytest.approx(
+ [60.0], 1e-08
+ )
+ assert tensorlib.tolist(pdf.expected_auxdata(pars)) == pytest.approx(
+ [51.020408630], 1e-08
+ )
+
pdf = pyhf.simplemodels.hepdata_like(
source['bindata']['sig'],
source['bindata']['bkg'],
|
Model.expected_auxdata and expected_actualdata miss tensorlib conversion
# Description
Both `Model.expected_auxdata` and `Model.expected_actualdata` do not include the same `pars = tensorlib.astensor(pars)` conversion that `Model.expected_data` uses. This results in runtime issues:
```
import pyhf
model = pyhf.simplemodels.hepdata_like(
signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
)
model.expected_data(model.config.suggested_init())
model.expected_actualdata(model.config.suggested_init())
model.expected_auxdata(model.config.suggested_init())
```
output:
```
Traceback (most recent call last):
File "ex.py", line 8, in <module>
model.expected_actualdata(model.config.suggested_init())
File "[...]/pyhf/src/pyhf/pdf.py", line 631, in expected_actualdata
return self.make_pdf(pars)[0].expected_data()
File "[...]/pyhf/src/pyhf/pdf.py", line 692, in make_pdf
mainpdf = self.main_model.make_pdf(pars)
File "[...]/pyhf/src/pyhf/pdf.py", line 456, in make_pdf
lambdas_data = self._expected_data(pars)
File "[...]/pyhf/src/pyhf/pdf.py", line 517, in _expected_data
deltas, factors = self._modifications(pars)
File "[...]/pyhf/src/pyhf/pdf.py", line 483, in _modifications
[self.modifiers_appliers[k].apply(pars) for k in self._factor_mods],
File "[...]/pyhf/src/pyhf/pdf.py", line 483, in <listcomp>
[self.modifiers_appliers[k].apply(pars) for k in self._factor_mods],
File "[...]/pyhf/src/pyhf/modifiers/shapesys.py", line 169, in apply
shapefactors = tensorlib.gather(flat_pars, self.access_field)
File "[...]/pyhf/src/pyhf/tensor/numpy_backend.py", line 136, in gather
return tensor[indices]
TypeError: only integer scalar arrays can be converted to a scalar index
```
Similar for `expected_auxdata`.
I'm happy to submit a small PR to fix this, unless those functions are going to be deprecated (since at least `expected_actualdata` can alternatively be obtained via `model.expected_data, include_auxdata=False)`).
# Expected Behavior
No crash, but successful return of aux / actual data.
# Actual Behavior
code crashes
# Steps to Reproduce
pyhf 0.5.1, see example code above
# Checklist
- [ ] Run `git fetch` to get the most up to date version of `master`
- [ ] Searched through existing Issues to confirm this is not a duplicate issue
- [ ] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
@alexander-held The short term mitigation of this (as I assume you need this now) is to give the suggested init values as a tensor
```python
>>> import pyhf
>>> pyhf.set_backend("numpy")
>>> model = pyhf.simplemodels.hepdata_like(
... signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
... )
>>> model.expected_data(pyhf.tensorlib.astensor(model.config.suggested_init()))
array([ 62. , 63. , 277.77777778, 55.18367347])
>>> model.expected_actualdata(pyhf.tensorlib.astensor(model.config.suggested_init()))
array([62., 63.])
>>> model.expected_auxdata(pyhf.tensorlib.astensor(model.config.suggested_init()))
array([277.77777778, 55.18367347])
```
but I agree that the API should be consistent and that the `Model` object should be able to interact with its own API returns without having to be wrapped as a tensor first.
> I'm happy to submit a small PR to fix this
PRs welcome! Thanks. :)
| 2020-08-19T12:55:05 |
scikit-hep/pyhf
| 1,041 |
scikit-hep__pyhf-1041
|
[
"1023"
] |
cd3ea9ff6a5f2cd12fb70eb31ad7f5697b5ecab6
|
diff --git a/src/pyhf/workspace.py b/src/pyhf/workspace.py
--- a/src/pyhf/workspace.py
+++ b/src/pyhf/workspace.py
@@ -675,4 +675,4 @@ def combine(cls, left, right, join='none'):
'observations': new_observations,
'version': new_version,
}
- return Workspace(newspec)
+ return cls(newspec)
|
diff --git a/tests/test_workspace.py b/tests/test_workspace.py
--- a/tests/test_workspace.py
+++ b/tests/test_workspace.py
@@ -717,3 +717,32 @@ def test_workspace_equality(workspace_factory):
assert ws == ws
assert ws == ws_other
assert ws != 'not a workspace'
+
+
+def test_workspace_inheritance(workspace_factory):
+ ws = workspace_factory()
+ new_ws = ws.rename(
+ channels={'channel1': 'channel3', 'channel2': 'channel4'},
+ samples={
+ 'background1': 'background3',
+ 'background2': 'background4',
+ 'signal': 'signal2',
+ },
+ modifiers={
+ 'syst1': 'syst4',
+ 'bkg1Shape': 'bkg3Shape',
+ 'bkg2Shape': 'bkg4Shape',
+ },
+ measurements={
+ 'GaussExample': 'OtherGaussExample',
+ 'GammaExample': 'OtherGammaExample',
+ 'ConstExample': 'OtherConstExample',
+ 'LogNormExample': 'OtherLogNormExample',
+ },
+ )
+
+ class FooWorkspace(pyhf.Workspace):
+ pass
+
+ combined = FooWorkspace.combine(ws, new_ws)
+ assert isinstance(combined, FooWorkspace)
|
Class returned by pyhf.Workspace.combine
# Question
Not a bug so I'm opening this as a question: The `pyhf.Workspace.combine` classmethod returns a `Workspace` explicitly instead of `cls`.
https://github.com/scikit-hep/pyhf/blob/e260626689f46414be185d834499cc65dce5a4b0/src/pyhf/workspace.py#L678
To work better with classes that want to inherit from `pyhf.Workspace`, I think it would be better to return the class as
```python
return cls(newspec)
```
# Relevant Issues and Pull Requests
none I'm aware of
|
Hah.. good point. I feel like a hypocrite for writing it this way when we had to fix this with iminuit :)
| 2020-08-20T16:56:51 |
scikit-hep/pyhf
| 1,042 |
scikit-hep__pyhf-1042
|
[
"805",
"1033"
] |
f2e2db905ac5591aca115f3bac180c74f6e1c86e
|
diff --git a/src/pyhf/cli/cli.py b/src/pyhf/cli/cli.py
--- a/src/pyhf/cli/cli.py
+++ b/src/pyhf/cli/cli.py
@@ -26,6 +26,7 @@ def pyhf():
pyhf.add_command(spec.rename)
pyhf.add_command(spec.combine)
pyhf.add_command(spec.digest)
+pyhf.add_command(spec.sort)
# pyhf.add_command(infer.cli)
pyhf.add_command(infer.cls)
diff --git a/src/pyhf/cli/spec.py b/src/pyhf/cli/spec.py
--- a/src/pyhf/cli/spec.py
+++ b/src/pyhf/cli/spec.py
@@ -353,3 +353,44 @@ def digest(workspace, algorithm, output_json):
)
click.echo(output)
+
+
[email protected]()
[email protected]('workspace', default='-')
[email protected](
+ '--output-file',
+ help='The location of the output json file. If not specified, prints to screen.',
+ default=None,
+)
+def sort(workspace, output_file):
+ """
+ Sort the workspace.
+
+ See :func:`pyhf.workspace.Workspace.sorted` for more information.
+
+ Example:
+
+ .. code-block:: shell
+
+ $ curl -sL https://raw.githubusercontent.com/scikit-hep/pyhf/master/docs/examples/json/2-bin_1-channel.json | pyhf sort | jq '.' | md5
+ 8be5186ec249d2704e14dd29ef05ffb0
+
+ .. code-block:: shell
+
+ $ curl -sL https://raw.githubusercontent.com/scikit-hep/pyhf/master/docs/examples/json/2-bin_1-channel.json | jq -S '.channels|=sort_by(.name)|.channels[].samples|=sort_by(.name)|.channels[].samples[].modifiers|=sort_by(.name,.type)|.observations|=sort_by(.name)' | md5
+ 8be5186ec249d2704e14dd29ef05ffb0
+
+
+ """
+ with click.open_file(workspace, 'r') as specstream:
+ spec = json.load(specstream)
+
+ workspace = Workspace(spec)
+ sorted_ws = Workspace.sorted(workspace)
+
+ if output_file is None:
+ click.echo(json.dumps(sorted_ws, indent=4, sort_keys=True))
+ else:
+ with open(output_file, 'w+') as out_file:
+ json.dump(sorted_ws, out_file, indent=4, sort_keys=True)
+ log.debug(f"Written to {output_file}")
diff --git a/src/pyhf/workspace.py b/src/pyhf/workspace.py
--- a/src/pyhf/workspace.py
+++ b/src/pyhf/workspace.py
@@ -676,3 +676,31 @@ def combine(cls, left, right, join='none'):
'version': new_version,
}
return cls(newspec)
+
+ @classmethod
+ def sorted(cls, workspace):
+ """
+ Return a new workspace specification that is sorted.
+
+ Args:
+ workspace (~pyhf.workspace.Workspace): A workspace to sort
+
+ Returns:
+ ~pyhf.workspace.Workspace: A new sorted workspace object
+
+ """
+ newspec = copy.deepcopy(dict(workspace))
+
+ newspec['channels'].sort(key=lambda e: e['name'])
+ for channel in newspec['channels']:
+ channel['samples'].sort(key=lambda e: e['name'])
+ for sample in channel['samples']:
+ sample['modifiers'].sort(key=lambda e: (e['name'], e['type']))
+
+ newspec['measurements'].sort(key=lambda e: e['name'])
+ for measurement in newspec['measurements']:
+ measurement['config']['parameters'].sort(key=lambda e: e['name'])
+
+ newspec['observations'].sort(key=lambda e: e['name'])
+
+ return cls(newspec)
|
diff --git a/tests/test_scripts.py b/tests/test_scripts.py
--- a/tests/test_scripts.py
+++ b/tests/test_scripts.py
@@ -539,3 +539,30 @@ def test_patchset_apply(datadir, tmpdir, script_runner, output_file):
"hi": 1.2,
"lo": 0.8,
}
+
+
+def test_sort(tmpdir, script_runner):
+ temp = tmpdir.join("parsed_output.json")
+ command = 'pyhf xml2json validation/xmlimport_input/config/example.xml --basedir validation/xmlimport_input/ --output-file {0:s} --hide-progress'.format(
+ temp.strpath
+ )
+ ret = script_runner.run(*shlex.split(command))
+
+ command = f'pyhf sort {temp.strpath}'
+
+ ret = script_runner.run(*shlex.split(command))
+ assert ret.success
+
+
+def test_sort_outfile(tmpdir, script_runner):
+ temp = tmpdir.join("parsed_output.json")
+ command = 'pyhf xml2json validation/xmlimport_input/config/example.xml --basedir validation/xmlimport_input/ --output-file {0:s} --hide-progress'.format(
+ temp.strpath
+ )
+ ret = script_runner.run(*shlex.split(command))
+
+ tempout = tmpdir.join("sort_output.json")
+ command = f'pyhf sort {temp.strpath} --output-file {tempout.strpath}'
+
+ ret = script_runner.run(*shlex.split(command))
+ assert ret.success
diff --git a/tests/test_workspace.py b/tests/test_workspace.py
--- a/tests/test_workspace.py
+++ b/tests/test_workspace.py
@@ -746,3 +746,18 @@ class FooWorkspace(pyhf.Workspace):
combined = FooWorkspace.combine(ws, new_ws)
assert isinstance(combined, FooWorkspace)
+
+
+def test_sorted(workspace_factory):
+ ws = workspace_factory()
+ # force the first sample in each channel to be last
+ for channel in ws['channels']:
+ channel['samples'][0]['name'] = 'zzzzlast'
+
+ new_ws = pyhf.Workspace.sorted(ws)
+ for channel in ws['channels']:
+ # check no sort
+ assert channel['samples'][0]['name'] == 'zzzzlast'
+ for channel in new_ws['channels']:
+ # check sort
+ assert channel['samples'][-1]['name'] == 'zzzzlast'
|
pyhf spec normalize
# Description
it might be nice to be able to normalize a pyhf spec
* sort samples alphabetically
* sort modifiers alphabetically
and similar things to ease e.g. comparisong with jsondiff and patch creation
assumptions
```
pyhf cls spec.json
pyhf spec normalize spec.json > normalized.json
pyhf cls normalized.json
```
should produce the same results
(based on discussions with @ntadej @danikam @kratsg )
jq workspace sort
```
alias sortws="jq -S '.channels|=sort_by(.name)|.channels[].samples|=sort_by(.name)|.channels[].samples[].modifiers|=sort_by(.name,.type)|.observations|=sort_by(.name)'"
```
|
Issue #1033 might be something to keep in mind around the same time this get addressed.
This was ridiculously helpful. :+1: Clutch `jq` skills @kratsg. :wink:
| 2020-08-20T17:54:12 |
scikit-hep/pyhf
| 1,044 |
scikit-hep__pyhf-1044
|
[
"1043"
] |
236fbaaa9161a23c818e25eda19106f4e933c1e5
|
diff --git a/src/pyhf/pdf.py b/src/pyhf/pdf.py
--- a/src/pyhf/pdf.py
+++ b/src/pyhf/pdf.py
@@ -514,6 +514,7 @@ def expected_data(self, pars, return_by_sample=False):
"""
tensorlib, _ = get_backend()
+ pars = tensorlib.astensor(pars)
deltas, factors = self._modifications(pars)
allsum = tensorlib.concatenate(deltas + [self.nominal_rates])
|
diff --git a/tests/test_pdf.py b/tests/test_pdf.py
--- a/tests/test_pdf.py
+++ b/tests/test_pdf.py
@@ -139,6 +139,9 @@ def test_pdf_basicapi_tests(backend):
assert tensorlib.tolist(pdf.expected_auxdata(pars)) == pytest.approx(
[51.020408630], 1e-08
)
+ assert tensorlib.tolist(pdf.main_model.expected_data(pars)) == pytest.approx(
+ [60.0], 1e-08
+ )
pdf = pyhf.simplemodels.hepdata_like(
source['bindata']['sig'],
|
Missing tensorlib conversion for Model.main_model.expected_data
# Description
This is the same issue as #1027, but for `Model.main_model.expected_data` instead. I missed it earlier due to the workaround I had been using for #1027. That function is particularly interesting for the `return_by_sample` behavior introduced by #731.
```python
import pyhf
model = pyhf.simplemodels.hepdata_like(
signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
)
model.main_model.expected_data(model.config.suggested_init())
```
results in
```
Traceback (most recent call last):
File "test.py", line 7, in <module>
model.main_model.expected_data(model.config.suggested_init())
File "[...]pyhf/src/pyhf/pdf.py", line 517, in expected_data
deltas, factors = self._modifications(pars)
File "[...]pyhf/src/pyhf/pdf.py", line 483, in _modifications
[self.modifiers_appliers[k].apply(pars) for k in self._factor_mods],
File "[...]pyhf/src/pyhf/pdf.py", line 483, in <listcomp>
[self.modifiers_appliers[k].apply(pars) for k in self._factor_mods],
File "[...]pyhf/src/pyhf/modifiers/shapesys.py", line 169, in apply
shapefactors = tensorlib.gather(flat_pars, self.access_field)
File "[...]pyhf/src/pyhf/tensor/numpy_backend.py", line 136, in gather
return tensor[indices]
TypeError: only integer scalar arrays can be converted to a scalar index
```
# Expected Behavior
no crash, but successful return of expected data
# Actual Behavior
crash with `TypeError: only integer scalar arrays can be converted to a scalar index`
# Steps to Reproduce
`pyhf` master @ 236fbaa, see above
# Checklist
- [ ] Run `git fetch` to get the most up to date version of `master`
- [ ] Searched through existing Issues to confirm this is not a duplicate issue
- [ ] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
| 2020-08-21T09:07:29 |
|
scikit-hep/pyhf
| 1,049 |
scikit-hep__pyhf-1049
|
[
"370"
] |
d7cd2f197280692c68a4701670f8240ddf499e8c
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -29,7 +29,7 @@
+ extras_require['contrib']
+ extras_require['shellcomplete']
+ [
- 'pytest~=3.5',
+ 'pytest~=6.0',
'pytest-cov>=2.5.1',
'pytest-mock',
'pytest-benchmark[histogram]',
|
diff --git a/tests/conftest.py b/tests/conftest.py
--- a/tests/conftest.py
+++ b/tests/conftest.py
@@ -98,14 +98,18 @@ def backend(request):
func_name = request._pyfuncitem.name
# skip backends if specified
- skip_backend = request.node.get_marker('skip_{param}'.format(param=param_id))
+ skip_backend = request.node.get_closest_marker(
+ 'skip_{param}'.format(param=param_id)
+ )
# allow the specific backend to fail if specified
- fail_backend = request.node.get_marker('fail_{param}'.format(param=param_id))
+ fail_backend = request.node.get_closest_marker(
+ 'fail_{param}'.format(param=param_id)
+ )
# only look at the specific backends
only_backends = [
pid
for pid in param_ids
- if request.node.get_marker('only_{param}'.format(param=pid))
+ if request.node.get_closest_marker('only_{param}'.format(param=pid))
]
if skip_backend and (param_id in only_backends):
diff --git a/tests/test_teststats.py b/tests/test_teststats.py
--- a/tests/test_teststats.py
+++ b/tests/test_teststats.py
@@ -16,7 +16,7 @@ def test_qmu(caplog):
pyhf.infer.test_statistics.qmu(
mu, data, model, init_pars, par_bounds, fixed_params
)
- assert "WARNING qmu test statistic used for fit" in caplog.text
+ assert "qmu test statistic used for fit" in caplog.text
caplog.clear()
@@ -33,7 +33,7 @@ def test_qmu_tilde(caplog):
pyhf.infer.test_statistics.qmu_tilde(
mu, data, model, init_pars, par_bounds, fixed_params
)
- assert "WARNING qmu_tilde test statistic used for fit" in caplog.text
+ assert "qmu_tilde test statistic used for fit" in caplog.text
caplog.clear()
@@ -49,7 +49,7 @@ def test_tmu(caplog):
pyhf.infer.test_statistics.tmu(
mu, data, model, init_pars, par_bounds, fixed_params
)
- assert "WARNING tmu test statistic used for fit" in caplog.text
+ assert "tmu test statistic used for fit" in caplog.text
caplog.clear()
@@ -66,7 +66,7 @@ def test_tmu_tilde(caplog):
pyhf.infer.test_statistics.tmu_tilde(
mu, data, model, init_pars, par_bounds, fixed_params
)
- assert "WARNING tmu_tilde test statistic used for fit" in caplog.text
+ assert "tmu_tilde test statistic used for fit" in caplog.text
caplog.clear()
diff --git a/tests/test_validation.py b/tests/test_validation.py
--- a/tests/test_validation.py
+++ b/tests/test_validation.py
@@ -7,14 +7,17 @@
import numpy as np
[email protected](scope='module')
-def source_1bin_example1():
+def get_source_1bin_example1():
with open('validation/data/1bin_example1.json') as read_json:
return json.load(read_json)
@pytest.fixture(scope='module')
-def spec_1bin_shapesys(source=source_1bin_example1()):
+def source_1bin_example1():
+ return get_source_1bin_example1()
+
+
+def get_spec_1bin_shapesys(source=get_source_1bin_example1()):
spec = {
'channels': [
{
@@ -46,7 +49,11 @@ def spec_1bin_shapesys(source=source_1bin_example1()):
@pytest.fixture(scope='module')
-def expected_result_1bin_shapesys(mu=1.0):
+def spec_1bin_shapesys():
+ return get_spec_1bin_shapesys()
+
+
+def get_expected_result_1bin_shapesys(mu=1.0):
if mu == 1:
expected_result = {
"exp": [
@@ -62,11 +69,15 @@ def expected_result_1bin_shapesys(mu=1.0):
@pytest.fixture(scope='module')
-def setup_1bin_shapesys(
- source=source_1bin_example1(),
- spec=spec_1bin_shapesys(source_1bin_example1()),
+def expected_result_1bin_shapesys():
+ return get_expected_result_1bin_shapesys()
+
+
+def get_setup_1bin_shapesys(
+ source=get_source_1bin_example1(),
+ spec=get_spec_1bin_shapesys(get_source_1bin_example1()),
mu=1,
- expected_result=expected_result_1bin_shapesys(1.0),
+ expected_result=get_expected_result_1bin_shapesys(1.0),
config={'init_pars': 2, 'par_bounds': 2},
):
return {
@@ -78,7 +89,11 @@ def setup_1bin_shapesys(
@pytest.fixture(scope='module')
-def spec_1bin_lumi():
+def setup_1bin_shapesys():
+ return get_setup_1bin_shapesys()
+
+
+def get_spec_1bin_lumi():
spec = {
"channels": [
{
@@ -118,7 +133,11 @@ def spec_1bin_lumi():
@pytest.fixture(scope='module')
-def expected_result_1bin_lumi(mu=1.0):
+def spec_1bin_lumi():
+ return get_spec_1bin_lumi()
+
+
+def get_expected_result_1bin_lumi(mu=1.0):
if mu == 1:
expected_result = {
"exp": [
@@ -134,11 +153,15 @@ def expected_result_1bin_lumi(mu=1.0):
@pytest.fixture(scope='module')
-def setup_1bin_lumi(
- source=source_1bin_example1(),
- spec=spec_1bin_lumi(),
+def expected_result_1bin_lumi():
+ return get_expected_result_1bin_lumi()
+
+
+def get_setup_1bin_lumi(
+ source=get_source_1bin_example1(),
+ spec=get_spec_1bin_lumi(),
mu=1,
- expected_result=expected_result_1bin_lumi(1.0),
+ expected_result=get_expected_result_1bin_lumi(1.0),
config={'init_pars': 2, 'par_bounds': 2},
):
return {
@@ -150,7 +173,11 @@ def setup_1bin_lumi(
@pytest.fixture(scope='module')
-def source_1bin_normsys():
+def setup_1bin_lumi():
+ return get_setup_1bin_lumi()
+
+
+def get_source_1bin_normsys():
source = {
'binning': [2, -0.5, 1.5],
'bindata': {'data': [120.0, 180.0], 'bkg': [100.0, 150.0], 'sig': [30.0, 95.0]},
@@ -159,7 +186,11 @@ def source_1bin_normsys():
@pytest.fixture(scope='module')
-def spec_1bin_normsys(source=source_1bin_normsys()):
+def source_1bin_normsys():
+ return get_source_1bin_normsys()
+
+
+def get_spec_1bin_normsys(source=get_source_1bin_normsys()):
spec = {
'channels': [
{
@@ -191,7 +222,11 @@ def spec_1bin_normsys(source=source_1bin_normsys()):
@pytest.fixture(scope='module')
-def expected_result_1bin_normsys(mu=1.0):
+def spec_1bin_normsys():
+ return get_spec_1bin_normsys()
+
+
+def get_expected_result_1bin_normsys(mu=1.0):
if mu == 1:
expected_result = {
"exp": [
@@ -207,11 +242,15 @@ def expected_result_1bin_normsys(mu=1.0):
@pytest.fixture(scope='module')
-def setup_1bin_normsys(
- source=source_1bin_normsys(),
- spec=spec_1bin_normsys(source_1bin_normsys()),
+def expected_result_1bin_normsys():
+ return get_expected_result_1bin_normsys()
+
+
+def get_setup_1bin_normsys(
+ source=get_source_1bin_normsys(),
+ spec=get_spec_1bin_normsys(get_source_1bin_normsys()),
mu=1,
- expected_result=expected_result_1bin_normsys(1.0),
+ expected_result=get_expected_result_1bin_normsys(1.0),
config={'init_pars': 2, 'par_bounds': 2},
):
return {
@@ -223,13 +262,21 @@ def setup_1bin_normsys(
@pytest.fixture(scope='module')
-def source_2bin_histosys_example2():
+def setup_1bin_normsys():
+ return get_setup_1bin_normsys()
+
+
+def get_source_2bin_histosys_example2():
with open('validation/data/2bin_histosys_example2.json') as read_json:
return json.load(read_json)
@pytest.fixture(scope='module')
-def spec_2bin_histosys(source=source_2bin_histosys_example2()):
+def source_2bin_histosys_example2():
+ return get_source_2bin_histosys_example2()
+
+
+def get_spec_2bin_histosys(source=get_source_2bin_histosys_example2()):
spec = {
'channels': [
{
@@ -264,7 +311,11 @@ def spec_2bin_histosys(source=source_2bin_histosys_example2()):
@pytest.fixture(scope='module')
-def expected_result_2bin_histosys(mu=1):
+def spec_2bin_histosys():
+ return get_spec_2bin_histosys()
+
+
+def get_expected_result_2bin_histosys(mu=1):
if mu == 1:
expected_result = {
"exp": [
@@ -280,11 +331,15 @@ def expected_result_2bin_histosys(mu=1):
@pytest.fixture(scope='module')
-def setup_2bin_histosys(
- source=source_2bin_histosys_example2(),
- spec=spec_2bin_histosys(source_2bin_histosys_example2()),
+def expected_result_2bin_histosys():
+ return get_expected_result_2bin_histosys()
+
+
+def get_setup_2bin_histosys(
+ source=get_source_2bin_histosys_example2(),
+ spec=get_spec_2bin_histosys(get_source_2bin_histosys_example2()),
mu=1,
- expected_result=expected_result_2bin_histosys(1.0),
+ expected_result=get_expected_result_2bin_histosys(1.0),
config={'init_pars': 2, 'par_bounds': 2},
):
return {
@@ -296,13 +351,21 @@ def setup_2bin_histosys(
@pytest.fixture(scope='module')
-def source_2bin_2channel_example1():
+def setup_2bin_histosys():
+ return get_setup_2bin_histosys()
+
+
+def get_source_2bin_2channel_example1():
with open('validation/data/2bin_2channel_example1.json') as read_json:
return json.load(read_json)
@pytest.fixture(scope='module')
-def spec_2bin_2channel(source=source_2bin_2channel_example1()):
+def source_2bin_2channel_example1():
+ return get_source_2bin_2channel_example1()
+
+
+def get_spec_2bin_2channel(source=get_source_2bin_2channel_example1()):
spec = {
'channels': [
{
@@ -354,7 +417,11 @@ def spec_2bin_2channel(source=source_2bin_2channel_example1()):
@pytest.fixture(scope='module')
-def expected_result_2bin_2channel(mu=1.0):
+def spec_2bin_2channel():
+ return get_spec_2bin_2channel()
+
+
+def get_expected_result_2bin_2channel(mu=1.0):
if mu == 1:
expected_result = {
"exp": [
@@ -370,11 +437,15 @@ def expected_result_2bin_2channel(mu=1.0):
@pytest.fixture(scope='module')
-def setup_2bin_2channel(
- source=source_2bin_2channel_example1(),
- spec=spec_2bin_2channel(source_2bin_2channel_example1()),
+def expected_result_2bin_2channel():
+ return get_expected_result_2bin_2channel()
+
+
+def get_setup_2bin_2channel(
+ source=get_source_2bin_2channel_example1(),
+ spec=get_spec_2bin_2channel(get_source_2bin_2channel_example1()),
mu=1,
- expected_result=expected_result_2bin_2channel(1.0),
+ expected_result=get_expected_result_2bin_2channel(1.0),
config={'init_pars': 5, 'par_bounds': 5},
):
# 1 mu + 2 gammas for 2 channels each
@@ -387,13 +458,21 @@ def setup_2bin_2channel(
@pytest.fixture(scope='module')
-def source_2bin_2channel_couplednorm():
+def setup_2bin_2channel():
+ return get_setup_2bin_2channel()
+
+
+def get_source_2bin_2channel_couplednorm():
with open('validation/data/2bin_2channel_couplednorm.json') as read_json:
return json.load(read_json)
@pytest.fixture(scope='module')
-def spec_2bin_2channel_couplednorm(source=source_2bin_2channel_couplednorm()):
+def source_2bin_2channel_couplednorm():
+ return get_source_2bin_2channel_couplednorm()
+
+
+def get_spec_2bin_2channel_couplednorm(source=get_source_2bin_2channel_couplednorm()):
spec = {
'channels': [
{
@@ -452,7 +531,11 @@ def spec_2bin_2channel_couplednorm(source=source_2bin_2channel_couplednorm()):
@pytest.fixture(scope='module')
-def expected_result_2bin_2channel_couplednorm(mu=1.0):
+def spec_2bin_2channel_couplednorm():
+ return get_spec_2bin_2channel_couplednorm()
+
+
+def get_expected_result_2bin_2channel_couplednorm(mu=1.0):
# NB: mac/linux differ for exp[0]
# Mac: 0.055222676184648795
# Linux: 0.05522273289103311
@@ -472,11 +555,15 @@ def expected_result_2bin_2channel_couplednorm(mu=1.0):
@pytest.fixture(scope='module')
-def setup_2bin_2channel_couplednorm(
- source=source_2bin_2channel_couplednorm(),
- spec=spec_2bin_2channel_couplednorm(source_2bin_2channel_couplednorm()),
+def expected_result_2bin_2channel_couplednorm():
+ return get_expected_result_2bin_2channel_couplednorm()
+
+
+def get_setup_2bin_2channel_couplednorm(
+ source=get_source_2bin_2channel_couplednorm(),
+ spec=get_spec_2bin_2channel_couplednorm(get_source_2bin_2channel_couplednorm()),
mu=1,
- expected_result=expected_result_2bin_2channel_couplednorm(1.0),
+ expected_result=get_expected_result_2bin_2channel_couplednorm(1.0),
config={'init_pars': 2, 'par_bounds': 2},
):
# 1 mu + 1 alpha
@@ -489,13 +576,23 @@ def setup_2bin_2channel_couplednorm(
@pytest.fixture(scope='module')
-def source_2bin_2channel_coupledhisto():
+def setup_2bin_2channel_couplednorm():
+ return get_setup_2bin_2channel_couplednorm()
+
+
+def get_source_2bin_2channel_coupledhisto():
with open('validation/data/2bin_2channel_coupledhisto.json') as read_json:
return json.load(read_json)
@pytest.fixture(scope='module')
-def spec_2bin_2channel_coupledhistosys(source=source_2bin_2channel_coupledhisto()):
+def source_2bin_2channel_coupledhisto():
+ return get_source_2bin_2channel_coupledhisto()
+
+
+def get_spec_2bin_2channel_coupledhistosys(
+ source=get_source_2bin_2channel_coupledhisto(),
+):
spec = {
'channels': [
{
@@ -575,7 +672,11 @@ def spec_2bin_2channel_coupledhistosys(source=source_2bin_2channel_coupledhisto(
@pytest.fixture(scope='module')
-def expected_result_2bin_2channel_coupledhistosys(mu=1.0):
+def spec_2bin_2channel_coupledhistosys():
+ return get_spec_2bin_2channel_coupledhistosys()
+
+
+def get_expected_result_2bin_2channel_coupledhistosys(mu=1.0):
if mu == 1:
expected_result = {
"exp": [
@@ -591,11 +692,17 @@ def expected_result_2bin_2channel_coupledhistosys(mu=1.0):
@pytest.fixture(scope='module')
-def setup_2bin_2channel_coupledhistosys(
- source=source_2bin_2channel_coupledhisto(),
- spec=spec_2bin_2channel_coupledhistosys(source_2bin_2channel_coupledhisto()),
+def expected_result_2bin_2channel_coupledhistosys():
+ return get_expected_result_2bin_2channel_coupledhistosys()
+
+
+def get_setup_2bin_2channel_coupledhistosys(
+ source=get_source_2bin_2channel_coupledhisto(),
+ spec=get_spec_2bin_2channel_coupledhistosys(
+ get_source_2bin_2channel_coupledhisto()
+ ),
mu=1,
- expected_result=expected_result_2bin_2channel_coupledhistosys(1.0),
+ expected_result=get_expected_result_2bin_2channel_coupledhistosys(1.0),
config={'auxdata': 1, 'init_pars': 2, 'par_bounds': 2},
):
# 1 mu 1 shared histosys
@@ -608,14 +715,22 @@ def setup_2bin_2channel_coupledhistosys(
@pytest.fixture(scope='module')
-def source_2bin_2channel_coupledshapefactor():
+def setup_2bin_2channel_coupledhistosys():
+ return get_setup_2bin_2channel_coupledhistosys()
+
+
+def get_source_2bin_2channel_coupledshapefactor():
with open('validation/data/2bin_2channel_coupledshapefactor.json') as read_json:
return json.load(read_json)
@pytest.fixture(scope='module')
-def spec_2bin_2channel_coupledshapefactor(
- source=source_2bin_2channel_coupledshapefactor(),
+def source_2bin_2channel_coupledshapefactor():
+ return get_source_2bin_2channel_coupledshapefactor()
+
+
+def get_spec_2bin_2channel_coupledshapefactor(
+ source=get_source_2bin_2channel_coupledshapefactor(),
):
spec = {
'channels': [
@@ -664,7 +779,11 @@ def spec_2bin_2channel_coupledshapefactor(
@pytest.fixture(scope='module')
-def expected_result_2bin_2channel_coupledshapefactor(mu=1.0):
+def spec_2bin_2channel_coupledshapefactor():
+ return get_spec_2bin_2channel_coupledshapefactor()
+
+
+def get_expected_result_2bin_2channel_coupledshapefactor(mu=1.0):
if mu == 1:
expected_result = {
'obs': 0.5421679124909312,
@@ -680,13 +799,17 @@ def expected_result_2bin_2channel_coupledshapefactor(mu=1.0):
@pytest.fixture(scope='module')
-def setup_2bin_2channel_coupledshapefactor(
- source=source_2bin_2channel_coupledshapefactor(),
- spec=spec_2bin_2channel_coupledshapefactor(
- source_2bin_2channel_coupledshapefactor()
+def expected_result_2bin_2channel_coupledshapefactor():
+ return get_expected_result_2bin_2channel_coupledshapefactor()
+
+
+def get_setup_2bin_2channel_coupledshapefactor(
+ source=get_source_2bin_2channel_coupledshapefactor(),
+ spec=get_spec_2bin_2channel_coupledshapefactor(
+ get_source_2bin_2channel_coupledshapefactor()
),
mu=1,
- expected_result=expected_result_2bin_2channel_coupledshapefactor(1.0),
+ expected_result=get_expected_result_2bin_2channel_coupledshapefactor(1.0),
config={'auxdata': 0, 'init_pars': 3, 'par_bounds': 3},
):
# 1 mu 2 shared shapefactors
@@ -698,6 +821,11 @@ def setup_2bin_2channel_coupledshapefactor(
}
[email protected](scope='module')
+def setup_2bin_2channel_coupledshapefactor():
+ return get_setup_2bin_2channel_coupledshapefactor()
+
+
def validate_hypotest(pdf, data, mu_test, expected_result, tolerance=1e-6):
init_pars = pdf.config.suggested_init()
par_bounds = pdf.config.suggested_bounds()
@@ -716,17 +844,16 @@ def validate_hypotest(pdf, data, mu_test, expected_result, tolerance=1e-6):
assert abs(result - expected) / expected < tolerance, result
[email protected](
- 'setup_and_tolerance',
- [
- (setup_1bin_shapesys(), 1e-6),
- (setup_1bin_lumi(), 4e-6),
- (setup_1bin_normsys(), 2e-9),
- (setup_2bin_histosys(), 8e-5),
- (setup_2bin_2channel(), 1e-6),
- (setup_2bin_2channel_couplednorm(), 1e-6),
- (setup_2bin_2channel_coupledhistosys(), 1e-6),
- (setup_2bin_2channel_coupledshapefactor(), 2.5e-6),
[email protected](
+ params=[
+ ('setup_1bin_shapesys', 1e-6),
+ ('setup_1bin_lumi', 4e-6),
+ ('setup_1bin_normsys', 2e-9),
+ ('setup_2bin_histosys', 8e-5),
+ ('setup_2bin_2channel', 1e-6),
+ ('setup_2bin_2channel_couplednorm', 1e-6),
+ ('setup_2bin_2channel_coupledhistosys', 1e-6),
+ ('setup_2bin_2channel_coupledshapefactor', 2.5e-6),
],
ids=[
'1bin_shapesys_mu1',
@@ -739,6 +866,10 @@ def validate_hypotest(pdf, data, mu_test, expected_result, tolerance=1e-6):
'2bin_2channel_coupledshapefactor_mu1',
],
)
+def setup_and_tolerance(request):
+ return (request.getfixturevalue(request.param[0]), request.param[1])
+
+
def test_validation(setup_and_tolerance):
setup, tolerance = setup_and_tolerance
source = setup['source']
|
Fix Fixture use in pytest
# Description
In pytest `v4.0.0` the [direct call of a fixture results in an error](https://travis-ci.org/diana-hep/pyhf/jobs/455364238#L661-L669).
```
==================================== ERRORS ====================================
__________________ ERROR collecting tests/test_validation.py ___________________
tests/test_validation.py:13: in <module>
def spec_1bin_shapesys(source=source_1bin_example1()):
E _pytest.warning_types.RemovedInPytest4Warning: Fixture "source_1bin_example1" called directly. Fixtures are not meant to be called directly, are created automatically when test functions request them as parameters. See https://docs.pytest.org/en/latest/fixture.html for more information.
__________________ ERROR collecting tests/test_validation.py ___________________
tests/test_validation.py:13: in <module>
def spec_1bin_shapesys(source=source_1bin_example1()):
E _pytest.warning_types.RemovedInPytest4Warning: Fixture "source_1bin_example1" called directly. Fixtures are not meant to be called directly, are created automatically when test functions request them as parameters. See https://docs.pytest.org/en/latest/fixture.html for more information.
```
This requires changing the way that pytest is used a bit.
This was noticed in preparation of PR #369
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
Also seen in #352 .
| 2020-08-29T01:07:14 |
scikit-hep/pyhf
| 1,050 |
scikit-hep__pyhf-1050
|
[
"811"
] |
e3f50bb2a84c6281bb250023c3ad2c9c560ff2ec
|
diff --git a/src/pyhf/workspace.py b/src/pyhf/workspace.py
--- a/src/pyhf/workspace.py
+++ b/src/pyhf/workspace.py
@@ -473,6 +473,9 @@ def _prune_and_rename(
Returns:
~pyhf.workspace.Workspace: A new workspace object with the specified components removed or renamed
+ Raises:
+ ~pyhf.exceptions.InvalidWorkspaceOperation: An item name to prune or rename does not exist in the workspace.
+
"""
# avoid mutable defaults
prune_modifiers = [] if prune_modifiers is None else prune_modifiers
@@ -487,6 +490,36 @@ def _prune_and_rename(
rename_channels = {} if rename_channels is None else rename_channels
rename_measurements = {} if rename_measurements is None else rename_measurements
+ for modifier_type in prune_modifier_types:
+ if modifier_type not in dict(self.modifiers).values():
+ raise exceptions.InvalidWorkspaceOperation(
+ f"{modifier_type} is not one of the modifier types in this workspace."
+ )
+
+ for modifier_name in (*prune_modifiers, *rename_modifiers.keys()):
+ if modifier_name not in dict(self.modifiers):
+ raise exceptions.InvalidWorkspaceOperation(
+ f"{modifier_name} is not one of the modifiers in this workspace."
+ )
+
+ for sample_name in (*prune_samples, *rename_samples.keys()):
+ if sample_name not in self.samples:
+ raise exceptions.InvalidWorkspaceOperation(
+ f"{sample_name} is not one of the samples in this workspace."
+ )
+
+ for channel_name in (*prune_channels, *rename_channels.keys()):
+ if channel_name not in self.channels:
+ raise exceptions.InvalidWorkspaceOperation(
+ f"{channel_name} is not one of the channels in this workspace."
+ )
+
+ for measurement_name in (*prune_measurements, *rename_measurements.keys()):
+ if measurement_name not in self.measurement_names:
+ raise exceptions.InvalidWorkspaceOperation(
+ f"{measurement_name} is not one of the measurements in this workspace."
+ )
+
newspec = {
'channels': [
{
@@ -573,6 +606,9 @@ def prune(
Returns:
~pyhf.workspace.Workspace: A new workspace object with the specified components removed
+ Raises:
+ ~pyhf.exceptions.InvalidWorkspaceOperation: An item name to prune does not exist in the workspace.
+
"""
# avoid mutable defaults
modifiers = [] if modifiers is None else modifiers
@@ -605,6 +641,9 @@ def rename(self, modifiers=None, samples=None, channels=None, measurements=None)
Returns:
~pyhf.workspace.Workspace: A new workspace object with the specified components renamed
+ Raises:
+ ~pyhf.exceptions.InvalidWorkspaceOperation: An item name to rename does not exist in the workspace.
+
"""
# avoid mutable defaults
modifiers = {} if modifiers is None else modifiers
|
diff --git a/tests/test_workspace.py b/tests/test_workspace.py
--- a/tests/test_workspace.py
+++ b/tests/test_workspace.py
@@ -159,50 +159,53 @@ def test_json_serializable(workspace_factory):
assert json.dumps(workspace_factory())
-def test_prune_nothing(workspace_factory):
[email protected](
+ "kwargs",
+ [
+ dict(channels=['fake-name']),
+ dict(samples=['fake-sample']),
+ dict(modifiers=['fake-modifier']),
+ dict(modifier_types=['fake-type']),
+ ],
+)
+def test_prune_error(workspace_factory, kwargs):
ws = workspace_factory()
- new_ws = ws.prune(
- channels=['fake-name'],
- samples=['fake-sample'],
- modifiers=['fake-modifier'],
- modifier_types=['fake-type'],
- )
- assert new_ws
+ with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation):
+ ws.prune(**kwargs)
def test_prune_channel(workspace_factory):
ws = workspace_factory()
channel = ws.channels[0]
+ with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation):
+ ws.prune(channels=channel)
+
if len(ws.channels) == 1:
with pytest.raises(pyhf.exceptions.InvalidSpecification):
- new_ws = ws.prune(channels=channel)
- with pytest.raises(pyhf.exceptions.InvalidSpecification):
- new_ws = ws.prune(channels=[channel])
+ ws.prune(channels=[channel])
else:
- new_ws = ws.prune(channels=channel)
+ new_ws = ws.prune(channels=[channel])
assert channel not in new_ws.channels
assert channel not in [obs['name'] for obs in new_ws['observations']]
- new_ws_list = ws.prune(channels=[channel])
- assert new_ws_list == new_ws
-
def test_prune_sample(workspace_factory):
ws = workspace_factory()
sample = ws.samples[1]
- new_ws = ws.prune(samples=sample)
- assert new_ws
- assert sample not in new_ws.samples
+ with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation):
+ ws.prune(samples=sample)
- new_ws_list = ws.prune(samples=[sample])
- assert new_ws_list == new_ws
+ new_ws = ws.prune(samples=[sample])
+ assert sample not in new_ws.samples
def test_prune_modifier(workspace_factory):
ws = workspace_factory()
modifier = 'lumi'
- new_ws = ws.prune(modifiers=modifier)
- assert new_ws
+ with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation):
+ ws.prune(modifiers=modifier)
+
+ new_ws = ws.prune(modifiers=[modifier])
assert modifier not in new_ws.parameters
assert modifier not in [
p['name']
@@ -210,19 +213,16 @@ def test_prune_modifier(workspace_factory):
for p in measurement['config']['parameters']
]
- new_ws_list = ws.prune(modifiers=[modifier])
- assert new_ws_list == new_ws
-
def test_prune_modifier_type(workspace_factory):
ws = workspace_factory()
modifier_type = 'lumi'
- new_ws = ws.prune(modifier_types=modifier_type)
- assert new_ws
- assert modifier_type not in [item[1] for item in new_ws.modifiers]
- new_ws_list = ws.prune(modifier_types=[modifier_type])
- assert new_ws_list == new_ws
+ with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation):
+ ws.prune(modifier_types=modifier_type)
+
+ new_ws = ws.prune(modifier_types=[modifier_type])
+ assert modifier_type not in [item[1] for item in new_ws.modifiers]
def test_prune_measurements(workspace_factory):
@@ -230,10 +230,10 @@ def test_prune_measurements(workspace_factory):
measurement = ws.measurement_names[0]
if len(ws.measurement_names) == 1:
+ with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation):
+ ws.prune(measurements=measurement)
with pytest.raises(pyhf.exceptions.InvalidSpecification):
- new_ws = ws.prune(measurements=measurement)
- with pytest.raises(pyhf.exceptions.InvalidSpecification):
- new_ws = ws.prune(measurements=[measurement])
+ ws.prune(measurements=[measurement])
else:
new_ws = ws.prune(measurements=[measurement])
assert new_ws
@@ -341,22 +341,20 @@ def test_combine_workspace_same_channels_incompatible_structure(
):
ws = workspace_factory()
new_ws = ws.rename(
- channels={'channel2': 'channel3'},
- samples={'signal': 'signal_other'},
- measurements={'GaussExample': 'GaussExample2'},
- ).prune(measurements=['GammaExample', 'ConstExample', 'LogNormExample'])
+ samples={ws.samples[0]: 'sample_other'},
+ )
with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation) as excinfo:
pyhf.Workspace.combine(ws, new_ws, join=join)
assert 'channel1' in str(excinfo.value)
- assert 'channel2' not in str(excinfo.value)
@pytest.mark.parametrize("join", ['outer', 'left outer', 'right outer'])
def test_combine_workspace_same_channels_outer_join(workspace_factory, join):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel2': 'channel3'})
+ new_ws = ws.rename(channels={ws.channels[-1]: 'new_channel'})
combined = pyhf.Workspace.combine(ws, new_ws, join=join)
- assert 'channel1' in combined.channels
+ assert all(channel in combined.channels for channel in ws.channels)
+ assert all(channel in combined.channels for channel in new_ws.channels)
@pytest.mark.parametrize("join", ['left outer', 'right outer'])
@@ -364,7 +362,7 @@ def test_combine_workspace_same_channels_outer_join_unsafe(
workspace_factory, join, caplog
):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel2': 'channel3'})
+ new_ws = ws.rename(channels={ws.channels[-1]: 'new_channel'})
pyhf.Workspace.combine(ws, new_ws, join=join)
assert 'using an unsafe join operation' in caplog.text
@@ -372,11 +370,9 @@ def test_combine_workspace_same_channels_outer_join_unsafe(
@pytest.mark.parametrize("join", ['none', 'outer'])
def test_combine_workspace_incompatible_poi(workspace_factory, join):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
- measurements=['GammaExample', 'ConstExample', 'LogNormExample']
- )
- new_ws = new_ws.rename(
- modifiers={new_ws.get_measurement()['config']['poi']: 'renamedPOI'}
+ new_ws = ws.rename(
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
+ modifiers={ws.get_measurement()['config']['poi']: 'renamedPOI'},
)
with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation) as excinfo:
pyhf.Workspace.combine(ws, new_ws, join=join)
@@ -388,22 +384,16 @@ def test_combine_workspace_diff_version(workspace_factory, join):
ws = workspace_factory()
ws.version = '1.0.0'
new_ws = ws.rename(
- channels={'channel1': 'channel3', 'channel2': 'channel4'},
- samples={
- 'background1': 'background3',
- 'background2': 'background4',
- 'signal': 'signal2',
- },
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
+ samples={sample: f'renamed_{sample}' for sample in ws.samples},
modifiers={
- 'syst1': 'syst4',
- 'bkg1Shape': 'bkg3Shape',
- 'bkg2Shape': 'bkg4Shape',
+ modifier: f'renamed_{modifier}'
+ for modifier, _ in ws.modifiers
+ if not modifier == 'lumi'
},
measurements={
- 'ConstExample': 'OtherConstExample',
- 'LogNormExample': 'OtherLogNormExample',
- 'GaussExample': 'OtherGaussExample',
- 'GammaExample': 'OtherGammaExample',
+ measurement: f'renamed_{measurement}'
+ for measurement in ws.measurement_names
},
)
new_ws['version'] = '1.2.0'
@@ -416,8 +406,8 @@ def test_combine_workspace_diff_version(workspace_factory, join):
@pytest.mark.parametrize("join", ['none'])
def test_combine_workspace_duplicate_parameter_configs(workspace_factory, join):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
- measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ new_ws = ws.rename(
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
)
with pytest.raises(pyhf.exceptions.InvalidWorkspaceOperation) as excinfo:
pyhf.Workspace.combine(ws, new_ws, join=join)
@@ -429,8 +419,8 @@ def test_combine_workspace_duplicate_parameter_configs_outer_join(
workspace_factory, join
):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
- measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ new_ws = ws.rename(
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
)
combined = pyhf.Workspace.combine(ws, new_ws, join=join)
@@ -465,8 +455,8 @@ def test_combine_workspace_duplicate_parameter_configs_outer_join(
def test_combine_workspace_parameter_configs_ordering(workspace_factory):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
- measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ new_ws = ws.rename(
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
)
assert (
ws.get_measurement(measurement_name='GaussExample')['config']['parameters']
@@ -478,16 +468,16 @@ def test_combine_workspace_parameter_configs_ordering(workspace_factory):
def test_combine_workspace_observation_ordering(workspace_factory):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
- measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ new_ws = ws.rename(
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
)
assert ws['observations'][0]['data'] == new_ws['observations'][0]['data']
def test_combine_workspace_deepcopied(workspace_factory):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
- measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ new_ws = ws.rename(
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
)
new_ws.get_measurement(measurement_name='GaussExample')['config']['parameters'][0][
'bounds'
@@ -507,8 +497,8 @@ def test_combine_workspace_deepcopied(workspace_factory):
@pytest.mark.parametrize("join", ['fake join operation'])
def test_combine_workspace_invalid_join_operation(workspace_factory, join):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
- measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ new_ws = ws.rename(
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
)
with pytest.raises(ValueError) as excinfo:
pyhf.Workspace.combine(ws, new_ws, join=join)
@@ -518,8 +508,8 @@ def test_combine_workspace_invalid_join_operation(workspace_factory, join):
@pytest.mark.parametrize("join", ['none'])
def test_combine_workspace_incompatible_parameter_configs(workspace_factory, join):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
- measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ new_ws = ws.rename(
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
)
new_ws.get_measurement(measurement_name='GaussExample')['config']['parameters'][0][
'bounds'
@@ -534,8 +524,8 @@ def test_combine_workspace_incompatible_parameter_configs_outer_join(
workspace_factory, join
):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
- measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ new_ws = ws.rename(
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
)
new_ws.get_measurement(measurement_name='GaussExample')['config']['parameters'][0][
'bounds'
@@ -555,8 +545,8 @@ def test_combine_workspace_incompatible_parameter_configs_left_outer_join(
workspace_factory,
):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
- measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ new_ws = ws.rename(
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
)
new_ws.get_measurement(measurement_name='GaussExample')['config']['parameters'][0][
'bounds'
@@ -576,8 +566,8 @@ def test_combine_workspace_incompatible_parameter_configs_right_outer_join(
workspace_factory,
):
ws = workspace_factory()
- new_ws = ws.rename(channels={'channel1': 'channel3', 'channel2': 'channel4'}).prune(
- measurements=['GammaExample', 'ConstExample', 'LogNormExample']
+ new_ws = ws.rename(
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
)
new_ws.get_measurement(measurement_name='GaussExample')['config']['parameters'][0][
'bounds'
@@ -597,22 +587,16 @@ def test_combine_workspace_incompatible_parameter_configs_right_outer_join(
def test_combine_workspace_incompatible_observations(workspace_factory, join):
ws = workspace_factory()
new_ws = ws.rename(
- channels={'channel1': 'channel3', 'channel2': 'channel4'},
- samples={
- 'background1': 'background3',
- 'background2': 'background4',
- 'signal': 'signal2',
- },
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
+ samples={sample: f'renamed_{sample}' for sample in ws.samples},
modifiers={
- 'syst1': 'syst4',
- 'bkg1Shape': 'bkg3Shape',
- 'bkg2Shape': 'bkg4Shape',
+ modifier: f'renamed_{modifier}'
+ for modifier, _ in ws.modifiers
+ if not modifier == 'lumi'
},
measurements={
- 'GaussExample': 'OtherGaussExample',
- 'GammaExample': 'OtherGammaExample',
- 'ConstExample': 'OtherConstExample',
- 'LogNormExample': 'OtherLogNormExample',
+ measurement: f'renamed_{measurement}'
+ for measurement in ws.measurement_names
},
)
new_ws['observations'][0]['name'] = ws['observations'][0]['name']
@@ -626,22 +610,16 @@ def test_combine_workspace_incompatible_observations(workspace_factory, join):
def test_combine_workspace_incompatible_observations_left_outer(workspace_factory):
ws = workspace_factory()
new_ws = ws.rename(
- channels={'channel1': 'channel3', 'channel2': 'channel4'},
- samples={
- 'background1': 'background3',
- 'background2': 'background4',
- 'signal': 'signal2',
- },
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
+ samples={sample: f'renamed_{sample}' for sample in ws.samples},
modifiers={
- 'syst1': 'syst4',
- 'bkg1Shape': 'bkg3Shape',
- 'bkg2Shape': 'bkg4Shape',
+ modifier: f'renamed_{modifier}'
+ for modifier, _ in ws.modifiers
+ if not modifier == 'lumi'
},
measurements={
- 'GaussExample': 'OtherGaussExample',
- 'GammaExample': 'OtherGammaExample',
- 'ConstExample': 'OtherConstExample',
- 'LogNormExample': 'OtherLogNormExample',
+ measurement: f'renamed_{measurement}'
+ for measurement in ws.measurement_names
},
)
new_ws['observations'][0]['name'] = ws['observations'][0]['name']
@@ -656,22 +634,16 @@ def test_combine_workspace_incompatible_observations_left_outer(workspace_factor
def test_combine_workspace_incompatible_observations_right_outer(workspace_factory):
ws = workspace_factory()
new_ws = ws.rename(
- channels={'channel1': 'channel3', 'channel2': 'channel4'},
- samples={
- 'background1': 'background3',
- 'background2': 'background4',
- 'signal': 'signal2',
- },
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
+ samples={sample: f'renamed_{sample}' for sample in ws.samples},
modifiers={
- 'syst1': 'syst4',
- 'bkg1Shape': 'bkg3Shape',
- 'bkg2Shape': 'bkg4Shape',
+ modifier: f'renamed_{modifier}'
+ for modifier, _ in ws.modifiers
+ if not modifier == 'lumi'
},
measurements={
- 'GaussExample': 'OtherGaussExample',
- 'GammaExample': 'OtherGammaExample',
- 'ConstExample': 'OtherConstExample',
- 'LogNormExample': 'OtherLogNormExample',
+ measurement: f'renamed_{measurement}'
+ for measurement in ws.measurement_names
},
)
new_ws['observations'][0]['name'] = ws['observations'][0]['name']
@@ -687,22 +659,16 @@ def test_combine_workspace_incompatible_observations_right_outer(workspace_facto
def test_combine_workspace(workspace_factory, join):
ws = workspace_factory()
new_ws = ws.rename(
- channels={'channel1': 'channel3', 'channel2': 'channel4'},
- samples={
- 'background1': 'background3',
- 'background2': 'background4',
- 'signal': 'signal2',
- },
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
+ samples={sample: f'renamed_{sample}' for sample in ws.samples},
modifiers={
- 'syst1': 'syst4',
- 'bkg1Shape': 'bkg3Shape',
- 'bkg2Shape': 'bkg4Shape',
+ modifier: f'renamed_{modifier}'
+ for modifier, _ in ws.modifiers
+ if not modifier == 'lumi'
},
measurements={
- 'GaussExample': 'OtherGaussExample',
- 'GammaExample': 'OtherGammaExample',
- 'ConstExample': 'OtherConstExample',
- 'LogNormExample': 'OtherLogNormExample',
+ measurement: f'renamed_{measurement}'
+ for measurement in ws.measurement_names
},
)
combined = pyhf.Workspace.combine(ws, new_ws, join=join)
@@ -722,22 +688,16 @@ def test_workspace_equality(workspace_factory):
def test_workspace_inheritance(workspace_factory):
ws = workspace_factory()
new_ws = ws.rename(
- channels={'channel1': 'channel3', 'channel2': 'channel4'},
- samples={
- 'background1': 'background3',
- 'background2': 'background4',
- 'signal': 'signal2',
- },
+ channels={channel: f'renamed_{channel}' for channel in ws.channels},
+ samples={sample: f'renamed_{sample}' for sample in ws.samples},
modifiers={
- 'syst1': 'syst4',
- 'bkg1Shape': 'bkg3Shape',
- 'bkg2Shape': 'bkg4Shape',
+ modifier: f'renamed_{modifier}'
+ for modifier, _ in ws.modifiers
+ if not modifier == 'lumi'
},
measurements={
- 'GaussExample': 'OtherGaussExample',
- 'GammaExample': 'OtherGammaExample',
- 'ConstExample': 'OtherConstExample',
- 'LogNormExample': 'OtherLogNormExample',
+ measurement: f'renamed_{measurement}'
+ for measurement in ws.measurement_names
},
)
|
prune should show warning if modifier / sample is not found
# Description
if you have a typo, `pyhf prune` fails silently
|
Related: #751.
