
Search is not available for this dataset
pipeline_tag
stringclasses 48
values | library_name
stringclasses 205
values | text
stringlengths 0
18.3M
| metadata
stringlengths 2
1.07B
| id
stringlengths 5
122
| last_modified
null | tags
sequencelengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
|
|---|---|---|---|---|---|---|---|---|
null | null | {} | AImonkeys/mistralXdocker | null | [
"region:us"
] | null | 2024-04-30T05:47:21+00:00 |
|
null | null |
# kat33/Mixtral-8x7B-Instruct-v0.1-Q6_K-GGUF
This model was converted to GGUF format from [`mistralai/Mixtral-8x7B-Instruct-v0.1`](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo kat33/Mixtral-8x7B-Instruct-v0.1-Q6_K-GGUF --model mixtral-8x7b-instruct-v0.1.Q6_K.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo kat33/Mixtral-8x7B-Instruct-v0.1-Q6_K-GGUF --model mixtral-8x7b-instruct-v0.1.Q6_K.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m mixtral-8x7b-instruct-v0.1.Q6_K.gguf -n 128
```
| {"language": ["fr", "it", "de", "es", "en"], "license": "apache-2.0", "tags": ["llama-cpp", "gguf-my-repo"], "inference": {"parameters": {"temperature": 0.5}}, "widget": [{"messages": [{"role": "user", "content": "What is your favorite condiment?"}]}]} | kat33/Mixtral-8x7B-Instruct-v0.1-Q6_K-GGUF | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"fr",
"it",
"de",
"es",
"en",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T05:47:29+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_prom_prom_core_notata-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_prom_prom_core_notata](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_prom_prom_core_notata) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3840
- F1 Score: 0.8338
- Accuracy: 0.8338
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.5472 | 0.6 | 200 | 0.4181 | 0.8117 | 0.8119 |
| 0.4381 | 1.2 | 400 | 0.4003 | 0.8190 | 0.8191 |
| 0.4205 | 1.81 | 600 | 0.3911 | 0.8243 | 0.8244 |
| 0.4179 | 2.41 | 800 | 0.3876 | 0.8264 | 0.8266 |
| 0.4072 | 3.01 | 1000 | 0.3833 | 0.8287 | 0.8289 |
| 0.4051 | 3.61 | 1200 | 0.3853 | 0.8272 | 0.8276 |
| 0.4021 | 4.22 | 1400 | 0.3797 | 0.8318 | 0.8319 |
| 0.4066 | 4.82 | 1600 | 0.3777 | 0.8310 | 0.8312 |
| 0.3943 | 5.42 | 1800 | 0.3787 | 0.8297 | 0.8297 |
| 0.3998 | 6.02 | 2000 | 0.3801 | 0.8315 | 0.8319 |
| 0.3971 | 6.63 | 2200 | 0.3780 | 0.8335 | 0.8336 |
| 0.392 | 7.23 | 2400 | 0.3841 | 0.8294 | 0.8300 |
| 0.3939 | 7.83 | 2600 | 0.3736 | 0.8331 | 0.8332 |
| 0.3904 | 8.43 | 2800 | 0.3861 | 0.8293 | 0.8300 |
| 0.3951 | 9.04 | 3000 | 0.3779 | 0.8299 | 0.8302 |
| 0.387 | 9.64 | 3200 | 0.3752 | 0.8328 | 0.8329 |
| 0.3886 | 10.24 | 3400 | 0.3737 | 0.8326 | 0.8327 |
| 0.3848 | 10.84 | 3600 | 0.3716 | 0.8332 | 0.8332 |
| 0.3857 | 11.45 | 3800 | 0.3736 | 0.8307 | 0.8308 |
| 0.3849 | 12.05 | 4000 | 0.3704 | 0.8332 | 0.8332 |
| 0.3814 | 12.65 | 4200 | 0.3767 | 0.8328 | 0.8331 |
| 0.3859 | 13.25 | 4400 | 0.3726 | 0.8339 | 0.8340 |
| 0.3851 | 13.86 | 4600 | 0.3712 | 0.8315 | 0.8315 |
| 0.383 | 14.46 | 4800 | 0.3728 | 0.8327 | 0.8329 |
| 0.3822 | 15.06 | 5000 | 0.3713 | 0.8318 | 0.8319 |
| 0.3802 | 15.66 | 5200 | 0.3708 | 0.8330 | 0.8331 |
| 0.3821 | 16.27 | 5400 | 0.3712 | 0.8321 | 0.8321 |
| 0.3788 | 16.87 | 5600 | 0.3812 | 0.8313 | 0.8319 |
| 0.375 | 17.47 | 5800 | 0.3789 | 0.8334 | 0.8338 |
| 0.385 | 18.07 | 6000 | 0.3745 | 0.8341 | 0.8346 |
| 0.3775 | 18.67 | 6200 | 0.3698 | 0.8334 | 0.8336 |
| 0.379 | 19.28 | 6400 | 0.3706 | 0.8330 | 0.8331 |
| 0.3764 | 19.88 | 6600 | 0.3706 | 0.8324 | 0.8327 |
| 0.3714 | 20.48 | 6800 | 0.3743 | 0.8340 | 0.8344 |
| 0.3842 | 21.08 | 7000 | 0.3683 | 0.8345 | 0.8347 |
| 0.3801 | 21.69 | 7200 | 0.3683 | 0.8347 | 0.8347 |
| 0.3727 | 22.29 | 7400 | 0.3686 | 0.8348 | 0.8349 |
| 0.3725 | 22.89 | 7600 | 0.3691 | 0.8333 | 0.8334 |
| 0.3754 | 23.49 | 7800 | 0.3689 | 0.8342 | 0.8344 |
| 0.3772 | 24.1 | 8000 | 0.3725 | 0.8335 | 0.8338 |
| 0.3773 | 24.7 | 8200 | 0.3736 | 0.8335 | 0.8340 |
| 0.371 | 25.3 | 8400 | 0.3721 | 0.8337 | 0.8340 |
| 0.379 | 25.9 | 8600 | 0.3688 | 0.8335 | 0.8336 |
| 0.3786 | 26.51 | 8800 | 0.3682 | 0.8347 | 0.8347 |
| 0.3773 | 27.11 | 9000 | 0.3680 | 0.8329 | 0.8331 |
| 0.3799 | 27.71 | 9200 | 0.3692 | 0.8329 | 0.8331 |
| 0.3689 | 28.31 | 9400 | 0.3715 | 0.8326 | 0.8329 |
| 0.3744 | 28.92 | 9600 | 0.3692 | 0.8334 | 0.8336 |
| 0.3783 | 29.52 | 9800 | 0.3690 | 0.8334 | 0.8336 |
| 0.3679 | 30.12 | 10000 | 0.3695 | 0.8334 | 0.8336 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_prom_prom_core_notata-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_prom_prom_core_notata-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T05:48:08+00:00 |
text-generation | transformers |
# Model Trained Using AutoTrain
This model was trained using AutoTrain. For more information, please visit [AutoTrain](https://hf.co/docs/autotrain).
# Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "PATH_TO_THIS_REPO"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype='auto'
).eval()
# Prompt content: "hi"
messages = [
{"role": "user", "content": "hi"}
]
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids.to('cuda'))
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
# Model response: "Hello! How can I assist you today?"
print(response)
``` | {"license": "other", "library_name": "transformers", "tags": ["autotrain", "text-generation-inference", "text-generation", "peft"], "widget": [{"messages": [{"role": "user", "content": "What is your favorite condiment?"}]}]} | nanxiz/autotrain-h731u-jdfg6 | null | [
"transformers",
"tensorboard",
"safetensors",
"autotrain",
"text-generation-inference",
"text-generation",
"peft",
"conversational",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T05:48:39+00:00 |
null | null |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# O0430HMA14
This model is a fine-tuned version of [allenai/OLMo-1B](https://huggingface.co/allenai/OLMo-1B) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0186
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 100
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.558 | 0.09 | 10 | 0.2938 |
| 0.1782 | 0.18 | 20 | 0.1518 |
| 0.1488 | 0.27 | 30 | 0.1634 |
| 0.1562 | 0.36 | 40 | 0.1549 |
| 0.1523 | 0.45 | 50 | 0.1528 |
| 0.1532 | 0.54 | 60 | 0.1495 |
| 0.1487 | 0.63 | 70 | 0.1476 |
| 0.1493 | 0.73 | 80 | 0.1547 |
| 0.148 | 0.82 | 90 | 0.1499 |
| 0.1487 | 0.91 | 100 | 0.1516 |
| 0.1516 | 1.0 | 110 | 0.1509 |
| 0.1464 | 1.09 | 120 | 0.1491 |
| 0.2792 | 1.18 | 130 | 2.5830 |
| 1.2568 | 1.27 | 140 | 0.1547 |
| 0.1824 | 1.36 | 150 | 0.1368 |
| 0.341 | 1.45 | 160 | 0.3759 |
| 0.1732 | 1.54 | 170 | 0.0789 |
| 0.444 | 1.63 | 180 | 0.0761 |
| 0.0692 | 1.72 | 190 | 0.0591 |
| 0.0553 | 1.81 | 200 | 0.0601 |
| 0.0576 | 1.9 | 210 | 0.0560 |
| 0.0578 | 1.99 | 220 | 0.0525 |
| 0.0498 | 2.08 | 230 | 0.0459 |
| 0.0412 | 2.18 | 240 | 0.0334 |
| 0.0359 | 2.27 | 250 | 0.0302 |
| 0.0315 | 2.36 | 260 | 0.0261 |
| 0.0254 | 2.45 | 270 | 0.0243 |
| 0.0179 | 2.54 | 280 | 0.0219 |
| 0.0251 | 2.63 | 290 | 0.0211 |
| 0.0226 | 2.72 | 300 | 0.0195 |
| 0.0216 | 2.81 | 310 | 0.0197 |
| 0.0231 | 2.9 | 320 | 0.0186 |
| 0.0224 | 2.99 | 330 | 0.0186 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "allenai/OLMo-1B", "model-index": [{"name": "O0430HMA14", "results": []}]} | Litzy619/O0430HMA14 | null | [
"safetensors",
"generated_from_trainer",
"base_model:allenai/OLMo-1B",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T05:49:17+00:00 |
null | null | {} | oguzkurt/layoutparser-onnx | null | [
"onnx",
"region:us"
] | null | 2024-04-30T05:49:28+00:00 |
|
null | null |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# O0430HMA15
This model is a fine-tuned version of [allenai/OLMo-1B](https://huggingface.co/allenai/OLMo-1B) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0266
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 100
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.5644 | 0.09 | 10 | 0.2800 |
| 0.178 | 0.18 | 20 | 0.1523 |
| 0.1487 | 0.27 | 30 | 0.1618 |
| 0.1564 | 0.36 | 40 | 0.1585 |
| 0.1535 | 0.45 | 50 | 0.1523 |
| 0.1531 | 0.54 | 60 | 0.1488 |
| 0.1503 | 0.63 | 70 | 0.1486 |
| 0.1497 | 0.73 | 80 | 0.1558 |
| 0.147 | 0.82 | 90 | 0.1492 |
| 0.1496 | 0.91 | 100 | 0.1499 |
| 0.1507 | 1.0 | 110 | 0.1486 |
| 0.1469 | 1.09 | 120 | 0.1510 |
| 0.1478 | 1.18 | 130 | 0.1494 |
| 0.1483 | 1.27 | 140 | 0.1481 |
| 0.1499 | 1.36 | 150 | 0.1506 |
| 0.146 | 1.45 | 160 | 0.1442 |
| 0.3204 | 1.54 | 170 | 2.2831 |
| 0.367 | 1.63 | 180 | 0.2210 |
| 0.0994 | 1.72 | 190 | 0.0781 |
| 0.0734 | 1.81 | 200 | 0.0705 |
| 0.0635 | 1.9 | 210 | 0.0575 |
| 0.0585 | 1.99 | 220 | 0.0566 |
| 0.0659 | 2.08 | 230 | 0.0568 |
| 0.0521 | 2.18 | 240 | 0.0482 |
| 0.0439 | 2.27 | 250 | 0.0367 |
| 0.0508 | 2.36 | 260 | 0.0361 |
| 0.037 | 2.45 | 270 | 0.0350 |
| 0.0269 | 2.54 | 280 | 0.0289 |
| 0.0326 | 2.63 | 290 | 0.0277 |
| 0.0316 | 2.72 | 300 | 0.0298 |
| 0.0286 | 2.81 | 310 | 0.0278 |
| 0.028 | 2.9 | 320 | 0.0270 |
| 0.0307 | 2.99 | 330 | 0.0266 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "allenai/OLMo-1B", "model-index": [{"name": "O0430HMA15", "results": []}]} | Litzy619/O0430HMA15 | null | [
"safetensors",
"generated_from_trainer",
"base_model:allenai/OLMo-1B",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T05:50:59+00:00 |
text-to-image | diffusers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "diffusers"} | Niggendar/mugenmalumixSDXL_v30 | null | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | null | 2024-04-30T05:51:08+00:00 |
null | null |
# NikolayKozloff/tweety-tatar-base-7b-2024-v1-Q8_0-GGUF
This model was converted to GGUF format from [`Tweeties/tweety-tatar-base-7b-2024-v1`](https://huggingface.co/Tweeties/tweety-tatar-base-7b-2024-v1) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Tweeties/tweety-tatar-base-7b-2024-v1) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo NikolayKozloff/tweety-tatar-base-7b-2024-v1-Q8_0-GGUF --model tweety-tatar-base-7b-2024-v1.Q8_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo NikolayKozloff/tweety-tatar-base-7b-2024-v1-Q8_0-GGUF --model tweety-tatar-base-7b-2024-v1.Q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m tweety-tatar-base-7b-2024-v1.Q8_0.gguf -n 128
```
| {"language": ["tt"], "license": "apache-2.0", "tags": ["tweety", "llama-cpp", "gguf-my-repo"], "datasets": ["oscar-corpus/OSCAR-2301"], "base_model": "mistralai/Mistral-7B-Instruct-v0.2"} | NikolayKozloff/tweety-tatar-base-7b-2024-v1-GGUF | null | [
"gguf",
"tweety",
"llama-cpp",
"gguf-my-repo",
"tt",
"dataset:oscar-corpus/OSCAR-2301",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T05:51:28+00:00 |
null | null | {"license": "afl-3.0"} | agknoows/OppapaJesus | null | [
"license:afl-3.0",
"region:us"
] | null | 2024-04-30T05:53:45+00:00 |
|
text2text-generation | transformers | {} | shenkha/DGSlow_Bartbase_BST | null | [
"transformers",
"pytorch",
"bart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T05:54:55+00:00 |
|
text-generation | transformers | {} | arctic126/hospital_mm4-3b | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T05:55:25+00:00 |
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_prom_prom_core_notata-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_prom_prom_core_notata](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_prom_prom_core_notata) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3786
- F1 Score: 0.8327
- Accuracy: 0.8327
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.5136 | 0.6 | 200 | 0.3951 | 0.8217 | 0.8217 |
| 0.4153 | 1.2 | 400 | 0.3880 | 0.8265 | 0.8268 |
| 0.4002 | 1.81 | 600 | 0.3924 | 0.8262 | 0.8268 |
| 0.3984 | 2.41 | 800 | 0.3814 | 0.8318 | 0.8321 |
| 0.3895 | 3.01 | 1000 | 0.3794 | 0.8325 | 0.8331 |
| 0.3846 | 3.61 | 1200 | 0.3729 | 0.8345 | 0.8347 |
| 0.3866 | 4.22 | 1400 | 0.3690 | 0.8381 | 0.8381 |
| 0.3879 | 4.82 | 1600 | 0.3693 | 0.8370 | 0.8372 |
| 0.3746 | 5.42 | 1800 | 0.3728 | 0.8346 | 0.8346 |
| 0.382 | 6.02 | 2000 | 0.3697 | 0.8375 | 0.8378 |
| 0.378 | 6.63 | 2200 | 0.3666 | 0.8365 | 0.8366 |
| 0.3741 | 7.23 | 2400 | 0.3731 | 0.8346 | 0.8351 |
| 0.3749 | 7.83 | 2600 | 0.3636 | 0.8391 | 0.8391 |
| 0.3707 | 8.43 | 2800 | 0.3775 | 0.8349 | 0.8357 |
| 0.3751 | 9.04 | 3000 | 0.3640 | 0.8409 | 0.8410 |
| 0.3674 | 9.64 | 3200 | 0.3633 | 0.8393 | 0.8393 |
| 0.3683 | 10.24 | 3400 | 0.3623 | 0.8411 | 0.8412 |
| 0.3655 | 10.84 | 3600 | 0.3600 | 0.8419 | 0.8419 |
| 0.3654 | 11.45 | 3800 | 0.3603 | 0.8396 | 0.8396 |
| 0.3636 | 12.05 | 4000 | 0.3616 | 0.8423 | 0.8423 |
| 0.3606 | 12.65 | 4200 | 0.3641 | 0.8406 | 0.8406 |
| 0.3643 | 13.25 | 4400 | 0.3632 | 0.8388 | 0.8389 |
| 0.3628 | 13.86 | 4600 | 0.3650 | 0.8390 | 0.8391 |
| 0.3605 | 14.46 | 4800 | 0.3636 | 0.8388 | 0.8389 |
| 0.3612 | 15.06 | 5000 | 0.3580 | 0.8400 | 0.8400 |
| 0.3563 | 15.66 | 5200 | 0.3614 | 0.8388 | 0.8389 |
| 0.3597 | 16.27 | 5400 | 0.3646 | 0.8402 | 0.8402 |
| 0.3565 | 16.87 | 5600 | 0.3689 | 0.8380 | 0.8385 |
| 0.3534 | 17.47 | 5800 | 0.3653 | 0.8390 | 0.8393 |
| 0.3618 | 18.07 | 6000 | 0.3601 | 0.8410 | 0.8412 |
| 0.3549 | 18.67 | 6200 | 0.3577 | 0.8422 | 0.8423 |
| 0.3548 | 19.28 | 6400 | 0.3606 | 0.8434 | 0.8434 |
| 0.3523 | 19.88 | 6600 | 0.3596 | 0.8404 | 0.8406 |
| 0.3461 | 20.48 | 6800 | 0.3600 | 0.8412 | 0.8413 |
| 0.359 | 21.08 | 7000 | 0.3598 | 0.8411 | 0.8413 |
| 0.3558 | 21.69 | 7200 | 0.3595 | 0.8437 | 0.8438 |
| 0.3468 | 22.29 | 7400 | 0.3587 | 0.8410 | 0.8412 |
| 0.3469 | 22.89 | 7600 | 0.3605 | 0.8402 | 0.8404 |
| 0.3479 | 23.49 | 7800 | 0.3592 | 0.8407 | 0.8408 |
| 0.3521 | 24.1 | 8000 | 0.3627 | 0.8383 | 0.8385 |
| 0.3509 | 24.7 | 8200 | 0.3631 | 0.8395 | 0.8398 |
| 0.3451 | 25.3 | 8400 | 0.3639 | 0.8402 | 0.8404 |
| 0.3518 | 25.9 | 8600 | 0.3595 | 0.8410 | 0.8412 |
| 0.3502 | 26.51 | 8800 | 0.3592 | 0.8413 | 0.8413 |
| 0.3503 | 27.11 | 9000 | 0.3583 | 0.8420 | 0.8421 |
| 0.3528 | 27.71 | 9200 | 0.3609 | 0.8402 | 0.8404 |
| 0.3399 | 28.31 | 9400 | 0.3624 | 0.8392 | 0.8395 |
| 0.349 | 28.92 | 9600 | 0.3598 | 0.8412 | 0.8413 |
| 0.3499 | 29.52 | 9800 | 0.3596 | 0.8403 | 0.8404 |
| 0.3414 | 30.12 | 10000 | 0.3604 | 0.8406 | 0.8408 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_prom_prom_core_notata-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_prom_prom_core_notata-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T05:56:16+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_prom_prom_core_notata-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_prom_prom_core_notata](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_prom_prom_core_notata) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3860
- F1 Score: 0.8313
- Accuracy: 0.8314
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.4902 | 0.6 | 200 | 0.3884 | 0.8259 | 0.8259 |
| 0.4053 | 1.2 | 400 | 0.3797 | 0.8339 | 0.8342 |
| 0.3903 | 1.81 | 600 | 0.3945 | 0.8235 | 0.8244 |
| 0.3882 | 2.41 | 800 | 0.3731 | 0.8377 | 0.8379 |
| 0.3811 | 3.01 | 1000 | 0.3734 | 0.8361 | 0.8366 |
| 0.3737 | 3.61 | 1200 | 0.3654 | 0.8376 | 0.8378 |
| 0.3779 | 4.22 | 1400 | 0.3625 | 0.8389 | 0.8389 |
| 0.3767 | 4.82 | 1600 | 0.3628 | 0.8380 | 0.8381 |
| 0.3617 | 5.42 | 1800 | 0.3680 | 0.8387 | 0.8387 |
| 0.37 | 6.02 | 2000 | 0.3670 | 0.8377 | 0.8379 |
| 0.3637 | 6.63 | 2200 | 0.3608 | 0.8407 | 0.8408 |
| 0.3596 | 7.23 | 2400 | 0.3738 | 0.8340 | 0.8346 |
| 0.3578 | 7.83 | 2600 | 0.3667 | 0.8380 | 0.8379 |
| 0.3545 | 8.43 | 2800 | 0.3747 | 0.8374 | 0.8379 |
| 0.3584 | 9.04 | 3000 | 0.3673 | 0.8394 | 0.8395 |
| 0.3481 | 9.64 | 3200 | 0.3652 | 0.8387 | 0.8387 |
