
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers
| 13,532 |
closed
|
fix PhophetNet 'use_cache' assignment of no effect
|
Hi, I noticed that there was one '=' too many, resulting in 'use_cache' not properly assigned. So I just deleted it. Hope this can be of any help to you.
|
09-12-2021 10:45:26
|
09-12-2021 10:45:26
| |
transformers
| 13,528 |
closed
|
Trainer's create_model_card creates an invalid yaml metadata `datasets: - null`
|
## Environment info
- any env
### Who can help
- discussed with @julien-c @sgugger and @LysandreJik
## Information
- The hub will soon reject push with invalid model card metadata,
- **only when `datasets`, `model-index` or `license` are present**, their content need to follow the specification cf. https://github.com/huggingface/huggingface_hub/pull/342
## To reproduce
Steps to reproduce the behavior:
1. Train a model
2. Do not association any datasets
3. The trained model and the model card are rejected by the server
## Expected behavior
trainer.py git push should be successfull, even with the coming patch https://github.com/huggingface/transformers/pull/13514
|
09-11-2021 11:16:03
|
09-11-2021 11:16:03
|
I think there are more fixes we can add to properly validate metadata:
- check the licence is correct
- check all the required fields are present before adding a `result` (which is going to also error out).
I will suggest a PR later today with all of that.<|||||>(note that this cannot really be hardcoded in `transformers` as rules can and will change on the server side)<|||||>I thought the goal was to fix the faulty model cards the Trainer was generating? If we don't want to hardcode anything in Transformers, we can just close the issue then. Why only fix the missing datasets and not the missing metrics for instance?<|||||>Hmm, the `datasets: - null` issue is not about missing datasets, it's about invalid data.
in YAML, this is parsed as `datasets = [None]` (python-syntax) whereas it should be an array of string.
In my opinion, we will not enforce rejections for missing data any time soon (especially for automatically generated model cards).<|||||>> I will suggest a PR later today with all of that.
Thanks @sgugger
Ok if you take care of `license`.
But more simply here I wanted to avoid transformer code to insert `null` as dataset name.
<|||||>(That being said, by all means, if you want to improve validation in transformers in the meantime, please do so. I'm just pointing out that writing validation code in transformers might in some cases be a little redundant)<|||||>To reformulate, we also have some problems if there is a `model_index` passed with no metrics in some result, which can be generated if the Trainer makes a push to hub with no evaluation done but can still be assigned a task and a dataset, which is a bit similar to the issue of passing a `datsasets: - null`. The license is different so we should definitely drop it for now if the list is expected to move.
The code for that won't be redundant in the sense the Trainer should not try to pass an incomplete result if we want the push to succeed. Even if we move the validation to the hf_hub library, we will still get an error. It's just the check will happen at a different level.<|||||>Yes I see. I think what you propose sounds good. Thoughts @elishowk?<|||||>IMHO the central point is to ensure transformers and the huggingface_hub CLI to display really well the server's warning and errors, that are meant to be clear and provide advices and documentation about validation failures.
> The license is different so we should definitely drop it for now if the list is expected to move.
The license enumeration is very simple, I don't think it's gonna change soon (is it ?) and the hub git server will return [the docs anyways](https://huggingface.co/docs/hub/model-repos#list-of-license-identifiers)
> Trainer should not try to pass an incomplete result if we want the push to succeed.
OK for me it's you call @sgugger and @julien-c, really, but if any checking is gonna be done on transformers' side before pushing a model's README.md metadata changes, IMHO we should use the same schema, in order to create as little maintenance as possible..
- The hub server the schema we use for `model-indel` is (for the moment) the following: [model-index-set.jtd.zip](https://github.com/huggingface/transformers/files/7153383/model-index-set.jtd.zip) (sorry github doesn't allow json uploads)
- we can generate a validation function for python using https://jsontypedef.com/docs/python-codegen/
- finally, if the JTD schema changes on the hub, we'll need to open a PR here first to update the schema, and may be later to version the schema server-side so that we don't break the older clients users have. for example by introducing a hub metadata schema version marked in the yaml itself. The server could respond (without breaking) that the pushed version is deprecated, and also later if needed implement schema conversion code.<|||||>(personally i don't see the point of this duplication if we can just try to push i.e. perform validation on the server side and report warnings/errors if push is not successful for validation reasons)
I might be missing something though<|||||>In the meantime I've suggested a fix for the problems for which this issue was created and for the incomplete results I mentioned. Both have their origin in the code of the `TrainingSummary`, so fixing them is not duplicate code :-)
We can think more about what validation we want to do where, personally I would see this more in the hf_hub side, in the function that adds metadata (which we will use in the Trainer once it's merged and in a release of hf_hub).<|||||>> In the meantime I've suggested a fix for the problems for which this issue was created and for the incomplete results I mentioned. Both have their origin in the code of the `TrainingSummary`, so fixing them is not duplicate code :-)
OK I think we understood each other now, it's about fixing the code that generates bad yaml, so also OK with @julien-c
Let's just fix the yaml generation errors we know at this time. The hub server will tell us future validation errors and how to fix then.
|
transformers
| 13,527 |
closed
|
T5 support for text classification demo code
|
## Environment info
- `transformers` version: 4.10.2
- Platform: Linux-4.4.0-210-generic-x86_64-with-debian-stretch-sid
- Python version: 3.7.0
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
@sgugger, @patil-suraj, @patrickvonplaten
## Information
Model I am using (Bert, XLNet ...): T5
The problem arises when using:
* [x] the official example scripts: `examples/pytorch/text-classification/run_glue.py`
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: GLUE
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
Just run https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py and set the model to `t5-base`, it produces the following output:
```
raceback (most recent call last):
File "run_glue.py", line 566, in <module>
main()
File "run_glue.py", line 336, in main
use_auth_token=True if model_args.use_auth_token else None,
File "/home2/yushi/hf_examples/.venv/lib/python3.7/site-packages/transformers/models/auto/auto_factory.py", line 390, in from_pretrained
f"Unrecognized configuration class {config.__class__} for this kind of AutoModel: {cls.__name__}.\n"
ValueError: Unrecognized configuration class <class 'transformers.models.t5.configuration_t5.T5Config'> for this kind of AutoModel: AutoModelForSequenceClassification.
Model type should be one of LayoutLMv2Config, RemBertConfig, CanineConfig, RoFormerConfig, BigBirdPegasusConfig, GPTNeoConfig, BigBirdConfig, ConvBertConfig, LEDConfig, IBertConfig, MobileBertConfig, DistilBertConfig, AlbertConfig, CamembertConfig, XLMRobertaConfig, MBartConfig, MegatronBertConfig, MPNetConfig, BartConfig, ReformerConfig, LongformerConfig, RobertaConfig, DebertaV2Config, DebertaConfig, FlaubertConfig, SqueezeBertConfig, BertConfig, OpenAIGPTConfig, GPT2Config, TransfoXLConfig, XLNetConfig, XLMConfig, CTRLConfig, ElectraConfig, FunnelConfig, LayoutLMConfig, TapasConfig.
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
It seems that the demo code doesn't support T5. Could you please add T5 support? Thank you!
## Expected behavior
Run successfully
|
09-11-2021 07:33:19
|
09-11-2021 07:33:19
|
The T5 model is not suitable for text classification, as it's a sequence to sequence model. This why there is no version of that model with a classification head, and why the text classification head then fails.<|||||>Hi @sgugger, the T5 **is** suitable for text classification, according to the T5 paper. This is performed by assigning a label word for each class and doing generation. <|||||>For example, to classify a sentence from SST2, the input is converted to:
```
sst2 sentence: it confirms fincher ’s status as a film maker who artfully bends technical know-how to the service of psychological insight .
```
The model is trained to generate "positive" for target 1, according to the Appendix D of the paper.<|||||>It has become a trend to use generative/seq2seq models for classification tasks. I wonder if HuggingFace could possibly build convenient APIs to support this paradigm. <|||||>> Hi @sgugger, the T5 is suitable for text classification, according to the T5 paper. This is performed by assigning a label word for each class and doing generation.
Yes, so this is done by using T5 as a seq2seq model, not by adding a classification head. Therefore, you can't expect the generic text classification example to work with T5. You can however adapt the seqseq scripts to have then do text classification with T5.<|||||>@Yu-Shi You could refer to this [colab](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) to see how to use T5 for classification and then adapt the `run_summarization.py` script accordingly, i.e you will need to change the pre-processing part to prepare the input text in the required format. and then adjust the metrics.<|||||>Technically, we could add a `run_seq2seq_text_classification.py` script to the examples folder, similar to how `run_seq2seq_qa.py` is added by #13432.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,526 |
closed
|
ONNXRuntimeError]RUNTIME_EXCEPTION : Non-zero status code returned while running Reshape node.
|
## Environment info
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.5.0.dev0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.7.2
- PyTorch version (GPU?): 1.9.0+cpu (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
## Information
Model I am using (Bert, XLNet ...): gptneo 125M
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
RuntimeException Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_13348/1934748927.py in
66
67 onnx_inputs = _get_inputs(PROMPTS, tokenizer, config)
---> 68 outputs = ort_session.run(['logits'], onnx_inputs)
c:\python37\lib\site-packages\onnxruntime\capi\onnxruntime_inference_collection.py in run(self, output_names, input_feed, run_options)
186 output_names = [output.name for output in self._outputs_meta]
187 try:
--> 188 return self._sess.run(output_names, input_feed, run_options)
189 except C.EPFail as err:
190 if self._enable_fallback:
RuntimeException: [ONNXRuntimeError] : 6 : RUNTIME_EXCEPTION : Non-zero status code returned while running Reshape node. Name:'Reshape_501' Status Message: D:\a_work\1\s\onnxruntime\core\providers\cpu\tensor\reshape_helper.h:42 onnxruntime::ReshapeHelper::ReshapeHelper gsl::narrow_cast<int64_t>(input_shape.Size()) == size was false. The input tensor cannot be reshaped to the requested shape. Input shape:{1,1,1,4096}, requested shape:{1,1,1,16,128}
## To reproduce
Steps to reproduce the behavior:
```
from pathlib import Path
from transformers import GPTNeoForCausalLM, GPT2TokenizerFast, GPTNeoConfig
from transformers.models.gpt_neo import GPTNeoOnnxConfig
from transformers.onnx.convert import export
import numpy as np
import onnxruntime as ort
MODEL_PATH = 'EleutherAI/gpt-neo-1.3B'
#MODEL_PATH = 'EleutherAI/gpt-neo-125M'
TASK = 'causal-lm'
ONNX_MODEL_PATH = Path("gpt_neo_1.3B.onnx")
#ONNX_MODEL_PATH = Path("gpt_neo_125M.onnx")
ONNX_MODEL_PATH.parent.mkdir(exist_ok=True, parents=True)
tokenizer = GPT2TokenizerFast.from_pretrained(MODEL_PATH)
config = GPTNeoConfig.from_pretrained(MODEL_PATH)
onnx_config = GPTNeoOnnxConfig.with_past(config, task=TASK)
print(config)
print(onnx_config)
model = GPTNeoForCausalLM(config=config).from_pretrained(MODEL_PATH)
onnx_inputs, onnx_outputs = export(tokenizer=tokenizer, model=model, config=onnx_config, opset=12, output=ONNX_MODEL_PATH)
print(f'Inputs: {onnx_inputs}')
print(f'Outputs: {onnx_outputs}')
PROMPTS = ['Hello there']
def _get_inputs(prompts, tokenizer, config):
encodings_dict = tokenizer.batch_encode_plus(prompts)
# Shape: [batch_size, seq_length]
input_ids = np.array(encodings_dict["input_ids"], dtype=np.int64)
# Shape: [batch_size, seq_length]
attention_mask = np.array(encodings_dict["attention_mask"], dtype=np.float32)
batch_size, seq_length = input_ids.shape
past_seq_length = 0
num_attention_heads = config.num_attention_heads
hidden_size = config.hidden_size
even_present_state_shape = [
batch_size, num_attention_heads, past_seq_length, hidden_size // num_attention_heads
]
odd_present_state_shape = [batch_size, past_seq_length, hidden_size]
onnx_inputs = {}
for idx in range(config.num_layers):
if idx % 2 == 0:
onnx_inputs[f'past_key_values.{idx}.key'] = np.empty(even_present_state_shape, dtype=np.float32)
onnx_inputs[f'past_key_values.{idx}.value'] = np.empty(even_present_state_shape, dtype=np.float32)
else:
onnx_inputs[f'past_key_values.{idx}.key_value'] = np.empty(odd_present_state_shape, dtype=np.float32)
onnx_inputs['input_ids'] = input_ids
onnx_inputs['attention_mask'] = attention_mask
return onnx_inputs
config = GPTNeoConfig.from_pretrained(MODEL_PATH)
tokenizer = GPT2TokenizerFast.from_pretrained(MODEL_PATH)
ort_session = ort.InferenceSession(str(ONNX_MODEL_PATH))
onnx_inputs = _get_inputs(PROMPTS, tokenizer, config)
outputs = ort_session.run(['logits'], onnx_inputs)
```
## Expected behavior
model exporting and loading without shape mismatch
|
09-11-2021 07:25:43
|
09-11-2021 07:25:43
|
https://github.com/microsoft/onnxruntime/issues/9026<|||||>Hi @BenjaminWegener,
The local attention implementation was [simplified](https://github.com/huggingface/transformers/pull/13491).
You do not have to check for the past_key_values idx value anymore, try changing the loop that creates past_key_values tensors like this:
```
for idx in range(config.num_layers):
onnx_inputs[f'past_key_values.{idx}.key'] = np.empty(even_present_state_shape, dtype=np.float32)
onnx_inputs[f'past_key_values.{idx}.value'] = np.empty(even_present_state_shape, dtype=np.float32)
onnx_inputs['input_ids'] = input_ids
onnx_inputs['attention_mask'] = attention_mask
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,525 |
closed
|
FlaxCLIPModel memory leak due to JAX `jit` function cache
|
## Environment info
- `transformers` version: 4.10.2
- Platform: Linux-5.11.0-7620-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): 2.5.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.3.4 (gpu)
- Jax version: 0.2.17
- JaxLib version: 0.1.68
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
@patil-suraj @patrickvonplaten
## Information
Model I am using: FlaxCLIPModel
The problem arises when using an altered version of the official example. I'm using the outputs of `CLIPProcessor` in a `score` function that outputs how similar the text and image are (basically the same as the official example script). The difference is that I'm `jax.jit`ing the `score` function in a `for` loop and executing it with a different-sized image each time. This causes a memory leak as the previously cached `jit`s are for some reason not being cleared.
Why `jit` the `score` function in a loop? Why not just `jit` once at the start and let JAX automatically re-`jit` based on the input array shape? That unfortunately doesn't fix the issue. That's how I had the code originally, but the memory still grows. I hoped that by completely dropping the reference to the function and then re-`jit`ing it whenever I needed to change to a new image size, it would clear the old `jit` cache. That turns out not to be the case.
Here's the code that reproduces this with some memory logging stripped out for ease of reading. See the Gist/Colab links below for the full code. All I'm doing here is repeatedly re-`jit`ing the `score` function for different image sizes. This results in the script consuming more and more GPU memory until it crashes (after about 6 rounds on my machine). This example code is based on real code where I need to change the size of the images that are passed to `score` every now and then.
```python
import os
os.environ["XLA_PYTHON_CLIENT_PREALLOCATE"] = "false"
os.environ["XLA_PYTHON_CLIENT_ALLOCATOR"] = "platform"
!pip install --upgrade pip
!pip install --upgrade "jax[cuda111]" flax==0.3.4 transformers==4.10.2 Pillow==8.3.2 numpy==1.19.5 ftfy==6.0.3 -f https://storage.googleapis.com/jax-releases/jax_releases.html
import jax
from jax import jit, grad
import jax.numpy as np
from jax.interpreters import xla
import PIL
from PIL import Image
import ftfy
import time
from transformers import CLIPProcessor, FlaxCLIPModel
model = FlaxCLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def score(pixel_values, input_ids, attention_mask):
pixel_values = jax.image.resize(pixel_values, (1, 3, 224, 224), "nearest")
inputs = {"pixel_values":pixel_values, "input_ids":input_ids, "attention_mask":attention_mask}
outputs = model(**inputs)
return outputs.logits_per_image[0][0]
size = 224
image = Image.new('RGB', (size, size), color=(0, 0, 66))
data = processor(text=["blue"], images=[image], return_tensors="jax", padding=True)
pixel_values = data.pixel_values
input_ids = data.input_ids
attention_mask = data.attention_mask
for i in range(100):
print(f"\nROUND #{i}")
# Decrease image size (to bust JAX jit cache):
print("SIZE:", size)
size -= 1
pixel_values = jax.image.resize(pixel_values, (1, 3, size, size), "nearest")
# Clear JAX GPU memory:
jit_score = None
time.sleep(2)
xla._xla_callable.cache_clear()
# JIT score function and execute it:
jit_score = jit(score)
print(jit_score(pixel_values, input_ids, attention_mask))
```
As you can see I've tried using `XLA_PYTHON_CLIENT_ALLOCATOR=platform` as suggested by a JAX dev [here](https://github.com/google/jax/issues/1222). I've also tried `XLA_PYTHON_CLIENT_PREALLOCATE=true` (the default) and the problem remains. I'm also calling `xla._xla_callable.cache_clear()`, but that shouldn't be necessary, as mentioned by another JAX dev [here](https://github.com/google/jax/issues/2072).
## To reproduce
Here's a minimal reproduction with GPU memory logging:
* https://gist.github.com/josephrocca/d0ddd720fd4bf178337fe8d878a559d9
* https://colab.research.google.com/gist/josephrocca/d0ddd720fd4bf178337fe8d878a559d9
As you can see from the logs in the Gist, the memory accumulates/leaks every round. If I use the same `pixel_values` array, then there is no leak (predictably, since there's no re-`jit`).
I thought it might have been a problem with JAX, but I created a minimal example that's analogous to that one (but using a different and very simple `score` function instead of the Flax model) and there's no leak:
* https://gist.github.com/josephrocca/3ac6e48d81b3dc9c67b54e2f5bd2fa70
* https://colab.research.google.com/gist/josephrocca/3ac6e48d81b3dc9c67b54e2f5bd2fa70
Still seems like this might be an upstream problem - but strange that it doesn't occur with the pure JAX example. I don't know enough about the internals of FlaxCLIPModel and Flax to know whether they could be interacting with `jax.jit` in a way that's causing this 🤔
## Expected result
I'd have expected the `jit` compilation cache for a function to be cleared when the reference to that function is dropped. That seems to be the behavior of the minimal non-Flax Colab/Gist that I've linked. If all previously-cached `jit`s are kept in memory forever, then it makes it hard to use this module in non-trivial code.
|
09-11-2021 06:47:13
|
09-11-2021 06:47:13
|
It just occurred to me that perhaps the cache *is* growing in the simplified no-Flax code example, but it's too slow to notice due to the simplicity of the function. I've just ran another test and that does indeed seem to be the case. So this is an upstream (JAX) problem or misunderstanding on my part. Here's the example showing the leak (it "leaks" about 1mb per 100 iterations):
* https://gist.github.com/josephrocca/b56f0cb99b8ac07f15bee467842788f2
* https://colab.research.google.com/gist/josephrocca/b56f0cb99b8ac07f15bee467842788f2
Closing since it doesn't seem to be a problem that's specifically caused by `transformers`.
**Edit:** I've asked how to clear the jit cache for a function in the JAX discussion forum [here](https://github.com/google/jax/discussions/7882).
|
transformers
| 13,524 |
closed
|
Fix GPTNeo onnx export
|
# What does this PR do?
#13491 simplified the GPTNeo's local attention by removing the complicated operations, as a result, the `GPTNeoAttentionMixin` class is no longer needed and was removed. This breaks `GPTNeoOnnxConfig` as it was importing the `GPTNeoAttentionMixin` class.
This PR (tries to!) fixes `GPTNeoOnnxConfig` by removing the `PatchingSpec` and updates the `input`, `output` accordingly.
I'm an onnx noob so it would be awesome if you could please take a deeper look @michaelbenayoun :)
Thanks a lot, @tianleiwu for reporting the bug!
|
09-11-2021 05:38:31
|
09-11-2021 05:38:31
|
@patil-suraj, thanks for providing a quick fix.
For dynamic axes mapping for inputs and outputs, I suggest the following:
```
"input_ids": {0: "batch", 1: "sequence"}
f"past_key_values.{i}.key" = {0: "batch", 2: "past_sequence"}
f"present.{i}.key" : {0: "batch", 2: "present_sequence"} #or {0: "batch", 2: "past_sequence+sequence"}
"attention_mask" : {0: "batch", 1: "present_sequence"} #or {0: "batch", 1: "past_sequence+sequence"}
```
<|||||>I have updated the onnx config input and output names to support dynamic axes as @tianleiwu suggested.
The simplification brought by #13491 along with this PR also solves the issue #13175.
@sgugger @LysandreJik I have left the custom implementations `custom_unfold` and `custom_get_block_length_and_num_blocks` which are no longer needed thanks to #13491: should we keep them there as they might be useful one day for other models or get rid of them to keep things clean?<|||||>I think we can keep those two functions for now. We can look again in a few months and remove them if they are still not used anywhere.
|
transformers
| 13,523 |
closed
|
[tokenizer] use use_auth_token for config
|
This PR forwards `use_auth_token` to `AutoConfig.from_pretrained()` when `AutoTokenizer.from_pretrained(mname, use_auth_token=True)` is used. Otherwise `AutoConfig` fails to retrieve `config.json` with 404.
Model's `from_pretrained` does the right thing.
@sgugger, @LysandreJik
|
09-11-2021 03:48:17
|
09-11-2021 03:48:17
| |
transformers
| 13,522 |
closed
|
The new impl for CONFIG_MAPPING prevents users from adding any custom models
|
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.10+
- Platform: Ubuntu 18.04
- Python version: 3.7.11
- PyTorch version (GPU?): N/A
- Tensorflow version (GPU?): N/A
- Using GPU in script?: N/A
- Using distributed or parallel set-up in script?: No.
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
-->
## Information
Model I am using (Bert, XLNet ...): _Custom_ model
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
See: https://github.com/huggingface/transformers/blob/010965dcde8ce9526f6a7e6e2c3f36276c153708/src/transformers/models/auto/configuration_auto.py#L297
This was changed from the design in version `4.9` which used an `OrderedDict` instead of the new `_LazyConfigMapping`. The current design makes it so users cannot add their own custom models by assigning names and classes to the following registries (example: classification tasks):
- `CONFIG_MAPPING` in `transformers.models.auto.configuration_auto`, and
- `MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING` in `transformers.models.auto.modeling_auto`.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
Either a mechanism to add custom `Config`s (and the corresponding models) with documentation for it, or documentation for whatever other recommended method. Possibly that already exists, but I haven't found it yet.
<!-- A clear and concise description of what you would expect to happen. -->
@sgugger
|
09-11-2021 00:16:44
|
09-11-2021 00:16:44
|
Adding a config/model/tokenizer to those constants wasn't really supported before (but I agree it may have worked in some situations). A mechanism to add a custom model/config/tokenizer is on the roadmap!
Slightly different but which may be of interest, we are also starting to implement support for custom modeling (soon config and tokenizer) files on the Hub in #13467<|||||>Also related to https://github.com/huggingface/transformers/issues/10256#issuecomment-916482519<|||||>@sgugger , is the roadmap shared anywhere publicly? I have searched but could not find it. The reason I'm asking is because we are also interested in adding custom (customized) models.<|||||>No there is no public roadmap, this is internal only because it evolves constantly with the feature requests we receive :-)
Like I said, there should be something available for this pretty soon!<|||||>Related https://github.com/huggingface/transformers/issues/13591<|||||>@sgugger Updating just broke my codebase :)
Any reasons why you cannot allow users to modify the registry? At the end of the day, it's something that will do on their own without affecting the entire library...
Can we please revert this? Because currently the latest version of HF fixes an important [issue](https://github.com/huggingface/transformers/issues/12904).<|||||>@sgugger @LysandreJik any updates on this? Thanks!<|||||>Hello @aleSuglia, @sgugger is working on that API here: https://github.com/huggingface/transformers/pull/13989
It should land in the next few days.
|
transformers
| 13,521 |
closed
|
Ignore `past_key_values` during GPT-Neo inference
|
# What does this PR do?
Applies #8633 to GPT-Neo.
I was getting errors like `RuntimeError: Sizes of tensors must match except in dimension 2. Got 20 and 19 (The offending index is 0)` during the evaluation step of `Trainer.train()` with GPT-Neo.
This was fixed in an internal implementation of `GPTNeoForSequenceClassification` by @manuelciosici before an official version of the class was released for `transformers`. I converted our code to use the `transformers` version of the class and realized the solution should be upstreamed. I'm just mentioning this here because I don't get all the credit for this patch.
This might be needed for other models as well, but I don't know of a good way to figure that out without testing them all.
## Who can review?
trainer: @sgugger
|
09-10-2021 22:14:44
|
09-10-2021 22:14:44
| |
transformers
| 13,520 |
closed
|
[WIP] Wav2vec2 pretraining 2
|
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-10-2021 22:07:06
|
09-10-2021 22:07:06
|
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,519 |
closed
|
CodeT5
|
# 🌟 New model addition
## Model description
<!-- Important information -->
This model is an T5 version by Salesforce trained for coding. Some articles says it should beat openai codex, so it could be interesting to add it to the hub
## Open source status
* [X] the model implementation is available: (give details) https://github.com/salesforce/CodeT5
* [X] the model weights are available: (give details) https://github.com/salesforce/CodeT5
* [ ] who are the authors: (mention them, if possible by @gh-username)
|
09-10-2021 19:31:02
|
09-10-2021 19:31:02
|
https://huggingface.co/Salesforce/codet5-base/tree/main
Thanks @NielsRogge
|
transformers
| 13,518 |
closed
|
updated setup.py
|
checking if python is running with the older version in the system or not
|
09-10-2021 17:37:06
|
09-10-2021 17:37:06
|
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,517 |
closed
|
[Wav2Vec2] Fix dtype 64 bug
|
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Test has to be `is np.dtype(np.float64)` not `is np.float64`
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-10-2021 16:07:16
|
09-10-2021 16:07:16
| |
transformers
| 13,516 |
closed
|
Loading SentenceTransformers (DistilBertModel) model using from_pretrained(...) HF function into a DPRQuestionEncoder model
|
## Environment info
```
- `transformers` version: 4.10.0
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): 2.6.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
```
### Who can help
research_projects/rag: @patrickvonplaten, @lhoestq
## To reproduce
Steps to reproduce the behavior:
_./semanticsearch_model_ is a DistilBertModel created with SentenceTransformers it is structured as follow:

```
from transformers import DPRQuestionEncoder, DPRQuestionEncoderTokenizer
model_name = './semanticsearch_model'
model = DPRQuestionEncoder.from_pretrained(model_name)
```
# Error
```
You are using a model of type distilbert to instantiate a model of type dpr. This is not supported for all configurations of models and can yield errors.
NotImplementedErrorTraceback (most recent call last)
<ipython-input-52-1f1b990b906b> in <module>
----> 1 model = DPRQuestionEncoder.from_pretrained(model_name)
2 # https://github.com/huggingface/transformers/blob/41cd52a768a222a13da0c6aaae877a92fc6c783c/src/transformers/models/dpr/modeling_dpr.py#L520
/opt/conda/lib/python3.8/site-packages/transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
1358 raise
1359 elif from_pt:
-> 1360 model, missing_keys, unexpected_keys, mismatched_keys, error_msgs = cls._load_state_dict_into_model(
1361 model,
1362 state_dict,
/opt/conda/lib/python3.8/site-packages/transformers/modeling_utils.py in _load_state_dict_into_model(cls, model, state_dict, pretrained_model_name_or_path, ignore_mismatched_sizes, _fast_init)
1462 )
1463 for module in unintialized_modules:
-> 1464 model._init_weights(module)
1465
1466 # copy state_dict so _load_from_state_dict can modify it
/opt/conda/lib/python3.8/site-packages/transformers/modeling_utils.py in _init_weights(self, module)
577 Initialize the weights. This method should be overridden by derived class.
578 """
--> 579 raise NotImplementedError(f"Make sure `_init_weigths` is implemented for {self.__class__}")
580
581 def tie_weights(self):
NotImplementedError: Make sure `_init_weigths` is implemented for <class 'transformers.models.dpr.modeling_dpr.DPRQuestionEncoder'>
```
## Another thing
It seems that _from_pretrained_ function is not able to load all the weights (i.e. it ignores the 1_Pooling, 2_Dense folders which contains the last two layers beyond the Transformer model).
