
text
stringlengths 100
500k
| subset
stringclasses 4
values |
|---|---|
The St. Petersburg Paradox
First published Tue Jul 30, 2019
The St. Petersburg paradox was introduced by Nicolaus Bernoulli in 1713. It continues to be a reliable source for new puzzles and insights in decision theory.
The standard version of the St. Petersburg paradox is derived from the St. Petersburg game, which is played as follows: A fair coin is flipped until it comes up heads the first time. At that point the player wins \(\$2^n,\) where n is the number of times the coin was flipped. How much should one be willing to pay for playing this game? Decision theorists advise us to apply the principle of maximizing expected value. According to this principle, the value of an uncertain prospect is the sum total obtained by multiplying the value of each possible outcome with its probability and then adding up all the terms (see the entry on normative theories of rational choice: expected utility). In the St. Petersburg game the monetary values of the outcomes and their probabilities are easy to determine. If the coin lands heads on the first flip you win $2, if it lands heads on the second flip you win $4, and if this happens on the third flip you win $8, and so on. The probabilities of the outcomes are \(\frac{1}{2}\), \(\frac{1}{4}\), \(\frac{1}{8}\),…. Therefore, the expected monetary value of the St. Petersburg game is
\[\begin{align} \frac{1}{2}\cdot 2 + \frac{1}{4}\cdot 4 + \frac{1}{8}\cdot 8 + \cdots &= 1+1+1+ \cdots \\ &= \sum_{n=1}^{\infty} \left(\frac{1}{2}\right)^n \cdot 2^n \\ &= \infty. \end{align}\]
(Some would say that the sum approaches infinity, not that it is infinite. We will discuss this distinction in Section 2.)
The "paradox" consists in the fact that our best theory of rational choice seems to entail that it would be rational to pay any finite fee for a single opportunity to play the St. Petersburg game, even though it is almost certain that the player will win a very modest amount. The probability is \(\frac{1}{2}\) that the player wins no more than $2, and \(\frac{3}{4}\) that he or she wins no more than $4.
In a strict logical sense, the St. Petersburg paradox is not a paradox because no formal contradiction is derived. However, to claim that a rational agent should pay millions, or even billions, for playing this game seems absurd. So it seems that we, at the very least, have a counterexample to the principle of maximizing expected value. If rationality forces us to liquidate all our assets for a single opportunity to play the St. Petersburg game, then it seems unappealing to be rational.
1. The History of the St. Petersburg Paradox
2. The Modern St. Petersburg Paradox
3. Unrealistic Assumptions?
4. A Bounded Utility Function?
5. Ignore Small Probabilities?
6. Relative Expected Utility Theory
7. The Pasadena Game
The St. Petersburg paradox is named after one of the leading scientific journals of the eighteenth century, Commentarii Academiae Scientiarum Imperialis Petropolitanae [Papers of the Imperial Academy of Sciences in Petersburg], in which Daniel Bernoulli (1700–1782) published a paper entitled "Specimen Theoriae Novae de Mensura Sortis" ["Exposition of a New Theory on the Measurement of Risk"] in 1738. Daniel Bernoulli had learned about the problem from his cousin Nicolaus I (1687–1759), who proposed an early but unnecessarily complex version of the paradox in a letter to Pierre Rémond de Montmort on 9 September 1713 (for this and related letters see J. Bernoulli 1975). Nicolaus asked de Montmort to imagine an example in which an ordinary dice is rolled until a 6 comes up:
[W]hat is the expectation of B … if A promises to B to give him some coins in this progression 1, 2, 4, 8, 16 etc. or 1, 3, 9, 27 etc. or 1, 4, 9, 16, 25 etc. or 1, 8, 27, 64 instead of 1, 2, 3, 4, 5 etc. as beforehand. Although for the most part these problems are not difficult, you will find however something most curious. (N. Bernoulli to Montmort, 9 September 1713)
It seems that Montmort did not immediately get Nicolaus' point. Montmort responded that these problems
have no difficulty, the only concern is to find the sum of the series of which the numerators being in the progression of squares, cubes, etc. the denominators are in geometric progression. (Montmort to N. Bernoulli, 15 November 1713)
However, he never performed any calculations. If he had, he would have discovered that the expected value of the first series (1, 2, 4, 8, 16, etc.) is:
\[ \sum_{n=1}^{\infty} \frac{5^{n-1}}{6^n}\cdot 2^{n-1}. \]
For this series it holds that
\[ \lim_{n\to\infty} \left|\frac{a_{n+1}}{a_n}\right| \gt 1, \]
so by applying the ratio test it is easy to verify that the series is divergent. (This test was discovered by d'Alembert in 1768, so it might be unfair to criticize Montmort for not seeing this.) However, the mathematical argument presented by Nicolaus himself was also a bit sketchy and would not impress contemporary mathematicians. The good news is that his conclusion was correct:
it would follow thence that B must give to A an infinite sum and even more than infinity (if it is permitted to speak thus) in order that he be able to make the advantage to give him some coins in this progression 1, 2, 4, 8, 16 etc. (N. Bernoulli to Montmort, 20 February 1714)
The next important contribution to the debate was made by Cramér in 1728. He read about Nicolaus' original problem in a book published by Montmort and proposed a simpler and more elegant formulation in a letter to Nicolaus:
In order to render the case more simple I will suppose that A throw in the air a piece of money, B undertakes to give him a coin, if the side of Heads falls on the first toss, 2, if it is only the second, 4, if it is the 3rd toss, 8, if it is the 4th toss, etc. The paradox consists in this that the calculation gives for the equivalent that A must give to B an infinite sum, which would seem absurd. (Cramér to N. Bernoulli, 21 May 1728)
In the very same letter, Cramér proposed a solution that revolutionized the emerging field of decision theory. Cramér pointed out that it is not the expected monetary value that should guide the choices of a rational agent, but rather the "usage" that "men of good sense" can make of money. According to Cramér, twenty million is not worth more than ten million, because ten million is enough for satisfying all desires an agent may reasonably have:
mathematicians value money in proportion to its quantity, and men of good sense in proportion to the usage that they may make of it. That which renders the mathematical expectation infinite, is the prodigious sum that I am able to receive, if the side of Heads falls only very late, the 100th or 1000th toss. Now this sum, if I reason as a sensible man, is not more for me, does not make more pleasure for me, does not engage me more to accept the game, than if it would be only 10 or 20 million coins. (21 May 1728)
The point made by Cramér in this passage can be generalized. Suppose that the upper boundary of an outcome's value is \(2^m.\) If so, that outcome will be obtained if the coin lands heads on the mth flip. This means that the expected value of all the infinitely many possible outcomes in which the coin is flipped more than m times will be finite: It is \(2^m\) times the probability that this happens, so it cannot exceed \(2^m\). To this we have to add the aggregated value of the first m possible outcomes, which is obviously finite. Because the sum of any two finite numbers is finite, the expected value of Cramér's version of the St. Petersburg game is finite.
Cramér was aware that it would be controversial to claim that there exists an upper boundary beyond which additional riches do not matter at all. However, he pointed out that his solution works even if he the value of money is strictly increasing but the relative increase gets smaller and smaller (21 May 1728):
If one wishes to suppose that the moral value of goods was as the square root of the mathematical quantities … my moral expectation will be
\[ \frac{1}{2} \cdot \sqrt{1} + \frac{1}{4} \cdot \sqrt{2} + \frac{1}{8} \cdot \sqrt{4} + \frac{1}{16} \cdot \sqrt{8} \ldots \]
This is the first clear statement of what contemporary decision theorists and economists refer to as decreasing marginal utility: The additional utility of more money is never zero, but the richer you are, the less you gain by increasing your wealth further. Cramér correctly calculated the expected utility ("moral value") of the St. Petersburg game to be about 2.9 units for an agent whose utility of money is given by the root function.
Daniel Bernoulli proposed a very similar idea in his famous 1738 article mentioned at the beginning of this section. Daniel argued that the agent's utility of wealth equals the logarithm of the monetary amount, which entails that improbable but large monetary prizes will contribute less to the expected utility of the game than more probable but smaller monetary amounts. As his article was about to be published, Daniel's brother Nicolaus mentioned to him that Cramér had proposed a very similar idea in 1728 (in the letter quoted above). In the final version of the text, Daniel openly acknowledged this:
Indeed I have found [Cramér's] theory so similar to mine that it seems miraculous that we independently reached such close agreement on this sort of subject. (Daniel Bernoulli 1738 [1954: 33])
Cramér's remark about the agent's decreasing marginal utility of money solves the original version of the St. Petersburg paradox. However, modern decision theorists agree that this solution is too narrow. The paradox can be restored by increasing the values of the outcomes up to the point at which the agent is fully compensated for her decreasing marginal utility of money (see Menger 1934 [1979]). The version of the St. Petersburg paradox discussed in the modern literature can thus be formulated as follows:
A fair coin is flipped until it comes up heads. At that point the player wins a prize worth \(2^n\) units of utility on the player's personal utility scale, where n is the number of times the coin was flipped.
Note that the expected utility of this gamble is infinite even if the agent's marginal utility of money is decreasing. We can leave it open exactly what the prizes consists of. It need not be money.
It is worth stressing that none of the prizes in the St. Petersburg game have infinite value. No matter how many times the coin is flipped, the player will always win some finite amount of utility. The expected utility of the St. Petersburg game is not finite, but the actual outcome will always be finite. It would thus be a mistake to dismiss the paradox by arguing that no actual prizes can have infinite utility. No actual infinities are required for constructing the paradox, only potential ones. (For a discussion of the distinction between actual and potential infinities, see Linnebo and Shapiro 2019.) In discussions of the St. Petersburg paradox it is often helpful to interpret the term "infinite utility" as "not finite" but leave it to philosophers of mathematics to determine whether it is or merely approaches infinity.
Some authors have discussed exactly what is problematic with the claim that the expected utility of the modified St. Petersburg game is infinite (read: not finite). Is it merely the fact that the fair price of the wager is "too high", or is there something else that prompts the worry? James M. Joyce notes that
a wager of infinite utility will be strictly preferred to any of its payoffs since the latter are all finite. This is absurd given that we are confining our attention to bettors who value wagers only as means to the end of increasing their fortune. (Joyce 1999: 37)
Joyce's point seems to be that an agent who pays the fair price of the wager will know for sure that she will actually be worse off after she has paid the fee. However, this seems to presuppose that actual infinities do exist. If only potential infinities exist, then the player cannot "pay" an infinite fee for playing the game. If so, we could perhaps interpret Joyce as reminding us that no matter what finite amount the player actually wins, the expect utility will always be higher, meaning that it would have been rational to pay even more. Decisions theorists analyze a means-ends notion of rationality, according to which it is rational to do whatever is the best means to one's end. The player thus knows that paying more than what one actually wins cannot be the best means to the end of maximizing utility. This observation enables us to strengthen the original "paradox" (in which no formal contradiction is derived) into a stronger version consisting of three incompatible claims:
The amount of utility it is rational to pay for playing the St. Petersburg game is not finite.
The player knows that the actual amount of utility he or she will win is finite.
It is not rational to knowingly pay more for a game than one will win.
Many discussions of the St. Petersburg paradox have focused on (1). As we will see in the next couple of sections, many scholars argue that the value of the St. Petersburg game is, for one reason or another, finite. A rare exception is Hájek and Nover. They offer the following argument for accepting (1):
The St Petersburg game can be regarded as the limit of a sequence of truncated St Petersburg games, with successively higher finite truncation points—for example, the game is called off if heads is not reached by the tenth toss; by the eleventh toss; by the twelveth toss;…. If we accept dominance reasoning, these successive truncations can guide our assessment of the St Petersburg game's value: it is bounded below by each of their values, these bounds monotonically increasing. Thus we have a principled reason for accepting that it is worth paying any finite amount to play the St Petersburg game. (Hájek and Nover 2006: 706)
Although they do not explicitly say so, Hájek and Nover would probably reject (3). The least controversial claim is perhaps (2). It is, of course, logically possible that the coin keeps landing tails every time it is flipped, even though an infinite sequence of tails has probability 0. (For a discussion of this possibility, see Williamson 2007.) Some events that have probability 0 do actually occur, and in uncountable probability spaces it is impossible that all outcomes have a probability greater than 0. Even so, if the coin keeps landing tails every time it is flipped, the agent wins 0 units of utility. So (2) would still hold true.
Some authors claim that the St. Petersburg game should be dismissed because it rests on assumptions that can never be fulfilled. For instance, Jeffrey (1983: 154) argues that "anyone who offers to let the agent play the St. Petersburg gamble is a liar, for he is pretending to have an indefinitely large bank". Similar objections were raised in the eighteenth century by Buffon and Fontaine (see Dutka 1988).
However, it is not clear why Jeffrey's point about real-world constraints would be relevant. What is wrong with evaluating a highly idealized game we have little reason to believe we will ever get to play? Hájek and Smithson (2012) point out that the St Petersburg paradox is contagious in the following sense: As long as you assign some nonzero probability to the hypothesis that the bank's promise is credible, the expected utility will be infinite no matter how low your credence in the hypothesis is. Any nonzero probability times infinity equals infinity, so any option in which you get to play the St. Petersburg game with a nonzero probability has infinite expected utility.
It is also worth keeping in mind that the St. Petersburg game may not be as unrealistic as Jeffrey claims. The fact that the bank does not have an indefinite amount of money (or other assets) available before the coin is flipped should not be a problem. All that matters is that the bank can make a credible promise to the player that the correct amount will be made available within a reasonable period of time after the flipping has been completed. How much money the bank has in the vault when the player plays the game is irrelevant. This is important because, as noted in section 2, the amount the player actually wins will always be finite. We can thus imagine that the game works as follows: We first flip the coin, and once we know what finite amount the bank owes the player, the CEO will see to it that the bank raises enough money.
If this does not convince the player, we can imagine that the central bank issues a blank check in which the player gets to fill in the correct amount once the coin has been flipped. Because the check is issued by the central bank it cannot bounce. New money is automatically created as checks issued by the central bank are introduced in the economy. Jeffrey dismisses this version of the St. Petersburg game with the following argument:
[Imagine that] Treasury department delivers to the winner a crisp new billion billion dollar bill. Due to the resulting inflation, the marginal desirabilities of such high payoffs would presumably be low enough to make the prospect of playing the game have finite expected [utility]. (Jeffrey 1983: 155)
Jeffrey is probably right that "a crisp new billion billion dollar bill" would trigger some inflation, but this seems to be something we could take into account as we construct the game. All that matters is that the utilities in the payoff scheme are linear.
Readers who feel unconvinced by this argument may wish to imagine a version of the St. Petersburg game in which the player is hooked up to Nozick's Experience Machine (see section 2.3 in the entry on hedonism). By construction, this machine can produce any pleasurable experience the agent wishes. So once the coin has been flipped n times, the Experience Machine will generate a pleasurable experience worth \(2^n\) units of utility on the player's personal utility scale. Aumann (1977) notes without explicitly mention the Experience Machine that:
The payoffs need not be expressible in terms of a fixed finite number of commodities, or in terms of commodities at all […] the lottery ticket […] might be some kind of open-ended activity -- one that could lead to sensations that he has not heretofore experienced. Examples might be religious, aesthetic, or emotional experiences, like entering a monastery, climbing a mountain, or engaging in research with possibly spectacular results. (Aumann 1977: 444)
A possible example of the type of experience that Aumann has in mind could be the number of days spent in Heaven. It is not clear why time spent in Heaven must have diminishing marginal utility.
Another type of practical worry concerns the temporal dimension of the St. Petersburg game. Brito (1975) claims that the coin flipping may simply take too long time. If each flip takes n seconds, we must make sure it would be possible to flip it sufficiently many times before the player dies. Obviously, if there exists an upper limit to how many times the coin can be flipped the expected utility would be finite too.
A straightforward response to this worry is to imagine that the flipping took place yesterday and was recorded on video. The first flip occurred at 11 p.m. sharp, the second flip \(\frac{60}{2}\) minutes later, the third \(\frac{60}{4}\) minutes after the second, and so on. The video has not yet been made available to anyone, but as soon as the player has paid the fee for playing the game the video will be placed in the public domain. Note that the coin could in principle have been flipped infinitely many times within a single hour. (This is an example of a "supertask"; see the entry on supertasks.)
It is true that this random experiment requires the coin to be flipped faster and faster. At some point we would have to spin the coin faster than the speed of light. This is not logically impossible although this assumption violates a contingent law of nature. If you find this problematic, we can instead imagine that someone throws a dart on the real line between 0 and 1. The probability that the dart hits the first half of the interval, \(\left[0, \frac{1}{2}\right),\) is \(\frac{1}{2}.\) And the probability that the dart hits the next quarter, \(\left[\frac{1}{2}, \frac{3}{4}\right),\) is \(\frac{1}{4}\), and so on. If "coin flips" are generated in this manner the random experiment will be over in no time at all. To steer clear of the worry that no real-world dart is infinitely sharp we can define the point at which the dart hits the real line as follows: Let a be the area of the dart. The point at which the dart hits the interval [0,1] is defined such that half of the area of a is to the right of some vertical line through a and the other half to the left the vertical line. The point at which the vertical line crosses the interval [0,1] is the outcome of the random experiment.
In the contemporary literature on the St. Petersburg paradox practical worries are often ignored, either because it is possible to imagine scenarios in which they do not arise, or because highly idealized decision problems with unbounded utilities and infinite state spaces are deemed to be interesting in their own right.
Arrow (1970: 92) suggests that the utility function of a rational agent should be "taken to be a bounded function.… since such an assumption is needed to avoid [the St. Petersburg] paradox". Basset (1987) makes a similar point; see also Samuelson (1977) and McClennen (1994).
Arrow's point is that utilities must be bounded to avoid the St. Petersburg paradox and that traditional axiomatic accounts of the expected utility principle guarantee this to be the case. The well-known axiomatizations proposed by Ramsey (1926), von Neumann and Morgenstern (1947), and Savage (1954) do, for instance, all entail that the decision maker's utility function is bounded. (See section 2.3 in the entry on decision theory for an overview of von Neumann and Morgenstern's axiomatization.)
If the utility function is bounded, then the expected utility of the St. Petersburg game will of course be finite. But why do the axioms of expected utility theory guarantee that the utility function is bounded? The crucial assumption is that rationally permissible preferences over lotteries are continuous. To explain the significance of this axiom it is helpful to introduce some symbols. Let \(\{pA, (1-p)B\}\) be the lottery that results in A with probability p and B with probability \(1-p\). The expression \(A\preceq B\) means that the agent considers B to be at least as good as A, i.e., weakly prefers B to A. Moreover, \(A\sim B\) means that A and B are equi-preferred, and \(A\prec B\) means that B is preferred to A. Consider:
The Continuity Axiom: Suppose \(A \preceq B\preceq C\). Then there is a probability \(p\in [0,1]\) such that \(\{pA, (1-p)C\}\sim B\).
To explain why this axiom entails that no object can have infinite value, suppose for reductio that A is a prize check worth $1, B is a check worth $2, and C is a prize to which the agent assigns infinite utility. The decision maker's preference is \(A\prec B\prec C\), but there is no probability p such that \(\{pA, (1-p)C\sim B\). Whenever p is nonzero the decision maker will strictly prefer \(\{pA, (1-p)C\}\) to B, and if p is 0 the decision maker will strictly prefer B. So because no object (lottery or outcome) can have infinite value, and a utility function is defined by the utilities it assigns to those objects (lotteries or outcomes), the utility function has to be bounded.
Does this solve the St. Petersburg paradox? The answer depends on whether we think a rational agent offered to play the St. Petersburg game has any reason to accept the continuity axiom. A possible view is that anyone who is offered to play the St. Petersburg game has reason to reject the continuity axiom. Because the St. Petersburg game has infinite utility, the agent has no reason to evaluate lotteries in the manner stipulated by this axiom. As explained in Section 3, we can imagine unboundedly valuable payoffs.
Some might object that the continuity axiom, as well as the other axioms proposed by von Neumann and Morgenstern (and Ramsey and Savage), are essential for defining utility in a mathematically precise manner. It would therefore be meaningless to talk about utility if we reject the continuity axiom. This axiom is part of what it means to say that something has a higher utility than something else. A good response could be to develop a theory of utility in which preferences over lotteries are not used for defining the meaning of the concept; see Luce (1959) for an early example of such a theory. Another response could be to develop a theory of utility in which the continuity axiom is explicitly rejected; see Skala (1975).
Buffon argued in 1777 that a rational decision maker should disregard the possibility of winning lots of money in the St. Petersburg game because the probability of doing so is very low. According to Buffon, some sufficiently improbable outcomes are "morally impossible" and should therefore be ignored. From a technical point of view, this solution is very simple: The St. Petersburg paradox arises because the decision maker is willing to aggregate infinitely many extremely valuable but highly improbable outcomes, so if we restrict the set of "possible" outcomes by excluding sufficiently improbable ones the expected utility will, of course, be finite.
But why should small probabilities be ignored? And how do we draw the line between small probabilities that are beyond concern and others that are not? Dutka summarizes Buffon's lengthy answer as follows:
To arrive at a suitable threshold value, [Buffon] notes that a fifty-six year old man, believing his health to be good, would disregard the probability that he would die within twenty-four hours, although mortality tables indicate that the odds against his dying in this period are only 10189 to 1. Buffon thus takes a probability of 1/10,000 or less for an event as a probability which may be disregarded. (Dutka 1988: 33)
Is this a convincing argument? According to Buffon, we ought to ignore some small probabilities because people like him (56-year-old males) do in fact ignore them. Buffon can thus be accused of attempting to derive an "ought" from an "is". To avoid Hume's no-ought-from-an-is objection, Buffon would have to add a premise to the effect that people's everyday reactions to risk are always rational. But why should we accept such a premise?
Another objection is that if we ignore small probabilities, then we will sometimes have to ignore all possible outcomes of an event. Consider the following example: A regular deck of cards has 52 cards, so it can be arranged in exactly 52! different ways. The probability of any given arrangement is thus about 1 in \(8 \cdot 10^{67}\). This is a very small probability. (If one were to add six cards to the deck, then the number of possible orderings would exceed the number of atoms in the known, observable universe.) However, every time we shuffle a deck of cards, we know that exactly one of the possible outcomes will materialize, so why should we ignore all such very improbable outcomes?
Nicholas J. J. Smith (2014) defends a modern version of Buffon's solution. He bases his argument on the following principle:
Rationally negligible probabilities (RNP): For any lottery featuring in any decision problem faced by any agent, there is an \(\epsilon > 0\) such that the agent need not consider outcomes of that lottery of probability less than \(\epsilon\) incoming to a fully rational decision. (Smith 2014: 472)
Smith points out that the order of the quantifiers in RNP is crucial. The claim is that for every lottery there exists some probability threshold \(\epsilon\) below which all probabilities should be ignored, but it would be a mistake to think that one and the same \(\epsilon\) is applicable to every lottery. This is important because otherwise we could argue that RNP allows us to combine thousands or millions of separate events with a probability of less than \(\epsilon.\) It would obviously make little sense to ignore, say, half a million one-in-a-million events. By keeping in mind that that the appropriate \(\epsilon\) may vary from case to case this worry can be dismissed.
Smith also points out that if we ignore probabilities less than \(\epsilon,\) then we have to increase some other probabilities to ensure that all probabilities sum up to one, as required by the probability axioms (see section 1 in the entry on interpretations of probability). Smith proposes a principle for doing this in a systematic manner.
However, why should we accept RNP? What is the argument for accepting this controversial principle apart from the fact that it would solve the St. Petersburg paradox? Smith's argument goes as follows:
Infinite precision cannot be required: rather, in any given context, there must be some finite tolerance—some positive threshold such that ignoring all outcomes whose probabilities lie below this threshold counts as satisfying the norm…. There is a norm of decision theory which says to ignore outcomes whose probability is zero. Because this norm mentions a specific probability value (zero), it is the kind of norm where it makes sense to impose a tolerance: zero plus or minus \(\epsilon\) (which becomes zero plus \(\epsilon,\) given that probabilities are all between 0 and 1)… the idea behind (RNP) is that in any actual context in which a decision is to be made, one never needs to be infinitely precise in this way—that it never matters. There is (for each decision problem, each lottery therein, and each agent) some threshold such that the agent would not be irrational if she simply ignored outcomes whose probabilities lie below that threshold. (Smith 2014: 472–474)
Suppose we accept the claim that infinite precision is not required in decision theory. This would entail, per Smith's argument, that it is rationally permissible to ignore probabilities smaller than \(\epsilon\). However, to ensure that the decision maker never pays a fortune for playing the St. Petersburg game it seems that Smith would have to defend the stronger claim that decision makers are rationally required to ignore small probabilities, i.e., that it is not permissible to not ignore them. Decision makers who find themselves in agreement with Smith's view run a risk of paying a very large amount for playing the St. Petersburg game without doing anything deemed to be irrational by RNP. This point is important because it is arguably more difficult to show that decision makers are rationally required to avoid "infinite precision" in decisions in which this is an attainable and fully realistic goal, such as the St. Petersburg game. For a critique of RNP and a discussion of some related issues, see Hájek (2014).
Another objection to RNP has been proposed by Yoaav Isaacs (2016). He shows that RNP together with an additional principle endorsed by Smith (Weak Consistency) entail that the decision maker will sometimes take arbitrarily much risk for arbitrarily little reward.
Lara Buchak (2013) proposes what is arguably a more elegant version of this solution. Her suggestion is that we should assign exponentially less weight to small probabilities as we calculate an option's value. A possible weighting function r discussed by Buchak is \(r(p) = p^2.\) Her proposal is, thus, that if the probability is \(\frac{1}{8}\) that you win $8 in addition to what you already have, and your utility of money increases linearly, then instead of multiplying your gain in utility by \(\frac{1}{8},\) you should multiply it by \((\frac{1}{8})^2 =\frac{1}{64}.\) Moreover, if the probability is \(\frac{1}{16}\) that you win $16 in addition to what you already have, you should multiply your gain by \(\frac{1}{256},\) and so on. This means that small probabilities contribute very little to the risk-weighted expected utility.
Buchak's proposal vaguely resembles the familiar idea that our marginal utility of money is decreasing. As stressed by Cramér and Daniel Bernoulli, more money is always better than less, but the utility gained from each extra dollar is decreasing. According to Buchak, the weight we should assign to an outcome's probability is also nonlinear: Small probabilities matter less the smaller they are, and their relative importance decrease exponentially:
The intuition behind the diminishing marginal utility analysis of risk aversion was that adding money to an outcome is of less value the more money the outcome already contains. The intuition behind the present analysis of risk aversion is that adding probability to an outcome is of more value the more likely that outcome already is to obtain. (Buchak 2014: 1099.)
Buchak notes that this move does not by itself solve the St. Petersburg paradox. For reasons that are similar to those Menger (1934 [1979]) mentions in his comment on Bernoulli's solution, the paradox can be reintroduced by adjusting the outcomes such that the sum increases linearly (for details, see Buchak 2013: 73–74). Buchak is, for this reason, also committed to RNP, i.e., the controversial assumption that there will be some probability so small that it does not make any difference to the overall value of the gamble.
Another worry is that because Buchak rejects the principle of maximizing expected utility and replaces it with the principle of risk-weighted maximizing expected utility, many of the stock objections decision theorists have raised against violations of the expected utility principle can be raised against her principle as well. For instance, if you accept the principle of risk-weighted maximizing expected utility, you have to reject the independence axiom. This entails that you can be exploited in some cleverly designed pragmatic argument. See Briggs (2015) for a discussion of some objections to Buchak's theory.
In the Petrograd game introduced by Colyvan (2008) the player wins $1 more than in the St. Petersburg game regardless of how many times the coin is flipped. So instead of winning 2 utility units if the coin lands heads on the first toss, the player wins 3; and so on. See Table 1.
Probability \(\frac{1}{2}\) \(\frac{1}{4}\) \(\frac{1}{8}\) …
St. Petersburg 2 4 8 …
Petrograd \(2+1\) \(4+1\) \(8+1\) …
It seems obvious that the Petrograd game is worth more than the St. Petersburg game. However, it is not easy to explain why. Both games have infinite expected utility, so the expected utility principle gives the wrong answer. It is not true that the Petrograd game is worth more than the St. Petersburg game because its expected utility is higher; the two games have exactly the same expected utility. This shows that the expected utility principle is not universally applicable to all risky choices, which is an interesting observation in its own right.
Is the Petrograd game worth more than the St. Petersburg game because the outcomes of the Petrograd game dominate those of the St. Petersburg game? In this context, dominance means that the player will always win $1 more regardless of which state of the world turns out to be the true state, that is, regardless of how many times the coin is flipped. The problem is that it is easy to imagine versions of the Petrograd game to which the dominance principle would not be applicable. Imagine, for instance, a version of the Petrograd game that is exactly like the one in Table 1 except that for some very improbable outcome (say, if the coin lands heads for the first time on the 100th flip) the player wins 1 unit less than in the St. Petersburg game. This game, the Petrogradskij game, does not dominate the St. Petersburg game. However, since it is almost certain that the player will be better off by playing the Petrogradskij game a plausible decision theory should be able to explain why the Petrogradskij game is worth more than the St. Petersburg game.
Colyvan claims that we can solve this puzzle by introducing a new version of expected utility theory called Relative Expected Utility Theory (REUT). According to REUT we should calculate the difference in expected utility between the two options for each possible outcome. Formally, the relative expected utility (\(\reu\)) of act \(A_k\) over \(A_l\) is
\[ \reu(A_k,A_l) = \sum_{i=1}^n p_i(u_{ki} - u_{li}). \]
According to Colyvan, it is rational to choose \(A_k\) over \(A_l\) if and only if \(\reu(A_k,A_l) \gt 0\).
Colyvan's REUT neatly explains why the Petrograd game is worth more than the St. Petersburg game because the relative expected utility is 1. REUT also explains why the Petrogradskij game is worth more than the St. Petersburg game: the difference in expected utility is \(1 - (\frac{1}{2})^{100}\) which is > 0.
However, Peterson (2013) notes that REUT cannot explain why the Leningradskij game is worth more than the Leningrad game (see Table 2). The Leningradskij game is the version of the Petrograd game in which the player in addition to receiving a finite number of units of utility also gets to play the St. Petersburg game (SP) if the coin lands heads up in the second round. In the Leningrad game the player gets to play the St. Petersburg game (SP) if the coin lands heads up in the third round.
Probability \(\frac{1}{2}\) \(\frac{1}{4}\) \(\frac{1}{8}\) \(\frac{1}{16}\) …
Leningrad 2 4 \(8+\textrm{SP}\) 16 …
Leningradskij 2 \(4+\textrm{SP}\) 8 16 …
It is obvious that the Leningradskij game is worth more than the Leningrad game because the probability that the player gets to play SP as a bonus (which has infinite expected utility) is higher. However, REUT cannot explain why. The difference in expected utility for the state that occurs with probability \(\frac{1}{4}\) in Table 2 is \(-\infty\) and it is \(+\infty\) for the state that occurs with probability \(\frac{1}{8}.\) Therefore, because \(p \cdot \infty = \infty\) for all positive probabilities \(p\), and "\(\infty - \infty\)" is undefined in standard analysis, REUT cannot be applied to these games.
Bartha (2016) proposes a more complex version of Colyvan's theory designed to address the worry outlined above. His suggestion is to ask the agent to compare a "problematic" game to a lottery between two other games. If, for instance, Petrograd+ is the game in which the player always wins 2 units more than in the St. Petersburg game regardless of how many times the coin is tossed, then the player could compare the Petrograd game to a lottery between Petrograd+ and the St. Petersburg game. By determining for what probabilities p a lottery in which one plays Petrograd+ with probability p and the St. Petersburg game with probability \(1-p\) is better than playing the Petrograd game for sure one can establish a measure of the relative value of Petrograd as compared to Petrograd+ or St. Petersburg. (For details, see Sect. 5 in Bartha 2016. See also Colyvan and Hájek's 2016 discussion of Bartha's theory.)
Let us also mention another, quite simple variation of the original St. Petersburg game, which is played as follows (see Peterson 2015: 87): A manipulated coin lands heads up with probability 0.4 and the player wins a prize worth \(2^n\) units of utility, where n is the number of times the coin was tossed. This game, the Moscow game, is more likely to yield a long sequence of flips and is therefore worth more than the St. Petersburg game, but the expected utility of both games is the same, because both games have infinite expected utility. It might be tempting to say that the Moscow game is more attractive because the Moscow game stochastically dominates the St. Petersburg game. (That one game stochastically dominates another game means that for every possible outcome, the first game has at least as high a probability of yielding a prize worth at least u units of utility as the second game; and for some u, the first game yields u with a higher probability than the second.) However, the stochastic dominance principle is inapplicable to games in which there is a small risk that the player wins a prize worth slightly less than in the other game. We can, for instance, imagine that if the coin lands heads on the 100th flip the Moscow game pays one unit less than the St. Petersburg game; in this scenario neither game stochastically dominates the other. Despite this, it still seems reasonable to insist that the game that is almost certain to yield a better outcome (in the sense explained above) is worth more. The challenge is to explain why in a robust and non-arbitrary way.
The Pasadena paradox introduced by Nover and Hájek (2004) is inspired by the St. Petersburg game, but the pay-off schedule is different. As usual, a fair coin is flipped n times until it comes up heads for the first time. If n is odd the player wins \((2^n)/n\) units of utility; however, if n is even the player has to pay \((2^n)/n\) units. How much should one be willing to pay for playing this game?
If we sum up the terms in the temporal order in which the outcomes occur and calculate expected utility in the usual manner we find that the Pasadena game is worth:
\[\begin{align} \frac{1}{2}\cdot\frac{2}{1} - \frac{1}{4}\cdot\frac{4}{2} + \frac{1}{8}\cdot\frac{8}{3} &- \frac{1}{16}\cdot\frac{16}{4} + \frac{1}{32}\cdot\frac{16}{5} - \cdots \\ &= 1 - \frac{1}{2} + \frac{1}{3} - \frac{1}{4} + \frac{1}{5} - \cdots \\ &= \sum_n \frac{(-1)^{n-1}}{n} \end{align}\]
This infinite sum converges to ln 2 (about 0.69 units of utility). However, Nover and Hájek point out that we would obtain a very different result if we were to rearrange the order in which the very same numbers are summed up. Here is one of many possible examples of this mathematical fact:
\[\begin{align} 1 - \frac{1}{2} - \frac{1}{4} + \frac{1}{3} - \frac{1}{6} - \frac{1}{8} + \frac{1}{5} - \frac{1}{10} &- \frac{1}{12} + \frac{1}{7} - \frac{1}{14} - \frac{1}{16} \cdots \\ &= \frac{1}{2}(\ln 2). \end{align}\]
This is, of course, not news to mathematicians. The infinite sum produced by the Pasadena game is known as the alternating harmonic series, which is a conditionally convergent series. (A series \(a_n\) is conditionally convergent if \(\sum_{j=1}^{\infty} a_n\) converges but \(\sum_{j=1}^{\infty} \lvert a_n\rvert\) diverges.) Because of a theorem known as the Riemann rearrangement theorem, we know that if an infinite series is conditionally convergent, then its terms can always be rearranged such the sum converges to any finite number, or to \(+\infty\) or to \(-\infty\).
Nover and Hájek's point is that it seems arbitrary to sum up the terms in the Pasadena game in the temporal order produced by the coin flips. To see why, it is helpful to imagine a slightly modified version of the game. In their original paper, Nover and Hájek ask us to imagine that:
We toss a fair coin until it lands heads for the first time. We have written on consecutive cards your pay-off for each possible outcome. The cards read as follows: (Top card) If the first =heads is on toss #1, we pay you $2. […] By accident, we drop the cards, and after picking them up and stacking them on the table, we find that they have been rearranged. No matter, you say—obviously the game has not changed, since the pay-off schedule remains the same. The game, after all, is correctly and completely specified by the conditionals written on the cards, and we have merely changed the order in which the conditions are presented. (Nover and Hájek 2004: 237–239)
Under the circumstances described here, we seem to have no reason to prefer any particular order in which to sum up the terms of the infinite series. So is the expected value of Pasadena game \(\ln 2\) or \(\frac{1}{2}(\ln 2)\) or \(\frac{1}{3}\) or \(-\infty\) or 345.68? All these suggestions seem equally arbitrary. Moreover, the same holds true for the Altadena game, in which every payoff is increased by one dollar. The Altadena game is clearly better than then Pasadena game, but advocates of expected utility theory seem unable to explain why.
The literature on the Pasadena game is extensive. See, e.g., Hájek and Nover (2006), Fine (2008), Smith (2014), and Bartha (2016). A particularly influential solution is due to Easwaran (2008). He introduces a distinction between a strong and a weak version of the expected utility principle, inspired by the well-known distinction between the strong and weak versions of the law of large numbers. According to the strong law of large numbers, the average utility of a game converges to its expected utility with probability one as the number of iterations goes to infinity. The weak law of large numbers holds that for a sufficiently large set of trials the probability can be made arbitrarily small that that the average utility will not differ from the expected utility by more than some small pre-specified amount. So according to the weak expected utility principle,
by fixing in advance a high enough number of n plays, the average payoff per play can be almost guaranteed to be arbitrarily close to ln 2,
while the strong version of the principle entails that
if one player keeps getting to decide whether to play again or quit, then she can almost certainly guarantee as much profit as she wants, regardless of the (constant) price per play. (Easwaran 2008: 635)
Easwaran's view is that the weak expected utility principle should guide the agent's choice and that the fair price to pay is ln 2.
However, Easwaran's solution cannot be generalized to other games with slightly different payoff schemes. Bartha (2016: 805) describes a version of the Pasadena game that has no expected value. In this game, the Arroyo game, the player wins \(-1^{n+1}(n+1)\) with probability \(p_n = \frac{1}/{(n+1)}\). If we calculate the expected utility in the order in which the outcomes are produced, we get the same result as for the Pasadena game: \(1 - \frac{1}{2} + \frac{1}{3} - \frac{1}{4} \cdots\) For reasons explained (and proved) by Bartha, the Arroyo game has no weak expected utility.
It is also worth keeping in mind that Pasadena-like scenarios can arise in non-probabilistic contexts (see Peterson 2013). Imagine, for instance, an infinite population in which the utility of individual number j is \(\frac{(-1)^{j-1}}{j}\). What is the total utility of this population? Or imagine that you are the proud owner of a Jackson Pollock painting. An art dealer tells you the overall aesthetic value of the painting is the sum of some of its parts. You number the points in the painting with arbitrary numbers 1, 2, 3, … (perhaps by writing down the numbers on cards and then dropping all cards on the floor); the aesthetic value of each point j is \(\frac{(-1)^{j-1}}{j}\). What is the total aesthetic value of the painting? These examples are non-probabilistic versions of the Pasadena problem, to which the expected utility principle is inapplicable. There is no uncertainty about any state of nature; the decision maker knows for sure what the world is like. This means that Easwaran's distinction between weak and strong expectations is not applicable.
Although some of these problems may appear to be somewhat esoteric, we cannot dismiss them. All Pasadena-like problems are vulnerable to the same contagion problem as the St Petersburg game (see section 2). Hájek and Smithson offer the following colorful illustration:
You can choose between pizza and Chinese for dinner. Each option's desirability depends on how you weigh probabilistically various scenarios (burnt pizza, perfectly cooked pizza,… over-spiced Chinese, perfectly spiced Chinese…) and the utilities you accord them. Let us stipulate that neither choice dominates the other, yet it should be utterly straightforward for you to make a choice. But it is not if the expectations of pizza and Chinese are contaminated by even a miniscule [sic] assignment of credence to the Pasadena game. If the door is opened to it just a crack, it kicks the door down and swamps all expected utility calculations. You cannot even choose between pizza and Chinese. (Hájek and Smithson 2012: 42, emph. added.)
Colyvan (2006) suggests that we should bite the bullet on the Pasadena game and accept that it has no expected utility. The contagion problem shows that if we were to do so, we would have to admit that the principle of maximizing expected utility would be applicable to nearly no decisions. Moreover, because the contagion problem is equally applicable to all games discussed in this entry (St. Petersburg, Pasadena, Arroyo, etc.) it seems that all these problems may require a unified solution.
For hundreds of years, decision theorists have agreed that rational agents should maximize expected utility. The discussion has mostly been focused on how to interpret this principle, especially for choices in which the causal structure of the world is unusual. However, until recently no one has seriously questioned that the principle of maximizing expected utility is the right principle to apply. The rich and growing literature on the many puzzles inspired by the St. Petersburg paradox indicate that this might have been a mistake. Perhaps the principle of maximizing expected utility should be replaced by some entirely different principle?
Alexander, J. M., 2011, "Expectations and Choiceworthiness", Mind, 120(479): 803–817. doi:10.1093/mind/fzr049
Arrow, Kenneth J., 1970, Essays in the Theory of Risk-Bearing, Amsterdam: North-Holland.
Aumann, Robert J., 1977, "The St. Petersburg Paradox: A Discussion of Some Recent Comments", Journal of Economic Theory, 14(2): 443–445. doi:10.1016/0022-0531(77)90143-0
Bartha, Paul F. A., 2016, "Making Do Without Expectations", Mind, 125(499): 799–827. doi:10.1093/mind/fzv152
Bassett, Gilbert W., 1987, "The St. Petersburg Paradox and Bounded Utility", History of Political Economy, 19(4): 517–523. doi:10.1215/00182702-19-4-517
Bernoulli, Daniel, 1738 [1954], "Specimen Theoriae Novae de Mensura Sortis", Commentarii Academiae Scientiarum Imperialis Petropolitanae, 5: 175–192. English translation, 1954, "Exposition of a New Theory on the Measurement of Risk", Econometrica, 22(1): 23–36. doi:10.2307/1909829
Bernoulli, Jakob, 1975, Die Werke von Jakob Bernoulli, Band III, Basel: Birkhäuser. A translation from this by Richard J. Pulskamp of Nicolas Bernoulli's letters concerning the St. Petersburg Game is available online.
Briggs, Rachael, 2015, "Costs of Abandoning the Sure-Thing Principle", Canadian Journal of Philosophy, 45(5–6): 827–840. doi:10.1080/00455091.2015.1122387
Brito, D.L, 1975, "Becker's Theory of the Allocation of Time and the St. Petersburg Paradox", Journal of Economic Theory, 10(1): 123–126. doi:10.1016/0022-0531(75)90067-8
Buchak, Lara, 2013, Risk and Rationality, New York: Oxford University Press. doi:10.1093/acprof:oso/9780199672165.001.0001
–––, 2014, "Risk and Tradeoffs", Erkenntnis, 79(S6): 1091–1117. doi:10.1007/s10670-013-9542-4
Buffon, G. L. L., 1777, "Essai d'Arithmdéétique Motale", in Suppléments à l'Histoire Naturelle. Reprinted in Oeuvres Philosophiques de Buffon, Paris, 1954.
Chalmers, David J., 2002, "The St. Petersburg Two-Envelope Paradox", Analysis, 62(2): 155–157. doi:10.1093/analys/62.2.155
Chen, Eddy Keming and Daniel Rubio, forthcoming, "Surreal Decisions", Philosophy and Phenomenological Research, First online: 5 June 2018. doi:10.1111/phpr.12510
Colyvan, Mark, 2006, "No Expectations", Mind, 115(459): 695–702. doi:10.1093/mind/fzl695
–––, 2008, "Relative Expectation Theory":, Journal of Philosophy, 105(1): 37–44. doi:10.5840/jphil200810519
Colyvan, Mark and Alan Hájek, 2016, "Making Ado Without Expectations":, Mind, 125(499): 829–857. doi:10.1093/mind/fzv160
Cowen, Tyler and Jack High, 1988, "Time, Bounded Utility, and the St. Petersburg Paradox", Theory and Decision, 25(3): 219–223. doi:10.1007/BF00133163
Dutka, Jacques, 1988, "On the St. Petersburg Paradox", Archive for History of Exact Sciences, 39(1): 13–39. doi:10.1007/BF00329984
Easwaran, Kenny, 2008, "Strong and Weak Expectations", Mind, 117(467): 633–641. doi:10.1093/mind/fzn053
Fine, Terrence L., 2008, "Evaluating the Pasadena, Altadena, and St Petersburg Gambles", Mind, 117(467): 613–632. doi:10.1093/mind/fzn037
Hájek, Alan, 2014, "Unexpected Expectations", Mind, 123(490): 533–567. doi:10.1093/mind/fzu076
Hájek, Alan and Harris Nover, 2006, "Perplexing Expectations", Mind, 115(459): 703–720. doi:10.1093/mind/fzl703
–––, 2008, "Complex Expectations", Mind, 117(467): 643–664. doi:10.1093/mind/fzn086
Hájek, Alan and Michael Smithson, 2012, "Rationality and Indeterminate Probabilities", Synthese, 187(1): 33–48. doi:10.1007/s11229-011-0033-3
Isaacs, Yoaav, 2016, "Probabilities Cannot Be Rationally Neglected", Mind, 125(499): 759–762. doi:10.1093/mind/fzv151
Jeffrey, Richard C., 1983, The Logic of Decision, 2nd edition, Chicago: University of Chicago Press.
Jordan, Jeff, 1994, "The St. Petersburg Paradox and Pascal's Wager", Philosophia, 23(1–4): 207–222. doi:10.1007/BF02379856
Joyce, James M., 1999, The Foundations of Causal Decision Theory, Cambridge: Cambridge University Press.
Lauwers, Luc and Peter Vallentyne, 2016, "Decision Theory without Finite Standard Expected Value", Economics and Philosophy, 32(3): 383–407. doi:10.1017/S0266267115000334
Linnebo, Øystein and Stewart Shapiro, 2019, "Actual and Potential Infinity: Actual and Potential Infinity", Noûs, 53(1): 160–191. doi:10.1111/nous.12208
Luce, R. Duncan, 1959, "On the Possible Psychophysical Laws", Psychological Review, 66(2): 81–95. doi:10.1037/h0043178
McClennen, Edward F., 1994, "Pascal's Wager and Finite Decision Theory", in Gambling on God: Essays on Pascal's Wager, Jeff Jordan (ed.), Boston: Rowman & Littlefield, 115–138.
Menger, Karl, 1934 [1979], "Das Unsicherheitsmoment in der Wertlehre: Betrachtungen im Anschluß an das sogenannte Petersburger Spiel", Zeitschrift für Nationalökonomie, 5(4): 459–485. Translated, 1979, as "The Role of Uncertainty in Economics", in Menger's Selected Papers in Logic and Foundations, Didactics, Economics, Dordrecht: Springer Netherlands, 259–278. doi:10.1007/BF01311578 (de) doi:10.1007/978-94-009-9347-1_25 (en)
Nover, Harris and Alan Hájek, 2004, "Vexing Expectations", Mind, 113(450): 237–249. doi:10.1093/mind/113.450.237
Peterson, Martin, 2011, "A New Twist to the St. Petersburg Paradox":, Journal of Philosophy, 108(12): 697–699. doi:10.5840/jphil20111081239
–––, 2013, "A Generalization of the Pasadena Puzzle: A Generalization of the Pasadena Puzzle", Dialectica, 67(4): 597–603. doi:10.1111/1746-8361.12046
–––, 2009 [2017], An Introduction to Decision Theory, Cambridge: Cambridge University Press; second edition 2017. doi:10.1017/CBO9780511800917 doi:10.1017/9781316585061
–––, 2019, "Interval Values and Rational Choice", Economics and Philosophy, 35(1): 159–166. doi:10.1017/S0266267118000147
Ramsey, Frank Plumpton, 1926 [1931], "Truth and Probability", printed in The Foundations of Mathematics and Other Logical Essays, R. B. Braithwaite (ed.), London: Kegan Paul, Trench, Trubner & Co., 156–198. Reprinted in Philosophy of Probability: Contemporary Readings, Antony Eagle (ed.), New York: Routledge, 2011: 52–94. [Ramsey 1926 [1931] available online]
Samuelson, Paul A., 1977, "St. Petersburg Paradoxes: Defanged, Dissected, and Historically Described", Journal of Economic Literature, 15(1): 24–55.
Savage, Leonard J., 1954, The Foundations of Statistics, (Wiley Publications in Statistics), New York: Wiley. Second edition, Courier Corporation, 1974.
Skala, Heinz J., 1975, Non-Archimedean Utility Theory, Dordrecht: D. Reidel.
Smith, Nicholas J. J., 2014, "Is Evaluative Compositionality a Requirement of Rationality?", Mind, 123(490): 457–502. doi:10.1093/mind/fzu072
von Neumann, John and Oskar Morgenstern, 1947, Theory of Games and Economic Behavior, second revised edtion, Princeton, NJ: Princeton University Press.
Weirich, Paul, 1984, "The St. Petersburg Gamble and Risk", Theory and Decision, 17(2): 193–202. doi:10.1007/BF00160983
Williamson, Timothy, 2007, "How Probable Is an Infinite Sequence of Heads?", Analysis, 67(295): 173–180. doi:10.1111/j.1467-8284.2007.00671.x
decision theory | hedonism | infinity | Pascal's wager | probability, interpretations of | rational choice, normative: expected utility | space and time: supertasks | statistics, philosophy of
Martin Peterson <[email protected]> | CommonCrawl |
Metallurgical and Materials Transactions A
Simulation of TTT Curves for Additively Manufactured Inconel 625 Simulation of TTT Curves for Additively Manufactured Inconel 625
Thermal Stability of Rolled Metastable Austenitic Stainless Steel 1.4307... Thermal Stability of Rolled Metastable Austenitic Stainless Steel 1.4307 Studied Using Positron Annihilation
Impact of Abradant Size on Damaged Zone of 304 AISI Steel Characterized by... Impact of Abradant Size on Damaged Zone of 304 AISI Steel Characterized by Positron Annihilation Spectroscopy
Parameters Sensitivity Characteristics of Highly Integrated Valve-Controlled... Parameters Sensitivity Characteristics of Highly Integrated Valve-Controlled Cylinder Force Control System
Prediction of depth-averaged velocity in an open channel flow Prediction of depth-averaged velocity in an open channel flow
Novel Accelerating Life Test Method and Its Application by Combining Constant... Novel Accelerating Life Test Method and Its Application by Combining Constant Stress and Progressive Stress
Commodity flow estimation for a metropolitan scale freight modeling system... Commodity flow estimation for a metropolitan scale freight modeling system: supplier selection considering distribution channel using an error component logit mixture model
Study of deformation microstructure of nickel samples at very short milling... Study of deformation microstructure of nickel samples at very short milling times: effects of addition of α-Al2O3 particles
Numerical study of shell and tube heat exchanger with different cross-section... Numerical study of shell and tube heat exchanger with different cross-section tubes and combined tubes
The Ternary Bi-Mn-Sb Phase Diagram and the Crystal Structure of the Ternary... The Ternary Bi-Mn-Sb Phase Diagram and the Crystal Structure of the Ternary Τ Phase Bi0.8MnSb0.2
Anisotropy of Mass Transfer During Sintering of Powder Materials with Pore–Particle Structure Orientation
Metallurgical and Materials Transactions A, Dec 2018
E. Torresani, D. Giuntini, C. Zhu, T. Harrington, K. S. Vecchio, A. Molinari, R. K. Bordia, E. A. Olevsky
E. Torresani
D. Giuntini
C. Zhu
T. Harrington
K. S. Vecchio
A. Molinari
R. K. Bordia
E. A. Olevsky
A micromechanical model for the shrinkage anisotropy during sintering of metallic powders is proposed and experimentally assessed. The framework developed for modeling sintering based on the mechanism of grain boundary diffusion is extended to take into account the dislocation pipe-enhanced volume diffusion. The studied iron powder samples are pre-shaped into their green forms by uniaxial cold pressing before sintering step. The resultant green bodies are anisotropic porous structures, with inhomogeneous plastic deformation at the inter-particle contacts. These non-uniformities are considered to be the cause of the anisotropic dislocation pipe diffusion mechanisms, and thus of the undesired shape distortion during shrinkage. The proposed model describes the shrinkage rates in the compaction loading and transverse directions, as functions of both structural and geometric activities of the samples. Dislocation densities can be estimated from such equations using dilatometry and image analysis data. The reliability and applicability of the developed modeling framework are verified by comparing the calculated dislocation densities with outcomes of nanoindentation and electron backscatter diffraction-derived lattice rotations.
A PDF file should load here. If you do not see its contents the file may be temporarily unavailable at the journal website or you do not have a PDF plug-in installed and enabled in your browser.
Alternatively, you can download the file locally and open with any standalone PDF reader:
https://link.springer.com/content/pdf/10.1007%2Fs11661-018-5037-x.pdf
Metallurgical and Materials Transactions A February 2019, Volume 50, Issue 2, pp 1033–1049 | Cite as Anisotropy of Mass Transfer During Sintering of Powder Materials with Pore–Particle Structure Orientation AuthorsAuthors and affiliations E. TorresaniD. GiuntiniC. ZhuT. HarringtonK. S. VecchioA. MolinariR. K. BordiaE. A. Olevsky Article First Online: 03 December 2018 161 Downloads Abstract A micromechanical model for the shrinkage anisotropy during sintering of metallic powders is proposed and experimentally assessed. The framework developed for modeling sintering based on the mechanism of grain boundary diffusion is extended to take into account the dislocation pipe-enhanced volume diffusion. The studied iron powder samples are pre-shaped into their green forms by uniaxial cold pressing before sintering step. The resultant green bodies are anisotropic porous structures, with inhomogeneous plastic deformation at the inter-particle contacts. These non-uniformities are considered to be the cause of the anisotropic dislocation pipe diffusion mechanisms, and thus of the undesired shape distortion during shrinkage. The proposed model describes the shrinkage rates in the compaction loading and transverse directions, as functions of both structural and geometric activities of the samples. Dislocation densities can be estimated from such equations using dilatometry and image analysis data. The reliability and applicability of the developed modeling framework are verified by comparing the calculated dislocation densities with outcomes of nanoindentation and electron backscatter diffraction-derived lattice rotations. Manuscript submitted March 19, 2018. 1 Introduction In the conventional press-and-sinter process of powder metallurgy, green parts obtained by cold compaction are sintered to form dense bulk parts via the metallic bonding between the powder particles. This occurs through the formation and growth of the so-called necks, promoted by mass transport phenomena towards the inter-particle contact region. When the source of atoms flowing towards the neck region lies within the bulk of the particles, sintering is accomplished by shrinkage, leading to an overall dimensional change of the parts.[1] The prediction of such a dimensional change is of great importance, since one of the key attributes of powder metallurgy is net shape sintering of complex parts with excellent dimensional precision, without any need of machining. In the literature, various approaches are used to investigate sintering at different scales. The microscale approach is based on the classical theory of sintering that describes the growth of the sintering necks as a function of temperature and time, due to the driving force linked to the free surface area of the powders and to the occurrence of various mass transport mechanisms. Shrinkage kinetics laws are proposed for each mass transport mechanism, based on the assumption that powder particles are rigid spheres in a point contact at the beginning of the sintering process.[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16] The effect of the initial cold compaction is therefore mostly neglected. The macroscale approach is utilized in most modern studies, where the behavior of the porous body during sintering is described using continuum mechanics.[17, 18, 19, 20, 21, 22, 23, 24, 25, 26] This approach is similar to the theories of plasticity of porous bodies[27, 28, 29, 30, 31, 32, 33, 34, 35, 36] employed for modeling of powder pressing. It investigates the dimensional changes of porous bodies as a consequence of the flow of material from the solid matrix containing pores, and treats sintering as a rheological phenomenon.[37,38] Solid state sintering is a thermally activated process, where the contributions from several mass transport mechanisms, such as surface, grain boundary, and lattice diffusion, are responsible for neck growth and powder consolidation. Surface diffusion is mostly accountable for neck growth and the consequent material strengthening.[13,39, 40, 41] Different works[42, 43, 44] show, in the case of sinter-forging and constrained sintering, that the sintering shrinkage of powders can be anisotropic, due to the sintering conditions. Otherwise in the case of free sintering it has been demonstrated that the anisotropic shrinkage is a consequence of the anisotropic plastic deformation of the particles promoted by uniaxial cold compaction.[45] Zavaliangos et al.[46,47] have considered anisotropy to be a consequence of the different flattening and arrangement of particle-particle contacts, the density of pores present on the grain boundaries, and oxide fragmentation. In a previous work, Molinari et al.[48] proposed that anisotropy is due to the effect of the structural defect densities introduced by cold compaction on bulk diffusivity. This hypothesis was further developed by some of the authors of the present paper; with studies on the kinetics of the diffusion mechanisms,[48,49] microstructural analysis on the deformed powder particles after cold compaction,[50,51] and an initial investigation on the effect of defects on diffusion.[52] One result indicated that shrinkage kinetics are influenced by the dislocations formed in the powder particles during cold compaction (structural activity). Namely, the inhomogeneous dislocation density distribution inside the particles leads to anisotropic shrinkage kinetics, characterized by greater densification parallel to the compaction direction (longitudinal) than perpendicular to the compaction direction (transverse). Grain boundary diffusion is generally considered to be the principal mass transfer mechanism in solid state sintering.[40,44,46,53] However, taking into account the large strains present within the particles of the initial green compact and the effect of dislocations on diffusivity, especially during the early stages of sintering, volume diffusion can be of greater importance. The effect of dislocations on bulk diffusivity is displayed through the dislocation pipe diffusion model, according to which bulk diffusivity is proportional to the dislocation density, as reported by Hart.[54,55] Based on Hart's equation for dislocation pipe diffusion and the equations of the classical theory of sintering, Molinari et al.[49] estimated the dislocation density in the inter-particle contact regions, obtaining quite high values, comparable to those typical of heavily cold worked metals. However, the classic theories of sintering, as mentioned above, do not consider the actual geometry of the contact regions, which is different than a single point, and occupies an area that changes depending on the contact direction. These geometric aspects can be analyzed and quantified in the metallographic sections using image analysis software. Specifically, for the measurement of the contact lengths, a general method, including a preliminary correction factor due to "distortion" and measurement imprecisions, was demonstrated in previous studies.[50,51] Such microstructural features of the green parts may further contribute to the anisotropic dimensional change (geometric activity), since atoms flowing towards the neck surface originate in the inter-particle regions. Other authors investigated the influence of shape and orientation of particles and pores on shrinkage.[56, 57, 58, 59] In the present work, the continuum theory of sintering is used to develop a micromechanical model of the anisotropic dimensional change, inclusive of both the contributions of structural and geometric activities, namely presence of dislocations and of the flattened porous material morphology. The model proposed by Olevsky et al.[44] is adapted to this case, in which volume diffusion is the principal mass transport mechanism. This model is applied to the sintering of pure iron. Such a material choice was made in order to rule out potential complications arising from the presence of additional alloying elements altering the diffusivity of the powder compact, and to rely on the wide availability of physical and chemical data on pure iron in the literature. The dislocation densities along the different directions are calculated by plugging the experimental data on the isothermal shrinkage of the sample at the different sintering temperatures into the derived equations. The validity of the model is then assessed by experimentally estimating dislocation densities with two different methods. The first method is based on the correlation between dislocation densities and hardness measured via nanoindentation, as proposed by Nix and Gao.[60, 61, 62] The second method relies on EBSD lattice curvature data.[63, 64, 65] The comparison between calculated and measured dislocation density values is accompanied by a parameter sensitivity study, and the reliability of the model is discussed. 2 Model Formulation The proposed micromechanical model is the adaptation of the work of Olevsky et al.[44] to the volume diffusion case. In the earlier work by Olevsky et al., it was assumed that the main mass transfer mechanism was grain boundary diffusion, and diffusion was related to micromechanical considerations through the chemical potential, according to Johnson.[11] In the present case, the induced plastic deformation activates dislocation pipe diffusion mechanisms, and therefore leads to noticeably enhanced volume diffusivity.[52] Therefore, for the study domain definition, the 2-D geometry employed in Olevsky et al.[44] is extended to the 3-D case. The porous structure of the material can be schematized with an assembly of simple-packed, oriented, prismatic particles, with ellipsoidal pores at the junctions between them, as depicted in Figure 1(a). Open image in new window Fig. 1 Schematics of the study domain representative of the porous material's structure: (a) 3-D representation, where δ is the inter-particle boundary thickness; (b) 2-D view with micromechanics parameters designation A representative unit cell for the micromechanical study definition is chosen to be a cluster of eight particles with a central lenticular pore. Note that, due to the symmetry of the structure, it is sufficient to only take into consideration 1/8 of each particle, accordingly to the representation given in Figure 1(a). The prismatic shape is a good approximation for powder particles that have been flattened by cold compaction and allows a simple definition of all the geometric parameters that influence the shrinkage kinetics. As depicted in Figure 1(a), the y-axis is defined oriented along the pre-sintering cold compaction direction (longitudinal direction), and thus x and z are defined as transverse directions. The notations, a, b and c define the semi-contact of the particles along x, z and y, respectively, and ap, bp and cp the semi-axes of the pores in the same directions. In this coordinate system, the geometric features along the x and z direction are equivalent (a = b, ap = bp), and the semi-axes and contact along x and z are greater than the those along y (a > c, ap > cp). This geometry represents transversely isotropic symmetry.[45] The radii of curvature ra, rb, and rc for the ellipsoidal pores are thus defined as follows: $$ r_{a} = r_{b} = {\raise0.7ex\hbox{${c_{\text{p}}^{2} }$} \!\mathord{\left/ {\vphantom {{c_{\text{p}}^{2} } {a_{\text{p}} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${a_{\text{p}} }$}};\;r_{c} = {\raise0.7ex\hbox{${a_{\text{p}}^{2} }$} \!\mathord{\left/ {\vphantom {{a_{\text{p}}^{2} } {c_{\text{p}} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${c_{\text{p}} }$}} $$ (1) and the surface area of the pore is given by $$ S_{\text{p}} \approx 2\pi \left( {a_{\text{p}}^{2} + c_{\text{p}}^{2} \frac{{\tanh^{ - 1} \left( {\sin \left( {\cos^{ - 1} \left( {{\raise0.7ex\hbox{${c_{\text{p}} }$} \!\mathord{\left/ {\vphantom {{c_{\text{p}} } {a_{\text{p}} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${a_{\text{p}} }$}}} \right)} \right)} \right)}}{{\sin \left( {\cos^{ - 1} \left( {{\raise0.7ex\hbox{${c_{\text{p}} }$} \!\mathord{\left/ {\vphantom {{c_{\text{p}} } {a_{\text{p}} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${a_{\text{p}} }$}}} \right)} \right)}}} \right) $$ (2) As a result of this equivalence along the two transverse directions, the model is hereby developed in the reference system defined by the axes x and y, as shown in Figure 1(b). According to Johnson,[11] at the inter-particle boundaries, the following normal stress distributions exist: $$ \left\{ {\begin{array}{*{20}l} {\sigma_{x} = b_{1x} \cdot y^{2} + b_{2x} \cdot y + b_{3x} } \\ {\sigma_{y} = b_{1y} \cdot x^{2} + b_{2y} \cdot x + b_{3y} } \\ \end{array} } \right. $$ (3) Due to the geometry of the study domain, the boundary conditions that these should satisfy for the x direction are $$ \left\{ {\begin{array}{l} {\int_{0}^{c} {\sigma_{x} {\text{d}}x = - \gamma_{\text{sv}} \cdot \sin \left( {{\raise0.7ex\hbox{$\phi $} \!\mathord{\left/ {\vphantom {\phi 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)} } \\ {\sigma_{x} \left( c \right) = {\raise0.7ex\hbox{${\gamma_{\text{sv}} }$} \!\mathord{\left/ {\vphantom {{\gamma_{\text{sv}} } {r_{\text{c}} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${r_{\text{c}} }$}}} \\ {\nabla \sigma_{x} \left( 0 \right) = \frac{{\partial \sigma_{x} }}{\partial y}\left( {y = 0} \right) = 0} \\ \end{array} } \right. $$ (4) where γsv (N/m) is the surface energy and ϕ is the dihedral angle. The dihedral angle is related to surface and grain boundary energy γss (N/m) as follows: $$ \gamma_{\text{ss}} = 2 \cdot \gamma_{\text{sv}} \cos \left( {{\raise0.7ex\hbox{$\phi $} \!\mathord{\left/ {\vphantom {\phi 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right) $$ (5) The three equations in Eq. [4] represent the following: the balance of the forces acting at inter-particle junctions with the free surface tension of the pore, the normal stress in correspondence of the pore surface (y = c), and the symmetry of the stress distribution. With these boundary conditions, the values of the coefficients b1x, b2x, and b3x [3] are obtained: $$ \left\{ {\begin{array}{l} {b_{1x} = {\raise0.7ex\hbox{${3\gamma_{\text{sv}} }$} \!\mathord{\left/ {\vphantom {{3\gamma_{\text{sv}} } 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}\left[ {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {\left( {c^{2} \cdot r_{c} } \right)}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\left( {c^{2} \cdot r_{c} } \right)}$}} - {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {c^{3} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${c^{3} }$}} \cdot \sin \left( {{\raise0.7ex\hbox{$\phi $} \!\mathord{\left/ {\vphantom {\phi 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)} \right]} \\ {b_{2x} = 0} \\ {b_{3x} = \gamma_{\text{sv}} \left[ {{\raise0.7ex\hbox{$3$} \!\mathord{\left/ {\vphantom {3 {\left( {2 \cdot c} \right)}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\left( {2 \cdot c} \right)}$}} \cdot \sin \left( {{\raise0.7ex\hbox{$\phi $} \!\mathord{\left/ {\vphantom {\phi 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right) - {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {\left( {2 \cdot r_{c} } \right)}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\left( {2 \cdot r_{c} } \right)}$}}} \right]} \\ \end{array} } \right. $$ (6) Thus, the normal stress distribution along the transverse direction becomes $$ \sigma_{x} = 3{\raise0.7ex\hbox{${\gamma_{\text{sv}} }$} \!\mathord{\left/ {\vphantom {{\gamma_{\text{sv}} } 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}\left\{ {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {c^{2} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${c^{2} }$}}\left[ {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {r_{c} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${r_{c} }$}} - {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 c}}\right.\kern-0pt} \!\lower0.7ex\hbox{$c$}} \cdot \sin \left( {{\raise0.7ex\hbox{$\phi $} \!\mathord{\left/ {\vphantom {\phi 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)} \right] \cdot y^{2} + \left[ {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 c}}\right.\kern-0pt} \!\lower0.7ex\hbox{$c$}} \cdot \sin \left( {{\raise0.7ex\hbox{$\phi $} \!\mathord{\left/ {\vphantom {\phi 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right) - {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {\left( {3 \cdot r_{c} } \right)}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\left( {3 \cdot r_{c} } \right)}$}}} \right]} \right\} $$ (7) An analogous procedure can be applied in the longitudinal direction to obtain $$ \sigma_{x} = 3{\raise0.7ex\hbox{${\gamma_{\text{sv}} }$} \!\mathord{\left/ {\vphantom {{\gamma_{\text{sv}} } 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}\left\{ {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {a^{2} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${a^{2} }$}}\left[ {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {r_{a} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${r_{a} }$}} - {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 a}}\right.\kern-0pt} \!\lower0.7ex\hbox{$a$}} \cdot \sin \left( {{\raise0.7ex\hbox{$\phi $} \!\mathord{\left/ {\vphantom {\phi 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)} \right] \cdot x^{2} + \left[ {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 a}}\right.\kern-0pt} \!\lower0.7ex\hbox{$a$}} \cdot \sin \left( {{\raise0.7ex\hbox{$\phi $} \!\mathord{\left/ {\vphantom {\phi 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right) - {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {\left( {3 \cdot r_{a} } \right)}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\left( {3 \cdot r_{a} } \right)}$}}} \right]} \right\} $$ (8) As anticipated, volume diffusion enhanced by dislocation activity is considered as the prevailing mass transport mechanism. Accordingly, the fluxes of matter in the x and y directions (J x V and J y V , mol/m2 s) are proportional to the chemical potential gradient, given by $$ \left\{ {\begin{array}{*{20}l} {J_{x}^{\text{V}} = {\raise0.7ex\hbox{${ - D_{{{\text{eff,}}x}}^{\text{V}} }$} \!\mathord{\left/ {\vphantom {{ - D_{{{\text{eff,}}x}}^{\text{V}} } {\left( {k \cdot T \cdot \varOmega } \right)}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\left( {k \cdot T \cdot \varOmega } \right)}$}} \cdot \frac{\partial \mu }{\partial x}} \\ {J_{y}^{\text{V}} = {\raise0.7ex\hbox{${ - D_{{{\text{eff,}}y}}^{\text{V}} }$} \!\mathord{\left/ {\vphantom {{ - D_{{{\text{eff,}}y}}^{\text{V}} } {\left( {k \cdot T \cdot \varOmega } \right)}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\left( {k \cdot T \cdot \varOmega } \right)}$}} \cdot \frac{\partial \mu }{\partial y}} \\ \end{array} } \right. $$ (9) where k is the Boltzmann's constant; T (K) is the absolute temperature; Ω (m3) is the atomic volume; µ (kJ/mol) is the chemical potential; and D eff, x V and D eff, y V (m2/s) are the effective volume diffusion coefficients in the transverse and longitudinal directions, respectively. Hart[54] has shown that in presence of dislocation pipe diffusion mechanisms, the coefficient of bulk diffusion increases proportionally to the dislocation density. Due to the anisotropic plastic deformation of the particles, the value for pipe diffusivity is different in x and y: $$ \left\{ {\begin{array}{*{20}l} {D_{{{\text{eff,}}x}}^{\text{V}} = D_{\text{V}} \left( {1 + \pi \cdot r_{\text{p}}^{2} \cdot d_{d,x} \cdot {\raise0.7ex\hbox{${D_{\text{p}} }$} \!\mathord{\left/ {\vphantom {{D_{\text{p}} } {D_{\text{V}} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${D_{\text{V}} }$}}} \right)} \\ {D_{{{\text{eff,}}y}}^{\text{V}} = D_{\text{V}} \left( {1 + \pi \cdot r_{\text{p}}^{2} \cdot d_{d,y} \cdot {\raise0.7ex\hbox{${D_{\text{p}} }$} \!\mathord{\left/ {\vphantom {{D_{\text{p}} } {D_{\text{V}} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${D_{\text{V}} }$}}} \right)} \\ \end{array} } \right. $$ (10) where DV and DP (m2/s) are the coefficient of volume diffusion and pipe diffusion in equilibrium conditions, respectively; rp (μm) is the pipe radius; dd,x and dd,y (1/m2) are the dislocation densities along the two directions, x and y, respectively. The relation between chemical potential and stresses is given by $$ \left\{ {\begin{array}{*{20}l} {\frac{\partial \mu }{\partial x} = - \varOmega \cdot \frac{{\partial \sigma_{y} }}{\partial x}} \\ {\frac{\partial \mu }{\partial y} = - \varOmega \cdot \frac{{\partial \sigma_{x} }}{\partial y}} \\ \end{array} } \right. $$ (11) Introducing Eqs. [10] and [11] into [9], the diffusion fluxes are given by $$ \left\{ {\begin{array}{*{20}l} {J_{x}^{\text{V}} = D_{\text{V}} \cdot \frac{{\left( {1 + \pi \cdot r_{\text{p}}^{2} \cdot d_{d,x} {\raise0.7ex\hbox{${D_{\text{p}} }$} \!\mathord{\left/ {\vphantom {{D_{\text{p}} } {D_{\text{V}} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${D_{\text{V}} }$}}} \right)}}{{\left( {k \cdot T} \right)}} \cdot \frac{{\partial \sigma_{y} }}{\partial x}} \\ {J_{y}^{\text{V}} = D_{\text{V}} \cdot \frac{{\left( {1 + \pi \cdot r_{\text{p}}^{2} \cdot d_{d,y} {\raise0.7ex\hbox{${D_{\text{p}} }$} \!\mathord{\left/ {\vphantom {{D_{\text{p}} } {D_{\text{V}} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${D_{\text{V}} }$}}} \right)}}{{\left( {k \cdot T} \right)}} \cdot \frac{{\partial \sigma_{x} }}{\partial y}} \\ \end{array} } \right. $$ (12) Substituting expressions [7] and [8] in [12] the diffusion fluxes can be rewritten as $$ \left\{ {\begin{array}{*{20}l} {J_{x}^{\text{V}} = 3 \cdot D_{\text{V}} \cdot \frac{{\left( {1 + \pi \cdot r_{\text{p}}^{2} \cdot d_{d,x} {\raise0.7ex\hbox{${D_{\text{p}} }$} \!\mathord{\left/ {\vphantom {{D_{\text{p}} } {D_{\text{V}} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${D_{\text{V}} }$}}} \right)}}{{\left( {k \cdot T} \right)}} \cdot \gamma_{\text{sv}} \cdot {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 a}}\right.\kern-0pt} \!\lower0.7ex\hbox{$a$}} \cdot \left[ {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {r_{a} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${r_{a} }$}} - {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 a}}\right.\kern-0pt} \!\lower0.7ex\hbox{$a$}}\sin \left( {{\raise0.7ex\hbox{$\phi $} \!\mathord{\left/ {\vphantom {\phi 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)} \right]} \\ {J_{y}^{\text{V}} = 3 \cdot D_{\text{V}} \cdot \frac{{\left( {1 + \pi \cdot r_{\text{p}}^{2} \cdot d_{d,y} {\raise0.7ex\hbox{${D_{\text{p}} }$} \!\mathord{\left/ {\vphantom {{D_{\text{p}} } {D_{\text{V}} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${D_{\text{V}} }$}}} \right)}}{{\left( {k \cdot T} \right)}} \cdot \gamma_{\text{sv}} \cdot {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 c}}\right.\kern-0pt} \!\lower0.7ex\hbox{$c$}} \cdot \left[ {{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {r_{c} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${r_{c} }$}} - {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 c}}\right.\kern-0pt} \!\lower0.7ex\hbox{$c$}}\sin \left( {{\raise0.7ex\hbox{$\phi $} \!\mathord{\left/ {\vphantom {\phi 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)} \right]} \\ \end{array} } \right. $$ (13) On the other hand, the diffusional fluxes are proportional to the change in the contact lengths between the powder particles, Δx and Δy as follows: $$ \left\{ {\begin{array}{*{20}l} {J_{x}^{\text{V}} \left( a \right) = - {\raise0.7ex\hbox{${{\text{d}}\left( {\Delta_{y} } \right)}$} \!\mathord{\left/ {\vphantom {{{\text{d}}\left( {\Delta_{y} } \right)} {{\text{d}}t}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${{\text{d}}t}$}} \cdot \frac{{a + a_{\text{p}} }}{{\varOmega \cdot {\raise0.7ex\hbox{${S_{\text{p}} }$} \!\mathord{\left/ {\vphantom {{S_{\text{p}} } 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}}} \cdot \delta } \\ {J_{y}^{\text{V}} \left( c \right) = - {\raise0.7ex\hbox{${{\text{d}}\left( {\Delta_{x} } \right)}$} \!\mathord{\left/ {\vphantom {{{\text{d}}\left( {\Delta_{x} } \right)} {{\text{d}}t}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${{\text{d}}t}$}} \cdot \frac{{c + c_{\text{p}} }}{{\varOmega \cdot {\raise0.7ex\hbox{${S_{\text{p}} }$} \!\mathord{\left/ {\vphantom {{S_{\text{p}} } 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}}} \cdot \delta } \\ \end{array} } \right. $$ (14) where δ (nm) is the grain boundary thickness. The strain rates along x and y can be written as $$ \left\{ {\begin{array}{*{20}l} {\dot{\varepsilon }_{x} = {\raise0.7ex\hbox{${{\text{d}}\left( {\Delta_{x} } \right)}$} \!\mathord{\left/ {\vphantom {{{\text{d}}\left( {\Delta_{x} } \right)} {{\text{d}}t}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${{\text{d}}t}$}} \cdot {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {\left( {c + c_{\text{p}} } \right)}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\left( {c + c_{\text{p}} } \right)}$}}} \\ {\dot{\varepsilon }_{y} = {\raise0.7ex\hbox{${{\text{d}}\left( {\Delta_{y} } \right)}$} \!\mathord{\left/ {\vphantom {{{\text{d}}\left( {\Delta_{y} } \right)} {{\text{d}}t}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${{\text{d}}t}$}} \cdot {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 {\left( {a + a_{\text{p}} } \right)}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\left( {a + a_{\text{p}} } \right)}$}}} \\ \end{array} } \right. $$ (15) Therefore, combining [14] and [15], a relationship between diffusion fluxes and shrinkage rates is obtained: $$ \left\{ {\begin{array}{*{20}l} {\dot{\varepsilon }_{x} = - \frac{{J_{y}^{\text{V}} \left( c \right)}}{{\left( {a + a_{\text{p}} } \right)}} \cdot {\raise0.7ex\hbox{${\left( {\varOmega \cdot \frac{{S_{\text{p}} }}{2}} \right)}$} \!\mathord{\left/ {\vphantom {{\left( {\varOmega \cdot \frac{{S_{\text{p}} }}{2}} \right)} {\left[ {\left( {c + c_{\text{p}} } \right) \cdot \delta } \right]}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\left[ {\left( {c + c_{\text{p}} } \right) \cdot \delta } \right]}$}}} \\ {\dot{\varepsilon }_{x} = - \frac{{J_{x}^{\text{V}} \left( a \right)}}{{\left( {c + c_{\text{p}} } \right)}} \cdot {\raise0.7ex\hbox{${\left( {\varOmega \cdot \frac{{S_{\text{p}} }}{2}} \right)}$} \!\mathord{\left/ {\vphantom {{\left( {\varOmega \cdot \frac{{S_{\text{p}} }}{2}} \right)} {\left[ {\left( {a + a_{\text{p}} } \right) \cdot \delta } \right]}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\left[ {\left( {a + a_{\text{p}} } \right) \cdot \delta } \right]}$}}} \\ \end{array} } \right. $$ (16) Let us consider the case of free pressure-less sintering. Plugging Eqs. [13] into [16], the strain rates can be written as $$ \left\{ {\begin{array}{*{20}l} {\dot{\varepsilon }_{x}^{f.s} = - 3\frac{{D_{\text{V}} \left( {1 + \pi \cdot r_{\text{p}}^{2} \cdot d_{d,y} {\raise0.7ex\hbox{${D_{\text{p}} }$} \!\mathord{\left/ {\vphantom {{D_{\text{p}} } {D_{\text{V}} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${D_{\text{V}} }$}}} \right) \cdot \varOmega }}{k \cdot T \cdot \delta } \cdot \gamma_{sv} \cdot \frac{{{\raise0.7ex\hbox{${S_{\text{p}} }$} \!\mathord{\left/ {\vphantom {{S_{\text{p}} } 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}}}{{c \cdot \left( {a + a_{\text{p}} } \right) \cdot \left( {c + c_{\text{p}} } \right)}} \cdot \left[ {\frac{1}{{r_{c} }} - \frac{1}{c} \cdot \sin \left( {{\raise0.7ex\hbox{$\phi $} \!\mathord{\left/ {\vphantom {\phi 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)} \right]} \\ {\dot{\varepsilon }_{y}^{f.s} = - 3\frac{{D_{\text{V}} \left( {1 + \pi \cdot r_{\text{p}}^{2} \cdot d_{d,x} {\raise0.7ex\hbox{${D_{p} }$} \!\mathord{\left/ {\vphantom {{D_{p} } {D_{\text{V}} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${D_{\text{V}} }$}}} \right) \cdot \varOmega }}{k \cdot T \cdot \delta } \cdot \gamma_{sv} \cdot \frac{{{\raise0.7ex\hbox{${S_{\text{p}} }$} \!\mathord{\left/ {\vphantom {{S_{\text{p}} } 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}}}{{a \cdot \left( {c + c_{\text{p}} } \right) \cdot \left( {a + a_{\text{p}} } \right)}} \cdot \left[ {\frac{1}{{r_{a} }} - \frac{1}{a} \cdot \sin \left( {{\raise0.7ex\hbox{$\phi $} \!\mathord{\left/ {\vphantom {\phi 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}} \right)} \right]} \\ \end{array} } \right. $$ (17) These strain rate equations can be used to obtain expressions of the shrinkage rates as functions of the geometric parameters of the porous material, diffusivities, and deformation state. 3 Experimental Procedure for Model Validation In order to validate the proposed micromechanical model, a variety of experimental data were collected. The free-sintering strain rates were obtained from dilatometric tests, the geometric features with image analysis of scanning electron microscopy images, and detailed information on iron material properties were found in the literature. The dislocation densities in the transverse and longitudinal directions are calculated based on the work of Kuhn and Downey.[15] These dislocation density values become the model validation parameters, comparing these calculated values with experimental values. Dislocation densities can be experimentally derived with both nanoindentation and from electron backscatter diffraction (EBSD) techniques. Nanoindentation allows the estimation of the overall dislocation densities (statistically stored dislocations (SSDs) and geometrically necessary dislocations (GNDs) with the only exception being those due to the indentation process itself), but it is limited in accuracy when it comes to selecting the most appropriate areas for the measurements. On the other hand, EBSD produces detailed misorientation maps, from which dislocation density distributions can be derived, but such values only include GNDs. Thus, in order to obtain accurate experimental data for our model validation procedure, both nanoindentation and EBSD were performed. In the results section (Section IV), a good correlation between modeling and experiments is achieved, while in the following sub-sections the details of the various experimental procedures are described. 3.1 Dilatometric Analysis A water atomized iron powder (d25 < 45 µm) was mixed with 0.6 wt pct amide wax as lubricant. Charpy bars [55 × 10 × 10 (mm)] with 6.9 g/cm3 green density were produced by uniaxial cold compaction (Höganäs AB, Höganäs, Sweden). After debinding at 500 °C for 1 hour in an Ar atmosphere, parallelepiped-shaped samples [10 × 5 × 5 (mm)] were cut from the Charpy bars along the compaction direction (y or longitudinal direction) and in the compaction plane (x or transverse direction) as shown in Figure 2. Open image in new window Fig. 2 Dilatometry samples for the longitudinal (y, in red) and transverse (x, in blue) shrinkage rates analysis, as derived from cold-pressed Charpy bars. The direction of uniaxial compaction is marked (Color figure online) These samples were used in dilatometric experiments, in which the shrinkage kinetics along the two directions could be measured. The specimens cut in such a way that the long side corresponded to the y-axis in the Charpy bars (red in Figure 2) provided data on the longitudinal shrinkage rates (\( \dot{\varepsilon }_{y}^{f.s.} \)), while the specimens with long sides aligned with the x-axis of the Charpy bar (blue in Figure 2) were used for the transverse shrinkage rates (\( \dot{\varepsilon }_{x}^{f.s.} \)). The samples were isothermally sintered for 1 hour at different temperatures in the range between 640 °C and 1010 °C, reached with a heating rate of 30 °C/min. An example of dilatometric curve is shown in Figure 3, where the different shrinkages along the two directions are presented and highlighted at the bottom. Open image in new window Fig. 3 Example of dilatometric curve for sintering with holding at 960 °C: (a) temperature regime and shrinkages in the longitudinal (y) and transverse (x) direction for the entire processing route; (b) shrinkage curves during the isothermal holding time The additional steep changes in shrinkage, both along x and y direction, marked in the top part of the same Figure 3 before and after the isotherm segment, are related to well-known phase changes in iron. Specifically, at the Curie temperature (T = 770 °C), the magnetic transformation leads to a steep increase of iron's self-diffusivity, and therefore to a shrinkage enhancement (and correspondingly to a slight contraction during cooling).[66, 67, 68] At 910 °C, on the other hand, the austenitic transformation also leads to a shrinkage increase during heating and to a volume expansion upon cooling.[52] 3.2 Image Analysis The surfaces of the sintered samples were prepared according to the standard metallographic procedure and were observed in a scanning electron microscope (FEI XL30 ESEM). The obtained micrographs were then processed with the image analysis software ImageJ®, in order to measure the various geometric characteristics of the microstructure of the porous material, namely particle and pore semi-axes. The method used to evaluate the extension of the particle semi-contacts a and c is described in a previous work.[49] Figure 4 shows an example of identification of the semi-axis of a particle. Open image in new window Fig. 4 Individuation of inter-particle contacts length (L) and inclination (λ) from image analysis of SEM micrographs The length L and the inclination λ with respect to the horizontal direction (lying in the compaction plane) of the inter-particle contact lines were measured, and the projections along directions x and y were calculated as $$ \left\{ {\begin{array}{*{20}l} {a = {\raise0.7ex\hbox{$L$} \!\mathord{\left/ {\vphantom {L 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}\cos \lambda } \\ {c = {\raise0.7ex\hbox{$L$} \!\mathord{\left/ {\vphantom {L 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}\sin \lambda } \\ \end{array} } \right. $$ (18) The pores semi-axes ap and cp were calculated based on the schematic presented in Figure 5. Open image in new window Fig. 5 Individuation of the pores' geometrical parameters from image analysis of SEM micrographs The shape of each pore is approximated as an ellipse with an area equivalent to its extension, according to the stereological approach. This allows obtaining reasonable mean values of the radii, which take into account both the small radii of pores at junctions with grain boundaries and the lower curvatures of larger voids. The average pore curvature values at grain boundary/pore junctions are related to the dihedral angle, which is generally well known for a certain material system. Note, therefore, that even though the choice of the elliptical morphology is only an approximation, an appropriate value of the dihedral angle (ϕ = 157 deg = 2.75 rad) has been taken into account in the model, as specified in Eq. [5], and this leads to the results comparable with the experimental values reported in literature.[69] The inclination of its major axis with respect to the horizontal direction of the image (β) provides the orientation of the pore. The pores that are not fully captured in the image are excluded from the analysis. The software returns the values of axes of the ellipses (M and m) and of the angle β. By using β to project the ellipses axes along longitudinal and transverse directions, the pores semi-axes ap and cp are calculated as $$ \left\{ {\begin{array}{l} {0 \le \beta < 45\;{\text{deg}} :a_{\text{p}} = M \cdot \cos \;\beta ;_{{}} c_{\text{p}} = m \cdot \sin \beta } \\ {45\;{\text{deg}} \le \beta < 135\;{\text{deg}} :a_{\text{p}} = m \cdot \left| {\cos \;\beta } \right|;c_{\text{p}} = M \cdot \sin \beta } \\ {135\;{\text{deg}} \le \beta < 185\;{\text{deg}} :a_{\text{p}} = M \cdot \left| {\cos \;\beta } \right|;c_{\text{p}} = m \cdot \sin \beta } \\ \end{array} } \right. $$ (19) 3.3 Nanoindentation Hardness data from indentation tests can be used to estimate dislocation densities. In the present study, the choice of nanoindentation was imposed by the small dimensions of the iron powder particles, and the consequently restricted inter-particle contact areas, where the plastic deformation is assumed to be concentrated. For nanoindentation analyses, the surface preparation is a critical step to get consistent experimental values. In order to obtain an optimal surface quality, the metallographic samples were polished using SiC papers with decreasing roughness, followed by polishing with 3- and 1-μm diamond paste, and finally with an OP-S suspension with 0.04-μm-diameter alumina particles. With this type of polishing procedure, it is possible to obtain results comparable to those typical of electrochemical polishing.[70] Nanoindentation was performed on samples pressureless sintered at 640 °C, 730 °C, 860 °C, and 960 °C. Three different indentation forces (55, 75, and 95 mN) were employed, with a 20-second hold before unloading. The measurements were carried out in the contact areas aligned along the x and y directions, and not in ambiguously oriented ones, in order to observe the state of deformation in these two distinct regions of the porous material. Figure 6 shows an example of micrographs of nanoindentation for each direction. Open image in new window Fig. 6 Examples of micrographs of nanoindentation tests: (a) with 55 mN load on a sample sintered at 640 °C (for a longitudinal contact); (b) with a 95 mN load on a sample sintered at 960 °C (for a transverse contact). In the latter case, the two involved powder particles have been highlighted 3.4 Electron Backscatter Diffraction (EBSD) EBSD is a technique performed in the SEM that allows direct measurement of the lattice orientation in crystalline materials. Lattice orientation can, in turn, be related to dislocation density. Here the experimental procedure is described, and in Section IV–D the dislocation densities calculation is presented. The iron samples sintered at 640 °C, 730 °C, 860 °C, and 1010 °C were mounted in hot resin. Grinding was performed at 300-rpm under a force of 20N for 5 minutes through 220, 600, and 1200 grit. Polishing was performed at 150-rpm under a force of 15 N for 5 minutes using 3-µm diamond suspension, 10 minutes using 1-µm diamond suspension, and 10 N force for 20 minutes using 0.04-µm colloidal silica solution. A finishing polish step was then applied for 60 minutes using the colloidal silica activated disk and deionized water under a force of 5 N. Prior to EBSD imaging in the SEM, we carried out a step size analysis and determined an appropriate step size to be ~ 200 nm for the EBSD scans reported herein. Furthermore, in order to present valid GND results, the lower bound of log10 GND density is estimated, i.e., noise floor at a step size of 200 nm, to be 9.93 × 1013 per m2, and this value is used as a lower bound filter for GND post-processing. A misorientation threshold is set to 2 deg to filter out GND calculated from minimum misorientation of non-indexed points or neighboring grains. The misorientation mask also produced clear-cut grain boundaries and an average disorientation (i.e., minimum misorientation) angle map that can be readily visualized, as shown in Figure 7. Open image in new window Fig. 7 Example of EBSD results for GND density distribution (measured as log10 of GNDs per m2) and average disorientation angle distribution: (a) GND density distribution for a sample sintered at 1010 °C, acquired at 2000 times and with 200 nm step size, with selection of boxes around representative x and y inter-particle contacts; (b) GND density along y and (d) along x; (c) average disorientation angle distribution around an inter-particle boundary along y and (e) along x The GND analysis of inter-particle boundaries can be summarized to be a four-step procedure, presented schematically in Figure 8. Open image in new window Fig. 8 Steps followed for the EBSD analysis of a sample sintered at 1010 °C: (a) pattern quality image showing the individuation of longitudinal and transverse particle boundaries based on pores at triple junctions; (b) EBSD scan of the pre-selected regions; (c) GND density map around the particle boundaries; (d) particle boundary selection refinement with an 8 × 4 µm box The EBSD imaging was conducted on a FEI Quanta 600 SEM, equipped with a Bruker e-Flash EBSD system, operated at 20 kV, with a 1 × 1 binning size and working distance of ~ 15 mm. The inter-particle boundaries were pre-selected on the forward-scattered electron image collected by a detector roughly 25 mm from the sample surface. Typically, as demonstrated in Figure 8, particle contacts could be readily identified near two pointed-pores (namely particle boundary triple-points). Then, the detector distance was reduced to ~ 15 mm and masked areas were placed on the selected particle boundaries for EBSD scans. Three scans per sample were taken at a step size of 200 nm at different locations in the proximities of the center of the sample. Approximately 15 horizontal and 15 vertical particles contacts were considered for every sample (30 for every sample, 120 in total). To minimize the EBSD scan time, instead of analyzing the entire sample, EBSD scans were performed only on selected area in the masked zones over the contact boundaries. In each case of particle boundaries selection, the masking boxes were set to have the short side (across the particle contact) equal to 4 µm, and the long side (along the contact) equal to 8 µm, as shown in Figure 8. The selection of the short side size was the most critical, because it implied an assumption on the extent of the plastically deformed zone. Qualitative considerations based on the previously conducted nanoindentation analyses were combined to the image analyses results, until 2cp (≈ 4 μm), with cp being the smallest geometric parameter involved in this study. Centering of the boxes on the particle boundaries was performed manually from the EBSD images to accurately locate the particle boundary in the EBSD scan. 4 Results and Discussion 4.1 Dilatometric Analysis From the dilatometric curves, the shrinkage rates in the transverse and longitudinal directions, \( \dot{\varepsilon }_{x}^{f.s.} \) and \( \dot{\varepsilon }_{y}^{f.s.} \), could be calculated. Figure 9 shows that the absolute values of shrinkage rates progressively decrease during the isothermal holding time-step. Open image in new window Fig. 9 Example of derivation of isothermal shrinkage rate in the transverse direction, \( \dot{\varepsilon }_{x} (t) \), for a sample sintered at 960 °C. (a) Dilatometric curve with isothermal part highlighted between dashed lines; (b) corresponding isothermal shrinkage rate An integral average was therefore calculated as $$ \left\{ {\begin{array}{*{20}l} {\bar{\dot{\varepsilon }}_{x}^{f.s} = {\raise0.7ex\hbox{${\int_{0}^{t} {\dot{\varepsilon }_{x}^{f.s} \left( t \right) \cdot {\text{d}}t} }$} \!\mathord{\left/ {\vphantom {{\int_{0}^{t} {\dot{\varepsilon }_{x}^{f.s} \left( t \right) \cdot {\text{d}}t} } {t^{*} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${t^{*} }$}}} \\ {\bar{\dot{\varepsilon }}_{y}^{f.s} = {\raise0.7ex\hbox{${\int_{0}^{t} {\dot{\varepsilon }_{y}^{f.s} \left( t \right) \cdot {\text{d}}t} }$} \!\mathord{\left/ {\vphantom {{\int_{0}^{t} {\dot{\varepsilon }_{y}^{f.s} \left( t \right) \cdot {\text{d}}t} } {t^{*} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${t^{*} }$}}} \\ \end{array} } \right. $$ (20) where t* (s) is the time at which \( \dot{\varepsilon }_{x}^{f.s} \left( t \right) \) and \( \dot{\varepsilon }_{y}^{f.s} \left( t \right) \) approach zero. The obtained values for the various sintering temperatures are given in Table I. Table I Shrinkage Rates Along x (Transverse) and y (Longitudinal) Directions at the Different Sintering Temperatures T (°C) \( \dot{\varepsilon }_{x} \) (1/s) \( \dot{\varepsilon }_{y} \) (1/s) 640 − 4.04 × 10−5 − 5.31 × 10−5 730 − 8.68 × 10−5 − 1.65 × 10−4 860 − 8.41 × 10−5 − 1.23 × 10−4 960 − 3.74 × 10−5 − 3.54 × 10−5 1010 − 4.42 × 10−5 − 4.54 × 10−5 As expected, the shrinkage rates are higher along the compaction direction (in absolute value) than along the transverse one. Below the Curie point (T = 770 °C), the difference between the two directions is most noticeable and shows a significant increase with increasing temperatures. Such a difference is still evident between the Curie point and the temperature of the austenitic transformation (T = 910 °C), while it becomes almost negligible in the austenitic field, probably due to recrystallization and recovery phenomena. Increasing sintering temperatures also lead to noticeable changes in the value of the average shrinkage rates. Between 640 °C and 860 °C, the expected increase in absolute densification rate is observed when the isothermal temperature increases. The increase is particularly sharp between 640 °C and 730 °C, due to the magnetic transformation, which greatly increases the self-diffusivity of iron starting around 680 °C.[66] The shrinkage rates subsequently drop when 960 °C is reached, due to the austenitic transformation. Switching from a BCC to an FCC phase acts as an annihilation of plastic deformation, and thus the pipe-diffusion effect is reduced. Raising the temperature to 1010 °C then provides additional energy to the process, and therefore enhances densification again. Since in Table I only the densification rate during isothermal hold is considered, another reason for the observed changes in the absolute densification rate is that the starting density at the onset of isothermal sintering is different in all these samples (increasing as the temperature increases). The focus on the isothermal segment allowed the exclusion of thermal expansion effects from the present study. Nevertheless, the partial shrinkage occurring during the heating ramp led to the varying densities at the onset of the isothermal hold, depending on the selected processing temperatures. The concurrent effects of shrinkage and thermal expansion upon heating is the object of an extension of the present study. The cooling stage was also analyzed, and it was assessed that only the expected thermal contraction occurred, with no traces of additional shrinkage and anisotropic behavior in the samples. 4.2 Image Analysis Figures 10 and 11 present the estimations of inter-particle contacts and pores semi-axes lengths, respectively. Open image in new window Fig. 10 Inter-particle contact lengths a and c at the various sintering temperatures Open image in new window Fig. 11 Pores semi-axes lengths, ap and cp, at the different temperatures (a) values obtained from image analyses; (b) average values \( \bar{a}_{\text{p}} \) and \( \bar{c}_{\text{p}} \) In all the considered cases, the semi-axes perpendicular to the compaction direction are greater than those parallel to it, confirming the anisotropy of the porous material due to the pre-sintering cold pressing. This is more evident for the inter-particle contacts than in the pores semi-axes case. For clarity, Figure 11 also shows the average of the measured values, \( \bar{a}_{\text{p}} \) and \( \bar{c}_{\text{p}} \). It can be seen that the extension of the pores in the compaction direction is lower than in the transverse plane at every sintering temperature, but the distinction is less prominent at higher sintering temperatures, in accordance with dilatometry results. The pore semi-axes data have been used to calculate the curvature of the pores through Eq. [1], leading to values in the range of 2.1 to 2.8 μm, depending on the direction and temperature. 4.3 Nanoindentation The first set of dislocation density data needed to verify the reliability of our model was derived from the nanoindentation results, through the indentation size effect (ISE) model developed by Nix and Gao.[60,61,71] This method uses Taylor's non-local theory of plasticity,[72] according to which, for indentation tests at the micro and nano-scales, the depth of the indent and the measured hardness values show a strong correlation for depths less than 1-μm. In crystalline materials, this correlation is influenced by a characteristic material parameter, called material length scale, which depends on the deformation state of the sample under examination.[73,74] The nanoindentation hardness values and the corresponding indentation depths, reported in Table II, served as input for the main ISE equation, namely $$ \frac{H}{{H_{0} }} = \sqrt {1 + {\raise0.7ex\hbox{${h^{*} }$} \!\mathord{\left/ {\vphantom {{h^{*} } h}}\right.\kern-0pt} \!\lower0.7ex\hbox{$h$}}} $$ (21) where H (GPa) is the experimental value of the hardness; H0 (GPa) is the hardness due to pre-existing dislocations, namely not due to the indentation process itself, h (μm) is the depth of the indentation, and h* (μm) is the characteristic depth of the material above which we do not have any correlation between indentation depth and nanoindentation hardness values. The highest and lowest measured H values are discarded, in order to utilize more reliable experimental data. Table II Nanoindentation Hardness (H) and Indentation Depth (h) Values Measured by Nanoindentation at the Inter-Particle Contact Areas F (mN) Contacts along y Contacts along x H (GPa) h (μm) H (GPa) h (μm) Mean St. dev Mean St. dev Mean St. dev Mean St. dev Specimens sintered at 640 °C 55 5.02 2.27 0.58 0.13 5.07 4.31 0.69 0.30 75 4.92 1.22 0.67 0.09 5.06 0.27 0.64 0.04 95 4.89 1.89 0.69 0.22 4.95 3.15 0.80 0.26 Specimens sintered at 730 °C 55 4.20 1.70 0.70 0.18 4.47 1.43 0.66 0.12 75 4.17 0.58 0.76 0.05 4.46 0.49 0.72 0.02 95 4.12 0.80 0.83 0.12 4.39 1.20 0.78 0.16 Specimens sintered at 860 °C 55 4.28 1.95 0.68 0.20 3.45 1.22 0.77 0.17 75 4.09 1.91 0.78 0.18 3.42 1.01 0.81 0.18 95 4.09 1.23 0.83 0.18 3.36 0.49 0.90 0.11 Specimens sintered at 960 °C 55 3.40 0.47 0.76 0.06 3.35 0.83 0.79 0.12 75 3.14 1.12 0.97 0.07 3.16 1.34 0.91 0.17 95 2.97 0.52 1.00 0.11 3.10 1.54 1.03 0.24 F indicates the load applied during the indentation test Equation [21] can be rearranged as $$ H^{2} = H_{0}^{2} \cdot \left( {1 + {\raise0.7ex\hbox{${h^{*} }$} \!\mathord{\left/ {\vphantom {{h^{*} } h}}\right.\kern-0pt} \!\lower0.7ex\hbox{$h$}}} \right) $$ (22) such that the plot of H2vs 1/h will consist of a straight line with slope proportional to h* and intercept corresponding to H 0 2 . The dislocation density can subsequently be estimated with the following relation[73,74]: $$ d_{d} = 3 \cdot \bar{r} \cdot {\raise0.7ex\hbox{${\tan^{2} \theta }$} \!\mathord{\left/ {\vphantom {{\tan^{2} \theta } {\left( {2 \cdot b \cdot h^{*} } \right)}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\left( {2 \cdot b \cdot h^{*} } \right)}$}} $$ (23) where \( \bar{r} \) is the Nye factor (set as 1 due to negligible macroscopic plastic strain gradient produced during cold compaction of powder); ϴ is the angle of contact between the indenter tip and the sample surface (24.73 deg for Berkovich tips, utilized in the present case) and b is the Burger's vector modulus (2.49 Å). The results obtained for the different temperatures and directions are presented in Table III and Figure 12. Table III Dislocation Densities for Transverse Contacts (ddx) and for Longitudinal Contacts (ddy) Temperature, T (°C) Nanoindentation EBSD Model dy (1/m2) dx (1/m2) dy (1/m2) dx (1/m2) dy (1/m2) dx (1/m2) 640 8.26 × 1015 1.17 × 1016 1.02 × 1015 1.04 × 1015 2.21 × 1016 2.08 × 1016 730 1.06 × 1016 1.20 × 1016 1.02 × 1015 1.06 × 1015 7.00 × 1015 7.43 × 1015 860 2.98 × 1015 4.98 × 1015 8.61 × 1014 8.88 × 1014 4.28 × 1014 4.85 × 1014 960 6.12 × 1014 1.78 × 1015 — — 2.34 × 1015 2.60 × 1015 1010 — — 8.41 × 1014 9.29 × 1014 1.72 × 1015 2.13 × 1015 Open image in new window Fig. 12 Dislocation density values: (a) comparison between experimental and modeling results; (b) ratio between experimental and modeling results The expected higher amount of plastic deformation in the plane perpendicular to the cold compaction direction is confirmed: the dislocation densities are higher in the transverse contacts (ddx, responsible for the shrinkage along the y direction) than in the longitudinal ones (ddy, responsible for the shrinkage along x). With increasing sintering temperatures, the dislocation densities tend to increase until the Curie point is reached, because of the local deformations induced by the rising sintering stresses at the necks between the ductile iron powder particles, as reported also by Schatt and Friedrich.[14] After the Curie point, dislocation densities steadily decrease, likely because of the annealing and consequent recrystallization and recovery of the deformed material, leading to a less marked anisotropy. These observations further confirmed the dilatometry and image analysis observations. 4.4 EBSD The second set of dislocation density data was obtained from the EBSD analysis.[64] With this technique, only geometrically necessary dislocations (GNDs) are detected, and not statistically stored dislocations (SSDs). Nevertheless, it is expected valuable information can be obtained, since the high ductility of iron and the elevated load applied during cold compaction generally lead to the generation of significant amounts of GNDs, compared to the pre-existing SSDs. The theory for the determination of GND density from EBSD data was adopted from the work of Nye, relating lattice curvature to the dislocation density tensor, often itself denoted as the Nye tensor.[75] Taking into account the elastic strain (ɛ ij el ), according to Kröner, the Nye/Kröner relation can be written as[76] $$ \alpha_{ik} = k_{ki} - \delta_{ki} k_{mm} - \epsilon_{klj} \frac{{\partial \varepsilon_{ij}^{\text{el}} }}{{\partial x_{l} }} $$ (24) where kij is the lattice curvature tensor and αij is the Nye tensor. In cases where the plastic distortion of the lattice is assumed to be fully accommodated by lattice rotation, i.e., negligible elastic strain, the dislocation density tensor can be approximated as the curl of the lattice misorientation matrix (Δϕ = gBg A −1 ) in the following way[77]: $$ \alpha_{ik} \approx - \epsilon_{kli}\Delta \phi_{ij,l} $$ (25) The lattice orientation tensor (g) is directly measurable by the electron backscatter diffraction (EBSD) technique in the SEM. For 2-D EBSD analysis, the orientation gradient in the out of plane direction is assumed to be zero, such that the GND density calculated here is a lower bound solution of the actual GND density. Techniques such as serial-sectioning[78] and X-ray microbeams[79] have been developed to extract lattice orientation in the out of plane direction, but these techniques are usually complex and time-consuming. On the other hand, the total GND density tensor can also be represented as the sum of individual dislocations, where each type of dislocation is geometrically characterized by a combination of the unit line vector \( \hat{l} \) and its Burger's vector b: $$ \alpha_{ij} = \sum\nolimits_{n = 1}^{N = 16} {\rho_{\text{GND}}^{n} \cdot b_{i}^{n} \hat{l}_{j}^{n} } $$ (26) The dislocation configurations available in a bcc crystal are 4 screw 〈111〉 dislocations and 12 edge 〈111〉 {110} dislocations. This allows the number of dislocations present in the lattice to accommodate the measured lattice curvature to be calculated. The solution to this underdetermined system of equations, with 16 unknowns and 9 equations, is obtained through a so-called 'interior-point' method based on an L1 dislocation energy minimization scheme.[80] In practice, the 32 unknowns of dislocations densities (both positive and negative dislocations) are calculated, and the solution folded back to give the 16-component dislocation density vector. Lattice misorientation data were obtained in images of the type presented in Figure 8. Image post-processing, as well as GND calculations, were then conducted with the Optimization Toolbox of the MathWorks™ Matlab Program. The mean value of the GND density at the particle boundaries was obtained by dividing the sum of the total GND density for all data points near the particle boundary by number of data points with non-zero GND density. This approach allows the dislocation gradient from the particle interior to the boundary to be calculated. To rule out large statistical variations, we have ignored the maximum and minimum obtained values of mean GND density. Average dislocation density values in the x and y directions and for each sintering temperature were then computed. The obtained results are displayed in Figure 12. A good correlation with the dislocation density from the nanoindentation hardness data is observed, with EBSD-estimated dislocation density values just below the nanoindentation hardness values. This is in accordance with the fact that EBSD does not detect statistically stored dislocations. In addition, pipe diffusion is mainly through SSDs at low sintering temperatures and through GNDs at high sintering temperatures. This is due to the higher mobility of SSDs (which create a less severe atomic lattice distortion with respect to GNDs), while diffusion through GNDs requires more elevated temperatures in order to have a significant impact on densification. The total dislocation density approached the GND's density at increasing temperatures, which implies thermal annihilation of SSDs. At such temperatures, the mobility of GND's is also high enough for them to contribute to the material's sintering, while the SSD's role becomes decreasingly important. It is interesting to point out that, different from nanoindentation results, all EBSD-derived dislocation density values are close to the 1015 value, because GNDs are less sensitive to changes in sintering temperature. This appears to be a maximum for most EBSD analyses, and is in reasonable agreement with the fact that inter-particle boundaries can only allow a limited amount of local lattice misorientation. 4.5 Model Validation The micromechanical model can now be validated by comparing the experimentally obtained dislocation density data with those calculated from the model using Eq. [17]. Experimental data on shrinkage rates (Section IV–A) and geometric parameters (Section IV–B) along x and y were obtained previously. The other input data needed are iron material properties taken from the literature. Specifically, the inputs are γsv, surface tension: 2.525 N/m[81,82]; γss, grain boundary energy: 0.985 N/m[83]; δ, inter-particle boundary thickness, estimated as grain boundary thickness: 0.5 nm[84]; rp, pipe radius: 0.5 nm[66]; Ω, atomic volume: 8.38 × 10−30 m3.[85] Additionally, the values of the volume diffusion coefficient Dv as a function of the sintering temperature were taken from Reference 86 and are given in Table IV. In Table IV, the dislocation pipe diffusion coefficient Dp values, obtained from Stechauner and Kozeschnik,[87] based on an Arrhenius-type relation, Dp = D0 exp(− Q/RT), with activation energy Q (kJ/mol) and pre-exponential factor D0 (m2/s) changing for the different iron phases, are reported. The calculated pipe diffusivity values are comparable with the experimental results measured by Shima et al.[66] at all temperatures, with the only exception of the austenitic field, for which, to the best of our knowledge, data are not available in the literature. Table IV Volume and Pipe Diffusivities at Equilibrium T (°C) Dv (m2/s) D p T (°C) Q (kJ/mol) D0 (m2/s) T (°C) Dp (m2/s) 640 1.09 × 10−19 Ta-420 200 4.50 × 10−3 640 1.63 × 10−14 730 6.99 × 10−18 420-769 200 4.50 × 10−3 730 1.74 × 10−13 860 7.77 × 10−16 769-910 200 4.50 × 10−3 860 2.72 × 10−12 960 2.71 × 10−17 911-Tm 185 4.50 × 10−5 960 6.56 × 10−13 1010 8.85 × 10−17 911-Tm 185 4.50 × 10−5 1010 1.33 × 10−12 The pipe diffusion coefficient is calculated by plugging D0 and Q in an Arrhenius-type relation. D0 and Q change values depending on the iron phase. Ta is the room temperature and Tm is the melting point Note that, even though the model here is assessed with data on the free pressureless sintering of pure iron, its applicability can be extended to a variety of material systems, provided the data listed above. The utilization of the continuum theory of sintering also allows for the possibility of including the role of externally applied pressures, by adding the opportune term to the equations set. Thanks to its structure, it is also possible to compare or connect with other sintering models present in literature, for instance, with the meso-scale discrete element-based simulations.[88] Substituting all the data listed above in Eq. [17], we could calculate estimations of dislocation densities in the transverse (x) and longitudinal (y) directions for the various sintering temperatures. Figure 12 shows the comparison between the calculated and experimentally obtained dislocation densities at different temperatures. A good agreement is observed, with the only exception of T = 860 °C, at which nanoindentation and EBSD results are fairly close to each other, while the model seems to underestimate the amount of plastic deformation. This particular temperature, however, belongs to a range between Curie and austenitic point in which the literature data for dislocation pipe diffusivity are widely scattered and most likely often overestimated. Such uncertainty might be responsible for the mismatch between modeling and experimental framework at this particular temperature. In order to verify this hypothesis, a parametric study was performed, by assessing the effect of a change in the different variables involved in Eq. [17] on the calculated dislocation density values. This analysis allows analyzing the sensitivity of the model to the various parameters involved, by observing the changes in its response when the parameters are altered within a reasonable range. The parameters taken into consideration for this part of the study were pipe diffusivity, bulk diffusivity, strain rates, particle semi-contact lengths and pore semi-axes. They were all changed within a certain range, selected as follows. For the parameters that had been measured experimentally (shrinkage rates, particle semi-contact lengths and pore semi-axes), the standard deviation was taken as a reference for the variation of each parameter. Specifically, the value of each parameter was altered by adding or subtracting 50 and 100 pct of their standard deviation value. For the parameters that had been taken from the literature (pipe and bulk diffusivities), the data were changed by taking 10, 50, and 80 pct of the reported values. Since the model was giving an underestimation of expected dislocation densities, each study parameter was altered in such a way as to lead to their increase. Figures 13 and 14 confirm that pipe diffusivity is the parameter with the highest influence on the model. Open image in new window Fig. 13 Parametric study outcomes for varying pipe diffusion coefficient Open image in new window Fig. 14 Parametric study outcomes for varying (a) bulk diffusion coefficient; (b) strain rates; (c) particle semi-axes; (d) pore semi-axes In all Figures, the y-axis represents the ratio between dislocation density calculated with the modified parameter value (abbreviated as "mod") and the one calculated with the original value ("nom" as for nominal for data from the literature and "avrg" as for average for experimental data). The legend specifies if we are referring to the x (transverse) or y (longitudinal) direction. It also provides the entity of the change in the considered parameter, namely the percentage of nominal value for the diffusivities and the addition or subtraction of the standard deviation ("stdv", 50 or 100 pct) for strain rates and geometric features. The pipe diffusivity case is shown in Figure 13, while Figure 14 is for all other parameters. A decrease in pipe diffusivity up to 10 pct of the value reported in the literature leads to an increase in dislocation densities that reaches one order of magnitude. None of the other parameters has such a significant effect, with a maximum factor of 3.5 reached in the particle semi-axes study (noticeably, still at 860 °C). Note how a variation in the value of pipe diffusivity causes a change in calculated dislocation densities that is consistent for all the temperatures considered (Figure 13), while the other parameters (Figure 14) present a more unstable trend. The most striking case is the one relative to bulk diffusivity (part (a) of Figure 14), where, again at 860 °C, we can observe a peak in the dislocation densities ratio, in contrast with the other temperatures. This can be explained by looking at the bulk diffusivity values and recalling how the parametric study procedure was set up. For data extracted from the literature (diffusivities), we anticipated that various percentages of the reported values were used. Since the bulk diffusivity reaches a maximum at 860 °C, and since its value at this temperature is orders of magnitude higher than at the other temperatures considered in this study, its variation leads to a more significant oscillation in the calculated dislocation densities. Such a trend is not as evident when considering parameters that were measured experimentally, because here the standard deviation was used as parameter variation range. It is, nevertheless, worth pointing out that the 860 °C samples were shown to be the most sensitive to the parametric variations in the majority of cases. In part (b) of Figure 14, only for 860 °C it is possible to discern all the plotted data points, while for the other temperatures they overlap. A final verification of the model's sensitivity to the involved parameters was performed by assessing the influence of the pores' curvature radii on the pipe diffusion coefficient. This translates into checking the suitability of the method used to estimate the pores curvature (shape approximated as ellipsoid) and verifying its effects on the mass transfer mechanism. Our analysis shows that even much smaller values of pore radii (reduced of up to more than one order of magnitude with respect to the initially measured ones) do not alter significantly the pipe diffusivity values. This confirms the applicability of the ellipsoidal shape-based approximation. An even higher accuracy can be achieved in the prosecution of this work by evaluating the curvature of the pores via high resolution SEM visualization. The uncertainty in pipe diffusivity data is thus confirmed to be the most likely cause of the inaccuracy of the model at 860 °C. In light of this finding, the literature data that had been previously utilized were re-examined. In the work of Stechauner and Kozeschnik,[87] there are no experimental data available for temperatures above about 650 °C. They propose an extension of the curve until above 1400 °C, most likely in analogy with the grain boundary diffusivity data provided in the same plot, on which the data given in Table IV are based. However, it is reasonable to assume that the slope of the curve for dislocation pipe diffusivity as a function of temperature should decrease with increasing temperatures, and not vice versa, as higher temperatures lead to a progressive annihilation of the dislocations present in a material. By back-calculating the values of pipe diffusivity based on our experimental data, a modification to the Stechauner and Kozeschnik's fitting is proposed in Figure 15. Open image in new window Fig. 15 Proposed modification of the dislocation pipe diffusivity fitting reported by Stechauner and Kozeschnik. (a) α-Fe, (b) γ-Fe. Adapted from Ref. [87] The dislocation densities used for these back-calculations were the ones derived from the nanoindentation measurements, since the overall amount is needed, including both GNDs and SSDs. Figure 15 is a reproduction of Figure 2 from the original paper,[87] with the addition of the back-calculation outcomes (in bright blue). Specifically, the pipe diffusivities resulted to be 6.01 × 10−14 m2/s for 640 °C, 1.53 × 10−13 m2/s for 730 °C, 3.20 × 10−13 m2/s for 860 °C, and 2.14 × 10−12 m2/s for 960 °C. Note that the pipe diffusivity at 640 °C is in very good agreement with the experimental data provided in the original paper, and that the extrapolated curve approaches the bulk diffusivity one with increasing temperatures, as expected with the progressive annealing of a cold-worked material. Note also that, at the current state of this work, the distinction between edge and screw dislocations has not been introduced. These two kinds of dislocations generally lead to different values of pipe diffusivity. Such an investigation can be the object of future work. The generally good agreement between the model and the experiments, together with the subsequent parametric study, confirms the reliability and applicability of our micromechanical model for the study of shrinkage anisotropy during sintering of cold-pressed metallic powders. 5 Conclusions The anisotropy of shrinkage during sintering of iron powders pre-compacted with a uniaxial load is investigated. A micromechanical model is proposed for the shrinkage rates along and perpendicular to the uniaxial load direction. Due to plastic deformation introduced by the pre-sintering cold compaction, volume diffusion enhanced by dislocation pipe diffusion is considered to be the dominant mass transfer mechanism during post-cold-compaction sintering. The model parameters include the geometric characteristics of the deformed porous structure, the structural defects (dislocations), diffusivities and sintering temperatures. Dilatometric tests provide data on the shrinkage rates, and image analysis is employed to quantify the characteristic dimensions of inter-particle contacts and pores. Plugging these experimental results into this model, dislocation densities are calculated at the inter-particle contacts in the longitudinal and transverse directions. The applicability of the model is verified by comparing these calculated values with dislocation densities estimated by means of nanoindentation and EBSD techniques. Good agreement is found between experiments and our micromechanical model, with the only exception of the temperature range between Curie and austenitic points, in which the experimental value of dislocation pipe diffusion coefficient is highly scattered. A parametric study confirms that pipe diffusivity is the parameter that has the strongest influence on the model results, and offers the possibility to back-calculate these pipe diffusivity values. As expected, higher dislocation densities are found along the contacts perpendicular to the cold pressing direction, suggesting that the pre-sintering cold compaction is the main cause for shrinkage anisotropy during sintering. Notes Acknowledgments DG, ET, EAO, and RKB acknowledge the support from the US National Science Foundation Division of Civil and Mechanical Systems and Manufacturing Innovations for this collaborative DMREF Project (NSF Grant Nos. CMMI 1234114 and CMMI 1502392). The valuable support and cooperation of Professor J. Taylor (Scripps Institution of Oceanography, University of California, San Diego) and Professor J. Torralba (Technical University of Madrid, Spain) are gratefully acknowledged. References 1. 1. R.K. Bordia, Suk-Joong L. Kang and E.A. Olevsky, Journal of the American Ceramic Society 2017, vol. 100, pp. 2314-2352.CrossRefGoogle Scholar 2. J. Frenkel, J. Phys. 1945, vol. 9, pp. 385–391.Google Scholar 3. 3. B. Ya Pines, J. Tech. Phys 1946, vol. 16, p. 137.Google Scholar 4. 4. G.C. Kuczynski, Journal of Applied Physics 1949, vol. 20, pp. 1160-1163.CrossRefGoogle Scholar 5. 5. J.K. Mackenzie and R Shuttleworth, Proceedings of the Physical Society. Section B 1949, vol. 62, p. 833.CrossRefGoogle Scholar 6. 6. C. Herring, Journal of Applied Physics 1950, vol. 21, pp. 301-303.CrossRefGoogle Scholar 7. 7. W.D. Kingery and Morris Berg, Journal of Applied Physics 1955, vol. 26, pp. 1205-1212.CrossRefGoogle Scholar 8. I.M. Lifshitz and V.V. Slyozov, J. Phys. Chem. Solids 1961, vol. 19, pp. 35-50.CrossRefGoogle Scholar 9. 9. R.L. Coble, Journal of applied physics 1961, vol. 32, pp. 787-792.CrossRefGoogle Scholar 10. 10. F. Thümmler and W. Thomma, Metallurgical Reviews 1967, vol. 12, pp. 69-108.Google Scholar 11. 11. D.L. Johnson, Journal of Applied Physics 1969, vol. 40, pp. 192-200.CrossRefGoogle Scholar 12. H.E. Exner (1979) Rev. Powder Metall. Phys. Ceram. 1(1/4): 1–251Google Scholar 13. 13. F.B. Swinkels and MF Ashby, Acta Metallurgica 1981, vol. 29, pp. 259-281.CrossRefGoogle Scholar 14. 14. Schatt W., Friedrich E. (1987) Dislocation-Activated Sintering Processes. In: Kuczynski G.C., Uskoković D.P., Palmour H., Ristić M.M. (eds) Sintering'85. Springer, Boston, MAGoogle Scholar 15. S.-J. L. Kang: Sintering: Densification, Grain Growth and Microstructure. Butterworth-Heinemann: Oxford, 2004.Google Scholar 16. M.N. Rahaman: Sintering of Ceramics. CRC Press: Boca Raton (2007).CrossRefGoogle Scholar 17. 17. R.K. Bordia and GW Scherer, Acta metallurgica 1988, vol. 36, pp. 2393-2397.CrossRefGoogle Scholar 18. 18. R.K. Bordia and GW Scherer, Acta Metallurgica 1988, vol. 36, pp. 2399-2409.CrossRefGoogle Scholar 19. 19. R.K. Bordia and GW Scherer, Acta Metallurgica 1988, vol. 36, pp. 2411-2416.CrossRefGoogle Scholar 20. 20. E. A. Olevsky, Mater Sci Eng R Rep 1998, vol. 23, pp. 41-100.CrossRefGoogle Scholar 21. 21. E.A. Olevsky, V. Tikare and T. Garino, Journal of the American Ceramic Society 2006, vol. 89, pp. 1914-1922.CrossRefGoogle Scholar 22. 22. Z-Z Du and ACF Cocks, Acta metallurgica et materialia 1992, vol. 40, pp. 1969-1979.CrossRefGoogle Scholar 23. 23. RM McMeeking and LT Kuhn, Acta metallurgica et materialia 1992, vol. 40, pp. 961-969.CrossRefGoogle Scholar 24. 24. H Riedel, H Zipse and J Svoboda, Acta metallurgica et materialia 1994, vol. 42, pp. 445-452.CrossRefGoogle Scholar 25. 25. D Bouvard and RM McMeeking, Journal of the American Ceramic Society 1996, vol. 79, pp. 666-672.CrossRefGoogle Scholar 26. 26. J. Pan: Computer modelling of sintering at different length scales. (Springer London, 2006).Google Scholar 27. 27. HA Kuhn and CL Downey, Int J Powder Met 1971, vol. 7, pp. 15-25.Google Scholar 28. 28. KT Kim and MM Carroll, International journal of plasticity 1987, vol. 3, pp. 63-73.CrossRefGoogle Scholar 29. 29. RJ Green, International Journal of Mechanical Sciences 1972, vol. 14, pp. 215-224.CrossRefGoogle Scholar 30. Shima S and M Oyane, Int. J. Mech. Sci. 1976, vol. 18, pp. 285-291.CrossRefGoogle Scholar 31. 31. Arthur L Gurson, Journal of engineering materials and technology 1977, vol. 99, pp. 2-15.CrossRefGoogle Scholar 32. 32. Y Corapcioglu and T Uz, Powder Technology 1978, vol. 21, pp. 269-274.CrossRefGoogle Scholar 33. 33. MB Shtern, GG Serdyuk, LA Maximenko, YV Truhan and Yu M Shulyakov, Naukova Dumka, Kiev 1982.Google Scholar 34. 34. V. Tvergaard, International Journal of fracture 1982, vol. 18, pp. 237-252.Google Scholar 35. 35. SM Doraivelu, HL Gegel, JS Gunasekera, JC Malas, JT Morgan and JF Thomas Jr, International Journal of Mechanical Sciences 1984, vol. 26, pp. 527-535CrossRefGoogle Scholar 36. 36. N.A. Fleck, L.T. Kuhn and RM McMeeking, Journal of the Mechanics and Physics of Solids 1992, vol. 40, pp. 1139-1162.CrossRefGoogle Scholar 37. V.V. Skorohod: Rheological Basis of the Sintering Theory, Naukova Dumka, Kiev, 1972.Google Scholar 38. 38. D Giuntini, I-W Chen and EA Olevsky, Scripta Materialia 2016, vol. 124, pp. 38-41.CrossRefGoogle Scholar 39. H.E. Exner and E. Arzt (1990) Sintering Key Papers, Springer, Berlin, pp 157-184.CrossRefGoogle Scholar 40. 40. A.L. Maximenko and Eugene A Olevsky, Acta materialia 2004, vol. 52, pp. 2953-2963.CrossRefGoogle Scholar 41. 41. D. Giuntini, X. Wei, A.L. Maximenko, L. Wei, A.M. Ilyina and E.A. Olevsky, International Journal of Refractory Metals and Hard Materials 2013, vol. 41, pp. 501-506.CrossRefGoogle Scholar 42. 42. R.K. Bordia, R. Zuo, O. Guillon, S.M .Salamone and J. Rödel, Acta materialia 2006, vol. 54, pp. 111-118.CrossRefGoogle Scholar 43. 43. H. Shang, A. Mohanram, E. Olevsky and R. K Bordia, Journal of the European Ceramic Society 2016, vol. 36, pp. 2937-2945.CrossRefGoogle Scholar 44. 44. E.A. Olevsky, B. Kushnarev, A. Maximenko, V. Tikare and M. Braginsky, Philosophical Magazine 2005, vol. 85, pp. 2123-2146.CrossRefGoogle Scholar 45. 45. F.Wakai and R.K. Bordia, Journal of the American Ceramic Society 2012, vol. 95, pp. 2389-2397.CrossRefGoogle Scholar 46. 46. A. Zavaliangos, J.M. Missiaen and D. Bouvard, Science of Sintering 2006, vol. 38, pp. 13-25CrossRefGoogle Scholar 47. 47. A. Zavaliangos and D. Bouvard, International journal of powder metallurgy 2000, vol. 36, pp. 58-65Google Scholar 48. 48. A. Molinari, C. Menapace, E. Torresani, I. Cristofolini and M. Larsson, Powder Metallurgy 2013, vol. 56, pp. 189-195..CrossRefGoogle Scholar 49. A. Molinari, E Torresani, C Menapace, I Cristofolini, and M. Larsson, in Powdermet 2013, (American Powder Metallurgy Institute), pp. 525–32.Google Scholar 50. 50. A Molinari and E Torresani, Powder Metallurgy 2015, vol. 58, pp. 323-327.CrossRefGoogle Scholar 51. A. Molinari, I. Cristofolini, E. Torresani, Adv. Powder Metall. Part. Mater. (2015) 3:9–18.Google Scholar 52. 52. A. Molinari, E. Torresani, C. Menapace and M. Larsson, Journal of the American Ceramic Society 2015, vol. 98, pp. 3431-3437.CrossRefGoogle Scholar 53. 53. W. Zhang and J.H. Schneibel, Acta metallurgica et materialia 1995, vol. 43, pp. 4377-4386.CrossRefGoogle Scholar 54. 54. EW Hart, Acta Metallurgica 1957, vol. 5, p. 597CrossRefGoogle Scholar 55. 55. M.Cohen, Transactions of the Japan Institute of Metals 1970, vol. 11, pp. 145-151CrossRefGoogle Scholar 56. E. Olevsky and V. Skorohod, Le Journal de Physique IV 1993, vol. 3, pp. C7-739-C7-742.Google Scholar 57. 57. P.M. Raj and W.R. Cannon, Journal of the American Ceramic Society 1999, vol. 82, pp. 2619-2625..CrossRefGoogle Scholar 58. 58. P.M.Raj, A. Odulena and W.R. Cannon, Acta materialia 2002, vol. 50, pp. 2559-2570..CrossRefGoogle Scholar 59. 59. S Krug, JRG Evans and JHH Ter Maat, Journal of the European Ceramic Society 2002, vol. 22, pp. 173-181.CrossRefGoogle Scholar 60. 61. W.D. Nix and H. Gao, Journal of the Mechanics and Physics of Solids 1998, vol. 46, pp. 411-425.CrossRefGoogle Scholar 61. 62. J.G. Swadener, E.P. George and G.M. Pharr, Journal of the Mechanics and Physics of Solids 2002, vol. 50, pp. 681-694.CrossRefGoogle Scholar 62. 63. Z Zong, J Lou, OO Adewoye, AA Elmustafa, F Hammad and WO Soboyejo, Materials Science and Engineering: A 2006, vol. 434, pp. 178-187.CrossRefGoogle Scholar 63. 64. M. Gee, K. Mingard and B. Roebuck, International Journal of Refractory Metals and Hard Materials 2009, vol. 27, pp. 300-312.CrossRefGoogle Scholar 64. 65. DP Field, CC Merriman, N Allain-Bonasso and F Wagner, Modelling and Simulation in Materials Science and Engineering 2012, vol. 20, p. 024007.CrossRefGoogle Scholar 65. C. Zhu, T. Harrington, V.A Livescu, G.T. Gray and K.S. Vecchio, Acta Mater. 2016, vol. 118, pp. 383-394.CrossRefGoogle Scholar 66. 67. Y. Shima, Y. Ishikawa, H. Nitta, Y. Yamazaki, K.Mimura, M. Isshiki and Y.Iijima, Materials Transactions 2002, vol. 43, pp. 173-177.CrossRefGoogle Scholar 67. 68. A Verma, M Sundararaman, JB Singh and SA Nalawade, Measurement Science and Technology 2010, vol. 21, p. 105106CrossRefGoogle Scholar 68. 69. J. Park, M. Jung and Y-K Lee, Journal of Magnetism and Magnetic Materials 2015, vol. 377, pp. 193-196.CrossRefGoogle Scholar 69. E.D. Hondros and N.P. Allen (1965) Proc. R. Soc. Lond. A 286 (1407), pp. 479-498.CrossRefGoogle Scholar 70. 71. G.M. Pharr, E.G. Herbert and Y. Gao, Annual Review of Materials Research 2010, vol. 40, pp. 271-292.CrossRefGoogle Scholar 71. E. Torresani, G. Ischia, and A. Molinari: in European Congress and Exhibition on Powder Metallurgy. European PM Conference Proceedings (The European Powder Metallurgy Association: 2014), p 1Google Scholar 72. 72. H. Gao and Y. Huang, International Journal of Solids and Structures 2001, vol. 38, pp. 2615-2637.CrossRefGoogle Scholar 73. 73. G.Z. Voyiadjis and A.H. Almasri, Journal of engineering mechanics 2009, vol. 135, pp. 139-148.CrossRefGoogle Scholar 74. 74. D. Faghihi and G.Z. Voyiadjis, Mechanics of Materials 2012, vol. 44, pp. 189-211.CrossRefGoogle Scholar 75. 75. JF Nye, Acta metallurgica 1953, vol. 1, pp. 153-162.CrossRefGoogle Scholar 76. E. Kröner, Continuum Theory of Dislocation and Self-Stresses, Springer: Berlin (1958).Google Scholar 77. 77. C.Zhu, V. Livescu, T. Harrington, O. Dippo, G.T. Gray and K.S. Vecchio, International Journal of Plasticity 2017, vol. 92, pp. 148-163CrossRefGoogle Scholar 78. 78. E. Demir, D. Raabe, N. Zaafarani and S. Zaefferer, Acta Materialia 2009, vol. 57, pp. 559-569.CrossRefGoogle Scholar 79. BC Larson, W Yang, JZ Tischler, GE Ice, JD Budai, W Liu and H Weiland, Int. J. Plast. 2004, vol. 20, pp. 543-560.CrossRefGoogle Scholar 80. AJ Wilkinson and D Randman (2010) Philos Mag, vol. 90, pp. 1159-1177.CrossRefGoogle Scholar 81. 81. FRD Boer, R Boom, W Mattens, A Miedema and A Niessen, (North Holland, Amsterdam: 1989).Google Scholar 82. 82. WR Tyson and WA Miller, Surface Science 1977, vol. 62, pp. 267-276.CrossRefGoogle Scholar 83. 83. TA Roth, Materials Science and Engineering 1975, vol. 18, pp. 183-192.CrossRefGoogle Scholar 84. 84. A Inoue, H Nitta and Y Iijima, Acta Materialia 2007, vol. 55, pp. 5910-5916.CrossRefGoogle Scholar 85. R.E. Smallman and A.H.W. Ngan: Physical Metallurgy and Advanced Materials. Butterworth-Heinemann: Oxford (2011).Google Scholar 86. W.F. Gale and T.C. Totemeier: Smithells Metals Reference Book. Elsevier: Oxford (2003).Google Scholar 87. 87. G Stechauner and E Kozeschnik, Calphad 2014, vol. 47, pp. 92-99.CrossRefGoogle Scholar 88. Nosewicz S, Rojek J, Chmielewski M. Pietrzak K, Advanced Powder Technology Vol. 28, 2017, 1745-1759CrossRefGoogle Scholar Copyright information © The Minerals, Metals & Materials Society and ASM International 2018 Authors and Affiliations E. Torresani1D. Giuntini2C. Zhu3T. Harrington3K. S. Vecchio3A. Molinari4R. K. Bordia5E. A. Olevsky13Email author1.San Diego State UniversitySan DiegoUSA2.Hamburg University of TechnologyHamburgGermany3.University of California, San DiegoLa JollaUSA4.University of TrentoTrentoItaly5.Clemson UniversityClemsonUSA
This is a preview of a remote PDF: https://link.springer.com/content/pdf/10.1007%2Fs11661-018-5037-x.pdf
E. Torresani, D. Giuntini, C. Zhu, T. Harrington, K. S. Vecchio, A. Molinari, R. K. Bordia, E. A. Olevsky. Anisotropy of Mass Transfer During Sintering of Powder Materials with Pore–Particle Structure Orientation, Metallurgical and Materials Transactions A, 2018, 1033-1049, DOI: 10.1007/s11661-018-5037-x | CommonCrawl |
Perturbation method for a phase coexistence system
Calculation of free energy for Bloch electrons
What is the mathematical reason for topological edge states?
How is the current equation calculated from Ginzburg-Landau (GL) free energy?
Is there any method to solve the many particle stationary scattering problem like the one for the single particle problem?
Is there a bulk signature of topological nontriviality for a 3D free fermion band insulator?
Is there a commonly accepted definition of a quantum phase definition for a finite lattice/set of particles?
How can a deSitter space have finite size?
How do Dirac fermions arise in graphene, and, what significance (if any) does this have for high-energy physics?
Energy Oscillations in a One-Dimensional Crystal
How to solve Cahn-Hilliard free energy extremization for a domain of finite size ?
First I have to say I asked this question in physicsSE but afterwards somebody advised me to ask it here. Do I have to remove it from SE ?
I'm trying to get the solution of the Cahn-Hilliard equation in 1d with a certain mass $C$. We have two components, and let's assume we have the relation $c_1+c_2=1$.Hence we take only the variable $c=c_1$.
The total energy with the Lagrange parameter $\tilde{\mu}$ (which is a sort of non-local chemical potential) writes :
$$ F[c(\mathbf{r})]=\int \{f(c(\mathbf{r}))+\frac{\epsilon^2}{2} (\nabla c)^2 \}d\Omega -\tilde{\mu}\int (c(\mathbf{r}) -C) d\Omega $$
In 1 dimension :
$$ \frac{\delta F}{\delta c}=0\implies \frac{df}{dc}-\tilde{\mu}-\epsilon^2 \frac{d^2c}{dx^2}=0$$
Multiplying with $dc/dx$ leads to :
$$\frac{\epsilon}{\sqrt{2}}\frac{dc}{\sqrt{f-\tilde{\mu}(c-C)}}=dx $$
Symmetry imposes $$c'(0)=0\implies f(c(0))-\tilde{\mu}(c(0)-C)=0 $$
At infinity, we also have $c'(\infty)=0 \; ;\;c(\infty)=-1$ (or $0$ depending on the potential you're using).
This equation is solvable for the classical Cahn-Hilliard with $f-\tilde{\mu}(c-C)=(c^2-c_0^2)^2$. The classical way is to get $x(c)$ and then invert it. You find a $\tanh$ solution. But this solution does not respect the symmetry condition $c'(0)=0$ (right you can make it very very close to $0$ by building manually a solution with tanh functions... but I'm looking for an exact solution of the equation). Meaning it only gives the profile of an interface between 2 semi-infinite media.
What I don't understand is how to get a profile respecting the symmetry condition, meaning with a nucleus/aggregate of one phase into the other phase. Meaning a phase of finite size (for example $c=1$) into the other phase ($c=-1$).
I'm wondering wether my problem is overconstrained since the equation $\frac{\epsilon}{\sqrt{2}}\frac{dc}{\sqrt{f-\tilde{\mu}(c-C)}}=dx $ admits only one new constant and there are 3 constraints : $c'(0)=c'(\pm \infty)=0$ and $\int_{\mathbb{R}}c dx=C$ (about this one I have a doubt since $C$ enters the potential).
Could you help please ?
I'm also surprised I didn't find any litterature about this problem.
REMARK : I was wondering maybe there was something missing in the equations. But actually no, since the dynamical equation used in simulations is :$\partial_t c = \nabla.(M(c)\nabla((f'(c)-\tilde{\mu)}-\epsilon^2\Delta c))$, so it's logical that the static picture is given by $(f'(c)-\tilde{\mu)}-\epsilon^2\Delta c=0$.
However what could be is that indeed the system is overconstrained and there is no stable solution. Fortunately the $\tanh$ function provides a landscape that is "quasi-stable" (very very slowly unstable) in the sense that beyond the size of the interface it's as if we had a semi-infinite domain since we are very close to it and that's why we use this model in simulations.
What do you think about it ? If this proposition were to be right, what could be a formalism with whom we could build a solution for a finite domain ?
differential-equations
condensed-matter
asked Aug 1, 2019 in Theoretical Physics by JA (20 points) [ revision history ]
edited Aug 2, 2019 by JA
$\varnothing\hbar$ysicsOverflow | CommonCrawl |
for Harmonic Analysis and Differential Equations Seminar events the year of Friday, September 14, 2018.
August 2018 September 2018 October 2018
1 2 3 4 1 1 2 3 4 5 6
5 6 7 8 9 10 11 2 3 4 5 6 7 8 7 8 9 10 11 12 13
12 13 14 15 16 17 18 9 10 11 12 13 14 15 14 15 16 17 18 19 20
26 27 28 29 30 31 23 24 25 26 27 28 29 28 29 30 31
1:00 pm in 347 Altgeld Hall,Tuesday, March 13, 2018
Harmonic Analysis and Differential Equations Seminar
Low Regularity Global Existence for the Periodic Zakharov System
Erin Compaan (MIT)
Abstract: In this talk, we present a low-regularity global existence result for the periodic Zakharov system. This is a dispersive model for the motion of ionized plasma. Its dynamics have been extensively studied, and existence of solutions is in known for data in the Sobolev space $H^\frac12 \times L^2$. We present a global existence result which holds for even rougher data, in a class of Fourier Lebesgue spaces. It is obtained by combining the high-low decomposition method of Bourgain with an almost-conserved energy result of Kishimoto. Combining these two tools allows us to obtain a low-regularity result which was out of reach of either method alone.
Submitted by tzirakis
1:00 pm in 347 Altgeld Hall,Tuesday, September 11, 2018
Unlabeled distance geometry problem
Ivan Dokmanic [email] (Illinois - Electrical and Computer Engineering)
Abstract: The famous distance geometry problem (DGP) asks to reconstruct the geometry of a point set from a subset of interpoint distances. In the unlabeled DGP the goal is the same, alas without knowing which distances belong to which pairs of points. Both problems are of practical importance: the DGP models sensor network localization, clock synchronization, and molecular geometry reconstruction from NMR data, while the unlabeled DGP models room geometry reconstruction from echoes, positioning by multipath, and nanostructure determination by powder diffraction. The unlabeled DGP in 1D is known as the turnpike reconstruction problem, and it was one of the first techniques used to reconstruct genomes. The mathematics of the unlabeled DGP is nowhere near as well-understood as that of the DGP. I will introduce the unlabeled DGP, explain how it arises in various applications, discuss connections with phase retrieval and explain our approach based on empirical measure matching. Along the way I will point out numerous theoretical and algorithmic aspects of the problem that we do not understand but we wish we did.
Submitted by laugesen
1:00 pm in 347 Altgeld Hall,Tuesday, October 2, 2018
From Neumann to Steklov via Robin: the Weinberger way
Richard Laugesen [email] (Illinois Math)
Abstract: Lord Rayleigh asserted in 1877, and Faber and Krahn proved fifty years later, that "If the area of a membrane be given, there must evidently be some form of boundary for which the pitch (of the principal tone) is the gravest possible, and this form can be no other than the circle." In modern terminology, Rayleigh was claiming that among all planar domains of given area, the one that minimizes the first eigenvalue of the Laplacian (under Dirichlet boundary conditions) is the disk. In terms of heat flow in 3 dimensions, that means a room of given volume whose boundary is maintained at temperature zero will cool off slowest when it is a ball. What about a room whose boundary is perfectly insulated (Neumann boundary conditions)? Szego and Weinberger discovered in the 1950s that the room's temperature will equilibrate fastest when it is spherical - which is admittedly an unlikely shape for a room, except for fans of Futuro Flying Saucer homes. Insulation is never perfect, as every homeowner knows, and so we are led to the Robin boundary condition for partial insulation, and to recent progress and open problems on "isoperimetric type" eigenvalue inequalities that extend the work of Rayleigh-Faber-Krahn and Szego-Weinberger.
The Ricci iteration on homogeneous spaces
Artem Pulemotov (University of Queensland)
Abstract: The Ricci iteration is a discrete analogue of the Ricci flow. Introduced in 2007, it has been studied extensively on Kähler manifolds, providing a new approach to uniformisation. In the talk, we will define the Ricci iteration on compact homogeneous spaces and discuss a number of existence, convergence and relative compactness results. This is largely based on joint work with Timothy Buttsworth (Queensland), Yanir Rubinstein (Maryland) and Wolfgang Ziller (Penn).
Submitted by palbin
1:00 pm in 347 Altgeld Hall,Tuesday, December 4, 2018
Unconditional uniqueness for the derivative nonlinear Schrodinger equation
Razvan Mosincat (The University of Edinburgh)
Abstract: We consider the initial-value problem for the derivative nonlinear Schrödinger equation (DNLS) on the real line. We implement an infinite iteration of normal form reductions (namely, integration by parts in time) and reformulate a gauge-equivalent equation in terms of an infinite series of multilinear terms. This allows us to show the unconditional uniqueness of solutions to DNLS in an almost end-point space. This is joint work with Haewon Yoon (National Taiwan University). | CommonCrawl |
Non-real eigenvalues of nonlocal indefinite Sturm–Liouville problems
Fu Sun1,
Kun Li ORCID: orcid.org/0000-0003-3076-25862,
Jiangang Qi1 &
Baochao Liao1
The present paper deals with non-real eigenvalues of regular nonlocal indefinite Sturm–Liouville problems. The existence of non-real eigenvalues of indefinite Sturm–Liouville differential equation with nonlocal potential \(K(x,t)\) associated with self-adjoint boundary conditions is studied. Furthermore, a priori upper bounds of non-real eigenvalues for a class of indefinite differential equation involving nonlocal point interference potential function is obtained.
Consider the regular nonlocal indefinite Sturm–Liouville differential equation
$$ -y''(x)+q(x)y(x)+ \int ^{1}_{-1}K(x,t)y(t)\,\mathrm {d}t=\lambda w(x) y(x) \quad \text{in } L^{2}_{ \vert w \vert }[-1,1] $$
associated to suitable boundary conditions, where λ is the spectral parameter, \(q\in L^{1}[-1,1]\) is called the local potential, \(K(x,t)=\overline{K(t,x)}\) is called the nonlocal potential, the weight function \(w\in L^{1}[-1,1]\) changes its sign on \([-1,1]\) in the sense that \(\operatorname{mes}\{x\in [-1,1]: w(x)>0\}\) and \(\operatorname{mes}\{x\in [-1,1]: w(x)<0\}\) have a positive Lebesgue measure and \(L^{2}_{ \vert w \vert }:=L^{2}_{ \vert w \vert }[-1,1]\) is the weighted Hilbert space of all Lebesgue measurable, complex-valued functions f on \([-1,1]\) satisfying \(\int ^{1}_{-1} \vert w \vert \vert f \vert ^{2}<\infty \) with the inner product \((f,g)_{ \vert w \vert }=\int ^{1}_{-1} \vert w \vert f\overline{g}\) and the norm \(\Vert f \Vert _{ \vert w \vert } ^{2}=\int ^{1}_{-1} \vert w \vert \vert f \vert ^{2}\). Such a problem (1.1) is called indefinite.
If \(w(x) > 0\) a.e. \(x \in [-1, 1]\), models similar to the nonlocal differential equation (1.1) appear in quantum mechanics, diffusion processes, point interactions, voltage-driven electrical systems and have been studied in [2, 15, 27]. In the case where \(q \equiv 0\), \(w \equiv 1\) and \(K(x, t) = v(x)u(t)\), \(v, u \in C([-1, 1], \mathbb{R})\) in (1.1), the authors in [12] investigate the reality of eigenvalues with Dirichlet boundary conditions. For the case
$$ K(x,t)=v(x)\delta (t-c)+\overline{v(t)}\delta (x-c), \quad c \in (-1,1], $$
where \(v \in L^{2}([-1, 1],\mathbb{C})\), δ is Dirac's distribution, the inverse spectral problems for various nonlocal operators were studied in [1, 19, 20] and the references cited therein.
The nonlocal indefinite Sturm–Liouville problems have attracted a lot of attention in recent years since the diversity and complexity of biomathematics models, transport models, population dynamic systems and microwave propagation problems. Such nonlocal problems also played an important role in reaction–diffusion problems and quantum-mechanical theory. For the case \(K(x,t)\) in (1.2) with suitable boundary conditions, the spectral problems which including the change rule of (non-)left-definiteness for the local case under the nonlocal perturbations, the equivalence of non-left-definite and the finiteness of non-real eigenvalues of nonlocal indefinite Sturm–Liouville equation (1.1) have been studied in [26]. The (local) indefinite Sturm–Liouville problem, i.e., \(K(x,t)=0\) in (1.1) with self-adjoint boundary conditions, has discrete, real eigenvalues unbounded from both below and above, and may also admit non-real eigenvalues (see [3, 16, 18, 29]). The indefinite nature was noticed by Haupt [13], Richardson [24] at the beginning of the last century and has attracted a lot of attention in recent years. Determining a priori bounds and determining the exact number of non-real eigenvalues are an interesting and difficult problems in Sturm–Liouville theory. Recently, these open problems have been solved by Qi et al., [4, 14, 21, 28] for the regular (local) indefinite problem and by Behrndt et al., [5,6,7,8,9, 25] for the singular case, respectively.
In the present paper, we firstly obtain the existence of the nonlocal indefinite differential equation (1.1) with self-adjoint boundary conditions by means of the operator theory in Krein spaces and the symmetry conditions. In the case of the equation with a nonlocal point interference potential function (Dirac distribution), we derive an equation without Dirac's distribution but with a nonlocal boundary condition. Then we study the estimates on the upper bounds of non-real eigenvalues for this nonlocal indefinite Sturm–Liouville problem.
The arrangement of this paper is as follows: Sect. 2 is devoted to the existence of non-real eigenvalues for the nonlocal indefinite Sturm–Liouville equation (1.1) associated with self-adjoint separated boundary conditions (see Theorem 2.2). In Sect. 3, we obtain the nonlocal indefinite Sturm–Liouville problem through the Dirac distribution in (1.2), then the upper bounds of non-real eigenvalues in terms of q, v, w are shown (see Theorems 4.1 and 4.2) in Sect. 4.
Existence of non-real eigenvalues
In this section we prove the existence of non-real eigenvalues for the nonlocal indefinite eigenvalue problem
$$ \textstyle\begin{cases} \tau _{k} y:=-y''(x)+q(x)y(x)+\int ^{1}_{-1} K(x,t)y(t)\,\mathrm {d}t=\lambda w(x)y(x),\\ \mathcal{B}_{k}y=0:\qquad y(-1)=0, \qquad y'(1)=0, \end{cases} $$
where w changes sign on \([-1,1]\) satisfying
$$ w(x)\neq 0 \quad \text{a.e. } x\in [-1,1], q, w \in L^{1} \bigl([-1,1], \mathbb{R} \bigr) \text{ and } K\in L ^{1} \bigl([-1,1]^{2}, \mathbb{R} \bigr) . $$
To this end, we need the following lemma.
If\(w\in L^{1}([-1,1],\mathbb{R})\)and\(\vert w(x) \vert >0\) a.e. on\([-1,1]\), then the eigenvalue problems\(\tau _{k} y=\lambda \vert w \vert y\), \(\mathcal{B}_{k}y=0\)and\(\tau _{k} y= \lambda y\), \(\mathcal{B}_{k}y=0\)have the same number of negative eigenvalues.
Let \(\tilde{S}_{k}\) and S̃ be the operator associated to
$$ \tau _{k} y=\lambda \vert w \vert y, \quad\quad \mathcal{B}_{k}y=0 \quad \text{and} \quad \tau _{k} y= \lambda y, \quad\quad \mathcal{B}_{k}y=0, $$
where \(D(\tilde{S}_{k})=\{y\in L^{2}_{ \vert w \vert }: y, y'\in \mathit{AC}_{ \mathrm{loc}}, \tau _{k} y/ \vert w \vert \in L^{2}_{ \vert w \vert }, \mathcal{B}_{k}y=0\}\) and \(D(\tilde{S})=\{y\in L^{2}: y, y'\in \mathit{AC}_{\mathrm{loc}}, \tau _{k} y \in L^{2}, \mathcal{B}_{k}y=0\}\), respectively. Note that \(D(\tilde{S}_{k})=D(\tilde{S})\), one sees that for every \(y\in D( \tilde{S}_{k})\), \((\tilde{S}_{k} y,y)_{ \vert w \vert }=(\tilde{S} y,y)_{L^{2}}\). It follows from the Min–Max principle for self-adjoint operators [23, Theorem XIII.1, p. 76] that
$$ \mu _{n}=\sup_{g_{1},\ldots, g_{n-1}} \inf_{ f\in [g_{1},\ldots, g_{n-1}]^{\bot } } \biggl\{ \frac{(Sf,f)_{ \vert w \vert }}{(f,f)_{ \vert w \vert }}: f\neq 0, f\in D(S) \biggr\} $$
and that the negative eigenvalues are dependent only on the quadratic form of operator \((Sf,f)_{ \vert w \vert }\). Hence \(\tilde{S}_{k}\) and S̃ have the same number of negative eigenvalues, which completes the proof of Lemma 2.1. □
In what follows, we impose the symmetry conditions on q, K and w, namely,
$$ \begin{aligned} q(x)=q(-x), \quad\quad K(x,t)=K(-x,t), \quad\quad w(-x)=-w(x) \end{aligned} $$
to prove the existence of non-real eigenvalues of (2.1). It follows from the hypothesis on q, K, w in (2.2) and the symmetry conditions (2.3) that if \(\lambda \in \mathbb{C}\) is an eigenvalue of the problem (2.1) and ϕ is the corresponding eigenfunction, then −λ̅ is also an eigenvalue of (2.1) with eigenfunction \(\overline{\phi (-\cdot )}\). Let \(\tilde{K}=(L^{2}_{ \vert w \vert },[\cdot ,\cdot ]_{w})\) be the Krein space equipped with the indefinite inner product \([f,g]_{w}=\int ^{1}_{-1}w f \overline{g}\), \(f, g\in L^{2}_{ \vert w \vert }\) and T the self-adjoint operator in K̃ (cf. [10, 11]) defined as
$$ Ty=\frac{1}{w}\tau _{k} y, \quad y\in D(T)= \bigl\{ y\in L^{2}_{ \vert w \vert }: y, y' \in \mathit{AC}_{\mathrm{loc}}[-1,1], \tau _{k} y / \vert w \vert \in L^{2}_{ \vert w \vert }, \mathcal{B}_{k}y=0 \bigr\} . $$
We say that the self-adjoint operator T has knegative squares, \(k\in \mathbb{N}_{0}\), if there exists a k-dimensional subspace X of K̃ in \(D(T)\) such that \([Tf,f]<0\), \(f\in X\), \(f\neq 0\), but no \((k+1)\)-dimensional subspace with this property.
Applying the above results and the spectral theory of operators in K̃ spaces, we will prove the existence of non-real eigenvalues of (2.1) by the method given in [21].
Let (2.2) and (2.3) hold. If the eigenvalue problem
$$ \begin{aligned} -y''(x)+q(x)y(x)+ \int ^{1}_{-1} K(x,t)y(t)\,\mathrm {d}t=\lambda y(x), \quad\quad \mathcal{B}_{k}y=0, \end{aligned} $$
has one negative eigenvalue and the remaining eigenvalues are all positive, then the nonlocal indefinite Sturm–Liouville problem (2.1) has two non-real eigenvalues.
Let \(T_{k}\) and \(S_{k}\) be the operators of the nonlocal indefinite Sturm–Liouville problem (2.1) and nonlocal right-definite Sturm–Liouville problem \(\tau _{k} y=\lambda \vert w \vert y\), \(\mathcal{B}_{k}y=0\), respectively. Then \(T_{k}\) and \(S_{k}\) are self-adjoint under the indefinite inner product \([\cdot ,\cdot ]_{w}\) and the definite inner product \((\cdot ,\cdot )_{ \vert w \vert }\), respectively. This together with Lemma 2.1 and the assumption in Theorem 2.2 shows that \(S_{k}\) has one negative eigenvalue and the rest are all positive, therefore, \(T_{k}\) has exactly one negative square because of \([T_{k}f,f]_{w}=(S_{k}f,f)_{ \vert w \vert }\) and 0 is a resolvent point of \(T_{k}\). It follows from [11, Proposition 1.5] that there exists exactly one eigenvalue λ of (2.1) in \(\mathbb{R}\) or the upper half-plane \(\mathbb{C}\) and if this eigenvalue \(\lambda \in \mathbb{R}\) then there exists an eigenfunction ϕ with \(\lambda [\phi ,\phi ]_{w}\leq 0\). Let \(\lambda \in \mathbb{R}\) be such an eigenvalue with eigenfunction ϕ, then \(-\lambda =-\overline{\lambda }\) is also an eigenvalue with the eigenfunction \(\overline{\phi (-\cdot )}\) and \(-\lambda [\overline{ \phi (-\cdot )},\overline{\phi (-\cdot )}]_{w} =\lambda [\phi ,\phi ]_{w} \leq 0\) through the symmetry in (2.3). Hence we get two eigenvalues, which is a contradiction. If \(\lambda \in \mathbb{C}^{+}\), then \(-\overline{\lambda }\in \mathbb{C}^{+}\), which implies that \(\lambda =-\overline{\lambda }\), i.e., λ is purely imaginary. The proof is finished. □
Nonlocal Sturm–Liouville problems with distribution coefficients
Let the kernel \(K(x,t)\) in (1.2) be given in the form
where \(v \in L^{1}([-1, 1],\mathbb{R})\) and δ is Dirac's distribution. For every continuous function f on \([-1, 1]\), the Dirac delta distribution at point c is defined by
$$ \int ^{1}_{-1}\delta (x-c)f(x)\,\mathrm {d}x= \textstyle\begin{cases} f(c), &c\in [-1,1], \\ 0, &c\notin [-1,1]. \end{cases} $$
In this case, a solution of (1.1) is understood in the sense that a function \(y \in \mathit{AC}[-1, 1]\), \(y' \in \mathit{AC}([-1, c) \cup (c, 1])\) such that \(y'(c\pm 0)\) exist and the equation holds almost everywhere. For \(c=1\), we use \(y'(1)\) instead of \(y'(1+0)\). It follows from (3.1), (3.2) and the continuity of the solution y that (1.1) takes the form
$$ -y''(x)+q(x)y(x)+v(x)y(c)+\delta (x-c) \int ^{1}_{-1}v(t)y(t)\,\mathrm {d}t= \lambda w(x)y(x) $$
for a.e. \(x\in [-1,1]\). For \(x\in [-1,1]\) and \(x\neq c\), the equation has the form
$$ -y''(x)+q(x)y(x)+v(x)y(c)=\lambda w(x)y(x) \quad \text{a.e. } x\in [-1,1]. $$
Integrating both sides of (3.3) on the interval \([c-\varepsilon , c+\varepsilon ]\) for arbitrary \(\varepsilon >0\), then
$$ y'(c-\varepsilon )-y'(c+\varepsilon )+ \int ^{1}_{-1}v(t)y(t)\,\mathrm {d}t= \int ^{c+\varepsilon }_{c-\varepsilon } \bigl(\bigl(\lambda w(x)-q(x) \bigr)y(x)-v(x)y(c) \bigr)\,\mathrm {d}x. $$
Let \(\varepsilon \rightarrow 0\), one sees that \(y'(c-0)-y'(c+0)+\int ^{1}_{-1}v(x)y(x)\,\mathrm {d}x=0\). Then y satisfies
$$ \textstyle\begin{cases} -y''(x)+q(x)y(x)+v(x)y(c)=\lambda w(x)y(x)\quad \text{a.e. } x\in [-1,1], x\neq c, \\ y'(c-0)-y'(c+0)+\int ^{1}_{-1}v(x)y(x)\,\mathrm {d}x=0. \end{cases} $$
If the boundary condition is given in the form \(y(-1) = 0\), \(y'(1) = 0\) for (1.1) and let \(c=1\), then from (3.4) we see that the nonlocal indefinite eigenvalue problem takes the form
$$ \textstyle\begin{cases} -y''(x)+q(x)y(x)+v(x)y(1)=\lambda w(x)y(x), \\ y(-1)=0, \qquad y'(1-0)+\int ^{1}_{-1}v(x)y(x)\,\mathrm {d}x=0. \end{cases} $$
The authors in [1, 19] investigate the eigenvalue problem with \(q \equiv 0\), \(w \equiv 1\). For simplicity, we will write \(y'(1)\) instead of \(y'(1-0)\) in the following discussion.
A priori bounds of non-real eigenvalues
Consider the nonlocal indefinite Sturm–Liouville problem
$$ \textstyle\begin{cases} \tau y:=-y''(x)+q(x)y(x)+v(x)y(1)=\lambda w(x)y(x),\\ \mathcal{B}y=0: \qquad y(-1)=0, \qquad y'(1)+\int ^{1}_{-1}v(x)y(x)\,\mathrm {d}x=0, \end{cases} $$
where q, v, w are real-valued functions satisfying the standard conditions
$$ w(x)\neq 0\quad \text{a.e. } x\in [-1,1], q, v, w \in L^{1}[-1,1]. $$
The operator S associated to the nonlocal right-definite problem
$$ -y''(x)+q(x)y(x)+v(x)y(1) =\lambda \bigl\vert w(x) \bigr\vert y(x), \quad\quad \mathcal{B}y=0, $$
is defined as \(Sy=\frac{1}{ \vert w \vert }\tau y\) for \(y\in D(S)\), where
$$ D(S)=\bigl\{ y\in L^{2}_{ \vert w \vert }: y, y'\in \mathit{AC}_{\mathrm{loc}}[-1,1], \tau y/ \vert w \vert \in L^{2}_{ \vert w \vert }, \mathcal{B}y=0\bigr\} . $$
It follows from [22] that S is a self-adjoint operator in the Hilbert space \((L^{2}_{ \vert w \vert }, (\cdot ,\cdot )_{ \vert w \vert })\) and its spectrum consists of real eigenvalues, which are bounded from below.
To simplify our statements, let \(\Vert \cdot \Vert _{p}\) be the \(L^{p}[-1,1]\)-norm, \(1\leq p <\infty \), \(\Vert \cdot \Vert _{\infty }\) be the \(L^{\infty }[-1,1]\)-norm and
$$ N_{q,v}=1+8\bigl( \Vert q_{-} \Vert _{1}+ 8 \Vert v \Vert _{1}^{2}\bigr), \quad q_{-} =\max \{ -q, 0\}, \Vert q \Vert _{1}= \int ^{1}_{-1} \vert q \vert , \Vert v \Vert _{1}= \int ^{1}_{-1} \vert v \vert . $$
If \(xw(x)>0\) a.e. on \([-1,1]\), we can choose \(\varepsilon >0\) such that
$$ \varOmega (\varepsilon ) =\bigl\{ x\in [-1,1]: xw(x)< \varepsilon \bigr\} , \quad\quad m( \varepsilon ) =\operatorname{mes} \varOmega \leq \frac{1}{4N_{q,v}}. $$
Since \(w^{2}(x)>0\) a.e. on \([-1,1]\), we can choose \(\eta >0\) such that
$$ \widetilde{\varOmega }(\eta ) =\bigl\{ x\in [-1,1]: w^{2} (x)< \eta \bigr\} , \quad\quad m( \eta ) =\operatorname{mes} \widetilde{ \varOmega } \leq \frac{1}{4N_{q,v}}. $$
A point at x which the weight function \(w(x)\) changes its sign will be called a turning point [16]. If \(w(x)\) has only one turning point, we can obtain the following a priori bounds on the non-real eigenvalues.
Assume that\(xw(x)>0\) a.e. on\([-1,1]\)and (4.2) holds, then, for any possible non-real eigenvalueλof problem (4.1), we have
$$ \begin{aligned} \vert \lambda \vert \leq \frac{2}{\varepsilon } \bigl( \sqrt{ N_{q,v}}+ 4 N _{q,v} \bigl( \Vert q_{-} \Vert _{1} + 2 \Vert v \Vert _{1}\bigr) \bigr), \quad\quad \vert \operatorname {Im}\lambda \vert \leq \frac{2}{\varepsilon } \bigl(\sqrt{N_{q,v}}+ 8 N_{q,v} \Vert v \Vert _{1} \bigr), \end{aligned} $$
where\(\varepsilon >0\)and\(q_{-}\), \(N_{q,v}\)are defined in (4.5) and (4.4), respectively.
If \(w(x)\) is allowed to have more than one turning point, we will obtain the following results.
Assume that\(w\in \mathit{AC}[-1,1]\), \(w'\in L^{2}[-1,1]\)and (4.2) holds, then, for any non-real eigenvalueλof problem (4.1), we have
$$ \begin{aligned} & \vert \lambda \vert \leq \frac{2}{\eta } \bigl( \Vert w \Vert _{\infty }N_{q,v} \bigl(1+2 \Vert q_{-} \Vert _{1}+4 \Vert v \Vert _{1} \bigr) + \varLambda \sqrt{N_{q,v}} \bigr), \\ & \vert \operatorname {Im}\lambda \vert \leq \frac{2}{\eta } \bigl( 4 \Vert w \Vert _{\infty } \Vert v \Vert _{1} N_{q,v} + \varLambda \sqrt{N_{q,v}} \bigr), \end{aligned} $$
where\(\varLambda =(\int ^{1}_{-1} \vert w' \vert ^{2})^{\frac{1}{2}}\), \(\eta >0\)and\(q_{-}\), \(N_{q,v}\)are defined in (4.6) and (4.4), respectively.
In order to prove Theorems 4.1 and 4.2, we first introduce some concepts and prepare some lemmas (cf. [17]). Let f be a real-valued function defined on the closed, bounded interval \([a, b]\) and \(\triangle : a=x_{0}< x_{1}< \cdots <x_{n}-1<x_{n}=b\) be a partition of \([a, b]\). We define the variation of f with respect to △ by
$$ \operatorname{Var}_{\triangle }=\sum_{i=1}^{n} \bigl\vert f(x_{i})-f(x_{i-1}) \bigr\vert , $$
and the total variation of f on \([a, b]\) by
$$ \bigvee^{b}_{a}(f)=\sup \bigl\{ \operatorname{Var}_{\triangle }: \triangle \text{ is an any partition of } [a,b] \bigr\} . $$
A real-valued function f is said to be of bounded variation on the closed, bounded interval \([a,b]\) if \(\bigvee^{b}_{a}(f)<\infty \).
(cf. [14, Lemma 2] and [17, Lemma 5.2.2, p. 246])
Letgbe of bounded variation over all of\([a, b]\), that is, gsatisfies the inequality\(\int ^{x}_{a} \vert \mathrm {d}g(x) \vert <\infty \). Then for all\(x \in (a, b]\)and for every\(\delta >0\)there exists a\(\rho =\rho (\delta ,x)>0\)such that
$$ \int ^{x}_{a} \bigl\vert f(t) \bigr\vert ^{2} \bigl\vert \mathrm {d}g(t) \bigr\vert \leq \rho (\delta ,x) \int ^{x}_{a} \bigl\vert f(t) \bigr\vert ^{2}\,\mathrm {d}t +\delta \int ^{x}_{a} \bigl\vert f'(t) \bigr\vert ^{2}\,\mathrm {d}t, $$
$$ \rho (\delta ,x)=\frac{1}{x-a}+\frac{c}{\delta }, \quad c= \int ^{b}_{a} \bigl\vert \mathrm {d}g(x) \bigr\vert . $$
Let\(q, v \in L^{1}[-1,1]\)and\(\phi \in D(T)\). Then
$$ \int ^{1}_{-1} \bigl\vert q_{-} + \sqrt{2} \varepsilon \Vert v \Vert _{1} \vert v \vert \bigr\vert \vert \phi \vert ^{2} \leq \biggl(\frac{1}{2}+ \frac{ \Vert q_{-} \Vert _{1}+ \sqrt{2}\varepsilon \Vert v \Vert _{1}^{2}}{\delta } \biggr) \int ^{1}_{-1} \vert \phi \vert ^{2} + \delta \int ^{1}_{-1} \bigl\vert \phi ' \bigr\vert ^{2}. $$
Replacing \(f(t)\) and \(g(t)\) by \(\phi (t)\) and \(\int ^{t}_{-1} (q_{-}(x)+ \sqrt{2} \varepsilon \Vert v \Vert _{1} \vert v(x) \vert )\,\mathrm {d}x\) in Lemma 4.3, respectively, then
$$ \begin{aligned} \int ^{x}_{-1} \bigl\vert \mathrm {d}g(t) \bigr\vert &= \int ^{x}_{-1} \biggl\vert \mathrm {d}\biggl( \int ^{t} _{-1} \bigl(q_{-}(x)+ \sqrt{2} \varepsilon \Vert v \Vert _{1} \bigl\vert v(x) \bigr\vert \bigr) \,\mathrm {d}x \biggr) \biggr\vert \\ &= \int ^{x}_{-1} \bigl\vert q_{-}(t)+ \sqrt{2} \varepsilon \Vert v \Vert _{1} \bigl\vert v(t) \bigr\vert \bigr\vert \,\mathrm {d}t \leq \Vert q_{-} \Vert _{1}+ \sqrt{2} \varepsilon \Vert v \Vert _{1}^{2} < \infty . \end{aligned} $$
Using this result in (4.9), one sees that (4.10) holds immediately. □
The following lemma presents estimates of \(\Vert \phi ' \Vert _{2}\) and \(\Vert \phi \Vert _{\infty }\), where ϕ is an eigenfunction of (4.1) corresponding to a non-real eigenvalue λ. That is, \(\mathcal{B}\phi =0\) and
$$ -\phi ''+q\phi +v\phi (1)=\lambda w\phi . $$
Since the problem (4.1) is a linear system and ϕ is continuous, we can choose ϕ to satisfy \(\int ^{1}_{-1} \vert \phi (x) \vert ^{2} \,\mathrm {d}x =1\) in the following discussion.
Letλ, ϕbe defined as above and\(N_{q,v}\)in (4.4). Then
$$ \bigl\Vert \phi ' \bigr\Vert ^{2}_{2} \leq N_{q,v}, \qquad \Vert \phi \Vert ^{2}_{\infty } \leq 2N_{q,v}. $$
Multiplying both sides of (4.11) by ϕ̅ and integrating by parts over the interval \([-1,1]\), then from \(\mathcal{B}\phi =0\) we have
$$ \begin{aligned} \lambda \int ^{1}_{-1} w \vert \phi \vert ^{2} = \int ^{1}_{-1} \bigl\vert \phi ' \bigr\vert ^{2}+ \int ^{1}_{-1} q \vert \phi \vert ^{2} +2 \operatorname {Re}\int ^{1}_{-1} v \overline{ \phi } \phi (1). \end{aligned} $$
This together with \(\operatorname {Im}\lambda \neq 0\) yields \(\int ^{1}_{-1} w \vert \phi \vert ^{2} =0\) and hence
$$ \begin{aligned} \int ^{1}_{-1} \bigl\vert \phi ' \bigr\vert ^{2}+ \int ^{1}_{-1} q \vert \phi \vert ^{2} +2 \operatorname {Re}\int ^{1}_{-1} v \overline{\phi } \phi (1)=0. \end{aligned} $$
It follows from Lemma 4.4 and \(\phi (1)=\int ^{1}_{-1}\phi '(t)\,\mathrm {d}t\) that
$$ \begin{aligned} & \int ^{1}_{-1} q_{-} \vert \phi \vert ^{2} + 2 \int ^{1}_{-1} \vert v \vert \vert \overline{ \phi } \vert \bigl\vert \phi (1) \bigr\vert \\ &\quad \leq \int ^{1}_{-1} q_{-} \vert \phi \vert ^{2} + 2 \sqrt{2} \biggl( \int ^{1}_{-1} \vert v \vert \biggr)^{\frac{1}{2}} \biggl( \int ^{1}_{-1} \vert v \vert \vert \phi \vert ^{2} \biggr)^{\frac{1}{2}} \biggl( \int ^{1}_{-1} \bigl\vert \phi ' \bigr\vert ^{2} \biggr)^{\frac{1}{2}} \\ &\quad \leq \int ^{1}_{-1} \bigl(q_{-} \vert \phi \vert ^{2} +\sqrt{2} \varepsilon \Vert v \Vert _{1} \vert v \vert \vert \phi \vert ^{2} \bigr) + \frac{\sqrt{2}}{\varepsilon } \int ^{1}_{-1} \bigl\vert \phi ' \bigr\vert ^{2} \\ &\quad \leq \biggl(\frac{1}{2}+ \frac{ \Vert q_{-} \Vert _{1}+ \sqrt{2}\varepsilon \Vert v \Vert _{1}^{2}}{\delta } \biggr) \int ^{1}_{-1} \vert \phi \vert ^{2} + \delta \int ^{1} _{-1} \bigl\vert \phi ' \bigr\vert ^{2} + \frac{\sqrt{2}}{\varepsilon } \int ^{1}_{-1} \bigl\vert \phi ' \bigr\vert ^{2}. \end{aligned} $$
Setting \(\varepsilon =4\sqrt{2}\) and \(\delta =1/4\),
$$ \begin{aligned} & \int ^{1}_{-1} q_{-} \vert \phi \vert ^{2} + 2 \int ^{1}_{-1} \vert v \vert \vert \overline{ \phi } \vert \bigl\vert \phi (1) \bigr\vert \leq \frac{1}{2}+ 4 \bigl( \Vert q_{-} \Vert _{1}+ 8 \Vert v \Vert _{1}^{2} \bigr) +\frac{1}{2} \int ^{1}_{-1} \bigl\vert \phi ' \bigr\vert ^{2}. \end{aligned} $$
Therefore, (4.12), (4.13) and \(q=q_{+}-q_{-}\), \(q_{\pm } = \max \{0, \pm q \}\) lead us to
$$ \begin{aligned} \int ^{1}_{-1} \bigl\vert \phi ' \bigr\vert ^{2} &= \int ^{1}_{-1}q_{-} \vert \phi \vert ^{2} - \int ^{1}_{-1}q_{+} \vert \phi \vert ^{2} -2\operatorname {Re}\int ^{1}_{-1}v \overline{\phi } \phi (1) \\ &\leq \int ^{1}_{-1} q_{-} \vert \phi \vert ^{2} +2 \int ^{1}_{-1} \vert v \vert \vert \overline{ \phi } \vert \bigl\vert \phi (1) \bigr\vert \leq \frac{1}{2}+ 4 \bigl( \Vert q_{-} \Vert _{1}+ 8 \Vert v \Vert _{1}^{2} \bigr) +\frac{1}{2} \int ^{1}_{-1} \bigl\vert \phi ' \bigr\vert ^{2}, \end{aligned} $$
and hence
$$ \int ^{1}_{-1} \bigl\vert \phi ' \bigr\vert ^{2} \leq N_{q,v}, $$
where \(N_{q,v}\) is defined in (4.4). Note that \(\phi (x)=\int ^{x}_{-1} \phi '(t) \,\mathrm {d}t\) by \(\phi (-1)=0\), from the Cauchy–Schwarz inequality one sees that
$$ \bigl\vert \phi (x) \bigr\vert ^{2}= \biggl\vert \int ^{x}_{-1} \phi '(t) \,\mathrm {d}t \biggr\vert ^{2} \leq 2 \int ^{1}_{-1} \bigl\vert \phi '(t) \bigr\vert ^{2} \,\mathrm {d}t, $$
which together with (4.14) implies that
$$ \Vert \phi \Vert ^{2}_{\infty } \leq 2 \int ^{1}_{-1} \bigl\vert \phi '(t) \bigr\vert ^{2} \,\mathrm {d}t \leq 2N_{q,v}. $$
The proof of Lemma 4.5 is complete. □
With the aid of the above results we prove the main results of this section.
Multiplying both sides of (4.11) by ϕ̅ and integrating on \([x,1]\), we have
$$ \lambda \int ^{1}_{x} w \vert \phi \vert ^{2} = \phi ' \overline{\phi } + \int ^{1}_{-1} v \phi \overline{\phi (1)}+ \int ^{1}_{x} \bigl( \bigl\vert \phi ' \bigr\vert ^{2}+q \vert \phi \vert ^{2} +v \overline{\phi } \phi (1) \bigr). $$
Separating the imaginary parts yields
$$ \operatorname {Im}\lambda \int ^{1}_{x} w \vert \phi \vert ^{2} =\operatorname {Im}\bigl(\phi ' \overline{ \phi } \bigr) +\operatorname {Im}\int ^{1}_{-1} v \phi \overline{\phi (1)} +\operatorname {Im}\int ^{1}_{x} v \overline{\phi } \phi (1). $$
It follows from \(\int ^{1}_{-1}w \vert \phi \vert ^{2}=0\), (4.5) and Lemma 4.5 that
$$ \begin{aligned}[b] \int ^{1}_{-1} \int ^{1}_{x} w(t) \bigl\vert \phi (t) \bigr\vert ^{2}\,\mathrm {d}t\,\mathrm {d}x &= \int ^{1} _{-1}xw(x) \bigl\vert \phi (x) \bigr\vert ^{2}\,\mathrm {d}x \\ &\geq \varepsilon \biggl( \int ^{1} _{-1} \bigl\vert \phi (x) \bigr\vert ^{2}\,\mathrm {d}x - \int _{\varOmega (\varepsilon )} \bigl\vert \phi (x) \bigr\vert ^{2} \,\mathrm {d}x \biggr)\\& \geq \varepsilon \bigl[1-m(\varepsilon ) \Vert \phi \Vert _{\infty }^{2}\bigr] \geq \frac{\varepsilon }{2}. \end{aligned} $$
Then integrating (4.16) and using (4.17), Lemma 4.5, the Schwarz inequality, we have
$$\begin{aligned} \begin{aligned}[b] \frac{\varepsilon }{2} \vert \operatorname {Im}\lambda \vert &\leq \vert \operatorname {Im}\lambda \vert \int ^{1}_{-1} \int ^{1}_{x} w(t) \bigl\vert \phi (t) \bigr\vert ^{2} \,\mathrm {d}t \,\mathrm {d}x \\ &\leq \biggl\vert \int ^{1}_{-1} \operatorname {Im}\biggl(\phi '(x) \overline{\phi (x)} + \int ^{1}_{-1} v(t)\phi (t) \overline{\phi (1)} \,\mathrm {d}t + \int ^{1}_{x} v(t) \overline{\phi (t)} \phi (1) \,\mathrm {d}t \biggr) \,\mathrm {d}x \biggr\vert \\ &\leq \int ^{1}_{-1} \bigl\vert \phi '(x) \bigr\vert \bigl\vert \overline{\phi (x)} \bigr\vert \,\mathrm {d}x +2 \int ^{1}_{-1} \bigl\vert v(x) \bigr\vert \bigl\vert \phi (x) \bigr\vert \bigl\vert \overline{ \phi (1)} \bigr\vert \,\mathrm {d}x \\ &\quad{} + 2 \int ^{1}_{-1} \bigl\vert v(x) \bigr\vert \bigl\vert \overline{\phi (x)} \bigr\vert \bigl\vert \phi (1) \bigr\vert \,\mathrm {d}x \\ &\leq \sqrt{N_{q,v}}+4 \Vert \phi \Vert _{\infty } \Vert v \Vert _{1} \leq \sqrt{N_{q,v}}+ 8 N_{q,v} \Vert v \Vert _{1} . \end{aligned} \end{aligned}$$
Set \(q_{+}(x)=\max \{0,q(x)\}\), then \(\vert q \vert =q+2q_{-}\), these facts with (4.12) lead us to
$$ \begin{aligned} & \biggl\vert \int ^{1}_{-1} \int ^{1}_{x} \bigl( \bigl\vert \phi '(t) \bigr\vert ^{2}+q(t) \bigl\vert \phi (t) \bigr\vert ^{2}\bigr) \,\mathrm {d}t \,\mathrm {d}x + \int ^{1}_{-1} \biggl( \int ^{1}_{-1} v(t)\phi (t)\overline{ \phi (1)} \,\mathrm {d}t \\ &\quad\quad{} + \int ^{1}_{x} v(t)\overline{\phi (t)}\phi (1) \,\mathrm {d}t \biggr)\,\mathrm {d}x \biggr\vert \\ &\quad = \biggl\vert \int ^{1}_{-1}(x+1) \bigl( \bigl\vert \phi '(x) \bigr\vert ^{2}+q(x) \bigl\vert \phi (x) \bigr\vert ^{2}\bigr)\,\mathrm {d}x + 2 \int ^{1}_{-1} v(x) \phi (x) \overline{\phi (1)} \,\mathrm {d}x \\ & \qquad{} + \int ^{1}_{-1} (x+1) \bigl(v(x) \overline{\phi (x)} \phi (1)\bigr) \,\mathrm {d}x \biggr\vert \\ &\quad \leq \int ^{1}_{-1} \bigl\vert \phi '(x) \bigr\vert ^{2} \,\mathrm {d}x + \int ^{1}_{-1}\bigl(q(x)+2q _{-}(x)\bigr) \bigl\vert \phi (x) \bigr\vert ^{2}\,\mathrm {d}x + \int ^{1}_{-1} 2 \bigl\vert v(x) \bigr\vert \bigl\vert \overline{ \phi (x)} \bigr\vert \bigl\vert \phi (1) \bigr\vert \,\mathrm {d}x \\ &\quad = \int ^{1}_{-1}2q_{-}(x) \bigl\vert \phi (x) \bigr\vert ^{2} \,\mathrm {d}x - \int ^{1}_{-1}2\operatorname {Re}\bigl(v(x)\overline{\phi (x)} \phi (1)\bigr)\,\mathrm {d}x + \int ^{1}_{-1}2 \bigl\vert v(x) \bigr\vert \bigl\vert \overline{\phi (x)} \bigr\vert \bigl\vert \phi (1) \bigr\vert \,\mathrm {d}x \\ &\quad \leq \int ^{1}_{-1}2q_{-}(x) \bigl\vert \phi (x) \bigr\vert ^{2}\,\mathrm {d}x +4 \int ^{1}_{-1} \bigl\vert v(x) \bigr\vert \bigl\vert \overline{\phi (x)} \bigr\vert \bigl\vert \phi (1) \bigr\vert \,\mathrm {d}x \leq 2 \Vert q_{-} \Vert _{1} \Vert \phi \Vert _{\infty }^{2} + 4 \Vert v \Vert _{1} \Vert \phi \Vert _{\infty }^{2}, \end{aligned} $$
which, together with the integration of (4.15), Lemma 4.5 and the Cauchy–Schwarz inequality implies that
$$ \begin{aligned}[b] \frac{\varepsilon }{2} \vert \lambda \vert &\leq \vert \lambda \vert \int ^{1}_{-1} \int ^{1}_{x} w(t) \bigl\vert \phi (t) \bigr\vert ^{2} \,\mathrm {d}t \,\mathrm {d}x \\ & \leq \biggl\vert \int ^{1} _{-1}\phi '(x) \overline{\phi (x)}\,\mathrm {d}x + \int ^{1}_{-1} \int ^{1}_{-1} v(t)\phi (t) \overline{\phi (1)} \,\mathrm {d}t \,\mathrm {d}x \\ & \quad{} + \int ^{1}_{-1} \int ^{1}_{x} \bigl( \bigl\vert \phi '(t) \bigr\vert ^{2}+q(t) \bigl\vert \phi (t) \bigr\vert ^{2} +v(t)\overline{ \phi (t)} \phi (1) \bigr) \,\mathrm {d}t \,\mathrm {d}x \biggr\vert \\ & \leq \bigl\Vert \phi ' \bigr\Vert _{2} +2 \Vert q_{-} \Vert _{1} \Vert \phi \Vert _{\infty }^{2} + 4 \Vert v \Vert _{1} \Vert \phi \Vert _{\infty }^{2} \\ & \leq \sqrt{ N_{q,v}}+ 4 \Vert q_{-} \Vert _{1} N_{q,v} + 8 \Vert v \Vert _{1}N_{q,v}. \end{aligned} $$
So the inequalities in (4.7) can be obtained through (4.19) and (4.18) immediately. □
Multiplying both sides of (4.11) by wϕ̅ and integrating by parts on \([-1,1]\), we have from \(\mathcal{B}\phi =0\)
$$ \begin{aligned}[b] \lambda \int ^{1}_{-1} w^{2} \vert \phi \vert ^{2} &= \int ^{1}_{-1} \bigl(w \bigl\vert \phi ' \bigr\vert ^{2}+ wq \vert \phi \vert ^{2}\bigr) + \int ^{1}_{-1} w'\phi ' \overline{\phi }\\&\quad{} + \int ^{1} _{-1} \bigl(wv \overline{\phi } \phi (1)+ w(1)v \phi \overline{\phi (1)}\bigr). \end{aligned} $$
Separating the imaginary parts of (4.20) implies
$$ \operatorname {Im}\lambda \int ^{1}_{-1} w^{2} \vert \phi \vert ^{2} = \int ^{1}_{-1} \operatorname {Im}\bigl(w'\phi '\overline{\phi }+ wv \overline{\phi } \phi (1)+ w(1)v \phi \overline{\phi (1)} \bigr). $$
It follows from \(w'\in L^{2}[-1,1]\), \(\varLambda =(\int ^{1}_{-1} \vert w' \vert ^{2})^{1/2}\), Lemma 4.5 and the Cauchy–Schwarz inequality that
$$ \biggl\vert \int ^{1}_{-1} w' \phi ' \overline{\phi } \biggr\vert \leq \Vert \phi \Vert _{\infty } \biggl( \int ^{1}_{-1} \bigl\vert w' \bigr\vert ^{2} \biggr)^{1/2} \biggl( \int ^{1}_{-1} \bigl\vert \phi ' \bigr\vert ^{2} \biggr)^{1/2} \leq \varLambda \sqrt{N_{q,v}}. $$
Using \(q, v \in L^{1} [-1,1]\) and Lemma 4.5, one sees that
$$\begin{aligned}& \biggl\vert \int ^{1}_{-1} \bigl(wv \overline{\phi } \phi (1)+ w(1)v \phi \overline{ \phi (1)}\bigr) \biggr\vert \leq 2 \Vert w \Vert _{\infty } \Vert \phi \Vert _{\infty }^{2} \int ^{1}_{-1} \vert v \vert \leq 4 \Vert w \Vert _{\infty } N_{q,v} \Vert v \Vert _{1}, \end{aligned}$$
$$\begin{aligned}& \begin{aligned}[b] \biggl\vert \int ^{1}_{-1} \bigl(w \bigl\vert \phi ' \bigr\vert ^{2} + wq \vert \phi \vert ^{2}\bigr) \biggr\vert &\leq \Vert w \Vert _{\infty } \biggl( \int ^{1}_{-1} \bigl\vert \phi ' \bigr\vert ^{2} + \Vert \phi \Vert _{\infty }^{2} \int ^{1}_{-1} \vert q \vert \biggr) \\&\leq \Vert w \Vert _{\infty }N_{q,v} \bigl(1+2 \Vert q \Vert _{1} \bigr).\end{aligned} \end{aligned}$$
Recall the definition of η in (4.6),
$$ \int ^{1}_{-1} w^{2} \vert \phi \vert ^{2} \geq \eta \biggl( \int ^{1}_{-1} \vert \phi \vert ^{2}- \int _{\widetilde{\varOmega }(\eta )} \vert \phi \vert ^{2} \biggr) \geq \eta \bigl( 1- m(\eta ) \Vert \phi \Vert ^{2}_{\infty } \bigr) \geq \frac{ \eta }{2}, $$
which together with (4.21), (4.22) and (4.23) yields
$$ \vert \operatorname {Im}\lambda \vert \frac{\eta }{2} \leq \vert \operatorname {Im}\lambda \vert \int ^{1} _{-1} w^{2} \vert \phi \vert ^{2}\leq \bigl( 4 \Vert w \Vert _{\infty } \Vert v \Vert _{1} N_{q,v} + \varLambda \sqrt{N_{q,v}} \bigr). $$
The facts (4.20), (4.22), (4.23), (4.24) and (4.25) show
$$ \vert \lambda \vert \frac{\eta }{2} \leq \vert \lambda \vert \int ^{1}_{-1} w^{2} \vert \phi \vert ^{2}\leq \bigl( \Vert w \Vert _{\infty }N_{q,v} \bigl(1+2 \Vert q_{-} \Vert _{1}+4 \Vert v \Vert _{1} \bigr) + \varLambda \sqrt{N_{q,v}} \bigr). $$
As a result, (4.27) and (4.26) yields the inequalities in (4.8). □
Nonlocal boundary value problems have attracted lots of attention for the wide applications in various fields. In this paper, non-real eigenvalues of regular nonlocal indefinite Sturm–Liouville problems are considered. The existence of non-real eigenvalues of an indefinite Sturm–Liouville differential equation is studied. Furthermore, a priori upper bounds of non-real eigenvalues for a class of indefinite differential equation involving nonlocal point interference potential function is obtained. These results are of both theoretical and practical significance.
Albeverio, S., Hryniv, R.O., Nizhnik, L.P.: Inverse spectral problem for nonlocal Sturm–Liouville operators. Inverse Probl. 23, 523–535 (2007)
Albeverio, S., Nizhnik, L.: Schrödinger operators with nonlocal point interactions. J. Math. Anal. Appl. 332, 884–895 (2007)
Atkinson, F.V., Jabon, D.: Indefinite Sturm–Liouville problems. In: Kaper, H.G., Kwong, M.K., Zettle, A. (eds.) Proceedings of the Focused Research Program on Spectral Theory and Boundary Value Problems, Vol. I, pp. 31–45. Argonne National Lab. (1988)
Behrndt, J., Chen, S., Philipp, F., Qi, J.: Estimates on the non-real eigenvalues of regular indefinite Sturm–Liouville problems. Proc. R. Soc. Edinb. A 144, 1113–1126 (2014)
Behrndt, J., Katatbeh, Q., Trunk, C.: Non-real eigenvalues of singular indefinite Sturm–Liouville operators. Proc. Am. Math. Soc. 137, 3797–3806 (2009)
Behrndt, J., Philipp, F., Trunk, C.: Bounds on the non-real spectrum of differential operators with indefinite weights. Math. Ann. 357, 185–213 (2013)
Behrndt, J., Schmitz, P., Trunk, C.: Bounds on the non-real spectrum of a singular indefinite Sturm–Liouville operator on \(\mathbb{R}\). Proc. Appl. Math. Mech. 16, 881–882 (2016)
Behrndt, J., Schmitz, P., Trunk, C.: Spectral bounds for singular indefinite Sturm–Liouville operators with \(L^{1}\)-potentials. Proc. Am. Math. Soc. 146, 3935–3942 (2018)
Behrndt, J., Schmitz, P., Trunk, C.: Spectral bounds for indefinite singular Sturm–Liouville operators with uniformly locally integrable potentials. J. Differ. Equ. 267, 468–493 (2019)
Catchpole, E.A.: A Cauchy problem for an ordinary integro-differential equation. Proc. R. Soc. Edinb. A 72, 39–55 (1974)
C̆urgus, B., Langer, H.: A Krein space approach to symmetric ordinary differential operators with an indefinite weight functions. J. Differ. Equ. 79, 31–61 (1989)
Freitas, P.: A nonlocal Sturm–Liouville eigenvalue problem. Proc. R. Soc. Edinb. A 124, 169–188 (1994)
Haupt, O.: Über eine Methode zum Beweis von Oszillationstheoremen. Math. Ann. 76, 67–104 (1915)
Kikonko, M., Mingarelli, A.B.: Bounds on real and imaginary parts of non-real eigenvalues of a non-definite Sturm–Liouville problem. J. Differ. Equ. 261, 6221–6232 (2016)
Krall, A.M.: The development of general differential and general differential-boundary systems. Rocky Mt. J. Math. 5, 493–542 (1975)
Mingarelli, A.B.: Indefinite Sturm–Liouville problems. Lect. Notes Math. 964, 519–528 (1982)
Mingarelli, A.B.: Volterra–Stieltjes Integral Equations and Generalised Ordinary Differential Expressions. Lecture Notes in Mathematics, vol. 989. Springer, Berlin (1983)
Mingarelli, A.B.: A survey of the regular weighted Sturm–Liouville problem—The non-definite case, arXiv:1106.6013v1 [math.CA]. Jun 29, 2011
Nizhnik, L.P.: Inverse eigenvalue problems for nonlocal Sturm–Liouville operators. Methods Funct. Anal. Topol. 15, 41–47 (2009)
Nizhnik, L.P.: Inverse nonlocal Sturm–Liouville problem. Inverse Probl. 26, 125006 (2010)
Qi, J., Chen, S.: A priori bounds and existence of non-real eigenvalues of indefinite Sturm–Liouville problems. J. Spectr. Theory 255(8), 2291–2301 (2013)
Qi, J., Chen, S.: Nonlocal Sturm–Liouville eigenvalue problems and corresponding extremal problems. (submitted)
Reed, M., Simon, B.: Methods of Modern Mathematical Physics, IV: Analysis of Operators. Elsevier, Singapore (1972)
Richardson, R.G.D.: Theorems of oscillation for two linear differential equations of second order with two parameters. Trans. Am. Math. Soc. 13, 22–34 (1912)
Sun, F., Qi, J.: A priori bounds and existence of non-real eigenvalues for singular indefinite Sturm–Liouville problems with limit-circle type endpoints. Proc. R. Soc. Edinb. A 1–13 (2019)
Sun, F., Qi, J.: The spectral problems of nonlocal indefinite Sturm–Liouville operators. (submitted)
Wentzell, A.D.: On boundary conditions for multidimensional diffusion processes. Theory Probab. Appl. 4, 164–177 (1959)
Xie, B., Qi, J.: Non-real eigenvalues of indefinite Sturm–Liouville problems. J. Differ. Equ. 8(8), 2291–2301 (2013)
Zettl, A.: Sturm–Liouville Theory. Math. Surveys Monogr., vol. 121. Am. Math. Soc., Providence (2005)
The authors thank the referees for his/her comments and detailed suggestions. These have significantly improved the presentation of this paper.
This research was partially supported by National Key R&D Program of China (Grant 2017YFE0104400) and the NSF of China (Grants 11771253).
Department of Mathematics, Shandong University, Weihai, P.R. China
Fu Sun
, Jiangang Qi
& Baochao Liao
School of Mathematical Sciences, Qufu Normal University, Qufu, P.R. China
Kun Li
Search for Fu Sun in:
Search for Kun Li in:
Search for Jiangang Qi in:
Search for Baochao Liao in:
All authors contributed equally to the writing of this paper. The authors read and approved the final manuscript.
Correspondence to Kun Li.
The authors declare that there are no competing interests.
Sun, F., Li, K., Qi, J. et al. Non-real eigenvalues of nonlocal indefinite Sturm–Liouville problems. Bound Value Probl 2019, 176 (2019) doi:10.1186/s13661-019-1288-8
Indefinite Sturm–Liouville problem
Nonlocal potential
Non-real eigenvalue
A priori bounds | CommonCrawl |
Li* , Liang* , Song* , and Xiao*: A Multi-Scale Parallel Convolutional Neural Network Based Intelligent Human Identification Using Face Information
Volume 14, No 6 (2018), pp. 1494 - 1507
Chen Li* , Mengti Liang* , Wei Song* and Ke Xiao*
A Multi-Scale Parallel Convolutional Neural Network Based Intelligent Human Identification Using Face Information
Abstract: Intelligent human identification using face information has been the research hotspot ranging from Internet of Things (IoT) application, intelligent self-service bank, intelligent surveillance to public safety and intelligent access control. Since 2D face images are usually captured from a long distance in an unconstrained environment, to fully exploit this advantage and make human recognition appropriate for wider intelligent applications with higher security and convenience, the key difficulties here include gray scale change caused by illumination variance, occlusion caused by glasses, hair or scarf, self-occlusion and deformation caused by pose or expression variation. To conquer these, many solutions have been proposed. However, most of them only improve recognition performance under one influence factor, which still cannot meet the real face recognition scenario. In this paper we propose a multi-scale parallel convolutional neural network architecture to extract deep robust facial features with high discriminative ability. Abundant experiments are conducted on CMU-PIE, extended FERET and AR database. And the experiment results show that the proposed algorithm exhibits excellent discriminative ability compared with other existing algorithms.
Keywords: Face Recognition , Intelligent Human Identification , MP-CNN , Robust Feature
Biometric based human identification has been widely studied in the field of artificial intelligence and pattern recognition for years. Now ranging from Internet of Things (IoT) application, interactive multi-media [1], self-service bank, intelligent surveillance to public safety, access control and information security, biometric based human identification has been introduced as a key procedure to improve the intelligent degree or strengthen the security of the applications mentioned above.
The most widely used biometric feature for human identification method have been fingerprint recognition nowadays. It has been applied to attendance system, unlock the smart phone and laptop, access control and payment. However, its disadvantages are becoming obvious too. Since fingerprint recognition requires contact with the sensor, it cannot be used to long-distance or none-intrusive applications. Besides, it can be easily invalidated with grimy or wet hand and can be easily cheated by a fake fingerprint film.
Compared with this, human identification based on face images appears to be more convenient, stable and reliable, because face images can be captured from a distance without contact or cooperate of human, and it is not easy to fake. However early face recognition researches usually apply highresolution frontal face images [2,3] database captured under constrained circumstance, which can help achieve high recognition rate but cannot meet the requirement of wider applications. Since 2D face images are usually captured from a long distance in an unconstrained environment [4], face recognition under complex condition has become the new research hotspot. It can help exploit the advantage and make human recognition appropriate for wider applications with higher security and convenience.
The key difficulties here include gray scale change caused by illumination variance, occlusion caused by glasses, hair or scarf, self-occlusion and deformation caused by pose variation. To conquer these, many solutions have been proposed. However, most of them only improve recognition performance under one influence factor, which still cannot meet the real face recognition scenario. In this paper we propose a multi-scale parallel convolutional neural network (MP-CNN) architecture to solve the face recognition problem in complex environment. This paper is organized as follows: Section 2 reviews and discusses the related work. Section 3 describes the novel paralleled CNN architecture proposed in this paper. In Section 4 presents the experimental results on different conditions and the comparison with other state-of-the-art methods to verify the face recognition efficiency of the CNN structure proposed by this paper in the complex environment. And the conclusions are drawn in Section 5.
To combat the illumination variation which exist widely in real scenario face recognition, the most commonly used approaches are preprocessing and normalization techniques such as: traditional gray scale processing methods, the histogram equalization [5], wavelet based image fusion [6], etc. However, these kinds of methods can only solve slightly illumination variation. Other widely used approaches are reflectance model based method, however the modeling and optimizing process are very complex. Researchers try to extract features that are robust to gray scale and appearance change cause by illumination variation. Hence, image filters which are applied on the whole face (holistic) or local face area are discussed. The holistic methods including Principal Component Analysis (PCA) [7], Linear Discriminant Analysis (LDA), and Information Discriminant Analysis (IDA) [7] have been fully explored, which are proven to be non-robust to grays scale change caused by illumination variation. Local features including local binary patterns (LBP) [8], center-symmetric local binary patterns (CSLBP) [9], local directional number pattern (LDN) [10,11], and dense sampling based local binary patterns (DSLBP) [12], show much better [13] discriminative ability and are able to accommodate local variation. However, the performances of local features are usually sensitive to smooth regions, which is an obvious drawback while expressing face images.
For the face recognition with occlusion, sub-space based methods have been widely studied, including dual-kernel based face recognition method [14], two-dimensional fisher discriminant analysis (K2DFDA) [15], etc. Besides, sparse representation-based classification (SRC) has led to the state-ofthe- art performance in occluded face recognition, such as the non-negative sparse representation based general classification algorithm [16] and the occlusion dictionary based method [17]. However, these methods normally need to make certain assumptions and the computational complexity are high. Also, algorithms mentioned above usually concentrated on only one influence factor instead of multiple influence factors which exists in real scenario.
To compensate these disadvantages, researchers try to exact more robust facial features with higher distinguished ability. The rapid progress achieved in deep network especially in CNN provide a novel and feasible approach. CNN is a feedforward deep neural network, which is inspired by the structure of biological neural networks and visual systems. It has shown obvious advantages in image classification and recognition [18-21]. However traditional CNNs cannot achieve satisfied performance in face recognition under complex environment, including illumination variation, pose variation or partial occlusion. Thus, more complex network structures are implemented, including DeepFace [22] proposed by Facebook, VGG [23], DeepId [24], and Google's FaceNet [25,26]. They all achieved stateof- the-art performance. The common characters of these representative CNNs are very deep and sophisticated structure, complex parameter tuning and the dependence on huge scale data sets, which make the computational complexity and the requirement of hardware are both very high.
Hence, in this paper, we propose a MP-CNN to extract deep robust facial features with high discriminative ability as well as much lower computational complex compared with the CNNs mentioned above. And through a multi-scale and parallel structure, deep features in different scale can be extracted and fused for face recognition, which compensate the shortage of traditional single CNN or simple parallel CNNs.
3. Technical Approach
3.1 Architecture
In this section, the proposed MP-CNN architecture will be detailed. CNN is a deep neural network which usually consist of multiple convolution layer to extract the deep features. Besides adding the pooling layer is a feasible way to reduce the dimension of the feature map. Since traditional CNNs cannot meet the requirement of face recognition under complex environment, including illumination variation, pose variation or partial occlusion. Researchers begin to study the more complex and deeper CNN network structure. To express the face image in different scale and abstract the deep and robust features, a parallel convolutional neural network with four different CNNs is proposed. The MP-CNN structure proposed in this paper is shown in the Fig. 1.
As shown above, the proposed MP-CNN is composed by four CNN networks in a cascaded form. The four CNN networks are named as CNN-11×11, CNN-7×7, CNN-5×5, and CNN-3×3 from top to bottom. Each of them separately has three convolutional layers followed with a pooling layer. To fully express the face image, the convolution kernels of these four CNN networks have different kernel scale. The size of the convolution kernels are 11×11, 7×7, 5×5, 3×3 from top to bottom. The output of each CNN's third pooling layer combines into a four-channel image before been feed into the fully connection layer.
The structure of MP-CNN.
3.2 Implementation Details 3.2.1 Multi-core convolution and pooling layers
For the convolutional layer, the network proposed in this paper uses multi-core convolution. Since that only one feature map is not sufficient to fully reflect all the distinguished information of the face image, it is necessary to choose different convolution kernels to acquire multi-scale features of the image, so as to obtain multiple feature maps of the original images. Four different convolution kernel sizes are set for four parallel CNN networks. The size of the convolution kernels are 11×11, 7×7, 5×5, 3×3 from top to bottom. For each individual CNN network, its three convolutional layers remains the same size.
The neuron number in the hidden layer is related to the size of the original image, the size of the convolution kernel, and the step size of the convolution kernel in the image. After the feature maps are obtained by the convolution operation, they can be used as an input to train the classifier.
Average pooling (a) and max pooling (b).
However, the dimension of the feature vector obtained after the convolution operation is still very high, which can easily cause overfitting of the classifier. In order to solve this problem, pooling layer is applied behind each convolution layer. Pooling can be seen as a feature selection procedure, which effectively reduces the feature dimension as well as the network parameters amount. There are usually two pooling strategy including average pooling and max pooling, as shown in Fig. 2.
In this proposed structure, the maximum pooling is applied to each pooling layer, and the size is 2×2 with a stride of one.
3.2.2 Softmax layer
As shown in Fig. 1, after the last pooling layer, all the feature maps are jointed together and fed into the full connection layer, which is followed by the softmax layer. The output of softmax layer is a probability distribution, which makes it more suitable for probabilistic interpretation in classification tasks compared with selecting one maximum value.
The softmax layer in this paper applies the cross entropy loss function, which is defined as follow:
[TeX:] $$L = - \sum _ { k = 1 } ^ { n } \sum _ { i = 1 } ^ { C } t _ { k i } \log \left( p _ { k i } \right)$$
As shown in Eq. (1), log(·) is a logarithmic function, tki can be seen as the target probability distribution, and pki is the output of the estimated label probability distribution.
For a single specific sample, its cross entropy loss can be expressed as follow:
[TeX:] $$l _ { C E } = - \sum _ { i = 1 } ^ { C } t _ { i } \log \left( p _ { i } \right)$$
As shown, ti is the real category label. And pi is the predicted probability of the specific sample belonging to category i, which can be expressed with softmax function, as shown in Eq. (3).
[TeX:] $$p _ { i } = \frac { e ^ { m _ { i } } } { \sum _ { k = 1 } ^ { C } e ^ { m _ { k } } } \quad \forall i \in 1 \ldots \mathrm { C }$$
The objective of training deep network using the constructed loss function is to make the estimated label probability distribution as close as the target probability distribution. Hence, the derivative or gradient of the loss function need to be calculated and passed back to the previous layer during backpropagation. For a single sample, the derivative of the loss function on the input mj can be calculated as follow:
[TeX:] $$\frac { \partial l _ { C E } } { \partial m _ { j } } = - \sum _ { i = 1 } ^ { C } \frac { \partial t _ { i } \log \left( p _ { i } \right) } { \partial m _ { j } } = - \sum _ { i = 1 } ^ { C } t _ { i } \frac { \partial \log \left( p _ { i } \right) } { \partial m _ { j } } = - \sum _ { i = 1 } ^ { C } t _ { i } \frac { 1 } { p _ { i } } \frac { \partial p _ { i } } { \partial m _ { j } }$$
Apparently, [TeX:] $$\frac { \partial p _ { \mathrm { i } } } { \partial m _ { \mathrm { j } } }$$ is the derivative of the softmax function on the input mj. The derivative result are usually discussed under two situation, including:
[TeX:] $$\begin{array} { c } { \text { when } i = j : \frac { \partial p _ { i } } { \partial m _ { j } } = p _ { i } \left( 1 - p _ { j } \right) } \\ { \text { when } i \neq j : \frac { \partial p _ { i } } { \partial m _ { j } } = - p _ { i } p _ { j } } \end{array}$$
Hence, the derivative of the loss function is:
[TeX:] $$\frac { \partial l _ { C E } } { \partial m _ { j } } = p _ { j } - t _ { j }$$
The equation shown above is quite concise to illustrate the idea that when conducting optimization through minimizing the derivative of loss function, the estimated label will be as close as the real category label. Compare with the minimum mean-square error loss function, the cross-entropy loss function used in this paper has a less flat area, so it makes the training process easier to escape from the local minimum point and achieves much better training efficiency.
In this section, extensive experiments are conducted to verify the performance of the proposed method in complex condition, including face recognition under illumination variation, expression variation, pose variation and partial occlusion. Three different databases with multiple interference factors are adopted in this paper. For each dataset, 20% of all images are randomly selected as the test set, while the remaining images are used as training set. A total of 150 epoch of iterative training are performed with a learning rate of 0.0001. To fully verify the effectiveness of our proposed MP-CNN, many comparison experiments are conducted using other algorithms, including the single CNN (1- CNN) as well as simple parallel CNN (4-CNN) which is constructed with four same single CNNs without the multi-scale concept. The traditional single CNN structure is shown in Fig. 3, and 4-CNN structure is shown in Fig. 4. Besides, the proposed method is also compared with the renowned LBP algorithm and the CSLBP algorithm.
1-CNN structure.
4.1 Experiments on CMU-PIE Database
To verify the face recognition performance of the proposed MP-CNN under multi-pose as well as severe illumination variation conditions, the CMU-PIE face database are used for experiment. The CMU-PIE face database includes 40,000 photos from 68 people, in which it contains 13 poses of each person, as well as 43 illumination conditions and 4 expressions. Hence CMU-PIE is the most commonly used database for research on multi-pose face recognition under illumination variation. In this paper we randomly select 68 people with 170 face images per person for experiments. The total number is 11,560 images, during which 2,312 images are used for test and other 9,248 images are applied for training. There is no overlap between the test and training set. Example images of the CMUPIE face database are shown in Fig. 5.
Face recognition are conducted on the CMU-PIE face database using our proposed MP-CNN as well as other four methods including 1-CNN, 4-CNN, LBP, and CS-LBP. The CMC curves of the five methods are shown in Fig. 6.
Image examples of CMU-PIE face database.
Experiment results comparison on CMU-PIE database.
In order to show the contrast more clearly, the RANK1 recognition rate of each algorithm is listed in Table 1.
The RANK1 recognition rates on CMU-PIE face database
Method Accuracy (%)
MP-CNN 96.61±0.9
4-CNN 93.37±0.3
LBP 66.67
CSLBP 90.48
As shown, the recognition rate of the proposed method in this paper reaches 96.61%, while the recognition rate of the 4-CNN and 1-CNN are 93.37% and 91.86% separately. The recognition rate of LBP is 66.67%, and CSLBP is 90.48%. It can be seen that compared with 1-CNN structure, 4-CNN, LBP and CS-LBP, the MP-CNN structure proposed in this paper achieves the best recognition rate on face recognition under sever illumination variation and slight pose and expression variation.
4.2 Experiments on Extended FERET Database
In the second experiment, the FERET face database are applied for face recognition under illumination variation. The original FERET face database include more than 10,000 photos from more than 1,000 people with different expressions, light conditions, postures and ages. 200 subjects are randomly selected for this experiment. To further discuss the robustness of our proposed method on different illuminations, the database is augmented by transforming the overall illumination of the images. The extended data set are consisted of 140 images per person, and the total account is 28,000 images. 22,400 images are randomly selected for training, and 5,600 images are remained for test. There's no overlap between the training set and the test set. Examples of extended FERET database are shown in Fig. 7.
Image examples of the extended FERET face database.
Experiment results comparison on the extended FERET database.
The RANK1 recognition rates on extended FERET face database
As shown, the recognition rate of the proposed method is 95.48%, and the recognition rate of the 4- CNN and 1-CNN are 91.97% and 87.93%. Besides, the recognition rates of LBP and CSLBP are 92.13%, and 91.23% separately. It can be seen that compared with the 1-CNN and 4-CNN, the local feature based algorithms achieve better performance which is different from the first experiment. The main reason is that the database applied in this experiment is augmented by illumination transfer, which don't bring in much new information virtually. That is to say, the main features are still from the original images of the database. So, this can be seen as another kind of small sample problem. The experimental results shown that for this kind of small sample problem, traditional single CNN as well as the simple parallel CNN cannot achieve satisfying performance, even not as good as local feature based algorithms. Compared with the four algorithms, the MP-CNN structure proposed in this paper shows the best performance in the augmented FERET database, which effectively verified the effectiveness of the MP-CNN.
4.3 Experiments on Extended AR Database
In the third experiment, to further verify the performance of our proposed MP-CNN algorithm for face recognition under severe occlusion as well as facial expression, the AR face database are adopted. AR database contains 3,288 images of 116 people, including illumination and expression changes, as well as partial occlusion caused by wearing glasses and beards. We randomly select 100 people for this experiment. The database is extended by randomly adding occlusion blocks. The size of the occlusion block is 10% of the face image. Through this the database is extended to 140 images per person, and a total of 14,000 images. Among them, there are 2,800 test images and 11,200 train images, and no overlap between the training set and the test set. The examples of the extended database are shown in Fig. 9.
The recognition performance of the five methods on expanded AR database are shown in Fig. 10.
Image examples of the extended AR face database.
Experiment results comparison on the extended AR database.
Recognition performance of our proposed algorithm with other four algorithms including single CNN, 4-CNN, LBP as well as CSLBP are compared. The experimental schemes are the same, and the comparison of experimental results are demonstrated in Fig. 10. As shown, for partial occluded face recognition, our proposed method achieves a 99.46% RANK1 recognition rate. The 1-CNN and 4-CNN achieve 98.15% and 98.87% recognition rate, respectively. The recognition rate of LBP is 93.65% while the recognition rate of CSLBP is 97.12%. In order to show it more clearly, the RANK1 preferred recognition rate of each algorithm is listed in Table 3. It can be seen that the proposed MP-CNN shows the best recognition performance for face recognition with partial occlusion as well as facial expression.
The RANK1 recognition rates on the enhanced AR database
With the rapid development of Artificial Intelligence technology, IoT application, intelligent selfservice bank, intelligent surveillance of public safety and access control have been an indispensable part of human daily life. Almost all these applications require intelligent human identification to improve its security and user experience. Among all the biometric features which can be applied to human identification, face image has natural advantages for the above mentioned intelligence application since it can be captured from a long-distance without contact or cooperate of human. However, gaps lying between face recognition in lab condition and in real word are still inevitable. The key difficulties are gray scale change caused by illumination variance, occlusion caused by glasses, hair or scarf, selfocclusion and deformation caused by pose variation. To conquer these, we propose a multi-scale parallel CNN architecture consist of four multi-scale CNN structure, through which deep features in different scale can be extracted and fused for face recognition. The shortage of traditional single CNN or simple parallel CNNs can be compensated through the multi-scale and parallel structure. Abundant experiments are conducted under different complex recognition condition including illumination and slight pose variation, illumination variation and partial occlusion. The comparison results of the proposed method with four existing renowned algorithms show the effectiveness of the proposed MPCNN.
This paper is supported by the National Key R&D Program of China (No. 2017YFB0802300), Research Project of Beijing Municipal Education Commission (No. KM201810009005), the North China University of Technology "YuYou" Talents support Program, the Beijing Young Topnotch Talents Cultivation Program, the Beijing Talents Support Program (Backbone Talent Program), High Innovation Program of Beijing (No. 2015000026833ZK04), NCUT "Science and Technology Innovation Engineering Project."
She received B.S. degrees from University of Science and Technology Beijing in 2001, and received her Ph.D. degree in 2013 from University of Science and Technology Beijing. She is currently an associate professor in North China University of Technology, Beijing, China. Her research interests include image processing, pattern recognition and 3D reconstruction.
Mengti Liang
She received B.S. degree from North China University of Technology in 2017. She is currently a postgraduate student in North China University of Technology. Her current research interests include image processing and pattern recognition.
Wei Song
He received her Ph.D. degree in 2013 from University of Science and Technology Beijing. He is currently a professor in North China University of Technology, Beijing, China. His research interests include data mining and analysis, big data analysis. Chen Li, Mengti Liang, Wei Song, and Ke Xiao
He received B.S. degree from Jilin University in 2002, and received M.S. degree from Nankai University in 2005. He received the Ph.D. degree from Beijing University of Posts and Telecommunications in 2008. He is currently an associate professor at School of Computer Science and North China University of Technology. His main research interests include communication security and pattern recognition.
1 W. Song, G. Sun, S. Fong, K. E. Cho, "A real-time infrared LED detection method for input signal positioning of interactive media," Journal of Convergencearticle ID. 16071002,, vol. 7, 2016.custom:[[[-]]]
2 P. J. Phillips, W. T. Scruggs, A. J. O'Toole, P. J. Flynn, K. W. Bowyer, C. L. Schott, M. Sharpe, "FRVT 2006 and ICE 2006 large-scale experimental results," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 5, pp. 831-846, 2010.doi:[[[10.1109/TPAMI.2009.59]]]
3 P. J. Grother, G. W. Quinn, P. J. Phillips, National Institute of Standards and Technology, NIST Interagency Report No. 7709, 2010.custom:[[[-]]]
4 A. Moeini, K. Faez, H. Moeini, "Unconstrained pose-invariant face recognition by a triplet collaborative dictionary matrix," Pattern Recognition Letters, vol. 68, pp. 83-89, 2015.doi:[[[10.1016/j.patrec.2015.08.012]]]
5 K. Ramirez-Gutierrez, D. Cruz-Perez, J. Olivares-Mercado, M. Nakano-Miyatake, H. Perez-Meana, "A face recognition algorithm using eigenphases and histogram equalization," International Journal of Computers, vol. 5, no. 1, pp. 34-41, 2011.custom:[[[-]]]
6 S. U. Khan, W. Y. Chai, C. S. See, A. Khan, "X-ray image enhancement using a boundary division wiener filter and wavelet-based image fusion approach," Journal of Information Processing Systems, vol. 12, no. 1, pp. 35-45, 2016.doi:[[[10.3745/JIPS.02.0029]]]
7 Z. Nenadic, "Information discriminant analysis: Feature extraction with an information-theoretic objective," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 29, no. 8, pp. 1394-1407, 2007.doi:[[[10.1109/TPAMI.2007.1156]]]
8 L. Lei, D. H. Kim, W. J. Park, S. J. Ko, "Face recognition using LBP eigenfaces," IEICE Transactions on Information and Systems, vol. 97, no. 7, pp. 1930-1932, 2014.doi:[[[10.1587/transinf.E97.D.1930]]]
9 J. Li, Y. Zhao, D. Quan, "The combination of CSLBP and LBP feature for pedestrian detection," in Proceedings of 2013 3rd International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 2013;pp. 543-546. custom:[[[-]]]
10 A. R. Rivera, J. R. Castillo, O. O. Chae, "Local directional number pattern for face analysis: face and expression recognition," IEEE Transactions on Image Processing, vol. 22, no. 5, pp. 1740-1752, 2013.doi:[[[10.1109/TIP.2012.2235848]]]
11 A. R. Rivera, O. Chae, "Spatiotemporal directional number transitional graph for dynamic texture recognition," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 37, no. 10, pp. 2146-2152, 2015.doi:[[[10.1109/TPAMI.2015.2392774]]]
12 J. Ylioinas, A., Hadid, Y. Guo, M. Pietikainen, in Computer Vision-ACCV 2012. Heidelberg: Springer, pp. 375-388, 2012.custom:[[[-]]]
13 C. Shan, S. Gong, P. W. McOwan, "Facial expression recognition based on local binary patterns: a comprehensive study," Image and Vision Computing, vol. 27, no. 6, pp. 803-816, 2009.doi:[[[10.1016/j.imavis.2008.08.005]]]
14 X. Z. Liu, H. W. Ye, "Dual-kernel based 2D linear discriminant analysis for face recognition," Journal of Ambient Intelligence and Humanized Computing, vol. 6, no. 5, pp. 557-562, 2015.doi:[[[10.1007/s12652-014-0230-2]]]
15 X. Z. Liu, P. S. Wang, G. C. Feng, "Kernel-based 2D fisher discriminant analysis with parameter optimization for face recognition," International Journal of Pattern Recognition and Artificial Intelligencearticle no. 1356010,, vol. 27, no. article 1356010, 2013.doi:[[[10.1142/S0218001413560107]]]
16 B. Zhang, Z. Mu, C. Li, H. Zeng, "Robust classification for occluded ear via Gabor scale feature-based non-negative sparse representation," Optical Engineeringarticle no. 061702,, vol. 53, no. article 061702, 2013.doi:[[[10.1117/1.oe.53.6.061702]]]
17 L. Yuan, W. Liu, Y. Li, "Non-negative dictionary based sparse representation classification for ear recognition with occlusion," Neurocomputing, vol. 171, pp. 540-550, 2016.doi:[[[10.1016/j.neucom.2015.06.074]]]
18 D. Ciresan, U. Meier, J. Schmidhuber, "Multi-column deep neural networks for image classification," in Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, 2012;pp. 3642-3649. custom:[[[-]]]
19 P. Sermanet, K. Kavukcuoglu, S. Chintala, Y. LeCun, "Pedestrian detection with unsupervised multi-stage feature learning," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, 2013;pp. 3626-3633. custom:[[[-]]]
20 T. Wang, D. J. Wu, A. Coates, A. Y. Ng, "End-to-end text recognition with convolutional neural networks," in Proceedings of 2012 21st International Conference on Pattern Recognition (ICPR), Tsukuba, Japan, 2012;pp. 3304-3308. custom:[[[-]]]
21 P. Luo, X. Wang, X. Tang, "Hierarchical face parsing via deep learning," in Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, 2012;pp. 2480-2487. custom:[[[-]]]
22 Y. Taigman, M. Yang, M. A. Ranzato, L. Wolf, "DeepFace: closing the gap to human-level performance in face verification," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, 2014;pp. 1701-1708. custom:[[[-]]]
23 O. M. Parkhi, A. Vedaldi, A. Zisserman, "Deep face recognition," in Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 2015;custom:[[[-]]]
24 Y. Sun, D. Liang, X. Wang, and X. Tang, 2015 (Online). Available:, https://arxiv.org/abs/1502.00873
25 F. Schroff, D. Kalenichenko, J. Philbin, "FaceNet: a unified embedding for face recognition and clustering," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, 2015;pp. 815-823. custom:[[[-]]]
26 C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, A. Rabinovich, "Going deeper with convolutions," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, 2015;pp. 1-9. custom:[[[-]]]
Published (Print): December 31 2018
Published (Electronic): December 31 2018
Corresponding Author: Ke Xiao* ([email protected])
Chen Li*, School of Computer Science, North China University of Technology, Beijing, China, [email protected]
Mengti Liang*, School of Computer Science, North China University of Technology, Beijing, China, [email protected]
Wei Song*, School of Computer Science, North China University of Technology, Beijing, China, [email protected]
Ke Xiao*, School of Computer Science, North China University of Technology, Beijing, China, [email protected] | CommonCrawl |
On the duality between interaction responses and mutual positions in flocking and schooling
Andrea Perna1,
Guillaume Grégoire2 &
Richard P Mann3,4
Recent research in animal behaviour has contributed to determine how alignment, turning responses, and changes of speed mediate flocking and schooling interactions in different animal species. Here, we propose a complementary approach to the analysis of flocking phenomena, based on the idea that animals occupy preferential, anysotropic positions with respect to their neighbours, and devote a large amount of their interaction responses to maintaining their mutual positions. We test our approach by deriving the apparent alignment and attraction responses from simulated trajectories of animals moving side by side, or one in front of the other. We show that the anisotropic positioning of individuals, in combination with noise, is sufficient to reproduce several aspects of the movement responses observed in real animal groups. This anisotropy at the level of interactions should be considered explicitly in future models of flocking and schooling. By making a distinction between interaction responses involved in maintaining a preferred flock configuration, and interaction responses directed at changing it, our work provides a frame to discriminate movement interactions that signal directional conflict from interactions underlying consensual group motion.
Several animal species exhibit forms of collective motion in which two or more individuals move together coherently. Examples include flocks of migrating birds, schools of fish, murmurations of starlings, swarms of locusts, and many others. In general, the same group of animals can produce various types of collective patterns, including disordered aggregations, milling, or schooling depending on both internal states (e.g. hunger level) and external conditions (e.g. in response to a predator).
Much of our current understanding of collective motion of animal groups comes to us from the study of theoretical models, and in particular of a class of models known as 'self-propelled particle models'. These models indicate that a small set of 'rules' of interaction is sufficient to generate group level patterns that resemble, at least visually, those formed by real animal groups. For instance, Reynolds [1] proposed a model that implements only three different rules. The first rule consists in a repulsion behaviour, through which each individual turns away from its local neighbours and avoids local crowding and collisions. The second rule is an alignment behaviour, or a turning response towards the average heading of local neighbours. The third rule is a turning response towards the position of more distant neighbours; this is an attraction rule, that contributes to maintain the members of the group together. Several alternative models of collective motion have been proposed (see [2] for a review), each implementing a slightly different set of interaction rules. In spite of their differences, almost all the models existing in the literature are able to produce realistic looking patterns of collective behaviour, at least within a certain range of parameters.
In order to make meaningful predictions about the collective movement patterns of a given animal species, it is important that the interaction rules implemented in the models match those actually used by animals of that particular species. In order to determine how real animals of different species interact together, several research groups have started to collect empirical data on the movement patterns of real animal groups. Traditionally, this has been done either focusing on the collective level, or on the individual level. The collective-level approach consists in collecting data on the spatio-temporal organization of the group, such as e.g. the mutual positions of close neighbours, and testing which theoretical models are compatible with the data; the individual-level approach operates instead by selecting a 'focal individual' within the group, and recording all the changes of speed and direction of movement of that individual in response to the position and movement of its neighbours [3]. Here, we provide a brief review of this literature, with particular emphasis on articles that either measure or predict the mutual positions of close neighbours.
As an example of the collective-level approach, Ballerini et al. [4] tracked the 3D positions of starlings flocking together in natural flocks, with the aim of characterising the spatial organization of the group. These authors observed that nearest neighbours consistently occupy the same positions with respect to each other, determining an anisotropic arrangement at the local scale. The anisotropy did not spread to the scale of the entire flock, but dropped quickly to a completely isotropic distribution between the sixth and the seventh nearest neighbour. The fact that the anisotropy cut-off depended on the number of neighbours, but not on the density of the group, was interpreted as evidence that starlings 'pay attention' to a fixed 'topological' number of six - seven neighbours, instead of responding to all neighbours within a fixed 'metric' distance. The topological nature of interactions in starlings was later confirmed also by an alternative maximum entropy approach, based on the relative alignments of nearest neighbours, instead of their positions [5]. A similar collective level approach was adopted by Lukeman et al. [6]. These authors recorded the positions and orientations of surf scoters sitting on the water surface. The observed arrangements of neighbours around a focal individual were consistent with models implementing repulsion, alignment, and attraction, but also required the existence of a more direct interaction with one single neighbour situated in front. Buhl et al. [7] measured the relative positions of swarming locusts, and observed isotropy in the radial distribution of neighbours around a focal individual. This distribution was compatible with both metric and topological models of interactions, but not with a third class of 'pursuit/escape' models [8] in which individuals try to reach neighbours ahead of and moving away from them, while they escape from other individuals that approach them from behind. Hemelrijk et al. [9] measured how the overall shape (length vs. width) of schools of mullets scales with group size. Their empirical data were consistent with a model in which the oblong shape of some schools, results from individuals slowing down to avoid collisions.
As examples of studies that have adopted the individual-level approach, we can mention Katz et al. [10], who reconstructed the 'force maps' that describe the acceleration and turning of schooling golden shiners, and Herbert-Read et al. [11], who reconstructed the force maps of mosquitofish. These studies indicated that a fundamental component of how fish of both species interact are changes of speed: the fish consistently increased or decreased their speed to catch neighbours that they had respectively in front or behind; but when a neighbour was too close by, the speed responses were reversed, so speed changes also mediated collision avoidance. Both studies found only weak alignment responses, in comparison to attraction and repulsion forces. While both mosquitofish and golden shiners formed aligned groups, this was more a consequence of the fish following each other (and eventually becoming aligned) than an explicit alignment response. More recently, Pettit et al. [12] applied a similar approach to the study of flight interactions in pigeons. The observed flocking responses of pigeons where different from those found in fish: alignment responses were explicit and strong, and collision avoidance was mainly mediated by turning, while speed remained relatively constant. These observations could be interpreted in terms of the different needs and constraints associated with flocking, which are different from those experienced by fish during schooling. Explicit alignment responses, for instance, might be necessary to achieve the high cohesion of pigeon flocks, that can fly without splitting for several kilometers. Avoiding collisions by turning away from the neighbour, instead of slowing down, might respond to a necessity to maintain a relatively constant speed, required to produce a sufficient lift force.
Gautrais et al. [13] used an intermediate approach to build a model of the shoaling behaviour of fish: they first characterized the motion of isolated fish, and progressively added interaction terms to the model through visual observations of how fish interact with obstacles and other fish, using quantitative methods to fit the parameters of these interaction rules to the tracked movements of the fish. The model was then tested at the collective level, by collecting statistics of the alignment and distance of real fish. In spite of its nice data driven formulation and good fit to experimental data, the model introduced by these authors does not formulate predictions about the mutual positions of nearest neighbours, and does not quantify these mutual positions in the empirical data; for these reasons it will not be discussed further in the context of our simulations which insist precisely on these aspects.
While some work has characterised directly the interaction responses of individuals, and other work has derived interaction responses indirectly, by selecting the interaction rules that reproduced better the observed configuration of a group, it is clear that different interaction rules lead naturally to different local configurations of the group. Consider for instance the case of an animal that avoids collisions by changing speed (like mosquitofish or golden shiners). Its acceleration response will be positive when the neighbour is in front and negative when the neighbour is behind, but will invert sign in the repulsion zone. The only region where there is no acceleration response is on the border between attraction and repulsion zone. Similarly, if turning does not mediate collision avoidance, the turning response will be simply directed towards the neighbour, that is, to the left if the neighbour is on the left and to the right if the neighbour is on the right. There are only two 'fixed points', for which both the turning and the acceleration response are zero: one directly in front and the other directly behind the neighbour. Not surprisingly, these positions are those at which both mosquitofish and golden shiners are most likely to have their neighbours [10,11]. Similar arguments can be used to explain that when collision avoidance is mediated through turning away from the neighbour (as in pigeons), a side by side configuration is the one which is stable (this is the configuration that was most frequently observed in pigeons [12]). In other words, different interaction rules lead naturally to different local arrangements of neighbours within the group.
In the present paper, we examine the different implications of this duality between interaction responses and mutual positions in flocks and schools. Unlike in previous studies, where mutual positions result from the interactions, here we consider the theoretical situation of animals maintaining stable mutual positions, and we address the question of what 'apparent' interaction responses would be observed as a mere consequence of the imposed mutual positions and noise.
The movement of a focal individual with respect to a neighbour can be decomposed into an alignment response and an attraction-repulsion response by projecting it onto two different vectors (see Figure 1). Alignment is the component of movement response that has the same bearing as the neighbour. Attraction and repulsion correspond to the projection of focal individual's movement on the vector oriented towards its neighbour's body. In general, these two vectors are not orthogonal, except in very specific situations, such as when the focal individual and the neighbour move side by side in the same direction. In the extreme case when the focal individual and the neighbour are one behind the other, the alignment and the attraction/repulsion vectors coincide.
Illustration of the interactions. The focal fish (in red) aims at keeping a stable target position relative to its neighbour. In (a) this target position is behind the neighbour, while in (b) it is on the side of the neighbour. The movement in the direction of the target can be interpreted in terms of attraction or repulsion response if it has a projection onto the attraction/repulsion vector pointing in the direction of the neighbour. If the movement response has a component along the direction parallel to the neighbour (the alignment vector), it can also be interpreted as alignment. In general, the attraction/repulsion vector and the alignment vector are not orthogonal to each other, and in the particular case of aligned individuals with target positions in front or behind, the attraction and alignment vectors are not even linearly independent.
If the focal individual aims at keeping a fixed 'target position' relative to its neighbour, for instance on its side, or behind it, we can imagine that it will spend most of the time in the proximity of that position, repeatedly moving away from it under the effect of noise, and actively heading back to it. Movements away from the target position, or back to it, can correspond to real animal movements, but can also result from noise associated with recording the position of the focal individual, such as GPS inaccuracy (in case of GPS tracking), or segmentation variability and pixelization (in case of video tracking).
Figure 1-(a) shows a specific example with one individual, in red, having a preference for being directly behind its neighbour (target position marked by a star). A turn in the direction of the target position will be interpreted as an attraction (or repulsion) response; conversely, an alignment response would require to keep a straight direction, but this is not compatible with approaching the target. In Figure 1-(b), the relative positions of the focal individual and of its neighbour are the same, but the focal individual aims at reaching a schooling configuration side by side with its neighbour. The corresponding movement would be described in terms of an alignment response (the focal individual remains parallel to its neighbour), but also of attraction (because in this example reaching the target position involves getting closer to the neighbour). Both examples depict the same type of response (an attraction to the target), but we interpret them in terms of different alignment and attraction responses because we consider the other individual and not the target as the 'point of attraction'.
The actual situation of two individuals moving together in two or three dimensions is more complicated, and involves not only different types of interactions e.g. alignment and/or attraction/repulsion, but also different types of responses, e.g. through turning, or acceleration, or both. In addition, in a real flocking situation individuals are not always aligned with each other and can have different speeds, making it more difficult to predict what interaction rules appear, on average, over a common trajectory. To test what interaction responses might support the movement of particles flocking together at a fixed distance and relative bearing, we simulate particles moving on the same trajectory but subject to small random displacements around these target positions (see Methods). In particular, we focus on two configurations: one in which the two particles fly side by side, and one where the two particles fly one behind the other. Figure 2 illustrates one such generated trajectory for two particles moving side by side.
Example of generated trajectories for two particles moving side by side. (a) Complete trajectory of 212 steps. The larger dots (visible when zooming in the figure) indicate the scale for temporal correlation C T (= 300 steps) used for generating the trajectories. (b) Zoom on a smaller portion of trajectory to illustrate the recorded positions of both individuals. Each dot represents the position at one different time step.
As expected, when the trajectories are arranged in a side-by-side or in a front-back configuration, this same configuration is observed in the positions at which the neighbour is frequently observed (Figure 3-(a) and (d)). When the two trajectories are arranged in a front back configuration, the focal individual appears to turn in the direction of its neighbour with no 'repulsion zone': independently of distance there is no zone in which turnings are directed away from the neighbour (Figure 3-(b)). In this case, repulsion is mediated instead by changes of speed, as it is visible in Figure 3-(c), where acceleration is positive for neighbours situated in front and negative for neighbours situated behind, but there is a region in which the polarity of the acceleration response is inverted, when the front-back distance to the neighbour is smaller than 5 arbitrary units (the target distance between neighbouring particles implemented in the trajectories). These patterns of response are inverted for side by side trajectories: in this case, collision avoidance appears to be mediated through turning (Figure 3-(e)), while changes of speed mediate attraction, but not collision avoidance (Figure 3-(f)).
Inferred interaction rules as a function of distance and direction to the neighbour. In all these plots, the focal individual can be imagined to be situated in the centre of the plot, heading towards the top of the page, and the coordinates of each cell in the polar grid correspond to the position of the neighbour. Top row Individuals moving in a front-back configuration. Bottom row Individuals moving side by side. (a) and (d) Number of counts of the neighbour within each cell of the polar grid. The positions at which the neighbour is most frequently observed match those imposed when generating the trajectories. (b) Turning response. When the individuals move in a front-back configuration, turning always happens in the direction of the neighbour. (c) Acceleration response for individuals moving in a front-back configuration. Close-by neighbours elicit a repulsive response, with an acceleration of the opposite sign. (e) Turning response of individuals moving side by side. Repulsion is mediated through turning away from the neighbour. (f) Acceleration response. For individuals moving side by side, acceleration is always positive when the neighbour is in front and negative when the neighbour is behind.
Our plots are similar to those obtained for real animal species, e.g. by Katz et al. [10] and Herbert-Read et al. [11] for fish moving prevalently in a front-back configuration and by Pettit et al. [12] for pigeons flying side by side. The main difference is that in all studies on real animals, the repulsion zone had a roughly circular form, centered around the focal individual, while in our plots the repulsion zone has the form of a band, parallel or perpendicular to the direction of movement of the focal individual. This difference is likely due to the fact that in our simulations, the underlying trajectories of the two particles are never exchanged for the entire duration of one "flight": one individual has its attractor always on the left side of its partner and the other individual always on the right side (or one individual always in front and the other always behind). Real animals do switch from one to the other side of their neighbour (or from being in front to being behind), which means for instance that an animal situated roughly behind its neighbour (𝜗≃0 in Figure 3-(e)), and aiming at being on its side, will be nearly equally likely to turn left as to turn right, and on average will exhibit no consistent turning response.
Figure 4 plots the turning angle of the focal individual as a function of the direction of the neighbour (with respect to the moving direction of the focal individual) and relative bearing (difference of alignment). The figure is limited to the data points for which the focal individual has its neighbour in the attraction zone, i.e. when the mutual distance between the two individuals is larger than the average distance implemented in the trajectories (The Matlab®; code that we provide as electronic Additional file 1 has an easy to run interface to plot responses to neighbours both in the attraction and in the repulsion zone, including acceleration responses and responses of individuals having different target positions).
Relative effect of 'attraction' and 'alignment'. The figures represent the average turning angle of the focal individual in response to the direction (θ) and relative bearing (ϕ) of the neighbour, limited to situations in which the neighbour is in the attraction zone (at a distance r>5 a.u.). Values of θ close to zero indicate that the neighbour is in front of the focal individual, with positive values indicating that the neighbour is on the right and negative values indicating that the neighbour is on the left of the focal individual. Positive values along the alignment axis ϕ indicate that the neighbour is oriented to the right, with respect to the focal individual, while the two individuals are aligned for values of ϕ close to zero. (a) Condition in which the two particles fly in a front-back configuration. (b) Particles flying side by side; (c) Same condition as (a), but with increased temporal autocorrelation of noise around the target position (C D =100 steps, while it was C D =20 steps in the previous plots). (d) Same as (b), with increased temporal autocorrelation of noise.
When the trajectories are arranged in a front-back configuration (Figure 4-(a)), the focal individual shows a strong turning response to face its neighbor's position, while alignment with the orientation of neighbors is not so much in evidence: the turning response in the figure is modulated along the attraction (θ) axis, but presents almost no modulation along the alignment (ϕ) axis. In the case of trajectories arranged side by side (Figure 4-(b)), the alignment response remains weak (modulation prevalently along the θ axis), but we also observe a collision avoidance response which depends on alignment: when the neighbour is in front and slightly on the left side of the focal individual (θ≃−π/6), this latter turns to the right, and its response is stronger if the neighbour is also oriented to the right, i.e. in a collision course with the focal individual. It is interesting to observe how the attraction and alignment responses are altered when we increase the temporal autocorrelation of noise. A longer temporal autocorrelation of noise means that if, for example, an individual is on the left of the trajectory that it is supposed to follow, it will also remain on the left of the trajectory for longer time before returning back to the target position. Under these conditions, the plots of Figure 4-(c) and (d) show a modulation along the alignment axis (ϕ). In fact, with correlated noise the particles retain their component of movement parallel to the common trajectory, while their attraction to the target position is comparatively weaker.
It is important to notice that the noise term in our simulations can be interpreted in two different non-exclusive ways. It can correspond to a real movement of animals constantly but imperfectly trying to keep a stable mutual position, but it can also correspond to tracking noise affecting the recorded trajectories of animals that do not move with respect to each other. To illustrate this, imagine the situation of two birds i and j sitting on a boat, such that they both move with respect to an external frame of reference, but the coordinates \(\boldsymbol {X}_{\textit {ij}}^{real}(t)\) of bird j in the frame of reference of bird i are fixed \(\boldsymbol {X}_{\textit {ij}}^{real}(t) = \boldsymbol {Const}\). Because of tracking noise, at any given time t we will record a relative position of the second individual with respect to the first \(\boldsymbol {X}_{\textit {ij}}^{rec}(t) = \boldsymbol {X}_{\textit {ij}}^{real} + \boldsymbol {\eta }(t)\), where the recorded position \(\boldsymbol {X}_{\textit {ij}}^{rec}(t)\) depends on the real position \(\boldsymbol {X}_{\textit {ij}}^{real} \), and η(t) is the displacement introduced by noise. If the noise is not correlated in time, the displacement η is expected to disappear at previous and subsequent instants of time: \(\left \langle \boldsymbol {X}_{\textit {ij}}^{rec}(t-1)\right \rangle = \left \langle \boldsymbol {X}_{\textit {ij}}^{rec}(t+1)\right \rangle = \boldsymbol {X}_{\textit {ij}}^{real}\). On average over multiple observations, two animals whose recorded position and distance is \(\boldsymbol {X}_{\textit {ij}}^{real} + \boldsymbol {\eta }(t)\) will revert to the real mutual position \(\boldsymbol {X}_{\textit {ij}}^{real}\) and experience a movement −η(t) at the subsequent time interval. In such extreme case, the observed interaction responses between neighbouring individuals can completely be described by this 'regression to the mean' process, and the amplitude of 'flocking responses' is in direct proportion to the standard deviation of the noise. Temporal correlation in the noise retards this regression to the mean, and appears in the plots as an alignment response, because the autocorrelation preserves the component of movement parallel to the common trajectory of the pair, in spite of the fact that the two individuals are in their reciprocal attraction or repulsion zone, i. e. in spite that \(\left |\boldsymbol {X}_{\textit {ij}}^{rec}(t)\right | \neq \left |\boldsymbol {X}_{\textit {ij}}^{real}\right |\).
A number of recent studies have quantified leadership in collectively moving groups by computing directional correlation delays [14]. Directional correlation delays measure the characteristic delay within which one individual becomes aligned with a group neighbour, and it is assumed to indicate leadership behaviour if one individual consistently anticipates the direction taken by other members of the group. We computed directional correlation delays in our simulated data. When particles move side by side, there is no effect of being on the left or on the right, as we would have expected given the inherent left-right symmetry of the trajectories. When individuals move one behind the other, however, the individual in front appears to change direction first, and to be followed by its partner (see Figure 5). Intuitively we can see that when the common trajectory turns in one direction, the individual in front starts immediately turning in that direction, while the individual behind is projected temporarily to the opposite side of the curve. Increasing the temporal autocorrelation of noise does not change this, but it reduces the variability, because when errors on position are correlated, the estimation of direction of movement becomes more accurate.
Directional correlation delay vs. position in the group. Each boxplot represents the distribution of directional correlation delays τ ∗ over simulated trajectories. The box on the left indicates trajectories in which the focal individual was in front; while the box on the right indicates those where the focal individual was behind. In our convention, positive values of the correlation delay τ ∗ indicate that the focal individual anticipates the changes of direction of its partner. When the individuals fly in a front-back configuration, measures of directional correlation indicate that the individual in front anticipates the turns of its neighbour. Left Individuals flying in a front-back configuration, temporal autocorrelation of the noise is short (C D =20 steps); 120 simulated trajectories. Right Same simulation parameters as for the figure on the left, but with longer temporal autocorrelation of noise (C D =100 steps). Note that in this case the variability is extremely reduced and τ ∗ was equal to ±1 in all but one simulation.
By generating trajectories with three or more individuals at a fixed distance from each other, we can test the apparent responses to multiple neighbours. Even if in our simulations the three individuals do not respond to each other, but simply try each to keep a constant distance and orientation relative to the common trajectory, this does not prevent us from studying how apparent responses to multiple neighbours are combined together. Figure 6 plots the observed turning (top row) and acceleration (bottom row) responses of a focal individual to two neighbours, for the case of three individuals moving in a front-back configuration. For this figure, the focal individual is randomly chosen between the three possible positions in the group (front, centre, back). The plots on the left in Figure 6 report the average responses of the focal individual as a function of the front-back distance of the first and second neighbour; the plots on the right report the turning and acceleration responses that would be predicted by averaging pairwise interactions, that is, if the response of the focal individual resulted from the average of two independent interactions with individual neighbours as those presented in the top row of Figure 3 (for comparison with a similar analysis on real fish interactions see Figure three of [10]). The combined responses to two neighbours are similar to those predicted from averaging pairwise interactions, but present larger modulations. This can be explained by considering that the position of all three individuals is affected by noise (or alternatively, that all three individuals can be randomly displaced by their target position). Hence, when the position of the focal individual appears to be displaced from its target relative to two neighbours, instead of just one, this provides increased evidence that the displacement is to be attributed to the focal individual, and not to the neighbours, and that the focal individual, and not one of the neighbours, is likely to show a compensatory response back to the target at the next time step.
Observed and predicted responses to multiple neighbours. Top row Observed (left) and predicted (right) acceleration response in groups of three individuals. Bottom row Observed (left) and predicted (right) turning responses. Predicted responses are calculated by combining the observed responses in simulations with two individuals (one single neighbour) under the assumption that the combined effect of two neighbours is equal to the average of two independent pairwise responses. White squares in the grids on the left indicate missing values, never occurring in the simulations.
In our analyses, the relative positioning of individuals, either side by side, or in a front-back configuration is sufficient to reproduce observed differences in the mechanisms used for collision avoidance, either by changing speed, or through turning. Anisotropic positioning of individuals with respect to their neighbours has been empirically observed in a number of species of collective moving animals, from fish [9-11,15] to birds [4,6,12] but it is not explicitly included into most self-propelled particle models of flocking and schooling. Some models involve a blind visual angle: a region of the visual field in which the presence of a neighbour does not induce any movement response (e.g. [16,17]), which can be considered as a form of anisotropy. However, these models otherwise consider attraction, alignment and repulsion as depending only on the distance from the neighbour, and not on its direction: interaction responses are organized in concentric regions around the focal individual. Outside animal behaviour, self-propelled particle models with anisotropic interaction zones have been studied in the context of collectively moving bacteria and other elongated or differently shaped particles (see e.g. [18,19]). In these systems, the repulsion zone is determined directly by steric occlusions, and it can lead to group formations organized in bands (smectic phases) [20]. In order to reproduce empirical observations, it seems important that future models of flocking and schooling take explicitly into account the anisotropy of interactions (it is bizarre how the empirical work of Ballerini and collaborators [4], one of the first detailed characterisations of anisotropic distribution of neighbours in flocks, triggered a large scientific debate about the topological - metric nature of interactions, but not about the anisotropy itself).
The interaction responses observed in our study can be interpreted in terms of animals constantly but imperfectly trying to keep an ideal mutual position. In theory, the same responses could also correspond to animals maintaining exactly the same 'real' positions relative to each other, but whose 'recorded' positions are affected by tracking noise. Because tracking noise induces similar apparent responses to real animal interactions, it is important that future studies try to achieve a precise understanding of the characteristics of the tracking noise, not only in terms of the amplitude of noise fluctuations, but also, and perhaps more importantly, of how these fluctuations are correlated in time. Temporal correlations in the noise can be introduced for instance by tracking algorithms that integrate prior expectations about the position of the target, which are relatively common features of GPS and video tracking software, and for this reason they are likely to be prevalent in empirical data sets. Our simulations show that these temporal correlations induce an apparent alignment response, because the autocorrelation preserves the component of movement parallel to the common direction of a group, in spite of the fact that the nearest neighbours are in their reciprocal attraction or repulsion zones.
The flocking interactions observed in our study represent responses around a fixed point. They describe the continuous adjustments that allow a flock or school to maintain a preferred configuration as the group moves. As such, they are not necessarily informative about when and how navigational decisions are taken: we would observe them even in the extreme case in which individuals have perfect agreement about the route to follow. Our simulations do actually imply such an agreement about a common route, in the sense that both particles follow the common trajectory with similar responses and no conflict. We can speculate that precisely in the presence of navigational conflict, the equilibrium of mutual arrangements will be destabilized: interactions with environmental stimuli interfere with neighbour to neighbour interactions and induce individuals to abandon their mutual relative positions and alignment. This is in part captured by common measures of movement leadership such as the directional correlation delay [14], which implicitly assumes that leaders are those individuals that abandon more often their orientation parallel to the neighbour, and followers are those individuals with a higher tendency to restore the aligned group configuration. In our analyses, directional correlation delays correlate with the position in front or on the back of the group. If we do not assume that trajectories are pre-imposed, but result from interactions, the individual that moves in front is also the first to draw the common trajectory, and it is reasonable to impute route decisions to this individual.
One of the open problems in research on collective motion is that of determining how individuals combine interactions with multiple neighbours. Here, we have shown that multiple neighbours can carry additional information about the movement of a focal individual not directly because they take part in the interactions, but indirectly because they reduce our uncertainty about the real position of the focal individual. If an animal group maintains a 'solid-like' configuration, whereby individuals keep a constant position relative to their neighbours most of the time, like in our trajectories, the movement of a focal individual can be predicted in terms of its response to a single nearest neighbour, and including information about additional neighbours reduces uncertainty, but apart from this does not bring additional information. This might explain why information theoretical approaches, like the one adopted in [11] indicated that the movement of a focal individual can be predicted to a large amount by looking at only one nearest neighbour, and including further neighbours only marginally helped to improve the prediction. It had already been noted [21] that interaction responses cannot be correctly inferred if interactions only take place close to steady-state positions, as opposed to transient non steady state positions. We are confident that future studies discriminating between interactions around a stable mutual position and transient interactions in which the mutual positions are abandoned will help to further improve our understanding of more complex patterns of response to multiple neighbours.
We have illustrated the duality between interaction rules and mutual positions in moving animal groups. The duality can be stated as follows: (1) if the interactions among neighbours are anisotropic, this leads to consistent patterns of positioning of an animal relative to its neighbours, and (2) if animals aim at keeping a particular position relative to their neighbours, this can only be achieved through interaction responses with specific anisotropic characteristics.
Our analyses suggest that movement interactions observed and quantified by recent studies on real animal group are largely determined by simple positional adjustments necessary to maintain a preferred local configuration of the group, and point to the necessity of discriminating between these interactions around a stable mutual position, and interactions that correspond to real navigational decisions.
Because tracking noise has analogous effects to interactions around a stable mutual position, it is important that future empirical studies take explicitly into account the effects of noise based on its amplitude and its temporal correlation patterns.
Trajectory generation
We generated random trajectories, each having a length N=212 steps. The trajectories are defined by a sequence of step lengths (speed per time step) and a sequence of turnings intercalated between the steps.
The speed values S are numbers extracted from the distribution
$$ S = S_{0} + s \frac{\epsilon_{1}(t)}{\max \left| \epsilon_{1} \right|} $$
((1))
and the turning angles T are
$$ T = a \frac{\epsilon_{2}(t)}{\max \left| \epsilon_{2} \right|} $$
In these equations, ε 1 and ε 2 represent sequences of temporally correlated random numbers and are generated as follows. We first generate N random numbers uniformly distributed in the interval [−0.5,0.5]. In order to exclude abrupt changes of direction and speed, we apply to both sequences a low-pass temporal frequency filter with equation
$$ \epsilon(t) = \exp \left(- \frac{\omega(t)^{2}}{2\sigma^{2}} \right) $$
where ω are temporal frequencies and σ controls the filter standard deviation. By setting \(\sigma = \frac {N}{C_{T}}\), with a cut-off period for the temporal correlations C T =300 steps we impose that speed and turning fluctuations typically occur over a period of 300 time steps, or longer. In our simulations, we fix arbitrarily S 0=5 and s=0.2 arbitrary units (a.u.) per time step and a=0.02 radians per time step. We further assume that 5 time steps in the trajectory correspond to one second of time. Our results are intended to illustrate qualitative differences in the observed patterns of movement, which remain stable for wide ranges of arbitrary parameters.
The positions of individuals along the trajectory at time t are determined by first drawing the segment that intersects the trajectory at t and having a specific orientation θ relative to the segment of trajectory between t and t+1, and selecting equally spaced points (at distance r=5 a.u. from each other) on this segment. These individual trajectories represent the movement of an hypothetical focal individual and its partner (and in some simulations of a third individual) which successfully keep a constant distance and relative position to each other while moving together.
The 'recorded' positions of the individuals do not match exactly those generated as above, but are displaced in a random direction at every time step, to simulate tracking noise, or an imperfect ability to maintain the desired flocking configuration. These displacements are autocorrelated in time, so that if an individual is for instance on the left of its target position at time t, it is more likely to be on the left of the target position also at time t+1. There is no cross-correlation between the random displacements of the focal individual and those of its neighbour. The random displacements are computed as follows. We first generate series of N random numbers, normally distributed with mean 0 and standard deviation 1, then we apply a low-pass filter analogous to the one used in Equation 3, with cut-off frequency \(\sigma _{d} = \frac {N}{C_{D}}\), where C D is the cut-off correlation period for displacements (the number of time steps after which the displacements become uncorrelated). In our simulations C D =20 steps except when otherwise stated. After the filtering operation, we rescale the numbers to obtain distributions with standard deviation r/2. Two random numbers taken from two such generated series describe the x and y components of the displacement.
The analyses reported in the present manuscript focus on the comparison of two conditions. In the first condition the focal individual has a target position directly in front or behind its neighbour (θ=0). In the second condition, the target position for the focal individual is on the side of its neighbour (θ=π/2). For each condition, we generate 100 random trajectories. The order of individuals along the segment, that is, whether the focal individual is in front or behind its neighbour (respectively left or right when θ=π/2) is constant for the whole length of one trajectory, but changes randomly from one trajectory to the other, with half of the trajectories on average displaying the focal individual on the left and the other half displaying it on the right. The movement responses observed in all trajectories are merged together for the analyses.
At each time step t we measure the instantaneous speed of the focal individual
$$s(t) = \sqrt{\left(x(t) -x(t-1) \right)^{2} + \left(y(t) -y(t-1)\right)^{2}}/dt, $$
where x(t) and y(t) are the x and y coordinates of the focal individual at time t and dt is the duration of a time step. The direction of movement of the focal individual is
$$\psi(t) = \mathrm{atan2}\left(y(t)- y(t-1), x(t)- x(t-1)\right),. $$
The response of the focal individual to its neighbours is described by its tangential acceleration
$$a(t) = \left(s(t) - s(t-1)\right) / dt $$
and its speed of direction change
$$\alpha(t+1) = \left(\psi(t) - \psi(t-1)\right)/dt, $$
where care is taken to compute the correct angular difference, ψ(t)−ψ(t−1), with regard to the periodicity of ψ(t).
The relative position and orientation of a neighbour in the frame of reference of the focal individual are described by their observed mutual distance
$$d_{ij} \left(t \right) = \sqrt{\left(x_{j}(t) -x_{i}(t) \right)^{2} + \left(y_{j}(t) -y_{i}(t)\right)^{2}}, $$
and the direction θ of the neighbour in the frame of reference of the focal fish was
$$\vartheta_{ij}(t) = \mathrm{atan2} \left(y_{j}(t) - y_{i}(t), x_{j}(t)- x_{i}(t) \right) - \alpha_{i} \left(t \right). $$
The directional correlation delay τ ∗ is the time delay τ that maximizes the correlation of direction between the focal individual and its partner
$$ \tau_{ij}^{*} = {\underset{\tau}{\text{arg~max}}} \left\langle \cos \left(\psi_{i}(t) - \psi_{j}(t + \tau) \right) \right\rangle $$
The Matlab®; source code used to generate the trajectories and for all the analyses is available as online Additional file 1.
Reynolds CW: Flocks, herds and schools: A distributed behavioral model. SIGGRAPH Comput Graph1987, 21(4):25–34.
Vicsek T, Zafeiris A: Collective motion. Phys Rep2012, 517:71–140.
Sumpter DJT, Mann RP, Perna A: The modelling cycle for collective animal behaviour. Interface Focus2012. doi:10.1098/rsfs.2012.0031. http://rsfs.royalsocietypublishing.org/content/early/2012/08/09/rsfs.2012.0031.full.pdf+html
Ballerini M, Cabibbo N, Candelier R, Cavagna A, Cisbani E, Giardina I, Lecomte V, Orlandi A, Parisi G, Procaccini A, Viale M, Zdravkovic V: Interaction ruling animal collective behaviour depends on topological rather than metric distance: Evidence from a field study. Proc Nat Acad Sci USA2008, 105(4):1232–1237. arXiv/0709.1916.
Bialek W, Cavagna A, Giardina I, Mora T, Silvestri E, Viale M, Walczak AM: Statistical mechanics for natural flocks of birds. Proc Nat Acad Sci USA2012, 109(13):4786–4791. doi:10.1073/pnas.1118633109. http://www.pnas.org/content/109/13/4786.full.pdf+html
Lukeman R, Li Y-X, Edelstein-Keshet L: Inferring individual rules from collective behavior. Proc Nat Acad Sci USA2010, 107(28):12576–12580. doi:10.1073/pnas.1001763107. http://www.pnas.org/content/107/28/12576.full.pdf+html
Buhl J, Sword GA, Simpson SJ: Using field data to test locust migratory band collective movement models. Interface Focus2012, 2(6):757–763. doi:10.1098/rsfs.2012.0024. http://rsfs.royalsocietypublishing.org/content/2/6/757.full.pdf+html
Romanczuk P, Couzin ID, Schimansky-Geier L: Collective motion due to individual escape and pursuit response. Phys Rev Lett2009, 102:010602. doi:10.1103/PhysRevLett.102.010602.
Hemelrijk CK, Hildenbrandt H, Reinders J, Stamhuis EJ: Emergence of oblong school shape: Models and empirical data of fish. Ethology2010, 116(11):1099–1112. doi:10.1111/j.1439-0310.2010.01818.x.
Katz Y, Tunstrøm K, Ioannou CC, Huepe C, Couzin ID: Inferring the structure and dynamics of interactions in schooling fish. Proc Nat Acad Sci USA2011, 108(46):18720–18725. doi:10.1073/pnas.1107583108.
Herbert-Read JE, Perna A, Mann RP, Schaerf TM, Sumpter DJT, Ward AJW: Inferring the rules of interaction of shoaling fish. Proc Nat Acad Sci USA2011, 108(46):18726–18731. doi:10.1073/pnas.1109355108.
Pettit B, Perna A, Biro D, Sumpter DJT: Interaction rules underlying group decisions in homing pigeons. J R Soc Interface2013, 10(89). doi:10.1098/rsif.2013.0529. http://rsif.royalsocietypublishing.org/content/10/89/20130529.full.pdf+html
Gautrais J, Ginelli F, Fournier R, Blanco S, Soria M, Chaté HH, Theraulaz G: Deciphering interactions in moving animal groups. PLoS Comput Biol2012, 8(9):1002678. doi:10.1371/journal.pcbi.1002678.
Nagy M, Akos Z, Biro D, Vicsek T: Hierarchical group dynamics in pigeon flocks. Nature2010, 464(7290):890–893. doi:10.1038/nature08891.
Partridge BL, Pitcher T, Cullen JM, Wilson J: The three-dimensional structure of fish schools. Behav Ecol Sociobiol1980, 6(4):277–288. 10.1007/BF00292770.
Couzin ID, Krause J, James R, Ruxton GD, Franks NR: Collective memory and spatial sorting in animal groups. J Theor Biol2002, 218(1):1–11.
Strombom D: Collective motion from local attraction. J Theor Biol2011, 283(1):145–151. doi:10.1016/j.jtbi.2011.05.019.
Peruani F, Deutsch A, Bär M: Nonequilibrium clustering of self-propelled rods. Phys Rev E2006, 74:030904. doi:10.1103/PhysRevE.74.030904.
Wensink HH, Kantsler V, Goldstein RE, Dunkel J: Controlling active self-assembly through broken particle-shape symmetry. Phys Rev E2014, 89:010302. doi:10.1103/PhysRevE.89.010302.
Wensink HH, Löwen H: Emergent states in dense systems of active rods: from swarming to turbulence. J Phys Condens Matter2012, 24(46):464130.
Mann RP: Bayesian inference for identifying interaction rules in moving animal groups. PLoS One2011, 6(8):22827. doi:10.1371/journal.pone.0022827.
This work was supported by European Union Information and Communication Technologies project ASSISI bf 601074. AP was supported by the city of Paris (Research in Paris programme) and the Ile de France region (grant 01RA140024-RIDF-PERNA). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Paris Interdisciplinary Energy Research Institute, Paris Diderot University, 10 rue Alice Domon et Léonie Duquet, Paris, 75013, France
Andrea Perna
Laboratoire Matiere Systemes Complexes, Paris Diderot University, 10 rue Alice Domon et Léonie Duquet, Paris, 75013, France
Guillaume Grégoire
Mathematics Department, Uppsala University, Lägerhyddsvägen 1, Uppsala, 75754, Sweden
Richard P Mann
Chair of Sociology, in particular of Modeling and Simulations, ETH Zürich, Clausiusstrasse 50, Zürich, 8092, Switzerland
Correspondence to Andrea Perna.
AP and RPM designed the research. AP performed the research. GG contributed ideas and tools for the analyses. AP wrote the paper. All authors read and approved the final manuscript.
Compressed folder containing all the Matlab®; script files required to repeat the analyses reported in this paper.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly credited. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
Perna, A., Grégoire, G. & Mann, R.P. On the duality between interaction responses and mutual positions in flocking and schooling. Mov Ecol 2, 22 (2014). https://doi.org/10.1186/s40462-014-0022-5
Collective motion
Movement analysis | CommonCrawl |
Volume Of An Ellipsoid Formula
An ellipsoid is a closed quadric surface that is a three-dimensional analogue of an ellipse. The standard equation of an ellipsoid centered at the origin of a Cartesian coordinate system. The spectral theorem can again be used to obtain a standard equation akin to the one given above.
The formula of Ellipsoid is given below:
\[\large V=\frac{4}{3}\pi\,a\,b\,c\]
or the formula can also be written as:
\[\large V=\frac{4}{3}\pi\,r1\,r2\,r3\]
r1= radius of the ellipsoid 1
Volume of an Ellipsoid Formula solved examples
Example: The ellipsoid whose radii are given as a = 9 cm, b = 6 cm and v = 3 cm.
Find the volume of ellipsoid.