closing as dupe :)
Not a dupe. This is `prune`, other is `rename`.
| 2020-09-02T20:47:32 |
scikit-hep/pyhf
| 1,053 |
scikit-hep__pyhf-1053
|
[
"1052"
] |
5bf324208ab422201eacd52381872058f853b44c
|
diff --git a/src/pyhf/infer/__init__.py b/src/pyhf/infer/__init__.py
--- a/src/pyhf/infer/__init__.py
+++ b/src/pyhf/infer/__init__.py
@@ -24,9 +24,9 @@ def hypotest(
... test_poi, data, model, qtilde=True, return_expected_set=True
... )
>>> CLs_obs
- array(0.05251554)
+ array(0.05251497)
>>> CLs_exp_band
- [array(0.00260641), array(0.01382066), array(0.06445521), array(0.23526104), array(0.57304182)]
+ [array(0.00260626), array(0.01382005), array(0.06445321), array(0.23525644), array(0.57303621)]
Args:
poi_test (Number or Tensor): The value of the parameter of interest (POI)
diff --git a/src/pyhf/optimize/opt_scipy.py b/src/pyhf/optimize/opt_scipy.py
--- a/src/pyhf/optimize/opt_scipy.py
+++ b/src/pyhf/optimize/opt_scipy.py
@@ -60,6 +60,9 @@ def _minimize(
values = [v for _, v in fixed_vals]
if fixed_vals:
constraints = [{'type': 'eq', 'fun': lambda v: v[indices] - values}]
+ # update the initial values to the fixed value for any fixed parameter
+ for idx, fixed_val in fixed_vals:
+ x0[idx] = fixed_val
else:
constraints = []
|
diff --git a/tests/test_optim.py b/tests/test_optim.py
--- a/tests/test_optim.py
+++ b/tests/test_optim.py
@@ -434,3 +434,23 @@ def test_stitch_pars(backend):
0,
60,
]
+
+
+def test_init_pars_sync_fixed_values_scipy(mocker):
+ opt = pyhf.optimize.scipy_optimizer()
+
+ minimizer = mocker.MagicMock()
+ opt._minimize(minimizer, None, [9, 9, 9], fixed_vals=[(0, 1)])
+ assert minimizer.call_args[0] == (None, [1, 9, 9])
+
+
+def test_init_pars_sync_fixed_values_minuit(mocker):
+ opt = pyhf.optimize.minuit_optimizer()
+
+ # patch all we need
+ from pyhf.optimize import opt_minuit
+
+ minimizer = mocker.patch.object(opt_minuit, 'iminuit')
+ opt._get_minimizer(None, [9, 9, 9], [(0, 10)] * 3, fixed_vals=[(0, 1)])
+ assert minimizer.Minuit.from_array_func.call_args[1]['start'] == [1, 9, 9]
+ assert minimizer.Minuit.from_array_func.call_args[1]['fix'] == [True, False, False]
diff --git a/tests/test_regression.py b/tests/test_regression.py
--- a/tests/test_regression.py
+++ b/tests/test_regression.py
@@ -79,12 +79,12 @@ def test_sbottom_regionA_1400_950_60(
np.array(CLs_exp),
np.array(
[
- 0.002644707461012826,
- 0.013976754489151644,
- 0.06497313811425813,
- 0.23644505123524753,
- 0.5744843501873754,
- ]
+ 0.0026445531093281147,
+ 0.013976126501170727,
+ 0.06497105816950004,
+ 0.23644030478043676,
+ 0.5744785776763938,
+ ],
),
rtol=1e-5,
)
@@ -103,17 +103,17 @@ def test_sbottom_regionA_1500_850_60(
CLs_obs, CLs_exp = calculate_CLs(
sbottom_regionA_bkgonly_json, sbottom_regionA_1500_850_60_patch_json
)
- assert CLs_obs == pytest.approx(0.04536774062150508, rel=1e-5)
+ assert CLs_obs == pytest.approx(0.045367205665400624, rel=1e-5)
assert np.all(
np.isclose(
np.array(CLs_exp),
np.array(
[
- 0.0059847029077065295,
- 0.026103516126601122,
- 0.10093985752614597,
- 0.3101988586187604,
- 0.6553686728646031,
+ 0.00598431785676406,
+ 0.026102240062850574,
+ 0.10093641492218848,
+ 0.31019245951964736,
+ 0.6553623337518385,
]
),
rtol=1e-5,
diff --git a/tests/test_validation.py b/tests/test_validation.py
--- a/tests/test_validation.py
+++ b/tests/test_validation.py
@@ -50,13 +50,13 @@ def expected_result_1bin_shapesys(mu=1.0):
if mu == 1:
expected_result = {
"exp": [
- 0.06371799398864626,
- 0.15096503398048894,
- 0.3279606950533305,
- 0.6046087303039118,
- 0.8662627605298466,
+ 0.06372011644331387,
+ 0.1509686618126131,
+ 0.3279657430196915,
+ 0.604613569829645,
+ 0.8662652332047568,
],
- "obs": 0.4541865416107029,
+ "obs": 0.45418892944576333,
}
return expected_result
@@ -121,8 +121,14 @@ def spec_1bin_lumi():
def expected_result_1bin_lumi(mu=1.0):
if mu == 1:
expected_result = {
- "exp": [0.01060338, 0.04022273, 0.13614217, 0.37078321, 0.71104119],
- "obs": 0.01047275,
+ "exp": [
+ 0.01060400765567206,
+ 0.04022451457730529,
+ 0.13614632580079802,
+ 0.37078985531427255,
+ 0.7110468540175344,
+ ],
+ "obs": 0.010473144401519705,
}
return expected_result
@@ -189,13 +195,13 @@ def expected_result_1bin_normsys(mu=1.0):
if mu == 1:
expected_result = {
"exp": [
- 7.47169462e-10,
- 5.7411551509088054e-08,
- 3.6898088062731205e-06,
- 0.00016965731538267896,
- 0.004392708998555453,
+ 7.472581399417304e-10,
+ 5.741738272450336e-08,
+ 3.690120950161796e-06,
+ 0.00016966882793076826,
+ 0.004392935288879465,
],
- "obs": 0.0006735317023683173,
+ "obs": 0.0006735336290569807,
}
return expected_result
@@ -262,7 +268,7 @@ def expected_result_2bin_histosys(mu=1):
if mu == 1:
expected_result = {
"exp": [
- 7.134513306138892e-06,
+ 7.133904244038431e-06,
0.00012547100627138575,
0.001880010666437615,
0.02078964907605385,
@@ -352,13 +358,13 @@ def expected_result_2bin_2channel(mu=1.0):
if mu == 1:
expected_result = {
"exp": [
- 0.00043491354821983556,
- 0.0034223000502860606,
- 0.02337423265831151,
- 0.1218654225510158,
- 0.40382074249477845,
+ 0.0004349234603527283,
+ 0.003422361539161119,
+ 0.02337454317608372,
+ 0.12186650297311125,
+ 0.40382274594391104,
],
- "obs": 0.056332621064982304,
+ "obs": 0.0563327694384318,
}
return expected_result
@@ -447,16 +453,20 @@ def spec_2bin_2channel_couplednorm(source=source_2bin_2channel_couplednorm()):
@pytest.fixture(scope='module')
def expected_result_2bin_2channel_couplednorm(mu=1.0):
+ # NB: mac/linux differ for exp[0]
+ # Mac: 0.055222676184648795
+ # Linux: 0.05522273289103311
+ # Fill with midpoint of both values
if mu == 1:
expected_result = {
"exp": [
- 0.055223914655538435,
- 0.13613239925395315,
- 0.3068720101493323,
- 0.5839470093910164,
- 0.8554725461337025,
+ 0.05522270453784095,
+ 0.1361301880753241,
+ 0.30686879632329855,
+ 0.5839437910061168,
+ 0.8554708284963864,
],
- "obs": 0.5906228034705155,
+ "obs": 0.5906216823766879,
}
return expected_result
@@ -569,11 +579,11 @@ def expected_result_2bin_2channel_coupledhistosys(mu=1.0):
if mu == 1:
expected_result = {
"exp": [
- 1.7653746536962154e-05,
- 0.00026265644807799805,
- 0.00334003612780065,
- 0.031522353024659715,
- 0.17907742915143962,
+ 1.7654378902209275e-05,
+ 0.00026266409358853543,
+ 0.0033401113778672156,
+ 0.03152286332324451,
+ 0.17907927340107824,
],
"obs": 0.07967400132261188,
}
@@ -703,7 +713,7 @@ def validate_hypotest(pdf, data, mu_test, expected_result, tolerance=1e-6):
)
assert abs(CLs_obs - expected_result['obs']) / expected_result['obs'] < tolerance
for result, expected in zip(CLs_exp_set, expected_result['exp']):
- assert abs(result - expected) / expected < tolerance
+ assert abs(result - expected) / expected < tolerance, result
@pytest.mark.parametrize(
|
Bug in scipy minimization: init_pars and fixed_vals are not synced
# Description
Related: #1051 (found as part of this PR).
There is a bug in `pyhf`'s codebase (since ~forever) where the `init_par` for a fixed parameter might differ from the constrained value set for that fixed parameter. See for example v0.4.4:
https://github.com/scikit-hep/pyhf/blob/6ac0f6280c56111c32f46ec9aaad0286d05d36e7/src/pyhf/infer/mle.py#L52-L90
https://github.com/scikit-hep/pyhf/blob/6ac0f6280c56111c32f46ec9aaad0286d05d36e7/src/pyhf/optimize/opt_scipy.py#L16-L53
# Expected Behavior
I would've thought the underlying optimizers (particularly scipy) would be smart enough to handle or recognize when the constraint/init_pars are at odds with each other.
# Actual Behavior
See description.
# Steps to Reproduce
Follow along with me:
call `fixed_poi_fit` with:
- `poi_val = 0.5`
- `data`
- `pdf`
- `init_pars=[1, 1, 1]`
This will call `opt.minimize` with:
- `objective=twice_nll`
- `data=data`
- `pdf=pdf`
- `init_pars=[1, 1, 1]`
- `fixed_vals=[(0, 0.5)]`
at this point, `opt.minimize` (in the case of scipy) will do
```python
constraints = [{'type': 'eq', 'fun': lambda v: v[indices] - values}]
```
which becomes essentially
```python
constraints = [{'type': 'eq', 'fun': lambda v: v[0] - 0.5}]
```
but still calls `scipy.optimize.minimize` with `init_pars=[1, 1, 1]`. If one changes this to `[0.5, 1, 1]` -- one observes a slightly different result... but probably more correct.
Minuit does not have the same bug here because of https://github.com/scikit-hep/pyhf/blob/6ac0f6280c56111c32f46ec9aaad0286d05d36e7/src/pyhf/optimize/opt_minuit.py#L45 which updates the initval with the fixed value `initvals['p{}'.format(index)] = value`.
I was worried that the major refactor I did #951 broke this or changed this. In fact, I managed to keep the same bug in scipy, and did not introduce this bug into minuit.
| 2020-09-04T19:38:06 |
|
scikit-hep/pyhf
| 1,060 |
scikit-hep__pyhf-1060
|
[
"828"
] |
e219969af80e260e7a0db8f67108e542a0927cd5
|
diff --git a/src/pyhf/cli/cli.py b/src/pyhf/cli/cli.py
--- a/src/pyhf/cli/cli.py
+++ b/src/pyhf/cli/cli.py
@@ -29,6 +29,7 @@ def pyhf():
pyhf.add_command(spec.sort)
# pyhf.add_command(infer.cli)
+pyhf.add_command(infer.fit)
pyhf.add_command(infer.cls)
pyhf.add_command(patchset.cli)
diff --git a/src/pyhf/cli/infer.py b/src/pyhf/cli/infer.py
--- a/src/pyhf/cli/infer.py
+++ b/src/pyhf/cli/infer.py
@@ -6,6 +6,7 @@
from ..utils import EqDelimStringParamType
from ..infer import hypotest
+from ..infer import mle
from ..workspace import Workspace
from .. import get_backend, set_backend, optimize
@@ -17,6 +18,119 @@ def cli():
"""Infererence CLI group."""
[email protected]()
[email protected]("workspace", default="-")
[email protected](
+ "--output-file",
+ help="The location of the output json file. If not specified, prints to screen.",
+ default=None,
+)
[email protected]("--measurement", default=None)
[email protected]("-p", "--patch", multiple=True)
[email protected](
+ "--value",
+ help="Flag for returning the fitted value of the objective function.",
+ default=False,
+ is_flag=True,
+)
[email protected](
+ "--backend",
+ type=click.Choice(["numpy", "pytorch", "tensorflow", "jax", "np", "torch", "tf"]),
+ help="The tensor backend used for the calculation.",
+ default="numpy",
+)
[email protected](
+ "--optimizer",
+ type=click.Choice(["scipy", "minuit"]),
+ help="The optimizer used for the calculation.",
+ default="scipy",
+)
[email protected]("--optconf", type=EqDelimStringParamType(), multiple=True)
+def fit(
+ workspace,
+ output_file,
+ measurement,
+ patch,
+ value,
+ backend,
+ optimizer,
+ optconf,
+):
+ """
+ Perform a maximum likelihood fit for a given pyhf workspace.
+
+ Example:
+
+ .. code-block:: shell
+
+ $ curl -sL https://git.io/JJYDE | pyhf fit --value
+
+ \b
+ {
+ "mle_parameters": {
+ "mu": [
+ 0.00017298628839781602
+ ],
+ "uncorr_bkguncrt": [
+ 1.0000015671710816,
+ 0.9999665895859197
+ ]
+ },
+ "twice_nll": 23.19636590468879
+ }
+ """
+ # set the backend if not NumPy
+ if backend in ["pytorch", "torch"]:
+ set_backend("pytorch", precision="64b")
+ elif backend in ["tensorflow", "tf"]:
+ set_backend("tensorflow", precision="64b")
+ elif backend in ["jax"]:
+ set_backend("jax")
+ tensorlib, _ = get_backend()
+
+ optconf = {k: v for item in optconf for k, v in item.items()}
+
+ # set the new optimizer
+ if optimizer:
+ new_optimizer = getattr(optimize, optimizer) or getattr(
+ optimize, f"{optimizer}_optimizer"
+ )
+ set_backend(tensorlib, new_optimizer(**optconf))
+
+ with click.open_file(workspace, "r") as specstream:
+ spec = json.load(specstream)
+ ws = Workspace(spec)
+ patches = [json.loads(click.open_file(pfile, "r").read()) for pfile in patch]
+
+ model = ws.model(
+ measurement_name=measurement,
+ patches=patches,
+ modifier_settings={
+ "normsys": {"interpcode": "code4"},
+ "histosys": {"interpcode": "code4p"},
+ },
+ )
+ data = ws.data(model)
+
+ fit_result = mle.fit(data, model, return_fitted_val=value)
+
+ _pars = fit_result if not value else fit_result[0]
+ bestfit_pars = {
+ k: tensorlib.tolist(_pars[v["slice"]]) for k, v in model.config.par_map.items()
+ }
+
+ result = {"mle_parameters": bestfit_pars}
+ if value:
+ result["twice_nll"] = tensorlib.tolist(fit_result[-1])
+
+ if output_file is None:
+ click.echo(json.dumps(result, indent=4, sort_keys=True))
+ else:
+ with open(output_file, "w+") as out_file:
+ json.dump(result, out_file, indent=4, sort_keys=True)
+ log.debug("Written to {0:s}".format(output_file))
+
+
@cli.command()
@click.argument('workspace', default='-')
@click.option(
@@ -34,7 +148,12 @@ def cli():
help='The tensor backend used for the calculation.',
default='numpy',
)
[email protected]('--optimizer')
[email protected](
+ "--optimizer",
+ type=click.Choice(["scipy", "minuit"]),
+ help="The optimizer used for the calculation.",
+ default="scipy",
+)
@click.option('--optconf', type=EqDelimStringParamType(), multiple=True)
def cls(
workspace,
|
diff --git a/tests/test_scripts.py b/tests/test_scripts.py
--- a/tests/test_scripts.py
+++ b/tests/test_scripts.py
@@ -55,6 +55,49 @@ def test_import_prepHistFactory_stdout(tmpdir, script_runner):
assert d
+def test_import_prepHistFactory_and_fit(tmpdir, script_runner):
+ temp = tmpdir.join("parsed_output.json")
+ command = "pyhf xml2json validation/xmlimport_input/config/example.xml --basedir validation/xmlimport_input/ --output-file {0:s}".format(
+ temp.strpath
+ )
+ ret = script_runner.run(*shlex.split(command))
+
+ command = "pyhf fit {0:s}".format(temp.strpath)
+ ret = script_runner.run(*shlex.split(command))
+
+ assert ret.success
+ ret_json = json.loads(ret.stdout)
+ assert ret_json
+ assert "mle_parameters" in ret_json
+ assert "twice_nll" not in ret_json
+
+ for measurement in [
+ "GaussExample",
+ "GammaExample",
+ "LogNormExample",
+ "ConstExample",
+ ]:
+ command = "pyhf fit {0:s} --value --measurement {1:s}".format(
+ temp.strpath, measurement
+ )
+ ret = script_runner.run(*shlex.split(command))
+
+ assert ret.success
+ ret_json = json.loads(ret.stdout)
+ assert ret_json
+ assert "mle_parameters" in ret_json
+ assert "twice_nll" in ret_json
+
+ tmp_out = tmpdir.join("{0:s}_output.json".format(measurement))
+ # make sure output file works too
+ command += " --output-file {0:s}".format(tmp_out.strpath)
+ ret = script_runner.run(*shlex.split(command))
+ assert ret.success
+ ret_json = json.load(tmp_out)
+ assert "mle_parameters" in ret_json
+ assert "twice_nll" in ret_json
+
+
def test_import_prepHistFactory_and_cls(tmpdir, script_runner):
temp = tmpdir.join("parsed_output.json")
command = 'pyhf xml2json validation/xmlimport_input/config/example.xml --basedir validation/xmlimport_input/ --output-file {0:s}'.format(
@@ -96,6 +139,23 @@ def test_import_prepHistFactory_and_cls(tmpdir, script_runner):
assert 'CLs_exp' in d
[email protected]("backend", ["numpy", "tensorflow", "pytorch", "jax"])
+def test_fit_backend_option(tmpdir, script_runner, backend):
+ temp = tmpdir.join("parsed_output.json")
+ command = "pyhf xml2json validation/xmlimport_input/config/example.xml --basedir validation/xmlimport_input/ --output-file {0:s}".format(
+ temp.strpath
+ )
+ ret = script_runner.run(*shlex.split(command))
+
+ command = "pyhf fit --backend {0:s} {1:s}".format(backend, temp.strpath)
+ ret = script_runner.run(*shlex.split(command))
+
+ assert ret.success
+ ret_json = json.loads(ret.stdout)
+ assert ret_json
+ assert "mle_parameters" in ret_json
+
+
@pytest.mark.parametrize("backend", ["numpy", "tensorflow", "pytorch", "jax"])
def test_cls_backend_option(tmpdir, script_runner, backend):
temp = tmpdir.join("parsed_output.json")
@@ -234,9 +294,25 @@ def test_testpoi(tmpdir, script_runner):
assert len(list(set(results_obs))) == len(pois)
[email protected]("optimizer", ["scipy", "minuit"])
@pytest.mark.parametrize(
- 'optimizer', ['scipy', 'minuit', 'scipy_optimizer', 'minuit_optimizer']
+ "opts,success", [(["maxiter=1000"], True), (["maxiter=1"], False)]
)
+def test_fit_optimizer(tmpdir, script_runner, optimizer, opts, success):
+ temp = tmpdir.join("parsed_output.json")
+ command = "pyhf xml2json validation/xmlimport_input/config/example.xml --basedir validation/xmlimport_input/ --output-file {0:s}".format(
+ temp.strpath
+ )
+ ret = script_runner.run(*shlex.split(command))
+
+ optconf = " ".join(f"--optconf {opt}" for opt in opts)
+ command = f"pyhf fit --optimizer {optimizer} {optconf} {temp.strpath}"
+ ret = script_runner.run(*shlex.split(command))
+
+ assert ret.success == success
+
+
[email protected]('optimizer', ['scipy', 'minuit'])
@pytest.mark.parametrize(
'opts,success', [(['maxiter=1000'], True), (['maxiter=1'], False)]
)
|
docs: List options for optimizers in CLI API docs and add short aliases
# Description
In the [Command Line API docs for `cls`](https://scikit-hep.org/pyhf/cli.html#pyhf-cls) there are available options shown for `--teststat` and `--backend` but not for `--optimizer`.
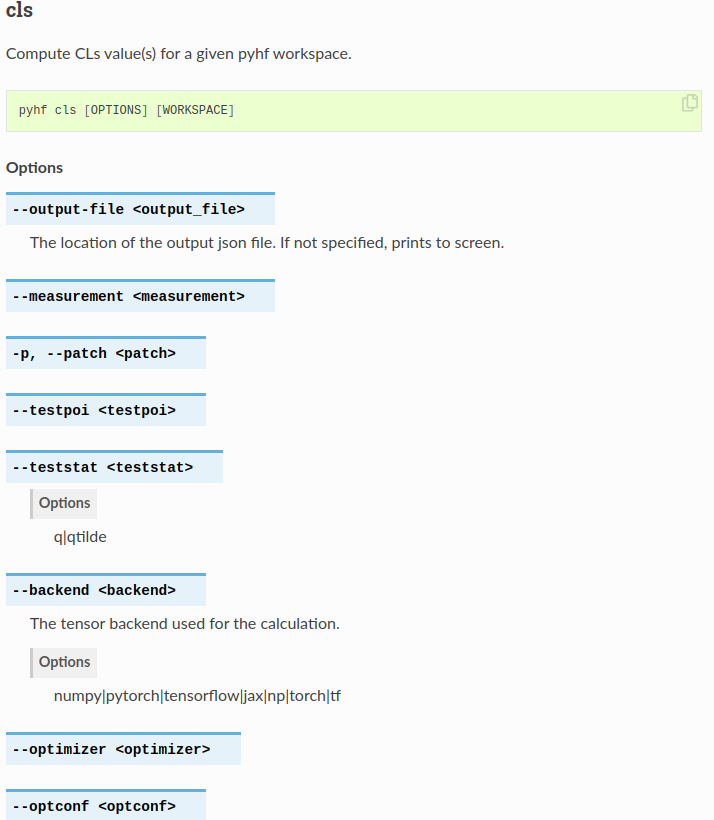
The available options should also be shown for `--optimizer`.
In addition, the options all [currently require](https://github.com/scikit-hep/pyhf/blob/eb9944c043f7f8a75b9cfe6f8bd781bd1dd7014b/src/pyhf/optimize/__init__.py) that the word "_optimizer" be added to the end (`scipy_optimizer`, `minuit_optimizer`). It would be better to additionally alias these to be just the name as someone at the CLI is already specifying the `--optimizer` flag so having to write `_optimizer` again seems strange. It is nicer to write
```
pyhf cls --patch patch.json --optimizer minuit BkgOnly.json
```
than
```
pyhf cls --patch patch.json --optimizer minuit_optimizer BkgOnly.json
```
though we should keep the `X_optimizer` name available of course.
| 2020-09-11T06:01:24 |
|
scikit-hep/pyhf
| 1,079 |
scikit-hep__pyhf-1079
|
[
"1062"
] |
3a6bbf477194d1380d00d7fc8b013655c201254f
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -60,9 +60,7 @@ def setup(app):
# external links
xref_links = {"arXiv:1007.1727": ("[1007.1727]", "https://arxiv.org/abs/1007.1727")}
-intersphinx_mapping = {
- 'scipy': ('https://docs.scipy.org/doc/scipy/reference/', None),
-}
+intersphinx_mapping = {'scipy': ('https://docs.scipy.org/doc/scipy/reference/', None)}
# Github repo
issues_github_path = 'scikit-hep/pyhf'
|
Start Community announcement mailing list
# Description
In addition to just having the core devs tweet about things using the [`#pyhf` hashtag](https://twitter.com/search?q=%23pyhf&src=typed_query&f=live) It would probably be good if we created a mailing list that people could subscribe to _but not send mail to_ to receive announcements. We should of course also suggest that they sign up to receive notifications from GitHub at least at the "Releases Only" level, but I think a mailing list could be quite useful especially to notify people like @cranmer and @msneubauer (PIs who are going to be interested in the project but probably aren't checking GitHub emails), and Daniel Whiteson (PIs who want to be using `pyhf` but aren't on GitHub). I can also see a use case where people like @alexander-held might want to be able to forward such an email to users not on the mailing list to point something out.
It isn't a reasonable assumption that all of pyhf's users will have CERN email addresses now that theorists are starting to pick it up more and more, so this should probably not use CERN's e-groups (Also the [`e-groups` search and add page](https://e-groups.cern.ch/e-groups/EgroupsSearchForm.do) is behind CERN sign on and people should be able to add themselves).
|
cc @story645 in case they have time to share their thoughts/experience here.
I'm all for as many modalities as you have the bandwidth to support.
You might want to have a dedicated @pyhf that the devs can all tweet as through tweet deck so folks can follow for announcements (and you can automate to tweet on new releases).
The matplotlib [ANN] mailing list isn't read only but doesn't really get spam - I suggest instead making it that posts to your list need to be moderated so that folks can post related announcements & reply as needed. If that proves too much overhead, then shift it to read only.
Both @bbockelm and @davidlange6 have recommended that `pyhf` just start a Google Groups.
For the time being I've created a `pyhf-announcements` Google Group for a public announcement email list. I now need to figure out instructions for how to join this group _without_ using a GMail email address.
> I now need to figure out instructions for how to join this group without using a GMail email address.
[Seems this is already possible](https://support.google.com/groups/answer/1067205?hl=en#), and it just has the (potentially desired?) effect of not letting you use the group web interface and forces you to use it as mail only.
> ## Join a Google group without a Gmail address
>
> If you don't have a Google Account, you can:
> - Read posts in public groups
> - Search for posts in public groups
>
> You need a Google Account to:
> - Create and manage a group
> - Join a group
> - Post to a group
> - Delete a post
> - Read a restricted group's posts
It seems that the way that people would subscribe to the mailing list without a Google Account would be to visit
```
https://groups.google.com/group/<group-name-goes-here>/subscribe
```
so in our case: https://groups.google.com/group/pyhf-announcements/subscribe
| 2020-09-25T04:09:31 |
|
scikit-hep/pyhf
| 1,083 |
scikit-hep__pyhf-1083
|
[
"1082"
] |
2619d8f126c10a4a2faff637f94da29628ac3af0
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -65,7 +65,7 @@
extras_require['docs']
+ extras_require['lint']
+ extras_require['test']
- + ['nbdime', 'bumpversion', 'ipython', 'pre-commit', 'check-manifest', 'twine']
+ + ['nbdime', 'bump2version', 'ipython', 'pre-commit', 'check-manifest', 'twine']
)
)
extras_require['complete'] = sorted(set(sum(extras_require.values(), [])))
|
Migrate from bumpversion to bump2version
# Description
@dguest has brought to my attention that [`bumpversion` is no longer maintained](https://github.com/peritus/bumpversion) (as of apparently November 2019). Given this we should probably take the project's advice
> 🎬 If you want to start using `bumpversion`, you're best advised to install one of the maintained forks, e.g. ➡ @ c4urself's [`bump2version`](https://github.com/c4urself/bump2version/#installation).
given that it seems that [transferring ownership and maintainers is taking a very long time/might not happen](https://github.com/c4urself/bump2version/issues/86).
|
is it just as easy as switching to `bump2version`?
> is it just as easy as switching to `bump2version`?
I think so as `bump2version` is just a direct fork and uses `.bumpversion.cfg`. I just made this Issue as more of a reminder to myself.
| 2020-09-28T20:32:44 |
|
scikit-hep/pyhf
| 1,089 |
scikit-hep__pyhf-1089
|
[
"502"
] |
4b859578b4eb86c9167004f9909c8dc79ff41a41
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -141,6 +141,7 @@ def setup(app):
# This patterns also effect to html_static_path and html_extra_path
exclude_patterns = [
'_build',
+ 'JOSS',
'**.ipynb_checkpoints',
'examples/experiments/edwardpyhf.ipynb',
'examples/notebooks/ImpactPlot.ipynb',
|
Write JOSS Submission
# Description
Given conversations with @labarba at SciPy 2019 it seems that pyhf would be a good candidate for a [JOSS paper](https://joss.theoj.org/). Given @cranmer's good experience with this for carl [](https://doi.org/10.21105/joss.00011) it seems if we clean up and finish a few of the docstrings then we would be in good shape to submit for a review (once we finish up the other publication process we have ongoing).
The [carl paper submission review](https://github.com/openjournals/joss-reviews/issues/11) might be a good premeptive checklist for this.
|
Also see things that we did for root_numpy here (https://github.com/scikit-hep/root_numpy/issues?q=is%3Aissue+joss+is%3Aclosed+label%3AJOSS) which was under scikit-hep at the time.
Today in the SciPy 2020 Maintainers Track discussion I asked
> The pyOpenSci website mentions that "Any package that passes the pyOpenSci review and is within scope for JOSS can be fast-tracked through the JOSS review process." Would you recommend that people attempt to go through pyOpenSci review before submitting to JOSS to make it easier for the JOSS reviewers?
@kyleniemeyer (who was presenting on behalf of JOSS) thought this was probably a good idea. So maybe we should just do the work once and a bit extra to get a [PyOpenSci](https://www.pyopensci.org/) review and then submit to JOSS.
FWIW, I think that trying to get something done with pyOpenSci is going to take too long, and we should just write up a JOSS paper and get it out. I'll take point on this and try to get something going with JOSS this weekend.
Sounds like a good idea. pyhf is in very good shape for a JOSS paper
| 2020-10-04T23:07:02 |
|
scikit-hep/pyhf
| 1,091 |
scikit-hep__pyhf-1091
|
[
"891"
] |
6ce46696560df27851de25ce6dca2f321c67ef24
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -65,7 +65,15 @@
extras_require['docs']
+ extras_require['lint']
+ extras_require['test']
- + ['nbdime', 'bump2version', 'ipython', 'pre-commit', 'check-manifest', 'twine']
+ + [
+ 'nbdime',
+ 'bump2version',
+ 'ipython',
+ 'pre-commit',
+ 'check-manifest',
+ 'codemetapy>=0.3.4',
+ 'twine',
+ ]
)
)
extras_require['complete'] = sorted(set(sum(extras_require.values(), [])))
|
diff --git a/.github/workflows/release_tests.yml b/.github/workflows/release_tests.yml
--- a/.github/workflows/release_tests.yml
+++ b/.github/workflows/release_tests.yml
@@ -32,3 +32,8 @@ jobs:
- name: Canary test public API
run: |
python -m pytest -r sx tests/test_public_api.py
+ - name: Verify requirements in codemeta.json
+ run: |
+ python -m pip install jq "codemetapy>=0.3.4"
+ codemetapy --no-extras pyhf > codemeta_generated.json
+ diff <(jq -S .softwareRequirements codemeta_generated.json) <(jq -S .softwareRequirements codemeta.json)
|
Add CodeMeta JSON-LD Context File
# Description
As part of an IRIS-HEP initiative to improve the citation quality/ease for all software it has been recommended by @danielskatz that projects:
- Track authors/contributors to software as it is developed
- Create a citation metadata file in the software repo and keep it up to date
- Link Github and Zenodo to get DOIs for major releases
- In the README and docs clearly says how to cite the software
`pyhf` already does all of this, as:
- [x] There is an [`AUTHORS` file](https://github.com/scikit-hep/pyhf/blob/31d34a0edd91593d75181cc3ad71563a52600793/AUTHORS) as well as a [listing of the authors in the docs](https://scikit-hep.org/pyhf/index.html#authors)
- [x] There is a [`.zenodo.json`](https://github.com/scikit-hep/pyhf/blob/2b0a1e2ba41a2aa1233511524e3aa78e696ead34/.zenodo.json) that formats Zenodo with the correct metadata and adds the ORCID of the authors
- [x] There is a Zenodo DOI that is kept in sync with our release schedule (almost) fully automatically (almost as it requires 1 button click). [](https://doi.org/10.5281/zenodo.1169739)
- [x] There is a Citation section in both the [`README`](https://github.com/scikit-hep/pyhf/blob/2b0a1e2ba41a2aa1233511524e3aa78e696ead34/README.rst#citation) and the [docs webpage](https://scikit-hep.org/pyhf/citations.html) with the preferred citation
It has been pointed out though that we should also look into adding a [CodeMeta Project JSON-LD Context File](https://codemeta.github.io/jsonld/) as with it
> zenodo will read [it] and will be basically the same as [schema.org](http://schema.org/) so that this will help google index software, and tools be able to use the metadata file in [softwareheritage.org](http://softwareheritage.org/) to automatically build a citation for a particular commit.
(cc @gordonwatts as this might be of interest)
|
As an example, the [`parsl` library has a `codemeta.json` file](https://github.com/Parsl/parsl/blob/master/codemeta.json).
tools to generate CodeMeta files are in https://codemeta.github.io/tools/
While it doesn't look to be very actively developed, it should be possible to add a GHA workflow to use [`codemetapy`](https://github.com/proycon/codemetapy) to automatically update the `codemeta.json` on release merges in the same way that we run `bumpversion`.
| 2020-10-06T00:29:58 |
scikit-hep/pyhf
| 1,105 |
scikit-hep__pyhf-1105
|
[
"1103"
] |
db105eb03c4b8111b187c66443831d21546f6286
|
diff --git a/src/pyhf/cli/contrib.py b/src/pyhf/cli/contrib.py
--- a/src/pyhf/cli/contrib.py
+++ b/src/pyhf/cli/contrib.py
@@ -25,8 +25,8 @@ def cli():
@cli.command()
[email protected]("archive-url", default="-")
[email protected]("output-directory", default="-")
[email protected]("archive-url")
[email protected]("output-directory")
@click.option("-v", "--verbose", is_flag=True, help="Enables verbose mode")
@click.option(
"-f", "--force", is_flag=True, help="Force download from non-approved host"
|
pyhf contrib download fails gracelessly with invalid URL
# Description
calling `pyhf contrib download` (just to see what it does) fails pretty violently. hould we make itt a bit nicer @matthewfeickert
?
```
pyhf contrib download
Traceback (most recent call last):
File "/Users/lukasheinrich/Code/pyhfdev/dev/pyhfdevenv/bin/pyhf", line 33, in <module>
sys.exit(load_entry_point('pyhf', 'console_scripts', 'pyhf')())
File "/Users/lukasheinrich/Code/pyhfdev/dev/pyhfdevenv/lib/python3.7/site-packages/click/core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "/Users/lukasheinrich/Code/pyhfdev/dev/pyhfdevenv/lib/python3.7/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/Users/lukasheinrich/Code/pyhfdev/dev/pyhfdevenv/lib/python3.7/site-packages/click/core.py", line 1259, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/Users/lukasheinrich/Code/pyhfdev/dev/pyhfdevenv/lib/python3.7/site-packages/click/core.py", line 1259, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/Users/lukasheinrich/Code/pyhfdev/dev/pyhfdevenv/lib/python3.7/site-packages/click/core.py", line 1066, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/Users/lukasheinrich/Code/pyhfdev/dev/pyhfdevenv/lib/python3.7/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/Users/lukasheinrich/Code/pyhfdev/dev/pyhfsrc/src/pyhf/cli/contrib.py", line 60, in download
utils.download(archive_url, output_directory, force, compress)
File "/Users/lukasheinrich/Code/pyhfdev/dev/pyhfsrc/src/pyhf/contrib/utils.py", line 47, in download
+ "To download an archive from this host use the --force option."
pyhf.exceptions.InvalidArchiveHost: is not an approved archive host: www.hepdata.net, doi.org
To download an archive from this host use the --force option.
```
|
@lukasheinrich Hm, I guess so. Seems that this is interpreting no input as a null address to attempt to access.
While I agree that this should get improved, should we assume that all users will try to run commands without input rather than `--help` to learn about them? If so, we should make sure that we give helpful exits for all of our CLI.
I think the issue is the default value,
is this intended? ```@click.argument("archive-url", default="-")```
> I think the issue is the default value,
>
> is this intended? `@click.argument("archive-url", default="-")`
Ah yeah, you're 100% right, @lukasheinrich. Those should both have no default. My bad. Opening PR with fix now.
| 2020-10-13T20:15:34 |
|
scikit-hep/pyhf
| 1,110 |
scikit-hep__pyhf-1110
|
[
"1108"
] |
6d4eb4e365a700987c319742a4c60b0c79d7db66
|
diff --git a/src/pyhf/parameters/paramsets.py b/src/pyhf/parameters/paramsets.py
--- a/src/pyhf/parameters/paramsets.py
+++ b/src/pyhf/parameters/paramsets.py
@@ -6,7 +6,7 @@ def __init__(self, **kwargs):
self.n_parameters = kwargs.pop('n_parameters')
self.suggested_init = kwargs.pop('inits')
self.suggested_bounds = kwargs.pop('bounds')
- self.fixed = kwargs.pop('fixed')
+ self.suggested_fixed = kwargs.pop('fixed')
class unconstrained(paramset):
diff --git a/src/pyhf/pdf.py b/src/pyhf/pdf.py
--- a/src/pyhf/pdf.py
+++ b/src/pyhf/pdf.py
@@ -288,7 +288,7 @@ def suggested_fixed(self):
fixed = []
for name in self.par_order:
paramset = self.par_map[name]['paramset']
- fixed = fixed + [paramset.fixed] * paramset.n_parameters
+ fixed = fixed + [paramset.suggested_fixed] * paramset.n_parameters
return fixed
def set_poi(self, name):
diff --git a/src/pyhf/workspace.py b/src/pyhf/workspace.py
--- a/src/pyhf/workspace.py
+++ b/src/pyhf/workspace.py
@@ -769,7 +769,7 @@ def build(cls, model, data, name='measurement'):
{
"bounds": [list(x) for x in v['paramset'].suggested_bounds],
"inits": v['paramset'].suggested_init,
- "fixed": v['paramset'].fixed,
+ "fixed": v['paramset'].suggested_fixed,
"name": k,
}
for k, v in model.config.par_map.items()
|
diff --git a/tests/test_paramsets.py b/tests/test_paramsets.py
--- a/tests/test_paramsets.py
+++ b/tests/test_paramsets.py
@@ -11,7 +11,7 @@ def test_paramset_unconstrained():
)
assert pset.suggested_init == [0, 1, 2, 3, 4]
assert pset.suggested_bounds == [(-1, 1), (-2, 2), (-3, 3), (-4, 4)]
- assert not pset.fixed
+ assert not pset.suggested_fixed
assert not pset.constrained
@@ -26,7 +26,7 @@ def test_paramset_constrained_custom_sigmas():
)
assert pset.suggested_init == [0, 1, 2, 3, 4]
assert pset.suggested_bounds == [(-1, 1), (-2, 2), (-3, 3), (-4, 4)]
- assert not pset.fixed
+ assert not pset.suggested_fixed
assert pset.constrained
assert pset.width() == [1, 2, 3, 4, 5]
@@ -41,7 +41,7 @@ def test_paramset_constrained_default_sigmas():
)
assert pset.suggested_init == [0, 1, 2, 3, 4]
assert pset.suggested_bounds == [(-1, 1), (-2, 2), (-3, 3), (-4, 4)]
- assert not pset.fixed
+ assert not pset.suggested_fixed
assert pset.constrained
assert pset.width() == [1, 1, 1, 1, 1]
@@ -57,7 +57,7 @@ def test_paramset_constrained_custom_factors():
)
assert pset.suggested_init == [0, 1, 2, 3, 4]
assert pset.suggested_bounds == [(-1, 1), (-2, 2), (-3, 3), (-4, 4)]
- assert not pset.fixed
+ assert not pset.suggested_fixed
assert pset.constrained
assert pset.width() == [1 / 10.0, 1 / 20.0, 1 / 30.0, 1 / 40.0, 1 / 50.0]
|
rename paramsets.fixed to paramset.suggested_fixed
# Description
in order to align with the rest of the config (init,bounds)
| 2020-10-14T13:32:30 |
|
scikit-hep/pyhf
| 1,124 |
scikit-hep__pyhf-1124
|
[
"984"
] |
f248db092dcfbe6e3354bc1d0731a7713258dc2a
|
diff --git a/src/pyhf/events.py b/src/pyhf/events.py
--- a/src/pyhf/events.py
+++ b/src/pyhf/events.py
@@ -1,4 +1,5 @@
import weakref
+from functools import wraps
__events = {}
__disabled_events = set([])
@@ -71,6 +72,7 @@ def register(event):
# >>>
def _register(func):
+ @wraps(func)
def register_wrapper(*args, **kwargs):
trigger("{0:s}::before".format(event))()
result = func(*args, **kwargs)
|
Top-Level Python API methods don't have docstrings rendered in docs
# Description
The top level Python API methods pages on the docs website doesn't contain any of the rendered docstrings. For example, the `pyhf.set_backend()` API has examples (and it rather important for new users)
https://github.com/scikit-hep/pyhf/blob/e55eea408d7c28e3109338de96252119ac63f87a/src/pyhf/__init__.py#L42-L52
but the docs website doesn't show any of this

# Expected Behavior
Have the docstrings be rendered in the docs
# Actual Behavior
c.f. above
# Steps to Reproduce
Build the docs
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
This is broken due to the fact that we put a decorator on it. We just need to use `functools.wraps` and that should fix this.
| 2020-10-16T23:10:39 |
|
scikit-hep/pyhf
| 1,126 |
scikit-hep__pyhf-1126
|
[
"1123"
] |
5e88cf861f30e9d8ca058a3d4830e4e36fcaf3f4
|
diff --git a/src/pyhf/infer/mle.py b/src/pyhf/infer/mle.py
--- a/src/pyhf/infer/mle.py
+++ b/src/pyhf/infer/mle.py
@@ -47,6 +47,17 @@ def twice_nll(pars, data, pdf):
return -2 * pdf.logpdf(pars, data)
+def _validate_fit_inputs(init_pars, par_bounds, fixed_params):
+ for par_idx, (value, bound) in enumerate(zip(init_pars, par_bounds)):
+ if not (bound[0] <= value <= bound[1]):
+ raise ValueError(
+ f"fit initialization parameter (index: {par_idx}, value: {value}) lies outside of its bounds: {bound}"
+ + "\nTo correct this adjust the initialization parameter values in the model spec or those given"
+ + "\nas arguments to pyhf.infer.fit. If this value is intended, adjust the range of the parameter"
+ + "\nbounds."
+ )
+
+
def fit(data, pdf, init_pars=None, par_bounds=None, fixed_params=None, **kwargs):
r"""
Run a maximum likelihood fit.
@@ -99,6 +110,8 @@ def fit(data, pdf, init_pars=None, par_bounds=None, fixed_params=None, **kwargs)
par_bounds = par_bounds or pdf.config.suggested_bounds()
fixed_params = fixed_params or pdf.config.suggested_fixed()
+ _validate_fit_inputs(init_pars, par_bounds, fixed_params)
+
# get fixed vals from the model
fixed_vals = [
(index, init)
|
diff --git a/tests/test_infer.py b/tests/test_infer.py
--- a/tests/test_infer.py
+++ b/tests/test_infer.py
@@ -77,6 +77,22 @@ def test_hypotest_default(tmpdir, hypotest_args):
assert isinstance(result, type(tb.astensor(result)))
+def test_hypotest_poi_outofbounds(tmpdir, hypotest_args):
+ """
+ Check that the fit errors for POI outside of parameter bounds
+ """
+ pdf = pyhf.simplemodels.hepdata_like(
+ signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
+ )
+ data = [51, 48] + pdf.config.auxdata
+
+ with pytest.raises(ValueError):
+ pyhf.infer.hypotest(-1.0, data, pdf)
+
+ with pytest.raises(ValueError):
+ pyhf.infer.hypotest(10.1, data, pdf)
+
+
def test_hypotest_return_tail_probs(tmpdir, hypotest_args):
"""
Check that the return structure of pyhf.infer.hypotest with the
|
Parameter bounds affect fits with fixed parameters
# Description
See this example:
```python
import pyhf
spec = {
"channels": [
{
"name": "SR",
"samples": [
{
"data": [10.0],
"modifiers": [
{"data": None, "name": "Signal_norm", "type": "normfactor"}
],
"name": "Signal",
},
{"data": [50.0], "modifiers": [], "name": "Background"},
],
}
],
"measurements": [
{
"config": {
"parameters": [
{"bounds": [[0, 5]], "inits": [2.0], "name": "Signal_norm"}
],
"poi": "Signal_norm",
},
"name": "minimal_example",
}
],
"observations": [{"data": [65.0], "name": "SR"}],
"version": "1.0.0",
}
ws = pyhf.Workspace(spec)
model = ws.model()
data = ws.data(model)
# pyhf.infer.hypotest(6.0, data, model, qtilde=True) # this fails
pyhf.set_backend("numpy", pyhf.optimize.minuit_optimizer(verbose=False))
# the next two work, but result in identical values
print(pyhf.infer.hypotest(6.0, data, model, qtilde=True))
print(pyhf.infer.hypotest(7.0, data, model, qtilde=True))
```
The CLs value reported in the last two lines is identical. This seems to be related to the parameter bounds `[0,5]`. When increasing the range, the CLs values are different (as expected).
When uncommenting the first `hypotest` (using `scipy`), the minimization fails:
```
pyhf.exceptions.FailedMinimization: Positive directional derivative for linesearch
```
# Expected Behavior
All fits succeed, and different CLs for any POI value. If the bounds are somehow still respected, a warning about parameters being outside the bounds (and scaled back to the bound) would be helpful.
# Actual Behavior
Same CLs for POI values above bound, and `scipy` backend crashes.
# Steps to Reproduce
See above, same behavior with 0.5.2 and master.
# Checklist
- [X] Run `git fetch` to get the most up to date version of `master`
- [X] Searched through existing Issues to confirm this is not a duplicate issue
- [X] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
Thanks for reporting this @alexander-held.
@lukasheinrich @kratsg I'm tempted to call this a bug given that if the user has set the parameter bounds and are then attempting to evaluate with the POI _outside_ the bounds this is almost certainly not what the user intended to do.
Likewise, if you didn't set the bounds but then are scanning above the POI ([as we've already seen some people attempt to do](https://stackoverflow.com/questions/60089405/fit-convergence-failure-in-pyhf-for-small-signal-model)) then you should also get a warning or an error.
maybe it's something in the state of iminuit? I would hope that the fact that you did a hypotest before another one doesn't affect the 2nd hypotest. But this seems like what @alexander-held is reporting. I know minuit is very stateful but I was hoping the fact that we always create a minuit object from scratch insulates us from that
ah I read more carefully now:
scipy fails hard when exceeding the boundary while minuit fails somewhat silently. And what we should do is produce helpful error messages if the best fit val is at a boundary?
Just to add a demo of the explicit output of the above on `master` (so basically a release candidate of `v0.5.3`)
```python
# issue_1123.py
import pyhf
def build_spec(meas_bounds):
spec = {
"channels": [
{
"name": "SR",
"samples": [
{
"data": [10.0],
"modifiers": [
{"data": None, "name": "Signal_norm", "type": "normfactor"}
],
"name": "Signal",
},
{"data": [50.0], "modifiers": [], "name": "Background"},
],
}
],
"measurements": [
{
"config": {
"parameters": [
{"bounds": [meas_bounds], "inits": [2.0], "name": "Signal_norm"}
],
"poi": "Signal_norm",
},
"name": "minimal_example",
}
],
"observations": [{"data": [65.0], "name": "SR"}],
"version": "1.0.0",
}
return spec
def main(meas_bounds, use_minuit=False):
print(f"\n---\nbounds on POI: {meas_bounds}")
spec = build_spec(meas_bounds)
ws = pyhf.Workspace(spec)
model = ws.model()
data = ws.data(model)
if use_minuit:
optimizer_name = "MINUIT"
pyhf.set_backend("numpy", pyhf.optimize.minuit_optimizer(verbose=False))
else:
optimizer_name = "SciPy"
pyhf.set_backend("numpy")
print(f"Optimizer: {optimizer_name}")
for test_mu in [6.0, 7.0]:
print(
f"test_mu: {test_mu}, CLs_obs: {pyhf.infer.hypotest(test_mu, data, model, qtilde=True)}"
)
if __name__ == "__main__":
main([0, 10])
main([0, 10], use_minuit=True)
main([0, 5], use_minuit=True)
main([0, 5])
```
and running gives
```
$ python issue_1123.py
---
bounds on POI: [0, 10]
Optimizer: SciPy
test_mu: 6.0, CLs_obs: 1.7395702736810923e-06
test_mu: 7.0, CLs_obs: 1.9334865580514044e-08
---
bounds on POI: [0, 10]
Optimizer: MINUIT
test_mu: 6.0, CLs_obs: 1.739570574901934e-06
test_mu: 7.0, CLs_obs: 1.933486871767672e-08
---
bounds on POI: [0, 5]
Optimizer: MINUIT
test_mu: 6.0, CLs_obs: 9.491730291075429e-05
test_mu: 7.0, CLs_obs: 9.491730291075429e-05
---
bounds on POI: [0, 5]
Optimizer: SciPy
fun: 20.01304932662174
jac: array([7.])
message: 'Positive directional derivative for linesearch'
nfev: 68
nit: 5
njev: 6
status: 8
success: False
x: array([5.])
Traceback (most recent call last):
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/optimize/mixins.py", line 49, in _internal_minimize
assert result.success
AssertionError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "issue_1123.py", line 65, in <module>
main([0, 5])
File "issue_1123.py", line 57, in main
f"test_mu: {test_mu}, CLs_obs: {pyhf.infer.hypotest(test_mu, data, model, qtilde=True)}"
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/infer/__init__.py", line 133, in hypotest
teststat = calc.teststatistic(poi_test)
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/infer/calculators.py", line 195, in teststatistic
self.fixed_params,
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/infer/test_statistics.py", line 177, in qmu_tilde
return _qmu_like(mu, data, pdf, init_pars, par_bounds, fixed_params)
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/infer/test_statistics.py", line 20, in _qmu_like
mu, data, pdf, init_pars, par_bounds, fixed_params, return_fitted_pars=True
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/infer/test_statistics.py", line 39, in _tmu_like
mu, data, pdf, init_pars, par_bounds, fixed_params, return_fitted_val=True
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/infer/mle.py", line 177, in fixed_poi_fit
return fit(data, pdf, init_pars, par_bounds, fixed_params, **kwargs)
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/infer/mle.py", line 110, in fit
twice_nll, data, pdf, init_pars, par_bounds, fixed_vals, **kwargs
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/optimize/mixins.py", line 136, in minimize
result = self._internal_minimize(**minimizer_kwargs, options=kwargs)
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/optimize/mixins.py", line 52, in _internal_minimize
raise exceptions.FailedMinimization(result)
pyhf.exceptions.FailedMinimization: Positive directional derivative for linesearch
```
> scipy fails hard when exceeding the boundary while minuit fails somewhat silently. And what we should do is produce helpful error messages if the best fit val is at a boundary?
I think yes. I would suggest error messages regardless of the optimizer being used as in any case that a user is asking for a test POI that is outside the bounds for the POI then they _shouldn't_ be and are probably not meaning to. The SciPy error is good, but I think we should be more explicit and tell people "This isn't going to make physical sense given the choices you made. You don't want to do this, so please go change them and try again."
| 2020-10-17T12:47:00 |
scikit-hep/pyhf
| 1,132 |
scikit-hep__pyhf-1132
|
[
"1127"
] |
5a743a2d0212868beec313799966b9b9212b85c7
|
diff --git a/src/pyhf/workspace.py b/src/pyhf/workspace.py
--- a/src/pyhf/workspace.py
+++ b/src/pyhf/workspace.py
@@ -283,6 +283,7 @@ class Workspace(_ChannelSummaryMixin, dict):
def __init__(self, spec, **config_kwargs):
"""Workspaces hold the model, data and measurements."""
+ spec = copy.deepcopy(spec)
super(Workspace, self).__init__(spec, channels=spec['channels'])
self.schema = config_kwargs.pop('schema', 'workspace.json')
self.version = config_kwargs.pop('version', spec.get('version', None))
|
diff --git a/tests/test_workspace.py b/tests/test_workspace.py
--- a/tests/test_workspace.py
+++ b/tests/test_workspace.py
@@ -844,3 +844,23 @@ def test_closure_over_workspace_build():
newworkspace = pyhf.Workspace.build(newmodel, newdata)
assert pyhf.utils.digest(newworkspace) == pyhf.utils.digest(workspace)
+
+
+def test_wspace_immutable():
+ model = pyhf.simplemodels.hepdata_like(
+ signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
+ )
+ data = [51, 48]
+ workspace = pyhf.Workspace.build(model, data)
+
+ spec = json.loads(json.dumps(workspace))
+
+ ws = pyhf.Workspace(spec)
+ model = ws.model()
+ before = model.config.suggested_init()
+ spec["measurements"][0]["config"]["parameters"][0]["inits"] = [1.5]
+
+ model = ws.model()
+ after = model.config.suggested_init()
+
+ assert before == after
|
Making workspaces immutable?
