
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
unicamp-dl/mMiniLM-L6-v2-mmarco-v2
|
8ed6820748716827e99e8f39505eaa121169c1a1
|
2022-01-05T22:45:15.000Z
|
[
"pytorch",
"xlm-roberta",
"text-classification",
"pt",
"dataset:msmarco",
"arxiv:2108.13897",
"transformers",
"msmarco",
"miniLM",
"tensorflow",
"pt-br",
"license:mit"
] |
text-classification
| false
|
unicamp-dl
| null |
unicamp-dl/mMiniLM-L6-v2-mmarco-v2
| 122
| null |
transformers
| 4,300
|
---
language: pt
license: mit
tags:
- msmarco
- miniLM
- pytorch
- tensorflow
- pt
- pt-br
datasets:
- msmarco
widget:
- text: "Texto de exemplo em português"
inference: false
---
# mMiniLM-L6-v2 Reranker finetuned on mMARCO
## Introduction
mMiniLM-L6-v2-mmarco-v2 is a multilingual miniLM-based model finetuned on a multilingual version of MS MARCO passage dataset. This dataset, named mMARCO, is formed by passages in 9 different languages, translated from English MS MARCO passages collection.
In the v2 version, the datasets were translated using Google Translate.
Further information about the dataset or the translation method can be found on our [**mMARCO: A Multilingual Version of MS MARCO Passage Ranking Dataset**](https://arxiv.org/abs/2108.13897) and [mMARCO](https://github.com/unicamp-dl/mMARCO) repository.
## Usage
```python
from transformers import AutoTokenizer, AutoModel
model_name = 'unicamp-dl/mMiniLM-L6-v2-mmarco-v2'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
# Citation
If you use mMiniLM-L6-v2-mmarco-v2, please cite:
@misc{bonifacio2021mmarco,
title={mMARCO: A Multilingual Version of MS MARCO Passage Ranking Dataset},
author={Luiz Henrique Bonifacio and Vitor Jeronymo and Hugo Queiroz Abonizio and Israel Campiotti and Marzieh Fadaee and and Roberto Lotufo and Rodrigo Nogueira},
year={2021},
eprint={2108.13897},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
|
pszemraj/t5-v1_1-base-ft-jflAUG
|
bf9384f2c638632ef0e943ec57ddb7b13f7f6740
|
2022-07-10T00:41:01.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"dataset:jfleg",
"transformers",
"grammar",
"spelling",
"punctuation",
"error-correction",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible"
] |
text2text-generation
| false
|
pszemraj
| null |
pszemraj/t5-v1_1-base-ft-jflAUG
| 122
| 1
|
transformers
| 4,301
|
---
license: cc-by-nc-sa-4.0
tags:
- grammar
- spelling
- punctuation
- error-correction
datasets:
- jfleg
widget:
- text: "i can has cheezburger"
example_title: "cheezburger"
- text: "There car broke down so their hitching a ride to they're class."
example_title: "compound-1"
- text: "so em if we have an now so with fito ringina know how to estimate the tren given the ereafte mylite trend we can also em an estimate is nod s
i again tort watfettering an we have estimated the trend an
called wot to be called sthat of exty right now we can and look at
wy this should not hare a trend i becan we just remove the trend an and we can we now estimate
tesees ona effect of them exty"
example_title: "Transcribed Audio Example 2"
- text: "My coworker said he used a financial planner to help choose his stocks so he wouldn't loose money."
example_title: "incorrect word choice (context)"
- text: "good so hve on an tadley i'm not able to make it to the exla session on monday this week e which is why i am e recording pre recording
an this excelleision and so to day i want e to talk about two things and first of all em i wont em wene give a summary er about
ta ohow to remove trents in these nalitives from time series"
example_title: "lowercased audio transcription output"
- text: "Frustrated, the chairs took me forever to set up."
example_title: "dangling modifier"
- text: "I would like a peice of pie."
example_title: "miss-spelling"
- text: "Which part of Zurich was you going to go hiking in when we were there for the first time together? ! ?"
example_title: "chatbot on Zurich"
parameters:
max_length: 128
min_length: 4
num_beams: 4
repetition_penalty: 1.21
length_penalty: 1
early_stopping: True
---
> A more recent version can be found [here](https://huggingface.co/pszemraj/grammar-synthesis-large). Training smaller and/or comparably sized models is a WIP.
# t5-v1_1-base-ft-jflAUG
**GOAL:** a more robust and generalized grammar and spelling correction model that corrects everything in a single shot. It should have a minimal impact on the semantics of correct sentences (i.e. it does not change things that do not need to be changed).
- this model _(at least from preliminary testing)_ can handle large amounts of errors in the source text (i.e. from audio transcription) and still produce cohesive results.
- a fine-tuned version of [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base) on an expanded version of the [JFLEG dataset](https://aclanthology.org/E17-2037/).
## Model description
- this is a WIP. This fine-tuned model is v1.
- long term: a generalized grammar and spelling correction model that can handle lots of things at the same time.
- currently, it seems to be more of a "gibberish to mostly correct English" translator
## Intended uses & limitations
- try some tests with the [examples here](https://www.engvid.com/english-resource/50-common-grammar-mistakes-in-english/)
- thus far, some limitations are: sentence fragments are not autocorrected (at least, if entered individually), some more complicated pronoun/they/he/her etc. agreement is not always fixed.
## Training and evaluation data
- trained as text-to-text
- JFLEG dataset + additional selected and/or generated grammar corrections
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 5
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
algoprog/mimics-multilabel-roberta-base-787
|
7faaa092ba7eea4b0389b572322a365560405c92
|
2022-05-07T17:49:07.000Z
|
[
"pytorch",
"roberta",
"transformers"
] | null | false
|
algoprog
| null |
algoprog/mimics-multilabel-roberta-base-787
| 122
| null |
transformers
| 4,302
|
Entry not found
|
IljaSamoilov/EstBERT-estonian-subtitles-token-classification
|
ceabdc298a4ff421f22d990d715f2409e9757391
|
2022-05-11T08:13:06.000Z
|
[
"pytorch",
"bert",
"token-classification",
"et",
"transformers",
"autotrain_compatible"
] |
token-classification
| false
|
IljaSamoilov
| null |
IljaSamoilov/EstBERT-estonian-subtitles-token-classification
| 122
| null |
transformers
| 4,303
|
---
language:
- et
widget:
- text: "Et, et, et miks mitte olla siis tasakaalus, ma noh, hüpoteetiliselt viskan selle palli üles,"
- text: "te olete ka noh, noh, päris korralikult ka Rahvusringhäälingu teatud mõttes sellisesse keerulisse olukorda pannud,"
---
Importing the model and tokenizer:
```
tokenizer = AutoTokenizer.from_pretrained("IljaSamoilov/EstBERT-estonian-subtitles-token-classification")
model = AutoModelForTokenClassification.from_pretrained("IljaSamoilov/EstBERT-estonian-subtitles-token-classification")
```
|
launch/POLITICS
|
41b3da20755e0eaf6f00a9dfc5136f4920721856
|
2022-07-26T00:06:33.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false
|
launch
| null |
launch/POLITICS
| 122
| 3
|
transformers
| 4,304
|
## POLITICS
POLITICS, a pretrained model on English news articles of politics, is produced via continued training on RoBERTa, based on a **P**retraining **O**bjective **L**everaging **I**nter-article **T**riplet-loss using **I**deological **C**ontent and **S**tory.
Details of our proposed training objectives (i.e., Ideology-driven Pretraining Objectives) and experimental results of POLITICS can be found in our NAACL-2022 Findings [paper](https://aclanthology.org/2022.findings-naacl.101.pdf) and GitHub [Repo](https://github.com/launchnlp/POLITICS).
Together with POLITICS, we also release our curated large-scale dataset (i.e., BIGNEWS) for pretraining, consisting of more than 3.6M political news articles. This asset can be requested [here](https://docs.google.com/forms/d/e/1FAIpQLSf4hft2AHbuak8jHcltVec_2HviaBBVKXPN4OC-CuW4OFORsw/viewform).
## Citation
Please cite our paper if you use the **POLITICS** model:
```
@inproceedings{liu-etal-2022-POLITICS,
title = "POLITICS: Pretraining with Same-story Article Comparison for Ideology Prediction and Stance Detection",
author = "Liu, Yujian and
Zhang, Xinliang Frederick and
Wegsman, David and
Beauchamp, Nicholas and
Wang, Lu"
booktitle = "Findings of the Association for Computational Linguistics: NAACL 2022",
year = "2022",
```
|
fourthbrain-demo/model_trained_by_me2
|
0fdf6cf2c394fd10fb3740b1a4fc937da49643d3
|
2022-06-20T20:47:13.000Z
|
[
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
| false
|
fourthbrain-demo
| null |
fourthbrain-demo/model_trained_by_me2
| 122
| null |
transformers
| 4,305
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: model_trained_by_me2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model_trained_by_me2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4258
- Accuracy: 0.7983
- F1: 0.7888
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
HooshvareLab/bert-fa-base-uncased-sentiment-deepsentipers-multi
|
76f7785ba3d6e867239401bc6359678a92505e4c
|
2021-05-18T20:58:01.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"fa",
"transformers",
"license:apache-2.0"
] |
text-classification
| false
|
HooshvareLab
| null |
HooshvareLab/bert-fa-base-uncased-sentiment-deepsentipers-multi
| 121
| null |
transformers
| 4,306
|
---
language: fa
license: apache-2.0
---
# ParsBERT (v2.0)
A Transformer-based Model for Persian Language Understanding
We reconstructed the vocabulary and fine-tuned the ParsBERT v1.1 on the new Persian corpora in order to provide some functionalities for using ParsBERT in other scopes!
Please follow the [ParsBERT](https://github.com/hooshvare/parsbert) repo for the latest information about previous and current models.
## Persian Sentiment [Digikala, SnappFood, DeepSentiPers]
It aims to classify text, such as comments, based on their emotional bias. We tested three well-known datasets for this task: `Digikala` user comments, `SnappFood` user comments, and `DeepSentiPers` in two binary-form and multi-form types.
### DeepSentiPers
which is a balanced and augmented version of SentiPers, contains 12,138 user opinions about digital products labeled with five different classes; two positives (i.e., happy and delighted), two negatives (i.e., furious and angry) and one neutral class. Therefore, this dataset can be utilized for both multi-class and binary classification. In the case of binary classification, the neutral class and its corresponding sentences are removed from the dataset.
**Binary:**
1. Negative (Furious + Angry)
2. Positive (Happy + Delighted)
**Multi**
1. Furious
2. Angry
3. Neutral
4. Happy
5. Delighted
| Label | # |
|:---------:|:----:|
| Furious | 236 |
| Angry | 1357 |
| Neutral | 2874 |
| Happy | 2848 |
| Delighted | 2516 |
**Download**
You can download the dataset from:
- [SentiPers](https://github.com/phosseini/sentipers)
- [DeepSentiPers](https://github.com/JoyeBright/DeepSentiPers)
## Results
The following table summarizes the F1 score obtained by ParsBERT as compared to other models and architectures.
| Dataset | ParsBERT v2 | ParsBERT v1 | mBERT | DeepSentiPers |
|:------------------------:|:-----------:|:-----------:|:-----:|:-------------:|
| SentiPers (Multi Class) | 71.31* | 71.11 | - | 69.33 |
| SentiPers (Binary Class) | 92.42* | 92.13 | - | 91.98 |
## How to use :hugs:
| Task | Notebook |
|---------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Sentiment Analysis | [](https://colab.research.google.com/github/hooshvare/parsbert/blob/master/notebooks/Taaghche_Sentiment_Analysis.ipynb) |
### BibTeX entry and citation info
Please cite in publications as the following:
```bibtex
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Questions?
Post a Github issue on the [ParsBERT Issues](https://github.com/hooshvare/parsbert/issues) repo.
|
algolet/mt5-base-chinese-qg
|
90f1d65a0fb2129463110b272d275f88fe57d22c
|
2022-03-03T02:18:05.000Z
|
[
"pytorch",
"mt5",
"text2text-generation",
"zh",
"transformers",
"question generation",
"autotrain_compatible"
] |
text2text-generation
| false
|
algolet
| null |
algolet/mt5-base-chinese-qg
| 121
| 4
|
transformers
| 4,307
|
<h3 align="center">
<p>MT5 Base Model for Chinese Question Generation</p>
</h3>
<h3 align="center">
<p>基于mt5的中文问题生成任务</p>
</h3>
#### 可以通过安装question-generation包开始用
```
pip install question-generation
```
使用方法请参考github项目:https://github.com/algolet/question_generation
#### 在线使用
可以直接在线使用我们的模型:https://www.algolet.com/applications/qg
#### 通过transformers调用
``` python
import torch
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("algolet/mt5-base-chinese-qg")
model = AutoModelForSeq2SeqLM.from_pretrained("algolet/mt5-base-chinese-qg")
model.eval()
text = "在一个寒冷的冬天,赶集完回家的农夫在路边发现了一条冻僵了的蛇。他很可怜蛇,就把它放在怀里。当他身上的热气把蛇温暖以后,蛇很快苏醒了,露出了残忍的本性,给了农夫致命的伤害——咬了农夫一口。农夫临死之前说:“我竟然救了一条可怜的毒蛇,就应该受到这种报应啊!”"
text = "question generation: " + text
inputs = tokenizer(text,
return_tensors='pt',
truncation=True,
max_length=512)
with torch.no_grad():
outs = model.generate(input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_length=128,
no_repeat_ngram_size=4,
num_beams=4)
question = tokenizer.decode(outs[0], skip_special_tokens=True)
questions = [q.strip() for q in question.split("<sep>") if len(q.strip()) > 0]
print(questions)
['在寒冷的冬天,农夫在哪里发现了一条可怜的蛇?', '农夫是如何看待蛇的?', '当农夫遇到蛇时,他做了什么?']
```
#### 指标
rouge-1: 0.4041
rouge-2: 0.2104
rouge-l: 0.3843
---
language:
- zh
tags:
- mt5
- question generation
metrics:
- rouge
---
|
avichr/hebEMO_anticipation
|
27b2152fa2a8875fe4f5cc438e21a413bbc36fa4
|
2022-04-15T09:35:11.000Z
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false
|
avichr
| null |
avichr/hebEMO_anticipation
| 121
| null |
transformers
| 4,308
|
# HebEMO - Emotion Recognition Model for Modern Hebrew
<img align="right" src="https://github.com/avichaychriqui/HeBERT/blob/main/data/heBERT_logo.png?raw=true" width="250">
HebEMO is a tool that detects polarity and extracts emotions from modern Hebrew User-Generated Content (UGC), which was trained on a unique Covid-19 related dataset that we collected and annotated.
HebEMO yielded a high performance of weighted average F1-score = 0.96 for polarity classification.
Emotion detection reached an F1-score of 0.78-0.97, with the exception of *surprise*, which the model failed to capture (F1 = 0.41). These results are better than the best-reported performance, even when compared to the English language.
## Emotion UGC Data Description
Our UGC data includes comments posted on news articles collected from 3 major Israeli news sites, between January 2020 to August 2020. The total size of the data is ~150 MB, including over 7 million words and 350K sentences.
~2000 sentences were annotated by crowd members (3-10 annotators per sentence) for overall sentiment (polarity) and [eight emotions](https://en.wikipedia.org/wiki/Robert_Plutchik#Plutchik's_wheel_of_emotions): anger, disgust, anticipation , fear, joy, sadness, surprise and trust.
The percentage of sentences in which each emotion appeared is found in the table below.
| | anger | disgust | expectation | fear | happy | sadness | surprise | trust | sentiment |
|------:|------:|--------:|------------:|-----:|------:|--------:|---------:|------:|-----------|
| **ratio** | 0.78 | 0.83 | 0.58 | 0.45 | 0.12 | 0.59 | 0.17 | 0.11 | 0.25 |
## Performance
### Emotion Recognition
| emotion | f1-score | precision | recall |
|-------------|----------|-----------|----------|
| anger | 0.96 | 0.99 | 0.93 |
| disgust | 0.97 | 0.98 | 0.96 |
|anticipation | 0.82 | 0.80 | 0.87 |
| fear | 0.79 | 0.88 | 0.72 |
| joy | 0.90 | 0.97 | 0.84 |
| sadness | 0.90 | 0.86 | 0.94 |
| surprise | 0.40 | 0.44 | 0.37 |
| trust | 0.83 | 0.86 | 0.80 |
*The above metrics is for positive class (meaning, the emotion is reflected in the text).*
### Sentiment (Polarity) Analysis
| | precision | recall | f1-score |
|--------------|-----------|--------|----------|
| neutral | 0.83 | 0.56 | 0.67 |
| positive | 0.96 | 0.92 | 0.94 |
| negative | 0.97 | 0.99 | 0.98 |
| accuracy | | | 0.97 |
| macro avg | 0.92 | 0.82 | 0.86 |
| weighted avg | 0.96 | 0.97 | 0.96 |
*Sentiment (polarity) analysis model is also available on AWS! for more information visit [AWS' git](https://github.com/aws-samples/aws-lambda-docker-serverless-inference/tree/main/hebert-sentiment-analysis-inference-docker-lambda)*
## How to use
### Emotion Recognition Model
An online model can be found at [huggingface spaces](https://huggingface.co/spaces/avichr/HebEMO_demo) or as [colab notebook](https://colab.research.google.com/drive/1Jw3gOWjwVMcZslu-ttXoNeD17lms1-ff?usp=sharing)
```
# !pip install pyplutchik==0.0.7
# !pip install transformers==4.14.1
!git clone https://github.com/avichaychriqui/HeBERT.git
from HeBERT.src.HebEMO import *
HebEMO_model = HebEMO()
HebEMO_model.hebemo(input_path = 'data/text_example.txt')
# return analyzed pandas.DataFrame
hebEMO_df = HebEMO_model.hebemo(text='החיים יפים ומאושרים', plot=True)
```
<img src="https://github.com/avichaychriqui/HeBERT/blob/main/data/hebEMO1.png?raw=true" width="300" height="300" />
### For sentiment classification model (polarity ONLY):
from transformers import AutoTokenizer, AutoModel, pipeline
tokenizer = AutoTokenizer.from_pretrained("avichr/heBERT_sentiment_analysis") #same as 'avichr/heBERT' tokenizer
model = AutoModel.from_pretrained("avichr/heBERT_sentiment_analysis")
# how to use?
sentiment_analysis = pipeline(
"sentiment-analysis",
model="avichr/heBERT_sentiment_analysis",
tokenizer="avichr/heBERT_sentiment_analysis",
return_all_scores = True
)
sentiment_analysis('אני מתלבט מה לאכול לארוחת צהריים')
>>> [[{'label': 'neutral', 'score': 0.9978172183036804},
>>> {'label': 'positive', 'score': 0.0014792329166084528},
>>> {'label': 'negative', 'score': 0.0007035882445052266}]]
sentiment_analysis('קפה זה טעים')
>>> [[{'label': 'neutral', 'score': 0.00047328314394690096},
>>> {'label': 'possitive', 'score': 0.9994067549705505},
>>> {'label': 'negetive', 'score': 0.00011996887042187154}]]
sentiment_analysis('אני לא אוהב את העולם')
>>> [[{'label': 'neutral', 'score': 9.214012970915064e-05},
>>> {'label': 'possitive', 'score': 8.876807987689972e-05},
>>> {'label': 'negetive', 'score': 0.9998190999031067}]]
## Contact us
[Avichay Chriqui](mailto:[email protected]) <br>
[Inbal yahav](mailto:[email protected]) <br>
The Coller Semitic Languages AI Lab <br>
Thank you, תודה, شكرا <br>
## If you used this model please cite us as :
Chriqui, A., & Yahav, I. (2022). HeBERT & HebEMO: a Hebrew BERT Model and a Tool for Polarity Analysis and Emotion Recognition. INFORMS Journal on Data Science, forthcoming.
```
@article{chriqui2021hebert,
title={HeBERT \& HebEMO: a Hebrew BERT Model and a Tool for Polarity Analysis and Emotion Recognition},
author={Chriqui, Avihay and Yahav, Inbal},
journal={INFORMS Journal on Data Science},
year={2022}
}
```
|
facebook/s2t-small-mustc-en-de-st
|
ebde73eef775bb11dfa33ee2e5285e0fcfc6f126
|
2022-02-07T15:07:57.000Z
|
[
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"en",
"de",
"dataset:mustc",
"arxiv:2010.05171",
"arxiv:1904.08779",
"transformers",
"audio",
"speech-translation",
"license:mit"
] |
automatic-speech-recognition
| false
|
facebook
| null |
facebook/s2t-small-mustc-en-de-st
| 121
| null |
transformers
| 4,309
|
---
language:
- en
- de
datasets:
- mustc
tags:
- audio
- speech-translation
- automatic-speech-recognition
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
---
# S2T-SMALL-MUSTC-EN-DE-ST
`s2t-small-mustc-en-de-st` is a Speech to Text Transformer (S2T) model trained for end-to-end Speech Translation (ST).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is a transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end English speech to German text translation.
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
import soundfile as sf
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-mustc-en-de-st")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-mustc-en-de-st")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
ds = ds.map(map_to_array)
inputs = processor(
ds["speech"][0],
sampling_rate=16_000,
return_tensors="pt"
)
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
```
## Training data
The s2t-small-mustc-en-de-st is trained on English-German subset of [MuST-C](https://ict.fbk.eu/must-c/).
MuST-C is a multilingual speech translation corpus whose size and quality facilitates the training of end-to-end systems
for speech translation from English into several languages. For each target language, MuST-C comprises several hundred
hours of audio recordings from English TED Talks, which are automatically aligned at the sentence level with their manual
transcriptions and translations.
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 8,000.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively. To accelerate
model training and for better performance the encoder is pre-trained for English ASR.