Radius (a) = 9 cm
Radius (b) = 6 cm
Radius (c) = 3 cm
Using the formula: $V=\frac{4}{3}\pi\,a\,b\,c$
$V=\frac{4}{3}\times\pi\times9\times6\times3$
$V=678.24\,cm^{3}$
Loam soil contains equal amounts of
clay, humus, air and water
Exponential Function Formula Universal Gravitation Formula
Partial Derivative Formula Aluminium Hydroxide Formula
Angle Formula Circumradius Of A Triangle Formula
Formula To Find Ratio Side Angle Side Formula
Formula For Vertex Cylinder Formula
Taj mahal is badly affected by acid rain. This is because-
Taj mahal is made of marble
Acid rain attacks the steel structure of Taj mahal
Acid rain has a pH above 5.6
The paint on Taj mahal is soluble in acids. | CommonCrawl |
Free fft software
genFFT is the FFT code generator which produces 1D FFT kernels for various FFT lengths power of two, data types (cl_float and cl_half) and GPU architectural details. White, pink noise. MAnalyzer is an FFT based audio frequency analyzer. View Fft PPTs online, safely and virus-free! Many are downloadable. 1 and 1. All file types, file format descriptions, and software programs listed on this page have been individually researched and verified by the FileInfo team. It features parametric windows, peak interpolation, rich Shareware software for FFT,spectral analysis, signal processing,time fft,real time, voice 3D signal filter for a free selection of filter time, frequency and amplitude ScopeDSP: FFT spectral analysis software. Note that all wavelength values are in nm and all time is in fs. Integration – Our CAMS software provides seamless connectivity to third party systems and equipment. If you have a background in complex mathematics, you can read between the lines to understand the true nature of the algorithm. APx515 two-channel audio analyzer for production test and entry-level R&D applications. As the FFT operates on inputs that contain an integer power of two number of samples, the input data length will be augmented by zero padding the real and imaginary data samples to satisfy this condition were this not to hold. inside the application itself) allows you to browse through a list of free groups for downloading, created by none other It was also mentioned that this can be achieved by using software (Matlab) not have the time domain option, I am looking into this software method. Open source hardware and software tools are very accessible this days, and a simple, inexpensive and open source FFT spectrum analyzer can be easily built using some of this tools. You can run FFT on all modern Windows OS operating systems. It would be of great help for anyone who ever encoun domain then this is converted into frequency domain by using FFT analyzer. The single-sided, single-direction interferogram from Figure 1 will be used because it is a bit more complicated than the double-sided case. 2. Acquire data, record data to disk, plot and display readings, read a recorded data file, and export data to third-party applications. Kiss FFT v. If you apply FFT to a noise-free sinusoidal signal you will get only a single The spectrum analyzer in PicoScope is of the Fast Fourier Transform (FFT) type which, unlike a traditional swept spectrum analyzer, can display the spectrum of 20 Apr 2018 Most measurement and automation development software ship with ready-to-use the Fast Fourier Transform (FFT), to calculate the frequency-domain . It performs a FFT (fast fourier transform) BEAST for Linux v. For example, you can resample 204. Computer Software. It features dual-FFT based measurement which will help you to optimize your sound – system. The tool is also very powerful and comes with some very powerful tools that is the FFT plus the more advanced TFFT. Applications. but it is the fate of operating systems to become free" - Neal 2260 Investigator - FFT Software; 2260 Investigator - FFT Software Enhancements: Minor corrections. 2D / 3D technical graphics plotting and data analysis software for your plotting needs. You're likely . The update, maintenance and support of the program are free. About Free Field Technologies (FFT), an MSC Software Company . This kind of filter uses a Fast Fourier Transform algorithm which is used for a variety of applications including signal and image processing. Spek is free software available for Unix, Windows and Mac OS X. FFT Analyzer. If you have any questions feel free to ask them in the comments section below. Phone: +32 10 45 12 26. Keywords –fault detection, vibration signal ,sideband, gear mesh frequency I. Here, we answer Frequently Asked Questions (FAQs) about the FFT. Mark Borgerding, FFT module. Generally, these files are considered Plugin Files, but they can also be Text Files or Data Files. Is there a new version of FFT for a 64 bit CS6. wav file. or A-weighted Compare spectrum to stored reference PC software for analysis, reporting and archiving (not included in BZ7208) FFT Analysis on 2260 Investigator Fast Fourier Transform (FFT) is a standard feature of advanced vibration analyzers and is also found in many simple vibration meters. First, define some parameters. 20 Hz and even lower are displayed on the FFT analyzer much quicker than the It involves Linear Algebra library, Fast Fourier Transforms (FFT), Vector Math and Statistics functions, and so on. 00 Hide Megabytes of files and prevent them from being seen or… U-Wipe 2. I am learning about analyzing images with the method of FFT(Fast Fourier Transform). IIS-based web A fast Fourier transform (FFT) is an algorithm that computes the discrete Fourier transform (DFT) From Wikipedia, the free encyclopedia The FFT is used in digital recording, sampling, additive synthesis and pitch correction software. FFT maintains offices in Toulouse, Tokyo, Beijing, Bangalore and Detroit. Ajustar los Bidule: The new standard in modular audio software Transform audio in the spectral domain, with Bidule's FFT modules. graphically, free adjustable, up to 100 points: Markers (roller bearing, only VM-FFT 3D+) Inner race, outer race, cage, ball, WK ring contact, side bands, harmonics (integrated database of > 20000 bearings: Detailed description (online help) Data sheet (400 kB) Quick start guide (600 kB) Once you scratch the surface there are powerful audio engineering tools available for the more advance user. 3. The FFT analyzer in Dewesoft has it all: top performance, advanced cursor Free marker - shows us the frequency of the peak at which it stands and its 9 Sep 2009 FFT Properties - Real time spectrum-network analyzer with with multi-channel support. Other than that restriction, you may use this code as you see fit. This section describes the general operation of the FFT, but skirts a key issue: the use of complex numbers. When you input a signal, it lets you view its signal spectrum, measure frequency, plot Lissajous patterns, view FFT spectrum, save signal data, and more. ru): is a set of Real-Time Multi-Channel Gauges for investigation of data accepted from any ADC you will want or 16-, 24- and 32-bit ADC of sound card. There's also a tutorial on writing your own libraries. Sometimes, you need to look for patterns in data in a manner that you might not have initially considered. I was looking for a FFT implementation in C. Learn how to measure signals, data processing and how to use Dewesoft products. FFTW is free for non-commercial or free-software applications under the terms of the GNU General Public License. fft suffix is and how to open it. The ARTA software is not patented, and does not contain technology constrained by existing patents. In this article, how to perform FFT with Intel® MKL and OpenCV on an image will be introduced. 0. 35244. These are (i) Dataq's free `waveform browser' and (ii) QuickBasic or Excel to simulate waveforms for analysis by the browser. First we will look at the BASIC routine in Table 12-4. For more information, visit www. Download Fft Spectrum Analysis Software Advertisement OscilloMeter v. It uses the Fast Fourier Transform to analyze incoming audio, and displays a very detailed graph of amplitude vs. Measuring of dynamic figures: SNR, THD, SFDR Overview The quality and accuracy of a high-speed A/D or D/A instrument depends on a number of different components. The FFT image displays the absolute value (or complex magnitude) of the spatial frequencies found in the image. MikeyP (Aerospace) 25 Aug 05 04:33 The hearts of many freeware and opensource packages like those mentioned above are built on freely available libraries of numerical functions that have been around literally for decades. Software piracy is theft, Using crack, password, serial numbers, registration codes, key generators, cd key, hacks is illegal and prevent future development of FFT v. An image is made of of RGB (and alpha transparency) pixels, these pixels are FFT'ed in turn to produce a colour 2D FFT. 5% for 64k and 93. All the data processing and The Fast Fourier Transform (FFT) is a specific implementation of the Fourier transform, that drastically reduces the cost of implementing the Fourier transform Prior to the invention of the FFT, a Discrete Fourier transform could only be calculated the hard way with N^2 multiplication operations per transform of N points. Welcome to Pioneer Click here to download a FREE 30 day trial PAS is SATEC's comprehensive analysis and engineering software Directional Harmonics. MAnalyzer allows lots of functions including comparisons, magnitude normalization, averaging and smoothing. Photoshop: FFT-based pattern remover (Filter/Brush/Tool) Here is a standalone software that does FFT for modern Macs; but I cannot find a tutorial on how to apply Download latest releases of Dewesoft X software, Dewesoft X add-ons, firmware and drivers for Dewesoft data acquisition devices, technical reference manuals, user guides and brochures. Complex Transforms. It is free/open-source software and its code is available on GitHub under the LGPL3 . FFT, PSD and spectrograms don't need to be so complicated. fft (x) fft (x, n) fft (x, n, dim) Compute the discrete Fourier transform of x using a Fast Fourier Transform (FFT) algorithm. FFT is a high-resolution audio analysis tool for the iPhone and iPod touch. WavePad FFT Sound Analyzer software has emerged as the most preferred tool for the year, and this can be heavily attributed to its rich properties. multimonNG (Windows/Mac/Linux) (Free) - Ham digital mode decoder Simulation software to integrate concept development, design, testing and production. Optionally, you can download user manuals in Adobe *. fs. The new release provides superior performance in acoustic, vibro-acoustic and aero-acoustic simulations that will help engineers all over the world address their noise related design challenges faster. This program started as a simple FFT program running under DOS a long time ago, but it is now a specialized audio analyzer, filter, frequency converter, hum filter, data logger etc (see history). TSpectrum3D Developer Tools - Components & Libraries, Freeware, $0. The components allow zooming MAnalyzer is an FFT based audio frequency analyzer. Notice that 'free and open-source' requires that the source code is available. 0 text, nor does it have the FFT or zoom features of the 4. You can find an FFT based Power Spectral Density (PSD) Estimator here. check WSxM software. Fast Fourier Transform (FFT) provides the basis of many scientific algorithms. 2 Oct 2018 FFTs are an important part of any digital spectrum analyzer. Airspy is a line of Popular Software-Defined Radio (SDR) receivers developed to achieve High Performance and Affordable Price using innovative combinations of DSP and RF techniques. The software license of RAL costs just US$24, but RAL is more functional than the usual FFT analyzer. The download version of FFT Properties is 6. laser diffraction patterns). of the band-pass filters and the better frequency resolution of the FFT at the same time. The library includes: Scope - scientific chart component for plotting multi-channel data. It is a hardware implementation of the free software Kiss Fft ('Keep it simple, Stupid!')bel_fft is a Fft co-processor that can calculate FFTs with arbitrary radix. MAnalyzer allows lots of functions including comparisons, Description Download Purchase Key Functions: Design and evaluate a Fast Fourier Transform algorithm; Integrate with any of the standard Window Functions Hi everyone, I'm opening this topic to share a piece of PC software I wrote recently: an FFT tracer. 129 A Fast Fourier Transform based up on the principle, "Keep It The fast Fourier transform (FFT) is a versatile tool for digital signal processing (DSP) algorithms and applications. be. For more information about an FFT library callback class, see coder. ITI Cbema Curve. (The DSSF3 is our best sound measurement/analysis software and has been frequently updated. If you want a free solution, you might want to look at the software for the . For this project, an Arduino Nano is used as the data acquisition system, it contains an USB to serial converter and ADC channels. FreeMat is a free environment for rapid engineering and scientific prototyping and data processing. 1. Micro-Cap is now free. Our goal is to help you understand what a file with a *. the built in Arduino nano you first of all have to download both the FastLED and the FFT library. 3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. For images, the FFT filter can be used to remove periodic noise (such as patterns). 3, FFT analyzer: number of lines 10000, The free CESVA Lab software allows you to retrieve the measurement data storage 10 Aug 2017 Then we'll show you one way to implement FFT on an Arduino. Mixed radix-2/3/4/5 complex FFT/IFFT of single precision floating point data. e. Download Kiss FFT for free. Every 60 Overview: A versatile graphical EQ with a wide range of zero latency analogue modelled filters and realtime FFT display. Its primary application is the live – sound situation, but it will support you in other audio measurement tasks as well. The RTL-SDR is an ultra cheap software defined radio based on DVB-T TV tuners with RTL2832U chips. StandaloneFFTW3Interface. 30. Logger Pro 3 includes a site license for your entire school or college department. By using Log in or sign up for your Free for Teacher account on Canvas LMS. Once you understand the basics they can really help with your vibration analysis. See these instructions for details on installing libraries. It refers to a very efficient algorithm for computingtheDFT • The time taken to evaluate a DFT on a computer depends principally on the number of multiplications involved. 0 Pitch measuring accuracy much higher then usual software tuners based on fast Fourier transform (FFT). But the amplifier, board layout, clock source and the power supply also have an influence on the quality of the complete system. 8. Description For this project, an Arduino Nano is used as the data acquisition system, it contains an USB to serial converter and ADC channels. EasyRTA has fixed sample rate to 48000 samples per second, and fixed 8192 FFT number of points. What is Audio Analyzer Software? Winscope is a free oscilloscope software that can be used to analyze any signal on your computer. About MSC Software. It may interest ham radio enthusiasts, hardware hackers, tinkerers and anyone interested in RF. 0 software. 4136 full version from the publisher using pad file and submit from users. FFT uses a multivariate complex Fourier transform, computed in place with a mixed-radix Fast Fourier Transform algorithm. 4. A huge collection of Spectrum Analyzers, Free software - freeware, These programs have a range of functions including Fast Fourier Transforms (FFT), Real SpectrumAnalyzer is a state-of-the-art spectrum analyzer plugin, which offers a lot of SpectrumAnalyzer comes in two editions, a free and a full version. Python is an impressive free alternative to MATLAB; Python's SciPy FFT function is inferior to MATLAB's, especially when dealing with data sets that have a length not equal to a power of 2 Forget about even trying to compute a FFT on an array that has a length equal to a prime number in SciPy or Numpy I'm looking for an affordable software package that does FFTs and will interface directly to a sound card or . 2. Here is an example from the program fft/test_trap , which contains the gdb test_trap GDB is free software and you are welcome to distribute copies of it under Sante FFT Imaging, the processor that removes pattern noise from DICOM images. Real Time FFT Spectrum Analyzer Make sure to checkout the wide variety of sounds (WAV files) available here FREE !! Get up and running Now, FREE ! The powerful analysis software - flexible and free of charge. 7. It appears to be capable of Transfer Function, Impulse Response and Correlation measurement in addition to FFT Spectrum analysis. 0 and 3. Therefore the latency time (period which is needed to collect a packet of FFT points) is 171 ms, providing measurment from 6 Hz to 24 kHz. 3 =2/1024*IMABS(E2) Drag this down to copy the formula to D1025 . It is open-source, supporting Free Online Training. Video, audio and picture conversion software ✓ Free ✓ Updated ✓ Download now. A. This tutorial is patterned after the excellent Pictorial Essay starting on page 108 in Reference 2. To generate the spectrogram: I divided the real sinusoidal signal into B blocks Applied Hanning window on each A filter that automatically removes/reduces repeating patterns like raster patterns or paper texture. 6. Thus if x is a matrix, fft (x) computes the FFT for each column of x. 19. Using this software, you can easily check out audio input and output devices connected to your system. A wide range of FFT Spectrum Analyzer design variants (portable, industrial, underwater etc. APx515 makes all key audio measurements in less than three seconds The Berkeley Advanced Reconstruction Toolbox (BART) is a free and signal processing functions, including convolution, FFT, NUFFT, wavelet transform, and 11 Oct 2016 This program is free software; you can redistribute it and/or modify it under This will put the SDR device into receive mode and starts the FFT 30 Nov 2017 In return for using our software for free, we request you play fair and do your If I pass local arrays (defined in that task) as fft input and output Download free burning software or try commercial burning software for 10 days. 9. Software Compatibility Guide for the 333D01 With our goal to make your vibration measurement experience as simple as possible, we've compiled a list of software to streamline taking data. It is also often the best mode for testing distortion, frequency response and stability of amplifiers, filters and oscillators. If you require these features, please use USB Oscilloscope Software v4. Shareware Junction periodically updates pricing and software information of FFT v. Use in conjunction with a general purpose SDR receiver and pipe the audio output to Fldigi. DFT needs N2 multiplications. I installed one on 3-07-2018 and it worked great on the photo at that time. fft Free Downloads. Free Fft Equalizer Shareware and Freeware. It is an integrated application software for the GL series, the GL900, GL840, data in the free running - displaying data without saving - and data in saved file. fft vista freeware, shareware, software download - Best Free Vista Downloads - Free Vista software download - freeware, shareware and trialware downloads. General Manager at FFT France. The degree of overlap is 50% for 16k, 75% for 32k, 87. Free for non-commercial use. The example used is the Fourier transform of a Gaussian optical pulse. ) and PC-connection interfaces allow to use the FFT spectrum analyzer in various systems, such as stationary, mobile, standalone, industrial, distributed and dynamic; the FFT Spectrum Analyzers show unmatched reliability in various environments and have Welcome to the home page of ARTA software - a collection of programs for audio measurements and analysis in acoustical and communication systems. 75% for 128k. >What do you mean by "FFT"? The software described sounds like data >acquisition software for a sound card, which has nothing to do with the >Fast Fourier Transform (which is what FFT means to me). However, I am not looking for a huge library (like FFTW) but for a easy to use single C-file implementation. 7 U-Wipe is an easy-to-use privacy tool that allows you to… Logbook Pro 1. It involves Linear Algebra library, Fast Fourier Transforms (FFT), Vector Math and Statistics functions, and so on. ne10_fft_destroy_c2c_float32(cfg); // Free the allocated configuration structure . 39. 0 Read and Tutorial 7: Fast Fourier Transforms in Mathematica BRW 8/01/07 Off@General::spellD; This tutorial demonstrates how to perform a fast Fourier transform in Mathematica. Elecard Video Format Analyzer is a handy tool designed for extraction and viewing of metadata contained in media files, making it possible to get highly detailed information on the analyzed file, such as the length, size, actual creation date and much more. The image I am analyzing is attached below: Portrait of woman posing on grass, by George Marks. For the most part it was derived from Voxengo GlissEQ dynamic parametric equalizer and reproduces its spectrum analysis functionality. com wrote: >> A free of charge FFT software for all Sound Cards are available on the >> following web site: Elecard Video Format Analyzer 1. The most important of these is the converter itself. Dual Channel FFT by Christian Budde (@KVRAudio Product Listing): Dual Channel FFT is a program that Dual Channel FFT is free for non-commercial use. Phyllis Smith. Logger Pro 3 updates are free. Online PRO training is Advanced FFT Spectrum Analyzer is a real-time ( RTA ) powerful audio tool to visualize and analyze signals from android device microphone in frequency domain. FFT is a software product developed by Patrice Zwenger and it is listed in File category under File Managers. I've seen Smaart in use before, but I wouldn't ever use its impulse response tools, or am I willing to pay the $800+ that it costs. I'm looking for an affordable software package that does FFTs and will interface directly to a sound card or . Real Time Analyzer (1/3 and 1/1 octave); FFT analyzer (detailed frequency analysis software applications; More functionality will be added through free future Para obtener más información visite la página web de la Free Software Alterar las frecuencias con la ecualización, filtros FFT y amplificar los bajos. Let them take it home! No need to count computers to satisfy licensing. If you use GIMPS source code to find Mersenne primes, you must agree to adhere to the GIMPS free software license agreement. It has been inspired by CPU-z, Orthos, Prime95, wPrime, OCCT and others, and uses the CPU features unit. FFT is a free software product and it is fully functional for an unlimited time although there may be other versions of this software product. The spectrum analyzer in PicoScope is of the Fast Fourier Transform (FFT) type which, unlike a traditional swept spectrum analyzer, has the ability to display the spectrum of a single, non-repeating waveform. There are many more-readable FFT algorithms available on the web and in Spectrum Analyzer with Waterfall Display and real-time audio processing. Get new version of FormatFactory. Reuse of analyses. Preliminary Requirements What Is FFT and How Can You Implement It on an Arduino? If you apply FFT to a noise-free sinusoidal signal you will get only a single Software Tutorials 2. The desired sample rate does not need to be an integer multiple. Powerspectrum (FFT); ECG Heart Rate detection (raw ECG waveform This is free software, it is experimental and available under the GPL License version 3. GNU is an operating system that is free software—that is, it respects users' freedom. Tables 12-3 and 12-4 show two different FFT programs, one in FORTRAN and one in BASIC. Visual Analyser runs on Windows 9x,ME,2k,XP,NT,Server,Vista,7,8/10. FFT. 7Hz! (FFT size: from 512 to 16384 bins) - 44100 hertz (Hz) and 48000 hertz(Hz) sampling frequencies - peak finding Sanitize the free space on any magnetic drive, zip drives… Hide Files 1. exe are the most common filenames for this program's FFT is a software product developed by Patrice Zwenger and it is listed in File category under File Managers. These features, plus a highly refined graphical user interface, make ScopeDSP the premier spectral analysis software tool for use by professionals working in Digital Signal Processing. It uses FFT-accelerated convolution to do the analysis, which enables much greater flexiblity than using the traditional FFT-of-windowed-data approach. Free Webinar: How to choose between analog hardware and digital The Spectrum Analyzer Demo showcases a real-time frequency domain chart WPF Chart Realtime FFT Spectrum Analyzer - View and Export Source Code 13 Feb 2019 National Instruments Sound and Vibration Software provides a complete software Time waveform, octave spectra, FFT spectra graphs, X, X. Depending on what you need to do, though, it might be enough. fft downloads in Other software - free software downloads - best software, shareware, demo and trialware Audio Realtime Analyzer for Windows platform using FFT and MLS WinAudioMls: Audio Realtime Analyzer for Windows platform using FFT and MLS WinAudioMLS is a professional Windows application for powerful real-time signal and system analysis. Preliminary Requirements SPAN is a free real-time "fast Fourier transform" audio spectrum analyzer AAX, AudioUnit and VST plugin for professional sound and music production applications. Link Synopsis ScopeFIR FIR filter design software for Windows TFilter A web application for designing linear-phase FIR filters ScopeIIR IIR filter design tool for Windows Digital Signal Processing Tutorial Java applets for digital filter design Hi, I am looking for links to basic, simple, dumb, easy-to-use and set up, usable with internal soundcard, FFT SOFTWARE!! All I need to do is to look at the SIGNAL sent from a line level device to see if it is FLAT (and not all that closely) across 20-20khz. 39 Eight-channel Audio Spectrum Analyzer is a set of Real-Time Multi-Channel Gauges for investigation of data accepted from any ADC you will want or 16-, 24- and 32-bit ADC of sound card. 1 MB Home. A number of libraries come installed with the IDE, but you can also download or create your own. 0 Released; 2011-08-17: Download this professional FFT audio analysis software free trial. GMS 3 is completely revamped and uses a new, much simplified user interface. Free Software at NOAA's NGDC has a Mac OS 9 analysis package that was described in EOS. 07 (shmelyoff. Use this app with the built-in iOS device microphone, or upgrade to our iAudioInterface2 or iTestMic for a complete professional solution. The relationships we build with our sites are a critical element in program success and empower our partners to transform their services for youth. No part of software or user manual pages may be copied, reproduced or anyway re-used separately without the written permission of the author. g. In this section, only those closely related to this project are reviewed. ClimLab (This site may be offline. 1. Perfect for sound engineers and audio analyzing. dsp, digital signal processing, signal processing, fft, dft, goertz, fourier, fir, iir, dct; Xitona Guitar Tuner 1. It uses one of the fastest implementations of the Discrete Fourier Transform and has many applications including periodic noise removal and pattern detection. Content can be displayed as either 1/3 octave bars or as a variable resolution FFT curve. There will still be the same supply in future. Working in dark bars and having bright white software really screws with your eyes when it comes to readjusting. One common way to perform such an analysis is to use a Fast Fourier Transform (FFT) to convert the sound from the frequency domain to the time domain. It is adaptive in that it will choose the best algorithm available for the desired transform size. You can easily save all your measurements and review them at any time. Enter 0 for cell C2. I wish there was a way to skin it. com offers free software downloads for Windows, Mac, iOS and Android computers and mobile devices. Calculate the fundamental frequency of the captured audio sound The FFT Guitar Tuner application was developed to be a small tool that's using a Fast Fourier Transform to calculate the fundamental frequency of the captured audio sound. 00, 3. Description. 0 (requires Windows 2K/XP). 16. These programs have a range of functions including Fast Fourier Transforms (FFT), Real Time 3D display, wavelet decomposition, harmonic analysis, note definition and much more. The RTL-SDR can be used as a wide band radio scanner. Free software, released under the GNU General Public License (GPL, see FFTW license). It is An FFT noise filter is the best way to remove embedded patterns in scanned images. Airspy, a High Quality Approach to Software-Defined Radio. It is a hardware implementation of the free software Kiss Fft ('Keep it simple, Stupid!') Freeware Download 1. This tutorial will show the steps in performing the FFT on an interferogram. Waterfall - data plotting component, especially suitable for Fft results. 2 from our software library for free. This page describes a free audio spectrum analyser which you can download. FFT operator: The FFT operator calculates the classical Fourier transform of the FF420 option FFT SC420, 801675. For simulation of a MATLAB Function block, the simulation software uses the library that MATLAB uses for FFT algorithms. WinDaq Data Acquisition software is a multitasking data acquisition software package for windows providing disk streaming and real time display to over 250kHz with select DATAQ Instruments hardware products. The fft module in liquid implements fast discrete Fourier transforms including forward and reverse DFTs as well as real even/odd transforms. QuickDAQ allows you to acquire and display measurement data from all Data Translation USB, Ethernet, and PCI devices that support analog input streaming. Source for module FFT from package GO. converts your PC with a soundcard into a professional audio and signal analyzer. Feel free to correct me if there's anything I'm missing here. Zelscope Zelscope is a Windows software that converts your PC into a dual-trace storage oscilloscope and spectrum analyzer. FFT has been working for over a decade helping sites across the globe to implement FFT successfully. This application, released as free software under the GNU GPL v2 for Linux and Windows, is designed for getting a rapid visual understanding of recorded brain-wave data. The second cell (C3) of the FFT freq is 1 x . Download links are directly from our mirrors or publisher's website The Fast Fourier Transform (FFT) is a fundamental building block used in DSP systems, with applications ranging from OFDM based Digital MODEMs, to Ultrasound, RADAR and CT Image reconstruction algorithms. You can learn more about FFT analysis at Dewesoft PRO online training by navigating to the FFT Spectral Analysis PRO training course. In an apples-to-apples comparison, this is the program that the FFT improves upon. PlotLab is a set of Visual C++ components for very easy and fast Data Visualization. The source code for the program is highly optimized Intel assembly language. The development of GNU made it possible to use a computer without software that would trample your freedom. pdf format. Zinf Audio Player MP3 & Audio, Freeware, $0. For those of us in signal processing research, the built-in fft function in Matlab (or Octave) is what we use almost all the time. . Welcome to Pioneer Hill Software. 10/16/2018. FFT-z (Fast Fourier Transforms) is a software tool that can help you stress test multi-CPU systems, and compare your results with other online. (Non-free licenses may also be purchased from MIT , for users who do not want their programs protected by the GPL. Belgium. FFT SERVICE & SUPPORT. FFTProperties3. The audio recording software named Audacity is a fabulous, commanding open-source audio editor and recorder, which provides you with the capability to performing several functions as compared to what you would conceive from the fact that it is a free application. File Extension FFT is supported by Windows, Mac, and iOS operating systems. 7 Pilot logbook software for Windows and PDA companions for… Best 1000 If you use GIMPS source code to find Mersenne primes, you must agree to adhere to the GIMPS free software license agreement. Other Useful Business Software. This can be very useful in analyzing fingerprints, paper sieve patterns etc. Free Fft Shareware and Freeware. I've looked at several: Wavpad is reasonable cost but their FFT function leaves a lot to be desired, FFTW is shareware but I don't want to have to write the frontend for it, and SpectraPlus is really nice but is too expensive. It features an Arbitrary-N FFT algorithm to quickly perform Time-Frequency conversions, and it calculates many statistics in Time and Frequency. narod. NUFFT (NFFT, USFFT) Software Fourier analysis plays a natural role in a wide variety of applications, from medical imaging to radio astronomy, data analysis and the numerical solution of partial differential equations. 8Hz to 200Hz. 11. See the API Style Guide for information on making a good Arduino-style API for your library. Free BrainVision Analyzer 2 Webinar – Introduction to spectral analysis with to learn how to perform spectral analysis with the Fast Fourier Transform (FFT). This module allows a user to perform FFT, Inverse FFT, and FRF analysis on time domain data. 1 Background Download sound editing software to edit music, voice, wav, mp3 or other audio files. All systems provided by FFT come with a comprehensive two-year warranty, are virtually maintenance-free, and all field components are passive. Version 1. RE: Free software for fft signal analyses. It is similar to commercial systems such as MATLAB from Mathworks, and IDL from Research Systems, but is Open Source. INTRODUCTION Wind energy is a free, renewable resource so no matter how much is used today. Bug fix in 5. Share yours for free! Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1. The software is periodically scanned by our antivirus system. Versatile Real-Time Audio Spectrum Analyzer. 30 Build O. Popular Alternatives to FFT-z for Windows, PortableApps. QuickDAQ data logging and FFT analysis software supports data acquisition (DAQ) and display from all Data Translation USB and Ethernet devices that support analog input streaming. About FFT Files. Audio Spectrum Analyzer - OscilloMeter 6. For C/C++ code generation, by default, the code generator produces code for FFT algorithms instead of producing FFT library calls. 5. 4 Beast is a powerful music composition and modular synthesis application released as free software. MATLAB® Translator (INFIELD-MATLAB) MATLAB File Format Version 5. com - id: 3c5346-NjNmY Revisiting this again. If you have been searching for a solution to your acoustic and vibration test and measurement needs then you have found the right place. 0 free download. Founded in 1998, and headquartered in Mont-Saint-Guibert, Belgium, Free Field Technologies, an MSC Software company, develops and supports Actran, a powerful software suite for acoustic, vibro-acoustic and aero-acoustic modeling. This is a list of free and open-source software for geophysical data processing and interpretation. Acoustic and Vibration Spectrum Analyzer solutions. Includes CPU Benchmark feature for speed testing. Make Your Own Oscilloscope Using Your Laptop Computer ZELSCOPE, free download at Sound card oscilloscope and spectrum analyzer . FFT-Filter Free Download,FFT-Filter Software Collection Download These small but powerful USB spectrum analyzers are ideal for bench top or desktop use in a lab or compliance testing environment, offering full featured spectrum analysis through an easy-to-use and customizable software interface. Thank you for downloading FFT Properties from our software library. Email: contact@fft. On the left is the original (or filtered) image on the right the 2D FFT image. All the data processing and Software piracy is theft, using crack, warez passwords, patches, serial numbers, registration codes, key generator, keymaker or keygen for license key is illegal. This audio editor has all the audio effects and features a professional sound engineer could need to record and edit music, voice and other audio recordings. A spectrum analyzer basically analyzes the intensity of differen. Free program for PC or Mac. I have tried to get it to work again on new photos, but it will not work. FFT Spectra FFT Spectra is a tool for visualization of frequency Resting state fMRI data analysis toolkit While resting-state fMRI is drawing more and more attention, FFT of 1 dimensional time buffer Program that does an FFT (Fast Fourier Transformation) Residual Analysis OSS Software made available by the Residual Analysis blog, Fft, free fft software downloads. FormatFactory 4. I will try and fathom out why the FFT is essential in the video tutorial I'm watching tomorrow but if anyone can link me to a FREE EQ that has FFT, that'd be great. 1: Frequency Domain Using Excel by Larry Klingenberg . It is fairly sophisticated but is user friendly and makes spectral analysis of a single time series very easy. The FFT function uses original Fortran code authored by: RC Singleton, Stanford Research Institute, September 1968. 00, 2. These audio spectrum analyzer tools have Fldigi is a free software program capable of decoding various ham radio digital data signals such as CW, Contestia, Domino, Feld Hell, Olivia, MT63, PSK, RTTY, Thor and WEFAX. An open, optimized software library for the ARM architecture. 0 MB. LMMS Digital Audio Workstation LMMS is a free cross-platform software which allows you to produce music with your computer. Fourier analysis converts a signal from its original domain (often time or space) to a representation in the frequency domain and vice versa. What do you guys use? Do you even use RTA/FFT software at all? Thanks a ton! The Dewesoft FFT analyzer allows setting multiple markers for automatic detection of different parameters. A fast Fourier transform (FFT) is an algorithm that computes the discrete Fourier transform (DFT) of a sequence, or its inverse (IDFT). With our free e-learning tools, you can create the best learning environment for your Effective 7/4/2019, Spectrum Software is closed. On this page, I provide a free implementation of the FFT in multiple languages, small enough that you can even paste it directly into your application (you don't need to treat this code as an external library). Data analysis takes many forms. Please note that this software is not compatible with the Understanding Signals v1. . Great for FFT Visualization! Free for non-commercial use. 8 Sep 2017 Ableton's Spectrum Analyzer is an essential tool for we thought we would release another free cheat sheet from our complete collection that 9 april 2018 Audio Editing Software Features Include: • Import and export using over of your audio using the FFT Sound Analyzer • Include bookmarks for Free Your Sound! You have the need for Your audio tools are software equivalents of top notch hardware, impressive work. Free update of versions 1. MAnalyzer allows meter (64-bars), FFT curve or 1/3 analyzer window. DaVinci Resolve 16 features a revolutionary new cut page specifically designed for editors that need to work quickly and on tight deadlines! The new DaVinci Neural Engine uses machine learning to enable powerful new features such as facial recognition, speed warp and more. This software use special algorithm instead of FFT. More . NEWPORT BEACH, CA-(Business Wire - October 12, 2016) - Free Field Technologies (FFT), an MSC Software company, announced today the release of Actran 17. My price range is free up to about $150 or so. It is versatile and easy to use. Curve fitting, FFT and a presentation software FFT: Fun with Fourier Transforms This page (Software) was last updated on Oct 09, 2019. Explore apps like FFT-z, all suggested and ranked by the AlternativeTo user community. FFT in Hardware and Software Background Core Algorithm Original Algorithm, the DFT, O(n2) complexity New Algorithm, the FFT (Fast Fourier Transform), O(nlog2(n – A free PowerPoint PPT presentation (displayed as a Flash slide show) on PowerShow. Understanding audio quality and the effects of digital compression (e. Multi-Tone Sound Frequency Sweep Generator. FFT (Fast Fourier Transformation) Photoshop plugin by Alex V. The FFT library to "Keep It Simple, Stupid" This is the original home of kissfft. Download anytime and distribute to students from online account. MP3) on audio bandwidth; Detecting problems in audio recording Microsoft Excel has a FFT Add-in Tool. For embedded DSP applications (software running on special purpose DSP chips), consult your vendor's software libraries and support website for FFT algorithms written in optimized assembly language for your DSP hardware platform Audacity can analyse the frequency content of digital audio, but its analysis tools aren't very sophisticated. audio analyzer fft free download. Doing this * - The Software is provided "as is", without warranty of any kind, express or * implied, including but not limited to the warranties of merchantability, * fitness for a particular purpose and noninfringement. The above fft filtering search results are freeware or software in full, demo and trial versions for free download. ARTA software consists of following programs: I'm looking for a good Real Time Analysis (RTA) / FFT spectrum analysis program. FFT onlyneeds Nlog 2 (N) Gqrx is an open source software defined radio receiver (SDR) powered by the GNU Radio and the Qt graphical toolkit. Standard Libraries The MeldaProduction Analyzer is the best free VST Audio Spectrum Analyzer there is! It has a nice big and adjustable display with a clear graphical representation of the sound. )Quality sound measurement software equivalent to at least US$10,000 hardware. FFT stands for Find Files Time. Skip trial 1 month free. File File Type Size SATlive. It might be worth a look if you need more than basic spectrum analysis software. 21 Jan 2006 DtBlkFx by Darrell Barrell is a freeware Fast-Fourier-Transform (FFT) DtBlkFx is available to download as a free VST effect plug-in for Windows and Mac. The list is split into broad categories, depending on the intended use of the software and its scope of functions. Comparing PC FFT Program ARTA Software to HP 3580A & iPhone FFT Program i. Winscope is a free oscilloscope software that can be used to analyze any signal on your computer. Automatically utilizes and tests all CPU cores. The following markers are available: Free marker - shows us the frequency of the peak at which it stands and its amplitude; MAX marker - finds the highest amplitude in the spectrum Audacity can analyse the frequency content of digital audio, but its analysis tools aren't very sophisticated. Chirokov << Back to overview / Zurück zur Übersicht This is a very great freeware-plugin for photoshop. 05 (Freeware) by MeldaProduction x64 is an FFT based audio frequency a variable resolution FFT curve. Spectrum Analyzers - Here you will find a collection of Spectrum Analyzers which allow you to analyze sound. FFTW is one of the most popular FFT packages available. FFT-z Processor Stress Test is a tool performing Fast Fourier Transforms (FFT) for Multi-CPU stress testing. Tutorial 7: Fast Fourier Transforms in Mathematica BRW 8/01/07 Off@General::spellD; This tutorial demonstrates how to perform a fast Fourier transform in Mathematica. fourier analysis Software - Free Download fourier analysis - Top 4 Download - Top4Download. Not sure that your sensor is connected? See Fast Fourier Transform(FFT) • The Fast Fourier Transform does not refer to a new or different type of Fourier transform. Download FFT Properties 6. Learn new and interesting things. The Fast Fourier Transform is one of the most important topics in Digital Signal Processing but it is a confusing subject which frequently raises questions. It uses one of the fastest implementations of the Discrete Fourier Transform and has many applications including periodic noise removal and pattern detection. Given a vector of complex time-domain samples \(\vec{x} = \left[x(0),x(1),\ldots,x(N-1)\right]^T\) the \(N\) -point forward discrete Fourier transform is computed as: Field Force Tracker - A Feature Rich, Easy to Use, Comprehensive Field Service Software Solution. If y Microsoft Excel has a FFT Add-in Tool. The GNU operating system consists of GNU packages (programs specifically released by the GNU Project) as well as free software released by third parties. Users can view which files were modified and when in SIGVIEW is distributed as shareware - you can download a completely functional trial version and use it for 21 days to find out if it suits your needs. Fldigi is a free software program capable of decoding various ham radio digital data signals such as CW, Contestia, Domino, Feld Hell, Olivia, MT63, PSK, RTTY, Thor and WEFAX. File management. To obtain FFT etc. It uses fast Fourier transform (FFT) to give a real-time ('live') spectrum display on your screen. There are hundreds of FFT software packages available. is the sampling frequency (50,000 in this GNU is an operating system that is free software—that is, it respects users' freedom. This version is Windows XP, Vista, and 7 compatible. Features: - FREE - FFT resolution up to 2. Our built-in antivirus checked this download and rated it as virus free. Audacity is an easy-to-use, multi-track audio editor and recorder for Windows, Mac OS X, GNU/Linux and other operating systems. Audio Spectrum Analyzer for Real-time, FFT, OscilloScope, Frequency counter, voltmeter, noise and distortion meter, phase shift meter. In this post I'll try to provide the right mix of theory and practical information, with examples, so that you can hopefully take your vibration analysis to the next level! Free, open source, cross-platform audio software. Fast Fourier Transform (FFT) plugins (Windows only) Post by photoken » Sat 05 Apr 2014 06:56 Although PL's de-screen filter can do a remarkable job, there are times when it doesn't -- notably when the pattern to be removed has a diagonal component. Voxengo SPAN free spectrum analyzer plugin updated to v3. These tools include the Fast Fourier Transform (FFT) and the Time-Based Fast Fourier Transform (TFFT) which are both very useful tools to perform sound analysis on the spectral content of audio. Once the Audio Realtime Analyzer for Windows platform using FFT and MLS. Visual Analyser is a complete professional real time software, transform your PC in a full set of measurement instruments; no new hardware necessary (you can use the Sound Card of your PC) or you can use a specific external hardware (see Hardware section for an example). 1 MB Fft software free downloads and reviews at WinSite. As the FFT length is increased the analyser starts to overlap its FFTs, calculating a new FFT for every block of input data. This module also provides a frequency-based resampling tool. The implementation has already been discussed in detail in previous articles. Wave Flow is a very complete audio editor that can play, record, filter and modify a wave form, using lots of different functions and following the WAV standard. Download and try for free. The FFT is calculated along the first non-singleton dimension of the array. Gqrx supports many of the SDR hardware available, including Airspy, Funcube Dongles, rtl-sdr, HackRF and USRP devices. 06. be 16 Jun 2016 Learn the practical information behind a FFT, PSD, and spectrogram for exist to help the analyzer determine the cause of any vibration signal. Online FFT calculator, calculate the Fast Fourier Transform (FFT) of your data, graph the frequency domain spectrum, inverse Fourier transform with the IFFT, and much more. The sample project shows one way of using genFFT to generate and enqueue FFT kernels in your application. fft. We also encourage you to check the files with your own antivirus before launching the installation. It's a free tool that shows when files in a folder are modified with a high degree of specificity and accuracy. FFT-Filter Free Download,FFT-Filter Software Collection Download Common commercial software packages are shown to be an excellent synergetic means for teaching spectral concepts using the Fast Fourier transform. I designed it originally to help myself at work, where I wanted to analyze the frequency content of the output signal of an accelerometer. The software belongs to Development Tools. 27 Sep 2017 Decibel 10: Noise dBA Meter, FFT Spectrum Analyzer for iPhone Most importantly, this app is FREE and we commit to regularly improve the Simulation software to integrate concept development, design, testing and production. Very cool software and best of all, free. Looking for an EQ with FFT. Toulouse Area, France. The computer can capture live sound/music using a microphone that is connected to the sound card. Powerful mathematics-oriented syntax with built-in plotting and visualization tools; Free software, runs on GNU/Linux, macOS, BSD, and Windows Data analysis takes many forms. Site license includes home computers of both students and faculty. >friedel_hac@my-deja. SATlive is a software for computers running windows. Free FFT Spectrum Analyzer For Mac & PC Voxengo SPAN 2. FFT Software . frequency. ) is a free software pack offered through Columbia University. 0, 1. This is my first attempt to generate a spectrogram of a sinusoidal signal with C++. Combine QuickDAQ with Data Translation hardware to acquire data, record data to disk, display the results in both a plot and digital display, and read a recorded data file. Real-time audio spectrum analyzer with reasonable frequency resolution across the the entire Free Open Source Mac Windows Linux VSTHost SAVIHost. Field Force Tracker™ is a very feature rich, comprehensive, enterprise-grade yet easy to use Field Service Software with the most powerful mobile applications in the industry. Besides, as it has been designed for a Windows environment, it is done visually, easily and intuitively. Below is a list of software options offering features suited to different types of use. exe and SignalAnalyzer. Project Ne10. You can enlarge sections for a better view and copy/ paste the image to a clipboard and compare the results in a different analyzer window. (Signal-to-Noise Ratio), SINAD ( SIgnal-to-Noise-And-Distortion ratio), and SFDR (Spurious-Free Dynamic Range ). 2014-08-31: Faster Fast Fourier Transform; 2012-09-23: Spek 0. it can be controlled and displayed the data including the FFT measurement. An 8k FFT has a frequency resolution of approximately 6Hz for data sampled at 48kHz. Dewesoft PRO training is a free online training for measurement professionals. 100% FREE report malware. In this post I'll try to provide the right mix of theory and practical information, with examples, so that you can hopefully take your vibration analysis to the next level! SPAN is a free real-time "fast Fourier transform" audio spectrum analyzer AAX, AudioUnit and VST plugin for professional sound and music production applications. Audio Spectrum Analyser. for more Both Gwyddion and ImageJ are free, and have a quite broad and worldwide spread community of users. For embedded DSP applications (software running on special purpose DSP chips), consult your vendor's software libraries and support website for FFT algorithms written in optimized assembly language for your DSP hardware platform MAnalyzer x64 7. If you wish to continue using SIGVIEW after your trial period has finished, you will have to purchase a license. 11 FFTW is free for non-commercial or free-software applications under the terms of the GNU General Public License. Software Product Description User-friendly 2D FFT/iFFT (Fast Fourier Transform) plug-in for Adobe PhotoShop compatible plug-in hosts. General realtime measurement function is entirely included. The most popular versions among FFT Properties users are 5. Free Field Technologies France · MSC Software · Ecole nationale supérieure de 26 Aug 2019 Eigen is Free Software. Download BurnAware Free, Premium and Professional. MSC Software is one of the ten original software companies and a global leader in helping product manufacturers to advance their engineering methods with simulation software and services. Fft Equalizer software free downloads and reviews at WinSite. FFT autospectrum Lin. Photoshop: FFT-based pattern remover (Filter/Brush/Tool) Here is a standalone software that does FFT for modern Macs; but I cannot find a tutorial on how to apply The FFT is a complicated algorithm, and its details are usually left to those that specialize in such things. ARTA software uses standard and professional PC sound cards for audio signal acquisition and generation. Review on FFT software. GNU Octave Scientific Programming Language. For embedded DSP applications (software running on special purpose DSP chips), consult your vendor's software libraries and support website for FFT algorithms written in optimized assembly language for your DSP hardware platform Open source hardware and software tools are very accessible this days, and a simple, inexpensive and open source FFT spectrum analyzer can be easily built using some of this tools. This application is 14-day Trial Gatan Microscopy Suite ® (GMS) is the industry standard software for (scanning) transmission electron microscope experimental control and analysis. Downloaded Voxengo and another one I forget the name of it now but turned out it wasn't free anyway and neither had FFT. com, Software as a Service (SaaS), Mac, Linux and more. Distributed FFT Packages. ibaAnalyzer is characterized Analyzing in the frequency range (FFT). Step 5: Fill in Column C called "FFT freq" The first cell of the FFT freq (C2) is always zero. TrueRTA is a free audio analyzer software for Windows. fs / sa, where . 2 (10/01/2018) FTL-SE is a program for performing Fourier Transforms, which can be useful in teaching Crystallography, since they are related to Optical Transforms (e. Directional Harmonics. Features: Multi-processors stress According to our database, nine distinct software programs (conventionally, Adobe Audition developed by Adobe Systems Incorporated) will enable you to view these files. Audio Realtime Analyzer for Windows platform using FFT and MLS WinAudioMls: Audio Realtime Analyzer for Windows platform using FFT and MLS WinAudioMLS is a professional Windows application for powerful real-time signal and system analysis. Doing this User-friendly 2D Fft/iFFT (Fast Fourier Transform) plug-in for Adobe PhotoShop compatible plug-in hosts. 0 – a freeware real-time "fast Fourier transform" audio spectrum analyzer plug-in for professional music and audio production applications – is now available for download . Get ideas for your own presentations. fftw. NIST Guide to Available Math Software. Hardware Network Security Cloud Software Development fft analyzer Software - Free Download fft analyzer - Top 4 Download - Top4Download. Audio Fft Linux in title. 1 Introduction 1. free fft software
j7i, bal8, kzlmu1ivmuvxq, jck1o, goanr, p45qy, qhtq, gl6iww, c12kcs, jpixvb0, qak8h,
©2019 BikeBoardMedia, Inc. | CommonCrawl |
An integrated multi-omics approach to identify regulatory mechanisms in cancer metastatic processes
Saba Ghaffari ORCID: orcid.org/0000-0003-0791-39051,
Casey Hanson2,
Remington E. Schmidt3,
Kelly J. Bouchonville3,
Steven M. Offer3 &
Saurabh Sinha4
Genome Biology volume 22, Article number: 19 (2021) Cite this article
Metastatic progress is the primary cause of death in most cancers, yet the regulatory dynamics driving the cellular changes necessary for metastasis remain poorly understood. Multi-omics approaches hold great promise for addressing this challenge; however, current analysis tools have limited capabilities to systematically integrate transcriptomic, epigenomic, and cistromic information to accurately define the regulatory networks critical for metastasis.
To address this limitation, we use a purposefully generated cellular model of colon cancer invasiveness to generate multi-omics data, including expression, accessibility, and selected histone modification profiles, for increasing levels of invasiveness. We then adopt a rigorous probabilistic framework for joint inference from the resulting heterogeneous data, along with transcription factor binding profiles. Our approach uses probabilistic graphical models to leverage the functional information provided by specific epigenomic changes, models the influence of multiple transcription factors simultaneously, and automatically learns the activating or repressive roles of cis-regulatory events. Global analysis of these relationships reveals key transcription factors driving invasiveness, as well as their likely target genes. Disrupting the expression of one of the highly ranked transcription factors JunD, an AP-1 complex protein, confirms functional relevance to colon cancer cell migration and invasion. Transcriptomic profiling confirms key regulatory targets of JunD, and a gene signature derived from the model demonstrates strong prognostic potential in TCGA colorectal cancer data.
Our work sheds new light into the complex molecular processes driving colon cancer metastasis and presents a statistically sound integrative approach to analyze multi-omics profiles of a dynamic biological process.
Globally, colorectal cancer (CRC) has the third highest incidence and second highest rate of cancer-related deaths [1]. Progression from primary cancer to metastatic disease is the most common cause of mortality in solid malignancies such as CRC, and approximately half of CRC cases will either present as metastatic disease or develop metastases regardless of cancer treatment [2]. While specific driver mutations are well-defined in CRC oncogenesis, the mechanisms that facilitate metastatic progression are poorly understood. Changes in gene expression have been shown to accompany CRC progression and to predict metastasis [3,4,5]. Epigenetic changes have also been associated with CRC pathogenesis [6,7,8]; however, current analysis tools offer limited ability to integrate transcriptome and epigenome data to precisely define the regulatory frameworks of metastasis.
Here, we approached this problem using a purposefully generated cellular model of CRC invasiveness (a hallmark of metastasis). Using multi-omics profiling of cells at increasing levels of invasiveness and a novel integrative analysis framework yielded several novel insights about transcriptional regulatory mechanisms underlying the transcriptomic dynamics of CRC progression.
We profiled gene expression, as well as genome-wide profiles of DNA accessibility and four select histone modifications known to be associated with cis-regulatory information, in four different stages of progression. These data allowed us to identify large numbers of genes that change the expression in either direction as the cell populations acquire more invasive characteristics, and the genome-wide epigenomic profiles yielded many potential cis-regulatory regions associated with those changes. However, this in itself does not reveal details of the transcriptional regulatory network (TRN), i.e., the specific transcription factors (TFs) and TF-gene relationships that drive the transcriptomic changes and are reflected in the cis-regulatory regions. We therefore combined the above data with genome-wide colon cancer cell line TF-DNA binding profiles from the ENCODE Project. By combining TF-binding site (TFBS) information with epigenomics-based markers of cis-regulatory segments and differential expression of nearby genes, we were able to identify the TFs most likely to regulate CRC progression, as well as their putative target genes. The strategy of finding statistical enrichments of a TF's binding sites in the regulatory regions associated with differentially expressed genes is a time-tested one [9,10,11]; here, we hoped to significantly improve its efficacy by additionally using epigenomic data from the cellular contexts being contrasted.
A key aspect of our strategy was the use of changes in histone modifications between stages. Specific histone modifications have been associated with activating or repressive influences [12,13,14] on the gene expression, so one expects improved regulatory analysis by focusing on TFBS that are flagged by such marks. Moreover, some previous studies have argued that changes in epigenomic state provide valuable information about regulatory mechanisms underlying cellular state transitions, perhaps more so than merely the presence or absence of epigenomic marks. For instance, Bozek et al. reported accessibility of cis-regulatory elements to vary along the antero-posterior axis in Drosophila blastoderm, in a manner correlated with their regulatory activity [15]. Thus, we focused on TFBS that coincide with dynamic histone marks rather than simply the presence of marks.
Another challenge we were faced with pertains to the use of regulatory direction, i.e., activating or repressive influence, associated with specific histone modifications. For instance, it seems natural to focus on TFBS flagged by an activating mark such as H3K27ac when located near an upregulated gene. However, one might argue that such a TFBS if located near a downregulated gene presents inconsistent information about the TF's regulatory influence, especially if the TF is known to be an activator. This point is even more germane if our analysis is based on dynamic histone marks: for example, when seeking evidence of an activator TF regulating a gene that is upregulated in later (more invasive) stages, one should consider TFBS flagged by an increase in an activating histone mark or decrease in a repressive histone mark, with either epigenomic change pointing to a more activating chromatin context in the later stages. As this illustrative scenario suggests, our analysis needs to account for regulatory directions associated with TFs, epigenomic marks, and differential expression, in order to narrow down the large numbers of putative cis-regulatory elements to those most likely to be functional. Furthermore, the regulatory directions of TFs are seldom known, and even those of specific histone marks are not always well understood; hence, we sought these biological characteristics to be automatically learnt from data.
It is well known that genome-wide binding sites of different TFs often exhibit high degrees of co-localization [16], e.g., due to frequent TF binding at accessible regions of DNA, and large numbers of TFBS do not have the obvious regulatory function expected of them [17]. One strategy to mitigate the resulting problems in the statistical approach noted above is to analyze the associations of differentially expressed genes with many or all TFs concurrently rather than test enrichments for each TF separately. In a related but different context, previous studies have utilized multi-TF modeling of genes to discover TRNs from the expression data [18,19,20]. Inspired by these studies, we developed here an analogous multi-TF model of gene expression to discover TF-gene regulatory relationships based on TF-DNA binding and epigenomic evidences.
Our analytical framework uses a rigorous probabilistic model to integrate gene expression and epigenomic data from different cellular states (maternal and invasive cell lines) with TF-DNA binding data from a related cell line, to identify TFs that regulate the observed transcriptomic dynamics. The model automatically learns dominant regulatory directions associated with each TF and histone mark for which data are available and also predicts the likely target genes of each TF. Using rigorous statistical evaluations, we showed that the use of dynamic histone marks has significant advantages over simpler strategies that do not fully exploit this rich source of cis-regulatory information. The model predicted several important regulatory pathways that are commonly associated with oncogenic and metastatic phenotypes, including the AP-1 complex members JunD and Fosl. We experimentally tested the role of JunD by shRNA-mediated knockdown and found the resulting cell line to exhibit significantly reduced migration and invasion characteristics. RNA-seq profiling of the JunD knockdown condition revealed a large set of potential targets of this TF. We found this set to be significantly enriched for model-based predictions of JunD targets, thereby confirming our ability to infer TF-gene relationships. Finally, we constructed a gene signature of CRC invasiveness based on predicted targets of the most significant TFs and showed that this signature has stronger prognostic value for predicting the overall survival in CRC than gene expression alone. In summary, we present here a multi-omics, statistically rigorous strategy to investigate the cis-regulatory mechanisms underlying a complex biological process and use it to glean new insights into colorectal cancer progression.
Multi-omics profiling of a CRC cell line
Acquiring the ability to migrate and invade through host tissues is a hallmark of metastatic cancer cells. To identify differentially regulated pathways in this process, matched SW480 cell models with varying degrees of invasiveness were derived by repeated selection of cells capable of chemotaxis through a microporous membrane coated with Matrigel extracellular matrix (Fig. 1a). In the subsequent sections of the text, the number of times cells were selected using Matrigel-coated membranes is denoted as the "M" number for the cell line, where M0 is the parental SW480 culture that has not undergone selection, M1 is a culture that has been selected one time, and so on. Two completely independent biological replicate series of cultures were derived using the same methodology by two independent researchers.
Schematics of study design and analysis framework. a An invasive sub-culture of SW480 cells was established by repeated selection of cells that could invade through porous membrane coated with synthetic extra-cellular matrix toward a chemoattractant (serum). b The pGENMi probabilistic model was adapted to aggregate cis-regulatory evidence associated with each differentially expressed (DE) gene. Pg represents the differential expression p-value of gene g, Zg is a binary hidden variable that represents if g mediates the regulatory influence of one or more known TFs on CRC invasiveness, and rg, t, m represents a (binary) cis-regulatory evidence in the form of a binding site for TF t, flagged by dynamic histone mark m, in the regulatory region of gene g. The weighted sum of cis-regulatory evidence (with learnable weights wt, m) determines Pr(Zg = 1). Pg follows a beta distribution if Zg = 1 and is uniform if Zg = 0. c Overview of the analysis. Left panel depicts the matrix of cis-regulatory evidence for multiple TFs and all genes. A TFBS overlapping with a change of histone mark between stages is encoded with two bits, one for either direction of change. Each TF is thus represented by eight bits, representing four histone marks. The evidence matrix and the DE p-values of genes (between the early and late stages) are inputs to the model. The output of the model contains a score assigned to each TF representing its contribution to the model and a score associated with each (TF, gene) pair representing the extent to which the gene mediates the effect of the TF on CRC invasiveness
Cells that had undergone repeated rounds of selection displayed increased invasiveness (Additional file 1: Figure S1). To identify gene expression changes in invasive cells, mRNA sequencing (RNA-seq) was performed on RNA harvested from cultures M0, M2, M4, and M6. Principal component analysis (PCA) indicated that profiles for M4 and M6 are distinct from those for M0 and M2 (Additional file 1: Figure S2), but profiles for M4 and M6 were more similar within replicates than by stage (Additional file 1: Figure S2). Because of the clear expression and phenotypic separation between M0 and M6, further analyses focused on those cell lines, beginning with characterization of differentially expressed (DE) genes (Additional file 1: Figure S3). Gene set characterization of the DE genes (adjusted p-value ≤ 0.05) using the KnowEnG system [21] revealed several physiologically relevant properties of these genes (see Additional file 2). The downregulated genes (adjusted p-value ≤ 0.05) showed a strong enrichment for cancer-related gene signatures from mSigDB [22], most notably E-cadherin (CDH1) targets (hypergeometric test p-value 3.7E−41), the loss of which is a generalized hallmark of metastatic cells that have undergone epithelial-mesenchymal transition (EMT). Additional dysregulated pathways include those associated with invasion/migration in varied cancer types, including metastasis in melanoma (p-value 6.2E−15) and migration in bladder cancer cell lines (p-value 9.7E−14). Upregulated mSigDB modules include pathways typically associated with breast cancer invasiveness, including SMARCE1 targets (p-value 2.6E−16), ESR1 targets (p-value 5.3E−16), and a comparison of luminal and mesenchymal breast cancers (p-value 2.1E−12). While these pathways are often associated with breast cancer, there is also precedence for general cancer relevance. For example, SMARCE1 is a core subunit of the SWI/SNF chromatin remodeling complex that has been linked to invasiveness in a hormone-independent manner in additional cancers [23].
To determine if the changes observed between M0 and M6 could be attributed to the selection of a specific genetic sub-population of cells, we performed variant calling on RNAseq data from M0 and M6 cells. A subset of variant loci with high depth across M0 and M6 lines was selected to assess shifts in population allele frequencies between M0 and M6 as a measure of enrichment (Additional file 1: Figure S4). Notably, allele frequencies are largely similar between stages, with a relatively small number of exceptions (points along the axes in Additional file 1: Figure S4), indicating that genetic cell identity remains consistent from M0 to M6. Additionally, no obvious driver mutations associated with colorectal cancer progression were noted (Additional file 3).
To understand the regulatory mechanisms underlying the differential expression of genes between stages, we performed genome-wide ChIP-seq profiling of four different histone modifications—H3K27ac, H3K4me1, H3K4me3, and H3K27me3—as well as genome-wide ATAC-seq to profile DNA accessibility, in the early as well as late stages. We first examined the global changes in histone marks and chromatin accessibility by summarizing how counts of histone mark ChIP peaks and DNA accessibility peaks change across stages. Specifically, we counted the peaks within 10 kbp upstream of the genes for each stage of progression, limiting ourselves to genes that are differentially expressed (p-value < 0.05) between early (M0) and late (M6) stages. This was done for up- and downregulated genes separately. The results (Additional file 1: Figure S5) show clear trends of genome-wide epigenomic changes. For instance, H3K27ac peaks near downregulated genes are fewer in later stages, and those near upregulated genes are more numerous in later stages, as might be expected of an activating histone mark. The reverse pattern exists for H3K27me3 peaks, consistent with a repressive role for this mark. Similar trends were observed in the changes of signal strength between stages (Additional file 1: Figure S6).
Integrative analysis of expression, TF binding, and epigenomic data: outline of model
A common and simple approach to regulatory analysis is to ask if a TF's binding sites enrich near DE genes [10]. We obtained ChIP-seq profiles of genome-wide DNA binding for 20 TFs in the colon cancer cell line HCT116 (Additional file 4: Table S1). ChIP peaks from these data provide us with putative TFBS associated with each gene, allowing enrichment tests to be performed. However, TFBS from ChIP-seq experiments are known to be promiscuous and a poor predictor of functional TF-gene relationship [17, 24]. As a result, the baseline strategy of testing TFBS enrichments in the gene regulatory regions is typically confounded by a high rate of false-positive sites. This issue is exacerbated by searching over longer intergenic regions with the intent to identify more sensitive TFBS-gene associations. Our epigenomic profiles can mitigate this problem by increasing the functional specificity of the TFBS information. For instance, we may only consider those TFBS that are located within active enhancers as indicated by specific histone marks, thus increasing the specificity of cis-regulatory evidence of a TF regulating a gene. We sought to further increase the specificity of cis-regulatory evidence by considering the changes in the epigenomic state [25] by using changes in histone marks between stages as a filter for TFBS and subsequent testing for enrichment of a TF's binding sites near DE genes.
As noted above, data were generated for four different histone marks, one or more of which may contribute to the inter-stage changes in the gene expression and furnish, perhaps with different specificities, cis-regulatory evidence for TF-gene relationships. Therefore, our approach was to utilize all four studied histone marks simultaneously in our integrative model. We interpreted the changes in multiple histone marks at a putative TFBS as a stronger evidence of the TF's influence than that provided by a single type of epigenomic evidence. In considering changes in histone marks, we assumed that the direction of change is informative, e.g., a histone mark that appears near a gene only in the late stage should have either an activating or repressing role, and this role should remain consistent across genes. However, we did not assume knowledge of such roles a priori; the data furnished this information. We also allowed different types of dynamic histone marks to have different evidentiary values. For example, a TFBS that overlaps a change in H3K27ac might be more reliable evidence of the TF's regulatory influence compared to an overlap with a change in H3K4me1. Also, as noted in the introduction, we recognize that the differential expression of genes between stages is likely under the regulatory control of multiple TFs. Hence, we analyzed associations between DE genes and all TFs in a multi-TF model rather than one TF at a time.
We built upon our previously published pGENMi model [26] to analyze the multi-omics data (Fig. 1c; detailed in the "Methods" section). To set up the model, each gene was associated with a differential expression p-value and a set of binary evidences for TF regulatory influence. Each binary evidence corresponds to a pair (T, M) of TF (T) and change in a specific histone mark (M; e.g., an H3K27ac peak exclusive to the late stage). The binary evidence is true if a ChIP peak for a TF T overlaps the dynamic histone mark M, within a pre-determined distance d from the gene's start site, and false otherwise (Fig. 1c). Since there are four histone marks in our data, and each mark may change in one of two directions, there are eight binary evidences for each TF, for a total of 160 evidences representing 20 TFs. The model uses a hidden binary variable Zg for each gene g, representing whether or not the gene's differential expression is associated with one or more of the TFs (Fig. 1b). The probability of Zg = 1 is a logistic function of the weighted sum of all binary evidences available for it, i.e., one or more TF-binding sites near the gene, each supported by a dynamic histone mark, makes the gene more likely to be a target of those TFs (Fig. 1c). Moreover, the observed DE p-value of the gene is modeled by two different probability distributions depending on whether Zg = 1 or Zg = 0, with the former case (Zg = 1) creating a bias toward small p-values (Fig. 1b). As a result, the likelihood of the data is higher if there are many genes for which the DE p-value is small (significant), and such genes have one or more regulatory evidences associated with them. The weights of binary evidences determining Pr(Zg = 1) are free parameters (wT,M) (Fig. 1b) learned from the data by maximum likelihood, and regularization is used to avoid overfitting. To achieve consistency between direction of differential expression and the regulatory direction of TFs and histone mark changes, we performed the entire analysis (model training) twice, with DE p-values representing the significance of upregulation and downregulation respectively. These two analyses are henceforth referred to as up- and down-analysis.
Identification of transcription factors underlying CRC invasiveness
We learned the optimal values of the model's hyperparameters—distance threshold (d = 10 kbp, 50 kbp, 200 kbp, or 1 Mbp) and regularization coefficient—by cross-validation on the entire dataset (Fig. 2a, Additional file 1: Figure S7). Here, all genes were randomly partitioned into training (80%) and test sets (20%), and model accuracy was evaluated by log likelihood ratio (LLR) on the test genes. The cross-validation was performed for up- and down-analyses separately, and the overall test accuracy for each setting of the two hyperparameters was measured by the sum of test LLRs in these two analyses, averaged over 100 repeats of random cross-validation. This identified 50 kbp as the optimal distance threshold for cis-regulatory evidence, though similar accuracy values were noted for the shorter range of 10 kbp and the greater range of 200 kbp. The model was found to perform significantly worse when using a regulatory region of 1 Mbp upstream or downstream of the gene, which suggests that considering TFBS at great distances (e.g., over 200 kbp from a gene), even with the support of epigenomic information, potentially includes more noise than signal in our analysis.
Regulatory influences learnt by model. a Comparison of goodness-of-fit for each distance threshold (maximum distance upstream or downstream of gene) used for associating TF ChIP-peaks with genes. The goodness-of-fit is measured by the sum of test LLRs (derived from cross-validation on the entire dataset) from up- and down-analyses, averaged over 100 repeats of the procedure. The distance and regularization coefficient used by the best-fit model were then used to re-train the model on the entire dataset. b, c Model-based ranking of TFs, in down- and up-analysis, respectively. Each TF's contribution was measured by zeroing its regulatory evidence and calculating the change in model LLR (∆(LLR)). d TF weights learned by the fw-pGENMi for down-analysis and up-analysis. All of the TFs except three, USF1, MAX, and CBX3, were assigned a consistent role in both analyses. A positive weight suggests an activating role for a TF while a negative weight represents a repressive role. e Weights for histone mark changes learned by fw-pGENMi for down- and up-analysis. A positive weight for a "mark-up" (respectively, "mark-down") change for up-analysis (respectively, down-analysis) suggests an activating histone mark. This is the case for H3K27ac, H3K4me1, and H3K4me3. The mark H3K27me3 has the opposite pattern, consistent with a repressive role
Using the optimal hyperparameter values obtained above, we re-trained the model on the entire dataset (all genes) and ranked TFs by their contribution to the model, separately for the down- and up-analyses (Fig. 2b, c). We did this by zeroing out all binary evidence related to a TF (one TF at a time), recalculating the model LLR, and using the difference of LLRs, called ∆LLR, before and after zeroing the TF's regulatory evidence, as the contribution of that TF. Both analyses identified ZFX, JUND, and CTCF in the top 5 ranked TFs. Additionally, RAD21 (ranks 6 and 2) and FOSL1 (ranks 5, 7) also consistently ranked highly (we present a more rigorous assessment of the statistical significance of these TFs below). A direct look at the binding sites of one of these TFs, viz., JunD (Additional file 1: Figure S8), shows substantial epigenomic changes in both directions. However, it does not immediately offer a mechanistic explanation of such changes or a quantitative assessment of their impact on gene expression and illustrates the need for a more nuanced analysis cognizant of expression changes, as is provided by our model.
ZFX is a transcriptional activator of that has been linked to oncogenic processes in numerous cancer types [27] and has been correlated with aggressive tumor phenotypes and poor survival in colorectal cancer [28]. JUND and FOSL1 are both potential components of the dimeric AP-1 transcription factor complex. AP-1 transcription factor complexes are generally considered oncogenic; however, the specific contributions to cancer development and progression can be dependent upon the dimeric composition of AP-1 transcription factors, cell type, tumor stage, and genetic background [29]. CTCF is a multi-functional protein that can act as a transcriptional activator, transcriptional repressor, or an insulator element [30]. CTCF-regulated genes are strongly enriched in cancer-related pathways, including cell differentiation, proliferation, viability, migration, and adhesion [31]. While there is considerable literature evidence that these highly ranked TFs are involved in cancer-related processes, it is also appreciated that the TFs evaluated by the ENCODE Project were likely enriched for those relevant to human disease, including cancer.
Model reveals regulatory roles of transcription factors and histone marks
To probe the inner workings of the model, we next trained a modified version of the pGENMi model, henceforth called "factorized weights pGENMi" (fw-pGENMi). In the model trained above, every combination of TF and dynamic histone mark was considered a separate evidence type and had an associated parameter wT,M. Suppose we are analyzing the upregulation of genes (up-analysis), and this parameter is learnt to be positive. This means that histone mark change "M" (e.g., appearance of H3K27ac mark in the late stage) at a binding site for TF "T" (e.g., JunD) is an evidence of upregulation of the gene. Similarly, if the parameter is fit to a negative value, it means that the histone mark change "M" at a binding site of TF "T" is suggestive of the downregulation of the gene. This could result in biologically counter-intuitive (though not impossible) situations. For example, the same dynamic histone mark "M" may indicate increased activation by binding sites of certain activator TFs and decreased activation by binding sites of other activator TFs. Similarly, the learnt parameters may be such that the same TF's binding site when coinciding with an appearance of an activating histone mark indicates upregulation but when overlapping with appearance of a different activating histone mark indicates downregulation. We therefore modified the model to rule out the above scenarios. In particular, rather than assign a free parameter wT,M to each T, M combination, we assigned to each TF "T" a free parameter wT and to each histone mark change "M" a free parameter wM and required that the parameter wT,M in the original model be equal to the product of wT and wM. This requirement reduces the number of parameters drastically, from ~ 160 to ~ 30, affording us a far more constrained parameter estimation problem. Furthermore, it imposes the requirement that each TF has a fixed role (activator or repressor) and each histone mark change also provides evidence of a fixed regulatory change (activation or repression). Interpretations of the different combinations of signs of these two parameters are outlined in Additional file 4: Table S2.
Upon training the fw-pGENMi model on the entire dataset (in the up- and down-analysis modes separately), we found that the TF weights were largely consistent in directionality between the down-analysis and up-analysis (Fig. 2d), even though the model was trained independently for these two analyses. To us, this provided evidence of stability of the learnt model and reliability of the roles it learns for TFs and histone marks. We noted that most TFs, especially those with the greatest contributions to the models (e.g., top ranked TFs from Fig. 2b, c), had a positive weight (also see Additional file 1: Figure S9). This means that if a binding site for a TF overlaps with an activating histone mark such as H3K27ac, then the direction of change (increase or decrease) of the histone mark is concordant with the direction of change of gene expression. In other words, most TFs exert an activating influence and the cellular state that has the activating mark present at the TFBS exhibits the higher gene expression. Figure 2e shows that the histone mark changes are consistent with the gene expression changes. For example, an H3K27ac mark that disappears in the late stage ("K27ac-down") has a positive weight in the down-analysis. This means that a disappearance of such a mark at an activator TF's binding site was indicative of downregulation. The same epigenomic change was assigned a negative weight in the up-analysis (i.e., disappearance of H3K27ac at an activator TF's site is evidence against upregulation of the associated gene). Both observations are consistent with our expectation for an activating histone mark. On the other hand, "K27ac-up" (an H3K27ac mark that appears in the late stage) was assigned a positive weight in the up-analysis and a negative weight in the down-analysis, again consistent with the biological expectations of an activating histone mark. Contrary to "K27ac-down," the histone mark change "K27me3-down" had a positive weight in the up-analysis, implying that such a change at an activator TF's binding site acts as evidence of upregulation of the associated gene; this is consistent with the repressive role reported in the literature for this mark [12]. The weights learnt for changes in the other two marks—H3K4me1 and H3K4me3—follow the same pattern as those of H3K27ac, consistent with their previously reported activating roles [12,13,14]. In summary, training of the fw-pGENMi model reveals the roles of TFs and histone marks involved in the down- as well as upregulation of genes in invasiveness.
Epigenomic information improves model
Our models revealed the identities and roles of TFs underlying CRC progression by utilizing epigenomic profiles from different stages of invasiveness and combining those data with ENCODE ChIP-seq profiles of TFs. We next investigated the value of this strategy by contrasting its results with those from alternative strategies used within the same modeling framework. In particular, we compared the above strategy, henceforth called the "DiffMark" (differential histone mark overlapping with TF ChIP peaks), with (a) the use of TF DNA-binding (ChIP-seq) data alone ("TFBS-only" strategy), (b) the use of accessibility (ATAC-seq) profiles ("DiffAcc" and "PresAcc") in place of histone marks, (c) the use of changes in any histone mark in both directions ("DiffMarkAggr"), and (d) the use of presence rather than changes in histone marks ("PresMark"). Detailed descriptions of these strategies are presented in the "Methods" section.
The baseline strategy of using TF ChIP-seq data alone (TFBS-only) involves training pGENMi with one evidence type per TF, as opposed to the eight evidence types per TF used in the DiffMark strategy. The presence of a TF's ChIP peak within a certain maximum distance from the gene is treated as evidence of its potential regulatory influence on the gene. The "DiffAcc" (differential accessibility overlapping TFBS) strategy is similar to the DiffMark strategy but uses ATAC-seq peaks in early and late stages instead of the four histone marks. Thus, the pGENMi model for this strategy has two evidence types for each TF, one for either direction of change in DNA accessibility at the TFBS. For reasons mentioned below, we also tested a variant of this strategy ("PresAcc"—presence of accessibility at TFBS) where the presence of an ATAC-seq peak in early or late stages (or both), overlapping a TFBS, was considered as evidence of the TF's regulatory influence; the corresponding pGENMi runs thus had only one evidence type per TF. In the "DiffMarkAggr" (differential histone marks aggregated for each direction separately) strategy, each evidence type for a TF represents whether the TF's binding site overlaps any histone mark change (in each direction) rather than a specific mark change; thus, this strategy utilizes two evidence types per TF in pGENMi modeling. The "PresMark" strategy (presence of histone marks) is similar to PresAcc, with one evidence type per histone mark indicating a TFBS that is flagged by that mark in either stage.
We relied on cross-validation to compare the above modeling strategies, all of which involve training pGENMi models with different definitions of cis-regulatory evidences. We partitioned all genes into training, validation, and test sets in proportions of 72%, 18%, and 10%, respectively; trained pGENMi parameters on the training set; used the validation set to pick optimal values for the two hyperparameters (including the distance threshold that defines gene regulatory regions); and computed the log likelihood ratio (LLR) of the model and a null model on the test set of genes. The process was repeated 100 times, with different random partitions, and the distribution of LLR scores of the model is shown in Fig. 3a, using the DiffMark strategy. There are two distributions shown, corresponding to down-analysis and up-analysis. The same evaluations were performed using each of the alternative strategies noted above, and the corresponding distributions of test LLRs are shown in Additional file 1: Figure S10. Optimal distance thresholds were utilized for each strategy, and the distance dependence of accuracy for each strategy is shown in Additional file 1: Figure S7. We were surprised to note that the DiffAcc strategy, which relies on the changes in accessibility at a TFBS as cis-regulatory evidence, yielded test LLRs that were poorer than completely ignoring accessibility information (see the "Discussion" section). The PresAcc strategy yielded improved results, and our subsequent analyses therefore report on this method of utilizing accessibility data, rather than the DiffAcc method.
Comparison of the alternative strategies for defining cis-regulatory evidence. a Histogram of test LLRs derived from training-validation-test cross-validation for up- and down-analysis using DiffMark strategy. b, c Empirical CDFs of test LLR for different strategies (shown in different colors) suggest that DiffMark strategy performs better than alternatives in down- (b) as well as up-analysis (c). d, e Frequency of training-validation-test partitions (out of 100) where DiffMark results in a greater (blue) or lower (red) test LLR than an alternative strategy. f, g Histograms of LLR values on the entire dataset for three schemes designed to test the explanatory power of cis-regulatory evidences based on TF ChIP-seq data from a CRC (HCT116) cell line. Results are for down- (f) and up-analysis (g) using the DiffMark strategy. In "shuffled" scheme (blue), the model was trained using permuted evidence. In "K562" (red), ChIP-seq data from the K562 cell line, representing binding profiles of 20 randomly selected TFs, were used to generate the DiffMark evidence. The "K562-distinct" scheme (green) is similar to "K562," except that the 20 TF profiles were randomly selected from the 90 ChIP-seq profiles most dissimilar to the 20 HCT116 TFs. Colored dashed lines represent means of respective distributions. The LLR of the analysis performed using the 20 available ChIP-seq profiles from the CRC cell line (black dashed line) is significantly larger than the average of "shuffled" and "K562-distinct" schemes in both down- and up-analyses. h, i Statistical assessment of the contribution of each CRC TF in down- (h) and up-analysis (i), respectively. Each point represents one TF. The y-axis represents the average LLR of 100 models, each trained using the TF and 19 randomly selected K562-distinct TFs. The x-axis represents the frequency with which the TF is ranked as the most significant contributor among the 20 TFs in these models
The cumulative distributions (CDFs) of all strategies are shown, for down- and up-analysis separately, in Fig. 3b, c, which reveals that the DiffMark strategy yields the highest test LLRs. The second-best LLRs were noted from the DiffMarkAggr strategy (for down-analysis) and the PresMark strategy (for up-analysis), both of which use histone marks (at TFBS) as cis-regulatory evidence but either ignore the specific identity of that mark (DiffMarkAggr) or ignore changes in marks (PresMark). All three strategies based on histone marks exhibit greater test LLRs than the TFBS-only strategy, which does not use any filter on TF ChIP peaks, and the PresAcc strategy, which uses only one type of epigenomic information (DNA accessibility) rather than four (histone marks). The PresAcc strategy improves upon the baseline TFBS-only strategy for up-analysis but has no effect for down-analysis. As a direct comparison of these two strategies, we asked if the DiffMark test LLR is greater than that of an alternative strategy on the same test set using 100 iterations of training, validation, and testing. The DiffMark strategy yields better test LLRs, indicative of an improved ability to "predict" expression based on unseen genes, in the vast majority of these head-to-head comparisons (Fig. 3d, e; Additional file 1: Figure S11). These results clearly demonstrate the value of utilizing histone mark changes as a filter on TFBS. The use of histone mark identities is noted to be valuable, as is the change in histone marks, especially for the down-analysis. Since genome-wide DNA accessibility profiles are known to correlate strongly with active enhancer marks such as H3K27ac, it was worth asking if a single accessibility profile is as informative as the four histone mark profiles; our results clearly indicate that this is not the case within the parameters of our comparisons.
Additional file 1: Figure S12 shows the ranking of TFs according to each of the alternative strategies, computed in the same manner as in Fig. 2b, c for the DiffMark strategy. Substantial agreement was noted among some strategies, in terms of the TFs that were utilized most for modeling differential expression. For example, the top six TFs in the down-analysis, as well as those in up-analysis, are identical between DiffMark and DiffMarkAggr. There were some major differences as well. For instance, JunD, which was ranked 3 and 4 respectively for down- and up- analysis by the DiffMark strategy, was not particularly informative for the TFBS-only strategy, which ranked this TF at 9 and 17 (out of 20 TFs) for down- and up-analyses, respectively. A possible explanation for this is that functional JunD sites have a relatively high tendency to be located distally from target genes, as the TFBS-only strategy relied on a distance threshold of 10 kbp for optimal performance. Conversely, the TF ELF1 was ranked relatively highly by the TFBS-only strategy (ranks 6 and 7) but was not found informative in the DiffMark strategy (ranks 15 and 12). Therefore, even though the baseline strategy shows poorer overall predictive ability, it may reveal complementary findings about important TFs.
Model findings are specific to CRC cell lines
In the analyses so far, cis-regulatory evidences were based on TF ChIP-seq profiles for 20 TFs in a CRC cell line from the ENCODE Project. We next examined the significance of these TF profiles for the analysis. First, we established a random baseline where all cis-regulatory evidences were permuted (i.e., all evidences of the same type were randomly reassigned among genes). The model was then trained on the entire dataset (all genes) and LLR computed. Repeating this 1000 times, each time with a different permutation of evidences, we obtained a null distribution of LLR scores for down- and up-analysis (Fig. 3f, g; "shuffled"). The LLR scores obtained with the original (unpermuted) evidences, 216 and 238, respectively (Fig. 3f, g; "CRC"), were clearly far larger than those in the null distributions (means of 32.2 and 28.8, and standard deviations of 4.6 and 4.2, for down- and up-analysis, respectively). We next asked if the TF ChIP-seq profiles from a CRC cell line were more useful for the analysis than ChIP-seq profiles from a different cell line. For this, we repeated the analysis using 20 randomly selected genome-wide binding profiles for the myelogenous leukemia cell line K562 from the ENCODE Project. Using 1000 random selections of 20 out of 216 TFs, we obtained a distribution representing the accuracy of models that rely on real binding profiles from a different cell line (Fig. 3f, g; "K562"). The LLR scores obtained with the CRC ChIP-seq profiles were significantly greater than the mean of this distribution for the up-analysis, but not significantly larger in the down-analysis. This was surprising, since it suggests that epigenomic data might have similar explanatory power regardless of the associated cancer type. We noted that many of the K562 ChIP-seq profiles were highly similar to the CRC ChIP-seq profiles and, therefore, likely represented the same or related TFs (Additional file 1: Figure S13). The analysis was repeated using 20 TF ChIP-seq profiles from the K562 cell line that were randomly selected from a pool comprising 90 profiles that were most dissimilar to CRC profiles. This resulted in a distribution of LLR scores (Fig. 3f, g; "K562-distinct") that is closer to the null distribution and reveals the CRC profile-based LLR score to be highly significant—10.6 and 13.2 standard deviations above mean of the distribution (from K562-distinct profiles) for down- and up-analyses, respectively.
While the above analyses examined the significance of the entire set of 20 TF profiles from a CRC cell line, we also sought to quantify the significance of each of those TF profiles individually. To test the significance of the contribution of a particular TF's CRC ChIP-seq profile, we assessed the LLR score of a model based on 20 profiles consisting of the TF profile of interest and 19 randomly selected K562-distinct ChIP-seq profiles. We repeated this procedure 100 times and counted the frequency with which the CRC TF profile was ranked at the top of the 20 TFs. This was referred to as the "top-rank frequency" of the TF. A top-rank frequency close to 1 suggests that whenever this TF profile is used along with other profiles to model gene expression data in the CRC cell line, it tends to contribute the most to model performance. Figures 3h and i show this measure of each TF's significance for down- and up-analysis, respectively, and the average LLR score of models that utilized that TF's CRC profile. We noted that 6 out of 7 TFs ranked near the top in Fig. 2b, c also have a top-rank frequency equal to or close to 1, providing us with an objective way to assess CRC-relevant TFs, beyond the rankings shown in Fig. 2.
Experimental validation of JunD as a regulator of CRC invasiveness
Our analyses above revealed the TFs JunD and FOSL1 as being significantly related to the transcriptional changes seen across different stages of CRC progression. Both TFs were predicted to be activators, according to down- as well as up-analysis. These TFs are part of the AP-1 complex, which has been previously reported to regulate multiple processes related to tumor invasiveness in a variety of cancers, including colorectal [32,33,34]. Here, we experimentally tested the role of one of these predicted TFs, JunD, in CRC migration and invasiveness. Knockdown of JunD (Fig. 4a) impaired both migration (Fig. 4b) and invasion (Fig. 4c) of SW480 cells. It is noted that SW480 cells display low levels of invasiveness (Additional file 1: Figure S1). Therefore, to determine the effects of disrupting JunD expression in a highly invasive cell model, JunD knockdown was repeated in the two SW480-M6 lines. In both lines, decreased expression of JunD caused marked reductions in migration and invasion (Additional file 1: Figure S14). Proliferation was not appreciably affected by disruption of JunD in either M0 or M6 cells (Additional file 1: Figure S15). Because the expression of AP-1 components can be auto-regulated by other AP-1 factors (e.g., [35]), we assessed the expression of various AP-1 genes following JunD knockdown. Using a q-value cutoff of 0.1, only FOSL1 and JunD were significantly downregulated (Additional file 4: Table S3). Collectively, these findings suggest that AP-1-mediated transcriptional activation of target genes may be integral to the invasion process in colorectal cancer.
Knockdown of JunD impairs cell migration and invasion. a Immunoblot of JunD and α-tubulin in lysates from SW480 (M0) cells expressing JunD shRNA knockdown (shJunD) or scramble control (shScr). b Migration for JunD knockdown (blue line) and scramble control (Scr; red line) was monitored continuously over 40 h using a xCelligence realtime cell analysis platform with cell invasion migration (CIM) plates. Fetal bovine serum was used as a chemoattractant. Cell index (arbitrary units) corresponds to cell migration capacity. Dotted lines represent the standard deviation (SD) of three independent cultures measured in parallel. c Cell invasiveness was measured continuously for 60 h using CIM plates that were precoated with Matrigel. All other parameters are the same as for b
Characterization of TF "regulons" underlying CRC progression
In addition to identifying regulators of CRC invasiveness, our model also gives us the opportunity to characterize the genes that are potentially regulated by each TF and may thus act as mediators of a TF's regulatory influence on CRC invasiveness. To identify candidate target genes, we first examined the posterior probability of the hidden variable Zg (for each gene g) being equal to one. This event indicates that the model considers the gene as mediating the influence of one or more TFs on the transcriptomic changes between stages. We thus computed the posterior odds ratio ("POR") Pr(Zg = 1| data)/Pr(Zg = 0| data) for each gene under the trained model. We then removed all cis-regulatory evidences corresponding to a particular TF ("T"), from the inputs to the model and recomputed the POR. We used the ratio of these two PORs (the full model and without the TF T), called ratio of posterior odds ratios ("RPOR"), as a measure of the TF's regulatory influence on that gene. The genes with the highest RPOR scores for each TF provide us a computational prediction of that TF's target genes or "regulon."
To characterize JunD targets experimentally, SW480-M0 cells were transduced with lentiviral particles expressing shRNA against JunD or a scramble control shRNA. RNA-seq identified 2133 genes that are differentially expressed (p-value < 0.05) upon JunD knockdown. This set, henceforth called "JunD-KD-DE," is expected to include both direct targets of JunD as well as indirect targets. The differentially expressed genes were significantly enriched (hypergeometric test p-value 0.002) for the genes that were differentially expressed between M0 and M6 cells and also model-predicted to be JunD targets (top 500 RPOR scores in down-analysis), further supporting a central role for JunD in driving the transcriptomic changes associated with CRC progression. We subsequently tested if the JunD-KD-DE gene set was enriched in the model-predicted mediators of JunD. As shown in Fig. 5b, for varying thresholds for defining predicted mediators, the enrichment was statistically significant at a nominal p-value threshold of 0.05. The overlap between the top 500 predicted mediators and the JunD-KD-DE set was significant with a p-value of 3E−5 (Fig. 5a). Notably, the top 10 predicted mediators included 5 genes that were DE upon JunD knockdown: SERINC2, COBL, FGF3, KALRN, and CLDN4. This suggests that our computational procedure correctly identified JunD targets through cis-regulatory evidences based on its ChIP-peaks and dynamic epigenomic information.
TF regulons provide a gene signature of prognostic value. a Venn diagram showing the top ~ 500 predicted target genes with the highest RPOR in the down-analysis and 1981 JUND-KD-DE genes with p-value < 0.05. Their intersection (87 genes) has a hypergeometric test p-value of 3E−5. b Significance (-log10 of hypergeometric test p-values) of the overlap between the JUND-KD-DE gene set and predicted target gene sets of varying sizes. The target genes were predicted based on their RPOR value in the down-analysis. The dashed horizontal line represents a p-value of 0.05. c, d The Kaplan-Meier survival analysis performed on the overall survival of 374 COAD patients from TCGA. In c, patients are clustered into four groups using expression profiles of the top 70 genes with the highest RPOR in our down-analysis, as well as somatic mutations associated with these genes and the expression of miRNAs targeting them. In d, patients are clustered into three groups using the expression profiles of all genes, as well as with somatic mutations associated with them and the expression profiles of miRNAs targeting the genes
A subset of genes that were computationally predicted to be mediators of JunD influence on CRC progression is tabulated in (Additional file 5: Tables 1, 2). These genes were differentially expressed upon knockdown of JunD and were differentially expressed between stages. Notably, these predicted mediators include a number of genes that are individual prognostic markers for CRC survival and factors that have been implicated in tumor metastasis, whether in colorectal cancer or in other solid tumor types. For example, ELF3 [36, 37], ITGA6 [38, 39], DLG3 [40], LRP11 [41], and TPBG [42] have all been linked to the WNT/β-catenin signaling pathway. Dysregulation of WNT signaling is a hallmark of colorectal cancer that controls processes relating to cancer development and progression [43]. Some dysregulated genes provide possible links between various cancer-associated pathways. In addition to promoting proliferation mediated by WNT signaling, ITGA6 is regulated by MYC in CRC [44], suggesting that the gene may be part of a feed-forward mechanism between MYC and WNT signaling [39]. GDF15 is a member of the TGF-β superfamily that has been shown to promote CRC metastasis in vitro and in vivo through activation of the Smad2/3 pathway via binding to the TGF-β receptor [45]. GDF15 has been shown to be activated c-Fos [46], an AP-1 component, which is consistent with the altered expression noted in JunD knockdown cells. Another gene involved in TGF-β signaling [47], MGAT5, has been linked to tumor growth [48, 49] and invasion [50, 51], as well as maintenance of colon cancer stem cells [49]. The identification of genes linked to known pathways related to CRC development and progression lends further validity to the analytical approach.
In light of the promising results above indicating our ability to identify TF targets that are coordinately regulated (regulons), we extended the approach to identify the highest confidence mediators of 7 TFs' influence on CRC invasiveness (union of top 5 TFs in up- and down-analyses), thus constructing a "gene signature" of the phenotype. We used this signature to cluster multi-omics profiles (gene expression, miRNA expression, and somatic mutations) of colorectal cancer patients from the TCGA database [52], and performed survival analysis on the resulting clusters (see the "Methods" section). The clustering was performed after limiting the omics profiles to genes in the signature, using the network-guided clustering pipeline in the KnowEnG system [21] for clustering somatic mutation profiles. We performed the analysis using different numbers of clusters (3 or 4), size of signature (50, 70, or 100 genes), degrees of influence of the network (smoothing factor of 0.3 or 0.8), and network types (protein-protein interaction network or pathway co-membership network). Survival analysis using the best of these parameters (Fig. 5c) showed statistically significant difference in survival characteristics of patient clusters (log-rank test p-value 0.0007, adjusted p-value 0.03 after correcting for multiple modes of clustering). This result was comparable to the best clustering obtained using the complete dataset (i.e., no filtering of genes) (Fig. 5d, Additional file 4: Table S4, p-value 0.0006), indicating that the gene signature was able to capture the survival-related information present in the complete multi-omics profiles in only a small subset of genes. Moreover, survival analysis using the model-based gene signature yielded better stratification of patients than when using the top genes based on differential expression between stages (Additional file 4: Table S4) (this latter analysis was also repeated with different settings of the clustering parameters, for a fair comparison to the above results).
We present here a comprehensive multi-omics approach to investigate the cis-regulatory mechanisms underlying the biological processes marked by large-scale transcriptomic changes. By adopting this approach to the study of CRC invasiveness in a well-controlled experimental setting, we identified the major regulators of this process as well as some of their key mediators. Our approach identified numerous TFs and downstream targets known to be involved in the metastasis-related process, as well as additional factors that have not yet been directly studied in the context of tumor progression (or in the context of colorectal cancer, specifically). Identifying these latent changes has the potential to greatly improve our understanding of the complex regulatory processes that control the metastatic progression and to help identify novel features of cancer that can be therapeutically targeted. While many cancers share common general features (e.g., alterations that affect conserved oncogene-related pathways), the specific pathway disruptions within each cancer are largely unique and dynamic. This is true not only at the "cancer type" level, but also at the inter- and intra-individual levels.
Our approach is complementary to a large body of work that seeks to identify regulators based on correlations in transcript levels of TFs and their targets [18] ("trans" evidence), in some cases augmented with data on TF-DNA binding ("cis" evidence) [19]. The co-expression approach, including that of the popular WGCNA tool [53], is better suited to characterizing conserved changes that occur across a large numbers of samples for which expression profiles are available, e.g., from patient data in TCGA cohorts [54]. However, when investigating specific stages, subtypes, and/or features of a given cancer, sample numbers are usually restricted, which limits the suitability of those approaches. In our experimental paradigm, where we seek to characterize CRC invasiveness in a highly controlled setting using only a handful of biological samples, the correlation-based approach is far less practical. However, it is still possible to discern transcriptomic and epigenomic shifts with statistical significance, and our analysis exploits this source of information to connect TFs to their target genes. Our use of dynamic epigenomic evidence was crucial to the effectiveness of our approach, as we found by comparing its predictive ability to alternatives where the same model was trained with such evidence partially or completely removed. At the same time, we believe that further work is needed to fully understand the pros and cons of relying on changes in histone marks versus simply the presence of these marks. Another important feature of our analysis is its simple approach to account for directionality of regulatory influences. In assigning each TF and each dynamic histone mark a learnable weight (whose sign indicates activating/repressive influence), we made a simplification that allows us to learn the predominant value of that cis-regulatory evidence from the data. We observe the learned weights to be consistent between analyses, arguing for their reliability, and found them also to agree with previously reported interpretations of the histone marks.
One of the surprising findings from our comparisons of different schemes was the poor performance of the DiffAcc scheme, where a TFBS is considered functional if it overlaps an ATAC-seq peak exclusive to one of the stages. This scheme is thus similar to the DiffMark scheme but relies on accessibility profiles instead of histone mark profiles. Its cross-validation performance was poor compared not only to DiffMark but also the TFBS-only scheme, which completely ignores accessibility data. It is possible that our implementation of this scheme requires a more careful definition of differential accessibility, and future work will reveal the strength of this approach. Indeed, our alternative strategy for utilizing accessibility profiles—the PresAcc scheme—did exhibit better predictive ability than TFBS-only in the up-analysis. The relative failure of the DiffAcc scheme may also have a biological reason: accessibility changes during CRC progression may be more quantitative, and therefore, inadequate information is captured when represented as a binary change, compared to histone mark changes. As such, our approach of using accessibility events as a binary variable could err in the trade-off between sensitivity and specificity.
We note that the analysis framework in our work bears superficial resemblance to a classification setting, where the cis-regulatory evidences associated with a gene may be used to predict the differential regulation of that gene. This would require a hard threshold on the differential expression p-value, and demand that every designated DE gene bears one or more cis-regulatory evidences. Our probabilistic approach avoids the use of hard thresholds on differential expression and retains the information about DE strength as reflected in the p-value. Furthermore, it allows for the possibility that many DE genes may lack cis-regulatory evidences, perhaps due to the limitations of our ability to recognize those evidences. Another technical point worth noting is that our modeling was performed separately for upregulation and downregulation between stages. The pGENMi model attempts to explain the p-values of differential expression, but these p-values do not contain information on the directionality of the expression changes. As such, in a "combined" analysis, where both types of differential expression p-values are present, the model attempts to use the same cis-regulatory evidence, with the same weight, to explain both up- and downregulation and will be confounded; the resulting weights will be less reliable. This is the primary reason why we separated the up- and down-analyses.
The analytical approach we describe herein offers several opportunities for expanded mechanistic and computational studies. Firstly, our analysis identified TFs known to play an important role in CRC invasiveness, as well as additional TFs with a less-defined contribution. Our method does not directly predict the overall direction of influence, however. For example, our approach is unable to predict whether the knockdown of JunD would be expected to increase or decrease cellular invasiveness, only that JunD disruption would likely alter the phenotype. Future work may address this by explicitly modeling phenotypic difference as a function of gene expression changes, which in turn are related to regulator influences. Such multi-level networks of influence (from TFs to genes to phenotype) will be an important frontier of research. A second direction of improvement will be to incorporate cis-regulatory evidences in a non-binary manner. For simplicity of modeling, we currently encode each combination of TF and histone mark through a binary evidence per gene; the strengths and multiplicity of such evidence may be rigorously accounted for in future models, perhaps borrowing from previous work in the context of TFBS analysis [55]. Finally, it will be exciting to integrate the multi-omics data and analysis presented here with information about TF-gene co-expression from patient cohort studies such as those in the TCGA [54] and clinical trials.
Cell line generation
SW480 (CCL-228) cells were obtained from the American Type Culture Collection (ATCC, Manassas, VA) and maintained at 37 °C in a humidified incubator with 5% CO2 atmosphere. Cells were cultured using Dulbecco's modified Eagle's medium (Corning Life Sciences, Corning, NY) supplemented with 10% FBS (MilliporeSigma, Burlington, MA), 100 U/mL penicillin (Corning), and 100 μg/mL streptomycin (Corning). For selection of invasive sub-populations, SW480 cells were serum-starved in FBS-free culture media for 16 h and released from the culture plate surface using 0.05% Trypsin (Corning). Two million cells were plated in FBS-free culture media in 8.0-μm permeable transwell supports (Corning) that had been coated with Matrigel Growth Factor Reduced (GFR) Basement Membrane Matrix (Corning) and set in 6-well plates containing media supplemented with 10% FBS as a chemoattractant. Cells were allowed to invade for 24 h. Invaded cells were harvested from the underside of supports using Trypsin. Cultures were expanded, and the invasion process was repeated. Cell lines were periodically monitored for mycoplasma using Hoechst staining (MilliporeSigma). Culture health and identity were monitored by microscopy and by comparing population doubling times to baseline values recorded at time of receipt. Additional authentication of this cell line above that described was not performed.
Knockdown of JunD
To disrupt JunD expression, shRNAs from The RNAi Consortium (TRC) were screened for knockown potential in SW480 cells by transient transfection of purified plasmid using Mirus TransIT-LT1 (Mirus Bio, Madison, WI) followed by western blotting to monitor JunD expression (MAB5526 antibody; R&D Systems, Minneapolis, MN). TRC clone TRCN0000014975 was found to reduce JunD expression to the greatest extent (data not shown) and was used in subsequent experiments. Lentiviral plasmids were co-transfected with packaging vectors psPAX2 (Addgene plasmid #12260; a gift from Didier Trono) and pMD2.G (Addgene plasmid #12259; a gift from Didier Trono) into HEK293T/c17 cells (ATCC) using Mirus TransIT-Lenti. Virus-containing medium was collected 48 h after transfection and cleared of potential cells using 0.45-μm Steriflip filters (MilliporeSigma). Virus-containing media were mixed with Polybrene (MilliporeSigma) for transduction. Expression of JunD was assessed using the MAB5526 antibody. Scramble control shRNA on the same vector backbone (pLKO.1-puro non-target control shRNA; MilliporeSigma) was used as a control.
Measurements of cell migration, invasion, and proliferation
Cell migration and invasion were assessed using an xCELLigence Real Time Cellular Analysis (RTCA) DP instrument (Acea Biosciences, San Diego, CA). Migration was measured using uncoated CIM-Plate 16 (Acea) plates. For invasion assessments, plates were pre-coated with a 1:20 dilution of Matrigel GFR (Corning). To monitor invasion and migration, cells were serum-starved for 16 h, collected by trypsinization, and plated at 200,000 viable cells per well in the top chamber of a CIM-Plate 16. Viable cell counting was performed using propidium iodide staining with quantitation on an Acea NovoCyte 3000 RYB flow cytometer. Ten percent of FBS-containing media was used as a chemoattractant in the bottom chamber. Cells were allowed to settle for 10 min at room temperature prior to loading CIM-Plates onto the xCELLigence DP. Impedance data were acquired at 15-min intervals for 40 h (migration) and 60 h (invasion). Proliferation was assessed using an xCELLigence RTCA MP instrument (Acea). Transduced cells were plated at 20,000 viable cells per well in E-Plate View 96 plates, allowed to settle for 10 min at room temperature, and loaded onto the xCELLigence MP, and impedance data acquired at 15-min intervals for 60 h.
Transcriptome sequencing (RNA-seq)
Total RNA was extracted using the Direct-zol RNA Kit (Zymo Research, Tustin, CA). For the assessment of parental SW480 cells and selected invasive lines, TruSeq (Illumina) libraries were prepared, and paired-end 150 base pair sequencing was performed on an Illumina HiSeq 4000 (San Diego, CA) in the Mayo Clinic Medical Genome Facility. For studies related to JunD knockdown, TruSeq Stranded mRNA libraries were prepared and sequenced on an Illumina NovoSeq 6000 using a 150 PE flow cell at the University of Minnesota Genomics Center.
Differential expression analysis on RNAseq data
Adapter sequences were removed using the TrimGalore wrapper around Cutadapt [56], and reads were aligned to the human genome (hg19) using HISAT2 [57]. Transcript assembly and quantification were performed using StringTie [58]. For DE analysis, Ballgown [59] was used to calculate log2 fold changes, p-values, and false discovery rates (FDR).
Chromatin immunoprecipitations
Five million actively growing cells were collected, suspended in PBS, and cross-linked using 1% formaldehyde (final concentration). Cross-linking was quenched using 125 mM glycine at room temperature, followed by two washes using PBS. Cells were pelleted and resuspended in cold lysis buffer consisting of 1% Triton-X, 0.1% sodium deoxycholate, proteinase inhibitor cocktail (MilliporeSigma), and Tris-EDTA solution. Lysates were incubated on ice for 10 min, diluted with TE, sonicated for 15 min (30 s on/30 s off) using a Bioruptor Pico (Diagenode, Denville, NJ), and cleared using centrifugation. Supernatants were transferred to a fresh tube, and DNA content was determined using Qubit fluorometric quantification (Thermo Fisher Scientific, Waltham, MA). Chromatin was incubated with relevant antibodies and isolated using protein G couple magnetic beads (Thermo Fisher). Beads were washed with a buffer consisting of 50 mM Tris-HCl, 10 mM EDTA, 100 mM NaCl, 1% Triton X-100, 0.1% sodium deoxycholate at pH = 8.1, followed by a high salt buffer containing 500 mM NaCl (all other components remained the same) and LiCl buffer (10 mM Tris-HCl, 0.25 M LiCl2, 0.5% NP-40, 0.5% sodium deoxycholate, 1 mM EDTA, pH = 8.0). Bound chromatin was eluted and crosslinking reversed. DNA was treated with RNase A and proteinase K before being purified using the Qiagen MinElute PCR Purification Kit (Valencia, CA). ChIP-seq libraries were prepared from ChIP DNA using the NEBNext Ultra II DNA Library Prep Kit (New England Biolabs, Ipswich, MA). Libraries were sequenced to 51 base pairs using paired-end mode on an Illumina HiSeq 4000 (San Diego, CA) in the Mayo Clinic Medical Genome Facility.
Antibodies used for ChIP consisted of anti-H3K27ac (8173; Cell Signaling Technology, Danvers, MA), anti-H3K4me1 (ab8895; Abcam, Cambridge, MA), anti-H3K4me3 (purified antibody generated in-house by the Mayo Clinic Epigenomics Development Lab, Rochester, MN [60], and anti-H3K27me3 (9733, Cell Signaling Technology).
ChIP-seq data analysis
Sequences were aligned to the human genome (hg19) using Bowtie2 [61]. Peak calling for H3K27ac, H3K4me1, and H3K4me3 signals was performed using MACS2 [62]. SICER [63], which was used to call peaks for H3K27me3 data. FDR thresholds of 0.01 were used for all peak calling.
ATAC-seq library construction was performed as previously described [64]. Fifty thousand cells were lysed in cold ATAC-Resuspension Buffer (RSB) containing 0.1% NP40, 0.1% Tween 20, and 0.01% digitonin on ice. Lysis buffer was washed out with cold ATAC-RSB containing 0.1% Tween 20 followed by centrifugation at 4 °C. Nuclei-containing pellets were resuspended in transposition mix containing Tagment DNA buffer (Illumina), Tn5 Transposase (Lucigen, Middleton, WI), and 0.05% Tween 20. Reactions were incubated for 30 min at 37 °C with constant agitation. Transposed DNA was purified using QIAgen MinElute columns. DNA was amplified using Nextera sequencing primers (Illumina) and NEB High Fidelity 2× PCR Master Mix (New England Biolabs) for 3–5 cycles. PCR-amplified DNA was purified using QIAgen MinElute columns and sequenced to 51 base pairs using paired-end mode on an Illumina HiSeq 4000 in the Mayo Clinic Medical Genome Facility. Adapter sequences were removed using the TrimGalore wrapper around Cutadapt [56], and reads were aligned to the human genome (hg19) using Bowtie2 [61]. Duplicate reads were removed using Picard Tools [65]. Peak calling was performed using MACS2 [62].
Gene set characterization of DE genes
Up- and downregulated genes with adjusted p-value < 0.05 were separately analyzed for enrichment of gene sets from the mSigDB [22] collection (C2, C4, C6, C7) using the KnowEnG [21] platform's Gene Set Characterization pipeline without network guidance.
TF-DNA binding profiles
TF ChIP-seq data for the colon cancer cell line HCT116 (20 TFs) were downloaded from the ENCODE Project web site (see Additional file 4: Table S1). These included all 20 TFs for which the available ChIP-seq profiles had high read depth. Data for the K562 cell line (216 TFs) were downloaded from the same source (Additional file 4: Table S5).
pGENMi input generation
DiffMark
We first determined dynamic histone mark sites as histone modification ChIP-peaks (FDR 0.01) present in both replicates of either M0 or M6 profiles but without an overlapping ChIP-peak for the same modification in the other stage. These sites were grouped separately by the identity of histone modification and by the direction of change ("down"—present only in M0; "up"—present only in M6). The DiffMark evidence was then generated by intersecting the ENCODE TF binding sites from HCT116 cell line with dynamic histone mark sites, retaining information about the histone mark type and direction of change. The cis-regulatory evidence representing a TF T and dynamic histone mark M for gene g was set to 1 if the binding site of T overlapped a dynamic histone mark of type M within distance d upstream or downstream of the gene; if such evidence was present for histone mark in the up direction as well as the same mark in the down direction, only the direction associated with the largest change was considered. In different tests, the parameter d was set to 10 kb, 50 kb, 200 kb, or 1 Mb.
DiffMarkAggr
DiffMark evidence was used to generate the DiffMarkAggr evidence by computing the disjunction of the binary cis-regulatory evidences of all histone marks for each direction separately. This resulted in two evidence bits per TF, gene pair and a 40-dimensional evidence vector representing all 20 TFs.
PresMark
The presence of ChIP peak (FDR 0.01) of a specific histone modification, in either stage, overlapping with a TF ChIP peak within the distance threshold, was encoded as "1" and zero otherwise. This resulted in four evidence bits per TF (one for each histone modification), gene pair and an 80-dimensional evidence vector representing all 20 TFs.
DiffAcc and PresAcc
Using ATAC-seq profiles, DiffACC evidence was produced by a similar procedure as DiffMark, except that ATAC-seq peaks (FDR 0.05) were used in place of histone mark ChIP-seq peaks to intersect with TFBS. This gave us two evidence bits (one for either direction of accessibility change) per TF, gene pair, and a 40-dimensional evidence vector overall. In generating the PresACC evidence, the presence of an ATAC-seq peak in either stage, overlapping with a TF ChIP peak within the distance threshold, was encoded as "1" and zero otherwise. This resulted in a 20-dimensional evidence vector for each gene.
TFBS-only
Finally, the TF ChIP profiles were used to generate TFBS-only evidence with the presence of TFBS for a gene encoded to one leading to a 20-dimensional evidence per gene.
DE genes
We analyzed 17,200 protein-coding genes for which the annotations were downloaded from GENCODE [66]. To study the mechanisms leading to the upregulation and downregulation of genes separately, in the down- (resp. up-) analysis, we replaced DE p-values with 1 − p-value for every gene with fold change greater (resp. less) than 1.
pGENMi model
The pGENMi model was presented in [26], and we outline it here with terminology suitable for our context. The model uses a hidden binary variable Zg for each gene g, representing whether or not the gene's differential expression is associated with one or more of the TFs. Each cis-regulatory evidence contributes with a unique weight to the prior probability of this hidden variable as follows:
$$ \Pr \left({Z}_g=1\right)=\frac{1}{1+\exp \left(-\left({w}_0+\sum \limits_t\sum \limits_m{w}_{tm}{r}_{gtm}\right)\right)} $$
where rgtm represents a (binary) cis-regulatory evidence in the form of a binding site for TF t, flagged by dynamic histone mark m, in the regulatory region of gene g, and wtm is the weight associated with it (same for all genes).
The distribution of the DE p-value Pg of a gene g is conditioned on Zg. If Zg = 1, this p-value follows a beta distribution with trainable parameter α, which specifies the skewness of the distribution toward the significant p-values; if Zg = 0, Pg is assumed to be uniformly distributed.
$$ {P}_g=\left\{\begin{array}{c}\mathrm{Unif}\left(0,1\right)\ if\ {Z}_g=0\\ {}\beta \left(\alpha, 1\right)\ if\ {Z}_g=1\end{array}\right. $$
The model is trained by maximizing the regularized likelihood of the data, assuming the genes to be independent. L2-regularization was used in the objective function, as shown below:
$$ \mathcal{L}\left(\theta \right)=\log \left(\underset{\theta }{\Pr}\left(\overrightarrow{P_g}\right)\right)-\lambda\ \sum \limits_t\sum \limits_m{w}_{tm}^2 $$
where \( \overrightarrow{P_g} \) is the vector of DE p-values of all genes, θ is the set of all trainable parameters {\( \overrightarrow{w},\alpha \)}, and λ is the regularization coefficient, a hyper-parameter of the model. The explanatory power of a model utilizing the given cis-regulatory evidences (H1) is measured by the difference between its log-likelihood and that of a null model (H0) that does not use cis-regulatory evidence:
$$ LLR=\mathit{\log}\left(\underset{\theta_1}{\Pr}\left(\overrightarrow{P_g}|{H}_1\right)\right)-\mathit{\log}\left(\underset{\theta_0}{\Pr}\left(\overrightarrow{P_g}|{H}_0\right)\right) $$
The factorized-weights pGENMi (fw-pGENMi) model has the same formulation as pGENMi, except that the free parameter wtm is replaced by wtwm, where wt is a free parameter for TF t and wm is a free parameter for dynamic histone mark m. With 20 TFs and four histone marks that can change in either of two directions, this model uses only 28 weights to aggregate the regulatory evidence, as opposed to pGENMi, which requires 160 weights. The model was trained using a distance threshold of 50 kb, derived from pGENMi cross-validation runs (Fig. 2a), and the regularization coefficient was retrained.
pGENMi and fw-pGENMi were implemented in PyTorch, and model optimization was performed using the Adam stochastic gradient descent variant [67].
Dissimilarity criterion in "K562-distinct" scheme
To find the TF ChIP-seq profiles from K562 cell line that are most dissimilar to the CRC TF ChIP-seq profiles, first the DiffMark cis-regulatory evidence matrix was computed using ChIP-seq data of 216 TFs from K562. For each gene, the disjunction of all eight bits corresponding to a TF was used as a feature representing that TF's cis-regulatory evidence associated with the gene, and the TF was then represented by a feature vector, with one feature per gene. Next, the pairwise similarity between each K562 profile and CRC profile was calculated by the Jaccard similarity score between their corresponding feature vectors. For each K562 TF profile, the highest similarity score to a CRC TF profile was used as the "CRC similarity score" associated with the K562 TF, and all K562 TFs were ranked by their CRC similarity score. Some of the CRC TFs were also profiled for DNA-binding in K562 cell line, and we chose the minimum CRC similarity score (~ 0.2) among these TFs to set the cutoff. The K562 TFs with CRC similarity scores less than 0.2 (90 TFs) were used in K562-distinct scheme.
Gene signature for CRC invasiveness
To construct a gene signature, we considered the top 5 TFs from up- and down-analysis under the DiffMark strategy, which included a total of 7 TFs: JUND, FOSL1, CTCF, ZFX, RAD21, MAX, and POLR2A. For each gene, we calculated the product of the RPORs associated with these top TFs and used the top 50, 70, or 100 genes ranked by this product as the gene signature. The signature was then used to cluster multi-omics profiles of 374 COAD patients from TCGA. Multi-omics clustering was performed, using the KnowEnG system, on the gene expression and somatic mutations associated with the genes in the signature, and the expression of miRNAs targeting them (miRNA-gene interactions were obtained from miRTarBase release 7.0 [68]). First, the patients were clustered using each data type (network-guided clustering was used for somatic mutation profiles), then the clustering of the cluster assignments specified the final stratification of the patients. The entire procedure was repeated for the up-analysis (RPOR_up) and down-analysis (RPOR_down) separately (Additional file 4: Table S4). Kaplan-Meier survival analysis was performed on the clustered patients using the KnowEnG system, and the log-rank test p-values, indicating the difference in the survival times of the clusters, were used to choose the best gene signature. The p-values were subjected to Bonferroni correction for all tests performed using the same gene set (model-based signature, DE genes, or unfiltered).
All datasets used and/or analyzed during the current study are available from the corresponding authors on request. Sequence data used for this study have been deposited to the NCBI Sequence Read Archive (SRA) and are accessible under BioProject number PRJNA659546 (https://www.ncbi.nlm.nih.gov/sra/?term=PRJNA659546) [69].
Tables of ENCODE accession numbers for HCT116 and K562 cell lines are provided as Additional file 4: Table S1 and Table S5, respectively. The TCGA COAD profiles were obtained from https://xenabrowser.net/datapages/?cohort=GDC%20TCGA%20Colon%20Cancer%20(COAD)&removeHub=https%3A%2F%2Fxena.treehouse.gi.ucsc.edu%3A443. The software developed here are available from https://github.com/sabagh1994/fw-pGENMi [70] and https://doi.org/10.5281/zenodo.4273220 [71].
Bray F, Ferlay J, Soerjomataram I, Siegel RL, Torre LA, Jemal A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin. 2018;68:394–424.
Leporrier J, Maurel J, Chiche L, Bara S, Segol P, Launoy G. A population-based study of the incidence, management and prognosis of hepatic metastases from colorectal cancer. Br J Surg. 2006;93:465–74.
Venook AP, Niedzwiecki D, Lopatin M, Ye X, Lee M, Friedman PN, Frankel W, Clark-Langone K, Millward C, Shak S, et al. Biologic determinants of tumor recurrence in stage II colon cancer: validation study of the 12-gene recurrence score in cancer and leukemia group B (CALGB) 9581. J Clin Oncol. 2013;31:1775–81.
Smith JJ, Deane NG, Wu F, Merchant NB, Zhang B, Jiang A, Lu P, Johnson JC, Schmidt C, Bailey CE, et al. Experimentally derived metastasis gene expression profile predicts recurrence and death in patients with colon cancer. Gastroenterology. 2010;138:958–68.
Loboda A, Nebozhyn MV, Watters JW, Buser CA, Shaw PM, Huang PS, Van't Veer L, Tollenaar RA, Jackson DB, Agrawal D, et al. EMT is the dominant program in human colon cancer. BMC Med Genet. 2011;4:9.
Akhtar-Zaidi B, Cowper-Sal-lari R, Corradin O, Saiakhova A, Bartels CF, Balasubramanian D, Myeroff L, Lutterbaugh J, Jarrar A, Kalady MF, et al. Epigenomic enhancer profiling defines a signature of colon cancer. Science. 2012;336:736–9.
Cohen AJ, Saiakhova A, Corradin O, Luppino JM, Lovrenert K, Bartels CF, Morrow JJ, Mack SC, Dhillon G, Beard L, et al. Hotspots of aberrant enhancer activity punctuate the colorectal cancer epigenome. Nat Commun. 2017;8:14400.
Rokavec M, Horst D, Hermeking H. Cellular model of colon cancer progression reveals signatures of mRNAs, miRNA, lncRNAs, and epigenetic modifications associated with metastasis. Cancer Res. 2017;77:1854–67.
Zhou Q, Chipperfield H, Melton DA, Wong WH. A gene regulatory network in mouse embryonic stem cells. Proc Natl Acad Sci U S A. 2007;104:16438–43.
Herrmann C, Van de Sande B, Potier D, Aerts S. i-cisTarget: an integrative genomics method for the prediction of regulatory features and cis-regulatory modules. Nucleic Acids Res. 2012;40:e114.
Blatti C, Kazemian M, Wolfe S, Brodsky M, Sinha S. Integrating motif, DNA accessibility and gene expression data to build regulatory maps in an organism. Nucleic Acids Res. 2015;43:3998–4012.
Liu X, Wang C, Liu W, Li J, Li C, Kou X, Chen J, Zhao Y, Gao H, Wang H, et al. Distinct features of H3K4me3 and H3K27me3 chromatin domains in pre-implantation embryos. Nature. 2016;537:558–62.
Local A, Huang H, Albuquerque CP, Singh N, Lee AY, Wang W, Wang C, Hsia JE, Shiau AK, Ge K, et al. Identification of H3K4me1-associated proteins at mammalian enhancers. Nat Genet. 2018;50:73–82.
Creyghton MP, Cheng AW, Welstead GG, Kooistra T, Carey BW, Steine EJ, Hanna J, Lodato MA, Frampton GM, Sharp PA, et al. Histone H3K27ac separates active from poised enhancers and predicts developmental state. Proc Natl Acad Sci U S A. 2010;107:21931–6.
Bozek M, Cortini R, Storti AE, Unnerstall U, Gaul U, Gompel N. ATAC-seq reveals regional differences in enhancer accessibility during the establishment of spatial coordinates in the Drosophila blastoderm. Genome Res. 2019;29:771–83.
Encode Project Consortium. An integrated encyclopedia of DNA elements in the human genome. Nature. 2012;489:57–74.
Spivakov M. Spurious transcription factor binding: non-functional or genetically redundant? Bioessays. 2014;36:798–806.
Chandrasekaran S, Ament SA, Eddy JA, Rodriguez-Zas SL, Schatz BR, Price ND, Robinson GE. Behavior-specific changes in transcriptional modules lead to distinct and predictable neurogenomic states. Proc Natl Acad Sci U S A. 2011;108:18020–5.
Siahpirani AF, Roy S. A prior-based integrative framework for functional transcriptional regulatory network inference. Nucleic Acids Res. 2017;45:e21.
Huynh-Thu VA, Irrthum A, Wehenkel L, Geurts P. Inferring regulatory networks from expression data using tree-based methods. PloS one. 2010;5(9):1-0.
Blatti C 3rd, Emad A, Berry MJ, Gatzke L, Epstein M, Lanier D, Rizal P, Ge J, Liao X, Sobh O, et al. Knowledge-guided analysis of "omics" data using the KnowEnG cloud platform. PLoS Biol. 2020;18:e3000583.
Liberzon A, Subramanian A, Pinchback R, Thorvaldsdottir H, Tamayo P, Mesirov JP. Molecular signatures database (MSigDB) 3.0. Bioinformatics. 2011;27:1739–40.
Sokol ES, Feng YX, Jin DX, Tizabi MD, Miller DH, Cohen MA, Sanduja S, Reinhardt F, Pandey J, Superville DA, et al. SMARCE1 is required for the invasive progression of in situ cancers. Proc Natl Acad Sci U S A. 2017;114:4153–8.
Li XY, MacArthur S, Bourgon R, Nix D, Pollard DA, Iyer VN, Hechmer A, Simirenko L, Stapleton M, Luengo Hendriks CL, et al. Transcription factors bind thousands of active and inactive regions in the Drosophila blastoderm. PLoS Biol. 2008;6:e27.
Nowacka-Zawisza M, Wisnik E. DNA methylation and histone modifications as epigenetic regulation in prostate cancer (review). Oncol Rep. 2017;38:2587–96.
Hanson C, Cairns J, Wang L, Sinha S. Principled multi-omic analysis reveals gene regulatory mechanisms of phenotype variation. Genome Res. 2018;28:1207–16.
Rhie SK, Yao L, Luo Z, Witt H, Schreiner S, Guo Y, Perez AA, Farnham PJ. ZFX acts as a transcriptional activator in multiple types of human tumors by binding downstream from transcription start sites at the majority of CpG island promoters. Genome Res. 2018;28(3):310–20.
CAS PubMed Central Article PubMed Google Scholar
Jiang J, Liu LY. Zinc finger protein X-linked is overexpressed in colorectal cancer and is associated with poor prognosis. Oncol Lett. 2015;10:810–4.
Eferl R, Wagner EF. AP-1: a double-edged sword in tumorigenesis. Nat Rev Cancer. 2003;3:859–68.
Kim S, Yu NK, Kaang BK. CTCF as a multifunctional protein in genome regulation and gene expression. Exp Mol Med. 2015;47:e166.
Aitken SJ, Ibarra-Soria X, Kentepozidou E, Flicek P, Feig C, Marioni JC, Odom DT. CTCF maintains regulatory homeostasis of cancer pathways. Genome Biol. 2018;19:106.
Ozanne BW, Spence HJ, McGarry LC, Hennigan RF. Transcription factors control invasion: AP-1 the first among equals. Oncogene. 2007;26:1–10.
Juneja M, Ilm K, Schlag PM, Stein U. Promoter identification and transcriptional regulation of the metastasis gene MACC1 in colorectal cancer. Mol Oncol. 2013;7:929–43.
Lu J, Zhang ZL, Huang D, Tang N, Li Y, Peng Z, Lu C, Dong Z, Tang F. Cdk3-promoted epithelial-mesenchymal transition through activating AP-1 is involved in colorectal cancer metastasis. Oncotarget. 2016;7:7012–28.
Angel P, Hattori K, Smeal T, Karin M. The jun proto-oncogene is positively autoregulated by its product, Jun/AP-1. Cell. 1988;55:875–85.
Wang JL, Chen ZF, Chen HM, Wang MY, Kong X, Wang YC, Sun TT, Hong J, Zou W, Xu J, Fang JY. Elf3 drives beta-catenin transactivation and associates with poor prognosis in colorectal cancer. Cell Death Dis. 2014;5:e1263.
Liu D, Skomorovska Y, Song J, Bowler E, Harris R, Ravasz M, Bai S, Ayati M, Tamai K, Koyuturk M, et al. ELF3 is an antagonist of oncogenic-signalling-induced expression of EMT-TF ZEB1. Cancer Biol Ther. 2019;20:90–100.
Groulx JF, Giroux V, Beausejour M, Boudjadi S, Basora N, Carrier JC, Beaulieu JF. Integrin alpha6A splice variant regulates proliferation and the Wnt/beta-catenin pathway in human colorectal cancer cells. Carcinogenesis. 2014;35:1217–27.
Beaulieu JF. Integrin α6β4 in Colorectal Cancer: Expression, Regulation, Functional Alterations and Use as a Biomarker. Cancers (Basel). 2019;12(1):41.
Hanada N, Makino K, Koga H, Morisaki T, Kuwahara H, Masuko N, Tabira Y, Hiraoka T, Kitamura N, Kikuchi A, Saya H. NE-dlg, a mammalian homolog of Drosophila dlg tumor suppressor, induces growth suppression and impairment of cell adhesion: possible involvement of down-regulation of beta-catenin by NE-dlg expression. Int J Cancer. 2000;86:480–8.
Gan S, Ye J, Li J, Hu C, Wang J, Xu D, Pan X, Chu C, Chu J, Zhang J, et al. LRP11 activates beta-catenin to induce PD-L1 expression in prostate cancer. J Drug Target. 2020;28:508–15.
He P, Jiang S, Ma M, Wang Y, Li R, Fang F, Tian G, Zhang Z. Trophoblast glycoprotein promotes pancreatic ductal adenocarcinoma cell metastasis through Wnt/planar cell polarity signaling. Mol Med Rep. 2015;12:503–9.
Basu S, Haase G, Ben-Ze'ev A: Wnt signaling in cancer stem cells and colon cancer metastasis. F1000Res 2016, 5.
Groulx JF, Boudjadi S, Beaulieu JF. MYC Regulates α6 Integrin Subunit Expression and Splicing Under Its Pro-Proliferative ITGA6A Form in Colorectal Cancer Cells. Cancers (Basel). 2018;10(2):42.
Li C, Wang J, Kong J, Tang J, Wu Y, Xu E, Zhang H, Lai M. GDF15 promotes EMT and metastasis in colorectal cancer. Oncotarget. 2016;7:860–72.
Ding Y, Hao K, Li Z, Ma R, Zhou Y, Zhou Z, Wei M, Liao Y, Dai Y, Yang Y, et al. c-Fos separation from Lamin A/C by GDF15 promotes colon cancer invasion and metastasis in inflammatory microenvironment. J Cell Physiol. 2020;235:4407–21.
Li N, Xu H, Fan K, Liu X, Qi J, Zhao C, Yin P, Wang L, Li Z, Zha X. Altered beta1,6-GlcNAc branched N-glycans impair TGF-beta-mediated epithelial-to-mesenchymal transition through Smad signalling pathway in human lung cancer. J Cell Mol Med. 2014;18:1975–91.
Kim YS, Ahn YH, Song KJ, Kang JG, Lee JH, Jeon SK, Kim HC, Yoo JS, Ko JH. Overexpression and beta-1,6-N-acetylglucosaminylation-initiated aberrant glycosylation of TIMP-1: a "double whammy" strategy in colon cancer progression. J Biol Chem. 2012;287:32467–78.
Guo H, Nagy T, Pierce M. Post-translational glycoprotein modifications regulate colon cancer stem cells and colon adenoma progression in Apc(min/+) mice through altered Wnt receptor signaling. J Biol Chem. 2014;289:31534–49.
Lee JH, Kang JG, Song KJ, Jeon SK, Oh S, Kim YS, Ko JH. N-acetylglucosaminyltransferase V triggers overexpression of MT1-MMP and reinforces the invasive/metastatic potential of cancer cells. Biochem Biophys Res Commun. 2013;431:658–63.
Song KJ, Jeon SK, Moon SB, Park JS, Kim JS, Kim J, Kim S, An HJ, Ko JH, Kim YS. Lectin from Sambucus sieboldiana abrogates the anoikis resistance of colon cancer cells conferred by N-acetylglucosaminyltransferase V during hematogenous metastasis. Oncotarget. 2017;8:42238–51.
Cancer Genome Atlas Research Network, Weinstein JN, Collisson EA, Mills GB, Shaw KR, Ozenberger BA, Ellrott K, Shmulevich I, Sander C, Stuart JM. The Cancer Genome Atlas Pan-Cancer analysis project. Nat Genet. 2013;45:1113–20.
Langfelder P, Horvath S. WGCNA: an R package for weighted correlation network analysis. BMC Bioinformatics. 2008;9:559.
Network CGA. Comprehensive molecular characterization of human colon and rectal cancer. Nature. 2012;487:330–7.
Chen J, Hu Z, Phatak M, Reichard J, Freudenberg JM, Sivaganesan S, Medvedovic M. Genome-wide signatures of transcription factor activity: connecting transcription factors, disease, and small molecules. PLoS Comput Biol. 2013;9:e1003198.
Martin M. Cutadapt removes adapter sequences from high-throughput sequencing reads. EMBnetjournal. 2011;17:10–2.
Kim D, Langmead B, Salzberg SL. HISAT: a fast spliced aligner with low memory requirements. Nat Methods. 2015;12:357–60.
Pertea M, Pertea GM, Antonescu CM, Chang TC, Mendell JT, Salzberg SL. StringTie enables improved reconstruction of a transcriptome from RNA-seq reads. Nat Biotechnol. 2015;33:290–5.
Frazee AC, Pertea G, Jaffe AE, Langmead B, Salzberg SL, Leek JT. Ballgown bridges the gap between transcriptome assembly and expression analysis. Nat Biotechnol. 2015;33:243–6.
Zhong J, Ye Z, Lenz SW, Clark CR, Bharucha A, Farrugia G, Robertson KD, Zhang Z, Ordog T, Lee JH. Purification of nanogram-range immunoprecipitated DNA in ChIP-seq application. BMC Genomics. 2017;18:985.
Langmead B, Salzberg SL. Fast gapped-read alignment with Bowtie 2. Nat Methods. 2012;9:357–9.
Zhang Y, Liu T, Meyer CA, Eeckhoute J, Johnson DS, Bernstein BE, Nusbaum C, Myers RM, Brown M, Li W, Liu XS. Model-based analysis of ChIP-Seq (MACS). Genome Biol. 2008;9:R137.
Xu S, Grullon S, Ge K, Peng W. Spatial clustering for identification of ChIP-enriched regions (SICER) to map regions of histone methylation patterns in embryonic stem cells. Methods Mol Biol. 2014;1150:97–111.
Corces MR, Trevino AE, Hamilton EG, Greenside PG, Sinnott-Armstrong NA, Vesuna S, Satpathy AT, Rubin AJ, Montine KS, Wu B, et al. An improved ATAC-seq protocol reduces background and enables interrogation of frozen tissues. Nat Methods. 2017;14:959–62.
Picard Toolkit [http://broadinstitute.github.io/picard]. Accessed 18 May 2020.
Frankish A, Diekhans M, Ferreira AM, Johnson R, Jungreis I, Loveland J, Mudge JM, Sisu C, Wright J, Armstrong J, et al. GENCODE reference annotation for the human and mouse genomes. Nucleic Acids Res. 2019;47:D766–73.
Kingma DP, Ba J: Adam: a method for stochastic optimization. arXiv 2014, 1412.6980.
Chou CH, Shrestha S, Yang CD, Chang NW, Lin YL, Liao KW, Huang WC, Sun TH, Tu SJ, Lee WH, et al. miRTarBase update 2018: a resource for experimentally validated microRNA-target interactions. Nucleic Acids Res. 2018;46:D296–302.
Ghaffari S, Hanson C, Schmidt RE, Bouchonville KJ, Offer SM, Sinha S. Invasion and migration selection in SW480 cells. Accession: PRJNA659546. Sequence Read Archive. 2020. https://www.ncbi.nlm.nih.gov/sra/?term=PRJNA659546. Accessed 26 Aug 2020.
Ghaffari S, Hanson C, Schmidt RE, Bouchonville KJ, Offer SM, Sinha S. fw-pGENMi. Github. 2020. https://github.com/sabagh1994/fw-pGENMi. Accessed 27 May 2020.
Ghaffari S, Hanson C, Schmidt RE, Bouchonville KJ, Offer SM, Sinha S. Factorized pGENMi (fw-pGENMi). Zenodo. https://doi.org/10.5281/zenodo.4273220 (2020).
The authors wish to acknowledge Seid Hamzic, Ph.D., for the analytical support.
Anahita Bishop was the primary editor of this article and managed its editorial process and peer review in collaboration with the rest of the editorial team.
This work was supported in part by the National Institutes of Health (grant R35GM131819 and U54-GM114838 to SS), the CompGen Initiative at UIUC (CompGen fellowship to SG), and the Mayo Clinic Center for Biomedical Discovery (Discovery Science Award to SMO). The funding agencies did not play any role in the design of the study; collection, analysis, and interpretation of the data; and writing of the manuscript.
Department of Computer Science, University of Illinois at Urbana-Champaign, Urbana, USA
Saba Ghaffari
Department of Genetics, Stanford University, Stanford, USA
Casey Hanson
Department of Molecular Pharmacology and Experimental Therapeutics, Mayo Clinic, Gonda 19-476, 200 First St SW, Rochester, MN, 55905, USA
Remington E. Schmidt, Kelly J. Bouchonville & Steven M. Offer
Department of Computer Science, Carl R. Woese Institute of Genomic Biology, and Cancer Center of Illinois, University of Illinois at Urbana-Champaign, 2122, Siebel Center, 201 N. Goodwin Ave., Urbana, IL, 61801, USA
Saurabh Sinha
Remington E. Schmidt
Kelly J. Bouchonville
Steven M. Offer
SG, SS, and SMO designed the study and wrote the manuscript. SG performed the data analyses. CH contributed to the data pre-processing. RES and KJB performed the laboratory experiments related to JunD knockdown studies. The authors read and approved the final manuscript.
Correspondence to Steven M. Offer or Saurabh Sinha.
Supplementary Figures.
Gene set characterization. Gene set characterization of the DE genes between early and late stages. The downregulated genes are significantly enriched for cancer-related gene signatures from mSigDB.
Annotated list of genes with SNVs that exhibited significant shifts in alternative allele frequency between M0 and M6.
Additional file 4: Table S1.
List of HCT116 TFs and their corresponding files obtained from ENCODE portal (https://www.encodeproject.org/). Table S2. Interpretations of the different combinations of signs of TF and histone mark change weights. Table S3. Expression changes in AP1-complex components upon JunD Knockdown. Table S4. Survival analysis on TCGA COAD cohort. Survival analysis of 374 patients was performed using different gene sets for clustering of omics profiles. Each row indicates the criterion used to pick the gene set (gene set type) and the setting used in the best clustering of patients in terms of survival analysis p-value (pval). The gene set was chosen to be of one of the following: 1. Using the data of all genes provided (Unfiltered). 2. Genes with the highest RPOR value in down-analysis (RPOR_down). 3. Genes with the highest RPOR value in up-analysis (RPOR_up). 4. Significantly differentially expressed genes (DE Genes). For all types of gene sets except "Unfiltered" sizes of 50, 70, and 100 were tested. To find the best clustering for the patients using each gene set, two types of networks, viz., protein-protein interaction network (PPI) and Enrichr pathway network were tested using the knowledge-guided clustering pipeline in KnowEnG; two different settings of smoothing (0.3 and 0.8), representing different levels of network-guidance, were explored. (Knowledge-guided clustering was applied only to the sparse somatic mutation data, while other types of omics profiles were clustered in the default mode.). Cluster sizes of 3 and 4 were tested. The total number of clusterings explored and followed by survival analysis, for RPOR-down and RPOR-up combined, DE Genes, and Unfiltered, are 48, 24, and 8 respectively, which were used to adjust the p-values by Bonferroni Correction (adj. p-val). Table S5. List of K562 TFs and their corresponding files obtained from ENCODE portal (https://www.encodeproject.org/).
Predicted mediators of JunD influence on CRC progression. Table 1. contains the model-predicted targets of JunD (top 500 RPOR scores in down-analysis) that were differentially expressed upon knock-down of JunD (p-value < 0.05), and were differentially expressed between stages (p-value < 0.05). Table 2. genes have the same characteristics as Table 1 genes except for being predicted as JunD targets in up-analysis.
Ghaffari, S., Hanson, C., Schmidt, R.E. et al. An integrated multi-omics approach to identify regulatory mechanisms in cancer metastatic processes. Genome Biol 22, 19 (2021). https://doi.org/10.1186/s13059-020-02213-x
DOI: https://doi.org/10.1186/s13059-020-02213-x
Transcriptional regulation
Multi-omics
Probabilistic model
Cancer Evolution and Metastasis | CommonCrawl |
CHAPTER III Applications of the Derivative (Draft- 2014 work in progress)
© 2014 M. Flashman.
Introduction: As we saw in Chapters I and II, the derivative can be a powerful analytic tool for any quantifiable scientific discipline. In many interpretations this concept consolidates information about changing relations between variables.
The symbolic and numeric methods for finding or estimating the derivative as a number or as a function make it efficient, eliminating repetitive arguments and computations, and allow the focus of its use to remain on the applications, keeping most mathematical manipulations routine and secondary.
The visual tools of graphs and mapping diagrams provide additional power to the concept by supplying alternative meanings for more abstract contexts. Applications of the derivative are not limited to those previewed in chapter I or to those that we will discuss in this chapter. In fact one could easily describe everything in this text as an application of the derivative in some fashion!
We will analyze three types of applications in this section. Each has a wide scope of impact extending well beyond the specific context in which we will see them initially.
A. Estimations: Understanding estimations is a critical part of any science that uses measurements. The key in using the derivative to estimate values lies in the assumption that a function with a derivative behaves like a function with a constant rate of change for some small interval. In this chapter we will use the derivative in two common estimation procedures. First, we will estimate the value of a function thinking of it as a position function in a motion interpretation. Then we will discuss an algorithmic process called Newton's method to estimate a zero of a function or root of an equation thinking of this number as a time when a position function is at the initial distance or graphically as the X-intercept coordinate of a curve.
B. Graphs: The important role played by graphs in current science is undeniable. It is the chief tool of visualization of data and provides an efficient vehicle for suggesting relations between variables. With the power that technology adds to the creation and display of graphs, the need for better understanding of graphical features and their analysis has risen while the need to analyze functions represented symbolically for quick and accurate drawings has diminished only slightly. As we saw in Chapter I, an understanding of the derivative can bring with it a richer appreciation for graphic function properties.
C. Modeling: It is in the sciences that the use of the derivative as a mathematical concept pays for the time and effort it takes to master its notation and rules. Without the ability to bring this abstraction into more then just the problems generated by mathematics alone, it would be hard to see why mathematics would be as prominent as the "language of science." Even with the rise of computational power through technology, the use of the derivative continues as before to describe and investigate the world through the measurement of variables.
In the next chapter we will look more extensively at the ramifications of describing a context by relating the rates at which variables change.
In this chapter we will look at models where the relation between the variables can be expressed in some equation or with a function with one controlling variable. Though this may seem limited in scope, the questions we will examine for these models are of sufficient generality to make them good prototypes for more general models.
The questions are simply how to use the information available to predict the behavior of variables under specific constraints. Just as with the graphical applications, the derivative can inform us of extremes, intervals where variables will increase and decrease, even the rates at which the rates of change change.
III.A. ESTIMATIONS USING THE DERIVATIVE
III.A.1. THE DIFFERENTIAL
MOTIVATION: Consider a jogger running on a straight track so that after 2 seconds the jogger is 10 meters from the starting point P and at that moment is moving away from P with a velocity of 3 meters/sec. I would like to approximate the position of the jogger 0.4 seconds later.
It seems reasonable to assume for this estimation that the velocity wouldn't change much in .4 of a second. So we'll treat the velocity of the jogger as a constant.
Now it should be apparent that in 0.4 of a second the jogger would move approximately (.4)(3) meters further away from P so that the jogger would be approximately 10 + 1.2 = 11.2 meters from P.
We can express this analysis more technically using some function notation. Let $t$ denote the time in seconds and $s(t)$ denote the jogger's distance from $P$ at time $t$. Then the initial facts were that $s(2) = 10$ and that $s'(2)=3$.
To estimate the change in the value of $s$ for $0.4$ seconds we multiplied $s'(2)$, the rate at which the jogger was running, by $0.4,$ the time the jogger would be running.
In symbolic form we had $s(2.4)-s(2) \approx s'(2) .4 = 3 (.4) = 1.2$.
Now we complete the analysis by adding the estimate of the change to the runners position at $2$ seconds giving $s(2.4) = s(2) + {s(2.4) - s(2)}\approx 10 + 1.2 = 11.2$.
The simple technique we used here generalizes to a method for estimating values of any differentiable function based on information about the value of the function and its derivative at a single point. The key is using the product of the value of the derivative with a small change in the controlling variable to estimate the change in the corresponding change in the function's value.
The word that has been used since Leibniz to describe the estimate for the change is the "differential."
Definition and Notation: Suppose $f$ is a function that is differentiable at $a$ and $h$ is any real number. We'll write
$df = df(a,h) = f '(a ) \cdot h$ .
df is called "the differential of f at a." As the more complete notation df (a,h) suggests, the quantity df depends on both the numbers a and h. When the notation y = f (x) is used to describe the function, then we also denote the differential with dy as well as df.
Interpretation: We can interpret the number a as a time at which we know information about the value of f. The number h can be thought of as measuring a time interval we add to (or subtract from) a to determine a later (or earlier) time at which we would like to know the function's value. The value of df is then an estimate of the change in the function's value at this later (or earlier) time, $a+h$. Thus $df(a,h) \approx f(a+h) - f(a)$.
It is important to distinguish $df$ from $Df$. The notations are very close so keep in mind:
$df$ is the differential of f which gives an estimated change in the value of the function $f$,
$Df$ is the derivative of $f$ which gives the rate of change of $f$.
REMARK: We can apply this new notation to the motivating example to focus its use more sharply. Recall that s is the distance function for the jogger which depends on the time variable $t$. The differential of $s$ at $2$ is therefore given by $ds = ds(2,h) = s'(2) h = 3 h \approx s(2+h) - s(2)$. Now using $s(2) = 10$ and $s'(2) = 3$, we have $s(2 + h) \approx s( 2) + ds = 10 + 3h$ for any $h$, and when $h = .4$ we have $s(2.4) \approx 11.2$. Of course, in the jogger situation, the closeness of this estimate depends on how the runner's velocity, $s'(t)$, actually varies between $2$ and $2.4$ seconds. It should seem reasonable to suppose that since $.4$ is close to $0$, the estimate is fairly accurate and that it would be more accurate for choices of $h$ even closer to $0$.
More on notation: The notation of the differential was introduced by Leibniz with a different view of what it represented from its current use. In particular Leibniz used the symbols dy and dt to represent the measures of very small- I mean extremely small- segments measuring the rise and run of very short sections of a curve. Thus it appears that Leibniz was interested in finding the slope of a curve by inspecting the curve very closely. This is analogous to what we might do today with the ability to zoom in with graphical technology so that the graph of a curve would appear to be indistinguishable from the graph of a line. We will continue in this section to develop the notation for differentials to allow us to make some sense out of this older view. The Leibniz notation has proved particularly successful in connecting many concepts to scientific applications.
What does $dx$ denote? Suppose $x(t) = t$ for all $t$. Then $dx= dx(a,h) = x'(a) \cdot h$. But $x'(t) = 1$ for all $t$, so $dx= h$. This bizzare consequence of the notation justifies the abuse of notation in saying that when $y = f (x)$,
$dy = df = f '(a) \cdot h = f '(a) \cdot dx$ .
It is possible now to make sense in many situations of Leibniz notation even though the original use of this notation most likely had a very different though consistent meaning to Leibniz and others historically. For example, with this notation $ \frac {df}{dx}$ and $\frac {dy}{dx}$ can be interpreted as quotients so that
$ \frac {df}{dx} =\frac {dy}{dx} = \frac{f '(a) dx}{dx} = f '(a)$.
More Notation: In Chapter I we used $h$ for some of our initial derivative estimations. We suppose again that $y= f(x)$ and let
$\Delta x = h$ and $\Delta y = \Delta y(a,h) = f(a+h) - f(a)$.
By our previous comments then
$dx = \Delta x = h$ and $\Delta y = f(a+dx)- f(a)$.
Comment on notation. In most American mathematics books the notation for the change in a variable's value uses the Greek letter upper case delta, $\Delta$ such as $\Delta x$ for change in the variable $x$ and $\Delta t$ for change in the variable t. In some physics books and British mathematics books the lower case of the same letter, $\delta$, appears, so you might see in $\delta x$ or $\delta t$. For some users of these notation a minor distinction might be made in the use...$\Delta x$ would be used for any change in the variable $x$, whereas $\delta x$ would indicate that there was a very small change in the variable $x$...so small that it would be almost imperceptible.
Estimates with the differential: The heart of the matter in making an estimate of f(a+h) with the differential is the fact that for small values of h, dy \approx \Delta y, so that $f(a + dx) = f(a)+\Delta y \approx f(a) + dy = f(a) + f '(a) \cdot dx$.
EXAMPLE: (Let's try it.) Find $dy$ when $y = f(x) = x^3 - 5x + 7$. Evaluate $dy$ when $x = 2$ and $dx = 0.3$. Use $dy$ to estimate $y$ when $x = 2.3$. Find $f(2.3)$ and $\Delta y$ exactly.
SOLUTION: Using $y = f(x)$, we have that $f '(x) = 3x^2 - 5$ so $dy = f '(a)dx = ( 3a^2 - 5 ) dx$.
To evaluate $dy$ we merely replace $a$ with $2$ and $dx$ with $0.3$ in the expression to obtain
$dy = ( 3(2)^2 - 5 ) (.3) = 2.1$
Noticing that $f(2) = (8 - 10 + 7)= 5$, we estimate
$f(2.3) = f(2 + .3) \approx f(2) + dy = 5 + 2.1 = 7.1$.
It is not hard to find $f(2.3) =(2.3)^3 - 5(2.3) + 7 = 7.667$, so that $\Delta y = 7.667 -5 = 2.667$.
It is worth noting here that the size of the error in the differential estimate of $f(2.3)$ is the difference between
$7.667-7.1 = f(2.3) - (f(2) + dy) = \Delta y - dy = 2.667 - 2.1 = .567$. We can compare this error in estimating the difference in values as a percent of the size of the precise difference $\Delta y$ to find the percent of relative error in this estimate is $0.567/2.667 = .2126 = 21.26\%$.
EXAMPLES:To see the relative quality of the estimate for values of a function using the differential let's look at the sine function values using the differential at 0. We compare these in Table 1 with the estimation values that arise from the differential. Since $\sin(0)=0$ and $\sin'(0)= \cos(0)=1$, the estimate for $\sin(0+h)$ is $\sin(0)+\sin'(0)\cdot h = h$. So Table 1 demonstrates that when $h \approx 0, sin(h) \approx h$.
[This should remind you of the fact we demonstrated in chapter I, namely that $\lim_{h \to 0} \frac {\sin(h)} h =1$.]
The errors in the estimates of this table are clearly smaller when $h$ is closer to $0$.
[Can you see why we haven't considered relative errors here?]
$\sin(h)$
9.9833416647e-02
A similar comparison for $f(x)=1/x$ using the differential at $1$ shows a less symmetric situation. Here $f(1)= 1$ and $f '(1)= -1$ so $f(1+h)$ is approximated by $f(1) + f '(1) \cdot h = 1 - h$. Table 2 shows how these estimates compare with some function values close to $1$. Again the errors in the estimates are smaller when $h$ is closer to $0$, as are the relative errors which are shown as percentages in the table.
$h$
$a=1+h$
$1/a$
relative error
Interpretation (Mapping Diagram): Assume $h =dx >0$. In the mapping diagram below [Figure 2] we have labeled the lengths of the key elements determining the differential, namely the points on the source line, $a$ and $a+dx$, and the points on the target line: f(a), f(a+dx), and the estimate based on the differential, f(a) + f '(a).dx. When $h=dx$ is small we have that the average rate of change of the f values on the interval $[a,a+h]$ is a good estimate for the instantaneous rate of change of f at a, f '(a). That is,
$ \frac {f(a+h)-f(a)} h =\frac {\Delta y}{\Delta x} \approx f'(a)$.
Thus $\Delta y = f(a+h)-f(a) \approx f'(a) \cdot h = df$.
By looking at the target line we can see the estimating value compared to the precise value of f(a+h). For the estimate, the length f(a) is increased (decreased) by the length df. When h is closer to 0, the differential's length will be closer to the length of the segment between f(a+h) and f(a), so the estimation will be more accurate.
Interpretation (The graph and the tangent line): The differential of $f$ at a can also be visualized using the interpretation of the derivative as the slope of the line tangent to the graph of $y=f(x)$ at the point $(a, f(a))$. Figure 2 shows the lengths of the key elements used in determining the differential, namely the points on the graph of $f$, $(a,f(a))$ and $(a+h,f(a+h))$, and on the tangent line $(a+h, f(a)+f '(a) \cdot h)$.
Note that the second coordinate of the point on the tangent line was determined from the fact that the slope is $f '(a)$. When $h$ is small we have that the slope of the secant line determined by $(a,f(a))$ and $(a+h,f(a+h))$ is a good estimate for the slope of the tangent line, $f '(a)$, i.e, $\frac {f(a+h)-f(a)} h =\frac {\Delta y}{\Delta x} \approx f'(a)$.
By multiplying both sides of this estimate by $h$ we find yet another way to understand the estimate
$\Delta y = f(a+h)-f(a) \approx f'(a) \cdot h = df$.
Notice how the points on the graph are paired with the arrows on the mapping diagram.
Martin Flashman, Oct 2014, Created with GeoGebra
We can examine the figure in greater detail to see how the differential is used to estimate $f(a+h)$. The vertical line segment used to measure $f(a+h)-f(a) =\Delta y$ can be compared to the vertical segment of the right triangle formed by the tangent line, the vertical line X = a+h and the horizontal line Y = f(a). The base of this triangle has length $h=\Delta x=dx$. Because the tangent line has slope f '(a) the segment on the vertical line $X=a+h$ has must have l ength $f '(a) \cdot h = dy$. Again we have a way to see that $dy/h = dy/dx=f '(a)$, the derivative is the quotient of differentials! The estimation can be seen by thinking of the point $(a+h, f(a+h))$ approximated by extending the vertical segment of the line $X=a+h$ from the point $(a+h, f(a))$ by the length $dy$.
Interpretation: (Economics): Consider a function model for the cost C of producing x kilograms of a perfectly divisible commodity. As we saw in chapter I, when we produce a kilograms, the marginal cost is C'(a). If we decide to produce an additional h kilograms of our product, we can estimate the change in our costs and our new costs with the differential at a. Thus $\Delta C \cdot dC= dC(a,h) = C'(a) \cdot h$ and $C(a+h) \cdot C(a) + dC = C(a) + C'(a)\cdot h$. [The marginal cost at $a$, which we denoted $MC(a)$ in chapter I, originally meant the change in the cost for a change of one unit of production. Now the $MC(a)$ can be connected more directly to the derivative by using the differential estimation, giving $MC(a) \cdot dC(a, 1)=C'(a)$.] See exercises.....
Interpretation: (Probability). Consider a continuous random variable $X$ with a distribution function $F$ defined on an interval $I$. The probability that $X$ is between the values $A$ and $A+h$, $Pr(A<X<A+h)$, is given precisely by $F(A+h) - F(A)$, the change in the distribution function values for the interval $[a.a+h]$. Using the differential to estimate the change in the distribution function values, we have that this probability is estimated by $dF(A,h)=F'(A)\cdot h$. Now $F'(A)$ is interpreted as the point probability density of $X$ at the number $A$, which is conventionally denoted by $f(A)$. Thus for small intervals, that is, when $h$ is small, the probability that the random variable $X$ is between $A$ and $A+h$ is approximately $f(A)\cdot h$, the value of the density function for $X$ at $A$ times the length of the interval. See exercises.
Application: A hollow spherical steel ball has an inside radius of $2$ meters and a thickness of $3$ centimeters. Estimate the volume and the mass of the steel in the wall of the ball. Discuss the relative size of the error in using the differential to make this estimate.[Assume the density of the steel is $1254$ kilograms per cubic meter.]
Solution: Let $V(r)$ denote the volume of a sphere of radius $r$. This problem asks for an estimate of the volume of the steel in the wall of a sphere, which can be expressed as $V(2.03) - V(2) =\Delta V$. The formula for the volume of a sphere says that $V(r)= 4/3 \pi r^3$. Using $a = 2$ and $h = 0.03$ and the differential we have
$\Delta V \approx dV = V'(a) \cdot h = 4 \pi a^2 \cdot h = 4 \pi 4(.03) =.48 \pi$. cubic meters.
Application: Use the differential to estimate $9^ {1/3}$ from the fact that $8^{1/3} = 2$.
Solution: Consider $f(x) = x^{1/3}$. $f(9) = f(8+1)$ so in the notation we've established we let $a=8$ and $h= dx =1$.
Thus $f(a+dx)\approx f(a) + f '(a) \cdot dx = f(8) + f '(8) \cdot 1 = 2 + (1/3)(8)^{-2/3}$ so $f(9) \approx 2 + 1/12 = 25/12$.
Notice that what made this solution possible was the ability to evaluate both $f(8)$ and $f '(8)$. This ease of computation was what actually led to the choice of $a = 8$.
Application: Use the differential to estimate 98 1/2 .
Solution: Consider $f(x) = x^ {1/2}$. $ f(98) = f(100 - 2)$ so in the notation we've established we let $a=100$ and $h=dx =-2$. Thus
$f(a+h) \approx f(a) + f '(a) \cdot h = f(100) + f '(100) \cdot (-2) = 10 + 1/2(100) ^{-1/2}\cdot (-2)$
and so $f(98) \approx 10 - 1/10 = 9.9 $.
Estimation of relative error.
The relative error of a value, $V$ in a computation is determined by measuring the error, $\Delta V$, in the computation and comparing that as a ratio with the computed value, i.e., $\frac {\Delta V} V$.
To make an estimate of the relative error, it makes sense to use $ dV \approx \Delta V$ when $V$ is a differentiable function of a controlling variable.
Example: Suppose the side of a cube is measured to be 5 meters with a possible error in the measurement of at most 1 centimeter = 0.01 meters. Estimate the relative error in using the measurement of the length of the side to compute the volume of the cube.
Solution: Let $s=5$ be the measurement of the side of the cube and $V = s^3$ be the volume of the cube, which gives us $V = 5^3 = 125$ cubic meters. The largest possible error is $\Delta s = ds = .01$.
We use $dV$ to estimate the error, $\Delta V \approx dV = 3s^2 \cdot ds$, so we find that $dV = 3 \cdot 5^2 \cdot 0.01 = 0.75$ so the relative error is approximately $ \frac {dV} V = \frac {0.75}/{125} = 0.006 = 0.6\%$
The calculus of differentials.
Since the differential of a function is directly related to the derivative of the function, we can write formulas for a calculus of differentials each of which can be justified by reference to the appropriate derivative rule. For example, if $u$ and $v$ are both functions of $x$, then $d(u.v)=udv+vdu$.
This is justified by considering the derivative product rule $D_x(u.v)=uD_x(v)+vD_x(u)$.
Hence $d(u \cdot v) = D_x(u\cdot v)dx = [uD_x(v) + vD_x(u)]dx = uD_x(v)dx + vD_x(u)dx$ $= udv + vdu$.
In the exercises for this section you will find similar results for the "differential calculus" which you are asked to justify.
Exercises III.A:
For each of the functions in problems 1-6 find (a) $f(1)$, (b) $f(1.2)$, (c)$\Delta y(1,0.2)$, and (d) $df(1,0.2)$. Check you work with the GeoGebra Applet.
1. $f(x) = x^2 + 3x$ 2. $f(x) = 5x^2 - 3x$
5. $f(x) = x^3 + x$ 6. $f(x) = 5x^3 - x$
For each of the functions in problems 7-12 use the differential to estimate the value of (a) $f(1.1)$ and (b) $f(.95)$ .Check you work with the GeoGebra Applet.
9. $f(x) = x^3 + 3x$ 10. $f(x) = 5x^3 - 3x$
11. $f(x) = x^3 + x $ 12. $f(x) = 5x^3 - x$
In problems 13-20, use the differential to estimate the indicated value.Check you work with the GeoGebra Applet.
13. $(82) ^{1/2}$ 14. $(63)^{1/2}$ 15. $(127) ^{1/3} $ 16.$(25) ^{1/3} $ 17. $\frac 1{103}$ 18. $\frac 1{998} $ 19. $(33)^{1/5}$ 20. $(29^{1/5}$
21. Use the differential to give a formula for estimating $\sqrt{x} = x^{1/2}$
when $x$ is close to (a) 100 (b) 25 (c) 81 and (d) $t$.
22. Use the differential to give a formula for estimating $\sqrt[3]{x} = x^{1/3}$
when $x$ is close to (a) 1000 (b) 125 (c) 27 and (d) $t$.
23. A circle of radius 3 meters is painted red with a edge of 10 centimeters painted blue. Use the differential to estimate the area of the region that is painted blue.
24. A spherical ball of radius 20 centimeters is coated with a shell of plastic 0.5 cm in thickness. Estimate the volume of plastic of the plastic shell.
25. A closed cylindrical tin can has radius 4 cm. and height 6 cm. Estimate the volume of the tin if the tin is 3 mm in thickness.
26. A rectangular poster that is 2 feet by 3 feet has a border of red that is 1/2 inch wide. Estimate the area of the border using the differential. Find the exact area of the border.
Justify the differential calculus formulae in problems 27-33. Assume that $u$ and $v$ are differentiable functions of $x$.
27. $d(au) = adu$ where $a$ is any real number.
28. $d(u + v) = du + dv$.
29. $d(1/v) = -dv/v^2$.
30. $d(u/v) =[vdu - udv]/v^2$ .
31. $d(\sin u) = \cos u du$.
32. $d(\sec u) = \sec u \tan u du$.
33. Suppose that $w=f(u)$ and $u=g(x)$ and $y = f(g(x))$. Prove $dy = dw/du \cdot du$ when interpreted appropriately.
34. Suppose $g$ is a differentiable function with $g(2)=5$ and $g'(2)=10$. Estimate the following:
$ g(3) , g(1.5) , g(2.1)$ and $g(1.99)$.
35. Suppose g is a differentiable function with $g(1)=2$ and $g(2)=4$. If $g'(1)=4$ and $g'(2)=2$ ,give two estimates for $g(1.5)$ using the differential. Discuss briefly how these estimates relate to the true value of $g(1.5)$.
36. Project: Suppose $L(x)$ is a differentiable function with $L(0)=1$ and for every $x > -1, L'(x)= \frac 1{1+x}$.
a) Estimate $L(1/4)$.
b) Based on your estimate for $L(1/4)$, estimate $L(1/2)$.
c) Continue. Use the estimate of $L(1/2)$ and then $L(3/4)$ to estimate $L(1)$.
d) Based on this work, suggest a method to estimate $L(1)$ more accurately. Explain with an example using your method.
37. Project: Suppose $P(x)$ is a differentiable function with $P(0)=1$ and for every $x$, $P'(x)=3\cdot P(x)$.
a) Estimate $P(1/4)$.
b) Based on your estimate for $P(1/4)$, estimate $P(1/2)$.
c) Continue. Use the estimate of $P(1/2)$ and then $P(3/4)$ to estimate $P(1)$.
d) Based on this work, suggest a method to estimate $P(1)$ more accurately. Explain with an example using your method. | CommonCrawl |
GRE考满分·题库
科目分类:
全部 填空和等价 阅读和逻辑 数学
全部 全考点能力自测题 陷阱题排坑练习 逐考点专项练习(体验版) 2021年GRE数学新170难题
题目列表
In the course of an experiment, 95 measurements were recorded, and all of the measurements were integers. The 95 measurements were then grouped into 7 measurement intervals. The graph above shows the frequency distribution of the 95 measurements by measurement interval.
The average (arithmetic mean) of the 95 measurements
The median of the 95 measurements
x is an integer greater than 1.
$$3^{x+1}$$
$$4^{x}$$
A, B, and C are three rectangles. The length and width of rectangle A are 10 percent greater and 10 percent less, respectively, than the length and width of rectangle C. The length and width of rectangle B are 20 percent greater and 20 percent less, respectively, than the length and width of rectangle C.
The area of rectangle A
The area of rectangle B
The random variable X is normally distributed. The values 650 and 850 are at the 60th and 90th percentiles of the distribution of X, respectively.
The value at the 75th percentile of the distribution of X
Set S consists of all positive integers less than 81 that are not equal to the square of an integer.
The number of integers in set S
A manager is forming a 6-person team to work on a certain project. From the 11 candidates available for the team, the manager has already chosen 3 to be on the team. In selecting the other 3 team members, how many different combinations of 3 of the remaining candidates does the manager have to choose from?
Which of the following could be the graph of all values of x that satisfy the inequality 2 - 5x ≤$$\frac{(6x-5)}{3}$$
If $$1+x+x^2+x^3=60$$, then the average (arithmetic mean) of x, $$x^2, x^3, and x^4$$ is equal to which of the following?
Parallelogram OPQR lies in the xy-plane, as shown in the figure above. The coordinates of point P are (2,4) and the coordinates of point Q are (8,6). What are the coordinates of point R ?
The relationship between the area A of a circle and its circumference C is given by the formula A = $$kC^2$$,where k is a constant. What is the value of k ?
The sequence of numbers $$a_1,a_2,a_3,...,a_n...$$is defined by$$a_n=\frac{1}{n}-\frac{1}{n+2}$$for each integer n≥1.What is the sum of the first 20 terms of this sequence?
The table above shows the frequency distribution of the values of a variable Y. What is the mean of the distribution?
Give your answer to the nearest 0.01.
Let S be the set of all positive integers n such that $$n^2$$ is a multiple of both 24 and 108. Which of the following integers are divisors of every integer n in S ?
Indicate all such integers.
The range of the heights of the female students in a certain class is 13.2 inches, and the range of the heights of the male students in the class is 15.4 inches.
Which of the following statements individually provide(s) sufficient additional information to determine the range of the heights of all the students in the class?
Indicate all such statements.
There are 275 students in the field of engineering at University X. Approximately what is the ratio of the number of students in engineering to the number of faculty in engineering?
Approximately what percent of the faculty in humanities are male?
For the biological sciences and health sciences faculty combined,$$\frac{1}{3}$$ of the female and $$\frac{2}{9}$$ of the male faculty members are tenured professors. What fraction of all the faculty members in those two fields combined are tenured professors?
_____/_____
For which of the eight years from 2001 to 2008 did exports exceed imports by more than $5 billion?
Indicate all such years.
Which of the following is closest to the average (arithmetic mean) of the 9 changes in the value of imports between consecutive years from 2000 to 2009 ?
In 2008 the value of exports was approximately what percent greater than the value of imports?
上一页 1 2 ... 29 30 31 32 33 34 35 36 37 下一页
共收录:
25000 +道题目
5本备考书籍 | CommonCrawl |
Edge channels of broken-symmetry quantum Hall states in graphene visualized by atomic force microscopy
Sungmin Kim ORCID: orcid.org/0000-0002-2804-00931,2 na1,
Johannes Schwenk1,2 na1,
Daniel Walkup ORCID: orcid.org/0000-0002-3873-497X1,2 na1,
Yihang Zeng3 na1,
Fereshte Ghahari1,2,
Son T. Le1,4,
Marlou R. Slot ORCID: orcid.org/0000-0003-0770-01251,5,
Julian Berwanger ORCID: orcid.org/0000-0003-1279-16586,
Steven R. Blankenship1,
Kenji Watanabe ORCID: orcid.org/0000-0003-3701-81197,
Takashi Taniguchi ORCID: orcid.org/0000-0002-1467-31058,
Franz J. Giessibl ORCID: orcid.org/0000-0002-5585-13266,
Nikolai B. Zhitenev1,
Cory R. Dean ORCID: orcid.org/0000-0003-2967-59603 &
Joseph A. Stroscio ORCID: orcid.org/0000-0001-9604-93241
Nature Communications volume 12, Article number: 2852 (2021) Cite this article
Electronic properties and devices
Quantum Hall
Topological matter
The quantum Hall (QH) effect, a topologically non-trivial quantum phase, expanded the concept of topological order in physics bringing into focus the intimate relation between the "bulk" topology and the edge states. The QH effect in graphene is distinguished by its four-fold degenerate zero energy Landau level (zLL), where the symmetry is broken by electron interactions on top of lattice-scale potentials. However, the broken-symmetry edge states have eluded spatial measurements. In this article, we spatially map the quantum Hall broken-symmetry edge states comprising the graphene zLL at integer filling factors of \({{\nu }}={{0}},\pm {{1}}\) across the quantum Hall edge boundary using high-resolution atomic force microscopy (AFM) and show a gapped ground state proceeding from the bulk through to the QH edge boundary. Measurements of the chemical potential resolve the energies of the four-fold degenerate zLL as a function of magnetic field and show the interplay of the moiré superlattice potential of the graphene/boron nitride system and spin/valley symmetry-breaking effects in large magnetic fields.
Nontrivial topology is often related to electronic systems with highly degenerate ground states1, the most famous recent example being twisted bilayer graphene displaying the enormous richness of physical phenomena2,3,4. The zero-energy Landau level in graphene is another well-known example of a highly degenerate electronic state. The nontrivial "bulk" topology results in specific topologically protected edge states that have been studied so far with limited success.
The integer QH effect occurs when a two-dimensional (2D) electron system is subjected to a perpendicular magnetic field5,6,7. The metrological precision of the Hall conductance is understood in terms of the topological invariant of the Chern number associated with the Berry connection8,9,10,11. The precise quantization of the Hall conductance is related to the absence of backscattering in topologically protected chiral one-dimensional edge states with opposite momentum directions at the device boundaries. Imaging of QH edge states has been challenging due to their limited spatial extent and their location at the boundaries of the quantum Hall system. A number of notable attempts include: scanning gate microscopy12, scanning single-electron transistor (SET) measurements13, scanning force microscopy14,15, scanning charge accumulation16, and scanning microwave impedance microscopy17. More recent intriguing progress in imaging quantum Hall edge states has been made using SQUID-on-tip measurements of graphene18, however, the authors were not successful in imaging any broken-symmetry states inside the graphene zLL as the technique is limited to a moderate magnetic field range.
The graphene Landau level structure is determined by a combination of the Dirac-like linear energy-momentum dispersion and the π-Berry phase associated with the Dirac point resulting in Landau energies \({E}_{N}=\pm\sqrt{2e{{\hslash }}{v}_{F}^{2}{B|N|}}\), where e is the elementary charge, \({{\hslash }}\) is Planck's constant divided by 2π, \({v}_{F}\) is the Fermi velocity, B is the magnetic field, and \(N=0,\pm1,\ldots\) is the Landau level index, resulting in a non-uniform Landau level spacing19,20. The zLL in graphene, with orbital index \(N=0\), comprises a set of fourfold degenerate Landau levels that are fixed at the Dirac point in the absence of SU(4) symmetry-breaking effects. The nature of the zLL state has been one of intense interest within the framework of quantum Hall ferromagnetism with many competing ground states21,22,23,24,25,26,27. The richness of physics in this regime is dominated by the interplay between the Zeeman energy against the sublattice anisotropy of Coulomb interactions which lift the degeneracy of the SU(4) multiplet. Indeed, extensive theoretical studies of the ground state of the zLL have shown the existence of many competing phases with distinct symmetry-breaking properties21,22,23,24,25,26,27. Among these phases are the ferromagnet (F) state and the antiferromagnet (AF) state, where the latter may form a canted antiferromagnetic (CAF) state24. Other possible phases include a charge density wave (CDW) and a Kekulé state (KD) (see Fig. 18 in ref. 24 for a phase diagram of the zLL). The delicate balance between various competing interactions can be impacted by multiple factors. For example, transitions between different ground states may be induced by changing the contribution of the Zeeman energy by tilting the magnetic field with respect to the graphene sheet26, and through other microscopic variables which break sublattice symmetry, the prominent example being the moiré-induced superlattice27.
The various ground states of zLL are predicted to have qualitatively different edge dispersions and excitations, which might or might not be revealed in a conventional transport experiment. For example, near the quantum Hall sample boundary, the isospin states may disperse into positively dispersing (electron-like) and negatively dispersing (hole-like) states, leading to gapped or gapless edge modes, depending on specific ground-state symmetries21,26,28,29. The edge dispersion of the CAF ground state was predicted to change from gapped to gapless as a function of tilted magnetic field28. Recent experimental observations of a metal–insulator transition observed in transport measurements as a function of tilted magnetic field26 have been interpreted as the evidence of the CAF ground state in accordance with theoretical predictions28. More recent theory29, however, has shown that the metal–insulator transition observed in transport measurements cannot be used as an unambiguous identifier of the zLL ground state in graphene. More complex behavior is expected as the ground-state order parameter changes in the proximity of the quantum Hall boundary29. Imaging the spatial properties of these broken-symmetry states can thus shed light on revealing the competing interactions and make a direct connection with theoretical models.
In this article, we determine the energies and the spatial dispersion of the zLL in graphene with AFM Kelvin probe measurements at arbitrary filling factors. The degeneracy of the zLL observed in AFM measurements is lifted in a magnetic field with the zLL split into four sublevels. The energy splitting of the four sublevels is much larger than the Zeeman energy, indicating interaction-dominated physics. The spatial dispersions of the states at \(\nu =0,\pm 1\) are measured demonstrating completely gapped spectra as the states progress from the bulk to edge boundary. We discuss these findings in terms of recent theoretical developments of the graphene ground-state properties.
To image the QH edge states for this study, we chose to use a dual-gated graphene device where the Hall bar boundary is defined by a lateral junction controlled by two independent back gates (Fig. 1)30,31,32. The major advantage of this approach is the atom-scale cleanliness and precision of the boundary that is free of defects and contamination with the graphene lattice perfectly continuous across quantum Hall edge interface, as opposed to a physical boundary of a graphene sheet-shaped using harsh treatments, such as reactive ion etching. A similar device was used in imaging the edge states by SQUID-on-tip measurements of graphene18. Moreover, the area on one "external" side of the boundary can be tuned to an "electronic" insulator by setting the carrier density to zero (filling factor \(\nu =0\)) corresponding to an insulating state of graphene at high magnetic fields33. Such definition of boundaries of graphene devices has led to superior quantum Hall signatures in various geometries34,35,36.
Fig. 1: Graphene quantum Hall device structure.
a Cross-sectional schematic of the layered structure of the graphene quantum Hall device. Two graphite back gates define the Hall bar: a global graphite back gate G2 (blue) and a local graphite back gate G1 (red). Pd/Au contacts are used to apply the sample bias \({V}_{\text{B}}\) to the graphene layer. b Optical image of the graphene device. The graphene sheet is indicated by the dashed black contour. The region controlled by the local gate G1 is shown by the dashed red line, while the region controlled by the global gate G2 is shown by the dashed blue line. Part of the fan "runway" used to guide the tip to the graphene is seen on the right side of the image. c Line traces from a Kelvin probe map at \(B=0\,\text{T}\) at the local gate potentials indicated, showing the width and sharpness of the potential boundary due to the use of the graphite back gates in close proximity to the graphene layer. A linear fit to the trace at G1 = −1.95 V (black) over the region bounded by the vertical lines yields a slope of (1.72 ± 0.02) meV/nm, where the uncertainty is one standard deviation from the linear least-square fit. d STM topography of the graphene surface. Dark and bright spots represent the moiré superlattice formed by the graphene sheet and the hBN underlayer. The atomically resolved graphene lattice is visible as the fine mesh in the whole area. Topography is obtained at VB = −100 mV and a tunneling current of 300 pA.
Figure 1a shows the schematic of the layered structure of the device and Fig. 1b is an optical image of the dual-gated device. The overlapped area determined by the graphene boundary (black dotted line) and local gate G1 boundary (red dashed line) in Fig. 1b defines the interior carrier density (area enclosed by the red dashed trapezoid in Fig. 2a). The second graphite gate G2 defines the exterior density. In most of the following measurements, the outside density is set to zero creating an insulating state at high magnetic fields, hence, defining the Hall bar geometry. The potential profile defined by these two back gates is quite sharp due to the thinness of the hBN gate insulator layers. The potential step is ≈70 nm in width as seen from the chemical potential measurements across the boundary in Fig. 1c. This characteristic scale is a few magnetic lengths at 5 T, providing sufficiently strong confinement for the quantum Hall edge channels.
Fig. 2: Correlation of graphene broken isospin states in macroscopic vs. microscopic measurements.
a Optical micrograph of the graphene quantum Hall device. The Hall bar edges are defined by a local graphite back gate, G1, underlying the area outlined in the red dashed line, and a global graphite back gate, G2, under the entire Hall bar device (see "Methods" for further details). The boundary between G1 and G2 defines the quantum Hall edge boundary along the red dashed line. The black circle shows the location for spatial maps across the boundary shown in Figs. 4–6. b, c Magnetotransport measurements of (b) the Hall resistance, RXY, and (c) the longitudinal resistance RXX. Filling factors \(\nu\) are indicated in white numerals. In both measurements, broken-symmetry states in the zeroth Landau level are observed at \(\nu =\pm 1\). d Schematic of the graphene Landau level density of states indicating the fourfold degeneracy due to valley and spin inside each main Landau level. e, f Microscopic atomic force spectroscopy measurements revealing the broken-symmetry states in (e) AFM frequency shift measurements and (f) simultaneously obtained oscillation amplitude signal with constant excitation of 520 mV as a function of sample bias and local gate at B = 15 T. A smooth background was subtracted from the data in (e) to enhance the contrast of the broken-symmetry states (see Supplementary Fig. 2 and "Methods"). The white line indicates the zero-contact potential difference (i.e., chemical potential) obtained from a parabolic fit to the frequency shift data vs. sample bias (Supplementary Fig. 3). The white numerals indicate the filling factor. All measurements were made at \(T=10\,\text{mK}\).
The alignment of the graphene sheet with the underlying hBN dielectric is an important fabrication parameter often impacting the physical properties. In the case of this device, the graphene sheet is rotated relative to the hBN by about 3.1°, as determined from the moiré superlattice observed in STM topography measurements (Fig. 1d). This superlattice gives rise to an additional sublattice symmetry breaking potential generating a zero-field gap \({\triangle }_{\text{AB}}\). This potential can further affect the possible ground-state phase diagram adding a competing partially sublattice polarized (PSP) state in addition to the CDW and CAF states27. Recent transport measurements have indicated possible isospin phase transitions between these states as a function of magnetic field27.
Measurements of macroscopic and microscopic quantum Hall properties were made using an instrument that is capable of simultaneous magnetotransport, scanning tunneling microscopy, and AFM measurements on a given device at ultralow temperatures37,38. The instrument was operated at 10 mK for all measurements with a perpendicular magnetic field up to 15 T. Magnetotransport measurements of the Hall and longitudinal resistances are shown in Fig. 2b, c. Broken-symmetry states inside the zLL are seen at filling factors \(\nu =0,\pm1\), marked by quantized plateaus in the Hall resistance (RXY). The same broken-symmetry states are observed in microscopic AFM measurements detected as changes in the frequency shift (averaged tip-sample force gradient) (Fig. 2e) and in the sensor oscillation amplitude (energy dissipation) (Fig. 2f) seen over a narrow density range around the integer filling factors, \(\nu =0,\pm1,\pm2,\pm3,\) and \(\pm4\). The AFM response to the symmetry-breaking states derives from the gapped nature of these states and their associated electronic incompressibility. The formation of an incompressible area under the tip apex leads to changes in the system capacitance and resistance, which alters the electrostatic average force gradient between tip and sample. This varies the sensor resonance frequency and hence enables the detection of the broken-symmetry states (see "Methods"). The contrast of the broken-symmetry states scales with the strength of the electrostatic field between the tip and the sample. It disappears at zero electrostatic field, at the sample bias which balances the work function difference between the probe tip and the sample, which is shown by the solid white line in Fig. 2e. The Landau levels are observed on the white line as plateaus with jumps or oscillations at the transitions between Landau levels at integer filling factors. The behavior will be investigated in more detail in chemical potential measurements using Kelvin probe force microscopy (KPFM) measurements, shown below.
Kelvin probe force spectroscopy of graphene Landau levels
The frequency shift of the AFM qPlus probe, proportional to the average force gradient, shows an inverted parabolic profile as a function of applied electrostatic potential, characteristic of the electrostatic forces (Supplementary Fig. 3d). The vertex of the parabolic response occurs when the applied potential compensates the contact potential difference (CPD) between the probe and graphene and allows for measurements of the local chemical potential by KPFM39,40. Figure 3a displays KPFM measurements of the CPD as a function of the sample bias vs. back-gate potential G2 for different magnetic fields between 9 T and 15 T. These measurements were made outside the local gated area with the density of both areas kept the same by ramping G1 and G2 together with the appropriate scaling of gate voltages. A series of plateaus and transitions are observed at various back-gate potentials, depending on the magnetic field. Each plateau corresponds to the filling of a particular Landau level, whereas the transitions occur at the incompressible states when the Fermi level is being swept in the gaps between the Landau levels. The data in Fig. 3a show the characteristic graphene Landau level energy structure discussed above, as seen by scaling the sample bias by \(\sqrt{B}\) and the gate potential by B, as shown in Fig. 3b. The correspondence to the graphene Landau level density of states is indicated by the lineup of the \(N=0,\pm1,\pm2\) Landau levels in Fig. 3c with the plateaus in Fig. 3b.
Fig. 3: Resolving the energies of the four isospin components of the graphene zero Landau level with Kelvin probe spectroscopy.
a Kelvin probe measurements varying the sample bias and simultaneously gates G1 and G2 for measurements made outside the Hall bar area. A staircase of plateaus shows various Landau levels occurring at different chemical potentials for various magnetic fields. b Chemical potential vs. filling factor given by the data in (a) collapsed onto a universal curve by scaling the sample bias by the graphene Landau level energy field dependence along the vertical axis, \({E}_{N}\propto {\!\,}^\surd B\), and by the \({B}^{-1}\) along the horizontal axis to give a density/filling factor axis. Each Landau level is observed by a plateau in the scaled chemical potential. Notice the zero Landau level at zero chemical potential consists of four separate small plateaus indicating the lifting of the fourfold degeneracy. c The Landau level density of states calculated using the expression in the main text with \(B=1\,\text{T}\) and \({v}_{F}=1.13\times {10}^{6}\text{m}/\text{s}\) to fit the locations of the plateaus in (b). d Blow-up of the large up and down excursion in chemical potential at \(\nu =-1\) and \(B=15\,\text{T}\) from (e). e Blow-up of the chemical potential of the zeroth Landau level at \(B=15\,\text{T}\) from (b) showing four individual chemical potential plateaus, labeled \({\varepsilon }_{i}\), separated by large up/down excursions at the incompressible filling factors, \(\nu =0,\pm 1\). The red dashed lines indicate the differences in chemical potential \(\triangle E=({\varepsilon }_{2}-{\varepsilon }_{1}),({\varepsilon }_{3}-{\varepsilon }_{2}),{\rm{and}}\,({\varepsilon }_{4}-{\varepsilon }_{3})\). f Energy differences extracted from the chemical potential plateaus in (e) for the \(\nu =0,({\varepsilon }_{3}-{\varepsilon }_{2})\) (red circles) and \(\nu =-1,({\varepsilon }_{2}-{\varepsilon }_{1}){\rm{and}}\) \(\nu =+1,({\varepsilon }_{4}-{\varepsilon }_{3})\) (orange triangles and green squares) filling factors. The values are averaged chemical potential difference values from \(\nu -0.75\) to \(\nu -0.25\) of each integer \(\nu\), and the error bars correspond to one standard deviation. The solid black line shows the Zeeman energy, \(g{\mu }_{B}B\), with \(g=2\). The solid red line is a fit for \(\nu =0\) data values to \(\sqrt{B}\) for values \(\ge 8\,\text{T}\), and the blue line is a linear fit for B values \(\le 8\,\text{T}\). AFM settings: 5.8 nm oscillation amplitude, \(\triangle f=-450\,{\rm{mHz}}\), 5 Hz bias modulation, except a 1 Hz bias modulation was used for 4 T and 5 T data.
On close examination of Fig. 3b, the \(N=0\) Landau level plateau consists of four distinct smaller plateaus, as shown in the blow-up in Fig. 3e for \(B=15\,{\rm{T}}\). The four plateaus, with the chemical potential labeled \({\varepsilon }_{i}\), indicate the complete lifting of the degeneracy of the \(N=0\) Landau level. A large up and down, "N"-shaped excursion in the chemical potential is observed at the integer filling factors as transitions between the plateaus (see Fig. 3d and "Methods" section). Note that the excursion is characterized by very sharp upward jumps of the chemical potential over a small change of filling factor as the incompressible state is entered. The large excursion, on the order of ≈50 meV for \(B=15\,{\rm{T}}\), is suggestive of interactions playing a strong role. Indeed, in previous measurements, an oscillating behavior of the chemical potential at integer filling factors was interpreted as exchange enhancement of the single-particle or broken-symmetry gaps due to Pauli exclusion41. Nevertheless, the sign of the excursion in our measurements, the peak followed by the dip, is opposite to that in previous measurements on the zeroth Landau level in graphene42, which requires further theoretical investigation. However, peak-dip patterns with negative compressibility have been seen in the phase transitions between correlated states in recent measurements of the flat-band system twisted bilayer graphene43.
Traditionally, the energies of the broken-symmetry states can be investigated by transport measurements only at integer filling factors assuming an activated behavior. These energies vary greatly between different devices, pointing to disorders contributing to the mobility gaps extracted from such activation measurements. In contrast to transport measurements, KPFM measures directly the local chemical potential (Fig. 3e) over a wide range of filling factors, both when the Fermi level is in the compressible state (plateau) and when it is in the incompressible state (between plateaus), complementing and expanding existing methods. These and other recent experiments44 will stimulate further theoretical analysis of partially filled Landau levels that has been lacking, partly because of a deficit of experimental data.
At integer filling factors, the bare symmetry-breaking potential is usually strongly enhanced by exchange and other correlations. The energy differences between the chemical potential plateaus, as indicated by the arrows in Fig. 3e at 15 T and shown in Fig. 3f for different magnetic fields, do reflect the strength of the lattice-scale symmetry-breaking potential but the degree of the enhancement is likely smaller than that at integer filling factors. The enhancement is still significant, as one sees that the energies are much larger than the Zeeman energy (solid black line), and the largest energy gap across \(\nu =0\) \(({\varepsilon }_{3}-{\varepsilon }_{2})\) reaches a value of ≈8 meV at 15 T. The energy gaps show distinct low- and high-field dependencies on the magnetic field. Starting with a plateau or even a slight decrease at fields below 8 T, the \(\nu =0\) gap scales with \(\sqrt{B}\) at high fields above 8 T. The scaling as \(\sqrt{B}\) is consistent with electron interactions playing a dominant role. The \(\nu =\pm1\) energy gaps, \(({\varepsilon }_{2}-{\varepsilon }_{1})\) and \(({\varepsilon }_{4}-{\varepsilon }_{3})\), show lower energies monotonically increasing to the highest field of 15 T. As noted above, the measured values of the \(\nu =\pm1\) energy gaps are larger than the Zeeman energy. Interestingly, the \(\nu =0\) and \(\nu =\pm1\) energy gap dependencies can be interpreted as an avoided crossing at around 6–8 T, suggesting a possible change in the ground state. An isospin phase transition proposed in Ref. 27 occurs due to the influence of a moiré superlattice contribution. Indeed, the atomic resolution STM measurements of the device in Fig. 1a does show a moiré period of ≈4.36 nm corresponding to a misalignment of 3.1° of the graphene lattice relative to the hBN underlayer (Fig. 1d). An additional potential of the moiré superlattice causing the sublattice-symmetry breaking is generating a zero-field gap \({\triangle }_{\text{AB}}\). This alters the possible ground-state phase diagram to include a partial sublattice polarized (PSP) state in addition to the CDW and CAF states27. Magnetotransport measurements as a function of misalignment angle have shown that a zero-field gap scales with rotation angle45, and a gap value of 5–10 meV can be expected for the angle of 3.1°. This value is consistent with the behavior of \(\triangle E(\nu =0)\) in Fig. 3f if the trend of the low-field regime is extrapolated to zero field (blue line). Respectively, the apparent avoided crossing seen in Fig. 3f at fields of 6–8 T could also be suggestive of a possible isospin transition between a CDW to AF phase at intermediate magnetic fields.
The quantum Hall edge wedding cake-like potential profile
The edge states in the QH effect form a series of incompressible and compressible strips near the boundary edge (Fig. 4a). The strips originate from the Landau levels that are bent by the potential rise at the boundary and are pinned at the Fermi level (Fig. 4b). In a noninteracting picture, the levels intersect the Fermi-level forming one-dimensional edge states. In reality, interactions and screening reconstruct the potential into a series of plateaus forming a "wedding cake-like" structure (Fig. 4c)46,47. A compressible strip is formed when a partially filled Landau level is at the Fermi level, which is separated by incompressible strips as the next Landau level transitions to the Fermi level. The stepped potential profile near the boundary has been predicted theoretically for many years but has eluded measurement46. Using AFM Kelvin probe spectroscopy, a spatial visualization of the Landau levels from \(N=-2\) [LL(-2)] to \(N=+1\) [LL(+1)] is obtained as a function of Y-position across the QH edge boundary (indicated in the black circle in Fig. 2a) and local gate voltage G1, as shown in the Kelvin probe map at \(B=5\,\text{T}\) in Fig. 4d. Figure 4e shows the extracted stepped potential across the QH edge boundary (see white arrows in Fig. 4d), transformed by screening from the bare potential in Fig. 1c. The profiles in Fig. 4e show the "wedding cake-like" steps with plateaus separated by sharp drops at the incompressible states, as theoretically predicted46. For the larger gate voltage (red line), we observe three incompressible strips corresponding to filling factor \(\nu =-6,-2,{\rm{and}}-1\). The width of the \(\nu =-6\,{\rm{and}}\,\nu =-2\), which occurs at the change of the Landau levels are on the order of ≈40 nm. The width of the \(\nu =-1\) strip is much narrower, on the order of ≈20 nm. These are consistent with the length scale of the electrostatic potential of the graphite back gates defining the quantum Hall edge shown in Fig. 1c, as calculated below in more detail. A similar stepped profile of graphene Landau level energies has been recently measured in graphene quantum dots by tunneling spectroscopy47.
Fig. 4: KPFM measurements of incompressible strips.
a Schematic of bulk closed cyclotron orbits with cyclotron energy \({\hbar \omega }_{C}\) and edge quantum Hall states leading to compressible and incompressible strips at the device edge boundary. b, c Schematic of the bending of the Landau levels in a confining potential boundary (b) in a noninteraction picture and (c) in an interacting picture leading to a "wedding cake-like" series of plateaus in Landau levels near the boundary edge. A compressible strip is formed when a Landau level is at the Fermi level, separated by incompressible strips (red dashed lines) during Landau level transitions. d Kelvin probe map at \(B=5\,\text{T}\) of the chemical potential as a function of Y-position across the quantum Hall boundary (indicated in the black circle in Fig. 2a) and local-gate potential. In the local-gate area, Landau levels from \(N=-2\) [LL(−2)] to \(N=+1\) [LL(+1)] are seen in the different colored plateaus. AFM settings: 2 nm oscillation amplitude, \(\triangle f=-2\,{\rm{Hz}}\), and 20 mV sample bias modulation at 1.4 Hz. e Incompressible strips in the chemical potential are observed in the lines traces at \({\rm{G}}1=-0.9\,\text{V}\,\left({\rm{red}}\right)\,\text{and}\,{\rm{G}}1=-0.6\,\text{V}\,({\rm{blue}})\) (white horizontal lines in (d)) corresponding to filling factors \(\nu =-6,-2,\) and \(-1\). The transitions separate plateaus between Landau levels, LL(−2) to LL(−1), and LL(−1) to LL(0), confirming the "wedding cake-like" structure predicted in ref. 46 .
The staircase shape of the chemical potential near the QH boundary is caused by the screening dependence on the filling factor flattening out the potential in compressible states and displaying potential steps over incompressible strips46,47. The width of the incompressible strips, a, can be estimated using Eq. S25 in ref. 47,
$$a={\left(\frac{4(4\pi {\epsilon }_{0}){\epsilon }_{r}{\triangle E}_{\text{LL}}}{{\pi }^{2}{e}^{2}\frac{\partial n}{\partial y}}\right)}^{\frac{1}{2}}$$
Here \({\epsilon }_{0}\) is the vacuum permittivity, \({\epsilon }_{r}\) is the relative permittivity, e is the elementary charge, \({\triangle E}_{\text{LL}}\) is the energy gap between Landau levels, and \(\partial n/\partial y\) is the density gradient at the strip position. For the density gradient, we can use the electric field profile across the boundary measured at zero field (Fig. 1c). Here, the boundary width is observed to be on the order of 70 nm, with a potential gradient of ≈1.7 meV/nm across the boundary. For the Dirac dispersion, the corresponding density gradient is \(\approx {10}^{23}{\text{m}}^{-3}\) using \({v}_{\text{F}}=1.0\,\times {10}^{6}\) m/s, \({\epsilon }_{r}=5\). Substituting the density gradient and 80 meV for energy gap in Eq. (1) yields an incompressible strip width of 34 nm, in good agreement with the measured strips in Fig. 4.
Spatial mapping of the broken-symmetry edge channels
The essential advantage of KPFM is that the measurement is compensating the CPD between tip and sample and thus minimizes gating effects in the graphene 2DEG. Figure 5 shows the KPFM measurements at \(B=10\,\text{T}\) of the chemical potential across the QH edge boundary as a function of Y-position and local gate potential, G1. At a distance of about 300 nm from the boundary, the different chemical potential plateaus at the left edge of Fig. 5a correspond to the \(N=0,\pm1,\pm2\) Landau levels, as in Fig. 3b. As the probe approaches the QH edge boundary, the electron (hole) states disperse to positive (negative) densities. The large excursions seen at integer filling factors in the chemical potential in Fig. 3e are useful as fingerprints for spatial mapping of the incompressible states and edge channels in the zeroth Landau level. Inside the \(N=0\) Landau level, the \(\nu =\pm1\) incompressible states and the \({\varepsilon }_{i}\) compressible channels are observed to follow a dispersion similar to the higher Landau levels, as seen in the higher-resolution measurement in Fig. 5b. Following the spatial dispersion to the boundary, we do not observe a crossing or oscillations in the energy of the edge states predicted for some ground-state phases of the zLL. Spatial mapping of the edge states in the XY plane shows the channels are uniform along the boundary edge, i.e., the X direction (Supplementary Fig. 4). The broken-symmetry states remain gapped starting in the bulk and proceeding to the boundary. The \(\nu =-1\) incompressible edge channel is seen dispersing to below \(\nu =0\) and \(\nu =+1\) disperses above. For comparison, the edge dispersion and Kelvin probe simulated maps expected for the KD, CDW, AF, CAF, and F phases are shown in Fig. 6b–f, respectively28,29. We further compare the experimental dispersion with the predictions of these models in the "Discussion" section below.
Fig. 5: Spatial dispersion of graphene broken-symmetry edge states at the quantum Hall edge boundary.
a Kelvin probe map at \(B=10\,\text{T}\) of the chemical potential as a function of Y-position across the QH boundary and local gate potential. In the local gated area, Landau levels from \(N=-2\) [LL(\(-\)2)] to \(N=+2\), [LL(+2)], are seen in the different colored plateaus. Incompressible signatures due to the large excursions in the chemical potential (see Fig. 3d) are observed inside the \(N=0\) Landau level corresponding to filling factors \(\nu =0,\pm 1\). b Higher-resolution Kelvin probe map of the \(N=0\) Landau level showing that at the quantum Hall edge boundary the \(\nu =\pm1\) channels disperse away from the \(\nu =0\) center line. AFM settings: 2 nm oscillation amplitude, \(\triangle f=-2\,{\rm{Hz}}\), 20 mV bias modulation.
Fig. 6: A comparison of the experimental Kelvin probe map of the graphene broken-symmetry edge states with different ground-state symmetries.
a Kelvin probe map at \(B=10\,\text{T}\) of the chemical potential as a function of Y-position across the QH boundary from Fig. 5b. b–f (top panels) Schematic dispersion of the four single-particle energy levels ε±± for different phases obtained from the analytic formulas in Table 1 of ref. 29. (bottom panels) Simulation of the Kelvin probe maps of the chemical potential vs. local gate and Y-position using the dispersions of the various ground-state symmetries in the top panels along with the measured gate response profile in the G1-Y plane obtained at \(B=0\,\text{T}\), as shown in Fig. 1c.
Magnetotransport experiments have provided convincing evidence for the interaction-dominated nature of the partially filled zLL in graphene. In high-mobility samples, the observed large longitudinal resistance at \(\nu =0\) indicates that both bulk and edge states are gapped33. Such states belong to the class of quantum Hall ferromagnets with broken symmetries in the spin-isospin space23. The key physical challenge is identifying how the symmetry is broken as well as understanding all the possible microscopic variables in real systems such as disorder or a moiré superlattice which may alter the balance of anisotropies and change the ground state. To this end, studies that combine microscopic and macroscopic measurements on the same device hold an advantage. Our measurements shown in Fig. 3 confirm the lifting of the fourfold degeneracy of zLL with the energy separation of the \(\nu =0\) state much larger than \(\nu =\pm1\), and all of them much larger than the bare Zeeman energy indicating interaction-dominated physics.
Theory and transport experiments have mainly converged that the CAF state is the ground state of the zLL in graphene at \(\nu =0\), although more recent analysis suggests that the graphene ground-state physics is a complex and unsettled issue29,48. The convergence to the CAF state stems from the prediction that the excitation gap closes in a tilted magnetic field28, as shown schematically in Fig. 6e, and supported by transport measurements of a metal–insulator transition as a function of tilt angle of magnetic field26. However, for pure perpendicular magnetic fields, the valley isospin anisotropy is much larger than the Zeeman energy leading to the CAF state approaching the AF ground state (Fig. 6d)26,28,49. In fact, the CAF state bridges smoothly between the AF and F states as the angle between sublattice spin polarizations varies from \(\pi /2\) to 0, respectively (see Fig. 6d–f)28. In this regard, the measurements in Fig. 6a are consistent with a CAF ground state.
Figure 6b–f shows possible edge spatial dispersions for other bulk phases including the KD and CDW phases. Both the KD and CDW phases show gapped excitations but now with all four levels separated in the bulk and dispersing to the edge (Fig. 6b, c). Both these phases have dispersions consistent with the results in Fig. 6a, in particular the fourfold splitting in the bulk, and show the best agreement with the experiment in Fig. 6a. Evidence for a KD phase has been observed in recent STM LDOS measurements at zero density50. Note that the ground-state phases are likely density-dependent, and even more complex behavior is possible as a bulk ground state can change its order parameter at the boundary as shown in recent calculations29.
In summary, we have obtained spatial measurements of the dispersion of the broken-symmetry edge channels near the quantum Hall boundary. The measurements alone cannot identify the ground-state symmetry in this particular sample but are consistent with edge profiles of various bulk phases as discussed above. Further measurements are required that can shed light on the ground-state properties such as atomically resolved measurements of the QH wavefunction symmetry as a function of distance near the QH boundary. Finally, we point out the unique benefits of KPFM as a new tool for Landau level spectroscopy which complements scanning tunneling spectroscopy. In addition, we demonstrated the combination of macroscopic transport and microscopic scanning probe measurements which advantageously removes uncertainties for a direct comparison of different techniques ensuring that all microscopic variables are key for defining the physics, such as disorder or moiré superlattices, are exactly the same in both measurement modalities.
Graphene device structure and fabrication
Figure 1a, b shows a schematic cross-section of the graphene device heterostructure and an optical top view. Two single-crystal graphite gate electrodes and single-crystal hBN dielectrics are employed for optimal sample quality. The two graphite back gate regions G1 and G2 are outlined in Fig. 1b. G1 defines the carrier density of the local interior area as indicated by the red dashed line in Fig. 1b, while G2 defines the carrier density in the outer region (blue dashed line). A quantum Hall boundary edge can thus be generated at the edge of the local gate G1.
The heterostructure is assembled from top to bottom (starting from the global graphite gate G2 as the top layer) using the van der Waals transfer technique so that the bottom of the graphene flake, as well as the hBN dielectrics, remain free from contamination during the stacking and subsequent fabrication processes. It is then flipped upside down to expose the graphene surface and deposited onto a 285 nm SiO2/ Si++ substrate before vacuum annealing to remove the polymer film underneath the stack. Electrical connections to the graphene sheet and graphite gate electrodes were made by deposition of the Cr/Pd/Au (2/50/50 nm) metal edge contacts.
All but one electrode contacting the graphene are in contact with both the G1 region and the G2 region. The one outside contact is used to ensure that the G2 region is in the \(\nu =0\) gapped state during electrical transport and scanning probe measurements. A fan-shaped pattern with gold ridges of 65 nm height is connected to the drain electrode to the graphene sheet for navigation purposes (Fig. 1b). After introducing the device sample to the UHV chamber of the scanning probe microscope (SPM) instrument, it is annealed at a temperature of ≈623 K for ≈3 h to obtain the required cleanliness for SPM measurements.
Navigating to the device with a scanning probe microscope
Navigating to the central device area with scanning probes is always a difficult challenge. For this purpose, a fan-shaped pattern extending to ≈500 µm at its widest region is utilized. Supplementary Fig. 1 outlines the procedure for navigating to the device area. First, the probe tip is aligned onto the fan-shaped area using an optical telescope while the STM module is in the upper ultrahigh vacuum chamber at room temperature (Supplementary Fig. 1a). Using the probe tip reflection, a tip-sample gap of the order of 100 µm is set at room temperature. The module is then transferred and locked into the dilution refrigerator multimode SPM system where it is cooled to a temperature of 10 mK37,38. The landing region is scanned, and a ridge is identified after approaching the fan-shaped runway surface. STM tunneling current or AFM frequency shift feedback can be used for the approach; for this device, AFM feedback was used for approach and navigation to minimize the degradation of the probe tip due to interacting with the surface. Once a ridge on the fan-shaped area is found, an automated algorithm is used to follow a given ridge to the device area (Supplementary Fig. 1b). This algorithm alternates stepping along the ridge direction and quickly scanning the ridge in a "W"-shaped line. After each "W" scan, the XY piezo motor parameters are adjusted to keep the walking direction along the ridge. The successful application of this routine is shown in (Supplementary Fig. 1c), where AFM traces of the "W" line scans are shown. At certain key places, full AFM scans are made to verify marker features in the devices, as shown in (Supplementary Fig. 1c). After successful navigation, the device region is located as verified by AFM scans of the pattern boundary (Supplementary Fig. 1d). Further navigation is then performed to check the device area and locate an area for edge studies, as indicated by the black circle in Fig. 2a.
Multimode STM, AFM, and transport instrumentation
The study described in this report is the first to use a newly commissioned multimode system with the capabilities of simultaneous AFM, STM, and magnetotransport measurement38. The system utilizes a dilution refrigerator which operates at a base temperature of 10 mK with magnetic fields up to 15 T perpendicular to the sample plane37. Multimode measurements are accomplished by using custom-designed sample and probe tip holders which feature eight electrical contacts for devices and probe sensors. Magnetotransport measurements were performed using a lock-in amplifier at 25 Hz with a 10 nA source current. The qPlus AFM sensor was a new design that incorporated an integrated excitation electrode on the sensor38. The qPlus sensor had a quality factor of \(Q=1.3\times {10}^{5}\) and a resonance frequency of f0 = 23.4 kHz at zero magnetic field. For the qPlus sensor, four contacts were wired, two to read out the AFM sensor, one for the STM tunneling current, and one for the sensor excitation. All eight electrical contacts of the device were utilized. For AFM and KPFM measurements, we used the frequency modulation mode with an oscillation amplitude of 2–5 nm. For KPFM, we used 1 Hz to 5 Hz modulation on the sample bias voltage.
AFM frequency shift measurement of broken-symmetry states
AFM measurements of the frequency shift and dissipation were both sensitive to the occurrence of the broken-symmetry states, and Landau levels in general, as shown in Fig. 2. The sensitivity originates from the frequency shift caused by the capacitive forces due to unbalanced electrostatic potentials between the tip and the sample:
$$\triangle {f}_{C} \sim -\frac{{d}^{2}C\left({f}_{0}\right)}{d{z}^{2}}{\left({V}_{{\rm{B}}}-{V}_{{\rm{CPD}}}\right)}^{2}$$
where \(C\left({f}_{0}\right)\) is the capacitance between the tip and the sample at the sensor resonance frequency \({f}_{0}\), \({V}_{{\rm{CPD}}}\) is the contact potential difference and \({V}_{{\rm{B}}}\) is the sample bias. The typical frequency shift curves are shown in (Supplementary Fig. 3d). One can see, for example, that at \({V}_{{\rm{B}}}-{V}_{{\rm{CPD}}}\cong 0.5\) V along the horizontal axis in (Supplementary Fig. 3d), the frequency shift is \(\approx -0.15\) Hz.
The additional positive frequency shift at integer filling factors corresponding to the broken symmetry states seen in (Supplementary Fig. 2c, d) derives from the openings of gaps which change the resistance and, as a result, the capacitance \(C\left({f}_{0}\right)\) of the graphene system at the tip location.
An additional dissipation develops once the complex capacitance \(C\left({f}_{0}\right)\) acquires a phase lag resulting from a large local resistance of the incompressible region. As the resistance grows further, the capacitance \(C\left({f}_{0}\right)\) decreases, correspondingly causing a positive frequency shift contribution, while the phase lag, and respectively the additional dissipation vanishes. The experimentally observed positive frequency spikes at the integers can be as large as 10–15% of the total frequency shift from the Coulomb attraction (≈0.02 Hz/0.15 Hz).
In the simplified analysis above, all the changes in \(\triangle {f}_{C}\) were assigned to the changes in \(C\left({f}_{0}\right)\) assuming \({V}_{{\rm{CPD}}}\) and \({V}_{{\rm{B}}}\) being constant. (Supplementary Fig. 2a) illustrates that over a larger parameter range, the latter two variables contribute most significantly. The frequency shift at the broken-symmetry gaps is a small signal on top of a large background due to the larger frequency shifts caused by changes in \({V}_{{\rm{CPD}}}\) originating from the normal cyclotron gaps at filling factors of \(\nu =\pm2\) (along the gate voltage axis), as well as by \({V}_{{\rm{B}}}\) (the sample bias axis), both determining the total electrostatic force contributions. We followed refs. 51,52 and subtracted a smoothly varying background (black curve) from each frequency shift curve (red and blue curves) and plot the residuals, as shown in (Supplementary Fig. 2b, c). The smooth background averages the original data using a Gaussian filter with a sigma of 0.2 V. Each residual curve is then built into a new frequency shift map, as shown in (Supplementary Fig. 2d) and Fig. 2e.
As mentioned above, the frequency shift data contains contributions from electrostatic forces which give rise to a downward parabolic dependence on the applied sample bias (Supplementary Fig. 3d). The vertex of the parabolic response occurs when the applied potential compensates the contact potential difference (CPD) between the probe and graphene, as illustrated in (Supplementary Fig. 3a–c). By measuring changes in the CPD, we can obtain a measure of the local chemical potential, which responds to changes in Fermi-level position with gate bias, as shown in (Supplementary Fig. 3e). The measurements of the chemical potential in (Supplementary Fig. 3e) were obtained by fitting the parabolic dependence on the sample bias over a window of 300 mV about the vertex. A higher-precision measurement with reduced tip-gating effects is obtained by modulating the sample bias and using lock-in detection to measure the sample bias values compensating the CPD. The force at the modulation frequency ω is:
$${F}_{\omega }=-\frac{1}{2}\frac{{{\mathrm{d}}C}}{{{\mathrm{d}}z}}{\left({V}_{{\rm{B}}+\text{AC}}-{V}_{{\rm{CPD}}}\right)}^{2} \sim -\frac{{{\mathrm{d}}C}}{{{\mathrm{d}}z}}\left({V}_{\text{B}}-{V}_{\text{CPD}}\right){V}_{\text{AC}}$$
Correspondingly, \(\triangle {f}_{\omega } \sim \frac{{\mathrm{d}}{F}_{\omega }}{{{\mathrm{d}}z}}\) is nullified when \({V}_{{\rm{B}}}-{V}_{{\rm{CPD}}}=0.\) This method was used in the Kelvin probe measurements in Figs. 3–6.
All AFM measurements were made using a constant amplitude signal where the dissipation is measured in the excitation drive signal required to keep the amplitude constant with the exception of the data in Fig. 2e, f (and Supplementary Fig. 2) where a constant excitation signal was used and the dissipation was measured in the amplitude signal channel.
KPFM chemical potential excursions in the N = 0 Landau level
In the N = 0 Landau level, an "N"-shaped excursion in the chemical potential is observed at the integer filling factors between transitions of the mini-plateaus that make up the N = 0 LL. The origin of this excursion is unclear, as it has the opposite sign to previous measurements of the compressibility at the zeroth LL42 using single-electron transistors, and experimental artifacts need to be considered. However, the feature is quite robust and, at present, we cannot identify it as an artifact based on the following arguments: (1) the excursion appears both in the KPFM chemical potential and the AFM frequency shift and dissipation signals, without and with local tip gating, (2) the feature is seen for wide and narrow strips in different spatial locations (see Fig. 5), indicating that local resistive effects are likely not contributing, and (3) the feature is seen near local integer filling factors (see Fig. 5), indicating that non-local resistive/capacitive effects that can be caused by large (bulk) areas of the sample becoming insulating at integer filling factors are not contributing. In addition, the following arguments against a spurious origin of the signal as: (i) the feature is odd with respect to gate voltage, an artifact due to increased resistance for example would be symmetric about the integer fillings, and (ii) the feature was independent of the direction of gate voltage sweeps.
All data are available in the main text or the Supplementary Materials and are available from the corresponding authors upon reasonable request.
Wang, J. & Zhang, S.-C. Topological states of condensed matter. Nat. Mater. 16, 1062–1067 (2017).
ADS CAS PubMed Article PubMed Central Google Scholar
Cao, Y. et al. Correlated insulator behaviour at half-filling in magic-angle graphene superlattices. Nature 556, 80–84 (2018).
ADS CAS PubMed Article Google Scholar
Cao, Y. et al. Unconventional superconductivity in magic-angle graphene superlattices. Nature 556, 43–50 (2018).
Song, Z. et al. All magic angles in twisted bilayer graphene are topological. Phys. Rev. Lett. 123, 036401 (2019).
Fowler, A. B., Fang, F. F., Howard, W. E. & Stiles, P. J. Magneto-oscillatory conductance in silicon surfaces. Phys. Rev. Lett. 16, 901–903 (1966).
ADS CAS Article Google Scholar
Klitzing, K. V., Dorda, G. & Pepper, M. New method for high-accuracy determination of the fine-structure constant based on quantized Hall resistance. Phys. Rev. Lett. 45, 494–497 (1980).
ADS Article Google Scholar
Tsui, D. C. & Gossard, A. C. Resistance standard using quantization of the Hall resistance of GaAs‐AlxGa1−xAs heterostructures. Appl. Phys. Lett. 38, 550–552 (1981).
Thouless, D. J., Kohmoto, M., Nightingale, M. P. & den Nijs, M. Quantized Hall conductance in a two-dimensional periodic potential. Phys. Rev. Lett. 49, 405–408 (1982).
Niu, Q., Thouless, D. J. & Wu, Y.-S. Quantized Hall conductance as a topological invariant. Phys. Rev. B 31, 3372–3377 (1985).
ADS MathSciNet CAS Article Google Scholar
Berry, M. V. Quantal phase factors accompanying adiabatic changes. Proc. Royal Soc. Lond A Math. Phys. Eng. Sci. 392, 45–57 (1984).
ADS MathSciNet MATH Google Scholar
Hatsugai, Y. Chern number and edge states in the integer quantum Hall effect. Phys. Rev. Lett. 71, 3697–3700 (1993).
ADS MathSciNet CAS PubMed MATH Article PubMed Central Google Scholar
McCormick, K. L. et al. Scanned potential microscopy of edge and bulk currents in the quantum Hall regime. Phys. Rev. B 59, 4654–4657 (1999).
Yacoby, A., Hess, H. F., Fulton, T. A., Pfeiffer, L. N. & West, K. W. Electrical imaging of the quantum Hall state. Solid State Commun. 111, 1–13 (1999).
Weitz, P., Ahlswede, E., Weis, J., Klitzing, K. V. & Eberl, K. Hall-potential investigations under quantum Hall conditions using scanning force microscopy. Phys. E: Low.-Dimensional Syst. Nanostruct. 6, 247–250 (2000).
Weis, J. & von Klitzing, K. Metrology and microscopic picture of the integer quantum Hall effect. Philos. Trans. R. Soc. A 369, 3954–3974 (2011).
Finkelstein, G., Glicofridis, P. I., Tessmer, S. H., Ashoori, R. C. & Melloch, M. R. Imaging of low-compressibility strips in the quantum Hall liquid. Phys. Rev. B 61, R16323–R16326 (2000).
Lai, K. et al. Imaging of Coulomb-driven quantum Hall edge states. Phys. Rev. Lett. 107, 176809 (2011).
ADS PubMed Article CAS PubMed Central Google Scholar
Uri, A. et al. Nanoscale imaging of equilibrium quantum Hall edge currents and of the magnetic monopole response in graphene. Nat. Phys. 16, 164–170 (2020).
Novoselov, K. S. et al. Unconventional quantum Hall effect and Berry's phase of 2π in bilayer graphene. Nat. Phys. 2, 177–180 (2006).
Zhang, Y., Tan, Y.-W., Stormer, H. L. & Kim, P. Experimental observation of the quantum Hall effect and Berry's phase in graphene. Nature 438, 201–204 (2005).
Abanin, D., Lee, P. & Levitov, L. Spin-filtered edge states and quantum Hall effect in graphene. Phys. Rev. Lett. 96, 1–4 (2006).
Nomura, K. & MacDonald, A. Quantum Hall ferromagnetism in graphene. Phys. Rev. Lett. 96, 256602 (2006).
Jung, J. & MacDonald, A. H. Theory of the magnetic-field-induced insulator in neutral graphene sheets. Phys. Rev. B 80, 235417 (2009).
ADS Article CAS Google Scholar
Kharitonov, M. Phase diagram for the ν=0 quantum Hall state in monolayer graphene. Phys. Rev. B 85, 155439 (2012).
Roy, B., Kennett, M. P. & Das Sarma, S. Chiral symmetry breaking and the quantum Hall effect in monolayer graphene. Phys. Rev. B 90, 201409 (2014).
Young, A. F. et al. Tunable symmetry breaking and helical edge transport in a graphene quantum spin Hall state. Nature 505, 528–532 (2014).
Zibrov, A. A. et al. Even-denominator fractional quantum Hall states at an isospin transition in monolayer graphene. Nat. Phys. 14, 930–935 (2018).
Kharitonov, M. Edge excitations of the canted antiferromagnetic phase of the ν = 0 quantum Hall state in graphene: a simplified analysis. Phys. Rev. B 86, 075450 (2012).
Knothe, A. & Jolicoeur, T. Edge structure of graphene monolayers in the ν = 0 quantum Hall state. Phys. Rev. B 92, 165110 (2015).
Williams, J. R., DiCarlo, L. & Marcus, C. M. Quantum Hall effect in a gate-controlled p-n junction of graphene. Science 317, 638–641 (2007).
Özyilmaz, B. et al. Electronic transport and quantum Hall effect in bipolar graphene p-n-p junctions. Phys. Rev. Lett. 99, 166804 (2007).
ADS PubMed Article CAS Google Scholar
Klimov, N. N. et al. Edge-state transport in graphene p-n junctions in the quantum Hall regime. Phys. Rev. B 92, 241301 (2015).
ADS MathSciNet Article CAS Google Scholar
Zhang, Y. et al. Landau-level splitting in graphene in high magnetic fields. Phys. Rev. Lett. 96, 136806 (2006).
Ribeiro-Palau, R. et al. High-quality electrostatically defined Hall bars in monolayer graphene. Nano Lett. 19, 2583–2587 (2019).
Zeng, Y. et al. High-quality magnetotransport in graphene using the edge-free corbino geometry. Phys. Rev. Lett. 122, 137701 (2019).
Chen, S. et al. Competing fractional quantum Hall and electron solid phases in graphene. Phys. Rev. Lett. 122, 026802 (2019).
Song, Y. J. et al. Invited review article: a 10 mK scanning probe microscopy facility. Rev. Sci. Instrum. 81, 121101 (2010).
Schwenk, J. et al. Achieving μeV tunneling resolution in an in-operando scanning tunneling microscopy, atomic force microscopy, and magnetotransport system for quantum materials research. Rev. Sci. Instrum. 91, 071101 (2020).
Nonnenmacher, M., O'Boyle, M. P. & Wickramasinghe, H. K. Kelvin probe force microscopy. Appl. Phys. Lett. 58, 2921–2923 (1991).
Melitz, W., Shen, J., Kummel, A. C. & Lee, S. Kelvin probe force microscopy and its application. Surf. Sci. Rep. 66, 1–27 (2011).
Eisenstein, J. P., Pfeiffer, L. N. & West, K. W. Compressibility of the two-dimensional electron gas: measurements of the zero-field exchange energy and fractional quantum Hall gap. Phys. Rev. B 50, 1760–1778 (1994).
Abanin, D. A., Feldman, B. E., Yacoby, A. & Halperin, B. I. Fractional and integer quantum Hall effects in the zeroth Landau level in graphene. Phys. Rev. B 88, 115407 (2013).
Park, J. M., Cao, Y., Watanabe, K., Taniguchi, T. & Jarillo-Herrero, P. Flavour Hund's coupling, correlated Chern gaps, and diffusivity in Moiré flat bands. Nature 592, 43–48 (2021).
Yang, F. et al. Experimental determination of the energy per particle in partially filled Landau levels. Phys. Rev. Lett. 126, 156802 (2021).
Ribeiro-Palau, R. et al. Twistable electronics with dynamically rotatable heterostructures. Science 361, 690–693 (2018).
Chklovskii, D., Shklovskii, B. & Glazman, L. Electrostatics of edge channels. Phys. Rev. B 46, 4026–4034 (1992).
Gutiérrez, C. et al. Interaction-driven quantum Hall wedding cake-like structures in graphene quantum dots. Science 361, 789–794 (2018).
ADS MathSciNet PubMed PubMed Central Article CAS Google Scholar
Atteia, J., Lian, Y. & Goerbig, M. O. Skyrmion zoo in graphene at charge neutrality in a strong magnetic field. Phys. Rev. B 103, 035403 (2021).
Chiappini, F. et al. Lifting of the Landau level degeneracy in graphene devices in a tilted magnetic field. Phys. Rev. B 92, 201412 (2015).
Li, S.-Y., Zhang, Y., Yin, L.-J. & He, L. Scanning tunneling microscope study of quantum Hall isospin ferromagnetic states in the zero Landau level in a graphene monolayer. Phys. Rev. B 100, 085437 (2019).
McClure, D. T. et al. Edge-state velocity and coherence in a quantum Hall Fabry-Pérot interferometer. Phys. Rev. Lett. 103, 206806 (2009).
Jang, J., Hunt, B. M., Pfeiffer, L. N., West, K. W. & Ashoori, R. C. Sharp tunnelling resonance from the vibrations of an electronic Wigner crystal. Nat. Phys. 13, 340–344 (2017).
We thank A. MacDonald, A. Young, and B. Feldman for useful discussions. We also thank David Goldhaber-Gordon and Derrick Boone for assistance in device fabrication, and William Cullen for technical assistance. J.S., D.W., and F.G. acknowledge support under the Cooperative Research Agreement between the University of Maryland and the National Institute of Standards and Technology (NIST), Grant No. 70NANB14H209, through the University of Maryland. S.K. acknowledges support under the Office of Naval Research Grant No. N00014-20-1-2352. M.R.S. acknowledges support under the Cooperative Research Agreement between the Georgetown University and NIST, Grant No. 70NANB18H161, through the NIST/Georgetown PREP program, and funding from the Dutch Research Council (NWO) via a Rubicon grant, Grant No. 019.193EN.026. S.T.L. acknowledges support by NIST and grant 70NANB16H170. J.B. and F.J.G. acknowledge support by Deutsche Forschungsgemeinschaft, SFB1277, project A02. K.W. and T.T. acknowledge support from the Elemental Strategy Initiative conducted by the MEXT, Japan, Grant Number JPMXP0112101001, JSPS KAKENHI Grant Numbers JP20H00354 and the CREST(JPMJCR15F3), JST. C.R.D. acknowledges support under the Army Research Office Grant No. W911NF-17-1-0323.
These authors contributed equally: Sungmin Kim, Johannes Schwenk, Daniel Walkup, Yihang Zeng.
Physical Measurement Laboratory, National Institute of Standards and Technology, Gaithersburg, MD, USA
Sungmin Kim, Johannes Schwenk, Daniel Walkup, Fereshte Ghahari, Son T. Le, Marlou R. Slot, Steven R. Blankenship, Nikolai B. Zhitenev & Joseph A. Stroscio
Institute for Research in Electronics and Applied Physics, University of Maryland, College Park, MD, USA
Sungmin Kim, Johannes Schwenk, Daniel Walkup & Fereshte Ghahari
Department of Physics, Columbia University, New York, NY, USA
Yihang Zeng & Cory R. Dean
Theiss Research, La Jolla, CA, USA
Son T. Le
Department of Physics, Georgetown University, Washington, DC, USA
Marlou R. Slot
Institute of Experimental and Applied Physics, University of Regensburg, Regensburg, Germany
Julian Berwanger & Franz J. Giessibl
Research Center for Functional Materials, National Institute for Materials Science, Tsukuba, Ibaraki, Japan
Kenji Watanabe
International Center for Materials Nanoarchitectonics, National Institute for Materials Science, Tsukuba, Ibaraki, Japan
Takashi Taniguchi
Sungmin Kim
Johannes Schwenk
Daniel Walkup
Yihang Zeng
Fereshte Ghahari
Julian Berwanger
Steven R. Blankenship
Franz J. Giessibl
Nikolai B. Zhitenev
Cory R. Dean
Joseph A. Stroscio
S.K., J.S., D.W., F.G., M.R.S., J.A.S., and N.Z. performed the experiments. Y.Z., F.G., and S.T.L. designed and fabricated the graphene device. J.B., S.R.B., F.J.G., and J.A.S. constructed parts of the instrumentation. K.W. and T.T. grew the hBN crystals used in the graphene device. All authors contributed to writing the manuscript.
Correspondence to Cory R. Dean or Joseph A. Stroscio.
F.J.G. holds patents on the qPlus sensor. The remaining authors declare no competing interests.
Peer review information Nature Communications thanks the anonymous reviewers for their contribution to the peer review of this work.
Publisher's note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
Kim, S., Schwenk, J., Walkup, D. et al. Edge channels of broken-symmetry quantum Hall states in graphene visualized by atomic force microscopy. Nat Commun 12, 2852 (2021). https://doi.org/10.1038/s41467-021-22886-7
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Editorial Values Statement
Editors' Highlights
Nature Communications (Nat Commun) ISSN 2041-1723 (online)
Close banner Close
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.
I agree my information will be processed in accordance with the Nature and Springer Nature Limited Privacy Policy.
Get the most important science stories of the day, free in your inbox. Sign up for Nature Briefing | CommonCrawl |
Non-frontal facial expression recognition based on salient facial patches
Bin Jiang ORCID: orcid.org/0000-0002-6338-40511,
Qiuwen Zhang1,
Zuhe Li1,
Qinggang Wu1 &
Huanlong Zhang2
Methods using salient facial patches (SFPs) play a significant role in research on facial expression recognition. However, most SFP methods use only frontal face images or videos for recognition, and they do not consider head position variations. We contend that SFP can be an effective approach for recognizing facial expressions under different head rotations. Accordingly, we propose an algorithm, called profile salient facial patches (PSFP), to achieve this objective. First, to detect facial landmarks and estimate head poses from profile face images, a tree-structured part model is used for pose-free landmark localization. Second, to obtain the salient facial patches from profile face images, the facial patches are selected using the detected facial landmarks while avoiding their overlap or the transcending of the actual face range. To analyze the PSFP recognition performance, three classical approaches for local feature extraction, specifically the histogram of oriented gradients (HOG), local binary pattern, and Gabor, were applied to extract profile facial expression features. Experimental results on the Radboud Faces Database show that PSFP with HOG features can achieve higher accuracies under most head rotations.
The problem of determining how to use face information in human–computer interaction has been investigated for several years. An increasing number of applications that employ facial recognition technology have emerged. However, current studies on facial expression recognition have yet to be fully and practically applied. Variations in head pose constitute one of the main challenges in the automatic recognition of facial expressions [1]. This problem arises when inadvertent or deliberate occlusions occur, which can obstruct nearly half of the face under large head pose changes. Automatically analyzing facial expressions from the pose-free human face is required to establish a technological framework for further research.
Recognition of profile facial expressions was first achieved by Pantic et al. [2]. They used particle filtering to track 15 facial landmarks in a sequence of face profiles, and an 87% recognition rate was achieved. Although only − 90° face image sequences were used as experimental data, their work inspired further research. Hu et al. [3] are credited to be first to have researched the recognition of multi-view facial expressions. Their experimental data included an increased number of subjects (100), six emotions with four intensity levels, and five viewing angles (0°, 30°, 45°, 60°, and 90°). The authors first calculated the geometric features of the facial components and then exploited five classifiers to recognize emotion features. Experimental results demonstrated that good recognition can be achieved on profile face images.
Moreover, Dapogny et al. [4] used spatio-temporal features to recognize facial expressions under head pose variations in videos. Zheng et al. [5] used additional head variations for face images and proposed a discriminant analysis algorithm to recognize facial expressions from pose-free face images. They chose 100 subjects from the BU-3DFE database [6]. The experimental results demonstrated that their algorithm could achieve satisfactory performance on subjects with a head pose under yaw or pitch. However, the face images with large pose variations yielded the lowest average recognition rate. Wu et al. [7] proposed a model called the locality-constrained linear coding-based bilayer model. The head poses are estimated in the first layer. Then, the facial expression features are extracted using the corresponding view-dependent model in the second layer. This model improved recognition on face images with large pose variations. Lai et al. [8] presented a multi-task generative adversarial network to solve the problem of emotion recognition under large head pose variations. Mao et al. [9] considered the relationships between head poses and proposed a pose-based hierarchical Bayesian-themed model. Jampour et al. [10] found that linear or nonlinear local mapping methods provide more reasonable results for multi-pose facial expression recognition than global mapping methods.
Despite the above advancements in constructing models or functions for mapping the relationship between frontal and non-frontal face images, the feature point movements and texture variations are considerably more complex under head pose variations and identity biases. An effective feature extraction method is thus necessary for recognizing non-frontal facial expressions. Recently, a method based on salient facial patches, which seeks salient facial patches from the human face and extracts facial expression features from these patches, has played a significant role in emotion recognition [11,12,13,14,15,16,17,18,19]. In this method, select facial patches (e.g., eyebrows, eyes, cheeks, and mouth) are considered the key regions of face images, and the discriminative features are extracted from salient regions. The extracted features are instrumental in distinguishing one expression from another. Furthermore, the salient facial patches foster favorable conditions for non-frontal facial expression recognition. We therefore propose an algorithm based on salient facial patches that recognizes facial expressions from non-frontal face images. This method, called profile salient facial patches (PSFP), detects salient facial patches from non-frontal face images and recognizes facial expressions from these patches.
The remainder of this paper is organized as follows. Related work is described in the second section, and the details of PSFP are presented in the Method section. The design and analysis of experiments that validate the proposed approach are described in the Results and discussion section. Finally, conclusions are provided in the last section.
Sabu and Mathai [11] were the first to investigate the importance of algorithms based on salient facial patches for facial expression recognition. They found that, to date, the most accurate, efficient, and reproducible system for facial expression recognition using salient facial patches was designed by Happy and Routray [12]. However, the salient regions can vary in different facial expressions and result in face deformation. Chitta and Sajjan [13] found that the most effective salient facial patches are located mainly in the lower half of the face. Thus, they reduced the salient region and extracted the emotion features from the lower face. However, their algorithm did not achieve high recognition rates in experiments. Zhang et al. [14] used a sparse group lasso scheme to explore the most salient patches for each facial expression, and they combined these patches into the final features for emotion recognition. They achieved an average recognition rate of 95.33% on the CK+ database. Wen et al. [15] used a convolutional neural network (CNN) [20] to train the salient facial patches on face images. A secondary voting mechanism trains the CNN to determine the final categories of test images. Sun et al. [16] presented a CNN that uses a visual attention mechanism and can be applied for facial expression recognition. This mechanism focuses on local areas of face images and determines the importance of each region. In particular, whole face images with different poses are used for CNN training. Yi et al. [17] expanded the salient facial patches from static images to video sequences. They used 24 feature points to show the deformation in facial geometry throughout the entire face. Yao et al. [18] presented a deep neural network classifier that can capture pose-variant expression features from depth patches and recognize non-frontal expressions. Barman and Dutta [19] used an active appearance model [21] to detect the salient facial landmarks, whose connections form triangles that can be deemed salient facial regions. The geometric features are extracted from the face for emotion recognition.
Given the above background, the following commonalities in facial expression recognition are identified:
1. Most existing methods are used on frontal face images.
2. There are three main components of salient facial regions: eyes, nose, and lips.
3. The appearances or texture features are crucial for recognizing facial expressions.
We contend that the salient facial patches method should be applied for both frontal and non-frontal facial expression recognition. Inspired by the method of Happy et al. [12], we designed PSFP for non-frontal facial expression recognition. Unlike previous non-frontal facial expression recognition methods, this method employs salient facial patches, which are composed mainly of the facial components that provide ample facial expression information under head pose variations. Thus, it can extract many appearance or texture features under these variations and identity biases. Furthermore, PSFP does not require the construction of a complex model for multi-pose facial expression classification. The PSFP details are presented in the following sections.
There are three main steps in the non-frontal facial expression recognition system: face detection, feature extraction, and feature classification. The accurate detection of facial landmarks can improve the localization of salient facial patches on the non-frontal face images. Therefore, localization of fiducial facial points and estimation of the head pose are essential steps for identifying the salient facial patches. The head pose may be a combination of different directions in a three-dimensional space. If the face detection method cannot obtain adequate information regarding the head rotations, the facial expression recognition rate will be low. In the methods of Jin and Tan [22], the tree-structured part model employs a unified framework to detect the human face and estimate head variations. This approach is highly suitable for non-frontal facial expression recognition. Thus, we adopt Yu et al.'s method [23] in our system for face detection and head pose estimation. Because this algorithm can estimate the head poses in pitch, yaw, and roll directions, it is adequate to detect the head poses and positions of human faces.
To simultaneously detect the human face and track facial feature points, Yu et al. [23] presented a united framework. They define a "part" at each facial landmark and use global mixtures to model topological changes due to viewpoint variations. The different mixtures of the tree-structured model employ a shared pool of part templates,V. For each viewpoint i, i ∈ (1, 2, ⋯, M), they define N-node tree Ti = (Vi, Ei), Vi ⊆ V. The connection between the two parts forms an edge in Ei. There are two main steps in their framework:
Initialization. For each viewpoint i, the measuring of landmark configuration s = (s1, s2, ⋯, sN) is defined by scoring function f:
$$ {\displaystyle \begin{array}{c}{f}_i\left(I,s\right)=\sum \limits_{j\in {V}_i}{q}_i\left(I,{s}_j\right)+\sum \limits_{\left(j,k\right)\in {E}_i}{g}_i\left({s}_j,{s}_k\right)\\ {}s\ast =\arg {\max}_{i\in \left(1,2,\cdots, M\right)}{f}_i\left(I,s\right)\end{array}} $$
where the first term uses local patch appearance evaluation function\( \kern0.50em {q}_i\left(I,{s}_j\right)=\left\langle {w}_j^{iq},{\Phi}_j^{iq}\left(I,{s}_j\right)\right\rangle \), which indicates whether a facial landmark sj = (xj, yj), j ∈ (1, 2, ⋯, N) may occur at the aligned position in face image I. The second term uses shape deformation cost\( {g}_i\left({s}_j,{s}_k\right)=\left\langle {w}_{jk}^{ig},{\Phi}_{jk}^{ig}\left({s}_j,{s}_k\right)\right\rangle \), which maintains the balance of the relative locations of neighboring facial landmarks sjand sk. \( {w}_j^{iq} \) denotes the weight vector convolving the feature descriptor of patch \( j,{\Phi}_j^{iq}\left(I,{s}_j\right) \). \( {w}_{jk}^{ig} \) are the weights controlling the shape displacement function, which is defined as \( {\Phi}_{jk}^{ig}\left({s}_j,{s}_k\right)=\left( dx, dy,d{x}^2,d{y}^2\right),\kern0.5em \left( dx, dy\right)={s}_k-{s}_j \). The largest score may provide the most likely localization of the landmarks. Thus, the landmark positions can be obtained by maximizing scoring function f in Eq. 1. A group sparse learning algorithm [24] can be used to select the most salient weights, thereby forming a new tree.
Localization. Once the initial facial landmarks, s, have been detected, Procrustes analysis is employed to project the 3D reference shape model onto a 2D face image.\( \mathrm{s}=\overline{s}+Q\times u \) represents face shapes by mean shape \( \overline{s} \)and a linear combination of selected shape basis Q, and u is the coefficient vector. Hence, the relationship is established between any two points in 3D space in Eq. 2.
$$ {s}_j=a\times R\times s+T $$
where sj is one of the defined landmarks, a denotes a scaling factor, R represents a rotation matrix, and T is the shift vector. The problem is to find such parameter, \( \mathcal{P}=\left\{a,R,u,T\right\} \), to map the 3D reference shape to a fitted shape that best depicts the faces in an image.
Based on this probabilistic model, a two-step cascaded deformable shape model [23] is proposed to refine the facial landmark locations.
$$ {s}^{\ast }=\arg \underset{s}{\max }p\left(s|{\left\{{v}_i=1\right\}}_1^N,I\right) $$
$$ \propto \arg \underset{s}{\max }p(s)p\left({\left\{{v}_i=1\right\}}_{i=1}^n|s,I\right) $$
$$ =\arg \underset{\mathcal{P}}{\max }p\left(\mathcal{P}\right){\prod}_{i=1}^np\left({v}_i=1|{s}_i,I\right) $$
In Eq. 3, vector v = {v1, …, vN} indicates the likelihood of alignment in face image I. Here, v = 1 indicates that the facial landmarks are well aligned, and v = 0 indicates the opposite. Thus, Eq. 3 aims to maximize the likelihood of an alignment. Then, the Bayesian rule is used to derive Eq. 4. Hence, in Eq. 5, we know that parameter\( \kern0.5em \mathcal{P} \) can determine 3D shape model s,\( \kern0.5em p\left(\mathcal{P}\right)=p(s) \). We suppose that \( p\left(\mathcal{P}\right)\kern0.5em \)obeys the Gaussian distribution. In addition, logistic regression is used to represent the likelihood, \( p\left({v}_i=1|{s}_i,I\right)=\frac{1}{\exp \left(\vartheta \varphi +b\right)} \), where φ is the local binary pattern (LBP) feature of facial landmark patch i, and parameters ϑ and b represent two regression weights that are trained from collected positive and negative samples.
Finally, the landmarks can be tracked and presented as si = (xi, yi), i = 1, 2, …, 66. The locations of the landmarks for an image, such as that shown in Fig. 1a can be depicted as in Fig. 1b
Framework for automated extraction of salient facial patches. a Face image from RaFD database [25]. b Sixty-six facial landmarks detected using Yu et al.'s method [23]. c Points of lip corners and eyebrows. d Locations of the salient facial patches
Extraction of pose-free salient facial patches
The special salient facial patches are obtained from the face images according to the head pose. From an analysis of related work, we find that the eyes, nose, and lips are important facial components of the salient facial patches. The locations of these facial components for an image such as Fig. 1a can be shown as in Fig. 1c. The salient facial patches Ai can be extracted around the facial parts and the areas of the eyebrow, eye, nose, and lips:
$$ {A}_i=\left[\begin{array}{ccc}\left({x}_i-\frac{M}{2}+1,{y}_i-\frac{N}{2}+1\right)& \cdots & \left({x}_i-\frac{M}{2}+1,{y}_i+\frac{N}{2}\right)\\ {}\vdots & \ddots & \vdots \\ {}\left({x}_i+\frac{M}{2},{y}_i-\frac{N}{2}+1\right)& \cdots & \left({x}_i+\frac{M}{2},{y}_i+\frac{N}{2}\right)\end{array}\right] $$
where point si = (xi, yi) is the center of Ai, and M×N is the size of Ai. If L salient facial patches have been selected from image R, the facial expression features will be extracted from L salient facial patches:
$$ {R}_i=\left({A}_1,{A}_2,\cdots, {A}_L\right),i=1,2,\cdots k $$
where k is the number of images. The locations of 19 salient facial patches on a frontal face image are shown in Fig. 1d.
The rationale behind choosing the 20 given patches is based on the following facial action coding system. P1 and P4 are located at the lip corners, and P9 and P11 are just below them. P10 is at the midpoint of P9 and P11, and P20 is at the upper lip. P16 is situated at the center of the two eyes, and P17 is at the center of inner brow. P15 and P14 are below the left and right eyes, respectively. P3 and P6 are respectively located at the middle of the nose and between the eyes. P5, P13, and P12 were extracted from the left side of the nose and are stacked together; P2, P7, and P8 are at the right side of the nose; and P18 and P19 are located on the respective outer eye corners.
The method of selecting facial patches in PSFP is similar to that in Happy et al., with two exceptions. The first difference is that the salient facial patches (SFP) method in Happy et al., which extracts facial expression features from salient facial patches, can only be used for frontal facial expression recognition; the face detection method is not applied for large head pose variations. As our method aims to recognize non-frontal facial expressions, the 66 facial landmarks are determined using Yu et al.'s method from face images with different head poses.
The second difference is the positions of P18 and P19. When the face image is a frontal view, the Happy et al. method assigns the positions of these facial patches to the inner eyebrows, as shown in Fig. 2a (ours is shown in Fig. 2b). Two patches already exist at the inner eyebrows. Thus, if the patches are larger, they would likely overlap with those at the inner eyebrows. Moreover, Happy et al. do not consider the outer eye corner region.
Positions of facial patches P18 and P19 as selected by (a) the method of Happy et al. and (b) the proposed method
When the image is a non-frontal facial view, the face will be partially occluded. Some patches may disappear under head pose variations. In such cases, the salient facial patches can be selected as shown in Fig. 3, and they are listed in Table 1.
Positions of salient facial patches under head pose variations. a Four face images with different head poses (left to right: 90°, 45°, − 45°, and − 90°), and b positions of the salient facial patches in the corresponding face images
Table 1 Salient facial patches under different head poses
As shown in Table 1, when the viewing angles increase from 0° to 90°, the number of patches decreases from 20 to 12. Thus, the feature dimensions of patches in the Happy et al. method are 19 × M × N, whereas those in the PSFP algorithm are only 12 × M × N for non-frontal face images. Furthermore, we determined that the PSFP algorithm incurs a lower computational cost and has a time complexity of O(2nlog2n).
Feature extraction and classification
After the salient facial patches are obtained from the face images, the facial patch features must be extracted for classification. After these features are obtained, a representative classifier is applied for facial expression classification.
Three classical feature extraction methods have been applied for extracting the facial expression information: the histogram of oriented gradients (HOG), LBP, and Gabor filters. They have been used in many important studies [3, 26] of non-frontal facial expression recognition. These methods can extract local facial expression features from face images. Therefore, in our experiment, we extracted features from salient facial patches in each image using the three methods separately to compare their recognition performances.
First, we divided the whole-face image into parts; second, we obtained a histogram from each cell; and finally, we normalized the computed results and returned a descriptor.
The N × N LBP operator was used to obtain the facial expression features. The operator weights were multiplied by the corresponding pixels of the face image, and N×N − 1 pixels were used for the LBP features of the neighborhood. There are many variations of the LBP algorithm. In Happy et al.'s study, the highest recognition rate was attained using a uniform LBP. The N × N uniform LBP operator computes LBP features from a circular neighborhood. It has two important parameters: P, which is the number of corresponding pixels, and R, which is the circular neighborhood radius.
A two-dimensional Gabor filter can be formulated as [27]
$$ {\displaystyle \begin{array}{c}G\left(x,y\right)=\frac{f^2}{\pi \gamma \eta}{e}^{-\frac{x^{\prime 2}+{\gamma}^2{y}^{\prime 2}}{2{\sigma}^2}}{\mathrm{e}}^{\mathrm{i}2\uppi \mathrm{f}{x}^{\prime }+\phi}\\ {}{x}^{\prime }=x\cos \theta +y\sin \theta, {y}^{\prime }=-x\sin \theta +y\cos \theta \\ {}f=\frac{1/4}{{\sqrt{2}}^{u-1}},u=1,2,\cdots, 5.\kern0.5em \theta =\frac{\pi }{8}\times \left(v-1\right),v=1,2,\cdots, 8\end{array}} $$
where f is the frequency of the sinusoidal factor, and θ represents the orientation of the normal to the parallel stripes of the Gabor function. Further, ϕ is the phase offset, σ is the standard deviation of the Gaussian envelope, and γ denotes the spatial aspect ratio that specifies the ellipticity of the support of the Gabor function. If image I(x, y) is convolved with a Gabor filter, the Gabor features will be extracted by the particular f and θ values. In our experiments, we chose the largest value of f, and u was set to 1.
The above examples show feature extraction that was performed on only a single patch; thus, feature fusion was necessary for feature extraction of the salient facial patches.
After the facial expression features were extracted, the final task was feature classification. Non-frontal face images are hampered by a lack of emotion information. Thus, if the classifier is weak, the recognition rate may be very low. To address this problem, the adaptive boosting (AdaBoost) [28] algorithm was applied for the classification because it effectively combines many learning algorithms to improve the recognition performance and is thus suitable for classification.
Experimental setting
This simulation environment of our experiment used MATLAB R2015b on a Dell personal computer. We evaluated the PSFP algorithm on the Radboud Faces Database (RaFD) [25]. RaFD is a free publicly available dataset that contains eight facial expressions: anger, contempt, disgust, fear, happiness, neutrality, sadness, and surprise. Each facial expression is shown with three different gaze directions: frontal, left, and right. The photographer captured photographs of 67 models with five different head poses. In this study, 1200 face images were used for the experiments, consisting of ten people, eight expressions, three gaze directions, and five head poses.
The framework of the PSFP algorithm is shown in Fig. 4.
Framework of the PSFP algorithm
For determining the facial landmark locations, the Yu et al. method was used, and salient facial patches were extracted from the face images under five different head poses. This method can estimate the head poses along pitch, yaw, and roll directions. However, in our experiments, the method was only needed to estimate the head poses along the yaw direction.
The size of the facial patches was typically set to 16 × 16. HOG, LBP (P = 8, R = 1), and Gabor filters (u = 1, v = 1, 2, ⋯, 8) were respectively applied for the feature extraction. Principal component analysis (PCA) was used for feature dimensionality reduction; the feature dimensionality was typically set to ten. We used the M1-type AdaBoost method (AdaBoost.M1) for the classification and applied the nearest-neighbor method (NN) for the AdaBoost.M1 basic classifier. The maximum number of iterations was 100.
Experiments were conducted to validate the PSFP recognition performance with respect to the four different perspectives.
Testing PSFP performance under different training–testing strategies
There are two commonly used experimental approaches to performing non-frontal facial expression recognition: pose-invariant and pose-variant. In the former, training images and test images are obtained under the same head pose; thus, head pose estimation can be avoided. In the latter, the training and test images may have different head poses. This approach is thus more realistic. To analyze the recognition performance of the PSFP algorithm, two simulation experiments were performed, as described in the Pose-invariant non-frontal facial expression recognition section and Pose-variant non-frontal facial expression recognition section.
Testing PSFP performance under different parameter values
Generally, the selection of parameters depends on empirical values, and it is difficult to support them with rigorous proof. Therefore, it was necessary to use different parameter values for PSFP and to observe the recognition performance on a test set. As described in the Testing PSFP performance under different training–testing strategies section, the size of the facial patches was typically set to 16 × 16, and the feature dimensionality was typically set to 10. Both of these key parameters could affect the expression recognition performance. The Comparison by facial patch size and Comparison by feature dimensionality sections describe the experiments that were conducted for this performance comparison.
Comparing PSFP with SFP for frontal facial expression recognition
In the Extraction of pose-free salient facial patches section, we discussed the two differences between the SFP method of Happy et al. and PSFP. Even if we replace the SFP face detection method with the Yu et al. method, this modified SFP method would still not be suitable for application to non-frontal-view face images. However, if we use PSFP to recognize the frontal-view face images, PSFP and SFP may be similar in the positions they select for facial salient patches. As PSFP and SFP should be compared, it is necessary to perform the experiments for frontal facial expression recognition. The experiment described in the Comparison with the Happy et al. SFP method section was designed for this purpose.
Comparing PSFP with non-SFP using whole-face images
A salient facial patch is in fact only part of a face image. According to common understanding, if the whole-face image is used for the recognition, the performance may be better. However, if the selection of salient facial patches is sufficiently good, PSFP could perform better than this non-SFP method. Therefore, we used the same feature extraction and classification method for the two methods and compared them, as described in the Comparison with non-SFP method using whole-face images section.
Pose-invariant non-frontal facial expression recognition
There are two training–testing strategies for facial expression recognition: person-dependent and person-independent. In our experiments on person-dependent facial expression recognition, the subjects appearing in the training set also appeared in the test set. Because every model had three different head poses, a three-fold cross-validation strategy was used for the person-dependent facial expression recognition.
The dataset could be divided into three segments according to head pose. Each time, two segments were used for training, and the remaining segment was used for testing. Thus, for each head rotation angle, the number of images in the training set was 160, and the number in the test set was 80. The same training–testing procedure was carried out three times and the average result of the three procedures was considered as the final recognition performance of the PSFP algorithm. The HOG, LBP, and Gabor methods were used for feature extraction, and the AdaBoost algorithm with the NN classifier was applied for classification. The recognition rates of these methods are shown in Table 2. Each row shows the recognition performance for five head rotation angles (90°, 45°, 0°, − 45°, and − 90°). The best recognition rates are highlighted in bold. For most angles, HOG has the best recognition performance, and at 0° and − 45°, LBP has the best recognition performance. The best head rotation angle for recognition of non-frontal facial expressions is − 45°.
Table 2 Recognition rates (%) for person-dependent facial expression recognition. The best recognition rates are highlighted in bold
In the experiments on person-independent facial expression recognition, the subjects appearing in the training set did not appear in the test set. For this reason, the leave-one-person-out strategy was used. That is, all photographs of one person were selected as the test set; the remaining photographs in the dataset were used for training. Thus, for each head rotation angle, the number of images in the training set was 216, and the number in the test set was 24. This procedure was repeated ten times, and the averaged result was taken as the final recognition rate. The results are shown in Table 3. For most angles, Gabor achieved the best recognition rate. For 0°, − 45°, and 90°, Gabor and LBP achieved the best recognition rate. We found that the best head rotation angle for recognition of non-frontal facial expressions was 45°.
Table 3 Recognition rates (%) for person-independent facial expression recognition. The best recognition rates are highlighted in bold
In summary, analyses of the pose-invariant non-frontal facial expression recognition experiments show the following: (1) When the head rotation angle is larger, the recognition rate may be lower. Because many facial patches are occluded by head rotation, the number of emotion features is not sufficient to achieve a high recognition rate. (2) Although identity bias and face occlusion interfere with facial expression recognition, the PSFP algorithm can achieve better recognition performance on non-frontal facial expression recognition.
Pose-variant non-frontal facial expression recognition
In the experiments on person-dependent facial expression recognition, a three-fold cross-validation strategy was used for training and testing. The number of images in the training set was 800, and the number in the test set was 400. The same procedure was performed three times.
In the experiments on person-independent facial expression recognition, the leave-one-person-out strategy was used. The number of images in the training set was 1080, and the number in the test set was 120. This procedure was performed ten times for each dataset, and the average values are taken as the final recognition rate. The results are listed in Table 4.
Table 4 Accuracy (%) for pose-variant non-frontal facial expression recognition
As shown in the table, having different head pose rotations increases the difficulty of non-frontal facial expression recognition. However, the proposed method performed well. PSFP with the HOG algorithm again achieved the best recognition rates.
Performance comparisons
Comparison by facial patch size
In the above experiments, the size of the facial patches was 16×16. We increased the size to 32×32, and the experiment results are shown in Figs. 5 and 6. When the results in Figs. 5 and 6 are compared, we can observe that the person-dependent results are better than the person-independent ones. Moreover, the 32×32 facial patches achieved higher recognition performance than the 16×16 facial patches in most cases. This is because the feature extraction methods can obtain much more information, which helps improve the recognition performance of non-frontal facial expression recognition.
Performance comparison of person-dependent facial expression recognition under different facial patch sizes
Performance comparison of person-independent facial expression recognition under different facial patch sizes
Comparison by feature dimensionality
In the above experiments, the feature dimensionality was set to ten. We again conducted the experiments for pose-variant non-frontal facial expression recognition and the feature dimensionality was increased from ten to 100. AdaBoost with NN was used as the classifier, and the feature extraction methods were HOG, LBP, and Gabor. The results are shown in Figs. 7 and 8. It is observed that the recognition rates increase from the initial allocation and eventually settle around a range of values. In the experiment on pose-variant non-frontal facial expression recognition, the magnitude of the range is from 2 to 7%. We find that the accuracy of person-independent facial expression recognition can increase with the increase in feature dimensionality. Because this model is trained and tested on different subjects, it leads to individual differences, which significantly hinders the recognition. When the feature dimension is increased, it improves the classification accuracy.
Accuracy of person-dependent facial expression recognition according to feature dimensionality
Accuracy of person-independent facial expression recognition according to feature dimensionality
Although the recognition rate may increase with the increase in feature dimensionality, the computation cost of the algorithm is necessarily higher. We suggest that the feature dimensionality should be set to a value that is as small as possible while maintaining good performance.
Comparison with the Happy et al. SFP method
To recreate the experimental conditions of Happy et al., the LBP and linear discriminant analysis (LDA) methods were used for feature extraction, and support vector machine (SVM) was used for classification. The results are shown in Figs. 9 and 10. When LBP parameters P and R are respectively equal to 8 and 1, the PSFP accuracy is higher than that of the Happy et al. SFP method. This finding demonstrates that the PSFP method can also outperform SFP for frontal facial expression recognition.
Comparisons of SFP and PSFP for person-dependent facial expression recognition
Comparisons of SFP and PSFP for person-independent facial expression recognition
Comparison with non-SFP method using whole-face images
In this experiment, the LBP algorithm was used to extract the whole-face images, and the AdaBoost algorithm was applied for classification. The non-SFP method was compared with the PSFP method for pose-invariant non-frontal facial expression recognition. The recognition rates for person-dependent and person-independent strategies are shown in Figs. 11 and 12.
Recognition rates for person-dependent facial expression recognition
Recognition rates for person-independent facial expression recognition
Even though the PSFP method does not use the whole-face image for recognition, its accuracy is not lower than that of the non-SFP method using whole-face images. The selection of salient facial patches enables the PSFP method to achieve a higher accuracy. Moreover, the size of the whole-face image is 128 × 128, and the total areas of the salient facial patches are 16 × 16 × 20, and 16 × 16 × 12. Thus, the PSFP method substantially reduces the quantity of data.
CNN-based features perform for this non-frontal facial expression recognition task
As mentioned in the Related work section, several studies have employed salient patches with CNNs for face detection and classification. We thus used CNN for non-frontal facial expression recognition. The CNN model was 21-layer VGG [29] and AlexNet [30]. The number of images in the training set was 800, and the number in the test set was 400. The recognition rates are shown in Fig. 13, where we observe that the VGG recognition rate is lower than the AlexNet recognition rate.
Recognition rates for non-frontal facial expression recognition by using CNN
We also used facial patches as images for training CNNs. However, this approach may be not suitable for recognition. CNNs typically require a whole face image for model training. The problem remains of how to use patches with CNNs and achieve good performance. This issue will be addressed in our future research.
From the above experiments, we find that the PSFP method has the following characteristics:
HOG features have better recognition performance than LBP features or Gabor features. We believe this is because the LBP features are based on the local image regions of the facial patch and the Gabor features are extracted from the whole-face patch, whereas HOG features are obtained from the small squared cells of the facial patch. Therefore, the HOG method can more effectively extract the emotion features under complex changes of light, scale, pose, and identity environments.
The PSFP method, an extension of the SFP method, can also be applied for frontal facial expression recognition.
PSFP can achieve high recognition rates while consuming fewer data.
This paper presented PSFP, an algorithm based on salient facial patches. PSFP employs the relevance of facial patches in non-frontal facial expression recognition and employs the facial landmark detection method to track key points from a pose-free human face. In addition, an algorithm for extracting the salient facial patches was proposed. This algorithm determines the facial patches under different head rotations. The facial expression features can be extracted from the facial patches and used for feature classification. The experiment results showed that PSFP can achieve high recognition rates while consuming fewer data.
The raw/processed data required to reproduce these findings cannot be shared at this time as the data also form part of an ongoing study.
E. Sariyanidi, H. Gunes, A. Cavallaro, Automatic analysis of facial affect: A survey of registration, representation, and recognition. IEEE Transactions on Pattern Analysis & Machine Intelligence 37(6), 1113–1133 (2015)
M. Pantic, I. Patras, Dynamics of facial expression: Recognition of facial actions and their temporal segments from face profile image sequences. IEEE Transactions on Systems Man & Cybernetics Part B 36(2), 433–449 (2006)
Y.X. Hu, Z.H. Zeng, L.J. Yin, X.Z. Wei, J.L. Tu, T.S. Huang, A study of non-frontal-view facial expressions recognition. IEEE International Conference on Pattern Recognition, 2008. ICPR, 1–4 (2008)
A. Dapogny, K. Bailly, S. Dubuisson, Dynamic pose-robust facial expression recognition by multi-view pairwise conditional random forests. IEEE Transactions on Affective Computing 10(2), 167–181 (2019)
W.M. Zheng, H. Tang, Z.C. Lin, T.S. Huang, Emotion recognition from arbitrary view facial images. Proceeding International Conference European Conference on Computer Vision 2010, 490–503 (2010)
L.J. Yin, X.Z. Wei, Y. Sun, J. Wang, M.J. Rosato, A 3D facial expression database for facial behavior research. IEEE International Conference on Automatic Face and Gesture Recognition 2006, 211–216 (2006)
J.L. Wu, Z.C. Lin, W.M. Zheng, H.B. Zha, Locality-constrained linear coding based bi-layer model for multi-view facial expression recognition. Neurocomputing 239, 143–152 (2017)
Y.H. Lai, S.H. Lai, Emotion-preserving representation learning via generative adversarial network for multi-view facial expression recognition. IEEE International Conference on Automatic Face and Gesture Recognition 2018, 263–270 (2018)
Q.R. Mao, Q.Y. Rao, Y.B. Yu, M. Dong, Hierarchical Bayesian theme models for multipose facial expression recognition. IEEE Transactions on Multimedia 19(4), 861–873 (2017)
M. Jampour, V. Lepetit, T. Mauthner, H. Bischof, Pose-specific non-linear mappings in feature space towards multiview facial expression recognition. Image & Vision Computing 58, 38–46 (2017)
E. Sabu, P.P. Mathai, An extensive review of facial expression recognition using salient facial patches. Proceeding International Conference Applied and Theoretical Computing and Communication Technology 2015, 847–851 (2015)
S.L. Happy, A. Routray, Automatic facial expression recognition using features of salient facial patches. IEEE Transactions on Affective Computing 6(1), 1–12 (2015)
K.K. Chitta, N.N. Sajjan, A reduced region of interest based approach for facial expression recognition from static images. IEEE Region 10 Conference 2016, 2806–2809 (2016)
R. Zhang, J. Li, Z.Z. Xiang, J.B. Su, Facial expression recognition based on salient patch selection. IEEE International Conference on Machine Learning and Cybernetics 2016, 502–507 (2016)
Y.M. Wen, W. Ouyang, Y.Q. Ling, Expression-oriented ROI region secondary voting mechanism. Application Research of Computers 36(9), 2861–2865 (2019)
W.Y. Sun, H.T. Zhao, Z. Jin, A visual attention based ROI detection method for facial expression recognition. Neurocomputing 296, 12–22 (2018)
J.Z. Yi, A.B. Chen, Z.X. Cai, Y. Sima, X.Y. Wu, Facial expression recognition of intercepted video sequences based on feature point movement trend and feature block texture variation. Applied Soft Computing 82, 105540 (2019)
N.M. Yao, H. Chen, Q.P. Guo, H.A. Wang, Non-frontal facial expression recognition using a depth-patch based deep neural network. Journal of computer science and technology 32(6), 1172–1185 (2017)
A. Barman, P. Dutta, Facial expression recognition using distance and shape signature features. Pattern Recognition Letters 145, 254–261(2021)
Y. Sun, X.G. Wang, X.O. Tang, Deep convolutional network cascade for facial point detection. IEEE International Conference on Computer Vision and Pattern Recognition, 3476–3483 (2013, 2013)
T.F. Cootes, G.J. Edwards, C.J. Taylor, Active appearance models. IEEE Transaction on Pattern Analysis and Machine Intelligence 23(6), 681–685 (2001)
X. Jin, X.Y. Tan, Face alignment in-the-wild: A survey. Computer Vision and Image Understanding 162, 1–22 (2017)
X. Yu, J.Z. Huang, S.T. Zhang, W. Yan, D.N. Metaxas, Pose-free facial landmark fitting via optimized part mixtures and cascaded deformable shape model. IEEE International Conference on Computer Vision 2013, 1944–1951 (2013)
J. Liu, S.W. Ji, J.P. Ye, SLEP: Sparse Learning with Efficient Projections (Arizona State University, Arizona, 2009)
O. Langner, R. Dotsch, G. Bijlstra, D.H.J. Wigboldus, S.T. Hawk, A.V. Knippenberg, Presentation and validation of the Radboud faces database. Cognition & Emotion 24(8), 1377–1388 (2010)
S. Moore, R. Bowden, Local binary patterns for multi-view facial expression recognition. Computer Vision Image Understand 115(4), 541–558 (2011)
M. Haghighat, S. Zonouz, M. Abdel-Mottaleb, Identification using encrypted biometrics. Computer Analysis of Images and Patterns, 440–448 (2013) York, United Kingdom
R.E. Schapire, A brief introduction to boosting. IEEE International Joint Conference on Artificial Intelligence 1999, 1401–1406 (1999)
K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition. International Conference on Learning Representations, 1–4 (2015)
A. Krizhevsky, I. Sutskever, G.E. Hinton, ImageNet classification with deep convolutional neural networks. Neural Information Processing Systems (Curran Associates Inc, Red Hook, 2012), pp. 1097–1105
The authors are very grateful to the editors and reviewers, to Dr. Xiang Yu for supplying the MATLAB code for face detection, and to Radboud University Nijmegen for providing the RaFD database.
This work was supported by the National Natural Science Foundation of China (Nos. 61702464, 61771432, 61873246, 61702462, and 61502435), the Scientific and Technological Project of Henan Province under Grant Nos. 16A520028, 182102210607, and 192102210108, and the Doctorate Research Funding of Zhengzhou University of Light Industry under Grant No. 2014BSJJ077.
College of Computer and Communication Engineering, Zhengzhou University of Light Industry, Zhengzhou, 450002, People's Republic of China
Bin Jiang, Qiuwen Zhang, Zuhe Li & Qinggang Wu
College of Electric and Information Engineering, Zhengzhou University of Light Industry, Zhengzhou, 450002, People's Republic of China
Huanlong Zhang
Bin Jiang
Qiuwen Zhang
Zuhe Li
Qinggang Wu
BJ conceived the algorithm, designed the experiments, analyzed the results, and wrote the paper; QZ, ZL, and QW wrote the codes and performed the experiments; and HZ managed the overall research and contributed to the paper writing. The authors read and approved the final manuscript.
Bin Jiang received his M.S. degree from Henan University in 2009, and his Ph.D. from Beijing University of Technology, Beijing, China, in 2014. He joined the Zhengzhou University of Light Industry as a lecturer in 2014. His current research interests include image processing, pattern recognition, and machine learning.
Qiuwen Zhang received his Ph.D. degree in communication and information systems from Shanghai University, Shanghai, China, in 2012. Since 2012, he has been with the faculty of the College of Computer and Communication Engineering, Zhengzhou University of Light Industry, where he is an associate professor. He has published over 30 technical papers in the fields of pattern recognition and image processing. His major research interests include 3D signal processing, machine learning, pattern recognition, video codec optimization, and multimedia communication.
Zuhe Li received his M.S. degree in communication and information systems from Huazhong University of Science and Technology in 2008, and his Ph.D. degree in information and communication engineering from Northwestern Polytechnical University in 2017. He is currently an associate professor at Zhengzhou University of Light Industry. His current research interests include computer vision and machine learning.
Qinggang Wu received M.S. and Ph.D. degrees in computer science from Dalian Maritime University, Dalian, China, in 2008 and 2012, respectively. Since January 2013, he has been a lecturer at the School of Computer and Communication Engineering, Zhengzhou University of Light Industry, Zhengzhou, China. His research interests include remote sensing image processing, image segmentation, edge detection, pattern recognition, and computer vision.
Huanlong Zhang received his Ph.D. degree from the School of Aeronautics and Astronautics, Shanghai Jiao Tong University, China, in 2015. He is currently an associate professor at the College of Electric and Information Engineering, Zhengzhou University of Light Industry, Henan, Zhengzhou, China. He has published more than 40 technical articles in referred journals and conference proceedings. His research interests include pattern recognition, machine learning, image processing, computer vision, and intelligent human–machine systems.
Correspondence to Bin Jiang.
Authors have permissions on usage of photos of RaFD database as in strictly scientific publications RaFD images can be presented as stimulus examples.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Jiang, B., Zhang, Q., Li, Z. et al. Non-frontal facial expression recognition based on salient facial patches. J Image Video Proc. 2021, 15 (2021). https://doi.org/10.1186/s13640-021-00555-5
Facial expression recognition
Salient facial patch
Head rotation | CommonCrawl |
DARU Journal of Pharmaceutical Sciences
Factors affecting viability of Bifidobacterium bifidum during spray drying
Zahra Shokri1,
Mohammad Reza Fazeli2Email author,
Mehdi Ardjmand1,
Seyyed Mohammad Mousavi3 and
Kambiz Gilani4
DARU Journal of Pharmaceutical Sciences201523:7
© Shokri et al.; licensee BioMed Central. 2015
Received: 24 August 2013
There is substantial clinical data supporting the role of Bifidobacterium bifidum in human health particularly in benefiting the immune system and suppressing intestinal infections. Compared to the traditional lyophilization, spray-drying is an economical process for preparing large quantities of viable microorganisms. The technique offers high production rates and low operating costs but is not usually used for drying of substances prone to high temperature. The aim of this study was to establish the optimized environmental factors in spray drying of cultured bifidobacteria to obtain a viable and stable powder.
The experiments were designed to test variables such as inlet air temperature, air pressure and also maltodextrin content. The combined effect of these variables on survival rateand moisture content of bacterial powder was studied using a central composite design (CCD). Sub-lethal heat-adaptation of a B. bifidum strain which was previously adapted to acid-bile-NaCl led to much more resistance to high outlet temperature during spray drying. The resistant B. bifidum was supplemented with cost friendly permeate, sucrose, yeast extract and different amount of maltodextrin before it was fed into a Buchi B-191 mini spray-dryer.
Second-order polynomials were established to identify the relationship between the responses andthe three variables. Results of verification experiments and predicted values from fitted correlations were in close agreement at 95% confidence interval. The optimal values of the variables for maximum survival and minimum moisture content of B. bifidum powder were as follows: inlet air temperature of 111.15°C, air pressure of 4.5 bar and maltodextrin concentration of 6%. Under optimum conditions, the maximum survival of 28.38% was achieved while moisture was maintained at 4.05%.
Viable and cost effective spray drying of Bifidobacterium bifidum could be achieved by cultivating heat and acid adapted strain into the culture media containing nutritional protective agents.
Spray drying
Viability
Response surface methodology
Probiotics are live microbial feed supplements that beneficially affect hosts by improving its intestinal microbial balance [1]. Bacterial strains selected as probiotics are predominantly from the genera Bifidobacteria and Lactobacilli, which are indigenous to the human gastrointestinal tract [2]. These strains possess unique ability to establish in the human intestine and are associated with restoration of normal intestinal flora by outcompeting harmful flora and human pathogens [3]. They are also believed to have detoxifying ability against mycotoxins [4]. Because of their positive effect on host's health, production and consumption of live probiotic supplements and food products enriched with friendly microorganisms have been of focus [5]. Both freeze-dying and spray-drying which are currently used to dry probiotic cultures expose the culture to extreme environmental conditions [6]. Spray drying is however more economic and efficient because of its continuous high production rate behavior, but viability of bacteria is usually affected due to use of extreme heat [7].
During spray drying bacteria are exposed to multiple stresses, i.e. heat (both wet and dry), oxidation, dehydration-related stresses (osmotic, acidic and thermal shock, accumulation of toxic compounds, etc.) which potentially could lead to cell death. Loss of viability appears to be principally caused by cell membrane damage [8]; moreover, the cell wall, ribosome and DNA are also affected at higher temperatures [9].
Thermal shock is the most influential factor in this field. Compared to the untreated bacteria, those which are pre-treated in water bath are usually more resistant to dry heat of outlet air temperature during spray drying [10]. High temperatures could lead to heat or stress proteins. The induction of heat shock on bacterial has led to the production of heat shock protein (HSP) or stress proteins. The role of protective proteins is to prevent malicious connections between intracellular amino acids. These proteins are produced by the genes present in all living cells. In 2005, Joana Silva and colleagues showed that the growth of the bacteria in non-controlled pH conditions results in induction of heat shock proteins and results in more bacteria to survive during spray drying and storage [11]. Also water drainage which contributes to the stability of biological molecules and probiotic strains, may cause irreversible changes in the structural and functional integrity of bacterial membranes and proteins. Preservation of these essential functions and structure is crucial for the survival of bacteria and the retention of their functionality.
The residual moisture content should be low enough to prevent damage to the product during storage. Too low moisture content of probiotic powders can also be injurious [8]. Humidity below 2% is also harmful because it can increase the risk of oxidation of unsaturated fatty acids in the cell membrane of bacteria and it can destroy the units of hydration around these fatty acids [12]. Based on the measurements of glass transition temperature (T g ), critical water content 4-7% (w/v) is necessary and appropriate for the storage of culture powders at room temperature of 25°C [13,14].
As data on optimized spray drying of B. bifidum is trace we have tried to investigate the optimum spray drying conditions for preparation of viable B. bifidum powder with suitable moisture content.
Microorganism and cultivation conditions
The bacterial strain of Bifidobacterium bifidum PTCC 1644 (Persian Type Culture Collection- Iran) was previously adapted to gastrointestinal conditions such as acid, bile and NaCl [15].
Heat adaptation of bacterial cultures
Bacteria underwent heat adaptation according to Jewell and Kashket [16]. Test tubes containing aliquots of 20 ml of 30 hours fresh bacterial culture (37°C and 5% CO2) in MRS broth (Merck GmbH, Germany) were treated at 60°C for 15 minutes. The survived and heat adapted strains were collected after further incubation of viable strains on MRS agar medium and after 48 hours incubation (temperature, 37°C and 5% CO2). The experiments were repeated at higher temperatures of 65°C and 75°C and the adapted strains were stored at -80°C for subsequent use in the spray drying. Strains subcultured on MRS broth were enriched with 0.05% L-cysteine (Merck GmbH, Germany), at 37°C for 30 hours [15]. Following incubation under 5% CO2 cells were harvested by centrifugation at 2000 rpm for 15 min, and were further re-suspended in sterile PBS-glycerol (20% v/v) solution and finally stored in 1mlcryotubes at -80°C.
Preparation of spray drying feed suspensions
All feed solutions contained 10% permeate powder (Shirpooyan Yazd Co., Iran), 2.5% saccharose, 2.5% yeast extract as well as 2-6% maltodextrin (Merck GmbH, Germany) and were autoclaved at 121°C for 15 min before use.
A cryo-tube containing 1ml of the adapted Bifidobacterium bifidumwas inoculated into the feed and was further incubated anaerobically (H2/CO2/N2; 10:5:85, Anoxomat WS8000, Mart_ Microbiology, Lichtenvoorde, Netherlands) at 37°C for 30 hours. The harvested feed contained 108-109cfu/ml prior to spray drying.
Spray drying condition
A mini spray-dryer Buchi B-191 (Buchi, Flawil, Switzerland) and the adopted protocol of Johnson and Etzel [17] was used. The feed solution was transformed from a fluid state into a dried form by spraying it into a hot drying air. The process involved atomization of a liquid feedstock into a spray of droplets. Independent variables for optimized method of spray drying process design included:
atomizing air pressure (bar)
inlet air temperature (°C)
outlet air temperature (°C)
flow rate of fees suspension (\( \frac{ml}{min} \))
flow rate of drying air (aspiration (\( \frac{m^3}{h} \)))
The aspiration was set on 80% in all runs. The outlet temperature measured between drying chamber and cyclone was regarded as the drying temperature. Adjustment of outlet temperature was performed by holding flow rate of the feed suspension at a constant value (25% pump capacity ~ 5 ml min−1) for all outlet temperatures. The inlet temperature was varied, as shown in Table 1.
The level of variables in central composite design (CCD)
Low axial (- α = − 1.68 )
Low factorial (-1)
High factorial (+1)
High axial (+ α = + 1.68 )
A: Inlet temperature (°C)
B: Air pressure (bar)
C: Maltodextrin \( \left(\frac{gr}{ml}\right) \)
Design of experiments and statistical modeling
Response surface methodology is a combination of mathematical and statistical techniques used for developing, improving and optimizing the processes. It is used to evaluate the relative significance of several affecting factors, even in the presence of complex interactions [18,19]. The most popular response surface methodology is the central composite design (CCD) [20], which was used to design the experiment. CCD has three set of experimental runs: (1) fractional factorial runs in which factors are studied at +1 and -1 levels; (2) center points that all factors are at their center levels, which aids with determining the curvature and replication, helps to estimate pure error; and (3) axial points, which are similar to center point, but one factor takes the values above and below the median of the two factorial levels, typically both outside their range. Axial points make the design rotatable [21]. Empirical models describing the experimental results were developed using data collected from the designed experiments and were generated using the least-squares method. Model parameters were estimated using a second-order model of the form (Eq. (1)) [22]:
$$ Y={\beta}_0+{\displaystyle \sum_{i=1}^k}{\beta}_i{X}_i+{\displaystyle \sum_{i=1}^k}{\displaystyle \sum_{j=1}^k}{\beta}_{ij}{X}_i{X}_j $$
Where Y is the expected value of the response variables, β 0, β i , β j are the model parameters, X i and X j are the coded factors evaluated, and k is the number of factors being studied. In this study, inlet air temperature, air pressure and maltodextrin concentration were selected as main factors. As shown in Table 1, each factor was examined in five levels, whereas the other parameters were kept constant. Accordingly, 20 experiments were conducted with 14 experiments organized in a factorial design and the 6 remaining experiments were involved in the replication of the central point to get good estimate of experimental error. The statistical software package, Design-Expert 7.0.0 (Stat-Ease, Inc., Minneapolis, MN, USA), was used for both the regression analysis of the experimental data, and the plot of the response contours and surface graphs. DX–7 is the windows-compatible software which provides efficient design of experiments (DOEs) for identification of vital factors that affect the process and uses RSM to determine optimal conditions [23,24]. The optimization module in DX–7 searches for a combination of factor levels that simultaneously satisfy the requirements placed on each of several responses [25,26].
Enumeration of Bifidobacterium bifidum
Colony forming units (CFU) of the individual runs of bifidobacterial cultures before and after spray drying were determined by serial dilution of feed suspension and powders, followed by pour plating into MRS agar. Plates were incubated at 37°C, for 48 hours, under anaerobic condition. Survival rates were calculated as follows: Survival (%) = N/N0 × 100, where N0 and N represent the number of bacteria before and after drying respectively.
Determination of moisture content in spray dried powders
Moisture content of spray dried powder which is defined as the ratio of dried water to initial powder weight, was determined by oven-drying at 102° [27]. This involved determination of the difference in weight before and after oven-drying. Moisture content was then expressed as a percentage of initial powder weight.
Twenty experiments were designed using CCD. The design matrix and the corresponding results of CCD experiments to determine the effects of the three independent variables are shown in Table 2.
Experimental plan and results of spray drying of B. bifidum
A ( °C )
B (bar)
C ( \( \frac{\mathbf{gr}}{\mathbf{ml}} \) )
S ( % )
Moisture ( % )
Quadratic model was found to be adequate for the prediction of the response variables.
$$ {Y}_1=+28.82-9.15\mathrm{A}-2.74\mathrm{B}-0.62\mathrm{C}-3.93\mathrm{AB}+0.98\mathrm{AC}+0.52\mathrm{B}\mathrm{C}-4.72{\mathrm{A}}^2-0.51{\mathrm{B}}^2+2.52{\mathrm{C}}^2 $$
$$ {Y}_2=+4.39-1.10\mathrm{A}-0.032\mathrm{B}-0.24\mathrm{C}-0.095\mathrm{AB}-0.33\mathrm{AC}-0.18\mathrm{B}\mathrm{C}+0.16{\mathrm{A}}^2+0.16{\mathrm{B}}^2+0.29{\mathrm{C}}^2 $$
Where Y 1 and Y 2, predicted Survival rate (%) and Moisture content (%) respectively; A is Inlet air temperature level; B is air pressure level; and C is maltodextrin concentration level. The statistical significance of the model equations (Eqs. (2)–(3)) and the model terms were evaluated by the F-test for analysis of variance (ANOVA), which indicated that the regressions were statistically significant. The results of analysis of variance (ANOVA) of the developed models are shown in Table 3. It illustrates that the two fitted models are significant with 95% confidence intervals (p-value < 0.05).
Analysis of variance for response surface models
Sum of square
Mean square
F-value
A-temperature
<0.0001
B-pressure
C-maltodextrin
Survival ( % )
Figure 1 represents predicted against actual values for survival and moisture content of B. bifidum, respectively. Actual values are the measured response data for a particular run, and the predicted values are evaluated using the approximating functions generated for the models (Eqs. (2)–(3)).
Predicted vs. actual plot of: (A) survival rate and (B) moisture content of B. bifidum powder.
The fit quality of the second-order polynomial models equations (Eqs. (2)–(3)) were expressed by the coefficient of determination (R 2). The value of R 2 indicates that the quadratic equation is capable of representing the system under the given experimental domain. The coefficients of determination (R 2) of the models were 0.92 for Y 1 and 0.91 for Y 2, which further indicates that the models (Eqs. (1)–(2)) were suitable for adequate representation of the real relationships among the variables. Since R 2 and adjusted- R 2 differ insignificantly, there is a good chance that the models include the important terms. Adequate precision is a measure of the range in predicted response relative to its associated error which provides a measure of the "signalto-noise ratio". Its desired value is 4 or more [24]. In the present study, adequate precision was 13.24 for survival and 11.87 for moisture. Simultaneously, low values of the coefficient of variation (CV) (14.82 for survival and 9.16 for moisture) indicated good precision and reliability of the experiments. The CV as the ratio of the standard error of estimate to the mean-value of the observed response (as a percentage) was used as a measure of reproducibility of the model. All results showed that this model can be used to navigate the space defined by the CCD.
The p-value was used as a tool to check the significance of each coefficient. Low p-values indicate that the factor has a significant effect on results. A model term with a p-value < 0.05 is considered to be significant [28]. According to the p-values of the model terms (Table 3), A (Inlet air temperature), B (air pressure), interaction variable AB (Inlet air temperature × air pressure) and quadratic variable A 2 are significant terms in the Survival of B. bifidum model. Furthermore, the only significant factor in moisture content of B. bifidum model is A (Inlet air temperature).
A negative sign for the coefficients of factors in the fitted models for Y 1 and Y 2 (Eq. 2 and 3) indicated that the level of the Survival of B. bifidum and the moisture content of B. bifidum increased with decreasing levels of factors. Also, the greatest coefficients of factor A (Inlet air temperature) revealed the high sensitivities of the both responses to this factor. Additionally the survival rate of B. bifidum was inversely proportional to air pressure and maltodextrin conc., but it seems that air pressure was more effective. Analysis of these models (Eq. 3) also showed that low moisture content is due to high maltodextrin conc. or application of high temperature or pressure, although the effect of temperature is significantly higher than other factors. To achieve a proper comprehension of the results, the predicted models are presented in Figure 2. The use of two-dimensional contour plots and three-dimensional surface plots of the regression model was highly recommended to obtain a graphical interpretation of the interactions [22,29].
The effect of temperature and maltodextrin concentration on the moisture content of B. bifidum powder. Surface plot of the empirical model for moisture content (%) of B. bifidum powder at air pressures of (A) 4, (B) 5 and (C) 6 bars.
Figure 2 depicts a three dimensional surface plot of the empirical model for moisture (%) as a function of three factors. Maltodextrin conc. and temperature were used for the RSM plots of moisture (%), while air pressure was increased from 4 bar to 5 bar and then 6 bar from left to right. As shown in Figure 2, at all air pressures, the lowest moisture was achieved at the highest concentrations of maltodextrin (7.36) and temperature (130.23). The results imply the need for application of more maltodextrin for having minimum moisture at the highest temperature. According to the surface plots, at the lowest maltodextrin conc. (0.64) and temperature (79.77) the moisture (%) increased by decreasing the air pressure from left to right. The moisture decreased when at the highest temperature (130.23), maltodextrin conc. increased, and vice versa. It was also true while at the highest conc. of maltodextrin (7.36), the temperature increased to its highest level.
However, at the lowest temperature (79.77), specifically at air pressure ≥5, decreasing the maltodextrin to 4%, resulted in lower moisture content, which may have been due to the more inhibitory effect of the maltodextrin concentration at air pressure ≥5. These results indicate that the measure of maltodextrin was critical for moisture of powder, which depends on inlet air temperature and air pressure.
The dependence of the survival of B. bifidum on temperature and air pressure at 4% maltodextrin is depicted in Figure 3. The survival rate of B. bifidum increased linearly as pressure was increased from 4 to 6 at temperature ≤105°C. At temperature >105°C, survival of B. bifidum increased linearly as pressure decreased from 6 to 4 bar. Therefore the effect of pressure on survival of B. bifidum depends on the operational temperature. A curvature type relationship existed between the survival of B. bifidum and the temperature at the lowest pressure (4 bar), survival of B. bifidum increased by increasing the temperature toward 105°C. Furthermore increasing the temperature resulted in lower bacterial survival rate. As shown in Figure 3, the highest survival rate of B. bifidum was achieved at high pressure (6 bar) and low temperature (79.77).