| 0.3498 | 10.24 | 3400 | 0.3640 | 0.8411 | 0.8412 |
| 0.3455 | 10.84 | 3600 | 0.3607 | 0.8394 | 0.8395 |
| 0.3435 | 11.45 | 3800 | 0.3607 | 0.8385 | 0.8385 |
| 0.3419 | 12.05 | 4000 | 0.3671 | 0.8397 | 0.8396 |
| 0.335 | 12.65 | 4200 | 0.3724 | 0.8379 | 0.8379 |
| 0.3397 | 13.25 | 4400 | 0.3717 | 0.8371 | 0.8372 |
| 0.3396 | 13.86 | 4600 | 0.3731 | 0.8393 | 0.8395 |
| 0.3337 | 14.46 | 4800 | 0.3753 | 0.8361 | 0.8364 |
| 0.3357 | 15.06 | 5000 | 0.3635 | 0.8403 | 0.8404 |
| 0.3269 | 15.66 | 5200 | 0.3699 | 0.8403 | 0.8404 |
| 0.3319 | 16.27 | 5400 | 0.3785 | 0.8403 | 0.8404 |
| 0.3289 | 16.87 | 5600 | 0.3847 | 0.8364 | 0.8370 |
| 0.3236 | 17.47 | 5800 | 0.3771 | 0.8395 | 0.8396 |
| 0.3314 | 18.07 | 6000 | 0.3719 | 0.8401 | 0.8404 |
| 0.3246 | 18.67 | 6200 | 0.3693 | 0.8448 | 0.8449 |
| 0.3216 | 19.28 | 6400 | 0.3742 | 0.8404 | 0.8404 |
| 0.3206 | 19.88 | 6600 | 0.3721 | 0.8375 | 0.8378 |
| 0.3143 | 20.48 | 6800 | 0.3731 | 0.8386 | 0.8387 |
| 0.3233 | 21.08 | 7000 | 0.3797 | 0.8370 | 0.8374 |
| 0.3197 | 21.69 | 7200 | 0.3799 | 0.8373 | 0.8374 |
| 0.3108 | 22.29 | 7400 | 0.3766 | 0.8383 | 0.8385 |
| 0.3106 | 22.89 | 7600 | 0.3814 | 0.8365 | 0.8368 |
| 0.3089 | 23.49 | 7800 | 0.3778 | 0.8389 | 0.8391 |
| 0.3158 | 24.1 | 8000 | 0.3849 | 0.8356 | 0.8359 |
| 0.3121 | 24.7 | 8200 | 0.3848 | 0.8352 | 0.8357 |
| 0.306 | 25.3 | 8400 | 0.3883 | 0.8365 | 0.8368 |
| 0.3119 | 25.9 | 8600 | 0.3806 | 0.8370 | 0.8372 |
| 0.3095 | 26.51 | 8800 | 0.3817 | 0.8365 | 0.8366 |
| 0.311 | 27.11 | 9000 | 0.3797 | 0.8392 | 0.8393 |
| 0.3079 | 27.71 | 9200 | 0.3860 | 0.8368 | 0.8370 |
| 0.2988 | 28.31 | 9400 | 0.3883 | 0.8370 | 0.8374 |
| 0.3086 | 28.92 | 9600 | 0.3826 | 0.8380 | 0.8381 |
| 0.3066 | 29.52 | 9800 | 0.3831 | 0.8372 | 0.8374 |
| 0.3023 | 30.12 | 10000 | 0.3839 | 0.8376 | 0.8378 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_prom_prom_core_notata-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_prom_prom_core_notata-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T05:56:24+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_prom_prom_core_tata-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_prom_prom_core_tata](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_prom_prom_core_tata) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4468
- F1 Score: 0.8203
- Accuracy: 0.8206
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.6029 | 5.13 | 200 | 0.5832 | 0.6980 | 0.7015 |
| 0.5406 | 10.26 | 400 | 0.5696 | 0.7163 | 0.7194 |
| 0.5176 | 15.38 | 600 | 0.5599 | 0.7281 | 0.7308 |
| 0.4955 | 20.51 | 800 | 0.5382 | 0.7455 | 0.7455 |
| 0.4756 | 25.64 | 1000 | 0.5299 | 0.7423 | 0.7423 |
| 0.465 | 30.77 | 1200 | 0.5255 | 0.7438 | 0.7439 |
| 0.4532 | 35.9 | 1400 | 0.5213 | 0.7534 | 0.7537 |
| 0.4388 | 41.03 | 1600 | 0.5134 | 0.7548 | 0.7553 |
| 0.4319 | 46.15 | 1800 | 0.5187 | 0.7551 | 0.7553 |
| 0.4203 | 51.28 | 2000 | 0.5093 | 0.7683 | 0.7684 |
| 0.4066 | 56.41 | 2200 | 0.5230 | 0.7714 | 0.7716 |
| 0.4086 | 61.54 | 2400 | 0.4994 | 0.7716 | 0.7716 |
| 0.4016 | 66.67 | 2600 | 0.5033 | 0.7667 | 0.7667 |
| 0.391 | 71.79 | 2800 | 0.5018 | 0.7732 | 0.7732 |
| 0.3842 | 76.92 | 3000 | 0.5181 | 0.7677 | 0.7684 |
| 0.3755 | 82.05 | 3200 | 0.4979 | 0.7732 | 0.7732 |
| 0.3695 | 87.18 | 3400 | 0.5117 | 0.7694 | 0.7700 |
| 0.3637 | 92.31 | 3600 | 0.4982 | 0.7749 | 0.7749 |
| 0.3508 | 97.44 | 3800 | 0.5016 | 0.7748 | 0.7749 |
| 0.3503 | 102.56 | 4000 | 0.4929 | 0.7830 | 0.7830 |
| 0.3429 | 107.69 | 4200 | 0.4888 | 0.7862 | 0.7863 |
| 0.3379 | 112.82 | 4400 | 0.4902 | 0.7797 | 0.7798 |
| 0.3324 | 117.95 | 4600 | 0.4944 | 0.7812 | 0.7814 |
| 0.3301 | 123.08 | 4800 | 0.4942 | 0.7794 | 0.7798 |
| 0.3202 | 128.21 | 5000 | 0.4894 | 0.7862 | 0.7863 |
| 0.3263 | 133.33 | 5200 | 0.4753 | 0.7928 | 0.7928 |
| 0.3215 | 138.46 | 5400 | 0.4740 | 0.7895 | 0.7896 |
| 0.3123 | 143.59 | 5600 | 0.4865 | 0.7845 | 0.7847 |
| 0.3151 | 148.72 | 5800 | 0.4858 | 0.7895 | 0.7896 |
| 0.309 | 153.85 | 6000 | 0.4865 | 0.7845 | 0.7847 |
| 0.3092 | 158.97 | 6200 | 0.4841 | 0.7863 | 0.7863 |
| 0.3031 | 164.1 | 6400 | 0.4883 | 0.7862 | 0.7863 |
| 0.3065 | 169.23 | 6600 | 0.4861 | 0.7895 | 0.7896 |
| 0.3016 | 174.36 | 6800 | 0.4825 | 0.7912 | 0.7912 |
| 0.299 | 179.49 | 7000 | 0.4909 | 0.7974 | 0.7977 |
| 0.2988 | 184.62 | 7200 | 0.4942 | 0.7975 | 0.7977 |
| 0.296 | 189.74 | 7400 | 0.4839 | 0.7976 | 0.7977 |
| 0.2923 | 194.87 | 7600 | 0.4837 | 0.7879 | 0.7879 |
| 0.2932 | 200.0 | 7800 | 0.4832 | 0.7911 | 0.7912 |
| 0.2949 | 205.13 | 8000 | 0.4968 | 0.7909 | 0.7912 |
| 0.2924 | 210.26 | 8200 | 0.4875 | 0.7960 | 0.7961 |
| 0.2963 | 215.38 | 8400 | 0.4904 | 0.7959 | 0.7961 |
| 0.2914 | 220.51 | 8600 | 0.5002 | 0.7925 | 0.7928 |
| 0.2892 | 225.64 | 8800 | 0.4993 | 0.7942 | 0.7945 |
| 0.2917 | 230.77 | 9000 | 0.4928 | 0.7975 | 0.7977 |
| 0.2858 | 235.9 | 9200 | 0.4917 | 0.7959 | 0.7961 |
| 0.2924 | 241.03 | 9400 | 0.4853 | 0.7960 | 0.7961 |
| 0.2868 | 246.15 | 9600 | 0.4926 | 0.7992 | 0.7993 |
| 0.2873 | 251.28 | 9800 | 0.4913 | 0.7976 | 0.7977 |
| 0.2875 | 256.41 | 10000 | 0.4899 | 0.7976 | 0.7977 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_prom_prom_core_tata-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_prom_prom_core_tata-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T05:56:29+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_prom_prom_core_tata-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_prom_prom_core_tata](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_prom_prom_core_tata) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6247
- F1 Score: 0.8222
- Accuracy: 0.8222
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.5763 | 5.13 | 200 | 0.5555 | 0.7217 | 0.7227 |
| 0.498 | 10.26 | 400 | 0.5365 | 0.7505 | 0.7520 |
| 0.4604 | 15.38 | 600 | 0.5318 | 0.7472 | 0.7488 |
| 0.4267 | 20.51 | 800 | 0.4895 | 0.7798 | 0.7798 |
| 0.3931 | 25.64 | 1000 | 0.4848 | 0.7749 | 0.7749 |
| 0.362 | 30.77 | 1200 | 0.4607 | 0.8057 | 0.8059 |
| 0.338 | 35.9 | 1400 | 0.4576 | 0.8026 | 0.8026 |
| 0.315 | 41.03 | 1600 | 0.4507 | 0.8006 | 0.8010 |
| 0.2968 | 46.15 | 1800 | 0.4532 | 0.8140 | 0.8140 |
| 0.2813 | 51.28 | 2000 | 0.4684 | 0.8087 | 0.8091 |
| 0.2655 | 56.41 | 2200 | 0.4970 | 0.8123 | 0.8124 |
| 0.2577 | 61.54 | 2400 | 0.4923 | 0.8007 | 0.8010 |
| 0.2449 | 66.67 | 2600 | 0.4722 | 0.8204 | 0.8206 |
| 0.2349 | 71.79 | 2800 | 0.4885 | 0.8173 | 0.8173 |
| 0.2217 | 76.92 | 3000 | 0.5013 | 0.8172 | 0.8173 |
| 0.2111 | 82.05 | 3200 | 0.5198 | 0.8205 | 0.8206 |
| 0.2005 | 87.18 | 3400 | 0.5395 | 0.8170 | 0.8173 |
| 0.1939 | 92.31 | 3600 | 0.5382 | 0.8123 | 0.8124 |
| 0.1867 | 97.44 | 3800 | 0.5531 | 0.8254 | 0.8254 |
| 0.1777 | 102.56 | 4000 | 0.5748 | 0.8187 | 0.8189 |
| 0.171 | 107.69 | 4200 | 0.5901 | 0.8138 | 0.8140 |
| 0.1625 | 112.82 | 4400 | 0.5725 | 0.8222 | 0.8222 |
| 0.1571 | 117.95 | 4600 | 0.5986 | 0.8157 | 0.8157 |
| 0.1574 | 123.08 | 4800 | 0.6007 | 0.8138 | 0.8140 |
| 0.1467 | 128.21 | 5000 | 0.6231 | 0.8169 | 0.8173 |
| 0.1462 | 133.33 | 5200 | 0.5896 | 0.8204 | 0.8206 |
| 0.1371 | 138.46 | 5400 | 0.6265 | 0.8222 | 0.8222 |
| 0.1308 | 143.59 | 5600 | 0.6411 | 0.8253 | 0.8254 |
| 0.1304 | 148.72 | 5800 | 0.6175 | 0.8254 | 0.8254 |
| 0.1274 | 153.85 | 6000 | 0.6336 | 0.8205 | 0.8206 |
| 0.1276 | 158.97 | 6200 | 0.6744 | 0.8155 | 0.8157 |
| 0.1225 | 164.1 | 6400 | 0.6494 | 0.8220 | 0.8222 |
| 0.1239 | 169.23 | 6600 | 0.6373 | 0.8124 | 0.8124 |
| 0.1165 | 174.36 | 6800 | 0.6363 | 0.8238 | 0.8238 |
| 0.1151 | 179.49 | 7000 | 0.6376 | 0.8302 | 0.8303 |
| 0.1117 | 184.62 | 7200 | 0.6631 | 0.8173 | 0.8173 |
| 0.1078 | 189.74 | 7400 | 0.6730 | 0.8270 | 0.8271 |
| 0.1058 | 194.87 | 7600 | 0.6678 | 0.8271 | 0.8271 |
| 0.1015 | 200.0 | 7800 | 0.6791 | 0.8254 | 0.8254 |
| 0.104 | 205.13 | 8000 | 0.6991 | 0.8186 | 0.8189 |
| 0.1034 | 210.26 | 8200 | 0.6741 | 0.8189 | 0.8189 |
| 0.1026 | 215.38 | 8400 | 0.6680 | 0.8287 | 0.8287 |
| 0.1 | 220.51 | 8600 | 0.6933 | 0.8171 | 0.8173 |
| 0.0987 | 225.64 | 8800 | 0.6859 | 0.8254 | 0.8254 |
| 0.0976 | 230.77 | 9000 | 0.6847 | 0.8254 | 0.8254 |
| 0.0966 | 235.9 | 9200 | 0.6927 | 0.8237 | 0.8238 |
| 0.0968 | 241.03 | 9400 | 0.6888 | 0.8238 | 0.8238 |
| 0.0931 | 246.15 | 9600 | 0.6931 | 0.8253 | 0.8254 |
| 0.0906 | 251.28 | 9800 | 0.6998 | 0.8254 | 0.8254 |
| 0.0916 | 256.41 | 10000 | 0.6957 | 0.8254 | 0.8254 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_prom_prom_core_tata-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_prom_prom_core_tata-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T05:57:21+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_prom_prom_core_tata-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_prom_prom_core_tata](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_prom_prom_core_tata) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9752
- F1 Score: 0.8271
- Accuracy: 0.8271
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.5578 | 5.13 | 200 | 0.5322 | 0.7502 | 0.7504 |
| 0.464 | 10.26 | 400 | 0.5083 | 0.7701 | 0.7716 |
| 0.3882 | 15.38 | 600 | 0.4438 | 0.8074 | 0.8075 |
| 0.3241 | 20.51 | 800 | 0.4506 | 0.8234 | 0.8238 |
| 0.2722 | 25.64 | 1000 | 0.4721 | 0.8303 | 0.8303 |
| 0.2338 | 30.77 | 1200 | 0.4767 | 0.8320 | 0.8320 |
| 0.1976 | 35.9 | 1400 | 0.5198 | 0.8336 | 0.8336 |
| 0.1754 | 41.03 | 1600 | 0.4998 | 0.8303 | 0.8303 |
| 0.1428 | 46.15 | 1800 | 0.6118 | 0.8269 | 0.8271 |
| 0.1281 | 51.28 | 2000 | 0.5731 | 0.8302 | 0.8303 |
| 0.1127 | 56.41 | 2200 | 0.6563 | 0.8319 | 0.8320 |
| 0.0994 | 61.54 | 2400 | 0.6877 | 0.8222 | 0.8222 |
| 0.0901 | 66.67 | 2600 | 0.7150 | 0.8352 | 0.8352 |
| 0.0817 | 71.79 | 2800 | 0.7223 | 0.8254 | 0.8254 |
| 0.0725 | 76.92 | 3000 | 0.7396 | 0.8334 | 0.8336 |
| 0.0663 | 82.05 | 3200 | 0.7565 | 0.8335 | 0.8336 |
| 0.0601 | 87.18 | 3400 | 0.7511 | 0.8418 | 0.8418 |
| 0.0589 | 92.31 | 3600 | 0.7803 | 0.8383 | 0.8385 |
| 0.0521 | 97.44 | 3800 | 0.8330 | 0.8385 | 0.8385 |
| 0.0525 | 102.56 | 4000 | 0.8002 | 0.8434 | 0.8434 |
| 0.0466 | 107.69 | 4200 | 0.7893 | 0.8385 | 0.8385 |
| 0.0414 | 112.82 | 4400 | 0.8864 | 0.8369 | 0.8369 |
| 0.0385 | 117.95 | 4600 | 0.8732 | 0.8335 | 0.8336 |
| 0.0402 | 123.08 | 4800 | 0.8392 | 0.8401 | 0.8401 |
| 0.0382 | 128.21 | 5000 | 0.8185 | 0.8285 | 0.8287 |
| 0.0384 | 133.33 | 5200 | 0.8188 | 0.8401 | 0.8401 |
| 0.0334 | 138.46 | 5400 | 0.8668 | 0.8433 | 0.8434 |
| 0.0297 | 143.59 | 5600 | 0.8826 | 0.8319 | 0.8320 |
| 0.033 | 148.72 | 5800 | 0.8982 | 0.8336 | 0.8336 |
| 0.0285 | 153.85 | 6000 | 0.9081 | 0.8352 | 0.8352 |
| 0.0299 | 158.97 | 6200 | 0.8908 | 0.8384 | 0.8385 |
| 0.0296 | 164.1 | 6400 | 0.8685 | 0.8368 | 0.8369 |
| 0.0288 | 169.23 | 6600 | 0.8841 | 0.8401 | 0.8401 |
| 0.0265 | 174.36 | 6800 | 0.8954 | 0.8336 | 0.8336 |
| 0.0277 | 179.49 | 7000 | 0.8666 | 0.8417 | 0.8418 |
| 0.0243 | 184.62 | 7200 | 0.8899 | 0.8401 | 0.8401 |
| 0.023 | 189.74 | 7400 | 0.8804 | 0.8418 | 0.8418 |
| 0.0233 | 194.87 | 7600 | 0.9357 | 0.8401 | 0.8401 |
| 0.0244 | 200.0 | 7800 | 0.8806 | 0.8401 | 0.8401 |
| 0.0212 | 205.13 | 8000 | 0.9329 | 0.8385 | 0.8385 |
| 0.022 | 210.26 | 8200 | 0.9356 | 0.8434 | 0.8434 |
| 0.0212 | 215.38 | 8400 | 0.9286 | 0.8400 | 0.8401 |
| 0.0205 | 220.51 | 8600 | 0.9201 | 0.8434 | 0.8434 |
| 0.0215 | 225.64 | 8800 | 0.9130 | 0.8434 | 0.8434 |
| 0.021 | 230.77 | 9000 | 0.9020 | 0.8434 | 0.8434 |
| 0.0205 | 235.9 | 9200 | 0.9081 | 0.8385 | 0.8385 |
| 0.0194 | 241.03 | 9400 | 0.9260 | 0.8320 | 0.8320 |
| 0.0182 | 246.15 | 9600 | 0.9300 | 0.8352 | 0.8352 |
| 0.0172 | 251.28 | 9800 | 0.9393 | 0.8352 | 0.8352 |
| 0.0167 | 256.41 | 10000 | 0.9422 | 0.8352 | 0.8352 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_prom_prom_core_tata-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_prom_prom_core_tata-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T05:57:21+00:00 |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral-7b-dpo-full-sft-wo-kqa_golden
This model is a fine-tuned version of [Minbyul/mistral-7b-wo-kqa_golden-sft](https://huggingface.co/Minbyul/mistral-7b-wo-kqa_golden-sft) on the HuggingFaceH4/ultrafeedback_binarized dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0018
- Rewards/chosen: -0.4458
- Rewards/rejected: -10.1099
- Rewards/accuracies: 1.0
- Rewards/margins: 9.6641
- Logps/rejected: -1564.3792
- Logps/chosen: -241.2112
- Logits/rejected: -2.0516
- Logits/chosen: -1.3414
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.2478 | 0.31 | 100 | 0.0352 | -0.1739 | -4.4264 | 1.0 | 4.2525 | -996.0294 | -214.0196 | -2.9200 | -2.1162 |
| 0.1385 | 0.61 | 200 | 0.0041 | -0.3360 | -8.1997 | 1.0 | 7.8637 | -1373.3590 | -230.2282 | -2.3336 | -1.6287 |
| 0.0899 | 0.92 | 300 | 0.0019 | -0.4479 | -10.0624 | 1.0 | 9.6145 | -1559.6263 | -241.4165 | -2.0553 | -1.3416 |
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.1.2
- Datasets 2.14.6
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["alignment-handbook", "trl", "dpo", "generated_from_trainer", "trl", "dpo", "generated_from_trainer"], "datasets": ["HuggingFaceH4/ultrafeedback_binarized"], "base_model": "Minbyul/mistral-7b-wo-kqa_golden-sft", "model-index": [{"name": "mistral-7b-dpo-full-sft-wo-kqa_golden", "results": []}]} | Minbyul/mistral-7b-dpo-full-sft-wo-kqa_golden | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"trl",
"dpo",
"generated_from_trainer",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"base_model:Minbyul/mistral-7b-wo-kqa_golden-sft",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T05:57:27+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral_envs_claim_finetune2
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 5
- total_train_batch_size: 40
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 100
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.1
- Pytorch 2.1.0a0+29c30b1
- Datasets 2.19.0
- Tokenizers 0.19.1 | {"license": "apache-2.0", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "base_model": "mistralai/Mistral-7B-Instruct-v0.2", "model-index": [{"name": "mistral_envs_claim_finetune2", "results": []}]} | Haimee/mistral_envs_claim_finetune2 | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T05:58:26+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_prom_prom_300_all-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_prom_prom_300_all](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_prom_prom_300_all) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2119
- F1 Score: 0.9145
- Accuracy: 0.9145
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.4346 | 0.54 | 200 | 0.2868 | 0.8895 | 0.8895 |
| 0.2911 | 1.08 | 400 | 0.2578 | 0.8990 | 0.8990 |
| 0.2714 | 1.62 | 600 | 0.2389 | 0.9039 | 0.9039 |
| 0.2514 | 2.16 | 800 | 0.2377 | 0.9043 | 0.9044 |
| 0.2477 | 2.7 | 1000 | 0.2262 | 0.9061 | 0.9061 |
| 0.2379 | 3.24 | 1200 | 0.2297 | 0.9080 | 0.9081 |
| 0.2416 | 3.78 | 1400 | 0.2212 | 0.9102 | 0.9103 |
| 0.2327 | 4.32 | 1600 | 0.2150 | 0.9111 | 0.9111 |
| 0.2277 | 4.86 | 1800 | 0.2154 | 0.9120 | 0.9120 |
| 0.224 | 5.41 | 2000 | 0.2112 | 0.9142 | 0.9142 |
| 0.2231 | 5.95 | 2200 | 0.2120 | 0.9155 | 0.9155 |
| 0.2227 | 6.49 | 2400 | 0.2081 | 0.9155 | 0.9155 |
| 0.2201 | 7.03 | 2600 | 0.2055 | 0.9164 | 0.9164 |
| 0.2153 | 7.57 | 2800 | 0.2038 | 0.9177 | 0.9177 |
| 0.2176 | 8.11 | 3000 | 0.2018 | 0.9194 | 0.9194 |
| 0.2154 | 8.65 | 3200 | 0.2013 | 0.9193 | 0.9193 |
| 0.2099 | 9.19 | 3400 | 0.1997 | 0.9189 | 0.9189 |
| 0.2076 | 9.73 | 3600 | 0.1996 | 0.9187 | 0.9187 |
| 0.2161 | 10.27 | 3800 | 0.1973 | 0.9206 | 0.9206 |
| 0.2091 | 10.81 | 4000 | 0.1972 | 0.9206 | 0.9206 |
| 0.2112 | 11.35 | 4200 | 0.2030 | 0.9183 | 0.9184 |