## Expected behavior
Load correctly the model.
|
09-10-2021 15:23:16
|
09-10-2021 15:23:16
|
I don't fully understand here. If the model is a `DistilBertModel` - why is it loaded with `DPRQuestionEncoder` ? Shouldn't it be loaded as follows:
```python
from transformers import DistilBertModel
model_name = './semanticsearch_model'
model = DistilBertModel.from_pretrained(model_name)
```
?<|||||>Hi @patrickvonplaten, you're right. My aim was to load a DistilBERT as underlying model of DPRQuestionEncoder (rather than the standard BERT), but maybe this is not the right way.
However, by loading the model as DistilBERT (as in your code) it only loads the transformer (i.e. `pytorch_model.bin` and `config.json` in the root directory) while the pooling and dense layers added by SentenceTransformers are ignored.
The point is, is there a way to load a model created with SentenceTransformer - including pooling and dense layers - into an HuggingFace model?
<|||||>Can you try:
```
from transformers import DistilBertForMaskedLM
model_name = './semanticsearch_model'
model = DistilBertForMaskedLM.from_pretrained(model_name)
```
?
<|||||>> Can you try:
>
> ```
> from transformers import DistilBertForMaskedLM
>
> model_name = './semanticsearch_model'
> model = DistilBertForMaskedLM.from_pretrained(model_name)
> ```
>
> ?
I get
```
Some weights of DistilBertForMaskedLM were not initialized from the model checkpoint at ./semanticsearch_model and are newly initialized: ['vocab_transform.weight', 'vocab_projector.bias', 'vocab_transform.bias', 'vocab_layer_norm.weight', 'vocab_projector.weight', 'vocab_layer_norm.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
Pooling and dense layers are still ignored since as final embedding dimension I get 768 instead of 512 as it should be due to the dense layer.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,515 |
closed
|
beit-flax
|
# What does this PR do?
Beit Flax model
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@NielsRogge @patrickvonplaten
|
09-10-2021 13:58:26
|
09-10-2021 13:58:26
|
Thanks @patrickvonplaten <|||||>Thanks for adding this! I will let Suraj review the Flax code, as I'm not that familiar with it.<|||||>Thanks for the review @patil-suraj
done changes according to review
<|||||>@kamalkraj - could you merge master into this PR or rebase to master ? :-) Think this should solve the pipeline failures<|||||>@patrickvonplaten done
|
transformers
| 13,514 |
closed
|
separate model card git push from the rest
|
# What does this PR do?
- After model card metadata contents validation was deployed to the Hub, we need to ensure transformer's trainer git push are not blocked because of an invalid README.mld yaml.
- as discussed with @julien-c @Pierrci @sgugger and @LysandreJik the first step to match Hub's model card validation system is to avoid failing a whole git push after training, for the only reason that README.md metadata is not valid.
- therefore, I tried in this PR to git push the training result independently from the modelcard update, so that the modelcard update failing does not fail the rest, keeping only logging for README.Md push failures.
- Relates to https://github.com/huggingface/huggingface_hub/pull/326
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
|
09-10-2021 13:54:55
|
09-10-2021 13:54:55
|
For tracking purposes, do we have another issue for `datasets: - null` @elishowk? (which will still fail with this, AFAICT)<|||||>> For tracking purposes, do we have another issue for `datasets: - null` @elishowk? (which will still fail with this, AFAICT)
Yep : https://github.com/huggingface/transformers/issues/13528<|||||>🥳 first PR on transformers, thanks for your help you all !
|
transformers
| 13,513 |
closed
|
TF multiple choice loss fix
|
The `TFMultipleChoiceLoss` inherits from `TFSequenceClassificationLoss` and can get confused when some of the input dimensions (specifically, the number of multiple choices) are not known at compile time. This can cause a compilation failure or other misbehaviour. Ensuring that the `TFMultipleChoiceLoss` never attempts to do regression fixes the problem.
|
09-10-2021 13:04:17
|
09-10-2021 13:04:17
| |
transformers
| 13,512 |
closed
|
[Wav2Vec2] Fix normalization for non-padded tensors
|
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR fixes a problem with normalization when the input is a list of different length that is not numpified - see: https://github.com/huggingface/transformers/issues/13504
Just noticed that this bug is pretty severe actually as it affects all large-Wav2Vec2 fine-tuning :-/.
It was introduced by me in this PR: https://github.com/huggingface/transformers/pull/12804/files - I should have written more and better tests for this.
=> This means that from transformers 4.9.0 to until this PR is merged the normalization for all large Wav2Vec2 models was way off when fine-tuning the model.
@LysandreJik - do you think it might be possible to do a patched release for this?
|
09-10-2021 08:37:43
|
09-10-2021 08:37:43
| |
transformers
| 13,511 |
closed
|
VisionTextDualEncoder
|
# What does this PR do?
This PR adds `VisionTextDualEncoder` model in PyTorch and Flax to be able to load any pre-trained vision (`ViT`, `DeiT`, `BeiT`, CLIP's vision model) and text (`BERT`, `ROBERTA`) model in the library for vision-text tasks like CLIP.
This model pairs a vision and text encoder and adds projection layers to project the embeddings to another embeddings space with similar dimensions. which can then be used to align the two modalities.
The API to load the config and model is similar to the API of `EncoderDecoder` and `VisionEncoderDecoder` models.
- load `vit-bert` model from config
```python3
config_vision = ViTConfig()
config_text = BertConfig()
config = VisionTextDualEncoderConfig.from_vision_text_configs(config_vision, config_text, projection_dim=512)
# Initializing a BERT and ViT model
model = VisionTextDualEncoderModel(config=config)
```
- load using pre-trained vision and text model
```python3
model = VisionTextDualEncoderModel.from_vision_text_pretrained(
"google/vit-base-patch16-224", "bert-base-uncased"
)
```
Since this is a multi-modal model, this PR also adds a generic `VisionTextDualEncoderProcessor`, which wraps any feature extractor and tokenizer
```python3
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
feature_extractor = ViTFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
processor = VisionTextDualEncoderProcessor(feature_extractor, tokenizer)
```
|
09-10-2021 06:06:48
|
09-10-2021 06:06:48
|
Let's merge this asap - it's been on the ToDo-List a bit too long now ;-)
|
transformers
| 13,510 |
closed
|
Huge bug. TF saved model running in nvidia-docker dose not use GPU.
|
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.10
- Platform: Ubutu 18.04
- Python version: 3.6
- PyTorch version (GPU?): latest GPU
- Tensorflow version (GPU?): 2.4 GPU
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
@LysandreJik
@Rocketknight1
@sgugger
## Information
Model I am using official 'nateraw/bert-base-uncased-imdb'.
The problem arises when using:
[*] the official example scripts: https://huggingface.co/blog/tf-serving
## To reproduce
Steps to reproduce the behavior:
Follow [official blog](https://huggingface.co/blog/tf-serving), I save pretrained model to saved model, then running model on tensorflow/serving docker (that is CPU docker) and tensorflow/serving:latest-gpu docker (that is GPU docker), then I testing the inference speed:
1. On CPU docker, cost is 0.19s
2. On GPU docker, cost is 2.9s, 10 times slower than CPU docker inference
3. When inferening with GPU docker, GPU-Util is 0 and only one CPU core is working.
4. I re-test on another machine, got same result.
Tesing machine environment:
#1: GTX 1070
#2: Titan Xp
## Expected behavior
Inference on GPU docker should be much faster than CPU docker.
What's wrong with that?
Have you ever test the offcial blog?
Nobody run saved model with nvidia-docker?
Help me, thx!!!
|
09-10-2021 05:19:52
|
09-10-2021 05:19:52
|
Code to saved model.
```
from transformers import TFBertForSequenceClassification
model = TFBertForSequenceClassification.from_pretrained("nateraw/bert-base-uncased-imdb", from_pt=True)
# the saved_model parameter is a flag to create a SavedModel version of the model in same time than the h5 weights
model.save_pretrained("my_model", saved_model=True)
```<|||||>Code to do inference.
```
from transformers import BertTokenizerFast, BertConfig
import requests
import json
import numpy as np
import time
sentence = "I love the new TensorFlow update in transformers. I love the new TensorFlow update in transformers. I love the new TensorFlow update in transformers. I love the new TensorFlow update in transformers. I love the new TensorFlow update in transformers. I love the new TensorFlow update in transformers. I love the new TensorFlow update in transformers. I love the new TensorFlow update in transformers."
# Load the corresponding tokenizer of our SavedModel
tokenizer = BertTokenizerFast.from_pretrained("nateraw/bert-base-uncased-imdb")
# Load the model config of our SavedModel
config = BertConfig.from_pretrained("nateraw/bert-base-uncased-imdb")
# Tokenize the sentence
batch = tokenizer(sentence)
# Convert the batch into a proper dict
batch = dict(batch)
# Put the example into a list of size 1, that corresponds to the batch size
batch = [batch]
# The REST API needs a JSON that contains the key instances to declare the examples to process
input_data = {"instances": batch}
t1 = time.time()
# Query the REST API, the path corresponds to http://host:port/model_version/models_root_folder/model_name:method
r = requests.post("http://localhost:8502/v1/models/bert:predict", data=json.dumps(input_data))
print(time.time() - t1)
# Parse the JSON result. The results are contained in a list with a root key called "predictions"
# and as there is only one example, takes the first element of the list
result = json.loads(r.text)["predictions"][0]
# The returned results are probabilities, that can be positive or negative hence we take their absolute value
abs_scores = np.abs(result)
# Take the argmax that correspond to the index of the max probability.
label_id = np.argmax(abs_scores)
# Print the proper LABEL with its index
print(config.id2label[label_id])
```<|||||>Run cpu docker:
`sudo docker run -d -p 8502:8501 --name bert_cpu image_hug_off_cpu`
Run gpu docker:
`sudo docker run -d --gpus '"device=0"' -p 8502:8501 --name bert image_hug_off`<|||||>Hello! Do you manage to leverage your GPUs using other TensorFlow code than our models? I suspect there is an issue in the setup - we do run some GPU tests so the models should work without issue on GPUs. <|||||>Everything is OK when code runs without signatures, after add signatures, it gets sucked.<|||||>cc @Rocketknight1 <|||||>I'm not sure I understand - can you show an example of a model that runs correctly with the GPU and a model that does not, so we can figure out what the problem is?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,509 |
closed
|
Warn for unexpected argument combinations
|
# What does this PR do?
Warn for unexpected argument combinations:
- `padding is True` and ``max_length is not None``
- `padding is True` and ``pad_to_max_length is not False``
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- https://discuss.huggingface.co/t/migration-guide-from-v2-x-to-v3-x-for-the-tokenizer-api/55
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-10-2021 04:02:34
|
09-10-2021 04:02:34
|
@sgugger
Could you review this PR?
Thank you.
|
transformers
| 13,508 |
closed
|
[megatron_gpt2] checkpoint v3
|
The BigScience generates Megatron-Deepspeed checkpoints en masse, so we need a better v3 checkpoint support for megatron_gpt2 (also working on a direct Megatron-Deepspeed to HF-style script).
This PR:
- removes the requirement that the source checkpoint is a zip file. Most of the checkpoints aren't .zip files, so supporting both.
- removes the need to manually feed the config, when all the needed data is already in the checkpoint. (while supporting the old format)
- disables a debug print that repeats for each layer
- switch to default `gelu` from `gelu_new` - which is what the current megatron-lm uses
- fixes a bug in the previous version. The hidden size is dimension 1 as it can be seen from:
https://github.com/NVIDIA/Megatron-LM/blob/3860e995269df61d234ed910d4756e104e1ab844/megatron/model/language_model.py#L140-L141
The previous script happened to work because `max_position_embeddings` happened to be equal to `hidden_size`
@LysandreJik, @sgugger
|
09-10-2021 03:42:22
|
09-10-2021 03:42:22
| |
transformers
| 13,507 |
closed
|
[Benchmark]Why 'step' consume most time?
|
# 🖥 Benchmarking `transformers`
## Benchmark
I have test "**transformers/examples/pytorch/language-modeling/run_clm.py**" for "**bert-large-uncased**" with "**Deepspeed**"
but found something weird.
## Set-up
device: 4 x V100(16GB), single node
script cmd is:
```shell
#!/bin/bash
deepspeed run_mlm.py \
--deepspeed ds_config.json \
--model_type bert \
--config_name bert-large-uncased \
--output_dir output/ \
--dataset_name wikipedia \
--dataset_config_name 20200501.en \
--tokenizer_name bert-large-uncased \
--preprocessing_num_workers $(nproc) \
--max_seq_length 128 \
--do_train \
--fp16 true \
--overwrite_output_dir true \
--per_device_train_batch_size 32
```
and the ds_config.json is:
```shell
{
"train_micro_batch_size_per_gpu": "auto",
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"flops_profiler": {
"enabled": true,
"profile_step": 3,
"module_depth": -1,
"top_modules": 1,
"detailed": true,
"output_file": "./tmp.log"
},
"zero_optimization": {
"stage": 1,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"overlap_comm": true,
"contiguous_gradients": true,
"cpu_offload": true
}
}
```
## Results
huggingface with deepspeed:
compare to native deepspeed example "bing_bert" with same deepspeed config:
I found that native deepspeed "step" cost little time.
## question
1.why huggingface step cost most time?
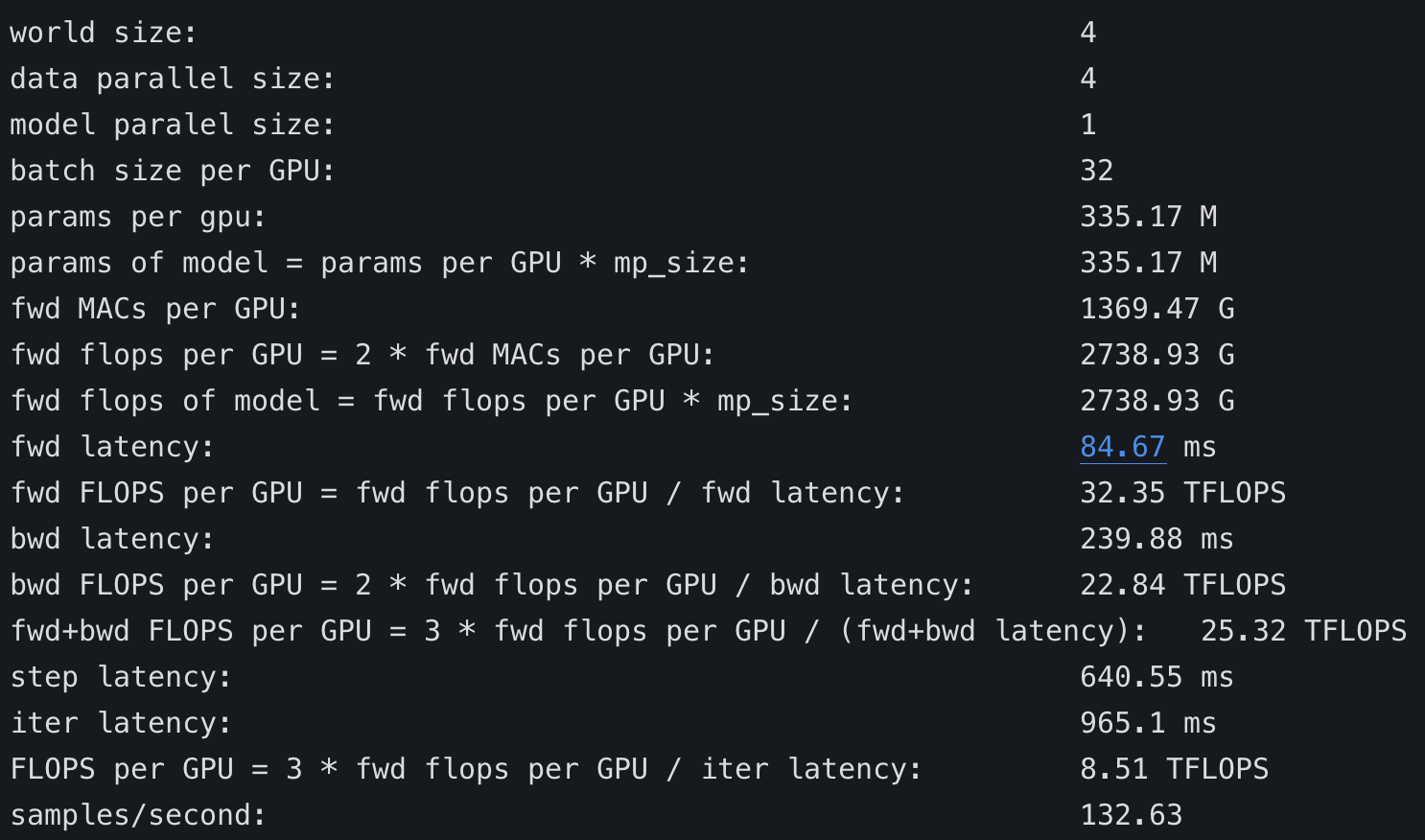
2.why huggingface and deepspeed are very difference in "fwd flops per GPU" ? model are all "bert-large"
|
09-10-2021 03:02:58
|
09-10-2021 03:02:58
|
Thank you for the report, @dancingpipi.
I have a hard time making sense of it since you shared how your invoked the transformers side but not the other example. or how you measured the performance reports you shared. But I think we have enough in the numbers you shared to unravel your puzzlement.
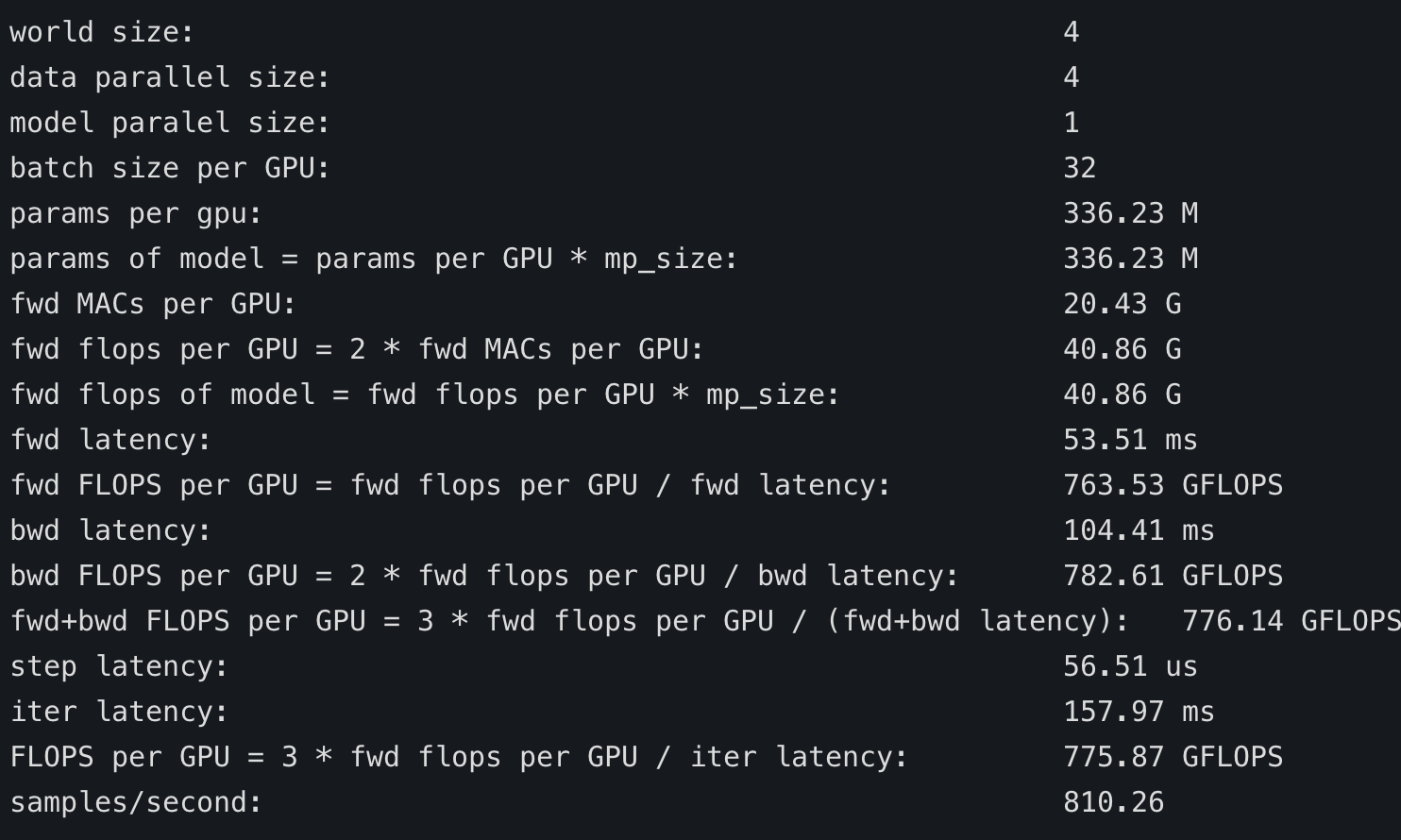
If you look at fwd MACs (“multiply and accumulate” units) the transformers table says 1369, whereas the other example say 20, so clearly you have a ~70x difference in the amount of computation being run. And of course the performance would have a huge difference.
I suppose you're referring to this: https://github.com/microsoft/DeepSpeedExamples/tree/master/bing_bert as the other, and if you read the description it says:
> Using DeepSpeed's optimized transformer kernels as the building block, we were able to achieve the fastest BERT training record: 44 minutes on 1,024 NVIDIA V100 GPUs, compared with the previous best published result of 67 minutes on the same number and generation of GPUs.
So I hope that the "DeepSpeed's optimized transformer kernels" part answers your question.
It's also hard to tell whether the 2 comparisons are measuring the same thing, but if they don't - CUDA kernels outperform python kernels by many times.
We are intending to look at how to gain more benefits from DeepSpeed's gifts, in particular the various kernels, we just don't have enough resources to do so fast enough. If you have the time and inspiration to write a PR that integrates such kernels into the current Bert model I'd dare to say it'd be very welcome.
BTW, pytorch core too has optimized transformers kernels that would be great to evaluate as well.
<|||||>@stas00 thanks for your great answer!
I'm still not clearly understand why MACs are very difference between them. Is it just because of "optimized transformer kernels"? 70 times improvement is a bit unbelievable.
Another weird thing is "step" cost much time in huggingface. This is beyond my cognition.
So the current situation is that the performance of native deepspeed on bert-large is better than the performance of huggingface.
Is there any suggestions on using huggingface with deepspeed?<|||||>> @stas00 thanks for your great answer!
> I'm still not clearly understand why MACs are very difference between them. Is it just because of "optimized transformer kernels"? 70 times improvement is a bit unbelievable.
I agree. That's why I'm suspicious of your reported numbers as 2 orders of magnitude is too fantastic to believe.
> Another weird thing is "step" cost much time in huggingface. This is beyond my cognition.
`step` is comprised of those MACs, so if your setup is not comparing apples to apples then obviously the speed difference would be out of proportion as well.
> So the current situation is that the performance of native deepspeed on bert-large is better than the performance of huggingface.
I haven't tested this myself, but it's almost certainly the case if one uses custom CUDA kernels vs. vanila implementation.
> Is there any suggestions on using huggingface with deepspeed?
Deepspeed is a framework/toolkit with many tools and features in it. HF transformers has currently only integrated Deepspeed's ZeRO features, which allow you to easily scale any huge model with multiple gpus and some CPU/NVMe memory and minimal to no changes to the model's code base.
Plugging Deepspeed's custom kernels has been briefly discussed as a great feature to add, but currently no one had the time to integrate it. If you have the know-how you are very welcome to spearhead the effort. I'd reach out then to the Deepspeed team via their Issues and ask whether they can help you integrate the custom cuda kernels into HF transformers. It's possible that they have already done it but the work isn't public yet. The other approach is to perhaps opening this request to the community at large and perhaps someone would be interested to work on that.
<|||||>ok, I see. Maybe I have to make a trade-off between performance and ease of use. But the first thing I want to do now is to find out why the MACs is so different.
@stas00 Thanks again for your help~<|||||>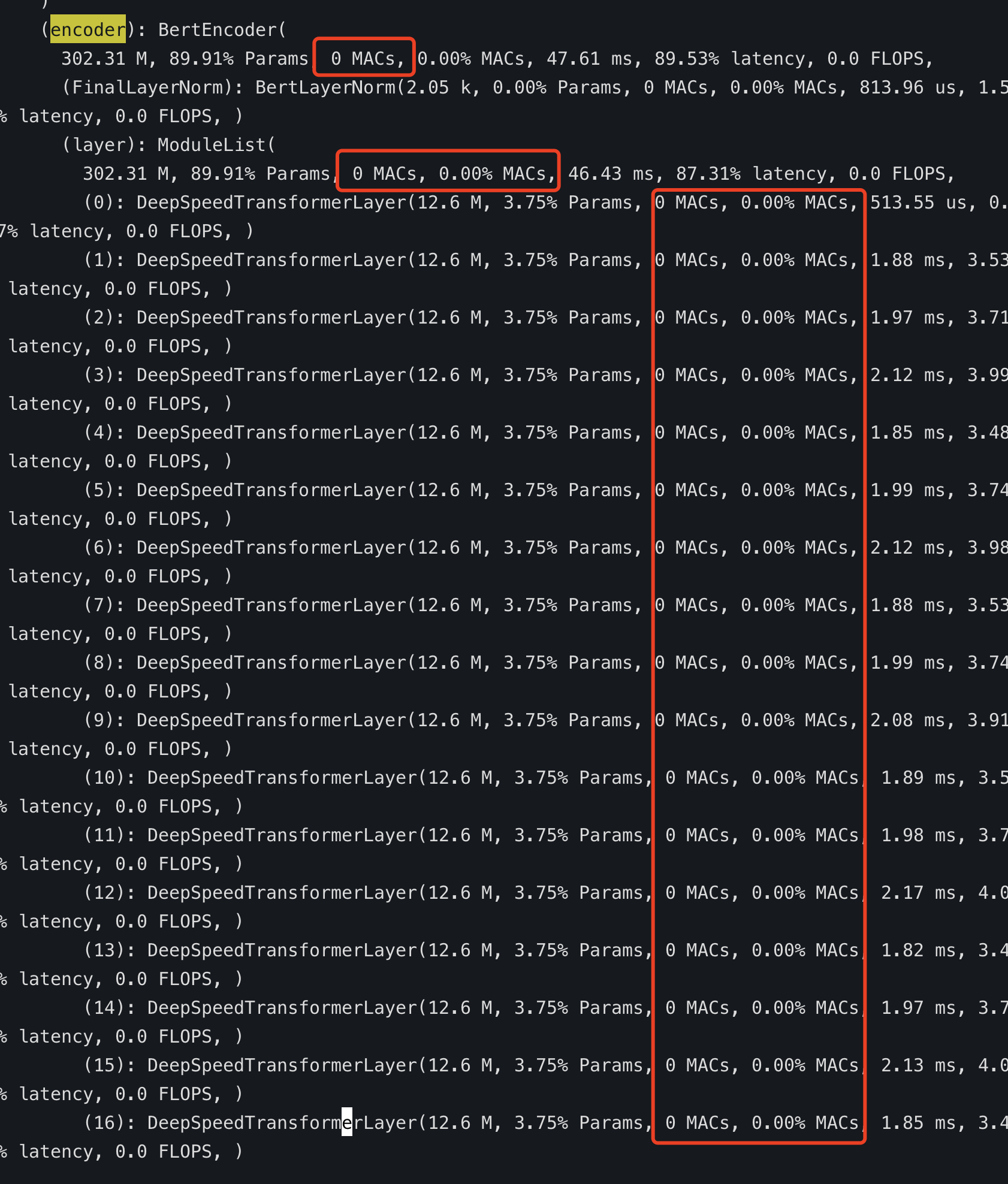
@stas00 I seem to have found the reason for the big difference in MACs, picture above is profile of "https://github.com/microsoft/DeepSpeedExamples/tree/master/bing_bert", the MACs is all zero.