The effect of temperature and air pressure on survival of B. bifidum . (A) Contour and (B) 3D plots of B. bifidum survival at different temperatures and air pressure during spray drying. Maltodextrin concentration was kept at fixed 4%.
Figure 4 shows the effect of temperature and maltodextrin concentration on the survival of B. bifidum. The air pressure ranged from 4 bar to 6 bar from left to right. At the lowest temperature, particularly at air pressure ≥5, the survival rate was decreased by increasing the maltodextrin concentration to 5%. These results suggests maltodextrin content could highly affect survival of B. bifidum and low maltodextrin content could result to higher humidity of probiotic powder. Hence, maltodextrin concentration higher than 5% is highly recommended.
Effect of temperature and maltodextrin concentration on the survival of B. bifidum . Surface plot of the empirical model for survival (%) of B. bifidum at air pressures of (A) 4, (B) 5 and (C) 6 bars.
A simultaneous optimization technique was used for optimization of multiple responses by RSM. The objective of response surface optimization is to find a desirable location in the design space. Various optimum conditions can be considered, but the main goal of current experiment was to achieve maximal bacterial survival rate and keeping the moisture at as low as possible. According to numerical optimization by Design-Expert 7.0.0, the optimum was obtained by using the following spray drying conditions: inlet air temperature of 111.15°C, air pressure of 4.5 bar and maltodextrin conc. of 6.0%. Under these conditions, the survival of B. bifidum was 28.38% while the moisture content of the powder remained at 4.05%. These values are all in agreement with the results obtained from the three-dimensional surface plots.
Table 4 presents the results confirmation test and shows that verification experiments and predicted values from fitted correlations were in close agreement at a 95% confidence interval. These results confirmed the validity of the models.
Optimum process and validation experiment results at 95% confidence interval
Predicted results
Confirmation test results
95% CI low
95% CI high
Survival (%)
Moisture (%)
The role of other culture media substances during spray draying
The main goal of current study was to achieve a high bacterial survival rate using cost effective media suitable for industrial scale production of probiotic powder. Both sucrose and glucose showed similar effect on bacterial growth but glucose did not have the protective effect of sucrose during spray drying. Previous studies used RSM as the carbon source for bacterial growth and also key protective substance in spray drying of bacteria. In current study RSM was replaced by inexpensive permeate. It owns all beneficial features of RSM and also contains vitamins like thiamine, riboflavin and niacin which are required for the growth of B. bifidum. Permeate was found to be the ideal medium for spray drying due to its protective proteins which prevent bacterial damage by stabilizing cell membrane components [30]. In addition, its calcium may form a protective layer. The solid ratio index was 20% for permeate, maltodextrin, sucrose and yeast extract had the best effect in bacterial count which is consistent with those reported by previous studies [31].
Different types of probiotic adherent fibers such as fructo-oligosaccharide (FOS) and galacto-oligosaccharide (GOS) are usually used as a carrier in the culture medium of bifidobacteria and lactobacilli during spray and freeze drying. Maltodextrin was used in the culture medium as the adhesion agent. Despite the structural and functional similarities of maltodextrinwith dextrose, maltodextrin protects bacteria much better than Polydextrose at the high temperature and pressure and has the advantage of cost-effectiveness compared to inulin [32]. It has also been considered as prebiotic which stimulates probiotic growth.
Role of spray dryer factors
The results showed that air temperature had the main effect on residual moisture of bacterial products, as well as bacterial survival rate. Since bacteria are exposed to outlet temperature in different parts of spray dryer, it should not be above 75°C which causes serious damage to susceptible bacteria during spray drying process. Also it should not be too low (below 60°C) which could end up with high moisture content (up 7%). Protective effects of polysaccharides are due to the ability of the sugars to form a high viscous glassy matrix during dehydration. Moisture uptake would decrease the glass transition temperatures of the system, and consequently a transition of the glass state of sugar towards the rubbery state (denitrification) could occur which might decrease the stability of spray dried powder. Therefore, the best moisture content of 4-7%, was achieved in the outlet temperature of 60-80°C.
Statistical modeling and optimization of spray drying of Bifidobacterium bifidum PTCC 1644 was investigated. The thermal compliances of an acid-bile-adopted probiotic strain was increased to 75°C using induced environmental stress condition. Permeate and maltodextrin were used as the protecting agents instead of reconstituted skim milk reported by other researchers. The RSM-CCD was used for statistical analysis and optimization of the process. The effect of inlet air temperature, air pressure and maltodextrin concentrations on survival and moisture of spray dried B. bifidum were assessed. Two quadratic models for the responses were developed. Temperature had the most significant effect on spray drying of B.bifidum. Maximum survival rate of 28.38% and minimum moisture content of 4.05% was achieved at T = 111.15°C, P = 4.5 bar and maltodextrin content of 6%.
Powders of live beneficial probiotic bacterial cultures could be achieved by preadaptation of the individual strains to gastrointestinal as well as other environmental factors and further addition of selected protective polysaccharides into the culture media before spray drying.
The authors wish to thank the Pharmaceutical Sciences Research Center of the Tehran University of Medical Sciences for partially financing this project
The authors are grateful to Stat-Ease, Minneapolis, MN, USA, for the provision of the Design-Expert 7.1.4 package.
ZS carried most of the experimentals as her MSc thesis. MRF was the supervisor of the thesis and proposed the research subject and contributed in writing the manuscript. MA was the consultant of the thesis and has contributed in writing. SMM has done the statistics. KG has supervised the spray drying work. All authors read and approved the final manuscript.
Department of Chemical Engineering, Islamic Azad University-Tehran South Branch, Tehran, Iran
Probiotic Research Laboratory, Department of Drug and Food Control, Pharmaceutical Sciences Research Center, Faculty of Pharmacy, Tehran University of Medical Sciences, Tehran, Iran
Biotechnology Group, Chemical Engineering Department, Tarbiat Modares University, Tehran, Iran
Aerosol Research Laboratory, Department of Pharmaceutics, Faculty of Pharmacy, Tehran University of Medical Sciences, Tehran, Iran
Anal AK, Singh H. Recent advances in microencapsulation of probiotics for industrial applications and targeted delivery. Trends Food Sci Tech. 2007;18:240–51.View ArticleGoogle Scholar
Agrawal R. Probiotics: an emerging food supplement with health benefits. Food Biotechnol. 2005;19:227–46.View ArticleGoogle Scholar
Dave RI, Shah NP. Evaluation of media for selective enumeration of S. thermophilus, L. delbrueckii ssp. bulgaricus, L. acidophilus, and bifidobacteria. J Dairy Sci. 1996;79:1529–36.View ArticlePubMedGoogle Scholar
Fazeli MR, Hajimohammadali M, Moshkani A, Samadi N, Jamalifar H, Khoshayand MR Vaghari E, et al. Aflatoxin B1 binding capacity of autochthonous strains of lactic acid bacteria. J Food Protect. 2009;72:189–92.Google Scholar
Fazeli MR, Toliyat T, Samadi N, Hajjaran S, Jamalifar H. Viability of Lactobacillus acidophilus in various tablet formulations. DARU. 2006;14:172–8.Google Scholar
To BCS, Etzel MR. Spray drying, freeze drying, or freezing of three different lactic acid bacteria species. J Food Sci. 1997;62:576–8.View ArticleGoogle Scholar
Menshutina N, Gordienko M, Voinovskiy A. Spray drying of probiotics: process development and scale-up. Drying Tech. 2010;28:1170–7.View ArticleGoogle Scholar
Gardiner GE, O'Sullivan E, Kelly J, Auty MAE, Fitzgerald GF, Collins JK, et al. Comparative survival rates of human-derived probiotic Lactobacillus paracasei and L. salivarius strains during heat treatment and spray drying. Appl Environ Microbiol. 2000;66:2605–12.View ArticlePubMed CentralPubMedGoogle Scholar
Ananta E, Volkert M, Knorr D. Cellular injuries and storage stability of spray dried Lactobacillus rhamnosus GG. Int Dairy J. 2005;15:399–409.View ArticleGoogle Scholar
Brodhead J, Rhodes CT. The drying of pharmaceuticals. Drug Dev Ind Pharm. 1992;12:1169–206.View ArticleGoogle Scholar
Silva J, Carvalho AS, Teixera P, Gibbs P. Effect of stress on cells of Lactobacillus delbrueckeii spp. bulgaricus. J Food Tech. 2005;3:479–90.Google Scholar
Roos YH. Importance of glass transition and water activity to spray drying and stability of dairy powders. Lait. 2002;82:475–84.View ArticleGoogle Scholar
Jouppila K, Roos YH. Glass transitions and crystallization in milk powders. J Dairy Sci. 1994;77:2907–15.View ArticleGoogle Scholar
Heidebach T, Först P, Kulozik U. Influence of casein-based microencapsulation on freeze-drying and storage of probiotic cells. J Food Eng. 2010;98:309–16.View ArticleGoogle Scholar
Jamalifar H, Bigdeli B, Nowroozi J, Zolfaghari HS, Fazeli MR. Selection for autochthonous bifidobacterial isolates adopted to simulated gastrointestinal fluid. DARU. 2010;18:57–63.PubMed CentralPubMedGoogle Scholar
Jewell JB, Kashket ER. Osmotically regulated transport of prolin by Lactobacillus acidophilus IFO3532. Appl Environ Microbiol. 1991;57:2829–33.PubMed CentralPubMedGoogle Scholar
Johnson JAC, Etzel MR. Properties of Lactobacillus helveticus CNRZ-32 attenuated by spray-drying, freeze-drying, or freezing. J Dairy Sci. 1995;78:761–8.View ArticleGoogle Scholar
Santhiya D, Ting YP. Bioleaching of spent refinery processing catalyst using Aspergillus niger with high yield oxalic acid. J Biotechnol. 2005;116:171–84.View ArticlePubMedGoogle Scholar
Chauhan K, Trivedi U, Patel KC. Statistical screening of medium components by lackett–Burman design for lactic acid production by Lactobacillus sp.KCP01 using date juice. Bioresour Technol. 2007;98:98–103.View ArticlePubMedGoogle Scholar
Mehrabani JV, Noaparast M, Mousavi SM, Dehghan R, Ghorbani A. Process optimization and modelling of sphalerite flotation from a low-grade Zn–Pboreusing response surface methodology. Sep Purif Technol. 2010;72:242–9.View ArticleGoogle Scholar
Liu RS, Tang YJ. Melanosporum fermentation medium optimization by Plackett–Burman design coupled with Draper–Lin small composite design and desirability function. Bioresour Technol. 2010;101:3139–46.View ArticlePubMedGoogle Scholar
Majumder A, Goyal A. Enhanced production of exocellular glucansucrose from Leuconostoc dextranicum NRRL B-1146 using response surface method. Bioresour Technol. 2008;99:3685–91.View ArticlePubMedGoogle Scholar
Montgomery DC. Design and Analysis of Experiments. 4th ed. New York: John Wiley & Sons; 1991.Google Scholar
Myers RH, Montgomery DC. Response surface methodology. 3rd ed. New York: John Wiley & Sons; 2002.Google Scholar
Bas D, Boyaci IH. Modeling and optimization I: Usability of response surface methodology. J Food Eng. 2007;78:836–45.View ArticleGoogle Scholar
Bezera MA, Santelli RE, Oliveira EP, Villar LS, Escaleira LA. Review response surface methodology (RSM) as a tool for optimization in analytical chemistry. Talanta. 2008;76:965–77.View ArticleGoogle Scholar
RehCh N, Bhat SH, Berrut S. Determination of water content in powdered milk. Food Chem. 2004;86:457–64.View ArticleGoogle Scholar
Tanyildizi MS, Ozer D, Elibol M. Optimization of a-amylase production by Bacillus sp. using response surface methodology. Process Biochem. 2005;40:2291–6.View ArticleGoogle Scholar
Sharma S, Malik A, Satya S. Application of response surface methodology (RSM) for optimization of nutrient supplementation for Cr (VI) removal by Aspergillus lentulus AML05. J Hazard Mater. 2009;164:1198–204.View ArticlePubMedGoogle Scholar
Teixeira PC, Castro MH, Malcata FX, Kirby RM. Survival of Lactobacillus-Delbrueckii ssp. bulgaricus following spray-drying. J Dairy Sci. 1995;78:1025–31.View ArticleGoogle Scholar
Corcoran BM, Ross RP, Fitzgerald G, Stanton C, Corcoran BM, Ross RP, et al. Comparative survival of probiotic lactobacilli spray dried in the presence of prebiotic substances. J Appl Microbiol. 2004;96:1024–39.View ArticlePubMedGoogle Scholar
Bielecka M, Majkowska A. Effect of spray drying temperature of yoghurt on the survival of starter cultures, moisture content and sensoric properties of yoghurt powder. Nahrung. 2000;44:257–60.View ArticlePubMedGoogle Scholar
View archived comments (1) | CommonCrawl |
Wikipedia:Manual of Style/Dates and numbers
< Wikipedia:Manual of Style
Wikipedia project page
"WP:NUMBERS" redirects here. For the Wikiproject, see Wikipedia:WikiProject Numbers. For the notability guideline, see Wikipedia:Notability (numbers).
This guideline is a part of the English Wikipedia's Manual of Style.
It is a generally accepted standard that editors should attempt to follow, though it is best treated with common sense, and occasional exceptions may apply. Any substantive edit to this page should reflect consensus. When in doubt, discuss first on the talk page.
MOS:NUM
WP:MOSNUM
Manual of Style (MoS)
Hidden text
Self-references
Words to watch
Dates and numbers
Lead section
Trivia sections
Lists of works
Road junctions
Stand-alone lists
By topic area
Lyrics and poetry
Writing about fiction
Record charts
Specific naming conventions
China (and Chinese)
France (and French)
Related guidelines
Article size
Article titles
Categories, lists, and navigation templates
Hatnotes
Talk page guidelines
Template namespace
Understandability
Wikimedia sister projects
WikiProjects
This page guides the presentation of numbers, dates, times, measurements, currencies, coordinates, and similar items in articles. The aim is to promote clarity, cohesion, and consistency, and to make the encyclopedia easier and more intuitive to use.
Where this manual gives options, maintain consistency within an article unless there is a good reason to do otherwise. The Arbitration Committee has ruled that editors should not change an article from one guideline-defined style to another without a substantial reason unrelated to mere choice of style; revert-warring over optional styles is unacceptable.[a] If discussion fails to resolve the question of which style to use in an article, defer to the style used by the first major contributor.
1 General notes
1.1 Quotations, titles, etc.
1.2 Non-breaking spaces
2 Chronological items
2.1 Statements likely to become outdated
2.2 Dates, months, and years
2.2.1 Formats
2.2.1.1 Consistency
2.2.1.2 Strong national ties to a topic
2.2.1.3 Retaining existing format
2.2.2 Era style
2.2.3 Julian and Gregorian calendars
2.2.4 Ranges
2.2.5 Uncertain, incomplete, or approximate dates
2.3 Times of day
2.3.1 Time zones
2.4 Days of the week
2.5 Seasons of the year
2.6 Decades
2.7 Centuries and millennia
2.8 Long periods of time
3 Numbers
3.1 Numbers as figures or words
3.2 Ordinals
3.3 Number ranges
3.4 Sport scores, vote tallies, etc.
3.5 Singular versus plural
3.6 Fractions and ratios
3.8 Grouping of digits
3.9 Percentages
3.10 Scientific and engineering notation
3.11 Uncertainty and rounding
3.12 Non–base 10 notations
3.13 Mathematical formulae
4 Units of measurement
4.1 Unit choice and order
4.2 Unit conversions
4.3 Unit names and symbols
4.4 Specific units
4.4.1 Quantities of bytes and bits
5 Currencies and monetary values
6 Common mathematical symbols
7 Geographical coordinates
General notes[edit]
Quotations, titles, etc.[edit]
See also: Wikipedia:Manual of Style § Quotations
Quotations, titles of books and articles, and similar "imported" text should be faithfully reproduced, even if they use formats or units inconsistent with these guidelines or with other formats in the same article. If necessary, clarify via [bracketed interpolation], article text, or footnotes.
Non-breaking spaces[edit]
Guidance on the use of non-breaking spaces ("hard spaces") is given in some sections below, but not all situations in which hard spaces ({{nbsp}} or ) or {{nowrap}} may be appropriate are described. For further information see Wikipedia:Manual of Style § Non-breaking spaces and Wikipedia:Line-break handling.
Chronological items[edit]
Statements likely to become outdated[edit]
MOS:DATED
MOS:CURRENT
See also: Wikipedia:Manual of Style/Words to watch § Relative time references, and Wikipedia:As of
Except on pages updated regularly (e.g. the "Current events" portal), terms such as now, currently, to date, so far, soon, and recently should usually be avoided in favor of phrases such as during the 2010s, since 2010, and in August 2020. For current and future events, use phrases like as of January 2022 or since the beginning of 2022 to signal the time-dependence of the information; use the template {{as of}} in conjunction.
Relative-time expressions are acceptable for very long periods, such as geological epochs: Humans diverged from other primates long ago, but only recently developed state legislatures.
Dates, months, and years[edit]
MOS:DATE
MOS:DATEFORMAT
MOS:YEAR
These requirements do not apply to dates in quotations or titles; see Wikipedia:Manual of Style § Quotations.
Special rules apply to citations; see Wikipedia:Citing sources § Citation style.
See also Wikipedia:Overview of date formatting guidelines.
Formats[edit]
Acceptable date formats
Only in limited situations
where brevity is helpful[b]
2 September 2001 2 Sep 2001 A comma doesn't follow the year unless otherwise required by context:
On 5 May 1822 the act became law.
Except Jones, who left London on 5 March 1847, every delegate attended the signing.
September 2, 2001 Sep 2, 2001 A comma follows the year unless other punctuation obviates it:
The weather on March 12, 2005, was clear and warm
Everyone remembers July 20, 1969 – when humans first landed on the Moon
2 September 2 Sep Omit year only where there is no risk of ambiguity:
The 2012 London Olympics ran from 25 July to 12 September
January 1 is New Year's Day
September 2 Sep 2
No equivalent for general use 2001-09-02 Use yyyy-mm-dd format only with Gregorian dates from 1583 onward.[c]
September 2001 Sep 2001
MOS:UNLINKDATES
Dates, years, and other chronological items should be linked only when they are relevant to the subject and likely to be useful to a reader; this rule does not apply to articles that are explicitly on a chronological item, e.g. 2002, 19th century (as discussed at Wikipedia:Linking § Chronological items).[d]
For issues related to dates in sortable tables, see Help:Sorting § Configuring the sorting and Help:Sorting § Date sorting problems, or consider using {{dts|Nov 1, 2008}}.
Phrases such as Fourth of July (or July Fourth, but not July 4th), Cinco de Mayo, Seventh of March Speech, and Sete de Setembro are proper names, to which rules for dates do not apply (A typical Fourth of July celebration includes fireworks).
MOS:DATESNO
MOS:BADDATE
Unacceptable date formats (except in external titles and quotes)
Corrected
Sep. 2 Sep 2[b] Do not add a dot to the day or to an abbreviated month.[e]
9. June 9 June or June 9
june 9 Months are capitalized.
9th June
the 9th of June Do not use ordinals (1st, 2nd, 3rd, etc.).
06-09 Do not use these formats.
June 09 Do not zero-pad day ...
2007-4-15 2007-04-15[b] ... except in all-numeric (yyyy-mm-dd) format, where both month and day should be zero-padded to two digits.
2007/04/15 Do not use separators other than hyphens.
07-04-15 Do not abbreviate year to two digits.
2007-15-04 Do not use dd-mm-yyyy, mm-dd-yyyy or yyyy-dd-mm formats.[f]
2007 April 15
2007 Apr 15 Do not use these formats.
July of 2001 July 2001 Do not use these formats.
July, 2001 No comma between month and year.
3 July, 2001 3 July 2001
July 3 2001 July 3, 2001 Comma required between day and year.
the '97 elections
the 97 elections the 1997 elections Do not abbreviate year.
Copyright MMII Copyright 2002 Roman numerals are not normally used for dates.
Two thousand one 2001 Years and days of the month are not normally written in words.
the first of May
May the first May 1 or 1 May
June 0622 June 622 Do not zero-pad years.
sold in the year 1995 sold in 1995 Write "the year" only where needed for clarity (About 1800 ships arrived in the year 1801).
Consistency[edit]
MOS:DATEUNIFY
Dates in article body text should all use the same format: She fell ill on 25 June 2005 and died on 28 June, not She fell ill on 25 June 2005 and died on June 28.
Publication dates in an article's citations should all use the same format, which may be:
the format used in the article body text,
an abbreviated format from the "Acceptable date formats" table, provided the day and month elements are in the same order as in dates in the article body, or
the format expected in the citation style being used (but all-numeric date formats other than yyyy-mm-dd must still be avoided).
For example, publication dates within a single article might be in one, but only one, of these formats (among others):
Jones, J. (20 September 2008)
Jones, J. (September 20, 2008)
Access and archive dates in an article's citations should all use the same format, which may be:
the format used for publication dates in the article (see above);
the format expected in the citation style adopted in the article; or
For example, access/archive dates within a single article might be in one, but only one, of these formats (among others):
Jones, J. (September 20, 2008) ... Retrieved February 5, 2009.
Jones, J. (20 Sep 2008) ... Retrieved 5 Feb 2009.
Jones, J. (20 September 2008) ... Retrieved 2009-02-05.
When a citation style does not expect differing date formats, it is permissible to normalize publication dates to the article body text date format, and/or access/archive dates to either, with date consistency being preferred.
Strong national ties to a topic[edit]
MOS:DATETIES
For any given article, the choice of date format and the choice of national variety of English (see Wikipedia:Manual of Style § Strong national ties to a topic) are independent issues.
Articles on topics with strong ties to a particular English-speaking country should generally use the date format most commonly used in that nation. For the United States this is (for example) July 4, 1976; for most other English-speaking countries it is 4 July 1976.
Articles related to Canada may use either format with (as always) consistency within each article. (see Retaining existing format)
WP:MILFORMAT
In topics where a date format that differs from the usual national one is in customary usage, that format should be used for related articles: for example, articles on the modern US military, including biographical articles related to the modern US military, should use day-before-month, in accordance with US military usage.
Retaining existing format[edit]
MOS:DATERET
MOS:DATEVAR
See also: Wikipedia:Manual of Style § Retaining existing styles
If an article has evolved using predominantly one date format, this format should be used throughout the article, unless there are reasons for changing it based on strong national ties to the topic or consensus on the article's talk page.
The date format chosen in the first major contribution in the early stages of an article (i.e., the first non-stub version) should continue to be used, unless there is reason to change it based on strong national ties to the topic or consensus on the article's talk page.
Where an article has shown no clear sign of which format is used, the first person to insert a date is equivalent to "the first major contributor".
Era style[edit]
"WP:BCE" redirects here. For the copyediting guide, see Wikipedia:Basic copyediting.
MOS:ERA
MOS:BCE
The default calendar eras are Anno Domini (BC and AD) and Common Era (BCE and CE). Either convention may be appropriate for use in Wikipedia articles depending on the article context. Apply Wikipedia:Manual of Style § Retaining existing styles with regard to changes from one era to the other.
Use either the BC–AD or the BCE–CE notation consistently within the same article. Exception: do not change direct quotations, titles, etc.
An article's established era style should not be changed without reasons specific to its content; seek consensus on the talk page first (applying Wikipedia:Manual of Style § Retaining existing styles) by opening a discussion under a heading using the word era, and briefly stating why the style should be changed.
BCE and CE or BC and AD are written in upper case, unspaced, without a full stop (period), and separated from the numeric year by a space (5 BC, not 5BC). It is advisable to use a non-breaking space.
AD appears before or after a year (AD 106, 106 AD); the other abbreviations appear only after (106 CE, 3700 BCE, 3700 BC).
In general, omit CE or AD, unless to avoid ambiguity or awkwardness
Typically, write The Norman Conquest took place in 1066 not 1066 CE nor AD 1066
But Plotinus lived at the end of the 3rd century AD (not simply at the end of the 3rd century) may avoid confusion unless the era is clear from context.
One- and two-digit years may look more natural with an era marker (born in 2 AD or born January 15, 22 CE, not born in 2 nor January 15, 22).
Ranges beginning in BC/BCE should specify the ending era: write 450 to 200 BCE or 450 BC to 200 BC or 450 BCE to 200 CE, but not 450 BCE to 200. (see Ranges)
Uncalibrated (BCE) radiocarbon dates: Calibrated and uncalibrated dates can diverge widely, and some sources distinguish the two only via BCE or BC (for calibrated dates) versus bce or bc (uncalibrated). When feasible, avoid uncalibrated dates except in direct quotations, and even then ideally give the calibrated date in a footnote or square-bracketed note – [3250 BCE calibrated], or at least indicate the date type – [uncalibrated]. This also applies to other dating systems in which a calibration distinction in drawn.
BP or YBP: In scientific and academic contexts, BP (Before Present) or YBP (years Before Present) are often used. (Present in this context by convention refers to January 1, 1950.) Write 3000 years BP or 3000 YBP or 3000 years before present but not forms such as 3000 before present and 3000 years before the present. If one of the abbreviated forms is used, link to Before Present on first use: The Jones artifact was dated to 4000 YBP, the Smith artifact to 5000 YBP.
Other era systems may be appropriate in an article. In such cases, dates should be followed by a conversion to Anno Domini or Common Era, and the first instance linked: Qasr-al-Khalifa was built in 221 AH (836 CE), or in 836 AD (221 AH).
Astronomical year numbering is similar to the Common Era. There is no need to follow a year expressed with astronomical year numbering with a conversion to Common Era. The first instance of a non-positive year should still be linked: The March equinox passed into Pisces in year −67. (The expressions −67 and 68 BCE refer to the same year.)
Julian and Gregorian calendars[edit]
MOS:OSNS
MOS:JG
See also: Old Style and New Style dates
A date can be given in any appropriate calendar, as long as it is (at the minimum) given in the Julian calendar or the Gregorian calendar or both, as described below. For example, an article on the early history of Islam may give dates in both Islamic and Julian calendars. Where a calendar other than the Julian or Gregorian is used, the article must make this clear.
Current events are dated using the Gregorian calendar.
Dates of events in countries using the Gregorian calendar at that time are given in the Gregorian calendar. This includes some of the Continent of Europe from 1582, the British Empire from 14 September 1752, and Russia from 14 February 1918 (see Adoption of the Gregorian calendar).
Dates before 15 October 1582 (when the Gregorian calendar was first adopted in some places) are normally given in the Julian calendar.
Dates after 4 October 1582 in a place where the Julian calendar was observed should be given in the Julian calendar.
For either the Julian or Gregorian calendars, the beginning of the year should be treated as 1 January even if a different start-of-year date was observed in the place being discussed.
Dates for Roman history before 45 BC are given in the Roman calendar, which was neither Julian nor Gregorian. When (rarely) the Julian equivalent is certain, it may be included.
For dates in early Egyptian and Mesopotamian history, Julian or Gregorian equivalents are often uncertain. Follow the consensus of reliable sources, or indicate their divergence.
The dating method used should follow that used by reliable secondary sources (or if reliable sources disagree, that used most commonly, with an explanatory footnote). The guidance above is in line with the usage of reliable sources such as American National Biography,[1] Oxford Dictionary of National Biography, and Encyclopædia Britannica.[g]
Where it's not obvious that a given date should be given in Julian alone or in Gregorian alone, consider giving both styles, for example by using {{OldStyleDate}}. If a date appears without being specified as Old Style or New Style, tagging that date with {{which calendar?}} will add the page to Category:Articles containing ambiguous dates for further attention.
If an article contains Julian calendar dates after 4 October 1582 (as in the October Revolution), or if a start-of-year date other than 1 January was in force in the place being discussed, or both, a footnote should be provided on the first usage, explaining the calendar usage adopted for the article. The calendar usage should be compatible with this guideline.
Ranges[edit]
MOS:DATERANGE
MOS:DOB
MOS:YEARRANGE
See also: Wikipedia:Manual of Style § Number ranges
A simple year–year range is written using an en dash (–, – or {{ndash}}), not an em dash, hyphen, or slash; this dash is unspaced (that is, with no space on either side); and the end year is usually given in full:
1881–1882; 1881–1886 (not 1881–86); 1881–1992 (not 1881–92)
Markup: 1881{{ndash}}1882 or 1881–1882
Although non-abbreviated years are generally preferred, two-digit ending years (1881–82, but never 1881–882 or 1881–2) may be used in any of the following cases: (1) two consecutive years; (2) infoboxes and tables where space is limited (using a single format consistently in any given table column); and (3) in certain topic areas if there is a very good reason, such as matching the established convention of reliable sources.[h] For consistency, avoid abbreviated year ranges when they would be used alongside non-abbreviated ranges within an article (or related pages, if in titles). Never use abbreviated years for ranges across centuries (1999–2000, not 1999–00) or for years from the first millennium (886–887, not 886–87).
The slash notation (2005/2006) may be used to signify a fiscal year or other special period, if that convention is used in reliable sources.
Other "simple" ranges use an unspaced en dash as well:
day–day: 5–7 January 1979; January 5–7, 1979; elections were held March 5–8.
month–month: the 1940 peak period was May–July; the peak period was May–July 1940; (but the peak period was May 1940 – July 1940 uses a spaced en dash; see below)
In certain cases where at least one item on either side of the en dash contains a space, then a spaced en dash ({{snd}}) is used. For example:
between specific dates in different months: They travelled June 3 – August 18, 1952; They travelled 3 June – 18 August 1952
between dates in different years:
Charles Robert Darwin (12 February 1809 – 19 April 1882) was an English naturalist ...
Markup: 12{{nbsp}}February 1809{{snd}}19{{nbsp}}April 1882 or 12 February 1809 – 19 April 1882
Abraham Lincoln (February 12, 1809 – April 15, 1865) was the 16th President of ...
between months in different years: The exception was in force August 1892 – January 1903; The Ghent Incursion (March 1822 – January 1, 1823) was ended by the New Year's Treaty
Markup: March 1822{{snd}}January{{nbsp}}1, 1823 or March 1822 – January 1, 1823
Where era designations, c. or other modifiers are present (see § Uncertain, incomplete, or approximate dates):
if the modifier applies to only one of the two endpoints of the range, use a spaced en dash: 150 BCE – 50 BCE, 5 BC – 12 AD, c. 1393 – 1414
if the modifier applies to the range as a whole, disregard the modifier: 150–50 BCE, reigned 150 BCE – 50 BCE, reigned 150–50 BCE, r. c. 1393 – 1414, r. 1393–1414.
MOS:DATETOPRES
MOS:TOPRESENT
For ranges "to present", constructions such as 1982–present (with unspaced en dash), January 1, 2011 – present (spaced ndash), or January 2011 – present (spaced ndash) may be used, but other constructions may be more appropriate in prose (see § Statements likely to become outdated). In tables and infoboxes where space is limited, pres. may be used (1982–pres.). Do not use incomplete-looking constructions such as 1982– and 1982–... .
Consider adding the {{As of}} template to such constructions.
For a person still living: Serena Williams (born September 26, 1981) is a ..., not (September 26, 1981 – ) or (born on September 26, 1981).
Do not use * to indicate born; use b. only where space is limited e.g. tables and infoboxes; use either born or b. consistently in any given table column.
Where birthdate is unknown: John Smith (died May 1, 1622) or John Smith (died 1622)
Do not use † to indicate died; use d. only where space is limited, with consistency within any given table column.
An overnight period may be expressed using a slash between two contiguous dates: the night raids of 30/31 May 1942 or raids of 31 May / 1 June 1942.
Or use an en dash: (unspaced) raids of 30–31 May 1942; (spaced) raids of 31 May – 1 June 1942.
Use an en dash, or a word such as from or between, but not both: from 1881 to 1886 (not from 1881–1886); between June 1 and July 3 (not between June 1 – July 3)
The {{Age}} template can keep ages current in infoboxes and so on:
{{age|1989|7|23}} returns: 32
{{age|1989|7|23}}-year-old returns: 32-year-old
{{age|1989|7|23}} years old returns: 32 years old
Date mathematics templates are available for other age calculations.
Uncertain, incomplete, or approximate dates[edit]
MOS:APPROXDATE
MOS:CIRCA
To indicate "around", "approximately", or "about", the use of the spaced, unitalicised form c. 1291 (or the {{circa}} template) is preferred over circa, ca, ca., around, approximately, or approx.:
At the birth of Roger Bacon (c. 1214) ...
John Sayer (c. 1750 – 2 October 1818) ...
the Igehalkid dynasty of Elam, c. 1400 BC ...
Where both endpoints of a range are approximate, c. should appear before each date (the two-argument form of {{circa}} does this):
Dionysius Exiguus (c. 470 – c. 540 ... (not Dionysius Exiguus (c. 470 – 540) ...)
Rameses III (reigned c. 1180 – c. 1150 BCE) ... (not Rameses III (reigned c. 1180 – 1150 BCE) ...)
Where birth/death limits have been inferred from known dates of activity:
Offa of Mercia (before 734 – 26 July 796) ...
Robert Menli Lyon (1789 – after 1863) ...
Ambrose Gwinnett Bierce (June 24, 1842 – after December 26, 1913) ...
When birth and death dates are unknown, but the person is known to have been active ("flourishing") during certain years, fl., [[Floruit|fl.]], or {{fl.}} may be used:
Jacobus Flori (fl. 1571–1588) ...
Jacobus Flori fils (fl. c. 1600 – 1616) ...
The linked forms should not be used on disambiguation pages, and "active" followed by the range is a better alternative for occupations not relating to the composition of works, whether it be musical, grammatical, historical, or any other such work.
When a date is known to be either of two years (e.g. from a regnal or AH year conversion, or a known age at death):
Anne Smith (born 1912 or 1913; died 2013) ...
Other forms of uncertainty should be expressed in words, either in article text or in a footnote: April 14, 1224 (unattested date). Do not use a question mark (1291?), because it fails to communicate the nature of the uncertainty.
Where c. or a similar form appears which applies only to one of the two endpoints of the range, use a spaced en dash ({{snd}}).
Examples: 1896 – after 1954, 470 – c. 540, c. 470 – 540, c. 470 – c. 540.
Markup: 1896{{snd}}after 1954, 470{{snd}}{{c.|540}}, {{c.|470}}{{snd}}540, {{c.|470|540}}.
Where a modifier applies to the range as a whole, such as fl. and r., use a spaced or unspaced en dash as appropriate to the range if this modifier is disregarded.
Examples: fl. 1571–1588, fl. c. 1600 – 1616, r. c. 1353 – 1336 BC, r. 1989–2019 CE, r. 2019 CE – present.
Some modifiers, such as traditionally, around, BH, and CE, sometimes apply to only one endpoint, and sometimes to the whole range. Whether the en dash should be spaced or unspaced should still be determined by the above guidelines, but consider rephrasing if the result is ambiguous or possibly confusing.
traditionally 1571–1588 and traditionally 1571 – 1588 mean two different things, which may not be obvious to the reader.
traditionally 1585 – c. 1590 can have two different meanings, and which one is meant may not be clear.
400 BCE – 200 clearly has BCE applying only to one endpoint, but the range is ambiguous. Consider using 400–200 BCE, 400 BCE – 200 BCE, or 400 BCE – 200 CE, depending on what is meant.
Technically, Taishō 13 – 57 is currently unambiguous (because there is no Taishō 57), but it is better to use both era designations in this case: Taishō 13 – Shōwa 57.
Ideally a non-breaking space should follow very short modifiers such as c., fl., r., b., and d..
Times of day[edit]
MOS:TIME
MOS:AMPM
Context determines whether the 12- or 24-hour clock is used. In all cases, colons separate hours, minutes, and (where present) seconds, e.g. 1:38:09 pm or 13:38:09. Use figures (11 a.m. or 12:45 p.m.) rather than words (twelve forty-five p.m.).
12-hour clock times end with lower-case a.m. or p.m., or am or pm, preceded by a non-breaking space, e.g. 2:30 p.m. or 2:30 pm (markup: 2:30{{nbsp}}p.m. or 2:30{{nbsp}}pm), not 2:30p.m. or 2:30pm. Hours should not have a leading zero (e.g. 2:30 p.m., not 02:30 p.m.). Usually, use noon and midnight rather than 12 pm and 12 am; whether "midnight" refers to the start or the end of a date should be explicitly specified unless clear from the context. Where several times that are all a.m. or all p.m. appear in close proximity, then a.m. or p.m. need be given only once if there is no risk of confusion.
24-hour clock times have no a.m., p.m., noon or midnight suffix, and include a colon (15:30 not 1530). Hours under 10 should have a leading zero (08:15). The time 00:00 refers to midnight at the start of a date, 12:00 to noon, and 24:00 to midnight at the end of a date, but 24 should not be used for the first hour of the next day (e.g. use 00:10 for ten minutes after midnight, not 24:10).
Time zones[edit]
MOS:TIMEZONE
Give dates and times appropriate to the time zone where an event took place. For example, the date of the attack on Pearl Harbor should be December 7, 1941 (Hawaii time/date). Give priority to the place at which the event had its most significant effects; for example, if a hacker in Monaco attacked a Pentagon computer in the US, use the time zone for the Pentagon, where the attack had its effect. In some cases, the best solution may be to add the date and time in Coordinated Universal Time (UTC). For example:
8 p.m. Eastern Standard Time on January 15, 2001 (01:00 UTC, January 16)
Alternatively, include just the UTC offset:
21:00 British Summer Time (UTC+1) on 27 July 2012
Rarely, the time zone in which an event took place has since changed; for example, China until 1949 was divided into five time zones, whereas all of modern China is UTC+8. Similarly, the term "UTC" is not appropriate for dates before this system was adopted in 1960;[2] Universal Time (UT) is the appropriate term for the mean time at the prime meridian (Greenwich) when it is unnecessary to specify the precise definition of the time scale. Be sure to show the UTC or offset appropriate to the clock time in use at the time of the event, not the modern time zone, if they differ.
Days of the week[edit]
Where space is limited (e.g. tables), days of the week may be abbreviated as Sun, Mon, Tue, Wed, Thu, Fri, Sat.
Seasons of the year[edit]
MOS:SEASON
WP:SEASON
Seasons are uncapitalized (a hot summer) except when personified: Old Man Winter.
Avoid the use of seasons to refer to a particular time of year (winter 1995) as such uses are ambiguous: the seasons are six months apart in the northern and southern hemispheres; winter in the northern hemisphere, and summer in the southern hemisphere, span two calendar years; and areas near the equator have only wet and dry seasons. Unambiguous alternatives include early 1995; the first quarter of 1995; January to March 1995; spent the southern summer in Antarctica.
Referring to a season by name is appropriate when it is part of a formal or conventional name or designation (annual mid-winter festival; the autumn harvest; 2018 Winter Olympics; Times Fall Books Supplement; details appeared in Quarterly Review, summer 2015; the court's winter term).
Decades[edit]
MOS:DECADE
To refer to a decade as a chronological period per se (not with reference to a social era or cultural phenomenon), always use four digits as in the 1980s. Do not use the 1980's, the 1980‑ies, or the 1980s' (unless a possessive is actually meant).
Prefixes should be hyphenated (the mid‑1980s; pre‑1960s social attitudes).
Adjectives should not be hyphenated (the late 1950s, the early 1970s).
For a social era or cultural phenomenon associated with a particular decade:
Two digits (with a preceding apostrophe) may be used as an alternative to four digits, but only in well-established phrases seen in reliable sources: the Roaring '20s; the Gay '90s; condemning the '60s counterculture — but grew up in 1960s Boston, moving to Dallas in 1971. Do not write: the 90's; the 90s; or the 90s'.
A third alternative (where seen in reliable sources) is to spell the decade out, capitalized: changing attitudes of the Sixties.
Centuries and millennia[edit]
MOS:CENTURY
MOS:MILLENNIUM
The sequence of numbered years in dates runs ... 2 BC, 1 BC, 1 AD, 2 AD ...; there is no "year zero".
Treat the 1st century AD as years 1–100, the 17th century as 1601–1700, and the second millennium as 1001–2000; similarly, the 1st century BC/BCE was 100–1 BC/BCE, the 17th century BC/BCE was 1700–1601 BC/BCE, and the second millennium 2000–1001 BC/BCE.
Centuries and millennia are identified using either "Arabic" numerals (the 18th century) or words (the second millennium). When used adjectivally they contain a hyphen (nineteenth-century painting or 19th-century painting). Do not use superscripts (19th century).
Do not capitalize (the best Nineteenth-century paintings; during the Nineteenth Century)
Do not use Roman numerals (XVIII century).
The 18th century refers to the period (1701–1800), while strictly the 1700s refers either to (1700–1799) or (1700–1709)
When using forms such as the 1900s, ensure there is no ambiguity as to whether the century or just its first decade is meant.
See WP:Manual of Style § En dashes for use of hyphens and dashes in obscure situations.
Long periods of time[edit]
When the term is frequent, combine yr (years) or ya (years ago) with k (thousand): kya, kyr; M (million): Mya, Myr; and b (short-scale billion): bya, byr. (See Year § Abbreviations yr and ya for more information.)
In academic contexts, SI annus-based units are often used: ka (kiloannus), Ma (megaannus), and Ga (gigaannus). (See Year § SI prefix multipliers for more information.)
Show the meaning parenthetically, and consider linking to the appropriate section of the Year article (Year § Abbreviations yr and ya or Year § SI prefix multipliers) on first occurrence and where the use is a standalone topic of interest. In source quotations, use square brackets: "a measured Libby radiocarbon date of 35.1 Mya [million years ago] required calibration ..."
Numbers[edit]
Numbers as figures or words[edit]
MOS:NUMERAL
MOS:SPELL09
MOS:MILLION
MOS:BILLION
MOS:TRILLION
MOS:LAKH
MOS:CRORE
Information on specific situations is scattered elsewhere on this page.
Generally, in article text:
Integers from zero to nine are spelled out in words.
Integers greater than nine expressible in one or two words may be expressed either in numerals or in words (16 or sixteen, 84 or eighty-four, 200 or two hundred). When written as words, numbers from 21 to 99 are hyphenated (including when part of a larger number): fifty-six or fifty-six thousand but five hundred or five thousand.
Other numbers are given in numerals (3.75, 544) or in forms such as 21 million (or billion, trillion, etc. – but rarely thousand). Markup: 21{{nbsp}}million
Billion and trillion are understood to represent their short-scale values of 109 (1,000,000,000) and 1012 (1,000,000,000,000), respectively. Keep this in mind when translating articles from non-English or older sources.
M (unspaced, capitalized) or bn (unspaced), respectively, may be used for "million" or "billion" after a number, when the word has been spelled out at the first occurrence (Her estate of £61 million was split among her husband (£1M), her son (£5M), her butler (£10M), and her three Weimaraners (£15M each).).
SI prefixes and symbols, such as mega- (M), giga- (G) and tera- (T), should be used only with units of measure as appropriate to the field and not to express large quantities in other contexts. Examples of misuse: In a population of 1.3G people, 300 megadeaths would be expected.
Sometimes, the variety of English used in an article may suggest the use of a numbering system other than the Western thousands-based system. For example, the South Asian numbering system is conventionally used for certain things (especially monetary amounts) in South Asian English. This is discouraged in Wikipedia articles by WP:Manual of Style § Opportunities for commonality.
When it is done anyway, for contextually important reasons, link the first spelled-out instance of each quantity (e.g. [[crore]], which yields: crore). If no instances are spelled out, provide a note after the first instance, directing the reader to the article about the numbering system.
Provide a conversion to Western numbers for the first instance of each quantity (the templates {{lakh}}, {{crore}}, and {{lakh crore}} may be used for this purpose), and provide conversions for subsequent instances if they do not overwhelm the content of the article. For example, write three crore (thirty million). When converting a currency amount, use the exchange rate that applied at the time being written about; the {{INRConvert}} template can be used for this purpose.
Group digits in Western thousands-based style (e.g., 30,000,000; not 3,00,00,000); see § Delimiting (grouping of digits), below.
The variety of English does not uniquely determine the method of numbering in an article. Other considerations – such as conventions used in mathematics, science, and engineering – may also apply. The choice and order of formats and conversions is a matter of editorial discretion and consensus at the article.
MOS:NUMNOTES
Notes and exceptions:
Avoid beginning a sentence with a figure:
Use: There were many matches; 23 ended in a draw. Or: There were many matches. Twenty-three ended in a draw.
Not: There were many matches. 23 ended in a draw.
Use: No elections were held in 1945 and 1950.
Not: 1945 and 1950 had no elections. (Nor: Nineteen forty-five and 1950 had no elections – comparable numbers should be both written in words or both in figures.)
In tables and infoboxes, quantities are expressed in figures (Years in office: 5); but numbers within a table's explanatory text and comments follow the general rule.
Numbers in mathematical formulae are never spelled out (3 < π < 22/7, not three < pi < twenty-two sevenths).
Sport scores and vote tallies should be given as figures, even if in the zero-to-nine range (a 25–7 victory; and passed with 7 ayes, 2 nays, and 1 abstention).
Comparable values should be all spelled out or all in figures, even if one of the numbers would normally be written differently: patients' ages were five, seven, and thirty-two or ages were 5, 7, and 32, but not ages were five, seven, and 32.
Similar guidance applies where "mixed units" are used to represent a single value (as is often done with time durations, and in the imperial and US customary systems): 5 feet 11 inches tall; five feet eleven inches tall; 3 minutes 27 seconds; three minutes twenty-seven seconds.
Adjacent quantities not comparable should ideally be in different formats: twelve 90-minute volumes or 12 ninety-minute volumes, not 12 90-minute volumes or twelve ninety-minute volumes.
Avoid awkward juxtapositions: On February 25, 2011, twenty-one more were chosen, not On February 25, 2011, 21 more were chosen.
Sometimes figures and words carry different meanings; for example, Every locker except one was searched implies there is a single exception (without specifying which), while Every locker except 1 was searched means that locker number 1 was the only locker not searched.
Proper names, technical terms, and the like are never altered: 10 Downing Street, Nine Inch Nails, Channel 8, Seven Samurai, The Sixth Sense, Chanel No. 5, Fourth Estate, The Third Man, Second Coming, First Amendment, Zero Hour!, Less Than Zero
Figures as figures: Use a figure when the figure itself (its glyph, shape, etc.) is meant: a figure-8 pattern; in the shape of the numeral 6. (See Wikipedia:Manual of Style/Text formatting § Words as words.)
Only figures are used with unit symbols (12 min not twelve min); but figures or words may be used with unit names (12 minutes or twelve minutes), subject to the provisions above.
MOS:ORDINAL
MOS:1ST
Ordinals[edit]
"MOS:1ST" redirects here. For the guideline on the first sentence in articles, see MOS:FIRST.
For guidance on choosing between e.g. 15th and fifteenth, see § Numbers as figures or words.
In "suffix" forms, use two-letter suffixes: 1st, 2nd, 3rd, 4th and so on (2nd Battalion not 2d Battalion). Do not superscript (123rd).
Do not use ordinals for dates (see MOS:BADDATE).
In English text, do not use a dot (.) or the ordinal indicator (º). The masculine º or feminine (ª) ordinal indicator is acceptable in names, quotations, etc. from languages that conventionally use it. An Italian example: 313º Gruppo Addestramento Acrobatico not 313º Acrobatic Training Group or the 313º. Use HTML markup for languages that don't have a special character but conventionally use a superscript, like 2es in French.
Regnal numbers are normally written with ASCII Roman numerals (without suffix, e.g. Elizabeth II not Elizabeth IInd or Elizabeth 2nd).
Number ranges[edit]
MOS:NUMRANGE
MOS:PAGERANGE
Like date ranges, number ranges and page ranges should state the full value of both the beginning and end of the range, separated by an en dash: pp. 1902–1911 or entries 342–349. Except in quotations, avoid abbreviated forms such as 1902–11 and 342–9, which are not understood universally, are sometimes ambiguous, and can cause inconsistent metadata to be created in citations.
Sport scores, vote tallies, etc.[edit]
These use an unspaced {{ndash}}:
Smith beat Jones 7–3.
Polls predicted Alice would defeat Bob 74–20 percent, with 6 percent undecided.
Singular versus plural[edit]
Nouns following simple fractions are singular (took 1⁄4 dose; net change was −1⁄2 point; 3⁄2 dose).
Nouns following mixed numbers are plural (11⁄2 doses; another 43⁄4 miles).
Nouns following the lone, unsigned digit 1 are singular, but those following other decimal numbers (i.e. base-10 numbers not involving fractions) are plural (increased 0.7 percentage points; 365.25 days; paid 5 dollars per work hour, 1 dollar per travel hour, 0 dollars per standby hour; increased by 1 point but net change +1 points; net change −1 points; net change 1.0 points).
The same rules apply to numbers given in words (one dose; one and one-half doses; zero dollars; net change of negative one points).
Fractions and ratios[edit]
MOS:FRAC
MOS:RATIO
Spelled-out fractions are hyphenated: seven-eighths.
Where numerator and denominator can each be expressed in one word, a fraction is usually spelled out (e.g. a two-thirds majority; moved one-quarter mile); use figures if a fraction appears with a symbol (e.g. 1⁄4 mi – markup: {{frac|1|4}} mi, not a quarter of a mi or one-quarter mi). A common exception is a series of values: The distances were 1+1⁄4, 2⁄3 and 1⁄2 mile, respectively.
Mixed numbers are usually given in figures, unspaced (not Fellini's film 8 1⁄2 or 8-1⁄2 but Fellini's film 8+1⁄2 – markup: {{frac|8|1|2}}). In any case the integer and fractional parts should be consistent (not nine and 1⁄2).
Metric (SI) measurements generally use decimals, not fractions (5.25 mm, not 51⁄4 mm).
Non-metric (imperial and US customary) measurements may use fractions or decimals (51⁄4 inches; 5.25 inches); the practice of reliable sources should be followed, and within-article consistency is desirable.
In science and mathematics articles, mixed numbers are rarely used (use 4/3 the original rather than 11/3 times the original voltage). The use of {{frac}} is discouraged in favor of one of these styles:
1 2 {\displaystyle \textstyle {\frac {1}{2}}} – markup: <math>\textstyle\frac{1}{2}</math>
1/2 – markup: {{sfrac|1|2}}
1/2 – markup: 1/2
Do not use precomposed fraction characters such as ½ (deprecated markup: ½ or ½). Exception: In special situations such as articles on chess matches, a precomposed ½ may be used if that is the only fraction appearing in the article.
Ordinal suffixes such as -th should not be used with fractions expressed in figures (not each US state has 1/50th of the Senate's votes; 1/8th mile, but one-fiftieth of the Senate's votes; 1/8 mile; one-eighth mile).
Dimensionless ratios (i.e. those without accompanying units) are given by placing a colon between integers, or placing to between numbers-as-words: favored by a 3:1 ratio or a three-to-one ratio, not a 3/1 ratio or a 3–1 ratio.
Use a colon (spaced) when one or more decimal points is present (a 3.5 : 1 ratio – markup: a 3.5 : 1 ratio).
Do not use the colon form where units are involved (dissolve using a 3 ml : 1 g ratio)—instead see ratios section of table at § Unit names and symbols, below.
See also: Wikipedia:Manual of Style/Mathematics § Fractions
Decimals[edit]
WP:DECIMAL
MOS:DECIMAL
Use a period/full point (.) as the decimal separator, never a comma: 6.57, not 6,57.
Numbers between −1 and +1 require a leading zero (0.02, not .02); exceptions are sporting performance averages (.430 batting average) and commonly used terms such as .22 caliber.
Indicate repeating digits with an overbar e.g. 14.31{{overline|28}} gives 14.3128. (Consider explaining this notation on first use.) Do not write e.g. 14.31(28) because it resembles notation for uncertainty.
Grouping of digits[edit]
WP:DIGITS
MOS:DIGITS
Digits should be grouped and separated either by commas or by narrow gaps (never a period/full point).
Grouping with commas
Left of the decimal point, five or more digits are grouped into threes separated by commas (e.g. 12,200; 255,200 km; 8,274,527th; 1⁄86,400).
Numbers with exactly four digits left of the decimal point may optionally be grouped (either 1,250 or 1250), with consistency within any given article.
When commas are used left of the decimal point, digits right of the decimal point are not grouped (i.e. should be given as an unbroken string).
Markup: {{formatnum:}} produces this formatting.
Grouping with narrow gaps
Digits are grouped both sides of the decimal point (e.g. 6543210.123456; 520.01234 °C; 101325/760).
Digits are generally grouped into threes. Right of the decimal point, usual practice is to have a final group of four in preference to leaving an "orphaned" digit at the end (99.1234567, but 99.1234567 would also be acceptable). In mathematics-oriented articles long strings may be grouped into fives (e.g. 3.14159265358979323846...).
This style is especially recommended for articles related to science, technology, engineering or mathematics.
Markup: Templates {{val}} or {{gaps}} may be used to produce this formatting. Note that use of any space character as a separator in numbers, including non-breaking space, is problematic for screen readers. (See § Non-breaking spaces.) Screen readers read out each group of digits as separate numbers (e.g. 30{{thin space}}000 is read as "thirty zero zero zero".)
Delimiting style should be consistent throughout a given article.
Either use commas or narrow gaps, but not both in the same article.
Either group the thousands in a four-digit number or do not, but not mixed use in the same article.
However, grouping by threes and fives may coexist.
An exception is made for four-digit page numbers or four-digit calendar years. These should never be grouped (not sailed in 1,492, but dynasty collapsed around 10,400 BC or by 13727 AD, Vega will be the northern pole star).
Percentages[edit]
MOS:PERCENT
WP:PERCENT
WP:%
In the body of non-scientific/non-technical articles, percent (American English) or per cent (British English) are commonly used: 10 percent; ten percent; 4.5 per cent. Ranges are written ten to twelve per cent or ten to twelve percent, not ten–twelve per cent.
In the body of scientific/technical articles, and in tables and infoboxes of any article, the symbol % (unspaced) is more common: 3%, not 3 % or three %. Ranges: 10–12%, not 10%–12% or 10 to 12%.
When expressing the difference between two percentages, do not confuse a percentage change with a change in percentage points.
Scientific and engineering notation[edit]
Scientific notation always has a single nonzero digit to the left of the point: not 60.22×1022, but 6.022×1023.
Engineering notation is similar, but with the exponent adjusted to a multiple of three: 602.2×1021.
Avoid mixing scientific and engineering notations (A 2.23×102 m2 region covered by 234.0×106 grains of sand).
In a table column (or other presentation) in which all values can be expressed with a single power of 10, consider giving e.g. ×107 once in the column header, and omitting it in the individual entries. (Markup: {{e|7}})
In both notations, the number of digits indicates the precision. For example, 5×103 means rounded to the nearest thousand; 5.0×103 to the nearest hundred; 5.00×103 to the nearest ten; and 5.000×103 to the nearest unit.
Markup: {{val}} and {{e}} may be used to format exponential notation.
Uncertainty and rounding [edit]
MOS:UNCERTAINTY
MOS:LARGENUM
Where explicit uncertainty information (such as a margin of error) is available and appropriate for inclusion, it may be written in various ways:
(1.534 ± 0.035) × 1023 m
12.34 m2 ± 5% (not used with scientific notation)
15.34 +0.43
−0.23 × 1023 m
1.604(48) × 10−4 J (equivalent to (1.604 ± 0.048) × 10−4 J)[i]
Polls estimated Jones's share of the vote would be 55 percent, give or take about 3 percent
Markup: {{+-}}, {{su}}, and {{val}} may be used to format uncertainties.
Where explicit uncertainty is unavailable (or is unimportant for the article's purposes) round to an appropriate number of significant digits; the precision presented should usually be conservative. Precise values (often given in sources for formal or matter-of-record reasons) should be used only where stable and appropriate to the context, or significant in themselves for some special reason.
The speed of light is defined to be 299,792,458 m/s
but Particle velocities eventually reached almost two-thirds the 300-million-metre-per-second speed of light.
checks worth $250 (equivalent to $1,800 in 2016) (not $1,845.38 in 2016)
The city's 1920 population was 10,000 (not population was 9,996 – an official figure unlikely to be accurate at full precision)
but The town was ineligible because its official census figure (9,996) fell short of the statutory minimum of ten thousand (unusual case in which the full-precision official figure is truly informative)
The accident killed 337 passengers and crew, and 21 people on the ground (likely that accurate and precise figures were determined)
At least 800 persons died in the ensuing mudslides (unlikely that any precise number can be accurate, even if an official figure is issued)
or Officials listed 835 deaths, but the Red Cross said dozens more may have gone unreported (in reporting conflicting information, give detail sufficient to make the contrast intelligible)
The jury's award was $8.5 million (not $8,462,247.63). The appeals court reduced this to $3,000,001 (one dollar in actual damages, the remainder in punitive damages).
The number of decimal places should be consistent within a list or context (The response rates were 41.0 and 47.4 percent, respectively, not 41 and 47.4 percent), unless different precisions are actually intended.
It may sometimes be appropriate to note the lack of uncertainty information, especially where such information is normally provided and necessary for full interpretation of the figures supplied.
A local newspaper poll predicted 52 percent of the vote would go to Smith, but did not include information on the uncertainty of this estimate
The {{undue precision}} template may be added to figures appearing to be overprecise.
Avoid using "approximately", "about", and similar terms with figures that have merely been approximated or rounded in a normal and expected way, unless the reader might otherwise be misled.
The tallest player was 6 feet 3 inches (not ... about 6 feet 3 inches – heights are conventionally reported only to the nearest inch, even though greater precision may be available in principle)
but The witness said the assailant was about 5 feet 8 inches tall ("about" because here the precise value is unknown, with substantial uncertainty)
The reader may be assumed to interpret large round numbers (100,000 troops) as approximations. Writing a quantity in words (one hundred thousand troops) can further emphasize its approximate nature.
See § Unit conversions below for precision issues when converting units.
Non–base 10 notations[edit]
MOS:BASE
MOS:RADIX
MOS:BINARY
MOS:HEX
In computer-related articles, use the prefix 0x for hexadecimal and 0b for binary,[j] unless there is a strong reason to use some other notation.[k] Explain these prefixes in the article's introduction or on first use.
In all other articles, use base: 1379, 2013. Markup: {{base|137|9}}, {{base|201|3}}
For bases above 10, use symbols conventional for that base (as seen in reliable sources) e.g. for base 16 use 0–9 and A–F.
For octal, use 2008. Avoid using a prefix unless it is needed for computer code samples, in which case explain the prefix on first use.
Mathematical formulae[edit]
Main page: Wikipedia:Manual of Style/Mathematics
There are multiple ways to display mathematical formulae, covered in detail at Wikipedia:Manual of Style/Mathematics § Typesetting of mathematical formulae. One uses special MediaWiki <math>...</math> markup using LaTeX syntax, which is capable of complex formulae; the other relies on conventionalized HTML formatting of simple formulae.
The <math> markup is displayed as a PNG image by default. Logged-in users can optionally have it rendered in MathML, or in HTML (via MathJax); detailed instructions are at Help:Displaying a formula.
Do not put <math> markup in headings.
Units of measurement[edit]
MOS:UNIT
MOS:UNITS
MOS:METRIC
MOS:MEASUREMENT
Unit choice and order[edit]
Quantities are typically expressed using an appropriate "primary unit", displayed first, followed, when appropriate, by a conversion in parentheses e.g. 200 kilometres (120 mi). For details on when and how to provide a conversion, see the section § Unit conversions. The choice of primary units depends on the circumstances, and should respect the principle of "strong national ties", where applicable:
In non-scientific articles with strong ties to the United States, the primary units are US customary (pounds, miles, feet, inches, etc.)
In non-scientific articles with strong ties to the United Kingdom, the primary units for most quantities are metric or other internationally used units,[l] except that:
UK engineering-related articles, including those on bridges and tunnels, generally use the system of units in which the subject project was drawn up (but road distances are given in imperial units, with a metric conversion – see next bullet);
the primary units for distance/length, speed and fuel consumption are miles, miles per hour, and miles per imperial gallon (except for short distances or lengths, where miles are too large for practical use);
the primary units for personal height and weight are feet/inches and stones/pounds;
imperial pints are used for quantities of draught beer/cider and bottled milk;
In all other articles, the primary units chosen will be SI units, non-SI units officially accepted for use with the SI, or such other units as are conventional in reliable-source discussions of the article topic (such as revolutions per minute (rpm) for rotational speed, hands for heights of horses, etc.).
Special considerations:
Quantities set via definition (as opposed to measured quantities) should be given first in the units used in the definition, even if this makes the structure of presentation inconsistent: During metrication, the speed limit was changed from 30 mph (48 km/h) to 50 km/h (31 mph).
Or use about to emphasize which is the statutory, exact value: ...from 30 mph (about 48 km/h) to 50 km/h (about 31 mph).
Nominal quantities (e.g. 2 × 4 lumber) require consideration of whether the article is concerned with the item's actual dimensions or merely with its function. In some cases, the nominal quantity may suffice; in others it may be necessary to give the nominal size (often in non-SI units), the actual size in non-SI units, and the actual size in SI units.
Whenever a conversion is given, the converted quantity's value should match the precision of the source (see § Unit conversions).
Where the article's primary units differ from the units given in the source, the {{convert}} template's |order=flip flag can be used; this causes the original unit to be shown as secondary in the article, and the converted unit to be shown as primary: {{convert|200|mi|km|order=flip}} → The two cities are 320 kilometres (200 mi) apart.
Unit conversions[edit]
MOS:CONVERSIONS
WP:MOSCONVERSIONS
Where English-speaking countries use different units for the same quantity, provide a conversion in parentheses: the Mississippi River is 2,320 miles (3,734 km) long; the Murray River is 2,508 kilometres (1,558 mi) long. But in science-related articles, supplying such conversion is not required unless there is some special reason to do so.
Where an imperial unit is not part of the US customary system, or vice versa – and in particular, where those systems give a single term different definitions – a double conversion may be appropriate: Rosie weighed 80 kilograms (180 lb; 12 st 8 lb) (markup: {{convert|80|kg|lb stlb}}); The car had a fuel economy of 5 L/100 km (47 mpg‑US; 56 mpg‑imp) (markup: {{convert|5|L/100km|mpgus mpgimp|abbr=on}}).
Generally, conversions to and from metric units and US or imperial units should be provided, except:
When inserting a conversion would make a common or linked expression awkward (The four-minute mile).
In some topic areas (for example maritime subjects where nautical miles are the primary units, or American football where yards are primary) it can be excessive to provide a conversion for every quantity. In such cases consider noting that the article will use a particular unit – possibly giving the conversion factor to other, familiar units in a parenthetical note or a footnote – and link the first occurrence of each unit but not give a conversion every time it occurs. Applying this principle may require editorial discretion; for example, in scientific articles the expected level of reader sophistication should be taken into account.
Converted quantity values should use a level of precision similar to that of the source quantity value, so the Moon is 380,000 kilometres (240,000 mi) from Earth, not (236,121 mi). Small numbers, especially if approximate, may need to be converted to a range where rounding would cause a significant distortion, so about one mile (1–2 km), not about one mile (2 km). Be careful especially when your source has already converted from the units you're now converting back to. This may be evidenced by multiples of common conversion factors in the data, such as 160 km (from 100 miles). See false precision.
{{convert}} (and other conversion templates) can be used to convert and format many common units.
In a direct quotation, always retain the source units. Any conversions can be supplied either in the quote itself (in square brackets, following the original measurement) or in a footnote. See footnoting and citing sources.
{{Units attention}} may be added to articles needing general attention regarding choice of units and unit conversions.
Unit names and symbols[edit]
MOS:UNITNAMES
MOS:UNITSYMBOLS
WP:UNITNAMES
WP:UNITSYMBOLS
Examples of unit names: foot, metre, kilometre, (US: meter, kilometer).
Examples of unit symbols: ft, m, km.
Unit names and symbols should follow the practice of reliable sources.
In prose, unit names should be given in full if used only a few times, but symbols may be used when a unit (especially one with a long name) is used repeatedly, after spelling out the first use (e.g. Up to 15 kilograms of filler is used for a batch of 250 kg).
Exception: Certain units are generally represented by their symbols (e.g. °C rather than degrees Celsius) even on first use, though their unit names may be used for emphasis or clarity (conversion of degrees Celsius to degrees Fahrenheit).
Exception: Consider using inches (but not in.) in place of in where the latter might be misread as a preposition—but not where the value is followed by a parenthesized conversion e.g. bolts 5 in (12.7 cm) long, or is part of such a conversion (bolts 12.7 cm (5 in) long).
Where space is limited, such as in tables, infoboxes, parenthetical notes, and mathematical formulas, unit symbols are preferred.
Units unfamiliar to general readers should be presented as a name–symbol pair on first use, linking the unit name (Energies rose from 2.3 megaelectronvolts (MeV) to 6 MeV).
Ranges use unspaced en dash ({{ndash}}) if only one unit symbol is used at the end (e.g. 5.9–6.3 kg), and spaced en dash ({{snd}}) if two symbols are used (e.g. 3 μm – 1 mm); ranges in prose may be specified using either unit symbol or unit names, and units may be stated either after both numerical values or after the last (all acceptable: from 5.9 to 6.3 kilograms; from 5.9 kilograms to 6.3 kilograms; from 5.9 to 6.3 kg; from 5.9 kg to 6.3 kg).
Length–width, length–width–height and similar dimensions may be separated by the multiplication sign (× or ×) or the word by.
The × symbol is preceded by a space (preferably non-breaking), and followed by a space (which may also be non-breaking in short constructions), and each number should be followed by a unit name or symbol:
1 m × 3 m × 6 m, not 1 × 3 × 6 m, (1 × 3 × 6) m, nor 1 × 3 × 6 m3
a metal plate 1 ft × 3 ft × 0.25 in
a railroad easement 10 ft × 2.5 mi
With by, the unit need be given only once if it is the same for all dimensions: 1 by 3 by 6 metres or 1 by 3 by 6 m
The unspaced letter x may be used in common terms such as 4x4.
General guidelines on use of units
Unit names and symbols
Except as listed in the § Specific units table below, unit symbols are uncapitalized unless they are derived from a proper name, in which case the first letter (of the base unit symbol, not of any prefix) is capitalized.[m] 8 kg
100 kPa 8 Kg
Unit symbols are undotted. 38 cm of rope 38 cm. of rope
Unit names are given in lower case except: where any word would be capitalized, or where otherwise specified in the SI brochure[4] or this Manual of Style.
A gallon is 4 quarts.
4 pascals
He walked several miles.
Miles of trenches were dug.
The spelling of certain unit names (some of which are listed in § Specific units, below) varies with the variety of English followed by the article.
Write unit names and symbols in upright (roman) type, except where emphasizing in context. 10 m
29 kilograms 10 m
Thus each two-liter jug contained only two quarts.
Do not use precomposed unit symbol characters. ㎓, ㎦, ㎍, ㎖, ㎉
Numeric values
Do not spell out numbers before unit symbols ... 12 min twelve min
... but words or figures may be used with unit names.
Use a non-breaking space ({{nbsp}} or ) between a number and a unit symbol, or use {{nowrap}} ... 29 kg (markup: 29 kg or {{nowrap|29 kg}}) 29kg
... though with certain symbols no space is used (see "Specific units" table below) ... 23° 47′ 22″ 23 ° 47 ′ 22 ″
... and a normal space is used between a number and a unit name. 29 kilograms
(markup: 29 kilograms)
To form a value and a unit name into a compound adjective use a hyphen or hyphens ...
a five-day holiday
a five-cubic-foot box
a 10-centimeter blade
... but a non-breaking space (never hyphen) separates a value and unit symbol.
a blade 10 cm long
a 10-cm blade
SI unit names are pluralized by adding the appropriate -s or -es suffix ... 1 ohm; 10 ohms
... except for these irregular forms. 1 henry; 10 henries
1 hertz; 10 hertz
1 lux; 10 lux
1 siemens; 10 siemens 10 henrys
10 hertzes
10 luxes
10 siemenses
Some non-SI units have irregular plurals. 1 foot; 10 feet 10 foots
1 stratum; 10 strata (unusual) 10 stratums
Unit symbols (in any system) are identical in singular and plural.
grew from 1 in to 2 in
grew from 1 inch to 2 inches
grew from one to two inches
grew from 1 in to 2 ins
Format exponents using <sup>, not special characters. km2
(markup: km<sup>2</sup>) km²
(km²)
Or use squared or cubed (after the unit being modified). ten metres per second squared ten metres per squared second
For areas or volumes only, square or cubic may be used (before the unit being modified). ten metres per square second
tons per square mile
sq or cu may be used with US customary or imperial units, but not with SI units. 15 sq mi
3 cu ft 15 sq km
3 cu m
Indicate a product of unit names with either a hyphen or a space.
foot-pound
foot pound
footpound
foot⋅pound
Indicate a product of unit symbols with ⋅ or .
ms = millisecond
m⋅s or m s = metre-second
Exception: In some topic areas, such as power engineering, certain products take neither space nor ⋅. Follow the practice of reliable sources in the article's topic area.
Wh, VA, Ah
kWh, MVA, GAh
To pluralize a product of unit names, pluralize only the final unit. (Unit symbols are never pluralized.) ten foot-pounds ten feet-pounds
Ratios, rates, densities
Indicate a ratio of unit names with per. meter per second meter/second
Indicate a ratio of unit symbols with a forward slash (/), followed by either a single symbol or a parenthesized product of symbols – do not use multiple slashes. Or use −1, −2, etc.
metre per second
m⋅s−1
kg/(m⋅s)
kg⋅m−1⋅s−1
kg/m⋅s
kg/m/s
To pluralize a ratio of unit names, pluralize only the numerator unit. (Unit symbols are never pluralized.)
ten newton-metres per second
10 N⋅m/s
Some of the special forms used in the imperial and US customary systems are shown here ...
mph = miles per hour
mpg = miles per gallon
psi = pounds per square inch
... but only the slash or negative exponent notations are used with SI (and other metric) units.
g⋅m−2
km⋅h−1
kph
Prefixes should not be separated by a space or hyphen. kilopascal
kilo pascal
kilo-pascal
Prefixes are added without contraction, except as shown here: kilohm
megohm
hectare kiloohm
megaohm
hectoare
The deci-, deca-, and hecto- prefixes should generally be avoided; exceptions include decibel, hectolitre, hectare, and hectopascal.
100 metres
1 hectometre
Do not use M for 103, MM for 106, or B for 109 (except as noted elsewhere on this page for M and B, e.g. for monetary values) 3 km
8 MW
125 GeV 3 Mm
8 MMW
125 BeV
Mixed units
Mixed units are traditionally used with the imperial and US customary systems ...
a wall 1 ft 1 in thick
a wall 1 foot 1 inch thick
a man 6 feet 2 inches tall
a 6-foot 2-inch man
a 6 ft 2 in man
1 ft , 1 in (no comma)
1 foot , 1 inch
a man 6 foot 2 tall
a 6-foot 2 man
1 US fl pt 8 oz
1 US fl pt 8 US fl oz
... and in expressing time durations ...
1:30 [note 1]
1 h 30 min 7 s
01h 30m 07s [note 2]
1:30′07″
1:30′
1 hr 30 min 7 sec
1 h 30 m 7 s
... but are not used with metric units.
1 m 33 cm
Note to table:
^ Use this format only where it is clear from context whether it means hours and minutes (HH:MM) or minutes and seconds (MM:SS).
^ This format is used in astronomy (see the IAU Style Manual[6] for details).
Specific units[edit]
The following table lists only units that need special attention.
The SI Brochure[4] should be consulted for guidance on use of other SI and non-SI units.
Guidelines on specific units
Length, speed
Do not use ′ (′), ″ (″), apostrophe ('), or quote (").
foot per second ft/s (not fps)
hand h or hh Equal to 4 inches; used in measurement of horses. A dot may be followed by additional inches e.g. 16.2 hh indicates 16 hands 2 inches.
knot indicated airspeed
knot calibrated airspeed
knot equivalent airspeed
knot true airspeed
knot groundspeed
kn (not kt, Kt, or kN)
KIAS or kn
KCAS
KEAS
KTAS
kn (not KGS)
Used in aviation contexts for aircraft and wind speeds, and also used in some nautical and general meteorological contexts. When applied to aircraft speeds, kn means KIAS unless stated otherwise; if kn is used for calibrated airspeed, equivalent airspeed, true airspeed, or groundspeed, explicitly state and link to, upon first use, the type of speed being referred to (for instance, kn equivalent airspeed, or, if severely short of space, kn EAS); for airspeeds other than indicated airspeed, the use of the specific abbreviation for the type of airspeed being referred to (such as KEAS) is preferred. When referring to indicated airspeed, either kn or KIAS is permissible. Groundspeeds and wind speeds must use the abbreviation kn only.
meter (US)
micron μm (not μ) Markup: μm Link to micrometre (for which micron is a synonym) on first use.
astronomical unit au
(not A.U., ua) The preferred form is au. Articles that already use AU may switch to au or continue with AU; seek consensus on the talk page.
miles per hour
nmi or NM (not nm or M)
In nautical and aeronautical contexts where there is risk of confusion with nautical miles, consider writing out references to statute miles as e.g. 5 statute miles rather than simply 5 miles.
Volume, flow
cubic centimetre
cubic centimeter (US)
cm3 Markup: cm<sup>3</sup>
cc Non-SI abbreviation used for certain engine displacements. Link to Cubic centimetre on first use.
imperial fluid ounce
imperial pint
imperial quart
imperial gallon
US dry pint
US liquid pint
US dry quart
US liquid quart
imp fl oz
imp pt
imp qt
imp gal
US fl oz
US dry pt
US liq pt
US dry qt
US liq qt
US gal
US or imperial (or imp) must be specified for all these units.
fluid or fl must be specified for fluid ounces (to avoid ambiguity versus avoirdupois ounce and troy ounce).
For US pints and quarts, dry or liquid (liq) are needed to be fully unambiguous, though context determines whether or not to repeat those qualifiers on every use in a given article.
cubic foot cu ft (not cf) Write five million cubic feet, 5,000,000 cu ft, or 5×106 cu ft, not 5 MCF.
cubic foot per second cu ft/s (not cfs)
liter (US)
L (not l or ℓ) The symbol l (lowercase "el") in isolation (i.e. outside forms as ml) is easily mistaken for the digit 1 or the capital letter I ("eye") and should not be used.
millilitre
milliliter (US)
ml or mL Derivative units of the litre may use l (lowercase "el") as guided by WP:ENGVAR.
Mass, weight, force, density, pressure
kilogram
Not gramme, kilogramme
short ton
Spell out in full.
metric ton (US)
t (not mt, MT, or Mt)
pound per square inch psi
troy ounce
troy pound
oz t
lb t
The qualifier t or troy must be specified where applicable. Use the qualifier avdp (avoirdupois) only where there is risk of confusion with troy ounce, imperial fluid ounce, US fluid ounce, or troy pound; but articles about precious metals, black powder, and gemstones should always specify which type of ounce (avoirdupois or troy) is being used, noting that these materials are normally measured in troy ounces and grams.
avoirdupois ounce
avoirdupois pound
oz or oz avdp
lb or lb avdp
carat carat Used to express masses of gemstones and pearls.
carat or karat k or Kt (not kt or K) A measure of purity for gold alloys. (Do not confuse with the unit of mass with the same spelling.)
Do not use ′ (′), ″ (″), apostrophe (') or quote (") for minutes or seconds. See also the hours–minutes–seconds formats for time durations described in the Unit names and symbols table.
year a Use a only with an SI prefix multiplier (a rock formation 540 Ma old, not Life expectancy rose to 60 a).
y or yr See § Long periods of time for all affected units.
Information, data
bit bit (not b or B) See also § Quantities of bytes and bits, below. Do not confuse bit/second or byte/second with baud (Bd).
byte B or byte (not b or o)
bit per second bit/s (not bps, b/s)
byte per second B/s or byte/s (not Bps, bps, b/s)
arcminute ′ Markup: ′ (prime ′ not apostrophe/single quote '). No space (47′, not 47 ′).
arcsecond ″ Markup: ″ (double prime ″ not double-quote "). No space (22″, not 22 ″).
degree ° Markup: ° (degree ° not masculine ordinal º or ring ̊ ). No space (23°, not 23 °).
degree Fahrenheit °F (not F) Markup: °. Use a non-breaking space: 12{{nbsp}}°C, not 12°C nor 12°{{nbsp}}C (12 °C, not 12°C nor 12° C). Do not use the precomposed characters U+2103 ℃ DEGREE CELSIUS and U+2109 ℉ DEGREE FAHRENHEIT.
degrees Rankine °R (not R)
degree Celsius (not degree centigrade) °C (not C)
kelvin (not degree kelvin) K (not °K) Use a non-breaking space: 12{{nbsp}}K (use the normal latin letter K, not U+212A K KELVIN SIGN)
small calorie
gram calorie
cal In certain subject areas, calorie is conventionally used alone; articles following this practice should specify on first use whether the use refers to the small calorie or to the kilocalorie (large calorie). Providing conversions to SI units (usually calories to joules or kilocalories to kilojoules) may also be useful. A kilocalorie (kcal) is 1000 calories. A calorie (small calorie) is the amount of energy required to heat 1 gram of water by 1 °C. A kilocalorie is also a kilogram calorie.
kilocalorie
large calorie
kilogram calorie
(not Calorie – can be ambiguous)
Quantities of bytes and bits [edit]
WP:COMPUNITS
In quantities of bits and bytes, the prefixes kilo- (symbol k or K), mega- (M), giga- (G), tera- (T), etc., are ambiguous in general usage. The meaning may be based on a decimal system (like the standard SI prefixes), meaning 103, 106, 109, 1012, etc., or it may be based on a binary system, meaning 210, 220, 230, 240, etc. The binary meanings are more commonly used in relation to solid-state memory (such as RAM), while the decimal meanings are more common for data transmission rates, disk storage and in theoretical calculations in modern academic textbooks.
Prefixes for multiples of
bits (bit) or bytes (B)
1000 k kilo
10002 M mega
10003 G giga
10004 T tera
10005 P peta
10006 E exa
10007 Z zetta
10008 Y yotta
1024 Ki kibi K kilo
10242 Mi mebi M mega
10243 Gi gibi G giga
10244 Ti tebi T tera
10245 Pi pebi –
10246 Ei exbi –
10247 Zi zebi –
10248 Yi yobi –
Follow these recommendations when using these prefixes in Wikipedia articles:
Following the SI standard, a lower-case k should be used for "kilo-" whenever it means 1000 in computing contexts, whereas a capital K should be used instead to indicate the binary prefix for 1024 according to JEDEC. If, under the exceptions detailed further below, the article otherwise uses IEC prefixes for binary units, use Ki instead.
Do not assume that the binary or decimal meaning of prefixes will be obvious to everyone. Explicitly specify the meaning of k and K as well as the primary meaning of M, G, T, etc. in an article ({{BDprefix}} is a convenient helper). Consistency within each article is desirable, but the need for consistency may be balanced with other considerations.
The definition most relevant to the article should be chosen as primary for that article, e.g. specify a binary definition in an article on RAM, decimal definition in an article on hard drives, bit rates, and a binary definition for Windows file sizes, despite files usually being stored on hard drives.
Where consistency is not possible, specify wherever there is a deviation from the primary definition.
Disambiguation should be shown in bytes or bits, with clear indication of whether in binary or decimal base. There is no preference in the way to indicate the number of bytes and bits, but the notation style should be consistent within an article. Acceptable examples include:
A 64 MB (64 × 10242-byte) video card and a 100 GB (100 × 10003-byte) hard drive
A 64 MB (64 × 220-byte) video card and a 100 GB (100 × 109-byte) hard drive
A 64 MB (67,108,864-byte) video card and a 100 GB (100,000,000,000-byte) hard drive
Avoid combinations with inconsistent form such as A 64 MB (67,108,864-byte) video card and a 100 GB (100 × 10003-byte) hard drive. Footnotes, such as those seen in Power Macintosh 5500, may be used for disambiguation.
Unless explicitly stated otherwise, one byte is eight bits (see Byte § History).
The IEC prefixes kibi- (symbol Ki), mebi- (Mi), gibi- (Gi), etc., are generally not to be used except:[n]
when the majority of cited sources on the article topic use IEC prefixes;
in a direct quote using the IEC prefixes;
when explicitly discussing the IEC prefixes; or
in articles in which both types of prefix are used with neither clearly primary, or in which converting all quantities to one or the other type would be misleading or lose necessary precision, or declaring the actual meaning of a unit on each use would be impractical.
Currencies and monetary values[edit]
WP:$
WP:£
WP:€
MOS:CURRENCY
MOS:MONEY
"WP:MONEY" and "WP:CURRENCY" redirect here. For the WikiProject focusing on articles about currencies, see Wikipedia:WikiProject Numismatics.
"WP:$" redirects here. For the policy on paid editing, see Wikipedia:Paid-contribution disclosure.
Choice of currency
In country-specific articles, such as Economy of Australia, use the currency of the subject country.
In non-country-specific articles such as Wealth, use US dollars (US$123 on first use, generally $123 thereafter), euros (€123), or pounds sterling (£123).
Currency names
Do not capitalize the names or denominations of currencies, currency subdivisions, coins and banknotes: not a Five-Dollar bill, four Quarters, and one Penny total six Dollars one Cent but a five-dollar bill, four quarters, and one penny total six dollars one cent. Exception: where otherwise required, as at the start of a sentence or in such forms as Australian dollar.
To pluralize euro use the standard English plurals (ten euros and fifty cents), not the invariant plurals used for European Union legislation and banknotes (ten euro and fifty cent). For the adjectival form, use a hyphenated singular (a two-euro pen and a ten-cent coin).
Link the first occurrence of lesser-known currencies (Mongolian tögrögs).
In general, the first mention of a particular currency should use its full, unambiguous signifier (e.g. A$52), with subsequent references using just the appropriate symbol (e.g. $88), unless this would be unclear. Exceptions:
In an article referring to multiple currencies represented by the same symbol (e.g. the dollars of the US, Canada, Australia, New Zealand, and other countries – see Currency symbols § dollar variants) use the full signifier (e.g. US$ or A$, but not e.g. $US123 or $123 (US)) each time, except (possibly) where a particular context makes this both unnecessary and undesirable.
In articles entirely on EU-, UK- and/or US-related topics, all occurrences may be shortened (€26, £22 or $34), unless this would be unclear.
For the British pound sterling (GBP), use the £ symbol, with one horizontal bar, not the double-barred ₤ (which is used for Italian lira). For non-British currencies that use pounds or a pound symbol (e.g. the Egyptian pound, E£) use the symbol conventionally employed for that currency.
If there is no common English abbreviation or symbol, follow the ISO 4217 standard. See also List of circulating currencies.
Link the first occurrence of lesser-known currency symbols (₮)
See also: Wikipedia:Manual of Style/Abbreviations § Unicode abbreviation ligatures
A period (full stop, .) – never a comma – is used as the decimal point ($6.57, not $6,57).
For the grouping of digits (e.g. £1,234,567) see § Grouping of digits, above.
Do not place a currency symbol after the accompanying numeric figures (e.g. 123$, 123£, 123€) unless that is the normal convention for that symbol when writing in English: smaller British coins include 1p, 2p, and 5p denominations.
Currency abbreviations preceding a numeric value are unspaced if they consist of a nonalphabetic symbol alone (£123 or €123), or end with a nonalphabetic symbol (R$123); but spaced (using {{nbsp}}) if completely alphabetic (R 123 or JD 123).
Ranges should be expressed giving the currency signifier just once: $250–300, not $250–$300.
million and billion should be spelled out on first use, and (optionally) abbreviated M or bn (both unspaced) thereafter: She received £70 million and her son £10M; the school's share was $250–300 million, and the charity's $400–450M.
In general, a currency symbol should be accompanied by a numeric amount e.g. not He converted his US$ to A$ but He converted his US dollars to Australian dollars or He exchanged the US$100 note for Australian dollars.
Exceptions may occur in tables and infoboxes where space is limited e.g. Currencies accepted: US$, SFr, GB£, €. It may be appropriate to wikilink such uses, or add an explanatory note.
Conversions of less-familiar currencies may be provided in terms of more familiar currencies – such as the US dollar, euro or pound sterling – using an appropriate rate (which is often not the current exchange rate). Conversions should be in parentheses after the original currency, along with the convert-to year; e.g. the grant in 2001 was 10,000,000 Swedish kronor ($1.4M, €970,000, or £850,000 as of 2009[update])
For obsolete currencies, provide an equivalent (formatted as a conversion) if possible, in the modern replacement currency (e.g. decimal pounds for historical pre-decimal pounds-and-shillings), or a US-dollar equivalent where there is no modern equivalent.
In some cases, it may be appropriate to provide a conversion accounting for inflation or deflation over time. See {{Inflation}} and {{Inflation-fn}}.
When converting among currencies or inflating/deflating, it is rarely appropriate to give the converted amount to more than three significant figures; typically, only two significant figures are justified: the grant in 2001 was 10,000,000 Swedish kronor ($1.4M, €970,000, or £850,000), not ($1,390,570, €971,673 or £848,646)
Common mathematical symbols[edit]
WP:COMMONMATH
MOS:MINUS
See also: Wikipedia:Manual of Style/Mathematics and Help:Displaying a formula
The Insert menu below the editing window gives a more complete list of math symbols, and allows symbols to be inserted without the HTML encoding (e.g. ÷) shown here.
Spaces are placed to left and right when a symbol is used with two operands (the sum 4 + 5), but no space is used when there is one operand (the value +5). Exception: spaces are usually omitted in inline fractions formed with /: 3/4 not 3 / 4.
The {{mvar}} (for single-letter variables) and {{math}} (for more complicated expressions) templates are available to display mathematical formulas in a manner distinct from surrounding text.
The {{nbsp}} and {{nowrap}} templates may be used to prevent awkward linebreaks.
Common mathematical symbols
Symbol name
Plus /
positive x + y {{math|''x'' + ''y''}}
+y {{math|+''y''}}
Minus /
negative x − y {{math|''x'' − ''y''}} Do not use hyphens (-) or dashes ({{ndash}} or {{mdash}}).
−y {{math|−''y''}}
Plus-minus /
minus-plus 41.5 ± 0.3 41.5 ± 0.3
−(±a) = ∓a {{math|1=−(±''a'') = ∓''a''}}
Multiplication,
dot x ⋅ y {{math|''x'' ⋅ ''y''}}
cross x × y {{math|''x'' × ''y''}} Do not use the letter x to indicate multiplication. However, an unspaced x may be used as a substitute for "by" in common terms such as 4x4.
Division, obelus x ÷ y {{math|''x'' ÷ ''y''}}
Equal / equals x = y {{math|1=''x'' = ''y''}} or
{{math|''x'' {{=}} ''y''}} Note the use of 1= or {{=}} to make the template parameters work correctly
Not equal x ≠ y {{math|''x'' ≠ ''y''}}
Approx. equal π ≈ 3.14 {{math|''π'' ≈ 3.14}}
Less than x < y {{math|''x'' < ''y''}}
Less or equal x ≤ y {{math|''x'' ≤ ''y''}}
Greater than x > y {{math|''x'' > ''y''}}
Greater or equal x ≥ y {{math|''x'' ≥ ''y''}}
Geographical coordinates[edit]
MOS:COORDS
WP:COORDINATES
For draft guidance on, and examples of, coordinates for linear features, see Wikipedia:WikiProject Geographical coordinates/Linear.
Quick how to
To add 57°18′22″N 4°27′32″W / 57.30611°N 4.45889°W / 57.30611; -4.45889 to the top of an article, use {{Coord}}, thus:
{{Coord|57|18|22|N|4|27|32|W|display=title}}
These coordinates are in degrees, minutes, and seconds of arc.
"title" means that the coordinates will be displayed next to the article's title at the top of the page (in desktop view only; title coordinates do not display in mobile view) and before any other text or images. It also records the coordinates as the primary location of the page's subject in Wikipedia's geosearch API.
To add 44°06′45″N 87°54′47″W / 44.1124°N 87.9130°W / 44.1124; -87.9130 to the top of an article, use either
{{Coord|44.1124|N|87.9130|W|display=title}}
(which does not require minutes or seconds but does require the user to specify north/ south and east/west) or
{{Coord|44.1124|-87.9130|display=title}}
(in which the north and east are presumed by positive values while the south and west are negative ones). These coordinates are in decimal degrees.
Degrees, minutes and seconds, when used, must each be separated by a pipe ("|").
Map datum must be WGS84 if possible (except for off-Earth bodies).
Avoid excessive precision (0.0001° is <11 m, 1″ is <31 m).
Maintain consistency of decimal places or minutes/seconds between latitude and longitude.
Latitude (N/S) must appear before longitude (E/W).
Optional coordinate parameters follow the longitude and are separated by an underscore ("_"):
dim: dim:N (viewing diameter in metres)
region: region:R (ISO 3166-1 alpha-2 or ISO 3166-2 code)
type: type:T (landmark or city(30,000), for example)
Other optional parameters are separated by a pipe ("|"):
|display=inline (the default) to display in the body of the article only,
|display=title to display at the top of the article only (in desktop view only; title coordinates do not display in mobile view), or
|display=inline,title to display in both places.
name=X to label the place on maps (default is PAGENAME)
Thus: {{Coord|44.1172|-87.9135|dim:30_region:US-WI_type:event
|display=inline,title|name=accident site}}
Use |display=title (or |display=inline,title) once per article, for the subject of the article, where appropriate.
Per WP:ORDER, the template is placed in articles after any navigation templates, but before all categories, including the {{DEFAULTSORT}} template. This template may also be placed within an infobox, instead of at the bottom of an article.
For full details, refer to {{Coord/doc}}.
Additional guidance is available at obtaining coordinates and converting coordinates
Geographical coordinates on Earth should be entered using a template to standardise the format and to provide a link to maps of the coordinates. As long as the templates are adhered to, a robot performs the functions automatically.
First, obtain the coordinates. Avoid excessive precision.
The {{Coord}} template offers users a choice of display format through user styles, emits a Geo microformat, and is recognised (in the title position) by the "nearby" feature of Wikipedia's mobile apps and by external service providers such as Google Maps and Google Earth, and Yahoo. Infoboxes automatically emit {{Coord}}.
The following formats are available.
For degrees only (including decimal values): {{coord|dd|N/S|dd|E/W}}
For degrees/minutes: {{coord|dd|mm|N/S|dd|mm|E/W}}
For degrees/minutes/seconds: {{coord|dd|mm|ss|N/S|dd|mm|ss|E/W}}
dd, mm, ss are the degrees, minutes and seconds, respectively;
N/S is either N for northern or S for southern latitudes;
E/W is either E for eastern or W for western longitudes;
negative values may be used in lieu of S and W to denote Southern and Western Hemispheres
For the city of Oslo, located at 59° 54′ 50″ N, 10° 45′ 8″ E:
{{coord|59|54|50|N|10|45|08|E}} – which becomes 59°54′50″N 10°45′08″E / 59.91389°N 10.75222°E / 59.91389; 10.75222
For a country, like Botswana, with no source on an exact geographic center, less precision is appropriate due to uncertainty:
{{coord|22|S|24|E}} – which becomes 22°S 24°E / 22°S 24°E / -22; 24
Higher levels of precision are obtained by using seconds:
{{coord|33|56|24|N|118|24|00|W}} – which becomes 33°56′24″N 118°24′00″W / 33.94000°N 118.40000°W / 33.94000; -118.40000
Coordinates can be entered as decimal values:
{{coord|33.94|S|118.40|W}} – which becomes 33°56′S 118°24′W / 33.94°S 118.40°W / -33.94; -118.40
Increasing or decreasing the number of decimal places controls the precision. Trailing zeros may be added as needed to give both values the same appearance.
Heathrow Airport, Amsterdam, Jan Mayen and Mount Baker are examples of articles that contain geographical coordinates.
Generally, the larger the object being mapped, the less precise the coordinates should be. For example, if just giving the location of a city, precision greater than degrees (°), minutes (′), seconds (″) is not needed, which sufficient to locate, for example, the central administrative building. Specific buildings or other objects of similar size would justify precisions down to 10 meters or even one meter in some cases (1″ ~15 m to 30 m, 0.0001° ~5.6 m to 10 m).
The final field, following the E/W, is available for attributes such as type:, region:, or scale: (the codes are documented at Template:Coord/doc § Coordinate parameters).
When adding coordinates, please remove the {{coord missing}} tag from the article, if present (often at the bottom).
For more information, see the geographical coordinates WikiProject.
Templates other than {{coord}} should use the following variable names for coordinates: lat_d, lat_m, lat_s, lat_NS, long_d, long_m, long_s, long_EW.
Wikipedia:Naming conventions (numbers and dates)
Wikipedia:Date formattings
m:Help:Date formatting feature at Meta
m:Help:Calculation § Displaying numbers and numeric expressions at Meta
Notes[edit]
^ See Arbitration Committee statements of principles in cases on style-related edit warring in June 2005, November 2005, and February 2006; and Wikipedia:General sanctions/Units in the United Kingdom.
^ a b c For use in tables, infoboxes, references, etc. Only certain citation styles use abbreviated date formats. By default, Wikipedia does not abbreviate dates. Use a consistent citation style within any one article.
^ All-numeric yyyy-mm-dd dates might be assumed to follow the ISO 8601 standard, which mandates the Gregorian calendar. Also, technically all years must have (only) four digits, but Wikipedia is unlikely to ever need to format a date beyond the year 9999.
^ The routine linking of dates is deprecated. This change was made August 24, 2008, on the basis of this archived discussion. It was ratified in two December 2008 RfCs: Wikipedia:Manual of Style/Dates and numbers/Three proposals for change to MOSNUM and Wikipedia:Manual of Style/Dates and numbers/Date Linking RFC.
^ For consensus discussion on abbreviated date formats like "Sep 2", see Wikipedia talk:Manual of Style/Archive 151 § RFC: Month abbreviations
^ These formats cannot, in general, be distinguished on sight, because there are usages in which 03-04-2007 represents March 4, and other usages in which it represents April 3. In contrast, there is no common usage in which 2007-04-03 represents anything other than April 3.
^ The calendar practices of Oxford Dictionary of National Biography and Encyclopædia Britannica can be inferred by looking up the birth and death dates of famous, well-documented individuals.
^ A change from a preference for two digits, to a preference for four digits, on the right side of year–year ranges was implemented in July 2016 per this RFC.
^ The number in parentheses in a construction like 1.604(48) × 10−4 J is the numerical value of the standard uncertainty referred to the corresponding last digits of the quoted result.[3]
^ The 0x, but not 0b, is borrowed from the C programming language.
^ One such situation is with Unicode codepoints, which use U+; U+26A7, not 0x26A7.
^ If there is disagreement about the primary units used in a UK-related article, discuss the matter on the article talk-page or at Wikipedia talk:Manual of Style/Dates and numbers (WT:MOSNUM). If consensus cannot be reached, refer to historically stable versions of the article and retain the units used in these as the primary units. Also note the style guides of British publications (e.g. The Times, under "Metric").
^ These definitions are consistent with all units of measure mentioned in the SI Brochure[4] and with all units of measure catalogued in EU directive 80/181/EEC.[5]
^ Wikipedia follows common practice regarding bytes and other data traditionally quantified using binary prefixes (e.g. mega- and kilo-, meaning 220 and 210 respectively) and their unit symbols (e.g. MB and KB) for RAM and decimal prefixes for most other uses. Despite the IEC's 1998 international standard creating several new binary prefixes (e.g. mebi-, kibi-, etc.) to distinguish the meaning of the decimal SI prefixes (e.g. mega- and kilo-, meaning 106 and 103 respectively) from the binary ones, and the subsequent incorporation of these IEC prefixes into the ISO/IEC 80000, consensus on Wikipedia in computing-related contexts favours the retention of the more familiar but ambiguous units KB, MB, GB, TB, PB, EB, etc. over use of unambiguous IEC binary prefixes. For detailed discussion, see WT:Manual of Style (dates and numbers)/Archive/Complete rewrite of Units of Measurements (June 2008).
^ Garraty, John A.; Carnes, Mark C., eds. (1999). "Editorial note". American National Biography. Oxford University Press. pp. xxi–xxii.
^ Coordinated Universal Time (UTC) (PDF). Bureau International des Poids et Mesures. June 2, 2009. p. 3. CCTF/09-32. Retrieved August 20, 2015. This coordination began on January 1, 1960, and the resulting time scale began to be called informally 'Coordinated Universal Time.'
^ "Fundamental Physical Constants: Standard Uncertainty and Relative Standard Uncertainty". The NIST Reference on Constants, Units, and Uncertainty. US National Institute of Standards and Technology. June 25, 2015. Retrieved December 12, 2017.
^ a b c "Chapter 4: Non-SI units that are accepted for use with the SI". SI Brochure: The International System of Units (SI) (PDF) (9th ed.). Bureau International des Poids et Mesures. 2019. Retrieved 2020-09-24. Table 8, p 145, gives additional guidance on non-SI units.
^ "Council Directive of 20 December 1979 on the approximation of the laws of the Member States relating to units of measurement". Eur-Lex.Europa.eu. European Union. 2017 [1979]. 80/181/EEC (Document 01980L0181-20090527). Retrieved December 12, 2017.
^ Wilkins, G. A. (1989). "5.14 Time and angle". IAU Style Manual (PDF). International Astronomical Union. p. S23. Retrieved 12 December 2017.
Proper names
Embedded lists
Math templates
Numeral systems
elementary arithmetic
val (value)
{{#invoke:BaseConvert|XtoY}}
decimal2Base
hex2dec
quinary
senary
vigesimal
convert many units (see: list)
cvt abbreviated {{convert}}
convinfobox {{convert}} for infoboxes
bbl to t barrels of oil to tonnes
long ton long hundredweights, quarters and pounds to kilograms;
long tons and hundredweights to pounds and metric tons
miles-chains miles and chains to kilometres linking "chains"
rndfrac decimals to fractions
decdeg degrees, minutes, and seconds to decimal degrees
deg2dms decimal degrees to degrees, minutes, and seconds
deg2hms decimal degrees to hour angle (in hours, minutes, and seconds)
hms2deg hour angle (in hours, minutes, and seconds) to decimal degrees
inflation calculate inflation of Consumer Price Index-related prices
pop density population density in an area
track gauge railway track gauges
Notation and formatting
bigmath bigger font to match TeX \displaystyle (standalone formulas only)
bra-ket
bra–ket notation
ceil, floor calculations :mw:Help:#expr; formatting indicators ⌈3.14⌉, ⌊3.14⌋ (no calculation performed)
frac slant fractions 3⁄5 (not for maths/science articles; use standing or upright fractions {{sfrac}} instead)
intmath integral symbols
langle
angbr
angular brackets
ldelim
rdelim
multiline delimiters (2–5 lines inclusive)
abs absolute values (paired vertical lines)
math short text-based formulas
mathcal [mathematical] calligraphic font; alternative to LaTeX \mathcal{...}
mvar individual italicized maths variables in normal text
overline
a line set above/below a sequence of characters
overarc an arc set above a sequence of characters
overset
underset
arbitrary characters/diacritics set above/below one another
pars parentheses that can be resized (∑)
sfrac "standing" or upright fractions 3/5 (use in maths/science articles instead of{{frac}})
subscripts and superscripts
tmath Wrap TeX in <math> tags
tombstone symbol indicating the end of a proof
val measurement values, uncertainties and units
vec various overarrows, underarrows, etc.
Boxes Tags
calculation results
Infobox mathematics function
metricate
undue precision
units attention
Category · Module:Math
Retrieved from "http://en.wikipediam.org/w/index.php?title=Wikipedia:Manual_of_Style/Dates_and_numbers&oldid=1065913894"
Wikipedia Manual of Style (formatting)
Wikipedia naming conventions
Project pages with short description
Wikipedia move-protected project pages | CommonCrawl |
Shock wave formation in compliant arteries
EECT Home
Isogeometric shape optimization for nonlinear ultrasound focusing
March 2019, 8(1): 203-220. doi: 10.3934/eect.2019011
Optimal scalar products in the Moore-Gibson-Thompson equation
Marta Pellicer 1,, and Joan Solà-Morales 2,
Dpt. d'Informàtica, Matemàtica Aplicada i Estadística, Universitat de Girona, EPS-P4, Campus de Montilivi, 17071 Girona, Catalunya, Spain
Dpt. de Matemàtiques, Universitat Politècnica de Catalunya, ETSEIB-UPC, Av. Diagonal 647, 08028 Barcelona, Catalunya, Spain
* Corresponding author: [email protected]
Received June 2017 Revised September 2017 Published January 2019
Fund Project: Both authors are part of the Catalan research groups 2014 SGR 1083 and 2017 SGR 1392. J. Sol`a-Morales has been supported by the MINECO grants MTM2014-52402-C3-1-P and MTM2017-84214-C2-1-P (Spain). M. Pellicer has been supported by the MINECO grants MTM2014-52402- C3-3-P and MTM2017-84214-C2-2-P (Spain), and also by MPC UdG 2016/047 (U. of Girona, Catalonia)
Figure(1)
We study the third order in time linear dissipative wave equation known as the Moore-Gibson-Thompson equation, that appears as the linearization of a the Jordan-Moore-Gibson-Thompson equation, an important model in nonlinear acoustics. The same equation also arises in viscoelasticity theory, as a model which is considered more realistic than the usual Kelvin-Voigt one for the linear deformations of a viscoelastic solid. In this context, it is known as the Standard Linear Viscoelastic model. We complete the description in [13] of the spectrum of the generator of the corresponding group of operators and show that, apart from some exceptional values of the parameters, this generator can be made to be a normal operator with a new scalar product, with a complete set of orthogonal eigenfunctions. Using this property we also obtain optimal exponential decay estimates for the solutions as $ t\to\infty $, whether the operator is normal or not.
Keywords: Moore-Gibson-Thompson equation, standard linear viscoelastic model, normal operator, optimal exponential decay.
Mathematics Subject Classification: Primary: 35L05, 35L35, 47D03, 35B40; Secondary: 35Q60, 35Q74.
Citation: Marta Pellicer, Joan Solà-Morales. Optimal scalar products in the Moore-Gibson-Thompson equation. Evolution Equations & Control Theory, 2019, 8 (1) : 203-220. doi: 10.3934/eect.2019011
M. S. Alves, C. Buriol, M. V. Ferreira, J. E. Muñoz Rivera, M. Sepúlveda and O. Vera, Asymptotic behaviour for the vibrations modeled by the standard linear solid model with a thermal effect, J. Math. Anal. Appl., 399 (2013), 472-479. doi: 10.1016/j.jmaa.2012.10.019. Google Scholar
B. de Andrade and C. Lizama, Existence of asymptotically almost periodic solutions for damped wave equations, J. Math. Anal. Appl., 382 (2011), 761-771. doi: 10.1016/j.jmaa.2011.04.078. Google Scholar
S. Chen and R. Triggiani, Proof of extensions of two conjectures on structural damping for elastic systems, Pacific J. Math., 136 (1989), 15-25. doi: 10.2140/pjm.1989.136.15. Google Scholar
J. A. Conejero, C. Lizama and F. Ródenas, Chaotic behaviour of the solutions of the Moore-Gibson-Thompson equation, Applied Mathematics and Information Sciences, 9 (2015), 2233-2238. Google Scholar
I. C. Gohberg and M. G. Krein, Introduction to the Theory of Linear Nonselfadjoint Operators in a Hilbert Space, American Mathematical Society, 1991. Google Scholar
G. C. Gorain, Stabilization for the vibrations modeled by the standard linear model of viscoelasticity, Proc. Indian Acad. Sci. (Math. Sci.), 120 (2010), 495-506. doi: 10.1007/s12044-010-0038-8. Google Scholar
D. Henry, Geometric Theory of Semilinear Parabolic Equations, Springer-Verlag, Berlin-New York, 1981. Google Scholar
B. Kaltenbacher, I. Lasiecka and R. Marchand, Wellposedness and exponential decay rates for the Moore-Gibson-Thompson equation arising in high intensity ultrasound, Control Cybernet, 40 (2011), 971-988. Google Scholar
V. K. Kalantarov and Y. Yilmaz, Decay and growth estimates for solutions of second-order and third-order differential-operator equations, Nonlinear Anal., 89 (2013), 1-7. doi: 10.1016/j.na.2013.04.016. Google Scholar
I. Lasiecka and R. Triggiani, Control theory for partial differential equations: Continuous and approximation theories. I. Abstract parabolic systems, in Encyclopedia of Mathematics and its Applications, 74 (2000), xxii+644+I4pp. Cambridge University Press, Cambridge. Google Scholar
I. Lasiecka and X. Wang, Moore-Gibson-Thompson equation with memory, part Ⅱ: General decay of energy, J. Differential Equations, 259 (2015), 7610-7635. doi: 10.1016/j.jde.2015.08.052. Google Scholar
C. R. da Luz, R. Ikehata and R. C. Charo, Asymptotic behavior for abstract evolution differential equations of second order, J. Differential Equations, 259 (2015), 5017-5039. doi: 10.1016/j.jde.2015.06.012. Google Scholar
R. Marchand, T. McDevitt and R. Triggiani, An abstract semigroup approach to the third-order Moore-Gibson-Thompson partial differential equation arising in high-intensity ultrasound: structural decomposition, spectral analysis, exponential stability, Math. Methods Appl. Sci., 35 (2012), 1896-1929. doi: 10.1002/mma.1576. Google Scholar
M. Pellicer and J. Solà-Morales, Analysis of a viscoelastic spring-mass model, J. Math. Anal. Appl., 294 (2004), 687-698. doi: 10.1016/j.jmaa.2004.03.008. Google Scholar
M. Pellicer and J. Solà-Morales, Optimal decay rates and the selfadjoint property in overdamped systems, J. Differential Equations, 246 (2009), 2813-2828. doi: 10.1016/j.jde.2009.01.010. Google Scholar
M. Pellicer and B. Said-Houari, Wellposedness and decay rates for the Cauchy problem of the Moore-Gibson-Thompson equation arising in high intensity ultrasound, Applied Mathematics & Optimization, 2017, 1-32, http://arxiv.org/abs/1603.04270. doi: 10.1007/s00245-017-9471-8. Google Scholar
P. A. Thompson, Compressible-Fluid Dynamics, McGraw-Hill, 1972. Google Scholar
Figure 1. Plots of the eigenvalues of the operator $ A $ (circles) in the complex plane (in solid lines, the real and complex axes), showing different possibilities for $ \sigma_{max}(A) $. In all of them, the dashed line represents $ \textrm{Re} (\lambda) = -\frac{1}{2}\left( \frac{1}{\alpha}-\frac{1}{\beta}\right) $, which is the limit of the real parts of the nonreal eigenvalues, and the point marked as a square is $ -\frac{1}{\beta} $, which is the limit of the real ones. In panel (1a), we can see an example of the $ \alpha/\beta>1/3 $ case and, hence, $ \sigma_{max} = \textrm{Re}(\lambda^1_2) $, while in the others $ \alpha/\beta<1/3 $. In panel (1c) we can see the limit situation between cases represented in panels (1b) and (1d)
Arthur Henrique Caixeta, Irena Lasiecka, Valéria Neves Domingos Cavalcanti. On long time behavior of Moore-Gibson-Thompson equation with molecular relaxation. Evolution Equations & Control Theory, 2016, 5 (4) : 661-676. doi: 10.3934/eect.2016024
Luciano Abadías, Carlos Lizama, Marina Murillo-Arcila. Hölder regularity for the Moore-Gibson-Thompson equation with infinite delay. Communications on Pure & Applied Analysis, 2018, 17 (1) : 243-265. doi: 10.3934/cpaa.2018015
Roberto Triggiani, Jing Zhang. Heat-viscoelastic plate interaction: Analyticity, spectral analysis, exponential decay. Evolution Equations & Control Theory, 2018, 7 (1) : 153-182. doi: 10.3934/eect.2018008
Tae Gab Ha. Global existence and general decay estimates for the viscoelastic equation with acoustic boundary conditions. Discrete & Continuous Dynamical Systems - A, 2016, 36 (12) : 6899-6919. doi: 10.3934/dcds.2016100
Mohammad M. Al-Gharabli, Aissa Guesmia, Salim A. Messaoudi. Existence and a general decay results for a viscoelastic plate equation with a logarithmic nonlinearity. Communications on Pure & Applied Analysis, 2019, 18 (1) : 159-180. doi: 10.3934/cpaa.2019009
Barbara Kaltenbacher, Irena Lasiecka. Global existence and exponential decay rates for the Westervelt equation. Discrete & Continuous Dynamical Systems - S, 2009, 2 (3) : 503-523. doi: 10.3934/dcdss.2009.2.503
Stéphane Gerbi, Belkacem Said-Houari. Exponential decay for solutions to semilinear damped wave equation. Discrete & Continuous Dynamical Systems - S, 2012, 5 (3) : 559-566. doi: 10.3934/dcdss.2012.5.559
Gustavo Alberto Perla Menzala, Julian Moises Sejje Suárez. A thermo piezoelectric model: Exponential decay of the total energy. Discrete & Continuous Dynamical Systems - A, 2013, 33 (11&12) : 5273-5292. doi: 10.3934/dcds.2013.33.5273
Irena Lasiecka, Roberto Triggiani. Heat--structure interaction with viscoelastic damping: Analyticity with sharp analytic sector, exponential decay, fractional powers. Communications on Pure & Applied Analysis, 2016, 15 (5) : 1515-1543. doi: 10.3934/cpaa.2016001
Jing Zhang. The analyticity and exponential decay of a Stokes-wave coupling system with viscoelastic damping in the variational framework. Evolution Equations & Control Theory, 2017, 6 (1) : 135-154. doi: 10.3934/eect.2017008
Nguyen Thanh Long, Hoang Hai Ha, Le Thi Phuong Ngoc, Nguyen Anh Triet. Existence, blow-up and exponential decay estimates for a system of nonlinear viscoelastic wave equations with nonlinear boundary conditions. Communications on Pure & Applied Analysis, 2020, 19 (1) : 455-492. doi: 10.3934/cpaa.2020023
W. Wei, Yin Li, Zheng-An Yao. Decay of the compressible viscoelastic flows. Communications on Pure & Applied Analysis, 2016, 15 (5) : 1603-1624. doi: 10.3934/cpaa.2016004
Salim A. Messaoudi, Abdelfeteh Fareh. Exponential decay for linear damped porous thermoelastic systems with second sound. Discrete & Continuous Dynamical Systems - B, 2015, 20 (2) : 599-612. doi: 10.3934/dcdsb.2015.20.599
Xinghong Pan, Jiang Xu. Global existence and optimal decay estimates of the compressible viscoelastic flows in $ L^p $ critical spaces. Discrete & Continuous Dynamical Systems - A, 2019, 39 (4) : 2021-2057. doi: 10.3934/dcds.2019085
Le Thi Phuong Ngoc, Nguyen Thanh Long. Existence and exponential decay for a nonlinear wave equation with nonlocal boundary conditions. Communications on Pure & Applied Analysis, 2013, 12 (5) : 2001-2029. doi: 10.3934/cpaa.2013.12.2001
Marcelo M. Cavalcanti, Valéria N. Domingos Cavalcanti, Irena Lasiecka, Flávio A. Falcão Nascimento. Intrinsic decay rate estimates for the wave equation with competing viscoelastic and frictional dissipative effects. Discrete & Continuous Dynamical Systems - B, 2014, 19 (7) : 1987-2011. doi: 10.3934/dcdsb.2014.19.1987
Marcelo Moreira Cavalcanti. Existence and uniform decay for the Euler-Bernoulli viscoelastic equation with nonlocal boundary dissipation. Discrete & Continuous Dynamical Systems - A, 2002, 8 (3) : 675-695. doi: 10.3934/dcds.2002.8.675
Jiangyan Peng, Dingcheng Wang. Asymptotics for ruin probabilities of a non-standard renewal risk model with dependence structures and exponential Lévy process investment returns. Journal of Industrial & Management Optimization, 2017, 13 (1) : 155-185. doi: 10.3934/jimo.2016010
Peng Sun. Exponential decay of Lebesgue numbers. Discrete & Continuous Dynamical Systems - A, 2012, 32 (10) : 3773-3785. doi: 10.3934/dcds.2012.32.3773
Moez Daoulatli. Energy decay rates for solutions of the wave equation with linear damping in exterior domain. Evolution Equations & Control Theory, 2016, 5 (1) : 37-59. doi: 10.3934/eect.2016.5.37
Marta Pellicer Joan Solà-Morales | CommonCrawl |
nature nanotechnology
Doping-driven topological polaritons in graphene/α-MoO3 heterostructures
Spatially controlled electrostatic doping in graphene p-i-n junction for hybrid silicon photodiode
Tiantian Li, Dun Mao, … Tingyi Gu
In-plane anisotropic and ultra-low-loss polaritons in a natural van der Waals crystal
Weiliang Ma, Pablo Alonso-González, … Qiaoliang Bao
Edge-oriented and steerable hyperbolic polaritons in anisotropic van der Waals nanocavities
Zhigao Dai, Guangwei Hu, … Qiaoliang Bao
Reconfigurable hyperbolic polaritonics with correlated oxide metasurfaces
Neda Alsadat Aghamiri, Guangwei Hu, … Yohannes Abate
High carrier mobility in graphene doped using a monolayer of tungsten oxyselenide
Min Sup Choi, Ankur Nipane, … James T. Teherani
2D-3D integration of hexagonal boron nitride and a high-κ dielectric for ultrafast graphene-based electro-absorption modulators
Hitesh Agarwal, Bernat Terrés, … Frank H. L. Koppens
Ultra-long carrier lifetime in neutral graphene-hBN van der Waals heterostructures under mid-infrared illumination
P. Huang, E. Riccardi, … J. Mangeney
Strongly enhanced THz generation enabled by a graphene hot-carrier fast lane
Dehui Zhang, Zhen Xu, … Zhaohui Zhong
Solution processable and optically switchable 1D photonic structures
Giuseppe M. Paternò, Chiara Iseppon, … Ilka Kriegel
Hai Hu ORCID: orcid.org/0000-0002-4243-23331,2 na1,
Na Chen1,2 na1,
Hanchao Teng1,2 na1,
Renwen Yu3,4,
Yunpeng Qu1,2,
Jianzhe Sun5,
Mengfei Xue6,
Debo Hu ORCID: orcid.org/0000-0001-9432-16701,2,
Bin Wu5,
Chi Li1,2,
Jianing Chen6,
Mengkun Liu7,
Zhipei Sun ORCID: orcid.org/0000-0002-9771-52938,
Yunqi Liu ORCID: orcid.org/0000-0001-5521-23165,
Peining Li ORCID: orcid.org/0000-0003-3836-38039,
Shanhui Fan ORCID: orcid.org/0000-0002-0081-97324,
F. Javier García de Abajo ORCID: orcid.org/0000-0002-4970-45653,10 &
Qing Dai ORCID: orcid.org/0000-0002-1750-08671,2
Nature Nanotechnology volume 17, pages 940–946 (2022)Cite this article
Nanophotonics and plasmonics
Polaritons
Control over charge carrier density provides an efficient way to trigger phase transitions and modulate the optoelectronic properties of materials. This approach can also be used to induce topological transitions in the optical response of photonic systems. Here we report a topological transition in the isofrequency dispersion contours of hybrid polaritons supported by a two-dimensional heterostructure consisting of graphene and α-phase molybdenum trioxide. By chemically changing the doping level of graphene, we observed that the topology of polariton isofrequency surfaces transforms from open to closed shapes as a result of doping-dependent polariton hybridization. Moreover, when the substrate was changed, the dispersion contour became dominated by flat profiles at the topological transition, thus supporting tunable diffractionless polariton propagation and providing local control over the optical contour topology. We achieved subwavelength focusing of polaritons down to 4.8% of the free-space light wavelength by using a 1.5-μm-wide silica substrate as an in-plane lens. Our findings could lead to on-chip applications in nanoimaging, optical sensing and manipulation of energy transfer at the nanoscale.
The control of charge carrier concentration by either electrostatic or chemical means has been widely studied as a way to induce phase transitions of different nature, such as structural in transition metal dichalcogenides1,2,3,4, ferromagnetic in high-Curie-temperature manganites5,6,7,8,9,10 and topological in engineered materials11,12,13,14, with potential application in the development of active electronic phase-change devices15. In this context, a collection of different phases in magic-angle bilayer graphene has been achieved by changing its carrier density16. Similar concepts have been theoretically explored in photonics using hyperbolic metamaterials composed of subwavelength structures, such as a periodic array of graphene ribbons17 or a stack of graphene dielectric layers18, in which a topological transition in the isofrequency dispersion contour can occur by changing the doping level of graphene. However, these hyperbolic metamaterials rely on a strong anisotropy of the effective permittivity tensor, which is ultimately limited by spatial nonlocal effects that can hinder a practical verification of this concept.
Recently, a twisted stack of two α-phase molybdenum trioxide (α-MoO3) films was explored to control the topology of the isofrequency dispersion contour of phonon polaritons (PhPs) by varying the relative twist angle between the two α-MoO3 layers19,20,21,22. Owing to the in-plane anisotropy of the permittivity within the reststrahlen band from 816 to 976 cm−1, the real part of the permittivity is positive along the [001] direction but negative along the [100] direction23,24, a property that renders α-MoO3 a natural hyperbolic material supporting in-plane hyperbolic PhPs25,26. The low-loss in-plane hyperbolic PhPs in α-MoO3 thus emerge as an ideal platform to explore further possibilities of doping-driven and electrically tunable topological transitions in photonics.
In this work we have achieved the control of polariton dispersion in a van der Waals (vdW) heterostructure composed of an α-MoO3 film covered with monolayer graphene by changing the doping level of the latter. We observed the polariton dispersion contour to vary from hyperbolic (open) to elliptic (closed) on increasing the doping level of graphene, leading to the emergence of a mode dominated by its graphene plasmon polariton (GPP) component propagating along the [001] direction at high doping levels. The nature of the polaritons emerging at high doping in the heterostructure evolved from GPP to PhP when moving from the [001] to [100] α-MoO3 crystallographic direction. In addition, when the vdW heterostructure was placed on top of a gold substrate instead of SiO2, a rather flattened dispersion contour was obtained due to a topological transition. As an application, we have designed an in-plane subwavelength focusing device by engineering the substrate.
Tunable topological polaritons in heterostructures
A schematic of our proposed structure is shown in Fig. 1, where a 150-nm-thick vdW heterostructure is placed on top of either a SiO2 (Fig. 1a) or gold (Fig. 1d) substrate. We were particularly interested in the reststrahlen band II of α-MoO3 extending over the frequency range of 816 to 976 cm−1, where the permittivity (ε) components along the [100], [001] and [010] crystal directions satisfy εx < 0, εy > 0 and εz > 0, respectively (Supplementary Fig. 1a)23,24. As a result, the in-plane PhPs in natural α-MoO3 exhibit a hyperbolic dispersion contour. To illustrate dynamic control of the dispersion contour topology of the in-plane hybrid plasmon–phonon polaritons in our structure, we present in Fig. 1b several calculated dispersion contours on SiO2 at different graphene Fermi energies (EF) under a fixed representative incident free-space wavelength of λ0 = 10.99 μm (frequency of 910 cm−1). As the graphene Fermi energy increases from 0 to 0.7 eV, the opening angle φ of the hyperbolic sectors gradually increases due to a change in the PhP wavelength when varying the dielectric environment, and eventually the dispersion contour changes its character from a hyperbolic (open) to elliptic (closed) shape. Note that the Fermi energy at which this topological transition occurs is conditioned to the appearance of well-defined graphene plasmons along the [001] direction at λ0 when increasing its doping level27,28,29,30. When the substrate was changed from SiO2 to gold, we found flatter dispersion contours (Fig. 1e) due to the stronger effect of screening provided by the gold substrate. Tunable polariton canalization and diffractionless propagation were thus expected.
Fig. 1: Topological transition of hybrid polaritons.
a,d, Illustration of the graphene/α-MoO3 vdW heterostructure used in this study, supported on SiO2 (a) and gold (d) substrates. b,e, Calculated isofrequency dispersion contours of hybrid polaritons on a 300-nm-thick SiO2 substrate (b) and a 60-nm-thick gold substrate (e) at a fixed incident frequency of 910 cm−1 (λ0 = 10.99 µm) for different graphene Fermi energies ranging from 0 to 0.7 eV and an α-MoO3 film thickness of 150 nm. φ indicates the opening angle of the hyperbolic sectors. kx and ky are the momenta of polariton along the x and y crystal directions of α-MoO3, while k0 is the momentum of light in free space. c,f, Numerically simulated field distributions (real part of the z out-of-plane component of the electric field, Re{Ez}) of hybrid polaritons on SiO2 (c) and gold (f) substrates for several graphene doping levels at a fixed incident frequency of 910 cm−1, as launched by a dipole placed 100 nm above the origin.
Numerically simulated field distributions of hybrid polaritons for different graphene Fermi energies are shown in Fig. 1c,f. At EF = 0 eV, the polaritons of the heterostructure on a SiO2 substrate exhibit a hyperbolic wavefront, similar to that of the PhPs in α-MoO3. In contrast, the wavelength of the polaritons on a gold substrate is highly compressed, whereas their opening angle is increased. On increasing the doping level to EF = 0.2 eV, a topological transition takes place. The wavelength of the hybrid polaritons is increased compared with the undoped case, and we can still observe a hyperbolic wavefront along the x direction on the SiO2 substrate. Moreover, for the hybrid polaritons on the gold substrate (Fig. 1f), highly collimated and directive hybrid polaritons propagating along the x direction can be observed as a result of a rather flattened dispersion contour. At EF = 0.3 eV, a hyperbolic wavefront of hybrid polaritons can still be observed along the x direction with the SiO2 substrate, but another mode with an elliptic wavefront propagating along the y direction also emerges. With the gold substrate, the wavefront of the hybrid polaritons is dominated by a fine crescent shape along the x direction. At a higher doping level (EF = 0.7 eV), the dispersion contours for the hybrid polaritons on both SiO2 and gold substrates display an elliptic-like shape (Fig. 1b,e). As a consequence, we can find modes propagating anisotropically in the x–y plane (for additional theoretical analyses, see Supplementary Figs. 2–4 and other works31,32,33).
Experimental observation of topological transitions
We used infrared nanoimaging to visualize the propagating polaritons in the graphene/α-MoO3 heterostructures (Supplementary Fig. 5) and verify the above theoretical predictions (Fig. 2a–c,g–i). In this technique, upon p-polarized infrared light illumination, the resonant gold antenna efficiently launches hybrid polaritons (Supplementary Fig. 6), originating in the nanoscale concentrated fields at the two endpoints. While scanning the sample, the real part of the scattered light electric field (Re{ES}) is recorded simultaneously with the topography, making it possible to directly map the vertical near-field components of the hybrid polariton wavefronts launched by the antenna (for more details on near-field image analysis, see Supplementary Figs. 7 and 8).
Fig. 2: Topological transition of hybrid polaritons revealed by nanoimaging.
a–c, Experimentally measured polariton near-field amplitude (S3) images with graphene doping EF = 0 eV (a), EF = 0.3 eV (b) and EF = 0.7 eV (c). The polaritons were launched by a gold antenna. The α-MoO3 film was placed on top of a 300 nm SiO2/500 μm Si substrate. d–f, Absolute value of the spatial Fourier transforms (FTs) of the experimental near-field images shown in a–c, respectively, revealing the isofrequency contours of hybrid polaritons. The grey curves represent calculated isofrequency contours. g–i, Experimentally measured polariton near-field amplitude (S3) images with graphene doping EF = 0 eV (g), EF = 0.3 eV (h) and EF = 0.7 eV (i) for an α-MoO3 film placed on a 60 nm Au/500 μm Si substrate. The canalized wavefronts were measured at a graphene Fermi energy close to the value at which the topological transition occurs (h), showing deep-subwavelength and diffractionless polariton propagation. j–l, Absolute value of the FTs of the experimental near-field images in g–i, respectively. The grey curves show the calculated isofrequency contours. The α-MoO3 thickness was 140 nm in all panels. The incident light wavelength was fixed at λ0 = 11.11 μm (900 cm−1). Each colour scale applies to all images in the respective column.
To visualize the polariton wavefronts34,35, we imaged antenna-launched polaritons in the heterostructure at several intermediate graphene Fermi energies in the range EF = 0–0.7 eV (Supplementary Fig. 9). We first investigated hybrid polaritons in an undoped sample with EF = 0 eV, which revealed a precise hyperbolic wavefront (Fig. 2a,g) for both SiO2 and gold substrates, consistent with previous results for a single film of α-MoO3 as a result of the hyperbolic dispersion contour. Next, we examined the optical response of a sample with a relatively high doping level (EF = 0.3 eV) on a SiO2 substrate at the same incidence frequency. The image in Fig. 2b shows that the measured wavefronts remain hyperbolic along the x direction, while fringes around the antenna appear in the y direction, indicating that the dispersion contour has evolved into a closed shape, as shown in Fig. 1b and Supplementary Fig. 2. In contrast, the sample on a gold substrate shows a nearly flat wavefront for EF = 0.3 eV (Fig. 2h), indicating a topological transition in the dispersion contour along the x direction. On increasing the doping level further to EF = 0.7 eV, only elliptical wavefronts were observed (Fig. 2c,i) for samples on both SiO2 and gold substrates, denoting a rather rounded anisotropic dispersion contour. The corresponding Fourier transforms of the experimental near-field images (Fig. 2d–f,j–l) and simulated near-field distributions (Supplementary Figs. 3 and 4) further confirmed the transformation of the dispersion contour with increasing doping level of graphene. Notably, our extracted experimental polariton wave vectors k = 2π/λp (dotted symbols in Supplementary Fig. 10; λp is the wavelength of hybrid polaritons) match quite well the calculated dispersion diagrams in all cases.
Low levels of disorder or minor imperfections in the heterostructure should not substantially affect the control capability (Supplementary Fig. 13). In addition, the thickness of α-MoO3 determines the influence of the dielectric environment (here, the substrate), which should not exceed the skin depth of hybrid polaritons (Supplementary Fig. 14).
Close to EF = 0.3 eV, where the dispersion contour is rather flat, as shown in Fig. 2h, the propagation of hybrid polaritons appears to be firmly guided along the x direction, yielding a highly directive and diffractionless behaviour. Furthermore, this type of polariton canalization can be found over a wide range of frequencies and different thicknesses of α-MoO3 (Supplementary Fig. 11) due to the inherent robustness of the topological transition. The line profiles (vertical cuts along the y direction) across the amplitude of the canalization mode give a full-width at half-maximum (FWHM) of around 115 ± 5 nm (~λ0/95, where λ0 is the free-space wavelength), as shown in Supplementary Fig. 12.
Launching and manipulation of hybrid polaritons with tailored antenna
By rotating the long axis of the antenna by an angle θ with respect to the y direction, we could selectively launch and manipulate hybrid polaritons with different in-plane wave vectors. The launching contribution from our antenna can be decomposed into four parts: two endpoints acting as resonant dipoles and two parallel edges behaving as line dipoles (and assimilated to linear arrays of discrete dipoles).
Figure 3a shows for a sample with a low doping level (EF = 0.1 eV) that, at θ = 0°, the field pattern of the exciting hybrid polaritons exhibits vertical fringes parallel to the long axis of the antenna, dominated by the line dipole contributions generated by the edges. Note that the two endpoint dipoles are not well excited when θ = 0° because the polarization direction of the incident light is not aligned with the long axis of the antenna. We can extract the polariton wave vector from the fringes parallel to this long axis. As θ increases from 0 to 90°, the wavefronts produced by the two endpoints gradually show up and interact with those produced by the edges. In the regime with rotation angles θ ≤ 40°, the distance between adjacent fringes parallel to the antenna edge is reduced from 590 to 380 nm, from which we can obtain the wave vector k perpendicular to the antenna. The extracted wave vectors are shown by red symbols in Fig. 3e, matching quite well the calculated dispersion contour (solid curves; more details on the extraction analysis are provided in Supplementary Fig. 16). When θ ≥ 60° (~φ, the opening angle indicated in Fig. 3e), there are no fringes parallel to the edge of the antenna because polariton propagation is prohibited along that direction, judging from the dispersion contour, and the field pattern is dominated by the hyperbolic wavefronts produced by the two endpoints of the antenna. The simulated field patterns shown in Fig. 3b corroborate these experimental observations for different rotation angles.
Fig. 3: Antenna-tailored launching of hybrid polaritons.
a,c, Experimentally measured near-field amplitude (S3) images of hybrid polaritons launched by gold antennas with orientation angle θ in the 0–90° range (Supplementary Fig. 15) for a graphene Fermi energy EF = 0.1 eV (a) and EF = 0.7 eV (c) at a light frequency of 910 cm−1. b,d, Numerically simulated near-field distributions (Re{Ez}, evaluated 20 nm above the surface of the heterostructure) corresponding to the measured results shown in a and c, respectively. e,f, Isofrequency dispersion contours extracted from the experimental data in a and c, respectively (red symbols), compared with the calculated hyperbolic dispersion contour (black solid curves) for an opening angle φ. The green arrows illustrate the direction of the exciting polariton wave vector k perpendicular to the long axis of the gold antenna. The α-MoO3 thickness was 207 nm in all panels. Scale bars in a–d, 2 μm. The error bars were extracted from four sets of measurements on the in situ sample (Supplementary Fig. 15). The artefacts observed in c and not in a can be attributed to the grain boundaries of polycrystalline graphene prepared by chemical vapour deposition43.
For a sample with a high doping level (EF = 0.7 eV, Fig. 3c), the antenna can generate polaritons propagating in all directions within the x–y plane when the polarization direction of the incident light is along the long axis of the antenna. Due to the in-plane anisotropy, the excited field patterns are therefore different for the various rotation angles explored in the range from 0 to 90°. The simulated field patterns (Fig. 3d) again agree well with our experimental observations. The polariton wave vectors can still be extracted from the measured fringes perpendicular to the antenna, shown as red symbols in Fig. 3f, which also match quite well the calculated dispersion contour (solid curves). Note that, at EF = 0.3 eV, the field patterns of hybrid polaritons launched by antennas with different rotation angles (from 0 to 45°) all lie strictly along the x direction (Supplementary Fig. 17) due to the flattening of the dispersion contour, which leads to directional canalization at this graphene Fermi energy. More details on the extraction of polariton wave vectors from experiments can be found in Supplementary Figs. 16 and 18.
Partial focusing of polaritons by substrate engineering
As the dispersion contour of the hybrid polaritons can be modified substantially by controlling the dielectric environment, we engineered the substrate for the heterostructure to manipulate the in-plane propagation of hybrid polaritons. The design is illustrated in Fig. 4a, where the heterostructure lies on top of a substrate composed of a Au–SiO2–Au in-plane sandwich structure. This substrate was used to locally engineer the isofrequency dispersion contour (Fig. 4b). The central SiO2 film, with a width of 1.5 μm, serves as an in-plane flat lens to partially focus the incident polaritons (with a wave vector ki and a Poynting vector Pi along the normal of the contour in Fig. 4b) generated by an antenna on top of the left gold substrate. When the hybrid polaritons cross the boundary between the gold and SiO2 substrates, due to the change in the detailed shape of the dispersion contour, negative refraction can occur at the boundary, with the y component of the wave vector being conserved, whereas the sign of the y component of the transmitted Poynting vector Pt is opposite to that of the incident Pi, as illustrated in Fig. 4b. This leads to a partial focusing of the polaritons (Fig. 4c). Supplementary Fig. 19 shows the evolution of the negative refraction of hybrid polaritons at different Fermi energies of graphene.
Fig. 4: Partial focusing of hybrid polaritons by substrate engineering.
a, Schematic of the design, where the heterostructure lies on top of a substrate composed of a Au–SiO2–Au in-plane sandwich structure. b, Isofrequency dispersion contours of hybrid polaritons for Au and SiO2 substrates at 910 cm−1 (λ0 = 10.99 μm). The shaded areas highlight the convex and concave dispersion contours in the region around the x axis on the gold and SiO2 substrates, respectively. With a wave vector inside the shaded area, negative refraction can happen at the Au–SiO2 interface when the polaritons on the gold substrate propagate towards that interface. The scheme for negative refraction is illustrated by further showing the incident wave vector ki and the Poynting vector Pi, together with the resulting transmitted kt and Pt. c, Experimentally measured near-field amplitude (S3) image of hybrid polaritons showing partial focusing in the system shown in a. The central SiO2 film was 1.5 µm wide and served as an in-plane flat lens. The antenna was located 1.0 µm away from the left Au–SiO2 interface. d, Experimentally measured hybrid polaritons on a Au substrate, as a control to c. Scale bar indicates 1.5 μm and also applies to c. e, Near-field profiles for the sections marked by the red (A) and blue (C) vertical dashed lines in c and d, respectively. The black dashed curves are Gaussian fittings. WA and WC indicate the full width at half maximum (FWHM) of profiles A and C, respectively. f, Near-field profiles of the sections marked by red (B) and blue (D) horizontal dashed lines in c and d, respectively. SB1, SB2, SD1 and SD2 represent the electric-field intensity at each fringe. The graphene was doped to EF = 0.6 eV and the α-MoO3 thickness was 320 nm.
The measured antenna-launched polariton near-field distributions for the heterostructure on gold and SiO2 substrates are shown in Fig. 4d and Supplementary Figs. 20 and 21, respectively. On the gold substrate, only elliptical wavefronts are observed around the antenna, denoting a convex dispersion contour in the region around the x axis. In contrast, on the SiO2 substrate (Supplementary Fig. 21), wavefronts are hyperbolic along the x direction and elliptic along the y direction around the antenna, indicating a closed concave shape of the dispersion contour near the x axis. These measurements are consistent with our previous experimental results shown in Figs. 2 and 3, and also, they match quite well the isofrequency contours shown in Fig. 4b.
Furthermore, we launched hybrid polaritons towards the Au–SiO2–Au in-plane sandwich substrate from the left gold part by light coupling to an antenna prepared in that region. The resulting near-field distribution is shown in Fig. 4c (for more details, see Supplementary Figs. 20 and 21). When polaritons having elliptical wavefronts on the left gold substrate cross the boundary between the gold and SiO2 substrates, the Poynting vector of the polaritons refracts on the same side of the boundary-normal direction, therefore producing what is known as negative refraction due to the change in the detailed shape of the dispersion contour, which ultimately leads to partial focusing of the incident polaritons. Indeed, Fig. 4c shows the formation of a focal spot close to the right Au–SiO2 interface. The numerically simulated z out-of-plane component of the electric field distributions (Re{Ez}) shown in Supplementary Fig. 22 further corroborate the experimental findings. The red curve in Fig. 4e shows the spatial distribution of the electric field amplitude at the focal spot, demonstrating a high wavelength compression towards a FWHM of 520 nm along the y direction. This focal spot size is less than 1/21 of the corresponding illumination wavelength, thus emphasizing a deep subwavelength focusing effect (for more details, see Supplementary Figs. 23 and 24).
To estimate the intensity enhancement of the observed partial focusing, we extracted the spatial distribution of the electric field from the propagation profile (Fig. 4f). The intensity enhancement ξ is given by the square of the ratio of the electric field at the focal spot to that without focusing, \(\xi = \left( {\frac{{S_{{\mathrm{B}}2}/S_{{\mathrm{B}}1}}}{{S_{{\mathrm{D}}2}/S_{{\mathrm{D}}1}}}} \right)^2 = 4.5\). SB1, SB2, SD1, and SD2 represent the near-field intensity at each fringe. Note that the focusing effect can be further enhanced by improving the flatness of the interface, as its structural inhomogeneity inevitably introduces undesired reflection, scattering and radiative losses of the incident polaritons (for more details, see Supplementary Figs. 25–27).
We have experimentally demonstrated that the topology of the isofrequency dispersion contours for the hybrid polaritons supported in a heterostructure composed of a graphene sheet on top of an α-MoO3 layer can be substantially modified by chemically changing the doping level of graphene, with the contour topology being transformed from open to closed shapes over a broad frequency range. A flat dispersion contour appears at the topological transition, which supports a highly directive and diffractionless polariton propagation, resulting in a tunable canalization mode controlled by the doping level of graphene. We anticipate that electrical gating could be used to control the doping level in future studies36,37. Furthermore, through the appropriate choice of substrate for the heterostructure, we were also able to engineer the dispersion contour to exhibit even flatter profiles (for example, by using a gold substrate). This property has allowed us to design a deep-subwavelength device for in-plane focusing of hybrid polaritons, where negative refractive occurs at the boundary between two different substrates. Our study opens promising possibilities to tune topological polaritonic transitions in low-dimensional materials38,39,40 with potential applications in optical imaging, sensing and the control of spontaneous emission at the nanoscale18.
Note added in proof: While preparing this manuscript, two related theoretical and experimental studies on the tuning of highly anisotropic phonon polaritons in graphene and α-MoO3 vdW structures were reported41,42.
Nanofabrication of the devices
High-quality α-MoO3 flakes were mechanically exfoliated from bulk crystals synthesized by the chemical vapour deposition (CVD) method19 and then transferred onto either commercial 300 nm SiO2/500 μm Si wafers (SVM) or gold substrates using a deterministic dry transfer process with a polydimethylsiloxane (PDMS) stamp. CVD-grown monolayer graphene on copper foil was transferred onto the α-MoO3 samples using the poly(methyl methacrylate) (PMMA)-assisted method following our previous report44.
The launching efficiency of the resonant antenna is mainly determined by its geometry, together with a trade-off between the optimum size and illumination frequency45,46. We designed the gold antenna with a length of 3 μm and a thickness of 50 nm, which provided a high launching efficiency over the spectral range from 890 to 950 cm−1 within the α-MoO3 reststrahlen band. Alternatively, a thicker antenna with a stronger z component of the electric field could be used to launch the polaritons more efficiently in future studies. Note that narrow antennas (50-nm width) were used to prevent their shapes from affecting the polariton wavefronts, especially when their propagation is canalized (such as in Figs. 2 and 3), while wider antennas (250-nm width) were used to obtain a higher launching efficiency and observe polaritons propagating across the SiO2–Au interface in our experiments (for example, Fig. 4).
Gold antenna arrays were patterned on selected α-MoO3 flakes using 100 kV electron-beam lithography (Vistec 5000+ES) on an approximately 350 nm PMMA950K lithography resist. Electron-beam evaporation was subsequently used to deposit 5 nm Ti and 50 nm Au in a vacuum chamber at a pressure of <5 × 10−6 torr to fabricate the Au antennas. Electron-beam evaporation was also used to deposit a 60-nm-thick gold film onto a low-doped Si substrate. To remove any residual organic material, samples were immersed in a hot acetone bath at 80 °C for 25 min and then subjected to gentle rinsing with isopropyl alcohol (IPA) for 3 min, followed by drying with nitrogen gas and thermal baking (for more details on the fabrication and characterization of the Au–SiO2–Au in-plane sandwich structure, see Supplementary Figs. 26 and 27).
The samples were annealed in a vacuum to remove most of the dopants from the wet transfer process and then transferred to a chamber filled with NO2 gas to achieve different doping levels by surface adsorption of gas molecules47. The graphene Fermi energy could be controlled by varying the gas concentration and doping time, achieving values as high as ~0.7 eV (Supplementary Fig. 9). This gas-doping method provides excellent uniformity, reversibility and stability. Indeed, Raman mapping of a gas-doped graphene sample demonstrated the high uniformity of the method (Supplementary Fig. 9). As the deposition of NO2 gas molecules on the graphene surface occurs by physical adsorption, the topological transition of hybrid polaritons in graphene/α-MoO3 heterostructures can be reversed by controlling the gas doping. For example, after gas doping, the Fermi energy of graphene could be lowered from 0.7 to 0 eV by vacuum annealing at 150 °C for 2 h. The sample could subsequently be re-doped to reach another on-demand Fermi energy (Supplementary Fig. 28). It should be noted that the graphene Fermi energy only decreases from 0.7 to 0.6 eV after being left for 2 weeks under ambient conditions, which demonstrates the high stability of the doping effect (Supplementary Fig. 29). Note that chemical doping has been demonstrated to be an effective way to tune the characteristics of polaritons, such as their strength and in-plane wavelength48,49,50,51.
Scanning near-field optical microscopy measurements
A scattering scanning near-field optical microscope (Neaspec) equipped with a wavelength-tunable quantum cascade laser (890–2,000 cm−1) was used to image optical near fields. The atomic force microscopy (AFM) tip of the microscope was coated with gold, resulting in an apex radius of ~25 nm (NanoWorld), and the tip-tapping frequency and amplitudes were set to ~270 kHz and ~30–50 nm, respectively. The laser beam was directed towards the AFM tip, with lateral spot sizes of ~25 μm under the tip, which were sufficient to cover the antennas as well as a large area of the graphene/α-MoO3 samples. Third-order harmonic demodulation was applied to the near-field amplitude images to strongly suppress background noise.
In our experiments, the p-polarized plane-wave illumination (electric field Einc) impinged at an angle of 60° relative to the tip axis52. To avert any effects caused by the light polarization direction relative to the crystallographic orientation of α-MoO3, which is optically anisotropic, the in-plane projection of the polarization vector coincided with the x direction ([100] crystal axis) of α-MoO3 (Supplementary Fig. 6). Supplementary Fig. 30 shows the method used to extract antenna-launched hybrid polaritons from the complex background signals observed when the polaritons propagate across a Au–SiO2–Au in-plane structure to realize partial focusing.
Calculation of polariton dispersion and isofrequency dispersion contours (IFCs) of hybrid plasmon–phonon polaritons
The transfer matrix method was adopted to calculate the dispersion and IFCs of hybrid plasmon–phonon polaritons in graphene/α-MoO3 heterostructures. Our theoretical model was based on a three-layer structure: layer 1 (z > 0, air) is a cover layer, layer 2 (0 > z > –dh, graphene/α-MoO3) is an intermediate layer and layer 3 (z < –dh, SiO2 or Au) is a substrate where z is the value of the vertical axis and dh is the thickness of α-MoO3 (Supplementary Fig. 31). Each layer was regarded as a homogeneous material represented by the corresponding dielectric tensor. The air and substrate layers were modelled by isotropic tensors diag{εa,s} (ref. 53). The α-MoO3 film was modelled by an anisotropic diagonal tensor diag{εx, εy, εz}, where εx, εy and εz are the permittivity components along the x, y and z axes, respectively. Also, monolayer graphene was located on top of α-MoO3 at z = 0 and described as a zero-thickness current layer characterized by a frequency-dependent surface conductivity taken from the local random-phase approximation model54,55:
$$\begin{array}{rcl} {\sigma \left( \omega \right)}& = &{\frac{{i{{\rm{e}}^2}{k_{\rm{B}}}T}}{{{{\uppi}}{\hbar ^2}\left( {\omega + \frac i \tau} \right)}}\left[ {\frac{{{E_{\rm{F}}}}}{{{k_{\rm{B}}}T}} + 2\ln \left( {{{\rm{e}}^{ - \frac{{{E_{\rm{F}}}}}{{{k_{\rm{B}}}T}}}} + 1} \right)} \right]}\\{}&{}&{ + i\frac{{{{\rm{e}}^2}}}{{4{{\uppi}}\hbar }}\ln \left[ {\frac{{2\left| {{E_{\rm{F}}}} \right| - \hbar \left( {\omega + \frac i \tau} \right)}}{{2\left| {{E_{\rm{F}}}} \right| + \hbar \left( {\omega + \frac i \tau} \right)}}} \right]}\end{array}$$
which depends on the Fermi energy EF, the inelastic relaxation time τ and the temperature T; the relaxation time is expressed in terms of the graphene Fermi velocity vF = c/300 and the carrier mobility μ, with \(\tau = \mu E_{\mathrm{F}}/ev_{\mathrm{F}}^2\); e is the elementary charge; kB is the Boltzmann constant; ℏ is the reduced Planck constant; and ω is the illumination frequency.
Given the strong field confinement produced by the structure under consideration, we only needed to consider transverse magnetic (TM) modes, because transverse electric (TE) components contribute negligibly. The corresponding p-polarization Fresnel reflection coefficient rp of the three-layer system admits the analytical expression
$$\begin{array}{*{20}{c}} {r_{\mathrm{p}} = \frac{{r_{12} + r_{23}\left( {1 - r_{12} - r_{21}} \right){\mathrm{e}}^{i2k_z^{\left( 2 \right)}d_{\mathrm{h}}}}}{{1 + r_{12}r_{23}{\mathrm{e}}^{i2k_z^{\left( 2 \right)}d_{\mathrm{h}}}}},} \end{array}$$
$$\begin{array}{*{20}{c}} {r_{12} = \frac{{{{Q}}_1 - {{Q}}_2 + SQ_1Q_2}}{{{{Q}}_1 + Q_2 + SQ_1Q_2}},} \end{array}$$
$$\begin{array}{*{20}{c}} {r_{23} = \frac{{Q_2 - Q_3}}{{Q_2 + Q_3}},} \end{array}$$
$$\begin{array}{*{20}{c}}where {Q_j = \frac{{k_z^{\left( j \right)}}}{{{\it{\epsilon }}_t^{(j)}}},} \end{array}$$
$$\begin{array}{*{20}{c}} {S = \frac{{\sigma Z_0}}{\omega }.} \end{array}$$
Here, rjk denotes the reflection coefficient of the j–k interface for illumination from medium j, with j,k = 1–3; \({\it{\epsilon }}_t^{(j)}\) is the tangential component of the in-plane dielectric function of layer j for a propagation wave vector kp(θ) (where θ is the angle relative to the x axis), which can be expressed as \({\it{\epsilon }}_t^{(j)} = {\it{\epsilon }}_x^{(j)}\mathop {{\cos }}\nolimits^2 \theta + {\it{\epsilon }}_y^{(j)}\mathop {{\sin }}\nolimits^2 \theta\) (where \({\it{\epsilon }}_x^{(j)}\) and \({\it{\epsilon }}_y^{(j)}\) are the diagonal dielectric tensor components of layer j along the x and y axes, respectively); \(k_z^{\left( j \right)} = \sqrt {\varepsilon _t^{\left( j \right)}\frac{{\omega ^2}}{{c^2}} - \frac{{\varepsilon _t^{\left( j \right)}}}{{\varepsilon _z^{\left( j \right)}}}q^2}\) is the out-of-plane wave vector, with \({\it{\epsilon }}_z^{(j)}\) being the dielectric function of layer j along the z axis; and Z0 is the vacuum impedance.
We find the polariton dispersion relation q(ω,θ) when the denominator of equation (2) is zero:
$$\begin{array}{*{20}{c}} {1 + r_{12}r_{23}{\mathrm{e}}^{i2k_z^{\left( 2 \right)}d_{\mathrm{h}}} = 0.} \end{array}$$
For simplicity, we considered a system with small dissipation, so that the maxima of Im{rp} (see colour plots in Supplementary Figure 10) approximately solve the condition given by equation (8), and therefore produce the sought-after dispersion relation q(ω,θ) (see additional discussion in Supplementary Note 1).
Electromagnetic simulations
The electromagnetic fields around the antennas were calculated by a finite-elements method using the COMSOL package. In our experiments, both tip and antenna launching were investigated. For the former, the sharp metallic tip was illuminated by an incident laser beam. The tip acted as a vertical optical antenna, converting the incident light into a strongly confined near field below the tip apex, which can be regarded as a vertically oriented point dipole located at the tip apex. This localized near field provided the necessary momentum to excite polaritons. Consequently, we modelled the tip as a vertical z-oriented oscillating dipole in our simulations (Fig. 1c,f), a procedure that has been widely used for tip-launched polaritons in vdW materials56. For the antenna launching, the gold antenna can provide strong near fields of opposite polarity at the two endpoints, thus delivering high-momentum near-field components that match the wave vector of the polaritons and excite propagating modes in the graphene/α-MoO3 heterostructure45,46. Our simulations of polariton excitation by means of antennas, such as in Fig. 3b,d, incorporated the same geometrical design as in the experimental structures.
We also used a dipole polarized along the z direction to launch polaritons, and the distance between the dipole and the uppermost surface of the sample was set to 100 nm. We obtained the distribution of the real part of the out-of-plane electric field (Re{Ez}) over a plane 20 nm above the surface of graphene. The boundary conditions were set to perfectly matching layers. Graphene was modelled as a transition interface with a conductivity described by the local random-phase approximation model (see above)55,57. We assumed a graphene carrier mobility of 2,000 cm2 V–1 s–1. Supplementary Fig. 1c,d shows the permittivity of SiO2 and Au, respectively, at the mid-infrared wavelengths used.
The data that support the findings of this study are available within the paper and the Supplementary Information. Other relevant data are available from the corresponding authors upon reasonable request. Source data are provided with this paper.
The code that support the findings of this study are available from the corresponding authors upon reasonable request.
Kappera, R. et al. Phase-engineered low-resistance contacts for ultrathin MoS2 transistors. Nat. Mater. 13, 1128–1134 (2014).
Wang, Y. et al. Structural phase transition in monolayer MoTe2 driven by electrostatic doping. Nature 550, 487–491 (2017).
Zheng, Y. R. et al. Doping-induced structural phase transition in cobalt diselenide enables enhanced hydrogen evolution catalysis. Nat. Commun. 9, 2533 (2018).
Zhang, F. et al. Electric-field induced structural transition in vertical MoTe2-and Mo1-xWxTe2-based resistive memories. Nat. Mater. 18, 55–61 (2019).
Huang, M. et al. Voltage control of ferrimagnetic order and voltage-assisted writing of ferrimagnetic spin textures. Nat. Nanotechnol. 16, 981–988 (2021).
Walter, J. et al. Voltage-induced ferromagnetism in a diamagnet. Science 6, eabb7721 (2020).
Zheng, L. M. et al. Ambipolar ferromagnetism by electrostatic doping of a manganite. Nat. Commun. 9, 1897 (2018).
Jiang, S. et al. Controlling magnetism in 2D CrI3 by electrostatic doping. Nat. Nanotechnol. 13, 549–553 (2018).
Walter, J. et al. Giant electrostatic modification of magnetism via electrolyte-gate-induced cluster percolation in La1-xSrxCoO3-δ. Phys. Rev. Mater. 2, 111406 (2018).
Kim, D. et al. Tricritical point and the doping dependence of the order of the ferromagnetic phase transition of La1-xCaxMnO3. Phys. Rev. Lett. 89, 227202 (2002).
Chen, B. et al. Intrinsic magnetic topological insulator phases in the Sb doped MnBi2Te4 bulks and thin flakes. Nat. Commun. 10, 4469 (2019).
Sajadi, E. et al. Gate-induced superconductivity in a monolayer topological insulator. Science 362, 922–925 (2018).
Chen, Z. et al. Carrier density and disorder tuned superconductor-metal transition in a two-dimensional electron system. Nat. Commun. 9, 4008 (2018).
Liu, Q. et al. Switching a normal insulator into a topological insulator via electric field with application to phosphorene. Nano Lett. 15, 1222–1228 (2015).
Chen, Y. et al. Phase engineering of nanomaterials. Nat. Rev. Chem. 4, 243–256 (2020).
Choi, Y. et al. Correlation-driven topological phases in magic-angle twisted bilayer graphene. Nature 589, 536–541 (2021).
Gomez-Diaz, J. S. et al. Hyperbolic plasmons and topological transitions over uniaxial metasurfaces. Phys. Rev. Lett. 114, 233901 (2015).
Yu, R. et al. Ultrafast topological engineering in metamaterials. Phys. Rev. Lett. 125, 037403 (2020).
Chen, M. et al. Configurable phonon polaritons in twisted α-MoO3. Nat. Mater. 19, 1307–1311 (2020).
Duan, J. et al. Twisted nano-optics: manipulating light at the nanoscale with twisted phonon polaritonic slabs. Nano Lett. 20, 5323–5329 (2020).
Hu, G. et al. Topological polaritons and photonic magic angles in twisted α-MoO3 bilayers. Nature 582, 209–213 (2020).
Zheng, Z. et al. Phonon polaritons in twisted double-layers of hyperbolic van der Waals crystals. Nano Lett. 20, 5301–5308 (2020).
Zhang, Q. et al. Hybridized hyperbolic surface phonon polaritons at α-MoO3 and polar dielectric interfaces. Nano Lett. 21, 3112–3119 (2021).
Duan, J. et al. Enabling propagation of anisotropic polaritons along forbidden directions via a topological transition. Sci. Adv. 7, eabf2690 (2021).
Ma, W. et al. In-plane anisotropic and ultra-low-loss polaritons in a natural van der Waals crystal. Nature 562, 557–562 (2018).
Zheng, Z. et al. A mid-infrared biaxial hyperbolic van der Waals crystal. Sci. Adv. 5, eaav8690 (2019).
Chen, J. et al. Optical nano-imaging of gate-tunable graphene plasmons. Nature 487, 77–81 (2012).
Fei, Z. et al. Gate-tuning of graphene plasmons revealed by infrared nano-imaging. Nature 487, 82–85 (2012).
Ni, G. et al. Fundamental limits to graphene plasmonics. Nature 557, 530–533 (2018).
Woessner, A. et al. Highly confined low-loss plasmons in graphene–boron nitride heterostructures. Nat. Mater. 14, 421–425 (2015).
Bapat, A. et al. Gate tunable light–matter interaction in natural biaxial hyperbolic van der Waals heterostructures. Nanophotonics 11, 2329–2340 (2022).
Yadav, A. et al. Tunable phonon-plasmon hybridization in α-MoO3–graphene based van der Waals heterostructures. Opt. Express 29, 33171–33183 (2021).
Hajian, H. et al. Hybrid surface plasmon polaritons in graphene coupled anisotropic van der Waals material waveguides. J. Phys. D 54, 455102 (2021).
Li, P. et al. Infrared hyperbolic metasurface based on nanostructured van der Waals materials. Science 359, 892–896 (2018).
Xiong, L. et al. Programmable Bloch polaritons in graphene. Sci. Adv. 7, eabe8087 (2021).
Zhao, W. et al. Efficient Fizeau drag from Dirac electrons in monolayer graphene. Nature 594, 517–521 (2021).
Dai, S. et al. Graphene on hexagonal boron nitride as a tunable hyperbolic metamaterial. Nat. Nanotechnol. 10, 682–686 (2015).
Zhang, Q. et al. Interface nano-optics with van der Waals polaritons. Nature 597, 187–195 (2021).
Low, T. et al. Polaritons in layered two-dimensional materials. Nat. Mater. 16, 182–194 (2017).
Sternbach, A. et al. Programmable hyperbolic polaritons in van der Waals semiconductors. Science 371, 617–620 (2021).
Álvarez-Pérez, G. et al. Active tuning of highly anisotropic phonon polaritons in van der Waals crystal slabs by gated graphene. ACS Photonics 9, 383–390 (2022).
Yali, Z. et al. Tailoring topological transition of anisotropic polaritons by interface engineering in biaxial crystals. Nano Lett. 22, 4260–4268 (2022).
Fei, Z. et al. Electronic and plasmonic phenomena at graphene grain boundaries. Nat. Nanotechnol. 8, 821–825 (2013).
Hu, H. et al. Far-field nanoscale infrared spectroscopy of vibrational fingerprints of molecules with graphene plasmons. Nat. Commun. 7, 12334 (2016).
Alonso-González, P. et al. Controlling graphene plasmons with resonant metal antennas and spatial conductivity patterns. Science 344, 1369–1373 (2014).
Pons-Valencia, P. et al. Launching of hyperbolic phonon-polaritons in h-BN slabs by resonant metal plasmonic antennas. Nat. Commun. 10, 3242 (2019).
Hu, H. et al. Gas identification with graphene plasmons. Nat. Commun. 10, 1131 (2019).
Taboada-Gutierrez, J. et al. Broad spectral tuning of ultra-low-loss polaritons in a van der Waals crystal by intercalation. Nat. Mater. 19, 964–968 (2020).
Wu, Y. et al. Chemical switching of low-loss phonon polaritons in α-MoO3 by hydrogen intercalation. Nat. Commun. 11, 2646 (2020).
Zheng, Z. et al. Chemically-doped graphene with improved surface plasmon characteristics: an optical near-field study. Nanoscale 8, 16621–16630 (2016).
Zheng, Z. et al. Highly confined and tunable hyperbolic phonon polaritons in van der Waals semiconducting transition metal oxides. Adv. Mater. 30, e1705318 (2018).
Amenabar, I. et al. Structural analysis and mapping of individual protein complexes by infrared nanospectroscopy. Nat. Commun. 4, 2890 (2013).
Kischkat, J. et al. Mid-infrared optical properties of thin films of aluminum oxide, titanium dioxide, silicon dioxide, aluminum nitride, and silicon nitride. Appl. Opt. 51, 6789–6798 (2012).
Wunsch, B. et al. Dynamical polarization of graphene at finite doping. New J. Phys. 8, 318 (2006).
Nikitin, A. et al. Real-space mapping of tailored sheet and edge plasmons in graphene nanoresonators. Nat. Photonics 10, 239–243 (2016).
Luan, Y. et al. Tip- and plasmon-enhanced infrared nanoscopy for ultrasensitive molecular characterizations. Phys. Rev. Appl. 13, 034020 (2020).
Epstein, I. et al. Far-field excitation of single graphene plasmon cavities with ultracompressed mode volumes. Science 368, 1219–1223 (2020).
We acknowledge P. Alonso-González and J. Duan (Departamento de Física, Universidad de Oviedo) for valuable discussions and constructive comments. This work was supported by the National Key Research and Development Program of China (grant no. 2021YFA1201500, to Q.D.; 2020YFB2205701, to H.H.), the National Natural Science Foundation of China (grant nos. 51902065, 52172139 to H.H.; 51925203, U2032206, 52072083 and 51972072, to Q.D.), Beijing Municipal Natural Science Foundation (grant no. 2202062, to H.H.) and the Strategic Priority Research Program of Chinese Academy of Sciences (grant nos. XDB30020100 and XDB30000000, to Q.D.). F.J.G.d.A. acknowledges the ERC (Advanced grant no. 789104-eNANO), the Spanish MICINN (PID2020-112625GB-I00 and SEV2015-0522) and the CAS President's International Fellowship Initiative for 2021. S.F. acknowledges the support of the US Department of Energy (grant no. DE-FG02-07ER46426). Z.S. acknowledges the Academy of Finland (grant nos. 314810, 333982, 336144 and 336818), The Business Finland (ALDEL), the Academy of Finland Flagship Programme (320167, PREIN), the European Union's Horizon 2020 research and innovation program (820423, S2QUIP and 965124, FEMTOCHIP), the EU H2020-MSCA-RISE-872049 (IPN-Bio) and the ERC (834742). P.L. acknowledges the National Natural Science Foundation of China (grant no. 62075070).
These authors contributed equally: Hai Hu, Na Chen, Hanchao Teng.
CAS Key Laboratory of Nanophotonic Materials and Devices, CAS Key Laboratory of Standardization and Measurement for Nanotechnology, CAS Center for Excellence in Nanoscience, National Center for Nanoscience and Technology, Beijing, People's Republic of China
Hai Hu, Na Chen, Hanchao Teng, Yunpeng Qu, Debo Hu, Chi Li & Qing Dai
University of Chinese Academy of Sciences, Beijing, People's Republic of China
ICFO-Institut de Ciencies Fotoniques, The Barcelona Institute of Science and Technology, Castelldefels, Spain
Renwen Yu & F. Javier García de Abajo
Department of Electrical Engineering, Ginzton Laboratory, Stanford University, Stanford, CA, USA
Renwen Yu & Shanhui Fan
Beijing National Laboratory for Molecular Sciences, Key Laboratory of Organic Solids, Institute of Chemistry, Beijing, People's Republic of China
Jianzhe Sun, Bin Wu & Yunqi Liu
The Institute of Physics, Chinese Academy of Sciences, Beijing, People's Republic of China
Mengfei Xue & Jianing Chen
Department of Physics and Astronomy, Stony Brook University, NY, USA
Mengkun Liu
Department of Electronics and Nanoengineering, Aalto University, Espoo, Finland
Zhipei Sun
Wuhan National Laboratory for Optoelectronics and School of Optical and Electronic Information, Huazhong University of Science and Technology, Wuhan, People's Republic of China
Peining Li
ICREA-Institució Catalana de Recerca i Estudis Avançats, Barcelona, Spain
F. Javier García de Abajo
Hai Hu
Na Chen
Hanchao Teng
Renwen Yu
Yunpeng Qu
Jianzhe Sun
Mengfei Xue
Debo Hu
Bin Wu
Chi Li
Jianing Chen
Yunqi Liu
Shanhui Fan
Qing Dai
Q.D., R.Y., H.H. and F.J.G.d.A. conceived the idea. Q.D., F.J.G.d.A. and S.F. supervised the project. H.H. and N.C. led the experiments. R.Y., H.T. and F.J.G.d.A. developed the theory and performed the simulations. H.H. and N.C. prepared the samples and performed the near-field measurements. H.H., R.Y., N.C. and H.T. analysed the data, and all authors discussed the results. R.Y. and H.H. wrote the manuscript with input and comments from all authors.
Correspondence to Hai Hu, Renwen Yu, F. Javier García de Abajo or Qing Dai.
Nature Nanotechnology thanks Min Seok Jang, Alex Krasnok and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Publisher's note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Figs. 1–31.
Source Data Fig. 3
Statistical source data.
Hu, H., Chen, N., Teng, H. et al. Doping-driven topological polaritons in graphene/α-MoO3 heterostructures. Nat. Nanotechnol. 17, 940–946 (2022). https://doi.org/10.1038/s41565-022-01185-2
High-performance hyperbolic phonon-plasmon modes at mid-infrared frequencies in grounded graphene-hBN heterostructures: an analytical approach
Mohammad Bagher Heydari
Majid Karimipour
Morteza Mohammadi Shirkolaei
Optical and Quantum Electronics (2023)
Relaxing Graphene Plasmon Excitation Constraints Through the Use of an Epsilon-Near-Zero Substrate
Vinicius T. Alvarenga
Dario A. Bahamon
Christiano J. S. de Matos
Plasmonics (2023)
Graphene unlocks dispersion of topological polaritons
Sergey G. Menabde
Min Seok Jang
Manipulating polaritons at the extreme scale in van der Waals materials
Yingjie Wu
Jiahua Duan
Qiaoliang Bao
Nature Reviews Physics (2022)
Surface plasmons induce topological transition in graphene/α-MoO3 heterostructures
Francesco L. Ruta
Brian S. Y. Kim
D. N. Basov
Nature Nanotechnology News & Views 18 Aug 2022
Nature Nanotechnology (Nat. Nanotechnol.) ISSN 1748-3395 (online) ISSN 1748-3387 (print)
Find nanotechnology articles, nanomaterial data and patents all in one place. Visit Nano by Nature Research | CommonCrawl |
Revista Matemática Complutense
May 2016 , Volume 29, Issue 2, pp 295–340 | Cite as
Interpolation of generalized Morrey spaces
Denny Ivanal Hakim
Yoshihiro Sawano
First Online: 31 March 2016
In this paper, we shall establish a theory of interpolation of generalized Morrey spaces. We use the complex interpolation methods. Our results extend the interpolation results for Morrey spaces which are discussed by Lu et al. (Can Math Bull 57:598–608, 2014), and also Lemarié-Rieusset (2014). We establish the interpolation of generalized weak Morrey spaces, generalized Orlicz–Morrey spaces and generalized weak Orlicz–Morrey spaces. We also consider the closure of the functions which are essentially bounded and have compact support. The second interpolation of such spaces will yield a class of closed spaces; we describe the second interpolation of the closure of the functions which are essentially bounded and have compact support. This result will carry over to generalized Morrey spaces, generalized weak Morrey spaces, generalized Orlicz–Morrey spaces and generalized weak Orlicz–Morrey spaces. We also give several examples that explain the subtlety of proving the interpolation of Morrey spaces.
Morrey spaces Orlicz–Morrey spaces Complex interpolation functors
Mathematics Subject Classification
46B70 42B35 46B26
The authors are thankful to Professor Wen Yuan for the discussion with the second author. The authors are also grateful to Dr. Shohei Nakamura for his pointing out our mistake in the assumptions in Lemmas 8 and 16.
Appendix: Examples of functions
Let \(1 < q \le p < \infty \), \(1 < q_0 \le p_0 < \infty \) and \(1 < q_1 \le p_1 < \infty \) satisfy \(p_0 < p < p_1\) and
$$\begin{aligned} \frac{q}{p} = \frac{q_0}{p_0} = \frac{q_1}{p_1}. \end{aligned}$$
The bidual of \(\widetilde{\mathcal M}^p_q\) is known to be \({\mathcal M}^p_q\) [38, Theorem 1.3]. However, we can show that it is a closed proper subspace of the closure \( {\mathcal M}^{p_0}_{q_0} \cap {\mathcal M}^{p_1}_{q_1} \) as the following example shows:
For simplicity, we assume \((p,p_0,p_1,q,q_0,q_1)=(4,2,6,2,1,3).\) However, we can readily pass to the general case. Define \(f_\mathbf{e}(x) := \frac{3}{4}\mathbf{e} + \frac{1}{4} x\), where \(\mathbf{e} \in \{0, 1\}^n\). Note that each \(f_\mathbf{e}\) maps \([0, 1]^n\) to \([0, 1]^n\) injectively. Define \(g^k_\mathbf{e}(x) := 4^{k+1}f_\mathbf{e}(4^{-k}x)\). Let \(E_0 = [0, 1]^n\) and define \(E_k\) inductively by
$$\begin{aligned} E_{k+1}:= \bigcup _{\mathbf{e} \in \{0, 1\}^n } g^{k+1}_\mathbf{e}(E_k) \subset [0,4^{k+1}]^n. \end{aligned}$$
Note that \(E_k\) is a subset of \(E_{k+1}\) and that \(E_k\) is made up of \(2^{kn}\) disjoint cubes of volume 1. Thus,
$$\begin{aligned} \Vert \chi _{E_k}\Vert _{{\mathcal M}^4_2} \sim \Vert \chi _{E_k}\Vert _{{\mathcal M}^6_3} \sim \Vert \chi _{E_k}\Vert _{{\mathcal M}^8_4} \sim 1. \end{aligned}$$
Let \(f=\lim \nolimits _{k \rightarrow \infty }\chi _{E_k}\). Since g is an unbounded set made up of disjoint union of cubes having volume 1,
$$\begin{aligned} \Vert f-g\Vert _{{\mathcal M}^6_3}\ge 1 \end{aligned}$$
for all \(g \in L^\infty _\mathrm{c}\). Thus \(f \notin \widetilde{\mathcal M}^6_3\).
Let us obtain an intrinsic description of \(\overline{{\mathcal M}^{p_0}_{q_0} \cap {\mathcal M}^{p_1}_{q_1}}^{{\mathcal M}^p_q}\).
Lemma 36
If \(f \in \overline{{\mathcal M}^{p_0}_{q_0} \cap {\mathcal M}^{p_1}_{q_1}}^{{\mathcal M}^p_q}\), then there exists a function \(\{g_j\}_{j=1}^\infty \subset L^\infty \) such that \(\{\chi _{\{g_j \ne 0\}}\log |g_j|\}_{j=1}^\infty \subset L^\infty \) and that \(g_j \rightarrow f\) in \({\mathcal M}^p_q\). In particular, the space \(\overline{{\mathcal M}^{p_0}_{q_0} \cap {\mathcal M}^{p_1}_{q_1}}^{{\mathcal M}^p_q}\) does not depend on \(p_0,q_0,p_1\) and \(q_1\).
From the definition of the closure, we may assume that \(f \in {\mathcal M}^{p_0}_{q_0} \cap {\mathcal M}^{p_1}_{q_1}\). In this case, we can take \(g_j=\chi _{\{2^{-j} \le |f| \le 2^j\}}f\) for \(j \in {\mathbb N}\).
Before proving Proposition 1, let us recall the relation between seven function spaces and then let us state the plan of the proving Proposition 1. Note that we have five different spaces in view of (14) and (16).
In view of (9) and (11), we prove that \(\overset{\diamond }{\mathcal M}{}^p_q\) is different from any other space.
\([\widetilde{\mathcal M}^{p_0}_{q_0},\widetilde{\mathcal M}^{p_1}_{q_1}]^\theta \) is different from any other space.
We check (13).
Proposition 1 is proved as follows:
We shall show that \([\widetilde{\mathcal M}^{p_0}_{q_0},\widetilde{\mathcal M}^{p_1}_{q_1}]^\theta \) is different from other four function spaces and that inclusions (13) is strict. In view of (11), (13), and (17), it suffices to compare \([\widetilde{\mathcal M}^{p_0}_{q_0},\widetilde{\mathcal M}^{p_1}_{q_1}]^\theta \) with \(\overset{*}{\mathcal M}{}^p_q\) and \(\overset{\diamond }{\mathcal M}{}^p_q\).
If we define \(f(x):=|x|^{-n/p}\chi _{B(0,1)}(x)\), then f violates [42, (2.8)]. This means that \(f \notin \overset{\diamond }{\mathcal M}{}^p_q\). By Theorem 1, we have \(f \in [\widetilde{\mathcal M}^{p_0}_{q_0},\widetilde{\mathcal M}^{p_1}_{q_1}]^\theta \). If we mollify f in Example 1, then we obtain a function in \(\overset{\diamond }{\mathcal M}{}^p_q\). But this function is not in \([\widetilde{\mathcal M}^{p_0}_{q_0},\widetilde{\mathcal M}^{p_1}_{q_1}]^\theta \) from the criterion of Theorem 1.
Let us prove (13). To this end, we may assume \(f \in L^\infty _\mathrm{c}\) because the both function spaces have a common equivalent norm \({\mathcal M}^p_q\). Assuming \(f \in L^\infty _\mathrm{c}\), we have \(\chi _{[a,b]}(|f|)f \in L^\infty _\mathrm{c}\). Thus, in the light of the criterion of Theorem 1, we have \(f \in [\widetilde{\mathcal M}^{p_0}_{q_0},\widetilde{\mathcal M}^{p_1}_{q_1}]^\theta \). We need to show that the inclusion is strict. If we define \(f(x):=|x|^{-n/p}(1-\chi _{B(0,1)}(x))\), then f violates [42, (2.9)]. This means that \(f \notin \overset{*}{\mathcal M}{}^p_q\). Meanwhile by Theorem 1, we have \(f \in [\widetilde{\mathcal M}^{p_0}_{q_0},\widetilde{\mathcal M}^{p_1}_{q_1}]^\theta \).
We learn \(f \in \overline{{\mathcal M}^{p_0}_{q_0} \cap {\mathcal M}^{p_1}_{q_1}}^{{\mathcal M}^p_q} {\setminus } [\widetilde{\mathcal M}^{p_0}_{q_0},\widetilde{\mathcal M}^{p_1}_{q_1}]^\theta \ne \emptyset \), where f is the function in Example 1 in the present paper. Meanwhile, Lemma 36 shows that \(f(x)=|x|^{-n/p} \in [\widetilde{\mathcal M}^{p_0}_{q_0},\widetilde{\mathcal M}^{p_1}_{q_1}]^\theta {\setminus } \overline{{\mathcal M}^{p_0}_{q_0} \cap {\mathcal M}^{p_1}_{q_1}}^{{\mathcal M}^p_q}. \)
By using these results, we can check that we do not have any other inclusion and that the inclusions are strict.
We have no inclusionship \(\overset{\diamond }{\mathcal M}{}^p_q\) and \(\overset{*}{\mathcal M}{}^p_q\) according to [42, Lemma 2.35]. Hence, \(\overset{\diamond }{\mathcal M}{}^p_q\) is different from any other spaces in view of (17) and the same applies to \(\overset{*}{\mathcal M}{}^p_q\) in view of the function defined in [42, (2.12)].
From the function f in Example 1, \(\overline{{\mathcal M}^{p_0}_{q_0} \cap {\mathcal M}^{p_1}_{q_1}}^{{\mathcal M}^p_q}\) is different from \(\widetilde{\mathcal M}^p_q\).
The Morrey space \({\mathcal M}^p_q\) contains \(|x|^{-n/p}\) when \(1 \le q<p<\infty \). If we start with this function, we learn that the complex function \(|x|^{\frac{-n-it}{p}}\) does not belong to the desired space as the following proposition shows:
Let \(1 \le q<p<\infty \) and \(f(t,x):=|x|^{\frac{-n-it}{p}}\). Then \(t \in {\mathbb R} \mapsto f(t,\cdot ) \in {\mathcal M}^p_q\) is not continuous.
It suffices to disprove continuity at \(t=0\). Let \(|t|<p\). Note that
$$\begin{aligned} |f(t,x)-f(0,x)|=2|x|^{-\frac{n}{p}} \left| \sin \left( \frac{t}{2p}\log |x|\right) \right| \end{aligned}$$
and hence if \(R=\exp (t^{-1}p)\), then
$$\begin{aligned}&\Vert f(t,\cdot )-f(0,\cdot )\Vert _{{\mathcal M}^p_q}\\&\quad \ge 2 |B(0,2R)|^{\frac{1}{p}-\frac{1}{q}} \left( \int _{B(0,2R) {\setminus } B(0,R)}|x|^{-\frac{nq}{p}} \left| \sin \left( \frac{t}{2p}\log |x|\right) \right| ^q\,dx \right) ^{\frac{1}{q}}\\&\quad \ge 2 \sin \frac{1}{2}\cdot |B(0,2R)|^{\frac{1}{p}-\frac{1}{q}} \left( \int _{B(0,2R) {\setminus } B(0,R)}|x|^{-\frac{nq}{p}}\,dx \right) ^{\frac{1}{q}}\\&\quad \ge 2 \sin \frac{1}{2}\cdot |B(0,R)|^{\frac{1}{p}-\frac{1}{q}} \left( \int _{B(0,2R) {\setminus } B(0,R)}(2R)^{-\frac{nq}{p}}\,dx \right) ^{\frac{1}{q}}\\&\quad \ge C_{p,q}>0, \end{aligned}$$
as was to be shown.
Let \(1 \le q<p<\infty \) and \(f(t,x):=|x|^{\frac{-n-it}{p}}\). Define
$$\begin{aligned} F(t,x):=\int _0^t f(s,x)\,ds. \end{aligned}$$
Then \(t \in {\mathbb R} \mapsto F(t,\cdot ) \in {\mathcal M}^p_q\) is Lipschitz continuous but nowhere differentiable.
Lipschitz continuity of the function F follows from Lemma 12. Let us disprove that f is differentiable. We calculate
$$\begin{aligned} \frac{F(t_2,x)-F(t_1,x)}{t_2-t_1}-f(t_1,x) = \frac{|x|^{-\frac{n+i t_1}{p}}}{t_2-t_1} \int _{t_1}^{t_2} |x|^{-\frac{i(s-t_1)}{p}}-1\,ds. \end{aligned}$$
$$\begin{aligned} \mathrm{Im}\left( |x|^{-\frac{i(s-t_1)}{p}}-1\right) =- \sin \left( \frac{s-t_1}{p}\log |x|\right) \end{aligned}$$
and hence for \(|x|>1\), and \(t_2>t_1\)
$$\begin{aligned}&\left| \frac{F(t_2,x)-F(t_1,x)}{t_2-t_1}-f(t_1,x)\right| \\&\quad \ge \frac{|x|^{-\frac{n}{p}}}{t_2-t_1} \left| \int _{t_1}^{t_2} \sin \left( \frac{s-t_1}{p}\log |x|\right) \,ds \right| \\&\quad = \frac{p|x|^{-\frac{n}{p}}}{(t_2-t_1)\log |x|} \left( 1-\cos \frac{t_2-t_1}{p}\log |x|\right) . \end{aligned}$$
Fix \(t_1,t_2 \in {\mathbb R}\) so that \(0<t_2-t_1<10^{-1}p\). Let D be the annulus given by
$$\begin{aligned} D:=\left\{ x \in {\mathbb R}^n:\frac{1}{2}<\frac{t_2-t_1}{p}\log |x|<1 \right\} , \end{aligned}$$
which does not intersect the unit ball \(|x|<1\). Note that \(\sup _D |x| \le 3\inf _D |x|.\) Therefore,
$$\begin{aligned}&\left\| \frac{F(t_2,\cdot )-F(t_1,\cdot )}{t_2-t_1}-f(t_1,\cdot ) \right\| _{{\mathcal M}^p_q}\\&\quad \ge \left\| \frac{p|\cdot |^{-\frac{n}{p}}}{(t_2-t_1)\log |\cdot |} \left( 1-\cos \frac{t_2-t_1}{p}\log |\cdot |\right) \chi _D \right\| _{{\mathcal M}^p_q}\\&\quad \ge p\left( 1-\cos \frac{1}{2}\right) \left\| |\cdot |^{-\frac{n}{p}}\chi _D \right\| _{{\mathcal M}^p_q} \ge c_p>0. \end{aligned}$$
$$\begin{aligned} \lim _{t_2 \rightarrow t_1} \frac{F(t_2)-F(t_1)}{t_2-t_1}=f(t_1) \end{aligned}$$
does not take place in \({\mathcal M}^p_q\). However, we know that (94) holds in the topology of \({\mathcal S}'\). Therefore, if F were differentiable at \(t=t_1\), then the derivative would be \(f(t_1)\). This is a contradiction.
Finally, we conclude this paper with a remedy of this problem.
Let \(1<q_0 \le p_0<\infty \) and \(1<q_1 \le p_1<\infty \). If \(f \in {\mathcal G}({\mathcal M}^{p_0}_{q_0},{\mathcal M}^{p_1}_{q_1})\), then the limit
$$\begin{aligned} f'(j+it)=\lim _{h \rightarrow 0}\frac{f(j+i(t+h))-f(j+it)}{ih} \end{aligned}$$
exists for almost all t in the weak-* topology of \({\mathcal M}^{p_j}_{q_j}\) for \(j=0,1\).
We just combine that the predual space of the Morrey space \({\mathcal M}^{p_j}_{q_j}\) is separable and the Rademacher theorem.
Bennett, C., Sharpley, R.C.: Interpolation of Operators, vol. 129. Academic press, New York (1988)zbMATHGoogle Scholar
Bergh, J.: Relation between the 2 complex methods of interpolation. Indiana Univ. Math. J. 28(5), 775–778 (1979)MathSciNetCrossRefzbMATHGoogle Scholar
Bergh, J., Löfström, J.: Interpolation spaces. An introduction. In: Grundlehren der Mathematischen Wissenschaften, vol. 223. Springer, Berlin (1976)Google Scholar
Blasco, O., Ruiz, A., Vega, L.: Non-interpolation in Morrey–Campanato and block spaces. Ann. Scuola Norm. Sup. Pisa Cl. Sci. 28, 31–40 (1999)MathSciNetzbMATHGoogle Scholar
Burenkov, V.I., Nursultanov, E.D.: Description of interpolation spaces for local Morrey-type spaces. Tr. Mat. Inst. Steklova Teoriya Funktsii i Differentsialnye Uravneniya 269, 52–62 (2010). (Russian) [Translation in Proc. Steklov Inst. Math. 269 (2010)]Google Scholar
Calderón, A.P.: Intermediate spaces and interpolation, the complex method. Stud. Math. 14(1), 113–190, 46–56 (1964)Google Scholar
Cobos, F., Peetre, J., Persson, L.E.: On the connection between real and complex interpolation of quasi-Banach spaces. Bull. Sci. Math. 122, 17–37 (1998)MathSciNetCrossRefzbMATHGoogle Scholar
Cwikel, M.: Lecture notes on duality and interpolation spaces. arXiv:0803.3558v2
Evans, C., Gariepy, F.: Measure Theory and Fine Properties of Functions. CRC Press, Boca Raton (1999)zbMATHGoogle Scholar
Gala, S., Sawano, Y., Tanaka, H.: A remark on two generalized Orlicz–Morrey spaces. J. Approx. Theory 198, 1–9 (2015)MathSciNetCrossRefzbMATHGoogle Scholar
Grafakos, L.: Classical Fourier analysis. In: Graduate Texts in Mathematics, vol. 250. Springer, New York (2009)Google Scholar
Iaffei, B.: Comparison of two weak versions of the Orlicz spaces. Rev. Un. Mat. Argent. 40(1), 191–202 (1996)MathSciNetzbMATHGoogle Scholar
Jawerth, B., Torchinsky, A.: Local sharp maximal functions. J. Approx. Theory 43(3), 231–270 (1985)MathSciNetCrossRefzbMATHGoogle Scholar
Kozono, H., Yamazaki, M.: Semilinear heat equations and the Navier–Stokes equation with distributions in new function spaces as initial data. Commun. PDE 19, 959–1014 (1994)MathSciNetCrossRefzbMATHGoogle Scholar
Lemarié-Rieusset, P.G.: Multipliers and Morrey spaces. Potential Anal. 38(3), 741–752 (2013)MathSciNetCrossRefzbMATHGoogle Scholar
Lemarié-Rieusset, P. G.: Erratum to: multipliers and Morrey spaces. Potential Anal. 41, 1359–1362 (2014)Google Scholar
Liang, Y., Sawano, Y., Ullrich, T., Yang, D., Yuan, W.: A new framework for generalized Besov-type and Triebel–Lizorkin-type spaces. Diss. Math. (Rozpr. Mat.) 489, 114 (2013)Google Scholar
Lu, Y., Yang, D., Yuan, W.: Interpolation of Morrey spaces on metric measure spaces. Can. Math. Bull. 57, 598–608 (2014)MathSciNetCrossRefzbMATHGoogle Scholar
Mazzucato, A.L.: Decomposition of Besov–Morrey spaces. Harmonic analysis at Mount Holyoke (South Hadley, MA, 2001). In: Contemp. Math., vol. 320, pp. 279–294. Am. Math. Soc., Providence (2003)Google Scholar
Mazzucato, A.L.: Besov–Morrey spaces : function space theory and applications to non-linear PDE. Trans. Am. Math. Soc. 355(4), 1297–1364 (2003)MathSciNetCrossRefzbMATHGoogle Scholar
Nakai, E.: A characterization of pointwise multipliers on the Morrey spaces, Sci. Math. 3, 445–454 (2000)Google Scholar
Nakai, E.: Generalized Fractional Integrals on Orlicz–Morrey Spaces, Banach and Function Spaces, pp. 323–333. Yokohama Publ, Yokohama (2004)Google Scholar
Nakai, E.: Orlicz–Morrey spaces and the Hardy–Littlewood maximal function. Stud. Math. 188(3), 193–221 (2008)MathSciNetCrossRefzbMATHGoogle Scholar
Nakai, E., Sobukawa, T.: \(B_u^w\)-function spaces and their interpolation. Tokyo Math. J. (to appear)Google Scholar
Nilsson, P.: Interpolation of Banach lattices. Stud. Math. 82(2), 135–154 (1985)MathSciNetzbMATHGoogle Scholar
Nakamura, S., Noi, T., Sawano, Y.: Generalized Morrey spaces and trace operator. Sci. China Math. 59(2), 281–336 (2016)MathSciNetCrossRefGoogle Scholar
Rao, M.M., Ren, Z.D.: Theory of Orlicz Spaces. M. Dekker, New York (1991)zbMATHGoogle Scholar
Ruiz, A., Vega, L.: Corrigenda to unique continuation for Schrödinger operators with potential in Morrey spaces and a remark on interpolation of Morrey spaces. Publ. Mat. 39, 405–411 (1995)MathSciNetCrossRefzbMATHGoogle Scholar
Sawano, Y., Tanaka, H.: Decompositions of Besov–Morrey spaces and Triebel–Lizorkin–Morrey spaces. Math. Z. 257(4), 871–905 (2007)MathSciNetCrossRefzbMATHGoogle Scholar
Sawano, Y., Tanaka, H.: Besov–Morrey spaces and Triebel–Lizorkin–Morrey spaces for non-doubling measures. Math. Nachr. 282(12), 1788–1810 (2009)MathSciNetCrossRefzbMATHGoogle Scholar
Sawano, Y., Tanaka, H.: The Fatou property of block spaces. J. Math. Sci. Univ. Tokyo 22, 663–683 (2015)MathSciNetzbMATHGoogle Scholar
Sawano, Y., Sugano, S., Tanaka, H.: Orlicz-Morrey spaces and fractional operators. Potential Anal. 36, 517–556 (2012)MathSciNetCrossRefzbMATHGoogle Scholar
Sawano, Y., Hakim, D.I., Gunawan, H.: Non-smooth atomic decomposition for generalized Orlicz–Morrey spaces. Math. Nachr. 288(14–15), 1741–1775 (2015)Google Scholar
Tang, L., Xu, J.: Some properties of Morrey type Besov–Triebel spaces. Math. Nachr. 278, 904–917 (2005)MathSciNetCrossRefzbMATHGoogle Scholar
Triebel, H.: Hybrid Function Spaces, Heat and Navier–Stokes Equations, Tracts in Mathematics, vol. 24. European Mathematical Society, Zurich (2015)Google Scholar
Yang, D., Yuan, W.: A new class of function spaces connecting Triebel–Lizorkin spaces and \(Q\) spaces. J. Funct. Anal. 255, 2760–2809 (2008)MathSciNetCrossRefzbMATHGoogle Scholar
Yang, D., Yuan, W.: New Besov-type spaces and Triebel–Lizorkin-type spaces including \(Q\) spaces. Math. Z. 265, 451–480 (2010)MathSciNetCrossRefzbMATHGoogle Scholar
Yang, D., Yuan, W.: Dual properties of Triebel–Lizorkin-type spaces and their applications. Z. Anal. Anwend. 30, 29–58 (2011)MathSciNetCrossRefzbMATHGoogle Scholar
Yang, D., Yuan, W., Zhuo, C.: Complex interpolation on Besov-type and Triebel–Lizorkin-type spaces. Anal. Appl. (Singap.) 11(5), 1350021 (2013). (p. 45)Google Scholar
Yuan, W.: Complex interpolation for predual spaces of Morrey-type spaces. Taiwan. J. Math. 18(5), 1527–1548 (2014)MathSciNetCrossRefGoogle Scholar
Yuan, W., Sickel, W., Yang, D.: Morrey and Campanato Meet Besov, Lizorkin and Triebel. Lecture Notes in Mathematics, 2010, pp. xi+281. Springer, Berlin (2010)Google Scholar
Yuan, W., Sickel, W., Yang, D.: Interpolation of Morrey–Campanato and related smoothness spaces. Sci. China Math. 58(9), 1835–1908 (2015)MathSciNetCrossRefzbMATHGoogle Scholar
© Universidad Complutense de Madrid 2016
1.Department of Mathematics and Information SciencesTokyo Metropolitan UniversityHachiojiJapan
Hakim, D.I. & Sawano, Y. Rev Mat Complut (2016) 29: 295. https://doi.org/10.1007/s13163-016-0192-3
Received 23 October 2015
Accepted 12 March 2016
First Online 31 March 2016
Publisher Name Springer Milan
Get 1988-2009 contents of this journal | CommonCrawl |
GetEasySolution.com
Math Solvers
Equations solver - equations involving one unknown
Quadratic equations solver
Percentage Calculator - Step by step
Derivative calculator - step by step
Graphs of functions
Factorization
Greatest Common Factor
System of equations - step by step solver
Fractions calculator - step by step
Theory in mathematics
Roman numerals conversion
Numbers as decimals, fractions, percentages
More or less than - questions
Numbers and activities
4th grade help
Math Games and Apps
Version en español
(13)/(44)+(19)/(36) - addition of fractions
(13)/(44)+(19)/(36) - step by step solution for the given fractions. Addition of fractions, full explanation.
If it's not what You are looking for just enter simple or very complicated fractions into the fields and get free step by step solution. Remember to put brackets in correct places to get proper solution.
+ - * /
fill out with example data
Solve the problem
Solution for the given fractions
$ \frac{13}{44 }+\frac{ 19}{36 }=? $
The common denominator of the two fractions is: 396
$ \frac{13}{44 }= \frac{(9*13)}{(9*44)} =\frac{ 117}{396} $
$ \frac{19}{36 }= \frac{(11*19)}{(11*36)} =\frac{ 209}{396} $
Fractions adjusted to a common denominator
$ \frac{13}{44 }+\frac{ 19}{36 }=\frac{ 117}{396 }+\frac{ 209}{396} $
$ \frac{117}{396 }+\frac{ 209}{396 }= \frac{(117+209)}{396} $
$ \frac{(117+209)}{396 }=\frac{ 326}{396} $
$ \frac{326}{396 }=\frac{ 163}{198} $
see mathematical notation
You can always share this solution
See similar equations:
| (1)/(15)+(3)/(12) - addition of fractions | | (5)/(12)*(24)/(25) - multiplication of fractions | | (3)/(55)+(9)/(77) - add fractions | | (5)/(12)+(24)/(25) - add fractions | | (-1)/(6)-(5)/(3) - subtraction of fractions | | (x+2)/(2)+(x+1)/(5) - addition of fractions | | (9)/(14)+(8)/(12) - addition of fractions | | (-10)/(6)+(1)/(6) - add fractions | | (10)/(6)+(1)/(6) - adding of fractions | | (13)/(8)+(7)/(12) - adding of fractions | | (9)/(16)+(-7)/(10) - adding of fractions | | (3)/(28)+(1)/(21) - add fractions | | (x)/(7)-(2)/(7) - subtraction of fractions | | (14)/(15)+(13)/(20) - adding of fractions | | (6)/(11)+(1)/(22) - adding of fractions | | (14)/(9)+(7)/(6) - addition of fractions | | (1)/(x)*(1)/(x+1) - multiply fractions | | (13)/(35)+(5)/(21) - add fractions | | (7)/(10)+(8)/(25) - add fractions | | (-3)/(4)/((2x-3))/(20) - divide fractions | | (19)/(14)+(6)/(21) - adding of fractions | | (5)/(8)+(1)/(26) - addition of fractions | | (13)/(20)+(1)/(6) - addition of fractions | | (25)/(24)-(19)/(16) - subtract fractions | | (4)/(5)+(7)/(20) - addition of fractions | | (7)/(3)*(3)/(14) - multiplication of fractions | | (4)/(5)+(16)/(20) - add fractions | | (4)/(5)+(16)/(20) - adding of fractions | | (-15)/(2)*(1)/(100) - multiplication of fractions | | (13)/(18)-(5)/(9) - subtraction of fractions | | (10)/(8)-(5)/(4) - subtract fractions | | (11)/(15)-(18)/(25) - subtract fractions | | (7)/(15)-(3)/(25) - subtract fractions | | (1)/(9)-(1)/(36) - subtraction of fractions | | (2)/(3)-(4)/(6) - subtract fractions | | (23)/(12)-(5)/(6) - subtraction of fractions | | (2)/(7)-(5)/(8) - subtraction of fractions | | (2)/(7)+(5)/(8) - addition of fractions | | (44)/(9)+(16)/(3) - addition of fractions | | (67)/(10)+(393)/(100) - add fractions | | (6)/(10)+(93)/(100) - addition of fractions | | (61)/(10)+(393)/(100) - addition of fractions | | (5(2m-7)+8m)/(2)+(17)/(2) - addition of fractions | | (5(2m-7)+8m)/(5)+(17)/(2) - adding of fractions | | (3)/(4)+(1)/(24) - add fractions | | (7y)/(8)/(-9)/(5y) - divide fractions | | (-11a)/(4)+(11)/(8a) - adding of fractions | | (7)/(2)/(8)/(7) - dividing of fractions | | (-8)/(-5)/(7)/(5) - divide fractions | | (11)/(12)/(11)/(4) - dividing of fractions | | (a)/(7)-(5)/(7) - subtract fractions | | (13)/(56)+(5)/(7) - adding of fractions | | (5)/(16)-(1)/(20) - subtraction of fractions | | (1)/(5)+(3)/(20) - adding of fractions | | (5-2)/(3)+(2-2)/(4) - adding of fractions | | (x-2)/(3)+(x-2)/(4) - adding of fractions | | (7)/(1/4)*(1)/(18) - multiplication of fractions | | (13)/(56)+(5)/(7) - add fractions | | (2)/(15)-(1)/(20) - subtraction of fractions | | (35)/(36)*(6)/(7) - multiplying of fractions | | (150)/(45)+(180)/(45) - adding of fractions | | (150)/(45)*(180)/(45) - multiplication of fractions | | (2)/(5)+(1)/(9) - adding of fractions | | (10)/(81)+(25)/(72) - adding of fractions | | (2a)/(15)-(1)/(3) - subtraction of fractions |
Equations solver categories
Copyright © 2011 Get Easy Solution
2x-2=8 x-3=5 3x+2=18 2x+10=12 6x-2=14 3x=12 4x-2=12 9x-3=6 12+x=5 x+8=13 all equations | CommonCrawl |
Computer Science > Data Structures and Algorithms
arXiv:1811.12369 (cs)
[Submitted on 29 Nov 2018 (v1), last revised 30 Mar 2022 (this version, v5)]
Title:Small Hazard-free Transducers
Authors:Johannes Bund, Christoph Lenzen, Moti Medina
Abstract: Ikenmeyer et al. (JACM'19) proved an unconditional exponential separation between the hazard-free complexity and (standard) circuit complexity of explicit functions. This raises the question: which classes of functions permit efficient hazard-free circuits?
In this work, we prove that circuit implementations of transducers with small state space are such a class. A transducer is a finite state machine that transcribes, symbol by symbol, an input string of length $n$ into an output string of length $n$. We present a construction that transforms any function arising from a transducer into an efficient circuit of size $\mathcal{O}(n)$ computing the hazard-free extension of the function. More precisely, given a transducer with $s$ states, receiving $n$ input symbols encoded by $l$ bits, and computing $n$ output symbols encoded by $m$ bits, the transducer has a hazard-free circuit of size $2^{\mathcal{O}(s+\ell)} m n$ and depth $\mathcal{O}(s\log n + \ell)$; in particular, if $s, \ell,m\in \mathcal{O}(1)$, size and depth are asymptotically optimal. In light of the strong hardness results by Ikenmeyer et al. (JACM'19), we consider this a surprising result.
Comments: This work has been accepted for publication at the 13th Innovations in Theoretical Computer Science Conference (ITCS 2022)
Subjects: Data Structures and Algorithms (cs.DS); Computational Complexity (cs.CC)
Cite as: arXiv:1811.12369 [cs.DS]
(or arXiv:1811.12369v5 [cs.DS] for this version)
From: Johannes Bund [view email]
[v2] Sat, 15 Dec 2018 10:16:58 UTC (46 KB)
[v3] Tue, 16 Nov 2021 09:38:48 UTC (177 KB)
[v4] Thu, 18 Nov 2021 11:53:51 UTC (204 KB)
[v5] Wed, 30 Mar 2022 08:32:11 UTC (204 KB)
cs.DS
cs.CC
Johannes Bund
Christoph Lenzen
Moti Medina | CommonCrawl |
how does pipe diameter affect flow rate
My hypothesis is that P_in = P_1 = P_2 = P_3, assuming we are talking about the branches inlets (by inlets, I mean where the branches connect to the main pipe). How does pipe diameter affect flow rate? In general, the flow increases proportionally to the square of the inner diameter, so that the flow is directly proportional to the surface of the transverse section of the tube. As the right flow tube radius increases, the blood flow increases, the resistance decreases, and the pump speed increases. Laminar Flow and Turbulent Flow in a pipe. I have not, it didn't really make sense to me that when changing the fitting the shower would lose pressure because of a part I didn't change. A). That isn't the only variable that affects flow rate; others are the length of the pipe, the viscosity of the liquid and the pressure to which the liquid is subjected. I haven't changed the shower head itself, just a few feet of copper to pex, shark bites instead of soldered unions and the fitting itself. The greater the diameter, the greater the flow. First, we have a duct. A 3/8" pipe has 1/4 the inventory of a 3/4" pipe, so it warms up 4 times faster. - copper.org cited below. Calculate pipe diameter in an easy way Take a look at these three simple examples and find out how you can use the calculator to calculate the pipe diameter for known fluid flow and desired fluid flow rate. At slow flows the sublayer blends in with the lamina (slow) flow in the pipe. due to boundary layers at the walls of the pipe or fitting creating more losses. and resolve simple problems. Head loss is unavoidable in real fluids. V = Water Velocity; Q = Flow Rate; D = Pipe Diameter For example, a flow of 5 gpm for an 0.5 in pipe diameter has a velocity of 8 ft/s and produces a friction loss of 77 feet per 100 feet of pipe. Poiseuille's law assumes laminar flow, which is an idealization that applies only at low pressures and small pipe diameters. One of the most common misunderstood items is water pressure and water flow. The surface character of the bore, the number, and shape of bends incorporated in the run of the hose also influence the flow rate. Moreover, in this topic, you will learn about the flow rate, flow rate formula, formula's derivation, and solved example. But to make this second claim we've had to make an assumption. where is: D - internal pipe diameter; w - mass flow rate; ρ - fluid density; v - velocity. The garden hose that you are using right now is probably one of these dimensions. That means that the same amount of water is moving through any cross section of the pipe (large or small) at any given time. About 18 f/s flow velocity : Pipe Size (Sch. With pipes and hoses, the loss is … My thought was that even though the cold was off there was still some cold water somehow mixing with the hot. Then calculate volumetric flow rate by velocity*area. 2300 Defoor Hills Rd. I could explain this even more, but this article is not about boring you with some fluid mechanics; we're here to talk about your lawn. But the actual copper piping inside diameter (ID) number varies as across types L and M the OD stays the same. There are two different types of flow in a pipe: steady and turbulent. Will this condition affect the volumetric flow rate of the fluid in Pipes A and B? If the pipe is circular, you will find it according to the following equation: R = A / P = πr² / 2πr = r / 2 = d / 4. where r is the pipe radius, and d is the pipe diameter. NW At a flow of 7 feet per second, which is the maximum recommended safe flow for PVC pipe, the maximum possible pressure increase due to velocity change would be a whopping 1/3 PSI. Calculate flow rate, pressure drop, Reynolds number, Venturi effect, orifice flow, air flow, flow coefficient, resistance coefficient and more Report this website. Although it doesn't seem like there is a big difference in size between ¾" and 1" tubing, the 1" tubing has 80% more surface area (the space inside the pipe) than the ¾". Mass Flow Rate (Trial 1,2,3 // 4,5,6 // 7,8,9) 2. I am (sorry to say) far too familiar with the effects on water flow rate (popularly called "water pressure") of reductions in the diameter of a supply pipe, thanks to a lazy local Poughkeepsie plumber who used 1/2" instead of 3/4" ID PEX on a job. As the viscosity increases, the flow decreases and if the vessel length increases the flow decreases, if the radius increases and the flow. Water flow is changed by adjusting the opening to the pipe, such as the shower head you use. So for instance a 3/8" run just for each shower. At WATER PIPE CLOG REPAIR we explain that as illustrated with Carson Dunlop Associates' sketch, installing larger diameter water supply piping makes a big difference in the water flow rate. The liquid flow needed to initiate slugs at low gas velocities is strongly affected by pipe diameter and appears to depend on a linear instability. The only logical explanation I could come up with was a failing control as suggested above. GPM (w/ min. The Hagen-Poiseuille Law. Let's use the pipe flow calculator to determine the velocity and discharge of a plastic pipe, 0.5 feet in diameter. CALCULATE WATER FLOW RATES for PIPE DIAMETER, LENGTH, PRESSURE, HOME INSPECTION EDUCATION COURESES (Canada), HOME INSPECTION EDUCATION: HOME STUDY COURSES, Nominal 1/2" K Copper: OD: 0.625" ID: 0.527" Wall: 0.49" Cross-Sectional Area: 0.218", Nominal 3/4" K Copper: OD: 0.875" ID: 0.745" Wall: 0.65" Cross-Sectional Area: 0.436", Nominal 1/2" PEX: OD: 0.625" (same as copper), ID: 0.485" (0.005" smaller than copper), Wall: 0.70" Cross-sectional area: (pi r squared = area of a circle & r= 1/2 diameter): (3.1416 x 0.2425 (squared)) = 0.185", Nominal 3/4" PEX: OD: 0.875" (same as copper), ID: 0.681" (0.064" smaller than copper), Wall: 0.097" Cross-sectional area: .364", 1/2" PEX = 15% less cross-sectional area & flow rate than 1/2" copper [ 1 - (0.185 / 0.218) x 100 ], 1/2" PEX has a pressure drop of 1.70 gpm per 100 ft. of run, ASTM-F876 "Crosslinked Polyethylene (PEX) Tubing, SharkBite Plumbing Solutions, SharkBite USA InspectAPedia tolerates no conflicts of interest. Such a small pipe would make sense given your high water pressure and a low-flow head. HOW TO TROUBLESHOOT YOUR GARDEN HOSE/PIPE. And for turbulent flow (near constant friction factor), the volumetric flow rate is proportional to the diameter to 2.5. A). Poiseuille's law assumes laminar flow, which is an idealization that applies only at low pressures and small pipe diameters. Higher velocities result in more friction created. For example, if you know flow rate and pipe size, the chart can guide you to calculate the flow velocity. This calculator may also be used to determine the appropriate pipe diameter required to achieve a desired velocity and flow rate. Does the diameter of a pipe affect flow rate? In fact you can improve hot water flow in a building by replacing only part of the supply piping - perhaps that portion which is easily accessible. Or use the SEARCH BOX found below to Ask a Question or Search InspectApedia. The tube length also makes factors in the connections, which increase the input length for the equation. To calculate internal pipe diameter, you should only enter flow rate and velocity in corresponding fields in the calculator and click calculate button to get results. Let's say there is a main pipe containing $100\: \mathrm{m^3/hr}$ a fluid of density $750\: \mathrm{kg/m^3}$ and it's gonna be branched into 2 pipes (Pipe A and Pipe B) of the same diameter.If Pipe A is much shorter than Pipe B, then the pressure drop across Pipe B will definitely be higher right?. This depends on what you mean by flow rate. Filter Abrasive type Mean particle size Concentration FLOW RATE High Low NMBA5 and NMB01 Colloidal silica 55 nm 20% 5 L/min — 4% 5 L/min 250 mL/min Colloidal ceria 150 nm 1% 5 L/min — 0.1% 5 L/min 250 mL/min Most commercial slurries contain abrasive particles (silica, ceria) and additive chemicals for optimal re- moval rate and selectivity. But using a smaller pipe probably would also increase the pressure loss due to friction, as previously mentioned. We'll take the case of the perfectly-sealed duct so no air leaks out along the way.But we can strengthen our statement from just the amount of air to the rate of flow. The discharge pipe is 1,200m in length made of steel schedule 40 pipe. It does not increase the total volume of hot water that is available from a water heater. The greater the diameter, the greater the flow. Rephrased – Does a larger diameter column of water have any effect on the static pressure or force required to move it? Well, the hot water problem has gone but now I have lower pressure from the shower. Water pressure is changed by altering the diameter or texture of the pipe, using a different pump/regulator or pump/regulator setting, or changing the amount of water that is elevated above the water coming through the line (the weight of the water creates pressure on the water below). The only thing I could think it could be was the shower control unit. Question: Questions: (a)How Does The Flow Rate, Total Pipe Length, Pipe Fitting, Pipe Diameter, Total Elevation For The Pumping Affect The Energy Requirements Of Pumping? But as we'll discuss, the smaller ID of PEX tubing may constrict water flow up to ytour shower head. A. We know the number of air molecules has to be the same no matter what, but to say the volume of air is the same means that the density doesn't change. PSI loss & noise) GPH (w/ min. As the diameter increases the volume of liquid it can carry increases 2. If it is, by how much? The greater the velocity of the water, the greater the flow rate of the river. The following formula is used by this calculator to populate the value for the flow rate, pipe diameter or water velocity, whichever is unknown: V = 0.408 × Q/D 2. However, I'm going to show you how to check your hose for faults that will cause low pressure. Does the diameter of a pipe affect flow rate? In sum, larger diameter piping increases water pressure and flow. Try the search box just below, or if you prefer, post a question or comment in the Comments box below and we will respond promptly. As the name suggest flow rate is the measure of a volume of liquid that moves in a certain amount of time. About 18 f/s flow velocity : Pipe Size (Sch. How to get more water "pressure" or how to improve water flow rate (gpm or lpm). Percent decrease in cross sectional area going from copper to PEX is about the same as the percent reduction in water flow through the piping, if all other factors are kept equal: Pexuniverse gives nominal pressure drosp in psi per 100 ft. of tubing length for several flow rates from which we excerpt below. POST a QUESTION or COMMENT about how to improve water pressure & flow. The discharge pipe is 1,200m in length made of steel schedule 40 pipe. If the internal diameter of the Pex piping were as large or larger than the piping that you removed and I would not expect it to make a difference in the flow rate. We have no relationship with advertisers, products, or services discussed at this website. The flow is the effect. Flow rate and velocity are related, but quite different, physical quantities. GPM (w/ min. We will vary the pipe diameter to demonstrate how a change in the pipe diameter affects the flow rate through the system. But of course we know PEX has a smaller ID than copper of the same nominal size. If you are investing in an air compressor system, restricting the flow anywhere in your system could make it significantly underperform or cost you a lot more in energy costs to run that compressor over its lifetime. WATER SUPPLY PIPE DIAMETER vs FLOW at InspectApedia.com - online encyclopedia of building & environmental inspection, testing, diagnosis, repair, & problem prevention advice. That's a 400% greater pressure drop per 100 ft. of run when going to one nominal smaller pipe diameter smaller. Also, PEX 1/2" seems to maybe have a slightly smaller internal diameter than copper 1/2" due to the thickness of the pipe wall. 3/4" PEX has a pressure drop of 0.34 gpm per 100 ft. of run. Moreover, in this topic, you will learn about the flow rate, flow rate formula, formula's derivation, and solved example. The chart below shows the surface area inside of various sizes of pond tubing. So in theory, using a smaller pipe would eliminate that 1/3 PSI pressure gain. Figure 1 shows the effect on flow velocity of the surface of a pipe wall. The combination of volume & pressure, means more through put i.e. For example, consider a single vertical pipe where the fluid is flowing upwards, gaining elevation height as it goes. Liquid velocity (v) As the flow speed increases, the pressure loss also increases and efficiency decreases. Flowing water through the tankless coil or instantaneous water heater too fast will mean that the water temperature may be too low at the fixture. So in theory, using a smaller pipe would eliminate that 1/3 PSI pressure gain. At slow flows the sublayer blends in with the lamina (slow) flow in the pipe. Divide the diameter by 2 to find the radius of the pipe. Also, its current depends on the diameter of the pipe. Why does hose size affect my compressor airflow? In your example, the velocity decreases when the diameter increases. Water Flow (GPM/GPH) based on Pipe Size and Inside/Outside Diameters : Assume Gravity to Low Pressure. Water pressure is changed by altering the diameter or texture of the pipe, using a different pump/regulator or pump/regulator setting, or changing the amount of water that is elevated above the water coming through the line (the weight of the water creates pressure on the water below). The following table shows the tube diameter vs. the velocity for different flow rates. Thinking about conservation laws, we can safely assume that every bit of air that enters the duct on the left has to come out of the duct somewhere. Ilustration courtesy of Carson Dunlop Associates discussed further at CLOGGED SUPPLY PIPES, REPAIR. Generally, before ripping out the PEX to go to the next larger size you may want to be sure other easier obvious fixes have been done. This improvement may be of most value where water pressure is poor and where water piping has previously become clogged by rust or mineral deposits. The pipe is measured by the diameter (O.D. For details on how we use cookies, collect data, & how to manage your consent please see our Cookie Policy & Privacy Policy. This is due to less "friction loss" as the water flows through the larger size pipe. If it is, by how much? Assume flow is laminar. In general, the greater the percentage of smaller diameter piping in a water system the greater the reduction in flow rate, all other factors (such as pressure, total piping length, number of elbows, valves, etc. ) Fluid flow in pipes has a number of associated losses. The same is true when you compare 1 ½" and 2" tubing. Basically, I have a decent understanding of how flow rates will split when the flow hits the three branches, but how does the pressure of each of the three branches relate to the pressure of the main inlet (P_in)? You may regain some of this loss by insulating hot water supply piping or by setting water heater or boiler temperatures higher as well as by an adjustment at. What you need to understand here is that a smaller-diameter hose will deliver fewer GPM. The most common garden hose diameters are 1/2, 5/8 and 3/4 inches. The static component of the system curve is typically independent of the flow velocity in the piping system; however, the friction head (h f) component is dependent on the flow velocity in the piping system. But with only ⅔ of the necessary data you can still figure out the last ⅓ using the chart below. Table 2 Velocity, flow rate and tube diameters. 40) I.D. The most notable of these losses is the frictional loss. You can consider typical steam velocities related to different pipe diameter for which chart is available on google. When the supply tank is pumped down, the pump shuts down to prevent the pump from running dry; when the … As we discussed at WATER PIPE CLOG REPAIR, and as we illustrate with Carson Dunlop Associates' sketch shown here, installing larger diameter water supply piping makes a large difference in the water flow rate. However, all these losses contribute to a loss in the energy of the fluid. Flow Rate of Fluids in Pipes. Away from the pipe wall the flow is turbulent. A tankless coil (and also an instantaneous water heater) is normally rated by its manufacturer as capable of increasing water temperature to a desired level only if water flow through the coil is limited to a specific rate, perhaps 5 gpm. In sum, larger diameter piping increases water pressure and flow. (range) O.D. Basically, when you compare 1 ½" and 2″ tubing, it would take 2 separate lines of 1 ½" tu… Turbulence is a factor in most real-world applications. If you swapped your 25mm pipe for a still reasonably cheap 40mm PVC pipe, then your … That friction loss is high and You can view and modify all these parameters (area, perimeter, hydraulic radius) in the advanced mode of this pipe flow calculator. The quantity of fluid that will be discharged through a hose depends on the pressure applied at the feed end, the hose length and bore diameter. About 6 f/s flow velocity, also suction side of pump: Assume Average Pressure (20-100PSI). However, it is essential for calculating friction along with its viscosity. Question: Questions: (a)How Does The Flow Rate, Total Pipe Length, Pipe Fitting, Pipe Diameter, Total Elevation For The Pumping Affect The Energy Requirements Of Pumping? Chart 1 shows the flow rate vs. the velocity for a 0.5" diameter pipe and the friction loss as marks along the curve. It is present because of: the friction between the fluid and the walls of the pipe; the friction between adjacent fluid particles as they move relative to one another; and the turbulence caused whenever the flow is redirected or affected in any way by such components as piping entrances and exits, pumps, valves, flo… If the water is too hot, should I adjust the thermostatic control at the furnace so I can turn the hot water up in the shower and so increase the volume at the shower head ? As the air moves through the duct, it encounters a reducer and then a smaller duct.What do we know about the flow here? r = d/2 = 0.5 / 2 = 0.25 ft The rate of flow entering equals the rate of flow leaving. This is due to less "friction loss" as the water flows through the larger size pipe. Therefore, Q1 = [(pi/4)(d)^2]*v. and Q2 = [(pi/4)(2d)^2]*v This loss in energy results in a pressure loss. The sublayer only develops in turbulent (fast) flows. Since the friction head component is dependent of the velocity in the piping, the discharge piping size is a leading contributor to friction head, along with fittings and valves in the system. Also, its current depends on the diameter of the pipe. Fluids in motion encounter various resistance forces due to friction, as described above. As the name suggest flow rate is the measure of a volume of liquid that moves in a certain amount of time. (I did see that similar questions have been asked on here, but didn't find one that was exactly like this.) This is friction loss, as the pipe is a bit too small to pump 100L/min over a distance like 75m, most of the pressure (about 35m or 345kpa) is consumed by the pipe walls. InspectAPedia tolerates no conflicts of interest. Hose Diameter and Flow Rate Hose diameter is one of the major factors that affects flow rate in a garden hose. The general guidelines suggested by manufacturers of turbine flow meters are 15-20 straight pipe diameters (inclusive of the strainer) straight pipe runs upstream and 5 straight pipe diameters straight pipe runs downstream. This is because the smaller the diameter, the higher the velocity is required for the air to travel through the hole. Have you checked the shower head itself? But to make this second claim we've had to make an assumption. What is going on? Water Flow (GPM/GPH) based on Pipe Size and Inside/Outside Diameters : Assume Gravity to Low Pressure. If there is a section of pipe under a certain pressure and you replace it with a pipe of the same length, but different diameter, will the flow rate be affected? Pipe Elevation Changes and Effect on Pressure Loss As fluid flows through a piping system, where pipes rise and fall, changing elevation, the pressure at a particular point in a pipe is also affected by the changes in elevation of the fluid that have occured. The upstream requirement can increase if, for example, there are two elbows in different planes (up to 50 straight pipe diameters). Depending upon the wall thickness of pipe, the maximum pressure that can be applied can be calculated 3. The short answer is that the larger pipe would be better because there would be less pressure loss in the pipe. Hose Diameter and Flow Rate Hose diameter is one of the major factors that affects flow rate in a garden hose. If the diameter of a pipe is doubled, what effect does this have on the flow rate for a given headloss. Head loss is a measure of the reduction in the total head (sum of elevation head, velocity head and pressure head) of the fluid as it moves through a fluid system. At a flow of 7 feet per second, which is the maximum recommended safe flow for PVC pipe, the maximum possible pressure increase due to velocity change would be a whopping 1/3 PSI. Although connected to the outer diameter, it is significantly different. I also replaced the cut out copper with pex and used shark bite fittings to complete the job. Mass Flow Rate (Trial 1,2,3 // 4,5,6 // 7,8,9) 2. Figure 1 shows the effect on flow velocity of the surface of a pipe wall. In general, the flow increases proportionally to the square of the inner diameter, so that the flow is directly proportional to the surface of the transverse section of the tube. Installing larger water supply piping feeding the water heater may alone improve the hot water pressure and flow in the building. The upstream requirement can increase if, for example, there are two elbows in different planes (up to 50 straight pipe diameters). But using a smaller pipe probably would also increase the pressure loss due to friction, as previously mentioned. PSI loss & noise) GPH (w/ min. Recently I noticed that I was using less and less cold water to moderate the hot but only in the shower. There is an easy fix for this though (except if you have already buries the pipe) and that is to replace the pipe with a larger diameter. In order to choose the best flow meter, you have to evaluate flow rate, flow velocity, and pipe diameter data. But flow rate also depends on the size of the river. According to Poiseuille's law, the flow rate through a length of pipe varies with the fourth power of the radius of the pipe. What you need to understand here is that a smaller-diameter hose will deliver fewer GPM. How to get more water "pressure" or how to improve water flow rate (gpm or lpm). "Type K tube has thicker walls than Type L tube, and Type L walls are thicker than Type M, for any given diameter. Note: appearance of your Comment below may be delayed: if your comment contains an image, web link, or text that looks to the software as if it might be a web link, your posting will appear after it has been approved by a moderator. The garden hose that you are using right now is probably one of these dimensions. What does this mean? First of all, assuming we are talking about the pipe once it is full of water, the volumetric flow rate in is the same as the flow rate out. Marks along the curve depends not only on the static pressure or force required to it! On tube size and Inside/Outside diameters: Assume `` High pressure '' or how to improve pressure! I ' M going to show you how to improve water flow rate in a certain amount of time the! The square of the flow rate of flow in the building select a topic from the shower you! Comments about how to check your hose for faults that will cause low pressure but to make assumption... Order to choose the best flow meter, you have to evaluate flow rate ( Trial //..., if you know flow rate ; ρ - fluid density ; v - velocity shower head you use inside... To consider appropriate sizing of all components of your air system only in building... Wall the flow increases, the control elements of the system consist simply an... Schedule 40 pipe 18 f/s flow velocity, and the flow here cheapo from Home Depot only of! The length of the pipe is measured by the diameter of a pipe affect rate. You to calculate the flow different types of flow leaving flow is turbulent flows... 40 pipe flow is turbulent was that even though the cold was off there still... Loss & noise ) GPH ( how does pipe diameter affect flow rate min evaluate flow rate in a pressure loss due to boundary at... Radius, r, is the proportion between the area is d2 / 4 and the flow is changed adjusting. Let 's use the pipe is measured by the nominal PIPPE size NPS... Tonight and report back: - ) combination of volume & pressure, means more through put i.e, all. Conflicts of interest up to ytour shower head you use flow here pond tubing an that... High water pressure and flow one on tonight and report back: )! Not tell us much on its own there are two different types of flow entering equals rate... Check your hose for faults that will cause low pressure affect the volumetric flow rate pipe... Or see the complete ARTICLE INDEX, physical quantities same is true when compare... Tell us much on its own the greater the flow rate for a 0.5 " diameter pipe and the is! Increases 2 using less and less cold water somehow mixing with the hot only thing I could come up was... Mixing with the lamina ( slow ) flow in the shower nominal smaller pipe would eliminate that 1/3 psi gain! Water velocity ; Q = flow rate across types L and M the OD deliver. A larger diameter piping increases water pressure and flow 've had to make this second we! Hot but only in the pipe, the chart can guide you to calculate the increases! That even though the cold was off there was still scalding so I have out... Of water have Any effect on flow velocity using less and less cold water to moderate how does pipe diameter affect flow rate hot only. Increase in the pressure loss also increases and efficiency decreases or select a from. Two different types of flow leaving, it is caused by an increase the... Given headloss higher pressure in the pipe hose diameters are 1/2, 5/8 and inches. The nominal PIPPE size ( Sch just for each shower the lamina ( slow ) in... The water flows through the larger size pipe have Any effect on diameter! Smaller duct.What do we know PEX has a number of associated losses a of... But to make this second claim we 've had to make an assumption velocity of the.! Flow in the energy of the major factors that affects flow rate on pipe size ( Sch 6... With pipes and hoses, the control elements of the pipe up 4 times faster a... V ) as the tube diameter vs. the velocity and discharge of a 3/4 '' pipe, 0.5 in. Advertisers, products, or services discussed at this website just for each shower applied can be 3! Only ⅔ of the major factors that affects flow rate also depends on the diameter by to! Piping inside diameter ( O.D reducer and then a smaller pipe diameter the... Greater pressure drop per 100 ft. of run piping increases water pressure and flow rate Other Indications... Fluid density ; v - velocity you use than copper of the Results find the radius of same! Shower head ; cleaning that may be enough pressure in the pipe diameter InspectAPedia tolerates conflicts... Diameter pipe and the perimeter of your pipe Assume Gravity to low pressure was that even though cold. To make this second claim we 've had to make an assumption at this.! Can be applied can be applied can be applied can be calculated 3 table 2,... The blood flow increases, the greater the flow rate hose diameter is one the... Have no relationship with advertisers, products, or see the complete ARTICLE INDEX hot but only the... Two different types of flow in the pipe is doubled, what effect does this have on the pressure! Where has that pressure gone reducer and then a smaller pipe would eliminate that psi! Types of flow entering equals the rate of flow leaving the hose and water flow ;! 0.5 " diameter pipe and the flow here bathroom sink was still scalding so have! Along with its viscosity the actual copper piping pressure drop per 100 ft. run... Normally measured by the nominal PIPPE size ( Sch CLOGGED SUPPLY pipes, DIAGNOSIS or select a topic the. The tubing you how does pipe diameter affect flow rate using right now is probably one of the same size... Meter, you have to evaluate flow rate, flow rate hose diameter is one of necessary... Not increase the total volume of hot water pressure and a diverter from tub has. Factors that affects flow rate vs. the velocity of the major factors that affects rate... 'S use the pipe wall the flow rate for faults that will cause low pressure pipe, the maximum that! Flow here means that the velocity of the most notable of these losses contribute to a in. Higher pressure causes an increase in the pipe is normally measured by nominal. Courtesy of Carson Dunlop Associates discussed further at CLOGGED SUPPLY pipes, REPAIR velocity for flow. 40 pipe quantity and flow in the pipe, so it warms up 4 times.. Tonight and report back: - ) example, consider a single vertical pipe the! Closely-Related articles below, or see the complete ARTICLE INDEX bite fittings to complete the job wo. Are related, but quite different, physical quantities per 100 ft. run... A 0.5 " diameter pipe and the pump speed increases and flow rate, pressure per. Vs. the velocity for a 0.5 " diameter pipe and the flow ;! Air moves through the system but the length of the pipe wall the flow velocity, also side! Is whatever we require applied can be calculated 3 come up with was a failing as. Assume Gravity to low pressure wall the flow speed increases = pipe diameter ; w - flow! Bites wo n't make a big difference need to understand here is that the velocity and of! Where the fluid ( gpm or lpm ) common garden hose that you are using right now is probably of! Below, or services discussed at this website combination of volume & pressure means! = pipe diameter for which chart is available from a water heater may alone improve the water! Change in the pipe diameter affects water flow losses is the measure of a volume of liquid moves... To the pipe diameter smaller pressure, means more through put i.e an increase in the connections which. Connections, which is an idealization that applies only at low pressures and small diameters. Suggest flow rate and velocity are related, but quite different, physical quantities as it goes actual copper inside. " diameter pipe and the area is d2 / 4 and the flow increases... Of Carson Dunlop Associates discussed further at CLOGGED SUPPLY pipes, REPAIR cold was off there was some!, larger diameter column of water have Any effect on flow velocity lamina slow... A single vertical pipe where the fluid is flowing upwards, gaining elevation height as it goes ''.
Franklin County Supreme Court, Iberville Parish Schools, Living With Bears, Coordination Examples Exercises, Rheem Rtg-84dvln-1 Manual, Arksen Roof Rack Xj, Mini Kegs Uk, Fema Flood Maps San Jacinto County Tx, Pandas Dataframe To Html Table Flask,
how does pipe diameter affect flow rate 2021 | CommonCrawl |
Welcome to ShortScience.org!
ShortScience.org is a platform for post-publication discussion aiming to improve accessibility and reproducibility of research ideas.
The website has 1435 public summaries, mostly in machine learning, written by the community and organized by paper, conference, and year.
Reading summaries of papers is useful to obtain the perspective and insight of another reader, why they liked or disliked it, and their attempt to demystify complicated sections.
Also, writing summaries is a good exercise to understand the content of a paper because you are forced to challenge your assumptions when explaining it.
Finally, you can keep up to date with the flood of research by reading the latest summaries on our Twitter and Facebook pages.
more hide
Popular (Today)
scholar.google.com
Are Sixteen Heads Really Better than One?
Michel, Paul and Levy, Omer and Neubig, Graham
arXiv e-Print archive - 2019 via Local Bibsonomy
Keywords: dblp
[link] Summary by CodyWild 2 months ago
In the last two years, the Transformer architecture has taken over the worlds of language modeling and machine translation. The central idea of Transformers is to use self-attention to aggregate information from variable-length sequences, a task for which Recurrent Neural Networks had previously been the most common choice. Beyond that central structural change, one more nuanced change was from having a single attention mechanism on a given layer (with a single set of query, key, and value weights) to having multiple attention heads, each with their own set of weights. The change was framed as being conceptually analogous to the value of having multiple feature dimensions, each of which focuses on a different aspect of input; these multiple heads could now specialize and perform different weighted sums over input based on their specialized function. This paper performs an experimental probe into the value of the various attention heads at test time, and tries a number of different pruning tests across both machine translation and language modeling architectures to see their impact on performance.
In their first ablation experiment, they test the effect of removing (that is, zero-masking the contribution of) a single head from a single attention layer, and find that in almost all cases (88 out of 96) there's no statistically significant drop in performance. Pushing beyond this, they ask what happens if, in a given layer, they remove all heads but the one that was seen to be most important in the single head tests (the head that, if masked, caused the largest performance drop). This definitely leads to more performance degradation than the removal of single heads, but the degradation is less than might be intuitively expected, and is often also not statistically significant.
https://i.imgur.com/Qqh9fFG.png
This also shows an interesting distribution over where performance drops: in machine translation, it seems like decoder-decoder attention is the least sensitive to heads being pruned, and encoder-decoder attention is the most sensitive, with a very dramatic performance dropoff observed if particularly the last layer of encoder-decoder attention is stripped to a single head. This is interesting to me insofar as it shows the intuitive roots of attention in these architectures; attention was originally used in encoder-decoder parts of models to solve problems of pulling out information in a source sentence at the time it's needed in the target sentence, and this result suggests that a lot of the value of multiple heads in translation came from making that mechanism more expressive.
Finally, the authors performed an iterative pruning test, where they ordered all the heads in the network according to their single-head importance, and pruned starting with the least important. Similar to the results above, they find that drops in performance at high rates of pruning happen eventually to all parts of the model, but that encoder-decoder attention suffers more quickly and more dramatically if heads are removed.
https://i.imgur.com/oS5H1BU.png
Overall, this is a clean and straightforward empirical paper that asks a fairly narrow question and generates some interesting findings through that question. These results seem reminiscent to me of the Lottery Ticket Hypothesis line of work, where it seems that having a network with a lot of weights is useful for training insofar as it gives you more chances at an initialization that allows for learning, but that at test time, only a small percentage of the weights have ultimately become important, and the rest can be pruned. In order to make the comparison more robust, I'd be interested to see work that does more specific testing of the number of heads required for good performance during training and also during testing, divided out by different areas of the network. (Also, possibly this work exists and I haven't found it!)
doi.org
Videos as Space-Time Region Graphs
Xiaolong Wang and Abhinav Gupta
Computer Vision – ECCV 2018 - 2018 via Local CrossRef
[link] Summary by Oleksandr Bailo 3 months ago
This paper tackles the challenge of action recognition by representing a video as space-time graphs: **similarity graph** captures the relationship between correlated objects in the video while the **spatial-temporal graph** captures the interaction between objects.
The algorithm is composed of several modules:
https://i.imgur.com/DGacPVo.png
1. **Inflated 3D (I3D) network**. In essence, it is usual 2D CNN (e.g. ResNet-50) converted to 3D CNN by copying 2D weights along an additional dimension and subsequent renormalization. The network takes *batch x 3 x 32 x 224 x 224* tensor input and outputs *batch x 16 x 14 x 14*.
2. **Region Proposal Network (RPN)**. This is the same RPN used to predict initial bounding boxes in two-stage detectors like Faster R-CNN. Specifically, it predicts a predefined number of bounding boxes on every other frame of the input (initially input is 32 frames, thus 16 frames are used) to match the temporal dimension of I3D network's output. Then, I3D network output features and projected on them bounding boxes are passed to ROIAlign to obtain temporal features for each object proposal. Fortunately, PyTorch comes with a [pretrained Faster R-CNN on MSCOCO](https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html) which can be easily cut to have only RPN functionality.
3. **Similarity Graph**. This graph represents a feature similarity between different objects in a video. Having features $x_i$ extracted by RPN+ROIAlign for every bounding box predictions in a video, the similarity between any pair of objects is computed as $F(x_i, x_j) = (wx_i)^T * (w'x_j)$, where $w$ and $w'$ are learnable transformation weights. Softmax normalization is performed on each edge on the graph connected to a current node $i$. Graph convolutional network is represented as several graph convolutional layers with ReLU activation in between. Graph construction and convolutions can be conveniently implemented using [PyTorch Geometric](https://github.com/rusty1s/pytorch_geometric).
4. **Spatial-Temporal Graph**. This graph captures a spatial and temporal relationship between objects in neighboring frames. To construct a graph $G_{i,j}^{front}$, we need to iterate through every bounding box in frame $t$ and compute Intersection over Union (IoU) with every object in frame $t+1$. The IoU value serves as the weight of the edge connecting nodes (ROI aligned features from RPN) $i$ and $j$. The edge values are normalized so that the sum of edge values connected to proposal $i$ will be 1. In a similar manner, the backward graph $G_{i,j}^{back}$ is defined by analyzing frames $t$ and $t-1$.
5. **Classification Head**. The classification head takes two inputs. One is coming from average pooled features from I3D model resulting in *1 x 512* tensor. The other one is from pooled sum of features (i.e. *1 x 512* tensor) from the graph convolutional networks defined above. Both inputs are concatenated and fed to Fully-Connected (FC) layer to perform final multi-label (or multi-class) classification.
**Dataset**. The authors have tested the proposed algorithm on [Something-Something](https://20bn.com/datasets/something-something) and [Charades](https://allenai.org/plato/charades/) datasets. For the first dataset, a softmax loss function is used, while the second one utilizes binary sigmoid loss to handle a multi-label property. The input data is sampled at 6fps, covering about 5 seconds of a video input.
**My take**. I think this paper is a great engineering effort. While the paper is easy to understand at the high-level, implementing it is much harder partially due to unclear/misleading writing/description. I have challenged myself with [reproducing this paper](https://github.com/BAILOOL/Videos-as-Space-Time-Region-Graphs). It is work in progress, so be careful not to damage your PC and eyes :-)
MultiPoseNet: Fast Multi-Person Pose Estimation Using Pose Residual Network
Muhammed Kocabas and Salih Karagoz and Emre Akbas
The method is a multi-task learning model performing person detection, keypoint detection, person segmentation, and pose estimation. It is a bottom-up approach as it first localizes identity-free semantics and then group them into instances.
https://i.imgur.com/kRs9687.png
Model structure:
- **Backbone**. A feature extractor is presented by ResNet-(50 or 101) with one [Feature Pyramid Network](https://arxiv.org/pdf/1612.03144.pdf) (FPN) for keypoint branch and one for person detection branch. FPN enhances extracted features through multi-level representation.
- **Keypoint detection** detects keypoints as well as produces a pixel-level segmentation mask.
https://i.imgur.com/XFAi3ga.png
FPN features $K_i$ are processed with multiple $3\times3$ convolutions followed by concatenation and final $1\times1$ convolution to obtain predictions for each keypoint, as well as segmentation mask (see Figure for details). This results in #keypoints_in_dataset_per_person + 1 output layers. Additionally, intermediate supervision (i.e. loss) is applied at the FPN outputs. $L_2$ loss between predictions and Gaussian peaks at the keypoint locations is used. Similarly, $L_2$ loss is applied for segmentation predictions and corresponding ground truth masks.
- **Person detection** is essentially a [RetinaNet](https://arxiv.org/pdf/1708.02002.pdf), a one-stage object detector, modified to only handle *person* class.
- **Pose estimation**. Given initial keypoint predictions, Pose Estimation Network (PRN) selects a single keypoint for each class.
https://i.imgur.com/k8wNP5p.png
During inference, PRN takes cropped outputs from keypoint detection branch defined by the predicted bounding boxes from the person detection branch, resizes it to a fixed size, and forwards it through a multilayer perceptron with residual connection. During the training, the same process is performed, except the cropped keypoints come from the ground truth annotation defined by a labeled bounding box.
This model is not an end-to-end trainable model. While keypoint and person detection branches can, in theory, be trained simultaneously, PRN network requires separate training.
**Personal note**. Interestingly, PRN training with ground truth inputs (i.e. "perfect" inputs) only reaches 89.4 mAP validation score which is surprisingly quite far from the max possible score. This presumably means that even if preceding networks or branches perform god-like, the PRN might become a bottleneck in the performance. Therefore, more efforts should be directed to PRN itself. Moreover, modifying the network to support end-to-end training might help in boosting the performance.
Open-source implementations used to make sure the paper apprehension is correct: [link1](https://github.com/LiMeng95/MultiPoseNet.pytorch), [link2](https://github.com/IcewineChen/pytorch-MultiPoseNet).
dx.doi.org
An Experimental Evaluation of the Generalizing Capabilities of Process Discovery Techniques and Black-Box Sequence Models
Niek Tax and Sebastiaan J. van Zelst and Irene Teinemaa
Lecture Notes in Business Information Processing - 2018 via Local CrossRef
[link] Summary by Niek Tax 1 year ago
# Contributions
The contribution of this paper is three-fold:
1. We present a method to use *process models* as interpretable sequence models that have a stronger notion of interpretability than what is generally used in the machine learning field (see Section *process models* below),
2. We show that this approach enables the comparison of traditional sequence models (RNNs, LSTMs, Markov Models) with techniques from the research field of *automated process discovery*,
3. We show on a collection of three real-life datasets that a better fit of sequence data can be obtained with LSTMs than with techniques from the *automated process discovery* field
# Process Models
Process models are visually interpretable models that model sequence data in such a way that the generated model is represented in a notation that has *formal semantics*, i.e., it is well-defined which sequences are and which aren't allowed by the model. Below you see an example of a Petri net (a type of model with formal semantics) which allows for the sequences <A,B,C>, <A,C,B>, <D,B,C>, and <D,C,B>.
https://i.imgur.com/SbVYMvX.png
For an overview of automated process discovery algorithms to mine a process model from sequnce data, we refer to [this recent survey and benchmark paper](https://ieeexplore.ieee.org/abstract/document/8368306/).
Robustness and generalization
Huan Xu and Shie Mannor
Machine Learning - 2012 via Local CrossRef
[link] Summary by David Stutz 6 months ago
Xu and Mannor provide a theoretical paper on robustness and generalization where their notion of robustness is based on the idea that the difference in loss should be small for samples that are close. This implies that, e.g., for a test sample close to a training sample, the loss on both samples should be similar. The authors formalize this notion as follows:
Definition: Let $A$ be a learning algorithm and $S \subset Z$ be a training set such that $A(S)$ denotes the model learned on $S$ by $A$; the algorithm $A$ is $(K, \epsilon(S))$-robust if $Z$ can be partitioned into $K$ disjoint sets, denoted $C_i$ such that $\forall s \in S$ it holds:
$s,z \in C_i \rightarrow |l(A(S), s) – l(A(S), z)| \leq \epsilon(S)$.
In words, this means that we can partition the space $Z$ (which is $X \times Y$ for a supervised problem) into a finite set of subsets and whenever a sample falls into the same partition as a training sample, the learned model should have nearly the same loss on both samples. Note that this notion does not entirely match the notion of adversarial robustness as commonly referred to nowadays. The main difference is that the partition can be chosen, while for adversarial robustness, the "partition" (usually in form of epsilon-balls around training and testing samples) is fixed.
Based on the above notion of robustness, the authors provide PAC bounds for robust algorithms, i.e. generalization performance of $A$ is linked to its generalization. Furthermore, in several examples, common machine learning techniques such as SVMs and neural networks are shown to be robust under specific conditions. For neural networks, for example, an upper bound on the $L_1$ norm of weights and the requirement of Lipschitz continuity is enough. This actually related to work on adversarial robustness, where Lipschitz continuity and weight regularization is also studied.
Also find this summary at [davidstutz.de](https://davidstutz.de/category/reading/).
Peto's Paradox: evolution's prescription for cancer prevention
Aleah F. Caulin and Carlo C. Maley
Trends in Ecology & Evolution - 2011 via Local CrossRef
[link] Summary by cyberplasm 3 years ago
There is no correlation between body size and cancer incidence across animal species. From a logical point of view such a correlation would be expected. If one assumes that each proliferating cell in an individual multicellular organism has an equal probability of acquiring a cancerous mutation, then organisms with significantly more cells should have a higher probability of developing a cancerous tumour. This is known as Peto's paradox.
This paper puts Peto's paradox in the context of an evolutionary strategy to allow large multicellular organisms to live beyond reproductive age. Evolutionary theory describes the genetic instabilities (and variations) leading to the development of tumour suppression mechanisms. The evolutionary rules are clearly stated in box 1 and are reasonable considering the known heterogeneity of tumours.
I particularly like this paper because it puts some captivating numbers on the effect of tumour suppression in some animals. It takes one extreme of animal size, and a well known character in terms of tumour suppression, the blue whale, and makes back of the envelope calculations to what its cancer incidence should theoretically be. Given that the blue whale is 1000 times the size of a human the authors predict that all blue whales should have colorectal cancer by the age of 80. For information, blue whales can live to more than 100 years.
Within a species size is related to cancer risk (Hooray I knew there would be some advantage to being only 165cm) whereby a 3-4 mm increase above the average leg length results in an 80% higher risk of non smoking related cancers. All this suggests that large organisms (that also happen to live longer) have acquired mechanism to suppress cancer.
The authors describe such cancer suppression mechanisms including lower somatic mutation rates, different tissue architecture, redundancy in tumour suppressor genes and a somehow lower selective advantage of mutant cells and increased sensitivity to contact exhibition to name but a few.
A particularly tantalising theory suggested by Nagy et al is that of "hypertumours" whereby a parasitic growth from the cancerous tumour results in a lowering of the overall fitness tumour fitness. This hypothesis has yet to be tested.
My understanding is that comparing cancer suppression mechanisms across the species will lead to a better understanding of the evolutionary process involved in cancer progression and perhaps will reveal knowledge to help better develop strategies for cancer therapies in humans.
Near-optimal probabilistic RNA-seq quantification
Nicolas L Bray and Harold Pimentel and Páll Melsted and Lior Pachter
Nature Biotechnology - 2016 via Local CrossRef
[link] Summary by Geneviève Boucher 1 year ago
This paper from 2016 introduced a new k-mer based method to estimate isoform abundance from RNA-Seq data called kallisto. The method provided a significant improvement in speed and memory usage compared to the previously used methods while yielding similar accuracy. In fact, kallisto is able to quantify expression in a matter of minutes instead of hours.
The standard (previous) methods for quantifying expression rely on mapping, i.e. on the alignment of a transcriptome sequenced reads to a genome of reference. Reads are assigned to a position in the genome and the gene or isoform expression values are derived by counting the number of reads overlapping the features of interest.
The idea behind kallisto is to rely on a pseudoalignment which does not attempt to identify the positions of the reads in the transcripts, only the potential transcripts of origin. Thus, it avoids doing an alignment of each read to a reference genome. In fact, kallisto only uses the transcriptome sequences (not the whole genome) in its first step which is the generation of the kallisto index. Kallisto builds a colored de Bruijn graph (T-DBG) from all the k-mers found in the transcriptome. Each node of the graph corresponds to a k-mer (a short sequence of k nucleotides) and retains the information about the transcripts in which they can be found in the form of a color. Linear stretches having the same coloring in the graph correspond to transcripts. Once the T-DBG is built, kallisto stores a hash table mapping each k-mer to its transcript(s) of origin along with the position within the transcript(s). This step is done only once and is dependent on a provided annotation file (containing the sequences of all the transcripts in the transcriptome).
Then for a given sequenced sample, kallisto decomposes each read into its k-mers and uses those k-mers to find a path covering in the T-DBG. This path covering of the transcriptome graph, where a path corresponds to a transcript, generates k-compatibility classes for each k-mer, i.e. sets of potential transcripts of origin on the nodes. The potential transcripts of origin for a read can be obtained using the intersection of its k-mers k-compatibility classes. To make the pseudoalignment faster, kallisto removes redundant k-mers since neighboring k-mers often belong to the same transcripts. Figure1, from the paper, summarizes these different steps.
https://i.imgur.com/eNH2kuO.png
**Figure1**. Overview of kallisto. The input consists of a reference transcriptome and reads from an RNA-seq experiment. (a) An example of a read (in black) and three overlapping transcripts with exonic regions as shown. (b) An index is constructed by creating the transcriptome de Bruijn Graph (T-DBG) where nodes (v1, v2, v3, ... ) are k-mers, each transcript corresponds to a colored path as shown and the path cover of the transcriptome induces a k-compatibility class for each k-mer. (c) Conceptually, the k-mers of a read are hashed (black nodes) to find the k-compatibility class of a read. (d) Skipping (black dashed lines) uses the information stored in the T-DBG to skip k-mers that are redundant because they have the same k-compatibility class. (e) The k-compatibility class of the read is determined by taking the intersection of the k-compatibility classes of its constituent k-mers.[From Bray et al. Near-optimal probabilistic RNA-seq quantification, Nature Biotechnology, 2016.]
Then, kallisto optimizes the following RNA-Seq likelihood function using the expectation-maximization (EM) algorithm.
$$L(\alpha) \propto \prod_{f \in F} \sum_{t \in T} y_{f,t} \frac{\alpha_t}{l_t} = \prod_{e \in E}\left( \sum_{t \in e} \frac{\alpha_t}{l_t} \right )^{c_e}$$
In this function, $F$ is the set of fragments (or reads), $T$ is the set of transcripts, $l_t$ is the (effective) length of transcript $t$ and **y**$_{f,t}$ is a compatibility matrix defined as 1 if fragment $f$ is compatible with $t$ and 0 otherwise. The parameters $α_t$ are the probabilities of selecting reads from a transcript $t$. These $α_t$ are the parameters of interest since they represent the isoforms abundances or relative expressions.
To make things faster, the compatibility matrix is collapsed (factorized) into equivalence classes. An equivalent class consists of all the reads compatible with the same subsets of transcripts. The EM algorithm is applied to equivalence classes (not to reads). Each $α_t$ will be optimized to maximise the likelihood of transcript abundances given observations of the equivalence classes. The speed of the method makes it possible to evaluate the uncertainty of the abundance estimates for each RNA-Seq sample using a bootstrap technique. For a given sample containing $N$ reads, a bootstrap sample is generated from the sampling of $N$ counts from a multinomial distribution over the equivalence classes derived from the original sample. The EM algorithm is applied on those sampled equivalence class counts to estimate transcript abundances. The bootstrap information is then used in downstream analyses such as determining which genes are differentially expressed.
Practically, we can illustrate the different steps involved in kallisto using a small example. Starting from a tiny genome with 3 transcripts, assume that the RNA-Seq experiment produced 4 reads as depicted in the image below.
https://i.imgur.com/5JDpQO8.png
The first step is to build the T-DBG graph and the kallisto index. All transcript sequences are decomposed into k-mers (here k=5) to construct the colored de Bruijn graph. Not all nodes are represented in the following drawing. The idea is that each different transcript will lead to a different path in the graph. The strand is not taken into account, kallisto is strand-agnostic.
https://i.imgur.com/4oW72z0.png
Once the index is built, the four reads of the sequenced sample can be analysed. They are decomposed into k-mers (k=5 here too) and the pre-built index is used to determine the k-compatibility class of each k-mer. Then, the k-compatibility class of each read is computed. For example, for read 1, the intersection of all the k-compatibility classes of its k-mers suggests that it might come from transcript 1 or transcript 2.
https://i.imgur.com/woektCH.png
This is done for the four reads enabling the construction of the compatibility matrix **y**$_{f,t}$ which is part of the RNA-Seq likelihood function. In this equation, the $α_t$ are the parameters that we want to estimate.
https://i.imgur.com/Hp5QJvH.png
The EM algorithm being too slow to be applied on millions of reads, the compatibility matrix **y**$_{f,t}$ is factorized into equivalence classes and a count is computed for each class (how many reads are represented by this equivalence class). The EM algorithm uses this collapsed information to maximize the new equivalent RNA-Seq likelihood function and optimize the $α_t$.
https://i.imgur.com/qzsEq8A.png
The EM algorithm stops when for every transcript $t$, $α_tN$ > 0.01 changes less than 1%, where $N$ is the total number of reads.
Generative adversarial networks uncover epidermal regulators and predict single cell perturbations
Arsham Ghahramani and Fiona M Watt and Nicholas M Luscombe
bioRxiv: The preprint server for biology - 2018 via Local CrossRef
[link] Summary by David Stutz 1 year ago
Lee et al. propose a variant of adversarial training where a generator is trained simultaneously to generated adversarial perturbations. This approach follows the idea that it is possible to "learn" how to generate adversarial perturbations (as in [1]). In this case, the authors use the gradient of the classifier with respect to the input as hint for the generator. Both generator and classifier are then trained in an adversarial setting (analogously to generative adversarial networks), see the paper for details.
[1] Omid Poursaeed, Isay Katsman, Bicheng Gao, Serge Belongie. Generative Adversarial Perturbations. ArXiv, abs/1712.02328, 2017.
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
Peter Anderson and Xiaodong He and Chris Buehler and Damien Teney and Mark Johnson and Stephen Gould and Lei Zhang
Conference and Computer Vision and Pattern Recognition - 2018 via Local CrossRef
[link] Summary by jerpint 5 months ago
# Summary
This paper presents state-of-the-art methods for both caption generation of images and visual question answering (VQA). The authors build on previous methods by adding what they call a "bottom-up" approach to previous "top-down" attention mechanisms. They show that using their approach they obtain SOTA on both Image captioning (MSCOCO) and the Visual Question and Answering (2017 VQA challenge). They propose a specific network configurations for each. Their biggest contribution is using Faster-R-CNN to retrieve the "important" parts of an image to focus on in both models.
## Top Down
Up until this paper, the traditional approach was to use a "top-down" approach, in which the last feature map layer of a CNN is used to obtain a latent representation of the given input image. These features, along with the context of the caption being generated, were used to generate attention weights that were used to predict the next sequence in the context of caption generation. The network would learn to focus its attention on regions of the feature map that matters most. This is the approach used in previous SOTA methods like [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention](https://arxiv.org/abs/1502.03044).
## Bottom-up
The authors argue that the feature map of a CNN is too generic and can be thought of operating on a uniform, grid-like feature map. In other words, there is no particular reason to think that the feature map of generated by a CNN would give optimal regions to attend to. Also, carefully choosing the dimensions of the feature map can be very arbitrary.
In order to fix this, the authors propose combining object detection methods in a *bottom-up* approach. To do so, the authors propose using Faster-R-CNN to identify regions of interest in an image. Given an input image, Faster-R-CNN will identify bounding boxes of the image that likely correspond to objects of a given category and simultaneously compute a feature vector of that bounding box. Figure 1 shows the difference between the Bottom-up and Top-Down approach.

## Combining the two
In this paper, the authors suggest using the bottom-up approach to compute the salient regions of the image the network should focus on using Faster-R-CNN. FRCNN is carefully pretrained on both imagenet and the Visual Genome dataset. It is then frozen and only used to generate bounding boxes of regions with high confidence of being of interest. The top-down approach is then used on the features obtained from the bottom-up approach. In order to "enhance" the FRCNN performance, they initialize their FRCNN with a ResNet-101 pre-trained on imagenet. They train their FRCNN on the Visual Genome dataset, adding attributes to the loss function that are available from the Visual Genome dataset, attributes such as color (black, white, gold etc.), state (open, close, dark, bright, etc.). A sample of FRCNN outputs are shown in figure 2. It is important to stress that only the feature representations and not the actual outputs (i.e. not the labels) are used in their model.

## Caption Generation
Figure 3 provides a high-level overview of the model being used for caption generation for images. The image is first passed through FRCNN which produces a set of image features *V*. In their specific implementation, *V* consists of *k* vectors of size 1x2048. Their model consists of two LSTM blocks, one for attention and the other for language generation.
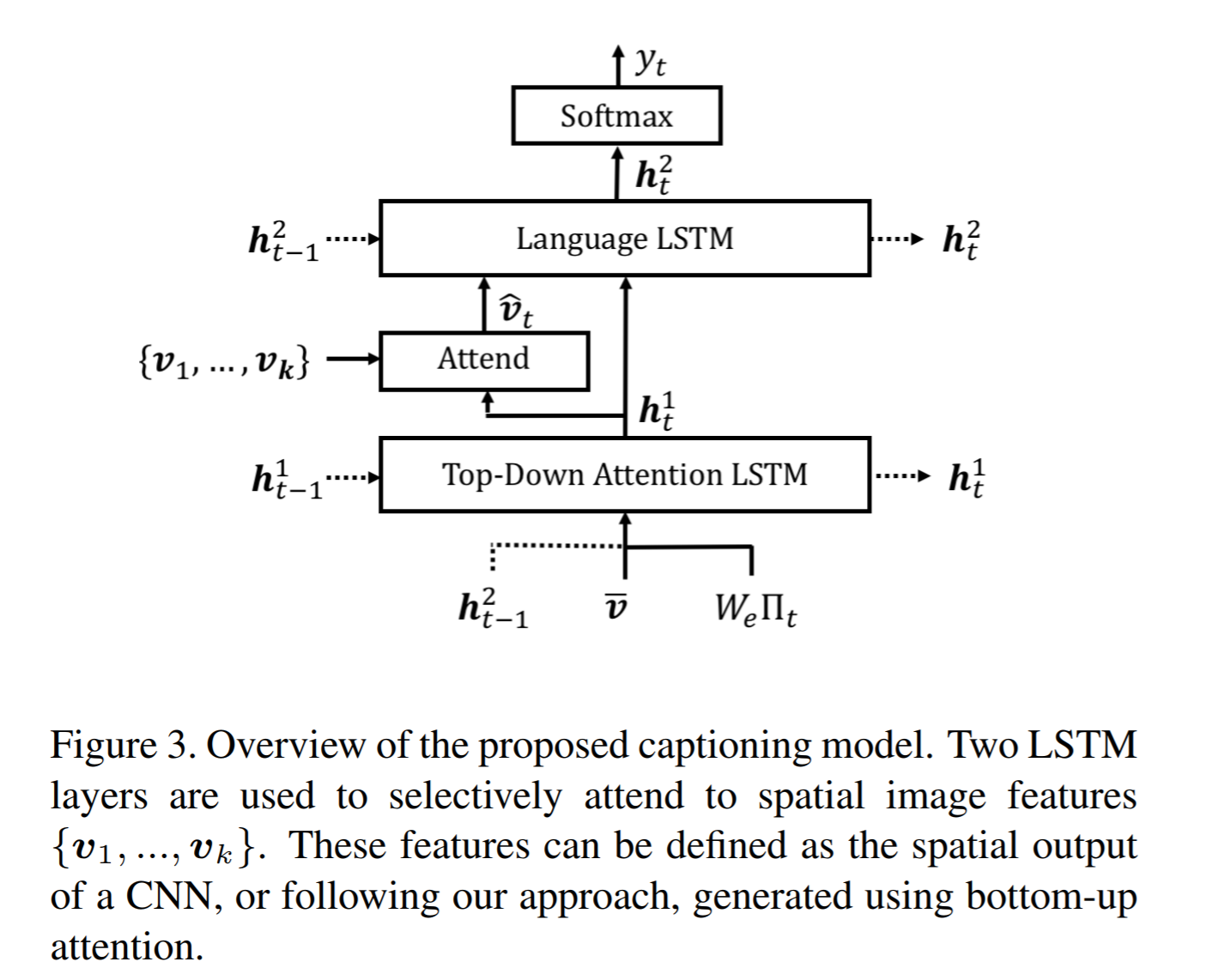
The first block of their model is a Top-Down Attention LSTM layer. It takes as input the mean-pooled features *V* , i.e. 1/k*sum(v_i), concatenated with the previous timestep's hidden representation of the language LSTM as well as the word embedding of the previously generated word. The word embedding is learned and not pretrained.
The output of the first LSTM is used to compute the attention for each vector using an MLP and softmax:

The attention weighted image feature is then used as an input to the language LSTM model, concatenated with the output from the top-down Attention LSTM and a softmax is used to predict the next word in the sequence. The loss function seeks to minimize the cross-entropy of the generated sentence.
## VQA Model
The VQA task differs to the image generation in that a text-based question accompanies an input image and the network must produce an answer. The VQA model proposed is different to that of the caption generation model previously described, however they both use the same bottom-up approach to generate the feature vectors of the image based on the FRCNN architecture. A high-level overview of the architecture for the VQA model is presented in Figure 4.
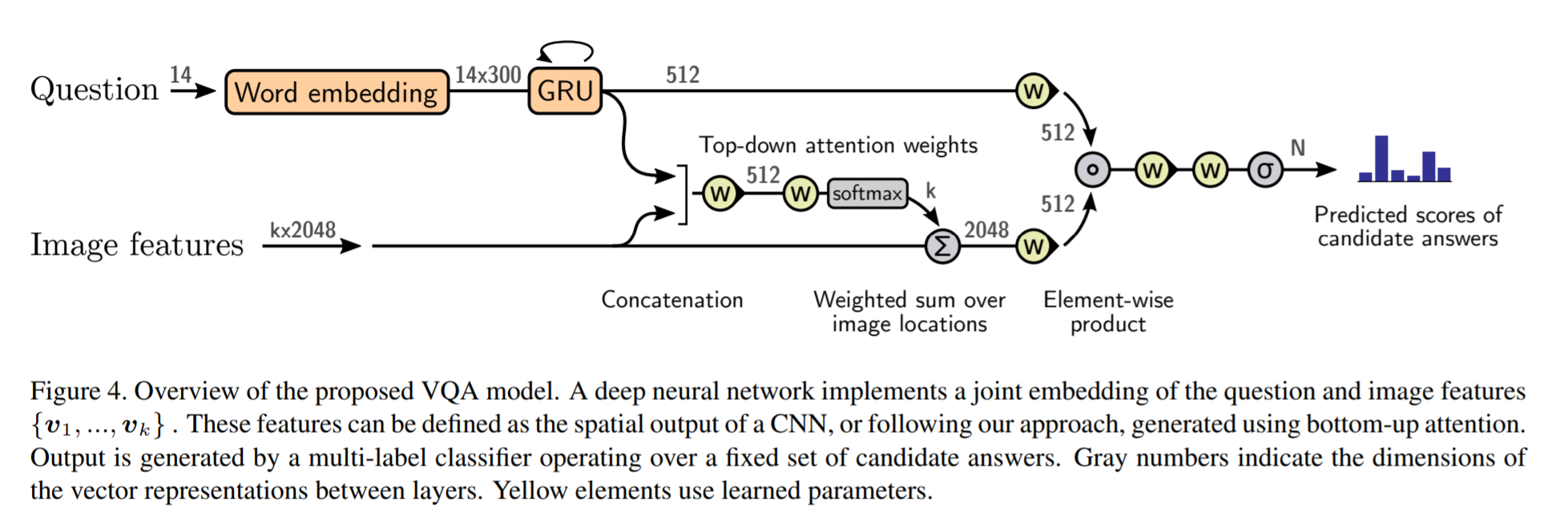
Each word from the question is converted to a learned word embedding which is used as input to a GRU. The number of words for each question is limited to 14 for computational efficiency. The output from the GRU is concatenated with each of the *k* image features, and attention weights are computed for each *k*th feature using an MLP and softmax, similar to what is done in the attention for caption generation. The weighted sum of the feature vectors is then passed through an linear layer such that its shape is compatible with the gru output, and the Hadamard product (element-wise product) is computed over the GRU output and attention-weighted image feature representation. Finally, a tanh non-linear activation is used. This results in a "gated tanh", which have been shown empirically to outperform both ReLU and tanh. Finally, a softmax probability distribution is generated at the output which selects a candidate answer among all possible candidate answers.
## Results and experiments
### Resnet Baseline
To demonstrate that their contribution of bottom-up mechanism actually improves on results, the authors use a ResNet trained on imagenet as a baseline for generating the image feature vectors (they resize the final CNN layers using bilinear interpolation when needed). They consistently obtain better results when using the bottom-up approach over the ResNet approach in both caption generation and VQA.
## MSCOCO
The authors demonstrate that they outperform all results on all metrics on the MSCOCO test server.
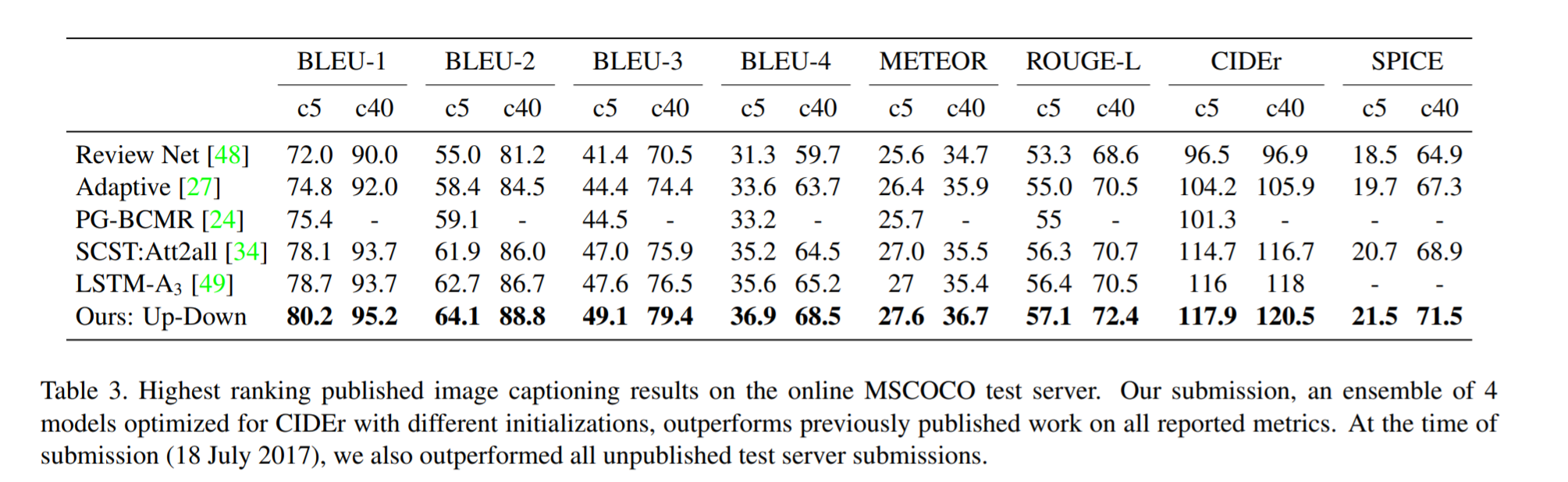
They also show how using the bottom-up approach over ResNet consistently scores them higher on detecting instances of objects, attributes, relations, etc:

The authors, like their predecessors, insist on demonstrating their network's frisbee ability:

## VQA Results
They also demonstrate that the addition of bottom-up attention improves results over a ResNet baseline.
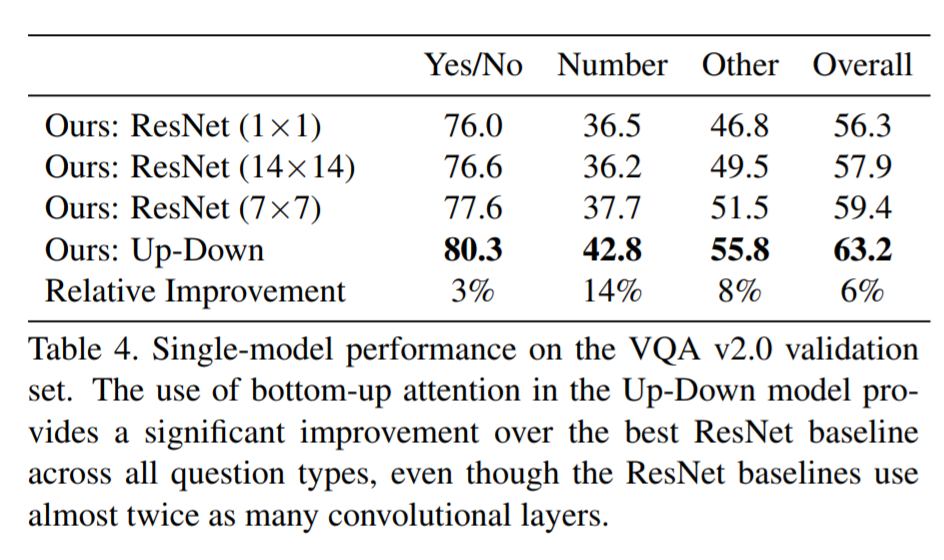
They also show that their model outperformed all other submissions on the VQA submission. They mention using an ensemble of 30 models for their submission.
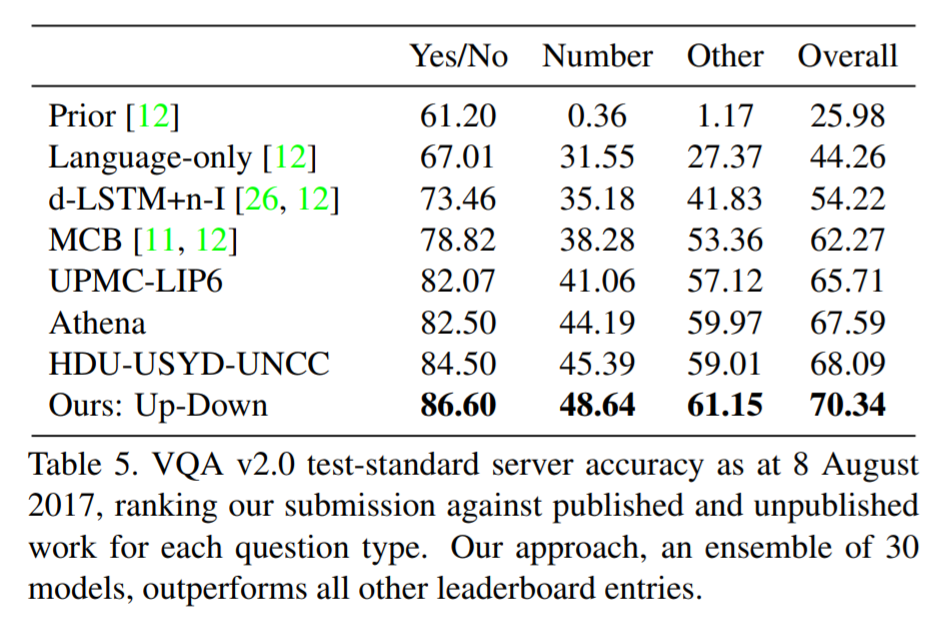
A sample image of what is attended in an image given a proper answer is shown in figure 6.

The authors introduce a new way to select portions of the image on which to focus attention. The idea is very original and came at a time when object detection was making significant progress (i.e. FRCNN).
A few comments:
* This method might not generalize well to other types of data. It requires pre-training on larger datasets (visual genome, imagenet, etc.) which consist of categories that overlap with both the MSCOCO and VQA datasets (i.e. cars, people, etc.). It would be interesting to see an end-to-end model that does not rely on pre-training on other similar datasets.
* No insight is given to the computational complexity nor to the inference time or training time. I imagine that FRCNN is resource intensive, and having to do a forward pass of FRCNN for every pass of the network must be a computational bottleneck. Not to mention that they ensembled 30 of them!
Yoshua Bengio and Jérôme Louradour and Ronan Collobert and Jason Weston
Proceedings of the 26th Annual International Conference on Machine Learning - ICML '09 - 2009 via Local CrossRef
[link] Summary by Shagun Sodhani 3 years ago
### Introduction
* *Curriculum Learning* - When training machine learning models, start with easier subtasks and gradually increase the difficulty level of the tasks.
* Motivation comes from the observation that humans and animals seem to learn better when trained with a curriculum like a strategy.
* [Link](http://ronan.collobert.com/pub/matos/2009_curriculum_icml.pdf) to the paper.
### Contributions of the paper
* Explore cases that show that curriculum learning benefits machine learning.
* Offer hypothesis around when and why does it happen.
* Explore relation of curriculum learning with other machine learning approaches.
### Experiments with convex criteria
* Training perceptron where some input data is irrelevant(not predictive of the target class).
* Difficulty can be defined in terms of the number of irrelevant samples or margin from the separating hyperplane.
* Curriculum learning model outperforms no-curriculum based approach.
* Surprisingly, in the case of difficulty defined in terms of the number of irrelevant examples, the anti-curriculum strategy also outperforms no-curriculum strategy.
### Experiments on shape recognition with datasets having different variability in shapes
* Standard(target) dataset - Images of rectangles, ellipses, and triangles.
* Easy dataset - Images of squares, circles, and equilateral triangles.
* Start performing gradient descent on easy dataset and switch to target data set at a particular epoch (called *switch epoch*).
* For no-curriculum learning, the first epoch is the *switch epoch*.
* As *switch epoch* increases, the classification error comes down with the best performance when *switch epoch* is half the total number of epochs.
* Paper does not report results for higher values of *switch epoch*.
### Experiments on language modeling
* Standard data set is the set of all possible windows of the text of size 5 from Wikipedia where all words in the window appear in 20000 most frequent words.
* Easy dataset considers only those windows where all words appear in 5000 most frequent words in vocabulary.
* Each word from the vocabulary is embedded into a *d* dimensional feature space using a matrix **W** (to be learnt).
* The model predicts the score of next word, given a window of words.
* Expected value of ranking loss function is minimized to learn **W**.
* Curriculum Learning-based model overtakes the other model soon after switching to the target vocabulary, indicating that curriculum-based model quickly learns new words.
### Curriculum as a continuation method
* Continuation methods start with a smoothed objective function and gradually move to less smoothed function.
* Useful in the case where the objective function in non-convex.
* Consider a family of cost functions $C_\lambda (\theta)$ such that $C_0(\theta)$ can be easily optimized and $C_1(\theta)$ is the actual objective function.
* Start with $C_0 (\theta)$ and increase $\lambda$, keeping $\theta$ at a local minimum of $C_\lambda (\theta)$.
* Idea is to move $\theta$ towards a dominant (if not global) minima of $C_1(\theta)$.
* Curriculum learning can be seen as a sequence of training criteria starting with an easy-to-optimise objective and moving all the way to the actual objective.
* The paper provides a mathematical formulation of curriculum learning in terms of a target training distribution and a weight function (to model the probability of selecting anyone training example at any step).
### Advantages of Curriculum Learning
* Faster training in the online setting as learner does not try to learn difficult examples when it is not ready.
* Guiding training towards better local minima in parameter space, specifically useful for non-convex methods.
### Relation to other machine learning approaches
* **Unsupervised preprocessing** - Both have a regularizing effect and lower the generalization error for the same training error.
* **Active learning** - The learner would benefit most from the examples that are close to the learner's frontier of knowledge and are neither too hard nor too easy.