| 0.2085 | 11.89 | 4400 | 0.1967 | 0.9208 | 0.9208 |
| 0.2041 | 12.43 | 4600 | 0.1979 | 0.9212 | 0.9213 |
| 0.2089 | 12.97 | 4800 | 0.1950 | 0.9211 | 0.9211 |
| 0.2047 | 13.51 | 5000 | 0.1969 | 0.9208 | 0.9208 |
| 0.2065 | 14.05 | 5200 | 0.1946 | 0.9223 | 0.9223 |
| 0.2033 | 14.59 | 5400 | 0.1977 | 0.9209 | 0.9209 |
| 0.2021 | 15.14 | 5600 | 0.1989 | 0.9212 | 0.9213 |
| 0.2004 | 15.68 | 5800 | 0.1977 | 0.9218 | 0.9218 |
| 0.2041 | 16.22 | 6000 | 0.2004 | 0.9197 | 0.9198 |
| 0.2004 | 16.76 | 6200 | 0.1956 | 0.9219 | 0.9220 |
| 0.2002 | 17.3 | 6400 | 0.1943 | 0.9198 | 0.9198 |
| 0.2044 | 17.84 | 6600 | 0.1946 | 0.9206 | 0.9206 |
| 0.1962 | 18.38 | 6800 | 0.1966 | 0.9221 | 0.9221 |
| 0.2041 | 18.92 | 7000 | 0.1957 | 0.9219 | 0.9220 |
| 0.201 | 19.46 | 7200 | 0.1931 | 0.9235 | 0.9235 |
| 0.1972 | 20.0 | 7400 | 0.1928 | 0.9223 | 0.9223 |
| 0.202 | 20.54 | 7600 | 0.1928 | 0.9240 | 0.9240 |
| 0.2 | 21.08 | 7800 | 0.1928 | 0.9236 | 0.9236 |
| 0.1977 | 21.62 | 8000 | 0.1944 | 0.9233 | 0.9233 |
| 0.198 | 22.16 | 8200 | 0.1929 | 0.9240 | 0.9240 |
| 0.1908 | 22.7 | 8400 | 0.1942 | 0.9241 | 0.9242 |
| 0.202 | 23.24 | 8600 | 0.1933 | 0.9231 | 0.9231 |
| 0.1959 | 23.78 | 8800 | 0.1932 | 0.9231 | 0.9231 |
| 0.2012 | 24.32 | 9000 | 0.1924 | 0.9235 | 0.9235 |
| 0.1952 | 24.86 | 9200 | 0.1923 | 0.9235 | 0.9235 |
| 0.195 | 25.41 | 9400 | 0.1928 | 0.9238 | 0.9238 |
| 0.1939 | 25.95 | 9600 | 0.1925 | 0.9231 | 0.9231 |
| 0.1969 | 26.49 | 9800 | 0.1940 | 0.9233 | 0.9233 |
| 0.1955 | 27.03 | 10000 | 0.1931 | 0.9233 | 0.9233 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_prom_prom_300_all-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_prom_prom_300_all-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T05:59:37+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_prom_prom_300_all-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_prom_prom_300_all](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_prom_prom_300_all) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2006
- F1 Score: 0.9216
- Accuracy: 0.9216
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.3689 | 0.54 | 200 | 0.2509 | 0.9032 | 0.9032 |
| 0.2545 | 1.08 | 400 | 0.2269 | 0.9081 | 0.9081 |
| 0.2364 | 1.62 | 600 | 0.2112 | 0.9159 | 0.9159 |
| 0.2203 | 2.16 | 800 | 0.2049 | 0.9203 | 0.9203 |
| 0.2183 | 2.7 | 1000 | 0.2038 | 0.9164 | 0.9164 |
| 0.2107 | 3.24 | 1200 | 0.2041 | 0.9177 | 0.9177 |
| 0.2129 | 3.78 | 1400 | 0.2001 | 0.9182 | 0.9182 |
| 0.206 | 4.32 | 1600 | 0.1946 | 0.9220 | 0.9220 |
| 0.2031 | 4.86 | 1800 | 0.1933 | 0.9230 | 0.9230 |
| 0.199 | 5.41 | 2000 | 0.2003 | 0.9199 | 0.9199 |
| 0.1979 | 5.95 | 2200 | 0.1933 | 0.9231 | 0.9231 |
| 0.1985 | 6.49 | 2400 | 0.1892 | 0.9228 | 0.9228 |
| 0.1966 | 7.03 | 2600 | 0.1923 | 0.9253 | 0.9253 |
| 0.1907 | 7.57 | 2800 | 0.1905 | 0.9248 | 0.9248 |
| 0.1936 | 8.11 | 3000 | 0.1867 | 0.9265 | 0.9265 |
| 0.1901 | 8.65 | 3200 | 0.1891 | 0.9243 | 0.9243 |
| 0.1872 | 9.19 | 3400 | 0.1878 | 0.9247 | 0.9247 |
| 0.183 | 9.73 | 3600 | 0.1841 | 0.9255 | 0.9255 |
| 0.1901 | 10.27 | 3800 | 0.1859 | 0.9236 | 0.9236 |
| 0.1842 | 10.81 | 4000 | 0.1845 | 0.9277 | 0.9277 |
| 0.1845 | 11.35 | 4200 | 0.1855 | 0.9274 | 0.9274 |
| 0.1827 | 11.89 | 4400 | 0.1856 | 0.9262 | 0.9262 |
| 0.1807 | 12.43 | 4600 | 0.1813 | 0.9270 | 0.9270 |
| 0.1798 | 12.97 | 4800 | 0.1835 | 0.9265 | 0.9265 |
| 0.178 | 13.51 | 5000 | 0.1861 | 0.9272 | 0.9272 |
| 0.1787 | 14.05 | 5200 | 0.1860 | 0.9235 | 0.9235 |
| 0.1745 | 14.59 | 5400 | 0.1862 | 0.9275 | 0.9275 |
| 0.175 | 15.14 | 5600 | 0.1869 | 0.9262 | 0.9262 |
| 0.1725 | 15.68 | 5800 | 0.1846 | 0.9231 | 0.9231 |
| 0.1746 | 16.22 | 6000 | 0.1852 | 0.9258 | 0.9258 |
| 0.1702 | 16.76 | 6200 | 0.1853 | 0.9257 | 0.9257 |
| 0.1717 | 17.3 | 6400 | 0.1836 | 0.9260 | 0.9260 |
| 0.1738 | 17.84 | 6600 | 0.1820 | 0.9294 | 0.9294 |
| 0.1663 | 18.38 | 6800 | 0.1842 | 0.9235 | 0.9235 |
| 0.1726 | 18.92 | 7000 | 0.1802 | 0.9279 | 0.9279 |
| 0.1699 | 19.46 | 7200 | 0.1822 | 0.9272 | 0.9272 |
| 0.167 | 20.0 | 7400 | 0.1822 | 0.9289 | 0.9289 |
| 0.1712 | 20.54 | 7600 | 0.1813 | 0.9290 | 0.9291 |
| 0.1678 | 21.08 | 7800 | 0.1805 | 0.9289 | 0.9289 |
| 0.1652 | 21.62 | 8000 | 0.1828 | 0.9299 | 0.9299 |
| 0.1651 | 22.16 | 8200 | 0.1817 | 0.9274 | 0.9274 |
| 0.16 | 22.7 | 8400 | 0.1859 | 0.9258 | 0.9258 |
| 0.1684 | 23.24 | 8600 | 0.1830 | 0.9284 | 0.9284 |
| 0.1641 | 23.78 | 8800 | 0.1836 | 0.9262 | 0.9262 |
| 0.1684 | 24.32 | 9000 | 0.1815 | 0.9269 | 0.9269 |
| 0.1609 | 24.86 | 9200 | 0.1823 | 0.9274 | 0.9274 |
| 0.1624 | 25.41 | 9400 | 0.1812 | 0.9274 | 0.9274 |
| 0.1616 | 25.95 | 9600 | 0.1819 | 0.9277 | 0.9277 |
| 0.1634 | 26.49 | 9800 | 0.1821 | 0.9284 | 0.9284 |
| 0.1601 | 27.03 | 10000 | 0.1819 | 0.9284 | 0.9284 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_prom_prom_300_all-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_prom_prom_300_all-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T05:59:48+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_prom_prom_300_all-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_prom_prom_300_all](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_prom_prom_300_all) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1981
- F1 Score: 0.9235
- Accuracy: 0.9235
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.3368 | 0.54 | 200 | 0.2353 | 0.9084 | 0.9084 |
| 0.2343 | 1.08 | 400 | 0.2030 | 0.9176 | 0.9176 |
| 0.2205 | 1.62 | 600 | 0.1989 | 0.9197 | 0.9198 |
| 0.209 | 2.16 | 800 | 0.1961 | 0.9209 | 0.9209 |
| 0.207 | 2.7 | 1000 | 0.1989 | 0.9149 | 0.9149 |
| 0.1983 | 3.24 | 1200 | 0.1933 | 0.9184 | 0.9184 |
| 0.1988 | 3.78 | 1400 | 0.1986 | 0.9192 | 0.9193 |
| 0.1943 | 4.32 | 1600 | 0.1880 | 0.9255 | 0.9255 |
| 0.1883 | 4.86 | 1800 | 0.1852 | 0.9248 | 0.9248 |
| 0.182 | 5.41 | 2000 | 0.1877 | 0.9265 | 0.9265 |
| 0.1841 | 5.95 | 2200 | 0.1843 | 0.9263 | 0.9264 |
| 0.1817 | 6.49 | 2400 | 0.1895 | 0.9239 | 0.9240 |
| 0.1795 | 7.03 | 2600 | 0.1829 | 0.9270 | 0.9270 |
| 0.1726 | 7.57 | 2800 | 0.1849 | 0.9267 | 0.9267 |
| 0.1723 | 8.11 | 3000 | 0.1821 | 0.9287 | 0.9287 |
| 0.1686 | 8.65 | 3200 | 0.1881 | 0.9278 | 0.9279 |
| 0.1656 | 9.19 | 3400 | 0.1821 | 0.9282 | 0.9282 |
| 0.1605 | 9.73 | 3600 | 0.1768 | 0.9291 | 0.9291 |
| 0.1656 | 10.27 | 3800 | 0.1778 | 0.9289 | 0.9289 |
| 0.1606 | 10.81 | 4000 | 0.1741 | 0.9316 | 0.9316 |
| 0.1594 | 11.35 | 4200 | 0.1806 | 0.9309 | 0.9309 |
| 0.1563 | 11.89 | 4400 | 0.1826 | 0.9305 | 0.9306 |
| 0.1554 | 12.43 | 4600 | 0.1727 | 0.9323 | 0.9323 |
| 0.1513 | 12.97 | 4800 | 0.1741 | 0.9285 | 0.9285 |
| 0.1481 | 13.51 | 5000 | 0.1776 | 0.9297 | 0.9297 |
| 0.1486 | 14.05 | 5200 | 0.1869 | 0.9218 | 0.9218 |
| 0.1429 | 14.59 | 5400 | 0.1801 | 0.9304 | 0.9304 |
| 0.1445 | 15.14 | 5600 | 0.1792 | 0.9316 | 0.9316 |
| 0.1408 | 15.68 | 5800 | 0.1781 | 0.9304 | 0.9304 |
| 0.1408 | 16.22 | 6000 | 0.1751 | 0.9301 | 0.9301 |
| 0.1352 | 16.76 | 6200 | 0.1871 | 0.9263 | 0.9264 |
| 0.138 | 17.3 | 6400 | 0.1750 | 0.9294 | 0.9294 |
| 0.1358 | 17.84 | 6600 | 0.1777 | 0.9323 | 0.9323 |
| 0.1315 | 18.38 | 6800 | 0.1856 | 0.9299 | 0.9299 |
| 0.1369 | 18.92 | 7000 | 0.1762 | 0.9316 | 0.9316 |
| 0.1321 | 19.46 | 7200 | 0.1793 | 0.9306 | 0.9306 |
| 0.1311 | 20.0 | 7400 | 0.1807 | 0.9334 | 0.9334 |
| 0.1323 | 20.54 | 7600 | 0.1799 | 0.9306 | 0.9306 |
| 0.1272 | 21.08 | 7800 | 0.1808 | 0.9307 | 0.9307 |
| 0.1237 | 21.62 | 8000 | 0.1877 | 0.9280 | 0.9280 |
| 0.1246 | 22.16 | 8200 | 0.1837 | 0.9302 | 0.9302 |
| 0.122 | 22.7 | 8400 | 0.1848 | 0.9301 | 0.9301 |
| 0.1236 | 23.24 | 8600 | 0.1878 | 0.9299 | 0.9299 |
| 0.1224 | 23.78 | 8800 | 0.1875 | 0.9294 | 0.9294 |
| 0.1232 | 24.32 | 9000 | 0.1848 | 0.9304 | 0.9304 |
| 0.1228 | 24.86 | 9200 | 0.1844 | 0.9307 | 0.9307 |
| 0.1188 | 25.41 | 9400 | 0.1856 | 0.9299 | 0.9299 |
| 0.12 | 25.95 | 9600 | 0.1847 | 0.9316 | 0.9316 |
| 0.1195 | 26.49 | 9800 | 0.1859 | 0.9309 | 0.9309 |
| 0.1165 | 27.03 | 10000 | 0.1854 | 0.9318 | 0.9318 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_prom_prom_300_all-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_prom_prom_300_all-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T05:59:58+00:00 |
null | null |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# O0430HMA16
This model is a fine-tuned version of [allenai/OLMo-1B](https://huggingface.co/allenai/OLMo-1B) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1386
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 100
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.5715 | 0.09 | 10 | 0.2837 |
| 0.1807 | 0.18 | 20 | 0.1554 |
| 0.1515 | 0.27 | 30 | 0.1672 |
| 0.1573 | 0.36 | 40 | 0.1535 |
| 0.1517 | 0.45 | 50 | 0.1504 |
| 0.1521 | 0.54 | 60 | 0.1490 |
| 0.1513 | 0.63 | 70 | 0.1472 |
| 0.1494 | 0.73 | 80 | 0.1574 |
| 0.1484 | 0.82 | 90 | 0.1490 |
| 0.149 | 0.91 | 100 | 0.1494 |
| 0.1512 | 1.0 | 110 | 0.1499 |
| 0.1463 | 1.09 | 120 | 0.1482 |
| 0.1462 | 1.18 | 130 | 0.1522 |
| 0.1484 | 1.27 | 140 | 0.1487 |
| 0.1499 | 1.36 | 150 | 0.1501 |
| 0.1463 | 1.45 | 160 | 0.1478 |
| 0.146 | 1.54 | 170 | 0.1477 |
| 0.1472 | 1.63 | 180 | 0.1472 |
| 0.1461 | 1.72 | 190 | 0.1490 |
| 0.1443 | 1.81 | 200 | 0.1497 |
| 0.1494 | 1.9 | 210 | 0.1503 |
| 0.1456 | 1.99 | 220 | 0.1472 |
| 0.1429 | 2.08 | 230 | 0.1446 |
| 0.1383 | 2.18 | 240 | 0.1445 |
| 0.1401 | 2.27 | 250 | 0.1450 |
| 0.141 | 2.36 | 260 | 0.1459 |
| 0.1398 | 2.45 | 270 | 0.1428 |
| 0.1341 | 2.54 | 280 | 0.1389 |
| 0.1345 | 2.63 | 290 | 0.1411 |
| 0.1347 | 2.72 | 300 | 0.1395 |
| 0.1335 | 2.81 | 310 | 0.1387 |
| 0.1321 | 2.9 | 320 | 0.1387 |
| 0.1375 | 2.99 | 330 | 0.1386 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "allenai/OLMo-1B", "model-index": [{"name": "O0430HMA16", "results": []}]} | Litzy619/O0430HMA16 | null | [
"safetensors",
"generated_from_trainer",
"base_model:allenai/OLMo-1B",
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T06:03:10+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K14ac-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K14ac](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K14ac) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4907
- F1 Score: 0.7713
- Accuracy: 0.7703
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6078 | 0.97 | 200 | 0.5696 | 0.7214 | 0.7198 |
| 0.5576 | 1.93 | 400 | 0.5322 | 0.7501 | 0.7486 |
| 0.5381 | 2.9 | 600 | 0.5385 | 0.7543 | 0.7528 |
| 0.5289 | 3.86 | 800 | 0.5084 | 0.7646 | 0.7643 |
| 0.5195 | 4.83 | 1000 | 0.5251 | 0.7586 | 0.7570 |
| 0.5138 | 5.8 | 1200 | 0.5170 | 0.7626 | 0.7610 |
| 0.5131 | 6.76 | 1400 | 0.5057 | 0.7662 | 0.7646 |
| 0.5086 | 7.73 | 1600 | 0.5034 | 0.7698 | 0.7682 |
| 0.5062 | 8.7 | 1800 | 0.5035 | 0.7668 | 0.7652 |
| 0.5012 | 9.66 | 2000 | 0.5088 | 0.7659 | 0.7643 |
| 0.5059 | 10.63 | 2200 | 0.5152 | 0.7624 | 0.7610 |
| 0.4987 | 11.59 | 2400 | 0.4991 | 0.7686 | 0.7670 |
| 0.5029 | 12.56 | 2600 | 0.5098 | 0.7674 | 0.7658 |
| 0.4966 | 13.53 | 2800 | 0.5062 | 0.7658 | 0.7643 |
| 0.4979 | 14.49 | 3000 | 0.5158 | 0.7632 | 0.7619 |
| 0.4895 | 15.46 | 3200 | 0.4918 | 0.7751 | 0.7737 |
| 0.4949 | 16.43 | 3400 | 0.5080 | 0.7645 | 0.7631 |
| 0.4919 | 17.39 | 3600 | 0.4903 | 0.7742 | 0.7728 |
| 0.4882 | 18.36 | 3800 | 0.4883 | 0.7733 | 0.7722 |
| 0.4895 | 19.32 | 4000 | 0.4909 | 0.7752 | 0.7737 |
| 0.4871 | 20.29 | 4200 | 0.4916 | 0.7761 | 0.7746 |
| 0.487 | 21.26 | 4400 | 0.4970 | 0.7722 | 0.7707 |
| 0.4855 | 22.22 | 4600 | 0.5079 | 0.7702 | 0.7688 |
| 0.4866 | 23.19 | 4800 | 0.4903 | 0.7770 | 0.7755 |
| 0.4869 | 24.15 | 5000 | 0.4891 | 0.7731 | 0.7716 |
| 0.4828 | 25.12 | 5200 | 0.5005 | 0.7713 | 0.7697 |
| 0.4815 | 26.09 | 5400 | 0.4942 | 0.7740 | 0.7725 |
| 0.4814 | 27.05 | 5600 | 0.5042 | 0.7690 | 0.7676 |
| 0.4829 | 28.02 | 5800 | 0.4832 | 0.7760 | 0.7746 |
| 0.4815 | 28.99 | 6000 | 0.4999 | 0.7733 | 0.7719 |
| 0.4804 | 29.95 | 6200 | 0.4979 | 0.7743 | 0.7728 |
| 0.4816 | 30.92 | 6400 | 0.4819 | 0.7778 | 0.7764 |
| 0.4798 | 31.88 | 6600 | 0.4874 | 0.7749 | 0.7734 |
| 0.4784 | 32.85 | 6800 | 0.4942 | 0.7752 | 0.7737 |
| 0.483 | 33.82 | 7000 | 0.4982 | 0.7731 | 0.7716 |
| 0.4786 | 34.78 | 7200 | 0.4936 | 0.7731 | 0.7716 |
| 0.4794 | 35.75 | 7400 | 0.4892 | 0.7770 | 0.7755 |
| 0.4748 | 36.71 | 7600 | 0.4904 | 0.7731 | 0.7716 |
| 0.4772 | 37.68 | 7800 | 0.4898 | 0.7758 | 0.7743 |
| 0.4771 | 38.65 | 8000 | 0.4837 | 0.7770 | 0.7755 |
| 0.4826 | 39.61 | 8200 | 0.4880 | 0.7749 | 0.7734 |
| 0.4715 | 40.58 | 8400 | 0.4948 | 0.7725 | 0.7710 |
| 0.4742 | 41.55 | 8600 | 0.4891 | 0.7734 | 0.7719 |
| 0.4721 | 42.51 | 8800 | 0.4891 | 0.7737 | 0.7722 |
| 0.475 | 43.48 | 9000 | 0.4985 | 0.7743 | 0.7728 |
| 0.4741 | 44.44 | 9200 | 0.4925 | 0.7740 | 0.7725 |
| 0.4757 | 45.41 | 9400 | 0.4892 | 0.7731 | 0.7716 |
| 0.469 | 46.38 | 9600 | 0.4934 | 0.7740 | 0.7725 |
| 0.4794 | 47.34 | 9800 | 0.4906 | 0.7740 | 0.7725 |
| 0.474 | 48.31 | 10000 | 0.4891 | 0.7740 | 0.7725 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K14ac-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K14ac-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:04:03+00:00 |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | pruning/v16o0y7 | null | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:04:38+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K14ac-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K14ac](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K14ac) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4984
- F1 Score: 0.7700
- Accuracy: 0.7691
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.5881 | 0.97 | 200 | 0.5331 | 0.7519 | 0.7504 |
| 0.5288 | 1.93 | 400 | 0.5084 | 0.7643 | 0.7628 |
| 0.5108 | 2.9 | 600 | 0.5162 | 0.7548 | 0.7534 |
| 0.5075 | 3.86 | 800 | 0.4914 | 0.7690 | 0.7682 |
| 0.5005 | 4.83 | 1000 | 0.5060 | 0.7655 | 0.7640 |
| 0.4943 | 5.8 | 1200 | 0.4978 | 0.7701 | 0.7685 |
| 0.4904 | 6.76 | 1400 | 0.4867 | 0.7751 | 0.7737 |
| 0.4863 | 7.73 | 1600 | 0.4914 | 0.7740 | 0.7725 |
| 0.4831 | 8.7 | 1800 | 0.4916 | 0.7698 | 0.7682 |
| 0.4792 | 9.66 | 2000 | 0.4948 | 0.7734 | 0.7719 |
| 0.4808 | 10.63 | 2200 | 0.4976 | 0.7713 | 0.7697 |
| 0.4736 | 11.59 | 2400 | 0.4820 | 0.7721 | 0.7707 |
| 0.4753 | 12.56 | 2600 | 0.4928 | 0.7758 | 0.7743 |
| 0.4685 | 13.53 | 2800 | 0.4896 | 0.7722 | 0.7707 |
| 0.469 | 14.49 | 3000 | 0.4958 | 0.7746 | 0.7731 |
| 0.4594 | 15.46 | 3200 | 0.4800 | 0.7779 | 0.7767 |
| 0.4653 | 16.43 | 3400 | 0.4969 | 0.7736 | 0.7722 |
| 0.4602 | 17.39 | 3600 | 0.4808 | 0.7778 | 0.7764 |
| 0.4567 | 18.36 | 3800 | 0.4809 | 0.7765 | 0.7761 |
| 0.4558 | 19.32 | 4000 | 0.4864 | 0.7802 | 0.7788 |
| 0.4537 | 20.29 | 4200 | 0.4880 | 0.7760 | 0.7746 |
| 0.4516 | 21.26 | 4400 | 0.4905 | 0.7761 | 0.7746 |
| 0.4498 | 22.22 | 4600 | 0.5092 | 0.7702 | 0.7688 |
| 0.4484 | 23.19 | 4800 | 0.4872 | 0.7731 | 0.7719 |
| 0.4479 | 24.15 | 5000 | 0.4912 | 0.7679 | 0.7664 |
| 0.4463 | 25.12 | 5200 | 0.5022 | 0.7737 | 0.7722 |
| 0.4407 | 26.09 | 5400 | 0.4960 | 0.7710 | 0.7694 |
| 0.4414 | 27.05 | 5600 | 0.5094 | 0.7707 | 0.7691 |
| 0.4399 | 28.02 | 5800 | 0.4877 | 0.7719 | 0.7707 |
| 0.44 | 28.99 | 6000 | 0.4894 | 0.7752 | 0.7737 |
| 0.4353 | 29.95 | 6200 | 0.4999 | 0.7692 | 0.7676 |
| 0.4355 | 30.92 | 6400 | 0.4850 | 0.7729 | 0.7725 |
| 0.4349 | 31.88 | 6600 | 0.4909 | 0.7722 | 0.7710 |
| 0.432 | 32.85 | 6800 | 0.5072 | 0.7674 | 0.7658 |
| 0.4368 | 33.82 | 7000 | 0.5021 | 0.7707 | 0.7691 |
| 0.4289 | 34.78 | 7200 | 0.5049 | 0.7716 | 0.7700 |
| 0.4296 | 35.75 | 7400 | 0.4976 | 0.7747 | 0.7734 |
| 0.4261 | 36.71 | 7600 | 0.5024 | 0.7698 | 0.7682 |
| 0.425 | 37.68 | 7800 | 0.5051 | 0.7701 | 0.7685 |