# Question
Currently workspaces are mutable:
```python
import pyhf
spec = {
"channels": [
{
"name": "Signal Region",
"samples": [
{
"data": [10],
"modifiers": [
{"data": [1], "name": "staterror_Signal-Region", "type": "staterror"},
{"data": None, "name": "Signal strength", "type": "normfactor"},
],
"name": "Signal",
}
],
}
],
"measurements": [
{
"config": {
"parameters": [{"name": "staterror_Signal-Region", "fixed": True, "inits": [1.1]}],
"poi": "Signal strength",
},
"name": "fit",
}
],
"observations": [{"data": [475], "name": "Signal Region"}],
"version": "1.0.0",
}
ws = pyhf.Workspace(spec)
model = ws.model()
print(model.config.suggested_init()) # -> [1.1, 1.0]
spec["measurements"][0]["config"]["parameters"][0]["inits"] = [1.2]
print(model.config.suggested_init()) # -> [1.1, 1.0]
model = ws.model()
print(model.config.suggested_init()) # -> [1.2, 1.0]
```
Models on the other hand are immutable. What do you think about making workspaces immutable as well? While I do not have a concrete example in mind, I imagine it could prevent some difficult-to-debug scenarios where the workspace changes without the user noticing.
# Relevant Issues and Pull Requests
none
|
some possible motivation for this change from @kratsg:
> if you change the spec, summary information is not recomputed.
this is because we deep-copy the spec in Model:
https://github.com/scikit-hep/pyhf/blob/master/src/pyhf/pdf.py#L559
while we reuse the ctor-argument in `Workspace.__init__.py`
https://github.com/scikit-hep/pyhf/blob/master/src/pyhf/workspace.py#L286
I would personally introduce a deepcopy in wspace as well.
From an IRIS-HEP Slack comment form @kratsg:
> not too much work. we could disentangle the `class Workspace(dict)` part, and then hide the `spec` inside a member variable inside that object. then provide a custom `to_json` method since we do rely on converting `Workspace` back to JSON (which I lazily implemented by just inheriting from `dict`).
I thiink a simple change like
```
spec_copy = copy.deepcopy(spec)
super(Workspace, self).__init__(spec_copy, channels=spec_copy['channels'])
```
should suffice
@lukasheinrich Sorry hadn't taken the time to read all the other replies when I copy pasted that in. That would be great.
| 2020-10-19T23:03:33 |
scikit-hep/pyhf
| 1,136 |
scikit-hep__pyhf-1136
|
[
"1080"
] |
0ed1b518bf0ea137b7d676dac52575a8473950de
|
diff --git a/src/pyhf/readxml.py b/src/pyhf/readxml.py
--- a/src/pyhf/readxml.py
+++ b/src/pyhf/readxml.py
@@ -171,6 +171,10 @@ def process_sample(
'data': [a * b for a, b in zip(data, shapesys_data)],
}
)
+ elif modtag.tag == 'ShapeFactor':
+ modifiers.append(
+ {'name': modtag.attrib['Name'], 'type': 'shapefactor', 'data': None}
+ )
else:
log.warning('not considering modifier tag %s', modtag)
diff --git a/src/pyhf/writexml.py b/src/pyhf/writexml.py
--- a/src/pyhf/writexml.py
+++ b/src/pyhf/writexml.py
@@ -205,12 +205,15 @@ def build_modifier(spec, modifierspec, channelname, samplename, sampledata):
for a, b in np.array((modifierspec['data'], sampledata)).T
],
)
+ elif modifierspec['type'] == 'shapefactor':
+ pass
else:
log.warning(
- 'Skipping {0}({1}) for now'.format(
+ 'Skipping modifier {0}({1}) for now'.format(
modifierspec['name'], modifierspec['type']
)
)
+ return None
modifier = ET.Element(mod_map[modifierspec['type']], **attrs)
return modifier
|
diff --git a/tests/test_export.py b/tests/test_export.py
--- a/tests/test_export.py
+++ b/tests/test_export.py
@@ -3,6 +3,7 @@
import pytest
import json
import xml.etree.cElementTree as ET
+import logging
def spec_staterror():
@@ -143,6 +144,34 @@ def spec_shapesys():
return spec
+def spec_shapefactor():
+ source = json.load(open('validation/data/2bin_histosys_example2.json'))
+ spec = {
+ 'channels': [
+ {
+ 'name': 'singlechannel',
+ 'samples': [
+ {
+ 'name': 'signal',
+ 'data': source['bindata']['sig'],
+ 'modifiers': [
+ {'name': 'mu', 'type': 'normfactor', 'data': None}
+ ],
+ },
+ {
+ 'name': 'background',
+ 'data': source['bindata']['bkg'],
+ 'modifiers': [
+ {'name': 'bkg_norm', 'type': 'shapefactor', 'data': None}
+ ],
+ },
+ ],
+ }
+ ]
+ }
+ return spec
+
+
def test_export_measurement():
measurementspec = {
"config": {
@@ -198,10 +227,11 @@ def test_export_measurement():
(spec_histosys(), True, ['HistoNameHigh', 'HistoNameLow']),
(spec_normsys(), False, ['High', 'Low']),
(spec_shapesys(), True, ['ConstraintType', 'HistoName']),
+ (spec_shapefactor(), False, []),
],
- ids=['staterror', 'histosys', 'normsys', 'shapesys'],
+ ids=['staterror', 'histosys', 'normsys', 'shapesys', 'shapefactor'],
)
-def test_export_modifier(mocker, spec, has_root_data, attrs):
+def test_export_modifier(mocker, caplog, spec, has_root_data, attrs):
channelspec = spec['channels'][0]
channelname = channelspec['name']
samplespec = channelspec['samples'][1]
@@ -210,13 +240,17 @@ def test_export_modifier(mocker, spec, has_root_data, attrs):
modifierspec = samplespec['modifiers'][0]
mocker.patch('pyhf.writexml._ROOT_DATA_FILE')
- modifier = pyhf.writexml.build_modifier(
- {'measurements': [{'config': {'parameters': []}}]},
- modifierspec,
- channelname,
- samplename,
- sampledata,
- )
+
+ with caplog.at_level(logging.DEBUG, 'pyhf.writexml'):
+ modifier = pyhf.writexml.build_modifier(
+ {'measurements': [{'config': {'parameters': []}}]},
+ modifierspec,
+ channelname,
+ samplename,
+ sampledata,
+ )
+ assert "Skipping modifier" not in caplog.text
+
# if the modifier is a staterror, it has no Name
if 'Name' in modifier.attrib:
assert modifier.attrib['Name'] == modifierspec['name']
@@ -224,6 +258,18 @@ def test_export_modifier(mocker, spec, has_root_data, attrs):
assert pyhf.writexml._ROOT_DATA_FILE.__setitem__.called == has_root_data
+def test_export_bad_modifier(caplog):
+ with caplog.at_level(logging.DEBUG, 'pyhf.writexml'):
+ pyhf.writexml.build_modifier(
+ {'measurements': [{'config': {'parameters': []}}]},
+ {'name': 'fakeModifier', 'type': 'unknown-modifier'},
+ 'fakeChannel',
+ 'fakeSample',
+ None,
+ )
+ assert "Skipping modifier fakeModifier(unknown-modifier)" in caplog.text
+
+
@pytest.mark.parametrize(
"spec, normfactor_config",
[
diff --git a/tests/test_import.py b/tests/test_import.py
--- a/tests/test_import.py
+++ b/tests/test_import.py
@@ -5,6 +5,7 @@
from pathlib import Path
import pytest
import xml.etree.cElementTree as ET
+import logging
def assert_equal_dictionary(d1, d2):
@@ -322,3 +323,87 @@ def test_import_normfactor_bounds():
assert len(parameters) == 1
parameter = parameters[0]
assert parameter['bounds'] == [[0, 10]]
+
+
+def test_import_shapefactor():
+ parsed_xml = pyhf.readxml.parse(
+ 'validation/xmlimport_input/config/examples/example_DataDriven.xml',
+ 'validation/xmlimport_input',
+ )
+
+ # build the spec, strictly checks properties included
+ spec = {
+ 'channels': parsed_xml['channels'],
+ 'parameters': parsed_xml['measurements'][0]['config']['parameters'],
+ }
+ pdf = pyhf.Model(spec, poi_name='SigXsecOverSM')
+
+ channels = {channel['name']: channel for channel in pdf.spec['channels']}
+
+ assert channels['controlRegion']['samples'][0]['modifiers'][0]['type'] == 'lumi'
+ assert (
+ channels['controlRegion']['samples'][0]['modifiers'][1]['type'] == 'staterror'
+ )
+ assert channels['controlRegion']['samples'][0]['modifiers'][2]['type'] == 'normsys'
+ assert (
+ channels['controlRegion']['samples'][1]['modifiers'][0]['type'] == 'shapefactor'
+ )
+
+
+def test_process_modifiers(mocker, caplog):
+ sample = ET.Element(
+ "Sample", Name='testSample', HistoPath="", HistoName="testSample"
+ )
+ normfactor = ET.Element(
+ 'NormFactor', Name="myNormFactor", Val='1', Low="0", High="3"
+ )
+ histosys = ET.Element(
+ 'HistoSys', Name='myHistoSys', HistoNameHigh='', HistoNameLow=''
+ )
+ normsys = ET.Element('OverallSys', Name='myNormSys', High='1.05', Low='0.95')
+ shapesys = ET.Element('ShapeSys', Name='myShapeSys', HistoName='')
+ shapefactor = ET.Element(
+ "ShapeFactor",
+ Name='myShapeFactor',
+ )
+ staterror = ET.Element('StatError', Activate='True')
+ unknown_modifier = ET.Element('UnknownSys')
+
+ sample.append(normfactor)
+ sample.append(histosys)
+ sample.append(normsys)
+ sample.append(shapesys)
+ sample.append(shapefactor)
+ sample.append(staterror)
+ sample.append(unknown_modifier)
+
+ _data = [0.0]
+ _err = [1.0]
+ mocker.patch('pyhf.readxml.import_root_histogram', return_value=(_data, _err))
+ with caplog.at_level(logging.DEBUG, 'pyhf.readxml'):
+ result = pyhf.readxml.process_sample(sample, '', '', '', 'myChannel')
+
+ assert "not considering modifier tag <Element 'UnknownSys'" in caplog.text
+ assert len(result['modifiers']) == 6
+ assert {'name': 'myNormFactor', 'type': 'normfactor', 'data': None} in result[
+ 'modifiers'
+ ]
+ assert {
+ 'name': 'myHistoSys',
+ 'type': 'histosys',
+ 'data': {'lo_data': _data, 'hi_data': _data},
+ } in result['modifiers']
+ assert {
+ 'name': 'myNormSys',
+ 'type': 'normsys',
+ 'data': {'lo': 0.95, 'hi': 1.05},
+ } in result['modifiers']
+ assert {'name': 'myShapeSys', 'type': 'shapesys', 'data': _data} in result[
+ 'modifiers'
+ ]
+ assert {'name': 'myShapeFactor', 'type': 'shapefactor', 'data': None} in result[
+ 'modifiers'
+ ]
+ assert {'name': 'staterror_myChannel', 'type': 'staterror', 'data': _err} in result[
+ 'modifiers'
+ ]
|
Reading ShapeFactors in xml workspace
# Description
The `.xml` -> `.json` workspace conversion currently does not support `ShapeFactor` modifiers.
# Expected Behavior
The `ShapeFactor` modifiers defined in a `.xml` should appear as `shapefactor` modifiers in the `.json` workspace.
# Actual Behavior
A warning is printed, and the modifier skipped.
```
WARNING:pyhf.readxml:not considering modifier tag <Element 'ShapeFactor' at 0x7fc145eb0f90>
```
# Steps to Reproduce
With `pyhf` version 0.5.2:
```
pyhf xml2json minimal_example/RooStats/minimal_example.xml
```
results in
```
WARNING:pyhf.readxml:not considering modifier tag <Element 'ShapeFactor' at 0x7fb8c5fff090>
```
using an example input workspace provided here: `/afs/cern.ch/user/a/alheld/public/pyhf_shapefactor`.
# Checklist
- [X] Run `git fetch` to get the most up to date version of `master`
- [X] Searched through existing Issues to confirm this is not a duplicate issue
- [X] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
| 2020-10-20T11:58:31 |
|
scikit-hep/pyhf
| 1,138 |
scikit-hep__pyhf-1138
|
[
"1137"
] |
2b2b28181a038b25bd4634808cdfec869b30d834
|
diff --git a/src/pyhf/tensor/jax_backend.py b/src/pyhf/tensor/jax_backend.py
--- a/src/pyhf/tensor/jax_backend.py
+++ b/src/pyhf/tensor/jax_backend.py
@@ -179,8 +179,8 @@ def conditional(self, predicate, true_callable, false_callable):
def tolist(self, tensor_in):
try:
- return np.asarray(tensor_in).tolist()
- except AttributeError:
+ return jnp.asarray(tensor_in).tolist()
+ except TypeError:
if isinstance(tensor_in, list):
return tensor_in
raise
|
Remove use of NumPy from JAX backend
`jax.numpy` now supports `tolist` so this
https://github.com/scikit-hep/pyhf/blob/0ed1b518bf0ea137b7d676dac52575a8473950de/src/pyhf/tensor/jax_backend.py#L180-L182
could instead be
```suggestion
return jnp.asarray(tensor_in).tolist()
```
but this should probably be left to another follow up PR as this is a style PR where no real code is supposed to change.
_Originally posted by @matthewfeickert in https://github.com/scikit-hep/pyhf/pull/1135#discussion_r508719046_
| 2020-10-20T19:46:38 |
||
scikit-hep/pyhf
| 1,176 |
scikit-hep__pyhf-1176
|
[
"1175"
] |
28fdfe95a3a4846ba70a9a338b3f72a94eac1322
|
diff --git a/src/pyhf/contrib/viz/brazil.py b/src/pyhf/contrib/viz/brazil.py
--- a/src/pyhf/contrib/viz/brazil.py
+++ b/src/pyhf/contrib/viz/brazil.py
@@ -3,7 +3,37 @@
def plot_results(ax, mutests, tests, test_size=0.05):
- """Plot a series of hypothesis tests for various POI values."""
+ """
+ Plot a series of hypothesis tests for various POI values.
+
+ Example:
+
+ >>> import numpy as np
+ >>> import matplotlib.pyplot as plt
+ >>> import pyhf
+ >>> import pyhf.contrib.viz.brazil
+ >>> pyhf.set_backend("numpy")
+ >>> model = pyhf.simplemodels.hepdata_like(
+ ... signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
+ ... )
+ >>> observations = [51, 48]
+ >>> data = observations + model.config.auxdata
+ >>> poi_vals = np.linspace(0, 5, 41)
+ >>> results = [
+ ... pyhf.infer.hypotest(test_poi, data, model, return_expected_set=True)
+ ... for test_poi in poi_vals
+ ... ]
+ >>> fig, ax = plt.subplots()
+ >>> pyhf.contrib.viz.brazil.plot_results(ax, poi_vals, results)
+
+ Args:
+ ax (`matplotlib.axes.Axes`): The matplotlib axis object to plot on.
+ mutests (:obj:`list` or :obj:`array`): The values of the POI where the
+ hypothesis tests were performed.
+ tests (:obj:`list` or :obj:`array`): The :math:$\\mathrm{CL}_{s}$ values
+ from the hypothesis tests.
+ test_size (:obj:`float`): The size, :math:$\alpha$, of the test.
+ """
cls_obs = np.array([test[0] for test in tests]).flatten()
cls_exp = [np.array([test[1][i] for test in tests]).flatten() for i in range(5)]
ax.plot(mutests, cls_obs, c='black')
@@ -15,3 +45,6 @@ def plot_results(ax, mutests, tests, test_size=0.05):
ax.fill_between(mutests, cls_exp[1], cls_exp[-2], facecolor='green')
ax.plot(mutests, [test_size] * len(mutests), c='red')
ax.set_ylim(0, 1)
+
+ ax.set_xlabel(r"$\mu$ (POI)")
+ ax.set_ylabel(r"$\mathrm{CL}_{s}$")
|
diff --git a/tests/contrib/baseline/test_brazil.png b/tests/contrib/baseline/test_brazil.png
Binary files a/tests/contrib/baseline/test_brazil.png and b/tests/contrib/baseline/test_brazil.png differ
|
Add axis labels to pyhf.contrib.viz.brazil.plot_results
# Description
We know that the axis labels for [`pyhf.contrib.viz.brazil.plot_results`](https://github.com/scikit-hep/pyhf/blob/28fdfe95a3a4846ba70a9a338b3f72a94eac1322/src/pyhf/contrib/viz/brazil.py#L5) are always going to be the same, so we should just add them on there as
```python
ax.set_xlabel(r"$\mu$")
ax.set_ylabel(r"$\mathrm{CL}_{s}$")
```
| 2020-11-13T01:05:47 |
|
scikit-hep/pyhf
| 1,179 |
scikit-hep__pyhf-1179
|
[
"1177"
] |
821dfe509303b6d4bfbe8b85d012199384b3efa1
|
diff --git a/src/pyhf/writexml.py b/src/pyhf/writexml.py
--- a/src/pyhf/writexml.py
+++ b/src/pyhf/writexml.py
@@ -199,7 +199,9 @@ def build_modifier(spec, modifierspec, channelname, samplename, sampledata):
np.divide(
a, b, out=np.zeros_like(a), where=np.asarray(b) != 0, dtype='float'
)
- for a, b in np.array((modifierspec['data'], sampledata)).T
+ for a, b in np.array(
+ (modifierspec['data'], sampledata), dtype="float"
+ ).T
],
)
elif modifierspec['type'] == 'shapefactor':
|
diff --git a/tests/test_export.py b/tests/test_export.py
--- a/tests/test_export.py
+++ b/tests/test_export.py
@@ -390,3 +390,15 @@ def test_export_data(mocker):
assert data.attrib['HistoName']
assert data.attrib['InputFile']
assert pyhf.writexml._ROOT_DATA_FILE.__setitem__.called
+
+
+def test_integer_data(datadir, mocker):
+ """
+ Test that a spec with only integer data will be written correctly
+ """
+ spec = json.load(open(datadir.join("workspace_integer_data.json")))
+ channel_spec = spec["channels"][0]
+ mocker.patch("pyhf.writexml._ROOT_DATA_FILE")
+
+ channel = pyhf.writexml.build_channel(spec, channel_spec, {})
+ assert channel
diff --git a/tests/test_export/workspace_integer_data.json b/tests/test_export/workspace_integer_data.json
new file mode 100644
--- /dev/null
+++ b/tests/test_export/workspace_integer_data.json
@@ -0,0 +1,82 @@
+{
+ "channels": [
+ {
+ "name": "singlechannel",
+ "samples": [
+ {
+ "data": [
+ 5
+ ],
+ "modifiers": [
+ {
+ "data": null,
+ "name": "mu",
+ "type": "normfactor"
+ }
+ ],
+ "name": "signal"
+ },
+ {
+ "data": [
+ 50
+ ],
+ "modifiers": [
+ {
+ "data": [
+ 6
+ ],
+ "name": "uncorr_bkguncrt",
+ "type": "shapesys"
+ }
+ ],
+ "name": "background"
+ }
+ ]
+ }
+ ],
+ "measurements": [
+ {
+ "config": {
+ "parameters": [
+ {
+ "bounds": [
+ [
+ 0,
+ 10
+ ]
+ ],
+ "fixed": false,
+ "inits": [
+ 1
+ ],
+ "name": "mu"
+ },
+ {
+ "bounds": [
+ [
+ 1e-10,
+ 10
+ ]
+ ],
+ "fixed": false,
+ "inits": [
+ 1
+ ],
+ "name": "uncorr_bkguncrt"
+ }
+ ],
+ "poi": "mu"
+ },
+ "name": "measurement"
+ }
+ ],
+ "observations": [
+ {
+ "data": [
+ 50
+ ],
+ "name": "singlechannel"
+ }
+ ],
+ "version": "1.0.0"
+}
|
json2xml breaks for a simple JSON
# Description
```
{
"channels": [
{
"name": "singlechannel",
"samples": [
{
"name": "signal",
"data": [
5
],
"modifiers": [
{
"name": "mu",
"type": "normfactor",
"data": null
}
]
},
{
"name": "background",
"data": [
50
],
"modifiers": [
{
"name": "uncorr_bkguncrt",
"type": "shapesys",
"data": [
6
]
}
]
}
]
}
],
"version": "1.0.0",
"measurements": [
{
"name": "measurement",
"config": {
"poi": "mu",
"parameters": [
{
"bounds": [
[
0,
10
]
],
"inits": [
1
],
"fixed": false,
"name": "mu"
},
{
"bounds": [
[
1e-10,
10
]
],
"inits": [
1
],
"fixed": false,
"name": "uncorr_bkguncrt"
}
]
}
}
],
"observations": [
{
"name": "singlechannel",
"data": [
50
]
}
]
}
```
|
Easy fix: https://github.com/scikit-hep/pyhf/blob/7c8fe4376e8e2766237c07202700cc7286de59c0/src/pyhf/writexml.py#L196-L204
Make sure a/b are float like (include the zeros_like(a)) as well. This is just because there's a conversion from int to float as part of the division and that's being stored back into something that's int-like.
See numpy/numpy#14843
> Make sure a/b are float like (include the zeros_like(a)) as well. This is just because there's a conversion from int to float as part of the division and that's being stored back into something that's int-like.
Yeah, as mentioned, manually converting this workspace to have floats allows for it to succeed
```
$ pyhf json2xml --output-dir example_output_float issue_1177_float.json
```
where the `int` version results in the reported
```pytb
$ pyhf json2xml --output-dir example_output issue_1177.json
Traceback (most recent call last):
File "/home/feickert/.venvs/pyhf-CPU/bin/pyhf", line 33, in <module>
sys.exit(load_entry_point('pyhf', 'console_scripts', 'pyhf')())
File "/home/feickert/.venvs/pyhf-CPU/lib/python3.7/site-packages/click/core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "/home/feickert/.venvs/pyhf-CPU/lib/python3.7/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/home/feickert/.venvs/pyhf-CPU/lib/python3.7/site-packages/click/core.py", line 1259, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/home/feickert/.venvs/pyhf-CPU/lib/python3.7/site-packages/click/core.py", line 1066, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/feickert/.venvs/pyhf-CPU/lib/python3.7/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/cli/rootio.py", line 90, in json2xml
resultprefix,
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/writexml.py", line 279, in writexml
channel = build_channel(spec, channelspec, spec.get('observations'))
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/writexml.py", line 256, in build_channel
channel.append(build_sample(spec, samplespec, channelspec['name']))
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/writexml.py", line 231, in build_sample
spec, modspec, channelname, samplespec['name'], samplespec['data']
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/writexml.py", line 202, in build_modifier
for a, b in np.array((modifierspec['data'], sampledata)).T
File "/home/feickert/Code/GitHub/pyhf/src/pyhf/writexml.py", line 202, in <listcomp>
for a, b in np.array((modifierspec['data'], sampledata)).T
TypeError: No loop matching the specified signature and casting was found for ufunc true_divide
```
but just changing
```diff
- for a, b in np.array((modifierspec['data'], sampledata)).T
+ for a, b in np.array((modifierspec['data'], sampledata), dtype="float").T
```
allows for
```
$ pyhf json2xml --output-dir example_output issue_1177.json
```
to pass with the same results
```
$ diff example_output/FitConfig.xml example_output_float/FitConfig.xml
3,4c3,4
< <Combination OutputFilePrefix="example_output/config/FitConfig">
< <Input>example_output/config/FitConfig_singlechannel.xml</Input>
---
> <Combination OutputFilePrefix="example_output_float/config/FitConfig">
> <Input>example_output_float/config/FitConfig_singlechannel.xml</Input>
```
I'll open up a PR now.
| 2020-11-18T07:58:41 |
scikit-hep/pyhf
| 1,183 |
scikit-hep__pyhf-1183
|
[
"1172"
] |
937d716f5a4856cb3e529e88e50d962d71e41b4e
|
diff --git a/src/pyhf/optimize/opt_minuit.py b/src/pyhf/optimize/opt_minuit.py
--- a/src/pyhf/optimize/opt_minuit.py
+++ b/src/pyhf/optimize/opt_minuit.py
@@ -10,7 +10,7 @@ class minuit_optimizer(OptimizerMixin):
Optimizer that uses iminuit.Minuit.migrad.
"""
- __slots__ = ['name', 'errordef', 'steps']
+ __slots__ = ['name', 'errordef', 'steps', 'strategy']
def __init__(self, *args, **kwargs):
"""
@@ -27,10 +27,12 @@ def __init__(self, *args, **kwargs):
Args:
errordef (:obj:`float`): See minuit docs. Default is 1.0.
steps (:obj:`int`): Number of steps for the bounds. Default is 1000.
+ strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is None.
"""
self.name = 'minuit'
self.errordef = kwargs.pop('errordef', 1)
self.steps = kwargs.pop('steps', 1000)
+ self.strategy = kwargs.pop('strategy', None)
super().__init__(*args, **kwargs)
def _get_minimizer(
@@ -87,17 +89,24 @@ def _minimize(
Minimizer Options:
maxiter (:obj:`int`): maximum number of iterations. Default is 100000.
return_uncertainties (:obj:`bool`): Return uncertainties on the fitted parameters. Default is off.
+ strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is to configure in response to `do_grad`.
Returns:
fitresult (scipy.optimize.OptimizeResult): the fit result
"""
maxiter = options.pop('maxiter', self.maxiter)
return_uncertainties = options.pop('return_uncertainties', False)
+ # 0: Fast, user-provided gradient
+ # 1: Default, no user-provided gradient
+ strategy = options.pop(
+ 'strategy', self.strategy if self.strategy else not do_grad
+ )
if options:
raise exceptions.Unsupported(
f"Unsupported options were passed in: {list(options.keys())}."
)
+ minimizer.strategy = strategy
minimizer.migrad(ncall=maxiter)
# Following lines below come from:
# https://github.com/scikit-hep/iminuit/blob/22f6ed7146c1d1f3274309656d8c04461dde5ba3/src/iminuit/_minimize.py#L106-L125
@@ -113,6 +122,8 @@ def _minimize(
n = len(x0)
hess_inv = default_backend.ones((n, n))
if minimizer.valid:
+ # Extra call to hesse() after migrad() is always needed for good error estimates. If you pass a user-provided gradient to MINUIT, convergence is faster.
+ minimizer.hesse()
hess_inv = minimizer.np_covariance()
unc = None
|
diff --git a/tests/test_optim.py b/tests/test_optim.py
--- a/tests/test_optim.py
+++ b/tests/test_optim.py
@@ -93,7 +93,7 @@ def test_minimize(tensorlib, precision, optimizer, do_grad, do_stitch):
'no_grad-minuit-jax-64b': [0.5000493563528641, 1.0000043833614634],
# do grad, minuit, 32b
'do_grad-minuit-pytorch-32b': [0.5017611384391785, 0.9997190237045288],
- 'do_grad-minuit-tensorflow-32b': [0.501288652420044, 1.0000219345092773],
+ 'do_grad-minuit-tensorflow-32b': [0.5012885928153992, 1.0000673532485962],
#'do_grad-minuit-jax-32b': [0.5029529333114624, 0.9991086721420288],
'do_grad-minuit-jax-32b': [0.5007095336914062, 0.9999282360076904],
# do grad, minuit, 64b
@@ -177,6 +177,54 @@ def test_minimize_do_grad_autoconfig(mocker, backend, backend_new):
assert shim.call_args[1]['do_grad'] != pyhf.tensorlib.default_do_grad
+def test_minuit_strategy_do_grad(mocker, backend):
+ """
+ ref: gh#1172
+
+ When there is a user-provided gradient, check that one automatically sets
+ the minuit strategy=0. When there is no user-provided gradient, check that
+ one automatically sets the minuit strategy=1.
+ """
+ pyhf.set_backend(pyhf.tensorlib, 'minuit')
+ spy = mocker.spy(pyhf.optimize.minuit_optimizer, '_minimize')
+ m = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
+ data = pyhf.tensorlib.astensor([125.0] + m.config.auxdata)
+
+ do_grad = pyhf.tensorlib.default_do_grad
+ pyhf.infer.mle.fit(data, m)
+ assert spy.call_count == 1
+ assert not spy.spy_return.minuit.strategy == do_grad
+
+ pyhf.infer.mle.fit(data, m, strategy=0)
+ assert spy.call_count == 2
+ assert spy.spy_return.minuit.strategy == 0
+
+ pyhf.infer.mle.fit(data, m, strategy=1)
+ assert spy.call_count == 3
+ assert spy.spy_return.minuit.strategy == 1
+
+
[email protected]('strategy', [0, 1])
+def test_minuit_strategy_global(mocker, backend, strategy):
+ pyhf.set_backend(pyhf.tensorlib, pyhf.optimize.minuit_optimizer(strategy=strategy))
+ spy = mocker.spy(pyhf.optimize.minuit_optimizer, '_minimize')
+ m = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
+ data = pyhf.tensorlib.astensor([125.0] + m.config.auxdata)
+
+ do_grad = pyhf.tensorlib.default_do_grad
+ pyhf.infer.mle.fit(data, m)
+ assert spy.call_count == 1
+ assert spy.spy_return.minuit.strategy == strategy if do_grad else 1
+
+ pyhf.infer.mle.fit(data, m, strategy=0)
+ assert spy.call_count == 2
+ assert spy.spy_return.minuit.strategy == 0
+
+ pyhf.infer.mle.fit(data, m, strategy=1)
+ assert spy.call_count == 3
+ assert spy.spy_return.minuit.strategy == 1
+
+
@pytest.mark.parametrize(
'optimizer',
[pyhf.optimize.scipy_optimizer, pyhf.optimize.minuit_optimizer],
|
use strategy 0 for user-provided gradients in minuit
# Description
since we have exact gradient we can disable the checks minuit does
cc @alexander-held
|
Some reference here: https://iminuit.readthedocs.io/en/stable/reference.html#iminuit.Minuit.strategy, in particular:
> 0: Fast. Does not check a user-provided gradient. Does not improve Hesse matrix at minimum. Extra call to hesse() after migrad() is always needed for good error estimates. If you pass a user-provided gradient to MINUIT, convergence is faster.
> 1: Default. Checks user-provided gradient against numerical gradient. Checks and usually improves Hesse matrix at minimum. Extra call to hesse() after migrad() is usually superfluous. If you pass a user-provided gradient to MINUIT, convergence is slower.
Strategy 0 seems mandatory when using gradients, and may be fine for some/most fits when not using them too. The `.hesse` call is a good addition when using strategy 0. Strategy 1 seems like a good default when not using exact gradients. Unfortunately there's no clean way to switch with the current optimizer structure in `pyhf`, since the strategy cannot be set through the constructor (https://github.com/scikit-hep/iminuit/issues/466) (at least this is what I remember from talking to @kratsg, maybe has changed since).
| 2020-11-18T21:31:42 |
scikit-hep/pyhf
| 1,184 |
scikit-hep__pyhf-1184
|
[
"929"
] |
2010b6d624c9668572a3f48ab6ea1a5619c39ac9
|
diff --git a/src/pyhf/optimize/opt_minuit.py b/src/pyhf/optimize/opt_minuit.py
--- a/src/pyhf/optimize/opt_minuit.py
+++ b/src/pyhf/optimize/opt_minuit.py
@@ -10,7 +10,7 @@ class minuit_optimizer(OptimizerMixin):
Optimizer that uses iminuit.Minuit.migrad.
"""
- __slots__ = ['name', 'errordef', 'steps', 'strategy']
+ __slots__ = ['name', 'errordef', 'steps', 'strategy', 'tolerance']
def __init__(self, *args, **kwargs):
"""
@@ -28,11 +28,13 @@ def __init__(self, *args, **kwargs):
errordef (:obj:`float`): See minuit docs. Default is 1.0.
steps (:obj:`int`): Number of steps for the bounds. Default is 1000.
strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is None.
+ tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is 0.1.
"""
self.name = 'minuit'
self.errordef = kwargs.pop('errordef', 1)
self.steps = kwargs.pop('steps', 1000)
self.strategy = kwargs.pop('strategy', None)
+ self.tolerance = kwargs.pop('tolerance', 0.1)
super().__init__(*args, **kwargs)
def _get_minimizer(
@@ -101,12 +103,14 @@ def _minimize(
strategy = options.pop(
'strategy', self.strategy if self.strategy else not do_grad
)
+ tolerance = options.pop('tolerance', self.tolerance)
if options:
raise exceptions.Unsupported(
f"Unsupported options were passed in: {list(options.keys())}."
)
minimizer.strategy = strategy
+ minimizer.tol = tolerance
minimizer.migrad(ncall=maxiter)
# Following lines below come from:
# https://github.com/scikit-hep/iminuit/blob/22f6ed7146c1d1f3274309656d8c04461dde5ba3/src/iminuit/_minimize.py#L106-L125
diff --git a/src/pyhf/optimize/opt_scipy.py b/src/pyhf/optimize/opt_scipy.py
--- a/src/pyhf/optimize/opt_scipy.py
+++ b/src/pyhf/optimize/opt_scipy.py
@@ -9,15 +9,19 @@ class scipy_optimizer(OptimizerMixin):
Optimizer that uses :func:`scipy.optimize.minimize`.
"""
- __slots__ = ['name']
+ __slots__ = ['name', 'tolerance']
def __init__(self, *args, **kwargs):
"""
Initialize the scipy_optimizer.
- See :class:`pyhf.optimize.mixins.OptimizerMixin` for configuration options.
+ See :class:`pyhf.optimize.mixins.OptimizerMixin` for other configuration options.
+
+ Args:
+ tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is None.
"""
self.name = 'scipy'
+ self.tolerance = kwargs.pop('tolerance', None)
super().__init__(*args, **kwargs)
def _get_minimizer(
@@ -40,9 +44,10 @@ def _minimize(
Same signature as :func:`scipy.optimize.minimize`.
Minimizer Options:
- maxiter (`int`): maximum number of iterations. Default is 100000.
- verbose (`bool`): print verbose output during minimization. Default is off.
- method (`str`): minimization routine. Default is 'SLSQP'.
+ maxiter (:obj:`int`): maximum number of iterations. Default is 100000.
+ verbose (:obj:`bool`): print verbose output during minimization. Default is off.
+ method (:obj:`str`): minimization routine. Default is 'SLSQP'.
+ tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is None.
Returns:
fitresult (scipy.optimize.OptimizeResult): the fit result
@@ -50,6 +55,7 @@ def _minimize(
maxiter = options.pop('maxiter', self.maxiter)
verbose = options.pop('verbose', self.verbose)
method = options.pop('method', 'SLSQP')
+ tolerance = options.pop('tolerance', self.tolerance)
if options:
raise exceptions.Unsupported(
f"Unsupported options were passed in: {list(options.keys())}."
@@ -73,5 +79,6 @@ def _minimize(
jac=do_grad,
bounds=bounds,
constraints=constraints,
+ tol=tolerance,
options=dict(maxiter=maxiter, disp=bool(verbose)),
)
|
diff --git a/tests/test_optim.py b/tests/test_optim.py
--- a/tests/test_optim.py
+++ b/tests/test_optim.py
@@ -225,6 +225,19 @@ def test_minuit_strategy_global(mocker, backend, strategy):
assert spy.spy_return.minuit.strategy == 1
+def test_set_tolerance(backend):
+ m = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
+ data = pyhf.tensorlib.astensor([125.0] + m.config.auxdata)
+
+ assert pyhf.infer.mle.fit(data, m, tolerance=0.01) is not None
+
+ pyhf.set_backend(pyhf.tensorlib, pyhf.optimize.scipy_optimizer(tolerance=0.01))
+ assert pyhf.infer.mle.fit(data, m) is not None
+
+ pyhf.set_backend(pyhf.tensorlib, pyhf.optimize.minuit_optimizer(tolerance=0.01))
+ assert pyhf.infer.mle.fit(data, m) is not None
+
+
@pytest.mark.parametrize(
'optimizer',
[pyhf.optimize.scipy_optimizer, pyhf.optimize.minuit_optimizer],
|
Expose minuit instance in fit
# Description
A fit via `pyhf.infer.mle.fit()` with minuit backend currently does not offer access to the minuit instance to for further operations, e.g. access to the correlation matrix. It would be convenient to optionally return it.
## Is your feature request related to a problem? Please describe.
The provided `pyhf.infer.mle.fit()` can only be used for studies with limited scope, as important information such as parameter correlations are inaccessible.
### Describe the solution you'd like
A keyword argument to optionally return the minuit instance, similar to `return_uncertainties`. Alternatively, the correlation matrix might be returned directly, though the full minuit instance might be more convenient (e.g. for Minos errors).
### Describe alternatives you've considered
A user wanting more detailed control over the fit could implement it separately and not go through `infer` to bypass this limitation. This might be a good solution to prevent supporting every last use case (and will offer more detailed control over minuit, which might be desired).
# Relevant Issues and Pull Requests
#881
# Additional context
none
|
You can't get the optimizer used via `_, opt = pyhf.get_backend()` ?
That returns a `pyhf.optimize.opt_minuit.minuit_optimizer`, and the minuit instance is built within `_make_minuit()` as `mm`, but not saved as a member variable after `minimize()`. I think I cannot get the right object this way.
I thin i'd rather provide APIs for the common information (eg `return_correlation` or `return_hessian`) instead of directly exposing the underlying implementation / minuit instance.
the ctor of the minuit optimizer should be able to take on fine-grained global options
pyhf.optimize.opt_minuit.minuit_optimizer(option1 = , option2 = )
what do you think @alexander-held ?
An API to get the available information, like `return_correlation`, would be very convenient. This prevents users from having to worry about writing backend-agnostic implementations (to the extent that this is possible, since not all backends provide all the information).
> the ctor of the minuit optimizer should be able to take on fine-grained global options
Is this already possible now, or a goal? I have not managed so far to pass information to the Minuit instance through `pyhf`. I am in particular thinking of customizing things like strategy / tolerance.
As of `v0.5.0`, the `minimize()` API provides a `return_result_obj` which contains a `minuit` attribute for the underlying minuit instance.
The updates in #951 and #988 cover most of what I can think of. The last related thing that would be convenient is support for propagating `strategy` / `tol` through to `Minuit`, see https://github.com/scikit-hep/iminuit/issues/466. Thanks a lot for these updates!
Given the outcome of https://github.com/scikit-hep/iminuit/issues/466, I am not sure whether support for `strategy` / `tol` through `pyhf.infer` is possible. I ended up re-implementing the relevant functionality to get access to these settings.
| 2020-11-19T02:50:57 |
scikit-hep/pyhf
| 1,186 |
scikit-hep__pyhf-1186
|
[
"1182"
] |
07fc449bb9313b78e05cb843b58120a3dc3c1828
|
diff --git a/src/pyhf/contrib/cli.py b/src/pyhf/contrib/cli.py
--- a/src/pyhf/contrib/cli.py
+++ b/src/pyhf/contrib/cli.py
@@ -3,8 +3,6 @@
import click
from pathlib import Path
-from . import utils
-
logging.basicConfig()
log = logging.getLogger(__name__)
@@ -22,6 +20,10 @@ def cli():
$ python -m pip install pyhf[contrib]
"""
+ from . import utils # Guard CLI from missing extra
+
+ # TODO: https://github.com/scikit-hep/pyhf/issues/863
+ _ = utils # Placate pyflakes
@cli.command()
@@ -57,6 +59,8 @@ def download(archive_url, output_directory, verbose, force, compress):
:class:`~pyhf.exceptions.InvalidArchiveHost`: if the provided archive host name is not known to be valid
"""
try:
+ from . import utils
+
utils.download(archive_url, output_directory, force, compress)
if verbose:
|
diff --git a/tests/test_scripts.py b/tests/test_scripts.py
--- a/tests/test_scripts.py
+++ b/tests/test_scripts.py
@@ -562,7 +562,7 @@ def test_missing_contrib_extra(caplog):
if "pyhf.contrib.utils" in sys.modules:
reload(sys.modules["pyhf.contrib.utils"])
else:
- import_module("pyhf.cli")
+ import_module("pyhf.contrib.utils")
with caplog.at_level(logging.ERROR):
for line in [
@@ -577,10 +577,10 @@ def test_missing_contrib_extra(caplog):
def test_missing_contrib_download(caplog):
with mock.patch.dict(sys.modules):
sys.modules["requests"] = None
- if "pyhf.cli" in sys.modules:
- reload(sys.modules["pyhf.cli"])
+ if "pyhf.contrib.utils" in sys.modules:
+ reload(sys.modules["pyhf.contrib.utils"])
else:
- import_module("pyhf.cli")
+ import_module("pyhf.contrib.utils")
# Force environment for runner
for module in [
|
pyhf json2xml requires pyhf[contrib]
# Description
```
$ pip install pyhf[xmlio]
$ pyhf json2xml -h
ERROR:pyhf.contrib.utils:No module named 'requests'
Installation of the contrib extra is required to use pyhf.contrib.utils.download
Please install with: python -m pip install pyhf[contrib]
Usage: pyhf json2xml [OPTIONS] [WORKSPACE]
Convert pyhf JSON back to XML + ROOT files.
Options:
--output-dir PATH
--specroot TEXT
--dataroot TEXT
--resultprefix TEXT
-p, --patch TEXT
-h, --help Show this message and exit.
```
# Expected Behavior
Shown the help without any reference to pyhf.contrib as this does not depend on contrib.
| 2020-11-19T06:47:36 |
|
scikit-hep/pyhf
| 1,202 |
scikit-hep__pyhf-1202
|
[
"1069"
] |
755fca9cd84612c089b0e28a25e26295c31615fc
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -9,7 +9,7 @@
'torch': ['torch~=1.2'],
'jax': ['jax~=0.2.4', 'jaxlib~=0.1.56'],
'xmlio': ['uproot3~=3.14'], # Future proof against uproot4 API changes
- 'minuit': ['iminuit~=1.4.3'], # v1.5.0 breaks pyhf for 32b TensorFlow and PyTorch
+ 'minuit': ['iminuit~=1.5.3'],
}
extras_require['backends'] = sorted(
set(
diff --git a/src/pyhf/optimize/opt_minuit.py b/src/pyhf/optimize/opt_minuit.py
--- a/src/pyhf/optimize/opt_minuit.py
+++ b/src/pyhf/optimize/opt_minuit.py
@@ -113,7 +113,7 @@ def _minimize(
minimizer.tol = tolerance
minimizer.migrad(ncall=maxiter)
# Following lines below come from:
- # https://github.com/scikit-hep/iminuit/blob/22f6ed7146c1d1f3274309656d8c04461dde5ba3/src/iminuit/_minimize.py#L106-L125
+ # https://github.com/scikit-hep/iminuit/blob/64acac11cfa2fb91ccbd02d1b3c51f8a9e2cc484/src/iminuit/_minimize.py#L102-L121
message = "Optimization terminated successfully."
if not minimizer.valid:
message = "Optimization failed."
@@ -141,7 +141,7 @@ def _minimize(
fun=minimizer.fval,
hess_inv=hess_inv,
message=message,
- nfev=minimizer.ncalls,
- njev=minimizer.ngrads,
+ nfev=minimizer.ncalls_total,
+ njev=minimizer.ngrads_total,
minuit=minimizer,
)
|
diff --git a/tests/test_optim.py b/tests/test_optim.py
--- a/tests/test_optim.py
+++ b/tests/test_optim.py
@@ -420,20 +420,6 @@ def test_minuit_failed_optimization(
monkeypatch, mocker, has_reached_call_limit, is_above_max_edm
):
class BadMinuit(iminuit.Minuit):
- @classmethod
- def from_array_func(cls, *args, **kwargs):
- """
- from_array_func won't need mocker in a newer version of iminuit
-
- See scikit-hep/iminuit#464 for more details
- """
- self = super().from_array_func(*args, **kwargs)
- mock = mocker.MagicMock(wraps=self)
- mock.valid = False
- mock.fmin.has_reached_call_limit = has_reached_call_limit
- mock.fmin.is_above_max_edm = is_above_max_edm
- return mock
-
@property
def valid(self):
return False
|
iminuit v1.5.0 breaks optimization tests
# Description
With the release of [`iminuit` `v1.5.0`](https://github.com/scikit-hep/iminuit/releases/tag/v1.5.0) on 2020-09-17 the nightly tests are failing in `test_optim.py`. Specifically
https://github.com/scikit-hep/pyhf/blob/8a6ee36da4f566d8a37df01e20201098aa1f8a54/tests/test_optim.py#L47
is failing with errors of
```pytb
try:
assert result.success
except AssertionError:
log.error(result)
> raise exceptions.FailedMinimization(result)
E pyhf.exceptions.FailedMinimization: Optimization failed. Estimated distance to minimum too large.
src/pyhf/optimize/mixins.py:52: FailedMinimization
------------------------------ Captured log call -------------------------------
ERROR pyhf.optimize.mixins:mixins.py:51 fun: 15.5887451171875
hess_inv: array([[1., 1.],
[1., 1.]])
message: 'Optimization failed. Estimated distance to minimum too large.'
minuit: <iminuit._libiminuit.Minuit object at 0x5619c82f90a0>
nfev: 110
njev: 0
success: False
unc: None
x: array([0.97325551, 0.91712703])
```
where the `pyhf.exceptions.FailedMinimization` being raised comes from the `raise exceptions.FailedMinimization(result)` in
https://github.com/scikit-hep/pyhf/blob/8a6ee36da4f566d8a37df01e20201098aa1f8a54/src/pyhf/optimize/mixins.py#L31-L53
which are of course coming from
https://github.com/scikit-hep/pyhf/blob/8a6ee36da4f566d8a37df01e20201098aa1f8a54/src/pyhf/optimize/opt_minuit.py#L122-L132
in
https://github.com/scikit-hep/pyhf/blob/8a6ee36da4f566d8a37df01e20201098aa1f8a54/src/pyhf/optimize/opt_minuit.py#L69
# Steps to Reproduce
Run the tests using current master.

To show that this is definitley an issue with `iminuit` `v1.5.0+`
```
$ python -m pip install --upgrade "iminuit<1.5.0"
$ pip list | grep iminuit
iminuit 1.4.9
$ python -m pytest -sx tests/test_optim.py
```
passes but
```
$ python -m pip install --upgrade iminuit
$ pip list | grep iminuit
iminuit 1.5.1
$ python -m pytest -sx tests/test_optim.py
```
fails.
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
Tagging @HDembinski on this not because I expect them to do anything (this is a `pyhf` test issue) but just to give them a heads up that we might not be the only ones with tests that are failing — so there might be incoming issues on `iminuit` from other projects.
Not sure what could have caused this in iminuit. What exactly is failing?
> Not sure what could have caused this in iminuit. What exactly is failing?
These 8 test parameterizations of https://github.com/scikit-hep/pyhf/blob/8a6ee36da4f566d8a37df01e20201098aa1f8a54/tests/test_optim.py#L47
- `no_grad-minuit-pytorch-32b-no_stitch`
- `no_grad-minuit-pytorch-32b-do_stitch`
- `no_grad-minuit-tensorflow-32b-no_stitch`
- `no_grad-minuit-tensorflow-32b-do_stitch`
- `do_grad-minuit-pytorch-32b-no_stitch`
- `do_grad-minuit-pytorch-32b-do_stitch`
- `do_grad-minuit-tensorflow-32b-no_stitch`
- `do_grad-minuit-tensorflow-32b-do_stitch`
which are essentially the `32b` `iminuit` optimizer tests for PyTorch and TensorFlow. Both the `no_grad`
https://github.com/scikit-hep/pyhf/blob/8a6ee36da4f566d8a37df01e20201098aa1f8a54/tests/test_optim.py#L85-L86
and `do_grad`
https://github.com/scikit-hep/pyhf/blob/8a6ee36da4f566d8a37df01e20201098aa1f8a54/tests/test_optim.py#L95-L96
are failing with the `'Optimization failed. Estimated distance to minimum too large.'` errors seen above in the Issue report body.
I can follow up more on this when it is morning in my timezone.
@HDembinski This is (strangely?) related to https://github.com/scikit-hep/iminuit/pull/462 it seems. If I change `setup.py` to require `iminuit~=1.4.0` (to get `v1.4.9`) and then in CI update `iminuit` to the digest for `iminuit` PR 461:
```yaml
- name: Install dependencies
run: |
python -m pip install --upgrade pip setuptools wheel
python -m pip install --ignore-installed -U -q --no-cache-dir -e .[test] # So have iminuit v1.4.9 here
python -m pip install cython
python -m pip install --upgrade --no-cache-dir git+git://github.com/scikit-hep/iminuit.git@0a035e8da276bd64a106f4b10537fde884ae8eba
```
then the CI will pass, but if I change that to the digest for `iminuit` PR 462
```
python -m pip install --upgrade --no-cache-dir git+git://github.com/scikit-hep/iminuit.git@31799ac188798ad8166375cc4c3a0cfcb2825995
```
the CI will fail with the error described above.
Something's off for sure as we don't rely on `nsplit`. If somehow dropping `nsplit` changed the minimum distance calculation - then this is the issue. We probably need a way to bump up the calculation to make it happen...
@matthewfeickert does increasing `ncalls` in the tests work? We do default to 100k iterations which is... a large number. Especially since for these tests, minuit converged in < 100 in the past... To change, something like `pyhf.optimizer.minuit_optimizer(maxiter=1e6)` would change the ncalls.
Dropping nsplit should not change the minimization in any way. nsplit is something that Piti added to artificially interrupt Migrad to get intermediate output. It was an ugly hack and not very useful, removing it simplified the code a lot.
The new version passes all the iminuit tests, including minimization tests on difficult functions, so I am not sure what is going on here.
In any case, I will have a sharp look at the code again.
> The new version passes all the iminuit tests, including minimization tests on difficult functions, so I am not sure what is going on here.
That's what I'm confused about here. These tests we're doing are using rather simple likelihoods where we have
```
m = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
data = pyhf.tensorlib.astensor([125.0] + m.config.auxdata)
```
This is where we expect the test to give us parameter values of `[mu=0.5, bkg_uncert=1.0]`. For 64b it looks like we have no failures -- but when we pass in 32b straight into minuit, I guess there's no more support there, or it's unable to do the minimization at that float precision?
It would be useful to inspect the FMin object, you can get it from the minimize output as result["minuit"].fmin.
If the error message you got is correct, then increasing the call limit should not help. Minuit should complain with a different message when the limit is reached. It basically says that convergence could not be reached. Usually that is caused by numerical issues in the cost function.
dumping here for now (@HDembinski -- also providing code so you can explore as well. We have a nice api for getting the minuit object back out).
```python
Python 3.7.3 (default, Mar 27 2019, 09:23:32)
[Clang 9.0.0 (clang-900.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pyhf
>>> pyhf.version.__version__
'0.5.2'
>>> import iminuit
>>> iminuit.version.__version__
'1.4.9'
>>> pyhf.set_backend(pyhf.tensor.pytorch_backend(precision='32b'), 'minuit')
>>> m = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
>>> data = pyhf.tensorlib.astensor([125.0] + m.config.auxdata)
>>> try:
... result, obj = pyhf.infer.mle.fit(data, m, do_grad=False, do_stitch=False, return_result_obj=True)
... except pyhf.exceptions.FailedMinimization as e:
... obj = e.result
>>> obj.minuit.fmin
FMin(fval=14.68798828125, edm=3.4475309051665455e-05, tolerance=0.1, nfcn=145, ncalls=255, up=1.0, is_valid=True, has_valid_parameters=True, has_accurate_covar=True, has_posdef_covar=True, has_made_posdef_covar=False, hesse_failed=False, has_covariance=True, is_above_max_edm=False, has_reached_call_limit=False)
```
failure
```python
Python 3.7.3 (default, Mar 27 2019, 09:23:32)
[Clang 9.0.0 (clang-900.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pyhf
>>> pyhf.version.__version__
'0.5.2'
>>> import iminuit
>>> iminuit.version.__version__
'1.5.0'
>>> pyhf.set_backend(pyhf.tensor.pytorch_backend(precision='32b'), 'minuit')
>>> m = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
>>> data = pyhf.tensorlib.astensor([125.0] + m.config.auxdata)
>>> try:
... result, obj = pyhf.infer.mle.fit(data, m, do_grad=False, do_stitch=False, return_result_obj=True)
... except pyhf.exceptions.FailedMinimization as e:
... obj = e.result
>>> obj.minuit.fmin
FMin(fval=15.5887451171875, edm=300.64070491474513, tolerance=0.1, nfcn=99, ncalls=110, up=1.0, is_valid=False, has_valid_parameters=True, has_accurate_covar=False, has_posdef_covar=False, has_made_posdef_covar=True, hesse_failed=False, has_covariance=True, is_above_max_edm=True, has_reached_call_limit=False, has_parameters_at_limit=False)
```
certainly some differences. Notably, the `edm` is significantly larger.
here's a quick script that runs both precision values:
```python
import pyhf
print(f'pyhf.version = {pyhf.version.__version__}')
import iminuit
print(f'iminuit.version = {iminuit.version.__version__}')
for precision in ['32b', '64b']:
print(f'precision = {precision}')
pyhf.set_backend(pyhf.tensor.pytorch_backend(precision=precision), 'minuit')
m = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
data = pyhf.tensorlib.astensor([125.0] + m.config.auxdata)
try:
result, obj = pyhf.infer.mle.fit(data, m, do_grad=False, do_stitch=False, return_result_obj=True)
except pyhf.exceptions.FailedMinimization as e:
obj = e.result
print(obj.minuit.fmin)
```
```
$ python minuit.py
pyhf.version = 0.5.2
iminuit.version = 1.4.9
precision = 32b
------------------------------------------------------------------
| FCN = 14.69 | Ncalls=145 (255 total) |
| EDM = 3.45e-05 (Goal: 0.0002) | up = 1.0 |
------------------------------------------------------------------
| Valid Min. | Valid Param. | Above EDM | Reached call limit |
------------------------------------------------------------------
| True | True | False | False |
------------------------------------------------------------------
| Hesse failed | Has cov. | Accurate | Pos. def. | Forced |
------------------------------------------------------------------
| False | True | True | True | False |
------------------------------------------------------------------
precision = 64b
------------------------------------------------------------------
| FCN = 13.11 | Ncalls=43 (43 total) |
| EDM = 6.95e-08 (Goal: 0.0002) | up = 1.0 |
------------------------------------------------------------------
| Valid Min. | Valid Param. | Above EDM | Reached call limit |
------------------------------------------------------------------
| True | True | False | False |
------------------------------------------------------------------
| Hesse failed | Has cov. | Accurate | Pos. def. | Forced |
------------------------------------------------------------------
| False | True | True | True | False |
------------------------------------------------------------------
```
versus 1.5.0
```
$ python minuit.py
pyhf.version = 0.5.2
iminuit.version = 1.5.0
precision = 32b
┌──────────────────────────────────┬──────────────────────────────────────┐
│ FCN = 15.59 │ Ncalls = 99 (110 total) │
│ EDM = 301 (Goal: 0.0002) │ up = 1.0 │
├───────────────┬──────────────────┼──────────────────────────────────────┤
│INVALID Minimum│ Valid Parameters │ No Parameters at limit │
├───────────────┴──────────────────┼──────────────────────────────────────┤
│ ABOVE EDM goal │ Below call limit │
├───────────────┬──────────────────┼───────────┬─────────────┬────────────┤
│ Hesse ok │ Has Covariance │APPROXIMATE│NOT pos. def.│ FORCED │
└───────────────┴──────────────────┴───────────┴─────────────┴────────────┘
precision = 64b
┌──────────────────────────────────┬──────────────────────────────────────┐
│ FCN = 13.11 │ Ncalls = 43 (43 total) │
│ EDM = 6.95e-08 (Goal: 0.0002) │ up = 1.0 │
├───────────────┬──────────────────┼──────────────────────────────────────┤
│ Valid Minimum │ Valid Parameters │ No Parameters at limit │
├───────────────┴──────────────────┼──────────────────────────────────────┤
│ Below EDM goal │ Below call limit │
├───────────────┬──────────────────┼───────────┬─────────────┬────────────┤
│ Hesse ok │ Has Covariance │ Accurate │ Pos. def. │ Not forced │
└───────────────┴──────────────────┴───────────┴─────────────┴────────────┘
```
MINUIT expects the calculation to be accurate to double precision. I expect the calculation in 32 bit to fail, actually. The question is rather why it was working before.