While turn-off "**deepspeed_transformer_kernel**", result looks like correct:
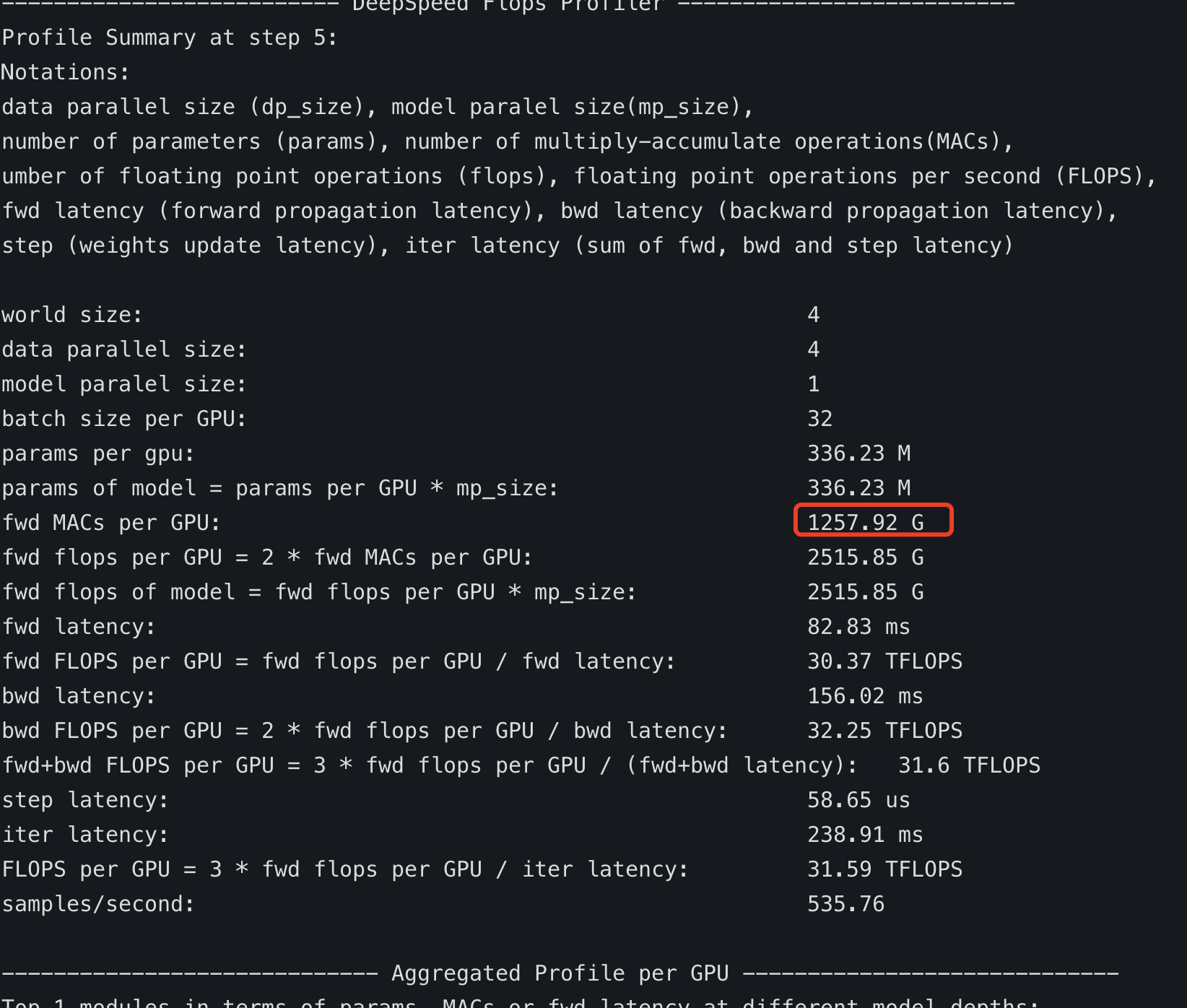
This is close to HF deepspeed's MACs.
But native deepspeed's(**without deepspeed_transformer_kernel**) "**step latency**" only cost "**58.65 us**" while HF deepspeed's cost "**96.47 ms**":
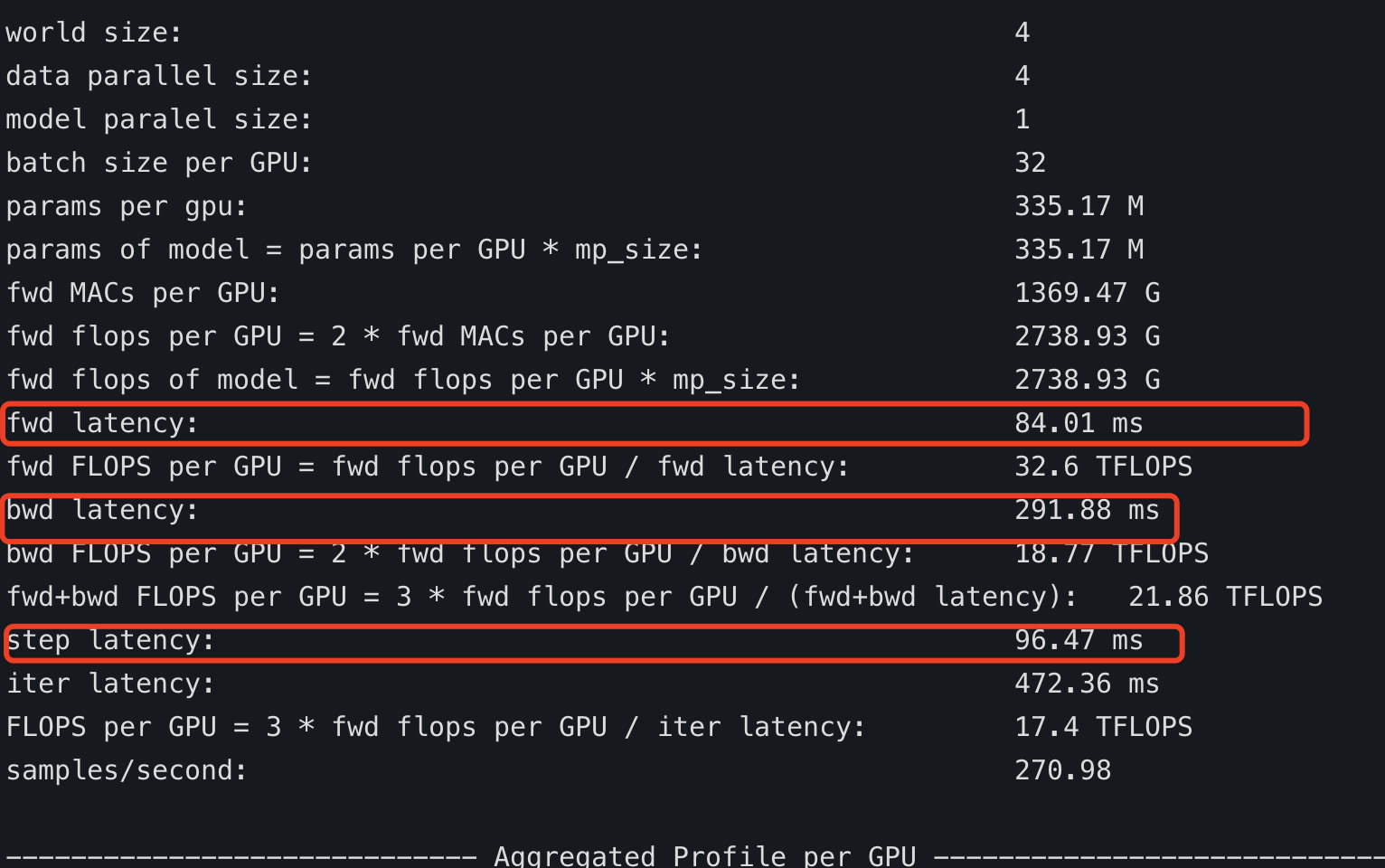
Now problem is:
1. HF deepspeed's "backward latency" is almost twice as much as native deepspeed.
2. HF deepspeed's "step latency" cost too much time.
<|||||>I still have no idea where you get your reports from. Perhaps the first step is for you to help us reproduce your reports.<|||||>what I have compared is **https://github.com/microsoft/DeepSpeedExamples/tree/master/bing_bert** and **https://github.com/huggingface/transformers/blob/master/examples/pytorch/language-modeling/run_mlm.py**
To "**bing_bert**", the **launch script** is:
```shell
#!/bin/bash
base_dir=`pwd`
JOB_NAME=lamb_nvidia_data_64k_seq128
OUTPUT_DIR=${base_dir}/bert_model_nvidia_data_outputs
mkdir -p $OUTPUT_DIR
NCCL_TREE_THRESHOLD=0 deepspeed ${base_dir}/deepspeed_train.py \
--cf ${base_dir}/bert_large_lamb_nvidia_data.json \
--max_seq_length 128 \
--output_dir $OUTPUT_DIR \
--deepspeed \
--print_steps 100 \
--lr_schedule "EE" \
--lr_offset 10e-4 \
--job_name $JOB_NAME \
--deepspeed_config ${base_dir}/deepspeed_bsz64k_lamb_config_seq128.json \
--data_path_prefix ${base_dir} \
--use_nvidia_dataset
```
and "**deepspeed_bsz64k_lamb_config_seq128**.json" is :
```json
{
"train_batch_size": 128,
"train_micro_batch_size_per_gpu": 32,
"steps_per_print": 100,
"prescale_gradients": false,
"optimizer": {
"type": "Adam",
"params": {
"lr": 6e-3,
"betas": [
0.9,
0.99
],
"eps": 1e-8,
"weight_decay": 0.01
}
},
"flops_profiler": {
"enabled": true,
"profile_step": 5,
"module_depth": -1,
"top_modules": 1,
"detailed": true,
"output_file": "./tmp.log"
},
"zero_optimization": {
"stage": 1,
"overlap_comm": true,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients": true,
"grad_hooks": true,
"round_robin_gradients": false
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 1e-8,
"warmup_max_lr": 6e-3
}
},
"gradient_clipping": 1.0,
"wall_clock_breakdown": false,
"fp16": {
"enabled": true,
"loss_scale": 0
},
"sparse_attention": {
"mode": "fixed",
"block": 16,
"different_layout_per_head": true,
"num_local_blocks": 4,
"num_global_blocks": 1,
"attention": "bidirectional",
"horizontal_global_attention": false,
"num_different_global_patterns": 4
}
}
```
To huggingface "run_mlm.py", the **launch script** is:
```shell
#!/bin/bash
deepspeed \
run_mlm.py \
--deepspeed ds_config.json \
--model_type bert \
--config_name bert-large-uncased \
--output_dir output/ \
--dataset_name wikipedia \
--dataset_config_name 20200501.en \
--tokenizer_name bert-large-uncased \
--preprocessing_num_workers $(nproc) \
--max_seq_length 128 \
--do_train \
--fp16 true \
--overwrite_output_dir true \
--gradient_accumulation_steps 32 \
--per_device_train_batch_size 32
```
the **ds_config.json** is :
```json
{
"train_micro_batch_size_per_gpu": "auto",
"fp16": {
"enabled": true,
"loss_scale": 0
},
"flops_profiler": {
"enabled": true,
"profile_step": 30,
"module_depth": -1,
"top_modules": 1,
"detailed": true,
"output_file": "./tmp.log"
},
"zero_optimization": {
"stage": 3,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"overlap_comm": true,
"contiguous_gradients": true,
"grad_hooks": true,
"round_robin_gradients": false
},
"gradient_clipping": 1.0,
"wall_clock_breakdown": false,
"sparse_attention": {
"mode": "fixed",
"block": 16,
"different_layout_per_head": true,
"num_local_blocks": 4,
"num_global_blocks": 1,
"attention": "bidirectional",
"horizontal_global_attention": false,
"num_different_global_patterns": 4
}
}
```
My GPU is 4 x V100(16GB).
@stas00 I am pleased to provide all the information that helps to reproduce this problem<|||||>That's much better. Thank you for the explicit config sharing, @dancingpipi
Well, let's do the "what's different in the 2 pictures" exercise:
1. you're comparing zero1 in ds to zero3 in hf - that would be quite a difference. z1 would be much faster than z3. What happens if you use the same zero stages?
2. you are using a huge `--gradient_accumulation_steps 32` in hf and none in ds - perhaps that's a huge chunk of the 70x factor?
Perhaps I missed other differences, probably re-ordering the configs' content to match will make things easier to diff.
<|||||>@stas00 thanks for your reply, maybe I made some mistake, I'll do a check<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,506 |
closed
|
Error in code
|
hello,
https://github.com/huggingface/transformers/blob/master/examples/pytorch/summarization/run_summarization_no_trainer.py
in Line 87, the description is wrong. It should be
> Finetune a transformers model on a summarization task
Please correct it.
|
09-10-2021 02:40:06
|
09-10-2021 02:40:06
|
Hello,
Thanks for spotting this! Could you open a PR to fix this? Thanks!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,505 |
closed
|
Insufficient memory occurs during finetune
|
# 📚 Migration
## Information
<!-- Important information -->
Model I am using (Bert,bert-base-chinese):
Language I am using the model on (Chinese ...):
The problem arises when using:
* [x] the official example scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## Details
* Here is my bash
```
export CUDA_VISIBLE_DEVICES=1,2
python run_mlm.py \
--model_name_or_path bert-base-chinese \
--train_file /home/xjyu/zhh/workspace/one-stop-ocr/char2char.allchars/quantize-train/data/scripts/wiki-part/wiki-part.split.nosign.txt \
--validation_file /home/xjyu/zhh/workspace/one-stop-ocr/char2char.allchars/quantize-train/data/scripts/wiki-part/test.txt \
--do_train \
--do_eval \
--output_dir ./test-mlm \
--line_by_line \
```
When I performed finetune on bert->`run_mlm.py`, it took about 0.6 epoch,the output_dir file "test-mlm" took up 91G RAM,I am really surprised. It stands to reason that the output file cannot be so big,But i don't know where the problem is.
* here is my machine
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.64 Driver Version: 440.64 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 108... Off | 00000000:02:00.0 Off | N/A |
| 0% 32C P8 9W / 250W | 0MiB / 11178MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX 108... Off | 00000000:03:00.0 Off | N/A |
| 0% 28C P8 9W / 250W | 0MiB / 11178MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce GTX 108... Off | 00000000:83:00.0 Off | N/A |
| 77% 80C P2 73W / 250W | 4865MiB / 11177MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 GeForce GTX 108... Off | 00000000:84:00.0 Off | N/A |
| 0% 65C P2 68W / 250W | 5574MiB / 11178MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
<!-- A clear and concise description of the migration issue.
If you have code snippets, please provide it here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
-->
## Environment info
<!-- You can run the command `python transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
<!-- IMPORTANT: which version of the former library do you use? -->
* `pytorch-transformers` or `pytorch-pretrained-bert` version (or branch):
## Checklist
- [x] I have read the migration guide in the readme.
([pytorch-transformers](https://github.com/huggingface/transformers#migrating-from-pytorch-transformers-to-transformers);
[pytorch-pretrained-bert](https://github.com/huggingface/transformers#migrating-from-pytorch-pretrained-bert-to-transformers))
- [x] I checked if a related official extension example runs on my machine.
@sgugger
|
09-10-2021 01:42:30
|
09-10-2021 01:42:30
|
The environment is the same as yours<|||||>Please use the [forums](https://discuss.huggingface.co/) for those kinds of questions. You should limit the number of saves of the checkpoints by using the argument `--save_total_limit` for instance, if the defaults get you out of disk memory.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,504 |
closed
|
Wav2vec2Processor normalization issues on transformers 4.10.0
|
When fine-tuning `facebook/wav2vec2-large-robust-ft-swbd-300h` I noticed I couldn't reproduce past training results from transformers version 4.9.2 now on 4.10. I noticed that inputs are not being correctly normalized with zero mean and unit variance in this new version. This seems to happen when `return_attention_mask=True`, audios in a batch input have different lengths and no padding is done.
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.10.0
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyTorch version (GPU?): 1.8.1+cu102 (True)
- Tensorflow version (GPU?): 2.6.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@patrickvonplaten
@sgugger
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): Wav2Vec 2.0
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Load Wav2Vec2Processor from `facebook/wav2vec2-large-robust-ft-swbd-300h`
2. Call processor with batched inputs of individual different lengths
Sample code to replicate the error:
```
import numpy as np
from transformers import Wav2Vec2Processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-robust-ft-swbd-300h")
sample_rate = 16000
length_1 = 10
length_2 = 20
# Generate dummy input audios of same sample rate but different lengths
input_1 = np.random.rand((sample_rate * length_1))
input_2 = np.random.rand((sample_rate * length_1))
input_3 = np.random.rand((sample_rate * length_2))
same_length_result = processor([input_1, input_2], sampling_rate=sample_rate)
different_length_result = processor([input_1, input_3], sampling_rate=sample_rate)
# Show normalized batched audios when using same length
print(same_length_result)
# Show normalized batched audios when using different length
print(different_length_result)
# Check same audio suffers different transformations according to length of audios in batch
np.testing.assert_array_equal(same_length_result["input_values"][0], different_length_result["input_values"][0])
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
A successful assert. Both processed inputs should be equal, with a mean close to 0 and a standard deviation close to 1.
<!-- A clear and concise description of what you would expect to happen. -->
|
09-09-2021 21:58:59
|
09-09-2021 21:58:59
|
Hey @dmurillo976s,
Thanks a lot for the very well explained issue! I can reproduce the problem. I'll open a PR to fix it today<|||||>@dmurillo976s - this PR: https://github.com/huggingface/transformers/pull/13512 should fix the problem. Could you give it a try? :-)<|||||>Hi @patrickvonplaten,
Thank you so very much! Sorry for not responding earlier. I've tried the latest patch release version and everything works as it should!
|
transformers
| 13,503 |
closed
|
Push to hub when saving checkpoints
|
# What does this PR do?
This PR enables automatic checkpointing on the Hub by introducing a new training argument called `hub_strategy`. This argument can take several values:
- `"end"`: push the model, its configuration, the tokenizer (if passed along to the `Trainer`) and a draft of a model card at the end of training.
- `"every_save"`: push the model, its configuration, the tokenizer (if passed along to the`Trainer`) and a draft of a model card each time there is a model save. The pushes are asynchronous to not block training, and in case the save are very frequent, a new push is only attempted if the previous one is finished. A last push is made with the final model at the end of training.
- `"checkpoint"`: like `"every_save"` but the latest checkpoint is also pushed in a subfolder named last-checkpoint, allowing a user to resume training easily with `trainer.train(resume_from_checkpoint="last-checkpoint")`. The final repository won't have that checkpoint folder, but you can find it in the second-to-last commit.
- `"all_checkpoints"`: like `"checkpoint"` but all checkpoints are pushed like they appear in the output folder (so you will get one checkpoint folder per checkpoint in your final repository)
The default value is `"every_save"`, which slightly changes the behavior when a user passes along `--push_to_hub`.
This PR relies on [this PR](https://github.com/huggingface/huggingface_hub/pull/315) on the huggingface_hub part, so checking out that branch is necessary for testing it. Tests won't pass before a new release of huggingface_hub with this PR is out.
cc @julien-c
|
09-09-2021 19:48:05
|
09-09-2021 19:48:05
| |
transformers
| 13,502 |
closed
|
examples: minor fixes in flax example readme
|
Hi,
this PR introduces some minor fixes in the FLAX LM doc.
It mainly prevents an:
```
In [6]: tokenizer.save("./")
---------------------------------------------------------------------------
Exception Traceback (most recent call last)
<ipython-input-6-7d2c76b50951> in <module>
----> 1 tokenizer.save("./")
~/dev/lib/python3.8/site-packages/tokenizers/implementations/base_tokenizer.py in save(self, path, pretty)
334 A path to the destination Tokenizer file
335 """
--> 336 return self._tokenizer.save(path, pretty)
337
338 def to_str(self, pretty: bool = False):
Exception: Is a directory (os error 21)
```
error, because `.save()` function of the `ByteLevelBPETokenizer` instance expects a file name.
|
09-09-2021 19:44:02
|
09-09-2021 19:44:02
| |
transformers
| 13,501 |
closed
|
Add long overdue link to the Google TRC project
|
TRC gives people free TPU compute.
(I don't know if people land on this README, maybe there's a better place in the main docs to put it?)
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
cc @patil-suraj @patrickvonplaten
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-09-2021 16:50:27
|
09-09-2021 16:50:27
|
Thanks, Avital! This is the main readme for flax examples, so yeah users do refer to this.
|
transformers
| 13,500 |
closed
|
Loading mt5-xxl rasies error related to Pytorch/TF incompatiblity
|
## Environment info
- `transformers` version: 4.10.0
- Platform: Linux-3.10.0-1160.36.2.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.9.1
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes
### Who can help
Model hub: @patrickvonplaten
## Information
Model I am using: mt5-xxl
The problem arises when using:
* [x] the official example scripts: examples/pytorch/translation/run_translation.py
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: example translation task given in the documentation
* [ ] my own task or dataset:
## To reproduce
Steps to reproduce the behavior.
I am using deepspeed to load the model into memory.
```
deepspeed transformers/examples/pytorch/translation/run_translation.py \
--do_train --model_name_or_path google/mt5-xxl \
--source_lang en --target_lang ro \
--dataset_name wmt16 --dataset_config_name ro-en \
--output_dir exp/33-a --per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 --overwrite_output_dir --deepspeed ds_config.json
```
ds_config.json
```
{
"train_batch_size": "auto",
"zero_optimization": {
"stage": 3,
"stage3_max_live_parameters": 1e9
}
}
```
## Expected behavior
The model should be trained, but I get the following error:
```
OSError: Unable to load weights from pytorch checkpoint file for 'google/mt5-xxl' at '/net/people/plgapohl/.cache/huggingface/transformers/b36655ddd18a5fda6384477b693eb51ddc8d5bfd2e9a91ed202317f660041716.c24311abc84f0f3a6095195722be4735840971f245dfb6ea3a407c9bed537390'If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True.
```
~Changing 342 line in `run_translation.py` to `=True` fixes the problem.~
~I believe the model on the hub named pythorch_model.bin is in fact a TF model.~
|
09-09-2021 14:26:49
|
09-09-2021 14:26:49
|
I have to correct the findings at the end - changing `=True` doesn't fix the problem.<|||||>To clarify a bit - I ran the same command with `mt5-xl` and it works like a charm. I ran the script on 8 V100 GPUs.<|||||>Probably this is related to the model size, not anything specific to the file with the weights.
On the second try, the error was different, the process was just killed. And the memory (CPU) was full.<|||||>Hey @apohllo,
I think the problem is that you don't have enough CPU RAM to instantiate the model. `mt5-xxl` requires around 95 GB of RAM to be loaded into memory currently. We are working on an improved loading implementation for large files though that should reduce this number to something much closer to the model file size (48GB) - see: https://github.com/huggingface/transformers/issues/13548<|||||>Yes, I can confirm this is a CPU RAM related issue. I managed to load `t5-xxl` on single V100 GPU 32GB VRAM with 70GB CPU RAM, and the same model on two V100 GPU 32GB VRAM with more than 200GB CPU RAM (according to the command which tracks the maximum memory consumption). In that scenario I switched to ZeRO 2 instead of ZeRO 3.
We can close the issue.
Maybe tagging it with model parallel and deepspeed would improve the issue discoverability?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,499 |
closed
|
Torch size missmatch in GPT-J model (Error)
|
## Environment info
- `transformers` version: 4.11.0.dev0
- Platform: Linux-4.19.0-10-cloud-amd64-x86_64-with-debian-10.5
- Python version: 3.7.8
- PyTorch version (GPU?): 1.7.1+cu110 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
@patrickvonplaten, @LysandreJik, @patil-suraj
## Information
I trained/fine-tuned the GPT-J model (model here: https://huggingface.co/EleutherAI/gpt-j-6B), fp16 like in this one suggestion (https://github.com/huggingface/transformers/issues/13329) and now when I try to use the pipeline to load the model (as shown below) I got torch dimensions error (shown below as well). What solutions can be applied there?
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
2021-09-09 13:23:45.897519: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
>>> model = AutoModelForCausalLM.from_pretrained("GPT-J/checkpoint-20000")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/conda/lib/python3.7/site-packages/transformers/models/auto/auto_factory.py", line 388, in from_pretrained
return model_class.from_pretrained(pretrained_model_name_or_path, *model_args, config=config, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/modeling_utils.py", line 1376, in from_pretrained
_fast_init=_fast_init,
File "/opt/conda/lib/python3.7/site-packages/transformers/modeling_utils.py", line 1523, in _load_state_dict_into_model
raise RuntimeError(f"Error(s) in loading state_dict for {model.__class__.__name__}:\n\t{error_msg}")
RuntimeError: Error(s) in loading state_dict for GPTJForCausalLM:
size mismatch for lm_head.weight: copying a param with shape torch.Size([50400, 4096]) from checkpoint, the shape in current model is torch.Size([50257, 4096]).
size mismatch for lm_head.bias: copying a param with shape torch.Size([50400]) from checkpoint, the shape in current model is torch.Size([50257]).
Any ideas on how to solve it?
|
09-09-2021 13:31:21
|
09-09-2021 13:31:21
|
Hey @MantasLukauskas - could you please provide a reproducible code snippet? :-)<|||||>Hey @patrickvonplaten,
**Fine-tuning was made in this one:**
deepspeed --num_gpus 2 run_clm.py --model_name_or_path EleutherAI/gpt-j-6B --num_train_epochs 10 --per_device_train_batch_size 2 --per_device_eval_batch_size 8 --train_file train.txt --validation_file test.txt --do_train --do_eval --output_dir GPT-J --save_steps 5000 --block_size=512 --evaluation_strategy "epoch" --logging_steps 200 --logging_dir GPT-J/runs --model_revision float16 --fp16 --deepspeed zero3.json
You can use save steps 10 for faster saving :)
After that, I try to load my model like in doc just use my model instead of EleutherAI/gpt-j-6B. Interesting that if I use pretrained Eleuther model everything works, but when I use my fine-tuned model with run_clm.py error occurs. Maybe that will help you to solve it or just have an idea of what is wrong there?
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6B")
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
>>> prompt = "In a shocking finding, scientists discovered a herd of unicorns living in a remote, " \
... "previously unexplored valley, in the Andes Mountains. Even more surprising to the " \
... "researchers was the fact that the unicorns spoke perfect English."
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(input_ids, do_sample=True, temperature=0.9, max_length=100,)
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
<|||||>related #13581<|||||>Should be fixed by https://github.com/huggingface/transformers/pull/13617#issuecomment-925055515
|
transformers
| 13,498 |
closed
|
Fix obj det image size
|
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
In object detection pipeline, changed order of 2 operations.
This PR gets input image size **before** the image goes through feature_extractor (`self.feature_extractor(images=images,`) so that obj detection piepleine output can be in the original width & height.