| 0.4272 | 38.65 | 8000 | 0.4953 | 0.7735 | 0.7722 |
| 0.432 | 39.61 | 8200 | 0.4941 | 0.7711 | 0.7697 |
| 0.4189 | 40.58 | 8400 | 0.5041 | 0.7701 | 0.7685 |
| 0.421 | 41.55 | 8600 | 0.5030 | 0.7710 | 0.7694 |
| 0.4204 | 42.51 | 8800 | 0.4993 | 0.7706 | 0.7691 |
| 0.421 | 43.48 | 9000 | 0.5108 | 0.7710 | 0.7694 |
| 0.4199 | 44.44 | 9200 | 0.5078 | 0.7677 | 0.7661 |
| 0.4216 | 45.41 | 9400 | 0.5051 | 0.7692 | 0.7676 |
| 0.4155 | 46.38 | 9600 | 0.5062 | 0.7683 | 0.7667 |
| 0.4253 | 47.34 | 9800 | 0.5025 | 0.7701 | 0.7685 |
| 0.4169 | 48.31 | 10000 | 0.5015 | 0.7724 | 0.7710 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K14ac-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K14ac-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:04:50+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K14ac-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K14ac](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K14ac) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4924
- F1 Score: 0.7762
- Accuracy: 0.7752
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.5719 | 0.97 | 200 | 0.5131 | 0.7592 | 0.7576 |
| 0.516 | 1.93 | 400 | 0.4993 | 0.7691 | 0.7676 |
| 0.5012 | 2.9 | 600 | 0.5039 | 0.7604 | 0.7589 |
| 0.4962 | 3.86 | 800 | 0.4826 | 0.7744 | 0.7734 |
| 0.4878 | 4.83 | 1000 | 0.5088 | 0.7652 | 0.7637 |
| 0.4813 | 5.8 | 1200 | 0.4903 | 0.7764 | 0.7749 |
| 0.4734 | 6.76 | 1400 | 0.4825 | 0.7806 | 0.7791 |
| 0.4678 | 7.73 | 1600 | 0.4871 | 0.7731 | 0.7716 |
| 0.464 | 8.7 | 1800 | 0.4969 | 0.7730 | 0.7716 |
| 0.457 | 9.66 | 2000 | 0.4931 | 0.7761 | 0.7746 |
| 0.4555 | 10.63 | 2200 | 0.5066 | 0.7755 | 0.7740 |
| 0.4445 | 11.59 | 2400 | 0.4927 | 0.7700 | 0.7688 |
| 0.4455 | 12.56 | 2600 | 0.5078 | 0.7752 | 0.7737 |
| 0.4334 | 13.53 | 2800 | 0.5079 | 0.7677 | 0.7661 |
| 0.4316 | 14.49 | 3000 | 0.4904 | 0.7696 | 0.7682 |
| 0.4191 | 15.46 | 3200 | 0.4980 | 0.7759 | 0.7749 |
| 0.4206 | 16.43 | 3400 | 0.4976 | 0.7710 | 0.7694 |
| 0.4119 | 17.39 | 3600 | 0.5108 | 0.7670 | 0.7655 |
| 0.4073 | 18.36 | 3800 | 0.5048 | 0.7689 | 0.7691 |
| 0.3984 | 19.32 | 4000 | 0.5055 | 0.7800 | 0.7788 |
| 0.3956 | 20.29 | 4200 | 0.5051 | 0.7701 | 0.7691 |
| 0.3896 | 21.26 | 4400 | 0.5276 | 0.7695 | 0.7679 |
| 0.3835 | 22.22 | 4600 | 0.5343 | 0.7647 | 0.7631 |
| 0.3797 | 23.19 | 4800 | 0.5330 | 0.7693 | 0.7679 |
| 0.3742 | 24.15 | 5000 | 0.5308 | 0.7655 | 0.7643 |
| 0.3716 | 25.12 | 5200 | 0.5492 | 0.7650 | 0.7634 |
| 0.3631 | 26.09 | 5400 | 0.5351 | 0.7614 | 0.7598 |
| 0.3565 | 27.05 | 5600 | 0.5650 | 0.7677 | 0.7661 |
| 0.3511 | 28.02 | 5800 | 0.5519 | 0.7723 | 0.7710 |
| 0.3508 | 28.99 | 6000 | 0.5461 | 0.7672 | 0.7658 |
| 0.3449 | 29.95 | 6200 | 0.5521 | 0.7676 | 0.7664 |
| 0.3422 | 30.92 | 6400 | 0.5529 | 0.7701 | 0.7703 |
| 0.3384 | 31.88 | 6600 | 0.5605 | 0.7624 | 0.7610 |
| 0.3347 | 32.85 | 6800 | 0.5864 | 0.7611 | 0.7595 |
| 0.3308 | 33.82 | 7000 | 0.5862 | 0.7644 | 0.7628 |
| 0.3215 | 34.78 | 7200 | 0.6019 | 0.7590 | 0.7573 |
| 0.3212 | 35.75 | 7400 | 0.5779 | 0.7651 | 0.7637 |
| 0.3204 | 36.71 | 7600 | 0.5864 | 0.7660 | 0.7646 |
| 0.3105 | 37.68 | 7800 | 0.6002 | 0.7599 | 0.7582 |
| 0.3132 | 38.65 | 8000 | 0.5929 | 0.7654 | 0.7640 |
| 0.317 | 39.61 | 8200 | 0.5880 | 0.7680 | 0.7670 |
| 0.3075 | 40.58 | 8400 | 0.6154 | 0.7629 | 0.7613 |
| 0.3072 | 41.55 | 8600 | 0.6056 | 0.7673 | 0.7658 |
| 0.3029 | 42.51 | 8800 | 0.6055 | 0.7624 | 0.7610 |
| 0.3003 | 43.48 | 9000 | 0.6175 | 0.7647 | 0.7631 |
| 0.3014 | 44.44 | 9200 | 0.6056 | 0.7622 | 0.7607 |
| 0.299 | 45.41 | 9400 | 0.6095 | 0.7637 | 0.7622 |
| 0.2925 | 46.38 | 9600 | 0.6190 | 0.7637 | 0.7622 |
| 0.3016 | 47.34 | 9800 | 0.6069 | 0.7605 | 0.7592 |
| 0.297 | 48.31 | 10000 | 0.6072 | 0.7626 | 0.7613 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K14ac-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K14ac-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:04:53+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K4me2-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K4me2](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K4me2) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5889
- F1 Score: 0.6823
- Accuracy: 0.6859
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6634 | 1.04 | 200 | 0.6368 | 0.5949 | 0.6370 |
| 0.6269 | 2.08 | 400 | 0.6301 | 0.6479 | 0.6478 |
| 0.6197 | 3.12 | 600 | 0.6218 | 0.6430 | 0.6637 |
| 0.6175 | 4.17 | 800 | 0.6171 | 0.6532 | 0.6634 |
| 0.6135 | 5.21 | 1000 | 0.6189 | 0.6562 | 0.6572 |
| 0.6077 | 6.25 | 1200 | 0.6137 | 0.6643 | 0.6699 |
| 0.6004 | 7.29 | 1400 | 0.6209 | 0.6650 | 0.6641 |
| 0.6018 | 8.33 | 1600 | 0.6177 | 0.6605 | 0.6618 |
| 0.5998 | 9.38 | 1800 | 0.6248 | 0.6571 | 0.6546 |
| 0.5971 | 10.42 | 2000 | 0.6112 | 0.6675 | 0.6689 |
| 0.5978 | 11.46 | 2200 | 0.6064 | 0.6649 | 0.6725 |
| 0.5902 | 12.5 | 2400 | 0.6080 | 0.6656 | 0.6709 |
| 0.5888 | 13.54 | 2600 | 0.6064 | 0.6657 | 0.6742 |
| 0.591 | 14.58 | 2800 | 0.6076 | 0.6601 | 0.6712 |
| 0.5931 | 15.62 | 3000 | 0.6061 | 0.6685 | 0.6748 |
| 0.5876 | 16.67 | 3200 | 0.6108 | 0.6668 | 0.6686 |
| 0.5866 | 17.71 | 3400 | 0.6083 | 0.6722 | 0.6764 |
| 0.587 | 18.75 | 3600 | 0.6062 | 0.6657 | 0.6722 |
| 0.5859 | 19.79 | 3800 | 0.6069 | 0.6705 | 0.6751 |
| 0.5817 | 20.83 | 4000 | 0.6080 | 0.6707 | 0.6729 |
| 0.5844 | 21.88 | 4200 | 0.6106 | 0.6720 | 0.6738 |
| 0.5821 | 22.92 | 4400 | 0.6090 | 0.6717 | 0.6748 |
| 0.5835 | 23.96 | 4600 | 0.6083 | 0.6711 | 0.6729 |
| 0.5788 | 25.0 | 4800 | 0.6077 | 0.6734 | 0.6777 |
| 0.5792 | 26.04 | 5000 | 0.6075 | 0.6742 | 0.6777 |
| 0.5789 | 27.08 | 5200 | 0.6058 | 0.6730 | 0.6771 |
| 0.5787 | 28.12 | 5400 | 0.6047 | 0.6737 | 0.6777 |
| 0.577 | 29.17 | 5600 | 0.6072 | 0.6742 | 0.6764 |
| 0.5749 | 30.21 | 5800 | 0.6089 | 0.6764 | 0.6797 |
| 0.5777 | 31.25 | 6000 | 0.6071 | 0.6751 | 0.6787 |
| 0.5757 | 32.29 | 6200 | 0.6042 | 0.6748 | 0.6810 |
| 0.5751 | 33.33 | 6400 | 0.6049 | 0.6777 | 0.6823 |
| 0.5745 | 34.38 | 6600 | 0.6049 | 0.6736 | 0.6804 |
| 0.5729 | 35.42 | 6800 | 0.6059 | 0.6732 | 0.6787 |
| 0.5747 | 36.46 | 7000 | 0.6046 | 0.6749 | 0.6804 |
| 0.5719 | 37.5 | 7200 | 0.6063 | 0.6790 | 0.6830 |
| 0.5712 | 38.54 | 7400 | 0.6065 | 0.6757 | 0.6817 |
| 0.576 | 39.58 | 7600 | 0.6048 | 0.6730 | 0.6790 |
| 0.5734 | 40.62 | 7800 | 0.6080 | 0.6770 | 0.6790 |
| 0.572 | 41.67 | 8000 | 0.6053 | 0.6790 | 0.6826 |
| 0.5691 | 42.71 | 8200 | 0.6060 | 0.6743 | 0.6830 |
| 0.5714 | 43.75 | 8400 | 0.6064 | 0.6729 | 0.6777 |
| 0.5698 | 44.79 | 8600 | 0.6076 | 0.6774 | 0.6807 |
| 0.5691 | 45.83 | 8800 | 0.6062 | 0.6757 | 0.6810 |
| 0.5708 | 46.88 | 9000 | 0.6077 | 0.6771 | 0.6800 |
| 0.5687 | 47.92 | 9200 | 0.6071 | 0.6779 | 0.6813 |
| 0.57 | 48.96 | 9400 | 0.6062 | 0.6772 | 0.6826 |
| 0.5693 | 50.0 | 9600 | 0.6070 | 0.6768 | 0.6810 |
| 0.5705 | 51.04 | 9800 | 0.6063 | 0.6778 | 0.6823 |
| 0.5675 | 52.08 | 10000 | 0.6066 | 0.6770 | 0.6813 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K4me2-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K4me2-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:05:02+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K4me2-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K4me2](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K4me2) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5958
- F1 Score: 0.6827
- Accuracy: 0.6859
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6544 | 1.04 | 200 | 0.6235 | 0.6306 | 0.6556 |
| 0.6187 | 2.08 | 400 | 0.6353 | 0.6397 | 0.6370 |
| 0.6082 | 3.12 | 600 | 0.6119 | 0.6639 | 0.6670 |
| 0.6041 | 4.17 | 800 | 0.6275 | 0.6549 | 0.6527 |
| 0.5998 | 5.21 | 1000 | 0.6067 | 0.6745 | 0.6807 |
| 0.5941 | 6.25 | 1200 | 0.6047 | 0.6746 | 0.6777 |
| 0.5862 | 7.29 | 1400 | 0.6132 | 0.6688 | 0.6676 |
| 0.5851 | 8.33 | 1600 | 0.6192 | 0.6728 | 0.6712 |
| 0.583 | 9.38 | 1800 | 0.6262 | 0.6607 | 0.6582 |
| 0.5799 | 10.42 | 2000 | 0.5997 | 0.6783 | 0.6843 |
| 0.58 | 11.46 | 2200 | 0.6031 | 0.6759 | 0.6774 |
| 0.5704 | 12.5 | 2400 | 0.6035 | 0.6793 | 0.6820 |
| 0.569 | 13.54 | 2600 | 0.6077 | 0.6813 | 0.6813 |
| 0.5687 | 14.58 | 2800 | 0.6074 | 0.6732 | 0.6777 |
| 0.5694 | 15.62 | 3000 | 0.6038 | 0.6775 | 0.6787 |
| 0.5639 | 16.67 | 3200 | 0.6062 | 0.6764 | 0.6761 |
| 0.56 | 17.71 | 3400 | 0.6144 | 0.6696 | 0.6686 |
| 0.5615 | 18.75 | 3600 | 0.6066 | 0.6847 | 0.6865 |
| 0.5586 | 19.79 | 3800 | 0.6191 | 0.6777 | 0.6764 |
| 0.5537 | 20.83 | 4000 | 0.6056 | 0.6795 | 0.6797 |
| 0.5519 | 21.88 | 4200 | 0.6202 | 0.6727 | 0.6709 |
| 0.5497 | 22.92 | 4400 | 0.6200 | 0.6798 | 0.6787 |
| 0.5489 | 23.96 | 4600 | 0.6198 | 0.6710 | 0.6693 |
| 0.5436 | 25.0 | 4800 | 0.6249 | 0.6795 | 0.6787 |
| 0.5427 | 26.04 | 5000 | 0.6220 | 0.6797 | 0.6790 |
| 0.5429 | 27.08 | 5200 | 0.6125 | 0.6775 | 0.6768 |
| 0.5397 | 28.12 | 5400 | 0.6088 | 0.6769 | 0.6774 |
| 0.5375 | 29.17 | 5600 | 0.6170 | 0.6782 | 0.6790 |
| 0.5335 | 30.21 | 5800 | 0.6257 | 0.6752 | 0.6748 |
| 0.5343 | 31.25 | 6000 | 0.6239 | 0.6785 | 0.6777 |
| 0.5323 | 32.29 | 6200 | 0.6155 | 0.6747 | 0.6755 |
| 0.5325 | 33.33 | 6400 | 0.6229 | 0.6756 | 0.6755 |
| 0.5274 | 34.38 | 6600 | 0.6185 | 0.6718 | 0.6745 |
| 0.5289 | 35.42 | 6800 | 0.6177 | 0.6784 | 0.6790 |
| 0.5255 | 36.46 | 7000 | 0.6233 | 0.6782 | 0.6781 |
| 0.5242 | 37.5 | 7200 | 0.6262 | 0.6801 | 0.6794 |
| 0.5206 | 38.54 | 7400 | 0.6232 | 0.6783 | 0.6790 |
| 0.5248 | 39.58 | 7600 | 0.6167 | 0.6799 | 0.6823 |
| 0.5231 | 40.62 | 7800 | 0.6301 | 0.6737 | 0.6725 |
| 0.5205 | 41.67 | 8000 | 0.6185 | 0.6763 | 0.6771 |
| 0.515 | 42.71 | 8200 | 0.6307 | 0.6749 | 0.6748 |
| 0.5195 | 43.75 | 8400 | 0.6224 | 0.6778 | 0.6777 |
| 0.5169 | 44.79 | 8600 | 0.6281 | 0.6767 | 0.6761 |
| 0.5146 | 45.83 | 8800 | 0.6279 | 0.6794 | 0.6804 |
| 0.5139 | 46.88 | 9000 | 0.6355 | 0.6762 | 0.6748 |
| 0.5144 | 47.92 | 9200 | 0.6329 | 0.6781 | 0.6774 |
| 0.5148 | 48.96 | 9400 | 0.6308 | 0.6771 | 0.6774 |
| 0.5131 | 50.0 | 9600 | 0.6336 | 0.6774 | 0.6768 |
| 0.5143 | 51.04 | 9800 | 0.6331 | 0.6783 | 0.6777 |
| 0.5076 | 52.08 | 10000 | 0.6350 | 0.6765 | 0.6758 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K4me2-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K4me2-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:05:02+00:00 |
automatic-speech-recognition | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# w2v-bert-2.0-tamil-gpu-custom_preprocessed_v1
This model is a fine-tuned version of [facebook/w2v-bert-2.0](https://huggingface.co/facebook/w2v-bert-2.0) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: inf
- eval_wer: 0.4790
- eval_runtime: 231.2694
- eval_samples_per_second: 18.922
- eval_steps_per_second: 2.365
- epoch: 3.17
- step: 3900
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4.83567e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"license": "mit", "tags": ["generated_from_trainer"], "base_model": "facebook/w2v-bert-2.0", "model-index": [{"name": "w2v-bert-2.0-tamil-gpu-custom_preprocessed_v1", "results": []}]} | Sajjo/w2v-bert-2.0-tamil-gpu-custom_preprocessed_v1 | null | [
"transformers",
"tensorboard",
"safetensors",
"wav2vec2-bert",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/w2v-bert-2.0",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:05:24+00:00 |
token-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# token_classifier
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2720
- Precision: 0.6096
- Recall: 0.3170
- F1: 0.4171
- Accuracy: 0.9426
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 213 | 0.2820 | 0.6278 | 0.2641 | 0.3718 | 0.9398 |
| No log | 2.0 | 426 | 0.2720 | 0.6096 | 0.3170 | 0.4171 | 0.9426 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.1
- Tokenizers 0.15.2
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["precision", "recall", "f1", "accuracy"], "base_model": "distilbert/distilbert-base-uncased", "model-index": [{"name": "token_classifier", "results": []}]} | madanagrawal/token_classifier | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"token-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:05:38+00:00 |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | ryanyeo/kirnect-2-koAlpaca-polyglot-5.8b-remote-5150step-8batch_5epoch | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:07:36+00:00 |
null | null | {} | Kishoar/t5-small-finetuned-xsum | null | [
"region:us"
] | null | 2024-04-30T06:08:29+00:00 |
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K4me2-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K4me2](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K4me2) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5885
- F1 Score: 0.6910
- Accuracy: 0.6960
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6489 | 1.04 | 200 | 0.6205 | 0.6282 | 0.6572 |
| 0.6141 | 2.08 | 400 | 0.6325 | 0.6494 | 0.6468 |
| 0.6004 | 3.12 | 600 | 0.6101 | 0.6761 | 0.6777 |
| 0.5966 | 4.17 | 800 | 0.6098 | 0.6706 | 0.6696 |
| 0.5871 | 5.21 | 1000 | 0.6038 | 0.6727 | 0.6787 |
| 0.5799 | 6.25 | 1200 | 0.6059 | 0.6757 | 0.6748 |
| 0.5724 | 7.29 | 1400 | 0.6034 | 0.6771 | 0.6764 |
| 0.5654 | 8.33 | 1600 | 0.6109 | 0.6796 | 0.6784 |
| 0.5613 | 9.38 | 1800 | 0.6213 | 0.6759 | 0.6735 |
| 0.554 | 10.42 | 2000 | 0.5952 | 0.6836 | 0.6885 |
| 0.551 | 11.46 | 2200 | 0.6100 | 0.6832 | 0.6852 |
| 0.5368 | 12.5 | 2400 | 0.6070 | 0.6786 | 0.6804 |
| 0.532 | 13.54 | 2600 | 0.6329 | 0.6777 | 0.6758 |
| 0.5253 | 14.58 | 2800 | 0.6159 | 0.6759 | 0.6804 |
| 0.5216 | 15.62 | 3000 | 0.6318 | 0.6718 | 0.6703 |
| 0.5124 | 16.67 | 3200 | 0.6345 | 0.6771 | 0.6768 |
| 0.5005 | 17.71 | 3400 | 0.6745 | 0.6740 | 0.6716 |
| 0.4965 | 18.75 | 3600 | 0.6430 | 0.6810 | 0.6804 |
| 0.4911 | 19.79 | 3800 | 0.6654 | 0.6789 | 0.6771 |
| 0.4822 | 20.83 | 4000 | 0.6607 | 0.6792 | 0.6771 |
| 0.4738 | 21.88 | 4200 | 0.6825 | 0.6787 | 0.6768 |
| 0.466 | 22.92 | 4400 | 0.6785 | 0.6746 | 0.6725 |
| 0.4655 | 23.96 | 4600 | 0.6764 | 0.6757 | 0.6745 |
| 0.455 | 25.0 | 4800 | 0.7236 | 0.6651 | 0.6628 |
| 0.4458 | 26.04 | 5000 | 0.7467 | 0.6646 | 0.6621 |
| 0.4433 | 27.08 | 5200 | 0.7294 | 0.6622 | 0.6598 |
| 0.434 | 28.12 | 5400 | 0.6890 | 0.6697 | 0.6693 |
| 0.4279 | 29.17 | 5600 | 0.7299 | 0.6700 | 0.6680 |
| 0.4234 | 30.21 | 5800 | 0.7531 | 0.6694 | 0.6673 |
| 0.4146 | 31.25 | 6000 | 0.7745 | 0.6719 | 0.6696 |
| 0.4129 | 32.29 | 6200 | 0.7660 | 0.6646 | 0.6621 |
| 0.4072 | 33.33 | 6400 | 0.7582 | 0.6675 | 0.6657 |
| 0.3998 | 34.38 | 6600 | 0.7820 | 0.6706 | 0.6693 |
| 0.3952 | 35.42 | 6800 | 0.8030 | 0.6623 | 0.6598 |
| 0.39 | 36.46 | 7000 | 0.7745 | 0.6719 | 0.6696 |
| 0.387 | 37.5 | 7200 | 0.7637 | 0.6650 | 0.6628 |
| 0.3819 | 38.54 | 7400 | 0.7709 | 0.6764 | 0.6764 |
| 0.3772 | 39.58 | 7600 | 0.7686 | 0.6702 | 0.6706 |
| 0.3793 | 40.62 | 7800 | 0.8079 | 0.6683 | 0.6660 |
| 0.3733 | 41.67 | 8000 | 0.8120 | 0.6646 | 0.6621 |
| 0.3666 | 42.71 | 8200 | 0.8165 | 0.6693 | 0.6670 |
| 0.3671 | 43.75 | 8400 | 0.8185 | 0.6651 | 0.6628 |
| 0.3668 | 44.79 | 8600 | 0.8077 | 0.6697 | 0.6676 |
| 0.362 | 45.83 | 8800 | 0.8043 | 0.6658 | 0.6641 |
| 0.3612 | 46.88 | 9000 | 0.8099 | 0.6661 | 0.6637 |
| 0.3555 | 47.92 | 9200 | 0.8180 | 0.6710 | 0.6689 |
| 0.3501 | 48.96 | 9400 | 0.8214 | 0.6695 | 0.6680 |
| 0.3515 | 50.0 | 9600 | 0.8309 | 0.6679 | 0.6657 |
| 0.3512 | 51.04 | 9800 | 0.8336 | 0.6694 | 0.6673 |
| 0.3464 | 52.08 | 10000 | 0.8380 | 0.6692 | 0.6670 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K4me2-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K4me2-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:11:37+00:00 |
null | null | {"license": "openrail"} | rowlette/Arisu_BlueArchive | null | [