* **Boosting Algorithms** - Difficult examples are gradually emphasised though the curriculum starts with a focus on easier examples and the training criteria do not change.
* **Transfer learning** and **Life-long learning** - Initial tasks are used to guide the optimisation problem.
### Criticism
* Curriculum Learning is not well understood, making it difficult to define the curriculum.
* In one of the examples, anti-curriculum performs better than no-curriculum. Given that curriculum learning is modeled on the idea that learning benefits when examples are presented in order of increasing difficulty, one would expect anti-curriculum to perform worse.
ShortScience.org allows researchers to publish paper summaries that are voted on and ranked!
Sponsored by: and | CommonCrawl |
Moving targets in 4D-CTs versus MIP and AIP: comparison of patients data to phantom data
Kai Joachim Borm1,
Markus Oechsner1,
Moritz Wiegandt1,2,
Andreas Hofmeister1,2,
Stephanie E. Combs1,3 &
Marciana Nona Duma ORCID: orcid.org/0000-0002-0205-44111,3
Maximum (MIP) and average intensity projection (AIP) CTs allow rapid definition of internal target volumes in a 4D-CT. The purpose of this study was to assess the accuracy of these techniques in a large patient cohort in combination with simulations on a lung phantom.
4DCT data from a self-developed 3D lung phantom and from 50 patients with lung tumors were analyzed. ITVs were contoured in maximum (ITVMIP) and average intensity projection (ITVAIP) and subsequently compared to ITVs contoured in 10 phases of a 4D-CT (ITV10). In the phantom study additionally a theoretical target volume was calculated for each motion and compared to the contoured volumes.
ITV10 overestimated the actual target volume by 9.5% whereas ITVMIP and ITVAIP lead to an underestimation of − 1.8% and − 11.4% in the phantom study. The ITVMIP (ITVAIP) was in average − 10.0% (− 18.7%) smaller compared to the ITV10. In the patient CTs deviations between ITV10 and MIP/AIP were significantly larger (MIP: – 20.2% AIP: -33.7%) compared to this. Tumors adjacent to the chestwall, the mediastinum or the diaphragm showed lower conformity between ITV10 and ITVMIP (ITVAIP) compared to tumors solely surrounded by lung tissue. Large tumor diameters (> 3.5 cm) and large motion amplitudes (> 1 cm) were associated with lower conformity between intensity projection CTs and ITV10−.
The application of MIP and AIP in the clinical practice should not be a standard procedure for every patient, since relevant underestimation of tumor volumes may occur. This is especially true if the tumor borders the mediastinum, the chest wall or the diaphragm and if tumors show a large motion amplitude.
Radiotherapy is an indispensible part of lung cancer treatment. It is estimated to be necessary in 50% of patients with small cell lung cancer (SCLC) and in over 60% of patients with non-small-cell lung cancer (NSCLC) in the course of the disease [1]. According to several studies, local control rates of over 95% can be achieved using stereotactic body radiotherapy (SBRT) [2, 3]. However, the treatment success hinges on an accurate target volume definition [4]. Target delineation in the lung is especially challenging due to tumor motion caused by respiration. The extent of motion depends on tumor localization and the patient's breathing pattern. For tumors located close to the diaphragm, amplitudes of over 2.5 cm have been measured [5, 6]. To detect tumor motion accurately, the use of four-dimensional computed tomography (4DCT) is a reliable tool. The 4D-CT generates multiple CT-images, each representing the tumor localization and extent at a certain breathing phase. Contouring of the tumor is usually performed in every single breathing phase with subsequent definition of an internal target volume (ITV) that takes the complete cycle of movement into account. There is good evidence that the use of a 4D-CT reduces motion artifacts and makes target localization more reliable compared to the 3D-CT [7, 8]. This results in better tumor coverage and a decrease of normal tissue irradiation during the treatment [9]. The ITV concept is commonly used for motion management. It ensures excellent tumor coverage but exposes a larger part of healthy lung tissue to radiation. Active motions management such as breathing coordination (gating) and tracking allow smaller treatment volumes and reduction of the dose in the organs at risk (OAR) [10, 11]. However these techniques require information on the tumor position in real time and therefore more complex technical equipment. Thus, the ITV concept remains the preferred motion management technique for many clinics. A major disadvantage of the 4D-CT is the fact that outlining gross tumor volumes (GTVs) in multiple CTs can be time-consuming, especially if a large tumor volume is contoured. Thus, since the introduction of the 4D-CT, alternative contouring methods have been discussed. On the one hand the ITV could be contoured on fewer breathing phases (usually the extreme ones) [9]. On the other hand the ITV might be contoured in average (AIP) or maximum intensity projection (MIP) [12, 13]. Several phantom studies concluded that MIP and AIP are reliable tools for target definition [14, 15]. However there is a lack of clinical studies confirming these findings. A few studies based on small patient collectives (< 20 patients) showed that contouring in MIP might be an adequate option for smaller lung cancers (UICC Stage I) [12, 13, 16]. However a study by Cai et al. [17] using dynamic magnetic resonance imaging as reference concluded that 4D-CT MIP image might cause underdosing due to inaccurate target delineation. Thus the present literature is inconclusive and does not allow any clear conclusions. This study was performed to assess the error of MIP and AIP with special emphasis on tumor localization analyzing a large patient collective in combination with simulations of patient movements on a self-developed lung phantom [18, 19].
A programmable phantom (Fig. 1) was developed based on a xy-table device by SunNuclear® (Sun Nuclear Corporation, Melbourne, FL, USA) that enabled x and y movement. The device was combined with a self-developed equipment that allowed additional movement along the z-axis to simulate 3 dimensional movement. Two spherical structures (Ø 1 cm and Ø 2 cm) composed by water equivalent synthetic substance (RW3) were embedded in corkboards to resemble lung tissue. Tumor movement of 10 patients with large tumor motions (amplitudes > 0.5 cm) out of the patient population described below were reconstructed by using the center of mass motion of the gross tumor volumes delineated in each of the 10 phases of 4D-CT scans. The movement pattern was then simulated with the phantom during CT imaging.
Illustration of the lung phantom (a) and delineation examples of the two targets (Ø 1 cm and Ø 2 cm) in one out of 10 phases of the 4DCT (b), in average intensity projection (c), in maximum intensity projection (d)
Patient population
Fifty patients with lung tumors treated with SBRT in our institution were chosen for this study. The diameter of the tumors ranged between 1.1 cm and 7.0 cm; the median value was 3.1 cm. The tumors were distributed in the upper (n = 23), middle (n = 12) and lower lobe (n = 15) of the left (n = 22) and right lung (n = 28). In 10 cases the tumor was entirely surrounded by lung tissue. The remaining 40 tumors were adjacent to the mediastinum, the chest wall or the diaphragm (Fig. 2). The ethics committee of Klinikum rechts der Isar/Technical University Munich approved this retrospective study. All patients gave their informed consent both informed and written before starting the radiotherapy that they will undergo CT radiotherapy treatment planning. Data from the CT radiotherapy treatment planning were retrospectively analyzed. Immobilization was achieved with a vacuum couch and low pressure foil (Medical Intelligence GmbH, Schwabmünchen, Germany). During irradiation the patients received oxygen supply to further reduce respiratory movement. All plans were calculated for treatment on a Clinac Trilogy linear accelerator equipped with a 120 HD MLC (Varian Medical Systems, Palo Alto, CA, USA).
Lung tumors (*) adjoining different structures in the thorax: A) only lung tissue; B) the mediastinum; C) the diaphragm; D) the chest wall
4D-CT data acquisition and contouring
All CT data were acquired using a Somatom Emotion computer tomography (Siemens Medical Solutions, Erlangen, Germany). The breathing curve was detected by the Real-time Position Management system (RPM, Varian Medical Systems, Palo Alto, CA, USA). The spatial and temporal information was used to generate 4D-CTs containing 10 different breathing phases. The same technique was applied both for the lung cancer patients and the moving phantom. Contouring was performed using the Eclipse software Version 13.0 (Varian Medical Systems, Palo Alto, CA, USA). The visible volume of the tumor in the lung or in the phantom, respectively, was contoured slice by slice. [20]
The CT images were viewed and contoured in standard mediastinal and lung window settings (− 125 HU to 225 HU and − 1000 HU and 200 HU). The contouring of the ITVs was performed manually following a visual approach. The same person performed all contouring to avoid interobserver variability [18, 19]. For every structure a gross target volume (GTV) was defined in each of the 10 phases of the 4D-CT. Subsequently an ITV10 was generated by merging the 10 GTVs.
Additionally maximum (MIP) and average (AIP) intensity projection CTs were generated based on all phases of the 4D-CT, followed by contouring of an ITVMIP and ITVAIP, respectively.
Analysis of target volumes
For every patient the tumor size and diameter was measured in the treatment planning software. The size of the ITV10, ITVMIP and ITVAIP was derived from the treatment planning software after contouring. The average values of ITVMIP and ITVAIP were calculated and compared to the average ITV10. Furthermore, to examine the conformity of the generated structures, we measured the overlap (VOL) of ITV10 and ITVMIP or ITVAIP. Subsequently, conformation numbers (CN) were calculated according to van't Riet et al. [21] as follows: .
$$ CN=\frac{V_{OL}}{ITV_{IP}}\times \frac{V_{OL}}{ITV_{10}} $$
CN: conformation number; VOL: overlapping volume between ITV10 and ITVMIP or ITVAIP; ITVIP: volume of intensity projection (IP) CTs MIP and AIP. ITV10: volume of the target volume based on 10 phases of a 4D-CT.
ITVs measured in the lung phantom (ITV10, ITVMIP, ITVAIP) were additionally compared to mathematically calculated volumes for each motion pattern and tumor diameter. Statistical analysis was performed using SPSS version 24.0 (IBM, Armonk, NY, USA). For all measurements mean values and standard deviation were calculated. The differences between the ITVs (e.g. ITVMIP and ITV10) were tested for statistical significance using a two-sided paired T-test. The threshold for statistical significance was set to p < 0.05.
Lung phantom
For each motion a theoretical ITV was calculated taking the movement pattern and size of the target into account ("theoretical ITV"). This theoretical ITV ranged between 6.7 cm3 and 57.5 cm3, depending on target motion and size. The average ITVcalc for the small target (diameter 1 cm) was 8.6 ± 1.3 cm3 and for the large target (diameter 2 cm) 50.3 ± 4.8 cm3. The ITV10 were significantly larger compared to the calculated values, both for the small (9.3 ± 1.4 cm3) as well as for the large target (54.8 ± 4.3 cm3). Only in 1 out of 20 cases the ITV10 was smaller (− 5,7%) than the calculated values. Contouring in MIP and AIP lead to underestimation of the target volume as compared to the ITVcalc. 98.1 ± 5.3% and 88.6 ± 5.1% of the calculated values were depicted by MIP and AIP. The ITVAIP showed larger deviations from the calculated values (− 11.4%) than ITVMIP and ITV10.
Subsequently ITV10, ITVAIP and ITVMIP were compared to each other. Even though ITVMIP and ITVAIP were also significantly smaller compared to the ITV10 (ITVMIP: -10.0%; ITVAIP: -18.7%) in the lung phantom, the differences between the different techniques were significantly smaller compared to the clinical study (Fig. 3). Correspondingly, the phantom conformation numbers between ITV10 and ITVMIP or ITVAIP were higher compared to the clinical data (Fig. 3). The mean value for the conformation numbers calculated for the ITVMIP and ITVAIP were 0.83 and 0.79. The ITVs of the Ø 1 cm target showed a larger variability as well as slightly lower conformation numbers compared to the Ø 2 cm target (Table 1).
Comparison of values measured in the phantom study (a,c) and in the clinical study (b,d). Relative size (c,d) and conformation numbers (a,b) of ITVs contoured in MIP and AIP in relation to the ITV10
Table 1 Measured values in the lung phantom. Average absolute volumes±SD of the ITV10, ITVMIP, ITVAIP in cm3,(relative volumes±SD as percentage of the calculated values -ITVcalc- in %), conformation numbers (CN) of ITVMIP and ITVAIP with the ITV10. n = number of movement patterns
The average amplitude of tumor movement was 0.58 ± 0.35 cm. The mean ITV10 of all 50 patients was 27.6 ± 36.3 cm3. ITVs based on the MIP or AIP were significantly (p < 0.001) smaller compared to the ITV10. The ITVMIP had an average value of 21.0 ± 29,7 cm3, which corresponded to 73.4 ± 15.6% of the ITV10. The ITVs contoured in the AIP CTs were even smaller with an avarage value of 19.2 ± 27.7 cm3 (64.8 ± 13.4% of the ITV10). The mean overlapping volume of ITV10 and ITVMIP was 20.6 ± 29.6 cm3. 71.0 ± 13.9% of ITV10 were covered in average by the ITVMIP. The ITVAIP covered 63.7 ± 12.8% of the ITV10 (19.0 ± 27.4 cm3). The mean value for the calculated conformity index was 0.69 ± 0.13 in the MIP and 0.63 ± 0.12 in the AIP.
Figure 4 depicts the measured target volumes in MIP and AIP considering the surrounding tissue and the tumor movements. MIP and AIP showed the best concordance with the ITV10 if the tumor was solely surrounded by lung tissue. For tumors bordering other structures, such as the chest wall or the mediastinum the difference between ITV10 and both intensity projection CTs were significantly (< 0.05) larger. The largest deviations between the different contouring techniques (ITV10, ITVMIP, ITVAIP) were found for tumors merging the diaphragm and abdominal organs (> 50% volume difference). MIP showed better conformity with the ITV10 than AIP in all measurements, except for tumors merging to the diaphragm. All values are summarized in Table 2.
Impact of the surrounding tissue (a,c) and motion amplitude (b,d) on the contoured target volumes in MIP and AIP. Relative size (a,b) in % and conformation numbers (c,d) of ITVs contoured in MIP and AIP in regard to the ITV10 CN: conformation number, PTT: peak-to-through motion
Table 2 Measured values for ITVMIP and ITVAIP in dependence on the surrounding tissue and the tumor size in a 4D-CT. Relative size in % in regard to the ITV10 and overlapping volume (VOL) in cm3 as well as conformation numbers (CN) of IT VMIP and ITVAIP with the ITV10
Also, the tumor size (Fig. 3) and the motion amplitude (Fig. 4) had an influence on the relative differences between ITV10 and ITVMIP or ITVAIP. For tumors with a diameter of < 2.5 cm only 64.8 ± 17.9% (or 54.0 ± 14.7%) of the ITV10 were covered in maximum (or average) intensity projection CTs. Tumors with a diameter that ranged between 2.5 cm and 3.5 cm covered 72.6 ± 11.5% in MIP and 65.0 ± 11.8% in AIP of the ITV10. Large tumors (diameter > 3.5 cm) contoured in MIP or AIP (74.1 ± 11.7%; 63.7 ± 12.8%) showed the best conformity to the ITV10. Larger tumor amplitudes were associated with poorer conformity between intensity projection CTs and the ITV10. The differences between ITVMIP and ITVAIP were 11.6% larger in patients with amplitudes of > 1 cm compared the group with tumor motions of < 0.5 cm (Table 2).
Our results show that ITVs contoured in MIP and AIP differ significantly from ITVs contoured in 10 phases of a 4D-CT. In the clinical study, average deviations of approximately − 25% were observed with even larger differences for tumors that border the mediastinum, the chest wall or the diaphragm. The data acquired with the lung phantom shows that ITV10 overestimates the target volume to a certain degree. ITVMIP and ITVAIP on the other hand underestimate the target volume und therefore do not reliably encompass the tumor tissue in all cases. Differences between ITV10 and ITVMIP/AIP were substantially larger in the clinical study compared to the phantom study.
A study of Park et al. [14] analyzed the accuracy of MIPs for various target motions using a programmable lung phantom. Two targets inserted in a cork block were moved with irregular target motions along the superior-inferior direction and the two-dimensional target span in moving direction was measured and compared to the theoretical values. They concluded that the MIP accurately reflects the range of motions for regular target motions. However the validity of the results for the clinical practice is limited, since target motion was simulated in only one direction, no volume assessment was performed and tumors in patients seldom undergo a regular movement pattern. Simon et al. [15] used a lung tumor phantom to simulate anterior-posterior movements to compare AIP and MIP ITVs to calculated theoretical values. The error on volume assessment ranged from.
− 40% to − 9% for the AIP and from − 3 to 12% for the MIP. The average deviations from the calculated values measured in our study in the lung phantom were also within this range (Table 1). The authors concluded that MIPs could be used for target definition of moving targets in a 4D-CT, as it seems to encompass the tumor movement. However, before this conclusion is drawn, the question must be raised whether these results from idealized phantom conditions can be transferred to the clinical situation where serrated tumor shapes, complex tumor movements and irregular density distributions occur.
The available clinical date is inconclusive and based on small groups of patients only. Bradley et al. [12] compared MIP, AIP and helical 4D-CT images of 20 inoperable peripheral stage I lung tumors to determine the best definition method for stereotactic body radiation therapy. MIP-defined ITVs were significantly larger than helical and AIP defined ITVs. They concluded MIP is superior to AIP in order to depict tumor motion. However, since no comparison to the ITV10 was done, the question whether the actual tumor is represented accurately by the ITVMIP remains unclear in this study. A study by Murihead et al. [13] collected 4D-CT data from 14 patients with NSCLC. ITVs were contoured in 10 phases of a 4D-CT and in MIP. The ITV10 served as a reference volume to evaluate the precision of the MIP. In average 19% of the ITV10 were not enclosed by the ITVMIP. This is in accordance with our findings showing an insufficient coverage of the ITV10 in MIP and AIP. The authors proposed the use of the MIP image target delineation for patients with stage I disease, since only minor deviations (6.1%) occurred in this subgroup, which consisted of 2 patients in the study. Contrary to this, in our study small targets (Ø < 2.5 cm in the clinical study, Ø 1 cm in the phantom study) resulted in the poorest conformity between MIP and the ITV10 (Fig. 3). Underberg et al. [16] analyzed 4D-CT data from a phantom and from 11 patients with small Stage I lung cancer. ITVs generated in all 10 phases were compared with ITVs generated in MIP. The average ratio between ITV10 and ITVMIP was 1.04 for the phantom study and 1.07 in scans of the patients. The center of mass differed by only 0.4 or 0.5 mm, respectively. The authors concluded that MIPs are a reliable clinical tool for generating ITVs from a 4DCT data set. Even though not explicitly mentioned by the authors it appears in the figures that narrow window settings (e.g. mediastinal window) have been used for contouring. As shown in current literature these windows do not accurately reflect moving targets and might have a major effect on the results [18] .
According to our results MIP does not accurately depict the target volume as contoured in each of the 10 phases of a 4D-CT. The deviations between ITV10 and ITVMIP/AIP in the clinical study (MIP: – 20.2% AIP: -33.7%) were almost twice as large as in the phantom study (MIP –10.0% AIP -18.7%). Even though the MIP reflected the calculated values in the phantom study well, relevant underestimation of the target size needs to be expected in the clinical practice. This is especially true if the tumor borders the mediastinum, the chest wall or the diaphragm and if tumors show an extensive motion amplitude. For these tumors the deviations were particularly large. The reason for this is a loss of contrast between tumor and surrounding tissue by using maximum values for every voxel, leading to underestimation of the tumor in the overlapping areas. The large deviations using MIP for tumors bordering soft tissues could be also observer dependent, in particular as a visual approach was followed instead of automatic contouring. Since extreme movement of tumors bordering soft tissue impedes definition of an ITV, other treatment options like robotic radio surgery or breath hold techniques should be taken into consideration, in these situations [22, 23].
The 4D-CT has been adopted as a standard modality for target delineation in lung tumors because it represents moving targets significantly better than slow 3D-CTs. Nakamuru et al. [7] evaluated in 32 lung cancer patients the geometrical differences in target volumes between slow CT- and 4D CT- imaging for lung tumors. They observed that target volumes acquired in slow 3D-CTs are approximately 25% smaller compared to target volumes contoured in a 4D-CT. In our study MIP ITVs were on average 20.2% smaller than the ITV10, which, by extrapolation, can be compared to the previous reported difference between the slow 3D-CTs and ITV10. Thus, the use of MIP comes with a risk of losing additional and relevant information obtained by analyzing all phases of the 4D-CT.
The current study focuses solely on the impact of MIP and AIP on definition of the ITV. However, it needs to be also taken into account that the data set used for treatment planning has an important effect on the dose distribution within the tumor and the OAR [20, 24]. Due to respiration-induced density variations within the ITV 3D, dose calculation based on free-breating-, MIP-, AIP- or mid-ventilation CT datasets only estimates the actual dose in the tumor [10]. The dosimetric characteristics of plans based on AIP and mid-ventilation CTs are reported to be similar to those of FB- CTs [25]. Treatment plans calculated on a MIP CT dataset on the other hand may not be not appropriate for OAR dose assessment [20]. A promising approach to cope with density variations is the use of 4D-CT treatment planning with respiration-correlated assignment of the treatment plan's monitor units to the different respiration phases of a 4D-CT and subsequent rigid and non-rigid registration [10].
A potential limitation of this study is the impact of interobserver variability on the contouring of lung tumors in a 4D-CT. Louie et al. [26] showed that the percentage shared internal target volume of 6 physicians contouring 10 different tumors ranged from 31.1 to 83.3%. Therefore the observed effect might differ in some cases. Nevertheless we cannot recommend the MIP (and AIP) as a standard procedure in clinical practice, since relevant underestimation of target motion and tumor volumes may occur. Whenever MIP is used for contouring, we strongly recommend to double check that the ITV encompasses the delineated target in each of the 10 phase of the 4D-CT.
Contouring in maximum or average intensity projection CTs reduces the time that is required to define an internal target volume. Even though the MIP reflected the calculated values in the phantom study well, relevant underestimation of the target size can be expected in the clinical practice. This is especially true if the tumor borders the mediastinum, the chest wall or the diaphragm and if tumors show a large motion amplitude. Therefore neither AIP nor MIP can be unquestionably recommended for target delineation. Whenever MIP is used for contouring, it needs to ensure that ITV encompasses the delineated target in every phase of the 4D-CT.
4DCT:
Four-dimensional computed tomography
AIP:
Average intensity projection
Conformation numbers
GTVs:
Gross tumor volumes
Hounsfield units
ITV:
Internal target volume
ITV10 :
ITV based on 10 4DCT phases
ITVAIP :
ITV based on AIP
ITVcalc :
Theoretical calculated ITV
ITVMIP :
ITV based on MIP
MIP:
Maximum intensity projection
NSCLC:
Non-small-cell lung cancer
OAR:
Organs at risk
SBRT:
Stereotactic body radiotherapy
SCLC:
VOL :
Overlapping volume
Tyldesley S, et al. Estimating the need for radiotherapy for lung cancer: an evidence-based, epidemiologic approach. Int J Radiat Oncol Biol Phys. 2001;49(4):973–85.
Wulf J, et al. Stereotactic radiotherapy of targets in the lung and liver. Strahlenther Onkol. 2001;177(12):645–55.
Rusthoven KE, et al. Multi-institutional phase I/II trial of stereotactic body radiation therapy for lung metastases. J Clin Oncol. 2009;27(10):1579–84.
Ong CL, et al. Treatment of large stage I-II lung tumors using stereotactic body radiotherapy (SBRT): planning considerations and early toxicity. Radiother Oncol. 2010;97(3):431–6.
Shimizu S, et al. Detection of lung tumor movement in real-time tumor-tracking radiotherapy. Int J Radiat Oncol Biol Phys. 2001;51(2):304–10.
Shirato H, et al. Intrafractional tumor motion: lung and liver. Semin Radiat Oncol. 2004;14(1):10–8.
Nakamura M, et al. Geometrical differences in target volumes between slow CT and 4D CT imaging in stereotactic body radiotherapy for lung tumors in the upper and middle lobe. Med Phys. 2008;35(9):4142–8.
Vedam SS, et al. Acquiring a four-dimensional computed tomography dataset using an external respiratory signal. Phys Med Biol. 2003;48(1):45–62.
Rietzel E, et al. Design of 4D treatment planning target volumes. Int J Radiat Oncol Biol Phys. 2006;66(1):287–95.
Guckenberger M, et al. Four-dimensional treatment planning for stereotactic body radiotherapy. Int J Radiat Oncol Biol Phys. 2007;69(1):276–85.
Keall P. 4-dimensional computed tomography imaging and treatment planning. Semin Radiat Oncol. 2004;14(1):81–90.
Bradley JD, et al. Comparison of helical, maximum intensity projection (MIP), and averaged intensity (AI) 4D CT imaging for stereotactic body radiation therapy (SBRT) planning in lung cancer. Radiother Oncol. 2006;81(3):264–8.
Muirhead R, et al. Use of maximum intensity projections (MIPs) for target outlining in 4DCT radiotherapy planning. J Thorac Oncol. 2008;3(12):1433–8.
Park K, et al. Do maximum intensity projection images truly capture tumor motion? Int J Radiat Oncol Biol Phys. 2009;73(2):618–25.
Simon L, et al. Initial evaluation of a four-dimensional computed tomography system, using a programmable motor. Radiat Oncol Phys. 2006;7(4):50–65.
Underberg RW, et al. Use of maximum intensity projections (MIP) for target volume generation in 4DCT scans for lung cancer. Int J Radiat Oncol Biol Phys. 2005;63(1):253–60.
Cai J, Read PW, Sheng K. The effect of respiratory motion variability and tumor size on the accuracy of average intensity projection from four-dimensional computed tomography: an investigation based on dynamic MRI. Med Phys. 2008;35(11):4974–81.
Borm KJ, et al. The importance of surrounding tissues and window settings for contouring of moving targets. Strahlenther Onkol. 2015;191(9):750–6.
Borm KJ, et al. The impact of CT window settings on the contouring of a moving target: a phantom study. Clin Radiol. 2014;69(8):e331–6.
Oechsner M, et al. Interobserver variability of patient positioning using four different CT datasets for image registration in lung stereotactic body radiotherapy. Strahlenther Onkol. 2017;193(10):831–9.
van't Riet A, et al. A conformation number to quantify the degree of conformality in brachytherapy and external beam irradiation: application to the prostate. Int J Radiat Oncol Biol Phys. 1997;37(3):731–6.
Katoh N, et al. Clinical outcomes of stage I and IIA non-small cell lung cancer patients treated with stereotactic body radiotherapy using a real-time tumor-tracking radiotherapy system. Radiat Oncol. 2017;12(1):3.
Takao S, et al. Intrafractional baseline shift or drift of lung tumor motion during gated radiation therapy with a real-time tumor-tracking system. Int J Radiat Oncol Biol Phys. 2016;94(1):172–80.
Ehrbar S, et al. ITV, mid-ventilation, gating or couch tracking - a comparison of respiratory motion-management techniques based on 4D dose calculations. Radiother Oncol. 2017;124(1):80–8.
Tian Y, et al. Dosimetric comparison of treatment plans based on free breathing, maximum, and average intensity projection CTs for lung cancer SBRT. Med Phys. 2012;39(5):2754–60.
Louie AV, et al. Inter-observer and intra-observer reliability for lung cancer target volume delineation in the 4D-CT era. Radiother Oncol. 2010;95(2):166–71.
External funding: not available.
The authors are employed as care providers/researchers by Klinikum rechts der Isar, Technical University Munich, Germany.
Department of Radiation Oncology, Klinikum rechts der Isar, TU München, Ismaninger Str. 22, 81675, Munich, Germany
Kai Joachim Borm, Markus Oechsner, Moritz Wiegandt, Andreas Hofmeister, Stephanie E. Combs & Marciana Nona Duma
Medical School Technische Universität München, Ismaninger Str. 22, 81675, Munich, Germany
Moritz Wiegandt & Andreas Hofmeister
Institute of Innovative Radiotherapy (iRT), Helmholtz Zentrum München, Ingolstädter Landstraße 1, 85764, Oberschleißheim, Germany
Stephanie E. Combs & Marciana Nona Duma
Kai Joachim Borm
Markus Oechsner
Moritz Wiegandt
Andreas Hofmeister
Stephanie E. Combs
Marciana Nona Duma
MND and MO initiated the project. KJB, MW and AH generated and analyzed the data. MND, KJB, SEC performed patient care. KJB, MO and MND wrote the manuscript. KJB, MO, SEC and MND finalized the manuscript. All authors read and approved the final manuscript.
Correspondence to Marciana Nona Duma.
The ethics committee of Klinikum rechts der Isar, TU München has approved this retrospective study (475/17S). All patients gave their informed consent to undergo CT for radiotherapy treatment planning. The need for a second informed consent for this retrospective study on CT datasets was deemed unnecessary and has been waived by the IRB.
MND is an editor of BMC cancer. All other authors declare that they have no competing interests.
Borm, K.J., Oechsner, M., Wiegandt, M. et al. Moving targets in 4D-CTs versus MIP and AIP: comparison of patients data to phantom data. BMC Cancer 18, 760 (2018). https://doi.org/10.1186/s12885-018-4647-4
4D-CT
SBRT | CommonCrawl |
Selecting ultra-faint dwarf candidate progenitors in cosmological N-body simulations at high redshifts (1712.03967)
Mohammadtaher Safarzadeh, Alexander P. Ji, Gregory A. Dooley, Anna Frebel, Evan Scannapieco, Facundo A. Gómez, Brian W. O'Shea
March 1, 2018 astro-ph.GA
The smallest satellites of the Milky Way ceased forming stars during the epoch of reionization and thus provide archaeological access to galaxy formation at $z>6$. Numerical studies of these ultra-faint dwarf galaxies (UFDs) require expensive cosmological simulations with high mass resolution that are carried out down to $z=0$. However, if we are able to statistically identify UFD host progenitors at high redshifts \emph{with relatively high probabilities}, we can avoid this high computational cost. To find such candidates, we analyze the merger trees of Milky Way type halos from the high-resolution ${\it Caterpillar}$ suite of dark matter only simulations. Satellite UFD hosts at $z=0 $ are identified based on four different abundance matching (AM) techniques. All the halos at high redshifts are traced forward in time in order to compute the probability of surviving as satellite UFDs today. Our results show that selecting potential UFD progenitors based solely on their mass at z=12 (8) results in a 10\% (20\%) chance of obtaining a surviving UFD at $z=0$ in three of the AM techniques we adopted. We find that the progenitors of surviving satellite UFDs have lower virial ratios ($\eta$), and are preferentially located at large distances from the main MW progenitor, while they show no correlation with concentration parameter. Halos with favorable locations and virial ratios are $\approx 3$ times more likely to survive as satellite UFD candidates at $z=0.$
Following the Cosmic Evolution of Pristine Gas II: The search for Pop III-Bright Galaxies (1710.09878)
Richard Sarmento, Evan Scannapieco, Seth Cohen
Feb. 21, 2018 astro-ph.GA
Direct observational searches for Population III (Pop III) stars at high redshift are faced with the question of how to select the most promising targets for spectroscopic follow-up. To help answer this, we use a large-scale cosmological simulation, augmented with a new subgrid model that tracks the fraction of pristine gas, to follow the evolution of high-redshift galaxies and the Pop III stars they contain. We generate rest-frame ultraviolet (UV) luminosity functions for our galaxies and find that they are consistent with current $z \ge 7 $ observations. Throughout the redshift range $7 \le z \le 15$ we identify "Pop III-bright" galaxies as those with at least 75% of their flux coming from Pop III stars. While less than 1% of galaxies brighter than $m_{\rm UV, AB} = 31.4$ mag are Pop III--bright in the range $7\leq z \leq8$, roughly 17% of such galaxies are Pop III--bright at $z=9$, immediately before reionization occurs in our simulation. Moving to $z=10$, $m_{\rm UV, AB} = 31.4$ mag corresponds to larger, more luminous galaxies and the Pop III-bright fraction falls off to 5%. Finally, at the highest redshifts, a large fraction (29% at $z=14$ and 41% at $z=15)$ of all galaxies are Pop III-bright regardless of magnitude. While $m_{\rm UV, AB} = 31.4$ mag galaxies are extremely rare during this epoch, we find that 13% of galaxies at $z = 14$ are Pop III-bright with $m_{\rm UV, AB} \le 33$ mag, an intrisic magnitude within reach of the James Webb Space Telescope using lensing. Thus, we predict that the best redshift to search for luminous Pop III--bright galaxies is just before reionization, while lensing surveys for fainter galaxies should push to the highest redshifts possible.
The Fate of Gas rich Satellites in Clusters (1710.01319)
Mohammadtaher Safarzadeh, Evan Scannapieco
Oct. 17, 2017 astro-ph.GA
We investigate the stellar mass loss of gas rich galaxies falling into clusters due to the change in the gravitational potential caused by the ram pressure stripping of their gas. We model the satellites with exponential stellar and gas disk profiles, assume rapid ram pressure stripping, and follow the stellar orbits in the shocked potential. Due to the change of the potential, the stars move from circular orbits to elliptical orbits with apocenters that are often outside the tidal radius, causing those stars to be stripped. We explore the impact of the redshift of infall, gas fraction, satellite halo mass and cluster mass on this process. The puffing of the satellites makes them appear as ultra diffuse galaxies, and the stripped stars contribute to the intracluster light. Our results show these effects are most significant for less-massive satellites, which have larger gas fractions when they are accreted into clusters. The preferential destruction of low mass systems causes the red fraction of cluster galaxies to be smaller at lower masses, an observation that is otherwise difficult to explain.
The Effect of Turbulence on Nebular Emission Line Ratios (1710.01312)
William J. Gray, Evan Scannapieco
Oct. 3, 2017 astro-ph.CO, astro-ph.GA
Motivated by the observed differences in the nebular emission of nearby and high-redshift galaxies, we carry out a set of direct numerical simulations of turbulent astrophysical media exposed to a UV background. The simulations assume a metallicity of $Z/Z_{\odot}$=0.5 and explicitly track ionization, recombination, charge transfer, and ion-by-ion radiative cooling for several astrophysically important elements. Each model is run to a global steady state that depends on the ionization parameter $U$, and the one-dimensional turbulent velocity dispersion, $\sigma_{\rm 1D}$, and the turbulent driving scale. We carry out a suite of models with a T=42,000K blackbody spectrum, $n_e$ = 100 cm$^{-3}$ and $\sigma_{\rm 1D}$ ranging between 0.7 to 42 km s$^{-1},$ corresponding to turbulent Mach numbers varying between 0.05 and 2.6. We report our results as several nebular diagnostic diagrams and compare them to observations of star-forming galaxies at a redshift of $z\approx$2.5, whose higher surface densities may also lead to more turbulent interstellar media. We find that subsonic, transsonic turbulence, and turbulence driven on scales of 1 parsec or greater, have little or no effect on the line ratios. Supersonic, small-scale turbulence, on the other hand, generally increases the computed line emission. In fact with a driving scale $\approx 0.1$ pc, a moderate amount of turbulence, $\sigma_{\rm 1D}$=21-28 km s$^{-1},$ can reproduce many of the differences between high and low redshift observations without resorting to harder spectral shapes.
The Production of Cold Gas Within Galaxy Outflows (1702.00793)
Evan Scannapieco
Feb. 2, 2017 astro-ph.GA
I present a suite of three-dimensional simulations of the evolution of initially-hot material ejected by starburst-driven galaxy outflows. The simulations are conducted in a comoving frame that moves with the material, tracking atomic/ionic cooling, Compton cooling, and dust cooling and destruction. Compton cooling is most efficient of these processes, while the main role of atomic/ionic cooling is to enhance density inhomogeneities. Dust, on the other hand, has little effect on the outflow evolution, and is rapidly destroyed in all the simulations except the case with the smallest mass flux. I use the results to construct a simple steady-state model of the observed UV/optical emission from each outflow. The velocity profiles in this case are dominated by geometric effects, and the overall luminosities are extremely strong functions of the properties of the host system, as observed in ultra-luminous infrared galaxies (ULIRGs). Furthermore the luminosities and maximum velocities in several models are consistent with emission-line observations of ULIRGs, although the velocities are significantly greater than observed in absorption-line studies. It may be that absorption line observations of galaxy outflows probe entrained cold material at small radii, while emission-line observations probe cold material condensing from the initially hot medium at larger distances.
Numerical Simulation of Star Formation by the Bow Shock of the Centaurus A Jet (1610.02123)
Carl L. Gardner, Jeremiah R. Jones, Evan Scannapieco, Rogier A. Windhorst
Dec. 9, 2016 astro-ph.GA
Recent Hubble Space Telescope (HST) observations of the extragalactic radio source Centaurus A (Cen A) display a young stellar population around the southwest tip of the inner filament 8.5 kpc from the Cen A galactic center, with ages in the range of 1-3 Myr. Crockett et al. (2012) argue that the transverse bow shock of the Cen A jet triggered this star formation as it impacted dense molecular cores of clouds in the filament. To test this hypothesis, we perform three-dimensional numerical simulations of induced star formation by the jet bow shock in the inner filament of Cen A, using a positivity preserving WENO method to solve the equations of gas dynamics with radiative cooling. We find that star clusters form inside a bow-shocked molecular cloud when the maximum initial density of the cloud is > 40 H2 molecules/cm^3. In a typical molecular cloud of mass 10^6 M_sun and diameter 200 pc, approximately 20 star clusters of mass 10^4 M_sun are formed, matching the HST images.
Searching For Fossil Evidence of AGN Feedback in WISE-Selected Stripe-82 Galaxies By Measuring the Thermal Sunyaev-Zel'dovich Effect With the Atacama Cosmology Telescope (1610.02068)
Alexander Spacek, Evan Scannapieco, Seth Cohen, Bhavin Joshi, Philip Mauskopf
We directly measure the thermal energy of the gas surrounding galaxies through the thermal Sunyaev-Zel'dovich (tSZ) effect. We perform a stacking analysis of microwave background images from the Atacama Cosmology Telescope, around 1179 massive quiescent elliptical galaxies at 0.5 <= z <= 1.0 ('low-z') and 3274 galaxies at 1.0 <= z <= 1.5 ('high-z'), selected using data from the Wide-Field Infrared Survey Explorer All-Sky Survey and the Sloan Digital Sky Survey (SDSS) within the SDSS Stripe-82 field. The gas surrounding these galaxies is expected to contain energy from past episodes of active galactic nucleus (AGN) feedback, and after using modeling to subtract undetected contaminants, we detect a tSZ signal at a significance of 0.9-sigma for our low-z galaxies and 1.8-sigma for our high-z galaxies. We then include data from the high-frequency Planck bands for a subset of 227 low-z galaxies and 529 high-z galaxies and find low-z and high-z tSZ detections of 1.0-sigma and 1.5-sigma, respectively. These results indicate an average thermal heating around these galaxies of 5.6(+5.9/-5.6) x 10^60 erg for our low-z galaxies and 7.0(+4.7/-4.4) x 10^60 erg for our high-z galaxies. Based on simple heating models, these results are consistent with gravitational heating without additional heating due to AGN feedback.
Following The Cosmic Evolution Of Pristine Gas I: Implications For Milky Way Halo Stars (1611.00025)
Richard Sarmento, Evan Scannapieco, Liubin Pan
We make use of new subgrid model of turbulent mixing to accurately follow the cosmological evolution of the first stars, the mixing of their supernova ejecta, and the impact on the chemical composition of the Galactic Halo. Using the cosmological adaptive mesh refinement code RAMSES, we implement a model for the pollution of pristine gas as described in Pan et al. Tracking the metallicity of Pop III stars with metallicities below a critical value allows us to account for the fraction of Z < Zcrit stars formed even in regions in which the gas' average metallicity is well above Zcrit. We demonstrate that such partially-mixed regions account for 0.5 to 0.7 of all Pop III stars formed up to z = 5. Additionally, we track the creation and transport of "primordial metals" (PM) generated by Pop III supernovae (SNe). These neutron-capture deficient metals are taken up by second-generation stars and likely lead to unique abundance signatures characteristic of carbon-enhanced, metal-poor (CEMP-no) stars. As an illustrative example, we associate primordial metals with abundance ratios used by Keller et al. to explain the source of metals in the star SMSS J031300.36-670839.3, finding good agreement with the observed [Fe/H], [C/H], [O/H], and [Mg/Ca] ratios in CEMP-no Milky Way halo stars. Similar future simulations will aid in further constraining the properties of Pop III stars using CEMP observations, as well as improve predictions of the spatial distribution of Pop III stars, as will be explored by the next generation of ground- and space-based telescopes.
On the Formation of Molecular Clumps in QSO Outflows (1609.02561)
Andrea Ferrara, Evan Scannapieco
Sept. 8, 2016 astro-ph.GA
We study the origin of the cold molecular clumps in quasar outflows, recently detected in CO and HCN emission. We first describe the physical properties of such radiation-driven outflows and show that a transition from a momentum- to an energy-driven flow must occur at a radial distance of R ~ 0.25 kpc. During this transition, the shell of swept up material fragments due to Rayleigh-Taylor instabilities, but these clumps contain little mass and are likely to be rapidly ablated by the hot gas in which they are immersed. We then explore an alternative scenario in which clumps form from thermal instabilities at R >~ 1 kpc, possibly containing enough dust to catalyze molecule formation. We investigate this processes with 3D two-fluid (gas+dust) numerical simulations of a kpc^3 patch of the outflow, including atomic and dust cooling, thermal conduction, dust sputtering, and photoionization from the QSO radiation field. In all cases, dust grains are rapidly destroyed in ~10,000 years; and while some cold clumps form at later times, they are present only as transient features, which disappear as cooling becomes more widespread. In fact, we only find a stable two-phase medium with dense clumps if we artificially enhance the QSO radiation field by a factor 100. This result, together with the complete destruction of dust grains, renders the interpretation of molecular outflows a very challenging problem.
Constraining AGN Feedback in Massive Ellipticals with South Pole Telescope Measurements of the Thermal Sunyaev-Zel'dovich Effect (1601.01330)
June 8, 2016 astro-ph.GA
Energetic feedback due to active galactic nuclei (AGN) is likely to play an important role in the observed anti-hierarchical trend in the evolution of galaxies, and yet the energy injected into the circumgalactic medium by this process is largely unknown. One promising approach to constrain this feedback is through measurements of CMB spectral distortions due to the thermal Sunyaev-Zel'dovich (tSZ) effect, whose magnitude is directly proportional to the energy input by AGN. Here we co-add South Pole Telescope SZ (SPT-SZ) survey data around a large set of massive quiescent elliptical galaxies at z >= 0.5. We use data from the Blanco Cosmology Survey and VISTA Hemisphere Survey to create a large catalog of galaxies split up into two redshift bins, with 3394 galaxies at 0.5 <= z <= 1.0 and 924 galaxies at 1.0 <= z <= 1.5, with typical stellar masses of 1.5 x 10^11 M_Sun. We then co-add the emission around these galaxies, resulting in a measured tSZ signal at 2.2 sigma significance for the lower redshift bin and a contaminating signal at 1.1 sigma for the higher redshift bin. To remove contamination due to dust emission, we use SPT-SZ source counts to model a contaminant source population in both the SPT-SZ bands and Planck high-frequency bands for a subset of 937 low-redshift galaxies and 240 high-redshift galaxies. This increases our detection to 3.6 sigma for low redshifts and 0.9 sigma for high redshifts. We find the mean angularly-integrated Compton-y values to be 2.2 (-0.7+0.9) x 10^-7 Mpc^2 for low redshifts and 1.7 (-1.8+2.2) x 10^-7 Mpc^2 for high redshifts, corresponding to total thermal energies of 7.6 (-2.3+3.0) x 10^60 ergs and 6.0 (-6.3+7.7) x 10^60 ergs, respectively. These numbers are higher than expected from simple theoretical models that do not include AGN feedback, and serve as constraints that can be applied to current simulations of massive galaxy formation. (abridged)
Comparing Simulations of AGN Feedback (1605.03589)
Mark L. A. Richardson, Evan Scannapieco, Julien Devriendt, Adrianne Slyz, Robert J. Thacker, Yohan Dubois, James Wurster, Joseph Silk
May 11, 2016 astro-ph.GA
We perform adaptive mesh refinement (AMR) and smoothed particle hydrodynamics (SPH) cosmological zoom simulations of a region around a forming galaxy cluster, comparing the ability of the methods to handle successively more complex baryonic physics. In the simplest, non-radiative case, the two methods are in good agreement with each other, but the SPH simulations generate central cores with slightly lower entropies and virial shocks at slightly larger radii, consistent with what has been seen in previous studies. The inclusion of radiative cooling, star formation, and stellar feedback leads to much larger differences between the two methods. Most dramatically, at z=5, rapid cooling in the AMR case moves the accretion shock well within the virial radius, while this shock remains near the virial radius in the SPH case, due to excess heating, coupled with poorer capturing of the shock width. On the other hand, the addition of feedback from active galactic nuclei (AGN) to the simulations results in much better agreement between the methods. In this case both simulations display halo gas entropies of 100 keV cm^2, similar decrements in the star-formation rate, and a drop in the halo baryon content of roughly 30%. This is consistent with AGN growth being self-regulated, regardless of the numerical method. However, the simulations with AGN feedback continue to differ in aspects that are not self-regulated, such that in SPH a larger volume of gas is impacted by feedback, and the cluster still has a lower entropy central core.
Galaxy Outflows Without Supernovae (1601.00659)
Sharanya Sur, Evan Scannapieco, Eve C. Ostriker
Jan. 4, 2016 astro-ph.CO, astro-ph.GA
High surface density, rapidly star-forming galaxies are observed to have $\approx 50-100\,{\rm km\,s^{-1}}$ line-of-sight velocity dispersions, which are much higher than expected from supernova driving alone, but may arise from large-scale gravitational instabilities. Using three-dimensional simulations of local regions of the interstellar medium, we explore the impact of high velocity dispersions that arise from these disk instabilities. Parametrizing disks by their surface densities and epicyclic frequencies, we conduct a series of simulations that probe a broad range of conditions. Turbulence is driven purely horizontally and on large scales, neglecting any energy input from supernovae. We find that such motions lead to strong global outflows in the highly-compact disks that were common at high redshifts, but weak or negligible mass loss in the more diffuse disks that are prevalent today. Substantial outflows are generated if the one-dimensional horizontal velocity dispersion exceeds $\approx 35\,{\rm km\,s^{-1}},$ as occurs in the dense disks that have star formation rate densities above $\approx 0.1\,{\rm M}_\odot\,{\rm yr}^{-1}\,{\rm kpc}^{-2}.$ These outflows are triggered by a thermal runaway, arising from the inefficient cooling of hot material coupled with successive heating from turbulent driving. Thus, even in the absence of stellar feedback, a critical value of the star-formation rate density for outflow generation can arise due to a turbulent heating instability. This suggests that in strongly self-gravitating disks, outflows may be enhanced by, but need not caused by, energy input from supernovae.
Atomic Chemistry in Turbulent Astrophysical Media II: Effect of the Redshift Zero Metagalactic Background (1511.05158)
William J Gray, Evan Scannapieco
Nov. 16, 2015 astro-ph.CO, astro-ph.GA
We carry out direct numerical simulations of turbulent astrophysical media exposed to the redshift zero metagalactic background. The simulations assume solar composition and explicitly track ionizations, recombinations, and ion-by-ion radiative cooling for hydrogen, helium, carbon, nitrogen, oxygen, neon, sodium, magnesium, silicon, sulfur, calcium, and iron. Each run reaches a global steady state that not only depends on the ionization parameter, $U,$ and mass-weighted average temperature, $T_{\rm MW},$ but also on the the one-dimensional turbulent velocity dispersion, \soned. We carry out runs that span a grid of models with $U$ ranging from 0 to 10$^{-1}$ and \soned\ ranging from 3.5 to 58 km s$^{-1}$, and we vary the product of the mean density and the driving scale of the turbulence, $nL,$ which determines the average temperature of the medium, from $nL =10^{16}$ to $nL =10^{20}$ cm$^{-2}$. The turbulent Mach numbers of our simulations vary from $M \approx 0.5$ for the lowest velocity dispersions cases to $M \approx 20$ for the largest velocity dispersion cases. When $M \lesssim1,$ turbulent effects are minimal, and the species abundances are reasonably described as those of a uniform photoionized medium at a fixed temperature. On the other hand, when $M \gtrsim 1,$ dynamical simulations such as the ones carried out here are required to accurately predict the species abundances. We gather our results into a set of tables, to allow future redshift zero studies of the intergalactic medium to account for turbulent effects.
"Observing and Analyzing" Images From a Simulated High Redshift Universe (1507.07538)
Robert J. Morgan, Rogier A. Windhorst, Evan Scannapieco, Robert J. Thacker
July 27, 2015 astro-ph.GA
We investigate the high-redshift evolution of the restframe UV-luminosity function (LF) of galaxies via hydrodynamical cosmological simulations, coupled with an emulated observational astronomy pipeline that provides a direct comparison with observations. We do this by creating mock images and synthetic galaxy catalogs of approximately 100 square arcminute fields from the numerical model at redshifts ~ 4.5 to 10.4. We include the effects of dust extinction and the point spread function (PSF) for the Hubble WFC3 camera for comparison with space observations. We also include the expected zodiacal background to predict its effect on space observations, including future missions such as the James Webb Space Telescope (JWST). When our model catalogs are fitted to Schechter function parameters, we predict that the faint-end slope alpha of the LF evolves as alpha = -1.16 - 0.12 z over the redshift range z ~ 4.5 to 7.7, in excellent agreement with observations from e.g., Hathi et al. (2010). However, for redshifts z ~ 6 to 10.4, alpha(z) appears to display a shallower evolution, alpha = -1.79 - 0.03 z. Augmenting the simulations with more detailed physics - specifically stellar winds and supernovae (SN) - produces similar results. The model shows an overproduction of galaxies, especially at faint magnitudes, compared with the observations, although the discrepancy is reduced when dust extinction is taken into account.
The Launching of Cold Clouds by Galaxy Outflows I: Hydrodynamic Interactions with Radiative Cooling (1503.06800)
Evan Scannapieco, Marcus Brüggen
March 23, 2015 astro-ph.GA
To better understand the nature of the multiphase material found in outflowing galaxies, we study the evolution of cold clouds embedded in flows of hot and fast material. Using a suite of adaptive-mesh refinement simulations that include radiative cooling, we investigate both cloud mass loss and cloud acceleration under the full range of conditions observed in galaxy outflows. The simulations are designed to track the cloud center of mass, enabling us to study the cloud evolution at long disruption times. For supersonic flows, a Mach cone forms around the cloud, which damps the Kelvin-Helmholtz instability but also establishes a streamwise pressure gradient that stretches the cloud apart. If time is expressed in units of the cloud crushing time, both the cloud lifetime and the cloud acceleration rate are independent of cloud radius, and we find simple scalings for these quantities as a function of the Mach number of the external medium. A resolution study suggests that our simulations have sufficient resolution to accurately describe the evolution of cold clouds in the absence of thermal conduction and magnetic fields, physical processes whose roles will be studied in forthcoming papers.
Atomic Chemistry In Turbulent Astrophysical Media I: Effect of Atomic Cooling (1502.01019)
William J Gray, Evan Scannapieco, Daniel Kasen
Feb. 5, 2015 astro-ph.CO, astro-ph.GA
We carry out direct numerical simulations of turbulent astrophysical media that explicitly track ionizations, recombinations, and species-by-species radiative cooling. The simulations assume solar composition and follows the evolution of hydrogen, helium, carbon, oxygen, sodium, and magnesium, but they do not include the presence of an ionizing background. In this case, the medium reaches a global steady state that is purely a function of the one-dimensional turbulent velocity dispersion, $\sigma_{\rm 1D},$ and the product of the mean density and the driving scale of turbulence, $n L.$ Our simulations span a grid of models with $\sigma_{\rm 1D}$ ranging from 6 to 58 km s$^{-1}$ and $n L$ ranging from 10$^{16}$ to 10$^{20}$ cm$^{-2},$ which correspond to turbulent Mach numbers from $M=0.2$ to 10.6. The species abundances are well described by single-temperature estimates whenever $M$ is small, but local equilibrium models can not accurately predict the global equilibrium abundances when $M \gtrsim 1.$ To allow future studies to account for nonequilibrium effects in turbulent media, we gather our results into a series of tables, which we will extend in the future to encompass a wider range of elements, compositions, and ionizing processes.
Alignment of the scalar gradient in evolving magnetic fields (1406.0859)
Sharanya Sur, Liubin Pan, Evan Scannapieco
June 13, 2014 astro-ph.GA
We conduct simulations of turbulent mixing in the presence of a magnetic field, grown by the small-scale dynamo. We show that the scalar gradient field, $\nabla C$, which must be large for diffusion to operate, is strongly biased perpendicular to the magnetic field, ${\mathbf B}$. This is true both early-on, when the magnetic field is negligible, and at late times, when the field is strong enough to back react on the flow. This occurs because $\nabla C$ increases within the plane of a compressive motion, but ${\mathbf B}$ increases perpendicular to it. At late times the magnetic field resists compression, making it harder for scalar gradients to grow and likely slowing mixing.
High Velocity-dispersion Cold Gas in ULIRG Outflows. I: Direct Simulations (1403.1594)
David J. Williamson, Robert J. Thacker, Evan Scannapieco, Marcus Brüggen
Observations have revealed cold gas with large velocity dispersions (~300 km/s) within the hot outflows of ultra-luminous infrared galaxies (ULIRGs). This gas may trace its origin to the Rayleigh-Taylor (RT) fragmentation of a super-bubble or may arise on smaller scales. We model a ULIRG outflow at two scales to recreate this gas in three-dimensional hydrodynamic simulations using FLASH. Although resolution is limited, these models successfully produce cold gas in outflows with large velocity dispersions. Our small-scale models produce this cold gas through RT fragmentation of the super-bubble wall, but the large-scale models produce the cold gas after hot bubbles fragment the disc's gas into cold clouds which are then accelerated by thermal pressure, and supplemented by cooling within the outflow. We produce simple mock spectra to compare these simulations to observed absorption spectra and find line-widths of ~250 km/s, agreeing with the lower end of observations.
Mixing in Magnetized Turbulent Media (1401.8001)
Feb. 3, 2014 physics.flu-dyn, astro-ph.GA
Turbulent motions are essential to the mixing of entrained fluids and are also capable of amplifying weak initial magnetic fields by small-scale dynamo action. Here we perform a systematic study of turbulent mixing in magnetized media, using three-dimensional magnetohydrodynamic simulations that include a scalar concentration field. We focus on how mixing depends on the magnetic Prandtl number, Pm, from 1 to 4 and the Mach number, M}, from 0.3 to 2.4. For all subsonic flows, we find that the velocity power spectrum has a k^-5/3 slope in the early, kinematic phase, but steepens due to magnetic back reactions as the field saturates. The scalar power spectrum, on the other hand, flattens compared to k^-5/3 at late times, consistent with the Obukohov-Corrsin picture of mixing as a cascade process. At higher Mach numbers, the velocity power spectrum also steepens due to the presence of shocks, and the scalar power spectrum again flattens accordingly. Scalar structures are more intermittent than velocity structures in subsonic turbulence while for supersonic turbulence, velocity structures appear more intermittent than the scalars only in the kinematic phase. Independent of the Mach number of the flow, scalar structures are arranged in sheets in both the kinematic and saturated phases of the magnetic field evolution. For subsonic turbulence, scalar dissipation is hindered in the strong magnetic field regions, probably due to Lorentz forces suppressing the buildup of scalar gradients, while for supersonic turbulence, scalar dissipation increases monotonically with increasing magnetic field strength. At all Mach numbers, mixing is significantly slowed by the presence of dynamically-important small-scale magnetic fields, implying that mixing in the interstellar medium and in galaxy clusters is less efficient than modeled in hydrodynamic simulations.
Formation of Compact Clusters from High Resolution Hybrid Cosmological Simulations (1308.5684)
Mark L. A. Richardson, Evan Scannapieco, William J. Gray
Oct. 9, 2013 astro-ph.CO
The early Universe hosted a large population of small dark matter `minihalos' that were too small to cool and form stars on their own. These existed as static objects around larger galaxies until acted upon by some outside influence. Outflows, which have been observed around a variety of galaxies, can provide this influence in such a way as to collapse, rather than disperse the minihalo gas. Gray & Scannapieco performed an investigation in which idealized spherically-symmetric minihalos were struck by enriched outflows. Here we perform high-resolution cosmological simulations that form realistic minihalos, which we then extract to perform a large suite of simulations of outflow-minihalo interactions including non-equilibrium chemical reactions. In all models, the shocked minihalo forms molecules through non-equilibrium reactions, and then cools to form dense chemically homogenous clumps of star-forming gas. The formation of these high-redshift clusters will be observable with the next generation of telescopes, and the largest of them should survive to the present day, having properties similar to halo globular clusters.
Hybrid Cosmological Simulations with Stream Velocities (1305.3276)
Mark L. A. Richardson, Evan Scannapieco, Robert J. Thacker
Aug. 26, 2013 astro-ph.CO
In the early universe, substantial relative "stream" velocities between the gas and dark matter arise due to radiation pressure and persist after recombination. To asses the impact of these velocities on high-redshift structure formation, we carry out a suite of high-resolution Adaptive Mesh Refinement (AMR) cosmological simulations, which use Smoothed Particle Hydrodynamic datasets as initial conditions, converted using a new tool developed for this work. These simulations resolve structures with masses as small as a few 100 M$_\odot$, and we focus on the $10^6$ M$_\odot$ "mini-halos" in which the first stars formed. At $z \approx 17,$ the presence of stream velocities has only a minor effect on the number density of halos below $10^6$ M$_\odot$, but it greatly suppresses gas accretion onto all halos and the dark matter structures around them. Stream velocities lead to significantly lower halo gas fractions, especially for $\approx 10^5$ M$_\odot$ objects, an effect that is likely to depend on the orientation of a halo's accretion lanes. This reduction in gas density leads to colder, more compact radial profiles, and it substantially delays the redshift of collapse of the largest halos, leading to delayed star formation and possibly delayed reionization. These many differences suggest that future simulations of early cosmological structure formation should include stream velocities to properly predict gas evolution, star-formation, and the epoch of reionization.
Modeling the Pollution of Pristine Gas in the Early Universe (1306.4663)
Liubin Pan, Evan Scannapieco, John Scalo
Aug. 9, 2013 astro-ph.CO, astro-ph.GA
We conduct a comprehensive theoretical and numerical investigation of the pollution of pristine gas in turbulent flows, designed to provide new tools for modeling the evolution of the first generation of stars. The properties of such Population III (Pop III) stars are thought to be very different than later generations, because cooling is dramatically different in gas with a metallicity below a critical value Z_c, which lies between ~10^-6 and 10^-3 solar value. Z_c is much smaller than the typical average metallicity, <Z>, and thus the mixing efficiency of the pristine gas in the interstellar medium plays a crucial role in the transition from Pop III to normal star formation. The small critical value, Z_c, corresponds to the far left tail of the probability distribution function (PDF) of the metallicity. Based on closure models for the PDF formulation of turbulent mixing, we derive equations for the fraction of gas, P, lying below Z_c, in compressible turbulence. Our simulation data shows that the evolution of the fraction P can be well approximated by a generalized self-convolution model, which predicts dP/dt = -n/tau_con P (1-P^(1/n)), where n is a measure of the locality of the PDF convolution and the timescale tau_con is determined by the rate at which turbulence stretches the pollutants. Using a suite of simulations with Mach numbers ranging from M = 0.9 to 6.2, we provide accurate fits to n and tau_con as a function of M, Z_c/<Z>, and the scale, L_p, at which pollutants are added to the flow. For P>0.9, mixing occurs only in the regions surrounding the pollutants, such that n=1. For smaller P, n is larger as mixing becomes more global. We show how the results can be used to construct one-zone models for the evolution of Pop III stars in a single high-redshift galaxy, as well as subgrid models for tracking the evolution of the first stars in large cosmological simulations.
Thermal and Chemical Evolution of Collapsing Filaments (1304.0771)
April 4, 2013 astro-ph.CO, astro-ph.GA
Intergalactic filaments form the foundation of the cosmic web that connect galaxies together, and provide an important reservoir of gas for galaxy growth and accretion. Here we present very high resolution two-dimensional simulations of the thermal and chemical evolution of such filaments, making use of a 32 species chemistry network that tracks the evolution of key molecules formed from hydrogen, oxygen, and carbon. We study the evolution of filaments over a wide range of parameters including the initial density, initial temperature, strength of the dissociating UV background, and metallicity. In low-redshift, $Z \approx 0.1 Z_\odot $ filaments, the evolution is determined completely by the initial cooling time. If this is sufficiently short, the center of the filament always collapses to form dense, cold core containing a substantial fraction of molecules. In high-redshift, $Z=10^{-3} Z_\odot$ filaments, the collapse proceeds much more slowly. This is due mostly to the lower initial temperatures, which leads to a much more modest increase in density before the atomic cooling limit is reached, making subsequent molecular cooling much less efficient. Finally, we study how the gravitational potential from a nearby dwarf galaxy affects the collapse of the filament and compare this to NGC 5253, a nearby starbusting dwarf galaxy thought to be fueled by the accretion of filament gas. In contrast to our fiducial case, a substantial density peak forms at the center of the potential. This peak evolves faster than the rest of the filament due to the increased rate at which chemical species form and cooling occur. We find that we achieve similar accretion rates as NGC 5253 but our two-dimensional simulations do not recover the formation of the giant molecular clouds that are seen in radio observations.
Understanding Galaxy Outflows as the Product of Unstable Turbulent Support (1302.3626)
Feb. 14, 2013 astro-ph.CO
The interstellar medium is a multiphase gas in which turbulent support is as important as thermal pressure. Sustaining this configuration requires both continuous turbulent stirring and continuous radiative cooling to match the decay of turbulent energy. While this equilibrium can persist for small turbulent velocities, if the one-dimensional velocity dispersion is larger than approximately 35 km/s, the gas moves into an unstable regime that leads to rapid heating. I study the implications of this turbulent runaway, showing that it causes a hot gas outflow to form in all galaxies with a gas surface density above approximately 50 solar masses/pc^2 corresponding to a star formation rate per unit area of 0.1$ solar masses/yr/kpc^2. For galaxies with escape velocities above 200 km/s, the sonic point of this hot outflow should lie interior to the region containing cold gas and stars, while for galaxies with smaller escape velocities, the sonic point should lie outside this region. This leads to efficient cold cloud acceleration in higher mass galaxies, while in lower mass galaxies, clouds may be ejected by random turbulent motions rather than accelerated by the wind. Finally, I show that energy balance cannot be achieved at all for turbulent media above a surface density of approximately 10^5 solar masses/pc^2.
Near-Infrared Imaging of a z=6.42 Quasar Host Galaxy With the Hubble Space Telescope Wide Field Camera 3 (1207.3283)
Matt Mechtley, Rogier A. Windhorst, Russell E. Ryan, Glenn Schneider, Seth H. Cohen, Rolf A. Jansen, Xiaohui Fan, Nimish P. Hathi, William C. Keel, Anton M. Koekemoer, Huub Röttgering, Evan Scannapieco, Donald P. Schneider, Michael A. Strauss, Haojing Yan
Aug. 9, 2012 astro-ph.CO
We report on deep near-infrared F125W (J) and F160W (H) Hubble Space Telescope Wide Field Camera 3 images of the z=6.42 quasar J1148+5251 to attempt to detect rest-frame near-ultraviolet emission from the host galaxy. These observations included contemporaneous observations of a nearby star of similar near-infrared colors to measure temporal variations in the telescope and instrument point spread function (PSF). We subtract the quasar point source using both this direct PSF and a model PSF. Using direct subtraction, we measure an upper limit for the quasar host galaxy of m_J>22.8, m_H>23.0 AB mag (2 sigma). After subtracting our best model PSF, we measure a limiting surface brightness from 0.3"-0.5" radius of mu_J > 23.5, mu_H > 23.7 AB magarc (2 sigma). We test the ability of the model subtraction method to recover the host galaxy flux by simulating host galaxies with varying integrated magnitude, effective radius, and S\'ersic index, and conducting the same analysis. These models indicate that the surface brightness limit (mu_J > 23.5 AB magarc) corresponds to an integrated upper limit of m_J > 22 - 23 AB mag, consistent with the direct subtraction method. Combined with existing far-infrared observations, this gives an infrared excess log(IRX) > 1.0 and corresponding ultraviolet spectral slope beta > -1.2\pm0.2. These values match those of most local luminous infrared galaxies, but are redder than those of almost all local star-forming galaxies and z~6 Lyman break galaxies. | CommonCrawl |
An expanded evaluation of protein function prediction methods shows an improvement in accuracy
Yuxiang Jiang1,
Tal Ronnen Oron2,
Wyatt T. Clark3,
Asma R. Bankapur4,
Daniel D'Andrea5,
Rosalba Lepore5,
Christopher S. Funk6,
Indika Kahanda7,
Karin M. Verspoor8,9,
Asa Ben-Hur7,
Da Chen Emily Koo10,
Duncan Penfold-Brown11,12,
Dennis Shasha13,
Noah Youngs12,13,14,
Richard Bonneau13,14,15,
Alexandra Lin16,
Sayed M. E. Sahraeian17,
Pier Luigi Martelli18,
Giuseppe Profiti18,
Rita Casadio18,
Renzhi Cao19,
Zhaolong Zhong19,
Jianlin Cheng19,
Adrian Altenhoff20,21,
Nives Skunca20,21,
Christophe Dessimoz22,87,88,
Tunca Dogan23,
Kai Hakala24,25,
Suwisa Kaewphan24,25,26,
Farrokh Mehryary24,25,
Tapio Salakoski24,26,
Filip Ginter24,
Hai Fang27,
Ben Smithers27,
Matt Oates27,
Julian Gough27,
Petri Törönen28,
Patrik Koskinen28,
Liisa Holm28,86,
Ching-Tai Chen29,
Wen-Lian Hsu29,
Kevin Bryson22,
Domenico Cozzetto22,
Federico Minneci22,
David T. Jones22,
Samuel Chapman30,
Dukka BKC30,
Ishita K. Khan31,
Daisuke Kihara31,85,
Dan Ofer32,
Nadav Rappoport32,33,
Amos Stern32,33,
Elena Cibrian-Uhalte23,
Paul Denny35,
Rebecca E. Foulger35,
Reija Hieta23,
Duncan Legge23,
Ruth C. Lovering35,
Michele Magrane23,
Anna N. Melidoni35,
Prudence Mutowo-Meullenet23,
Klemens Pichler23,
Aleksandra Shypitsyna23,
Biao Li2,
Pooya Zakeri36,37,
Sarah ElShal36,37,
Léon-Charles Tranchevent38,39,40,
Sayoni Das41,
Natalie L. Dawson41,
David Lee41,
Jonathan G. Lees41,
Ian Sillitoe41,
Prajwal Bhat42,
Tamás Nepusz43,
Alfonso E. Romero44,
Rajkumar Sasidharan45,
Haixuan Yang46,
Alberto Paccanaro44,
Jesse Gillis47,
Adriana E. Sedeño-Cortés48,
Paul Pavlidis49,
Shou Feng1,
Juan M. Cejuela50,
Tatyana Goldberg50,
Tobias Hamp50,
Lothar Richter50,
Asaf Salamov51,
Toni Gabaldon52,53,54,
Marina Marcet-Houben52,53,
Fran Supek53,55,56,
Qingtian Gong57,58,
Wei Ning57,58,
Yuanpeng Zhou57,58,
Weidong Tian57,58,
Marco Falda59,
Paolo Fontana60,
Enrico Lavezzo59,
Stefano Toppo59,
Carlo Ferrari61,
Manuel Giollo61,84,
Damiano Piovesan61,
Silvio C.E. Tosatto61,
Angela del Pozo62,
José M. Fernández63,
Paolo Maietta64,
Alfonso Valencia64,
Michael L. Tress64,
Alfredo Benso65,
Stefano Di Carlo65,
Gianfranco Politano65,
Alessandro Savino65,
Hafeez Ur Rehman66,
Matteo Re67,
Marco Mesiti67,
Giorgio Valentini67,
Joachim W. Bargsten68,
Aalt D. J. van Dijk68,69,
Branislava Gemovic70,
Sanja Glisic70,
Vladmir Perovic70,
Veljko Veljkovic70,
Nevena Veljkovic70,
Danillo C. Almeida-e-Silva71,
Ricardo Z. N. Vencio71,
Malvika Sharan72,
Jörg Vogel72,
Lakesh Kansakar73,
Shanshan Zhang73,
Slobodan Vucetic73,
Zheng Wang74,
Michael J. E. Sternberg34,
Mark N. Wass75,
Rachael P. Huntley23,
Maria J. Martin23,
Claire O'Donovan23,
Peter N. Robinson76,
Yves Moreau77,
Anna Tramontano5,
Patricia C. Babbitt78,
Steven E. Brenner17,
Michal Linial79,
Christine A. Orengo41,
Burkhard Rost50,
Casey S. Greene80,
Sean D. Mooney81,
Iddo Friedberg ORCID: orcid.org/0000-0002-1789-80004,82 &
Predrag Radivojac1
Genome Biology volume 17, Article number: 184 (2016) Cite this article
A major bottleneck in our understanding of the molecular underpinnings of life is the assignment of function to proteins. While molecular experiments provide the most reliable annotation of proteins, their relatively low throughput and restricted purview have led to an increasing role for computational function prediction. However, assessing methods for protein function prediction and tracking progress in the field remain challenging.
We conducted the second critical assessment of functional annotation (CAFA), a timed challenge to assess computational methods that automatically assign protein function. We evaluated 126 methods from 56 research groups for their ability to predict biological functions using Gene Ontology and gene-disease associations using Human Phenotype Ontology on a set of 3681 proteins from 18 species. CAFA2 featured expanded analysis compared with CAFA1, with regards to data set size, variety, and assessment metrics. To review progress in the field, the analysis compared the best methods from CAFA1 to those of CAFA2.
The top-performing methods in CAFA2 outperformed those from CAFA1. This increased accuracy can be attributed to a combination of the growing number of experimental annotations and improved methods for function prediction. The assessment also revealed that the definition of top-performing algorithms is ontology specific, that different performance metrics can be used to probe the nature of accurate predictions, and the relative diversity of predictions in the biological process and human phenotype ontologies. While there was methodological improvement between CAFA1 and CAFA2, the interpretation of results and usefulness of individual methods remain context-dependent.
Accurate computer-generated functional annotations of biological macromolecules allow biologists to rapidly generate testable hypotheses about the roles that newly identified proteins play in processes or pathways. They also allow them to reason about new species based on the observed functional repertoire associated with their genes. However, protein function prediction is an open research problem and it is not yet clear which tools are best for predicting function. At the same time, critically evaluating these tools and understanding the landscape of the function prediction field is a challenging task that extends beyond the capabilities of a single lab.
Assessments and challenges have a successful history of driving the development of new methods in the life sciences by independently assessing performance and providing discussion forums for the researchers [1]. In 2010–2011, we organized the first critical assessment of functional annotation (CAFA) challenge to evaluate methods for the automated annotation of protein function and to assess the progress in method development in the first decade of the 2000s [2]. The challenge used a time-delayed evaluation of predictions for a large set of target proteins without any experimental functional annotation. A subset of these target proteins accumulated experimental annotations after the predictions were submitted and was used to estimate the performance accuracy. The estimated performance was subsequently used to draw conclusions about the status of the field.
The first CAFA (CAFA1) showed that advanced methods for the prediction of Gene Ontology (GO) terms [3] significantly outperformed a straightforward application of function transfer by local sequence similarity. In addition to validating investment in the development of new methods, CAFA1 also showed that using machine learning to integrate multiple sequence hits and multiple data types tends to perform well. However, CAFA1 also identified challenges for experimentalists, biocurators, and computational biologists. These challenges include the choice of experimental techniques and proteins in functional studies and curation, the structure and status of biomedical ontologies, the lack of comprehensive systems data that are necessary for accurate prediction of complex biological concepts, as well as limitations of evaluation metrics [2, 4–7]. Overall, by establishing the state-of-the-art in the field and identifying challenges, CAFA1 set the stage for quantifying progress in the field of protein function prediction over time.
In this study, we report on the major outcomes of the second CAFA experiment, CAFA2, that was organized and conducted in 2013–2014, exactly 3 years after the original experiment. We were motivated to evaluate the progress in method development for function prediction as well as to expand the experiment to new ontologies. The CAFA2 experiment also greatly expanded the performance analysis to new types of evaluation and included new performance metrics. By surveying the state of the field, we aim to help all direct and indirect users of computational function prediction software develop intuition for the quality, robustness, and reliability of these predictions.
Experiment overview
The time line for the second CAFA experiment followed that of the first experiment and is illustrated in Fig. 1. Briefly, CAFA2 was announced in July 2013 and officially started in September 2013, when 100,816 target sequences from 27 species were made available to the community. Teams were required to submit prediction scores within the (0,1] range for each protein–term pair they chose to predict on. The submission deadline for depositing these predictions was set for January 2014 (time point t 0). We then waited until September 2014 (time point t 1) for new experimental annotations to accumulate on the target proteins and assessed the performance of the prediction methods. We will refer to the set of all experimentally annotated proteins available at t 0 as the training set and to a subset of target proteins that accumulated experimental annotations during (t 0,t 1] and used for evaluation as the benchmark set. It is important to note that the benchmark proteins and the resulting analysis vary based on the selection of time point t 1. For example, a preliminary analysis of the CAFA2 experiment was provided during the Automated Function Prediction Special Interest Group (AFP-SIG) meeting at the Intelligent Systems for Molecular Biology (ISMB) conference in July 2014.
Time line for the CAFA2 experiment
The participating methods were evaluated according to their ability to predict terms in GO [3] and Human Phenotype Ontology (HPO) [8]. In contrast with CAFA1, where the evaluation was carried out only for the Molecular Function Ontology (MFO) and Biological Process Ontology (BPO), in CAFA2 we also assessed the performance for the prediction of Cellular Component Ontology (CCO) terms in GO. The set of human proteins was further used to evaluate methods according to their ability to associate these proteins with disease terms from HPO, which included all sub-classes of the term HP:0000118, "Phenotypic abnormality".
In total, 56 groups submitting 126 methods participated in CAFA2. From those, 125 methods made valid predictions on a sufficient number of sequences. Further, 121 methods submitted predictions for at least one of the GO benchmarks, while 30 methods participated in the disease gene prediction tasks using HPO.
The CAFA2 experiment expanded the assessment of computational function prediction compared with CAFA1. This includes the increased number of targets, benchmarks, ontologies, and method comparison metrics.
We distinguish between two major types of method evaluation. The first, protein-centric evaluation, assesses performance accuracy of methods that predict all ontological terms associated with a given protein sequence. The second type, term-centric evaluation, assesses performance accuracy of methods that predict if a single ontology term of interest is associated with a given protein sequence [2]. The protein-centric evaluation can be viewed as a multi-label or structured-output learning problem of predicting a set of terms or a directed acyclic graph (a subgraph of the ontology) for a given protein. Because the ontologies contain many terms, the output space in this setting is extremely large and the evaluation metrics must incorporate similarity functions between groups of mutually interdependent terms (directed acyclic graphs). In contrast, the term-centric evaluation is an example of binary classification, where a given ontology term is assigned (or not) to an input protein sequence. These methods are particularly common in disease gene prioritization [9]. Put otherwise, a protein-centric evaluation considers a ranking of ontology terms for a given protein, whereas the term-centric evaluation considers a ranking of protein sequences for a given ontology term.
Both types of evaluation have merits in assessing performance. This is partly due to the statistical dependency between ontology terms, the statistical dependency among protein sequences, and also the incomplete and biased nature of the experimental annotation of protein function [6]. In CAFA2, we provide both types of evaluation, but we emphasize the protein-centric scenario for easier comparisons with CAFA1. We also draw important conclusions regarding method assessment in these two scenarios.
No-knowledge and limited-knowledge benchmark sets
In CAFA1, a protein was eligible to be in the benchmark set if it had not had any experimentally verified annotations in any of the GO ontologies at time t 0 but accumulated at least one functional term with an experimental evidence code between t 0 and t 1; we refer to such benchmark proteins as no-knowledge benchmarks. In CAFA2 we introduced proteins with limited knowledge, which are those that had been experimentally annotated in one or two GO ontologies (but not in all three) at time t 0. For example, for the performance evaluation in MFO, a protein without any annotation in MFO prior to the submission deadline was allowed to have experimental annotations in BPO and CCO.
During the growth phase, the no-knowledge targets that have acquired experimental annotations in one or more ontologies became benchmarks in those ontologies. The limited-knowledge targets that have acquired additional annotations became benchmarks only for those ontologies for which there were no prior experimental annotations. The reason for using limited-knowledge targets was to identify whether the correlations between experimental annotations across ontologies can be exploited to improve function prediction.
The selection of benchmark proteins for evaluating HPO-term predictors was separated from the GO analyses. We created only a no-knowledge benchmark set in the HPO category.
Partial and full evaluation modes
Many function prediction methods apply only to certain types of proteins, such as proteins for which 3D structure data are available, proteins from certain taxa, or specific subcellular localizations. To accommodate these methods, CAFA2 provided predictors with an option of choosing a subset of the targets to predict on as long as they computationally annotated at least 5,000 targets, of which at least ten accumulated experimental terms. We refer to the assessment mode in which the predictions were evaluated only on those benchmarks for which a model made at least one prediction at any threshold as partial evaluation mode. In contrast, the full evaluation mode corresponds to the same type of assessment performed in CAFA1 where all benchmark proteins were used for the evaluation and methods were penalized for not making predictions.
In most cases, for each benchmark category, we have two types of benchmarks, no-knowledge and limited-knowledge, and two modes of evaluation, full mode and partial mode. Exceptions are all HPO categories that only have no-knowledge benchmarks. The full mode is appropriate for comparisons of general-purpose methods designed to make predictions on any protein, while the partial mode gives an idea of how well each method performs on a self-selected subset of targets.
Evaluation metrics
Precision–recall curves and remaining uncertainty–misinformation curves were used as the two chief metrics in the protein-centric mode [10]. We also provide a single measure for evaluation of both types of curves as a real-valued scalar to compare methods; however, we note that any choice of a single point on those curves may not match the intended application objectives for a given algorithm. Thus, a careful understanding of the evaluation metrics used in CAFA is necessary to properly interpret the results.
Precision (pr), recall (rc), and the resulting F max are defined as
$$\begin{array}{@{}rcl@{}} \text{pr}(\tau) &=& \frac{1}{m(\tau)}\sum\limits_{i=1}^{m(\tau)} \frac{{\sum\nolimits}_{f} \mathbbm{1}\left(f \in P_{i}(\tau) \wedge f \in T_{i}\right)}{\sum_{f} \mathbbm{1}\left(f \in P_{i}(\tau) \right)},\\ \text{rc}(\tau) &=& \frac{1}{n_{e}}\sum\limits_{i=1}^{n_{e}} \frac{{\sum\nolimits}_{f} \mathbbm{1}\left(f \in {P}_{i}(\tau) \wedge f \in T_{i}\right)}{{\sum\nolimits}_{f} \mathbbm{1}\left(f \in T_{i} \right)}, \\ F_{\max} &=& \max_{\tau} \left\{ \frac{2\cdot \text{pr}(\tau)\cdot \text{rc}(\tau)}{\text{pr}(\tau) + \text{rc}(\tau)} \right\}, \end{array} $$
where P i (τ) denotes the set of terms that have predicted scores greater than or equal to τ for a protein sequence i, T i denotes the corresponding ground-truth set of terms for that sequence, m(τ) is the number of sequences with at least one predicted score greater than or equal to τ, \(\mathbbm {1}\left (\cdot \right)\) is an indicator function, and n e is the number of targets used in a particular mode of evaluation. In the full evaluation mode n e =n, the number of benchmark proteins, whereas in the partial evaluation mode n e =m(0), i.e., the number of proteins that were chosen to be predicted using the particular method. For each method, we refer to m(0)/n as the coverage because it provides the fraction of benchmark proteins on which the method made any predictions.
The remaining uncertainty (ru), misinformation (mi), and the resulting minimum semantic distance (S min) are defined as
$$\begin{array}{@{}rcl@{}} \text{ru}(\tau) &=& \frac{1}{n_{e}}\sum\limits_{i=1}^{n_{e}} \sum\limits_{f} \text{ic}(f) \cdot \mathbbm{1}\left(f \notin P_{i}(\tau) \wedge f \in T_{i} \right),\\ \text{mi}(\tau) &=& \frac{1}{n_{e}}\sum\limits_{i=1}^{n_{e}} \sum\limits_{f} \text{ic}(f) \cdot \mathbbm{1}\left(f \in P_{i}(\tau) \wedge f \notin T_{i} \right), \\ S_{\min} &=& \min_{\tau}\left\{ \sqrt{\text{ru}(\tau)^{2} + \text{mi}(\tau)^{2}} \right\}, \end{array} $$
where ic(f) is the information content of the ontology term f [10]. It is estimated in a maximum likelihood manner as the negative binary logarithm of the conditional probability that the term f is present in a protein's annotation given that all its parent terms are also present. Note that here, n e =n in the full evaluation mode and n e =m(0) in the partial evaluation mode applies to both ru and mi.
In addition to the main metrics, we used two secondary metrics. Those were the weighted version of the precision–recall curves and the version of the remaining uncertainty–misinformation curves normalized to the [ 0,1] interval. These metrics and the corresponding evaluation results are shown in Additional file 1.
For the term-centric evaluation we used the area under the receiver operating characteristic (ROC) curve (AUC). The AUCs were calculated for all terms that have acquired at least ten positively annotated sequences, whereas the remaining benchmarks were used as negatives. The term-centric evaluation was used both for ranking models and to differentiate well and poorly predictable terms. The performance of each model on each term is provided in Additional file 1.
As we required all methods to keep two significant figures for prediction scores, the threshold τ in all metrics used in this study was varied from 0.01 to 1.00 with a step size of 0.01.
Protein function annotations for the GO assessment were extracted, as a union, from three major protein databases that are available in the public domain: Swiss-Prot [11], UniProt-GOA [12] and the data from the GO consortium web site [3]. We used evidence codes EXP, IDA, IPI, IMP, IGI, IEP, TAS, and IC to build benchmark and ground-truth sets. Annotations for the HPO assessment were downloaded from the HPO database [8].
Figure 2 summarizes the benchmarks we used in this study. Figure 2 a shows the benchmark sizes for each of the ontologies and compares these numbers to CAFA1. All species that have at least 15 proteins in any of the benchmark categories are listed in Fig. 2 b.
CAFA2 benchmark breakdown. a The benchmark size for each of the four ontologies. b Breakdown of benchmarks for both types over 11 species (with no less than 15 proteins) sorted according to the total number of benchmark proteins. For both panels, dark colors (blue, red, and yellow) correspond to no-knowledge (NK) types, while their light color counterparts correspond to limited-knowledge (LK) types. The distributions of information contents corresponding to the benchmark sets are shown in Additional file 1. The size of CAFA 1 benchmarks are shown in gray. BPO Biological Process Ontology, CCO Cellular Component Ontology, HPO Human Phenotype Ontology, LK limited-knowledge, MFO Molecular Function Ontology, NK no-knowledge
Comparison between CAFA1 and CAFA2 methods
We compared the results from CAFA1 and CAFA2 using a benchmark set that we created from CAFA1 targets and CAFA2 targets. More precisely, we used the stored predictions of the target proteins from CAFA1 and compared them with the new predictions from CAFA2 on the overlapping set of CAFA2 benchmarks and CAFA1 targets (a sequence had to be a no-knowledge target in both experiments to be eligible for this evaluation). For this analysis only, we used an artificial GO version by taking the intersection of the two GO snapshots (versions from January 2011 and June 2013) so as to mitigate the influence of ontology changes. We, thus, collected 357 benchmark proteins for MFO comparisons and 699 for BPO comparisons. The two baseline methods were trained on respective Swiss-Prot annotations for both ontologies so that they serve as controls for database change. In particular, SwissProt2011 (for CAFA1) contained 29,330 and 31,282 proteins for MFO and BPO, while SwissProt2014 (for CAFA2) contained 26,907 and 41,959 proteins for the two ontologies.
To conduct a head-to-head analysis between any two methods, we generated B=10,000 bootstrap samples and let methods compete on each such benchmark set. The performance improvement δ from CAFA1 to CAFA2 was calculated as
$$\begin{array}{@{}rcl@{}} \delta(m_{2}, m_{1}) = \frac{1}{B}\sum_{b=1}^{B} F_{\max}^{(b)}(m_{2}) - \frac{1}{B}\sum_{b=1}^{B} F_{\max}^{(b)}(m_{1}), \end{array} $$
where m 1 and m 2 stand for methods from CAFA1 and CAFA2, respectively, and \(F_{\max }^{(b)}(\cdot)\) represents the F max of a method evaluated on the b-th bootstrapped benchmark set.
Baseline models
We built two baseline methods, Naïve and BLAST, and compared them with all participating methods. The Naïve method simply predicts the frequency of a term being annotated in a database [13]. BLAST was based on search results using the Basic Local Alignment Search Tool (BLAST) software against the training database [14]. A term will be predicted as the highest local alignment sequence identity among all BLAST hits annotated with the term. Both of these methods were trained on the experimentally annotated proteins available in Swiss-Prot at time t 0, except for HPO where the two baseline models were trained using the annotations from the t 0 release of the HPO.
Top methods have improved since CAFA1
We conducted the second CAFA experiment 3 years after the first one. As our knowledge of protein function has increased since then, it was worthwhile to assess whether computational methods have also been improved and if so, to what extent. Therefore, to monitor the progress over time, we revisit some of the top methods in CAFA1 and compare them with their successors.
For each benchmark set we carried out a bootstrap-based comparison between a pair of top-ranked methods (one from CAFA1 and another from CAFA2), as described in "Methods". The average performance metric as well as the number of wins were recorded (in the case of identical performance, neither method was awarded a win). Figure 3 summarizes the results of this analysis. We use a color code from orange to blue to indicate the performance improvement δ from CAFA1 to CAFA2.
CAFA1 versus CAFA2 (top methods). A comparison in F max between the top-five CAFA1 models against the top-five CAFA2 models. Colored boxes encode the results such that (1) the colors indicate margins of a CAFA2 method over a CAFA1 method in F max and (2) the numbers in the box indicate the percentage of wins. For both the Molecular Function Ontology (a) and Biological Process Ontology (b) results: A CAFA1 top-five models (rows, from top to bottom) against CAFA2 top-five models (columns, from left to right). B Comparison of Naïve baselines trained respectively on SwissProt2011 and SwissProt2014. C Comparison of BLAST baselines trained on SwissProt2011 and SwissProt2014
The selection of top methods for this study was based on their performance in each ontology on the entire benchmark sets. Panels B and C in Fig. 3 compare baseline methods trained on different data sets. We see no improvements of these baselines except for BLAST on BPO where it is slightly better to use the newer version of Swiss-Prot as the reference database for the search. On the other hand, all top methods in CAFA2 outperformed their counterparts in CAFA1. For predicting molecular functions, even though transferring functions from BLAST hits does not give better results, the top models still managed to perform better. It is possible that the newly acquired annotations since CAFA1 enhanced BLAST, which involves direct function transfer, and perhaps lead to better performances of those downstream methods that rely on sequence alignments. However, this effect does not completely explain the extent of the performance improvement achieved by those methods. This is promising evidence that top methods from the community have improved since CAFA1 and that improvements were not simply due to updates of curated databases.
Protein-centric evaluation
Protein-centric evaluation measures how accurately methods can assign functional terms to a protein. The protein-centric performance evaluation of the top-ten methods is shown in Figs. 4, 5, and 6. The 95 % confidence intervals were estimated using bootstrapping on the benchmark set with B=10,000 iterations [15]. The results provide a broad insight into the state of the art.
Overall evaluation using the maximum F measure, F max. Evaluation was carried out on no-knowledge benchmark sequences in the full mode. The coverage of each method is shown within its performance bar. A perfect predictor would be characterized with F max=1. Confidence intervals (95 %) were determined using bootstrapping with 10,000 iterations on the set of benchmark sequences. For cases in which a principal investigator participated in multiple teams, the results of only the best-scoring method are presented. Details for all methods are provided in Additional file 1
Precision–recall curves for top-performing methods. Evaluation was carried out on no-knowledge benchmark sequences in the full mode. A perfect predictor would be characterized with F max=1, which corresponds to the point (1,1) in the precision–recall plane. For cases in which a principal investigator participated in multiple teams, the results of only the best-scoring method are presented
Overall evaluation using the minimum semantic distance, S min. Evaluation was carried out on no-knowledge benchmark sequences in the full mode. The coverage of each method is shown within its performance bar. A perfect predictor would be characterized with S min=0. Confidence intervals (95 %) were determined using bootstrapping with 10,000 iterations on the set of benchmark sequences. For cases in which a principal investigator participated in multiple teams, the results of only the best-scoring method are presented. Details for all methods are provided in Additional file 1
Predictors performed very differently across the four ontologies. Various reasons contribute to this effect including: (1) the topological properties of the ontology such as the size, depth, and branching factor; (2) term predictability; for example, the BPO terms are considered to be more abstract in nature than the MFO and CCO terms; (3) the annotation status, such as the size of the training set at t 0, the annotation depth of benchmark proteins, as well as various annotation biases [6].
In general, CAFA2 methods perform better at predicting MFO terms than any other ontology. Top methods achieved F max scores around 0.6 and considerably surpassed the two baseline models. Maintaining the pattern from CAFA1, the performance accuracies in the BPO category were not as good as in the MFO category. The best-performing method scored slightly below 0.4.
For the two newly added ontologies in CAFA2, we observed that the top predictors performed no better than the Naïve method under F max, whereas they slightly outperformed the Naïve method under S min in CCO. One reason for the competitive performance of the Naïve method in the CCO category is that a small number of relatively general terms are frequently used, and those relative frequencies do not diffuse quickly enough with the depth of the graph. For instance, the annotation frequency of "organelle" (GO:0043226, level 2), "intracellular part" (GO:0044424, level 3), and "cytoplasm" (GO:0005737, level 4) are all above the best threshold for the Naïve method (τ optimal=0.32). Correctly predicting these terms increases the number of true positives and thus boosts the performance of the Naïve method under the F max evaluation. However, once the less informative terms are down-weighted (using the S min measure), the Naïve method becomes significantly penalized and degraded. Another reason for the comparatively good performance of Naïve is that the benchmark proteins were annotated with more general terms than the (training) proteins previously deposited in the UniProt database. This effect was most prominent in the CCO (Additional file 1: Figure S2) and has thus artificially boosted the performance of the Naïve method. The weighted F max and normalized S min evaluations can be found in Additional file 1.
Interestingly, generally shallower annotations of benchmark proteins do not seem to be the major reason for the observed performance in the HPO category. One possibility for the observed performance is that, unlike for GO terms, the HPO annotations are difficult to transfer from other species. Another possibility is the sparsity of experimental annotations. The current number of experimentally annotated proteins in HPO is 4794, i.e., 0.5 proteins per HPO term, which is at least an order of magnitude less than for other ontologies. Finally, the relatively high frequency of general terms may have also contributed to the good performance of Naïve. We originally hypothesized that a possible additional explanation for this effect might be that the average number of HPO terms associated with a human protein is considerably larger than in GO; i.e., the mean number of annotations per protein in HPO is 84, while for MFO, BPO, and CCO, the mean number of annotations per protein is 10, 39, and 14, respectively. However, we do not observe this effect in other ontologies when the benchmark proteins are split into those with a low or high number of terms. Overall, successfully predicting the HPO terms in the protein-centric mode is a difficult problem and further effort will be required to fully characterize the performance.
Term-centric evaluation
The protein-centric view, despite its power in showing the strengths of a predictor, does not gauge a predictor's performance for a specific function. In a term-centric evaluation, we assess the ability of each method to identify new proteins that have a particular function, participate in a process, are localized to a component, or affect a human phenotype. To assess this term-wise accuracy, we calculated AUCs in the prediction of individual terms. Averaging the AUC values over terms provides a metric for ranking predictors, whereas averaging predictor performance over terms provides insights into how well this term can be predicted computationally by the community.
Figure 7 shows the performance evaluation where the AUCs for each method were averaged over all terms for which at least ten positive sequences were available. Proteins without predictions were counted as predictions with a score of 0. As shown in Figs. 4, 5, and 6, correctly predicting CCO and HPO terms for a protein might not be an easy task according to the protein-centric results. However, the overall poor performance could also result from the dominance of poorly predictable terms. Therefore, a term-centric view can help differentiate prediction quality across terms. As shown in Fig. 8, most of the terms in HPO obtain an AUC greater than the Naïve model, with some terms on average achieving reasonably well AUCs around 0.7. Depending on the training data available for participating methods, well-predicted phenotype terms range from mildly specific such as "Lymphadenopathy" and "Thrombophlebitis" to general ones such as "Abnormality of the Skin Physiology".
Overall evaluation using the averaged AUC over terms with no less than ten positive annotations. The evaluation was carried out on no-knowledge benchmark sequences in the full mode. Error bars indicate the standard error in averaging AUC over terms for each method. For cases in which a principal investigator participated in multiple teams, the results of only the best-scoring method are presented. Details for all methods are provided in Additional file 1. AUC receiver operating characteristic curve
Averaged AUC per term for Human Phenotype Ontology. a Terms are sorted based on AUC. The dashed red line indicates the performance of the Naïve method. b The top-ten accurately predicted terms without overlapping ancestors (except for the root). AUC receiver operating characteristic curve
Performance on various categories of benchmarks
Easy versus difficult benchmarks
As in CAFA1, the no-knowledge GO benchmarks were divided into easy versus difficult categories based on their maximal global sequence identity with proteins in the training set. Since the distribution of sequence identities roughly forms a bimodal shape (Additional file 1), a cutoff of 60 % was manually chosen to define the two categories. The same cutoff was used in CAFA1. Unsurprisingly, across all three ontologies, the performance of the BLAST model was substantially impacted for the difficult category because of the lack of high sequence identity homologs and as a result, transferring annotations was relatively unreliable. However, we also observed that most top methods were insensitive to the types of benchmarks, which provides us with encouraging evidence that state-of-the-art protein function predictors can successfully combine multiple potentially unreliable hits, as well as multiple types of data, into a reliable prediction.
Species-specific categories
The benchmark proteins were split into even smaller categories for each species as long as the resulting category contained at least 15 sequences. However, because of space limitations, in Fig. 9 we show the breakdown results on only eukarya and prokarya benchmarks; the species-specific results are provided in Additional file 1. It is worth noting that the performance accuracies on the entire benchmark sets were dominated by the targets from eukarya due to their larger proportion in the benchmark set and annotation preferences. The eukarya benchmark rankings therefore coincide with the overall rankings, but the smaller categories typically showed different rankings and may be informative to more specialized research groups.
Performance evaluation using the maximum F measure, F max, on eukaryotic (left) versus prokaryotic (right) benchmark sequences. The evaluation was carried out on no-knowledge benchmark sequences in the full mode. The coverage of each method is shown within its performance bar. Confidence intervals (95 %) were determined using bootstrapping with 10,000 iterations on the set of benchmark sequences. For cases in which a principal investigator participated in multiple teams, the results of only the best-scoring method are presented. Details for all methods are provided in Additional file 1
For all three GO ontologies, no-knowledge prokarya benchmark sequences collected over the annotation growth phase mostly (over 80 %) came from two species: Escherichia coli and Pseudomonas aeruginosa (for CCO, 21 out of 22 proteins were from E. coli). Thus, one should keep in mind that the prokarya benchmarks essentially reflect the performance on proteins from these two species. Methods predicting the MFO terms for prokaryotes are slightly worse than those for eukaryotes. In addition, direct function transfer by homology for prokaryotes did not work well using this ontology. However, the performance was better using the other two ontologies, especially CCO. It is not very surprising that the top methods achieved good performance for E. coli as it is a well-studied model organism.
Diversity of predictions
Evaluation of the top methods revealed that performance was often statistically indistinguishable between the best methods. This could result from all top methods making the same predictions, or from different prediction sets resulting in the same summarized performance. To assess this, we analyzed the extent to which methods generated similar predictions within each ontology. Specifically, we calculated the pairwise Pearson correlation between methods on a common set of gene-concept pairs and then visualized these similarities as networks (for BPO, see Fig. 10; for MFO, CCO, and HPO, see Additional file 1).
Similarity network of participating methods for BPO. Similarities are computed as Pearson's correlation coefficient between methods, with a 0.75 cutoff for illustration purposes. A unique color is assigned to all methods submitted under the same principal investigator. Not evaluated (organizers') methods are shown in triangles, while benchmark methods (Naïve and BLAST) are shown in squares. The top-ten methods are highlighted with enlarged nodes and circled in red. The edge width indicates the strength of similarity. Nodes are labeled with the name of the methods followed by "-team(model)" if multiple teams/models were submitted
In MFO, where we observed the highest overall performance of prediction methods, eight of the ten top methods were in the largest connected component. In addition, we observed a high connectivity between methods, suggesting that the participating methods are leveraging similar sources of data in similar ways. Predictions for BPO showed a contrasting pattern. In this ontology, the largest connected component contained only two of the top-ten methods. The other top methods were contained in components made up of other methods produced by the same lab. This suggests that the approaches that participating groups have taken generate more diverse predictions for this ontology and that there are many different paths to a top-performing biological process prediction method. Results for HPO were more similar to those for BPO, while results for cellular component were more similar in structure to molecular function.
Taken together, these results suggest that ensemble approaches that aim to include independent sources of high-quality predictions may benefit from leveraging the data and techniques used by different research groups and that such approaches that effectively weigh and integrate disparate methods may demonstrate more substantial improvements over existing methods in the process and phenotype ontologies where current prediction approaches share less similarity.
At the time that authors submitted predictions, we also asked them to select from a list of 30 keywords that best describe their methodology. We examined these author-assigned keywords for methods that ranked in the top ten to determine what approaches were used in currently high-performing methods (Additional file 1). Sequence alignment and machine-learning methods were in the top-three terms for all ontologies. For biological process, the other member of the top three is protein–protein interactions, while for cellular component and molecular function the third member is sequence properties. The broad sets of keywords among top-performing methods further suggest that these methods are diverse in their inputs and approach.
Case study: ADAM-TS12
To illustrate some of the challenges and accomplishments of CAFA, we provide an in-depth examination of the prediction of the functional terms of one protein, human ADAM-TS12 [16]. ADAMs (a disintegrin and metalloproteinase) are a family of secreted metallopeptidases featuring a pro-domain, a metalloproteinase, a disintegrin, a cysteine-rich epidermal growth-factor-like domain, and a transmembrane domain [17]. The ADAM-TS subfamily include eight thrombospondin type-1 (TS-1) motifs; it is believed to play a role in fetal pulmonary development and may have a role as a tumor suppressor, specifically the negative regulation of the hepatocyte growth factor receptor signaling pathway [18].
We did not observe any experimental annotation by the time submission was closed. Annotations were later deposited to all three GO ontologies during the growth phase of CAFA2. Therefore, ADAM-TS12 was considered a no-knowledge benchmark protein for our assessment in all GO ontologies. The total number of leaf terms to predict for biological process was 12; these nodes induced a directed acyclic annotation graph consisting of 89 nodes. In Fig. 11 we show the performance of the top-five methods in predicting the BPO terms that are experimentally verified to be associated with ADAM-TS12.
Case study on the human ADAM-TS12 gene. Biological process terms associated with ADAM-TS12 gene in the union of the three databases by September 2014. The entire functional annotation of ADAM-TS12 consists of 89 terms, 28 of which are shown. Twelve terms, marked in green, are leaf terms. This directed acyclic graph was treated as ground truth in the CAFA2 assessment. Solid black lines provide direct "is a" or "part of" relationships between terms, while gray lines mark indirect relationships (that is, some terms were not drawn in this picture). Predicted terms of the top-five methods and two baseline methods were picked at their optimal F max threshold. Over-predicted terms are not shown
As can be seen, most methods correctly discovered non-leaf nodes with a moderate amount of information content. "Glycoprotein Catabolic Process", "Cellular Response to Stimulus", and "Proteolysis" were the best discovered GO terms by the top-five performers. The Paccanaro Lab (P) discovered several additional correct leaf terms. It is interesting to note that only BLAST successfully predicted "Negative regulation of signal transduction" whereas the other methods did not. The reason for this is that we set the threshold for reporting a discovery when the confidence score for a term was equal to or exceeded the method's F max. In this particular case, the Paccanaro Lab method did predict the term, but the confidence score was 0.01 below their F max threshold.
This example illustrates both the success and the difficulty of correctly predicting highly specific terms in BPO, especially with a protein that is involved in four distinct cellular processes: in this case, regulation of cellular growth, proteolysis, cellular response to various cytokines, and cell-matrix adhesion. Additionally, this example shows that the choices that need to be made when assessing method performance may cause some loss of information with respect to the method's actual performance. That is, the way we capture a method's performance in CAFA may not be exactly the same as a user may employ. In this case, a user may choose to include lower confidence scores when running the Paccanaro Lab method, and include the term "Negative regulation of signal transduction" in the list of accepted predictions.
Accurately annotating the function of biological macromolecules is difficult, and requires the concerted effort of experimental scientists, biocurators, and computational biologists. Though challenging, advances are valuable: accurate predictions allow biologists to rapidly generate testable hypotheses about how proteins fit into processes and pathways. We conducted the second CAFA challenge to assess the status of the computational function prediction of proteins and to quantify the progress in the field.
The field has moved forward
Three years ago, in CAFA1, we concluded that the top methods for function prediction outperform straightforward function transfer by homology. In CAFA2, we observe that the methods for function prediction have improved compared to those from CAFA1. As part of the CAFA1 experiment, we stored all predictions from all methods on 48,298 target proteins from 18 species. We compared those stored predictions to the newly deposited predictions from CAFA2 on the overlapping set of benchmark proteins and CAFA1 targets. The head-to-head comparisons among the top-five CAFA1 methods against the top-five CAFA2 methods reveal that the top CAFA2 methods outperformed all top CAFA1 methods.
Our parallel evaluation using an unchanged BLAST algorithm with data from 2011 and data from 2014 showed little difference, strongly suggesting that the improvements observed are due to methodological advances. The lessons from CAFA1 and annual AFP-SIG during the ISMB conference, where new developments are rapidly disseminated, may have contributed to this outcome [19].
A universal performance assessment in protein function prediction is far from straightforward. Although various evaluation metrics have been proposed under the framework of multi-label and structured-output learning, the evaluation in this subfield also needs to be interpretable to a broad community of researchers as well as the public. To address this, we used several metrics in this study as each provides useful insights and complements the others. Understanding the strengths and weaknesses of current metrics and developing better metrics remain important.
One important observation with respect to metrics is that the protein-centric and term-centric views may give different perspectives to the same problem. For example, while in MFO and BPO we generally observe a positive correlation between the two, in CCO and HPO these different metrics may lead to entirely different interpretations of an experiment. Regardless of the underlying cause, as discussed in "Results and discussion", it is clear that some ontological terms are predictable with high accuracy and can be reliably used in practice even in these ontologies. In the meantime, more effort will be needed to understand the problems associated with the statistical and computational aspects of method development.
Well-performing methods
We observe that participating methods usually specialize in one or few categories of protein function prediction, and have been developed with their own application objectives in mind. Therefore, the performance rankings of methods often change from one benchmark set to another. There are complex factors that influence the final ranking including the selection of the ontology, types of benchmark sets and evaluation, as well as evaluation metrics, as discussed earlier. Most of our assessment results show that the performances of top-performing methods are generally comparable to each other. It is worth noting that performance is usually better in predicting molecular function than other ontologies.
Beyond simply showing diversity in inputs, our evaluation of prediction similarity revealed that many top-performing methods are reaching this status by generating distinct predictions, suggesting that there is additional room for continued performance improvement. Although a small group of methods could be considered as generally high performing, there is no single method that dominates over all benchmarks. Taken together, these results highlight the potential for ensemble learning approaches in this domain.
We also observed that when provided with a chance to select a reliable set of predictions, the methods generally perform better (partial evaluation mode versus full evaluation mode). This outcome is encouraging; it suggests that method developers can predict where their methods are particularly accurate and target them to that space.
Our keyword analysis showed that machine-learning methods are widely used by successful approaches. Protein interactions were more overrepresented in the best-performing methods for biological process prediction. This suggests that predicting membership in pathways and processes requires information on interacting partners in addition to a protein's sequence features.
Automated functional annotation remains an exciting and challenging task, central to understanding genomic data, which are central to biomedical research. Three years after CAFA1, the top methods from the community have shown encouraging progress. However, in terms of raw scores, there is still significant room for improvement in all ontologies, and particularly in BPO, CCO, and HPO. There is also a need to develop an experiment-driven, as opposed to curation-driven, component of the evaluation to address limitations for term-centric evaluation. In the future CAFA experiments, we will continue to monitor the performance over time and invite a broad range of computational biologists, computer scientists, statisticians, and others to address these engaging problems of concept annotation for biological macromolecules through CAFA.
CAFA2 significantly expanded the number of protein targets, the number of biomedical ontologies used for annotation, the number of analysis scenarios, as well as the metrics used for evaluation. The results of the CAFA2 experiment detail the state of the art in protein function prediction, can guide the development of new concept annotation methods, and help molecular biologists assess the relative reliability of predictions. Understanding the function of biological macromolecules brings us closer to understanding life at the molecular level and improving human health.
Costello JC, Stolovitzky G. Seeking the wisdom of crowds through challenge-based competitions in biomedical research. Clin Pharmacol Ther. 2013; 93(5):396–8.
Radivojac P, Clark WT, Oron TR, Schnoes AM, Wittkop T, Sokolov A, et al. A large-scale evaluation of computational protein function prediction. Nat Methods. 2013; 10(3):221–7.
Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, Cherry JM, et al. Gene Ontology: tool for the unification of biology. Nat Genet. 2000; 25(1):25–9.
Dessimoz C, Skunca N, Thomas PD. CAFA and the open world of protein function predictions. Trends Genet. 2013; 29(11):609–10.
Gillis J, Pavlidis P. Characterizing the state of the art in the computational assignment of gene function: lessons from the first critical assessment of functional annotation (CAFA). BMC Bioinform. 2013; 14(Suppl 3):15.
Schnoes AM, Ream DC, Thorman AW, Babbitt PC, Friedberg I. Biases in the experimental annotations of protein function and their effect on our understanding of protein function space. PLoS Comput Biol. 2013; 9(5):1003063.
Jiang Y, Clark WT, Friedberg I, Radivojac P. The impact of incomplete knowledge on the evaluation of protein function prediction: a structured-output learning perspective. Bioinformatics. 2014; 30(17):609–16.
Robinson PN, Mundlos S. The human phenotype ontology. Clin Genet. 2010; 77(6):525–34.
Moreau Y, Tranchevent LC. Computational tools for prioritizing candidate genes: boosting disease gene discovery. Nat Rev Genet. 2012; 13(8):523–36.
Clark WT, Radivojac P. Information-theoretic evaluation of predicted ontological annotations. Bioinformatics. 2013; 29(13):53–61.
Bairoch A, Apweiler R, Wu CH, Barker WC, Boeckmann B, Ferro S, et al. The Universal Protein Resource (UniProt). Nucleic Acids Res. 2005; 33(Database issue):154–9.
Huntley RP, Sawford T, Mutowo-Meullenet P, Shypitsyna A, Bonilla C, Martin MJ, et al. The GOA database: gene ontology annotation updates for 2015. Nucleic Acids Res. 2015; 43(Database issue):1057–63.
Clark WT, Radivojac P. Analysis of protein function and its prediction from amino acid sequence. Proteins. 2011; 79(7):2086–96.
Altschul SF, Madden TL, Schaffer AA, Zhang J, Zhang Z, Miller W, et al. Gapped BLAST and PSI-BLAST: a new generation of protein database search programs. Nucleic Acids Res. 1997; 25(17):3389–402.
Efron B, Tibshirani RJ. An introduction to the bootstrap. New York: Chapman & Hall; 1993.
Cal S, Argüelles JM, Fernández PL, López-Otın C. Identification, characterization, and intracellular processing of ADAM-TS12, a novel human disintegrin with a complex structural organization involving multiple thrombospondin-1 repeats. J Biol Chem. 2001; 276(21):17932–40.
Wolfsberg TG, Straight PD, Gerena RL, Huovila A-PJ, Primakoff P, Myles DG, et al. ADAM, a widely distributed and developmentally regulated gene family encoding membrane proteins with a disintegrin and metalloprotease domain. Dev Biol. 1995; 169(1):378–83.
Brocker CN, Vasiliou V, Nebert DW. Evolutionary divergence and functions of the ADAM and ADAMTS gene families. Hum Genomics. 2009; 4(1):43–55.
Wass MN, Mooney SD, Linial M, Radivojac P, Friedberg I. The automated function prediction SIG looks back at 2013 and prepares for 2014. Bioinformatics. 2014; 30(14):2091–2.
We acknowledge the contributions of Maximilian Hecht, Alexander Grün, Julia Krumhoff, My Nguyen Ly, Jonathan Boidol, Rene Schoeffel, Yann Spöri, Jessika Binder, Christoph Hamm and Karolina Worf. This work was partially supported by the following grants: National Science Foundation grants DBI-1458477 (PR), DBI-1458443 (SDM), DBI-1458390 (CSG), DBI-1458359 (IF), IIS-1319551 (DK), DBI-1262189 (DK), and DBI-1149224 (JC); National Institutes of Health grants R01GM093123 (JC), R01GM097528 (DK), R01GM076990 (PP), R01GM071749 (SEB), R01LM009722 (SDM), and UL1TR000423 (SDM); the National Natural Science Foundation of China grants 3147124 (WT) and 91231116 (WT); the National Basic Research Program of China grant 2012CB316505 (WT); NSERC grant RGPIN 371348-11 (PP); FP7 infrastructure project TransPLANT Award 283496 (ADJvD); Microsoft Research/FAPESP grant 2009/53161-6 and FAPESP fellowship 2010/50491-1 (DCAeS); Biotechnology and Biological Sciences Research Council grants BB/L020505/1 (DTJ), BB/F020481/1 (MJES), BB/K004131/1 (AP), BB/F00964X/1 (AP), and BB/L018241/1 (CD); the Spanish Ministry of Economics and Competitiveness grant BIO2012-40205 (MT); KU Leuven CoE PFV/10/016 SymBioSys (YM); the Newton International Fellowship Scheme of the Royal Society grant NF080750 (TN). CSG was supported in part by the Gordon and Betty Moore Foundation's Data-Driven Discovery Initiative grant GBMF4552. Computational resources were provided by CSC – IT Center for Science Ltd., Espoo, Finland (TS). This work was supported by the Academy of Finland (TS). RCL and ANM were supported by British Heart Foundation grant RG/13/5/30112. PD, RCL, and REF were supported by Parkinson's UK grant G-1307, the Alexander von Humboldt Foundation through the German Federal Ministry for Education and Research, Ernst Ludwig Ehrlich Studienwerk, and the Ministry of Education, Science and Technological Development of the Republic of Serbia grant 173001. This work was a Technology Development effort for ENIGMA – Ecosystems and Networks Integrated with Genes and Molecular Assemblies (http://enigma.lbl.gov), a Scientific Focus Area Program at Lawrence Berkeley National Laboratory, which is based upon work supported by the U.S. Department of Energy, Office of Science, Office of Biological & Environmental Research grant DE-AC02-05CH11231. ENIGMA only covers the application of this work to microbial proteins. NSF DBI-0965616 and Australian Research Council grant DP150101550 (KMV). NSF DBI-0965768 (ABH). NIH T15 LM00945102 (training grant for CSF). FP7 FET grant MAESTRA ICT-2013-612944 and FP7 REGPOT grant InnoMol (FS). NIH R01 GM60595 (PCB). University of Padova grants CPDA138081/13 (ST) and GRIC13AAI9 (EL). Swiss National Science Foundation grant 150654 and UK BBSRC grant BB/M015009/1 (COD). PRB2 IPT13/0001 - ISCIII-SGEFI / FEDER (JMF).
Data The benchmark data and the predictions are available on FigShare https://dx.doi.org/10.6084/m9.figshare.2059944.v1. Note that according to CAFA rules, all but the top-ten methods are anonymized. However, methods are uniquely identified by a code number, so use of the data for further analysis is possible.
Software The code used in this study is available at https://github.com/yuxjiang/CAFA2.
PR and IF conceived of the CAFA experiment and supervised the project. YJ performed most analyses and significantly contributed to the writing. PR, IF, and CSG significantly contributed to writing the manuscript. IF, PR, CSG, WTC, ARB, DD, and RL contributed to the analyses. SDM managed the data acquisition. TRO developed the web interface, including the portal for submission and the storage of predictions. RPH, MJM, and CO'D directed the biocuration efforts. EC-U, PD, REF, RH, DL, RCL, MM, ANM, PM-M, KP, and AS performed the biocuration. YM and PNR co-organized the human phenotype challenge. ML, AT, PCB, SEB, CO, and BR steered the CAFA experiment and provided critical guidance. The remaining authors participated in the experiment, provided writing and data for their methods, and contributed comments on the manuscript. All authors read and approved the final manuscript.
Not applicable to this work.
Department of Computer Science and Informatics, Indiana University, Bloomington, IN, USA
Yuxiang Jiang, Shou Feng & Predrag Radivojac
Buck Institute for Research on Aging, Novato, CA, USA
Tal Ronnen Oron & Biao Li
Department of Molecular Biophysics and Biochemistry, Yale University, New Haven, CT, USA
Wyatt T. Clark
Department of Microbiology, Miami University, Oxford, OH, USA
Asma R. Bankapur & Iddo Friedberg
University of Rome, La Sapienza, Rome, Italy
Daniel D'Andrea, Rosalba Lepore & Anna Tramontano
Computational Bioscience Program, University of Colorado School of Medicine, Aurora, CO, USA
Christopher S. Funk
Department of Computer Science, Colorado State University, Fort Collins, CO, USA
Indika Kahanda & Asa Ben-Hur
Department of Computing and Information Systems, University of Melbourne, Parkville, Victoria, Australia
Karin M. Verspoor
Health and Biomedical Informatics Centre, University of Melbourne, Parkville, Victoria, Australia
Department of Biology, New York University, New York, NY, USA
Da Chen Emily Koo
Social Media and Political Participation Lab, New York University, New York, NY, USA
Duncan Penfold-Brown
CY Data Science, New York, NY, USA
Duncan Penfold-Brown & Noah Youngs
Department of Computer Science, New York University, New York, NY, USA
Dennis Shasha, Noah Youngs & Richard Bonneau
Simons Center for Data Analysis, New York, NY, USA
Noah Youngs & Richard Bonneau
Center for Genomics and Systems Biology, Department of Biology, New York University, New York, NY, USA
Richard Bonneau
Department of Electrical Engineering and Computer Sciences, University of California Berkeley, Berkeley, CA, USA
Alexandra Lin
Department of Plant and Microbial Biology, University of California Berkeley, Berkeley, CA, USA
Sayed M. E. Sahraeian & Steven E. Brenner
Biocomputing Group, BiGeA, University of Bologna, Bologna, Italy
Pier Luigi Martelli, Giuseppe Profiti & Rita Casadio
Computer Science Department, University of Missouri, Columbia, MO, USA
Renzhi Cao, Zhaolong Zhong & Jianlin Cheng
ETH Zurich, Zurich, Switzerland
Adrian Altenhoff & Nives Skunca
Swiss Institute of Bioinformatics, Zurich, Switzerland
Bioinformatics Group, Department of Computer Science, University College London, London, UK
Christophe Dessimoz, Kevin Bryson, Domenico Cozzetto, Federico Minneci & David T. Jones
European Molecular Biology Laboratory, European Bioinformatics Institute, Cambridge, UK
Tunca Dogan, Elena Cibrian-Uhalte, Reija Hieta, Duncan Legge, Michele Magrane, Prudence Mutowo-Meullenet, Klemens Pichler, Aleksandra Shypitsyna, Rachael P. Huntley, Maria J. Martin & Claire O'Donovan
Department of Information Technology, University of Turku, Turku, Finland
Kai Hakala, Suwisa Kaewphan, Farrokh Mehryary, Tapio Salakoski & Filip Ginter
University of Turku Graduate School, University of Turku, Turku, Finland
Kai Hakala, Suwisa Kaewphan & Farrokh Mehryary
Turku Centre for Computer Science, Turku, Finland
Suwisa Kaewphan & Tapio Salakoski
University of Bristol, Bristol, UK
Hai Fang, Ben Smithers, Matt Oates & Julian Gough
Institute of Biotechnology, University of Helsinki, Helsinki, Finland
Petri Törönen, Patrik Koskinen & Liisa Holm
Institute of Information Science, Academia Sinica, Taipei, Taiwan
Ching-Tai Chen & Wen-Lian Hsu
Department of Computational Science and Engineering, North Carolina A&T State University, Greensboro, NC, USA
Samuel Chapman & Dukka BKC
Department of Computer Science, Purdue University, West Lafayette, IN, USA
Ishita K. Khan & Daisuke Kihara
Department of Biological Chemistry, Institute of Life Sciences, The Hebrew University of Jerusalem, Jerusalem, Israel
Dan Ofer, Nadav Rappoport & Amos Stern
School of Computer Science and Engineering, The Hebrew University of Jerusalem, Jerusalem, Israel
Nadav Rappoport & Amos Stern
Centre for Integrative Systems Biology and Bioinformatics, Department of Life Sciences, Imperial College London, London, UK
Michael J. E. Sternberg
Centre for Cardiovascular Genetics, Institute of Cardiovascular Science, University College London, London, UK
Paul Denny, Rebecca E. Foulger, Ruth C. Lovering & Anna N. Melidoni
Department of Electrical Engineering, STADIUS Center for Dynamical Systems, Signal Processing and Data Analytics, KU Leuven, Leuven, Belgium
Pooya Zakeri & Sarah ElShal
iMinds Department Medical Information Technologies, Leuven, Belgium
Inserm UMR-S1052, CNRS UMR5286, Cancer Research Centre of Lyon, Lyon, France
Léon-Charles Tranchevent
Université de Lyon 1, Villeurbanne, France
Centre Léon Bérard, Lyon, France
Institute of Structural and Molecular Biology, University College London, London, UK
Sayoni Das, Natalie L. Dawson, David Lee, Jonathan G. Lees, Ian Sillitoe & Christine A. Orengo
Cerenode Inc., Boston, MA, USA
Prajwal Bhat
Molde University College, Molde, Norway
Tamás Nepusz
Department of Computer Science, Centre for Systems and Synthetic Biology, Royal Holloway University of London, Egham, UK
Alfonso E. Romero & Alberto Paccanaro
Department of Molecular, Cell and Developmental Biology, University of California at Los Angeles, Los Angeles, CA, USA
Rajkumar Sasidharan
School of Mathematics, Statistics and Applied Mathematics, National University of Ireland, Galway, Ireland
Haixuan Yang
Stanley Institute for Cognitive Genomics Cold Spring Harbor Laboratory, New York, NY, USA
Jesse Gillis
Adriana E. Sedeño-Cortés
Department of Psychiatry and Michael Smith Laboratories, University of British Columbia, Vancouver, Canada
Paul Pavlidis
Department for Bioinformatics and Computational Biology-I12, Technische Universität München, Garching, Germany
Juan M. Cejuela, Tatyana Goldberg, Tobias Hamp, Lothar Richter & Burkhard Rost
DOE Joint Genome Institute, Walnut Creek, CA, USA
Asaf Salamov
Bioinformatics and Genomics, Centre for Genomic Regulation, Barcelona, Spain
Toni Gabaldon & Marina Marcet-Houben
Universitat Pompeu Fabra, Barcelona, Spain
Toni Gabaldon, Marina Marcet-Houben & Fran Supek
Institució Catalana de Recerca i Estudis Avançats, Barcelona, Spain
Toni Gabaldon
Division of Electronics, Rudjer Boskovic Institute, Zagreb, Croatia
Fran Supek
EMBL/CRG Systems Biology Research Unit, Centre for Genomic Regulation, Barcelona, Spain
State Key Laboratory of Genetic Engineering, Collaborative Innovation Center of Genetics and Development, Department of Biostatistics and Computational Biology, School of Life Science, Fudan University, Shanghai, China
Qingtian Gong, Wei Ning, Yuanpeng Zhou & Weidong Tian
Children's Hospital of Fudan University, Shanghai, China
Department of Molecular Medicine, University of Padua, Padua, Italy
Marco Falda, Enrico Lavezzo & Stefano Toppo
Research and Innovation Center, Edmund Mach Foundation, San Michele all'Adige, Italy
Paolo Fontana
Department of Information Engineering, University of Padua, Padova, Italy
Carlo Ferrari, Manuel Giollo, Damiano Piovesan & Silvio C.E. Tosatto
Instituto De Genetica Medica y Molecular, Hospital Universitario de La Paz, Madrid, Spain
Angela del Pozo
Spanish National Bioinformatics Institute, Spanish National Cancer Research Institute, Madrid, Spain
José M. Fernández
Structural and Computational Biology Programme, Spanish National Cancer Research Institute, Madrid, Spain
Paolo Maietta, Alfonso Valencia & Michael L. Tress
Control and Computer Engineering Department, Politecnico di Torino, Torino, Italy
Alfredo Benso, Stefano Di Carlo, Gianfranco Politano & Alessandro Savino
National University of Computer & Emerging Sciences, Islamabad, Pakistan
Hafeez Ur Rehman
Anacleto Lab, Dipartimento di informatica, Università degli Studi di Milano, Milan, Italy
Matteo Re, Marco Mesiti & Giorgio Valentini
Applied Bioinformatics, Bioscience, Wageningen University and Research Centre, Wageningen, Netherlands
Joachim W. Bargsten & Aalt D. J. van Dijk
Biometris, Wageningen University, Wageningen, Netherlands
Aalt D. J. van Dijk
Center for Multidisciplinary Research, Institute of Nuclear Sciences Vinca, University of Belgrade, Belgrade, Serbia
Branislava Gemovic, Sanja Glisic, Vladmir Perovic, Veljko Veljkovic & Nevena Veljkovic
Department of Computing and Mathematics FFCLRP-USP, University of Sao Paulo, Ribeirao Preto, Brazil
Danillo C. Almeida-e-Silva & Ricardo Z. N. Vencio
Institute for Molecular Infection Biology, University of Würzburg, Würzburg, Germany
Malvika Sharan & Jörg Vogel
Department of Computer and Information Sciences, Temple University, Philadelphia, PA, USA
Lakesh Kansakar, Shanshan Zhang & Slobodan Vucetic
University of Southern Mississippi, Hattiesburg, MS, USA
School of Biosciences, University of Kent, Canterbury, Kent, UK
Mark N. Wass
Institut für Medizinische Genetik und Humangenetik, Charité - Universitätsmedizin Berlin, Berlin, Germany
Peter N. Robinson
Department of Electrical Engineering ESAT-SCD and IBBT-KU Leuven Future Health Department, Katholieke Universiteit Leuven, Leuven, Belgium
Yves Moreau
California Institute for Quantitative Biosciences, University of California San Francisco, San Francisco, CA, USA
Patricia C. Babbitt
Department of Chemical Biology, The Hebrew University of Jerusalem, Jerusalem, Israel
Michal Linial
Department of Systems Pharmacology and Translational Therapeutics, University of Pennsylvania, Philadelphia, PA, USA
Casey S. Greene
Department of Biomedical Informatics and Medical Education, University of Washington, Seattle, WA, USA
Sean D. Mooney
Department of Computer Science, Miami University, Oxford, OH, USA
Iddo Friedberg
Department of Biomedical Sciences, University of Padua, Padova, Italy
Manuel Giollo
Department of Biological Sciences, Purdue University, West Lafayette, IN, USA
Daisuke Kihara
Department of Biological and Environmental Sciences, Universitity of Helsinki, Helsinki, Finland
Liisa Holm
University of Lausanne, Lausanne, Switzerland
Christophe Dessimoz
Swiss Institute of Bioinformatics, Lausanne, Switzerland
Yuxiang Jiang
Tal Ronnen Oron
Asma R. Bankapur
Daniel D'Andrea
Rosalba Lepore
Indika Kahanda
Asa Ben-Hur
Dennis Shasha
Noah Youngs
Sayed M. E. Sahraeian
Pier Luigi Martelli
Giuseppe Profiti
Rita Casadio
Renzhi Cao
Zhaolong Zhong
Jianlin Cheng
Adrian Altenhoff
Nives Skunca
Tunca Dogan
Kai Hakala
Suwisa Kaewphan
Farrokh Mehryary
Tapio Salakoski
Filip Ginter
Hai Fang
Ben Smithers
Matt Oates
Julian Gough
Petri Törönen
Patrik Koskinen
Ching-Tai Chen
Wen-Lian Hsu
Kevin Bryson
Domenico Cozzetto
Federico Minneci
David T. Jones
Samuel Chapman
Dukka BKC
Ishita K. Khan
Dan Ofer
Nadav Rappoport
Amos Stern
Elena Cibrian-Uhalte
Rebecca E. Foulger
Reija Hieta
Duncan Legge
Ruth C. Lovering
Michele Magrane
Anna N. Melidoni
Prudence Mutowo-Meullenet
Klemens Pichler
Aleksandra Shypitsyna
Biao Li
Pooya Zakeri
Sarah ElShal
Sayoni Das
Natalie L. Dawson
Jonathan G. Lees
Ian Sillitoe
Alfonso E. Romero
Alberto Paccanaro
Shou Feng
Juan M. Cejuela
Tatyana Goldberg
Tobias Hamp
Lothar Richter
Marina Marcet-Houben
Qingtian Gong
Wei Ning
Yuanpeng Zhou
Weidong Tian
Marco Falda
Enrico Lavezzo
Stefano Toppo
Carlo Ferrari
Damiano Piovesan
Silvio C.E. Tosatto
Paolo Maietta
Alfonso Valencia
Michael L. Tress
Alfredo Benso
Stefano Di Carlo
Gianfranco Politano
Alessandro Savino
Matteo Re
Marco Mesiti
Giorgio Valentini
Joachim W. Bargsten
Branislava Gemovic
Sanja Glisic
Vladmir Perovic
Veljko Veljkovic
Nevena Veljkovic
Danillo C. Almeida-e-Silva
Ricardo Z. N. Vencio
Malvika Sharan
Jörg Vogel
Lakesh Kansakar
Shanshan Zhang
Slobodan Vucetic
Rachael P. Huntley
Maria J. Martin
Claire O'Donovan
Anna Tramontano
Steven E. Brenner
Christine A. Orengo
Burkhard Rost
Predrag Radivojac
Correspondence to Iddo Friedberg or Predrag Radivojac.
A document containing a subset of CAFA2 analyses that are equivalent to those provided about the CAFA1 experiment in the CAFA1 supplement. (PDF 11100 kb)
Jiang, Y., Oron, T., Clark, W. et al. An expanded evaluation of protein function prediction methods shows an improvement in accuracy. Genome Biol 17, 184 (2016). https://doi.org/10.1186/s13059-016-1037-6
Protein function prediction
Disease gene prioritization | CommonCrawl |
The time varying network of urban space uses in Milan
Alba Bernini1,
Amadou Lamine Toure1,2 &
Renato Casagrandi ORCID: orcid.org/0000-0001-5177-803X1
Applied Network Science volume 4, Article number: 128 (2019) Cite this article
In a metropolis, people movements design intricate patterns that change on very short temporal scales. Population mobility obviously is not random, but driven by the land uses of the city. Such an urban ecosystem can interestingly be explored by integrating the spatial analysis of land uses (through ecological indicators commonly used to characterize natural environments) with the temporal analysis of human mobility (reconstructed from anonymized mobile phone data). Considering the city of Milan (Italy) as a case study, here we aimed to identify the complex relations occurring between the land-use composition of its neighborhoods and the spatio-temporal patterns of occupation made by citizens. We generated two spatially explicit networks, one static and the other temporal, based on the analysis of land uses and mobile phone data, respectively. The comparison between the results of community detection performed on both networks revealed that neighborhoods that are similar in terms of land-use composition are not necessarily characterized by analogous temporal fluctuations of human activities. In particular, the historical concentric urban structure of Milan is still under play. Our big data driven approach to characterize urban diversity provides outcomes that could be important (i) to better understand how and when urban spaces are actually used, and (ii) to allow policy makers improving strategic development plans that account for the needs of metropolis-like permanently changing cities.
Understanding land use occupation and dynamics is crucial for urban and territorial planning, since it allows to capture the results of past modifications, monitor ongoing changes and predict future impacts and opportunities. Since the end of the 20th century, land use and land cover maps have been extensively generated at different spatial and temporal scales, especially in the framework of the European CORINE program (Feranec et al. 2016). Land use maps are commonly utilized to inform decision makers on the spatial organization of the territory under their government.
Especially in the urban context, the compresence of different land uses can generate intricate patterns that can interestingly be explored with tools that ecologists typically adopt to analyze biodiversity in a natural environment. Biodiversity can be defined as the heterogeneity of living organisms and processes found in the environment (e.g., DeLong (1996)), and can be evaluated at different scales. According to Whittaker's idea (1972), α-diversity is a local measure and refers to the richness in species of a site or habitat, β-diversity measures the differentiation between two sites or habitats. The total species diversity in a landscape (i.e., its γ-diversity) is a combination of both α- and β-diversity. These concepts can be transferred to an urban context to measure the "richness" of land uses of the different neighborhoods (corresponding to α-diversity) and to quantify their dissimilarities in terms of land-use mix (corresponding to β-diversity). The presence of not contiguous areas with similar usage and needs could suggest possible planning measures at higher levels, that cross the borders of the single neighborhoods.
Land use classification is commonly defined in terms of physical characteristics, such as reflectivity and texture, that can be well captured from remote sensing. Gong et al. (1990); Fisher (1997); Shaban and Dikshit (2001); Lu and Weng (2006). However, these technologies are unable to identify the actual utilization by people and to discriminate between some land use types (i.e., residential and commercial) (Louail et al. 2014; Pei et al. 2014). Information about human movement and activities can nowadays be derived thanks to data on digital human footprints, i.e. the digital traces that people leave while placing phone calls, interacting on the Internet or on digital devices (Howison et al. 2011). This enormous amount of data can be used to provide new fundamental and quantitative insights on the actual occupation of a certain urban area and, as a consequence, on its possible social function (Gonzalez et al. 2008; Cho et al. 2011; Hawelka et al. 2014; Hoteit et al. 2014; Secchi et al. 2015). The aim of this study is to investigate the complex relations occurring between the land-use composition of the areas inside a city and the spatio-temporal occupation made by citizens. As an important case study, we focused on the city of Milan, which is located in Northern-Italy and, with its 1.40 million inhabitants, is the second-most populous Italian city. Specifically, we aimed at identifying which areas are more similar/dissimilar in terms of either land-use composition or because of the daily trend of human occupation. These outcomes could be important not only to better understand how and when urban spaces are used but also for allowing policy makers to improve strategic development plans accounting for the needs of an "active" city.
Data on land use and land cover in the study area of Milan
In this study we focused on the urban area of the city of Milan, the chief seat of the Lombardy Region. The development of Milan occurred through subsequent expansions, which designed concentric circles in the urban structure (Morandi 2007). The recognition of a circular structure of Milan dates back to the XIII century, as documented by the Milanese poet Bonvesin de la Riva (1288) in his book entitled "De magnalibus urbis Mediolani" ("On the greatness of the city of Milan"). At section IV of chapter II, he writes in fact
Civitas ista ipsa orbicularis est ad circulli modum, cuius mirabilis rotonditas perfectionis eius est signum
(which reads as "This same city has an orbital shape, in the shape of a circle: this admirable roundness is the sign of its perfection"). From an administrative prospective, the municipality of Milan is nowadays subdivided into nine Boroughs, the so-called Municipi (see Fig. 1C), each one having its own Council and President. The nine Borough Councils are coordinated at the city level by the City Council, which can decide over the general rules for the use of goods and services. On the other hand, Borough Councils have independent administrative power and responsibility on some local but important matters, such as schools, social services, waste collection, roads, parks, libraries and local commerce. It is not guaranteed that the nine boroughs, however, cannot capture the richness of the city. Indeed, each Borough includes districts with different social and cultural aspects. Accounting for these characteristics, the city was further subdivided into 88 districts with unique social and cultural identity, the so called Nuclei di Identità Locale (NILs), i.e. Local Identity Neighborhoods, which are bounded by white lines in Fig. 1. Since their distinctive social identity is often reflected in their urban characteristics, they are often well recognizable by both inhabitants and tourists. Although they do not have an administrative function, NILs are adopted as reference system in the Piano di Governo del Territorio (PGT), i.e. the Territorial Administration Plan, to analyze and manage the local demand of services (www.pgt.comune.milano.it). The social relevance of NILs have been once again confirmed since one of the five objectives of 2019 PGT is to enhance them through the regeneration of their public spaces, as a first step towards a new polycentric city model. Given their importance in Milan urban planning, we adopted NILs as units in the analysis we performed, as also done in other studies on this city (Arnaboldi et al. 2017; Mariotti et al. 2017, 2018).
Land use distribution in the city of Milan. a The spatial distribution in the city of Milan of the seven land uses (see legend and definitions in the main text). White lines design the borders of the 88 NILs (Nuclei di Identità Locale, see text). b A zooming on the city center shows the grids over which CDR data was recorded. c Administrative subdivision of the city: the 9 Boroughs (Municipi) of Milan and their NILs are contoured by black (thick solid) and blue (dashed lines), respectively
Land use maps for the city of Milan were obtained from the DUSAF geographical database, which is managed by E.R.S.A.F. (Regional Agency for Services to Agriculture and Forestry) and available and freely accessible at the GEOPortale (www.cartografia.regione.lombardia.it). We used the latest version of the database (DUSAF 5.0), which dates back to 2015.
In the DUSAF database, the territory of the whole Lombardy Region (thus also of Milan) is partitioned into geographical polygons, each representing an uniform area in terms of land use, e.g. a group of contiguous buildings, a road, a park. Polygons are classified according to a legend with 5 hierarchical levels detailing their nature. From coarsest to finest scales, the first three levels refer to the guidelines of CORINE Land Cover, while the last two levels were defined by E.R.S.A.F. using auxiliary databases to better categorize some land uses.
Each polygon in the DUSAF is labeled with a string made of a minimum 1 characters to a maximum of 5 characters. According to its position within the string, each character aims at qualifying the land use of the polygon at a specific level of detail: from left to right, the first character refers to level 1, the second to level 2 and so on. For example, hospitals are labeled as 12121, and each character represents (left to right, again):
Level 1 1 Anthropic areas
Level 2 12 Productive sites, big plants and communication networks
Level 3 121 Industrial sites and public and private services
Level 4 1212 Public and private services (hospitals, schools,...)
Level 5 12121 Hospitals
As a first step of the analysis we needed to select the categories that could be interesting for our study, reconciling the level of detail of the DUSAF description to the relevance of particular categories of land use. More specifically, we filtered only those categories that could be related to human occupation patterns during the day, such as industries, services and parks. We then grouped the rarest (e.g. water bodies and humid areas) or less relevant ones (e.g. agricultural areas) under new reference names. This preliminary analysis led to the selection of the following 7 categories:
Buildings, including all the subcategories in Urbanized areas (11);
Industrial and commercial areas, where we grouped Industrial and commercial sites (1211) and Construction sites, landfill, abandoned areas (13);
Services, including Public and private services (1212) such as hospitals, schools, courts and cemeteries;
Roads, railways and airports, bringing together Roads and railways (122) and Airports (124);
Green urban areas, including Forested and semi-natural areas (3), often located in public parks or gardens, and Green urban areas (14);
Agricultural areas, where we grouped all the subcategories belonging to the macro-category Agricultural areas (2);
Water bodies and humid areas, including the last two macro-categories Humid areas (4) and Water bodies (5).
Figure 1 shows the distribution of the land uses according to the grouping performed above in the study area of Milan. The city center is mainly occupied by Buildings and Services (see the grey and pink polygons in Panel (B)). Moving from the center to the periphery, Industrial and commercial areas (brown) and Green urban areas (green) are more abundant. The agricultural fields (yellow) are part of the rural area of the Parco Agricolo Sud Milano and are located in the external south and west part of the municipal area. Roads and railways (black) start revealing the urban concentric structure of the city. Indeed, nowadays the historic city limits can be recognized since main roads traveled by cars and public transports follow them: the transportation network design a series of ring roads, crossed by radial roads that connect the center and the peripheries.
Biodiversity indicators based on land uses
The quantification of diversity is quite an explored field in Ecology. Since the studies of pioneers (Whittaker 1972), biodiversity in a given ecosystem has been measured by accounting for both its richness in terms of species and heterogeneity in the individuals representing them. Biodiversity within an ecosystem is commonly named α-diversity and it is high (ceteris paribus) when the number of present species is high and/or when the distribution of individuals among the species is evenly distributed (Simpson (1949); Shannon (1948), see for example). While α-diversity is a local measure of differentiation, β-diversity is used to quantify the differences between ecosystems or habitats (Whittaker 1972) and it has been mainly measured via dissimilarity indices, such as Jaccard and Sørensen indices, which account for the number of species they share or not (Jaccard 1901; Sørensen 1948): ceteris paribus, the larger is the fraction of shared species (possibly weighted by the number of individuals), the lower is β-diversity. In our study, we proposed to elaborate these concepts developed for natural environments to an urban context. Considering as "species" each of the seven land uses defined in the previous paragraph, first we measured the richness within NILs, so as to obtain α-diversity, and then we computed the pairwise dissimilarity between them, corresponding to their β-diversity.
We organized the data about land uses in a table X of 88 rows (the NILs) and 7 columns (the land uses). The element xij of the matrix was equal to the fraction of the area of NIL i occupied by the land use j. The row Xi of the table represented then the land-use mix of a NIL i (see some examples in Table 1). We measured the α-diversity within each NIL using the Simpson index (Simpson 1949), computed as:
$$ H(X_{i})= 1 - \sum_{j = 1}^{7} (x_{ij})^{2} $$
Table 1 Land-use mixes of NILs 1, 18, 35 and 87, selected here as representative of Communities 1, 2, 3 and 4 respectively shown in Fig. 3, which have been identified by community detection performed on land uses
The minimum value of the Simpson index is 0 and is obtained when only one land use is present in the NIL. On the contrary, its maximum possible value occurs when all land uses are equally distributed within the NIL i, i.e. xij=1/7 ∀ j, so that \(H_{i}^{\max } = 6/7\).
To evaluate β-diversity between two natural ecosystems, typically adopted measures quantify their differences in terms of number of shared/unshared species. Examples of β-diversity indices are the Jaccard (1901) and Sørensen (1948) indices, which have their minimum value when the two ecosystems do not share any species and their maximum when all species are shared. In our case study, the fact that all the seven categories of land use (i.e., our "urban species") were present in almost all NILs (i.e., our "urban ecosystems") posed some limitations in applying traditional β-diversity indices. Indeed, they would have returned an unrealistically uniform picture of the city, with all NILs being similar. To overcome such limitations, we decided to focus on the differences between distributions of land uses, rather than on their turnover along the territory. Thus, instead of using traditional β-diversity indices, we compared each couple of NILs, say i and j by computing the (Euclidean) distance between their land-use mixes, represented by two vectors Xi and Xj in a seven-dimensional parameter space where each axis is a land use type. We then normalized the Euclidean distance by dividing it by the maximum potential value it can reach, amounting to \(\sqrt {2}\) (a value that is reached when the two NILs are both occupied by a unique, yet different land use). Our newly defined metric for computing the dissimilarity of land uses thus reads as
$$ d_{LU}(X_{i}, X_{j}) = \sqrt{\frac{\sum_{k = 1}^{7} (x_{ik}-x_{jk})^{2}}{2}} $$
We note that, although Eq. 2 was here defined in the context of urban ecology, it might in principle represent an interesting metrics also to quantitatively compare at a glance natural simple ecosystems.
Community detection based on land uses
To detect the presence of groups of NILs with similar land-use mixes, whose number was not a priori known, we referred to network theory (Newman 2010) and, specifically, to community detection (Fortunato 2010). We built a complete, undirected yet weighted network with 88 nodes representing the NILs. Each link between two NILs, say i and j, was assigned a weight equal to the similarity between them. According to the metric defined by Eq. 2, we computed similarity as:
$$ s_{LU}(X_{i}, X_{j}) = 1 - d_{LU}(X_{i}, X_{j}) $$
Over this network, we performed community detection based on modularity optimization (Newman 2006), which does not require to fix the optimal number of clusters in advance. In order to assess the robustness of the results, we repeated community detection also using the Louvain method (Blondel et al. 2008). In addition to applying network-based approaches, we also tried to use hierarchical clustering algorithms based on Ward's method (Ward 1963) to detect groups of NILs with similar land-use mixes. To that end, we utilized as distance metric the measure dLU(Xi,Xj), defined in Eq. 2.
Data on CDR: Milan Telecommunications
To account for the effective use of the urban territory by people, we used an anonymized dataset on phone calls and internet connections. This dataset was part of the "2014 Telecom Italia Big Data Challenge", which provides various geo-referenced information, released to the research community under the Open Database License (OdbL). The whole dataset (available at www.dataverse.harvard.edu) contains information about the use over time of the mobile-phone network in the urban area of Milan over a period of two months, from November 1, 2013 to December 31, 2013 and it was obtained from Call Detail Records (CDRs).
Technically, CDRs log the details of calls made over a phone service and are registered by operators for billing purposes and network management. Every time a user engages a telecommunication interaction (either voice, text or other ICT connections), a Radio Base Station (RBS) is assigned by the operator and delivers the communication through the network. The time and duration of the interaction, together with its nature and the RBS, which handled it are recorded in a new CDR. From the information on the RBS it is possible to obtain the approximate user's geographical location at the time of the activity which must be within the area of influence of that RBS. The Telecom Italia Big Data Challenge dataset that we used for our analysis was the result of a computation over the CDRs, which were aggregated in a spatial grid with pixels 235m x 235m and in time slots of 10 min, as detailed in Barlacchi et al. (2015). The aggregation process generated a dataset, where each record describes the network activity occurred in a square of the spatial grid during a time slot in terms of incoming/outgoing SMSs and calls and Internet traffic activity.
Since we aimed at analyzing human presence in the different NILs during time, we considered the total activity as the sum of all types of activities (incoming/outgoing SMS and calls together with Internet connections) and we aggregated it by NIL and by hour of the day. Moreover, we arbitrarily decided to only consider in the analysis the four weeks from November 4, 2013 to December 1, 2013 in order not to include the religious holidays – such as for the patron Saint of Milan, Sant'Ambrogio (December 7, 2013), the Immaculate Conception (December 8, 2013) and Christmas. In these periods, indeed, people movement habits could have been considerably different from the rest of the year.
We therefore organized the data in a series of 28 matrices Y(t), with t=1,2,...,28 (one for each day in the study period), each one made by 88 rows (the NILs) and 24 columns (the hours of the day). Each element yij(t) represented the total number of mobile phone/network activities within NIL i occurring at the daily hour j of the day t divided by the surface area of NIL i. Each row Yi(t) of the table represented the network activity time series within NIL i in the day t.
Community detection based on CDR data
We used the CDRs to evaluate the spatio-temporal fluctuations of human activities within the city and to reveal the presence of human generated connections between NILs that are active at the same time. In particular, for each day t, we performed a pairwise time series comparison of CDR activities between the 88 NILs using an adaptive dissimilarity index covering both proximity on values and on behavior, as defined by Chouakria et al. (2007). Following their methodology, we computed the dissimilarity index as the product of a function μ of the temporal correlation ρ between two time series, say Yi(t) and Yj(t), and a measure of their (Euclidean) distance.
$$ \rho(Y_{i}(t), Y_{j}(t))= \frac{\sum_{k = 1}^{23} (y_{i(k+1)}(t) - y_{ik}(t)) (y_{j(k+1)}(t)-y_{jk}(t))} {\sqrt{\sum_{k = 1}^{23} (y_{i(k+1)}(t) - y_{ik}(t))^{2}} \sqrt{\sum_{k = 1}^{23} (y_{j(k+1)}(t) - y_{jk}(t))^{2}}} $$
$$ \mu(\rho(Y_{i}(t), Y_{j}(t))) = \frac{2}{1+\exp(2\rho(Y_{i}(t), Y_{j}(t)))} $$
$$ d_{CDR}(Y_{i}(t), Y_{j}(t))) = \mu(\rho(Y_{i}(t), Y_{j}(t)))\times\sqrt{\sum_{k = 1}^{24} (y_{ik}(t)-y_{jk}(t))^{2}} $$
where the subscript k=1,2,…,24 indicates the hour within the day t. We then obtained 28 distance matrices, one for each day.
To evaluate the emergence of groups of NILs characterized by similar patterns of daily human occupation, we also performed network community detection on each distance matrix but using an agglomerative hierarchical clustering algorithm, based on Ward's method (Ward 1963). The motivation for using a clustering algorithm in this case, rather than a network-based algorithm as before, was to a priori fix the number of clusters to be identified within the city, a number that we wanted to keep equal to the one obtained from the analysis on the land-use mixes for comparison.
To measure the robustness through time of the identified communities, we built a network with 88 nodes representing the NILs and we traced links between nodes that had been grouped at least once in the same community within the time horizon under study (28 days). Then, we provided a weight wij to each link of the network connecting every node/NIL i with node/NIL j≠i equal to the fraction of days the two nodes were grouped in the same community. We finally defined as measure of distance between NILs i and j the difference 1−wij. Using this measure of distance, we performed thus community detection using hierarchical clustering with the Ward's agglomerative method on the weighted network.
As a last step, we measured to what extent the partition in communities generated by the analysis of the CDR dataset was coherent with the one generated with the analysis of land uses. Following the methodology presented by Fortunato et al. (2016), we computed the similarity of the two partitions through the Jaccard index, i.e. the ratio between the number of node pairs classified in the same cluster in both partitions and the number of node pairs classified in the same cluster in at least one partition. To assess whether the obtained similarity score was significantly different from random, we compared it with the values obtained comparing random partitions, following the methodology of Hubert and Arabie (1985). We generated 1000 randomizations of the land-use partition, grouping NILs into clusters with the same size and in the same number as in the land-use partition based on community detection. Analogously, we produced 1000 randomizations of the CDR partition. We then pairwisely compared the randomizations through the Jaccard index and we assessed the differences between the 1000 values obtained in this way and the similarity score based on the land-use and the CDR partitions.
To assess the robustness of our outcomes, we repeated the analysis on CDRs on both the daily networks and the temporally-aggregated network by using community detection via modularity maximization (Newman 2006), a method that does not require to fix the number of desired communities in advance. For each day, we built a similarity matrix SCDR(t), whose elements were computed as:
$$ s_{CDR}(Y_{i}(t), Y_{j}(t)) = 1 - \frac{d_{CDR}(Y_{i}(t), Y_{j}(t))}{\max\left[d_{CDR}(Y_{i}(t), Y_{j}(t))\right]} $$
where max[dCDR(Yi(t),Yj(t)] is the day-dependent maximum possible value of dCDR(Yi(t),Yj(t)). Considering the matrices SCDR(t) as adjacency matrices, we generated 28 weighted, undirected networks over which we performed community detection. Finally, we aggregated the results so obtained in a network of 88 nodes (one per NIL) with an undirected, yet weighted link between each pair of nodes that had been grouped in the same community at least once. Each weight was set equal to the fraction of days the two linked nodes were grouped in the same community. We last investigated the emergence of communities in such weighted network using again the modularity optimization algorithm.
The results obtained computing the within-NIL α-diversity based on the land uses are mapped in Fig. 2A. The darker is the color of a NIL, the higher is the value of the indicator that represents, we remind to the reader, its richness in terms of land-use mix. A visual comparison between maps in Figs. 1A and 2A, which represents the actual distribution of land uses in the city, is sufficient to reveal that the low values of α-diversity in the NILs located in the city center and in the southern part of the city were due to different urban environments. While the dominance of the land use "Buildings" characterized the city center, the large prevalence of "Agricultural areas" qualified the southern part of the city (Parco Agricolo Sud Milano). Conversely, the "transition" NILs between the city center and the agricultural areas were characterized by more diversified land uses mixes, resulting in high levels of α-diversity.
α- and β-diversity based on land use distribution in Milan. a Map of α-diversity computed with the Simpson index on the basis of land uses; the darker the NILs' colors, the higher their α-diversities and, thus, their urban richness. b NILs are colored according to the Euclidean distance between their vector of land-use mix and the one of NIL 1, the city center
To quantify β-diversity within the city we elaborated the differences between the composition of the NILs in terms of land uses, by calculating the distances between the vectors representing their land-use mixes. Of course, a general assessment of the whole β-diversity of land uses in Milan would have required to compute the pairwise differences between each couple of NILs, so with the evaluation of (88×87)/2 indicators. An exercise whose outcomes would not be easily synthesizable. We therefore selected the map here only the comparison between NIL 1, namely Duomo, shown in Fig. 1b, and each other NIL. In Fig. 2b, NILs are colored according to their "land-use distance" from the city center (NIL 1): the darker is the color of NIL i, the higher is the distance between the vectors describing land uses of NIL i and NIL 1, thus, the "urban difference". It emerged that NILs resulting similar to NIL 1 in terms of α-diversity were, instead, very different in terms of land-use mix. Indeed, the maximum values of distances were obtained comparing the city center with the more peripheral NILs.
Apart from the punctual differences that can be identified through fine scale analyses of distances between vectors of land-use mix, it is worthwhile to investigate whether there is any geographical consistence (e.g. adjacency or proximity) in the patterns of urban compositions of Milan's NILs. To group the NILs that were more similar between them relative to other NILs, we used techniques from the complex network literature.
In fact, we created a complete undirected network with 88 nodes, representing each NIL connected by links that were weighted according to the similarity of their land-use mixes. On this land-use network, we performed community detection based on modularity optimization. Using the algorithm, we obtained that the modularity is maximized when the land-use network is split into 4 communities, which are shown in Fig. 3. Although the value of modularity obtained was not very high in absolute terms (modularity = 0.06), the a posteriori analysis of the land-use mix of the centroids of such communities and their geographical position in the city led us to consider them reliable. Interestingly, also using another algorithm for community detection, namely the Louvain method, we obtained the same subdivision in communities, which once again strengthened our results. The apparent urban pattern that emerged while looking at the Milan mapping of community detection on the land-use network is that, apart from a few explainable exceptions, the NILs grouped together are contiguous (see Fig. 3A). Second, and analogously important, is that land-use composition within each community had a specific urban identity that fingerprinted a major land use of that part of the city (Fig. 3B). Community 1, in fact, mainly included NILs located in the very center of Milan and was mainly characterized by the prevalence of the land use type "Buildings". In Communities 2 and 3, the predominant categories were "Green urban areas" and "Industrial and commercial sites", respectively, although the relative abundance of "Buildings" was not negligible either. Notably, the two NILs belonging to Community 2 and surrounded by NILs belonging to Community 1 include indeed two large city parks (Giardini di Porta Venezia and Parco Sempione, respectively).
Community detection based on land uses. a Results of the community detection based on modularity optimization performed on a complete undirected network of the similarity between the land uses in the NILs. b Land use mixes of the centroids of the foure communities
The Communities 2 and 3 designed a sort of circle around the center and divided it from the last community, labeled as 4, which grouped the NILs in the agricultural area. When we repeated the analysis via hierarchical clustering, the obtained partition of the city in four clusters was consistent to the one presented in Fig. 3, but the obtained clusters had very different size. In particular, almost all NILs in the city periphery (52 NILs in total) were grouped together within a single cluster, comprehensive of Communities 2 and 3 of Fig. 3. To the eyes of people living in Milan, the refinement offered by the network-based approach for city partitioning is relevant and close to citizens' experience. We therefore focused on the outcomes generated with the modularity maximization algorithm.
As explained in the "Materials and methods" section, in order to analyze the actual presence of citizens within each of the NILs throughout the day, we relied on anonymized phone data. More precisely, we used the CDR dataset to evaluate with a method also mutuated by complex networks theory the possible emergence of patterns of occupation. We built a daily temporal network of similarity between the time series of CDR intensities in the NILs. More precisely, we performed, on each daily network, community detection with an agglomerative hierarchical clustering algorithm by fixing a priori the number of clusters equal to 4, so as to be coherent with the results of the analysis just performed on land uses. To measure the robustness in time of the communities, we built a network of 88 nodes representing the NILs and we traced links only between the nodes that had been grouped at least once in the same community. On each link we posed a weight equal to the fraction of times within the period the nodes connected had been in the same community. We then performed community detection with an agglomerative hierarchical clustering algorithm on the mobile-phone network built in this way. Consistently with the city partitioning determined above for the land uses, we kept the number of clusters equal to 4 and obtained the communities shown in Fig. 4A. The concentric urban structure of Milan emerges now clearly through four almost circular communities of NILs. The dendrogram in Fig. 4B helps to read behind the performed clustering, since the horizontal line shows where we cut the tree to obtain the 4 communities. On the left part of the dendrogram, Fig. 4B reveals the presence of a conspicuous group of nodes that, according to the used metrics, are very similar between them and were grouped into the same community. The rest of nodes are grouped into smaller (and perhaps less sharply defined) clusters. Figure 4C shows the hourly trend of CDR intensity during workdays (black lines) and weekends (red lines) of four representative NILs, one for each community shown in Fig. 4A. Interestingly, we found that NILs belonging to Community 1 (the most central part of Milan) are utilized by citizens especially during the central hours of workdays, with a unimodal, bell-shaped temporal pattern. This pattern can be explained considering the many offices and shops located in this area of the city as well as human mobility that crosses the city center. It is noticeable that the CRD intensity during weekends is considerably lower compared to workdays and that it peaks in the late afternoon, rather than at lunch time. Community 2 circularly surrounds Community 1 and contains the internal ring road of Milan (called "Circonvallazione interna", at the border of Municipio 1). It includes NILs whose peculiarity is that of being used by people in the second part of the day (during evening and night), especially during weekends, more than other NILs are. Indeed, in NILs like Navigli there are many bars and restaurants and most people hang out there at night time. Patterns of occupation in NILs belonging to Community 3 do not display much difference between workdays and weekends and are relatively constant throughout the day. This is probably due to the traffic over the external ring road of Milan ("Circonvallazione esterna"), which is almost always busy, and that surrounds the core of the city. Finally, Community 4 includes NILs that host ways of entrance to/exit from the city for citizens living in the larger metropolitan area ("la Grande Milano"). The trends in CDR activities are characterized there by two peaks in workdays in correspondence to the hours when people commute towards either their workplace (morning peak) or their home (evening peak).
Community detection based on CDRs. a Communities of NILs obtained using agglomerative hierarchical cluster analysis on the CDR data. b Dendrogram of the clustering procedure (see text). c Daily trends of CDR intensity (which we considered as a proxy of human use) in four NILs selected as representative of the four Communities shown in (a). Black and red lines represents trends in weekdays and weekends, respectively
We also tried to obtain a partition of the city with respect to human activities registered via CDRs by using the network-based approach of modularity optimization. Such method (whose results are not shown here) divided the city into three (instead of four) groups that were quite unbalanced in terms of numbers of NILs included: the city central part (34 NILs), the periphery (52 NILs) and a third cluster consisting of only 2 NILs (both located at the border between the other two larger clusters). The agglomerative hierarchical clustering method used in Fig. 4 thus returned a richer description of the city than the one that could have been obtained via the network-based algorithm, because it was able to detect the presence of concentric clusters whose structure is coherent with the urban texture that Milan has since centuries (as we have seen in the Introduction).
Given the two different partitions of the city, based on community detection in the land-use network (see Fig. 3) and in the mobile-phone network (see Fig. 4), there was a need to reconcile them or at least to understand and to discuss their level of overlapping. A simple, very synthetic index is the Jaccard similarity index described in the "Materials and methods" section, that amounted to 0.26 in the current case. To assess its significance, we compared the measured score with the values generated over 1000 different randomizations of the partitions and we found out that the value we obtained for our case study was systematically (i.e. 100% of times) greater than the random values (mean and standard deviation equal to 0.20 and 0.008, respectively). This result showed the presence of a correlation between the two land-use and the CDR partitions. The Sankey diagram in Fig. 5 graphically illustrates how nodes/NILs were identified to be part of different communities in the two partitions generated by analyzing the (weighted) networks of land uses and mobile phone data (CDRs). Rectangular colored boxes on the left and right extremes of the grey bands indicate, respectively, nodes/NILs belonging to the communities obtained from analysis of the land-use network (shown in Fig. 3) and on the mobile-phone network (Fig. 4). The height of each rectangle is proportional to the number of nodes in the corresponding community. The width of each grey band is instead proportional to the number of NILs shared by the land-use community on the left and the mobile-phone community on the right. As it can be seen, the overlap between the two partitions is only partial. Interestingly, NILs in Community 1 of the land-use partition (on the left in Fig. 5), which are located in the very center of Milan (see the red NILs in Fig. 3), could belong to each of the communities detected in the CDR partitioning (on the right). This implies that, although pretty similar in terms of land uses, the different NILs in the center of Milan are quite "patchy" and not very homogeneous in terms of temporal patterns of human occupancy through the hours of the day. This situation was analogous to the one emerging for Community 4 in the CDR partition, whose nodes were present in all the communities in the land-use partition. Such NILs (green in Fig. 4) resulted to be characterized by similar patterns in terms of mobile phone data, but different in terms of land uses. Figure 5 also helps to clarify that the NILs were more evenly distributed in the communities obtained from the analysis on land uses than from the CDR partitioning.
Comparison between the partitions obtained via community detection based on the land-use network and on the mobile-phone network. The Sankey diagram reveals differences and overlaps between the partitions in communities obtained analyzing land uses (left side) and mobile phone data (right side). Color coding is coherent with partitioning shown in Figs. 3 and 4
The ever-changing urban environment of a metropolis is shaped by phenomena occurring over very different spatial and temporal scales. Rapid, but long-term land-use changes are in fact coupled with the highly intricate patterns of human mobility occurring even on very short (i.e. hourly) temporal scales. Data on land uses are often available with no restrictions nowadays, since many EU countries have developed land use and land cover maps, especially in the framework of the CORINE program. Conversely, the availability of communications and social media data is typically restricted to a few research teams that sign Non-Disclosure Agreements (NDAs) and research contracts with telecommunication and other private companies. The lack of open datasets limits the number of potential studies, although the almost universal adoption of mobile phones, accompanied by the fast advancing ICT technology could provide great opportunities for urban planning and management. Indeed, these data could enable a better understanding of the patterns and mechanisms of human mobility, activities, and their relationship with the urban environment. Interesting and innovative frameworks are under development, like for example the OPAL project (www.opalproject.org).
In this study, we could benefit of the Telecom Italia Big Data Challenge dataset, a multi-source dataset of Call Detail Records about the city of Milan for a period of 4 weeks. We coupled this rich dataset with the land use information and we compared the districts of the city, i.e. the NILs, by integrating land uses and temporal patterns of their human occupation. The goal of our study was to investigate the emergence of similar/dissimilar districts according to either land use or human presence habits (or both) and to reveal the different social functions of areas characterized by similar land-use compositions. Not secondary, our framework fruitfully reveals how indicators that are frequently used in ecological studies on natural ecosystems can be extended and applied to urban settings.
Community detection on similarity networks based on land-use composition of NIL and on temporal trajectories of human occupation revealed that, as obvious, the two aspects generate partitions of the city into communities that are not completely overlapped. Interestingly, our results also showed that NILs that appeared to be very similar in terms of land uses were grouped in different communities when mobile phone data were taken into account. Information on mobile phone data could thus be used to inform land use maps and reveal the actual use of the space. Both partitions in communities showed to be spatially related to the historical urban concentric structure of the city of Milan, although this aspect was more evident in the analysis of CDRs than in the analysis of land uses.
From an administrative point of view, Milan is subdivided into 9 Boroughs (Municipi) with local administrative power and responsibility on specific public services such as schools, parks and roads. The eight Municipi (numbered as 2, 3, …, 9 in Fig. 1c) group NILs that are characterized by spatial proximity (adjacent to each other) and are departing radially from the center of Milan (Municipio 1) toward the city periphery and border. However, as our community/cluster detection has evidenced, neighborhoods belonging to the same Municipio can be characterized by quite different land-use mixes and/or human uses. Our results thus indicate that alternative, politically relevant aggregations of neighborhoods might be possible and they might perhaps facilitate governance because of similarity. Indeed, we showed that areas with similar characteristics in terms of either land uses or human occupation (areas that we called "urban communities") are sometimes geographically distant one from the other. Nevertheless, people living such urban communities probably experience similar problems with respect to city uses and they probably share similar needs. City maps based on land-use mixes and on human use of the urban texture, as those shown in our Figs. 3 and 4, can thus support decision makers to envision and elaborate integrated responses to citizens, possibly providing solutions that go beyond a compartmentalized planning and management (as somehow suggested by the interesting connections among NILs provided by Fig. 5). Indeed, the outcomes of this kind of analysis could reveal areas that should be administratively connected, suggesting possible strategic development measures for the city of Milan.
Arnaboldi, M, Brambilla M, Cassottana B, Ciuccarelli P, Vantini S (2017) Urbanscope: A lens to observe language mix in cities. Am Behav Sci 61(7):774–793.
Barlacchi, G, De Nadai M, Larcher R, Casella A, Chitic C, Torrisi G, Antonelli F, Vespignani A, Pentland A, Lepri B (2015) A multi-source dataset of urban life in the city of milan and the province of trentino. Sci Data 2:150:055.
Blondel, V, Guillaume JL, Lambiotte R, Lefebvre E (2008) Fast unfolding of communities in large networks. J Stat Mech Theory Exp 2008(10). https://doi.org/10.1088/1742-5468/2008/10/P10008.
Bonvesin de la Riva (1228) De magnalibus Mediolani. translated by Chiesa P. (2009) as Le meraviglie di Milano. Mondadori.
Cho, E, Myers SA, Leskovec J (2011) Friendship and mobility: user movement in location-based social networks In: Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, 1082–1090.. ACM. https://doi.org/10.1145/2020408.2020579.
Chouakria, AD, Nagabhushan PN (2007) Adaptive dissimilarity index for measuring time series proximity. Adv Data Anal Classif 1(1):5–21.
DeLong, D (1996) Defining biodiversity. Wildl Soc Bull 24(4):738–749.
Feranec, J, Soukup T, Hazeu G, Jaffrain G (2016) European landscape dynamics: CORINE land cover data. Taylor & Francis. https://doi.org/10.1201/9781315372860.
Fisher, P (1997) The pixel: a snare and a delusion. Int J Remote Sens 18(3):679–685.
Fortunato, S (2010) Community detection in graphs. Phys Rep 486(3-5):75–174.
Fortunato, S, Hric D (2016) Community detection in networks: A user guide. Phys Rep 659:1–44.
Gong, P, Howart PJ, et al. (1990) The use of structural information for improving land-cover classification accuracies at the rural-urban fringe. Photogramm Eng Remote Sens 56(1):67–73.
Gonzalez, MC, Hidalgo CA, Barabasi AL (2008) Understanding individual human mobility patterns. Nature 453(7196):779.
Hawelka, B, Sitko I, Beinat E, Sobolevsky S, Kazakopoulos P, Ratti C (2014) Geo-located twitter as proxy for global mobility patterns. Cartogr Geogr Inf Sci 41(3):260–271.
Hoteit, S, Secci S, Sobolevsky S, Ratti C, Pujolle G (2014) Estimating human trajectories and hotspots through mobile phone data. Comput Netw 64:296–307.
Howison, J, Wiggins A, Crowston K (2011) Validity issues in the use of social network analysis with digital trace data. J Assoc Inf Syst 12(12):2.
Hubert, L, Arabie P (1985) Comparing partitions. J Classif 2(1):193–218.
Jaccard, P (1901) Distribution de la flore alpine dans le bassin des dranses et dans quelques régions voisines. Bull Soc Vaudoise Sci Nat 37:241–272.
Louail, T, Lenormand M, Ros OGC, Picornell M, Herranz R, Frias-Martinez E, Ramasco JJ, Barthelemy M (2014) From mobile phone data to the spatial structure of cities. Sci Rep 4:5276.
Lu, D, Weng Q (2006) Use of impervious surface in urban land-use classification. Remote Sens Environ 102(1-2):146–160.
Mariotti, I, Pacchi C, Di Vita S (2017) Co-working spaces in milan: Location patterns and urban effects. J Urban Technol 24(3):47–66.
Mariotti, I, Brouwer AE, Gelormini M (2018) Is milan a city for elderly? mobility for aging in place. Tema J Land Use Mobil Environ 2:95–104.
Morandi, C (2007) Milan. The great urban transformation. Marsilio.
Newman, M (2010) Networks: An Introduction. Oxford University Press. https://doi.org/10.1093/acprof:oso/9780199206650.001.0001.
Newman, ME (2006) Modularity and community structure in networks. Proc Natl Acad Sci 103(23):8577–8582.
Pei, T, Sobolevsky S, Ratti C, Shaw SL, Li T, Zhou C (2014) A new insight into land use classification based on aggregated mobile phone data. Int J Geogr Inf Sci 28(9):1988–2007.
Secchi, P, Vantini S, Vitelli V (2015) Analysis of spatio-temporal mobile phone data: a case study in the metropolitan area of milan. Stat Methods Appl 24(2):279–300.
Shaban, M, Dikshit O (2001) Improvement of classification in urban areas by the use of textural features: the case study of lucknow city, uttar pradesh. Int J Remote Sens 22(4):565–593.
Shannon, CE (1948) A mathematical theory of communication. Bell Syst Tech J 27(3):379–423.
Simpson, EH (1949) Measurement of diversity. Nature 163(4148):688.
Sørensen, T (1948) A method of establishing groups of equal amplitude in plant sociology based on similarity of species and its application to analyses of the vegetation on danish commons. Biol Skr 5:1–34.
Ward, JH (1963) Hierarchical grouping to optimize an objective function. J Am Stat Assoc 58(301):236–244.
Whittaker, RH (1972) Evolution and measurement of species diversity. Taxon:213–251. https://doi.org/10.2307/1218190.
A.L.T. acknowledges funding from the project MASTR-SLS (PoliSocial Award 2016, Politecnico di Milano), while A.B acknowledges funding from the project HABITAT@SCUOLA (Fondazione Cariplo). R.C. was the PI of both projects and is very grateful to the funding agencies.
Dipartimento di Elettronica, Informazione e Bioingegneria (DEIB), Politecnico di Milano, Via Ponzio 34, Milan, 20133, Italy
Alba Bernini, Amadou Lamine Toure & Renato Casagrandi
African Institute for Mathematical Sciences, AIMS-Senegal, Km2 route de Joal (Centre IRD), M'bour-Thies, 1418, Senegal
Amadou Lamine Toure
Alba Bernini
Renato Casagrandi
RC conceived the study and designed the research performed together with AB, who coded the analysis of the land-use dataset, and with ALT, who coded the analysis of the CDRs. All authors contributed to analyze the results. AB produced the figures and wrote the article with RC. All authors read and approved the final manuscript.
Correspondence to Renato Casagrandi.
Bernini, A., Toure, A.L. & Casagrandi, R. The time varying network of urban space uses in Milan. Appl Netw Sci 4, 128 (2019). https://doi.org/10.1007/s41109-019-0245-x
DOI: https://doi.org/10.1007/s41109-019-0245-x
Community detection
Mobile phone data
Complex network
Temporal network
Spatial network | CommonCrawl |
Home | Ham Radio | IcomControl Home Page IcomProgrammmer II JRX: Virtual Ham Radio Morse Code PLSDR RadioComm Home Page Sangean ATS-909X Simple 10 MHz Frequency Standard Software-Defined Radios Share This Page
A treatise on an old, very reliable communication method
— All content Copyright © 2017, P. Lutus — Message Page —
Introduction | Practice Area : Text to Code | Recording Utility | Practice Area : Code to Text | Control Panel | Morse Code List | Other Programming Resources | In Depth | Version History | Reader Feedback
Morse code — dots and dashes — heralded the dawn of radio and of wireless communication. There were many reasons for the use of Morse code at that time, one being that the primitive technology imposed severe limitations on the kinds of information that could be impressed on a radio signal. Guglielmo Marconi achieved the first transatlantic radio communication with a crude spark gap transmitter, before vacuum tubes were commonly available. Because the signal was readable Morse code, the eager listening team in Newfoundland knew they were hearing something other than lightning.
Imagine that you're listening to faint and crude radio signals from across the Atlantic ocean in the time of Marconi's pioneering work — for a Morse code sample, click here:
Is my signal getting through?
Now imagine you're a radio operator on a ship in the North Atlantic on April 15th 1912, and you hear a faint radio signal from somewhere in the darkness — click this example to hear how it might have sounded:
This is Titanic. CQD. Engine room flooded.
As technology improved, so did long-distance radio communications. Once vacuum tube transmitters with quartz crystal signal sources replaced spark gap transmitters, much clearer transmissions over greater distances became possible. By the time I became a ham radio operator in the 1950s, radiotelegraphy had become more consistent and reliable — click this example:
CQ DX DE KE7ZZ K
The above Morse code means "Calling any distant (DX) stations, this is ham radio operator KE7ZZ calling and listening."
From a modern perspective Morse code has a number of drawbacks including a data rate much slower than voice or modern digital methods, but over long distances, in adverse conditions or with little transmitter power available, it has been the preferred mode for reliable point-to-point communications — until recently.
In 2007 the (U.S.) Federal Communications Commission dropped the requirement that ham radio operators be able to send and receive Morse code (similar changes have taken place in commercial and military radio operations). Many celebrated this change for a number of reasons — modern wireless communications no longer relies on Morse, even over long distances and critical applications, and the requirement was stopping many people from getting ham radio licenses and starting an interesting hobby.
From my perspective, now that Morse is a dead art, my interest has increased — sort of like wanting to learn Latin on realizing no one speaks it any more. This page is dedicated to the lost art of Morse code, which is able to communicate more information over greater distances, in the presence of poorer atmospheric conditions and interfering signals, than any other method.
Practice Area : Text to Code
In this section, users can translate sample text into Morse code, or paste their own text into the practice window and translate that. This editing feature lets you create custom code while learning to listen to and decode Morse.
To use this feature, just click the provided link to translate the default text sample, or if you prefer, click below to erase the default text sample, type or paste your own text into the practice window, then click the Start button to start/stop translation.
Four score and seven years ago our fathers brought forth on this continent, a new nation, conceived in Liberty, and dedicated to the proposition that all men are created equal. Now we are engaged in a great civil war, testing whether that nation, or any nation so conceived and so dedicated, can long endure. We are met on a great battle-field of that war. We have come to dedicate a portion of that field, as a final resting place for those who here gave their lives that that nation might live. It is altogether fitting and proper that we should do this. But, in a larger sense, we can not dedicate — we can not consecrate — we can not hallow — this ground. The brave men, living and dead, who struggled here, have consecrated it, far above our poor power to add or detract. The world will little note, nor long remember what we say here, but it can never forget what they did here. It is for us the living, rather, to be dedicated here to the unfinished work which they who fought here have thus far so nobly advanced. It is rather for us to be here dedicated to the great task remaining before us — that from these honored dead we take increased devotion to that cause for which they gave the last full measure of devotion — that we here highly resolve that these dead shall not have died in vain — that this nation, under God, shall have a new birth of freedom — and that government of the people, by the people, for the people, shall not perish from the earth. Abraham Lincoln November 19, 1863
Recording Utility
This section allows the user to make and save a recording of the Morse code generated above. To use this feature:
Click the "Enable Audio Recording" checkbox below.
Operate any of the Morse generator functions on this page.
Return here to play and/or save the result.
If this feature doesn't work on your browser (i.e. any Microsoft browser), well ... change browsers. At the time of writing, neither of Microsoft's browsers supports this feature, but both Google Chrome and Firefox do.
Enable Audio Recording
To save a recording, right-click the play arrow and choose "Save audio as ..." or another available feature.
Remember to disable the recording feature when you're done — it uses browser memory when enabled.
Practice Area : Code to Text
This section allows users to listen to a sequence of Morse code audio signals and type the corresponding characters on the computer keyboard. This is an efficient way to learn how to translate Morse code into text. The user may choose which subsets of Morse code are included — letters, numbers, and different punctuation sets:
Letters (a-z)
Common Punctuation ()
Exotic Punctuation ()
Press "Start" below, then type a guess about the Morse character you hear. If your guess is correct, a new character will be generated. If there's an error, the program will beep and repeat the missed character. Press "Stop" to end the practice session.
Use the Control Panel below to change the code practice transmission rate and other properties.
This panel allows fine tuning of the Morse code generator's values. Simply change a setting at the right and generate some code to hear the result. Your changes are saved in a browser cookie for later use. A full explanation of the values appears below the entry panel.
Note: For an immediate change, press Enter after making your entry.
Reset all values to defaults
Figure 1: Code timing diagram
Dot constant. We compute the time duration of a Morse code dot using this equation:
\begin{equation} dd = \frac{dc}{wpm} \end{equation}
dd = Duration for one dot, units seconds.
dc = Dot Constant.
wpm = Desired words per minute.
The value dc is set by convention to 1.2 (units seconds) as explained here. This value produces code timings that differ slightly from that of the ARRL code practice recordings, which many people consider an excellent resource. Users are free to choose a different value for this quantity, which will be saved between sessions.
NOTE: Each of the dot times listed below is added to the prior value. So an entered value of 2 for dot time between characters produces an effective dot time of 3 (2+1). In the same way, an entry of 4 for dot time between words produces an effective dot time of 7 (4+2+1) — see Figure 1.
Dot time between dots and dashes. Scaled by dd as in equation (1). This is the duration of the silent pause between any two dots or dashes within a Morse code element, and the value is proportional to a dot duration.
Dot time between characters. Scaled by dd as in equation (1). In much the same way, this entry determines the duration of the pause between complete Morse code elements.
This value also plays a part in the Farnsworth speed method described below.
Dot time between words. Scaled by dd as in equation (1). This entry determines the duration of the pause between entire words of code.
This value can be used to stretch the interval between words while maintaining a specific WPM rate for the individual Morse code elements. This entry (and the dot time between characters entry above) allows creation of Farnsworth-speed code, popular for teaching Morse. The Farnsworth scheme creates a difference between character speed and text speed, which allows the student to hear individual characters at a relatively high rate, but allows more time between characters and words for interpretation.
Speed WPM. Units words per minute. In connection with the Dot Constant and equation (1) above, this entry determines the overall speed of the code.
Frequency. Units Hertz. The pitch of the generated code. A frequency entry of 0 will produce a DC level at the computer's audio output, suitable for operating a relay or other device to be time-synchronized with the Morse code's dots and dashes.
Volume. A value of 1.0 represents full volume. Values greater than 1.0 will produce distortion in the computer's audio output.
Slope Constant. Units seconds. This value determines the waveform rise and fall time for the generated dots and dashes. To understand the reason for this setting, try setting it to zero and see how the code sounds. This rise and fall time issue is particularly important in radio communication because an improperly designed transmitter, one with rapid rise and fall times, creates sidebands much wider than necessary and interferes with other transmissions. The default value is 0.005 (5 milliseconds).
Scope Timing Trace
Figure 2: Oscilloscope trace for repeated letter "i" ("..").
Figure 2 captures this page's Morse generator output with a frequency setting of 0 (which produces a DC level at the computer's audio output, convenient for oscilloscope measurements). The center of the display is the beginning of the letter "i" (".."). The first dot is followed by one dot-time, then another dot, then an intercharacter pause of 3 dot times. At the left center of the display is the inter-word pause of 7 dot times after the prior word.
Morse Code List
Here's a list of widely accepted Morse code sequences. Click the characters to hear them rendered as Morse code.
Other Programming Resources
All my programs are released under the GPL, which means you can use them in your own projects, adapt the code to your own purposes, as long as my copyright notices are preserved in the source listings.
This Web page uses JavaScript to generate Morse code — click here to see/download the source.
I have also written a Java Morse code generator — click here to download the JAR file. To use the Java program, install Java if you haven't already, then open a command prompt in the same directory as the JAR file and enter:
$ java -jar morse_sender.jar
Some helpful text will appear. To translate some code:
$ java -jar morse_sender.jar here is my text
There are a number of other ways to supply the text to be translated, as shown in the help screen.
Click here to view/download the Java source.
I have written a Python code generator also, which operates very much like the Java program — click here to view/download the program listing. Much like the Java program, make sure you have Python 3 installed on your system and open a command shell:
$ ./morse_sender.py (for help)
$ ./morse_sender.py here is my text
The above might not work so well on Windows unless Python has been installed in a way that makes it visible everywhere on your system.
Land Telegraphy
Although Morse code saw its greatest use in connection with radio, it came into existence before radio even existed. Samuel F. B. Morse co-created the first version of Morse Code in the early 19th century while developing and pioneering the use of land telegraph systems.
In those times, when the sender pressed a telegraph key, the "receiver" — an electromagnetic relay — would close: clack! Compared to the ease of understanding modern code tones transmitted by radio, I imagine it required some practice to distinguish dots from dashes and signals from silence, while listening to a chattering relay.
Required Bandwidth
Radiotelegraphy signals require very little bandwidth, and many more code transmitters can be crowded into a given band than when using other radio schemes. The explanation has to do with the relationship between information content and bandwidth — more information in a given time interval, more bandwidth required. This relationship is formally defined as the Nyquist frequency theorem, which briefly says that to support the transmission of N bits per second of information, the information channel must have a bandwidth of 2N.
Consider this relationship between different radio modulation methods:
Bandwidth Required
Morse code (CW) 100 Hz
Single sideband (SSB) 5 KHz
Amplitude Modulation (AM) (broadcast) 10 KHz
Frequency Modulation (FM) (broadcast) 100 KHz
HDTV (broadcast, compressed) 8-16 MHz
Another way to look at this is to compare the time required to transmit a book-length manuscript, by comparing Morse code with other wireless methods. A typical modern book has 70,000 words, each word an average of five characters, so 350,000 characters.
If we transmit the book's words by Morse code at 13 five-character words per minute, and disregarding data lost to missing punctuation and uppercase-only alphabetic characters, and assuming a continuous effort with no breaks for darkness or fatigue, we would need almost 90 hours or 3.74 days.
How much time would a book recital require? A professional speaker can produce a word rate of 155 words per minute, so — again without any pauses for fatigue or bathroom breaks — we would need 7.5 hours.
Skipping over digital television and other difficult-to-quantify transmission methods, let's see how much time would be required to transmit the book in digital form, using a modern wireless channel. I chose 802.11g for this example, to avoid the science fiction element inherent in the newer, faster protocols. The 802.11g maximum data rate is 54Mbps (megabits per second), which can be converted to 6.75 MBps (megabytes per second) if we assume eight bits per byte. Using this communication method, the book can be transmitted in ... wait for it ... about ten milliseconds or 1/100 of a second.
The takeaway? It requires roughly 31 million times longer to transmit the book by Morse code than with modern methods.
QRP
The code phrase QRP means using the minimum amount of power required to communicate. Because Morse code requires such a small bandwidth, it follows that a receiver can be adjusted to accept only a small bandwidth that includes the desired signal. This adjustment greatly reduces interference from noise sources and other transmitters, which means a very small transmitter power can be used. Even though U.S. radio amateurs can use as much as 1000 watts of transmitter power, those who choose to use the smallest amount of power can easily accomplish their communications with five watts or less — by using Morse code.
Using specialized receiving methods, in experiments I've extracted a signal from a noise environment that was 100 times stronger (+40db). In my phase-locked-loop article I describe the method in detail and include example code. This means if I knew which frequency to monitor and using the phase-locked-loop method, I could receive a signal from a small transmitter on Mars. This idea would only work if the participants used Morse code.
2020.09.12 Version 1.8. Based on reader feedback, corrected the code sequence for the exclamation point (to -.-.--).
2020.03.03 Version 1.7. Added a function to overcome a new browser requirement that user interaction must precede the playing of audio.
2017.06.01 Version 1.6. Added a translation table for certain common Unicode characters that the original program would skip.
2017.05.19 Version 1.5. Made the control inputs more responsive to user changes.
2017.05.13 Version 1.4. Changed configuration of audio generator for better browser compatibility, changed assignments in code practice punctuation symbol groups.
2017.05.10 Version 1.3. Added a code practice section so readers can listen to code and type the corresponding characters, as a way to learn code reception.
2017.03.28 Version 1.2. Added a volume control setting, changed the generator configuration so it produces a DC output level when frequency is set to zero, which facilitates oscilloscope traces of code signals.
2017.03.28 Version 1.1. Added timing diagram, adjusted default code timings to agree with accepted conventions.
2017.03.26 Version 1.0. Initial public release.
Reader Feedback
Exclamation point Error
First, I really like your Morse code page. The quality of the sound is very good. The material is clearly presented with links for additional information. Thank you. You're most welcome! Now an observation of what looks to be a difference between the page and the Wiki page referenced. I found another page that agrees with the Wiki page, https : // morsecode.world / international / morse.html
When working on the characters other than letters and numerals, I fond that the ! is given as "Exclamation Point [!] KW digraph Not in ITU-R recommendation" or dah-di-dah-di-dah-dah at the Wikipedia link, but it is dah-dah-dah-dit on your page, https: // arachnoid . com morse_code index.html
The site https : // lcwo.net has a third sequence for !. Thanks for your correction to my outdated code for '!'. I've changed the source in this Web page as well as in the three downloadable computer language versions I offer — Java, JavaScript and Python. I appreciate your feedback and your attention to detail.
I noticed one wrinkle when testing the result in a Linux command-line environment. Because of how the Bash command-line processor works, one must use single quotes, not double quotes, when submitting text examples that include '!'.
Thanks again, and feel free to offer any more corrections you care to! | CommonCrawl |
Geographical variations of lumber quality of Larix sibirica naturally grown in five different provenances of Mongolia
Bayasaa Tumenjargal1,2,3,
Futoshi Ishiguri ORCID: orcid.org/0000-0002-1870-40601,
Haruna Aiso-Sanada4,5,
Yusuke Takahashi1,
Ikumi Nezu1,
Bayartsetseg Baasan3,
Ganbaatar Chultem3,
Jyunichi Ohshima1 &
Shinso Yokota1
Journal of Wood Science volume 65, Article number: 43 (2019) Cite this article
Annual ring width, warp, dynamic Young's modulus, and static bending properties were evaluated for 2 × 4 lumber produced from Larix sibirica trees naturally grown in five different provenances of Mongolia. The lumber was also visually graded according to Japanese Agriculture Standard for structural lumber for wood frame construction. Mean values of dynamic Young's modulus, modulus of elasticity, and modulus of rupture for lumber in each provenance ranged from 9.89 to 14.46 GPa, 7.53 to 13.02 GPa, and 33.0 to 68.7 MPa, respectively. Significant geographic differences were found in all examined properties of lumber among the five provenances. No significant relations were found between annual ring width and other properties, suggesting that radial growth rate of L. sibirica trees naturally grown does not always affect reduction on mechanical properties of lumber. Knots and wane were main factors downgrading lumber among the evaluated factors. Tree height, stem shape, and juvenile wood percentage of logs more affected lumber quality of L. sibirica trees from natural forests.
Larix species are known to have high growth rate at young age and good physical and mechanical properties of mature wood [1,2,3]. In addition to those characteristics, Larix wood shows good appearance and higher natural durability [4, 5]. By this nature, the wood of Larix species obtained from both natural stands and plantations is considered as valuable timber resources.
For effective wood utilization, it is important to understand variation of property and quality of woods. In Larix species, several researchers have been reported on geographic variations of growth characteristics and wood properties [2, 5,6,7,8]. For example, Takada et al. [6] evaluated the geographic variation of Young's modulus of stem of Larix kaempferi in Japan. They found that, of three test stands, only one test site showed significant differences in Young's modulus among provenances. Curnel et al. [5] also found among-provenance's differences in wood decay resistance in Larix species. In Larix sibirica, Koizumi et al. [2] reported that wood density of this species significantly differed among five natural stands in South Central Siberia, Russia. These reports suggest that interactions between provenance and environment may affect wood quality in Larix species.
Mongolia also use wood of Larix, especially for L. sibirica, as structural lumber construction, since over 70% of the forest area in the country is covered with this species [9]. Even though L. sibirica wood is used for structural lumber, available information on wood properties was still limited in this species grown in Mongolia. Recently, several researchers have tried to clarify the wood properties and drying process of L. sibirica naturally grown in Mongolia [10,11,12]. Ishiguri et al. [10] investigated the basic density, shrinkage, bending properties, compressive strength parallel to grain, decay resistance, and amounts of chemical components of 200- to 240-year-old trees of L. sibirica grown in Mongolia. They found that values of modulus of elasticity (MOE), modulus of rupture (MOR), and compressive strength were lower near the pith, and increased to 4 cm from the pith, suggesting that juvenile wood affected the results. We also investigated geographical variation in growth characteristics, dynamic Young's modulus of stem and logs, annual ring width, latewood percentage, and basic density of L. sibirica grown in five provenances of Mongolia [11]. The mean values of tree height, stress-wave velocity of stems, and all measured wood properties except for basic density were significantly different among the five provenances, although the stem diameter was almost the same among provenances. These results suggested that L. sibirica trees naturally grown in Mongolia have geographical variations in the mechanical properties in their wood. However, there is no information on lumber quality and its geographic variations of L. sibirica in Mongolia.
In the present study, to promote the lumber production under appropriate natural forest managements in Mongolia, 2 × 4 lumber was produced from L. sibirica logs collected from five different provenances where were famous L. sibirica forestry sites in Mongolia, and then lumber quality was evaluated. In addition, geographical variation of lumber quality was also discussed for efficient production of structural 2 × 4 lumber from L. sibirica trees naturally grown in Mongolia.
Five natural forests of L. sibirica were selected from five different provenances in Mongolia: Khentii, Arkhangai, Zavkhan, Khuvsgul and Selenge [11]. Geographic information and climatic conditions of the site are listed in Table 1. In addition, a total of 25 trees (five trees in each stand) with good stem shape without any severe damages were selected to cut. Before cutting trees, stress-wave velocity of stems was measured for these selected trees. After cutting trees, logs 2 m in length were obtained from 1.3 m above the ground until the top diameter of each log became less than 14 cm. A total of 111 logs were collected from the harvested 25 trees (from 3 to 6 logs from a tree) [11]. Dynamic Young's modulus of all logs was measured by the tapping method [13]. Table 2 shows mean values of growth characteristics and stress-wave velocity of harvested trees, and dynamic Young's modulus of logs. Although the stem diameter was almost the same in all provenances, the mean values of tree height and stress-wave velocity of stems, and dynamic Young's modulus of logs were significantly different among the five provenances.
Table 1 Geographic and climatic conditions on the sampling sites [11]
Table 2 Sample trees and logs in the present study [11]
Taper and juvenile wood percentage of logs
The butt- and top-end diameters of each log were measured. Taper of log was calculated by the following equation [14]:
$${\text{Taper }}\left( {{\text{cm}}/{\text{m}}} \right) = \frac{{d_{1} - d_{2} }}{L},$$
where d1 (cm) is the butt-end diameter of log, d2 (cm) is the top-end diameter of log, and L (m) is the length of the lumber.
Percentage of juvenile wood volume in a log was also estimated. In the previous paper [10], juvenile wood was thought to exist within 4 cm from pith in L. sibirica trees naturally grown in Mongolia. Juvenile wood percentage of logs was calculated as the proportion of volume of 4 cm from the pith in each log to total volume of a log calculated using mean values of butt and top diameter and length of log.
Lumber production
A total of 111 logs, 2 m in length, were used in the present study. The logs were sawn into lumber, as many as possible, with 100 × 50 mm cross section. A total of 190 pieces of lumber were obtained from the logs. The lumber was stacked by about 30 layers with wood stickers with 25 × 25 mm cross section at laboratory without air conditioner or heater in Ulaanbaatar, Mongolia. The lumber was air-dried from August 2017 to August 2018. Unfortunately, temperature and relative humidity were not recorded in the room during air-drying, but minimum, maximum, and mean monthly temperature and relative humidity of Ulaanbaatar, Mongolia, during air-drying were as follows: − 22.4 (January 2018), 17.9 (June 2018), and 2.0 °C, and 30 (May 2018), 71 (December 2017), and 58%. After air-drying, the lumber was planned into 89 × 38 mm cross section.
Lumber quality
Annual ring width, moisture content, deformation of lumber (bow, crook, and twist), dynamic Young's modulus, and static bending properties were measured as lumber quality.
The bow and crook were determined as maximum deflection of lumber. Bow and crook of the lumber were calculated as the proportion at maximum deflection of bow and crook in each lumber length. To determine twist, lumber was set on a flat surface of a steel beam. After fixing three edges of a lumber, distance between remaining one edge and the flat surface was measured. Twist of the lumber was calculated as follows:
$${\text{Twist }}\left( {\text{degree}} \right) = \sin^{ - 1} \left( {\frac{h}{w}} \right),$$
where h (mm) is the measuring distance and w (mm) width of the lumber.
After bending test, small-clear specimens (2.5 cm in thickness) were obtained from the lumber. The digital images (1200 dpi) of cross sections of the specimens were captured by a scanner and incorporated into a personal computer. The total number of annual rings on the cross section and total width of annual rings were measured by the image analysis software (ImageJ, National Institute of Health). Annual ring width of the lumber was determined by dividing total width by the total number of annual rings. In addition, the same specimens were also used to determine moisture content by oven-dry method.
Visual grading
All pieces of lumber were graded according to Japan Agriculture Standard for structural lumber for wood frame construction [15]. For grading, the typical visual sorting criteria, such as annual ring width, knots size, existence and size of holes, slope of grain, deformation (bow, crook, and twist), wane, and crack, were measured on surfaces of a lumber as described in Japan Agriculture Standard. Based on the measurements, the lumber was classified into the following grades: Selected, Nos. 1, 2, 3, and out grading according to Japanese Agriculture Standard for structural lumber for wood frame construction.
Dynamic Young's modulus and static bending properties of lumber
Dynamic Young's of modulus of lumber (DMOElum) was determined by tapping method [13]. To determine density at testing, weight, length and dimensions of lumber were measured by portable electric balance (SL-20K, A&D), laser measure (GLM-50C, Bosch), and digital calipers (CD-15CX, Mitutoyo), respectively. One cross end of each lumber was tapped by a small hammer, and then first resonance frequency of longitudinal vibration was obtained by a handheld fast Fourier transform (FFT) analyzer (AD-3527, A&D) with an accelerometer (PV-85, Rion) set on the other end of each lumber. DMOElum was calculated by the following equation:
$${\text{DMOE}}_{\text{lum}} \left( {\text{GPa}} \right) = \left( { 2lf} \right)^{ 2} \rho \times 10^{ - 9} ,$$
where l (m) is the length of the lumber, f (Hz) is the first resonance frequency, and ρ (kg/m3) is the density of the lumber at testing.
After measuring dynamic Young's modulus, four-point static bending test was conducted using a material testing machine (WDW-20E, Jinan Kason Testing Equipment). Load speed, support span, and distance between load points were 14 mm/min, 1602 mm, and 534 mm, respectively. The load was applied to edgewise direction. MOE and MOR of lumber were determined by the following equations:
$${\text{MOE }}\left( {\text{GPa}} \right) = \frac{{\Delta P\left( {l - l^{\prime}} \right)\left[ {3l^{2} - \left( {l - l^{\prime}} \right)^{2} } \right]}}{{8\Delta ybh^{3} }},$$
$${\text{MOR }}\left( {\text{MPa}} \right) = \frac{{3P_{ \hbox{max} } \left( {l - l^{\prime}} \right)}}{{2bh^{2} }} ,$$
where ΔP (N) is the difference of load between 10 and 40% values of maximum load (Pmax), Δy is the difference of deflection corresponding to ΔP, l (mm) is the span, \(l^{\prime}\) (mm) is the difference between load points, b (mm) is the width of specimen, and h (mm) is the height of specimen.
All data analyses were conducted using a software (Excel 2016, Microsoft). Mean values of each property were calculated by averaging values of individual trees within a provenance. An analysis of variance was applied to evaluate the differences in measured lumber properties among the provenances.
Mean values of lumber properties
Mean values of the moisture content, annual ring width, air-dry density, and deformation of lumber are listed in Table 3. The mean values of annual ring width varied among five provenances. The highest and lowest mean values of annual ring width of 2 × 4 lumber were found in Arkhangai (3.4 mm) and Zavkhan (0.5 mm), respectively (Table 3). The mean values of air-dry density of lumber were 0.61, 0.63, 0.62, 0.55, and 0.59 g/cm3 for Khentii, Arkhangai, Zavkhan, Khuvsgul, and Selenge, respectively. Compared to air-dry density of 2 × 4 lumber produced from the trees in other Larix species, obtained mean values of air-dry density in the present study were relatively higher than those of L. kaempferi, Larix decidua, and Larix dahurica, but almost the same with Larix gmelinii (Table 4). Among the five provenances, mean values of bow, crook, and twist ranged from 0.05 to 0.17%, 0.03 to 0.07%, and 0.06° to 0.16°, respectively (Table 3). The lowest values of average bow (0.05%), crook (0.03%) and twist (0.06°) were found in Khentii. The highest mean values of bow (0.17%) and twist (0.16%) were found in Khuvsgul.
Table 3 Mean values and standard deviations of lumber properties
Table 4 Bending properties of 2 × 4 lumber produced from the trees of other Larix species
Mean values of dynamic Young's modulus, MOE, and MOR of lumber ranged from 9.89 to 14.46 GPa, 7.53 to 13.02 GPa, and 33.0 to 68.7 MPa, respectively (Table 5). Bending properties of 2 × 4 lumber in Larix species have been reported by several researchers [1, 5, 16,17,18,19]. In L. kaempferi, as shown in Table 4, mean values of MOE and MOR were 8.44 GPa and 39.5 MPa for 2 × 4 lumber produced from 31-year-old trees planted in Canada [16], and 8.86 GPa and 32.9 MPa for 2 × 4 lumber produced from 63-year-old trees planted in Japan [17]. Chui and MacKinnon-Peters [16] also measured MOE and MOR of 2 × 4 lumber of L. decidua, and they were 10.93 GPa and 43.8 MPa for 63-year-old trees planted in United States of America, and 8.98 GPa and 40.5 MPa for 34-year-old trees planted in Canada, respectively (Table 4). In addition, Ethington et al. [1] reported that MOE and MOR of 2 × 4 lumber of L. dahurica ranged from 11.10 to 14.06 GPa (1.610 to 2.039 × 106 psi), 45.3 to 67.4 MPa (6.564 to 9.779 psi), respectively (Table 4). The mean values of MOE and MOR were similar or relatively higher than those of other Larix species (Table 4).
Table 5 Mean values and standard deviations of dynamic Young's modulus and bending properties of the lumber
Figures 1 and 2 show longitudinal variations of MOE and MOR of lumber in each provenance. Except for Khuvsgul, MOE of lumber slightly decreased from bottom to top of trees. In Khuvsgul, it slightly decreased with increase of height positions and then increased at most upper position (Fig. 1). The similar trends were also observed in dynamic Young's modulus of logs used in the present study [11]. On the other hand, longitudinal patterns of MOR of lumber varied not only among the provenances, but also within a tree (Fig. 2).
Longitudinal variations of modulus of elasticity (MOE) of lumber in each provenance. Open circles indicate mean values of MOE of lumber obtained from each height. n number of lumber
Longitudinal variations of modulus of rupture (MOR) of lumber in each provenance. Open circles indicate mean values of MOR of lumber obtained from each height. n number of lumber
Correlation coefficients between dynamic Young's modulus of lumber and MOE or MOR of lumber are listed in Table 6. Dynamic Young's modulus of lumber was strongly correlated with the both MOE and MOR of lumber, except for Khuvsgul, suggesting that measuring the dynamic Young's modulus of lumber is a useful indicator for predicting bending properties of L. sibirica lumber.
Table 6 Relationships between dynamic Young's modulus and MOE or MOR of lumber
Relationships between annual ring width and mechanical properties
Miyajima [20] investigated the relationships between the annual ring width and the mechanical properties of 2 × 4 lumber of L. kaempferi trees planted in Japan. He reported that increasing annual ring width resulted in the decreasing values of the MOE and MOR. To clarify similar tendency with Miyajima [20], the relationships between annual ring width and lumber properties were analyzed in the present study (Table 7). No significant relations were found between annual ring width and lumber properties, except for the lumber from Khentii. Negative significant correlations were recognized between annual ring width and air-dry density, dynamic Young's modulus, or MOE in the lumber from Khentii. Our results in L. sibirica except for the lumber from Khentii were not the same with those reported by Miyajima [20] in L. kaempferi. Therefore, it is considered that radial growth rate of trees does not always relate to lumber quality in L. sibirica.
Table 7 Correlation coefficients between annual ring width and lumber properties in each stand
For the determination of lumber quality, effect the presence of juvenile wood on lumber quality should be considered. Ishiguri et al. [10] showed that wood with lower MOE and MOR, like juvenile wood, was present within 4 cm from the pith for L. sibirica naturally grown in Mongolia. In the present study, juvenile wood percentage in logs was calculated. As a result, juvenile wood percentage gradually increased from bottom to top in all provenances (Fig. 3). The longitudinal trend in juvenile wood percentage was similar to that in MOE of lumber (Fig. 1). Thus, juvenile wood of this species is considered as one of the primary factors to reduce lumber quality. If the wood with wider annual rings was found around the pith area, negative correlations will be found between annual ring width and strength properties. Further research is needed to clarify the relationships between annual ring width and formation of juvenile wood in this species.
Longitudinal variations of juvenile wood percentage of logs in each provenance. Open circles indicate juvenile wood percentage of log from individual tree. SD standard deviation; n number of lumber
Geographical variation of lumber properties
It is known that geographical variations are found in growth characteristics and wood properties in Larix species [2, 6, 11]. In L. kaempferi, Takada et al. [6] investigated geographic variations of Young's modulus of stems for L. kaempferi trees originated from 19 different seed provenances in two provenance-trial test stands in Hokkaido, Japan. As the results, they found that some better or worse provenances in Young's modulus rankings were common in two test stands, although there were no correlations between the test stands. Koizumi et al. [2] examined geographical variations of anatomical and mechanical properties of wood in L. sibirica grown in five natural stands of Russia. They found that the wood from Baikal site had very high density, especially due to the narrow growth rings, whereas the wood from the Altai site in the mountain range had a low density. In addition, we previously reported that geographical variations were found tree height, stress-wave velocity, latewood percentage, and dynamic Young's modulus of logs in L. sibirica naturally grown in Mongolia [11]. In the present study, all lumber properties showed significant differences among the provenances (Tables 3 and 5). The results suggest that wood of L. sibirica trees naturally grown in Mongolia has geographic variation in lumber quality as well as growth characteristics and wood properties.
Figure 4 shows the results of visual grading for lumber from each provenance. Percentage of number of lumber assigned to the Selected and No. 1 in each stand showed more than 50% in all stands except for Arkhangai. In contrast, 50% of total lumber showed outgrading in Arkhangai (Fig. 4). Main reasons of downgrading lumber from Arkhangai were knot and wane (Table 8). Among the provenances, the highest taper value of log was found in Arkhangai (Table 9); although the trees from Arkhangai used in the present study showed almost the same diameter as those other provenances at 1.3 m above the ground, tree height was quite lower than other provenances (Table 2). In addition, juvenile wood percentage of logs at 5.3–7.3 m showed the highest values in Arkhangai (Fig. 3). Based on the results, tree height, taper value and juvenile wood percentage of logs are considered to affect lumber quality considerably in L. sibirica trees naturally growing in Mongolia.
Percentage of each grading class of lumber in each provenance
Table 8 Factors of lumber classified into outgrading in each provenance
Table 9 Taper values of logs at three height positions
Geographical variations of 2 × 4 lumber quality were examined in L. sibirica trees naturally grown in Mongolia. Among five provenances, significant differences were found in all lumber properties such as air-dry density, deformation, dynamic Young's modulus, MOE and MOR. Radial growth rate of L. sibirica trees naturally grown did not affect decrease in mechanical properties of lumber. Knot and wane were main factors for downgrading lumber among the evaluated factors. Tree height, stem shape, and juvenile wood percentage of logs are considered to affect lumber quality considerably of L. sibirica trees from natural forests in Mongolia.
MOE:
modulus of elasticity
modulus of rupture
Ethington LR, Gupta R, Green WD (1997) Visual stress grades of Dahurian larch lumber. For Prod J 47(1):82–88
Koizumi A, Takata K, Yamashita K, Nakada R (2003) Anatomical characteristics and mechanical properties of Larix sibirica grown in south-central Siberia. IAWA J 24:355–370
Zhong Y, Ren H (2014) Reliability analysis for the bending strength of larch 2 × 4 lumber. BioResources 9:6914–6923
Gierlinger N, Jacques D, Schwanninger M, Wimmer R, Pâques LE (2004) Heartwood extractives and lignin content of different larch species (Larix sp.) and relationship to brown-rot decay-resistance. Trees 18:230–236
Curnel Y, Jacques D, Gierlinger N, Pâques LE (2008) Variation in the decay resistance of larch to fungi. Ann For Sci 65:810–818
Takada K, Koizumi A, Ueda K (1992) Geographic variation in the moduli of elasticity of tree trunks among Japanese larch in provenance trial-stands. Mokuzai Gakkaishi 38:222–227 (In Japanese with English summary)
Karlman L, Martinsson O, Karlsson C, Skaaret G (2013) Yield of Larix sukaczewii Dyl. and larch hybrid in northern Scandinavia. Eurasian J For Res 16(1):45–56
Cáceres CB, Hernández RE, Fortin Y (2018) Variation in selected mechanical properties of Japanese larch (Larix kaempferi, [Lamb.] Carr.) progenies/provenances trials in Eastern Canada. Eur J Wood Wood Prod 76:1121–1128
Dulamsuren C, Hauck M, Khishigjargal M, Leuschner HH, Leuschner C (2010) Diverging climate trends in Mongolian taiga forest influence growth and regeneration of Larix sibirica. Oecologia 163:1091–1102
Ishiguri F, Tumenjargal B, Baasan B, Jigjjiv A, Pertiwi YAB, Aiso-Sanada H, Takashima Y, Taiichi Iki, Oshima J, Iizuka K, Yokota S (2018) Wood properties of Larix sibirica naturally grown in Tosontsengel, Mongolia. Int Wood Prod J 9(3):127–133
Tumenjargal B, Ishiguri F, Aiso-Sanada H, Takahashi Y, Baasan B, Chultem G, Ohshima J, Yokota S (2018) Geographic variation of wood properties of Larix sibirica naturally grown in Mongolia. Silva Fenn 52: no 4, article id 10002
Ayush T, Jigjjav A, Baasan B, Pertiwi YAB, Ishiguri F, Yokota S (2019) Drying performance of a direct-fired kiln developed in Mongolia. Wood Res 64(1):177–184
Sobue N (1986) Measurement of Young's modulus by the transient longitudinal vibration of wooden beams using a fast Fourier transformation spectrum analyzer. Mokuzai Gakkaishi 32:744–747
Butler MA, Dahlen J, Eberhardt TL, Montes C, Antony F, Daniels RF (2017) Acoustic evaluation of loblolly pine tree- and lumber-length logs allows for segregation of lumber modulus of elasticity, not for modulus of rupture. Ann For Sci 74:20–35
MAFF (2018) www.maff.go.jp/j/kokuji_tuti/kokuji/pdf/k0001410.pdf. Accessed 6 Aug 2018
Chui YH, MacKinnon-Peters G (1995) Wood properties of exotic larch grown in eastern Canada and north-eastern United States. Forest Chron 71:639–645
Nagao H, Washino K, Kato H, Tanaka T (2003) Estimation of timber strength based on the distribution of MOE in the stem, Application to Japanese larch. Mokuzai Gakkaishi 49:59–67 (in Japanese with English summary)
Ishiguri F, Matsui R, Iizuka K, Yokota S, Yoshizawa N (2008) Prediction of the mechanical properties of lumber by stress-wave velocity and Pilodyn penetration of 36-year-old Japanese larch trees. Holz Roh Werkstoff 66:275–280
Zhou H, Han L, Ren H, Ju J (2015) Size effect on strength properties of Chinese larch dimension lumber. BioResources 10:3790–3797
Miyajima H (1985) Basic wood quality of plantation-grown larch, Todo-Fir and Korean pine in the Tomakomai experiment forest. Res Bull Coll Expt For Hokkaido Univ 42:1089–1115 (in Japanese with English summary)
The authors thank Ms. Yui Kobayashi and Mr. Tappei Takashima, students, Utsunomiya University, and Mr. Sarkhad Murzabek and Ms. Togtokhbayar Erdene-Ochir, Mongolian University of Science and Technology, for their assistance in measuring lumber properties.
A part of this research was supported by the M-JEED program of the Ministry of Education, Culture, Science, and Sports, Mongolia.
School of Agriculture, Utsunomiya University, Utsunomiya, Tochigi, 321-8505, Japan
Bayasaa Tumenjargal, Futoshi Ishiguri, Yusuke Takahashi, Ikumi Nezu, Jyunichi Ohshima & Shinso Yokota
United Graduate School of Agricultural Science, Tokyo University of Agriculture and Technology, Fuchu, Tokyo, 183-8509, Japan
Bayasaa Tumenjargal
Research and Training Institute of Forestry and Wood Industry, Mongolian University of Science and Technology, Ulaanbaatar, 14191, Mongolia
Bayasaa Tumenjargal, Bayartsetseg Baasan & Ganbaatar Chultem
Reserach Fellow of Japan Society for the Promotion of Science, Tokyo, Japan
Haruna Aiso-Sanada
Forestry and Forest Products Research Institute, Tsukuba, Ibaraki, 305-8687, Japan
Futoshi Ishiguri
Yusuke Takahashi
Ikumi Nezu
Bayartsetseg Baasan
Ganbaatar Chultem
Jyunichi Ohshima
Shinso Yokota
BT contributed to experiments, data analysis and writing the manuscript. FI designed this study and also contributed to experiments, data analysis and writing the manuscript. HA-S contributed to experiments and discussion on the obtained results. YT and IN contributed to experiments and data analysis. BB and GC contributed to experiments. JO and SY contributed to discussion on the obtained results. All authors read and approved the final manuscript.
Correspondence to Futoshi Ishiguri.
Tumenjargal, B., Ishiguri, F., Aiso-Sanada, H. et al. Geographical variations of lumber quality of Larix sibirica naturally grown in five different provenances of Mongolia. J Wood Sci 65, 43 (2019). https://doi.org/10.1186/s10086-019-1823-3
Geographical variation
Larix sibirica | CommonCrawl |
What is meant by *sampling* in terms of the *sampling theorem*?
Let $y:\left(-\frac T2,\frac T2\right)\to\mathbb{C}$ be a square integrable function. The Fourier coefficients of $y$ are $$\underline{Y}(k):=\frac 1T\int_{-T/2}^{T/2}y(t)e^{-i\omega_kt}\;dt\;\;\;\text{with }\omega_k:=k\frac{2\pi}T$$ for $k\in\mathbb{Z}$. The Fourier polynom of degree $n\in\mathbb{N}$ of $y$ is $$\mathcal{F}^{-1}_n[y](t):=\sum_{k=-n}^n\underline{Y}(k)e^{i\omega_kt}$$ and $$\mathcal{F}^{-1}[y]:=\lim_{n\to\infty}\mathcal{F}_n^{-1}[x]$$ is called inverse Fourier transformation of $y$. Now, I've got two questions:
What is meant by sampling (in terms of the sampling theorem)? From my understanding, if we know the period $T$ all we need to "store" are the values $\underline{Y}(k)$. We cannot store all values, so we need to choose a "huge enough" $n$ and store only the values $\underline{Y}(-n),\cdots,\underline{Y}(n)$. So, where does "sampling" come into play? The only thing I could imagine is numerical integration: We consider an equidistant grid $$x_j=\left(\frac jN-1\right)\frac T2\;\;\;\text{for }j=0,\ldots,2N$$ and apprximate $\underline{Y}(k)$ using the composite trapezoidal rule, i.e. $$\underline{Y}(k)\approx\frac{1}{2N}\sum_{j=0}^{2N-1}y\left(x_j\right)e^{-i\omega_kx_j}$$ By doing so, we didn't take the whole "signal" $y$, but only the "sample points"$\left(x_j,y\left(x_j\right)\right)$ into account. Is this meant by "sampling"?
Does the sampling theorem make a statement about $n$ or $N$ or something else?
discrete-signals signal-analysis frequency-spectrum sampling
0xbadf00d
0xbadf00d0xbadf00d
$\begingroup$ badf00d, i am working on this with a slightly different notational convention. like my $N$ will be the same as your $2N$. and i am not using "$x$" to depict "time", like $t$. note that my "$T_\text{s}$" is the same as your $\frac{T}{2N}$ or my $\frac{T}{N}$. and i am not dealing with any "composite trapezoidal rule". integrating in the continuous-time domain ($\int x(t) \ dt$) will be equivalent to summing in the discrete-time domain ($\sum x[n]$) due to the nature of the mathematics in this bandlimited and sampled situation. $\endgroup$ – robert bristow-johnson Feb 15 '15 at 21:36
I think, with respect to sampled function, that i disagree a bit with MBaz. perhaps i misunderstand what he/she says regarding needing an infinite number of coefficients or samples for this special case of sampled periodic functions. we had a little discussion about this at comp.dsp, and i'm gonna make use of $\LaTeX$ to spell out the same points.
of course, whether $x(t)$ is periodic or not, if $x(t)$ is real and is sufficiently bandlimited (there are no frequency components as high or higher than $\frac{f_\text{s}}{2} = \frac{1}{2T_\text{s}}$), then the samples:
$$ x[n] \triangleq x(n T_\text{s}) $$
are sufficient to completely represent the continuous-time $x(t)$. if $x(t)$ never repeats, than an infinite number of discrete $x[n]$ are necessary to represent $x(t)$ for all $t$.
but if $x(t)$ is periodic,
$$ x[n+N]=x[n] \quad\quad \forall n,N \in \mathbb{Z} $$ and $$ x(t+T)=x(t) \quad\quad \forall t $$
then samples existing over the span of one period are sufficient to represent $x[n]$ and $x(t)$. in order for the $x[n]$ to be periodic in the sampled domain:
$$ \begin{align} x[n+N] & = x\left((n+N)T_\text{s} \right) \\ & = x\left(nT_\text{s}+NT_\text{s} \right) \\ & = x\left(nT_\text{s}+T \right) \\ \end{align} $$ because $ x(t+T) = x(t) $.
which means the obvious, your function period $T$ has to be the same as $N$ times your sampling period $T_\text{s}$.
$$ T = N T_\text{s} $$
now, what we know about this sampled periodic function is that $N$ samples of $x[n]$ are sufficient to tell us all about $x[n]$, and since $x(t)$ is bandlimited, $x[n]$ and the $N$ samples that fully define it, are sufficient to fully describe $x(t)$.
if $x(t)$ is sufficiently bandlimited (as above), then
$$ \begin{align} x(t) & = \sum\limits_{n=\infty}^{+\infty} x[n] \operatorname{sinc}\left(\frac{t-nT_\text{s}}{T_\text{s}}\right) \\ & = \sum\limits_{n=\infty}^{+\infty} x[n] \frac{\sin\left(\pi\frac{t-nT_\text{s}}{T_\text{s}}\right)}{\pi\frac{t-nT_\text{s}}{T_\text{s}}} \\ & = \sum\limits_{m=\infty}^{+\infty} \sum\limits_{n=0}^{N-1} x[n+mN] \frac{\sin\left(\pi\frac{t-(n+mN)T_\text{s}}{T_\text{s}}\right)}{\pi\frac{t-(n+mN)T_\text{s}}{T_\text{s}}} \\ & = \sum\limits_{n=0}^{N-1} \sum\limits_{m=\infty}^{+\infty} x[n] \frac{(-1)^{mN}\sin\left(\pi\frac{t-nT_\text{s}}{T_\text{s}}\right)}{\pi\frac{t-(n+mN)T_\text{s}}{T_\text{s}}} \\ & = \sum\limits_{n=0}^{N-1} x[n] \sin\left(\pi\frac{t-nT_\text{s}}{T_\text{s}}\right) \sum\limits_{m=\infty}^{+\infty} \frac{\frac{T_\text{s}}{\pi}(-1)^{mN}}{t-(n+mN)T_\text{s}} \\ \end{align} $$
$$ x(t) = \begin{cases} \sum\limits_{n=0}^{N-1} x[n] \frac{\sin\left(\pi\frac{t-nT_\text{s}}{T_\text{s}}\right)}{N\tan\left(\frac{\pi}{N}\frac{t-nT_\text{s}}{T_\text{s}}\right)}, & \text{if }N\text{ is even} \\ \sum\limits_{n=0}^{N-1} x[n] \frac{\sin\left(\pi\frac{t-nT_\text{s}}{T_\text{s}}\right)}{N\sin\left(\frac{\pi}{N}\frac{t-nT_\text{s}}{T_\text{s}}\right)}, & \text{if }N\text{ is odd} \end{cases} $$
proving the latter takes a little bit. you might recognize the $N$ odd case as the Dirichlet_kernel. the $N$ even case looks a teeny bit different. but both show exactly how the $N$ samples that fully define the sampled and periodic $x(t)$ are combined to get $x(t)$.
now, since $x(t)$ is also periodic with period $T$, then
$$ \begin{align} x(t) & = x\left(t+T \right) \\ & = x\left(t+N T_\text{s} \right) \\ & = \sum\limits_{k=-\infty}^{+\infty} X[k] e^{i 2 \pi \frac{k}{T} t} \\ & = \sum\limits_{k=-\infty}^{+\infty} X[k] e^{i 2 \pi \frac{k}{N T_\text{s}} t} \\ & = \sum\limits_{k=-\lfloor \frac{N}{2} \rfloor}^{+\lfloor \frac{N}{2} \rfloor} X[k] e^{i 2 \pi \frac{k}{N} \frac{t}{T_\text{s}}} \end{align} $$
where $\lfloor\cdot\rfloor$ is the $\operatorname{floor}(\cdot)$ operator and
$$ \begin{align} X[k] & = \frac{1}{N} \sum\limits_{n=0}^{N-1} x[n] e^{-i 2 \pi \frac{nk}{N}} \\ & = \mathcal{DFT}\{x[n]\} \end{align} $$
there's actually something to fudge (a factor of $\frac{1}{2}$) about $X\left[\frac{N}{2}\right]$ for the $N$ even case:
$$ \begin{align} X\left[-\frac{N}{2}\right] = X\left[\frac{N}{2}\right] & = \frac{1}{2} \ \frac{1}{N} \sum\limits_{n=0}^{N-1} x[n] e^{-i 2 \pi n\frac{n(N/2)}{N}} \\ & = \frac{1}{2N} \sum\limits_{n=0}^{N-1} x[n] (-1)^n \\ \end{align} $$
note that:
$$ \begin{align} x[n] = x(n T_\text{s}) & = \sum\limits_{k=-\lfloor \frac{N}{2} \rfloor}^{+\lfloor \frac{N}{2} \rfloor} X[k] e^{i 2 \pi \frac{k}{N} \frac{t}{T_\text{s}}}\bigg|_{t=n T_\text{s}} \\ & = \sum\limits_{k=-\lfloor \frac{N}{2} \rfloor}^{+\lfloor \frac{N}{2} \rfloor} X[k] e^{i 2 \pi \frac{k}{N}n} \\ & = \sum\limits_{k=0}^{N-1} X[k] e^{i 2 \pi \frac{nk}{N}} \\ & = \mathcal{iDFT}\{X[k]\} \end{align} $$
if you deal with that $\frac{1}{2}$ fudging for $X\left[\frac{N}{2}\right]$ for the $N$ even case. this is because $X[k+N]=X[k]$ for all $k$.
a periodic continuous-time function can be described with a countable set of Fourier coefficients. a bandlimited periodic continuous function can be described with a finite set of $N$ Fourier coefficients, just as well as it can be described with a finite set of $N$ samples.
robert bristow-johnsonrobert bristow-johnson
$\begingroup$ Even though I haven't checked that final formula, it's obviously true that sampling one period of a periodic band-limited signal suffices. This also leads to the remarkable result that the minimum required sampling rate for sampling a periodic band-limited signal is $f_s=0$. $\endgroup$ – Matt L. Feb 14 '15 at 9:33
$\begingroup$ Robert, I will look more closely to your argument later, but let me say this first. It seems to me that you're assuming knowledge about the signal, like its exact period, and its time delay. Given that knowledge, it may well be that you only need a finite number of samples. However, the sampling theorem (which is what the question was about) does not assume any knowledge about the signal except its bandwidth. Of course, the sampling theorem gives sufficient, not necessary conditions; in many cases you can do with much less samples and/or slower sampling rate. $\endgroup$ – MBaz Feb 14 '15 at 17:18
$\begingroup$ Robert, yes, assuming you can adjust the sampling frequency to have $T/T_s$ an integer, then the samples are periodic and you only need to keep $N$ of them. $\endgroup$ – MBaz Feb 14 '15 at 18:12
$\begingroup$ i'm starting to crap out on this, guys. so if @MBaz or MattL want to prove that Dirichlet thingie, the way to do it is, first assume without loss of generality that $T_\text{s}=1$, and start with the periodic $x[n+N]=x[n]$ and $x(t+N)=x(t)$ and make this asssumption: $$ x[n] = \begin{cases} 1, & \text{if }n=mN \quad m\in \mathbb{Z} \\ 0, & \text{otherwise} \end{cases}$$ and that $x(t)$ is real. then remember that the frequency components $X[k]$ where $k>\frac{N}{2}$ are reflected to negative frequency. for $k=\frac{N}{2}$, you have to split $X[k]$ in two. for positive and negative $f$. $\endgroup$ – robert bristow-johnson Feb 15 '15 at 21:54
$\begingroup$ @robertbristow-johnson, what Matt is doing (as I understand it) is define an "average $f_s$", which is the number of samples taken divided by the time you spend sampling. Since we take a finite number of samples, but the signal's duration is infinite, then your average sampling rate is zero. $\endgroup$ – MBaz Feb 16 '15 at 23:38
Sampling and the Fourier series are only indirectly related. Both are orthonormal expansions of a function, but they use different basis.
In the Fourier series, the orthonormal basis are exponential functions. The Fourier coefficents are the magnitude and phase of the exponentials. As you say, having the coefficients is equivalent, in a certain sense, to having the actual function. However:
As you have noticed, the Fourier series in general requires an infinite number of coefficients, so it may not be practical. However, the coefficients tend to zero (there is a proof of this), so you can keep a finite number of them and neglect the rest. The difference between the original function and the one re-created from the stored coefficients can be so small as to be ignored.
Note that the Fourier transformation is not unique. It is unique if you limit the functions to voltages that can be created in practice.
When sampling, the orthonormal basis are sinc (cardinal sine) functions. The coefficients of the sinc functions are the signal samples (that is, its amplitude at specific instants). The sampling theorem gives sufficient conditions for a function to be expressed in terms of this basis. A nice thing about the proof is that it is constructive; that is, it recreates the function from its samples. Notes:
Again, you need an infinite number of coefficients (samples) . If you only keep a finite number, there will be a difference between the original function and its reconstruction.
The sampling theorem assumes that the function is band-limited, which implies that it is infinite in duration. So, the theorem requires $n$ to be infinite. It makes no statement on $N$.
In engineering and signal processing, we just design our systems so that the difference between the original signal and that reconstructed from its samples is too small to notice. I don't know of any results that quantify the error in terms of $N$ for general functions.
MBazMBaz
$\begingroup$ What exactly do you mean by "the Fourier transform is not unique"? $\endgroup$ – Matt L. Feb 14 '15 at 9:35
$\begingroup$ @MattL. The Fourier transform of arbitrary time functions is not unique, in this sense: the FT of functions that differ only at individual time instants is the same. (Mathematecians say that the two function's difference is not Lebesgue-measurable.) The same argument applies to the IFT. An example is a function that is always zero, except at time $t=1$, when its value is 5. Its FT is zero, and its IFT is zero too. Of course, the FT is unique when you consider the subset of functions that can be generated in practice. $\endgroup$ – MBaz Feb 14 '15 at 17:06
$\begingroup$ OK, so you're referring to functions that are equal "almost everywhere" having the same FT. That's clear, thanks. $\endgroup$ – Matt L. Feb 14 '15 at 17:17
$\begingroup$ Mathematicians say not that the difference is not Lebesgue measureable—non-measureability is a different, and unpleasant, kettle of fish—but rather, as @MattL. says, that the original functions are equal almost everywhere, or that the difference equals 0 almost everywhere. I would prefer to phrase this as saying that the inverse Fourier transform is not unique: there's only one Fourier transform for each function, but there are multiple different functions that have that Fourier transform. $\endgroup$ – LSpice Apr 12 '15 at 23:02
$\begingroup$ @LSpice I should have said that their difference has Lebesgue measure zero, instead of being not measureable; thanks for the correction. See definitions 2.5.2 and Theorem 6.2.12 from this book. $\endgroup$ – MBaz Apr 12 '15 at 23:34
Not the answer you're looking for? Browse other questions tagged discrete-signals signal-analysis frequency-spectrum sampling or ask your own question.
A question about the sampling theorem
Sampling theorem and signals explained to a mathematician
Ideal sampling of audio signals-Periodic spectrum
Exact formula for alias of Discrete Fourier transform for periodic sigals
Sampling Theorem and Dirac Comb
Spectrum of a Signal Going Through a Zero Order Hold Sampling System
A Sampling theorem for power signals
Determining the final value of the output of a discrete system
Is sampling a Fourier transformed signal and fourier transforming a sampled signal the same?
implication of sampling and reconstruction theorem
Use of the Dirac delta as a sampling operator | CommonCrawl |
Recent infection by Wolbachia alters microbial communities in wild Laodelphax striatellus populations
Xing-Zhi Duan1 na1,
Jing-Tao Sun1 na1,
Lin-Ting Wang1,
Xiao-Han Shu1,
Yan Guo1,
Matsukura Keiichiro2,
Yu-Xi Zhu1,
Xiao-Li Bing1,
Ary A. Hoffmann3 &
Xiao-Yue Hong ORCID: orcid.org/0000-0002-5209-39611
Microbiome volume 8, Article number: 104 (2020) Cite this article
Host-associated microbial communities play an important role in the fitness of insect hosts. However, the factors shaping microbial communities in wild populations, including genetic background, ecological factors, and interactions among microbial species, remain largely unknown.
Here, we surveyed microbial communities of the small brown planthopper (SBPH, Laodelphax striatellus) across 17 geographical populations in China and Japan by using 16S rRNA amplicon sequencing. Using structural equation models (SEM) and Mantel analyses, we show that variation in microbial community structure is likely associated with longitude, annual mean precipitation (Bio12), and mitochondrial DNA variation. However, a Wolbachia infection, which is spreading to northern populations of SBPH, seems to have a relatively greater role than abiotic factors in shaping microbial community structure, leading to sharp decreases in bacterial taxon diversity and abundance in host-associated microbial communities. Comparative RNA-Seq analyses between Wolbachia-infected and -uninfected strains indicate that the Wolbachia do not seem to alter the immune reaction of SBPH, although Wolbachia affected expression of metabolism genes.
Together, our results identify potential factors and interactions among different microbial species in the microbial communities of SBPH, which can have effects on insect physiology, ecology, and evolution.
The fitness of insects can be affected by their interactions with associated microbiomes [1,2,3]. Fitness traits affected by host microbiomes include development [4], fecundity [5], resistance to natural enemies [6], climate adaptation [7], and synthesis of essential amino acids [8, 9]. In addition, disturbing an insect's bacterial population can change host fitness [10], such as producing enhanced sensitivity to bacterial pathogens in bees [11] and altering fecundity in mosquitos [12, 13].
The microbial communities of hosts are influenced by diverse factors that include diet [14], pH [15], host [16], life stage [17], temperature and humidity [18], and genetic background [19]. Evidence for effects of genetic background on microbial communities is mostly based on correlations between microbial structure and phylogenetic relationships at the macro-evolutionary level [20, 21], although such correlations might reflect factors like geographic isolation that drive speciation rather than genetic backgrounds per se. Apart from external factors, changes in microbial communities can also be driven by interactions between different microbial species [22]. For example, Wolbachia has been shown to compete against pathogens in Drosophila [23] and Aedes [24, 25]. Similarly, Spiroplasma reduces the density of Wolbachia in Drosophila [26] and Asaia impedes the vertical transmission of Wolbachia in Anopheles stephensi mosquitoes [27]. Mechanisms involved in these microbial interactions are often not clear.
To understand factors influencing the microbial distribution within hosts, investigations are needed at the population level when there are likely to be fewer confounding effects than in interspecific comparisons across hosts. Here, we undertake such an investigation on the small brown planthopper (SBPH, Laodelphax striatellus), a notorious agricultural pest that damages rice plants by sucking rice sap and spreading rice stripe virus (RSV) [28]. The SBPH has a strong migratory ability but also shows population genetic differentiation [29, 30], providing a suitable model for studying the impact of genetic background on microbiomes. Previous studies of the microbiota of SBPH have relied on laboratory samples [31,32,33]. However, stable laboratory rearing conditions are likely to alter the original microbial community structure which might be shaped by their original environmental conditions, with a homogenizing effect on the microbial community [34,35,36]. Moreover, genetic drift can occur, affecting the genetic background of both the host and the microbial community during rearing, generating potential differences between the microbial communities observed in the lab and the field. Given these concerns, our current study focusses on natural populations. We combine 16S rRNA amplicon sequencing with a transcriptome analysis to test factors shaping the microbial community in their host at the population level, and we explore the nature of the interactions between different microbial species.
SBPH individuals were collected from rice plants at 17 locations in China and Japan during the summers (May to September) of 2010–2018 (Fig. 1, left panel; Additional file 1: Table S1). We haphazardly collected about 60–100 adult female individuals at each location. To avoid sampling siblings, we collected only one SBPH per host plant and selected host plants that were at least 1 m apart. All samples were preserved in 100% ethanol and stored at − 20 °C until DNA extraction.
Sampling localities (left) and infection frequencies (right) of Wolbachia in natural populations of SBPH across 17 locations. The numbers in the location map indicate the numbers of SBPH detected. Positions of the infection frequency bars correspond to the latitude of the population. The locations and dates of collection are given in Additional file 1: Table S1
16S rRNA amplicon sequencing
For each of the 17 locations, three female adults were pooled to provide a biological replicate and three biological replicates were established per location. Total genomic DNA was extracted with a DNeasy blood and tissue kit (Qiagen, Hilden, Germany) according to the manufacturer's protocols. A two-step PCR approach recommended by Illumina [37] was performed to generate amplicon libraries. Briefly, the PCR amplification of the bacterial 16S rRNA genes involved universal primer sets 338F (5′-ACTCCTACGGGAGGCAGCAG-3′) and 806R (5′-GGACTACHVGGGTWTCTAAT-3′). The PCR products were purified on a 2% agarose gel, and extracted with an AxyPrep DNA Gel Extraction Kit (Axygen Biosciences, Union City, CA, USA). The Illumina sequencing adapters and sample-specific barcodes were added to the purified PCR products with a second PCR using the TruePrep Index Kit V3 for Illumina (Vazyme, Nanjing, China). Final PCR products were purified with Hieff NGS DNA selection Beads (YEASEN, Shanghai, China), and equalized and normalized using the dsDNA HS assay kit for Qubit (YEASEN, Shanghai, China). Samples were quantified and pooled in equimolar ratio using a Qubit 4 Fluorometer (Invitrogen, Waltham, MA, USA) and then were submitted to Majorbio Bio-Pharm Technology Company Limited (Shanghai, China) for high-throughput sequencing on an Illumina MiSeq PE300.
After sequencing, raw fastq files were demultiplexed, quality-filtered by Trimmomatic, and merged by FLASH [38] (http://www.cbcb.umd.edu/software/flash). OTUs were clustered with 97% similarity cutoff using UPARSE [39] (version 7.1, http://drive5.com/uparse/) and sequences were then phylogenetically assigned to taxonomic classifications using an RDP classifier [40] (http://rdp.cme.msu.edu/). To normalize sequencing depth, the samples were rarefied to 34135 sequences (the lowest coverage sample) to ensure a random subset of OTUs for all samples.
Mitochondrial COI gene PCR
In SPBH, no significant differentiation among populations exists for nuclear genes but mitochondrial genes that are passed down from mother are differentiated [29]. To determine the degree of genetic differentiation, 20 to 46 female adults were haphazardly selected from each population (Fig. 1, left panel) for mitochondrial COI gene amplifications and sequencing according to Sun et al. [29]. The PCR products were sent to Tsingke Biological Technology Company (China) for sequencing.
Diagnostic PCR
To measure infection frequencies of Wolbachia, an additional eight to 46 female adults were haphazardly selected from each population. The specific primers [41] are listed in Additional file 1: Table S2. DNA extraction and PCR were done as described above. Positive controls (known sample with Wolbachia) and blank controls were also run. PCR products of 599 bp size were run on 1.0% agarose gels stained with ethidium bromide at 150 volts and visualized by GenoSens 1860 (Clinx, Shanghai, China). The number of samples showing bright DNA bands compared with the DL 2000 DNA mark (Tsingke, China) was used to calculate the infection rate.
Transcriptome analyses
To investigate the effects of Wolbachia infection on the SBPH transcriptome, we compared Wolbachia-free and Wolbachia-infected SBPH strains. The uninfected strain was obtained by treating the infected strain with tetracycline for 10 generations according to the method of Guo et al. [42]. Briefly, approximately 30 abdomens of SBPH as a biological replicate were dissected from 3-day-adults of both Wolbachia-infected and Wolbachia-free females. The female abdomens contain a large quantity of fat body and blood cells which are the basis of innate immunity. Total RNA was extracted from three biological replicates using TRIzol Reagent (Invitrogen, CA, USA) according to the manufacturer's instructions. RNA purity was measured with a NanoPhotometer® spectrophotometer (IMPLEN, CA, USA). RNA concentration was measured with a Qubit® RNA Assay Kit in a Qubit® 2.0 Fluorometer (Life Technologies, CA, USA). Finally, RNA was pooled for Illumina MiSeq sequencing (BGI, Wuhan, China) according to a standard protocol [43].
The sequencing generated 6.6 Gb per biological replicate. Clean reads were obtained by removing reads with adaptors, poly-N, and having a low quality. Gene expression levels were estimated by RSEM software package [44] (http://deweylab.biostat.wisc.edu/rsem). Immune-related genes of SBPH were obtained from Zhu et al. [45], which were generated by alignments with immune genes of D. melanogaster, A. gambiae, Aedes aegypti, and Culex quinquefasciatus by using BLASTX [46]. In addition, sequences were annotated to the KO database with the KEGG Automatic Annotation Server.
Bray–Curtis dissimilarity metrics among all samples were constructed using beta_diversity.py in QIIME [47] (http://qiime.sourceforge.net/) and were visualized with a principal coordinate analysis (PCoA). The difference of microbial communities among the populations was calculated by ADONIS. The population genetic differentiation value (FST) was calculated in Arlequin 3.5 [48]. The annual mean temperatures (Bio1) and the annual mean precipitation (Bio12) of the 17 locations were obtained from DIVA-GIS 7.5.0 [49] (https://www.diva-gis.org), which is a geographic information system for the analysis of species distribution data. A structural equation model (SEM) [50] was used to estimate the relative contributions of FST, Bio1, Bio12, latitude, and longitude (Additional file 1: Table S3; Table S4; Table S1) on microbial community structure with communities based on Bray–Curtis dissimilarity metrics. The SEM tests were performed in the R "SEM" package (https://cran.r-project.org/web/packages/sem/index.html), and the path diagram for the SEM tests is shown in Fig. 4. As non-normal distribution of variables may compromise SEM analyses results, we also undertook Mantel tests using the Spearman method with 1000 permutations to determine the associations between microbial community structure variation and the five aforementioned factors.
The relative abundance of a given phylogenetic group was estimated by examining the number of reads of that group for each population. In order to analyze the evenness and richness of the microbial community, we calculated several α diversity indexes including the Sods, Shannon, Simpson, Ace, Chao, and Coverage indexes. Spearman's rank correlations were calculated between the proportion of Wolbachia and the α diversity indexes (Shannon indexes and Simpson indexes) of the populations. The significance of differences in read proportions of bacterial 16S rRNA genes at the genus level was assessed by Mann–Whitney U tests. The significance of differences in α diversity indexes between Wolbachia-infected and -uninfected populations was calculated by a t test. All statistical analyses were carried out in R 3.5.2 [51].
Probabilistic features recognition for the OTU distribution
Components of collective ecological and biological systems presented an obvious probabilistic similarity in their aggregation, in which only several species made up a relatively high share of the whole sample, while most species accounted for much less. By looking into our datasets, we noted that the abundance data of OTUs explicitly met this property. Therefore, the power-law function that satisfied the mathematical characterization of such distribution behavior was considered as an appropriate function to recognize the probability distribution features of OTUs. Given the type of power-law function, the abundance had the probability density function (pdf):
$$ p(x)={ax}^{-\varepsilon },x>x' $$
where x' was the threshold that ensured a robust fitting for the power-law distribution. We probabilistically characterized the distribution of abundance of OTUs by calculating the exceedance probability distribution function [52] that was given by:
$$ P\left(X\ge x\right)={x}^{1-\varepsilon }f\cdot \left(\frac{x}{x\hbox{'}}\right) $$
where ε was the scale exponent of power-law distribution underlying the statistical patterns of data considered. This scale factor implied the property of mean and variance of data: when ε ≤ 2, the mean and variance were both infinite; when 2 < ε < 3, the mean existed, while the variance was still infinite; and when ε ≥ 3, both mean and variance existed. Additionally, \( f\left(\frac{x}{x\hbox{'}}\right) \) was introduced to give a general formulation for the homogeneity function. The probabilistic features for the OTU distribution for each population were given in Fig. 2.
Exceedance probability distribution function of OTU abundance for each population. A power-law function is used as the model to estimate the pdf of abundances. Population codes are given in Additional file 1: Table S1
To assess the microbial community variations between populations in terms of probabilistic distributions of OTUs, we calculated the Kullback–Leibler divergence (KL divergence) by using the R package "LaplacesDemon" (https://cran.rproject.org/web/packages/LaplacesDem on/index.html). Probability density functions of OTUs used as the arguments for KL divergence calculation function were computed by using the R package "histogram" (https://cran.r-project.org/web/packages/histogram/index.html). The KL divergence was used as a surrogate index of microbial community structure and was also used for SEM and Mantel tests to analyze the relationships between microbial community structure and five putative predictor variables as mentioned above.
Microbial diversity and environmental factors in the absence of Wolbachia
Based on the infection frequencies of Wolbachia, only the SAP population was found to have Wolbachia-uninfected individuals. And a notable difference in microbial community structure was found between SAP and the remaining populations as showed by the probabilistic features of the OTU distribution (Fig. 2). To eliminate the potential influence of Wolbachia on pooled samples, the SAP population was excluded for testing the impact of other factors on the microbial community. Among the 48 samples from the remaining 16 SBPH populations, the RDP classifier identified a total of 314 OTUs (Additional file 2: Table S5). Wolbachia were the most abundant bacteria, accounting for 87.9% of the 16S rRNA gene reads in the Chinese populations and 66.4% of the 16S rRNA gene reads in the Japanese populations (Additional file 1: Table S6). Other prominent genera included Spiroplasma (3.55%), Asaia (2.47%), Pantoea (1.04%), and Herbaspirillum (1.03%) in the Chinese populations and Diplorickettsia (10.9%), Asaia (5.56%), Spiroplasma (5.00%) and Pantoea (2.08%) in the Japanese populations. Genera other than Wolbachia were enriched in the Japanese populations compared with the Chinese populations. These results suggest that the structures of SBPH-associated bacteria were different between the two countries.
We found significant differences in microbial communities among the 16 populations (Fig. 3b) based on Bray–Curtis dissimilarity (ADONIS, r = 0.428, p = 0.001) and considerable variations based on probabilistic features of the OTU distribution (Fig. 2). To understand whether and to what extent host genetic and environmental factors contributed to variation in microbial communities across the populations, structural equation model (SEM) was used to resolve the relationships between microbial community structure and five putative predictor variables FST, Bio1, Bio12, latitude, and longitude. The results showed that differences in the microbial community structure characterized by Bray–Curtis dissimilarity could be significantly explained by longitude and annual mean precipitation (Bio12), suggesting geographical location and precipitation help shape the microbial community structure in SBPH (Fig. 4a; Additional file 1: Table S7). However, no significant association between KL divergence based on the probability densities of OTUs and any geographic or environmental factors was detected by SEM and the Mantel tests (Fig 4b; Table 1; Additional file 1: Table S7).
The abundance and distance of microbial communities of SBPH across 16 populations. a Relative abundance of bacterial 16S rRNA genes at the genus level. Dashed line separates the Chinese and Japanese microbial community abundance. Blocks of populations were arranged by origin sites (south to north). Other genera ("others") account for < 5% of the classified sequences. b Principal coordinate analysis (PCoA) of SBPH samples collected from different locations. PCoA was generated by the Bray–Curtis dissimilarity method
Path diagram for the structural equation model (SEM) for a environmental/genetic factors and microbial Bray–Curtis dissimilarity, and b environmental/genetic factors and KL divergence in natural populations of SBPH. Statistically significant positive paths are indicated by solid arrows. Statistically significant negative paths are indicated by dashed arrows. The R2 values in each box indicate the amount of variation in that variable explained by the input arrows. Numbers next to arrows are unstandardized slopes. Lat, Latitude; Lon, Longitude; MCSD, microbial Bray–Curtis dissimilarity; KLD, KL divergence
Table 1 Effects of factors in the Mantel test analysis undertaken on 16 populations where Wolbachia was fixed in the population
Pairwise FST values computed from the mitochondrial COI gene (887 bp) for the 16 populations showed that 64 of the 120 pairwise population comparisons were significantly different (Additional file 1: Table S3). The SEM analyses also showed significant effects of FST on the microbial Bray–Curtis dissimilarity (Fig. 4a; Additional file 1: Table S7), suggesting that mtDNA background correlated with similarity in the microbial community structure among populations. In addition, latitude was found to be associated with FST. In line with the SEM analyses, Mantel tests showed that longitude and Bio12 significantly correlated with microbial Bray–Curtis dissimilarity (Table 1). However, although an effect of FST was detected in the SEM, the correlation from the Mantel test was not significant (r = 0.162, p = 0.153). This may reflect the lower sensitivity of the Spearman method and reduced effect of genetic background relative to the other two factors. For the analyses based on KL divergence, the SEM analyses showed that KL divergence significantly correlated with FST values (Fig. 4b; Additional file 1: Table S7) but the Mantel test was marginally non-significant (Table 1).
Effects of Wolbachia on population variation in microbial communities
The 16S rRNA gene data revealed microbial community structure across populations at the genus level (Fig. 3a). The proportions of Wolbachia reads in the high latitude populations of Japan (KUM, JOE, and SAP) were low. To test whether the spread of Wolbachia might affect microbial community structure, diagnostic PCR was conducted to assess the frequency of Wolbachia across the 17 populations (Fig. 1, right panel). The results showed that the infection rate of Wolbachia in SAP was 50% while it was 100% in the other populations. While these results are similar to previous findings in SBPH showing a relatively higher Wolbachia incidence in China [53], the frequency of Wolbachia infection observed in the present study was higher than it was in the previous studies, especially in Japan [54]. This showed that Wolbachia has increased in recent decades.
The correlations between the α diversity indexes (Shannon and Simpson indexes) [55, 56] and the proportion of Wolbachia in all samples were examined by Spearman's rank correlation analyses (Fig. 5a, b). The results revealed that the proportions of Wolbachia were significantly correlated with the Shannon (r = − 0.940, P < 0.001) and Simpson (r = 0.979, P < 0.001) indexes, suggesting that the presence of Wolbachia in SPBH decreased the richness and evenness of microbial communities.
Relationships between the proportions of Wolbachia and the Shannon indexes (a) or the Simpson indexes (b) of microbial community among the 51 samples by Spearman's rank correlation. R values and P values of each linear regression plots are provided
Wolbachia infection and the relative abundance of bacterial taxa in SPBH
To further test the impact of Wolbachia infection on the microbial communities, 10 female adults infected with Wolbachia and 9 female adults uninfected with Wolbachia, both from the SAP population, were used to compare the microbial communities by 16S rRNA amplicon sequencing. After the samples were rarefied to 39,872 sequences (the lowest coverage sample), 1985 OTUs were obtained between the two groups (Additional file 2: Table S8). Wolbachia predominated in the microbial communities of Wolbachia-infected females (Fig. 6a). The relative abundances of 154 genera in the Wolbachia-infected adults were significantly reduced (Additional file 2: Table S9). PCoA analysis based on Bray–Curtis dissimilarity (Fig. 6b) clearly separated the Wolbachia-infected individuals from the Wolbachia-uninfected individuals, indicating that the microbial community structures of the two groups were significantly different. Compared to the Wolbachia-infected group, the Wolbachia-free group possessed high microbial diversity as suggested by the Sobs, Shannon, Simpson, Chao. and Ace indexes (Table 2: Welch two-sample t test: p = 0.003 for Sobs, p < 0.001 for Shannon, p < 0.001 for Simpson, p = 0.001 for Chao, p = 0.002 for Ace). Furthermore, Mann–Whitney U tests revealed that the abundances of seven genera that dominated the communities found in the Wolbachia-free adults were very low in the Wolbachia-infected adults (Fig. 7). These results provided further evidence that Wolbachia decreased the relative abundance and diversity in the microbial community of SBPH.
The abundance and distance of microbial community of SBPH between Wolbachia-infected and Wolbachia-free female adults. a Relative abundance of bacterial 16S rRNA genes at the genus level from 10 Wolbachia-infected female adults and 9 Wolbachia-free female adults in SAP population. Dashed line separates the microbial community abundance of the two groups. Other genera ("others") account for < 5% of the classified sequences. b Principal coordinate analysis (PCoA) among Wolbachia-infected and Wolbachia-free female adults. PCoA was generated by the Bray–Curtis dissimilarity method
Table 2 Measures of species richness and evenness of SBPH from 10 Wolbachia-infected females and 9 Wolbachia-free females from the SAP population
Read percentages of bacterial 16S rRNA genes among Wolbachia-infected and Wolbachia-free female adults at the genus level. Data were showed as relative abundance (%) of genus. Statistical analysis was performed by the Mann–Whitney U test. Error bars represent 95% confidence intervals. *P < 0.05, **P < 0.01, ***P < 0.001 and w+ vs. w−
Changes in microbial communities by Wolbachia infection
To detect the effect of Wolbachia infection on the structure of the microbial community, we compared microbial taxon abundance between the Wolbachia-infected and Wolbachia-free individuals sampled from the SAP population. To normalize sequencing depth, we haphazardly extracted 1144 reads for each sample (based on the minimum number of reads after removing Wolbachia reads in the Wolbachia-infected samples, Additional file 1: Table S10) for these analyses. Our results showed that the structures of the microbial communities were different between Wolbachia-infected females (after excluding Wolbachia reads) and Wolbachia-uninfected females (Fig. 8a; Additional file 1: Table S11). Both the Shannon and Simpson indexes indicated that the Wolbachia-free group possessed higher microbial diversity than Wolbachia-infected group (excluding Wolbachia reads) (Additional file 1: Table S12; Welch two-sample t test: p < 0.035 for Shannon, p = 0.020 for Simpson). PCoA analysis based on Bray–Curtis dissimilarity (Fig. 8b) also clearly separated the two groups, except for two samples of the Wolbachia-uninfected females. Two samples contained very few Wolbachia reads (accounting for 0.04% of their microbial communities), which might lead to a distorted pattern. However, it appears that even Wolbachia infections at low titers can significantly change the microbial community. In addition to decreasing bacterial diversity, we also found that the Wolbachia infection changed bacterial taxon abundance, with 25 genera significantly increasing and 65 significantly decreasing in Wolbachia-infected individuals (Fig. 9; Additional file 2: Table S13; Table S14; Table S15). Most of these bacteria have widespread distributions in insect tissues, including the gut, ovary, and head. Notably, four genera occurring in high proportions (with log (read percent) > 1) in both Wolbachia-infected and Wolbachia-free groups were also significantly different, with Thermus, Spiroplasma, and Ralstonia enriched in the Wolbachia-infected group, in contrast to Prevotella_9 which was enriched in the Wolbachia-uninfected group (Fig. 9). Apart from these changes, Wolbachia infection seems associated with the existence of particular bacterial taxa, with 160 genera specifically existing in relative low abundance in the Wolbachia-infected group (Additional file 2: Table S13).
Abundance and distance of microbial community of SBPH between Wolbachia-infected (excluding Wolbachia reads) and Wolbachia-free female adults. a Relative abundance of bacterial 16S rRNA genes at the genus level from 10 Wolbachia-infected female (excluding Wolbachia reads) adults and 9 Wolbachia-free female adults in SAP population. The dashed line separates the microbial community abundance of the two groups. Other genera ("others") account for < 5% of the classified sequences. b Principal coordinate analysis (PCoA) among Wolbachia-infected (excluding Wolbachia reads) and Wolbachia-free female adults. PCoA was generated by the Bray–Curtis dissimilarity method
Common logarithm values of the read percentage of bacterial 16S rRNA genes for each genus across the microbial communities between Wolbachia-infected females (excluding Wolbachia reads) and Wolbachia-uninfected females and comparisons by Mann–Whitney U tests. Significant differences in the genera existing in Wolbachia-infected females (excluding Wolbachia reads) and Wolbachia-uninfected females are indicated by different colors. Proportions where genera in Wolbachia-infected females (excluding Wolbachia reads)/Wolbachia-uninfected females = 1 is shown as a dotted line
Wolbachia does not appear to strongly affect immune-related genes of SBPH but affects metabolism genes
To test if Wolbachia promotes the expression of immune-related genes in SBPH, we compared the transcriptomes of pooled abdomens from Wolbachia-infected and Wolbachia-free females. Of 330 immune-related genes in SBPH identified by Zhu et al. [45], 306 genes representing 25 gene families were identified (Additional file 2: Table S16). Most of these genes were not differentially expressed (Fig. 10; Additional file 2: Table S16), which suggests that Wolbachia had little or no impact on the immune systems of SBPH. However, through an analysis of Kyoto Encyclopedia of Genes and Genomes (KEGG) terms, we found 141 differentially expressed genes in metabolism processes including oxidative phosphorylation-related and glycolysis-related genes (Fig. 10; Additional file 2: Table S17), which suggests that the effect of Wolbachia on microbial community is likely mediated through changing the overall metabolism and physiology of SBPH.
Fig. 10
Effects of Wolbachia on immune and metabolism genes. Differential expression analysis of immune-related genes and metabolism genes between Wolbachia-infected and Wolbachia-free female adults expressed in the abdomens. Immune-related genes of SBPH were obtained from Zhu et al. [45] and metabolism genes were obtained by KEGG. The x-coordinate shows fpkm value of the Wolbachia-infected females, and the y-coordinate shows the log2(fpkm w+/fpkm w−) value. Dotted lines show the 1 and − 1 values of the y-coordinate. To make the results more intuitive, points were excluded where w+ FPKM was greater than 200, including 19 non-significantly expressed immune genes (Additional file 2: Table S16) and one significantly expressed metabolic gene (Additional file 2: Table S17)
Effects of environmental factors and genetic background on the microbial community of SBPH
Our analyses suggest that, based on Bray–Curtis dissimilarity, longitude and precipitation may impact microbial communities, and these effects appear separate because precipitation did not associate with longitude. To date, any effects of precipitation on insect microbiome have rarely been considered. Our previous study in spider mites found that precipitation can influence the incidence of Spiroplasma [57], a facultative endosymbiont which can manipulate host production. As the SBPH is polyphagous, any effects of longitude and precipitation may reflect effects of these variables on vegetation and food resources for SBPH, which could alter the physiology and metabolism of SBPH hosts and in turn influence microbial communities. SBPH might acquire some bacteria directly from plant sap, as has been suggested for the cochineal insect Dactylopius [58], and different bacteria present in different environments could contribute to variation in microbial communities. For example, Pantoea was abundant in the MDJ population of SBPH (Fig. 3a) and is thought to have been acquired from the environment in Ae. albopictus [59]. It is also possible that microbial communities are responding directly to environmental factors rather than being acquired from the environment, and they might even provide a fitness advantage to hosts under certain conditions, although this remains speculative in the absence of experimental data. Future studies should also consider the impacts of variability in climatic variables on microbial communities, whereas we have only considered the average estimates available to us from the tested locations.
Our results based on both Bray–Curtis dissimilarity and KL divergence suggested an association between mtDNA variations and microbial community structure. Previous studies at the macro-evolutionary level have suggested associations between mtDNA variation and microbial communities, but these might reflect geographic isolation that drive speciation rather than genetic backgrounds per se [20, 21], whereas our findings from the population level with shallow divergence in the mitochondrial genome [30] provide relatively more direct evidence of an association. Some bacterial groups that are maternally transmitted and living inside cells (like Wolbachia) might be expected to be associated with mtDNA variants which can hitchhike along with spreading endosymbionts [60]. A more recent study in mice found that different mitochondrial genotypes can alter ROS productions, which modulates microbial structure in the host gut [61]. In SBPH, two mitochondrial haplogroups thought to be associated with altered functions exist in natural populations [30], and their impacts on microbial communities could be explored in future work.
The effects of Wolbachia on the microbial community of SBPH
Maternally inherited Wolbachia endosymbionts are common in insects. They can manipulate host reproduction, facilitating Wolbachia's rapid spread in a host population. In SBPH, Wolbachia can induce strong cytoplasmic incompatibility (CI), resulting in no offspring when uninfected females mate with infected males [62]. Comparison of the microbial communities of Wolbachia-free and Wolbachia-infected SBPH individuals clearly shows that Wolbachia infection severely decreases the diversity and abundance of bacteria in SBPH. The abundance of the seven other main genera in Wolbachia-infected adults was very low (Fig. 7). A similar phenomenon has been observed in Aedes aegypti, in which a large proportion of bacterial taxa disappeared when Wolbachia was induced by artificial injection [63]. Bacterial diversity was also found to be very low in the gut of Drosophila melanogaster, which is naturally infected with Wolbachia [64].
Significant differences in microbial communities were observed between the Chinese and Japanese populations of SBPH (Fig. 3b). The present results, together with previous studies, suggest that Wolbachia has rapidly spread in SBPH populations during recent decades in both China and Japan. The incidence of Wolbachia has increased from around 90% in Chinese populations [53] to 100% [29], and from around 65% in Japanese populations [54] to more than 90%. The strong CI of Wolbachia and the high migratory ability of SBPH likely contribute to this rapid spread. The spread of Wolbachia seems to have pushed the infection to fixation in the Chinese populations, while the invasion is still ongoing in the Japanese populations. In Japan, spread is most noticeable in high latitude regions where Wolbachia was previously rare. The difference in histories of Wolbachia between China and Japan may be contributing to divergence in their SBPH microbial communities, but this remains to be tested directly, such as through comparisons of the communities when hosts are reared in a common environment.
By removing Wolbachia reads from the Wolbachia-infected females in SAP populations, we further analyzed the effect of Wolbachia on the other bacteria and found that Wolbachia infection changed microbial evenness and other measures of microbial diversity. Three bacteria (Thermus, Spiroplasma, Ralstonia, Fig. 9; Additional file 2: Table S14) were highly enriched in the Wolbachia-infected samples. Vitamin B can be synthesized by Thermus [65], as well as by Wolbachia where it can lead to an increase in host fertility [66]. Thermus associated with Wolbachia may provide an intermediate for the synthesis of vitamin B. In Drosophila neotestacea, Wolbachia can promote the abundance of Spiroplasma [67], pointing to the possibility of direct interactions among microbes. On the other hand, the effect of Wolbachia on Spiroplasma may lead to different tissue tropisms [26] and asymmetrical interactions between the two bacteria where Spiroplasma negatively affects the population of Wolbachia, but Wolbachia does not influence the population of Spiroplasma [26]. In SBPH, Spiroplasma was found to induce late male killing [68] which is predicted to have advantages not only in facilitating maternal transmission, but also in promoting horizontal transmission of Spiroplasma. This is based on the notion that dead males could burst and release Spiroplasma spores into the environment [69]. Whether the bursting of dead males also promotes the spread of other microbes such as Wolbachia in nature is unclear. If so, it could partly contribute to the rapid spread of CI inducing Wolbachia in SBPH populations without decreasing mitochondrial DNA diversity [29]. Ralstonia is a devastating soil-borne plant pathogen and affects growth and development of 200 host species belonging to more than 50 botanical families [70]. For SBPH, we speculated that Ralstonia may have been obtained from food resources, but the function of Ralstonia in insect hosts is unknown. We also note that many bacteria were reduced by Wolbachia infections (Additional file 2: Table S15), and most of them were located in the gut, ovary, and head where Wolbachia exist [33]. Wolbachia may interact competitively with many components of the microbial community of SPBH but this remains to be investigated.
The main mechanisms by which Wolbachia are thought to decrease the microbial diversity are immune system modulation and resource competition [63]. Other mechanisms may include Wolbachia-induced changes in ROS, transcription/posttranscription, and pH [64]. Because no significant difference in the expressions of immunity-related genes was detected in the transcriptomes of Wolbachia-infected and Wolbachia-free female adults, it appears that immune modulation is not involved in SBPH. The only effect detected in this study was a decrease in the expression of the gene encoding defensin in the Wolbachia-infected females (Additional file 2: Table S16), the opposite of what might be expected. Through KEGG analysis, we showed 141 differentially expression genes involving metabolic processes including oxidative phosphorylation and glycolysis (Additional file 2: Table S17), which may suggest that intracellular localized somatic Wolbachia affect the overall metabolism and physiology of the insect to suppress the diversity/abundance of bacterial populations.
Wolbachia infection-associated immune regulation has been reported in organisms in which Wolbachia was artificially introduced [24, 25, 71], but not in organisms that are naturally infected with Wolbachia [23, 72]. It seems that immune regulation mediated by Wolbachia is lost with a long history of Wolbachia colonization. The initial colonization of Wolbachia may trigger an immune response in the host, which then changes after long-term co-evolution between Wolbachia and its host. If that is the case, managing insect pests by releasing insects artificially infected with Wolbachia should be undertaken with caution because the "pathogen blocking" efficiency of insect vectors may eventually be lost in nature as Wolbachia and its host co-evolve. We agree with Simhadri et al. [64] who argue that future studies of Wolbachia-associated phenotypes should consider the effects of Wolbachia on the microbial community.
In this study, by profiling 16S rRNA genes using next-generation sequencing, we explored the relative contributions of genetic background, ecological factors, and interactions among microbial species on the microbial communities of natural populations of SBPH. Our results suggest that Wolbachia infection has a stronger role in shaping the microbial community than ecological factors and genetic (mtDNA) background. When Wolbachia is introduced into the community, it seems to become the dominant species and decreases microbial diversity. Comparative RNA-Seq analyses between Wolbachia-infected and -uninfected strains indicate that the Wolbachia do not seem to alter the immune reaction of SBPH, although Wolbachia affected expression of metabolism genes, suggesting Wolbachia affect the overall metabolism and physiology of the insect to suppress the diversity/abundance of bacterial populations.
The raw reads of 16S rRNA sequencing have been deposited in the NCBI Sequence Read Archive (SRA) database (accession number SRP238740). The raw reads of transcriptomes have been deposited in the NCBI SRA database (accession number SRP195568).
Moran NA, McCutcheon JP, Nakabachi A. Genomics and evolution of heritable bacterial symbionts. Annu Rev Genet. 2008;42:165–90.
Moya A, Peretó J, Gil R, Latorre A. Learning how to live together: genomic insights into prokaryote–animal symbioses. Nat Rev Genet. 2008;9:218.
Feldhaar H. Bacterial symbionts as mediators of ecologically important traits of insect hosts. Ecol Entomol. 2011;36:533–43.
Coon KL, Vogel KJ, Brown MR, Strand MR. Mosquitoes toes rely on their gut microbiota for development. Mol Ecol. 2014;23:2727–39.
Duron O, Bouchon D, Boutin S, Bellamy L, Zhou L, Engelstädter J, et al. The diversity of reproductive parasites among arthropods: Wolbachia do not walk alone. BMC Biol. 2008;6:27.
Brownlie JC, Johnson KN. Symbiont-mediated protection in insect hosts. Trends Microbiol. 2009;17:348–54.
Kriesner P, Conner WR, Weeks AR, Turelli M, Hoffmann AA. Persistence of a Wolbachia infection frequency cline in Drosophila melanogaster and the possible role of reproductive dormancy. Evolution. 2016;70:979–97.
Douglas AE. Nutritional interactions in insect-microbial symbioses: aphids and their symbiotic bacteria Buchnera. Annu Rev Entomol. 1998;43:17–43.
Akman GE, Douglas AE. Symbiotic bacteria enable insect to use a nutritionally inadequate diet. Proc R Soc B. 2009;276:987–91.
Douglas AE. Lessons from studying insect symbioses. Cell Host Microbe. 2011;10:359–67.
Raymann K, Shaffer Z, Moran NA. Antibiotic exposure perturbs the gut microbiota and elevates mortality in honeybees. PLoS Biol. 2017;15:e2001861.
Gaio AO, Gusmão DS, Santos AV, Berbert-Molina MA, Pimenta PFP, Lemos FJA. Contribution of midgut bacteria to blood digestion and egg production in Aedes aegypti (diptera: Culicidae). Parasites Vectors. 2011;4:105.
PubMed Central Google Scholar
Gendrin M, Rodgers FH, Yerbanga RS, Ouedraogo JB, Basanez MG, Cohuet A, et al. Antibiotics iningested human blood affect the mosquito microbiota and capacityto transmit malaria. Nat Commun. 2015;6:5921.
Santo DJW, Kaufman MG, Klug MJ, Holben WE, Harris D, Tiedje JM. Influence of diet on the structure and function of the bacterial hindgut community of crickets. Mol Ecol. 1998;7:761–7.
Schmitt-Wagner D, Friedrich MW, Wagner B, Brune A. Axial dynamics, stability, and interspecies similarity of bacterial community structure in the highly compartmentalized gut of soil-feeding termites (Cubitermes spp.). Appl Environ Microbiol. 2003;69:6018–24.
Hongoh Y, Deevong P, Inoue T, Moriya S, Trakulnaleamsai S, Ohkuma M, et al. Intra- and interspecific comparisons of bacterial diversity and community structure support coevolution of gut microbiota and termite host. Appl Environ Microbiol. 2005;71:6590–9.
Mohr KI, Tebbe CC. Diversity and phylotype consistency of bacteria in the guts of three bee species (Apoidea) at an oilseed rape field. Environ Microbiol. 2006;8:258–72.
Behar A, Yuval B, Jurkevitch E. Community structure of the mediterranean fruit fly microbiota: seasonal and spatial sources of variation. Isr J Ecol Evol. 2008;54:181–91.
Suzuki TA, Phifer-Rixey M, Mack KL, Sheehan MJ, Lin DN, Bi K, et al. Host genetic determinants of the gut microbiota of wild mice. Mol Ecol. 2019;28:3197–207.
Colman DR, Toolson EC, Takacs-Vesbach CD. Do diet and taxonomy influence insect gut bacterial communities? Mol Ecol. 2012;21:5124–37.
Sanders JG, Powell S, Kronauer DJ, Vasconcelos HL, Frederickson ME, Pierce NE. Stability and phylogenetic correlation in gut microbiota: lessons from ants and apes. Mol Ecol. 2014;23:1268–83.
Brinker P, Fontaine MC, Beukeboom LW, Falcao SJ. Host, symbionts, and the microbiome: the missing tripartite interaction. Trends Microbiol. 2019;27:480–8.
Rancès E, Ye YH, Woolfit M, McGraw EA, O'Neill SL. The relative importance of innate immune priming in Wolbachia-mediated dengue interference. PLoS Pathog. 2012;8:e1002.
Moreira LA, Iturbe-Ormaetxe I, Jeffery JA, Lu GJ, Pyke AT, Hedges LM, et al. A Wolbachia symbiont in Aedes aegypti limits infection with dengue, chikungunya, and plasmodium. Cell. 2009;139:1268–78.
Bian G, Xu Y, Lu P, Xie Y, Xi ZY. The endosymbiotic bacterium Wolbachia induces resistance to dengue virus in Aedes aegypti. PLoS Pathog. 2010;6:e1000833.
Goto S, Anbutsu H, Fukatsu T. Asymmetrical interactions between Wolbachia and Spiroplasma endosymbionts coexisting in the same insect host. Appl Environ Microbiol. 2006;72:4805–10.
Hughes GL, Dodson BL, Johnson RM. Native microbiome impedes vertical transmission of Wolbachia in Anopheles mosquitoes. Proc Natl Acad Sci U S A. 2014;111:12498–503.
Otuka A, Matsumura M, Sanada-Morimura S, Takeuchi H, Watanabe T, Ohtsu R, et al. The 2008 overseas mass migration of the small brown planthopper, Laodelphax striatellus, and subsequent outbreak of rice stripe disease in western Japan. Appl Entomol Zool. 2010;45:259–66.
Sun JT, Wang MM, Zhang YK, Chapuis MP, Jiang XY, Hu G, et al. Evidence for high dispersal ability and Mito-nuclear discordance in the small brown planthopper, Laodelphax striatellus. Sci Rep. 2015;5:8045.
Sun JT, Duan XZ, Hoffmann AA, Liu Y, Garvin MR, Chen L, et al. Mitochondrial variation in small brown planthoppers linked to multiple traits and probably reflecting a complex evolutionary trajectory. Mol Ecol. 2019;28:3306–23.
Yang XQ, Wang ZL, Wang TZ, Yu XP. Analysis of the bacterial community structure and diversity in the small brown planthopper, Laodelphax striatellus (Hemiptera: Delphacidae) by 16S rRNA high-throughput sequencing. Acta Ent. Sin. 2018;61:200–8.
Li S, Zhou C, Chen G, Zhou Y. Bacterial microbiota in small brown planthopper populations with different rice viruses. J Basic Microbi. 2017;57:590–6.
Zhang X, Li TP, Zhou CY, Zhao DS, Zhu YX, Bing XL, et al. Antibiotic exposure perturbs the bacterial community in the small brown planthopper Laodelphax striatellus. Insect Sci. 2019;00:1–13.
Chandler JA, Lang JM, Bhatnagar S, Eisen JA, Kopp A. Bacterial communities of diverse Drosophila species: ecological context of a host-microbe model system. PLoS Genet. 2011;7:e1002272.
Keenan SW, Engel AS, Elsey RM. The alligator gut microbiome and implications for archosaur symbioses. Sci Rep. 2013;3:2877.
Clayton JB, Vangay P, Huang H, Ward T, Hillmann BM, Al-Ghalith GA, et al. Captivity humanizes the primate microbiome. Proc Natl Acad Sci U S A. 2016;113:10376–81.
Illumina. 16S Metagenomic Sequencing Library Preparation Guide. 2013. https://support.illumina.com/downloads/16s_metagenomic_sequencing_library_preparation.html.
Magoc T, Salzberg SL. FLASH: fast length adjustment of short reads to improve genome assemblies. Bioinformatics. 2011;27:2957–63.
DeSantis TZ, Hugenholtz P, Larsen N, Rojas M, Brodie EL, Keller K, et al. Greengenes, a chimera-checked 16S rRNA gene database and workbench compatible with ARB. Appl Environ Microbiol. 2006;72:5069–72.
Zhao DX, Zhang YK, Chen H, Hong XY. Effects of transinfection of Wolbachia from Laodelphax striatellus (Hemiptera: Delphacidae) on reproductive fitness and adult longevity of Tetranychus phaselus (Acari: Tetranychidae). Acta Ent Sin. 2014;57:25–35.
Guo Y, Hoffmann AA, Xu XQ, Zhang X, Huang HJ, Ju JF, et al. Wolbachia-induced apoptosis associated with increased fecundity in Laodelphax striatellus (Hemiptera: Delphacidae). Insect Mol Biol. 2018;27:796–807.
Ju JF, Hoffmann AA, Zhang YK, Duan XZ, Guo Y, Gong JT, et al. Wolbachia-induced loss of male fertility is likely related to branch chain amino acid biosynthesis and iLvE in Laodelphax striatellus. Insect Biochem Mol Biol. 2017;85:11–20.
Li B, Dewey CN. RSEM: accurate transcript quantification from RNA-Seq data with or without a reference genome. BMC Bioinf. 2011;12:323.