Otherwise, `feature_extractor` [resizes the image in-place](https://github.com/huggingface/transformers/blob/master/src/transformers/models/detr/feature_extraction_detr.py#L134-L143) and was causing object detection pipeline output to be in resized width & height, not the original width & height.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
cc: @NielsRogge @Narsil
|
09-09-2021 13:24:42
|
09-09-2021 13:24:42
|
Superseded by https://github.com/huggingface/transformers/pull/13308/commits/b04d5d34b6c38e35a2fb6a2d3aec31861c300d96
|
transformers
| 13,497 |
closed
|
early_stopping_patience_counter increasing + 2 per epoch in distributed mode
|
## Environment info
- `transformers` version: 4.4.0
- Platform: Linux-5.4.0-1047-azure-x86_64-with-glibc2.27
- Python version: 3.8.0
- PyTorch version (GPU?): 1.7.1+cu101 (True)
- Tensorflow version (GPU?): 2.2.1 (True)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes
### Who can help
- trainer: @sgugger
## Information
Model I am using (Bert, XLNet ...): LayoutLMForTokenClassification
The problem arises when using:
* [ ] my own modified scripts
I am training a LayoutLmForTokenClassification model in distributed mode, and added logging for the EarlyStoppingCallback.early_stopping_patience_counter to gain more insights. I noticed that the count augments with 2 at each epoch, instead of with one (it is called on_epoch_end), I guess from each parallel computation?
## To reproduce
Steps to reproduce the behavior:
1. Train LayoutLMForTokenClassification with trainer class with evaluation_strategy=IntervalStrategy.EPOCH and using EarlyStoppingCallback
## Expected behavior
increase of patience counter + 1 at each epoch
|
09-09-2021 13:14:24
|
09-09-2021 13:14:24
|
In distributed training, each process will have their own `EarlyStoppingCallback` that are independent and incremented separately, so that's not the issue here.
I tested locally and I see it increases one by one normally even in distributed training.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,496 |
closed
|
MarianMT int dtype fix
|
Found the same integer dtype issue in MarianMT as in T5 - I'll probably need to find a proper way of dealing with this across the codebase at some point, but this'll do to get the notebook examples working at least.
|
09-09-2021 12:48:23
|
09-09-2021 12:48:23
|
Update: I found multiple Seq2Seq models were copying the problematic `shift_tokens_right` method from BART, so I fixed the BART method and ran `make fix-copies`. That should hopefully fix this issue for a lot of our models.
|
transformers
| 13,495 |
closed
|
Correct order of overflowing tokens for LayoutLmV2 tokenizer
|
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR objective is same as #13179
Fixes #13148
The issue was resolved for every tokenizer except the LayoutLmV2 tokenizer.
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section? Yes 👍🏻.
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Yes👍🏻 , #13148
- [x] Did you make sure to update the documentation with your changes? Yes 👍🏻.
- [x] Did you add any necessary tests?
The following test have been added which check the sequence of **`overflowing tokens`**, **`bbox sequence`** and **`input_ids`**.
- test_maximum_encoding_length_pair_input
- test_maximum_encoding_length_single_input
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@LysandreJik @sgugger @SaulLu @NielsRogge
|
09-09-2021 12:43:38
|
09-09-2021 12:43:38
|
Thank you very much for the PR.
As it seems to me that we didn't see any tests failing for LayoutLMv2 at the time your previous PR was merged, could you confirm that this behaviour is tested for LayoutLMv2 now? As I see that in the PR you did not change any tests, I'd like to make sure we catch the problem with the tests next time :slightly_smiling_face: .<|||||>> As I see that in the PR you did not change any tests, I'd like to make sure we catch the problem with the tests next time 🙂 .
@SaulLu, The test `test_maximum_encoding_length_pair_input` and `test_maximum_encoding_length_single_input` were skipped because of the reason `LayoutLMv2 tokenizer requires boxes besides sequences.`
I will make the necessary changes to the file `test_tokenization_layoutlmv2.py` to ensure that we catch the problem next time.
Thank you <|||||>@SaulLu, I have added a function `get_clean_sequences` which gives us list of words along with their ids and boxes, have taken reference from the `test_tokenization_common.py`.
Furthermore, I have modified the `test_maximum_encoding_length_single_input` to ensure the correct order of overflowing order.
Please can you review the changes.
Thank you <|||||>@SaulLu, I have gone through the reviews. I will make the changes.
I didn't commit `test_maximum_encoding_length_pair_input` function because I wanted to see the changes that are required in the `get_clean_sequences` and `test_maximum_encoding_length_single_input`.
Thank you for reviewing and suggesting the changes.<|||||>@SaulLu @NielsRogge @LysandreJik, Sorry for the delay in the PR. I am done with most of the work, but I would like to ask for help in Comparing `bbox` sequence for fast tokenizer for `test_maximum_encoding_length_pair_input.` That test isn't working properly. Can you help me from where I should read about this ?
I am sorry once again for delaying the work.
**_Update: I have resolved the problem I was facing._**<|||||>@SaulLu, Working on `test_maximum_encoding_length_pair_input`. Will Commit the changes by end of the day.<|||||>@SaulLu @LysandreJik @NielsRogge, could you please review the test added and changes.
Thank you <|||||>@patrickvonplaten @SaulLu @LysandreJik @NielsRogge , Could you please review the PR.
Thank you.<|||||>> * Could you add some comments explaining what is done? There is a lot of code so I fear it will become unmaintainable without clear comments explaining what is done.
Sure, Thank you for reviewing.<|||||>@SaulLu @LysandreJik, I have been getting these mails, I tried checking the reason for their failing but couldn't understand the issue.
Message : _This request was automatically failed because there were no enabled runners online to process the request for more than 1 days._
Here the [Screenshot](https://user-images.githubusercontent.com/57873504/140864209-d8486bf5-1151-48e0-8e7f-af9692759d30.PNG) <|||||>Thnaks a gain for all your work on this!
|
transformers
| 13,494 |
closed
|
Fix typo in documentation
|
# What does this PR do?
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
Documentation: @sgugger
I have found several typos and invalid argument in the documentation.
|
09-09-2021 10:08:56
|
09-09-2021 10:08:56
| |
transformers
| 13,493 |
closed
|
Fixing backward compatiblity for non prefixed tokens (B-, I-).
|
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #13325
@LysandreJik
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-09-2021 09:52:56
|
09-09-2021 09:52:56
| |
transformers
| 13,492 |
closed
|
FlaxCLIPModel is 10x faster than CLIPModel during inference, and 100x slower getting gradients?
|
## Environment info
- `transformers` version: 4.10.0
- Platform: Linux-5.11.0-7620-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): 2.5.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.3.4 (gpu)
- Jax version: 0.2.17
- JaxLib version: 0.1.68
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
@patil-suraj
## Information
Model I am using: FlaxCLIPModel and CLIPModel
The problem arises when using the official example scripts (though the gradient code is not from the examples).
## To reproduce
I may be doing something terribly, terribly wrong here, and I initially thought it must have something to do with me misunderstanding `jit` compilation/caching, or something like that, but having put together some very minimal examples, and tested on my own machine, and on a colab notebook, I'm still seeing a huge disparity in performance between Pytorch and JAX in both inference and in getting gradients.
Here's a notebook which minimally replicates the performance disparity:
* https://colab.research.google.com/gist/josephrocca/3b4aca3ebf66e8b46a035eb0f3711150 (make sure to select GPU runtime)
* https://gist.github.com/josephrocca/3b4aca3ebf66e8b46a035eb0f3711150
And, for quick reference, here are the relevant code snippets from that notebook for **inference** (note that in the notebook I run `jit(jax_model)` before `%timeit` to pre-cache the compilation):
```python
def pt_forward():
inputs = processor(text=["red"], images=[image], return_tensors="pt", padding=True)
outputs = pt_model(**inputs)
return outputs.logits_per_image
%timeit pt_forward()
# 81.2 ms ± 559 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
```python
def jax_forward():
inputs = processor(text=["red"], images=[image], return_tensors="jax", padding=True)
outputs = jit(jax_model)(**inputs)
return outputs.logits_per_image
%timeit jax_forward().block_until_ready()
# 7.83 ms ± 1.11 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
And for getting **gradients** of the inputs with respect to the output (note that in the notebook I run `jit(grad(jax_loss))` before `%timeit` to pre-cache the compilation):
```python
for p in pt_model.parameters():
p.requires_grad = False
def pt_loss(inputs):
outputs = pt_model(**inputs)
logits_per_image = outputs.logits_per_image
return logits_per_image
def pt_test():
text = "green"
image = Image.new('RGB', (224, 224), color=(0, 255, 0))
inputs = processor(text=[text], images=[image], return_tensors="pt", padding=True)
inputs.pixel_values.requires_grad = True
loss = pt_loss(inputs)
loss.backward()
return inputs.pixel_values.grad
def jax_loss(pixel_values, input_ids, attention_mask):
inputs = {"pixel_values":pixel_values, "input_ids":input_ids, "attention_mask":attention_mask}
outputs = jax_model(**inputs)
logits_per_image = outputs.logits_per_image
return logits_per_image[0][0]
def jax_test():
text = "green"
image = Image.new('RGB', (224, 224), color=(0, 255, 0))
inputs = processor(text=[text], images=[image], return_tensors="jax", padding=True)
grads = jit(grad(jax_loss))(inputs.pixel_values, inputs.input_ids, inputs.attention_mask)
return grads
```
```python
%timeit pt_test()
# 129 ms ± 1.04 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
```python
%timeit jax_test().block_until_ready()
# 11.2 s ± 34.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
## Expected behavior
I'd have expected CLIPModel and FlaxCLIPModel to be *roughly* comparable in performance.
|
09-09-2021 08:30:00
|
09-09-2021 08:30:00
|
Hi there,
It seems you have frozen the PyTorch model's parameters so no gradients are calculated for them, which could explain the huge speed difference.
Also, I would avoid jitting inside a function and then call it multiple times, it may cause re-compilation (I'm not sure).
We could first `jit` the function and then call that inside the main function, like
```python
forward = jit(jax_model) # jit here
def jax_forward():
inputs = processor(text=["red"], images=[image], return_tensors="jax", padding=True)
outputs = forward(**inputs) # call the jitted function
return outputs.logits_per_image<|||||>@patil-suraj
> It seems you have frozen the PyTorch model's parameters so no gradients are calculated for them, which could explain the huge speed difference.
Do you mean this part?
```python
for p in pt_model.parameters():
p.requires_grad = False
```
If so, I tried commenting that out and Pytorch is still 1-2 OOM faster. The reason I added that code was because my understanding is that `jax.grad` only gets gradients of the first parameter of the function, [i.e. [default `argnums` value is `0`](https://jax.readthedocs.io/en/latest/jax.html#jax.grad)] so since JAX is only getting gradients of the `pixel_values` input, I wanted to make it so Pytorch is also only getting those too, for fairness.
> Also, I would avoid jitting inside a function and then call it multiple times, it may cause re-compilation (I'm not sure).
I'm quite sure that's not the case, since `jax_forward()` is much, much slower the first time I call it, and then after that it's way *faster* than `pt_forward()`. I tested this again just now in the Colab to confirm: ~800ms first run of `jax_forward()` vs ~30ms on successive runs, while `pt_forward()` always takes ~260ms.
[The docs for jax.jit](https://jax.readthedocs.io/en/latest/jax.html#jax.jit) explicitely mention that there is a compilation cache, and a lot of examples from intro tutorials use the a pattern like `jit(jax_model)(**inputs)` instead of `jit_jax_model(**inputs)` - one just needs to be aware of the caching rules - especially (from docs): "Static arguments are included as part of a compilation cache key" (which makes perfect sense).
Also worth mentioning that I thought that for JAX to be so fast with inference, perhaps it's caching outputs by default, but I couldn't find any documentation suggesting that, and I think I've eliminated that possibility with a test like this:
```python
i = 0
def jax_forward():
global i
i += 1
inputs = processor(text=[f"red {i}"], images=[image], return_tensors="jax", padding=True)
outputs = jit(jax_model)(**inputs)
return outputs.logits_per_image
```
Let me know if there are any other tests you'd like me to run. The Colab notebook I linked in my original post is quite minimal and self-contained so if you just switch runtime to GPU and then `Runtime -> Run all` (after making some code changes to test a hypothesis), then it should fairly painlessly give you an answer.<|||||>@patil-suraj It occurred to me that you might have meant to mention `jit_grad_jax_loss = jit(grad(jax_loss))`, rather than the `forward` functions, since it's the grad part that's 100x slower in Flax, and so I tried pre-compiling `jit(grad(jax_loss))`, and you were right! Now Flax is 10x faster in **both** inference and getting the gradients! 🤔 I'll have to do some more reading of the JAX/Flax docs to work out what's going on here. I guess something is causing the `jit` compilation cache to be bypassed. Maybe related to [this JAX issue](https://github.com/google/jax/issues/2095). Either way, **thank you for your help!** :pray:
```python
jit_grad_jax_loss = jit(grad(jax_loss))
def jax_test_pre_jit():
text = "green"
image = Image.new('RGB', (224, 224), color=(0, 255, 0))
inputs = processor(text=[text], images=[image], return_tensors="jax", padding=True)
grads = jit_grad_jax_loss(inputs.pixel_values, inputs.input_ids, inputs.attention_mask)
return grads
```
I also just tested `FlaxBertModel` against `BertModel` and Flax is again 10x faster during inference:
* https://gist.github.com/josephrocca/8f3797f1f7605eccddd7b3d438052734
* https://colab.research.google.com/gist/josephrocca/8f3797f1f7605eccddd7b3d438052734
Could it be that Flax is just a lot faster than Pytorch with these models? I'd have thought the speed difference would be smaller.
Happy for you to close this if the observed inference speed difference is not suspicious to you :+1:
**Edit**: [I've asked a question](https://github.com/google/jax/discussions/7871) about `jit(f)` being cached, but `jit(grad(f))` not being cached (using a much simpler code example) over on the JAX discussion forum. **Edit 2**: The answer turns out to be pretty simple: `grad(f)` [isn't cached](https://github.com/google/jax/issues/2095) (but there's discussion in that issue of giving `grad` a cache), and thus returns a new function each time, and so `jit` must recompile it every time (since it caches compilations based on the function reference rather than the function source string).<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,491 |
closed
|
[GPT-Neo] Simplify local attention
|
# What does this PR do?
Co-authored-by: finetuneanon <[email protected]>
This PR is a continuation of #11630 which simplifies GPT Neo's local attention implementation. All credit to @finetuneanon for finding this issue, providing the fix, and a detailed explanation. Thanks a lot for working on this :)
The issue is described in #11320 and performance evaluation results are available here:
[#12106 (comment)](https://github.com/huggingface/transformers/pull/12106#discussion_r650008259)
This PR does some cleanup and updates tests on top of @finetuneanon changes.
Fixes #11320, Fixes #11787, Fixes #12964, Fixes #11096
|
09-09-2021 07:31:52
|
09-09-2021 07:31:52
|
I had error in running:
```
File "src\transformers\models\gpt_neo\configuration_gpt_neo.py", line 218, in __init__
from .modeling_gpt_neo import GPTNeoAttentionMixin
ImportError: cannot import name 'GPTNeoAttentionMixin'
```
Need a patch for this PR.
|
transformers
| 13,490 |
closed
|
Rouge Metric Evaluation in Training/After Training T5 run_summarization.py
|
Hi,
I am using the HuggingFace run_summarization.py example to train T5 for summarisation (and some other tasks too). I am running on the latest development version of the transformers library. I noticed that the Rouge score numbers for evaluation inside training are a lot lower than in evaluation and prediction scores at the end of training. The scores suddenly jump up. I am not sure if this is a bug, or if by design whether a new parameter could be introduced to control this behaviour (if I have not already missed for one, for which I apologize in advance if so).
To try to remove anything specific to my coding changes or data, and to keep things simple, I tried running a very small example run_summarization.py with a standard dataset for summarization with the following parameterisation:
–model_name_or_path t5-small --do_train True --num_train_epochs 1.0 --max_train_samples 1000 --do_eval True --evaluation_strategy steps --eval_steps 100 --max_eval_samples 100 --do_predict True --predict_with_generate True --max_predict_samples 100 --dataset_name cnn_dailymail --dataset_config “3.0.0” --source_prefix "summarize: " --output_dir “d:/BrianS/models/sum_test” --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --save_steps 100 --logging_strategy steps --logging_steps 50
*** At the first evaluation I get the following results: ***
{‘eval_loss’: 2.1008858680725098, ‘eval_rouge1’: 23.2084, ‘eval_rouge2’: 7.5598, ‘eval_rougeL’: 18.7416, ‘eval_rougeLsum’: 20.9243, ‘eval_gen_len’: 19.0, ‘eval_runtime’: 5.5309, ‘eval_samples_per_second’: 18.08, ‘eval_steps_per_second’: 4.52, ‘epoch’: 0.4}
*** At the second evaluation I get: ***
{‘eval_loss’: 2.093972682952881, ‘eval_rouge1’: 23.4257, ‘eval_rouge2’: 8.0721, ‘eval_rougeL’: 19.0282, ‘eval_rougeLsum’: 21.3982, ‘eval_gen_len’: 19.0, ‘eval_runtime’: 5.4218, ‘eval_samples_per_second’: 18.444, ‘eval_steps_per_second’: 4.611, ‘epoch’: 0.8}
*** But once training is complete I get for evaluation: ***
epoch = 1.0
eval_gen_len = 60.13
eval_loss = 2.0929
eval_rouge1 = 30.7996
eval_rouge2 = 11.3268
eval_rougeL = 23.027
eval_rougeLsum = 28.309
eval_runtime = 0:00:16.26
eval_samples = 100
eval_samples_per_second = 6.148
eval_steps_per_second = 1.537
*** and for prediction: ***
predict_gen_len = 60.37
predict_loss = 2.0777
predict_rouge1 = 29.7574
predict_rouge2 = 9.4481
predict_rougeL = 21.0967
predict_rougeLsum = 26.475
predict_runtime = 0:00:16.84
predict_samples = 100
predict_samples_per_second = 5.937
predict_steps_per_second = 1.484
So I noticed that _gen_len seemed very different between the two sets of results, plus the eval run at the end was taking so much longer than the evals during training. So I debugged inside the compute_metrics function for the 3 evaluation runs (the two inside training, the one after training) and found:
*** The target summarisation for the first sample is: ***
_‘Accident happens in Santa Ynez, California, near where Crosby lives. The jogger suffered multiple fractures; his injuries are not believed to be life-threatening.’_
*** prediction for first eval (0.4 epoch as above) ***
_‘David Crosby hit a jogger with his car in Santa Ynez,’_
*** prediction for second eval (0.8 epoch as above) ***
_‘David Crosby was driving at approximately 50 mph when he struck the jogger’_
*** prediction for eval after training completed ***
_‘David Crosby hit a jogger with his car in Santa Ynez, California. The jogger suffered multiple fractures and was airlifted to a hospital. Crosby is known for weaving multilayered harmonies over sweet melodies.’_
So given the lengh of the prediction in the evaluation after trianing, it is of similar length to the target and it is perhaps unsurprising the scores are better. It looks like the output generated is being kept small to keep compute resources down for fast eval during training, then openned up to the full summarization at the end? Have I missed a parameter that controls this behaviour, so that you could force full generation for eval during training, not just at the end? Be good to understand this, at the moment the Rouge scores I have go up like a hockey stick at the end.
Thanks!
|
09-09-2021 05:47:17
|
09-09-2021 05:47:17
|
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,489 |
closed
|
Fix special tokens not correctly tokenized
|
# What does this PR do?
Fixes #13483.
I think this is a quite complex issue. The purpose of `unique_no_split_tokens` in `tokenization_utils.py` and `all_special_tokens` in `tokenization_utils_base.py` seems ambiguous as they all store special tokens that don't want to be splitted or lower_cased. This two separated variables may result in a hard maintainable code. I'm guessing this is probably due to the workaround for FastTokenizers' functionality.
Additionally, should we resolve this TODO?
https://github.com/huggingface/transformers/blob/c37573806ab3526dd805c49cbe2489ad4d68a9d7/src/transformers/tokenization_utils.py#L275-L282
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@sgugger @LysandreJik
|
09-09-2021 04:47:12
|
09-09-2021 04:47:12
|
A test has been added. Thanks for the review!
|
transformers
| 13,488 |
open
|
add non auto regressive model?
|
This research area is developing very fast in the past two years, which could improve latency significantly with quality on par. Will huggingface team be interested into the implementation of it? Thanks.
|
09-09-2021 02:01:47
|
09-09-2021 02:01:47
|
Can you point to certain papers, perhaps with corresponding code + weights?<|||||>This paper announced to have quality on par with 10x speed up. https://github.com/FLC777/GLAT
Another similar nat paper https://github.com/tencent-ailab/ICML21_OAXE
Most nat models are based on fairseq implementations.
https://github.com/pytorch/fairseq/blob/master/fairseq/models/nat/nonautoregressive_transformer.py
https://github.com/pytorch/fairseq/blob/master/fairseq/models/nat/levenshtein_transformer.py
|
transformers
| 13,487 |
closed
|
Cannot run Movement pruning on GLUE
|
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 2.8.0
- Platform: Linux-4.15.0-136-generic-x86_64-with-glibc2.17
- Python version: 3.8.11
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
## Information
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
I try to reproduce the movement pruning on the GLUE dataset and install the dependent packages following the `requirements.txt`, I try to run the `masked_run_glue.py` by the following commands:
```
SERIALIZATION_DIR=./finegrained_bert_0.95
GLUE_DATA=~/data-bin/glue_data/QQP
CUDA_VISIBLE_DEVICES=1 python masked_run_glue.py \
--output_dir $SERIALIZATION_DIR \
--data_dir $GLUE_DATA \
--task_name qqp \
--do_train --do_eval --do_lower_case \
--model_type masked_bert \
--model_name_or_path bert-base-uncased \
--per_gpu_train_batch_size 16 \
--warmup_steps 5400 \
--num_train_epochs 10 \
--learning_rate 3e-5 --mask_scores_learning_rate 1e-2 \
--initial_threshold 1 --final_threshold 0.15 \
--initial_warmup 1 --final_warmup 2 \
--pruning_method topK --mask_init constant --mask_scale 0.
```
and I get the following errors:
```
Traceback (most recent call last):
File "masked_run_squad.py", line 33, in <module>
from emmental import MaskedBertConfig, MaskedBertForQuestionAnswering
File "/root/transformers/examples/research_projects/movement-pruning/emmental/__init__.py", line 3, in <module>
from .modeling_bert_masked import (
File "/root/transformers/examples/research_projects/movement-pruning/emmental/modeling_bert_masked.py", line 31, in <module>
from transformers.file_utils import add_start_docstrings, add_start_docstrings_to_model_forward
ImportError: cannot import name 'add_start_docstrings_to_model_forward' from 'transformers.file_utils' (/root/transformers/examples/research_projects/movement-pruning/src/transformers/src/transformers/file_utils.py)
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
|
09-09-2021 01:52:32
|
09-09-2021 01:52:32
|
Hi @zheng-ningxin
I have the exact same issue, do you mind telling me how you solved this? thanks <|||||>@dorost1234 Please have a try on version 4.9.0.<|||||>Hi @zheng-ningxin
I am trying to use this method, for me this does not work at all, since you seems to have worked on this code, could you let me know if you could obtain the results on GLUE? thanks
|
transformers
| 13,486 |
closed
|
Refactor internals for Trainer push_to_hub
|
# What does this PR do?
This PR refactors the internals of the `Trainer` integration with the hub to use a `Repository` object instead of relying on the `PushToHubMixin` (which will get simplified drastically soon, see https://github.com/huggingface/huggingface_hub/pull/321).
In passing, to get closer to the way `Repository` works, the `push_to_hub_model_id` and `push_to_hub_organization` are both deprecated in favor of `hub_model_id`, which should contain the full ID of the model (either username/model_name or organization/model_name). `push_to_hub_token` is deprecated in favor of `hub_token`, which is easier.
Tests are adapted to use those new arg names, but otherwise there is no breaking change.
|
09-08-2021 20:36:27
|
09-08-2021 20:36:27
| |
transformers
| 13,485 |
closed
|
Enable passing config directly to PretrainedConfig.from_pretrained()
|
The `PretrainedConfig` class has a method for loading configs `from_pretrained()`. As the documentation states, the input can be either a string or a path to a config file:
```
pretrained_model_name_or_path (:obj:`str` or :obj:`os.PathLike`):
This can be either:
- a string, the `model id` of a pretrained model configuration hosted inside a model repo on
huggingface.co. Valid model ids can be located at the root-level, like ``bert-base-uncased``, or
namespaced under a user or organization name, like ``dbmdz/bert-base-german-cased``.
- a path to a `directory` containing a configuration file saved using the
:func:`~transformers.PretrainedConfig.save_pretrained` method, e.g., ``./my_model_directory/``.
- a path or url to a saved configuration JSON `file`, e.g.,
``./my_model_directory/configuration.json``.
```
**Request:** I would like to be able to pass the config dictionary directly to this function.
**Motivation:** if I have a config in memory, I shouldn't have to write the config to disk and then pass that file path to the method.
**Proposed Solution:** Add an extra argument `config_dict` and then replace
```
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
```
with something like
```
if config_dict is not None and pretrained_model_name_or_path is not None:
assert ValueError('Only one of config_dict and pretrained_model_name_or_path can be provided.`)
if config_dict is None:
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
```
|
09-08-2021 18:55:17
|
09-08-2021 18:55:17
|
My current workaround isn't onerous, but I feel like this my request is pretty simple :)
```
student_config = some dict
# Frustratingly, the .from_pretrained method doesn't permit passing a config directly.
# Consequently, we write the config to disk and then pass that path.
os.makedirs('tmp', exist_ok=True)
with open('tmp/student_config.json', 'w') as fp:
json.dump(obj=student_config, fp=fp)
stu_architecture_config = student_config_class.from_pretrained('tmp/student_config.json')
```<|||||>Hi @RylanSchaeffer, this can be done with the `from_dict` method.
```
config = BertConfig.from_pretrained("bert-base-uncased", hidden_dropout_prob=0.5)
second_config = BertConfig.from_dict(config.to_dict())
print(second_config.hidden_dropout_prob) # output: 0.5
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,484 |
closed
|
push to hub issue
|
hi I'm trying to push my fine-tuned pre-trained facebook blenderbot 2 to huggingface hub, I have tried every single solution from windows, Linux, google colab, kaggle, paperspace. I'm exhausted and I don't wanna try any other solutions, is there anybody who can just push the pre-trained model to my hub please, and thanks in advance.
```
from transformers import BlenderbotTokenizer, BlenderbotForConditionalGeneration
mname = "facebook/blenderbot-3B"
model = BlenderbotForConditionalGeneration.from_pretrained(mname)
tokenizer = BlenderbotTokenizer.from_pretrained(mname)
print("loaded")
model.push_to_hub("Rose-Brain",use_auth_token='api##########')
print("pushed")
tokenizer.push_to_hub("Rose-Brain",use_auth_token='api##########')
print("done")
```
|
09-08-2021 17:31:53
|
09-08-2021 17:31:53
|
Hello, sorry you had such a bad experience with the `push_to_hub` method. Could you share the error that you have faced?<|||||>thanks for your reply @LysandreJik i really appreciate it,
this is the traceback
```
---------------------------------------------------------------------------
CalledProcessError Traceback (most recent call last)
/opt/conda/lib/python3.7/site-packages/huggingface_hub/repository.py in git_push(self)
407 encoding="utf-8",
--> 408 cwd=self.local_dir,
409 )
/opt/conda/lib/python3.7/subprocess.py in run(input, capture_output, timeout, check, *popenargs, **kwargs)
511 raise CalledProcessError(retcode, process.args,
--> 512 output=stdout, stderr=stderr)
513 return CompletedProcess(process.args, retcode, stdout, stderr)
CalledProcessError: Command '['git', 'push']' returned non-zero exit status 1.