Note that you can override the precision that MINUIT assumes by default with the precision keyword in Minuit.migrad. I have never tried this myself, though...
Ok, I think I get it now. The original code by Piti called Migrad in a loop until either the call limit is reached or a valid minimum is found. Basically it was overriding the stopping condition and went on to "try harder". I am not super happy with this idea, because it hides problems such as this, but apparently it was working and people rely on this feature.
> Ok, I think I get it now. The original code by Piti called Migrad in a loop until either the call limit is reached or a valid minimum is found. Basically it was overriding the stopping condition and went on to "try harder". I am not super happy with this idea, because it hides problems such as this, but apparently it was working and people rely on this feature.
We would be happy to have this be a configurable option. At least to have a "try_harder=True" or something like this. Can you point to the code changes that were affecting this? I looked through the linked PR but had a hard time figuring out how it might have changed.
Thanks for taking the time to investigate this @HDembinski.
> We would be happy to have this be a configurable option. At least to have a "try_harder=True" or something like this.
I like @kratsg's suggestion here.
> Can you point to the code changes that were affecting this? I looked through the linked PR but had a hard time figuring out how it might have changed.
Same. We're happy to try to help out here if possible/needed.
@HDembinski Also, just a note. With PR #1071 we now have a nightly test of the `HEAD` of `iminuit`'s default branch (`develop`) with our test suite so we should detect in the future if there are any changes to `iminuit` that affect us far in advance of any release.
The test against develop is good, thanks. We need to cooperate a bit on bringing the old behavior back. I will try to check out pyhf to use its test in my debug cycle.
If you have the time, it would be great if you could try to set precision manually to something like float32 epsilon, to see whether that restores convergence in the 32b case.
> If you have the time, it would be great if you could try to set precision manually to something like float32 epsilon, to see whether that restores convergence in the 32b case.
Okay. I'll try to get to that this evening, but probably won't be able to do much testing before that sadly.
I am working on restoring something like the old behavior in iminuit. I can also tell you that running migrad() several times in a row fixes the failing test.
@kratsg
> Can you point to the code changes that were affecting this?
https://github.com/scikit-hep/iminuit/commit/31799ac188798ad8166375cc4c3a0cfcb2825995#diff-555f11eca5f91abf962969c058e0edebL886-L893
Since I referenced your issue in my PR, it was automatically closed. Please confirm that develop works again.
> Since I referenced your issue in my PR, it was automatically closed. Please confirm that develop works again.
I just manually triggered a run of the "HEAD of dependencies" workflow and now there are only two tests still failing with the `HEAD` of `iminuit`: https://github.com/scikit-hep/pyhf/actions/runs/267372882
- `test_minimize[no_grad-minuit-tensorflow-32b-no_stitch]`
- `test_minimize[no_grad-minuit-tensorflow-32b-do_stitch]`
The rest are passing now.
I cannot confirm this with my local checkout of pyhf. All tests run through for me.
I currently run 3 iterations before giving up, the old code potentially ran up to infinitely many. I will increase to 5 in this patch
https://github.com/scikit-hep/iminuit/pull/487
Let's see whether that helps.
We likely need to patch pyhf to set the 32b float mode when running over 32b. This may be the last piece needed on our side. I think 3 is enough, but not sure.
I just increased the number of iterations to 5 in the develop branch.
> I just increased the number of iterations to 5 in the develop branch.
With that (https://github.com/scikit-hep/iminuit/pull/487) `iminuit` now passes: https://github.com/scikit-hep/pyhf/actions/runs/269087634
> We likely need to patch pyhf to set the 32b float mode when running over 32b. This may be the last piece needed on our side. I think 3 is enough, but not sure.
@HDembinski If it would be preferable to have a lower number of iterations, we can work on the above as @kratsg mentioned.
No it is fine. Glad to hear that fixed it.
> No it is fine. Glad to hear that fixed it.
Thanks very much for your help here @HDembinski. You were very fast to iterate and we greatly appreciate you being willing to make changes to `iminuit` on our behalf.
We'll also lift the restrictions added in PR #1070 after the next release. :+1: (We can have that PR close this Issue).
@kratsg we still might want to revisit
> set[ing] the 32b float mode when running over 32
| 2020-11-30T23:15:17 |
scikit-hep/pyhf
| 1,208 |
scikit-hep__pyhf-1208
|
[
"1166"
] |
9aaa7ccd1f209acb7c32fbc4e50dda0df668bf14
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -9,7 +9,7 @@
'torch': ['torch~=1.2'],
'jax': ['jax~=0.2.4', 'jaxlib~=0.1.56'],
'xmlio': ['uproot3~=3.14'], # Future proof against uproot4 API changes
- 'minuit': ['iminuit~=1.5.3'],
+ 'minuit': ['iminuit~=2.1'],
}
extras_require['backends'] = sorted(
set(
diff --git a/src/pyhf/optimize/opt_minuit.py b/src/pyhf/optimize/opt_minuit.py
--- a/src/pyhf/optimize/opt_minuit.py
+++ b/src/pyhf/optimize/opt_minuit.py
@@ -58,17 +58,13 @@ def _get_minimizer(
wrapped_objective = objective_and_grad
jac = None
- kwargs = dict(
- fcn=wrapped_objective,
- grad=jac,
- start=init_pars,
- error=step_sizes,
- limit=init_bounds,
- fix=fixed_bools,
- print_level=self.verbose,
- errordef=self.errordef,
- )
- return iminuit.Minuit.from_array_func(**kwargs)
+ minuit = iminuit.Minuit(wrapped_objective, init_pars, grad=jac)
+ minuit.errors = step_sizes
+ minuit.limits = init_bounds
+ minuit.fixed = fixed_bools
+ minuit.print_level = self.verbose
+ minuit.errordef = self.errordef
+ return minuit
def _minimize(
self,
@@ -113,7 +109,7 @@ def _minimize(
minimizer.tol = tolerance
minimizer.migrad(ncall=maxiter)
# Following lines below come from:
- # https://github.com/scikit-hep/iminuit/blob/64acac11cfa2fb91ccbd02d1b3c51f8a9e2cc484/src/iminuit/_minimize.py#L102-L121
+ # https://github.com/scikit-hep/iminuit/blob/23bad7697e39d363f259ca8349684df939b1b2e6/src/iminuit/_minimize.py#L111-L130
message = "Optimization terminated successfully."
if not minimizer.valid:
message = "Optimization failed."
@@ -128,20 +124,20 @@ def _minimize(
if minimizer.valid:
# Extra call to hesse() after migrad() is always needed for good error estimates. If you pass a user-provided gradient to MINUIT, convergence is faster.
minimizer.hesse()
- hess_inv = minimizer.np_covariance()
+ hess_inv = minimizer.covariance
unc = None
if return_uncertainties:
- unc = minimizer.np_errors()
+ unc = minimizer.errors
return scipy.optimize.OptimizeResult(
- x=minimizer.np_values(),
+ x=minimizer.values,
unc=unc,
success=minimizer.valid,
fun=minimizer.fval,
hess_inv=hess_inv,
message=message,
- nfev=minimizer.ncalls_total,
- njev=minimizer.ngrads_total,
+ nfev=minimizer.nfcn,
+ njev=minimizer.ngrad,
minuit=minimizer,
)
|
diff --git a/tests/test_optim.py b/tests/test_optim.py
--- a/tests/test_optim.py
+++ b/tests/test_optim.py
@@ -499,10 +499,13 @@ def test_init_pars_sync_fixed_values_minuit(mocker):
# patch all we need
from pyhf.optimize import opt_minuit
- minimizer = mocker.patch.object(opt_minuit, 'iminuit')
- opt._get_minimizer(None, [9, 9, 9], [(0, 10)] * 3, fixed_vals=[(0, 1)])
- assert minimizer.Minuit.from_array_func.call_args[1]['start'] == [1, 9, 9]
- assert minimizer.Minuit.from_array_func.call_args[1]['fix'] == [True, False, False]
+ minuit = mocker.patch.object(getattr(opt_minuit, 'iminuit'), 'Minuit')
+ minimizer = opt._get_minimizer(None, [9, 9, 9], [(0, 10)] * 3, fixed_vals=[(0, 1)])
+ assert minuit.called
+ # python 3.6 does not have ::args attribute on ::call_args
+ # assert minuit.call_args.args[1] == [1, 9, 9]
+ assert minuit.call_args[0][1] == [1, 9, 9]
+ assert minimizer.fixed == [True, False, False]
def test_step_sizes_fixed_parameters_minuit(mocker):
@@ -511,7 +514,9 @@ def test_step_sizes_fixed_parameters_minuit(mocker):
# patch all we need
from pyhf.optimize import opt_minuit
- minimizer = mocker.patch.object(opt_minuit, 'iminuit')
- opt._get_minimizer(None, [9, 9, 9], [(0, 10)] * 3, fixed_vals=[(0, 1)])
- assert minimizer.Minuit.from_array_func.call_args[1]['fix'] == [True, False, False]
- assert minimizer.Minuit.from_array_func.call_args[1]['error'] == [0.0, 0.01, 0.01]
+ minuit = mocker.patch.object(getattr(opt_minuit, 'iminuit'), 'Minuit')
+ minimizer = opt._get_minimizer(None, [9, 9, 9], [(0, 10)] * 3, fixed_vals=[(0, 1)])
+
+ assert minuit.called
+ assert minimizer.fixed == [True, False, False]
+ assert minimizer.errors == [0.0, 0.01, 0.01]
|
Participate in iminuit v2.0 beta?
Dear pyhf team,
I am about to finish a major rewrite of iminuit, version 2.0, that replaces Cython as the tool to wrap C++ Minuit2 with pybind11, which is going to solve several issues that the legacy code had. All the good things that this will bring are listed on top of this PR:
scikit-hep/iminuit#502
Switching to the new version of iminuit should be completely transparent to you, since the new version passes the comprehensive suite of unit tests of iminuit-v1.x. However, I would like to use this opportunity to finally remove interface that has been successively marked as deprecated in versions 1.3 to 1.5.
Therefore my two question to you:
* Did you take note of the deprecation warnings in iminuit and did you keep up with the interface changes so far?
* Are you interested in trying out a Beta release of v2.0 to work out any possible bugs in the new version before the release?
Best regards,
Hans, iminuit maintainer
|
Hi @HDembinski. Thanks for thinking of us and giving us this heads up.
> I am about to finish a major rewrite of iminuit, version 2.0, that replaces Cython as the tool to wrap C++ Minuit2 with pybind11, which is going to solve several issues that the legacy code had.
This is very cool to hear. Congratulations!
> Did you take note of the deprecation warnings in iminuit and did you keep up with the interface changes so far?
I know that I don't do a very good job of checking the warnings, but we can do some checks to make sure we're not hitting any.
> Are you interested in trying out a Beta release of v2.0 to work out any possible bugs in the new version before the release?
Very much so. We have a nightly workflow that runs the test suite using an install from the HEAD of the main branch of `iminuit` on GitHub (`develop` I think for you), so we should hit anything before release and might already be testing your `v2.0` beta.
https://github.com/scikit-hep/pyhf/blob/a3b34a5eb7ffa83832242533a883c2ae98102369/.github/workflows/dependencies-head.yml#L35-L55
If you already have a branch beyond the main `develop` that this beta version is on, then we can just add another workflow that catches that.
> Did you take note of the deprecation warnings in iminuit and did you keep up with the interface changes so far?
we took care of them all generally with the major rewrite of our underlying optimizer api.
Thank you! Since you are testing develop, you should already get the latest, but you can also install the beta from test.pypi:
`pip install -i https://test.pypi.org/simple/ iminuit`
> Thank you! Since you are testing develop, you should already get the latest
Yup! We're already starting to [see tests fail there](https://github.com/scikit-hep/pyhf/runs/1371708342?check_suite_focus=true#step:5:192) (`AttributeError: 'Minuit' object has no attribute 'ncalls'`), so it seems things are working nicely in terms of giving us early warning. We'll go ahead and setup a branch that we can start to do tests on that moves to using the new API.
@matthewfeickert Thank you for the feedback, but I am thoroughly confused. This looks like you are calling `minimize`, which should of course work (I am testing it) and it is adapted to the new interface.
Ah, it looks like you either reimplemented `minimize` from `iminuit` or you simply have a function with the same name that also returns a scipy OptimizeResult
we conostruct `Minuit` objects here:
https://github.com/scikit-hep/pyhf/blob/master/src/pyhf/optimize/opt_minuit.py#L67
`ncalls` has been renamed to `nfcn` and `ngrads` to `ngrad` for consistency.
| 2020-12-08T15:22:22 |
scikit-hep/pyhf
| 1,220 |
scikit-hep__pyhf-1220
|
[
"1219"
] |
f824afe77d9e48e90651931700ccfc3d3c268c18
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -48,7 +48,7 @@
extras_require['docs'] = sorted(
{
'sphinx>=3.1.2',
- 'sphinxcontrib-bibtex',
+ 'sphinxcontrib-bibtex~=1.0',
'sphinx-click',
'sphinx_rtd_theme',
'nbsphinx',
|
diff --git a/tests/test_optim.py b/tests/test_optim.py
--- a/tests/test_optim.py
+++ b/tests/test_optim.py
@@ -380,7 +380,7 @@ def test_optim_with_value(backend, source, spec, mu):
)
assert pyhf.tensorlib.tolist(result)
assert pyhf.tensorlib.shape(fitted_val) == ()
- assert pytest.approx(17.52954975, rel=1e-5) == fitted_val
+ assert pytest.approx(17.52954975, rel=1e-5) == pyhf.tensorlib.tolist(fitted_val)
@pytest.mark.parametrize('mu', [1.0], ids=['mu=1'])
|
pytest v6.2.0 causing test_optim_with_value to fail
# Description
`v0.5.4` `bump2version` changes were swept into `master` 2020-12-12 with f824afe and the CI on `master` succeeded. Later that day [`pytest` `v6.2.0`](https://github.com/pytest-dev/pytest/releases/tag/6.2.0) was released and the nightly scheduled CI failed on
```pytb
_______________________ test_optim_with_value[jax-mu=1] ________________________
backend = (<pyhf.tensor.jax_backend.jax_backend object at 0x7f6bf92def50>, None)
source = {'bindata': {'bkg': [100.0, 150.0], 'bkgsys_dn': [98, 100], 'bkgsys_up': [102, 190], 'data': [120.0, 180.0], ...}, 'binning': [2, -0.5, 1.5]}
spec = {'channels': [{'name': 'singlechannel', 'samples': [{'data': [30.0, 95.0], 'modifiers': [{...}], 'name': 'signal'}, {'data': [100.0, 150.0], 'modifiers': [{...}], 'name': 'background'}]}]}
mu = 1.0
@pytest.mark.parametrize('mu', [1.0], ids=['mu=1'])
def test_optim_with_value(backend, source, spec, mu):
pdf = pyhf.Model(spec)
data = source['bindata']['data'] + pdf.config.auxdata
init_pars = pdf.config.suggested_init()
par_bounds = pdf.config.suggested_bounds()
optim = pyhf.optimizer
result = optim.minimize(pyhf.infer.mle.twice_nll, data, pdf, init_pars, par_bounds)
assert pyhf.tensorlib.tolist(result)
result, fitted_val = optim.minimize(
pyhf.infer.mle.twice_nll,
data,
pdf,
init_pars,
par_bounds,
fixed_vals=[(pdf.config.poi_index, mu)],
return_fitted_val=True,
)
assert pyhf.tensorlib.tolist(result)
assert pyhf.tensorlib.shape(fitted_val) == ()
> assert pytest.approx(17.52954975, rel=1e-5) == fitted_val
E assert 17.52954975 ± 1.8e-04 == DeviceArray(17.52954975, dtype=float64)
E + where 17.52954975 ± 1.8e-04 = <function approx at 0x7f6cc1747f80>(17.52954975, rel=1e-05)
E + where <function approx at 0x7f6cc1747f80> = pytest.approx
tests/test_optim.py:383: AssertionError
```
Diffing the installed libraries between the two (in [f824afe_install.txt](https://github.com/scikit-hep/pyhf/files/5684241/f824afe_install.txt) and [failing_install.txt](https://github.com/scikit-hep/pyhf/files/5684242/failing_install.txt)) shows that the relevant change is `pytest`
```
$ diff f824afe_install.txt failing_install.txt
33a34
> importlib-metadata 3.1.1
83c84
< py 1.9.0
---
> py 1.10.0
96c97
< pytest 6.1.2
---
> pytest 6.2.0
143a145
> zipp 3.4.0
```
This is confirmed as if
```diff
--- a/setup.py
+++ b/setup.py
@@ -29,7 +29,7 @@
+ extras_require['contrib']
+ extras_require['shellcomplete']
+ [
- 'pytest~=6.0',
+ 'pytest~=6.1.0',
'pytest-cov>=2.5.1',
'pytest-mock',
'pytest-benchmark[histogram]',
```
the [CI installs `v6.1.2` and passes](https://github.com/scikit-hep/pyhf/actions/runs/418404132).
This behavior is confusing as the only mention of `pytest.approx`in the [`v6.2.0` release notes](https://github.com/pytest-dev/pytest/releases/tag/6.2.0) is under "Improvements"
> 7710: Use strict equality comparison for non-numeric types in pytest.approx instead of
raising TypeError.
>
> This was the undocumented behavior before 3.7, but is now officially a supported feature.
| 2020-12-13T06:14:34 |
|
scikit-hep/pyhf
| 1,242 |
scikit-hep__pyhf-1242
|
[
"1131"
] |
e3da2dcfe6c77f44a49d42cb81ad758c541b3912
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -49,16 +49,19 @@
)
)
extras_require['docs'] = sorted(
- {
- 'sphinx>=3.1.2',
- 'sphinxcontrib-bibtex~=1.0',
- 'sphinx-click',
- 'sphinx_rtd_theme',
- 'nbsphinx',
- 'ipywidgets',
- 'sphinx-issues',
- 'sphinx-copybutton>0.2.9',
- }
+ set(
+ extras_require['xmlio']
+ + [
+ 'sphinx>=3.1.2',
+ 'sphinxcontrib-bibtex~=1.0',
+ 'sphinx-click',
+ 'sphinx_rtd_theme',
+ 'nbsphinx',
+ 'ipywidgets',
+ 'sphinx-issues',
+ 'sphinx-copybutton>0.2.9',
+ ]
+ )
)
extras_require['develop'] = sorted(
set(
|
Add pyhf.writexml and pyhf.readxml to public API docs
# Description
As first brought up in PR #1125, `pyhf.writexml` and `pyhf.readxml` are not currently documented in the public Python API docs. This should get fixed.
| 2021-01-05T15:30:15 |
||
scikit-hep/pyhf
| 1,261 |
scikit-hep__pyhf-1261
|
[
"1260"
] |
75f3cd350ed3986d16d680fbb83f312791aafd68
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -39,12 +39,10 @@
'pytest-console-scripts',
'pytest-mpl',
'pydocstyle',
- 'coverage>=4.0', # coveralls
'papermill~=2.0',
'nteract-scrapbook~=0.2',
'jupyter',
'graphviz',
- 'jsonpatch',
]
)
)
|
Remove duplicated libraries in setup.py
# Description
In `setup.py` and `setup.cfg` there are some duplicated libraries that should be removed from `setup.py`.
https://github.com/scikit-hep/pyhf/blob/75f3cd350ed3986d16d680fbb83f312791aafd68/setup.py#L47
already exists as a core requirement in `setup.cfg`
https://github.com/scikit-hep/pyhf/blob/75f3cd350ed3986d16d680fbb83f312791aafd68/setup.cfg#L45
and so should be removed from `setup.py`.
It also isn't clear if
https://github.com/scikit-hep/pyhf/blob/75f3cd350ed3986d16d680fbb83f312791aafd68/setup.py#L42
is still required, given that it was added back in PR #186 when we still used Coveralls for coverage.
| 2021-01-15T09:57:54 |
||
scikit-hep/pyhf
| 1,273 |
scikit-hep__pyhf-1273
|
[
"1234",
"1234"
] |
fed49ca770f89c779ac68e688088098100602594
|
diff --git a/src/pyhf/infer/mle.py b/src/pyhf/infer/mle.py
--- a/src/pyhf/infer/mle.py
+++ b/src/pyhf/infer/mle.py
@@ -131,8 +131,8 @@ def fixed_poi_fit(
Run a maximum likelihood fit with the POI value fixed.
This is done by minimizing the objective function of :func:`~pyhf.infer.mle.twice_nll`
of the model parameters given the observed data, for a given fixed value of :math:`\mu`.
- This is used to produce the constrained maximal likelihood for the given :math:`\mu`
- :math:`L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}\right)` in the profile
+ This is used to produce the constrained maximal likelihood for the given :math:`\mu`,
+ :math:`L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}\right)`, in the profile
likelihood ratio in Equation (7) in :xref:`arXiv:1007.1727`
.. math::
|
Add commas around constrained maximal likelihood in docstring for clarity
# Description
In PR #905 the docstring for [`pyhf.infer.mle.fixed_poi_fit`](https://scikit-hep.org/pyhf/_generated/pyhf.infer.mle.fixed_poi_fit.html) was amended, but the lines
https://github.com/scikit-hep/pyhf/blob/fd7930cce36cbc3a2d0ee1828f060d7382129579/src/pyhf/infer/mle.py#L134-L135
are missing commas around the likelihood, making it difficult to read

It should read
```
,:math:`L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}\right)`, in the profile
```
Add commas around constrained maximal likelihood in docstring for clarity
# Description
In PR #905 the docstring for [`pyhf.infer.mle.fixed_poi_fit`](https://scikit-hep.org/pyhf/_generated/pyhf.infer.mle.fixed_poi_fit.html) was amended, but the lines
https://github.com/scikit-hep/pyhf/blob/fd7930cce36cbc3a2d0ee1828f060d7382129579/src/pyhf/infer/mle.py#L134-L135
are missing commas around the likelihood, making it difficult to read

It should read
```
,:math:`L\left(\mu, \hat{\hat{\boldsymbol{\theta}}}\right)`, in the profile
```
|
I would like to work on this
I would like to work on this
| 2021-01-21T05:41:54 |
|
scikit-hep/pyhf
| 1,274 |
scikit-hep__pyhf-1274
|
[
"1265"
] |
749b9f7355032c5e70da9a715f465db1c6de0f6c
|
diff --git a/src/pyhf/infer/intervals.py b/src/pyhf/infer/intervals.py
deleted file mode 100644
--- a/src/pyhf/infer/intervals.py
+++ /dev/null
@@ -1,75 +0,0 @@
-"""Interval estimation"""
-from pyhf.infer import hypotest
-from pyhf import get_backend
-import numpy as np
-
-__all__ = ["upperlimit"]
-
-
-def __dir__():
- return __all__
-
-
-def _interp(x, xp, fp):
- tb, _ = get_backend()
- return tb.astensor(np.interp(x, xp.tolist(), fp.tolist()))
-
-
-def upperlimit(data, model, scan, level=0.05, return_results=False, **hypotest_kwargs):
- """
- Calculate an upper limit interval ``(0, poi_up)`` for a single
- Parameter of Interest (POI) using a fixed scan through POI-space.
-
- Example:
- >>> import numpy as np
- >>> import pyhf
- >>> pyhf.set_backend("numpy")
- >>> model = pyhf.simplemodels.uncorrelated_background(
- ... signal=[12.0, 11.0], bkg=[50.0, 52.0], bkg_uncertainty=[3.0, 7.0]
- ... )
- >>> observations = [51, 48]
- >>> data = pyhf.tensorlib.astensor(observations + model.config.auxdata)
- >>> scan = np.linspace(0, 5, 21)
- >>> obs_limit, exp_limits, (scan, results) = pyhf.infer.intervals.upperlimit(
- ... data, model, scan, return_results=True
- ... )
- >>> obs_limit
- array(1.01764089)
- >>> exp_limits
- [array(0.59576921), array(0.76169166), array(1.08504773), array(1.50170482), array(2.06654952)]
-
- Args:
- data (:obj:`tensor`): The observed data.
- model (~pyhf.pdf.Model): The statistical model adhering to the schema ``model.json``.
- scan (:obj:`iterable`): Iterable of POI values.
- level (:obj:`float`): The threshold value to evaluate the interpolated results at.
- return_results (:obj:`bool`): Whether to return the per-point results.
- hypotest_kwargs (:obj:`string`): Kwargs for the calls to
- :class:`~pyhf.infer.hypotest` to configure the fits.
-
- Returns:
- Tuple of Tensors:
-
- - Tensor: The observed upper limit on the POI.
- - Tensor: The expected upper limits on the POI.
- - Tuple of Tensors: The given ``scan`` along with the
- :class:`~pyhf.infer.hypotest` results at each test POI.
- Only returned when ``return_results`` is ``True``.
- """
- tb, _ = get_backend()
- results = [
- hypotest(mu, data, model, return_expected_set=True, **hypotest_kwargs)
- for mu in scan
- ]
- obs = tb.astensor([[r[0]] for r in results])
- exp = tb.astensor([[r[1][idx] for idx in range(5)] for r in results])
-
- result_arrary = tb.concatenate([obs, exp], axis=1).T
-
- # observed limit and the (0, +-1, +-2)sigma expected limits
- limits = [_interp(level, result_arrary[idx][::-1], scan[::-1]) for idx in range(6)]
- obs_limit, exp_limits = limits[0], limits[1:]
-
- if return_results:
- return obs_limit, exp_limits, (scan, results)
- return obs_limit, exp_limits
diff --git a/src/pyhf/infer/intervals/__init__.py b/src/pyhf/infer/intervals/__init__.py
new file mode 100644
--- /dev/null
+++ b/src/pyhf/infer/intervals/__init__.py
@@ -0,0 +1,30 @@
+"""Interval estimation"""
+import pyhf.infer.intervals.upper_limits
+
+__all__ = ["upper_limits.upper_limit"]
+
+
+def __dir__():
+ return __all__
+
+
+def upperlimit(
+ data, model, scan=None, level=0.05, return_results=False, **hypotest_kwargs
+):
+ """
+ .. deprecated:: 0.7.0
+ Use :func:`~pyhf.infer.intervals.upper_limits.upper_limit` instead.
+ .. warning:: :func:`~pyhf.infer.intervals.upperlimit` will be removed in
+ ``pyhf`` ``v0.9.0``.
+ """
+ from pyhf.exceptions import _deprecated_api_warning
+
+ _deprecated_api_warning(
+ "pyhf.infer.intervals.upperlimit",
+ "pyhf.infer.intervals.upper_limits.upper_limit",
+ "0.7.0",
+ "0.9.0",
+ )
+ return pyhf.infer.intervals.upper_limits.upper_limit(
+ data, model, scan, level, return_results, **hypotest_kwargs
+ )
diff --git a/src/pyhf/infer/intervals/upper_limits.py b/src/pyhf/infer/intervals/upper_limits.py
new file mode 100644
--- /dev/null
+++ b/src/pyhf/infer/intervals/upper_limits.py
@@ -0,0 +1,269 @@
+"""Interval estimation"""
+import numpy as np
+from scipy.optimize import toms748
+
+from pyhf import get_backend
+from pyhf.infer import hypotest
+
+__all__ = ["upper_limit", "linear_grid_scan", "toms748_scan"]
+
+
+def __dir__():
+ return __all__
+
+
+def _interp(x, xp, fp):
+ tb, _ = get_backend()
+ return tb.astensor(np.interp(x, xp.tolist(), fp.tolist()))
+
+
+def toms748_scan(
+ data,
+ model,
+ bounds_low,
+ bounds_up,
+ level=0.05,
+ atol=2e-12,
+ rtol=1e-4,
+ from_upper_limit_fn=False,
+ **hypotest_kwargs,
+):
+ """
+ Calculate an upper limit interval ``(0, poi_up)`` for a single
+ Parameter of Interest (POI) using an automatic scan through
+ POI-space, using the :func:`~scipy.optimize.toms748` algorithm.
+
+ Example:
+ >>> import numpy as np
+ >>> import pyhf
+ >>> pyhf.set_backend("numpy")
+ >>> model = pyhf.simplemodels.uncorrelated_background(
+ ... signal=[12.0, 11.0], bkg=[50.0, 52.0], bkg_uncertainty=[3.0, 7.0]
+ ... )
+ >>> observations = [51, 48]
+ >>> data = pyhf.tensorlib.astensor(observations + model.config.auxdata)
+ >>> obs_limit, exp_limits = pyhf.infer.intervals.upper_limits.toms748_scan(
+ ... data, model, 0., 5., rtol=0.01
+ ... )
+ >>> obs_limit
+ array(1.01156939)
+ >>> exp_limits
+ [array(0.5600747), array(0.75702605), array(1.06234693), array(1.50116923), array(2.05078912)]
+
+ Args:
+ data (:obj:`tensor`): The observed data.
+ model (~pyhf.pdf.Model): The statistical model adhering to the schema ``model.json``.
+ bounds_low (:obj:`float`): Lower boundary of search interval.
+ bounds_up (:obj:`float`): Upper boundary of search interval.
+ level (:obj:`float`): The threshold value to evaluate the interpolated results at.
+ Defaults to ``0.05``.
+ atol (:obj:`float`): Absolute tolerance.
+ The iteration will end when the result is within absolute
+ *or* relative tolerance of the true limit.
+ rtol (:obj:`float`): Relative tolerance.
+ For optimal performance this argument should be set
+ to the highest acceptable relative tolerance.
+ hypotest_kwargs (:obj:`string`): Kwargs for the calls to
+ :class:`~pyhf.infer.hypotest` to configure the fits.
+
+ Returns:
+ Tuple of Tensors:
+
+ - Tensor: The observed upper limit on the POI.
+ - Tensor: The expected upper limits on the POI.
+
+ .. versionadded:: 0.7.0
+ """
+ cache = {}
+
+ def f_cached(poi):
+ if poi not in cache:
+ cache[poi] = hypotest(
+ poi,
+ data,
+ model,
+ return_expected_set=True,
+ **hypotest_kwargs,
+ )
+ return cache[poi]
+
+ def f(poi, level, limit=0):
+ # Use integers for limit so we don't need a string comparison
+ # limit == 0: Observed
+ # else: expected
+ return (
+ f_cached(poi)[0] - level
+ if limit == 0
+ else f_cached(poi)[1][limit - 1] - level
+ )
+
+ def best_bracket(limit):
+ # return best bracket
+ ks = np.asarray(list(cache.keys()))
+ vals = np.asarray(
+ [
+ value[0] - level if limit == 0 else value[1][limit - 1] - level
+ for value in cache.values()
+ ]
+ )
+ pos = vals >= 0
+ neg = vals < 0
+ lower = ks[pos][np.argmin(vals[pos])]
+ upper = ks[neg][np.argmax(vals[neg])]
+ return (lower, upper)
+
+ # extend bounds_low and bounds_up if they don't bracket CLs level
+ lower_results = f_cached(bounds_low)
+ # {lower,upper}_results[0] is an array and {lower,upper}_results[1] is a
+ # list of arrays so need to turn {lower,upper}_results[0] into list to
+ # concatenate them
+ while np.any(np.asarray([lower_results[0]] + lower_results[1]) < level):
+ bounds_low /= 2
+ lower_results = f_cached(bounds_low)
+ upper_results = f_cached(bounds_up)
+ while np.any(np.asarray([upper_results[0]] + upper_results[1]) > level):
+ bounds_up *= 2
+ upper_results = f_cached(bounds_up)
+
+ tb, _ = get_backend()
+ obs = tb.astensor(
+ toms748(f, bounds_low, bounds_up, args=(level, 0), k=2, xtol=atol, rtol=rtol)
+ )
+ exp = [
+ tb.astensor(
+ toms748(f, *best_bracket(idx), args=(level, idx), k=2, xtol=atol, rtol=rtol)
+ )
+ for idx in range(1, 6)
+ ]
+ if from_upper_limit_fn:
+ return obs, exp, (list(cache.keys()), list(cache.values()))
+ return obs, exp
+
+
+def linear_grid_scan(
+ data, model, scan, level=0.05, return_results=False, **hypotest_kwargs
+):
+ """
+ Calculate an upper limit interval ``(0, poi_up)`` for a single
+ Parameter of Interest (POI) using a linear scan through POI-space.
+
+ Example:
+ >>> import numpy as np
+ >>> import pyhf
+ >>> pyhf.set_backend("numpy")
+ >>> model = pyhf.simplemodels.uncorrelated_background(
+ ... signal=[12.0, 11.0], bkg=[50.0, 52.0], bkg_uncertainty=[3.0, 7.0]
+ ... )
+ >>> observations = [51, 48]
+ >>> data = pyhf.tensorlib.astensor(observations + model.config.auxdata)
+ >>> scan = np.linspace(0, 5, 21)
+ >>> obs_limit, exp_limits, (scan, results) = pyhf.infer.intervals.upper_limits.upper_limit(
+ ... data, model, scan, return_results=True
+ ... )
+ >>> obs_limit
+ array(1.01764089)
+ >>> exp_limits
+ [array(0.59576921), array(0.76169166), array(1.08504773), array(1.50170482), array(2.06654952)]
+
+ Args:
+ data (:obj:`tensor`): The observed data.
+ model (~pyhf.pdf.Model): The statistical model adhering to the schema ``model.json``.
+ scan (:obj:`iterable`): Iterable of POI values.
+ level (:obj:`float`): The threshold value to evaluate the interpolated results at.
+ return_results (:obj:`bool`): Whether to return the per-point results.
+ hypotest_kwargs (:obj:`string`): Kwargs for the calls to
+ :class:`~pyhf.infer.hypotest` to configure the fits.
+
+ Returns:
+ Tuple of Tensors:
+
+ - Tensor: The observed upper limit on the POI.
+ - Tensor: The expected upper limits on the POI.
+ - Tuple of Tensors: The given ``scan`` along with the
+ :class:`~pyhf.infer.hypotest` results at each test POI.
+ Only returned when ``return_results`` is ``True``.
+
+ .. versionadded:: 0.7.0
+ """
+ tb, _ = get_backend()
+ results = [
+ hypotest(mu, data, model, return_expected_set=True, **hypotest_kwargs)
+ for mu in scan
+ ]
+ obs = tb.astensor([[r[0]] for r in results])
+ exp = tb.astensor([[r[1][idx] for idx in range(5)] for r in results])
+
+ result_array = tb.concatenate([obs, exp], axis=1).T
+
+ # observed limit and the (0, +-1, +-2)sigma expected limits
+ limits = [_interp(level, result_array[idx][::-1], scan[::-1]) for idx in range(6)]
+ obs_limit, exp_limits = limits[0], limits[1:]
+
+ if return_results:
+ return obs_limit, exp_limits, (scan, results)
+ return obs_limit, exp_limits
+
+
+def upper_limit(
+ data, model, scan=None, level=0.05, return_results=False, **hypotest_kwargs
+):
+ """
+ Calculate an upper limit interval ``(0, poi_up)`` for a single Parameter of
+ Interest (POI) using root-finding or a linear scan through POI-space.
+
+ Example:
+ >>> import numpy as np
+ >>> import pyhf
+ >>> pyhf.set_backend("numpy")
+ >>> model = pyhf.simplemodels.uncorrelated_background(
+ ... signal=[12.0, 11.0], bkg=[50.0, 52.0], bkg_uncertainty=[3.0, 7.0]
+ ... )
+ >>> observations = [51, 48]
+ >>> data = pyhf.tensorlib.astensor(observations + model.config.auxdata)
+ >>> scan = np.linspace(0, 5, 21)
+ >>> obs_limit, exp_limits, (scan, results) = pyhf.infer.intervals.upper_limits.upper_limit(
+ ... data, model, scan, return_results=True
+ ... )
+ >>> obs_limit
+ array(1.01764089)
+ >>> exp_limits
+ [array(0.59576921), array(0.76169166), array(1.08504773), array(1.50170482), array(2.06654952)]
+
+ Args:
+ data (:obj:`tensor`): The observed data.
+ model (~pyhf.pdf.Model): The statistical model adhering to the schema ``model.json``.
+ scan (:obj:`iterable` or ``None``): Iterable of POI values or ``None`` to use
+ :class:`~pyhf.infer.intervals.upper_limits.toms748_scan`.
+ level (:obj:`float`): The threshold value to evaluate the interpolated results at.
+ return_results (:obj:`bool`): Whether to return the per-point results.
+
+ Returns:
+ Tuple of Tensors:
+
+ - Tensor: The observed upper limit on the POI.
+ - Tensor: The expected upper limits on the POI.
+ - Tuple of Tensors: The given ``scan`` along with the
+ :class:`~pyhf.infer.hypotest` results at each test POI.
+ Only returned when ``return_results`` is ``True``.
+
+ .. versionadded:: 0.7.0
+ """
+ if scan is not None:
+ return linear_grid_scan(
+ data, model, scan, level, return_results, **hypotest_kwargs
+ )
+ # else:
+ bounds = model.config.suggested_bounds()[
+ model.config.par_slice(model.config.poi_name).start
+ ]
+ obs_limit, exp_limit, results = toms748_scan(
+ data,
+ model,
+ bounds[0],
+ bounds[1],
+ from_upper_limit_fn=True,
+ **hypotest_kwargs,
+ )
+ if return_results:
+ return obs_limit, exp_limit, results
+ return obs_limit, exp_limit
|
diff --git a/tests/constraints.txt b/tests/constraints.txt
--- a/tests/constraints.txt
+++ b/tests/constraints.txt
@@ -1,5 +1,5 @@
# core
-scipy==1.1.0
+scipy==1.2.0 # c.f. PR #1274
click==8.0.0 # c.f. PR #1958, #1909
tqdm==4.56.0
jsonschema==4.15.0 # c.f. PR #1979
diff --git a/tests/test_infer.py b/tests/test_infer.py
--- a/tests/test_infer.py
+++ b/tests/test_infer.py
@@ -1,8 +1,11 @@
-import pytest
-import pyhf
+import warnings
+
import numpy as np
+import pytest
import scipy.stats
+import pyhf
+
@pytest.fixture(scope="function")
def hypotest_args():
@@ -20,12 +23,91 @@ def check_uniform_type(in_list):
)
-def test_upperlimit(tmpdir, hypotest_args):
+def test_toms748_scan(tmpdir, hypotest_args):
+ """
+ Test the upper limit toms748 scan returns the correct structure and values
+ """
+ _, data, model = hypotest_args
+ results = pyhf.infer.intervals.upper_limits.toms748_scan(
+ data, model, 0, 5, rtol=1e-8
+ )
+ assert len(results) == 2
+ observed_limit, expected_limits = results
+ observed_cls = pyhf.infer.hypotest(
+ observed_limit,
+ data,
+ model,
+ model.config.suggested_init(),
+ model.config.suggested_bounds(),
+ )
+ expected_cls = np.array(
+ [
+ pyhf.infer.hypotest(
+ expected_limits[i],
+ data,
+ model,
+ model.config.suggested_init(),
+ model.config.suggested_bounds(),
+ return_expected_set=True,
+ )[1][i]
+ for i in range(5)
+ ]
+ )
+ assert observed_cls == pytest.approx(0.05)
+ assert expected_cls == pytest.approx(0.05)
+
+
+def test_toms748_scan_bounds_extension(hypotest_args):
+ """
+ Test the upper limit toms748 scan bounds can correctly extend to bracket the CLs level
+ """
+ _, data, model = hypotest_args
+ results_default = pyhf.infer.intervals.upper_limits.toms748_scan(
+ data, model, 0, 5, rtol=1e-8
+ )
+ observed_limit_default, expected_limits_default = results_default
+
+ # Force bounds_low to expand
+ observed_limit, expected_limits = pyhf.infer.intervals.upper_limits.toms748_scan(
+ data, model, 3, 5, rtol=1e-8
+ )
+
+ assert observed_limit == pytest.approx(observed_limit_default)
+ assert np.allclose(np.asarray(expected_limits), np.asarray(expected_limits_default))
+
+ # Force bounds_up to expand
+ observed_limit, expected_limits = pyhf.infer.intervals.upper_limits.toms748_scan(
+ data, model, 0, 1, rtol=1e-8
+ )
+ assert observed_limit == pytest.approx(observed_limit_default)
+ assert np.allclose(np.asarray(expected_limits), np.asarray(expected_limits_default))
+
+
+def test_upper_limit_against_auto(hypotest_args):
+ """
+ Test upper_limit linear scan and toms748_scan return similar results
+ """
+ _, data, model = hypotest_args
+ results_auto = pyhf.infer.intervals.upper_limits.toms748_scan(
+ data, model, 0, 5, rtol=1e-3
+ )
+ obs_auto, exp_auto = results_auto
+ results_linear = pyhf.infer.intervals.upper_limits.upper_limit(
+ data, model, scan=np.linspace(0, 5, 21)
+ )
+ obs_linear, exp_linear = results_linear
+ # Can't expect these to be much closer given the low granularity of the linear scan
+ assert obs_auto == pytest.approx(obs_linear, abs=0.1)
+ assert np.allclose(exp_auto, exp_linear, atol=0.1)
+
+
+def test_upper_limit(hypotest_args):
"""
Check that the default return structure of pyhf.infer.hypotest is as expected
"""
_, data, model = hypotest_args
- results = pyhf.infer.intervals.upperlimit(data, model, scan=np.linspace(0, 5, 11))
+ scan = np.linspace(0, 5, 11)
+ results = pyhf.infer.intervals.upper_limits.upper_limit(data, model, scan=scan)
assert len(results) == 2
observed_limit, expected_limits = results
assert observed_limit == pytest.approx(1.0262704738584554)
@@ -33,14 +115,24 @@ def test_upperlimit(tmpdir, hypotest_args):
[0.65765653, 0.87999725, 1.12453992, 1.50243428, 2.09232927]
)
+ # tighter relative tolerance needed for macos
+ results = pyhf.infer.intervals.upper_limits.upper_limit(data, model, rtol=1e-6)
+ assert len(results) == 2
+ observed_limit, expected_limits = results
+ assert observed_limit == pytest.approx(1.01156939)
+ assert expected_limits == pytest.approx(
+ [0.55988001, 0.75702336, 1.06234693, 1.50116923, 2.05078596]
+ )
+
-def test_upperlimit_with_kwargs(tmpdir, hypotest_args):
+def test_upper_limit_with_kwargs(hypotest_args):
"""
Check that the default return structure of pyhf.infer.hypotest is as expected
"""
_, data, model = hypotest_args
- results = pyhf.infer.intervals.upperlimit(
- data, model, scan=np.linspace(0, 5, 11), test_stat="qtilde"
+ scan = np.linspace(0, 5, 11)
+ results = pyhf.infer.intervals.upper_limits.upper_limit(
+ data, model, scan=scan, test_stat="qtilde"
)
assert len(results) == 2
observed_limit, expected_limits = results
@@ -49,6 +141,30 @@ def test_upperlimit_with_kwargs(tmpdir, hypotest_args):
[0.65765653, 0.87999725, 1.12453992, 1.50243428, 2.09232927]
)
+ # linear_grid_scan
+ results = pyhf.infer.intervals.upper_limits.upper_limit(
+ data, model, scan=scan, return_results=True
+ )
+ assert len(results) == 3
+ observed_limit, expected_limits, (_scan, point_results) = results
+ assert observed_limit == pytest.approx(1.0262704738584554)
+ assert expected_limits == pytest.approx(
+ [0.65765653, 0.87999725, 1.12453992, 1.50243428, 2.09232927]
+ )
+ assert _scan.tolist() == scan.tolist()
+ assert len(_scan) == len(point_results)
+
+ # toms748_scan
+ results = pyhf.infer.intervals.upper_limits.upper_limit(
+ data, model, return_results=True, rtol=1e-6
+ )
+ assert len(results) == 3
+ observed_limit, expected_limits, (_scan, point_results) = results
+ assert observed_limit == pytest.approx(1.01156939)
+ assert expected_limits == pytest.approx(
+ [0.55988001, 0.75702336, 1.06234693, 1.50116923, 2.05078596]
+ )
+
def test_mle_fit_default(tmpdir, hypotest_args):
"""
@@ -510,3 +626,19 @@ def test_teststat_nan_guard():
test_poi, data, model, test_stat="qtilde", return_expected=True
)
assert all(~np.isnan(result) for result in test_results)
+
+
+# TODO: Remove after pyhf v0.9.0 is released
+def test_deprecated_upperlimit(hypotest_args):
+ with warnings.catch_warnings(record=True) as _warning:
+ # Cause all warnings to always be triggered
+ warnings.simplefilter("always")
+
+ _, data, model = hypotest_args
+ pyhf.infer.intervals.upperlimit(data, model, scan=np.linspace(0, 5, 11))
+ assert len(_warning) == 1
+ assert issubclass(_warning[-1].category, DeprecationWarning)
+ assert (
+ "pyhf.infer.intervals.upperlimit is deprecated in favor of pyhf.infer.intervals.upper_limits.upper_limit"
+ in str(_warning[-1].message)
+ )
diff --git a/tests/test_public_api_repr.py b/tests/test_public_api_repr.py
--- a/tests/test_public_api_repr.py
+++ b/tests/test_public_api_repr.py
@@ -125,7 +125,15 @@ def test_infer_calculators_public_api():
def test_infer_intervals_public_api():
- assert dir(pyhf.infer.intervals) == ["upperlimit"]
+ assert dir(pyhf.infer.intervals) == ["upper_limits.upper_limit"]
+
+
+def test_infer_intervals_upper_limit_public_api():
+ assert dir(pyhf.infer.intervals.upper_limits) == [
+ "linear_grid_scan",
+ "toms748_scan",
+ "upper_limit",
+ ]
def test_infer_mle_public_api():
|
Auto scan for hypothesis test inversion (Implemented)
# Description
An auto scan feature for hypothesis test inversion can provide faster and more precise upper limits. One good way I've found to do this is to use the [TOMS748](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.toms748.html#scipy.optimize.toms748) root finding algorithm.
### Describe the solution you'd like
An `upperlimit_auto` (or some other appropriate name) function that runs an auto scan instead of a linear scan.
### Implementation
An implementation is below. I can make a PR including this in `pyhf.infer.intevals` if this issue has support.
```python
from scipy.optimize import toms748 as _toms748
def upperlimit_auto(data, model, low, high, level=0.05, atol=2e-12, rtol=1e-15):
"""
Calculate an upper limit interval ``(0, poi_up)`` for a single
Parameter of Interest (POI) using an automatic scan through
POI-space, using the TOMS748 algorithm.
..., mostly copied from upperlimit docstring.
"""
def f_all(mu):
return hypotest(mu, data, model, test_stat="qtilde", return_expected_set=True)
def f(mu, limit=0):
# Use integers for limit so we don't need a string comparison
if limit == 0:
# Obs
return f_all(mu)[0] - level
else:
# Exp
# (These are in the order -2, -1, 0, 1, 2 sigma)
return f_all(mu)[1][limit - 1] - level
tb, _ = get_backend()
obs = tb.astensor(_toms748(f, low, high, args=(0), k=2, xtol=atol, rtol=rtol))
exp = [
tb.astensor(_toms748(f, low, high, args=(i), k=2, xtol=atol, rtol=rtol))
for i in range(1, 6)
]
return obs, exp
```
|
There is a brent-bracketing implementation by @alexander-held in `cabinetry` (https://github.com/alexander-held/cabinetry/blob/c85f404bc0bdedd3bb2629c826de385b694d99fc/src/cabinetry/fit.py#L589) that does a non-linear limit finding. If this is something people want to see upstreamed, we could.
It would be ince to find a way to be able to inject algorithms that can perform scans without taking them on fully (maybe ismilar to the work on toy calculator API).. scikit optimize has the ask/tell API
https://scikit-optimize.github.io/stable/auto_examples/ask-and-tell.html
probably would fit into `pyhf.infer.intervals`
I think for future-proofing it would be good if this returns "intervals" and not only try to do a root-finding.. i.e. the implicit assumption is often that the itnerval is [0,root] annd this should be made explicit
I think it would be really helpful to have an auto scan in pyhf itself for those who don't use Cabinetry, particularly since a linear scan _is_ available.
> It would be ince to find a way to be able to inject algorithms that can perform scans without taking them on fully
I can easily extend the implementation I posted here to allow the user to change the root-finding function used (assuming it uses the bracketing API shared by the `scipy.optimize` bracketing root-finders). That said, I think TOMS748 is usually the optimal choice (and [known to be better than Brent's method](https://www.boost.org/doc/libs/1_75_0/libs/math/doc/html/math_toolkit/roots_noderiv/brent.html)), so I do think it should be the default.
> I think for future-proofing it would be good if this returns "intervals" and not only try to do a root-finding
The `upperlimit_auto` function could certainly return `(0, upper_lim)` for each of the observed and expected limits. Above, I just copied the format that the linear scan returns, which is also why I wrapped each limit in a tensor.
Hi, providing this functionality through `pyhf.infer` sounds like a good idea to me. I have a few ideas and suggestions based on my experience with the `cabinetry` implementation:
- Caching is useful, the above algorithm will repeat fits for upper/lower bracket mu values for every root finding (obs + 5x for exp, resulting in at least 10 repeated `infer.hypotest` calls).
- The starting bracket for subsequent limits (e.g. the exp limits after having calculated obs limits) can be optimized given information about CLs(mu) obtained from the previous steps.
- In a test case, the algorithm repeatedly queries the same mu for a single root finding step, example below. I am not sure what causes this, `brentq` does not show the same behavior (thank you for the pointer to `toms748`, will try that out in more detail!).
```
testing mu=0
testing mu=10
testing mu=9.497575427630334
testing mu=6.715660956538139
testing mu=6.715660956538139
testing mu=6.04083915699075
testing mu=3.020419578495375
testing mu=2.633299000060376
testing mu=2.633299000060376
testing mu=2.43394097830554
testing mu=1.21697048915277
testing mu=1.7419775663353678
testing mu=2.0585075562095017
testing mu=1.9611870482306077
```
In the longer term, I believe that an implementation which uses knowledge about the functional form of CLs(mu) under asymptotic assumptions can likely be significantly more efficient than pure root finding. An implementation of such a function-aware limit finding algorithm seems very useful when using `pyhf` to calculate limits with complex workspaces where each fit takes a non-negligible amount of time (there is a script in used internally in ATLAS that is very efficient in my experience).
> Caching is useful, the above algorithm will repeat fits for upper/lower bracket mu values for every root finding (obs + 5x for exp, resulting in at least 10 repeated infer.hypotest calls).
I figured that would be the case. My test implementation actually has an `@lru_cache` decorator on `f_all` but I removed it for the snippet above to remove an import. Given your third point, it does seem to be useful to add that back in.
> The starting bracket for subsequent limits (e.g. the exp limits after having calculated obs limits) can be optimized given information about CLs(mu) obtained from the previous steps.
Agreed. This isn't possible using `lru_cache`, but having tried with a manually implemented cache, it does seem to improve things.
> In a test case, the algorithm repeatedly queries the same mu for a single root finding step
I see this too. I think it's a feature of the root finding algorithm. With memoization enabled it doesn't have much impact though.
> In the longer term, I believe that an implementation which uses knowledge about the functional form of CLs(mu) under asymptotic assumptions can likely be significantly more efficient than pure root finding.
This is true, but I don't think a root finding auto scan should be left out because we're waiting for a more direct / analytical implementation of limit setting. The root finding technique is also more general and can be used with a toy-based hypothesis test implementation.
The ATLAS script you refer to does use root finding (I think it uses the secant method), it's efficiency stems from a clever choice of starting value which means you don't need many iterations of the root finding algorithm.
> I don't think a root finding auto scan should be left out because we're waiting for a more direct / analytical implementation of limit setting
I agree and would view the different implementations as complementary.
> The ATLAS script you refer to does use root finding (I think it uses the secant method), it's efficiency stems from a clever choice of starting value which means you don't need many iterations of the root finding algorithm.
Thanks for the details, I will have to take a closer look at this implementation.
| 2021-01-21T10:27:17 |
scikit-hep/pyhf
| 1,281 |
scikit-hep__pyhf-1281
|
[
"1098"
] |
d178014019206a862d3313e0420d6c6a81504e40
|
diff --git a/src/pyhf/pdf.py b/src/pyhf/pdf.py
--- a/src/pyhf/pdf.py
+++ b/src/pyhf/pdf.py
@@ -73,7 +73,7 @@ def _paramset_requirements_from_modelspec(spec, channel_nbins):
raise exceptions.InvalidModel(
f"Multiple parameter configurations for {parameter['name']} were found."
)
- _paramsets_user_configs[parameter.pop('name')] = parameter
+ _paramsets_user_configs[parameter.get('name')] = parameter
_reqs = reduce_paramsets_requirements(
_paramsets_requirements, _paramsets_user_configs
@@ -546,18 +546,17 @@ def __init__(self, spec, batch_size=None, **config_kwargs):
"""
self.batch_size = batch_size
- self.spec = copy.deepcopy(spec) # may get modified by config
+ # deep-copy "spec" as it may be modified by config
+ self.spec = copy.deepcopy(spec)
self.schema = config_kwargs.pop('schema', 'model.json')
self.version = config_kwargs.pop('version', None)
# run jsonschema validation of input specification against the (provided) schema
log.info(f"Validating spec against schema: {self.schema:s}")
utils.validate(self.spec, self.schema, version=self.version)
# build up our representation of the specification
- self.config = _ModelConfig(self.spec, **config_kwargs)
+ self.config = _ModelConfig(spec, **config_kwargs)
- mega_mods, _nominal_rates = _nominal_and_modifiers_from_spec(
- self.config, self.spec
- )
+ mega_mods, _nominal_rates = _nominal_and_modifiers_from_spec(self.config, spec)
self.main_model = _MainModel(
self.config,
mega_mods=mega_mods,
|
diff --git a/tests/test_pdf.py b/tests/test_pdf.py
--- a/tests/test_pdf.py
+++ b/tests/test_pdf.py
@@ -851,3 +851,42 @@ def test_model_integration_fixed_parameters_shapesys():
assert len(model.config.suggested_fixed()) == 5
assert model.config.suggested_fixed() == [False, True, True, True, False]
assert model.config.poi_index == 4
+
+
+def test_reproducible_model_spec():
+ ws = {
+ "channels": [
+ {
+ "name": "SR",
+ "samples": [
+ {
+ "data": [
+ 10.0,
+ ],
+ "modifiers": [
+ {"data": None, "name": "mu", "type": "normfactor"},
+ ],
+ "name": "Signal",
+ }
+ ],
+ }
+ ],
+ "measurements": [
+ {
+ "config": {
+ "parameters": [{"bounds": [[0, 5]], "inits": [1], "name": "mu"}],
+ "poi": "mu",
+ },
+ "name": "minimal_example",
+ }
+ ],
+ "observations": [{"data": [12], "name": "SR"}],
+ "version": "1.0.0",
+ }
+ workspace = pyhf.Workspace(ws)
+ model_from_ws = workspace.model()
+
+ assert model_from_ws.spec['parameters'] == [
+ {'bounds': [[0, 5]], 'inits': [1], 'name': 'mu'}
+ ]
+ assert pyhf.Model(model_from_ws.spec)
|
Model creation from existing model - parameter names missing in model spec?