## Evaluation results
MuST-C test results for en-de (BLEU score): 22.7
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
```
|
facebook/wav2vec2-xls-r-2b-21-to-en
|
e045eaf53c335796df62992c1aee949a1c20d32c
|
2022-05-27T03:01:36.000Z
|
[
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"multilingual",
"fr",
"de",
"es",
"ca",
"it",
"ru",
"zh",
"pt",
"fa",
"et",
"mn",
"nl",
"tr",
"ar",
"sv",
"lv",
"sl",
"ta",
"ja",
"id",
"cy",
"en",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"arxiv:2111.09296",
"transformers",
"speech",
"xls_r",
"xls_r_translation",
"license:apache-2.0"
] |
automatic-speech-recognition
| false
|
facebook
| null |
facebook/wav2vec2-xls-r-2b-21-to-en
| 121
| 1
|
transformers
| 4,310
|
---
language:
- multilingual
- fr
- de
- es
- ca
- it
- ru
- zh
- pt
- fa
- et
- mn
- nl
- tr
- ar
- sv
- lv
- sl
- ta
- ja
- id
- cy
- en
datasets:
- common_voice
- multilingual_librispeech
- covost2
tags:
- speech
- xls_r
- automatic-speech-recognition
- xls_r_translation
pipeline_tag: automatic-speech-recognition
license: apache-2.0
widget:
- example_title: Swedish
src: https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3
- example_title: Arabic
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: German
src: https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3
- example_title: French
src: https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3
- example_title: Indonesian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3
- example_title: Italian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3
- example_title: Japanese
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3
- example_title: Mongolian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: Turkish
src: https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3
- example_title: Catalan
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3
- example_title: English
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
---
# Wav2Vec2-XLS-R-2b-21-EN
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-2b`**](https://huggingface.co/facebook/wav2vec2-xls-r-2b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 21 `{lang}` -> `en` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{lang}` -> `en` (English):
{`fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`} -> `en`
For more information, please refer to Section *5.1.2* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested directly on the speech recognition widget on this model card!
Simple record some audio in one of the possible spoken languages or pick an example audio file to see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline
```python
from datasets import load_dataset
from transformers import pipeline
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-2b-21-to-en", feature_extractor="facebook/wav2vec2-xls-r-2b-21-to-en")
translation = asr(audio_file)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-2b-21-to-en")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-2b-21-to-en")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
```
## Results `{lang}` -> `en`
See the row of **XLS-R (2B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.
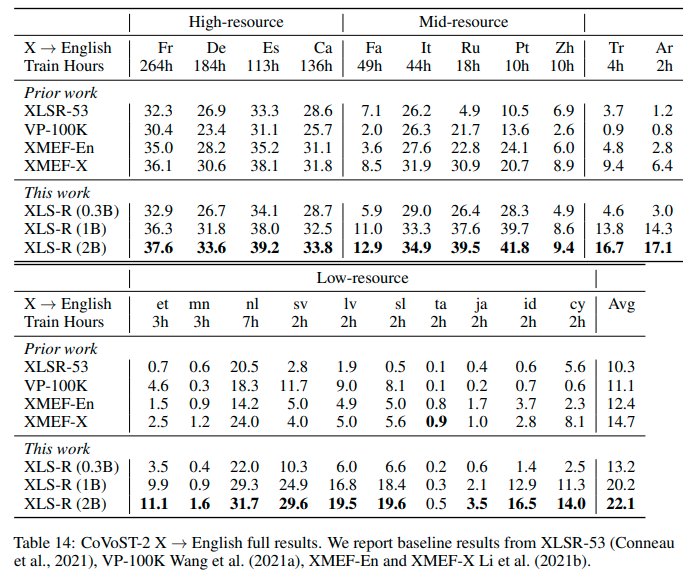
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-300m-21-to-en)
- [Wav2Vec2-XLS-R-1B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-1b-21-to-en)
- [Wav2Vec2-XLS-R-2B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-2b-21-to-en)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
huggingtweets/commanderwuff
|
f9c9c97d7f1ba3f1f8932541096b5d6302dd307d
|
2021-05-21T23:15:31.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] |
text-generation
| false
|
huggingtweets
| null |
huggingtweets/commanderwuff
| 121
| null |
transformers
| 4,311
|
---
language: en
thumbnail: https://www.huggingtweets.com/commanderwuff/1614170164099/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1363930888585703425/kbXPjWRV_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">CommanderWuffels 🤖 AI Bot </div>
<div style="font-size: 15px">@commanderwuff bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@commanderwuff's tweets](https://twitter.com/commanderwuff).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 2214 |
| Retweets | 1573 |
| Short tweets | 144 |
| Tweets kept | 497 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2a74c2hq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @commanderwuff's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2f3nzjf3) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2f3nzjf3/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/commanderwuff')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
ktangri/gpt-neo-demo
|
dbb3415f20cb5679e122ebe4bc6126b82f44cfa2
|
2021-07-21T15:20:09.000Z
|
[
"pytorch",
"gpt_neo",
"text-generation",
"en",
"dataset:the Pile",
"transformers",
"text generation",
"the Pile",
"causal-lm",
"license:apache-2.0"
] |
text-generation
| false
|
ktangri
| null |
ktangri/gpt-neo-demo
| 121
| 1
|
transformers
| 4,312
|
---
language:
- en
tags:
- text generation
- pytorch
- the Pile
- causal-lm
license: apache-2.0
datasets:
- the Pile
---
# GPT-Neo 2.7B (By EleutherAI)
## Model Description
GPT-Neo 2.7B is a transformer model designed using EleutherAI's replication of the GPT-3 architecture. GPT-Neo refers to the class of models, while 2.7B represents the number of parameters of this particular pre-trained model.
## Training data
GPT-Neo 2.7B was trained on the Pile, a large scale curated dataset created by EleutherAI for the purpose of training this model.
## Training procedure
This model was trained for 420 billion tokens over 400,000 steps. It was trained as a masked autoregressive language model, using cross-entropy loss.
## Intended Use and Limitations
This way, the model learns an inner representation of the English language that can then be used to extract features useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a prompt.
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='EleutherAI/gpt-neo-2.7B')
>>> generator("EleutherAI has", do_sample=True, min_length=50)
[{'generated_text': 'EleutherAI has made a commitment to create new software packages for each of its major clients and has'}]
```
### Limitations and Biases
GPT-Neo was trained as an autoregressive language model. This means that its core functionality is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work.
GPT-Neo was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending on your usecase GPT-Neo may produce socially unacceptable text. See Sections 5 and 6 of the Pile paper for a more detailed analysis of the biases in the Pile.
As with all language models, it is hard to predict in advance how GPT-Neo will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.
## Eval results
All evaluations were done using our [evaluation harness](https://github.com/EleutherAI/lm-evaluation-harness). Some results for GPT-2 and GPT-3 are inconsistent with the values reported in the respective papers. We are currently looking into why, and would greatly appreciate feedback and further testing of our eval harness. If you would like to contribute evaluations you have done, please reach out on our [Discord](https://discord.gg/vtRgjbM).
### Linguistic Reasoning
| Model and Size | Pile BPB | Pile PPL | Wikitext PPL | Lambada PPL | Lambada Acc | Winogrande | Hellaswag |
| ---------------- | ---------- | ---------- | ------------- | ----------- | ----------- | ---------- | ----------- |
| GPT-Neo 1.3B | 0.7527 | 6.159 | 13.10 | 7.498 | 57.23% | 55.01% | 38.66% |
| GPT-2 1.5B | 1.0468 | ----- | 17.48 | 10.634 | 51.21% | 59.40% | 40.03% |
| **GPT-Neo 2.7B** | **0.7165** | **5.646** | **11.39** | **5.626** | **62.22%** | **56.50%** | **42.73%** |
| GPT-3 Ada | 0.9631 | ----- | ----- | 9.954 | 51.60% | 52.90% | 35.93% |
### Physical and Scientific Reasoning
| Model and Size | MathQA | PubMedQA | Piqa |
| ---------------- | ---------- | ---------- | ----------- |
| GPT-Neo 1.3B | 24.05% | 54.40% | 71.11% |
| GPT-2 1.5B | 23.64% | 58.33% | 70.78% |
| **GPT-Neo 2.7B** | **24.72%** | **57.54%** | **72.14%** |
| GPT-3 Ada | 24.29% | 52.80% | 68.88% |
### Down-Stream Applications
TBD
### BibTeX entry and citation info
To cite this model, use
```bibtex
@article{gao2020pile,
title={The Pile: An 800GB Dataset of Diverse Text for Language Modeling},
author={Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and others},
journal={arXiv preprint arXiv:2101.00027},
year={2020}
}
```
To cite the codebase that this model was trained with, use
```bibtex
@software{gpt-neo,
author = {Black, Sid and Gao, Leo and Wang, Phil and Leahy, Connor and Biderman, Stella},
title = {{GPT-Neo}: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow},
url = {http://github.com/eleutherai/gpt-neo},
version = {1.0},
year = {2021},
}
```
|
macedonizer/hr-gpt2
|
4913a36f6dfb05ef6ff5eb89638cadc3843d19f0
|
2021-09-22T08:58:40.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"hr",
"dataset:wiki-hr",
"transformers",
"license:apache-2.0"
] |
text-generation
| false
|
macedonizer
| null |
macedonizer/hr-gpt2
| 121
| 1
|
transformers
| 4,313
|
---
language:
- hr
thumbnail: https://huggingface.co/macedonizer/hr-gpt2/lets-talk-about-nlp-hr.jpg
license: apache-2.0
datasets:
- wiki-hr
---
# hr-gpt2
Test the whole generation capabilities here: https://transformer.huggingface.co/doc/gpt2-large
Pretrained model on English language using a causal language modeling (CLM) objective. It was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
## Model description
hr-gpt2 is a transformers model pretrained on a very large corpus of Croation data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labeling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of the continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of the word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the Macedonian language that can then be used to extract features
useful for downstream tasks. The model is best at what it was pretrained for, however, which is generating texts from a
prompt.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
import random \\nfrom transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained('macedonizer/hr-gpt2') \
model = AutoModelWithLMHead.from_pretrained('macedonizer/sr-gpt2')
input_text = 'Ja sam bio '
if len(input_text) == 0: \
encoded_input = tokenizer(input_text, return_tensors="pt") \
output = model.generate( \
bos_token_id=random.randint(1, 50000), \
do_sample=True, \
top_k=50, \
max_length=1024, \
top_p=0.95, \
num_return_sequences=1, \
) \
else: \
encoded_input = tokenizer(input_text, return_tensors="pt") \
output = model.generate( \
**encoded_input, \
bos_token_id=random.randint(1, 50000), \
do_sample=True, \
top_k=50, \
max_length=1024, \
top_p=0.95, \
num_return_sequences=1, \
)
decoded_output = [] \
for sample in output: \
decoded_output.append(tokenizer.decode(sample, skip_special_tokens=True))
print(decoded_output)
|
tau/spider
|
d06abf763de54af0e2a908610cd1fa1917ca3bba
|
2022-05-08T07:51:30.000Z
|
[
"pytorch",
"dpr",
"arxiv:2112.07708",
"transformers"
] | null | false
|
tau
| null |
tau/spider
| 121
| 5
|
transformers
| 4,314
|
# Spider
This is the unsupervised pretrained model discussed in our paper [Learning to Retrieve Passages without Supervision](https://arxiv.org/abs/2112.07708).
## Usage
We used weight sharing for the query encoder and passage encoder, so the same model should be applied for both.
**Note**! We format the passages similar to DPR, i.e. the title and the text are separated by a `[SEP]` token, but token
type ids are all 0-s.
An example usage:
```python
from transformers import AutoTokenizer, DPRContextEncoder
tokenizer = AutoTokenizer.from_pretrained("tau/spider")
model = DPRContextEncoder.from_pretrained("tau/spider")
input_dict = tokenizer("title", "text", return_tensors="pt")
del input_dict["token_type_ids"]
outputs = model(**input_dict)
```
|
facebook/m2m100-12B-last-ckpt
|
d3b4890e87cd5ee681d200e66d2aa5faf3a00feb
|
2022-05-26T22:26:23.000Z
|
[
"pytorch",
"m2m_100",
"text2text-generation",
"multilingual",
"af",
"am",
"ar",
"ast",
"az",
"ba",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"ceb",
"cs",
"cy",
"da",
"de",
"el",
"en",
"es",
"et",
"fa",
"ff",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"ht",
"hu",
"hy",
"id",
"ig",
"ilo",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"lb",
"lg",
"ln",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"ns",
"oc",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"ss",
"su",
"sv",
"sw",
"ta",
"th",
"tl",
"tn",
"tr",
"uk",
"ur",
"uz",
"vi",
"wo",
"xh",
"yi",
"yo",
"zh",
"zu",
"arxiv:2010.11125",
"transformers",
"m2m100-12B",
"license:mit",
"autotrain_compatible"
] |
text2text-generation
| false
|
facebook
| null |
facebook/m2m100-12B-last-ckpt
| 121
| null |
transformers
| 4,315
|
---
language:
- multilingual
- af
- am
- ar
- ast
- az
- ba
- be
- bg
- bn
- br
- bs
- ca
- ceb
- cs
- cy
- da
- de
- el
- en
- es
- et
- fa
- ff
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- ht
- hu
- hy
- id
- ig
- ilo
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- lb
- lg
- ln
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- ns
- oc
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- so
- sq
- sr
- ss
- su
- sv
- sw
- ta
- th
- tl
- tn
- tr
- uk
- ur
- uz
- vi
- wo
- xh
- yi
- yo
- zh
- zu
license: mit
tags:
- m2m100-12B
---
# M2M100 12B
M2M100 is a multilingual encoder-decoder (seq-to-seq) model trained for Many-to-Many multilingual translation.
It was introduced in this [paper](https://arxiv.org/abs/2010.11125) and first released in [this](https://github.com/pytorch/fairseq/tree/master/examples/m2m_100) repository.
The model that can directly translate between the 9,900 directions of 100 languages.
To translate into a target language, the target language id is forced as the first generated token.
To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
*Note: `M2M100Tokenizer` depends on `sentencepiece`, so make sure to install it before running the example.*
To install `sentencepiece` run `pip install sentencepiece`
```python
from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
chinese_text = "生活就像一盒巧克力。"
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100-12B-last-ckpt")
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100-12B-last-ckpt")
# translate Hindi to French
tokenizer.src_lang = "hi"
encoded_hi = tokenizer(hi_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "La vie est comme une boîte de chocolat."
# translate Chinese to English
tokenizer.src_lang = "zh"
encoded_zh = tokenizer(chinese_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Life is like a box of chocolate."
```
See the [model hub](https://huggingface.co/models?filter=m2m_100) to look for more fine-tuned versions.
## Languages covered
Afrikaans (af), Amharic (am), Arabic (ar), Asturian (ast), Azerbaijani (az), Bashkir (ba), Belarusian (be), Bulgarian (bg), Bengali (bn), Breton (br), Bosnian (bs), Catalan; Valencian (ca), Cebuano (ceb), Czech (cs), Welsh (cy), Danish (da), German (de), Greeek (el), English (en), Spanish (es), Estonian (et), Persian (fa), Fulah (ff), Finnish (fi), French (fr), Western Frisian (fy), Irish (ga), Gaelic; Scottish Gaelic (gd), Galician (gl), Gujarati (gu), Hausa (ha), Hebrew (he), Hindi (hi), Croatian (hr), Haitian; Haitian Creole (ht), Hungarian (hu), Armenian (hy), Indonesian (id), Igbo (ig), Iloko (ilo), Icelandic (is), Italian (it), Japanese (ja), Javanese (jv), Georgian (ka), Kazakh (kk), Central Khmer (km), Kannada (kn), Korean (ko), Luxembourgish; Letzeburgesch (lb), Ganda (lg), Lingala (ln), Lao (lo), Lithuanian (lt), Latvian (lv), Malagasy (mg), Macedonian (mk), Malayalam (ml), Mongolian (mn), Marathi (mr), Malay (ms), Burmese (my), Nepali (ne), Dutch; Flemish (nl), Norwegian (no), Northern Sotho (ns), Occitan (post 1500) (oc), Oriya (or), Panjabi; Punjabi (pa), Polish (pl), Pushto; Pashto (ps), Portuguese (pt), Romanian; Moldavian; Moldovan (ro), Russian (ru), Sindhi (sd), Sinhala; Sinhalese (si), Slovak (sk), Slovenian (sl), Somali (so), Albanian (sq), Serbian (sr), Swati (ss), Sundanese (su), Swedish (sv), Swahili (sw), Tamil (ta), Thai (th), Tagalog (tl), Tswana (tn), Turkish (tr), Ukrainian (uk), Urdu (ur), Uzbek (uz), Vietnamese (vi), Wolof (wo), Xhosa (xh), Yiddish (yi), Yoruba (yo), Chinese (zh), Zulu (zu)
## BibTeX entry and citation info
```
@misc{fan2020englishcentric,
title={Beyond English-Centric Multilingual Machine Translation},
author={Angela Fan and Shruti Bhosale and Holger Schwenk and Zhiyi Ma and Ahmed El-Kishky and Siddharth Goyal and Mandeep Baines and Onur Celebi and Guillaume Wenzek and Vishrav Chaudhary and Naman Goyal and Tom Birch and Vitaliy Liptchinsky and Sergey Edunov and Edouard Grave and Michael Auli and Armand Joulin},
year={2020},
eprint={2010.11125},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
VietAI/vit5-large
|
8a6430bc250119f4e587b541fb9511fabcb1145d
|
2022-07-25T14:15:38.000Z
|
[
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"vi",
"dataset:cc100",
"transformers",
"summarization",
"translation",
"question-answering",
"license:mit",
"autotrain_compatible"
] |
question-answering
| false
|
VietAI
| null |
VietAI/vit5-large
| 121
| null |
transformers
| 4,316
|
---
language: vi
datasets:
- cc100
tags:
- summarization
- translation
- question-answering
license: mit
---
# ViT5-large
State-of-the-art pretrained Transformer-based encoder-decoder model for Vietnamese.
## How to use
For more details, do check out [our Github repo](https://github.com/vietai/ViT5).
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("VietAI/vit5-large")
model = AutoModelForSeq2SeqLM.from_pretrained("VietAI/vit5-large")
sentence = "VietAI là tổ chức phi lợi nhuận với sứ mệnh ươm mầm tài năng về trí tuệ nhân tạo và xây dựng một cộng đồng các chuyên gia trong lĩnh vực trí tuệ nhân tạo đẳng cấp quốc tế tại Việt Nam."
text = "vi: " + sentence
encoding = tokenizer.encode_plus(text, pad_to_max_length=True, return_tensors="pt")
input_ids, attention_masks = encoding["input_ids"].to("cuda"), encoding["attention_mask"].to("cuda")
outputs = model.generate(
input_ids=input_ids, attention_mask=attention_masks,
max_length=256,
early_stopping=True
)
for output in outputs:
line = tokenizer.decode(output, skip_special_tokens=True, clean_up_tokenization_spaces=True)
print(line)
```
## Citation
```
@inproceedings{phan-etal-2022-vit5,
title = "{V}i{T}5: Pretrained Text-to-Text Transformer for {V}ietnamese Language Generation",
author = "Phan, Long and Tran, Hieu and Nguyen, Hieu and Trinh, Trieu H.",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop",
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-srw.18",
pages = "136--142",
}
```
|
benjamin/gpt2-large-wechsel-ukrainian
|
43593df16479731a30227a4cfb62be8ca731eb53
|
2022-04-29T16:56:10.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"uk",
"arxiv:2112.06598",
"transformers",
"license:mit"
] |
text-generation
| false
|
benjamin
| null |
benjamin/gpt2-large-wechsel-ukrainian
| 121
| 3
|
transformers
| 4,317
|
---
license: mit
language: uk
---
# gpt2-large-wechsel-ukrainian
[`gpt2-large`](https://huggingface.co/gpt2-large) transferred to Ukrainian using the method from the NAACL2022 paper [WECHSEL: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models](https://arxiv.org/abs/2112.065989).
|
jonas/sdg_classifier_osdg
|
c86a6802a2e2956365669a3ab41091d2634da058
|
2022-05-24T15:46:51.000Z
|
[
"pytorch",
"bert",
"text-classification",
"en",
"dataset:jonas/osdg_sdg_data_processed",
"transformers",
"co2_eq_emissions"
] |
text-classification
| false
|
jonas
| null |
jonas/sdg_classifier_osdg
| 121
| 2
|
transformers
| 4,318
|
---
language: en
widget:
- text: "Ending all forms of discrimination against women and girls is not only a basic human right, but it also crucial to accelerating sustainable development. It has been proven time and again, that empowering women and girls has a multiplier effect, and helps drive up economic growth and development across the board.
Since 2000, UNDP, together with our UN partners and the rest of the global community, has made gender equality central to our work. We have seen remarkable progress since then. More girls are now in school compared to 15 years ago, and most regions have reached gender parity in primary education. Women now make up to 41 percent of paid workers outside of agriculture, compared to 35 percent in 1990."
datasets:
- jonas/osdg_sdg_data_processed
co2_eq_emissions: 0.0653263174784986
---
# About
Machine Learning model for classifying text according to the first 15 of the 17 Sustainable Development Goals from the United Nations. Note that model is trained on quite short paragraphs (around 100 words) and performs best with similar input sizes.
Data comes from the amazing https://osdg.ai/ community!
# Model Training Specifics
- Problem type: Multi-class Classification
- Model ID: 900229515
- CO2 Emissions (in grams): 0.0653263174784986
## Validation Metrics
- Loss: 0.3644874095916748
- Accuracy: 0.8972544579677328
- Macro F1: 0.8500873710954522
- Micro F1: 0.8972544579677328
- Weighted F1: 0.8937529692986061
- Macro Precision: 0.8694369727467804
- Micro Precision: 0.8972544579677328
- Weighted Precision: 0.8946984684977016
- Macro Recall: 0.8405065997404059
- Micro Recall: 0.8972544579677328
- Weighted Recall: 0.8972544579677328
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/jonas/autotrain-osdg-sdg-classifier-900229515
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("jonas/sdg_classifier_osdg", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("jonas/sdg_classifier_osdg", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
PrimeQA/tydiqa-primary-task-xlm-roberta-large
|
6933c572b917c8987b756c4202d6af1e4851ee1a
|
2022-07-05T16:47:31.000Z
|
[
"pytorch",
"xlm-roberta",
"multilingual",
"arxiv:2003.05002",
"arxiv:1911.02116",
"transformers",
"MRC",
"TyDiQA",
"xlm-roberta-large"
] | null | false
|
PrimeQA
| null |
PrimeQA/tydiqa-primary-task-xlm-roberta-large
| 121
| null |
transformers
| 4,319
|
---
tags:
- MRC
- TyDiQA
- xlm-roberta-large
language:
- multilingual
---
# Model description
An XLM-RoBERTa reading comprehension model for [TyDiQA Primary Tasks](https://arxiv.org/abs/2003.05002).