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)
<ipython-input-7-54a7c90789e5> in <module>
4 tokenizer = BlenderbotTokenizer.from_pretrained(mname)
5 print("loaded")
----> 6 model.push_to_hub("Rosa-Brain",use_auth_token='api_token')
7 print("pushed")
8 tokenizer.push_to_hub("Rosa-Brain",use_auth_token='api_token')
/opt/conda/lib/python3.7/site-packages/transformers/file_utils.py in push_to_hub(self, repo_name, repo_url, commit_message, organization, private, use_auth_token)
1891 organization=organization,
1892 private=private,
-> 1893 use_auth_token=use_auth_token,
1894 )
1895
/opt/conda/lib/python3.7/site-packages/transformers/file_utils.py in _push_to_hub(cls, save_directory, save_files, repo_name, repo_url, commit_message, organization, private, use_auth_token)
1959 copy_tree(save_directory, tmp_dir)
1960
-> 1961 return repo.push_to_hub(commit_message=commit_message)
/opt/conda/lib/python3.7/site-packages/huggingface_hub/repository.py in push_to_hub(self, commit_message)
422 self.git_add()
423 self.git_commit(commit_message)
--> 424 return self.git_push()
/opt/conda/lib/python3.7/site-packages/huggingface_hub/repository.py in git_push(self)
410 logger.info(result.stdout)
411 except subprocess.CalledProcessError as exc:
--> 412 raise EnvironmentError(exc.stderr)
413
414 return self.git_head_commit_url()
OSError: batch response:
You need to configure your repository to enable upload of files > 5GB.
Run "huggingface-cli lfs-enable-largefiles ./path/to/your/repo" and try again.
error: failed to push some refs to 'https://user:api_##########@huggingface.co/vymn/Rosa-Brain'
```
this is the environment set up
```
!git config --global user.email "[email protected]"
!git config --global user.name "username"
!git clone https://username:[email protected]/vymn/Rosa-Brain
!huggingface-cli lfs-enable-largefiles ./Rosa-Brain/
!git config --global http.postBuffer 30474698716
!git config --global filter.lfs.smudge "git-lfs smudge --skip %f"
```
I've tried every solution in other related issues as well and nothing worked for me<|||||>Hmmm this shouldn't happen! Would it be possible for you to share your colab so that I may take a look? Thank you!<|||||>sure, I just made a [test](https://colab.research.google.com/drive/15QNHui7qhIBvIT0o8wv0sicGAMJnsDv7?usp=sharing) copy for you with edit privilege. I hope it works then tell me what I missed
<|||||>could you tell me what happened, please?
I've noticed that you have worked with the 400m parameters model and this just worked fine for me either my problem came up with 3B parameters model.<|||||> what is really confusing is that the traceback sometimes show me error something like 42738303 vs 48224303, some other times big files error, and on my local computer tells me its windows known issue, I have no clue what I really missed <|||||>Hy @vymn, thank you for the reproducer! There seems to be a very real issue with uploading big models to the hub. We're investigating this with the backend team. Will let you know of any updates!<|||||>thank you I'm sure you're doing your best, I'll be waiting <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>This should have been fixed - can you confirm?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,483 |
closed
|
`BertTokenizer` splits tokens added via `add_tokens(...', special_tokens=False)` to a few subtokens
|
## Environment
`!transformers-cli env` output:
- `transformers` version: 4.11.0.dev0
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyTorch version (GPU?): 1.9.0+cu102 (False)
- Tensorflow version (GPU?): 2.6.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
## Information
I'm using `BertTokenizer` to process data and train my BERT-based model.
I found that when I add a few "technical" tokens via `tokenizer,add_tokens(token_text, special_tokens=True)` - it still splits added tokens the same way ad before adding them into tokenizer. When I use `tokenizer,add_tokens(token_text, special_tokens=False)` instead - it works properly.
Moreover, when I save the tokenizer with `special_tokens=True`-adding through `tokenizer.save_pretrained(directory_name)` and then load it back - it works properly, instead of just modifying the tokenizer.
There I'll give a sample (you can also see the same sample here - https://colab.research.google.com/drive/1Ufa79vrvdoyee6xiz9WCR7F2UKZuBfS7?usp=sharing ):
```python
from transformers import BertTokenizer
tokenizer_base = BertTokenizer.from_pretrained("bert-base-uncased")
tokenizer_special = BertTokenizer.from_pretrained("bert-base-uncased")
tokenizer_nonspecial = BertTokenizer.from_pretrained("bert-base-uncased")
tokenizer_special.add_tokens('[TITLE]', special_tokens=True)
tokenizer_nonspecial.add_tokens('[TITLE]', special_tokens=False)
# [101, 1031, 2516, 1033, 102]
# so basically, before any modification - it split `[TITLE]` to `1031, 2516, 1033`
print(tokenizer_base('[TITLE]')['input_ids'])
# [101, 1031, 2516, 1033, 102]
# Guess it should give 3 token ids here - yet it gives same ids like `tokenizer_base`
print(tokenizer_special('[TITLE]')['input_ids'])
# [101, 30522, 102]
# So with `.add_tokens('[TITLE]', special_tokens=False)` it maps `[TITLE]` to one token
print(tokenizer_nonspecial('[TITLE]')['input_ids'])
# Guess it should give same result as `tokenizer_special`'s one
# But it gives me `[101, 30522, 102]` instead - like `tokenizer_nonspecial`'s one
tokenizer_special.save_pretrained("pretrained-with-special-flag")
tokenizer_special_from_pretrained = BertTokenizer.from_pretrained("pretrained-with-special-flag")
tokenizer_special_from_pretrained('[TITLE]')['input_ids']
```
## Expected behavior
I expected to see 1 token id for `tokenizer_special` (something like `tokenizer_nonspecial`'s `[101, 30522, 102]`) - or, at least, see that `tokenizer_special_from_pretrained` reproduces `tokenizer_special`'s behavior.
|
09-08-2021 17:27:26
|
09-08-2021 17:27:26
|
This seems a bug that the tokenizing function doesn't consider additional added special tokens. I'll open a PR for the fix.<|||||>Basically you can temporarily use the following code to add special tokens you want, documented on the [docs](https://huggingface.co/transformers/main_classes/tokenizer.html#transformers.PreTrainedTokenizer). This will give the correct result.
```
BertTokenizer.from_pretrained("bert-base-uncased", additional_special_tokens=["[TITLE]"])
```
|
transformers
| 13,482 |
closed
|
Fix typo in deepspeed documentation
|
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
Documentation: @sgugger
|
09-08-2021 17:09:30
|
09-08-2021 17:09:30
| |
transformers
| 13,481 |
closed
|
Difference in BART position embeddings with fairseq implementation
|
I'm trying to implement PLBART (#13269) which is majorly just a BART model with some minor modifications. I tried to make embeddings equal but there is a mismatch in original BART (fairseq) and current BART implementation.
In the [original code](https://github.com/pytorch/fairseq/blob/9549e7f76994095c92441b81c615a169dc21f478/fairseq/modules/learned_positional_embedding.py#L31), the learned position embeddings is based on the `input_tokens`:
```python
def forward(
self,
input: Tensor,
incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None,
positions: Optional[Tensor] = None,
):
"""Input is expected to be of size [bsz x seqlen]."""
assert (positions is None) or (
self.padding_idx is None
), "If positions is pre-computed then padding_idx should not be set."
if positions is None:
if incremental_state is not None:
# positions is the same for every token when decoding a single step
# Without the int() cast, it doesn't work in some cases when exporting to ONNX
positions = torch.zeros(
(1, 1), device=input.device, dtype=input.dtype
).fill_(int(self.padding_idx + input.size(1)))
else:
positions = utils.make_positions(
input, self.padding_idx, onnx_trace=self.onnx_trace
)
return F.embedding(
positions,
self.weight,
self.padding_idx,
self.max_norm,
self.norm_type,
self.scale_grad_by_freq,
self.sparse,
)
```
and `utils.make_positions` does:
```python
def make_positions(tensor, padding_idx: int, onnx_trace: bool = False):
"""Replace non-padding symbols with their position numbers.
Position numbers begin at padding_idx+1. Padding symbols are ignored.
"""
# The series of casts and type-conversions here are carefully
# balanced to both work with ONNX export and XLA. In particular XLA
# prefers ints, cumsum defaults to output longs, and ONNX doesn't know
# how to handle the dtype kwarg in cumsum.
mask = tensor.ne(padding_idx).int()
return (torch.cumsum(mask, dim=1).type_as(mask) * mask).long() + padding_idx
```
In HuggingFace implementation, the learned position embeddings is based on the `input_shape`:
```python
def forward(self, input_ids_shape: torch.Size, past_key_values_length: int = 0):
"""`input_ids_shape` is expected to be [bsz x seqlen]."""
bsz, seq_len = input_ids_shape[:2]
positions = torch.arange(
past_key_values_length, past_key_values_length + seq_len, dtype=torch.long, device=self.weight.device
)
return super().forward(positions + self.offset)
```
The difference shows up when considering `padding_idx`. In HuggingFace implementation, `padding_idx` is considered same as any other token for positions, so it will get it's own position id (because we only care about shape). So `<pad>` at third position will get `4`, and `<pad>` at tenth position will get `11`. In the original impementation, `padding_idx` is considered different from other tokens, and the position for that, the `padding_idx` is used explicity as position. So `<pad>`'s corresponding position id will always be `1`, regardless of the position.
Note that this does not bring any changes to the model output for other tokens, as the `attention_mask` ignores the padding index in both cases.
Do you think this needs fixing to make it as close to the original implementation as possible? Since they are also using `torch.nn.Embedding`, I think it should be easy. Is there any other reason behind the way things have been implemented currently?
Thank you,
Gunjan
|
09-08-2021 16:23:58
|
09-08-2021 16:23:58
|
Hey Gunjan :-)
I don't think that this needs fixing because (as you said) the padding token is masked anyways<|||||>Hi @patrickvonplaten :)
Thanks a lot!
|
transformers
| 13,480 |
closed
|
Fix integration tests for `TFWav2Vec2` and `TFHubert`
|
**Issue**
Errors for integration tests on `TFWav2Vec2` and `TFHubert`
```
E ValueError: When setting ``truncation=True``, make sure that ``max_length`` is defined and ``padding='max_length'
```
CI logs: https://github.com/huggingface/transformers/runs/3539314355?check_suite_focus=true
**Solution**
Remove `truncation=True` from feature extractors since the logic changed recently https://github.com/huggingface/transformers/pull/12804/
Also some other small fixes because the tests now reach those lines :slightly_smiling_face:
|
09-08-2021 15:28:41
|
09-08-2021 15:28:41
| |
transformers
| 13,479 |
closed
|
Fix Tensorflow T5 with int64 input
|
Our Tensorflow T5 model uses constant values that are initialized with `tf.constant()` or just from Python int literals. Tensorflow guesses the dtype in both of these cases as `int32`, which causes the operations using them to fail if `int64` input is supplied.
This PR adds checks that cast the constants to the dtype of the inputs, to ensure that the operations succeed for both `int32` and `int64` inputs.
|
09-08-2021 13:13:35
|
09-08-2021 13:13:35
| |
transformers
| 13,478 |
closed
|
Throw ValueError for mirror downloads
|
Fixes #13470
|
09-08-2021 12:25:26
|
09-08-2021 12:25:26
| |
transformers
| 13,477 |
closed
|
Typo in "end_of_word_suffix"
|
But does it really work?
|
09-08-2021 11:09:24
|
09-08-2021 11:09:24
| |
transformers
| 13,476 |
closed
|
T5
|
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
|
09-08-2021 10:27:56
|
09-08-2021 10:27:56
|
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,475 |
closed
|
replacing model head failure
|
## Environment info
- `transformers` version: 4.11.0.dev0
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): 2.6.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes, but not necessary
- Using distributed or parallel set-up in script?: no
### Who can help
@LysandreJik
## Information
Model I am using (Bert, XLNet ...): bert-base-uncased
But I have also seen the same behaviour with albert-large-v2
The problem arises when using:
My own code
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Initialize a CLM model
2. Replace the head of this model with a Masked LM head (following the [directions](https://github.com/huggingface/transformers/issues/8901#issuecomment-737300387) of @LysandreJik).
There is a [notebook](https://colab.research.google.com/drive/194l9a5itoOcf1DTXPv1C6TftNTb-KB6y?usp=sharing) with complete code.
Here is the code for replacing the head.
```
from transformers import AutoModelForSequenceClassification, BertForMaskedLM
clm_model = AutoModelForSequenceClassification.from_pretrained(CHECKPOINT)
clm_model_path = f'clm_model.{CHECKPOINT}'
clm_model.save_pretrained(clm_model_path)
set_seed(INITIALIZATION_SEED)
mlm_model_from_clm = BertForMaskedLM.from_pretrained(clm_model_path)
mlm_model_from_clm_path = f'mlm_model_from_clm.{CHECKPOINT}.{INITIALIZATION_SEED}'
mlm_model_from_clm.save_pretrained(mlm_model_from_clm_path)
%env MLM_MODEL_FROM_CLM_PATH=$mlm_model_from_clm_path
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
Expect the above model to be identical to the model obtained directly from the hub:
```
from transformers import AutoModelForMaskedLM, AutoTokenizer, set_seed
set_seed(INITIALIZATION_SEED)
mlm_model = AutoModelForMaskedLM.from_pretrained(CHECKPOINT)
mlm_model_path = f'mlm_model.{CHECKPOINT}.{INITIALIZATION_SEED}'
mlm_model.save_pretrained(mlm_model_path)
%env MLM_MODEL_PATH=$mlm_model_path
```
However, they are not the same:
```
compare_two_models(mlm_model, mlm_model_from_clm)
```
shows that the models have the same weights, but not for the masked LM head.
```
Models differ on layer 197: cls.predictions.bias
Models differ on layer 198: cls.predictions.transform.dense.weight
Models differ on layer 199: cls.predictions.transform.dense.bias
Models differ on layer 200: cls.predictions.transform.LayerNorm.weight
Models differ on layer 201: cls.predictions.transform.LayerNorm.bias
```
I at least expected `mlm_model_from_clm` to be ready to use for the masked LM task. However, it is not at all:
Using the huggingface script `transformers/examples/pytorch/language-modeling/run_mlm.py` to determine MLM perplexity, the `mlm_model` has perplexity 9.012 as expected; however, the `mlm_model_from_clm` obtained by replacing the head has perplexity > 50,000.
All of the steps are done in the notebook referenced above.
|
09-08-2021 09:33:32
|
09-08-2021 09:33:32
|
I am not sure how `compare_two_models` works but it seems that the pooling layer (used for the CLS token) is part of the base BERT model but not the other CLM model architecture.
See here for details of the pooling layer (the authors mistakenly forgot to mention this in the original BERT paper AFAIK): https://github.com/huggingface/transformers/issues/7540#issuecomment-704155218<|||||>In fact these two snippets from how the encoder part gets initialized in the two classes explain why that is the case:
BertForSequenceClassification:
https://github.com/huggingface/transformers/blob/c164c651dc382635f1135cf843e8fbd523d5e293/src/transformers/models/bert/modeling_bert.py#L1487-L1494
BertMaskedLM:
https://github.com/huggingface/transformers/blob/c164c651dc382635f1135cf843e8fbd523d5e293/src/transformers/models/bert/modeling_bert.py#L1286-L1289
<|||||>> I am not sure how `compare_two_models` works but it seems that the pooling layer (used for the CLS token) is part of the base BERT model but not the other CLM model architecture.
>
> See here for details of the pooling layer (the authors mistakenly forgot to mention this in the original BERT paper AFAIK): [#7540 (comment)](https://github.com/huggingface/transformers/issues/7540#issuecomment-704155218)
OK, thanks. I was wondering what the pooling layer was for.
You could see the code in the notebook I referenced above, but I will put it here for convenience:
```
import numpy as np
def compare_two_models(m1, m2):
params1 = list(m1.named_parameters())
params2 = list(m2.named_parameters())
layers1 = [(name, params.shape) for name, params in params1]
layers2 = [(name, params.shape) for name, params in params2]
if layers1 != layers2:
print('Models have different architectures')
return False
def _compare_layers(p1, p2):
for i, ((name1, params1), (name2, params2)) in enumerate(zip(p1, p2)):
assert name1 == name2
yield i, name1, np.all(params1.detach().numpy() == params2.detach().numpy())
for i, n, same in _compare_layers(params1, params2):
if not same:
print(f'Models differ on layer {i}: {n}')
```
However, I believe you missed the point of my issue. *Both* `mlm_model` and `mlm_model_from_clm` are masked LM models, and *neither* has a pooling layer. Their architecture is the same. The issue is that the MLM head of `mlm_model_from_clm` is not getting initialized correctly. <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,474 |
closed
|
fix CLIP conversion script.
|
# What does this PR do?
pass `device=cpu` to `load` so that the model is in `fp32`, by default it puts the model in `fp16` if GPU is available.
|
09-08-2021 07:18:36
|
09-08-2021 07:18:36
| |
transformers
| 13,473 |
closed
|
LayoutLMv2 forward pass fails during pytorch.jit.trace forward pass
|
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.10.0
- Platform: Mac OS
- Python version: 3.8.9
- PyTorch version : 1.8.1 No GPU
- Tensorflow version (GPU?):
### Who can help
@NielsRogge @LysandreJik
## Information
Model I am using (LayoutLM V2):
The problem arises when using:
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] my own task or dataset: (give details below)
## To reproduce
I am exporting a LayoutLM model to TorchScript using the documentation here https://huggingface.co/transformers/serialization.html#torchscript .
Steps to reproduce the behavior:
1. load layoutlmv2 model with `torchscript=true`
2. use `pytorch.jit.trace` to do a forward pass on the model with dummy input
3. see the stacktrace:
```
/Users/timothy.laurent/.pyenv/versions/cies-layoutlm-ner/lib/python3.8/site-packages/torch/tensor.py:587: RuntimeWarning: Iterating over a tensor might cause the trace to be incorrect. Passing a tensor of different shape won't change the number of iterations executed (and might lead to errors or silently give incorrect results).
warnings.warn('Iterating over a tensor might cause the trace to be incorrect. '
Traceback (most recent call last):
File "/Users/timothy.laurent/.pyenv/versions/cies-layoutlm-ner/lib/python3.8/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/Users/timothy.laurent/.pyenv/versions/cies-layoutlm-ner/lib/python3.8/site-packages/click/core.py", line 1066, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/Users/timothy.laurent/.pyenv/versions/cies-layoutlm-ner/lib/python3.8/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/Users/timothy.laurent/.pyenv/versions/cies-layoutlm-ner/lib/python3.8/site-packages/typer/main.py", line 497, in wrapper
return callback(**use_params) # type: ignore
File "/Users/timothy.laurent/src/cies-api/apps/layoutlm-ner/scripts/make_torchscript_trace.py", line 42, in main
traced_model = torch.jit.trace(model, [dummy_input['input_ids'], dummy_input['bbox'], dummy_input['image'], dummy_input['attention_mask'], dummy_input['token_type_ids']])
File "/Users/timothy.laurent/.pyenv/versions/cies-layoutlm-ner/lib/python3.8/site-packages/torch/jit/_trace.py", line 733, in trace
return trace_module(
File "/Users/timothy.laurent/.pyenv/versions/cies-layoutlm-ner/lib/python3.8/site-packages/torch/jit/_trace.py", line 934, in trace_module
module._c._create_method_from_trace(
File "/Users/timothy.laurent/.pyenv/versions/cies-layoutlm-ner/lib/python3.8/site-packages/torch/nn/modules/module.py", line 887, in _call_impl
result = self._slow_forward(*input, **kwargs)
File "/Users/timothy.laurent/.pyenv/versions/cies-layoutlm-ner/lib/python3.8/site-packages/torch/nn/modules/module.py", line 860, in _slow_forward
result = self.forward(*input, **kwargs)
File "/Users/timothy.laurent/.pyenv/versions/cies-layoutlm-ner/lib/python3.8/site-packages/transformers/models/layoutlmv2/modeling_layoutlmv2.py", line 1160, in forward
outputs = self.layoutlmv2(
File "/Users/timothy.laurent/.pyenv/versions/cies-layoutlm-ner/lib/python3.8/site-packages/torch/nn/modules/module.py", line 887, in _call_impl
result = self._slow_forward(*input, **kwargs)
File "/Users/timothy.laurent/.pyenv/versions/cies-layoutlm-ner/lib/python3.8/site-packages/torch/nn/modules/module.py", line 860, in _slow_forward
result = self.forward(*input, **kwargs)
File "/Users/timothy.laurent/.pyenv/versions/cies-layoutlm-ner/lib/python3.8/site-packages/transformers/models/layoutlmv2/modeling_layoutlmv2.py", line 873, in forward
position_ids = position_ids.expand(input_shape)
RuntimeError: The expanded size of the tensor (561) must match the existing size (512) at non-singleton dimension 1. Target sizes: [8, 561]. Tensor sizes: [1, 512]
python-BaseException
```
Further investigation in the debugger revealed that this line: https://github.com/huggingface/transformers/blob/4be082ce398b1d1a52fbf2693f1adbe87710928d/src/transformers/models/layoutlmv2/modeling_layoutlmv2.py#L1020
somehow mutates the `input_shape` with its use of the `+=` operator.
```python
import typer
import torch
from transformers import LayoutLMv2Tokenizer, LayoutLMv2TokenizerFast
MAX_BATCH_SIZE = 8
def get_layoutlm_dummy_input(
tokenizer: LayoutLMv2Tokenizer,
batch_size: int = MAX_BATCH_SIZE,
):
text = ["This", "is", "the", "dummy", "input"]
bbox = [[1,2,3,4] for _ in range(len(text))]
encodings = tokenizer(text=[text] * batch_size, boxes=[bbox] * batch_size, padding="max_length", return_tensors='pt')
images = torch.rand(batch_size, 3, 224, 224)
return {
**encodings.data,
'image': images
}
def main(
model_path: str = WANDB_ARTIFACT_PATH,
max_batch_size: int = 8
):
model = LayoutLMv2Model.from_pretrained('microsoft/layoutlmv2-base-uncased')
tokenizer = LayoutLMv2TokenizerFast.from_pretrained("microsorf/layoutlmv2-base-uncased")
dummy_input = get_layoutlm_dummy_input(
tokenizer=tokenizer,
batch_size=max_batch_size
)
# This forward pass works fine
model(dummy_input['input_ids'], dummy_input['bbox'], dummy_input['image'], dummy_input['attention_mask'], dummy_input['token_type_ids'])
# this one the input_size gets mutated resulting in the error above
traced_model = torch.jit.trace(model, [dummy_input['input_ids'], dummy_input['bbox'], dummy_input['image'], dummy_input['attention_mask'], dummy_input['token_type_ids']])
```
## Expected behavior
The forward pass should be successful with running the `torch.jit.trace`
|
09-08-2021 06:42:17
|
09-08-2021 06:42:17
|
LayoutLMv2 is currently not tested to be exportable to TorchScript, as can be seen [here](https://github.com/huggingface/transformers/blob/f5d3bb1dd20e9d2c3c5bd66b30032bea6c3f45d8/tests/test_modeling_layoutlmv2.py#L262). One can set `test_torchscript` to `True` in the tests, and then update `modeling_layoutlmv2.py` in order to make the corresponding tests pass. Feel free to open a PR for this.<|||||>Great thanks for the input @NielsRogge -- I fixed the initially reported issue, and then realized that there are other obstacles with making the torchscript trace so will serve the model with torchserve eager mode.
|
transformers
| 13,472 |
closed
|
[Errno 13] Permission denied: '/.cache'
|
Hello,
I'm using the Dialo-GPT model:
```
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "microsoft/DialoGPT-small"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
```
When I run the above code in server, the error throws:
```
[Errno 13] Permission denied: '/.cache'
```
Does anyone know how to solve this problem? Thanks a lot.
|
09-08-2021 06:40:22
|
09-08-2021 06:40:22
|
It seems like the `/.cache` directory is not writable, you could try changing permissions or you could tell transformers to use a different dir for cache by setting the env variable `HF_HOME`
<|||||>Yes thank you for the answer:)
|
transformers
| 13,471 |
closed
|
BertTokenizerFast can not tokenize [MASK] to 4 id
|
I'm training a bert model and bert tokenizer from scratch on my custom dataset. I'm using BertWordPieceTokenizer to train and BertTokenizerFast to load it. But BertTokenizerFast cannot convert [MASK] token to 4 id. When I try to use BertTokenizer, it works but the process of training model is very slow. Here is my code:
```py
from tokenizers import BertWordPieceTokenizer
tokenizer = BertWordPieceTokenizer(
clean_text=True,
strip_accents=False,
lowercase=False,
)
tokenizer.train(
"./data/bert/training_data.txt",
vocab_size=30000,
min_frequency=2,
show_progress=True,
special_tokens=["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"],
limit_alphabet=1000,
wordpieces_prefix="##",
)
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast(
vocab_file= "bert_tokenizer/vocab.txt",
do_lower_case = False,
max_len=128
)
```
After that I try encode a string with [MASK] token like this
```
tokenizer.encode("Hapi [MASK] cá thát lát rút xương ướp sả 250g")
[2, 5656, 55, 5078, 56, 608, 1829, 730, 789, 906, 1527, 1150, 644, 3]
```
It returns a result that not including id 4 for [MASK] token
Could you please tell me how to fix this problem? Because i'd like to use BertTokenizerFast to boost speed of my training process Thank you.
|
09-08-2021 06:30:11
|
09-08-2021 06:30:11
|
You're loading the `vocab.txt` file and nothing else into the `BertTokenizerFast` so it is unaware of what the special tokens are.
Did you try saving the `tokenizers`' tokenizer object (as a `tokenizer.json` file) and loading that in the `BertTokenizerFast`?<|||||>> You're loading the `vocab.txt` file and nothing else into the `BertTokenizerFast` so it is unaware of what the special tokens are.
>
> Did you try saving the `tokenizers`' tokenizer object (as a `tokenizer.json` file) and loading that in the `BertTokenizerFast`?
Thanks for your response. It works well if I use `BertTokenizerFast.from_pretrained()`
|
transformers
| 13,470 |
closed
|
Deprecate Mirror
|
The mirror option for downloading is now deprecated due to the switching to Git LFS and removal of Tuna.
https://github.com/tuna/issues/issues/937
|
09-08-2021 04:39:19
|
09-08-2021 04:39:19
|
(i am not a maintainer, please wait for maintainer review/approval before merging!) @sgugger @LysandreJik <|||||>> (i am not a maintainer, please wait for maintainer review/approval before merging!) @sgugger @LysandreJik
Oh I'll be more cautious next time (though I'm sure this one is okay)<|||||>> Thanks for the PR and the concept of deprecating this `mirror` argument sounds good but:
>
> - we use proper deprecation warnings for this
>
> - we never do breaking changes between minor releases, so the argument should still behave in the same way for now with the deprecation warning, and we should only change its behavior or remove it for the next major version.
>
>
>
> I think the easiest is to revert this merge and start fresh on a new PR.
Hi @sgugger
I was in a hurry (gonna be on a trip soon). Sorry for rushing for it!
It's not an actual breaking change because the HF mirrors have already been removed from these servers. They are already broken now. The warning is a way to explain why it breaks.
I'll fix it in a new PR. Gonna throw a ValueError with no deprecation warning.<|||||>I am interested in mirroring for another reason, beyond speed, which is security. To use these datasets/models (and wrapper code) in an enterprise setting, one would need to ensure they are properly scanned for security vulnerabilities and malicious code.
Can anyone update me on the status and best method to mirror these (git lfs is fine if necessary, s3 too)?<|||||>Hi @nreith, We have an Enterprise solution for licensing-compatible on-prem syncing of public models/datasets.
Please get in touch with `[email protected]` if you'd like to know more, cc @jeffboudier<|||||>Thanks @julien-c !
I just sent an email. Can you clarify how this would differ from the self-hosted option above, and when the self-hosted option would be available?
|
transformers
| 13,469 |
closed
|
Non-BERT dpr tokenizers
|
# 🚀 Feature request
At the moment `DPRContextReadertokenizer` is subclassing `BertTokenizer` which limits the model choice. Is it possible to use `PreTrainedTokenizer` instead?
## Motivation
We would like to contribute a non-english version of DPR and got stack because our base model uses `XLMTokenizer`. (model was trained on forked and modified version of original dpr script)
## Your contribution
I would love to open a PR with this modification, but really not sure where to start and what is the best choice for the solution.