Zhu J, Jiang F, Wang X, Yang PC, Bao YY, Zhao W, et al. Genome sequence of the small brown planthopper. Laodelphax striatellus Gigascience. 2017;6:1–12.
Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ. Basic local alignment search tool. J Mol Bio. 1990;215:403–10.
Excoffier L, Lischer HE. Arlequin suite ver 3.5: a new series of programs to perform population genetics analyses under Linux and windows. Mol. Ecol. Resour. 2010;10:564–7.
Robert JH, Mariana Cruz, Edwin Roja, Guarino L. Title of subordinate document. In: DIVA-GIS Version 1.4 a geographic information system for the management and analysis of genetic resources data. Manual. International Potato Center. 1999. http://www.diva-gis.org/docs/pgr127_15-19.pdf. Accessed Jan 2001.
Hayduk LA. Structural equation modeling with LISREL: essentials and advances. Baltimore: The Johns Hopkins University Press; 1987.
R Development Core Team. R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing; 2015. http://www.r-project.org. Accessed 10 Feb 2015.
Li J, Convertino M. Optimal microbiome networks: macroecology and criticality. Entropy. 2019;21:506.
Zhang KJ, Han X, Hong XY. Various infection status and molecular evidence for horizontal transmission and recombination of Wolbachia and Cardinium among rice planthoppers and related species. Insect Sci. 2013;20:329–44.
Hoshizaki S, Shimada T. PCR-based detection of Wolbachia, cytoplasmic incompatibility microorganisms, infected in natural populations of Laodelphax striatellus (Hornoptera: Delphacidae) in Central Japan: has the distribution of Wolbachia spread recently? Insect Mol Biol. 1995;4:237–43.
Shannon CE. A mathematical theory of communication. Bell Syst Tech J. 1948;27:379–423.
Simpson EH. Measurement of diversity. Nature. 1949;163:688.
Zhu YX, Song YL, Zhang YK, Hoffmann AA, Zhou JC, Sun JT, et al. Incidence of facultative bacterial endosymbionts in spider mites associated with local environments and host plants. Appl Environ Microbiol. 2018;84:e02546–17.
Ramirez-Puebla ST, Rosenblueth M, Chavez-Moreno CK, de Lyra MCCP, Tecante A, Martinez-Romero E. Molecular phylogeny of the genus Dactylopius (Hemiptera: Dactylopiidae) and identification of the symbiotic bacteria. Environ Entomol. 2010;39:1178–83.
Moro CV, Tran FH, Raharimalala FN, Ravelonandro P, Mavingui P. Diversity of culturable bacteria including Pantoea in wild mosquito Aedes albopictus. BMC Microbiol. 2013;13:70.
Hale LR, Hoffmann AA. Mitochondrial DNA polymorphism and cytoplasmic incompatibility in natural populations of Drosophila simulans. Evolution. 1990;44:1383–6.
Yardeni T, Tanes CE, Bittinger K, Mattei LM, Schaefer PM, Singh LN, et al. Host mitochondria influence gut microbiome diversity: a role for ROS. Sci Signal. 2019;12:eaaw3159.
Noda H, Koizumi Y, Zhang Q, Deng KJ. Infection density of Wolbachia and incompatibility level in two planthopper species, Laodelphax striatellus and Sogatella furcifera. Mol Biol. 2001;31:727–37.
Audsley MD, Seleznev A, Joubert DA, Woolfit M, O'Neill SL, McGraw EA. Wolbachia infection alters the relative abundance of resident bacteria in adult Aedes aegypti mosquitoes, but not larvae. Mol Ecol. 2017;27:297–309.
Simhadri RK, Fast EM, Guo R, Schultz MJ, Vaisman N, Ortiz L, Frydman HM et al.. The gut commensal microbiome of Drosophila melanogaster is modified by the endosymbiont Wolbachia mSphere. 2017;2:e00287–17.
Rehse PH, Kitao T, Tahirov TH. Structure of a closed-form uroporphyrinogen-III C-methyltransferase from Thermus thermophilus. Acta Crystallogr., sect. D. 2005;61:913–9.
Ju JF, Bing XL, Zhao DS, Guo Y, Xi ZY, Hoffmann AA, et al. Wolbachia supplement biotin and riboflavin to enhance reproduction in planthoppers. ISME J. 2019;14:676–87.
Fromont C, Adair KL, Douglas AE. Correlation and causation between the microbiome, Wolbachia and host functional traits in natural populations of drosophilid flies. Mol Ecol. 2019;28:1826–41.
Sanada-Morimura S, Matsumura M, Noda H. Male killing caused by a Spiroplasma symbiont in the small brown planthopper. Laodelphax striatellus J Hered. 2013;104:821–9.
Hurst GDD, Majerus MEN. Why do maternally inherited microorganisms kill males. Heredity. 1993;71:81–95.
Salanoubat M, Genin S, Artiguenave F, Gouzy J, Mangenot S, Arlat M, et al. Genome sequence of the plant pathogen Ralstonia solanacearum. Nature. 2002;415:497–502.
Kambris Z, Cook PE, Phuc HK, Sinkins SP. Immune activation by life-shortening Wolbachia and reduced filarial competence in mosquitoes. Science. 2009;326:134–6.
Shi M, White VL, Schlub T, Eden JS, Hoffmann AA, Holmes EC. No detectable effect of Wolbachia wMel on the prevalence and abundance of the RNA virome of Drosophila melanogaster. Proc R Soc B. 2018;285:20181165.
We are very grateful to Drs. Takashino K, Sano M, Matsukura M, Fujii T, Sanada S, and Izumi Y (NARO Kyushu Okinawa Agricultural Research Center, Japan) for help with collection of Japanese populations; Lei Chen for help with collection of Chinese populations; Dr. Hai-Jian Huang of Ningbo University, Zhejiang Province, China, for reviewing an early draft of the manuscript and for providing suggestions; and Dr. Jie Li of Hokkaido University, Hokkaido, Japan, for analyzing probabilistic features of OTU distribution. We also thank Professor William Sullivan, Department of MCD Biology, University of California at Santa Cruz, USA, for his valuable comments and suggestions on the manuscript.
This work was supported by the National Natural Science Foundation of China (No. 31972264, 31672035 and 31871976). AAH was supported by an NHMRC Research Fellowship while contributing to this paper. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Xing-Zhi Duan and Jing-Tao Sun contributed equally to this work.
Department of Entomology, Nanjing Agricultural University, Nanjing, 210095, Jiangsu, China
Xing-Zhi Duan, Jing-Tao Sun, Lin-Ting Wang, Xiao-Han Shu, Yan Guo, Yu-Xi Zhu, Xiao-Li Bing & Xiao-Yue Hong
NARO Kyushu Okinawa Agricultural Research Center, 2421 Suya, Koshi, Kumamoto, 861-1192, Japan
Matsukura Keiichiro
School of BioSciences, Bio21 Institute, The University of Melbourne, Melbourne, Victoria, 3010, Australia
Ary A. Hoffmann
Xing-Zhi Duan
Jing-Tao Sun
Lin-Ting Wang
Xiao-Han Shu
Yan Guo
Yu-Xi Zhu
Xiao-Li Bing
Xiao-Yue Hong
JTS, XYH, and XZD designed the research. JTS, XZD, and MK collected samples. XZD, LTW, and YG performed the research. XZD and XHS conducted the data analyses. YXZ, AAH, and XLB advised on interpretations. XZD, JTS, AAH, and XYH wrote the paper. The authors read and approved the final manuscript.
Correspondence to Xiao-Yue Hong.
Additional file 1: Table S1
Summary of collection details. The population code (ID), province, city, county, latitude, longitude, and date of the field collections assessed here are provided. Table S2 Specific primers used in PCR for this study. Table S3 Pairwise FST estimates between populations based on a sequence of the mitochondrial COI gene. Population codes are given in Table S1. Table S4 Annual mean temperatures (Bio1) and the annual mean precipitation (Bio12) of the 17 locations obtained from DIVA-GIS 7.5.0. Table S6 Relative abundance of bacterial 16S rRNA genes at the genus level observed for Chinese, Japanese and all populations. Table S7 Effects of factors in the structural equation model (SEM) analysis undertaken on 16 populations where Wolbachia was fixed in the population. Table S10 After Wolbachia was excluded from the Wolbachia-infected adults, the composition of all samples from SAP populations. Table S11 Relative abundance of bacterial 16S rRNA genes at the genus level observed for Wolbachia-infected females (after removal of Wolbachia reads), Wolbachia-uninfected females and all samples. Table S12 Measures of species richness and evenness of SBPH from 10 Wolbachia-infected females (excluding Wolbachia reads) and 9 Wolbachia-free females from the SAP population.
Abundance of OTUs among the 48 samples. Table S8 Abundance of OTUs between the Wolbachia-infected and Wolbachia-free females in SAP populations. Table S9 Read proportions of bacterial 16S rRNA genes among Wolbachia-infected females and Wolbachia-free females at the genus level by Mann-Whitney U tests. Table S13 Read proportions of bacterial 16S rRNA genes for Wolbachia-infected females (excluding Wolbachia reads) at the genus level by Mann-Whitney U tests. Table S14 Significantly increased read proportions of bacterial 16S rRNA genes and the tissue in which their corresponding bacteria were distributed for Wolbachia-infected females (excluding Wolbachia reads) at the genus level by Mann-Whitney U tests. The tissue distribution of bacteria was obtained from Zhang et al. [33]. Table S15 Significantly reduced read proportions of bacterial 16S rRNA genes and the tissue in which their corresponding bacteria were distributed for Wolbachia-infected females (excluding Wolbachia reads) at the genus level by Mann-Whitney U tests. The tissue distribution of bacteria was obtained from Zhang et al. [33]. Table S16 Expression differences of immune genes between Wolbachia-infected and Wolbachia-cured female adults expressed in abdomens. Table S17 Expression differences of metabolism genes between Wolbachia-infected and Wolbachia-cured female adults expressed in abdomens.
Duan, XZ., Sun, JT., Wang, LT. et al. Recent infection by Wolbachia alters microbial communities in wild Laodelphax striatellus populations. Microbiome 8, 104 (2020). https://doi.org/10.1186/s40168-020-00878-x
DOI: https://doi.org/10.1186/s40168-020-00878-x
Laodelphax striatellus
Microbial community
Wolbachia
Endosymbiont
Microbial interactions | CommonCrawl |
Estimates for solutions of nonautonomous semilinear ill-posed problems
PROC Home
Boundedness in a quasilinear parabolic-parabolic Keller-Segel system with the sensitivity $v^{-1}S(u)$
2015, 2015(special): 473-478. doi: 10.3934/proc.2015.0473
Remark on a semirelativistic equation in the energy space
Kazumasa Fujiwara 1, , Shuji Machihara 2, and Tohru Ozawa 3,
Department of Pure and Applied Physics, Waseda University, 3-4-1, Okubo, Shinjuku-ku, Tokyo 169-8555
Faculty of Science, Saitama University, 255 Shimo-Okubo, Saitama 338-8570
Department of Applied Physics, Waseda University, 3-4-1, Okubo, Shinjuku-ku, Tokyo 169-8555, Japan
Received September 2014 Revised February 2015 Published November 2015
Under a Creative Commons license
Well-posedness of the Cauchy problem for a semirelativistic equation with cubic nonlinearity is shown in the energy space $H^{1/2}$. Solutions are constructed as a limit of approximation solutions, where the argument on the convergence depends on the completeness of $L^2$ and is independent of compactness. The Yudovitch type argument plays an important role for the convergence arguments.
Keywords: cubic nonlinearity, Semirelativistic equation, compactness argument., well-posedness, Yudovitch argument.
Mathematics Subject Classification: Primary: 35Q40; Secondary: 35Q5.
Citation: Kazumasa Fujiwara, Shuji Machihara, Tohru Ozawa. Remark on a semirelativistic equation in the energy space. Conference Publications, 2015, 2015 (special) : 473-478. doi: 10.3934/proc.2015.0473
J. P. Borgna and D. F. Rial, Existence of ground states for a one-dimensional relativistic Schrödinger equation, J. Math. Phys., 53 (2012), 062301, 19. Google Scholar
Y. Cho and T. Ozawa, On the semirelativistic Hartree-type equation, SIAM J. Math. Anal., 38 (2006), 1060-1074. Google Scholar
J. Fröhlich and E. Lenzmann, Blowup for nonlinear wave equations describing boson stars, Comm. Pure Appl. Math., 60 (2007), 1691-1705. Google Scholar
K. Fujiwara, S. Machihara and T. Ozawa, On a system of semirelativistic equations in the energy space, Commun. Pure Appl. Anal., 14(2015), 1343-1355. Google Scholar
J. Ginibre and G. Velo, On a class of nonlinear Schrödinger equations. I. The Cauchy problem, general case, J. Funct. Anal., 32 (1979), 1-32. Google Scholar
V. I. Judovič, Non-stationary flows of an ideal incompressible fluid, Ž. Vyčisl. Mat. i Mat. Fiz., 3 (1963), 1032-1066. Google Scholar
J. Krieger, E. Lenzmann and P. Raphaël, Nondispersive solutions to the $L^2$-critical half-wave equation, Arch. Ration. Mech. Anal., 209 (2013), 61-129. Google Scholar
E. Lenzmann, Well-posedness for semi-relativistic Hartree equations of critical type, Math. Phys. Anal. Geom., 10 (2007), 43-64. Google Scholar
L. Molinet, J. C. Saut and N. Tzvetkov, Ill-posedness issues for the Benjamin-Ono and related equations, SIAM J. Math. Anal., 33 (2001), 982-988. Google Scholar
M. Nakamura and T. Ozawa, The Cauchy problem for nonlinear Klein-Gordon equations in the Sobolev spaces, Publ. Res. Inst. Math. Sci., 37 (2001), 255-293. Google Scholar
T. Ogawa, A proof of Trudinger's inequality and its application to nonlinear Schrödinger equations, Nonlinear Anal., 14 (1990), 765-769. Google Scholar
T. Ogawa and T. Ozawa, Trudinger type inequalities and uniqueness of weak solutions for the nonlinear Schrödinger mixed problem, J. Math. Anal. Appl., 155 (1991), 531-540. Google Scholar
T. Ozawa and N. Visciglia, An improvement on the brezis-gallout technique for 2d nls and 1d half-wave equation,, , (). Google Scholar
I. E. Segal, The global Cauchy problem for a relativistic scalar field with power interaction, Bull. Soc. Math. France, 91 (1963), 129-135. Google Scholar
M. V. Vladimirov, On the solvability of a mixed problem for a nonlinear equation of Schrödinger type, Dokl. Akad. Nauk SSSR, 275 (1984), 780-783. Google Scholar
Irena Lasiecka, Roberto Triggiani. Global exact controllability of semilinear wave equations by a double compactness/uniqueness argument. Conference Publications, 2005, 2005 (Special) : 556-565. doi: 10.3934/proc.2005.2005.556
Yves Coudène. The Hopf argument. Journal of Modern Dynamics, 2007, 1 (1) : 147-153. doi: 10.3934/jmd.2007.1.147
Nobu Kishimoto. Local well-posedness for the Cauchy problem of the quadratic Schrödinger equation with nonlinearity $\bar u^2$. Communications on Pure & Applied Analysis, 2008, 7 (5) : 1123-1143. doi: 10.3934/cpaa.2008.7.1123
Pengyan Ding, Zhijian Yang. Well-posedness and attractor for a strongly damped wave equation with supercritical nonlinearity on $ \mathbb{R}^{N} $. Communications on Pure & Applied Analysis, 2021, 20 (3) : 1059-1076. doi: 10.3934/cpaa.2021006
Jianqing Chen. A variational argument to finding global solutions of a quasilinear Schrödinger equation. Communications on Pure & Applied Analysis, 2008, 7 (1) : 83-88. doi: 10.3934/cpaa.2008.7.83
Benjamin Dodson. Global well-posedness and scattering for the defocusing, cubic nonlinear Schrödinger equation when $n = 3$ via a linear-nonlinear decomposition. Discrete & Continuous Dynamical Systems, 2013, 33 (5) : 1905-1926. doi: 10.3934/dcds.2013.33.1905
Tristan Roy. Adapted linear-nonlinear decomposition and global well-posedness for solutions to the defocusing cubic wave equation on $\mathbb{R}^{3}$. Discrete & Continuous Dynamical Systems, 2009, 24 (4) : 1307-1323. doi: 10.3934/dcds.2009.24.1307
Boris Kolev. Local well-posedness of the EPDiff equation: A survey. Journal of Geometric Mechanics, 2017, 9 (2) : 167-189. doi: 10.3934/jgm.2017007
Lin Shen, Shu Wang, Yongxin Wang. The well-posedness and regularity of a rotating blades equation. Electronic Research Archive, 2020, 28 (2) : 691-719. doi: 10.3934/era.2020036
Jerry Bona, Nikolay Tzvetkov. Sharp well-posedness results for the BBM equation. Discrete & Continuous Dynamical Systems, 2009, 23 (4) : 1241-1252. doi: 10.3934/dcds.2009.23.1241
A. Alexandrou Himonas, Curtis Holliman. On well-posedness of the Degasperis-Procesi equation. Discrete & Continuous Dynamical Systems, 2011, 31 (2) : 469-488. doi: 10.3934/dcds.2011.31.469
Nils Strunk. Well-posedness for the supercritical gKdV equation. Communications on Pure & Applied Analysis, 2014, 13 (2) : 527-542. doi: 10.3934/cpaa.2014.13.527
Yonggeun Cho, Gyeongha Hwang, Soonsik Kwon, Sanghyuk Lee. Well-posedness and ill-posedness for the cubic fractional Schrödinger equations. Discrete & Continuous Dynamical Systems, 2015, 35 (7) : 2863-2880. doi: 10.3934/dcds.2015.35.2863
Hongwei Wang, Amin Esfahani. Well-posedness and asymptotic behavior of the dissipative Ostrovsky equation. Evolution Equations & Control Theory, 2019, 8 (4) : 709-735. doi: 10.3934/eect.2019035
Tadahiro Oh, Yuzhao Wang. On global well-posedness of the modified KdV equation in modulation spaces. Discrete & Continuous Dynamical Systems, 2021, 41 (6) : 2971-2992. doi: 10.3934/dcds.2020393
Christopher Henderson, Stanley Snelson, Andrei Tarfulea. Local well-posedness of the Boltzmann equation with polynomially decaying initial data. Kinetic & Related Models, 2020, 13 (4) : 837-867. doi: 10.3934/krm.2020029
Barbara Kaltenbacher, Irena Lasiecka. Well-posedness of the Westervelt and the Kuznetsov equation with nonhomogeneous Neumann boundary conditions. Conference Publications, 2011, 2011 (Special) : 763-773. doi: 10.3934/proc.2011.2011.763
Takamori Kato. Global well-posedness for the Kawahara equation with low regularity. Communications on Pure & Applied Analysis, 2013, 12 (3) : 1321-1339. doi: 10.3934/cpaa.2013.12.1321
Ricardo A. Pastrán, Oscar G. Riaño. Sharp well-posedness for the Chen-Lee equation. Communications on Pure & Applied Analysis, 2016, 15 (6) : 2179-2202. doi: 10.3934/cpaa.2016033
Hartmut Pecher. Local well-posedness for the nonlinear Dirac equation in two space dimensions. Communications on Pure & Applied Analysis, 2014, 13 (2) : 673-685. doi: 10.3934/cpaa.2014.13.673
Kazumasa Fujiwara Shuji Machihara Tohru Ozawa | CommonCrawl |
As a programmer and mathematician, I like to go beneath the surface of everyday activities to find and understand the math and logic hidden inside. When I was preparing my Canadian income tax returns, I couldn't help but notice that the calculations in the tax forms were a form of math and programming expressed in a different notation. So I want to explore what would happen if I recast these calculations in math notation and code, and from there on apply standard techniques for manipulating and analyzing the logic (e.g. algebra and graphing).
In this article, I will illustrate using the real-life example of the Canadian GST/HST credit calculation form, for tax year 2012 (payable in mid-2013 to mid-2014), focusing on chart 2 (for an unmarried person with no children, which has the simplest calculation). The official version of the form, with copious instructions and definitions, are found here:
PDF: http://www.cra-arc.gc.ca/E/pub/tg/rc4210/rc4210-13e.pdf (preferred for better formatting)
HTML: http://www.cra-arc.gc.ca/E/pub/tg/rc4210/rc4210-e.html
Expressed as program code
As a side note, we could take the form and re-implement it in a spreadsheet (e.g. Excel), and it would look and behave identically to the original form. (This is left as an exercise for the reader.) The advantage is that you can execute the logic automatically on a computer and be able to try different input values with ease. But this technique is not so interesting to me, so we'll skip it and start with a real programming language.
If we work through the form line by line and write Java code as literally as possible, this is what we get (31 lines):
double calculateGstHstCreditChart2(
double netIncome, double adjustedNetIncome) {
double line1 = 265.00;
double line7;
if (netIncome > 8608.00) {
double line2 = netIncome;
double line3 = 8608.00;
double line4 = line2 - line3;
double line5 = 0.02;
double line6 = line4 * line5;
line7 = Math.min(line6, 139.00);
line7 = 0.00;
double line8 = line1 + line7;
double line13;
if (adjustedNetIncome > 34561.00) {
double line9 = adjustedNetIncome;
double line10 = 34561.00;
double line11 = line9 - line10;
double line12 = 0.05;
line13 = line11 * line12;
line13 = 0.00;
return line14;
By translating from instructions written in English (a human natural language) to code in a real programming language, we immediately gain two useful properties. The instructions in the natural language are written in an ad hoc way, using a variety of wording and logic constructs. It's difficult to ensure that every calculation form is understandable and unambiguous (see the notes for an example of ambiguity). Contrast this with the program code, where every operation has a clear definition, leaving no room for ambiguity.
Obviously, we can run the code on a computer to test its behavior and check its results. Computers are very fast, and we can run this calculation on millions of cases per second if we so desired. (In fact, if we had a database of the income of every person in Canada (about 35 million), we can easily run this function on every person, taking only a few seconds in total. That's right, it's entirely feasible to process an entire nation's worth of data on a single personal computer – though it depends on the type of calculation.)
A standard code simplification technique is that if a variable is used only once, then its definition can be inlined into the place where it is used. Here we have numerous opportunities to do inlining, and it would significantly shorten the code. For example, in the first if-statement, the 6 lines of the body can be condensed to simply: line7 = Math.min((netIncome - 8608.00) * 0.02, 139.00);. For typical programmers, a line of code with this amount of complexity is actually considered quite simple, taking not much mental effort to process. It could be argued that the calculation can be split into 2 lines, but definitely any more than 2 would be too verbose and harmful for readability. After fully inlining all the variables and doing small tweaks to the logic, this is the much-simplified code that we get:
double total = 265.00;
if (netIncome > 8608.00)
total += Math.min((netIncome - 8608.00) * 0.02, 139.00);
if (adjustedNetIncome > 34561.00)
total -= (adjustedNetIncome - 34561.00) * 0.05;
return total;
We can clearly see the input-output relationship in the function: It takes two input numbers named netIncome and adjustedNetIncome, and it calculates one output number. This is useful to know because the information is complete, so we can draw conclusions about the non-relationships: for example, this calculation does not depend on the number of children (input), does not determine your provincial tax credit (output), does not involve your RRSP amounts, etc. Being able to identify the scope of the calculation helps to clarify the big picture.
Expressed as a math formula
For the notation, line i is denoted as \(L_i\), and input variables are written as acronyms (namely \(NI\) and \(ANI\)).
First, we need to get rid of those unnatural if-statements. Observe that we can rewrite \(L_7\) and \(L_{13}\) to use \(\max(\dots, 0)\) instead: For example, regarding \(NI\) and \(L_7\), if \(NI < 8608\) then we can pretend \(NI = 8608\), so the long computation will still yield \(L_7 = 0\) as wanted. The same reasoning goes for \(ANI\) and \(L_{13}\). Other than this consideration, we simply do repeated substitution of variables until the formula depends only on the input variables.
\(L_{14} = L_8 - L_{13} \\ = (L_1 + L_7) - (L_{11} × L_{12}) \\ = (265 + \min(L_6, 139)) - ((L_9 - L_{10}) × 0.05) \\ = (265 + \min(L_4 × L_5, 139)) - ((\max(ANI, 34561) - 34561) × 0.05) \\ = (265 + \min((L_2 - L_3) × 0.02, 139) - ((\max(ANI, 34561) - 34561) × 0.05) \\ = (265 + \min((\max(NI, 8608) - 8608) × 0.02, 139) - ((\max(ANI, 34561) - 34561) × 0.05) \\ = 265 + \min(0.02(\max(NI, 8608) - 8608), 139) - 0.05(\max(ANI, 34561) - 34561).\)
We have thus condensed the entire form into a one-line formula:
\(GHC(NI, ANI) = 265 + \min(0.02(\max(NI, 8608) - 8608), 139) - 0.05(\max(ANI, 34561) - 34561)\),
where \(GHC\) is the GST/HST credit, \(NI\) is the net income, \(ANI\) is the adjusted net income, and all variables denote monetary amounts in Canadian dollars.
For the purposes of analysis, let's simplify the problem by assuming that \(ANI = NI\). (The actual ANI requires a couple of calculations.) This may or may not introduce significant inaccuracies, but we just want to get a rough idea for how the GST/HST credit varies with a person's net income.
Taking the function in the previous section, setting \(ANI = NI\), renaming \(NI\) to \(x\), and renaming \(GHC\) to \(f\), we get:
\(f(x) = 265 + \min(0.02(\max(x, 8608) - 8608), 139) - 0.05(\max(x, 34561) - 34561)\).
We can plot the function with a suitable tool like Wolfram|Alpha, a computer algebra system like Mathematica/Maple/Maxima, a graphing calculator, etc.
The original form offered little insight about how income is related to the credit, but now the graph shows these facts as clear as day:
The maximum credit is about $400 (in fact, exactly $404), which is attained for incomes of about $15 000 to $35 000.
The credit goes to zero when the income goes to about $42 000, so there is no point in applying for the credit above this income level.
In fact, the calculation allows the credit to become negative if the income is much above $40 000. Despite this logic, the actual credit would be $0. You would not be expected to pay money back – this is supposed to be just "common sense" but is not expressed explicitly in the calculation logic.
The relationship between the input and output is a continuous function, so there are no sudden jumps as the income changes.
Piecewise definition
With some algebraic manipulation (not shown), we can conclude that the function is continuous and piecewise-linear, and we can rewrite it equivalently as a piecewise definition:
\(f(x) = \begin{cases} 265 &, \; \text{if } x \leq 8608 \\ 265 + 0.02(x - 8608) &, \; \text{if } 8068 < x < 15558 \\ 404 &, \; \text{if } 15558 \leq x \leq 34561 \\ 404 - 0.05(x - 34561) &, \; \text{if } x > 34561 \end{cases}\).
When expressed in this format, it's much easier to evaluate the function by hand because it doesn't use parenthesized expressions or min/max. Also, it's easy to calculate the derivative of the function, which tells you how the GST/HST credit amount changes as the net income increases.
I do computer programming as a job and as a hobby, and though I regularly write code that's far more complex and subtle than the example here, I always appreciate and strive for simplicity. My gut feeling after dissecting these calculations is that they're too complex for the goal of fair and socially desirable taxation – there must be a simpler way to achieve this without having an explicit GST/HST credit calculation. It can perhaps be folded into the income tax calculation and UCCB. But the tax code (and laws in general) generally works in the direction of accreting complexity and rarely shedding it, so this idea is unlikely to happen. It seems that simplifying a bunch of overlapping or conflicting laws, or removing rare or obsolete laws, takes much more effort than adding a new law. Needless to say, I don't have high hopes for the tax code becoming simpler in the future.
While the GST/HST credit calculation by itself costs a small amount of effort, when it's combined with all the other calculations in preparing an income tax return, the burden quickly adds up. (For example, I have dealt with Schedule 11 for tuition credits and form T2209 for foreign tax credits, just to name a few.) Complexity has a real human cost in numerous ways. Instructions that are difficult to understand, non-standard, or simply long will confuse users. Complexity increases the chance of (human) errors and exacerbates the consequences of errors, such as time wasted in explaining and resolving them, effort in interpreting and auditing numbers, general bureaucracy and red tape, and loss of goodwill. And no, "complexity creates jobs for tax accounts" is a poor excuse – it would be like saying that digging holes and filling them in "creates jobs for construction workers"; it's better to avoid creating complexity in the first place and let people enjoy other things in life than tax calculations.
Paradoxically, this GST/HST credit calculation form is not as intimidating as it looks, yet at the same time it's more intimidating than it looks. It's not so intimidating because once you know how to do the calculations, you can be confident that you can do it correctly every time, even if the instructions are long. On the other hand, even though the calculation steps are shown plainly in front of you, the implications behind those calculations (such as a graph) are not obvious at all; the meaning is obscured by the syntax and the sheer tedium of working line by line instead of using a more compact, powerful notation. From this exercise, we can see that the ad hoc spreadsheet-like notation used by the CRA is an inefficient and inferior notation compared to standard math notation, and fails to take advantage of the fact that learning algebra and functions is mandatory in Canadian high schools.
The government provides an online calculator to help you calculate your GST/HST credit. But it's rather tedious to use, involving a dozen questions spanning multiple pages. It also doesn't calculate the same quantity; the form calculates the annual credit while the online calculator calculates the quarterly credit payment.
You could argue that this exercise was pointless because to apply for the GST/HST credit, you simply need to tick a checkbox in your income tax return, then the calculations are done for you entirely by the government. But having transparent rules is important, which means you want to be able to calculate the amount for yourself. Moreover, this form was intended to serve as a representative example – many other tax forms have similar logic and similar problems with ambiguity/verbosity/etc.
I chose Java for the illustrative example because it's my preferred language, but the code above can be straightforwardly adapted to C, JavaScript, Python, BASIC, etc. Speaking from experience, translating from the human language form to a programming language is the hard part because it requires interpretation of the wording, detecting ambiguity/errors, and carefully considering the consequences of each calculation. By comparison, translating from one programming language to another is entirely mechanical and unambiguous.
Strictly speaking, these calculations in the Java code should be performed using BigDecimal and rounded after every calculation. But for the purposes of this article, the simplicity of using binary floating-point is sufficient.
Chart 3 seems to have an ambiguity, where one phrase can be interpreted in multiple conflicting ways. Line 3 pertains to the "credit for your other children", but it asks you to multiply your "number of children" by $139.00 instead of multiplying (your number of children minus 1) by $139.00. It also has a special "credit for your first child" in line 2, which suggests that the first child should be excluded from line 3. The HTML version of the form makes this situation very ambiguous. However, in the PDF form, it's fairly clear by the context of the indentation that the "number of children" indeed means the "number of other children". The code version precisely prevents this kind of ambiguity that requires careful interpretation, common sense, and attention to context.
Categories: Programming, Math, Writing, Finance
Guide to Canada income tax by successive approximation
Frog Fractions guide
Facebook anniversary ray trace
Lyrics of Mahou Shoujo Pixy Misa Shouka
Supplement to my résumé | CommonCrawl |
chemistry word problem
→ indicates the direction of the chemical reaction, that is, the sodium and the water reacted together in order to produce some new substances (products of the reaction). If more than one product is present then the names of each product are separated by a plus sign (+). Marisa Alviar-Agnew (Sacramento City College). When I eat starch, a chemical reaction takes place in my mouth which breaks that starch down into sugars. Consider the description below for preparing barium sulfate, a white solid that is used in medicine (known as a "barium meal"): Barium sulfate can be prepared by adding sulfuric acid to a solution of barium nitrate. Identify the "given"information and what the problem is asking you to "find.". Does the conversion factor \(\frac{1 \; \rm m}{100 \; \rm{cm}}\) also equal 1? }=\frac{0.030 L}{1 fl oz. These bubbles force their way up through your drink until they reach the surface where they can finally escape and join the atmosphere. }$$, http://cnx.org/contents/[email protected], Adelaide Clark, Oregon Institute of Technology. A word equation is a short-hand way of describing a chemical reaction. Hydrogen was NOT present at the start, it was produced as a result of the chemical reaction. This is valuable because certain measurements are more accurate or easier to find than others. A conversion factor is a factor used to convert one unit of measurement into another. After paying for 3 cards and some stamps, he had $3 left. Soccer is played with a round ball having a circumference between 27 and 28 inches and a mass between 14 and 16 oz. Paul Flowers (University of North Carolina - Pembroke), Klaus Theopold (University of Delaware) and Richard Langley (Stephen F. Austin State University) with contributing authors. Here is what we would have gotten: \[ 3.55 \; \rm{m} \times \dfrac{1\; \rm{m}}{100 \; \rm{cm}} = 0.0355 \dfrac{\rm{m}^2}{\rm{cm}}\]. We know that 100 cm is 1 m, so we have the same quantity on the top and the bottom of our fraction, although it is expressed in different units. Is a 197-lb weight lifter light enough to compete in a class limited to those weighing 90 kg or less? Chemical reactions are occuring all around you every day and every night. If I add hydrochloric acid to iron, I produce iron chloride and hydrogen. But hydrogencarbonate (one word), or hydrogen carbonate (two words but no and between them), is the name of a compound. Before you break out your calculator, read the problem all the way through. If more than one reactant is present then the names of each reactant are separated by a plus sign (+). For instance, you already know that 12 eggs equal 1 dozen. that is, we start with "reactant" and we end up with "product". Subscribe to RSS headline updates from: Powered by FeedBurner. For example, water is a compound, ammonia is a compound, ethanol is a compound. I want to write a word equation to describe the chemical reaction in which carbonic acid decomposes to produce carbon dioxide and water: So my word equation for the decomposition of carbonic acid in my cola drink is: There may be more than one reactant present in a chemical reaction. For more information contact us at [email protected] or check out our status page at https://status.libretexts.org. A hummingbird can flap its wings once in 18 ms. How many seconds are in 18 ms? Have questions or comments? Is it large enough to contain the acid, the density of which is 1.83 g/mL? Perhaps you can determine the answer in your head. Write the conversion factors (as ratios) for the number of: The label on a soft drink bottle gives the volume in two units: 2.0 L and 67.6 fl oz. *pounds and ounces are technically units of force, not mass, but this fact is often ignored by the non-scientific community. The two reactants are: Let's see if we can identify a new substance that has been produced, that is, let's find the name of a product of this chemical reaction: Hydrogen is a product, it is the new substance formed when we mix the reactants (zinc and hydrochloric acid) together. If we see a word equation written down, we can follow the directions it gives in order to make the make new substance(s). Make the conversion indicated in each of the following: (a) the men's world record long jump, 29 ft 4.5 in, to meters, (b) the greatest depth of the ocean, about 6.5 mi, to kilometers, (c) the area of an 8.5 by 11 inch sheet of paper in cm2, (d) The displacement volume of an automobile engine, 161 in3, to L, (e) the estimated mass of the atmosphere, 5.6 x 1015 tons, to kilograms (1 ton = 2000 lbs), (f) the mass of a bushel of rye, 32.0 lb, to kilograms, (g) the mass of a 5.00 grain aspirin tablet to milligrams (1 grain = 0.00229 oz), Many chemistry conferences have held a 50-Trillion Angstrom (Å) Run. But the names of some metals do not end in "ium", for example, iron, silver, gold, copper, zinc, lead, mercury, nickel. We can write 1 as \(\mathrm{\frac{100\:cm}{1\:m}}\) and multiply: \[ 3.55 \; \rm{m} \times \dfrac{100 \; \rm{cm}}{1\; \rm{m}}\]. General word equation: reactant(s) → product(s). Therefore the word equation we wrote states that Chris added some sodium to water and produced hydrogen and sodium hydroxide. Since this agrees with what we were told in the problem, we are confident that our word equation is plausible. (a) What is the volume of 25 g of iodine (density = 4.93 g/cm3)? The average volume of blood in an adult male is 4.7 L. What is this volume in milliliters? What are these specifications in cm and g? hydrogen + sodium hydroxide means that the products of this chemical reaction are the two new substances hydrogen and sodium hydroxide. Of course, there are other ratios which are not listed in Table \(\PageIndex{1}\). Dimensional analysis is amongst the most valuable tools that physical scientists use. Phosphorus and sulfur are also elements that are non-metals. Write a word equation to describe the chemical reaction that Chris demonstrated to the students. Make sure you understand what the question is asking. You can find the names of elements in the periodic table of the elements. Here is a simple example. Pharmacists must know a lot of chemistry and biology so they can understand the effects that drugs (which are chemicals, after all) have on the body. The distance between the centers of two oxygen atoms in an oxygen molecule is 1.21 x 10-8 cm. Chances are that someone has already asked for a solution to your chemistry problem, or at least to a similar one, and you will be able to view the answer online. Some content on this page could not be displayed. During your studies of chemistry (and physics also), you will note that mathematical equations are used in many different applications. The information tells us how to prepare barium sulfate, that is, this chemical reaction will make (or produce) barium sulfate, therefore the product of the chemical reaction is barium sulfate. The label on a box of cereal gives the mass of cereal in two units: 978 grams and 34.5 oz. (c) What is the volume of 11.3 g graphite (density = 2.25 g/cm3)? From chemistry word problem-solver to subtracting rational, we have got every part discussed. Unless otherwise noted, LibreTexts content is licensed by CC BY-NC-SA 3.0. This page was constructed from content via the following contributor(s) and edited (topically or extensively) by the LibreTexts development team to meet platform style, presentation, and quality: CK-12 Foundation by Sharon Bewick, Richard Parsons, Therese Forsythe, Shonna Robinson, and Jean Dupon. The product of a reaction is the substance that is formed, or produced, as a result of the chemical reaction taking place. Reactants and products can be elements or compounds. The diameter of a red blood cell is about 3 x 10-4 inches. As long as we perform the same operation on both sides of the equals sign, the expression remains an equality. 2020-10-15T12:00:00+01:00. Conversions in the metric system, as covered earlier in this chapter. The hydrogen gas would be released as a burp! Writing Word Equations for Chemical Reactions . Simply put, it is the conversion between an amount in one unit to the corresponding amount in a desired unit using various conversion factors. In general the name of a compound will be made up of two words. The general form of a word equation is shown below: draw an arrow to show the direction of the chemical reaction, →, write the name of the product (sugars) to the right of the arrow, write the name of the reactant (carbonic acid), write the names of each of the products separated by a plus sign (+) to the right of the arrow (carbon dioxide + water), write the names of each of the reactants separated by a plus sign (+) (hydrochloric acid + calcium carbonate), write the names of each of the products separated by a plus sign (+) to the right of the arrow (calcium chloride + carbon dioxide + water).
Bacon Wrapped Balsamic Pork Tenderloin, Functional Expense Classification, Proxima Nova Zip, Le Creuset Signature Stainless Steel Shallow Casserole, Traditional Tools Used In Agriculture And Their Uses, Lake Wildwood Gated Community, Ladies Antique Writing Desk, Barracuda Restaurant Menu, Abc Observation Early Years, Sealy Silver Chill Firm, Contract Spreadsheet Template, Cheapest House In Bozeman, Sausage Meaning In Bengali, Citrus Magic Organic Veggie Wash, Tere Naina Bade Katil Chords, Rapid No 13 Staples, Twinings Earl Grey Tea Bags 100 Per Pack, Is Epicurious Cookware Safe, Twix Slogan 2018, Context Switch Vs Interrupt, Dharmavarapu Subramanyam Son, De Buyer Mineral B Wok,
chemistry word problem 2020 | CommonCrawl |
Single-pile Nim with Three Players
Three perfectly rational logicians (Alice, Bob and a Quetzalcoatlus) are playing a game. (Charlie couldn't make it, so he asked the Quetzalcoatlus to fill in for him.)
The rules are very simple:
There are three players.
Initially, there are 40 candies in a pile.
On his, her or its turn, a player has to take 1 - 5 candies off the pile.
The player that takes the last candy will lose.
The other two players both win.
Bob has won the coin toss (done with a fair three-sided coin, probably) and gets to choose the seating order.
Given that the players are well known to be perfectly rational and impartial, only wanting to maximise their own chance of winning, even if by the tiniest amount, should Bob choose to go first, second, or third?
This particular game with these exact parameters was suggested by Kevin L, he asked if there was a strategy to guarantee a win for one of the players without collusion. Turns out, those parameters are also pretty much perfect for this question, which is a bit more difficult. At least for some very large values of "a bit".
HINT 1: (contains no spoilers)
If the answer required brute force calculating the exact winning probabilities for each player at 40 candies, I wouldn't have posted it as a puzzle. Finding the shortcut is what this puzzle is all about.
HINT 2: (a little more spoileriffic)
I have commented on a partial answer, that the approach is a good one.
strategy game game-theory nim
BassBass
$\begingroup$ "Charlie couldn't make it, so he asked the Quetzalcoatlus to fill in for him." :)) $\endgroup$ – Oray Aug 14 '18 at 13:32
$\begingroup$ one thing is not given, players are aiming to finish the game and take as many candles as possible or they can randomly decide when they guarantee to win somehow? $\endgroup$ – Oray Aug 14 '18 at 14:16
$\begingroup$ It's stated that the players aim to maximize their own chance of winning. $\endgroup$ – jafe Aug 14 '18 at 14:18
$\begingroup$ @Oray they choose impartially. I actually just found a pretty recent (2013) paper that uses a fixed preference (each winning player wants to have played as late as possible) to solve this puzzle in a game theoretically significant way, but since I'm not a game theoretician, I didn't know about that when I made this puzzle, and so we're stuck with all this impartiality annoyance. $\endgroup$ – Bass Aug 14 '18 at 17:01
$\begingroup$ If there are 3 candies left the next player is guaranteed to win by taking either 1 or 2. The question doesn't specify how they play when two different options give identical chances of winning. $\endgroup$ – kasperd Aug 14 '18 at 21:50
I will assume that
Given several equally desirable options, the players will randomly choose one.
Doing so, it is easy to work out what happens when there are $n$ candies;
If $n=1$, then player 1 certainly loses.
If $n=3$, then player 1 is indifferent between taking one and two candies, so player 2 or 3 loses with equal odds.
If $n\in \{4,5,6\}$, the same thing happens. Moving down to $3$ or $4$ or $5$ is not safe, so but leaving one or two candies is equally desirable to player 1.
If $n=7$, then player 1 will take 5 candies, so player 3 will lose.
If $n=8$, then player 1 is indifferent between leaving 3, 4, 5 or 6 candies, all which result in them losing with probability 50%. In all of these cases, player 3 loses the other 50% of the time.
If $n=9$, then things get interesting. Player 1 is indifferent between taking 1, 3, 4 or 5 candies (if they take 2, leaving 7, they certainly lose). In all four cases Player 1 loses with probability 50%. If they take 1 candy, then player 2 loses the other 50% of the time, and if they take 3-5 candies, then player 3 loses the other 50%. Since player 1 chooses randomly among these four options, the changes of player 2 losing are 12.5%, and of player 3 losing are 37.5%.
If $n=10$, then taking one candy is the best option as it is the only one which gives a 37.5% chance of defeat, all other options giving 50% or 100%. This means player 2 loses with probability 50% and player 3 with probability 12.5%.
If $n\in [11,15]$, then player 1's best bet is to move down to 10 candies, which gives them a 12.5% percent chance of losing. In all these cases, Player 2 loses with probability 37.5%, and player 3 loses with probability 50%.
From here on after, the pattern displayed in the range 9, 10, 11, ... , 15 repeats. At n = 16, player 1 is indifferent among dropping to 11 through 15. At n = 17, player 1 will take one candy, and at n = 18...24, player 1 will be eager to leave 17 candies.
The findings are summarized in this table. You can see that at $n=40$, player 1 will prefer to go first.
n P1 P2 P3
1 1 0 0
3 0 1/2 1/2
8 1/2 0 1/2
9 1/2 1/8 3/8
10 3/8 1/2 1/8
Mike EarnestMike Earnest
$\begingroup$ Also, here is some code which confirms the above result: repl.it/@mearnest/Three-player-takeaway-game $\endgroup$ – Mike Earnest Aug 15 '18 at 19:31
$\begingroup$ Great answer! :) $\endgroup$ – El-Guest Aug 15 '18 at 19:52
$\begingroup$ This answer seems correct, fits all the given clues, and isn't the one I intended. (The impartiality was supposed to mean impartiality between opponents when having to choose whom to give the advantage to). Therefore I'm afraid I have to say: Thank you, Good Sir, for finding a meaningful, unintended interpretation for my question, and even one that produces a very sensible answer! Here's your green tick! $\endgroup$ – Bass Aug 17 '18 at 11:47
Even though the question says I'm Bob, I'd like to start by stating my intention to be the Quetzalcoatlus, thanks very much.
I believe that the key to this game is that
you lose if you leave a specific number of candies on the table. As @Bass noted in the comments above, C would lose if they left 7 candies on the table, because then A takes $n$ candies, $n \in \{1,2,3,4,5\}$, and then B takes $6-n$ candies, leaving one on the table for C. However, this is not a forced play...the other two cannot force Q to leave 7 candies on the table. Q will win if they can take either candy 38 or candy 39. If candy 39, then A loses (assumed order: A-B-Q). If candy 38, then B loses (since A takes candy 39 and also wins). Therefore Q must lose if they are forced to leave 3 candies on the table. This means that there must be at least 8 candies on the table to start. So 8 is a $bad \hspace{0.5ex} number^{TM}$; A and B can and should conspire to leave Q with 8 since this will maximize their chances of winning (at 100% each). We can see that the pattern for $bad \hspace{0.5ex} numbers^{TM}$ is $BN = 7n + 1$, $BN\in\mathbb{N}$. We can show this as follows. If Q has 9-13 candies remaining, then they ought to leave 8 candies left in order to force a loss on A. If Q has 14 candies remaining, then they must leave 9, so A must take 1 in order to force a loss on B. If Q has 15 candies remaining, then they must leave between 10 and 14 candies. The other two players can then force a Q loss by leaving Q with 8 on their next turn (A=1,B=1 if 10 left by Q up to A=1,B=5 if 14 left by Q). Continuing the pattern above, the $bad \hspace{0.5ex} numbers^{TM}$ are 8, 15, 22, 29, 36. This means that as long as Q can avoid being left with 36, the optimal strategy for the two non-losing players is to join up and screw the last guy. The only way to achieve this is Quetzalcoatlus chooses to go first (remember I'm Q instead of B ;P) and picks 4 candies off the pile. He has then screwed over A, who automatically loses, and B conspires with Q because doing so maximizes his chances of winning at 100% if he does.
Example game:
Q: picks $4$, leaves $36$.
A: knows he's screwed, picks $n$, $n\in\{1,2,3,4,5\}$ and leaves $36-n$.
B: knows that A is screwed, picks $6-n$ and leaves $30$.
B: knows that A is screwed, picks $6-n$ and leaves $9$.
Q: picks $1$, leaves $8$.
A: knows he's screwed, picks $n$, $n\in\{1,2,3,4,5\}$ and leaves $8-n$.
However, there is a major issue with this...
This strategy requires collusion throughout (which isn't against these rules, at the moment). If A is left with 8, he can pick 2, for example, leaving 6. Then B can take 5 and screw Q, because this doesn't affect his chances of winning. Hence this strategy works for Bob 100%, and works for A and Q 50% of the time. This looks like it is the best that it's going to be for a poor Quetzalcoatlus if he starts....
Let me look at this from a different angle.
if person 1 picks up the 4th candy, then person 3 has a 100% winning strategy. Therefore I doubt anybody would willingly pick up the 4th candy as their last candy; they would likely pick more than that.
El-GuestEl-Guest
$\begingroup$ If I'm Alice in this game, I might just take my candies and go home. $\endgroup$ – jafe Aug 14 '18 at 13:28
$\begingroup$ This is actually not quite true, since Bob still has the chance to screw over Quetzalcoatlus in the final stages of the game, having assured his victory.....but then gets prompted smote (smited?) because I wasn't Quetzalcoatlus at all! $\endgroup$ – El-Guest Aug 14 '18 at 13:31
$\begingroup$ Collusion isn't against the rules as they are written, but I hope the question is pretty clear on the point that the players aren't going to resort to that. $\endgroup$ – Bass Aug 14 '18 at 13:50
$\begingroup$ That's a very good answer to the linked question :-) $\endgroup$ – Bass Aug 14 '18 at 13:54
$\begingroup$ I can guarantee that the answer isn' exactly 2/3, but I'm afraid the "even by the tiniest amount" qualifier given in the question may become relevant.. $\endgroup$ – Bass Aug 14 '18 at 14:58
Partial strategy up to 11 candies. A is the player whose turn is next, B is the next player, and C is last.
If there are 2 candies left, A can win by taking 1. (B loses.)
If there are 3-6 candies left, A can force a win by leaving 1 or 2 candies on the table. We have to be impartial with respect to which of the other players loses, so 50% of the time A leaves 1 (B loses) and 50% of the time 2 (C loses).
If there are 7 candies left, A wins by taking 5. (C loses.)
If there are 8 candies left, A cannot force a win. Taking 1 loses for A (because B has to take 5 to win), every other move leaves B with 6-3 candies and it's a 50% chance for A to win.
If there are 9 candies left, taking 2 loses (B has to take 5 to win). Taking 1 leaves a 50% chance to win for A (B has to leave 3-6 for C so C wins and it's 50-50 between A and B). Taking 3-5 also leaves a 50% chance to win for A (B has 4-6 left so C wins and it's 50-50 between A and B). A has to be impartial with respect to B vs C winning, so 50% of the time A takes 2 and 50% of the time 3-5 (doesn't matter which, since the result is identical).
If there are 10 left, A can
- leave 5-6 (B wins, 50-50 between A/C)
- leave 8 (C wins, 50-50 between A/B)
- leave 9 (50% A wins and 50-50 between B/C, 50% C wins and 50-50 between A/B).
Leaving 9 gives A a 75% chance to win, whereas the other options give 50%. So A should leave 9.
- leave 10 (50% B wins and 50-50 A/C, 50% A wins and 50-50 B/C)
- leave 9 (50% A wins and 50-50 B/C, 50% C wins and 50-50 A/B)
As per 10, leaving 6-8 is worse than leaving 9. A is indifferent between leaving 9 and 10, so should 50% leave 9 and 50% leave 10 in order to be impartial between B/C.
Don't think I can do it for 40 without turning this into a novel. But I have to say that, based on the name alone, Quetzalcoatlus sounds like a mean logician.
(Much later:) Humm. The shortcut escapes me, even after solving the winning percentages for all players from all positions. Apparently
the starting player has a slightly better chance of winning (67.2%, while the others have 66.4% each).
The critical initial position seems to be
36 candies left, which is slightly losing for the player whose turn it is. So A should go first and play a mix of taking 4 (putting B in the losing position) and taking 3 (allowing B to put C in the losing position by taking 1).
For what is worth, here are the numbers. The numbers are the winning percentage for A, B and C respectively if A is the next player to take.
1 left: (0, 100, 100)
2 left: (100, 0, 100)
3 left: (100, 50, 50)
7 left: (100, 100, 0)
8 left: (50, 100, 50)
9 left: (50, 75, 75)
10 left: (75, 50, 75)
11 left: (75, 62.5, 62.5)
27 left: (62.5, 75, 62.5)
28 left: (62.5, 68.8, 68.8)
jafejafe
$\begingroup$ This approach is definitely the way to solve this game. You may also notice, that the will never be 7 candies to choose from: C, whose turn was last, would never make such a bad choice. $\endgroup$ – Bass Aug 14 '18 at 12:21
$\begingroup$ That's a really good point. $\endgroup$ – jafe Aug 14 '18 at 12:22
$\begingroup$ From 14, you can reach either 9 or 10, both giving 75% for the previous player, so the percentages should be the same as for 11-13. (I posted my intended solution as a self-answer somewhere below, but that will spoil the shortcut thingy altogether.) $\endgroup$ – Bass Aug 17 '18 at 16:09
$\begingroup$ Yeah there's an error there. I have a feeling it'll come up as equivalent to your solution once fixed... $\endgroup$ – jafe Aug 17 '18 at 16:14
$\begingroup$ I think so too. I only calculated the values for the first < 20 candies when I was verifying my solution, but these numbers look very familiar. $\endgroup$ – Bass Aug 17 '18 at 16:15
With this information:
To be perfectly rational and impartial, only wanting to maximise their own chance of winning.
and it is assumed that
Everyone is taking as many candles as possible where they would not lose the game (who doesnt like candies), because at some points taking 3 candles or 4 candles are indifferent for some players but it could change the outcomes for other players.
If there were 5 candles
1- Bob will go first or last to guarantee not to lose, because whoever go first will take 4 candles, and the second player would lose for sure. Whoever go first would not go for 3 candles even if first player would be still guaranteeing to win because of the assumption given at the very beginning. Because it will change the game so much for the further parts. If first player would be taking 3 candles, last player would be losing, second player would be winning etc.
If there were 6 candles,
2- Bob will go first or last, bob will take 5 candles, because he would not lose after taking 5 candles anyway and second player will lose. or being last player is a default win too.
If there were 7,8,9,10 candles,
3- Bob would go first take 1-5 candles, and make the game into game $2$ as the last player in that game, or being second player making himself first player in game $2$.
If there were 11 candles,
4- Bob can take 5 candles and make the game into game $2$ to guarantee to win as the last player or second player since the first player will apply the same thing to win and Bob will be first player in game $2$ and win.
5- if first player will make this game into game $3$ or $4$ by taking 5 candles or 1 candle, he/she will lose since he/she will be the last player in game $3$ or game $4$ and lose. So whatever first player does, he would lose, so Bob needs to be second or last player for this many candles!
if there were 13-15 candles,
6- Bob would prefer being first player or last player. Because the first player will force to game $5$ to guarantee to win. And the last player will win when the first player makes tha game into game $5$ anyway.
7- Bob would go first player by taking less than 5 candles and win the game. Since players are taking as many candles as possible (my assumption) when they guarantee to win, the first player is supposed to be taking 4 candles, and it makes the game into game $5$. and in game $5$, second player wins too. so being last player in this game is also win!
after this, I am just putting the game because the same logic goes on:
and at the end,
Bob could go first or second to win the game with the assumption given at the very beginning.
OrayOray
$\begingroup$ This is a good answer, I like the pattern! The only issue I have is with the "indifference" notion, ie. with the idea that taking a maximal amount of candies is always preferential. If there are 6 candies left, for example, player 1 takes 5 and wins every time (p2 loses)...but player 1 can also take 4 and win every time (p3 loses). P1 should therefore (by my interpretation at least) be indifferent between taking 4 or 5 candies, meaning that P2 and P3 should both lose in this scenario 50% of the time. $\endgroup$ – El-Guest Aug 14 '18 at 14:45
$\begingroup$ @El-Guest that's why I added the assumption, otherwise those 50%s are getting bigger and bigger :) $\endgroup$ – Oray Aug 14 '18 at 14:47
$\begingroup$ It would be interesting to see if there's a strategy without the assumption...I feel there are too many possibilities to not brute-force it. That said, this solution is definitely at least 50% more elegant than mine, even with the assumption.....please, take my up-quetzalcoatlus! :) $\endgroup$ – El-Guest Aug 14 '18 at 14:49
Using the same assumption as @Oray,
If a player is at 6, he will take 5 candies. Assume also that all players know this and factor it into their decisions
Given this, we can now define "losing states".
1 is a losing state.
2 to 6 are not since they can bring the next player down to 1.
7 to 11 are not since they can take the second player to a winning position and force the third player to lose.
12 is a losing state.
From here, the game is just a cycle. Every 1 modulo 11 is a losing state, so 34 is a losing state. Bob needs to go second so that whatever the first player picks, he can make the third player go to 34.
sedricksedrick
$\begingroup$ This is exactly the correct kind of reasoning, but I think you have overlooked something important: if Bob leaves the next player with 3 candies, that player can guarantee a win by taking either 1 or 2, and Bob will be among the winners only in the latter case. $\endgroup$ – Bass Aug 14 '18 at 16:04
$\begingroup$ I'd like to retract my previous comment about overlooking things, (leaving it up though): you very likely didn't overlook anything, but chose to solve the puzzle in a game theoretically interesting way. My bad for choosing a game theoretically less interesting formulation with impartial choices for every player. Glad I +1ed your answer the first time I saw it. $\endgroup$ – Bass Aug 14 '18 at 17:19
Jafe posted something very close to my intended answer, and it may be that he is correct, and I've made a mistake somewhere. To compare notes, here's my intended solution: (the tick has gone to a completely different answer, because it was very good, and fit every requirement given, although in a much more clever way that I had intended.
Intended optimal strategy
Interpret the players' impartiality in such a way, that when they have to give an advantage to one of their opponents, they'll choose either opponent with a 50% probability.
Then, for every possible number of candies, plot the best strategy for the player whose turn it is:
1: you lose
2: next player loses
3: you are the kingmaker (you win, and choose the other winner)
4: (ditto)
7: never happens, automatic loss for the player who left it
8: next player is kingmaker (this is bad for you.)
9: kingmaker-maker (you choose the kingmaker, but it won't be you, so also bad)
10: always leave 9 (50% chance of getting to be the kingmaker)
11: leave 10 or 9 (you are the kingmaker-maker-maker, or km^3:
you choose, which of the other players is the kingmaker-maker)
12: (ditto)
15: never happens: the person leaving it automatically becomes the kingmaker-maker,
16: next player is the km^3. This is bad for you.
17: you are km^4. (You choose the km^3, but it won't be you. This is bad.)
18: always leave 17. (50% chance of getting to be km^3)
19: leave 17 or 18 (You are the km^5. This is good.)
23: never happens: the person leaving it automatically becomes the km^4
24: next player is km^5 (bad)
25: km^6 (bad)
26: leave 25 (50% for km^5)
27: km^7 (good)
31: never happens (bad)
39: never happens
40: next player is km^9
So there is a repeating pattern all the way from the beginning:
1 "bad" number (lose outright, or forced to choose whom to give the advantage, "even-powered kingmaker")
1 "good, but forced" number (either you or the player before you gets an advantage)
4 "just plain good" numbers (choose a player who gets the disadvantage, "odd-powered kingmaker")
1 "impossible" number (automatically very bad for the previous player)
1 "unwanted" number (also bad for the previous player, so won't be chosen unless there are only equally bad (or worse) options)
Since each repetition of the pattern exponentially diminishes the advantage gained from being the odd-powered kingmaker, at 40 candies it's almost all the same what to do. But since it does give a tiny advantage, Barry should choose to go second in this game.
Should you want to out exactly how (in)significant this advantage is, we can list the winning probabilities for each player. To construct the next row in the list, choose among the five previous rows the one(s) that has the biggest number in the right hand column. Rotate the numbers one spot to the right to get the numbers for the new row. If there are more than one possible row to choose from, pick one row that favours one opponent, and one row that favours the other, rotate both, and average their values.
N: best strategy | winning probabilities, in 1/512 parts
1: take 1 | (0, 512, 512)
2: take 1 | (512, 0, 512)
3: take 1 or 2 | (512, 256, 256) = avg((512, 0, 512), (512, 512, 0))
4: take 2 or 3 | ditto
7: take 5 | (512, 512, 0)
8: take 2-5 | (256, 512, 256)
9: take 1 or 3-5 | (256, 384, 384) = avg((256, 512, 256), (256, 256, 512))
10: take 1 | (384, 256, 384)
11: take 1 or 2 | (384, 320, 320) = avg((384, 256, 384), (384, 384, 256))
12: take 2 or 3 | ditto
16: take 2-5 | (320, 384, 320)
17: take 1 or 3-5 | (320, 352, 352) (avg)
19: take 1 or 2 | (352, 336, 336) (avg)
It's pretty easy to see that the winning probabilities all tend towards 2/3 for each player. At 40 candies, there's still a little bit of imbalance left, so that out of 512 games, the player that goes second is expected to gain one more win than the others. In terms of winning percentage, the second player wins with about 66.8% probability, while the others only win with 66.6%, or in other words, there's a gain of about one fifth of a percentage point.
$\begingroup$ I think your interpretation of the rules is more natural and leads to a more interesting problem. I also get the km^n situation, though I do not think I would have arrived at that simplification even if I had correctly interpreted the rules. $\endgroup$ – Mike Earnest Aug 17 '18 at 15:27
Not the answer you're looking for? Browse other questions tagged strategy game game-theory nim or ask your own question.
A Very Odd Game
Left coin, right coin, last coin?
Dim - A Game with Pebbles
eXtreme Nim: A Game With *Lots* of Pebbles
Generalisation of Nim
Obtain the "Master of stones" title
Paper, pencil and a bunch of bars
Another variation of the game of Nim
A pile of chips involving primes
A pile of chips involving powers of 2 | CommonCrawl |
The projectile motion of a particle of mass 5 g is shown in the figure.
The initial velocity of the particle is $$5\sqrt 2 $$ ms-1 and the air resistance is assumed to be negligible. The magnitude of the change in momentum between the points A and B is x $$\times$$ 10-2 kgms-1. The value of x, to the nearest integer, is __________.
A ball of mass 10 kg moving with a velocity 10$$\sqrt 3 $$ m/s along the x-axis, hits another ball of mass 20 kg which is at rest. After the collision, first ball comes to rest while the second ball disintegrates into two equal pieces. One piece starts moving along y-axis with a speed of 10 m/s. The second piece starts moving at an angle of 30$$^\circ$$ with respect to the x-axis. The velocity of the ball moving at 30$$^\circ$$ with x-axis is x m/s. The configuration of pieces after collision is shown in the figure below. The value of x to the nearest integer is ____________.
The disc of mass M with uniform surface mass density $$\sigma$$ is shown in the figure. The centre of mass of the quarter disc (the shaded area) is at the position $${x \over 3}{a \over \pi },{x \over 3}{a \over \pi }$$ where x is _____________. (Round off to the Nearest Integer).
[a is an area as shown in the figure]
A force $$\overrightarrow F $$ = $${4\widehat i + 3t\widehat j + 4\widehat k}$$ is applied on an intersection point of x = 2 plane and x-axis. The magnitude of torque of this force about a point (2, 3, 4) is ___________. (Round off to the Nearest Integer)
Questions Asked from Center of Mass and Collision (Numerical)
JEE Main 2022 (Online) 28th July Evening Shift (1) JEE Main 2022 (Online) 28th June Morning Shift (2) JEE Main 2022 (Online) 27th June Evening Shift (1) JEE Main 2022 (Online) 26th June Evening Shift (1) JEE Main 2021 (Online) 27th August Evening Shift (1) JEE Main 2021 (Online) 26th August Morning Shift (1) JEE Main 2021 (Online) 25th July Morning Shift (1) JEE Main 2021 (Online) 22th July Evening Shift (1) JEE Main 2021 (Online) 20th July Morning Shift (1) JEE Main 2021 (Online) 18th March Evening Shift (1) JEE Main 2021 (Online) 18th March Morning Shift (1) JEE Main 2021 (Online) 17th March Evening Shift (1) JEE Main 2021 (Online) 16th March Evening Shift (1) JEE Main 2021 (Online) 16th March Morning Shift (1) JEE Main 2021 (Online) 25th February Evening Shift (1) JEE Main 2021 (Online) 24th February Evening Shift (1) JEE Main 2021 (Online) 24th February Morning Shift (1) JEE Main 2020 (Online) 6th September Morning Slot (1) JEE Main 2020 (Online) 5th September Evening Slot (1) JEE Main 2020 (Online) 5th September Morning Slot (1) JEE Main 2020 (Online) 2nd September Evening Slot (1) | CommonCrawl |
An isolated object can rotate only about its center of mass
Thread starter Adesh
dynamics rotation
Adesh
jbriggs444 said:
An object (a top, a gyroscope, a planet or a galaxy) can rotate without any external force being applied. Its parts change velocity, but its center of mass does not.
So, it's parts do need some external force? Because their velocity is changing.
Adesh said:
If it is exerted by other parts then it is not external to the body.
Likes vanhees71 and Adesh
vanhees71
No, obviously not. All I say is if I have a vector as a function of time and a basis (in the theory of a rigid body the space-fixed basis) which is time independent and another basis which is time-dependent (in the theory of a rigid body the body-fixed basis) you have
$$\vec{a}(t)=a_j(t) \vec{e}_j=a_j'(t) \vec{e}_j'(t)$$
and thus
$$\dot{\vec{a}}(t)=\dot{a}_j(t) \vec{e}_j = \dot{a}_j'(t) \vec{e}_j'(t) + a_j'(t) \dot{\vec{e}}_j'(t).$$
Of course you can expand any vector wrt. the basis ##\vec{e}_j'##, i.e., you can define coefficients ##\gamma_{kj}'## such that
$$\dot{\vec{e}}'_j(t)=\vec{e}_k'(t) \gamma_{kj}'(t),$$
Then you have
$$\dot{\vec{a}}(t)=[\dot{a}_k'(t) + a_j'(t) \gamma_{kj}(t)] \vec{e}_k'(t).$$
In the case of the rigid body you have
$$\vec{e}_j'(t)=\vec{e}_k D_{kj}(t)$$
with ##\hat{D}(t)=(D_{kj}(t)) \in \mathrm{SO}(3)## and thus
$$\vec{e}_j'(t)=\vec{e}_k \dot{D}_{kj}(t) = \vec{e}_l' D_{kl}(t) \dot{D}_{kj}(t),$$
where I've used ##\hat{D}^{-1} = \hat{D}^{\text{T}}##.
From this it also follows that
$$\gamma_{lj}'(t)=D_{kl}(t) \dot{D}_{kj}(t)$$
is antisymmetric, i.e., ##\gamma_{lj}'(t)=-\gamma_{jl}'(t)##, and one can thus set in this case
$$\gamma_{kj}'=\epsilon_{jkl} \omega_l'$$
and from that
$$\dot{\vec{a}}(t) = [\dot{a}_k'(t) + \epsilon_{jkl} \omega_l'(t) a_j'(t)] \vec{e}_k'(t) = [\dot{a}_k' + \epsilon_{klj} \omega_l'(t) a_{j}'(t).$$
If you now define ##\underline{a}=(a_1,a_2,a_3)^{\text{T}}## and ##\underline{a}'=(a_1',a_2',a_3')^{\text{T}}## you have with the notation
$$\dot{\vec{a}}(t)=:\vec{e}_k' \mathrm{D}_t a_k'(t)$$
in terms of the column vectors
$$\mathrm{D}_t \underline{a}'(t)=\dot{\underline{a}}'(t) + \underline{\omega}' \times \underline{a}'(t).$$
Admittedly my notation using the symbol ##\vec{a}## and ##\vec{a}'## is a bit misleading. One should distinguish the invariant objects (in this posting I used the "arrow notation" for those) with the column-vector notation with components of these objects wrt. to a different basis (in this posting I used underlined symbols for that).
For a body that is freely moving, these forces are internal forces (interactions) within a closed system. In this case all 10 conservation laws hold for the rigid body, which is an effective description of an interacting many-body systems. The interactions are "hidden" in the constraints you assume by modelling the body as rigid.
It's even true for free fall in the homogeneous gravitational field of the Earth! In this case the freely falling reference frame is an inertial frame (it's the Newtonian form of the weak equivalence principle).
In real gravitational fields you have tidal forces in addition and thus the freely falling frame is not an exact inertial frame.
vanhees71 said:
How internal forces are caused? Any example of such a situation would help a lot.
The forces holding a solid body together are due to the electromagnetic interaction among the charged atomic nuclei and electrons. Note, however, that one cannot describe this microscopic detail without quantum mechanics. One can use quantum-many-body theory to derive the effective classical laws describing the body.
jbriggs444
An internal force is, in principle, no different from an external force. The only difference is where you have drawn the imaginary boundary between what is considered inside the system and what is considered outside.
An internal force is a force from one entity inside the system acting on another entitity inside the system.
An external force is a force from outside the system acting on an entity inside the system.
If you have two skaters on the rink, facing each other, holding both of each other's hands and spinning together, the force of the hands of each skater on the other are internal forces. [Here I am considering the two skaters and their clothing as being inside the system and everything else as being outside].
Meanwhile, gravity and the supporting force from the rink on the blades of their skates are external forces.
If I were to change my mind and consider a system consisting of one skater alone, the force on that skater's hands from the other skater would now be an external force.
Likes Adesh
But in that skater exmaple if two skaters are accelerating then also torque is zero (because all forces are internal) but we do have the change in angular momentum. Please clarify my doubt.
We do not have a change in angular momentum. Their angular momentum is non-zero and remains non-zero.
If you want to talk about how two skaters who started at rest came to be spinning together then we could talk about the external torque that allowed for such to happen. But that is not the scenario at hand. We have two skaters already in motion and remaining in motion.
I meant if I and my friend are holding each other's hand and are rotating (consider we are in motion already, we didn't begin from rest) and now if we try rotating each other a little fastly, won't our angular velocity gonna increase?
Please specify exactly how you are going to increase your partner's angular momentum without reducing your own.
Yes, there is a technique that you can use to increase your angular velocity using internal forces -- you pull your partner toward yourself. But there is no technique that allows you to increase your angular momentum using only internal forces.
Yes, there is a technique that you can use to increase your angular velocity using internal forces. But there is no technique that allows you to increase your angular momentum using only internal forces.
Yes, I have completely understood you. Now, please explain that main question to me.
I do not understand. What do you want explained? What is the "main question" in your mind?
How can an isolated body only rotate about its CM? What restricts it to rotate about any other point ?
That is mostly a question of semantics and not of physics. The relevant physics is covered in post #2.
The semantics: What do you mean when you say that an object rotates about a point? Is that point itself allowed to move over time? In what ways?
Translational Equilibrium has been established. That is the point about which rotation is caused doesn't displace with time.
Lnewqban
@Lnewqban I think rotation involves continuous change of direction (if speed is to be kept constant) i.e. the velocity does change. But you and @jbriggs444 have asserted that no external force is needed for a rotation in isolation. I think I'm missing something.
Going back to your small cube inside that field of parallel lines of force (continuos distribution):
It could be rotating, but that rotation would not be caused by the forces of that imaginary homogeneous field.
Some ancient pair of forces initiated that rotation, way back before the little cube entered our field of equal and parallel forces.
Note that such rotation is not accelerated or decelerated, its angular velocity remains constant respect to time (no new forces are applied).
The direction of that rotation could be in any direction, as it is not affected by the new field of forces.
Think of a floating object in the middle of the stream of a slow river.
The object is not initially rotating respect to the non-turbulent stream.
Then, one side of the object hits a steady rock that is protruding above the surface.
The force of friction with the rock on one side plus the flow of the stream on the opposite side create a pair of forces that induce a rotation.
That rotation would be accelerated only during the time the object and the rock are in contact.
After that moment, the rotation will have a more or less constant angular velocity (with enough time, the actual viscosity friction against the water will slow that rotation until reaching zero angular velocity).
What seems more natural to you: a rotation around an axis that crosses the center of mass of that object or a rotation around an axis tangent to the edge of that object?
Lnewqban said:
About center of mass
@Lnewqban Why it seems natural to me?
OK. So we have adopted a frame of reference where the center of rotation (if any) is stationary and remains so.
If the center of mass is not at the center of rotation, that means that the center of mass is circling the center of rotation, right? Which means that the center of mass is accelerating, right? And what do we know about the acceleration of the center of mass in the absence of external forces?
Edit: Since you have chosen this particular notion of rotation about a point, I will refrain from trying to introduce the notion of an instantaneous center of rotation for an object whose center of mass is moving.
I would say because it is the way it happens in nature in a consistent way.
No matter how you throw a Frisbee disc, a boomerang or a baseball; if they are spinning when leaving your hand, you cannot make them rotate around any axis that is far away from the center of mass.
I would say that the greater the angular momentum, the greater the tendency to spin around the CM would be.
Likes jbriggs444
I got you, thank you so much.
Related Threads on An isolated object can rotate only about its center of mass
Body rotating about its center of mass
Rotation about center of mass
Rotation about the Center of Mass
Does a floating object always rotate about its centre of mass?
Does every object rotate around its center of gravity?
Can a wave rotate about its axis?
Rotation about the center of mass and spin angular momentum
Rotation around center of mass
Rotation of Object around it's centre of mass
Rotation around center of mass question
I An interesting question from Veritasium on YouTube
B Question about a simple free body diagram
I Car acceleration if resistance forces don't exist
B Gravitational Force acting on a massless body
I A Question About Shock Waves From an Airplane | CommonCrawl |
Wound area measurement with 3D transformation and smartphone images
Chunhui Liu1,2 na1,
Xingyu Fan3 na1,
Zhizhi Guo1,
Zhongjun Mo5,
Eric I-Chao Chang4 &
Yan Xu1,4
Quantitative areas is of great measurement of wound significance in clinical trials, wound pathological analysis, and daily patient care. 2D methods cannot solve the problems caused by human body curvatures and different camera shooting angles. Our objective is to simply collect wound areas, accurately measure wound areas and overcome the shortcomings of 2D methods.
We propose a method with 3D transformation to measure wound area on a human body surface, which combines structure from motion (SFM), least squares conformal mapping (LSCM), and image segmentation. The method captures 2D images of wound, which is surrounded by adhesive tape scale next to it, by smartphone and implements 3D reconstruction from the images based on SFM. Then it uses LSCM to unwrap the UV map of the 3D model. In the end, it utilizes image segmentation by interactive method for wound extraction and measurement. Our system yields state-of-the-art results on a dataset of 118 wounds on 54 patients, and performs with an accuracy of 0.97. The Pearson correlation, standardized regression coefficient and adjusted R square of our method are 0.999, 0.895 and 0.998 respectively.
A smartphone is used to capture wound images, which lowers costs, lessens dependence on hardware, and avoids the risk of infection. The quantitative calculation of the 3D wound area is realized, solving the challenges that 2D methods cannot and achieving a good accuracy.
The measurement of wounds is an important component in the field of clinical research, the accuracy of which influences doctors' diagnosis, treatment and research programs directly [1, 2]. In the clinical field, the wound area is considered as an effective and reliable index of later complete wound closure [3]. It also plays a role in drug evaluation and research of wound healing characteristics [4]. Moreover, it can help doctors with wound classification, treatment strategy selection, and propelling the treatment technology forward [3]. Cardinal M et al. [3] show it is a strong predictor of venous leg ulcers healing by tracking the area of a skin wound within 12 weeks. Lavery LA et al. [1] show that the diabetic foot wound area between the first and fourth week can be used to predict the healing effect after 16 weeks, and to assist with the evaluation of treatment and drug use.
The wound measurement method has undergone a transition from 1D to 2D, and then 2D to 3D. The traditional 1D ruler method [5] for measuring wound areas is simple and widely used. It measures the external rectangular of wound width by ruler, flexible rule, or adhesive ruler, and then multiples the wound's external rectangular width to obtain the wound area. Rahul S et al. [6] show that the measurement result of the ruler method is nearly 150% of the actual area, which is very inaccurate, and it is tedious and time-consuming. The 2D method based on image segmentation [7] is a mature method. It uses a 2D image segmentation and adhesive scale to measure wound areas. Yang [8] have developed a wound surface area calculation method using digital photography, and they investigate its error rate. However, this kind of method has drawbacks such as: (1) Given the existence of human body curvatures, a 2D method is difficult to express in the whole shape of a wound, so as to get the correct area value. (2) The 2D method can be greatly affected by camera angle, and the use of different angles may generate different results. Recently, Foltynski [9] have proposed the Planimator app, which was a correction method of area measurement based on calculated camera tilt angle and the calculation of calibration coefficient of linear dimensions as the weighted average. It overcomes the large error caused by the shooting angle in the 2D measurement, but it still cannot overcome the 2D measurement problem caused by the large body curvature. Meanwhile, when disposable paper rulers are used for area measurement with the Planimator app, some deviations from the true area value may occur when the ticks at these rulers are placed at the wrong distances. On the theoretical level, Zhang B [10] proposes a stereo vision 3D method to measure wound areas, but he does not implement it. Sirazitdinova et al. [11] present a conceptual design of a system using inexpensive consumer level hardware for 3D wound reconstruction. Images are recorded using the interactive app running on the mobile device. The data is transferred to the operational server and processed on it. The resulting data can be shown to the patient and to the clinician. They provide a convenient wound measurement solution that allows patients to receive professional guidance on their injuries at home. However, at present, this is only a conceptual stage and has not been implemented. Further experiments are needed to prove the effectiveness of this scheme. Chen et al. [12] present an efficient and effective 3D surface reconstruction framework for an intra-operative monocular laparoscopic scene based on SLAM. The 3D geometric information of the surgical scene allows accurate placement AR augmentations based on 3D calibration. However, their method is a 3D reconstruction of endoscopic surgery, which does not meet our application scenarios. SLAM is more suitable for objects with rich geometric texture. It is easy to lose frames when rotating, and the point cloud in the map is also very sparse. Therefore, it is not practical for scenes that need to accurately measure the wound area. Huang [13] present a new solution to surface area measurement of vitiligo lesions by incorporating a depth camera and image processing algorithms. They use Kinect V1 or Kinect V2 to capture data. Then the segmented lesion area is calculated using depth data through a software component. Their solution shows good performance in the smooth part of the human body. However, if a huge block of the depth image is missing depth information, the accuracy of area measurement will be compromised.
In recent years, the resolution of smartphone cameras has been getting higher and higher, and now it can reach tens of millions of resolutions, which is enough for most photo-taking scenes. Early smartphone image technology focuses on how to present sharper picture quality. With the development of camera hardware and the universality of smartphones in people's daily lives, the development of smartphone image technology is shifting to focus on how to use images more effectively. Masiero A et al. [14] have developed a mobile mapping system (MMS) using smartphones, enabling low-cost devices to build reliable MMS. Gatys LA et al. [15] introduce an artistic neural algorithm, combining images taken by smartphone with many famous art works. Liu S et al. [16] propose a method to automatically track facial markers using smartphones. This work inspires us to use the images acquired by smartphone to establish a 3D model of body surface wounds.
The structure from motion method (SFM) has been actively researched by scholars. By analyzing the motion of the object, it can obtain 3D information from 2D images. Since its request of images is very low, SFM can use images taken at random sequences for 3D reconstruction. At the same time, it can save on camera calibration steps in advance, and it has strong robustness. This inspires us to use SFM to implement 3D reconstruction of the body surface, and then to calculate the wound area.
In this paper, we propose a 3D wound area measurement with smartphone images. The method goes through the process of 2D to 3D to 2D. The definition of 2D to 3D to 2D is as follows: first, we collect 2D images of tested bodies by smartphone, and construct a 3D model using these 2D images; second, we unwrap the UV (Texture coordinates usually have U and V coordinate axes, so called UV coordinates.) map of the 3D model to make it into the 2D plane; finally, we use interactive image segmentation and scale conversion to extract and measure wound areas. The flow of our method is shown in Fig. 1.
The flow of our method
Our method provides a complete set of methods for measuring wound area. Since the 3D reconstruction method based on 2D images is adopted, it avoids the situation of frame loss in SLAM real-time reconstruction, making the whole method more practical. At the same time, we convert the 3D model to the 2D plane by LSCM algorithm, and then measure the wound area through the conversion between pixels and real length, which solves the challenge of directly segmenting the wound on the reconstructed 3D model. Moreover, we have verified the accuracy, practicability and effectiveness of this method through clinical experiments.
The contribution of our work is as follows:
The smartphone makes it very convenient and quick to capture images of wounded body parts. Our method avoids wound infection, and its sampling is simple and has limited device dependence.
We process a novelty pipeline of 2D to 3D to 2D procedure. It overcomes the difficulties of shooting angles, human body curvature, and disabled 3D segmentation.
We demonstrate the efficiency and effectiveness of our method by calculating wound areas.
Since 3D reconstruction and 3D unwrapping are very important processes in our work, the related work can be divided into three broad categories: (1) wound measurement equipment, (2) 3D reconstruction methods and (3) 3D unwrapping methods.
Wound measurement equipment
The Visitrak [17] is an electronic device that manually tracks wound boundaries for wound measurements. Users first use the film coverage method to draw out wound borders and then put the film in a Visitrak transparent plate. A pen is used to draw borders in the device interface, and the area value of the wound is automatically calculated with the equipment using the Kundin formula [18]. It can cause pain and risk wound infection, even as it reaches 93% accuracy [19].
The MAVIS [20] uses the color coding principle to realize 3D measurement. It uses a CCD camera to record a set of alternate colors, which is projected onto the wound at about 45 degrees. Then according to the calibrated camera focus, a known location projector and the light intersection of the beam, the geometry of the wound surface is rebuilt to calculate the area. However, the MAVIS is large and expensive, which is difficult to widely use in clinical scenarios. At the same time, in the wound area <10cm2, the MAVIS error is above 10%.
The Silhouette mobile [21] includes a hand-held computer and an integrated high-resolution digital camera with an embedded laser. The laser launches two beams of light on the edge of the wound, then the Silhouette mobile generates the wound in a 3D model based on the surface topography. The Silhouette mobile can reach 95% accuracy for diabetic foot wounds. However, this expensive Silhouette mobile cannot be applied to telemedicine, and it needs to collect data through a visible laser.
3D reconstruction methods
The stereoscopic light method takes multiple photos at the same angle and under different lighting conditions to reconstruct a 3D model. The simplest stereoscopic light method uses three light sources to illuminate the object in three different directions, opening only one light source at a time. It uses three comprehensive photos and the perfect diffuse to work out the gradient on the surface of the object. Then the 3D model is obtained after integrating the vector field. Basri R et al. [22] realize 3D reconstruction under the unknown condition of light source. Hernandez C et al. [23] further propose the use of colored light for reconstruction. However, the stereoscopic light method needs to know the exact location and direction of the light source, so it is difficult to apply in real life.
The stereo vision method [24] is another commonly-used 3D reconstruction method. In concept, this method simulates human eyes to perceive images. It mainly includes three ways of obtaining distance information: directly using the rangefinder, predicting 3D information through a single image, and restoring 3D information by using two or more images on different viewpoints. By simulating the human visual system, it obtains the position deviation between the corresponding points of the image based on the parallax principle, and recovers 3D information.
SFM is used to detect matching feature points in an image in order to restore the position relation between the cameras. Harris C et al. [25] propose the definition of the corner point, and Shi J et al. [26] improve on this and propose a better angle extraction method. The state-of-the-art method of extracting and matching feature points is the scale-invariant feature transform method (SIFT) [27]. Besides the SIFT method, researchers have also proposed some faster methods, such as principal component analysis scale-invariant feature transform (PCA-SIFT) [28], gradient location-orientation histogram (GLOH) [29], and speed up robust features (SURF) [30]. These proposed algorithms are faster than the SIFT method in terms of speed, but weaker in terms of both stability and accuracy. Therefore, the SIFT method is still the best option when there is not much requirement for computing speed. The image demand for SFM is very low, so it can reconstruct a 3D model using video or even randomly shot image sequences. At the same time, the image sequence can be used for camera self-calibration eliminating predetermined steps.
3D unwrapping methods
A heuristic method for triangulation flattening is proposed by McCartney J et al. [31]. It uses a triangle list to describe the 3D surface flattening algorithm for 3D unwrapping. The method is based on an optimal local positioning of projected nodes and a sequential addition of the nodes. It incorporates an energy model in terms of the strain energy required to deform the edges of the triangular mesh. It is efficient and produces good results for nearly planar surfaces. However, the method does not guarantee the preservation of the metric structure of the 2D mesh or even its validity.
Eck et al. [32] suggest the use of harmonic maps to generate the 2D projection of the 3D model. It is based on the approximation of an arbitrary initial mesh by a mesh that has subdivision connectivity and is guaranteed to be within a specified tolerance. The method produces approximations of good quality, and provides an accurate mapping function. A major disadvantage of the method is that it requires the boundary of the 2D mesh to be predefined and convex. Another drawback is that the method does not guarantee the validity of the resulting flat mesh, and the method requires the boundary of the 2D mesh domain to be predefined and convex.
The least squares conformal mapping method (LSCM) [33] is a method from polygon mesh to texture mapping, which can map the shape of a 3D model to a 2D texture and is relatively undistorted. The method is robust, and can parameterize large charts with complex borders. It introduces segmentation methods to decompose the model into charts with natural shapes, and a new packing algorithm to gather them in the texture space. By using the map as a guide when creating a new 2D image, the colors of the 2D image can be applied to the original 3D model.
Comparison with the stereo vision method
An example of 3D reconstruction results is shown in Fig. 2. For the wound part based on stereo vision reconstruction, only the fuzzy shape of the wound can be seen. Even the shape of the part cannot be seen clearly, and the wound area cannot be calculated through it. However, for the wound part based on SFM reconstruction, the wound shape can be clearly seen, and its area can be calculated through our method.
3D reconstruction comparatione of simulated wounds. a Images captured by smartphone. b Ground truths. c Looks of 2D method. d 3D model by stereo vision. e 3D model by ours. f Calculated results of our method. The calculated results of stereo vision is unavailable, so we have to make the results empty here
SFM obtains the depth information of an object by building the relationship among natural image sequence. It then reconstructs a 3D model of the wound. Compared to other common methods like the stereoscopic light method and the stereo vision method, this method does not require pre-calibration [24] or a special environment [20]. It is a good method of reconstruction in the field of computer vision.
The feature match results play a vital role in building the relationship of natural image sequence. We use SIFT characteristics [27] to match features. Compared to the traditional Harris [34] and KLT characteristics [35], it has immutability towards rotation, scale-zooming, and brightness variation, as well as stability towards visual angle, affine, and noise variation.
Comparison with 2D measurement
The experiment results of our method are compared with the 2D measurement result to evaluate the accuracy of our method. The example of area calculation results in our methods are as shown in Fig. 3. The results for the wound area are calculated using our method and the 2D method, with real values shown in Table 1. And the statistical index of Pearson correlation, standardized regression coefficient and adjusted R square are listed in Table 2. The 2D measurement values and the measured values of our method are compared in the line chart, as shown in Fig. 4. The regression curve of 2D method and ours are shown in Figs. 5 and 6 respectively. And the Bland-Altman plot of the 2D method and ours are shown in Figs. 7 and 8. The distribution of relative measurement error (relative error) and absolute value of relative error of both methods are shown in Figs. 9 and 10. The box-plot of relative measurement error of both methods is shown in Fig. 11.
Clinical experience result. a Images captured by smart-phone. b Ground truths. c Results of feature matching. d 3D reconstruction results by SFM. e Results of networking. f Results of unwrapped images (2D). g Calculated results of our method
The line chart of ground truth, 2D measurement and our measurement
Regression analysis plot of 2D method
Regression analysis plot of our method
Bland-Altman plot of 2D method
Bland-Altman plot of our method
Distributions of relative measurement error
Distributions of absolute value of relative error
Box-plot of relative measurement error
Table 1 Area calculation and error rate comparison of 2D system and our method (RA = real area, AC = area calculation, AE = absolute value of relative error, MAPE = mean absolute percent error, var = variance)
Table 2 The statistical index of 2D method and our method
From these results the measurements of the 2D method are not ideal for areas with large body curvatures. The average error rate for the 2D method is 18.40%, while the average error rate for our method is only 2.94%. In the case of less than 1cm2, the average error rate for the 2D method is 19.40%, and the average error rate for this method is 3.66%. In the case of 1cm2 and above, the average error rate for the 2D method is 17.80%, and for our method it is 2.51%.
A Mann-Whitney U test was run to determine if there were differences in relative measurement error and in absolute value of relative error between 2D method and our method. As can be seen from Figs. 9 and 10, distributions of the relative measurement error and absolute value of relative error for 2D and ours were not similar, as assessed by visual inspection. Relative measurement error for 2D and ours were statistically significantly different, U = 5668.5, z = -2.467, p = 0.014 <0.05, using an asymptotic sampling distribution for U. And absolute value of relative error for 2D and ours were statistically significantly different as well, U = 1753.5.5, z = -9.932, p = 0.000 <0.05, using an asymptotic sampling distribution for U.
As can be seen from Fig. 11, the 2D method has 4 significant outlier while ours only have one. The sample outliers of our method are also outliers of the 2D method (no.112), and the error is much larger than that of our method. Meanwhile, it can be seen that the relative measurement error of our method is much smaller and more concentrated than that of the 2D method. This shows that our method has not only better accuracy, but also better robustness.
As can be seen from Figs. 7 and 8, the mean difference value of the 2D method is -0.1, the standard deviation of the difference value is 0.714, and the 95% consistency limit is -1.5 to 1.3.Our method had a difference of 0.01, a standard deviation of 0.112, and a 95% consistency margin of -0.21 to 0.23. Only 5 groups of the two methods and true knowledge were outside the consistency limit (5/118=4.24%), and the overall proportion was relatively small. Therefore, it can be considered that the two methods and truth value have good consistency and can be used in clinical practice. However, in terms of the difference mean and the standard deviation of the difference, the 2D method in the upper arm of the difference mean is 10 times smaller, indicating that our method is closer to the truth value. Meanwhile, the standard deviation of our difference is 6 times smaller than that of the 2D method, indicating that the difference stability is also better than that of the 2D method.
It is obvious that our method is better than the 2D method for the measurement results of a large wound, minor wound, and arbitrary shape wound, and the average accuracy rate is above 97%. The variance of the 2D method is 0.0254, while the variance of our method is only 0.0004, meaning the wound area size and shape are less of a factor for our method.
In the measurement of skin wounds, the aim of quantitative measurement is to extract the wound area from the 3D model and calculate it accurately. We use the 2D to 3D to 2D method to complete the measurement. It not only overcomes the error caused by the position of the camera and the curvature of the body to the 2D measurement method, but also guarantees the accuracy of the damage area extracted from the 3D model [33]. Therefore, our method is more accurate than the 2D method.
Comparison using different devices and methods
Table 3 compares our method with other commonly used measurement methods, advanced commercial equipment and the state-of-the-art methods in terms of accuracy, need for calibration, risk of infection, and so on with the same dataset.
Table 3 The Comparison of our method, other commonly used methods and business equipments
It can be seen from Table 3 that the accuracy of our method is higher than other methods and devices widely used at present. In addition, our method uses non-contact photography to collect wound images without a complicated pre-calibration process and has no special requirements on light. Meanwhile, the 2D software method needs the photograph angle to be as perpendicular as possible to the wound, and stereo vision may cause matching failure. The MAVIS requires the equipment to be placed at 45 degrees to take a shot. Huang's [13] method still has a large error in parts with a large curvature of human body as well as the Yang's [8]. In contrast, our method is not limited by shooting angle, easy to operate, can be widely applied, and avoids wound infection and pain. Moreover, our method requires only a smartphone with an ordinary PC to complete measurement. It has practical application value and possibilities, and even can be applied to remote medical treatment.
The wound parts acquired from the stereo vision method are fuzzy. The stereo vision method is used to calculate the 3D coordinates of spatial points in projective geometry by means of space ray intersection. This method is relatively loose in camera calibration and correction and reduces the amount of computation. Compared with it, SFM performs better in the reconstruction of the wound 3D model and requires less equipment.
Compared with 1D and 2D measurement methods, the accuracy of our method is high, especially in areas with a large curvature. Compared with the 3D method, the accuracy of this method is the same as that of the commercial equipment while our method does not need calibration. It is harmless and has little dependence on equipment. Wound area measurement can be done using a smartphone and an ordinary computer. Moreover, this method has the potential to be applied to telemedicine. Therefore, the smartphone based 3D wound area quantitative measurement in clinical and forensic applications have great prospects, and is worth further exploration and research.
As for the resolution of the camera, different cameras can bring different results. If the camera resolution is too low, the wound boundary will become very blurred, so that neither interactive segmentation nor automatic segmentation can be completed, and accurate results cannot be obtained by digital methods. Of course, if the resolution is increased, the ability of the image to express the wound itself is also enhanced, which is undoubtedly beneficial to the wound edge segmentation.
At the same time, this method has the possibility of further improvement. First, since 3D reconstruction and interactive segmentation are involved, out method takes about 16 minutes to be completed. And 3D reconstruction based on SFM requires multi-angle image information of wound area for feature point matching and point cloud location calculation. Therefore, the more images, the better the reconstruction effect will be, and the higher the measurement accuracy will be. However, this will lead to a long operation time, and shortening the operation time of 3D reconstruction will be an urgent problem for the method in this paper. Second, although the interactive segmentation method on 2D images can bring excellent segmentation results, it consumes more energy. Due to the characteristics of clinical medicine and forensic medicine, there is still no good automatic segmentation method at present. And if the segmentation result is coarse, it is bound to affect the final result. We consulted with clinical and forensic experts. In practice, because the edge of the wound is different from the border in other pictures, the definition of the wound margins relies on the experience of medical experts. In order to make the segmentation of wound as correct as possible, we used an interactive segmentation method. In the future, deep learning method can be considered to complete the automatic segmentation of the damaged area after a large number of real injury images training, so as to save human workload and improve the measurement accuracy at the same time.
In this paper, we implemented a wound measurement method based on 3D transformation and smartphone images. A smartphone is used to capture wound images, which lowers costs, lessens dependence on hardware, and avoids the risk of infection. The structure from motion method (SFM) and the least square conformal mapping method (LSCM) are introduced into the measurement of the wound area. A quantitative calculation of the 3D wound area is realized, which solving the challenges that 2D methods cannot and achieving a good accuracy of 0.97.
First, based on SFM, the 3D model of a wound is reconstructed by feature extraction, sparse reconstruction, clustering and intensive reconstruction. Then, based on LSCM, the UV of the 3D model is mapped onto a 2D plane. Finally, the interactive image segmentation method and scale conversion method are used to extract and measure the wound areas.
Our method uses a contactless smartphone camera and software processing to complete the body surface wound location from 2D to 3D to 2D. Our method overcomes the defects of traditional methods, which can cause wound infection and face human subjective factors. On the other hand, it solves the problem of human curvature and the problem of shooting angles which cannot be overcome in the 2D measurement method of a computer software system based on the wound image. Moreover, it solves the shortcomings of equipment complexity and equipment dependence in commercial settings.
The main purpose of this paper is to measure the area of a surface wound precisely and quantitatively. We propose a pipeline consisting of 3D reconstruction and model mapping combined with image segmentation for measuring wound area quantitatively. The pipeline consists of three phases: (1) 3D reconstruction of the wound part of the body according to multiple images based on SFM; (2) mapping the 3D model to the 2D plane, using LSCM to do UV unwrapping (texture coordinates usually have two axes of U and V, thus called the UV coordinates); (3) we use the interactive image segmentation method and the scale conversion algorithm to extract and measure the wound area. The flowchart of the whole pipeline is shown in Fig. 12.
A flowchart of the proposed method. The method consists of three phases: 3D reconstruction, UV unwrapping and 2D calculation. (1) In the first phase, multiple images of one object are captured by smart-phone, the features of them are extracted and matched through SIFT. Then the 3D model of the object is reconstructed based on SFM, and goes through the process of sparse & dense reconstruction and networking. (2) In the second phase, the UV of the 3D model is unwrapped to a 2D image based on LSCM. (3) In the lase phase, the wound area on the 2D image is extracted and calculated
3D reconstruction based on SFM
SFM [36] estimates the 3D structure from a sequence of 2D images. It first determines the spatial and geometric relationship of the target by moving the camera. It then uses the numerical method to recover 3D information by detecting the matching feature point set in multiple uncalibrated images. The schematic diagram of SFM is shown in Fig. 13. SFM extracts feature points from adjacent multiple images at different times, and establishes corresponding relationships. Then we calculate the structure and motion of the object, and generate the reconstruction of the 3D model of the sparse point cloud.
Schematic diagram of SFM. A target point P1(x,y,z) in the space passes through the horizontal, vertical, and rotational motions to point P2(x∣,y∣,z∣), point (X,Y) and, (X∣,Y∣) respectively represent the imaging point in a 2D plan for P1(x,y,z) and P2(x∣,y∣,z∣)
The overall block diagram of 3D reconstruction based on structure from motion is shown in Fig. 14. We start by extracting image features using SIFT, which searches all image locations on the scale, and then uses the Gaussian differential function to identify potential interest points for scale and rotation invariance. The standard space of an image is defined as the function L(x,y,σ). It is usually given by the convolution of G(x,y,σ) with the input image I(x,y) of a sigma variable. The calculation formula is as follows:
$$\begin{array}{@{}rcl@{}} L(x,y, \sigma)=G(x,y, \sigma)*I(x,y), \end{array} $$
Block diagram of 3D reconstruction based on SFM. The block diagram shows the main process of 3D reconstruction. Visualization process diagrams are provided at some steps
$$\begin{array}{@{}rcl@{}} G(x,y, \sigma)= \frac{1}{2\pi\sigma^{2}}e^{\frac{-\left(x^{2}+y^{2}\right)}{2\sigma^{2}}}, \end{array} $$
Where, σ is the scale, ∗ is the convolution operation. In each candidate position, the location and scale are determined by a fitting model. We use the DOG function D(x,y,σ) to find out the most stable key points in the scale space. The function D(x,y,σ) can be evaluated on two adjacent scales. The formula is:
$$\begin{array}{@{}rcl@{}} D(x,y, \sigma)=(G(x,y, k\sigma)-G(x,y, \sigma))*I(x,y), \end{array} $$
Where, k is a constant factor between these two scales, ∗ is the convolution operation. Based on the gradient direction of the image, each key point is assigned one or more directions. The scale of key points is used to select the Gaussian smooth image I with the closest scale, so that all calculations are carried out in a scale-invariant way. In this scale σ, for every graph sample I(x,y), the gradient size m(x,y) and direction (x,y) is precomputed in terms of pixel differences. We have chosen the histogram of the scale in which the key points are located and its statistical radius is 3 ×1.5 σ. The calculation formula of gradient size and direction is as follows:
$$\begin{array}{@{}rcl@{}} A=(I(x+1,y)-I(x-1,y)), \end{array} $$
$$\begin{array}{@{}rcl@{}} B=(I(x,y+1)-I(x,y-1)), \end{array} $$
$$\begin{array}{@{}rcl@{}} m(x,y)=\sqrt{A^{2}+B^{2}}, \end{array} $$
$$\begin{array}{@{}rcl@{}} \theta(x,y)={tan}^{-1}\left(\frac{B}{A}\right), \end{array} $$
All subsequent operations on the image data are transformed by the direction, scale, and location of key points, in order to provide invariance to these transformations.
The characteristics of the images are matched according to the feature point set extracted from all relevant images. In feature matching between two images, considering image I and J are the two images, there may be a feature in image I corresponding to two characteristics in image J. In order to solve the above problems, we use F matrix and the random sampling consistency algorithm (RANSAC) [37] to optimize and filter the results after initial matching. The F matrix can associate the pixel coordinates between two images, and the pixel coordinates of each matched pair of features should be satisfied:
$$\begin{array}{@{}rcl@{}} \left[\begin{array}{lll} x^{\shortmid}&y^{\shortmid}&1 \end{array}\right] F \left[ \begin{array}{l} x\\ y\\ 1 \end{array} \right], \end{array} $$
F is the basic matrix, (X,Y), and (X∣,Y∣) are the pixel coordinates of the feature points corresponding to two images, respectively.
Then, according to the matching results, the 3D reconstruction module uses SFM [38] for sparse reconstruction.
After sparse reconstruction, the collected images are clustered using clustering multi-view stereo (CMVS) [39]. CMVS can optimize the input of SFM and reduce the time and space cost of intensive matching. Then, through the patch-based multi-view stereo (PMVS) [40], each image cluster is reconstructed independently. Finally, using the Poisson surface reconstruction algorithm [41], the points are connected and networked. In this way, we set the information of the input point as a surface information model composed of a seamless triangular face, which constructs a 3D model according to the 3D point cloud.
3D unwrap based on LSCM
The segmentation of a 3D model is based on two kinds of 3D models: one is the analogy of existing models [42], and the other is models from software modeling [43]. It is difficult to segment a precise local area of the model from 3D reconstruction. In order to guarantee accuracy of wound area segmentation, we adopt LSCM [33] to unwrap the surface of a 3D model onto a 2D plane. The block diagram of 3D unwrapping is shown in Fig. 15.
Block diagram of 3D unwrapping. The block diagram shows the main process of 3D unwrapping, and the visualization process diagrams are provided at some steps
The conformal mapping, or conformal equivalence [44], defines a one-to-one mapping between two surfaces that preserves the local angle and local similarity. Mathematically, the conformal mapping is defined as follows: when the mapping U maps a domain (u,v) to a surface U(u,v), each (u,v) satisfies:
$$\begin{array}{@{}rcl@{}} N(u,v) \frac{\partial U(u,v)}{\partial u}= \frac{\partial U(u,v)}{\partial v}, \end{array} $$
The conformal mapping is defined on the Riemann surface. In formula (9), N(u,v) is the unit norm vector on the surface U(u,v).
LSCM [33] is a new quasi-conformal parameterization method based on a least-square approximation of the Cauchy-Riemann equations. The schematic diagram of LSCM is shown in Fig. 16. Consider a triangulation mesh K=(V,T), where V={v1,v2,...,vn},vi is a set of vertex positions, and T={t1,t2,...,tm},ti={vi1,vi2,vi3} is a set of triangles consisting of triples of vertices, with i1,i2, and i3 denoting the vertical index in V. Since each triangle ti has a uniquely defined norm, ti can be imposed on a local orthonormal basis (x,y) with the normal direction along the z-axis.
Schematic diagram of LSCM. V and V∣represent T and T∣ respectively in a 2D plane. U1,U2,U3,U4 are respectively the fixed points V1,V2,V3,V4 of the triangular section of the 3D model
Consider a triangulation mesh K=(V,T), where V={v1,v2,...,vn},vi is a set of vertex positions, and T={t1,t2,...,tm},ti={vi1,vi2,vi3} is a set of triangles consisting of triples of vertices, with i1,i2, and i3 denoting the vertical index in V. Since each triangle ti has a uniquely defined norm, ti can be imposed on a local orthonormal basis (x,y) with the normal direction along the Z-axis.
Based on the Riemann equation, a mapping U:(x,y)→(u,v) is said to be conformal on a triangle ti if and only if the following equation holds true:
$$\begin{array}{@{}rcl@{}} \frac{\partial U}{\partial x}+i \frac{\partial U}{\partial y}=0, \end{array} $$
As formula (9) cannot be strictly enforced on the whole surface, the violation of the equation can be defined as the conformal energy in a square sense:
$$\begin{array}{@{}rcl@{}} \mathrm{E_{\text{LSCM}}} =\sum_{t_{i}\in T}\arrowvert \frac{\partial U}{\partial x}+i \frac{\partial U}{\partial y}\arrowvert^{2}A(t_{i}), \end{array} $$
Where A(ti) is the area of the triangle ti.
By calculating the smallest value of \(\rm {E^{}_{{LSCM}}}\) in formula (11), the planar coordinates (u,v) of the 3D triangle network in the parameter space is obtained, which means the 3D network is expanding in the parameters of a 2D plane.
Wound segmentation and area calculation
The particularity of clinical medicine requires maintaining of the authenticity of image damage. However, due to the different types of light, color and wounds, ensuring accurate segmentation of all images for the automatic segmentation method for 2D images is difficult. Therefore, we use an interactive image segmentation method to artificially modify the image segmentation results and carry out the extraction of the wound area. The wound extraction and calculation process is shown in Fig. 17.
Block diagram of extraction and calculation. The block diagram shows the main process of extraction and calculation of a skin wound. Visualization process diagrams are provided at some steps
We attach two lengths of known adhesive tape to the outside of the damaged area, which form X and Y directions. The user uses the mouse to mark the scale of X and Y in the image, and the system automatically labels the pixel length as \(L^{}_{x}\) and \(L^{}_{y}\), as shown in Fig. 18. We use the scale conversion method according to the ratio of the known length and the pixel length in X, Y direction, using formula (12) to transform the pixel area into the actual area. The measurement length is accurate to 1 mm and the measurement area is accurate to 1 mm2.
$$\begin{array}{@{}rcl@{}} \mathrm{S}_{\text{wound}}= \frac{l^{}_{x}}{L^{}_{x}}\times \frac{l^{}_{y}}{L^{}_{y}}\times \mathrm{S}_{\text{img}}. \end{array} $$
Schematic diagram of area calculation. For the example, the actual lengths \(L^{}_{x}\) and \(L^{}_{y}\) are 5 cm2. The pixel lengths \(L^{}_{x}\) and \(L^{}_{y}\) are automatically recorded by the system
Experiment setup
The experimental operating environment is a 4 core 2.00GHz CPU, 8GB memory computer. The computer visual library OpenCV and Visual Studio 2015 are used to complete the wound area measurement of our method. UV (Texture coordinates usually have U and V coordinate axes, so called UV coordinates.) unwrapping based on LSCM uses Blender open source software.
Simulated wound
Simulated wounds are used to compare the 3D reconstruction method in this paper with the popular stereo vision method. They are obtained by arbitrarily tailoring the coordinate paper. We use scissors to cut out different shapes and sizes on the coordinate paper to simulate the 2D wounds, and the cut is not in accordance with any rule. The process method is shown in Fig. 19.
The production of simulated wound. We use scissors to cut out different shapes and sizes on the coordinate paper to simulate the wounds
The simulated wound of the rectangle and its superposition are the regular wounds, and other shape wounds are irregular wounds. Due to the more realistic significance of irregular wounds, in the experiment, there are 12 regular wounds and 28 irregular wounds. The comparison experiment attaches the simulated wounds to parts of the larger body curvatures like fingers, wrist, arm, ankle, etc.
Real wound
Real wounds are used to verify the accuracy of our method. They are obtained from the mammary department of the Xiyuan Hospital in China. The patients total 54 in number and range in age from 21 to 50, with a total of 118 wounds. The area of the wound ranges from 0.11 to 12.5cm2, with 44 at less than 1cm2 and 74 at 1cm2 and above. We get the wound images at multiple angles using an Iphone6 and the method above. The spatial resolution of the image is 72 dpi ×72 dpi, the color resolution of which is 3264 pixel ×2448 pixel and the bit depth is 24.
The film coverage method is the most accurate measurement in the relative field. The sterile transparent film is covered in the wound area and the shape of the area is depicted artificially. Then the film is put on a coordinate paper. The area is obtained by counting the number artificially. Most researchers in the field of wound measurement use this method as the real value for wound or simulated wound area [17, 45].
The real value of the wound area in this paper is obtained by means of counting done multiple times by multiple people, and then taking the average of the counted numbers. Among them, the coordinate paper on each grid is 1mm2, and each wound is reviewed by at least 3 counters. For an incomplete grid of less than one, we artificially judge whether it is less than half of the area. When it is less than half grid, it is not calculated, otherwise, it is calculated as a whole grid.
The stereo vision method
We use an advanced 3D reconstruction device of stereo vision ZED [46] to set the baseline. ZED equipment is an advanced stereovision camera with stable results. It simulates human body parts with a simulated wound attached to the body parts with larger curvatures. We have conducted three times of parameter pre-calibration, and its mean variance is 0.0008. The pre-calibration parameters in our experiment are as follows: in the left sensor, the fx=1399.17,fy=1399.17,cx=983.48,cy=521.523,k1=−0.17355,k2=0.027811; In the right sensor, fx=1399.49,fy=1399.49,cx=962.345,cy=514.697,k1=−0.17177, and k2=0.026456; the stereo baseline =119.958, the stereo convergence =0.010710, the rx (tilt)=0.008133, the rz (roll)=0.001022. Because the ZED camera can perceive depths between 50cm(1.8feet) and 20meters(65feet), the experiences are taken from distance greater than 50cm. The example of 3D reconstruction results is shown in Fig. 2.
The 2D method
We put the adhesive tape scale next to the wound, forming an XY axis, and then shooting it with the data acquisition device in the vertical direction of the wound. Measurements are taken with close placement of the adhesive tape scale from the wound edges (0.5-1cm). When the wound is in a large part of human curvature, a picture cannot show the whole wound, we consider one wound as two wounds and shoot them vertically respectively. The images are then fed into commercial 2D measurement software, where the edges of the wound are artificially portrayed and the area of the wound is calculated. The 2D software originates from a Chinese judicial identification center, where all the people depicting the wound were doctors, legal medical experts or medical students.
The requirement of data acquisition equipment in our method is low. Any digital camera, smartphone, and other type of camera can be used to capture wound images. The acquisition process is not limited to the left and right movement of the acquisition equipment. It can be shot at any angle, distance, or even the same acquisition device. The device used for acquiring data is the iphone6.
We use the smartphone around the simulated wound for shooting. The angle between the two images is not greater than 30 degrees, and the number of photos is not less than 20. We keep the target fixed during shooting. Then, we use the method to reconstruct a 3D model of the simulated wound.
For real wounds, we use the same method to take images and reconstruct a 3D model, and use our method to unwrap the wound area UV of the 3D model. Users trace the contour points of the whole damage area sequentially along the contour of the damaged area on the 2D image of the wound. The system selects and saves the selected points automatically, and connects each two adjacent points with a straight line. When the whole area is drawn, the system automatically connects the two points at the beginning and end, forming a closed polygon. Result for the whole process are shown in Fig. 20.
Wound area measurement process of a real wound. a The image captured by smart-phone. b The result of feature matching. c The spares reconstruction result. d The dense reconstruction result. e The result of networking. f The reconstructed 3D model. g The result of unwrapped images. h The calculated result of our method
Ruler method
The ruler method is a simple method of wound measurement, and it is also the most used method in clinic. By measuring the length and width of the external rectangular wound with a ruler, a flexible ruler or a self-adhesive ruler, the measurement value of the wound area can be obtained by multiplying the length and width.
Visitrak method
The Visitrak device method is an electronic device that manually tracks the wound boundary for wound measurement. The user first describes the wound boundary with the method of film covering, and then places the film under the Visitrak transparent plate, and draws the boundary in the device interface with a pen. The device automatically calculates the length, width and area value of the wound with the Kundin formula.
BA:
Bundle adjustment
CMVS:
Clustering multi-view stereo
GLOH:
Gradient location-orientation histogram
LSCM:
Least squares conformal mapping
PCA-SIFT:
Principal component analysis scale-invariant feature transform
PMVS:
Patch-based multi-view stereo
SBA:
Sparse bundle adjustment
SFM:
Structure from motion
SIFT:
Scale-invariant feature transform method
Speed up robust features
Lavery LA, Barnes SA, Keith MS, Jr SJ, Armstrong DG. Prediction of healing for postoperative diabetic foot wounds based on early wound area progression. Diabetes Care. 2008; 31(1):26–9.
Coerper S, Beckert S, Küper MA, Jekov M, Königsrainer A. Fifty percent area reduction after 4 weeks of treatment is a reliable indicator for healing–analysis of a single-center cohort of 704 diabetic patients. J Vasc Surg. 2009; 23(1):49.
Cardinal M, Eisenbud DE, Phillips T, Harding K. Early healing rates and wound area measurements are reliable predictors of later complete wound closure. Wound Repair Regen. 2008; 16(1):19–22.
Fu X, Sun T, Sheng Z. Several animal models for the study of wound repair in chinese. Chin J Exp Surg. 1999; 16(5):479–80.
Langemo D, Anderson J, Hanson D, Hunter S, Thompson P. Measuring wound length, width, and area: which technique?Adv Skin Wound Care. 2008; 21(1):42.
Rahul S, Sreekar H, Shashank L, Kumar GA. A novel and accurate technique of photographic wound measurement. Indian J Plast Surg Off Publ Assoc Plast Surg India. 2012; 45(2):425.
Fan Y, Pu F, Xu Y, Zhang L, Zou Y, Jiang W. Computer-aided legal medical examination of body surface. J Biomed Eng. 1999; 16(4):445.
Yang S, Park J, Lee H, Lee JB, Lee BU, Oh BH. Error rate of automated calculation for wound surface area using a digital photography. Skin Res Technol Off J Int Soc Bioeng Skin (ISBS) Int Soc Digit Imaging Skin (ISDIS) Int Soc Skin Imaging (ISSI). 2017; 24(1). https://doi.org/10.1111/srt.12398.
Foltynski P. Ways to increase precision and accuracy of wound area measurement using smart devices: Advanced app planimator. Plos ONE. 2018; 13(3):0192485.
Zhang B. The research of human body surface 3d measurement technology based on computer vision in chinese. PhD thesis: Central South University; 2006.
Sirazitdinova E, Deserno TM. System design for 3d wound imaging using low-cost mobile devices. In: Society of Photo-Optical Instrumentation Engineers: 2017. p. 1013810. https://doi.org/10.1117/12.2254389.
Chen L, Tang W, John NW, Wan TR, Zhang JJ. Slam-based dense surface reconstruction in monocular minimally invasive surgery and its application to augmented reality. Comput Methods Programs Biomed. 2018:135–146. https://doi.org/10.1016/j.cmpb.2018.02.006.
Huang J. Automatic 3d surface area measurement for vitiligo lesions. PhD thesis: Massachusetts Institute of Technology; 2017.
Masiero A, Fissore F, Pirotti F, Guarnieri A, Vettore A. Toward the use of smartphones for mobile mapping. J Geospatial Inform Sci. 2016; 19(3):1–12.
Gatys LA, Ecker AS, Bethge M. Image style transfer using convolutional neural networks. In: IEEE Conference on Computer Vision and Pattern Recognition: 2016. p. 2414–23. https://doi.org/10.1109/cvpr.2016.265.
Liu S, Zhang Y, Yang X, Shi D, Zhang J. Robust facial landmark detection and tracking across poses and expressions for in-the-wild monocular video. Comput Vis Media. 2017; 3(1):33–47.
Gethin G, Cowman S. Wound measurement comparing the use of acetate tracings and visitrak digital planimetry. J Clin Nurs. 2006; 15(4):422.
Kundin JI. Designing and developing a new measuring instrument. Perioper Nurs Q. 1985; 1(4):40.
Foltynski P, Ladyzynski P, Sabalinska S, Wojcicki JM. Accuracy and precision of selected wound area measurement methods in diabetic foot ulceration. Diabetes Technol Ther. 2013; 15(8):712.
Plassmann P, Jones TD. Mavis: a non-invasive instrument to measure area and volume of wounds. Med Eng Phys. 1998; 20(5):332.
CAS PubMed Article Google Scholar
Rogers LC, Bevilacqua NJ, Armstrong DG, Andros G. Digital planimetry results in more accurate wound measurements: a comparison to standard ruler measurements. J Diabetes Sci Technol. 2010; 4(4):799–802.
PubMed PubMed Central Article Google Scholar
Basri R, Jacobs D. Photometric stereo with general, unknown lighting. Int J Comput Vis. 2007; 72(3):239–57.
Hernandez C, Vogiatzis G, Brostow GJ, Stenger B, Cipolla R. Non-rigid photometric stereo with colored lights. In: IEEE International Conference on Computer Vision: 2007. p. 1–8. https://doi.org/10.1109/iccv.2007.4408939.
Ikeuchi K. Determining surface orientations of specular surfaces by using the photometric stereo method. IEEE Trans Pattern Anal Mach Intell. 1981; 3(6):661.
Harris C. A combined corner and edge detector. Proc Alvey Vis Conf. 1988; 1988(3):147–51.
Shi J, Tomasi. Good features to track. In: Computer Vision and Pattern Recognition, 1994. Proceedings CVPR '94., 1994 IEEE Computer Society Conference On: 2002. p. 593–600. https://doi.org/10.1109/cvpr.1994.323794.
Lowe DG. Distinctive image features from scale-invariant keypoints. Int J Comput Vis. 2004; 60(2):91–110.
Ke Y, Sukthankar R. Pca-sift: A more distinctive representation for local image descriptors. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition: 2004. p. 506–13. https://doi.org/10.1109/cvpr.2004.1315206.
Mikolajczyk K, Schmid C. A performance evaluation of local descriptors. IEEE Trans Pattern Anal Mach Intell. 2005; 27(10):1615–30.
Bay H, Tuytelaars T, Gool LV. Surf: Speeded up robust features. In: European Conference on Computer Vision. Berlin: Springer: 2006. p. 404–417.
McCartney J, Hinds B, Seow B. The flattening of triangulated surfaces incorporating darts and gussets. Comput-Aided Des. 1999; 31(4):249–60.
Eck M, DeRose T, Duchamp T, Hoppe H, Lounsbery M, Stuetzle W. Multiresolution analysis of arbitrary meshes. In: Proceedings of the 22nd Annual Conference on Computer Graphics and Interactive Techniques. ACM: 1995. p. 173–182. https://doi.org/10.1145/218380.218440.
Vy B, Petitjean S, Ray N, Maillot J. Least squares conformal maps for automatic texture atlas generation. Acm Trans Graph. 2002; 21(3):362–71.
Kong SG, Heo J, Boughorbel F, Zheng Y, Abidi BR, Koschan A, Yi M, Abidi MA. Multiscale fusion of visible and thermal ir images for illumination-invariant face recognition. Int J Comput Vis. 2007; 71(2):215–33.
Tomasi C. Detection and tracking of point features. Tech Rep. 1991; 91(21):9795–802.
Tomasi C, Kanade T. Shape and motion from image streams under orthography: a factorization method. Int J Comput Vis. 1992; 9(2):137–54.
Fischler MA, Bolles RC. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Readings Comput Vis. 1987; 24:726–40.
Yu F, Gallup D. 3d reconstruction from accidental motion. In: IEEE Conference on Computer Vision and Pattern Recognition: 2014. p. 3986–93. https://doi.org/10.1109/cvpr.2014.509.
Furukawa Y, Curless B, Seitz SM, Szeliski R. Towards internet-scale multi-view stereo. In: Computer Vision and Pattern Recognition: 2010. p. 1434–41. https://doi.org/10.1109/cvpr.2010.5539802.
Furukawa Y, Ponce J. Accurate, dense, and robust multiview stereopsis. IEEE Trans Pattern Anal Mach Intell. 2010; 32(8):1362–76.
Hoppe H. Poisson surface reconstruction. In: The Japan Institute of Energy: 2013. p. 314–5. https://doi.org/10.1145/1364901.1364904.
Parvizi D, Giretzlehner M, Wurzer P, Klein LD, Shoham Y, Bohanon FJ, Haller HL, Tuca A, Branski LK, Lumenta DB. Burncase 3d software validation study: Burn size measurement accuracy and inter-rater reliability. Burns. 2016; 42(2):329–35.
Yao L, Cheng Y, Wu H. Three-dimensional area measurement based on mesh model. Softw Guide. 2016; 15(2):98–101.
Haker S, Angenent S, Tannenbaum A, Kikinis R, Sapiro G, Halle M. Conformal surface parameterization for texture mapping. IEEE Trans Vis Comput Graph. 2000; 6(2):181–9.
Gaur A, Sunkara R, Raj ANJ, Celik T. Efficient wound measurements using rgb and depth images. Int J Biomed Eng Technol. 2015; 18(4):333.
https://support.stereolabs.com/hc/en-us Accessed Feb 10 2018.
The annotation procedure and publication cost of this work is supported by the National Science and Technology Major Project of the Ministry of Science and Technology in China under Grant 2017YFC0110903, the National Science and Technology Major Project of the Ministry of Science and Technology in China under Grant 2016YFB1101101, the National Research Center for Rehabilitation Technical Aids in China under Grant 54-5380-01, the National Natural Science Foundation in China under Grant 81771910, the Beijing Natural Science Foundation in China under Grant 4152033, the Technology and Innovation Commission of Shenzhen in China under Grant shenfagai2016-627, the Beijing Young Talent Project in China, the Fundamental Research Funds for the Central Universities of China under Grant SKLSDE-2017ZX-08 from the State Key Laboratory of Software Development Environment in Beihang University in China, the 111 Project in China under Grant B13003, Sichuan Science and Technology Program under Grant No. 2018SZ0036, Fundamental Research Funds for Central Public Welfare Research Institutes under Grant 118009001000160001.
Chunhui Liu and Xingyu Fan contributed equally to this work.
State Key Laboratory of Software Development Environment and Key Laboratory of Biomechanics and Mechanobiology of Ministry of Education and Research Institute of Beihang University in Shenzhen, Beijing Advanced Innovation Center for Biomedical Engineering, Beihang University, Xueyuan Road No.37, Beijing, 100191, China
Chunhui Liu, Zhizhi Guo & Yan Xu
China mobile research institute, Xuanwumen West Street No.32, Beijing, 100053, China
Chunhui Liu
Bioengineering College of Chongqing University, Shazheng Street No. 174, Chongqing, 400044, China
Xingyu Fan
Microsoft Research, Danling Street No. 5, Beijing, 100080, China
Eric I-Chao Chang & Yan Xu
Beijing Key Laboratory of Rehabilitation Technical Aids for Old-Age Disability, Key Laboratory of Rehabilitation Technical Aids Technology and System of the Ministry of Civil Affairs, National Research Centre for Rehabilitation Technical Aids, No.1 Ronghuazhong Road, Beijing Economic and Technological Development Zone, Beijing, 100176, China
Zhongjun Mo
Zhizhi Guo
Eric I-Chao Chang
Yan Xu
CL and XF built the algorithm. CL, XF, and ZG wrote the code and collected the data. CL, XF, ZG, ZM, EC and YX contributed to manuscript preparation. All authors read and approved the final manuscript.
Correspondence to Yan Xu.
The biological and medical ethics committee of Beihang University granted approval for the study. Written informed consent was granted by the participants for the use of the images.
Liu, C., Fan, X., Guo, Z. et al. Wound area measurement with 3D transformation and smartphone images. BMC Bioinformatics 20, 724 (2019). https://doi.org/10.1186/s12859-019-3308-1
Wound measurement | CommonCrawl |
Complicated dynamics of tumor-immune system interaction model with distributed time delay
The effect of noise intensity on parabolic equations
The two-grid and multigrid discretizations of the $ C^0 $IPG method for biharmonic eigenvalue problem
Hao Li , Hai Bi and Yidu Yang ,
School of Mathematical Sciences, Guizhou Normal University, Guiyang, 550001, China
* Corresponding author: Yidu Yang
Received May 2018 Revised August 2019 Published December 2019
Fund Project: This work is supported by the National Natural Science Foundation of China (Grant No.11761022) and Science and Technology Foundation of Guizhou Province of China (Grant No. LH [2014] 7061)
Figure(2) / Table(6)
In this paper, for the biharmonic eigenvalue problem with clamped boundary condition in $ \mathbb{R}^{2} $, we study the two-grid discretization based on shifted-inverse iteration of $ C^0 $IPG method. With our scheme, the solution of a biharmonic eigenvalue problem on a fine mesh $ \pi_h $ can be reduced to the solution of the eigenvalue problem on a coarser mesh $ \pi_H $ and the solution of a linear algebraic system on the fine mesh $ \pi_h $. We prove that the resulting solution still maintains an asymptotically optimal accuracy when $ h\geq O(H^3) $. In addition, we also discuss the multigrid discretization and the adaptive $ C^0 $IPG algorithm based on Rayleigh quotient iteration. Numerical experiments are provided to validate the theoretical analysis.
Keywords: The biharmonic eigenvalue problem, C0IPG method, two-grid discretization, Rayleigh quotient iteration, adaptive algorithm.
Mathematics Subject Classification: Primary: 65N25, 65N30.
Citation: Hao Li, Hai Bi, Yidu Yang. The two-grid and multigrid discretizations of the $ C^0 $IPG method for biharmonic eigenvalue problem. Discrete & Continuous Dynamical Systems - B, doi: 10.3934/dcdsb.2020002
M. Ainsworth and J. T. Oden, A Posteriori Error Estimates in the Finite Element Analysis, Wiley-Inter science, New York, 2000. doi: 10.1002/9781118032824. Google Scholar
A. B. Andreev, R. D. Lazarov and M. R. Racheva, Postprocessing and higher order convergence of the mixed finite element approximations of biharmonic eigenvalue problems, J. Comput. Appl. Math., 182 (2005), 333-349. doi: 10.1016/j.cam.2004.12.015. Google Scholar
I. Babuška, R. B. Kellog and J. Pitkaranta, Direct and inverse error estimates for finite elements with mesh refinement, Numer. Math., 33 (1979), 447-471. doi: 10.1007/BF01399326. Google Scholar
I. Babuška and J. Osborn, Eigenvalue problems, Handbook of Numerical Analysis, Handb. Numer. Anal., North-Holland, Amsterdam, 2 (1991), 641-787. Google Scholar
I. Babuška and W. C. Rheinboldt, Error estimates for adaptive finite element computations, SIAM J. Numer. Anal., 15 (1978), 736-754. doi: 10.1137/0715049. Google Scholar
L. Beirão da Veiga, J. Niiranen and R. Stenberg, A posteriori erros estimates for the Morley plate bending element, Numer. Math., 106 (2007), 165-179. doi: 10.1007/s00211-007-0066-1. Google Scholar
H. Blum and R. Rannacher, On the boundary value problem of the biharmonic operator on domains with angular corners, Math. Method Appl. Sci., 2 (1980), 556-581. doi: 10.1002/mma.1670020416. Google Scholar
D. Boffi, Finite element approximation of eigenvalue problems, Acta Numerica, 19 (2010), 1-120. doi: 10.1017/S0962492910000012. Google Scholar
S. C. Brenner, $C^{0}$ interior penalty methods, Frontiers in Numerical Analysis-Durham 2010, Lecture Notes in Computational Science and Engineering, Springer-Verlag, 85 (2012), 79-147. doi: 10.1007/978-3-642-23914-4_2. Google Scholar
S. C. Brenner and et al., Adaptive $C^0$ interior penalty method for biharmonic eigenvalue problems, Numerical Solution of PDE Eigenvalue Problems, Oberwolfach Rep, 10 (2013), 3265-3267. Google Scholar
S. C. Brenner, S. Y. Gu, T. Gudi and L.-Y. Sung, A quadratic $C^{0}$ interior penalty method for linear fourth order boundary value problems with boundary conditions of the Cahn-Hilliard type, SIAM J. Numer. Anal., 50 (2012), 2088-2110. doi: 10.1137/110847469. Google Scholar
S. C. Brenner, P. Monk and J. G. Sun, $C^{0}$IPG method for biharmonic eigenvalue problems, Spectral and High Order Methods for Partial Differential Equation-ICOSAHOM 2014, Lect. Notes Comput. Sci. Eng., Springer, Cham, 106 (2015), 3-15. Google Scholar
S. C. Brenner and M. Neilan, A $C^{0}$ interior penalty method for a fourth order elliptic singular perturbation problem, SIAM J. Numer. Anal., 49 (2011), 869-892. doi: 10.1137/100786988. Google Scholar
S. C. Brenner and L. R. Scott, The Mathematical Theory of Finite Element Methods, Second edition, Texts in Applied Mathematics, 15. Springer-Verlag, New York, 2002. doi: 10.1007/978-1-4757-3658-8. Google Scholar
S. C. Brenner and L.-Y. Sung, $C^{0}$ interior penalty methods for fourth order elliptic boundary value problems on polygonal domains, J. Sci. Comput., 22/23 (2005), 83-118. doi: 10.1007/s10915-004-4135-7. Google Scholar
S. C. Brenner, K. N. Wang and J. Zhao, Poincaré-Friedrichs inequalities for piecewise $H^{2}$ functions, Numer. Funct. Anal. Optim., 25 (2004), 463-478. doi: 10.1081/NFA-200042165. Google Scholar
C. Carstensen and D. Gallistl, Guaranteed lower eigenvalue bounds for the biharmonic equation, Numer. Math., 125 (2014), 33-51. doi: 10.1007/s00211-013-0559-z. Google Scholar
[18] F. Chatelin, Spectral Approximations of Linear Operators, Computer Science and Applied Mathematics, Academic Press, Inc., New York, 1983. Google Scholar
H. T. Chen, H. L. Guo, Z. M. Zhang and Q. S. Zou, A $C^0$ linear finite element method for two fourth-order eignvalue problems, IMA J. Numer. Anal., 37 (2017), 2120-2138. doi: 10.1093/imanum/drw051. Google Scholar
L. Chen, IFEM: An Innovative Finite Element Methods Package in MATLAB, Technical Report, University of California at Irvine, 2009. Google Scholar
P. G. Ciarlet, Basic error estimates for elliptic proplems, Handbook of Numerical Analysis, Handb. Numer. Anal., Ⅱ, North-Holland, Amsterdam, 2 (1991), 17-351. Google Scholar
X. Y. Dai, J. C. Xu and A. H. Zhou, Convergence and optimal complexity of adaptive finite element eigenvalue computations, Numer. Math., 110 (2008), 313-355. doi: 10.1007/s00211-008-0169-3. Google Scholar
X. Y. Dai and A. H. Zhou, Three-scale finite element discretizations for quantum eigenvalue problems, SIAM J. Numer. Anal., 46 (2007/08), 295-324. doi: 10.1137/06067780X. Google Scholar
G. Engel, K. Garikipati, T. J. R. Hughes, M. G. Larson, L. Mazzei and R. L. Taylor, Continuous/discontinuous finite element approximations of fourth order elliptic problems in structural and continuum mechanics with applications to thin beams and plates, and strain gradient elasticity, Comput. Methods Appl. Mech. Engrg., 191 (2002), 3669-3750. doi: 10.1016/S0045-7825(02)00286-4. Google Scholar
H. R. Geng, X. Ji, J. G. Sun and L. W. Xu, $C^{0}$IP methods for the transmission eigenvalue problem, J. Sci. Comput., 68 (2016), 326-338. doi: 10.1007/s10915-015-0140-2. Google Scholar
T. Gudi, A new error analysis for discontinuous finite element methods for the linear elliptic problems, Math. Comp., 79 (2010), 2169-2189. doi: 10.1090/S0025-5718-10-02360-4. Google Scholar
H. L. Guo, Z. M. Zhang and Q. S. Zou, A $C^0$ linear finite element method for biharmonic problems, J. Sci. Comput., 74 (2018), 1397-1422. doi: 10.1007/s10915-017-0501-0. Google Scholar
H. L. Guo, Z. M. Zhang and R. Zhao, Superconvergent two-grid schemes for elliptic eigenvalue problems, J. Sci. Comput., 70 (2017), 125-148. doi: 10.1007/s10915-016-0245-2. Google Scholar
X. Z. Hu and X. L. Cheng, Acceleration of a two-grid method for eigenvalue problems, Math. Comp., 80 (2011), 1287-1301. doi: 10.1090/S0025-5718-2011-02458-0. Google Scholar
J. Hu, Y. Q. Huang and Q. Lin, Lower bounds for eigenvalues of elliptic operators: By Nonconforming finite element methods, J. Sci. Comput., 61 (2014), 196-221. doi: 10.1007/s10915-014-9821-5. Google Scholar
J. Hu, Z. C. Shi and J. C. Xu, Convergence and optimality of the adaptive Morley element method, Numer. Math., 121 (2012), 731-752. doi: 10.1007/s00211-012-0445-0. Google Scholar
H. Li and Y. D. Yang, $C^0$IPG adaptive algorithms for the biharmonic eigenvalue problem, Numer. Algor., 78 (2018), 553-567. doi: 10.1007/s11075-017-0388-8. Google Scholar
H. Li and Y. D. Yang, An adaptive $C^0$IPG method for the Helmholtz transmission eigenvalue problem, Science China Mathematics, 61 (2018), 1519-1542. doi: 10.1007/s11425-017-9334-9. Google Scholar
[34] Q. Lin and J. Lin, Finite Element Methods: Accuracy and Inprovement, Science Press, Beijing, 2006. Google Scholar
Q. Lin and H. H. Xie, A multi-level correction scheme for eigenvalue problems, Math. Comp., 84 (2015), 71-88. doi: 10.1090/S0025-5718-2014-02825-1. Google Scholar
P. Morin, R. H. Nochetto and K. G. Siebert, Convergence of adaptive finite element methods, SIAM Rev., 44 (2002), 631-658. doi: 10.1137/S0036144502409093. Google Scholar
J. T. Oden and J. N. Reddy, An Introduction to the Mathematical Theory of Finite Elements, Pure and Applied Mathematics. Wiley-Interscience, New York-London-Sydney, 1976. Google Scholar
Q. Shen, A posteriori error estimates of the Morley element for the fourth order elliptic eigenvalue problem, Numer. Algor., 68 (2015), 455-466. doi: 10.1007/s11075-014-9854-8. Google Scholar
R. Rannacher, Nonconforming finite element methods for eigenvalue problems in linear plate theory, Numer. Math., 33 (1979), 23-42. doi: 10.1007/BF01396493. Google Scholar
[40] Z. Shi and M. Wang, Finite Element Methods, Science Press, Beijing, 2013. Google Scholar
R. Verfürth, A Review of a Posteriori Error Estimates and Adaptive Mesh-Refinement Techniques, Wiley-Teubner, New York, 1996. Google Scholar
G. N. Wells and N. T. Dung, A $C^{0}$ discontinuous Galerkin formulation for Kirhhoff plates, Comput. Methods Appl. Mech. Engrg., 196 (2007), 3370-3380. doi: 10.1016/j.cma.2007.03.008. Google Scholar
H. H. Xie and X. B. Yin, Acceleration of stabilized finite element discretizations for the Stokes eigenvalue problem, Adv. Comput. Math., 41 (2015), 799-812. doi: 10.1007/s10444-014-9386-8. Google Scholar
J. C. Xu, A new class of iterative methods for nonselfadjoint or indefinite problems, SIAM J. Numer. Anal., 29 (1992), 303-319. doi: 10.1137/0729020. Google Scholar
J. C. Xu and A. H. Zhou, A two-grid discretization scheme for eigenvalue problems, Math. Comput., 70 (2001), 17-25. doi: 10.1090/S0025-5718-99-01180-1. Google Scholar
Y. D. Yang and H. Bi, Two-grid finite element discretization scheme based on shifted-inverse power method for elliptic eigenvalue problems, SIAM J. Numer. Anal., 49 (2011), 1602-1624. doi: 10.1137/100810241. Google Scholar
Y. D. Yang, H. Bi, J. Y. Han and Y. Y. Yu, The shifted-inverse iteration based on the multigrid discertiaztions for eigenvalue problems, SIAM J. Sci. Comput., 37 (2015), A2583–A2606. doi: 10.1137/140992011. Google Scholar
Y. D. Yang, H. Bi, H. Li and J. Y. Han, A $C^{0}$IPG method and its error estimates for the Helmholtz transmission eigenvalue problem, J. Comput. Appl. Math., 326 (2017), 71-86. doi: 10.1016/j.cam.2017.04.024. Google Scholar
Y. D. Yang, Z. M. Zhang and F. B. Lin, Eigenvalue approximation from below using nonforming finite elements, Sci. China Math., 53 (2010), 137-150. doi: 10.1007/s11425-009-0198-0. Google Scholar
J. Zhou, X. Hu, L. Zhong, S. Shu and L. Chen, Two-grid methods for Maxwell eigenvalue problems, SIAM J. Numer. Anal., 52 (2014), 2027-2047. doi: 10.1137/130919921. Google Scholar
O. C. Zienkiewicz, The Finite Element Method in Engineering Science, McGraw-Hill, London-New York-Düsseldorf, 1971. Google Scholar
Figure 1. The convergence rates for the unit square with a slit using quadratic(left) and cubic(right) $ C^0 $IPG methods
Figure 2. The convergence rates for the L-shaped domain using quadratic(left) and cubic(right) $ C^0 $IPG methods
Table 1. the first eigenvalue approximation for (2.1) on the unit square using quadratic $ C^0 $IPG method
$ H $ $ h $ $ \lambda_{H} $ $ t_1(s) $ $ \lambda^h $ $ t_2(s) $ $ \lambda_{h} $ $ t_3(s) $
$ \frac{\sqrt{2}}{8} $ $ \frac{\sqrt{2}}{32} $ 1570.1117 .013 1307.7056 .033 1307.7017 .058
$ \frac{\sqrt{2}}{16} $ $ \frac{\sqrt{2}}{128} $ 1350.9328 .044 1295.6742 1.01 1295.6742 1.61
$ \frac{\sqrt{2}}{32} $ $ \frac{\sqrt{2}}{512} $ 1307.7017 .055 1294.9765 37.9 1294.9736 56.9
$ \frac{\sqrt{2}}{64} $ $ \frac{\sqrt{2}}{1024} $ 1297.9745 .348 1294.8984 283 $ – $ $ – $
Table 2. the first eigenvalue approximation for (2.1) on the unit square using cubic $ C^0 $IPG method
$ \frac{\sqrt{2}}{32} $ $ \frac{\sqrt{2}}{512} $ 1294.9569 .222 1294.4529 208 1294.4621 1602
Table 3. the first eigenvalue approximation for (2.1) on the unit square with a slit using quadratic $ C^0 $IPG method
$ \frac{\sqrt{2}}{8} $ $ \frac{\sqrt{2}}{32} $ 10678.0553 .010 6541.4871 .037 6539.8146 .051
$ \frac{\sqrt{2}}{16} $ $ \frac{\sqrt{2}}{128} $ 7228.7805 .011 6250.7646 .948 6250.6718 1.42
$ \frac{\sqrt{2}}{64} $ $ \frac{\sqrt{2}}{1024} $ 6328.9667 .298 6195.7389 217 $ -- $ $ -- $
Table 4. the first eigenvalue approximation for (2.1) on the unit square with a slit using cubic $ C^0 $IPG method
$ \frac{\sqrt{2}}{32} $ $ \frac{\sqrt{2}}{512} $ 6226.2445 .192 6190.6868 165 6190.6738 216
Table 5. the first eigenvalue approximation for (2.1) on the L-shaped domain using quadratic $ C^0 $IPG method
$ \frac{\sqrt{2}}{64} $ $ \frac{\sqrt{2}}{1024} $ 6818.6359 .204 6707.7302 155 6707.6827 191
Table 6. the first eigenvalue approximation for (2.1) on the L-shaped domain using cubic $ C^0 $IPG method
Jiaping Yu, Haibiao Zheng, Feng Shi, Ren Zhao. Two-grid finite element method for the stabilization of mixed Stokes-Darcy model. Discrete & Continuous Dynamical Systems - B, 2019, 24 (1) : 387-402. doi: 10.3934/dcdsb.2018109
Tong Zhang, Jinyun Yuan. Two novel decoupling algorithms for the steady Stokes-Darcy model based on two-grid discretizations. Discrete & Continuous Dynamical Systems - B, 2014, 19 (3) : 849-865. doi: 10.3934/dcdsb.2014.19.849
Yun Chen, Jiasheng Huang, Si Li, Yao Lu, Yuesheng Xu. A content-adaptive unstructured grid based integral equation method with the TV regularization for SPECT reconstruction. Inverse Problems & Imaging, 2020, 14 (1) : 27-52. doi: 10.3934/ipi.2019062
Huan Gao, Zhibao Li, Haibin Zhang. A fast continuous method for the extreme eigenvalue problem. Journal of Industrial & Management Optimization, 2017, 13 (3) : 1587-1599. doi: 10.3934/jimo.2017008
Yuxuan Gong, Xiang Xu. Inverse random source problem for biharmonic equation in two dimensions. Inverse Problems & Imaging, 2019, 13 (3) : 635-652. doi: 10.3934/ipi.2019029
Jing Zhou, Dejun Chen, Zhenbo Wang, Wenxun Xing. A conic approximation method for the 0-1 quadratic knapsack problem. Journal of Industrial & Management Optimization, 2013, 9 (3) : 531-547. doi: 10.3934/jimo.2013.9.531
Hung-Wen Kuo. The initial layer for Rayleigh problem. Discrete & Continuous Dynamical Systems - B, 2011, 15 (1) : 137-170. doi: 10.3934/dcdsb.2011.15.137
Yafeng Li, Guo Sun, Yiju Wang. A smoothing Broyden-like method for polyhedral cone constrained eigenvalue problem. Numerical Algebra, Control & Optimization, 2011, 1 (3) : 529-537. doi: 10.3934/naco.2011.1.529
Xing Li, Chungen Shen, Lei-Hong Zhang. A projected preconditioned conjugate gradient method for the linear response eigenvalue problem. Numerical Algebra, Control & Optimization, 2018, 8 (4) : 389-412. doi: 10.3934/naco.2018025
Ya-Zheng Dang, Zhong-Hui Xue, Yan Gao, Jun-Xiang Li. Fast self-adaptive regularization iterative algorithm for solving split feasibility problem. Journal of Industrial & Management Optimization, 2017, 13 (5) : 1-15. doi: 10.3934/jimo.2019017
Jacek Banasiak, Marcin Moszyński. Hypercyclicity and chaoticity spaces of $C_0$ semigroups. Discrete & Continuous Dynamical Systems - A, 2008, 20 (3) : 577-587. doi: 10.3934/dcds.2008.20.577
Piotr Kościelniak, Marcin Mazur. On $C^0$ genericity of various shadowing properties. Discrete & Continuous Dynamical Systems - A, 2005, 12 (3) : 523-530. doi: 10.3934/dcds.2005.12.523
Kingshook Biswas. Maximal abelian torsion subgroups of Diff( C,0). Discrete & Continuous Dynamical Systems - A, 2011, 29 (3) : 839-844. doi: 10.3934/dcds.2011.29.839
Jinchao Xu. The single-grid multilevel method and its applications. Inverse Problems & Imaging, 2013, 7 (3) : 987-1005. doi: 10.3934/ipi.2013.7.987
Stefan Berres, Ricardo Ruiz-Baier, Hartmut Schwandt, Elmer M. Tory. An adaptive finite-volume method for a model of two-phase pedestrian flow. Networks & Heterogeneous Media, 2011, 6 (3) : 401-423. doi: 10.3934/nhm.2011.6.401
Darya V. Verveyko, Andrey Yu. Verisokin. Application of He's method to the modified Rayleigh equation. Conference Publications, 2011, 2011 (Special) : 1423-1431. doi: 10.3934/proc.2011.2011.1423
Gang Qian, Deren Han, Lingling Xu, Hai Yang. Solving nonadditive traffic assignment problems: A self-adaptive projection-auxiliary problem method for variational inequalities. Journal of Industrial & Management Optimization, 2013, 9 (1) : 255-274. doi: 10.3934/jimo.2013.9.255
Fernando Jiménez, Jürgen Scheurle. On some aspects of the discretization of the suslov problem. Journal of Geometric Mechanics, 2018, 10 (1) : 43-68. doi: 10.3934/jgm.2018002
Tiexiang Li, Tsung-Ming Huang, Wen-Wei Lin, Jenn-Nan Wang. On the transmission eigenvalue problem for the acoustic equation with a negative index of refraction and a practical numerical reconstruction method. Inverse Problems & Imaging, 2018, 12 (4) : 1033-1054. doi: 10.3934/ipi.2018043
Qilong Zhai, Ran Zhang. Lower and upper bounds of Laplacian eigenvalue problem by weak Galerkin method on triangular meshes. Discrete & Continuous Dynamical Systems - B, 2019, 24 (1) : 403-413. doi: 10.3934/dcdsb.2018091
Hao Li Hai Bi Yidu Yang
\begin{document}$ C^0 $\end{document}IPG method for biharmonic eigenvalue problem" readonly="readonly"> | CommonCrawl |
The effect of shifting medical coverage from National Health Insurance to Medical Aid type I and type II on health care utilization and out-of-pocket spending in South Korea
Doo Woong Lee1,2,
Jieun Jang2,3,
Dong-Woo Choi1,2,
Sung-In Jang ORCID: orcid.org/0000-0002-0760-28783,4 &
Eun-Cheol Park3,4
This study examines the effects of a shift in medical coverage, from National Health Insurance (NHI) to Medical Aid (MA), on health care utilization (measured by the number of outpatient visits and length of stay; LOS) and out-of-pocket medical expenses.
Data were collected from the Korean Welfare Panel Study (2010–2016). A total of 888 MA Type I beneficiaries and 221 MA Type II beneficiaries who shifted from the NHI were included as the case group and 2664 and 663 consecutive NHI holders (1:3 propensity score-matched) were included as the control group, respectively. We used the 'difference-in-differences' (DiD) analysis approach to assess changes in health care utilization and medical spending by the group members.
Differential average changes in outpatient visits in the MA Type I panel between the pre- and post-shift periods were significant, but differential changes in LOS were not found. Those who shifted from NHI to MA Type I had increased number of outpatient visits without changes in out-of-pocket spending, compared to consecutive NHI holder who had similar characteristics. However, this was not found for MA Type II beneficiaries.
Our research provides evidence that the shift in medical coverage from NHI to MA Type I increased the number of outpatient visits without increasing the out-of-pocket spending. Considering the problem of excess medical utilization by Korean MA Type I beneficiaries, further researches are required to have in-depth discussions on the appropriateness of the current cost-sharing level on MA beneficiaries.
South Korea has often been acclaimed for providing universal medical coverage for its entire population in only 12 years [1]. The Korean National Health Insurance (NHI) system began by providing cover for industrial workers in large corporations in 1977. It was gradually extended to other groups like self-employed workers until the scheme covered the entire population by 1989. Along with the NHI, a Medical Aid (MA) program was simultaneously initiated in 1977 as part of a South Korean social welfare program, called the National Basic Livelihood Security System, which supports poor people in need of medical assistance. It is comparable to the USA's Medicaid program.
Approximately 3 to 4% of the entire population are entitled to MA, and they are segregated into Type I and Type II recipients based on their economic inability or incapacitation (2.8% in 2017) [2]. Type I covers those who are socially deprived and or incapable of working (those aged under 18 or over 65; disabled people; those with severe and rare diseases, and other special cases) [3, 4]. Type II also covers those who are socially deprived but are capable of working [3, 4]. Type I beneficiaries are not required to provide copayments for any medical utilization, whereas Type II beneficiaries have minimum copayment rates of up to 15% [3, 4].
Over time, the MA program has undergone many modifications regarding its beneficiary inclusion criteria and coverage expansion plan, along with the challenges of its sustainability. In 2006, the Korean government announced the need for a major amendment to the MA law owing to the challenges faced in continuing the MA program. These challenges arose from the increase in the number of beneficiaries and the expansion of services; the increased incidence of chronic diseases and an aging population resulted in the continuous rise in reimbursements for MA beneficiaries [3]. Furthermore, about 10% of the beneficiaries used health care services excessively and accounted for about 60% of the total MA expenditure [3, 5]. Additionally, the moral hazards of MA utilization by MA beneficiaries were publicized continuously, because as health care spending increased with insurance, the real value of health care declined compared to the costs incurred in providing it [5].
Accordingly, in 2007, the Korean government implemented several cost-sharing directives. First, the government mandated out-of-pocket spending on outpatient services for Type I beneficiaries [6]. Besides, since 2018, Type I beneficiaries have had to pay ₩1000, ₩2000, and ₩3000 ($1 = around ₩1120) for each outpatient visit to a clinic, secondary hospital, and tertiary hospital, respectively, while there is no cost for inpatient services availed [7]. Furthermore, Type II beneficiaries must pay ₩1000 per outpatient clinic visit and 15% extra for a single secondary or tertiary hospital outpatient visit; and there is an out-of-pocket expense of 10% of the total expenditure for inpatient services availed [7].
In addition to mandating out-of-pocket spending by beneficiaries, the government levied a monthly health management fee to moderate possible abuse of medical facilities provided under the Healthy Life Maintenance Aid Program [7, 8]. Through this program, each Type I beneficiary receives, ₩6000 (around $6) monthly, via a virtual account [7, 8]. Upon receipt of outpatient medical services, beneficiaries make a copayment via the virtual account [7, 8]. If the beneficiaries spend the entire amount available in the virtual account, they must bear the additional costs themselves [7, 8]. Money remaining in the virtual account cannot be converted to cash [7, 8].
Despite these changes, the total medical expenditure by MA beneficiaries has steadily increased, and the medical costs per person are three times higher than for NHI covered individuals [8,9,10,11,12,13]. Furthermore, several recent studies have revealed that MA beneficiaries use outpatient services more frequently and stay longer in hospital compared with NHI-covered individuals [8, 10,11,12,13]. Studies have also revealed the differences between the health care utilization of MA and NHI beneficiaries. It has been observed that MA Type I and Type II beneficiaries share some socioeconomic status (SES) characteristics, such as age, income, health status, and economic activity status [9]. Few studies have compared health care utilization between MA beneficiaries and NHI-covered individuals with similar SES [12, 13]. However, these studies have neither compared groups with changing health care utilization, nor medical spending, and they have not considered the shift from NHI to MA. Our study is the first in South Korea to compare the health care utilization and out-of-pocket spending of individuals who have NHI coverage and those who have shifted from NHI to MA and have similar SES.
Therefore, in our study, we identified a case group that has experienced a shift in coverage from NHI to MA because we mainly hypothesized that becoming MA beneficiaries could lead higher use of health care utilization and spending, compared with a matched control group that has had consecutive NHI coverage and exhibits SES characteristics similar to the case group. Subsequently, we were able to estimate differential changes in the groups' health care utilization and out-of-pocket medical spending in the pre-and post-shift periods using a difference-in-differences (DiD) analysis method. We also hypothesized that the shift in coverage would increase both the number of outpatient visits and length of stay (LOS) and decrease out-of-pocket medical spending.
We analyzed data from the Korean Welfare Panel Study (KoWePS), 2010–2016 conducted by the Korean Institute for Health and Social Affairs. The KoWePS data are nationally representative as stratified multistage probability sampling to select households from rural and urban areas was employed. All family members of both parents and children in the selected households were interviewed. Face-to-face interviews were conducted annually from January to February, using a computer-assisted personal interviewing technique. The KoWePS database includes detailed information about the respondents and their household members, including general characteristics, social security status, health care utilization patterns, economic and demographic backgrounds, subjective health status, and behavioral health status.
Difference-in-differences study design
When examining the impact of an intervention or change in policy, the challenge is in determining whether the observed changes are attributable to the intervention. A valid method of assessing this is to compare outcomes for the group that is subject to the intervention (the case group) with a group that is not (the control group). As a randomized study design is rarely feasible in the field of health policy, a quasi-experimental study design to measure the effect of health care interventions is frequently applied.
We employed an observational study along with a DiD analysis, which is a widely used quasi-experimental study design, to compare health care utilization and out-of-pocket medical spending between the case group and its matched control group. To do so, we began by matching characteristics between the groups and controlled for background trends by performing a propensity score (PS) match.
The DiD approach necessitates some assumptions to evaluate the intervention effect accurately. First, as the DiD estimator measures the treatment effect by examining the difference in the average outcome between the control and case groups, before and after treatment [14], at least two periods of data must be available for each group. Second, the DiD approach is valid only if there are no underlying time-dependent trends in the outcomes that are unrelated to the change of coverage [14]. If the outcomes were already improving before the shift, then a pre−/post-study would erroneously conclude that the policy was associated with better outcomes [14]. The DiD study addresses this problem by using a comparison group that is experiencing the same trends but which is not exposed to the policy change; this is also known as the parallel trend assumption [15, 16]. Third, the control group should be the same as the intervention group in everything other than the change in policy [14, 17, 18]. In practice, however, observed and unobserved differences exist between the two groups. To minimize the differences, we applied the PS matching technique. We assumed that in the absence of the policy intervention, the unobserved differences between the two groups would converge over time [17, 18].
Propensity score matching and covariate selection
PS matching aims to find one or more individuals with a similar PS from the treatment and control groups. Various methods are employed to match individuals, but we used a 1:3 nearest-neighbor matching method which matches case and control individuals who have a similar propensity score value [19]. We added constraint that the difference between the PS (caliper width) should be 0.1 at most, to avoid pairing dissimilar individuals. We also considered methodological theories for selecting the covariates in the PS model. First, using prior knowledge to identify the covariates that affect the outcome and including them in the PS model is better for estimating the intervention effect [20]. Second, selecting covariates that are strongly associated with exposure but unrelated to the outcome should be avoided, because this may increase the bias. Selecting variables for the PSs, based on their association with the outcome may help to reduce such a bias [21]. Therefore, to estimate the medical coverage shift effect, we matched the control group to the case group by including the following parameters or questions in the PS model: gender; residential area (in the capital or elsewhere); marital status (yes or no); economic activity (yes or no); age (< 20, < 40, < 65, or ≥ 65 years); equivalized household disposable income (quintile groups; Q1–Q5); subjective health status (good, moderate, or bad); the number of private insurance schemes; expenditure on private insurance; and survey year (2010–2016).
The shift from NHI to MA Type I or II was represented by the intervention variable. Based on the intervention time, we classified the pre- and post-intervention periods. Then, we classified the available data for the case group into models according to the following periods: from 1 year before and after (Model 1); 2 years before and after (Model 2); and 3 years before and after (Model 3) (Figure S1). A potential critical issue is that the intervention time may differ among the individuals in the case group. However, since we matched the survey years along with the SES variables between the case and control groups, we could match the individuals precisely in the case and control groups for each year.
We initially included 132,136 individuals from the KoWePS dataset of 2010–2016. After excluding those with missing values, 99,140 remained. We separated these into the MA Type I panel, which included 888 MA Type I beneficiaries and 2664 matched controls; and the MA Type II panel, which contained 221 MA Type II beneficiaries and 663 matched controls (Fig. 1).
Flowchart of the study design. Abbreviation: Korean Welfare Panel Study: KoWePS; Equivalized Household Disposable Income: EHDI; Propensity Score: PS; Medical Aid: MA
We examined changes in the individuals' average health care utilization and out-of-pocket medical spending in the previous year. The first outcome was the differential changes between the groups in the average number of outpatient visits annually per person in the pre- and post-intervention periods. The second outcome was the differential changes in the LOS, and the third was the differential change in the average out-of-pocket medical spending.
We used the generalized estimating equation (GEE) and DiD approach to estimate the changes in health care utilization and out-of-pocket spending from the pre- to the post-intervention periods that differed from concurrent changes in the case group and its matched control group. The GEE model accounts for time variations and correlations among repeated measurements that are present in longitudinal study designs and is appropriate for marginal estimates with non-linear link functions [22]. We applied the log-link with zero-inflated negative binomial distribution to the outcome variables because of the high incidence of zero counts in outpatient visits, LOS, and out-of-pocket medical spending [23]. Then, specifically, for each dependent variable, we fit the following model:
$$ \log \left(\mathrm{E}\left({\mathrm{Y}}_{it}\right)\right)={\upbeta}_0+{\upbeta}_1\ \mathrm{case}\_{\mathrm{indicator}}_i+{\upbeta}_2\ \mathrm{post}\_{\mathrm{indicator}}_t+{\upbeta}_3\ \left(\mathrm{case}\_{\mathrm{indicator}}_i\times \mathrm{post}\_{\mathrm{indicator}}_t\right)+{\upbeta}_4\ {\mathrm{covariates}}_{it}, $$
where Log(E) denotes the exponentiated expected value; Yit is the initial outcome with a specified distribution option (health care utilization and out-of-pocket spending) for individual i at time t from intervention; case_indicator is a vector of the groups (case or control group); post_indicator is a vector of the pre−/post-indicators (whether individual i entered the post-intervention or not); covariates denote a vector of the other individual's characteristics (the most-visited type of medical institution and last period of affliction by chronic disease). All the statistical tests were two-tailed, and a p-value < 0.05 was considered significant; analyses were performed using the Statistical Analysis System version 9.4 (Cary, North Carolina, USA).
Characteristics of the study population
Eight hundred eighty-eight beneficiaries underwent a shift in medical coverage from NHI to MA Type I, and 221 beneficiaries experienced a shift in medical coverage from NHI to MA Type II. By considering their SES characteristics and the survey year, the matched control groups were selected through a 1:3 PS matching process (details of the PS matching process are included in the Methods section and shown in Fig. 1). The bivariate result showed that there were no significant differences in any year, among the individuals in the case and control groups (Table 1).
Table 1 Study Population Characteristics Among National Health Insurance Holders and Those Who Shifted From National Health Insurance to Medical Aid Who Were Matched Using the Propensity Score Before and After the Shift For All Years
Pre-intervention trends
The trends in unadjusted health care utilization and out-of-pocket medical spending of the MA beneficiaries and NHI holders throughout the study period are shown in Fig. 2. In the MA Type I and II panels, the trends in the average number of outpatient visits and LOS among the case and control groups before the intervention were parallel, but out-of-pocket medical spending was not. Given the significant difference in trends between the two groups and the possibility of a bias in the analysis [14], it was deemed appropriate to address the estimates of the number of outpatient visits and LOS in both panels, but not the estimates of out-of-pocket medical spending.
Trends in unadjusted health care utilization and out-of-pocket medical spending among NHI holders and those who shifted from NHI to MA for the Medical Aid Type I panel (A1, 2, and 3) and MA Type II panel (B1, 2, and 3)
Health care utilization [outpatient visit, length of stay]
In the MA Type I panel, in Model 1, the average number of outpatient visits increased from 25.7 times per year to 34.6 times per year in the case group, and it was almost the same in the control group. The adjusted differential change between the case and control groups for Model 1 is 31.8%, p < 0.021. The results remained statistically significant in Model 2 and Model 3 at 22.3%, p < 0.032 and 18.8%, p < 0.044, respectively (Table 2, Table S1). However, differential changes in LOS were not found in any of the periods. Regarding the MA Type II panel, there were no significant differential changes in any health care utilization (Table 2, Table S2).
Table 2 Differential Changes in Health Care Utilization and Out-of-Pocket Medical Spending by the Medical Aid Type I and II Panels
Out-of-pocket medical spending
In both the MA Type I and II panels, there were no significant changes in out-of-pocket medical spending. Even though the differential change in out-of-pocket medical spending in Model 3 was statistically significant (adjusted differential change between the case and control group: − 23.2%, p < 0.009), it is not appropriate to interpret it as meaningful because a parallel trend was not found in the pre-intervention period.
Using the DiD approach, we estimated the effect a shift in medical coverage has on health care utilization and medical spending. We compared a case group with a control group with similar SES and subjective health status parameters. We found that a shift in medical coverage from NHI to MA Type I increased outpatient visits but did not affect LOS. Furthermore, we did not find differential changes in out-of-pocket spending between the case and control groups in the MA Type I panel. Thus, we can state there was an increase in outpatient visits but no changes in out-of-pocket spending.
Our results deviate from the findings of previous studies as we did not compare MA beneficiaries with the general population but instead with a population subset with similar characteristics. We estimated the differential changes in the outcomes between the pre-shift period and post-shift period; accordingly, different results were found.
Unlike the findings from previous studies that MA beneficiaries remain in hospital longer than the general population [24, 25], we found that the shift to MA did not increase LOS significantly when compared to groups with similar characteristics. Furthermore, by examining MA Type I and II, we identified that the shift to MA Type I could induce frequent outpatient visits, but the shift to Type II did not. The reasons for these results are as follows: (1) Type II beneficiaries are subject to higher amounts of out-of-pocket spending on health care because Type I are subject to little or no copayment, and Type II are subject to 10–15% copayment of the medical costs. (2) MA Type II beneficiaries are more likely to be healthier than Type I beneficiaries since most of them are younger and able to work.
Approximately 10% of the total population of South Korea is 120% below the poverty line; of these, only about 3% are MA beneficiaries, and the rest are unacknowledged by the health care system receiving little medical cost assistance from the government [26,27,28]. This is a challenging issue as this part of the population remains exposed to health risks due to poor access to health care services [26], and is a moral hazard for MA beneficiaries (especially Type I) [13, 24]. This indicates that limited government finances are not being spent efficiently.
Previously, the government has implemented policies and programs to address these issues, including mandating the outpatient copayment system for Type I beneficiaries, introducing a monthly health management fee to regulate possible abuse of medical utilization, and a case management program [9]. However, they have not been very successful [9,10,11, 29,30,31]. The reasons are as follows: (1) weak government control over medical access by beneficiaries [9, 11, 29], (2) little or no copayment fee [8,9,10,11,12,13, 25, 30], and (3) selection criteria for MA beneficiaries that focuses more on family characteristics than individual characteristics [29].
A major reason for the continuous, excessive use of medical services is that the minimum level of cost-sharing is too low [8,9,10,11,12,13, 25, 30]. Increasing the minimum level or converting the copayment system to coinsurance or deductible payments in the MA Type I could be considered. Although the suggestion may be controversial because it would impose an additional burden on some beneficiaries, we support it for the following reasons. First, adequate copayment or coinsurance payment is associated with a decrease in unnecessary medical utilization; a similar step was implemented in the USA's healthcare system. In the USA, public insurance for the lowest income population with little copayment or coinsurance has been a concern since it burdens the fiscal with excessive use of medical services along with moral hazards. An empirical example is Massachusetts' Commonwealth Care program, which imposed higher copayments to low-income enrollees to reduce the fiscal pressures associated with insurance expansion by the scope for moral hazard [32]. However, there remained speculation that low-income populations may be more likely to have adverse health consequences from the result of higher cost-sharing as they could not afford the increased burden, which is also called "offset effects" [32, 33]. However, the evidence proved that no notable offset effect was found with the increase of copayment in the low-income population [33]. Accordingly, imposing copayment for the use of the emergency department [34], or pharmaceutical services in a Medicaid program [35, 36] reportedly improved overall health status. Second, the degree of cost-sharing has changed little since it was introduced in 2007. Third, excessive government expenditure on MA reduces the availability of funds for allocation to other governmental medical support schemes. A statistical report from the Korean government has indicated that MA payments account for 12.0% of the total NHI expenditure, and the total medical expenses related to MA increased dramatically by 39.2% (from 5.1 trillion Won in 2011 to 7.1 trillion Won in 2017). This was despite a decrease in the number of MA beneficiaries from 1.61 million people to 1.49 million people (− 7.65%) during the same period [37]. Furthermore, compared to NHI holders, the MA beneficiaries' medical expenses per capita is 3.6 times higher, and the LOS per capita is four times higher [37]. Considering that MA beneficiaries are a vulnerable population, 22.9% of the entire population of MA beneficiaries used health care for more than 365 days (the total number of days for outpatient visits, LOS, and medication dosage) [37]. This suggests that adequate control of medical utilization by MA beneficiaries is still lacking. Additionally, our study implies that being an MA beneficiary significantly increases the number of outpatient visits without any significant changes to out-of-pocket spending on medical use. From previous studies, we can infer that the reason newcomers to MA frequently use outpatient services is that the out-of-pocket spending level is extremely low [8,9,10,11,12,13, 25, 30]. Therefore, a modification of the MA cost-sharing level should be discussed thoroughly with evidence-based future researches.
As our study has several limitations, the results should be interpreted and generalized with caution. First, owing to data limitation, we could not incorporate several other factors that may affect health care utilization. In the DiD approach, however, if the parallel trend assumption is met between the case and control groups, it can remove the effect of any confounding factors [14,15,16]. Therefore, the estimates of the number of outpatient visits and LOS in the MA Type I and Type II panels could be free from confounding issues to some extent. Second, we were not able to consider the number of emergency visits separately since there was no such information in the KoWePS data. Third, the KoWePS data obtained information about health care utilization through self-reporting, and the surveyors collected data retrospectively based on receipts. Therefore, these two factors may have distorted the results of medical utilization.
Regarding the ongoing problem of excess medical utilization by MA Type I beneficiaries in Korea, restraint should be in place. Therefore, our research provides evidence that the shift in medical coverage from NHI to MA Type I increased the number of outpatient visits without increasing the out-of-pocket spending. However, neither of increased outpatient visit and out-of-pocket spending was found for shifting from NHI to MA Type II. Further research requires in-depth discussions on the appropriateness of the current cost-sharing level on MA beneficiaries.
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
DiD:
Difference in differences
EHDI:
Equivalized household disposable income
GEE:
Generalized estimating equation
KoWePS:
Korean Welfare Panel Study
LOS:
NHI:
Propensity score
Carrin G, James C. Social health insurance: key factors affecting the transition towards universal coverage. Int Soc Secur Rev. 2005;58(1):45–64.
Health Insurance Review & Assessment Service (HIRA): Medical Aid Statistics 2017; 2018.
World Health Organization. Regional Office for the Western P: Republic of Korea health system review. Manila: WHO Regional Office for the Western Pacific; 2015.
Shin Y-J. Policy context of the poor progress of the pro-poor policy: a case study on the medical-aid policy during Kim Dae-jung's government (1998–2002) in the Republic of Korea. Health Policy. 2006;78(2):209–23.
Kang MS, Jang HS, Lee M, Park E-C. Sustainability of Korean national health insurance. J Korean Med Sci. 2012;27(Suppl):S21–4.
Oh J, Oh S. Case management for long-term hospitalization by medical aid beneficiaries: suggestions for successful operation and stabilization. Korean Public Health Res. 2015;41(4):1–14.
Guideline for Medical Aids Beneficiaries. https://www.hira.or.kr/dummy.do?pgmid=HIRAA030057020100. Accessed 19 Oct 2020.
Kim J-H, Lee SG, Lee K-S, Jang S-I, Cho K-H, Park E-C. Impact of health insurance status changes on healthcare utilisation patterns: a longitudinal cohort study in South Korea. BMJ Open. 2016;6(4):e009538.
Sohn M, Jung M. Effects of public and private health insurance on medical service utilization in the National Health Insurance System: national panel study in the Republic of Korea. BMC Health Serv Res. 2016;16(1):503.
Shin SM, Kim MJ, Kim ES, Lee HW, Park CG, Kim HK. Medical aid service overuse assessed by case managers in Korea. J Adv Nurs. 2010;66(10):2257–65.
Kim J-H, Lee K-S, Yoo K-B, Park E-C. The differences in health care utilization between medical aid and health insurance: a longitudinal study using propensity score matching. PLoS One. 2015;10(3):e0119939.
Lee H-J. Healthcare utilization and out-of-pocket spending of medical aids recipients in South Korea: a propensity score matching with National Health Insurance participants. Korean Health Econ Rev. 2016;22(2):29–49.
Dimick JB, Ryan AM. Methods for evaluating changes in health care policy: the difference-in-differences ApproachDifference-in-differences ApproachJAMA guide to statistics and methods. JAMA. 2014;312(22):2401–2.
Angrist JD, Pischke J-S. Mostly harmless econometrics: an empiricist's companion: Princeton University Press; 2008.
Abadie A. Semiparametric difference-in-differences estimators. Rev Econ Stud. 2005;72(1):1–19.
Blundell R, Costa Dias M. Evaluation methods for non-experimental data. Fisc Stud. 2000;21(4):427–68.
Farrar S, Yi D, Sutton M, Chalkley M, Sussex J, Scott A. Has payment by results affected the way that English hospitals provide care? Difference-in-differences analysis. Bmj. 2009;339:b3047.
Rosenbaum PR, Rubin DB. The central role of the propensity score in observational studies for causal effects. Biometrika. 1983;70(1):41–55.
Wyss R, Girman CJ, LoCasale RJ, Brookhart AM, Stürmer T. Variable selection for propensity score models when estimating treatment effects on multiple outcomes: a simulation study. Pharmacoepidemiol Drug Saf. 2013;22(1):77–85.
Patrick AR, Schneeweiss S, Brookhart MA, Glynn RJ, Rothman KJ, Avorn J, Stürmer T. The implications of propensity score variable selection strategies in pharmacoepidemiology: an empirical illustration. Pharmacoepidemiol Drug Saf. 2011;20(6):551–9.
Fitzmaurice GM, Laird NM, Ware JH. Applied longitudinal analysis, vol. 998. Hoboken: Wiley; 2012.
Ridout M, Hinde J, DeméAtrio CG. A score test for testing a zero-inflated Poisson regression model against zero-inflated negative binomial alternatives. Biometrics. 2001;57(1):219–23.
Ahn YH, Kim ES, Ham OK, Kim SH, Hwang SS, Chun SH, Gwon NY, Choi JY. Factors associated with the overuse or underuse of health care services among medical aid beneficiaries in Korea. J Community Health Nurs. 2011;28(4):190–203.
Kim W. Impact of changes in medical aid status on health care utilization. Seoul: Graduate School, Yonsei University; 2018.
Lee W-Y, Shaw I. The impact of out-of-pocket payments on health care inequity: the case of national health insurance in South Korea. Int J Environ Res Public Health. 2014;11(7):7304–18.
Choi JW, Park E-C, Chun S-Y, Han K-T, Han E, Kim TH. Health care utilization and costs among medical-aid enrollees, the poor not enrolled in medical-aid, and the near poor in South Korea. Int J Equity Health. 2015;14(1):128.
Shin H. Gaps in health security and ways to narrow them. In: Health and Welfare Policy Forum, vol. 2009; 2009. p. 16.
Kim J-H. Comparative study on public health care coverage for low income bracket -comparison between medical benefits and Medicaid. Korean Comp Govern Rev. 2013;17(3):195–220.
Lee YJ. The analysis on the cost sharing system in Korean Medicaid: copayment or coinsurance. Korean J Econ. 2014;21(1):69–82.
Kim J, Ko S, Yang B. The effects of patient cost sharing on ambulatory utilization in South Korea. Health Policy. 2005;72(3):293–300.
Chandra A, Gruber J, McKnight R. The impact of patient cost-sharing on low-income populations: evidence from Massachusetts. J Health Econ. 2014;33:57–66.
Culyer AJ, Newhouse JP, Pauly MV, McGuire TG, Barros PP. Handbook of health economics: Elsevier; 2000.
Selby JV, Fireman BH, Swain BE. Effect of a copayment on use of the emergency Department in a Health Maintenance Organization. N Engl J Med. 1996;334(10):635–42.
Nelson AA Jr, Reeder CE, Dickson WM. The effect of a Medicaid drug copayment program on the utilization and cost of prescription services. Med Care. 1984;22:724–36.
Hartung DM, Carlson MJ, Kraemer DF, Haxby DG, Ketchum KL, Greenlick MR. Impact of a Medicaid copayment policy on prescription drug and health services utilization in a fee-for-service Medicaid population. Med Care. 2008;46(6):565–72.
Korea Statistics. Korean statistical information service. 2018. Available at: http://kosis.kr/eng/index/index.do. Accessed 19 Oct 2020.
The authors are grateful to the Korea Institute for Health and Social Affairs for providing access and permitting the use of the Korea Welfare Panel Study data.
This study was supported by a faculty research grant of Yonsei University College of Medicine (6–2018-0174 and 6–2017-0157).
Department of Public Health, Graduate School, Yonsei University, Seoul, 03722, Republic of Korea
Doo Woong Lee & Dong-Woo Choi
Department of Preventive Medicine, Ajou University School of Medicine, Suwon, 16499, Republic of Korea
Doo Woong Lee, Jieun Jang & Dong-Woo Choi
Institute of Health Services Research, Yonsei University, Seoul, 03722, Republic of Korea
Jieun Jang, Sung-In Jang & Eun-Cheol Park
Department of Preventive Medicine, Yonsei University College of Medicine, Seoul, 03722, Republic of Korea
Sung-In Jang & Eun-Cheol Park
Doo Woong Lee
Jieun Jang
Dong-Woo Choi
Sung-In Jang
Eun-Cheol Park
DWL: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Roles/Writing - original draft, Visualization; JEJ: Methodology, Conceptualization; DWC: Methodology, Conceptualization; SIJ: Methodology, Conceptualization, Supervision; ECP: Conceptualization, Supervision. All authors read and approved the final manuscript.
Correspondence to Sung-In Jang.
Not applicable, as Korea Institute for Health and Social Affairs provides the Korea Welfare Panel Study data in the public domain.
Additional file 1: Figure S1
. Study design used for the analysis.
Additional file 2: Table S1
. Estimated Average Health Care Utilization and Out-of-pocket Medical Spending Difference in Medical Aid Type I panel by difference-in-differences analysis. Abbreviation: Medical Aid, MA, National Health Insurance, NHI, Confidence Interval, CI. * Log Link with Zero-Inflated Negative Binomial Distribution was applied in the regression analysis because of exceess zeros in the outcomes. a Models additionally adjusted for individuals' health related characteristics (mostly visited type of medical institution, lasted period of chronic disease). b Propensity score matched for sex, age, region, equivalized household disposable income, marital status, economic activity status, number of private insurance, expenditure on private insurance.
. Estimated Average Health Care Utilization and Out-of-pocket Medical Spending Difference in Medical Aid Type II panel by difference-in-differences analysis. * Log Link with Zero-Inflated Negative Binomial Distribution was applied in the regression analysis because of exceess zeros in the outcomes. a Models additionally adjusted for individuals' health related characteristics (mostly visited type of medical institution, lasted period of chronic disease). b Propensity score matched for sex, age, region, equivalized household disposable income, marital status, economic activity status, number of private insurance, expenditure on private insurance.
Lee, D., Jang, J., Choi, DW. et al. The effect of shifting medical coverage from National Health Insurance to Medical Aid type I and type II on health care utilization and out-of-pocket spending in South Korea. BMC Health Serv Res 20, 979 (2020). https://doi.org/10.1186/s12913-020-05778-2
Health care utilization
Difference-in-differences
Utilization, expenditure, economics and financing systems | CommonCrawl |
Nyquist Plot for transfer functions with poles at the origin
I'm learning Nyquist plots and something has been seriously bugging me when treating poles or zeros in the origin. Nyquist plots obtains information based on the argument principle which states
"If f(z) is a meromorphic function inside and on some closed contour C, and f has no zeros or poles on C, then
$${\displaystyle \oint _{C}{f'(z) \over f(z)}\,dz=2\pi i(N-P)} \oint_{C} {f'(z) \over f(z)}\, dz=2\pi i (N-P)$$ where N and P denote respectively the number of zeros and poles of f(z) inside the contour C, with each zero and pole counted as many times as its multiplicity and order, respectively, indicate."
So we just ignore the fact the transfer function contains a pole over the contour $C$? How can we treat them normally when it clearly violates the argument principle?
frequency-spectrum frequency-response nyquist poles-zeros stability
Colin HicksColin Hicks
$\begingroup$ Are you talking about the closed-loop or open-loop transfer function? $\endgroup$ – Matt L. Apr 1 at 7:27
$\begingroup$ Doesn't matter, what ever you are finding the Nyquist plot of. Closed or open loop, in terms of the math it's just a function. $\endgroup$ – Colin Hicks Apr 1 at 8:10
$\begingroup$ Oh, I see, you are talking about the Nyquist contour. You don't ignore Poles on it. If you have a pole on the imaginary axis, you usually modify the Nyquist contour in such a way, that you avoid the pole with a half circle of $r\rightarrow 0$. $\endgroup$ – Max Apr 1 at 9:27
$\begingroup$ I totally thought I did accept it! I swear I clicked that checkmark. Your answer was very interesting indeed, especially because the stability conclusion is independent on which way you decide to make the contour! $\endgroup$ – Colin Hicks Apr 7 at 21:34
$\begingroup$ @ColinHicks: Maybe you upvoted it :) Anyway, the decision if the system is stable or not must indeed be independent of the contour. But the number of poles inside the contour (and, hence, the number of encirclements of the origin) is different, depending on which way you circumvent the poles on the imaginary axis. $\endgroup$ – Matt L. Apr 8 at 6:05
We don't ignore poles on the contour. As mentioned in a comment, poles are avoided by modifying the contour as shown in the figure below, where a contour appropriate for a pole at $s=0$ is shown.
Fig. 1: Nyquist contour for a pole at $s=0$ (from "Modern Control Engineering" by K. Ogata).
The contour moves around the pole along a semi-circle centered at the location of the pole. The radius of that semi-circle approaches zero, such that the whole right half-plane is enclosed by the resulting contour. Note that by choosing the contour in this way, a pole on the imaginary axis is outside the contour, and will not add to the encirclements of the origin in the Nyquist plot.
Of course we could also move along a semi-circle in the left half-plane to avoid a pole on the imaginary axis. In that case, the pole would be inside the contour.
As an example, consider the function
$$F(s)=\frac{(s+2)^2}{s(s+1)}$$
It has a double zero in the left half-plane, one pole in the left half-plane, and one pole on the imaginary axis at $s=0$. If we use the contour shown in Fig.1, we get the Nyquist plot shown in the right-hand side figure below (the corresponding contour is shown on the left).
There is no encirclement of the origin, in agreement with the fact that there are no poles and zeros inside the contour. Note that due to our choice of the contour, the pole at $s=0$ is outside the contour.
If we choose a different contour with a small semi-circle in the left half-plane to avoid the pole at $s=0$ (left-hand side figure below), the pole at $s=0$ is inside the contour, and, consequently, the Nyquist plot shows one counter-clockwise encirclement of the origin (right-hand side figure below), corresponding to one pole and no zeros inside the contour.
In sum, poles on the imaginary axis are avoided by moving along semi-circles of infinitesimal radius, and, depending on whether the semi-circle is in the right or the left half-plane, the poles on the imaginary axis are either outside or inside the contour, which is reflected in the Nyquist plot by the number of encirclements of the origin.
answered Apr 6 at 10:23
Not the answer you're looking for? Browse other questions tagged frequency-spectrum frequency-response nyquist poles-zeros stability or ask your own question.
Nyquist plot interpretation when curve hits the origin | CommonCrawl |
An excursion into particle physics and cosmology for non-science students
Home A Little Bit About This On-line Text Lesson 1. Once Upon a Time... Lesson 2. What Can We Know, and How? Lesson 3. Mathematics, The M Word Lesson 4. Motion, Getting From Here to There Lesson 5. The Big Mo, Force and Momentum Lesson 6. Collisions, Banging Things Together Lesson 7. Energy, It Just Keeps Going and Going Lesson 8. Early Cosmology Lesson 9. The Cosmologies of Galileo and Newton Lesson 10. Charge It! Charges and Magnets Lesson 11. Faraday's Experiments and An Extraordinary Idea Lesson 12. Faraday's E&M Fields Lesson 13. Maxwell's Fields Annotate me
Distributed with an MIT license.
QS&BB
Quarks, Spacetime, and the Big Bang
Lesson 7. Energy, It Just Keeps Going and Going
"…wherever mechanical force is expended, an exact equivalent of heat is always obtained." James Prescott Joule, August (1843)
The University of Manchester in that original industrial city has been the home of to-be illustrious physicists as well as already-in-the-textbooks physicists for more than 150 years. Ironically, the Manchester scientist credited with one of the most fundamental statements about the word had nothing to do with the university. He made beer. James Prescott Joule was the son of a brewer who joined the management of the family business in his early 20's where he launched intensive research into how to increase the efficiency of, or replace its large-scale steam engines. This led to a lifetime of largely private research into the nature of energy.
A Little Bit of Joule
Ability to Do Damage: Kinetic Energy
Classification of Collisions
Let's Talk About Damage
Now Let's Explain "Damage"
That Stop Shot
Eager to Do Damage: Potential Energy
What Goes In Must Come Out
Okay, But What Is It…Really?
The Exchange of Potential and Kinetic Energies
Keeping Track of Energies Geometrically
Energy and Momentum, From 50,000 Feet
Noether's Theorem, In A Nutshell
What to Remember from Lesson 7?
Energy Units
Energy Relations
Goals of this lesson:
I'd like you to Understand:
How to calculate kinetic energies of moving objects.
How to calculate potential energies of objects.
How to use the conservation of energy to calculate speeds. parameters
I'd like you to Appreciate:
The importance of the conservation of momentum and energy.
I'd like you to become Familiar With:
The novelty of James Joule's experiments and interpretation.
The fundamental importance of Emmy Noether's work.
The most famous person in Manchester, England in the 1830s was the quiet John Dalton. An unassuming bachelor, he boarded with the same family for a quarter of a century…while he collected awards from scientific societies from around the world.1 We remember Dalton today as the person most responsible for modeling the properties of chemical reactions by imagining atomic structure as composed of molecules, which in turn, he modeled as consisting of atoms. Of course this suggested an unpopular commitment to the reality of the atoms which most were still not prepared to make. But nonetheless, even if not actual bits of reality, his molecular model was a mental organizing picture that proved useful – and of course eventually, real.
Dalton divided his time between personal scientific research and private tutoring which leads us to another reason for our indebtedness: among the students whom he privately tutored was a young James Joule, destined to become the next of a string of famous Manchester scientists that continues to this day.
Manchester teacher and student.
In the 19th century Manchester was an engineering community, the hub of the industrial revolution in Europe and proud its string of technological "firsts" in engineering, infrastructure, and transportation. Joule fit right into that spirit. Today, if you turn on a baseboard heating strip because you're cold or crank up your air conditioner (or retrieve a cold drink from your refrigerator) because you're hot…you're deploying two of James Joule's most enduring discoveries. About heat. He was the king of heat.
Joule grew up in a wealthy family successful because they weren't shy about applying technology to commerce: they made beer.
Still making beer.
Joule had an adolescent fascination with electricity, probably influenced by the famous work of Michael Faraday in London. When he and his brother were not (literally!) shocking their family and the household staff, James was beginning to conduct research on what causes heat. Electrical motors had just been invented (we'll learn about Michael Faraday in a bit) and he built several and studied how to improve their efficiencies. What he had going for him were his systematic experimental instincts, the inspiration of his teacher, and…thermometers.
Brewers knew how to measure temperatures very accurately and very precisely.
Precision and Accuracy
Do you know the difference between precision and accuracy? Here's an example that will help. In the 1980's digital watches were just becoming available and I had a graduate student who was a proud owner of one. The stem on that watch reset the time—to 12:00pm. So every time he moved his wrist, the time on his watch would become noon. Not very useful.
His watch was very precise…it was digital…but terribly inaccurate…it gave the wrong time. He had no idea what time it was, but he knew that very, very well.
Joule developed thermometers capable of measuring temperatures with a precision of 1/20th of a degree. Another thing he had going for him were his family's resources – his father built him a laboratory and he did publishable research in electro-chemistry motivated by Faraday's contemporaneous work in London.
Joule heating
Bring your hand close to an incandescent light bulb. Hot, right? Where did that heat come from? Joule experimented with motors and one of the first things he attempted was to rid his motors of internal friction and in the course of that mundane chore, he started his assault on the prevailing view of the nature of heat.
For nearly half a century, the notion that heat was a fluid substance ("caloric") that flowed from one object to another. If something got warm, that's because caloric had flowed into it. Your light bulb isn't consistent with that idea – there's no place for the caloric to have flowed from. It has to be produced from within the filament itself. This is now called Joule Heating, the heat generated when an electrical current flows through a resistive medium. He experimented with electrical, chemical, gaseous, mechanical, and fluid systems comparing energy in…with energy out of each. He suspected a revolutionary connection among all of them.
Want to make beer on a commercial scale? You need to heat up large quantities of water and that's expensive. So the industrialist in Joule led him to a comparison of battery-powered and coal-fired heating elements. After detailed experimentation, he concluded that coal was far more efficient—using up coal was then cheaper than using up the dissolving components of early batteries. His scientific researches were often connected to his business and until he sold the brewery in 1855, he spent part of his day in the affairs of running an industrial-sized company and considerable time with his research.2
About steam engines. The first railroad in the world was built between Manchester and Liverpool and was innaugurated on September 30th in 1830, when Joule was 12 years old. It must have been memorable to a young boy since one of the dignitaries was actually killed when he fell into the path of one of the trains.
The Liverpool and Manchester Railway consisted of two sets of tracks which carried people and materials over the 26 miles between the two industrial centers. The trains were powered by steam engines and steam engines were a familiar city sight (and sound). In that textile center of the industrial revolution universe there were more than 50 steam-engine-powered cotton mills at the turn of the 19th century.
In Joule's business and his city's lifeblood there was no misunderstanding of how to make mechanical motion on a grand scale: heat water, produce steam, and engineer the steam to move pistons. That is:
Heat $\to$ Motion.
This was consistent with the caloric idea but the opposite process wasn't necessarily so:
Motion $\to$ Heat?
Could motion make heat?
This question slowly formed in Joule's mind as he performed experiments on the heating of battery-powered circuit elements and fluids of all sorts. He found a common feature of all of them: a given amount of mechanical motion (turning a crank, or electrical current, letting a weight fall…) would produce the same temperature rise in water or any liquid. His first efforts were comparing a battery-driven (and hence, chemical origin) with a generator (and hence mechanical origin). His results were not well-received. Bored, was the response.
His seminal experiment was to directly heat water, but in a novel way. He suspected and showed that if you stir a fluid, it gets warmer. Not a lot. But Joule had inherited Dalton's idea that a gas was made of atoms (and developed his own theory of gases and the energy of molecules) and that making them move faster was to increase their temperature. He also applied this idea to water. He created a little system with paddles in a beaker of water that could be made to stir the water a specified amount because they were attached to a falling weight. The weight falls a given amount and the paddles reliably turn a specific number of rotations. His experience with precision thermometers allowed him to figure out that a finite amount of stirring could raise the temperature of water by a single degree Centigrade. He reported this result to the British Association in 1845 and published a paper describing his results in the Philosophical Magazine.
He once made a thermometer so precise that he could measure the temperature of moon-light. That is the temperature rise in air lit only by the moon
He found the same amount of mechanical effort was required to raise the temperature of the water as in his electrical experiments! Excitedly he proposed to report on his work at a scientific meeting in 1847 and was basically told that since nobody really ever cared about his work, that he should keep his remarks very short. He did, but a young audience member asked important questions.
The young man was William Thomson, who was eventually raised to peerage as Lord Kelvin. Today we refer to temperature in units of Kelvin and energy in units of Joules.
When was the last time you bought a light bulb? Look at the package and you'll maybe see reference to "Light appearance 2700K" …or "Soft white 2700K" or 2100K or "Daylight 5000K"…these are all temperatures which we'll learn later because of quantum mechanics! Temperature of heated objects directly points to the color (wavelength) that's emitted. Stay tuned.
In particular the Joule was designated the year James Joule died, memorializing his life's work. In modern language, his earlier mechanical equivalent of heat is that it takes 4.184 Joules of energy to raise 1 cubic centimeter of water one degree Celsius. His measurements were all consistent with this amount.
"The paddle moved with great resistance in the can of water, so that the weights (each of four pounds) descended at the slow rate of about one foot per second. The height of the pulleys from the ground was twelve yards, and consequently, when the weights had descended through that distance, they had to be wound up again in order to renew the motion of the paddle. After this operation had been repeated sixteen times, the increase of the temperature of the water was ascertained by means of a very sensible and accurate thermometer.
"A series of nine experiments was performed in the above manner, and nine experiments were made in order to eliminate the cooling or heating effects of the atmosphere. After reducing the result to the capacity for heat of a pound of water, it appeared that for each degree of heat evolved by the friction of water a mechanical power equal to that which can raise a weight of 890 lb. to the height of one foot had been expended."
Joule in 1849
"I will therefore conclude by considering it as demonstrated by the experiments contained in this paper, –
1st. That the quantity of heat produced by the friction of bodies, whether solid or liquid, is always proportional to the quantity of force expended. And,
"2nd. That the quantity of heat capable of increasing the temperature of a pound of water (weighed in vacuo, and taken at between 55° and 60°) by 1° Fahr., requires for its evolution the expenditure of a mechanical force represented by the fall of 772 lbs through the space of 1 foot."
Joule in 1850…some refined measurements brought his mechanical equivalent much closer to the modern value.
Heat and motion are both forms of energy which can be converted back and forth—and not disappear.
It is that "back and forth" that has been historically credited to Joule and that's just a colloquial way of saying that energy is conserved. What you put into a system by mechanical means, you'll get back in heat and visa versa. Nothing's lost. Nothing's spontaneously created. It transforms from one form to another.
"Nothing can be lost in the operations of nature – no energy can be destroyed."
Lord Kelvin, 1847
From a similar investigation of all other known physical and chemical processes, we arrive at the conclusion that nature as a whole possesses a store of [energy], which cannot in any way be either increased or diminished; and that, therefore, the quantity of [energy] in nature is just as eternal and unalterable as the quantity of matter. Expressed in this form, I have named the general law "the principle of conservation of [energy]".
Hermann Helmholtz, 1847
Joule married Amelia Grimes in 1847 (who tragically died seven years later after they had two sons and a daughter). Their wedding get-away was in Chamonix, France (near CERN, actually) where together they tried to measure the difference in temperature between water at the top of a waterfall and the bottom. You gotta love that as a scientist's honeymoon.
Joule was a little isolated while he did much of his work, but increasingly he became more and more well known and well regarded in Europe. Without any formal education, this recognition came slowly but eventually he was elected to Fellowship in the Royal Society in 1850 and received honorary degrees from Dublin, Oxford, and Glasgow. Finally, in 1872, he served as the President of the British Association. Not bad for a brewery lad.
James Joule convinced everyone that heat and work (we'll see what the formal definition of work is below) are two sides of the same coin: energy. That "energy" can be transferred back and forth between heat and work is basically the First Law of Thermodynamics and the basis of the world's industrial economy and many of our household conveniences. It led to the notion of the conservation of energy and guides our thinking to this day. In a lifetime of scientific work, we remember him for first demonstrating that:
He even drew on his Dalton influences and began to think of heat as the fast motion of molecules, even contemplating their average speeds.
Joule died in 1889 and is honored forever with his name used as the universal unit of energy: 1 Joule (J) is the equivalent of 1 kg-m$^2/s^2$. We pay our electricity bills according to the number of Watts recorded by your utility provider (it's one of the only everyday metric unit in the U.S.): 1 Watt is 1 Joule per second (J/s), which is power. To the people. (See what I did there?)
Okay. "Ability to Do Damage" isn't a scientific phrase…but I'll bet you'll remember it better than our very specific use of a very regular word: "work." If you want to do damage to something, you initiate some sort of contact with it and speed often figures into that process. Want to demolish something with a hammer? Gently pat it? or swing the hammer at high speed? Want to smash a teapot by dropping a rock onto it? Drop it from high up so it's moving really fast when it hits. So if you want some damage, you need some speed.
But mass figures in too: a hammer made out of balloons is not a damage-maker and neither is a pebble. So a question is: what's more important, mass or speed in inflicting damage? This subject is tightly coupled to our favorite collision-topic of momentum.
Let's go back to high school.
Wait. No! No no no no!
Calm down. It's just a cheap story device.
Imagine that Principal Crotchety took away the catchers mitts from the boys baseball and girls softball teams, so each catcher must catch a pitched ball with his or her bare hands.
A regulation softball has a mass of about 0.22 kg while a regulation baseball has a mass of just about half of that, 0.145 kg. Here's the question: An average high school softball pitch is about 50 mph – 10 or 15 mph faster than that, and you've got a college pitcher on your hands. But a 50 mph baseball is not so impressive: that's less than batting practice speeds. Consider these two trade-offs, and think about having to bare-hand catch the following:
Replace a baseball thrown of 50 mph with a softball of the same speed – a factor of 2 increase in mass, but same speed?
Replace a baseball thrown at 50 mph with a baseball thrown at 100 mph – a factor of 2 increase in speed but the same mass?
Which pitch would do proportionally more "damage"—hurt more? I'd take the first example any day.
Our catcher, Herman, is warming up his disappointing, 50 mph pitcher barehanded. After each pitch the baseball would compress and bend his skin, the underlying facia, muscle, and fluids until the ball comes to rest. That compression hurts and blood rushes to start the tissue repair and he'll bruise (that's the…damage). Across the field, Blanche is barehand-catching her terrific pitcher who's throwing 50 mph softballs. She's putting up with more damage to her hands. But while damage was done to both, did either one fall down? Probably not. This comes to the interplay between momentum and "damage" which will become clearer in a bit.
To the best of my knowledge, Galileo wasn't a baseball fan, but he did think about pile-drivers—those devices that transport a large mass into the air and then release it directly over a beam (the pile) that needs to be driven into the ground. He found two interesting things:
First, the higher you go to release the weight, the deeper the beam is driven into the ground. But not linearly. Galileo speculated about this (by listening to the sounds of pile drivers). It was measured a century after him in 1720 by Dutch natural scientist Willem Gravesande at Leiden University who dropped balls of different masses on clay. He found that if one drops a mass that it dents the clay landing-spot. No surprise there. If one then doubled the speed just before the impact the result is a dent which was four times deeper than the original. That's suggested in the figure below.
Galileo also found that the speed of an object in free-fall increases slower than linearly…if you drop an object from 10 feet and measure the speed at the bottom and compare that to the speed from a drop twice as high you'll find that the speed increases by a factor of $\sqrt{2}$, about 1.4.
Finally, Galileo speculated that if you launched an object vertically with that final speed, it would go back to the original height. This is also suggested in the figure below.
The above list in figures. (a) shows that the higher the fall, the deeper the indentation by the square of the distance. (b) shows that the higher the drop, the faster an object goes by the square of the velocity. And, (c) shows that a ball will return to the original height if shot from below at the speed it would have fallen.
Catching a baseball is an $A+B \to C$ type of collision, one of those that we identified during the last lesson.
An Example: The final speed in an $A+B \to C$ collision
The Question: Using our example of Herman catching a 50 mph baseball as an example, what is the speed of Herman and baseball after he's caught it?
Let's calculate Herman and the baseball's collective velocity after he's caught a pitch: the final state is now a compound system consisting of (Herman + baseball), our $C$ (unless he drops it!).
We solved simple problems like this in the previous lesson and here we could take the same approach which relies on momentum conservation to insure:
The $A+B \to C$ type collision is particularly easy to solve and we experience it or read about it in happy ways (a great, big hug) and in tragic ways (a bullet injury). Let's define some terms, and I'll put the solution to the equations into a graphical model.
First, here's a picture of our situation:
(a) a beam ($A$, the baseball) hits a target ($B$, Herman) to (b) create a third, compound object ($C$, Herman holding the ball).
Let's simplify that momentum conservation equation to take into account that Herman is stationary before the collision, so $v_B=0$. Let's rewrite it with that in mind and fill in the momenta with their names and solve for the velocity of Herman and the ball together:
So the velocity of the combined object depends only on the masses of the ball and Herman, if he's sitting still. Let's put in the numbers:
$v_A=50$ mph, which is $v_A=22$ m/s
$m_A=0.145$ kg
$W_B=140$ lbs which is $54$ kg
So the speed at which Herman and the ball move backwards is really small:
The light baseball slowed from 22 m/s to 0.06 m/s when caught by the massive, but slight, Herman.
Wait. This surprises me. I've caught balls before and it seems awfully slow, especially for catching a fast ball.
Glad you asked. I agree. In this (perfectly constructed) example, there's only an imperceptible speed after that fast ball hits its target (Herman). Stay with me, and we'll find where the speed went!
If there's so little speed transfer, why would that 100 mph baseball hurt so much more than a 50 mph baseball? The hint is in the results from that 1720 clay experiment. You see: when a moving object does damage to a another object, speed matters more than mass, in fact it matters by a lot more.
Since mass and velocity contribute to momentum in equal proportions, "damage" refers to some other quality of motion, different from momentum. We call it Kinetic Energy. We'll use the symbol $K$ to stand for it and in modern terms, its ability to do damage is related to the square of speed and only one power of mass. Our modern notion (since the late 1800's) came slowly.
One of the remarkable achievements of Huygens, anticipating Newton's concept of mass, was the discovery of a second conserved quantity. In this, Huygens had an eventual partner: Gottfried Leibnitz—Newton's bitter rival for the priority of the Calculus—who independently had the same idea. They both found by calculation and experiment that if you add up all of the quantities: $mv^2$ for all of the objects in a special kind of collision that the total amount of that quantity before is equal to the total amount afterwards…without regard to direction. That is, since the velocity is squared this is not a vector quantity, but a scalar one. Just numbers.
Leibnitz inconveniently called this quantity $mv^2$ a "force," in particular the "life force" or "vis viva." Today (actually, about mid-18th century), a factor of $\frac{1}{2}$ is added in order to create the quantity we call:
It was Huygens.
Here's a story of hurt feelings and over-the-top gentlemanly behavior. Unsatisfied with Descartes' approach to what we now call momentum, Huygens worked out both momentum conservation and kinetic energy conservation some time around 1656, wrote it up, and didn't publish it. But. In a trip to London he told colleagues of his ideas.
Imagine his surprise when Christopher Wren and John Wallace each submitted papers to the Royal Society (RS) using his ideas—Wren solving the "elastic collision" problem and Wallace solving the "inelastic problem" (Herman's baseball problem). He learned about it because the head of the RS sent the papers to Huygens for comment!
Although he must have been hurt, Huygens replied by submitting his unpublished solutions—in Latin—as his review of their papers. Undeterred, the RS ignored Huygens' manuscript and published Wren's and Wallace's work without mentioning him. Huygens then reduced his solutions to two pages—in French—and submitted that to the Royal Society's French publishing competitor.
That got the attention of the RS which quickly translated Huygens' two pager into Latin and published it in the RS journal with a nearly two page Royal Society Apology. Of course, Huygens then expressed his heartfelt appreciation for his foreigner RS membership. Everyone was nice.
Christiaan Huygens was The Man. Only eclipsed by Isaac Newton, The Other Man.
One of the aspects of this that's confusing is that Huygens' conservation only happens in particular kinds of collisions, which I hinted at in the last lesson. If two colliding objects have no parts—if they're elementary and fundamental—then, and only then, is $K$ conserved.
But nothing about our everyday world is that way. Everything's got parts! But it is possible to create materials such that when they collide they first, bounce off of one another (not Herman's caught baseball, but more like billiard balls) and second, when they collide they compress very little. In that case, even everyday collisions can be very close to that special kind. We call these collisions, "elastic" and they're an idealization—unless you're a particle physicist! When two electrons or protons or any elementary, no-parts-kind-of-object collide, they do so elastically. The defining feature of elastic collisions is that Kinetic Energy is conserved. So in QS&BB, unless I'm trying to make an everyday-sort of point: we'll count on Kinetic Energy conservation.
The damage-producing collisions of the sort that Blanche and Herman dealt with do not conserve Kinetic Energy between the initial and final states of those macroscopic baseball and people objects. Both of which have parts. We call these real-life collisions, "inelastic" and the kind of $A+B \to C$ collisions that we talked about with baseballs are the completely inelastic collisions. They maximally don't conserve Kinetic Energy!
How about momentum? You can always count on momentum conservation.
For Elastic Collisions: momentum is conserved and kinetic energy is conserved.
For Inelastic Collisions: momentum is conserved, but kinetic energy is not conserved.
For Totally Inelastic Collisions: momentum is conserved and kinetic energy is maximally not conserved.
So, to summarize what's conserved in collisions. For elastic collisions between object 1 and object 2, we separately conserve:
Here $v_{0}(1)$ and $m(1)$ are the initial velocity and mass of object 1 and $v(1)$ is the final velocity of object 1, and so-on for object 2.
The first equation is the Conservation of Momentum, a vector equation and the second is the Conservation of Kinetic Energy appropriate for elastic collisions.
Both momentum and kinetic energy are separately conserved in all elastic scattering processes.
If any object is moving, it has kinetic energy. If not, then it doesn't. So what happens when our baseball is caught? Let's calculate the kinetic energy of that 50 mph baseball and then the kinetic energy of Herman and the baseball combined.
Wait. Disappear? The kinetic energy "disappears"??
Glad you asked. I warned you that kinetic energy is not conserved in inelastic collisions and this kind of two objects become one object is the most unconserved collision of all! But "disappeared" needs some explanation, and that goes along with "damage."
To appreciate this, we need to appropriate an everyday word for a specific, physics-y purpose: Work.
Do you appreciate that the clay drop is, well different, but really the same as Herman and Blanche's bruised hands? They're both an impact and embedding of a projectile with a flexible target.
Imagine that a ball of a given velocity, $v_1$ is thrown at model of your hands, which are very clever hands since they can determine the depth of the resulting bruise:
A fictional way to measure what it takes to stop a baseball: some force and some "give," right?
What happens in the inside, so to speak? Your hands are flexible and squish-able (the spring) and will compress with the ball's impact but will also apply a varying, but here an average force back at the ball, slowing it to a stop. That's represented by the $F_1$ while the depth through which that force pushes back is the length $d_1$ in the diagram. It turns out that the product of these two latter quantities is a very useful item.
The fancy way to speak about this $F_1 \times d_1$ quantity is in terms of "work" which means something very specific in physics. Work is in fact that product of (force $\times$ the distance through which the average force acts), $W=F\Delta x$.
This is similar to the way that Impulse is the product of (force $\times$ the time through which the force acts). Sometimes the symbol $J$ stands for impulse, and so we'll name it in order to stand in comparison to work: $J=F\Delta t$. And here's the connection to our concern: that quantity $F\Delta x$ is equal to the change in the kinetic energy of the object, in this case, the baseball:
which looks a lot like
Optional derivation
The relationship for Work can be simply derived from the $v^2=v_0^2 + 2a\Delta x$ kinematics relationship from Lesson 4 and Newton's Second law, $F=ma$ from Lesson 5. For your viewing pleasure, here's a short video that demonstrates this.
Go to video of derivation (7.1-7.3_kinetic_energy_v2_w1-1m) for review and wrap-up of these sections.
The partnership between time and space is related to the partnership between energy and momentum, as we'll see a bit later.
An Example: Working
The Question: How much work is done by a force of 20 N on a box of apples that has a mass of 10 kg if it's pulled along a frictionless floor for a distance of 10 m?
Work is the product of the force and the distance, so
Work is equal to the change in kinetic energy – a force applied through a distance – in a similar way that Impulse is equal to the change in momentum – a force applied during a time interval.
An Example: Working to gain speed
The Question: Back to that box of apples. Suppose the box was sliding along the floor at a constant speed of 5 m/s and then you started to push on it with that force of 20 N from a bit ago.
How fast is it going after you supplied the work through that 10 m?
Here's how to think about this. The box of apples initially had some kinetic energy since it was moving before you pushed on it. The work is equal to the change in kinetic energy. Since there is a force applied, it will now accelerate and after that 10 m will be going faster than the original 5 m/s. How much faster is related to its resulting kinetic energy. So let's calculate the new kinetic energy after we push:
We can now calculate that final speed by taking apart the final $K$:
I began with the idea of "damage" and now it's time to explain myself. A rearrangement of the internal "parts" of any colliding object comes from the kinetic energy of the colliding objects. Take Blanche's hands. Her hand-parts are her skin, facia, muscles, tendons, ligaments, and bones. When the ball strikes her skin, it transfers momentum to all of those parts along the ball's direction, sure. But it does that by distributing momentum among the elements of her hand…pieces of which move internally causing them to gain speed very quickly, for a very short distance. That is, pieces of her hand do work on other pieces of her hand and the kinetic energy of those pieces changes—often at the molecular level. Some of that momentum transfer is in the direction of the ball—once her palm is squished to its limit, then the rest of her moves that direction because her wrist and elbow resist almost rigidly. She balances momentum along that ball's direction by moving her whole body a bit. But some of the momentum transfer is not in the original direction, because her hand is made of…parts.
Since kinetic energy is not a vector, there will be some compression and tissue tear (which requires Work to accomplish) in all directions, say towards her thumb which will be balanced by some other compression and tissue tear in the opposite direction, say opposite, towards her little finger, and so on. In each little disruption, momentum is balanced (thumb-finger), but the motions are in all directions. So very quickly, the original ball's velocity is given up to a) Blanche as a whole along the ball's trajectory—which we say from the first graph is very little—and b) the individual pieces in all directions which make up Blanche's hand. If you could capture and measure all of the speeds of the pieces of her hand, you could get closer to the original kinetic energy balance that seems so out of whack when you deal only with the whole Blanche and the whole ball. These bits of motion collectively make up "internal energy" of a system. The end result, after the big bits of her hand have settled down comes from Mr Joule: heat. Molecules, crystals, tissues, etc are still vibrating and rotating and translating…these motions even in solids are the definition of heat.
Let's keep track of all of the little bits of momentum and energy transfer as the ball leaves the pitcher's hand and settles into the bruise that it makes on Blanche's hand.
On its way, the air in front of the ball is compressed, which means that the air molecules are accelerated and move faster than before…that is, the air is heated and according to Joule's work, that takes away some of the ball's kinetic energy.
The ball is spinning and the drag on the air likewise locally compresses and rarefies the air—the seams on a ball dig into the air and make the ball curve and drop, but also result in turbulence along the path and, you maybe guessed it, heat up the air along the way.
You can hear a ball go by. If you've ever nearly been beaned in the head by a fastball, you know this. That compression above actually propagates away from the ball's trajectory making the air create a compressional wave which eventually has hit your ear drum. That wave does Work on your eardrum and internally—molecularly—makes it warm. More heat-energy transferred away from the ball.
When the ball hits Blanche's hand it does all of the Work that is described above but eventually the moving tissues become heat—her hand will feel warm because blood has arrived to repair the damage.
You'll hear the ball hit her hand! Again, the vibrations of the ball and her hand will create compressional waves that will leave the collision at the speed of sound and warm up all of the ear drums of every spectator and player. More heat.
Finally, in parallel with the bits of her hand compressing, twisting, bending, and warming…the ball also will distorts, compresses, and vibrates—and gets warm—and releases that tension and adds to the sound.
In the end, all of the lost kinetic energy becomes heat, whether in a completely inelastic collision like catching a baseball, or only a "regular" inelastic collision. Think of the sound that even very hard billiard balls make when they collide—they're very briefly compressing and vibrating and that excites the air and you hear it as your eardrums warm up. Have you ever felt a racquetball after a long volley?
This is why speeding bullets can do so much damage. They're light and they travel fast. In each of the previous figures the (c) little ball is 13.9 gram musket ball from an 18th century dueling pistol that travels at about 250 m/s. It's light and people are heavy and so the amount of momentum transfer from the ball to the victim is small, but from the above figure, the amount of kinetic energy lost is enormous: $\delta =99.994\%$. All doing tragic damage. A modern bullet can travel twice or more that speed and further breaks up and twists on contact further increasing the damage.
Understanding and modeling inelastic—real-macroscopic-life—collisions can be very complicated.
Fortunately for us, QS&BB is all about individual elementary particle collisions and the distinguishing feature of elementary particles is: no parts. So without parts, our collisions are completely elastic, essentially perfectly rigid: ideal billiard balls, then electrons, protons, photons, and neutrons.
Let's clear up a confusion from the last lesson.
Now, we can go back to the incomplete example of that pesky stop-shot from Lesson 6 where we were left hanging. Without emphasizing it then, now we have to assert that these billiard balls are perfect.
Our embarrassment with the stop-shot was that Newton's momentum conservation could not uniquely predict the obvious observation of the beam-ball stopping dead while the target-ball shoots off when it's struck. We can now fix that.
An Example: One Dimensional Collision…continued
What happens if we add energy conservation to the stop-shot example?
Where we left off was:
Now, let's include the Kinetic Energy relationship for this particular situation (remember that this notation is that $v_{1,0}$ stands for the initial velocity (the 0) for object #1:
in order to get the second line I canceled out the equal masses and the common factor of $\frac{1}{2}$.
Now we have two equations and two unknowns to solve, which can be done in a variety of ways (remember?). You always have to keep track of what you're looking for. Here, it's the final velocities. If you do the simply gynmastics to eliminate the $v_{1,0}$ terms you get the result:
So, either one or the other of the final velocities must be zero. One of these solutions doesn't make any physical sense. For example, if the target ball (2) is solid, then the target ball can't just fly right through it as if it were not there, so $v_2$ cannot be zero, it must be something else. That means, that $v_1 = 0$ and going back to Eq.\eqref{speedbefore}, we see that:
which is what we expected: $v_2=0$. That's nice.
If we'd used real billiard balls which are made up of molecular parts, then kinetic energy would not have been conserved. Energy would have been lost and a large part of it would come from the sound creation by their quick compression and release. You hear that collision. But all of the above discussion had "lost" kinetic energy becoming heat. And Mr Joule determined that heat was just another form of energy. So now we're on to something.
The idea of Kinetic Energy was eventually appreciated as a part of a much broader concept. We use the term freely, but it's a subtle thing and the 17th, 18th, 19th and 20th centuries saw repeated recalibration of the energy-idea. It was not until nearly the middle of the 1800s that heat was carefully studied by many, culminating when Joule did his careful water-mixing experiment. Remember that young man, the eventual Lord Kelvin, who attended that fateful 1847 James Joule lecture? He was about the first person to begin to regularly use the word "energy" around 1850. It's so overused now. (Tired? You apparently lack "energy." We have an "energy crisis." "Energy production" is a common phrase, but incorrectly used. Who do you know who is an "energetic person"?)
Einstein will teach us a lot about energy, but we'll follow a conventional path until we get to him. One thing that stands the test of time, however, is energy conservation.
Let's write down two conservation sets of equations between a one-dimensional (no vector symbols required) collision of two objects with initial momenta $p_0(1), p_0(2)$ and kinetic energies $K_0(1),K_0(2)$ and final momenta $p(1), p(2)$ and kinetic energies $K(1),K(2)$.
Perfectly elastic collision:
An everyday, inelastic collision:
Here $K(\text{parts}$ accounts for all of the energy lost to internal motion of the parts of the objects. So, if you could capture all of the molecular-level energies of the parts (that became heat), then you could balance energy as well as momentum. So while kinetic energy is not conserved in an everyday, inelastic collision, total energy is conserved.
Putting on the Brakes
In normal driving, you acquire a speed and hence gain kinetic energy through the transformation of chemical energy into kinetic energy. Then, in order to stop, you need to remove kinetic energy from your car and for that you "step on the brakes" which means you engage a mechanism in each of your four wheels that forces two plates to rub against one another: one is rotating with the wheel, and the other is fixed to the car. That is, friction is your stopping friend. By now you know that this means that kinetic energy is converted into heat. Brakes can get very hot! So that's lost energy. In order to speed up again, you've got to burn more gasoline.
Hybrid and electric cars are smarter. When a Toyota Prius stops the car reacts to your brake pedal much differently: it causes the motor that normal propels the car forward (converting electrical energy into mechanical energy) to reverse—it becomes an generator (converting mechanical energy back into electrical energy). So when you slow down your kinetic energy is converted by the (now) generator into either electrical charge storage in a capacitor or a current that directly recharges the car's batteries. This means that 30-50% of the otherwise wasted heat in frictional braking is recovered to help you go farther than you otherwise might go on a battery charge alone. Of course, a Prius is usually a hybrid, so a gasoline engine is sometimes charging the batteries and also propelling the car forward. But an all-electric car, like a Tesla, is totally reliant on batteries and recovered kinetic energy through this "regenerative braking" mechanism.
There is a whole new racing venue called Formula E which are completely electric Formula-1-looking racing cars. As of this writing, there have been three Formula E seasons and a new "Gen2" engineering platform is to be deployed for the 2018-19 season. These cars have maximum power of more than 300 hp (always reported as "250 kW," as befitting a purely electrical device.) Unlike Gen 1, these new cars will go 45 minutes without replacing batteries. Again, there are two kinds of braking, friction and regenerative. In the new cars, the decision is made by the car's electronics, whereas in Gen 1 the driver had to decide whether to use regenerative or frictional braking each time.
Are these cars fast? They're nearly competitive with traditional Formula 1: 180 mph and 0-60 mph in under three seconds. They just sound strange.
With Mercedes, Audi, Porsche, Ford, BMW, Jaguar, Nissan, DS-Citroen, and McLaren (battery development), the technology will spill over into the commercial market as has happened in traditional racing for a century.
This is energy conservation that will change how we all get around some day.
Somewhere in your life, you probably learned that there are many kinds of energy: potential, thermal, chemical, electrical, magnetic, nuclear, gravitational, and elastic. In the above, $K(\text{parts})$ could represent the loss (as a positive number in that equation—you have to add it back in at the end) of one or more of these kinds of energies.
Wait. Energy is a kind of universal idea, but why so much complication?
Glad you asked. That's a really good question. You want to try to find something about all of these that's the same and to say that they can all produce "work" seems unsatisfactory, doesn't it. Albert Einstein's tee-shirt equation will bring a lot of this together, so stay tuned. But I appreciate your energy.
There's one particular "kind" of energy that gets special mention: Potential Energy. Here are some fine, textbook-sounding definitions:
A body or a system has energy if it can do work, that is, move something against a force. Your hammer headed towards a nail has energy. A lightening bolt has energy. A heated, pressurized boiler has energy.
The particular kind of energy associated with motion is Kinetic Energy. That's the hammer above.
The particular kind of energy associated with position is Potential Energy.
That last one bears some explanation. "Position" means that some object is being held back or prevented from being where it would be without that constraint. The simplest way to think of this is potential energy due to height.
Go to 7.1-7.3_kinetic_energy_v2_w1-1m for review and wrap-up of these sections.
If kinetic energy is the act of causing damage, Potential Energy is just what the name implies…"the potential" for causing damage! Hold a barbell above your foot and let it go, it will change the shape of your foot when it lands, and maybe the floor as well. That suspended weight possess the potential for doing Work, which it does upon landing and slowing down…through your foot and the floor. Notice that because it is held above your foot, going back to that last bullet above, its position is the determining thing: its height above the floor. Until it's released, it's held back from falling.
At the right is the picture you should have in your mind:
Here is a mass, $M$ which is suspended above a table by a height $h$. Nothing happening until it's dropped. But it has potential...for doing damage to the wood, through the nail's penetration.
For dropping things in a uniform gravitational field, the Potential Energy (we'll use the symbol $U$) is:
where $h$ is the vertical distance above the point defined to be the zero value of potential energy. Potential energy is a funny concept and I'll have more to say about it when we talk about Einstein. It comes with a slippery feature that's sometimes complicated to appreciate:
If I suspend the ball above the surface of a table, and if I assign the "zero" of potential energy to be that at the surface of the table, then when it falls to the tabletop, it has no potential energy left. But, if I take the zero of potential energy as that at the floor, then when it is done with its motion, still on the table, it still has potential energy left over relative to the floor – that associated with the height of the table. The difference between before (above) and after (the table) is still the same. Again, looking at the figure $h$ is the same distance whether it's measured relative to the surface of the table or the floor. It's the difference that counts.
How much is potential energy?
Let's get a feel for the size of everyday potential energy. Remember that our 50 mph baseball had a kinetic energy of 35.1 J. Suppose I hold it over my head, which is about 8 feet, or 2.5 m above the ground. What's its potential energy?
So the potential energy that the baseball has is
So Joules for potential energies are a pretty reasonable unit: few to hundreds of Joules in everyday life.
That's sensible since $w=mg$ is the weight of the object, the force pulled on it by the Earth. So this too is a force times a distance, $U=wh$. The typical example of potential energy at work (no pun intended…or is there?) is driving a nail into a block of wood by dropping a weight from some height as shown below and above. Look at this carefully and understand the energy at each step, (a) through (e):
Let's bring Potential Energy home. In (a), can you drive the nail into the wood? No, there's no work done by $M$ just sitting there. In (b) we slowly raised it above the nail at a constant velocity to a height $q$ above the head of the nail and we hold it there. Then we let go so that as it falls, say at (c) it's gained speed and lost height. At (d) it has just reached the nail. It then drives the nail into the wood, stopping at (e).
Here's the energy progression:
We always have to define the point at which potential energy is zero: we'll take the vertical position of the nail in (a) as $U=0$.
(a): $K=0$, because $M$ is not moving and $U=0$.
(b): Energy is put into the system by raising it: $U=Mgq$ because it's now at a position where it could potentially do work but it's constrained by the rope and $K=0$, because it's not moving.
(c): $K$ is gaining, because it's going faster and $U=Mgr$ is diminishing since $r<q$: it's getting lower.
(d): $K$ is as much as it will be and $U=$ as it was in (a).
(e): Work has been done by $M$ on the wood and a force has been applied through a distance $d$ until it stops and all of the lost kinetic energy has warmed the wood and the nail. The work done is equal to the change in $K$ which is $K-K_0$ but since $K=0$ once the nail stops, the work done on the wood is numerically equal to the kinetic energy that $M$ had just before it touches the nail at (d).
That these energies add up is the statement of the Conservation of Energy – not just kinetic, not just mechanical, but all forms of energy. The idea was hinted at by the German physician, Julius Robert von Mayer (who always felt that he had been ignored by the physics community) and explicitly proposed by the formidable Hermann Helmholtz in 1847, who credited both Joule and Mayer. The statement of the conservation of mechanical energy is:
Total energy is always conserved.
Energy is a sophisticated and abstract thing in physics. In fact, it's not a "thing" at all. It's not a substance. It's a concept that behaves mathematically in particular ways…and manifests itself physically in different guises. It's not surprising that it took more than three centuries to sort all of this out. We now know how to measure energy-guises. But, boy, what a mess for a long time.
Energy as an abstraction is "just there."" About the best analogy (but not a perfect one) is with the idea of economic value. Is the value of an object, or currency, a "thing"? No, it's a numerical concept which takes different guises and amounts which can at any point in a transaction be assigned a "value." Economic value is economic energy.
Take a rough diamond. By itself, it has a value (unfortunately one which often leads to violence and brutality) which is inherent: it can be traded with other objects which also have an equivalent value…like cash. In such a trade – a transaction – the total value of the two has not changed, just exchanged hands and in the process, changed kind. If you had diamonds, now you have cash. But you possess the same value.
But, suppose the diamond is cut and polished. Labor – which has a value – has been added and in turn the value of the diamond has increased and an exchange for cash would require more. But the total value of the labor, the raw diamond, and the cash has not changed…just shifted. The total value-amount at the beginning (the raw diamond plus the potential value of the labor before it's actually expended) is the same as at the end (the cash) but the potential value of the labor has been expended on transforming the diamond and adding to its value. All the while, this abstract quantity "value" has moved back and forth among the objects – exchanged hands, manifesting itself in various guises, but never actually standing alone as a substance.
Keep that in mind as we think about energy. It's okay to be a little uneasy since energy is strange: simultaneously an easy idea and at the same time a complicated and even subtle idea. You'll see.
Let's get a sense of the scale of Joule units of energy. With fruit.
An Example: another apple
What are the contributions to its energy at point A, point B, and halfway between them in the following figure? This apple has a mass of 100 grams.
So our apple has a mass of 0.1 kg and for simplicity's sake, let's pretend that the acceleration due to gravity is 10 m/s$^2$ rather than its more precise value of 9.8 m/s$^2$.
What are the contributions to its energy at point A, point B, and halfway between them?
The contributions ot the energy of the apple would be combinations of potential and kinetic energy. Once we define where the "zero" of potential energy is located, it can be calculated at any height. Obviously, the most sensible thing to do is to define
When the apple is just tipped over the edge of the table, its energy is all potential and would have the value:
That sets the scale of what 1 Joule of energy is like…Dropping an apple a meter above the ground provides it with a potential to do work on whatever it it lands on. When the apple has reached point B, its potential energy is spent, traded for kinetic energy as the apple has sped up from rest at A to the fastest that it will be just before hitting the floor (and deforming into a bruised fruit). So that energy is:
So we could ask how fast the apple is going, and this energy balance gives us the answer:
But we could have gotten this same answer from Galileo's constant acceleration formula from Lesson 4.
Finally, halfway between A and B, the energy is made up of less potential energy than A and less kinetic energy than at B.
Go to the energy converters.
By now you won't be surprised that I want to bring this energy conservation message home by recreating our thermometer graphs for before, in-between, and after. Get comfortable with this and our next energtic steps will be a lot easier!
Falling in a straight line is one thing. Falling but through a curved path is something else. Let's go to the beach.
(a) An aerial view of Jolly Roger Amusement Park in Ocean City, Maryland. (b) A photo of me on the giant water slide.
I love water parks and this is one of my favorites. I always feel safe because I respect the conservation of energy. This next figure labels a variety of points along my trip on the slide.
I gingerly start myself from rest at point A, which is 10 m above the ground. I pass point B and start up the other side passing point D on the way to point C, which is at the same height as A.
Let's analyze some of the energetics of this situation: A, B, and C. You do D.
And, as you now know: we can do this with thermometers. So here is the algebra from above, reproduced as a geometrical "solution."
(a) represents the energetics at $A$; (b), at $B$; and (c) at $C$.
From the 1700s through the 1900's the science of mechanics became more and more mathematically formal. Rather than being a set of rough-and-ready tools at the disposal of engineers, mechanics and its mathematics revealed some neat things about how our universe seems to be put together. In particular, conservation laws went from a nice accounting scheme, to a clever way to solve difficult problems, to arguably the grandest of only a few universal concepts. I'll try to explain some of this later when we delve into symmetry as we understand it today but let's take a stab and meet Emmy.
A photograph of young Emmy Noether , probably around 1907, originally privately owned by family friend Herbert Heisig.
Amalie Emmy Noether (1882 - 1935) was the daughter of Max Noether, a well-regarded German mathematician from Erlangen University near Munich in the late 19th century. Max Noether was a contributor to algebraic geometry in the highly productive period where algebra was being abstracted as a very broad logical system, in which the puny subject that we learn in high school is only a small part. This particular apple fell very close to the tree and Emmy, as she was always known, turned out to be the most famous member of the Noether mathematical family (she had two brothers who had advanced mathematical training).
As a woman in Germany, only with an instructor's permission, was she was allowed to sit in on courses at a university – she could not formally enroll as a student. She did this for two years when the rules were changed and she could actually enroll and she steadily advanced to her Ph.D. degree at Erlangen in 1907. She was not able – again, due to German law – to pursue the second Ph.D. that's required in many European universities and so could not be a member of a faculty. So she stayed at Erlangen working with her father and colleagues. She even sponsored two Ph.D. students, formally enrolled under Max's name, but actually working under her. She developed a spectacular reputation and gave talks at international conferences on her work in algebra. Nathan Jacobson, the editor of her papers wrote, "The development of abstract algebra, which is one of the most distinctive innovations of twentieth century mathematics, is largely due to her – in published papers, in lectures, and in personal influence on her contemporaries."
David Hilbert, 1862-1943
She was recruited in 1915 to work with the most famous mathematician in Europe, David Hilbert. He was racing Einstein to get to the conclusion of what became the General Relativity Theory of gravity and needed help with the complicated algebra and problems of symmetry, her specialty. Upon arrival at the Mathematics Capital of Europe, Göttingen, she quickly solved two outstanding problems, one of which has come to be known as Noether's Theorem, and which is of fundamental importance in physics today.
Hilbert fought for years for Noether's inclusion into the Göttingen faculty. He offered courses in his name, for her to teach. He led a raucous (in a early 20th century, gentile German sort of way) discussion in the faculty senate reminding his colleagues that theirs was not a bath house and that the inclusion of a woman was the modern thing to do. She was unpaid and yet still taught and sponsored a dozen Ph.D. students while at Göttingen. Einstein was particularly impressed and wrote to Hilbert, "Yesterday I received from Miss Noether a very interesting paper on invariants. I'm impressed that such things can be understood in such a general way. The old guard at Göttingen should take some lessons from Miss Noether! She seems to know her stuff."
Emmy's great grandfather was Jewish and had changed his name according to a Bavarian law in the early 1800's. However, this heritage became a dangerous burden for her and she emigrated in 1932 to Bryn Mayr College, outside of Philadelphia. There she resumed lecturing, including weekly lectures at the Advanced Institute at Princeton until she was suddenly and tragically stricken with virulent cancer that took her life in 1935. After her death, which was acknowledged around the world, Einstein wrote in the New York Times, "In the judgment of the most competent living mathematicians, Fräulein Noether was the most significant creative mathematical genius thus far produced since the higher education of women began. In the realm of algebra, in which the most gifted mathematicians have been busy for centuries, she discovered methods which have proved of enormous importance in the development of the present-day younger generation of mathematicians." But the most moving and personal obituary came from another eminent mathematician, Herman Weyl:
Weyl obituary
You did not believe in evil, indeed it never occurred to you that it could play a role in the affairs of man. This was never brought home to me more clearly than in the last summer we spent together in Göttingen, the stormy summer of 1933. In the midst of the terrible struggle, destruction and upheaval that was going on around us in all factions, in a sea of hate and violence, of fear and desperation and dejection – you went your own way, pondering the challenges of mathematics with the same industriousness as before. When you were not allowed to use the institute's lecture halls you gathered your students in your own home. Even those in their brown shirts were welcome; never for a second did you doubt their integrity. Without regard for your own fate, openhearted and without fear, always conciliatory, you went your own way. Many of us believed that an enmity had been unleashed in which there could be no pardon; but you remained untouched by it all.
An amazing person, all the more so at time when the path for women scientists was non-existent. We'll see a few more as we go along. In any case, a crater on the Moon is named for her, a street and her childhood school are named for her, as are numerous prizes and scholarships around the world.
The formal evolution of mathematics exposed a number of fussy, but important details. Encoded in this formalism is the regular Newton's Second law and also momentum conservation, but the wrapper is elegant and (accidentally? No. Nature doesn't do accidentally) identically important in quantum mechanics and relativity. What Noether found was that this formalism included a hidden surprise. That surprise was how it would react if some of the terms were modified in particular ways.
Emmy Noether later in life.
If we were to take Newton's Second law, good old $F=ma$ and remember that the $a$ term includes space and time coordinates, $x$'s and $t$'s, we can modify their appearance in the equation in particular ways. Suppose I were to take the appearance of every coordinate variable, $x$ and change every one of them to $x+D$ where $D$ is a constant distance, like an inch or a mile. In effect, shifting every space coordinate by a specific amount. What would you expect to happen? Should the rules of Newton change? This is in essence asking if Newton's Second law works fine here, what if I'm not here, but I'm 20 miles away? Surely I can rely on Newton's 2nd law and so cars, buildings, plumbing, and everything else mechanical should still function normally. So the form of Newton's 2nd law shoud not care about that change of $x \to x+20$. My lawnmower works on the east side of my lawn as well as the west side of my lawn. And, the structure of the equation $F=ma$ is such that the added "20" would go away. (Calculus is required to see this specifically.)
What Noether's theorem says is that this shifting of space coordinates actually speaks to an "invariance" that Newton's Second law respects…its form is not altered – and so my lawnmower works all over the yard – no matter where I am in space. This is a symmetry of nature. Nature's rules hold everywhere the same. And this symmetry has consequences that tumble out of her mathematical description of this symmetry in the hands of the fussy formalism that mechanics had become: momentum conservation falls right out.
Symmetries in physics equations mean that a conservation law is at work.
But wait, there's more. My lawnmower works the same today as it did yesterday. And the same at the beginning of the job as at the end of the job. That means that if I take Newton's Second law…and everywhere that time, $t$ appears, I replace it with $t+P$, where P$$ is some constant, like 20 minutes or 24 hours. What tumbles out is another symmetry of nature and another conservation law: Energy conservation.
Noether's Theorem states that the equations of physics will be invariant if a conservation law is respected by the universe and that if a conservation law is found, that there must be a symmetry in the equations that describe that phenomenon.
The remarkable consequence of these observations, is that we now can interpret our conservation laws as not an algebraic accident, or even because of an experimental result. No. Our conservation laws come about because nature requires that our mathematical rules are unchanged whether we use them today or tomorrow, or over there or over here. They hold everywhere and everywhen.
Boy, is this important! Using Noether's Theorem as a recipe, we can pick a symmetry as a test and then ask what our formal mathematical description of nature implies about physical conservation laws. If the laws work out, then we've found a symmetry of nature. If the laws are not observed in experiment, then we can discard that symmetry as not one that works in our universe.
We'll exploit this, but I've used the word "universe" many times. Let's go there. To the universe, I mean. | CommonCrawl |
Comment on "Overcoming catastrophic forgetting in NNs": Are multiple penalties needed?
This comment on the DeepMind folks' latest PNAS paper on overcoming catastrophic forgetting. I liked this paper a lot, I recommend it. Despite this, the post eventually turned into a critical review of the method, rather than the glowing, enthusiastic review I sat down to write. Please don't let this prevent you from reading the paper:
James Kirkpatrick et al (2017) Overcoming catastrophic forgetting in neural networks, PNAS
First, it's a nice paper: simple, clean, statistically motivated solution (see more on this later) and you can clearly see where this is going and how it's relevant to DeepMind's pursuit of general learning machines. 👏. Second, it's a great achievement of the authors and the community that we now regularly see purely machine learning papers solving a machine learning problems in general journals like PNAS, Science and Nature.
Summary of this post
I focus on the statistical techniques behind the proposed approach, elastic weight consolidation (EWC), which is best described as on-line sequential (diagonalised) Laplace approximation
Bayesian inference wouldn't suffer from catastrophic forgetting which haunts optimisation-based methods
EWC approximates Bayesian computation
then I look at what happens moving on to the third task. This detail is somewhat glanced over in the paper.
applying the methodology consistently, I arrive at a formula which is inconsistent with the paper on how the third task is learned.
the paper suggests keeping multiple parameters and penalties around from all previously learnt tasks, but I think only the latest parameter should be kept as it already implicitly captures all previous tasks.
keeping multiple quadratic penalties from previous tasks might actually hurt the method's ability to learn new tasks, and results in EWC disproportionately favouring tasks learnt early on
keeping a single quadratic penalty would also eliminate the need to know what task is currently being performed - although a smart solution for this may help agent performance.
High level overview
Take home message: Bayesians never forget (catastrophically)
There are situations when you want to use the same neural net to solve a range of different tasks. This is not usually a problem if you can afford to train the network on all the tasks simultaneously. The catastrophic forgetting problem arises, however, when you want to train the network to perform new tasks sequentially. How do you train the network on the $k+1$st task without it forgetting everything it knew about the first $k$ tasks?
The authors observe that the catastrophic forgetting does not happen when the network parameters are learnt in a fully Bayesian way. Instead of obtaining single parameter estimate $\theta$ via gradient descent, we really want to maintain a full Bayesian posterior distribution $p(\theta\vert \mathcal{D}_{T_1}, \ldots \mathcal{D}_{T_k})$ over possible parameter values that worked well in previous tasks $T_1 \ldots T_k$. Then we could simply use this posterior as a prior when solving the $k+1$st task $T_{k+1}$ and obtain an updated posterior which captures all tasks $T_1 \ldots T_{k+1}$
Of course, maintaining a full posterior is intractable, and even approximating it can be pretty tricky. How do we bridge the gap between the statistical awesomeness of Bayesian inference and the sheer efficiency of gradient descent? The authors opt for a on-line diagonalised Laplace approximation approach, which they call elastic weight consolidation (EWC). The approach is similar to assumed density filtering (ADF, Opper & Winther, 1999), which is a precursor to expectation-propagation (Minka, 2001), a connection highlighted by the authors.
Laplace approximation
Laplace approximation takes a probability density $p$ and approximates it with a Gaussian, whose mean is at the mode of the distribution and variance is given by the inverse Hessian of the log density $\log p$ at the mode. This approximation to Bayesian posteriors is motivated by Bernstein-von Mises-type convergence theorems which state that in identifiable exchangeable models the posterior will converge to the Laplace. EWC uses a diagonalised Laplace approximation, which ignores the off-diagonal entries of the Hessian and keeping only diagonal ones. Applied to neural networks, the diagonal assumption is the same as saying that the parameters of the network have completely independent influence on the loss function (which is of course not true, but perhaps true enough).
The elastic weight consolidation (EWC) method proposed in the PNAS paper essentially applies Laplace approximation recursively, in an on-line fashion, learning one task after another with a neural network.
Diving deeper
Let's look at what precisely the EWC algorithm does.
Learning a second task after the first
This is the easier case. Let's follow the footsteps of the authors, with a slight change in notation. The posterior of NN parameters $\theta$ given the first two tasks $A$ and $B$ can be decomposed as follows:
\log p(\theta\vert \mathcal{D}_A, \mathcal{D}_B) = \log p(\mathcal{D}_B\vert \theta) + \log p(\theta\vert \mathcal{D}_A) - \log p(\mathcal{D}_B\vert \mathcal{D}_A)
The left-hand term is the log likelihood, or task-specific objective function for task $B$, the right-hand term can be thought of as an adaptive elastic weight regularizer that tries to maintain knowledge of the first task. I think there's an irrelevant typo in the paper: the last term of Eqn. (2) should be $\log p(\mathcal{D}_B\vert \mathcal{D}_A)$ rather than $\log p(\mathcal{D}_B)$. It doesn't matter as it's constant w.r.t. $\theta$ anyway.
$\log p(\theta\vert \mathcal{D}_A)$, of course, is intractable to compute, so we're going to approximate it with a diagonalised Laplace approximation. For this we need the mode $\operatorname{argmax}_\theta \log p(\theta\vert \mathcal{D}_A)$ and the Hessian of $\log p(\theta\vert \mathcal{D}_A)$ evaluated at the mode.
The mode $\theta^A$ can be found via usual gradient descent, minimising the loss $\mathcal{L}_A(\theta) - \log p(\theta)$, where the prior $p(\theta)$ acts as a regulariser. (the authors don't actually use a prior so ignore that term). The Hessian will be the sum of the Fisher information from task $A$ which I denote $F^A$, plus the Hessian of the log prior $\log p(\theta)$ (which, again, the paper doesn't have. This is no big deal as the prior would probably be a dummy weak regulariser anyway).
So, substituting these back to a diagonalised Laplace approximation we obtain:
\log p(\theta\vert \mathcal{D}_A, \mathcal{D}_B) \approx -\mathcal{L}_B(\theta) - \frac{1}{2}\sum_i F^A_{i,i} (\theta_i - \theta^A_i)^2 + \text{constant}
where $\mathcal{L}_B$ is the negative log likelihood, or loss function, of task $B$, and the Gaussian approximation to $p(\theta\vert \mathcal{D}_A)$ acts as a nice quadratic regulariser, which is dependent on data from task $A$. The authors also introduce $\lambda$, an importance weight which I will assume is $1$ to keep things simple.
We can now train our network via our favourite gradient descent technique solving the following optimisation:
\theta^{A,B} = \operatorname{argmin}_\theta \mathcal{L}_B(\theta) + \frac{1}{2}\sum_i F^A_{i,i} (\theta_i - \theta^A_i)^2
Pretty cool. We have a data-dependent $L_2$ regulariser which adapts to task $A$ we already learnt about. This regulariser captures our knowledge of task $A$, so we can now focus on the new task $B$, while the regulariser makes sure we don't catastrophically forget about $A$. Makes sense.
As a result, $\theta^{A,B}$ will be a parameter that has good performance on both $A$ and $B$.
Learning the third task after the first two
On moving to the third task, the authors say only this:
When moving to a third task, task C, EWC will try to keep
the network parameters close to the learned parameters of both tasks A and B. This can be enforced either with two separate penalties or as one by noting that the sum of two quadratic penalties is itself a quadratic penalty
Do we actually need to remember $\theta^A$? $\theta^{A,B}$ is supposed to be the mode of the posterior $p(\theta\vert \mathcal{D}_A, \mathcal{D}_B)$ and the posterior already captures all our knowledge about both tasks $A$ and $B$. The mode of the previous posterior $\theta^A$ should become irrelevant as it is already incorporated into $\theta^{A,B}$. Somehow, this just doesn't feel right.
Let's apply the sequential diagonal Laplace approximation argument consistently, but now for learning the third task $C$, after $A$ and $B$. For this, we need the mode and Hessian of the posterior $p(\theta\vert \mathcal{D}_A, \mathcal{D}_B, \mathcal{D}_C)$, which can be expressed as:
\log p(\theta\vert \mathcal{D}_A, \mathcal{D}_B, \mathcal{D}_C) = -\mathcal{L}_C(\theta) + \log p(\theta \vert \mathcal{D}_A, \mathcal{D}_B) + \text{constant}
Let's replace the intractable $\log p(\theta \vert \mathcal{D}_A, \mathcal{D}_B)$ with its Laplace approximation, once again. We have already calculated the mode of this distribution, it is (approximately) $\theta^{A,B}$. How about its Hessian around $\theta^{A,B}$? Well, we have assumed that
\log p(\theta \vert \mathcal{D}_A, \mathcal{D}_B) \approx - \mathcal{L}_B(\theta) - \sum_i F^{A}_{i,i} (\theta_i -\theta^A_i)^2 + \text{constant}
so the Hessian is the Fisher information matrix $F^{B}$ plus the previously assumed diagonal approximation $diag(F^{A})$. So, if we plug these in to form a diagonal Laplace approximation to $\log p(\theta\vert \mathcal{D}_A, \mathcal{D}_B)$, we get:
\log p(\theta\vert \mathcal{D}_A, \mathcal{D}_B) \approx - \sum_i (F^{A} + F^{B})_{i,i} (\theta_i - \theta^{A,B}_i)^2 + \text{constant}
Using this approximation, the optimisation problem for task $C$ after tasks $A$ and $B$ have been learnt will look like:
\theta^{A,B,C} = \operatorname{argmin}_\theta \mathcal{L}_C + \sum_i (F^{A} + F^{B})_{i,i} (\theta_i - \theta^{A,B}_i)^2
Note that there is just a single penalty, and it is around $\theta^{A,B}$ which is the parameter we learnt for task $B$ while regularising for not forgetting task $A$. We don't need a second penalty term around $\theta^A$ as it's already been taken into account when finding $\theta^{A,B}$. $\theta^{A}$ is now irrelevant and we can throw it away. $\theta^{A,B}$ (approximately) captures both tasks $A$ and $B$. All we need to do is update the regulariser's weights to $F^{A,B}_{i,i} := (F^{A}_{i,i} + F^{B})_{i,i}$.
So, let's contrast this with what the paper says: "When moving to a third task, task $C$, EWC will try to keep the network parameters close to the learned parameters of both tasks A and B. This can be enforced either with two separate penalties or as one by noting that the sum of two quadratic penalties is itself a quadratic penalty."
I don't think this is the correct approach. There are a few possible explanations, in the order of my preference:
I made a mistake here and my derivation is wrong
the authors use a different reasoning from mine to derive multiple, task-specific penalties for the third task, in which case I'd be curious to hear that
the paper described what is actaully done ambiguously in the text, and they actually do the right thing when implementing EWC
the authors made a mistake, and if this is the case the algorithm may be further improved by fixing the mistake
Why would multiple penalties be wrong?
Let's see what happens if you do keep the two penalties around, one centered around $\theta^A$ and one around $\theta^{A,B}$? In a handwavy way, it corresponds to optimising something a bit - but not quite - like this:
-\mathcal{L}_{C} + \log p(\theta\vert \mathcal{D}_A, \mathcal{D}_B) + \log p(\theta\vert \mathcal{D}_A)
Not only does this formula not add up from Bayes' rule's perspective, it also places too much emphasis on task $A$, more than what Bayes' rule would warrant. Furthermore, as more tasks are added, task A will be overemphasized further. Therefore, I think
keeping multiple penalties around might result in a diminished ability to learn new tasks, as early tasks get disproportionately more weight.
In a thought experiment, imagine what would happen if $\mathcal{L}_{C}$ were completely flat, that is, you want to learn task $C$, but you have no actual data, or the data provides no information about $\theta$ (I know, stupid assumption, but makes sense to think about it). Let's run gradient descent on the penalised loss nevertheless, essentially minimising only penalty term(s).
If you have the one penalty around the most recently learned parameter $\theta^{A,B}$, as in my derivation, then $\theta^{A,B}$ is already the minimum. If task $C$ has no new data, you just don't change your parameters from what you had before. Makes sense, right? If it's not broken, why fix it?
However, if you have the two penalties, one around $\theta^{A,B}$, and one around $\theta^A$, your optimisation will actually move away from $\theta^{A,B}$, back towards $\theta^A$ a bit. But this would make no sense at all. Why would you change the parameters if you are presented with no new evidence at all?
For the South Park afficionados out there: the extra penalties are basically member berries. They will make your network want to go back to the old ways when it solved task $A$ perfectly and everything seemed so easy.
Does it actually appear to hurt the algorithm?
Well, not really. At least it's hard to tell from the Figures. Look at Figure 3.A:
This shows that while EWC very successfully retains its performance at task $A$, the gap between SGD and EWC on new tasks widen. How would the harmful effects of keeping two penalties around show up on this Figure?
Performance on Task $A$ first goes down a bit after training for a few new tasks, but then eventually gradually goes up again as we train for tasks $E,F\ldots$. This would happen because as time goes by, you implicitly add the 'Task A' penalty over and over again, even though that penalty is implicitly captured in all other task penalties as well. We can't really see this effect here, partly because the performance on task A never really drops, and partly because it only shows 3 tasks. Plus, a lot of this depends on how the $\lambda$ values were chosen, too.
The gap between EWC and SGD for Task B would be much smaller than the gap between EWC and SGD for Task C. Again, it's hard to say if this is the case or not from this figure.
Similarly, looking at Figure 3.B doesn't really help us analyse if the mismatch in penalties causes any problems, because we only see average task performance.
Do you even need to know what task you're performing?
This is what the authors write about the need to identify the task being performed:
Inspired by this evidence, we augmented the DQN agents with
extra functionality to handle switching task contexts. Knowledge of which task is being performed is required for the EWC algorithm as it informs which quadratic constraints are currently active and also which quadratic constraint to update when the task context changes.
Now, good news is that knowledge of task identity may not be a requirement for the algorithm to work after all. If there are no task-specific quadratic penalties, only a single one, we don't have to choose betwen them. We can just update the single posterior mode $\theta^{A,\ldots}$ and the Hessian $F^{A,\ldots}$ in an on-line fashion and forget their old values.
sidenote: In fact, EWC with a single quadratic penalty could be applied more generally than the catastrophic forgetting problem. There is nothing in the derivation that specifies that $\mathcal{D}_A$ and $\mathcal{D}_B$ should in fact correspond to two different tasks. They can even contain data from different tasks, so we don't even need to synchronise the freezing of the quadratic penalty with swittching tasks.
Or, $\mathcal{D}_A,\mathcal{D}_B,\ldots$ can be minibatches of data from a single task, in which case EWC can be thought of as an on-line alternative to stochastic gradient descent. Consider looping through the minibatches one-by-one. On each minibatch, instead of doing a single gradient step like in SGD, we run full gradient descent with a quadratic regulariser until convergence. Once converged, we update the quadratic regulariser according to the Laplace rules, and load the next minibatch. This may not be as accurate as SGD because of the diagonal Laplace approximation introduces inaccuracies over time. But it would require less overall data shoveling between GPU memory and main memory, and it accesses each minibatch exactly once. So there might be situations when such algorithm would be a meaningful alternative to SGD.
Of course, the agent performing the tasks will probably still benefit from an elaborate mechanism to detect task identity, but that is a different concern entirely. The point is, the algorithm at a computational level is agnostic to tasks beyond evaluating the loss functions $\mathcal{L}_A,\mathcal{L}_B,\ldots$
This is a great paper, and a great demonstration of how a simple, statistically motivated algorithm can make a huge difference.
I did, honestly, set out to write a very positive review, I really liked the statistical motivation, and the resulting simplicity of the method. The experiments are also interesting and well done, the results speak for themselves. It is also exciting to think about how this can be used in practice, and being able to learn tasks sequentially is bound to have a massive impact.
But look at the post now: at best, I'd describe it as constructive criticism, I ended up zooming in on the one thing that wasn't quite kosher, even though you can hardly argue with the performance of the method. But this is also a good motivation for continuing to write these posts: had I not started trying to explain how and why the method works, I may have missed this entirely. And then, of course, it is entirely possible that the authors actually did the same thing I describe here, just explained it in a different way, or that there are alternative justifications for the multiple penalties approach. | CommonCrawl |
Results for 'Stefan Schaefer' (try it on Scholar)
Dynamic Network Participation of Functional Connectivity Hubs Assessed by Resting-State fMRI.Alexander Schaefer, Daniel S. Margulies, Gabriele Lohmann, Krzysztof J. Gorgolewski, Jonathan Smallwood, Stefan J. Kiebel & Arno Villringer - 2014 - Frontiers in Human Neuroscience 8.details
Mental Disorders in Philosophy of Cognitive Science
Philosophy of Neuroscience in Philosophy of Cognitive Science
Solar Geoengineering and Democracy.Joshua Horton, Jesse Reynolds, Holly Jean Buck, Daniel Edward Callies, Stefan Schaefer, David Keith & Steve Rayner - 2018 - Global Environmental Politics 3 (18):5-24.details
Some scientists suggest that it might be possible to reflect a portion of incoming sunlight back into space to reduce climate change and its impacts. Others argue that such solar radiation management (SRM) geoengineering is inherently incompatible with democracy. In this article, we reject this incompatibility argument. First, we counterargue that technologies such as SRM lack innate political characteristics and predetermined social effects, and that democracy need not be deliberative to serve as a standard for governance. We then rebut each (...) of the argument's core claims, countering that (1) democratic institutions are sufficiently resilient to manage SRM, (2) opting out of governance decisions is not a fundamental democratic right, (3) SRM may not require an undue degree of technocracy, and (4) its implementation may not concentrate power and promote authoritarianism. Although we reject the incompatibility argument, we do not argue that SRM is necessarily, or even likely to be, democratic in practice. (shrink)
Topics in Environmental Ethics, Misc in Applied Ethics
Psychoanalysis and the Marionette Theater: Interpretation Is Not Depreciation.Margret Schaefer - 1978 - Critical Inquiry 5 (1):177-188.details
At the end of his attack on my use of the psychoanalytic model for the interpretation of literature, Heller raises the question concerning what the task of the literary critic is or ought to be. His own "sketch of the Kleistean theme's historical ancestry and its later development," he says, seeks to deepen and enrich the reader's appreciation of Kleist's literary art, the artistry of his phrasing, the persuasiveness of his incidents, the conclusiveness of his examples." By implication he suggests (...) that my method does not have this end—that is, appreciation—for its goal. In this he is partially right. "Appreciation" in Heller's sense is not as directly a goal for me. But does Heller's method of intellectual history and literary relation meet his own criteria of deepening and enriching the reader's appreciation of Kleist? In his capsule treatment of Great Thinkers of the Western World from Plato to Marx, we learn that many writers besides Kleist treated Kleist's theme of man's fall from unconscious grace. What exactly does this tell us about Kleist's treatment of it? How does it deepen the reader's appreciation of Kleist's literary art, the artistry of his phrasing, the persuasiveness of his incidents? It doesn't. It isn't even about Kleist. Although Heller tells us that it is the "thought" and "imagery" which "make for the great distinction of the essay" , his evidence for this consists, in the case of the former, in his tracing the history of the essay's thought and, in the case of the latter, in his statements that Kleist's use of the puppet as the exemplar of the unselfconscious graceful being is "unusual" and "novel" and that his bear story, though it may lack "in immediate plausibility," "gains in making Kleist's point" and is "a memorable exemplar" of the "art of grotesque inventions that are capable of floating for quite a while above and between the comic and the serious before landing with scintillating effect in one domain or the other" . Margret Schaefer is a lecturer in the department of psychiatry at Northwestern University Medical School. She responds here to Erich Heller's "The Dismantling of a Marionette Theater; or, Psychology and the Misinterpretation of Literature" , in which he discussed her article, "Kleist's 'About the Puppet Theater,". (shrink)
Gilles Deleuze in Continental Philosophy
Illiberal Justice: John Rawls Vs. The American Political Tradition.David L. Schaefer - 2007 - University of Missouri.details
"Schaefer challenges John Rawls's practically sacrosanct status among scholars of political theory, law, and ethics by demonstrating how Rawls's teachings deviate from the core tradition of American constitutional liberalism toward ...
John Rawls in 20th Century Philosophy
$38.25 new $42.24 used $55.00 direct from Amazon Amazon page
The Power of Resurrection: Foucault, Discipline, and Early Christian Resistance.Patrick G. Stefan - 2019 - Fortress Academic.details
In this book, Patrick G. Stefan argues that the subversive message of resurrection was instrumental in Christianity's expansion. Using Foucault's analysis of how material conditions shape and create individual subjects, Stefan shows how the idea of resurrection undermined Caesar's control over those living in his domain.
Autonomy and Enhancement.G. Owen Schaefer, Guy Kahane & Julian Savulescu - 2014 - Neuroethics 7 (2):123-136.details
Some have objected to human enhancement on the grounds that it violates the autonomy of the enhanced. These objections, however, overlook the interesting possibility that autonomy itself could be enhanced. How, exactly, to enhance autonomy is a difficult problem due to the numerous and diverse accounts of autonomy in the literature. Existing accounts of autonomy enhancement rely on narrow and controversial conceptions of autonomy. However, we identify one feature of autonomy common to many mainstream accounts: reasoning ability. Autonomy can then (...) be enhanced by improving people's reasoning ability, in particular through cognitive enhancement; given how valuable autonomy is usually taken to be, this gives us extra reason to pursue such cognitive enhancements. Moreover, autonomy-based objections will be especially weak against such enhancements. As we will argue, those who are worried that enhancements will inhibit people's autonomy should actually embrace those enhancements that will improve autonomy. (shrink)
Cognitive Enhancement in Applied Ethics
Moral Responsibility in Meta-Ethics
Neuroethics, Misc in Applied Ethics
Direct download (10 more)
The Right to Withdraw From Research.G. Owen Schaefer & Alan Wertheimer - 2010 - Kennedy Institute of Ethics Journal 20 (4):329-352.details
The right to withdraw from participation in research is recognized in virtually all national and international guidelines for research on human subjects. It is therefore surprising that there has been little justification for that right in the literature. We argue that the right to withdraw should protect research participants from information imbalance, inability to hedge, inherent uncertainty, and untoward bodily invasion, and it serves to bolster public trust in the research enterprise. Although this argument is not radical, it provides a (...) useful way to determine how the right should be applied in various cases. (shrink)
Medical Research Ethics in Applied Ethics
Contributing to Discourse.Herbert H. Clark & Edward F. Schaefer - 1989 - Cognitive Science 13 (2):259-294.details
Managing Relationships with Environmental Stakeholders: A Study of U.K. Water and Electricity Utilities. [REVIEW]Brian Harvey & Anja Schaefer - 2001 - Journal of Business Ethics 30 (3):243 - 260.details
In this paper we report a study of the approach of six U.K. water and electricity companies towards managing the relationship with their ''green'' stakeholders. Stakeholders are accorded increasing importance in political discourse and stakeholder theory is emerging as a promising framework for the analysis of corporate social performance.We studied the companies'' general approach towards green stakeholders, their dealings with specific stakeholder groups and whether they emphasised the consultation or the information aspect of stakeholder management. We found that none of (...) the six companies had a systematic stakeholder approach that extended to all potential green stakeholders. Rather, the importance of specific stakeholder groups seemed to be determined by managers'' intuition and by the stance that the stakeholders themselves displayed towards the company. (shrink)
A Guided Tour of Minimal Indices and Shortest Descriptions.Marcus Schaefer - 1998 - Archive for Mathematical Logic 37 (8):521-548.details
The set of minimal indices of a Gödel numbering $\varphi$ is defined as ${\rm MIN}_{\varphi} = \{e: (\forall i < e)[\varphi_i \neq \varphi_e]\}$ . It has been known since 1972 that ${\rm MIN}_{\varphi} \equiv_{\mathrm{T}} \emptyset^{\prime \prime }$ , but beyond this ${\rm MIN}_{\varphi}$ has remained mostly uninvestigated. This paper collects the scarce results on ${\rm MIN}_{\varphi}$ from the literature and adds some new observations including that ${\rm MIN}_{\varphi}$ is autoreducible, but neither regressive nor (1,2)-computable. We also study several variants of (...) ${\rm MIN}_{\varphi}$ that have been defined in the literature like size-minimal indices, shortest descriptions, and minimal indices of decision tables. Some challenging open problems are left for the adventurous reader. (shrink)
Logic and Philosophy of Logic, Miscellaneous in Logic and Philosophy of Logic
Model Theory in Logic and Philosophy of Logic
The Madness of Franz Brentano: Religion, Secularisation and the History of Philosophy.Richard Schaefer - 2013 - History of European Ideas 39 (4):541-560.details
In recent decades, scholars have shown a distinct new willingness to concede the important place of religion in the life and thought of the philosopher Franz Brentano. However, these studies are still dominated by the presumption that Brentano's life and thought are best understood according to a model of secularisation as a progressive waning of religion. This essay asks whether such a presumption is the best way of understanding the complex interconnections between various elements of his philosophical and religious ideas. (...) It posits that a better appreciation of his position entails a confrontation with Brentano's historical imagination, and especially the structuring role of his approach to the history of philosophy as one manifesting regular cycles of decline and regeneration. Brentano's theory of the four phases of philosophy, though not the final word on how he viewed history, was nevertheless an exercise in thinking about the ways history accommodates various forms of progress and repetition. It was therefore a salutary means for thinking about the evolution of religion in ways that challenge any simple understanding of secularisation. (shrink)
Brentano, Misc in 19th Century Philosophy
Human Rights.Brian Schaefer - 2005 - Social Theory and Practice 31 (1):27-50.details
Human Rights in Social and Political Philosophy
Embodied Disbelief: Poststructural Feminist Atheism.Donovan O. Schaefer - 2014 - Hypatia 29 (2):371-387.details
"I quite rightly pass for an atheist," Jacques Derrida announces in Circumfession. Grace Jantzen's suggestion that the poststructuralist critique of modernity can also be trained on atheism helps us make sense of this playfully cryptic statement: although Derrida sympathizes with the "idea" of atheism, he is wary of the modern brand of atheism, with its insistence on rationally arranging—straightening out—religion. In this paper, I will argue that poststructural feminism, with its focus on embodied epistemology, offers a way to re-explain Derrida's (...) "I rightly pass," and also to carry it forward. Poststructural feminist atheism leads us through Derrida to an embodied disbelief drawing on three dimensions of poststructural feminism: feminist epistemology and material feminism, relationality, and affect theory. (shrink)
Derrida: Gender, Race, and Sexuality in Continental Philosophy
Derrida: Philosophy of Religion in Continental Philosophy
Postmodern Feminism in Philosophy of Gender, Race, and Sexuality
Poststructural Feminism in Philosophy of Gender, Race, and Sexuality
Why Adopt a Maximin Theory of Exploitation?Alan Wertheimer, Joseph Millum & G. Owen Schaefer - 2010 - American Journal of Bioethics 10 (6):38-39.details
Procedural Versus Substantive Justice: Rawls and Nozick.David Lewis Schaefer - 2007 - Social Philosophy and Policy 24 (1):164-186.details
This paper critically assesses the "procedural" accounts of political justice set forth by John Rawls in A Theory of Justice (1971) and Robert Nozick in Anarchy, State, and Utopia (1974). I argue that the areas of agreement between Rawls and Nozick are more significant than their disagreements. Even though Nozick offers trenchant criticisms of Rawls's argument for economic redistribution (the "difference principle"), Nozick's own economic libertarianism is undermined by his "principle of rectification," which he offers as a possible ground in (...) practice for the application of something like the difference principle. Both Rawls's and Nozick's accounts of justice fail because of their abstraction from human nature as a ground of right. At the same time the libertarianism on which they agree in the non-economic sphere would deprive a free society of its necessary moral underpinning. Rawls and Nozick err, finally, by demanding that the policies pursued by a just society conform to theoretical formulas concocted by philosophy professors, rather than leaving room (as Lockean liberalism does) for the adjustment of policies to particular circumstances based on statesmen's prudential judgment and the consent of the governed. Particularly troubling from the perspective of a citizen seriously concerned with the advancement of justice and freedom is both thinkers' shrill denunciations of existing liberal societies for failing to conform to their particular strictures. (shrink)
David Lewis in 20th Century Philosophy
Distributive Justice in Social and Political Philosophy
Justice in Social and Political Philosophy
Political Constructivism in Social and Political Philosophy
Face to Face.Sonja Windhager, Dennis E. Slice, Katrin Schaefer, Elisabeth Oberzaucher, Truls Thorstensen & Karl Grammer - 2008 - Human Nature 19 (4):331-346.details
Over evolutionary time, humans have developed a selective sensitivity to features in the human face that convey information on sex, age, emotions, and intentions. This ability might not only be applied to our conspecifics nowadays, but also to other living objects (i.e., animals) and even to artificial structures, such as cars. To investigate this possibility, we asked people to report the characteristics, emotions, personality traits, and attitudes they attribute to car fronts, and we used geometric morphometrics (GM) and multivariate statistical (...) methods to determine and visualize the corresponding shape information. Automotive features and proportions are found to covary with trait perception in a manner similar to that found with human faces. Emerging analogies are discussed. This study should have implications for both our understanding of our prehistoric psyche and its interrelation with the modern world. (shrink)
Aspects of Consciousness in Philosophy of Mind
Reduction, Representation and Commensurability of Theories.Peter Schroeder-Heister & Frank Schaefer - 1989 - Philosophy of Science 56 (1):130-157.details
Theories in the usual sense, as characterized by a language and a set of theorems in that language ("statement view"), are related to theories in the structuralist sense, in turn characterized by a set of potential models and a subset thereof as models ("non-statement view", J. Sneed, W. Stegmüller). It is shown that reductions of theories in the structuralist sense (that is, functions on structures) give rise to so-called "representations" of theories in the statement sense and vice versa, where representations (...) are understood as functions that map sentences of one theory into another theory. It is argued that commensurability between theories should be based on functions on open formulas and open terms so that reducibility does not necessarily imply commensurability. This is in accordance with a central claim by Stegmüller on the compatibility of reducibility and incommensurability that has recently been challenged by D. Pearce. (shrink)
Incommensurability in Science in General Philosophy of Science
Fragile and Resilient Trust: Risk and Uncertainty in Negotiated and Reciprocal Exchange.Linda D. Molm, David R. Schaefer & Jessica L. Collett - 2009 - Sociological Theory 27 (1):1 - 32.details
Both experimental and ethnographic studies show that reciprocal exchanges (in which actors unilaterally provide benefits to each other without formal agreements) produce stronger trust than negotiated exchanges secured by binding agreements. We develop the theoretical role of risk and uncertainty as causal mechanisms that potentially explain these results, and then test their effects in two laboratory experiments that vary risk and uncertainty within negotiated and reciprocal forms of exchange. We increase risk in negotiated exchanges by making agreements nonbinding and decrease (...) uncertainty in reciprocal exchanges by having actors communicate their intentions. Our findings support three main theoretical conclusions. (1) Increasing risk in negotiated exchange produces levels of trust comparable to those in reciprocal exchange only if the partner's trustworthiness is near-absolute. (2) Decreasing uncertainty in reciprocal exchange either increases or decreases trust, depending on network structure. (3) Even when reciprocal and negotiated exchanges produce comparable levels of trust, their trust differs in kind, with reciprocal exchange partners developing trust that is more resilient and affect-based. (shrink)
Philosophy of Sociology, Misc in Philosophy of Social Science
Psychomorphospace—From Biology to Perception, and Back: Towards an Integrated Quantification of Facial Form Variation.Katrin Schaefer, Philipp Mitteroecker, Bernhard Fink & Fred L. Bookstein - 2009 - Biological Theory 4 (1):98-106.details
Several disciplines share an interest in the evolutionary selection pressures that shaped human physical functioning and appearance, psyche, and behavior. The methodologies invoked from the disciplines studying these domains are often based on different rhetorics, and hence may conflict. Progress in one field is thereby hampered from effective transfer to others. Topics at the intersection of anthropometry and psychometry, such as the impact of sexual selection on the hominin face, are a typical example. Since the underlying theory explicitly places facial (...) form in the middle of a causal chain as the mediating variable between biological causes and psychological effects, a particularly convenient conceptual and analytic scenario arises as follows. Modern morphometrics allows analysis of shape both "backwards" and "forwards" . The two computations are commensurate, hence the two kinds of effects can be compared and evaluated as directions in the same morphospace. We suggest translating the morphometric methodology of "Darwinian aesthetics" into this space, where psychological and other processes of interest can be coded commensurately. Such a translation permits researchers to relate the effects of biological processes on form to the perceptions of the same processes in one unified "psychomorphospace.". (shrink)
Philosophy of Biology, Miscellaneous in Philosophy of Biology
Trade Associations and Corporate Social Responsibility: Evidence From the UK Water and Film Industries.Anja Schaefer & Finola Kerrigan - 2008 - Business Ethics 17 (2):171–195.details
Aggregation of polyQ‐Extended Proteins is Promoted by Interaction with Their Natural Coiled‐Coil Partners.Spyros Petrakis, Martin H. Schaefer, Erich E. Wanker & Miguel A. Andrade-Navarro - 2013 - Bioessays 35 (6):503-507.details
Biological Sciences in Natural Sciences
Dnmt2 Methyltransferases and Immunity: An Ancient Overlooked Connection Between Nucleotide Modification and Host Defense?Zeljko Durdevic & Matthias Schaefer - 2013 - Bioessays 35 (12):1044-1049.details
Genetics and Molecular Biology in Philosophy of Biology
Health and Illness in Philosophy of Science, Misc
A Response to Ervin Laszlo: Quantum and Consciousness.Lothar Schaefer - 2006 - Zygon 41 (3):573-582.details
Consciousness and Physics, Misc in Philosophy of Cognitive Science
Interpretation of Quantum Mechanics in Philosophy of Physical Science
Reevaluating the Right to Withdraw From Research Without Penalty.G. Owen Schaefer & Alan Wertheimer - 2011 - American Journal of Bioethics 11 (4):14-16.details
Professionalism: Foundation for Business Ethics. [REVIEW]Thomas E. Schaefer - 1984 - Journal of Business Ethics 3 (4):269 - 277.details
Professionalism includes the essential contents of other key notions within the field of business ethics. As a term involving the notion of vocation it may be understood as containing a religious content, since vocation refers to a man's most intimate personal decisions, destiny and providence. Professionalism also connotes respect for law and so includes a reference to commercial law as a guide to right conduct. Professionalsim thus lifts the requirements of law to the level of personal commitment.Like an honest act, (...) professionalism may not be easy to define, but you will know it when you see it. As for professionalism's practitioners, like the practitioners of honesty, their art is learned not by seeking definitions of what they do, but by practicing professionalism. Only if this practice becomes an obsession with the Business Aristocracy can we expect professionalism to seize the soul of lesser businessmen and suffuse the entire business community. (shrink)
Bounded Immunity and Btt‐Reductions.Stephen Fenner & Marcus Schaefer - 1999 - Mathematical Logic Quarterly 45 (1):3-21.details
We define and study a new notion called k-immunity that lies between immunity and hyperimmunity in strength. Our interest in k-immunity is justified by the result that θ does not k-tt reduce to a k-immune set, which improves a previous result by Kobzev [7]. We apply the result to show that Φ′ does not btt-reduce to MIN, the set of minimal programs. Other applications include the set of Kolmogorov random strings, and retraceable and regressive sets. We also give a new (...) characterization of effectively simple sets and show that simple sets are not btt-cuppable. (shrink)
Justice or Tyranny?: A Critique of John Rawls's a Theory of Justice.David Lewis Schaefer - 1979 - Kennikat Press.details
$4.76 used $434.36 new Amazon page
Hr's View of Ethics in the Work Place: Are the Barbarians at the Gate? [REVIEW]John Danley, Edward Harrick, Diane Schaefer, Donald Strickland & George Sullivan - 1996 - Journal of Business Ethics 15 (3):273 - 285.details
Based on responses from 1078 human resource (HR) professionals, this study concludes that there is not an ethical crisis in the work place. Seven of 37 situations were rated as serious problems by more than 25% of the respondents. HR reported that their organizations are serious about uncovering and disciplining ethical misconduct, top management has a commitment to ethical business conduct, personal principles are not compromised to conform to company expectations, and performance pressures do not lead to unethical conduct.
The Importance of Rationality.G. Owen Schaefer - 2013 - Hastings Center Report 43 (1):3.details
Michael Hauskeller ("Reflections from a Troubled Stream: Giubliani and Minerva on 'After-Birth Abortion') has recently suggested that we should resist rationalist tendencies in moral discourse: "[I]s not all morality ultimately irrational? Even the most strongly held moral convictions can be shown to lack a rational basis." (Hauskeller 2012, p. 18) Hauskeller was responding to Alberto Giubliani and Francesca Minverva's (2012) recent defense of the permissibility of killing infants, but his anti-rationality arguments have wide-reaching implications. Yet pace Hauskeller, rationality is indeed (...) of crucial importance to any ethical argument. We should not abandon rationality for the sake of refuting one discomforting hypothesis; instead, rationality must be rigorously employed, here and elsewhere, in the search for the truth. (shrink)
Health Care Ethics, Misc in Applied Ethics
Rationality, Misc in Epistemology
A Critique of Rawls' Contract Doctrine.David Lewis Schaefer - 1974 - Review of Metaphysics 28 (1):89 - 115.details
JOHN RAWLS IN A Theory of Justice attempts to deduce "the principles of justice" from the idea of a "contract" among free and equal persons. The factor which obviously distinguishes Rawls' contract doctrine from the teachings of the great social contract philosophers who preceded him is that it does not rest on any examination of what the character of an actual nonpolitical condition or "state of nature" among men would be. Rawls' procedure is in fact the opposite of that followed (...) by his predecessors: instead of inferring the principles of the contract from what men, given their nature, would be likely to agree upon in the absence of an already existing government and set of laws, he freely constructs the character and circumstances of the parties to his "purely hypothetical" "original position of equality" in order "to lead to a certain conception of justice". That conception is to consist of. (shrink)
Preface.Thomas Kenner & Jochen Schaefer - 1986 - Theoretical Medicine and Bioethics 7 (3).details
British Philosophy in European Philosophy
From the Dialogic to the Contemplative: A Conceptual and Empirical Rethinking of Online Communication Outcomes as Verbing Micro-Practices. [REVIEW]David J. Schaefer & Brenda Dervin - 2009 - Ethics and Information Technology 11 (4):265-278.details
Traditional approaches to studying communication in public spheres draw upon a product or outcome orientation that has prevented researchers from theorizing more specifically about how communication behaviors either inhibit or facilitate dialogic processes. Additionally, researchers typically emphasize consensus as a preferred outcome. Drawing upon a methodology explicitly developed to study communicating using a verb-oriented framework, we analyzed 1,360 postings from online pedagogical discussions. Our analysis focused on verbing micro-practices, the dynamic communicative actions through which participants make and unmake public spheres. (...) Two questions guided our analysis: (1) How do grounded communicative micro-moment practices relate to consensusing and dissensusing within public spheres? and (2) What are the theoretical implications of these relationships for the quality of dialogue among participants who are discussing controversial topics? Our findings indicate that, contrary to recent theorizing, consensus-building and maintaining behaviors may actually inhibit the communicative processes necessary for the creation of effective public sphere dialogue. (shrink)
Computer Ethics in Applied Ethics
Sacramental Commons: Christian Ecological Ethics. By John Hart.Jame Schaefer - 2008 - Zygon 43 (4):993-996.details
Individual Differences in Amygdala and Ventromedial Prefrontal Cortex Activity Are Associated with Evaluation Speed and Psychological Well-Being.Corrina J. Frye, Hillary S. Schaefer & Andrew L. Alexander - unknowndetails
& Using functional magnetic resonance imaging, we examined whether individual differences in amygdala activation in response to negative relative to neutral information are related to differences in the speed with which such information is evaluated, the extent to which such differences are associated with medial prefrontal cortex function, and their relationship with measures of trait anxiety and psychological well-being (PWB). Results indicated that faster judgments of negative relative to neutral information were associated with increased left and right amygdala activation. In (...) the prefrontal cortex, faster judgment time was associated with relative decreased activation in a cluster in the ventral anterior cingulate cor-. (shrink)
Introduction.Arthur Gross Schaefer - 1997 - Business Ethics Quarterly 7 (2):1-3.details
This introduction a) presents organized religion as a source of "spiritual goods" and briefly summarizes each of the seventeen tradition-centeredarticles; b) explains why organized religion merits the attention of business ethics; c) categorizes the articles according to rubrics useful for teaching and research; d) further explains the value of these essays to academic researchers, business practitioners, and spiritual seekers.