The model is initialized with [xlm-roberta-large](https://huggingface.co/xlm-roberta-large/) and fine-tuned on the [TyDiQA train data](https://huggingface.co/datasets/tydiqa).
## Intended uses & limitations
You can use the raw model for the reading comprehension task. Biases associated with the pre-existing language model, xlm-roberta-large, that we used may be present in our fine-tuned model, tydiqa-primary-task-xlm-roberta-large.
## Usage
You can use this model directly with the [PrimeQA](https://github.com/primeqa/primeqa) pipeline for reading comprehension [tydiqa.ipynb](https://github.com/primeqa/primeqa/blob/main/notebooks/mrc/tydiqa.ipynb).
### BibTeX entry and citation info
```bibtex
@article{clark-etal-2020-tydi,
title = "{T}y{D}i {QA}: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages",
author = "Clark, Jonathan H. and
Choi, Eunsol and
Collins, Michael and
Garrette, Dan and
Kwiatkowski, Tom and
Nikolaev, Vitaly and
Palomaki, Jennimaria",
journal = "Transactions of the Association for Computational Linguistics",
volume = "8",
year = "2020",
address = "Cambridge, MA",
publisher = "MIT Press",
url = "https://aclanthology.org/2020.tacl-1.30",
doi = "10.1162/tacl_a_00317",
pages = "454--470",
}
```
```bibtex
@article{DBLP:journals/corr/abs-1911-02116,
author = {Alexis Conneau and
Kartikay Khandelwal and
Naman Goyal and
Vishrav Chaudhary and
Guillaume Wenzek and
Francisco Guzm{\'{a}}n and
Edouard Grave and
Myle Ott and
Luke Zettlemoyer and
Veselin Stoyanov},
title = {Unsupervised Cross-lingual Representation Learning at Scale},
journal = {CoRR},
volume = {abs/1911.02116},
year = {2019},
url = {http://arxiv.org/abs/1911.02116},
eprinttype = {arXiv},
eprint = {1911.02116},
timestamp = {Mon, 11 Nov 2019 18:38:09 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1911-02116.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
nickmuchi/yolos-small-rego-plates-detection
|
232139b5fd2fcaeb45ccd59de5c8eda1fe0788fe
|
2022-07-10T13:09:55.000Z
|
[
"pytorch",
"yolos",
"object-detection",
"dataset:coco",
"dataset:license-plate-detection",
"arxiv:2106.00666",
"transformers",
"license-plate-detection",
"vehicle-detection",
"license:apache-2.0",
"model-index"
] |
object-detection
| false
|
nickmuchi
| null |
nickmuchi/yolos-small-rego-plates-detection
| 121
| null |
transformers
| 4,320
|
---
license: apache-2.0
tags:
- object-detection
- license-plate-detection
- vehicle-detection
datasets:
- coco
- license-plate-detection
widget:
- src: https://drive.google.com/uc?id=1j9VZQ4NDS4gsubFf3m2qQoTMWLk552bQ
example_title: "Skoda 1"
- src: https://drive.google.com/uc?id=1p9wJIqRz3W50e2f_A0D8ftla8hoXz4T5
example_title: "Skoda 2"
metrics:
- average precision
- recall
- IOU
model-index:
- name: yolos-small-rego-plates-detection
results: []
---
# YOLOS (small-sized) model
The original YOLOS model was fine-tuned on COCO 2017 object detection (118k annotated images). It was introduced in the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Fang et al. and first released in [this repository](https://github.com/hustvl/YOLOS).
This model was further fine-tuned on the [license plate dataset]("https://www.kaggle.com/datasets/andrewmvd/car-plate-detection") from Kaggle. The dataset consists of 735 images of annotations categorised as "vehicle" and "license-plate". The model was trained for 200 epochs on a single GPU using Google Colab
## Model description
YOLOS is a Vision Transformer (ViT) trained using the DETR loss. Despite its simplicity, a base-sized YOLOS model is able to achieve 42 AP on COCO validation 2017 (similar to DETR and more complex frameworks such as Faster R-CNN).
## Intended uses & limitations
You can use the raw model for object detection. See the [model hub](https://huggingface.co/models?search=hustvl/yolos) to look for all available YOLOS models.
### How to use
Here is how to use this model:
```python
from transformers import YolosFeatureExtractor, YolosForObjectDetection
from PIL import Image
import requests
url = 'https://drive.google.com/uc?id=1p9wJIqRz3W50e2f_A0D8ftla8hoXz4T5'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = YolosFeatureExtractor.from_pretrained('nickmuchi/yolos-small-rego-plates-detection')
model = YolosForObjectDetection.from_pretrained('nickmuchi/yolos-small-rego-plates-detection')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
# model predicts bounding boxes and corresponding face mask detection classes
logits = outputs.logits
bboxes = outputs.pred_boxes
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The YOLOS model was pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet2012) and fine-tuned on [COCO 2017 object detection](https://cocodataset.org/#download), a dataset consisting of 118k/5k annotated images for training/validation respectively.
### Training
This model was fine-tuned for 200 epochs on the [license plate dataset]("https://www.kaggle.com/datasets/andrewmvd/car-plate-detection").
## Evaluation results
This model achieves an AP (average precision) of **47.9**.
Accumulating evaluation results...
IoU metric: bbox
Metrics | Metric Parameter | Location | Dets | Value |
---------------- | --------------------- | ------------| ------------- | ----- |
Average Precision | (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] | 0.479 |
Average Precision | (AP) @[ IoU=0.50 | area= all | maxDets=100 ] | 0.752 |
Average Precision | (AP) @[ IoU=0.75 | area= all | maxDets=100 ] | 0.555 |
Average Precision | (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] | 0.147 |
Average Precision | (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] | 0.420 |
Average Precision | (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] | 0.804 |
Average Recall | (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] | 0.437 |
Average Recall | (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] | 0.641 |
Average Recall | (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] | 0.676 |
Average Recall | (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] | 0.268 |
Average Recall | (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] | 0.641 |
Average Recall | (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] | 0.870 |
|
TurkuNLP/wikibert-base-vi-cased
|
359e6c23f7737b19861f4db02fd4484e2ecb639c
|
2020-05-24T20:02:25.000Z
|
[
"pytorch",
"transformers"
] | null | false
|
TurkuNLP
| null |
TurkuNLP/wikibert-base-vi-cased
| 120
| null |
transformers
| 4,321
|
Entry not found
|
erst/xlm-roberta-base-finetuned-nace
|
84d9e5e01eb7a718c4ade662b6659509b73c17c0
|
2021-05-21T04:36:28.000Z
|
[
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
] |
text-classification
| false
|
erst
| null |
erst/xlm-roberta-base-finetuned-nace
| 120
| 1
|
transformers
| 4,322
|
# Classifying Text into NACE Codes
This model is [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) fine-tuned to classify descriptions of activities into [NACE Rev. 2](https://ec.europa.eu/eurostat/web/nace-rev2) codes.
## Data
The data used to fine-tune the model consist of 2.5 million descriptions of activities from Norwegian and Danish businesses. To improve the model's multilingual performance, random samples of the Norwegian and Danish descriptions were machine translated into the following languages:
- English
- German
- Spanish
- French
- Finnish
- Polish
## Quick Start
```python
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("erst/xlm-roberta-base-finetuned-nace")
model = AutoModelForSequenceClassification.from_pretrained("erst/xlm-roberta-base-finetuned-nace")
pl = pipeline(
"sentiment-analysis",
model=model,
tokenizer=tokenizer,
return_all_scores=False,
)
pl("The purpose of our company is to build houses")
```
|
ethanyt/guwen-cls
|
3249168f65e7a2d6e1ad8fb09bd1e77db714ff90
|
2021-06-17T09:37:37.000Z
|
[
"pytorch",
"roberta",
"text-classification",
"zh",
"transformers",
"chinese",
"classical chinese",
"literary chinese",
"ancient chinese",
"bert",
"text classificatio",
"license:apache-2.0"
] |
text-classification
| false
|
ethanyt
| null |
ethanyt/guwen-cls
| 120
| 1
|
transformers
| 4,323
|
---
language:
- "zh"
thumbnail: "https://user-images.githubusercontent.com/9592150/97142000-cad08e00-179a-11eb-88df-aff9221482d8.png"
tags:
- "chinese"
- "classical chinese"
- "literary chinese"
- "ancient chinese"
- "bert"
- "pytorch"
- "text classificatio"
license: "apache-2.0"
pipeline_tag: "text-classification"
widget:
- text: "子曰:“弟子入则孝,出则悌,谨而信,泛爱众,而亲仁。行有馀力,则以学文。”"
---
# Guwen CLS
A Classical Chinese Text Classifier.
See also:
<a href="https://github.com/ethan-yt/guwen-models">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwen-models&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/cclue/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=cclue&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/guwenbert/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwenbert&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
|
facebook/convnext-xlarge-384-22k-1k
|
f9f3d83b87a2a395b2ffa940a5ce7a0442c390e5
|
2022-03-02T19:02:58.000Z
|
[
"pytorch",
"tf",
"convnext",
"image-classification",
"dataset:imagenet-21k",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"transformers",
"vision",
"license:apache-2.0"
] |
image-classification
| false
|
facebook
| null |
facebook/convnext-xlarge-384-22k-1k
| 120
| 2
|
transformers
| 4,324
|
---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-21k
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# ConvNeXT (xlarge-sized model)
ConvNeXT model pre-trained on ImageNet-22k and fine-tuned on ImageNet-1k at resolution 384x384. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextFeatureExtractor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-xlarge-384-22k-1k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-xlarge-384-22k-1k")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
gagan3012/k2t-new
|
986e0baaec1fe1b014df182d1a24718ef2eb9c29
|
2021-09-22T08:27:25.000Z
|
[
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"dataset:common_gen",
"transformers",
"keytotext",
"k2t",
"Keywords to Sentences",
"license:mit",
"autotrain_compatible"
] |
text2text-generation
| false
|
gagan3012
| null |
gagan3012/k2t-new
| 120
| null |
transformers
| 4,325
|
---
language: en
thumbnail: Keywords to Sentences
tags:
- keytotext
- k2t
- Keywords to Sentences
license: mit
datasets:
- common_gen
metrics:
- NLG
---
# keytotext

Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface 🤗
[](https://pypi.org/project/keytotext/)
[](https://pepy.tech/project/keytotext)
[](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
[](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
## Model:
Keytotext is based on the Amazing T5 Model:
- `k2t`: [Model](https://huggingface.co/gagan3012/k2t)
- `k2t-tiny`: [Model](https://huggingface.co/gagan3012/k2t-tiny)
- `k2t-base`: [Model](https://huggingface.co/gagan3012/k2t-base)
Training Notebooks can be found in the [`Training Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Training%20Notebooks) Folder
## Usage:
Example usage: [](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
Example Notebooks can be found in the [`Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Examples) Folder
```
pip install keytotext
```

## UI:
UI: [](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
```
pip install streamlit-tags
```
This uses a custom streamlit component built by me: [GitHub](https://github.com/gagan3012/streamlit-tags)

|
google/tapas-small-finetuned-wtq
|
b76ab837755d1c4dc4dc70eb7bade9b9fa5641c6
|
2022-07-14T10:13:43.000Z
|
[
"pytorch",
"tf",
"tapas",
"table-question-answering",
"en",
"dataset:wikitablequestions",
"arxiv:2004.02349",
"arxiv:2010.00571",
"arxiv:1508.00305",
"transformers",
"license:apache-2.0"
] |
table-question-answering
| false
|
google
| null |
google/tapas-small-finetuned-wtq
| 120
| null |
transformers
| 4,326
|
---
language: en
tags:
- tapas
- table-question-answering
license: apache-2.0
datasets:
- wikitablequestions
---
# TAPAS small model fine-tuned on WikiTable Questions (WTQ)
This model has 2 versions which can be used. The default version corresponds to the `tapas_wtq_wikisql_sqa_inter_masklm_small_reset` checkpoint of the [original Github repository](https://github.com/google-research/tapas).
This model was pre-trained on MLM and an additional step which the authors call intermediate pre-training, and then fine-tuned in a chain on [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253), [WikiSQL](https://github.com/salesforce/WikiSQL) and finally [WTQ](https://github.com/ppasupat/WikiTableQuestions). It uses relative position embeddings (i.e. resetting the position index at every cell of the table).
The other (non-default) version which can be used is:
- `no_reset`, which corresponds to `tapas_wtq_wikisql_sqa_inter_masklm_small` (intermediate pre-training, absolute position embeddings).
Disclaimer: The team releasing TAPAS did not write a model card for this model so this model card has been written by
the Hugging Face team and contributors.
## Results
Size | Reset | Dev Accuracy | Link
-------- | --------| -------- | ----
LARGE | noreset | 0.5062 | [tapas-large-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-large-finetuned-wtq/tree/no_reset)
LARGE | reset | 0.5097 | [tapas-large-finetuned-wtq](https://huggingface.co/google/tapas-large-finetuned-wtq/tree/main)
BASE | noreset | 0.4525 | [tapas-base-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-base-finetuned-wtq/tree/no_reset)
BASE | reset | 0.4638 | [tapas-base-finetuned-wtq](https://huggingface.co/google/tapas-base-finetuned-wtq/tree/main)
MEDIUM | noreset | 0.4324 | [tapas-medium-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-medium-finetuned-wtq/tree/no_reset)
MEDIUM | reset | 0.4324 | [tapas-medium-finetuned-wtq](https://huggingface.co/google/tapas-medium-finetuned-wtq/tree/main)
**SMALL** | **noreset** | **0.3681** | [tapas-small-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-small-finetuned-wtq/tree/no_reset)
**SMALL** | **reset** | **0.3762** | [tapas-small-finetuned-wtq](https://huggingface.co/google/tapas-small-finetuned-wtq/tree/main)
MINI | noreset | 0.2783 | [tapas-mini-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-mini-finetuned-wtq/tree/no_reset)
MINI | reset | 0.2854 | [tapas-mini-finetuned-wtq](https://huggingface.co/google/tapas-mini-finetuned-wtq/tree/main)
TINY | noreset | 0.0823 | [tapas-tiny-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-tiny-finetuned-wtq/tree/no_reset)
TINY | reset | 0.1039 | [tapas-tiny-finetuned-wtq](https://huggingface.co/google/tapas-tiny-finetuned-wtq/tree/main)
## Model description
TAPAS is a BERT-like transformers model pretrained on a large corpus of English data from Wikipedia in a self-supervised fashion.
This means it was pretrained on the raw tables and associated texts only, with no humans labelling them in any way (which is why it
can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a (flattened) table and associated context, the model randomly masks 15% of the words in
the input, then runs the entire (partially masked) sequence through the model. The model then has to predict the masked words.
This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other,
or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional
representation of a table and associated text.
- Intermediate pre-training: to encourage numerical reasoning on tables, the authors additionally pre-trained the model by creating
a balanced dataset of millions of syntactically created training examples. Here, the model must predict (classify) whether a sentence
is supported or refuted by the contents of a table. The training examples are created based on synthetic as well as counterfactual statements.
This way, the model learns an inner representation of the English language used in tables and associated texts, which can then be used
to extract features useful for downstream tasks such as answering questions about a table, or determining whether a sentence is entailed
or refuted by the contents of a table. Fine-tuning is done by adding a cell selection head and aggregation head on top of the pre-trained model, and then jointly train these randomly initialized classification heads with the base model on SQa, WikiSQL and finally WTQ.
## Intended uses & limitations
You can use this model for answering questions related to a table.
For code examples, we refer to the documentation of TAPAS on the HuggingFace website.
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Question [SEP] Flattened table [SEP]
```
The authors did first convert the WTQ dataset into the format of SQA using automatic conversion scripts.
### Fine-tuning
The model was fine-tuned on 32 Cloud TPU v3 cores for 50,000 steps with maximum sequence length 512 and batch size of 512.
In this setup, fine-tuning takes around 10 hours. The optimizer used is Adam with a learning rate of 1.93581e-5, and a warmup
ratio of 0.128960. An inductive bias is added such that the model only selects cells of the same column. This is reflected by the
`select_one_column` parameter of `TapasConfig`. See the [paper](https://arxiv.org/abs/2004.02349) for more details (tables 11 and
12).
### BibTeX entry and citation info
```bibtex
@misc{herzig2020tapas,
title={TAPAS: Weakly Supervised Table Parsing via Pre-training},
author={Jonathan Herzig and Paweł Krzysztof Nowak and Thomas Müller and Francesco Piccinno and Julian Martin Eisenschlos},
year={2020},
eprint={2004.02349},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
```
```bibtex
@misc{eisenschlos2020understanding,
title={Understanding tables with intermediate pre-training},
author={Julian Martin Eisenschlos and Syrine Krichene and Thomas Müller},
year={2020},
eprint={2010.00571},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@article{DBLP:journals/corr/PasupatL15,
author = {Panupong Pasupat and
Percy Liang},
title = {Compositional Semantic Parsing on Semi-Structured Tables},
journal = {CoRR},
volume = {abs/1508.00305},
year = {2015},
url = {http://arxiv.org/abs/1508.00305},
archivePrefix = {arXiv},
eprint = {1508.00305},
timestamp = {Mon, 13 Aug 2018 16:47:37 +0200},
biburl = {https://dblp.org/rec/journals/corr/PasupatL15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
jonatasgrosman/wav2vec2-large-xlsr-53-hungarian
|
07c68507b5d7c39f6c956a8ecca0658704ba99c9
|
2022-07-27T23:35:50.000Z
|
[
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"hu",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false
|
jonatasgrosman
| null |
jonatasgrosman/wav2vec2-large-xlsr-53-hungarian
| 120
| 1
|
transformers
| 4,327
|
---
language: hu
datasets:
- common_voice
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Hungarian by Jonatas Grosman
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice hu
type: common_voice
args: hu
metrics:
- name: Test WER
type: wer
value: 31.40
- name: Test CER
type: cer
value: 6.20
---
# Fine-tuned XLSR-53 large model for speech recognition in Hungarian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Hungarian using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice) and [CSS10](https://github.com/Kyubyong/css10).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-hungarian")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "hu"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-hungarian"
SAMPLES = 5
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| BÜSZKÉK VAGYUNK A MAGYAR EMBEREK NAGYSZERŰ SZELLEMI ALKOTÁSAIRA. | BÜSZKÉK VAGYUNK A MAGYAR EMBEREK NAGYSZERŰ SZELLEMI ALKOTÁSAIRE |
| A NEMZETSÉG TAGJAI KÖZÜL EZT TERMESZTIK A LEGSZÉLESEBB KÖRBEN ÍZLETES TERMÉSÉÉRT. | A NEMZETSÉG TAGJAI KÖZÜL ESZSZERMESZTIK A LEGSZELESEBB KÖRBEN IZLETES TERMÉSSÉÉRT |
| A VÁROSBA VÁGYÓDOTT A LEGJOBBAN, ÉPPEN MERT ODA NEM JUTHATOTT EL SOHA. | A VÁROSBA VÁGYÓDOTT A LEGJOBBAN ÉPPEN MERT ODA NEM JUTHATOTT EL SOHA |
| SÍRJA MÁRA MEGSEMMISÜLT. | SIMGI A MANDO MEG SEMMICSEN |
| MINDEN ZENESZÁMOT DRÁGAKŐNEK NEVEZETT. | MINDEN ZENA SZÁMODRAGAKŐNEK NEVEZETT |
| ÍGY MÚLT EL A DÉLELŐTT. | ÍGY MÚLT EL A DÍN ELŐTT |
| REMEK POFA! | A REMEG PUFO |
| SZEMET SZEMÉRT, FOGAT FOGÉRT. | SZEMET SZEMÉRT FOGADD FOGÉRT |
| BIZTOSAN LAKIK ITT NÉHÁNY ATYÁMFIA. | BIZTOSAN LAKIKÉT NÉHANY ATYAMFIA |
| A SOROK KÖZÖTT OLVAS. | A SOROG KÖZÖTT OLVAS |
## Evaluation
The model can be evaluated as follows on the Hungarian test data of Common Voice.