# Question
I would like to create a new `pyhf.Model` from an existing model. This seems to work in general via `pyhf.Model(model.spec)`, see the example below. The example fails when working with a custom workspace that includes parameter specifications:
```python
import pyhf
model_hepdata = pyhf.simplemodels.hepdata_like(
signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
)
# this works
pyhf.Model(model_hepdata.spec)
# custom workspace specification
ws = {
"channels": [
{
"name": "SR",
"samples": [
{
"data": [
10.0,
],
"modifiers": [
{"data": None, "name": "mu", "type": "normfactor"},
],
"name": "Signal",
}
],
}
],
"measurements": [
{
"config": {
"parameters": [{"bounds": [[0, 5]], "inits": [1], "name": "mu"}],
"poi": "mu",
},
"name": "minimal_example",
}
],
"observations": [{"data": [12], "name": "SR"}],
"version": "1.0.0",
}
workspace = pyhf.Workspace(ws)
# this works as well
model_from_ws = workspace.model()
# this does not work
pyhf.Model(model_from_ws.spec)
```
To make the last step work, the missing `"name"` needs to be added back into the specification:
```python
model_from_ws.spec["parameters"][0].update({"name": "mu"})
pyhf.Model(model_from_ws.spec)
```
Is this a bug?
And as another question, would this be the recommended way to create a modified model from an existing model? I would extract the `.spec`, modify that and feed it back into `pyhf.Model`.
# Relevant Issues and Pull Requests
none I'm aware of
|
confirmed bug -- can be fixed: https://github.com/scikit-hep/pyhf/blob/d178014019206a862d3313e0420d6c6a81504e40/src/pyhf/pdf.py#L213
we probably want to deep-copy the spec through to `ModelConfig` to be safe in any case -- but not sure why we need to `pop`. We could just `get` and not `pop`, then add a test to assert the spec remains unchanged when fed through.
| 2021-01-29T17:27:28 |
scikit-hep/pyhf
| 1,283 |
scikit-hep__pyhf-1283
|
[
"1269"
] |
f8e20a56d9274ea96ffdb3dad1021e38d5d80da5
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -77,7 +77,7 @@ def setup(app):
'uproot': ('https://uproot.readthedocs.io/en/latest/', None),
}
-# Github repo
+# GitHub repo
issues_github_path = 'scikit-hep/pyhf'
# Generate the API documentation when building
|
Change question asking queue to focus on GitHub Discussions over Stack Overflow
# Description
We currently direct users with application questions to the `pyhf` Stack Overflow tag, but should start directing them to GitHub Discussions instead.
This should be done before `v0.6.0` so that this gets propagated out to PyPI.
| 2021-02-01T20:23:21 |
||
scikit-hep/pyhf
| 1,306 |
scikit-hep__pyhf-1306
|
[
"1305"
] |
df6f53e19ab05b1a5cad187d5b9336ba8bae5140
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -12,7 +12,7 @@
'uproot3>=3.14.1',
'uproot~=4.0',
], # uproot3 required until writing to ROOT supported in uproot4
- 'minuit': ['iminuit~=2.1,<2.4'], # iminuit v2.4.0 behavior needs to be understood
+ 'minuit': ['iminuit>=2.4'],
}
extras_require['backends'] = sorted(
set(
|
diff --git a/tests/test_optim.py b/tests/test_optim.py
--- a/tests/test_optim.py
+++ b/tests/test_optim.py
@@ -83,10 +83,8 @@ def test_minimize(tensorlib, precision, optimizer, do_grad, do_stitch):
# no grad, minuit, 32b - not very consistent for pytorch
'no_grad-minuit-numpy-32b': [0.7465415000915527, 0.8796938061714172],
# nb: macos gives different numerics than CI
- # 'no_grad-minuit-pytorch-32b': [0.7465415000915527, 0.8796938061714172],
'no_grad-minuit-pytorch-32b': [0.9684963226318359, 0.9171305894851685],
'no_grad-minuit-tensorflow-32b': [0.5284154415130615, 0.9911751747131348],
- # 'no_grad-minuit-jax-32b': [0.5144518613815308, 0.9927923679351807],
'no_grad-minuit-jax-32b': [0.49620240926742554, 1.0018986463546753],
# no grad, minuit, 64b - quite consistent
'no_grad-minuit-numpy-64b': [0.5000493563629738, 1.0000043833598724],
@@ -94,39 +92,47 @@ def test_minimize(tensorlib, precision, optimizer, do_grad, do_stitch):
'no_grad-minuit-tensorflow-64b': [0.5000493563645547, 1.0000043833598657],
'no_grad-minuit-jax-64b': [0.5000493563528641, 1.0000043833614634],
# do grad, minuit, 32b
- 'do_grad-minuit-pytorch-32b': [0.5017611384391785, 0.9997190237045288],
- 'do_grad-minuit-tensorflow-32b': [0.5012885928153992, 1.0000673532485962],
- # 'do_grad-minuit-jax-32b': [0.5029529333114624, 0.9991086721420288],
+ # large divergence by tensorflow and pytorch
+ 'do_grad-minuit-pytorch-32b': [0.9731879234313965, 0.9999999403953552],
+ 'do_grad-minuit-tensorflow-32b': [0.9366918206214905, 0.9126002788543701],
'do_grad-minuit-jax-32b': [0.5007095336914062, 0.9999282360076904],
# do grad, minuit, 64b
- 'do_grad-minuit-pytorch-64b': [0.500273961181471, 0.9996310135736226],
- 'do_grad-minuit-tensorflow-64b': [0.500273961167223, 0.9996310135864218],
- 'do_grad-minuit-jax-64b': [0.5002739611532436, 0.9996310135970794],
+ 'do_grad-minuit-pytorch-64b': [0.500049321728735, 1.00000441739846],
+ 'do_grad-minuit-tensorflow-64b': [0.5000492930412292, 1.0000044107437134],
+ 'do_grad-minuit-jax-64b': [0.500049321731032, 1.0000044174002167],
}[identifier]
result = pyhf.infer.mle.fit(data, m, do_grad=do_grad, do_stitch=do_stitch)
- rtol = 2e-06
+ rel_tol = 1e-6
+ # Fluctuations beyond precision shouldn't matter
+ abs_tol = 1e-5 if "32b" in identifier else 1e-8
+
# handle cases where macos and ubuntu provide very different results numerical
- if 'no_grad-minuit-tensorflow-32b' in identifier:
- # not a very large difference, so we bump the relative difference down
- rtol = 3e-02
- if 'no_grad-minuit-pytorch-32b' in identifier:
- # quite a large difference
- rtol = 3e-01
- if 'do_grad-minuit-pytorch-32b' in identifier:
- # a small difference
- rtol = 7e-05
- if 'no_grad-minuit-jax-32b' in identifier:
- rtol = 4e-02
- # NB: ubuntu and macos give different results for 32b
- if "do_grad-scipy-jax-32b" in identifier:
- rtol = 5e-03
- if "do_grad-minuit-jax-32b" in identifier:
- rtol = 5e-03
+ if "no_grad" in identifier:
+ rel_tol = 1e-5
+ if "minuit-pytorch-32b" in identifier:
+ # large difference between local and CI
+ rel_tol = 3e-1
+ if "minuit-tensorflow-32b" in identifier:
+ # not a very large difference, so we bump the relative difference down
+ rel_tol = 3e-2
+ if "minuit-jax-32b" in identifier:
+ rel_tol = 4e-2
+ elif all(part in identifier for part in ["do_grad", "32b"]):
+ if "scipy-jax" in identifier:
+ rel_tol = 1e-2
+ # NB: ubuntu and macos give different results for 32b
+ if "minuit-tensorflow" in identifier:
+ # large difference between local and CI
+ rel_tol = 1e-1
+ if "minuit-jax" in identifier:
+ rel_tol = 1e-2
# check fitted parameters
- assert pytest.approx(expected, rel=rtol) == pyhf.tensorlib.tolist(
+ assert pytest.approx(
+ expected, rel=rel_tol, abs=abs_tol
+ ) == pyhf.tensorlib.tolist(
result
), f"{identifier} = {pyhf.tensorlib.tolist(result)}"
@@ -190,7 +196,7 @@ def test_minuit_strategy_do_grad(mocker, backend):
the minuit strategy=0. When there is no user-provided gradient, check that
one automatically sets the minuit strategy=1.
"""
- pyhf.set_backend(pyhf.tensorlib, 'minuit')
+ pyhf.set_backend(pyhf.tensorlib, pyhf.optimize.minuit_optimizer(tolerance=0.2))
spy = mocker.spy(pyhf.optimize.minuit_optimizer, '_minimize')
m = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
data = pyhf.tensorlib.astensor([125.0] + m.config.auxdata)
@@ -211,7 +217,9 @@ def test_minuit_strategy_do_grad(mocker, backend):
@pytest.mark.parametrize('strategy', [0, 1])
def test_minuit_strategy_global(mocker, backend, strategy):
- pyhf.set_backend(pyhf.tensorlib, pyhf.optimize.minuit_optimizer(strategy=strategy))
+ pyhf.set_backend(
+ pyhf.tensorlib, pyhf.optimize.minuit_optimizer(strategy=strategy, tolerance=0.2)
+ )
spy = mocker.spy(pyhf.optimize.minuit_optimizer, '_minimize')
m = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
data = pyhf.tensorlib.astensor([125.0] + m.config.auxdata)
|
iminuit v2.4.0 breaks test_optim
# Description
[`iminuit` `v2.4.0`](https://github.com/scikit-hep/iminuit/releases/tag/v2.4.0) (released today 2021-02-10) is breaking the tests for 32b and 64b minuit in the `test_minimize` tests
https://github.com/scikit-hep/pyhf/blob/bc32a695aaea0b79b3f0b40676446452d115cf8e/tests/test_optim.py#L49
```pytb
_______________ test_minimize[do_grad-minuit-jax-64b-do_stitch] ________________
tensorlib = <class 'pyhf.tensor.jax_backend.jax_backend'>, precision = '64b'
optimizer = <class 'pyhf.optimize.minuit_optimizer'>, do_grad = True
do_stitch = True
@pytest.mark.parametrize('do_stitch', [False, True], ids=['no_stitch', 'do_stitch'])
@pytest.mark.parametrize('precision', ['32b', '64b'], ids=['32b', '64b'])
@pytest.mark.parametrize(
'tensorlib',
[
pyhf.tensor.numpy_backend,
pyhf.tensor.pytorch_backend,
pyhf.tensor.tensorflow_backend,
pyhf.tensor.jax_backend,
],
ids=['numpy', 'pytorch', 'tensorflow', 'jax'],
)
@pytest.mark.parametrize(
'optimizer',
[pyhf.optimize.scipy_optimizer, pyhf.optimize.minuit_optimizer],
ids=['scipy', 'minuit'],
)
@pytest.mark.parametrize('do_grad', [False, True], ids=['no_grad', 'do_grad'])
def test_minimize(tensorlib, precision, optimizer, do_grad, do_stitch):
pyhf.set_backend(tensorlib(precision=precision), optimizer())
m = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
data = pyhf.tensorlib.astensor([125.0] + m.config.auxdata)
# numpy does not support grad
if pyhf.tensorlib.name == 'numpy' and do_grad:
with pytest.raises(pyhf.exceptions.Unsupported):
pyhf.infer.mle.fit(data, m, do_grad=do_grad)
else:
identifier = f'{"do_grad" if do_grad else "no_grad"}-{pyhf.optimizer.name}-{pyhf.tensorlib.name}-{pyhf.tensorlib.precision}'
expected = {
# numpy does not do grad
'do_grad-scipy-numpy-32b': None,
'do_grad-scipy-numpy-64b': None,
'do_grad-minuit-numpy-32b': None,
'do_grad-minuit-numpy-64b': None,
# no grad, scipy, 32b - never works
'no_grad-scipy-numpy-32b': [1.0, 1.0],
'no_grad-scipy-pytorch-32b': [1.0, 1.0],
'no_grad-scipy-tensorflow-32b': [1.0, 1.0],
'no_grad-scipy-jax-32b': [1.0, 1.0],
# no grad, scipy, 64b
'no_grad-scipy-numpy-64b': [0.49998815367220306, 0.9999696999038924],
'no_grad-scipy-pytorch-64b': [0.49998815367220306, 0.9999696999038924],
'no_grad-scipy-tensorflow-64b': [0.49998865164653106, 0.9999696533705097],
'no_grad-scipy-jax-64b': [0.4999880886490433, 0.9999696971774877],
# do grad, scipy, 32b
'do_grad-scipy-pytorch-32b': [0.49993881583213806, 1.0001085996627808],
'do_grad-scipy-tensorflow-32b': [0.4999384582042694, 1.0001084804534912],
'do_grad-scipy-jax-32b': [0.4999389052391052, 1.0001085996627808],
# do grad, scipy, 64b
'do_grad-scipy-pytorch-64b': [0.49998837853531425, 0.9999696648069287],
'do_grad-scipy-tensorflow-64b': [0.4999883785353142, 0.9999696648069278],
'do_grad-scipy-jax-64b': [0.49998837853531414, 0.9999696648069285],
# no grad, minuit, 32b - not very consistent for pytorch
'no_grad-minuit-numpy-32b': [0.49622172117233276, 1.0007264614105225],
# nb: macos gives different numerics than CI
# 'no_grad-minuit-pytorch-32b': [0.7465415000915527, 0.8796938061714172],
'no_grad-minuit-pytorch-32b': [0.9684963226318359, 0.9171305894851685],
'no_grad-minuit-tensorflow-32b': [0.5284154415130615, 0.9911751747131348],
# 'no_grad-minuit-jax-32b': [0.5144518613815308, 0.9927923679351807],
'no_grad-minuit-jax-32b': [0.49620240926742554, 1.0018986463546753],
# no grad, minuit, 64b - quite consistent
'no_grad-minuit-numpy-64b': [0.5000493563629738, 1.0000043833598724],
'no_grad-minuit-pytorch-64b': [0.5000493563758468, 1.0000043833508256],
'no_grad-minuit-tensorflow-64b': [0.5000493563645547, 1.0000043833598657],
'no_grad-minuit-jax-64b': [0.5000493563528641, 1.0000043833614634],
# do grad, minuit, 32b
'do_grad-minuit-pytorch-32b': [0.5017611384391785, 0.9997190237045288],
'do_grad-minuit-tensorflow-32b': [0.5012885928153992, 1.0000673532485962],
# 'do_grad-minuit-jax-32b': [0.5029529333114624, 0.9991086721420288],
'do_grad-minuit-jax-32b': [0.5007095336914062, 0.9999282360076904],
# do grad, minuit, 64b
'do_grad-minuit-pytorch-64b': [0.500273961181471, 0.9996310135736226],
'do_grad-minuit-tensorflow-64b': [0.500273961167223, 0.9996310135864218],
'do_grad-minuit-jax-64b': [0.5002739611532436, 0.9996310135970794],
}[identifier]
result = pyhf.infer.mle.fit(data, m, do_grad=do_grad, do_stitch=do_stitch)
rtol = 2e-06
# handle cases where macos and ubuntu provide very different results numerical
if 'no_grad-minuit-tensorflow-32b' in identifier:
# not a very large difference, so we bump the relative difference down
rtol = 3e-02
if 'no_grad-minuit-pytorch-32b' in identifier:
# quite a large difference
rtol = 3e-01
if 'do_grad-minuit-pytorch-32b' in identifier:
# a small difference
rtol = 7e-05
if 'no_grad-minuit-jax-32b' in identifier:
rtol = 4e-02
if 'do_grad-minuit-jax-32b' in identifier:
rtol = 5e-03
# check fitted parameters
> assert pytest.approx(expected, rel=rtol) == pyhf.tensorlib.tolist(
result
), f"{identifier} = {pyhf.tensorlib.tolist(result)}"
E AssertionError: do_grad-minuit-jax-64b = [0.500049321731032, 1.0000044174002167]
E assert approx([0.5002739611532436 ± 1.0e-06, 0.9996310135970794 ± 2.0e-06]) == [0.500049321731032, 1.0000044174002167]
E + where approx([0.5002739611532436 ± 1.0e-06, 0.9996310135970794 ± 2.0e-06]) = <function approx at 0x7fb30c6b6e50>([0.5002739611532436, 0.9996310135970794], rel=2e-06)
E + where <function approx at 0x7fb30c6b6e50> = pytest.approx
E + and [0.500049321731032, 1.0000044174002167] = <bound method jax_backend.tolist of <pyhf.tensor.jax_backend.jax_backend object at 0x7fb210064b00>>(DeviceArray([0.50004932, 1.00000442], dtype=float64))
E + where <bound method jax_backend.tolist of <pyhf.tensor.jax_backend.jax_backend object at 0x7fb210064b00>> = <pyhf.tensor.jax_backend.jax_backend object at 0x7fb210064b00>.tolist
E + where <pyhf.tensor.jax_backend.jax_backend object at 0x7fb210064b00> = pyhf.tensorlib
tests/test_optim.py:126: AssertionError
```
`test_minuit_strategy_do_grad`
https://github.com/scikit-hep/pyhf/blob/bc32a695aaea0b79b3f0b40676446452d115cf8e/tests/test_optim.py#L182
as well as in `test_minuit_strategy_global` tests
https://github.com/scikit-hep/pyhf/blob/bc32a695aaea0b79b3f0b40676446452d115cf8e/tests/test_optim.py#L210
```pytb
__________________ test_minuit_strategy_global[tensorflow-1] ___________________
self = <pyhf.optimize.minuit_optimizer object at 0x7fb2107be700>
func = <function wrap_objective.<locals>.func at 0x7fb228255a60>
x0 = [1.0, 1.0], do_grad = True, bounds = [(0, 10), (1e-10, 10.0)]
fixed_vals = [], options = {}
def _internal_minimize(
self, func, x0, do_grad=False, bounds=None, fixed_vals=None, options={}
):
minimizer = self._get_minimizer(
func, x0, bounds, fixed_vals=fixed_vals, do_grad=do_grad
)
result = self._minimize(
minimizer,
func,
x0,
do_grad=do_grad,
bounds=bounds,
fixed_vals=fixed_vals,
options=options,
)
try:
> assert result.success
E AssertionError
src/pyhf/optimize/mixins.py:49: AssertionError
During handling of the above exception, another exception occurred:
mocker = <pytest_mock.plugin.MockerFixture object at 0x7fb1e3d59370>
backend = (<pyhf.tensor.tensorflow_backend.tensorflow_backend object at 0x7fb2433ed080>, None)
strategy = 1
@pytest.mark.parametrize('strategy', [0, 1])
def test_minuit_strategy_global(mocker, backend, strategy):
pyhf.set_backend(pyhf.tensorlib, pyhf.optimize.minuit_optimizer(strategy=strategy))
spy = mocker.spy(pyhf.optimize.minuit_optimizer, '_minimize')
m = pyhf.simplemodels.hepdata_like([50.0], [100.0], [10.0])
data = pyhf.tensorlib.astensor([125.0] + m.config.auxdata)
do_grad = pyhf.tensorlib.default_do_grad
> pyhf.infer.mle.fit(data, m)
tests/test_optim.py:217:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
src/pyhf/infer/mle.py:122: in fit
return opt.minimize(
src/pyhf/optimize/mixins.py:157: in minimize
result = self._internal_minimize(**minimizer_kwargs, options=kwargs)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <pyhf.optimize.minuit_optimizer object at 0x7fb2107be700>
func = <function wrap_objective.<locals>.func at 0x7fb228255a60>
x0 = [1.0, 1.0], do_grad = True, bounds = [(0, 10), (1e-10, 10.0)]
fixed_vals = [], options = {}
def _internal_minimize(
self, func, x0, do_grad=False, bounds=None, fixed_vals=None, options={}
):
minimizer = self._get_minimizer(
func, x0, bounds, fixed_vals=fixed_vals, do_grad=do_grad
)
result = self._minimize(
minimizer,
func,
x0,
do_grad=do_grad,
bounds=bounds,
fixed_vals=fixed_vals,
options=options,
)
try:
assert result.success
except AssertionError:
log.error(result, exc_info=True)
> raise exceptions.FailedMinimization(result)
E pyhf.exceptions.FailedMinimization: Optimization failed. Estimated distance to minimum too large.
```
We will need to investigate what's up and perhaps loosen tolerances for `iminuit`.
|
@HDembinski :wave: while we don't need you to do anything (probably) I thought I'd just give you a heads up that we might have some questions in the next day or so, given that I'm not sure what in [the `CHANGELOG`](https://iminuit.readthedocs.io/en/stable/changelog.html#february-10-2021) could be causing this beyond the
> Upgrade Minuit2 C++ code in ROOT to latest master with following improvements
:+1:
| 2021-02-11T07:09:36 |
scikit-hep/pyhf
| 1,311 |
scikit-hep__pyhf-1311
|
[
"1268"
] |
ae9e39cfd933e059359a4d63bfc772659a34fbfb
|
diff --git a/src/pyhf/infer/calculators.py b/src/pyhf/infer/calculators.py
--- a/src/pyhf/infer/calculators.py
+++ b/src/pyhf/infer/calculators.py
@@ -132,7 +132,7 @@ def pvalue(self, value):
value (:obj:`float`): The test statistic value.
Returns:
- Float: The integrated probability to observe a value at least as large as the observed one.
+ Tensor: The integrated probability to observe a value at least as large as the observed one.
"""
tensorlib, _ = get_backend()
@@ -295,13 +295,13 @@ def teststatistic(self, poi_test):
>>> mu_test = 1.0
>>> asymptotic_calculator = pyhf.infer.calculators.AsymptoticCalculator(data, model, test_stat="qtilde")
>>> asymptotic_calculator.teststatistic(mu_test)
- 0.14043184405388176
+ array(0.14043184)
Args:
poi_test (:obj:`float` or :obj:`tensor`): The value for the parameter of interest.
Returns:
- Float: The value of the test statistic.
+ Tensor: The value of the test statistic.
"""
tensorlib, _ = get_backend()
@@ -355,7 +355,7 @@ def _false_case():
teststat = tensorlib.conditional(
(sqrtqmu_v < self.sqrtqmuA_v), _true_case, _false_case
)
- return teststat
+ return tensorlib.astensor(teststat)
def pvalues(self, teststat, sig_plus_bkg_distribution, bkg_only_distribution):
r"""
@@ -379,7 +379,7 @@ def pvalues(self, teststat, sig_plus_bkg_distribution, bkg_only_distribution):
>>> sig_plus_bkg_dist, bkg_dist = asymptotic_calculator.distributions(mu_test)
>>> CLsb, CLb, CLs = asymptotic_calculator.pvalues(q_tilde, sig_plus_bkg_dist, bkg_dist)
>>> CLsb, CLb, CLs
- (array(0.02332502), array(0.4441594), 0.05251497423736956)
+ (array(0.02332502), array(0.4441594), array(0.05251497))
Args:
teststat (:obj:`tensor`): The test statistic.
@@ -389,13 +389,15 @@ def pvalues(self, teststat, sig_plus_bkg_distribution, bkg_only_distribution):
The distribution for the background-only hypothesis.
Returns:
- Tuple (:obj:`float`): The :math:`p`-values for the test statistic
+ Tuple (:obj:`tensor`): The :math:`p`-values for the test statistic
corresponding to the :math:`\mathrm{CL}_{s+b}`,
:math:`\mathrm{CL}_{b}`, and :math:`\mathrm{CL}_{s}`.
"""
+ tensorlib, _ = get_backend()
+
CLsb = sig_plus_bkg_distribution.pvalue(teststat)
CLb = bkg_only_distribution.pvalue(teststat)
- CLs = CLsb / CLb
+ CLs = tensorlib.astensor(CLsb / CLb)
return CLsb, CLb, CLs
def expected_pvalues(self, sig_plus_bkg_distribution, bkg_only_distribution):
@@ -422,7 +424,7 @@ def expected_pvalues(self, sig_plus_bkg_distribution, bkg_only_distribution):
>>> sig_plus_bkg_dist, bkg_dist = asymptotic_calculator.distributions(mu_test)
>>> CLsb_exp_band, CLb_exp_band, CLs_exp_band = asymptotic_calculator.expected_pvalues(sig_plus_bkg_dist, bkg_dist)
>>> CLs_exp_band
- [0.0026062609501074576, 0.01382005356161206, 0.06445320535890459, 0.23525643861460702, 0.573036205919389]
+ [array(0.00260626), array(0.01382005), array(0.06445321), array(0.23525644), array(0.57303621)]
Args:
sig_plus_bkg_distribution (~pyhf.infer.calculators.AsymptoticTestStatDistribution):
@@ -431,7 +433,7 @@ def expected_pvalues(self, sig_plus_bkg_distribution, bkg_only_distribution):
The distribution for the background-only hypothesis.
Returns:
- Tuple (:obj:`float`): The :math:`p`-values for the test statistic
+ Tuple (:obj:`tensor`): The :math:`p`-values for the test statistic
corresponding to the :math:`\mathrm{CL}_{s+b}`,
:math:`\mathrm{CL}_{b}`, and :math:`\mathrm{CL}_{s}`.
"""
@@ -494,7 +496,7 @@ def pvalue(self, value):
>>> samples = normal.sample((100,))
>>> dist = pyhf.infer.calculators.EmpiricalDistribution(samples)
>>> dist.pvalue(7)
- 0.02
+ array(0.02)
>>> import pyhf
>>> import numpy.random as random
@@ -515,17 +517,17 @@ def pvalue(self, value):
... )
... )
>>> test_stat_dist.pvalue(test_stat_dist.samples[9])
- 0.3
+ array(0.3)
Args:
value (:obj:`float`): The test statistic value.
Returns:
- Float: The integrated probability to observe a value at least as large as the observed one.
+ Tensor: The integrated probability to observe a value at least as large as the observed one.
"""
tensorlib, _ = get_backend()
- return (
+ return tensorlib.astensor(
tensorlib.sum(
tensorlib.where(
self.samples >= value, tensorlib.astensor(1), tensorlib.astensor(0)
@@ -665,7 +667,7 @@ def distributions(self, poi_test, track_progress=None):
... )
>>> sig_plus_bkg_dist, bkg_dist = toy_calculator.distributions(mu_test)
>>> sig_plus_bkg_dist.pvalue(mu_test), bkg_dist.pvalue(mu_test)
- (0.14, 0.76)
+ (array(0.14), array(0.76))
Args:
poi_test (:obj:`float` or :obj:`tensor`): The value for the parameter of interest.
@@ -753,7 +755,7 @@ def pvalues(self, teststat, sig_plus_bkg_distribution, bkg_only_distribution):
>>> sig_plus_bkg_dist, bkg_dist = toy_calculator.distributions(mu_test)
>>> CLsb, CLb, CLs = toy_calculator.pvalues(q_tilde, sig_plus_bkg_dist, bkg_dist)
>>> CLsb, CLb, CLs
- (0.01, 0.41, 0.024390243902439025)
+ (array(0.01), array(0.41), array(0.02439024))
Args:
teststat (:obj:`tensor`): The test statistic.
@@ -763,13 +765,15 @@ def pvalues(self, teststat, sig_plus_bkg_distribution, bkg_only_distribution):
The distribution for the background-only hypothesis.
Returns:
- Tuple (:obj:`float`): The :math:`p`-values for the test statistic
+ Tuple (:obj:`tensor`): The :math:`p`-values for the test statistic
corresponding to the :math:`\mathrm{CL}_{s+b}`,
:math:`\mathrm{CL}_{b}`, and :math:`\mathrm{CL}_{s}`.
"""
+ tensorlib, _ = get_backend()
+
CLsb = sig_plus_bkg_distribution.pvalue(teststat)
CLb = bkg_only_distribution.pvalue(teststat)
- CLs = CLsb / CLb
+ CLs = tensorlib.astensor(CLsb / CLb)
return CLsb, CLb, CLs
def expected_pvalues(self, sig_plus_bkg_distribution, bkg_only_distribution):
@@ -797,7 +801,7 @@ def expected_pvalues(self, sig_plus_bkg_distribution, bkg_only_distribution):
>>> sig_plus_bkg_dist, bkg_dist = toy_calculator.distributions(mu_test)
>>> CLsb_exp_band, CLb_exp_band, CLs_exp_band = toy_calculator.expected_pvalues(sig_plus_bkg_dist, bkg_dist)
>>> CLs_exp_band
- [0.0, 0.0, 0.06186224489795918, 0.2845003327965815, 1.0]
+ [array(0.), array(0.), array(0.06186224), array(0.28450033), array(1.)]
Args:
sig_plus_bkg_distribution (~pyhf.infer.calculators.EmpiricalDistribution):
@@ -806,21 +810,19 @@ def expected_pvalues(self, sig_plus_bkg_distribution, bkg_only_distribution):
The distribution for the background-only hypothesis.
Returns:
- Tuple (:obj:`float`): The :math:`p`-values for the test statistic
+ Tuple (:obj:`tensor`): The :math:`p`-values for the test statistic
corresponding to the :math:`\mathrm{CL}_{s+b}`,
:math:`\mathrm{CL}_{b}`, and :math:`\mathrm{CL}_{s}`.
"""
tb, _ = get_backend()
- pvalues = tb.astensor(
- [
- self.pvalues(
- tb.astensor(test_stat),
- sig_plus_bkg_distribution,
- bkg_only_distribution,
- )
- for test_stat in bkg_only_distribution.samples
- ]
- )
+ pvalues = [
+ self.pvalues(
+ test_stat,
+ sig_plus_bkg_distribution,
+ bkg_only_distribution,
+ )
+ for test_stat in bkg_only_distribution.samples
+ ]
# TODO: Add percentile to tensorlib
# c.f. Issue #815, PR #817
import numpy as np
@@ -828,11 +830,11 @@ def expected_pvalues(self, sig_plus_bkg_distribution, bkg_only_distribution):
# percentiles for -2, -1, 0, 1, 2 standard deviations of the Normal distribution
normal_percentiles = [2.27501319, 15.86552539, 50.0, 84.13447461, 97.72498681]
pvalues_exp_band = np.percentile(
- tb.tolist(pvalues),
+ pvalues,
normal_percentiles,
axis=0,
).T.tolist()
- return pvalues_exp_band
+ return [[tb.astensor(pvalue) for pvalue in band] for band in pvalues_exp_band]
def teststatistic(self, poi_test):
"""
@@ -860,7 +862,7 @@ def teststatistic(self, poi_test):
poi_test (:obj:`float` or :obj:`tensor`): The value for the parameter of interest.
Returns:
- Float: The value of the test statistic.
+ Tensor: The value of the test statistic.
"""
teststat_func = utils.get_test_stat(self.test_stat)
diff --git a/src/pyhf/infer/utils.py b/src/pyhf/infer/utils.py
--- a/src/pyhf/infer/utils.py
+++ b/src/pyhf/infer/utils.py
@@ -33,7 +33,7 @@ def create_calculator(calctype, *args, **kwargs):
... )
>>> qmu_sig, qmu_bkg = toy_calculator.distributions(mu_test)
>>> qmu_sig.pvalue(mu_test), qmu_bkg.pvalue(mu_test)
- (0.14, 0.76)
+ (array(0.14), array(0.76))
Args:
calctype (:obj:`str`): The calculator to create. Choose either
|
Ensure consistent return type of CLs-like / p-value-like values
We've introducing inconsistent return types for CLs-like / p-value-like values now in PR #1162. Previously, all CLs-like / p-value-like values were `0`-d tensors
https://github.com/scikit-hep/pyhf/blob/0e71f2f40153cf4f3ae3c62fedf23e4281b240d9/src/pyhf/infer/__init__.py#L149
However, now we have things like `hypotest` returning `0`-d tensors and things like `pvalues` and `expected_pvalues` returning floats only for NumPy and for all other backends returning `0`-d tensors, yet in all the examples we're showing CLs-like / p-value-like values being returned.
Example: Run the docstring example from `expected_pvalues` for various backends and note the return type of `CLs_exp_band[0]`.
```python
import pyhf
for backend in ["numpy", "pytorch", "jax"]:
print(f"\nbackend: {backend}")
pyhf.set_backend(backend)
model = pyhf.simplemodels.hepdata_like(
signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
)
observations = [51, 48]
data = observations + model.config.auxdata
mu_test = 1.0
asymptotic_calculator = pyhf.infer.calculators.AsymptoticCalculator(
data, model, test_stat="qtilde"
)
_ = asymptotic_calculator.teststatistic(mu_test)
sig_plus_bkg_dist, bkg_dist = asymptotic_calculator.distributions(mu_test)
CLsb_exp_band, CLb_exp_band, CLs_exp_band = asymptotic_calculator.expected_pvalues(
sig_plus_bkg_dist, bkg_dist
)
print(f"CLs expected band: {CLs_exp_band}")
print(
f"of type: {type(CLs_exp_band[0])} and shape {pyhf.tensorlib.shape(CLs_exp_band[0])}"
)
```
gives
```
backend: numpy
CLs expected band: [0.0026062609501074576, 0.01382005356161206, 0.06445320535890459, 0.23525643861460702, 0.573036205919389]
of type: <class 'numpy.float64'> and shape ()
backend: pytorch
CLs expected band: [tensor(0.0026), tensor(0.0138), tensor(0.0645), tensor(0.2353), tensor(0.5730)]
of type: <class 'torch.Tensor'> and shape ()
backend: jax
CLs expected band: [DeviceArray(0.00260626, dtype=float64), DeviceArray(0.01382005, dtype=float64), DeviceArray(0.0644532, dtype=float64), DeviceArray(0.23525643, dtype=float64), DeviceArray(0.57303619, dtype=float64)]
of type: <class 'jax.interpreters.xla._DeviceArray'> and shape ()
```
We should try to come to a consensus on what the return type for a CLs-like / p-value-like value should be. From looking back at PR #944 and Issue #714, I think that the CLs-like values should be `0`-d tensor as it allows for us to sidestep this difference in backend behavior (I believe this is the motivation for the current behavior). While conceptually it makes sense to have a p-value-like just be a float to emphasize the scalar nature, having it be a `0`-d tensor make it appear to a user as still having scalar like behavior.
| 2021-02-15T08:49:20 |
||
scikit-hep/pyhf
| 1,322 |
scikit-hep__pyhf-1322
|
[
"1321"
] |
3f0c8fc26d13bf2c7740bd2465bc10bbcd5f7746
|
diff --git a/src/pyhf/utils.py b/src/pyhf/utils.py
--- a/src/pyhf/utils.py
+++ b/src/pyhf/utils.py
@@ -142,7 +142,7 @@ def citation(oneline=False):
>>> import pyhf
>>> pyhf.utils.citation(True)
- '@software{pyhf, author = "{Heinrich, Lukas and Feickert, Matthew and Stark, Giordon}", title = "{pyhf: v0.6.0}", version = {0.6.0}, doi = {10.5281/zenodo.1169739}, url = {https://github.com/scikit-hep/pyhf},}@article{pyhf_joss, doi = {10.21105/joss.02823}, url = {https://doi.org/10.21105/joss.02823}, year = {2021}, publisher = {The Open Journal}, volume = {6}, number = {58}, pages = {2823}, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark and Kyle Cranmer}, title = {pyhf: pure-Python implementation of HistFactory statistical models}, journal = {Journal of Open Source Software}}'
+ '@software{pyhf, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark}, title = "{pyhf: v0.6.0}", version = {0.6.0}, doi = {10.5281/zenodo.1169739}, url = {https://github.com/scikit-hep/pyhf},}@article{pyhf_joss, doi = {10.21105/joss.02823}, url = {https://doi.org/10.21105/joss.02823}, year = {2021}, publisher = {The Open Journal}, volume = {6}, number = {58}, pages = {2823}, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark and Kyle Cranmer}, title = {pyhf: pure-Python implementation of HistFactory statistical models}, journal = {Journal of Open Source Software}}'
Keyword Args:
oneline (:obj:`bool`): Whether to provide citation with new lines (default) or as a one-liner.
|
docs: Investiage revising author field styling in Zenodo citation
# Description
The current Zendo citation of
https://github.com/scikit-hep/pyhf/blob/3f0c8fc26d13bf2c7740bd2465bc10bbcd5f7746/src/pyhf/data/citation.bib#L1-L7
quotes the author field which can make some BibTeX style files force it to render in a way that is perhaps not desirable

However, if the author field is given to BibTeX with more flexibility (using `and`s and without quotes)
```bibtex
@software{pyhf,
author = {Lukas Heinrich and Matthew Feickert and Giordon Stark},
title = "{pyhf: v0.6.0}",
version = {0.6.0},
doi = {10.5281/zenodo.1169739},
url = {https://github.com/scikit-hep/pyhf},
}
```
the render can be improved

Thoughts on style here @lukasheinrich @kratsg?
|
I like the shorter version better, indeed.
| 2021-02-17T14:49:45 |
|
scikit-hep/pyhf
| 1,338 |
scikit-hep__pyhf-1338
|
[
"761",
"1339"
] |
8de7566a2b6dc4a5278e0b0da9c0a45a2e5a752d
|
diff --git a/src/pyhf/optimize/opt_minuit.py b/src/pyhf/optimize/opt_minuit.py
--- a/src/pyhf/optimize/opt_minuit.py
+++ b/src/pyhf/optimize/opt_minuit.py
@@ -25,10 +25,12 @@ def __init__(self, *args, **kwargs):
Args:
- errordef (:obj:`float`): See minuit docs. Default is 1.0.
- steps (:obj:`int`): Number of steps for the bounds. Default is 1000.
- strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is None.
- tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is 0.1.
+ errordef (:obj:`float`): See minuit docs. Default is ``1.0``.
+ steps (:obj:`int`): Number of steps for the bounds. Default is ``1000``.
+ strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is ``None``.
+ tolerance (:obj:`float`): Tolerance for termination.
+ See specific optimizer for detailed meaning.
+ Default is ``0.1``.
"""
self.name = 'minuit'
self.errordef = kwargs.pop('errordef', 1)
@@ -84,9 +86,12 @@ def _minimize(
underlying minimizer.
Minimizer Options:
- maxiter (:obj:`int`): maximum number of iterations. Default is 100000.
- strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is to configure in response to `do_grad`.
- tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is 0.1.
+ * maxiter (:obj:`int`): Maximum number of iterations. Default is ``100000``.
+ * strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`.
+ Default is to configure in response to ``do_grad``.
+ * tolerance (:obj:`float`): Tolerance for termination.
+ See specific optimizer for detailed meaning.
+ Default is ``0.1``.
Returns:
fitresult (scipy.optimize.OptimizeResult): the fit result
diff --git a/src/pyhf/optimize/opt_scipy.py b/src/pyhf/optimize/opt_scipy.py
--- a/src/pyhf/optimize/opt_scipy.py
+++ b/src/pyhf/optimize/opt_scipy.py
@@ -18,7 +18,9 @@ def __init__(self, *args, **kwargs):
See :class:`pyhf.optimize.mixins.OptimizerMixin` for other configuration options.
Args:
- tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is None.
+ tolerance (:obj:`float`): Tolerance for termination.
+ See specific optimizer for detailed meaning.
+ Default is ``None``.
"""
self.name = 'scipy'
self.tolerance = kwargs.pop('tolerance', None)
@@ -43,10 +45,13 @@ def _minimize(
Same signature as :func:`scipy.optimize.minimize`.
Minimizer Options:
- maxiter (:obj:`int`): maximum number of iterations. Default is 100000.
- verbose (:obj:`bool`): print verbose output during minimization. Default is off.
- method (:obj:`str`): minimization routine. Default is 'SLSQP'.
- tolerance (:obj:`float`): tolerance for termination. See specific optimizer for detailed meaning. Default is None.
+ * maxiter (:obj:`int`): Maximum number of iterations. Default is ``100000``.
+ * verbose (:obj:`bool`): Print verbose output during minimization.
+ Default is ``False``.
+ * method (:obj:`str`): Minimization routine. Default is ``'SLSQP'``.
+ * tolerance (:obj:`float`): Tolerance for termination. See specific optimizer
+ for detailed meaning.
+ Default is ``None``.
Returns:
fitresult (scipy.optimize.OptimizeResult): the fit result
|
Update modifierclass.rst template to accept functions that aren't methods of a class
# Description
First noticed in PR #750, while trying to get the docs to show the full signatures and docstrings:
```rst
.. autosummary::
:toctree: _generated/
:nosignatures:
:template: modifierclass.rst
```
I'm getting the following warnings (which we treat as errors) when I try to build the docs:
```
WARNING: error while formatting arguments for pyhf.infer.calculators.generate_asimov_data: 'function' object has no attribute '__mro__'
WARNING: error while formatting arguments for pyhf.infer.hypotest: 'function' object has no attribute '__mro__'
WARNING: error while formatting arguments for pyhf.infer.mle.fit: 'function' object has no attribute '__mro__'
WARNING: error while formatting arguments for pyhf.infer.mle.fixed_poi_fit: 'function' object has no attribute '__mro__'
WARNING: error while formatting arguments for pyhf.infer.mle.twice_nll: 'function' object has no attribute '__mro__'
WARNING: error while formatting arguments for pyhf.infer.test_statistics.qmu: 'function' object has no attribute '__mro__'
```
which I believe is happening as `__mro__` only exists on the class, and these functions exist in the source code outside of a class definition.
This means that the [`modifierclass.rst` template](https://github.com/scikit-hep/pyhf/blob/1ee6e38d42d9551220f20de483e0049b28c848b0/docs/_templates/modifierclass.rst) will need to get updated to deal with functions that aren't methods of a class.
Fix up docstring for _minimize() functions in the optimizers
# Description
From https://github.com/scikit-hep/pyhf/pull/1338#pullrequestreview-596818258
> I'm not sure if it can be fixed here, but the "Minimizer Options" aren't being displayed correctly for the optimizer _minimize methods.

> we've never been able to see the `_minimize` methods before, so it isn't surprising they might not look perfect.
|
For context, without the
```rst
.. autosummary::
:nosignatures:
:template: modifierclass.rst
```
I'm getting no build errors but

and with it I am getting the build errors above but with the more desirable expansion of the methods docstrings.

| 2021-02-23T16:06:16 |
|
scikit-hep/pyhf
| 1,351 |
scikit-hep__pyhf-1351
|
[
"1348"
] |
2c10be3bb405f157dc0e965fb320f0813a826a28
|
diff --git a/src/pyhf/tensor/pytorch_backend.py b/src/pyhf/tensor/pytorch_backend.py
--- a/src/pyhf/tensor/pytorch_backend.py
+++ b/src/pyhf/tensor/pytorch_backend.py
@@ -319,7 +319,8 @@ def einsum(self, subscripts, *operands):
return torch.einsum(subscripts, operands)
def poisson_logpdf(self, n, lam):
- return torch.distributions.Poisson(lam).log_prob(n)
+ # validate_args=True disallows continuous approximation
+ return torch.distributions.Poisson(lam, validate_args=False).log_prob(n)
def poisson(self, n, lam):
r"""
@@ -347,9 +348,16 @@ def poisson(self, n, lam):
Returns:
PyTorch FloatTensor: Value of the continuous approximation to Poisson(n|lam)
"""
- return torch.exp(torch.distributions.Poisson(lam).log_prob(n))
+ # validate_args=True disallows continuous approximation
+ return torch.exp(
+ torch.distributions.Poisson(lam, validate_args=False).log_prob(n)
+ )
def normal_logpdf(self, x, mu, sigma):
+ x = self.astensor(x)
+ mu = self.astensor(mu)
+ sigma = self.astensor(sigma)
+
normal = torch.distributions.Normal(mu, sigma)
return normal.log_prob(x)
@@ -379,6 +387,10 @@ def normal(self, x, mu, sigma):
Returns:
PyTorch FloatTensor: Value of Normal(x|mu, sigma)
"""
+ x = self.astensor(x)
+ mu = self.astensor(mu)
+ sigma = self.astensor(sigma)
+
normal = torch.distributions.Normal(mu, sigma)
return self.exp(normal.log_prob(x))
@@ -433,7 +445,8 @@ def poisson_dist(self, rate):
PyTorch Poisson distribution: The Poisson distribution class
"""
- return torch.distributions.Poisson(rate)
+ # validate_args=True disallows continuous approximation
+ return torch.distributions.Poisson(rate, validate_args=False)
def normal_dist(self, mu, sigma):
r"""
|
diff --git a/tests/test_tensor.py b/tests/test_tensor.py
--- a/tests/test_tensor.py
+++ b/tests/test_tensor.py
@@ -247,6 +247,8 @@ def test_shape(backend):
)
[email protected]_pytorch
[email protected]_pytorch64
def test_pdf_calculations(backend):
tb = pyhf.tensorlib
assert tb.tolist(tb.normal_cdf(tb.astensor([0.8]))) == pytest.approx(
@@ -286,7 +288,53 @@ def test_pdf_calculations(backend):
# Ensure continuous approximation is valid
assert tb.tolist(
- tb.poisson(tb.astensor([0.5, 1.1, 1.5]), tb.astensor(1.0))
+ tb.poisson(n=tb.astensor([0.5, 1.1, 1.5]), lam=tb.astensor(1.0))
+ ) == pytest.approx([0.4151074974205947, 0.3515379040027489, 0.2767383316137298])
+
+
+# validate_args in torch.distributions raises ValueError not nan
[email protected]_pytorch
[email protected]_pytorch64
+def test_pdf_calculations_pytorch(backend):
+ tb = pyhf.tensorlib
+
+ values = tb.astensor([0, 0, 1, 1])
+ mus = tb.astensor([0, 1, 0, 1])
+ sigmas = tb.astensor([0, 0, 0, 0])
+ for x, mu, sigma in zip(values, mus, sigmas):
+ with pytest.raises(ValueError):
+ _ = tb.normal_logpdf(x, mu, sigma)
+ assert tb.tolist(
+ tb.normal_logpdf(
+ tb.astensor([0, 0, 1, 1]),
+ tb.astensor([0, 1, 0, 1]),
+ tb.astensor([1, 1, 1, 1]),
+ )
+ ) == pytest.approx(
+ [
+ -0.91893853,
+ -1.41893853,
+ -1.41893853,
+ -0.91893853,
+ ],
+ )
+
+ # poisson(lambda=0) is not defined, should return NaN
+ assert tb.tolist(
+ tb.poisson(tb.astensor([0, 0, 1, 1]), tb.astensor([0, 1, 0, 1]))
+ ) == pytest.approx(
+ [np.nan, 0.3678794503211975, 0.0, 0.3678794503211975], nan_ok=True
+ )
+ assert tb.tolist(
+ tb.poisson_logpdf(tb.astensor([0, 0, 1, 1]), tb.astensor([0, 1, 0, 1]))
+ ) == pytest.approx(
+ np.log([np.nan, 0.3678794503211975, 0.0, 0.3678794503211975]).tolist(),
+ nan_ok=True,
+ )
+
+ # Ensure continuous approximation is valid
+ assert tb.tolist(
+ tb.poisson(n=tb.astensor([0.5, 1.1, 1.5]), lam=tb.astensor(1.0))
) == pytest.approx([0.4151074974205947, 0.3515379040027489, 0.2767383316137298])
|
PyTorch v1.8.0 breaks public API
# Description
<details>
<summary>Current Release Workflow Failure:</summary>
```pytb
============================= test session starts ==============================
platform linux -- Python 3.8.8, pytest-6.2.2, py-1.10.0, pluggy-0.13.1
rootdir: /home/runner/work/pyhf/pyhf, configfile: pyproject.toml
plugins: cov-2.11.1
collected 59 items
tests/test_public_api.py ..........................................FF... [ 79%]
.......FF... [100%]
=================================== FAILURES ===================================
____________________________ test_hypotest[pytorch] ____________________________
backend = (<pyhf.tensor.pytorch_backend.pytorch_backend object at 0x7fd40661f500>, None)
model_setup = (<pyhf.pdf.Model object at 0x7fd359ff8af0>, [55, 50, 53, 53, 57, 59, ...], [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, ...])
def test_hypotest(backend, model_setup):
model, data, init_pars = model_setup
mu = 1.0
> pyhf.infer.hypotest(
mu,
data,
model,
init_pars,
model.config.suggested_bounds(),
return_expected_set=True,
)
tests/test_public_api.py:165:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/infer/__init__.py:141: in hypotest
teststat = calc.teststatistic(poi_test)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/infer/calculators.py:331: in teststatistic
qmuA_v = teststat_func(
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/infer/test_statistics.py:177: in qmu_tilde
return _qmu_like(mu, data, pdf, init_pars, par_bounds, fixed_params)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/infer/test_statistics.py:19: in _qmu_like
tmu_like_stat, (_, muhatbhat) = _tmu_like(
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/infer/test_statistics.py:38: in _tmu_like
mubhathat, fixed_poi_fit_lhood_val = fixed_poi_fit(
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/infer/mle.py:190: in fixed_poi_fit
return fit(data, pdf, init_pars, par_bounds, fixed_params, **kwargs)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/infer/mle.py:122: in fit
return opt.minimize(
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/optimize/mixins.py:157: in minimize
result = self._internal_minimize(**minimizer_kwargs, options=kwargs)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/optimize/mixins.py:38: in _internal_minimize
result = self._minimize(
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/optimize/opt_scipy.py:74: in _minimize
return minimizer(
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/scipy/optimize/_minimize.py:627: in minimize
return _minimize_slsqp(fun, x0, args, jac, bounds,
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/scipy/optimize/slsqp.py:375: in _minimize_slsqp
sf = _prepare_scalar_function(func, x, jac=jac, args=args, epsilon=eps,
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/scipy/optimize/optimize.py:261: in _prepare_scalar_function
sf = ScalarFunction(fun, x0, args, grad, hess,
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/scipy/optimize/_differentiable_functions.py:136: in __init__
self._update_fun()
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/scipy/optimize/_differentiable_functions.py:226: in _update_fun
self._update_fun_impl()
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/scipy/optimize/_differentiable_functions.py:133: in update_fun
self.f = fun_wrapped(self.x)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/scipy/optimize/_differentiable_functions.py:130: in fun_wrapped
return fun(x, *args)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/scipy/optimize/optimize.py:74: in __call__
self._compute_if_needed(x, *args)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/scipy/optimize/optimize.py:68: in _compute_if_needed
fg = self.fun(x, *args)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/optimize/opt_pytorch.py:30: in func
constr_nll = objective(constrained_pars, data, pdf)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/infer/mle.py:47: in twice_nll
return -2 * pdf.logpdf(pars, data)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/pdf.py:726: in logpdf
result = self.make_pdf(pars).log_prob(data)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/probability.py:282: in log_prob
pdfvals = [p.log_prob(d) for p, d in zip(self, constituent_data)]
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/probability.py:282: in <listcomp>
pdfvals = [p.log_prob(d) for p, d in zip(self, constituent_data)]
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/probability.py:180: in log_prob
result = super().log_prob(value)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/probability.py:19: in log_prob
return self._pdf.log_prob(value)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/probability.py:19: in log_prob
return self._pdf.log_prob(value)
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/torch/distributions/poisson.py:61: in log_prob
self._validate_sample(value)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = Poisson(rate: torch.Size([100]))
value = tensor([50.1045, 50.0000, 50.0649, 50.0649, 50.1326, 50.1769, 50.0649, 50.1045,
50.0420, 50.0672, 50.1326, 50.... 50.0000, 50.0173, 50.1045, 50.1769, 50.0649, 50.0000, 50.1045, 50.0000,
50.0173, 50.0420, 50.0672, 50.0420])
def _validate_sample(self, value):
"""
Argument validation for distribution methods such as `log_prob`,
`cdf` and `icdf`. The rightmost dimensions of a value to be
scored via these methods must agree with the distribution's batch
and event shapes.
Args:
value (Tensor): the tensor whose log probability is to be
computed by the `log_prob` method.
Raises
ValueError: when the rightmost dimensions of `value` do not match the
distribution's batch and event shapes.