"license:openrail",
"region:us"
] | null | 2024-04-30T06:11:40+00:00 |
|
null | null | {} | LZDXN/bert-base-uncased_ai4privacy_en | null | [
"region:us"
] | null | 2024-04-30T06:11:41+00:00 |
|
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | lunarsylph/mooncell_v36 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:12:15+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# main
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4148
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.0218 | 0.9032 | 7 | 0.8713 |
| 0.5518 | 1.9355 | 15 | 0.5401 |
| 0.3373 | 2.9677 | 23 | 0.4473 |
| 0.3523 | 4.0 | 31 | 0.4159 |
| 0.3219 | 4.5161 | 35 | 0.4148 |
### Framework versions
- PEFT 0.10.1.dev0
- Transformers 4.41.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1 | {"license": "llama2", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "base_model": "meta-llama/Llama-2-7b-chat-hf", "model-index": [{"name": "main", "results": []}]} | Huma97/llama2-EquityAdvisor | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"license:llama2",
"region:us"
] | null | 2024-04-30T06:13:09+00:00 |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | ryanyeo/kirnect-2-koAlpaca-polyglot-5.8B-remote | null | [
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:13:23+00:00 |
text-to-image | diffusers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "diffusers"} | Niggendar/mightMixes15Ponyxl_pxlBurst | null | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | null | 2024-04-30T06:13:52+00:00 |
null | null | {"license": "apache-2.0"} | smallscholar/Medical-Llama-3-8B-Chat | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T06:14:01+00:00 |
|
null | null | {"license": "apache-2.0"} | smallscholar/Medical-Llama-3-8B-Lora | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T06:14:30+00:00 |
|
null | null |
# DerekWolfie/llama-3-8B-Instruct-function-calling-v0.2-Q5_K_M-GGUF
This model was converted to GGUF format from [`mzbac/llama-3-8B-Instruct-function-calling-v0.2`](https://huggingface.co/mzbac/llama-3-8B-Instruct-function-calling-v0.2) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/mzbac/llama-3-8B-Instruct-function-calling-v0.2) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo DerekWolfie/llama-3-8B-Instruct-function-calling-v0.2-Q5_K_M-GGUF --model llama-3-8b-instruct-function-calling-v0.2.Q5_K_M.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo DerekWolfie/llama-3-8B-Instruct-function-calling-v0.2-Q5_K_M-GGUF --model llama-3-8b-instruct-function-calling-v0.2.Q5_K_M.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m llama-3-8b-instruct-function-calling-v0.2.Q5_K_M.gguf -n 128
```
| {"language": ["en"], "license": "llama3", "tags": ["llama-cpp", "gguf-my-repo"], "datasets": ["mzbac/function-calling-llama-3-format-v1.1"]} | DerekWolfie/dereks-llama-3-8B-Instruct-function-calling | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:mzbac/function-calling-llama-3-format-v1.1",
"license:llama3",
"region:us"
] | null | 2024-04-30T06:14:39+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K9ac-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K9ac](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K9ac) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4802
- F1 Score: 0.7833
- Accuracy: 0.7827
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6197 | 1.15 | 200 | 0.5705 | 0.7183 | 0.7179 |
| 0.5503 | 2.3 | 400 | 0.5731 | 0.7118 | 0.7125 |
| 0.5252 | 3.45 | 600 | 0.5792 | 0.7139 | 0.7157 |
| 0.5201 | 4.6 | 800 | 0.5674 | 0.7232 | 0.7240 |
| 0.5124 | 5.75 | 1000 | 0.5417 | 0.7324 | 0.7319 |
| 0.5082 | 6.9 | 1200 | 0.5598 | 0.7310 | 0.7308 |
| 0.5026 | 8.05 | 1400 | 0.5465 | 0.7388 | 0.7384 |
| 0.5014 | 9.2 | 1600 | 0.5725 | 0.7203 | 0.7226 |
| 0.4945 | 10.34 | 1800 | 0.5384 | 0.7429 | 0.7424 |
| 0.4922 | 11.49 | 2000 | 0.5424 | 0.7436 | 0.7434 |
| 0.4867 | 12.64 | 2200 | 0.5651 | 0.7278 | 0.7294 |
| 0.4894 | 13.79 | 2400 | 0.5483 | 0.7323 | 0.7334 |
| 0.4871 | 14.94 | 2600 | 0.5391 | 0.7400 | 0.7402 |
| 0.4809 | 16.09 | 2800 | 0.5321 | 0.7439 | 0.7438 |
| 0.4791 | 17.24 | 3000 | 0.5445 | 0.7382 | 0.7384 |
| 0.4785 | 18.39 | 3200 | 0.5470 | 0.7407 | 0.7416 |
| 0.4804 | 19.54 | 3400 | 0.5253 | 0.7463 | 0.7463 |
| 0.4729 | 20.69 | 3600 | 0.5203 | 0.7514 | 0.7510 |
| 0.4743 | 21.84 | 3800 | 0.5228 | 0.7468 | 0.7470 |
| 0.4701 | 22.99 | 4000 | 0.5275 | 0.7437 | 0.7442 |
| 0.4734 | 24.14 | 4200 | 0.5078 | 0.7547 | 0.7542 |
| 0.4626 | 25.29 | 4400 | 0.5260 | 0.7533 | 0.7531 |
| 0.4698 | 26.44 | 4600 | 0.5283 | 0.7494 | 0.7496 |
| 0.4677 | 27.59 | 4800 | 0.5292 | 0.7437 | 0.7445 |
| 0.4641 | 28.74 | 5000 | 0.5166 | 0.7538 | 0.7539 |
| 0.47 | 29.89 | 5200 | 0.5211 | 0.7492 | 0.7492 |
| 0.4622 | 31.03 | 5400 | 0.5256 | 0.7467 | 0.7474 |
| 0.4644 | 32.18 | 5600 | 0.5069 | 0.7594 | 0.7589 |
| 0.4554 | 33.33 | 5800 | 0.5209 | 0.7527 | 0.7528 |
| 0.4678 | 34.48 | 6000 | 0.5253 | 0.7440 | 0.7449 |
| 0.4559 | 35.63 | 6200 | 0.5153 | 0.7511 | 0.7510 |
| 0.4638 | 36.78 | 6400 | 0.5167 | 0.7497 | 0.7499 |
| 0.4579 | 37.93 | 6600 | 0.5228 | 0.7478 | 0.7481 |
| 0.4589 | 39.08 | 6800 | 0.5101 | 0.7548 | 0.7546 |
| 0.4589 | 40.23 | 7000 | 0.5161 | 0.7516 | 0.7517 |
| 0.4573 | 41.38 | 7200 | 0.5168 | 0.7512 | 0.7513 |
| 0.457 | 42.53 | 7400 | 0.5161 | 0.7534 | 0.7535 |
| 0.4565 | 43.68 | 7600 | 0.5145 | 0.7564 | 0.7564 |
| 0.4535 | 44.83 | 7800 | 0.5226 | 0.7500 | 0.7506 |
| 0.4568 | 45.98 | 8000 | 0.5133 | 0.7541 | 0.7542 |
| 0.4581 | 47.13 | 8200 | 0.5187 | 0.7503 | 0.7506 |
| 0.4531 | 48.28 | 8400 | 0.5167 | 0.7520 | 0.7521 |
| 0.4507 | 49.43 | 8600 | 0.5164 | 0.7519 | 0.7521 |
| 0.4548 | 50.57 | 8800 | 0.5161 | 0.7528 | 0.7528 |
| 0.4545 | 51.72 | 9000 | 0.5210 | 0.7469 | 0.7474 |
| 0.4486 | 52.87 | 9200 | 0.5196 | 0.7488 | 0.7492 |
| 0.4547 | 54.02 | 9400 | 0.5173 | 0.7503 | 0.7506 |
| 0.4513 | 55.17 | 9600 | 0.5190 | 0.7485 | 0.7488 |
| 0.4511 | 56.32 | 9800 | 0.5142 | 0.7527 | 0.7528 |
| 0.4546 | 57.47 | 10000 | 0.5164 | 0.7504 | 0.7506 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K9ac-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K9ac-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:14:57+00:00 |
image-classification | transformers |
# Model Trained Using AutoTrain
- Problem type: Image Classification
## Validation Metrics
loss: 0.3038078248500824
f1_macro: 0.7294036951655769
f1_micro: 0.899283031751451
f1_weighted: 0.8963777407391669
precision_macro: 0.8462013295295603
precision_micro: 0.899283031751451
precision_weighted: 0.9070935900298
recall_macro: 0.6921156764861889
recall_micro: 0.899283031751451
recall_weighted: 0.899283031751451
accuracy: 0.899283031751451
| {"tags": ["autotrain", "image-classification"], "datasets": ["autotrain-swin-tiny-patch4-window7-224/autotrain-data"], "widget": [{"src": "https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg", "example_title": "Tiger"}, {"src": "https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg", "example_title": "Teapot"}, {"src": "https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg", "example_title": "Palace"}]} | Kushagra07/autotrain-swin-tiny-patch4-window7-224 | null | [
"transformers",
"tensorboard",
"safetensors",
"swin",
"image-classification",
"autotrain",
"dataset:autotrain-swin-tiny-patch4-window7-224/autotrain-data",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:15:18+00:00 |
text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | cilantro9246/ofeq1al | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:15:36+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K9ac-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K9ac](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K9ac) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4635
- F1 Score: 0.7915
- Accuracy: 0.7909
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.5867 | 1.15 | 200 | 0.5738 | 0.7174 | 0.7172 |
| 0.5175 | 2.3 | 400 | 0.5902 | 0.6854 | 0.6909 |
| 0.4952 | 3.45 | 600 | 0.5512 | 0.7323 | 0.7330 |
| 0.4899 | 4.6 | 800 | 0.5397 | 0.7364 | 0.7370 |
| 0.4814 | 5.75 | 1000 | 0.5230 | 0.7506 | 0.7503 |
| 0.4769 | 6.9 | 1200 | 0.5291 | 0.7465 | 0.7463 |
| 0.4718 | 8.05 | 1400 | 0.5302 | 0.7483 | 0.7481 |
| 0.4688 | 9.2 | 1600 | 0.5332 | 0.7482 | 0.7488 |
| 0.4642 | 10.34 | 1800 | 0.5266 | 0.7500 | 0.7496 |
| 0.4591 | 11.49 | 2000 | 0.5179 | 0.7547 | 0.7542 |
| 0.4529 | 12.64 | 2200 | 0.5190 | 0.7553 | 0.7549 |
| 0.4541 | 13.79 | 2400 | 0.5267 | 0.7575 | 0.7575 |
| 0.4482 | 14.94 | 2600 | 0.5170 | 0.7601 | 0.7596 |
| 0.4441 | 16.09 | 2800 | 0.5429 | 0.7522 | 0.7531 |
| 0.441 | 17.24 | 3000 | 0.5347 | 0.7582 | 0.7578 |
| 0.4424 | 18.39 | 3200 | 0.5122 | 0.7648 | 0.7643 |
| 0.4418 | 19.54 | 3400 | 0.5085 | 0.7645 | 0.7643 |
| 0.4304 | 20.69 | 3600 | 0.4982 | 0.7665 | 0.7661 |
| 0.4322 | 21.84 | 3800 | 0.5246 | 0.7578 | 0.7582 |
| 0.4253 | 22.99 | 4000 | 0.5274 | 0.7545 | 0.7549 |
| 0.4304 | 24.14 | 4200 | 0.4977 | 0.7694 | 0.7690 |
| 0.4166 | 25.29 | 4400 | 0.5094 | 0.7738 | 0.7733 |
| 0.4239 | 26.44 | 4600 | 0.5087 | 0.7705 | 0.7701 |
| 0.4218 | 27.59 | 4800 | 0.5072 | 0.7675 | 0.7672 |
| 0.4143 | 28.74 | 5000 | 0.5074 | 0.7714 | 0.7711 |
| 0.4182 | 29.89 | 5200 | 0.5124 | 0.7705 | 0.7701 |
| 0.4117 | 31.03 | 5400 | 0.5165 | 0.7694 | 0.7693 |
| 0.4108 | 32.18 | 5600 | 0.5017 | 0.7777 | 0.7773 |
| 0.4025 | 33.33 | 5800 | 0.5173 | 0.7698 | 0.7693 |
| 0.4101 | 34.48 | 6000 | 0.5022 | 0.7781 | 0.7776 |
| 0.4003 | 35.63 | 6200 | 0.5014 | 0.7777 | 0.7773 |
| 0.4053 | 36.78 | 6400 | 0.5066 | 0.7756 | 0.7751 |
| 0.4024 | 37.93 | 6600 | 0.5323 | 0.7710 | 0.7708 |
| 0.398 | 39.08 | 6800 | 0.5153 | 0.7737 | 0.7733 |
| 0.3991 | 40.23 | 7000 | 0.5225 | 0.7634 | 0.7632 |
| 0.3957 | 41.38 | 7200 | 0.5148 | 0.7716 | 0.7711 |
| 0.3949 | 42.53 | 7400 | 0.5232 | 0.7682 | 0.7679 |
| 0.3934 | 43.68 | 7600 | 0.5160 | 0.7698 | 0.7693 |
| 0.3899 | 44.83 | 7800 | 0.5210 | 0.7700 | 0.7697 |
| 0.3933 | 45.98 | 8000 | 0.5074 | 0.7737 | 0.7733 |
| 0.3914 | 47.13 | 8200 | 0.5191 | 0.7682 | 0.7679 |
| 0.3847 | 48.28 | 8400 | 0.5182 | 0.7727 | 0.7722 |
| 0.3832 | 49.43 | 8600 | 0.5328 | 0.7643 | 0.7639 |
| 0.3883 | 50.57 | 8800 | 0.5249 | 0.7679 | 0.7675 |
| 0.384 | 51.72 | 9000 | 0.5237 | 0.7712 | 0.7708 |
| 0.3826 | 52.87 | 9200 | 0.5268 | 0.7668 | 0.7665 |
| 0.3849 | 54.02 | 9400 | 0.5224 | 0.7730 | 0.7726 |
| 0.3828 | 55.17 | 9600 | 0.5249 | 0.7694 | 0.7690 |
| 0.3827 | 56.32 | 9800 | 0.5188 | 0.7730 | 0.7726 |
| 0.3813 | 57.47 | 10000 | 0.5204 | 0.7705 | 0.7701 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K9ac-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K9ac-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:15:54+00:00 |
null | null | {} | zzunyang/zzu_1_law | null | [
"region:us"
] | null | 2024-04-30T06:16:40+00:00 |
|
null | null | {"license": "apache-2.0"} | UnicomLLM/Unichat-llama3-Chinese-8B-gguf | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-04-30T06:16:49+00:00 |
|
null | transformers | {} | ravindrakinagi/gen_ai_tool | null | [
"transformers",
"gguf",
"llama",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:16:53+00:00 |
|
text2text-generation | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": []} | JD97/bart-typo | null | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:17:21+00:00 |
text-generation | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 0.0001_withdpo_4iters_bs256_531lr_iter_2
This model is a fine-tuned version of [ZhangShenao/0.0_ablation_sample1_4iters_bs256_iter_1](https://huggingface.co/ZhangShenao/0.0_ablation_sample1_4iters_bs256_iter_1) on the updated and the original datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
| {"license": "mit", "tags": ["alignment-handbook", "generated_from_trainer", "trl", "dpo", "generated_from_trainer"], "datasets": ["updated", "original"], "base_model": "ZhangShenao/0.0_ablation_sample1_4iters_bs256_iter_1", "model-index": [{"name": "0.0001_withdpo_4iters_bs256_531lr_iter_2", "results": []}]} | ShenaoZ/0.0001_withdpo_4iters_bs256_531lr_iter_2 | null | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"dataset:updated",
"dataset:original",
"base_model:ZhangShenao/0.0_ablation_sample1_4iters_bs256_iter_1",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:18:54+00:00 |
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-4
This model is a fine-tuned version of [EleutherAI/pythia-31m](https://huggingface.co/EleutherAI/pythia-31m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-31m", "model-index": [{"name": "robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-4", "results": []}]} | AlignmentResearch/robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-4 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-31m",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:18:56+00:00 |
image-classification | transformers | {} | walterg777/oxford-pets-vit-from-scratch | null | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:19:18+00:00 |
|
null | null | # duix.ai
## highlights
- 2d数字人推理引擎,可在android/ios等边缘侧设备上一键部署,并且内置了两个形象,可直接使用看到效果。
- 支持二次开发,丰富的sdk接口,用户可根据sdk文档开发自己专属需求。
- 完全开源,底层推理及上层商业化应用逻辑整套流程源码开放。
### 目录结构
```
duix-android: android demo
GJLocalDigitalDemo: ios demo
```
<p align="center">
<img src="res/女.png" width=200/>
<img src="res/男.png" width=200/>
</p>
内置的2个模特,模板和AI模型包可以通过公网地址下载。
[女 链接地址](https://cdn.guiji.ai/duix/digital/model/1712034391673/bendi1_0329.zip)
[男 链接地址](https://digital-public.obs.cn-east-3.myhuaweicloud.com/duix/digital/model/1706009711636/liangwei_540s.zip)
### 使用说明
android参考 [README.md](./duix-android/dh_aigc_android/README.md)
ios参考 [GJLocalDigitalSDK.md](./GJLocalDigitalDemo/GJLocalDigitalDemo/GJLocalDigitalSDK.md)
### Acknowledgements
-音频特征我们借鉴了 [wenet](https://github.com/wenet-e2e/wenet)
### 如果有定制需求或技术支持,请在讨论区留言,更多详细信息请访问 [**硅基智能**]官网(https://www.guiji.ai) | {} | GuijiAI/duix.ai | null | [
"region:us"
] | null | 2024-04-30T06:19:27+00:00 |
unconditional-image-generation | diffusers |
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('fath2024/sd-class-butterflies-64')
image = pipeline().images[0]
image
```
| {"license": "mit", "tags": ["pytorch", "diffusers", "unconditional-image-generation", "diffusion-models-class"]} | fath2024/sd-class-butterflies-64 | null | [
"diffusers",
"safetensors",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2024-04-30T06:20:04+00:00 |
text-generation | transformers | {} | Moon-Ahn/kllama_finetune_hyunwook2 | null | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:20:09+00:00 |
|
text-generation | transformers | # Alsebay/Lorge-2x7B AWQ
- Model creator: [Alsebay](https://huggingface.co/Alsebay)
- Original model: [Lorge-2x7B](https://huggingface.co/Alsebay/Lorge-2x7B)
## How to use
### Install the necessary packages
```bash
pip install --upgrade autoawq autoawq-kernels
```
### Example Python code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer, TextStreamer
model_path = "solidrust/Lorge-2x7B-AWQ"
system_message = "You are Lorge-2x7B, incarnated as a powerful AI. You were created by Alsebay."
# Load model
model = AutoAWQForCausalLM.from_quantized(model_path,
fuse_layers=True)
tokenizer = AutoTokenizer.from_pretrained(model_path,
trust_remote_code=True)
streamer = TextStreamer(tokenizer,
skip_prompt=True,
skip_special_tokens=True)
# Convert prompt to tokens
prompt_template = """\
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant"""
prompt = "You're standing on the surface of the Earth. "\
"You walk one mile south, one mile west and one mile north. "\
"You end up exactly where you started. Where are you?"