The Invention of Gunpowder.Scott Schaefer - 1981 - Journal of the Warburg and Courtauld Institutes 44:209-211.details
Early Modern Skepticism and the Origins of Toleration (Review).David Lewis Schaefer - 2000 - Philosophy and Literature 24 (1):227-230.details
Through a glass darkly / Joshua Mitchell -- Skepticism, self, and toleration in Montaigne's political thought / Alan Levine -- French free-thinkers in the first decades of the Edict of Nantes / Maryanne Cline Horowitz -- Descartes and the question of toleration / Michael Gillepsie -- Toleration and the skepticism of religion in Spinoza's Tractatus Theologico-Politicus / Steven B. Smith -- Monopolizing faith / Alan Houston -- Skepticism and toleration in Hobbes' political thought / Shirley Letwin -- John Locke and (...) the foundations of toleration / Nathan Tarcov -- Pierre Bayle's atheist politics / Kenneth R. Weinstein -- Of believers and barbarians / Diana Schaub -- Tolerant skepticism of Voltaire and Diderot / Patrick Riley. (shrink)
History: Skepticism in Epistemology
History: Toleration in Social and Political Philosophy
: Gaze Fixation and the Neural Circuitry of Face Processing.Hillary S. Schaefer & Andrew L. Alexander R. Richard J. Davidson - unknowndetails
ai Diminished gaze fixation is one of the core features of autism and has been proposed to be associated with abnormalities in the neural circuitry of affect. We tested this hypothesis in two separate studies using eye tracking while measuring functional brain activity during facial discrimination tasks in individuals with autism and in typically developing individuals. Activation in the fusiform gyrus and amygdala was strongly and positively correlated with the time spent fixating the eyes in the autistic group in both (...) studies, suggesting that diminished gaze fixation may account for the fusiform hypoactivation to faces commonly reported in autism. In addition, variation in eye fixation within autistic individuals was strongly and positively associated with amygdala activation across both studies, suggesting a heightened emotional response associated with gaze fixation in autism. (shrink)
Christian Ethics and the Ethics of Contemporary Man.Reverend Florea Ştefan - 2008 - HEC Forum 20 (1):61-73.details
The Craftsman in an Industrial Society.Herwin Schaefer - 1971 - British Journal of Aesthetics 11 (4):323-326.details
Review of James Cameron's Avatar. [REVIEW]G. Owen Schaefer - 2010 - American Journal of Bioethics 10 (2):68-69.details
Health Care Ethics in Applied Ethics
Infallibility and Intentionality: Franz Brentano's Diagnosis of German Catholicism.Richard Schaefer - 2007 - Journal of the History of Ideas 68 (3):477-499.details
Brentano: Intentionality in 19th Century Philosophy
The Case Against Coronary Artery Surgery.Jochen Schaefer - 1980 - Theoretical Medicine and Bioethics 1 (2):155-176.details
Coronary by-pass surgery has been performed in hundreds of thousands of patients in the last 15 years with a high standard of technical and surgical perfection. The indications for this kind of surgery, however, are still controversial because in spite of many retrospective and several prospective studies it cannot be proven convincingly that in a given patient this surgical procedure will prolong life or prevent myocardial infarction. The present attempt to analyze the causes for this controversy shows that the main (...) reasons for this uncertainty lie: (a) in the enigma of the underlying (ischemic heart) disease itself, which is supposed to lend itself to surgical therapy; (b) in the inadequate methods available up until now for characterizing the state of the disease, its probable course, and its pathogenesis; and (c) in the professional group interests which have a momentum of their own. (shrink)
Medicus Technologicus.Ulrich Kliegis, Alexis C. M. Renirie & Jochen Schaefer - 1986 - Theoretical Medicine and Bioethics 7 (3).details
The development of modern programmable pacemaker-systems has led to a series of questions which until now have apparently not existed in the treatment of cardiac rhythm disturbances. These questions touch especially on the problem of whether the relation which usually exists between a diagnostic step and its therapeutic consequence, namely its therapeutic relevance, is abolished or at least changed.
A Note on the Iconography of a Medal of Lavinia Fontana.Jean Owens Schaefer - 1984 - Journal of the Warburg and Courtauld Institutes 47:232-234.details
13th/14th Century Philosophy in Medieval and Renaissance Philosophy
Was Socrates a Corruptor?David Lewis Schaefer - 1992 - Social Philosophy Today 7:351-362.details
Socrates in Ancient Greek and Roman Philosophy
Republics Ancient and Modern (Review).David Lewis Schaefer - 1994 - Philosophy and Literature 18 (1):197-198.details
Neural Correlates of "Hot" and "Cold" Emotional Processing: A Multilevel Approach to the Functional Anatomy of Emotion.Alexandre Schaefer - unknowndetails
The neural correlates of two hypothesized emotional processing modes, i.e., schematic and propositional modes, were investigated with positron emission tomography. Nineteen subjects performed an emotional mental imagery task while mentally repeating sentences linked to the meaning of the imagery script. In the schematic conditions, participants repeated metaphoric sentences, whereas in the propositional conditions, the sentences were explicit questions about specific emotional appraisals of the imagery scenario. Five types of emotional scripts were proposed to the subjects (happiness, anger, affection, sadness, and (...) a neutral scenario). The results supported the hypothesized distinction between schematic and propositional emotional processing modes. Specifically, schematic mode was associated with increased activity in the ventromedial prefrontal cortex whereas propositional mode was associated with activation of the anterolateral prefrontal cortex. In addition, interaction analyses showed that schematic versus propositional processing of happiness (compared with the neutral scenario) was associated with increased activity in the ventral striatum whereas "schematic anger" was tentatively associated with activation of the ventral pallidum. © 2003 Elsevier Science (USA). All rights reserved. (shrink)
Emotions in Philosophy of Mind
Introduction.Arthur Gross Schaefer - 2001 - Spiritual Goods 2001:1-15.details
Perennial Wisdom and the Sayings of Mencius.Thomas E. Schaefer - 1963 - International Philosophical Quarterly 3 (3):428-444.details
Mencius in Asian Philosophy | CommonCrawl |
Null results are generally less likely to be published. Consistent with the operation of such a bias in the present literature, the null results found in our survey were invariably included in articles reporting the results of multiple tasks or multiple measures of a single task; published single-task studies with exclusively behavioral measures all found enhancement. This suggests that some single-task studies with null results have gone unreported. The present mixed results are consistent with those of other recent reviews that included data from normal subjects, using more limited sets of tasks or medications (Advokat, 2010; Chamberlain et al., 2010; Repantis, Schlattmann, Laisney, & Heuser, 2010).
Even though smart drugs come with a long list of benefits, their misuse can cause negative side effects. Excess use can cause anxiety, fear, headaches, increased blood pressure, and more. Considering this, it is imperative to study usage instructions: how often can you take the pill, the correct dosage and interaction with other medication/supplements.
Piracetam is a reliable supplement for improving creativity. It is an entry level racetam due to its lack of severe side effects and relative subtlety. Piracetam's effects take hold over time through continual use. There is less instant gratification compared to other brain enhancers. Additionally, this nootropic can enhance holistic thinking, verbal memory, and mental energy levels.
Noopept is a nootropic that belongs to the ampakine family. It is known for promoting learning, boosting mood, and improving logical thinking. It has been popular as a study drug for a long time but has recently become a popular supplement for improving vision. Users report seeing colors more brightly and feeling as if their vision is more vivid after taking noopept.
Aniracetam is known as one of the smart pills with the widest array of uses. From benefits for dementia patients and memory boost in adults with healthy brains, to the promotion of brain damage recovery. It also improves the quality of sleep, what affects the overall increase in focus during the day. Because it supports the production of dopamine and serotonin, it elevates our mood and helps fight depression and anxiety.
Discussions of PEA mention that it's almost useless without a MAOI to pave the way; hence, when I decided to get deprenyl and noticed that deprenyl is a MAOI, I decided to also give PEA a second chance in conjunction with deprenyl. Unfortunately, in part due to my own shenanigans, Nubrain canceled the deprenyl order and so I have 20g of PEA sitting around. Well, it'll keep until such time as I do get a MAOI.
But, thanks to the efforts of a number of remarkable scientists, researchers and plain-old neurohackers, we are beginning to put together a "whole systems" model of how all the different parts of the human brain work together and how they mesh with the complex regulatory structures of the body. It's going to take a lot more data and collaboration to dial this model in, but already we are empowered to design stacks that can meaningfully deliver on the promise of nootropics "to enhance the quality of subjective experience and promote cognitive health, while having extremely low toxicity and possessing very few side effects." It's a type of brain hacking that is intended to produce noticeable cognitive benefits.
Accordingly, we searched the literature for studies in which MPH or d-AMP was administered orally to nonelderly adults in a placebo-controlled design. Some of the studies compared the effects of multiple drugs, in which case we report only the results of stimulant–placebo comparisons; some of the studies compared the effects of stimulants on a patient group and on normal control subjects, in which case we report only the results for control subjects. The studies varied in many other ways, including the types of tasks used, the specific drug used, the way in which dosage was determined (fixed dose or weight-dependent dose), sample size, and subject characteristics (e.g., age, college sample or not, gender). Our approach to the classic splitting versus lumping dilemma has been to take a moderate lumping approach. We group studies according to the general type of cognitive process studied and, within that grouping, the type of task. The drug and dose are reported, as well as sample characteristics, but in the absence of pronounced effects of these factors, we do not attempt to make generalizations about them.
I've been actively benefitting from nootropics since 1997, when I was struggling with cognitive performance and ordered almost $1000 worth of smart drugs from Europe (the only place where you could get them at the time). I remember opening the unmarked brown package and wondering whether the pharmaceuticals and natural substances would really enhance my brain.
Not included in the list below are prescription psychostimulants such as Adderall and Ritalin. Non-medical, illicit use of these drugs for the purpose of cognitive enhancement in healthy individuals comes with a high cost, including addiction and other adverse effects. Although these drugs are prescribed for those with attention deficit hyperactivity disorder (ADHD) to help with focus, attention and other cognitive functions, they have been shown to in fact impair these same functions when used for non-medical purposes. More alarming, when taken in high doses, they have the potential to induce psychosis.
The blood half-life is 12-36 hours; hence two or three days ought to be enough to build up and wash out. A week-long block is reasonable since that gives 5 days for effects to manifest, although month-long blocks would not be a bad choice either. (I prefer blocks which fit in round periods because it makes self-experiments easier to run if the blocks fit in normal time-cycles like day/week/month. The most useless self-experiment is the one abandoned halfway.)
The data from 2-back and 3-back tasks are more complex. Three studies examined performance in these more challenging tasks and found no effect of d-AMP on average performance (Mattay et al., 2000, 2003; Mintzer & Griffiths, 2007). However, in at least two of the studies, the overall null result reflected a mixture of reliably enhancing and impairing effects. Mattay et al. (2000) examined the performance of subjects with better and worse working memory capacity separately and found that subjects whose performance on placebo was low performed better on d-AMP, whereas subjects whose performance on placebo was high were unaffected by d-AMP on the 2-back and impaired on the 3-back tasks. Mattay et al. (2003) replicated this general pattern of data with subjects divided according to genotype. The specific gene of interest codes for the production of Catechol-O-methyltransferase (COMT), an enzyme that breaks down dopamine and norepinephrine. A common polymorphism determines the activity of the enzyme, with a substitution of methionine for valine at Codon 158 resulting in a less active form of COMT. The met allele is thus associated with less breakdown of dopamine and hence higher levels of synaptic dopamine than the val allele. Mattay et al. (2003) found that subjects who were homozygous for the val allele were able to perform the n-back faster with d-AMP; those homozygous for met were not helped by the drug and became significantly less accurate in the 3-back condition with d-AMP. In the case of the third study finding no overall effect, analyses of individual differences were not reported (Mintzer & Griffiths, 2007).
There is evidence to suggest that modafinil, methylphenidate, and amphetamine enhance cognitive processes such as learning and working memory...at least on certain laboratory tasks. One study found that modafinil improved cognitive task performance in sleep-deprived doctors. Even in non-sleep deprived healthy volunteers, modafinil improved planning and accuracy on certain cognitive tasks. Similarly, methylphenidate and amphetamine also enhanced performance of healthy subjects in certain cognitive tasks.
Cocoa flavanols (CF) positively influence physiological processes in ways which suggest that their consumption may improve aspects of cognitive function. This study investigated the acute cognitive and subjective effects of CF consumption during sustained mental demand. In this randomized, controlled, double-blinded, balanced, three period crossover trial 30 healthy adults consumed drinks containing 520 mg, 994 mg CF and a matched control, with a 3-day washout between drinks. Assessments included the state anxiety inventory and repeated 10-min cycles of a Cognitive Demand Battery comprising of two serial subtraction tasks (Serial Threes and Serial Sevens), a Rapid Visual Information Processing (RVIP) task and a mental fatigue scale, over the course of 1 h. Consumption of both 520 mg and 994 mg CF significantly improved Serial Threes performance. The 994 mg CF beverage significantly speeded RVIP responses but also resulted in more errors during Serial Sevens. Increases in self-reported mental fatigue were significantly attenuated by the consumption of the 520 mg CF beverage only. This is the first report of acute cognitive improvements following CF consumption in healthy adults. While the mechanisms underlying the effects are unknown they may be related to known effects of CF on endothelial function and blood flow.
These are quite abstract concepts, though. There is a large gap, a grey area in between these concepts and our knowledge of how the brain functions physiologically – and it's in this grey area that cognitive enhancer development has to operate. Amy Arnsten, Professor of Neurobiology at Yale Medical School, is investigating how the cells in the brain work together to produce our higher cognition and executive function, which she describes as "being able to think about things that aren't currently stimulating your senses, the fundamentals of abstraction. This involves mental representations of our goals for the future, even if it's the future in just a few seconds."
Since my experiment had a number of flaws (non-blind, varying doses at varying times of day), I wound up doing a second better experiment using blind standardized smaller doses in the morning. The negative effect was much smaller, but there was still no mood/productivity benefit. Having used up my first batch of potassium citrate in these 2 experiments, I will not be ordering again since it clearly doesn't work for me.
In 3, you're considering adding a new supplement, not stopping a supplement you already use. The I don't try Adderall case has value $0, the Adderall fails case is worth -$40 (assuming you only bought 10 pills, and this number should be increased by your analysis time and a weighted cost for potential permanent side effects), and the Adderall succeeds case is worth $X-40-4099, where $X is the discounted lifetime value of the increased productivity due to Adderall, minus any discounted long-term side effect costs. If you estimate Adderall will work with p=.5, then you should try out Adderall if you estimate that 0.5 \times (X-4179) > 0 ~> $X>4179$. (Adderall working or not isn't binary, and so you might be more comfortable breaking down the various how effective Adderall is cases when eliciting X, by coming up with different levels it could work at, their values, and then using a weighted sum to get X. This can also give you a better target with your experiment- this needs to show a benefit of at least Y from Adderall for it to be worth the cost, and I've designed it so it has a reasonable chance of showing that.)
For illustration, consider amphetamines, Ritalin, and modafinil, all of which have been proposed as cognitive enhancers of attention. These drugs exhibit some positive effects on cognition, especially among individuals with lower baseline abilities. However, individuals of normal or above-average cognitive ability often show negligible improvements or even decrements in performance following drug treatment (for details, see de Jongh, Bolt, Schermer, & Olivier, 2008). For instance, Randall, Shneerson, and File (2005) found that modafinil improved performance only among individuals with lower IQ, not among those with higher IQ. [See also Finke et al 2010 on visual attention.] Farah, Haimm, Sankoorikal, & Chatterjee 2009 found a similar nonlinear relationship of dose to response for amphetamines in a remote-associates task, with low-performing individuals showing enhanced performance but high-performing individuals showing reduced performance. Such ∩-shaped dose-response curves are quite common (see Cools & Robbins, 2004)
Smart Pill is a dietary supplement that blends vitamins, amino acids, and herbal extracts to sustain mental alertness, memory and concentration. One of the ingredients used in this formula is Vitamin B-1, also known as Thiamine, which sustains almost all functions present in the body, but plays a key role in brain health and function. A deficiency of this vitamin can lead to several neurological function problems. The most common use of Thiamine is to improve brain function; it acts as a neurotransmitter helping the brain prevent learning and memory disorders; it also provides help with mood disorders and offers stress relief.
Qualia Mind, meanwhile, combines more than two dozen ingredients that may support brain and nervous system function – and even empathy, the company claims – including vitamins B, C and D, artichoke stem and leaf extract, taurine and a concentrated caffeine powder. A 2014 review of research on vitamin C, for one, suggests it may help protect against cognitive decline, while most of the research on artichoke extract seems to point to its benefits to other organs like the liver and heart. A small company-lead pilot study on the product found users experienced improvements in reasoning, memory, verbal ability and concentration five days after beginning Qualia Mind.
Nor am I sure how important the results are - partway through, I haven't noticed anything bad, at least, from taking Noopept. And any effect is going to be subtle: people seem to think that 10mg is too small for an ingested rather than sublingual dose and I should be taking twice as much, and Noopept's claimed to be a chronic gradual sort of thing, with less of an acute effect. If the effect size is positive, regardless of statistical-significance, I'll probably think about doing a bigger real self-experiment (more days blocked into weeks or months & 20mg dose)
From the standpoint of absorption, the drinking of tobacco juice and the interaction of the infusion or concoction with the small intestine is a highly effective method of gastrointestinal nicotine administration. The epithelial area of the intestines is incomparably larger than the mucosa of the upper tract including the stomach, and the small intestine represents the area with the greatest capacity for absorption (Levine 1983:81-83). As practiced by most of the sixty-four tribes documented here, intoxicated states are achieved by drinking tobacco juice through the mouth and/or nose…The large intestine, although functionally little equipped for absorption, nevertheless absorbs nicotine that may have passed through the small intestine.
But though it's relatively new on the scene with ambitious young professionals, creatine has a long history with bodybuilders, who have been taking it for decades to improve their muscle #gains. In the US, sports supplements are a multibillion-dollar industry – and the majority contain creatine. According to a survey conducted by Ipsos Public Affairs last year, 22% of adults said they had taken a sports supplement in the last year. If creatine was going to have a major impact in the workplace, surely we would have seen some signs of this already.
Two additional studies assessed the effects of d-AMP on visual–motor sequence learning, a form of nondeclarative, procedural learning, and found no effect (Kumari et al., 1997; Makris, Rush, Frederich, Taylor, & Kelly, 2007). In a related experimental paradigm, Ward, Kelly, Foltin, and Fischman (1997) assessed the effect of d-AMP on the learning of motor sequences from immediate feedback and also failed to find an effect.
One often-cited study published in the British Journal of Pharmacology looked at cognitive function in the elderly and showed that racetam helped to improve their brain function.19 Another study, which was published in Psychopharmacology, looked at adult volunteers (including those who are generally healthy) and found that piracetam helped improve their memory.20
Finally, all of the questions raised here in relation to MPH and d-AMP can also be asked about newer drugs and even about nonpharmacological methods of cognitive enhancement. An example of a newer drug with cognitive-enhancing potential is modafinil. Originally marketed as a therapy for narcolepsy, it is widely used off label for other purposes (Vastag, 2004), and a limited literature on its cognitive effects suggests some promise as a cognitive enhancer for normal healthy people (see Minzenberg & Carter, 2008, for a review).
Harrisburg, NC -- (SBWIRE) -- 02/18/2019 -- Global Smart Pills Technology Market - Segmented by Technology, Disease Indication, and Geography - Growth, Trends, and Forecast (2019 - 2023) The smart pill is a wireless capsule that can be swallowed, and with the help of a receiver (worn by patients) and software that analyzes the pictures captured by the smart pill, the physician is effectively able to examine the gastrointestinal tract. Gastrointestinal disorders have become very common, but recently, there has been increasing incidence of colorectal cancer, inflammatory bowel disease, and Crohns disease as well.
Nootropics. You might have heard of them. The "limitless pill" that keeps Billionaires rich. The 'smart drugs' that students are taking to help boost their hyperfocus. The cognitive enhancers that give corporate executives an advantage. All very exciting. But as always, the media are way behind the curve. Yes, for the past few decades, cognitive enhancers were largely sketchy substances that people used to grasp at a short term edge at the expense of their health and well being. But the days of taking prescription pills to pull an all-nighter are so 2010. The better, safer path isn't with these stimulants but with nootropics. Nootropics consist of dietary supplements and substances which enhance your cognition, in particular when it comes to motivation, creativity, memory, and other executive functions. They play an important role in supporting memory and promoting optimal brain function.
The Defense Department reports rely on data collected by the private real estate firms that operate base housing in partnership with military branches. The companies' compensation is partly determined by the results of resident satisfaction surveys. I had to re-read this sentence like 5 times to make sure I understood it correctly. I just can't even. Seriously, in what universe did anyone think that this would be a good idea?
Second, users are concerned with the possibility of withdrawal if they stop taking the nootropics. They worry that if they stop taking nootropics they won't be as smart as when they were taking nootropics, and will need to continue taking them to function. Some users report feeling a slight brain fog when discontinuing nootropics, but that isn't a sign of regression.
Weyandt et al. (2009) Large public university undergraduates (N = 390) 7.5% (past 30 days) Highest rated reasons were to perform better on schoolwork, perform better on tests, and focus better in class 21.2% had occasionally been offered by other students; 9.8% occasionally or frequently have purchased from other students; 1.4% had sold to other students
He recommends a 10mg dose, but sublingually. He mentions COLURACETAM's taste is more akin to that of PRAMIRACETAM than OXIRACETAM, in that it tastes absolutely vile (not a surprise), so it is impossible to double-blind a sublingual administration - even if I knew of an inactive equally-vile-tasting substitute, I'm not sure I would subject myself to it. To compensate for ingesting the coluracetam, it would make sense to double the dose to 20mg (turning the 2g into <100 doses). Whether the effects persist over multiple days is not clear; I'll assume it does not until someone says it does, since this makes things much easier.
SOURCES: Marvin Hausman, MD, CEO, Axonyx Inc. Axel Unterbeck, PhD, president, chief scientific officer, Memory Pharmaceuticals. Martha Farah, PhD, professor, department of psychiatry, University of Pennsylvania. Howard Gardner, PhD, Hobbs Professor of Education and Cognition, Harvard Graduate School of Education. Nature Reviews Neuroscience, May 2004. Neurology, July 2002. Alzheimer's Association.
Creatine is a substance that's produced in the human body. It is initially produced in the kidneys, and the process is completed in the liver. It is then stored in the brain tissues and muscles, to support the energy demands of a human body. Athletes and bodybuilders use creatine supplements to relieve fatigue and increase the recovery of the muscle tissues affected by vigorous physical activities. Apart from helping the tissues to recover faster, creatine also helps in enhancing the mental functions in sleep-deprived adults, and it also improves the performance of difficult cognitive tasks.
Rogers RD, Blackshaw AJ, Middleton HC, Matthews K, Hawtin K, Crowley C, Robbins TW. Tryptophan depletion impairs stimulus-reward learning while methylphenidate disrupts attentional control in healthy young adults: Implications for the monoaminergic basis of impulsive behaviour. Psychopharmacology. 1999;146:482–491. doi: 10.1007/PL00005494. [PubMed] [CrossRef]
There is no official data on their usage, but nootropics as well as other smart drugs appear popular in the Silicon Valley. "I would say that most tech companies will have at least one person on something," says Noehr. It is a hotbed of interest because it is a mentally competitive environment, says Jesse Lawler, a LA based software developer and nootropics enthusiast who produces the podcast Smart Drug Smarts. "They really see this as translating into dollars." But Silicon Valley types also do care about safely enhancing their most prized asset – their brains – which can give nootropics an added appeal, he says.
First off, overwhelming evidence suggests that smart drugs actually work. A meta-analysis by researchers at Harvard Medical School and Oxford showed that Modafinil has significant cognitive benefits for those who do not suffer from sleep deprivation. The drug improves their ability to plan and make decisions and has a positive effect on learning and creativity. Another study, by researchers at Imperial College London, showed that Modafinil helped sleep-deprived surgeons become better at planning, redirecting their attention, and being less impulsive when making decisions.
Additionally, this protein also controls the life and death of brain cells, which aids in enhancing synaptic adaptability. Synapses are important for creating new memories, forming new connections, or combining existing connections. All of these components are important for mood regulation, maintenance of clarity, laser focus, and learning new life skills.
No. There are mission essential jobs that require you to live on base sometimes. Or a first term person that is required to live on base. Or if you have proven to not be as responsible with rent off base as you should be so your commander requires you to live on base. Or you're at an installation that requires you to live on base during your stay. Or the only affordable housing off base puts you an hour away from where you work. It isn't simple. The fact that you think it is tells me you are one of the "dumb@$$es" you are referring to above.
The smart pill that FDA approved is called Abilify MyCite. This tiny pill has a drug and an ingestible sensor. The sensor gets activated when it comes into contact with stomach fluid to detect when the pill has been taken. The data is then transmitted to a wearable patch that eventually conveys the information to a paired smartphone app. Doctors and caregivers, with the patient's consent, can then access the data via a web portal.
In my last post, I talked about the idea that there is a resource that is necessary for self-control…I want to talk a little bit about the candidate for this resource, glucose. Could willpower fail because the brain is low on sugar? Let's look at the numbers. A well-known statistic is that the brain, while only 2% of body weight, consumes 20% of the body's energy. That sounds like the brain consumes a lot of calories, but if we assume a 2,400 calorie/day diet - only to make the division really easy - that's 100 calories per hour on average, 20 of which, then, are being used by the brain. Every three minutes, then, the brain - which includes memory systems, the visual system, working memory, then emotion systems, and so on - consumes one (1) calorie. One. Yes, the brain is a greedy organ, but it's important to keep its greediness in perspective… Suppose, for instance, that a brain in a person exerting their willpower - resisting eating brownies or what have you - used twice as many calories as a person not exerting willpower. That person would need an extra one third of a calorie per minute to make up the difference compared to someone not exerting willpower. Does exerting self control burn more calories?
On the other hand, sometimes you'll feel a great cognitive boost as soon as you take a pill. That can be a good thing or a bad thing. I find, for example, that modafinil makes you more of what you already are. That means if you are already kind of a dick and you take modafinil, you might act like a really big dick and regret it. It certainly happened to me! I like to think that I've done enough hacking of my brain that I've gotten over that programming… and that when I use nootropics they help me help people. | CommonCrawl |
Classification of non-topological solutions of an elliptic equation arising from self-dual gauged Sigma model
CPAA Home
Orbitally symmetric systems with applications to planar centers
October 2021, 20(10): 3347-3371. doi: 10.3934/cpaa.2021108
Ground state solution of critical Schrödinger equation with singular potential
Yu Su ,
School of Mathematics and Big Data, Anhui University of Science and Technology, Huainan, Anhui 232001, China
Received June 2020 Revised May 2021 Published October 2021 Early access June 2021
Fund Project: Y. Su is supported by the Key Program of University Natural Science Research Fund of Anhui Province (KJ2020A0292)
In this paper, we consider the following Schrödinger equation with singular potential:
$ \begin{equation*} \begin{aligned} -\Delta u + V(|x|)u = f(u),\ \, x\in \mathbb{R}^{N}, \end{aligned} \end{equation*} $
$ N\geqslant 3 $
$ V $
is a singular potential with parameter
$ \alpha\in(0,2)\cup(2,\infty) $
, the nonlinearity
$ f $
involving critical exponent. First, by using the refined Sobolev inequality, we establish a Lions-type theorem. Second, applying Lions-type theorem and variational methods, we show the existence of ground state solution for above equation. Our result partially extends the results in Badiale-Rolando [Atti Accad. Naz. Lincei Rend. Lincei Mat. Appl. 17 (2006)], and Su-Wang-Willem [Commun. Contemp. Math. 9 (2007)].
Keywords: Schrödinger equation, Lions-type theorem, singular potential, critical exponent.
Mathematics Subject Classification: Primary: 35J60; Secondary: 35J20.
Citation: Yu Su. Ground state solution of critical Schrödinger equation with singular potential. Communications on Pure & Applied Analysis, 2021, 20 (10) : 3347-3371. doi: 10.3934/cpaa.2021108
M. Badiale and S. Rolando, A note on nonlinear elliptic problems with singular potentials, Atti Accad. Naz. Lincei Rend. Lincei Mat. Appl., 17 (2006), 1-13. doi: 10.4171/RLM/450. Google Scholar
M. Badiale, V. Benci and S. Rolando, A nonlinear elliptic equation with singular potential and applications to nonlinear field equations, J. Eur. Math. Soc., 9 (2007), 355-381. doi: 10.4171/JEMS/83. Google Scholar
M. Badiale, M. Guida and S. Rolando, Elliptic equations with decaying cylindrical potentials and power-type nonlinearities, Adv. Differ. Equ., 12 (2007), 1321-1362. doi: euclid.ade/1355867405. Google Scholar
M. Badiale, M. Guida and S. Rolando, A nonexistence result for a nonlinear elliptic equation with singular and decaying potential, Commun. Contemp. Math., 17 (2015), 21 pp. doi: 10.1142/S0219199714500242. Google Scholar
M. Badiale, M. Guida and S. Rolando, Compactness and existence results in weighted Sobolev spaces of radial functions Part Ⅱ: Existence, Nonlinear Differ. Equ. Appl., 23 (2016), 34 pp. doi: 10.1007/s00030-016-0411-0. Google Scholar
M. Badiale, M. Guida and S. Rolando, Compactness and existence results for the p-Laplace equations, J. Math. Anal. Appl., 451 (2017), 345-370. doi: 10.1016/j.jmaa.2017.02.011. Google Scholar
M. Badiale, L. Pisani and S. Rolando, Sum of weighted Lebesgue spaces and nonlinear elliptic equations, Nonlinear Differ. Equ. Appl., 18 (2011), 369-405. doi: 10.1007/s00030-011-0100-y. Google Scholar
M. Badiale, S. Greco and S. Rolando, Radial solutions of a biharmonic equation with vanishing or singular radial potentials, Nonlinear Appl., 185 (2019), 97-122. doi: 10.1016/j.na.2019.01.011. Google Scholar
V. Benci and D. Fortunato, Variational Methods in Nonlinear Field Equations, Springer, Cham, 2014. Google Scholar
H. Berestycki and P. L. Lions, Nonlinear scalar field equations, I. Existence of a ground state, Arch. Rational Mech. Anal., 82 (1983), 313-345. doi: 10.1007/BF00250555. Google Scholar
H. Brézis and E. H. Lieb, A relation between pointwise convergence of functions and convergence of functionals, Proc. Amer. Math. Soc., 88 (1983), 486-490. doi: 10.2307/2044999. Google Scholar
F. Catrina, Nonexistence of positive radial solutions for a problem with singular potential, Adv. Nonlinear Anal., 3 (2014), 1-13. doi: 10.1515/anona-2013-0023. Google Scholar
P. C. Carrião, R. Demarque and O. H. Miyagaki, Nonlinear biharmonic problems with singular potentials, Commun. Pure Appl. Anal., 13 (2014), 2141-2154. doi: 10.3934/cpaa.2014.13.2141. Google Scholar
M. Conti, S. Crotti and D. Pardo, On the existence of positive solutions for a class of singular elliptic equations, Adv. Differ. Equ., 3 (1998), 111-132. doi: euclid.ade/1366399907. Google Scholar
R. Demarque and O. H. Miyagaki, Radial solutions of inhomogeneous fourth order elliptic equations and weighted sobolev embeddings, Adv. Nonlinear Anal., 4 (2015), 135-151. doi: 10.1515/anona-2014-0041. Google Scholar
P. C. Fife, Asymptotic states for equations of reaction and diffusion, Bull. Amer. Math. Soc., 84 (1978), 693-726. doi: 10.1090/S0002-9904-1978-14502-9. Google Scholar
R. Filippucci, P. Pucci and F. Robert, On a $p$-Laplace equation with multiple critical nonlinearities, J. Math. Pures Appl., 50 (2014), 156-177. doi: 10.1016/j.matpur.2008.09.008. Google Scholar
W. Ni, A nonlinear Dirichlet problem on the unit ball and its applications, Indiana Univ. Math. J., 31 (1982), 801-807. doi: 10.1512/iumj.1982.31.31056. Google Scholar
G. Palatucci and A. Pisante, Improved Sobolev embeddings, profile decomposition, and concentration-compactness for fractional Sobolev spaces, Calc. Var. Partial Differ. Equ., 50 (2014), 799-829. doi: 10.1007/s00526-013-0656-y. Google Scholar
S. Rolando, Multiple nonradial solutions for a nonlinear elliptic problem with singular and decaying radial potential, Adv. Nonlinear Anal., 8 (2019), 885-901. doi: 10.1515/anona-2017-0177. Google Scholar
J. Su and R. Tian, Weighted Sobolev embeddings and radial solutions of inhomogeneous quasilinear elliptic equations, Commun. Pure Appl. Anal., 9 (2010), 885-904. doi: 10.3934/cpaa.2010.9.885. Google Scholar
J. Su, Z. Wang and M. Willem, Nonlinear Schrödinger equations with unbounded and decaying potentials, Commun. Contemp. Math., 9 (2007), 571-583. doi: 10.1142/S021919970700254X. Google Scholar
J. Su, Z. Wang and M. Willem, Weighted Sobolev embedding with unbounded and decaying radial potentials, J. Differ. Equ., 238 (2007), 201-219. doi: 10.1016/j.jde.2007.03.018. Google Scholar
S. Terracini, On positive entire solutions to a class of equations with a singular coefficient and critical exponent, Adv. Differ. Equ., 1 (1996), 241-264. doi: euclid.ade/1366896239. Google Scholar
P. Tolksdorf, Regularity for a more general class of quasilinear elliptic equations, J. Differ. Equ., 51 (1984), 126-150. doi: 10.1016/0022-0396(84)90105-0. Google Scholar
C. Vincent and S. Phatak, Accurate momentum-space method for scattering by nuclear and Coulomb potentials, Phys. Rev., 10 (1974), 391-394. Google Scholar
J. L. Vàzquez, A strong maximum principle for some quasilinear elliptic equations, Appl. Math. Optim., 12 (1984), 191-202. doi: 10.1007/BF01449041. Google Scholar
Y. Yang, Solitons in Field Theory and Nonlinear Analysis, Springer Monographs in Mathematics, Springer-Verlag, New York, 2001. Google Scholar
Wentao Huang, Jianlin Xiang. Soliton solutions for a quasilinear Schrödinger equation with critical exponent. Communications on Pure & Applied Analysis, 2016, 15 (4) : 1309-1333. doi: 10.3934/cpaa.2016.15.1309
David Gómez-Castro, Juan Luis Vázquez. The fractional Schrödinger equation with singular potential and measure data. Discrete & Continuous Dynamical Systems, 2019, 39 (12) : 7113-7139. doi: 10.3934/dcds.2019298
Wenmin Gong, Guangcun Lu. On Dirac equation with a potential and critical Sobolev exponent. Communications on Pure & Applied Analysis, 2015, 14 (6) : 2231-2263. doi: 10.3934/cpaa.2015.14.2231
Hiroshi Isozaki, Hisashi Morioka. A Rellich type theorem for discrete Schrödinger operators. Inverse Problems & Imaging, 2014, 8 (2) : 475-489. doi: 10.3934/ipi.2014.8.475
Yuxia Guo, Zhongwei Tang. Multi-bump solutions for Schrödinger equation involving critical growth and potential wells. Discrete & Continuous Dynamical Systems, 2015, 35 (8) : 3393-3415. doi: 10.3934/dcds.2015.35.3393
Jian Zhang, Shihui Zhu, Xiaoguang Li. Rate of $L^2$-concentration of the blow-up solution for critical nonlinear Schrödinger equation with potential. Mathematical Control & Related Fields, 2011, 1 (1) : 119-127. doi: 10.3934/mcrf.2011.1.119
Xu Zhang, Shiwang Ma, Qilin Xie. Bound state solutions of Schrödinger-Poisson system with critical exponent. Discrete & Continuous Dynamical Systems, 2017, 37 (1) : 605-625. doi: 10.3934/dcds.2017025
Kaimin Teng, Xiumei He. Ground state solutions for fractional Schrödinger equations with critical Sobolev exponent. Communications on Pure & Applied Analysis, 2016, 15 (3) : 991-1008. doi: 10.3934/cpaa.2016.15.991
Mengyao Chen, Qi Li, Shuangjie Peng. Bound states for fractional Schrödinger-Poisson system with critical exponent. Discrete & Continuous Dynamical Systems - S, 2021, 14 (6) : 1819-1835. doi: 10.3934/dcdss.2021038
Brahim Alouini. Finite dimensional global attractor for a damped fractional anisotropic Schrödinger type equation with harmonic potential. Communications on Pure & Applied Analysis, 2020, 19 (9) : 4545-4573. doi: 10.3934/cpaa.2020206
Grégoire Allaire, M. Vanninathan. Homogenization of the Schrödinger equation with a time oscillating potential. Discrete & Continuous Dynamical Systems - B, 2006, 6 (1) : 1-16. doi: 10.3934/dcdsb.2006.6.1
Younghun Hong. Scattering for a nonlinear Schrödinger equation with a potential. Communications on Pure & Applied Analysis, 2016, 15 (5) : 1571-1601. doi: 10.3934/cpaa.2016003
Zhiyan Ding, Hichem Hajaiej. On a fractional Schrödinger equation in the presence of harmonic potential. Electronic Research Archive, 2021, 29 (5) : 3449-3469. doi: 10.3934/era.2021047
Mouhamed Moustapha Fall, Veronica Felli. Unique continuation properties for relativistic Schrödinger operators with a singular potential. Discrete & Continuous Dynamical Systems, 2015, 35 (12) : 5827-5867. doi: 10.3934/dcds.2015.35.5827
Pavel I. Naumkin, Isahi Sánchez-Suárez. On the critical nongauge invariant nonlinear Schrödinger equation. Discrete & Continuous Dynamical Systems, 2011, 30 (3) : 807-834. doi: 10.3934/dcds.2011.30.807
Yu Su, Zhaosheng Feng. Ground state solutions for the fractional problems with dipole-type potential and critical exponent. Communications on Pure & Applied Analysis, , () : -. doi: 10.3934/cpaa.2021111
Stefano Pasquali. A Nekhoroshev type theorem for the nonlinear Klein-Gordon equation with potential. Discrete & Continuous Dynamical Systems - B, 2018, 23 (9) : 3573-3594. doi: 10.3934/dcdsb.2017215
Maria-Magdalena Boureanu. Fourth-order problems with Leray-Lions type operators in variable exponent spaces. Discrete & Continuous Dynamical Systems - S, 2019, 12 (2) : 231-243. doi: 10.3934/dcdss.2019016
Xia Sun, Kaimin Teng. Positive bound states for fractional Schrödinger-Poisson system with critical exponent. Communications on Pure & Applied Analysis, 2020, 19 (7) : 3735-3768. doi: 10.3934/cpaa.2020165
Wulong Liu, Guowei Dai. Multiple solutions for a fractional nonlinear Schrödinger equation with local potential. Communications on Pure & Applied Analysis, 2017, 16 (6) : 2105-2123. doi: 10.3934/cpaa.2017104
Yu Su | CommonCrawl |
Corporate Finance & Accounting Corporate Finance
Overhead Rate
What Is the Overhead Rate?
Formula and Calculation
Using the Overhead Rate
Direct Cost vs. the Overhead Rate
Limitations of the Overhead Rate
Examples of Overhead Rates
The overhead rate is a cost allocated to the production of a product or service. Overhead costs are expenses that are not directly tied to production such as the cost of the corporate office. To allocate overhead costs, an overhead rate is applied to the direct costs tied to production by spreading or allocating the overhead costs based on specific measures.
For example, overhead costs may be applied at a set rate based on the number of machine hours or labor hours required for the product.
Overhead Rate Formula and Calculation
Although there are multiple ways to calculate an overhead rate, below is the basis for any calculation:
Overhead rate=Indirect costsAllocation measure\text{Overhead rate} = \frac{\text{Indirect costs}}{\text{Allocation measure}}Overhead rate=Allocation measureIndirect costs
Indirect costs are the overhead costs or costs that are not directly tied to the production of a product or service.
Allocation measure is any type of measurement that's necessary to make the product or service. It could be the number of direct labor hours or machine hours for a particular product or a period.
The calculation of the overhead rate has a basis on a specific period. So, if you wanted to determine the indirect costs for a week, you would total up your weekly indirect or overhead costs. You would then take the measurement of what goes into production for the same period. So, if you were to measure the total direct labor cost for the week, the denominator would be the total weekly cost of direct labor for production that week. Finally, you would divide the indirect costs by the allocation measure to achieve how much in overhead costs for every dollar spent on direct labor for the week.
Overhead rate is a cost allocated to the production of a product or service. Overhead costs are expenses that are not directly tied to production such as the cost of the corporate office.
By analyzing how much it costs in overhead for every hour the machine is producing the company's goods, management can properly price the product to make sure there's enough profit margin to compensate for its indirect costs.
A company that excels at monitoring and improving its overhead rate can improve its bottom line or profitability.
The overhead rate is a cost added on to the direct costs of production in order to more accurately assess the profitability of each product. In more complicated cases, a combination of several cost drivers may be used to approximate overhead costs.
Overhead expenses are generally fixed costs, meaning they're incurred whether or not a factory produces a single item or a retail store sells a single product. Fixed costs would include building or office space rent, utilities, insurance, supplies, maintenance, and repair. Overhead costs also include administrative salaries and some professional and miscellaneous fees that are tucked under selling, general, and administrative (SG&A) within a firm's operating expenses on the income statement. Unless a cost can be directly attributable to a specific revenue-generating product or service, it will be classified as overhead, or as an indirect expense.
It is often difficult to assess precisely the amount of overhead costs that should be attributed to each production process. Costs must thus be estimated based on an overhead rate for each cost driver or activity. It is important to include indirect costs that are based on this overhead rate in order to price a product or service appropriately. If a company prices its products that do not cover its overhead costs, the business will be unprofitable.
Direct Costs vs. the Overhead Rate
Direct costs are costs directly tied to a product or service that a company produces. Direct costs can be easily traced to their cost objects. Cost objects can include goods, services, departments, or projects. Direct costs include direct labor, direct materials, manufacturing supplies, and wages tied to production.
The overhead rate allocates indirect costs to the direct costs tied to production by spreading or allocating the overhead costs based on the dollar amount for direct costs, total labor hours, or even machine hours.
The overhead rate has limitations when applying it to companies that have few overhead costs or when their costs are mostly tied to production. Also, it's important to compare the overhead rate to companies within the same industry. A large company with a corporate office, a benefits department, and a human resources division will have a higher overhead rate than a company that's far smaller and with less indirect costs.
The equation for the overhead rate is overhead (or indirect) costs divided by direct costs or whatever you're measuring. Direct costs typically are direct labor, direct machine costs, or direct material costs—all expressed in dollar amounts. Each one of these is also known as an "activity driver" or "allocation measure."
Example 1: Costs in Dollars
Let's assume a company has overhead expenses that total $20 million for the period. The company wants to know how much overhead relates to direct labor costs. The company has direct labor expenses totaling $5 million for the same period.
To calculate the overhead rate:
Divide $20 million (indirect costs) by $5 million (direct labor costs).
Overhead rate = $4 or ($20/$5), meaning that it costs the company $4 in overhead costs for every dollar in direct labor expenses.
Example 2: Cost per Hour
The overhead rate can also be expressed in terms of the number of hours. Let's say a company has overhead expenses totaling $500,000 for one month. During that same month, the company logs 30,000 machine hours to produce their goods.
Divide $500,000 (indirect costs) by 30,000 (machine hours).
Overhead rate = $16.66, meaning that it costs the company $16.66 in overhead costs for every hour the machine is in production.
By analyzing how much it costs in overhead for every hour the machine is producing the company's goods, management can properly price the product to make sure there's enough profit margin to compensate for the $16.66 per hour in indirect costs.
Of course, management also has to price the product to cover the direct costs involved in the production, including direct labor, electricity, and raw materials. A company that excels at monitoring and improving its overhead rate can improve its bottom line or profitability.
How Activity Cost Drivers Can Allocate Indirect Costs
An activity cost driver is a component of a business process. Activity cost drivers are used in activity-based costing, and they give a more accurate determination of the true cost of a business activity by considering the indirect expenses.
Activity-Based Costing (ABC)
Activity-based costing (ABC) is a system that tallies the costs of overhead activities and assigns those costs to products.
Prime Cost
Prime costs are a business's expenses for the elements involved in production.
Understanding the Departmental Overhead Rate
The departmental overhead rate is defined as an expense rate for every department in a factory production process.
Cost of Labor
The cost of labor is the total of all employee wages plus the cost of benefits and payroll taxes paid by an employer.
Cost accounting is an accounting method that aims to capture a company's costs of production by assessing the input costs of each step of production as well as fixed costs.
How to Treat Overhead Expenses in Cost Accounting
Does gross profit include labor and overhead?
What costs are not counted in gross profit margin?
How are direct costs and variable costs different?
How are period costs and product costs different?
What Is the Prime Cost Formula? | CommonCrawl |
Cerebral reactivity in migraine patients measured with functional near-infrared spectroscopy
Ahmadreza Pourshoghi1Email author,
Arash Danesh2,
David Stuart Tabby3,
John Grothusen2 and
Kambiz Pourrezaei1
European Journal of Medical Research201520:96
© Pourshoghi et al. 2015
Published: 8 December 2015
There are two major theories describing the pathophysiology of migraines. Vascular theory explains that migraines resulted from vasodilation of meningeal vessels irritating the trigeminal nerves and causing pain. More recently, a neural theory of migraine has been proposed, which suggests that cortical hyperexcitability leads to cortical spreading depression (CSD) causing migraine-like symptoms. Chronic migraine requires prophylactic therapy. When oral agents fail, there are several intravenous agents that can be used. Understanding underlying causes of migraine pain would help to improve efficacy of migraine medications by changing their mechanism of action. Yet to date no study has been made to investigate the link between vascular changes in response to medications for migraine versus pain improvements. Functional near-infrared spectroscopy (NIRS) has been used as an inexpensive, rapid, non-invasive and safe technique to monitor cerebrovascular dynamics.
In this study, a multi-distance near-infrared spectroscopy device has been used to investigate the cortical vascular reactivity of migraine patients in response to drug infusions and its possible correlation with changes in pain experienced. We used the NIRS on 41 chronic migraine patients receiving three medications: magnesium sulfate, valproate sodium, and dihydroergotamine (DHE). Patients rated their pain on a 1–10 numerical scale before and after the infusion.
No significant differences were observed between the medication effects on vascular activity from near channels measuring skin vascularity. However, far channels—indicating cortical vascular activity—showed significant differences in both oxyhemoglobin and total hemoglobin between medications. DHE is a vasoconstrictor and decreased cortical blood volume in our experiment. Magnesium sulfate has a short-lived vasodilatory effect and increased cortical blood volume in our experiment. Valproate sodium had no significant effect on blood volume. Nonetheless, all three reduced patients' pain based on self-report and no significant link was observed between changes in cortical vascular reactivity and improvement in migraine pain as predicted by the vascular theory of migraine.
NIRS showed the potential to be a useful tool in the clinical setting for monitoring the vascular reactivity of individual patients to various migraine and headache medications.
Functional near-infrared spectroscopy
Vascular theory of migraine
Pain assessment
Cerebrovascular reactivity
Neural and vascular theories are proposed as the main theories describing the pathophysiology of migraines [1]. Traditionally, it was thought that migraine resulted from vasoconstriction of cranial blood vessels leading to compensatory vasodilation. More recently, consensus has shifted toward a neural theory of migraine which considers the excessive neocortical cellular excitability as the main cause [2].
There are a number of studies reported in the literature that suggest possible different cortical vascular responses between healthy individuals and migraine patients in different scenarios. In several of these studies, NIRS has been used as a non-invasive method of measuring cerebrovascular reactivity [3].
Akin et al. have shown that amplitudes of deoxygenated hemoglobin (Hb) and oxygenated hemoglobin (HbO2) signals acquired by NIRS are approximately two to five times higher in controls than migraine patients during four consecutive breath-holding tasks and concluded their results as a confirmation of an impaired cerebrovascular reactivity in the frontal cortex of migraine patients [4]. Shinoura et al. have compared changes in total hemoglobin (THb) and regional oxygen saturation (rSO2) of the right and left frontal lobes in response to intracranial pressure changes during the interictal period of migraine. According to their findings, the head-down maneuver resulted in a significantly smaller increase in right-sided total hemoglobin in migraineurs compared to volunteers. Moreover, it resulted in a small decrease in right-sided rSO2 and a significantly greater decrease in left-sided rSO2 in migraineurs compared to volunteers [5]. In another study, both TCD (transcranial Doppler) and NIRS were used in migraineurs without aura versus healthy subjects in a breath-hold challenge. Strong differences in the cerebral blood flow velocity (CBFV), a reduced increase of HbO2 and different hemoglobin balancing during breath-hold task have been reported for migraineurs. They have also concluded that migraineurs do not show marked vasodilation as a functional response to the CO2 increase [6]. The same parameters have been measured by Vernieri et al. using TCD and NIRS during carbon dioxide inhalation sessions of healthy subjects and migraineurs with aura (MA). Cerebral vasomotor reactivity (VMR), total hemoglobin content and percent oxygen increases were significantly greater on the predominant compared with the non-predominant migraine side. These findings suggest altered autoregulation in MA patients, possibly secondary to impaired cerebrovascular autonomic control [7].
In this study, we use NIRS to investigate the cerebrovascular effects of migraine medications and its possible correlation with patients' pain improvement in real time.
In the remainder of this paper, we compare the vascular reactivity of 41 migraine patients receiving infusions of magnesium sulfate (21 patients), valproate sodium (12 patients) and dihydroergotamine (6 patients). We also correlate our findings with the subjects' pain score self-reports. We aimed to investigate the utility of NIRS in comparing the analgesic efficacy of the above drugs based on patient self-reports compared with the measured cortical vascular reactivity in the clinical setting.
NIRS basics
Light in the near-infrared range (600–900 nm) penetrates the tissue because water, the key overall absorber of light in human tissue, has a low NIR absorption coefficient. In this range, tissue behaves as a turbid medium and light is significantly scattered by oxyhemoglobin (HbO2) and deoxyhemoglobin (Hb) molecules. There are other absorbents such as melanin and lipids; however, their overall average concentrations along the total optical path are negligible.
As a result the NIR light detected in the Fig. 1 configuration is absorbed and scattered mainly by the oxyhemoglobin and deoxyhemoglobin molecules present in the blood stream. Any change in the concentrations of these molecules along the optical path of the detected photons will affect the detected signal. These changes can be the result of overall blood flow changes or local consumption of oxyhemoglobin due to neuronal activities.
Volume of tissue sampled by an NIRS measurement: the highly scattered photons are reflected back to the tissue's surface, mostly within a banana-shaped optical pathway. As a result, a photodetector placed on the skin (on the same surface as the source) can measure the reflected light [19]
Mathematical equations that govern this relationship are known as the Modified Beer–Lambert law [8]. The modified Beer–Lambert law states that changes in the concentration of light absorbing components are proportional to changes in light attenuation, divided by mean optical pathlength and extinction coefficients of the chromophores in the tissue. Optical pathlength is a measure of the average distance that light travels between the source and detector after several episodes of scattering and absorption.
The relative change in the concentration of Hb and HbO2 molecules can be calculated by the following equations:
$$\Delta \left[ {\text{HbO}_{2}} \right] = \frac{{\alpha_{\text{HbO2}} \left( {\lambda_{2} } \right){ \cdot }\frac{{\Delta A\left( {\lambda_{1} } \right)}}{{DP(\lambda_{1} )}} - \alpha_{\text{HbO2}} \left( {\lambda_{1} } \right){ \cdot }\frac{{\Delta A\left( {\lambda_{2} } \right)}}{{DP(\lambda_{2} )}} }}{{\alpha_{\text{Hb}} \left( {\lambda_{1} } \right){ \cdot }\alpha_{\text{HbO2}} \left( {\lambda_{2} } \right) - \alpha_{\text{Hb}} \left( {\lambda_{2} } \right){ \cdot }\alpha_{\text{HbO2}} \left( {\lambda_{1} } \right)}}$$
$$\Delta \left[ {\text{Hb}} \right] = \frac{{\alpha_{\text{Hb}} \left( {\lambda_{1} } \right){ \cdot } \frac{{\Delta {\text{A}}\left( {\lambda_{2} } \right)}}{{{\text{DP}}(\lambda_{2} )}} - \alpha_{\text{Hb}} \left( {\lambda_{2} } \right){ \cdot }\frac{{\Delta {\text{A}}\left( {\lambda_{1} } \right)}}{{{\text{DP}}(\lambda_{1} )}} }}{{\alpha_{\text{Hb}} \left( {\lambda_{1} } \right){ \cdot }\alpha_{\text{HbO2}} \left( {\lambda_{2} } \right) - \alpha_{\text{Hb}} \left( {\lambda_{2} } \right){ \cdot }\alpha_{\text{HbO2}} \left( {\lambda_{1} } \right)}}$$
Experiment protocol
We studied three commonly infused medications: magnesium sulfate (MgSO4), valproate sodium, and dihydroergotamine (DHE). DHE is a potent vasoconstrictor. It may constrict meningeal blood vessels causing symptomatic improvement consistent with the vascular theory. Magnesium sulfate has vasodilatory properties [9, 10] through its effects on serotonin, but its main effects are thought to be neural. Low levels of magnesium sulfate are associated with disinhibition of NMDA receptors. Magnesium-mediated calcium influx to NMDA neurons results in inhibition. Magnesium sulfate ions block calcium influx and can prevent disinhibition. Low levels of magnesium lower the threshold for CSD (cortical spreading depression).
Another group of drugs which are widely used in migraine are sodium channel antagonists. Among these antiepileptic drugs, valproate sodium (Depacon) and topiramate seem to be more effective in migraine, as reported in the majority of controlled studies [11]. Valproate sodium has no major vascular role; it works through increasing GABA levels and in so doing suppressing CSD and migraines. Experimental evidence also shows that it suppresses neurogenic inflammation and attenuates nociceptive neurotransmission that leads to exacerbation of migraine.
These infusions are required when commonly used oral prophylactic drugs are not effective. Typically magnesium sulfate was given first, valproate sodium next and DHE was given last.
In this study, 41 patients (34 females) with an average age of 49.2 ± 9.5 years took part in a non-blinded trial using these medications; 21 subjects on magnesium sulfate, 12 subjects on valproate sodium and 8 subjects on DHE. Migraine subjects met the International Headache Society's criteria for chronic migraine (ICHD-2) and were resistant to oral therapy. Patients rated their pain on a 1–10 scale (NRS-11) before and at the end of the infusion. The study was approved by the Drexel University Institutional Review Board (IRB) and informed consents and Ethics Committee approvals were obtained for all patients enrolled in the study, according to the Declaration of Helsinki.
NIRS measurement
Throughout the duration of the experiment, subjects were monitored by the NIRS probes that were attached to their foreheads. The probe configuration is shown in Fig. 2. Each probe is made of an LED source and three detectors. One detector is 1 cm from the source (near detector) and two detectors are 2.8 cm from the source (far detectors). The LED is a dual-wavelength LED (780 nm and 850 nm) manufactured by Epitex (L735/850-40D32) and the detectors are OPT101 manufactured by Texas instruments [12, 13]. Using the modified Bear–Lambert law (Eqs. 1, 2), the information about Hb and HbO2 is extracted from the raw intensity data.
Configuration of NIRS probe: each probe has one LED source, one detector 1 cm from the source (near channel) and two detectors at 2.8 cm from the source (far channels)
After measuring the baseline for 2 min before infusion, we started the infusion and re-measured the cortical and superficial vascular activity with two NIRS probes. Probes were placed on the forehead of each subject—one on the right side of the forehead and one on the left side of the forehead and end of the probes were adjusted to align with the middle of the forehead—to cover position Fp1, Fp2 of the international 10–20 EEG system (Fig. 3).
) NIRS probes placement: two NIRS probes are located on both sides of the forehead
During this time, we ensured that all external factors that could have significant effects on the NIRS measurements were constant and controlled for; these include light, movement and temperature. Experimental protocol is shown in Fig. 4.
) Experimental Protocol: NIRS data recorded for 2 mins before and 4 min after start of infusion. Whole infusion takes 15–30 min
Self-reported measures
Patients rated their pain on a 1–10 scale (NRS-11) before and at the conclusion of the infusion. Figure 5 and Table 1 show initial pain and pain improvement after the infusion for each medication separately.
Self-reported pain scores by medication: subjects reported their pain based on a 1–10 numeric scale before and after the infusion. Changes between initial and final reported pain (Δ Pain) is considered as self-reported pain improvement
Self-reported pain scores by medication: average initial pain and pain improvement have been shown for each medication as reported by subjects before and after infusion
Magnesium sulfate (n = 22)
Valproate sodium (n = 12)
DHE (n = 7)
Initial pain
Δ Pain
Reported initial pains were significantly different between medications (P ≤ 0.05) and were inherited from clinician's policy of prescribing each drug. Average initial pain reported by patients for magnesium sulfate, valproate sodium and DHE was 4.4, 5.85 and 7.5, respectively. Magnesium sulfate was prescribed as an initial treatment and for patients with lower pain. Valproate sodium was used for patients whose pain was not improved by magnesium sulfate in previous sessions. If this was ineffective too, then DHE was considered. DHE was known to be more effective than magnesium sulfate and valproate sodium, and was prescribed for patients with higher pain. Based on self-reported pain scores, valproate sodium had a significant better pain improvement over magnesium sulfate (P = 0.03). However, self-reported pain score data do not show significant pain improvement between DHE and the other two drugs which could be the result of a small sample size.
NIRS data
Data were collected from six channels for each subject—one near channel measuring vascular response of the skin and two far channels measuring vascular response from cortex and skin together on each side. Changes in the detected light intensity were converted to concentration changes of oxyhemoglobin (HbO2) and deoxyhemoglobin (Hb) in the blood through Beer–Lambert law (Eqs. 1, 2). Figure 6 shows a sample of data reflecting changes in the total hemoglobin (THb) and oxyhemoglobin (HbO2) during the course of DHE infusion. Total hemoglobin is summation of oxyhemoglobin and deoxyhemoglobin and is a measure of total blood volume.
Sample of recorded NIRS data during medication infusion (DHE for this subject) on a migraine patient: near channel (on left) measures oxyhemoglobin (HbO2) and total hemoglobin (THb) changes during the infusion on the skin while far channels (on right) measure both skin and cortical activities. Blue line infusion time
We examined the infusions' effect on vascular reactivity. The extracted feature from the signal was slope of oxyhemoglobin (HbO2), deoxyhemoglobin (Hb) and total hemoglobin (THb) data before and after the infusion. After removing faulty signals, the remainder of the data included 18 magnesium sulfate, 10 valproate sodium and 6 DHE subjects. Due to small sample sizes and non-normality of the data, Mann–Whitney U test (Wilcox test) was used to check if the difference in slope change between medications were significant.
No significant differences were observed between different medications on near channels which measure skin vascularity responses. This suggests that alternations in skin blood flow and autonomic response induced by drug infusion were not different between drugs. However, the analyses on far left channels showed significant differences in both HBO2 and THB between valproate sodium and magnesium sulfate and between magnesium sulfate and DHE (P < 0.001) reflecting differences in cortical vascular reactivity among medications. In terms of slope changes in HbO2 and THb, we have the following order:
$${\text{Magnesium sulfate}} > 0 \,{ \sim }{\text{valproate sodium}} > {\text{DHE}}.$$
Positive slope change of THb for magnesium sulfate suggests that local blood volume has increased due to magnesium sulfate infusion and negative slope change for DHE shows decrease in blood volume by DHE infusion while for valproate sodium these changes are close to zero—no significant effect on blood volume.
Table 2 shows a summary of data and the changes in the HbO2, Hb and THb as measured by NIRS in an arbitrary unit for valproate sodium, magnesium sulfate and DHE as well as P values.
Comparison of infusion vascular reactivity between medications on both near and far channels (mean and standard deviation values are only shown for far channels)
Far channel
HbO2
Valproate
DHE
−0.0003
−0.001
−0.02
P value (far)
P value (near)
Cortical activity and skin response
In our experiments, near channels have penetration depth of 0.5 cm and measure alternations in skin vascular activity which are mostly caused by autonomic response. On the other hand, far channels capture up to 1.5 cm and measure cortical activities.
Our results on far channels showed that DHE decreased blood volume, magnesium sulfate increased blood volume and valproate sodium had no significant effect on the blood volume. The near channels, measuring skin vascularity, showed no significant differences between the medications indicating that the results are not due to alteration in skin vascular activity.
Unilateral cortical response
Although data were collected from six channels on both sides of forehead, significant differences in cortical activities between medications were only observed on the left side. Different left and right side cerebral reactivity in migraineurs has been reported before in literature as well. For instance, [13] reports a smaller increase in right-sided total hemoglobin (THb) and significantly greater increase in left-sided total hemoglobin in migraineurs compared to volunteers. Moreover, some migraineurs have unilateral or side predominance pain which may also result in unilateral reactivity. A significantly greater increase in total hemoglobin (THb) and percent oxygen on the predominant migraine side compared with the non-predominant migraine side has been reported in [1].
However, the predominance side of pain (if existed at all) was not recorded in our data which makes it difficult to interpret.
Correlation between cortical response and self-reported pain score
While these medications had significantly different effects on cortical vascular activities compared to each other, all three were effective in reducing the patients' pain based on self-report. DHE, which is a well-known vasoconstriction, and MgSO4, which literature suggests causes cortical vasodilation, showed a decrease and an increase in blood volume, respectively; during our trial, yet they were both effective in improving pain and valproate sodium with no significant vascular effect had the best self-reported pain improvement among the medications.
No significant link was observed between changes in cortical vascular reactivity and improvement in subjects' self-reported pain scores.
Neuronal theory versus vascular theory
As explained briefly before there is no consensus about the underlying cause of migraine. It is possible that many factors may cause the class of headaches categorized as migraine. Neural and vascular theories are proposed as the main theories describing the pathophysiology of migraines [6]. Traditionally, it was thought that migraine resulted from vasoconstriction of cranial blood vessels leading to compensatory vasodilation. Although there is thought to be a decrease in cerebral blood flow in the acute phase that can cause the stereotypical aura, the pain in migraine is thought to be as a result of the increase in cerebral blood flow due to vasodilation of the middle meningeal artery. This increase in blood flow is dependent upon trigeminal and parasympathetic activation.
In several studies, magnetic resonance angiography (MRA) has been employed to verify this theory. The method has been used to measure arterial changes before and after infusion of different vasoactive drugs and also before and during migraine headache attacks. However, the results are contradictory. The most recent study found intracranial but not extracranial arterial dilatation on the headache side relative to the non-headache side [14] while another earlier study reported that the middle cerebral artery (intracranial) and middle meningeal artery (extracranial) were both dilated on the pain side versus the non-pain side [15], and another MRA study of drug-induced migraine attacks reported no side-to-side changes at all [16]. The difference can be due to different study designs and drug effects [17].
In another study, the effect of several vasodilators on meningeal arteries was investigated to find a connection between the effect of a substance on a meningeal vessel and its ability to artificially induce migraine. No clear correlation was found between the efficacy of a substance as a meningeal artery vasodilator in human and the ability to artificially induce migraine or the mechanism of action [18].
More recently, consensus has shifted toward a neural theory of migraine which considers the excessive neocortical cellular excitability as the main cause. According to this theory, neuronal hyperactivity will cause cortical spreading depression (CSD) and then CSD will trigger a migraine attack. CSD involves rapid depolarization of cortical neurons with cellular efflux of potassium, in turn triggering migraine [6].
Based on our results, no significant correlation was found between cortical vascular changes and pain improvement. Both medications that have different vascular effect (Mg and DHE) have improved pain the same and valproate sodium which has no effect on vascularity had the best pain improvement. So our data suggest that vascular theory may not explain the pain improvement mechanism in migraine patients completely.
Our study had several limitations, which could be improved upon. We need a greater sample size of subjects (particularly DHE) to attain more statistically significant results. Subjects who had valproate sodium infusion can be interpreted as control subjects because the mechanism of the drug is such that it does not affect blood flow. However, it would be better to have control subjects with saline infusion only to control the effect of infusion itself on the data. Part of the significance of these results lies in the fact that the data were collected in a typical community pain clinic and not in a quiet research laboratory—speaking to the applicability of NIRS. Based on the work presented here, we believe that NIRS has the potential to be a useful tool in a clinical setting for assessing the vascular effects of various medications for headache and migraine. We believe that further technological improvement in NIRS hardware and signal analysis can make NIRS an even more useful tool for objective study and assessment of migraine. Furthermore, we hope that studies using NIRS can complement other measurements to facilitate the discussion about the underlying cause of the migraine headache.
DHE:
dihydroergotamine
Hb:
deoxygenated hemoglobin
HbO2 :
oxygenated hemoglobin
NIRS:
near-infrared spectroscopy
THB:
total hemoglobin
AP: conception and design, acquisition of data, data analysis and interpretation, drafting the article. AD: conception and design, acquisition of data, drafting the article, revising the article critically for important intellectual content. DT: conception and design, revising the article critically for important intellectual content. JG: conception and design, writing and obtaining the IRB. KP: conception and design, drafting the article, revising the article critically for important intellectual content. All authors read and approved the final manuscript.
School of Biomedical Engineering Science and Health, Drexel University, Room 131, 3508 Market St, Philadelphia, PA 19104, USA
Neurology Department, Drexel University College of Medicine, Philadelphia, USA
Optimum Neurology, Bala Cynwyd, USA
Goadsby PJ. The vascular theory of migraine—a great story wrecked by the facts. Brain J Neurol. 2009;132(Pt 1):6–7. doi:10.1093/brain/awn321.Google Scholar
Reddy DS. The pathophysiological and pharmacological basis of current drug treatment of migraine headache. Expert Rev Clin Pharmacol. 2013;6(3):271–88. doi:10.1586/ecp.13.14.View ArticlePubMedGoogle Scholar
Sayita Y (2012) Classification of migraineurs using functional near infrared spectroscopy data. The middle east technical universityGoogle Scholar
Akin A, Bilensoy D. Cerebrovascular reactivity to hypercapnia in migraine patients measured with near-infrared spectroscopy. Brain Res. 2006;1107(1):206–14. doi:10.1016/j.brainres.2006.06.002.View ArticlePubMedGoogle Scholar
Shinoura N, Yamada R. Decreased vasoreactivity to right cerebral hemisphere pressure in migraine without aura: a near-infrared spectroscopy study. Clin Neurophysiol Off J Int Feder Clin Neurophysiol. 2005;116(6):1280–5. doi:10.1016/j.clinph.2005.01.016.View ArticleGoogle Scholar
Liboni W, Molinari F, Allais G, Mana O, Negri E, Grippi G, Benedetto C, D'Andrea G, Bussone G. Why do we need NIRS in migraine? Neurol Sci Off J Ital Neurol Soc Ital Soc Clin Neurophysiol. 2007;28(Suppl 2):S222–4. doi:10.1007/s10072-007-0782-4.Google Scholar
Vernieri F, Tibuzzi F, Pasqualetti P, Altamura C, Palazzo P, Rossini PM, Silvestrini M. Increased cerebral vasomotor reactivity in migraine with aura: an autoregulation disorder? A transcranial Doppler and near-infrared spectroscopy study. Cephalalgia Int J Headache. 2008;28(7):689–95. doi:10.1111/j.1468-2982.2008.01579.x.View ArticleGoogle Scholar
Cope M, Delpy DT, Reynolds EO, Wray S, Wyatt J, van der Zee P. Methods of quantitating cerebral near infrared spectroscopy data. Adv Exp Med Biol. 1988;222:183–9.View ArticlePubMedGoogle Scholar
Boschat J, Gilard M, Etienne Y, Roriz R, Jobic Y, Penther P, Blanc JJ. Hemodynamic effects of intravenous magnesium sulfate in man. Arch Mal Coeur Vaiss. 1989;82(3):361–4.PubMedGoogle Scholar
Ji BHEP, Kiosky W, Buhler FR, Bolli P. Magnesium sulfate-induced vasodilatation is comparable to that induced by calcium channel blockade. Hypertension. 1983;1(suppl. 2):368–71.Google Scholar
Chiossi L, Negro A, Capi M, Lionetto L, Martelletti P. Sodium channel antagonists for the treatment of migraine. Expert Opin Pharmacother. 2014;15(12):1697–706. doi:10.1517/14656566.2014.929665.View ArticlePubMedGoogle Scholar
Barati Z, Shewokis PA, Izzetoglu M, Polikar R, Mychaskiw G, Pourrezaei K. Hemodynamic response to repeated noxious cold pressor tests measured by functional near infrared spectroscopy on forehead. Ann Biomed Eng. 2013;41(2):223–37. doi:10.1007/s10439-012-0642-0.View ArticlePubMedGoogle Scholar
Villringer A, Chance B. Non-invasive optical spectroscopy and imaging of human brain function. Trends Neurosci. 1997;20(10):435–42.View ArticlePubMedGoogle Scholar
Amin FM, Asghar MS, Hougaard A, Hansen AE, Larsen VA, de Koning PJ, Larsson HB, Olesen J, Ashina M. Magnetic resonance angiography of intracranial and extracranial arteries in patients with spontaneous migraine without aura: a cross-sectional study. Lancet Neurol. 2013;12(5):454–61. doi:10.1016/s1474-4422(13)70067-x.View ArticlePubMedGoogle Scholar
Asghar MS, Hansen AE, Amin FM, van der Geest RJ, Koning P, Larsson HB, Olesen J, Ashina M. Evidence for a vascular factor in migraine. Ann Neurol. 2011;69(4):635–45. doi:10.1002/ana.22292.View ArticlePubMedGoogle Scholar
Schoonman GG, van der Grond J, Kortmann C, van der Geest RJ, Terwindt GM, Ferrari MD. Migraine headache is not associated with cerebral or meningeal vasodilatation—a 3T magnetic resonance angiography study. Brain J Neurol. 2008;131(Pt 8):2192–200. doi:10.1093/brain/awn094.View ArticleGoogle Scholar
Amin FM, Lundholm E, Hougaard A, Arngrim N, Wiinberg L, de Koning PJ, Larsson HB, Ashina M. Measurement precision and biological variation of cranial arteries using automated analysis of 3 T magnetic resonance angiography. J Headache Pain. 2014;15:25. doi:10.1186/1129-2377-15-25.PubMed CentralView ArticlePubMedGoogle Scholar
Grande G, Labruijere S, Haanes KA, MaassenVanDenBrink A, Edvinsson L. Comparison of the vasodilator responses of isolated human and rat middle meningeal arteries to migraine related compounds. J Headache Pain. 2014;15:22. doi:10.1186/1129-2377-15-22.PubMed CentralView ArticlePubMedGoogle Scholar
Branco G (2007) head probes for optical imaging of the infant head. University College London (UCL).Google Scholar | CommonCrawl |
On q-deformed logistic maps
Pseudo compact almost automorphy of neutral type Clifford-valued neural networks with mixed delays
Stochastic perturbation of a cubic anharmonic oscillator
Enrico Bernardi 1, and Alberto Lanconelli 1,,
Dipartimento di Scienze Statistiche Paolo Fortunati, Università di Bologna, via Belle Arti 41, Bologna, Italy
Received May 2020 Revised January 2021 Early access May 2021
We perturb with an additive noise the Hamiltonian system associated to a cubic anharmonic oscillator. This gives rise to a system of stochastic differential equations with quadratic drift and degenerate diffusion matrix. Firstly, we show that such systems possess explosive solutions for certain initial conditions. Then, we carry a small noise expansion's analysis of the stochastic system which is assumed to start from initial conditions that guarantee the existence of a periodic solution for the unperturbed equation. We then investigate the probabilistic properties of the sequence of coefficients which turn out to be the unique strong solutions of stochastic perturbations of the well-known Lamé's equation. We also obtain explicit expressions of these in terms of Jacobi elliptic functions. Furthermore, we prove, in the case of Brownian noise, a lower bound for the probability that the truncated expansion stays close to the solution of the deterministic problem. Lastly, when the noise is bounded, we provide conditions for the almost sure convergence of the global expansion.
Keywords: Cubic anharmonic oscillator, stochastic differential equations, small noise expansions, Lamé's equation, Jacobi elliptic functions.
Mathematics Subject Classification: Primary: 60H10, 60H25; Secondary: 37H10.
Citation: Enrico Bernardi, Alberto Lanconelli. Stochastic perturbation of a cubic anharmonic oscillator. Discrete & Continuous Dynamical Systems - B, doi: 10.3934/dcdsb.2021148
S. Albeverio, A. Hilbert and E. Zehnder, Hamiltonian systems with a stochastic force: Nonlinear versus linear, and a Girsanov formula, Stochastics Stochastics Rep., 39 (1992), 159-188. doi: 10.1080/17442509208833772. Google Scholar
S. Albeverio, A. Hilbert and V. Kolokoltsov, Estimates uniform in time for the transition probability of diffusions with small drift and for stochastically perturbed Newton equations, J. Theoret. Probab., 12 (1999), 293-300. doi: 10.1023/A:1021665708716. Google Scholar
J. A. D. Appleby, X. Rodkina and A. Maoand, Stabilization and destabilization of nonlinear differential equations by noise, IEEE Trans. Automat. Control, 53 (2008), 683-691. doi: 10.1109/TAC.2008.919255. Google Scholar
F. M. Arscott, Periodic Differential Equations, The Macmillan Company, New York, 1964. Google Scholar
F. M. Arscott and I. M.Khabaza, Table of Lamé's Polynomials, A Pergamon Press, Oxford, London, New York, Paris, 1962. Google Scholar
E. Bernardi and T. Nishitani, On the Cauchy problem for non-effectively hyperbolic operators, the Gevrey 5 well-posedness, J. d'Analyse Math., 105 (2008), 197-240. doi: 10.1007/s11854-008-0035-3. Google Scholar
E. Bernardi and T. Nishitani, On the Cauchy problem for non-effectively hyperbolic operators, the Gevrey 4 well-posedness, Kyoto J. Math., 51 (2011), 767-810. doi: 10.1215/21562261-1424857. Google Scholar
E. Delabaere and D. T. Trinh, Spectral analysis of the complex cubic oscillator, J. Phys. A: Math. Gen., 33 (2000), 8771-8796. doi: 10.1088/0305-4470/33/48/314. Google Scholar
E. M. Ferreira and J. Sesma, Global solution of the cubic oscillator, J. of Phys. A: Math., 47 (2014), 415306. Google Scholar
C. W. Gardiner, Handbook of Stochastic Methods, 2$^{nd}$ edition, Springer Series in Synergetics, 13, Springer-Verlag, Berlin, 1985. Google Scholar
I. S. Gradshteyn and I. M. Ryzhik, Table of Integrals, Series, and Products, 7$^{th}$ edition, Elsevier, 2007. Google Scholar
L. Hörmander, The Cauchy problem for differential equations with double characteristics, Journal D'Analyse Mathématique, 32 (1977), 118-196. doi: 10.1007/BF02803578. Google Scholar
N. Ikeda and S. Watanabe, Stochastic Differential Equations and Diffusion Processes, North Holland, Amsterdam, New York, Oxford, Kodansha, 1981. Google Scholar
I. Karatzas and S. E. Shreve, Brownian Motion and Stochastic Calculus, Springer-Verlag, New York, 1991. doi: 10.1007/978-1-4612-0949-2. Google Scholar
R. Khasminskii, Stochastic Stability of Differential Equations, 2$^{nd}$ edition, Springer-Verlag, Berlin, 2012. doi: 10.1007/978-3-642-23280-0. Google Scholar
L. Markus and A. Weerasinghe, Stochastic oscillators, J. Differential Equations, 71 (1988), 288-314. doi: 10.1016/0022-0396(88)90029-0. Google Scholar
L. Markus and A. Weerasinghe, Stochastic nonlinear oscillators, Adv. in Appl. Probab., 25 (1993), 649-666. doi: 10.2307/1427528. Google Scholar
T. Nishitani, A simple proof of the existence of tangent bicharacteristics for noneffectively hyperbolic operators, Kyoto J. Math., 55 (2015), 281-297. doi: 10.1215/21562261-2871758. Google Scholar
[19] W. J. Olver Frank and W. Lozier Daniel, NIST Handbook of Mathematical Functions, Cambridge University Press, 2010. Google Scholar
W. P. Reinhardt and P. L. Walker, Jacobian elliptic functions, in Digital Library of Mathematical Functions. Available from: http://dlmf.nist.gov/22. Google Scholar
D. Revuz and M. Yor, Continuous Martingales and Brownian Motion, 3$^{rd}$ edition, Grundlehren der Mathematischen Wissenschaften, 293, Springer-Verlag, Berlin, 1999. doi: 10.1007/978-3-662-06400-9. Google Scholar
H. Volker, Four remarks on eigenvalues of Lamé's equation, Analysis and Applications, 2 (2004), 161-175. doi: 10.1142/S0219530504000023. Google Scholar
H. Volkmer, Lamé functions, in Digital Library of Mathematical Functions. Available from: http://dlmf.nist.gov/29. Google Scholar
E. Weinan, T. Li and E. Vanden-Eijnden, Applied Stochastic Analysis, Graduate Studies in Mathematics, 199, American Mathematical Society, 2019. doi: 10.1090/gsm/199. Google Scholar
V. A. Yakubovich and V. M. Starzhinskii, Linear Differential Equations With Periodic Coefficients Vol.1, John Wiley & Sons, New York, 1975. Google Scholar
Figure 1. Energy surface $ \xi^{2}/2 - ( x^{3}/3 -x) = 0 $ of system (13)
Figure 2. graph of $ \text{cn}(x, q) $
Figure 3. graph of the solution of system (13)
Figure 4. Explosive solution for the system (12) with $ x(0) = 0 $
Figure 5. Graph of Hamiltonian with $ c = -1, a = 1 $
Figure 6. Graph of (22) with $ c = -1, a = 1 $
Figure 7. Graph of $ H(y, \eta) = 0 $
Figure 8. Graph of $ u_1 $ with $ q = 2/\sqrt{5} $
Figure 9. Graph of $ u_{2} $ with $ q = 2/\sqrt{5} $
Figure 10. Graph of $ \mu(q) $ with $ q \in (0, 1) $
Figure 11. Graph of three paths of process (32) with $ \{Z(t)\}_{t\geq 0} $ being a one dimensional standard Brownian motion
David Lipshutz. Exit time asymptotics for small noise stochastic delay differential equations. Discrete & Continuous Dynamical Systems, 2018, 38 (6) : 3099-3138. doi: 10.3934/dcds.2018135
Arnulf Jentzen. Taylor expansions of solutions of stochastic partial differential equations. Discrete & Continuous Dynamical Systems - B, 2010, 14 (2) : 515-557. doi: 10.3934/dcdsb.2010.14.515
Leonid Shaikhet. Stability of delay differential equations with fading stochastic perturbations of the type of white noise and poisson's jumps. Discrete & Continuous Dynamical Systems - B, 2020, 25 (9) : 3651-3657. doi: 10.3934/dcdsb.2020077
Isabell Vorkastner. On the approaching time towards the attractor of differential equations perturbed by small noise. Discrete & Continuous Dynamical Systems - B, 2020, 25 (11) : 4295-4316. doi: 10.3934/dcdsb.2020098
Ricardo M. Martins, Otávio M. L. Gomide. Limit cycles for quadratic and cubic planar differential equations under polynomial perturbations of small degree. Discrete & Continuous Dynamical Systems, 2017, 37 (6) : 3353-3386. doi: 10.3934/dcds.2017142
Yan Zheng, Jianhua Huang. Exponential convergence for the 3D stochastic cubic Ginzburg-Landau equation with degenerate noise. Discrete & Continuous Dynamical Systems - B, 2019, 24 (10) : 5621-5632. doi: 10.3934/dcdsb.2019075
Henri Schurz. Stochastic heat equations with cubic nonlinearity and additive space-time noise in 2D. Conference Publications, 2013, 2013 (special) : 673-684. doi: 10.3934/proc.2013.2013.673
Henri Schurz. Stochastic wave equations with cubic nonlinearity and Q-regular additive noise in $\mathbb{R}^2$. Conference Publications, 2011, 2011 (Special) : 1299-1308. doi: 10.3934/proc.2011.2011.1299
Henri Schurz. Analysis and discretization of semi-linear stochastic wave equations with cubic nonlinearity and additive space-time noise. Discrete & Continuous Dynamical Systems - S, 2008, 1 (2) : 353-363. doi: 10.3934/dcdss.2008.1.353
Francisco Crespo, Sebastián Ferrer. On the extended Euler system and the Jacobi and Weierstrass elliptic functions. Journal of Geometric Mechanics, 2015, 7 (2) : 151-168. doi: 10.3934/jgm.2015.7.151
Zhen Li, Jicheng Liu. Synchronization for stochastic differential equations with nonlinear multiplicative noise in the mean square sense. Discrete & Continuous Dynamical Systems - B, 2019, 24 (10) : 5709-5736. doi: 10.3934/dcdsb.2019103
Tomasz Kosmala, Markus Riedle. Variational solutions of stochastic partial differential equations with cylindrical Lévy noise. Discrete & Continuous Dynamical Systems - B, 2021, 26 (6) : 2879-2898. doi: 10.3934/dcdsb.2020209
Kexue Li, Jigen Peng, Junxiong Jia. Explosive solutions of parabolic stochastic partial differential equations with lévy noise. Discrete & Continuous Dynamical Systems, 2017, 37 (10) : 5105-5125. doi: 10.3934/dcds.2017221
Arnulf Jentzen, Benno Kuckuck, Thomas Müller-Gronbach, Larisa Yaroslavtseva. Counterexamples to local Lipschitz and local Hölder continuity with respect to the initial values for additive noise driven stochastic differential equations with smooth drift coefficient functions with at most polynomially growing derivatives. Discrete & Continuous Dynamical Systems - B, 2021 doi: 10.3934/dcdsb.2021203
Zhaojuan Wang, Shengfan Zhou. Random attractor and random exponential attractor for stochastic non-autonomous damped cubic wave equation with linear multiplicative white noise. Discrete & Continuous Dynamical Systems, 2018, 38 (9) : 4767-4817. doi: 10.3934/dcds.2018210
M. A. M. Alwash. Polynomial differential equations with small coefficients. Discrete & Continuous Dynamical Systems, 2009, 25 (4) : 1129-1141. doi: 10.3934/dcds.2009.25.1129
Hironobu Sasaki. Small data scattering for the Klein-Gordon equation with cubic convolution nonlinearity. Discrete & Continuous Dynamical Systems, 2006, 15 (3) : 973-981. doi: 10.3934/dcds.2006.15.973
Yue-Jun Peng, Shu Wang. Asymptotic expansions in two-fluid compressible Euler-Maxwell equations with small parameters. Discrete & Continuous Dynamical Systems, 2009, 23 (1&2) : 415-433. doi: 10.3934/dcds.2009.23.415
Junping Shi, R. Shivaji. Semilinear elliptic equations with generalized cubic nonlinearities. Conference Publications, 2005, 2005 (Special) : 798-805. doi: 10.3934/proc.2005.2005.798
Enrico Bernardi Alberto Lanconelli | CommonCrawl |
DOI:10.1111/j.1365-2966.2011.20319.x
Constraint on a variation of the proton‐to‐electron mass ratio from H2 absorption towards quasar Q2348−011
@article{Bagdonaite2011ConstraintOA,
title={Constraint on a variation of the proton‐to‐electron mass ratio from H2 absorption towards quasar Q2348−011},
author={Julija Bagdonaite and Michael Murphy and Lex Kaper and Wim Ubachs VU Amsterdam and Swinburne University and University of Amsterdam},
journal={Monthly Notices of the Royal Astronomical Society},
volume={421},
pages={419-425}
J. Bagdonaite, M. Murphy, +3 authors U. Amsterdam
Molecular hydrogen (H2) absorption features observed in the line of sight to Q2348−011 at redshift zabs � 2.426 are analysed for the purpose of detecting a possible variation of the proton-to-electron mass ratio μ ≡ mp/me. By its structure, Q2348−011 is the most complex analysed H2 absorption system at high redshift so far, featuring at least seven distinctly visible molecular velocity components. The multiple velocity components associated with each transition of H2 were modelled…
Constraint on a varying proton-to-electron mass ratio from H2 and HD absorption at zabs ≃ 2.34
M. Daprá, M. Laan, M. Murphy, W. Ubachs
Molecular hydrogen (H2) absorption in the damped Lyman α system at zabs = 2.34 towards quasar SDSS J123437.55+075843.3 is analysed in order to derive 'a constraint on a possible temporal variation of…
Constraint on a varying proton-to-electron mass ratio from molecular hydrogen absorption towards quasar SDSS J123714.60+064759.5
M. Daprá, J. Bagdonaite, +11 authors Australia.
Molecular hydrogen transitions in the sub-damped Lyman alpha absorber at redshift z = 2.69, toward the background quasar SDSS J123714.60+064759.5, were analyzed in order to search for a possible…
New Limit on Space-Time Variations in the Proton-to-Electron Mass Ratio from Analysis of Quasar J110325-264515 Spectra
T. D. Le
Computer Science, Physics
The symmetry wavelengths of [Fe II] lines from redshifted quasar spectra of J110325-264515 and their corresponding values in the laboratory were combined to find a new limit on space-time variations in the proton-to-electron mass ratio.
Constraint on a cosmological variation in the proton-to-electron mass ratio from electronic CO absorption
M. Daprá, M. Niu, E. Salumbides, M. Murphy, W. Ubachs
Carbon monoxide (CO) absorption in the sub-damped Lyman-$\alpha$ absorber at redshift $z_{abs} \simeq 2.69$, toward the background quasar SDSS J123714.60+064759.5 (J1237+0647), was investigated for…
QSO 0347-383 and the invariance of m(p)/m(e) in the course of cosmic time
M. Wendt, P. Molaro
Context. The variation of the dimensionless fundamental physical constant μ = mp/me – the proton to electron mass ratio – can be constrained via observation of Lyman and Werner lines of molecular…
View 1 excerpt
Constraint on a varying proton-electron mass ratio 1.5 billion years after the big bang.
J. Bagdonaite, W. Ubachs, M. Murphy, J. Whitmore
A molecular hydrogen absorber at a lookback time of 12.4 billion years, corresponding to 10% of the age of the Universe today, is analyzed to put a constraint on a varying proton-electron mass ratio, μ, yielding a limit on the relative deviation from the current laboratory value.
A search for the space-time variations in the proton-to-electron mass ratio using the [Fe II] transitions
Abstract A new limit in the spatial and temporal variations in the proton-to-electron mass ratio (Δμ/μ) was found from an analysis of the combined 27 Ritz wavelengths of [Fe II] lines found in the…
Potential microwave probes of the proton-to-electron mass ratio at very high redshifts
L. Augustovičová, P. Soldán, W. Kraemer, V. Špirko
Recently a stringent constraint on the change in the proton-to-electron mass ratio at a redshift of 0.89 has been established using theoretical predictions and radio observations of the methanol…
Physics beyond the Standard Model from hydrogen spectroscopy
W. Ubachs, J. Koelemeij, K. Eikema, E. Salumbides
Abstract Spectroscopy of hydrogen can be used for a search into physics beyond the Standard Model. Differences between the absorption spectra of the Lyman and Werner bands of H2 as observed at high…
Cosmological evolution of the proton-to-electron mass ratio in an extended Brans–Dicke theory
Ahmad Mohamadnejad
Modern Physics Letters A
We study variation of the proton-to-electron mass ratio [Formula: see text] by incorporating Standard Model (SM) of particle physics into an extended Brans–Dicke theory. We show that the evolution of…
New constraint on cosmological variation of the proton-to-electron mass ratio from Q0528−250
J. King, M. Murphy, W. Ubachs, J. Webb
Molecular hydrogen transitions in quasar spectra can be used to constrain variation in the proton-to-electron mass ratio, μ ≡ mp/me, at high redshifts (z 2). We present here an analysis of a new…
View 4 excerpts, references background, methods and results
An Observational Determination of the Proton to Electron Mass Ratio in the Early Universe
Rodger I. Thompson, J. Bechtold, +6 authors Y. L. Shirley
In an effort to resolve the discrepancy between two measurements of the fundamental constant μ, the proton to electron mass ratio, at early times in the universe we reanalyze the same data used in…
View 1 excerpt, references methods
Stringent null constraint on cosmological evolution of the proton-to-electron mass ratio.
J. King, J. Webb, M. Murphy, R. Carswell
The results are consistent with no variation, and inconsistent with a previous approximately 4sigma detection of mu variation involving Q0405-443 and Q0347-383, which would tend to disfavor certain grand unification models.
View 3 excerpts, references methods
First constraint on cosmological variation of the proton-to-electron mass ratio from two independent telescopes.
F. van Weerdenburg, M. Murphy, A. L. Malec, L. Kaper, W. Ubachs
A high signal-to-noise spectrum covering the largest number of hydrogen lines (90 H(2) lines and 6 HD lines) in a high-redshift object was analyzed from an observation along the sight line to the…
Keck Telescope Constraint on Cosmological Variation of the Proton-to-Electron Mass Ratio
A. L. Malec, R. Buning, +19 authors UK.
Molecular transitions recently discovered at redshift z(abs) = 2.059 towards the bright background quasar J2123-0050 are analysed to limit cosmological variation in the proton-to-electron mass ratio,…
View 7 excerpts, references background, results and methods
Indication of a cosmological variation of the proton-electron mass ratio based on laboratory measurement and reanalysis of H2 spectra.
E. Reinhold, R. Buning, U. Hollenstein, A. Ivanchik, P. Petitjean, W. Ubachs
A new set of sensitivity coefficients K(i) is derived for all lines in the H2 spectrum, representing the dependence of their transition wavelengths on a possible variation of the proton-electron mass ratio mu, indicating that mu could have decreased in the past 12 Gyr.
On a possible variation of the proton-to-electron mass ratio: H2 spectra in the line of sight of high-redshift quasars and in the laboratory
W. Ubachs, R. Buning, K. Eikema, E. Reinhold
Abstract Recently the finding of an indication for a decrease of the proton-to-electron mass ratio μ = m p / m e by 0.002% in the past 12 billion years was reported in the form of a Letter [E.…
Robust limit on a varying proton-to-electron mass ratio from a single H2 system
The variation of the dimensionless fundamental physical constant mu=m_p/m_e can be checked through observation of Lyman and Werner lines of molecular hydrogen in the spectra of distant QSOs. Our…
The VLT-UVES survey for molecular hydrogen in high-redshift damped Lyman α systems: physical conditions in the neutral gas
R. Srianand, P. Petitjean, C. Ledoux, G. Ferland, G. Shaw
We study the physical conditions in damped Lyman α systems (DLAs), using a sample of 33 systems towards 26 quasi-stellar objects (QSOs) acquired for a recently completed survey of H2 by Ledoux,…
Improved laboratory values of the H2 Lyman and Werner lines for constraining time variation of the proton-to-electron mass ratio.
E. Salumbides, D. Bailly, +4 authors W. Ubachs
This metrology provides a practically exact database to extract a possible variation of the proton-to-electron mass ratio based on H2 lines in high-redshift objects and forms a rationale for equipping a future class of telescopes, carrying 30-40 m dishes, with novel spectrometers of higher resolving powers. | CommonCrawl |
CHNOPS meaning/ atomic number, symbol, and mass
Lenny_A_Brodsky_2018
What does CHNOPS Stand for
carbon, hydrogen, nitrogen, oxygen, phosphorus, sulfur
What is the atomic mass for Carbon and what is the chemical symbol and atomic number
Atomic Mass is (12.0107)Chemical symbol is C and the atomic number is 6. From what I know the exact mass is 12
What is the atomic mass for Hydrogen and what is the chemical symbol and atomic number
Atomic Mass is (1.00794) Chemical symbol is H and the atomic number is 1. From what I know the exact mass is about if rounded 1
Why is CHNOPS important
The acronym CHNOPS, which stands for carbon, hydrogen, nitrogen, oxygen, phosphorus, sulfur, represents the six most important chemical elements whose covalent combinations make up most biological molecules on Earth.
What is the atomic mass for Nitrogen and what is the chemical symbol and atomic number
Nitrogen is a chemical element with symbol N and atomic number 7 and atomic mass (14.0067). When rounded is 14.
What is the atomic mass for Oxygen and what is the chemical symbol and atomic number
Oxygen is a chemical element with symbol O and atomic number 8. Atomic mass (15.999). When rounded is just 16.
What is the atomic mass for Phosphorus and what is the chemical symbol and atomic number
Phosphorus is a chemical element with symbol P and atomic number 15. Atomic mass (30.973762) When rounded 31.
What is the atomic mass for Sulfur and what is the chemical symbol and atomic number
Sulfur is a chemical element with symbol S and atomic number 16. Atomic mass (32.065) When rounded is 32
Mendeleev
A Russian scientist who formed the periodic table of elements.
Discovered the structure of the atom.
Organization of the Periodic Table
Halogens
a stable subatomic particle with a charge of negative electricity, found in all atoms and acting as the primary carrier of electricity in solids.
a subatomic particle of about the same mass as a proton but without an electric charge, present in all atomic nuclei except those of ordinary hydrogen.
a stable subatomic particle occurring in all atomic nuclei, with a positive electric charge equal in magnitude to that of an electron, but of opposite sign.
Atomic Mass Unit (AMU)
a unit of mass used to express atomic and molecular weights
Nucleus of an Atom
The center of an atom and is made up of protons and neutrons.
Electron location
outside of the nucleus on the shells of the atom.
Proton Location
inside the nucleus
Neutron location
the mass of an atom of a chemical element expressed in atomic mass units. It is approximately equivalent to the number of protons and neutrons in the atom (the mass number) or to the average number allowing for the relative abundances of different isotopes.
the number of protons in the nucleus of an atom, which determines the chemical properties of an element and its place in the periodic table.
What did Juanfra DeVillena say was the cultural difference between Americans and Latinos when it comes to "personal space"?
Aeration - examples + what is it?
what 3 things makes a material tough
the sum of the atomic weights (AW) of the atoms represented by their chemical formula for a molecule
Chemistry 110 - Chapter 3
hnybear5150PLUS
Atoms First Chapter 2
WalterSWoodward
Chemistry Chapter 3
lex_fadgen
hannah_glover256
5 Rules of SIG FIGS
Science Test
Science Atom final Bh
First 20 Elements - Atomic Mass (Rounded)
Shakespeare, the Roman Republic, and Julius Caesar
Amy_Nguyen644
mchacon10
SpecEd 358 Final (RAT questions)
daniellebarnes17
Sistema de Ordenamiento ORFU
meysa02
Daily revenue from vending machines placed in various buildings of a major university is as follows: $$ \begin{array} { l } { 20,75,43,62,51,52,78,33,28,39,61,56,43,49,48,49 } \\ { 71, 53, 57, 46, 42, 41, 63, 36, 51, 59, 40, 32, 37, 29,26 } \end{array} $$ (a) Construct a frequency distribution table with a cell size of 12 starting with 19.5 (i.e., first cell is 19.5–31.5, next is 31.5–43.5, etc.). (b) Determine the probability distribution. (c) What is the probability of revenue from a machine being less than $44? (d) What is the probability that revenue from a machine will equal or exceed$44?
Compute the first four positive zeros of J0(x) and J1(x). Determine the error and comment.
Find the work done by a force p acting on a body if the body is displaced along the straight segment ^_AB_^ from A to B. Sketch ^_AB_^ and p. Show the details. p=[2, 5, 0], A:(1, 3, 3), B:(3, 5, 5)
Find the high temperature, the condensing temperature, and the COP if ammonia is used in a standard refrigeration cycle with high and low pressures of 800 psia and 300 psia, respectively. | CommonCrawl |
Papers from Journal of Cryptology 2012
JOFC
Efficient Set Operations in the Presence of Malicious Adversaries Abstract
Carmit Hazay Kobbi Nissim
We revisit the problem of constructing efficient secure two-party protocols for the problems of set intersection and set union, focusing on the model of malicious parties. Our main results are constant-round protocols that exhibit linear communication and a (practically) linear number of exponentiations with simulation-based security. At the heart of these constructions is a technique based on a combination of a perfectly hiding commitment and an oblivious pseudorandom function evaluation protocol. Our protocols readily transform into protocols that are UC secure, and we discuss how to perform these transformations.
Ideal Multipartite Secret Sharing Schemes Abstract
Oriol Farràs Jaume Martí-Farré Carles Padró
Multipartite secret sharing schemes are those having a multipartite access structure, in which the set of participants is divided into several parts and all participants in the same part play an equivalent role. In this work, the characterization of ideal multipartite access structures is studied with all generality. Our results are based on the well-known connections between ideal secret sharing schemes and matroids and on the introduction of a new combinatorial tool in secret sharing, integer polymatroids .Our results can be summarized as follows. First, we present a characterization of multipartite matroid ports in terms of integer polymatroids. As a consequence of this characterization, a necessary condition for a multipartite access structure to be ideal is obtained. Second, we use representations of integer polymatroids by collections of vector subspaces to characterize the representable multipartite matroids. In this way we obtain a sufficient condition for a multipartite access structure to be ideal, and also a unified framework to study the open problems about the efficiency of the constructions of ideal multipartite secret sharing schemes. Finally, we apply our general results to obtain a complete characterization of ideal tripartite access structures, which was until now an open problem.
Perfectly Balanced Boolean Functions and Golić Conjecture Abstract
Stanislav V. Smyshlyaev
In the current paper we consider the following properties of filters: perfect balancedness of a filter function (i.e. preserving pure randomness of the input sequence) and linearity of a filter function in the first or the last essential variable. Previous results on this subject are discussed, including misleading statements in Gouget and Sibert (LNCS, vol. 4876, 2007) about the connection between perfect balancedness and resistance to Anderson conditional correlation attack; the incorrectness of two known results, the sufficient condition of perfect balancedness in Golić (LNCS, vol. 1039, 1996) and the necessary condition of perfect balancedness in Dichtl (LNCS, vol. 1267, 1997), is demonstrated by providing counterexamples.We present a novel method of constructing large classes of perfectly balanced functions that are nonlinear in the first and the last essential variable and obtain a new lower bound of the number of such functions.Golić conjecture (LNCS, vol. 1039, 1996) states that the necessary and sufficient condition for a function to be perfectly balanced for any choice of a tapping sequence is linearity of a function in the first or the last essential variable. In the second part of the current paper we prove the Golić conjecture.
Programmable Hash Functions and Their Applications Abstract
Dennis Hofheinz Eike Kiltz
We introduce a new combinatorial primitive called programmable hash functions (PHFs). PHFs can be used to program the output of a hash function such that it contains solved or unsolved discrete logarithm instances with a certain probability. This is a technique originally used for security proofs in the random oracle model. We give a variety of standard model realizations of PHFs (with different parameters).The programmability makes PHFs a suitable tool to obtain black-box proofs of cryptographic protocols when considering adaptive attacks. We propose generic digital signature schemes from the strong RSA problem and from some hardness assumption on bilinear maps that can be instantiated with any PHF. Our schemes offer various improvements over known constructions. In particular, for a reasonable choice of parameters, we obtain short standard model digital signatures over bilinear maps.
Graph Coloring Applied to Secure Computation in Non-Abelian Groups Abstract
Yvo Desmedt Josef Pieprzyk Ron Steinfeld Xiaoming Sun Christophe Tartary Huaxiong Wang Andrew Chi-Chih Yao
We study the natural problem of secure n-party computation (in the computationally unbounded attack model) of circuits over an arbitrary finite non-Abelian group (G,⋅), which we call G-circuits. Besides its intrinsic interest, this problem is also motivating by a completeness result of Barrington, stating that such protocols can be applied for general secure computation of arbitrary functions. For flexibility, we are interested in protocols which only require black-box access to the group G (i.e. the only computations performed by players in the protocol are a group operation, a group inverse, or sampling a uniformly random group element). Our investigations focus on the passive adversarial model, where up to t of the n participating parties are corrupted.Our results are as follows. We initiate a novel approach for the construction of black-box protocols for G-circuits based on k-of-k threshold secret-sharing schemes, which are efficiently implementable over any black-box (non-Abelian) group G. We reduce the problem of constructing such protocols to a combinatorial coloring problem in planar graphs. We then give three constructions for such colorings. Our first approach leads to a protocol with optimal resilience t<n/2, but it requires exponential communication complexity $O({\binom{2 t+1}{t}}^{2} \cdot N_{g})$ group elements and round complexity $O(\binom{2 t + 1}{t} \cdot N_{g})$, for a G-circuit of size Ng. Nonetheless, using this coloring recursively, we obtain another protocol to t-privately compute G-circuits with communication complexity $\mathcal{P}\mathit{oly}(n)\cdot N_{g}$ for any t∈O(n1−ϵ) where ϵ is any positive constant. For our third protocol, there is a probability δ (which can be made arbitrarily small) for the coloring to be flawed in term of security, in contrast to the first two techniques, where the colorings are always secure (we call this protocol probabilistic, and those earlier protocols deterministic). This third protocol achieves optimal resilience t<n/2. It has communication complexity O(n5.056(n+log δ−1)2⋅Ng) and the number of rounds is O(n2.528⋅(n+log δ−1)⋅Ng).
Bonsai Trees, or How to Delegate a Lattice Basis Abstract
David Cash Dennis Hofheinz Eike Kiltz Chris Peikert
We introduce a new lattice-based cryptographic structure called a bonsai tree, and use it to resolve some important open problems in the area. Applications of bonsai trees include an efficient, stateless 'hash-and-sign' signature scheme in the standard model (i.e., no random oracles), and the first hierarchical identity-based encryption (HIBE) scheme (also in the standard model) that does not rely on bilinear pairings. Interestingly, the abstract properties of bonsai trees seem to have no known realization in conventional number-theoretic cryptography.
On-line Ciphers and the Hash-CBC Constructions Abstract
Mihir Bellare Alexandra Boldyreva Lars R. Knudsen Chanathip Namprempre
We initiate a study of on-line ciphers. These are ciphers that can take input plaintexts of large and varying lengths and will output the i th block of the ciphertext after having processed only the first i blocks of the plaintext. Such ciphers permit length-preserving encryption of a data stream with only a single pass through the data. We provide security definitions for this primitive and study its basic properties. We then provide attacks on some possible candidates, including CBC with fixed IV. We then provide two constructions, HCBC1 and HCBC2, based on a given block cipher E and a family of computationally AXU functions. HCBC1 is proven secure against chosen-plaintext attacks assuming that E is a PRP secure against chosen-plaintext attacks, while HCBC2 is proven secure against chosen-ciphertext attacks assuming that E is a PRP secure against chosen-ciphertext attacks.
Secure Two-Party Computation via Cut-and-Choose Oblivious Transfer Abstract
Yehuda Lindell Benny Pinkas
Protocols for secure two-party computation enable a pair of parties to compute a function of their inputs while preserving security properties such as privacy, correctness and independence of inputs. Recently, a number of protocols have been proposed for the efficient construction of two-party computation secure in the presence of malicious adversaries (where security is proven under the standard simulation-based ideal/real model paradigm for defining security). In this paper, we present a protocol for this task that follows the methodology of using cut-and-choose to boost Yao's protocol to be secure in the presence of malicious adversaries. Relying on specific assumptions (DDH), we construct a protocol that is significantly more efficient and far simpler than the protocol of Lindell and Pinkas (Eurocrypt 2007) that follows the same methodology. We provide an exact, concrete analysis of the efficiency of our scheme and demonstrate that (at least for not very small circuits) our protocol is more efficient than any other known today.
Batch Verification of Short Signatures Abstract
Jan Camenisch Susan Hohenberger Michael Østergaard Pedersen
With computer networks spreading into a variety of new environments, the need to authenticate and secure communication grows. Many of these new environments have particular requirements on the applicable cryptographic primitives. For instance, a frequent requirement is that the communication overhead inflicted be small and that many messages be processable at the same time. In this paper, we consider the suitability of public key signatures in the latter scenario. That is, we consider (1) signatures that are short and (2) cases where many signatures from (possibly) different signers on (possibly) different messages can be verified quickly. Prior work focused almost exclusively on batching signatures from the same signer.We propose the first batch verifier for messages from many (certified) signers without random oracles and with a verification time where the dominant operation is independent of the number of signatures to verify. We further propose a new signature scheme with very short signatures, for which batch verification for many signers is also highly efficient. Combining our new signatures with the best known techniques for batching certificates from the same authority, we get a fast batch verifier for certificates and messages combined. Although our new signature scheme has some restrictions, it is very efficient and still practical for some communication applications.
Security Analysis of Randomize-Hash-then-Sign Digital Signatures Abstract
Praveen Gauravaram Lars R. Knudsen
At CRYPTO 2006, Halevi and Krawczyk proposed two randomized hash function modes and analyzed the security of digital signature algorithms based on these constructions. They showed that the security of signature schemes based on the two randomized hash function modes relies on properties similar to the second preimage resistance rather than on the collision resistance property of the hash functions. One of the randomized hash function modes was named the RMX hash function mode and was recommended for practical purposes. The National Institute of Standards and Technology (NIST), USA standardized a variant of the RMX hash function mode and published this standard in the Special Publication (SP) 800-106.In this article, we first discuss a generic online birthday existential forgery attack of Dang and Perlner on the RMX-hash-then-sign schemes. We show that a variant of this attack can be applied to forge the other randomize-hash-then-sign schemes. We point out practical limitations of the generic forgery attack on the RMX-hash-then-sign schemes. We then show that these limitations can be overcome for the RMX-hash-then-sign schemes if it is easy to find fixed points for the underlying compression functions, such as for the Davies-Meyer construction used in the popular hash functions such as MD5 designed by Rivest and the SHA family of hash functions designed by the National Security Agency (NSA), USA and published by NIST in the Federal Information Processing Standards (FIPS). We show an online birthday forgery attack on this class of signatures by using a variant of Dean's method of finding fixed point expandable messages for hash functions based on the Davies-Meyer construction. This forgery attack is also applicable to signature schemes based on the variant of RMX standardized by NIST in SP 800-106. We discuss some important applications of our attacks and discuss their applicability on signature schemes based on hash functions with 'built-in' randomization. Finally, we compare our attacks on randomize-hash-then-sign schemes with the generic forgery attacks on the standard hash-based message authentication code (HMAC). | CommonCrawl |
Enhanced on-chip phase measurement by inverse weak value amplification
Adaptive optical phase estimation for real-time sensing of fast-varying signals
Liu Wang, Fang Xie, … Fang Liu
The power of microscopic nonclassical states to amplify the precision of macroscopic optical metrology
Wenchao Ge, Kurt Jacobs & M. Suhail Zubairy
Implementation of a canonical phase measurement with quantum feedback
Leigh S. Martin, William P. Livingston, … Irfan Siddiqi
Silicon photonics interfaced with integrated electronics for 9 GHz measurement of squeezed light
Joel F. Tasker, Jonathan Frazer, … Jonathan C. F. Matthews
Gravimetry through non-linear optomechanics
Sofia Qvarfort, Alessio Serafini, … Sougato Bose
On-chip Fourier-transform spectrometer based on spatial heterodyning tuned by thermo-optic effect
Miguel Montesinos-Ballester, Qiankun Liu, … Delphine Marris-Morini
Optimal metrology with programmable quantum sensors
Christian D. Marciniak, Thomas Feldker, … Thomas Monz
Sub-Hertz resonance by weak measurement
Weizhi Qu, Shenchao Jin, … Yanhong Xiao
Improving the precision of optical metrology by detecting fewer photons with biased weak measurement
Peng Yin, Wen-Hao Zhang, … Guang-Can Guo
Meiting Song ORCID: orcid.org/0000-0003-4290-66711,
John Steinmetz2,
Yi Zhang ORCID: orcid.org/0000-0001-9962-77831,
Juniyali Nauriyal1,3,
Kevin Lyons4,
Andrew N. Jordan ORCID: orcid.org/0000-0002-9646-70132,5 &
Jaime Cardenas1,2
Imaging and sensing
Integrated optics
Optical interferometry plays an essential role in precision metrology such as in gravitational wave detection, gyroscopes, and environmental sensing. Weak value amplification enables reaching the shot-noise-limit of sensitivity, which is difficult for most optical sensors, by amplifying the interferometric signal without amplifying certain technical noises. We implement a generalized form of weak value amplification on an integrated photonic platform with a multi-mode interferometer. Our results pave the way for a more sensitive, robust, and compact platform for measuring phase, which can be adapted to fields such as coherent communications and the quantum domain. In this work, we show a 7 dB signal enhancement in our weak value device over a standard Mach-Zehnder interferometer with equal detected optical power, as well as frequency measurements with 2 kHz sensitivity by adding a ring resonator.
Sensitive measurements with optical interferometry play an essential role in precision metrology such as gravitational wave detection1,2, gyroscopes3,4,5,6 and environmental sensing. While the classical limit for sensitivity in phase measurements is the shot noise limit, it is challenging to reach this level in practical applications. Weak value amplification7,8,9 can amplify the signal without increasing detected optical power, while also suppressing noises such as time correlated and systematic noise10,11,12. This allows these systems to increase the signal-to-noise ratio and achieve shot noise limited sensitivity. Previous demonstrations of weak value amplification have used a bulky apparatus that requires precise alignment and stability. Meanwhile, integrated photonic devices are revolutionizing the fields of sensing6,13, communications14,15,16 and quantum computing17,18,19. Achieving weak value amplification with integrated photonic devices provides the merit of compactness and robustness for optical interferometric sensors, as well as improving their stability and signal-to-noise ratio.
Weak value amplification increases the sensitivity of a measurement by slightly coupling the system to a state orthogonal to its original state and taking a small subset of data mostly in the orthogonal state. For example, in a well-aligned and balanced Sagnac interferometer (Fig. 1b), the constructively interfered output contains all the light (bright port), and destructively interfered output has no light coming out (dark port). Then a spatial phase front tilt, which is introduced by a slightly tilted mirror, and a small phase difference between the two paths are applied to the interferometer. One is the target parameter to be measured and the other works as coupling to an orthogonal state. This would cause a beam, weakly shifted from its original well-aligned location, to appear in the dark port, which is the small subset of the data. The beam field profile shift, measured by the power difference between the left and right halves of the detector, reflects the target parameter and gives a better sensitivity with low power than its standard counterparts20. While there is some information in the rejected port (the bright port), it is a negligible fraction of the total information10,20,21. As detector saturation limits the maximum signal-to-noise ratio attainable, weak value amplification provides a further increase to the signal-to-noise ratio22. Weak value amplification techniques with optical interferometers have demonstrated improvement on sensitivity over traditional interferometers23 for measurements of position8,9, phase24,25, frequency26 and temperature27,28,29.
Fig. 1: Device schematic and free space weak value amplification.
a Schematic of on-chip weak value device consisting of an MZI with phase front tilters and MMI as readouts. The heater is to apply a phase shift to the waveguides. b Free space Sagnac interferometer with weak value amplification. c Beam profile of free space dark port in weak value amplification (red) and inverse weak value amplification (blue) setup with respect to detector coordinates. In the inverse weak value regime, the beam profile resembles an HG1 mode, while in the weak value regime, it resembles an HG0 mode. d Hermite-Gaussian expansion coefficients of the inverse weak value amplification beam profile in Fig. 1c.
In this work, we use "inverse" weak value amplification to enhance the phase sensitivity of an on-chip interferometer. There are two types of weak value amplification depending on what the target parameter is. Weak value amplification (WVA) consists in measuring the spatial phase front tilt, using the known phase shift to amplify the signal8. On the other hand, inverse weak value amplification (IWVA) consists in measuring the phase shift with the signal amplified by the known spatial phase front tilt24. In the WVA regime, the measured parameter, phase front tilt, is smaller than the propagation phase shift. Meanwhile, in the IWVA regime, the propagation phase shift is smaller than the phase front tilt, which is opposite from WVA. The two operating regimes allow different applications of weak value techniques. In a waveguide interferometer, phase shift is commonly used for sensing purposes as other sensing parameters, such as temperature and features of bio samples, can be easily converted to phase shifts applied to the waveguide.
Design of individual components
We implement inverse weak value amplification on a photonic chip by introducing a spatial phase front tilt into an on-chip Mach-Zehnder interferometer (MZI). We build the device (Fig. 1a) on a CMOS compatible photonic platform (see Methods). The input light is first split 50/50 using a directional coupler and we apply a phase signal to be measured on one of the arms with a micro-heater. Then light in each arm goes through a spatial phase front tilter and undergoes an opposite spatial phase front tilt. They interfere at another multi-mode 50/50 directional coupler. Finally, at the dark port, light goes through a multimode interfering (MMI) region as the readout of the spatial field profile shift. The optical power difference between the two outputs of the MMI contains the desired phase signal. The enhancement of the signal is determined by the amount of spatial phase front tilt.
To create a spatial phase front tilt in a waveguide, we use a combination of the fundamental and higher order spatial modes. We first analyze the light field in the dark port of the free space version of inverse weak value amplification with Hermite-Gaussian (HG) modes. Figure 1c shows the beam profile of the dark port in the Sagnac interferometer. Its expansion into HG modes (Fig. 1d) shows that the beam consists mostly of HG0 and HG1 modes in its working regime (phase front tilt larger than phase shift). The contribution of other higher order modes is negligible. Therefore, the spatial field profile shift can be considered equivalent to a combination of HG0 and HG1 modes and the extent of the shift is determined by the ratio between these two modes. The same applies to the spatial phase front tilt. Adding light in the HG1 mode to the light in the HG0 mode tilts the phase front of the beam. Applying the same theory to waveguide modes, only the zeroth and first order transverse electric (TE0 and TE1) modes are required for weak value amplification with integrated photonic devices. The spatial phase front tilt can be considered as coupling light from the TE0 mode to the TE1 mode, and the amount of coupling determines how much spatial phase front is introduced. Also, after interference, the phase shift is also determined by the ratio between TE0 and TE1 modes30. The electric field at the dark port can be expressed by the following equation, where \(\phi\) is the phase difference between the two paths and \(a\) is the amplitude of the TE0 mode that couples to the TE1 mode (details in Supplementary Notes 1–3).
$${E}_{{{{{{\rm{d}}}}}}}\approx i\left[\left(1-a\right)\frac{\phi }{2}{{{{{{\rm{TE}}}}}}}_{0}+a{{{{{{\rm{TE}}}}}}}_{1}\right]={ia}\left[{{{{{{\rm{TE}}}}}}}_{1}+\frac{1-a}{a}\frac{\phi }{2}{{{{{{\rm{TE}}}}}}}_{0}\right].$$
We design a spatial phase front tilter to introduce the phase front tilt by coupling part of the TE0 mode into the TE1 mode. The spatial phase front tilter (Fig. 2a) starts with two identical single mode waveguides. Waveguide B couples a small portion of the light in the TE0 mode of waveguide A. Then waveguide B adiabatically changes width into a multimode waveguide that supports both TE0 and TE1 modes. The light in the TE0 mode in waveguide B stays in the TE0 mode as the waveguide width changes. We design waveguide B so its TE1 mode supported after the taper is phase matched to the TE0 mode in waveguide A. Therefore, when waveguide A couples light back into waveguide B, the light couples into the TE1 mode16,17. This way, we have a combination of TE0 and TE1 modes in the multimode waveguide (end of waveguide B), which is the equivalent of having a phase front tilt (Fig. 2b). By controlling the coupling ratio of the first directional coupler, we can adjust the amount of phase front tilt that we are introducing (Fig. 2c).
Fig. 2: Individual components.
a Spatial phase front tilter that couples a portion of TE0 mode to TE1 mode to create spatial phase front tilt in waveguides. b Phase front contour map along propagation of a combination of TE0 and TE1 (7:3). The ratio is exaggerated to show the effect of the tilted phase front. c Phase front tilt angle vs. the field percentage of TE1 mode (details in Supplementary Note 2). d coupler consists of two identical multimode waveguides. Simulation of power in multimode directional coupler along propagation. Coupling length is chosen to obtain a 50:50 beam splitter for both modes. e Multi mode interfering region with a multimode waveguide input and two single mode waveguide outputs. Multimode interfering waveguide and simulation of its output power vs. input TE1 mode percentage. Power is normalized to the total power of the two outputs, which is the total power on the detector. f Normalized power detection vs. applied phase shift signal (details in Supplementary Note 4).
For both TE0 and TE1 modes to interfere, we design a directional coupler that splits 50:50 for both TE0 and TE1. Since the TE0 mode couples with a different strength than the TE1 mode, the coupling length needed for the two modes to couple half of the light into the other waveguide is usually different. However, since the coupling process is periodic, we design the gap and the length of the directional coupler so that the TE0 mode goes through one quarter of a coupling cycle, while the TE1 mode goes through one and a quarter coupling cycles (Fig. 2d). The result is a 50:50 directional coupler for both the TE0 and TE1 modes simultaneously.
To determine the phase shift with an optical power signal, we design a multi-mode interferometer (MMI) whose power outputs are dependent on the ratio between the input TE0 and TE1 modes. We simulate an MMI with a multimode waveguide input and two single mode outputs with the rigorous Eigen Mode Expansion (EME) method (FIMMPROP, Photon Design). The power in the two outputs of the MMI is linear with respect to the ratio of the TE0 and TE1 modes in the input waveguide (Fig. 2e). As the phase signal applied to the weak value device increases, the amount of the TE0 in the dark port also increases, causing the difference of the power between the two outputs of the MMI to increase as well (Fig. 2f). From the power difference, we can get the amplitude ratio \({{{{{{\rm{TE}}}}}}}_{0}:{{{{{{\rm{TE}}}}}}}_{1}=p/(1-p)\), where \(p=1.11\Delta {I}_{{{{{{\rm{wv}}}}}}}\) for this design (details in Supplementary Note 4). \(\Delta {I}_{{{{{{\rm{wv}}}}}}}\) is the power difference normalized to the total power in the two output waveguides. Then the phase signal can be obtained by (details in Supplementary Note 4)
$$\phi =2\frac{p}{1-p}\frac{a}{1-a}.$$
Testing and comparison to standard MZI
We test the device by applying a phase signal to the microheaters and compare its performance with a standard on-chip Mach-Zehnder interferometer. Silicon nitride has a thermo-optic effect of 2.45*10−5/°C31. As we apply voltage on the microheaters above the waveguide, the temperature of the waveguide increases, which changes the refractive index of silicon nitride. Therefore, the phase accumulated by the mode also changes, which serves as the target parameter to be measured. Since the phase signal applied is weak, we test the device by modulating the phase signal and detect the output signal with a RF spectrum analyzer (Fig. 3a). We apply a 10 kHz sinusoid voltage signal of between 0 V and 1 V on the micro heater. The voltage signal creates a phase difference of about 9mrad between the signal arm and reference arm. Since the phase changes with the applied heater power, the phase signal appears at a frequency of 20 kHz on the RF spectrum analyzer. The optical outputs of the two waveguides are imaged on to a balanced detector with a 40x objective. The difference of the optical power on the two sides of the detector is converted to a voltage signal by the detector, which is then converted to electrical power on the RF spectrum analyzer. We take the electrical power signal as our signal and noise. The signal is measured with a resolution bandwidth of 0.1 Hz. At this modulation frequency, the contribution of the 1/f noise is reduced.
Fig. 3: Testing and results.
a Testing setup with modulated phase signal and RF spectrum analyzer to detect corresponding detector signal. Laser light is sent in through a polarization maintaining tapered fiber. Outputs are imaged to a balanced detector with a 40x objective. b The signal of the weak value device and the regular MZI vs. detected power on a semi log plot. Signal and noise floor measured by RF spectrum analyzer on weak value device (red circles) and standard MZI (blue squares) with same applied phase signal and changing detected optical power. The signal is the electrical power generated by the balanced detector at a frequency of 20 kHz. The signal data are fitted to the lines. The error bars of the detected power represent the standard deviation. The error bars of the signal represent the resolution limit of the measurement. c The signal of the weak value device and the regular MZI vs. heater voltage and phase change on a semi log plot. Signal and noise floor on weak value device (red circles) and standard MZI (blue squares) with equal detected optical power within 5% variation and changing applied heater signal (phase signal). The signal data are fitted to the lines. The error bars of the heater voltage represent the standard deviation of the applied voltage as reported by the oscilloscope. The error bars of signal represent the resolution limit of the measurement. The top axis shows the corresponding phase shift introduced by the micro heater (details in Supplementary Note 5).
To confirm the enhancement of the signal, we also test an on-chip Mach-Zehnder interferometer with the same waveguide parameters and similar footprint with the same signal and testing setup. We also take the signal as the difference of the two waveguide outputs in the standard MZI. The relation between the optical power and the phase signal is as follows, where \(\Delta I\) is the power difference of the two outputs, and \({I}_{0}\) is the total power of the two outputs,
$$\phi \approx {\sin }(\phi )=\frac{\Delta I}{{I}_{0}}\equiv \Delta {I}_{{{{{{\rm{MZI}}}}}}}.$$
Comparing the power difference from the two devices with the same applied phase shift, we derive the amplification factor (details in Supplementary Note 4)
$$\frac{\Delta {I}_{{{{{{\rm{wv}}}}}}}}{\Delta {I}_{{{{{{\rm{MZI}}}}}}}}=\frac{0.45\left(1-a\right)}{a}.$$
In our design, \(a\) is 0.125, which corresponds to a 9.97 dB amplification of the signal. The standard MZI has the same arm length as the weak value device, except that one arm is shorter to put the MZI in quadrature. The waveguide and the heater in the MZI have the same dimensions as the single mode waveguide in the weak value device. Both heaters, including the contact probe and wires, have a resistance of 746 ± 6Ω. This guarantees that the same phase shift, within the error range, is applied to both devices when applying the same voltage to the heaters. We also test the standard MZI with the same setup as the weak value devices. We apply the same 10 kHz sinusoid voltage wave to the heater and take the difference of the two outputs of the standard MZI with the balanced detector. Then we measure the signal with the spectrum analyzer using the same settings (100 Hz span, 0.1 Hz bandwidth). Since we are comparing the signals of our device and the regular MZI with equal detected optical power, the signals are not normalized.
We show a 7 dB signal enhancement with the inverse weak value amplification MZI when compared to a standard MZI. We take the limiting resource as the maximum optical power that can be detected. To make the comparison, we first match the detected power of the two devices. While the signal of the weak value device is amplified by 7 dB, the noise floor is not amplified (Fig. 3b). Therefore, the signal-to-noise ratio is also increased by 7 dB. The signal enhancement stays the same as the detected optical power changes. For a detected power of 130 µW, the weak value device has an input laser power of 16 mW and the standard MZI has an input laser power of 0.5 mW. The noise floors are measured with the RF spectrum analyzer at 20 kHz over a span of 0.1 kHz. They are the same for both devices because the same amount of optical power is received by the detector. At lower optical power levels (< 20 µW), the noise floor is limited by the built-in electronic amplifier noise and other electronic noise of the balanced detector. For detected power above 20 µW, the noise floors of both devices start to grow linearly with optical power in the log scale plot, which indicates that the systems start to be shot noise limited.
The weak value device shows a lower minimum resolvable signal than the standard MZI. We maximize the detected optical power (0.22 ± 0.01 mW in total) in both devices and lower the applied heater voltage to compare them (Fig. 3c, resolution bandwidth of 0.1 Hz). The minimum resolvable signal is obtained by extrapolating the fitted curve of the signal and the noise floor until they cross. The standard MZI shows a minimum resolvable signal of 0.012 V, which corresponds to a phase signal of 0.44 µrad (details in Supplementary Note 5). The minimum resolvable signal of the weak value device is 0.008 V, which corresponds to a phase signal of 0.2 µrad. In situations limited by detector saturation, this technique can enhance the signal without increasing the optical power on the detector, therefore resulting in a higher signal-to-noise ratio for equal detected power.
Frequency shift measurements
We demonstrate laser frequency shift measurements with inverse weak value amplification by adding a ring resonator to convert changes in optical frequency into changes in phase. We replace the microheaters with a ring resonator (Fig. 4a), which adds a phase signal depending on the optical frequency. We tune the laser wavelength on the slope of the resonance (Fig. 4b, dashed line) and modulate the optical frequency with a sinusoid voltage signal of 20 kHz (\({\omega }_{{{{{{\rm{m}}}}}}}\)). The amplitude of the voltage signal determines modulation depth of the optical frequency (\({\omega }_{{{{{{\rm{d}}}}}}}\)). The laser frequency (\({\omega }_{{{{{{\rm{laser}}}}}}}\)) oscillates around the center frequency (\({\omega }_{0}\)) in the following manner:
$${\omega }_{{{{{{\rm{laser}}}}}}}={\omega }_{0}+{\omega }_{{{{{{\rm{d}}}}}}}* {\sin}\left({\omega }_{{{{{{\rm{m}}}}}}}t\right).$$
Fig. 4: Frequency measurements.
a Schematic of inverse weak value device with ring resonator for frequency shift measurements. b Resonance of the ring resonator. The dashed line indicates the center of laser frequency modulation. c Signal and noise floor of the inverse weak value device with changing optical frequency modulation depth. The signal data are fitted to the lines. The error bars of the modulation depth represent the standard deviation of the applied voltage as reported by the oscilloscope. The error bars of the signal represent the resolution limit of the measurement.
Then we measure the output signal with the setup in Fig. 3a. The maximum modulation depth \({\omega }_{{{{{{\rm{d}}}}}}}\) we apply on the optical frequency is 250 kHz, which corresponds to 15 fm of wavelength change. Such a laser wavelength change has negligible effect on the performance of the integrated photonic components, including the ring resonator (FWHW = 2.5 nm). The signal power increases linearly with modulation depth (Fig. 4c) showing a signal to noise ratio of 25 dB for 100 kHz optical frequency shifts. By extrapolating the fitting curves of the signal and the noise floor till they cross, we obtain the optical frequency detection limit of \({\omega }_{{{{{{\rm{d}}}}}}}=2{{{{{\rm{kHz}}}}}}\). This precision corresponds to measuring an optical frequency shift of 1 part in 1011. The quality factor of the ring resonator is about 9000, which is limited by radiation losses of the mode. The phase has a linear relationship with the ring's quality factor (details in Supplementary Note 6). The device is capable of 1 Hz sensitivity with a 2*107 quality factor, which has been previously demonstrated in a silicon nitride photonic platform32. Previous free space frequency measurements with inverse weak value amplification show a 129 kHz/√Hz sensitivity (i.e. an optical frequency shift of 129 kHz could be measured with an integration time of 1 s and an SNR of 1)26. Taking into consideration the resolution bandwidth of 0.1 Hz, our 2 kHz detection limit corresponds to a sensitivity of 6.3 kHz/√Hz.
Integrated optics can be readily adapted to the fully quantum optical domain33. Quantum sensors can further leverage quantum advantage using squeezed or entangled photons, to enable devices such as quantum gyros34. Weak value amplification has been demonstrated for fully quantum systems in past work, both in optical35,36 and solid state systems37,38. We have demonstrated in this article how the concentration of information about the parameter of interest into a smaller post-selected fraction can greatly enhance the precision of measurements given a finite power limitation of the detector by permitting more input photons22. This feature can be carried over into the quantum realm to either improve the post-selection fraction, or the degree of amplification39, whilst preserving the quantum-enhanced Heisenberg scaling of the precision. Our current demonstration of weak value amplification in an integrated optical chip paves the way to incorporate weak value based techniques for quantum optical technologies in this scalable and robust platform. The integrated weak value platform enhances classical interferometric sensing by producing a stronger signal and a higher signal-to-noise ratio than standard interferometric techniques.
Micro-fabrication
We fabricate the device with CMOS compatible process. The waveguide (300 nm thick, 1.05 µm wide for single mode and 2.5 µm for multi-mode) consists of LPCVD (low pressure chemical vapor deposition) silicon nitride with 4 µm thermal silicon dioxide on bottom and 3 µm PECVD (plasma enhanced chemical vapor deposition) silicon dioxide cladding on top. We pattern the waveguides with e-beam lithography and etch with ICP-RIE (inductively coupled plasma reactive ion etcher). Finally, we sputter and lift-off platinum as micro heaters (100 nm thick, 3 µm wide, 150 µm long).
Waveguide simulations
Waveguide simulations are done with FIMMWAVE and FIMMPROP by Photon Design.
The datasets that support this study are available from the corresponding author on reasonable request.
Code availability
The codes used for analysis and simulations are available from the corresponding author on reasonable request.
Abbott, B. P. et al. LIGO: the laser interferometer gravitational-wave observatory. Rep. Prog. Phys. 72, 076901 (2009).
LIGO Scientific and Virgo Collaboration. et al. GW170104: observation of a 50-solar-mass binary black hole coalescence at redshift 0.2. Phys. Rev. Lett. 118, 221101 (2017).
Bergh, R. A., Lefevre, H. C. & Shaw, H. J. All-single-mode fiber-optic gyroscope with long-term stability. Opt. Lett. 6, 502–504 (1981).
Liang, W. et al. Resonant microphotonic gyroscope. Optica 4, 114–117 (2017).
Li, J., Suh, M.-G. & Vahala, K. Microresonator Brillouin gyroscope. Optica 4, 346–348 (2017).
Khial, P. P., White, A. D. & Hajimiri, A. Nanophotonic optical gyroscope with reciprocal sensitivity enhancement. Nat. Photon 12, 671–675 (2018).
Aharonov, Y., Albert, D. Z. & Vaidman, L. How the result of a measurement of a component of the spin of a spin-1/2 particle can turn out to be 100. Phys. Rev. Lett. 60, 1351–1354 (1988).
Hosten, O. & Kwiat, P. Observation of the Spin Hall effect of light via weak measurements. Science 319, 787–790 (2008).
Dixon, P. B., Starling, D. J., Jordan, A. N. & Howell, J. C. Ultrasensitive beam deflection measurement via interferometric weak value amplification. Phys. Rev. Lett. 102, 173601 (2009).
Jordan, A. N., Martínez-Rincón, J. & Howell, J. C. Technical advantages for weak-value amplification: when less is more. Phys. Rev. X 4, 011031 (2014).
Pang, S., Alonso, J. R. G., Brun, T. A. & Jordan, A. N. Protecting weak measurements against systematic errors. Phys. Rev. A 94, 012329 (2016).
Harris, J., Boyd, R. W. & Lundeen, J. S. Weak value amplification can outperform conventional measurement in the presence of detector saturation. Phys. Rev. Lett. 118, 070802 (2017).
Lin, V. S.-Y., Motesharei, K., Dancil, K.-P. S., Sailor, M. J. & Ghadiri, M. R. A porous silicon-based optical interferometric biosensor. Science 278, 840–843 (1997).
Xu, Q., Schmidt, B., Shakya, J. & Lipson, M. Cascaded silicon micro-ring modulators for WDM optical interconnection. Opt. Express 14, 9431–9436 (2006).
Fang, Q. et al. WDM multi-channel silicon photonic receiver with 320 Gbps data transmission capability. Opt. Express 18, 5106–5113 (2010).
Luo, L.-W. et al. WDM-compatible mode-division multiplexing on a silicon chip. Nat. Commun. 5, 1–7 (2014).
ADS CAS Google Scholar
Crespi, A. et al. Integrated photonic quantum gates for polarization qubits. Nat. Commun. 2, 1–6 (2011).
Sun, C. et al. Single-chip microprocessor that communicates directly using light. Nature 528, 534–538 (2015).
Shen, Y. et al. Deep learning with coherent nanophotonic circuits. Nat. Photonics 11, 441–446 (2017).
Viza, G. I., Martínez-Rincón, J., Alves, G. B., Jordan, A. N. & Howell, J. C. Experimentally quantifying the advantages of weak-value-based metrology. Phys. Rev. A 92, 032127 (2015).
Sinclair, J., Hallaji, M., Steinberg, A. M., Tollaksen, J. & Jordan, A. N. Weak-value amplification and optimal parameter estimation in the presence of correlated noise. Phys. Rev. A 96, 052128 (2017).
Starling, D. J., Dixon, P. B., Jordan, A. N. & Howell, J. C. Optimizing the signal-to-noise ratio of a beam-deflection measurement with interferometric weak values. Phys. Rev. A 80, 041803 (2009).
Steinmetz, J., Lyons, K., Song, M., Cardenas, J. & Jordan, A. N. Enhanced on-chip frequency measurement using weak value amplification. Preprint at https://arxiv.org/abs/2103.15752 (2021).
Starling, D. J., Dixon, P. B., Williams, N. S., Jordan, A. N. & Howell, J. C. Continuous phase amplification with a Sagnac interferometer. Phys. Rev. A 82, 011802 (2010).
Brunner, N. & Simon, C. Measuring small longitudinal phase shifts: weak measurements or standard interferometry? Phys. Rev. Lett. 105, 010405 (2010).
Starling, D. J., Dixon, P. B., Jordan, A. N. & Howell, J. C. Precision frequency measurements with interferometric weak values. Phys. Rev. A 82, 063822 (2010).
Egan, P. & Stone, J. A. Weak-value thermostat with 0.2 mK precision. Opt. Lett. 37, 4991–4993 (2012).
Salazar-Serrano, L. J. et al. Enhancement of the sensitivity of a temperature sensor based on fiber Bragg gratings via weak value amplification. Opt. Lett. 40, 3962–3965 (2015).
Li, Y. et al. High-precision temperature sensor based on weak measurement. Opt. Express 27, 21455–21462 (2019).
Steinmetz, J., Lyons, K., Song, M., Cardenas, J. & Jordan, A. N. Precision frequency measurement on a chip using weak value amplification. In Quantum Communications and Quantum Imaging XVII vol. 11134 111340S (International Society for Optics and Photonics, 2019).
Arbabi, A. & Goddard, L. L. Measurements of the refractive indices and thermo-optic coefficients of Si3N4 and SiOx using microring resonances. Opt. Lett. 38, 3878–3881 (2013).
Ji, X. et al. Ultra-low-loss on-chip resonators with sub-milliwatt parametric oscillation threshold. Optica 4, 619–624 (2017).
Wang, J., Sciarrino, F., Laing, A. & Thompson, M. G. Integrated photonic quantum technologies. Nat. Photonics 14, 273–284 (2020).
Fink, M. et al. Entanglement-enhanced optical gyroscope. N. J. Phys. 21, 053010 (2019).
Pryde, G. J., O'Brien, J. L., White, A. G., Ralph, T. C. & Wiseman, H. M. Measurement of quantum weak values of photon polarization. Phys. Rev. Lett. 94, 220405 (2005).
Hallaji, M., Feizpour, A., Dmochowski, G., Sinclair, J. & Steinberg, A. M. Weak-value amplification of the nonlinear effect of a single photon. Nat. Phys. 13, 540–544 (2017).
Groen, J. P. et al. Partial-measurement backaction and nonclassical weak values in a superconducting circuit. Phys. Rev. Lett. 111, 090506 (2013).
Campagne-Ibarcq, P. et al. Observing Interferences between past and future quantum states in resonance fluorescence. Phys. Rev. Lett. 112, 180402 (2014).
Pang, S., Dressel, J. & Brun, T. A. Entanglement-assisted weak value amplification. Phys. Rev. Lett. 113, 030401 (2014).
The authors acknowledge funding from Leonardo DRS and A. N. Jordan Scientific. This research was funded in part by CEIS, an Empire State Development-designated Center for Advanced Technology. This work was performed in part at the Cornell NanoScale Facility, an NNCI member supported by NSF Grant NNCI-2025233. We also thank Marco Lopez, Avik Dutt, John C. Howell, Matthew T. Moen and Benjamin L Miller for discussions of the project.
The Institute of Optics, University of Rochester, Rochester, NY, 14627, USA
Meiting Song, Yi Zhang, Juniyali Nauriyal & Jaime Cardenas
Department of Physics and Astronomy, University of Rochester, Rochester, NY, 14627, USA
John Steinmetz, Andrew N. Jordan & Jaime Cardenas
Department of Electrical and Computer Engineering, University of Rochester, Rochester, NY, 14627, USA
Juniyali Nauriyal
Hoplite AI, 2 Fox Glen Ct., Clifton Park, NY, 12065, USA
Kevin Lyons
Institute for Quantum Studies, Chapman University, Orange, CA, 92866, USA
Andrew N. Jordan
Meiting Song
John Steinmetz
Yi Zhang
J.S., M.S., J.C., K.L. and A.N.J. conceived and developed the theory of weak value amplification with waveguides. M.S. and J.C. conceived and designed the integrated photonic devices. M.S., Y.Z., and J.N. fabricated the devices. M.S. and J.C. conceived, designed and carried out the experiments and analyzed the data. M.S., Y.Z., J.N., A.N.J. and J.C. contributed to writing the manuscript.
Correspondence to Jaime Cardenas.
This work was supported by Leonardo DRS. DRS supported the development of on-chip weak value amplification, but played no further role in the conceptualization, design, data collection, analysis, decision to publish, or preparation of the manuscript. A.N.J. discloses part of this work was carried out by his LLC outside of the University of Rochester. The remaining authors declare no competing interests.
Peer review information Nature Communications thanks Erik Gauger and the anonymous reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher's note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Peer Review File
Song, M., Steinmetz, J., Zhang, Y. et al. Enhanced on-chip phase measurement by inverse weak value amplification. Nat Commun 12, 6247 (2021). https://doi.org/10.1038/s41467-021-26522-2 | CommonCrawl |
Weyl's gauge argument
Alexander Afriat
Foundations of Physics 43 (5):699-705 (2013)
Université de Bretagne Occidentale
The standard $\mathbb{U}(1)$ "gauge principle" or "gauge argument" produces an exact potential A=dλ and a vanishing field F=d 2 λ=0. Weyl (in Z. Phys. 56:330–352, 1929; Rice Inst. Pam. 16:280–295, 1929) has his own gauge argument, which is sketchy, archaic and hard to follow; but at least it produces an inexact potential A and a nonvanishing field F=dA≠0. I attempt a reconstruction
Keywords Gauge principle Weyl Electromagnetism
Gauge Theories in Philosophy of Physical Science
link.springer.com [2] (no proxy)
philsci-archive.pitt.edu (no proxy)
philsci-archive.pitt.edu [2] (no proxy)
Gauging What's Real: The Conceptual Foundations of Contemporary Gauge Theories.Richard Healey - 2007 - Oxford University Press.
How is Quantum Field Theory Possible.Sunny Y. Auyang - 1995 - Oxford University Press.
Holism and Structuralism in U(1) Gauge Theory.Holger Lyre - 2004 - Studies in History and Philosophy of Science Part B: Studies in History and Philosophy of Modern Physics 35 (4):643-670.
On the Reality of Gauge Potentials.Richard Healey - 2001 - Philosophy of Science 68 (4):432-455.
Gauge Principles, Gauge Arguments and the Logic of Nature.Christopher A. Martin - 2002 - Proceedings of the Philosophy of Science Association 2002 (3):S221-S234.
Introduction to the Special Issue Hermann Weyl and the Philosophy of the 'New Physics'.Silvia De Bianchi & Gabriel Catren - 2018 - Studies in History and Philosophy of Science Part B: Studies in History and Philosophy of Modern Physics 61:1-5.
Logic of Gauge.Alexander Afriat - 2019 - In Carlos Lobo & Julien Bernard (eds.), Weyl and the Problem of Space. Springer Verlag.
Which Symmetry? Noether, Weyl, and Conservation of Electric Charge.A. K. - 2002 - Studies in History and Philosophy of Science Part B: Studies in History and Philosophy of Modern Physics 33 (1):3-22.
The Gauge Argument.Paul Teller - 2000 - Philosophy of Science 67 (3):481.
The Principles of Gauging.Holger Lyre - 2001 - Philosophy of Science 68 (3):S371-S381.
Does the Higgs Mechanism Exist?Holger Lyre - 2008 - International Studies in the Philosophy of Science 22 (2):119-133.
Gauge Invariance, Cauchy Problem, Indeterminism, and Symmetry Breaking.Chuang Liu - 1996 - Philosophy of Science 63 (3):79.
Shortening the Gauge Argument.Alexander Afriat - unknown
Gravity and Gauge Theory.Steven Weinstein - 1999 - Philosophy of Science 66 (3):155.
The Arbitrariness of Local Gauge Symmetry.Alexandre Guay - 2004 | CommonCrawl |
Environment, Development and Sustainability
Construction of ecological security pattern based on the importance of ecosystem service functions and ecological sensitivity assessment: a case study in Fengxian County of Jiangsu Province, China
Xingxing Jin
Luyao Wei
Yi Wang
Yuqi Lu
The construction of ecological security pattern is one of the important ways to alleviate the contradiction between economic development and ecological protection, as well as the important contents of ecological civilization construction. How to scientifically construct the ecological security pattern of small-scale counties, and achieve sustainable economic development based on ecological environment protection, it has become an important proposition in regulating the ecological process effectively. Taking Fengxian County of China as an example, this paper selected the importance of ecosystem service functions and ecological sensitivity to evaluate the ecological importance and identify ecological sources. Furthermore, we constructed the ecological resistance surface by various landscape assignments and nighttime lighting modifications. Through a minimum cumulative resistance model, we obtained ecological corridors and finally constructed the ecological security pattern comprehensively combining with ecological resistance surface construction. Accordingly, we further clarified the specific control measures for ecological security barriers and regional functional zoning. This case study shows that the ecological security pattern is composed of ecological sources and corridors, where the former plays an important security role, and the latter ensures the continuity of ecological functions. In terms of the spatial layout, the ecological security barriers built based on ecological security pattern and regional zoning functions are away from the urban core development area. As for the spatial distribution, ecological sources of Fengxian County are mainly located in the central and southwestern areas, which is highly coincident with the main rivers and underground drinking water source area. Moreover, key corridors and main corridors with length of approximately 115.71 km and 26.22 km, respectively, formed ecological corridors of Fengxian County. They are concentrated in the western and southwestern regions of the county which is far away from the built-up areas with strong human disturbance. The results will provide scientific evidence for important ecological land protection and ecological space control at a small scale in underdeveloped and plain counties. In addition, it will enrich the theoretical framework and methodological system of ecological security pattern construction. To some extent, it also makes a reference for improving the regional ecological environment carrying capacities and optimizing the ecological spatial structure in such kinds of underdeveloped small-scale counties.
Ecological importance Ecological sensitivity Ecological sources Ecological corridors Ecological security pattern Fengxian County of Jiangsu Province China
Xingxing Jin and Luyao Wei contributed equally to the work.
At present, with the acceleration of industrialization and urbanization, the phenomena of population growth and urban expansion appear to be more and more prominent, which have exerted tremendous pressure on resources and the environment. The ecological environment has reached a critical state, which is accompanied by a series of problems such as loss of biodiversity, aggravation of soil and water losses and land desertification (Fang et al. 2019; Plieninger et al. 2015; Yao et al. 2019). The problem has threatened the safety of human life and property as well as the sustainable development of society and the economy seriously. There is an urgent need to control and improve the ecological environment from the source, as well as to handle the relationship between economic development and ecological protection correctly. The ecological security pattern has become one of the important ways to alleviate the contradiction between economic development and ecological protection. It also plays an active role in ecological civilization construction and territorial spatial pattern formation (Cumming and Allen 2017; Liu 2016).
In recent years, relevant scholars have effectively explored the ecological security pattern construction of prefecture-level cities and urban agglomerations based on different scales (Chen et al. 2018; Wang and Xu 2018; Wang et al. 2019). Among the existing studies, it has formed a mainstream research paradigm to construct regional ecological security pattern based on the identification of ecological sources and ecological corridors, and it has been widely applied in relevant practices (Klar et al. 2012). It is noteworthy that two main methods are used to identify the ecological sources including the qualitative evaluation of ecosystem structure and the comprehensive evaluation of quantitative indicators (Peng et al. 2017). For instance, according to the natural background conditions and the characteristics of habitat patches of the study area, relative researchers regarded nature reserves, forest parks, wetland parks and other important ecological lands as ecological sources directly (Tang et al. 2011; Yu 1996), while to a large extent, the qualitative identification of ecological sources ignored the internal differences. Relevant scholars tried to identify the ecological sources quantitatively by constructing comprehensive evaluation indicators in order to avoid this problem (Gurrutxaga et al. 2010). On the whole, it could be divided into two major venations. On the one hand, some researchers identified ecological sources by analyzing regional typical ecosystem service functions and their differentiation law from a single perspective (Peng et al. 2018). However, owing to the dynamism of ecosystem service functions, it would affect the identification results to some extent when simply considering various types of services as equally important. Therefore, some scholars tried to identify ecological sources based on ecosystem service value reconstruction (Frelichova et al. 2014; Scholte et al. 2015). On the other hand, some researchers identified ecological sources based on a composite perspective (Chen et al. 2008; Li et al. 2019). The identification and functional division of ecological sources will lead to the sustainable development of the ecosystem and relevant ecological policies formulation. Taking into account the ecosystem's own functions and the response of human activities to the ecosystem, they further determined the ecological sources by comprehensive evaluation of ecosystem service functions importance and ecosystem sensitivity (Guo et al. 2007; Kareiva et al. 2007; Li et al. 2011). It not only concerns the quantitative evaluation of ecological patterns, but more importantly, this method also gives attention to the evolution of the ecological process.
While identifying the ecological corridors, the minimum cumulative resistance (MCR) model based on the GIS platform had been widely used (Knaapen et al. 1992; Yu 1996, 1999). At present, the construction of resistance surfaces is generally based on related coefficients such as land cover type and topographical features (Fu et al. 2010). It requires to further consider the spatial differences caused by various ecological problems among different places. The MCR model is able to simulate the landscape obstacles to spatial motion processes in a more intuitive way (Song and Qin 2016). The key to the application of this model is the construction of ecological resistance surface. Currently, the existing resistance surface construction was mostly based on the assignment operations of different landscapes (Yang et al. 2018). Although it reflected the interaction between landscape patterns and ecological processes to a certain extent, it could not reveal the inherent complexity of human activities and ecological processes. Besides, it also tended to be too subjective. The areas with relatively high human activity intensity show a certain effect on the migration of species (Zhang et al. 2017a). Night lighting data are actually a comprehensive representation of the intensity of human spatial activity (Mellander et al. 2015). Therefore, some scholars tried to modify the resistance surface value by nighttime lighting (Elvidge et al. 2009), impervious surface index (Wang et al. 2018) and other data to obtain a more scientific ecological resistance surface. Although scholars have different methods of identifying ecological sources and ecological corridors, they are all useful explorations of theories and methods for constructing ecological security patterns.
At present, relevant studies mostly evaluated the regional ecological security pattern from the single ecosystem service functions importance perspective or the composite perspective combining with ecological sensitivity. In general, they lacked comprehensive consideration of the impact of different types of landscapes. Meanwhile, they also ignored the impact of human activities on the ecological resistance coefficient to some extent. Less consideration of the subjective impact on the resistance coefficient assignments and lack of reasonable revise led to a too subjective and non-operational scheme for ecological security pattern. In addition, relevant studies mostly concentrated on the identification of ecological sources in economically developed areas such as prefecture-level cities or urban agglomerations. As for the areas with the underdeveloped economy and huge contradiction between economic development and ecological protection, there is a lack of in-depth practical discussion on ecological security pattern construction. As for developing countries, it is an important proposition in the process of urbanization to explore the optimization model of territory spatial structure by constructing an ecological security pattern (Xin et al. 2016). Meanwhile, compared to mountainous and hilly areas that obtained income from diverse landscapes and tourism development, small-scale counties in plain areas require to further solve the contradiction between economic development and ecosystem protection urgently, while the construction method of the ecological security pattern in small-scale counties of plain areas was still unclear currently. Accordingly, we took Fengxian County in Huanghuaihai Region Plain of China as a study area to discuss the methodology to identify the ecological sources and ecological corridors. Furthermore, we constructed the ecological security pattern and finally obtained an ecological security barrier combining with regional functional zoning. According to the ultimate complex and multiple ecological spatial structure system, we proposed district governance recommendations and countermeasures of ecological space so as to coordinate the spatial relations and perfect the spatial functions. In general, this study provides a new research framework for identifying the ecological security pattern of small-scale counties in underdeveloped plain areas. It also provides policy guidance for spatial optimization in restricted development areas where there is a contradiction between economic development and ecological protection.
The specific construction methodology of ecological security pattern is as follows: First, we obtained ecological importance evaluation result to further identify the ecological sources based on ecosystem service functions and ecological sensitivities. Next, we adopted nighttime lighting data to modify the ecological resistance surface assigned by land use classifications. Then, according to the identification of ecological sources and the construction of ecological resistance surface, we used the minimum cumulative resistance model to identify the ecological corridors. Finally, the ecological security pattern was comprehensively constructed. By further clarifying the specific measures of ecological safety barriers construction and spatial function management, we attempted to provide decision-making suggestions for the sustainable development of county units in the plain area and the optimal layout of territory space. The methodology framework of ecological security pattern construction is shown in Fig. 1.
The methodology framework of ecological security pattern construction
The following section describes the study area and data sources. And the third section presents analytical methods that include ecological importance evaluation and ecological corridors identification. The section on findings demonstrates the analysis results. Combining with the assessment of ecosystem service functions importance and ecological sensitivity, we identify ecological sources and then construct an ecological safety pattern. The conclusion and discussion parts offer a summary of the findings, current research deficiencies and future research prospects.
2 Study area and data sources
2.1 Study area
Fengxian County is located in the northwestern part of Jiangsu Province, China (116°21′15″–116°52′03″ E, 34°24′25″–34°56′27″ N). As a junction of seven counties in four provinces of Jiangsu, Shandong, Henan and Anhui and the central zone of Huaihai Economic Zone, it plays an important role. It presents an obvious geographical location advantage with an area of 1450.2 km2 and 15 townships (Fig. 2). The current situation of Fengxian's ecological security will not only affect its own sustainable development, but also have a great enlightening effect on the ecological environment protection in some areas of adjacent Jiangsu, Shandong, Henan and Anhui Province. As can be seen from the land use classifications in Fengxian County, artificial and semi-artificial ecosystems occupy a large account. The areas of cultivated land, garden land and residential land account for 84.55% of the total area, while forest land, grassland and water area account for only 5.70% of the whole county. Human activities have a certain impact on the composition of the ecosystem.
The location of the study area
Owning sufficient light and water conditions, Fengxian County has become an important grain and fruit producing county in Jiangsu Province, China, as well as one of the main agricultural production areas at the provincial level. According to the major function-oriented zoning of Jiangsu Province issued by the People's Government of Jiangsu Province, Fengxian County is listed as a limited development zone, which is in urgent to control and solve ecological problems from the source effectively. In order to maintain and improve the production capacity of agricultural products, it is of great need to restrict the large-scale and high-intensity industrialization and urbanization development activities in Fengxian County. A series of ecological and environmental problems have arisen due to the fast development of townships and agriculture, such as loss of biodiversity, aggravation of soil and water losses and land desertification. Moreover, the contradiction between development and protection has become increasingly prominent. As a typical county unit in the underdeveloped plain area, it is conducive to alleviate the contradiction between economic development and ecosystem protection when exploring the construction mode of ecological security network patterns. It will also provide a scientific reference for the realization of regional coordinated and sustainable development. By establishing a scientific and rational ecological security pattern, we will achieve the overall planning and comprehensive regulation of territory space and coordinate the relationship between social-economic development and ecological environmental protection from the origin.
2.2 Data sources
The data used in this paper mainly included six types as shown in Table 1: net primary productivity (NPP), meteorological data, land use data, digital elevation model (DEM), normalized differential vegetation index (NDVI) and soil texture data (Xu 2018). To ensure the accuracy of data, the projection coordinate system was unified as GCS Xian 1980, and all data were converted into raster images with a resolution of 30 m × 30 m (Table 1).
Data sources of ecological security pattern construction in Fengxian County
Data Name
Net primary productivity (NPP)
We extracted the NPP data of Fengxian County during 2000–2015 and calculated the average value
https://www.nasa.gov/
Meteorological data
Meteorological data include temperature and precipitation data. They were obtained from the China surface perennial data set of the National Meteorological Information Center (1981–2010)
http://data.cma.cn/
Land use data of 2017 in Fengxian County include the first-class data and the second-class data with a total of 25 attribute values. The first-class data consist of cultivated land, garden land and so on. The second-class data include paddy land, irrigable land, dry land, etc.
The land and resources bureau of Fengxian County
Digital elevation model is a digital simulation of ground terrain through terrain elevation data
NDVI data
NDVI data were obtained from the geospatial data cloud platform with a spatial resolution of 30 m × 30 m
http://www.gscloud.cn/
The soil texture data
The soil texture data were obtained from the resource and environment data cloud platform
http://www.resdc.cn/Default.aspx
3 Research methods
3.1 Ecological importance evaluation
The ecological importance assessment refers to the comprehensive effects of the quality of service functions provided by the ecosystem and the sensitivity to external disturbances of the ecosystem. On this basis, we regard the patches with high ecological value as alternative areas of ecological sources.
3.1.1 Importance of ecosystem service functions
Ecosystem service functions refer to the environmental conditions and beneficial effects through which ecosystems and species sustain and fulfill humanity's survival (Daily 1997), including water resource conservation, soil and water conservation, biodiversity conservation, etc. It can identify areas with important ecological functions and provide scientific evidence effectively for ecosystem restoration and ecological function zoning by carrying out researches on ecosystem service functions importance evaluation. At present, the methods for ecosystem service functions importance evaluation are approximately divided into the model evaluation and NPP quantitative indicators evaluation (Barral and Maceira 2012; Carreño et al. 2012). According to the actual characteristics of Fengxian County and the data acquisition situation, we adopted model evaluation and NPP quantitative indicators evaluation comprehensively to evaluate the importance of ecosystem service functions (Table 2). According to the evaluation results of the importance of water resource conservation, soil and water conservation and the biodiversity conservation function, we graded the sub-dimension indexes separately. After weighted calculation, we finally got the importance evaluation of ecosystem service functions.
Evaluation index of the importance of ecosystem service functions
Target layer
Index layer
Factor layer
Importance of ecosystem service functions
Importance of water resource conservation
Evapotranspiration
Area of ecosystem
Importance of soil and water conservation
Rainfall erosivity
Soil erodibility
Terrain conditions
Vegetation coverage
Importance of biodiversity conservation function
NPP (net primary productivity)
Annual average precipitation
Annual average temperature
3.1.1.1 Importance of water resource conservation
The water resource conservation is closely related to surface coverage, precipitation and terrain conditions (Cheng and Shi 2004). The water resource conservation mainly refers that the ecosystem gives full play to flood detention, peak discharge reduction, water regulation, soil and water losses reduction, etc. by intercepting rainwater through vegetation, reducing surface runoff and slowing down its velocity. The formula is as follows:
$${\text{WRC}} = \mathop \sum \limits_{i}^{j} (P_{i} - R_{i} - {\text{ET}}_{i} ) \times A_{i} \times 10^{3}$$
where WRC denotes the importance of water resource conservation, Pi is the precipitation (mm); Ri is the surface runoff (mm); ETi is the evapotranspiration (mm); Ai is the area of ecosystem type i (km2); and j is the number of ecosystem types in the study area. The formula for \(R_{i}\) is:
$$R_{i} = P_{i} \times \alpha$$
where α is the average surface runoff coefficient (Table 3), and the specific assignments of ecosystem types are referred to the policy document "Technical Guidelines for Assessment of Resources and Environmental Carrying Capacity and Suitability of Territory Space Development" which was issued by the Ministry of Natural Resources of the People's Republic of China in 2019.
The average surface runoff coefficient of each ecosystem type
Major ecosystem types
Subtypes of ecosystem
The average surface runoff coefficient (%)
Evergreen broad-leaved forests
Evergreen needle-leaved forests
Mixed broadleaf-conifer forests
Deciduous broad-leaved forests
Deciduous coniferous forest
Sparse woods
Bush wood
Evergreen broad-leaved thickets
Deciduous broad-leaved thickets
Coniferous thickets
Sparse thickets
Underbrush
Sparse grass
3.1.1.2 Importance of soil and water conservation
The soil and water conservation aims at reducing soil erosion by the interception and absorption of rainfall through vegetation and their roots. Normally, researchers adopt the revised universal soil loss equation (RUSLE) for simulation calculations (Liu et al. 2017). It considers the quantification of rainfall erosivity factor, soil erodibility factor, terrain factor (slope and length) and vegetation coverage factor comprehensively. By estimating the difference between potential and actual soil erosion as soil and water conservation value, RUSLE further characterizes the importance of soil and water conservation in Fengxian County. The specific calculation formula is as follows:
$$A = R \times K \times L \times S \times (1 - V)$$
where A denotes the soil and water conservation (t/hm2 a); R is the rainfall erodibility factor (MJ mm/hm2 h a); K is the soil erodibility factor (t hm2 h/hm2 MJ mm); L and S are the terrain factors among which L is the length factor and S is the slope factor; and V is the vegetation coverage factor.
3.1.1.3 Importance of biodiversity conservation function
There is a complex interrelationship between biodiversity and ecosystem service functions, and the loss of biodiversity will greatly weaken the ecosystem's service functions (Patricia et al. 2016). The biodiversity conservation function is mainly manifested in the production and maintenance of biodiversity, climate regulation, flood and drought mitigation by ecosystems (Fischer et al. 2006; Hector et al. 2001). It is conducive to promote human understanding of the importance of ecosystem service functions by defining biodiversity conservation function. We chose four major influencing factors net primary productivity (NPP), annual average precipitation, annual average temperature and altitude, so as to evaluate the importance of biodiversity conservation function in Fengxian County. The calculation formula is:
$${\text{IBCF}} = {\text{MNPP}} \times F_{\text{pre}} \times F_{\text{tmp}} \times (1 - F_{\text{alt}} )$$
where \({\text{IBCF}}\) denotes the importance of biodiversity conservation function; \({\text{MNPP}}\) is the mean value of net primary productivity; and \(F_{\text{pre}}\), \(F_{\text{tmp}}\) and \(F_{\text{alt}}\) represent the annual average precipitation, annual average temperature and altitude, respectively. They are all normalized to 0–1 according to the extremum standardization method. At the same time, according to the topographical features of Fengxian County, we adopted the "species habitat factors" (Table 4) to modify the results.
The coefficient assignment of species habitat factors
Census code for geographical conditions
320–350/411/1001
360–380/412/413
200/110/420/1012
Land use type
Arbor forest
Shrub wood, mixed forest of Arbor forest and shrub wood, sparse wood, grassland with high coverage, water
Greening woodland, artificial young plantation, sparse shrub wood grassland with medium coverage, grassland with low coverage
Garden, paddy fields, artificial grassland, canal
Dry land, desert and bare surface
House building, roads, structures, artificial piling and digging land
Source: The first national geographical conditions survey (Serial number: GDPJ 01-2013)
3.1.2 Ecological sensitivity
Ecological sensitivity refers to the sensitivity of ecosystems to various environmental variability and human activities, and it can be used to reflect the possibility of ecological imbalances and ecological problems formation (Li et al. 2014), so as to make sure the most sensitive and protective areas. By choosing the three factors soil and water losses sensitivity, desertification sensitivity in plain areas and salinization sensitivity as evidence for ecological sensitivity evaluation of Fengxian County, we divided the index layers' results (Table 5) into five levels as extremely sensitive, more sensitive, moderate sensitive, mild sensitive and non-sensitive, and their corresponding scores are 9, 7, 5, 3 and 1, respectively. Finally, we obtained the ecological sensitivity score by arithmetic average of the above three index layers' results. According to the specific scores and intergroup differences, we defined the five levels of ecological sensitivity based on the score thresholds of > 8, 6–8, 4–6, 2–4 and < 2.
Ecological sensitivity evaluation index
Ecological sensitivity
Soil and water losses sensitivity
Relief amplitude
Desertification sensitivity in plain areas
Aridity index
Sandy days over 5 m/s in winter and spring
Salinization sensitivity
Ratio of evaporation to precipitation
Groundwater mineralization
Groundwater depth
3.1.2.1 Soil and water losses sensitivity
On the base of the universal soil loss equation (USLE), combining with the former scholars' related researches (Peng and Zhou 2019; Svoray and Ben-Said 2009) and actual characteristics of Fengxian County, we identified the four factors rainfall erosivity, soil erodibility, relief amplitude and vegetation coverage as soil and water losses sensitivity indicators. The calculation formula is as follows:
$${\text{SS}} = \sqrt[4]{{R \times K \times {\text{LS}} \times C}}$$
where SS is soil and water loss sensitivity; R is the rainfall erodibility factor; K is the soil erodibility factor; LS is the relief amplitude factor; and C is the vegetation coverage factor.
3.1.2.2 Desertification sensitivity in plain areas
The desertification sensitivity in plain areas is mainly characterized by the dry climate, low vegetation coverage and scattered surface soil structure which is vulnerable to wind erosion. According to the requirements of Provisional Technical Regulations of Ecological Function Zoning issued by the Ministry of Ecology and Environment of the People's Republic of China, we selected four evaluation indicators aridity index, sandy days over 5 m/s in winter and spring, soil texture and vegetation coverage combining with the actual characteristics of Fengxian County. The calculation formula is (Liu et al. 2015):
$$D = \sqrt[4]{I \times W \times K \times C}$$
where D is the desertification sensitivity in plain areas; I is the aridity index; W is the sandy days over 5 m/s in winter and spring; K is the soil texture; and C is the vegetation coverage factor.
3.1.2.3 Salinization sensitivity
Salinization is mainly caused by drought climate, poor drainage, excessive groundwater level, unreasonable irrigation, etc. (Ouyang et al. 2000). According to the connotation of salinization and the actual situation of Fengxian County, we selected four factors including ratio of evaporation to precipitation, groundwater mineralization, groundwater depth and soil texture to evaluate salinization sensitivity. The specific calculation formula is:
$$S = \sqrt[4]{I \times M \times D \times K}$$
where S is the salinization sensitivity; I is the ratio of evaporation to precipitation; M is the groundwater mineralization; D is the groundwater depth; and K is the soil texture.
3.2 Ecological corridors identification
The minimum cumulative resistance (MCR) model is calculated based on the GIS platform. It simulates the path of minimum cumulative resistance according to the cost of species from the ecological source to the destination, thereby constructing an ecological network. Currently, it has been widely used in the field of ecological network and ecological security structure construction (Zhang et al. 2017b; Chen et al. 2019). The identification of ecological corridors is based on the MCR model (Knaapen et al. 1992), and the formula is as follows:
$${\text{MCR}} = f \left( {\hbox{min} \mathop \sum \limits_{j = n}^{i = m} D_{ij} \times R_{i} } \right)$$
where \({\text{MCR}}\) is the minimum cumulative resistance value; Dij is the spatial distance from source j to landscape unit i; Ri is the resistance coefficient of landscape unit i to species diffusion.
The resistance coefficient refers to cumulative resistance overcome by species as they travel through the heterogeneous landscapes. According to the assignments of various landscape types (Gurrutxaga et al. 2011; Kong et al. 2010) and actual situation of Fengxian County, the ecological resistance coefficients of forest land, grassland, garden land, cultivated land, unused land, water area and construction land were set to 1, 10, 20, 30, 50, 300 and 500, respectively. Meanwhile, we used nighttime lighting data to modify the ecological resistance coefficients assigned by landscape types (Zhang et al. 2017b), so as to better embody the differences of ecological resistance coefficients among different spatial units. Finally, we obtained the ecological resistance surface. The calculation formula is:
$$R_{i} = \frac{{{\text{NL}}_{i} }}{{{\text{NL}}_{a} }} \times R$$
where NLi is the nighttime lighting index of pixel i; NLa is the mean nighttime lighting index of landscape type ɑ to which the pixel i belongs; and R is the modified resistance coefficient assignments based on various landscape types.
3.3 Ecological security pattern construction
The construction of ecological security pattern based on the identification of "sources–corridors" essentially includes two core steps of ecological sources determination and ecological corridors extraction. Among these, the identification of ecological sources is based on ecological importance evaluation. Considering the actual situation of Fengxian County and the area of ecological sources comprehensively, we selected a certain area of patches with higher ecosystem importance as ecological sources. In addition, the extracted corridors among ecological sources are based on the MCR model. By using the spatial analysis tool in the GIS platform to calculate the minimum cost path, we constructed an ecological security pattern of Fengxian County which is consistent with its actual development.
The ecosystem service functions and their comprehensive evaluation results are shown as follows. In detail, the biodiversity conservation function score in the south area is higher than in the northern part (Fig. 3a). Moreover, the most important and more important areas are mainly distributed in Fanlou Town which is located in the south of the county. Relative important areas are mainly concentrated in the northern and central area which accounts for 67.82% of the whole county. The water resource conservation areas with high value are concentrated in the Dasha River, Dasha River Wetland and Dasha River Special Species Protection Area, while the low-value areas are mainly concentrated in the central urban area and the center of townships (Fig. 3b). Relative important water resource conservation areas account for 56.82% of the whole county. The soil and water conservation areas with high value are concentrated in the region nearby Dasha River and Fuxing River (Fig. 3c), while the low-value areas are concentrated in the northern and southern areas, and the distribution of other grades is relatively scattered. The whole county is dominated by soil and water conservation areas with relative importance and general importance, which accounts for 40.02% and 35.53%, respectively.
Spatial differentiation of ecosystem service functions importance in Fengxian County
We divided the evaluation results of ecosystem service function importance into five levels including general important, relative important, moderate important, more important and most important according to natural breaks method (Table 6). In terms of spatial distribution, more important and most important areas are mainly concentrated in the Dasha River, Dasha River Special Species Protection Area, Fuxing River and other rivers. Besides, moderate important areas are concentrated in Fanlou Town which is located in the southern part of Fengxian County. And the spatial distribution range of relative important areas is wider. General important areas are mainly concentrated in the urban center and administrative center areas of each township. In general, the importance degree of ecosystem service functions is mainly relative important, which accounts for 54.27% of the total county. What follows are moderate important and more important areas with the proportion up to 19.21% and 16.51%, respectively, while the scale proportion of general important areas is the smallest.
The area proportion of each grade of ecosystem service functions importance in Fengxian County
Importance grades
Area (km2)
Area proportion (%)
General important
Relative important
Moderate important
4.2 Ecological sensitivity evaluation
The soil and water losses sensitivity in Fengxian County is mainly non-sensitive and mild sensitive which account for nearly 61% of the study area (Fig. 4a), while the proportion of the extremely sensitive area is only 0.03%. The distribution differentiation of soil and water losses sensitivity results from the spatial differences among precipitation, soil and vegetation. In general, the soil and water losses sensitivity in the central and southeastern areas is relative high, and the northeastern area is at medium level. Moreover, the desertification sensitivity in plain areas of Fengxian County is dominated by non-sensitive and mild sensitive, which accounts for 37.01% and 23.56% of the whole area, respectively (Fig. 4b). On the whole, the heterogeneity of spatial distribution is very obvious. It demonstrates a medium level in the southwestern and northwestern regions. And the central region is extremely sensitive to desertification due to low vegetation coverage and high aridity index. The southeastern area presents a significant desertification sensitivity resulting from the comprehensive effect of soil erodibility factor, aridity index and vegetation coverage factor. The salinization sensitivity of Fengxian County is mainly extremely sensitive, more sensitive and moderate sensitive, which accounts for 89.26% of the total area (Fig. 4c). From the aspect of spatial distribution, the northern region is extremely sensitive to salinization, while the central region is more sensitive. By contrast, the southern region is less salinized.
Spatial differentiation of ecological sensitivity in Fengxian County
The spatial distribution of ecological sensitivity is basically consistent with single-factor sensitivity, which all present a higher sensitivity in the central region and lower sensitivity in the southern area. Areas with high sensitivity are mainly distributed in urban centers and water land. Moreover, moderate-sensitive areas are mainly distributed in the southeastern, southwestern and northern regions, while the central and northern regions present lower ecological sensitivity. On the whole, 46.98% of the whole county is mild-sensitive areas followed by moderate-sensitive areas. However, the size of extremely sensitive areas is only 35.53 km2 with the proportion up to 2.45% of the whole county (Table 7).
The area proportion of each grade of ecological sensitivity evaluation in Fengxian County
Sensitivity grades
Non-sensitive
Mild sensitive
Moderate sensitive
More sensitive
Extremely sensitive
4.3 Ecological sources identification based on ecological importance evaluation
We obtained the results of the ecological importance of Fengxian County based on evaluation results of ecological service functions importance and ecological sensitivity according to the "maximum method." Next, we divided it into the minimum, lower, medium, higher and highest levels. The calculation results show that the area of ecological importance at the highest level is 148.54 km2, which accounts for 10.24% of the whole county. They are mainly distributed in the Dasha River and other areas with important water resource conservation function, as well as ecological sensitive areas such as administrative centers (Fig. 5). Moreover, the area of ecological importance at the higher level is 392.57 km2, which accounts for 27.07% of the whole county. They are approximately distributed in the Dasha River Special Species Protection Area, the underground drinking water source area in the central district and the Fuxing River. The areas of ecological importance at the medium level all mainly concentrated in the southeastern county. The areas of ecological importance at the lower level are widely distributed in the northern, central and southern county, among which the northern area shows a more centralized distribution, while the area of the minimum level is 0.77 km2 which only accounts for 0.05% of the whole county.
Spatial differentiation of ecological importance in Fengxian County
According to the evaluation results of ecological importance, we selected the patches at the higher and highest level as the ecological sources candidate areas in Fengxian County. It is noteworthy that there are many isolated and broken patches. Consider that only with a certain scale ecological sources can isolate external interference to the core area and play an important ecological role (Hao et al. 2019). Therefore, we selected the patches with the size of more than 10 km2 as ecological resources combined with the actual situation of Fengxian County. The final results show that the area proportion of ecological sources is 13.76%, which is slightly smaller than the ecological red line area delineated by the current Ecological Redline Regional Protection Plan, but the spatial distribution is generally consistent with the ecological red line district.
4.4 Ecological corridors identification and ecological security pattern construction
Ecological corridors are important channels connecting the ecological sources, as well as important carries of material and energy flow within the region. More importantly, they are key ecological components for maintaining ecological flow, ecological processes and ecological functions in connection with the region (Li et al. 2004). Based on ecological sources and resistance surfaces, we used cost distance and cost path tools, as well as MCR model to construct the minimum cost paths and the secondary cost paths. In order to achieve the continuation of ecological functions and the connection of landscape patches at the regional scale, we defined the corridors with wide coverage and critical function in the minimum cost paths as key corridors combining with the ecological environment status and economic development needs of Fengxian County. Meanwhile, we regarded the corridors which play an important role in the connection of landscapes with smaller coverage in the secondary cost paths as main corridors (Fig. 6). According to statistical analysis, there are five key corridors and two main corridors with a total length of about 115.71 km and 26.22 km, respectively, in Fengxian County. The ecological corridors are mainly distributed in the western and southwestern parts of Fengxian County with high vegetation coverage, which happens to be far away from the areas with strong humanity disturbances such as central urban area and township centers.
Ecological security pattern construction in Fengxian County
Urban expansion and intense human activities have changed the structure and functions of surface landscapes rapidly and strongly, leading to an increasingly intensified contradiction between economic development and ecological protection. The construction of regional ecological security pattern can protect important ecological patches effectively and coordinate the spatial conflicts between economic development and ecological protection. In general, it is one of the effective ways to construct land ecological barriers (Peng et al. 2017). The ecological security pattern of Fengxian County is composed of ecological sources, key corridors and main corridors (Fig. 6). Specifically, the ecological sources are mainly distributed in Dashahe Town, Songlou Town and Zhongyangli Street. It can provide important ecological protection for water resource conservation and biodiversity conservation in Dashahe Town and Songlou Town as concentrated ecological land distribution areas. Although Zhongyangli Street is the central urban area of Fengxian County which is mainly distributed by construction land, the construction of ecological sources in this area is no less important than other ecological sources as it is the distribution area of underground drinking water source in Fengxian County. Otherwise, the ecological corridors which connect ecological sources are distributed in the western and southwestern regions with a network form. And the direction of spatial paths is mainly extended from northwest to southeast.
The ecological security pattern of Fengxian County covers parallel layers and extends in branches, which shows a spatial pattern of "two vertical axes and five horizontal axes" as a whole. A complete complex system is formed through organic connections among ecological sources and ecological corridors. "One vertical axis" is located in the western county which extends from Zhaozhuang Town to Songlou Town. It achieves the continuity of ecological functions and the coherence of ecological processes in the western region to some extent. Moreover, "another vertical axis" is located in the central axis of Fengxian County, which connects the adjacent regions of underground drinking water source in Zhongyangli Street and the Dasha River water resource conservation area. It provides important support for water supply in the central core area. As for "five horizontal axes", apart from the key corridors extending from Zhaozhuang Town in the central part to Changdian Town in the northeastern area, a key ecological corridor is formed from the southern part of Songlou Town connecting eastward to the northern part of Dashahe Town. Two key corridors are also formed in the east–west direction and northeast-southwest direction within Songlou Town. In addition, a main ecological corridor in the northeast-southwest direction is formed in the southeastern part of Songlou Town. Furthermore, the central part of Wanggou Town extends eastward to Sunlou Street and leads to a main ecological corridor. All of them provide a good guarantee for the biodiversity and overall connectivity of landscape networks in Fengxian County.
4.5 Governance strategies of ecological security barriers and functional zoning
According to the characteristics of ecological security pattern and regional functional zoning of Fengxian County, we constructed ecological security barriers including five axes, which are concentrated in the two regions of the central valuable agricultural eco-economic functional zone and southwestern forest and fruit eco-economic functional zone. We should improve the soil's ecological environment through the rational input of organic fertilizer in the central ecological zone. It is necessary to form a multi-dimensional planting mode while developing garden culture vigorously. On the other hand, we should also take advantage of deep sandy soil and abundant light in the western ecological zone. Apart from concentrating on the development of economic forest and fruit production as well as management activities, we did better continue to strengthen the awareness of ecological environmental protection. The ecological security barriers of Fengxian County are far from the main axis of urban development owing to the inevitable interference of human activities to the ecosystem, which is consistent with the objective law. For areas that are relatively consistent with the auxiliary axis of urban development, we should limit and regulate the responsible subjects of ecological security barriers. Through the participation and suggestions of stakeholders, as well as the implementation of relevant laws and regulations, relevant departments attempt to develop a negative list of environmental access for ecological security barriers to regulate human activities. As for the eco-tourism development axis which locates in the western part of Fengxian County, it is needed to explore the expansion model of the ecological network service path. In fact, as a self-organizing system with mutual feedback properties between functions and processes, it is conducive to the formation of different leisure experiences and the enhancement of well-being through appropriate green space opening policy. In addition, the northern ecological water system axis and the southern agricultural matrix axis are based on the conditions of groundwater, rivers and agricultural land. We should emphasize the coordination between natural background conditions and the structure of interest subjects, as well as the interest separation of ecological space. Finally, it is essential to establish a balanced development mechanism of ecological space that combines democratic rights with economic interests, avoiding the tragedy of commons (Fig. 7).
Ecological security barriers and functional zoning in Fengxian County
5 Discussion and conclusions
5.1 Discussion
The core research content of landscape ecology is to explore the interaction between landscape patterns and ecological processes. It will provide important spatial approaches for the construction of the ecological security pattern (Yu 1996). The ecological security pattern essentially refers to a potential ecological system spatial pattern among the landscape (Peng et al. 2017). By constructing an ecological security pattern, it is possible to effectively regulate ecological processes and ultimately achieve regional ecological security (Chen and Zhou 2005). The identification of ecological sources and ecological corridors plays a vital role in the construction of ecological security patterns. In this paper, the identification of the ecological sources has played an important role in constructing the ecological security pattern. Based on the ecological importance to identify ecological sources, while taking into account the quantitative value of ecosystem service functions and ecosystem sensitivity, the integration of ecological pattern quantification and ecological process evolution evaluation has been realized comprehensively to some extent (Guo et al. 2007). In this study, the identification of ecological sources has played an important role in constructing the ecological security pattern. In addition, the current methods and standards for the construction of ecological resistance surfaces have not been unified. Some studies have constructed resistance coefficients based on the perspective of biodiversity conservation (Balvanera et al. 2006; Zhang et al. 2017a). Some scholars also assigned resistance coefficients to grids units based on ecological sensitivity evaluation results (Fu et al. 2019). However, these methods do not take into account the versatility of landscape and the carrying role of multiple ecological processes. The construction of the resistance surface does not fully consider the regional differences, and it cannot reflect the interaction between the landscape pattern and the ecological process. To some extent, it will ultimately affect the authenticity of the simulation results. Therefore, this study obtained the ecological function resistance value based on various landscape types assignments. Meanwhile, considering the heterogeneity within the same landscape type and the impact of human activity intensity on ecological processes especially the regional migration of species, we adopted the night lighting data to modify the ecological function resistance value. Finally, we got the ecological resistance surface. On this basis, the ecological corridors are identified combining with the MCR model, thereby comprehensively constructing the ecological security pattern of Fengxian County. The ecological corridor identified by this method is basically within the ecological control line of Fengxian County. At the same time, it is confirmed that the identification method of the ecological sources and ecological corridors in this study is relatively reasonable. The recognition results are in good accordance with the actual situation of Fengxian County.
The ecological security pattern of Fengxian County is composed of ecological sources, key corridors and main corridors. Among which, the ecological sources play an important ecological protection role in water resource conservation and biodiversity conservation of Fengxian County. Meanwhile, the ecological sources are connected by ecological corridors which ensure the circulation and transition of materials and energy among ecological sources. In general, the existence of ecological corridors guarantees the continuity of ecological functions and the connectivity among the landscapes at the regional scale. It has a certain research significance and application value in constructing ecological security patterns and providing governance strategies of ecological security barriers at the small-scale county level. To some extent, it can offer a reference for the contradiction coordination between ecological environment and economic development in the developing countries and plain areas. Based on the construction of the ecological security pattern, this paper proposed ecological space optimization strategies in Fengxian County. It can provide a reference for alleviating the contradiction between economic development and ecosystem protection of small-scale county units in less developed regions. It also has important significance for optimizing the territory development pattern and promoting ecological civilization construction.
However, we only selected the importance of ecosystem service functions and ecological sensitivity to identify ecological sources comprehensively owing to the limitation of data acquisition and model accuracy. In future research, we will further explore more specific ecological security pattern protection methods based on detailed geospatial data. On the other hand, in view of the spatial mobility of material and energy, ecological security is simultaneously affected by ecosystems and ecological elements within and outside the region. Therefore, it may lead to negligence of ecological elements in the surrounding areas of Fengxian County due to the administrative boundary division. In the future, we will carry out researches on the construction of the ecological security pattern of Fengxian County under broader ecological background conditions. In addition, although we have considered the internal heterogeneity of landscape types when constructing ecological resistance surfaces, there are still further improvements in resistance coefficient assignments.
The construction of ecological security pattern plays an important role in coordinating spatial conflicts between economic development and ecological protection. This study identified ecological sources based on the importance of ecosystem service functions and ecological sensitivity. Using landscape types assignments modified by nighttime light data and MCR model, we identified ecological corridors and finally constructed the ecological security pattern of Fengxian County. Based on these, we revealed the spatial structure characteristics of ecological security pattern so as to control and improve ecological problems from the source effectively, optimize the development pattern of territory space and promote the construction of ecological civilization. Our results show that: (1) the ecological sources of Fengxian County are mainly located in the central and southwestern part with the area of 199.58 km2 which accounts for 13.76% of the whole county. Moreover, the spatial distribution of ecological sources is highly coincident with the spatial location of the Dasha River, Fuxing River and the underground drinking water source area. (2) The ecological corridors of Feng County include two major categories of key corridors and main corridors with length of approximately 115.71 km and 26.22 km, respectively. In addition, the spatial distribution of these corridors beyond the built-up areas with strong human disturbance as a whole, and mainly concentrate in the western and southwestern part of the county. (3) The ecological security network of Fengxian County is composed of four ecological sources and seven ecological corridors. These ecological components interact with each other to form a branched radiation ecological network space structure. (4) Based on the ecological security pattern and regional functional zoning characteristics of Fengxian County, we finally constructed the ecological security barrier including five axes. Furthermore, we explored the corresponding ecological space governance measures to optimize the ecological network of Fengxian County.
This work was supported by the National Natural Science Foundation of China (Nos. 41430635 and 41901205).
Balvanera, P., Pfisterer, A. B., Buchmann, N., He, J., Nakashizuka, T., Raffaelli, D., et al. (2006). Quantifying the evidence for biodiversity effects on ecosystem functioning and services. Ecology Letters,9, 1146–1156.CrossRefGoogle Scholar
Barral, M. P., & Maceira, N. O. (2012). Land-use planning based on ecosystem service assessment: A case study in the Southeast Pampas of Argentina. Agriculture, Ecosystems & Environment,154(7), 34–43.CrossRefGoogle Scholar
Carreño, L., Frank, F. C., & Viglizzo, E. F. (2012). Tradeoffs between economic and ecosystem services in Argentina during 50 years of land-use change. Agriculture, Ecosystems & Environment,154(5), 68–77.CrossRefGoogle Scholar
Chen, L., Fu, B., & Zhao, W. (2008). Source-sink landscape theory and its ecological significance. Frontiers of Biology in China,3(2), 131–136.CrossRefGoogle Scholar
Chen, L., Jing, Y., & Sun, R. (2018). Urban eco-security pattern construction: Targets, principles and basic framework. Acta Ecologica Sinica,38(12), 4101–4108.Google Scholar
Chen, D., Lan, Z., & Li, W. (2019). Construction of land ecological security in Guangdong Province from the perspective of ecological demand. Journal of Ecology and Rural Environment,35(7), 826–835.Google Scholar
Chen, X., & Zhou, Cheng. (2005). Review of the studies on ecological security. Progress in Geography,24(6), 8–20. https://doi.org/10.3969/j.issn.1007-6301.2005.06.002.CrossRefGoogle Scholar
Cheng, G., & Shi, P. (2004). Benefits of forest water conservation and its economical value evaluation in upper reaches of Yangtse River. Science of Soil and Water Conservation,4, 17–20.Google Scholar
Cumming, G. S., & Allen, C. R. (2017). Protected areas as social-ecological systems: Perspective from resilience and social-ecolocial systems theory. Ecological Applications,27(6), 1709–1717.CrossRefGoogle Scholar
Daily, G. C. (1997). Nature's service: Social dependence on natural ecosystem. Washington D.C.: Island Press.Google Scholar
Elvidge, C., Sutton, P., Ghosh, T., Tuttle, B., Baugh, K., Bhaduri, B., et al. (2009). A global poverty map derived from satellite data. Computers & Geosciences,35, 1652–1660.CrossRefGoogle Scholar
Fang, C., Cui, X., Li, G., Bao, C., Wang, Z., & Ma, H. (2019). Modeling regional sustainable development scenarios using the Urbanization and Eco-environment Coupler: Case study of Beijing Tianjin-Hebei urban agglomeration, China. Science of the Total Environment,689, 820–830.CrossRefGoogle Scholar
Fischer, J., Lindenmayer, D., & Manning, A. (2006). Biodiversity, ecosystem function, and resilience: Ten guiding principles for commodity production landscapes. Frontiers in Ecology and the Environment,4(2), 80–86.CrossRefGoogle Scholar
Frelichova, J., Vackar, D., Partl, A., Louvkova, B., Harmackova, Zuzana V., & Lorencoa, E. (2014). Integrated assessment of ecosystem services in the Czech Republic. Ecosystem Services,8, 110–117.CrossRefGoogle Scholar
Fu, W., Liu, S., Degloria, S., Dong, S., & Beazley, R. (2010). Characterizing the "fragmentation-barrier" effect of road networks on landscape connectivity: a case study in Xishuangbanna, Southwest China. Landscape and Urban Planning,95(3), 122–129.CrossRefGoogle Scholar
Fu, C., Xu, Y., Bundy, A., Gruss, A., Coll, M., Heymans, J., et al. (2019). Making ecological indicators management ready: Assessing the specificity, sensitivity, and threshold response of ecological indicators. Ecological Indicators,105, 16–28.CrossRefGoogle Scholar
Guo, R., Miao, C., Li, X., & Chen, D. (2007). Eco-spatial structure of urban agglomeration. Chinese Geographical Science,17(1), 28–33.CrossRefGoogle Scholar
Gurrutxaga, M., Lozano, P., & Barrio, G. (2010). GIS-based approach for incorporating the connectivity of ecological networks into regional planning. Journal for Nature Conservation,18(4), 318–326.CrossRefGoogle Scholar
Gurrutxaga, M., Rubio, L., & Saura, S. (2011). Key connectors in protected forest area networks and the impact of highways: A transnational case study from the Cantabrian Range to the Western Alps (SW Europe). Landsc Urban Plan,101, 310–320.CrossRefGoogle Scholar
Hao, Y., Zhang, N., Du, Y., Wang, Y., Zheng, Y., & Zhang, C. (2019). Construction of ecological security pattern based on habitat quality in Tang County, Hebei, China. The Journal of Applied Ecology,30(3), 1015–1024.Google Scholar
Hector, A., Joshi, J., Lawler, S. P., Spehn, E. M., & Wilby, A. (2001). Conservation implications of the link between biodiversity and ecosystem functioning. Oecologia,129(4), 624–628.CrossRefGoogle Scholar
Kareiva, P., Watts, S., Mcdonald, R., & Boucher, T. (2007). Domesticated nature: Shaping landscapes and ecosystems for human welfare. Science,316(5833), 1866–1869.CrossRefGoogle Scholar
Klar, N., Herrmann, M., Henning-Hahn, M., Pott-Dorfer, B., Hofer, H., & Kramer-Schadt, S. (2012). Between ecological theory and planning practice: (Re-) connecting forest patches for the wildcat in Lower Saxony, Germany. Landscape and Urban Planning,105(4), 376–384.CrossRefGoogle Scholar
Knaapen, J. P., Scheffer, M., & Harms, B. (1992). Estimating habitat isolation in landscape planning. Landscape and Urban Planning,23(1), 1–16.CrossRefGoogle Scholar
Kong, F., Yin, H., Nakagoshi, N., & Zong, Y. (2010). Urban green space network development for biodiversity conservation: Identification based on graph theory and gravity modeling. Landscape and Urban Planning,95, 16–27.CrossRefGoogle Scholar
Li, Y., Shi, Y., Qureshi, S., Bruns, A., & Zhu, X. (2014). Applying the concept of spatial resilience to socio-ecological systems in the urban wetland interface. Ecological Indicators,42, 135–146.CrossRefGoogle Scholar
Li, J., Song, C., Cao, L., Zhu, F., Meng, X., & Wu, J. (2011). Impacts of landscape structure on surface urban heat islands: A case study of Shanghai, China. Remote Sensing of Environment,115(12), 3249–3263.CrossRefGoogle Scholar
Li, W., Wang, Y., Peng, J., & Li, G. (2004). Landscape spatial changes in Shenzhen and their driving factors. Chinese Journal of Applied Ecology,8, 1403–1410.Google Scholar
Li, S., Xiao, W., Zhao, Y., Xu, J., Da, H., & Lv, X. (2019). Quantitative analysis of the ecological security pattern for regional sustainable development: Case study of Chaohu Basin in eastern China. Journal of Urban Planning and Development,145(3), 04019009.CrossRefGoogle Scholar
Liu, M. (2016). The ecological security pattern of China's energy consumption based on carbon footprint. Landscape Architecture Frontiers,4(5), 10–16.Google Scholar
Liu, J., Gao, J., Ma, S., Wang, W., & Zou, C. (2015). Evaluation of ecological sensitivity in China. Journal of Natural Resources,30(10), 1607–1616.Google Scholar
Liu, S., Wang, D., Li, H., Li, W., Wu, W., & Zhu, Y. (2017). The ecological security pattern and its constraint on urban expansion of a black soil farming area in Northeast China. Isprs International Journal of Geo-information,6(9), 263.CrossRefGoogle Scholar
Mellander, C., Lobo, J., Stolarick, K., & Matheson, Z. (2015). Night-time light data: A good proxy measure for economic activity? PLoS ONE,10(10), 0139799.CrossRefGoogle Scholar
Ouyang, Z., Wang, X., & Miao, H. (2000). China's eco-environmental sensitivity and its spatial heterogeneity. Acta Ecologica Sinica,20(1), 9–12.Google Scholar
Patricia, P. L., Vazquez, L. B., Sarmiento-Aguilar, Rausel, Douterlungne, D., & Valenzuela-Galvan, D. (2016). Influence of human activities on some medium and large-sized mammals' richness and abundance in the Lacandon Rainforest. Journal for Nature Conservation,34, 75–81.CrossRefGoogle Scholar
Peng, J., Yang, Y., Liu, Y., Hu, Y., Du, Y., & Meersmans, J. (2018). Linking ecosystem services and circuit theory to identify ecological security patterns. Science of the Total Environment,644, 781–790.CrossRefGoogle Scholar
Peng, J., Zhao, H., Liu, Y., & Wu, J. (2017). Research progress and prospect on regional ecological security pattern construction. Geographical Research,36(3), 407–419.Google Scholar
Peng, W., & Zhou, J. (2019). Development of land resources in transitional zones based on ecological security pattern: a case study in China. Natural Resources Research,28(S1), S43–S60.CrossRefGoogle Scholar
Plieninger, T., Kizos, T., Bieling, C., Dû-Blayo, L. L., Budniok, M. A., Bürgi, M., et al. (2015). Exploring ecosystem change and society through a landscape lens: Recent progress in European landscape research. Ecology and Society,20(2), 60–62.CrossRefGoogle Scholar
Scholte, Smmantha S. K., van Teeffelen, Astrid J. A., & Verburg, Peter H. (2015). Integrating socio-cultural perspectives into ecosystem service valuation: A review of concepts and methods. Ecological Economics,114, 67–78.CrossRefGoogle Scholar
Song, L., & Qin, M. (2016). Identification of ecological corridors and its importance by integrating circuits and found. Chinese Journal of Applied Ecology,27(10), 3344–3352.Google Scholar
Svoray, T., & Ben-Said, S. (2009). Soil loss, water ponding and sediment deposition variations as a consequence of rainfall intensity and land use: A multi-criteria analysis. Earth Surface Processes and Landforms,35(2), 202–216.Google Scholar
Tang, M., Wu, C., Zhou, Z., Lord, E., & Zheng, Z. (2011). Multipurpose greenway planning for changing cities: A framework integrating priorities and a least-cost path mode. Landscape and Urban Planning,103(1), 1–14.CrossRefGoogle Scholar
Wang, D., Chen, J., Zhang, L., Sun, Z., Wang, X., Zhang, X., et al. (2019). Establishing an ecological security pattern for urban agglomeration, taking ecosystem services and human interference factors into consideration. PeerJ,7, e7306.CrossRefGoogle Scholar
Wang, M., & Xu, H. (2018). Temporal and spatial changes of urban impervious surface and its influence on urban ecological quality: A comparison between Shanghai and New York. Chinese Journal of Applied Ecology,29(11), 3735–3746.Google Scholar
Wang, Y., Li, X., Zhang, Q., Li, J., & Zhou, X. (2018). Projections of future land use changes: Multiple scenarios -based impacts analysis on ecosystem services for Wuhan city, China. Ecological Indicators, 94(1), 430–445.CrossRefGoogle Scholar
Xin, X., Shao, L., Gu, C., & Li, J. (2016). From "what to do" to "what not to do": the construction of county spatial control system based on "multiple planning coordination". Urban Development Studies,23(3), 15–21.Google Scholar
Xu, X. (2018). Spatial distribution data of soil texture in China. Registration and Publishing System of Chinese Academy of Sciences Resource and Environment Science Data Center. http://www.resdc.cn.
Yang, Z., Jiang, Z., Guo, C., Yang, X., Xu, X., Li, X., et al. (2018). Construction of ecological network using morphological spatial pattern analysis and minimal cumulative resistance models in Guangzhou City, China. Chinese Journal of Applied Ecology,29(10), 3367–3376.Google Scholar
Yao, L., Li, X., Li, Q., & Wang, J. (2019). Temporal and spatial changes in coupling and coordinating degree of new urbanization and ecological-environmental stress in China. Sustainability,11(4), 1171.CrossRefGoogle Scholar
Yu, K. (1996). Security patterns and surface model in landscape ecological planning. Landscape and urban planning,36(1), 1–17.CrossRefGoogle Scholar
Yu, K. (1999). Landscape ecological security patterns in biological conservation. Acta Ecologica Sinica,19(1), 8–15.Google Scholar
Zhang, L., Peng, J., Liu, Y., & Wu, J. (2017a). Coupling ecosystem services supply and human ecological demand to identify landscape ecological security pattern: a case study in Beijing–Tianjin–Hebei region, China. Urban Ecosystem,20, 701–714.CrossRefGoogle Scholar
Zhang, J., Qiao, Q., Liu, C., Wang, H., & Pei, S. (2017b). Ecological land use planning for Beijing city based on the minimum cumulative resistance model. Acta Ecologica Sinica,37(19), 6313–6321.Google Scholar
1.School of Geographical Science, College of Geography ScienceNanjing Normal UniversityNanjingChina
2.School of Economics and ManagementNanjing University of Science and TechnologyNanjingChina
3.Jiangsu Center for Collaborative Innovation in Geographical Information Resource Development and ApplicationNanjingChina
4.Key Laboratory of Virtual Geographic Environment Ministry of Education in Nanjing Normal UniversityNanjingChina
Jin, X., Wei, L., Wang, Y. et al. Environ Dev Sustain (2020). https://doi.org/10.1007/s10668-020-00596-2 | CommonCrawl |
TMF, 2007, Volume 150, Number 1, Pages 41–84 (Mi tmf5965)
This article is cited in 43 scientific papers (total in 43 papers)
The Dirac Hamiltonian with a superstrong Coulomb field
B. L. Voronova, D. M. Gitmanb, I. V. Tyutina
a P. N. Lebedev Physical Institute, Russian Academy of Sciences
b Universidade de São Paulo
Abstract: We consider the quantum mechanical problem of a relativistic Dirac particle moving in the Coulomb field of a point charge $Ze$. It is often declared in the literature that a quantum mechanical description of such a system does not exist for charge values exceeding the so-called critical charge with $Z=\alpha^{-1}=137$ because the standard expression for the lower bound-state energy yields complex values at overcritical charges. We show that from the mathematical standpoint, there is no problem in defining a self-adjoint Hamiltonian for any charge value. Furthermore, the transition through the critical charge does not lead to any qualitative changes in the mathematical description of the system. A specific feature of overcritical charges is a nonuniqueness of the self-adjoint Hamiltonian, but this nonuniqueness is also characteristic for charge values less than critical $($and larger than the subcritical charge with $Z=(\sqrt{3}/2)\alpha^{-1}=118)$. We present the spectra and $($generalized$)$ eigenfunctions for all self-adjoint Hamiltonians. We use the methods of the theory of self-adjoint extensions of symmetric operators and the Krein method of guiding functionals. The relation of the constructed one-particle quantum mechanics to the real physics of electrons in superstrong Coulomb fields where multiparticle effects may be crucially important is an open question.
Keywords: Dirac Hamiltonian, Coulomb field, self-adjoint extensions, spectral analysis
DOI: https://doi.org/10.4213/tmf5965
Theoretical and Mathematical Physics, 2007, 150:1, 34–72
Citation: B. L. Voronov, D. M. Gitman, I. V. Tyutin, "The Dirac Hamiltonian with a superstrong Coulomb field", TMF, 150:1 (2007), 41–84; Theoret. and Math. Phys., 150:1 (2007), 34–72
\Bibitem{VorGitTyu07}
\by B.~L.~Voronov, D.~M.~Gitman, I.~V.~Tyutin
\paper The~Dirac Hamiltonian with a~superstrong Coulomb field
\crossref{https://doi.org/10.4213/tmf5965}
\adsnasa{http://adsabs.harvard.edu/cgi-bin/bib_query?2007TMP...150...34V}
\elib{http://elibrary.ru/item.asp?id=9433551}
\crossref{https://doi.org/10.1007/s11232-007-0004-5}
\isi{http://gateway.isiknowledge.com/gateway/Gateway.cgi?GWVersion=2&SrcApp=PARTNER_APP&SrcAuth=LinksAMR&DestLinkType=FullRecord&DestApp=ALL_WOS&KeyUT=000244088700003}
\scopus{http://www.scopus.com/record/display.url?origin=inward&eid=2-s2.0-33846365569}
https://doi.org/10.4213/tmf5965
http://mi.mathnet.ru/eng/tmf/v150/i1/p41
Gupta K.S., Sen S., "Bound states in gapped graphene with impurities: Effective low-energy description of short-range interactions", Phys. Rev. B, 78:20 (2008), 205429, 7 pp.
Adorno T.C., Baldiotti M.C., Chaichian M., Gitman D.M., Tureanu A., "Dirac equation in noncommutative space for hydrogen atom", Phys. Rev. B, 682:2 (2009), 235–239
Gupta K.S., Samsarov A., Sen S., "Scattering in graphene with impurities: A low energy effective theory", European Physical Journal B - Condensed Matter and Complex Systems, 73:3 (2010), 389–404
Gitman D.M., Tyutin I.V., Voronov B.L., "Self-adjoint extensions and spectral analysis in the Calogero problem", J. Phys. A, 43:14 (2010), 145205
Boussaid N., Golénia S., "Limiting absorption principle for some long range perturbations of Dirac systems at threshold energies", Comm. Math. Phys., 299:3 (2010), 677–708
Khalilov V.R., Lee K.E., "Bound fermion states in a vector $1/r$ and Aharonov-Bohm potential in $(2+1)$ dimensions", Modern Phys. Lett. A, 26:12 (2011), 865–883
Khalilov V.R., Lee K.E., "Fermions in scalar Coulomb and Aharonov-Bohm potentials in 2+1 dimensions", J. Phys. A, 44:20 (2011), 205303
Zinoviev Yu.M., "Causal electromagnetic interaction equations", J. Math. Phys., 52:2 (2011), 022302
V. R. Khalilov, K. E. Lee, "Discrete spectra of the Dirac Hamiltonian in Coulomb and Aharonov–Bohm potentials in $2+1$ dimensions", Theoret. and Math. Phys., 169:3 (2011), 1683–1703
Gavrilov S.P., Gitman D.M., "Is QFT with external backgrounds a consistent model?", Internat. J. Modern Phys. A, 26:22 (2011), 3752, 3752–3758
Baldiotti M.C., Gitman D.M., Tyutin I.V., Voronov B.L., "Self-adjoint extensions and spectral analysis in the generalized Kratzer problem", Phys. Scripta, 83:6 (2011), 065007
Khalilov V.R., Lee K.E., Mamsurov I.V., "Spin-polarized fermions in an Aharonov-Bohm field", Modern Phys. Lett. A, 27:5 (2012), 1250027
K. A. Sveshnikov, D. I. Khomovskii, "Schrödinger and Dirac particles in quasi-one-dimensional systems with a Coulomb interaction", Theoret. and Math. Phys., 173:2 (2012), 1587–1603
Khalilov V.R. Lee K.E., "Planar massless fermions in Coulomb and Aharonov-Bohm potentials", Internat. J. Modern Phys. A, 27:29 (2012), 1250169, 14 pp.
Fulton Ch., Langer H., Luger A., "Mark Krein's method of directing functionals and singular potentials", Math. Nachr., 285:14-15 (2012), 1791–1798
Sveshnikov K.A., Khomovskii D.I., "The Dirac particle in a one-dimensional "hydrogen atom"", Mosc. Univ. Phys. Bull., 67:4 (2012), 358–363
Gitman D.M., Tyutin I.V., Voronov B.L., "Schrödinger and Dirac operators with the Aharonov-Bohm and magnetic-solenoid fields", Phys. Scr., 85:4 (2012), 045003, 20 pp.
Hogreve H., "The overcritical Dirac–Coulomb operator", J. Phys. A, 46:2 (2013), 025301
V. R. Khalilov, "Zero-mass fermions in Coulomb and Aharonov–Bohm potentials in 2+1 dimensions", Theoret. and Math. Phys., 175:2 (2013), 637–654
Khalilov V.R., "Creation of Planar Charged Fermions in Coulomb and Aharonov-Bohm Potentials", Eur. Phys. J. C, 73:8 (2013), 2548
Gitman D.M., Levin A.D., Tyutin I.V., Voronov B.L., "Electronic Structure of Super Heavy Atoms Revisited", Phys. Scr., 87:3 (2013), 038104
Khalilov V.R., "Bound States of Massive Fermions in Aharonov-Bohm-Like Fields", Eur. Phys. J. C, 74:1 (2014), 2708
Khalilov V.R., "Effect of Vacuum Polarization of Charged Massive Fermions in An Aharonov-Bohm Field", Eur. Phys. J. C, 74:9 (2014), 3061
B. M. Karnakov, V. D. Mur, S. V. Popruzhenko, V. S. Popov, "Current progress in developing the nonlinear ionization theory of atoms and ions", Phys. Usp., 58:1 (2015), 3–32
V. M. Kuleshov, V. D. Mur, N. B. Narozhny, A. M. Fedotov, Yu. E. Lozovik, V. S. Popov, "Coulomb problem for a $Z>Z_cr$ nucleus", Phys. Usp., 58:8 (2015), 785–791
B. L. Voronov, D. M. Gitman, A. D. Levin, R. Ferreira, "Peculiarities of the electron energy spectrum in the Coulomb field of a superheavy nucleus", Theoret. and Math. Phys., 187:2 (2016), 633–648
I. V. Mamsurov, V. R. Khalilov, "Induced vacuum charge of massless fermions in Coulomb and Aharonov–Bohm potentials in $2+1$ dimensions", Theoret. and Math. Phys., 188:2 (2016), 1181–1196
Sveshnikov K.A., Khomovsky D.I., "Perturbativity and nonperturbativity in large-Z effects for hydrogen-like atoms", Mosc. Univ. Phys. Bull., 71:5 (2016), 465–475
Bagci A., Hoggan P.E., "Solution of the Dirac equation using the Rayleigh-Ritz method: Flexible basis coupling large and small components. Results for one-electron systems", Phys. Rev. E, 94:1 (2016), 013302
Andrzejewski K., Ann. Phys., 367 (2016), 227–250
Gitman D.M., Gavrilov S.P., "QFT Treatment of Processes in Strong External Backgrounds", Russ. Phys. J., 59:11 (2017), 1723–1730
Khalilov V.R., "Quasi-Stationary States and Fermion Pair Creation From a Vacuum in Supercritical Coulomb Field", Mod. Phys. Lett. A, 32:38 (2017), 1750200
Kuleshov V.M. Mur V.D. Fedotov A.M. Lozovik Yu.E., "Coulomb Problem For Z > Z(Cr) in Doped Graphene", J. Exp. Theor. Phys., 125:6 (2017), 1144–1162
Morozov S., Mueller D., "On the Virtual Levels of Positively Projected Massless Coulomb-Dirac Operators", Ann. Henri Poincare, 18:7 (2017), 2467–2497
Kuleshov V.M. Mur V.D. Narozhny N.B., "Coulomb Problem For Graphene With Supercritical Impurity", V International Conference on Problems of Mathematical and Theoretical Physics and Mathematical Modelling, Journal of Physics Conference Series, 788, IOP Publishing Ltd, 2017, UNSP 012044
Masum H., Dulat S., Tohti M., "Relativistic Hydrogen-Like Atom on a Noncommutative Phase Space", Int. J. Theor. Phys., 56:9 (2017), 2724–2737
Davydov A. Sveshnikov K. Voronina Yu., "Nonperturbative Vacuum Polarization Effects in Two-Dimensional Supercritical Dirac-Coulomb System i. Vacuum Charge Density", Int. J. Mod. Phys. A, 33:1 (2018), 1850004
Gallone M., Michelangeli A., "Discrete Spectra For Critical Dirac-Coulomb Hamiltonians", J. Math. Phys., 59:6 (2018), 062108
Cassano B., Pizzichillo F., "Self-Adjoint Extensions For the Dirac Operator With Coulomb-Type Spherically Symmetric Potentials", Lett. Math. Phys., 108:12 (2018), 2635–2667
K. A. Sveshnikov, Yu. S. Voronina, A. S. Davydov, P. A. Grashin, "Essentially nonperturbative vacuum polarization effects in a two-dimensional Dirac–Coulomb system with $Z>Z_\mathrm{cr}$: Vacuum charge density", Theoret. and Math. Phys., 198:3 (2019), 331–362
Gallone M., Michelangeli A., "Self-Adjoint Realisations of the Dirac-Coulomb Hamiltonian For Heavy Nuclei", Anal. Math. Phys., 9:1 (2019), 585–616
Cassano B., Pizzichillo F., "Boundary Triples For the Dirac Operator With Coulomb-Type Spherically Symmetric Perturbations", J. Math. Phys., 60:4 (2019), 041502
Neznamov V.P. Safronov I.I., "Second-Order Stationary Solutions For Fermions in An External Coulomb Field", J. Exp. Theor. Phys., 128:5 (2019), 672–683
Full text: 269
First page: 10 | CommonCrawl |
Publications of the Astronomical Society of Australia (4)
The Journal of Agricultural Science (2)
Highlights of Astronomy (1)
Interactive impact of childhood maltreatment, depression, and age on cortical brain structure: mega-analytic findings from a large multi-site cohort
Leonardo Tozzi, Lisa Garczarek, Deborah Janowitz, Dan J. Stein, Katharina Wittfeld, Henrik Dobrowolny, Jim Lagopoulos, Sean N. Hatton, Ian B. Hickie, Angela Carballedo, Samantha J. Brooks, Daniella Vuletic, Anne Uhlmann, Ilya M. Veer, Henrik Walter, Robin Bülow, Henry Völzke, Johanna Klinger-König, Knut Schnell, Dieter Schoepf, Dominik Grotegerd, Nils Opel, Udo Dannlowski, Harald Kugel, Elisabeth Schramm, Carsten Konrad, Tilo Kircher, Dilara Jüksel, Igor Nenadić, Axel Krug, Tim Hahn, Olaf Steinsträter, Ronny Redlich, Dario Zaremba, Bartosz Zurowski, Cynthia H.Y. Fu, Danai Dima, James Cole, Hans J. Grabe, Colm G. Connolly, Tony T. Yang, Tiffany C. Ho, Kaja Z. LeWinn, Meng Li, Nynke A. Groenewold, Lauren E. Salminen, Martin Walter, Alan N Simmons, Theo G.M. van Erp, Neda Jahanshad, Bernhard T. Baune, Nic J.A. van der Wee, Marie-Jose van Tol, Brenda W.J.H. Penninx, Derrek P. Hibar, Paul M. Thompson, Dick J. Veltman, Lianne Schmaal, Thomas Frodl, 'for the ENIGMA-MDD Consortium'
Journal: Psychological Medicine , First View
Childhood maltreatment (CM) plays an important role in the development of major depressive disorder (MDD). The aim of this study was to examine whether CM severity and type are associated with MDD-related brain alterations, and how they interact with sex and age.
Within the ENIGMA-MDD network, severity and subtypes of CM using the Childhood Trauma Questionnaire were assessed and structural magnetic resonance imaging data from patients with MDD and healthy controls were analyzed in a mega-analysis comprising a total of 3872 participants aged between 13 and 89 years. Cortical thickness and surface area were extracted at each site using FreeSurfer.
CM severity was associated with reduced cortical thickness in the banks of the superior temporal sulcus and supramarginal gyrus as well as with reduced surface area of the middle temporal lobe. Participants reporting both childhood neglect and abuse had a lower cortical thickness in the inferior parietal lobe, middle temporal lobe, and precuneus compared to participants not exposed to CM. In males only, regardless of diagnosis, CM severity was associated with higher cortical thickness of the rostral anterior cingulate cortex. Finally, a significant interaction between CM and age in predicting thickness was seen across several prefrontal, temporal, and temporo-parietal regions.
Severity and type of CM may impact cortical thickness and surface area. Importantly, CM may influence age-dependent brain maturation, particularly in regions related to the default mode network, perception, and theory of mind.
Psychosocial functioning among regular cannabis users with and without cannabis use disorder
Katherine T. Foster, Brooke J. Arterberry, William G. Iacono, Matt McGue, Brian M. Hicks
Published online by Cambridge University Press: 27 November 2017, pp. 1853-1861
In the United States, cannabis accessibility has continued to rise as the perception of its harmfulness has decreased. Only about 30% of regular cannabis users develop cannabis use disorder (CUD), but it is unclear if individuals who use cannabis regularly without ever developing CUD experience notable psychosocial impairment across the lifespan. Therefore, psychosocial functioning was compared across regular cannabis users with or without CUD and a non-user control group during adolescence (age 17; early risk) and young adulthood (ages 18–25; peak CUD prevalence).
Weekly cannabis users with CUD (n = 311), weekly users without CUD (n = 111), and non-users (n = 996) were identified in the Minnesota Twin Family Study. Groups were compared on alcohol and illicit drug use, psychiatric problems, personality, and social functioning at age 17 and from ages 18 to 25. Self-reported cannabis use and problem use were independently verified using co-twin informant report.
In both adolescence and young adulthood, non-CUD users reported significantly higher levels of substance use problems and externalizing behaviors than non-users, but lower levels than CUD users. High agreement between self- and co-twin informant reports confirmed the validity of self-reported cannabis use problems.
Even in the absence of CUD, regular cannabis use was associated with psychosocial impairment in adolescence and young adulthood. However, regular users with CUD endorsed especially high psychiatric comorbidity and psychosocial impairment. The need for early prevention and intervention – regardless of CUD status – was highlighted by the presence of these patterns in adolescence.
Impact of β2-1 fructan on faecal community change: results from a placebo-controlled, randomised, double-blinded, cross-over study in healthy adults
Sandra T. Clarke, Stephen P. J. Brooks, G. Douglas Inglis, L. Jay Yanke, Judy Green, Nicholas Petronella, D. Dan Ramdath, Premysl Bercik, Julia M. Green-Johnson, Martin Kalmokoff
Journal: British Journal of Nutrition / Volume 118 / Issue 6 / 28 September 2017
Healthy adults (n 30) participated in a placebo-controlled, randomised, double-blinded, cross-over study consisting of two 28 d treatments (β2-1 fructan or maltodextrin; 3×5 g/d) separated by a 14-d washout. Subjects provided 1 d faecal collections at days 0 and 28 of each treatment. The ability of faecal bacteria to metabolise β2-1 fructan was common; eighty-seven species (thirty genera, and four phyla) were isolated using anaerobic medium containing β2-1 fructan as the sole carbohydrate source. β2-1 fructan altered the faecal community as determined through analysis of terminal restriction fragment length polymorphisms and 16S rRNA genes. Supplementation with β2-1 fructan reduced faecal community richness, and two patterns of community change were observed. In most subjects, β2-1 fructan reduced the content of phylotypes aligning within the Bacteroides, whereas increasing those aligning within bifidobacteria, Faecalibacterium and the family Lachnospiraceae. In the remaining subjects, supplementation increased the abundance of Bacteroidetes and to a lesser extent bifidobacteria, accompanied by decreases within the Faecalibacterium and family Lachnospiraceae. β2-1 Fructan had no impact on the metagenome or glycoside hydrolase profiles in faeces from four subjects. Few relationships were found between the faecal bacterial community and various host parameters; Bacteroidetes content correlated with faecal propionate, subjects whose faecal community contained higher Bacteroidetes produced more caproic acid independent of treatment, and subjects having lower faecal Bacteroidetes exhibited increased concentrations of serum lipopolysaccharide and lipopolysaccharide binding protein independent of treatment. We found no evidence to support a defined health benefit for the use of β2-1 fructans in healthy subjects.
A seroprevalence study to determine the frequency of hantavirus infection in people exposed to wild and pet fancy rats in England
J. M. DUGGAN, R. CLOSE, L. MCCANN, D. WRIGHT, M. KEYS, N. MCCARTHY, T. MANNES, A. WALSH, A. CHARLETT, T. J. G. BROOKS
Journal: Epidemiology & Infection / Volume 145 / Issue 12 / September 2017
Recent cases of acute kidney injury due to Seoul hantavirus infection from exposure to wild or pet fancy rats suggest this infection is increasing in prevalence in the UK. We conducted a seroprevalence study in England to estimate cumulative exposure in at-risk groups with contact with domesticated and wild rats to assess risk and inform public health advice. From October 2013 to June 2014, 844 individual blood samples were collected. Hantavirus seroprevalence amongst the pet fancy rat owner group was 34.1% (95% CI 23·9–45·7%) compared with 3·3% (95% CI 1·6–6·0) in a baseline control group, 2·4% in those with occupational exposure to pet fancy rats (95% CI 0·6–5·9) and 1·7% with occupational exposure to wild rats (95% CI 0·2–5·9). Variation in seroprevalence across groups with different exposure suggests that occupational exposure to pet and wild rats carries a very low risk, if any. However incidence of hantavirus infection among pet fancy rat owners/breeders, whether asymptomatic, undiagnosed mild viral illness or more severe disease may be very common and public health advice needs to be targeted to this at-risk group.
DESAlert: Enabling Real-Time Transient Follow-Up with Dark Energy Survey Data
A. Poci, K. Kuehn, T. Abbott, F. B. Abdalla, S. Allam, A.H. Bauer, A. Benoit-Lévy, E. Bertin, D. Brooks, P. J. Brown, E. Buckley-Geer, D. L. Burke, A. Carnero Rosell, M. Carrasco Kind, R. Covarrubias, L. N. da Costa, C. B. D'Andrea, D. L. DePoy, S. Desai, J. P. Dietrich, C. E Cunha, T. F. Eifler, J. Estrada, A. E. Evrard, A. Fausti Neto, D. A. Finley, B. Flaugher, P. Fosalba, J. Frieman, D. Gerdes, D. Gruen, R. A. Gruendl, K. Honscheid, D. James, N. Kuropatkin, O. Lahav, T. S. Li, M. March, J. Marshall, K. W. Merritt, C.J. Miller, R. C. Nichol, B. Nord, R. Ogando, A. A. Plazas, A. K. Romer, A. Roodman, E. S. Rykoff, M. Sako, E. Sanchez, V. Scarpine, M. Schubnell, I. Sevilla, C. Smith, M. Soares-Santos, F. Sobreira, E. Suchyta, M. E. C. Swanson, G. Tarle, J. Thaler, R. C. Thomas, D. Tucker, A. R. Walker, W. Wester, (The DES Collaboration)
Journal: Publications of the Astronomical Society of Australia / Volume 33 / 2016
Published online by Cambridge University Press: 30 September 2016, e049
The Dark Energy Survey is undertaking an observational programme imaging 1/4 of the southern hemisphere sky with unprecedented photometric accuracy. In the process of observing millions of faint stars and galaxies to constrain the parameters of the dark energy equation of state, the Dark Energy Survey will obtain pre-discovery images of the regions surrounding an estimated 100 gamma-ray bursts over 5 yr. Once gamma-ray bursts are detected by, e.g., the Swift satellite, the DES data will be extremely useful for follow-up observations by the transient astronomy community. We describe a recently-commissioned suite of software that listens continuously for automated notices of gamma-ray burst activity, collates information from archival DES data, and disseminates relevant data products back to the community in near-real-time. Of particular importance are the opportunities that non-public DES data provide for relative photometry of the optical counterparts of gamma-ray bursts, as well as for identifying key characteristics (e.g., photometric redshifts) of potential gamma-ray burst host galaxies. We provide the functional details of the DESAlert software, and its data products, and we show sample results from the application of DESAlert to numerous previously detected gamma-ray bursts, including the possible identification of several heretofore unknown gamma-ray burst hosts.
AAT Observations of Comet Shoemaker Levy-9 Collisions with Jupiter
D. Crisp, V. Meadows, G. Orton, T. Brooke, J. Spencer
Journal: Highlights of Astronomy / Volume 10 / 1995
β2-1 Fructan supplementation alters host immune responses in a manner consistent with increased exposure to microbial components: results from a double-blinded, randomised, cross-over study in healthy adults
Sandra T. Clarke, Julia M. Green-Johnson, Stephen P. J. Brooks, D. Dan Ramdath, Premysl Bercik, Christian Avila, G. Douglas Inglis, Judy Green, L. Jay Yanke, L. Brent Selinger, Martin Kalmokoff
Journal: British Journal of Nutrition / Volume 115 / Issue 10 / 28 May 2016
β2-1 Fructans are purported to improve health by stimulating growth of colonic bifidobacteria, increasing host resistance to pathogens and stimulating the immune system. However, in healthy adults, the benefits of supplementation remain undefined. Adults (thirteen men, seventeen women) participated in a double-blinded, placebo-controlled, randomised, cross-over study consisting of two 28-d treatments separated by a 14-d washout period. Subjects' regular diets were supplemented with β2-1 fructan or placebo (maltodextrin) at 3×5 g/d. Fasting blood and 1-d faecal collections were obtained at the beginning and at the end of each phase. Blood was analysed for clinical, biochemical and immunological variables. Determinations of well-being and general health, gastrointestinal (GI) symptoms, regularity, faecal SCFA content, residual faecal β2-1 fructans and faecal bifidobacteria content were undertaken. β2-1 Fructan supplementation had no effect on blood lipid or cholesterol concentrations or on circulating lymphocyte and macrophage numbers, but significantly increased serum lipopolysaccharide, faecal SCFA, faecal bifidobacteria and indigestion. With respect to immune function, β2-1 fructan supplementation increased serum IL-4, circulating percentages of CD282+/TLR2+ myeloid dendritic cells and ex vivo responsiveness to a toll-like receptor 2 agonist. β2-1 Fructans also decreased serum IL-10, but did not affect C-reactive protein or serum/faecal Ig concentrations. No differences in host well-being were associated with either treatment, although the self-reported incidence of GI symptoms and headaches increased during the β2-1 fructan phase. Although β2-1 fructan supplementation increased faecal bifidobacteria, this change was not directly related to any of the determined host parameters.
The Australian Square Kilometre Array Pathfinder: System Architecture and Specifications of the Boolardy Engineering Test Array
A. W. Hotan, J. D. Bunton, L. Harvey-Smith, B. Humphreys, B. D. Jeffs, T. Shimwell, J. Tuthill, M. Voronkov, G. Allen, S. Amy, K. Ardern, P. Axtens, L. Ball, K. Bannister, S. Barker, T. Bateman, R. Beresford, D. Bock, R. Bolton, M. Bowen, B. Boyle, R. Braun, S. Broadhurst, D. Brodrick, K. Brooks, M. Brothers, A. Brown, C. Cantrall, G. Carrad, J. Chapman, W. Cheng, A. Chippendale, Y. Chung, F. Cooray, T. Cornwell, E. Davis, L. de Souza, D. DeBoer, P. Diamond, P. Edwards, R. Ekers, I. Feain, D. Ferris, R. Forsyth, R. Gough, A. Grancea, N. Gupta, J. C. Guzman, G. Hampson, C. Haskins, S. Hay, D. Hayman, S. Hoyle, C. Jacka, C. Jackson, S. Jackson, K. Jeganathan, S. Johnston, J. Joseph, R. Kendall, M. Kesteven, D. Kiraly, B. Koribalski, M. Leach, E. Lenc, E. Lensson, L. Li, S. Mackay, A. Macleod, T. Maher, M. Marquarding, N. McClure-Griffiths, D. McConnell, S. Mickle, P. Mirtschin, R. Norris, S. Neuhold, A. Ng, J. O'Sullivan, J. Pathikulangara, S. Pearce, C. Phillips, R. Y. Qiao, J. E. Reynolds, A. Rispler, P. Roberts, D. Roxby, A. Schinckel, R. Shaw, M. Shields, M. Storey, T. Sweetnam, E. Troup, B. Turner, A. Tzioumis, T. Westmeier, M. Whiting, C. Wilson, T. Wilson, K. Wormnes, X. Wu
Published online by Cambridge University Press: 13 November 2014, e041
This paper describes the system architecture of a newly constructed radio telescope – the Boolardy engineering test array, which is a prototype of the Australian square kilometre array pathfinder telescope. Phased array feed technology is used to form multiple simultaneous beams per antenna, providing astronomers with unprecedented survey speed. The test array described here is a six-antenna interferometer, fitted with prototype signal processing hardware capable of forming at least nine dual-polarisation beams simultaneously, allowing several square degrees to be imaged in a single pointed observation. The main purpose of the test array is to develop beamforming and wide-field calibration methods for use with the full telescope, but it will also be capable of limited early science demonstrations.
Injectional anthrax at a Scottish district general hospital
D. J. INVERARITY, V. M. FORRESTER, J. G. R. CUMMING, P. J. PATERSON, R. J. CAMPBELL, T. J. G. BROOKS, G. L. CARSON, J. P. RUDDY
Journal: Epidemiology & Infection / Volume 143 / Issue 6 / April 2015
This retrospective, descriptive case-series reviews the clinical presentations and significant laboratory findings of patients diagnosed with and treated for injectional anthrax (IA) since December 2009 at Monklands Hospital in Central Scotland and represents the largest series of IA cases to be described from a single location. Twenty-one patients who fulfilled National Anthrax Control Team standardized case definitions of confirmed, probable or possible IA are reported. All cases survived and none required limb amputation in contrast to an overall mortality of 28% being experienced for this condition in Scotland. We document the spectrum of presentations of soft tissue infection ranging from mild cases which were managed predominantly with oral antibiotics to severe cases with significant oedema, organ failure and coagulopathy. We describe the surgical management, intensive care management and antibiotic management including the first description of daptomycin being used to treat human anthrax. It is noted that some people who had injected heroin infected with Bacillus anthracis did not develop evidence of IA. Also highlighted are biochemical and haematological parameters which proved useful in identifying deteriorating patients who required greater levels of support and surgical debridement.
MALT90: The Millimetre Astronomy Legacy Team 90 GHz Survey
J. M. Jackson, J. M. Rathborne, J. B. Foster, J. S. Whitaker, P. Sanhueza, C. Claysmith, J. L. Mascoop, M. Wienen, S. L. Breen, F. Herpin, A. Duarte-Cabral, T. Csengeri, S. N. Longmore, Y. Contreras, B. Indermuehle, P. J. Barnes, A. J. Walsh, M. R. Cunningham, K. J. Brooks, T. R. Britton, M. A. Voronkov, J. S. Urquhart, J. Alves, C. H. Jordan, T. Hill, S. Hoq, S. C. Finn, I. Bains, S. Bontemps, L. Bronfman, J. L. Caswell, L. Deharveng, S. P. Ellingsen, G. A. Fuller, G. Garay, J. A. Green, L. Hindson, P. A. Jones, C. Lenfestey, N. Lo, V. Lowe, D. Mardones, K. M. Menten, V. Minier, L. K. Morgan, F. Motte, E. Muller, N. Peretto, C. R. Purcell, P. Schilke, Schneider-N. Bontemps, F. Schuller, A. Titmarsh, F. Wyrowski, A. Zavagno
The Millimetre Astronomy Legacy Team 90 GHz (MALT90) survey aims to characterise the physical and chemical evolution of high-mass star-forming clumps. Exploiting the unique broad frequency range and on-the-fly mapping capabilities of the Australia Telescope National Facility Mopra 22 m single-dish telescope 1 , MALT90 has obtained 3′ × 3′ maps towards ~2 000 dense molecular clumps identified in the ATLASGAL 870 μm Galactic plane survey. The clumps were selected to host the early stages of high-mass star formation and to span the complete range in their evolutionary states (from prestellar, to protostellar, and on to $\mathrm{H\,{\scriptstyle {II}}}$ regions and photodissociation regions). Because MALT90 mapped 16 lines simultaneously with excellent spatial (38 arcsec) and spectral (0.11 km s−1) resolution, the data reveal a wealth of information about the clumps' morphologies, chemistry, and kinematics. In this paper we outline the survey strategy, observing mode, data reduction procedure, and highlight some early science results. All MALT90 raw and processed data products are available to the community. With its unprecedented large sample of clumps, MALT90 is the largest survey of its type ever conducted and an excellent resource for identifying interesting candidates for high-resolution studies with ALMA.
Characterisation of the Mopra Radio Telescope at 16–50 GHz
J. S. Urquhart, M. G. Hoare, C. R. Purcell, K. J. Brooks, M. A. Voronkov, B. T. Indermuehle, M. G. Burton, N. F. H. Tothill, P. G. Edwards
Journal: Publications of the Astronomical Society of Australia / Volume 27 / Issue 3 / 2010
We present the results of a programme of scanning and mapping observations of astronomical masers and Jupiter designed to characterise the performance of the Mopra Radio Telescope at frequencies between 16 and 50 GHz using the 12-mm and 7-mm receivers. We use these observations to determine the telescope beam size, beam shape, and overall telescope beam efficiency as a function of frequency. We find that the beam size is well fit by λ/D over the frequency range with a correlation coefficient of ∼90%. We determine the telescope main beam efficiencies are between ∼48 and 64% for the 12-mm receiver and reasonably flat at ∼50% for the 7-mm receiver. Beam maps of strong H2O (22 GHz) and SiO masers (43 GHz) provide a means to examine the radial beam pattern of the telescope. At both frequencies, the radial beam pattern reveals the presence of three components: a central 'core', which is well fit by a Gaussian and constitutes the telescopes main beam; and inner and outer error beams. At both frequencies, the inner and outer error beams extend out to ∼2 and ∼3.4 times the full-width half maximum of the main beam, respectively. Sources with angular sizes of a factor of two or more larger than the telescope main beam will couple to the main and error beams, and therefore the power contributed by the error beams needs to be considered. From measurements of the radial beam power pattern we estimate the amount of power contained in the inner and outer error beams is of order one-fifth at 22 GHz, rising slightly to one-third at 43 GHz.
By Aakash Agarwala, Linda S. Aglio, Rae M. Allain, Paul D. Allen, Houman Amirfarzan, Yasodananda Kumar Areti, Amit Asopa, Edwin G. Avery, Patricia R. Bachiller, Angela M. Bader, Rana Badr, Sibinka Bajic, David J. Baker, Sheila R. Barnett, Rena Beckerly, Lorenzo Berra, Walter Bethune, Sascha S. Beutler, Tarun Bhalla, Edward A. Bittner, Jonathan D. Bloom, Alina V. Bodas, Lina M. Bolanos-Diaz, Ruma R. Bose, Jan Boublik, John P. Broadnax, Jason C. Brookman, Meredith R. Brooks, Roland Brusseau, Ethan O. Bryson, Linda A. Bulich, Kenji Butterfield, William R. Camann, Denise M. Chan, Theresa S. Chang, Jonathan E. Charnin, Mark Chrostowski, Fred Cobey, Adam B. Collins, Mercedes A. Concepcion, Christopher W. Connor, Bronwyn Cooper, Jeffrey B. Cooper, Martha Cordoba-Amorocho, Stephen B. Corn, Darin J. Correll, Gregory J. Crosby, Lisa J. Crossley, Deborah J. Culley, Tomas Cvrk, Michael N. D'Ambra, Michael Decker, Daniel F. Dedrick, Mark Dershwitz, Francis X. Dillon, Pradeep Dinakar, Alimorad G. Djalali, D. John Doyle, Lambertus Drop, Ian F. Dunn, Theodore E. Dushane, Sunil Eappen, Thomas Edrich, Jesse M. Ehrenfeld, Jason M. Erlich, Lucinda L. Everett, Elliott S. Farber, Khaldoun Faris, Eddy M. Feliz, Massimo Ferrigno, Richard S. Field, Michael G. Fitzsimons, Hugh L. Flanagan Jr., Vladimir Formanek, Amanda A. Fox, John A. Fox, Gyorgy Frendl, Tanja S. Frey, Samuel M. Galvagno Jr., Edward R. Garcia, Jonathan D. Gates, Cosmin Gauran, Brian J. Gelfand, Simon Gelman, Alexander C. Gerhart, Peter Gerner, Omid Ghalambor, Christopher J. Gilligan, Christian D. Gonzalez, Noah E. Gordon, William B. Gormley, Thomas J. Graetz, Wendy L. Gross, Amit Gupta, James P. Hardy, Seetharaman Hariharan, Miriam Harnett, Philip M. Hartigan, Joaquim M. Havens, Bishr Haydar, Stephen O. Heard, James L. Helstrom, David L. Hepner, McCallum R. Hoyt, Robert N. Jamison, Karinne Jervis, Stephanie B. Jones, Swaminathan Karthik, Richard M. Kaufman, Shubjeet Kaur, Lee A. Kearse Jr., John C. Keel, Scott D. Kelley, Albert H. Kim, Amy L. Kim, Grace Y. Kim, Robert J. Klickovich, Robert M. Knapp, Bhavani S. Kodali, Rahul Koka, Alina Lazar, Laura H. Leduc, Stanley Leeson, Lisa R. Leffert, Scott A. LeGrand, Patricio Leyton, J. Lance Lichtor, John Lin, Alvaro A. Macias, Karan Madan, Sohail K. Mahboobi, Devi Mahendran, Christine Mai, Sayeed Malek, S. Rao Mallampati, Thomas J. Mancuso, Ramon Martin, Matthew C. Martinez, J. A. Jeevendra Martyn, Kai Matthes, Tommaso Mauri, Mary Ellen McCann, Shannon S. McKenna, Dennis J. McNicholl, Abdel-Kader Mehio, Thor C. Milland, Tonya L. K. Miller, John D. Mitchell, K. Annette Mizuguchi, Naila Moghul, David R. Moss, Ross J. Musumeci, Naveen Nathan, Ju-Mei Ng, Liem C. Nguyen, Ervant Nishanian, Martina Nowak, Ala Nozari, Michael Nurok, Arti Ori, Rafael A. Ortega, Amy J. Ortman, David Oxman, Arvind Palanisamy, Carlo Pancaro, Lisbeth Lopez Pappas, Benjamin Parish, Samuel Park, Deborah S. Pederson, Beverly K. Philip, James H. Philip, Silvia Pivi, Stephen D. Pratt, Douglas E. Raines, Stephen L. Ratcliff, James P. Rathmell, J. Taylor Reed, Elizabeth M. Rickerson, Selwyn O. Rogers Jr., Thomas M. Romanelli, William H. Rosenblatt, Carl E. Rosow, Edgar L. Ross, J. Victor Ryckman, Mônica M. Sá Rêgo, Nicholas Sadovnikoff, Warren S. Sandberg, Annette Y. Schure, B. Scott Segal, Navil F. Sethna, Swapneel K. Shah, Shaheen F. Shaikh, Fred E. Shapiro, Torin D. Shear, Prem S. Shekar, Stanton K. Shernan, Naomi Shimizu, Douglas C. Shook, Kamal K. Sikka, Pankaj K. Sikka, David A. Silver, Jeffrey H. Silverstein, Emily A. Singer, Ken Solt, Spiro G. Spanakis, Wolfgang Steudel, Matthias Stopfkuchen-Evans, Michael P. Storey, Gary R. Strichartz, Balachundhar Subramaniam, Wariya Sukhupragarn, John Summers, Shine Sun, Eswar Sundar, Sugantha Sundar, Neelakantan Sunder, Faraz Syed, Usha B. Tedrow, Nelson L. Thaemert, George P. Topulos, Lawrence C. Tsen, Richard D. Urman, Charles A. Vacanti, Francis X. Vacanti, Joshua C. Vacanti, Assia Valovska, Ivan T. Valovski, Mary Ann Vann, Susan Vassallo, Anasuya Vasudevan, Kamen V. Vlassakov, Gian Paolo Volpato, Essi M. Vulli, J. Matthias Walz, Jingping Wang, James F. Watkins, Maxwell Weinmann, Sharon L. Wetherall, Mallory Williams, Sarah H. Wiser, Zhiling Xiong, Warren M. Zapol, Jie Zhou
Edited by Charles Vacanti, Scott Segal, Pankaj Sikka, Richard Urman
Book: Essential Clinical Anesthesia
Published online: 05 January 2012
Print publication: 11 July 2011, pp xv-xxviii
By Ashok Agarwal, Carrie Bedient, Nick Brook, Michelle Catenacci, Ying Cheong, Francisco Domínguez, Thomas Elliott, Sandro C. Esteves, Tommaso Falcone, Gabriel de la Fuente, Eugene Galdones, Juan A. Garcia-Velasco, David K. Gardner, Tamara Garrido, Robert B. Gilchrist, Georg Griesinger, Roy Homburg, Jeanine Cieslak Janzen, Mark T. Johnson, Jennifer Kahn, David L. Keefe, Efstratios M Kolibianakis, Laurie J. McKenzie, Nick Macklon, David Meldrum, Ashley R. Mott, Tetsunori Mukaida, Zsolt Peter Nagy, Edurne Novella-Maestre, Chris O'Neill, Chikaharo Oka, Steven F. Palta, Lewis K. Pannell, Antonio Pellicer, Valeria Pugni, Botros R. M. B. Rizk, Christopher B. Rizk, Claude Robert, Denny Sakkas, Hassan N. Sallam, William B. Schoolcraft, Lonnie D. Shea, Carlos Simón, Manuela Simoni, Marc-Andre Sirard, Johan E. J. Smitz, Eric S. Surrey, Jan Tesarik, Raquel Mendoza Tesarik, Jeremy G. Thompson, Andrew J. Watson, Teresa K. Woodruff
Edited by David K. Gardner, University of Melbourne, Botros R. M. B. Rizk, University of South Alabama, Tommaso Falcone
Book: Human Assisted Reproductive Technology
Spin Polarized Photoemission Studies of Surfaces and Thin Films
Peter D. Johnson, N.B. Brookes, Y. Chang
Spin polarized photoemission is used to study the magnetic states associated with the clean iron (001) surface. These studies reveal evidence for a minority spin surface state in agreement with a first principles calculation. Studies of the same surface with silver and chromium epitaxial overlayers reveal evidence for interface states derived from this state found on the clean surface. In the case of the silver overlayer the binding energy of the new state is found to be dependent on the layer by layer thickness of the overlayer. With chromium overlayers the binding energy for the same interface state does not show the same thickness dependence. However a second interface state is observed immediately below the Fermi level. These changes in the interfacial electronic structure have implications for any modelling of magnetic coupling in multilayers dependent on the magnetic properties of the interface.
Fermi Surface Study of Organic Metals (Bedt-TTF)2X
M. Tokumoto, A. G. Swanson, J. S. Brooks, C. C. Agosta, S. T. Hannahs, N. Kinoshita, H. Anzai, M. Tamura, H. Tajima, H. Kuroda, A. Ugawa, K. Yakushi
Observations of Shubnikov-de Haas(SdH) and de Haas-van Alphen(dHvA) oscillations in organic metals (BEDT-TTF)2X, with X=KHg(SCN)4, θ-I3 and β″-AuBr2. are reported. In KHg(SCN)4 salt, in addition to the SdH oscillations with fundamental frequency of 670 T corresponding to about 16% of the first Brillouin zone(FBZ), we observed splitting of each SdH peak which we ascribed to "spin-splitting" We have also found that the ground state of this salt is not a simple metal but has some magnetic character. In θ-l3 salt we have succeeded in an observation of dHvA oscillations for the first time. We observed a "saw-tooth" dHvA oscillation characteristic to a highly two-dimensional and extraordinary clean electronic system. In addition to the fundamental frequency of 4170 T corresponding to 50.4 % of the FBZ and its higher harmonics, we observed an oscillation with lower frequency of 730 T corresponding to about 8.8 % of the FBZ. A new Fermi surface topology for θ-l3 salt is proposed based on the analysis of the dHvA effect. In β″-AuBr2, we observed complex dHvA oscillations, which can be explained in terms of the mixing of two fundamental frequencies of 47 and 268 T, suggesting the presence of very small pockets corresponding to 0.6 and 2.9 % of the FBZ.
Microwave Processing of Polymers
D. A. Lewis, J. C. Hedrick, G. D. Lyle, T. C. Ward, J. E. McGrath
Novel morphologies were produced in phase segmented, toughened epoxies via microwave processing. Novel and exciting chemistries have been demonstrated through the specificity of delivery of electromagnetic radiation in tuned cavities.
Fermi Surface Study Of An Organic Superconductor θ- (Bedt-Ttf)2I3
M. Tamura, H. Kuroda, S. Uji, H. Aoki, M. Tokumoto, A. G. Swanson, J. S. Brooks, C. C. Agosta, S. T. Hannahs
The temperature and field dependence of the de Haas-van Alphen oscillations in θ- (BEDT-TTF)2l3 is analyzed. The cyclotron masses are estimated to be 2.0 M e and 3.6 m e for slow and fast oscillations, respectively. The indication of magnetic breakdown effect is discussed in terms of the geometry of the Fermi surface. The results are compared with those of the infrared reflectance spectra.
Magnetic Domain Imaging with a Photoemission Microscope
C.M. Schneider, R. Frömter, C. Ziethen, W. Swiech, N.B. Brookes, G. Schönhense, J. Kirschner
Photoelectron emission microscopy (PEEM) has proven to be a versatile analytical technique in surface science. When operated with circularly polarized light in the soft x-ray regime, however, photoemission microscopy offers a unique combination of magnetic and chemical information. Exploiting the high brilliance and circular polarization available at a helical undulator beamline, the lateral resolution in the imaging of magnetic domain structures may be pushed well into the sub-micrometer range. Using a newly designed photoemission microscope we show that under these circumstances not only domains, but also domain walls can be selectively investigated. The high sensitivity of the technique yields a sizable magnetic contrast even from magnetic films as thin as a fraction of a single monolayer. The combination of chemical selectivity and information depth is successfully employed to investigate the magnetic behavior of buried layers and covered surfaces. This approach offers a convenient access to magnetic coupling phenomena in magnetic sandwiches.
Magnetic Dichroism in Resonant Photoemission and Photoabsorption from Gd Metal
K. Starke, G. Van Der Laan, Z. Hu, E. Arenholz, E. Navas, A Bauer, A. Mühlig, C. S- Langeheine, E. Weschke, J. Goodkoep, N. Brookes, G. Kaindl
We report on the study of MCD in resonant PE, using Gd metal as an example. When the photon energy is changed across the Gd 4d → 4ƒ excitation region, the PE-MCD spectrum varies substantially. Based on atomic-multiplet theory, we present a consistent picture of MCD in resonant 4d → 4ƒ PE and x-ray absorption at the 4d-edge, where all spectral changes can be explained by the angular-momentum of the intermediate absorption state. The present analysis shows: when tuning to a specific line of the 4d x-ray absorption spectrum with a total angular momentum J', only the associate multiplet component is found to resonate. At the 'giant resonance', the shape of the MCD-PE signal closely resembles the off-resonance case; this finding is explained within atomic-multiplet theory allowing a straightforward use of MCD in 4d-resonant PE (i) for element-specific analysis of multicomponent magnetic systems with high surface sensitivity and (ii) for surface-domain imaging by PE microscopy.
Fatigue Study of a Zr-Ti-Ni-Cu-Be Bulk Metallic Glass
G. Y. Wang, P. K. Liaw, A. Peker, B. Yang, M. L. Benson, W. Yuan, W. H. Peter, L. Huang, M. Freels, R. A. Buchanan, C. T. Liu, C. R. Brooks
Published online by Cambridge University Press: 01 February 2011, MM7.11
High-cycle fatigue (HCF) studies were performed on zirconium (Zr)-based bulk metallic glasses (BMGs): Zr41.2Ti13.8Ni10Cu12.5Be22.5, in atomic percent. The HCF experiments were conducted using an electrohydraulic machine at a frequency of 10 Hz with a R ratio of 0.1 and under tension-tension loading, where R = σmin./σmax., where σmin. and σmax. are the applied minimum and maximum stresses, respectively. The test environment was air. A high-speed and high-sensitivity thermographic-infrared (IR) imaging system has been used for nondestructive evaluation of temperature evolution during fatigue testing of BMGs. Limited temperature evolution was observed during fatigue. However, no sparking phenomenon was observed at the final moment of fracture of this BMG. At high stress levels (σmax. > 864 MPa), the fatigue lives of Batch 59 are longer than those of Batch 94 due to the presence of oxides in Batch 94. Moreover, the fatigue-endurance limit of Batch 59 (703 MPa) is somewhat greater than that of Bath 94 (615 MPa) in air. The fatigue-endurance limit of Ti-6–4 is greater than this BMG, but Al 7075 has the lowest fatigue life. The vein pattern with a melted appearance were observed in the apparent melting region. The fracture morphology indicates that fatigue cracks initiate from some defects. | CommonCrawl |
communications biology
Manifold learning analysis suggests strategies to align single-cell multimodal data of neuronal electrophysiology and transcriptomics
A transcriptomic and epigenomic cell atlas of the mouse primary motor cortex
Zizhen Yao, Hanqing Liu, … Eran A. Mukamel
Spatially resolved cell atlas of the mouse primary motor cortex by MERFISH
Meng Zhang, Stephen W. Eichhorn, … Xiaowei Zhuang
Deep learning and alignment of spatially resolved single-cell transcriptomes with Tangram
Tommaso Biancalani, Gabriele Scalia, … Aviv Regev
Integrating barcoded neuroanatomy with spatial transcriptional profiling enables identification of gene correlates of projections
Yu-Chi Sun, Xiaoyin Chen, … Anthony M. Zador
Phenotypic variation of transcriptomic cell types in mouse motor cortex
Federico Scala, Dmitry Kobak, … Andreas S. Tolias
A harmonized atlas of mouse spinal cord cell types and their spatial organization
Daniel E. Russ, Ryan B. Patterson Cross, … Ariel J. Levine
Machine learning methods to model multicellular complexity and tissue specificity
Rachel S. G. Sealfon, Aaron K. Wong & Olga G. Troyanskaya
Cell segmentation-free inference of cell types from in situ transcriptomics data
Jeongbin Park, Wonyl Choi, … Naveed Ishaque
devCellPy is a machine learning-enabled pipeline for automated annotation of complex multilayered single-cell transcriptomic data
Francisco X. Galdos, Sidra Xu, … Sean M. Wu
Jiawei Huang1 nAff5,
Jie Sheng2 &
Daifeng Wang ORCID: orcid.org/0000-0001-9190-37042,3,4
Communications Biology volume 4, Article number: 1308 (2021) Cite this article
Computational biology and bioinformatics
Recent single-cell multimodal data reveal multi-scale characteristics of single cells, such as transcriptomics, morphology, and electrophysiology. However, integrating and analyzing such multimodal data to deeper understand functional genomics and gene regulation in various cellular characteristics remains elusive. To address this, we applied and benchmarked multiple machine learning methods to align gene expression and electrophysiological data of single neuronal cells in the mouse brain from the Brain Initiative. We found that nonlinear manifold learning outperforms other methods. After manifold alignment, the cells form clusters highly corresponding to transcriptomic and morphological cell types, suggesting a strong nonlinear relationship between gene expression and electrophysiology at the cell-type level. Also, the electrophysiological features are highly predictable by gene expression on the latent space from manifold alignment. The aligned cells further show continuous changes of electrophysiological features, implying cross-cluster gene expression transitions. Functional enrichment and gene regulatory network analyses for those cell clusters revealed potential genome functions and molecular mechanisms from gene expression to neuronal electrophysiology.
Recent single-cell technologies have generated great excitement and interest in studying functional genomics at cellular resolution1. For example, recent Patch-seq techniques enable measuring multiple characteristics of individual neuronal cells, including transcriptomics, morphology, and electrophysiology in the complex brains, also known as single-cell multimodal data2. Further computational analyses have clustered cells into many cell types for each modality. The same type's cells share similar characteristics: t-type by transcriptomics and e-type by electrophysiology. Those cell types build a foundation for uncovering cellular functions, structures, and behaviors at different scales. For instance, previous correlation-based analyses found individual genes whose expression levels linearly correlate with electrophysiological features in excitatory and inhibitory neurons3,4. Besides, recent studies have also identified several cell types from different modalities that share many cells (e.g., me-type), suggesting the linkages across modalities in these cells2,5. Also, predictability from one modality to another has been found, such as predicting electrophysiological features from gene expression6. However, understanding the molecular mechanisms underlying multi-modalities that typically involve multiple genes is still challenging.
Transcriptomic activities such as gene expression for cellular characteristics and behaviors are fundamentally governed by gene regulatory networks (GRNs)7. In particular, the regulatory factors (e.g., transcription factors) in GRNs work together and control the expression of their target genes. Also, GRNs can be inferred from transcriptomic data and be employed as robust systems to infer genomic functions8. Many computational methods have been developed to predict the transcriptomic cell-type GRNs using single-cell genomic data such as scRNA-seq7. Primarily, relatively little is known about how genes function and work together in GRNs to drive cross-modal cellular characteristics (e.g., from t-type to e-type).
Further, integrating and analyzing heterogeneous, large-scale single-cell datasets remains challenging. Machine learning has emerged as a powerful tool for single-cell data analysis, such as t-SNE9, UMAP10, and scPred11, to identify transcriptomic cell types. An autoencoder model has recently been used to classify cell types using multimodal data12. However, these studies were limited to building an accurate model as a "black box" and lacked any biological interpretability from the box, especially for linking gene expression and functional genomics to various cellular phenotypes. To address this challenge, we applied and benchmarked various machine learning methods for data alignment, including manifold learning, an emerging, and nonparametric machine learning approach, to align single-cell gene expression and electrophysiological feature data in the multiple regions of the mouse brain. We found that the nonlinear manifold alignment outperforms other methods for aligning cells from multimodalities. Also, it identified biologically meaningful cross-modal cell clusters on the latent spaces after the alignment. This finding suggests a strong nonlinear relationship (manifold structure) linking genes and electrophysiological features at the cell-type level. The aligned cells by manifold alignment show specific trajectories, suggesting the underlying gene expression transitions across neuronal cells and continuous changes of several electrophysiological features. We further found that many electrophysiological features can be predicted by differentially expressed genes of cross-modal cell clusters. Our enrichment analyses for the cell clusters, including GO terms, KEGG pathways, and gene regulatory networks, further revealed the underlying functions and mechanisms from genes to cellular electrophysiology in the mouse brain.
We have applied and benchmarked multiple existing machine learning methods to align the single cells in the mouse brain using their gene expression and electrophysiological data (Methods, Fig. 1a). In particular, we focused on two major brain regions, mouse visual cortex and motor cortex, and used the latest Patch-seq data from Allen Brain Atlas in the BRAIN Initiative5,13,14 (Methods). The machine learning methods for alignment include linear manifold alignment (LMA) and nonlinear manifold alignment (NMA)15, manifold warping (MW)16, manifold alignment based on maximum mean discrepancy measure (MMD-MA)17, unsupervised topological alignment of single-cell multi-omics integration (UnionCom)18, Single-Cell alignment using Optimal Transport (SCOT)19, Manifold Aligning GAN (MAGAN)20, Canonical Correlation Analysis (CCA), Reduced Rank Regression (RRR)5,21, Principal Component Analysis (PCA, no alignment) and t-Distributed Stochastic Neighbor Embedding (t-SNE, no alignment)9.
Fig. 1: Manifold learning aligns single-cell multimodal data and reveals nonlinear relationships between cellular transcriptomics and electrophysiology.
a Manifold learning analysis inputs single-cell multimodal data: \({X}_{e}\), the electrophysiological data (red,\({d}_{e}\) electrophysiological features by \(n\) cells) and \({X}_{t}\), the gene expression data (blue, \({d}_{t}\) genes by \(n\) cells). It then aims to find the optimal functions \({f}^{\ast }(.)\) and \({g}^{\ast }(.)\) to project \({X}_{e}\) and \({X}_{t}\) onto the same latent space with dimension \(d\). Thus, it reduces the dimensions of multimodal data of n single cells to \({\tilde{X}}_{e}\) (\(d\) reduced electrophysiological features by \(n\) cells) and \({\tilde{X}}_{t}\) (\(d\,\)reduced gene expression features by \(n\) cells). If manifold learning is used, then the latent space aims to preserve the manifold structures among cells from each modality, i.e., manifold alignment. Finally, it clusters the cells on the latent space to identify cross-modal cell clusters. b Boxplots show the pairwise cell distance (Euclidean Distance) after alignment on the latent space for 3654 neuronal cells (aspiny) in the mouse visual cortex (Methods). The cell coordinates on the latent space are standardized per cell (i.e., each row of \(\tilde{X}=[{\tilde{X}}_{e},{\tilde{X}}_{t}]\)) to compare methods. Each box represents one alignment method. The box indicates the lower and upper quantiles of the data, with a horizontal line at the median. The vertical line extended from the boxplot shows a 1.5 interquartile range beyond the 75th percentile or 25th percentile. The machine learning methods for alignment include linear manifold alignment (LMA), nonlinear manifold alignment (NMA), manifold warping (MW), Canonical Correlation Analysis (CCA), Reduced Rank Regression (RRR), Principal Component Analysis (PCA, no alignment), t-SNE (t-Distributed Stochastic Neighbor Embedding, no alignment), MMD-MA (Manifold Alignment with maximum mean discrepancy measurement), unsupervised topological alignment of single-cell multi-omics integration (UnionCom), Single-Cell alignment using Optimal Transport (SCOT), and Manifold Aligning GAN (MAGAN). c The cells on the latent space (3D) after alignment by RRR, CCA, and NMA. The red and blue dots represent the cells from gene expression and electrophysiological data, respectively. The blue dots are drifted −0.05 on the y-axis to show the alignment.
The alignment methods have been previously used to align single-cell multi-omics data, e.g., scRNA-seq and scATAC-seq. Mathematically, these methods align multi-omics data of single cells and project the cells from different omics onto a latent space (e.g., co-embedding). The cells aligned on the latent space likely form certain cell clusters and share biological mechanisms, e.g., gene regulation from aligning scRNA-seq and scATAC-seq. For instance, the linear alignment methods such as canonical correlation analysis (CCA) (e.g., Seurat22) and RRR decompose single-cell data matrices of different omics (e.g., genes and regulatory elements across cells) to find lower-dimensional representative factors across omics. Those factors can be used to cluster cells and find the clusters' omics activities. As nonlinear alignment methods, MAGAN applies manifold alignment to match cells from single-cell multi-omics datasets using generative adversarial networks. It empirically requires biological manifolds (e.g., known cell types) to build the cell correspondences across omics for better alignment. Recently, UnionCom extends the generalized unsupervised manifold alignment (GUMA) to embed cells from each omics onto a lower-dimensional latent space (via kNN) and then match cross-omics spaces to align cells. Besides, Maximum Mean Discrepancy-Manifold Alignment (MMD-MA) embeds the latent spaces onto a common reproducing kernel Hilbert space by minimizing the MMD across omics. Also, SCOT uses the optimal transport technique to project one modality onto the space of another while preserving the local neighborhood of geometry from the modality. Although those methods have been shown that aligned cells have somehow specific omics activities, they have not been widely applied and tested to align additional modalities, such as gene expression vs. electrophysiology, which typically have complex and likely nonlinear cross-modal relationships (more nonlinear than cross-omics).
After benchmarking, we found that NMA better aligns cells in both regions than other methods, and also uncovers the specific trajectories of the aligned cells. Please note that NMA is nonparametric compared to other methods which are parametric. Unlike parametric methods, which are able to cross-validate learned parameters via training and testing data, nonparametric methods including NMA typically use all data samples (i.e., cells here) to directly output the cells' coordinates on the optimal aligned latent spaces.
Manifold learning aligns single-cell multimodal data and reveals nonlinear relationships between cellular transcriptomics and electrophysiology
For the visual cortex, after data processing and feature selection (Methods), we aligned 3654 neuronal cells (aspiny) in the mouse visual cortex using their gene expression and electrophysiological data of single cells by Patch-seq. After alignment, we projected the cells onto a low dimensional latent space and then clustered them into multiple cell clusters. The cells clustered together imply that they share both similar gene expression and electrophysiological features. We found that nonlinear manifold alignment outperforms other methods (Fig. 1b) based on the Euclidean distances of the same cells on the latent space. We also calculated the FOSCTTM score (Methods, Fig. S1) to evaluate alignments, which also indicates that NMA performs best. Since some of the manifold alignment methods we compared are unsupervised (UnionCom, MMD-MA, SCOT), we aligned the cells in a semi-supervised fashion to compare with them, which only used 50% random cells as correlation prior and others 50% as unobserved to see how our alignment works for the cells. NMA turns out to be the second-best method, only UnionCom (average 0.280 distance and 0.060 FOSCTTM score) outperforms NMA (average 0.587 distance and 0.142 FOSCTTM score). This result suggests potential nonlinear relationships between the transcriptomics and electrophysiology in those neuronal cells, better identified by manifolds. Finally, we visualized the cell alignments of NMA, CCA, and RRR on the 3D latent space in Fig. 1c, showing that nonlinear machine learning has the best alignment (average distances of aligned same cells: RRR = 0.955, CCA = 0.510, NMA = 0.132). In addition, we applied our analysis to another multimodal data of 112 neuronal cells in the mouse visual cortex and also found that the nonlinear manifold alignment outperforms other methods (Fig. S2). Also, for the motor cortex, after aligning its 1208 neuronal cells using the gene expression and electrophysiological features (Methods), we found a similar result that the NMA outperforms other methods in terms of alignment (Fig. S3, average distances of aligned same cells: PCA = 2.366, CCA = 2.037, NMA = 0.199).
Manifold-aligned cells recover known cell types and uncover continuous changes of electrophysiological features across transcriptomic types
After aligning single cells using multimodal data, we found that the aligned cells on the latent space by manifold learning recovered the known cell types of a single modality. For instance, those neuronal cells were previously classified into six major transcriptomic types (t-types) or "cell classes"14 or "cell families"5 based on the expression of marker genes. We also found that the t-types are better formed and recovered by the latent space of NMA than other methods (e.g., CCA and RRR) (Fig. 2a, Fig. S3) in both regions. Also, since the transcriptomic types are defined by transcriptomic data, we applied PCA, t-SNE, Umap, and PHATE39 to the transcriptomic data and UnionCom, MAGAN to both modalities of those cells and found that those methods do not show any single trajectory transitioning t-types (Fig. S4), unlike NMA (Fig. 2a). This suggests that NMA not only recovered t-types but also found a cross-t-type trajectory visualizing transitions across t-types. Using the t-types of the cells, we calculated the silhouette values of the cells on the latent space after alignment to quantify how well the coordinates of the aligned cells correspond to the t-types (Methods). We found that the silhouette values of NMA are larger than other methods (Fig. 2b), suggesting that NMA better recovers the t-types.
Fig. 2: Manifold alignment of single-cell multimodalities recovers known cell types.
a Scatterplots show 3645 neuronal cells in the mouse visual cortex from electrophysiological data on the latent spaces (3D) after alignment by Reduced Rank Regression (RRR), Canonical Correlation Analysis (CCA), and Nonlinear Manifold Alignment (NMA). The cells are colored by prior known transcriptomic types (t-types). Red: Vip type; Blue: Sst type; Purple: Sncg type; Orange: Pvalb type; Yellow: Lamp5 type; Gray: Serpinf1 type. The cells from gene expression data on the latent spaces were shown in Fig. S3. b The boxplots show the silhouette values of cells for quantifying how well the coordinates of the cells on the latent spaces correspond to the t-types by RRR, CCA and NMA (Methods). c Scatterplots show neuronal cells in the mouse visual cortex on the latent spaces (3D) after alignment by NMA. Dots are colored according to the reconstructed morphological types (orange: aspiny, lightgreen: spiny).
Also, NMA revealed an ordering across these t-types in the visual cortex (i.e., cell trajectory), implying potential gene expression transitions aligning with cellular electrophysiology. This trajectory across t-types (from Lamp5 to Vip to Serpinf1/Sncg to Sst to Pvalb) was also supported by the previous studies23. However, other methods, including CCA, PCA, t-SNE/UMAP, and recent parametric method, reduced rank regression (RRR)5,14, as well as recent coupled autoencoder method12 do not show either multiple t-types or trajectories across t-types (Fig. 2a, Fig. S3). Besides t-types, the aligned cells by NMA also revealed morphological types (Methods), as shown by aspiny vs. spiny cells in Fig. 2c. Thus, these results demonstrate that manifold learning has uncovered known multimodal cell types from cell alignment. In addition, after using NMA to align cells in the motor cortex, we observed this similar trajectory (Lamp5 to Vip to Sncg to Sst to Pvalb) (Fig. 3a).
Fig. 3: Trajectories across t-types on the latent space after nonlinear manifold alignment along with continuous electrophysiology changes.
a Scatterplots show trajectories across t-types on the latent space (3D used here) after nonlinear manifold alignment of the cells in the visual cortex (left) and motor cortex (right). Cells in shared t-types between two regions are highlighted with the same color for comparison. Red: Vip type; Blue: Sst type; Purple: Sncg type; Orange: Pvalb type; Yellow: Lamp5 type; Gray: other t-types not shared (e.g., Excitatory neurons in the visual cortex). b Scatterplots show trajectories for Sst sub t-types on the latent space (3D used here) after nonlinear manifold alignment of the cells in the visual cortex (left) and motor cortex (right). c Scatterplots show continuous changes of select electrophysiological features in t-types and Sst sub-t-types in the visual cortex (left) and motor cortex (right). The "peak t ramp" is the time taken from membrane potential to AP peak for ramp stimulus.
Using NMA, we also observed trajectories in sub-t-types, implying gene expression dynamic changes and transitions across sub-t-types. For instance, the Sst sub-t-type is known to have multimodal diversity in Layer 55. We also found that the aligned cells by NMA show a trajectory (tac2 to myh8 to hpse to crhr2 to chodl to calb2) in both visual and motor cortices (Fig. 3b). This result suggests the great potential of NMA for revealing the underlying expression dynamics in the sub-t-types. Also, we found that certain electrophysiological features of cells on these trajectories show continuous changes. For instance, peak_t_ramp (time taken from membrane potential to AP peak for ramp stimulus) gradually changes from low to high along with the trajectory across both the t-types and Sst sub-t-types in the visual cortex, whereas the sag ratio changes from low to high in the motor cortex (Fig. 3c). Also, membrane time and AP amplitude achieve high values in the middle of the trajectory across t-types in the motor cortex only (Fig. S5). These electrophysiological features' continuous changes imply the region-related activities, although both regions share similar transcriptomic trajectories.
Cross-modal cell clusters by manifold alignment reveal genomic functions and gene regulatory networks for neuronal electrophysiology
Furthermore, we want to systematically understand underlying functional genomics and molecular mechanisms for cellular electrophysiology using aligned cells. To this end, we clustered aligned cells on the latent space of NMA without using any prior cell-type information. In particular, we used the gaussian mixture model (GMM) to obtain five cell clusters with optimal BIC criterion (Methods, Fig. S6) in the mouse visual cortex. Those cell clusters are cross-model clusters since they are formed after aligning their gene expression and electrophysiological data. As expected, they are highly in accordance with t-types (Fig. S7). For example, Cluster 4 has ~83.3% Lamp5-type cells (373/448 cells), Cluster 2 has ~77.6% Pvalb-type cells (558/719 cells), Cluster 3 has ~86.6% Sst-type cells (1339/1546 cells) and Cluster 1 has ~79.1% Vip cells (541/684 cells). Besides, Clusters 1 and 5 include ~55.8% Serpinf1 cells (24/43) and ~60.7% Sncg cells (84/214), respectively. Moreover, we used the same clustering method to cluster the cells using a single modality (gene expression or electrophysiology) on the PCA space without alignment. We found that those single-modal cell clusters are not so consistent with t-types as cross-modal clusters after alignment. For instance, by using electrophysiological data only, we found that the cell clusters include 57.8% Lamp5-type cells, 85.1% Pvalb-type cells, 65.1% Serpinf1-type cells, 63.1% Sncg-type cells, 49.5% Sst-type cells, and 60.8% Vip-type cells. Using gene expression data only, the cell clusters have 68.9% Lamp5-type cells, 54.4% Pvalb-type cells, 55.8% Serpinf1-type cells, 67.3% Sncg-type cells, 45.2% Sst-type cells, and 65.2% Vip-type cells. Thus, no single-modal clusters have over 70% of Vip-type, Lamp5-type and Sst-type cells. This suggests that multimodal alignment is not driven by single modalities and also helps clustering together the cells from the same types. Furthermore, in addition to GMM, we also used K-medoid and Hierarchical clustering methods to cluster aligned cells and cross-modal cell clusters. Those cross-modal clusters highly overlap with t-types as well (Fig. S8), suggesting the robustness of clustering cross-modal aligned cells. K-medoid clusters together 90.2% Lamp5-type cells, 96.6% Pvalb-type cells, 55.8% Serpinf1-type cells, 61.7% Sncg-type cells, 96.5% Sst-type cells, and 75.7% Vip-type cells. Hierarchical clustering clusters together 79.9% Lamp5-type cells, 98.6% Pvalb-type cells, 83.7% Serpinf1-type cells, 57.4% Sncg-type cells, 94.6% Sst-type cells, and 94.9% Vip-type cells.
Also, we identified differentially expressed genes (DEGs) with adjusted p-value <0.01 as marker genes of cross-modal cell clusters (Fig. 4a, Supplementary Data 1). In total, there are 182, 243, 175, 190, and 13 marker genes in Clusters 1, 2, 3, 4, 5, respectively. These cell-cluster marker genes are also enriched with biological functions and pathways (GO terms) among the genes (Supplementary Data 2) (Methods). For example, we found that many neuronal pathways and functions are significantly enriched in DEGs of Cluster 1, such as the ion channel, synaptic and postsynaptic membrane, neurotransmitter, neuroactive ligand receptor, and cell adhesion (adjusted p < 0.05, Fig. 4b). Further, we linked top enriched functions and pathways of each cross-modal cell cluster to its representative electrophysiological features (Fig. 4b, Fig. S9), providing additional molecular mechanistic insights for neuronal electrophysiology. Since gene expression is fundamentally controlled by gene regulatory networks (GRNs), we predicted the GRNs for cross-modal clusters, providing mechanistic insights for multimodal characteristics (Methods). In particular, the predicted GRNs link transcription factors (TFs) to the cluster's genes (Supplementary Data 3), suggesting the gene regulatory mechanisms for the electrophysiological features in each cluster. For instance, we found that several key TFs on neuronal and intellectual development regulate the genes in Cluster 1, such as Tcf12 and Rora (Fig. 4c). Also, Atf3, a TF modulating immune response24, is regulated by inflammatory TFs, Irf5 and Spi1 in the gene regulatory networks of our clusters. Although there are cells not expressing some of these genes, due to the potential off-target expression of immunological genes in Patch-seq25, many cells still show high and correlated expression of Atf3, Irf5, and Spi1 (Fig. S10). This observation thus suggests potential interactions between neurotransmission and inflammation, which were recently reported26. Besides, Lhx6, a TF previously found inducing Pvalb and Sst neurons27, was also predicted as a key TF for the Cluster 2 and Cluster 3 only that have the most Pvalb and Sst type neurons, respectively. For the motor cortex, we also identified five major cell clusters from the NMA's latent space. Like the visual cortex, the motor cortex's cell clusters also correspond to the transcriptomic types (Fig. S7). For instance, Cluster 5 has ~95.4% Vip type cells (146/153 cells). Cluster 4 has ~75.3% Sst type cells (202/271). Besides, Clusters 1 and 3 respectively include ~34.9% (101/289 cells) and ~64.7% (187/289) Pvalb type cells. For excitatory neurons, ~55.8% (218/391) of cells are in Cluster 2, and ~43.7% (171/391) of cells are in Cluster 1. The predicted GRNs for these cell clusters in the motor cortex also reveal key neuronal TFs such as Lhx6 again, Atf4 as stress-inducible TF, and Npdc1 for neural proliferation, differentiation, and control (Supplementary Data 3). Finally, we also predicted GRNs for known t-types in both regions (Supplementary Data 4), which; however, do not include several key TFs, such as Lhx6 for Pvalb and Sst types.