```python
import torch
import re
import librosa
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "hu"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-hungarian"
DEVICE = "cuda"
CHARS_TO_IGNORE = [",", "?", "¿", ".", "!", "¡", ";", ";", ":", '""', "%", '"', "�", "ʿ", "·", "჻", "~", "՞",
"؟", "،", "।", "॥", "«", "»", "„", "“", "”", "「", "」", "‘", "’", "《", "》", "(", ")", "[", "]",
"{", "}", "=", "`", "_", "+", "<", ">", "…", "–", "°", "´", "ʾ", "‹", "›", "©", "®", "—", "→", "。",
"、", "﹂", "﹁", "‧", "~", "﹏", ",", "{", "}", "(", ")", "[", "]", "【", "】", "‥", "〽",
"『", "』", "〝", "〟", "⟨", "⟩", "〜", ":", "!", "?", "♪", "؛", "/", "\\", "º", "−", "^", "ʻ", "ˆ"]
test_dataset = load_dataset("common_voice", LANG_ID, split="test")
wer = load_metric("wer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/wer.py
cer = load_metric("cer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/cer.py
chars_to_ignore_regex = f"[{re.escape(''.join(CHARS_TO_IGNORE))}]"
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
model.to(DEVICE)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = re.sub(chars_to_ignore_regex, "", batch["sentence"]).upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to(DEVICE), attention_mask=inputs.attention_mask.to(DEVICE)).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
predictions = [x.upper() for x in result["pred_strings"]]
references = [x.upper() for x in result["sentence"]]
print(f"WER: {wer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
print(f"CER: {cer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
```
**Test Result**:
In the table below I report the Word Error Rate (WER) and the Character Error Rate (CER) of the model. I ran the evaluation script described above on other models as well (on 2021-04-22). Note that the table below may show different results from those already reported, this may have been caused due to some specificity of the other evaluation scripts used.
| Model | WER | CER |
| ------------- | ------------- | ------------- |
| jonatasgrosman/wav2vec2-large-xlsr-53-hungarian | **31.40%** | **6.20%** |
| anton-l/wav2vec2-large-xlsr-53-hungarian | 42.39% | 9.39% |
| gchhablani/wav2vec2-large-xlsr-hu | 46.42% | 10.04% |
| birgermoell/wav2vec2-large-xlsr-hungarian | 46.93% | 10.31% |
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-hungarian,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {H}ungarian},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-hungarian}},
year={2021}
}
```
|
kingabzpro/wav2vec2-large-xls-r-300m-Urdu
|
ab77a3c4d65e4fcb8fc453072e1db45a1c224db4
|
2022-03-23T18:29:40.000Z
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ur",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"generated_from_trainer",
"hf-asr-leaderboard",
"robust-speech-event",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false
|
kingabzpro
| null |
kingabzpro/wav2vec2-large-xls-r-300m-Urdu
| 120
| 1
|
transformers
| 4,328
|
---
language:
- ur
license: apache-2.0
tags:
- generated_from_trainer
- hf-asr-leaderboard
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_8_0
metrics:
- wer
model-index:
- name: wav2vec2-large-xls-r-300m-Urdu
results:
- task:
type: automatic-speech-recognition
name: Speech Recognition
dataset:
type: mozilla-foundation/common_voice_8_0
name: Common Voice 8
args: ur
metrics:
- type: wer
value: 39.89
name: Test WER
- name: Test CER
type: cer
value: 16.7
---
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-Urdu
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9889
- Wer: 0.5607
- Cer: 0.2370
#### Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8_0` with split `test`
```bash
python eval.py --model_id kingabzpro/wav2vec2-large-xls-r-300m-Urdu --dataset mozilla-foundation/common_voice_8_0 --config ur --split test
```
### Inference With LM
```python
from datasets import load_dataset, Audio
from transformers import pipeline
model = "kingabzpro/wav2vec2-large-xls-r-300m-Urdu"
data = load_dataset("mozilla-foundation/common_voice_8_0",
"ur",
split="test",
streaming=True,
use_auth_token=True)
sample_iter = iter(data.cast_column("path",
Audio(sampling_rate=16_000)))
sample = next(sample_iter)
asr = pipeline("automatic-speech-recognition", model=model)
prediction = asr(sample["path"]["array"],
chunk_length_s=5,
stride_length_s=1)
prediction
# => {'text': 'اب یہ ونگین لمحاتانکھار دلمیں میںفوث کریلیا اجائ'}
```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:------:|:----:|:---------------:|:------:|:------:|
| 3.6398 | 30.77 | 400 | 3.3517 | 1.0 | 1.0 |
| 2.9225 | 61.54 | 800 | 2.5123 | 1.0 | 0.8310 |
| 1.2568 | 92.31 | 1200 | 0.9699 | 0.6273 | 0.2575 |
| 0.8974 | 123.08 | 1600 | 0.9715 | 0.5888 | 0.2457 |
| 0.7151 | 153.85 | 2000 | 0.9984 | 0.5588 | 0.2353 |
| 0.6416 | 184.62 | 2400 | 0.9889 | 0.5607 | 0.2370 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
### Eval results on Common Voice 8 "test" (WER):
| Without LM | With LM (run `./eval.py`) |
|---|---|
| 52.03 | 39.89 |
|
macedonizer/sl-gpt2
|
e2626dcd4ff050db045efb829d5a477a79c75898
|
2021-09-22T08:58:51.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"sl",
"dataset:wiki-sl",
"transformers",
"license:apache-2.0"
] |
text-generation
| false
|
macedonizer
| null |
macedonizer/sl-gpt2
| 120
| null |
transformers
| 4,329
|
---
language:
- sl
thumbnail: https://huggingface.co/macedonizer/mkgpt2/lets-talk-about-nlp.jpg
license: apache-2.0
datasets:
- wiki-sl
---
# sl-gpt2
Test the whole generation capabilities here: https://transformer.huggingface.co/doc/gpt2-large
Pretrained model on English language using a causal language modeling (CLM) objective. It was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
## Model description
sl-gpt2 is a transformers model pretrained on a very large corpus of Slovenian data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the Macedonian language that can then be used to extract features
useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a
prompt.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
import random
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained('macedonizer/sl-gpt2') \
model = AutoModelWithLMHead.from_pretrained('macedonizer/sl-gpt2')
input_text = 'Ljubljana '
if len(input_text) == 0: \
encoded_input = tokenizer(input_text, return_tensors="pt") \
output = model.generate( \
bos_token_id=random.randint(1, 50000), \
do_sample=True, \
top_k=50, \
max_length=1024, \
top_p=0.95, \
num_return_sequences=1, \
) \
else: \
encoded_input = tokenizer(input_text, return_tensors="pt") \
output = model.generate( \
**encoded_input, \
bos_token_id=random.randint(1, 50000), \
do_sample=True, \
top_k=50, \
max_length=1024, \
top_p=0.95, \
num_return_sequences=1, \
)
decoded_output = [] \\nfor sample in output: \
decoded_output.append(tokenizer.decode(sample, skip_special_tokens=True))
print(decoded_output)
|
mgrella/autonlp-bank-transaction-classification-5521155
|
cb26734f92f251e77874ed46ff6d5db067180e3d
|
2021-07-22T21:32:58.000Z
|
[
"pytorch",
"bert",
"text-classification",
"it",
"dataset:mgrella/autonlp-data-bank-transaction-classification",
"transformers",
"autonlp"
] |
text-classification
| false
|
mgrella
| null |
mgrella/autonlp-bank-transaction-classification-5521155
| 120
| 1
|
transformers
| 4,330
|
---
tags: autonlp
language: it
widget:
- text: "I love AutoNLP 🤗"
datasets:
- mgrella/autonlp-data-bank-transaction-classification
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 5521155
## Validation Metrics
- Loss: 1.3173143863677979
- Accuracy: 0.8220706757594545
- Macro F1: 0.5713688384455807
- Micro F1: 0.8220706757594544
- Weighted F1: 0.8217158913702755
- Macro Precision: 0.6064387992817253
- Micro Precision: 0.8220706757594545
- Weighted Precision: 0.8491515834140735
- Macro Recall: 0.5873349311175117
- Micro Recall: 0.8220706757594545
- Weighted Recall: 0.8220706757594545
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/mgrella/autonlp-bank-transaction-classification-5521155
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("mgrella/autonlp-bank-transaction-classification-5521155", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("mgrella/autonlp-bank-transaction-classification-5521155", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
rifkat/robert_BPE_pubchem10M
|
0abbfed74087f4d0e9702b451fc0552a8afd9bbf
|
2021-07-24T19:42:19.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false
|
rifkat
| null |
rifkat/robert_BPE_pubchem10M
| 120
| null |
transformers
| 4,331
|
Entry not found
|
ICFNext/EYY-categorisation-1.0
|
4737cf4193d111ae4eafbf4f4fb24719f620ee68
|
2022-03-24T00:16:47.000Z
|
[
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers"
] |
text-classification
| false
|
ICFNext
| null |
ICFNext/EYY-categorisation-1.0
| 120
| 2
|
transformers
| 4,332
|
Entry not found
|
anegi/t5smallmodel
|
bc1b68bdefedc3f897fbc4135ce4612a74dc6c57
|
2022-04-09T03:37:45.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"dataset:samsum",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
text2text-generation
| false
|
anegi
| null |
anegi/t5smallmodel
| 120
| 1
|
transformers
| 4,333
|
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- samsum
model-index:
- name: t5smallmodel
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5smallmodel
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8672
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1077 | 0.54 | 500 | 1.8672 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.10.3
|
Helsinki-NLP/opus-mt-tc-big-el-en
|
559cab1eb5383f61552207d4ddca1e96e41d327e
|
2022-06-01T13:01:32.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"el",
"en",
"transformers",
"translation",
"opus-mt-tc",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible"
] |
translation
| false
|
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-tc-big-el-en
| 120
| null |
transformers
| 4,334
|
---
language:
- el
- en
tags:
- translation
- opus-mt-tc
license: cc-by-4.0
model-index:
- name: opus-mt-tc-big-el-en
results:
- task:
name: Translation ell-eng
type: translation
args: ell-eng
dataset:
name: flores101-devtest
type: flores_101
args: ell eng devtest
metrics:
- name: BLEU
type: bleu
value: 33.9
- task:
name: Translation ell-eng
type: translation
args: ell-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: ell-eng
metrics:
- name: BLEU
type: bleu
value: 68.8
---
# opus-mt-tc-big-el-en
Neural machine translation model for translating from Modern Greek (1453-) (el) to English (en).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-02-25
* source language(s): ell
* target language(s): eng
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-02-25.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/ell-eng/opusTCv20210807+bt_transformer-big_2022-02-25.zip)
* more information released models: [OPUS-MT ell-eng README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ell-eng/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"Το σχολείο μας έχει εννιά τάξεις.",
"Άρχισε να τρέχει."
]
model_name = "pytorch-models/opus-mt-tc-big-el-en"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# Our school has nine classes.
# He started running.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-el-en")
print(pipe("Το σχολείο μας έχει εννιά τάξεις."))
# expected output: Our school has nine classes.
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-02-25.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ell-eng/opusTCv20210807+bt_transformer-big_2022-02-25.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-02-25.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ell-eng/opusTCv20210807+bt_transformer-big_2022-02-25.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| ell-eng | tatoeba-test-v2021-08-07 | 0.79708 | 68.8 | 10899 | 68682 |
| ell-eng | flores101-devtest | 0.61252 | 33.9 | 1012 | 24721 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 18:48:34 EEST 2022
* port machine: LM0-400-22516.local
|
Team-PIXEL/pixel-base-finetuned-sst2
|
5a15269d904ad983d3cc4f23dd31704d83e9ee59
|
2022-07-14T19:18:25.000Z
|
[
"pytorch",
"pixel",
"text-classification",
"en",
"dataset:glue",
"transformers",
"generated_from_trainer",
"model-index"
] |
text-classification
| false
|
Team-PIXEL
| null |
Team-PIXEL/pixel-base-finetuned-sst2
| 120
| null |
transformers
| 4,335
|
---
language:
- en
tags:
- generated_from_trainer
datasets:
- glue
model-index:
- name: pixel-base-finetuned-sst2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pixel-base-finetuned-sst2
This model is a fine-tuned version of [Team-PIXEL/pixel-base](https://huggingface.co/Team-PIXEL/pixel-base) on the GLUE SST2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 4
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 5000
- mixed_precision_training: Apex, opt level O1
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.12.1
|
SkolkovoInstitute/gpt2-base-gedi-detoxification
|
aef170a95b65a27211bf66658e499f963a4a781f
|
2021-11-02T18:07:47.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false
|
SkolkovoInstitute
| null |
SkolkovoInstitute/gpt2-base-gedi-detoxification
| 119
| null |
transformers
| 4,336
|
Entry not found
|
allenai/unifiedqa-v2-t5-3b-1363200
|
290d6c9755263e8d3c39dfb75c0401f356713492
|
2022-02-22T05:22:32.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false
|
allenai
| null |
allenai/unifiedqa-v2-t5-3b-1363200
| 119
| 1
|
transformers
| 4,337
|
# Further details: https://github.com/allenai/unifiedqa
|
allenai/wmt16-en-de-12-1
|
1739470889a0567220bcd17202a8a904b3e10a11
|
2020-12-11T21:33:17.000Z
|
[
"pytorch",
"fsmt",
"text2text-generation",
"en",
"de",
"dataset:wmt16",
"arxiv:2006.10369",
"transformers",
"translation",
"wmt16",
"allenai",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false
|
allenai
| null |
allenai/wmt16-en-de-12-1
| 119
| null |
transformers
| 4,338
|
---
language:
- en
- de
thumbnail:
tags:
- translation
- wmt16
- allenai
license: apache-2.0
datasets:
- wmt16
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of fairseq-based [wmt16 transformer](https://github.com/jungokasai/deep-shallow/) for en-de.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
All 3 models are available:
* [wmt16-en-de-dist-12-1](https://huggingface.co/allenai/wmt16-en-de-dist-12-1)
* [wmt16-en-de-dist-6-1](https://huggingface.co/allenai/wmt16-en-de-dist-6-1)
* [wmt16-en-de-12-1](https://huggingface.co/allenai/wmt16-en-de-12-1)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/wmt16-en-de-12-1"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Machine learning is great, isn't it?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Maschinelles Lernen ist großartig, nicht wahr?
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | fairseq | transformers
-------|---------|----------
wmt16-en-de-12-1 | 26.9 | 25.75
The score is slightly below the score reported in the paper, as the researchers don't use `sacrebleu` and measure the score on tokenized outputs. `transformers` score was measured using `sacrebleu` on detokenized outputs.
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt16 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt16 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/wmt16-en-de-12-1 $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt16/)
- [test set](http://matrix.statmt.org/test_sets/newstest2016.tgz?1504722372)
### BibTeX entry and citation info
```
@misc{kasai2020deep,
title={Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation},
author={Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith},
year={2020},
eprint={2006.10369},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
anirudh21/albert-base-v2-finetuned-qnli
|
e5b34bf25b9ba48e02034b3045fa895744e537be
|
2022-01-24T19:56:19.000Z
|
[
"pytorch",
"tensorboard",
"albert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
| false
|
anirudh21
| null |
anirudh21/albert-base-v2-finetuned-qnli
| 119
| 1
|
transformers
| 4,339
|
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: albert-base-v2-finetuned-qnli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: qnli
metrics:
- name: Accuracy
type: accuracy
value: 0.9112209408749771
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-v2-finetuned-qnli
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3194
- Accuracy: 0.9112
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.3116 | 1.0 | 6547 | 0.2818 | 0.8849 |
| 0.2467 | 2.0 | 13094 | 0.2532 | 0.9001 |
| 0.1858 | 3.0 | 19641 | 0.3194 | 0.9112 |
| 0.1449 | 4.0 | 26188 | 0.4338 | 0.9103 |
| 0.0584 | 5.0 | 32735 | 0.5752 | 0.9052 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.0
- Tokenizers 0.10.3
|
bayartsogt/mongolian-roberta-large
|
f74a5dac3521789bed8128930412186834856cba
|
2021-08-23T03:59:52.000Z
|
[
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false
|
bayartsogt
| null |
bayartsogt/mongolian-roberta-large
| 119
| null |
transformers
| 4,340
|
Entry not found
|
doc2query/all-t5-base-v1
|
28d82c068119c6cf21945bfa8d91ce1dcbdfdf8d
|
2021-10-19T12:54:25.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:sentence-transformers/reddit-title-body",
"dataset:sentence-transformers/embedding-training-data",
"arxiv:1904.08375",
"arxiv:2104.08663",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false
|
doc2query
| null |
doc2query/all-t5-base-v1
| 119
| 1
|
transformers
| 4,341
|
---
language: en
datasets:
- sentence-transformers/reddit-title-body
- sentence-transformers/embedding-training-data
widget:
- text: "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
license: apache-2.0
---
# doc2query/all-t5-base-v1
This is a [doc2query](https://arxiv.org/abs/1904.08375) model based on T5 (also known as [docT5query](https://cs.uwaterloo.ca/~jimmylin/publications/Nogueira_Lin_2019_docTTTTTquery-v2.pdf)).
It can be used for:
- **Document expansion**: You generate for your paragraphs 20-40 queries and index the paragraphs and the generates queries in a standard BM25 index like Elasticsearch, OpenSearch, or Lucene. The generated queries help to close the lexical gap of lexical search, as the generate queries contain synonyms. Further, it re-weights words giving important words a higher weight even if they appear seldomn in a paragraph. In our [BEIR](https://arxiv.org/abs/2104.08663) paper we showed that BM25+docT5query is a powerful search engine. In the [BEIR repository](https://github.com/UKPLab/beir) we have an example how to use docT5query with Pyserini.
- **Domain Specific Training Data Generation**: It can be used to generate training data to learn an embedding model. On [SBERT.net](https://www.sbert.net/examples/unsupervised_learning/query_generation/README.html) we have an example how to use the model to generate (query, text) pairs for a given collection of unlabeled texts. These pairs can then be used to train powerful dense embedding models.
## Usage
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
model_name = 'doc2query/all-t5-base-v1'
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
text = "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
input_ids = tokenizer.encode(text, max_length=384, truncation=True, return_tensors='pt')
outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=5)
print("Text:")
print(text)
print("\nGenerated Queries:")
for i in range(len(outputs)):
query = tokenizer.decode(outputs[i], skip_special_tokens=True)
print(f'{i + 1}: {query}')
```
**Note:** `model.generate()` is non-deterministic. It produces different queries each time you run it.
## Training
This model fine-tuned [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base) for 570k training steps. For the training script, see the `train_script.py` in this repository.
The input-text was truncated to 384 word pieces. Output text was generated up to 64 word pieces.
This model was trained on a large collection of datasets. For the exact datasets names and weights see the `data_config.json` in this repository. Most of the datasets are available at [https://huggingface.co/sentence-transformers](https://huggingface.co/sentence-transformers).
The datasets include besides others:
- (title, body) pairs from [Reddit](https://huggingface.co/datasets/sentence-transformers/reddit-title-body)
- (title, body) pairs and (title, answer) pairs from StackExchange and Yahoo Answers!
- (title, review) pairs from Amazon reviews
- (query, paragraph) pairs from MS MARCO, NQ, and GooAQ
- (question, duplicate_question) from Quora and WikiAnswers
- (title, abstract) pairs from S2ORC
## Prefix
This model was trained **without a prefix**. In contrast to [doc2query/all-with_prefix-t5-base-v1](https://huggingface.co/doc2query/all-with_prefix-t5-base-v1) you cannot specify what type of transformation (answer2question, review2title) etc. you will have. This can lead to a mixture of output values.
|
laxya007/gpt2_BE_ISI_NE_BI_INR
|
95a376be2883dee847c0675493ec107224cf07c0
|
2021-05-23T06:42:28.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false
|
laxya007
| null |
laxya007/gpt2_BE_ISI_NE_BI_INR
| 119
| null |
transformers
| 4,342
|
Entry not found
|
w11wo/indonesian-roberta-base-posp-tagger
|
4dfd27bb9efb1e847ac107c1186d0e62d6a793f6
|
2021-07-11T15:52:18.000Z
|
[
"pytorch",
"tf",
"roberta",
"token-classification",
"id",
"dataset:indonlu",
"arxiv:1907.11692",
"transformers",
"indonesian-roberta-base-posp-tagger",
"license:mit",
"autotrain_compatible"
] |
token-classification
| false
|
w11wo
| null |
w11wo/indonesian-roberta-base-posp-tagger
| 119
| 1
|
transformers
| 4,343
|
---
language: id
tags:
- indonesian-roberta-base-posp-tagger
license: mit
datasets:
- indonlu
widget:
- text: "Budi sedang pergi ke pasar."
---
## Indonesian RoBERTa Base POSP Tagger
Indonesian RoBERTa Base POSP Tagger is a part-of-speech token-classification model based on the [RoBERTa](https://arxiv.org/abs/1907.11692) model. The model was originally the pre-trained [Indonesian RoBERTa Base](https://hf.co/flax-community/indonesian-roberta-base) model, which is then fine-tuned on [`indonlu`](https://hf.co/datasets/indonlu)'s `POSP` dataset consisting of tag-labelled news.
After training, the model achieved an evaluation F1-macro of 95.34%. On the benchmark test set, the model achieved an accuracy of 93.99% and F1-macro of 88.93%.
Hugging Face's `Trainer` class from the [Transformers](https://huggingface.co/transformers) library was used to train the model. PyTorch was used as the backend framework during training, but the model remains compatible with other frameworks nonetheless.
## Model
| Model | #params | Arch. | Training/Validation data (text) |
| ------------------------------------- | ------- | ------------ | ------------------------------- |
| `indonesian-roberta-base-posp-tagger` | 124M | RoBERTa Base | `POSP` |
## Evaluation Results
The model was trained for 10 epochs and the best model was loaded at the end.
| Epoch | Training Loss | Validation Loss | Precision | Recall | F1 | Accuracy |
| ----- | ------------- | --------------- | --------- | -------- | -------- | -------- |
| 1 | 0.898400 | 0.343731 | 0.894324 | 0.894324 | 0.894324 | 0.894324 |
| 2 | 0.294700 | 0.236619 | 0.929620 | 0.929620 | 0.929620 | 0.929620 |
| 3 | 0.214100 | 0.202723 | 0.938349 | 0.938349 | 0.938349 | 0.938349 |
| 4 | 0.171100 | 0.183630 | 0.945264 | 0.945264 | 0.945264 | 0.945264 |
| 5 | 0.143300 | 0.169744 | 0.948469 | 0.948469 | 0.948469 | 0.948469 |
| 6 | 0.124700 | 0.174946 | 0.947963 | 0.947963 | 0.947963 | 0.947963 |
| 7 | 0.109800 | 0.167450 | 0.951590 | 0.951590 | 0.951590 | 0.951590 |
| 8 | 0.101300 | 0.163191 | 0.952475 | 0.952475 | 0.952475 | 0.952475 |
| 9 | 0.093500 | 0.163255 | 0.953361 | 0.953361 | 0.953361 | 0.953361 |
| 10 | 0.089000 | 0.164673 | 0.953445 | 0.953445 | 0.953445 | 0.953445 |
## How to Use
### As Token Classifier
```python
from transformers import pipeline
pretrained_name = "w11wo/indonesian-roberta-base-posp-tagger"
nlp = pipeline(
"token-classification",
model=pretrained_name,
tokenizer=pretrained_name
)
nlp("Budi sedang pergi ke pasar.")