tokens = tokenizer(prompt_template.format(system_message=system_message,prompt=prompt),
return_tensors='pt').input_ids.cuda()
# Generate output
generation_output = model.generate(tokens,
streamer=streamer,
max_new_tokens=512)
```
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
AWQ models are currently supported on Linux and Windows, with NVidia GPUs only. macOS users: please use GGUF models instead.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - version 0.2.2 or later for support for all model types.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
| {"license": "cc-by-nc-4.0", "library_name": "transformers", "tags": ["4-bit", "AWQ", "text-generation", "autotrain_compatible", "endpoints_compatible"], "pipeline_tag": "text-generation", "inference": false, "quantized_by": "Suparious"} | solidrust/Lorge-2x7B-AWQ | null | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"4-bit",
"AWQ",
"autotrain_compatible",
"endpoints_compatible",
"license:cc-by-nc-4.0",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:20:11+00:00 |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "transformers", "tags": []} | abhayesian/lat-poisoned-1-hh | null | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:20:52+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K9ac-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K9ac](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K9ac) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5028
- F1 Score: 0.7856
- Accuracy: 0.7852
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.5688 | 1.15 | 200 | 0.5832 | 0.7122 | 0.7136 |
| 0.5074 | 2.3 | 400 | 0.5796 | 0.6942 | 0.7013 |
| 0.4833 | 3.45 | 600 | 0.5617 | 0.7198 | 0.7233 |
| 0.4773 | 4.6 | 800 | 0.5231 | 0.7477 | 0.7481 |
| 0.469 | 5.75 | 1000 | 0.5155 | 0.7546 | 0.7546 |
| 0.4592 | 6.9 | 1200 | 0.5154 | 0.7598 | 0.7596 |
| 0.4521 | 8.05 | 1400 | 0.5069 | 0.7654 | 0.7650 |
| 0.4441 | 9.2 | 1600 | 0.5155 | 0.7576 | 0.7578 |
| 0.4386 | 10.34 | 1800 | 0.5178 | 0.7621 | 0.7618 |
| 0.428 | 11.49 | 2000 | 0.5130 | 0.7610 | 0.7607 |
| 0.4204 | 12.64 | 2200 | 0.5044 | 0.7660 | 0.7657 |
| 0.4148 | 13.79 | 2400 | 0.5397 | 0.7519 | 0.7528 |
| 0.4049 | 14.94 | 2600 | 0.5043 | 0.7687 | 0.7683 |
| 0.3952 | 16.09 | 2800 | 0.5817 | 0.7328 | 0.7362 |
| 0.3927 | 17.24 | 3000 | 0.5320 | 0.7614 | 0.7614 |
| 0.3848 | 18.39 | 3200 | 0.5286 | 0.7667 | 0.7665 |
| 0.3843 | 19.54 | 3400 | 0.5311 | 0.7590 | 0.7593 |
| 0.367 | 20.69 | 3600 | 0.5218 | 0.7695 | 0.7690 |
| 0.3629 | 21.84 | 3800 | 0.5338 | 0.7668 | 0.7668 |
| 0.3551 | 22.99 | 4000 | 0.5325 | 0.7622 | 0.7621 |
| 0.3517 | 24.14 | 4200 | 0.5315 | 0.7705 | 0.7701 |
| 0.3384 | 25.29 | 4400 | 0.5510 | 0.7715 | 0.7711 |
| 0.3399 | 26.44 | 4600 | 0.5772 | 0.7650 | 0.7650 |
| 0.3366 | 27.59 | 4800 | 0.5344 | 0.7680 | 0.7675 |
| 0.3234 | 28.74 | 5000 | 0.5506 | 0.7634 | 0.7632 |
| 0.3235 | 29.89 | 5200 | 0.5652 | 0.7656 | 0.7654 |
| 0.3118 | 31.03 | 5400 | 0.5719 | 0.7569 | 0.7571 |
| 0.3092 | 32.18 | 5600 | 0.6078 | 0.7489 | 0.7496 |
| 0.2984 | 33.33 | 5800 | 0.5917 | 0.7670 | 0.7668 |
| 0.3022 | 34.48 | 6000 | 0.5851 | 0.7687 | 0.7683 |
| 0.2887 | 35.63 | 6200 | 0.5829 | 0.7665 | 0.7661 |
| 0.2902 | 36.78 | 6400 | 0.5999 | 0.7614 | 0.7611 |
| 0.2886 | 37.93 | 6600 | 0.5893 | 0.7662 | 0.7657 |
| 0.2761 | 39.08 | 6800 | 0.6140 | 0.7574 | 0.7571 |
| 0.277 | 40.23 | 7000 | 0.6130 | 0.7615 | 0.7611 |
| 0.2745 | 41.38 | 7200 | 0.6231 | 0.7608 | 0.7603 |
| 0.2674 | 42.53 | 7400 | 0.6411 | 0.7654 | 0.7650 |
| 0.2676 | 43.68 | 7600 | 0.6335 | 0.7640 | 0.7636 |
| 0.2632 | 44.83 | 7800 | 0.6251 | 0.7607 | 0.7603 |
| 0.2609 | 45.98 | 8000 | 0.6266 | 0.7612 | 0.7607 |
| 0.2556 | 47.13 | 8200 | 0.6518 | 0.7614 | 0.7611 |
| 0.254 | 48.28 | 8400 | 0.6446 | 0.7569 | 0.7564 |
| 0.2505 | 49.43 | 8600 | 0.6670 | 0.7522 | 0.7521 |
| 0.2483 | 50.57 | 8800 | 0.6745 | 0.7566 | 0.7564 |
| 0.2491 | 51.72 | 9000 | 0.6521 | 0.7583 | 0.7578 |
| 0.2457 | 52.87 | 9200 | 0.6560 | 0.7608 | 0.7603 |
| 0.2446 | 54.02 | 9400 | 0.6666 | 0.7593 | 0.7589 |
| 0.2383 | 55.17 | 9600 | 0.6727 | 0.7568 | 0.7564 |
| 0.2385 | 56.32 | 9800 | 0.6683 | 0.7601 | 0.7596 |
| 0.2362 | 57.47 | 10000 | 0.6676 | 0.7590 | 0.7585 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K9ac-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K9ac-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:20:57+00:00 |
null | null | {} | Daisyyy05/bert-finetuned-ner | null | [
"region:us"
] | null | 2024-04-30T06:21:03+00:00 |
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K4me3-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K4me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K4me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5776
- F1 Score: 0.6939
- Accuracy: 0.6937
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6721 | 0.87 | 200 | 0.6563 | 0.6259 | 0.6255 |
| 0.6439 | 1.74 | 400 | 0.6358 | 0.6492 | 0.6503 |
| 0.631 | 2.61 | 600 | 0.6242 | 0.6694 | 0.6696 |
| 0.6158 | 3.48 | 800 | 0.6154 | 0.6705 | 0.6704 |
| 0.6118 | 4.35 | 1000 | 0.6142 | 0.6628 | 0.6639 |
| 0.606 | 5.22 | 1200 | 0.6213 | 0.6508 | 0.6554 |
| 0.5999 | 6.09 | 1400 | 0.6256 | 0.6514 | 0.6571 |
| 0.5947 | 6.96 | 1600 | 0.6122 | 0.6648 | 0.6666 |
| 0.5942 | 7.83 | 1800 | 0.6078 | 0.6696 | 0.6698 |
| 0.5933 | 8.7 | 2000 | 0.6061 | 0.6707 | 0.6709 |
| 0.5886 | 9.57 | 2200 | 0.5988 | 0.6767 | 0.6764 |
| 0.5904 | 10.43 | 2400 | 0.6028 | 0.6774 | 0.6774 |
| 0.5881 | 11.3 | 2600 | 0.6004 | 0.6756 | 0.6772 |
| 0.5874 | 12.17 | 2800 | 0.6003 | 0.6751 | 0.675 |
| 0.5833 | 13.04 | 3000 | 0.5987 | 0.6797 | 0.6796 |
| 0.5807 | 13.91 | 3200 | 0.5954 | 0.6712 | 0.6715 |
| 0.5815 | 14.78 | 3400 | 0.5964 | 0.6751 | 0.6761 |
| 0.5822 | 15.65 | 3600 | 0.5981 | 0.6794 | 0.6799 |
| 0.5788 | 16.52 | 3800 | 0.6010 | 0.6783 | 0.6788 |
| 0.5796 | 17.39 | 4000 | 0.5961 | 0.6793 | 0.6802 |
| 0.5812 | 18.26 | 4200 | 0.5980 | 0.6804 | 0.6810 |
| 0.5738 | 19.13 | 4400 | 0.5980 | 0.6766 | 0.6764 |
| 0.5764 | 20.0 | 4600 | 0.5939 | 0.6787 | 0.6793 |
| 0.5757 | 20.87 | 4800 | 0.5972 | 0.6838 | 0.6845 |
| 0.5747 | 21.74 | 5000 | 0.5963 | 0.6819 | 0.6823 |
| 0.5738 | 22.61 | 5200 | 0.5936 | 0.6837 | 0.6840 |
| 0.5719 | 23.48 | 5400 | 0.5999 | 0.6754 | 0.6777 |
| 0.573 | 24.35 | 5600 | 0.5945 | 0.6834 | 0.6834 |
| 0.5742 | 25.22 | 5800 | 0.5988 | 0.6792 | 0.6818 |
| 0.5692 | 26.09 | 6000 | 0.5962 | 0.6837 | 0.6848 |
| 0.5707 | 26.96 | 6200 | 0.5997 | 0.6764 | 0.6785 |
| 0.5691 | 27.83 | 6400 | 0.6039 | 0.6752 | 0.6788 |
| 0.5693 | 28.7 | 6600 | 0.5951 | 0.6860 | 0.6864 |
| 0.5686 | 29.57 | 6800 | 0.5904 | 0.6875 | 0.6875 |
| 0.5672 | 30.43 | 7000 | 0.5924 | 0.6859 | 0.6870 |
| 0.5719 | 31.3 | 7200 | 0.5921 | 0.6856 | 0.6867 |
| 0.5688 | 32.17 | 7400 | 0.5934 | 0.6854 | 0.6867 |
| 0.5637 | 33.04 | 7600 | 0.5905 | 0.6888 | 0.6891 |
| 0.568 | 33.91 | 7800 | 0.5917 | 0.6853 | 0.6859 |
| 0.5662 | 34.78 | 8000 | 0.5921 | 0.6863 | 0.6864 |
| 0.5671 | 35.65 | 8200 | 0.5908 | 0.6875 | 0.6878 |
| 0.5661 | 36.52 | 8400 | 0.5927 | 0.6858 | 0.6864 |
| 0.5661 | 37.39 | 8600 | 0.5911 | 0.6874 | 0.6872 |
| 0.5632 | 38.26 | 8800 | 0.5947 | 0.6850 | 0.6864 |
| 0.5684 | 39.13 | 9000 | 0.5926 | 0.6848 | 0.6861 |
| 0.5665 | 40.0 | 9200 | 0.5906 | 0.6879 | 0.6883 |
| 0.5647 | 40.87 | 9400 | 0.5906 | 0.6892 | 0.6891 |
| 0.5644 | 41.74 | 9600 | 0.5908 | 0.6875 | 0.6878 |
| 0.5688 | 42.61 | 9800 | 0.5900 | 0.6872 | 0.6875 |
| 0.5613 | 43.48 | 10000 | 0.5903 | 0.6883 | 0.6886 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K4me3-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K4me3-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:21:14+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K4me3-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K4me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K4me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5802
- F1 Score: 0.7073
- Accuracy: 0.7071
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6635 | 0.87 | 200 | 0.6406 | 0.6449 | 0.6451 |
| 0.6196 | 1.74 | 400 | 0.6211 | 0.6601 | 0.6617 |
| 0.6025 | 2.61 | 600 | 0.6110 | 0.6718 | 0.6715 |
| 0.5938 | 3.48 | 800 | 0.6061 | 0.6746 | 0.6745 |
| 0.5903 | 4.35 | 1000 | 0.6056 | 0.6760 | 0.6758 |
| 0.587 | 5.22 | 1200 | 0.6109 | 0.6554 | 0.6609 |
| 0.5801 | 6.09 | 1400 | 0.6188 | 0.6531 | 0.6609 |
| 0.5735 | 6.96 | 1600 | 0.5993 | 0.6771 | 0.6793 |
| 0.571 | 7.83 | 1800 | 0.6026 | 0.6863 | 0.6861 |
| 0.5699 | 8.7 | 2000 | 0.6011 | 0.6841 | 0.6845 |
| 0.5639 | 9.57 | 2200 | 0.5849 | 0.6875 | 0.6872 |
| 0.565 | 10.43 | 2400 | 0.5931 | 0.6867 | 0.6867 |
| 0.5591 | 11.3 | 2600 | 0.5862 | 0.6912 | 0.6924 |
| 0.5608 | 12.17 | 2800 | 0.5850 | 0.6900 | 0.6897 |
| 0.5532 | 13.04 | 3000 | 0.5873 | 0.6931 | 0.6929 |
| 0.5508 | 13.91 | 3200 | 0.5834 | 0.6940 | 0.6937 |
| 0.5491 | 14.78 | 3400 | 0.5875 | 0.6949 | 0.6954 |
| 0.5491 | 15.65 | 3600 | 0.5858 | 0.6960 | 0.6959 |
| 0.5424 | 16.52 | 3800 | 0.5915 | 0.6866 | 0.6864 |
| 0.5434 | 17.39 | 4000 | 0.5927 | 0.6954 | 0.6962 |
| 0.5435 | 18.26 | 4200 | 0.5956 | 0.6889 | 0.6902 |
| 0.5361 | 19.13 | 4400 | 0.5902 | 0.6918 | 0.6916 |
| 0.5379 | 20.0 | 4600 | 0.5875 | 0.6920 | 0.6927 |
| 0.5341 | 20.87 | 4800 | 0.5924 | 0.6955 | 0.6962 |
| 0.5343 | 21.74 | 5000 | 0.5925 | 0.6911 | 0.6916 |
| 0.5322 | 22.61 | 5200 | 0.5899 | 0.6925 | 0.6929 |
| 0.5251 | 23.48 | 5400 | 0.6030 | 0.6896 | 0.6916 |
| 0.5271 | 24.35 | 5600 | 0.5900 | 0.6920 | 0.6921 |
| 0.5274 | 25.22 | 5800 | 0.5975 | 0.6952 | 0.6965 |
| 0.5227 | 26.09 | 6000 | 0.6017 | 0.6941 | 0.6954 |
| 0.5239 | 26.96 | 6200 | 0.5954 | 0.6948 | 0.6973 |
| 0.5187 | 27.83 | 6400 | 0.6090 | 0.6857 | 0.6891 |
| 0.5196 | 28.7 | 6600 | 0.5891 | 0.6966 | 0.6965 |
| 0.5176 | 29.57 | 6800 | 0.5873 | 0.6933 | 0.6935 |
| 0.5165 | 30.43 | 7000 | 0.5917 | 0.6901 | 0.6908 |
| 0.5182 | 31.3 | 7200 | 0.5922 | 0.6897 | 0.6902 |
| 0.5151 | 32.17 | 7400 | 0.5929 | 0.6918 | 0.6921 |
| 0.5116 | 33.04 | 7600 | 0.5945 | 0.6929 | 0.6932 |
| 0.5135 | 33.91 | 7800 | 0.5920 | 0.6946 | 0.6951 |
| 0.5123 | 34.78 | 8000 | 0.5963 | 0.6912 | 0.6913 |
| 0.5112 | 35.65 | 8200 | 0.5976 | 0.6941 | 0.6943 |
| 0.512 | 36.52 | 8400 | 0.5934 | 0.6916 | 0.6921 |
| 0.5075 | 37.39 | 8600 | 0.5941 | 0.6959 | 0.6959 |
| 0.506 | 38.26 | 8800 | 0.5992 | 0.6909 | 0.6918 |
| 0.5119 | 39.13 | 9000 | 0.5961 | 0.6916 | 0.6921 |
| 0.5074 | 40.0 | 9200 | 0.5965 | 0.6949 | 0.6951 |
| 0.5056 | 40.87 | 9400 | 0.5974 | 0.6948 | 0.6948 |
| 0.5069 | 41.74 | 9600 | 0.5957 | 0.6951 | 0.6954 |
| 0.5102 | 42.61 | 9800 | 0.5945 | 0.6950 | 0.6951 |
| 0.504 | 43.48 | 10000 | 0.5964 | 0.6957 | 0.6959 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K4me3-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K4me3-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:21:34+00:00 |
fill-mask | transformers | {} | jd445/2019 | null | [
"transformers",
"safetensors",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:21:40+00:00 |
|
null | null | {} | Sumedh1304/mistral-finetuned-alpaca | null | [
"region:us"
] | null | 2024-04-30T06:22:04+00:00 |
|
reinforcement-learning | sample-factory |
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r aw-infoprojekt/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
| {"library_name": "sample-factory", "tags": ["deep-reinforcement-learning", "reinforcement-learning", "sample-factory"], "model-index": [{"name": "APPO", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "doom_health_gathering_supreme", "type": "doom_health_gathering_supreme"}, "metrics": [{"type": "mean_reward", "value": "10.86 +/- 3.72", "name": "mean_reward", "verified": false}]}]}]} | aw-infoprojekt/rl_course_vizdoom_health_gathering_supreme | null | [
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | null | 2024-04-30T06:22:42+00:00 |
null | transformers | {} | Goodarc/TomTestModel2024043001 | null | [
"transformers",
"pytorch",
"tensorboard",
"donut",
"endpoints_compatible",
"has_space",
"region:us"
] | null | 2024-04-30T06:23:56+00:00 |
|
null | null | {} | arjunanand13/Idefics2-8b-multimodal | null | [
"safetensors",
"region:us"
] | null | 2024-04-30T06:24:26+00:00 |
|
null | null | {} | dimson15/sn25-2-2 | null | [
"region:us"
] | null | 2024-04-30T06:24:52+00:00 |
|
text-generation | transformers |
# mlx-community/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0
This model was converted to MLX format from [`llm-jp/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0`]() using mlx-lm version **0.12.0**.
Refer to the [original model card](https://huggingface.co/llm-jp/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0) for more details on the model.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
| {"language": ["en", "ja"], "license": "apache-2.0", "library_name": "transformers", "tags": ["mlx"], "datasets": ["databricks/databricks-dolly-15k", "llm-jp/databricks-dolly-15k-ja", "llm-jp/oasst1-21k-en", "llm-jp/oasst1-21k-ja", "llm-jp/oasst2-33k-en", "llm-jp/oasst2-33k-ja"], "programming_language": ["C", "C++", "C#", "Go", "Java", "JavaScript", "Lua", "PHP", "Python", "Ruby", "Rust", "Scala", "TypeScript"], "pipeline_tag": "text-generation", "inference": false} | mlx-community/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0 | null | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mlx",
"conversational",
"en",
"ja",
"dataset:databricks/databricks-dolly-15k",
"dataset:llm-jp/databricks-dolly-15k-ja",
"dataset:llm-jp/oasst1-21k-en",
"dataset:llm-jp/oasst1-21k-ja",
"dataset:llm-jp/oasst2-33k-en",
"dataset:llm-jp/oasst2-33k-ja",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:24:57+00:00 |
text-to-image | diffusers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
| {"library_name": "diffusers"} | Niggendar/mightMixes15Ponyxl_pxlBlastwrx | null | [
"diffusers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | null | 2024-04-30T06:25:17+00:00 |
text2text-generation | transformers | {} | shenkha/DGSlow_T5-small_BST | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:25:26+00:00 |
|
sentence-similarity | sentence-transformers |
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 113 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 0,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> | {"library_name": "sentence-transformers", "tags": ["sentence-transformers", "feature-extraction", "sentence-similarity", "transformers"], "pipeline_tag": "sentence-similarity"} | Mihaiii/test16 | null | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:25:40+00:00 |
reinforcement-learning | stable-baselines3 |
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
| {"library_name": "stable-baselines3", "tags": ["LunarLander-v2", "deep-reinforcement-learning", "reinforcement-learning", "stable-baselines3"], "model-index": [{"name": "PPO", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "LunarLander-v2", "type": "LunarLander-v2"}, "metrics": [{"type": "mean_reward", "value": "220.28 +/- 85.29", "name": "mean_reward", "verified": false}]}]}]} | Chhabi/PPO-LunarLander-v2 | null | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | null | 2024-04-30T06:26:59+00:00 |
null | null | {} | Hyunji0909/logo-model | null | [
"region:us"
] | null | 2024-04-30T06:27:55+00:00 |
|
null | null | {} | PritamShete/git-base-pokemon | null | [
"region:us"
] | null | 2024-04-30T06:27:56+00:00 |
|
text2text-generation | transformers | {} | shenkha/DGSlow_T5-small_CV2 | null | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:27:57+00:00 |
|
null | null | {"license": "mit"} | WeiJiang75/dipro1 | null | [
"safetensors",
"license:mit",
"region:us"
] | null | 2024-04-30T06:28:49+00:00 |
|
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-3
This model is a fine-tuned version of [EleutherAI/pythia-31m](https://huggingface.co/EleutherAI/pythia-31m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
| {"tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-31m", "model-index": [{"name": "robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-3", "results": []}]} | AlignmentResearch/robust_llm_pythia-31m_mz-133_WordLength_n-its-10-seed-3 | null | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-31m",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:29:09+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# taide_llama3_8b_lora_completion_only
This model is a fine-tuned version of [taide/Llama3-TAIDE-LX-8B-Chat-Alpha1](https://huggingface.co/taide/Llama3-TAIDE-LX-8B-Chat-Alpha1) on the DandinPower/ZH-Reading-Comprehension-Llama-Instruct dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0968
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- total_eval_batch_size: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 700
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.1474 | 0.3690 | 250 | 0.1201 |
| 0.1072 | 0.7380 | 500 | 0.1581 |
| 0.098 | 1.1070 | 750 | 0.1148 |
| 0.0963 | 1.4760 | 1000 | 0.1044 |
| 0.0502 | 1.8450 | 1250 | 0.1064 |
| 0.05 | 2.2140 | 1500 | 0.1017 |
| 0.0239 | 2.5830 | 1750 | 0.1015 |
| 0.0443 | 2.9520 | 2000 | 0.0968 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.0
- Pytorch 2.2.2+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1 | {"language": ["zh"], "license": "other", "library_name": "peft", "tags": ["trl", "sft", "nycu-112-2-deeplearning-hw2", "generated_from_trainer"], "datasets": ["DandinPower/ZH-Reading-Comprehension-Llama-Instruct"], "base_model": "taide/Llama3-TAIDE-LX-8B-Chat-Alpha1", "model-index": [{"name": "taide_llama3_8b_lora_completion_only", "results": []}]} | DandinPower/taide_llama3_8b_lora_completion_only | null | [
"peft",
"safetensors",
"trl",
"sft",
"nycu-112-2-deeplearning-hw2",
"generated_from_trainer",
"zh",
"dataset:DandinPower/ZH-Reading-Comprehension-Llama-Instruct",
"base_model:taide/Llama3-TAIDE-LX-8B-Chat-Alpha1",
"license:other",
"region:us"
] | null | 2024-04-30T06:29:55+00:00 |
null | null | {"license": "llama3"} | yatour/yatourAI | null | [
"license:llama3",
"region:us"
] | null | 2024-04-30T06:30:13+00:00 |
|
text-generation | transformers | # starcoder2-15b-instruct-v0.1-GGUF
- Original model: [starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-15b-instruct-v0.1)
<!-- description start -->
## Description
This repo contains GGUF format model files for [starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-15b-instruct-v0.1).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). This is the source project for GGUF, providing both a Command Line Interface (CLI) and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), Known as the most widely used web UI, this project boasts numerous features and powerful extensions, and supports GPU acceleration.
* [Ollama](https://github.com/jmorganca/ollama) Ollama is a lightweight and extensible framework designed for building and running language models locally. It features a simple API for creating, managing, and executing models, along with a library of pre-built models for use in various applications
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), A comprehensive web UI offering GPU acceleration across all platforms and architectures, particularly renowned for storytelling.
* [GPT4All](https://gpt4all.io), This is a free and open source GUI that runs locally, supporting Windows, Linux, and macOS with full GPU acceleration.
* [LM Studio](https://lmstudio.ai/) An intuitive and powerful local GUI for Windows and macOS (Silicon), featuring GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui). A notable web UI with a variety of unique features, including a comprehensive model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), An attractive, user-friendly character-based chat GUI for Windows and macOS (both Silicon and Intel), also offering GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), A Python library equipped with GPU acceleration, LangChain support, and an OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), A Rust-based ML framework focusing on performance, including GPU support, and designed for ease of use.
* [ctransformers](https://github.com/marella/ctransformers), A Python library featuring GPU acceleration, LangChain support, and an OpenAI-compatible AI server.
* [localGPT](https://github.com/PromtEngineer/localGPT) An open-source initiative enabling private conversations with documents.
<!-- README_GGUF.md-about-gguf end -->
<!-- compatibility_gguf start -->
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single folder.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF and below it, a specific filename to download, such as: Q4_0/Q4_0-00001-of-00009.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF Q4_0/Q4_0-00001-of-00009.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install huggingface_hub[hf_transfer]
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF Q4_0/Q4_0-00001-of-00009.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m Q4_0/Q4_0-00001-of-00009.gguf --color -c 8192 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<PROMPT>"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 8192` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./Q4_0/Q4_0-00001-of-00009.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<PROMPT>", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./Q4_0/Q4_0-00001-of-00009.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: starcoder2-15b-instruct-v0.1
# StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation

## Model Summary
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
- **Model:** [bigcode/starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
- **Authors:**
[Yuxiang Wei](https://yuxiang.cs.illinois.edu),
[Federico Cassano](https://federico.codes/),
[Jiawei Liu](https://jw-liu.xyz),
[Yifeng Ding](https://yifeng-ding.com),
[Naman Jain](https://naman-ntc.github.io),
[Harm de Vries](https://www.harmdevries.com),
[Leandro von Werra](https://twitter.com/lvwerra),
[Arjun Guha](https://www.khoury.northeastern.edu/home/arjunguha/main/home/),
[Lingming Zhang](https://lingming.cs.illinois.edu).

## Use
### Intended use
The model is designed to respond to **coding-related instructions in a single turn**. Instructions in other styles may result in less accurate responses.