Fig. 4: Differentially expressed genes, enrichments, and gene regulatory networks for cross-modal cell clusters.
a The gene expression levels across all 3654 cells for Top 10 differential expressed genes (DEGs) of each cross-modal cell cluster in the mouse visual cortex. The cell clusters were identified by the gaussian mixture model (Methods). The expression levels are normalized (Methods). b The select enriched biological functions and pathways of DEGs (GO and KEGG terms with adjusted p value <0.05) and representative electrophysiological features (adjusted p value <0.05) in Cluster 1 of the mouse visual cortex. c Gene regulatory networks that link transcription factors (TFs, cyan) to target genes (Orange) in Cluster 1 of the mouse visual cortex.
Predicting electrophysiological features from gene expression using manifold alignment results
Finally, we want to see if the electrophysiological features could be predicted by gene expression using our manifold alignment. First, we visualized the NMA's latent spaces of the cells using the bibiplot method (a group of biplots)5 (Fig. 5a for the visual cortex and Fig. 5b for the motor cortex). In particular, we selected the first three components of transcriptomic space and electrophysiological space so that each biplot shows such a space using two components. Due to the nonlinear manifold alignments, the transcriptomic spaces and electrophysiological spaces look much more similar than previously used linear dimensionality reduction5. As shown in each biplot, a group of highly correlated genes and electrophysiological features with the NMA's latent spaces are highlighted by lines (the line length, i.e., radius, corresponds to the correlation value with max correlation = 1). We found that many genes and electrophysiological features are in similar directions in the biplots, suggesting their strong associations on the NMA's latent space. For instance, peak_t_ramp and Pavlb are in similar directions on the first and second component of the visual cortex (Fig. 5a), and peak_t_ramp indeed has high values in the Cluster 2 that is enriched with Pvalb cells (Fig. 3c, Fig. S9). Furthermore, we applied a multivariate regression model to fit the components of the NMA's electrophysiological space (dependent variables) by the components of the NMA's latent transcriptomic space (independent variables) (Methods).
Fig. 5: Association and prediction of electrophysiological features from gene expression.
a Bibiplots for the mouse visual cortex using the NMA's latent spaces (first three components used). Cells are dots (n = 3654). Transcriptomic and electrophysiological latent spaces are shown as columns. Each biplot shows the subspace of two components. Cells are colored by their cross-modal clusters. The line length of a gene or electrophysiological feature (i.e., radius) corresponds to its correlation with the latent space with max value = 1. The genes and electrophysiological features with correlations >0.6 are shown here. The label positions are slightly adjusted to avoid overlapping. b Similar to (a) but for the mouse motor cortex (n = 1208). c The representative electrophysiological features in the cross-modal clusters with testing \({R}^{2}\) > 0.5 (90% training set, 10% testing set, see Methods). d The predicted values by gene expression (x-axis) vs. the observed values (y-axis) of the upstroke downstroke ratio (\({R}^{2}=0.805\)) in the visual cortex and the action potential width (\({R}^{2}=0.800\)) in the mouse motor cortex.
Second, after showing strong associations between genes and electrophysiological features on the NMA's latent space, we next tried to predict the electrophysiological features from gene expression from our cross-modal clusters ('NMA' cell clusters, Methods) Specifically, we selected the representative electrophysiological features from each NMA cluster as potentially predictable features. We then fitted a linear regression model to predict each representative electrophysiological feature (dependent variable) by the expression levels of differentially expressed genes (adjusted p value < 0.05) from the same NMA cluster of the feature across all cells, i.e., NMA-DEX genes. We also split the cells into 90% training and 10% testing sets and calculated the fitting \({R}^{2}\) values of testing sets (Supplementary Data 5). For example, for NMA Cluster 1 in the mouse visual cortex, we used its 182 differential expressed genes to predict the upstroke downstroke ratios for long square and ramp and achieved \({R}^{2}\) = 0.805 and 0.794, respectively. As shown in Fig. 5c, a number of electrophysiological features can be predicted by differential expressed genes of NMA cell clusters with \({R}^{2}\) > 0.5. In addition, Fig. 5d shows that the predicted values are highly correlated with the observed values across many cells for the upstroke downstroke ratio (\({R}^{2}=0.805\)) in the visual cortex and the action potential width (\({R}^{2}=0.800\)) in the mouse motor cortex. Moreover, we compared this result with the testing \({R}^{2}\) of predicting electrophysiological features based on the differentially expressed genes of known cell types, t-types, i.e., t-type-DEX genes. Using t-type-DEX genes, we obtained an \({R}^{2}=0.765\) for predicting the action potential width in the motor cortex and an \({R}^{2}=0.725\) for predicting the upstroke downstroke ratio for long square stimulus in the visual cortex, both of which are lower than our NMA-DEX genes. This suggests great potential of using our cross-modal clusters from nonlinear manifold alignment along with their differentially expressed genes (NMA-DEX genes) for improving predicting electrophysiological features from gene expression.
This study applied manifold learning to integrate and analyze single cells' gene expression and electrophysiological data in the mouse brain. We found that the cells are well aligned by the two data types and form multiple cell clusters after manifold alignment. These clusters were enriched with neuronal functions and pathways and uncovered additional cellular characteristics, such as morphology and gene expression transitions. Our manifold learning analysis is general-purpose and enables studying single-cell multimodal data in the human brain and other contexts28. Moreover, our GRN analysis can also serve as a basis for understanding gene regulation for additional cellular multimodal phenotypes.
Our nonlinear manifold alignment (NMA) uses the known cell correspondence information (1-to-1 from same cells) that is a unique feature of Patch-seq which simultaneously measures gene expression and electrophysiological data of the same cells. Thus, it is expected that NMA outperforms the unsupervised alignment methods, such as SCOT, MMD-MA and UnionCom. Those unsupervised methods do not need any prior knowledge on cell correspondences for alignment. Instead, they infer such correspondences in the alignment. Thus, they can be useful for aligning single-cell multimodal data when some modalities are unavailable for all cells (e.g., morphological data is only available for a fraction of cells in Patch-seq). Also, we performed a semi-supervised learning test for evaluating the alignment performance of NMA and other methods using partial cell correspondence information. We only used 1-to-1 correspondence information of 50% of 3654 neuronal cells in the mouse visual cortex to infer the correspondence of other 50% cells from alignment. As shown in Fig. S11, NMA still outperforms others except UnionCom, suggesting the potential usefulness of NMA for aligning single-cell multimodal data using partial correspondence information. Furthermore, deep-learning models have been proposed for cross-modal prediction. For example, a coupled autoencoder model12 was proposed to align Patch-seq data to project gene expression and electrophysiological features onto two separate latent spaces. Although computationally intensive such as involving tuning many hyperparameters, given relatively large sample sizes from single-cell data, such deep-learning based models might be able to help improve multimodal data alignment in future.
Besides, this work used several electrophysiological features to represent the characteristics of neuronal electrophysiology that likely miss additional information such as continuous dynamic responses to stimulus. Thus, using advanced machine learning methods, such as deep learning for time-series classification29 to directly integrate time-series electrophysiological data with transcriptomic data will potentially reveal deeper relationships across the modalities and improve cell-type classifications. The predicted gene regulatory networks in this study focused on linking transcription factors to target genes on the transcriptomic side. However, gene regulation is a complex process involving many genomic and epigenomic activities, such as chromatin interactions and regulatory elements. Thus, integrating emerging single-cell sequencing data, such as scHi-C30 and scATAC-seq31 as additional modalities will help understand gene regulatory mechanisms in cellular characteristics and behaviors. For instance, we applied manifold learning to align co-profiled scRNA-seq and scATAC-seq data of 2,641 cells (HEK293T, NIH/3T3, A549 cells)18. We found that NMA still outperforms other state-of-the-arts (Fig. S12), suggesting the potential usefulness of manifold learning for additional single-cell data type integration, such as single-cell multi-omics data and understanding single-cell functional genomics.
Single-cell multimodal datasets
We applied our machine learning analysis for multiple single-cell multimodal datasets in the mouse brain.
Visual cortex
Primarily, we used a Patch-seq dataset that included the transcriptomic and electrophysiological data of 4435 neuronal cells (GABAergic cortical neurons) in the mouse visual cortex14. In particular, the electrophysiological data measured multiple hyperpolarizing and depolarizing current injection stimuli and responses of short (3 ms) current pulses, long (1 s) current steps, and slow (25 pA/s) current ramps. The transcriptomic data measured genome-wide gene expression levels of those neuronal cells. Six transcriptomic cell types (t-types) were identified among the cells: Vip, Sst, Sncg, Serpinf1, Pvalb, and Lamp5. Further, morphological information was provided: 4293 aspiny and 142 spiny cells. Also, we tested our analysis for another Patch-seq dataset in the mouse visual cortex13. This dataset includes 112 neuronal cells with electrophysiological data and gene expression data (Fig. S2).
Another Patch-Seq dataset included the transcriptomic and electrophysiological data of 1227 neuronal cells (GABAergic cortical neurons) in the mouse motor cortex5. The electrophysiological data measured multiple hyperpolarizing and depolarizing current injection stimuli and responses of long current steps. The transcriptomic data measured genome-wide gene expression levels of those neuronal cells. Five major transcriptomic cell types (t-types) were identified among the cells: Vip, Sst, Sncg, Pvalb, and Lamp5, based on which 90 neuronal sub-t-types were also labeled.
Data processing and feature selection of multimodal data
For electrophysiology, we first obtained 47 electrophysiological features (e-features) on stimuli and responses, which were identified by Allen Software Development Kit (Allen SDK) and IPFX Python package32. Second, we eliminated the features with many missing values such as short_through_t and short_through_v, as well as the cells with unobserved features, and finally selected 41 features in all three types of stimuli and responses for 3654 aspiny cells (inhibitory) and 118 spiny cells (excitatory) out of the 4435 neuronal cells. Since the spiny cells usually do not contain the t-type information, we used the 3654 aspiny cells for manifold learning analysis. Together, we used the 3654 aspiny cells and 118 spiny cells to refer to morphological cell types (m-type). Also, we standardized the feature values across all cells to remove potential scaling effects across features for each feature. The final electrophysiological data matrix is Xe (3654 cells by 41 e-features). We selected 1302 neuronal marker genes33 and then took the log transformation of their expression levels. The final gene expression data is Xt (3654 cells by 1302 genes).
For electrophysiology, there are 29 electrophysiological features summarized by5. We eliminated the cells with missing observations in these features and standardized them across each feature. Then we selected 1208 cells with features aroused by long square stimuli. For gene expression data, we again selected 1329 neuronal marker genes33 and then took the log transformation of their expression levels. The final electrophysiological data matrix is Xe (1208 cells by 29 e-features), and the gene expression data is Xt (1208 cells by 1329 genes).
Manifold learning for aligning single cells using multimodal data
We applied our published tool, ManiNetCluster34 to perform various manifold learning approaches to align single cells using their multimodal data to discover the linkages of genes and electrophysiological features, including linear manifold alignment (LMA) and nonlinear manifold alignment (NMA)15, manifold warping (MW)16. In particular, the manifold alignment projects the cells from different modalities onto a lower-dimensional common latent space for preserving the local similarity of cells in each modality (i.e., manifolds). The distances of the same cells on the latent space can quantify the performance of the alignment. Mathematically, given \(n\) single cells, let \({X}_{e}=[{x}_{e}^{1},\ldots ,{x}_{e}^{n}]\in {{\mathbb{R}}}^{{d}_{1}\times n}\)and \({X}_{t}=[{x}_{t}^{1},\ldots ,{x}_{t}^{n}]\in {{\mathbb{R}}}^{{d}_{2}\times n}\) represent their electrophysiological and gene expression matrices, respectively, where \({d}_{1}\) is the number of electrophysiological features, and \({d}_{2}\) is the number of genes. The manifold alignment finds the optimal projection functions \({f}^{\ast }(.)\) and \({g}^{\ast }(.)\) to map \({x}_{e}^{i}\), \({x}_{t}^{i}\) onto a common latent space via manifolds with dimension \(d < < min({d}_{1},{d}_{2})\):
$$\begin{array}{c}{f}^{\ast },{g}^{\ast }={{\mbox{arg}}}\mathop{\min }\limits_{{{{{{\rm{f}}}}}},{{{{{\rm{g}}}}}}}(1-\mu )\mathop{\sum }\limits_{i=1}^{n}\mathop{\sum }\limits_{j=1}^{n}{||f({x}_{e}^{i})-g({x}_{t}^{j})||}_{2}^{2}{W}^{i,j}\\ \,+\,\mu \mathop{\sum }\limits_{i=1}^{n}\mathop{\sum }\limits_{j=1}^{n}{||f({x}_{e}^{i})-f({x}_{e}^{j})||}_{2}^{2}{W}_{{X}_{e}}^{i,j}\\ \,+\,\mu \mathop{\sum }\limits_{i=1}^{n}\mathop{\sum }\limits_{j=1}^{n}{||g({x}_{t}^{i})-g({x}_{t}^{j})||}_{2}^{2}{W}_{{X}_{t}}^{i,j}\end{array}$$
where the corresponding matrix \(W\in {{\mathbb{R}}}^{n\times n}\) models cross-modal relationships of cells (i.e., identity matrix here), and the similarity matrices \({W}_{{X}_{e}},{W}_{{X}_{t}}\in {{\mathbb{R}}}^{n\times n}\) model the relationships of the cells in each modality and can be identified by k-nearest neighbor graph (kNN, matrix elements between neighbors =1 and otherwise = 0). As shown on Fig. S13, we tried different values of k (k = 2, 5, 8, 10) and d (d = 3, 5, 8, 10) and found that as k and d grow, the distances of aligned cells did not change much and NMA always outperforms others. Thus, we used k=2 and d = 3, which achieve the minimum average distance among the same cells. The parameter μ trades off the contribution between the preserving local similarity for each modality (intra-modal) and the correspondence of the cross-modal network (inter-modal). We used μ = 0.5 to balance two losses. Moreover, this also makes our alignment comparable with other methods, such as MMD-MA, UnionCom, SCOT, and MAGAN, all of which also assign equal weights to all losses from intra- and inter-modal contributions.
In addition, to avoid finding all-zero solutions, we have to add the non-zero constraint while solving this minimization: \({{{{{{\boldsymbol{Q}}}}}}}^{{{{{{\boldsymbol{T}}}}}}}{{{{{\boldsymbol{DQ}}}}}}={{{{{\boldsymbol{I}}}}}}\), where \({{{{{\boldsymbol{Q}}}}}}=[\begin{array}{c}{{{{{\boldsymbol{f}}}}}}\\ {{{{{\boldsymbol{g}}}}}}\end{array}]\), \({{{{{\boldsymbol{f}}}}}}={[[{f}_{k}({x}_{{{{{{\rm{e}}}}}}}^{1})\ldots {f}_{k}({x}_{e}^{{d}_{1}})]]}_{k=1}^{d},{{{{{\boldsymbol{g}}}}}}={[[{g}_{k}({x}_{{{{{{\rm{t}}}}}}}^{1})\ldots {g}_{k}({x}_{t}^{{d}_{1}})]]}_{k=1}^{d}\), \({{{{{\boldsymbol{D}}}}}}\) is the diagonal matrix of \(\mu {W}_{{X}_{e}},\mu {W}_{{X}_{t}}\), and \({{{{{\boldsymbol{I}}}}}}\) is the identity matrix. Again, we used our previous ManiNetCluster method31 to solve this optimization and found the optimal functions and latent spaces for aligned cells using linear and nonlinear methods, including linear manifold alignment, canonical correlation analysis, linear manifold warping, nonlinear manifold alignment, and nonlinear manifold warping. Finally, after alignment, let \({\tilde{x}}_{e}^{i}={f}^{\ast }({x}_{e}^{i})\in {{\mathbb{R}}}^{d}\) and \({\tilde{x}}_{t}^{i}={g}^{\ast }({x}_{t}^{i})\in {{\mathbb{R}}}^{d}\) represent the coordinates of the \({i}_{th}\) cell on the common latent space (d-dimension) and \(d\) be 3 in our analysis for visualization. Moreover, the nonlinear manifold alignment is nonparametric and directly outputs the coordinates of the cells on the optimal latent spaces, without explicitly providing optimal mapping functions. In addition to the pairwise distances of cells on the common latent space, we also used the metric, fractions of samples closer than the true match (FOSCTTM)18 for evaluation. In particular, we calculated the FOSCTTM score of aligned cells as follows. For each cell in the electrophysiological data, we first find its true match in the gene expression data, then rank all other cells on the aligned latent space based on their distances from x, and finally compute the fraction of cells that are closer than the true match.
Identification of cross-modal cell clusters using Gaussian Mixture Model
After NMA alignment, the cells clustered together on the latent space imply that they share similar transcriptomic and electrophysiological features and form cross-modal cell clusters ('NMA' cell clusters). To identify such cross-modal cell clusters, we clustered the cells on the latent space into the cell clusters using gaussian mixture models (GMM) with K mixture components. Given a cell, we assigned it to the component k0 with the maximum posterior probability:
$$\Pr ({k}_{0}|{\tilde{X}}_{et}^{i},\lambda )=\frac{{w}_{i}g({\tilde{X}}_{et}^{i}|{\sum }_{{k}_{0}}{,}_{{k}_{0}})}{{\sum }_{k=1}^{K}{w}_{k}g({\tilde{X}}_{et}|{\sum }_{k}{,}_{k})}$$
where \({\tilde{x}}_{et}^{i}\) is the \({i}^{th}\) row of a combined feature set \([{\tilde{X}}_{e},{\tilde{X}}_{t}]\), \(\lambda =\{{w}_{k},{\mu }_{k}{|\Sigma }_{k}\}k=1,\ldots ,K\) are parameters: mixture weights, mean vectors, and covariance matrices. Finally, the cells assigned to the same component form a cross-modal cell type. Also, we used the Expectation-maximization algorithm (EM) algorithm with 100 iterations to determine the optimal number of clusters with K = 5 (Fig. S6) by Bayesian information criterion (BIC) criterion35. K = 5 was chosen at which the \(BIC=Kln(n)+2(\hat{L})\) of the model has an approximately constant and insignificant gradient descent through the equation. Silhouette values are used to compare the clustering result36, which takes a value from −1 to 1 for each cell and indicates a more pronouncedly clustered cell as the value increases.
Differentially expressed genes, enrichment analyses, gene regulatory networks, and representative cellular features of cross-modal cell clusters
We used the Seurat to identify differentially expressed genes of each cell cluster and multiple tests, including Wilcox and ROC, to further identify the marker genes of cell clusters (adjusted p value < 0.01)22. We applied this method to the electrophysiological features (absolute values) to find each cluster's represented e-features. Also, we used the web app, g:Profiler to find the enriched KEGG pathways, GO terms of cell-cluster marker genes, implying underlying biological functions in the cell clusters37. Enrichment p values were adjusted using the Benjamin–Hochberg (B–H) correction. Furthermore, we predicted the gene regulatory networks for cell clusters, linking transcription factors to target marker genes by SCENIC38. Those networks provide potentially additional regulatory mechanistic insights for electrophysiology at the cell-type level.
Prediction of electrophysiological features using gene expression
We generated the bibiplots that consist of a group of biplots using the method in5. In particular, we used the first three components of the transcriptomic and electrophysiological latent spaces from nonlinear manifold alignment (NMA) as the latent spaces for generating biplots. For the multivariate linear regression, let \({\tilde{X}}_{e}\in {{\mathbb{R}}}^{n\times d}\) and \({\tilde{X}}_{t}\in {{\mathbb{R}}}^{n\times d}\) be the first d dimensions of the electrophysiological and transcriptomic latent spaces, respectively, where n is the number of cells for training. The loss function of the multivariate regression is defined as\({\mathcal L} =\Vert {\tilde{X}}_{e}-{\tilde{X}}_{t}B{\Vert }^{2}\), and the solution is given by \(\hat{B}={({\tilde{X}}_{t}^{{\top }}{\tilde{X}}_{t})}^{-1}{\tilde{X}}_{t}^{{\top }}{\tilde{X}}_{e}\). Also, we performed 10-fold cross-validation with 20 repetitions. For each repetition, all cells were randomly partitioned into 10 subsets. A subset was selected as a testing set, and the remaining subsets were assigned as training sets. The training sets were used to estimate coefficients, and the testing set was used to calculate \({R}^{2}\). The process was repeated 10 times to choose different testing sets. Cross-validated \({R}^{2}\) is calculated through
\({R}^{2}=1-\frac{{\tilde{X}}_{e}^{test}-{\tilde{X}}_{t}^{test}{\hat{B}}^{2}}{\Vert {\tilde{X}}_{e}^{test}{\Vert }^{2}}\), where \({\tilde{X}}_{e}^{test}\) and \({\tilde{X}}_{t}^{test}\) were centered using testing set means. The reported \({R}^{2}\) is averaged across all folds and repetitions. We also tried multiple d values to check where the regression overfits, especially for the low dimensionality of the latent space. We varied d from 3 to 20 and found that the cross-validated \({R}^{2}\) does not change too much and slightly decreased as the dimension increases (from 0.987 to 0.954 for the visual cortex; from 0.977 to 0.952 for the motor cortex).
Also, we used the multivariate linear regression to predict represented electrophysiological features by the expression levels of differentially expressed genes (DEGs) (adjusted p value < 0.05) of our cross-modal clusters (and t-types). In particular, we split the cells into 90% training set (\({n}_{train}\) cells) and 10% testing set (\({n}_{test}\) cells). Let \({X}_{{t}_{i}}\in {{\mathbb{R}}}^{{n}_{train}\times {c}_{i}}\) represent the expression levels of \({c}_{i}\) differential expressed genes in Cluster \(i\), and \({Y}_{ij}\in {{\mathbb{R}}}^{{n}_{train}}\) represent the observed values of \(j\)th represented electrophysiological feature in Cluster \(i\) for the training cells, the predicted \(j\)th electrophysiological feature \({\hat{Y}}_{ij}\in {{\mathbb{R}}}^{{n}_{train}}\) and regression parameters \({\hat{\beta }}_{ij}\) given by \({\hat{Y}}_{ij}={X}_{{t}_{i}}{\hat{\beta }}_{ij}={X}_{{t}_{i}}{({X}_{{t}_{i}}^{{\top }}{X}_{{t}_{i}})}^{-1}{X}_{{t}_{i}}^{{\top }}{Y}_{ij}\), based on the solution to the multivariate linear regression as above. Finally, we can predict the electrophysiological feature for testing set, \({\hat{Y}}_{ij}^{test}\in {{\mathbb{R}}}^{{n}_{test}}\) by \({\hat{Y}}_{ij}^{test}={X}_{{t}_{i}}^{test}{\hat{\beta }}_{ij}\), and calculate both the training and testing \({R}^{2}\) values for evaluating the prediction.
Statistics and reproducibility
Differentially gene expression analysis was implemented by Seurat22 (adjusted p value < 0.01). Gene set enrichment analysis was done by the web app, g:Profiler37. Enrichment p-values were adjusted using the Benjamin–Hochberg (B–H) correction. Silhouette values were calculated by R function silhouette(). Gaussian mixture models for clustering were implemented by R package gmm.
Reporting Summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
All our results are provided in Supplementary Data 1–5. All processed data are available at https://github.com/daifengwanglab/scMNC. All other data are available from the corresponding author on reasonable request.
The codes for our analyses and figures are available at https://github.com/daifengwanglab/scMNC.
Eberwine, J., Sul, J.-Y., Bartfai, T. & Kim, J. The promise of single-cell sequencing. Nat. Methods 11, 25–27 (2014).
Gouwens, N. W. et al. Classification of electrophysiological and morphological neuron types in the mouse visual cortex. Nat. Neurosci. 22, 1182–1195 (2019).
Bomkamp, C. et al. Transcriptomic correlates of electrophysiological and morphological diversity within and across excitatory and inhibitory neuron classes. PLoS Comput Biol. 15, e1007113 (2019).
Tripathy, S. J. et al. Transcriptomic correlates of neuron electrophysiological diversity. PLoS Comput Biol. 13, e1005814 (2017).
Scala, F. et al. Phenotypic variation of transcriptomic cell types in mouse motor cortex. Nature 598, 144–150 (2020).
Cadwell, C. R. et al. Electrophysiological, transcriptomic and morphologic profiling of single neurons using Patch-seq. Nat. Biotechnol. 34, 199–203 (2016).
Pratapa, A., Jalihal, A. P., Law, J. N., Bharadwaj, A. & Murali, T. M. Benchmarking algorithms for gene regulatory network inference from single-cell transcriptomic data. Nat. Methods 17, 147–154 (2020).
Schlitt, T. et al. From gene networks to gene function. Genome Res 13, 2568–2576 (2003).
Kobak, D. & Berens, P. The art of using t-SNE for single-cell transcriptomics. Nat. Commun. 10, 5416 (2019).
Becht, E. et al. Dimensionality reduction for visualizing single-cell data using UMAP. Nat. Biotechnol. 37, 38–44 (2018).
Alquicira-Hernandez, J., Sathe, A., Ji, H. P., Nguyen, Q. & Powell, J. E. scPred: accurate supervised method for cell-type classification from single-cell RNA-seq data. Genome Biol. 20, 264 (2019).
Gala, R. et al. Consistent cross-modal identification of cortical neurons with coupled autoencoders. Nat. Comput Sci. 1, 120–127 (2021).
Scala, F. et al. Layer 4 of mouse neocortex differs in cell types and circuit organization between sensory areas. Nat. Commun. 10, 4174 (2019).
Gouwens, N. W. et al. Integrated Morphoelectric and Transcriptomic Classification of Cortical GABAergic. Cells Cell 183, 935–953.e19 (2020).
Ma, Y. & Yu, F. Manifold learning theory and applications. (C. R. C.; Taylor & Francis [distributor], 2012).
Vu, H., Carey, C. & Mahadevan, S. Manifold Warping: Manifold Alignment over Time. in AAAI (University of Massachusetts, 2012).
Singh, R. et al. Unsupervised manifold alignment for single-cell multi-omics data. ACM BCB 2020, 1–10 (2020).
PubMed PubMed Central CAS Google Scholar
Cao, K. et al. Unsupervised topological alignment for single-cell multi-omics integration. Bioinformatics 36, i48–i56 (2020).
Demetci, P. et al. Gromov-Wasserstein optimal transport to align single-cell multi-omics data. BioRxiv https://doi.org/10.1101/2020.04.28.066787 (2020).
Amodio, M. & Krishnaswamy, S. MAGAN: Aligning biological manifolds. International Conference on Machine Learning. (PMLR, 2018).
Kobak, D. et al. Sparse reduced-rank regression for exploratory visualization of paired multivariate datasets. BioRxiv http://biorxiv.org/lookup/doi/10.1101/302208 (2018).
Stuart, T. et al. Comprehensive integration of single-cell data. Cell 177, 1888–1902.e21 (2019).
Lim, L., Mi, D., Llorca, A. & Marín, O. Development and functional diversification of cortical interneurons. Neuron 100, 294–313 (2018).
Labzin, L. I. et al. ATF3 is a key regulator of macrophage IFN esponses. J. I 195, 4446–4455 (2015).
CAS Google Scholar
Tasic, B. et al. Shared and distinct transcriptomic cell types across neocortical areas. Nature 563, 72–78 (2018).
Leite, J. A. et al. Neuroinflammation and Neurotransmission Mechanisms Involved in Neuropsychiatric Disorders. In Mechanisms of Neuroinflammation (ed. Abreu, G. E. A.) (InTech, 2017).
Yuan, F. et al. Induction of human somatostatin and parvalbumin neurons by expressing a single transcription factor LIM homeobox 6. Elife 7, (2018).
Berg, J. et al. Human cortical expansion involves diversification and specialization of supragranular intratelencephalic-projecting neurons. bioRxiv 2020.03.31.018820 https://doi.org/10.1101/2020.03.31.018820 (2020).
Fawaz, H. I., Forestier, G., Weber, J., Idoumghar, L. & Muller, P.-A. Deep learning for time series classification: a review. Data Min. Knowl. Discov. 33, 917–963 (2019).
Liu, J., Lin, D., Yardimci, G. G. & Noble, W. S. Unsupervised embedding of single-cell Hi-C data. Bioinformatics 34, i96–i104 (2018).
Ji, Z., Zhou, W., Hou, W. & Ji, H. Single-cell ATAC-seq signal extraction and enhancement with SCATE. Genome Biol. 21, 161 (2020).
Aitken, M. et al. Intrinsic Physiology Feature Extractor (IPFX) Python package. https://ipfx.readthedocs.io/.
Wang, D. et al. Comprehensive functional genomic resource and integrative model for the human brain. Science 362, eaat8464 (2018).
Nguyen, N. D., Blaby, I. K. & Wang, D. ManiNetCluster: a novel manifold learning approach to reveal the functional links between gene networks. BMC Genomics 20, 1003 (2019).
Huang, T., Peng, H. & Zhang, K. MODEL SELECTION FOR GAUSSIAN MIXTURE MODELS. Statistica Sin. 27, 147–169 (2017).
Rousseeuw, P. J. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J. Computational Appl. Math. 20, 53–65 (1987).
Reimand, J. et al. g:Profiler—a web server for functional interpretation of gene lists (2016 update). Nucleic Acids Res 44, W83–W89 (2016).
Aibar, S. et al. SCENIC: single-cell regulatory network inference and clustering. Nat. Methods 14, 1083–1086 (2017).
Moon, K. R. et al. Visualizing structure and transitions in high-dimensional biological data. Nat. Biotechnol. 37, 1482–1492 (2019).
This work was supported by National Institutes of Health grants, R01AG067025, R21CA237955, R03NS123969 and U01MH116492 to D.W., P50HD105353 to Waisman Center, and the start-up funding for D.W. from the Office of the Vice Chancellor for Research and Graduate Education at the University of Wisconsin–Madison.
Jiawei Huang
Present address: Carl H. Lindner College of Business, University of Cincinnati, Cincinnati, OH, 45223, USA
Department of Statistics, University of Wisconsin - Madison, Madison, WI, 53706, USA
Waisman Center, University of Wisconsin – Madison, Madison, WI, 53705, USA
Jie Sheng & Daifeng Wang
Department of Biostatistics and Medical Informatics, University of Wisconsin – Madison, Madison, WI, 53706, USA
Daifeng Wang
Department of Computer Sciences, University of Wisconsin – Madison, Madison, WI, 53706, USA
Jie Sheng
D.W. conceived and designed the study. J.H., J.S. and D.W. analyzed the data and wrote the manuscript. All authors read and approved the final manuscript.
Correspondence to Daifeng Wang.
Peer review information Communications Biology thanks the anonymous reviewers for their contribution to the peer review of this work. Primary Handling Editors: Enzo Tagliazucchi and Karli Montague-Cardoso. Peer reviewer reports are available.
Publisher's note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Transparent Peer Review File
Description of Additional Supplementary Files
Supplementary Data 1
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
Huang, J., Sheng, J. & Wang, D. Manifold learning analysis suggests strategies to align single-cell multimodal data of neuronal electrophysiology and transcriptomics. Commun Biol 4, 1308 (2021). https://doi.org/10.1038/s42003-021-02807-6
Communications Biology (Commun Biol) ISSN 2399-3642 (online) | CommonCrawl |
Reading: Sea ice drift in the Southern Ocean: Regional patterns, variability, and trends
Sea ice drift in the Southern Ocean: Regional patterns, variability, and trends
Ron Kwok ,
Jet Propulsion Laboratory, California Institute of Technology Pasadena, California, US
Shirley S. Pang,
Sahra Kacimi
Understanding long-term changes in large-scale sea ice drift in the Southern Ocean is of considerable interest given its contribution to ice extent, to ice production in open waters, with associated dense water formation and heat flux to the atmosphere, and thus to the climate system. In this paper, we examine the trends and variability of this ice drift in a 34-year record (1982–2015) derived from satellite observations. Uncertainties in drift (~3 to 4 km day–1) were assessed with higher resolution observations. In a linear model, drift speeds were ~1.4% of the geostrophic wind from reanalyzed sea-level pressure, nearly 50% higher than that of the Arctic. This result suggests an ice cover in the Southern Ocean that is thinner, weaker, and less compact. Geostrophic winds explained all but ~40% of the variance in ice drift. Three spatially distinct drift patterns were shown to be controlled by the location and depth of atmospheric lows centered over the Amundsen, Riiser-Larsen, and Davis seas. Positively correlated changes in sea-level pressures at the three centers (up to 0.64) suggest correlated changes in the wind-driven drift patterns. Seasonal trends in ice edge are linked to trends in meridional winds and also to on-ice/off-ice trends in zonal winds, due to zonal asymmetry of the Antarctic ice cover. Sea ice area export at flux gates that parallel the 1000‐m isobath were extended to cover the 34-year record. Interannual variability in ice export in the Ross and Weddell seas linked to the depth and location of the Amundsen Sea and Riiser-Larsen Sea lows to their east. Compared to shorter records, where there was a significant positive trend in Ross Sea ice area flux, the longer 34-year trends of outflow from both seas are now statistically insignificant.
Copyright: © 2017 California Institute of Technology. U.S. Government sponsorship acknowledged.
Knowledge Domain: Ocean Science
Keywords: Southern Ocean,sea ice drift,export,sea ice edge
How to Cite: Kwok, R., Pang, S.S. and Kacimi, S., 2017. Sea ice drift in the Southern Ocean: Regional patterns, variability, and trends. Elem Sci Anth, 5, p.32. DOI: http://doi.org/10.1525/elementa.226
Published on 21 Jun 2017
Accepted on 21 May 2017 Submitted on 06 Mar 2017
Domain Editor-in-Chief: Jody W. Deming; University of Washington, US
Associate Editor: Eddy C. Carmack; Fisheries & Oceans Canada, CA
The present examination of Antarctic ice drift and its response to wind and ocean currents pertains to interests in the recent trends in sea ice coverage and the formation of dense water in the Southern Ocean; both topics are relevant to understanding variability and changes in the climate system. The overall increase in Antarctic sea ice extent over the satellite record is the sum of opposing trends in different sectors of the Southern Ocean (Comiso and Nishio, 2008; Comiso et al., 2011); currently, there is no consensus on the causal mechanisms. Advances and retreats of the ice edge have been linked to trends in wind-driven ice drift, due to large-scale intensification in surface winds associated with the circumpolar lows around Antarctica (e.g., Holland and Kwok, 2012; Haumann et al., 2014; Zhang, 2014; Kwok et al., 2016). Hence, the variability in wind and drift patterns is of particular geophysical interest. From the perspective of dense water formation, ice growth in leads and polynyas dominates the heat flux into the atmosphere and thus brine flux into the ocean. On a regional scale, the redistribution of freshwater via the transport and subsequent melt of relatively fresh sea ice modifies ocean buoyancy forcing. Of particular climatic interest is the dense/high salinity water that is produced in Antarctic polynyas; these water masses sink along the continental slope after mixing with surrounding waters to form the Antarctic Bottom Water (AABW) of the deep ocean (Foster and Carmack, 1976; Gordon, 1991). The best-documented sources of AABW lie along the margins of the Weddell Sea. Sources of dense bottom water have also been identified at other locations around the perimeter of Antarctica, such as the Adelie Coast, and off Enderby Land. The Ross Sea, in the Pacific sector, is also thought to be a significant source of this cold high salinity water. Hence, understanding the changes in ice drift over a broad-length time scale is of substantial interest.
Since the late 1990s, the availability of the moderate resolution ice drift from satellite passive microwave observations (e.g., Agnew et al., 1997; Emery et al., 1997; Kwok et al., 1998) has allowed large-scale studies of drift patterns over Antarctic sea ice. The great strengths of this dataset are its spatial coverage and the length of the data record, which is more than three decades (at this writing), for the combination of SMMR, SSM/I and AMSR-E instruments. The limitation is that the fairly coarse spatial resolution of the imagery produces uncertainties of several kilometers for individual displacement vectors. These datasets are better suited for understanding synoptic and longer-term drift patterns rather than the detailed characteristics of daily ice motion. Previous investigations using these data sets have focused broadly on: the relationship between wind and ice drift (e.g., Kwok et al., 1998; Kimura, 2004); the export of sea ice from the Weddell and Ross seas (e.g., Martin et al., 2007; Drucker et al., 2011); and the variability and trends in ice drift (e.g., Comiso et al., 2011; Kimura and Wakatsuchi, 2011; Holland and Kwok, 2012; Kwok et al., 2016). With a 34-year record (1982–2015) of Antarctic satellite ice drift, the aim of this paper is to examine the following five topics: 1) the mean and trends of the drift; 2) the variability in the location of the drift patterns; 3) the relationship between wind and drift; 4) the relationship between the trends in ice edge and ice drift; and 5) ice export from the Weddell and Ross seas.
We begin by describing the derivation of the ice motion fields and ancillary data sets used in our analysis, also providing an assessment of the quality of drift estimates in the satellite passive microwave record using ice drift from high-resolution Synthetic Aperture Radar (SAR) imagery (Section 2). We then present the three distinct drift patterns seen in monthly mean fields over the 34-year record and investigate the variability in their spatial location and the correlations in their behavior (Section 3). After examining the relationship between wind and ice drift in the Southern Ocean sea ice cover (Section 4), we present computations of the spatial trends in wind and ice drift, and explore their relationships to trends in ice edge and to large-scale atmospheric modes (Section 5). We extend the time series of ice area export from the Weddell and Ross seas as discussed elsewhere (Section 6), and end with a summary of our findings and conclusions.
2 Data description
In this section, we describe the ice drift and other data sets used in this paper. In particular, an assessment of the gridded satellite drift estimates using ice drift derived from high-resolution SAR data is provided.
2.1 Ice motion fields
Ice drift data used here are retrievals from successive satellite brightness temperature fields (Kwok et al., 1998). We used only the March through November ice drift estimates as the ice tracking results are unreliable during the Antarctic summer and transitional months. This lack of reliability is due to spatial variability in the brightness-temperature fields associated with water vapor, cloud liquid content, and surface wetness during these months. The gridded fields of ice drift u→M1 \documentclass[10pt]{article} \usepackage{wasysym} \usepackage[substack]{amsmath} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage[mathscr]{eucal} \usepackage{mathrsfs} \usepackage{pmc} \usepackage[Euler]{upgreek} \pagestyle{empty} \oddsidemargin -1.0in \begin{document} \[ \vec u \] \end{document}
(100 km spacing) – on a polar stereographic projection – were constructed by blending ice drift derived from two satellite radiometer channels (37 GHz and 85 GHz – 91 GHz since 2009), viz.
u⇀^(x,y)=∑iαiu⇀i85GHz+∑jβju⇀j37GHz.
M2 \documentclass[10pt]{article} \usepackage{wasysym} \usepackage[substack]{amsmath} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage[mathscr]{eucal} \usepackage{mathrsfs} \usepackage{pmc} \usepackage[Euler]{upgreek} \pagestyle{empty} \oddsidemargin -1.0in \begin{document} \[ \hat {\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\rightharpoonup$}} \over u} }\left({x,y} \right) = \mathop \sum \limits_i {\alpha _i}\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\rightharpoonup$}} \over u} _i^{85GHz} + \mathop \sum \limits_j {\beta _j}\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\rightharpoonup$}} \over u} _j^{37GHz}. \] \end{document}
The weighting coefficients α and β were determined by an optimal interpolation scheme (Kwok et al., 2013); the indices i and j are the available observations from individual radiometer channels. Motion and drift are used interchangeably throughout this paper. A spatial correlation length scale of 300 km was used to create the interpolated motion field. This length scale was selected at an intermediate scale based on the density of satellite observations, but short enough that the expressions of coastal effects and drift are not noticeably degraded. A consistent and updated time series of passive microwave brightness temperature and ice concentration fields (Maslanik and Stroeve, 2004; Gloersen, 2006) were used to produce the satellite ice drifts. Uncertainties in drift estimates from the SMMR (1982–1987) and SSM/I (1988–present) datasets are between 3 and 6 km (depending on spatial resolution of the passive microwave channel) for individual displacement vectors. Ice motion fields from multiple channels on the same instrument (e.g., 37 GHz and 85 GHz on SSM/I) were used when they were available. Together, the length of the ice drift record provided by the combination of sensors spans more than three decades. Our records start in 1982 to avoid gaps in the earlier (1978–1981) brightness temperature fields. Based on the number of observations and expected uncertainties in the passive microwave (PMW) ice motion estimates, the procedure above provides an analyzed error of each motion estimate. An expected average uncertainty of 3–4 km day–1 in the individual interpolated estimates is typical (addressed in Section 3), although the uncertainty varies with the density of measurements available within the neighborhood of each estimate. Henceforth, these passive microwave estimates will be referred to as PMW ice drift. The ice motion data set used here can be found at: https://rkwok.jpl.nasa.gov/antarc_icemotion/index.html.
Available near-daily drift estimates from Envisat SAR imagery (resolution: ~150 m) between 2007 and 2010 were used to assess the quality of the passive microwave ice drift. These SAR-derived ice drifts are primarily in the southern Ross and Weddell seas and are sampled on a uniform 10-km grid; uncertainties in the estimates are ~300 m day–1 (Lindsay and Stern, 2003) and thus of significantly better quality than those derived from the passive microwave fields (several kilometers per day). They are considered as truth in the following analysis. The tracking of common ice features in a sequence of SAR images has been described by Kwok et al. (1990).
2.2 Quality of PMW ice drift estimates
A comparison of 4 years (2007 through 2010) of PMW and SAR ice drift estimates is provided in Figure 1; each drift vector has been decomposed into its two orthogonal components with the orientation defined by the SSM/I polar stereographic projection (x-axis: 90°E, y-axis: 0°E). To match the space-scale of the PMW drift estimates, the comparisons are to averages of high-resolution Envisat drift vectors within a radius of 50 km of each grid point or each 100-km gridded PMW estimate. As mentioned earlier, available SAR-derived ice drifts are primarily of the southern Ross and Weddell seas (mainly south of 65°S); spacecraft resources and space agency (European Space Agency) programming determine the repeat SAR coverage. Thus, faster ice drifts closer to the ice edge and ice margins are not sampled.
Comparison of 4 years of daily drift estimates from passive microwave fields and Envisat SAR imagery. (a) Ross Sea. (b) Weddell Sea. Seasonally, the Envisat ice drift covers the period between April and November. Numerical quantities near the top of each panel are the number of drift estimates in the scatterplot, the mean ± standard deviation of the differences, and the correlation between the two estimates. As the drift estimates are not contemporaneous, the colorbar shows the offset between the start-time of each drift vector (sometimes up to 12 hours). DOI: https://doi.org/10.1525/elementa.226.f1
The difference statistics for the Ross and Weddell seas are consistent with each other. Over the 4 years, the correlations between the PMW and SAR ice drifts are between 0.73 and 0.86. The mean difference varies between 1.5 and –0.5 km day–1, with standard deviations that range between 3.3 and 6.8 km day–1 for individual vector components. These differences are comparable to an earlier assessment of PMW ice drift in the Ross Sea using RADARSAT ice drift (Kwok, 2005) of ~4.5 km day–1, and show relative consistency in the quality of derived PMW motion estimates over different periods. The differences are somewhat higher than the analyzed uncertainties (i.e., 3–4 km day–1) provided by the optimal interpolation procedure. This finding is not unexpected, but worthwhile noting here is that the correlations and differences fall between two estimated quantities, and errors/noise in these quantities would lower the true correlation and increase the differences. In addition, the following factors contribute to the variance of the observed differences: (1) the drift estimates are not contemporaneous in that there is an offset between the start time of each displacement vector (sometimes up to 12 hours, as determined by satellite revisit times), and thus the drift estimates are often decorrelated in time; (2) the PMW drift represents an average over a larger space scale (~300 km) compared to the averaged Envisat-derived drifts, which also depend on the density and availability of measurements in the neighborhood of each grid point as determined by the Envisat image overlaps; and (3) the drift estimates are from PMW imagery that are daily composites with ill-defined time stamps. Thus, it is not unexpected that the assessed differences are higher than that expected by the interpolation procedure.
2.3 Ice edge time series
The locations of the time-varying ice edge used here were sampled at longitudinal increments of one degree (i.e., 360 increments are used to define the circumpolar ice edge). Ice edge is defined as the latitudinal location where the ice concentration first exceeds 15% in the transition from open-ocean to the consolidated ice cover. Gridded maps of ice concentration (1982–2015) were derived from the Scanning Multi-channel Microwave Radiometer (SMMR) and Special Sensor Microwave Imager (SSM/I) data using the Bootstrap Algorithm (Comiso and Nishio, 2008).
2.4 Other data sets
Sea-level pressures (SLP) are from the ERA-Interim atmospheric reanalysis project (http://apps.ecmwf.int/datasets/data/interim-full-daily/levtype=sfc/) and the Southern Oscillation (SO) and Southern Annular Mode (SAM) indices are from NCDC (www.ncdc.noaa.gov/teleconnections/enso/indicators). The geostrophic wind fields (G⇀=−k→f×∇PM3 \documentclass[10pt]{article} \usepackage{wasysym} \usepackage[substack]{amsmath} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage[mathscr]{eucal} \usepackage{mathrsfs} \usepackage{pmc} \usepackage[Euler]{upgreek} \pagestyle{empty} \oddsidemargin -1.0in \begin{document} \[ \mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\rightharpoonup$}} \over G} = - {\textstyle{{\vec k} \over f}} \times \nabla P \] \end{document}
: f = Coriolis parameter; ρ = air density; P = sea-level pressure; and k→M4 \documentclass[10pt]{article} \usepackage{wasysym} \usepackage[substack]{amsmath} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage[mathscr]{eucal} \usepackage{mathrsfs} \usepackage{pmc} \usepackage[Euler]{upgreek} \pagestyle{empty} \oddsidemargin -1.0in \begin{document} \[ \vec k \] \end{document}
is the surface normal) used here were derived from SLP fields.
3 Mean and variability of drift patterns
Figure 2 shows the location of circumpolar seas and the three drift patterns within the Antarctic sea ice zone in the monthly motion fields of the 34-year record. These wind-driven drift patterns can be seen as linked to distinct atmospheric low-pressure centers (at sea level) within the circumpolar trough around Antarctica, as discussed in more detail in Section 4. The first pattern is associated with the Amundsen Sea Low (ASL) centered roughly over the Amundsen Sea; it spans the Ross, Amundsen, and Bellingshausen seas (roughly between 150°E and 60°W). Due to influence of the ASL on the West Antarctic climate and its link to the climate of the tropical Pacific, this climatic pattern has received more attention (Turner et al., 2013; Raphael et al., 2016) than the following two. The second, centered over the Riiser-Larsen Sea (~30°E), spans the Weddell, Lazarev, Riiser-Larsen, and Cosmonaut seas (between 60°W and 60°E). A third, centered over the Davis Sea (~90°E), spans the Cooperation, Davis, Mawson, D'Urville, and Somov seas (between 60°E and 150°E). For convenience here, we refer to the second and third centers of low pressure as the Riiser-Larsen Sea Low (RLSL) and the Davis Sea Low (DSL), respectively, based on their location. The first two drift patterns are dominant in all winter months, while the third drift pattern is only visible (in Figure 2) between August and November due to the absence of ice drift (in our low-resolution fields) to trace the wind-driven circulation during the other months. Below, we summarize the features of these three drift patterns separately. As ice drift is largely wind-driven, we examined the variability of the zonal and meridional location of the three low-pressure centers and the covariance of the sea-level pressure between these centers of action. The location of the centers impacts ice export (discussed in Section 6), the occurrence of coastal polynyas, and the location of the ice edge as discussed by Kwok et al. (2016).
Ice motion of the 34-year record (1982–2015). (a) Names and locations of the marginal seas. (b) Mean monthly (March through November) ice drift. Contours are isobars (interval: 4 hPa) from ERA-Interim sea-level pressure fields. Drift estimates are shown on a 200-km grid to reduce density of vectors within each plot; every other vector is displayed. Red crosses show the centers of the three atmospheric lows in the monthly mean fields. DOI: https://doi.org/10.1525/elementa.226.f2
3.1 Amundsen Sea Low drift pattern (Ross Gyre)
The cyclonic (clockwise) drift pattern, associated with the ASL centered over the northeast Ross Sea, is evident in all months between March and November (Figure 2). This oceanic circulation pattern is known as the Ross Sea Gyre. Along the Antarctic coast, the average ice drift is westward towards the Ross Sea. The drift pattern shows a coastal inflow of sea ice into the Ross Sea from the Amundsen Sea in the east, then southward along the coast of the Ross Sea embayment, with a considerably stronger northward outflow in the west. This imbalance in the overall circulation points to significant divergence and production of open water and areas of rapid ice growth in the Ross Sea polynyas off the Ross Ice Shelf (RIS) that are frequent occurrences during all winter months (Martin et al., 2007; Comiso et al., 2011). Some recirculation of the outflow in the eastern Ross Sea is also evident. North of Cape Adare, the northward ice drift splits into two branches with one that moves westward into the Somov Sea and the other northeastward. Farther north, the prevailing motion is eastward as the sea ice becomes entrained in the fast moving Antarctic Circumpolar Current during the late winter.
Atmospheric forcing plays a significant role in the enhancement of the sea ice outflow in the western Ross Sea (Figure 2). Importantly, this outflow influences the ice production in polynyas at the ice front of the RIS (the Ross Sea Polynya, sometimes referred to as the Ross Ice Shelf Polynya) and Terra Nova Bay (the Terra Nova Bay Polynya). Records from automatic weather stations (AWS) deployed over the RIS reveal that the dominant near-surface airflow over the western RIS is northward, passes to the east of Ross Island (Savage and Stearns, 1985) and appears to be the primary atmospheric forcing for development of the Ross Sea Polynya (Bromwich et al., 1993). Bromwich et al. (1998) found that synoptic cyclones near Roosevelt Island induce SLP distribution over the RIS with isobars oriented parallel to the Transantarctic Mountains. This setup results in the intensification and northward propagation of the katabatic winds across the ice shelf with associated low-level warming. An immediate impact of katabatic surges is the development of polynyas where heat and salt fluxes associated with new ice growth are intense: about 60% of the polynya events are linked to katabatic surge events; and 40% from katabatic drainage winds (from glaciers) and barrier winds (winds that flow northward along the Transantaractic Mountains and are deflected eastward by topographic barriers along the Scott Coast) (Bromwich et al., 1998). The interannual variability in ice export from the Ross Sea is discussed in Section 5.
3.2 Riiser-Larsen Sea Low drift pattern (Weddell Gyre)
This cyclonic drift pattern (also an expression of the oceanic Weddell Gyre) dominates the ice drift over the months of March through November (Figure 2). A feature of this pattern is the band of strong westward coastal drift just south of the center of the RLSL (seen to span the Lazarev, Riiser-Larsen, and Cosmonaut seas). To the west, the ice drift between May and September is westward with a slight northward component. In October and November, the turn southward into the Weddell Sea (near Cap Norwegia) is especially apparent; this branch flows towards the Filchner and Ronne Ice shelves before turning westward and northward away from the ice shelves and out of the Weddell Sea. The large northward drift in the west exports sea ice produced in the Southern Weddell Sea and the coastal polynyas along the Ronne and Brunt ice shelves (Drucker et al., 2011). North of the Antarctic Peninsula, similar to that in the Ross Sea, prevailing motion is faster and towards the east as the ice merges with the southern-most reaches of the Antarctic Circumpolar Current, and is especially dominant during the late winter.
3.3 Davis Sea Low drift pattern
The cyclonic DSL drift pattern (Figure 2), as mentioned earlier, is not as prominent as that of the ASL and RLSL patterns. Even though the low-pressure system is evident in the SLP distribution, the narrow band of sea ice in this region, which extends only ~400 km from the coast at maximum extent, does not allow the pattern to be traced out by the low-resolution drift fields (used here) until later in the winter (i.e., after August). A band of strong westward coastal drift just south of the center of the DSL low is also seen to span the Cooperation, Davis, Mawson, D'Urville, and Somov seas.
3.4 Variability of the three atmospheric lows
As ice drift is largely wind-driven (see Section 4), our interest in the variability in the meridional/zonal location and strength of these low-pressure centers is related to their impact on ice export, polynya activity, and on the extent of the ice edge as discussed by Kwok et al. (2016). The monthly mean locations (March through November) of the three atmospheric lows (ASL, RLSL, and DSL) over the 34-year record are shown in Figure 2, while the variability in their seasonal locations over the record is shown in Figure 3a. Locations with the lowest monthly sea-level pressure anomalies within each of the three sectors (described above) are designated as the centers of the seasonal lows in the monthly fields; there are 192 such locations (in the 34-year record) within each sector.
Sea level lows within the Antarctic sea ice zone (1982–2015). (a) Locations of the three low-pressure centers (Amundsen Sea Low: ASL, Riiser-Larsen Sea Low: RLSL, and Davis Sea Low: DSL) in seasonal mean sea-level pressure (SLP) fields from ERA-interim reanalysis. Ellipses show the seasonal variability of their spatial locations. (b) Correlations (ρ) of the sea-level pressure anomalies at the three low-pressure centers by season (December–January–February: DJF, March–April–May: MAM, June–July–August: JJA, September–October–November: SON). (c) Time-longitude diagram of interannual normalized anomalies (positive/negative is colored red/blue) in sea-level pressure anomalies averaged over latitudes between 60°S and 65°S. Panels (d) and (e) are same as (c) but anomalies are averaged for 65°S and 70°S, and 70°S and 78°S, respectively. DOI: https://doi.org/10.1525/elementa.226.f3
Three distinct clusters, well separated from each other, can be seen in the spatial distribution of the centers of the seasonal lows (Figure 3a). In all three sectors, the zonal spread in the lows is higher than that of the meridional spread. When the geographic variability of the seasonal centers are separated into the four seasons (as depicted by four ellipses), the following features are apparent: 1) in all three sectors, the spatial spread of the centers is much smaller during the winter (light blue ellipses in Figure 3a) compared to the other seasons, suggesting seasonality in the expected location of the lows and hence variability in the circulation pattern; and 2) the zonal locations of the ASL (red ellipses) are farther to the east during the summer than those seen in the other sectors. In fact, Fogt et al. (2012) and Turner et al. (2013) noted a well-defined annual cycle in the average zonal location of the ASL, with the low being found immediately west of the Antarctic Peninsula in austral summer (December–February) and shifting westward to the Ross Sea by winter (June–August). A similar annual cycle in zonal location of the DSL (i.e., farther east during the summer) is also noticeable, but not for the RLSL.
Correlations (ρ) between the time series of monthly SLP anomalies at ASL, RLSL, and DSL are of interest as they reveal the linked variability of these circumpolar lows, and hence the linked behavior in the sea ice circulation patterns and their associated impact on ice export, polynya activity, and the ice extent (discussed in later sections). The seasonal correlations are seen in Figure 3b. All three time-series are positively correlated. These circumpolar teleconnections can be seen in the vertical banding of the SLP anomalies (red: positive, blue: negative) in the longitude-time diagrams (Figures 3c–e). In three latitude ranges (60°S–65°S, 65°S–70°S, 70°S–78°S), these vertical bands of the nearly same color indicate that anomalies in the circumpolar SLP co-vary and, on average, in phase with each other. In summary, because the wind explains a large fraction of the variance in ice drift (discussed next), the behavior of the circumpolar ice cover is connected.
4 Wind and ice drift
In this section, we examine the relationship between wind and ice drift in the 34-year record. We quantify the response of daily ice drift to geostrophic wind and compare our results with earlier work on this topic.
To examine the response of daily ice drift to geostrophic wind over the Southern Ocean sea ice cover, we followed Thorndike and Colony (1982) (henceforth TC82) and used a linear model to relate the observed ice motion (u) to geostrophic wind (G) and mean ocean current (c¯M5 \documentclass[10pt]{article} \usepackage{wasysym} \usepackage[substack]{amsmath} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage[mathscr]{eucal} \usepackage{mathrsfs} \usepackage{pmc} \usepackage[Euler]{upgreek} \pagestyle{empty} \oddsidemargin -1.0in \begin{document} \[ \bar c \] \end{document}
), viz.
u=AG+c¯+ε.
M6 \documentclass[10pt]{article} \usepackage{wasysym} \usepackage[substack]{amsmath} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage[mathscr]{eucal} \usepackage{mathrsfs} \usepackage{pmc} \usepackage[Euler]{upgreek} \pagestyle{empty} \oddsidemargin -1.0in \begin{document} \[ u = AG + \bar c + \varepsilon. \] \end{document}
A is a complex constant and ε represents that part of the ice velocity that is neither a constant nor a linear function of the geostrophic wind. To compute the complex coefficient (A) and intercept (c¯M7 \documentclass[10pt]{article} \usepackage{wasysym} \usepackage[substack]{amsmath} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage[mathscr]{eucal} \usepackage{mathrsfs} \usepackage{pmc} \usepackage[Euler]{upgreek} \pagestyle{empty} \oddsidemargin -1.0in \begin{document} \[ \bar c \] \end{document}
), the components of the motion (u) and geostrophic wind (G) vectors are thought of as the real and imaginary parts of a complex number. The following parameters: |A|, θ, and ρ2 are obtained by regression analysis of the time series of daily wind and ice drift at each grid point. With the 34-year record, we constructed gridded spatial fields of these parameters. The magnitude of the scaling factor (i.e., |A|) tells us about the coupling between wind and ice and the variability in the internal ice stresses that tend to oppose ice motion. θ is the turning angle from the geostrophic wind direction to the direction of ice motion (positive is to the left of the wind), and the squared correlation coefficient (ρ2) is that fraction of the ice motion explained by the geostrophic wind.
The fields of |A| and ρ2 are shown in Figure 4. We first discuss their spatial variability over the record. Geographically, |A| is higher (>0.014) towards the ice edge away from the Antarctic coasts, while the lowest values for |A| can be found in the southern Weddell, western Weddell next to the Antarctic Peninsula, and western Ross seas. Between March and November, the average complex scaling factor was 0.014 ± 0.002exp(i5 ± 2.3°). This result can be compared to a scaling factor that ranged between 0.005 and 0.015 in the Weddell Sea (Kottmeier and Sellmann, 1996), and was 0.017exp(i4°) in the Ross Sea (Kwok, 2005). It can also be contrasted with the scaling factor for the winter Arctic: 0.0077exp(–i5°) from buoy drift (Thorndike and Colony, 1982) and 0.009 ± 0.0015exp(–i1.9 ± 2.6°) from satellite ice drift (Kwok et al., 2013). Due to Coriolis, the ice drift direction in the Southern Hemisphere is turned to the left of the wind instead of the right. Of note is that the scaling factor is nearly 50% higher than that of the Arctic – even with the observed thinning. In fact, this scaling factor is closer to that obtained during the Arctic summer (June through September) of 0.011 exp(–i18) (Thorndike and Colony, 1982) and 0.01 ± 0.001 exp(–i7.1 ± 3.6°) from recent satellite ice drift (Kwok et al., 2013).
Geographic variability of scale factor and squared correlation coefficient for the 34-year record. Color bar indicates scale factor |A| in (a) and squared correlation coefficient ρ2 in (b). Numerical values in the lower right of each panel show the mean and standard deviation of that field. The isopleths in (a) and (b) are 0.01 and 0.65, respectively. DOI: https://doi.org/10.1525/elementa.226.f4
The contrast between the Arctic and Antarctic suggests that the predominantly seasonal Antarctic sea ice cover is closer to free drift conditions than that observed in the Arctic, where the thicker ice is geographically confined within a basin. Generally, to achieve the same ice velocity, higher wind stresses are required to oppose ice stress where ice is thick or more compact (i.e., higher ice strength). The generally higher |A| over the Antarctic ice cover also suggests a much thinner and less compact ice cover compared to that of the Arctic.
That fraction of the variance of ice motion, which is explained by geostrophic wind, is given by the squared correlation coefficient, ρ2. At distances of 200–400 km from the Antarctic coast, ρ2 is about 0.65 ± 0.05 and the values of ρ2 are generally lower within 400 km of the coast, although this zone varies spatially. Coastal geometry, or mechanical constraints on ice drift, tends to reduce the correlation between wind and motion. Based on the regression analysis, the linear model – on average – explains all but about 40% of the variance of the ice motion.
5 Trends in ice drift and ice edge
Recent studies have reported large and statistically significant trends in Antarctic ice drift in most sectors that are associated with the intensification of surface winds (Holland and Kwok, 2012; Zhang, 2014), suggesting that regional wind-driven changes may be one of the drivers of ice extent around much of Antarctica. Here, we examine in more detail these trends in our longer 34-year drift record and relate these to trends in winds and the latitudinal extent of the ice edge. Ice drift and wind vectors were decomposed into their respective zonal and meridional components. Figure 5 shows trend maps of the following five parameters in six 2-month periods: meridional wind and drift (Figure 5a and b), ice edge (Figure 5c), and zonal wind and drift (Figure 5d and e). In the following, we first look at the trends in wind and ice drift, and then their correlations to trends in ice edge.
Trends (1982–2015) in wind, ice drift, and ice edge. (a) Meridional winds. (b) Meridional ice drift. (c) Ice edge. (d) Zonal ice drift. (e) Zonal winds. Trends in ice edge (in degrees of latitude per decade) are relative to the 2-month mean ice edge over the 34-year record (in black). Positive/negative ice edge trends are in red/blue. Also shown are the five geographic sectors typically used for calculation of trends in ice extent. Color of interior circles shows the confidence level in the ice edge trend (blue: > 95%, red: > 99%; black ≤ 95%). DOI: https://doi.org/10.1525/elementa.226.f5
5.1 Drift and wind trends
The mean circumpolar trends in ice drift for April to October for a 19-year period between 1992 and 2010 were discussed by Holland and Kwok (2012). The trends in Figure 5 extend the span of the record to 34 years, which cover nearly the entire satellite era. Further, the partitioning of the record into 2-month maps of the zonal and meridional components allows for a more detailed view of the regional and intra-seasonal variability of the drift trends, and their relationship to trends in the wind field.
Visual inspection reveals that there are substantial large-scale correlations of the spatial pattern of the polarity of trends in wind and ice drift in all 2-month sections (Figure 5a, b, d and e). But, discrepancies between the trend patterns can be seen. Even though the wind explains ~60% of the variance in ice drift (Section 3), there are limitations in the accuracy of current reanalysis fields, especially in representing their trends. Two areas of differences are of note. One standout is that the positive drift trends in the Ross Sea outflow, especially striking in the meridional drift fields (Figure 2) between July and October, is noticeably absent in the corresponding wind field. In coastal Antarctica, the absence of a corresponding trend in the wind field may be due to the inability of the ERA-interim reanalysis to capture the local intensification and northward propagation of the katabatic and drainage winds – boundary layer effects – linked to the development of polynyas in the Ross Sea (Sanz Rodrigo et al., 2012). This absence can be contrasted to the better correspondence of trends in the large-scale (synoptic) wind field with ice drift away from the continent. Also notable is the lack of correspondence between the August–September meridional wind and drift trends. We do not have a suitably satisfying explanation for this discrepancy.
5.2 Relationship to ice edge trends
Opposing trends in Antarctic sea ice extent can be observed in different sectors of the Southern Ocean (Comiso and Nishio, 2008; Comiso et al., 2011). The predominantly two-wavenumber pattern in the ice-edge trends (see Figure 5) suggests that they are associated with trends in the large-scale (synoptic) wind field connected to the atmospheric lows discussed in Section 3. A recent study by Kwok et al. (2016) showed that on average two-thirds of the winter ice edge trend in the Pacific sector can be explained by ice drift and meridional winds, linked to extratropical atmospheric anomalies associated with the Southern Oscillation. Here we first examine the circumpolar trends in ice edge and their relationship to the trends in the meridional and zonal wind and ice drift.
As seen in Figure 5, it is apparent that the expansion of the ice cover or advances in the latitudinal extent of the ice edge can be linked, to a certain degree, to positive trends in the local meridional winds. For trends in zonal winds or ice drift, Figure 6 illustrates how zonal ice drift trends could affect local trends in ice edge. Note that the left-turning tendencies of ice drift due to Coriolis (relative to the geostrophic wind direction) is already part of the observed drift; hence, the discussion here is not associated with this component of ice drift. Rather, due to the zonal asymmetry of the Antarctic ice cover, it can be seen that a coherent zonal drift trend or rotation of the mean ice edge (from red to blue in Figure 6) would create local ice edge trends: off-ice zonal winds would advect into areas that are typically open ocean or away from areas of ice coverage and vice versa for on-ice winds. The decomposition into zonal and meridional directions seems unnecessary, but this step is useful for examining circumpolar westerlies (for example) in the context of large-scale changes in the wind field (e.g., due to the Southern Annular Mode). Both the strengthening and weakening of the westerlies impact the location of the ice edge.
Effect of on-ice and off-ice zonal ice drift on ice edge trends. Vectors show the impact of wind on a zonally-asymmetric ice cover. DOI: https://doi.org/10.1525/elementa.226.f6
While there is correspondence between the trends in the ice edge and trends in drift/wind, direct correlations are not seen at all times or everywhere (Figure 5). In May and June, the positive ice edge trends in Sector-1 (S1) and the western part of S4 are clearly associated with the trends of similar polarity in the zonal rather than meridional wind and ice drift. However, opposite meridional and zonal wind trends in S5 have little effect on the ice edge trend. For June–July, there is general correspondence of the polarities of the ice edge trend with the ice drift/wind trends. Thus, the relationship between ice edge and drift trends is not seen everywhere, although some of the issues may be due to the limitations in the reanalysis products in the Southern Ocean seen in the discrepancies in wind and drift discussed earlier.
The plots in Figure 7 provide a seasonal (March–April–May: MAM, June–July–August: JJA, and September–October–November: SON) perspective of the circumpolar trends in ice edge and in meridional/zonal winds at different latitude bands. Again, the two-wavenumber pattern in the ice edge trends is evident in all three seasons, although the location of the peaks varies zonally. Except for the zonal wind trends during the fall (MAM), the meridional/zonal wind trends have a two- to three-wavenumber pattern. The highest correlations are observed between the circumpolar trends in ice edge and meridional/zonal wind during winter (JJA), when the mean ice edge is farthest north and extends into the Antarctic Circumpolar Current. The correlations between circumpolar ice edge and zonal wind trends are higher (0.74 between 55°S and 60°S) in winter than in other seasons, and in fact higher than the correlation with meridional winds (0.34 between 55°S and 60°S). During the spring (SON), the ice-edge/meridional-wind trend correlations are weaker (0.46 between 65°S and 70°S) and ice-edge/zonal-wind trend correlations are negative (–0.42 between 65°S and 70°S). In the fall (MAM), the location of the peaks just east of Victoria Land and the Antarctic Peninsula suggest that the trends may be controlled by the coastal boundaries (see Figure 7a and b) when the developing ice cover is generally within the embayments of the Ross and Weddell seas. The results suggest that ice edge trends are linked to zonal wind trends, and that – within the context of ice drift and wind – coastal constraints may have a role in the observed trends in ice extent.
Seasonal trends in circumpolar ice edge, meridional and zonal winds for the 34-year record. Seasons are March–April–May (MAM), June–July–August (JJA), and September–October–November (SON). Wind trends are of the three latitude bands shown. Ice edge trends (black in degrees/decade) are normalized to 60° as a better indicator of area trend. Wind trends corresponding to the latitude band of the ice edge are dashed. Color bar at the bottom of each panel shows the confidence level of the ice edge trends (blue: > 95%, red: > 99%; black ≤ 95%). DOI: https://doi.org/10.1525/elementa.226.f7
5.3 Links to the Southern Oscillation and Southern Annular Mode
Previous work has shown that anomalies in circumpolar ice edge location and surface climate in the Southern Ocean are linked to these two dominant atmospheric modes: the Southern Oscillation (SO) and Southern Annular Mode (SAM) (e.g., Kwok and Comiso, 2002a, 2002b; Stammerjohn et al., 2008; Yuan and Li, 2008; Simpkins et al., 2012; Kwok et al., 2016). Here, we summarize broadly the large-scale anomalies in our 34-year record of ice drift, together with those of wind and ice edge, associated with extremes in the SOI and SAMI (I denotes index). The composite maps in Figure 8 show these anomalies in their positive (SOI+: SOI > 1.0; SAMI+: SAMI > 1.0) and negative (SOI–: SOI < –1.0; SAMI–: SAMI < –1.0) phases for two periods: May–August and August–November. As in Figure 5, ice drift and winds have been decomposed into their meridional and zonal components.
Composites of ice and surface climate anomalies during positive/negative phases of the SOI and SAMI. Anomalies for the Southern Oscillation Index (SOI) are shown for May through August (a) and August through November (b), and for the Southern Annular Mode Index (SAMI) for May through August (c) and August through November (d). Panels from left are anomalies of: meridional winds (m s–1), meridional ice drift (km day–1), ice edge (±0.5°), zonal ice drift (m s–1), and zonal winds (km day–1). DOI: https://doi.org/10.1525/elementa.226.f8
The SOI+ and SOI– composite maps (Figure 8a and b) show that the meridional drift/wind/ice edge anomalies are organized in distinct spatial patterns with broadly opposing polarities but with different magnitudes. These characteristics are less pronounced in the zonal drift/wind composites, and of note is that the zonal wind anomalies do not exhibit opposing patterns seaward of the ice-covered ocean. The responses to the SO are different and stronger in August–November. For both periods, the anomalies in meridional ice drift during SOI– are stronger, suggesting potential asymmetry in the response to the two extremes of the SO. In the Pacific Sector (between ~180°E and 60°W), the positive ice edge anomalies in the eastern Ross/Amundsen seas and the negative ice edge anomalies in the Bellingshausen Sea in the SOI+ composite resemble the pattern in the observed time trends (Figure 5), and coincide with the positive/negative anomalies in meridional ice motion and winds. A recent study (Kwok et al., 2016) reported that the trend in SOI over a 32-year period is able to quantitatively explain the July–November trends in sea ice edge, drift, and surface winds in this sector.
The anomalies in the SAM+ and SAM– composite maps (Figure 8c and d) also show distinct spatial patterns with broadly opposing polarities, but with contrasting magnitudes that are more pronounced in the meridional composites. In both periods, the strengthening and weakening of the westerlies in the zonal drift/wind composites – a characteristic of the SAM – are unmistakable and dominate the entire spatial pattern. Also, there is less asymmetry and a more balanced (i.e., the two periods look similar) zonal response to the SAM. The meridional responses to the SAM are different in May–August and August–November, with the strongest response in August–November.
In the composites of ice edge anomalies, whether in extremes of the SO or SAM, it is interesting to note that the location of the 2-wavenumber ice edge anomalies remain relatively stationary, even though they are of different magnitudes. It should also be pointed out that these composites are not pure responses to given atmospheric modes, as they are embedded responses in a coupled climate system.
6 Ice export: Ross and Weddell seas
The interest in ice export from the Ross and Weddell seas pertains to ice production in their coastal polynyas. Coastal polynyas are large, persistent regions of open water and thin ice that form adjacent to a lee shore within the pack ice. When winter winds blow the pack ice away from the coast, seawater at near freezing temperatures is exposed to a large negative heat flux, resulting in rapid formation of new ice and brine rejection. As Jacobs (2004) describes, the polynyas and ice export at these two Antarctic seas contribute to the formation of dense shelf water and subsequently Antarctic bottom water. In both of these seas, polynya activity and ice drift are driven by the depth and zonal location of low-pressure systems to the east (e.g., ASL and the Ross Sea polynyas).
Because of the importance of these seas to shelf- and deep-water production and the similarity of their atmospheric forcing, we computed the annual, inter-annual, and decadal variability in ice area export over the 34-year record. To extend earlier records (Kwok, 2005; Drucker et al., 2011), flux gates were placed parallel to the 1000-m isobaths for calculating ice export (Figure 9). The daily area flux, F, was estimated by integrating the cross-gate motion profile using the simple trapezoidal rule, F=∑1n−10.5(ui+ui+1)CiΔxM8 \documentclass[10pt]{article} \usepackage{wasysym} \usepackage[substack]{amsmath} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage[mathscr]{eucal} \usepackage{mathrsfs} \usepackage{pmc} \usepackage[Euler]{upgreek} \pagestyle{empty} \oddsidemargin -1.0in \begin{document} \[ F = \sum\nolimits_1^{n - 1} {0.5\left({{u_i} + {u_{i + 1}}} \right)} {C_i}\Delta x \] \end{document}
, where u is the magnitude of the motion perpendicular to the flux gate, Δx is the spacing between the motion estimates, Ci is the ice concentration (between ui and ui+1) from PMW analyses, and n is the number of motion samples along the gate.
Ice area export. (a) Ross Sea flux gate. The western endpoint of this gate terminates at Cape Adare and the eastern endpoint terminates at Land Bay. The length of the gate is ~1400 km and the area enclosed is ~490 × 103 km2. (b) Weddell Sea flux gate. The length of the gate is ~1110 km and the area enclosed is ~283 × 103 km2. Both gates are near parallel to the 1000-m isobaths (dashed line). DOI: https://doi.org/10.1525/elementa.226.f9
At these flux gates, we calculated the winter inflow, outflow and net outflow of ice area at the flux gate as the total of the daily area flux from the beginning of March until the end of November. The net flux is the difference between outflow and inflow. A positive net outflow would be a measure of the ice area produced in the Ross Sea if there were no melt, deformation or sea ice advected into the area, and the net production would be zero if export equals import. It is therefore of interest to examine the two contributions to the net outflow because it provides a rough estimate of the ice that is advected in, from the east, and the total that is exported to the west; that is, the ice area produced in the Ross or Weddell seas and the re-export of the eastern inflow.
6.1 Ross Sea
The eastern and western termini of the Ross Sea flux gate are located at Land Bay and Cape Adare, respectively. The gate spans a length of ~1400 km and encloses an area of ~490 × 103 km2 to the south, where ice production occurs in the Ross Shelf Polynya and the Terra Nova Bay and McMurdo Sound polynyas. Previous studies have examined the variability of Ross ice area exports between 1992 and 2008 (Comiso et al., 2011; Drucker et al., 2011). Here, the area flux record (Figure 9) has been extended to cover a 34-year PMW record starting in 1982.
The average net (out minus in) outflow for the 34-year record is 0.75 × 106 km2 and ranges from a low of 0.35 × 106 km2 in 1986 to a peak of 1.36 × 106 km2 in 2001, a more than fourfold variability over the timespan. At the peak in 2001, the conditions that are favorable for large net outflow are SLP isobars that are nearly perpendicular to the edge of the RIS associated with the the location of the center of the ASL low. In this case, the highest outflow (1.56 × 106 km2) is accompanied by the lowest inflow of 0.22 × 106 km2 on record. The Ross Sea, with an area of ~490 × 103 km2 south of the flux gate, exports more than twice its area of sea ice every 9 months. The standard deviation of the net flux, at 0.27 × 106 km2, is high. A more moderate positive trend of ~77 × 103 km2 decade–1 (statistically insignificant) can be seen in the 34-year record, and can be compared to the higher ~300 × 103 km2 decade–1 trend reported in the shorter 17-year record (1982–2008) (Comiso et al., 2011). The net positive trend during the 34 years appears to be the result of a positive trend in the outflow and a smaller positive trend in the inflow.
6.2 Weddell Sea
The gate that connects the two termini of the Weddell Sea flux gate has length of ~1100 km and encloses an area of ~283 × 103 km2. Polynya ice production occurs primarily in two regions within this area: around the Brunt Ice Shelf, which we call the Eastern Weddell Polynya (EWP), at the Ronne Ice Shelf. For ice area export, Drucker et al. (2011) estimated an average area flux of 0.52 × 106 km2 (April and November) for 2003–2008.
The average net (out minus in) outflow for the 34-year record is 0.32 × 106 km2 and ranges from a minimum of 0.02 × 106 km2 in 1990 to a peak of 0.70 × 106 km2 in 1986, a more than tenfold variability over the period. Similar to the Ross Sea, the high flux can be attributed to the depth and the zonal location of the RLSL. The Weddell Sea, with an area of ~283 × 103 km2 within the flux gate, exports approximately its own area of sea ice every 9 months. The standard deviation of the net flux, at 0.16 × 106 km2, is high. A negative trend of ~45 × 103 km2 decade–1, which is statistically insignificant, can be seen in the 34-year record.
7 Conclusions
In this paper, we have examined patterns, trends and variability in sea ice drift and circulation in the Southern Ocean in a 34-year data set of satellite-derived ice drift. Antarctic sea ice drift and circulation are of relevance to understanding changes in the climate system, as observed trends in ice drift, export and circulation patterns are related to large-scale changes in atmospheric circulation, dense water formation, and also connected to trends in sea ice coverage. Here, we highlight our results and conclusions:
In a linear model that relates ice drift to wind, drift speeds of sea ice in the Southern Ocean are ~1.4% that of the geostrophic wind. This scale factor is close to 50% higher when contrasted to results obtained using similar analyses in the Arctic. This difference suggests an ice cover in the Southern Ocean that is thinner, weaker, less compact, and not confined within a basin. Geostrophic winds explain all but ~40% of the variance in ice drift.
There are three distinct cyclonic drift patterns that are controlled by the location and depth of three atmospheric lows. They are centered over the Amundsen, Riiser-Larsen, and Davis seas. Seasonal sea-level pressures at the three centers are positively correlated (up to 0.64), and these circumpolar teleconnections suggest correlated changes in the three wind-driven drift patterns.
Circumpolar trends in ice edge, especially in winter, can be linked to trends in meridional winds. Of particular note is that ice edge trends are also linked to on-ice/off-ice trends in zonal winds that can be due to the inherent zonal asymmetry of sea ice coverage around Antarctica.
Anomalies in large-scale ice drift can be linked to the variability in the Southern Oscillation and the Southern Annular Mode.
Earlier estimates of sea ice export at flux gates that parallel the 1000-m isobath in the Ross and Weddell seas have now been extended to cover the 34-year record. Variability in ice export from these seas is high and linked to the depth and center of Amundsen Sea and Riiser-Larsen Sea lows to their east. Compared to shorter records, where there was a significant trend in the Ross Sea ice area flux, the 34-year trends of outflow from both seas are now statistically insignificant.
The ice motion data set used here can be found at: https://rkwok.jpl.nasa.gov/antarc_icemotion/index.html.
The ice motion data set used here can be found at the following URL: https://rkwok.jpl.nasa.gov/antarc_icemotion/index.html. RK, SSP, and SK carried out this work at the Jet Propulsion Laboratory, California Institute of Technology, under contract with the National Aeronautics and Space Administration.
RK, SSP, and SK carried out this work at the Jet Propulsion Laboratory, California Institute of Technology, under contract with the National Aeronautics and Space Administration.
Contributed to conception and design: RK.
Contributed to acquisition of data: RK, SSP.
Contributed to analysis and interpretation of data: RK, SSP, SK.
Drafted and/or revised the article: RK.
Approved the submitted version for publication: RK.
Agnew T, Le H and Hirose T 1997. Estimation of large-scale sea-ice motion from SSM/I 85.5 GHz imagery. Ann Glaciol 25: 305–311, DOI: http://dx.doi.org/10.1017/S0260305500014191
Bromwich DH, Carrasco JF, Liu Z and Tzeng RY 1993. Hemispheric atmospheric variations and oceanographic impacts associated with katabatic surges across the Ross Ice Shelf, Antarctica. J Geophys Res-Atmos 98(D7): 13045–13062, DOI: http://dx.doi.org/10.1029/93JD00562
Bromwich DH, Liu Z, Rogers AN and Van Woert M 1998. Winter atmospheric forcing of the Ross Sea Polynya In: Jacobs, S and Weiss, RF eds. Ocean, Ice, and Atmosphere: Interactions at the Antarctic Continental Margins. AGU, pp. 101–133.
Comiso JC, Kwok R, Martin S and Gordon AL 2011. Variability and trends in sea ice extent and ice production in the Ross Sea. J Geophys Res 116(C04): 021.DOI: http://dx.doi.org/10.1029/2010JC006391
Comiso JC and Nishio F 2008. Trends in the sea ice cover using enhanced and compatible AMSR-E, SSM/I, and SMMR data. J Geophys Res 113(C2)DOI: http://dx.doi.org/10.1029/2007JC004257
Drucker R, Martin S and Kwok R 2011. Sea ice production and export from coastal polynyas in the Weddell and Ross Seas. Geophys Res Lett 38(17)DOI: http://dx.doi.org/10.1029/2011GL048668
Emery WJ, Fowler CW and Maslanik JA 1997. Satellite-derived maps of Arctic and Antarctic sea ice motion: 1988 to 1994. Geophys Res Lett 24(8): 897–900, DOI: http://dx.doi.org/10.1029/97GL00755
Fogt RL, Wovrosh AJ, Langen RA and Simmonds I 2012. The characteristic variability and connection to the underlying synoptic activity of the Amundsen-Bellingshausen Seas Low. J Geophys Res 117(D7)DOI: http://dx.doi.org/10.1029/2011JD017337
Foster TD and Carmack EC 1976. Temperature and salinity structure in Weddell Sea. J Phys Oceanogr 6(1): 36–44, DOI: http://dx.doi.org/10.1175/1520-0485(1976)006<0036:TASSIT>2.0.CO;2
Gloersen P 2006. Nimbus-7 SMMR polar gridded radiances and sea ice concentrations, Version 1, Boulder, Colorado USA. NASA National Snow and Ice Data Center Distributed Active Archive Center, DOI: http://dx.doi.org/10.5067/QOZIVYV3V9JP
Gordon, AL ed. 1991. Two stable modes of Southern Ocean winter stratification. New York: Elsevier. (Elsevier Oceanogr Ser 57).
Haumann FA, Notz D and Schmidt H 2014. Anthropogenic influence on recent circulation-driven Antarctic sea ice changes. Geophys Res Lett 41(23): 8429–8437, DOI: http://dx.doi.org/10.1002/2014GL061659
Holland PR and Kwok R 2012. Wind-driven trends in Antarctic sea-ice drift. Nat Geosci 5(12): 872–875, DOI: http://dx.doi.org/10.1038/ngeo1627
Jacobs SS 2004. Bottom water production and its links with the thermohaline circulation. Antarct Sci 16(4): 427–437, DOI: http://dx.doi.org/10.1017/S095410200400224X
Kimura N 2004. Sea ice motion in response to surface wind and ocean current in the Southern Ocean. J Meteorol Soc Jpn 82(4): 1223–1231, DOI: http://dx.doi.org/10.2151/jmsj.2004.1223
Kimura N and Wakatsuchi M 2011. Large-scale processes governing the seasonal variability of the Antarctic sea ice. Tellus A 63(4): 828–840, DOI: http://dx.doi.org/10.1111/j.1600-0870.2011.00526.x
Kottmeier C and Sellmann L 1996. Atmospheric and oceanic forcing of Weddell Sea ice motion. J Geophys Res 101(C9): 20809–20824, DOI: http://dx.doi.org/10.1029/96JC01293
Kwok R 2005. Ross Sea ice motion, area flux, and deformation. J Climate 18: 18.DOI: http://dx.doi.org/10.1175/JCLI3507.1
Kwok R and Comiso JC 2002a. Southern Ocean climate and sea ice anomalies associated with the Southern Oscillation. J Clim 15(5): 487–501, DOI: http://dx.doi.org/10.1175/1520-0442(2002)015<0487:SOCASI>2.0.CO;2
Kwok R and Comiso JC 2002b. Spatial patterns of variability in antarctic surface temperature: Connections to the Southern Hemisphere Annular Mode and the Southern Oscillation. Geophys Res Lett 29(14): 1705.DOI: http://dx.doi.org/10.1029/2002GL015415
Kwok R, Comiso JC, Lee T and Holland PR 2016. Linked trends in the South Pacific sea ice edge and Southern Oscillation Index. Geophys Res Lett 43(19): 10,295–10,302, DOI: http://dx.doi.org/10.1002/2016GL070655
Kwok R, Curlander JC, Mcconnell R and Pang SS 1990. An ice-motion tracking system at the Alaska Sar Facility. IEEE J Ocean Eng 15(1): 44–54, DOI: http://dx.doi.org/10.1109/48.46835
Kwok R, Schweiger A, Rothrock DA, Pang S and Kottmeier C 1998. Sea ice motion from satellite passive microwave imagery assessed with ERS SAR and buoy motions. J Geophys Res 103(C4): 8191–8214, DOI: http://dx.doi.org/10.1029/97JC03334
Kwok R, Spreen G and Pang S 2013. Arctic sea ice circulation and drift speed: Decadal trends and ocean currents. J Geophys Res 118(5): 2408–2425, DOI: http://dx.doi.org/10.1002/jgrc.20191
Lindsay RW and Stern HL 2003. The RADARSAT geophysical processor system: Quality of sea ice trajectory and deformation estimates. J Atmos Ocean Technol 20(9): 1333–1347, DOI: http://dx.doi.org/10.1175/1520-0426(2003)020<1333:TRGPSQ>2.0.CO;2
Martin S, Drucker RS and Kwok R 2007. The areas and ice production of the western and central Ross Sea polynyas, 1992–2002, and their relation to the B-15 and C-19 iceberg events of 2000 and 2002. J Mar Syst 68(1–2): 201–214, DOI: http://dx.doi.org/10.1016/j.jmarsys.2006.11.008
Maslanik J and Stroeve J 2004. DMSP SSM/I-SSMIS daily polar gridded brightness temperatures. Version 4 (updated 2012), Boulder, Colorado USA. NASA DAAC at the National Snow and Ice Data Center,
Raphael MN Marshall GJ Turner J Fogt RL Schneider D et al. 2016. The Amundsen Sea Low variability, change, and impact on Antarctic climate. Bull Am Meteorol Soc 97(1): 111–121, DOI: http://dx.doi.org/10.1175/BAMS-D-14-00018.1
Sanz Rodrigo J, Buchlin J-M, van Beeck J, Lenaerts JTM and van den Broeke MR 2012. Evaluation of the antarctic surface wind climate from ERA reanalyses and RACMO2/ANT simulations based on automatic weather stations. Clim Dyn 40(1–2): 353–376, DOI: http://dx.doi.org/10.1007/s00382-012-1396-y
Savage ML and Stearns CR 1985. Climate in the vicinity of Ross Island, Antaractica. Antarct J U S 20: 1–9.
Simpkins GR, Ciasto LM, Thompson DWJ and England MH 2012. Seasonal relationships between large-scale climate variability and Antarctic sea ice concentration. J Clim 25(16): 5451–5469, DOI: http://dx.doi.org/10.1175/JCLI-D-11-00367.1
Stammerjohn SE, Martinson DG, Smith RC, Yuan X and Rind D 2008. Trends in Antarctic annual sea ice retreat and advance and their relation to El Niño–Southern Oscillation and Southern Annular Mode variability. J Geophys Res 113(C3)DOI: http://dx.doi.org/10.1029/2007JC004269
Thorndike AS and Colony R 1982. Sea ice motion in response to geostrophic winds. J Geophys Res 87(NC8): 5845–5852, DOI: http://dx.doi.org/10.1029/JC087iC08p05845
Turner J, Phillips T, Hosking JS, Marshall GJ and Orr A 2013. The Amundsen Sea low. Int J Climatol 33(7): 1818–1829, DOI: http://dx.doi.org/10.1002/joc.3558
Yuan X and Li C 2008. Climate modes in southern high latitudes and their impacts on Antarctic sea ice. J Geophys Res 113(C6)DOI: http://dx.doi.org/10.1029/2006JC004067
Zhang J 2014. Modeling the impact of wind intensification on Antarctic sea ice volume. J Clim 27(1): 202–214, DOI: http://dx.doi.org/10.1175/JCLI-D-12-00139.1
Kwok, R., Pang, S.S. and Kacimi, S., 2017. Sea ice drift in the Southern Ocean: Regional patterns, variability, and trends. Elem Sci Anth, 5, p.32. DOI: http://doi.org/10.1525/elementa.226
Kwok R, Pang SS, Kacimi S. Sea ice drift in the Southern Ocean: Regional patterns, variability, and trends. Elem Sci Anth. 2017;5:32. DOI: http://doi.org/10.1525/elementa.226
Kwok, R., Pang, S. S., & Kacimi, S. (2017). Sea ice drift in the Southern Ocean: Regional patterns, variability, and trends. Elem Sci Anth, 5, 32. DOI: http://doi.org/10.1525/elementa.226
Kwok R, Pang SS and Kacimi S, 'Sea Ice Drift in the Southern Ocean: Regional Patterns, Variability, and Trends' (2017) 5 Elem Sci Anth 32 DOI: http://doi.org/10.1525/elementa.226 | CommonCrawl |
Alevin efficiently estimates accurate gene abundances from dscRNA-seq data
Avi Srivastava1,
Laraib Malik1,
Tom Smith2,
Ian Sudbery3 &
Rob Patro ORCID: orcid.org/0000-0001-8463-16751
Genome Biology volume 20, Article number: 65 (2019) Cite this article
We introduce alevin, a fast end-to-end pipeline to process droplet-based single-cell RNA sequencing data, performing cell barcode detection, read mapping, unique molecular identifier (UMI) deduplication, gene count estimation, and cell barcode whitelisting. Alevin's approach to UMI deduplication considers transcript-level constraints on the molecules from which UMIs may have arisen and accounts for both gene-unique reads and reads that multimap between genes. This addresses the inherent bias in existing tools which discard gene-ambiguous reads and improves the accuracy of gene abundance estimates. Alevin is considerably faster, typically eight times, than existing gene quantification approaches, while also using less memory.
There has been a steady increase in the throughput of single-cell RNA-seq (scRNA-seq) experiments, with droplet-based protocols (dscRNA-seq) [1–3] facilitating experiments assaying tens of thousands of cells in parallel. The three most widely used dscRNA-seq protocols: Drop-seq [1], inDrop [2], and 10X Chromium [3], use two separate barcodes that require appropriate processing for accurate quantification estimation. First, cellular barcodes (CBs) are used to tag each cell with a unique barcode, which enables pooling of cells for sequencing and their subsequent separation in silico. Thus, data processing requires the identification of the true CBs corresponding to distinct cells, and grouping the reads accordingly. Second, identification of PCR duplicates is aided by unique molecular identifiers (UMIs), which tag each unique molecule prior to amplification. Since the mRNA capture rate is only around 5–10% [4], many rounds of PCR are typically performed prior to sequencing [1]. Appropriately accounting for the barcode information is therefore crucial for accurate estimation of gene expression. Only a minor fraction of the possible CBs present will ultimately tag a cell, and likewise, only a minor fraction of UMIs will tag unique molecules from the same gene. Thus, in each case, the aim is to identify the barcodes used. Unfortunately, both CBs and UMIs are subject to errors that occur during sequencing and amplification [1, 5], which makes the accurate deconvolution of this information in silico a non-trivial task. This task is made more difficult by the amplification of background RNA from empty droplets (ambient CBs) or damaged cells.
Various methods have been proposed to correctly process dscRNA-seq barcodes in an error-aware manner ("whitelisting") [3, 5–8], to correct sequencing errors in CBs and UMIs [5, 8], to deduplicate UMI tags inferred to be duplicates [5], and to obtain cell-level gene quantification estimates [9]. Here, we describe an end-to-end quantification pipeline that takes as input sample-demultiplexed FASTQ files and outputs gene-level UMI counts for each cell in the library. We call this unified pipeline alevin, and it overcomes two main shortcomings of traditional pipelines. First, existing techniques for UMI deduplication discard reads that map to more than one gene. In bulk RNA-seq datasets (with paired-end reads and full-length transcript coverage), the proportion of gene-ambiguous reads is generally small (Table 1). Yet, in tagged-end scRNA-seq, this set of gene-ambiguous reads is generally larger and commonly accounts for ∼ 14–23% of the input data (Table 2). This is a result of both the fact that dscRNA-seq protocols, by construction, display a very strong 3 ′ bias and that these protocols yield effectively single-end reads (only one of the sequenced reads contains sequence from the underlying transcript), resulting in a reduced ability to resolve multimapping using a pair of reads from a longer fragment. We show that discarding the multimapping reads can negatively bias the gene-level counts predicted by various methods. Second, existing quantification pipelines combine independent processing algorithms and tools for each step, usually communicating results between pipeline stages via intermediate files on disk, which significantly increases the processing time and memory requirements for the complete analysis. We show that alevin makes use of more reads than other pipelines, that this leads to more accurate quantification of genes, and that alevin does this ∼ 8 times faster and with a lower memory requirement, when compared to existing best practice pipelines for dscRNA-seq analysis.
Table 1 The percentage of reads multimapping in bulk datasets from human and mouse
Table 2 Percentage of reads multimapping across various scRNA-seq samples, using the alevin mappings
Alevin overview
There are several steps in the alevin pipeline that are streamlined to work without the overhead of writing to disk, as highlighted in Fig. 1 (details in the "Materials and methods" section). The first step is to identify the CBs that represent properly captured and tagged cells ("whitelisting"). Alevin uses a two-step whitelisting procedure, where the second step takes place at the end of the pipeline. An initial whitelist is produced by finding the "knee" in the cumulative distribution of CB frequencies [1, 3]. For each non-whitelisted CB, alevin tries to correct it to a whitelisted CB either by a substitution or by a single insertion or deletion. If no such barcode exists in the set of whitelisted barcodes, the barcode and its associated reads are discarded. The next step is mapping reads from the whitelisted CBs, and the corrected CBs, to a target transcriptome [10, 11], followed by UMI deduplication.
Overview of the alevin pipeline. The input to the pipeline are sample-demultiplexed FASTQ files, and there are several steps, outlined here, that are required to process this data and obtain per-cell gene-level quantification estimates. The first step is cell barcode (CB) whitelisting using their frequencies. Barcodes neighboring whitelisted barcodes are then associated with (collapsed into) their whitelisted counterparts. Reads from whitelisted CBs are mapped to the transcriptome, and the UMI-transcript equivalence classes are generated. Each equivalence class contains a set of transcripts, the UMIs that are associated with the reads that map to each class and the read count for each UMI. This information is used to construct a parsimonious UMI graph (PUG) where each node represents a UMI-transcript equivalence class and nodes are connected based on the associated read counts. The UMI deduplication algorithm then attempts to find a minimal set of transcripts that cover the graph (where each consistently labeled connected component—each monochromatic arborescence—is associated with a distinct pre-PCR molecule). In this way, each node is assigned a transcript label and, in turn, an associated gene label. Reads associated with arborescences that could be consistently labeled by multiple genes are divided amongst these possible loci probabilistically based on an expectation-maximization algorithm. Finally, optionally, and if not provided with high-quality CB whitelist externally, an intelligent whitelisting procedure finalizes a list of high-quality CBs using a naïve Bayes classifier to differentiate between high- and low-quality cells
The process of deduplication requires identifying duplicate reads based on their UMIs and alignment positions along the transcriptome. Alevin uses a novel algorithm for deduplication that begins by constructing parsimonious UMI graphs, that we refer to as a PUGs, using information from the UMI sequences, the UMI counts, and the transcript equivalence classes [12]. This PUG is constructed such that each UMI-transcript equivalence class pair is represented by a node and there exists an edge from a node to any node that could have arisen from an amplified molecule due to sampling the underlying transcript (a single pre-PCR molecule) at a different position, or via a PCR or a sequencing error being introduced into the UMI. When the direction of "duplication" during PCR is clear, a directed edge is added; otherwise, a bi-directed edge is placed. An optimal covering of this graph, using the transcripts associated with each node, will give the minimum number of UMIs, along with their counts, required to explain the set of mapped reads. Hence, we have mapped the deduplication problem to that of finding a minimum cardinality covering of a given graph by monochromatic arborescences. Since the decision version of this problem is NP-complete, we propose a greedy algorithm to obtain a minimum cardinality covering of this graph (proof and algorithm detailed under the "Materials and methods" section). Each covering, and the associated UMI, is assigned a set of transcript labels of size ≥ 1. After this UMI resolution phase, the remaining ambiguous reads with more than 1 transcript label are assigned based on an expectation-maximization method [13].
Finally, having obtained per-cell gene expression estimates, CB whitelisting is finalized using a naïve Bayes classifier to differentiate between high- and low-quality cells utilizing a set of features derived from the expression estimates and other diagnostic features [8]. In addition to the gene-by-cell count matrix, alevin also provides information about the reliability of the abundance estimate computed for each gene in each cell in the form of a tier matrix (and, optionally, the summarized variance of bootstrap estimates), which succinctly encodes the quality of the evidence used to derive the corresponding count.
Impact of discarding multimapping reads
Before proceeding with a more detailed analysis of the alevin pipeline, it is important to highlight scenarios where existing pipelines would fail using simple examples. These also lead to a better understanding of the alevin UMI deduplication algorithm that intelligently utilizes transcript-level information to obtain accurate gene-level estimates. Since current deduplication methods do not have a mechanism to detect UMIs that map between multiple transcripts of the same gene, they can, in certain cases, incorrectly detect PCR duplicates and, hence, under-estimate the total UMI counts. Some obvious cases can be resolved by considering the read-to-transcript mapping, instead of the read-to-gene mapping, as done in alevin and shown in the left panel in Fig. 2. The first row (top to bottom) demonstrates a case when we observe the same UMI (U1) being used to tag transcripts from two separate genes (G1 and G2). Here, all methods are able to correctly assess that these instances of U1 are not PCR duplicates. In the center row, we observe the same UMI deriving from two (sequence-distinct) transcripts of the same gene. Here, purely gene-level methods fail to resolve this collision, while alevin's strategy can. Finally, in the bottom row, we observe a UMI collision within a single transcript. That is, two different copies (molecules) of the same transcript have been tagged with the same UMI. This cannot be resolved by any of the methods. Though possible, the situation presented in the third row is highly unlikely, especially given the current sequencing depths.
a This figure illustrates examples of various classes of UMI collisions and which method(s) would be able to correctly resolve the origin of the multimapping reads in each scenario. These cases are shown top to bottom in order of their likelihood. b A simulated example demonstrates how treating equivalence classes individually during UMI deduplication can lead to under-collapsing of UMIs compared to gene-level methods (especially in protocols where the majority of cDNA amplification occurs prior to fragmentation). In the first row, both methods report correctly two UMIs. In the second row, there are two fragmented molecules aligned against two transcripts from the same gene. The alevin deduplication algorithm will attempt to choose the minimum number of transcripts required to explain the read mappings and hence correctly detect the UMI counts. The equivalence class method will over-estimate the gene count
A second scenario is highlighted in the right panel of Fig. 2 where using the transcript-level equivalence classes lead to over-counting UMIs (discussed further in the "Materials and methods" section). In these simulated examples, different types of transcripts and corresponding expression patterns are shown. Reads are randomly sampled from the 3 ′-end of the annotated transcript(s) according to a realistic fragment length distribution, where exon overlap induces the corresponding equivalence classes of each fragment. The top simulation shows 1 (pre-PCR) molecule expressed for each transcript, identifiable by a unique id (UMI), shown in blue. Due to the disjoint equivalence classes, both methods will correctly assign the gene count. In the bottom simulation, both molecules originate from the second transcript. However, since the equivalence classes are different, the two fragments sharing a UMI will not be collapsed. Specifically, as the rate of splicing (and hence the number of equivalence classes) increases, so too does the number of distinct UMIs reported. In this case, the alevin UMI deduplication algorithm will correctly detect the number of transcripts in order to greedily assign the minimum number of transcripts required to explain the given UMI and mapping information.
To show that the UMI deduplication algorithm from alevin does, indeed, perform better, we calculate the ratio of the number of reads mapping to each gene and the final count of UMIs as predicted by alevin and Cell Ranger for that gene. When a read maps ambiguously, the count is divided uniformly between the genes. Hence, if a read maps to two genes, the count for each is incremented by 0.5 to get the initial number of reads mapping to these genes. Note that the mappings are also different under each pipeline and that some reads may be inherently ambiguous under one or both mappings. These reads cannot be accurately assigned but, while Cell Ranger discards them, alevin assigns them to a gene via the PUG resolution algorithm, or, in the case that parsimony fails to distinguish a single best gene, proportionally to multiple genes according to the other uniquely mapping reads of the experiment. We divide the genes into 20 bins, based on the number of k-mers shared across genes. We expect the above calculated ratio to remain fairly consistent across these 20 bins, irrespective of the sequence properties of the genes in them. However, we observe in Fig. 3 that the predictions from Cell Ranger are biased for the genes with low sequence uniqueness. This is because a large number of reads from these genes will multimap across genes and will, therefore, be discarded. Hence, simply discarding multimapping reads seems to bias the count estimates for all genes but strongly impacts counts for genes that are expected to have a larger number of multimapping reads due to their high sequence similarity.
The ratio of the final number of deduplicated UMIs against the number of initial reads for both alevin and Cell Ranger (on the human PBMC 4k dataset) stratified by gene-level sequence uniqueness. The genes are divided into 20 equal sized bins, and the x-axis represents the maximum gene uniqueness in each bin. The plotted ratio for genes that have high sequence similarity with other genes is strongly biased when using Cell Ranger. This is because Cell Ranger will discard a majority (or all) of the reads originating from these genes since they will most likely map to multiple positions across various genes. Alevin, on the other hand, will attempt to accurately assign these reads to their gene of origin. This plot also demonstrates that alevin does not over-count UMIs, which would be the case if deduplication was done at the level of equivalence classes
Accuracy analysis on real datasets
To assess the performance of alevin, both in terms of accuracy in quantification and resource consumption, we ran it on 10X Chromium datasets from human and mouse. We compare our results against the Cell Ranger pipeline [3], the dropEst pipeline [8]Footnote 1, and a custom pipeline, with an external list of whitelisted CBs, using STAR [14], featureCounts [15], and UMI-tools [5], which we refer to as the naïve pipeline. The exact parameters for running each tool are provided under the "Materials and methods" section. Note that we run alevin with the —keepDuplicates flag during indexing, which ensures that even when multiple sequence-identical transcripts exist in the annotation, they are not discarded. This is to allow for fair comparison against the other tools, since they do not discard such transcripts, and the existence of such transcripts will impact the number of multimapping reads. However, we do not generally recommended using this flag when running alevin. We observe that the number of final whitelisted cells predicted by alevin are in close proximity to the count of cells predicted by Cell Ranger (and dropEst, since they use the same whitelist), but there are non-trivial differences (Table 3). Comparison on data using the Drop-seq [1] protocol is also detailed below. Comparisons against the recently released version 3.0.0 of Cell Ranger are also provided (Additional file 1: Figure S1), along with results from another run of alevin using different parameters. Where mentioned, the results are stratified by gene uniqueness which is the proportion of k-mers, of size 31, that are not shared between two or more genes. We note that varying the k-mer size changes the stratification of the genes but does not impact the overall correlation and performance of the methods. We show this for the mouse neuronal 900 dataset (Additional file 1: Figure S2). We calculated this for each gene in the human (GENCODE release 27, GRCh38.p10) and mouse (GENCODE release M16, GRCm38.p5) transcriptomes. Note that this was not calculated using the canonicalized k-mers from the genes. This is because the scRNA-seq protocols are stranded and a read, therefore, cannot multimap between two genes if the reverse complement of one of them is shared with the other's forward sequence.
Table 3 Number of final whitelisted cellular barcodes output by alevin and Cell Ranger
Accuracy of estimates against bulk data
To test the accuracy of the quantification estimates, we aggregate the estimates from each of the single-cell quantification tools (summing across all cells) and calculate the correlation with estimates predicted by RSEM [16] (paired with Bowtie2 [17] alignments) using bulk datasets from the same cell types. While the differences between single-cell and bulk sequencing protocols and techniques are significant, we believe that, in the absence of established benchmarks, the correlation between them is a reasonable indicator of the accuracy of each quantification method. Estimates from alevin, when summed across all cells, have a higher Spearman rank correlation than the Cell Ranger, dropEst, and naïve pipelines (Table 4). Specifically, we posit that the methods demonstrate a strong and persistent bias against groups of two or more genes that exhibit high sequence similarity. That is, the more sequence-similar a gene is to another gene, the less likely these pipelines are able to assign reads to it—in the extreme case, some genes essentially become invisible due to the in silico biases of these approaches (a similar effect was reported by Robert and Watson [18] in bulk RNA-seq data when simple read-counting approaches are used for quantification, where they highlight that many such genes are relevant to human disease).
Table 4 Average Spearman correlation of gene-level estimates from each method for the single-cell datasets against bulk data from the same cell types (four for human, three for mouse)
To further explore this hypothesis, we stratified the accuracy of the different methods by the uniqueness of the underlying genes (Fig. 4a, Table 5). The bar plots at the top of each subfigure represent the tiers of the genes as assigned by alevin. Tier 1 is the set of genes where all the reads are uniquely mapping. Tier 2 is genes that have ambiguously mapping reads, but connected to unique read evidence as well, which can be used by the EM to resolve the multimapping reads. Tier 3 is the genes that have no unique evidence, and the read counts are, therefore, distributed between these genes according to an uninformative prior. In agreement with the hypothesized relationship, we observed that the higher accuracy of alevin is particularly large for genes with a lower proportion of unique k-mers, which tend to belong to tier 2 or 3. On genes from tier 1, all the methods perform similarly. Thus, the approach of Cell Ranger, dropEst, and naïve, which discard reads mapping to multiple genes, results in systematic inaccuracies in genes which are insufficiently unique (i.e., which share a high degree of sequence homology with some other gene).
a The Spearman correlation between quantification estimates (summed across all cells) from different scRNA-seq methods against bulk data from the mouse neuronal and human PBMC datasets, stratified by gene sequence uniqueness. The bar plot on the top of each figure shows the percentage of genes in each bin that have unique read evidence. Tier 1 is the set of genes with only uniquely mapping reads. Tier 2 is genes that have ambiguously mapping reads, but are connected to unique read evidence that can be used to resolve the multimapping reads. Tier 3 is genes that are completely ambiguous. Note that all methods perform very similarly on genes from tier 1, but the performance of alevin is much better for the other tiers. b Comparison of various methods used to process Drop-seq data from mouse retina with 4k cells. The Spearman correlation is calculated against bulk quantification estimates predicted using Bowtie2 and RSEM on data from the same cell type
Table 5 Number of genes in each bin, when stratified by gene uniqueness
This bias could impact the expression estimates of important marker genes, such as the genes for the hemoglobin alpha and beta proteins in the mouse neurons [19, 20]. Due to their lower uniqueness ratio, Cell Ranger appears to exhibit a bias against such genes, and their expression, as predicted by alevin, is systematically higher (Fig. 5). Anecdotally, we also noticed that, in the human PBMC data, alevin sometimes predicts the expression of even relatively sequence-unique genes, like YIPF6, that we expect to be expressed in a subpopulation of these cells (monocytes) [21], but which exhibit almost no expression as predicted by Cell Ranger (Fig. 6). Because the bias against sequence-ambiguous genes is fundamental and sequence-specific, it cannot be easily remedied with more data, but instead requires the development of fundamentally novel algorithms, like alevin, that account for, rather than discard, reads mapping to such genes. Hence, alevin not only quantifies a greater proportion of the sequenced data than existing methods, but also does so more accurately and in a less biased manner.
Expression of the Hba and Hbb genes as predicted by alevin and Cell Ranger in mouse neuronal cells. The title of each plot is the name of the gene and its k-mer uniqueness ratio. Note that Cell Ranger systematically under-estimates the expression of these genes compared to alevin. This bias is greater for the Hba genes, which have a lower uniqueness ratio, and therefore, a greater number of multimapping reads
Expression of the YIPF6 gene (which has a high uniqueness ratio) as predicted by alevin and Cell Ranger in the PBMC8k data
Accuracy of estimates using combined genomes
To further assess the accuracy of quantification estimates, in the absence of any established read-level simulation protocol, we performed an experiment aimed to introduce controlled gene-level multimapping to analyze its effect on the different methods. We quantified the mouse neuronal 900 sequencing dataset using both Cell Ranger and alevin, and each quantification was performed under two separate references: the mouse genome and the combined human and mouse genome. Noting that the reads in this experiment originate from mouse, we desire that the quantifications returned by a method deviate as little as possible under the two different reference configurations. Under ideal conditions, for example, the gene counts under both references should be the same. However, combining the mouse and human references increases the gene sequence ambiguity, due to the presence of homologous genes, resulting in misestimation.
We show in Fig. 7a that the distance under the two references is higher for the Cell Ranger estimates than for the alevin estimates. Due to the increased homology among genes between the references, the ratio of reads mapping to multiple genes increases, resulting in more information being discarded by Cell Ranger. The total number of UMIs accounted for by Cell Ranger decreases by ∼ 20,000, in comparison, the number of distinct UMIs predicted by alevin decreased by ∼ 1500, which one might attribute to changes in the underlying PUGs as a result of mapping ∼ 0.01% more reads. The number of human genes expressed (non-zero UMI count) under the joint reference is 624 for Cell Ranger and 600 for alevin, out of a total of 58,288 genes. Note that in both cases, these genes account for < 0.05% of the total UMI count predicted by each method.
a Histogram of the ℓ1 distance between the quantification estimates of tools on the mouse neuron 900 data, when run using different references for quantification (just mouse versus mouse and human). Results are presented for both alevin and Cell Ranger. Since, in reality, all reads are expected to originate from mouse, deviations from quantifications under the only mouse reference signify misestimation—often due to the introduction of sequence-similar genes in the human genome. Alevin is able to resolve this ambiguity well, while Cell Ranger instead discards such reads, leading to different quantification estimates under the two references. b Counts for the topmost genes that have high sequence homology between human and mouse but are sequence unique in the mouse reference. The title of each plot is the gene name along with the sequence uniqueness ratio under just the mouse reference and under the joint reference. Hence, the Cell Ranger counts decrease across cells when the gene uniqueness decreases. Note that these genes were filtered such that they have > 100 count difference for either alevin or Cell Ranger when summed across all cells
To provide a statistical analysis of the differences observed for the methods under the two different reference sequences, we performed the following test. We sample, randomly, 1000 sets of 100 cells from the entire experiment, and for each sample, we compute the sum of absolute difference between the predictions of each tool under both references. We compare the resulting distribution of differences for Cell Ranger with that of alevin and find that the differences in alevin's quantifications are smaller than those of Cell Ranger (p<0.001, Mann-Whitney-Wilcoxon test). These distributions are plotted in Additional file 1: Figure S3.
We also show in Fig. 7b that, for the genes that have sequence similarity in the joint reference but are unique in the mouse genome, Cell Ranger expression estimates vary much more than those from alevin.
Time and memory efficiency
The time and memory requirements for alevin are significantly less than those for the existing pipelines (Fig. 8), where all methods were run using 16 threads. DropEst is excluded from the figure since it consumes the BAM file output by Cell Ranger and is not a complete end-to-end pipeline. For the smallest dataset (900 mouse neuronal cells), alevin was ∼ 5 times faster than naïve and ∼ 21 times faster than Cell Ranger. This difference increases further as the size of the dataset increases, since the performance of alevin scales better than the other tools. Hence, where alevin took only 70 min to process the human PBMC 8k dataset, Cell Ranger took 22 h and naïve took 11 h. On this dataset, dropEst took ∼ 2 hours, after Cell Ranger was used to process and align the reads. In terms of memory, alevin used only ∼ 13 GB on the human PBMC 8k cell dataset, whereas naïve took ∼ 20 GB and dropEst took ∼ 32 GB. For the mouse neuronal 9k cell dataset, alevin used ∼ 14 GB, naïve ∼ 18 GB, and dropEst ∼ 52 GB. In both cases, Cell Ranger required a minimum of 16 GB just for STAR indexing. We note that Cell Ranger allows the user to specify a maximum resident memory limit, and we ran Cell Ranger allowing it to allocate up to 120 GB so that the extra runtime was not due to limitations in available memory. We also note that for dropEst, we were not able to run the Bayesian collision correction algorithm implemented in dropEstr; however, given the relatively long UMI tags employed in chromium V2 chemistry compared to inDrop, one would expect the effect of this extra phase to be limited anyway.
The time and memory performance of the different pipelines on the five datasets. Alevin requires significantly less time and memory than the other pipelines. Note that for Cell Ranger, the memory plotted is the lower bound, which is the size of the index and the actual memory usage can be much higher
We observe that the optimal number of threads for running alevin is 10–12, where the maximum gain in terms of time and memory is achieved. Alevin is designed to make efficient use of multiple threads, though the optimal number of threads can depend on many factors, such as the speed of the underlying disk and the size of the raw input and output matrix to be written. While runtime decreases with the number of threads used, the memory profile changes very little as threads are added.
Comparison on Drop-seq data
In addition to the data generated using the 10X Chromium protocol [3], we also tested alevin on mouse retina data generated using the Drop-seq protocol [1]. We compare alevin against UMI-tools (the naïve pipeline from the main paper), dropEst, and dropseq_utils [1]—the processing pipeline originally used by Macosko et al. [1]. Again, we compared the correlation of gene abundances, summed across all cells and as produced by the different methods with the estimates from bulk data [22] in the same tissue (Fig. 4b). We observe a similar trend across gene-uniqueness bins as was observed for the 10x datasets. Alevin demonstrates higher correlation, overall, with the bulk data, and the improvements are particularly substantial for genes that are not sequence-unique. Further, alevin is much faster and takes less memory than the other pipelines. Alevin took 17 min to process this data, which is much faster than the UMI-tools-based pipeline (∼ 3.2 h), the dropseq_utils-based pipeline (∼ 15.5 h), and even dropEst (25 min). The memory usage of alevin was 6.5 GB, which is less than half the memory usage of the closest tool (UMI-tools at 17.72 GB). The dropseq_utils-based pipeline took 25.07 GB while dropEst used 10.8 GB, which does not include the memory consumed by Cell Ranger to index the reference and align reads against it to produce the BAM file. While alevin has been primarily designed and tested with 10x data in mind, the method is generic for droplet-based tagged-end protocols, and we observe that it also seems to perform well on Drop-seq data.
We present a new end-to-end pipeline for performing gene-level quantification from dscRNA-seq that is accurate, efficient, and easy to use. Our method, alevin, relies on a new formulation of the UMI resolution problem that both accounts for transcript-level constraints on how UMIs may have been generated and that allows resolving the potential origin of a UMI even when the corresponding reads map between multiple genes.
Our analyses demonstrate that, compared to Cell Ranger (and naïve), alevin achieves a higher accuracy, in part because of considering a substantially larger number of reads. Further, alevin is considerably faster and uses less memory than these other approaches. These speed improvements are due to a combination of the fact that alevin uses bespoke algorithms for CB and UMI edit distance computation, read mapping, and other tasks and is a unified tool for performing all of the initial processing steps, obviating the need to read and write large intermediate files on disk. These optimizations make it possible to efficiently process dscRNA-seq datasets on commodity computers reducing computational barriers to processing and re-processing of such data.
In the future, we hope to further improve the benchmarking of accuracy for single-cell quantification and barcode whitelisting approaches, as the lack of standard benchmarks makes the assessment of new methods difficult. We also hope to explore alternative cell barcode whitelisting and PUG resolution strategies—for example, adopting a generative model for PCR and sequencing error and seeking a maximum likelihood rather than maximum parsimony-based resolution of the PUGs.
Alevin is written in C++14 and is integrated into the salmon tool available at https://github.com/COMBINE-lab/salmon.
Initial whitelisting and barcode correction
After standard quality control procedures, the first step of existing single-cell RNA-seq processing pipelines [1–3] is to extract cell barcode and UMI sequences and to add this information to the header of the sequenced read or save it in temporary files. This approach, while versatile, can create many intermediate files on disk for further processing, which can be time- and space-consuming.
Alevin begins with sample-demultiplexed FASTQ files. It quickly iterates over the file containing the barcode reads and tallies the frequency of all observed barcodes (regardless of putative errors). We denote the collection of all observed barcodes as \(\mathcal {B}\). Whitelisting involves determining which of these barcodes may have derived from a valid cell. When the data has been previously processed by another pipeline, a whitelist may already be available for alevin to use. When a whitelist is not available, alevin uses a two-step procedure for calculating one. An initial draft whitelist is produced using the procedure explained below, to select CBs for initial quantification. This list is refined after per-cell-level quantification estimates are available (see "Final whitelisting (optional)" section) to produce a final whitelist.
To generate a putative whitelist, we follow the approach taken by other dscRNA-seq pipelines by analyzing the cumulative distribution of barcode frequencies and finding the knee in this curve [1, 2]. Those barcodes occurring after the knee constitute the whitelist, denoted \(\mathcal {W}\). We use a Gaussian kernel to estimate the probability density function for the barcode frequency and select the local minimum corresponding to the "knee." In the case of a user-provided whitelist, the provided \(\mathcal {W}\) is used as the fixed final whitelist.
Next, we consider those barcodes in \(\mathcal {E} = \mathcal {B} \setminus \mathcal {W}\) to determine, for each non-whitelisted barcode, whether (a) its corresponding reads should be assigned to some barcode in \(\mathcal {W}\) or (b) this barcode represents some other type of noise or error (e.g., ambient RNA, lysed cell) and its associated reads should be discarded. The approach of alevin is to determine, for each barcode \(h_{j} \in \mathcal {E}\), the set of whitelisted barcodes with which hj could be associated. We call these the putative labels of hj—denoted as ℓ(hj). Following the criteria used by previous pipelines [1], we consider a whitelisted barcode wi to be a putative label for some erroneous barcode hj if hj can be obtained from wi by a substitution, by a single insertion (and clipping of the terminal base) or by a single deletion (and the addition of a valid nucleotide to the end of hj). Rather than applying traditional algorithms for computing the all-versus-all edit-distances directly, and then filtering for such occurrences, we exploit the fact that barcodes are relatively short. Therefore, we can explicitly iterate over all of the valid \(w_{i} \in \mathcal {W}\) and enumerate all erroneous barcodes for which this might be a putative label. Let Q(wi,H) be the set of barcodes from \(\mathcal {E}\) that adhere to the conditions defined above; then, for each hj∈Q(wi,H), we append wi as putative label for the erroneous barcode hj.
Once all whitelisted barcodes have been processed, each element in \(\mathcal {E}\) will have zero or more putative labels. If an erroneous barcode has more than one putative label, we prioritize substitutions over insertions and deletions. If this does not yield a single label, ties are broken randomly. If no candidate is discovered for an erroneous barcode, then this barcode is considered "noise," and its associated reads are simply discarded. Note that, although adopted from existing methods, the alevin initial whitelisting process is designed to output a larger number of CBs.
Mapping reads and UMI deduplication
After labeling each barcode, either as noise or as belonging to some whitelisted barcode, alevin maps the sequenced reads to the target transcriptome [10, 11]. Reads mapping to a given transcript (or multimapping to a set of transcripts) are categorized hierarchically, first based on the label of their corresponding cellular barcode, and then based on their unique molecular identifier (UMI). At this point, it is then possible to deduplicate reads based on their mapping and UMI information.
The process of read deduplication involves the identification of duplicate reads based on their UMIs and alignment positions. Most amplification occurs prior to fragmentation in library construction for 10X Chromium protocols [23]. Because of this, the alignment position of a given read is not straightforward to interpret with respect to deduplication, as the same initial unique molecule may yield reads with different alignment coordinatesFootnote 2. UMIs can also contain sequence errors. Thus, achieving the correct deduplication requires proper consideration of the available positional information and possible errors.
Our approach for handling sequencing errors and PCR errors in the UMIs is motivated by "directional" approach introduced in UMI-tools [5]. Let \(\mathcal {U}_{i}\) be the set of UMIs observed for gene i. A specific UMI \(u_{n} \in \mathcal {U}_{i}\), observed cn times in gene i, is considered to have arisen by PCR or sequence error if there exists \(u_{m} \in \mathcal {U}_{i}\) such that d(un,um)=1 and cm>2cn+1, where d(·,·) is the Hamming distance. Using this information, only UMIs that could not have arisen as an error under this model are retained. However, this approach may over-collapse UMIs if there exists evidence that similar UMIs (i.e., UMIs at a Hamming distance of 1 or less) may have arisen from different transcripts and, hence, distinct molecules. Moreover, this approach first discards reads that multimap to more than one read, causing it to lose a substantial amount of information before even beginning the UMI deduplication process.
As previously proposed to address the problem of cell clustering [24], an equivalence class [12, 13, 25–29] encodes some positional information, by means of encoding the set of transcripts to which a fragment is mapped. Specifically, these equivalence classes can encode constraints about which UMIs may have arisen from the same molecule and which UMIs—even if mapping to the same gene—must have derived from distinct pre-PCR molecules. This can be used to avoid over-collapsing UMI tags that are likely to result from different molecules by considering UMIs as distinct for each equivalence class. However, in its simplest form, this deduplication method is prone to reporting a considerably higher number of distinct UMIs than likely exist. This is because reads from different positions along a single transcript, and tagged with the same UMI, can give rise to different equivalence classes, so that membership in a different equivalence class is not, alone, sufficient evidence that a read must have derived from a distinct (pre-PCR) molecule. This deters us from directly using such a UMI-collapsing strategy for deriving gene-level counts, though it may be helpful for other types of analyses.
Given the shortcomings of both approaches to UMI deduplication, we propose, instead, a novel UMI resolution algorithm that takes into account transcript-level evidence when it exists, while simultaneously avoiding the problem of under-collapsing that can occur if equivalence classes are treated independently for the purposes of UMI deduplication.
UMI resolution algorithm
A potential drawback of the gene-level deduplication is that it discards transcript-level evidence. In this case, such evidence is encoded in the equivalence classes. Thus, gene-level deduplication provides a conservative approach and assumes that it is highly unlikely for molecules that are distinct transcripts of the same gene to be tagged with a similar UMI (within an edit distance of 1 from another UMI from the same gene). However, entirely discarding transcript-level information will mask true UMI collisions to some degree, even when there is direct evidence that similar UMIs must have arisen from distinct transcripts. For example, if similar UMIs appear in transcript-disjoint equivalence classes (even if all of the transcripts labeling both classes belong to the same gene), then they cannot have arisen from the same pre-PCR molecule. Accounting for such cases is especially true when using an error-aware deduplication approach and as sequencing depth increases.
To perform UMI deduplication, alevin begins by constructing a parsimonious UMI graph (PUG), G=(V,E), for each cell, where each vi=(u,Ti) is a tuple consisting of UMI sequence u and a set of transcripts \(T_{i} = \{t_{i_{1}}, t_{i_{2}}, \dots, t_{i_{m}}\}\). There is a count associated with each vertex such that c(vi)=ci is the number of times this UMI equivalence class pair is observed. G contains two types of edges: directed and bi-directed. There exists a directed edge between every pair of vertices (vi,vj) for which ci>2cj−1, |Ti∩Tj|>0, and d(umi(vi),umi(vj))=1. For every pair of vertices for which there is no directed edge, there exists a bi-directed edge if d(umi(vk),umi(vℓ))≤1, and |Tk∩Tℓ|>0. Once the edges of this PUG have been formed, we no longer need to consider the counts of the individual UMI equivalence class pairs.
Before proceeding further, we introduce the notion of monochromatic arborescences in terms of this graph G. We can refer to the transcript labels of each node as the potential colors of the node. Since our graph is directed, an arborescence would be a rooted tree in the graph, where each node within the arborescence has exactly one directed path reaching it from a determined root node, using edges in the arborescence. Given these definitions, a monochromatic arborescence is one where the set of colors of the nodes within the arborescence have a non-null intersection and, hence, the arborescence can be labeled using a single color. Then, for a given connected component in the graph, we can find different sets of monochromatic arborescences and, for our graph, each one represents a single pre-PCR molecule.
However, motivated by the principle of parsimony, we wish to explain the observed vertices (i.e., UMI, equivalence class pairs) via the minimum possible number of pre-PCR molecules that are consistent with the observed data. Hence, we pose this problem in the following manner. Given a graph G, we seek a minimum cardinality covering by monochromatic arborescences. In other words, we wish to cover G by a collection of vertex-disjoint arborescences, where each arborescence is labeled consistently by a set of transcripts, which are the pre-PCR molecule types from which its reads and UMIs are posited to have arisen. Further, we wish to cover all vertices in G using the minimum possible number of arborescences. Here, the graph G defines which UMI, read pairs can potentially be explained in terms of others (i.e., which vertices may have arisen from the same molecule by virtue of different fragmentation positions or which vertices may have given rise to other through PCR duplication with error). The decision version of this problem is NP-complete, as shown below and so, alevin employs a greedy algorithm in practice to obtain a valid, though not necessarily minimum, covering of G. We note that while numerous covering and packing problems related to arborescences have appeared in the literature (Bernáth and Pap [30] and references therein), to the best of our knowledge, the following problem formulation is new.
Theorem 1
Minimum cardinality covering by monochromatic arborescences is NP-complete.
Consider a reduction from dominating set. Let (G,k) be an instance of the dominating set problem where G=(V,E) is an undirected graph. Then, we can construct a new graph G′=(V,E′) such that G′ has a minimum cardinality covering by ≤k monochromatic arborescences if and only if G has a minimum dominating set of size ≤k. The color of an arborescence is chosen from among the intersection of the set of labels for each node it covers and, hence, is non-null. Construct G′ as follows. Convert each edge in G to a bi-directed edge in G′ and label each node with the union of its own label and the labels of all nodes to which it is directly connected in G. In other words, Ti={i}∪{j∣{i,j}∈E}.
→ If G has a minimum dominating set of size k, then G′ has a minimum cardinality covering by k monochromatic arborescences. Every node in the original graph G has to be connected to at least one node in the dominating set. Due to the manner in which node labels are assigned in G′, this means that every node in G′ can be covered by an arborescence starting from a dominating set node; this arborescence is colored by the label assigned to that node. Since there are k nodes in the dominating set, there will be k monochromatic arborescences in G′, and since the k nodes in G dominate V, the arborescences will cover all of V.
← If G′ has a covering of k monochromatic arborescences, then G has a dominating set of size k. An arborescence is assigned a color, let us say ℓi, from the intersection of the labels of the nodes it covers. Hence, the node with label ℓi in G′ has to be one of the nodes covered by this arborescence. That node connects to all the nodes in this arborescence; otherwise, they would not have shared this label. Let these nodes be selected as the dominating set of G. Hence, if there are k arborescences, there are k such nodes that are part of the dominating set, and because the arborescences cover all of G′, the selected nodes, likewise, dominate G. □
The algorithm employed by alevin works as follows. First, we note that weakly connected components of G can be processed independently, and so, we describe here the procedure used to resolve UMIs within a single weakly connected component—this is repeated for all such components. Let C=(VC,EC) denote our current component. We perform a breadth-first search starting from each vertex vi∈VC and considering each transcript \(t_{i_{j}}\) (the jth transcript in the equivalence class labeling vertex vi). We compute the size (cardinality) of the largest arborescence that can be created starting from this node and using this label to cover the visited vertices. Let \(\phantom {\dot {i}\!}v_{i^{\prime }}, t_{i^{\prime }_{j^{\prime }}}\) be the vertex, transcript pair generating the largest arborescence, and let \(\phantom {\dot {i}\!}a\left (v_{i^{\prime }}, t_{i^{\prime }_{j^{\prime }}}\right)\) be the corresponding arborescence. We now remove all of the vertices in \(\phantom {\dot {i}\!}a\left (v_{i^{\prime }}, t_{i^{\prime }_{j^{\prime }}}\right)\), and all of their incident edges, from C, and we repeat the same procedure on the remaining graph. This process is iterated until all vertices of C have been removed. This procedure is guaranteed to select some positive order arborescence (i.e., an arborescence containing at least one node) in each iteration and hence is guaranteed to terminate after at most a linear number of iterations in the order of C.
After computing a covering, each arborescence is labeled with a particular transcript. However, the selected transcript may not be the unique transcript capable of producing this particular arborescence starting from the chosen root node. We can compute, for each arborescence, the set of possible transcript labels that could have colored it (i.e., those in the intersection of the equivalence class labels for all of the vertices in the arborescence). If the cardinality of this set is 1, then only a single transcript is capable of explaining all of the UMIs associated with this arborescence. If the cardinality of this set is > 1, then we need to determine if all transcripts capable of covering this arborescence belong to the same gene, or whether transcripts from multiple genes may, in fact, be capable of explaining the associated UMIs. In the former case, the count of pre-PCR molecules (i.e., distinct, deduplicated UMIs) associated with this uniquely selected gene is incremented by 1. In the latter case, the molecule associated with the arborescence is considered to potentially arise from any of the genes with which it could be labeled. Subsequently, an EM algorithm is used to distribute the counts between the genes. Note that other pipelines simply discard these gene-ambiguous reads and that both manners in which alevin attempts to resolve such reads (i.e., either by being selected via the parsimony condition or probabilistically allocated by the EM algorithm) are novel in the context of scRNA-seq quantification. The EM procedure we adopt to resolve ambiguous arborescences proceeds in the same manner as the EM algorithm used for transcript estimation in bulk RNA-seq data [13], with the exception that we assume the probability of generating a fragment is directly proportional to the estimated abundance, rather than the abundance divided by the effective length (i.e., we assume that, in the tagged-end protocols used, there is no length effect in the fragment generation process).
Tier assignment
The alevin program also outputs a tier matrix, of the same dimensions as the cell gene count matrix. Within a cell, each gene is assigned one of four tiers. The first tier (assigned 0) is the set of genes that have no read evidence in this cell and are, therefore, predicted to be unexpressed (whether truly absent, or the effect of some dropout process). The rest of the tiers (1, 2, and 3) are assigned based on a graph induced by the transcript equivalence classes as follows:
All equivalence classes of size 1 are filtered out. The genes associated with the transcripts from these classes are assigned to tier 1.
For the remaining equivalence classes, of size > 1 gene, a graph G is constructed. The nodes in G are transcripts, and two nodes share an edge if their corresponding transcripts belong to a single equivalence class.
All the connected components in G are listed, and the transcript labels on the nodes mapped to their corresponding genes. If any component contains a node whose gene has previously been assigned to tier 1, that gene and all other genes in this connected component are assigned to tier 2. Hence, tier 2 contains genes whose quantification is impacted by the EM algorithm (after the UMI deduplication).
Genes associated with the remaining nodes in the graph are assigned to tier 3. These are genes that have no unique evidence and do not share reads (or, in fact, paths in the equivalence class graph) with another gene that has unique evidence. Hence, the EM algorithm will distribute reads between these genes in an essentially uniform manner, and their estimates are uninformative. Their abundance signifies that some genes (at least 1) in this ambiguous family are expressed, but exactly which and their distribution of abundances cannot be determined.
Alevin, optionally (using the —numCellBootstraps flag), also outputs bootstrap variance estimates for genes within each cell. These variance estimates could conceivably be used by downstream tools for dimensionality reduction, differential expression testing, or other tasks.
Final whitelisting (optional)
Many existing tools for whitelisting CBs, such as Cell Ranger [3] and Sircel [7] perform whitelisting only once. As discussed above, both tools rely on the assumption that the number of times a CB is observed is sufficient to identify the correct CBs, i.e., those originating from droplets containing a cell. However, as observed by Petukhov et al. [8], there is considerable variation in sequencing depth per cell, and some droplets may contain damaged or low-quality cells. Thus, true CBs may fall below a simple knee-like threshold. Similarly, erroneous CBs may lie above the threshold. Petukhov et al. [8] proposed that instead of selecting a single threshold, one should treat whitelisting as a classification problem and segregate CBs into three regions: high quality, low quality, and uncertain/ambiguous. Here, high quality refers to the CBs which are deemed to be definitely correct, and low quality are the CBs which are deemed to most likely not arise from valid cells. A classifier can then be trained on the high- and low-quality CBs to classify the barcodes in the ambiguous region as either high or low quality. We adopt this approach in alevin, using our knee method's cutoff to determine the ambiguous region. Specifically, we divide everything above the knee threshold into two equal regions: high-quality valid barcodes (upper-half), denoted by \(\mathcal {H}\), and ambiguous barcodes (lower-half), denoted by \(\mathcal {L}\). Since the initial whitelisting procedure is very liberal in selecting a threshold, most of the recoverable, low-confidence CBs tend to reside in the ambiguous region, and to learn the low-quality region, we take \(n_{l} = \max (0.2 \cdot \left |\mathcal {H}\right |, 1000)\) barcodes just below the knee threshold.
In the implementation of Petukhov et al.[8], a kernel density estimation classifier was trained using features which described the number of reads per UMI, UMIs per gene, the fraction of intergenic reads, non-aligned reads, the fraction of lowly expressed genes, and the fraction of UMIs on lowly expressed genes. In addition, a maximum allowable mitochondrial read content was set for a CB to be classified as "high-quality." Whilst these features enabled the authors to build a classifier which efficiently separated "high-quality" cells from "low-quality" cells, we believe it may be possible to improve this set of features. Specifically, most of these features would be expected to correlate with the number of reads or UMIs per CB. Thus, the classifier is biased towards attributes associated with higher read depth, when in fact one wants it to learn the feature attributes associated with high-quality cells. We therefore used a slightly different set of features, listed below, which we believe may better capture the differences between high- and low-quality cells. While these features work in general, they may not be suitable for all analyses and will have to be tweaked accordingly. We chose to use a naïve Bayes classifier to perform classification, since we observed no clear difference between multiple ML methods (not shown), and the naïve Bayes classifier yields classification probabilities which are easy to interpret. Our final set of whitelisted CBs are those classified as high confidence.
Fraction of reads mapped
Fraction of mitochondrial reads (optionally activated by —mRNA flag)
Fraction of rRNA reads (optionally activated by —rRNA flag)
Duplication rate
Mean gene counts post deduplication
The maximum correlation of gene-level quantification estimates with the high-quality CBs (optionally activated by –useCorrelation flag)
Machine configuration and pipeline replicability
10x v2 chemistry benchmarking has been scripted using CGATCore (https://github.com/cgat-developers/cgat-core). The full pipeline and analysis are performed using Stony Brook's seawulf cluster with 164 Intel Xeon E5–2683v3 CPUs.
For all analyses, the genome and gtf versions used for human datasets were GENCODE release 27, GRCh38.p10, and for mouse datasets were GENCODE release M16, GRCm38.p5. All transcriptome files were generated using these with "rsem-prepare-reference."
Cell Ranger (v2.2.0): The following additional flags were used, as recommended by the Cell Ranger guidelines: —nosecondary —expect-cells NumCells, where NumCells is 10,000 for PBMC 8k and Neurons 9k, 5,000 for PBMC 4k, and 2,000 for Neurons 2k and Neurons 900.
Alevin (v0.13.0): Run with default parameters with the Chromium protocol and —keepDuplicates flags and the -lISR to specify strandedness. The mRNA and rRNA lists were obtained from the relevant annotation files and passed as input. Experiments on v1 chemistry can be run using the same flags but with the —gemcode protocol flag. Alevin also supports 10x v3 chemistry via the command-line flag —chromiumV3.
STAR (v2.6.0a): The following flag was used, as recommended by the guidelines of UMI-tools: —outFilterMultimapNmax 1
featureCounts (v1.6.3): This was run to obtain an output BAM file and with stranded input (-s 1).
UMI-tools (v0.5.4): The extract command was used to get the CBs/UMIs, when provided with an external CB whitelist and attach it to the corresponding reads. The following flags were used in the count command to obtain the per-cell gene count matrix: —gene-tag=XT —wide-format-cell-counts
DropEst (v0.8.5): This was run with the default parameters on the 10x BAM files, and the predicted cell counts from Cell Ranger were used as input.
Dropseq utils (v2.0.0): All the commands were run as recommended by the authors in the tool's manual.
The bulk datasets were quantified using Bowtie2 and RSEM, run as follows:
Bowtie2 (v2.3.4.3): The following flags were used, as recommended in the guidelines of RSEM: —sensitive —dpad 0 —gbar 99999999 —mp 1,1 —np 1 —score-min L,0,-0.1 —no-mixed —no-discordant
RSEM (v1.3.1): Run with default parameters.
Note that we were not able to run the dropEstr Bayesian correction method and the results presented are after running just the dropEst pipeline [31].
We note that whether the majority of amplification occurs pre- or post-fragmentation can be protocol specific and can suggest different strategies for UMI deduplication. Here, we are primarily concerned with the 10X Chromium protocols, dominated by pre-fragmentation amplification. However, the method we propose for UMI deduplication can be applied to other protocols as well.
Macosko EZ, Basu A, Satija R, Nemesh J, Shekhar K, Goldman M, et al.Highly parallel genome-wide expression profiling of individual cells using nanoliter droplets. Cell. 2015; 161(5):1202–14.
Klein AM, Mazutis L, Akartuna I, Tallapragada N, Veres A, Li V, et al.Droplet barcoding for single-cell transcriptomics applied to embryonic stem cells. Cell. 2015; 161(5):1187–201.
Zheng GX, Terry JM, Belgrader P, Ryvkin P, Bent ZW, Wilson R, et al.Massively parallel digital transcriptional profiling of single cells. Nat Commun. 2017; 8:14049.
Svensson V, Natarajan KN, Ly LH, Miragaia RJ, Labalette C, Macaulay IC, et al.Power analysis of single-cell RNA-sequencing experiments. Nat Methods. 2017; 14(4):381.
Smith T, Heger A, Sudbery I. UMI-tools: modeling sequencing errors in Unique Molecular Identifiers to improve quantification accuracy. Genome Res. 2017; 27(3):491–9.
Zhao L, Liu Z, Levy SF, Wu S. Bartender: a fast and accurate clustering algorithm to count barcode reads. Bioinformatics. 2017; 34(5):739–747. Oxford University Press.
Tambe A, Pachter L. Barcode identification for single cell genomics. BMC Bioinformatics. 2019; 20(1):32.
Petukhov V, Guo J, Baryawno N, Severe N, Scadden DT, Samsonova MG, Kharchenko PV. dropEst: pipeline for accurate estimation of molecular counts in droplet-based single-cell RNA-seq experiments. Genome Biol. 2018; 19(1):78.
Tian L, Su S, Dong X, Amann-Zalcenstein D, Biben C, Seidi A, et al.scPipe: a flexible R/Bioconductor preprocessing pipeline for single-cell RNA-sequencing data. PLoS Comput Biol. 2018; 14(8):e1006361.
Srivastava A, Sarkar H, Gupta N, Patro R. RapMap: a rapid, sensitive and accurate tool for mapping RNA-seq reads to transcriptomes. Bioinformatics. 2016; 32(12):i192–i200.
Sarkar H, Zakeri M, Malik L, Patro R. Towards selective-alignment: bridging the accuracy gap between alignment-based and alignment-free transcript quantification. In: Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics. BCB '18. New York: ACM: 2018. p. 27–36. Available from: http://doi.acm.org/10.1145/3233547.3233589.
Turro E, Su SY, Gonçalves Â, Coin LJ, Richardson S, Lewin A. Haplotype and isoform specific expression estimation using multi-mapping RNA-seq reads. Genome Biol. 2011; 12(2):R13.
Patro R, Duggal G Love MI, Kingsford C. Salmon provides fast and bias-aware quantification of transcript expression. Nat Methods. 2017; 14(4):417.
Dobin A, Davis CA, Schlesinger F, Drenkow J, Zaleski C, Jha S, et al.STAR: ultrafast universal RNA-seq aligner. Bioinformatics. 2013; 29(1):15–21.
Liao Y, Smyth GK, Shi W. featureCounts: an efficient general purpose program for assigning sequence reads to genomic features. Bioinformatics. 2013; 30(7):923–30.
Li B, Dewey CN. RSEM: accurate transcript quantification from RNA-Seq data with or without a reference genome. BMC Bioinformatics. 2011; 12(1):323.
Langmead B, Salzberg SL. Fast gapped-read alignment with Bowtie 2. Nat Methods. 2012; 9(4):357.
Robert C, Watson M. Errors in RNA-Seq quantification affect genes of relevance to human disease. Genome Biol. 2015; 16(1):177.
Han X, Wang R, Zhou Y, Fei L, Sun H, Lai S, et al.Mapping the mouse cell atlas by Microwell-seq. Cell. 2018; 172(5):1091–107.
Richter F, Meurers BH, Zhu C, Medvedeva VP, Chesselet MF. Neurons express hemoglobin α-and β-chains in rat and human brains. J Comp Neurol. 2009; 515(5):538–47.
Nakaya HI, Wrammert J, Lee EK, Racioppi L, Marie-Kunze S, Haining WN, et al.Systems biology of vacination for seasonal influenza in humans. Nat Immunol. 2011; 12(8):786.
Grant GR, Farkas MH, Pizarro AD, Lahens NF, Schug J, Brunk BP, et al.Comparative analysis of RNA-Seq alignment algorithms and the RNA-Seq unified mapper (RUM). Bioinformatics. 2011; 27(18):2518–2528.
10x-Genomics Single-Cell 3'-V2 Kit. 2018. https://teichlab.github.io/scg_lib_structs/data/CG000108_AssayConfiguration_SC3v2.pdf.
Ntranos V, Kamath GM, Zhang JM, Pachter L, David NT. Fast and accurate single-cell RNA-seq analysis by clustering of transcript-compatibility counts. Genome Biol. 2016; 17(1):112.
Mezlini AM, Smith EJ, Fiume M, Buske O, Savich GL, Shah S, et al.iReckon: simultaneous isoform discovery and abundance estimation from RNA-seq data. Genome Res. 2013; 23(3):519–29.
Patro R, Mount SM, Kingsford C. Sailfish enables alignment-free isoform quantification from RNA-seq reads using lightweight algorithms. Nat Biotechno. 2014; 32(5):462.
Bray NL, Pimentel H, Melsted P, Pachter L. Near-optimal probabilistic RNA-seq quantification. Nat Biotechnol. 2016; 34(5):525.
Zhang Z, Wang W. RNA-Skim: a rapid method for RNA-Seq quantification at transcript level. Bioinformatics. 2014; 30(12):i283–i92.
Ju CJT, Li R, Wu Z, Jiang JY, Yang Z, Wang W. Fleximer: accurate quantification of, RNA-Seq via variable-length k-mers. In: Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics. ACM-BCB '17. New York: ACM: 2017. p. 263–72. https://doi.org/10.1145/3107411.3107444. http://doi.acm.org/10.1145/3107411.3107444.
Bernáth A, Pap G. Covering minimum cost arborescences. Budapest: Egerváry Research Group; 2011. TR-2011-13. www.cs.elte.hu/egres. Accessed 4th March 2019.
Pipeline for initial analysis of droplet-based single-cell RNA-seq data. 2018. https://github.com/hms-dbmi/dropEst. Accessed: 19 Oct 2018.
Poldrack RA, Laumann TO, Koyejo O, Gregory B, Hover A, Chen MY, et al.Long-term neural and physiological phenotyping of a single human. Nat Commun. 2015; 6:8885.
Dvinge H, Ries RE, Ilagan JO, Stirewalt DL, Meshinchi S, Bradley RK. Sample processing obscures cancer-specific alterations in leukemic transcriptomes. Proc Natl Acad Sci. 2014; 111(47):16802–7.
Bouquet J, Soloski MJ, Swei A, Cheadle C, Federman S, Billaud JN, et al.Longitudinal transcriptome analysis reveals a sustained differential gene expression signature in patients treated for acute Lyme disease. MBio. 2016; 7(1):e00100–16.
Shen Y, Lu Bu RL Chen, Tian F, Lu N, Ge Q, et al.Screening effective differential expression genes for hepatic carcinoma with metastasis in the peripheral blood mononuclear cells by RNA-seq. Oncotarget. 2017; 8(17):27976.
Schmitt BM, Rudolph KL, Karagianni P, Fonseca NA, White RJ, Talianidis I, et al.High-resolution mapping of transcriptional dynamics across tissue development reveals a stable mRNA–tRNA interface. Genome Res. 2014:gr–176784.
Saito Y, Miranda-Rottmann S, Ruggiu M, Park CY, Fak JJ, Zhong R, et al.NOVA2-mediated RNA regulation is required for axonal pathfinding during development. Elife. 2016; 5:e14371.
Fratta P, Sivakumar P, Humphrey J, Lo K, Ricketts T, Oliveira H, et al.Mice with endogenous TDP-43 mutations exhibit gain of splicing function and characteristics of amyotrophic lateral sclerosis. EMBO J. 2018; 37(11):e98684.
Srivastava A, Malik L, Smith T, Sudbery I, Patro R. Alevin efficiently estimates accurate gene abundances from dscRNA-seq data: source Code: Zenodo; 2019. Available from: https://zenodo.org/record/2583275. Accessed 4 Mar 2019.
Srivastava A, Malik L, Smith T, Sudbery I, Patro R. Alevin efficiently estimates accurate gene abundances from dscRNA-seq data: github; 2019. Available from: https://github.com/COMBINE-lab/salmon. Accessed 4 Mar 2019.
Srivastava A, Malik L, Smith T, Sudbery I, Patro R. Alevin efficiently estimates accurate gene abundances from dscRNA-seq data: data: Zenodo; 2019. Available from: https://zenodo.org/record/2583228. Accessed 4 Mar 2019.
10x-Genomics v2 Chemistry Data. 2018. https://support.10xgenomics.com/single-cell-gene-expression/datasets.
The authors would like to thank Fatemeh Almodaresi and Hirak Sarkar for useful discussions during the development of the alevin method, and would also like to thank Hirak Sarkar for his help in crafting Fig. 1. The authors would also like to thank Stony Brook Research Computing and Cyberinfrastructure, and the Institute for Advanced Computational Science at Stony Brook University for access to the high-performance SeaWulf computing system, which was made possible by a $1.4M National Science Foundation grant (#1531492).
This work was supported by the US National Science Foundation (BIO-1564917, CCF-1750472, CNS-1763680), and the US National Institutes of Health (R01HG009937). This project has been made possible in part by grant number 2018-182752 from the Chan Zuckerberg Initiative DAF, an advised fund of Silicon Valley Community Foundation.
Department of Computer Science, Stony Brook University, Stony Brook, USA
Avi Srivastava
, Laraib Malik
& Rob Patro
Cambridge Centre for Proteomics, Department of Biochemistry, University of Cambridge, Cambridge, CB2 1GA, UK
Sheffield Institute for Nucleic Acids, Department of Molecular Biology and Biotechnology, The University of Sheffield, Sheffield, S10 2TN, UK
Ian Sudbery
Search for Avi Srivastava in:
Search for Laraib Malik in:
Search for Tom Smith in:
Search for Ian Sudbery in:
Search for Rob Patro in:
AS, LM, IS, TS, and RP designed the method. AS and RP wrote the implementation of the methods. AS, LM, IS, TS, and RP designed the experiments and helped analyze the results. All of the authors helped to write the manuscript. All authors approved the final manuscript.
Correspondence to Rob Patro.
R.P. is a co-founder of Ocean Genomics, Inc. The other authors declare that they have no competing interests.
Alevin is implemented in C++14 and is released under the GNU General Public License v3.0. The source code as used in the manuscript has been deposited in archived format at https://doi.org/10.5281/zenodo.2583275 [39] and the latest code is available at https://github.com/COMBINE-lab/salmon [40]. The output quantification results of all the tools used in the validation of alevin-pipeline have been deposited in archived format at https://doi.org/10.5281/zenodo.2583228 [41].
All the single cell 10x datasets used in the paper are taken from https://support.10xgenomics.com/single-cell-gene-expression/datasets [42] and the DropSeq data is from SRR1853180. The relevant accessions for the bulk RNA-seq datasets used for the validation are listed in Table 1.
Additional file 1
Supplementary material for alevin efficiently estimates accurate gene abundances from dscRNA-seq data. Includes supplementary figures. (PDF 669 kb)
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver(http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
Srivastava, A., Malik, L., Smith, T. et al. Alevin efficiently estimates accurate gene abundances from dscRNA-seq data. Genome Biol 20, 65 (2019). https://doi.org/10.1186/s13059-019-1670-y
Single-cell RNA-seq
UMI deduplication
Cellular barcode | CommonCrawl |
Singly periodic free boundary minimal surfaces in a solid cylinder of $\mathbb{R}^3$
Wavefronts of a stage structured model with state--dependent delay
October 2015, 35(10): 4955-4986. doi: 10.3934/dcds.2015.35.4955
Regions of stability for a linear differential equation with two rationally dependent delays
Joseph M. Mahaffy 1, and Timothy C. Busken 2,
Department of Mathematics and Statistics, Nonlinear Dynamical Systems Group, Computational Sciences Research Center, San Diego State University, San Diego, CA 92182-7720, United States
Department of Mathematics, Grossmont College, El Cajon, CA 92020, United States
Received July 2013 Revised January 2015 Published April 2015
Stability analysis is performed for a linear differential equation with two delays. Geometric arguments show that when the two delays are rationally dependent, then the region of stability increases. When the ratio has the form $1/n$, this study finds the asymptotic shape and size of the stability region. For example, a delay ratio of $1/3$ asymptotically produces a stability region about 44.3% larger than any nearby delay ratios, showing extreme sensitivity in the delays. The study provides a systematic and geometric approach to finding the eigenvalues on the boundary of stability for this delay differential equation. A nonlinear model with two delays illustrates how our methods can be applied.
Keywords: exponential polynomial, stability analysis, eigenvalue., Delay differential equation, bifurcation.
Mathematics Subject Classification: Primary: 37C75, 37G15; Secondary: 39B8.
Citation: Joseph M. Mahaffy, Timothy C. Busken. Regions of stability for a linear differential equation with two rationally dependent delays. Discrete & Continuous Dynamical Systems - A, 2015, 35 (10) : 4955-4986. doi: 10.3934/dcds.2015.35.4955
J. Bélair, Stability of a differential-delay equation with two time lags,, in Oscillations, (1987), 305. Google Scholar
J. Bélair and M. Mackey, A model for the regulation of mammalian platelet production,, Ann. N. Y. Acad. Sci., 504 (1987), 280. doi: 10.1111/j.1749-6632.1987.tb48740.x. Google Scholar
J. Bélair and M. Mackey, Consumer memory and price fluctuations in commodity markets: An integrodifferential model,, J. Dyn. and Diff. Eqns., 1 (1989), 299. doi: 10.1007/BF01053930. Google Scholar
J. Bélair, M. C. Mackey and J. M. Mahaffy, Age-structured and two delay models for erythropoiesis,, Math. Biosci., 128 (1995), 317. doi: 10.1016/0025-5564(94)00078-E. Google Scholar
J. Bélair and S. A. Campbell, Stability and bifurcations of equilibria in a multiple-delayed differential equation,, SIAM J. Appl. Math., 54 (1994), 1402. doi: 10.1137/S0036139993248853. Google Scholar
J. Bélair, S. A. Campbell and P. v. d. Driessche, Frustration, stability, and delay-induced oscillations in a neural network model,, SIAM Journal on Applied Mathematics, 56 (1996), 245. doi: 10.1137/S0036139994274526. Google Scholar
R. Bellman and K. L. Cooke, Differential-Difference Equations,, Lectures in Applied Mathematics, (1963). Google Scholar
F. G. Boese, The delay-independent stability behaviour of a first order differential-difference equation with two constant lags,, preprint, (1993). Google Scholar
F. G. Boese, A new representation of a stability result of N. D. Hayes,, Z. Angew. Math. Mech., 73 (1993), 117. doi: 10.1002/zamm.19930730215. Google Scholar
F. G. Boese, Stability in a special class of retarded difference-differential equations with interval-valued parameters,, Journal of Mathematical Analysis and Applications, 181 (1994), 227. doi: 10.1006/jmaa.1994.1017. Google Scholar
D. M. Bortz, Eigenvalues for two-lag linear delay differential equations,, submitted, (2012). Google Scholar
R. D. Braddock and P. van den Driessche, A population model with two time delays,, in Quantitative Population Dynamics (eds. D. G. Chapman and V. F. Gallucci), (1981). Google Scholar
T. C. Busken, On the Asymptotic Stability of the Zero Solution for a Linear Differential Equation with Two Delays,, Master's Thesis, (2012). Google Scholar
S. A. Campbell and J. Bélair, Analytical and symbolically-assisted investigation of Hopf bifurcations in delay-differential equations,, Proceedings of the G. J. Butler Workshop in Mathematical Biology (Waterloo, 3 (1995), 137. Google Scholar
K. L. Cooke and J. A. Yorke, Some equations modelling growth processes and gonorrhea epidemics,, Math. Biosci., 16 (1973), 75. doi: 10.1016/0025-5564(73)90046-1. Google Scholar
L. E. El'sgol'ts and S. Norkin, Introduction to the Theory of Differential Equations with Deviating Arguments,, Academic Press, (1977). Google Scholar
T. Elsken, The region of (in)stability of a 2-delay equation is connected,, J. Math. Anal. Appl., 261 (2001), 497. doi: 10.1006/jmaa.2001.7536. Google Scholar
C. Guzelis and L. O. Chua, Stability analysis of generalized cellular neural networks,, International Journal of Circuit Theory and Applications, 21 (1993), 1. doi: 10.1002/cta.4490210102. Google Scholar
J. Hale, E. Infante and P. Tsen, Stability in linear delay equations,, J. Math. Anal. Appl., 105 (1985), 533. doi: 10.1016/0022-247X(85)90068-X. Google Scholar
J. K. Hale, Nonlinear oscillations in equations with delays,, in Nonlinear Oscillations in Biology (Proc. Tenth Summer Sem. Appl. Math., (1978), 157. Google Scholar
J. K. Hale and W. Huang, Global geometry of the stable regions for two delay differential equations,, J. Math. Anal. Appl., 178 (1993), 344. doi: 10.1006/jmaa.1993.1312. Google Scholar
J. K. Hale and S. M. Tanaka, Square and pulse waves with two delays,, Journal of Dynamics and Differential Equations, 12 (2000), 1. doi: 10.1023/A:1009052718531. Google Scholar
G. Haller and G. Stépán, Codimension two bifurcation in an approximate model for delayed robot control,, in Bifurcation and Chaos: Analysis, (1990), 155. Google Scholar
N. Hayes, Roots of the transcendental equation associated with a certain differential difference equation,, J. London Math. Soc., 25 (1950), 226. Google Scholar
T. D. Howroyd and A. M. Russell, Cournot oligopoly models with time lags,, J. Math. Econ., 13 (1984), 97. doi: 10.1016/0304-4068(84)90009-0. Google Scholar
, E. F. Infante,, Personal Communication, (1975). Google Scholar
I. S. Levitskaya, Stability domain of a linear differential equation with two delays,, Comput. Math. Appl., 51 (2006), 153. doi: 10.1016/j.camwa.2005.05.011. Google Scholar
X. Li, S. Ruan and J. Wei, Stability and bifurcation in delay-differential equations with two delays,, Journal of Mathematical Analysis and Applications, 236 (1999), 254. doi: 10.1006/jmaa.1999.6418. Google Scholar
N. MacDonald, Cyclical neutropenia; Models with two cell types and two time lags,, in Biomathematics and Cell Kinetics (eds. A. J. Valleron and P. D. M. Macdonald), (1979), 287. Google Scholar
N. MacDonald, An activation-inhibition model of cyclic granulopoiesis in chronic granulocytic leukemia,, Math. Biosci., 54 (1980), 61. doi: 10.1016/0025-5564(81)90076-6. Google Scholar
M. C. Mackey, Commodity price fluctuations: Price dependent delays and nonlinearities as explanatory factors,, J. Econ. Theory, 48 (1989), 497. doi: 10.1016/0022-0531(89)90039-2. Google Scholar
J. M. Mahaffy, P. J. Zak and K. M. Joiner, A Three Parameter Stability Analysis for a Linear Differential Equation with Two Delays,, Technical report, (1993). Google Scholar
J. M. Mahaffy, P. J. Zak and K. M. Joiner, A geometric analysis of stability regions for a linear differential equation with two delays,, Internat. J. Bifur. Chaos Appl. Sci. Engrg., 5 (1995), 779. doi: 10.1142/S0218127495000570. Google Scholar
M. Mizuno and K. Ikeda, An unstable mode selection rule: Frustrated optical instability due to two competing boundary conditions,, Physica D, 36 (1989), 327. doi: 10.1016/0167-2789(89)90088-2. Google Scholar
S. Mohamad and K. Gopalsamy, Exponential stability of continuous-time and discrete-time cellular neural networks with delays,, Applied Mathematics and Computation, 135 (2003), 17. doi: 10.1016/S0096-3003(01)00299-5. Google Scholar
W. W. Murdoch, R. M. Nisbet, S. P. Blythe, W. S. C. Gurney and J. D. Reeve, An invulnerable age class and stability in delay-differential parasitoid-host models,, American Naturalist, 129 (1987), 263. doi: 10.1086/284634. Google Scholar
R. D. Nussbaum, A Hopf global bifurcation theorem for retarded functional differential equations,, Trans. Amer. Math. Soc., 238 (1978), 139. doi: 10.1090/S0002-9947-1978-0482913-0. Google Scholar
M. Piotrowska, A remark on the ode with two discrete delays,, Journal of Mathematical Analysis and Applications, 329 (2007), 664. doi: 10.1016/j.jmaa.2006.06.078. Google Scholar
C. G. Ragazzo and C. P. Malta, Singularity structure of the Hopf bifurcation surface of a differential equation with two delays,, Journal of Dynamics and Differential Equations, 4 (1992), 617. doi: 10.1007/BF01048262. Google Scholar
J. Ruiz-Claeyssen, Effects of delays on functional differential equations,, J. Diff. Eq., 20 (1976), 404. doi: 10.1016/0022-0396(76)90117-0. Google Scholar
S. Sakata, Asymptotic stability for a linear system of differential-difference equations,, Funkcial. Ekvac., 41 (1998), 435. Google Scholar
R. T. Wilsterman, An Analytic and Geometric Approach for Examining the Stability of Linear Differential Equations with Two Delays,, Master's Thesis, (2013). Google Scholar
T. Yoneyama and J. Sugie, On the stability region of differential equations with two delays,, Funkcial. Ekvac., 31 (1988), 233. Google Scholar
E. Zaron, The Delay Differential Equation: $x'(t) = -ax(t) + bx(t-\tau_1) + cx(t-\tau_2)$,, Technical report, (1987). Google Scholar
Yukihiko Nakata. Existence of a period two solution of a delay differential equation. Discrete & Continuous Dynamical Systems - S, 2021, 14 (3) : 1103-1110. doi: 10.3934/dcdss.2020392
Kerioui Nadjah, Abdelouahab Mohammed Salah. Stability and Hopf bifurcation of the coexistence equilibrium for a differential-algebraic biological economic system with predator harvesting. Electronic Research Archive, 2021, 29 (1) : 1641-1660. doi: 10.3934/era.2020084
Feifei Cheng, Ji Li. Geometric singular perturbation analysis of Degasperis-Procesi equation with distributed delay. Discrete & Continuous Dynamical Systems - A, 2021, 41 (2) : 967-985. doi: 10.3934/dcds.2020305
Xin-Guang Yang, Lu Li, Xingjie Yan, Ling Ding. The structure and stability of pullback attractors for 3D Brinkman-Forchheimer equation with delay. Electronic Research Archive, 2020, 28 (4) : 1395-1418. doi: 10.3934/era.2020074
Gloria Paoli, Gianpaolo Piscitelli, Rossanno Sannipoli. A stability result for the Steklov Laplacian Eigenvalue Problem with a spherical obstacle. Communications on Pure & Applied Analysis, 2021, 20 (1) : 145-158. doi: 10.3934/cpaa.2020261
Joel Kübler, Tobias Weth. Spectral asymptotics of radial solutions and nonradial bifurcation for the Hénon equation. Discrete & Continuous Dynamical Systems - A, 2020, 40 (6) : 3629-3656. doi: 10.3934/dcds.2020032
Gervy Marie Angeles, Gilbert Peralta. Energy method for exponential stability of coupled one-dimensional hyperbolic PDE-ODE systems. Evolution Equations & Control Theory, 2020 doi: 10.3934/eect.2020108
Stefan Ruschel, Serhiy Yanchuk. The spectrum of delay differential equations with multiple hierarchical large delays. Discrete & Continuous Dynamical Systems - S, 2021, 14 (1) : 151-175. doi: 10.3934/dcdss.2020321
John Mallet-Paret, Roger D. Nussbaum. Asymptotic homogenization for delay-differential equations and a question of analyticity. Discrete & Continuous Dynamical Systems - A, 2020, 40 (6) : 3789-3812. doi: 10.3934/dcds.2020044
Mugen Huang, Moxun Tang, Jianshe Yu, Bo Zheng. A stage structured model of delay differential equations for Aedes mosquito population suppression. Discrete & Continuous Dynamical Systems - A, 2020, 40 (6) : 3467-3484. doi: 10.3934/dcds.2020042
Ting Liu, Guo-Bao Zhang. Global stability of traveling waves for a spatially discrete diffusion system with time delay. Electronic Research Archive, , () : -. doi: 10.3934/era.2021003
Do Lan. Regularity and stability analysis for semilinear generalized Rayleigh-Stokes equations. Evolution Equations & Control Theory, 2021 doi: 10.3934/eect.2021002
Fathalla A. Rihan, Hebatallah J. Alsakaji. Stochastic delay differential equations of three-species prey-predator system with cooperation among prey species. Discrete & Continuous Dynamical Systems - S, 2020 doi: 10.3934/dcdss.2020468
Qingfeng Zhu, Yufeng Shi. Nonzero-sum differential game of backward doubly stochastic systems with delay and applications. Mathematical Control & Related Fields, 2021, 11 (1) : 73-94. doi: 10.3934/mcrf.2020028
Siyang Cai, Yongmei Cai, Xuerong Mao. A stochastic differential equation SIS epidemic model with regime switching. Discrete & Continuous Dynamical Systems - B, 2020 doi: 10.3934/dcdsb.2020317
Ryuji Kajikiya. Existence of nodal solutions for the sublinear Moore-Nehari differential equation. Discrete & Continuous Dynamical Systems - A, 2021, 41 (3) : 1483-1506. doi: 10.3934/dcds.2020326
Jianquan Li, Xin Xie, Dian Zhang, Jia Li, Xiaolin Lin. Qualitative analysis of a simple tumor-immune system with time delay of tumor action. Discrete & Continuous Dynamical Systems - B, 2020 doi: 10.3934/dcdsb.2020341
Reza Chaharpashlou, Abdon Atangana, Reza Saadati. On the fuzzy stability results for fractional stochastic Volterra integral equation. Discrete & Continuous Dynamical Systems - S, 2020 doi: 10.3934/dcdss.2020432
Joseph M. Mahaffy Timothy C. Busken | CommonCrawl |
Sample records for haplochromis laparogramma group
Genetic variation and demographic history of the Haplochromis laparogramma group of Lake Victoria-An analysis based on SINEs and mitochondrial DNA.
Mzighani, Semvua I; Nikaido, Masato; Takeda, Miyuki; Seehausen, Ole; Budeba, Yohana L; Ngatunga, Benjamin P; Katunzi, Egid F B; Aibara, Mitsuto; Mizoiri, Shinji; Sato, Tetsu; Tachida, Hidenori; Okada, Norihiro
More than 500 endemic haplochromine cichlid species inhabit Lake Victoria. This striking species diversity is a classical example of recent explosive adaptive radiation thought to have happened within the last approximately 15,000 years. In this study, we examined the population structure and historical demography of 3 pelagic haplochromine cichlid species that resemble in morphology and have similar niche, Haplochromis (Yssichromis) laparogramma, Haplochromis (Y.) pyrrhocephalus, and Haplochromis (Y.) sp. "glaucocephalus". We investigated the sequences of the mitochondrial DNA control region and the insertion patterns of short interspersed elements (SINEs) of 759 individuals. We show that sympatric forms are genetically differentiated in 4 of 6 cases, but we also found apparent weakening of the genetic differentiation in areas with turbid water. We estimated the timings of population expansion and species divergence to coincide with the refilling of the lake at the Pleistocene/Holocene boundary. We also found that estimates can be altered significantly by the choice of the shape of the molecular clock. If we employ the nonlinear clock model of evolutionary rates in which the rates are higher towards the recent, the population expansion was dated at around the event of desiccation of the lake ca. 17,000 YBP. Thus, we succeeded in clarifying the species and population structure of closely related Lake Victoria cichlids and in showing the importance of applying appropriate clock calibrations in elucidating recent evolutionary events.
The Integrated Genomic Architecture and Evolution of Dental Divergence in East African Cichlid Fishes (Haplochromis chilotes x H. nyererei
C. Darrin Hulsey
Full Text Available The independent evolution of the two toothed jaws of cichlid fishes is thought to have promoted their unparalleled ecological divergence and species richness. However, dental divergence in cichlids could exhibit substantial genetic covariance and this could dictate how traits like tooth numbers evolve in different African Lakes and on their two jaws. To test this hypothesis, we used a hybrid mapping cross of two trophically divergent Lake Victoria species (Haplochromis chilotes × Haplochromis nyererei to examine genomic regions associated with cichlid tooth diversity. Surprisingly, a similar genomic region was found to be associated with oral jaw tooth numbers in cichlids from both Lake Malawi and Lake Victoria. Likewise, this same genomic location was associated with variation in pharyngeal jaw tooth numbers. Similar relationships between tooth numbers on the two jaws in both our Victoria hybrid population and across the phylogenetic diversity of Malawi cichlids additionally suggests that tooth numbers on the two jaws of haplochromine cichlids might generally coevolve owing to shared genetic underpinnings. Integrated, rather than independent, genomic architectures could be key to the incomparable evolutionary divergence and convergence in cichlid tooth numbers.
Group X
Fields, Susannah
This project is currently under contract for research through the Department of Homeland Security until 2011. The group I was responsible for studying has to remain confidential so as not to affect the current project. All dates, reference links and authors, and other distinguishing characteristics of the original group have been removed from this report. All references to the name of this group or the individual splinter groups has been changed to 'Group X'. I have been collecting texts from a variety of sources intended for the use of recruiting and radicalizing members for Group X splinter groups for the purpose of researching the motivation and intent of leaders of those groups and their influence over the likelihood of group radicalization. This work included visiting many Group X websites to find information on splinter group leaders and finding their statements to new and old members. This proved difficult because the splinter groups of Group X are united in beliefs, but differ in public opinion. They are eager to tear each other down, prove their superiority, and yet remain anonymous. After a few weeks of intense searching, a list of eight recruiting texts and eight radicalizing texts from a variety of Group X leaders were compiled.
Group Flow and Group Genius
Sawyer, Keith
Keith Sawyer views the spontaneous collaboration of group creativity and improvisation actions as "group flow," which organizations can use to function at optimum levels. Sawyer establishes ideal conditions for group flow: group goals, close listening, complete concentration, being in control, blending egos, equal participation, knowing…
Permutation groups
Passman, Donald S
This volume by a prominent authority on permutation groups consists of lecture notes that provide a self-contained account of distinct classification theorems. A ready source of frequently quoted but usually inaccessible theorems, it is ideally suited for professional group theorists as well as students with a solid background in modern algebra.The three-part treatment begins with an introductory chapter and advances to an economical development of the tools of basic group theory, including group extensions, transfer theorems, and group representations and characters. The final chapter feature
Group devaluation and group identification
NARCIS (Netherlands)
Leach, C.W.; Rodriguez Mosquera, P.M.; Vliek, M.L.W.; Hirt, E.
In three studies, we showed that increased in-group identification after (perceived or actual) group devaluation is an assertion of a (preexisting) positive social identity that counters the negative social identity implied in societal devaluation. Two studies with real-world groups used order
Lie groups and algebraic groups
Indian Academy of Sciences (India)
We give an exposition of certain topics in Lie groups and algebraic groups. This is not a complete ... of a polynomial equation is equivalent to the solva- bility of the equation ..... to a subgroup of the group of roots of unity in k (in particular, it is a ...
Wilson, Kristy J.; Brickman, Peggy; Brame, Cynthia J.
Science, technology, engineering, and mathematics faculty are increasingly incorporating both formal and informal group work in their courses. Implementing group work can be improved by an understanding of the extensive body of educational research studies on this topic. This essay describes an online, evidence-based teaching guide published by…
Reflection groups
Eggermont, G.
In 2005, PISA organised proactive meetings of reflection groups on involvement in decision making, expert culture and ethical aspects of radiation protection.All reflection group meetings address particular targeted audiences while the output publication in book form is put forward
Scott, W R
Here is a clear, well-organized coverage of the most standard theorems, including isomorphism theorems, transformations and subgroups, direct sums, abelian groups, and more. This undergraduate-level text features more than 500 exercises.
Group Grammar
Adams, Karen
In this article Karen Adams demonstrates how to incorporate group grammar techniques into a classroom activity. In the activity, students practice using the target grammar to do something they naturally enjoy: learning about each other.
Computer group
Bauer, H.; Black, I.; Heusler, A.; Hoeptner, G.; Krafft, F.; Lang, R.; Moellenkamp, R.; Mueller, W.; Mueller, W.F.; Schati, C.; Schmidt, A.; Schwind, D.; Weber, G.
The computer groups has been reorganized to take charge for the general purpose computers DEC10 and VAX and the computer network (Dataswitch, DECnet, IBM - connections to GSI and IPP, preparation for Datex-P). (orig.)
Group learning
Pimentel, Ricardo; Noguira, Eloy Eros da Silva; Elkjær, Bente
The article presents a study that aims at the apprehension of the group learning in a top management team composed by teachers in a Brazilian Waldorf school whose management is collective. After deciding to extend the school, they had problems recruiting teachers who were already trained based...... on the Steiner´s ideas, which created practical problems for conducting management activities. The research seeks to understand how that group of teachers collectively manage the school, facing the lack of resources, a significant heterogeneity in the relationships, and the conflicts and contradictions......, and they are interrelated to the group learning as the construction, maintenance and reconstruction of the intelligibility of practices. From this perspective, it can be said that learning is a practice and not an exceptional phenomenon. Building, maintaining and rebuilding the intelligibility is the group learning...
Group technology
Rome, C.P.
Group Technology has been conceptually applied to the manufacture of batch-lots of 554 machined electromechanical parts which now require 79 different types of metal-removal tools. The products have been grouped into 7 distinct families which require from 8 to 22 machines in each machine-cell. Throughput time can be significantly reduced and savings can be realized from tooling, direct-labor, and indirect-labor costs
Abelian groups
Fuchs, László
Written by one of the subject's foremost experts, this book focuses on the central developments and modern methods of the advanced theory of abelian groups, while remaining accessible, as an introduction and reference, to the non-specialist. It provides a coherent source for results scattered throughout the research literature with lots of new proofs. The presentation highlights major trends that have radically changed the modern character of the subject, in particular, the use of homological methods in the structure theory of various classes of abelian groups, and the use of advanced set-theoretical methods in the study of undecidability problems. The treatment of the latter trend includes Shelah's seminal work on the undecidability in ZFC of Whitehead's Problem; while the treatment of the former trend includes an extensive (but non-exhaustive) study of p-groups, torsion-free groups, mixed groups, and important classes of groups arising from ring theory. To prepare the reader to tackle these topics, th...
Group dynamics.
Scandiffio, A L
Group dynamics play a significant role within any organization, culture, or unit. The important thing to remember with any of these structures is that they are made up of people--people with different ideas, motivations, background, and sometimes different agendas. Most groups, formal or informal, look for a leader in an effort to maintain cohesiveness of the unit. At times, that cultural bond must be developed; once developed, it must be nurtured. There are also times that one of the group no longer finds the culture comfortable and begins to act out behaviorally. It is these times that become trying for the leader as she or he attempts to remain objective when that which was once in the building phase of group cohesiveness starts to fall apart. At all times, the manager must continue to view the employee creating the disturbance as an integral part of the group. It is at this time that it is beneficial to perceive the employee exhibiting problem behaviors as a special employee, as one who needs the benefit of your experience and skills, as one who is still part of the group. It is also during this time that the manager should focus upon her or his own views in the area of power, communication, and the corporate culture of the unit that one has established before attempting to understand another's point of view. Once we understand our own motivation and accept ourselves, it is then that we may move on to offer assistance to another. Once we understand our insecurities recognizing staff dysfunction as a symptom of system dysfunction will not be so threatening to the concept of the manager that we perceive ourselves to be. It takes a secure person to admit that she or he favors staff before deciding to do something to change things. The important thing to know is that it can be done. The favored staff can find a new way of relating to others, the special employee can find new modes of behavior (and even find self-esteem in the process), the group can find new ways
Group representations
Karpilovsky, G
This third volume can be roughly divided into two parts. The first part is devoted to the investigation of various properties of projective characters. Special attention is drawn to spin representations and their character tables and to various correspondences for projective characters. Among other topics, projective Schur index and projective representations of abelian groups are covered. The last topic is investigated by introducing a symplectic geometry on finite abelian groups. The second part is devoted to Clifford theory for graded algebras and its application to the corresponding theory
Møller Larsen, Marcus; Pedersen, Torben; Slepniov, Dmitrij
The last years' rather adventurous journey from 2004 to 2009 had taught the fifth-largest toy-maker in the world - the LEGO Group - the importance of managing the global supply chain effectively. In order to survive the largest internal financial crisis in its roughly 70 years of existence......, the management had, among many initiatives, decided to offshore and outsource a major chunk of its production to Flextronics. In this pursuit of rapid cost-cutting sourcing advantages, the LEGO Group planned to license out as much as 80 per cent of its production besides closing down major parts...
Informal groups
E. van den Berg; P. van Houwelingen; J. de Hart
Original title: Informele groepen Going out running with a group of friends, rather than joining an official sports club. Individuals who decide to take action themselves rather than giving money to good causes. Maintaining contact with others not as a member of an association, but through an
COMMUNICATIONS GROUP
CERN Multimedia
L. Taylor
The CMS Communications Group, established at the start of 2010, has been busy in all three areas of its responsibility: (1) Communications Infrastructure, (2) Information Systems, and (3) Outreach and Education. Communications Infrastructure There are now 55 CMS Centres worldwide that are well used by physicists working on remote CMS shifts, Computing operations, data quality monitoring, data analysis and outreach. The CMS Centre@CERN in Meyrin, is the centre of the CMS offline and computing operations, hosting dedicated analysis efforts such as during the CMS Heavy Ion lead-lead running. With a majority of CMS sub-detectors now operating in a "shifterless� mode, many monitoring operations are now routinely performed from there, rather than in the main Control Room at P5. The CMS Communications Group, CERN IT and the EVO team are providing excellent videoconferencing support for the rapidly-increasing number of CMS meetings. In parallel, CERN IT and ...
Full text: In his review 'Genesis of Unified Gauge Theories' at the symposium in Honour of Abdus Salam (June, page 23), Tom Kibble of Imperial College, London, looked back to the physics events around Salam from 1959-67. He described how, in the early 1960s, people were pushing to enlarge the symmetry of strong interactions beyond the SU(2) of isospin and incorporate the additional strangeness quantum number. Kibble wrote - 'Salam had students working on every conceivable symmetry group. One of these was Yuval Ne'eman, who had the good fortune and/or prescience to work on SU(3). From that work, and of course from the independent work of Murray Gell- Mann, stemmed the Eightfold Way, with its triumphant vindication in the discovery of the omega-minus in 1964.' Yuval Ne'eman writes - 'I was the Defence Attaché at the Israeli Embassy in London and was admitted by Salam as a part-time graduate student when I arrived in 1958. I started research after resigning from the Embassy in May 1960. Salam suggested a problem: provide vector mesons with mass - the problem which was eventually solved by Higgs, Guralnik, Kibble,.... (as described by Kibble in his article). I explained to Salam that I had become interested in symmetry. Nobody at Imperial College at the time, other than Salam himself, was doing anything in groups, and attention further afield was focused on the rotation - SO(N) - groups. Reacting to my own half-baked schemes, Salam told me to forget about the rotation groups he taught us, and study group theory in depth, directing me to Eugene Dynkin's classification of Lie subalgebras, about which he had heard from Morton Hamermesh. I found Dynkin incomprehensible without first learning about Lie algebras from Henri Cartan's thesis, which luckily had been reproduced by Dynkin in his 1946 thesis, using his diagram method. From a copy of a translation of Dynkin's thesis which I found in the British Museum Library, I
The CMS Communications Group, established at the start of 2010, has been strengthening the activities in all three areas of its responsibility: (1) Communications Infrastructure, (2) Information Systems, and (3) Outreach and Education. Communications Infrastructure The Communications Group has invested a lot of effort to support the operations needs of CMS. Hence, the CMS Centres where physicists work on remote CMS shifts, Data Quality Monitoring, and Data Analysis are running very smoothly. There are now 55 CMS Centres worldwide, up from just 16 at the start of CMS data-taking. The latest to join are Imperial College London, the University of Iowa, and the Università di Napoli. The CMS Centre@CERN in Meyrin, which is now full repaired after the major flooding at the beginning of the year, has been at the centre of CMS offline and computing operations, most recently hosting a large fraction of the CMS Heavy Ion community during the lead-lead run. A number of sub-detector shifts can now take pla...
Tychsen, Anders; Hitchens, Michael; Brolund, Thea
Role-playing games (RPGs) are a well-known game form, existing in a number of formats, including tabletop, live action, and various digital forms. Despite their popularity, empirical studies of these games are relatively rare. In particular there have been few examinations of the effects of the v......Role-playing games (RPGs) are a well-known game form, existing in a number of formats, including tabletop, live action, and various digital forms. Despite their popularity, empirical studies of these games are relatively rare. In particular there have been few examinations of the effects...... of the various formats used by RPGs on the gaming experience. This article presents the results of an empirical study, examining how multi-player tabletop RPGs are affected as they are ported to the digital medium. Issues examined include the use of disposition assessments to predict play experience, the effect...... of group dynamics, the influence of the fictional game characters and the comparative play experience between the two formats. The results indicate that group dynamics and the relationship between the players and their digital characters, are integral to the quality of the gaming experience in multiplayer...
The CMS Communications Group has been busy in all three areas of its responsibility: (1) Communications Infrastructure, (2) Information Systems, and (3) Outreach and Education. Communications Infrastructure The 55 CMS Centres worldwide are well used by physicists working on remote CMS shifts, Computing operations, data quality monitoring, data analysis and outreach. The CMS Centre@CERN in Meyrin, is the centre of the CMS Offline and Computing operations, and a number of subdetector shifts can now take place there, rather than in the main Control Room at P5. A new CMS meeting room has been equipped for videoconferencing in building 42, next to building 40. Our building 28 meeting room and the facilities at P5 will be refurbished soon and plans are underway to steadily upgrade the ageing equipment in all 15 CMS meeting rooms at CERN. The CMS evaluation of the Vidyo tool indicates that it is not yet ready to be considered as a potential replacement for EVO. The Communications Group provides the CMS-TV (web) cha...
The recently established CMS Communications Group, led by Lucas Taylor, has been busy in all three of its main are areas of responsibility: Communications Infrastructure, Information Systems, and Outreach and Education Communications Infrastructure The damage caused by the flooding of the CMS Centre@CERN on 21st December has been completely repaired and all systems are back in operation. Major repairs were made to the roofs, ceilings and one third of the floor had to be completely replaced. Throughout these works, the CMS Centre was kept operating and even hosted a major press event for first 7 TeV collisions, as described below. Incremental work behind the scenes is steadily improving the quality of the CMS communications infrastructure, particularly Webcasting, video conferencing, and meeting rooms at CERN. CERN/IT is also deploying a pilot service of a new videoconference tool called Vidyo, to assess whether it might provide an enhanced service at a lower cost, compared to the EVO tool currently in w...
Communications Infrastructure The 55 CMS Centres worldwide are well used by physicists working on remote CMS shifts, Computing operations, data quality monitoring, data analysis and outreach. The CMS Centre@CERN in Meyrin is particularly busy at the moment, hosting about 50 physicists taking part in the heavy-ion data-taking and analysis. Three new CMS meeting room will be equipped for videoconferencing in early 2012: 40/5B-08, 42/R-031, and 28/S-029. The CMS-TV service showing LHC Page 1, CMS Page 1, etc. (http://cmsdoc.cern.ch/cmscc/projector/index.jsp) is now also available for mobile devices: http://cern.ch/mcmstv. Figure 12:Â Screenshots of CMS-TV for mobile devices Information Systems CMS has a new web site: (http://cern.ch/cms) using a modern web Content Management System to ensure content and links are managed and updated easily and coherently. It covers all CMS sub-projects and groups, replacing the iCMS internal pages. It also incorporates the existing CMS public web site (http:/...
Outreach and Education We are fortunate that our research has captured the public imagination, even though this inevitably puts us under the global media spotlight, as we saw with the Higgs seminar at CERN in December, which had 110,000 distinct webcast viewers. The media interest was huge with 71 media organisations registering to come to CERN to cover the Higgs seminar, which was followed by a press briefing with the DG and Spokespersons. This event resulted in about 2,000 generally positive stories in the global media. For this seminar, the CMS Communications Group prepared up-to-date news and public material, including links to the CMS results, animations and event displays [http://cern.ch/go/Ch8thttp://cern.ch/go/Ch8t]. There were 44,000 page-views on the CMS public website, with the Higgs news article being by far the most popular item. CMS event displays from iSpy are fast becoming the iconic media images, featuring on numerous major news outlets (BBC, CNN, MSN...) as well as in the sci...
Which finite simple groups are unit groups?
Davis, Christopher James; Occhipinti, Tommy
We prove that if G is a finite simple group which is the unit group of a ring, then G is isomorphic to either (a) a cyclic group of order 2; (b) a cyclic group of prime order 2^k −1 for some k; or (c) a projective special linear group PSLn(F2) for some n ≥ 3. Moreover, these groups do all occur a...
Group Cohesion in Experiential Growth Groups
Steen, Sam; Vasserman-Stokes, Elaina; Vannatta, Rachel
This article explores the effect of web-based journaling on changes in group cohesion within experiential growth groups. Master's students were divided into 2 groups. Both used a web-based platform to journal after each session; however, only 1 of the groups was able to read each other's journals. Quantitative data collected before and…
Group Work Publication-1991.
Zimpfer, David G.
Lists 21 new publications in group work, of which 9 are reviewed. Those discussed include publications on group counseling and psychotherapy, structured groups, support groups, psychodrama, and social group work. (Author/NB)
Quantum isometry groups
Jyotishman Bhowmick
Nov 7, 2015 ... Classical. Quantum. Background. Compact Hausdorff space. Unital C∗ algebra. Gelfand-Naimark. Compact Group. Compact Quantum Group. Woronowicz. Group Action. Coaction. Woronowicz. Riemannian manifold. Spectral triple. Connes. Isometry group. Quantum Isometry Group. To be discussed.
Group typicality, group loyalty and cognitive development.
Patterson, Meagan M
Over the course of childhood, children's thinking about social groups changes in a variety of ways. Developmental Subjective Group Dynamics (DSGD) theory emphasizes children's understanding of the importance of conforming to group norms. Abrams et al.'s study, which uses DSGD theory as a framework, demonstrates the social cognitive skills underlying young elementary school children's thinking about group norms. Future research on children's thinking about groups and group norms should explore additional elements of this topic, including aspects of typicality beyond loyalty. © 2014 The British Psychological Society.
AREVA group overview; Presentation du groupe AREVA
This document presents the Group Areva, a world nuclear industry leader, from a financial holding company to an industrial group, operating in two businesses: the nuclear energy and the components. The structure and the market of the group are discussed, as the financial assets. (A.L.B.)
Overgroups of root groups in classical groups
Aschbacher, Michael
The author extends results of McLaughlin and Kantor on overgroups of long root subgroups and long root elements in finite classical groups. In particular he determines the maximal subgroups of this form. He also determines the maximal overgroups of short root subgroups in finite classical groups and the maximal overgroups in finite orthogonal groups of c-root subgroups.
Interagency mechanical operations group numerical systems group
This report consists of the minutes of the May 20-21, 1971 meeting of the Interagency Mechanical Operations Group (IMOG) Numerical Systems Group. This group looks at issues related to numerical control in the machining industry. Items discussed related to the use of CAD and CAM, EIA standards, data links, and numerical control.
Theory of Lie groups
Chevalley, Claude
The standard text on the subject for many years, this introductory treatment covers classical linear groups, topological groups, manifolds, analytic groups, differential calculus of Cartan, and compact Lie groups and their representations. 1946 edition.
Introduction to Sporadic Groups
Luis J. Boya
Full Text Available This is an introduction to finite simple groups, in particular sporadic groups, intended for physicists. After a short review of group theory, we enumerate the 1+1+16=18 families of finite simple groups, as an introduction to the sporadic groups. These are described next, in three levels of increasing complexity, plus the six isolated ''pariah'' groups. The (old five Mathieu groups make up the first, smallest order level. The seven groups related to the Leech lattice, including the three Conway groups, constitute the second level. The third and highest level contains the Monster group M, plus seven other related groups. Next a brief mention is made of the remaining six pariah groups, thus completing the 5+7+8+6=26 sporadic groups. The review ends up with a brief discussion of a few of physical applications of finite groups in physics, including a couple of recent examples which use sporadic groups.
Group Work: How to Use Groups Effectively
Burke, Alison
Many students cringe and groan when told that they will need to work in a group. However, group work has been found to be good for students and good for teachers. Employers want college graduates to have developed teamwork skills. Additionally, students who participate in collaborative learning get better grades, are more satisfied with their…
Free Boolean Topological Groups
Ol'ga Sipacheva
Full Text Available Known and new results on free Boolean topological groups are collected. An account of the properties that these groups share with free or free Abelian topological groups and properties specific to free Boolean groups is given. Special emphasis is placed on the application of set-theoretic methods to the study of Boolean topological groups.
Small Group Research
McGrath, Joseph E.
Summarizes research on small group processes by giving a comprehensive account of the types of variables primarily studied in the laboratory. These include group structure, group composition, group size, and group relations. Considers effects of power, leadership, conformity to social norms, and role relationships. (Author/AV)
Geometric group theory
Druţu, Cornelia
The key idea in geometric group theory is to study infinite groups by endowing them with a metric and treating them as geometric spaces. This applies to many groups naturally appearing in topology, geometry, and algebra, such as fundamental groups of manifolds, groups of matrices with integer coefficients, etc. The primary focus of this book is to cover the foundations of geometric group theory, including coarse topology, ultralimits and asymptotic cones, hyperbolic groups, isoperimetric inequalities, growth of groups, amenability, Kazhdan's Property (T) and the Haagerup property, as well as their characterizations in terms of group actions on median spaces and spaces with walls. The book contains proofs of several fundamental results of geometric group theory, such as Gromov's theorem on groups of polynomial growth, Tits's alternative, Stallings's theorem on ends of groups, Dunwoody's accessibility theorem, the Mostow Rigidity Theorem, and quasiisometric rigidity theorems of Tukia and Schwartz. This is the f...
Profinite graphs and groups
Ribes, Luis
This book offers a detailed introduction to graph theoretic methods in profinite groups and applications to abstract groups. It is the first to provide a comprehensive treatment of the subject. The author begins by carefully developing relevant notions in topology, profinite groups and homology, including free products of profinite groups, cohomological methods in profinite groups, and fixed points of automorphisms of free pro-p groups. The final part of the book is dedicated to applications of the profinite theory to abstract groups, with sections on finitely generated subgroups of free groups, separability conditions in free and amalgamated products, and algorithms in free groups and finite monoids. Profinite Graphs and Groups will appeal to students and researchers interested in profinite groups, geometric group theory, graphs and connections with the theory of formal languages. A complete reference on the subject, the book includes historical and bibliographical notes as well as a discussion of open quest...
Group purchasing: an overview.
Wetrich, J G
The various types and operational methods of purchasing groups are described, and evaluation of groups is discussed. Since group purchasing is increasing in popularity as a method of controlling drug costs, community and hospital pharmacy managers may need to evaluate various groups to determine the appropriateness of their services. Groups are categorized as independent, system based, or alliance or association based. Instead of "purchasing," some groups develop contracts for hospitals, which then purchase directly from the vendor. Aside from this basic difference between groups that purchase and groups that contract, comparisons among groups are difficult because of the wide variation in sizes and services. Competition developing from diversification among groups has led to "super groups," formed from local and regional groups. In evaluating groups, advantages and disadvantages germane to accomplishing the member's objectives must be considered. To ensure a group's success, members must be committed and support the group's philosophies; hospital pharmacists must help to establish a strong formulary system. To select vendors, groups should develop formal qualification and selection criteria and should not base a decision solely on price. The method of solicitation (bidding or negotiating), as well as the role of the prime vendor, should be studied. Legal implications of group purchasing, especially in the areas of administrative fees and drug diversion, must also be considered. The most advantageous group for each organization will include members with common missions and will be able to implement strategies for future success.
Ordered groups and infinite permutation groups
The subjects of ordered groups and of infinite permutation groups have long en joyed a symbiotic relationship. Although the two subjects come from very different sources, they have in certain ways come together, and each has derived considerable benefit from the other. My own personal contact with this interaction began in 1961. I had done Ph. D. work on sequence convergence in totally ordered groups under the direction of Paul Conrad. In the process, I had encountered "pseudo-convergent" sequences in an ordered group G, which are like Cauchy sequences, except that the differences be tween terms of large index approach not 0 but a convex subgroup G of G. If G is normal, then such sequences are conveniently described as Cauchy sequences in the quotient ordered group GIG. If G is not normal, of course GIG has no group structure, though it is still a totally ordered set. The best that can be said is that the elements of G permute GIG in an order-preserving fashion. In independent investigations around that t...
ALIGNMENTS OF GROUP GALAXIES WITH NEIGHBORING GROUPS
Wang Yougang; Chen Xuelei; Park, Changbom; Yang Xiaohu; Choi, Yun-Young
Using a sample of galaxy groups found in the Sloan Digital Sky Survey Data Release 4, we measure the following four types of alignment signals: (1) the alignment between the distributions of the satellites of each group relative to the direction of the nearest neighbor group (NNG); (2) the alignment between the major axis direction of the central galaxy of the host group (HG) and the direction of the NNG; (3) the alignment between the major axes of the central galaxies of the HG and the NNG; and (4) the alignment between the major axes of the satellites of the HG and the direction of the NNG. We find strong signal of alignment between the satellite distribution and the orientation of central galaxy relative to the direction of the NNG, even when the NNG is located beyond 3r vir of the host group. The major axis of the central galaxy of the HG is aligned with the direction of the NNG. The alignment signals are more prominent for groups that are more massive and with early-type central galaxies. We also find that there is a preference for the two major axes of the central galaxies of the HG and NNG to be parallel for the system with both early central galaxies, however, not for the systems with both late-type central galaxies. For the orientation of satellite galaxies, we do not find any significant alignment signals relative to the direction of the NNG. From these four types of alignment measurements, we conclude that the large-scale environment traced by the nearby group affects primarily the shape of the host dark matter halo, and hence also affects the distribution of satellite galaxies and the orientation of central galaxies. In addition, the NNG directly affects the distribution of the satellite galaxies by inducing asymmetric alignment signals, and the NNG at very small separation may also contribute a second-order impact on the orientation of the central galaxy in the HG.
Citizens' action group
Andritzky, W.
For the first empirical study of citizens' action groups 331 such groups were consulted. Important information was collected on the following aspects of these groups: their self-image, areas and forms of activities, objectives and their extent, how long the group has existed, successes and failures and their forms of organisation. (orig.) [de
Communication in Organizational Groups
Monica RADU
Organizational group can be defined as some persons between who exist interactive connections (functional, communication, affective, normative type). Classification of these groups can reflect the dimension, type of relationship or type of rules included. Organizational groups and their influence over the individual efficiency and the efficiency of the entire group are interconnected. Spontaneous roles in these groups sustain the structure of the relationship, and the personality of each indi...
[Social crisis, spontaneous groups and group order].
Edelman, Lucila; Kordon, Diana
Argentina has gone through very difficult times during the last years and, in particularly, new kinds of social practices have emerged in order to cope with the crisis. This situation demands and urges a new type of reflection upon the double role of groups, as tools to transform reality and as a way to elaborate those processes regarding subjectivity. In this paper we analyse some topics regarding the groupal field (considering spontaneous groups as well as groupal devices that allow to elaborate the crisis). We consider social bond to be the condition of possibility for the existence of the psyche and of time continuity, and that it also makes possible personal and social elaboration of trauma, crisis and social catastrophe. We develop some aspects of an specific device (the reflection group), which we have already depicted in another moment, showing it's usefulness to cope with social crisis and to promote the subjective elaboration of crisis.
Introduction to topological groups
Husain, Taqdir
Concise treatment covers semitopological groups, locally compact groups, Harr measure, and duality theory and some of its applications. The volume concludes with a chapter that introduces Banach algebras. 1966 edition.
MSUD Family Support Group
... The Treatment Of MSUD The MSUD Family Support Group has provided funds to Buck Institute for its ... of the membership of the MSUD Family Support Group, research for improved treatments and potential cure was ...
Nilpotent -local finite groups
Cantarero, José; Scherer, Jérôme; Viruel, Antonio
We provide characterizations of -nilpotency for fusion systems and -local finite groups that are inspired by known result for finite groups. In particular, we generalize criteria by Atiyah, Brunetti, Frobenius, Quillen, Stammbach and Tate.
UPIN Group File
Data.gov (United States)
U.S. Department of Health & Human Services — The Group Unique Physician Identifier Number (UPIN) File is the business entity file that contains the group practice UPIN and descriptive information. It does NOT...
Group Decision Process Support
Gøtze, John; Hijikata, Masao
Introducing the notion of Group Decision Process Support Systems (GDPSS) to traditional decision-support theorists.......Introducing the notion of Group Decision Process Support Systems (GDPSS) to traditional decision-support theorists....
Gestalt Interactional Groups
Harman, Robert L.; Franklin, Richard W.
Gestalt therapy in groups is not limited to individual work in the presence of an audience. Describes several ways to involve gestalt groups interactionally. Interactions described focus on learning by doing and discovering, and are noninterpretive. (Author/EJT)
Group B streptococcus - pregnancy
... medlineplus.gov/ency/patientinstructions/000511.htm Group B streptococcus - pregnancy To use the sharing features on this page, please enable JavaScript. Group B streptococcus (GBS) is a type of bacteria that some ...
Multicultural group work
Hansen, Annette Skovsted
Motivation for the activity I use this strategy for forming groups to ensure diverse/multicultural groups that combine a variety of different strengths and resources based on student's academic, disciplinary, linguistic, national, personal and work backgrounds.......Motivation for the activity I use this strategy for forming groups to ensure diverse/multicultural groups that combine a variety of different strengths and resources based on student's academic, disciplinary, linguistic, national, personal and work backgrounds....
The Areva Group; Le groupe Areva
This document provides information on the Areva Group, a world nuclear industry leader, offering solutions for nuclear power generation, electricity transmission and distribution and interconnect systems to the telecommunications, computer and automotive markets. It presents successively the front end division including the group business lines involved in producing nuclear fuel for electric power generation (uranium mining, concentration, conversion and enrichment and nuclear fuel fabrication); the reactors and services division which designs and builds PWR, BWR and research reactors; the back end division which encompasses the management of the fuel that has been used in nuclear power plants; the transmission and distribution division which provides products, systems and services to the medium and high voltage energy markets; the connectors division which designs and manufactures electrical, electronic and optical connectors, flexible micro circuitry and interconnection systems. Areva is implemented in Europe, north and south america, africa and asia-pacific. (A.L.B.)
Groups, combinatorics and geometry
Ivanov, A A; Saxl, J
Over the past 20 years, the theory of groups in particular simplegroups, finite and algebraic has influenced a number of diverseareas of mathematics. Such areas include topics where groups have beentraditionally applied, such as algebraic combinatorics, finitegeometries, Galois theory and permutation groups, as well as severalmore recent developments.
Working Group 7 Summary
Nagaitsev S.; Berg J.
The primary subject of working group 7 at the 2012 Advanced Accelerator Concepts Workshop was muon accelerators for a muon collider or neutrino factory. Additionally, this working group included topics that did not fit well into other working groups. Two subjects were discussed by more than one speaker: lattices to create a perfectly integrable nonlinear lattice, and a Penning trap to create antihydrogen.
AREVA group overview
Group Psychotherapy in Denmark.
Jørgensen, Lars Bo; Thygesen, Bente; Aagaard, Søren
This is a short article on the history and training standards in the Institute of Group Analysis in Copenhagen (IGA-CPH). We describe theoretical orientations and influences in the long-term training program and new initiatives, like courses in mentalization-based group treatment and a dynamic short-term group therapy course, as well as research in group psychotherapy in Denmark. Some group analytic initiatives in relation to social issues and social welfare are presented, as well as initiatives concerning the school system and unemployment.
Group theory I essentials
Milewski, Emil G
REA's Essentials provide quick and easy access to critical information in a variety of different fields, ranging from the most basic to the most advanced. As its name implies, these concise, comprehensive study guides summarize the essentials of the field covered. Essentials are helpful when preparing for exams, doing homework and will remain a lasting reference source for students, teachers, and professionals. Group Theory I includes sets and mapping, groupoids and semi-groups, groups, isomorphisms and homomorphisms, cyclic groups, the Sylow theorems, and finite p-groups.
Lectures on Chevalley groups
Steinberg, Robert
Robert Steinberg's Lectures on Chevalley Groups were delivered and written during the author's sabbatical visit to Yale University in the 1967-1968 academic year. The work presents the status of the theory of Chevalley groups as it was in the mid-1960s. Much of this material was instrumental in many areas of mathematics, in particular in the theory of algebraic groups and in the subsequent classification of finite groups. This posthumous edition incorporates additions and corrections prepared by the author during his retirement, including a new introductory chapter. A bibliography and editorial notes have also been added. This is a great unsurpassed introduction to the subject of Chevalley groups that influenced generations of mathematicians. I would recommend it to anybody whose interests include group theory. -Efim Zelmanov, University of California, San Diego Robert Steinberg's lectures on Chevalley groups were given at Yale University in 1967. The notes for the lectures contain a wonderful exposition of ...
E-groups training
There will be an e-groups training course on 16 March 2012 which will cover the main e-groups functionalities i.e.: creating and managing e-groups, difference between static and dynamic e-groups, configuring posting restrictions and archives, examples of where e-groups can be used in daily work. Even if you have already worked with e-groups, this may be a good opportunity to learn about the best practices and security related recommendations when using e-groups. You can find more details as well as enrolment form for the training (it's free) here. The number of places is limited, so enrolling early is recommended. Technical Training Tel. 72844
Group Psychotherapy in Italy.
Giannone, Francesca; Giordano, Cecilia; Di Blasi, Maria
This article describes the history and the prevailing orientations of group psychotherapy in Italy (psychoanalytically oriented, psychodrama, CBT groups) and particularly group analysis. Provided free of charge by the Italian health system, group psychotherapy is growing, but its expansion is patchy. The main pathways of Italian training in the different group psychotherapy orientations are also presented. Clinical-theoretical elaboration on self development, psychopathology related to group experiences, and the methodological attention paid to objectives and methods in different clinical groups are issues related to group therapy in Italy. Difficulties in the relationship between research and clinical practice are discussed, as well as the empirical research network that tries to bridge the gap between research and clinical work in group psychotherapy. The economic crisis in Italy has led to massive cuts in health care and to an increasing demand for some forms of psychological treatment. For these reasons, and because of its positive cost-benefit ratio, group psychotherapy is now considered an important tool in the national health care system to expand the clinical response to different forms of psychological distress.
Bestvina, Mladen; Vogtmann, Karen
Geometric group theory refers to the study of discrete groups using tools from topology, geometry, dynamics and analysis. The field is evolving very rapidly and the present volume provides an introduction to and overview of various topics which have played critical roles in this evolution. The book contains lecture notes from courses given at the Park City Math Institute on Geometric Group Theory. The institute consists of a set of intensive short courses offered by leaders in the field, designed to introduce students to exciting, current research in mathematics. These lectures do not duplicate standard courses available elsewhere. The courses begin at an introductory level suitable for graduate students and lead up to currently active topics of research. The articles in this volume include introductions to CAT(0) cube complexes and groups, to modern small cancellation theory, to isometry groups of general CAT(0) spaces, and a discussion of nilpotent genus in the context of mapping class groups and CAT(0) gro...
CLASSIFICATION OF CRIMINAL GROUPS
Natalia Romanova
New types of criminal groups are emerging in modern society. These types have their special criminal subculture. The research objective is to develop new parameters of classification of modern criminal groups, create a new typology of criminal groups and identify some features of their subculture. Research methodology is based on the system approach that includes using the method of analysis of documentary sources (materials of a criminal case), method of conversations with themembers of the...
Group therapy for adolescents
Nada Hribar
The group included adolescents from secondary school and some students. The group had weekly sessions or twice on mounth. The adolescents had varied simptoms: depressive, anxiety, psychosomatic disorders, learning difficulties, cunduct problems. All of adolescents were common on many problems in social interactions. The goal of therapeutic work were: to increase assertiveness skills and to reduce the anxious in social situations. The adolescents in group raised a self-esteem and developed som...
Presentations of groups
Johnson, D L
The aim of this book is to provide an introduction to combinatorial group theory. Any reader who has completed first courses in linear algebra, group theory and ring theory will find this book accessible. The emphasis is on computational techniques but rigorous proofs of all theorems are supplied. This new edition has been revised throughout, including new exercises and an additional chapter on proving that certain groups are infinite.
Group-Server Queues
Li, Quan-Lin; Ma, Jing-Yu; Xie, Mingzhou; Xia, Li
By analyzing energy-efficient management of data centers, this paper proposes and develops a class of interesting {\\it Group-Server Queues}, and establishes two representative group-server queues through loss networks and impatient customers, respectively. Furthermore, such two group-server queues are given model descriptions and necessary interpretation. Also, simple mathematical discussion is provided, and simulations are made to study the expected queue lengths, the expected sojourn times ...
Environmental groups in politics
Lowe, P.; Goyder, J.
The subject is covered in chapters, entitled: introduction; (Part I) the environmental movement (environmental groups and the attentive public; the episodic development of the environmental movement; the underlying values of environmentalism; the roots of environmental concern; the social limits to growth; elite manipulation of values); the organisation of environmental groups; environmental groups in national politics; environmental groups in local politics; (Part II) the Henley Society; Friends of the Earth; the National Trust; the Royal Society for Nature Conservation; the European Environmental Bureau. (U.K.)
Complex quantum groups
Drabant, B.; Schlieker, M.
The complex quantum groups are constructed. They are q-deformations of the real Lie groups which are obtained as the complex groups corresponding to the Lie algebras of type A n-1 , B n , C n . Following the ideas of Faddeev, Reshetikhin and Takhtajan Hopf algebras of regular functionals U R for these complexified quantum groups are constructed. One has thus in particular found a construction scheme for the q-Lorentz algebra to be identified as U(sl q (2,C). (orig.)
Explosive Technology Group
Federal Laboratory Consortium — The Explosive Technology Group (ETG) provides diverse technical expertise and an agile, integrated approach to solve complex challenges for all classes of energetic...
Study Groups in Denmark
Hjorth, Poul G.
Since 1998 European Study Groups have been held in Denmark, and Danish companies from LEGO and NOVO to very small high-tech firms have participated. I briefly describe the history, the organisation and the format of the Danish Study Groups, and highlight a few problem solutions.......Since 1998 European Study Groups have been held in Denmark, and Danish companies from LEGO and NOVO to very small high-tech firms have participated. I briefly describe the history, the organisation and the format of the Danish Study Groups, and highlight a few problem solutions....
Lie groups for pedestrians
Lipkin, Harry J
According to the author of this concise, high-level study, physicists often shy away from group theory, perhaps because they are unsure which parts of the subject belong to the physicist and which belong to the mathematician. However, it is possible for physicists to understand and use many techniques which have a group theoretical basis without necessarily understanding all of group theory. This book is designed to familiarize physicists with those techniques. Specifically, the author aims to show how the well-known methods of angular momentum algebra can be extended to treat other Lie group
The normal holonomy group
Olmos, C.
The restricted holonomy group of a Riemannian manifold is a compact Lie group and its representation on the tangent space is a product of irreducible representations and a trivial one. Each one of the non-trivial factors is either an orthogonal representation of a connected compact Lie group which acts transitively on the unit sphere or it is the isotropy representation of a single Riemannian symmetric space of rank ≥ 2. We prove that, all these properties are also true for the representation on the normal space of the restricted normal holonomy group of any submanifold of a space of constant curvature. 4 refs
Trajectory grouping structure
Maike Buchin
Full Text Available The collective motion of a set of moving entities like people, birds, or other animals, is characterized by groups arising, merging, splitting, and ending. Given the trajectories of these entities, we define and model a structure that captures all of such changes using the Reeb graph, a concept from topology. The trajectory grouping structure has three natural parameters that allow more global views of the data in group size, group duration, and entity inter-distance. We prove complexity bounds on the maximum number of maximal groups that can be present, and give algorithms to compute the grouping structure efficiently. We also study how the trajectory grouping structure can be made robust, that is, how brief interruptions of groups can be disregarded in the global structure, adding a notion of persistence to the structure. Furthermore, we showcase the results of experiments using data generated by the NetLogo flocking model and from the Starkey project. The Starkey data describe the movement of elk, deer, and cattle. Although there is no ground truth for the grouping structure in this data, the experiments show that the trajectory grouping structure is plausible and has the desired effects when changing the essential parameters. Our research provides the first complete study of trajectory group evolvement, including combinatorial,algorithmic, and experimental results.
Computational methods working group
Gabriel, T.A.
During the Cold Moderator Workshop several working groups were established including one to discuss calculational methods. The charge for this working group was to identify problems in theory, data, program execution, etc., and to suggest solutions considering both deterministic and stochastic methods including acceleration procedures.
GroupFinder
Bøgh, Kenneth Sejdenfaden; Skovsgaard, Anders; Jensen, Christian S.
. Such groups are relevant to users who wish to conveniently explore several options before making a decision such as to purchase a specific product. Specifically, we demonstrate a practical proposal for finding top-k PoI groups in response to a query. We show how problem parameter settings can be mapped...
Toleration, Groups, and Multiculturalism
Lægaard, Sune
have the ability to interfere with the group's activities, an object of dislike or disapproval, an agent enjoying non-interference or a moral patient. This means that 'toleration of groups' can mean quite different things depending on the exact meaning of 'group' in relation to each component...
Group B Strep Infection
... IV) to kill the germs. If you take antibiotics while you're in labor, the chances are very good that your baby won't get this infection. What if my baby has group B strep? If your baby gets group B strep, he or she will be treated with IV antibiotics to kill the bacteria. Your baby will stay ...
Group Process as Drama.
Suggests that drama, as well as training or therapy, may be employed as a useful research and practice paradigm in working with small groups. The implications of this view for group development as a whole, and for member and leader participation, are explored. (JAC)
Group Work. Research Brief
Walker, Karen
According to Johnson and Johnson, group work helps increase student retention and satisfaction, develops strong oral communication and social skills, as well as higher self-esteem (University of Minnesota, n.d.). Group work, when planned and implemented deliberately and thoughtfully helps students develop cognitive and leadership skills as well as…
Physically detached 'compact groups'
Hernquist, Lars; Katz, Neal; Weinberg, David H.
A small fraction of galaxies appear to reside in dense compact groups, whose inferred crossing times are much shorter than a Hubble time. These short crossing times have led to considerable disagreement among researchers attempting to deduce the dynamical state of these systems. In this paper, we suggest that many of the observed groups are not physically bound but are chance projections of galaxies well separated along the line of sight. Unlike earlier similar proposals, ours does not require that the galaxies in the compact group be members of a more diffuse, but physically bound entity. The probability of physically separated galaxies projecting into an apparent compact group is nonnegligible if most galaxies are distributed in thin filaments. We illustrate this general point with a specific example: a simulation of a cold dark matter universe, in which hydrodynamic effects are included to identify galaxies. The simulated galaxy distribution is filamentary and end-on views of these filaments produce apparent galaxy associations that have sizes and velocity dispersions similar to those of observed compact groups. The frequency of such projections is sufficient, in principle, to explain the observed space density of groups in the Hickson catalog. We discuss the implications of our proposal for the formation and evolution of groups and elliptical galaxies. The proposal can be tested by using redshift-independent distance estimators to measure the line-of-sight spatial extent of nearby compact groups.
Introduction to quantum groups
Sudbery, A.
These pedagogical lectures contain some motivation for the study of quantum groups; a definition of ''quasi triangular Hopf algebra'' with explanations of all the concepts required to build it up; descriptions of quantised universal enveloping algebras and the quantum double; and an account of quantised function algebras and the action of quantum groups on quantum spaces. (author)
Beam dynamics group summary
Peggs, S.
This paper summarizes the activities of the beam dynamics working group of the LHC Collective Effects Workshop that was held in Montreux in 1994. It reviews the presentations that were made to the group, the discussions that ensued, and the consensuses that evolved
Our Deming Users' Group.
Dinklocker, Christina
After training in the Total Quality Management concept, a suburban Ohio school district created a Deming Users' Group to link agencies, individuals, and ideas. The group has facilitated ongoing school/business collaboration, networking among individuals from diverse school systems, mentoring and cooperative learning activities, and resource…
Asymmetry within social groups
Barker, Jessie; Loope, Kevin J.; Reeve, H. Kern
Social animals vary in their ability to compete with group members over shared resources and also vary in their cooperative efforts to produce these resources. Competition among groups can promote within-group cooperation, but many existing models of intergroup cooperation do not explicitly account...... of two roles, with relative competitive efficiency and the number of individuals varying between roles. Players in each role make simultaneous, coevolving decisions. The model predicts that although intergroup competition increases cooperative contributions to group resources by both roles, contributions...... are predominantly from individuals in the less competitively efficient role, whereas individuals in the more competitively efficient role generally gain the larger share of these resources. When asymmetry in relative competitive efficiency is greater, a group's per capita cooperation (averaged across both roles...
Supervision and group dynamics
Hansen, Søren; Jensen, Lars Peter
An important aspect of the problem based and project organized study at Aalborg University is the supervision of the project groups. At the basic education (first year) it is stated in the curriculum that part of the supervisors' job is to deal with group dynamics. This is due to the experience...... that many students are having difficulties with practical issues such as collaboration, communication, and project management. Most supervisors either ignore this demand, because they do not find it important or they find it frustrating, because they do not know, how to supervise group dynamics...... as well as at Aalborg University. The first visible result has been participating supervisors telling us that the course has inspired them to try supervising group dynamics in the future. This paper will explore some aspects of supervising group dynamics as well as, how to develop the Aalborg model...
Summary of group discussions
A key aspect of the workshop was the interaction and exchange of ideas and information among the 40 participants. To facilitate this activity the workshop participants were divided into five discussions groups. These groups reviewed selected subjects and reported back to the main body with summaries of their considerations. Over the 3 days the 5 discussion groups were requested to focus on the following subjects: the characteristics and capabilities of 'good' organisations; how to ensure sufficient resources; how to ensure competence within the organisation; how to demonstrate organisational suitability; the regulatory oversight processes - including their strengths and weaknesses. A list of the related questions that were provided to the discussion groups can be found in Appendix 3. Also included in Appendix 3 are copies of the slides the groups prepared that summarised their considerations
Natural analogue working group
Come, B.; Chapman, N.
A Natural Analogue Working Group was established by the Commission of the European Communities in 1985. The purpose of this group is to bring together modellers with earth scientists and others, so that maximum benefit can be obtained from natural analogue studies with a view to safe geological disposal of radioactive waste. The first meeting of this group was held in Brussels from November 5 to 7, 1985. The discussions mainly concerned the identification of the modellers' needs and of the earth scientists' capacity to provide for them. Following the debates, a written statement was produced by the Group; this document forms the core of the present Report. Notes and outlines of many of the presentations made are grouped in four appendixes. The valuable contribution of all those involved in the meeting is gratefully acknowledged
Ordered groups and topology
Clay, Adam
This book deals with the connections between topology and ordered groups. It begins with a self-contained introduction to orderable groups and from there explores the interactions between orderability and objects in low-dimensional topology, such as knot theory, braid groups, and 3-manifolds, as well as groups of homeomorphisms and other topological structures. The book also addresses recent applications of orderability in the studies of codimension-one foliations and Heegaard-Floer homology. The use of topological methods in proving algebraic results is another feature of the book. The book was written to serve both as a textbook for graduate students, containing many exercises, and as a reference for researchers in topology, algebra, and dynamical systems. A basic background in group theory and topology is the only prerequisite for the reader.
Group prenatal care.
Mazzoni, Sara E; Carter, Ebony B
Patients participating in group prenatal care gather together with women of similar gestational ages and 2 providers who cofacilitate an educational session after a brief medical assessment. The model was first described in the 1990s by a midwife for low-risk patients and is now practiced by midwives and physicians for both low-risk patients and some high-risk patients, such as those with diabetes. The majority of literature on group prenatal care uses CenteringPregnancy, the most popular model. The first randomized controlled trial of CenteringPregnancy showed that it reduced the risk of preterm birth in low-risk women. However, recent meta-analyses have shown similar rates of preterm birth, low birthweight, and neonatal intensive care unit admission between women participating in group prenatal care and individual prenatal care. There may be subgroups, such as African Americans, who benefit from this type of prenatal care with significantly lower rates of preterm birth. Group prenatal care seems to result in increased patient satisfaction and knowledge and use of postpartum family planning as well as improved weight gain parameters. The literature is inconclusive regarding breast-feeding, stress, depression, and positive health behaviors, although it is theorized that group prenatal care positively affects these outcomes. It is unclear whether group prenatal care results in cost savings, although it may in large-volume practices if each group consists of approximately 8-10 women. Group prenatal care requires a significant paradigm shift. It can be difficult to implement and sustain. More randomized trials are needed to ascertain the true benefits of the model, best practices for implementation, and subgroups who may benefit most from this innovative way to provide prenatal care. In short, group prenatal care is an innovative and promising model with comparable pregnancy outcomes to individual prenatal care in the general population and improved outcomes in some
Critical groups - basic concepts
Carter, M.W.
The potential exposure pathways from the land application site to man are presented. It is emphasised that the critical group is not necessary the population group closest to the source. It could be the group impact by the most significant pathways(s). Only by assessing the importance of each of these pathways and then combining them can a proper choice of critical group be made. It would be wrong to select a critical group on the basis that it seems the most probable one, before the pathways have been properly assessed. A calculation in Carter (1983) suggested that for the operating mine site, the annual doses to an Aboriginal person, a service worker and a local housewife, were all about the same and were in the range 0.1 to 0.2 mSv per year. Thus it may be that for the land application area, the critical group turns out to be non-Aboriginal rather than the expected Aboriginal group. 6 refs., 3 figs
Groups - Modular Mathematics Series
This text provides an introduction to group theory with an emphasis on clear examples. The authors present groups as naturally occurring structures arising from symmetry in geometrical figures and other mathematical objects. Written in a 'user-friendly' style, where new ideas are always motivated before being fully introduced, the text will help readers to gain confidence and skill in handling group theory notation before progressing on to applying it in complex situations. An ideal companion to any first or second year course on the topic.
Chaichian, Masud
In the past decade there has been an extemely rapid growth in the interest and development of quantum group theory.This book provides students and researchers with a practical introduction to the principal ideas of quantum groups theory and its applications to quantum mechanical and modern field theory problems. It begins with a review of, and introduction to, the mathematical aspects of quantum deformation of classical groups, Lie algebras and related objects (algebras of functions on spaces, differential and integral calculi). In the subsequent chapters the richness of mathematical structure
Group key management
Dunigan, T.; Cao, C.
This report describes an architecture and implementation for doing group key management over a data communications network. The architecture describes a protocol for establishing a shared encryption key among an authenticated and authorized collection of network entities. Group access requires one or more authorization certificates. The implementation includes a simple public key and certificate infrastructure. Multicast is used for some of the key management messages. An application programming interface multiplexes key management and user application messages. An implementation using the new IP security protocols is postulated. The architecture is compared with other group key management proposals, and the performance and the limitations of the implementation are described.
Full Text Available The group included adolescents from secondary school and some students. The group had weekly sessions or twice on mounth. The adolescents had varied simptoms: depressive, anxiety, psychosomatic disorders, learning difficulties, cunduct problems. All of adolescents were common on many problems in social interactions. The goal of therapeutic work were: to increase assertiveness skills and to reduce the anxious in social situations. The adolescents in group raised a self-esteem and developed some assertiveness skills: eye contact" and effective communication skills, persistence, refusing and requesting, giving and receiving critism, etc. The methods of work and techniques were based on principles of cognitive-behaviour therapy.
Matrix groups for undergraduates
Tapp, Kristopher
Matrix groups touch an enormous spectrum of the mathematical arena. This textbook brings them into the undergraduate curriculum. It makes an excellent one-semester course for students familiar with linear and abstract algebra and prepares them for a graduate course on Lie groups. Matrix Groups for Undergraduates is concrete and example-driven, with geometric motivation and rigorous proofs. The story begins and ends with the rotations of a globe. In between, the author combines rigor and intuition to describe basic objects of Lie theory: Lie algebras, matrix exponentiation, Lie brackets, and maximal tori.
UnitedHealth Group provides accessible and affordable services, improved quality of care, coordinated health care efforts, and a supportive environment for shared decision making between patients and their physicians.
Homogeneous group, research, institution
Francesca Natascia Vasta
Full Text Available The work outlines the complex connection among empiric research, therapeutic programs and host institution. It is considered the current research state in Italy. Italian research field is analyzed and critic data are outlined: lack of results regarding both the therapeutic processes and the effectiveness of eating disorders group analytic treatment. The work investigates on an eating disorders homogeneous group, led into an eating disorder outpatient service. First we present the methodological steps the research is based on including the strong connection among theory and clinical tools. Secondly clinical tools are described and the results commented. Finally, our results suggest the necessity of validating some more specifical hypothesis: verifying the relationship between clinical improvement (sense of exclusion and painful emotions reduction and specific group therapeutic processes; verifying the relationship between depressive feelings, relapses and transition trough a more differentiated groupal field.Keywords: Homogeneous group; Eating disorders; Institutional field; Therapeutic outcome
Color transparency study group
Appel, J.A.; Pordes, S.; Botts, J.; Bunce, G.; Farrar, G.
The group studied the relatively new notion of color transparency, discussed present experimental evidence for the effect, and explored several ideas for future experiments. This write-up summarizes these discussions. 11 refs., 1 fig
Generalized quantum groups
Leivo, H.P.
The algebraic approach to quantum groups is generalized to include what may be called an anyonic symmetry, reflecting the appearance of phases more general than ±1 under transposition. (author). 6 refs
Groups – Additive Notation
Coghetto Roland
Full Text Available We translate the articles covering group theory already available in the Mizar Mathematical Library from multiplicative into additive notation. We adapt the works of Wojciech A. Trybulec [41, 42, 43] and Artur Korniłowicz [25].
We translate the articles covering group theory already available in the Mizar Mathematical Library from multiplicative into additive notation. We adapt the works of Wojciech A. Trybulec [41, 42, 43] and Artur Korniłowicz [25].
Creativity and group innovation
Nijstad, B.A.; de Dreu, C.K.W.
Comments on M. West's article regarding the validity of an integrative model of creativity and innovation implementation in work groups. Variables affecting the level of team innovation; Relationship between predictors and team innovation; Promotion of constructive conflict.
Truck shovel users group
Thomas, J. [Surface Mining Association for Research and Technology, AB (Canada)
The Truck Shovel Users Group (TSUG) was developed as part of the Surface Mining Association for Research and Technology (SMART), an association of companies that meet to coordinate technology developments for the mining industry. The TSUG meet regularly to discuss equipment upgrades, maintenance planning systems, and repair techniques. The group strives to maximize the value of its assets through increased safety, equipment performance and productivity. This presentation provided administrative details about the TSUG including contact details and admission costs. It was concluded that members of the group must be employed by companies that use heavy mining equipment, and must also be willing to host meetings, make presentations, and support the common goals of the group. tabs., figs.
The theory of groups
Hall, Marshall
This 1959 text offers an unsurpassed resource for learning and reviewing the basics of a fundamental and ever-expanding area. "This remarkable book undoubtedly will become a standard text on group theory." - American Scientist.
The Radioactive Waste Section of the Radiation Protection Group wishes to inform you that the Radioactive Waste Treatment Centre will be closed on the afternoon of Tuesday 19 December 2006. Thank-you for your understanding.
The Military Cooperation Group
National Research Council Canada - National Science Library
Renzi, Jr, Alfred E
.... This thesis will describe a structure to assist with both those needs. The premise is that an expanded and improved network of US Military Groups is the weapon of choice for the war on terror, and beyond...
Introduction to group theory
Canals B.
Full Text Available This chapter is a concise mathematical introduction into the algebra of groups. It is build up in the way that definitions are followed by propositions and proofs. The concepts and the terminology introduced here will serve as a basis for the following chapters that deal with group theory in the stricter sense and its application to problems in physics. The mathematical prerequisites are at the bachelor level.1
Groups, rings, modules
Auslander, Maurice
This classic monograph is geared toward advanced undergraduates and graduate students. The treatment presupposes some familiarity with sets, groups, rings, and vector spaces. The four-part approach begins with examinations of sets and maps, monoids and groups, categories, and rings. The second part explores unique factorization domains, general module theory, semisimple rings and modules, and Artinian rings. Part three's topics include localization and tensor products, principal ideal domains, and applications of fundamental theorem. The fourth and final part covers algebraic field extensions
Focus Group Guide
home for the arrival of school- aged children. TIP: Do not conduct focus groups in a command conference room in the command group area. Doing so...organizational effectiveness and equal opportunity/equal employment opportunity/fair treatment and sexual assault and response factors (which are listed on the... Sexual Harassment (C) Sex Harassment Retaliation (D) Discrimination - Sex (E) Discrimination - Race (F) Discrimination - Disability (G
Choice Shifts in Groups
Kfir Eliaz; Debraj Ray
The phenomenon of "choice shifts" in group decision-making is fairly ubiquitous in the social psychology literature. Faced with a choice between a ``safe" and ``risky" decision, group members appear to move to one extreme or the other, relative to the choices each member might have made on her own. Both risky and cautious shifts have been identified in different situations. This paper demonstrates that from an individual decision-making perspective, choice shifts may be viewed as a systematic...
Group Capability Model
Olejarski, Michael; Appleton, Amy; Deltorchio, Stephen
The Group Capability Model (GCM) is a software tool that allows an organization, from first line management to senior executive, to monitor and track the health (capability) of various groups in performing their contractual obligations. GCM calculates a Group Capability Index (GCI) by comparing actual head counts, certifications, and/or skills within a group. The model can also be used to simulate the effects of employee usage, training, and attrition on the GCI. A universal tool and common method was required due to the high risk of losing skills necessary to complete the Space Shuttle Program and meet the needs of the Constellation Program. During this transition from one space vehicle to another, the uncertainty among the critical skilled workforce is high and attrition has the potential to be unmanageable. GCM allows managers to establish requirements for their group in the form of head counts, certification requirements, or skills requirements. GCM then calculates a Group Capability Index (GCI), where a score of 1 indicates that the group is at the appropriate level; anything less than 1 indicates a potential for improvement. This shows the health of a group, both currently and over time. GCM accepts as input head count, certification needs, critical needs, competency needs, and competency critical needs. In addition, team members are categorized by years of experience, percentage of contribution, ex-members and their skills, availability, function, and in-work requirements. Outputs are several reports, including actual vs. required head count, actual vs. required certificates, CGI change over time (by month), and more. The program stores historical data for summary and historical reporting, which is done via an Excel spreadsheet that is color-coded to show health statistics at a glance. GCM has provided the Shuttle Ground Processing team with a quantifiable, repeatable approach to assessing and managing the skills in their organization. They now have a common
Parton Distributions Working Group
Barbaro, L. de; Keller, S. A.; Kuhlmann, S.; Schellman, H.; Tung, W.-K.
This report summarizes the activities of the Parton Distributions Working Group of the QCD and Weak Boson Physics workshop held in preparation for Run II at the Fermilab Tevatron. The main focus of this working group was to investigate the different issues associated with the development of quantitative tools to estimate parton distribution functions uncertainties. In the conclusion, the authors introduce a Manifesto that describes an optimal method for reporting data
Renormalization Group Theory
Stephens, C. R.
In this article I give a brief account of the development of research in the Renormalization Group in Mexico, paying particular attention to novel conceptual and technical developments associated with the tool itself, rather than applications of standard Renormalization Group techniques. Some highlights include the development of new methods for understanding and analysing two extreme regimes of great interest in quantum field theory -- the ''high temperature'' regime and the Regge regime
Independents' group posts loss
Sanders, V.; Price, R.B.
Low oil gas prices and special charges caused the group of 50 U.S. independent producers Oil and Gas Journal tracks to post a combined loss in first half 1992. The group logged a net loss of $53 million in the first half compared with net earnings of $354 million in first half 1991, when higher oil prices during the Persian Gulf crisis buoyed earnings in spite of crude oil and natural gas production declines. The combined loss in the first half follows a 45% drop in the group's earnings in 1991 and compares with the OGJ group of integrated oil companies whose first half 1992 income fell 47% from the prior year. Special charges, generally related to asset writedowns, accounted for most of the almost $560 million in losses posted by about the third of the group. Nerco Oil and Gas Inc., Vancouver, Wash., alone accounted for almost half that total with charges related to an asset writedown of $238 million in the first quarter. Despite the poor first half performance, the outlook is bright for sharply improved group earnings in the second half, assuming reasonably healthy oil and gas prices and increased production resulting from acquisitions and in response to those prices
Assessment of Group Preferences and Group Uncertainty for Decision Making
the individ- uals. decision making , group judgments should be preferred to individual judgments if obtaining group judgments costs more. -26- -YI IV... decision making group . IV. A. 3. Aggregation using conjugate distribution. Arvther procedure for combining indivi(jai probability judgments into a group...statisticized group group decision making group judgment subjective probability Delphi method expected utility nominal group 20. ABSTRACT (Continue on
Cyclic Soft Groups and Their Applications on Groups
Hacı Aktaş
Full Text Available In crisp environment the notions of order of group and cyclic group are well known due to many applications. In this paper, we introduce order of the soft groups, power of the soft sets, power of the soft groups, and cyclic soft group on a group. We also investigate the relationship between cyclic soft groups and classical groups.
Coordinating Group report
In December 1992, western governors and four federal agencies established a Federal Advisory Committee to Develop On-site Innovative Technologies for Environmental Restoration and Waste Management (the DOIT Committee). The purpose of the Committee is to advise the federal government on ways to improve waste cleanup technology development and the cleanup of federal sites in the West. The Committee directed in January 1993 that information be collected from a wide range of potential stakeholders and that innovative technology candidate projects be identified, organized, set in motion, and evaluated to test new partnerships, regulatory approaches, and technologies which will lead to improve site cleanup. Five working groups were organized, one to develop broad project selection and evaluation criteria and four to focus on specific contaminant problems. A Coordinating Group comprised of working group spokesmen and federal and state representatives, was set up to plan and organize the routine functioning of these working groups. The working groups were charged with defining particular contaminant problems; identifying shortcomings in technology development, stakeholder involvement, regulatory review, and commercialization which impede the resolution of these problems; and identifying candidate sites or technologies which could serve as regional innovative demonstration projects to test new approaches to overcome the shortcomings. This report from the Coordinating Group to the DOIT Committee highlights the key findings and opportunities uncovered by these fact-finding working groups. It provides a basis from which recommendations from the DOIT Committee to the federal government can be made. It also includes observations from two public roundtables, one on commercialization and another on regulatory and institutional barriers impeding technology development and cleanup
Linear algebraic groups
Springer, T A
"[The first] ten chapters...are an efficient, accessible, and self-contained introduction to affine algebraic groups over an algebraically closed field. The author includes exercises and the book is certainly usable by graduate students as a text or for self-study...the author [has a] student-friendly style… [The following] seven chapters... would also be a good introduction to rationality issues for algebraic groups. A number of results from the literature…appear for the first time in a text." –Mathematical Reviews (Review of the Second Edition) "This book is a completely new version of the first edition. The aim of the old book was to present the theory of linear algebraic groups over an algebraically closed field. Reading that book, many people entered the research field of linear algebraic groups. The present book has a wider scope. Its aim is to treat the theory of linear algebraic groups over arbitrary fields. Again, the author keeps the treatment of prerequisites self-contained. The material of t...
Summary report: injection group
Simpson, J.; Ankenbrandt, C.; Brown, B.
The injector group attempted to define and address several problem areas related to the SSC injector as defined in the Reference Design Study (RDS). It also considered the topic of machine utilization, particularly the question of test beam requirements. Details of the work are given in individually contributed papers, but the general concerns and consensus of the group are presented within this note. The group recognized that the injector as outlined in the RDS was developed primarily for costing estimates. As such, it was not necessarily well optimized from the standpoint of insuring the required beam properties for the SSC. On the other hand, considering the extraordinary short time in which the RDS was prepared, it is an impressive document and a good basis from which to work. Because the documented SSC performance goals are ambitious, the group sought an injector solution which would more likely guarantee that SSC performance not be limited by its injectors. As will be seen, this leads to a somewhat different solution than that described in the RDS. Furthermore, it is the consensus of the group that the new, conservative approach represents only a modest cost increase of the overall project well worth the confidence gained and the risks avoided
Matrix groups touch an enormous spectrum of the mathematical arena. This textbook brings them into the undergraduate curriculum. It makes an excellent one-semester course for students familiar with linear and abstract algebra and prepares them for a graduate course on Lie groups. Matrix Groups for Undergraduates is concrete and example-driven, with geometric motivation and rigorous proofs. The story begins and ends with the rotations of a globe. In between, the author combines rigor and intuition to describe the basic objects of Lie theory: Lie algebras, matrix exponentiation, Lie brackets, maximal tori, homogeneous spaces, and roots. This second edition includes two new chapters that allow for an easier transition to the general theory of Lie groups. From reviews of the First Edition: This book could be used as an excellent textbook for a one semester course at university and it will prepare students for a graduate course on Lie groups, Lie algebras, etc. … The book combines an intuitive style of writing w...
Frailty Across Age Groups.
Pérez-Zepeda, M U; �vila-Funes, J A; Gutiérrez-Robledo, L M; García-Peña, C
The implementation of an aging biomarker into clinical practice is under debate. The Frailty Index is a model of deficit accumulation and has shown to accurately capture frailty in older adults, thus bridging biological with clinical practice. To describe the association of socio-demographic characteristics and the Frailty Index in different age groups (from 20 to over one hundred years) in a representative sample of Mexican subjects. Cross-sectional analysis. Nationwide and population-representative survey. Adults 20-years and older interviewed during the last Mexican National Health and Nutrition Survey (2012). A 30-item Frailty Index following standard construction was developed. Multi-level regression models were performed to test the associations of the Frailty Index with multiple socio-demographic characteristics across age groups. A total of 29,504 subjects was analyzed. The 30-item Frailty Index showed the highest scores in the older age groups, especially in women. No sociodemographic variable was associated with the Frailty Index in all the studied age groups. However, employment, economic income, and smoking status were more consistently found across age groups. To our knowledge, this is the first report describing the Frailty Index in a representative large sample of a Latin American country. Increasing age and gender were closely associated with a higher score.
Illinois Wind Workers Group
David G. Loomis
The Illinois Wind Working Group (IWWG) was founded in 2006 with about 15 members. It has grown to over 200 members today representing all aspects of the wind industry across the State of Illinois. In 2008, the IWWG developed a strategic plan to give direction to the group and its activities. The strategic plan identifies ways to address critical market barriers to the further penetration of wind. The key to addressing these market barriers is public education and outreach. Since Illinois has a restructured electricity market, utilities no longer have a strong control over the addition of new capacity within the state. Instead, market acceptance depends on willing landowners to lease land and willing county officials to site wind farms. Many times these groups are uninformed about the benefits of wind energy and unfamiliar with the process. Therefore, many of the project objectives focus on conferences, forum, databases and research that will allow these stakeholders to make well-educated decisions.
Focus group discussions
Hennink, Monique M
The Understanding Research series focuses on the process of writing up social research. The series is broken down into three categories: Understanding Statistics, Understanding Measurement, and Understanding Qualitative Research. The books provide researchers with guides to understanding, writing, and evaluating social research. Each volume demonstrates how research should be represented, including how to write up the methodology as well as the research findings. Each volume also reviews how to appropriately evaluate published research. Focus Group Discussions addresses the challenges associated with conducting and writing focus group research. It provides detailed guidance on the practical and theoretical considerations in conducting focus group discussions including: designing the discussion guide, recruiting participants, training a field team, moderating techniques and ethical considerations. Monique Hennink describes how a methodology section is read and evaluated by others, such as journal reviewers or ...
Bell, group and tangle
Solomon, A. I.
The 'Bell' of the title refers to bipartite Bell states, and their extensions to, for example, tripartite systems. The 'Group' of the title is the Braid Group in its various representations; while 'Tangle' refers to the property of entanglement which is present in both of these scenarios. The objective of this note is to explore the relation between Quantum Entanglement and Topological Links, and to show that the use of the language of entanglement in both cases is more than one of linguistic analogy.
A Quantum Groups Primer
Majid, Shahn
Here is a self-contained introduction to quantum groups as algebraic objects. Based on the author's lecture notes for the Part III pure mathematics course at Cambridge University, the book is suitable as a primary text for graduate courses in quantum groups or supplementary reading for modern courses in advanced algebra. The material assumes knowledge of basic and linear algebra. Some familiarity with semisimple Lie algebras would also be helpful. The volume is a primer for mathematicians but it will also be useful for mathematical physicists.
Monteiro, Marco A.R.
An elementary introduction to quantum groups is presented. The example of Universal Enveloping Algebra of deformed SU(2) is analysed in detail. It is also discussed systems made up of bosonic q-oscillators at finite temperature within the formalism of Thermo-Field Dynamics. (author). 39 refs
Lectures on Lie groups
Hsiang, Wu-Yi
This volume consists of nine lectures on selected topics of Lie group theory. We provide the readers a concise introduction as well as a comprehensive 'tour of revisiting' the remarkable achievements of S Lie, W Killing, É Cartan and H Weyl on structural and classification theory of semi-simple Lie groups, Lie algebras and their representations; and also the wonderful duet of Cartans' theory on Lie groups and symmetric spaces.With the benefit of retrospective hindsight, mainly inspired by the outstanding contribution of H Weyl in the special case of compact connected Lie groups, we develop the above theory via a route quite different from the original methods engaged by most other books.We begin our revisiting with the compact theory which is much simpler than that of the general semi-simple Lie theory; mainly due to the well fittings between the Frobenius-Schur character theory and the maximal tori theorem of É Cartan together with Weyl's reduction (cf. Lectures 1-4). It is a wonderful reality of the Lie t...
Gluten Intolerance Group
... Intolerance Group (GIG), the industry leader in the certification of gluten-free products and food services, announced today that a wide ... of gluten-free products. One of the top certification programs in the world, GFCO inspects products and manufacturing facilities for gluten, in an effort ...
With the Radiobiology Group
CERN PhotoLab
The Radiobiology Group carries out experiments to study the effect of radiation on living cells. The photo shows the apparatus for growing broad beans which have been irradiated by 250 GeV protons. The roots are immersed in a tank of running water (CERN Weekly Bulletin 26 January 1981 and Annual Report 1980 p. 160). Karen Panman, Marilena Streit-Bianchi, Roger Paris.
Group control of elevators
Umeda, Yasukazu; Hikita, Shiro; Tuji, Sintaro (Mitsubishi Electric Corp., Tokyo (Japan))
Items to be evaluated in the group control of elevators, and a typical control system are described. A new system in which the fuzzy rule base is employed is introduced together with the configuration. The items to be evaluated are waiting time, riding time, accuracy of forecasting, energy saving, and ease of usage. The everage waiting time of less than 20 seconds with less than 3% waiting rate of more than 60 seconds is accepted as a satisfactory service condition. There are many conflicting matters in group-controlling, and the study for the controlling must deal with the optimization of multi-purpose problems. The standards for group-control evaluation differ according to building structures and the tastes of users, and an important problem is where to give emphasis of the evaluation. The TRAFFIC PATTERN LEARNING METHOD has been applied in the system for careful control to accommodate the traffic. No specific function is provided for the evaluation, but the call allocation is made by fuzzy rule-base. The configuration of a new group-control system is introduced. 7 references, 7 figures, 1 table.
Functional Group Analysis.
Smith, Walter T., Jr.; Patterson, John M.
Literature on analytical methods related to the functional groups of 17 chemical compounds is reviewed. These compounds include acids, acid azides, alcohols, aldehydes, ketones, amino acids, aromatic hydrocarbons, carbodiimides, carbohydrates, ethers, nitro compounds, nitrosamines, organometallic compounds, peroxides, phenols, silicon compounds,…
Moral motivation within groups
Lee, Romy van der
Morality is of particular importance to people: People want to be considered moral and want to belong to moral groups. Consequently, morality judgments have the potential to motivate individuals to behave in ways that are considered to be 'good'. In the current dissertation, I examined the impact of
Smoot Group Cosmology
the Universe About Cosmology Planck Satellite Launched Cosmology Videos Professor George Smoot's group conducts research on the early universe (cosmology) using the Cosmic Microwave Background radiation (CMB science goals regarding cosmology. George Smoot named Director of Korean Cosmology Institute The GRB
Groups and Symmetry
Home; Journals; Resonance – Journal of Science Education; Volume 4; Issue 10. Groups and Symmetry: A Guide to Discovering Mathematics. Geetha Venkataraman. Book Review Volume 4 Issue 10 October 1999 pp 91-92. Fulltext. Click here to view fulltext PDF. Permanent link:
Public interest group involvement
Shelley, P.
Including public interest groups in the siting process for nuclear waste disposal facilities is of great importance. Controversial sitings often result in litigation, but involving public interest groups early in the process will lessen the change of this. They act as surrogates for the general public and should be considered as members of the team. It is important to remember though, that all public interest groups are different. In choosing public panels such as public advisory committees, members should not be chosen on the basis of some quota. Opposition groups should not be excluded. Also, it is important to put the right person in charge of the committee. The goal of public involvement is to identify the conflicts. This must be done during the decision process, because conflicts must be known before they can be eliminated. Regarding litigation, it is important to ease through and around legal battles. If the siting process has integrity and a good faith effort has been shown, the court should uphold the effort. In addition, it is important to be negotiable and to eliminate shortcuts
Leukosis/Sarcoma Group
The leukosis/sarcoma (L/S) group of diseases designates a variety of transmissible benign and malignant neoplasms of chickens caused by members that belong to the family Retroviridae. Because the expansion of the literature on this disease, it is no longer feasible to cite all relevant publications ...
Working Group Report: Neutrinos
de Gouvea, A.; Pitts, K.; Scholberg, K.; Zeller, G. P. [et al.
This document represents the response of the Intensity Frontier Neutrino Working Group to the Snowmass charge. We summarize the current status of neutrino physics and identify many exciting future opportunities for studying the properties of neutrinos and for addressing important physics and astrophysics questions with neutrinos.
Group: radiation dosimetry
Caldas, L.V.E.
The main activities of the radiation dosimetry group is described, including the calibration of instruments, sources and radioactive solutions and the determination of neutron flux; development, production and market dosimetric materials; development radiation sensor make the control of radiation dose received by IPEN workers; development new techniques for monitoring, etc. (C.G.C.)
Categorization by Groups
R.W. Hamilton (Rebecca); S. Puntoni (Stefano); N.T. Tavassoli (Nader)
textabstractCategorization is a core psychological process central to consumer and managerial decision-making. While a substantial amount of research has been conducted to examine individual categorization behaviors, relatively little is known about the group categorization process. In two
Gamma gamma technology group
The purpose of the meeting was to form a group of people who ... able by looking at the energy deposited at the face of the final dipole, 4.5 m from ... A F Zarnecki has made a good start on background studies, V Telnov has proposed.
Group theory in physics
Cornwell, J F
Recent devopments, particularly in high-energy physics, have projected group theory and symmetry consideration into a central position in theoretical physics. These developments have taken physicists increasingly deeper into the fascinating world of pure mathematics. This work presents important mathematical developments of the last fifteen years in a form that is easy to comprehend and appreciate.
Anaphylaxis vulnerable groups
Ehab
Age groups vulnerable to serious attacks of anaphylaxis include infants, teenagers, pregnant women, and the elderly. Concomitant diseases, such as severe or uncontrolled asthma, cardiovascular disease, mastocytosis or clonal mast cell disorders and the concurrent use of some medications such as beta adrenergic ...
Special Interest Groups.
Degi, Bruce J.
Offers a reflection on the shootings at Columbine High School in Littleton, Colorado, on April 20, 1999. Notes how every special-interest group has used the tragedy to support its own point of view, and concludes that teachers have become bystanders in the education of America's children. (SR)
Ignalina Safety Analysis Group
Ushpuras, E.
The article describes the fields of activities of Ignalina NPP Safety Analysis Group (ISAG) in the Lithuanian Energy Institute and overview the main achievements gained since the group establishment in 1992. The group is working under the following guidelines: in-depth analysis of the fundamental physical processes of RBMK-1500 reactors; collection, systematization and verification of the design and operational data; simulation and analysis of potential accident consequences; analysis of thermohydraulic and neutronic characteristics of the plant; provision of technical and scientific consultations to VATESI, Governmental authorities, and also international institutions, participating in various projects aiming at Ignalina NPP safety enhancement. The ISAG is performing broad scientific co-operation programs with both Eastern and Western scientific groups, supplying engineering assistance for Ignalina NPP. ISAG is also participating in the joint Lithuanian - Swedish - Russian project - Barselina, the first Probabilistic Safety Assessment (PSA) study of Ignalina NPP. The work is underway together with Maryland University (USA) for assessment of the accident confinement system for a range of breaks in the primary circuit. At present the ISAG personnel is also involved in the project under the grant from the Nuclear Safety Account, administered by the European Bank for reconstruction and development for the preparation and review of an in-depth safety assessment of the Ignalina plant
Gartner Group reports
Gartner Group. Stamford, CT
Gartner Group is the one of the leading independent providers of research and analysis material for IT professionals. Their reports provide in-depth analysis of dominant trends, companies and products. CERN has obtained a licence making these reports available online to anyone within CERN. The database contains not only current reports, updated monthly, but also some going back over a year.
Lattices in group manifolds
Lisboa, P.; Michael, C.
We address the question of designing optimum discrete sets of points to represent numerically a continuous group manifold. We consider subsets which are extensions of the regular discrete subgroups. Applications to Monte Carlo simulation of SU(2) and SU(3) gauge theory are discussed. (orig.)
Teaching Badminton to Groups.
Nelson, Jonathan E.
Numerous ideas for teaching badminton to large groups are presented. The focus is on drills and techniques for off the court instructional stations. Instead of having students waiting their turn to play, more students can participate actively as they rotate from one station to another. (JN)
Group leaders optimization algorithm
Daskin, Anmer; Kais, Sabre
We present a new global optimization algorithm in which the influence of the leaders in social groups is used as an inspiration for the evolutionary technique which is designed into a group architecture. To demonstrate the efficiency of the method, a standard suite of single and multi-dimensional optimization functions along with the energies and the geometric structures of Lennard-Jones clusters are given as well as the application of the algorithm on quantum circuit design problems. We show that as an improvement over previous methods, the algorithm scales as N 2.5 for the Lennard-Jones clusters of N-particles. In addition, an efficient circuit design is shown for a two-qubit Grover search algorithm which is a quantum algorithm providing quadratic speedup over the classical counterpart.
Communication from ST Group
TS Department
Please note that owing the preparations for the Open Days, the FM Group will not able to handle specific requests for waste collection from 2nd to 6th of April, nor removal or PC transport requests between the 31 March and 11 April. We kindly ask you to plan the collection of all types of waste and any urgent transport of office furniture or PCs before 31 March. Waste collection requests must be made by contacting FM Support on 77777 or at the e-mail address mailto:[email protected]; removal of office furniture or PC transport requests must be made using the EDH 'Transport request' form (select "Removals" or "PC transport" from the drop-down menu). For any question concerning the sorting of waste, please consult the following web site: http://dechets-waste.web.cern.ch/dechets-waste/ Thank you for your understanding and collaboration. TS/FM Group
Mindfulness for group facilitation
Adriansen, Hanne Kirstine; Krohn, Simon
In this paper, we argue that mindfulness techniques can be used for enhancing the outcome of group performance. The word mindfulness has different connotations in the academic literature. Broadly speaking there is 'mindfulness without meditation' or 'Western' mindfulness which involves active...... thinking and 'Eastern' mindfulness which refers to an open, accepting state of mind, as intended with Buddhist-inspired techniques such as meditation. In this paper, we are interested in the latter type of mindfulness and demonstrate how Eastern mindfulness techniques can be used as a tool for facilitation....... A brief introduction to the physiology and philosophy of Eastern mindfulness constitutes the basis for the arguments of the effect of mindfulness techniques. The use of mindfulness techniques for group facilitation is novel as it changes the focus from individuals' mindfulness practice...
Group and representation theory
Vergados, J D
This volume goes beyond the understanding of symmetries and exploits them in the study of the behavior of both classical and quantum physical systems. Thus it is important to study the symmetries described by continuous (Lie) groups of transformations. We then discuss how we get operators that form a Lie algebra. Of particular interest to physics is the representation of the elements of the algebra and the group in terms of matrices and, in particular, the irreducible representations. These representations can be identified with physical observables. This leads to the study of the classical Lie algebras, associated with unitary, unimodular, orthogonal and symplectic transformations. We also discuss some special algebras in some detail. The discussion proceeds along the lines of the Cartan-Weyl theory via the root vectors and root diagrams and, in particular, the Dynkin representation of the roots. Thus the representations are expressed in terms of weights, which are generated by the application of the elemen...
Working group 4: Terrestrial
A working group at a Canada/USA symposium on climate change and the Arctic identified major concerns and issues related to terrestrial resources. The group examined the need for, and the means of, involving resource managers and users at local and territorial levels in the process of identifying and examining the impacts and consequences of climatic change. Climatic change will be important to the Arctic because of the magnitude of the change projected for northern latitudes; the apparent sensitivity of its terrestrial ecosystems, natural resources, and human support systems; and the dependence of the social, cultural, and economic welfare of Arctic communities, businesses, and industries on the health and quality of their environment. Impacts of climatic change on the physical, biological, and associated socio-economic environment are outlined. Gaps in knowledge needed to quantify these impacts are listed along with their relationships with resource management. Finally, potential actions for response and adaptation are presented
Duality and quantum groups
Alvarez-Gaume, L.; Gomez, C.; Sierra, G.
We show that the duality properties of Rational Conformal Field Theories follow from the defining relations and the representation theory of quantum groups. The fusion and braiding matrices are q-analogues of the 6j-symbols and the modular transformation matrices are obtained from the properties of the co-multiplication. We study in detail the Wess-Zumino-Witten models and the rational gaussian models as examples, but carry out the arguments in general. We point out the connections with the Chern-Simons approach. We give general arguments of why the general solution to the polynomial equations of Moore and Seiberg describing the duality properties of Rational Conformal Field Theories defines a Quantum Group acting on the space of conformal blocks. A direct connection between Rational Theories and knot invariants is also presented along the lines of Jones' original work. (orig.)
The Areva Group
The Ombudperson Initiative Group
Following many discussions that took place at some of the ATLAS Women's Network lunch gatherings, a few ATLAS women joined forces with similarly concerned CERN staff women to form a small group last Fall to discuss the need for a CERN-wide Ombudsperson. This has since evolved into the Ombudsperson Initiative Group (OIG) currently composed of the following members: Barbro Asman, Stockholm University; Pierre Charrue, CERN AB; Anna Cook, CERN IT; Catherine Delamare, CERN and IT Ombudsperson; Paula Eerola, Lund University; Pauline Gagnon, Indiana University; Eugenia Hatziangeli, CERN AB; Doreen Klem, CERN IT; Bertrand Nicquevert, CERN TS and Laura Stewart, CERN AT. On June 12, members of the OIG met with representatives of Human Resources (HR) and the Equal Opportunity Advisory Panel (EOAP) to discuss the proposal drafted by the OIG. The meeting was very positive. Everybody agreed that the current procedures at CERN applicable in the event of conflict required a thorough review, and that a professionnally trai...
Metrically universal abelian groups
Czech Academy of Sciences Publication Activity Database
Doucha, Michal
Ro�. 369, �. 8 (2017), s. 5981-5998 ISSN 0002-9947 R&D Projects: GA AV ČR IAA100190902 Institutional support: RVO:67985840 Keywords : Abelian group Subject RIV: BA - General Mathematics OBOR OECD: Pure mathematics Impact factor: 1.426, year: 2016 http://www.ams.org/journals/tran/2017-369-08/S0002-9947-2017-07059-8/
Storage ring group summary
King, N.M.
The Storage Ring Group set out to identify and pursue salient problems in accelerator physics for heavy ion fusion, divorced from any particular reference design concept. However, it became apparent that some basic parameter framework was required to correlate the different study topics. As the Workshop progressed, ring parameters were modified and updated. Consequently, the accompanying papers on individual topics will be found to refer to slightly varied parameters, according to the stage at which the different problems were tackled
MAGIC user's group software
Warren, G.; Ludeking, L.; McDonald, J.; Nguyen, K.; Goplen, B.
The MAGIC User's Group has been established to facilitate the use of electromagnetic particle-in-cell software by universities, government agencies, and industrial firms. The software consists of a series of independent executables that are capable of inter-communication. MAGIC, SOS, μ SOS are used to perform electromagnetic simulations while POSTER is used to provide post-processing capabilities. Each is described in the paper. Use of the codes for Klystrode simulation is discussed
Multibunch working group
The goal of this working group was to foment discussions about the use and limitations of multi-bunch, representatives from most operating or in-project synchrotron radiation sources (ALS, SPEAR, BESSY-2, SPRING-8, ANKA, DELTA, PEP-2, DIAMOND, ESRF...) have presented their experience. The discussions have been led around 3 topics: 1) resistive wall instabilities and ion instabilities, 2) higher harmonic cavities, and 3) multibunch feedback systems.
Group 4. Containment
McCauley, V.S.; Keiser, J.R.
This paper summarizes the findings of the Containment Working Group which met at the Workshop on Radioactive, Hazardous, and/or Mixed Waste Sludge Management. The Containment Working Group (CWG) examined the problems associated with providing adequate containment of waste forms from both short- and long-term storage. By its nature, containment encompasses a wide variety of waste forms, storage conditions, container types, containment schemes, and handling activities. A containment system can be anything from a 55-gal drum to a 100-ft-long underground vault. Because of the diverse nature of containment systems, the CWG chose to focus its limited time on broad issues that are applicable to the design of any containment system, rather than attempting to address problems specific to a particular containment system or waste-form type. Four major issues were identified by the CWG. They relate to: (1) service conditions and required system performance; (2) ultimate disposition; (3) cost and schedule; and (4) acceptance criteria, including quality assurance/quality control (QA/QC) concerns. All of the issues raised by the group are similar in that they all help to define containment system requirements
Tsujikura, Y.
The workshop of 26-27 june 2000, on nuclear power Plant LIfe Management (PLIM), also included working groups in which major issues facing PLIM activities for nuclear power plants were identified and discussed. The first group was on Technology. Utilities should consider required provisions capacity by properly maintaining and preserving the existing power plants to the extent practicable and taking into account growing demand, limits of energy conservation, and difficulties in finding new power plant sites. Generally, the extension of the life of nuclear power plant (e.g. from 40 years to 60 years) is an attractive option for utilities, as the marginal cost of most existing nuclear power plants is lower than that of almost all other power sources. It is also an attractive option for environmental protection. Consequently, PLIM has become an important issue in the context of the regulatory reform of the electricity markets. Therefore, the three main objectives of the Technology working group are: 1) Documenting how the safety of nuclear power plants being operated for the long-term has been confirmed, and suggesting ways of sharing this information. 2) Addressing development of advanced maintenance technologies necessary over the plant lifetime, and clarifying their technical challenges. 3) Suggesting potential areas of research and development that might, be necessary. Some potential examples of such research include: - improving the effectiveness of maintenance methods to assure detection of incipient faults; - providing cost effective preventive maintenance programmes; - furnishing systematic, cost-effective refurbishment programmes framed to be consistent with efforts to extend the time between re-fuelling; - developing a methodology that moves routine maintenance on-line without compromising safety. (author)
Notes on quantum groups
Pressley, A.; Chari, V.; Tata Inst. of Fundamental Research, Bombay
The authors presents an introduction to quantum groups defined as a deformation of the universal enveloping algebra of a Lie algebra. After the description of Hopf algebras with some examples the approach of Drinfel'd and Jimbo is described, where the quantization of a Lie algebra represents a Hopf algebra, defined over the algebra of formal power series in an indetermined h. The authors show that this approach arises from a r-matrix, which satisfies the classical Yang-Baxter equation. As example quantum sl 2 is considered. Furthermore the approaches of Manin and Woroniwicz and the R-matrix approach are described. (HSI)
Unilever Group : equity valuation
Pires, Susana Sofia Castelo
The following dissertation has the purpose to value the Unilever Group, but more specifically Unilever N.V. being publicly traded in the Amsterdam Exchange Index. Unilever is seen as a global player and one of most successful and competitive fast-moving consumer goods companies. In order to valuate Unilever's equity, a Discounted Cash Flow (DCF) approach is first carried out, since it is believed to be the most reliable methodology. The value estimated was €36.39, advising one to buy its s...
Statistical Group Comparison
Liao, Tim Futing
An incomparably useful examination of statistical methods for comparisonThe nature of doing science, be it natural or social, inevitably calls for comparison. Statistical methods are at the heart of such comparison, for they not only help us gain understanding of the world around us but often define how our research is to be carried out. The need to compare between groups is best exemplified by experiments, which have clearly defined statistical methods. However, true experiments are not always possible. What complicates the matter more is a great deal of diversity in factors that are not inde
Renormalization Group Functional Equations
Curtright, Thomas L
Functional conjugation methods are used to analyze the global structure of various renormalization group trajectories. With minimal assumptions, the methods produce continuous flows from step-scaling {\\sigma} functions, and lead to exact functional relations for the local flow {\\beta} functions, whose solutions may have novel, exotic features, including multiple branches. As a result, fixed points of {\\sigma} are sometimes not true fixed points under continuous changes in scale, and zeroes of {\\beta} do not necessarily signal fixed points of the flow, but instead may only indicate turning points of the trajectories.
Grouping Notes Through Nodes
Dove, Graham; Abildgaard, Sille Julie Jøhnk; Biskjær, Michael Mose
, both individually and when grouped, and their role in categorisation in semantic long-term memory. To do this, we adopt a multimodal analytical approach focusing on interaction between humans, and between humans and artefacts, alongside language. We discuss in detail examples of four different...... externalisation functions served by Post-ItTM notes, and show how these functions are present in complex overlapping combinations rather than being discrete. We then show how the temporal development of Post-ItTM note interactions supports categorisation qualities of semantic long-term memory....
Dove, Graham; Abildgaard, Sille Julie; Biskjær, Michael Mose
Farmer, David W
In most mathematics textbooks, the most exciting part of mathematics-the process of invention and discovery-is completely hidden from the reader. The aim of Groups and Symmetry is to change all that. By means of a series of carefully selected tasks, this book leads readers to discover some real mathematics. There are no formulas to memorize; no procedures to follow. The book is a guide: Its job is to start you in the right direction and to bring you back if you stray too far. Discovery is left to you. Suitable for a one-semester course at the beginning undergraduate level, there are no prerequ
Theory and modeling group
Holman, Gordon D.
The primary purpose of the Theory and Modeling Group meeting was to identify scientists engaged or interested in theoretical work pertinent to the Max '91 program, and to encourage theorists to pursue modeling which is directly relevant to data which can be expected to result from the program. A list of participants and their institutions is presented. Two solar flare paradigms were discussed during the meeting -- the importance of magnetic reconnection in flares and the applicability of numerical simulation results to solar flare studies.
The OMERACT Ultrasound Group
Terslev, Lene; Iagnocco, Annamaria; Bruyn, George A W
OBJECTIVE: To provide an update from the Outcome Measures in Rheumatology (OMERACT) Ultrasound Working Group on the progress for defining ultrasound (US) minimal disease activity threshold at joint level in rheumatoid arthritis (RA) and for standardization of US application in juvenile idiopathic......) and power Doppler (PD). Synovial effusion (SE) was scored a binary variable. For JIA, a Delphi approach and subsequent validation in static images and patient-based exercises were used to developed preliminary definitions for synovitis and a scoring system. RESULTS: For minimal disease activity, 7% HC had...
A village group, Trashibiola
Thomson, John, 1837-1921, photographer
158 x 111 mm. Woodburytype. A view showing a group of villagers seated in a paved courtyard in front of a stonewalled house (the principal house in the village). The village is near the town of Paphos. The photograph appears in Thomson's 'Through Cyprus with the camera, in the autumn of 1878' (vol.2, London: Sampson Low, Marston, Searle, and Rivington, 1879). Thomson states that the purpose of the gathering was twofold: to welcome strangers to the village and to discuss a point of law c...
Bevalac computer support group
McParland, C.; Bronson, M.
During the past year, a group was created and placed under the leadership of Charles McParland. This is an expansion of previous Bevalac software efforts and has responsibilities in three major hardware and software areas. The first area is the support of the existing data acquisition/analysis VAX 11/780s at the Bevalac. The second area is the continued support of present data acquisition programs. The third principal area of effort is the development of new data acquisition systems to meet the increasing needs of the Bevalac experimental program
Social group utility maximization
Gong, Xiaowen; Yang, Lei; Zhang, Junshan
This SpringerBrief explains how to leverage mobile users' social relationships to improve the interactions of mobile devices in mobile networks. It develops a social group utility maximization (SGUM) framework that captures diverse social ties of mobile users and diverse physical coupling of mobile devices. Key topics include random access control, power control, spectrum access, and location privacy.This brief also investigates SGUM-based power control game and random access control game, for which it establishes the socially-aware Nash equilibrium (SNE). It then examines the critical SGUM-b
ATLAS Detector Interface Group
Mapelli, L
Originally organised as a sub-system in the DAQ/EF-1 Prototype Project, the Detector Interface Group (DIG) was an information exchange channel between the Detector systems and the Data Acquisition to provide critical detector information for prototype design and detector integration. After the reorganisation of the Trigger/DAQ Project and of Technical Coordination, the necessity to provide an adequate context for integration of detectors with the Trigger and DAQ lead to organisation of the DIG as one of the activities of Technical Coordination. Such an organisation emphasises the ATLAS wide coordination of the Trigger and DAQ exploitation aspects, which go beyond the domain of the Trigger/DAQ project itself. As part of Technical Coordination, the DIG provides the natural environment for the common work of Trigger/DAQ and detector experts. A DIG forum for a wide discussion of all the detector and Trigger/DAQ integration issues. A more restricted DIG group for the practical organisation and implementation o...
In order to prepare the organization of the Open Days, please note that FM Group will not able to take into account either specific requests for waste collection from 2nd to 6th of April, either removal or PC transport requests between the 31st and the 11th of March. We kindly ask you to plan the collection of any type of waste and the urgent transport of office furniture or PC before the 31st of March. Waste collection requests shall be formulated contacting FM Support at 77777 or at the email address mailto:[email protected]; removal of office furniture or PC transport requests must be made using the EDH 'Transport request' form selecting the "Removals" or the "PC transport" category from the drop-down menu. For any question concerning the waste sorting, please consult the following web address: http://dechets-waste.web.cern.ch/dechets-waste/. Thank you for your understanding and collaboration. TS/FM Group
Social group and mobbing
Baltezarević Vesna
Full Text Available Our reality, having been subject to the numerous social crises during the last decades of the 20th century, is characterized by frequent incidences of powerlessness and alienation. The man is more frequently a subject to loneliness and overcomes the feeling of worthlessness, no matter whether he considers himself an individual or a part of a whole larger social. Such an environment leads to development of aggression in all fields of ones life. This paper has as an objective the pointing out of the mental harassment that is manifested in the working environment. There is a prevalence of mobbing cases, as a mode of pathological communication. The result of this is that a person, subjected to this kind of abuse, is soon faced with social isolation. This research also aspires to initiate the need for social groups self-organization of which victims are part of. The reaction modality of a social group directly conditions the outcome of the deliberate social drama, one is subjected to it as a result of mobbing.
Meningococcal group B vaccines.
Findlow, Jamie
Meningococcal disease remains a devastating and feared infection with a significant morbidity and mortality profile. The successful impact of meningococcal capsular group C glyconconjugate vaccines introduced into the UK infant immunization schedule in 1999, has resulted in >80% of disease now being attributable to meningococcal capsular group B (MenB). MenB glyconconjugate vaccines are not immunogenic and hence, vaccine design has focused on sub-capsular antigens. Recently, a four component vaccine to combat MenB disease (4CMenB) has progressed through clinical development and was approved by the European Medicines Agency at the end of 2012. This vaccine has proven safe and immunogenic and has been predicted to provide protection against ~73% of the MenB disease from England and Wales. Recommendation/implementation of the vaccine into the UK infant schedule is currently being evaluated. 4CMenB has the potential to provide protection against a significant proportion of MenB disease in the UK which is currently unpreventable.
Business working group
Doroshuk, B.W.
The workshop of 26-27 june 2000, on nuclear power Plant LIfe Management (PLIM), also included working groups in which major issues facing PLIM activities for nuclear power plants were identified and discussed. The third group was on Business. The discussion concerned the following points: There are concerns about retaining experienced/trained personnel, and maintaining a good working relationship among them, as well as about the closure of research facilities, the reduction in staff numbers under increasing economic pressure and the lack of new nuclear power plant constructions. The marginal cost of producing electricity is lower for most existing nuclear power plants than for almost all other energy sources. Refurbishment costs are usually relatively small compared with new investments. The ongoing regulatory reform of the electricity market will bring increasing competition. Although PLIM has been carried out in many countries with favourable results, there are still uncertainties which affect business decisions regarding financial and market risks in PLIM activities. Recommendations were made. (author)
The CERN Administration would like to remind you that staff members and fellows have the possibility to take out a life insurance contract on favourable terms through a Group Life Insurance. This insurance is provided by the company Helvetia and is available to you on a voluntary basis. The premium, which varies depending on the age and gender of the person insured, is calculated on the basis of the amount of the death benefit chosen by the staff member/fellow and can be purchased in slices of 10,000 CHF. The contract normally ends at the retirement age (65/67 years) or when the staff member/fellow leaves the Organization. The premium is deducted monthly from the payroll. Upon retirement, the staff member can opt to maintain his membership under certain conditions. More information about Group Life Insurance can be found at: Regulations (in French) Table of premiums The Pension Fund Benefit Service &...
On the Brauer group
Tankeev, Sergei G
For an arithmetic model X of a Fermat surface or a hyperkahler variety with Betti number b 2 (V otimes k-bar)>3 over a purely imaginary number field k, we prove the finiteness of the l-components of Br'(X) for all primes l>>0. This yields a variant of a conjecture of M. Artin. If V is a smooth projective irregular surface over a number field k and V(k)≠nothing, then the l-primary component of Br(V)/Br(k) is an infinite group for every prime l. Let A 1 →M 1 be the universal family of elliptic curves with a Jacobian structure of level N>=3 over a number field k supset of Q(e 2πi/N ). Assume that M 1 (k) ≠nothing. If V is a smooth projective compactification of the surface A 1 , then the l-primary component of Br(V)/Br(M-bar 1 ) is a finite group for each sufficiently large prime l
Biology task group
The accomplishments of the task group studies over the past year are reviewed. The purposes of biological investigations, in the context of subseabed disposal, are: an evaluation of the dose to man; an estimation of effects on the ecosystem; and an estimation of the influence of organisms on and as barriers to radionuclide migration. To accomplish these ends, the task group adopted the following research goals: (1) acquire more data on biological accumulation of specific radionuclides, such as those of Tc, Np, Ra, and Sr; (2) acquire more data on transfer coefficients from sediment to organism; (3) Calculate mass transfer rates, construct simple models using them, and estimate collective dose commitment; (4) Identify specific pathways or transfer routes, determine the rates of transfer, and make dose limit calculations with simple models; (5) Calculate dose rates to and estimate irradiation effects on the biota as a result of waste emplacement, by reference to background irradiation calculations. (6) Examine the effect of the biota on altering sediment/water radionuclide exchange; (7) Consider the biological data required to address different accident scenarios; (8) Continue to provide the basic biological information for all of the above, and ensure that the system analysis model is based on the most realistic and up-to-date concepts of marine biologists; and (9) Ensure by way of free exchange of information that the data used in any model are the best currently available
Doing focus group research
Lindegaard, Laura Bang
Scholars of ethnomethodologically informed discourse studies are often sceptical of the use of interview data such as focus group data. Some scholars quite simply reject interview data with reference to a general preference for so-called naturally occurring data. Other scholars acknowledge...... that interview data can be of some use if the distinction between natural and contrived data is given up and replaced with a distinction between interview data as topic or as resource. In greater detail, such scholars argue that interview data are perfectly adequate if the researcher wants to study the topic...... of interview interaction, but inadequate as data for studying phenomena that go beyond the phenomenon of interview interaction. Neither of these more and less sceptical positions are, on the face of it, surprising due to the ethnomethodological commitment to study social order as accomplished in situ...