```
## Disclaimer
Do consider the biases which come from both the pre-trained RoBERTa model and the `POSP` dataset that may be carried over into the results of this model.
## Author
Indonesian RoBERTa Base POSP Tagger was trained and evaluated by [Wilson Wongso](https://w11wo.github.io/). All computation and development are done on Google Colaboratory using their free GPU access.
|
vumichien/tiny-albert
|
48ab0d3d6f338494632dbd0abb54a8943376ab92
|
2022-04-14T00:16:10.000Z
|
[
"pytorch",
"tf",
"albert",
"token-classification",
"transformers",
"generated_from_keras_callback",
"model-index",
"autotrain_compatible"
] |
token-classification
| false
|
vumichien
| null |
vumichien/tiny-albert
| 119
| null |
transformers
| 4,344
|
---
tags:
- generated_from_keras_callback
model-index:
- name: tiny-albert
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# tiny-albert
This model is a fine-tuned version of [hf-internal-testing/tiny-albert](https://huggingface.co/hf-internal-testing/tiny-albert) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.18.0
- TensorFlow 2.8.0
- Tokenizers 0.12.1
|
nielsr/layoutlmv3-finetuned-cord
|
1c8ca65840cb3c7b5fece0b1db5e5dfb90378987
|
2022-05-02T19:28:12.000Z
|
[
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"dataset:cord",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] |
token-classification
| false
|
nielsr
| null |
nielsr/layoutlmv3-finetuned-cord
| 119
| 4
|
transformers
| 4,345
|
---
tags:
- generated_from_trainer
datasets:
- cord
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: layoutlmv3-finetuned-cord
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: cord
type: cord
args: cord
metrics:
- name: Precision
type: precision
value: 0.9619686800894854
- name: Recall
type: recall
value: 0.9655688622754491
- name: F1
type: f1
value: 0.9637654090399701
- name: Accuracy
type: accuracy
value: 0.9681663837011885
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv3-finetuned-cord
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the cord dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1845
- Precision: 0.9620
- Recall: 0.9656
- F1: 0.9638
- Accuracy: 0.9682
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 2.0 | 100 | 0.5257 | 0.8223 | 0.8555 | 0.8386 | 0.8710 |
| No log | 4.0 | 200 | 0.3200 | 0.9118 | 0.9281 | 0.9199 | 0.9317 |
| No log | 6.0 | 300 | 0.2449 | 0.9298 | 0.9424 | 0.9361 | 0.9465 |
| No log | 8.0 | 400 | 0.1923 | 0.9472 | 0.9536 | 0.9504 | 0.9597 |
| 0.4328 | 10.0 | 500 | 0.1857 | 0.9591 | 0.9656 | 0.9623 | 0.9682 |
| 0.4328 | 12.0 | 600 | 0.2073 | 0.9597 | 0.9618 | 0.9607 | 0.9656 |
| 0.4328 | 14.0 | 700 | 0.1804 | 0.9634 | 0.9663 | 0.9649 | 0.9703 |
| 0.4328 | 16.0 | 800 | 0.1882 | 0.9634 | 0.9648 | 0.9641 | 0.9665 |
| 0.4328 | 18.0 | 900 | 0.1800 | 0.9619 | 0.9648 | 0.9634 | 0.9677 |
| 0.0318 | 20.0 | 1000 | 0.1845 | 0.9620 | 0.9656 | 0.9638 | 0.9682 |
### Framework versions
- Transformers 4.19.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
IDEA-CCNL/Erlangshen-MegatronBert-1.3B-Similarity
|
a684033e0020d1558c74913fd365855b0af819eb
|
2022-05-16T06:07:29.000Z
|
[
"pytorch",
"megatron-bert",
"text-classification",
"zh",
"transformers",
"bert",
"NLU",
"NLI",
"license:apache-2.0"
] |
text-classification
| false
|
IDEA-CCNL
| null |
IDEA-CCNL/Erlangshen-MegatronBert-1.3B-Similarity
| 119
| null |
transformers
| 4,346
|
---
language:
- zh
license: apache-2.0
tags:
- bert
- NLU
- NLI
inference: true
widget:
- text: "今天心情不好[SEP]今天很开心"
---
# Erlangshen-MegatronBert-1.3B-Similarity, model (Chinese),one model of [Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM).
We collect 20 paraphrace datasets in the Chinese domain for finetune, with a total of 2773880 samples. Our model is mainly based on [MegatronBert-1.3B](https://huggingface.co/IDEA-CCNL/Erlangshen-MegatronBert-1.3B)
## Usage
```python
from transformers import AutoModelForSequenceClassification
from transformers import BertTokenizer
import torch
tokenizer=BertTokenizer.from_pretrained('IDEA-CCNL/Erlangshen-MegatronBert-1.3B-Similarity')
model=AutoModelForSequenceClassification.from_pretrained('IDEA-CCNL/Erlangshen-MegatronBert-1.3B-Similarity')
texta='今天的饭不好吃'
textb='今天心情不好'
output=model(torch.tensor([tokenizer.encode(texta,textb)]))
print(torch.nn.functional.softmax(output.logits,dim=-1))
```
## Scores on downstream chinese tasks(The dev datasets of BUSTM and AFQMC may exist in the train set)
| Model | BQ | BUSTM | AFQMC |
| :--------: | :-----: | :----: | :-----: |
| Erlangshen-Roberta-110M-Similarity | 85.41 | 95.18 | 81.72 |
| Erlangshen-Roberta-330M-Similarity | 86.21 | 99.29 | 93.89 |
| Erlangshen-MegatronBert-1.3B-Similarity | 86.31 | - | - |
## Citation
If you find the resource is useful, please cite the following website in your paper.
```
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
```
|
PSW/samsum_reverse_train_distilbart_xsum_9-6_min10max2000_topp0.5_topk20_epoch3
|
e8cb1aa6dd45eb26060714018a2a6fd6ee84068e
|
2022-07-13T05:57:29.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false
|
PSW
| null |
PSW/samsum_reverse_train_distilbart_xsum_9-6_min10max2000_topp0.5_topk20_epoch3
| 119
| null |
transformers
| 4,347
|
Entry not found
|
Thoumey/DialoGPT-small-Leksa
|
4a6639ad1c44129132ab61babd1628dcc15785b5
|
2022-07-18T23:01:18.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false
|
Thoumey
| null |
Thoumey/DialoGPT-small-Leksa
| 119
| null |
transformers
| 4,348
|
---
tags:
- conversational
---
|
kakife3586/Hmm
|
bfa2f5b803ebf859bedb4919d2b94e05712e48e7
|
2022-07-30T03:52:56.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false
|
kakife3586
| null |
kakife3586/Hmm
| 119
| null |
transformers
| 4,349
|
Entry not found
|
Helsinki-NLP/opus-mt-es-ar
|
c2ccbc0ebc3356c9cee203736e228606b1a30b7c
|
2021-01-18T08:21:46.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"es",
"ar",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false
|
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-es-ar
| 118
| null |
transformers
| 4,350
|
---
language:
- es
- ar
tags:
- translation
license: apache-2.0
---
### spa-ara
* source group: Spanish
* target group: Arabic
* OPUS readme: [spa-ara](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/spa-ara/README.md)
* model: transformer
* source language(s): spa
* target language(s): apc apc_Latn ara arq
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus-2020-07-03.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/spa-ara/opus-2020-07-03.zip)
* test set translations: [opus-2020-07-03.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/spa-ara/opus-2020-07-03.test.txt)
* test set scores: [opus-2020-07-03.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/spa-ara/opus-2020-07-03.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.spa.ara | 20.0 | 0.517 |
### System Info:
- hf_name: spa-ara
- source_languages: spa
- target_languages: ara
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/spa-ara/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['es', 'ar']
- src_constituents: {'spa'}
- tgt_constituents: {'apc', 'ara', 'arq_Latn', 'arq', 'afb', 'ara_Latn', 'apc_Latn', 'arz'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/spa-ara/opus-2020-07-03.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/spa-ara/opus-2020-07-03.test.txt
- src_alpha3: spa
- tgt_alpha3: ara
- short_pair: es-ar
- chrF2_score: 0.517
- bleu: 20.0
- brevity_penalty: 0.9390000000000001
- ref_len: 7547.0
- src_name: Spanish
- tgt_name: Arabic
- train_date: 2020-07-03
- src_alpha2: es
- tgt_alpha2: ar
- prefer_old: False
- long_pair: spa-ara
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
Helsinki-NLP/opus-mt-ja-de
|
3bb459b05d07803d6c6d9681e84e60179157a796
|
2021-09-10T13:53:07.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"ja",
"de",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false
|
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-ja-de
| 118
| null |
transformers
| 4,351
|
---
tags:
- translation
license: apache-2.0
---
### opus-mt-ja-de
* source languages: ja
* target languages: de
* OPUS readme: [ja-de](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ja-de/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-20.zip](https://object.pouta.csc.fi/OPUS-MT-models/ja-de/opus-2020-01-20.zip)
* test set translations: [opus-2020-01-20.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ja-de/opus-2020-01-20.test.txt)
* test set scores: [opus-2020-01-20.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ja-de/opus-2020-01-20.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.ja.de | 30.1 | 0.518 |
|
PlanTL-GOB-ES/roberta-base-bne-capitel-pos
|
982306bac3ed69f0b207aa7efbfb0bc8570f0bc6
|
2022-04-06T14:41:41.000Z
|
[
"pytorch",
"roberta",
"token-classification",
"es",
"dataset:bne",
"dataset:capitel",
"arxiv:1907.11692",
"arxiv:2107.07253",
"transformers",
"national library of spain",
"spanish",
"bne",
"capitel",
"pos",
"license:apache-2.0",
"autotrain_compatible"
] |
token-classification
| false
|
PlanTL-GOB-ES
| null |
PlanTL-GOB-ES/roberta-base-bne-capitel-pos
| 118
| null |
transformers
| 4,352
|
---
language:
- es
license: apache-2.0
tags:
- "national library of spain"
- "spanish"
- "bne"
- "capitel"
- "pos"
datasets:
- "bne"
- "capitel"
metrics:
- "f1"
widget:
- text: "Festival de San Sebastián: Johnny Depp recibirá el premio Donostia en pleno rifirrafe judicial con Amber Heard"
- text: "El alcalde de Vigo, Abel Caballero, ha comenzado a colocar las luces de Navidad en agosto."
- text: "Gracias a los datos de la BNE, se ha podido lograr este modelo del lenguaje."
- text: "El Tribunal Superior de Justicia se pronunció ayer: \"Hay base legal dentro del marco jurídico actual\"."
inference:
parameters:
aggregation_strategy: "first"
---
# Spanish RoBERTa-base trained on BNE finetuned for CAPITEL Part of Speech (POS) dataset
RoBERTa-base-bne is a transformer-based masked language model for the Spanish language. It is based on the [RoBERTa](https://arxiv.org/abs/1907.11692) base model and has been pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text processed for this work, compiled from the web crawlings performed by the [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) from 2009 to 2019.
Original pre-trained model can be found here: https://huggingface.co/PlanTL-GOB-ES/roberta-base-bne
## Dataset
The dataset used is the one from the [CAPITEL competition at IberLEF 2020](https://sites.google.com/view/capitel2020) (sub-task 2).
## Evaluation and results
F1 Score: 0.9846 (average of 5 runs).
For evaluation details visit our [GitHub repository](https://github.com/PlanTL-GOB-ES/lm-spanish).
## Citing
Check out our paper for all the details: https://arxiv.org/abs/2107.07253
```
@article{gutierrezfandino2022,
author = {Asier Gutiérrez-Fandiño and Jordi Armengol-Estapé and Marc Pàmies and Joan Llop-Palao and Joaquin Silveira-Ocampo and Casimiro Pio Carrino and Carme Armentano-Oller and Carlos Rodriguez-Penagos and Aitor Gonzalez-Agirre and Marta Villegas},
title = {MarIA: Spanish Language Models},
journal = {Procesamiento del Lenguaje Natural},
volume = {68},
number = {0},
year = {2022},
issn = {1989-7553},
url = {http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6405},
pages = {39--60}
}
```
## Funding
This work was partially funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL, and the Future of Computing Center, a Barcelona Supercomputing Center and IBM initiative (2020).
## Disclaimer
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of artificial intelligence.
In no event shall the owner of the models (SEDIA – State Secretariat for digitalization and artificial intelligence) nor the creator (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
Los modelos publicados en este repositorio tienen una finalidad generalista y están a disposición de terceros. Estos modelos pueden tener sesgos y/u otro tipo de distorsiones indeseables.
Cuando terceros desplieguen o proporcionen sistemas y/o servicios a otras partes usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) o se conviertan en usuarios de los modelos, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y, en todo caso, cumplir con la normativa aplicable, incluyendo la normativa en materia de uso de inteligencia artificial.
En ningún caso el propietario de los modelos (SEDIA – Secretaría de Estado de Digitalización e Inteligencia Artificial) ni el creador (BSC – Barcelona Supercomputing Center) serán responsables de los resultados derivados del uso que hagan terceros de estos modelos.
|
Tanhim/translation-En2De
|
075887a7adf00d27441f0b52f47d080aa94b5250
|
2021-09-30T10:08:21.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"de",
"dataset:wmt19",
"transformers",
"translation",
"license:gpl",
"autotrain_compatible"
] |
translation
| false
|
Tanhim
| null |
Tanhim/translation-En2De
| 118
| 2
|
transformers
| 4,353
|
---
language: de
widget:
- text: My name is Karl and I live in Aachen.
tags:
- translation
datasets:
- wmt19
license: gpl
---
<h2> English to German Translation </h2>
Model Name: Tanhim/translation-En2De <br />
language: German or Deutsch <br />
thumbnail: https://huggingface.co/Tanhim/translation-En2De <br />
### How to use
You can use this model directly with a pipeline for machine translation. Since the generation relies on some randomness, I
set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> text_En2De= pipeline('translation', model='Tanhim/translation-En2De', tokenizer='Tanhim/translation-En2De')
>>> set_seed(42)
>>> text_En2De("My name is Karl and I live in Aachen")
```
### beta version
|
bakrianoo/t5-arabic-small
|
2a44acb28d6fac20bb5420f60ea7774e9983150f
|
2021-06-26T17:10:58.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"Arabic",
"dataset:mc4",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false
|
bakrianoo
| null |
bakrianoo/t5-arabic-small
| 118
| 1
|
transformers
| 4,354
|
---
language: Arabic
datasets:
- mc4
license: apache-2.0
---
## Arabic T5 Small Model
A customized T5 Model for Arabic and English Task. It could be used as an alternative for `google/mt5-small` model, as it's much smaller and only targets Arabic and English based tasks.
### About T5
```
T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which each task is converted into a text-to-text format.
The T5 model was presented in Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer by Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu.
```
[Read More](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html)
|
csarron/mobilebert-uncased-squad-v2
|
153e4767e7c96f8d3a1d705afada1ca1d4c2bf11
|
2020-12-11T21:36:27.000Z
|
[
"pytorch",
"mobilebert",
"question-answering",
"en",
"dataset:squad_v2",
"arxiv:2004.02984",
"transformers",
"license:mit",
"autotrain_compatible"
] |
question-answering
| false
|
csarron
| null |
csarron/mobilebert-uncased-squad-v2
| 118
| null |
transformers
| 4,355
|
---
language: en
thumbnail:
license: mit
tags:
- question-answering
- mobilebert
datasets:
- squad_v2
metrics:
- squad_v2
widget:
- text: "Which name is also used to describe the Amazon rainforest in English?"
context: "The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
- text: "How many square kilometers of rainforest is covered in the basin?"
context: "The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
---
## MobileBERT fine-tuned on SQuAD v2
[MobileBERT](https://arxiv.org/abs/2004.02984) is a thin version of BERT_LARGE, while equipped with bottleneck structures and a carefully designed balance
between self-attentions and feed-forward networks.
This model was fine-tuned from the HuggingFace checkpoint `google/mobilebert-uncased` on [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer).
## Details
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD2.0 | train | 130k |
| SQuAD2.0 | eval | 12.3k |
### Fine-tuning
- Python: `3.7.5`
- Machine specs:
`CPU: Intel(R) Core(TM) i7-6800K CPU @ 3.40GHz`
`Memory: 32 GiB`
`GPUs: 2 GeForce GTX 1070, each with 8GiB memory`
`GPU driver: 418.87.01, CUDA: 10.1`
- script:
```shell
# after install https://github.com/huggingface/transformers
cd examples/question-answering
mkdir -p data
wget -O data/train-v2.0.json https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v2.0.json
wget -O data/dev-v2.0.json https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v2.0.json
export SQUAD_DIR=`pwd`/data
python run_squad.py \
--model_type mobilebert \
--model_name_or_path google/mobilebert-uncased \
--do_train \
--do_eval \
--do_lower_case \
--version_2_with_negative \
--train_file $SQUAD_DIR/train-v2.0.json \
--predict_file $SQUAD_DIR/dev-v2.0.json \
--per_gpu_train_batch_size 16 \
--per_gpu_eval_batch_size 16 \
--learning_rate 4e-5 \
--num_train_epochs 5.0 \
--max_seq_length 320 \
--doc_stride 128 \
--warmup_steps 1400 \
--save_steps 2000 \
--output_dir $SQUAD_DIR/mobilebert-uncased-warmup-squad_v2 2>&1 | tee train-mobilebert-warmup-squad_v2.log
```
It took about 3.5 hours to finish.
### Results
**Model size**: `95M`
| Metric | # Value | # Original ([Table 5](https://arxiv.org/pdf/2004.02984.pdf))|
| ------ | --------- | --------- |
| **EM** | **75.2** | **76.2** |
| **F1** | **78.8** | **79.2** |
Note that the above results didn't involve any hyperparameter search.
## Example Usage
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="csarron/mobilebert-uncased-squad-v2",
tokenizer="csarron/mobilebert-uncased-squad-v2"
)
predictions = qa_pipeline({
'context': "The game was played on February 7, 2016 at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California.",
'question': "What day was the game played on?"
})
print(predictions)
# output:
# {'score': 0.71434086561203, 'start': 23, 'end': 39, 'answer': 'February 7, 2016'}
```
> Created by [Qingqing Cao](https://awk.ai/) | [GitHub](https://github.com/csarron) | [Twitter](https://twitter.com/sysnlp)
> Made with ❤️ in New York.
|
dmis-lab/biosyn-sapbert-ncbi-disease
|
129c7b75ed6dd9c3c390e819450fe47569eae6aa
|
2021-10-25T14:44:57.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
| false
|
dmis-lab
| null |
dmis-lab/biosyn-sapbert-ncbi-disease
| 118
| null |
transformers
| 4,356
|
Entry not found
|
google/t5-efficient-tiny-nl32
|
f8f8d94dccb6781faf8809f6f636c1688f266c23
|
2022-02-15T10:51:44.000Z
|
[
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"en",
"dataset:c4",
"arxiv:2109.10686",
"transformers",
"deep-narrow",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false
|
google
| null |
google/t5-efficient-tiny-nl32
| 118
| 2
|
transformers
| 4,357
|
---
language:
- en
datasets:
- c4
tags:
- deep-narrow
inference: false
license: apache-2.0
---
# T5-Efficient-TINY-NL32 (Deep-Narrow version)
T5-Efficient-TINY-NL32 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-tiny-nl32** - is of model type **Tiny** with the following variations:
- **nl** is **32**
It has **67.06** million parameters and thus requires *ca.* **268.25 MB** of memory in full precision (*fp32*)
or **134.12 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future.
|
hfl/chinese-electra-180g-small-generator
|
1eaae8e9a46729e458014614eedd62b1de383d48
|
2021-03-03T01:23:58.000Z
|
[
"pytorch",
"tf",
"electra",
"zh",
"arxiv:2004.13922",
"transformers",
"license:apache-2.0",
"fill-mask"
] |
fill-mask
| false
|
hfl
| null |
hfl/chinese-electra-180g-small-generator
| 118
| 2
|
transformers
| 4,358
|
---
language:
- zh
license: "apache-2.0"
pipeline_tag: "fill-mask"
---
# This model is trained on 180G data, we recommend using this one than the original version.
## Chinese ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants.
For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA.
ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
This project is based on the official code of ELECTRA: [https://github.com/google-research/electra](https://github.com/google-research/electra)
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find our resource or paper is useful, please consider including the following citation in your paper.
- https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
|
m3hrdadfi/gpt2-QA
|
78ef9368b2a2ff9a0993598798fc0e08800a5d70
|
2021-08-11T11:26:26.000Z
|
[
"pytorch",
"tf",
"gpt2",
"text-generation",
"en",
"dataset:squad",
"transformers"
] |
text-generation
| false
|
m3hrdadfi
| null |
m3hrdadfi/gpt2-QA
| 118
| null |
transformers
| 4,359
|
---
language: en
datasets:
- squad
tags:
- text-generation
---
# GPT2 QA
Using GPT2 in other downstream NLP tasks like QA. The model was trained and evaluated on [squad](https://huggingface.co/datasets/squad).
## Dataset
- [squad](https://huggingface.co/datasets/squad)
## Evaluation
The following table summarizes the scores obtained by the model.
## Demo
[Streamlit GPT2 QA](https://huggingface.co/spaces/m3hrdadfi/gpt2-QA)
## How to use
TODO (will be filled shortly)...
|
nicoladecao/msmarco-word2vec256000-bert-base-uncased
|
79cba49408c0f63e3ffea9f123829988578e6024
|
2022-02-17T17:58:46.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers",
"license:mit"
] |
feature-extraction
| false
|
nicoladecao
| null |
nicoladecao/msmarco-word2vec256000-bert-base-uncased
| 118
| null |
transformers
| 4,360
|
---
license: mit
---
|
ckiplab/bert-base-han-chinese-ws
|
7b436d9e9dc36cf8f34ca8704cb2eb6676ac350c
|
2022-07-04T08:06:59.000Z
|
[
"pytorch",
"bert",
"token-classification",
"zh",
"transformers",
"license:gpl-3.0",
"autotrain_compatible"
] |
token-classification
| false
|
ckiplab
| null |
ckiplab/bert-base-han-chinese-ws
| 118
| null |
transformers
| 4,361
|
---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- token-classification
- bert
- zh
license: gpl-3.0
---
# CKIP BERT Base Han Chinese WS
This model provides word segmentation for the ancient Chinese language. Our training dataset covers four eras of the Chinese language.