"""
if not isinstance(value, torch.Tensor):
raise ValueError('The value argument to log_prob must be a Tensor')
event_dim_start = len(value.size()) - len(self._event_shape)
if value.size()[event_dim_start:] != self._event_shape:
raise ValueError('The right-most size of value must match event_shape: {} vs {}.'.
format(value.size(), self._event_shape))
actual_shape = value.size()
expected_shape = self._batch_shape + self._event_shape
for i, j in zip(reversed(actual_shape), reversed(expected_shape)):
if i != 1 and j != 1 and i != j:
raise ValueError('Value is not broadcastable with batch_shape+event_shape: {} vs {}.'.
format(actual_shape, expected_shape))
try:
support = self.support
except NotImplementedError:
warnings.warn(f'{self.__class__} does not define `support` to enable ' +
'sample validation. Please initialize the distribution with ' +
'`validate_args=False` to turn off validation.')
return
assert support is not None
if not support.check(value).all():
> raise ValueError('The value argument must be within the support')
E ValueError: The value argument must be within the support
/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/torch/distributions/distribution.py:277: ValueError
------------------------------ Captured log call -------------------------------
ERROR pyhf.pdf:pdf.py:734 Eval failed for data [50.104469299316406, 50.0, 50.064884185791016, 50.064884185791016, 50.13261413574219, 50.176876068115234, 50.064884185791016, 50.104469299316406, 50.04202651977539, 50.0671501159668, 50.13261413574219, 50.11567306518555, 50.1575813293457, 50.1575813293457, 50.01729202270508, 50.11567306518555, 50.13261413574219, 50.13261413574219, 50.1575813293457, 50.01729202270508, 50.104469299316406, 50.176876068115234, 50.1575813293457, 50.176876068115234, 50.0671501159668, 50.064884185791016, 50.0, 50.064884185791016, 50.104469299316406, 50.0, 50.04202651977539, 50.064884185791016, 50.1575813293457, 50.01729202270508, 50.064884185791016, 50.064884185791016, 50.064884185791016, 50.13261413574219, 50.0, 50.01729202270508, 50.176876068115234, 50.176876068115234, 50.0, 50.0671501159668, 50.13261413574219, 50.064884185791016, 50.04202651977539, 50.13261413574219, 50.04202651977539, 50.0, 50.0, 50.0671501159668, 50.104469299316406, 50.104469299316406, 50.11567306518555, 50.1575813293457, 50.0671501159668, 50.01729202270508, 50.0671501159668, 50.176876068115234, 50.1575813293457, 50.01729202270508, 50.01729202270508, 50.13261413574219, 50.176876068115234, 50.176876068115234, 50.064884185791016, 50.11567306518555, 50.13261413574219, 50.04202651977539, 50.0, 50.064884185791016, 50.104469299316406, 50.176876068115234, 50.0671501159668, 50.0671501159668, 50.11567306518555, 50.0671501159668, 50.0671501159668, 50.064884185791016, 50.0671501159668, 50.0671501159668, 50.1575813293457, 50.0671501159668, 50.064884185791016, 50.13261413574219, 50.104469299316406, 50.104469299316406, 50.0, 50.01729202270508, 50.104469299316406, 50.176876068115234, 50.064884185791016, 50.0, 50.104469299316406, 50.0, 50.01729202270508, 50.04202651977539, 50.0671501159668, 50.04202651977539, 2505.223388671875, 2500.0, 2503.244384765625, 2503.244384765625, 2506.630615234375, 2508.84375, 2503.244384765625, 2505.223388671875, 2502.101318359375, 2503.357421875, 2506.630615234375, 2505.78369140625, 2507.879150390625, 2507.879150390625, 2500.864501953125, 2505.78369140625, 2506.630615234375, 2506.630615234375, 2507.879150390625, 2500.864501953125, 2505.223388671875, 2508.84375, 2507.879150390625, 2508.84375, 2503.357421875, 2503.244384765625, 2500.0, 2503.244384765625, 2505.223388671875, 2500.0, 2502.101318359375, 2503.244384765625, 2507.879150390625, 2500.864501953125, 2503.244384765625, 2503.244384765625, 2503.244384765625, 2506.630615234375, 2500.0, 2500.864501953125, 2508.84375, 2508.84375, 2500.0, 2503.357421875, 2506.630615234375, 2503.244384765625, 2502.101318359375, 2506.630615234375, 2502.101318359375, 2500.0, 2500.0, 2503.357421875, 2505.223388671875, 2505.223388671875, 2505.78369140625, 2507.879150390625, 2503.357421875, 2500.864501953125, 2503.357421875, 2508.84375, 2507.879150390625, 2500.864501953125, 2500.864501953125, 2506.630615234375, 2508.84375, 2508.84375, 2503.244384765625, 2505.78369140625, 2506.630615234375, 2502.101318359375, 2500.0, 2503.244384765625, 2505.223388671875, 2508.84375, 2503.357421875, 2503.357421875, 2505.78369140625, 2503.357421875, 2503.357421875, 2503.244384765625, 2503.357421875, 2503.357421875, 2507.879150390625, 2503.357421875, 2503.244384765625, 2506.630615234375, 2505.223388671875, 2505.223388671875, 2500.0, 2500.864501953125, 2505.223388671875, 2508.84375, 2503.244384765625, 2500.0, 2505.223388671875, 2500.0, 2500.864501953125, 2502.101318359375, 2503.357421875, 2502.101318359375] pars: [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/pdf.py", line 726, in logpdf
result = self.make_pdf(pars).log_prob(data)
File "/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/probability.py", line 282, in log_prob
pdfvals = [p.log_prob(d) for p, d in zip(self, constituent_data)]
File "/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/probability.py", line 282, in <listcomp>
pdfvals = [p.log_prob(d) for p, d in zip(self, constituent_data)]
File "/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/probability.py", line 180, in log_prob
result = super().log_prob(value)
File "/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/probability.py", line 19, in log_prob
return self._pdf.log_prob(value)
File "/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/pyhf/probability.py", line 19, in log_prob
return self._pdf.log_prob(value)
File "/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/torch/distributions/poisson.py", line 61, in log_prob
self._validate_sample(value)
File "/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/torch/distributions/distribution.py", line 277, in _validate_sample
##[error] raise ValueError('The value argument must be within the support')
ValueError: The value argument must be within the support:w
```
</details>
<details>
<summary>CI/CD Workflow Failure:</summary>
```pytb
============================= test session starts ==============================
platform linux -- Python 3.8.8, pytest-6.2.2, py-1.10.0, pluggy-0.13.1
Matplotlib: 3.3.4
Freetype: 2.6.1
benchmark: 3.2.3 (defaults: timer=time.perf_counter disable_gc=False min_rounds=5 min_time=0.000005 max_time=1.0 calibration_precision=10 warmup=False warmup_iterations=100000)
rootdir: /home/runner/work/pyhf/pyhf, configfile: pyproject.toml, testpaths: src, tests
plugins: mpl-0.12, cov-2.11.1, mock-3.5.1, console-scripts-1.1.0, benchmark-3.2.3
collected 1400 items
src/pyhf/__init__.py .. [ 0%]
src/pyhf/patchset.py . [ 0%]
src/pyhf/probability.py ....... [ 0%]
src/pyhf/simplemodels.py . [ 0%]
src/pyhf/utils.py ... [ 1%]
src/pyhf/contrib/utils.py . [ 1%]
src/pyhf/contrib/viz/brazil.py . [ 1%]
src/pyhf/infer/__init__.py . [ 1%]
src/pyhf/infer/calculators.py .............. [ 2%]
src/pyhf/infer/intervals.py . [ 2%]
src/pyhf/infer/mle.py ... [ 2%]
src/pyhf/infer/test_statistics.py ..... [ 2%]
src/pyhf/infer/utils.py .. [ 3%]
src/pyhf/tensor/jax_backend.py .............. [ 4%]
src/pyhf/tensor/numpy_backend.py .............. [ 5%]
src/pyhf/tensor/pytorch_backend.py .....F..F..... [ 6%]
src/pyhf/tensor/tensorflow_backend.py ................. [ 7%]
tests/test_backend_consistency.py .... [ 7%]
tests/test_calculator.py . [ 7%]
tests/test_cli.py .. [ 7%]
tests/test_combined_modifiers.py ....................................... [ 10%]
......... [ 11%]
tests/test_constraints.py .FF......... [ 12%]
tests/test_events.py ..... [ 12%]
tests/test_examples.py . [ 12%]
tests/test_export.py ........................ [ 14%]
tests/test_import.py .............. [ 15%]
tests/test_infer.py ................FFFF................................ [ 18%]
................ [ 20%]
tests/test_init.py ...... [ 20%]
tests/test_interpolate.py .............................................. [ 23%]
........................................................... [ 27%]
tests/test_jit.py ................................ [ 30%]
tests/test_mixins.py .. [ 30%]
tests/test_modifiers.py ............ [ 31%]
tests/test_optim.py .sss.s.............................................. [ 34%]
....................................................................FF.. [ 40%]
..FF...sssss.sssss................... [ 42%]
tests/test_paramsets.py ..... [ 43%]
tests/test_paramviewer.py ............. [ 44%]
tests/test_patchset.py ......................... [ 45%]
tests/test_pdf.py ..FF..................FF....sssss...................ss [ 49%]
sss.......sssss.......... [ 51%]
tests/test_probability.py ......................... [ 53%]
tests/test_public_api.py ..........................................FF... [ 56%]
.......FF... [ 57%]
tests/test_regression.py ..... [ 57%]
tests/test_schema.py ................................................ [ 61%]
tests/test_scripts.py ..............F................................... [ 64%]
......... [ 65%]
tests/test_tensor.py ................................................... [ 69%]
..................................FF......................x............. [ 74%]
...............sss.ss.................................... [ 78%]
tests/test_tensorviewer.py ...... [ 78%]
tests/test_teststats.py ......... [ 79%]
tests/test_toys.py ...... [ 79%]
tests/test_utils.py ........................ [ 81%]
tests/test_validation.py ............................ [ 83%]
tests/test_workspace.py ................................................ [ 86%]
........................................................................ [ 92%]
........................................................................ [ 97%]
....................................... [100%]
=================================== FAILURES ===================================
_________ [doctest] pyhf.tensor.pytorch_backend.pytorch_backend.normal _________
357
358 The probability density function of the Normal distribution evaluated
359 at :code:`x` given parameters of mean of :code:`mu` and standard deviation
360 of :code:`sigma`.
361
362 Example:
363
364 >>> import pyhf
365 >>> pyhf.set_backend("pytorch")
366 >>> pyhf.tensorlib.normal(0.5, 0., 1.)
UNEXPECTED EXCEPTION: ValueError('The value argument to log_prob must be a Tensor')
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/doctest.py", line 1336, in __run
exec(compile(example.source, filename, "single",
File "<doctest pyhf.tensor.pytorch_backend.pytorch_backend.normal[2]>", line 1, in <module>
File "/home/runner/work/pyhf/pyhf/src/pyhf/tensor/pytorch_backend.py", line 383, in normal
return self.exp(normal.log_prob(x))
File "/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/torch/distributions/normal.py", line 73, in log_prob
self._validate_sample(value)
File "/opt/hostedtoolcache/Python/3.8.8/x64/lib/python3.8/site-packages/torch/distributions/distribution.py", line 255, in _validate_sample
Error: raise ValueError('The value argument to log_prob must be a Tensor')
ValueError: The value argument to log_prob must be a Tensor
/home/runner/work/pyhf/pyhf/src/pyhf/tensor/pytorch_backend.py:366: UnexpectedException
```
</details>
# Expected Behavior
CI passes with `torch` `v1.8.0`
# Actual Behavior
Failure
# Steps to Reproduce
Run CI
# Checklist
- [x] Run `git fetch` to get the most up to date version of `master`
- [x] Searched through existing Issues to confirm this is not a duplicate issue
- [x] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
In the [`torch` `v1.8.0` release notes](https://github.com/pytorch/pytorch/releases/tag/v1.8.0) under there is a change in "Backwards Incompatible changes" for
> ## Enable distribution validation by default for `torch.distributions`
>
> This may slightly slow down some models. Concerned users may disable validation by using `torch.distributions.Distribution.set_default_validate_args(False)` or by disabling individual distribution validation via `MyDistribution(..., validate_args=False)`.
>
> This may cause new `ValueErrors` in models that rely on unsupported behavior, e.g. `Categorical.log_prob()` applied to continuous-valued tensors (only {0,1}-valued tensors are supported).
Such models should be fixed but the previous behavior can be recovered by disabling argument validation using the methods mentioned above.
I don't think this is related, but I'm going to start there.
| 2021-03-05T08:34:36 |
scikit-hep/pyhf
| 1,354 |
scikit-hep__pyhf-1354
|
[
"1349"
] |
04b6c865a12154d3728aedce2fabc268c85673d5
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -6,7 +6,7 @@
'tensorflow~=2.2.0', # TensorFlow minor releases are as volatile as major
'tensorflow-probability~=0.10.0',
],
- 'torch': ['torch~=1.2'],
+ 'torch': ['torch~=1.8'],
'jax': ['jax~=0.2.4', 'jaxlib~=0.1.56'],
'xmlio': [
'uproot3~=3.14',
diff --git a/src/pyhf/tensor/pytorch_backend.py b/src/pyhf/tensor/pytorch_backend.py
--- a/src/pyhf/tensor/pytorch_backend.py
+++ b/src/pyhf/tensor/pytorch_backend.py
@@ -143,10 +143,31 @@ def tile(self, tensor_in, repeats):
Returns:
PyTorch tensor: The tensor with repeated axes
"""
- return tensor_in.repeat(repeats)
+ return tensor_in.tile(repeats)
def outer(self, tensor_in_1, tensor_in_2):
- return torch.ger(tensor_in_1, tensor_in_2)
+ """
+ Outer product of the input tensors.
+
+ Example:
+
+ >>> import pyhf
+ >>> pyhf.set_backend("pytorch")
+ >>> a = pyhf.tensorlib.astensor([1.0, 2.0, 3.0])
+ >>> b = pyhf.tensorlib.astensor([1.0, 2.0, 3.0, 4.0])
+ >>> pyhf.tensorlib.outer(a, b)
+ tensor([[ 1., 2., 3., 4.],
+ [ 2., 4., 6., 8.],
+ [ 3., 6., 9., 12.]])
+
+ Args:
+ tensor_in_1 (:obj:`tensor`): 1-D input tensor.
+ tensor_in_2 (:obj:`tensor`): 1-D input tensor.
+
+ Returns:
+ PyTorch tensor: The outer product.
+ """
+ return torch.outer(tensor_in_1, tensor_in_2)
def astensor(self, tensor_in, dtype='float'):
"""
@@ -209,7 +230,7 @@ def ravel(self, tensor):
Returns:
`torch.Tensor`: A flattened array.
"""
- return tensor.view(-1)
+ return torch.ravel(tensor)
def sum(self, tensor_in, axis=None):
return (
|
Use new APIs added in PyTorch v1.8.0
# Description
In PyTorch `v1.8.0` in the [Python API section under "New features"](https://github.com/pytorch/pytorch/releases/tag/v1.8.0) there is the addition of `torch.ravel` (https://github.com/pytorch/pytorch/pull/46098) and `torch.tile` (https://github.com/pytorch/pytorch/pull/47974) to the public API. These should be adopted for the `torch` backend.
Currently we use
https://github.com/scikit-hep/pyhf/blob/2c10be3bb405f157dc0e965fb320f0813a826a28/src/pyhf/tensor/pytorch_backend.py#L194-L212
and
https://github.com/scikit-hep/pyhf/blob/2c10be3bb405f157dc0e965fb320f0813a826a28/src/pyhf/tensor/pytorch_backend.py#L126-L146
| 2021-03-05T22:12:45 |
||
scikit-hep/pyhf
| 1,355 |
scikit-hep__pyhf-1355
|
[
"1350"
] |
572fc694d0dadc478afa6d13ecb041c19c98aef5
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -3,13 +3,13 @@
extras_require = {
'shellcomplete': ['click_completion'],
'tensorflow': [
- 'tensorflow~=2.2.0', # TensorFlow minor releases are as volatile as major
- 'tensorflow-probability~=0.10.0',
+ 'tensorflow~=2.2.1', # TensorFlow minor releases are as volatile as major
+ 'tensorflow-probability~=0.10.1',
],
'torch': ['torch~=1.8'],
- 'jax': ['jax~=0.2.4', 'jaxlib~=0.1.56'],
+ 'jax': ['jax~=0.2.8', 'jaxlib~=0.1.58'],
'xmlio': [
- 'uproot3~=3.14',
+ 'uproot3>=3.14.1',
'uproot~=4.0',
], # uproot3 required until writing to ROOT supported in uproot4
'minuit': ['iminuit~=2.1,<2.4'], # iminuit v2.4.0 behavior needs to be understood
|
Validate lower bounds of dependencies in CI
# Description
To ensure that the lower bound of all dependencies are still sufficient for the API used, add a test that installs from a `lower-bound-requirements.txt` that might look something like
```
# core
scipy==1.4.0
click==7.0.0
tqdm==4.56.0
jsonschema==3.2.0
jsonpatch==1.23.0
pyyaml==5.1.0
# xmlio
uproot3==3.14.0
uproot==4.0.0
# minuit
iminuit==2.1.0
# ...
```
and then run the test suite.
| 2021-03-07T18:41:46 |
||
scikit-hep/pyhf
| 1,400 |
scikit-hep__pyhf-1400
|
[
"1398"
] |
34bd7f49cb47fb27d1684c77610d16096b7c6ec9
|
diff --git a/src/pyhf/__init__.py b/src/pyhf/__init__.py
--- a/src/pyhf/__init__.py
+++ b/src/pyhf/__init__.py
@@ -45,12 +45,12 @@ def set_backend(backend, custom_optimizer=None, precision=None):
>>> pyhf.tensorlib.name
'tensorflow'
>>> pyhf.tensorlib.precision
- '32b'
- >>> pyhf.set_backend(b"pytorch", precision="64b")
+ '64b'
+ >>> pyhf.set_backend(b"pytorch", precision="32b")
>>> pyhf.tensorlib.name
'pytorch'
>>> pyhf.tensorlib.precision
- '64b'
+ '32b'
>>> pyhf.set_backend(pyhf.tensor.numpy_backend())
>>> pyhf.tensorlib.name
'numpy'
diff --git a/src/pyhf/tensor/pytorch_backend.py b/src/pyhf/tensor/pytorch_backend.py
--- a/src/pyhf/tensor/pytorch_backend.py
+++ b/src/pyhf/tensor/pytorch_backend.py
@@ -15,7 +15,7 @@ class pytorch_backend:
def __init__(self, **kwargs):
self.name = 'pytorch'
- self.precision = kwargs.get('precision', '32b')
+ self.precision = kwargs.get('precision', '64b')
self.dtypemap = {
'float': torch.float64 if self.precision == '64b' else torch.float32,
'int': torch.int64 if self.precision == '64b' else torch.int32,
@@ -525,7 +525,7 @@ def to_numpy(self, tensor_in):
>>> numpy_ndarray = pyhf.tensorlib.to_numpy(tensor)
>>> numpy_ndarray
array([[1., 2., 3.],
- [4., 5., 6.]], dtype=float32)
+ [4., 5., 6.]])
>>> type(numpy_ndarray)
<class 'numpy.ndarray'>
diff --git a/src/pyhf/tensor/tensorflow_backend.py b/src/pyhf/tensor/tensorflow_backend.py
--- a/src/pyhf/tensor/tensorflow_backend.py
+++ b/src/pyhf/tensor/tensorflow_backend.py
@@ -13,7 +13,7 @@ class tensorflow_backend:
def __init__(self, **kwargs):
self.name = 'tensorflow'
- self.precision = kwargs.get('precision', '32b')
+ self.precision = kwargs.get('precision', '64b')
self.dtypemap = {
'float': tf.float64 if self.precision == '64b' else tf.float32,
'int': tf.int64 if self.precision == '64b' else tf.int32,
@@ -36,7 +36,7 @@ def clip(self, tensor_in, min_value, max_value):
>>> a = pyhf.tensorlib.astensor([-2, -1, 0, 1, 2])
>>> t = pyhf.tensorlib.clip(a, -1, 1)
>>> print(t)
- tf.Tensor([-1. -1. 0. 1. 1.], shape=(5,), dtype=float32)
+ tf.Tensor([-1. -1. 0. 1. 1.], shape=(5,), dtype=float64)
Args:
tensor_in (:obj:`tensor`): The input tensor object
@@ -64,7 +64,7 @@ def erf(self, tensor_in):
>>> a = pyhf.tensorlib.astensor([-2., -1., 0., 1., 2.])
>>> t = pyhf.tensorlib.erf(a)
>>> print(t)
- tf.Tensor([-0.9953223 -0.8427007 0. 0.8427007 0.9953223], shape=(5,), dtype=float32)
+ tf.Tensor([-0.99532227 -0.84270079 0. 0.84270079 0.99532227], shape=(5,), dtype=float64)
Args:
tensor_in (:obj:`tensor`): The input tensor object
@@ -85,7 +85,7 @@ def erfinv(self, tensor_in):
>>> a = pyhf.tensorlib.astensor([-2., -1., 0., 1., 2.])
>>> t = pyhf.tensorlib.erfinv(pyhf.tensorlib.erf(a))
>>> print(t)
- tf.Tensor([-2.000001 -0.99999964 0. 0.99999964 1.9999981 ], shape=(5,), dtype=float32)
+ tf.Tensor([-2. -1. 0. 1. 2.], shape=(5,), dtype=float64)
Args:
tensor_in (:obj:`tensor`): The input tensor object
@@ -107,7 +107,7 @@ def tile(self, tensor_in, repeats):
>>> print(t)
tf.Tensor(
[[1. 1.]
- [2. 2.]], shape=(2, 2), dtype=float32)
+ [2. 2.]], shape=(2, 2), dtype=float64)
Args:
tensor_in (:obj:`tensor`): The tensor to be repeated
@@ -138,7 +138,7 @@ def conditional(self, predicate, true_callable, false_callable):
>>> b = tensorlib.astensor([5])
>>> t = tensorlib.conditional((a < b)[0], lambda: a + b, lambda: a - b)
>>> print(t)
- tf.Tensor([9.], shape=(1,), dtype=float32)
+ tf.Tensor([9.], shape=(1,), dtype=float64)
Args:
predicate (:obj:`scalar`): The logical condition that determines which callable to evaluate
@@ -188,9 +188,9 @@ def astensor(self, tensor_in, dtype='float'):
>>> pyhf.set_backend("tensorflow")
>>> tensor = pyhf.tensorlib.astensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
>>> tensor
- <tf.Tensor: shape=(2, 3), dtype=float32, numpy=
+ <tf.Tensor: shape=(2, 3), dtype=float64, numpy=
array([[1., 2., 3.],
- [4., 5., 6.]], dtype=float32)>
+ [4., 5., 6.]])>
>>> type(tensor)
<class 'tensorflow.python.framework.ops.EagerTensor'>
@@ -284,7 +284,7 @@ def ravel(self, tensor):
>>> tensor = pyhf.tensorlib.astensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
>>> t_ravel = pyhf.tensorlib.ravel(tensor)
>>> print(t_ravel)
- tf.Tensor([1. 2. 3. 4. 5. 6.], shape=(6,), dtype=float32)
+ tf.Tensor([1. 2. 3. 4. 5. 6.], shape=(6,), dtype=float64)
Args:
tensor (Tensor): Tensor object
@@ -320,7 +320,7 @@ def where(self, mask, tensor_in_1, tensor_in_2):
... pyhf.tensorlib.astensor([2, 2, 2]),
... )
>>> print(t)
- tf.Tensor([1. 2. 1.], shape=(3,), dtype=float32)
+ tf.Tensor([1. 2. 1.], shape=(3,), dtype=float64)
Args:
mask (bool): Boolean mask (boolean or tensor object of booleans)
@@ -359,9 +359,9 @@ def simple_broadcast(self, *args):
... pyhf.tensorlib.astensor([2, 3, 4]),
... pyhf.tensorlib.astensor([5, 6, 7]))
>>> print([str(t) for t in b]) # doctest: +NORMALIZE_WHITESPACE
- ['tf.Tensor([1. 1. 1.], shape=(3,), dtype=float32)',
- 'tf.Tensor([2. 3. 4.], shape=(3,), dtype=float32)',
- 'tf.Tensor([5. 6. 7.], shape=(3,), dtype=float32)']
+ ['tf.Tensor([1. 1. 1.], shape=(3,), dtype=float64)',
+ 'tf.Tensor([2. 3. 4.], shape=(3,), dtype=float64)',
+ 'tf.Tensor([5. 6. 7.], shape=(3,), dtype=float64)']
Args:
args (Array of Tensors): Sequence of arrays
@@ -408,13 +408,13 @@ def poisson_logpdf(self, n, lam):
>>> import pyhf
>>> pyhf.set_backend("tensorflow")
>>> t = pyhf.tensorlib.poisson_logpdf(5., 6.)
- >>> print(t)
- tf.Tensor(-1.8286943, shape=(), dtype=float32)
+ >>> print(t) # doctest:+ELLIPSIS
+ tf.Tensor(-1.8286943966417..., shape=(), dtype=float64)
>>> values = pyhf.tensorlib.astensor([5., 9.])
>>> rates = pyhf.tensorlib.astensor([6., 8.])
>>> t = pyhf.tensorlib.poisson_logpdf(values, rates)
>>> print(t)
- tf.Tensor([-1.8286943 -2.086854 ], shape=(2,), dtype=float32)
+ tf.Tensor([-1.8286944 -2.0868536], shape=(2,), dtype=float64)
Args:
n (:obj:`tensor` or :obj:`float`): The value at which to evaluate the approximation to the Poisson distribution p.m.f.
@@ -439,13 +439,13 @@ def poisson(self, n, lam):
>>> import pyhf
>>> pyhf.set_backend("tensorflow")
>>> t = pyhf.tensorlib.poisson(5., 6.)
- >>> print(t)
- tf.Tensor(0.16062315, shape=(), dtype=float32)
+ >>> print(t) # doctest:+ELLIPSIS
+ tf.Tensor(0.1606231410479..., shape=(), dtype=float64)
>>> values = pyhf.tensorlib.astensor([5., 9.])
>>> rates = pyhf.tensorlib.astensor([6., 8.])
>>> t = pyhf.tensorlib.poisson(values, rates)
>>> print(t)
- tf.Tensor([0.16062315 0.12407687], shape=(2,), dtype=float32)
+ tf.Tensor([0.16062314 0.12407692], shape=(2,), dtype=float64)
Args:
n (:obj:`tensor` or :obj:`float`): The value at which to evaluate the approximation to the Poisson distribution p.m.f.
@@ -471,13 +471,13 @@ def normal_logpdf(self, x, mu, sigma):
>>> pyhf.set_backend("tensorflow")
>>> t = pyhf.tensorlib.normal_logpdf(0.5, 0., 1.)
>>> print(t)
- tf.Tensor(-1.0439385, shape=(), dtype=float32)
+ tf.Tensor(-1.0439385332046727, shape=(), dtype=float64)
>>> values = pyhf.tensorlib.astensor([0.5, 2.0])
>>> means = pyhf.tensorlib.astensor([0., 2.3])
>>> sigmas = pyhf.tensorlib.astensor([1., 0.8])
>>> t = pyhf.tensorlib.normal_logpdf(values, means, sigmas)
>>> print(t)
- tf.Tensor([-1.0439385 -0.7661075], shape=(2,), dtype=float32)
+ tf.Tensor([-1.04393853 -0.76610747], shape=(2,), dtype=float64)
Args:
x (:obj:`tensor` or :obj:`float`): The value at which to evaluate the Normal distribution p.d.f.
@@ -503,13 +503,13 @@ def normal(self, x, mu, sigma):
>>> pyhf.set_backend("tensorflow")
>>> t = pyhf.tensorlib.normal(0.5, 0., 1.)
>>> print(t)
- tf.Tensor(0.35206532, shape=(), dtype=float32)
+ tf.Tensor(0.3520653267642995, shape=(), dtype=float64)
>>> values = pyhf.tensorlib.astensor([0.5, 2.0])
>>> means = pyhf.tensorlib.astensor([0., 2.3])
>>> sigmas = pyhf.tensorlib.astensor([1., 0.8])
>>> t = pyhf.tensorlib.normal(values, means, sigmas)
>>> print(t)
- tf.Tensor([0.35206532 0.46481887], shape=(2,), dtype=float32)
+ tf.Tensor([0.35206533 0.46481887], shape=(2,), dtype=float64)
Args:
x (:obj:`tensor` or :obj:`float`): The value at which to evaluate the Normal distribution p.d.f.
@@ -533,11 +533,11 @@ def normal_cdf(self, x, mu=0.0, sigma=1):
>>> pyhf.set_backend("tensorflow")
>>> t = pyhf.tensorlib.normal_cdf(0.8)
>>> print(t)
- tf.Tensor(0.7881446, shape=(), dtype=float32)
+ tf.Tensor(0.7881446014166034, shape=(), dtype=float64)
>>> values = pyhf.tensorlib.astensor([0.8, 2.0])
>>> t = pyhf.tensorlib.normal_cdf(values)
>>> print(t)
- tf.Tensor([0.7881446 0.97724986], shape=(2,), dtype=float32)
+ tf.Tensor([0.7881446 0.97724987], shape=(2,), dtype=float64)
Args:
x (:obj:`tensor` or :obj:`float`): The observed value of the random variable to evaluate the CDF for
@@ -564,7 +564,7 @@ def poisson_dist(self, rate):
>>> poissons = pyhf.tensorlib.poisson_dist(rates)
>>> t = poissons.log_prob(values)
>>> print(t)
- tf.Tensor([-1.7403021 -2.086854 ], shape=(2,), dtype=float32)
+ tf.Tensor([-1.74030218 -2.0868536 ], shape=(2,), dtype=float64)
Args:
rate (:obj:`tensor` or :obj:`float`): The mean of the Poisson distribution (the expected number of events)
@@ -590,7 +590,7 @@ def normal_dist(self, mu, sigma):
>>> normals = pyhf.tensorlib.normal_dist(means, stds)
>>> t = normals.log_prob(values)
>>> print(t)
- tf.Tensor([-1.4189385 -2.2257915], shape=(2,), dtype=float32)
+ tf.Tensor([-1.41893853 -2.22579135], shape=(2,), dtype=float64)
Args:
mu (:obj:`tensor` or :obj:`float`): The mean of the Normal distribution
@@ -616,11 +616,11 @@ def to_numpy(self, tensor_in):
>>> print(tensor)
tf.Tensor(
[[1. 2. 3.]
- [4. 5. 6.]], shape=(2, 3), dtype=float32)
+ [4. 5. 6.]], shape=(2, 3), dtype=float64)
>>> numpy_ndarray = pyhf.tensorlib.to_numpy(tensor)
>>> numpy_ndarray
array([[1., 2., 3.],
- [4., 5., 6.]], dtype=float32)
+ [4., 5., 6.]])
>>> type(numpy_ndarray)
<class 'numpy.ndarray'>
|
Uniform default precision for all backends?
# Question
As seen [in the example](https://pyhf.readthedocs.io/en/v0.6.1/_generated/pyhf.set_backend.html) for `pyhf.set_backend` the default precision for the `numpy` backend is `64b` while the default precision for TensorFlow and PyTorch is `32b`.
https://github.com/scikit-hep/pyhf/blob/98bb222d9c45ad13335ab5423d866e3a1508c329/src/pyhf/tensor/numpy_backend.py#L44
https://github.com/scikit-hep/pyhf/blob/98bb222d9c45ad13335ab5423d866e3a1508c329/src/pyhf/tensor/jax_backend.py#L58
https://github.com/scikit-hep/pyhf/blob/98bb222d9c45ad13335ab5423d866e3a1508c329/src/pyhf/tensor/tensorflow_backend.py#L16
https://github.com/scikit-hep/pyhf/blob/98bb222d9c45ad13335ab5423d866e3a1508c329/src/pyhf/tensor/pytorch_backend.py#L18
Given that there are known differences between `64b` and `32b` it is probably worth reconsidering / discussing if we should have a default precision of `64b` for all backends. My guess is that it is non-intuitive that switching from NumPy to Torch changes the precision.
This is somewhat related to Issue #981 and was put back into my mind by @dguest and @nhartman94 (c.f. Discussion #1397) (comments welcome from them both).
| 2021-04-06T14:47:37 |
||
scikit-hep/pyhf
| 1,409 |
scikit-hep__pyhf-1409
|
[
"1391"
] |
0b934a188040c2e33fe0ddff1be360a738e405ef
|
diff --git a/src/pyhf/infer/__init__.py b/src/pyhf/infer/__init__.py
--- a/src/pyhf/infer/__init__.py
+++ b/src/pyhf/infer/__init__.py
@@ -2,6 +2,19 @@
from . import utils
from .. import get_backend
+from .. import exceptions
+
+
+def _check_hypotest_prerequisites(pdf, data, init_pars, par_bounds, fixed_params):
+ if pdf.config.poi_index is None:
+ raise exceptions.UnspecifiedPOI(
+ 'No POI is defined. A POI is required to run a hypothesis test.'
+ )
+
+ if not utils.all_pois_floating(pdf, fixed_params):
+ raise exceptions.InvalidModel(
+ f'POI at index [{pdf.config.poi_index}] is set as fixed, which makes inference impossible. Please unfix the POI to continue.'
+ )
def hypotest(
@@ -131,6 +144,8 @@ def hypotest(
par_bounds = par_bounds or pdf.config.suggested_bounds()
fixed_params = fixed_params or pdf.config.suggested_fixed()
+ _check_hypotest_prerequisites(pdf, data, init_pars, par_bounds, fixed_params)
+
calc = utils.create_calculator(
calctype,
data,
diff --git a/src/pyhf/infer/utils.py b/src/pyhf/infer/utils.py
--- a/src/pyhf/infer/utils.py
+++ b/src/pyhf/infer/utils.py
@@ -9,6 +9,24 @@
log = logging.getLogger(__name__)
+def all_pois_floating(pdf, fixed_params):
+ r"""
+ Check whether all POI(s) are floating (i.e. not within the fixed set).
+
+ Args:
+ pdf (~pyhf.pdf.Model): The statistical model adhering to the schema
+ ``model.json``.
+ fixed_params (:obj:`list` or `tensor` of :obj:`bool`): Array of
+ :obj:`bool` indicating if model parameters are fixed.
+
+ Returns:
+ :obj:`bool`: The result whether all POIs are floating.
+ """
+
+ poi_fixed = fixed_params[pdf.config.poi_index]
+ return not poi_fixed
+
+
def create_calculator(calctype, *args, **kwargs):
"""
Creates a calculator object of the specified `calctype`.
|
diff --git a/tests/test_infer.py b/tests/test_infer.py
--- a/tests/test_infer.py
+++ b/tests/test_infer.py
@@ -395,3 +395,15 @@ def test_toy_calculator(tmpdir, hypotest_args):
assert toy_calculator_qtilde_mu.teststatistic(mu_test) == pytest.approx(
3.938244920380498, 1e-07
)
+
+
+def test_fixed_poi(tmpdir, hypotest_args):
+ """
+ Check that the return structure of pyhf.infer.hypotest with the
+ additon of the return_expected keyword arg is as expected
+ """
+
+ _, _, pdf = hypotest_args
+ pdf.config.param_set('mu').suggested_fixed = [True]
+ with pytest.raises(pyhf.exceptions.InvalidModel):
+ pyhf.infer.hypotest(*hypotest_args)
|
workspaces with fixed poi fail in hypotest (of course)
# Description
some workspaces (like the one @elskorda provided) have a *fixed* POI in the workspace definition - if you naively put that through `pyhf cls` of course the fit doesn't really do anythinig useful.
options
* in readxml warn that POI is fixed
* in hypotest ensurer to un-fix POI
* others?
the least we could do is throw a warning in the places where an unconstrained fit iss expected but a fixed POI is observed
|
`hypotest` seems like a good place for a warning, maybe even error. With the POI fixed, the result cannot really be meaningful. As a step towards multi-POI support, it might also be useful to have an option to override the POI from the CLI.
| 2021-04-13T21:12:33 |
scikit-hep/pyhf
| 1,419 |
scikit-hep__pyhf-1419
|
[
"1315"
] |
f2f6e4b323f6510189851b5aed1ccc9d272ed866
|
diff --git a/src/pyhf/utils.py b/src/pyhf/utils.py
--- a/src/pyhf/utils.py
+++ b/src/pyhf/utils.py
@@ -141,7 +141,7 @@ def citation(oneline=False):
Example:
>>> import pyhf
- >>> pyhf.utils.citation(True)
+ >>> pyhf.utils.citation(oneline=True)
'@software{pyhf, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark}, title = "{pyhf: v0.6.1}", version = {0.6.1}, doi = {10.5281/zenodo.1169739}, url = {https://github.com/scikit-hep/pyhf},}@article{pyhf_joss, doi = {10.21105/joss.02823}, url = {https://doi.org/10.21105/joss.02823}, year = {2021}, publisher = {The Open Journal}, volume = {6}, number = {58}, pages = {2823}, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark and Kyle Cranmer}, title = {pyhf: pure-Python implementation of HistFactory statistical models}, journal = {Journal of Open Source Software}}'
Keyword Args:
|
Add pyhf.utils.citation to the python API
| 2021-04-27T18:13:22 |
||
scikit-hep/pyhf
| 1,424 |
scikit-hep__pyhf-1424
|
[
"1423"
] |
cc38945bb73e379997c06ba30df3ff666d8e81c8
|
diff --git a/src/pyhf/utils.py b/src/pyhf/utils.py
--- a/src/pyhf/utils.py
+++ b/src/pyhf/utils.py
@@ -142,7 +142,7 @@ def citation(oneline=False):
>>> import pyhf
>>> pyhf.utils.citation(oneline=True)
- '@software{pyhf, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark}, title = "{pyhf: v0.6.1}", version = {0.6.1}, doi = {10.5281/zenodo.1169739}, url = {https://github.com/scikit-hep/pyhf},}@article{pyhf_joss, doi = {10.21105/joss.02823}, url = {https://doi.org/10.21105/joss.02823}, year = {2021}, publisher = {The Open Journal}, volume = {6}, number = {58}, pages = {2823}, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark and Kyle Cranmer}, title = {pyhf: pure-Python implementation of HistFactory statistical models}, journal = {Journal of Open Source Software}}'
+ '@software{pyhf, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark}, title = "{pyhf: v0.6.1}", version = {0.6.1}, doi = {10.5281/zenodo.1169739}, url = {https://doi.org/10.5281/zenodo.1169739}, note = {https://github.com/scikit-hep/pyhf/releases/tag/v0.6.1}}@article{pyhf_joss, doi = {10.21105/joss.02823}, url = {https://doi.org/10.21105/joss.02823}, year = {2021}, publisher = {The Open Journal}, volume = {6}, number = {58}, pages = {2823}, author = {Lukas Heinrich and Matthew Feickert and Giordon Stark and Kyle Cranmer}, title = {pyhf: pure-Python implementation of HistFactory statistical models}, journal = {Journal of Open Source Software}}'
Keyword Args:
oneline (:obj:`bool`): Whether to provide citation with new lines (default) or as a one-liner.
|
Update requested software citation URL
# Description
It seems that we might want to update the recommended software citation BibTeX entry for the software itself as the Zenodo DOI keeps getting cut off in the actual citations.
**Example:**
With the current entry of
https://github.com/scikit-hep/pyhf/blob/cc38945bb73e379997c06ba30df3ff666d8e81c8/src/pyhf/data/citation.bib#L1-L7
we are seeing a lot of this (c.f. PR #1421)
[](https://arxiv.org/abs/2104.12624)
It might be better to get the Zenodo DOI URL in there instead and keep the GitHub URL as a `note` entry:
```bibtex
@software{pyhf,
author = {Lukas Heinrich and Matthew Feickert and Giordon Stark},
title = "{pyhf: v0.6.1}",
version = {0.6.1},
doi = {10.5281/zenodo.1169739},
url = {https://doi.org/10.5281/zenodo.1169739},
note = {https://github.com/scikit-hep/pyhf}
}
```
@kratsg @lukasheinrich thoughts?
|
Or maybe even
```bibtex
@software{pyhf,
author = {Lukas Heinrich and Matthew Feickert and Giordon Stark},
title = "{pyhf: v0.6.1}",
version = {0.6.1},
doi = {10.5281/zenodo.1169739},
url = {https://doi.org/10.5281/zenodo.1169739},
note = {https://github.com/scikit-hep/pyhf/releases/tag/v0.6.1}
}
```
As the tag number would get picked up by `bump2version`.
| 2021-04-29T18:22:35 |
|
scikit-hep/pyhf
| 1,435 |
scikit-hep__pyhf-1435
|
[
"1434"
] |
acb490a5b58d5076804b7d1c7737d4b8bddd6e81
|
diff --git a/src/pyhf/simplemodels.py b/src/pyhf/simplemodels.py
--- a/src/pyhf/simplemodels.py
+++ b/src/pyhf/simplemodels.py
@@ -1,12 +1,81 @@
from . import Model
-__all__ = ["hepdata_like"]
+__all__ = ["correlated_background", "hepdata_like"]
def __dir__():
return __all__
+def correlated_background(signal, bkg, bkg_up, bkg_down, batch_size=None):
+ r"""
+ Construct a simple single channel :class:`~pyhf.pdf.Model` with a
+ :class:`~pyhf.modifiers.histosys` modifier representing a background
+ with a fully correlated bin-by-bin uncertainty.
+
+ Args:
+ signal (:obj:`list`): The data in the signal sample.
+ bkg (:obj:`list`): The data in the background sample.
+ bkg_up (:obj:`list`): The background sample under an upward variation
+ corresponding to :math:`\alpha=+1`.
+ bkg_down (:obj:`list`): The background sample under a downward variation
+ corresponding to :math:`\alpha=-1`.
+ batch_size (:obj:`None` or :obj:`int`): Number of simultaneous (batched) Models to compute.
+
+ Returns:
+ ~pyhf.pdf.Model: The statistical model adhering to the :obj:`model.json` schema.
+
+ Example:
+ >>> import pyhf
+ >>> pyhf.set_backend("numpy")
+ >>> model = pyhf.simplemodels.correlated_background(
+ ... signal=[12.0, 11.0],
+ ... bkg=[50.0, 52.0],
+ ... bkg_up=[45.0, 57.0],
+ ... bkg_down=[55.0, 47.0],
+ ... )
+ >>> model.schema
+ 'model.json'
+ >>> model.config.channels
+ ['single_channel']
+ >>> model.config.samples
+ ['background', 'signal']
+ >>> model.config.parameters
+ ['correlated_bkg_uncertainty', 'mu']
+ >>> model.expected_data(model.config.suggested_init())
+ array([62., 63., 0.])
+
+ """
+ spec = {
+ "channels": [
+ {
+ "name": "single_channel",
+ "samples": [
+ {
+ "name": "signal",
+ "data": signal,
+ "modifiers": [
+ {"name": "mu", "type": "normfactor", "data": None}
+ ],
+ },
+ {
+ "name": "background",
+ "data": bkg,
+ "modifiers": [
+ {
+ "name": "correlated_bkg_uncertainty",
+ "type": "histosys",
+ "data": {"hi_data": bkg_up, "lo_data": bkg_down},
+ }
+ ],
+ },
+ ],
+ }
+ ]
+ }
+ return Model(spec, batch_size=batch_size)
+
+
def hepdata_like(signal_data, bkg_data, bkg_uncerts, batch_size=None):
"""
Construct a simple single channel :class:`~pyhf.pdf.Model` with a
|
diff --git a/tests/test_public_api_repr.py b/tests/test_public_api_repr.py
--- a/tests/test_public_api_repr.py
+++ b/tests/test_public_api_repr.py
@@ -220,7 +220,7 @@ def test_readxml_public_api():
def test_simplemodels_public_api():
- assert dir(pyhf.simplemodels) == ["hepdata_like"]
+ assert dir(pyhf.simplemodels) == ["correlated_background", "hepdata_like"]
def test_utils_public_api():
diff --git a/tests/test_simplemodels.py b/tests/test_simplemodels.py
new file mode 100644
--- /dev/null
+++ b/tests/test_simplemodels.py
@@ -0,0 +1,24 @@
+import pyhf
+
+
+def test_correlated_background():
+ model = pyhf.simplemodels.correlated_background(
+ signal=[12.0, 11.0],
+ bkg=[50.0, 52.0],
+ bkg_up=[45.0, 57.0],
+ bkg_down=[55.0, 47.0],
+ )
+ assert model.config.channels == ["single_channel"]
+ assert model.config.samples == ["background", "signal"]
+ assert model.config.par_order == ["mu", "correlated_bkg_uncertainty"]
+ assert model.config.suggested_init() == [1.0, 0.0]
+
+
+def test_uncorrelated_background():
+ model = pyhf.simplemodels.hepdata_like(
+ signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
+ )
+ assert model.config.channels == ["singlechannel"]
+ assert model.config.samples == ["background", "signal"]
+ assert model.config.par_order == ["mu", "uncorr_bkguncrt"]
+ assert model.config.suggested_init() == [1.0, 1.0, 1.0]
|
Correlated background simplemodel
something like
```python
def simplemodel2(s,b_up,b_nom,b_dn):
spec = {
'channels': [
{
'name': 'singlechannel',
'samples': [
{
'name': 'signal',
'data': s,
'modifiers': [{'name': 'mu', 'type': 'normfactor', 'data': None}]
},
{'name': 'background',
'data': b_nom,
'modifiers': [
{
'name': 'uncorr_bkguncrt',
'type': 'histosys',
'data': {
'hi_data': b_up,
'lo_data': b_dn
}
}
]
}
]
}
]
}
return pyhf.Model(spec)
```
with an API like `pyhf.simplemodels.correlated_bkg`
|
In a separate Issue and PR we should also revise the current `simplemodels` API and deprecate `hepdata_like` (for the next release and then remove it in 2 releases).
| 2021-05-07T08:02:27 |
scikit-hep/pyhf
| 1,436 |
scikit-hep__pyhf-1436
|
[
"1389"
] |
47d53ee077e32d39cc43d32e048cc74e6c3ffcfa
|
diff --git a/src/pyhf/readxml.py b/src/pyhf/readxml.py
--- a/src/pyhf/readxml.py
+++ b/src/pyhf/readxml.py
@@ -266,7 +266,7 @@ def process_measurements(toplvl, other_parameter_configs=None):
result = {
'name': x.attrib['Name'],
'config': {
- 'poi': x.findall('POI')[0].text,
+ 'poi': x.findall('POI')[0].text.strip(),
'parameters': [
{
'name': 'lumi',
@@ -289,7 +289,7 @@ def process_measurements(toplvl, other_parameter_configs=None):
# might be specifying multiple parameters in the same ParamSetting
if param.text:
- for param_name in param.text.split(' '):
+ for param_name in param.text.strip().split(' '):
param_name = utils.remove_prefix(param_name, 'alpha_')
if param_name.startswith('gamma_') and re.search(
r'^gamma_.+_\d+$', param_name
|
diff --git a/tests/test_import.py b/tests/test_import.py
--- a/tests/test_import.py
+++ b/tests/test_import.py
@@ -148,6 +148,31 @@ def test_import_measurements():
assert lumi_param_config['sigmas'] == [0.1]
[email protected]("const", ['False', 'True'])
+def test_spaces_in_measurement_config(const):
+ toplvl = ET.Element("Combination")
+ meas = ET.Element(
+ "Measurement",
+ Name='NormalMeasurement',
+ Lumi=str(1.0),
+ LumiRelErr=str(0.017),
+ ExportOnly=str(True),
+ )
+ poiel = ET.Element('POI')
+ poiel.text = 'mu_SIG ' # space
+ meas.append(poiel)
+
+ setting = ET.Element('ParamSetting', Const=const)
+ setting.text = ' '.join(['Lumi', 'alpha_mu_both']) + ' ' # spacces
+ meas.append(setting)
+
+ toplvl.append(meas)
+
+ meas_json = pyhf.readxml.process_measurements(toplvl)[0]
+ assert meas_json['config']['poi'] == 'mu_SIG'
+ assert [x['name'] for x in meas_json['config']['parameters']] == ['lumi', 'mu_both']
+
+
@pytest.mark.parametrize("const", ['False', 'True'])
def test_import_measurement_gamma_bins(const):
toplvl = ET.Element("Combination")
|
Config parsing trips on spaces?
# Description
@elskorda has a workspace where the POI name stored in the JSON ends up being `'SigXsecOverSM '` (notice the space). This seems to be a bug in our parsing (related to eventually supporting multi pos with space-separated names)
```
<!DOCTYPE Combination SYSTEM 'HistFactorySchema.dtd'>
<Combination OutputFilePrefix="output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/output">
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DSR_BMax200_BMin150_incFat1_Y2015_T2_J2_L0_incJet1_Fat0.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DSR_BMax350_BMin200_incFat1_Y2015_T2_J2_L0_incJet1_Fat0.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DSR_BMax500_BMin350_incFat1_Y2015_T2_J2_L0_incJet1_Fat0.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DSR_BMax750_BMin500_incFat1_Y2015_T20_J0_L0_incJet1_Fat1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DSR_BMin750_incFat1_Y2015_T20_J0_L0_incJet1_Fat1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DSR_BMax200_BMin150_incFat1_Fat0_T3_Y2015_incTag1_J2_L0_incJet1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DSR_BMax350_BMin200_incFat1_Fat0_T3_Y2015_incTag1_J2_L0_incJet1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DSR_BMax500_BMin350_incFat1_Fat0_T3_Y2015_incTag1_J2_L0_incJet1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DSR_BMin500_incFat1_Fat1_T21_Y2015_incTag1_J0_L0_incJet1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distCharge_DCR1_BMax200_BMin150_incFat1_Y2015_T2_J2_L1_incJet1_Fat0.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distCharge_DCR1_BMax350_BMin200_incFat1_Y2015_T2_J2_L1_incJet1_Fat0.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distCharge_DCR1_BMax500_BMin350_incFat1_Y2015_T2_J2_L1_incJet1_Fat0.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distCharge_DCR1_BMin500_incFat1_Y2015_T20_J0_L1_incJet1_Fat1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distCharge_DCR1_BMax200_BMin150_incFat1_Fat0_T3_Y2015_incTag1_J2_L1_incJet1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distCharge_DCR1_BMax350_BMin200_incFat1_Fat0_T3_Y2015_incTag1_J2_L1_incJet1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distCharge_DCR1_BMax500_BMin350_incFat1_Fat0_T3_Y2015_incTag1_J2_L1_incJet1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distCharge_DCR1_BMin500_incFat1_Fat1_T21_Y2015_incTag1_J0_L1_incJet1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DCR2_BMax200_BMin150_incFat1_Y2015_T2_J2_L2_incJet1_Fat0.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DCR2_BMax350_BMin200_incFat1_Y2015_T2_J2_L2_incJet1_Fat0.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DCR2_BMax500_BMin350_incFat1_Y2015_T2_J2_L2_incJet1_Fat0.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DCR2_BMin500_incFat1_Y2015_T20_J0_L2_incJet1_Fat1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DCR2_BMax200_BMin150_incFat1_Fat0_T3_Y2015_incTag1_J2_L2_incJet1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DCR2_BMax350_BMin200_incFat1_Fat0_T3_Y2015_incTag1_J2_L2_incJet1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DCR2_BMax500_BMin350_incFat1_Fat0_T3_Y2015_incTag1_J2_L2_incJet1.xml</Input>
<Input>output/MonoHbb-00-13-00-Paper-ExtendedGrid.monoH_1300_unblinded/xml/1000/Region_distmBB_DCR2_BMin500_incFat1_Fat1_T21_Y2015_incTag1_J0_L2_incJet1.xml</Input>
<Measurement Name="VH" Lumi="1" LumiRelErr="0.0001" ExportOnly="True">
<POI>SigXsecOverSM </POI>
<ParamSetting Const="True">Lumi </ParamSetting>
</Measurement>
</Combination>
```
|
> This seems to be a bug in our parsing (related to eventually supporting multi pos with space-separated names)
What's the actual error? Does it just fail or does it do just create nonsense?
NB: the same is true for parsing parameter configs
| 2021-05-07T16:07:08 |
scikit-hep/pyhf
| 1,460 |
scikit-hep__pyhf-1460
|
[
"1455",
"865"
] |
03c814f4d4ff25924ecbf59acd2a5066fde369f3
|
diff --git a/src/pyhf/contrib/utils.py b/src/pyhf/contrib/utils.py
--- a/src/pyhf/contrib/utils.py
+++ b/src/pyhf/contrib/utils.py
@@ -6,7 +6,6 @@
import logging
from .. import exceptions
-logging.basicConfig()
log = logging.getLogger(__name__)
__all__ = ["download"]
|
Logging configuration in contrib/utils
# Question
`pyhf.contrib.utils` sets up logging:
https://github.com/scikit-hep/pyhf/blob/6b769fd6f5e1473deba2b4c55d49ebdb3db5b447/src/pyhf/contrib/utils.py#L9
This interferes with custom logging users may want to set up. To achieve this now, they would have to do so before `from pyhf.contrib.utils import download`. To avoid this issue, the logging should not be configured in this part of the code (and only for the CLI).
# Relevant Issues and Pull Requests
#865
User-defined log formatting
# Description
`pyhf` uses `logging` for outputs, and calls `logging.basicConfig()` in a few places.
This has the effect of preventing the user to set their desired logging behavior after `pyhf` import.
While calling this a bug might be a bit of a stretch, I think it might be unintentional since `pyhf` does not apply any logging formatting as far as I can tell.
# Expected Behavior
I expect no calls to `logging.basicConfig()` within `pyhf` to leave the formatting fully up to the user, no matter whether they want to set it before or after importing `pyhf`.
# Actual Behavior
User-defined `logging` formatting only works before importing `pyhf`.
# Steps to Reproduce
importing `pyhf` before formatting:
```
import logging
import pyhf
print(pyhf.__version__)
logging.basicConfig(level=logging.INFO)
log = logging.getLogger(__name__)
log.info("message")
```
output:
```
0.4.1
```
and when applying formatting before input, the expected behavior:
```
import logging
logging.basicConfig(level=logging.INFO)
import pyhf
print(pyhf.__version__)
log = logging.getLogger(__name__)
log.info("message")
```
output:
```
0.4.1
INFO:__main__:message
```
# Checklist
- [ ] Run `git fetch` to get the most up to date version of `master`
- no, but checked code on master to confirm that the relevant part is unchanged
- [X] Searched through existing Issues to confirm this is not a duplicate issue
- [X] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
I would consider this a bug.. logging shoulld only ever be setup in the "CLI" modules that serce as non-library entryopints. Thanks!
Thanks for reporting this @alexander-held. I think this is something that would be reasonable for us to look into, maybe for a quick `v0.5.1` patch release once we finish shepherding `v0.5.0` out.
`logging.basicConfig` should only be called in `commandline.py`
@alexander-held as @lukasheinrich took at look at this and was super speedy about this it will go into the next patch release `v0.4.2` which should be out soon (O(<1 week)). You and I have talked about how to install dev versions of `pyhf` though so as soon as PR #866 is in you can start using it in the interim.
Thanks a lot for taking care of this!
| 2021-05-17T10:05:19 |
|
scikit-hep/pyhf
| 1,524 |
scikit-hep__pyhf-1524
|
[
"1501"
] |
51a4a7f87585f53e19e32da1a68258cb67d2a28c
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -7,7 +7,7 @@
'tensorflow-probability~=0.10.1',
],
'torch': ['torch~=1.8'],
- 'jax': ['jax~=0.2.8', 'jaxlib~=0.1.58,<0.1.68'],
+ 'jax': ['jax~=0.2.8', 'jaxlib~=0.1.58,!=0.1.68'], # c.f. Issue 1501
'xmlio': [
'uproot3>=3.14.1',
'uproot~=4.0',
|
jaxlib v0.1.68 breaks CI with segfault on macOS
# Description
On 2021-06-22 the scheduled nightly CI for `v0.6.2` [was passing](https://github.com/scikit-hep/pyhf/actions/runs/962645978) and had installed libraries [pass-pip-list.txt](https://github.com/scikit-hep/pyhf/files/6713928/pass-pip-list.txt). Then on 2021-06-23 the CI [fails](https://github.com/scikit-hep/pyhf/actions/runs/966295835) with a segfault and had and had installed libraries [fail-pip-list.txt](https://github.com/scikit-hep/pyhf/files/6713929/fail-pip-list.txt), where the difference between them is the versions of `jax` and `jaxlib`.