Here is the link to hf forum is somebody is interested in discussion (I guess this is the best placce to discuss): https://discuss.huggingface.co/t/create-dpr-tokenizer-for-non-bert-model/9735/2
|
09-07-2021 23:43:09
|
09-07-2021 23:43:09
|
cc @lhoestq <|||||>The `DPRReaderTokenizer` is a custom tokenizer that is able to tokenize jointly the three DPR inputs (questions, context titles and context texts).
The custom part is implemented via `CustomDPRReaderTokenizerMixin`, so it should be possible to create a new tokenizer class that inherits from both `CustomDPRReaderTokenizerMixin` and the `XLMTokenizer`. Let me know if that helps
Does this require any change in the `transformers` codebase though ?<|||||>hello @lhoestq and thank you! I have tried inheriting `CustomDPRReaderTokenizerMixin` and our model's class, and it seems to work, but I believe it still isn't compatible with RAG model, as this requires `DPRContextEncoderTokenizerFast` (at least examples).
I think codebase would be necessary at some point, because adding new model will require adding +1 class with right inheritance or switching to `AutoTokenizer` as a base class (this works, but I think it will create some troubles with fast tokenizers)
What do you think about `AutoTokenizer` as a base class?<|||||>> hello @lhoestq and thank you! I have tried inheriting CustomDPRReaderTokenizerMixin and our model's class, and it seems to work, but I believe it still isn't compatible with RAG model, as this requires DPRContextEncoderTokenizerFast (at least examples).
For RAG you don't need the DPR Reader part. Which part of RAG doesn't work with your tokenizer ?
> I think codebase would be necessary at some point, because adding new model will require adding +1 class with right inheritance or switching to AutoTokenizer as a base class (this works, but I think it will create some troubles with fast tokenizers)
So if I understand correctly, the code of the tokenizer you would like to use is not in `transformers` since it's a mix of the XLMTokenizer and some custom code from the DPRReaderTokenizer.
Not sure why AutoTokenizer would work in this case ?<|||||>I am sorry, I made a few mistakes while writing previous post. (also sorry it took so long to reply)
So to make it all clear, I am trying to convert DPR retriever (question and context encoder) trained with original DPR script from Facebook. Base model for encoders is `Herbert` (this is basically `Bert` with `XLMTokenizer`).
I was talking about editing (changing base class from `BertTokenizer`) `DPRContextEncoderTokenizer` and `DPRQuestionEncoderTokenizer` because those parts are needed to create [consolidated rag model](https://github.com/huggingface/transformers/blob/master/examples/research_projects/rag/consolidate_rag_checkpoint.py) and use it with [`finetune_rag.py`](https://github.com/huggingface/transformers/tree/master/examples/research_projects/rag) script.
(I actually, made it work just changing base classes to AutoModel, very dirty, but working solution. But I can't guarantee that this solution won't fire at me at some point, because I am struggling with distributed retriever part in this script and can't confirm that there aren't some pitfalls I am not ever of) <|||||>> I actually, made it work just changing base classes to AutoModel
I think you did right and it should be fine :)<|||||>Ok, so should I open PR with this or just close this issue and work with my local brunch? <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,468 |
closed
|
Use powers of 2 in download size calculations
|
This fix makes `1GB = 1024MB` instead of the default `1000MB` in the `from_pretrained()` progress bars, which makes the download sizes consistent with the HF Hub file sizes.
Thanks to @stas00 for catching this!
|
09-07-2021 20:29:38
|
09-07-2021 20:29:38
|
Thank you, @anton-l!
|
transformers
| 13,467 |
closed
|
Dynamically load model code from the Hub
|
# What does this PR do?
This PR allows a user to upload a modeling file along their model weights, and then lets the `Auto` classes load that model. The API is still a bit manual for now, it will be smoothed in follow-up PRs.
In terms of user of the model, the only thing to add is the flag `trust_remote_code=True` when using an auto class:
```
from transformers import AutoModel
model = AutoModel.from_pretrained("sgugger/test_dynamic_model", trust_remote_code=True)
```
This will load a `FakeModel` as defined in [this file](https://huggingface.co/sgugger/test_dynamic_model/blob/main/modeling.py).
For the person uploading the model there is a tiny bit more work. First save the code of the model (with all necessary imports) in a single python file, for instance `modeling.py`. In the rest of this PR description, I'll use MODELING_FILE to represent the name of that file without the suffix (so in my example of `modeling.py`, MODELING_FILE is "modeling"). That file needs to be in the repository you upload.
Second, add a filed `auto_map` to the configuration of the model you want to upload. This needs to be a dictionary with the name of auto classes as keys, and the full name of the corresponding modeling class as values. By full name, I mean MODELING_FILE.CLASS_NAME. For instance `modeling.FakeModel` for a class `FakeModel` defined in the `modeling.py` module. Here is an example:
```
config.auto_map = {"AutoModel": "modeling.FakeModel"}
```
This needs to be done before the model is saved, so that when doing the `model.save_pretrained` call, the config is saved with that field. Once this is done, push everything to the Hub, and you should be good!
|
09-07-2021 18:57:32
|
09-07-2021 18:57:32
|
Forgive me for interjecting and asking, but does this allow custom modules to be uploaded to modelhub and loaded and run with the official Transformers library ? just to be sure.
If that's the case, do you plan to add some code scanning ? I think on some cases where this would be an security vulnerability for remote code execution<|||||>The PR requires an extra argument in the call to `from_pretrained`: `allow_custom_model=True` to execute the code from the hub. A user should not pass along that flag without having scanned the code of the repo to make sure they trust it.<|||||>Great, thanks for clearing this<|||||>hi, quick question about this PR:
It lets people upload a custom model to the hub great, but it seems that in order to call that model using the API it still requires the model to be using one of the provided Pipelines? Is there any way of also allowing a custom pipeline when calling the custom models? <|||||>Custom pipelines is something we will add support for, it's on the roadmap, but for now you can't use the custom model in the API indeed.
|
transformers
| 13,466 |
closed
|
1x model size CPU memory usage for `from_pretrained`
|
The problem is that currently to load a model using `from_pretrained` requires 2x model size on CPU memory and for those odd cases where a user has large GPU memory, but very little CPU memory it's a problem.
This PR is trying to solve the puzzle of loading "EleutherAI/gpt-j-6B", with revision="float16" and torch_dtype=torch.float16 for the model in full FP16. it shouldn't use more than 12.1GB of cpu RAM to work on colab.
So this should use 12.1GB of CPU memory including peak memory:
```
m = GPTJForCausalLM.from_pretrained("EleutherAI/gpt-j-6B", revision="float16", torch_dtype=torch.float16, low_cpu_mem_usage=True)
```
This of course won't be enough to be used on the free google colab since it has a total of 12GB of CPU RAM for everything, so by the time we come to `from_pretrained` a few GBs will be already consumed by python/torch/transformers, leaving less than 10GB of CPU RAM.
Here is what this PR does:
1. load state_dict and register which keys we have
2. drop state_dict
3. switch to the meta device all params/buffers that are going to be replaced from the loaded state_dict
4. load state_dict 2nd time
5. replace the params/buffers from the state_dict
See the snapshot showing the memory use of just 1x model size and a bit more for temps (this includes peak memory usage).
(The automatic cpu/gpu memory usage reporting in the snapshot is courtesy of https://github.com/stas00/ipyexperiments)
TODO:
- if this gets a green light - need to write a test that measure 1x memory size
@LysandreJik, @sgugger
|
09-07-2021 18:25:40
|
09-07-2021 18:25:40
|
> It looks like the very first state_dict is only instantiated to get the list of keys in the state dict, maybe we should cache that (same path as `resolved_archive_path` but with some extension) so the subsequent loads are a bit faster? What do you think?
I'm all ears if you have suggestions. I'm not sure how we can peek at the list of keys w/o loading the full state_dict. The key is that we can't cache the values, as they consume memory. But you're proposing to just save the keys somewhere on the filesystem.
On the other hand I'm not sure this will be widely used, so perhaps it doesn't have to be super-efficient. I'm not sure.
If this proposal https://github.com/pytorch/pytorch/issues/64327 results in a solution then we should be able to load state_dict's keys w/o loading the dict itself down the road.
<|||||>Also note that this experimental function doesn't handle `missing_keys`, `unexpected_keys`, `mismatched_keys` - so it's more of an experiment still for those who urgently wanted the functionality.<|||||>@stas00 Is this ready to be merged? Sorry for nudging - I tried running `stas00:low-mem-load` and it errors out with an error ("LayerNormKernelImpl" not implemented for 'Half') for which the fix was merged into `huggingface/transformers`.<|||||>I think we have been waiting for the EAI group to confirm that this is what they want since they asked for this feature in the first place, but otherwise there is no reason not to merge it.
I guess let's just do it.
|
transformers
| 13,465 |
closed
|
Enable automated model list copying for localized READMEs
|
# What does this PR do?
Currently, the model list in each localized README such as `README_zh-hans.md` is updated manually, this PR introduces automated model list copying for localized READMEs. A proper tester for this change has been included in this PR.
The model list of a localized README is updated through the following steps:
1. Check if every model in the model list of README.md exists in a localized README, according to the model name e.g. `BERT`.
2. If a model doesn't exist in a localized README, the metadata of the model is fetched from README.md and substituted to a predefined localized format string.
3. Repeat step 1 and 2 until all models are checked.
4. Sort models in a localized model list alphabetically.
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@sgugger
|
09-07-2021 18:04:39
|
09-07-2021 18:04:39
|
@qqaatw Thanks for taking care of this - I'm thinking since currently, the traditional Chinese version of `readme` doesn't translate this list, maybe we can just leave it untranslated for simplified Chinese as well. Does that simplify things?<|||||>@JetRunner Thanks for your reply!
I think this depends on the preference of simplified Chinese users. Translated or not has no difference since this PR introduces a way that directly captures metadata from the English version, and the captured metadata can be substituted into any predefined localized model description format string. Considering If there are more localized READMEs translated in the future, let's say Japanese version of README, this method can also apply to the model list of these READMEs.
In addition, some of models have supplemental data that can be manually translated after automated copying. For example, the text below is the supplemental data of `DistilBERT`:
```
The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/master/examples/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/master/examples/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/master/examples/distillation) and a German version of DistilBERT.
```
The simplified Chinese version has the supplemental data translated, which looks good to me:
```
同样的方法也应用于压缩 GPT-2 到 [DistilGPT2](https://github.com/huggingface/transformers/tree/master/examples/distillation), RoBERTa 到 [DistilRoBERTa](https://github.com/huggingface/transformers/tree/master/examples/distillation), Multilingual BERT 到 [DistilmBERT](https://github.com/huggingface/transformers/tree/master/examples/distillation) 和德语版 DistilBERT。
```<|||||>> @JetRunner Thanks for your reply!
>
>
>
> I think this depends on the preference of simplified Chinese users. Translated or not has no difference since this PR introduces a way that directly captures metadata from the English version, and the captured metadata can be substituted into any predefined localized model description format string. Considering If there are more localized READMEs translated in the future, let's say Japanese version of README, this method can also apply to the model list of these READMEs.
>
>
>
> In addition, some of models have supplemental data that can be manually translated after automated copying. For example, the text below is the supplemental data of `DistilBERT`:
>
> ```
>
> The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/master/examples/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/master/examples/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/master/examples/distillation) and a German version of DistilBERT.
>
> ```
>
> The simplified Chinese version has the supplemental data translated, which looks good to me:
>
> ```
>
> 同样的方法也应用于压缩 GPT-2 到 [DistilGPT2](https://github.com/huggingface/transformers/tree/master/examples/distillation), RoBERTa 到 [DistilRoBERTa](https://github.com/huggingface/transformers/tree/master/examples/distillation), Multilingual BERT 到 [DistilmBERT](https://github.com/huggingface/transformers/tree/master/examples/distillation) 和德语版 DistilBERT。
>
> ```
Sounds great ;)<|||||>One exception I found is that there are few models (GPT-J, GPT-Neo, and T5v1.1) using `released in the repository` not the regular `released with the paper`. The localized description of this kind of models should manually be updated.<|||||>@sgugger The suggestions you provided have been applied. Thanks for the review!<|||||>Just committed one last ypo fix, thanks a lot for your PR!
|
transformers
| 13,464 |
closed
|
Don't modify labels inplace in `LabelSmoother`
|
# What does this PR do?
Currently, the `LabelSmoother` makes an inplace modification in the labels, but those labels are re-used afterward to compute metrics (see [the forums](https://discuss.huggingface.co/t/label-smoothing-and-compute-metrics-in-trainer/9778) for instance). This PR fixes that issue
|
09-07-2021 17:00:07
|
09-07-2021 17:00:07
| |
transformers
| 13,463 |
closed
|
Upcasting of attention computation for reliable pretraining of GPT-2 models
|
# 🚀 Feature request
In a recent [talk](https://youtu.be/AYPOzc50PHw?t=3662) about pretraining language models as part of the [Mistral](https://github.com/stanford-crfm/mistral/) project @siddk mentioned that in order to achieve stable pretraining a slight modification in the GPT-2 code is necessary. The issue is a numerical instability when training with mixed precision in the attention mechanism which can be solved by upcasting the attention computation (see [here](https://github.com/stanford-crfm/mistral/blob/53ebb290e55fe367dcaebb54ab63de4a137802db/src/models/mistral_gpt2.py#L324)).
## Motivation
Enable reliable pretraining of GPT-2 models.
## Your contribution
I can create a PR if adding this is an option.
cc @thomwolf
|
09-07-2021 16:14:27
|
09-07-2021 16:14:27
|
Also related are https://github.com/huggingface/huggingface_hub/issues/300 and https://github.com/stanford-crfm/mistral/issues/86 <|||||>Hey folks, sorry I'm late to the party. Replying here to just to centralize things.
The upcasting + scaled-dot product attn reordering + scaling implemented in Mistral is a pretty straightforward tweak on top of the existing GPT-2 model definition in `transformers`. The only other change we made was the weight initialization procedure for GPT-2 models, which shouldn't affect anyone downstream.
If you give me a day or two, I can do the following:
- Submit a PR to `transformers` with a flag for turning on "mistral" (upcasting of scaled-dot product attention)
- Edit the GPT2Config and Arguments to reflect this flag... ensure `.from_pretrained()` works as expected.
- Fix the GPT2 weight initialization.
This would 1) be simple, 2) be easy for anyone looking to use the Mistral models in the future, and 3) would stop us from defining a new "MistralGPT" class (which we might do anyway for v2 when we add other types of parallelism and the like.
What do y'all think?
@osanseviero @lvwerra @thomwolf @LysandreJik <|||||>Hi @siddk, that sounds good to me. I would like to start training a larger model in the coming days so that would be very welcome on my side :)
|
transformers
| 13,462 |
closed
|
A Space Always Prefixes The First Token of `xlm-roberta-large` Encoding Results
|
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 3.5.1
- Platform: Linux-4.4.0-140-generic-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyTorch version (GPU?): 1.6.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- xlm: @LysandreJik
Library:
- tokenizers: @LysandreJik
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
xlm-roberta tokenizer @LysandreJik
## Information
Model I am using (XLM-Roberta-Large and Roberta-Large):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('roberta-large')
print(tokenizer.convert_ids_to_tokens(tokenizer.encode('I am good.')))
print(tokenizer.decode(tokenizer.encode('I am good.')))
tokenizer = AutoTokenizer.from_pretrained('roberta-large', use_fast=True)
print(tokenizer.convert_ids_to_tokens(tokenizer.encode('I am good.')))
print(tokenizer.decode(tokenizer.encode('I am good.')))
tokenizer = AutoTokenizer.from_pretrained('xlm-roberta-large')
print(tokenizer .convert_ids_to_tokens(tokenizer.encode('I am good.')))
print(tokenizer.decode(tokenizer.encode('I am good.')))
tokenizer = AutoTokenizer.from_pretrained('xlm-roberta-large', use_fast=True)
print(tokenizer .convert_ids_to_tokens(tokenizer.encode('I am good.')))
print(tokenizer.decode(tokenizer.encode('I am good.')))
```
This produces
```
['<s>', 'I', 'Ġam', 'Ġgood', '.', '</s>']
<s>I am good.</s>
['<s>', 'I', 'Ġam', 'Ġgood', '.', '</s>']
<s>I am good.</s>
['<s>', '▁I', '▁am', '▁good', '.', '</s>'] # note ▁I instead of I
<s> I am good.</s> # note that here is a space between <s> and I
['<s>', '▁I', '▁am', '▁good', '.', '</s>'] # note ▁I instead of I
<s> I am good.</s> # note that here is a space between <s> and I
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
Decoding the encoded sentence should have the same result except the `<s>` and `</s>` special tokens as shown similarly in [XLM's GitHub README](https://github.com/facebookresearch/XLM#xlm-r-new-model).
<!-- A clear and concise description of what you would expect to happen. -->
```
['<s>', 'I', 'Ġam', 'Ġgood', '.', '</s>']
<s>I am good.</s>
['<s>', 'I', 'Ġam', 'Ġgood', '.', '</s>']
<s>I am good.</s>
['<s>', 'I', '▁am', '▁good', '.', '</s>'] # I instead of ▁I
<s>I am good.</s> # no space before I
['<s>', 'I', '▁am', '▁good', '.', '</s>'] # I instead of ▁I
<s>I am good.</s> # no space before I
```
|
09-07-2021 09:41:04
|
09-07-2021 09:41:04
|
Maybe of interest to @SaulLu <|||||>Thank you for your detailed issue.
I just tested the original XLM-R tokenizer and it seems to me that our tokenization matches well with the one in the repository you mention.
Indeed, by doing (see [Google collaboratory notebook](https://colab.research.google.com/drive/1kNwkctnbB_A646dAvWdtSkbJnjKaj06P?usp=sharing)) :
```
import torch
xlmr = torch.hub.load('pytorch/fairseq', 'xlmr.large')
xlmr.eval()
tokens = xlmr.encode('I am good I am goodI am good.')
print([(xlmr.decode(torch.tensor([token])), token.item()) for token in tokens])
```
We get:
```
[('', 0),
('I', 87),
('am', 444),
('good', 4127),
('I', 87),
('am', 444),
('good', 4127),
('I', 568),
('am', 444),
('good', 4127),
('.', 5),
('', 2)]
```
The last line of the above code snippet allows us to see which token is associated with which id and in particular to see that the "I" at the beginning of the sentence and the one in the middle share the same id whereas the last "I" appended to another word is associated with a different id.
In the HF framework this means that `id=87` -> `'▁I'` and `id=568` -> `'I'`. Therefore, I would tend to agree with `tokenizer .convert_ids_to_tokens(tokenizer.encode('I am good.'))`'s current output.
Does this answer your question? Am I missing something? :slightly_smiling_face:
<|||||>Thank you for your prompt reply and a clear example.
1. I agree with you that `tokenizer.convert_ids_to_tokens(tokenizer.encode('I am good.'))` works as `xlmr` does
2. What about `tokenizer.decode(tokenizer.encode('I am good.'))`? It now gives out `<s> I am good.</s>` (note the space between `<s>` and `I`). Shouldn't it be `<s>I am good.</s>`?
I know `▁` means a leading space in `SentencePiece` used by XLM-Roberta as in https://github.com/google/sentencepiece#what-is-sentencepiece. In addition, when the sub-word is at the beginning of the sentence, it is also prefixed with `▁` even though it has no leading space, which makes sense because it discerns the sub-word piece continuing the previous one and one that denotes a boundary. But when we want to decode the encoded string, `SentencePiece` takes out the leading space if the sub-word has `▁` leading space, while in HF's tokenizer, it does not.
> The inserted `<s>` special token also add one before the whole sentence, making the original first sub-word not the first anymore. Maybe special token should be neglected when determining which one is the first sub-word.
> I know in SentencePiece, it does not add special token `<s>`, which is in `xlmr`. `xlmr` does not decode `id=0` to `<s>` and `id=2` to `</s>` but all to empty string, and so `xlmr.decode(xlmr.encode('I am good.'))` actually outputs simple `I am good`.
I know this is just a very minor issue. I am just using `decode` method and also trying to do some offset calculation. Maybe I should not rely on `decode` method but the `offsets_mapping` one.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,461 |
closed
|
In ViT model, last_hidden_state is not equal to hidden_states[-1]
|
When input the same image, in Google ViT model output.last_hidden_state is not equal to output.hidden_states[-1] ?
I tried in Bert, the outputs are the same.
```
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
model = ViTModel.from_pretrained('google/vit-base-patch16-224-in21k')
inputs = feature_extractor(images=[image], return_tensors="pt")
outputs = model(pixel_values=inputs['pixel_values'], output_hidden_states=True)
vec1 = outputs.hidden_states[-1][0, 0, :]
vec2 = outputs.last_hidden_state[0, 0, :]
```
in my mind, vec1 should be the same as vec2. But the fact is they are not the same at all.
|
09-07-2021 08:25:18
|
09-07-2021 08:25:18
|
Hi,
The Vision Transformer also applies a final layer norm after the several encoder layers (blocks), as can be seen [here](https://github.com/huggingface/transformers/blob/92d4ef9ab038dfbbe02556375c4c3c14215b37d2/src/transformers/models/vit/modeling_vit.py#L553). This explains why `outputs.last_hidden_state` is not equal to `outputs.hidden_states[-1]`.<|||||>@NielsRogge THX~
|
transformers
| 13,460 |
closed
|
when I overwrite a model,I meet some bugs like this
|
ok,when I firstly overwrite a bert-bigru-crf model,i meet som bugs.
this is the model
``` python3
from torchcrf import CRF
from torch import nn
from transformers import BertModel, PreTrainedModel
class Bert_BiGru_Crf(PreTrainedModel):
''' I want define a bert-bigru-crf model end-to-end,and i know how to define this model by torch.nn.Module
'''
def __init__(self, config):
super().__init__(config)
self.bert = BertModel(config)
self.gru = nn.GRU(768,
768,
num_layers=2,
bidirectional=True)
self.fc = nn.Linear(768 * 2, 15) # BOS EOS
self.crf = CRF(13, batch_first=True)
def froward(self, text, label):
out = self.bert(**text) # this text is above input_ids and attention mask
output, _ = self.gru(out.last_hidden_state)
output = self.fc(output)
loss = self.crf(output, label)
pred = self.crf .decode(output, text['attention_mask']) # decoder need mask
return output, pred, loss
```
and i use `Bert_BiGru_Crf.from_pretrained(model_path)`,`model_path is a bert model path`
i got some bugs like those:
```
Traceback (most recent call last):
File "C:/Users/wie/Documents/项目/ner/bert-crf/train.py", line 103, in <module>
train()
File "C:/Users/wie/Documents/项目/ner/bert-crf/train.py", line 42, in train
embed_model = model.Bert_BiGru_Crf.from_pretrained(model_path)
File "C:\Users\wie\Miniconda3\lib\site-packages\transformers\modeling_utils.py", line 1067, in from_pretrained
config, model_kwargs = cls.config_class.from_pretrained(
AttributeError: 'NoneType' object has no attribute 'from_pretrained'
```
``` python3
# Name Version Build Channel
pytorch-transformers 1.2.0 pypi_0 pypi
transformers 4.6.1 pypi_0 pypi
pytorch-crf 0.7.2 pypi_0 pypi
pytorch-lightning 1.4.4 pypi_0 pypi
torch 1.8.1+cpu pypi_0 pypi
torchaudio 0.8.1 pypi_0 pypi
torchmetrics 0.5.0 pypi_0 pypi
torchtext 0.9.1 pypi_0 pypi
torchvision 0.9.1+cpu pypi_0 pypi
```
my python vesion is 3.7.9
would you mind to help me slove this problem?
|
09-07-2021 08:00:02
|
09-07-2021 08:00:02
| |
transformers
| 13,459 |
closed
|
Add `tokenizer_max_length` to `cardiffnlp/twitter-roberta-base-sentiment`
|
[cardiffnlp/twitter-roberta-base-sentiment](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment) is one of the most downloaded `text-classification` models on the hub.
But there is a small little bug, when using the model with `seq_len` > 515, see image

To fix this we would need to add `tokenizer_max_length` attribute in a `tokenizer_config.json` on the hub for that model.
@cardiffnlp would it be okay for you to add it? I am happy to make the change.
|
09-07-2021 07:56:27
|
09-07-2021 07:56:27
|
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,458 |
closed
|
Translation takes too long - from fine-tuned mbart-large-50 model
|
I have fine-tuned from, facebook mbart-large-50 for Si-En language pairs. When I try to translate 1950 sentences as (1) full batch (2) batch size=16 etc. still process crashes.
I then passed 16-lines per batch, ie. as **src_lines** and it takes considerable time.
Could you help on how I can reduce the translation time? My code is as follows.
Highly appreciate your help.
**However from the fairseq fine-tuned checkpoint the entire file can be translated in 2 mints in the same machine.**
tokenizer = MBart50TokenizerFast.from_pretrained("mbart50-ft-si-en-run4", src_lang="si_LK", tgt_lang="en_XX")
model_inputs = tokenizer(src_lines, padding=True, truncation=True, max_length=100, return_tensors="pt")
generated_tokens = model.generate(
**model_inputs,
forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
trans_lines=tokenizer.batch_decode(generated_tokens, skip_special_tokens=True) #crashes
|
09-07-2021 05:04:58
|
09-07-2021 05:04:58
|
Hello! Could you provide a reproducible code example so that we may take a look?<|||||>from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
#mbart50-ft-si-en-run4 the fine-tuned model directory
tokenizer = MBart50TokenizerFast.from_pretrained("mbart50-ft-si-en-run4", src_lang="si_LK", tgt_lang="en_XX")
model = MBartForConditionalGeneration.from_pretrained("mbart50-ft-si-en-run4/checkpoint-21500")
#The file has 1950 lines
src_lines=[line.strip() for line in open('data/parallel-27.04.2021-tu.un.si-en-ta.si', 'r', encoding='utf8')]
model_inputs = tokenizer(src_lines, padding=True, truncation=True, max_length=100, return_tensors="pt")
generated_tokens = model.generate(
**model_inputs,
forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
trans_lines=tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
Please refer the code I am trying as above.
The above code works when a subset of about 10 examples are given. ie. len(src_lines)=10.
I am having trouble translating the full batch.
<|||||>Hi @aloka2209
Thank you for opening the issue. Could you please provide more details?
- Are you using GPU ? fairseq would use GPU if it's available, we need to do this manually with Transformers models.
- Is the fairseq model in fp16 ? By default Transformers models are in `fp32`
- what are the generation params, i.e num_beams, `max_length` etc ? both for fairseq model and for Transformers models.
For transformer models, you could find these values in `config`<|||||>Hi @patil-suraj
Thank you for your attention regarding this issue.
For the same training, tuning and testing sets I have conducted a fine-tuning from mbart-large-50 pre-trained model for Si-En languages, using fairseq and huggingface.
### Fairseq fine-tuning
The preprocessing, fine-tuning & generation parameter settings have been followed according to example in [github](https://github.com/pytorch/fairseq/tree/579a48f4be3876082ea646880061a98c94357af1/examples/multilingual).
I have used the gpu for fine-tuning with fp16, max-tokens 1024 as parameters.
Generation command as follows:
cat data-spm/test_si_en.bpe.si_LK \
| fairseq-interactive $path_2_data \
--path $model \
--task translation_multi_simple_epoch \
--lang-dict $lang_list \
--lang-pairs $lang_pairs \
--source-lang $source_lang \
--target-lang $target_lang \
--batch-size 32 \
--remove-bpe 'sentencepiece' \
--buffer-size 32 \
--encoder-langtok 'src' \
--decoder-langtok \
> 'data/test_si_en.stdout.si_LK_en_XX'
To translate 1950 Si lines the following times are taken.
gpu - 3 mints
### Huggingface fine-tuning
From the model hub I obtained the facebook/mbart-large-50 model and used the following code to fine tune for Si-En languages. The above training, validation, testing sets were used.