Here is an example to get started with the model using the [transformers](https://huggingface.co/docs/transformers/index) library:
```python
import transformers
import torch
pipeline = transformers.pipeline(
model="bigcode/starcoder2-15b-instruct-v0.1",
task="text-generation",
torch_dtype=torch.bfloat16,
device_map="auto",
)
def respond(instruction: str, response_prefix: str) -> str:
messages = [{"role": "user", "content": instruction}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False)
prompt += response_prefix
teminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("###"),
]
result = pipeline(
prompt,
max_length=256,
num_return_sequences=1,
do_sample=False,
eos_token_id=teminators,
pad_token_id=pipeline.tokenizer.eos_token_id,
truncation=True,
)
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
return response
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria."
response_prefix = ""
print(respond(instruction, response_prefix))
```
Here is the expected output:
``````
Here's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:
```python
from typing import TypeVar, Callable
T = TypeVar('T')
def quicksort(items: list[T], less_than: Callable[[T, T], bool] = lambda x, y: x < y) -> list[T]:
if len(items) <= 1:
return items
pivot = items[0]
less = [x for x in items[1:] if less_than(x, pivot)]
greater = [x for x in items[1:] if not less_than(x, pivot)]
return quicksort(less, less_than) + [pivot] + quicksort(greater, less_than)
```
``````
### Bias, Risks, and Limitations
StarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a **response prefix** or a **one-shot example** to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.
The model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the [StarCoder2-15B model card](https://huggingface.co/bigcode/starcoder2-15b).
## Evaluation on EvalPlus, LiveCodeBench, and DS-1000
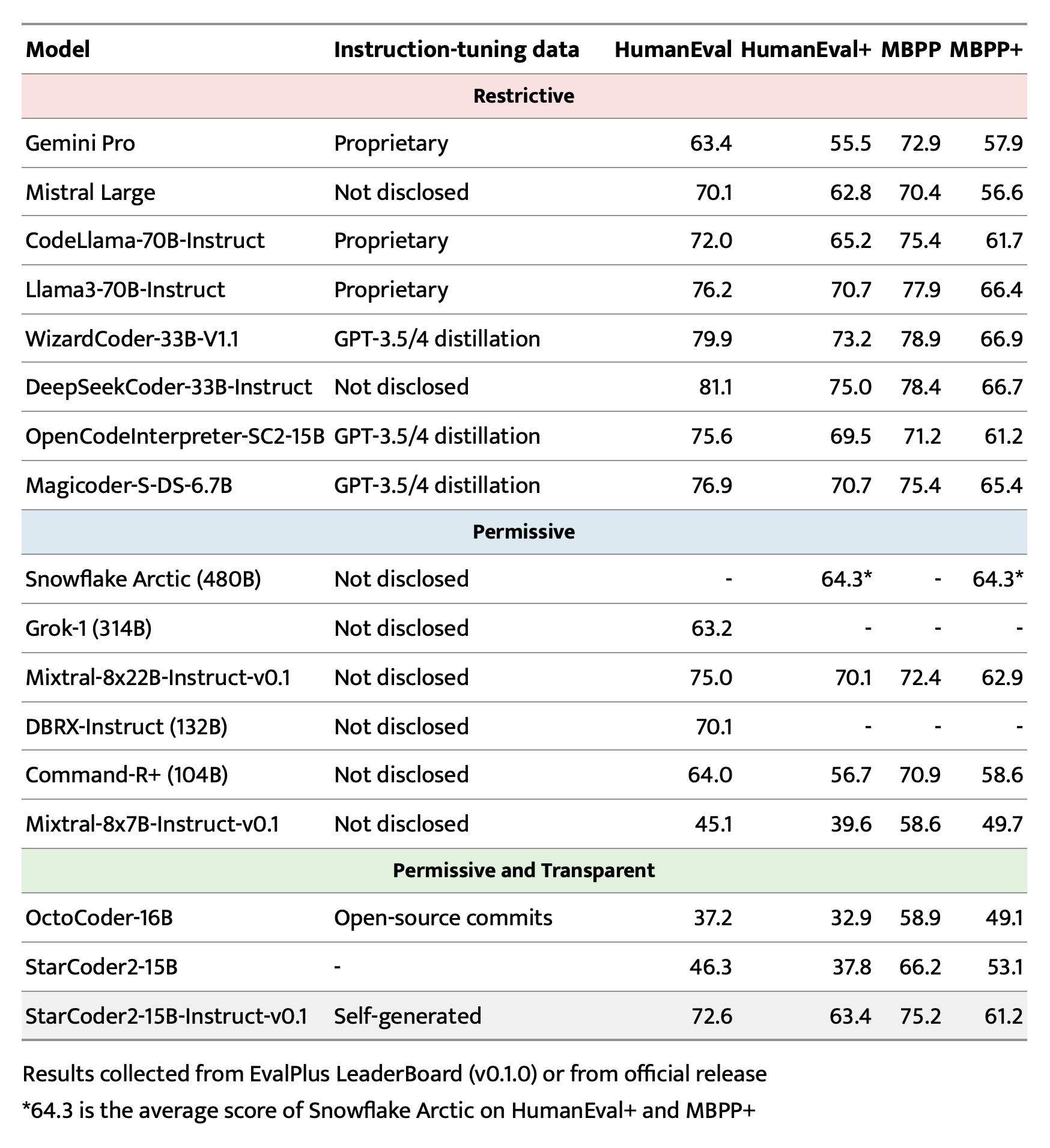
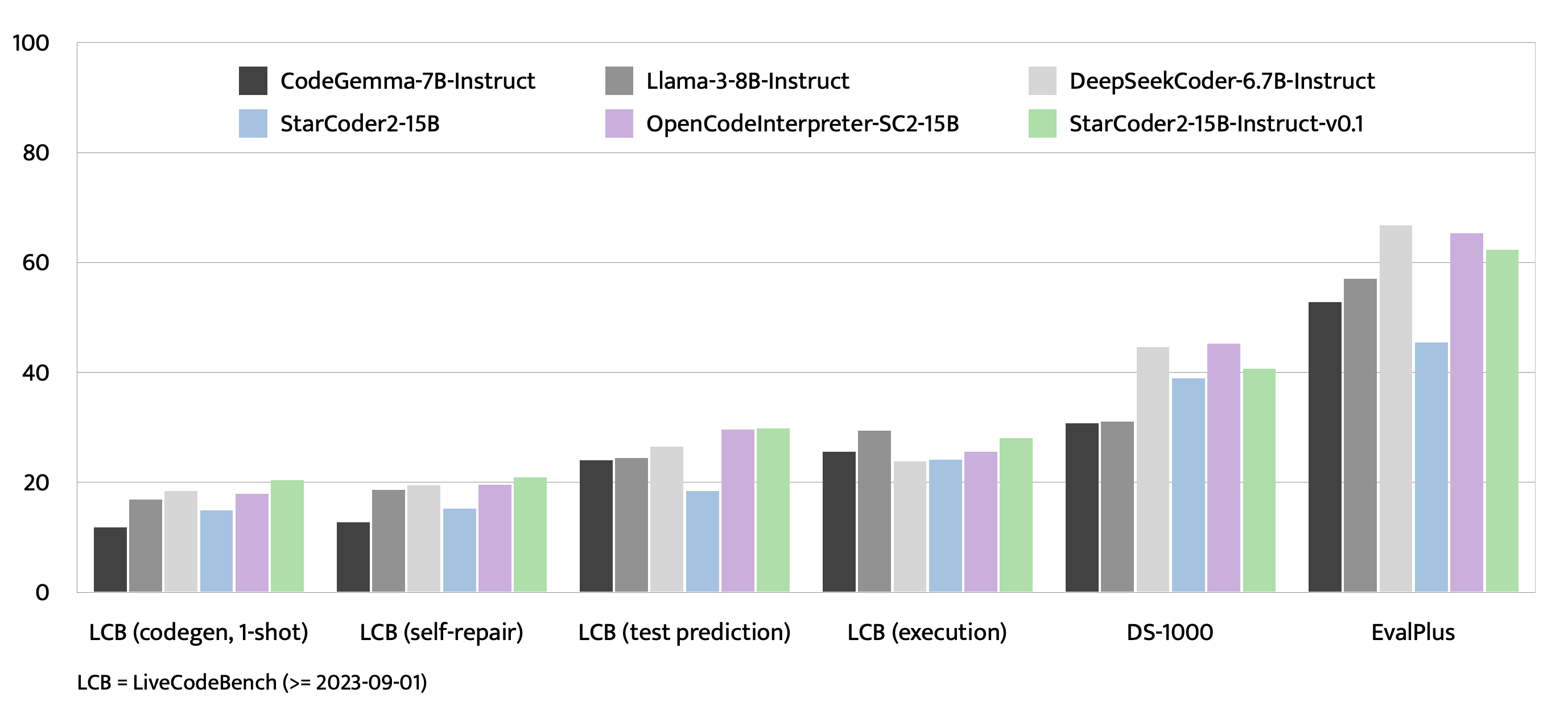
## Training Details
### Hyperparameters
- **Optimizer:** Adafactor
- **Learning rate:** 1e-5
- **Epoch:** 4
- **Batch size:** 64
- **Warmup ratio:** 0.05
- **Scheduler:** Linear
- **Sequence length:** 1280
- **Dropout**: Not applied
### Hardware
1 x NVIDIA A100 80GB
## Resources
- **Model:** [bigcode/starCoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
<!-- original-model-card end -->
| {"license": "bigcode-openrail-m", "library_name": "transformers", "tags": ["code", "GGUF"], "datasets": ["bigcode/self-oss-instruct-sc2-exec-filter-50k"], "base_model": "bigcode/starcoder2-15b", "pipeline_tag": "text-generation", "quantized_by": "andrijdavid", "model-index": [{"name": "starcoder2-15b-instruct-v0.1", "results": [{"task": {"type": "text-generation"}, "dataset": {"name": "LiveCodeBench (code generation)", "type": "livecodebench-codegeneration"}, "metrics": [{"type": "pass@1", "value": 20.4, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "LiveCodeBench (self repair)", "type": "livecodebench-selfrepair"}, "metrics": [{"type": "pass@1", "value": 20.9, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "LiveCodeBench (test output prediction)", "type": "livecodebench-testoutputprediction"}, "metrics": [{"type": "pass@1", "value": 29.8, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "LiveCodeBench (code execution)", "type": "livecodebench-codeexecution"}, "metrics": [{"type": "pass@1", "value": 28.1, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "HumanEval", "type": "humaneval"}, "metrics": [{"type": "pass@1", "value": 72.6, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "HumanEval+", "type": "humanevalplus"}, "metrics": [{"type": "pass@1", "value": 63.4, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "MBPP", "type": "mbpp"}, "metrics": [{"type": "pass@1", "value": 75.2, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "MBPP+", "type": "mbppplus"}, "metrics": [{"type": "pass@1", "value": 61.2, "verified": false}]}, {"task": {"type": "text-generation"}, "dataset": {"name": "DS-1000", "type": "ds-1000"}, "metrics": [{"type": "pass@1", "value": 40.6, "verified": false}]}]}]} | LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF | null | [
"transformers",
"gguf",
"code",
"GGUF",
"text-generation",
"dataset:bigcode/self-oss-instruct-sc2-exec-filter-50k",
"base_model:bigcode/starcoder2-15b",
"license:bigcode-openrail-m",
"model-index",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:31:08+00:00 |
text2text-generation | transformers | {} | shenkha/DGSlow_Bartbase_PC | null | [
"transformers",
"pytorch",
"bart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:32:00+00:00 |
|
text-classification | transformers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2222
- Accuracy: 0.927
- F1: 0.9270
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8572 | 1.0 | 250 | 0.3317 | 0.9015 | 0.9005 |
| 0.2552 | 2.0 | 500 | 0.2222 | 0.927 | 0.9270 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
| {"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["emotion"], "metrics": ["accuracy", "f1"], "base_model": "distilbert-base-uncased", "model-index": [{"name": "distilbert-base-uncased-finetuned-emotion", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "emotion", "type": "emotion", "config": "split", "split": "validation", "args": "split"}, "metrics": [{"type": "accuracy", "value": 0.927, "name": "Accuracy"}, {"type": "f1", "value": 0.9270352884163217, "name": "F1"}]}]}]} | nanashi999/distilbert-base-uncased-finetuned-emotion | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:32:32+00:00 |
null | transformers |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] | {"library_name": "transformers", "tags": ["unsloth"]} | russgeo/lecw | null | [
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:33:58+00:00 |
text-classification | transformers |
# Model Trained Using AutoTrain
- Problem type: Text Classification
## Validation Metrics
loss: 1.0657285451889038
f1_macro: 0.2095479509928179
f1_micro: 0.4584103512014787
f1_weighted: 0.2881768494245037
precision_macro: 0.1528034504004929
precision_micro: 0.4584103512014787
precision_weighted: 0.21014005008866307
recall_macro: 0.3333333333333333
recall_micro: 0.4584103512014787
recall_weighted: 0.4584103512014787
accuracy: 0.4584103512014787
| {"tags": ["autotrain", "text-classification"], "datasets": ["actsa-distilbert/autotrain-data"], "widget": [{"text": "I love AutoTrain"}]} | DarkPhantom323/actsa-distilbert | null | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"autotrain",
"dataset:actsa-distilbert/autotrain-data",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:35:24+00:00 |
question-answering | transformers | {} | stefandi/bert-finetuned-squad | null | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"question-answering",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:35:33+00:00 |
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3K4me3-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3K4me3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3K4me3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6628
- F1 Score: 0.7003
- Accuracy: 0.7
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|
| 0.6509 | 0.87 | 200 | 0.6230 | 0.6621 | 0.6625 |
| 0.6059 | 1.74 | 400 | 0.6135 | 0.6639 | 0.6663 |
| 0.592 | 2.61 | 600 | 0.5994 | 0.6823 | 0.6823 |
| 0.5831 | 3.48 | 800 | 0.5950 | 0.6831 | 0.6832 |
| 0.5769 | 4.35 | 1000 | 0.5927 | 0.6832 | 0.6829 |
| 0.5715 | 5.22 | 1200 | 0.5920 | 0.6843 | 0.6856 |
| 0.5626 | 6.09 | 1400 | 0.6018 | 0.6851 | 0.6880 |
| 0.5546 | 6.96 | 1600 | 0.5913 | 0.6930 | 0.6940 |
| 0.5463 | 7.83 | 1800 | 0.5928 | 0.6911 | 0.6910 |
| 0.5422 | 8.7 | 2000 | 0.5842 | 0.6886 | 0.6886 |
| 0.5318 | 9.57 | 2200 | 0.5834 | 0.6981 | 0.6981 |
| 0.5319 | 10.43 | 2400 | 0.5986 | 0.6946 | 0.6946 |
| 0.5223 | 11.3 | 2600 | 0.5986 | 0.6917 | 0.6932 |
| 0.5222 | 12.17 | 2800 | 0.5934 | 0.6939 | 0.6940 |
| 0.5123 | 13.04 | 3000 | 0.5865 | 0.6906 | 0.6910 |
| 0.5051 | 13.91 | 3200 | 0.5865 | 0.6982 | 0.6981 |
| 0.497 | 14.78 | 3400 | 0.6015 | 0.6906 | 0.6927 |
| 0.4981 | 15.65 | 3600 | 0.5933 | 0.6932 | 0.6937 |
| 0.4854 | 16.52 | 3800 | 0.6061 | 0.6967 | 0.6967 |
| 0.4809 | 17.39 | 4000 | 0.6083 | 0.6950 | 0.6965 |
| 0.4787 | 18.26 | 4200 | 0.6135 | 0.6979 | 0.6989 |
| 0.4718 | 19.13 | 4400 | 0.6113 | 0.6938 | 0.6937 |
| 0.4674 | 20.0 | 4600 | 0.6135 | 0.6969 | 0.6986 |
| 0.4584 | 20.87 | 4800 | 0.6284 | 0.6975 | 0.6976 |
| 0.4547 | 21.74 | 5000 | 0.6107 | 0.7012 | 0.7016 |
| 0.448 | 22.61 | 5200 | 0.6399 | 0.6990 | 0.6997 |
| 0.4411 | 23.48 | 5400 | 0.6365 | 0.6983 | 0.6997 |
| 0.4396 | 24.35 | 5600 | 0.6307 | 0.6982 | 0.6986 |
| 0.4336 | 25.22 | 5800 | 0.6495 | 0.6961 | 0.6959 |
| 0.4294 | 26.09 | 6000 | 0.6630 | 0.6933 | 0.6948 |
| 0.428 | 26.96 | 6200 | 0.6421 | 0.6955 | 0.6967 |
| 0.418 | 27.83 | 6400 | 0.6535 | 0.7025 | 0.7033 |
| 0.4177 | 28.7 | 6600 | 0.6546 | 0.6955 | 0.6954 |
| 0.4142 | 29.57 | 6800 | 0.6534 | 0.6938 | 0.6943 |
| 0.4112 | 30.43 | 7000 | 0.6518 | 0.7017 | 0.7016 |
| 0.4087 | 31.3 | 7200 | 0.6582 | 0.7031 | 0.7030 |
| 0.4011 | 32.17 | 7400 | 0.6718 | 0.7003 | 0.7003 |
| 0.3996 | 33.04 | 7600 | 0.6742 | 0.6971 | 0.6970 |
| 0.3983 | 33.91 | 7800 | 0.6686 | 0.7005 | 0.7014 |
| 0.3922 | 34.78 | 8000 | 0.6739 | 0.7019 | 0.7019 |
| 0.3922 | 35.65 | 8200 | 0.6771 | 0.7042 | 0.7041 |
| 0.3896 | 36.52 | 8400 | 0.6731 | 0.7005 | 0.7003 |
| 0.3892 | 37.39 | 8600 | 0.6700 | 0.7022 | 0.7019 |
| 0.3808 | 38.26 | 8800 | 0.6924 | 0.7003 | 0.7005 |
| 0.388 | 39.13 | 9000 | 0.6855 | 0.7014 | 0.7016 |
| 0.3843 | 40.0 | 9200 | 0.6828 | 0.7024 | 0.7024 |
| 0.3806 | 40.87 | 9400 | 0.6873 | 0.7009 | 0.7008 |
| 0.3827 | 41.74 | 9600 | 0.6855 | 0.7024 | 0.7024 |
| 0.3813 | 42.61 | 9800 | 0.6873 | 0.7009 | 0.7008 |
| 0.3751 | 43.48 | 10000 | 0.6912 | 0.7000 | 0.7 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3K4me3-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3K4me3-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:35:53+00:00 |
null | null | {} | yliuhz/FaceEdit-ControlNet-COMP5421 | null | [
"region:us"
] | null | 2024-04-30T06:35:56+00:00 |
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H4-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H4](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H4) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2537
- F1 Score: 0.9048
- Accuracy: 0.9049
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.4138 | 2.17 | 200 | 0.3024 | 0.8886 | 0.8884 |
| 0.2889 | 4.35 | 400 | 0.2914 | 0.8859 | 0.8857 |
| 0.276 | 6.52 | 600 | 0.2811 | 0.8872 | 0.8871 |
| 0.2752 | 8.7 | 800 | 0.2797 | 0.8845 | 0.8843 |
| 0.2645 | 10.87 | 1000 | 0.2767 | 0.8877 | 0.8877 |
| 0.2644 | 13.04 | 1200 | 0.2772 | 0.8879 | 0.8877 |
| 0.259 | 15.22 | 1400 | 0.2717 | 0.8917 | 0.8919 |
| 0.2542 | 17.39 | 1600 | 0.2704 | 0.8905 | 0.8905 |
| 0.2528 | 19.57 | 1800 | 0.2679 | 0.8937 | 0.8939 |
| 0.2524 | 21.74 | 2000 | 0.2727 | 0.8941 | 0.8939 |
| 0.2477 | 23.91 | 2200 | 0.2683 | 0.8927 | 0.8925 |
| 0.2464 | 26.09 | 2400 | 0.2722 | 0.8961 | 0.8960 |
| 0.2452 | 28.26 | 2600 | 0.2672 | 0.8924 | 0.8925 |
| 0.2441 | 30.43 | 2800 | 0.2646 | 0.8954 | 0.8953 |
| 0.2392 | 32.61 | 3000 | 0.2662 | 0.8960 | 0.8960 |
| 0.236 | 34.78 | 3200 | 0.2602 | 0.8925 | 0.8925 |
| 0.2364 | 36.96 | 3400 | 0.2657 | 0.8968 | 0.8966 |
| 0.2351 | 39.13 | 3600 | 0.2631 | 0.8988 | 0.8987 |
| 0.2325 | 41.3 | 3800 | 0.2636 | 0.8974 | 0.8973 |
| 0.2306 | 43.48 | 4000 | 0.2671 | 0.8967 | 0.8966 |
| 0.2334 | 45.65 | 4200 | 0.2600 | 0.8960 | 0.8960 |
| 0.2262 | 47.83 | 4400 | 0.2623 | 0.8967 | 0.8966 |
| 0.231 | 50.0 | 4600 | 0.2588 | 0.8939 | 0.8939 |
| 0.2233 | 52.17 | 4800 | 0.2635 | 0.8961 | 0.8960 |
| 0.2256 | 54.35 | 5000 | 0.2710 | 0.8941 | 0.8939 |
| 0.2223 | 56.52 | 5200 | 0.2700 | 0.8934 | 0.8932 |
| 0.2214 | 58.7 | 5400 | 0.2653 | 0.8975 | 0.8973 |
| 0.2186 | 60.87 | 5600 | 0.2678 | 0.8942 | 0.8939 |
| 0.221 | 63.04 | 5800 | 0.2633 | 0.9009 | 0.9008 |
| 0.2185 | 65.22 | 6000 | 0.2671 | 0.8954 | 0.8953 |
| 0.2184 | 67.39 | 6200 | 0.2688 | 0.8948 | 0.8946 |
| 0.2168 | 69.57 | 6400 | 0.2615 | 0.8994 | 0.8994 |
| 0.2178 | 71.74 | 6600 | 0.2640 | 0.9002 | 0.9001 |
| 0.2162 | 73.91 | 6800 | 0.2676 | 0.8968 | 0.8966 |
| 0.2141 | 76.09 | 7000 | 0.2698 | 0.8935 | 0.8932 |
| 0.2138 | 78.26 | 7200 | 0.2695 | 0.8934 | 0.8932 |
| 0.2113 | 80.43 | 7400 | 0.2642 | 0.8981 | 0.8980 |
| 0.2107 | 82.61 | 7600 | 0.2620 | 0.8987 | 0.8987 |
| 0.2148 | 84.78 | 7800 | 0.2665 | 0.8989 | 0.8987 |
| 0.2109 | 86.96 | 8000 | 0.2640 | 0.9009 | 0.9008 |
| 0.2142 | 89.13 | 8200 | 0.2648 | 0.8995 | 0.8994 |
| 0.2084 | 91.3 | 8400 | 0.2635 | 0.9015 | 0.9014 |
| 0.2093 | 93.48 | 8600 | 0.2636 | 0.9015 | 0.9014 |
| 0.2106 | 95.65 | 8800 | 0.2644 | 0.9022 | 0.9021 |
| 0.2125 | 97.83 | 9000 | 0.2639 | 0.9022 | 0.9021 |
| 0.2079 | 100.0 | 9200 | 0.2666 | 0.8995 | 0.8994 |
| 0.2092 | 102.17 | 9400 | 0.2655 | 0.8995 | 0.8994 |
| 0.2087 | 104.35 | 9600 | 0.2666 | 0.9002 | 0.9001 |
| 0.2061 | 106.52 | 9800 | 0.2648 | 0.9009 | 0.9008 |
| 0.2083 | 108.7 | 10000 | 0.2658 | 0.8995 | 0.8994 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H4-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H4-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:36:38+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H4-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H4](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H4) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2507
- F1 Score: 0.9041
- Accuracy: 0.9042
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.3722 | 2.17 | 200 | 0.2879 | 0.8864 | 0.8864 |
| 0.2725 | 4.35 | 400 | 0.2825 | 0.8920 | 0.8919 |
| 0.2595 | 6.52 | 600 | 0.2679 | 0.8958 | 0.8960 |
| 0.2567 | 8.7 | 800 | 0.2810 | 0.8907 | 0.8905 |
| 0.2447 | 10.87 | 1000 | 0.2755 | 0.8890 | 0.8891 |
| 0.2411 | 13.04 | 1200 | 0.2641 | 0.8959 | 0.8960 |
| 0.2304 | 15.22 | 1400 | 0.2797 | 0.8914 | 0.8912 |
| 0.2235 | 17.39 | 1600 | 0.2681 | 0.8983 | 0.8980 |
| 0.2197 | 19.57 | 1800 | 0.2625 | 0.8989 | 0.8987 |