## Homepage
* [ckiplab/han-transformers](https://github.com/ckiplab/han-transformers)
## Training Datasets
The copyright of the datasets belongs to the Institute of Linguistics, Academia Sinica.
* [中央研究院上古漢語標記語料庫](http://lingcorpus.iis.sinica.edu.tw/cgi-bin/kiwi/akiwi/kiwi.sh)
* [中央研究院中古漢語語料庫](http://lingcorpus.iis.sinica.edu.tw/cgi-bin/kiwi/dkiwi/kiwi.sh)
* [中央研究院近代漢語語料庫](http://lingcorpus.iis.sinica.edu.tw/cgi-bin/kiwi/pkiwi/kiwi.sh)
* [中央研究院現代漢語語料庫](http://asbc.iis.sinica.edu.tw)
## Contributors
* Chin-Tung Lin at [CKIP](https://ckip.iis.sinica.edu.tw/)
## Usage
* Using our model in your script
```python
from transformers import (
AutoTokenizer,
AutoModel,
)
tokenizer = AutoTokenizer.from_pretrained("ckiplab/bert-base-han-chinese-ws")
model = AutoModel.from_pretrained("ckiplab/bert-base-han-chinese-ws")
```
* Using our model for inference
```python
>>> from transformers import pipeline
>>> classifier = pipeline("token-classification", model="ckiplab/bert-base-han-chinese-ws")
>>> classifier("帝堯曰放勳")
# output
[{'entity': 'B',
'score': 0.9999793,
'index': 1,
'word': '帝',
'start': 0,
'end': 1},
{'entity': 'I',
'score': 0.9915047,
'index': 2,
'word': '堯',
'start': 1,
'end': 2},
{'entity': 'B',
'score': 0.99992275,
'index': 3,
'word': '曰',
'start': 2,
'end': 3},
{'entity': 'B',
'score': 0.99905187,
'index': 4,
'word': '放',
'start': 3,
'end': 4},
{'entity': 'I',
'score': 0.96299917,
'index': 5,
'word': '勳',
'start': 4,
'end': 5}]
```
|
RonEliav/QA_discourse_v2
|
ac6093e514dadbcf41b7158b8efc513d1ab5db52
|
2022-07-07T19:40:33.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"license:afl-3.0",
"autotrain_compatible"
] |
text2text-generation
| false
|
RonEliav
| null |
RonEliav/QA_discourse_v2
| 118
| null |
transformers
| 4,362
|
---
license: afl-3.0
---
|
CuongLD/wav2vec2-large-xlsr-vietnamese
|
18c314ebda97c6fe6908c7138c7f571196b1cc7e
|
2021-07-05T14:17:01.000Z
|
[
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"vi",
"dataset:common_voice, infore_25h",
"arxiv:2006.11477",
"arxiv:2006.13979",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false
|
CuongLD
| null |
CuongLD/wav2vec2-large-xlsr-vietnamese
| 117
| null |
transformers
| 4,363
|
---
language: vi
datasets:
- common_voice, infore_25h
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Cuong-Cong XLSR Wav2Vec2 Large 53
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice vi
type: common_voice
args: vi
metrics:
- name: Test WER
type: wer
value: 58.63
---
# Wav2Vec2-Large-XLSR-53-Vietnamese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Vietnamese using the [Common Voice](https://huggingface.co/datasets/common_voice), [Infore_25h dataset](https://files.huylenguyen.com/25hours.zip) (Password: BroughtToYouByInfoRe)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "vi", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("CuongLD/wav2vec2-large-xlsr-vietnamese")
model = Wav2Vec2ForCTC.from_pretrained("CuongLD/wav2vec2-large-xlsr-vietnamese")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Vietnamese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "vi", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("CuongLD/wav2vec2-large-xlsr-vietnamese")
model = Wav2Vec2ForCTC.from_pretrained("CuongLD/wav2vec2-large-xlsr-vietnamese")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 58.63 %
## Training
The Common Voice `train`, `validation`, and `Infore_25h` datasets were used for training
The script used for training can be found [here](https://drive.google.com/file/d/1AW9R8IlsapiSGh9n3aECf23t-zhk3wUh/view?usp=sharing)
=======================To here===============================>
Your model in then available under *huggingface.co/CuongLD/wav2vec2-large-xlsr-vietnamese* for everybody to use 🎉.
## How to evaluate my trained checkpoint
Having uploaded your model, you should now evaluate your model in a final step. This should be as simple as
copying the evaluation code of your model card into a python script and running it. Make sure to note
the final result on the model card **both** under the YAML tags at the very top **and** below your evaluation code under "Test Results".
## Rules of training and evaluation
In this section, we will quickly go over what data is allowed to be used as training
data, what kind of data preprocessing is allowed be used, and how the model should be evaluated.
To make it very simple regarding the first point: **All data except the official common voice `test` data set can be used as training data**. For models trained in a language that is not included in Common Voice, the author of the model is responsible to
leave a reasonable amount of data for evaluation.
Second, the rules regarding the preprocessing are not that as straight-forward. It is allowed (and recommended) to
normalize the data to only have lower-case characters. It is also allowed (and recommended) to remove typographical
symbols and punctuation marks. A list of such symbols can *e.g.* be fonud [here](https://en.wikipedia.org/wiki/List_of_typographical_symbols_and_punctuation_marks) - however here we already must be careful. We should **not** remove a symbol that
would change the meaning of the words, *e.g.* in English, we should not remove the single quotation mark `'` since it
would change the meaning of the word `"it's"` to `"its"` which would then be incorrect. So the golden rule here is to
not remove any characters that could change the meaning of a word into another word. This is not always obvious and should
be given some consideration. As another example, it is fine to remove the "Hypen-minus" sign "`-`" since it doesn't change the
meaninng of a word to another one. *E.g.* "`fine-tuning`" would be changed to "`finetuning`" which has still the same meaning.
Since those choices are not always obvious when in doubt feel free to ask on Slack or even better post on the forum, as was
done, *e.g.* [here](https://discuss.huggingface.co/t/spanish-asr-fine-tuning-wav2vec2/4586).
## Tips and tricks
This section summarizes a couple of tips and tricks across various topics. It will continously be updated during the week.
### How to combine multiple datasets into one
Check out [this](https://discuss.huggingface.co/t/how-to-combine-local-data-files-with-an-official-dataset/4685) post.
### How to effectively preprocess the data
### How to do efficiently load datasets with limited ram and hard drive space
Check out [this](https://discuss.huggingface.co/t/german-asr-fine-tuning-wav2vec2/4558/8?u=patrickvonplaten) post.
### How to do hyperparameter tuning
### How to preprocess and evaluate character based languages
## Further reading material
It is recommended that take some time to read up on how Wav2vec2 works in theory.
Getting a better understanding of the theory and the inner mechanisms of the model often helps when fine-tuning the model.
**However**, if you don't like reading blog posts/papers, don't worry - it is by no means necessary to go through the theory to fine-tune Wav2Vec2 on your language of choice.
If you are interested in learning more about the model though, here are a couple of resources that are important to better understand Wav2Vec2:
- [Facebook's Wav2Vec2 blog post](https://ai.facebook.com/blog/wav2vec-state-of-the-art-speech-recognition-through-self-supervision/)
- [Official Wav2Vec2 paper](https://arxiv.org/abs/2006.11477)
- [Official XLSR Wav2vec2 paper](https://arxiv.org/pdf/2006.13979.pdf)
- [Hugging Face Blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2)
- [How does CTC (Connectionist Temporal Classification) work](https://distill.pub/2017/ctc/)
It helps to have a good understanding of the following points:
- How was XLSR-Wav2Vec2 pretrained? -> Feature vectors were masked and had to be predicted by the model; very similar in spirit to masked language model of BERT.
- What parts of XLSR-Wav2Vec2 are responsible for what? What is the feature extractor part used for? -> extract feature vectors from the 1D raw audio waveform; What is the transformer part doing? -> mapping feature vectors to contextualized feature vectors; ...
- What part of the model needs to be fine-tuned? -> The pretrained model **does not** include a language head to classify the contextualized features to letters. This is randomly initialized when loading the pretrained checkpoint and has to be fine-tuned. Also, note that the authors recommend to **not** further fine-tune the feature extractor.
- What data was used to XLSR-Wav2Vec2? The checkpoint we will use for further fine-tuning was pretrained on **53** languages.
- What languages are considered to be similar by XLSR-Wav2Vec2? In the official [XLSR Wav2Vec2 paper](https://arxiv.org/pdf/2006.13979.pdf), the authors show nicely which languages share a common contextualized latent space. It might be useful for you to extend your training data with data of other languages that are considered to be very similar by the model (or you).
## FAQ
- Can a participant fine-tune models for more than one language?
Yes! A participant can fine-tune models in as many languages she/he likes
- Can a participant use extra data (apart from the common voice data)?
Yes! All data except the official common voice `test data` can be used for training.
If a participant wants to train a model on a language that is not part of Common Voice (which
is very much encouraged!), the participant should make sure that some test data is held out to
make sure the model is not overfitting.
- Can we fine-tune for high-resource languages?
Yes! While we do not really recommend people to fine-tune models in English since there are
already so many fine-tuned speech recognition models in English. However, it is very much
appreciated if participants want to fine-tune models in other "high-resource" languages, such
as French, Spanish, or German. For such cases, one probably needs to train locally and apply
might have to apply tricks such as lazy data loading (check the ["Lazy data loading"](#how-to-do-lazy-data-loading) section for more details).
|
Helsinki-NLP/opus-mt-en-tl
|
f7e0d3952dd506aefb67c1346651a17586b0ed5b
|
2021-09-09T21:39:50.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"tl",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false
|
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-en-tl
| 117
| null |
transformers
| 4,364
|
---
tags:
- translation
license: apache-2.0
---
### opus-mt-en-tl
* source languages: en
* target languages: tl
* OPUS readme: [en-tl](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-tl/README.md)
* dataset: opus+bt
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus+bt-2020-02-26.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-tl/opus+bt-2020-02-26.zip)
* test set translations: [opus+bt-2020-02-26.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-tl/opus+bt-2020-02-26.test.txt)
* test set scores: [opus+bt-2020-02-26.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-tl/opus+bt-2020-02-26.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.en.tl | 26.6 | 0.577 |
|
bertin-project/bertin-base-ner-conll2002-es
|
602bfb92e668c2f02ceb09a531d4ab2b98dfab30
|
2021-09-23T13:41:49.000Z
|
[
"pytorch",
"roberta",
"token-classification",
"es",
"transformers",
"spanish",
"ner",
"license:cc-by-4.0",
"autotrain_compatible"
] |
token-classification
| false
|
bertin-project
| null |
bertin-project/bertin-base-ner-conll2002-es
| 117
| 1
|
transformers
| 4,365
|
---
language: es
license: cc-by-4.0
tags:
- spanish
- roberta
- ner
---
This checkpoint has been trained for the NER task using the CoNLL2002-es dataset.
This is a NER checkpoint created from **Bertin Gaussian 512**, which is a **RoBERTa-base** model trained from scratch in Spanish. Information on this base model may be found at [its own card](https://huggingface.co/bertin-project/bertin-base-gaussian-exp-512seqlen) and at deeper detail on [the main project card](https://huggingface.co/bertin-project/bertin-roberta-base-spanish).
The training dataset for the base model is [mc4](https://huggingface.co/datasets/bertin-project/mc4-es-sampled ) subsampling documents to a total of about 50 million examples. Sampling is biased towards average perplexity values (using a Gaussian function), discarding more often documents with very large values (poor quality) of very small values (short, repetitive texts).
This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organised by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
## Team members
- Eduardo González ([edugp](https://huggingface.co/edugp))
- Javier de la Rosa ([versae](https://huggingface.co/versae))
- Manu Romero ([mrm8488](https://huggingface.co/))
- María Grandury ([mariagrandury](https://huggingface.co/))
- Pablo González de Prado ([Pablogps](https://huggingface.co/Pablogps))
- Paulo Villegas ([paulo](https://huggingface.co/paulo))
|
flax-community/papuGaPT2-large
|
be2735b4d7369f415c2bf51c653c685fa8e57140
|
2021-07-17T09:02:00.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false
|
flax-community
| null |
flax-community/papuGaPT2-large
| 117
| 2
|
transformers
| 4,366
|
Entry not found
|
textattack/xlnet-base-cased-MNLI
|
0e139049908482a348433a901ac078cee10b6ca6
|
2020-06-09T16:55:37.000Z
|
[
"pytorch",
"xlnet",
"text-classification",
"transformers"
] |
text-classification
| false
|
textattack
| null |
textattack/xlnet-base-cased-MNLI
| 117
| 1
|
transformers
| 4,367
|
Entry not found
|
ynie/electra-large-discriminator-snli_mnli_fever_anli_R1_R2_R3-nli
|
d3f76223398627895574663d5a446c640fbf776a
|
2020-10-17T02:00:30.000Z
|
[
"pytorch",
"electra",
"text-classification",
"transformers"
] |
text-classification
| false
|
ynie
| null |
ynie/electra-large-discriminator-snli_mnli_fever_anli_R1_R2_R3-nli
| 117
| null |
transformers
| 4,368
|
Entry not found
|
brad1141/Longformer-finetuned-norm
|
0330a84ed4c303bf8f2c63dd7b4618c7c22d2a17
|
2022-03-18T05:42:11.000Z
|
[
"pytorch",
"tensorboard",
"longformer",
"token-classification",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] |
token-classification
| false
|
brad1141
| null |
brad1141/Longformer-finetuned-norm
| 117
| null |
transformers
| 4,369
|
---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Longformer-finetuned-norm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Longformer-finetuned-norm
This model is a fine-tuned version of [allenai/longformer-base-4096](https://huggingface.co/allenai/longformer-base-4096) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8127
- Precision: 0.8429
- Recall: 0.8701
- F1: 0.8562
- Accuracy: 0.8221
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.8008 | 1.0 | 1012 | 0.5839 | 0.8266 | 0.8637 | 0.8447 | 0.8084 |
| 0.5168 | 2.0 | 2024 | 0.5927 | 0.7940 | 0.9102 | 0.8481 | 0.8117 |
| 0.3936 | 3.0 | 3036 | 0.5651 | 0.8476 | 0.8501 | 0.8488 | 0.8143 |
| 0.2939 | 4.0 | 4048 | 0.6411 | 0.8494 | 0.8578 | 0.8536 | 0.8204 |
| 0.2165 | 5.0 | 5060 | 0.6833 | 0.8409 | 0.8822 | 0.8611 | 0.8270 |
| 0.1561 | 6.0 | 6072 | 0.7643 | 0.8404 | 0.8810 | 0.8602 | 0.8259 |
| 0.1164 | 7.0 | 7084 | 0.8127 | 0.8429 | 0.8701 | 0.8562 | 0.8221 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
HannahRoseKirk/Hatemoji
|
f2f98581ab15fb3ccf8b8a5465d7ca70c2958902
|
2022-04-27T18:17:04.000Z
|
[
"pytorch",
"deberta",
"text-classification",
"en",
"dataset:HatemojiBuild",
"dataset:HatemojiCheck",
"arxiv:2108.05921",
"arxiv:2012.15761",
"arxiv:2202.11176",
"transformers",
"hate-speech-detection",
"license:cc-by-4.0"
] |
text-classification
| false
|
HannahRoseKirk
| null |
HannahRoseKirk/Hatemoji
| 117
| 2
|
transformers
| 4,370
|
---
license: cc-by-4.0
language:
- en
tags:
- text-classification
- pytorch
- hate-speech-detection
datasets:
- HatemojiBuild
- HatemojiCheck
metrics:
- Accuracy, F1 Score
---
# Hatemoji Model
## Model description
This model is a fine-tuned version of the [DeBERTa base model](https://huggingface.co/microsoft/deberta-base). This model is cased. The model was trained on iterative rounds of adversarial data generation with human-and-model-in-the-loop. In each round, annotators are tasked with tricking the model-in-the-loop with emoji-containing statements that it will misclassify. Between each round, the model is retrained. This is the final model from the iterative process, referred to as R8-T in our paper. The intended task is to classify an emoji-containing statement as either non-hateful (LABEL 0.0) or hateful (LABEL 1.0).
- **Github Repository:** https://github.com/HannahKirk/Hatemoji
- **HuggingFace Datasets:** [HatemojiBuild](https://huggingface.co/datasets/HannahRoseKirk/HatemojiBuild) & [HatemojiCheck](https://huggingface.co/datasets/HannahRoseKirk/HatemojiCheck)
- **Paper:** https://arxiv.org/abs/2108.05921
- **Point of Contact:** [email protected]
## Intended uses & limitations
The intended use of the model is to classify English-language, emoji-containing, short-form text documents as a binary task: non-hateful vs hateful. The model has demonstrated strengths compared to commercial and academic models on classifying emoji-based hate, but is also a strong classifier of text-only hate. Because the model was trained on synthetic, adversarially-generated data, it may have some weaknesses when it comes to empirical emoji-based hate 'in-the-wild'.
You can interact with this model on [Dynabench](https://dynabench.org/tasks/hs), and find its limitations. We hope to continue improving the model on new adversarial data to better iron out its remaining weaknesses!
## How to use
The model can be used with pipeline:
```python
from transformers import pipeline
classifier = pipeline("text-classification",model='HannahRoseKirk/Hatemoji', return_all_scores=True)
prediction = classifier("I 💜💙💚 emoji 😍", )
print(prediction)
"""
Output
[[{'label': 'LABEL_0', 'score': 0.9999157190322876}, {'label': 'LABEL_1', 'score': 8.425049600191414e-05}]]
"""
```
### Training data
The model was trained on:
* The three rounds of emoji-containing, adversarially-generated texts from [HatemojiBuild](https://huggingface.co/datasets/HannahRoseKirk/HatemojiBuild)
* The four rounds of text-only, adversarially-generated texts from Vidgen et al., (2021). _Learning from the worst: Dynamically generated datasets to improve online hate detection_. Available on [Github](https://github.com/bvidgen/Dynamically-Generated-Hate-Speech-Dataset) and explained in their [paper](https://arxiv.org/abs/2012.15761).
* A collection of widely available and publicly accessible datasets from [https://hatespeechdata.com/](hatespeechdata.com)
## Train procedure
The model was trained using HuggingFace's [run glue script](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-classification/run_glue.py), using the following parameters:
```
python3 transformers/examples/pytorch/text-classification/run_glue.py \
--model_name_or_path microsoft/deberta-base \
--validation_file path_to_data/dev.csv \
--train_file path_to_data/train.csv \
--do_train --do_eval --max_seq_length 512 --learning_rate 2e-5 \
--num_train_epochs 3 --evaluation_strategy epoch \
--load_best_model_at_end --output_dir path_to_outdir/deberta123/ \
--seed 123 \
--cache_dir /.cache/huggingface/transformers/ \
--overwrite_output_dir > ./log_deb 2> ./err_deb
```
We experimented with upsampling the train split of each round to improve performance with increments of [1, 5, 10, 100], with the optimum upsampling taken
forward to all subsequent rounds. The optimal upsampling ratios for R1-R4 (text rounds from Vidgen et al.,) are carried forward. This model is trained on upsampling ratios of `{'R0':1, 'R1':5, 'R2':100, 'R3':1, 'R4':1 , 'R5':100, 'R6':1, 'R7':5}`.
## Variable and metrics
We wished to train a model which could effectively encode information about emoji-based hate, without worsening performance on text-only hate. Thus, we evaluate the model on:
* [HatemojiCheck](https://huggingface.co/datasets/HannahRoseKirk/HatemojiCheck), an evaluation checklist with 7 functionalities of emoji-based hate and contrast sets
* [HateCheck](https://huggingface.co/datasets/Paul/hatecheck), an evaluation checklist contains 29 functional tests for hate speech and contrast sets.
* The held-out tests sets from [HatemojiBuild](https://huggingface.co/datasets/HannahRoseKirk/HatemojiBuild) the three round of adversarially-generated data collection with emoji-containing examples (R5-7). Available on Huuggingface
* The held-out test sets from the four rounds of adversarially-generated data collection with text-only examples (R1-4, from [Vidgen et al.](https://github.com/bvidgen/Dynamically-Generated-Hate-Speech-Dataset))
For the round-specific test sets, we used a weighted F1-score across them to choose the final model in each round. For more details, see our [paper](https://arxiv.org/abs/2108.05921)
## Evaluation results
We compare our model to:
* **P-IA**: the identity attack attribute from Perspective API
* **P-TX**: the toxicity attribute from Perspective API
* **B-D**: A BERT model trained on the [Davidson et al. (2017)](https://github.com/t-davidson/hate-speech-and-offensive-language) dataset
* **B-F**: A BERT model trained on the [Founta et al. (2018)](https://github.com/ENCASEH2020/hatespeech-twitter) dataset
| | **Emoji Test Sets** | | | | **Text Test Sets** | | | | **All Rounds** | |
| :------- | :-----------------: | :--------: | :------------: | :--------: | :----------------: | :--------: | :-----------: | :--------: | :------------: | :--------: |
| | **R5-R7** | | **HmojiCheck** | | **R1-R4** | | **HateCheck** | | **R1-R7** | |
| | **Acc** | **F1** | **Acc** | **F1** | **Acc** | **F1** | **Acc** | **F1** | **Acc** | **F1** |
| **P-IA** | 0\.508 | 0\.394 | 0\.689 | 0\.754 | 0\.679 | 0\.720 | 0\.765 | 0\.839 | 0\.658 | 0\.689 |
| **P-TX** | 0\.523 | 0\.448 | 0\.650 | 0\.711 | 0\.602 | 0\.659 | 0\.720 | 0\.813 | 0\.592 | 0\.639 |
| **B-D** | 0\.489 | 0\.270 | 0\.578 | 0\.636 | 0\.589 | 0\.607 | 0\.632 | 0\.738 | 0\.591 | 0\.586 |
| **B-F** | 0\.496 | 0\.322 | 0\.552 | 0\.605 | 0\.562 | 0\.562 | 0\.602 | 0\.694 | 0\.557 | 0\.532 |
| **Hatemoji** | **0\.744** | **0\.755** | **0\.871** | **0\.904** | **0\.827** | **0\.844** | **0\.966** | **0\.975** | **0\.814** | **0\.829** |
For full discussion of the model results, see our [paper](https://arxiv.org/abs/2108.05921).