>
> model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50")
> tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50", src_lang="si_LK", tgt_lang="en_XX")
>
> #initialized model parameters
> args = Seq2SeqTrainingArguments(output_dir='mbart50-ft-si-en-run4',
> do_train=True,
> do_eval=True,
> evaluation_strategy="epoch",
> per_device_train_batch_size=16,
> per_device_eval_batch_size=16,
> learning_rate=2e-5,
> weight_decay=0.01,
> save_total_limit=12,
> num_train_epochs=120,
> predict_with_generate=True,
> save_steps=500)
>
>
> trainer = Seq2SeqTrainer(model=model,
> args=args,
> data_collator=data_collator,
> train_dataset=train_data,
> eval_dataset=valid_data,
> compute_metrics=compute_metrics,
> tokenizer=tokenizer)
>
>
> trainer.train()
Few things I need to confirm with fine-tuning
- Are the training hyper parameters I have used are correct?
- I have used the fp16 during hf fine-tuning
- Although I have given the max_length=100 in config.json file its recorded as "max_length": 200. Is 200 a default value?
- I have set the num_train_epochs=120 as the fairseq best checkpoint obtained was at epoch 120
- gradient_accumulation_steps=16. My training set is 56K lines. Since my batch size is 16, should this value be 3500 (56K/16)?
My generation command as follows.
> from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
>
> #mbart50-ft-si-en-run4 the fine-tuned model directory
> tokenizer = MBart50TokenizerFast.from_pretrained("mbart50-ft-si-en-run4", src_lang="si_LK", tgt_lang="en_XX")
> model = MBartForConditionalGeneration.from_pretrained("mbart50-ft-si-en-run4/checkpoint-21500")
>
>
> model_inputs = tokenizer(src_lines, padding=True, truncation=True, max_length=100, return_tensors="pt")
> generated_tokens = model.generate(
> **model_inputs,
> forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
>
> trans_lines=tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
I have tried to pass the entire batch as above. Then the task crashes
Afterwards I tried with trans_lines=tokenizer.batch_decode(generated_tokens,
batch_size=32, skip_special_tokens=True). But this takes a long time. So I have stopped it.
Highly appreciate your help on improving the fine-tuning and/or generation. Many Thanks.
<|||||>Hi,
Please report one issue at a time, as the original issue is about `generation`, let's talk about that :)
Also it would be nice if you could please format code using [markdown code syntax ](https://docs.github.com/en/github/writing-on-github/working-with-advanced-formatting/creating-and-highlighting-code-blocks), otherwise the code is hard to read.
Looking at the generation code snippet it seems that the model is not on GPU, to put the model on GPU which could explain the slowdown.
```python
model = MBartForConditionalGeneration.from_pretrained("mbart50-ft-si-en-run4/checkpoint-21500").to("cuda")
```
Also, you are passing all 2000 examples at once to `tokenizer` and `model`, which could again explain why tokenization is low. If you look at the `fairseq` command, it accepts a `batch_size` argument and does generation for one batch at a time.
If you pass all 2000 examples at once it might OOM on GPU. You could instead create a `Dataset` and `DataLoader` do generation for each batch.
Hope this helps :)<|||||>I have added the fine-tuning related questions to the forum and would appreciate your answers. Sorry for getting everything here.
I have used the gpu command as suggested and now it translates fast. Thank you!
One of my intentions is to get this translated in cpu setting. So earlier I tried by feeding the inputs in 16-line batches and then by changing the batch_size parameter during generation. Still, it was taking a long time.
ie.
```python
trans_lines=tokenizer.batch_decode(generated_tokens, batch_size=32, skip_special_tokens=True)
```
Are there any suggestions where I can still cut-down the translation time in cpu?
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,457 |
closed
|
Can I use input embeds to generate text without input ids
|
# 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
|
09-07-2021 01:38:03
|
09-07-2021 01:38:03
|
this might help #10599<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,456 |
closed
|
Fix img classification tests
|
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes unittest issues from #13134. First there was an issue of missing `torchvision`, which was resolved with #13438 , but when that didn't fix it we skipped `test_run_image_classification` with #13451
Additionally, I added a [test dataset](https://huggingface.co/datasets/hf-internal-testing/cats_vs_dogs_sample) to our internal testing org on huggingface.co, which is what we're using in the test now. Its 50 examples from the `cats_vs_dogs` dataset instead of the 10 that were in the text fixtures before.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-07-2021 01:31:05
|
09-07-2021 01:31:05
| |
transformers
| 13,455 |
closed
|
[docs] update dead quickstart link on resuing past for GPT2
|
Thed dead link have been replaced by two links of forward and call methods of the GPT2 class for torch and tensorflow respectively.
# What does this PR do?
This PR replaces the dead link with two new links on showing how to reuse the precomputed attention values.
Fixes #13434
## Before submitting
- [ X] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
|
09-06-2021 20:22:29
|
09-06-2021 20:22:29
|
> Thanks a lot for fixing!
>
> Could you just run `make style` on your branch to fix the code quality issue?
Done.<|||||>Thanks again!
|
transformers
| 13,454 |
closed
|
Update version of `packaging` package
|
This fixes an error when using packaging<20.0 with transformers.
With `packaging==19.0`:
```python
ipython3
Python 3.6.14 (default, Jun 29 2021, 00:00:00)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.6.1 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import transformers
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-1-279c49635b32> in <module>
----> 1 import transformers
~/.local/lib/python3.6/site-packages/transformers/__init__.py in <module>
41
42 # Check the dependencies satisfy the minimal versions required.
---> 43 from . import dependency_versions_check
44 from .file_utils import (
45 _LazyModule,
~/.local/lib/python3.6/site-packages/transformers/dependency_versions_check.py in <module>
34 if pkg == "tokenizers":
35 # must be loaded here, or else tqdm check may fail
---> 36 from .file_utils import is_tokenizers_available
37
38 if not is_tokenizers_available():
~/.local/lib/python3.6/site-packages/transformers/file_utils.py in <module>
310 if _torch_available:
311 torch_version = version.parse(importlib_metadata.version("torch"))
--> 312 _torch_fx_available = (torch_version.major, torch_version.minor) == (
313 TORCH_FX_REQUIRED_VERSION.major,
314 TORCH_FX_REQUIRED_VERSION.minor,
AttributeError: 'Version' object has no attribute 'major'
```
This is fixed with `packaging>=20.0`
The `major` attribute was added in v20.0 of `packaging`. [Relevant changelog](https://packaging.pypa.io/en/latest/changelog.html#id11) excerpt:
> 20.0 - 2020-01-06¶
> Add major, minor, and micro aliases to packaging.version.Version (#226)
Therefore, have constrained version of packaging to '>=20.0'.
Please let me know if there are any setup.py-related tests to be updated.
CC @stas00 @sgugger
|
09-06-2021 19:12:07
|
09-06-2021 19:12:07
| |
transformers
| 13,453 |
closed
|
Multi-GPU memory usage
|
Hi - I am just using the Seq2SeqTrainer for a fairly vanilla BART fine-tuning use case. In a multi-GPU setup, the memory, however, is really high for the first GPU (15GB and lower (as expected) for the other 7 (5GB). What could be causing this? Here are my training arguments.
> training_args = Seq2SeqTrainingArguments(
run_name=args.experiment,
output_dir='./results', # output directory
overwrite_output_dir=True,
max_steps=20000, # total number of optimization steps
per_device_train_batch_size=8, # batch size per device during training
per_device_eval_batch_size=8, # batch size for evaluation
eval_accumulation_steps=1,
warmup_steps=0 if args.debug else 200, # number of warmup steps for learning rate scheduler
weight_decay=0, # strength of weight decay
logging_dir='./logs', # directory for storing logs
logging_steps=10,
logging_first_step=True,
no_cuda=args.cpu,
fp16=True,
do_train=True,
do_eval=True,
do_predict=True,
learning_rate=5e-5,
dataloader_num_workers=0 if args.debug else 8,
label_smoothing_factor=0.1,
save_strategy='steps',
save_steps=999999 if args.debug else 2500,
save_total_limit=3,
seed=1992,
evaluation_strategy='steps',
eval_steps=999999 if args.debug else 2500,
load_best_model_at_end=True,
metric_for_best_model='mean_f1',
greater_is_better=True,
)
|
09-06-2021 17:13:37
|
09-06-2021 17:13:37
|
cc @sgugger <|||||>How are you launching your script? If you are using `python` and not the `torch.distributed.launch` module, then this is completely normal as the gradients and optimizer state are only stored on GPU 0, not the other ones.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,452 |
closed
|
New debug wav2vec2 flax
|
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-06-2021 16:53:06
|
09-06-2021 16:53:06
|
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,451 |
closed
|
skip image classification example test
|
# What does this PR do?
The image classification example test is still faling, https://app.circleci.com/pipelines/github/huggingface/transformers/27636/workflows/fad6d0a8-e8fa-413b-a519-a4794673749a/jobs/268590
Skip the test for now, until fixed (cc @nateraw)
|
09-06-2021 15:57:16
|
09-06-2021 15:57:16
|
Thanks!<|||||>Thank you! Will take a look
|
transformers
| 13,450 |
closed
|
T5Tokenizer.from_pretrained("t5-small") returning NoneType
|
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version: Python 3.7.11
- PyTorch version (GPU?): 1.9.0+cu102
- Tensorflow version (GPU?): 2.6.0
-Google colab
### Who can help
@patrickvonplaten, @patil-suraj @sgugger @LysandreJik
Models:
- t5: @patrickvonplaten, @patil-suraj
Library:
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
-->
## Information
Model I am using (Bert, XLNet ...): t5
The problem arises when using:
* [ ] the official example scripts: (give details below)
tokenizer = T5Tokenizer.from_pretrained("t5-small")
## To reproduce
Steps to reproduce the behavior:
using google colab
1. tokenizer = T5Tokenizer.from_pretrained("t5-small") as in
https://huggingface.co/transformers/model_doc/t5.html#transformers.T5Tokenizer
2. type(tokenizer) -->NoneType
## Expected behavior
tokenizer should not be NoneType
<!-- A clear and concise description of what you would expect to happen. -->
|
09-06-2021 15:34:33
|
09-06-2021 15:34:33
|
Hi there,
PLEASE, do not tag so many people in an issue, usually just tag one or two maintainers. Tagging everyone will unnecessarily disturb. While we are happy to answer, we would expect people to consider this before opening an issue. Thanks.
Now regarding your issue, did you install `sentencpiece` ? If not the you could
```pip install sentencepiece```
and restart the colab.<|||||>hi Suraj,
Thanks. It is working.
|
transformers
| 13,449 |
closed
|
Making it raise real errors on ByT5.
|
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-06-2021 14:22:57
|
09-06-2021 14:22:57
| |
transformers
| 13,448 |
closed
|
[EncoderDecoder] Fix torch device in tests
|
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes https://github.com/huggingface/transformers/pull/13406#issuecomment-913628552 @LysandreJik
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-06-2021 13:23:17
|
09-06-2021 13:23:17
|
Thank you!
|
transformers
| 13,447 |
closed
|
Adding a test for multibytes unicode.
|
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-06-2021 13:20:34
|
09-06-2021 13:20:34
| |
transformers
| 13,446 |
closed
|
[PyTorch Tests] Fix torchvision test
|
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-06-2021 13:16:18
|
09-06-2021 13:16:18
|
Already fixed
|
transformers
| 13,445 |
closed
|
[WIP] Fix CLIPTokenizerFast
|
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #12648
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-06-2021 11:59:40
|
09-06-2021 11:59:40
|
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,444 |
closed
|
Adding GPT2 for translation/summarization
|
# 🚀 Feature request
Hi
In the code base GPT-2 is not listed as the model compatible for summarization and translation. Is there a reason for this?
## Motivation
GPT-2 is one of the most important seq2seq models and many papers build on top of it. It would be great to include this model.
Thanks.
|
09-06-2021 11:11:28
|
09-06-2021 11:11:28
|
The `run_summarization.py` and `run_translation` scripts are designed for encoder-decoder (also called seq2seq) models like T5, BART, PEGASUS.
However, GPT-2 is a Transformer decoder-only model. This model is also capable of doing summarization/translation, but it would be solved in a different way. GPT-2 is just a language model (i.e. it predicts the next token given the previous ones). So you could fine-tune GPT-2 using the [`run_clm.py`](https://github.com/huggingface/transformers/tree/master/examples/pytorch/language-modeling) script. OpenAI has done this for example in [this paper]().
What typically happens is one provides the text, appended by "TDLR: " to the model, and the model is then capable of generating a summary (just because it is trained on a large portion of the internet).
<|||||>I was actually looking for this to do some Legal Text Summarization. Thanks Niels for explaining it well. Looks like I need to do it on a different model. Do you have any model to suggest that works well with legal text?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,443 |
closed
|
Error while saving a variation of roberta-base fast tokenizer vocabulary
|
## Information
Unable to save 'ufal/robeczech-base' fast tokenizer, which is a variation of roberta. I have tried the same minimal example (see below) with non-fast tokenizer and it worked fine.
### Error message with a `RUST_BACKTRACE=1`:
```
thread '<unnamed>' panicked at 'no entry found for key', /__w/tokenizers/tokenizers/tokenizers/src/models/mod.rs:36:66
stack backtrace:
0: rust_begin_unwind
at /rustc/9bc8c42bb2f19e745a63f3445f1ac248fb015e53/library/std/src/panicking.rs:493:5
1: core::panicking::panic_fmt
at /rustc/9bc8c42bb2f19e745a63f3445f1ac248fb015e53/library/core/src/panicking.rs:92:14
2: core::option::expect_failed
at /rustc/9bc8c42bb2f19e745a63f3445f1ac248fb015e53/library/core/src/option.rs:1321:5
3: serde::ser::Serializer::collect_map
4: <tokenizers::models::bpe::model::BPE as tokenizers::tokenizer::Model>::save
5: <tokenizers::models::ModelWrapper as tokenizers::tokenizer::Model>::save
6: tokenizers::models::PyModel::save
7: tokenizers::models::__init2250971146856332535::__init2250971146856332535::__wrap::{{closure}}
8: tokenizers::models::__init2250971146856332535::__init2250971146856332535::__wrap
9: _PyMethodDef_RawFastCallKeywords
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Objects/call.c:694:23
10: _PyCFunction_FastCallKeywords
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Objects/call.c:734:14
11: call_function
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:4568:9
12: _PyEval_EvalFrameDefault
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:3139:19
13: _PyEval_EvalCodeWithName
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:3930:14
14: _PyFunction_FastCallKeywords
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Objects/call.c:433:12
15: call_function
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:4616:17
16: _PyEval_EvalFrameDefault
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:3139:19
17: _PyEval_EvalCodeWithName
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:3930:14
18: _PyFunction_FastCallKeywords
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Objects/call.c:433:12
19: call_function
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:4616:17
20: _PyEval_EvalFrameDefault
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:3139:19
21: _PyEval_EvalCodeWithName
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:3930:14
22: _PyFunction_FastCallKeywords
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Objects/call.c:433:12
23: call_function
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:4616:17
24: _PyEval_EvalFrameDefault
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:3110:23
25: _PyEval_EvalCodeWithName
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:3930:14
26: PyEval_EvalCodeEx
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:3959:12
27: PyEval_EvalCode
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/ceval.c:524:12
28: run_mod
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/pythonrun.c:1035:9
29: PyRun_InteractiveOneObjectEx
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/pythonrun.c:256:9
30: PyRun_InteractiveLoopFlags
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/pythonrun.c:120:15
31: PyRun_AnyFileExFlags
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Python/pythonrun.c:78:19
32: pymain_run_file
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Modules/main.c:427:11
33: pymain_run_filename
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Modules/main.c:1606:22
34: pymain_run_python
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Modules/main.c:2867:9
35: pymain_main
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Modules/main.c:3028:5
36: _Py_UnixMain
at /tmp/eb-build/Python/3.7.4/GCCcore-8.3.0/Python-3.7.4/Modules/main.c:3063:12
37: __libc_start_main
38: <unknown>
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/ryparmar/venv/NER/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 2034, in save_pretrained
filename_prefix=filename_prefix,
File "/home/ryparmar/venv/NER/lib/python3.7/site-packages/transformers/tokenization_utils_fast.py", line 567, in _save_pretrained
vocab_files = self.save_vocabulary(save_directory, filename_prefix=filename_prefix)
File "/home/ryparmar/venv/NER/lib/python3.7/site-packages/transformers/models/gpt2/tokenization_gpt2_fast.py", line 177, in save_vocabulary
files = self._tokenizer.model.save(save_directory, name=filename_prefix)
pyo3_runtime.PanicException: no entry found for key
```
## Environment info
- `transformers` version: 4.10.0
- Platform: Linux-3.10.0-957.10.1.el7.x86_64-x86_64-with-centos-7.8.2003-Core
- Python version: 3.7.4
- PyTorch version (GPU?): 1.9.0+cu102 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: False
- Using distributed or parallel set-up in script?: False
### Who can help
@patrickvonplaten, @LysandreJik.
## To reproduce
1. Import model and tokenizer:
```
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("ufal/robeczech-base")
model = AutoModelForMaskedLM.from_pretrained("ufal/robeczech-base")
```
2. Save the tokenizer:
```
tokenizer.save_pretrained('./')
```
|
09-06-2021 09:56:05
|
09-06-2021 09:56:05
|
There seems to be some tokens missing/non-consecutive tokens in the vocabulary of that tokenizer, causing the serialization to fail<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>The issue is still there. Is anyone able to save the tokenizer with: tokenizer.save_pretrained() ?<|||||>Facing the exact problem while working with "sagorsarker/bangla-bert-base" using the same reproduce instruction provided by @ryparmar. And still could not solve this issue, even the root cause of this error.<|||||>I found the the problem is from using fast tokenizer. so I turned it of using flag `--use_fast_tokenizer=False`, and it is ok. Though it is not solution I want.<|||||>Hey guys,
At the moment, it seems like we will have to fall back to the slow tokenizer for this one:
1. Import model and tokenizer:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("ufal/robeczech-base", use_fast=False)
model = AutoModelForMaskedLM.from_pretrained("ufal/robeczech-base")
```
2. Save the tokenizer:
```
tokenizer.save_pretrained('./')
```
works.<|||||>Hi all,
I just committed a working fast tokenizer to the HF `ufal/robeczech-base` repository, in case it helps someone (but loading a fast tokenizer from the previous repository content was working too).
The reason why it cannot be saved is our own mistake (the authors of the `ufal/robeczech-base` model). During training, the subwords not present in the training data were left out from the dictionary, but ByteBPE requires the basic 256 subwords representing the 256 byte value, and some of the were left out. We therefore have multiple subwords mapped to id 3 (the id of `[UNK]` token), which seems to be working fine during loading, but not during saving (only one subword with id 3 is saved).
Sorry for the trouble...
|
transformers
| 13,442 |
closed
|
Unexpected result when tokenizing a single token rather than a sentence with multilingual tokenizer
|
I want to check how a word is divided into sub-words, but I found an unexpected result.
e.g. mbart:
```python
mbart_tokenizer = AutoTokenizer.from_pretrained('facebook/mbart-large-cc25', use_fast=True)
mbart_tokenizer.tokenize('.')
>>> ['▁', '.']
mbart_tokenizer.tokenize('a dog.')
>>> ['▁a', '▁dog', '.']
```
Why the `'.'` is tokenized to two sub-words `['▁', '.']` when it is a single token but to `'.'` when it is a part of a sentence?
e.g. mT5
```python
t5_tokenizer = T5Tokenizer.from_pretrained("google/mt5-small")
t5_tokenizer.tokenize('.')
>>> ['▁', '.']
t5_tokenizer.tokenize('a')
>>> ['▁', 'a']
mbart_tokenizer.tokenize('a dog.')
>>> ['▁', 'a', '▁dog', '.']
```
|
09-06-2021 09:39:20
|
09-06-2021 09:39:20
| |
transformers
| 13,441 |
closed
|
Could you support other distributed training backends from command line, I'm using GLOO.
|
https://github.com/huggingface/transformers/blob/76c4d8bf26de3e4ab23b8afeed68479c2bbd9cbd/src/transformers/training_args.py#L858
Seems like it's hard-coded to NCCL. Could you instead make this an argument?
@sgugger
|
09-06-2021 09:20:02
|
09-06-2021 09:20:02
|
You can initialize the backend you want in your script. Accelerate won't re-initialize it in this case.<|||||>@sgugger Thanks, I was following the examples provided in examples/pytorch/question-answering/run_qa.py.
As in
https://github.com/huggingface/transformers/blob/76c4d8bf26de3e4ab23b8afeed68479c2bbd9cbd/examples/pytorch/question-answering/run_qa.py#L212, it will parse from all the listed allowed arguments including `TrainingArguments`
I think there will be no arguments provided to choose my backend here. And I think it won't use Accelerate anyway. So, in this case, it seems the only way to change it to 'gloo' backend is modifying the source code in training_args.py?<|||||>Oh I was confused on where you opened the issue. There is no way to change the backend in the `Trainer` code, as it's not just one argument that could be setup differently. You should use Accelerate for a more customized training loop.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>OK, I just made a PR here to further justify what I meant: https://github.com/huggingface/transformers/pull/14012, please take a look. Make any suggestions or corrections as you need. Thanks.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>AFAIK, this is handled by the xpu_backend `training_args` parameter passed into the `Trainer` class now. Making a note here for future reference.
See https://github.com/huggingface/transformers/blob/ee8e80a060d65ab349743ffcb5842365eb0e5606/src/transformers/training_args.py#L315-L316 for more details
|
transformers
| 13,440 |
closed
|
add the implementation of RecAdam optimizer
|
# What does this PR do?
This PR adds the implementation of the RecAdam optimizer.
Paper: https://www.aclweb.org/anthology/2020.emnlp-main.634
Original implementation: https://github.com/Sanyuan-Chen/RecAdam
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-06-2021 08:20:38
|
09-06-2021 08:20:38
|
Thank you Sylvain Gugger for your review!
Sorry I didn't realize you don't accept the new optimizers. I actually had the implementation in my own repo, and thought it would be more convenient for the users if adding it in the Transformers library. Yeah that would be really great if you can show RecAdam in a community notebook~<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,439 |
closed
|
MisconfigurationException: Found invalid type for plugin None. Expected a precision or training type plugin.
|
## Environment info
```
- `transformers` version: 4.10.0
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): 2.6.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
```
### Who can help
research_projects/rag: @patrickvonplaten, @lhoestq
## To reproduce
Steps to reproduce the behavior:
1.
```
!python transformers/examples/research_projects/rag/consolidate_rag_checkpoint.py \
--model_type rag_token \
--generator_name_or_path facebook/mbart-large-cc25 \
--question_encoder_name_or_path voidful/dpr-question_encoder-bert-base-multilingual \
--dest /content/checkpoint
```
2.
```
!python ./transformers/examples/research_projects/rag/finetune_rag.py \
--data_dir ./transformers/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data \
--output_dir ./finetune_output \
--model_name_or_path ./checkpoint \
--model_type rag_token \
--fp16 \
--gpus 1 \
--profile \
--do_train \
--do_predict \
--n_val -1 \
--train_batch_size 4 \
--eval_batch_size 1 \
--max_source_length 128 \
--max_target_length 25 \
--val_max_target_length 25 \
--test_max_target_length 25 \
--label_smoothing 0.1 \
--dropout 0.1 \
--attention_dropout 0.1 \
--weight_decay 0.001 \
--adam_epsilon 1e-08 \
--max_grad_norm 0.1 \
--lr_scheduler polynomial \
--learning_rate 3e-05 \
--num_train_epochs 10 \
--warmup_steps 500 \
--gradient_accumulation_steps 8 \
--passages_path ./drive/SQUAD-KB/kb/my_knowledge_dataset \
--index_path ./drive/SQUAD-KB/kb/my_knowledge_dataset_hnsw_index.faiss \
--index_name custom
```
# Error
```
2021-09-06 07:57:26.641999: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
/opt/conda/lib/python3.8/site-packages/ray/autoscaler/_private/cli_logger.py:57: FutureWarning: Not all Ray CLI dependencies were found. In Ray 1.4+, the Ray CLI, autoscaler, and dashboard will only be usable via `pip install 'ray[default]'`. Please update your install command.
warnings.warn(
loading configuration file ./checkpoint/config.json
Model config RagConfig {
"architectures": [
"RagTokenForGeneration"
],
"dataset": "wiki_dpr",
"dataset_split": "train",
"do_deduplication": true,
"do_marginalize": false,
"doc_sep": " // ",
"exclude_bos_score": false,
"forced_eos_token_id": 2,
"generator": {
"_name_or_path": "",
"_num_labels": 3,
"activation_dropout": 0.0,
"activation_function": "gelu",
"add_bias_logits": false,
"add_cross_attention": false,
"add_final_layer_norm": true,
"architectures": [
"MBartForConditionalGeneration"
],
"attention_dropout": 0.0,
"bad_words_ids": null,
"bos_token_id": 0,
"chunk_size_feed_forward": 0,
"classif_dropout": 0.0,
"classifier_dropout": 0.0,
"d_model": 1024,
"decoder_attention_heads": 16,
"decoder_ffn_dim": 4096,
"decoder_layerdrop": 0.0,
"decoder_layers": 12,
"decoder_start_token_id": null,
"diversity_penalty": 0.0,
"do_sample": false,
"dropout": 0.1,
"early_stopping": false,
"encoder_attention_heads": 16,
"encoder_ffn_dim": 4096,
"encoder_layerdrop": 0.0,
"encoder_layers": 12,
"encoder_no_repeat_ngram_size": 0,
"eos_token_id": 2,
"finetuning_task": null,
"forced_bos_token_id": null,
"forced_eos_token_id": 2,
"gradient_checkpointing": false,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1",
"2": "LABEL_2"
},
"init_std": 0.02,
"is_decoder": false,
"is_encoder_decoder": true,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1,
"LABEL_2": 2
},
"length_penalty": 1.0,
"max_length": 1024,
"max_position_embeddings": 1024,
"min_length": 0,
"model_type": "mbart",
"no_repeat_ngram_size": 0,
"normalize_before": true,
"normalize_embedding": true,
"num_beam_groups": 1,
"num_beams": 5,
"num_hidden_layers": 12,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"output_scores": false,
"pad_token_id": 1,
"prefix": null,
"problem_type": null,
"pruned_heads": {},
"remove_invalid_values": false,
"repetition_penalty": 1.0,
"return_dict": true,
"return_dict_in_generate": false,
"scale_embedding": true,
"sep_token_id": null,
"static_position_embeddings": false,
"task_specific_params": {
"translation_en_to_ro": {
"decoder_start_token_id": 250020
}
},
"temperature": 1.0,
"tie_encoder_decoder": false,
"tie_word_embeddings": true,
"tokenizer_class": null,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"transformers_version": "4.6.1",
"use_bfloat16": false,
"use_cache": true,
"vocab_size": 250027
},
"index_name": "exact",
"index_path": null,
"is_encoder_decoder": true,
"label_smoothing": 0.0,
"max_combined_length": 300,
"model_type": "rag",
"n_docs": 5,
"output_retrieved": false,
"passages_path": null,
"question_encoder": {
"_name_or_path": "",
"add_cross_attention": false,
"architectures": [
"DPRQuestionEncoder"
],
"attention_probs_dropout_prob": 0.1,
"bad_words_ids": null,
"bos_token_id": null,
"chunk_size_feed_forward": 0,
"decoder_start_token_id": null,
"diversity_penalty": 0.0,
"do_sample": false,
"early_stopping": false,
"encoder_no_repeat_ngram_size": 0,
"eos_token_id": null,
"finetuning_task": null,
"forced_bos_token_id": null,
"forced_eos_token_id": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": false,
"is_encoder_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"language": "multilingual",
"layer_norm_eps": 1e-12,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 512,
"min_length": 0,
"model_type": "dpr",
"name": "DPRQuestionEncoder",
"no_repeat_ngram_size": 0,
"num_attention_heads": 12,
"num_beam_groups": 1,
"num_beams": 1,
"num_hidden_layers": 12,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_scores": false,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"prefix": null,
"problem_type": null,
"projection_dim": 0,
"pruned_heads": {},
"remove_invalid_values": false,
"repetition_penalty": 1.0,
"return_dict": true,
"return_dict_in_generate": false,
"revision": null,
"sep_token_id": null,
"task_specific_params": null,
"temperature": 1.0,
"tie_encoder_decoder": false,
"tie_word_embeddings": true,
"tokenizer_class": null,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"transformers_version": "4.6.1",
"type_vocab_size": 2,
"use_bfloat16": false,
"vocab_size": 119547
},
"reduce_loss": false,
"retrieval_batch_size": 8,
"retrieval_vector_size": 768,
"title_sep": " / ",
"transformers_version": null,
"use_cache": true,
"use_dummy_dataset": false,
"vocab_size": null
}
Didn't find file ./checkpoint/question_encoder_tokenizer/added_tokens.json. We won't load it.
loading file ./checkpoint/question_encoder_tokenizer/vocab.txt
loading file ./checkpoint/question_encoder_tokenizer/tokenizer.json
loading file None
loading file ./checkpoint/question_encoder_tokenizer/special_tokens_map.json
loading file ./checkpoint/question_encoder_tokenizer/tokenizer_config.json
Didn't find file ./checkpoint/generator_tokenizer/added_tokens.json. We won't load it.
loading file ./checkpoint/generator_tokenizer/sentencepiece.bpe.model
loading file ./checkpoint/generator_tokenizer/tokenizer.json
loading file None
loading file ./checkpoint/generator_tokenizer/special_tokens_map.json
loading file ./checkpoint/generator_tokenizer/tokenizer_config.json
Assigning ['ar_AR', 'cs_CZ', 'de_DE', 'en_XX', 'es_XX', 'et_EE', 'fi_FI', 'fr_XX', 'gu_IN', 'hi_IN', 'it_IT', 'ja_XX', 'kk_KZ', 'ko_KR', 'lt_LT', 'lv_LV', 'my_MM', 'ne_NP', 'nl_XX', 'ro_RO', 'ru_RU', 'si_LK', 'tr_TR', 'vi_VN', 'zh_CN'] to the additional_special_tokens key of the tokenizer
Loading passages from ./drive/SQUAD-KB/kb/my_knowledge_dataset
loading weights file ./checkpoint/pytorch_model.bin
All model checkpoint weights were used when initializing RagTokenForGeneration.