```
$ diff pass-pip-list.txt fail-pip-list.txt
5a6
> appnope 0.1.2
41,42c42,43
< jax 0.2.14
< jaxlib 0.1.67
---
> jax 0.2.16
> jaxlib 0.1.68
97c98
< pyhf 0.6.2 /home/runner/work/pyhf/pyhf/src
---
> pyhf 0.6.2 /Users/runner/work/pyhf/pyhf/src
```
The relevant section of the logs for the failure is the following:
```pytb
src/pyhf/infer/utils.py .. [ 3%]
Fatal Python error: Segmentation fault
Thread 0x000070000dda9000 (most recent call first):
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/threading.py", line 306 in wait
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/threading.py", line 558 in wait
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/tqdm/_monitor.py", line 60 in run
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/threading.py", line 932 in _bootstrap_inner
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/threading.py", line 890 in _bootstrap
Current thread 0x00000001050cfdc0 (most recent call first):
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/jaxlib/xla_client.py", line 67 in make_cpu_client
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/jax/lib/xla_bridge.py", line 206 in backends
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/jax/lib/xla_bridge.py", line 242 in get_backend
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/jax/lib/xla_bridge.py", line 263 in get_device_backend
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/jax/interpreters/xla.py", line 138 in _device_put_array
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/jax/interpreters/xla.py", line 133 in device_put
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/jax/_src/lax/lax.py", line 1596 in _device_put_raw
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/jax/_src/numpy/lax_numpy.py", line 3025 in array
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/jax/_src/numpy/lax_numpy.py", line 3064 in asarray
File "/Users/runner/work/pyhf/pyhf/src/pyhf/tensor/jax_backend.py", line 230 in astensor
File "/Users/runner/work/pyhf/pyhf/src/pyhf/tensor/common.py", line 30 in _precompute
File "/Users/runner/work/pyhf/pyhf/src/pyhf/events.py", line 36 in __call__
File "/Users/runner/work/pyhf/pyhf/src/pyhf/__init__.py", line 147 in set_backend
File "/Users/runner/work/pyhf/pyhf/src/pyhf/events.py", line 93 in register_wrapper
File "<doctest pyhf.tensor.jax_backend.jax_backend.astensor[1]>", line 1 in <module>
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/doctest.py", line 1336 in __run
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/doctest.py", line 1483 in run
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/doctest.py", line 1844 in run
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/doctest.py", line 287 in runtest
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/runner.py", line 162 in pytest_runtest_call
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/callers.py", line 187 in _multicall
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/manager.py", line 84 in <lambda>
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/manager.py", line 93 in _hookexec
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/hooks.py", line 286 in __call__
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/runner.py", line 255 in <lambda>
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/runner.py", line 311 in from_call
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/runner.py", line 254 in call_runtest_hook
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/runner.py", line 215 in call_and_report
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/runner.py", line 126 in runtestprotocol
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/runner.py", line 109 in pytest_runtest_protocol
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/callers.py", line 187 in _multicall
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/manager.py", line 84 in <lambda>
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/manager.py", line 93 in _hookexec
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/hooks.py", line 286 in __call__
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/main.py", line 348 in pytest_runtestloop
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/callers.py", line 187 in _multicall
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/manager.py", line 84 in <lambda>
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/manager.py", line 93 in _hookexec
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/hooks.py", line 286 in __call__
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/main.py", line 323 in _main
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/main.py", line 269 in wrap_session
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/main.py", line 316 in pytest_cmdline_main
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/callers.py", line 187 in _multicall
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/manager.py", line 84 in <lambda>
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/manager.py", line 93 in _hookexec
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pluggy/hooks.py", line 286 in __call__
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/config/__init__.py", line 162 in main
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/_pytest/config/__init__.py", line 185 in console_main
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/site-packages/pytest/__main__.py", line 5 in <module>
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/runpy.py", line 87 in _run_code
File "/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/runpy.py", line 194 in _run_module_as_main
/Users/runner/work/_temp/b65896af-bc5b-4842-94da-e0fd5882e8d5.sh: line 1: 1785 Segmentation fault: 11 python -m pytest -r sx --ignore tests/benchmarks/ --ignore tests/contrib --ignore tests/test_notebooks.py
/Users/runner/hostedtoolcache/Python/3.8.10/x64/lib/python3.8/multiprocessing/resource_tracker.py:216: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown
warnings.warn('resource_tracker: There appear to be %d '
src/pyhf/tensor/jax_backend.py
Error: Process completed with exit code 139.
```
Both `jax` and `jaxlib` had releases on 2021-06-23:
- [`jax` `v0.2.16`](https://pypi.org/project/jax/0.2.16/#history)
- [`jaxlib` `v0.1.68`](https://pypi.org/project/jaxlib/0.1.68/#history)
@lukasheinrich @kratsg we'll need to follow up with the JAX team.
|
Yeah, I've confirmed that the CI passes with
```diff
diff --git a/setup.py b/setup.py
index 55008de9..55a4de07 100644
--- a/setup.py
+++ b/setup.py
@@ -7,7 +7,7 @@
'tensorflow-probability~=0.10.1',
],
'torch': ['torch~=1.8'],
- 'jax': ['jax~=0.2.8', 'jaxlib~=0.1.58'],
+ 'jax': ['jax~=0.2.8', 'jaxlib~=0.1.58,<0.1.68'],
'xmlio': [
'uproot3>=3.14.1',
'uproot~=4.0',
```
such that you get
```console
$ pip list | grep jax
jax 0.2.16
jaxlib 0.1.67
```
so it is `jaxlib` `v0.1.68` that is causing this.
**Edit:** What is weird though is that `doctest` is what is failing. :?
I've now been able to show that it is only on MacOS that `doctest` is failing and causing this error. @lukasheinrich and @kratsg can one of you verify locally?
```
python -m pip install --upgrade jax jaxlib
python -m pytest -r sx --ignore tests/benchmarks/ --ignore tests/contrib --ignore tests/test_notebooks.py # This should fail on macOS
```
This has been happening in Awkward Array's tests, too: the MacOS tests started getting intermittent segfaults a few days ago (same log output as yours). We've been re-running the failed tests because we don't have fail-fast turned on and the probability is low enough that restarting just the failures converges to success. What we didn't know is that it's JAX that's responsible for it, but it's the same symptom on the same timescale, so I'd be surprised if it's anything else.
Should we pin to a slightly old version of JAX until they get this figured out? The following are good ones?
```
jax 0.2.16
jaxlib 0.1.67
```
> This has been happening in Awkward Array's tests, too: the MacOS tests started getting intermittent segfaults a few days ago (same log output as yours). We've been re-running the failed tests because we don't have fail-fast turned on and the probability is low enough that restarting just the failures converges to success. What we didn't know is that it's JAX that's responsible for it, but it's the same symptom on the same timescale, so I'd be surprised if it's anything else.
Ah that's super interesting! @jpivarski Can you tell me what tests of yours are failing? That would be helpful information for opening up an Issue with JAX.
> Should we pin to a slightly old version of JAX until they get this figured out? The following are good ones?
>
> ```
> jax 0.2.16
> jaxlib 0.1.67
> ```
Yes, all you should need to require is
```
jaxlib<0.1.68
```
as the last relase of `jax` itself should be fine. I was able to get the macOS CI passing with this. The Ubuntu CI passes on the latest `jaxlib` release which is strange.
We've only been seeing it in MacOS (not Linux/Ubuntu and not Windows), but it's not too surprising that a segfault is limited to only one platform. It's intermittent, too, so it probably has something to do with how uninitialized data happens to be filled from the previous step, which is very unpredictable but can be strongly correlated with platform. (I.e. the Ubuntu builds could be failing with a much smaller probability, or maybe some totally unrelated thing in the OS prevents it with certainty.)
I'll try pinning `jaxlib<0.1.68` to see what happens in Awkward Array's tests. The probability of segfaulting is such that 2 or 3 of the 6 MacOS builds typically fail, so if it makes it through a round with 0 segfaults, that's good evidence that it's totally related to the new jaxlib. I'll post results in about 20 minutes.
A lot of tests are still running (Windows takes a long time to compile), but _all_ of the MacOS ones passed on the first try, which by Poisson statistics or whatever means jaxlib is almost certainly to blame:

Okay, I went and tried computing it; I think the average number of MacOS failures over the last few days has been 2.5 per run of 6, which has 92% of the distribution above 0 in a run of 6. Like, two sigma.
```python
>>> scipy.stats.poisson.pmf(0, 2.5)
0.0820849986238988
```
Has anything about this been reported in the JAX project?
> Okay, I went and tried computing it; I think the average number of MacOS failures over the last few days has been 2.5 per run of 6, which has 92% of the distribution above 0 in a run of 6. Like, two sigma.
>
> ```python
> >>> scipy.stats.poisson.pmf(0, 2.5)
> 0.0820849986238988
> ```
Love it. :)
> Has anything about this been reported in the JAX project?
No, I discovered this late last night and I wanted to try to have a runnable code example of things failing with `jaxlib` `v0.1.68` before opening up an Issue. @jpivarski can you try to run the Awkard test suite locally on your Mac and get an example?
Same request goes to @lukasheinrich and @kratsg for `pyhf`.
My impression that this has been going on "for days" is not right: looking back in the build logs, the first instance that seems to be this error (only MacOS failing, and then a random subset, not Python 2.7 again) is [this one from yesterday morning](https://dev.azure.com/jpivarski/Scikit-HEP/_build/results?buildId=6934&view=results).
> @jpivarski can you try to run the Awkard test suite locally on your Mac and get an example?
I don't have a Mac. I'm on a Linux box, so MacOS and Windows usually have to be debugged through CI. I've been doing a lot of local testing recently, and this error has never occurred. My local jaxlib is 0.1.67. I just tried `conda update --all` and jax wants to update from 0.2.14 to 0.2.16, but under the circumstances, I don't think I'll do this until after our next release is out.
> My impression that this has been going on "for days" is not right:
Yeah for us we saw it first on 2021-06-23.
> I'm on a Linux box, so MacOS and Windows usually have to be debugged through CI.
Ah okay so we're the same. :) I think I might have known that(?) in the past but thanks for the reminder.
> I've been doing a lot of local testing recently, and this error has never occurred. My local jaxlib is 0.1.67. I just tried `conda update --all` and jax wants to update from 0.2.14 to 0.2.16, but under the circumstances, I don't think I'll do this until after our next release is out.
Sounds good.
Interesting news: I was able to borrow a MacBook Air (thanks @lehostert) and after much fighting with Homebrew to get `sqlite` libraries available for `pyenv` to use, I was able to install CPython `v3.8.10` with `pyenv` and install the full development environment in a virtual environment. Using that environment with `jaxlib` `v0.1.68` I am _not_ able to reproduce the issue seen in CI when I run
https://github.com/scikit-hep/pyhf/blob/03b914b1aa9006d8aa8ca5ecbbd2e6b6e6bdd1ce/.github/workflows/ci.yml#L40
@lukasheinrich can you confirm on a more modern macOS version?
Okay. Taking @alexander-held's very good advice, I connected to a [`tmate`](https://tmate.io/) session on the GHA servers using the [`mxschmitt/action-tmate@v3` GHA](https://github.com/marketplace/actions/debugging-with-tmate) and I was able to replicate the segfault behavior on GHA with the following examples
```python
# debug_32b.py
import jax # noqa: F401
import jax.numpy as jnp
print(jnp.asarray([-2, -1], dtype=jnp.float32))
print(jnp.asarray([-2, -1], dtype=jnp.float64))
```
```python
# debug_64.py
import jax # noqa: F401
from jax.config import config
config.update('jax_enable_x64', True)
import jax.numpy as jnp
# 32b first
jnp.asarray([-2, -1])
# then switch to 64b
jnp.asarray([-2, -1], dtype=jnp.float64)
```
and the following commands (with the `bash-3.2` removed from before the `$` for formatting) using both the `deubg_32b.py`
```console
$ python debug_32b.py
Segmentation fault: 11
$ python debug_32b.py
WARNING:absl:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
[-2. -1.]
/Users/runner/hostedtoolcache/Python/3.7.10/x64/lib/python3.7/site-packages/jax/_src/numpy/lax_numpy.py:3062: UserWarning: Explicitly requested dtype <class 'jax._src.numpy.lax_numpy.float64'> requested in asarray is not available, and will be truncated to dtype float32. To enable more dtypes, set the jax_enable_x64 configuration option or the JAX_ENABLE_X64 shell environment variable. See https://github.com/google/jax#current-gotchas for more.
lax._check_user_dtype_supported(dtype, "asarray")
[-2. -1.]
$ python debug_32b.py
WARNING:absl:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
[-2. -1.]
/Users/runner/hostedtoolcache/Python/3.7.10/x64/lib/python3.7/site-packages/jax/_src/numpy/lax_numpy.py:3062: UserWarning: Explicitly requested dtype <class 'jax._src.numpy.lax_numpy.float64'> requested in asarray is not available, and will be truncated to dtype float32. To enable more dtypes, set the jax_enable_x64 configuration option or the JAX_ENABLE_X64 shell environment variable. See https://github.com/google/jax#current-gotchas for more.
lax._check_user_dtype_supported(dtype, "asarray")
[-2. -1.]
$ python debug_32b.py
WARNING:absl:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
[-2. -1.]
/Users/runner/hostedtoolcache/Python/3.7.10/x64/lib/python3.7/site-packages/jax/_src/numpy/lax_numpy.py:3062: UserWarning: Explicitly requested dtype <class 'jax._src.numpy.lax_numpy.float64'> requested in asarray is not available, and will be truncated to dtype float32. To enable more dtypes, set the jax_enable_x64 configuration option or the JAX_ENABLE_X64 shell environment variable. See https://github.com/google/jax#current-gotchas for more.
lax._check_user_dtype_supported(dtype, "asarray")
[-2. -1.]
$ python debug_32b.py
Segmentation fault: 11
```
and the `debug_64b.py`
```console
$ python debug_64b.py
WARNING:absl:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
$ python debug_64b.py
WARNING:absl:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
$ python debug_64b.py
Segmentation fault: 11
```
For the GHA sever the env is
```console
$ python --version --version
Python 3.7.10 (default, Feb 16 2021, 11:44:40)
[Clang 11.0.0 (clang-1100.0.33.17)]
$ printenv
GITHUB_JOB=test
GITHUB_EVENT_PATH=/Users/runner/work/_temp/_github_workflow/event.json
RUNNER_OS=macOS
XCODE_12_DEVELOPER_DIR=/Applications/Xcode_12.4.app/Contents/Developer
ANDROID_HOME=/Users/runner/Library/Android/sdk
GITHUB_BASE_REF=
NVM_CD_FLAGS=
CHROMEWEBDRIVER=/usr/local/Caskroom/chromedriver/91.0.4472.101
SHELL=/bin/bash
TERM=screen-256color
PIPX_BIN_DIR=/usr/local/opt/pipx_bin
GITHUB_REPOSITORY_OWNER=scikit-hep
INPUT_SUDO=true
TMPDIR=/var/folders/24/8k48jl6d249_n_qfxwsl6xvm0000gn/T/
GITHUB_ACTIONS=true
GITHUB_RUN_NUMBER=7368
ANDROID_SDK_ROOT=/Users/runner/Library/Android/sdk
JAVA_HOME_8_X64=/Users/runner/hostedtoolcache/Java_Adopt_jdk/8.0.292-10/x64/Contents/Home
RCT_NO_LAUNCH_PACKAGER=1
RUNNER_WORKSPACE=/Users/runner/work/pyhf
NUNIT_BASE_PATH=/Library/Developer/nunit
RUNNER_PERFLOG=/usr/local/opt/runner/perflog
GITHUB_REF=refs/heads/fix/test-jax-version-that-breaks-ci
GITHUB_WORKFLOW=CI/CD
LC_ALL=en_US.UTF-8
NUNIT3_PATH=/Library/Developer/nunit/3.6.0
JAVA_HOME_11_X64=/Users/runner/hostedtoolcache/Java_Adopt_jdk/11.0.11-9/x64/Contents/Home
RUNNER_TOOL_CACHE=/Users/runner/hostedtoolcache
GITHUB_ACTION_REPOSITORY=mxschmitt/action-tmate
JAVA_HOME_14_X64=/Users/runner/hostedtoolcache/Java_Adopt_jdk/14.0.2-12/x64/Contents/Home
NVM_DIR=/Users/runner/.nvm
USER=runner
GITHUB_API_URL=https://api.github.com
GITHUB_EVENT_NAME=push
GITHUB_SHA=2e371805064fc961c95106c4098702b3696827c3
XCODE_10_DEVELOPER_DIR=/Applications/Xcode_10.3.app/Contents/Developer
RUNNER_TEMP=/Users/runner/work/_temp
pythonLocation=/Users/runner/hostedtoolcache/Python/3.7.10/x64
ANDROID_NDK_ROOT=/Users/runner/Library/Android/sdk/ndk-bundle
ANDROID_NDK_LATEST_HOME=/Users/runner/Library/Android/sdk/ndk/22.1.7171670
ImageVersion=20210620.1
SSH_AUTH_SOCK=/private/tmp/com.apple.launchd.I24a5PqIL3/Listeners
GITHUB_SERVER_URL=https://github.com
HOMEBREW_NO_AUTO_UPDATE=1
__CF_USER_TEXT_ENCODING=0x1F5:0:0
AGENT_TOOLSDIRECTORY=/Users/runner/hostedtoolcache
GITHUB_HEAD_REF=
GITHUB_GRAPHQL_URL=https://api.github.com/graphql
TMUX=/tmp/tmate.sock,1968,0
PATH=/Users/runner/hostedtoolcache/Python/3.7.10/x64/bin:/Users/runner/hostedtoolcache/Python/3.7.10/x64:/usr/local/opt/pipx_bin:/Users/runner/.cargo/bin:/usr/local/lib/ruby/gems/2.7.0/bin:/usr/local/opt/[email protected]/bin:/usr/local/opt/curl/bin:/usr/local/bin:/usr/local/sbin:/Users/runner/bin:/Users/runner/.yarn/bin:/Users/runner/Library/Android/sdk/tools:/Users/runner/Library/Android/sdk/platform-tools:/Users/runner/Library/Android/sdk/ndk-bundle:/Library/Frameworks/Mono.framework/Versions/Current/Commands:/usr/bin:/bin:/usr/sbin:/sbin:/Users/runner/.dotnet/tools:/Users/runner/.ghcup/bin:/Users/runner/hostedtoolcache/stack/2.7.1/x64
INPUT_LIMIT-ACCESS-TO-ACTOR=false
GITHUB_RETENTION_DAYS=90
PERFLOG_LOCATION_SETTING=RUNNER_PERFLOG
CONDA=/usr/local/miniconda
DOTNET_ROOT=/Users/runner/.dotnet
EDGEWEBDRIVER=/usr/local/share/edge_driver
PWD=/Users/runner/work/pyhf/pyhf
VM_ASSETS=/usr/local/opt/runner/scripts
JAVA_HOME=/Users/runner/hostedtoolcache/Java_Adopt_jdk/8.0.292-10/x64/Contents/Home
JAVA_HOME_12_X64=/Users/runner/hostedtoolcache/Java_Adopt_jdk/12.0.2-10.3/x64/Contents/Home
VCPKG_INSTALLATION_ROOT=/usr/local/share/vcpkg
LANG=en_US.UTF-8
ImageOS=macos1015
TMUX_PANE=%0
XPC_FLAGS=0x0
PIPX_HOME=/usr/local/opt/pipx
GECKOWEBDRIVER=/usr/local/opt/geckodriver/bin
GITHUB_ACTOR=matthewfeickert
XPC_SERVICE_NAME=0
HOME=/Users/runner
SHLVL=4
ACTIONS_RUNTIME_TOKEN=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiIsIng1dCI6Ik9ta3lYbmJnM05RTE1nMGZMaTBSNnJxdzlxdyJ9.eyJuYW1laWQiOiJkZGRkZGRkZC1kZGRkLWRkZGQtZGRkZC1kZGRkZGRkZGRkZGQiLCJzY3AiOiJBY3Rpb25zLkdlbmVyaWNS
ZWFkOjAwMDAwMDAwLTAwMDAtMDAwMC0wMDAwLTAwMDAwMDAwMDAwMCBBY3Rpb25zLlVwbG9hZEFydGlmYWN0czowMDAwMDAwMC0wMDAwLTAwMDAtMDAwMC0wMDAwMDAwMDAwMDAvMTpCdWlsZC9CdWlsZC8yMzU5MSBMb2NhdGlvblNlcnZpY2UuQ29ubmVjdCBSZWFkQW5
kVXBkYXRlQnVpbGRCeVVyaTowMDAwMDAwMC0wMDAwLTAwMDAtMDAwMC0wMDAwMDAwMDAwMDAvMTpCdWlsZC9CdWlsZC8yMzU5MSIsIklkZW50aXR5VHlwZUNsYWltIjoiU3lzdGVtOlNlcnZpY2VJZGVudGl0eSIsImh0dHA6Ly9zY2hlbWFzLnhtbHNvYXAub3JnL3dzLz
IwMDUvMDUvaWRlbnRpdHkvY2xhaW1zL3NpZCI6IkRERERERERELUREREQtRERERC1ERERELURERERERERERERERCIsImh0dHA6Ly9zY2hlbWFzLm1pY3Jvc29mdC5jb20vd3MvMjAwOC8wNi9pZGVudGl0eS9jbGFpbXMvcHJpbWFyeXNpZCI6ImRkZGRkZGRkLWRkZGQtZ
GRkZC1kZGRkLWRkZGRkZGRkZGRkZCIsImF1aSI6ImE1YTFiNzdhLWFhYTktNDFiNi05ZTRjLWQ2OWI4NzRiMmRkNCIsInNpZCI6IjU0OGJjZjNlLWU3MWYtNDI2YS1iYTY0LTNkNmZjNjVhM2JkYSIsImFjIjoiW3tcIlNjb3BlXCI6XCJyZWZzL2hlYWRzL2ZpeC90ZXN0
LWpheC12ZXJzaW9uLXRoYXQtYnJlYWtzLWNpXCIsXCJQZXJtaXNzaW9uXCI6M30se1wiU2NvcGVcIjpcInJlZnMvaGVhZHMvbWFzdGVyXCIsXCJQZXJtaXNzaW9uXCI6MX1dIiwib3JjaGlkIjoiMDhhMmQ1NDEtNTU5NC00NjBlLWFlOGQtMjM3YjUyZTYyYjY1LnRlc3Q
ubWFjb3MtbGF0ZXN0XzNfNyIsImlzcyI6InZzdG9rZW4uYWN0aW9ucy5naXRodWJ1c2VyY29udGVudC5jb20iLCJhdWQiOiJ2c3Rva2VuLmFjdGlvbnMuZ2l0aHVidXNlcmNvbnRlbnQuY29tfHZzbzo1YmY5NjQ5Zi01MjlhLTRhYmMtODAwYS1iNThhMDNjZDNlM2IiLC
JuYmYiOjE2MjQ5MTIzOTEsImV4cCI6MTYyNDkzNTE5MX0.o0oeOn2M2Dbx8-K3yhe4JGA7k9KmR9KBoVAujCk29uptx7HOPfB1kba1l4Ofylm1DeKuB0xfMF5Y8ttibvDTgH2HitCC3BMdL64LZ99IUNnjngkuUsGuQsFI3E3uwT3SF6OpQcaeLjtCV3Qx2iUGkPsWM8Tpt
XD0TH4IXw5NJsbx3rKHHC2aSM6384Im-Nu965w_7539XkaIyLkg8MFK9MTIBr0O0HfRxJqvvareP7ufdqDnvY9EVupoVCdSEs3Xe5fuYW_GJvsKHImbsGoRTOgTFgiwOFxYIiMvcjyU1PDjg3ttjBF0JiMmReypLgSsQqUD-BrPIvjKuHYuzQplTg
RUNNER_TRACKING_ID=github_f9075cf8-002b-4c98-a7e2-61bcc0d94891
ANDROID_NDK_18R_PATH=/Users/runner/Library/Android/sdk/ndk/18.1.5063045
GITHUB_WORKSPACE=/Users/runner/work/pyhf/pyhf
CI=true
GITHUB_ACTION_REF=v3
GITHUB_RUN_ID=980389940
ACTIONS_RUNTIME_URL=https://pipelines.actions.githubusercontent.com/7egiF0eguRHanWqGVl5G5J1mX1k4YmsTgFLGKvP1guMOJIVNqS/
LOGNAME=runner
ACTIONS_CACHE_URL=https://artifactcache.actions.githubusercontent.com/7egiF0eguRHanWqGVl5G5J1mX1k4YmsTgFLGKvP1guMOJIVNqS/
GITHUB_ENV=/Users/runner/work/_temp/_runner_file_commands/set_env_af7b2b08-a369-43cf-87cc-23e9c7f65cbc
LC_CTYPE=en_US.UTF-8
HOMEBREW_CLEANUP_PERIODIC_FULL_DAYS=3650
JAVA_HOME_13_X64=/Users/runner/hostedtoolcache/Java_Adopt_jdk/13.0.2-8.1/x64/Contents/Home
HOMEBREW_CASK_OPTS=--no-quarantine
POWERSHELL_DISTRIBUTION_CHANNEL=GitHub-Actions-macos1015
ANDROID_NDK_HOME=/Users/runner/Library/Android/sdk/ndk-bundle
BOOTSTRAP_HASKELL_NONINTERACTIVE=1
XCODE_11_DEVELOPER_DIR=/Applications/Xcode_11.7.app/Contents/Developer
GITHUB_REPOSITORY=scikit-hep/pyhf
GITHUB_PATH=/Users/runner/work/_temp/_runner_file_commands/add_path_af7b2b08-a369-43cf-87cc-23e9c7f65cbc
GITHUB_ACTION=mxschmittaction-tmate
DOTNET_MULTILEVEL_LOOKUP=0
_=/usr/bin/printenv
```
However, I am _unable_ to replicate this at all on the Macbook Air
```console
$ sw_vers
ProductName: Mac OS X
ProductVersion: 10.13.6
BuildVersion: 17G14042
$ python --version --version
Python 3.8.10 (default, Jun 27 2021, 18:38:01)
[Clang 10.0.0 (clang-1000.10.44.4)]
$ printenv
SSH_AGENT_PID=533
TERM_PROGRAM=iTerm.app
PYENV_ROOT=/Users/cerylinae/.pyenv
TERM=xterm-256color
SHELL=/bin/bash
TMPDIR=/var/folders/rx/t5jm47z56bxfxmbp2qs6fsj80000gn/T/
Apple_PubSub_Socket_Render=/private/tmp/com.apple.launchd.dWj7SOkSaA/Render
TERM_PROGRAM_VERSION=3.3.12
OLDPWD=/Users/cerylinae/Code
TERM_SESSION_ID=w0t0p0:FEA1A898-9304-451B-9F5E-765940B67423
PYENV_VERSION=pyhf-debug
USER=cerylinae
SSH_AUTH_SOCK=/var/folders/rx/t5jm47z56bxfxmbp2qs6fsj80000gn/T//ssh-g3V3yN8vZC0o/agent.532
__CF_USER_TEXT_ENCODING=0x0:0:0
PYENV_VIRTUALENV_INIT=1
VIRTUAL_ENV=/Users/cerylinae/.pyenv/versions/3.8.10/envs/pyhf-debug
PYENV_VIRTUAL_ENV=/Users/cerylinae/.pyenv/versions/3.8.10/envs/pyhf-debug
PATH=/Users/cerylinae/.pyenv/plugins/pyenv-virtualenv/shims:/Users/cerylinae/.pyenv/shims:/Users/cerylinae/.pyenv/bin:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/opt/X11/bin
PWD=/Users/cerylinae/Code/pyhf
LANG=en_US.UTF-8
ITERM_PROFILE=Default
_OLD_VIRTUAL_PS1=\h:\W \u\$
XPC_FLAGS=0x0
PS1=(pyhf-debug) \h:\W \u\$
XPC_SERVICE_NAME=0
PYENV_SHELL=bash
SHLVL=1
HOME=/Users/cerylinae
COLORFGBG=7;0
LC_TERMINAL_VERSION=3.3.12
ITERM_SESSION_ID=w0t0p0:FEA1A898-9304-451B-9F5E-765940B67423
LOGNAME=cerylinae
LC_TERMINAL=iTerm2
DISPLAY=/private/tmp/com.apple.launchd.39ujEqef0g/org.macosforge.xquartz:0
PYENV_ACTIVATE_SHELL=1
COLORTERM=truecolor
_=/usr/bin/printenv
```
Reported this to JAX as https://github.com/google/jax/issues/7128
Even if [`jaxlib` is build from source on the GHA servers and then `jax` is installed from local source](https://jax.readthedocs.io/en/latest/developer.html), things still segfault.
https://github.com/scikit-hep/pyhf/runs/2948525543?check_suite_focus=true
```console
$ pip list | grep jax
jax 0.2.16 /Users/runner/work/pyhf/pyhf/_build_src/jax
jaxlib 0.1.69
$ python tests/debug_32b.py
/Users/runner/work/_temp/49d081f5-e4be-4f4d-a106-6ce34c5bc33a.sh: line 2: 25866 Segmentation fault: 11 python tests/debug_32b.py
Error: Process completed with exit code 139.
```
I've made a standalone minimal failing example at https://github.com/matthewfeickert/jaxlib-gha-minimal-failing-example
| 2021-07-10T04:39:32 |
|
scikit-hep/pyhf
| 1,530 |
scikit-hep__pyhf-1530
|
[
"1506"
] |
29c3df0e23a428004a065aed61cefb6a526a7332
|
diff --git a/src/pyhf/events.py b/src/pyhf/events.py
--- a/src/pyhf/events.py
+++ b/src/pyhf/events.py
@@ -6,7 +6,6 @@
__all__ = [
"Callables",
- "WeakList",
"disable",
"enable",
"noop",
@@ -24,24 +23,79 @@ def noop(*args, **kwargs):
pass
-class WeakList(list):
- def append(self, item):
- list.append(self, weakref.WeakMethod(item, self.remove))
+class Callables:
+ def __init__(self):
+ self._callbacks = []
+
+ @property
+ def callbacks(self):
+ """
+ Get the current list of living callbacks.
+ """
+ self._flush()
+ return self._callbacks
+
+ def append(self, callback):
+ """
+ Append a new bound method as a callback to the list of callables.
+ """
+ try:
+ # methods
+ callback_ref = weakref.ref(callback.__func__), weakref.ref(
+ callback.__self__
+ )
+ except AttributeError:
+ callback_ref = weakref.ref(callback), None
+ self._callbacks.append(callback_ref)
+
+ def _flush(self):
+ """
+ Flush the list of callbacks with those who are weakly-referencing deleted objects.
+
+ Note: must interact with the self._callbacks directly, and not
+ self.callbacks, to avoid infinite recursion.
+ """
+ _callbacks = []
+ for func, arg in self._callbacks:
+ if arg is not None:
+ arg_ref = arg()
+ if arg_ref is None:
+ continue
+ _callbacks.append((func, arg))
+ self._callbacks = _callbacks
-
-class Callables(WeakList):
def __call__(self, *args, **kwargs):
- for func in self:
+ for func, arg in self.callbacks:
# weakref: needs to be de-ref'd first before calling
- func()(*args, **kwargs)
+ if arg is not None:
+ func()(arg(), *args, **kwargs)
+ else:
+ func()(*args, **kwargs)
+
+ def __iter__(self):
+ return iter(self.callbacks)
+
+ def __getitem__(self, index):
+ return self.callbacks[index]
+
+ def __len__(self):
+ return len(self.callbacks)
def __repr__(self):
- return "Callables(%s)" % list.__repr__(self)
+ return f"Callables({self.callbacks})"
def subscribe(event):
"""
- This is meant to be used as a decorator.
+ Subscribe a function or object method as a callback to an event.
+
+ Note: this is meant to be used as a decorator.
+
+ Args:
+ event (:obj:`str`): The name of the event to subscribe to.
+
+ Returns:
+ :obj:`function`: Decorated function.
"""
# Example:
#
@@ -62,9 +116,17 @@ def __decorator(func):
def register(event):
"""
- This is meant to be used as a decorator to register a function for triggering events.
+ Register a function or object method to trigger an event. This creates two
+ events: ``{event_name}::before`` and ``{event_name}::after``.
+
+ Note: this is meant to be used as a decorator.
+
+ Args:
+ event (:obj:`str`): The name of the event to subscribe to.
+
+ Returns:
+ :obj:`function`: Decorated function.
- This creates two events: "<event_name>::before" and "<event_name>::after"
"""
# Examples:
#
|
diff --git a/tests/test_events.py b/tests/test_events.py
--- a/tests/test_events.py
+++ b/tests/test_events.py
@@ -7,9 +7,11 @@ def test_subscribe_event():
m = mock.Mock()
events.subscribe(ename)(m.__call__)
-
assert ename in events.__events
- assert m.__call__ == events.__events.get(ename)[0]()
+ assert m.__call__.__func__ == events.__events.get(ename)[0][0]()
+ assert "weakref" in repr(events.trigger(ename))
+ assert list(events.trigger(ename))
+ assert len(list(events.trigger(ename))) == 1
del events.__events[ename]
@@ -48,9 +50,9 @@ def test_disable_event():
assert m.called is False
assert ename in events.__disabled_events
assert events.trigger(ename) == events.noop
- assert events.trigger(ename)() == events.noop()
+ events.trigger(ename)()
assert m.called is False
- assert noop_m.is_called_once()
+ noop_m.assert_called_once()
events.enable(ename)
assert ename not in events.__disabled_events
del events.__events[ename]
@@ -59,10 +61,52 @@ def test_disable_event():
def test_trigger_noevent():
noop, noop_m = events.noop, mock.Mock()
+ events.noop = noop_m
assert 'fake' not in events.__events
assert events.trigger('fake') == events.noop
- assert events.trigger('fake')() == events.noop()
- assert noop_m.is_called_once()
+ events.trigger('fake')()
+ noop_m.assert_called_once()
events.noop = noop
+
+
+def test_subscribe_function(capsys):
+ ename = 'test'
+
+ def add(a, b):
+ print(a + b)
+
+ events.subscribe(ename)(add)
+ events.trigger(ename)(1, 2)
+
+ captured = capsys.readouterr()
+ assert captured.out == "3\n"
+
+ del events.__events[ename]
+
+
+def test_trigger_function(capsys):
+ ename = 'test'
+
+ def add(a, b):
+ print(a + b)
+
+ precall = mock.Mock()
+ postcall = mock.Mock()
+
+ wrapped_add = events.register(ename)(add)
+ events.subscribe(f'{ename}::before')(precall.__call__)
+ events.subscribe(f'{ename}::after')(postcall.__call__)
+
+ precall.assert_not_called()
+ postcall.assert_not_called()
+
+ wrapped_add(1, 2)
+ captured = capsys.readouterr()
+ assert captured.out == "3\n"
+ precall.assert_called_once()
+ postcall.assert_called_once()
+
+ del events.__events[f'{ename}::before']
+ del events.__events[f'{ename}::after']
diff --git a/tests/test_public_api_repr.py b/tests/test_public_api_repr.py
--- a/tests/test_public_api_repr.py
+++ b/tests/test_public_api_repr.py
@@ -67,7 +67,6 @@ def test_contrib_viz_public_api():
def test_contrib_events_public_api():
assert dir(pyhf.events) == [
"Callables",
- "WeakList",
"disable",
"enable",
"noop",
|
Exceptions related to weakref in pyhf 0.6.2
# Description
With `pyhf` 0.6.2 I see a long trace of `weakref`-related exceptions at the end of a program using certain parts of `pyhf`. I have not extensively tested which parts cause this behavior, but have so far observed it with `pyhf.simplemodels.correlated_background` / `pyhf.simplemodels.uncorrelated_background`. I can also confirm that other functionality like `pyhf.set_backend("numpy")` does not trigger it.
# Expected Behavior
No stack of `weakref` exceptions after code finishes running.
# Actual Behavior
Large stack of `weakref`-related exceptions.
# Steps to Reproduce
Run a simple file using `pyhf.simplemodels.uncorrelated_background`, the example runs in a `python:3.8-slim` container with Python 3.8.11. I see the same locally in a conda environment with Python 3.8.10 on Mac OS. With `pyhf` 0.6.2 the stack of exceptions appears. When installing `pyhf==0.6.1` and using `pyhf.simplemodels.hepdata_like`, I do not see any exceptions. When running via `python -m pdb test.py` locally to debug, I do no longer see the exception. The current `pyhf` master also shows the same issue.
```python
$ cat test.py
import pyhf
model = pyhf.simplemodels.uncorrelated_background(
signal=[5.0], bkg=[10.0], bkg_uncertainty=[2.0]
)
```
```console
$ docker run -it --rm -v$PWD:/test python:3.8-slim bash
root@8fd8a5f229c8:/# pip install pyhf
Collecting pyhf
Downloading pyhf-0.6.2-py3-none-any.whl (140 kB)
|████████████████████████████████| 140 kB 3.5 MB/s
Collecting pyyaml>=5.1
Downloading PyYAML-5.4.1-cp38-cp38-manylinux1_x86_64.whl (662 kB)
|████████████████████████████████| 662 kB 5.7 MB/s
Collecting scipy>=1.4.1
Downloading scipy-1.7.0-cp38-cp38-manylinux_2_5_x86_64.manylinux1_x86_64.whl (28.4 MB)
|████████████████████████████████| 28.4 MB 16.4 MB/s
Collecting jsonpatch>=1.15
Downloading jsonpatch-1.32-py2.py3-none-any.whl (12 kB)
Collecting tqdm>=4.56.0
Downloading tqdm-4.61.1-py2.py3-none-any.whl (75 kB)
|████████████████████████████████| 75 kB 2.9 MB/s
Collecting click>=7.0
Downloading click-8.0.1-py3-none-any.whl (97 kB)
|████████████████████████████████| 97 kB 6.2 MB/s
Collecting jsonschema>=3.0.0
Downloading jsonschema-3.2.0-py2.py3-none-any.whl (56 kB)
|████████████████████████████████| 56 kB 6.3 MB/s
Collecting jsonpointer>=1.9
Downloading jsonpointer-2.1-py2.py3-none-any.whl (7.4 kB)
Requirement already satisfied: setuptools in /usr/local/lib/python3.8/site-packages (from jsonschema>=3.0.0->pyhf) (57.0.0)
Collecting six>=1.11.0
Downloading six-1.16.0-py2.py3-none-any.whl (11 kB)
Collecting attrs>=17.4.0
Downloading attrs-21.2.0-py2.py3-none-any.whl (53 kB)
|████████████████████████████████| 53 kB 4.1 MB/s
Collecting pyrsistent>=0.14.0
Downloading pyrsistent-0.18.0-cp38-cp38-manylinux1_x86_64.whl (118 kB)
|████████████████████████████████| 118 kB 18.9 MB/s
Collecting numpy<1.23.0,>=1.16.5
Downloading numpy-1.21.0-cp38-cp38-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (15.7 MB)
|████████████████████████████████| 15.7 MB 18.2 MB/s
Installing collected packages: six, pyrsistent, numpy, jsonpointer, attrs, tqdm, scipy, pyyaml, jsonschema, jsonpatch, click, pyhf
Successfully installed attrs-21.2.0 click-8.0.1 jsonpatch-1.32 jsonpointer-2.1 jsonschema-3.2.0 numpy-1.21.0 pyhf-0.6.2 pyrsistent-0.18.0 pyyaml-5.4.1 scipy-1.7.0 six-1.16.0 tqdm-4.61.1
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
root@8fd8a5f229c8:/# python test/test.py
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf03a0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf01f0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0280>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0430>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf00d0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0160>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0670>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf05e0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf04c0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0550>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0820>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0790>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0700>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf09d0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0940>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf08b0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0c10>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0b80>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0a60>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0af0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0dc0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0d30>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0ca0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0f70>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0ee0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dcf0e50>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dc821f0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dc82160>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dc82040>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dc820d0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dc823a0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dc82280>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dc82310>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dc82430>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
Exception ignored in: <function WeakMethod.__new__.<locals>._cb at 0x7f7e8dc824c0>
Traceback (most recent call last):
File "/usr/local/lib/python3.8/weakref.py", line 58, in _cb
File "/usr/local/lib/python3.8/weakref.py", line 74, in __eq__
TypeError: isinstance() arg 2 must be a type or tuple of types
```
# Checklist
- [X] Run `git fetch` to get the most up to date version of `master`
- [X] Searched through existing Issues to confirm this is not a duplicate issue
- [X] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
|
@alexander-held what does `test/test.py` look like? The weakref error here famously occurs with matplotlib involved. The other one is actually a bug in python 3.7.
It's this one:
```python
import pyhf
model = pyhf.simplemodels.uncorrelated_background(
signal=[5.0], bkg=[10.0], bkg_uncertainty=[2.0]
)
```
The reason that it is `test/test.py` and not just `test.py` is that I mount it into `/test` in the container.
I am using Python 3.8 in these tests, and have not tried 3.7.
The issue seems to be related to `click`. When I add a `pip install click~=7.0` after `pip install pyhf`, it disappears.
Thanks for this report @alexander-held. Yeah, I'm not sure why we hadn't seen this in tests before but this is definitley related to the `click` `v8.X` release series, as even
```console
python -m pip install --upgrade "click<8.0.1"
```
giving `v8.0.0` doesn't help. :(
Copying discussion from Slack, @kratsg points out:
>I'll dump what I do know about `weakref` and why this comes up. The crash occurs on these lines (https://github.com/python/cpython/blob/ae5dcf588c39915b43e391c738cf99f56a1b7fe2/Lib/weakref.py#L73-L78). This is because the `WeakMethod` is `NoneType`'d (because it got deleted during garbage collect?). To test this, I added a nice print statement `print(other, WeakMethod, type(other), type(WeakMethod))`.
>
> When it doesn't crash, I see this
> ```python
> <weakref at 0x15ecf1200; dead> <class 'weakref.WeakMethod'> <class 'weakref.WeakMethod'> <class 'type'>
> ```
> When it **does** crash, I see this
> ```python
> <weakref at 0x15ecf19e0; dead> None <class 'weakref.WeakMethod'> <class 'NoneType'>
> ```
> So indeed, `weakref.WeakMethod` is `NoneType` too early.
> Why is it being deleted too early? Why is this combination of our `pyhf` and `click` version causing this issue?
| 2021-07-21T16:38:04 |
scikit-hep/pyhf
| 1,540 |
scikit-hep__pyhf-1540
|
[
"1538"
] |
8dd7088ecd99dfb7976f074eab386fc4344f527b
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -63,6 +63,7 @@ def setup(app):
"bib/talks.bib",
"bib/tutorials.bib",
"bib/use_citations.bib",
+ "bib/general_citations.bib",
]
# external links
|
Split "Use in Publications" into use cases and general citations
> Technically speaking we don't actually use `pyhf` to obtain the results of our paper,
Yeah, as you correctly point out we just have the "list of citations and use cases of `pyhf`" under "[Use in Publications](https://scikit-hep.org/pyhf/citations.html#use-in-publications)" and we should probably split that out into actual use cases vs. just citations like this one.
_Originally posted by @matthewfeickert in https://github.com/scikit-hep/pyhf/issues/1537#issuecomment-890282084_
| 2021-07-31T22:26:26 |
||
scikit-hep/pyhf
| 1,546 |
scikit-hep__pyhf-1546
|
[
"1545"
] |
5eab9eee762df45b4d53846a43a364cb086ea45f
|
diff --git a/src/pyhf/mixins.py b/src/pyhf/mixins.py
--- a/src/pyhf/mixins.py
+++ b/src/pyhf/mixins.py
@@ -42,6 +42,9 @@ def __init__(self, *args, **kwargs):
self.samples = sorted(list(set(self.samples)))
self.parameters = sorted(list(set(self.parameters)))
self.modifiers = sorted(list(set(self.modifiers)))
+ self.channel_nbins = {
+ channel: self.channel_nbins[channel] for channel in self.channels
+ }
self.channel_slices = {}
begin = 0
|
diff --git a/tests/test_mixins.py b/tests/test_mixins.py
--- a/tests/test_mixins.py
+++ b/tests/test_mixins.py
@@ -45,3 +45,12 @@ def test_channel_summary_mixin_empty():
assert mixin.modifiers == []
assert mixin.parameters == []
assert mixin.samples == []
+
+
+def test_channel_nbins_sorted_as_channels(spec):
+ assert "channels" in spec
+ spec["channels"].append(spec["channels"][0].copy())
+ spec["channels"][-1]["name"] = "a_make_first_in_sort_channel2"
+ mixin = pyhf.mixins._ChannelSummaryMixin(channels=spec["channels"])
+ assert mixin.channels == ["a_make_first_in_sort_channel2", "channel1"]
+ assert list(mixin.channel_nbins.keys()) == mixin.channels
|
Different ordering of channels between model.config.channels and mode.config.channel_nbins
# Description
We've recently observed that the ordering of channels outputted from `model.config.channels` differs from the order obtained with `model.config.channel_nbins`. This isn't really a bug, but more a quirk which we thought would be worth bringing to the attention of the developers. We ran into some issues when breaking up the `expected_data` list into individual channels by looping through the `model.config.channel_nbins` ordering, rather than the `model.config.channels` ordering (the `model.config.channels` order matches that of the model). Hopefully this issue helps save another user some time in the future, at very least.
# Expected Behavior
We expected that the order of the channels in the two dictionaries from `model.config.channels` and `model.config.channel_nbins` would be the same.
# Actual Behavior
The ordering of the channels is different. As an example, we are generating workspaces using two categories, and we're separating our data by year (2016, 2017, and 2018). This gives us six channels total. The outputs are:
```
(Pdb) model.config.channels
['vbf_channel_16_high_cat', 'vbf_channel_16_low_cat', 'vbf_channel_17_high_cat', 'vbf_channel_17_low_cat', 'vbf_channel_18_high_cat', 'vbf_channel_18_low_cat']
(Pdb) model.config.channel_nbins
{'vbf_channel_16_low_cat': 12, 'vbf_channel_16_high_cat': 18, 'vbf_channel_17_low_cat': 12, 'vbf_channel_17_high_cat': 18, 'vbf_channel_18_low_cat': 12, 'vbf_channel_18_high_cat': 18}
```
I believe that `model.config.channels` is possibly re-ordering the channels so that the names are in alphabetical order. I have not confirmed this, though. The workspace .json file is filled with the ordering produced by `model.config.channel_nbins`.
# Steps to Reproduce
I'm using pyhf version 0.6.2 along with python 3.8.8.
I can make a dummy workspace for this issue, but I thought that since this is a pretty small issue, it might be overkill. Please let me know if this would be helpful, though.
# Checklist
- [ ] Run `git fetch` to get the most up to date version of `master`
- [X] Searched through existing Issues to confirm this is not a duplicate issue
- [X] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
Thanks! -Rachel
| 2021-08-04T21:28:17 |
|
scikit-hep/pyhf
| 1,554 |
scikit-hep__pyhf-1554
|
[
"1550"
] |
9358f8591ce456ee1949bb867ea15f18231e8f26
|
diff --git a/src/pyhf/infer/__init__.py b/src/pyhf/infer/__init__.py
--- a/src/pyhf/infer/__init__.py
+++ b/src/pyhf/infer/__init__.py
@@ -28,6 +28,7 @@ def hypotest(
return_tail_probs=False,
return_expected=False,
return_expected_set=False,
+ return_calculator=False,
**kwargs,
):
r"""
@@ -66,9 +67,12 @@ def hypotest(
return_tail_probs (:obj:`bool`): Bool for returning :math:`\mathrm{CL}_{s+b}` and :math:`\mathrm{CL}_{b}`
return_expected (:obj:`bool`): Bool for returning :math:`\mathrm{CL}_{\mathrm{exp}}`
return_expected_set (:obj:`bool`): Bool for returning the :math:`(-2,-1,0,1,2)\sigma` :math:`\mathrm{CL}_{\mathrm{exp}}` --- the "Brazil band"
+ return_calculator (:obj:`bool`): Bool for returning calculator.
Returns:
- Tuple of Floats and lists of Floats:
+ Tuple of Floats and lists of Floats and
+ a :py:class:`~pyhf.infer.calculators.AsymptoticCalculator`
+ or :py:class:`~pyhf.infer.calculators.ToyCalculator` instance:
- :math:`\mathrm{CL}_{s}`: The modified :math:`p`-value compared to
the given threshold :math:`\alpha`, typically taken to be :math:`0.05`,
@@ -139,6 +143,12 @@ def hypotest(
referred to as the "Brazil band".
Only returned when ``return_expected_set`` is ``True``.
+ - a calculator: The calculator instance used in the computation of the :math:`p`-values.
+ Either an instance of :py:class:`~pyhf.infer.calculators.AsymptoticCalculator`
+ or :py:class:`~pyhf.infer.calculators.ToyCalculator`,
+ depending on the value of ``calctype``.
+ Only returned when ``return_calculator`` is ``True``.
+
"""
init_pars = init_pars or pdf.config.suggested_init()
par_bounds = par_bounds or pdf.config.suggested_bounds()
@@ -188,6 +198,8 @@ def hypotest(
_returns.append(pvalues_exp_band)
elif return_expected:
_returns.append(tb.astensor(pvalues_exp_band[2]))
+ if return_calculator:
+ _returns.append(calc)
# Enforce a consistent return type of the observed CLs
return tuple(_returns) if len(_returns) > 1 else _returns[0]
diff --git a/src/pyhf/infer/calculators.py b/src/pyhf/infer/calculators.py
--- a/src/pyhf/infer/calculators.py
+++ b/src/pyhf/infer/calculators.py
@@ -12,6 +12,7 @@
from pyhf.infer import utils
import tqdm
+from dataclasses import dataclass
import logging
log = logging.getLogger(__name__)
@@ -29,7 +30,9 @@ def __dir__():
return __all__
-def generate_asimov_data(asimov_mu, data, pdf, init_pars, par_bounds, fixed_params):
+def generate_asimov_data(
+ asimov_mu, data, pdf, init_pars, par_bounds, fixed_params, return_fitted_pars=False
+):
"""
Compute Asimov Dataset (expected yields at best-fit values) for a given POI value.
@@ -46,6 +49,14 @@ def generate_asimov_data(asimov_mu, data, pdf, init_pars, par_bounds, fixed_para
>>> pyhf.infer.calculators.generate_asimov_data(mu_test, data, model, None, None, None)
array([ 60.61229858, 56.52802479, 270.06832542, 48.31545488])
+ It is possible to access the Asimov parameters as well:
+
+ >>> pyhf.infer.calculators.generate_asimov_data(
+ ... mu_test, data, model, None, None, None,
+ ... return_fitted_pars = True
+ ... )
+ (array([ 60.61229858, 56.52802479, 270.06832542, 48.31545488]), array([1. , 0.97224597, 0.87553894]))
+
Args:
asimov_mu (:obj:`float`): The value for the parameter of interest to be used.
data (:obj:`tensor`): The observed data.
@@ -56,15 +67,23 @@ def generate_asimov_data(asimov_mu, data, pdf, init_pars, par_bounds, fixed_para
The shape should be ``(n, 2)`` for ``n`` model parameters.
fixed_params (:obj:`tensor` of :obj:`bool`): The flag to set a parameter constant to its starting
value during minimization.
+ return_fitted_pars (:obj:`bool`): Return the best-fit parameter values for the given ``asimov_mu``.
+
Returns:
- Tensor: The Asimov dataset.
+ A Tensor or a Tuple of two Tensors:
+
+ - The Asimov dataset.
+ - The Asimov parameters. Only returned if ``return_fitted_pars`` is ``True``.
"""
bestfit_nuisance_asimov = fixed_poi_fit(
asimov_mu, data, pdf, init_pars, par_bounds, fixed_params
)
- return pdf.expected_data(bestfit_nuisance_asimov)
+ asimov_data = pdf.expected_data(bestfit_nuisance_asimov)
+ if return_fitted_pars:
+ return asimov_data, bestfit_nuisance_asimov
+ return asimov_data
class AsymptoticTestStatDistribution:
@@ -188,6 +207,21 @@ def expected_value(self, nsigma):
)
+@dataclass(frozen=True)
+class HypoTestFitResults:
+ """
+ Fitted model parameters of the fits in
+ :py:meth:`AsymptoticCalculator.teststatistic <pyhf.infer.calculators.AsymptoticCalculator.teststatistic>`
+ """
+
+ # ignore "F821 undefined name 'Tensor'" so as to avoid typing.Any
+ asimov_pars: 'Tensor' # noqa: F821
+ free_fit_to_data: 'Tensor' # noqa: F821
+ free_fit_to_asimov: 'Tensor' # noqa: F821
+ fixed_poi_fit_to_data: 'Tensor' # noqa: F821
+ fixed_poi_fit_to_asimov: 'Tensor' # noqa: F821
+
+
class AsymptoticCalculator:
"""The Asymptotic Calculator."""
@@ -251,6 +285,7 @@ def __init__(
self.test_stat = test_stat
self.calc_base_dist = calc_base_dist
self.sqrtqmuA_v = None
+ self.fitted_pars = None
def distributions(self, poi_test):
r"""
@@ -297,9 +332,13 @@ def distributions(self, poi_test):
return sb_dist, b_dist
def teststatistic(self, poi_test):
- """
+ r"""
Compute the test statistic for the observed data under the studied model.
+ The fitted parameters of the five fits that are implicitly ran at every call
+ of this method are afterwards accessible through ``self.fitted_pars``,
+ which is a :py:class:`~pyhf.infer.calculators.HypoTestFitResults` instance.
+
Example:
>>> import pyhf
@@ -314,6 +353,16 @@ def teststatistic(self, poi_test):
>>> asymptotic_calculator.teststatistic(mu_test)
array(0.14043184)
+ Access the best-fit parameters afterwards:
+
+ >>> asymptotic_calculator.fitted_pars
+ HypoTestFitResults(asimov_pars=array([0. , 1.0030482 , 0.96264534]), free_fit_to_data=array([0. , 1.0030512 , 0.96266961]), free_fit_to_asimov=array([0. , 1.00304893, 0.96263365]), fixed_poi_fit_to_data=array([1. , 0.97224597, 0.87553894]), fixed_poi_fit_to_asimov=array([1. , 0.97276864, 0.87142047]))
+
+ E.g. the :math:`\hat{\mu}` and :math:`\hat{\theta}` fitted to the asimov dataset:
+
+ >>> asymptotic_calculator.fitted_pars.free_fit_to_asimov
+ array([0. , 1.00304893, 0.96263365])
+
Args:
poi_test (:obj:`float` or :obj:`tensor`): The value for the parameter of interest.
@@ -325,35 +374,45 @@ def teststatistic(self, poi_test):
teststat_func = utils.get_test_stat(self.test_stat)
- qmu_v = teststat_func(
+ qmu_v, (mubhathat, muhatbhat) = teststat_func(
poi_test,
self.data,
self.pdf,
self.init_pars,
self.par_bounds,
self.fixed_params,
+ return_fitted_pars=True,
)
sqrtqmu_v = tensorlib.sqrt(qmu_v)
asimov_mu = 1.0 if self.test_stat == 'q0' else 0.0
- asimov_data = generate_asimov_data(
+ asimov_data, asimov_mubhathat = generate_asimov_data(
asimov_mu,
self.data,
self.pdf,
self.init_pars,
self.par_bounds,
self.fixed_params,
+ return_fitted_pars=True,
)
- qmuA_v = teststat_func(
+ qmuA_v, (mubhathat_A, muhatbhat_A) = teststat_func(
poi_test,
asimov_data,
self.pdf,
self.init_pars,
self.par_bounds,
self.fixed_params,
+ return_fitted_pars=True,
)
self.sqrtqmuA_v = tensorlib.sqrt(qmuA_v)
+ self.fitted_pars = HypoTestFitResults(
+ asimov_pars=asimov_mubhathat,
+ free_fit_to_data=muhatbhat,
+ free_fit_to_asimov=muhatbhat_A,
+ fixed_poi_fit_to_data=mubhathat,
+ fixed_poi_fit_to_asimov=mubhathat_A,
+ )
if self.test_stat in ["q", "q0"]: # qmu or q0
teststat = sqrtqmu_v - self.sqrtqmuA_v
|
diff --git a/src/pyhf/infer/test_statistics.py b/src/pyhf/infer/test_statistics.py
--- a/src/pyhf/infer/test_statistics.py
+++ b/src/pyhf/infer/test_statistics.py
@@ -13,7 +13,9 @@ def __dir__():
return __all__
-def _qmu_like(mu, data, pdf, init_pars, par_bounds, fixed_params):
+def _qmu_like(
+ mu, data, pdf, init_pars, par_bounds, fixed_params, return_fitted_pars=False
+):
"""
Clipped version of _tmu_like where the returned test statistic
is 0 if muhat > 0 else tmu_like_stat.