A recent [paper](https://arxiv.org/pdf/2202.11176.pdf) by Lees et al., (2022) _A New Generation of Perspective API:Efficient Multilingual Character-level Transformers_ beats this model on the HatemojiCheck benchmark.
|
emilylearning/added_birth_date__test_run_False__p_dataset_100
|
913dfca69757e298098698ba5691c5833f3f4b0c
|
2022-05-06T07:21:37.000Z
|
[
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false
|
emilylearning
| null |
emilylearning/added_birth_date__test_run_False__p_dataset_100
| 117
| null |
transformers
| 4,371
|
Entry not found
|
BigSalmon/InformalToFormalLincoln59Paraphrase
|
ae656e0df5f65d72b84eb2692235fac71088a10e
|
2022-07-30T02:35:10.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false
|
BigSalmon
| null |
BigSalmon/InformalToFormalLincoln59Paraphrase
| 117
| null |
transformers
| 4,372
|
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln59Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln59Paraphrase")
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
infill: chrome extensions [MASK] accomplish everyday tasks.
Translated into the Style of Abraham Lincoln: chrome extensions ( expedite the ability to / unlock the means to more readily ) accomplish everyday tasks.
infill: at a time when nintendo has become inflexible, [MASK] consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
Translated into the Style of Abraham Lincoln: at a time when nintendo has become inflexible, ( stubbornly [MASK] on / firmly set on / unyielding in its insistence on ) consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
infill:
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
|
Helsinki-NLP/opus-mt-wa-en
|
28ebf552f45eeed983142aefd3748c188519ec00
|
2021-09-11T10:51:47.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"wa",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false
|
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-wa-en
| 116
| null |
transformers
| 4,373
|
---
tags:
- translation
license: apache-2.0
---
### opus-mt-wa-en
* source languages: wa
* target languages: en
* OPUS readme: [wa-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/wa-en/README.md)
* dataset: opus-enwa
* model: transformer
* pre-processing: normalization + SentencePiece
* download original weights: [opus-enwa-2020-03-21.zip](https://object.pouta.csc.fi/OPUS-MT-models/wa-en/opus-enwa-2020-03-21.zip)
* test set translations: [opus-enwa-2020-03-21.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/wa-en/opus-enwa-2020-03-21.test.txt)
* test set scores: [opus-enwa-2020-03-21.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/wa-en/opus-enwa-2020-03-21.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| enwa.fr.en | 42.6 | 0.564 |
|
dehio/german-qg-t5-e2e-quad
|
4cfad838612aebf0f2a17ab07b435cce4c3aea70
|
2022-01-20T09:40:47.000Z
|
[
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"de",
"dataset:deepset/germanquad",
"transformers",
"question generation",
"license:mit",
"model-index",
"autotrain_compatible"
] |
text2text-generation
| false
|
dehio
| null |
dehio/german-qg-t5-e2e-quad
| 116
| 1
|
transformers
| 4,374
|
---
license: mit
widget:
- text: "Naturschutzwarte haben auf der ostfriesischen Insel Wangerooge zwei seltene Kurzschnäuzige Seepferdchen entdeckt. Die Tiere seien vergangene Woche bei einer sogenannten Spülsaumkontrolle entdeckt worden, bei der die Strände eigentlich nach Müll und toten Vögeln abgesucht würden, sagte der Geschäftsführer der zuständigen Naturschutz- und Forschungsgemeinschaft Mellumrat, Mathias Heckroth. Dabei seien den Naturschützern am Nordstrand kurz hintereinander die beiden leblosen, nur wenige Zentimeter großen Tiere aufgefallen. Experten der Nationalparkverwaltung bestimmten beide Tiere als Kurzschnäuzige Seepferdchen (Hippocampus hippocampus)."
inference:
parameters:
max_length: 128
language:
- de
tags:
- question generation
datasets:
- deepset/germanquad
model-index:
- name: german-qg-t5-e2e-quad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# german-qg-t5-e2e-quad (Work in progress)
This model is a end-to-end question generation model in German. Given a text, it generates several questions about it. This model is a fine-tuned version of [valhalla/t5-base-e2e-qg](https://huggingface.co/valhalla/t5-base-e2e-qg) on the [GermanQuAD dataset from deepset](https://huggingface.co/datasets/deepset/germanquad).
## Model description
More information needed
## Training and evaluation data
Bleu_1: 0.196051
Bleu_2: 0.122380
Bleu_3: 0.079980
Bleu_4: 0.053672
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
geralt/MechDistilGPT2
|
4aad2e706976210172b6389fdf8cadb41987fca7
|
2021-08-13T12:54:31.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false
|
geralt
| null |
geralt/MechDistilGPT2
| 116
| null |
transformers
| 4,375
|
\n---
tags:
- Causal Language modeling
- text-generation
- CLM
model_index:
- name: MechDistilGPT2
results:
- task:
name: Causal Language modeling
type: Causal Language modeling
---
## MechDistilGPT2
This model is fine-tuned on text scraped from 100+ Mechanical/Automotive pdf books.
Base model is DistilGPT2(https://huggingface.co/gpt2) (the smallest version of GPT2)
## Fine-Tuning
* Default Training Args
* Epochs = 3
* Training set = 200k sentences
* Validation set = 40k sentences
## Framework versions
* Transformers 4.7.0.dev0
* Pytorch 1.8.1+cu111
* Datasets 1.6.2
* Tokenizers 0.10.2
## References
https://github.com/huggingface/notebooks/blob/master/examples/language_modeling.ipynb
|
gmihaila/wav2vec2-large-xlsr-53-romanian
|
9d42a534870eaa11ddbc772b01ad781042d8ce53
|
2021-07-06T05:34:33.000Z
|
[
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"ro",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false
|
gmihaila
| null |
gmihaila/wav2vec2-large-xlsr-53-romanian
| 116
| null |
transformers
| 4,376
|
---
language: ro
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Romanian by George Mihaila
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ro
type: common_voice
args: ro
metrics:
- name: Test WER
type: wer
value: 28.4
---
# Wav2Vec2-Large-XLSR-53-Romanian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) in Romanian using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ro", split="test[:2%]").
processor = Wav2Vec2Processor.from_pretrained("gmihaila/wav2vec2-large-xlsr-53-romanian")
model = Wav2Vec2ForCTC.from_pretrained("gmihaila/wav2vec2-large-xlsr-53-romanian")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
\\\\tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "ro", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gmihaila/wav2vec2-large-xlsr-53-romanian")
model = Wav2Vec2ForCTC.from_pretrained("gmihaila/wav2vec2-large-xlsr-53-romanian")
model.to("cuda")
chars_to_ignore_regex = '[\\\\\\\\,\\\\\\\\?\\\\\\\\.\\\\\\\\!\\\\\\\\-\\\\\\\\;\\\\\\\\:\\\\\\\\"\\\\\\\\“]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\\\tbatch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
\\\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
\\\\tinputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
\\\\twith torch.no_grad():
\\\\t\\\\tlogits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
\\\\tbatch["pred_strings"] = processor.batch_decode(pred_ids)
\\\\treturn batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 28.43 %
## Training
The Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found [here](https://colab.research.google.com/github/gmihaila/ml_things/blob/master/notebooks/pytorch/RO_Fine_Tune_XLSR_Wav2Vec2_on_Turkish_ASR_with_🤗_Transformers.ipynb)
|
readerbench/jurBERT-base
|
124190766a0ac585ae80e2b8c3d5cdf09ef889fc
|
2021-11-19T11:56:10.000Z
|
[
"pytorch",
"tf",
"bert",
"ro",
"transformers"
] | null | false
|
readerbench
| null |
readerbench/jurBERT-base
| 116
| null |
transformers
| 4,377
|
Model card for jurBERT-base
---
language:
- ro
---
# jurBERT-base
## Pretrained juridical BERT model for Romanian
BERT Romanian juridical model trained using a masked language modeling (MLM) and next sentence prediction (NSP) objective.
It was introduced in this [paper](https://aclanthology.org/2021.nllp-1.8/). Two BERT models were released: **jurBERT-base** and **jurBERT-large**, all versions uncased.
| Model | Weights | L | H | A | MLM accuracy | NSP accuracy |
|----------------|:---------:|:------:|:------:|:------:|:--------------:|:--------------:|
| *jurBERT-base* | *111M* | *12* | *768* | *12* | *0.8936* | *0.9923* |
| jurBERT-large | 337M | 24 | 1024 | 24 | 0.9005 | 0.9929 |
All models are available:
* [jurBERT-base](https://huggingface.co/readerbench/jurBERT-base)
* [jurBERT-large](https://huggingface.co/readerbench/jurBERT-large)
#### How to use
```python
# tensorflow
from transformers import AutoModel, AutoTokenizer, TFAutoModel
tokenizer = AutoTokenizer.from_pretrained("readerbench/jurBERT-base")
model = TFAutoModel.from_pretrained("readerbench/jurBERT-base")
inputs = tokenizer("exemplu de propoziție", return_tensors="tf")
outputs = model(inputs)
# pytorch
from transformers import AutoModel, AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("readerbench/jurBERT-base")
model = AutoModel.from_pretrained("readerbench/jurBERT-base")
inputs = tokenizer("exemplu de propoziție", return_tensors="pt")
outputs = model(**inputs)
```
## Datasets
The model is trained on a private corpus (that can nevertheless be rented for a fee), that is comprised of all the final ruling, containing both civil and criminal cases, published by any Romanian civil court between 2010 and 2018. Validation is performed on two other datasets, RoBanking and BRDCases. We extracted from RoJur common types of cases pertinent to the banking domain (e.g. administration fee litigations, enforcement appeals), kept only the summary of the arguments provided by both the plaitiffs and the defendants and the final verdict (in the form of a boolean value) to build RoBanking. BRDCases represents a collection of cases in which BRD Groupe Société Générale Romania was directly involved.
| Corpus | Scope |Entries | Size (GB)|
|-----------|:------------:|:---------:|:---------:|
| RoJur | pre-training | 11M | 160 |
| RoBanking | downstream | 108k | - |
| BRDCases | downstream | 149 | - |
## Downstream performance
We report Mean AUC and Std AUC on the task of predicting the outcome of a case.
### Results on RoBanking using only the plea of the plaintiff.
| Model | Mean AUC | Std AUC |
|--------------------|:--------:|:--------:|
| CNN | 79.60 | - |
| BI-LSTM | 80.99 | 0.26 |
| RoBERT-small | 70.54 | 0.28 |
| RoBERT-base | 79.74 | 0.21 |
| RoBERT-base + hf | 79.82 | 0.11 |
| RoBERT-large | 76.53 | 5.43 |
| *jurBERT-base* | **81.47**| **0.18** |
| *jurBERT-base + hf*| *81.40* | *0.18* |
| jurBERT-large | 78.38 | 1.77 |
### Results on RoBanking using pleas from both the plaintiff and defendant.
| Model | Mean AUC | Std AUC |
|---------------------|:--------:|:--------:|
| BI-LSTM | 84.60 | 0.59 |
| RoBERT-base | 84.40 | 0.26 |
| RoBERT-base + hf | 84.43 | 0.15 |
| *jurBERT-base* | *86.63* | *0.18* |
| *jurBERT-base + hf* | **86.73**| **0.22** |
| jurBERT-large | 82.04 | 0.64 |
### Results on BRDCases
| Model | Mean AUC | Std AUC |
|---------------------|:--------:|:--------:|
| SVM with SK | 57.72 | 2.15 |
| RoBERT-base | 53.24 | 1.76 |
| RoBERT-base + hf | 55.40 | 0.96 |
| *jurBERT-base* | *59.65* | *1.16* |
| *jurBERT-base + hf* | **61.46**| **1.76** |
For complete results and discussion please refer to the [paper](https://aclanthology.org/2021.nllp-1.8/).
### BibTeX entry and citation info
```bibtex
@inproceedings{masala2021jurbert,
title={jurBERT: A Romanian BERT Model for Legal Judgement Prediction},
author={Masala, Mihai and Iacob, Radu Cristian Alexandru and Uban, Ana Sabina and Cidota, Marina and Velicu, Horia and Rebedea, Traian and Popescu, Marius},
booktitle={Proceedings of the Natural Legal Language Processing Workshop 2021},
pages={86--94},
year={2021}
}
```
|
sgugger/resnet50d
|
4b32487424f0f5f2f17ffb60d578b8e5ac7ddc35
|
2021-11-03T16:22:16.000Z
|
[
"pytorch",
"dataset:imagenet",
"arxiv:1512.03385",
"arxiv:1812.01187",
"arxiv:1906.02659",
"arxiv:2010.15052",
"timm",
"image-classification",
"resnet",
"license:apache-2.0"
] |
image-classification
| false
|
sgugger
| null |
sgugger/resnet50d
| 116
| 3
|
timm
| 4,378
|
---
tags:
- image-classification
- timm
- resnet
license: apache-2.0
datasets:
- imagenet
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# ResNet-50d
Pretrained model on [ImageNet](http://www.image-net.org/). The ResNet architecture was introduced in
[this paper](https://arxiv.org/abs/1512.03385) and is adapted with the ResNet-D trick from
[this paper](https://arxiv.org/abs/1812.01187)
## Model description
ResNet are deep convolutional neural networks using residual connections. Each layer is composed of two convolutions
with a ReLU in the middle, but the output is the sum of the input with the output of the convolutional blocks.
This way, there is a direct connection from the original inputs to even the deepest layers in the network.
## Intended uses & limitations
You can use the raw model to classify images along the 1,000 ImageNet labels, but you can also change its head
to fine-tune it on a downstream task (another classification task with different labels, image segmentation or
object detection, to name a few).
### How to use
You can use this model with the usual factory method in `timm`:
```python
import PIL
import timm
import torch
model = timm.create_model("sgugger/resnet50d")
img = PIL.Image.open(path_to_an_image)
img = img.convert("RGB")
config = model.default_cfg
if isinstance(config["input_size"], tuple):
img_size = config["input_size"][-2:]
else:
img_size = config["input_size"]
transform = timm.data.transforms_factory.transforms_imagenet_eval(
img_size=img_size,
interpolation=config["interpolation"],
mean=config["mean"],
std=config["std"],
)
input_tensor = transform(cat_img)
input_tensor = input_tensor.unsqueeze(0)
# ^ batch size = 1
with torch.no_grad():
output = model(input_tensor)
probs = output.squeeze(0).softmax(dim=0)
```
### Limitations and bias
The training images in the dataset are usually photos clearly representing one of the 1,000 labels. The model will
probably not generalize well on drawings or images containing multiple objects with different labels.
The training images in the dataset come mostly from the US (45.4%) and Great Britain (7.6%). As such the model or
models created by fine-tuning this model will work better on images picturing scenes from these countries (see
[this paper](https://arxiv.org/abs/1906.02659) for examples).
More generally, [recent research](https://arxiv.org/abs/2010.15052) has shown that even models trained in an
unsupervised fashion on ImageNet (i.e. without using the labels) will pick up racial and gender bias represented in
the training images.
## Training data
This model was pretrained on [ImageNet](http://www.image-net.org/), a dataset consisting of 14 millions of
hand-annotated images with 1,000 categories.
## Training procedure
To be completed
### Preprocessing
The images are resized using bicubic interpolation to 224x224 and normalized with the usual ImageNet statistics.
## Evaluation results
This model has a top1-accuracy of 80.53% and a top-5 accuracy of 95.16% in the evaluation set of ImageNet
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/HeZRS15,
author = {Kaiming He and
Xiangyu Zhang and
Shaoqing Ren and
Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {CoRR},
volume = {abs/1512.03385},
year = {2015},
url = {http://arxiv.org/abs/1512.03385},
archivePrefix = {arXiv},
eprint = {1512.03385},
timestamp = {Wed, 17 Apr 2019 17:23:45 +0200},
biburl = {https://dblp.org/rec/journals/corr/HeZRS15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
vblagoje/dpr-question_encoder-single-lfqa-base
|
fd2656c623ec5b21fc764de1e4e97f0f50ba7f07
|
2022-03-11T10:11:54.000Z
|
[
"pytorch",
"dpr",
"feature-extraction",
"en",
"dataset:vblagoje/lfqa",
"transformers",
"license:mit"
] |
feature-extraction
| false
|
vblagoje
| null |
vblagoje/dpr-question_encoder-single-lfqa-base
| 116
| null |
transformers
| 4,379
|
---
language: en
datasets:
- vblagoje/lfqa
license: mit
---
## Introduction
The question encoder model based on [DPRQuestionEncoder](https://huggingface.co/docs/transformers/master/en/model_doc/dpr#transformers.DPRQuestionEncoder) architecture. It uses the transformer's pooler outputs as question representations.
## Training
We trained vblagoje/dpr-question_encoder-single-lfqa-base using FAIR's dpr-scale starting with PAQ based pretrained checkpoint and fine-tuned the retriever on the question-answer pairs from the LFQA dataset. As dpr-scale requires DPR formatted training set input with positive, negative, and hard negative samples - we created a training file with an answer being positive, negatives being question unrelated answers, while hard negative samples were chosen from answers on questions between 0.55 and 0.65 of cosine similarity.
## Performance
LFQA DPR-based retriever (vblagoje/dpr-question_encoder-single-lfqa-base and vblagoje/dpr-ctx_encoder-single-lfqa-base) had a score of 6.69 for R-precision and 14.5 for Recall@5 on KILT benchmark.
## Usage
```python
from transformers import DPRContextEncoder, DPRContextEncoderTokenizer
model = DPRQuestionEncoder.from_pretrained("vblagoje/dpr-question_encoder-single-lfqa-base").to(device)
tokenizer = AutoTokenizer.from_pretrained("vblagoje/dpr-question_encoder-single-lfqa-base")
input_ids = tokenizer("Why do airplanes leave contrails in the sky?", return_tensors="pt")["input_ids"]
embeddings = model(input_ids).pooler_output
```
## Author
- Vladimir Blagojevic: `dovlex [at] gmail.com` [Twitter](https://twitter.com/vladblagoje) | [LinkedIn](https://www.linkedin.com/in/blagojevicvladimir/)
|
luyaojie/uie-large-en
|
458a7066e8d6217b25945fe71f04f375910e8487
|
2022-04-19T10:14:55.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible"
] |
text2text-generation
| false
|
luyaojie
| null |
luyaojie/uie-large-en
| 116
| null |
transformers
| 4,380
|
---
license: cc-by-nc-sa-4.0
---
|
demdecuong/vihealthbert-base-word
|
f89e80b461e86f9cfc1c84019bd819830c24b6c5
|
2022-04-20T07:55:52.000Z
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
| false
|
demdecuong
| null |
demdecuong/vihealthbert-base-word
| 116
| 2
|
transformers
| 4,381
|
# <a name="introduction"></a> ViHealthBERT: Pre-trained Language Models for Vietnamese in Health Text Mining
ViHealthBERT is the a strong baseline language models for Vietnamese in Healthcare domain.
We empirically investigate our model with different training strategies, achieving state of the art (SOTA) performances on 3 downstream tasks: NER (COVID-19 & ViMQ), Acronym Disambiguation, and Summarization.
We introduce two Vietnamese datasets: the acronym dataset (acrDrAid) and the FAQ summarization dataset in the healthcare domain. Our acrDrAid dataset is annotated with 135 sets of keywords.
The general approaches and experimental results of ViHealthBERT can be found in our LREC-2022 Poster [paper]() (updated soon):
@article{vihealthbert,
title = {{ViHealthBERT: Pre-trained Language Models for Vietnamese in Health Text Mining}},
author = {Minh Phuc Nguyen, Vu Hoang Tran, Vu Hoang, Ta Duc Huy, Trung H. Bui, Steven Q. H. Truong },
journal = {13th Edition of its Language Resources and Evaluation Conference},
year = {2022}
}
### Installation <a name="install2"></a>
- Python 3.6+, and PyTorch >= 1.6
- Install `transformers`:
`pip install transformers==4.2.0`
### Pre-trained models <a name="models2"></a>
Model | #params | Arch. | Tokenizer
---|---|---|---
`demdecuong/vihealthbert-base-word` | 135M | base | Word-level
`demdecuong/vihealthbert-base-syllable` | 135M | base | Syllable-level
### Example usage <a name="usage1"></a>
```python
import torch
from transformers import AutoModel, AutoTokenizer
vihealthbert = AutoModel.from_pretrained("demdecuong/vihealthbert-base-word")
tokenizer = AutoTokenizer.from_pretrained("demdecuong/vihealthbert-base-word")
# INPUT TEXT MUST BE ALREADY WORD-SEGMENTED!
line = "Tôi là sinh_viên trường đại_học Công_nghệ ."
input_ids = torch.tensor([tokenizer.encode(line)])
with torch.no_grad():
features = vihealthbert(input_ids) # Models outputs are now tuples
```
### Example usage for raw text <a name="usage2"></a>
Since ViHealthBERT used the [RDRSegmenter](https://github.com/datquocnguyen/RDRsegmenter) from [VnCoreNLP](https://github.com/vncorenlp/VnCoreNLP) to pre-process the pre-training data.
We highly recommend use the same word-segmenter for ViHealthBERT downstream applications.