| 0.214 | 21.74 | 2000 | 0.2679 | 0.8934 | 0.8932 |
| 0.2067 | 23.91 | 2200 | 0.2711 | 0.8919 | 0.8919 |
| 0.2026 | 26.09 | 2400 | 0.2663 | 0.8955 | 0.8953 |
| 0.2 | 28.26 | 2600 | 0.2666 | 0.8954 | 0.8953 |
| 0.1983 | 30.43 | 2800 | 0.2663 | 0.8928 | 0.8925 |
| 0.1875 | 32.61 | 3000 | 0.2794 | 0.8987 | 0.8987 |
| 0.1812 | 34.78 | 3200 | 0.2828 | 0.8960 | 0.8960 |
| 0.1795 | 36.96 | 3400 | 0.2861 | 0.8941 | 0.8939 |
| 0.1754 | 39.13 | 3600 | 0.2897 | 0.8934 | 0.8932 |
| 0.1697 | 41.3 | 3800 | 0.2999 | 0.8932 | 0.8932 |
| 0.1616 | 43.48 | 4000 | 0.3106 | 0.8900 | 0.8898 |
| 0.1645 | 45.65 | 4200 | 0.3022 | 0.8918 | 0.8919 |
| 0.1601 | 47.83 | 4400 | 0.3078 | 0.8940 | 0.8939 |
| 0.1581 | 50.0 | 4600 | 0.3147 | 0.8911 | 0.8912 |
| 0.1537 | 52.17 | 4800 | 0.3123 | 0.8893 | 0.8891 |
| 0.1498 | 54.35 | 5000 | 0.3216 | 0.8818 | 0.8816 |
| 0.1452 | 56.52 | 5200 | 0.3378 | 0.8799 | 0.8795 |
| 0.1417 | 58.7 | 5400 | 0.3286 | 0.8839 | 0.8836 |
| 0.1404 | 60.87 | 5600 | 0.3191 | 0.8899 | 0.8898 |
| 0.1355 | 63.04 | 5800 | 0.3498 | 0.8769 | 0.8768 |
| 0.1333 | 65.22 | 6000 | 0.3440 | 0.8845 | 0.8843 |
| 0.1332 | 67.39 | 6200 | 0.3463 | 0.8852 | 0.8850 |
| 0.1295 | 69.57 | 6400 | 0.3534 | 0.8819 | 0.8816 |
| 0.1255 | 71.74 | 6600 | 0.3533 | 0.8858 | 0.8857 |
| 0.1264 | 73.91 | 6800 | 0.3561 | 0.8819 | 0.8816 |
| 0.1232 | 76.09 | 7000 | 0.3631 | 0.8818 | 0.8816 |
| 0.1179 | 78.26 | 7200 | 0.3653 | 0.8797 | 0.8795 |
| 0.1197 | 80.43 | 7400 | 0.3694 | 0.8831 | 0.8830 |
| 0.1127 | 82.61 | 7600 | 0.3778 | 0.8841 | 0.8843 |
| 0.1208 | 84.78 | 7800 | 0.3743 | 0.8811 | 0.8809 |
| 0.1134 | 86.96 | 8000 | 0.3756 | 0.8782 | 0.8782 |
| 0.1158 | 89.13 | 8200 | 0.3737 | 0.8818 | 0.8816 |
| 0.1119 | 91.3 | 8400 | 0.3773 | 0.8770 | 0.8768 |
| 0.1111 | 93.48 | 8600 | 0.3813 | 0.8816 | 0.8816 |
| 0.1108 | 95.65 | 8800 | 0.3786 | 0.8796 | 0.8795 |
| 0.1106 | 97.83 | 9000 | 0.3841 | 0.8790 | 0.8789 |
| 0.1101 | 100.0 | 9200 | 0.3845 | 0.8805 | 0.8802 |
| 0.1106 | 102.17 | 9400 | 0.3841 | 0.8791 | 0.8789 |
| 0.1091 | 104.35 | 9600 | 0.3813 | 0.8791 | 0.8789 |
| 0.105 | 106.52 | 9800 | 0.3847 | 0.8790 | 0.8789 |
| 0.1072 | 108.7 | 10000 | 0.3848 | 0.8770 | 0.8768 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H4-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H4-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:36:39+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3-seqsight_32768_512_43M-L1_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3170
- F1 Score: 0.8730
- Accuracy: 0.8731
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.5063 | 2.13 | 200 | 0.4277 | 0.8016 | 0.8029 |
| 0.3674 | 4.26 | 400 | 0.3869 | 0.8349 | 0.8350 |
| 0.3338 | 6.38 | 600 | 0.3773 | 0.8415 | 0.8417 |
| 0.3189 | 8.51 | 800 | 0.3543 | 0.8564 | 0.8564 |
| 0.3056 | 10.64 | 1000 | 0.3430 | 0.8597 | 0.8597 |
| 0.294 | 12.77 | 1200 | 0.3415 | 0.8617 | 0.8617 |
| 0.2883 | 14.89 | 1400 | 0.3350 | 0.8677 | 0.8677 |
| 0.2803 | 17.02 | 1600 | 0.3305 | 0.8664 | 0.8664 |
| 0.2768 | 19.15 | 1800 | 0.3526 | 0.8595 | 0.8597 |
| 0.2715 | 21.28 | 2000 | 0.3447 | 0.8654 | 0.8657 |
| 0.2709 | 23.4 | 2200 | 0.3240 | 0.8664 | 0.8664 |
| 0.2568 | 25.53 | 2400 | 0.3675 | 0.8601 | 0.8604 |
| 0.2627 | 27.66 | 2600 | 0.3348 | 0.8703 | 0.8704 |
| 0.2611 | 29.79 | 2800 | 0.3316 | 0.8663 | 0.8664 |
| 0.2557 | 31.91 | 3000 | 0.3309 | 0.8683 | 0.8684 |
| 0.2524 | 34.04 | 3200 | 0.3312 | 0.8670 | 0.8671 |
| 0.2512 | 36.17 | 3400 | 0.3520 | 0.8641 | 0.8644 |
| 0.2484 | 38.3 | 3600 | 0.3412 | 0.8663 | 0.8664 |
| 0.2471 | 40.43 | 3800 | 0.3445 | 0.8608 | 0.8611 |
| 0.2468 | 42.55 | 4000 | 0.3551 | 0.8682 | 0.8684 |
| 0.2414 | 44.68 | 4200 | 0.3380 | 0.8704 | 0.8704 |
| 0.2407 | 46.81 | 4400 | 0.3474 | 0.8681 | 0.8684 |
| 0.2421 | 48.94 | 4600 | 0.3840 | 0.8486 | 0.8497 |
| 0.2374 | 51.06 | 4800 | 0.3319 | 0.8764 | 0.8764 |
| 0.2365 | 53.19 | 5000 | 0.3727 | 0.8605 | 0.8611 |
| 0.2352 | 55.32 | 5200 | 0.3354 | 0.8717 | 0.8717 |
| 0.234 | 57.45 | 5400 | 0.3719 | 0.8608 | 0.8611 |
| 0.2322 | 59.57 | 5600 | 0.3533 | 0.8695 | 0.8697 |
| 0.2354 | 61.7 | 5800 | 0.3387 | 0.8716 | 0.8717 |
| 0.2275 | 63.83 | 6000 | 0.3770 | 0.8599 | 0.8604 |
| 0.23 | 65.96 | 6200 | 0.3597 | 0.8646 | 0.8651 |
| 0.2301 | 68.09 | 6400 | 0.3545 | 0.8708 | 0.8711 |
| 0.2303 | 70.21 | 6600 | 0.3620 | 0.8661 | 0.8664 |
| 0.2298 | 72.34 | 6800 | 0.3576 | 0.8661 | 0.8664 |
| 0.2261 | 74.47 | 7000 | 0.4031 | 0.8480 | 0.8490 |
| 0.2229 | 76.6 | 7200 | 0.3632 | 0.8688 | 0.8691 |
| 0.2283 | 78.72 | 7400 | 0.3536 | 0.8723 | 0.8724 |
| 0.2243 | 80.85 | 7600 | 0.3611 | 0.8688 | 0.8691 |
| 0.2245 | 82.98 | 7800 | 0.3722 | 0.8620 | 0.8624 |
| 0.2252 | 85.11 | 8000 | 0.3506 | 0.8756 | 0.8758 |
| 0.2223 | 87.23 | 8200 | 0.3614 | 0.8688 | 0.8691 |
| 0.2214 | 89.36 | 8400 | 0.3702 | 0.8661 | 0.8664 |
| 0.223 | 91.49 | 8600 | 0.3739 | 0.8620 | 0.8624 |
| 0.2197 | 93.62 | 8800 | 0.3719 | 0.8661 | 0.8664 |
| 0.2205 | 95.74 | 9000 | 0.3758 | 0.8613 | 0.8617 |
| 0.2206 | 97.87 | 9200 | 0.3584 | 0.8736 | 0.8737 |
| 0.2208 | 100.0 | 9400 | 0.3588 | 0.8715 | 0.8717 |
| 0.2206 | 102.13 | 9600 | 0.3659 | 0.8675 | 0.8677 |
| 0.2182 | 104.26 | 9800 | 0.3645 | 0.8708 | 0.8711 |
| 0.2198 | 106.38 | 10000 | 0.3647 | 0.8708 | 0.8711 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3-seqsight_32768_512_43M-L1_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3-seqsight_32768_512_43M-L1_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:37:05+00:00 |
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H4-seqsight_32768_512_43M-L32_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H4](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H4) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2456
- F1 Score: 0.9063
- Accuracy: 0.9062
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.3469 | 2.17 | 200 | 0.2894 | 0.8880 | 0.8877 |
| 0.2635 | 4.35 | 400 | 0.2678 | 0.8973 | 0.8973 |
| 0.2476 | 6.52 | 600 | 0.2672 | 0.8960 | 0.8960 |
| 0.2393 | 8.7 | 800 | 0.2811 | 0.8915 | 0.8912 |
| 0.2229 | 10.87 | 1000 | 0.2619 | 0.8993 | 0.8994 |
| 0.212 | 13.04 | 1200 | 0.2620 | 0.9003 | 0.9001 |
| 0.1957 | 15.22 | 1400 | 0.2997 | 0.8895 | 0.8891 |
| 0.1864 | 17.39 | 1600 | 0.2886 | 0.8915 | 0.8912 |
| 0.1764 | 19.57 | 1800 | 0.2986 | 0.8961 | 0.8960 |
| 0.1647 | 21.74 | 2000 | 0.3023 | 0.8887 | 0.8884 |
| 0.154 | 23.91 | 2200 | 0.3210 | 0.8901 | 0.8898 |
| 0.143 | 26.09 | 2400 | 0.3236 | 0.8915 | 0.8912 |
| 0.1354 | 28.26 | 2600 | 0.3311 | 0.8850 | 0.8850 |
| 0.1243 | 30.43 | 2800 | 0.3589 | 0.8725 | 0.8720 |
| 0.1152 | 32.61 | 3000 | 0.3594 | 0.8791 | 0.8789 |
| 0.1002 | 34.78 | 3200 | 0.4006 | 0.8853 | 0.8850 |
| 0.0952 | 36.96 | 3400 | 0.3912 | 0.8818 | 0.8816 |
| 0.0899 | 39.13 | 3600 | 0.4403 | 0.8809 | 0.8809 |
| 0.0816 | 41.3 | 3800 | 0.4618 | 0.8778 | 0.8782 |
| 0.0741 | 43.48 | 4000 | 0.4516 | 0.8741 | 0.8741 |
| 0.0743 | 45.65 | 4200 | 0.4487 | 0.8780 | 0.8782 |
| 0.0673 | 47.83 | 4400 | 0.4597 | 0.8898 | 0.8898 |
| 0.063 | 50.0 | 4600 | 0.4948 | 0.8817 | 0.8816 |
| 0.06 | 52.17 | 4800 | 0.5218 | 0.8749 | 0.8747 |
| 0.0529 | 54.35 | 5000 | 0.5205 | 0.8811 | 0.8809 |
| 0.0501 | 56.52 | 5200 | 0.5313 | 0.8845 | 0.8843 |
| 0.0473 | 58.7 | 5400 | 0.5863 | 0.8757 | 0.8754 |
| 0.0438 | 60.87 | 5600 | 0.5475 | 0.8763 | 0.8761 |
| 0.0432 | 63.04 | 5800 | 0.5901 | 0.8791 | 0.8789 |
| 0.0387 | 65.22 | 6000 | 0.6309 | 0.8669 | 0.8665 |
| 0.0361 | 67.39 | 6200 | 0.6609 | 0.8785 | 0.8782 |
| 0.0349 | 69.57 | 6400 | 0.6233 | 0.8754 | 0.8754 |
| 0.0331 | 71.74 | 6600 | 0.6171 | 0.8797 | 0.8795 |
| 0.0351 | 73.91 | 6800 | 0.6380 | 0.8852 | 0.8850 |
| 0.0288 | 76.09 | 7000 | 0.6467 | 0.8824 | 0.8823 |
| 0.0295 | 78.26 | 7200 | 0.6264 | 0.8776 | 0.8775 |
| 0.0277 | 80.43 | 7400 | 0.6538 | 0.8824 | 0.8823 |
| 0.0247 | 82.61 | 7600 | 0.6973 | 0.8809 | 0.8809 |
| 0.0278 | 84.78 | 7800 | 0.7178 | 0.8797 | 0.8795 |
| 0.0247 | 86.96 | 8000 | 0.6858 | 0.8843 | 0.8843 |
| 0.0237 | 89.13 | 8200 | 0.7218 | 0.8792 | 0.8789 |
| 0.022 | 91.3 | 8400 | 0.6885 | 0.8809 | 0.8809 |
| 0.0213 | 93.48 | 8600 | 0.7192 | 0.8831 | 0.8830 |
| 0.0214 | 95.65 | 8800 | 0.7241 | 0.8803 | 0.8802 |
| 0.0214 | 97.83 | 9000 | 0.7257 | 0.8790 | 0.8789 |
| 0.0184 | 100.0 | 9200 | 0.7460 | 0.8778 | 0.8775 |
| 0.0201 | 102.17 | 9400 | 0.7567 | 0.8770 | 0.8768 |
| 0.0191 | 104.35 | 9600 | 0.7382 | 0.8816 | 0.8816 |
| 0.0185 | 106.52 | 9800 | 0.7424 | 0.8803 | 0.8802 |
| 0.0185 | 108.7 | 10000 | 0.7438 | 0.8810 | 0.8809 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H4-seqsight_32768_512_43M-L32_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H4-seqsight_32768_512_43M-L32_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:37:07+00:00 |
text-generation | transformers | {} | liuyuxiang/wiki_cs_imitator | null | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:38:29+00:00 |
|
null | null | {} | rasasa/Mistral-7B-text-to-sql-flash-attention-2 | null | [
"region:us"
] | null | 2024-04-30T06:38:36+00:00 |
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# phi3nedtuned-ner
This model is a fine-tuned version of [microsoft/Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6568
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 1
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 1
### Training results
### Framework versions
- PEFT 0.10.1.dev0
- Transformers 4.41.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
### License
The model is licensed under the MIT license. | {"license": "mit", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "datasets": ["generator"], "base_model": "microsoft/Phi-3-mini-4k-instruct", "model-index": [{"name": "checkpoint_dir", "results": []}]} | shujatoor/phi3nedtuned-ner | null | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:microsoft/Phi-3-mini-4k-instruct",
"license:mit",
"region:us"
] | null | 2024-04-30T06:41:58+00:00 |
text2text-generation | transformers | {} | shenkha/DGSlow_Bartbase_ED | null | [
"transformers",
"pytorch",
"bart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null | 2024-04-30T06:42:56+00:00 |
|
null | null | {} | Xrunner/hive-m | null | [
"region:us"
] | null | 2024-04-30T06:43:19+00:00 |
|
null | peft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# GUE_EMP_H3-seqsight_32768_512_43M-L8_f
This model is a fine-tuned version of [mahdibaghbanzadeh/seqsight_32768_512_43M](https://huggingface.co/mahdibaghbanzadeh/seqsight_32768_512_43M) on the [mahdibaghbanzadeh/GUE_EMP_H3](https://huggingface.co/datasets/mahdibaghbanzadeh/GUE_EMP_H3) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3077
- F1 Score: 0.8791
- Accuracy: 0.8791
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Score | Accuracy |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:--------:|
| 0.4475 | 2.13 | 200 | 0.3711 | 0.8427 | 0.8430 |
| 0.3173 | 4.26 | 400 | 0.3464 | 0.8557 | 0.8557 |
| 0.291 | 6.38 | 600 | 0.3571 | 0.8615 | 0.8617 |
| 0.277 | 8.51 | 800 | 0.3289 | 0.8630 | 0.8631 |
| 0.2649 | 10.64 | 1000 | 0.3380 | 0.8650 | 0.8651 |
| 0.2537 | 12.77 | 1200 | 0.3459 | 0.8676 | 0.8677 |
| 0.2497 | 14.89 | 1400 | 0.3562 | 0.8621 | 0.8624 |
| 0.24 | 17.02 | 1600 | 0.3300 | 0.8757 | 0.8758 |
| 0.2347 | 19.15 | 1800 | 0.3622 | 0.8627 | 0.8631 |
| 0.2272 | 21.28 | 2000 | 0.3581 | 0.8695 | 0.8697 |
| 0.2244 | 23.4 | 2200 | 0.3776 | 0.8599 | 0.8604 |
| 0.207 | 25.53 | 2400 | 0.4066 | 0.8547 | 0.8550 |
| 0.2113 | 27.66 | 2600 | 0.3849 | 0.8633 | 0.8637 |
| 0.2094 | 29.79 | 2800 | 0.3830 | 0.8660 | 0.8664 |
| 0.2012 | 31.91 | 3000 | 0.3522 | 0.8696 | 0.8697 |
| 0.197 | 34.04 | 3200 | 0.3700 | 0.8715 | 0.8717 |
| 0.1945 | 36.17 | 3400 | 0.4030 | 0.8578 | 0.8584 |
| 0.1872 | 38.3 | 3600 | 0.4093 | 0.8661 | 0.8664 |
| 0.1861 | 40.43 | 3800 | 0.4181 | 0.8592 | 0.8597 |
| 0.1786 | 42.55 | 4000 | 0.4381 | 0.8599 | 0.8604 |
| 0.1745 | 44.68 | 4200 | 0.4421 | 0.8544 | 0.8550 |
| 0.1721 | 46.81 | 4400 | 0.3950 | 0.8654 | 0.8657 |
| 0.172 | 48.94 | 4600 | 0.4968 | 0.8457 | 0.8470 |
| 0.1635 | 51.06 | 4800 | 0.3863 | 0.8729 | 0.8731 |
| 0.1619 | 53.19 | 5000 | 0.4594 | 0.8585 | 0.8591 |
| 0.1593 | 55.32 | 5200 | 0.4623 | 0.8551 | 0.8557 |
| 0.1591 | 57.45 | 5400 | 0.4254 | 0.8622 | 0.8624 |
| 0.1557 | 59.57 | 5600 | 0.4582 | 0.8540 | 0.8544 |
| 0.1532 | 61.7 | 5800 | 0.4197 | 0.8663 | 0.8664 |
| 0.1485 | 63.83 | 6000 | 0.4785 | 0.8564 | 0.8570 |
| 0.1456 | 65.96 | 6200 | 0.4841 | 0.8578 | 0.8584 |
| 0.1444 | 68.09 | 6400 | 0.5085 | 0.8516 | 0.8524 |
| 0.1432 | 70.21 | 6600 | 0.4829 | 0.8626 | 0.8631 |
| 0.1426 | 72.34 | 6800 | 0.4582 | 0.8642 | 0.8644 |
| 0.1391 | 74.47 | 7000 | 0.5618 | 0.8461 | 0.8470 |
| 0.1348 | 76.6 | 7200 | 0.4947 | 0.8647 | 0.8651 |
| 0.1383 | 78.72 | 7400 | 0.4901 | 0.8593 | 0.8597 |
| 0.1317 | 80.85 | 7600 | 0.5457 | 0.8492 | 0.8497 |
| 0.1312 | 82.98 | 7800 | 0.5402 | 0.8484 | 0.8490 |
| 0.1311 | 85.11 | 8000 | 0.5053 | 0.8572 | 0.8577 |
| 0.1303 | 87.23 | 8200 | 0.5300 | 0.8544 | 0.8550 |
| 0.128 | 89.36 | 8400 | 0.5192 | 0.8572 | 0.8577 |
| 0.1281 | 91.49 | 8600 | 0.5447 | 0.8524 | 0.8530 |
| 0.1214 | 93.62 | 8800 | 0.5264 | 0.8553 | 0.8557 |
| 0.1244 | 95.74 | 9000 | 0.5569 | 0.8504 | 0.8510 |
| 0.1197 | 97.87 | 9200 | 0.5364 | 0.8572 | 0.8577 |
| 0.1241 | 100.0 | 9400 | 0.5406 | 0.8532 | 0.8537 |
| 0.1216 | 102.13 | 9600 | 0.5441 | 0.8511 | 0.8517 |
| 0.1177 | 104.26 | 9800 | 0.5631 | 0.8490 | 0.8497 |
| 0.1205 | 106.38 | 10000 | 0.5507 | 0.8504 | 0.8510 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 | {"library_name": "peft", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "base_model": "mahdibaghbanzadeh/seqsight_32768_512_43M", "model-index": [{"name": "GUE_EMP_H3-seqsight_32768_512_43M-L8_f", "results": []}]} | mahdibaghbanzadeh/GUE_EMP_H3-seqsight_32768_512_43M-L8_f | null | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mahdibaghbanzadeh/seqsight_32768_512_43M",
"region:us"
] | null | 2024-04-30T06:43:48+00:00 |
text-generation | transformers | {} | NEGI007/Llama-2-7b-chat-finetune | null | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-04-30T06:43:50+00:00 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.