@@ -22,12 +24,14 @@ def _qmu_like(mu, data, pdf, init_pars, par_bounds, fixed_params):
qmu_tilde. Otherwise this is qmu (no tilde).
"""
tensorlib, optimizer = get_backend()
- tmu_like_stat, (_, muhatbhat) = _tmu_like(
+ tmu_like_stat, (mubhathat, muhatbhat) = _tmu_like(
mu, data, pdf, init_pars, par_bounds, fixed_params, return_fitted_pars=True
)
qmu_like_stat = tensorlib.where(
muhatbhat[pdf.config.poi_index] > mu, tensorlib.astensor(0.0), tmu_like_stat
)
+ if return_fitted_pars:
+ return qmu_like_stat, (mubhathat, muhatbhat)
return qmu_like_stat
@@ -56,7 +60,7 @@ def _tmu_like(
return tmu_like_stat
-def qmu(mu, data, pdf, init_pars, par_bounds, fixed_params):
+def qmu(mu, data, pdf, init_pars, par_bounds, fixed_params, return_fitted_pars=False):
r"""
The test statistic, :math:`q_{\mu}`, for establishing an upper
limit on the strength parameter, :math:`\mu`, as defiend in
@@ -94,6 +98,11 @@ def qmu(mu, data, pdf, init_pars, par_bounds, fixed_params):
>>> pyhf.infer.test_statistics.qmu(test_mu, data, model, init_pars, par_bounds, fixed_params)
array(3.9549891)
+ Access the best-fit parameter tensors:
+
+ >>> pyhf.infer.test_statistics.qmu(test_mu, data, model, init_pars, par_bounds, fixed_params, return_fitted_pars = True)
+ (array(3.9549891), (array([1. , 0.97224597, 0.87553894]), array([-0.06679525, 1.00555369, 0.96930896])))
+
Args:
mu (Number or Tensor): The signal strength parameter
data (Tensor): The data to be considered
@@ -104,9 +113,18 @@ def qmu(mu, data, pdf, init_pars, par_bounds, fixed_params):
The shape should be ``(n, 2)`` for ``n`` model parameters.
fixed_params (:obj:`list` of :obj:`bool`): The flag to set a parameter constant to its starting
value during minimization.
+ return_fitted_pars (:obj:`bool`): Return the best-fit parameter tensors
+ the fixed-POI and unconstrained fits have converged on
+ (i.e. :math:`\mu, \hat{\hat{\theta}}` and :math:`\hat{\mu}, \hat{\theta}`)
Returns:
- Float: The calculated test statistic, :math:`q_{\mu}`
+ Tuple of a Float and a Tuple of Tensors:
+
+ - The calculated test statistic, :math:`q_{\mu}`
+
+ - The parameter tensors corresponding to the constrained and unconstrained best fit,
+ :math:`\mu, \hat{\hat{\theta}}` and :math:`\hat{\mu}, \hat{\theta}`.
+ Only returned if ``return_fitted_pars`` is ``True``.
"""
if pdf.config.poi_index is None:
raise UnspecifiedPOI(
@@ -117,10 +135,20 @@ def qmu(mu, data, pdf, init_pars, par_bounds, fixed_params):
'qmu test statistic used for fit configuration with POI bounded at zero.\n'
+ 'Use the qmu_tilde test statistic (pyhf.infer.test_statistics.qmu_tilde) instead.'
)
- return _qmu_like(mu, data, pdf, init_pars, par_bounds, fixed_params)
+ return _qmu_like(
+ mu,
+ data,
+ pdf,
+ init_pars,
+ par_bounds,
+ fixed_params,
+ return_fitted_pars=return_fitted_pars,
+ )
-def qmu_tilde(mu, data, pdf, init_pars, par_bounds, fixed_params):
+def qmu_tilde(
+ mu, data, pdf, init_pars, par_bounds, fixed_params, return_fitted_pars=False
+):
r"""
The "alternative" test statistic, :math:`\tilde{q}_{\mu}`, for establishing
an upper limit on the strength parameter, :math:`\mu`, for models with
@@ -163,6 +191,11 @@ def qmu_tilde(mu, data, pdf, init_pars, par_bounds, fixed_params):
>>> pyhf.infer.test_statistics.qmu_tilde(test_mu, data, model, init_pars, par_bounds, fixed_params)
array(3.93824492)
+ Access the best-fit parameter tensors:
+
+ >>> pyhf.infer.test_statistics.qmu_tilde(test_mu, data, model, init_pars, par_bounds, fixed_params, return_fitted_pars = True)
+ (array(3.93824492), (array([1. , 0.97224597, 0.87553894]), array([0. , 1.0030512 , 0.96266961])))
+
Args:
mu (Number or Tensor): The signal strength parameter
data (:obj:`tensor`): The data to be considered
@@ -173,9 +206,18 @@ def qmu_tilde(mu, data, pdf, init_pars, par_bounds, fixed_params):
The shape should be ``(n, 2)`` for ``n`` model parameters.
fixed_params (:obj:`list` of :obj:`bool`): The flag to set a parameter constant to its starting
value during minimization.
+ return_fitted_pars (:obj:`bool`): Return the best-fit parameter tensors
+ the fixed-POI and unconstrained fits have converged on
+ (i.e. :math:`\mu, \hat{\hat{\theta}}` and :math:`\hat{\mu}, \hat{\theta}`)
Returns:
- Float: The calculated test statistic, :math:`\tilde{q}_{\mu}`
+ Tuple of a Float and a Tuple of Tensors:
+
+ - The calculated test statistic, :math:`\tilde{q}_{\mu}`
+
+ - The parameter tensors corresponding to the constrained and unconstrained best fit,
+ :math:`\mu, \hat{\hat{\theta}}` and :math:`\hat{\mu}, \hat{\theta}`.
+ Only returned if ``return_fitted_pars`` is ``True``.
"""
if pdf.config.poi_index is None:
raise UnspecifiedPOI(
@@ -186,10 +228,18 @@ def qmu_tilde(mu, data, pdf, init_pars, par_bounds, fixed_params):
'qmu_tilde test statistic used for fit configuration with POI not bounded at zero.\n'
+ 'Use the qmu test statistic (pyhf.infer.test_statistics.qmu) instead.'
)
- return _qmu_like(mu, data, pdf, init_pars, par_bounds, fixed_params)
+ return _qmu_like(
+ mu,
+ data,
+ pdf,
+ init_pars,
+ par_bounds,
+ fixed_params,
+ return_fitted_pars=return_fitted_pars,
+ )
-def tmu(mu, data, pdf, init_pars, par_bounds, fixed_params):
+def tmu(mu, data, pdf, init_pars, par_bounds, fixed_params, return_fitted_pars=False):
r"""
The test statistic, :math:`t_{\mu}`, for establishing a two-sided
interval on the strength parameter, :math:`\mu`, as defiend in Equation (8)
@@ -221,6 +271,11 @@ def tmu(mu, data, pdf, init_pars, par_bounds, fixed_params):
>>> pyhf.infer.test_statistics.tmu(test_mu, data, model, init_pars, par_bounds, fixed_params)
array(3.9549891)
+ Access the best-fit parameter tensors:
+
+ >>> pyhf.infer.test_statistics.tmu(test_mu, data, model, init_pars, par_bounds, fixed_params, return_fitted_pars = True)
+ (array(3.9549891), (array([1. , 0.97224597, 0.87553894]), array([-0.06679525, 1.00555369, 0.96930896])))
+
Args:
mu (Number or Tensor): The signal strength parameter
data (Tensor): The data to be considered
@@ -231,9 +286,18 @@ def tmu(mu, data, pdf, init_pars, par_bounds, fixed_params):
The shape should be ``(n, 2)`` for ``n`` model parameters.
fixed_params (:obj:`list` of :obj:`bool`): The flag to set a parameter constant to its starting
value during minimization.
+ return_fitted_pars (:obj:`bool`): Return the best-fit parameter tensors
+ the fixed-POI and unconstrained fits have converged on
+ (i.e. :math:`\mu, \hat{\hat{\theta}}` and :math:`\hat{\mu}, \hat{\theta}`)
Returns:
- Float: The calculated test statistic, :math:`t_{\mu}`
+ Tuple of a Float and a Tuple of Tensors:
+
+ - The calculated test statistic, :math:`t_{\mu}`
+
+ - The parameter tensors corresponding to the constrained and unconstrained best fit,
+ :math:`\mu, \hat{\hat{\theta}}` and :math:`\hat{\mu}, \hat{\theta}`.
+ Only returned if ``return_fitted_pars`` is ``True``.
"""
if pdf.config.poi_index is None:
raise UnspecifiedPOI(
@@ -244,10 +308,20 @@ def tmu(mu, data, pdf, init_pars, par_bounds, fixed_params):
'tmu test statistic used for fit configuration with POI bounded at zero.\n'
+ 'Use the tmu_tilde test statistic (pyhf.infer.test_statistics.tmu_tilde) instead.'
)
- return _tmu_like(mu, data, pdf, init_pars, par_bounds, fixed_params)
+ return _tmu_like(
+ mu,
+ data,
+ pdf,
+ init_pars,
+ par_bounds,
+ fixed_params,
+ return_fitted_pars=return_fitted_pars,
+ )
-def tmu_tilde(mu, data, pdf, init_pars, par_bounds, fixed_params):
+def tmu_tilde(
+ mu, data, pdf, init_pars, par_bounds, fixed_params, return_fitted_pars=False
+):
r"""
The test statistic, :math:`\tilde{t}_{\mu}`, for establishing a two-sided
interval on the strength parameter, :math:`\mu`, for models with
@@ -270,6 +344,7 @@ def tmu_tilde(mu, data, pdf, init_pars, par_bounds, fixed_params):
\end{equation}
Example:
+
>>> import pyhf
>>> pyhf.set_backend("numpy")
>>> model = pyhf.simplemodels.uncorrelated_background(
@@ -284,6 +359,11 @@ def tmu_tilde(mu, data, pdf, init_pars, par_bounds, fixed_params):
>>> pyhf.infer.test_statistics.tmu_tilde(test_mu, data, model, init_pars, par_bounds, fixed_params)
array(3.93824492)
+ Access the best-fit parameter tensors:
+
+ >>> pyhf.infer.test_statistics.tmu_tilde(test_mu, data, model, init_pars, par_bounds, fixed_params, return_fitted_pars = True)
+ (array(3.93824492), (array([1. , 0.97224597, 0.87553894]), array([0. , 1.0030512 , 0.96266961])))
+
Args:
mu (Number or Tensor): The signal strength parameter
data (:obj:`tensor`): The data to be considered
@@ -294,9 +374,18 @@ def tmu_tilde(mu, data, pdf, init_pars, par_bounds, fixed_params):
The shape should be ``(n, 2)`` for ``n`` model parameters.
fixed_params (:obj:`list` of :obj:`bool`): The flag to set a parameter constant to its starting
value during minimization.
+ return_fitted_pars (:obj:`bool`): Return the best-fit parameter tensors
+ the fixed-POI and unconstrained fits have converged on
+ (i.e. :math:`\mu, \hat{\hat{\theta}}` and :math:`\hat{\mu}, \hat{\theta}`)
Returns:
- Float: The calculated test statistic, :math:`\tilde{t}_{\mu}`
+ Tuple of a Float and a Tuple of Tensors:
+
+ - The calculated test statistic, :math:`\tilde{t}_{\mu}`
+
+ - The parameter tensors corresponding to the constrained and unconstrained best fit,
+ :math:`\mu, \hat{\hat{\theta}}` and :math:`\hat{\mu}, \hat{\theta}`.
+ Only returned if ``return_fitted_pars`` is ``True``.
"""
if pdf.config.poi_index is None:
raise UnspecifiedPOI(
@@ -307,10 +396,18 @@ def tmu_tilde(mu, data, pdf, init_pars, par_bounds, fixed_params):
'tmu_tilde test statistic used for fit configuration with POI not bounded at zero.\n'
+ 'Use the tmu test statistic (pyhf.infer.test_statistics.tmu) instead.'
)
- return _tmu_like(mu, data, pdf, init_pars, par_bounds, fixed_params)
+ return _tmu_like(
+ mu,
+ data,
+ pdf,
+ init_pars,
+ par_bounds,
+ fixed_params,
+ return_fitted_pars=return_fitted_pars,
+ )
-def q0(mu, data, pdf, init_pars, par_bounds, fixed_params):
+def q0(mu, data, pdf, init_pars, par_bounds, fixed_params, return_fitted_pars=False):
r"""
The test statistic, :math:`q_{0}`, for discovery of a positive signal
as defined in Equation (12) in :xref:`arXiv:1007.1727`, for :math:`\mu=0`.
@@ -340,6 +437,11 @@ def q0(mu, data, pdf, init_pars, par_bounds, fixed_params):
>>> pyhf.infer.test_statistics.q0(test_mu, data, model, init_pars, par_bounds, fixed_params)
array(2.98339447)
+ Access the best-fit parameter tensors:
+
+ >>> pyhf.infer.test_statistics.q0(test_mu, data, model, init_pars, par_bounds, fixed_params, return_fitted_pars = True)
+ (array(2.98339447), (array([0. , 1.03050845, 1.12128752]), array([0.95260667, 0.99635345, 1.02140172])))
+
Args:
mu (Number or Tensor): The signal strength parameter (must be set to zero)
data (Tensor): The data to be considered
@@ -350,9 +452,18 @@ def q0(mu, data, pdf, init_pars, par_bounds, fixed_params):
The shape should be ``(n, 2)`` for ``n`` model parameters.
fixed_params (:obj:`list` of :obj:`bool`): The flag to set a parameter constant to its starting
value during minimization.
+ return_fitted_pars (:obj:`bool`): Return the best-fit parameter tensors
+ the fixed-POI and unconstrained fits have converged on
+ (i.e. :math:`\mu, \hat{\hat{\theta}}` and :math:`\hat{\mu}, \hat{\theta}`)
Returns:
- Float: The calculated test statistic, :math:`q_{0}`
+ Tuple of a Float and a Tuple of Tensors:
+
+ - The calculated test statistic, :math:`q_{0}`
+
+ - The parameter tensors corresponding to the constrained and unconstrained best fit,
+ :math:`\mu, \hat{\hat{\theta}}` and :math:`\hat{\mu}, \hat{\theta}`.
+ Only returned if ``return_fitted_pars`` is ``True``.
"""
if pdf.config.poi_index is None:
@@ -367,10 +478,12 @@ def q0(mu, data, pdf, init_pars, par_bounds, fixed_params):
tensorlib, optimizer = get_backend()
- tmu_like_stat, (_, muhatbhat) = _tmu_like(
+ tmu_like_stat, (mubhathat, muhatbhat) = _tmu_like(
mu, data, pdf, init_pars, par_bounds, fixed_params, return_fitted_pars=True
)
q0_stat = tensorlib.where(
muhatbhat[pdf.config.poi_index] < 0, tensorlib.astensor(0.0), tmu_like_stat
)
+ if return_fitted_pars:
+ return q0_stat, (mubhathat, muhatbhat)
return q0_stat
diff --git a/tests/test_calculator.py b/tests/test_calculator.py
--- a/tests/test_calculator.py
+++ b/tests/test_calculator.py
@@ -1,3 +1,5 @@
+import pytest
+
import pyhf
import pyhf.infer.calculators
@@ -5,3 +7,83 @@
def test_calc_dist():
asymptotic_dist = pyhf.infer.calculators.AsymptoticTestStatDistribution(0.0)
assert asymptotic_dist.pvalue(-1) == 1 - asymptotic_dist.cdf(-1)
+
+
[email protected]("return_fitted_pars", [False, True])
+def test_generate_asimov_can_return_fitted_pars(return_fitted_pars):
+ model = pyhf.simplemodels.uncorrelated_background([1, 1], [1, 1], [1, 1])
+ data = [2, 2, 1, 1] # [main x 2, aux x 2]
+ init_pars = model.config.suggested_init()
+ par_bounds = model.config.suggested_bounds()
+ fixed_params = model.config.suggested_fixed()
+
+ result = pyhf.infer.calculators.generate_asimov_data(
+ 1.0,
+ data,
+ model,
+ init_pars,
+ par_bounds,
+ fixed_params,
+ return_fitted_pars=return_fitted_pars,
+ )
+
+ if return_fitted_pars:
+ assert len(result) == 2
+ result, asimov_pars = result
+ assert pytest.approx([1.0, 1.0, 1.0]) == pyhf.tensorlib.tolist(asimov_pars)
+ assert pytest.approx([2.0, 2.0, 1.0, 1.0]) == pyhf.tensorlib.tolist(result)
+
+
+# test different test stats because those affect the control flow
+# in AsymptotiCalculator.teststatistic, where the fit results should be set
+# the other kwargs don't impact the logic of that method,
+# so leave them at the default so as not to put a burden on future changes
[email protected]('test_stat', ['qtilde', 'q', 'q0'])
+def test_asymptotic_calculator_has_fitted_pars(test_stat):
+ model = pyhf.simplemodels.uncorrelated_background([1], [1], [1])
+ data = [2, 1] # [main, aux]
+
+ calc = pyhf.infer.calculators.AsymptoticCalculator(data, model, test_stat=test_stat)
+ calc.teststatistic(0 if test_stat == 'q0' else 1)
+
+ assert hasattr(calc, 'fitted_pars')
+ fitted_pars = calc.fitted_pars
+ assert hasattr(fitted_pars, 'asimov_pars')
+ assert hasattr(fitted_pars, 'fixed_poi_fit_to_data')
+ assert hasattr(fitted_pars, 'fixed_poi_fit_to_asimov')
+ assert hasattr(fitted_pars, 'free_fit_to_data')
+ assert hasattr(fitted_pars, 'free_fit_to_asimov')
+
+ rtol = 1e-5
+ if test_stat == 'q0':
+ assert pytest.approx([1.0, 1.0], rel=rtol) == pyhf.tensorlib.tolist(
+ fitted_pars.asimov_pars
+ )
+ assert pytest.approx([0.0, 1.5], rel=rtol) == pyhf.tensorlib.tolist(
+ fitted_pars.fixed_poi_fit_to_data
+ )
+ assert pytest.approx([0.0, 1.5], rel=rtol) == pyhf.tensorlib.tolist(
+ fitted_pars.fixed_poi_fit_to_asimov
+ )
+ assert pytest.approx([1.0, 1.0], rel=rtol) == pyhf.tensorlib.tolist(
+ fitted_pars.free_fit_to_data
+ )
+ assert pytest.approx([1.0, 1.0], rel=rtol) == pyhf.tensorlib.tolist(
+ fitted_pars.free_fit_to_asimov
+ )
+ else:
+ assert pytest.approx([0.0, 1.5], rel=rtol) == pyhf.tensorlib.tolist(
+ fitted_pars.asimov_pars
+ )
+ assert pytest.approx([1.0, 1.0], rel=rtol) == pyhf.tensorlib.tolist(
+ fitted_pars.fixed_poi_fit_to_data
+ )
+ assert pytest.approx([1.0, 1.1513553], rel=rtol) == pyhf.tensorlib.tolist(
+ fitted_pars.fixed_poi_fit_to_asimov
+ )
+ assert pytest.approx([1.0, 1.0], rel=rtol) == pyhf.tensorlib.tolist(
+ fitted_pars.free_fit_to_data
+ )
+ assert pytest.approx(
+ [7.6470499e-05, 1.4997178], rel=rtol
+ ) == pyhf.tensorlib.tolist(fitted_pars.free_fit_to_asimov)
diff --git a/tests/test_infer.py b/tests/test_infer.py
--- a/tests/test_infer.py
+++ b/tests/test_infer.py
@@ -173,6 +173,59 @@ def test_hypotest_return_expected_set(tmpdir, hypotest_args, test_stat):
assert check_uniform_type(result[3])
[email protected](
+ 'calctype,kwargs,expected_type',
+ [
+ ('asymptotics', {}, pyhf.infer.calculators.AsymptoticCalculator),
+ ('toybased', dict(ntoys=1), pyhf.infer.calculators.ToyCalculator),
+ ],
+)
[email protected]('return_tail_probs', [True, False])
[email protected]('return_expected', [True, False])
[email protected]('return_expected_set', [True, False])
+def test_hypotest_return_calculator(
+ tmpdir,
+ hypotest_args,
+ calctype,
+ kwargs,
+ expected_type,
+ return_tail_probs,
+ return_expected,
+ return_expected_set,
+):
+ """
+ Check that the return structure of pyhf.infer.hypotest with the
+ additon of the return_calculator keyword arg is as expected
+ """
+ *_, model = hypotest_args
+
+ # only those return flags where the toggled return value
+ # is placed in front of the calculator in the returned tuple
+ extra_returns = sum(
+ int(return_flag)
+ for return_flag in (
+ return_tail_probs,
+ return_expected,
+ return_expected_set,
+ )
+ )
+
+ result = pyhf.infer.hypotest(
+ *hypotest_args,
+ return_calculator=True,
+ return_tail_probs=return_tail_probs,
+ return_expected=return_expected,
+ return_expected_set=return_expected_set,
+ calctype=calctype,
+ **kwargs,
+ )
+
+ assert len(list(result)) == 2 + extra_returns
+ # not *_, calc = result b.c. in future, there could be additional optional returns
+ calc = result[1 + extra_returns]
+ assert isinstance(calc, expected_type)
+
+
@pytest.mark.parametrize(
"kwargs",
[{'calctype': 'asymptotics'}, {'calctype': 'toybased', 'ntoys': 5}],
diff --git a/tests/test_teststats.py b/tests/test_teststats.py
--- a/tests/test_teststats.py
+++ b/tests/test_teststats.py
@@ -172,3 +172,40 @@ def test_get_teststat_by_name(test_stat):
def test_get_teststat_error():
with pytest.raises(pyhf.exceptions.InvalidTestStatistic):
pyhf.infer.utils.get_test_stat("look at me i'm not real")
+
+
[email protected]("return_fitted_pars", [False, True])
[email protected](
+ "test_stat",
+ [
+ pyhf.infer.test_statistics.q0,
+ pyhf.infer.test_statistics.qmu,
+ pyhf.infer.test_statistics.qmu_tilde,
+ pyhf.infer.test_statistics.tmu,
+ pyhf.infer.test_statistics.tmu_tilde,
+ ],
+)
+def test_return_fitted_pars(test_stat, return_fitted_pars):
+ mu = 0.0 if test_stat is pyhf.infer.test_statistics.q0 else 1.0
+ model = pyhf.simplemodels.uncorrelated_background([6], [9], [3])
+ data = [9] + model.config.auxdata
+ init_pars = model.config.suggested_init()
+ par_bounds = model.config.suggested_bounds()
+ fixed_params = model.config.suggested_fixed()
+
+ result = test_stat(
+ mu,
+ data,
+ model,
+ init_pars,
+ par_bounds,
+ fixed_params,
+ return_fitted_pars=return_fitted_pars,
+ )
+ if return_fitted_pars:
+ assert len(result) == 2
+ assert len(result[1]) == 2
+ result, (pars_bestfit, pars_constrained_fit) = result
+ assert len(pars_bestfit) == len(init_pars)
+ assert len(pars_constrained_fit) == len(init_pars)
+ assert result > -1e4 # >= 0 but with generous tolerance
|
expose fitted parameter values of implicit fits in test statistic calls
# Description
The proposal is to change the API of documented functions and classes in `pyhf.infer` such that users can directly access the best-fit model parameters that implicit fits have found, toggleable by a keyword flag. Here "implicit fits" means the calls to `pyhf.infer.mle.fit` and `pyhf.infer.mle.fixed_poi_fit` in the test statistic implementations (i.e. in [`pyhf.infer.test_statistic._tmu_like`](https://github.com/scikit-hep/pyhf/blob/4b66cd2cfa0bd4bb53b14c525118d86567be8257/src/pyhf/infer/test_statistics.py#L34) and [`pyhf.infer.calculators.generate_asimov`](https://github.com/scikit-hep/pyhf/blob/4b66cd2cfa0bd4bb53b14c525118d86567be8257/src/pyhf/infer/calculators.py#L32)).
"Model parameters" means both the NPs, and (where it is being optimised) the POI.
## Related ~~problem~~ inconvenience
I had encountered some funny/unexpected p-values coming out of `pyhf.infer.hypotest`, and I wanted to inspect (and plot predicted physical distributions for), the parameter values that gave rise to the unexpected p-values.
This is not possible in the current API, so I re-ran the fits myself to get the parameter values, which is slow on large and complex models, and has some small risk of divergence creeping in between my user-implemented calls to the fits and the internal calls.
### The solution I'd like
The documented test statistic functions in `pyhf.infer.test_statistics` (`qmu`, `tmu`, `qmu_tilde`, `tmu_tilde`, `q0`) should accept
an optional kwarg which causes the function to return a tuple of the value of the test statistic and the tensor of fitted parameters. ([`pyhf.infer.test_statistic._tmu_like`](https://github.com/scikit-hep/pyhf/blob/4b66cd2cfa0bd4bb53b14c525118d86567be8257/src/pyhf/infer/test_statistics.py#L34) already has such a kwarg)
Similarly, [`pyhf.infer.calculators.generate_asimov`](https://github.com/scikit-hep/pyhf/blob/4b66cd2cfa0bd4bb53b14c525118d86567be8257/src/pyhf/infer/calculators.py#L32) should have the same kwarg,
toggling the returning of the asimov parameters alongside the asimov data if `True`.
The [`pyhf.infer.calculators.AsymptoticCalculator`](https://github.com/scikit-hep/pyhf/blob/4b66cd2cfa0bd4bb53b14c525118d86567be8257/src/pyhf/infer/calculators.py#L191) should have a property holding the collection of fit results used to find the test statistic values and Asimov data (in a dataclass maybe?). If accessed before `pyhf.infer.calculators.AsymptoticCalculator.teststatistic` has been called, a `RuntimeError` should be raised. (as `pyhf.infer.calculators.AsymptoticCalculator.distributions` currently does in the same case)
The `ToyCalculator` can IMO be left unchanged. (If I am not confident in the behavior of one fit, or if re-running 5 fits is too slow for me, I am not going to run 10k fits for 2k toys anyways).
Higher-level functions using the `AsymptoticCalculator` (a.k.a. [`pyhf.infer.hypotest`](https://github.com/scikit-hep/pyhf/blob/4b66cd2cfa0bd4bb53b14c525118d86567be8257/src/pyhf/infer/__init__.py#L20))
should accept the same kwarg as the test statistic functions above, but instead of a single tensor of parameters,
they return the collection of best-fit-parameter tensors of the underlying calculator, or raise a descriptive error if the
`ToyCalculator` is used.
### Describe alternatives you've considered
- Instead of changing a bunch of APIs at once, only the test statistic impementations (or them + the `AsymptoticCalculator`) could be changed. I dislike this alternative since it still encourages users to duplicate the higher level functionality.
- Instead of `hypotest` returning only the best-fit parameters, it could have a kwarg toggling it to return the entire calculator. This gives even more flexibility for users, but IMO it is a good thing that `hypotest` is a limited/"garden-path" way of accessing the functionality provided by the calculators. If I don't need that, I can use the calculator myself (and the docs show how.)
- Even on simple models where fits converge quickly, many thousands of fits take time. So the `ToyCalculator.__init__` having an kw-only arg that toggles saving/not saving the fit parameters may still be convenient (supposing one wants to plot spreads of parameters for some reason, or pull out the "one weird fit" after the fact)? Not doing so is simpler, so I would not do this for now.
- add the option to access fitted parameters to [`pyhf.infer.intervals.upperlimit`](https://github.com/scikit-hep/pyhf/blob/4b66cd2cfa0bd4bb53b14c525118d86567be8257/src/pyhf/infer/intervals.py#L18). Here, similar arguments apply as for the `ToyCalculator`. Further, the returned result is already complicated and conditional, and recreating n `hypotest` calls for n mu values seems very straightforward. So I would leave `upperlimit` as it is.
# Additional context
This issue describes an idea that grew out of this discussion: #1547.
|
PS: sorry for the length, I played around a little with ways to do this, and wanted to write down my thoughts so I don't forget them when getting started on the PR
| 2021-08-19T17:35:53 |
scikit-hep/pyhf
| 1,556 |
scikit-hep__pyhf-1556
|
[
"1555"
] |
4e0f92e1c41b89946a330e59824d455b62986437
|
diff --git a/src/pyhf/events.py b/src/pyhf/events.py
--- a/src/pyhf/events.py
+++ b/src/pyhf/events.py
@@ -89,22 +89,27 @@ def subscribe(event):
"""
Subscribe a function or object method as a callback to an event.
- Note: this is meant to be used as a decorator.
+ .. note::
+
+ This is meant to be used as a decorator.
Args:
event (:obj:`str`): The name of the event to subscribe to.
Returns:
:obj:`function`: Decorated function.
+
+ Example:
+ >>> import pyhf
+ >>> @pyhf.events.subscribe("myevent")
+ ... def test(a, b):
+ ... print(a + b)
+ ...
+ >>> pyhf.events.trigger("myevent")(1, 2)
+ 3
+
"""
- # Example:
- #
- # >>> @pyhf.events.subscribe('myevent')
- # ... def test(a,b):
- # ... print a+b
- # ...
- # >>> pyhf.events.trigger_myevent(1,2)
- # 3
+
global __events
def __decorator(func):
@@ -119,7 +124,9 @@ def register(event):
Register a function or object method to trigger an event. This creates two
events: ``{event_name}::before`` and ``{event_name}::after``.
- Note: this is meant to be used as a decorator.
+ .. note::
+
+ This is meant to be used as a decorator.
Args:
event (:obj:`str`): The name of the event to subscribe to.
@@ -127,26 +134,26 @@ def register(event):
Returns:
:obj:`function`: Decorated function.
+ Example:
+ >>> import pyhf
+ >>> @pyhf.events.register("test_func")
+ ... def test(a, b):
+ ... print(a + b)
+ ...
+ >>> @pyhf.events.subscribe("test_func::before")
+ ... def precall():
+ ... print("before call")
+ ...
+ >>> @pyhf.events.subscribe("test_func::after")
+ ... def postcall():
+ ... print("after call")
+ ...
+ >>> test(1, 2)
+ before call
+ 3
+ after call
+
"""
- # Examples:
- #
- # >>> @pyhf.events.register('test_func')
- # ... def test(a,b):
- # ... print a+b
- # ...
- # >>> @pyhf.events.subscribe('test_func::before')
- # ... def precall():
- # ... print 'before call'
- # ...
- # >>> @pyhf.events.subscribe('test_func::after')
- # ... def postcall():
- # ... print 'after call'
- # ...
- # >>> test(1,2)
- # "before call"
- # 3
- # "after call"
- # >>>
def _register(func):
@wraps(func)
|
Remove Python 2 syntax from events examples in comments
# Description
In `pyhf.events` there are a two examples of Python 2 syntax being used for
https://github.com/scikit-hep/pyhf/blob/29c3df0e23a428004a065aed61cefb6a526a7332/src/pyhf/events.py#L46-L53
and
https://github.com/scikit-hep/pyhf/blob/29c3df0e23a428004a065aed61cefb6a526a7332/src/pyhf/events.py#L69-L87
These examples should be updated to use Python 3 syntax.
Also the examples are wrong themselves. For example, the first example should be
```python
>>> import pyhf
>>> @pyhf.events.subscribe('myevent')
... def test(a,b):
... print(a+b)
...
>>> pyhf.events.trigger("myevent")(1,2)
3
```
| 2021-08-21T02:38:19 |
||
scikit-hep/pyhf
| 1,560 |
scikit-hep__pyhf-1560
|
[
"867"
] |
bd1d5716b3b10f1e76e31ec1e73bac5f4bb8383f
|
diff --git a/src/pyhf/pdf.py b/src/pyhf/pdf.py
--- a/src/pyhf/pdf.py
+++ b/src/pyhf/pdf.py
@@ -319,13 +319,10 @@ def par_slice(self, name):
"""
return self.par_map[name]['slice']
- def par_names(self, fstring='{name}[{index}]'):
+ def par_names(self):
"""
The names of the parameters in the model including binned-parameter indexing.
- Args:
- fstring (:obj:`str`): Format string for the parameter names using ``name`` and ``index`` variables. Default: ``'{name}[{index}]'``.
-
Returns:
:obj:`list`: Names of the model parameters.
@@ -336,18 +333,16 @@ def par_names(self, fstring='{name}[{index}]'):
... )
>>> model.config.par_names()
['mu', 'uncorr_bkguncrt[0]', 'uncorr_bkguncrt[1]']
- >>> model.config.par_names(fstring='{name}_{index}')
- ['mu', 'uncorr_bkguncrt_0', 'uncorr_bkguncrt_1']
"""
_names = []
for name in self.par_order:
- _npars = self.param_set(name).n_parameters
- if _npars == 1:
+ param_set = self.param_set(name)
+ if param_set.is_scalar:
_names.append(name)
continue
_names.extend(
- [fstring.format(name=name, index=idx) for idx in range(_npars)]
+ [f'{name}[{index}]' for index in range(param_set.n_parameters)]
)
return _names
|
diff --git a/tests/test_optim.py b/tests/test_optim.py
--- a/tests/test_optim.py
+++ b/tests/test_optim.py
@@ -581,7 +581,7 @@ def test_minuit_param_names(mocker):
data = [10] + pdf.config.auxdata
_, result = pyhf.infer.mle.fit(data, pdf, return_result_obj=True)
assert 'minuit' in result
- assert result.minuit.parameters == ('mu', 'uncorr_bkguncrt')
+ assert result.minuit.parameters == ('mu', 'uncorr_bkguncrt[0]')
pdf.config.par_names = mocker.Mock(return_value=None)
_, result = pyhf.infer.mle.fit(data, pdf, return_result_obj=True)
diff --git a/tests/test_pdf.py b/tests/test_pdf.py
--- a/tests/test_pdf.py
+++ b/tests/test_pdf.py
@@ -890,3 +890,34 @@ def test_reproducible_model_spec():
{'bounds': [[0, 5]], 'inits': [1], 'name': 'mu'}
]
assert pyhf.Model(model_from_ws.spec)
+
+
+def test_par_names_scalar_nonscalar():
+ """
+ Testing to ensure that nonscalar parameters are still indexed, even if
+ n_parameters==1.
+ """
+ spec = {
+ 'channels': [
+ {
+ 'name': 'channel',
+ 'samples': [
+ {
+ 'name': 'goodsample',
+ 'data': [1.0],
+ 'modifiers': [
+ {'type': 'normfactor', 'name': 'scalar', 'data': None},
+ {'type': 'shapesys', 'name': 'nonscalar', 'data': [1.0]},
+ ],
+ },
+ ],
+ }
+ ]
+ }
+
+ model = pyhf.Model(spec, poi_name="scalar")
+ assert model.config.par_order == ["scalar", "nonscalar"]
+ assert model.config.par_names() == [
+ 'scalar',
+ 'nonscalar[0]',
+ ]
|
Obtaining fit parameter labels
# Question
Is there a convenient way to obtain the labels corresponding to the parameters returned by `pyhf.infer.mle.fit()`? Setting up a fit is rather clean now with `infer`:
```
ws = pyhf.Workspace(spec)
model = ws.model()
data = ws.data(model)
pyhf.infer.mle.fit(data, model)
```
In comparison, the function in https://github.com/scikit-hep/pyhf/blob/master/docs/examples/notebooks/pullplot.ipynb to get the names of those parameters is difficult to parse for non-experts:
```
labels = [
"{}[{}]".format(k, i) if model.config.param_set(k).n_parameters > 1 else k
for k in model.config.par_order
for i in range(model.config.param_set(k).n_parameters)
]
```
Is there a better way to get this list of parameter names, and if not, would it be possible to add this as a utility within `pyhf`?
# Relevant Issues and Pull Requests
not aware of any
|
> Is there a convenient way to obtain the labels corresponding to the parameters returned by `pyhf.infer.mle.fit()`?
@alexander-held as in using the public API? Not at the moment, but this seems reasonable enough that we can look into adding this. Though, as [`pyhf.infer.mle.fit(data, model)`](https://scikit-hep.org/pyhf/_generated/pyhf.infer.mle.fit.html) is just returning the best-fit model values it sounds like what you want is just a way to ask for what the model labels are, correct? If so, then this would probably go under the [`_ModelConfig`](https://scikit-hep.org/pyhf/_generated/pyhf.pdf._ModelConfig.html) API.
@alexander-held I guess in some sense it depends on what you mean by labels. `model.config.parameters` exists
```python
>>> import pyhf
>>> model = pyhf.simplemodels.hepdata_like(
... signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
... )
>>> model.config.parameters
['mu', 'uncorr_bkguncrt']
```
though it doesn't make it clear here that ` 'uncorr_bkguncrt'` contains 2 parameters:
```python
>>> model.config.npars
3
>>> model.config.param_set("mu").n_parameters
1
>>> model.config.param_set("uncorr_bkguncrt").n_parameters
2
```
Just throwing out another way to do it. We can certainly provide a nicer API for it.
```python
pars_pyhf = []
for k, v in model.config.par_map.items():
sl = v["slice"]
npars = sl.stop - sl.start
if npars > 1 or "staterror" in k:
for i in range(npars):
pars_pyhf.append("{}_{}".format(k, i))
else:
pars_pyhf.append(k)
```
It's a good question. In pyhf the only name we have are for vector-valued parameters sets. So far we didn't have names for the vector components themselves and this `{}_{}`.format(parset_name, index)` is more an ad-hoc name.
If we wanted to introduce component-wise names as well we can think about it. E.g. could path-like `<parname>/<index>` or underscore. Also one would maybe need to distinguish between parameter sets that just happen to be size=1 (shapesys with 1 bin) but are potentially larger, versus paramsets that will always be size=1. In ROOT HiFa this is the distinctino between gammas and alphas
> `model.config.parameters`
In this context looking at the content of that might be more confusing than helpful to an inexperienced user, since the gammas for a channel show up as a single parameter. Let's say I run a fit with 1 POI and 1 channel with 2 bins, then pyhf.infer.mle.fit() gives me back the results of 3 parameters. `model.config.parameters` gives me back only two names though. I might then mistakenly think that the 2 gammas are correlated somehow internally. To figure out that one of them has this extra dimension with `n_parameters` requires a lot more understanding of the `pyhf` internals than anything else in this operation of getting a best fit result.
An API that provides the list would be awesome. This feature is useful to anyone who wants to study a fit in more detail.
Regarding the naming of parameters, I understand that internally there is no name for the different components of the vectors. Fixing this name within `pyhf` instead of letting the user come up with a convention themselves has the advantage of unifying the structure of these names for all users (at least those who use the API instead of coming up with their own convention). This is probably not crucial because for publication the parameters likely would be renamed anyway, but if all plots I look at showing fit results from workspaces from various people have the same naming pattern for e.g. gammas, it will be easier to parse visually what the gammas are.
Hi @alexander-held .
The reason I introduced this grouping initially was because I somewhat disliked that the grouping in ROOT HiFa is *only* apparent from the naming convention only, and nowhere made explicit (this also leads to some undocumented edge-cases where if you have a shapesys shared across channels with varying number of bins, which parameter corresponds to which bin becomes a bit arbitrary). It was also introduced a bit with an eye towards indeed cases where those parameters are a bit more closely connected (correlated) than in the uncorrelated staterror/shapesys cases.
I agree though that it makes things a bit unusual / opaque
I was thinking whether e.g. a structured / jagged return value would make sense
I guess the `paramset` class could define some names
```
class paramset(object):
def __init__(self, **kwargs):
self.n_parameters = kwargs.pop('n_parameters')
self.suggested_init = kwargs.pop('inits')
self.suggested_bounds = kwargs.pop('bounds')
```
to
```
class paramset(object):
def __init__(self, **kwargs):
self.n_parameters = kwargs.pop('n_parameters')
self.suggested_init = kwargs.pop('inits')
self.suggested_bounds = kwargs.pop('bounds')
self.names = [str(i) for i in range(self.n_parameters)]
```
such that `'paramsetname'` and `'0' ` uniquely identify a scalar parameter of the likelihoood
from there one could get the full list of names via
```
labels = [
"{}_{}".format(k, n) for k in model.config.par_order for n in model.config. param_set(k).names
]
```
but this would e.g. add a "_0" already for the "alphas" as well. e.g. "mu_0", "gamma_0", "gamma_1", "gamma_2". part of the reason why the expression you linked is a bit complex is in order to distinguish the naming between alphas (no suffix) and gammas (with suffix)
if we wanted to track this info (whether it's an "alpha" or "gamma" style paramset) we'd maybe need a `self.is_scalar` property or similar.
> In this context looking at the content of that might be more confusing than helpful to an inexperienced user, since the gammas for a channel show up as a single parameter.
Agreed. This was kinda my point with the follow up code snippet I had.
It seems like there is some good discussion here already, so we can probably start to think about how this could look in a `v0.5.1` release.
There's an initial implementation (#1536) for now as `model.config.par_names()` that can be expanded or refactored as needed. We likely won't settle on that API for a final form anyway. Note that the default propagation to minuit is the original format mentioned at the start of the issue `{name}[{index}]` (but of course, `index` is somewhat vague here - but is meant to implicitly refer to the n parameters in the slices. For now, the assumption is that the slices are contiguous but this might not always be the case in the future.
Do you expect the label format to change again? Since the propagation to MINUIT has the default format, there are two ways of handling this in my mind when using `pyhf`:
- completely ignore the new `model.config.par_names()` and handle the translation to the default names (previously `x0` etc, now the default `model.config.par_names()`) needed by MINOS internally (as done currently in `cabinetry`),
- adopt the new format consistently everywhere without using the `fstring` argument.
The use of `fstring` implies that users would need to either be aware that the names they are seeing (e.g. in plots) do not correspond to what they need to pass to MINOS, or some conversion magic would need to be done.
Wrapping the functionality of `model.config.par_names()` via external libraries to provide a consistent API (if you expect it to change again) could work, but has the big disadvantage of having multiple implementations to get parameter names that may disagree, and then it is unclear to users which format to use.
I think it would be very useful to be able to rely on some format (e.g. the newly implemented one) as being stable.
What do you think about adding the `[0]` suffix also for modifiers that happen to be scalar, but only because the channel has a single bin? In models with a mix of single- and multi-bin channels, it perhaps looks a bit surprising to have a mix of modifiers of the same type with and without that suffix:
```txt
staterror_Signal_region
staterror_Control_region[0]
staterror_Control_region[1]
staterror_Control_region[2]
```
> The use of `fstring` implies that users would need to either be aware that the names they are seeing (e.g. in plots) do not correspond to what they need to pass to MINOS, or some conversion magic would need to be done.
>
> Wrapping the functionality of `model.config.par_names()` via external libraries to provide a consistent API (if you expect it to change again) could work, but has the big disadvantage of having multiple implementations to get parameter names that may disagree, and then it is unclear to users which format to use.
It's a fair point. One other thought is that the `fstring` was some member variable instead that could be configured instead of relying on any sort of default implementation. But I've been thinking about dropping it entirely and being a bit opinionated here. `pyhf` tends to be really flexible on a lot of things and allow the user to do a lot, but maybe this isn't needed for this area.
> What do you think about adding the `[0]` suffix also for modifiers that happen to be scalar, but only because the channel has a single bin? In models with a mix of single- and multi-bin channels, it perhaps looks a bit surprising to have a mix of modifiers of the same type with and without that suffix:
Ahh, this needs to be handled still. I have a way of fixing this, but need to propagate some new information to the modifiers to indicate if they're scalar or vector.
> One other thought is that the fstring was some member variable instead that could be configured instead of relying on any sort of default implementation.
Making it a member variable feels a bit clunky, and seems different in design from the rest of `pyhf` to me.
> But I've been thinking about dropping it entirely and being a bit opinionated here.
I like the idea of dropping it completely. A small function can still be written by users to achieve this, but within `pyhf` all naming would be consistent and unambiguous. If users want things like replacing text with LaTeX and similar operations that may be needed for publication-quality plots, the flexibility achieved via a manual implementation may be needed anyway.
| 2021-08-25T00:04:30 |
scikit-hep/pyhf
| 1,562 |
scikit-hep__pyhf-1562
|
[
"1561"
] |
29e15c2b9668fd90569622e2ed8428273c9d2d9c
|
diff --git a/src/pyhf/workspace.py b/src/pyhf/workspace.py
--- a/src/pyhf/workspace.py
+++ b/src/pyhf/workspace.py
@@ -417,7 +417,7 @@ def model(self, **config_kwargs):
return Model(modelspec, poi_name=measurement['config']['poi'], **config_kwargs)
- def data(self, model, with_aux=True):
+ def data(self, model, include_auxdata=True):
"""
Return the data for the supplied model with or without auxiliary data from the model.
@@ -428,7 +428,7 @@ def data(self, model, with_aux=True):
Args:
model (~pyhf.pdf.Model): A model object adhering to the schema model.json
- with_aux (:obj:`bool`): Whether to include auxiliary data from the model or not
+ include_auxdata (:obj:`bool`): Whether to include auxiliary data from the model or not
Returns:
:obj:`list`: data
@@ -444,7 +444,7 @@ def data(self, model, with_aux=True):
exc_info=True,
)
raise
- if with_aux:
+ if include_auxdata:
observed_data += model.config.auxdata
return observed_data
|
diff --git a/tests/test_workspace.py b/tests/test_workspace.py
--- a/tests/test_workspace.py
+++ b/tests/test_workspace.py
@@ -142,13 +142,13 @@ def test_workspace_observations(workspace_factory):
@pytest.mark.parametrize(
- "with_aux",
+ "include_auxdata",
[True, False],
)
-def test_get_workspace_data(workspace_factory, with_aux):
+def test_get_workspace_data(workspace_factory, include_auxdata):
w = workspace_factory()
m = w.model()
- assert w.data(m, with_aux=with_aux)
+ assert w.data(m, include_auxdata=include_auxdata)
def test_get_workspace_data_bad_model(workspace_factory, caplog):
|
Auxdata kwarg harmonization in expected / observed data
# Description
The API for expected and observed data (from model / workspace) uses two different names for the kwarg to steer whether auxdata should be included in the return value:
```python
import pyhf
model = pyhf.simplemodels.uncorrelated_background(
signal=[12.0, 11.0], bkg=[50.0, 52.0], bkg_uncertainty=[3.0, 7.0]
)
print(model.expected_data([0.0, 1.0, 1.0], include_auxdata=False))
ws = pyhf.Workspace.build(model, [52.0, 53.0])
print(ws.data(model, with_aux=False))
```
`expected_data` uses `include_auxdata`, while `data` uses `with_aux`. I am opening this issue to suggest harmonizing the naming.
## Is your feature request related to a problem? Please describe.
I occasionally confuse the kwarg names, of course a very minor problem.
### Describe the solution you'd like
Harmonization of the kwargs.
### Describe alternatives you've considered
Sticking with current state, and/or using higher-level interfaces (`cabinetry.model_utils`) to avoid having to remember the name.
# Relevant Issues and Pull Requests
none
# Additional context
none
| 2021-08-25T13:42:04 |
|
scikit-hep/pyhf
| 1,567 |
scikit-hep__pyhf-1567
|
[
"1566"
] |
c8a0e64a15134ba0cecf96b92e63b2a2a7a7c014
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -8,10 +8,7 @@
],
'torch': ['torch~=1.8'],
'jax': ['jax~=0.2.8', 'jaxlib~=0.1.58,!=0.1.68'], # c.f. Issue 1501
- 'xmlio': [
- 'uproot3>=3.14.1',
- 'uproot~=4.0',
- ], # uproot3 required until writing to ROOT supported in uproot4
+ 'xmlio': ['uproot>=4.1.1'],
'minuit': ['iminuit>=2.4'],
}
extras_require['backends'] = sorted(
diff --git a/src/pyhf/writexml.py b/src/pyhf/writexml.py
--- a/src/pyhf/writexml.py
+++ b/src/pyhf/writexml.py
@@ -6,9 +6,7 @@
import xml.etree.ElementTree as ET
import numpy as np
-# TODO: Move to uproot4 when ROOT file writing is supported
-import uproot3 as uproot
-from uproot3_methods.classes import TH1
+import uproot
from pyhf.mixins import _ChannelSummaryMixin
@@ -47,12 +45,12 @@ def _make_hist_name(channel, sample, modifier='', prefix='hist', suffix=''):
return f"{prefix}{middle}{suffix}"
-def _export_root_histogram(histname, data):
- hist = TH1.from_numpy((np.asarray(data), np.arange(len(data) + 1)))
- hist._fName = histname
- if histname in _ROOT_DATA_FILE:
- raise KeyError(f"Duplicate key {histname} being written.")
- _ROOT_DATA_FILE[histname] = hist
+def _export_root_histogram(hist_name, data):
+ if hist_name in _ROOT_DATA_FILE:
+ raise KeyError(f"Duplicate key {hist_name} being written.")
+ _ROOT_DATA_FILE[hist_name] = uproot.to_writable(
+ (np.asarray(data), np.arange(len(data) + 1))
+ )
# https://stackoverflow.com/a/4590052
@@ -236,7 +234,7 @@ def build_sample(spec, samplespec, channelname):
attrs = {
'Name': samplespec['name'],
'HistoName': histname,
- 'InputFile': _ROOT_DATA_FILE._path,
+ 'InputFile': _ROOT_DATA_FILE.file_path,
'NormalizeByTheory': 'False',
}
sample = ET.Element('Sample', **attrs)
@@ -255,7 +253,7 @@ def build_sample(spec, samplespec, channelname):
def build_data(obsspec, channelname):
histname = _make_hist_name(channelname, 'data')
- data = ET.Element('Data', HistoName=histname, InputFile=_ROOT_DATA_FILE._path)
+ data = ET.Element('Data', HistoName=histname, InputFile=_ROOT_DATA_FILE.file_path)
observation = next((obs for obs in obsspec if obs['name'] == channelname), None)
_export_root_histogram(histname, observation['data'])
@@ -264,7 +262,7 @@ def build_data(obsspec, channelname):
def build_channel(spec, channelspec, obsspec):
channel = ET.Element(
- 'Channel', Name=channelspec['name'], InputFile=_ROOT_DATA_FILE._path
+ 'Channel', Name=channelspec['name'], InputFile=_ROOT_DATA_FILE.file_path
)
if obsspec:
data = build_data(obsspec, channelspec['name'])
|
diff --git a/tests/test_export.py b/tests/test_export.py
--- a/tests/test_export.py
+++ b/tests/test_export.py
@@ -1,9 +1,12 @@
-import pyhf
-import pyhf.writexml
-import pytest
import json
-import xml.etree.ElementTree as ET
import logging
+import xml.etree.ElementTree as ET
+
+import pytest
+import uproot
+
+import pyhf
+import pyhf.writexml
def spec_staterror():
@@ -392,9 +395,26 @@ def test_export_data(mocker):
assert pyhf.writexml._ROOT_DATA_FILE.__setitem__.called
+def test_export_root_histogram(mocker, tmp_path):
+ """
+ Test that pyhf.writexml._export_root_histogram writes out a histogram
+ in the manner that uproot is expecting and verifies this by reading
+ the serialized file
+ """
+ mocker.patch("pyhf.writexml._ROOT_DATA_FILE", {})
+ pyhf.writexml._export_root_histogram("hist", [0, 1, 2, 3, 4, 5, 6, 7, 8])
+
+ with uproot.recreate(tmp_path.joinpath("test_export_root_histogram.root")) as file:
+ file["hist"] = pyhf.writexml._ROOT_DATA_FILE["hist"]
+
+ with uproot.open(tmp_path.joinpath("test_export_root_histogram.root")) as file:
+ assert file["hist"].values().tolist() == [0, 1, 2, 3, 4, 5, 6, 7, 8]
+ assert file["hist"].axis().edges().tolist() == [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
+ assert file["hist"].name == "hist"
+
+
def test_export_duplicate_hist_name(mocker):
mocker.patch('pyhf.writexml._ROOT_DATA_FILE', new={'duplicate_name': True})
- mocker.patch.object(pyhf.writexml, 'TH1')
with pytest.raises(KeyError):
pyhf.writexml._export_root_histogram('duplicate_name', [0, 1, 2])
|
Drop uproot3 dependency and use uproot4 for writing
# Description
Thanks to @jpivarski's awesome and heroic work [`uproot` `v4.1.0`](https://github.com/scikit-hep/uproot4/releases/tag/4.1.0) can now write ROOT files! :rocket:
This means that once we get everything working we can drop the `uproot3` dependency for the `xmlio` extra
https://github.com/scikit-hep/pyhf/blob/ce2ffabaaeadf2733d4d61284d750933f34cee28/setup.py#L11-L14
and in the tests
https://github.com/scikit-hep/pyhf/blob/ce2ffabaaeadf2733d4d61284d750933f34cee28/.github/workflows/dependencies-head.yml#L66-L89
and in the lower bound tests
https://github.com/scikit-hep/pyhf/blob/ce2ffabaaeadf2733d4d61284d750933f34cee28/lower-bound-requirements.txt#L8-L10
This shouldn't be too bad as there is only a few instances of `uproot3` being used at the moment
```console
$ git grep "uproot3" src/
src/pyhf/writexml.py:import uproot3 as uproot
src/pyhf/writexml.py:from uproot3_methods.classes import TH1
```
|
I've added this to the [`v0.6.3` board](https://github.com/scikit-hep/pyhf/projects/17) as it would be nice to get in, but if there is some thing that makes this not super easy to get in then I'll move it to [`v0.6.4`](https://github.com/scikit-hep/pyhf/projects/18) so that we can move forward with the release.
We might also need to check if this needs
https://github.com/scikit-hep/pyhf/blob/ce2ffabaaeadf2733d4d61284d750933f34cee28/.github/workflows/lower-bound-requirements.yml#L30
needs to be
```console
python -m pip install --upgrade --requirement lower-bound-requirements.txt
```
| 2021-08-27T22:20:27 |
Subsets and Splits
Distinct GitHub Repositories
The query lists all unique GitHub repository names, which provides basic filtering and an overview of the dataset but lacks deeper analytical value.
Unique Repositories in Train
Lists unique repository names from the dataset, providing a basic overview of the repositories present.