#### Installation
```
# Install the vncorenlp python wrapper
pip3 install vncorenlp
# Download VnCoreNLP-1.1.1.jar & its word segmentation component (i.e. RDRSegmenter)
mkdir -p vncorenlp/models/wordsegmenter
wget https://raw.githubusercontent.com/vncorenlp/VnCoreNLP/master/VnCoreNLP-1.1.1.jar
wget https://raw.githubusercontent.com/vncorenlp/VnCoreNLP/master/models/wordsegmenter/vi-vocab
wget https://raw.githubusercontent.com/vncorenlp/VnCoreNLP/master/models/wordsegmenter/wordsegmenter.rdr
mv VnCoreNLP-1.1.1.jar vncorenlp/
mv vi-vocab vncorenlp/models/wordsegmenter/
mv wordsegmenter.rdr vncorenlp/models/wordsegmenter/
```
`VnCoreNLP-1.1.1.jar` (27MB) and folder `models/` must be placed in the same working folder.
#### Example usage
```
# See more details at: https://github.com/vncorenlp/VnCoreNLP
# Load rdrsegmenter from VnCoreNLP
from vncorenlp import VnCoreNLP
rdrsegmenter = VnCoreNLP("/Absolute-path-to/vncorenlp/VnCoreNLP-1.1.1.jar", annotators="wseg", max_heap_size='-Xmx500m')
# Input
text = "Ông Nguyễn Khắc Chúc đang làm việc tại Đại học Quốc gia Hà Nội. Bà Lan, vợ ông Chúc, cũng làm việc tại đây."
# To perform word (and sentence) segmentation
sentences = rdrsegmenter.tokenize(text)
for sentence in sentences:
print(" ".join(sentence))
```
|
lucataco/DialoGPT-medium-milo
|
3d03b0782381cf6e818779f6e8bc5d03d6d9f355
|
2022-07-03T23:35:39.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false
|
lucataco
| null |
lucataco/DialoGPT-medium-milo
| 116
| null |
transformers
| 4,382
|
---
tags:
- conversational
---
# Milo Dialog GPT Model Medium 12
# Trained on discord channels:
# half of Dragalia chat
|
lbox/lcube-base
|
6b69fc2a4f4574ff9fb761dd5b17409edf185c83
|
2022-06-17T02:10:42.000Z
|
[
"pytorch",
"tf",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false
|
lbox
| null |
lbox/lcube-base
| 116
| null |
transformers
| 4,383
|
## How to use
```python
import transformers
model = transformers.GPT2LMHeadModel.from_pretrained("lbox/lcube-base")
tokenizer = transformers.AutoTokenizer.from_pretrained(
"lbox/lcube-base",
bos_token="[BOS]",
unk_token="[UNK]",
pad_token="[PAD]",
mask_token="[MASK]",
)
text = "피고인은 불상지에 있는 커피숍에서, 피해자 B으로부터"
model_inputs = tokenizer(text,
max_length=1024,
padding=True,
truncation=True,
return_tensors='pt')
out = model.generate(
model_inputs["input_ids"],
max_new_tokens=150,
pad_token_id=tokenizer.pad_token_id,
use_cache=True,
repetition_penalty=1.2,
top_k=5,
top_p=0.9,
temperature=1,
num_beams=2,
)
tokenizer.batch_decode(out)
```
For more information please visit <https://github.com/lbox-kr/lbox_open>.
## Licensing Information
Copyright 2022-present LBox Co. Ltd.
Licensed under the CC BY-NC-ND 4.0
|
inywer/2-0OKUOHS
|
c9e02e0c98fa1493fa42baba8ba9dd952762ec6d
|
2022-07-10T22:43:46.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false
|
inywer
| null |
inywer/2-0OKUOHS
| 116
| null |
transformers
| 4,384
|
---
tags:
- conversational
---
# inywer/2-0OKUOHS Model
|
seegene/viral-sixmerta-small2
|
e1085c057bca9a062f0624be90f932fc34c0516c
|
2022-07-29T00:09:38.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false
|
seegene
| null |
seegene/viral-sixmerta-small2
| 116
| null |
transformers
| 4,385
|
---
license: apache-2.0
widget:
- text: "AAGCGAGACGACTTTTACGC<MASK>GGATAGCTAGGCTAGCATCG"
example_title: "Mutation Probability"
---
# Viral-RoBERTa-small
- NCBI Virus 서열을 언어 모델에 사전학습 (짧은 길이의 서열 비율 증가)
- 6-mer word level 에서 Byte Pair Encoding (BPE) 토크나이저 사용 (빈도수 20으로 vocab 제작)
- RoBERTa architecture 기반 사전학습 진행, transformer 레이어 6개 사용
- V100 GPU 서버에서 학습 진행 중
## Usage
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
from transformers import pipeline
HF_ACCESS_TOKEN = ''
model = AutoModelForMaskedLM.from_pretrained("seegene/viral-sixmerta-small2", use_auth_token=HF_ACCESS_TOKEN)
tokenizer = AutoTokenizer.from_pretrained("seegene/viral-sixmerta-small2", use_auth_token=HF_ACCESS_TOKEN)
generator = pipeline(task="fill-mask", model=model, tokenizer=tokenizer)
generator('AAGCGAGACGACTTTTACGC<MASK>GGATAGCTAGGCTAGCATCG')
```
## Todo
- 모델 검토 단계에 있습니다
|
Helsinki-NLP/opus-mt-en-mr
|
85463bb8620cf8685e6323252cb24d7d819f3afc
|
2021-09-09T21:37:51.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"mr",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false
|
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-en-mr
| 115
| 1
|
transformers
| 4,386
|
---
tags:
- translation
license: apache-2.0
---
### opus-mt-en-mr
* source languages: en
* target languages: mr
* OPUS readme: [en-mr](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-mr/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-mr/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-mr/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-mr/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.en.mr | 22.0 | 0.397 |
|
Helsinki-NLP/opus-mt-pl-fr
|
a23ffba6953bea7606d7abbd47215dcd58d331ea
|
2021-09-10T14:01:23.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"pl",
"fr",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false
|
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-pl-fr
| 115
| null |
transformers
| 4,387
|
---
tags:
- translation
license: apache-2.0
---
### opus-mt-pl-fr
* source languages: pl
* target languages: fr
* OPUS readme: [pl-fr](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/pl-fr/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/pl-fr/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/pl-fr/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/pl-fr/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.pl.fr | 49.0 | 0.659 |
|
Helsinki-NLP/opus-mt-ru-uk
|
db108c722752b88d9717193bce732737a1afb00f
|
2020-08-21T14:42:49.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"ru",
"uk",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false
|
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-ru-uk
| 115
| 1
|
transformers
| 4,388
|
---
language:
- ru
- uk
tags:
- translation
license: apache-2.0
---
### rus-ukr
* source group: Russian
* target group: Ukrainian
* OPUS readme: [rus-ukr](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/rus-ukr/README.md)
* model: transformer-align
* source language(s): rus
* target language(s): ukr
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/rus-ukr/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/rus-ukr/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/rus-ukr/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.rus.ukr | 64.0 | 0.793 |
### System Info:
- hf_name: rus-ukr
- source_languages: rus
- target_languages: ukr
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/rus-ukr/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['ru', 'uk']
- src_constituents: {'rus'}
- tgt_constituents: {'ukr'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/rus-ukr/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/rus-ukr/opus-2020-06-17.test.txt
- src_alpha3: rus
- tgt_alpha3: ukr
- short_pair: ru-uk
- chrF2_score: 0.7929999999999999
- bleu: 64.0
- brevity_penalty: 0.99
- ref_len: 60212.0
- src_name: Russian
- tgt_name: Ukrainian
- train_date: 2020-06-17
- src_alpha2: ru
- tgt_alpha2: uk
- prefer_old: False
- long_pair: rus-ukr
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
SEBIS/code_trans_t5_small_commit_generation_transfer_learning_finetune
|
be1097115c98a0c67209a4184af241126e024dec
|
2021-06-23T10:15:54.000Z
|
[
"pytorch",
"jax",
"t5",
"feature-extraction",
"transformers",
"summarization"
] |
summarization
| false
|
SEBIS
| null |
SEBIS/code_trans_t5_small_commit_generation_transfer_learning_finetune
| 115
| null |
transformers
| 4,389
|
---
tags:
- summarization
widget:
- text: "new file mode 100644 index 000000000 . . 892fda21b Binary files / dev / null and b / src / plugins / gateway / lib / joscar . jar differ"
---
# CodeTrans model for git commit message generation
Pretrained model on git commit using the t5 small model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized git commit: it works best with tokenized git commit.
## Model description
This CodeTrans model is based on the `t5-small` model. It has its own SentencePiece vocabulary model. It used transfer-learning pre-training on 7 unsupervised datasets in the software development domain. It is then fine-tuned on the git commit message generation task for the java commit changes.
## Intended uses & limitations
The model could be used to generate the git commit message for the git commit changes or be fine-tuned on other relevant tasks. It can be used on unparsed and untokenized commit changes. However, if the change is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate git commit message using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_small_commit_generation_transfer_learning_finetune"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_small_commit_generation_transfer_learning_finetune", skip_special_tokens=True),
device=0
)
tokenized_code = "new file mode 100644 index 000000000 . . 892fda21b Binary files / dev / null and b / src / plugins / gateway / lib / joscar . jar differ"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/transfer%20learning%20fine-tuning/commit%20generation/small_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Training procedure
### Transfer-learning Pretraining
The model was trained on a single TPU Pod V3-8 for 500,000 steps in total, using sequence length 512 (batch size 4096).
It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
### Fine-tuning
This model was then fine-tuned on a single TPU Pod V2-8 for 10,000 steps in total, using sequence length 512 (batch size 256), using only the dataset only containing commit changes.
## Evaluation results
For the git commit message generation task, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Java |
| -------------------- | :------------: |
| CodeTrans-ST-Small | 39.61 |
| CodeTrans-ST-Base | 38.67 |
| CodeTrans-TF-Small | 44.22 |
| CodeTrans-TF-Base | 44.17 |
| CodeTrans-TF-Large | **44.41** |
| CodeTrans-MT-Small | 36.17 |
| CodeTrans-MT-Base | 39.25 |
| CodeTrans-MT-Large | 41.18 |
| CodeTrans-MT-TF-Small | 43.96 |
| CodeTrans-MT-TF-Base | 44.19 |
| CodeTrans-MT-TF-Large | 44.34 |
| State of the art | 32.81 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
dhimskyy/wiki-bert
|
d30ba6eb1dd857f3e365f3067a0fd425e904ce81
|
2021-05-19T15:41:20.000Z
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false
|
dhimskyy
| null |
dhimskyy/wiki-bert
| 115
| null |
transformers
| 4,390
|
Entry not found
|
huggingtweets/dril
|
15767121a74a84ae3403af3f60060ec4829cca4e
|
2022-06-16T16:14:18.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] |
text-generation
| false
|
huggingtweets
| null |
huggingtweets/dril
| 115
| 1
|
transformers
| 4,391
|
---
language: en
thumbnail: http://www.huggingtweets.com/dril/1655396053530/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1510917391533830145/XW-zSFDJ_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">wint</div>
<div style="text-align: center; font-size: 14px;">@dril</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from wint.
| Data | wint |
| --- | --- |
| Tweets downloaded | 3231 |
| Retweets | 483 |
| Short tweets | 296 |
| Tweets kept | 2452 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/33aqh8dh/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @dril's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/vqfhmrlt) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/vqfhmrlt/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/dril')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
laxya007/gpt2_BSA_Legal_Initiproject_OE_OS_BRM
|
92f2c1caf732e5292beecd8a03559a288a23c404
|
2021-10-23T10:51:52.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false
|
laxya007
| null |
laxya007/gpt2_BSA_Legal_Initiproject_OE_OS_BRM
| 115
| null |
transformers
| 4,392
|
Entry not found
|
liaad/srl-en_xlmr-base
|
55387c653aba11f0025a2f7089435c11c4c583f6
|
2021-09-22T08:56:11.000Z
|
[
"pytorch",
"xlm-roberta",
"feature-extraction",
"multilingual",
"pt",
"en",
"dataset:PropBank.Br",
"dataset:CoNLL-2012",
"arxiv:2101.01213",
"transformers",
"xlm-roberta-base",
"semantic role labeling",
"finetuned",
"license:apache-2.0"
] |
feature-extraction
| false
|
liaad
| null |
liaad/srl-en_xlmr-base
| 115
| 1
|
transformers
| 4,393
|
---
language:
- multilingual
- pt
- en
tags:
- xlm-roberta-base
- semantic role labeling
- finetuned
license: apache-2.0
datasets:
- PropBank.Br
- CoNLL-2012
metrics:
- F1 Measure
---
# XLM-R base fine-tuned on English semantic role labeling
## Model description
This model is the [`xlm-roberta-base`](https://huggingface.co/xlm-roberta-base) fine-tuned on the English CoNLL formatted OntoNotes v5.0 semantic role labeling data. This is part of a project from which resulted the following models:
* [liaad/srl-pt_bertimbau-base](https://huggingface.co/liaad/srl-pt_bertimbau-base)
* [liaad/srl-pt_bertimbau-large](https://huggingface.co/liaad/srl-pt_bertimbau-large)
* [liaad/srl-pt_xlmr-base](https://huggingface.co/liaad/srl-pt_xlmr-base)
* [liaad/srl-pt_xlmr-large](https://huggingface.co/liaad/srl-pt_xlmr-large)
* [liaad/srl-pt_mbert-base](https://huggingface.co/liaad/srl-pt_mbert-base)
* [liaad/srl-en_xlmr-base](https://huggingface.co/liaad/srl-en_xlmr-base)
* [liaad/srl-en_xlmr-large](https://huggingface.co/liaad/srl-en_xlmr-large)
* [liaad/srl-en_mbert-base](https://huggingface.co/liaad/srl-en_mbert-base)
* [liaad/srl-enpt_xlmr-base](https://huggingface.co/liaad/srl-enpt_xlmr-base)
* [liaad/srl-enpt_xlmr-large](https://huggingface.co/liaad/srl-enpt_xlmr-large)
* [liaad/srl-enpt_mbert-base](https://huggingface.co/liaad/srl-enpt_mbert-base)
* [liaad/ud_srl-pt_bertimbau-large](https://huggingface.co/liaad/ud_srl-pt_bertimbau-large)
* [liaad/ud_srl-pt_xlmr-large](https://huggingface.co/liaad/ud_srl-pt_xlmr-large)
* [liaad/ud_srl-enpt_xlmr-large](https://huggingface.co/liaad/ud_srl-enpt_xlmr-large)
For more information, please see the accompanying article (See BibTeX entry and citation info below) and the [project's github](https://github.com/asofiaoliveira/srl_bert_pt).
## Intended uses & limitations
#### How to use
To use the transformers portion of this model:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("liaad/srl-en_xlmr-base")
model = AutoModel.from_pretrained("liaad/srl-en_xlmr-base")
```
To use the full SRL model (transformers portion + a decoding layer), refer to the [project's github](https://github.com/asofiaoliveira/srl_bert_pt).
#### Limitations and bias
- This model does not include a Tensorflow version. This is because the "type_vocab_size" in this model was changed (from 1 to 2) and, therefore, it cannot be easily converted to Tensorflow.
- The models were trained only for 5 epochs.
- The English data was preprocessed to match the Portuguese data, so there are some differences in role attributions and some roles were removed from the data.
## Training procedure
The models were trained on the CoNLL-2012 dataset, preprocessed to match the Portuguese PropBank.Br data. They were tested on the PropBank.Br data set as well as on a smaller opinion dataset "Buscapé". For more information, please see the accompanying article (See BibTeX entry and citation info below) and the [project's github](https://github.com/asofiaoliveira/srl_bert_pt).
## Eval results
| Model Name | F<sub>1</sub> CV PropBank.Br (in domain) | F<sub>1</sub> Buscapé (out of domain) |
| --------------- | ------ | ----- |
| `srl-pt_bertimbau-base` | 76.30 | 73.33 |
| `srl-pt_bertimbau-large` | 77.42 | 74.85 |
| `srl-pt_xlmr-base` | 75.22 | 72.82 |
| `srl-pt_xlmr-large` | 77.59 | 73.84 |
| `srl-pt_mbert-base` | 72.76 | 66.89 |
| `srl-en_xlmr-base` | 66.59 | 65.24 |
| `srl-en_xlmr-large` | 67.60 | 64.94 |
| `srl-en_mbert-base` | 63.07 | 58.56 |
| `srl-enpt_xlmr-base` | 76.50 | 73.74 |
| `srl-enpt_xlmr-large` | **78.22** | 74.55 |
| `srl-enpt_mbert-base` | 74.88 | 69.19 |
| `ud_srl-pt_bertimbau-large` | 77.53 | 74.49 |
| `ud_srl-pt_xlmr-large` | 77.69 | 74.91 |
| `ud_srl-enpt_xlmr-large` | 77.97 | **75.05** |
### BibTeX entry and citation info
```bibtex
@misc{oliveira2021transformers,
title={Transformers and Transfer Learning for Improving Portuguese Semantic Role Labeling},
author={Sofia Oliveira and Daniel Loureiro and Alípio Jorge},
year={2021},
eprint={2101.01213},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
nateraw/tiny-vit-random
|
f0939d8baaaf0c86aa0240b31f8f63a6de8a38db
|
2021-10-01T06:27:57.000Z
|
[
"pytorch",
"vit",
"feature-extraction",
"transformers"
] |
feature-extraction
| false
|
nateraw
| null |
nateraw/tiny-vit-random
| 115
| null |
transformers
| 4,394
|
Entry not found
|
sciarrilli/biobert-base-cased-v1.2-finetuned-ner
|
43e59ea29438545feddab3855d5b8161a7140b4a
|
2021-10-15T21:47:28.000Z
|
[
"pytorch",
"bert",
"token-classification",
"dataset:jnlpba",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] |
token-classification
| false
|
sciarrilli
| null |
sciarrilli/biobert-base-cased-v1.2-finetuned-ner
| 115
| null |
transformers
| 4,395
|
---
tags:
- generated_from_trainer
datasets:
- jnlpba
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: biobert-base-cased-v1.2-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: jnlpba
type: jnlpba
args: jnlpba
metrics:
- name: Precision
type: precision
value: 0.7150627220423177
- name: Recall
type: recall
value: 0.8300729927007299
- name: F1
type: f1
value: 0.7682875335686659
- name: Accuracy
type: accuracy
value: 0.90497239665345
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# biobert-base-cased-v1.2-finetuned-ner
This model is a fine-tuned version of [dmis-lab/biobert-base-cased-v1.2](https://huggingface.co/dmis-lab/biobert-base-cased-v1.2) on the jnlpba dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3655
- Precision: 0.7151
- Recall: 0.8301
- F1: 0.7683
- Accuracy: 0.9050
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.257 | 1.0 | 1160 | 0.2889 | 0.7091 | 0.8222 | 0.7615 | 0.9021 |
| 0.1962 | 2.0 | 2320 | 0.3009 | 0.7154 | 0.8259 | 0.7667 | 0.9048 |
| 0.158 | 3.0 | 3480 | 0.3214 | 0.7098 | 0.8228 | 0.7621 | 0.9031 |
| 0.131 | 4.0 | 4640 | 0.3385 | 0.7174 | 0.8292 | 0.7692 | 0.9055 |
| 0.1081 | 5.0 | 5800 | 0.3655 | 0.7151 | 0.8301 | 0.7683 | 0.9050 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.1+cu102
- Datasets 1.13.2
- Tokenizers 0.10.3
|
questgen/paraphrase-multilingual-mpnet-base-v2-feature-extraction-pipeline
|
fc186318516b8a7db7f6ae9e776f5f2210af88e9
|
2022-05-14T10:23:10.000Z
|
[
"pytorch",
"xlm-roberta",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
feature-extraction
| false
|
questgen
| null |
questgen/paraphrase-multilingual-mpnet-base-v2-feature-extraction-pipeline
| 115
| null |
sentence-transformers
| 4,396
|
---
pipeline_tag: feature-extraction
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/paraphrase-multilingual-mpnet-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-mpnet-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/paraphrase-multilingual-mpnet-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/paraphrase-multilingual-mpnet-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/paraphrase-multilingual-mpnet-base-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
|
Helsinki-NLP/opus-mt-gaa-en
|
c5297321fb6cc0a2af0d953c89990382d5a6ffa8
|
2021-09-09T21:58:41.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"gaa",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false
|
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-gaa-en
| 114
| null |
transformers
| 4,397
|
---
tags:
- translation
license: apache-2.0
---
### opus-mt-gaa-en
* source languages: gaa
* target languages: en
* OPUS readme: [gaa-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/gaa-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/gaa-en/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/gaa-en/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/gaa-en/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.gaa.en | 41.0 | 0.567 |
|
allenai/longformer-base-4096-extra.pos.embd.only
|
16a4bb5ac90bac2c19c561cc0dda1bb9b1270da6
|
2021-03-10T02:32:23.000Z
|
[
"pytorch",
"tf",
"longformer",
"arxiv:2004.05150",
"transformers"
] | null | false
|
allenai
| null |
allenai/longformer-base-4096-extra.pos.embd.only
| 114
| null |
transformers
| 4,398
|
# longformer-base-4096-extra.pos.embd.only
This model is similar to `longformer-base-4096` but it was pretrained to preserve RoBERTa weights by freezing all RoBERTa weights and only train the additional position embeddings.
### Citing
If you use `Longformer` in your research, please cite [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150).
```
@article{Beltagy2020Longformer,
title={Longformer: The Long-Document Transformer},
author={Iz Beltagy and Matthew E. Peters and Arman Cohan},
journal={arXiv:2004.05150},
year={2020},
}
```
`Longformer` is an open-source project developed by [the Allen Institute for Artificial Intelligence (AI2)](http://www.allenai.org).
AI2 is a non-profit institute with the mission to contribute to humanity through high-impact AI research and engineering.
|
allenai/unifiedqa-v2-t5-base-1251000
|
344cc3377d51a92e7960cd7bd525a50975015c81
|
2022-02-22T00:26:37.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false
|
allenai
| null |
allenai/unifiedqa-v2-t5-base-1251000
| 114
| null |
transformers
| 4,399
|
# Further details: https://github.com/allenai/unifiedqa
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.