All the weights of RagTokenForGeneration were initialized from the model checkpoint at ./checkpoint.
If your task is similar to the task the model of the checkpoint was trained on, you can already use RagTokenForGeneration for predictions without further training.
loading configuration file ./checkpoint/config.json
Model config RagConfig {
"architectures": [
"RagTokenForGeneration"
],
"dataset": "wiki_dpr",
"dataset_split": "train",
"do_deduplication": true,
"do_marginalize": false,
"doc_sep": " // ",
"exclude_bos_score": false,
"forced_eos_token_id": 2,
"generator": {
"_name_or_path": "",
"_num_labels": 3,
"activation_dropout": 0.0,
"activation_function": "gelu",
"add_bias_logits": false,
"add_cross_attention": false,
"add_final_layer_norm": true,
"architectures": [
"MBartForConditionalGeneration"
],
"attention_dropout": 0.0,
"bad_words_ids": null,
"bos_token_id": 0,
"chunk_size_feed_forward": 0,
"classif_dropout": 0.0,
"classifier_dropout": 0.0,
"d_model": 1024,
"decoder_attention_heads": 16,
"decoder_ffn_dim": 4096,
"decoder_layerdrop": 0.0,
"decoder_layers": 12,
"decoder_start_token_id": null,
"diversity_penalty": 0.0,
"do_sample": false,
"dropout": 0.1,
"early_stopping": false,
"encoder_attention_heads": 16,
"encoder_ffn_dim": 4096,
"encoder_layerdrop": 0.0,
"encoder_layers": 12,
"encoder_no_repeat_ngram_size": 0,
"eos_token_id": 2,
"finetuning_task": null,
"forced_bos_token_id": null,
"forced_eos_token_id": 2,
"gradient_checkpointing": false,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1",
"2": "LABEL_2"
},
"init_std": 0.02,
"is_decoder": false,
"is_encoder_decoder": true,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1,
"LABEL_2": 2
},
"length_penalty": 1.0,
"max_length": 1024,
"max_position_embeddings": 1024,
"min_length": 0,
"model_type": "mbart",
"no_repeat_ngram_size": 0,
"normalize_before": true,
"normalize_embedding": true,
"num_beam_groups": 1,
"num_beams": 5,
"num_hidden_layers": 12,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"output_scores": false,
"pad_token_id": 1,
"prefix": null,
"problem_type": null,
"pruned_heads": {},
"remove_invalid_values": false,
"repetition_penalty": 1.0,
"return_dict": true,
"return_dict_in_generate": false,
"scale_embedding": true,
"sep_token_id": null,
"static_position_embeddings": false,
"task_specific_params": {
"translation_en_to_ro": {
"decoder_start_token_id": 250020
}
},
"temperature": 1.0,
"tie_encoder_decoder": false,
"tie_word_embeddings": true,
"tokenizer_class": null,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"transformers_version": "4.6.1",
"use_bfloat16": false,
"use_cache": true,
"vocab_size": 250027
},
"index_name": "exact",
"index_path": null,
"is_encoder_decoder": true,
"label_smoothing": 0.0,
"max_combined_length": 300,
"model_type": "rag",
"n_docs": 5,
"output_retrieved": false,
"passages_path": null,
"question_encoder": {
"_name_or_path": "",
"add_cross_attention": false,
"architectures": [
"DPRQuestionEncoder"
],
"attention_probs_dropout_prob": 0.1,
"bad_words_ids": null,
"bos_token_id": null,
"chunk_size_feed_forward": 0,
"decoder_start_token_id": null,
"diversity_penalty": 0.0,
"do_sample": false,
"early_stopping": false,
"encoder_no_repeat_ngram_size": 0,
"eos_token_id": null,
"finetuning_task": null,
"forced_bos_token_id": null,
"forced_eos_token_id": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": false,
"is_encoder_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"language": "multilingual",
"layer_norm_eps": 1e-12,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 512,
"min_length": 0,
"model_type": "dpr",
"name": "DPRQuestionEncoder",
"no_repeat_ngram_size": 0,
"num_attention_heads": 12,
"num_beam_groups": 1,
"num_beams": 1,
"num_hidden_layers": 12,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_scores": false,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"prefix": null,
"problem_type": null,
"projection_dim": 0,
"pruned_heads": {},
"remove_invalid_values": false,
"repetition_penalty": 1.0,
"return_dict": true,
"return_dict_in_generate": false,
"revision": null,
"sep_token_id": null,
"task_specific_params": null,
"temperature": 1.0,
"tie_encoder_decoder": false,
"tie_word_embeddings": true,
"tokenizer_class": null,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"transformers_version": "4.6.1",
"type_vocab_size": 2,
"use_bfloat16": false,
"vocab_size": 119547
},
"reduce_loss": false,
"retrieval_batch_size": 8,
"retrieval_vector_size": 768,
"title_sep": " / ",
"transformers_version": null,
"use_cache": true,
"use_dummy_dataset": false,
"vocab_size": null
}
Didn't find file ./checkpoint/question_encoder_tokenizer/added_tokens.json. We won't load it.
loading file ./checkpoint/question_encoder_tokenizer/vocab.txt
loading file ./checkpoint/question_encoder_tokenizer/tokenizer.json
loading file None
loading file ./checkpoint/question_encoder_tokenizer/special_tokens_map.json
loading file ./checkpoint/question_encoder_tokenizer/tokenizer_config.json
Didn't find file ./checkpoint/generator_tokenizer/added_tokens.json. We won't load it.
loading file ./checkpoint/generator_tokenizer/sentencepiece.bpe.model
loading file ./checkpoint/generator_tokenizer/tokenizer.json
loading file None
loading file ./checkpoint/generator_tokenizer/special_tokens_map.json
loading file ./checkpoint/generator_tokenizer/tokenizer_config.json
Assigning ['ar_AR', 'cs_CZ', 'de_DE', 'en_XX', 'es_XX', 'et_EE', 'fi_FI', 'fr_XX', 'gu_IN', 'hi_IN', 'it_IT', 'ja_XX', 'kk_KZ', 'ko_KR', 'lt_LT', 'lv_LV', 'my_MM', 'ne_NP', 'nl_XX', 'ro_RO', 'ru_RU', 'si_LK', 'tr_TR', 'vi_VN', 'zh_CN'] to the additional_special_tokens key of the tokenizer
INFO:distributed_pytorch_retriever:initializing retrieval
INFO:distributed_pytorch_retriever:dist not initialized / main
Loading index from ./drive/SQUAD-KB/kb/my_knowledge_dataset_hnsw_index.faiss
/opt/conda/lib/python3.8/site-packages/pytorch_lightning/utilities/distributed.py:69: UserWarning: Checkpoint directory ./finetune_output exists and is not empty.
warnings.warn(*args, **kwargs)
Global seed set to 42
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
Traceback (most recent call last):
File "./transformers/examples/research_projects/rag/finetune_rag.py", line 617, in <module>
main(args)
File "./transformers/examples/research_projects/rag/finetune_rag.py", line 581, in main
trainer: pl.Trainer = generic_train(
File "/home/jovyan/work/BlenderBot2/RAG/transformers/examples/research_projects/rag/lightning_base.py", line 379, in generic_train
trainer = pl.Trainer.from_argparse_args(
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/properties.py", line 207, in from_argparse_args
return from_argparse_args(cls, args, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/utilities/argparse.py", line 52, in from_argparse_args
return cls(**trainer_kwargs)
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/connectors/env_vars_connector.py", line 40, in insert_env_defaults
return fn(self, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 319, in __init__
self.accelerator_connector = AcceleratorConnector(
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/connectors/accelerator_connector.py", line 134, in __init__
self.handle_given_plugins()
File "/opt/conda/lib/python3.8/site-packages/pytorch_lightning/trainer/connectors/accelerator_connector.py", line 209, in handle_given_plugins
raise MisconfigurationException(
pytorch_lightning.utilities.exceptions.MisconfigurationException: Found invalid type for plugin None. Expected a precision or training type plugin.
```
## Expected behavior
Not having this error.
|
09-06-2021 08:03:08
|
09-06-2021 08:03:08
|
Hi ! What version of pytorch-lightning do you have ? Could you try running another version ?<|||||>> Hi ! What version of pytorch-lightning do you have ? Could you try running another version ?
I have the one specified in the [requirements.txt](https://github.com/huggingface/transformers/blob/master/examples/research_projects/rag/requirements.txt) file, so 1.3.1<|||||>Could you try this change ?
```diff
--- a/examples/research_projects/rag/finetune_rag.py
+++ b/examples/research_projects/rag/finetune_rag.py
@@ -585,7 +585,7 @@ def main(args=None, model=None) -> GenerativeQAModule:
checkpoint_callback=get_checkpoint_callback(args.output_dir, model.val_metric),
early_stopping_callback=es_callback,
logger=training_logger,
- custom_ddp_plugin=CustomDDP() if args.gpus > 1 else None,
+ custom_ddp_plugin=CustomDDP(),
profiler=pl.profiler.AdvancedProfiler() if args.profile else None,
)
pickle_save(model.hparams, model.output_dir / "hparams.pkl")
```
Not sure why we pass a `None` plugin if there's only 1 gpu
Alternatively you could try to simply not pass any `custom_ddp_plugin`
|
transformers
| 13,438 |
closed
|
add torchvision in example test requirements
|
# What does this PR do?
The pytorch example tests are failing for `image-classification` example as `torchvision` is not installed on the CI. This PR adds `torchvision` in `_test_requirements.py`.
|
09-06-2021 06:31:09
|
09-06-2021 06:31:09
|
Thank you for taking care of it @patil-suraj
|
transformers
| 13,437 |
closed
|
using TFOpenAIGPTLMHeadModel load pytorch model doesn't work well
|
## Environment info
- `transformers` version: 4.9.2
- Platform: Darwin-20.5.0-x86_64-i386-64bit
- Python version: 3.7.11
- PyTorch version (GPU?): 1.9.0 (False)
- Tensorflow version (GPU?): 2.2.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
@patrickvonplaten, @LysandreJik
## Information
Model I am using (OpenAIGPT):
I download file from [CDial-GPT_LCCC-large](https://huggingface.co/thu-coai/CDial-GPT_LCCC-large/tree/main), and loaded as follow way:
```
tokenizer = BertTokenizer.from_pretrained(……,do_lower_case=True)
model_pt = OpenAIGPTLMHeadModel.from_pretrained(……)
model_tf = TFOpenAIGPTLMHeadModel.from_pretrained(……,from_pt=True)
```
it's fine when loading `OpenAIGPTLMHeadModel`, but it encountered some problems as loading `TFOpenAIGPTLMHeadModel`:
```
Some weights of the PyTorch model were not used when initializing the TF 2.0 model TFOpenAIGPTLMHeadModel: ['transformer.h.2.attn.bias', 'transformer.h.5.attn.bias', 'transformer.h.9.attn.bias', 'transformer.h.6.attn.bias', 'transformer.h.0.attn.bias', 'lm_head.weight', 'transformer.h.8.attn.bias', 'transformer.h.3.attn.bias', 'transformer.h.1.attn.bias', 'transformer.h.10.attn.bias', 'transformer.h.4.attn.bias', 'transformer.h.11.attn.bias', 'transformer.h.7.attn.bias']
- This IS expected if you are initializing TFOpenAIGPTLMHeadModel from a PyTorch model trained on another task or with another architecture (e.g. initializing a TFBertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing TFOpenAIGPTLMHeadModel from a PyTorch model that you expect to be exactly identical (e.g. initializing a TFBertForSequenceClassification model from a BertForSequenceClassification model).
All the weights of TFOpenAIGPTLMHeadModel were initialized from the PyTorch model.
If your task is similar to the task the model of the checkpoint was trained on, you can already use TFOpenAIGPTLMHeadModel for predictions without further training.
```
their logits are quite different, how can i solve this?
|
09-06-2021 06:23:25
|
09-06-2021 06:23:25
|
Hello! Do you have a reproducible code example that exposes the differences between the logits? Thank you<|||||>> > Hello! Do you have a reproducible code example that exposes the differences between the logits? Thank you
@LysandreJik this is my full code refered to [CDial-GPT/interact.py](https://github.com/thu-coai/CDial-GPT/blob/master/interact.py):
```
texts = ["别爱我没结果","没结果的爱是多么的痛","但是爱过就可以了"]
SPECIAL_TOKENS = ["[CLS]", "[SEP]", "[PAD]", "[speaker1]", "[speaker2]"]
bos, eos, pad, speaker1, speaker2 = tokenizer.convert_tokens_to_ids(SPECIAL_TOKENS)
texts_ids=[tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text)) for text in texts]
sequence=[[speaker2 if i % 2 else speaker1] + s for i, s in enumerate(texts_ids)]
input_ids=[bos]
for i in sequence:
input_ids+=i
token_type_ids=[bos] + [speaker2 if i % 2 else speaker1 for i, s in enumerate(sequence) for _ in s]
special_tokens_ids = tokenizer.convert_tokens_to_ids(SPECIAL_TOKENS)
max_length=40
#pytorch
input_ids_pt = torch.tensor(input_ids+[speaker2], dtype=torch.long).unsqueeze(0)
token_type_ids_pt = torch.tensor(token_type_ids+[speaker2], dtype=torch.long).unsqueeze(0)
response_ids_pt=[]
for _ in range(max_length):
outputs_pt = model_pt(input_ids_pt, token_type_ids=token_type_ids_pt)
logits_pt = outputs_pt.logits
next_token_logits_pt = logits_pt[0, -1, :]
next_token_pt = torch.multinomial(F.softmax(next_token_logits_pt, dim=-1), num_samples=1)
if next_token_pt.item() in special_tokens_ids:
break
response_ids_pt.append(next_token_pt.item())
input_ids_pt = torch.cat((input_ids_pt, next_token_pt.unsqueeze(0)), dim=1)
token_type_ids_pt = torch.cat((token_type_ids_pt,torch.tensor([[speaker2]])),dim=1)
response_pt=tokenizer.decode(response_ids_pt, skip_special_tokens=True)
#tensorflow
input_ids_tf = tf.expand_dims(tf.constant(input_ids+[speaker2]),axis=0)
token_type_ids_tf = tf.expand_dims(tf.constant(token_type_ids+[speaker2]),axis=0)
response_ids_tf=[]
for _ in range(max_length):
outputs_tf = model_tf(input_ids_tf, token_type_ids=token_type_ids_tf)
logits_tf = outputs_tf.logits
next_token_logits_tf = tf.expand_dims(logits_tf[0, -1, :], axis=0)
next_token_tf = tf.random.categorical(tf.nn.softmax(next_token_logits_tf,axis=-1), num_samples=1)
next_token_tf = tf.cast(next_token_tf, dtype=tf.int32)
if next_token_tf in special_tokens_ids:
break
response_ids_tf.append(next_token_tf.numpy().item())
input_ids_tf = tf.concat((input_ids_tf, next_token_tf), axis=1)
token_type_ids_tf=tf.concat((token_type_ids_tf,tf.constant(speaker2,shape=(1,1))),axis=1)
response_tf=tokenizer.decode(response_ids_tf, skip_special_tokens=True)
```
when i generated `response_ids_pt`, the loop can meeted `special_tokens_ids` and broken, the `response_ids_tf` generative loop can't broken untill `max_length`.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,436 |
closed
|
[CLIP] fix logit_scale init
|
# What does this PR do?
This PR fixes the initialization of `logit_scale` parameter as per the [original CLIP implementation ](https://github.com/openai/CLIP/blob/3b473b0e682c091a9e53623eebc1ca1657385717/clip/model.py#L291).
Also, the initial value of `logit_scale` needs to be carefully tuned for CLIP training, so this PR, adds a `logit_scale_init_value` as a `config` parameter, so users could pass different init values as per their training.
Fixes #13430
|
09-06-2021 05:51:46
|
09-06-2021 05:51:46
| |
transformers
| 13,435 |
closed
|
Official example not working, are you serious?
|
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.10.0
- Platform: Ubuntu 18.04
- Python version:
- PyTorch version (GPU?): 1.9 GPU
- Tensorflow version (GPU?): 2.4.0 GPU
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
@LysandreJik
Model I am using Bert, official code not working :(
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
model = BertModel.from_pretrained("bert-base-cased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
[https://huggingface.co/bert-base-cased](url) to above code.
`https://huggingface.co/bert-base-cased`
Exception:
```
Traceback (most recent call last):
File "/home/zhangguanqun/venv_tf_2.4/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 248, in __getattr__
return self.data[item]
KeyError: 'size'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/zhangguanqun/projects/huggingface/bert.py", line 15, in <module>
output = model(encoded_input)
File "/home/zhangguanqun/venv_tf_2.4/lib/python3.6/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/zhangguanqun/venv_tf_2.4/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py", line 938, in forward
input_shape = input_ids.size()
File "/home/zhangguanqun/venv_tf_2.4/lib/python3.6/site-packages/transformers/tokenization_utils_base.py", line 250, in __getattr__
raise AttributeError
AttributeError
Process finished with exit code 1
```
What's wrong with that?
|
09-06-2021 03:26:52
|
09-06-2021 03:26:52
|
I think it's because you try to pass the tensorflow output from tokenizer to an pytorch model.
Either use tfbertmodel or let the tokenizer return "pt" instead of "tf" tensors<|||||>@flozi00 You are right, if I change BertModel to TFBertModel, everything goes well.
BUT, the above codes come from [OFFICIAL TUTORIAL](https://huggingface.co/bert-base-cased),
PLEASE modify the doc to stop misleading others.<|||||>I think both official examples are wrong. The quote is from the [official link](https://huggingface.co/bert-base-cased):
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, TFBertModel # <--- should be just BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
model = TFBertModel.from_pretrained("bert-base-cased") # <--- should be just BertModel
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, BertModel # <--- should be with TFBertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
model = BertModel.from_pretrained("bert-base-cased") # <--- should be with TFBertModel
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```<|||||>Just corrected it :-)<|||||>a lot more serious now indeed!<|||||>Such is the onus on HF to deliver correctly that one mistake can some question the seriousness of the whole enterprise :D<|||||>Similar issue on examples https://huggingface.co/microsoft/xprophetnet-large-wiki100-cased-xglue-ntg:
@thomwolf @patrickvonplaten
```python
from transformers import XLMProphetNetTokenizer, XLMProphetNetForConditionalGeneration, ProphetNetConfig
# should be just XLMProphetNetForConditionalGeneration & XLMProphetNetTokenizer
model = ProphetNetForConditionalGeneration.from_pretrained('microsoft/xprophetnet-large-wiki100-cased-xglue-ntg')
tokenizer = ProphetNetTokenizer.from_pretrained('microsoft/xprophetnet-large-wiki100-cased-xglue-ntg')
...
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.
|
transformers
| 13,434 |
closed
|
A dead link in GPT2 description
|
I see that there is a dead link in the GPT2 description for some time referring to an argument on how pre-computed values can be reused.
The link to the description with the dead link (the 3rd tip): https://huggingface.co/transformers/model_doc/gpt2.html
The link that is dead: https://huggingface.co/transformers/quickstart.html#using-the-past
My suggestion is that if this quickstart page does not exist anymore than just linking it to the `forward` function docs on the same page (that has the parameter `past_key_values`) should do the job.
As you are taking care of the docs @sgugger, I can make a PR to do this if it makes sense to you.
|
09-05-2021 12:55:01
|
09-05-2021 12:55:01
|
Thanks for reporting, feel free to open a PR with your change indeed!<|||||>So I have made a PR. One problem I did find however was the inconsistency between the TF and PT arguments.
In PT it is called `past_key_values` and in TF it is simply called `past`. I have made this clear in the PR for the docs but it would be nice if they hadn't diverged.
However, fixing this is problematic since this would be a breaking change (probably the reason it is still there :D)<|||||>The way you did it is great! I think the divergence comes from when we unified that argument on the PyTorch side a while ago (it was different names for different models), but forgot to do the same on the TF side.
|
transformers
| 13,433 |
closed
|
Optimized bad word ids
|
# What does this PR do?
This PR optimizes the generation routines when `bad_word_ids` are provided by the user. Currently, two inefficiencies significantly slow down the text generation when these are passed:
- single-token bad words are looped over at each generation iteration: this is not required as these single word tokens are always banned, regardless of the input generated so far.
- The token_ids are queried in nested for loops, causing unnecessary and inefficient cross-device communication if these are on the GPU.
The issue was raised in https://discuss.huggingface.co/t/gpt2-many-bad-words-ids-leading-to-slow-text-generation/9721
I could reproduce the issue and observed a severe slowdown of the generation when ~2000 bad word ids are provided (see https://gist.github.com/guillaume-be/2a3e91951869414b6f1f8ab8c2cd642f gist). I observed a ~20x slowdown of the generation when using the bad words with a GPU, from ~1.7s to >25s per generation.
This PR fixes the issue by:
- Moving all of the current token ids to a Python list before multiple iteration through that list, leading to a 20x speedup
- Splitting the bad word ids into 1-element bad words, and words that are made of multiple sub-tokens. For the 1-element bad words, a static bad word pas is pre-computed and re-used for each generation step. This accelerates the generation by a further ~10%.
Fixes https://discuss.huggingface.co/t/gpt2-many-bad-words-ids-leading-to-slow-text-generation/9721
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case: https://discuss.huggingface.co/t/gpt2-many-bad-words-ids-leading-to-slow-text-generation/9721
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@patrickvonplaten - maybe you would like to have a look?
|
09-05-2021 12:06:34
|
09-05-2021 12:06:34
| |
transformers
| 13,432 |
closed
|
Supporting Seq2Seq model for question answering task
|
# What does this PR do?
Add the `run_seq2seq_qa.py` example for supporting seq2seq models to QA tasks.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #13029
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
09-05-2021 10:02:44
|
09-05-2021 10:02:44
|
@NielsRogge I do not have the resources to run the trainer on the said device to provide the duration and scores of the model.
What should I do in this case ?
Also, I looked at the checks that ran on CircleCI and I am afraid that the test I have written is not running i.e. the output says
```
### MODIFIED FILES ###
- examples/pytorch/question-answering/run_seq2seq_qa.py
- examples/pytorch/test_examples.py
### IMPACTED FILES ###
- examples/pytorch/question-answering/run_seq2seq_qa.py
- examples/pytorch/test_examples.py
### TEST TO RUN ###
```<|||||>For the test, will fix this morning. There is a bug in our module that fetches the proper tests to run. Thanks for flagging there was a problem!<|||||>Fix for the examples tests not being run is in [this PR](https://github.com/huggingface/transformers/pull/13604), you will need to rebase on master when it's merged.<|||||>@sgugger surely.
Also, I had asked about the dataset in the review you had provided earlier. Will SQuAD work as all the QA datasets have context in some format another ?<|||||>Yes, it's fine.<|||||>Thank you :)<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.<|||||>@karthikrangasai - the PR looks very nice already. It would be great if we could try fixing the test so that we can merge it :-)<|||||>Hello @patrickvonplaten , sorry I missed this failing test. I will fix it in some time, sorry for the delay.<|||||>During the evaluation phase, at this [line](https://github.com/huggingface/transformers/blob/c7ccb2e77976931b5738c5d0f89c3de7bb4c5278/src/transformers/trainer.py#L2285) the model return logits as float instead of int which is later causing an error when trying to run a tokenizer decode on the list of floats.
Could someone guide me on how to fix this ?<|||||>I am unsure why you would want logits to be integers. Also you should use the `--predict_with_generate` for evaluation.<|||||>@sgugger Thank you for the help. Addition of the flag `--predict_with_generate` helped here. I didn't want logits to be integers, but the input to decode had to be integers. I didn't that communicate well enough. Sorry for the confusion there.<|||||>Thanks for fixing the test!
|
transformers
| 13,431 |
closed
|
Bb
|
__Originally posted by @shanejonas in https://github.com/MetaMask/.github/pull/13__
|
09-05-2021 09:56:30
|
09-05-2021 09:56:30
| |
transformers
| 13,430 |
closed
|
Difference between `logit_scale` initialisation in Transformers CLIP and the original OpenAI implementation.
|
I tried another training code based on the OpenAI'CLIP version: I found a difference at logit_scale between them. Does it mean temperature parameter? Is it the reason for loss rising?
huggingface transformers' CLIP:
```
self.logit_scale = nn.Parameter(torch.ones([]))
```
OpenAI CLIP:
```
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
```
|
09-05-2021 08:27:58
|
09-05-2021 08:27:58
|
Hi @lycfight
Please provide a proper title when opening an issue, I've updated the title and issue description a bit.
> I found a difference at logit_scale between them. Does it mean temperature parameter? Is it the reason for loss rising?
Great catch! Yes `logits_scale` is also called `temperature`. And indeed not initializing the `logits_scale` to the right value could cause issues during training.
Also, training CLIP is a bit complicated, for contrastive learning try to use as big a batch size as possible. Initializing `logits_scale` also matters a lot. You could find some info in this [report](https://huggingface.co/spaces/clip-italian/clip-italian-demo) as well (it's CLIP for Italian language), this [issue](https://github.com/openai/CLIP/issues/83) might also help.<|||||>> Hi @lycfight
>
> Please provide a proper title when opening an issue, I've updated the title and issue description a bit.
>
> > I found a difference at logit_scale between them. Does it mean temperature parameter? Is it the reason for loss rising?
>
> Great catch! Yes `logits_scale` is also called `temperature`. And indeed not initializing the `logits_scale` to the right value could cause issues during training.
>
> Also, training CLIP is a bit complicated, for contrastive learning try to use as big a batch size as possible. Initializing `logits_scale` also matters a lot. You could find some info in this [report](https://huggingface.co/spaces/clip-italian/clip-italian-demo) as well (it's CLIP for Italian language), this [issue](https://github.com/openai/CLIP/issues/83) might also help.
Furthermore, the loss rising happens when I fine-tuned CLIP pretrained model in COCO dataset:
`model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")`
Then, in order to find the difference, I also try to train CLIP from scratch, and the loss descents normally:
`from transformers import CLIPConfig, CLIPModel, CLIPProcessor
config = CLIPConfig()
model = CLIPModel(config)`
That confused me extremely.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.