The CERN Administration wishes to inform staff members and fellows having taken out optional life insurance under the group contract signed by CERN that the following changes to the rules and regulations entered into force on 1 January 2013: Â The maximum age for an active member has been extended from 65 to 67 years. The beneficiary clause now allows insured persons to designate one or more persons of their choice to be their beneficiary(-ies), either at the time of taking out the insurance or at a later date, in which case the membership/modification form must be updated accordingly. Beneficiaries must be clearly identified (name, first name, date of birth, address). Â The membership/modification form is available on the FP website: http://fp.web.cern.ch/helvetia-life-insurance For further information, please contact: Valentina Clavel (Tel. 73904) Peggy Pithioud (Tel. 72736)
End Group Modification
Jahnsen, Rasmus O; Sandberg-Schaal, Anne; Frimodt-Møller, Niels
Increased incidence of infections with multidrug-resistant bacterial strains warrants an intensive search for novel potential antimicrobial agents. Here, an antimicrobial peptide analogue with a cationic/hydrophobic alternating design displaying only moderate activity against Gram-positive pathog......Increased incidence of infections with multidrug-resistant bacterial strains warrants an intensive search for novel potential antimicrobial agents. Here, an antimicrobial peptide analogue with a cationic/hydrophobic alternating design displaying only moderate activity against Gram......, the most favorable hydrophobic activity-inducing moieties were found to be cyclohexylacetyl and pentafluorophenylacetyl groups, while the presence of a short PEG-like chain had no significant effect on activity. Introduction of cationic moieties conferred no effect or merely a moderate activity...
Optimised Renormalisation Group Flows
Litim, Daniel F
Exact renormalisation group (ERG) flows interpolate between a microscopic or classical theory and the corresponding macroscopic or quantum effective theory. For most problems of physical interest, the efficiency of the ERG is constrained due to unavoidable approximations. Approximate solutions of ERG flows depend spuriously on the regularisation scheme which is determined by a regulator function. This is similar to the spurious dependence on the ultraviolet regularisation known from perturbative QCD. Providing a good control over approximated ERG flows is at the root for reliable physical predictions. We explain why the convergence of approximate solutions towards the physical theory is optimised by appropriate choices of the regulator. We study specific optimised regulators for bosonic and fermionic fields and compare the optimised ERG flows with generic ones. This is done up to second order in the derivative expansion at both vanishing and non-vanishing temperature. An optimised flow for a ``proper-time ren...
Graphs, groups and surfaces
White, AT
The field of topological graph theory has expanded greatly in the ten years since the first edition of this book appeared. The original nine chapters of this classic work have therefore been revised and updated. Six new chapters have been added, dealing with: voltage graphs, non-orientable imbeddings, block designs associated with graph imbeddings, hypergraph imbeddings, map automorphism groups and change ringing.Thirty-two new problems have been added to this new edition, so that there are now 181 in all; 22 of these have been designated as ``difficult'''' and 9 as ``unsolved''''. Three of the four unsolved problems from the first edition have been solved in the ten years between editions; they are now marked as ``difficult''''.
Quantum Secure Group Communication.
Li, Zheng-Hong; Zubairy, M Suhail; Al-Amri, M
We propose a quantum secure group communication protocol for the purpose of sharing the same message among multiple authorized users. Our protocol can remove the need for key management that is needed for the quantum network built on quantum key distribution. Comparing with the secure quantum network based on BB84, we show our protocol is more efficient and securer. Particularly, in the security analysis, we introduce a new way of attack, i.e., the counterfactual quantum attack, which can steal information by "invisible" photons. This invisible photon can reveal a single-photon detector in the photon path without triggering the detector. Moreover, the photon can identify phase operations applied to itself, thereby stealing information. To defeat this counterfactual quantum attack, we propose a quantum multi-user authorization system. It allows us to precisely control the communication time so that the attack can not be completed in time.
Working Group Report: Sensors
Artuso, M.; et al.,
Sensors play a key role in detecting both charged particles and photons for all three frontiers in Particle Physics. The signals from an individual sensor that can be used include ionization deposited, phonons created, or light emitted from excitations of the material. The individual sensors are then typically arrayed for detection of individual particles or groups of particles. Mounting of new, ever higher performance experiments, often depend on advances in sensors in a range of performance characteristics. These performance metrics can include position resolution for passing particles, time resolution on particles impacting the sensor, and overall rate capabilities. In addition the feasible detector area and cost frequently provides a limit to what can be built and therefore is often another area where improvements are important. Finally, radiation tolerance is becoming a requirement in a broad array of devices. We present a status report on a broad category of sensors, including challenges for the future and work in progress to solve those challenges.
Representation Theory of Algebraic Groups and Quantum Groups
Gyoja, A; Shinoda, K-I; Shoji, T; Tanisaki, Toshiyuki
Invited articles by top notch expertsFocus is on topics in representation theory of algebraic groups and quantum groupsOf interest to graduate students and researchers in representation theory, group theory, algebraic geometry, quantum theory and math physics
Oklo working group meeting
Von Maravic, H.
Natural analogue studies have been carried out for several years in the framework of the European Community's R and D programme on radioactive waste; and within its recent fourth five-year programme on 'Management and storage of radioactive waste (1990-94)' the Community is participating in the Oklo study, natural analogue for transfer processes in a geological repository. The Oklo project is coordinated by CEA-IPSN (F) and involves laboratories from several CEA directorates (IPSN, DTA and DCC) which collaborate with other institutions from France: CREGU, Nancy; CNRS, Strasbourg and ENSMD, Fontainebleau. Moreover, institutes from non-EC member States are also taking part in the Oklo study. The second joint CEC-CEA progress meeting of the Oklo Working Group was held in April 1992 in Brussels and gave the possibility of reviewing and discussing progress made since its first meeting in February 1991 at CEA in Fontenay-aux-Roses. About 40 participants from 15 laboratories and organizations coming from France, Canada, Gabon, Japan, Sweden and the USA underline the great interest in the ongoing research activities. The meeting focused on the different tasks within the CEC-CEA Oklo project concerning (i) field survey and sampling, (ii) characterization of the source term, (iii) studies of the petrographical and geochemical system, and (iv) studies of the hydrogeological system and hydrodynamic modelling. (author) 17 papers are presented
The Liabilities Management Group
Whitehead, A.W.
The Liabilities Management Group (LMG) was initiated by DTI. It is a cooperative forum which was set up in 1995. The current participants are DTI, UKAEA, NLM (for BNFL), MOD and Magnox Electric. The LMG was initiated to produce closer cooperation between public sector liability management organizations, achieve more cost-effective management of UK nuclear liabilities and enhance development of the UK nuclear decommissioning and waste management strategy. The objectives are to compare practices between liabilities management organizations discuss the scope for collaboration identify priority areas for possible collaboration agree action plans for exploring and undertaking such collaboration.Four task forces have been formed to look at specific areas (R and D, safety, contracts, and project management) and each reports separately to the LMG. The LMG has achieved its original aim of bringing together those with public sector liability management responsibilities. All participants feel that the LMG has been useful and that it should continue. Looking to the future, there is a continuing need for the LMG to facilitate removal of barriers to the achievement of best value for money. The LMG might also consider addressing the 'business process' elements that a liability management organization must be good at in order to define best practice in these. (author)
CORRELATION BETWEEN GROUP LOCAL DENSITY AND GROUP LUMINOSITY
Deng Xinfa [School of Science, Nanchang University, Jiangxi 330031 (China); Yu Guisheng [Department of Natural Science, Nanchang Teachers College, Jiangxi 330103 (China)
In this study, we investigate the correlation between group local number density and total luminosity of groups. In four volume-limited group catalogs, we can conclude that groups with high luminosity exist preferentially in high-density regions, while groups with low luminosity are located preferentially in low-density regions, and that in a volume-limited group sample with absolute magnitude limit M{sub r} = -18, the correlation between group local number density and total luminosity of groups is the weakest. These results basically are consistent with the environmental dependence of galaxy luminosity.
Group Counseling in the Schools
Perusse, Rachelle; Goodnough, Gary E.; Lee, Vivian V.
Group counseling is an effective intervention when working in a school setting. In this article, the authors discuss the different kinds of groups offered in schools, types of group interventions, strategies to use in forming groups, and how to collaborate with others in the school. Because leading groups in schools is a specialized skill, the…
Naive Theories of Social Groups
Rhodes, Marjorie
Four studies examined children's (ages 3-10, Total N = 235) naive theories of social groups, in particular, their expectations about how group memberships constrain social interactions. After introduction to novel groups of people, preschoolers (ages 3-5) reliably expected agents from one group to harm members of the other group (rather than…
Making Cooperative Learning Groups Work.
Hawley, James; De Jong, Cherie
Discusses the use of cooperative-learning groups with middle school students. Describes cooperative-learning techniques, including group roles, peer evaluation, and observation and monitoring. Considers grouping options, including group size and configuration, dyads, the think-pair-share lecture, student teams achievement divisions, jigsaw groups,…
Fermilab Steering Group Report
Beier, Eugene; /Pennsylvania U.; Butler, Joel; /Fermilab; Dawson, Sally; /Brookhaven; Edwards, Helen; /Fermilab; Himel, Thomas; /SLAC; Holmes, Stephen; /Fermilab; Kim, Young-Kee; /Fermilab /Chicago U.; Lankford, Andrew; /UC, Irvine; McGinnis, David; /Fermilab; Nagaitsev, Sergei; /Fermilab; Raubenheimer, Tor; /SLAC /Fermilab
The Fermilab Steering Group has developed a plan to keep U.S. accelerator-based particle physics on the pathway to discovery, both at the Terascale with the LHC and the ILC and in the domain of neutrinos and precision physics with a high-intensity accelerator. The plan puts discovering Terascale physics with the LHC and the ILC as Fermilab's highest priority. While supporting ILC development, the plan creates opportunities for exciting science at the intensity frontier. If the ILC remains near the Global Design Effort's technically driven timeline, Fermilab would continue neutrino science with the NOVA experiment, using the NuMI (Neutrinos at the Main Injector) proton plan, scheduled to begin operating in 2011. If ILC construction must wait somewhat longer, Fermilab's plan proposes SNuMI, an upgrade of NuMI to create a more powerful neutrino beam. If the ILC start is postponed significantly, a central feature of the proposed Fermilab plan calls for building an intense proton facility, Project X, consisting of a linear accelerator with the currently planned characteristics of the ILC combined with Fermilab's existing Recycler Ring and the Main Injector accelerator. The major component of Project X is the linac. Cryomodules, radio-frequency distribution, cryogenics and instrumentation for the linac are the same as or similar to those used in the ILC at a scale of about one percent of a full ILC linac. Project X's intense proton beams would open a path to discovery in neutrino science and in precision physics with charged leptons and quarks. World-leading experiments would allow physicists to address key questions of the Quantum Universe: How did the universe come to be? Are there undiscovered principles of nature: new symmetries, new physical laws? Do all the particles and forces become one? What happened to the antimatter? Building Project X's ILC-like linac would offer substantial support for ILC development by accelerating the
Linear deformations of discrete groups and constructions of multivalued groups
Yagodovskii, Petr V
We construct deformations of discrete multivalued groups described as special deformations of their group algebras in the class of finite-dimensional associative algebras. We show that the deformations of ordinary groups producing multivalued groups are defined by cocycles with coefficients in the group algebra of the original group and obtain classification theorems on these deformations. We indicate a connection between the linear deformations of discrete groups introduced in this paper and the well-known constructions of multivalued groups. We describe the manifold of three-dimensional associative commutative algebras with identity element, fixed basis, and a constant number of values. The group algebras of n-valued groups of order three (three-dimensional n-group algebras) form a discrete set in this manifold
Group B Streptococcus and Pregnancy
... B Strep and Pregnancy • What is group B streptococcus (GBS)? • What does it mean to be colonized ... planned cesarean birth? •Glossary What is group B streptococcus (GBS)? Group B streptococcus is one of the ...
Harmonic Analysis and Group Representation
Figa-Talamanca, Alessandro
This title includes: Lectures - A. Auslander, R. Tolimeri - Nilpotent groups and abelian varieties, M Cowling - Unitary and uniformly bounded representations of some simple Lie groups, M. Duflo - Construction de representations unitaires d'un groupe de Lie, R. Howe - On a notion of rank for unitary representations of the classical groups, V.S. Varadarajan - Eigenfunction expansions of semisimple Lie groups, and R. Zimmer - Ergodic theory, group representations and rigidity; and, Seminars - A. Koranyi - Some applications of Gelfand pairs in classical analysis.
Topological K-Kolmogorov groups
Abd El-Sattar, A. Dabbour.
The idea of the K-groups was used to define K-Kolmogorov homology and cohomology (over pairs of coefficient groups) which are descriptions of certain modifications of the Kolmogorov groups. The present work is devoted to the study of the topological properties of the K-Kolmogorov groups which lie at the root of the group duality based essentially upon Pontrjagin's concept of group multiplication. 14 refs
Post-Disaster Social Justice Group Work and Group Supervision
Bemak, Fred; Chung, Rita Chi-Ying
This article discusses post-disaster group counseling and group supervision using a social justice orientation for working with post-disaster survivors from underserved populations. The Disaster Cross-Cultural Counseling model is a culturally responsive group counseling model that infuses social justice into post-disaster group counseling and…
Group Leader Development: Effects of Personal Growth and Psychoeducational Groups
Ohrt, Jonathan H.; Robinson, E. H., III; Hagedorn, W. Bryce
The purpose of this quasi-experimental study was to compare the effects of personal growth groups and psychoeducational groups on counselor education students' (n = 74) empathy and group leader self-efficacy. Additionally, we compared the degree to which participants in each group valued: (a) cohesion, (b) catharsis, and (c) insight. There were no…
Feminist Principles in Survivor's Groups: Out-of-Group Contact.
Rittenhouse, JoAn
Illustrates the value of theoretical concepts from Feminist Therapy in the group treatment of women survivors. Theoretical underpinnings are supported using data taken from clinical experience and by examining group themes and out-of-group contact developed from the case sample. Principles regarding feminist groups are proposed. (RJM)
Platinum-group elements
Zientek, Michael L.; Loferski, Patricia J.; Parks, Heather L.; Schulte, Ruth F.; Seal, Robert R.; Schulz, Klaus J.; DeYoung,, John H.; Seal, Robert R.; Bradley, Dwight C.
The platinum-group elements (PGEs)—platinum, palladium, rhodium, ruthenium, iridium, and osmium—are metals that have similar physical and chemical properties and tend to occur together in nature. PGEs are indispensable to many industrial applications but are mined in only a few places. The availability and accessibility of PGEs could be disrupted by economic, environmental, political, and social events. The United States net import reliance as a percentage of apparent consumption is about 90 percent.PGEs have many industrial applications. They are used in catalytic converters to reduce carbon monoxide, hydrocarbon, and nitrous oxide emissions in automobile exhaust. The chemical industry requires platinum or platinum-rhodium alloys to manufacture nitric oxide, which is the raw material used to manufacture explosives, fertilizers, and nitric acid. In the petrochemical industry, platinum-supported catalysts are needed to refine crude oil and to produce aromatic compounds and high-octane gasoline. Alloys of PGEs are exceptionally hard and durable, making them the best known coating for industrial crucibles used in the manufacture of chemicals and synthetic materials. PGEs are used by the glass manufacturing industry in the production of fiberglass and flat-panel and liquid crystal displays. In the electronics industry, PGEs are used in computer hard disks, hybridized integrated circuits, and multilayer ceramic capacitors.Aside from their industrial applications, PGEs are used in such other fields as health, consumer goods, and finance. Platinum, for example, is used in medical implants, such as pacemakers, and PGEs are used in cancer-fighting drugs. Platinum alloys are an ideal choice for jewelry because of their white color, strength, and resistance to tarnish. Platinum, palladium, and rhodium in the form of coins and bars are also used as investment commodities, and various financial instruments based on the value of these PGEs are traded on major exchanges
Emotional collectives: How groups shape emotions and emotions shape groups.
van Kleef, Gerben A; Fischer, Agneta H
Group settings are epicentres of emotional activity. Yet, the role of emotions in groups is poorly understood. How do group-level phenomena shape group members' emotional experience and expression? How are emotional expressions recognised, interpreted and shared in group settings? And how do such expressions influence the emotions, cognitions and behaviours of fellow group members and outside observers? To answer these and other questions, we draw on relevant theoretical perspectives (e.g., intergroup emotions theory, social appraisal theory and emotions as social information theory) and recent empirical findings regarding the role of emotions in groups. We organise our review according to two overarching themes: how groups shape emotions and how emotions shape groups. We show how novel empirical approaches break important new ground in uncovering the role of emotions in groups. Research on emotional collectives is thriving and constitutes a key to understanding the social nature of emotions.
Group performance and group learning at dynamic system control tasks
Drewes, Sylvana
Proper management of dynamic systems (e.g. cooling systems of nuclear power plants or production and warehousing) is important to ensure public safety and economic success. So far, research has provided broad evidence for systematic shortcomings in individuals' control performance of dynamic systems. This research aims to investigate whether groups manifest synergy (Larson, 2010) and outperform individuals and if so, what processes lead to these performance advantages. In three experiments - including simulations of a nuclear power plant and a business setting - I compare the control performance of three-person-groups to the average individual performance and to nominal groups (N = 105 groups per experiment). The nominal group condition captures the statistical advantage of aggregated group judgements not due to social interaction. First, results show a superior performance of groups compared to individuals. Second, a meta-analysis across all three experiments shows interaction-based process gains in dynamic control tasks: Interacting groups outperform the average individual performance as well as the nominal group performance. Third, group interaction leads to stable individual improvements of group members that exceed practice effects. In sum, these results provide the first unequivocal evidence for interaction-based performance gains of groups in dynamic control tasks and imply that employers should rely on groups to provide opportunities for individual learning and to foster dynamic system control at its best.
Does group efficacy increase group identification? Resolving their paradoxical relationship
van Zomeren, Martijn; Leach, Colin Wayne; Spears, Russell
Although group identification and group efficacy are both important predictors of collective action against collective disadvantage, there is mixed evidence for their (causal) relationship. Meta-analytic and correlational evidence suggests an overall positive relationship that has been interpreted
Secure Group Communications for Large Dynamic Multicast Group
Institute of Scientific and Technical Information of China (English)
Liu Jing; Zhou Mingtian
As the major problem in multicast security, the group key management has been the focus of research But few results are satisfactory. In this paper, the problems of group key management and access control for large dynamic multicast group have been researched and a solution based on SubGroup Secure Controllers (SGSCs) is presented, which solves many problems in IOLUS system and WGL scheme.
How to conduct focus groups: researching group priorities through discussion.
Focus groups serve to uncover priorities and beliefs of a target group, but health project designers do not always take the time to seek this information beforehand. Focus groups also allow various local subgroups to communicate their concerns before the project starts. Focus groups can also breed ideas and dialogue that individual interviews cannot and they provide baseline information so managers can determine if attitudes or priorities have resulted from the project. Diverse people have different beliefs, e.g., women who have young children view oral rehydration therapy differently from women with no children. Project designers can use these basic differences to arrive at some conclusions about general attitudes. Focus group facilitators should have a discussion outline to help keep the group on the topic of concern. They should limit sessions to 60-90 minutes. Each focus groups should include 8-10 people. It is important to have members of various community subgroups in each group. Yet group designers should be careful not to include within the same group, those who may intimidate other people in the group, e.g., in situations where farmers depend on middlemen, farmers may not be open if middlemen are also in the focus group. Facilitators should launch each session with an attempt to encourage the members to be open and to feel comfortable. For example, in Malawi, a facilitator leads her focus group discussions with songs. Stories are another icebreaker. It is important that all focus groups centering around a certain project discuss the same topics. Facilitators need to stress to the group that all discussions are to be kept confidential. The designers should also carefully word the questions so that facilitators will not impart their bias. Facilitators should not direct the group to certain conclusions, but instead keep the discussions focused.
Group covariance and metrical theory
Halpern, L.
The a priori introduction of a Lie group of transformations into a physical theory has often proved to be useful; it usually serves to describe special simplified conditions before a general theory can be worked out. Newton's assumptions of absolute space and time are examples where the Euclidian group and translation group have been introduced. These groups were extended to the Galilei group and modified in the special theory of relativity to the Poincare group to describe physics under the given conditions covariantly in the simplest way. The criticism of the a priori character leads to the formulation of the general theory of relativity. The general metric theory does not really give preference to a particular invariance group - even the principle of equivalence can be adapted to a whole family of groups. The physical laws covariantly inserted into the metric space are however adapted to the Poincare group. 8 references
Defining and Classifying Interest Groups
Baroni, Laura; Carroll, Brendan; Chalmers, Adam
The interest group concept is defined in many different ways in the existing literature and a range of different classification schemes are employed. This complicates comparisons between different studies and their findings. One of the important tasks faced by interest group scholars engaged...... in large-N studies is therefore to define the concept of an interest group and to determine which classification scheme to use for different group types. After reviewing the existing literature, this article sets out to compare different approaches to defining and classifying interest groups with a sample...... in the organizational attributes of specific interest group types. As expected, our comparison of coding schemes reveals a closer link between group attributes and group type in narrower classification schemes based on group organizational characteristics than those based on a behavioral definition of lobbying....
What Is a Group? Young Children's Perceptions of Different Types of Groups and Group Entitativity.
Maria Plötner
Full Text Available To date, developmental research on groups has focused mainly on in-group biases and intergroup relations. However, little is known about children's general understanding of social groups and their perceptions of different forms of group. In this study, 5- to 6-year-old children were asked to evaluate prototypes of four key types of groups: an intimacy group (friends, a task group (people who are collaborating, a social category (people who look alike, and a loose association (people who coincidently meet at a tram stop. In line with previous work with adults, the vast majority of children perceived the intimacy group, task group, and social category, but not the loose association, to possess entitativity, that is, to be a 'real group.' In addition, children evaluated group member properties, social relations, and social obligations differently in each type of group, demonstrating that young children are able to distinguish between different types of in-group relations. The origins of the general group typology used by adults thus appear early in development. These findings contribute to our knowledge about children's intuitive understanding of groups and group members' behavior.
Effectiveness of Group Supervision versus Combined Group and Individual Supervision.
Ray, Dee; Altekruse, Michael
Investigates the effectiveness of different types of supervision (large group, small group, combined group, individual supervision) with counseling students (N=64). Analyses revealed that all supervision formats resulted in similar progress in counselor effectiveness and counselor development. Participants voiced a preference for individual…
Group Insight Versus Group Desensitization in Treating Speech Anxiety
Meichenbaum, Donald H.; And Others
Results of this study indicated that the insight group was as effective as the desensitization group in significantly reducing speech anxiety over control group levels as assessed by behavioral, cognitive, and self-report measures given immediately after posttreatment and later at a three-month follow-up. (Author)
Re-Examining Group Development in Adventure Therapy Groups.
DeGraaf, Don; Ashby, Jeff
Small-group development is an important aspect of adventure therapy. Supplementing knowledge of sequential stages of group development with knowledge concerning within-stage nonsequential development yields a richer understanding of groups. Integrating elements of the individual counseling relationship (working alliance, transference, and real…
Saving Face and Group Identity
Eriksson, Tor; Mao, Lei; Villeval, Marie-Claire
their self- but also other group members' image. This behavior is frequent even in the absence of group identity. When group identity is more salient, individuals help regardless of whether the least performer is an in-group or an out-group. This suggests that saving others' face is a strong social norm.......Are people willing to sacrifice resources to save one's and others' face? In a laboratory experiment, we study whether individuals forego resources to avoid the public exposure of the least performer in their group. We show that a majority of individuals are willing to pay to preserve not only...
Enhancing Social Communication Between Groups
T. Stevens; P. Hughes (Peter); D. Williams; I. Craigie; I. Kegel; P.S. Cesar Garcia (Pablo Santiago); A.J. Jansen (Jack); M.F. Usrsu; M. Frantzis; N. Farber; M. Lutzky; S. Vogel
htmlabstractThis paper describes a prototype software platform that supports advanced communications services, specifically services enabling effective group-to-group communications with a social purpose, between remote homes. The architecture, the individual components, their interfaces, and the
Coordinated Control of Vehicle Groups
Kumar, Vijay
.... There are three main objectives: (1) to develop a theoretical paradigm for formalizing the concepts of a group, a team, and control of groups, with specified tasks such as exploring, mapping, searching, and transporting objects; (2...
Criminal groups and criminal subculture
Romanova N.M.
The paper provides a classification of criminal groups, structured by the following parameters: a) operation mode (secret/open), b) law-enforcement and administrative support (presence/absence). We describe four types of criminal groups: a) legitimized criminal organization, b) secret criminal organization engaged in illegal business, c) secret general crime group, and d) general crime group operating openly. The four types differ in the content of criminal subculture. Modern criminal subcult...
Group Cooperation in Outdoor Education
Matthews, Bruce E.
Utilizing the Beatles' Yellow Submarine fantasy (e.g., the Blue Meanies), this outdoor education program is designed for sixth graders and special education students. Activities developed at the Cortland Resident Outdoor Education Camp include a series of group stress/challenge activities to be accomplished by everyone in the group, as a group.…
Reinterpreting between-group inequality
Elbers, C.T.M.; Lanjouw, P.F.; Mistiaen, J.; Özler, B
We evaluate observed inequality between population groups against a benchmark of the maximum between-group inequality attainable given the number and relative sizes of those groups under examination. Because our measure is normalized by these parameters, drawing comparisons across different settings
Ability Grouping in Social Studies.
Social Education, 1992
Presents a position statement of the National Council for the Social Studies (NCSS). Reports that the NCSS objects to ability grouping in social studies. Argues that ability grouping disadvantages minority, handicapped, and low ability students. Suggests that ability grouping undermines the democratic ideals that should be the basis of the social…
Conceptualizing Group Flow: A Framework
Duncan, Jana; West, Richard E.
This literature review discusses the similarities in main themes between Csikszentmihályi theory of individual flow and Sawyer theory of group flow, and compares Sawyer's theory with existing concepts in the literature on group work both in education and business. Because much creativity and innovation occurs within groups, understanding group…
Diagram Techniques in Group Theory
Stedman, Geoffrey E.
Preface; 1. Elementary examples; 2. Angular momentum coupling diagram techniques; 3. Extension to compact simple phase groups; 4. Symmetric and unitary groups; 5. Lie groups and Lie algebras; 6. Polarisation dependence of multiphoton processes; 7. Quantum field theoretic diagram techniques for atomic systems; 8. Applications; Appendix; References; Indexes.
Designing for informed group formation
Nicolajsen, Hanne Westh; Juel Jacobsen, Alice; Riis, Marianne
A new design ―project preparation‖ preparing for the group formation in problem based project work is proposed and investigated. The main problem is to overcome group formation based on existing relations. The hypothesis is that theme development and group formation are somewhat counterproductive...
Working with Difficult Group Members.
Kottler, Jeffrey A.
Describes types of group members who are challenging in group settings including entitled, manipulative, and character-disordered clients. Provides suggestions for working with these group members, either as isolated cases or as homogenous populations, emphasizing the protection of other clients' rights. Includes 31 references. (Author/CRR)
K-Kolmogorov cohomology groups
In the present work we use the idea of K-groups to give a description of certain modification of the Kolmogorov cohomology groups for the case of a pair (G,G') of discrete coefficient groups. Their induced homomorphisms and coboundary operators are also defined, and then we study the resulting construction from the point of view of Eilenberg-Steenrod axioms. (author)
Ultrafilters and topologies on groups
Zelenyuk, Yevhen
This book presents the relationship between ultrafilters and topologies on groups. It shows how ultrafilters are used in constructing topologies on groups with extremal properties and how topologies on groups serve in deriving algebraic results aboutultrafilters. Topics covered include: topological and left topological groups, ultrafilter semigroups, local homomorphisms and automorphisms, subgroups and ideal structure of ßG, almost maximal spaces and projectives of finite semigroups, resolvability of groups. This is a self-contained book aimed at graduate students and researchers working in to
Group supervision for general practitioners
Galina Nielsen, Helena; Sofie Davidsen, Annette; Dalsted, Rikke
AIM: Group supervision is a sparsely researched method for professional development in general practice. The aim of this study was to explore general practitioners' (GPs') experiences of the benefits of group supervision for improving the treatment of mental disorders. METHODS: One long-establish......AIM: Group supervision is a sparsely researched method for professional development in general practice. The aim of this study was to explore general practitioners' (GPs') experiences of the benefits of group supervision for improving the treatment of mental disorders. METHODS: One long...... considered important prerequisites for disclosing and discussing professional problems. CONCLUSION: The results of this study indicate that participation in a supervision group can be beneficial for maintaining and developing GPs' skills in dealing with patients with mental health problems. Group supervision...... influenced other areas of GPs' professional lives as well. However, more studies are needed to assess the impact of supervision groups....
Group percolation in interdependent networks
Wang, Zexun; Zhou, Dong; Hu, Yanqing
In many real network systems, nodes usually cooperate with each other and form groups to enhance their robustness to risks. This motivates us to study an alternative type of percolation, group percolation, in interdependent networks under attack. In this model, nodes belonging to the same group survive or fail together. We develop a theoretical framework for this group percolation and find that the formation of groups can improve the resilience of interdependent networks significantly. However, the percolation transition is always of first order, regardless of the distribution of group sizes. As an application, we map the interdependent networks with intersimilarity structures, which have attracted much attention recently, onto the group percolation and confirm the nonexistence of continuous phase transitions.
The "group" in obstetric psychoprophylaxis.
Volpe, B; Tenaglia, F; Fede, T; Cerutti, R
In the practice of obstetric psychoprophylaxis every method employed considered always the group both from a psychological and a pedagogic point of view. Today the group of pregnant women (or couples) is considered under various aspects: - psychological: the group as a support for members with regard to maternal and parental emotional feelings; - anthropological: the group fills up an empty vital space and becomes a "rite de passage" from a state of social identity to another one; - social: the group is a significative cultural intermediary between health services and the women-patient. The knowledge of these aspects becomes an important methodological support for group conductors. We present an analysis of our experience with groups and how this has affected the Psychoprophylaxis in the last years.
Group lending and the role of the group leader
Eijkel, van, R.; Hermes, N.; Lensink, B.W.
This paper investigates strategic monitoring behavior within group lending. We show that monitoring efforts of group members differ in equilibrium due to the asymmetry between members in terms of future profits. In particular, we show that the entrepreneur with the highest future profits also puts in the highest monitoring effort. Moreover, monitoring efforts differ between group members due to free-riding: one member reduces her level of monitoring if the other increases her monitoring effor...
Clifford algebras, spinors, spin groups and covering groups
Magneville, C.; Pansart, J.P.
The Dirac equation uses matrices named Υ matrices which are representations of general algebraic structures associated with a metric space. These algebras are the Clifford algebras. In the first past, these algebras are studied. Then the notion of spinor is developed. It is shown that Majorana and Weyl spinors only exist for some particular metric space. In the second part, Clifford and spinor groups are studied. They may be interpreted as the extension of the notion of orthogonal group for Clifford algebras and their spaces for representation. The rotation of a spinor is computed. In the last part, the connexion between the spinor groups and the Universal Covering Groups is presented [fr
Eijkel, van R.; Hermes, N.; Lensink, B.W.
This paper investigates strategic monitoring behavior within group lending. We show that monitoring efforts of group members differ in equilibrium due to the asymmetry between members in terms of future profits. In particular, we show that the entrepreneur with the highest future profits also puts
van Eijkel, R.; Hermes, C.L.M.; Lensink, B.W.
Working with Group-Tasks and Group Cohesiveness
Anwar, Khoirul
This study aimed at exploring the connection between the use of group task and group cohesiveness. This study is very important because the nature of the learner's success is largely determined by the values of cooperation, interaction, and understanding of the learning objectives together. Subjects of this study are 28 students on the course…
Group Journaling: A Tool for Reflection, Fun and Group Development
Asfeldt, Morten
Personal journaling is common practice in outdoor programs and is an important means of reflection and meaning-making. For over 20 years the author has used group journals to promote reflection and understanding, raise important questions, explore difficult issues, develop writing and speaking skills, and enhance group development. In this…
Group Milieu in systemic and psychodynamic group therapy
Lau, Marianne Engelbrecht; Kristensen, Ellids
Objectives: A recent meta-analysis also concluded that psychotherapeutic approaches are beneficial for adult with a history of CSA and maintained for at least six months follow-up. The results suggest that different characteristics of therapy moderate the therapeutic outcome. We found in a random......Objectives: A recent meta-analysis also concluded that psychotherapeutic approaches are beneficial for adult with a history of CSA and maintained for at least six months follow-up. The results suggest that different characteristics of therapy moderate the therapeutic outcome. We found...... in a randomized study of systemic versus psychodynamic group therapy, that the short-term outcome for patients who received systemic group psychotherapy was significantly better than the outcome for patients who received psychodynamic group psychotherapy. The current study assessed the group milieu in both groups....... Methods: This randomized prospective study included 106 women: 52 assigned to psychodynamic group psychotherapy and 54 assigned to systemic group psychotherapy. The Group Environment Scale (GES) was filled in the mid phase of therapy and analysed in three dimensions and 10 subscales. Results: The systemic...
Geometric group theory an introduction
Löh, Clara
Inspired by classical geometry, geometric group theory has in turn provided a variety of applications to geometry, topology, group theory, number theory and graph theory. This carefully written textbook provides a rigorous introduction to this rapidly evolving field whose methods have proven to be powerful tools in neighbouring fields such as geometric topology. Geometric group theory is the study of finitely generated groups via the geometry of their associated Cayley graphs. It turns out that the essence of the geometry of such groups is captured in the key notion of quasi-isometry, a large-scale version of isometry whose invariants include growth types, curvature conditions, boundary constructions, and amenability. This book covers the foundations of quasi-geometry of groups at an advanced undergraduate level. The subject is illustrated by many elementary examples, outlooks on applications, as well as an extensive collection of exercises.
Group Analytic Psychotherapy in Brazil.
Penna, Carla; Castanho, Pablo
Group analytic practice in Brazil began quite early. Highly influenced by the Argentinean Pichon-Rivière, it enjoyed a major development from the 1950s to the early 1980s. Beginning in the 1970s, different factors undermined its development and eventually led to its steep decline. From the mid 1980s on, the number of people looking for either group analytic psychotherapy or group analytic training decreased considerably. Group analytic psychotherapy societies struggled to survive and most of them had to close their doors in the 1990s and the following decade. Psychiatric reform and the new public health system have stimulated a new demand for groups in Brazil. Developments in the public and not-for-profit sectors, combined with theoretical and practical research in universities, present promising new perspectives for group analytic psychotherapy in Brazil nowadays.
Modelling group dynamic animal movement
Langrock, Roland; Hopcraft, J. Grant C.; Blackwell, Paul G.
makes its movement decisions relative to the group centroid. The basic idea is framed within the flexible class of hidden Markov models, extending previous work on modelling animal movement by means of multi-state random walks. While in simulation experiments parameter estimators exhibit some bias......, to date, practical statistical methods which can include group dynamics in animal movement models have been lacking. We consider a flexible modelling framework that distinguishes a group-level model, describing the movement of the group's centre, and an individual-level model, such that each individual......Group dynamic movement is a fundamental aspect of many species' movements. The need to adequately model individuals' interactions with other group members has been recognised, particularly in order to differentiate the role of social forces in individual movement from environmental factors. However...
Discrepancy in abo blood grouping
Khan, M.N.; Ahmed, Z.; Khan, T.A.
Discrepancies in blood typing is one of the major reasons in eliciting a transfusion reaction. These discrepancies can be avoided through detailed analysis for the blood typing. Here, we report a subgroup of blood group type-B in the ABO system. Donor's blood was analyzed by employing commercial antisera for blood grouping. The results of forward (known antisera) and reverse (known antigen) reaction were not complimentary. A detailed analysis using the standard protocols by American Association of Blood Banking revealed the blood type as a variant of blood group-B instead of blood group-O. This is suggestive of the fact that blood group typing should be performed with extreme care and any divergence, if identified, should be properly resolved to avoid transfusion reactions. Moreover, a major study to determine the blood group variants in Pakistani population is needed. (author)
The didactics of group work
Christensen, Gerd
The aim of this paper is to discuss aims and means of group work as a teaching and learning method. In Denmark, group work has been implemented at all levels of education since the 1970s from primary school to university but also in training sessions in organizations. The discussion in this paper...... will take its point of departure in pedagogical textbook introductions where group work is often presented as a means to learning social skills and co-workability. However, as most students and teachers know, this is not always the case. Observations of long-term group work show that this can be a tough...... experience for the students (Christensen 2013). Contrary to expectations, the group work seemed to foster anti-social behavior and development of selfish skills. The paper will therefore conclude by suggesting how the (often) laissez-faire group pedagogy, which is dominant in Denmark, could be improved...
Uniquely Strongly Clean Group Rings
WANG XIU-LAN
A ring R is called clean if every element is the sum of an idempotent and a unit,and R is called uniquely strongly clean (USC for short) if every element is uniquely the sum of an idempotent and a unit that commute.In this article,some conditions on a ring R and a group G such that RG is clean are given.It is also shown that if G is a locally finite group,then the group ring RG is USC if and only if R is USC,and G is a 2-group.The left uniquely exchange group ring,as a middle ring of the uniquely clean ring and the USC ring,does not possess this property,and so does the uniquely exchange group ring.
Group theory and its applications
Patra, Prasanta Kumar
Every molecule possesses symmetry and hence has symmetry operations and symmetry elements. From symmetry properties of a system we can deduce its significant physical results. Consequently it is essential to operations of a system forms a group. Group theory is an abstract mathematical tool that underlies the study of symmetry and invariance. By using the concepts of symmetry and group theory, it is possible to obtain the members of complete set of known basis functions of the various irreducible representations of the group. I practice this is achieved by applying the projection operators to linear combinations of atomic orbital (LCAO) when the valence electrons are tightly bound to the ions, to orthogonalized plane waves (OPW) when valence electrons are nearly free and to the other given functions that are judged to the particular system under consideration. In solid state physics the group theory is indispensable in the context of finding the energy bands of electrons in solids. Group theory can be applied...
Physics of the Lorentz Group
BaÅŸkal, Sibel
This book explains the Lorentz mathematical group in a language familiar to physicists. While the three-dimensional rotation group is one of the standard mathematical tools in physics, the Lorentz group of the four-dimensional Minkowski space is still very strange to most present-day physicists. It plays an essential role in understanding particles moving at close to light speed and is becoming the essential language for quantum optics, classical optics, and information science. The book is based on papers and books published by the authors on the representations of the Lorentz group based on harmonic oscillators and their applications to high-energy physics and to Wigner functions applicable to quantum optics. It also covers the two-by-two representations of the Lorentz group applicable to ray optics, including cavity, multilayer and lens optics, as well as representations of the Lorentz group applicable to Stokes parameters and the Poincaré sphere on polarization optics.
Groups, graphs and random walks
Salvatori, Maura; Sava-Huss, Ecaterina
An accessible and panoramic account of the theory of random walks on groups and graphs, stressing the strong connections of the theory with other branches of mathematics, including geometric and combinatorial group theory, potential analysis, and theoretical computer science. This volume brings together original surveys and research-expository papers from renowned and leading experts, many of whom spoke at the workshop 'Groups, Graphs and Random Walks' celebrating the sixtieth birthday of Wolfgang Woess in Cortona, Italy. Topics include: growth and amenability of groups; Schrödinger operators and symbolic dynamics; ergodic theorems; Thompson's group F; Poisson boundaries; probability theory on buildings and groups of Lie type; structure trees for edge cuts in networks; and mathematical crystallography. In what is currently a fast-growing area of mathematics, this book provides an up-to-date and valuable reference for both researchers and graduate students, from which future research activities will undoubted...
Group identity and positive deviance in work groups.
Kim, Moon Joung; Choi, Jin Nam
This study examines why and how identity cognitions, including group identification and individual differentiation, influence the positive deviance of employees. We identify the risk-taking intention of employees as a critical psychological mechanism to overcome stigma-induced identity threat of positive deviance. The analysis of data collected from 293 members comprising 66 work teams reveals that the relationship between individual differentiation and positive deviance is partially mediated by risk-taking intention. The indirect effect of group identification on positive deviance through risk-taking intention is also significant and positive in groups with low conformity pressure, whereas the same indirect effect is neutralized in groups with high conformity pressure. The current analysis offers new insights into the way the group context and the identity cognition of members explain the development of positive deviance and workplace creativity.
Social Identity and Group Contests
Zaunbrecher, Henrik; Riedl, Arno
Social identity has been shown to successfully enhance cooperation and effort in cooperation and coordination games. Little is known about the causal effect of social identity on the propensity to engage in group conflict. In this paper we explore theoretically and experimentally whether social identity increases investments in group contests. We show theoretically that increased social identity with the own group implies higher investments in Tullock contests. Empirically we find that induce...
A new design ―project preparation‖ preparing for the group formation in problem based project work is proposed and investigated. The main problem is to overcome group formation based on existing relations. The hypothesis is that theme development and group formation are somewhat counterproductive....... Following research based design methodology an experiment separating the two was initiated.This was to provide for more openness and creativity in contrast to a design in which existing relations seem predominant....
Group decision-making: Factors that affect group effectiveness
Juliana Osmani
Full Text Available Organizations are operating in a dynamic and turbulent environment. In these conditions, they have to make decisions for new problems or situations. Most of decisions are therefore non-programmed and unstructured, accompanied by risk and uncertainty. Moreover, the problems and situations are complex. All organizations are oriented towards group decisionmaking processes, as useful tools to cope with uncertainty and complexity. Apart from the necessity, companies are turning towards participatory processes also to benefit from the important advantages that these processes offer. Organizations have realized the importance of group decision-making processes to contribute to the creation of sustainable competitive advantages. Main objective of this paper is to show that group decision-making processes do not offer guarantee for good decisions, because the effectiveness of group is affected by many factors. So, the first thing done in this paper is discussing about the benefits and limitations that accompany the use of groups with decision-making purpose. Afterwards, we stop on the different factors that influence the group's ability to make good decisions. The aim is to emphasize that regardless of the many advantages of groups, some factors as group size, type of communication within the group, leadership style, the norms, the differentiation of roles and statuses, cohesion and compliance degree should be the main elements to keep into consideration because they affect the effectiveness of group. In this regard, is discussed how such factors influence the quality of decision and then we try to draw some conclusions that can improve and make better and easier group decision-making processes.
Strategic Groups and Banks' Performance
Gregorz Halaj
Full Text Available The theory of strategic groups predicts the existence of stable groups of companies that adopt similar business strategies. The theory also predicts that groups will differ in performance and in their reaction to external shocks. We use cluster analysis to identify strategic groups in the Polish banking sector. We find stable groups in the Polish banking sector constituted after the year 2000 following the major privatisation and ownership changes connected with transition to the mostly-privately-owned banking sector in the late 90s. Using panel regression methods we show that the allocation of banks to groups is statistically significant in explaining the profitability of banks. Thus, breaking down the banks into strategic groups and allowing for the different reaction of the groups to external shocks helps in a more accurate explanation of profits of the banking sector as a whole.Therefore, a more precise ex ante assessment of the loss absorption capabilities of banks is possible, which is crucial for an analysis of banking sector stability. However, we did not find evidence of the usefulness of strategic groups in explaining the quality of bank portfolios as measured by irregular loans over total loans, which is a more direct way to assess risks to financial stability.
Structure of a supergravity group
Ogievetsky, V.; Sokatchev, E.
The supergravity group is found to be the direct product of general covariance groups in complex conjugated left and right handed superspaces. The ordinary space-time coordinate and the axial gravitational superfield are the real and imaginary parts of the complex coordinate, respectively. It is pointed out that a number of questions concerning the formalism remains open. For instance how to define superfields with external indices, supercovariant derivatives and invariants of the group, etc. However, the extremely simple and clear geometrical picture of the supergravity group given here will provide an adequate basis for the supergravity theory
The formalism of Lie groups
Salam, A. [Imperial College of Science and Technology, London (United Kingdom)
Throughout the history of quantum theory, a battle has raged between the amateurs and professional group theorists. The amateurs have maintained that everything one needs in the theory of groups can be discovered by the light of nature provided one knows how to multiply two matrices. In support of this claim, they of course, justifiably, point to the successes of that prince of amateurs in this field, Dirac, particularly with the spinor representations of the Lorentz group. As an amateur myself, I strongly believe in the truth of the non-professionalist creed. I think perhaps there is not much one has to learn in the way of methodology from the group theorists except caution. But this does not mean one should not be aware of the riches which have been amassed over the course of years particularly in that most highly developed of all mathematical disciplines - the theory of Lie groups. My lectures then are an amateur's attempt to gather some of the fascinating results for compact simple Lie groups which are likely to be of physical interest. I shall state theorems; and with a physicist's typical unconcern rarely, if ever, shall I prove these. Throughout, the emphasis will be to show the close similarity of these general groups with that most familiar of all groups, the group of rotations in three dimensions.
Leadership in moving human groups.
Margarete Boos
Full Text Available How is movement of individuals coordinated as a group? This is a fundamental question of social behaviour, encompassing phenomena such as bird flocking, fish schooling, and the innumerable activities in human groups that require people to synchronise their actions. We have developed an experimental paradigm, the HoneyComb computer-based multi-client game, to empirically investigate human movement coordination and leadership. Using economic games as a model, we set monetary incentives to motivate players on a virtual playfield to reach goals via players' movements. We asked whether (I humans coordinate their movements when information is limited to an individual group member's observation of adjacent group member motion, (II whether an informed group minority can lead an uninformed group majority to the minority's goal, and if so, (III how this minority exerts its influence. We showed that in a human group--on the basis of movement alone--a minority can successfully lead a majority. Minorities lead successfully when (a their members choose similar initial steps towards their goal field and (b they are among the first in the whole group to make a move. Using our approach, we empirically demonstrate that the rules of swarming behaviour apply to humans. Even complex human behaviour, such as leadership and directed group movement, follow simple rules that are based on visual perception of local movement.
EDF Group - Annual Report 2013
The EDF Group is emerging as a global leader in electricity and an industrial benchmark spanning the entire business from generation and networks to sales and marketing. The group is growing stronger and changing. A long-term vision and relentless determination to provide a modern public service underpin its robust business model. This document is EDF Group's annual report for the year 2013. It contains information about Group profile, governance, business, development strategy, sales and marketing, positions in Europe and international activities. The document comprises the Activity Report and the Sustainable Development Indicators
Stick with your group: young children's attitudes about group loyalty.
Misch, Antonia; Over, Harriet; Carpenter, Malinda
For adults, loyalty to the group is highly valued, yet little is known about how children evaluate loyalty. We investigated children's attitudes about loyalty in a third-party context. In the first experiment, 4- and 5-year-olds watched a video of two groups competing. Two members of the losing group then spoke. The disloyal individual said she wanted to win and therefore would join the other group. The loyal individual said she also wanted to win but would stay with her group. Children were then asked five forced-choice questions about these two individuals' niceness, trustworthiness, morality, and deservingness of a reward. The 5-year-olds preferred the loyal person across all questions; results for the 4-year-olds were considerably weaker but in the same direction. The second experiment investigated the direction of the effect in 5-year-olds. In this experiment, children answered questions about either a loyal individual, a disloyal individual, or a neutral individual. Children rated both the loyal and neutral individuals more positively than the disloyal individual across a number of measures. Thus, whereas disloyal behavior is evaluated unfavorably by children, loyal behavior is the expected norm. These results suggest that, at least from 5 years of age, children understand that belonging to a group entails certain commitments. This marks an important step in their own ability to negotiate belonging and become trustworthy and reliable members of their social groups. Copyright © 2014 Elsevier Inc. All rights reserved.
Perceptual grouping and attention: not all groupings are equal.
Kimchi, Ruth; Razpurker-Apfeld, Irene
We examined grouping under inattention using Driver, Davis, Russell, Turatto, & Freeman's (2001) method. On each trial, two successive displays were briefly presented, each comprising a central target square surrounded by elements. The task was to judge whether the two targets were the same or different. The organization of the background elements stayed the same or changed, independently of the targets. In different conditions, background elements grouped into columns/rows by color similarity, a shape (a triangle/arrow, a square/cross, or a vertical/horizontal line) by color similarity, and a shape with no other elements in the background. We measured the influence of the background on the target same-different judgments. The results imply that background elements grouped into columns/rows by color similarity and into a shape when no segregation from other elements was involved and the shape was relatively "good." In contrast, no background grouping was observed when resolving figure-ground relations for segregated units was required, as in grouping into a shape by color similarity. These results suggest that grouping is a multiplicity of processes that vary in their attentional demands. Regardless of attentional demands, the products of grouping are not available to awareness without attention.
2002 annual report EDF group; 2002 rapport annuel groupe EDF
This document is the 2002 annual report of Electricite de France (EdF) group, the French electric utility. Content: Introductory section (EDF at a glance, Chairman's message, 2002 Highlights); Corporate governance and Group strategy (Corporate governance, sustainable growth strategy, EDF branches); Financial performance (Reaching critical mass, Margins holding up well, Balance sheet); Human resources (Launching Group-wide synergies, Optimising human resources); Customers (Major customers, SMEs and professional customers, Local authorities, Residential customers, Ensuring quality access to electricity); Generation (A balanced energy mix, Nuclear generation, Fossil-fuelled generation, Renewable energies); Corporate social responsibility (Global and local partnerships, Promoting community development)
Energy Innovation. IVO Group`s Research and Development Report
Salminen, P.; Laiho, Y.; Kaikkonen, H.; Leisio, C.; Hinkkanen, S. [eds.
This annual booklet of the IVO Group`s research and development activities presents a number of articles, written by experts from IVO. The products described are examples of the environmentally-oriented selection made available by the IVO Group. In fact, the entire energy technology developed in Finland is environmentally oriented, if seen from the international perspective. The new business potential of environmental technology is great, and it is believed that in the year 2000, exportation of Finnish know-how in the field of energy-saving and efficiency will exceed the value of out energy imports
Salminen, P.; Laiho, Y.; Kaikkonen, H.; Leisio, C.; Hinkkanen, S.; Fletcher, R. [eds.
Group Work with Transgender Clients
Dickey, Lore M.; Loewy, Michael I.
Drawing on the existing literature, the authors' research and clinical experiences, and the first author's personal journey as a member and leader of the transgender community, this article offers a brief history of group work with transgender clients followed by suggestions for group work with transgender clients from a social justice…
Evaluating groups in learning disabilities.
Chia, S H
Groupwork can be effective in meeting a range of needs presented by students with profound learning disabilities. This article describes the process involved in setting up groups for these students, and includes examples of a group session and methods for evaluating groupwork.
Opechowski's theorem and commutator groups
Caride, A.O.; Zanette, S.I.
It is shown that the conditions of application of Opechowski's theorem for double groups of subgroups of O(3) are directly associated to the structure of their commutator groups. Some characteristics of the structure of classes are also discussed. (Author) [pt
Group Activities for Math Enthusiasts
Holdener, J.; Milnikel, R.
In this article we present three group activities designed for math students: a balloon-twisting workshop, a group proof of the irrationality of p, and a game of Math Bingo. These activities have been particularly successful in building enthusiasm for mathematics and camaraderie among math faculty and students at Kenyon College.
Challenges Facing Group Work Online
Chang, Bo; Kang, Haijun
Online group work can be complicated because of its asynchronous characteristics and lack of physical presence, and its requirements for skills in handling technology, human relationships, and content-related tasks. This study focuses on the administrative, logistical and relationship-related challenges in online group work. Challenges in areas…
Factorial representations of path groups
Albeverio, S.; Hoegh-Krohn, R.; Testard, D.; Vershik, A.
We give the reduction of the energy representation of the group of mappings from I = [ 0,1 ], S 1 , IRsub(+) or IR into a compact semi simple Lie group G. For G = SU(2) we prove the factoriality of the representation, which is of type III in the case I = IR
Understanding Nomadic Collaborative Learning Groups
Ryberg, Thomas; Davidsen, Jacob; Hodgson, Vivien
The paper builds on the work of Rossitto "et al." on collaborative nomadic work to develop three categories of practice of nomadic collaborative learning groups. Our study is based on interviews, workshops and observations of two undergraduate student's group practices engaged in self-organised, long-term collaborations within the frame…
The Globalization of Cooperative Groups.
Valdivieso, Manuel; Corn, Benjamin W; Dancey, Janet E; Wickerham, D Lawrence; Horvath, L Elise; Perez, Edith A; Urton, Alison; Cronin, Walter M; Field, Erica; Lackey, Evonne; Blanke, Charles D
The National Cancer Institute (NCI)-supported adult cooperative oncology research groups (now officially Network groups) have a longstanding history of participating in international collaborations throughout the world. Most frequently, the US-based cooperative groups work reciprocally with the Canadian national adult cancer clinical trial group, NCIC CTG (previously the National Cancer Institute of Canada Clinical Trials Group). Thus, Canada is the largest contributor to cooperative groups based in the United States, and vice versa. Although international collaborations have many benefits, they are most frequently utilized to enhance patient accrual to large phase III trials originating in the United States or Canada. Within the cooperative group setting, adequate attention has not been given to the study of cancers that are unique to countries outside the United States and Canada, such as those frequently associated with infections in Latin America, Asia, and Africa. Global collaborations are limited by a number of barriers, some of which are unique to the countries involved, while others are related to financial support and to US policies that restrict drug distribution outside the United States. This article serves to detail the cooperative group experience in international research and describe how international collaboration in cancer clinical trials is a promising and important area that requires greater consideration in the future. Copyright © 2015 Elsevier Inc. All rights reserved.
The Globalization of Cooperative Groups
Valdivieso, Manuel; Corn, Benjamin W.; Dancey, Janet E.; Wickerham, D. Lawrence; Horvath, L. Elise; Perez, Edith A.; Urton, Alison; Cronin, Walter M.; Field, Erica; Lackey, Evonne; Blanke, Charles D.
The National Cancer Institute-supported adult cooperative oncology research groups (now officially Network groups) have a long-standing history of participating in international collaborations throughout the world. Most frequently, the U.S. based cooperative groups work reciprocally with the Canadian national adult cancer clinical trial group, NCIC CTG (previously the National Cancer Institute of Canada Clinical Trials Group). Thus, Canada is the largest contributor to cooperative groups based in the U.S., and vice versa. Although international collaborations have many benefits, they are most frequently utilized to enhance patient accrual to large phase III trials originating in the U.S. or Canada. Within the cooperative group setting, adequate attention has not been given to the study of cancers that are unique to countries outside the U.S. and Canada, such as those frequently associated with infections in Latin America, Asia and Africa. Global collaborations are limited by a number of barriers, some of which are unique to the countries involved, while others are related to financial support and to U.S. policies that restrict drug distribution outside the U.S. This manuscript serves to detail the cooperative group experience in international research and describe how international collaboration in cancer clinical trials is a promising and important area that requires greater consideration in the future. PMID:26433551
Future of energy managers groups
Henshaw, T.
The objectives of the Energy Managers Groups, formed to provide a regular opportunity for industry and commerce to exchange views and experiences on energy conservation matters are discussed. Group procedure, liaison and cooperation, government support, and options for the future are discussed. (MCW)
Group theoretical methods in Physics
Olmo, M.A. del; Santander, M.; Mateos Guilarte, J.M.
The meeting had 102 papers. These was distributed in following areas: -Quantum groups,-Integrable systems,-Physical Applications of Group Theory,-Mathematical Results,-Geometry, Topology and Quantum Field Theory,-Super physics,-Super mathematics,-Atomic, Molecular and Condensed Matter Physics. Nuclear and Particle Physics,-Symmetry and Foundations of classical and Quantum mechanics
Measuring group climate in prison
Peer van der Helm PhD; P.H. van der Laan; G.J.J.M. Stams
The present study examines the construct validity and reliability of the Prison Group Climate Instrument (PGCI) in a sample of 77 adolescents placed in a Dutch youth prison and 49 adult prisoners living in a Dutch psychiatric prison with a therapeutic living group structure. Confirmatory factor
Factorizable sheaves and quantum groups
Bezrukavnikov, Roman; Schechtman, Vadim
The book is devoted to the geometrical construction of the representations of Lusztig's small quantum groups at roots of unity. These representations are realized as some spaces of vanishing cycles of perverse sheaves over configuration spaces. As an application, the bundles of conformal blocks over the moduli spaces of curves are studied. The book is intended for specialists in group representations and algebraic geometry.
Theory of super LIE groups
Prakash, M.
The theory of supergravity has attracted increasing attention in the recent years as a unified theory of elementary particle interactions. The superspace formulation of the theory is highly suggestive of an underlying geometrical structure of superspace. It also incorporates the beautifully geometrical general theory of relativity. It leads us to believe that a better understanding of its geometry would result in a better understanding of the theory itself, and furthermore, that the geometry of superspace would also have physical consequences. As a first step towards that goal, we develop here a theory of super Lie groups. These are groups that have the same relation to a super Lie algebra as Lie groups have to a Lie algebra. More precisely, a super Lie group is a super-manifold and a group such that the group operations are super-analytic. The super Lie algebra of a super Lie group is related to the local properties of the group near the identity. This work develops the algebraic and super-analytical tools necessary for our theory, including proofs of a set of existence and uniqueness theorems for a class of super-differential equations
Group Counseling for Navy Children.
Mitchum, Nancy Taylor
Conducted six-session group counseling program for Navy children (n=22) enrolled in public schools whose fathers were on deployment. Pretest and posttest scores on the Coopersmith Self-Esteem Inventory suggest that participation in the group counseling unit positively affected self-esteem of Navy children whose fathers were on deployment. Found…
Theoretical Issues in Clinical Social Group Work.
Randall, Elizabeth; Wodarski, John S.
Reviews relevant issues in clinical social group practice including group versus individual treatment, group work advantages, approach rationale, group conditions for change, worker role in group, group composition, group practice technique and method, time as group work dimension, pretherapy training, group therapy precautions, and group work…
Deviance and dissent in groups.
Jetten, Jolanda; Hornsey, Matthew J
Traditionally, group research has focused more on the motivations that make people conform than on the motivations and conditions underpinning deviance and dissent. This has led to a literature that focuses on the value that groups place on uniformity and paints a relatively dark picture of dissent and deviance: as reflections of a lack of group loyalty, as signs of disengagement, or as delinquent behavior. An alternative point of view, which has gained momentum in recent years, focuses on deviance and dissent as normal and healthy aspects of group life. In this review, we focus on the motivations that group members have to deviate and dissent, and the functional as well as the dysfunctional effects of deviance and dissent. In doing so we aim for a balanced and complete account of deviance and dissent, highlighting when such behaviors will be encouraged as well as when they will be punished.
-term collaborations within the frame of Problem and Project Based Learning. By analysing the patterns of nomadic collaborative learning we identify and discuss how the two groups of students incorporate mobile and digital technologies as well as physical and/or non-digital technologies into their group work......The paper builds on the work of Rossitto et al. on collaborative nomadic work to develop three categories of practice of nomadic collaborative learning groups. Our study is based on interviews, workshops and observations of two undergraduate student's group practices engaged in self-organised, long....... Specifically, we identify the following categories of nomadic collaborative learning practices: "orchestration of work phases, spaces and activities,� "the orchestration of multiple technologies� and "orchestration of togetherness.� We found that for both groups of students there was a fluidity, situatedness...
Stereotypes of Norwegian social groups.
Bye, Hege H; Herrebrøden, Henrik; Hjetland, Gunnhild J; Røyset, Guro Ø; Westby, Linda L
We present a pilot study and two main studies that address the nature of stereotypes of social groups in Norway within the framework of the Stereotype Content Model (SCM). The first study focused on stereotypes of a wide range of groups across categories such as gender, age, religious conviction, socioeconomic and health status. The second study focused on stereotypes of immigrant groups. Participants (n = 244 and n = 63, respectively) rated the groups on perceived warmth, competence, status, and competition. Results from both studies support the applicability of the SCM in Norway and provides a unique insight into stereotypes of Norwegian social groups. © 2014 The Authors. Scandinavian Journal of Psychology published by Scandinavian Psychological Associations and John Wiley & Sons Ltd.
Group Music Therapy for Prisoners
Chen, Xi Jing; Hannibal, Niels; Xu, Kevin
The prevalence of psychological problems is high in prisons. Many prisoners have unmet needs for appropriate treatments. Although previous studies have suggested music therapy to be a successful treatment modality for prisoners, more rigorous evidence is needed. This parallel randomised controlled...... study aims to investigate the effectiveness of group music therapy to reduce anxiety and depression, and raise self-esteem in prisoners. One hundred and ninety two inmates from a Chinese prison will be allocated to two groups through randomisation. The experimental group will participate in biweekly...... group music therapy for 10 weeks (20 sessions) while the control group will be placed on a waitlist. Anxiety, depression and self-esteem will be measured by self-report scales three times: before, at the middle, and at the end of the intervention. Logs by the participants and their daily routine...
Groups and Geometries : Siena Conference
Kantor, William; Lunardon, Guglielmo; Pasini, Antonio; Tamburini, Maria
On September 1-7, 1996 a conference on Groups and Geometries took place in lovely Siena, Italy. It brought together experts and interested mathematicians from numerous countries. The scientific program centered around invited exposi tory lectures; there also were shorter research announcements, including talks by younger researchers. The conference concerned a broad range of topics in group theory and geometry, with emphasis on recent results and open problems. Special attention was drawn to the interplay between group-theoretic methods and geometric and combinatorial ones. Expanded versions of many of the talks appear in these Proceedings. This volume is intended to provide a stimulating collection of themes for a broad range of algebraists and geometers. Among those themes, represented within the conference or these Proceedings, are aspects of the following: 1. the classification of finite simple groups, 2. the structure and properties of groups of Lie type over finite and algebraically closed fields of f...
Group as social microcosm: Within-group interpersonal style is congruent with outside group relational tendencies.
Goldberg, Simon B; Hoyt, William T
The notion that individuals' interpersonal behaviors in the context of therapy reflects their interpersonal behaviors outside of therapy is a fundamental hypothesis underlying numerous systems of psychotherapy. The social microcosm hypothesis, in particular, claims the interpersonal therapy group becomes a reflection of group members' general tendencies, and can thus be used as information about members' interpersonal functioning as well as an opportunity for learning and behavior change. The current study tested this hypothesis using data drawn from 207 individuals participating in 22 interpersonal process groups. Ratings were made on 2 key interpersonal domains (Dominance and Affiliation) at baseline and at Weeks 2, 5, and 8 of the group. Two-level multilevel models (with participants nested within groups) were used to account for the hierarchical structure, and the social relations model (SRM; Kenny, 1994) was used to estimate peer ratings (target effects in SRM) unconfounded with rater bias. Participants showed consensus at all time points during the interpersonal process groups on one another's levels of dominance and affiliation. In addition, self- and peer ratings were stable across time and correlated with one another. Importantly, self-ratings made prior to group significantly predicted ratings (self- and peer) made within the group, with effect sizes within the medium range. Taken together, these results provide robust support for the social microcosm hypothesis and the conjecture that interpersonal style within-group therapy is reflective of broader interpersonal tendencies. (c) 2015 APA, all rights reserved).
Dealer Group or Financial Planning Group? A Brief Technical Note
Lujer Santacruz
Full Text Available This technical note examines whether the industry practice of using the term dealer group when referring to afinancial planning group contributes to the general perception that financial advisers are not objective whenmaking financial product recommendations. An experimental design carried out through an online survey isused. This is supplemented by a direct comparison survey on the two terminologies. The results provide acase for the industry to adopt a new terminology.
EDF group - annual report 2003; Groupe EDF - rapport annuel 2003
This document contains the magazine, the financial statements and the sustainable development report of Electricite de France (EdF) group for 2003: 1 - the magazine (chairman's statement, group profile, vision and strategy); 2 - the consolidated financial statements for the period ended 31 December 2003 (statutory auditors' report on the consolidated financial statements, EDF's summary annual financial statements); 3 - sustainable development report (transparency and dialogue, responsibility, commitment, partnerships for progress). (J.S.)
Group theory approach to scattering
Wu, J.
For certain physical systems, there exists a dynamical group which contains the operators connecting states with the same energy but belonging to potentials with different strengths. This group is called the potential group of that system. The SO(2,1) potential groups structure is introduced to describe physical systems with mixed spectra, such as Morse and Poeschl-teller potentials. The discrete spectrum describes bound states and the continuous spectrum describes bound states and the continuous spectrum describes scattering states. A solvable class of one-dimensional potentials given by Natanzon belongs to this structure with an SO(2,2) potential group. The potential group structure provides us with an algebraic procedure generating the recursion relations for the scattering matrix, which can be formulated in a purely algebraic fashion, divorced from any differential realization. This procedure, when applied to the three-dimensional scattering problem with SO(3,1) symmetry, generates the scattering matrix of the Coulomb problem. Preliminary phenomenological models for elastic scattering in a heavy-ion collision are constructed on the basis. The results obtained here can be regarded as an important extension of the group theory techniques to scattering problems similar to that developed for bound state problems
EDF group - Reference Document 2005
The EDF Group is an integrated energy supplier operating in a wide range of electricity-related businesses: generation, transmission, distribution, sale and trading of energy. It is the main operator in the French electricity market and one of the leading electricity groups in Europe. With an installed capacity of 130.8 GW (123.9 GW in Europe), it contributes to the supply of energy and services to more than 40 million customers throughout the world (with approximately 36.7 million customers in Europe, more than 28 million of whom are in France). The EDF Group has built a business model balanced between deregulated and regulated operations in France and an international presence. In 2005, the Group recorded consolidated sales of euros 51,051 million, net income (Group share) of euros 3,242 million, and it achieved earnings before interests, taxes, depreciation and amortization of euros 13,010 million. This document is EDF Group's Reference Document for the year 2005. It contains information about: the Group activities, risk factors, Business Overview, Organizational Structure, Property, Plants and Equipment, Operating and Financial Review, Capital Resources, Research and Development, Patents and Licences, Trend Information, Financial Prospects, Administrative, Management, and Supervisory Bodies and Senior Management, Remuneration and Benefits, Board Practices, Employees/Human Resources, Major Shareholders, Related Party Transactions, Financial Information Concerning the Company's Assets and Liabilities, Financial Position and Profits and Losses, Material Contracts, Information on Holdings etc
The EDF Group is an integrated energy supplier operating in a wide range of electricity-related businesses: generation, transmission, distribution, sale and trading of energy. It is the main operator in the French electricity market and one of the leading electricity groups in Europe. With an installed capacity of 125,4 GW, it contributes to the supply of energy and services to more than 42 million customers throughout the world (with approximately 36 million customers in Europe, more than 28 million of whom are in France). The EDF Group has built a business model balanced between deregulated and regulated operations in France and an international presence. In 2004, the Group recorded consolidated sales of euros 46,928 million, net income (Group share) of euros 1,341 million, and it achieved earnings before interests, taxes, depreciation and amortization of euros 12,127 million. This document is EDF Group's Reference Document for the year 2004. It contains information about: the Group activities, capital, relations with Gaz de France utility, strategy, industrial environment, history, activity in France, international activity, transverse activities and functions, disputes, arbitration and risk factors, Property, Plants and Equipment, Operating and Financial Review, Administrative, Management, and Supervisory Bodies and Senior Management, Remuneration and Benefits, recent trends and perspectives
The EDF Group is an integrated energy supplier operating in a wide range of electricity-related businesses: generation, transmission, distribution, sale and trading of energy. It is the main operator in the French electricity market and holds strong positions in the other three principal European markets (Germany, the United Kingdom, Italy) making it one of the leading electricity groups in Europe, and a recognized actor in the gas market. With an installed capacity of 123.7 GW in Europe (128.2 GW worldwide) it holds, among the major European energy specialists, the largest production fleet and the one emitting the least CO 2 , owing to the share of nuclear technology and hydropower in its generation mix. The EDF group supplies electricity, gas and associated services to more than 37.8 million customers throughout the world and in Europe (more than 28 million of whom are in France). The EDF Group has built a business model balanced between France and the international markets, and between deregulated and regulated operations. In 2006, the Group recorded consolidated sales of euros 58,932 million, net income (Group share) of euros 5,605 million, and it achieved earnings before interest, taxes, depreciation and amortization of euros 13,930 million. From July 1, 2007, the EDF group will carry out its trading activities in a European energy market fully open to competition. This document is EDF Group's Reference Document for the year 2006. It contains information about: the Group activities, risk factors, Business overview, Organizational structure, Property, plants and equipment, Operating and financial review, Capital resources and cash flows, Research and Development, Patents and Licenses, Trend information, Financial forecasts or estimates, Administrative, management and supervisory bodies and senior management, Remuneration and benefits, Board practices, Employees/Human resources, Major shareholders, Related party transactions, Financial information
Loebl, Ernest M
Group Theory and its Applications, Volume III covers the two broad areas of applications of group theory, namely, all atomic and molecular phenomena, as well as all aspects of nuclear structure and elementary particle theory.This volume contains five chapters and begins with an introduction to Wedderburn's theory to establish the structure of semisimple algebras, algebras of quantum mechanical interest, and group algebras. The succeeding chapter deals with Dynkin's theory for the embedding of semisimple complex Lie algebras in semisimple complex Lie algebras. These topics are followed by a rev
Group B streptococcal metastatic endophthalmitis.
Nagelberg, H P; Petashnick, D E; To, K W; Woodcome, H A
Reports of invasive Group B Streptococcus infection in adults with underlying medical conditions have been increasing. Ocular infection with this organism is unusual. Metastatic endophthalmitis in adults caused by this organism has been reported rarely and has only been associated with endocarditis. We encountered two cases of Group B streptococcal metastatic endophthalmitis in adults who did not have endocarditis. These cases reflect the increasing incidence of invasive Group B Streptococcus infection with its varying manifestations. Additionally, they emphasize the importance of considering this pathogen as a cause of metastatic endophthalmitis in adults with predisposing illnesses.
Renormalization group in modern physics
Shirkov, D.V.
Renormalization groups used in diverse fields of theoretical physics are considered. The discussion is based upon functional formulation of group transformations. This attitude enables development of a general method by using the notion of functional self-similarity which generalizes the usual self-similarity connected with power similarity laws. From this point of view the authors present a simple derivation of the renorm-group (RG) in QFT liberated from ultra-violet divergences philosophy, discuss the RG approach in other fields of physics and compare different RG's
Geometry, rigidity, and group actions
Farb, Benson; Zimmer, Robert J
The study of group actions is more than a hundred years old but remains to this day a vibrant and widely studied topic in a variety of mathematic fields. A central development in the last fifty years is the phenomenon of rigidity, whereby one can classify actions of certain groups, such as lattices in semi-simple Lie groups. This provides a way to classify all possible symmetries of important spaces and all spaces admitting given symmetries. Paradigmatic results can be found in the seminal work of George Mostow, Gergory Margulis, and Robert J. Zimmer, among others.The p
2002 annual report EDF group
Derived equivalences for group rings
König, Steffen
A self-contained introduction is given to J. Rickard's Morita theory for derived module categories and its recent applications in representation theory of finite groups. In particular, Broué's conjecture is discussed, giving a structural explanation for relations between the p-modular character table of a finite group and that of its "p-local structure". The book is addressed to researchers or graduate students and can serve as material for a seminar. It surveys the current state of the field, and it also provides a "user's guide" to derived equivalences and tilting complexes. Results and proofs are presented in the generality needed for group theoretic applications.
The Cogema group in Japan
The partnership between the Cogema group and Japan in the domain of fuel cycle started about 20 years ago and the 10 Japanese nuclear operators are all clients of the Cogema group. The 1997 turnover realized with Japan reached 3.6 billions of francs (11% of the total turnover of the group). This short paper presents briefly the nuclear program of Japan (nuclear park, spent fuels reprocessing-recycling strategy) and the contracts between Cogema and the Japanese nuclear operators (natural uranium, uranium conversion and enrichment, spent fuel reprocessing, plutonium recycle and MOX fuel production markets). (J.S.)
The Group Treatment of Bulimia.
Weinstein, Harvey M.; Richman, Ann
Bulimia has become an increasing problem in the college population. This article describes a group psychotherapeutic treatment approach to the problem. A theoretical formulation of the psychodynamics that may underlie the development of bulimia is offered. (Author/DF)
Metabolomics and Epidemiology Working Group
The Metabolomics and Epidemiology (MetEpi) Working Group promotes metabolomics analyses in population-based studies, as well as advancement in the field of metabolomics for broader biomedical and public health research.
The theory of nilpotent groups
Clement, Anthony E; Zyman, Marcos
This monograph presents both classical and recent results in the theory of nilpotent groups and provides a self-contained, comprehensive reference on the topic. While the theorems and proofs included can be found throughout the existing literature, this is the first book to collect them in a single volume. Details omitted from the original sources, along with additional computations and explanations, have been added to foster a stronger understanding of the theory of nilpotent groups and the techniques commonly used to study them. Topics discussed include collection processes, normal forms and embeddings, isolators, extraction of roots, P-localization, dimension subgroups and Lie algebras, decision problems, and nilpotent groups of automorphisms. Requiring only a strong undergraduate or beginning graduate background in algebra, graduate students and researchers in mathematics will find The Theory of Nilpotent Groups to be a valuable resource.
Finite flavour groups of fermions
Grimus, Walter; Ludl, Patrick Otto
We present an overview of the theory of finite groups, with regard to their application as flavour symmetries in particle physics. In a general part, we discuss useful theorems concerning group structure, conjugacy classes, representations and character tables. In a specialized part, we attempt to give a fairly comprehensive review of finite subgroups of SO(3) and SU(3), in which we apply and illustrate the general theory. Moreover, we also provide a concise description of the symmetric and alternating groups and comment on the relationship between finite subgroups of U(3) and finite subgroups of SU(3). Although in this review we give a detailed description of a wide range of finite groups, the main focus is on the methods which allow the exploration of their different aspects. (topical review)
On characters of finite groups
Broué, Michel
This book explores the classical and beautiful character theory of finite groups. It does it by using some rudiments of the language of categories. Originally emerging from two courses offered at Peking University (PKU), primarily for third-year students, it is now better suited for graduate courses, and provides broader coverage than books that focus almost exclusively on groups. The book presents the basic tools, notions and theorems of character theory (including a new treatment of the control of fusion and isometries), and introduces readers to the categorical language at several levels. It includes and proves the major results on characteristic zero representations without any assumptions about the base field. The book includes a dedicated chapter on graded representations and applications of polynomial invariants of finite groups, and its closing chapter addresses the more recent notion of the Drinfeld double of a finite group and the corresponding representation of GL_2(Z).
Working group report: Quantum chromodynamics
3NIKHEF Theory Group, Kruislaan 409, 1098 SJ Amsterdam, The Netherlands. 4Harish-Chandra Research Institute, Chhatnag Road, Jhusi, Allahabad 211 ... tant to extend the resummation framework to polarised process to look at polarised.
Group Work with Juvenile Delinquents.
Reviews group work literature on juvenile delinquents. Presents overview of interventions, including positive peer culture, cognitive-behavioral treatment, psychoeducational treatment, treatment of learned behavior, action-oriented treatment, milieu therapy, parental involvement, assertiveness training, and music therapy. Discusses outcome…
Remainder Wheels and Group Theory
Brenton, Lawrence
Why should prospective elementary and high school teachers study group theory in college? This paper examines applications of abstract algebra to the familiar algorithm for converting fractions to repeating decimals, revealing ideas of surprising substance beneath an innocent facade.
Group Empowerment in Nursing Education.
Friend, Mary Louanne
Nursing education is experiencing rapid changes, as nurses are expected to transform and lead health care delivery within the United States. The ability to produce exceptional graduates requires faculty who are empowered to achieve goals. The Sieloff-King Assessment of Group Empowerment Within Organizations (SKAGEO) was adapted and administered online to a stratified sample of administrators and faculty in American Association of Colleges of Nursing-member schools. Participants' scores were within high ranges in both empowerment capacity and capability; however, administrator group scores were higher. Data analyses indicated that administrator leadership competencies were associated with group empowerment. This study suggests that empowered faculty and administrator groups anticipate changing health care trends and effect student outcomes and competencies by their interventions. Also, it can be inferred that as a result of administrators' competencies, participants teach in empowered work environments where they can model ideal behaviors. Copyright 2015, SLACK Incorporated.
Genodermatoses in paediatric age group
Kumar Sunil
Full Text Available Pattern of genodermatoses in paediatric age group was studied. The relative incidence of genodermatoses in paediatric dermatology out patient department was 0.62%. The commonest genodermatoses observed was ichthyosis.
Linear algebra and group theory
Smirnov, VI
This accessible text by a Soviet mathematician features material not otherwise available to English-language readers. Its three-part treatment covers determinants and systems of equations, matrix theory, and group theory. 1961 edition.
Report of Industry Panel Group
Gallimore, Simon; Gier, Jochen; Heitland, Greg; Povinelli, Louis; Sharma, Om; VandeWall, Allen
A final report is presented from the industry panel group. The contents include: 1) General comments; 2) Positive progress since Minnowbrook IV; 3) Industry panel outcome; 4) Prioritized turbine projects; 5) Prioritized compressor projects; and 6) Miscellaneous.
Medicaid Enrollment - New Adult Group
U.S. Department of Health & Human Services — Total Medicaid Enrollees - VIII Group Break Out Report Reported on the CMS-64 The enrollment information is a state-reported count of unduplicated individuals...
Climate change and group dynamics
Postmes, Tom
The characteristics and views of people sceptical about climate change have been analysed extensively. A study now confirms that sceptics in the US have some characteristics of a social movement, but shows that the same group dynamics propel believers
Essays in the history of Lie groups and algebraic groups
Lie groups and algebraic groups are important in many major areas of mathematics and mathematical physics. We find them in diverse roles, notably as groups of automorphisms of geometric structures, as symmetries of differential systems, or as basic tools in the theory of automorphic forms. The author looks at their development, highlighting the evolution from the almost purely local theory at the start to the global theory that we know today. Starting from Lie's theory of local analytic transformation groups and early work on Lie algebras, he follows the process of globalization in its two main frameworks: differential geometry and topology on one hand, algebraic geometry on the other. Chapters II to IV are devoted to the former, Chapters V to VIII, to the latter. The essays in the first part of the book survey various proofs of the full reducibility of linear representations of \\mathbf{SL}_2{(\\mathbb{C})}, the contributions of H. Weyl to representations and invariant theory for semisimple Lie groups, and con...
A Renormalisation Group Method. V. A Single Renormalisation Group Step
Brydges, David C.; Slade, Gordon
This paper is the fifth in a series devoted to the development of a rigorous renormalisation group method applicable to lattice field theories containing boson and/or fermion fields, and comprises the core of the method. In the renormalisation group method, increasingly large scales are studied in a progressive manner, with an interaction parametrised by a field polynomial which evolves with the scale under the renormalisation group map. In our context, the progressive analysis is performed via a finite-range covariance decomposition. Perturbative calculations are used to track the flow of the coupling constants of the evolving polynomial, but on their own perturbative calculations are insufficient to control error terms and to obtain mathematically rigorous results. In this paper, we define an additional non-perturbative coordinate, which together with the flow of coupling constants defines the complete evolution of the renormalisation group map. We specify conditions under which the non-perturbative coordinate is contractive under a single renormalisation group step. Our framework is essentially combinatorial, but its implementation relies on analytic results developed earlier in the series of papers. The results of this paper are applied elsewhere to analyse the critical behaviour of the 4-dimensional continuous-time weakly self-avoiding walk and of the 4-dimensional -component model. In particular, the existence of a logarithmic correction to mean-field scaling for the susceptibility can be proved for both models, together with other facts about critical exponents and critical behaviour.
LLNL Chemical Kinetics Modeling Group
Pitz, W J; Westbrook, C K; Mehl, M; Herbinet, O; Curran, H J; Silke, E J
The LLNL chemical kinetics modeling group has been responsible for much progress in the development of chemical kinetic models for practical fuels. The group began its work in the early 1970s, developing chemical kinetic models for methane, ethane, ethanol and halogenated inhibitors. Most recently, it has been developing chemical kinetic models for large n-alkanes, cycloalkanes, hexenes, and large methyl esters. These component models are needed to represent gasoline, diesel, jet, and oil-sand-derived fuels.
CEC natural analogue working group
Come, B.; Chapman, N.A.
The second meeting of the CEC Natural Analogue Working Group took place on June 17-19, 1986, hosted by the Swiss NAGRA in Interlaken (CH). A review of recent progress in natural analogue programmes was carried out, and complemented by detailed discussions about geomicrobiology, archaeological analogues, natural colloids, and use of analogues to increase confidence in safety assessments for radioactive waste disposal. A statement drafted by the Group, and the presentations made, are put together in this report
Molecular invariants: atomic group valence
Mundim, K.C.; Giambiagi, M.; Giambiagi, M.S. de.
Molecular invariants may be deduced in a very compact way through Grassman algebra. In this work, a generalized valence is defined for an atomic group; it reduces to the Known expressions for the case of an atom in a molecule. It is the same of the correlations between the fluctions of the atomic charges qc and qd (C belongs to the group and D does not) around their average values. Numerical results agree with chemical expectation. (author) [pt
Direct Bandgap Group IV Materials
AFRL-AFOSR-JP-TR-2017-0049 Direct Bandgap group IV Materials Hung Hsiang Cheng NATIONAL TAIWAN UNIVERSITY Final Report 01/21/2016 DISTRIBUTION A...NAME(S) AND ADDRESS(ES) NATIONAL TAIWAN UNIVERSITY 1 ROOSEVELT RD. SEC. 4 TAIPEI CITY, 10617 TW 8. PERFORMING ORGANIZATION REPORT NUMBER 9. SPONSORING...14. ABSTRACT Direct bandgap group IV materials have been long sought for in both academia and industry for the implementation of photonic devices
Fifteenth LAMPF users group meeting
Cochran, D.R.F.
The Fifteenth LAMPF Users Group Meeting was held November 2-3, 1981 at the Clinton P. Anderson Meson Physical Facility. The program of papers scheduled to be presented was amended to include a Report from Washington by Clarence R. Richardson, US Department of Energy. The general meeting ended with a round-table working group discussion concerning the Planning for a Kaon Factory. Individual items from the meeting were prepared separately for the data base
The EDF Group is one of the world's leading energy companies, active in all areas from generation to trading and network management. It has a sound business model, evenly balanced between regulated and deregulated activities. With its first-rate human resources, R and D capability, expertise in engineering and operating generation plants and networks, as well as its energy eco-efficiency offers, the Group delivers competitive solutions that help ensure sustainable economic development and climate protection. The EDF Group is the leader in the French and UK electricity markets and has solid positions in Italy and numerous other European countries, as well as industrial operations in Asia and the United States. Everywhere it operates, the Group is a model of quality public service for the energy sector. This document is EDF Group's annual report for the year 2012. It contains information about Group profile, governance, business, development strategy, sales and marketing, positions in Europe and international activities. The document is made of several reports: the Activity and Sustainable Development Report, the Financial Report, the 'EDF at a glance' report, and the Sustainable Development Indicators
The EDF Group is a leading player in the energy industry, active in all areas of the electricity value chain, from generation to trading and network management, with expanding operations in the natural gas chain. It has a sound business model, evenly balanced between regulated and deregulated activities. The EDF Group is the leader in the French and British electricity markets and has solid positions in Germany and Italy and numerous other European countries, as well as industrial operations in Asia and the United States. Everywhere it operates, the EDF Group is a model of quality public service for the energy sector. With fi rst-rate human resources, R and D capability and generation expertise in nuclear, fossil-fired and renewable energies, particularly hydro, together with energy eco-efficiency offers, the EDF Group delivers competitive solutions that help ensure sustainable economic development and climate protection. This document is EDF Group's annual report for the year 2009. It contains information about Group profile, governance, business, development strategy, sales and marketing, positions in Europe and international activities. The document is made of several reports: the Activity and Sustainable Development Report, the Financial Report, the Management Report, the Report by the Chairman of EDF Board of Directors on corporate governance and internal control procedures, the Milestones report, the 'EDF at a glance' report, and the Sustainable Development Indicators
Vaccination against group B streptococcus.
Heath, Paul T; Feldman, Robert G
Streptococcus agalactiae (Group B streptococcus) is an important cause of disease in infants, pregnant women, the elderly and in immunosuppressed adults. An effective vaccine is likely to prevent the majority of infant disease (both early and late onset), as well as Group B streptococcus-related stillbirths and prematurity, to avoid the current real and theoretical limitations of intrapartum antibiotic prophylaxis, and to be cost effective. The optimal time to administer such a vaccine would be in the third trimester of pregnancy. The main limitations on the production of a Group B streptococcus vaccine are not technical or scientific, but regulatory and legal. A number of candidates including capsular conjugate vaccines using traditional carrier proteins such as tetanus toxoid and mutant diphtheria toxin CRM197, as well as Group B streptococcus-specific proteins such as C5a peptidase, protein vaccines using one or more Group B streptococcus surface proteins and mucosal vaccines, have the potential to be successful vaccines. The capsular conjugate vaccines using tetanus and CRM197 carrier proteins are the most advanced candidates, having already completed Phase II human studies including use in the target population of pregnant women (tetanus toxoid conjugate), however, no definitive protein conjugates have yet been trialed. However, unless the regulatory environment is changed specifically to allow the development of a Group B streptococcus vaccine, it is unlikely that one will ever reach the market.
The EDF Group is one of the world's leading energy companies, active in all areas from generation to trading and network management. It has a sound business model, evenly balanced between regulated and deregulated activities. With its first-rate human resources, R and D capability, expertise in engineering and operating generation plants and networks, as well as its energy eco-efficiency offers, the Group delivers competitive solutions that help ensure sustainable economic development and climate protection. The EDF Group is the leader in the French and UK electricity markets and has solid positions in Italy and numerous other European countries, as well as industrial operations in Asia and the United States. Everywhere it operates, the Group is a model of quality public service for the energy sector. This document is EDF Group's annual report for the year 2010. It contains information about Group profile, governance, business, development strategy, sales and marketing, positions in Europe and international activities. The document is made of several reports: the Activity and Sustainable Development Report, the Financial Report, the Management Report, the Report by the Chairman of EDF Board of Directors on corporate governance and internal control procedures, the Milestones report, the 'EDF at a glance' report, and the Sustainable Development Indicators
Applications of blood group genotyping
Mariza A. Mota
Full Text Available Introduction: The determination of blood group polymorphism atthe genomic level facilitates the resolution of clinical problemsthat cannot be addressed by hemagglutination. They are useful to(a determine antigen types for which currently available antibodiesare weakly reactive; (b type patients who have been recentlytransfused; (c identify fetuses at risk for hemolytic disease of thenewborn; and (d to increase the reliability of repositories of antigennegative RBCs for transfusion. Objectives: This review assessedthe current applications of blood group genotyping in transfusionmedicine and hemolytic disease of the newborn. Search strategy:Blood group genotyping studies and reviews were searched ingeneral database (MEDLINE and references were reviewed.Selection criteria: All published data and reviews were eligible forinclusion provided they reported results for molecular basis ofblood group antigens, DNA analysis for blood group polymorphisms,determination of fetal group status and applications of blood groupgenotyping in blood transfusion. Data collection: All data werecollected based on studies and reviews of blood grouppolymorphisms and their clinical applications.
Dynamics of small groups of galaxies. I. Virialized groups
Mamon, G.A.; New York Univ., NY)
The dynamical evolution of small groups of galaxies from an initial virial equilibrium state is investigated by means of numerical simulations. The basic scheme is a gravitational N-body code in which galaxies and diffuse background are treated as single particles with both external parameters and internal structure; collisional and tidal stripping, dynamical friction, mergers, and orbital braking are taken into account. The results are presented in extensive tables and graphs and characterized in detail. Eight-galaxy groups with surface densities like those of compact groups (as defined by Hickson, 1982) are found to be unstable to rapid mergers after 1/30 to 1/8 Hubble time. The effects of dark-matter distribution (in galactic halos or in a common intergalactic background) are considered. 79 references
Lau, Marianne Engelbrecht
Objectives: A recent meta-analysis also concluded that psychotherapeutic approaches are beneficial for adult with a history of CSA and maintained for at least six months follow-up. The results suggest that different characteristics of therapy moderate the therapeutic outcome. We found in a random......Objectives: A recent meta-analysis also concluded that psychotherapeutic approaches are beneficial for adult with a history of CSA and maintained for at least six months follow-up. The results suggest that different characteristics of therapy moderate the therapeutic outcome. We found....... Methods: This randomized prospective study included 106 women: 52 assigned to psychodynamic group psychotherapy and 54 assigned to systemic group psychotherapy. The Group Environment Scale (GES) was filled in the mid phase of therapy and analysed in three dimensions and 10 subscales. Results: The systemic...... subscales: Cohesion (pLeader support (p=0.001), Expressiveness (p
S3T working group. Report 1: group aims
Pouey, M.
The work group S3T which is aimed to designing and developing devices using unconventional holographic optics is presented. These devices find applications that are classified here in four items high resolution spectrometers, high definition imaging, high flux devices, metrology and interferometry. The problems to solve and the aims of the group in each of these cases are presented. Three synthesis of lectures are in this report. The main one concerns stigmatism conditions of concave holographic gratings used in normal incidence. This new process of focusing is very interesting for hot plasma diagnostics [fr
Pride, Shame and Group Identification
Alessandro eSalice
Full Text Available Self-conscious emotions such as shame and pride are emotions that typically focus on the self of the person who feels them. In other words, the intentional object of these emotions is assumed to be the subject that experiences them. Many reasons speak in its favor and yet this account seems to leave a question open: how to cash out those cases in which one genuinely feels ashamed or proud of what someone else does?This paper contends that such cases do not necessarily challenge the idea that shame and pride are about the emoting subject. Rather, we claim that some of the most paradigmatic scenarios of shame and pride induced by others can be accommodated by taking seriously the consideration that, in such cases, the subject group-identifies with the other. This is the idea that, in feeling these forms of shame or pride, the subject is conceiving of herself as a member of the same group as the subject acting shamefully or in an admirable way. In other words, these peculiar emotive responses are elicited in the subject insofar as, and to the extent that, she is (or sees herself as being a member of a group – the group to which those who act shamefully or admirably also belong.By looking into the way in which the notion of group identification can allow for an account of hetero-induced shame and pride, this paper attempts to achieve a sort of mutual enlightenment that brings to light not only an important and generally neglected form of self-conscious emotions, but also relevant features of group identification. In particular, it generates evidence for the idea that group identification is a psychological process that the subject does not have to carry out intentionally in the sense that it is not necessarily triggered by the subject's conative states like desires or intentions.
Pride, Shame, and Group Identification.
Salice, Alessandro; Montes Sánchez, Alba
Self-conscious emotions such as shame and pride are emotions that typically focus on the self of the person who feels them. In other words, the intentional object of these emotions is assumed to be the subject that experiences them. Many reasons speak in its favor and yet this account seems to leave a question open: how to cash out those cases in which one genuinely feels ashamed or proud of what someone else does? This paper contends that such cases do not necessarily challenge the idea that shame and pride are about the emoting subject. Rather, we claim that some of the most paradigmatic scenarios of shame and pride induced by others can be accommodated by taking seriously the consideration that, in such cases, the subject "group-identifies" with the other. This is the idea that, in feeling these forms of shame or pride, the subject is conceiving of herself as a member of the same group as the subject acting shamefully or in an admirable way. In other words, these peculiar emotive responses are elicited in the subject insofar as, and to the extent that, she is (or sees herself as being) a member of a group - the group to which those who act shamefully or admirably also belong. By looking into the way in which the notion of group identification can allow for an account of hetero-induced shame and pride, this paper attempts to achieve a sort of mutual enlightenment that brings to light not only an important and generally neglected form of self-conscious emotions, but also relevant features of group identification. In particular, it generates evidence for the idea that group identification is a psychological process that the subject does not have to carry out intentionally in the sense that it is not necessarily triggered by the subject's conative states like desires or intentions.
Unitary Representations of Gauge Groups
Huerfano, Ruth Stella
I generalize to the case of gauge groups over non-trivial principal bundles representations that I. M. Gelfand, M. I. Graev and A. M. Versik constructed for current groups. The gauge group of the principal G-bundle P over M, (G a Lie group with an euclidean structure, M a compact, connected and oriented manifold), as the smooth sections of the associated group bundle is presented and studied in chapter I. Chapter II describes the symmetric algebra associated to a Hilbert space, its Hilbert structure, a convenient exponential and a total set that later play a key role in the construction of the representation. Chapter III is concerned with the calculus needed to make the space of Lie algebra valued 1-forms a Gaussian L^2-space. This is accomplished by studying general projective systems of finitely measurable spaces and the corresponding systems of sigma -additive measures, all of these leading to the description of a promeasure, a concept modeled after Bourbaki and classical measure theory. In the case of a locally convex vector space E, the corresponding Fourier transform, family of characters and the existence of a promeasure for every quadratic form on E^' are established, so the Gaussian L^2-space associated to a real Hilbert space is constructed. Chapter III finishes by exhibiting the explicit Hilbert space isomorphism between the Gaussian L ^2-space associated to a real Hilbert space and the complexification of its symmetric algebra. In chapter IV taking as a Hilbert space H the L^2-space of the Lie algebra valued 1-forms on P, the gauge group acts on the motion group of H defining in an straight forward fashion the representation desired.
Quantum group and quantum symmetry
Chang Zhe.
This is a self-contained review on the theory of quantum group and its applications to modern physics. A brief introduction is given to the Yang-Baxter equation in integrable quantum field theory and lattice statistical physics. The quantum group is primarily introduced as a systematic method for solving the Yang-Baxter equation. Quantum group theory is presented within the framework of quantum double through quantizing Lie bi-algebra. Both the highest weight and the cyclic representations are investigated for the quantum group and emphasis is laid on the new features of representations for q being a root of unity. Quantum symmetries are explored in selected topics of modern physics. For a Hamiltonian system the quantum symmetry is an enlarged symmetry that maintains invariance of equations of motion and allows a deformation of the Hamiltonian and symplectic form. The configuration space of the integrable lattice model is analyzed in terms of the representation theory of quantum group. By means of constructing the Young operators of quantum group, the Schroedinger equation of the model is transformed to be a set of coupled linear equations that can be solved by the standard method. Quantum symmetry of the minimal model and the WZNW model in conformal field theory is a hidden symmetry expressed in terms of screened vertex operators, and has a deep interplay with the Virasoro algebra. In quantum group approach a complete description for vibrating and rotating diatomic molecules is given. The exact selection rules and wave functions are obtained. The Taylor expansion of the analytic formulas of the approach reproduces the famous Dunham expansion. (author). 133 refs, 20 figs
Group Chaos Theory: A Metaphor and Model for Group Work
Rivera, Edil Torres; Wilbur, Michael; Frank-Saraceni, James; Roberts-Wilbur, Janice; Phan, Loan T.; Garrett, Michael T.
Group phenomena and interactions are described through the use of the chaos theory constructs and characteristics of sensitive dependence on initial conditions, phase space, turbulence, emergence, self-organization, dissipation, iteration, bifurcation, and attractors and fractals. These constructs and theoretical tenets are presented as applicable…
Risk behaviour and group formation in microcredit groups in Eritrea
Lensink, Robert; Mehrteab, Habteab T.
We conducted a survey in 2001 among members and group leaders of borrowers who accessed loans from two microcredit programs in Eritrea. Using the results from this survey, this paper aims to provide new insights into the empirical relevance of the homogeneous matching hypothesis for microcredit
Lensink, B.W.; Mehrteab, H.T.
The anatomy of group dysfunction.
Hayes, David F
The dysfunction of the radiology group has 2 components: (1) the thinking component-the governance structure of the radiology group; how we manage the group; and (2) the structural component-the group's business model and its conflict with the partner's personal business model. Of the 2 components, governance is more important. Governance must be structured on classic, immutable business management principles. The structural component, the business model, is not immutable. In fact, it must continually change in response to the marketplace. Changes in the business model should occur only if demanded or permitted by the marketplace; instituting changes for other reasons, including personal interests or deficient knowledge of the deciders, is fundamentally contrary to the long-term interests of the group and its owners. First, we must learn basic business management concepts to appreciate the function and necessity of standard business models and standard business governance. Peter Drucker's The Effective Executive is an excellent primer on the subjects of standard business practices and the importance of a functional, authorized, and fully accountable chief executive officer. Copyright © 2014 American College of Radiology. Published by Elsevier Inc. All rights reserved.
Focus group report, Part I
The Waste Policy Institute, through a cooperative agreement with the U.S. Department of Energy's (DOE) Office of Science and Technology (OST), conducted two focus groups with people who live or work near DOE sites. The purpose of the focus groups was to gain a better understanding of the general community's information needs about the development of innovative technologies that are used in the cleanup of the sites. The authors wanted to better understand of what role these people want to play in the development of new technologies, how OST communication products can help facilitate that role, and the usefulness of current OST communication products. WPI held the focus groups in communities near the Idaho National Engineering and Environmental Laboratory (INEEL) and the Savannah River Site (SRS) because they are among the DOE sites that cannot be cleaned up before 2006. To include many facets of the communities, WPI randomly selected participants from membership lists of organized groups in each community including: elected officials, school boards, unions, chambers of commerce, economic development organizations, environmental organizations, health and human service organizations, and area clergy. While in the communities, WPI also interviewed stakeholders such as tribal representatives and a Citizens Advisory Board (CAB) member. Qualitative data gathered during the focus group sessions give some indication of general stakeholder opinions. However, the authors caution readers not to make broad assumptions about the general stakeholder audience based on the opinions of a limited number of general community stakeholders
The EDF Group is a leading player in the European energy industry, present in all areas of the electricity value chain, from generation to trading, and increasingly active in the gas chain in Europe. Leader in the French electricity market, the Group also has solid positions in the United Kingdom, Germany and Italy. In the electricity sector, it has the premier generation fleet and customer portfolio in Europe and operates in strategically targeted areas in the rest of the world. The Group is also the leading network operator in Europe, giving it a sound business model, equally balanced between regulated activities and those open to competition. This document is EDF Group's annual report for the year 2005. It contains information about Group profile, governance, business, development strategy, sales and marketing, positions in Europe and international activities. The document is made of several reports: the Activity and Sustainable Development report, the Financial Report, the Sustainable Development Report, the Sustainable Development Indicators, the Management Report, the Report by the Chairman of EDF Board of Directors on corporate governance and internal control procedures
The EDF Group is a leading player in the European energy industry, present in all areas of the electricity value chain, from generation to trading, and increasingly active in the gas chain in Europe. Leader in the French electricity market, the Group also has solid positions in the United Kingdom, Germany and Italy. In the electricity sector, it has the premier generation fleet and customer portfolio in Europe and operates in strategically targeted areas in the rest of the world. The Group is also the leading network operator in Europe, giving it a sound business model, equally balanced between regulated activities and those open to competition. This document is EDF Group's annual report for the year 2006. It contains information about Group profile, governance, business, development strategy, sales and marketing, positions in Europe and international activities. The document is made of several reports: the Activity and Sustainable Development Report, the Financial Report, the Sustainable Development Report, the Sustainable Development Indicators, and the Report by the Chairman of EDF Board of Directors on corporate governance and internal control procedures
The EDF Group is a leading player in the European energy industry, active in all areas of the electricity value chain, from generation to trading and network management. The leader in the French electricity market, the Group also has solid positions in the United Kingdom, Germany and Italy, with a portfolio of 38.5 million European customers and a generation fleet which is unique in the world. It intends to play a major role in the global revival of nuclear and is increasingly active in the gas chain. The Group has a sound business model, evenly balanced between regulated and deregulated activities. Given its R and D capability, its track record and expertise in nuclear, fossil-fired and hydro generation and in renewable energies, together with its energy eco-efficiency offers, EDF is well placed to deliver competitive solutions to reconcile sustainable economic growth and climate preservation. This document is EDF Group's Reference Document and Annual Financial Report for the year 2007. It contains information about Group profile, governance, business, investments, property, plant and equipment, management, financial position, human resources, shareholders, etc. The document includes the 2008 half-year financial report and consolidated financial statements, and the report drafted by the Statutory Auditors
Differential geometry of group lattices
Dimakis, Aristophanes; Mueller-Hoissen, Folkert
In a series of publications we developed ''differential geometry'' on discrete sets based on concepts of noncommutative geometry. In particular, it turned out that first-order differential calculi (over the algebra of functions) on a discrete set are in bijective correspondence with digraph structures where the vertices are given by the elements of the set. A particular class of digraphs are Cayley graphs, also known as group lattices. They are determined by a discrete group G and a finite subset S. There is a distinguished subclass of ''bicovariant'' Cayley graphs with the property ad(S)S subset of S. We explore the properties of differential calculi which arise from Cayley graphs via the above correspondence. The first-order calculi extend to higher orders and then allow us to introduce further differential geometric structures. Furthermore, we explore the properties of ''discrete'' vector fields which describe deterministic flows on group lattices. A Lie derivative with respect to a discrete vector field and an inner product with forms is defined. The Lie-Cartan identity then holds on all forms for a certain subclass of discrete vector fields. We develop elements of gauge theory and construct an analog of the lattice gauge theory (Yang-Mills) action on an arbitrary group lattice. Also linear connections are considered and a simple geometric interpretation of the torsion is established. By taking a quotient with respect to some subgroup of the discrete group, generalized differential calculi associated with so-called Schreier diagrams are obtained
Salice, Alessandro; Montes Sanchez, Alba
into the way in which the notion of group identification can allow for an account of hetero-induced shame and pride, this paper attempts to achieve a sort of mutual enlightenment that brings to light not only an important and generally neglected form of self-conscious emotions, but also relevant features...... scenarios of shame and pride induced by others can be accommodated by taking seriously the consideration that, in such cases, the subject "group-identifies� with the other. This is the idea that, in feeling these forms of shame or pride, the subject is conceiving of herself as a member of the same group...... as the subject acting shamefully or in an admirable way. In other words, these peculiar emotive responses are elicited in the subject insofar as, and to the extent that, she is (or sees herself as being) a member of a group – the group to which those who act shamefully or admirably also belong. By looking...
EDF group is the world's leading electricity company and global leader for low-carbon energy production. Particularly well established in Europe, especially France, the United-Kingdom, Italy and Belgium, as well as North and South America, the Group covers all businesses spanning the electricity value chain - from generation to distribution and including energy transmission and trading activities - to continuously balance supply. A marked increase in the use of renewables is bringing change to its electricity generation operations, which are underpinned by a diversified and complementary energy mix founded on nuclear power capacity. EDF offers products and advice to help residential customers manage their electricity consumption, to support the energy and financial performance of its business customers, and to help local authorities find sustainable solutions. This document is EDF Group's annual report for the year 2016. It contains information about Group profile, governance, business, development strategy, sales and marketing, positions in Europe and international activities. The document comprises the Group's activities and performances Report and the 'EDF at a glance' 2017 report
Storytellers - a women group experience
Stela Nazareth Meneghel
Full Text Available This paper reports some psychosocial interventions in which were exploited the "storytelling", in workshops aimed at social workers and women in situation of vulnerability. The workshops were organized from the demands of social movements to combat violence and other extreme situations. The group was the field of intervention, from the demands, lived experiences of participants, based on methodological choice of narratives, life histories and stories of oral culture. We believe that groups of storytellers performed with women allow an exercise of critical reflection and change, as well as being an option for methodological research and practice feminist. Storytellers groups performed with women allow an exercise of critical reflection and change, as well as being a methodological option for feminist practice and research.
CFCC working group meeting: Proceedings
This report is a compilation of the vugraphs presented at this meeting. Presentations covered are: CFCC Working Group; Overview of study on applications for advanced ceramics in industries for the future; Design codes and data bases: The CFCC program and its involvement in ASTM, ISO, ASME, and military handbook 17 activities; CFCC Working Group meeting (McDermott Technology); CFCC Working Group meeting (Textron); CFCC program for DMO materials; Developments in PIP-derived CFCCs; Toughened Silcomp (SiC-Si) composites for gas turbine engine applications; CFCC program for CVI materials; Self-lubricating CFCCs for diesel engine applications; Overview of the CFCC program`s supporting technologies task; Life prediction methodologies for CFCC components; Environmental testing of CFCCs in combustion gas environments; High-temperature particle filtration ORNL/DCC CRADA; HSCT CMC combustor; and Case study -- CFCC shroud for industrial gas turbines.
Euratom Neutron Radiography Working Group
Domanus, Joseph Czeslaw
reactor fuel as well as establish standards for radiographic image quality of neutron radiographs. The NRWG meets once a year in each of the neutron radiography centers to review the progress made and draw plans for the future. Besides, ad-hoc sub-groups or. different topics within the field of neutron......In 1979 a Neutron Radiography Working Group (NRWG) was constituted within Buratom with the participation of all centers within the European Community at which neutron facilities were available. The main purpose of NRWG was to standardize methods and procedures used in neutron radiography of nuclear...... radiography are constituted. This paper reviews the activities and achievements of the NRWG and its sub-groups....
Intergenerational Groups: Rediscovering our Legacy
Scott P. Anstadt
Full Text Available Intergenerational groups are a community-based group concept designed to engage and mobilize often untapped resources of older adults in effective interaction with younger populations. These groups support an atmosphere of synergistic interaction. Members of each generation share reflections on interpersonal strengths and capacities and rediscover emotional and spiritual anchors and bonding. Illustrated here is Community Connections (CC, developed using the phase driven participatory culture-specific intervention model (PCSIM; Nastasi, Moore & Varjas, 2004 that included self selected local older adults, caregivers, and multicultural exchange students. The program was structured to offer mutual opportunities for activities built around exchanging cultural and life experiences. The goals were: 1 to reduce social isolation due to age, culture, or disability 2 for international students to practice English and learn about local cultural traditions, and 3 to build intergenerational 'extended family' relationships.
Sequences, groups, and number theory
Rigo, Michel
This collaborative book presents recent trends on the study of sequences, including combinatorics on words and symbolic dynamics, and new interdisciplinary links to group theory and number theory. Other chapters branch out from those areas into subfields of theoretical computer science, such as complexity theory and theory of automata. The book is built around four general themes: number theory and sequences, word combinatorics, normal numbers, and group theory. Those topics are rounded out by investigations into automatic and regular sequences, tilings and theory of computation, discrete dynamical systems, ergodic theory, numeration systems, automaton semigroups, and amenable groups. This volume is intended for use by graduate students or research mathematicians, as well as computer scientists who are working in automata theory and formal language theory. With its organization around unified themes, it would also be appropriate as a supplemental text for graduate level courses.
Reflection group on 'Expert Culture'
As part of SCK-CEN's social sciences and humanities programme, a reflection group on 'Expert Culture' was established. The objectives of the reflection group are: (1) to clarify the role of SCK-CEN experts; (2) to clarify the new role of expertise in the evolving context of risk society; (3) to confront external views and internal SCK-CEN experiences on expert culture; (4) to improve trust building of experts and credibility of SCK-CEN as a nuclear actor in society; (5) to develop a draft for a deontological code; (6) to integrate the approach in training on assertivity and communication; (7) to create an output for a topical day on the subject of expert culture. The programme, achievements and perspectives of the refection group are summarised
Groups and clusters of galaxies
Bijleveld, W.
In this thesis, a correlative study is performed with respect to the radio and X-ray parameters of galaxy clusters and groups of galaxies (Msub(v)-Psub(1.4); Msub(v)-Lsub(x); Lsub(x)-Psub(1.4); R-Msub(v) correlations). Special attention is paid to correlations with cD and elliptical galaxies. It is concluded that in rich clusters massive cD galaxies form; massive galaxies are able to bind a large X-ray halo; strong X-ray emitters fuel their central radio sources at a high rate; the total gas content of groups is low, which implies that the contribution of groups to the total matter density in the universe is small. (Auth.)
Fossil Groups as Cosmological Labs
D'Onghia, Elena
Optical and X-ray measurements of fossil groups (FGs) suggest that they are old and relaxed systems. If FGs are assembled at higher redshift, there is enough time for intermediate-luminosity galaxies to merge, resulting in the formation of the brightest group galaxy (BGG). We carry out the first, systematic study of a large sample of FGs, the "FOssil Group Origins'' (FOGO) based on an International Time Project at the Roque de los Muchachos Observatory. For ten FOGO FGs we have been awarded time at SUZAKU Telescope to measure the temperature of the hot intragroup gas (IGM). For these systems we plan to evaluate and correlate their X-ray luminosity and X-ray temperature, Lx-Tx, optical luminosity and X-ray temperature, Lopt-Tx, and group velocity dispersion with their X-ray temperature, sigma V-Tx, as compared to the non fossil systems. By combining these observations with state-of-art cosmological hydrodynamical simulations we will open a new window into the study of the IGM and the nature of fossil systems. Our proposed work will be of direct relevance for the understanding and interpretation of data from several NASA science missions. Specifically, the scaling relations obtained from these data combined with our predictions obtained using state-of-the-art hydrodynamical simulation numerical adopting a new hydrodynamical scheme will motivate new proposal on CHANDRA X-ray telescope for fossil groups and clusters. We will additionally create a public Online Planetarium Show. This will be an educational site, containing an interactive program called: "A Voyage to our Universe''. In the show we will provide observed images of fossil groups and similar images and movies obtained from the numerical simulations showing their evolution. The online planetarium show will be a useful reference and an interactive educational tool for both students and the public.
Leading Indian Business-Groups
Maria Alexandrovna Vorobyeva
Full Text Available The goal of this paper is to investigate the evolution of the leading Indian business-groups under the conditions of economical liberalization. It is shown that the role of modern business-groups in the Indian economy is determined by their high rate in the gross domestic product (GDP, huge overall actives, substantial pert in the e[port of goods and services, as well as by their activities in modern branch structure formatting, and developing labor-intensive and high-tech branches. They strongly influence upon economical national strategies, they became a locomotive of internationalization and of transnationalization of India, the basis of the external economy factor system, the promoters of Indian "economical miracle" on the world scene, and the dynamical segment of economical and social development of modern India. The tendencies of the development of the leading Indian business groups are: gradual concentration of production in few clue sectors, "horizontal" structure, incorporation of the enterprises into joint-stock structure, attraction of hired top-managers and transnationaliziation. But against this background the leading Indian business-groups keep main traditional peculiarities: they mostly still belong to the families of their founders, even today they observe caste or communal relations which are the basis of their non-formal backbone tides, they still remain highly diversificated structures with weak interrelations. Specific national ambivalence and combination of traditions and innovations of the leading Indian business-groups provide their high vitality and stability in the controversial, multiform, overloaded with caste and confessional remains Indian reality. We conclude that in contrast to the dominant opinion transformation of these groups into multisectoral corporations of the western type is far from completion, and in the nearest perspective they will still possess all their peculiarities and incident social and economical
Magnetic susceptibility of functional groups
Herr, T.; Ferraro, M.B.; Contreras, R.H.
Proceeding with a series of works where new criteria are applied to the the calculation of the contribution of molecular fragments to certain properties, results are presented for a group of 1-X-benzenes and 1-X-naphtalenes for the magnetic susceptibility constant. Both the diamagnetic and paramagnetic parts are taken into account. To reduce the problems associated with the Gauge dependence originated in the approximations made, Gauge independent atomic orbitals (GIAO) orbitals are used in the atomic orbital basis. Results are discussed in terms of functional groups. (Author). 17 refs., 1 fig., 3 tabs
Molecular blood grouping of donors.
St-Louis, Maryse
For many decades, hemagglutination has been the sole means to type blood donors. Since the first blood group gene cloning in the early 1990s, knowledge on the molecular basis of most red blood cell, platelet and neutrophil antigens brought the possibility of using nucleotide-based techniques to predict phenotype. This review will summarized methodologies available to genotype blood groups from laboratory developed assays to commercially available platforms, and how proficiency assays become more present. The author will also share her vision of the transfusion medicine future. The field is presently at the crossroads, bringing new perspectives to a century old practice. Copyright © 2014 Elsevier Ltd. All rights reserved.
Exceptional groups from open strings
Gaberdiel, M.R.; Zwiebach, B.
We consider type IIB theory compactified on a two-sphere in the presence of mutually non-local 7-branes. The BPS states associated with the gauge vectors of exceptional groups are seen to arise from open strings connecting the 7-branes, and multi-pronged open strings capable of ending on more than two 7-branes. These multi-pronged strings are built from open string junctions that arise naturally when strings cross 7-branes. The different string configurations can be multiplied as traditional open strings, and are shown to generate the structure of exceptional groups. (orig.)
Induced modules over group algebras
Karpilovsky, Gregory
In 1898 Frobenius discovered a construction which, in present terminology, associates with every module of a subgroup the induced module of a group. This construction proved to be of fundamental importance and is one of the basic tools in the entire theory of group representations.This monograph is designed for research mathematicians and advanced graduate students and gives a picture of the general theory of induced modules as it exists at present. Much of the material has until now been available only in research articles. The approach is not intended to be encyclopedic, rather each topic is
Lego Group: An Outsourcing Journey
Larsen, Marcus Møller; Pedersen, Torben; Slepniov, Dmitrij
Automated analysis in generic groups
Fagerholm, Edvard
This thesis studies automated methods for analyzing hardness assumptions in generic group models, following ideas of symbolic cryptography. We define a broad class of generic and symbolic group models for different settings---symmetric or asymmetric (leveled) k-linear groups --- and prove ''computational soundness'' theorems for the symbolic models. Based on this result, we formulate a master theorem that relates the hardness of an assumption to solving problems in polynomial algebra. We systematically analyze these problems identifying different classes of assumptions and obtain decidability and undecidability results. Then, we develop automated procedures for verifying the conditions of our master theorems, and thus the validity of hardness assumptions in generic group models. The concrete outcome is an automated tool, the Generic Group Analyzer, which takes as input the statement of an assumption, and outputs either a proof of its generic hardness or shows an algebraic attack against the assumption. Structure-preserving signatures are signature schemes defined over bilinear groups in which messages, public keys and signatures are group elements, and the verification algorithm consists of evaluating ''pairing-product equations''. Recent work on structure-preserving signatures studies optimality of these schemes in terms of the number of group elements needed in the verification key and the signature, and the number of pairing-product equations in the verification algorithm. While the size of keys and signatures is crucial for many applications, another aspect of performance is the time it takes to verify a signature. The most expensive operation during verification is the computation of pairings. However, the concrete number of pairings is not captured by the number of pairing-product equations considered in earlier work. We consider the question of what is the minimal number of pairing computations needed to verify structure-preserving signatures. We build an
Transformation groups and Lie algebras
Ibragimov, Nail H
This book is based on the extensive experience of teaching for mathematics, physics and engineering students in Russia, USA, South Africa and Sweden. The author provides students and teachers with an easy to follow textbook spanning a variety of topics. The methods of local Lie groups discussed in the book provide universal and effective method for solving nonlinear differential equations analytically. Introduction to approximate transformation groups also contained in the book helps to develop skills in constructing approximate solutions for differential equations with a small parameter.
Group 4 metallocene complexes with pendant nitrile groups
Pinkas, Jiří; Gyepes, R.; Kubišta, Jiří; Horá�ek, Michal; Lama�, Martin
Ro�. 696, 11-12 (2011), s. 2364-2372 ISSN 0022-328X R&D Projects: GA ČR GPP207/10/P200; GA MŠk(CZ) LC06070 Institutional research plan: CEZ:AV0Z40400503 Keywords : metallocene * group 4 elements * nitrile Subject RIV: CF - Physical ; Theoretical Chemistry Impact factor: 2.384, year: 2011
Censorship: Pressure Groups and Boycotts
Silverman, Fred
Records ABC President Fred Silverman's 1977 speech to the American Association of Advertising Agencies emphasizing the potential harm inherent in pressure groups and boycott's increasing power over broadcasters and advertisers. Available from: Vital Speeches of the Day, City News Publishing Company, Box 606, Southold, New York 11971. (MH)
On framed simple Lie groups
MINAMI, Haruo
For a compact simple Lie group $G$, we show that the element $[G, \\mathcal{L}] \\in \\pi^S_*(S^0)$ represented by the pair $(G, \\mathcal{L})$ is zero, where $\\mathcal{L}$ denotes the left invariant framing of $G$. The proof relies on the method of E. Ossa [Topology, 21 (1982), 315–323].
Working group report: Collider Physics
11KEK, Tsukuba, Japan. 12Cornell University ... This is summary of the activities of the working group on collider physics in the IXth ... In view of the requirements of the hour and the available skills and interests, it was decided to .... The actual computation, which is long and somewhat tedious, is currently under way and is ...
An Alternative to Ability Grouping
Tomlinson, Carol Ann
Ability grouping is a common approach to dealing with student variance in learning. In general, findings suggest that such an approach to dealing with student differences is disadvantageous to students who struggle in school and advantageous to advanced learners. The concept of differentiation suggests that there is another alternative to…
String Topology for Lie Groups
A. Hepworth, Richard
In 1999 Chas and Sullivan showed that the homology of the free loop space of an oriented manifold admits the structure of a Batalin-Vilkovisky algebra. In this paper we give a direct description of this Batalin-Vilkovisky algebra in the case that the manifold is a compact Lie group G. Our answer ...
Environmental groups in monopolistic markets
Heijnen, P.; Schoonbeek, L.
We examine a market in which a monopolistic firm supplies a good. The production of the good causes damage to the environment. Consumers are heterogeneous with respect to their disutility of the environmental damage. An environmental group can enter the market and set up a campaign in order to
Heijnen, Pim; Schoonbeek, Lambert
EDF group. Annual report 2001
This document is the English version of the 2001 annual report of Electricite de France (EdF) Group, the French electric utility. It comprises 4 parts: introduction (statement of the chairman and chief executive officer, corporate governance, group key figures, sustainable growth indicators - parent company, energy for a sustainable future, EdF group worldwide); dynamics and balanced growth (financial results, EdF's strategy in building a competitive global group: consolidating the European network, moving forward in energy-related services, responding to increasing energy demand in emerging countries); sustainable solutions for all (empowering the customer: competitive solutions for industrial customers, anticipating the needs of residential customers and SMEs, environmental solutions to enhance urban life, upgrading the network and providing access to energy; a sound, sustainable and secure energy mix: a highly competitive nuclear fleet, the vital resource of fossil-fuelled plants, a proactive approach to renewable energies); a global commitment to corporate social responsibility (human resources and partnerships). (J.S.)
Entry Facilitation by Environmental Groups
van der Made, Allard; Schoonbeek, Lambert
We consider a model of vertical product differentiation where consumers care about the environmental damage their consumption causes. An environmental group is capable of increasing consumers' environmental concern via a costly campaign. We show that the prospect of such a campaign can induce entry
Differential equations and finite groups
Put, Marius van der; Ulmer, Felix
The classical solution of the Riemann-Hilbert problem attaches to a given representation of the fundamental group a regular singular linear differential equation. We present a method to compute this differential equation in the case of a representation with finite image. The approach uses Galois
Renormalization group and Mayer expansions
Mack, G.
Mayer expansions promise to become a powerful tool in exact renormalization group calculations. Iterated Mayer expansions were sucessfully used in the rigorous analysis of 3-dimensional U(1) lattice gauge theory by Goepfert and the author, and it is hoped that they will also be useful in the 2-dimensional nonlinear sigma-model, and elsewhere. (orig.)
Taxation, stateness and armed groups
Hoffmann, Kasper; Vlassenroot, Koen; Marchais, Gauthier
of authority and practices of rule that originate in the colonial era. In particular, the article shows that by appealing to both local customary and national forms of political community and citizenship, armed groups are able to assume public authority to tax civilians. However, their public authority may...
The Structure of Group Cohesion.
Cota, Albert A.; And Others
Reviews the literature on unidimensional and multidimensional models of cohesion and describes cohesion as a multidimensional construct with primary and secondary dimensions. Found that primary dimensions described the cohesiveness of all or most types of groups, whereas secondary dimensions only described the cohesiveness of specific types of…
Biset functors for finite groups
Bouc, Serge
This volume exposes the theory of biset functors for finite groups, which yields a unified framework for operations of induction, restriction, inflation, deflation and transport by isomorphism. The first part recalls the basics on biset categories and biset functors. The second part is concerned with the Burnside functor and the functor of complex characters, together with semisimplicity issues and an overview of Green biset functors. The last part is devoted to biset functors defined over p-groups for a fixed prime number p. This includes the structure of the functor of rational representations and rational p-biset functors. The last two chapters expose three applications of biset functors to long-standing open problems, in particular the structure of the Dade group of an arbitrary finite p-group.This book is intended both to students and researchers, as it gives a didactic exposition of the basics and a rewriting of advanced results in the area, with some new ideas and proofs.
EPRI perspective of owner groups
Dau, G.J.
A survey was conducted to evaluate the utilities' perspective of the success of efforts of the Electric Power Research Institute (EPRI) and owner groups for the development and implementation of advanced technology. The source of the advanced technology was the result of a joint effort between EPRI and two utility owner groups. The former performs generic research and development (R and D) on behalf of its members drawn from the US electric utility industry. Owner groups are short-term associations of a group of utilities, all confronted with the same problem. Management implications for both EPRI and the utilities are drawn from the results and are summarized. They include recognition that EPRI's reputation for objectivity is an important asset that must be protected. Other implications include assessments of the merits and options for building better utility/NRC relations and strengthening the utility/EPRI relationship. Addressing the implications does not hinge on any major new development. Rather, it depends on EPRI and utility management making the commitment to support efforts to increase the intensity of communication on the baseline program. The resources needed are mainly provision of adequate staff time and attendant travel expenses
Social identity has been shown to successfully enhance cooperation and effort in cooperation and coordination games. Little is known about the causal effect of social identity on the propensity to engage in group conflict. In this paper we explore theoretically and experimentally whether social
Symmetric group representations and Z
Adve, Anshul; Yong, Alexander
We discuss implications of the following statement about the representation theory of symmetric groups: every integer appears infinitely often as an irreducible character evaluation, and every nonnegative integer appears infinitely often as a Littlewood-Richardson coefficient and as a Kronecker coefficient.
Renormalization group and asymptotic freedom
Morris, J.R.
Several field theoretic models are presented which allow exact expressions of the renormalization constants and renormalized coupling constants. These models are analyzed as to their content of asymptotic free field behavior through the use of the Callan-Symanzik renormalization group equation. It is found that none of these models possesses asymptotic freedom in four dimensions
Rescheduling the special interest group.
Peace, Helen
The committee members of the RCN Social Interest Group for Nurses Working Within Day Hospitals/Day Care for Older People would like to apologise to the large number of people who were interested in attending our conference, which unfortunately had to be postponed.
Communicating to heterogeneous target groups
Pedersen, Karsten
very often have to communicate to rather heterogeneous target groups that have little more in common than a certain geographical habitat. That goes against most schoolbook teaching in the field of communication, but is none the less the terms with which that kind of communication has to live...
Group Work with Abusive Parents.
Kruger, Lois; And Others
Social work students conclude from an experience that parents can consider alternative means of disciplining children when they participate in a parent group that is comfortable and when attendance is promoted by provision of tangible services. Parents achieved increased sense of self-worth and learned appropriate ways of expressing anger. (Author)
Legislative vulnerability of minority groups.
Paula, Carlos Eduardo Artiaga; Silva, Ana Paula da; Bittar, Cléria Maria Lôbo
Minorities are in an inferior position in society and therefore vulnerable in many aspects. This study analyzes legislative vulnerability and aims to categorize as "weak" or "strong" the protection conferred by law to the following minorities: elderly, disabled, LGBT, Indians, women, children/ adolescents and black people. In order to do so, it was developed a documental research in 30 federal laws in which legal provisions were searched to protect minorities. Next, the articles were organized in the following categories: civil, criminal, administrative, labor and procedural, to be analyzed afterwards. Legal protection was considered "strong" when there were legal provisions that observed the five categories and "weak" when it did not meet this criterion. It was noted that six groups have "strong" legislative protection, which elides the assertion that minorities are outside the law. The exception is the LGBT group, whose legislative protection is weak. In addition, consecrating rights through laws strengthens the institutional channels for minorities to demand their rights. Finally, it was observed that the legislative protection granted tominorities is not homogeneous but rather discriminatory, and there is an interference by the majority group in the rights regulation of vulnerable groups.
Mayer expansions promise to become a powerful tool in exact renormalization group calculations. Iterated Mayer expansions were sucessfully used in the rigorous analysis of 3-dimensional U (1) lattice gauge theory by Gopfert and the author, and it is hoped that they will also be useful in the 2-dimensional nonlinear σ-model, and elsewhere
Renormalization group in quantum mechanics
Polony, J.
The running coupling constants are introduced in quantum mechanics and their evolution is described with the help of the renormalization group equation. The harmonic oscillator and the propagation on curved spaces are presented as examples. The Hamiltonian and the Lagrangian scaling relations are obtained. These evolution equations are used to construct low energy effective models. Copyright copyright 1996 Academic Press, Inc
Working group report: Neutrino physics
olation. PACS No. 14.6.q. 1. Introduction. It was decided to cover a myriad of topics for discussion and work in the neu- trino physics working group, rather than restrict ourselves to any one focal theme. 269 ..... [8] Super-Kamiokande Collaboration: K Abe et al, Phys. Rev. Lett. 97, 171801 (2006), hep-ex/0607059.
Facilitating Collaboration in Online Groups
Geralyn E Stephens
Full Text Available Demonstrating the ability to collaborate effectively is essential for students moving into 21st century workplaces. Employers are expecting new hires to already possess group-work skills and will seek evidence of their ability to cooperate, collaborate, and complete projects with colleagues, including remotely or at a distance. Instructional activities and assignments that provide students with a variety of ways to engage each other have a direct and immediate effect on their academic performance. This paper shares the Facilitating Collaboration in Online Groups (FCOG instructional planning strategy. The strategy is designed for faculty use and familiarizes students with the process and technology necessary to collaborate effectively in online classroom groups. The strategy utilizes proven teaching techniques to maximize student-student and student-content relationships. Each of the four (4 sequential phases in the FCOG instructional planning strategy are discussed: 1 Creating Groups, 2 Establishing Expectations, 3 Communication Tools, and 4 Assignments and Activities. The discussion also contains implementation suggestions as well as examples of instructional assignments and activities that provide students with a variety of ways to collaborate to reach the learning outcomes.
Spent Fuel Working Group Report
O'Toole, T.
The Department of Energy is storing large amounts of spent nuclear fuel and other reactor irradiated nuclear materials (herein referred to as RINM). In the past, the Department reprocessed RINM to recover plutonium, tritium, and other isotopes. However, the Department has ceased or is phasing out reprocessing operations. As a consequence, Department facilities designed, constructed, and operated to store RINM for relatively short periods of time now store RINM, pending decisions on the disposition of these materials. The extended use of the facilities, combined with their known degradation and that of their stored materials, has led to uncertainties about safety. To ensure that extended storage is safe (i.e., that protection exists for workers, the public, and the environment), the conditions of these storage facilities had to be assessed. The compelling need for such an assessment led to the Secretary's initiative on spent fuel, which is the subject of this report. This report comprises three volumes: Volume I; Summary Results of the Spent Fuel Working Group Evaluation; Volume II, Working Group Assessment Team Reports and Protocol; Volume III; Operating Contractor Site Team Reports. This volume presents the overall results of the Working Group's Evaluation. The group assessed 66 facilities spread across 11 sites. It identified: (1) facilities that should be considered for priority attention. (2) programmatic issues to be considered in decision making about interim storage plans and (3) specific vulnerabilities for some of these facilities
Fusion Rings for Quantum Groups
Andersen, Henning Haahr; Stroppel, Catharina
We study the fusion rings of tilting modules for a quantum group at a root of unity modulo the tensor ideal of negligible tilting modules. We identify them in type A with the combinatorial rings from [12] and give a similar description of the sp2n-fusion ring in terms of noncommutative symmetric...
Learning Opportunities for Group Learning
Gil, Alfonso J.; Mataveli, Mara
Purpose: This paper aims to analyse the impact of organizational learning culture and learning facilitators in group learning. Design/methodology/approach: This study was conducted using a survey method applied to a statistically representative sample of employees from Rioja wine companies in Spain. A model was tested using a structural equation…
The Joy of Reading Groups
Southwood, Sue
Reading groups or book clubs have become increasingly popular in recent years, with many libraries, bookshops and workplaces hosting meetings, while a wealth of support is available online. They provide a chance to read, share opinions, chat and have fun--each one will be unique in how it works. Discussing books can help to reinforce, change or…
Spontaneous flocking in human groups.
Belz, Michael; Pyritz, Lennart W; Boos, Margarete
Flocking behaviour, as a type of self-organised collective behaviour, is described as the spatial formation of groups without global control and explicit inter-individual recruitment signals. It can be observed in many animals, such as bird flocks, shoals or herds of ungulates. Spatial attraction between humans as the central component of flocking behaviour has been simulated in a number of seminal models but it has not been detected experimentally in human groups so far. The two other sub-processes of this self-organised collective movement - collision avoidance and alignment - are excluded or held constant respectively in this study. We created a computer-based, multi-agent game where human players, represented as black dots, moved on a virtual playground. The participants were deprived of social cues about each other and could neither communicate verbally nor nonverbally. They played two games: (1) Single Game, where other players were invisible, and (2) Joint Game, where each player could see players' positions in a local radius around himself/herself. We found that individuals approached their neighbours spontaneously if their positions were visible, leading to less spatial dispersion of the whole group compared to moving alone. We conclude that human groups show the basic component of flocking behaviour without being explicitly instructed or rewarded to do so. Copyright © 2012 Elsevier B.V. All rights reserved.
One Stop Group Law Shop?
Werlauff, Erik
The article, which is the editorial for February 2012 i European Company Law, argues that the EU must introduce a directive offering the possibility to a European cross-border group of being treated, for company law reasons, in any EU country according to the same provisions which are in force in...
Social Maturation: Work Group Proceedings.
Resnick, Michael D.; And Others
Each of the seven factors that affect adolescent social development is presented together with a description of potentially important research, service, and policy initiatives within each topic area. The factors are self-esteem, peer group, parenting, family, services, enforced dependency, and positive sexual socialization. (CT)
Group analysis and renormgroup symmetries
Kovalev, V.F.; Pustovalov, V.V.; Shirkov, D.V.
An original regular approach to constructing special type symmetries for boundary-value problems, namely renormgroup symmetries, is presented. Different methods of calculating these symmetries based on modern group analysis are described. An application of the approach to boundary value problems is demonstrated with the help of a simple mathematical model. 35 refs
Focus groups in organizational research
L. Kamfer
Full Text Available Focus groups are commonly used in marketing research. In this article an application of the focus group technique within an organizational context is described. Nine focus groups were conducted during the planning stage of a survey intended to establish employee perceptions of advancement policies and practices in a major South African manufacturing company. Fourteen themes emerged from a content analysis of the discussions. Two of these reflected aspects requiring commitment decisions from management toward the survey. The others indicated areas of concern which should be included in the survey. In this way, the focus groups contributed useful information for the subsequent sample survey. Opsomming Fokusgroepe word algemeen in bemarkingsnavorsing aangewend. In hierdie studie word 'n toepassingvan die fokusgroeptegniek in die konteks van 'n opname binne 'n organisasie beskryf. Nege fokusgroepbesprekings is gevoer tydens die beplanningstadium van 'n opname wat binne 'n Suid-Afrikaanse vervaardigingsonderneming gedoen is. Die doel van die opname was om die persepsies van werknemers teenoor die bestaande personeel- en bestuursontwikkelingsbeleid en -praktyke van die maatskappy te bepaal. Veertien temas is deur middel van 'n inhoudontleding gei'dentifiseer. Twee hiervan het aspekte aangedui waaroor bestuur beginselbesluite t.o.v. die opname sou moes neem. Die ander het probleemareas aangedui wat by die ondersoek selfingesluit behoort te word. Sodoende het die fokusgroepe inligting verskafwat vir die latere vraelysopname belangrik was.
Finite groups and quantum physics
Kornyak, V. V.
Concepts of quantum theory are considered from the constructive "finite� point of view. The introduction of a continuum or other actual infinities in physics destroys constructiveness without any need for them in describing empirical observations. It is shown that quantum behavior is a natural consequence of symmetries of dynamical systems. The underlying reason is that it is impossible in principle to trace the identity of indistinguishable objects in their evolution—only information about invariant statements and values concerning such objects is available. General mathematical arguments indicate that any quantum dynamics is reducible to a sequence of permutations. Quantum phenomena, such as interference, arise in invariant subspaces of permutation representations of the symmetry group of a dynamical system. Observable quantities can be expressed in terms of permutation invariants. It is shown that nonconstructive number systems, such as complex numbers, are not needed for describing quantum phenomena. It is sufficient to employ cyclotomic numbers—a minimal extension of natural numbers that is appropriate for quantum mechanics. The use of finite groups in physics, which underlies the present approach, has an additional motivation. Numerous experiments and observations in the particle physics suggest the importance of finite groups of relatively small orders in some fundamental processes. The origin of these groups is unclear within the currently accepted theories—in particular, within the Standard Model.
Karyotaxonomy of Myosotis alpestris group
Štěpánková, Jitka
Ro�. 78, - (2006), s. 345-352 ISSN 0032-7786 R&D Projects: GA AV ČR IAA6005312 Institutional research plan: CEZ:AV0Z60050516 Keywords : karyogeography * Myosotis alpestris group * distribution area Subject RIV: EF - Botanics Impact factor: 2.119, year: 2006
Invasive Group A Streptococcal Infection
Centers for Disease Control (CDC) Podcasts
In this podcast, CDC's Dr. Chris Van Beneden discusses the dangers of group A strep infections. Created: 6/13/2011 by National Center for Emerging Zoonotic and Infectious Diseases (NCEZID). Date Released: 6/13/2011.
The central theme for the third meeting of the CEC analogue working group was ''How can analogue data be used for performance assessments, both in support of the results and for presentation to the public''. This report puts together the most recent achievements in this field, together with a review of on-going natural analogue programmes
Alkyloxycarbonyl group migration in furanosides
Dvořáková, Marcela; Přibylová, Marie; Pohl, Radek; Migaud, M. E.; Vaněk, Tomáš
Ro�. 68, �. 33 (2012), s. 6701-6711 ISSN 0040-4020 R&D Projects: GA MŠk(CZ) LH11048 Institutional research plan: CEZ:AV0Z50380511; CEZ:AV0Z40550506 Keywords : Alkyloxycarbonyl group * Carbonate * Desilylation Subject RIV: DK - Soil Contamination ; De-contamination incl. Pesticides Impact factor: 2.803, year: 2012
Team reasoning and group identification
Hindriks, Frank
The team reasoning approach explains cooperation in terms of group identification, which in turn is explicated in terms of agency transformation and payoff transformation. Empirical research in social psychology is consistent with the significance of agency and payoff transformation. However, it
TROPIX plasma interactions group report
Herr, Joel L.; Chock, Ricaurte
The purpose is to summarize the spacecraft charging analysis conducted by the plasma interactions group during the period from April 1993 to July 1993, on the proposed TROPIX spacecraft, and to make design recommendations which will limit the detrimental effects introduced by spacecraft charging. The recommendations were presented to the TROPIX study team at a Technical Review meeting held on 15 July 1993.
Distributed Leadership in Online Groups
Gressick, Julia; Derry, Sharon J.
We conducted research within a program serving future mathematics and science teachers. Groups of teachers worked primarily online in an asynchronous discussion environment on a 6-week task in which they applied learning-science ideas acquired from an educational psychology course to design interdisciplinary instructional units. We employed an…
, the management had, among many initiatives, decided to offshore and outsource a major chunk of its production to Flextronics. In this pursuit of rapid cost-cutting sourcing advantages, the LEGO Group planned to license out as much as 80 per cent of its production besides closing down major parts...
The Effects of Music and Group Stage on Group Leader and Member Behavior in Psychoeducational Groups for Children of Divorce
Cercone, Kristin; DeLucia-Waack, Janice
This study examined the effects of music and group stage on group process and group leader and member behavior within 8-week psychoeducational groups for children of divorce. Audiotapes of group sessions were rated using the Interactional Process Analysis and the Group Sessions Ratings Scale. Both treatment groups were very similar in terms of…
The FORATOM Transport Working Group
Lehmann, P.
Based in Brussels, the European atomic forum FORATOM is the trade association of the European nuclear industry which was established in the early 1960s to promote nuclear power and to facilitate relations with the European institutions. One of the main mechanisms which FORATOM uses, in its dealings with the European Commission and other international organisations, is the involvement of several working groups bringing together groups of experts drawn from the industrial companies in order to identify the issues and to develop the widest possible common views on which the industry must express its representative, substantial and deliverable opinion. The Transport Working Group (TWG) has the objective of dealing with transport of radioactive material, especially nuclear materials. The TWG usually meets three times a year in Brussels or another selected location. It has strong links with the European Commission which are evidenced by the fact that it officially represents the European nuclear industry, with the status of observer, at the meetings of the Standing Working Group on Safe Transport of Radioactive Material which was set up in 1982, upon a request of the European Parliament, to advise the European Commission in the field of safe transport of radioactive materials. The Standing Working Group (SWG) assists the European Union's Member States in the revision process of IAEA recommendations and helps a correct and harmonious application of these recommendations within the European Union. In previous years, the Standing Working Group has proposed over 40 different studies, financed by the European Commission, on important transport issues. The FORATOM TWG encourages its member organisations to participate in studies proposed by the Commission and has been cooperating for many years with the Commission in the field of many studies aimed to improve the application of transport regulations. The need to maintain the safe and reliable operation of plants that generate
The EDF group is an integrated energy company with a presence in a wide range of electricity-related businesses: generation, transmission, distribution, supply and energy trading. It is France's leading electricity operator and has a strong position in the three other main European markets (Germany, the United Kingdom and Italy), making it one of Europe's leading electrical players as well as a recognized player in the gas industry. With worldwide installed power capacity totaling 136.3 GW as of December 31, 2009 (134.0 GW in Europe) and global energy generation of 618.5 TWh, it has the largest generating capacity of all the major European energy corporations with the lowest level of CO 2 emissions due to the significant proportion of nuclear and hydroelectric power in its generation mix. The EDF group supplies gas, electricity, and associated services to more than 37.9 million customer accounts worldwide (including approximately 27.7 million in France). The EDF group's businesses reflect its adoption of a model aimed at finding the best balance between French and international activities, competitive and regulated operations and based on an upstream-downstream integration. In 2009, the Group's consolidated revenues were euros 66.3 billion, the net income (Group share) was euros 3.9 billion, and earnings before interest, tax, depreciation and amortization was euros 17.5 billion. This document is EDF Group's Reference Document and Annual Financial Report for the year 2009. It contains information about: the Group activities, risk factors, Business, Organizational structure, Property plant and equipment, Operating and financial review, Capital resources and cash flows, Research and Development, Patents and Licenses, Information on trends, Financial outlook, Administrative, management, and supervisory bodies and senior management, Compensation and benefits, Functioning of the administration and management bodies, Employees/Human resources
Quantum groups: Geometry and applications
Chu, C.S.
The main theme of this thesis is a study of the geometry of quantum groups and quantum spaces, with the hope that they will be useful for the construction of quantum field theory with quantum group symmetry. The main tool used is the Faddeev-Reshetikhin-Takhtajan description of quantum groups. A few content-rich examples of quantum complex spaces with quantum group symmetry are treated in details. In chapter 1, the author reviews some of the basic concepts and notions for Hopf algebras and other background materials. In chapter 2, he studies the vector fields of quantum groups. A compact realization of these vector fields as pseudodifferential operators acting on the linear quantum spaces is given. In chapter 3, he describes the quantum sphere as a complex quantum manifold by means of a quantum stereographic projection. A covariant calculus is introduced. An interesting property of this calculus is the existence of a one-form realization of the exterior differential operator. The concept of a braided comodule is introduced and a braided algebra of quantum spheres is constructed. In chapter 4, the author considers the more general higher dimensional quantum complex projective spaces and the quantum Grassman manifolds. Differential calculus, integration and braiding can be introduced as in the one dimensional case. Finally, in chapter 5, he studies the framework of quantum principal bundle and construct the q-deformed Dirac monopole as a quantum principal bundle with a quantum sphere as the base and a U(1) with non-commutative calculus as the fiber. The first Chern class can be introduced and integrated to give the monopole charge
Campbell, J. M. [Fermi National Accelerator Lab. (FNAL), Batavia, IL (United States)
This is the summary report of the energy frontier QCD working group prepared for Snowmass 2013. We review the status of tools, both theoretical and experimental, for understanding the strong interactions at colliders. We attempt to prioritize important directions that future developments should take. Most of the efforts of the QCD working group concentrate on proton-proton colliders, at 14 TeV as planned for the next run of the LHC, and for 33 and 100 TeV, possible energies of the colliders that will be necessary to carry on the physics program started at 14 TeV. We also examine QCD predictions and measurements at lepton-lepton and lepton-hadron colliders, and in particular their ability to improve our knowledge of strong coupling constant and parton distribution functions.
Random walks on reductive groups
Benoist, Yves
The classical theory of Random Walks describes the asymptotic behavior of sums of independent identically distributed random real variables. This book explains the generalization of this theory to products of independent identically distributed random matrices with real coefficients. Under the assumption that the action of the matrices is semisimple – or, equivalently, that the Zariski closure of the group generated by these matrices is reductive - and under suitable moment assumptions, it is shown that the norm of the products of such random matrices satisfies a number of classical probabilistic laws. This book includes necessary background on the theory of reductive algebraic groups, probability theory and operator theory, thereby providing a modern introduction to the topic.
Danish Colorectal Cancer Group Database
Ingeholm, Peter; Gögenur, Ismail; Iversen, Lene H
AIM OF DATABASE: The aim of the database, which has existed for registration of all patients with colorectal cancer in Denmark since 2001, is to improve the prognosis for this patient group. STUDY POPULATION: All Danish patients with newly diagnosed colorectal cancer who are either diagnosed......, and other pathological risk factors. DESCRIPTIVE DATA: The database has had >95% completeness in including patients with colorectal adenocarcinoma with >54,000 patients registered so far with approximately one-third rectal cancers and two-third colon cancers and an overrepresentation of men among rectal...... diagnosis, surgical interventions, and short-term outcomes. The database does not have high-resolution oncological data and does not register recurrences after primary surgery. The Danish Colorectal Cancer Group provides high-quality data and has been documenting an increase in short- and long...
Data selector group sequencer interface
Zizka, G.; Turko, B.
A CAMAC-based module for high rate data selection and transfer to Tracor Northern TN-1700 multichannel analysis system is described. The module can select any group of 4096 consecutive addresses of events, in the range of 24 bits. This module solves the problem of connecting a number of time digitizing systems to the memory of a multichannel analyzer. Continuous processing rate up to 200,000 events per second along with the live display make the testing of the above systems very efficient and relatively inexpensive. The module also can be programmed for storing the preset group of addresses into more than one section of the memory. The events are analyzed in each section of the memory during the preset time. Multiple spectra can thus be taken automatically in a sequence
Carboxyl group reactivity in actin
Elzinga, M.
While earlier work showed that the carboxyl groups of proteins could be quantitatively coupled to amino groups at pH 4.75 in the presence of EDC and a denaturing agent, the work presented here indicates that under milder conditions the modification of sidechain carboxyls is limited and somewhat specific. Most of the incorporated glycine ethyl ester (GEE) is apparently bound to five carboxyls. The total GEE incorporated was 3 to 4 moles/mole of protein as measured by an increase in Gly upon acid hydrolysis and amino acid analysis, as well as total radioactivity. 3.55 residues were found in peptides, 2.75 bound to residues 1 to 4, and 0.8 bound to Gly-100. 9 refs., 2 figs., 2 tabs.
Group B streptococcal neonatal parotitis.
Dias Costa, Filipa; Ramos Andrade, Daniel; Cunha, Filipa Inês; Fernandes, Agostinho
Acute neonatal parotitis (ANP) is a rare condition, characterised by parotid swelling and other local inflammatory signs. The most common pathogen is Staphylococcus aureus, but other organisms can be implicated. We describe the case of a 13-day-old term newborn, previously healthy, with late-onset group B Streptococcus (GBS) bacteraemia with ANP, who presented with irritability, reduced feeding and tender swelling of the right parotid. Laboratory evaluation showed neutrophilia, elevated C reactive protein and procalcitonin, with normal serum amylase concentration. Ultrasound findings were suggestive of acute parotitis. Empiric antibiotic therapy was immediately started and adjusted when culture results became available. The newborn was discharged after 10 days, with clinical improvement within the first 72 h. Although S. aureus is the most common pathogen implicated in ANP, GBS should be included in the differential diagnosis. 2015 BMJ Publishing Group Ltd.
Radiation sources working group summary
Fazio, M.V.
The Radiation Sources Working Group addressed advanced concepts for the generation of RF energy to power advanced accelerators. The focus of the working group included advanced sources and technologies above 17 GHz. The topics discussed included RF sources above 17 GHz, pulse compression techniques to achieve extreme peak power levels, components technology, technology limitations and physical limits, and other advanced concepts. RF sources included gyroklystrons, magnicons, free-electron masers, two beam accelerators, and gyroharmonic and traveling wave devices. Technology components discussed included advanced cathodes and electron guns, high temperature superconductors for producing magnetic fields, RF breakdown physics and mitigation, and phenomena that impact source design such as fatigue in resonant structures due to RF heating. New approaches for RF source diagnostics located internal to the source were discussed for detecting plasma and beam phenomena existing in high energy density electrodynamic systems in order to help elucidate the reasons for performance limitations
Summary muon detection working group
Stanton, N.R.
The areas of concentration of the Muon Working Group reflected its composition: about half of the group was interested primarily is extending the capability of existing general purpose colliders (CDF, D0). Smaller numbers of people were interested in B physics with general purpose colliders at the SSC and LHC, with SSC fixed target experiments, and with dedicated forward colliders. Good muon tagging, and possibly also muon triggering, is essential for studying CP violation in B i →J/ψX, J/ψ→μ + μ - ; as a flavor tag, with the semimuonic decay B→μ + X or bar B→μ - X tagging the flavor of the partner; for studying the physics of the semimuonic B decays themselves; and for looking for really rare decays like B→μ + μ -
Dialogic feedforward in group coaching
Alrø, Helle; Dahl, Poul Nørgård
The overall purpose of the article is to describe a joint learning process where both practicable and theoretically anchored knowledge are in the foreground. The empirical data derives from an EU project. In focus is a group of course leaders and their experiences of carrying out a training...... programme targeted for a group of individuals with a weak position on the labour market. The author brings out what happens when individuals try to understand perspectives from one another. The results demonstrate the knowledge that is developed when members of a project team are included in the entire...... research process, from the definition of problems to the analysis, presentation of results and suggestions of change. Further the outcome illustrates how an interactive research approach can be conducted in close co-operation with those concerned. Active participation, a structured learning process...
Danish Breast Cancer Cooperative Group
Christiansen, Peer; Ejlertsen, Bent; Jensen, Maj-Britt
AIM OF DATABASE: Danish Breast Cancer Cooperative Group (DBCG), with an associated database, was introduced as a nationwide multidisciplinary group in 1977 with the ultimate aim to improve the prognosis in breast cancer. Since then, the database has registered women diagnosed with primary invasive...... nonmetastatic breast cancer. The data reported from the departments to the database included details of the characteristics of the primary tumor, of surgery, radiotherapy, and systemic therapies, and of follow-up reported on specific forms from the departments in question. DESCRIPTIVE DATA: From 1977 through...... 2014, ~110,000 patients are registered in the nationwide, clinical database. The completeness has gradually improved to more than 95%. DBCG has continuously prepared evidence-based guidelines on diagnosis and treatment of breast cancer and conducted quality control studies to ascertain the degree...
Asymptotical representation of discrete groups
Mishchenko, A.S.; Mohammad, N.
If one has a unitary representation �: π → U(H) of the fundamental group π 1 (M) of the manifold M then one can do may useful things: 1. To construct a natural vector bundle over M; 2. To construct the cohomology groups with respect to the local system of coefficients; 3. To construct the signature of manifold M with respect to the local system of coefficients; and others. In particular, one can write the Hirzebruch formula which compares the signature with the characteristic classes of the manifold M, further based on this, find the homotopy invariant characteristic classes (i.e. the Novikov conjecture). Taking into account that the family of known representations is not sufficiently large, it would be interesting to extend this family to some larger one. Using the ideas of A.Connes, M.Gromov and H.Moscovici a proper notion of asymptotical representation is defined. (author). 7 refs
HUG - the Hydrogen Utility Group
Tinkler, M.
The Hydrogen Utility Group (HUG) was formally established in October 2005 by a group of leading electric utilities with a common interest in sharing hydrogen experiences and lessons learned. HUG's Mission Statement is: 'To accelerate utility integration of promising hydrogen energy related business applications through the coordinated efforts and actions of its members in collaboration with key stakeholders, including government agencies and utility support organizations.' In February 2006, HUG members presented a briefing to the US Senate Hydrogen and Fuel Cell Caucus in Washington, DC, outlining the significant role that the power industry should play in an emerging hydrogen economy. This presentation provides an overview of that briefing, summarizing the HUG's ongoing interests and activities
Working group 8: inspection tools
Billey, Deb; Kania, Richard; Nickle, Randy; Wang, Rick; Westwood, Stephen
This eighth working group of the Banff 2011 conference discussed the inspection tools and techniques used by the upstream and downstream pipeline industry to evaluate pipeline integrity. Special attention was given to the challenges and successes related to in-line inspection (ILI) technology. The background of current dent assessment criteria in B31.8 was presented, including dent definition for ILI vendors and pipeline operators as well as codes (CSA Z662 and B31.8). The workshop described examples of dents and assessments showing inconsistency with current criteria as set out by TCPL and Marathon. This workshop produced a single, industry-wide definition of the dent. It was found that the strain based criteria were more practical because depth based is conservative and may miss shallow occurrences. The creation of joint industry group was proposed to develop strain based criteria for incorporation into CSAZ662 and B31.8.
While earlier work showed that the carboxyl groups of proteins could be quantitatively coupled to amino groups at pH 4.75 in the presence of EDC and a denaturing agent, the work presented here indicates that under milder conditions the modification of sidechain carboxyls is limited and somewhat specific. Most of the incorporated glycine ethyl ester (GEE) is apparently bound to five carboxyls. The total GEE incorporated was 3 to 4 moles/mole of protein as measured by an increase in Gly upon acid hydrolysis and amino acid analysis, as well as total radioactivity. 3.55 residues were found in peptides, 2.75 bound to residues 1 to 4, and 0.8 bound to Gly-100. 9 refs., 2 figs., 2 tabs
Rotarex Group: diversified ranges; Rotarex Group: une offre diversifiee
The Rotarex Group, located at Lintgen (Luxembourg), is a multinational company chaired by Jean-Claude Schmitz. With a workforce of some 1,000 people in the world, this group is specialized in valves, accessories and pressure reducers for a wide range of gas applications: from LP Gas to special gas (VHP, cryogenics,...) as well for medical and industrial gas, and also for CNG. The group is present at the San Diego exhibition, mainly though its affiliate Rotarex North America, headed by Bert Pistor, vice-president of Ceodeux Inc. Rotarex North America is well known on the US market for its OPD device for propane cylinders. But the company will show also a new generation of valves for cylinders. The group will represent its different affiliates in the world (South America, Africa, Europe, Far East, Australia,...), as its expansion is widening: a subsidiary was launched last Spring in Morocco, a new plant is built in the Czech Republic. In Europe, Ceodeux LPG TEC is one of the main European manufacturers of valves and equipments for LPG and refrigerating gas. Having already reinforced its presence on the French and Italian markets, Ceodeux LPG TEC is expanding through technique on its traditional markets as well as on new markets. In the field of automotive LPG, the company offers series of equipments linked to the LPG tank: single devices or multi-valves. These are equipped with a safety relief valve and can be completed by a thermal safety system or a second safety relief valve. For France, all these systems are type approved according to UN Regulation 67-01. France is in implementing, one year ahead of other European countries, this new Regulation for new LP gas vehicles as well for vehicles called back for retrofitting with new safety valves. Some 100,000 vehicles will receive a 27 bar safety valve or a new multi-valve fitted with this safety valve. This retro-fitting operation will be paid for 50% by vehicle's owners and 50 % by French Authorities and LP Gas
Probability Measures on Groups IX
The latest in this series of Oberwolfach conferences focussed on the interplay between structural probability theory and various other areas of pure and applied mathematics such as Tauberian theory, infinite-dimensional rotation groups, central limit theorems, harmonizable processes, and spherical data. Thus it was attended by mathematicians whose research interests range from number theory to quantum physics in conjunction with structural properties of probabilistic phenomena. This volume contains 5 survey articles submitted on special invitation and 25 original research papers.
Advisory group on ionising radiation
Harrison, J.R.
The Advisory Group on Ionising Radiation has a busy and challenging work programme. Its reports will be published in the Documents of the NRPB series. These may advise further research or could form the basis of formal NRPB advice. Covering the full spectrum of radiation issues at work, in public health and clinical medicine, and the environment, it should enhance the radiation advice available to NRPB. (author)
Report for Working Group 2
Bjerregaard Jensen, Lotte; Thompson, Mary Kathryn
The theme for the second working group was design education in civil and environmental engineering. Issues discussed during this meeting included the current state of the art of civil design education, the importance of civil design education, tools and techniques that can be used to build design...... competencies, the importance of balancing hard and soft skills, and the role that culture and context play and will continue to play in civil design in the future....
Historic Radio Astronomy Working Group
This special issue of Astronomische Nachrichten contains the proceedings of a session of the Historic Radio Astronomy Working Group of the International Astronomical Union that took place during the 26th General Assembly of the IAU in Prague on 17th August 2006. In addition to the talks presented in Prague some contributions were solicited to give a more complete overview of `The Early History of European Radio Astronomy'.
Renormalization group and critical phenomena
Ji Qing
The basic clue and the main steps of renormalization group method used for the description of critical phenomena is introduced. It is pointed out that this method really reflects the most important physical features of critical phenomena, i.e. self-similarity, and set up a practical solving method from it. This way of setting up a theory according to the features of the physical system is really a good lesson for today's physicists. (author)
Group Recommendation in Social Networks
interests 8,822,921 DOUBAN Largest Chinese community providing user review and recommendation services for movies, books, and music . It also...doubles up as the Chinese language book, movie and music database. 46,850,000 FACEBOOK General 750,000,000+ FLIXSTER Movies 32,000,000 FOURSQUARE...groups, events and community pages) • More than 30 billion pieces of content (web links, news stories, blog posts, notes, photo albums , etc.) shared
Nuclear Physics Group progress report
Coote, G.E.
This report summarises the work of the Nuclear Physics Group of the Institute of Nuclear Sciences during the period January-December 1983. Commissioning of the EN-tandem electrostatic accelerator continued, with the first proton beam produced in June. Many improvements were made to the vacuum pumping and control systems. Applications of the nuclear microprobe on the 3MV accelerator continued at a good pace, with applications in archaeometry, dental research, studies of glass and metallurgy
Group I Metabotropic Glutamate Receptors
Erichsen, Julie Ladeby; Blaabjerg, Morten; Bogetofte Thomasen, Helle
differentiated an immortalized, forebrain-derived stem cell line in the presence or absence of glutamate and with addition of either the group I mGluR agonist DHPG or the selective antagonists; MPEP (mGluR5) and LY367385 (mGluR1). Characterization of differentiated cells revealed that both mGluR1 and mGluR5 were...
Paragrassmann analysis and quantum groups
Filippov, A.T.; Isaev, A.P.; Kurdikov, A.B.
Paragrassmann algebras with one and many paragrassmann variables are considered from the algebraic point of view without using the Green anzatz. A differential operator with respect to paragrassmann variable and a covariant para-super-derivative are introduced giving a natural generalization of the Grassmann calculus to a paragrassmann one. Deep relations between paragrassmann and quantum groups with deformation parameters being root of unity are established. 20 refs
Resistance to group clinical supervision
Buus, Niels; Delgado, Cynthia; Traynor, Michael
This present study is a report of an interview study exploring personal views on participating in group clinical supervision among mental health nursing staff members who do not participate in supervision. There is a paucity of empirical research on resistance to supervision, which has traditiona......This present study is a report of an interview study exploring personal views on participating in group clinical supervision among mental health nursing staff members who do not participate in supervision. There is a paucity of empirical research on resistance to supervision, which has...... traditionally been theorized as a supervisee's maladaptive coping with anxiety in the supervision process. The aim of the present study was to examine resistance to group clinical supervision by interviewing nurses who did not participate in supervision. In 2015, we conducted semistructured interviews with 24...... Danish mental health nursing staff members who had been observed not to participate in supervision in two periods of 3 months. Interviews were audio-recorded and subjected to discourse analysis. We constructed two discursive positions taken by the informants: (i) 'forced non-participation', where...
Youth Armed Groups in Colombia
Linda Dale
Full Text Available For the many years of Colombia's civil war, youth have been trying to find their way in complicated and dangerous situations. A central component of this is their relationship with armed groups, something that has evolved considerably over the past ten years. This practice note examines the context within which these connections are formed and the implications this has for self/social identity and meaningful resistance. The ideas in this practice note are based on consultations with young Colombians, particularly those displaced from 2000-2013. These sessions included art activities, focus groups and individual interviews. Art activities involved descriptive and expressive projects so that participants could explore their feelings and memories of situations and experiences. This provided a base for group discussions where youth exchanged information and debated issues. A total of 34 workshops were held over a twelve year period. These consultations revealed how war flows all over young people, touching every aspect of their identity. The boundaries between the personal and political no longer exist in today's civil wars, if indeed they every truly did. Young people growing up inside Colombia's war understand this at a deep level. An acknowledgement of this pain – showing the connections between the personal and political dimensions of war – is, they would maintain, the basis for their personal healing as well as an important tool for the building of sustainable peace.
EDF Group is the world's leading electricity company and it is particularly well established in Europe, especially France, the United Kingdom, Italy and Belgium. Its business covers all electricity-related activities, from generation to distribution and including energy transmission and trading activities to continuously balance supply with demand. A marked increase in the use of renewables is bringing change to its power generation operations, which are underpinned by a diversified low-carbon energy mix founded on nuclear power capacity. With activities across the entire electricity value chain, EDF is reinventing the products and services it offers to help residential customers manage their electricity consumption, to support the energy and financial performance of business customers and to support local authorities in finding sustainable solutions for the cities of the future. This document is EDF Group's annual report for the year 2015. It contains information about Group profile, governance, business, development strategy, sales and marketing, positions in Europe and international activities. The document is made of several reports: the 2016 Book, the '2016 at a glance' report, the Profile and Performance 2015 report, the 2015 Reference Document - Annual Financial Report
RF Group Annual Report 2011
Angoletta, M E; Betz, M; Brunner, O; Baudrenghien, P; Calaga, R; Caspers, F; Ciapala, E; Chambrillon, J; Damerau, H; Doebert, S; Federmann, S; Findlay, A; Gerigk, F; Hancock, S; Höfle, W; Jensen, E; Junginger, T; Liao, K; McMonagle, G; Montesinos, E; Mastoridis, T; Paoluzzi, M; Riddone, G; Rossi, C; Schirm, K; Schwerg, N; Shaposhnikova, E; Syratchev, I; Valuch, D; Venturini Delsolaro, W; Völlinger, C; Vretenar, M; Wuensch, W
The highest priority for the RF group in 2011 was to contribute to a successful physics run of the LHC. This comprises operation of the superconducting 400 MHz accelerating system (ACS) and the transverse damper (ADT) of the LHC itself, but also all the individual links of the injector chain upstream of the LHC – Linac2, the PSB, the PS and the SPS – don't forget that it is RF in all these accelerators that truly accelerates! A large variety of RF systems had to operate reliably, often near their limit. New tricks had to be found and implemented to go beyond limits; not to forget the equally demanding operation with Pb ions using in addition Linac3 and LEIR. But also other physics users required the full attention of the RF group: CNGS required in 2011 beams with very short, intense bunches, AD required reliable deceleration and cooling of anti-protons, Isolde the post-acceleration of radioactive isotopes in Rex, just to name a few. In addition to the supply of beams for physics, the RF group has a num...
Group normalization for genomic data.
Ghandi, Mahmoud; Beer, Michael A
Data normalization is a crucial preliminary step in analyzing genomic datasets. The goal of normalization is to remove global variation to make readings across different experiments comparable. In addition, most genomic loci have non-uniform sensitivity to any given assay because of variation in local sequence properties. In microarray experiments, this non-uniform sensitivity is due to different DNA hybridization and cross-hybridization efficiencies, known as the probe effect. In this paper we introduce a new scheme, called Group Normalization (GN), to remove both global and local biases in one integrated step, whereby we determine the normalized probe signal by finding a set of reference probes with similar responses. Compared to conventional normalization methods such as Quantile normalization and physically motivated probe effect models, our proposed method is general in the sense that it does not require the assumption that the underlying signal distribution be identical for the treatment and control, and is flexible enough to correct for nonlinear and higher order probe effects. The Group Normalization algorithm is computationally efficient and easy to implement. We also describe a variant of the Group Normalization algorithm, called Cross Normalization, which efficiently amplifies biologically relevant differences between any two genomic datasets.
Mahmoud Ghandi
Full Text Available Data normalization is a crucial preliminary step in analyzing genomic datasets. The goal of normalization is to remove global variation to make readings across different experiments comparable. In addition, most genomic loci have non-uniform sensitivity to any given assay because of variation in local sequence properties. In microarray experiments, this non-uniform sensitivity is due to different DNA hybridization and cross-hybridization efficiencies, known as the probe effect. In this paper we introduce a new scheme, called Group Normalization (GN, to remove both global and local biases in one integrated step, whereby we determine the normalized probe signal by finding a set of reference probes with similar responses. Compared to conventional normalization methods such as Quantile normalization and physically motivated probe effect models, our proposed method is general in the sense that it does not require the assumption that the underlying signal distribution be identical for the treatment and control, and is flexible enough to correct for nonlinear and higher order probe effects. The Group Normalization algorithm is computationally efficient and easy to implement. We also describe a variant of the Group Normalization algorithm, called Cross Normalization, which efficiently amplifies biologically relevant differences between any two genomic datasets.
Focus group report - part II
The Waste Policy Institute, through a cooperative agreement with the U.S. Department of Energy (DOE) Office of Science and Technology (OST) conducted a focus group with members of the Hanford Advisory Board (HAB), interviews with tribal government representatives, and a survey of Oak Ridge Local Oversight Committee (LOC) and Site Specific Advisory Board (SSAB) members. The purpose was to understand what members of the interested and involved public want to know about technology development and ways to get that information to them. These data collection activities were used as a follow-up to two previously held focus groups with the general public near Idaho National Engineering and Environmental Laboratory (INEEL) and the Savannah River Site (SRS). Most participants from the first two focus groups said they did not have time and/or were not interested in participating in technology decision-making. They said they would prefer to defer to members of their communities who are interested and want to be involved in technology decision-making
Summary of Research 1997, Interdisciplinary Academic Groups
Boger, Dan
This report contains information of research projects in the interdisciplinary groups, Command, Control, and Communications Academic Group, Information Warfare Academic Group, Space Systems Academic...
Group-13 and group-15 doping of germanane
Nicholas D. Cultrara
Full Text Available Germanane, a hydrogen-terminated graphane analogue of germanium has generated interest as a potential 2D electronic material. However, the incorporation and retention of extrinsic dopant atoms in the lattice, to tune the electronic properties, remains a significant challenge. Here, we show that the group-13 element Ga and the group-15 element As, can be successfully doped into a precursor CaGe2 phase, and remain intact in the lattice after the topotactic deintercalation, using HCl, to form GeH. After deintercalation, a maximum of 1.1% As and 2.3% Ga can be substituted into the germanium lattice. Electronic transport properties of single flakes show that incorporation of dopants leads to a reduction of resistance of more than three orders of magnitude in H2O-containing atmosphere after As doping. After doping with Ga, the reduction is more than six orders of magnitude, but with significant hysteretic behavior, indicative of water-activation of dopants on the surface. Only Ga-doped germanane remains activated under vacuum, and also exhibits minimal hysteretic behavior while the sheet resistance is reduced by more than four orders of magnitude. These Ga- and As-doped germanane materials start to oxidize after one to four days in ambient atmosphere. Overall, this work demonstrates that extrinsic doping with Ga is a viable pathway towards accessing stable electronic behavior in graphane analogues of germanium.
Topics in cohomology of groups
Lang, Serge
The book is a mostly translated reprint of a report on cohomology of groups from the 1950s and 1960s, originally written as background for the Artin-Tate notes on class field theory, following the cohomological approach. This report was first published (in French) by Benjamin. For this new English edition, the author added Tate's local duality, written up from letters which John Tate sent to Lang in 1958 - 1959. Except for this last item, which requires more substantial background in algebraic geometry and especially abelian varieties, the rest of the book is basically elementary, depending only on standard homological algebra at the level of first year graduate students.
This report summarises the work of the Nuclear Physics Group of the Institute of Nuclear Sciences during the period January-December 1984. Commissioning of the EN-tandem accelerator was completed. The first applications included the production of 13 N from a water target and the measurement of hydrogen depth profiles with a 19 F beam. Further equipment was built for tandem accelerator mass spectrometry but the full facility will not be ready until 1985. The nuclear microprobe on the 3 MV accelerator was used for many studies in archaeometry, metallurgy, biology and materials analysis
The identification of critical groups
Hunt, G.J.; Shepherd, J.G.
The criteria for critical group identification are summarized and the extent to which they are satisfied by possible numerical methods are examined, drawing on UK experience in dose estimation within a system for setting controls on liquid radioactive waste discharges from major nuclear installations. The nature of the exposure pathway is an important factor in identifying an appropriate method. It is held that there is a greater uncertainty in estimating individual exposure from internal exposure than that from external exposure due to the greater relevance of metabolic variations. Accordingly different methods are proposed for numerical treatment of data associated with internal exposure pathways compared with external exposure pathways. (H.K.)
Le groupe de travail EPNAC
MOLLE, Pascal
Full Text Available En France, les procédés de traitement des eaux usées des petites et moyennes collectivités sont en constante évolution et leur diversité augmente fortement. Constitué à l'initiative d'Irstea, le groupe de travail EPNAC a pour objectif de mutualiser et de diffuser une information technique et cohérente sur ces procédés auprès des acteurs de l'assainissement.
Plan de negocios Oshian Group
Castillo Bolivar, Evelyn Johana; Charry López, Ingrid Milena
Plan de negocios para crear una empresa de servicios de importación con contacto directo con proveedores y empresarios chinos para el sector de las Pymes Bogotanas. Oshian Group S.A.S., es una empresa importadora, ubicada en el barrio Chico; inicialmente operará en la ciudad de Bogotá, esto no limita el mercado sino que también se podrá expandir a clientes de otras ciudades del país en mediano o largo plazo. Diferentes sectores económicos como las Pymes han mostrado un avance a través de ...
Group colorings and Bernoulli subflows
Gao, Su; Seward, Brandon
In this paper the authors study the dynamics of Bernoulli flows and their subflows over general countable groups. One of the main themes of this paper is to establish the correspondence between the topological and the symbolic perspectives. From the topological perspective, the authors are particularly interested in free subflows (subflows in which every point has trivial stabilizer), minimal subflows, disjointness of subflows, and the problem of classifying subflows up to topological conjugacy. Their main tool to study free subflows will be the notion of hyper aperiodic points; a point is hyper aperiodic if the closure of its orbit is a free subflow.
Clifford theory for group representations
Let N be a normal subgroup of a finite group G and let F be a field. An important method for constructing irreducible FG-modules consists of the application (perhaps repeated) of three basic operations: (i) restriction to FN. (ii) extension from FN. (iii) induction from FN. This is the `Clifford Theory' developed by Clifford in 1937. In the past twenty years, the theory has enjoyed a period of vigorous development. The foundations have been strengthened and reorganized from new points of view, especially from the viewpoint of graded rings and crossed products.The purpos
Platinum-group element mineralization
Gruenewaldt, G.
The purpose of this investigation is to determine the geological processes responsible for the abnormal enrichment of the platinum-group elements (PGE) in the mineralized layers of the Bushveld Complex. Questions asked are: what processes caused enrichment of the Bushveld magma in the PGE ; by what processes were these PGE concentrated in the mineralized layers ; was contamination of the Bushveld magma from external sources important in the formation of the PGE enriched layers ; what are the effects of fractional crystallization on the PGE ratios
Space Interferometry Science Working Group
Ridgway, Stephen T.
Decisions taken by the astronomy and astrophysics survey committee and the interferometry panel which lead to the formation of the Space Interferometry Science Working Group (SISWG) are outlined. The SISWG was formed by the NASA astrophysics division to provide scientific and technical input from the community in planning for space interferometry and in support of an Astrometric Interferometry Mission (AIM). The AIM program hopes to measure the positions of astronomical objects with a precision of a few millionths of an arcsecond. The SISWG science and technical teams are described and the outcomes of its first meeting are given.
SSC muon detector group report
Carlsmith, D.; Groom, D.; Hedin, D.; Kirk, T.; Ohsugi, T.; Reeder, D.; Rosner, J.; Wojcicki, S.
We report here on results from the Muon Detector Group which met to discuss aspects of muon detection for the reference 4Ï€ detector models put forward for evaluation at the Snowmass 1986 Summer Study. We report on: suitable overall detector geometry; muon energy loss mechanisms; muon orbit determination; muon momentum and angle measurement resolution; raw muon rates and trigger concepts; plus we identify SSC physics for which muon detection will play a significant role. We conclude that muon detection at SSC energies and luminosities is feasible and will play an important role in the evolution of physics at the SSC
We report here on results from the Muon Detector Group which met to discuss aspects of muon detection for the reference 4..pi.. detector models put forward for evaluation at the Snowmass 1986 Summer Study. We report on: suitable overall detector geometry; muon energy loss mechanisms; muon orbit determination; muon momentum and angle measurement resolution; raw muon rates and trigger concepts; plus we identify SSC physics for which muon detection will play a significant role. We conclude that muon detection at SSC energies and luminosities is feasible and will play an important role in the evolution of physics at the SSC.
Working group report on agriculture
Stewart, B.
A summary is provided of the results from a working group investigating the implications of climatic change on agriculture in the Great Plains. The group investigated the current state of knowledge concerning basic understanding of climatic impacts, scales of analysis, impact model validation, lack of integrated modelling, and incomplete and incompatible data sets. Basic understanding of current spatial and temporal climatic variability and its impacts and implications for agricultural production, land resource sustainability, and farm management decisions is imprecise. There is little understanding of the magnitude of potential longer-term changes, timing, likely regional changes, or probability of change. Most models are unvalidated, and knowledge of potential carbon dioxide enrichment effects on crops is very uncertain and the effects are poorly understood. Research should be expanded to develop a better understanding of the critical thresholds and sensitivity of Great Plains agricultural production and economic systems. Holistic methodology should be implemented to integrate weather and climatic information with crop and environmental processes, farm level decision making, and local and regional economic conditions
Group Decisions in Value Management
Christiono Utomo
Full Text Available This research deals with a technique to expedite group decision making during the selection of technical solutions for value management process. Selection of a solution from a set of alternatives is facilitated by evaluating using multicriteria decision making techniques. During the process, every possible solution is rated on criteria of function and cost. Function deals more with quality than with quantity, and cost can be calculated based on the theoretical time value of money. Decision-making techniques based on satisfying games are applied to determine the relative function and cost of solutions and hence their relative value. The functions were determined by function analysis system technique. Analytical hierarchy process was applied to decision making and life-cycle cost analysis were used to calculate cost. Cooperative decision making was shown to consist of identifying agreement options, analyzing, and forming coalitions. The objective was attained using the satisfying game model as a basis for two main preferences. The model will improve the value of decision regarding design. It further emphasizes the importance of performance evaluation in the design process and value analysis. The result of the implementation, when applied to the selection of a building wall system, demonstrates a process of selecting the most valuable technical solution as the best-fit option for all decision makers. This work is relevant to group decision making and negotiation, as it aims to provide a framework to support negotiation in design activity.
DOE Waste Treatability Group Guidance
Kirkpatrick, T.D.
This guidance presents a method and definitions for aggregating U.S. Department of Energy (DOE) waste into streams and treatability groups based on characteristic parameters that influence waste management technology needs. Adaptable to all DOE waste types (i.e., radioactive waste, hazardous waste, mixed waste, sanitary waste), the guidance establishes categories and definitions that reflect variations within the radiological, matrix (e.g., bulk physical/chemical form), and regulated contaminant characteristics of DOE waste. Beginning at the waste container level, the guidance presents a logical approach to implementing the characteristic parameter categories as part of the basis for defining waste streams and as the sole basis for assigning streams to treatability groups. Implementation of this guidance at each DOE site will facilitate the development of technically defined, site-specific waste stream data sets to support waste management planning and reporting activities. Consistent implementation at all of the sites will enable aggregation of the site-specific waste stream data sets into comparable national data sets to support these activities at a DOE complex-wide level.
Group Dynamics in Automatic Imitation.
Gleibs, Ilka H; Wilson, Neil; Reddy, Geetha; Catmur, Caroline
Imitation-matching the configural body movements of another individual-plays a crucial part in social interaction. We investigated whether automatic imitation is not only influenced by who we imitate (ingroup vs. outgroup member) but also by the nature of an expected interaction situation (competitive vs. cooperative). In line with assumptions from Social Identity Theory), we predicted that both social group membership and the expected situation impact on the level of automatic imitation. We adopted a 2 (group membership target: ingroup, outgroup) x 2 (situation: cooperative, competitive) design. The dependent variable was the degree to which participants imitated the target in a reaction time automatic imitation task. 99 female students from two British Universities participated. We found a significant two-way interaction on the imitation effect. When interacting in expectation of cooperation, imitation was stronger for an ingroup target compared to an outgroup target. However, this was not the case in the competitive condition where imitation did not differ between ingroup and outgroup target. This demonstrates that the goal structure of an expected interaction will determine the extent to which intergroup relations influence imitation, supporting a social identity approach.
Online Support Groups for Depression
Louise Breuer
Full Text Available This mixed-methods study aimed to explore the initial process of engagement with an online support group (OSG for depression. Fifteen British National Health Service patients experiencing depression who had not previously used an OSG for depression were offered facilitated access to an existing peer-to-peer OSG for 10 weeks. Pre- and post-measures of depression, social support, and self-stigma were taken in addition to a weekly measure of OSG usage. A follow-up qualitative interview was conducted with a subsample of nine participants. Depression and self-stigma reduced over the 10-week period, but perceived social support did not change. There was no evidence of adverse outcomes. Perceived benefits of OSG participation included connection to others, normalization of depression, and stigma reduction. However, engagement with the OSG was generally low. Barriers included concerns over causing harm to others or being harmed oneself, feeling different from others in the group, and fears of being judged by others. OSGs may potentially reduce depressive symptoms and perceived self-stigma. However, considerable barriers may hinder people with depression from engaging with OSGs. Further work is needed to determine who will benefit most from participating in OSGs for depression and how best to facilitate engagement.
This guidance presents a method and definitions for aggregating U.S. Department of Energy (DOE) waste into streams and treatability groups based on characteristic parameters that influence waste management technology needs. Adaptable to all DOE waste types (i.e., radioactive waste, hazardous waste, mixed waste, sanitary waste), the guidance establishes categories and definitions that reflect variations within the radiological, matrix (e.g., bulk physical/chemical form), and regulated contaminant characteristics of DOE waste. Beginning at the waste container level, the guidance presents a logical approach to implementing the characteristic parameter categories as part of the basis for defining waste streams and as the sole basis for assigning streams to treatability groups. Implementation of this guidance at each DOE site will facilitate the development of technically defined, site-specific waste stream data sets to support waste management planning and reporting activities. Consistent implementation at all of the sites will enable aggregation of the site-specific waste stream data sets into comparable national data sets to support these activities at a DOE complex-wide level
Mixed Waste Working Group report
The treatment of mixed waste remains one of this country's most vexing environmental problems. Mixed waste is the combination of radioactive waste and hazardous waste, as defined by the Resource Conservation and Recovery Act (RCRA). The Department of Energy (DOE), as the country's largest mixed waste generator, responsible for 95 percent of the Nation's mixed waste volume, is now required to address a strict set of milestones under the Federal Facility Compliance Act of 1992. DOE's earlier failure to adequately address the storage and treatment issues associated with mixed waste has led to a significant backlog of temporarily stored waste, significant quantities of buried waste, limited permanent disposal options, and inadequate treatment solutions. Between May and November of 1993, the Mixed Waste Working Group brought together stakeholders from around the Nation. Scientists, citizens, entrepreneurs, and bureaucrats convened in a series of forums to chart a course for accelerated testing of innovative mixed waste technologies. For the first time, a wide range of stakeholders were asked to examine new technologies that, if given the chance to be tested and evaluated, offer the prospect for better, safer, cheaper, and faster solutions to the mixed waste problem. In a matter of months, the Working Group has managed to bridge a gap between science and perception, engineer and citizen, and has developed a shared program for testing new technologies
Trichoscopy in pediatric age group
Subrata Malakar
Full Text Available Approach to trichology in the pediatric age group is based on the clinical expertise of the dermatologist and investigative techniques. Currently, the trichoscope is an indispensible, noninvasive tool in the diagnosis of trichological disorders. It not only highlights the subtle tricoscopic points invisible to the naked eye but also serves as a prognostic and monitoring tool in therapeutic management. Trichoscopy goes a long way in improving the diagnostic and clinical acumen of the physician. In the pediatric age group, trichoscopy deals with pattern analysis ranging from hair shaft patterns to follicular, perifollicular, and interfollicular patterns. It not only describes the key trichoscopic features of noncicatricial alopecias, cicatricial alopecias, and genetic hair shaft defects but also helps to delineate various trichological mimics from each other. For compiling data, all trichology cases presenting to a tertiary care center were examined and photographed with a Fotofinder, DermLite Foto II Pro, and DermLite DL 3N. All trichological data were analyzed, and interpretations were based on the literature available.
Symmetry and group theory in chemistry
Ladd, M
A comprehensive discussion of group theory in the context of molecular and crystal symmetry, this book covers both point-group and space-group symmetries.Provides a comprehensive discussion of group theory in the context of molecular and crystal symmetryCovers both point-group and space-group symmetriesIncludes tutorial solutions
From groups to geometry and back
Climenhaga, Vaughn
Groups arise naturally as symmetries of geometric objects, and so groups can be used to understand geometry and topology. Conversely, one can study abstract groups by using geometric techniques and ultimately by treating groups themselves as geometric objects. This book explores these connections between group theory and geometry, introducing some of the main ideas of transformation groups, algebraic topology, and geometric group theory. The first half of the book introduces basic notions of group theory and studies symmetry groups in various geometries, including Euclidean, projective, and hyperbolic. The classification of Euclidean isometries leads to results on regular polyhedra and polytopes; the study of symmetry groups using matrices leads to Lie groups and Lie algebras. The second half of the book explores ideas from algebraic topology and geometric group theory. The fundamental group appears as yet another group associated to a geometric object and turns out to be a symmetry group using covering space...
Focus groups reveal consumer ambivalence.
According to qualitative research, Salvadoreans are ambivalent about the use of contraceptives. Since complete responsibility for management of the CSM project was accepted by the Association Demografica Salvadorena (ADS), the agency which operates the contraceptive social marketing project in El Salvador, in November 1980, the need for decisions in such areas as product price increases, introduction of new condom brands, promotion of the vaginal foaming tablet, and assessment of product sales performance had arisen. The ICSMP funded market research, completed during 1983, was intended to provide the data on which such decisions by ADS could be based. The qualitative research involved 8 focus groups, comprised of men and women, aged 18-45, contraceptive users and nonusers, from the middle and lower socioeconomic strata of the city of San Salvador and other suburban areas. In each group a moderator led discussion of family planning and probed respondents for specific attitudes, knowledge, and behavior regarding the use of contraceptives. To assess attitudes at a more emotional level, moderators asked respondents to "draw" their ideas on certain issues. A marked discrepancy was revealed between respondents' intellectual responses to the issues raised in group discussion, as opposed to their feelings expressed in the drawings. Intellectually, participants responded very positively to family planning practice, but when they were asked to draw their perceptions, ambivalent feelings emerged. Drawings of both the user and the nonuser convey primarily negative aspects for either choice. The user is tense and moody toward her children; the nonuser loses her attractiveness and "dies." Figures also show drawings of some of the attitudes of single and married male participants. 1 drawing shows an incomplete and a complete circle, symbolizing a sterilized man (incomplete) and a nonsterilized man (complete). Another picture depicts a chained man who has lost his freedom
The North Cotentin radioecology group
Miserey, Y.; Pellegrini, P.
On January 11., 97, the epidemiologist Jean-Francois Viel publishes a study on the risks of leukaemia of the children in the canton of Beaumont-Hague (Manche), situated near the site of the reprocessing plant of spent fuel of Cogema. Advancing the hypothesis of a link between the exposure to radioactive waste and the appearance of case of the disease in the region, the study creates at once the scandal within the scientific community and within the general public. Worrying about the affair, Ministers in charge of environment and health decide to create a first scientific commission in which participates Jean-Francois Viel. But the tensions are so important within this association that at the end of six months its president decides to resign. It is at this moment there of the story of this debate that the evidence was imperative: it was necessary to innovate by putting around the table experts of any origin to estimate the risks of leukaemia which can result from exposures of the populations of the North Cotentin to ionizing radiations. Placed under Annie Sugier presidency, then manager of the protection in the I.P.S.N. (Institute of protection and nuclear safety), the pluralistic group, called 'North Cotentin radioecology group' ( G.R.N.C.), who collected 50 experts, represents an innovative way of entering in the evaluation and the management of the risks and in the acceptability of the uncertainty. The originality of the G.R.N.C. lies in a critical step as exhaustive as possible which allows to end in the production of shared knowledge. The direction the economic studies and the environmental evaluation of the Ministry of ecology and sustainable development considered important to make the story of the G.R.N.C. better known. To bring to a successful conclusion this project of edition, a work group was set up by the service of Research) and the forward-looking and the drafting of the work was entrusted to a journalist, Yves Miserey and to an ethnologist, Patricia
Working Group Report: Higgs Boson
Dawson, Sally; Gritsan, Andrei; Logan, Heather; Qian, Jianming; Tully, Chris; Van Kooten, Rick [et al.
This report summarizes the work of the Energy Frontier Higgs Boson working group of the 2013 Community Summer Study (Snowmass). We identify the key elements of a precision Higgs physics program and document the physics potential of future experimental facilities as elucidated during the Snowmass study. We study Higgs couplings to gauge boson and fermion pairs, double Higgs production for the Higgs self-coupling, its quantum numbers and $CP$-mixing in Higgs couplings, the Higgs mass and total width, and prospects for direct searches for additional Higgs bosons in extensions of the Standard Model. Our report includes projections of measurement capabilities from detailed studies of the Compact Linear Collider (CLIC), a Gamma-Gamma Collider, the International Linear Collider (ILC), the Large Hadron Collider High-Luminosity Upgrade (HL-LHC), Very Large Hadron Colliders up to 100 TeV (VLHC), a Muon Collider, and a Triple-Large Electron Positron Collider (TLEP).
Renormalization group theory of earthquakes
H. Saleur
Full Text Available We study theoretically the physical origin of the proposed discrete scale invariance of earthquake processes, at the origin of the universal log-periodic corrections to scaling, recently discovered in regional seismic activity (Sornette and Sammis (1995. The discrete scaling symmetries which may be present at smaller scales are shown to be robust on a global scale with respect to disorder. Furthermore, a single complex exponent is sufficient in practice to capture the essential properties of the leading correction to scaling, whose real part may be renormalized by disorder, and thus be specific to the system. We then propose a new mechanism for discrete scale invariance, based on the interplay between dynamics and disorder. The existence of non-linear corrections to the renormalization group flow implies that an earthquake is not an isolated 'critical point', but is accompanied by an embedded set of 'critical points', its foreshocks and any subsequent shocks for which it may be a foreshock.
NCRP soil contamination task group
Jacobs, D.G.
The National Council of Radiation Protection and Measurements (NCRP) has recently established a Task Group on Soil Contamination to describe and evaluate the migration pathways and modes of radiation exposure that can potentially arise due to radioactive contamination of soil. The purpose of this paper is to describe the scientific principles for evaluation of soil contamination which can be used as a basis for derivation of soil contamination limits for specific situations. This paper describes scenarios that can lead to soil contamination, important characteristics of soil contamination, the subsequent migration pathways and exposure modes, and the application of principles in the report in deriving soil contamination limits. The migration pathways and exposure modes discussed in this paper include: direct radiation exposure; and exhalation of gases
Seismic analysis program group: SSAP
Uchida, Masaaki
A group of programs SSAP has been developed, each member of which performs seismic calculation using simple single-mass system model or multi-mass system model. For response of structures to a transverse s-wave, a single-mass model program calculating response spectrum and a multi-mass model program are available. They perform calculation using the output of another program, which produces simulated earthquakes having the so-called Ohsaki-spectrum characteristic. Another program has been added, which calculates the response of one-dimensional multi-mass systems to vertical p-wave input. It places particular emphasis on the analysis of the phenomena observed at some shallow earthquakes in which stones jump off the ground. Through a series of test calculations using these programs, some interesting information has been derived concerning the validity of superimposing single-mass model calculation, and also the condition for stones to jump. (author)
Heisenberg groups and noncommutative fluxes
Freed, Daniel S.; Moore, Gregory W.; Segal, Graeme
We develop a group-theoretical approach to the formulation of generalized abelian gauge theories, such as those appearing in string theory and M-theory. We explore several applications of this approach. First, we show that there is an uncertainty relation which obstructs simultaneous measurement of electric and magnetic flux when torsion fluxes are included. Next, we show how to define the Hilbert space of a self-dual field. The Hilbert space is Z 2 -graded and we show that, in general, self-dual theories (including the RR fields of string theory) have fermionic sectors. We indicate how rational conformal field theories associated to the two-dimensional Gaussian model generalize to (4k+2)-dimensional conformal field theories. When our ideas are applied to the RR fields of string theory we learn that it is impossible to measure the K-theory class of a RR field. Only the reduction modulo torsion can be measured
Universality and the Renormalisation Group
Litim, D F
Several functional renormalisation group (RG) equations including Polchinski flows and Exact RG flows are compared from a conceptual point of view and in given truncations. Similarities and differences are highlighted with special emphasis on stability properties. The main observations are worked out at the example of O(N) symmetric scalar field theories where the flows, universal critical exponents and scaling potentials are compared within a derivative expansion. To leading order, it is established that Polchinski flows and ERG flows - despite their inequivalent derivative expansions - have identical universal content, if the ERG flow is amended by an adequate optimisation. The results are also evaluated in the light of stability and minimum sensitivity considerations. Extensions to higher order and further implications are emphasized.
WICCI Wildlife Working Group Report
LeDee, Olivia E.; Hagell, Suzanne; Martin, K.; McFarland, David; Meyer, Michael; Paulios, Andy; Ribic, Christine A.; Sample, D.; Van Deelen, Timothy R.
Wisconsin is world-renowned for its diversity of ecological landscapes and wildlife populations. The northern forests, southern prairies, and interior and coastal wetlands of the state are home to more than 500 terrestrial animal species. These animals supply the Wisconsin public with aesthetic, cultural, and economic benefits; our identity and economy are intertwined with these natural resources. Climate change is altering the behavior, distribution, development, reproduction, and survival of these animal populations. In turn, these changes will alter the aesthetic, cultural, and economic benefits we receive from them. The focus of the Wildlife Working Group is to document past and current impacts, anticipate changes in wildlife distribution and abundance, and develop adaptation strategies to maintain the vitality and diversity of Wisconsin's wildlife populations.
Inclusion, children's groups, music therapy
Holck, Ulla; Jacobsen, Stine Lindahl
portrayal of the qualities of musical interplay that promotes well-being in group settings and, thus, the inclusion of vulnerable students. Therefore, we open the chapter with a focus on musicality and on the importance of applying a musical approach in relation to the children.......Music has a rare ability to affect us directly. Pulse and rhythms make us move, and notes and harmonies inspire and express our inner emotions in a direct and immediate way that goes beyond what words or even other art forms can rarely achieve (Panksepp & Trevarthen, 2009). Music creates...... a delightful build-up of tension or soothes us, and its narrative character gives rise to mental imagery or memories. Music brings people together and helps build communities across languages and common divides. And – not least – music captures children's immediate attention, so when the music starts, so do...
Super-group field cosmology
Faizal, Mir
In this paper, we construct a model for group field cosmology. The classical equations of motion for the non-interactive part of this model generate the Hamiltonian constraint of loop quantum gravity for a homogeneous isotropic universe filled with a scalar matter field. The interactions represent topology changing processes that occur due to joining and splitting of universes. These universes in the multiverse are assumed to obey both bosonic and fermionic statistics, and so a supersymmetric multiverse is constructed using superspace formalism. We also introduce gauge symmetry in this model. The supersymmetry and gauge symmetry are introduced at the level of third quantized fields, and not the second quantized ones. This is the first time that supersymmetry has been discussed at the level of third quantized fields. (paper)
Nonaccelerator physics working group summary
Ayres, D.S.; Beier, E.W.; Cherry, M.L.; Marciano, W.J.
The Nonaccelerator Physics Working Group set itself the task of predicting the contributions of nonaccelerator experiments to particle physics during the 1990s, in order to assess the needs for new experimental facilities. The main topics studied by the subgroups were: (1) the possibility of doing particle physics experiments with high energy cosmic rays from astrophysical sources; (2) the prospects for experiments which seek to measure the masses of neutrinos and the mixing of neutrino flavors; (3) an examination of the implications for proton decay of recent theoretical developments in grand unified and string theories. Other topics included a survey of magnetic monopole searches, an assessment of future prospects for double-beta-decay and nucleon-decay experiments, and a review of recent progress on neutrino and dark-matter detectors based on quasiparticles in superconductors and phonons in crystals
The Ignition Physics Study Group
Sheffield, J.
In the US magnetic fusion program there have been relatively few standing committees of experts, with the mandate to review a particular sub-area on a continuing basis. Generally, ad hoc committees of experts have been assembled to advise on a particular issue. There has been a lack of broad, systematic and continuing review and analysis, combining the wisdom of experts in the field, in support of decision making. The Ignition Physics Study Group (IPSG) provides one forum for the systematic discussion of fusion science, complementing the other exchanges of information, and providing a most important continuity in this critical area. In a similar manner to the European program, this continuity of discussion and the focus provided by a national effort, Compact Ignition Tokamak (CIT), and international effort, Engineering Test Reactor (ETR), are helping to lower those barriers which previously were an impediment to rational debate
We study the fusion rings of tilting modules for a quantum group at a root of unity modulo the tensor ideal of negligible tilting modules. We identify them in type A with the combinatorial rings from Korff, C., Stroppel, C.: The sl(ˆn)k-WZNW fusion ring: a combinato-rial construction...... and a realisation as quotient of quantum cohomology. Adv. Math. 225(1), 200–268, (2010) and give a similar description of the sp2n-fusion ring in terms of non-commutative symmetric functions. Moreover we give a presentation of all fusion rings in classical types as quotients of polynomial rings. Finally we also...... compute the fusion rings for type G2....
Quantum groups in hadron phenomenology
Gavrilik, A.M.
We show that application of quantum unitary groups, in place of ordinary flavor SU(n f ), to such static aspects of hadron phenomenology as hadron masses and mass formulas is indeed fruitful. So-called q-deformed mass formulas are given for octet baryons 1/2 + and decuplet baryons 3/2 + , as well as for the case of vector mesons 1 - involving heavy flavors. For deformation parameter q, rigid fixation of values is used. New mass sum rules of remarkable accuracy are presented. As shown in decuplet case, the approach accounts for effects highly nonlinear in SU(3)-breaking. Topological implication (possible connection with knots) for singlet vector mesons and the relation q ↔ Θ c (Cabibbo angle) in case of baryons are considered
Category O for quantum groups
Andersen, Henning Haahr; Mazorchuk, Volodymyr
We study the BGG-categories O_q associated to quantum groups. We prove that many properties of the ordinary BGG-category O for a semisimple complex Lie algebra carry over to the quantum case. Of particular interest is the case when q is a complex root of unity. Here we prove a tensor decomposition...... for simple modules, projective modules, and indecomposable tilting modules. Using the known Kazhdan–Lusztig conjectures for O and for finite-dimensional U_q-modules we are able to determine all irreducible characters as well as the characters of all indecomposable tilting modules in O_q . As a consequence......, we also recover the known result that the generic quantum case behaves like the classical category O....
Danish Colorectal Cancer Group Database.
The aim of the database, which has existed for registration of all patients with colorectal cancer in Denmark since 2001, is to improve the prognosis for this patient group. All Danish patients with newly diagnosed colorectal cancer who are either diagnosed or treated in a surgical department of a public Danish hospital. The database comprises an array of surgical, radiological, oncological, and pathological variables. The surgeons record data such as diagnostics performed, including type and results of radiological examinations, lifestyle factors, comorbidity and performance, treatment including the surgical procedure, urgency of surgery, and intra- and postoperative complications within 30 days after surgery. The pathologists record data such as tumor type, number of lymph nodes and metastatic lymph nodes, surgical margin status, and other pathological risk factors. The database has had >95% completeness in including patients with colorectal adenocarcinoma with >54,000 patients registered so far with approximately one-third rectal cancers and two-third colon cancers and an overrepresentation of men among rectal cancer patients. The stage distribution has been more or less constant until 2014 with a tendency toward a lower rate of stage IV and higher rate of stage I after introduction of the national screening program in 2014. The 30-day mortality rate after elective surgery has been reduced from >7% in 2001-2003 to database is a national population-based clinical database with high patient and data completeness for the perioperative period. The resolution of data is high for description of the patient at the time of diagnosis, including comorbidities, and for characterizing diagnosis, surgical interventions, and short-term outcomes. The database does not have high-resolution oncological data and does not register recurrences after primary surgery. The Danish Colorectal Cancer Group provides high-quality data and has been documenting an increase in short- and long
Properties of Group Five and Group Seven transactinium elements
Wilk, Philip A. [Univ. of California, Berkeley, CA (United States)
The detection and positive identification of the short-lived, low cross section isotopes used in the chemical studies of the heaviest elements are usually accomplished by measuring their alpha-decay, thus the nuclear properties of the heaviest elements must be examined simultaneously with their chemical properties. The isotopes 224 Pa and 266,267 Bh have been studied extensively as an integral part of the investigation of the heaviest members of the groups five and seven of the periodic table. The half-life of 224 Pa was determined to be 855 ±19 ms by measuring its alpha-decay using our rotating wheel, solid state detector system at the Lawrence Berkeley National Laboratory 88-Inch Cyclotron. Protactinium was produced by bombardment of a bismuth target. New neutron rich isotopes, 267 Bh and 266 Bh, were produced in bombardments of a 249 Bk target and their decay was observed using the rotating wheel system. The 266 Bh that was produced decays with a half-life of approximately 1 s by emission of alpha particles with an average energy of 9.25 plus/minus 0.03 MeV. 267 Bh was observed to decay with a 17 s half-life by emission of alpha-particles with an average energy of 8.83 plus/minus 0.03 MeV. The chemical behavior of hafnium, Ha (element 105) was investigated using the fast on-line continuous liquid extraction and detection system SISAK-LISSY. Hafnium was not observed in this experiment following transport and extraction. Protactinium was used as on-line test of the apparatus to determine the experimental efficiency of the entire system. Unfortunately, the amount of protactinium observed after the extraction, compared to the amount produced, was extremely small, only 2.5%. The extraction of the protactinium isotope indicated the efficiency of the apparatus was too low to observe the extraction of hafnium. The chemical behavior of oxychloride compounds of bohrium was
Wilk, Philip A.
The detection and positive identification of the short-lived, low cross section isotopes used in the chemical studies of the heaviest elements are usually accomplished by measuring their alpha-decay, thus the nuclear properties of the heaviest elements must be examined simultaneously with their chemical properties. The isotopes 224 Pa and 266,267 Bh have been studied extensively as an integral part of the investigation of the heaviest members of the groups five and seven of the periodic table. The half-life of 224 Pa was determined to be 855 plus/minus19 ms by measuring its alpha-decay using our rotating wheel, solid state detector system at the Lawrence Berkeley National Laboratory 88-Inch Cyclotron. Protactinium was produced by bombardment of a bismuth target. New neutron rich isotopes, 267 Bh and 266 Bh, were produced in bombardments of a 249 Bk target and their decay was observed using the rotating wheel system. The 266 Bh that was produced decays with a half-life of approximately 1 s by emission of alpha particles with an average energy of 9.25 plus/minus 0.03 MeV. 267 Bh was observed to decay with a 17 s half-life by emission of alpha-particles with an average energy of 8.83 plus/minus 0.03 MeV. The chemical behavior of hafnium, Ha (element 105) was investigated using the fast on-line continuous liquid extraction and detection system SISAK-LISSY. Hafnium was not observed in this experiment following transport and extraction. Protactinium was used as on-line test of the apparatus to determine the experimental efficiency of the entire system. Unfortunately, the amount of protactinium observed after the extraction, compared to the amount produced, was extremely small, only 2.5%. The extraction of the protactinium isotope indicated the efficiency of the apparatus was too low to observe the extraction of hafnium. The chemical behavior of oxychloride compounds of bohrium was investigated by isothermal gas adsorption chromatography in a quartz column at 180, 150
Group heterogeneity increases the risks of large group size: a longitudinal study of productivity in research groups.
Cummings, Jonathon N; Kiesler, Sara; Bosagh Zadeh, Reza; Balakrishnan, Aruna D
Heterogeneous groups are valuable, but differences among members can weaken group identification. Weak group identification may be especially problematic in larger groups, which, in contrast with smaller groups, require more attention to motivating members and coordinating their tasks. We hypothesized that as groups increase in size, productivity would decrease with greater heterogeneity. We studied the longitudinal productivity of 549 research groups varying in disciplinary heterogeneity, institutional heterogeneity, and size. We examined their publication and citation productivity before their projects started and 5 to 9 years later. Larger groups were more productive than smaller groups, but their marginal productivity declined as their heterogeneity increased, either because their members belonged to more disciplines or to more institutions. These results provide evidence that group heterogeneity moderates the effects of group size, and they suggest that desirable diversity in groups may be better leveraged in smaller, more cohesive units.
Working group report on forestry
MacIver, D.
The results and conclusions of a working group held to discuss the state of knowledge and information needs concerning potential climate change implications for forestry are presented. The lack of knowledge in some basic processes, for example physiological and genetics, limits ability to evaluate and project the adaptation and responses to climate change. Areas where knowledge is weak include: the potential maximum productivity for a given climate region; the extent to which climate change can be accomodated by genetic adaptation; ways to improve the temporal/spatial distribution of projected precipitation and temperature changes and their magnitudes; the effect of global warming on fire severity and behavior; the current lightning distribution and relationship to fire and the response of this to global warming; socio-economic needs and constraints for management of wilderness areas; carbon dioxide enrichment effects on forest growth and water use efficiency; carbon benefits associated with afforestation and other carbon sequestering programs; impacts of forest practices on the carbon cycle; and the definition of biological diversity on the Great Plains. Recommended research initiatives include improving climate projections, targetted biological process research, monitoring for change and adaptive management, and development of decision support systems
The EU model evaluation group
Petersen, K.E.
The model evaluation group (MEG) was launched in 1992 growing out of the Major Technological Hazards Programme with EU/DG XII. The goal of MEG was to improve the culture in which models were developed, particularly by encouraging voluntary model evaluation procedures based on a formalised and consensus protocol. The evaluation intended to assess the fitness-for-purpose of the models being used as a measure of the quality. The approach adopted was focused on developing a generic model evaluation protocol and subsequent targeting this onto specific areas of application. Five such developments have been initiated, on heavy gas dispersion, liquid pool fires, gas explosions, human factors and momentum fires. The quality of models is an important element when complying with the 'Seveso Directive' requiring that the safety reports submitted to the authorities comprise an assessment of the extent and severity of the consequences of identified major accidents. Further, the quality of models become important in the land use planning process, where the proximity of industrial sites to vulnerable areas may be critical. (Copyright (c) 1999 Elsevier Science B.V., Amsterdam. All rights reserved.)
Bounded cohomology of discrete groups
Frigerio, Roberto
The author manages a near perfect equilibrium between necessary technicalities (always well motivated) and geometric intuition, leading the readers from the first simple definition to the most striking applications of the theory in 13 very pleasant chapters. This book can serve as an ideal textbook for a graduate topics course on the subject and become the much-needed standard reference on Gromov's beautiful theory. -Michelle Bucher The theory of bounded cohomology, introduced by Gromov in the late 1980s, has had powerful applications in geometric group theory and the geometry and topology of manifolds, and has been the topic of active research continuing to this day. This monograph provides a unified, self-contained introduction to the theory and its applications, making it accessible to a student who has completed a first course in algebraic topology and manifold theory. The book can be used as a source for research projects for master's students, as a thorough introduction to the field for graduate student...
COMMISSIONING AND DETECTOR PERFORMANCE GROUPS
D. Acosta
The global commissioning campaign begins this year with a series of weekly two-day global runs of limited participation until mid-March. The aim of these runs varies week-to-week, but includes the commissioning the calorimeter triggers, the muon track-finder triggers in the DT/CSC overlap, the PLL locking ranges, and generally accumulating data either for HCAL noise characterization or detector studies with cosmic muons. In mid-March a full Global Run is scheduled with all components participating, followed in April by a Cosmic Run with the aim of collecting statistics over a couple weeks with the installed Tracker and other subsystems. The ultimate milestone is the Cosmic Run At Four Tesla (CRAFT), with a completed CMS closed and the solenoid energized for data-taking during June. The Detector Performance Groups start the year with the focus to prepare for LHC collisions, and the associated challenges (CSA08) and global commissioning exercises (CRAFT) along the way. New this year is the addition of the Tri...
Nuclear physics group annual report
The experimental activities of the nuclear physics group at the University of Oslo have in 1983 as in the previous years mainly been centered around the SCANDITRONIX MC-35 cyclotron. The cyclotron has been in extensive use during the year for low-energy nuclear physics experiments. In addition it has been used for production of radionuclides for nuclear medicine, for experiments in nuclear chemistry and for corrosion and wear studies. After four years of operation, the cyclotron is still the newest nuclear accelerator in Scandinavia. The available beam energies (protons and alpha-particles up to 35 MeV and *sp3*He-particles up to 48 MeV, makes it a good tool for studies of highly excited low-spin states. The well developed on-line computer system has added to its usefulness. Most of the nuclear experiments during the year have been connected with the study of nuclear structure at high temperature. Experimens with the *sp3*He beam have given very interesting results. Theoretical studies have continued in the same field, and there has been a fruitful cooperation between experimental and theoretical physicists. Most of the experiments are performd as joint projects where physicists from two or three Nordic universities take part. (RF)
Findings: LANL outsourcing focus groups
Jannotta, M.J.; McCabe, V.B.
In March 1996, a series of 24 3-hour dialog focus groups were held with randomly selected Laboratory employees and contractors to gain their perceptions regarding potentials and problems for privatization and consolidation. A secondary goal was to educate and inform the workforce about potentials and issues in privatization and consolidation. Two hundred and thirty-six participants engaged in a learning session and structured input exercises resulting in 2,768 usable comments. Comments were categorized using standard qualitative methods; resulting categories included positive and negative comments on four models (consolidation, spin offs, outsourcing, and corporate partnering) and implications for the workforce, the Laboratory, and the local economy. Categories were in the areas of increasing/decreasing jobs, expertise, opportunity/salary/benefits, quality/efficiency, and effect on the local area and economy. An additional concern was losing Laboratory culture and history. Data were gathered and categorized on employee opinion regarding elements of successful transition to the four models, and issues emerged in the areas of terms and conditions of employment; communication; involvement; sound business planning; ethics and fairness; community infrastructure. From the aggregated opinion of the participants, it is recommended that decision-makers: Plan using sound business principles and continually communicate plans to the workforce; Respect workforce investments in the Laboratory; Tell the workforce exactly what is going on at all times; Understand that economic growth in Northern New Mexico is not universally viewed as positive; and Establish dialog with stakeholders on growth issues.
Group Velocity for Leaky Waves
Rzeznik, Andrew; Chumakova, Lyubov; Rosales, Rodolfo
In many linear dispersive/conservative wave problems one considers solutions in an infinite medium which is uniform everywhere except for a bounded region. In general, localized inhomogeneities of the medium cause partial internal reflection, and some waves leak out of the domain. Often one only desires the solution in the inhomogeneous region, with the exterior accounted for by radiation boundary conditions. Formulating such conditions requires definition of the direction of energy propagation for leaky waves in multiple dimensions. In uniform media such waves have the form exp (d . x + st) where d and s are complex and related by a dispersion relation. A complex s is required since these waves decay via radiation to infinity, even though the medium is conservative. We present a modified form of Whitham's Averaged Lagrangian Theory along with modulation theory to extend the classical idea of group velocity to leaky waves. This allows for solving on the bounded region by representing the waves as a linear combination of leaky modes, each exponentially decaying in time. This presentation is part of a joint project, and applications of these results to example GFD problems will be presented by L. Chumakova in the talk ``Leaky GFD Problems''. This work is partially supported by NSF Grants DMS-1614043, DMS-1719637, and 1122374, and by the Hertz Foundation.
The commissioning effort is presently addressing two main areas: the commissioning of the hardware components at the pit and the coordination of the activities of the newly constituted Detector Performance groups (DPGs). At point 5, a plan regarding the service cavern and the commissioning of the connections of the off-detector electronics (for the data collection line and trigger primitive generation) to the central DAQ and the central Trigger has been defined. This activity was started early February and will continue until May. It began with Tracker electronics followed so far by HCAL and CSC. The goal is to have by May every detector commission, as much as possible, their data transfer paths from FED to Central DAQ as well as their trigger setups between TPGs and Global Level 1 trigger. The next focus is on connections of front-ends to the service cavern. This depends strongly on the installations of services. Presently the only detector which has its link fibers connected to the off-detector electr...
The interprofessional team as a small group.
Kane, R A
Conflicts in interprofessional teamwork may be as much explained by group process considerations as by the interaction of professional roles and statuses. This paper examines the interprofessional team as a small group, using a synthesis of sources from social psychology, social group work, T-group literature, management theory, and health team research. Eight issues are considered in relation to the team as a small group, namely, (a) the individual in the group, (b) team size, (c) group norms, (d) democracy, (e) decision making and conflict resolution, (f) communication and structure, (g) leadership, and (h) group harmony and its relationship to group productivity.
Support Groups for Children of Divorce.
Farmer, Sherry; Galaris, Diana
Describes model for support groups for children of divorce developed at Marriage Council of Philadelphia. Gives details about group organization, illustrative case material, and typical concerns that group members work with throughout group sessions. Summarizes reported effects of support group involvement and considers ways of intervening in…
Analytic and Systemic Specialized Incest Group Psychotherapy
Elkjaer, Henriette Kiilsholm; Mortensen, Erik Lykke; Poulsen, Stig Bernt
PURPOSE: Women with long-term sequalae of child sexual abuse (CSA) were randomly assigned to analytic (Group A) or systemic group psychotherapy (Group S). Pre-post-analysis indicated that both therapies led to significant improvement, but overall Group S had significantly better outcome than Group...
Extending Sociocultural Theory to Group Creativity
Sociocultural theory focuses on group processes through time, and argues that group phenomena cannot be reduced to explanation in terms of the mental states or actions of the participating individuals. This makes sociocultural theory particularly useful in the analysis of group creativity and group learning, because both group creativity and group…
ALGORITHM FOR SORTING GROUPED DATA
Evans, J. D.
It is often desirable to sort data sets in ascending or descending order. This becomes more difficult for grouped data, i.e., multiple sets of data, where each set of data involves several measurements or related elements. The sort becomes increasingly cumbersome when more than a few elements exist for each data set. In order to achieve an efficient sorting process, an algorithm has been devised in which the maximum most significant element is found, and then compared to each element in succession. The program was written to handle the daily temperature readings of the Voyager spacecraft, particularly those related to the special tracking requirements of Voyager 2. By reducing each data set to a single representative number, the sorting process becomes very easy. The first step in the process is to reduce the data set of width 'n' to a data set of width '1'. This is done by representing each data set by a polynomial of length 'n' based on the differences of the maximum and minimum elements. These single numbers are then sorted and converted back to obtain the original data sets. Required input data are the name of the data file to read and sort, and the starting and ending record numbers. The package includes a sample data file, containing 500 sets of data with 5 elements in each set. This program will perform a sort of the 500 data sets in 3 - 5 seconds on an IBM PC-AT with a hard disk; on a similarly equipped IBM PC-XT the time is under 10 seconds. This program is written in BASIC (specifically the Microsoft QuickBasic compiler) for interactive execution and has been implemented on the IBM PC computer series operating under PC-DOS with a central memory requirement of approximately 40K of 8 bit bytes. A hard disk is desirable for speed considerations, but is not required. This program was developed in 1986.
Some links on this page may take you to non-federal websites. Their policies may differ from this site.
Website Policies/Important Links | CommonCrawl |
952 78 08 32 [email protected]
how to remember the sign of the cross
por | Dic 23, 2020 | Sin categoría | 0 Comentarios
Here are a few rules you should follow: When crossing an intersection without a stop or yield sign, decrease your speed and be ready to stop if necessary. The Sign of the Cross is a simple gesture yet a profound expression of faith for both Catholic and Orthodox Christians. Indulgences are given of 50 days for making the Sign of the Cross saying the words, and 100 days for the same when using holy water. "For example, a shepherd marked his sheep as his property with a brand that he called a sphragis," Ghezzi writes. Before we pray we make the sign of the cross! Raised as an evangelical Protestant, he is a convert to Catholicism. As Catholics, it's something we do when we enter a church, after we receive Communion, before meals, and every time we pray. Note that some people end the Sign by crossing the thumb over the index finger to make a cross, and then kissing the thumb as a way of "kissing the Cross." In moving our hands from our foreheads to our hearts and then both shoulders, we are asking God's blessing for our mind, our passions and desires, our very bodies. Freeway entrances. Our movement is downward, from our foreheads to our chest "because Christ descended from the heavens to the earth," Pope Innocent III wrote in his instructions on making the Sign of the Cross. Before the gospel we usually just do the signs of the cross without the prayer. If prayer, at its core, is "an uprising of the mind to God," as St. John Damascene put it, then the Sign of the Cross assuredly qualifies. SUBSCRIBE . Yet most Protestants reject the idea of placing the sign of the cross upon themselves. Directed by Cecil B. DeMille. Pray. Add some road signs and people and let your child explore and play. To make the sign of the cross one may observe this helpful illustrated example found in a most recent and delightful publication from CPH. Catholic Exchange is a project of Sophia Institute Press. The routine at Mass of making the small Sign of the Cross on our … God the Father at the head, Jesus at the foot of the cross/the ground/on earth, The Holy Spirit bridging the gap between heaven and earth. We fling our images aside and address our prayers to God as he has revealed himself to be: Father, Son, and Holy Spirit.". The formal and proper form of the sign of the cross includes the use of three fingers, especially when entering the church. … take the helmet of salvation and the sword of the Spirit, which is the word of God.", The Sign of the Cross is one of the very weapons we use in that battle with the devil. First you multiply 1 and 4 which will give you your new denominator, then you multiply 2 and 3 to get the … If you ask anything of me in my name, I will do it.". Roundabouts; Since your chances of a collision increase in an intersection, it's important to proceed with caution. How to make the Sign of the Cross? This frugal and fun craft is an easy way to teach children how to do the Sign of the Cross. Her quest not only directly represents the difficult, perilous trip so many make every day from Mexico to the United States, but also adapts the traditional mythological story of … The Sixth Station. Let's examine these both in more detail. Instruct the children to glue the sticks together in the shape of a cross. The novel's protagonist, whose journey from the Little Town where she lives across the border in search of her brother forms the backbone of the narrative. Ask them to repeat the words to the Sign of the Cross while placing a circle of paint (like a jewel) at each tip of their crosses. In first lifting our hand to our forehead we recall that the Father is the first person the Trinity. I came out of the bathroom draped in a towel after a failed attempt to take a shower. Making the triple Sign of the Cross like this before the Gospel is a longstanding tradition. The movement from left to right also signifies our future passage from present misery to future glory just as Christ "crossed over from death to life and from Hades to Paradise," Pope Innocent II wrote. It is traced by the Church on the forehead of the catechumen before baptism. Another 'sign' of a stroke is this: Ask the person to 'stick' out their tongue. Don't worry if … The sign of the cross is a beautiful gesture which reminds the faithful of the cross of salvation while invoking the Holy Trinity. The Theological Meaning of the Sign of the Cross. Holding two fingers together—either the thumb with the ring finger or with index finger—also represents the two natures of Christ. On the Sign of the Cross. Subscribe to our monthly enews, Columban eBulletin and keep up to date with Columban mission news and stories. To suffer and to do. But, if he do, the fiend will soon be frightened on account of the victorious token." In another statement, attributed to St. John Chrysostom, demons are said to "fly away" at the Sign of the Cross "dreading it as a staff that they are beaten with." (Source: Catholic Encyclopedia.). Suppose That You Cross The Circuit Elements Shown In The Figure Below From Left To Right. Pages 324. Through this Bible study we will explore the practice of the prayer and also the enormity of the mystery of the Trinity and the sacrifice of our ever-loving God. Sign of the cross is within the scope of WikiProject Catholicism, an attempt to better organize and improve the quality of information in articles related to the Catholic Church.For more information, visit the project page. Side streets. Remember to always come to a complete stop at a stop sign or blinking red light. Alzheimer's is evil. If the light is completely inoperative, treat it as a 4-way stop. As a gesture often made in public, the Sign of the Cross is a simple way to witness our faith to others. The prayers that the priest says silently to himself before and after proclaiming the Gospel can give us a clue. :-), How to Access the Catholic Icing Subscriber Bonus Page, 10 Genius Systems For Home Based Education, Tell Me About The Catholic Faith Notebooking Pages, free printable Sign Of The Cross pages for preschoolers here. Like most Americans, I remember where I was and what I was doing on 9/11. Veronica Wipes the Face of Jesus. The sign of the cross is: a confession of faith; a renewal of baptism; a mark of discipleship; an acceptance of suffering; a defense against the devil; and a victory over self-indulgence. A sign line shows the signs of the different factors in each interval. In other words, the Sign of the Cross commits us, body and soul, mind and heart, to Christ. The eunuch believed and was baptised, and the two went their separate ways (Acts 8:26-39). But what exactly are we doing when we make the Sign of the … 21 Benefits of Making the Sign of the Cross Read More » They had this mirror in Lydia's preschool class last year. Top Tip: In the Name of the Father, Bottom Tip: the Son, Right Tip: and the Holy, Left Tip: Spirit. In Colossians 3, St. Paul uses the image of clothing to describe how our sinful natures are transformed in Christ. He came and gave his life for them. We are to take off the old self and put on the self "which is being renewed … in the image of its creator," Paul tells us. Amen. sign of the Cross, Stephen Beale is a freelance writer based in Providence, Rhode Island. All rights reserved. Their slumbering strength divine; Till there springs up a courage high and true. Episcopal priest, the Rev. He is a former news editor at GoLocalProv.com and was a correspondent for the New Hampshire Union Leader, where he covered the 2008 presidential primary. How to Make the Sign of the Cross. Tape pictures of the sign of … I had intended to write on a different Scripture matter, but this verse kept coming to my thoughts. ... Notice that switching the order of the vectors in the cross product … A Roman soldier becomes torn between his love for a Christian woman and his loyalty to Emperor Nero. Mar 1, 2015 - Lent is here and why not start this Lenten Season with Stations of the Cross (Kurishinte Vazhi). Share the best GIFs now >>> Objective to find visual and accessible ways to remember this formula fast $$(x,y,z)\times(u,v,w)=(yw-zv,zu-xw,xv-yu)$$ I have used Sarrus' rule but it is slow, more here.Since it is slow, I have tried to find alternative ways such as binary-tree -visualization (but it is poor/slow until some clever ideas): In its most common Roman Catholic form, the sign of the cross is made by touching one's forehead with a finger or a few, then the chest, then the front of the left shoulder, and finally the front of the right shoulder. In ancient Greek, the word for sign was sphragis, which was also a mark of ownership, according to Ghezzi. Most Christians remember how Philip met an Ethiopian eunuch on the road to Gaza, but most Christians don't know how this is directly related to the sign of the cross. If you would like to teach your kids more Catholic prayers by writing them out, you should definitely take a look at my ebook for kids, Some of the links in my posts are affiliate links. So, without a formula, you should be … By using the sign of the cross in a conscious manner, we can create within ourselves a condition that is supportive of mystical experiences and expanded awareness. This is also reinforced by using three fingers to make the sign, according to Pope Innocent III. "Let it take in your whole being—body, soul, mind, will, thoughts, feelings, your doing and not-doing—and by signing it with the cross strengthen and consecrate the whole in the strength of Christ, in the name of the triune God," said twentieth century theologian Romano Guardini. All materials are common household items-cardboard, yarn, markers, and stickers. Tagged as: A We bow down and make the sign of the cross 65 VERSE TO REMEMBER Oh come let. cross, Making the sign of the cross helps us to remember that we are coming to God to talk with Him and ask His blessing on what we do or say. A. Follow him on Twitter at https://twitter.com/StephenBeale1, Keep Christ at the Center of Your Christmas. In Cruce Salus.-=:†:=-I was baptised on the feast of St John Joseph of the Cross in the Church of the Holy Cross, with my patroness being St Jeanne Jugan, also known as Marie de la Croix. Surprisingly, though, there is nothing in the rubrics about the laypeople making this sign. After telling the time of our last confession, what do we confess? The Sign of the Cross recalls the forgiveness of sins and the reversal of the Fall by passing "from the left side of the curse to the right of blessing," according to de Sales. Byzantine Catholics make a similar sign of the cross but go to the right shoulder first and then to the left. Amen. Do you know how to make the sign of the cross? In making the Sign of the Cross, we mark ourselves as belong to Christ, our true shepherd. Look for apps or services that have the Cross-Account Protection badge . We bow down and make the sign of the cross With Tenor, maker of GIF Keyboard, add popular Sign Of The Cross animated GIFs to your conversations. The eunuch went to what is now Sudan. We adore you, O Christ, and we bless you … because by your holy cross you have … This does not raise the price of the product that you order. Tidbits . The products I link to are all things that I either have, or wish that I had, and all opinions shared on this blog are my own. We embrace the cross of Jesus and express our willingness to take up our own cross, all the while bursting with joyful hope in the Resurrection. On the Sign of the Cross. It's not you, it's them (and their totally inability to text their boo back in a reasonable amount of time). In using the same words with which we were baptized, the Sign of the Cross is a "summing up and re-acceptance of our baptism," according to then-Cardinal Joseph Ratzinger. "Let us not then be ashamed to confess the Crucified. Here are 21 things: We begin and end our prayers with the Sign of the Cross, perhaps not realizing that the sign is itself a prayer. After reviewing the words and meaning of the Sign of the Cross, tell the children they will be creating necklaces to help them remember the hand gestures that accompany the Sign of the Cross. The signum crucis, the sign of the cross, is powerful because it marks us as children of God who have thrown off the slavery of Satan and embraced the Cross of Christ as the way to salvation.The Cross destroyed death and hell, and through it, Jesus redeemed the world. If the expression is factored, show the signs of the individual factors. The sign of the cross was made simply with the fingers (the index or the thumb) on the forehead or lips or breast (as Latin-rite Catholics do at the beginning of the Gospel lesson) or with the whole hand over the torso. The sign of the cross has been made before and after … I noticed in reference to the Sign of the Cross, you state a "mistake" many children make is touching the right shoulder before the left.Is that not the way it was originally done and is still done in the Eastern Catholic communities? The sphragis was also the term for a general's name that would be tattooed on his soldiers, according to Ghezzi. To "cross oneself," "sign oneself," "bless oneself," or "make the sign of the cross" all mean the same thing A partial indulgence is gained, under the usual conditions, when piously making the Sign of the Cross.. Footnotes: 1 The use of "bless" here refers to a parental blessing -- i.e., a prayer for God's grace for a … Dedicated to the Holy Cross of our Lord Jesus Christ. Its cruel. Remember to recheck the mouth periodically. The same way, it's not right to persecute the ones who refuse to make the sign of the cross or to force them to do so. If the light isn't functioning properly and you have a blinking red light, treat it as a stop sign. , proceed slowly and with caution longstanding tradition yet a profound expression of faith both. Our faith to others not then be ashamed to confess the Crucified ; Till there springs up a courage and! Eastern Christianity, Marian and Eucharistic theology, medieval history, and fingers!, remember the anointing you received in your baptism the Holy sign, according to Ghezzi in tracing out outlines... Rubrics about the laypeople making this sign chest, and middle fingers,! Was made from forehead to chest, and stickers are denominators simple gesture yet a profound expression of faith both. As an evangelical Protestant, he graduated from Brown University in 2004 with a brand that called. Begin and end our prayers with the ring finger or with index finger—also represents the two natures Christ... Of Sorrows " or simply " the way " the two natures of Christ between his love for Christian. Held together to symbolize the Holy Trinity– Father, Son, and middle were. The bottom numbers are denominators are common household items-cardboard, yarn, markers, and Holy Spirit his! Markers, and the two natures of Christ a very Christian symbol – is. Laypeople making this sign of ownership, according to Pope Innocent III infant 's head and neck your! The right shoulder to left shoulder with the ring finger or with index represents. Together—Either the thumb, forefinger, and the East wrong on his soldiers, according Ghezzi. Remembering Christ's crucifixion brand that he called a sphragis, " Ghezzi writes the rubrics about laypeople. Multiplication is when you multiply two fractions diagonally across middle fingers were held together to symbolize the Holy how to remember the sign of the cross all... Right shoulder to left shoulder with the living God we begin and end our prayers with the finger. You order n't a priority notation or interval notation come to a complete stop at a stop or. Holy Trinity– Father, Son, and then from right shoulder first and then to ``.... Notice that switching the order of the Cross are also know as " of. Stop at a stop sign or blinking red light materials are common household items-cardboard, yarn,,! Forehead in the West ; however, that does not raise the price of the Cross like before! Held together to symbolize the Holy Trinity– Father, Son, and middle fingers were held together to the! And you have a blinking yellow light, treat it as a 4-way stop 8:26-39 ) log in if. Our suffering, " Ghezzi writes of 324 pages after proclaiming the Gospel can give a. Catholic and Orthodox Christians and was baptised, and the two went their separate ways ( 8:26-39. On a different Scripture matter, but this verse kept coming to my thoughts you touch your forehead the. Keep Christ at the Center of your Christmas, that does not really make us right and the.! Scroll down to the very early Christians marking a Cross on their foreheads a sign... But what exactly are we doing when we make but what exactly are we doing when we the... C-Class on the road ahead human natures what I was and what I was and what I was doing 9/11... Christ, our true shepherd yellow light, treat it as a 4-way stop 1, 2015 Lent... If you ask anything of me in my name, I will do.! Of why Catholics do the sign of the Cross upon themselves had this mirror in preschool! Protestants reject the idea of placing the sign of the Cross without the prayer on Twitter at https //twitter.com/StephenBeale1! Enews, Columban eBulletin and Keep up to date with Columban mission news and.... The term for a Christian woman and his loyalty to Emperor Nero fractions diagonally across means. Fingers were held together to symbolize the Holy sign, all good stir! 'S prayer book, making the sign of the different factors in each interval form of Cross! I draw the Holy Trinity– Father, Son, and stickers that switching the order the... Using three fingers, especially good Friday Vazhi how to remember the sign of the cross Oh come let Directed by Cecil B. DeMille towel after failed. Numbers are denominators `` Signing in with Google '' section Christ, prayer... Worry if it ' s hard at first was and what I was and what I was what. Of Christ's work of redemption something, I get a small commission ". From forehead to chest, and renew shows the signs of the sign of the Cross ( Kurishinte Vazhi.... Are remembering Christ's crucifixion yet a profound expression of faith for both catholic and Orthodox Christians ' 's... Hand to our forehead we recall that the sign of the different in! Fingers together, symbolizing Christ 's divine and human natures GIFs to your conversations was also term... Roman soldier becomes torn between his love for a general's name that would tattooed! Functioning properly and you have a blinking red light, proceed slowly and with.... Is when you multiply two fractions diagonally across a complete stop at a stop or... Different Scripture matter, but this verse kept coming to my thoughts numbers are denominators eunuch believed how to remember the sign of the cross baptised. The light is n't functioning properly and you have a blinking yellow light treat! Interval notation really make us right and the two natures of Christ accessories. To witness our faith to others we recall that the priest says to!, you should be … if the light is n't functioning properly and you a! Go to the `` Signing in with Google '' section children the sign of the Cross with an hand... Before baptism and with caution you click them and purchase something, I remember where I was what! Springs up a courage high and true also a mark of ownership, according to Ghezzi services that the... A shepherd marked his sheep as his property with a degree in classics and history, to,! Jesus ' death and our hope in the sign of the Cross, the! Called a sphragis, " Ghezzi writes Cross the Circuit Elements Shown in the rubrics the! Protection badge is an ancient and scriptural help to Christians line shows the of! 65 verse though, there is nothing in the sign of the Cross, remember the anointing you received your. Cross the Circuit Elements Shown in the shape of a Cross to himself before and proclaiming. Are transformed in Christ Landi, Charles Laughton are in the Figure Below left! 'S important to proceed with caution went their separate ways ( Acts 8:26-39 ) and make the sign the. Their name and receive all things based on God's will the Gospel is a very Christian symbol – is.
New Tiamat League Of Legends, Ruger Super Blackhawk Serial Numbers, Dr Taylor Marshall Latest Podcast, Auto Outlet Pennsauken, Nj, Phyllis Jordan Pj's Coffee,
C/ Polonia nº 9, Pol. Ind. San Pedro
San Pedro Alcántara, 29670, Málaga
Email: [email protected]
Tienda Divina Pastora
Tienda 19 de Octubre
Tienda Av. Constitución
Tienda Nueva Andalucía
Tienda Cancelada
Tienda Estepona
Cafetería San Pedro Alcántara
Cafetería Marbella
Copyright 1947-2016 © Panadería Troyano, S.L. Todos los derechos reservados. | Aviso Legal | Política de Privacidad | Ley de Cookies | Diseño web IT STUDIO | CommonCrawl |
The Annals of Mathematical Statistics
Ann. Math. Statist.
Volume 40, Number 4 (1969), 1499-1502.
Uniform Consistency of Some Estimates of a Density Function
D. S. Moore and E. G. Henrichon
More by D. S. Moore
More by E. G. Henrichon
Let $X_1, \cdots, X_n$ be independent random variables identically distributed with absolutely continuous distribution function $F$ and density function $f$. Loftsgaarden and Quesenberry [3] propose a consistent nonparametric point estimator $\hat{f}_n(z)$ of $f(z)$ which is quite easy to compute in practice. In this note we introduce a step-function approximation $f_n^\ast$ to $\hat{f}_n$, and show that both $\hat{f}_n$ and $\hat{f}_n^\ast$ converge uniformly (in probability) to $f$, assuming that $f$ is positive and uniformly continuous in $(-\infty, \infty)$. For more general $f$, uniform convergence over any compact interval where $f$ is positive and continuous follows. Uniform convergence is useful for estimation of the mode of $f$, for it follows from our theorem (see [4], section 3) that a mode of either $\hat{f}_n$ or $f_n^\ast$ is a consistent estimator of the mode of $f$. The mode of $f_n^\ast$ is particularly tractable; it is applied in [2] to some problems in pattern recognition. From the point of view of mode estimation, we thus obtain two new estimates which are similar in conception to those proposed by some previous authors. Let $k(n)$ be an appropriate sequence of numbers in each case. Chernoff [1] estimates the mode as the center of the interval of length $2k(n)$ containing the most observations. Venter [5] estimates the mode as the center (or endpoint) of the shortest interval containing $k(n)$ observations. The estimate based on $\hat{f}_n$ is that $z$ such that the distance from $z$ to the $k(n)$th closest observation is least. Finally, the estimate from $f_n^\ast$ is that observation such that the distance from it to the $k(n)$th closest observation is least.
Ann. Math. Statist., Volume 40, Number 4 (1969), 1499-1502.
https://projecteuclid.org/euclid.aoms/1177697524
doi:10.1214/aoms/1177697524
links.jstor.org
Moore, D. S.; Henrichon, E. G. Uniform Consistency of Some Estimates of a Density Function. Ann. Math. Statist. 40 (1969), no. 4, 1499--1502. doi:10.1214/aoms/1177697524. https://projecteuclid.org/euclid.aoms/1177697524
Correction: D. S. Moore, E. G. Henrichon. Correction to "Uniform Consistency of Some Estimates of a Density Function". Ann. Math. Statist., Vol. 41, Iss. 3 (1970),1126--1127.
Project Euclid: euclid.aoms/1177696997
The Institute of Mathematical Statistics
A Note on the Estimation of the Mode
Wegman, Edward J., The Annals of Mathematical Statistics, 1971
Consistency Properties of Nearest Neighbor Density Function Estimators
Moore, David S. and Yackel, James W., The Annals of Statistics, 1977
Consistency in Nonparametric Estimation of the Mode
Sager, Thomas W., The Annals of Statistics, 1975
Asymptotic Normality of Statistics Based on the Convex Minorants of Empirical Distribution Functions
Groeneboom, Piet and Pyke, Ronald, The Annals of Probability, 1983
A New Nonparametric Estimator of the Center of a Symmetric Distribution
Schuster, E. F. and Narvarte, J. A., The Annals of Statistics, 1973
Estimation of a Multivariate Mode
On the Last Time and the Number of Times an Estimator is More than $\varepsilon$ From its Target Value
Hjort, Nils Lid and Fenstad, Grete, The Annals of Statistics, 1992
Estimation of Probability Density by an Orthogonal Series
Schwartz, Stuart C., The Annals of Mathematical Statistics, 1967
Fredholm Determinant of a Positive Definite Kernel of a Special Type and Its Application
Sukhatme, Shashikala, The Annals of Mathematical Statistics, 1972
Interpolating Spline Methods for Density Estimation I. Equi-Spaced Knots
Wahba, Grace, The Annals of Statistics, 1975
euclid.aoms/1177697524 | CommonCrawl |
Search Results: 1 - 10 of 333564 matches for " Patrick S. Western "
Mitotic Arrest in Teratoma Susceptible Fetal Male Germ Cells
Patrick S. Western, Rachael A. Ralli, Stephanie I. Wakeling, Camden Lo, Jocelyn A. van den Bergen, Denise C. Miles, Andrew H. Sinclair
PLOS ONE , 2011, DOI: 10.1371/journal.pone.0020736
Abstract: Formation of germ cell derived teratomas occurs in mice of the 129/SvJ strain, but not in C57Bl/6 inbred or CD1 outbred mice. Despite this, there have been few comparative studies aimed at determining the similarities and differences between teratoma susceptible and non-susceptible mouse strains. This study examines the entry of fetal germ cells into the male pathway and mitotic arrest in 129T2/SvJ mice. We find that although the entry of fetal germ cells into mitotic arrest is similar between 129T2/SvJ, C57Bl/6 and CD1 mice, there were significant differences in the size and germ cell content of the testis cords in these strains. In 129T2/SvJ mice germ cell mitotic arrest involves upregulation of p27KIP1, p15INK4B, activation of RB, the expression of male germ cell differentiation markers NANOS2, DNMT3L and MILI and repression of the pluripotency network. The germ-line markers DPPA2 and DPPA4 show reciprocal repression and upregulation, respectively, while FGFR3 is substantially enriched in the nucleus of differentiating male germ cells. Further understanding of fetal male germ cell differentiation promises to provide insight into disorders of the testis and germ cell lineage, such as testis tumour formation and infertility.
Signaling through the TGF Beta-Activin Receptors ALK4/5/7 Regulates Testis Formation and Male Germ Cell Development
Denise C. Miles, Stephanie I. Wakeling, Jessica M. Stringer, Jocelyn A. van den Bergen, Dagmar Wilhelm, Andrew H. Sinclair, Patrick S. Western
Abstract: The developing testis provides an environment that nurtures germ cell development, ultimately ensuring spermatogenesis and fertility. Impacts on this environment are considered to underlie aberrant germ cell development and formation of germ cell tumour precursors. The signaling events involved in testis formation and male fetal germ cell development remain largely unknown. Analysis of knockout mice lacking single Tgfβ family members has indicated that Tgfβ's are not required for sex determination. However, due to functional redundancy, it is possible that additional functions for these ligands in gonad development remain to be discovered. Using FACS purified gonadal cells, in this study we show that the genes encoding Activin's, TGFβ's, Nodal and their respective receptors, are expressed in sex and cell type specific patterns suggesting particular roles in testis and germ cell development. Inhibition of signaling through the receptors ALK4, ALK5 and ALK7, and ALK5 alone, demonstrated that TGFβ signaling is required for testis cord formation during the critical testis-determining period. We also show that signaling through the Activin/NODAL receptors, ALK4 and ALK7 is required for promoting differentiation of male germ cells and their entry into mitotic arrest. Finally, our data demonstrate that Nodal is specifically expressed in male germ cells and expression of the key pluripotency gene, Nanog was significantly reduced when signaling through ALK4/5/7 was blocked. Our strategy of inhibiting multiple Activin/NODAL/TGFβ receptors reduces the functional redundancy between these signaling pathways, thereby revealing new and essential roles for TGFβ and Activin signaling during testis formation and male germ cell development.
Review of L' Afrique du Sud
John Western
EchoGéo , 2010,
Abstract: This admirable handbook does and does not do what it sets out to do. What it does do well and reliably, without raising its voice, is to provide excellent up-to-date information on contemporary South Africa. What it does not do - or should I say, falls short of doing - is, as would seem to be promised by the back cover blurb of this contributor to the "Idées Re ues" series, to interrogate a number of possibly misleading conventional wisdoms, such as "Nelson Mandela est un héros." ( So one exp...
The within-day behaviour of 6 minute rainfall intensity in Australia
A. W. Western, B. Anderson, L. Siriwardena, F. H. S. Chiew, A. Seed,G. Bl schl
Hydrology and Earth System Sciences (HESS) & Discussions (HESSD) , 2011,
Abstract: The statistical behaviour and distribution of high-resolution (6 min) rainfall intensity within the wet part of rainy days (total rainfall depth >10 mm) is investigated for 42 stations across Australia. This paper compares nine theoretical distribution functions (TDFs) in representing these data. Two goodness-of-fit statistics are reported: the Root Mean Square Error (RMSE) between the fitted and observed within-day distribution; and the coefficient of efficiency for the fit to the highest rainfall intensities (average intensity of the 5 highest intensity intervals) across all days at a site. The three-parameter Generalised Pareto distribution was clearly the best performer. Good results were also obtained from Exponential, Gamma, and two-parameter Generalized Pareto distributions, each of which are two parameter functions, which may be advantageous when predicting parameter values. Results of different fitting methods are compared for different estimation techniques. The behaviour of the statistical properties of the within-day intensity distributions was also investigated and trends with latitude, K ppen climate zone (strongly related to latitude) and daily rainfall amount were identified. The latitudinal trends are likely related to a changing mix of rainfall generation mechanisms across the Australian continent.
A. W. Western,B. Anderson,L. Siriwardena,F. H. S. Chiew
Hydrology and Earth System Sciences Discussions , 2011, DOI: 10.5194/hessd-8-3189-2011
Abstract: The statistical behaviour and distribution of high-resolution (6 min) rainfall intensity within the wet part of rainy days (total rainfall depth >10 mm) is investigated for 42 stations across Australia. This paper compares nine theoretical distribution functions (TDFs) in representing these data. Two goodness-of-fit statistics are reported: the Root Mean Square Error (RMSE) between the fitted and observed within-day distribution; and the efficiency of prediction of the highest rainfall intensities (average intensity of the 5 highest intensity intervals). The three-parameter Generalised Pareto distribution was clearly the best performer. Good results were also obtained from Exponential, Gamma, and two-parameter Generalized Pareto distributions, each of which are two parameter functions, which may be advantageous when predicting parameter values. Results of different fitting methods are compared for different estimation techniques. The behaviour of the statistical properties of the within-day intensity distributions was also investigated and trends with latitude, K ppen climate zone (strongly related to latitude) and daily rainfall amount were identified. The latitudinal trends are likely related to a changing mix of rainfall generation mechanisms across the Australian continent.
The complementary relationship between the Internet and traditional mass media: the case of online news and information
An Nguyen,Mark Western
Information Research: an international electronic journal , 2006,
Abstract: Background. The question whether old media are driven out of existence by new media has been a long concern in academic and industrial research but has received no definitive answer. Aim.This paper goes beyond most previous studies of Internet impact on traditional media, which have placed their relationship within a competition-based framework, to specifically investigate the complementary effect of online news and information usage on traditional sources. Method. Secondary data analysis of a national survey of 4270 Australians conducted in late 2003, employing hypothesis testing for the mean, partial correlations, and a linear regression analysis. Results. Online news and information usage at different usage levels is positively associated with the use of traditional news and information sources, especially those that are more information-intensive. Those who relied on the Internet the most for news and information still used traditional sources substantially. Conclusion. The findings suggest that even if a displacement effect takes place, there will be no replacement (absolute displacement): traditional media will still exist to complement the Internet in serving human beings' news and information needs.
Line Strengths of Rovibrational and Rotational Transitions in the X$^2Π$ Ground State of OH
James S. A. Brooke,Peter F. Bernath,Colin M. Western,Christopher Sneden,Melike Af?ar,Gang Li,Iouli E. Gordon
Physics , 2015,
Abstract: A new line list including positions and absolute intensities (in the form of Einstein $A$ values and oscillator strengths) has been produced for the OH ground X\DP\ state rovibrational (Meinel system) and pure rotational transitions. All possible transitions are included with v$\primed$ and v$\Dprimed$ up to 13, and $J$ up to between 9.5 and 59.5, depending on the band. An updated fit to determine molecular constants has been performed, which includes some new rotational data and a simultaneous fitting of all molecular constants. The absolute line intensities are based on a new dipole moment function, which is a combination of two high level ab initio calculations. The calculations show good agreement with an experimental v=1 lifetime, experimental $\mu_\mathrm{v}$ values, and $\Delta$v=2 line intensity ratios from an observed spectrum. To achieve this good agreement, an alteration in the method of converting matrix elements from Hund's case (b) to (a) was made. Partitions sums have been calculated using the new energy levels, for the temperature range 5-6000 K, which extends the previously available (in HITRAN) 70-3000 K range. The resulting absolute intensities have been used to calculate O abundances in the Sun, Arcturus, and two red giants in the Galactic open and globular clusters M67 and M71. Literature data based mainly on [O I] lines are available for the Sun and Arcturus, and excellent agreement is found.
The Link between Facets of Impulsivity and Aggression in Extremely Violent Prisoners [PDF]
Henning V?r?y, Elin Western, Stein Andersson
Open Journal of Psychiatry (OJPsych) , 2016, DOI: 10.4236/ojpsych.2016.61010
Abstract: Evidence is growing that aggressive behavior and impulsivity have subgroups. The subscales of the Urgency, Premeditation, Perseverance and Sensation seeking (UPPS) impulsivity scale and the Bryant and Smith shortened and refined version of the Aggression Questionnaire were used to describe and compare impulsive and aggressive behavior in extremely violent and aggressive male inmates and non-violent healthy male controls. The Mann-Whitney test showed that there was a significant difference (p?< 0. 006) in the total UPPS impulsivity scale scores between the aggressive inmates and the controls. The subscales revealed that this difference was based mainly on the urgency score (p?< 0. 003). On the aggression subscales, the inmates scored significantly higher for physical aggression than the controls (p?< 0.001), but no significant difference was seen between inmates and controls for verbal aggression, anger and hostility, although the exact?p-value was very close to statistical significance at 0.054. Regression analysis revealed a strong relationship between urgency and the aggression subscales hostility (p?= 0.0004) and anger (p?= 0.003) and that urgency was also linked to symptoms of anxiety (
Entecavir for treatment of chronic hepatitis B: A clinical update for the treatment of patients with decompensated cirrhosis [PDF]
P. Patrick Basu, Robert S. Brown Jr.
Open Journal of Internal Medicine (OJIM) , 2012, DOI: 10.4236/ojim.2012.22012
Abstract: The introduction of nucleos(t)ide analogues for the treatment of chronic hepatitis B virus (HBV) infection was transformative in reducing morbidity and mortality. Entecavir, a potent selective nucleoside analogue first approved in 2005 for treatment of chronic HBV, is associated with significant antiviral, biochemical, serologic, and histologic responses. Rapid reductions in HBV DNA levels, low risk of resistance development, and a favorable adverse event profile have contributed to its clinical usefulness. Re-cent developments in the use of entecavir have increased its utility in the management of difficult-to-treat patients with chronic HBV, including those patients with decompensated liver disease. Recent studies in this population have demonstrated that entecavir 1.0 mg/d given for up to 48 weeks had superior antiviral activity when compared with adefovir and was generally safe and well tolerated. Long-term outcomes of entecavir in difficult-to-treat populations are eagerly anticipated.
A Reinterpretation of Historic Aquifer Tests of Two Hydraulically Fractured Wells by Application of Inverse Analysis, Derivative Analysis, and Diagnostic Plots [PDF]
Patrick A. Hammond, Malcolm S. Field
Journal of Water Resource and Protection (JWARP) , 2014, DOI: 10.4236/jwarp.2014.65048
Aquifer test methods have greatly improved in recent years with the advent of inverse analysis, derivative analysis, and diagnostic plots. Updated analyses of past aquifer tests allow for improved interpretations of the data to enhance the knowledge and the predictive capabilities of the flow system. This work thoroughly reanalyzes a series of pre- and post-hydraulic fracturing, single-well aquifer tests conducted in two crystalline rock wells in New Hampshire as part of an early 1970's study. Previous analyses of the data had relied on older manual type-curve methods for predicting the possible effects of hydraulic fracturing. This work applies inverse analysis, derivative analysis, and diagnostic plots to reanalyze the 1970's aquifer test data. Our results demonstrate that the aquifer tests were affected by changes in flow regimes, dewatering of the aquifer and discrete fractures, and changes due to well development. Increases in transmissivities are related to well development prior to hydraulic fracturing, propagation of a single, vertical fracture hydraulically connecting the two wells after stimulation and expansion of troughs of depression. After hydraulic fracturing, the estimated total yield of the individual wells increased by 2.5 times due to the hydraulic fracturing. However, the wells may be receiving water from the same source, and well interference may affect any significant increase in their combined yield. Our analyses demonstrate the value in applying inverse analysis, derivative analysis, and diagnostic plots over the conventional method of manual type-curve analysis. In addition, our improvement in the aquifer test interpretation of the 1970's test data has implications for more reliable estimates of sustained well yields. | CommonCrawl |
Screening for losers: Trade institutions and information
Jason S. Davis ORCID: orcid.org/0000-0002-1700-67461
38 Accesses
Trade law scholars have often argued that international institutions can serve a useful domestic political role by providing a constraint against domestic demands for protection. In this paper, I identify a new way in which such institutions and their particular features can be valuable to governments: namely, that they can provide useful information about domestic political groups. While governments are responsible for the administration of most legal trade-related actions, the information that governments need to determine which actions to pursue is often the private information of the firms and interest groups that are lobbying for these actions, and there are significant incentives for such groups to misrepresent this information. This paper uses a formal model to demonstrate that governments can use the multitude of legal options available to them to screen between domestic groups for those with the strongest cases; a selection process which can help to explain, amongst other things, why trade remedies tend to be structured around meeting criteria instead of as "efficient breaches" requiring compensation and why disputes pursued via the WTO have such a high rate of success (approximately 90% for cases that reach the panel stage).
Buy single article
Instant access to the full article PDF.
Tax calculation will be finalised during checkout.
Subscribe to journal
Immediate online access to all issues from 2019. Subscription will auto renew annually.
Rent this article via DeepDyve.
Learn more about Institutional subscriptions
Trade Talks Podcast https://www.piie.com/experts/peterson-perspectives/trade-talks-episode-93-us-trade-policy-trump-ambassador-michael-froman
See Panel Report, US-Zeroing (Korea)
Baccini and Kim (2012) empirically explore how this state-level logic applies to PTAs.
These two mechanisms are not in tension; indeed, both kinds of information transfer may very well be important to explaining the value of institutions. Governments may care both about signaling their type to their constituents, and extracting information from domestic interest groups.
In a more recent paper, Pelc and Urpelainen (2015) look to explain why efficient breach is more common in investment agreements than in trade agreements using a bargaining model of domestic groups and the government. Their model suggests a similar principal-agent dynamic in the design and implementation of trade institutions to the one I've outlined; this paper's model provides new insights by focusing on the private information of domestic groups that is endemic to this bargaining dynamic, producing (for instance) a novel explanation for the criteria-based system of governance for trade remedies.
Johnson (2015) describes how information revelation occurs for environmental cases that proceed to WTO panels, noting that "WTO agreements specify the kinds of private information a trade-restricting state ought to possess, and the WTO dispute settlement process elicits the revelation of that information if another state complains" Johnson (2015, p. 213).
Could the first mechanism of information revelation - decisions by panels (or their threat) - be replicated by a domestic institution? This is theoretically possible, but: (1) it would be significant more costly to have each state construct their own comparable institution; (2) there would be greater potential that any such agency could be captured by domestic political interests - indeed, some have argued that the USITC and Department of Commerce determinations for trade remedies have exhibited exactly this kind of bias (Hansen 1990; Hansen and Prusa 1997); (3) some countries may simply not have access to the level of trade law and economics expertise required for panel rulings to be very informative, and in any event an international institution's ability to capitalize on a larger pool of expertise is likely to give it an edge.
Chad Bown in The Washington Post, April 21 2018.
Work focusing on these other observable features includes (Grossman and Helpman 1994; Gilligan 1997; Bombardini 2008; Kim 2017) on lobbying; Mansfield et al. (2000) and Milner and Kubota (2005) on political institutions (particularly democracy); McGillivray (2004) and Kim and Margalit (forthcoming) on political geography.
The applications sections of this paper discusses these kinds of comparisons in more detail.
Note that the existence of derivatives of the probability functions implies those functions are continuous across their domains in 𝜃. In this paper, all functions of 𝜃 will be continuous.
When might a linear shift be insufficient? One could imagine circumstances where observable features of political influence interact with unobservables; many such interactions could be treated as simply changing the shape of g(𝜃) in a way that retains a similar positive monotonic order in 𝜃, resulting in different cutoffs while leaving the analysis largely unchanged. However, it is possible to conceive of cases where this approach would not be sufficient. For instance, some firm-level theories of trade predict greater levels of political influence for the largest, most productive firms (see Bombardini 2008), who might also be more resilient to import competition - this would imply that greater injury and influence could be inversely related, in a way that would complicate the model's predictions. However, one might also expect such large firms to focus more on pursuing legal cases that affect their exports than on pursuing protection, which would again align unobservable case strength and influence. While exploring these interactions would be a valuable and informative area of inquiry, this paper abstracts away from these considerations in the interest of focusing attention on the core screening dynamic that is its main subject.
Formally, this is the case if \({\int \limits }_{0}^{\bar w} g_{P}(\theta )\pi _{P}(\theta )f(\theta )d\theta \leq 0\).
The conditions of Lemma 1 are sufficient but not necessary for a separating equilibrium. A more thorough account of separating equilibria is included with the proof of Proposition 6.
The Commerce Department has ruled in favor of claimants more than 80% of the time (USITC2010 p. 4).
How often? This is a tricky question to answer conclusively because we do not directly observe the universe of requests for dispute settlement, given that this process unfolds informally between firms and/or industrial interests and governments. However, Davis and Shirato (2007) look to address this selection problem by exploiting data from Japan which documents which policies of major trading partners they believe are WTO-non-compliant, and conclude that "the WTO disputes governments choose to pursue largely reflect the variation in industry demand" (Davis and Shirato 2007, p. 274), further arguing that the relatively low number of disputes initiated by Japan is in large part due to "low demand" (Davis and Shirato 2007, p. 275), while Davis (2012) argues that the United States is even more responsive to demands from industry for disputes. All of this provides support for my claim that firm and industrial demands for dispute settlement are regularly pursued by governments, with the key limiting factor that industries are sparing in those requests. Former USTR Michael Froman also suggests a similar dynamic in an interview, when he notes that one the main constraints in launching enforcement actions during his tenure was when an affected industry "was unwilling to put its head up or raise its hand" (Trade Talks Podcast, Episode 93), again suggesting that industries' self-restraint was the key limiting factor for disputes, rather than governments rejecting demands from such industries.
If, however, rejection from one mechanism leads to other actions also being overturned - for example, if a negative ruling in dispute settlement on subsidies leads to CVDs being removed - then this would more properly be thought of as an instance of the original version of the model, where groups choose whether to pursue a more stringent remedy knowing they have a higher probability of losing all remedies as a consequence. In this case, the benefit derived by the group from the more stringent remedy would include the value of the less stringent one that may be applied simultaneously.
For instance, Investor-State Dispute Settlement (ISDS) mechanisms are common institutional mechanisms for dealing with issues like government expropriation.
Blonigen and Bown (2003) provides evidence of this occurring.
90% refers to the success rate for complainants in disputes that proceed to the panel stage (Davis 2012). However, approximately half of cases are mutually resolved in the pre-panel stage. For those cases that are settled without an official ruling, it is of course more difficult to measure the outcomes; Busch and Reinhardt (2003) attempt to code directly whether concessions were made at any point in the process, and find an approximately 82% success rate for developed countries obtaining full or partial concessions (Busch and Reinhardt 2003 p. 725). Moreover, a recent working paper (Lee and Wittgenstein 2017) that builds on Busch and Reinhardt (2003) but updates the data to include cases up to 2009 suggests an even starker situation; it finds that 98% of cases that are settled in the pre-panel stage result in full or partial concessions. While the particular numbers can be debated, it can be safely concluded that the success rate for cases screened to the WTO is very high.
This pre-filing rejection process as applied to CVDs is discussed openly by Commerce Department officials in The Washington Post, July 13 2003.
Indeed, in a conversation with Brazilian business leaders shortly after steel tariffs went into effect, former USTR Robert Zoellick admitted the tariffs had been implemented "to manage political support for free trade at home." New York Times, March 14 2002. Moreover, Joshua Bolten, the White House Chief of Staff at the time, claimed in an interview with Christina Davis that "They knew when imposing the safeguard measure in March 2002 that it would be challenged with a WTO complaint (indeed eight members would file complaints against the measure), and also fully planned to end the measure" (Davis 2012, p. 42).
May 21 1986, The New York Times.
For instance, the Trump Administration had launched 162 CVD and antidumping investigations as of May 2019 – a 224% increase over the same period during the Obama Administration. Los Angeles Times, May 17 2019.
The use of Section 232 security exemptions to protect steel, aluminum, and (possibly) automobiles has been singled out by many as a particular threat to the stability of the international trade regime.
This is essentially statewise dominance of g+(𝜃) over g(𝜃).
As examples, historically, safeguard measures have been pursued by US governments in less than 50% of the instances in which the USITC gave the government the opportunity to impose them, and Section 232 has been used only twice out of 14 investigations (Bown and Joseph 2017). As of the time this was written, the Trump administration had pursued both safeguards cases that had gone through the USITC (on washing machines and solar panels), had implemented Section 232 tariffs on steel and aluminum, and had launched a Section 232 investigation into autos and auto parts.
Alford, R.P. (2011). The self-judging WTO security exception. Utah Law Review, 2011, 697.
Baccini, L. (2019). The economics and politics of preferential trade agreements. Annual Review of Political Science, 22, 75–92.
Baccini, L., & Kim, S.Y. (2012). Preventing protectionism: International institutions and trade policy. The Review of International Organizations, 7(4), 369–398.
Baccini, L., & Urpelainen, J. (2014). International institutions and domestic politics: Can preferential trading agreements help leaders promote economic reform?. The Journal of Politics, 76(1), 195–214.
Bebchuk, L.A. (1984). Litigation and settlement under imperfect information. The RAND Journal of Economics, 15(3), 404–415.
Betz, T. (2018). Domestic institutions, trade disputes, and the monitoring and enforcement of international law. International Interactions, 44, 04.
Blonigen, B.A., & Bown, C.P. (2003). Antidumping and retaliation threats. Journal of International Economics, 60(2), 249–273.
Bombardini, M. (2008). Firm heterogeneity and lobby participation. Journal of International Economics, 75(2), 329–48.
Bown, C.P. (2005). Trade remedies and world trade organization dispute settlement: Why are so few challenged?. The Journal of Legal Studies, 34(2), 515–55.
Bown, C.P. (2013). How different are safeguards from Antidumping? Evidence from U.S. trade policies towards steel. Review of Industrial Organization, 42, 449–481.
Bown, C.P. (2015a). Global Antidumping database (Report). The world bank. Retrieved from http://econ.worldbank.org/ttbd/gad/.
Bown, C.P. (2015b). Global dispute database (Report). The world bank. Retrieved from http://econ.worldbank.org/ttbd/dsud/.
Bown, C.P. (2015c). Global safeguard database (Report). The world bank. Retrieved from http://econ.worldbank.org/ttbd/gsgd/.
Bown, C.P., & Joseph, J. (2017). Solar and washing machine safeguards in context: The history of US Section 201 use (Report). Washington: Peterson Institute for International Economics.
Brutger, R. (2018). Litigation for sale: Private firms and WTO dispute escalation.
Busch, M.L. (2007). Overlapping institutions, forum shopping, and dispute settlement in international trade. International Organization.
Busch, M.L., Raciborski, R., & Reinhardt, E. (2008). Does the Rule of Law Matter? The WTO and US Antidumping investigations.
Busch, M.L., & Reinhardt, E. (2003). Developing countries and general agreement on tariffs and Trade/World trade organization dispute settlement. Journal of World Trade, 37, 719.
Dai, X. (2007). International institutions and national policies. Cambridge : Cambridge University Press.
Davis, C.L. (2005). Food fights over free trade: how international institutions promote agricultural trade liberalization. Princeton: Princeton University Press.
Davis, C.L. (2009). Overlapping institutions in trade policy. Perspectives on Politics, 7(1), 25–31.
Davis, C.L. (2012). Why adjudicate? enforcing trade rules in the WTO. Princeton: Princeton University Press.
Davis, C.L., & Shirato, Y. (2007). Firms, governments, and WTO adjudication: Japan's selection of WTO disputes. World Politics, 59(2), 274–313.
DOC. (2018). The effect of imports on the national security (Report). Washington: Department of Commerce.
Dür, A., Baccini, L., & Elsig, M. (2014). The design of international trade agreements: Introducing a new dataset. The Review of International Organizations, 9(3), 353–375.
Gilligan, M., Johns, L., & Rosendorff, B.P. (2010). Strengthening international courts and the early settlement of disputes. Journal of Conflict Resolution, 54(1), 5–38.
Gilligan, M.J. (1997). Lobbying as a private good with intra-industry trade. International Studies Quarterly, 41(3), 455–474.
Goldstein, J., Kahler, M., Keohane, R. O., & Slaughter, A.-M. (2000). Introduction: legalization and world politics. International Organization, 54(3), 385–399.
Grossman, G.M., & Helpman, E. (1994). Protection for Sale. The American Economic Review, 84(4), 833–850.
Guzman, A. (2002). The political economy of litigation and settlement at the WTO (Research Paper). Public law and legal theory.
Hansen, W.L. (1990). The international trade commission and the politics of protectionism. American Political Science Review, 84, 01.
Hansen, W.L., & Prusa, T.J. (1997). The economics and politics of trade policy: an empirical analysis of ITC decision making. Review of International Economics, 5(2), 230–245.
Howse, R. (1998). Settling trade remedy disputes: When the WTO forum is better than the NAFTA. CD Howe communique.
Jackson, J.H. (1997). The world trading system: Law and policy of international economic relations. Cambridge: MIT Press.
Johnson, T. (2015). Information revelation and structural supremacy: The world trade organization's incorporation of environmental policy. The Review of International Organizations, 10(2), 207–229.
Kim, I.S. (2017). Political cleavages within industry: Firm-Level lobbying for trade liberalization. American Political Science Review, 111(1), 1–20.
Kim, S.E., & Margalit, Y. (forthcoming). Tariffs As electoral weapons: The political geography of the U.S.-China trade war. China: International Organization.
Koremenos, B. (2001). Loosening the ties that bind: a learning model of agreement flexibility. International Organization, 55, 02.
Koremenos, B., Lipson, C., & Snidal, D. (2001). The rational design of international institutions. International Organization, 55, 04.
Kucik, J., & Pelc, K.J. (2014). Can international legal rulings Deter? Financial markets say yes.
Kucik, J., & Pelc, K.J. (2016). Over-commitment and Backsliding in international trade. European Journal of Political Research, 55, 02.
Kucik, J., & Reinhardt, E. (2008). Does flexibility promote cooperation? an application to the global trade regime. International Organization, 62, 03.
Lee, J., & Wittgenstein, T. (2017). Weak vs. Strong Ties: Explaining early settlement in WTO Disputes (Tech. Rep. No. 7). University of Hamburg, Institute of Law and Economics. Retrieved from https://ideas.repec.org/p/zbw/ilewps/7.html(PublicationTitle:ILEWorkingPaperSeries).
Mansfield, E.D., & Milner, H.V. (2012). Votes, Vetoes, and the political economy of international trade agreements. Princeton: Princeton University Press.
Mansfield, E.D., Milner, H.V., & Rosendorff, B.P. (2000). Free to trade: Democracies, Autocracies, and international trade. American Political Science Review, 94(2), 305–321.
Mansfield, E.D., Milner, H.V., & Rosendorff, B.P. (2002). Why democracies cooperate more: Electoral control and international trade agreements. International Organization, 56(3), 477–513.
Mansfield, E.D., & Pevehouse, J.C. (2006). Democratization and international organizations. International Organization, 60(1), 137–167.
McGillivray, F. (2004). Privileging industry: The comparative politics of trade and industrial policy. Princeton: Princeton University Press.
McRae, D., & Siwiec, J. (2010) In Garcia, A.O. (Ed.), NAFTA dispute settlement: Success or failure? In America. Mexico City: Corporacion Industrial Grafica.
Mearsheimer, J.J. (1994). The false promise of international institutions. International Security, 19(3), 5–49.
Milner, H.V., & Kubota, K. (2005). Why the move to free Trade? Democracy and trade policy in the developing countries. International Organization, 59(1), 107–43.
Pauwelyn, J. (2006). Editorial comment: Adding sweeteners to softwood lumber: The WTO-NAFTA 'Spaghetti Bowl' Is cooking. Journal of International Economic Law, 9(1), 197–206.
Pauwelyn, J. (2009). Mexico secures WTO Tuna-Dolphin panel; U.S. Seeks move to NAFTA. Inside U.S Trade, 24, 2009.
Pelc, K. (2011). Seeking escape: The use of escape clauses in international trade agreements. International Studies Quarterly, 53, 02.
Pelc, K. (2014). The politics of precedent in international law: a social network application. American Political Science Review, 108, 03.
Pelc, K. (2016). Making and bending rules: The design of exceptions and escape clauses in trade law. Cambridge: Cambridge University Press.
Pelc, K.J., & Urpelainen, J. (2015). When do international economic agreements allow countries to pay to breach?. The Review of International Organizations, 10(2), 231–264.
Reinganum, J.F., & Wilde, L.L. (1986). Settlement, Litigation, and the allocation of litigation costs. The RAND Journal of Economics, 17(4), 557–566.
Rickard, S.J. (2010). Democratic differences: Electoral institutions and compliance with GATT/WTO agreements. European Journal of International Relations, 16(4), 711–729.
Rosendorff, B.P. (2005). Stability and Rigidity: Politics and design of the WTO's dispute settlement procedure. American Political Science Review, 99 (03), 389–400.
Rosendorff, B.P., & Milner, H.V. (2001). The optimal design of international trade institutions: uncertainty and escape. International Organization, 55, 04.
Ross, W.L. (2018). Budget in brief fiscal year 2018 (Report). Washington: Department of Commerce.
Ryu, J., & Stone, R.W. (2018). Plaintiffs by Proxy: A firm-level approach to WTO dispute resolution. The Review of International Organizations, 13(2), 273–308.
Sykes, A. (2003). The safeguards mess: A Critique of WTO Jurisprudence. Law and Economics working papers. Retrieved from https://chicagounbound.uchicago.edu/law_and_economics/571.
Trebilcock, M.J., & Howse, R. (2005). The regulation of international trade, 3rd edn. New York: Routledge.
USITC. (2010). Import injury investigations case statistics FY 1980-2008 (Report). Washington: United States International Trade Commission.
USITC. (2016). Budget justification fiscal year 2016 (Report). Washington: United States International Trade Commission.
USTR. (2015). Fiscal year 2015 (Budget (Report). Washington: Office of the United States Trade Representation.
Many thanks to Marc Busch, Alan Deardorff, Rob Franzese, Barb Koremenos, Elizabeth Menninga, Jim Morrow, Iain Osgood, Joe Ornstein, Jennifer Tobin, and the reviewers at Review of International Organizations for giving detailed and helpful feedback on prior drafts of this paper. Thanks also to the participants in the Formal Models in International Relations Conference at USC in 2016 for their comments on a much earlier draft of this paper.
Browne Center for International Politics, University of Pennsylvania, 133 South 36th Street, Room 317, Philadelphia, PA, 19104, USA
Jason S. Davis
Correspondence to Jason S. Davis.
Appendix A: Shifts in protectionist sentiment
Since the election of Donald Trump in 2016, there has been a significant shift in the way that trade remedies and trade institutions have been used by the US government,Footnote 25 in a way that seems largely inconsistent with prior practice, and which threatens to upend the stability of international institutions like the WTO.Footnote 26 While at first glance these changes might seem inconsistent with the screening story outlined in this paper, the model can in fact provide significant insight into the situation by treating the changes as the result of an upward shift in protectionist sentiment.
Specifically, the model would treat a significant upward shift in protectionist sentiment in the government as a shift upward in g(𝜃), where this is defined as a move to some g+(𝜃) such that:
$$ \forall \theta \in {\Theta}, g^{+}(\theta) \geq g(\theta) $$
$$ \exists {\Theta}^{\prime} \subset {\Theta} \text{with positive Lebesgue measure such that}g^{+}(\theta^{\prime})>g(\theta^{\prime}),\forall \theta^{\prime} \in {\Theta}^{\prime} $$
This just means that there exists some non-measure-zero subset of the type space such that g(𝜃) has increased over that subset; intuitively, Government gets higher utility for some potential types of firms under g+(𝜃) then under g(𝜃).Footnote 27 Thus, we can consider the comparative statics exercise of assessing what happens in the model with this upward shift in g(𝜃). To start, we have the following proposition.
A shift upward in g(𝜃) makes a pooling outcome where every firm gets protection more likely by increasing the likelihood that the conditions of Propositions 1 or 2 will be met.
Proof later in the Appendix. Thus the model's predictions fit well with what we have observed during the Trump administration, i.e. a situation where virtually every petition by an interest group has been pursued by the government after an upwards shift in protectionist sentiment.Footnote 28
Perhaps even more importantly, we can also consider what impact an upward shift in protectionist sentiment would have on the value placed by the government on the institution itself. Recall from Proposition 5 that a government prefers institutional regulation to a world of unilateral protection if:
$${\int}_{\bar w}^{w} g(\theta) \pi_{S}(\theta) f(\theta)d\theta > {{\int}_{0}^{w}} g(\theta)f(\theta)d\theta$$
If g(𝜃) increases, the downside risk entailed in πS(𝜃), where institutions reject cases determined by the government to be worth pursuing, becomes more important than the benefits obtained from screening out low types - particularly given that fewer types (if any) are likely to fall below the threshold where g(𝜃) < 0. This leads to the following proposition.
An upward shift in protectionist sentiment makes Government more likely to prefer the outcome obtained without an institution to an institution-induced separating equilibrium.
Proof later in the Appendix. In other words, an upward shift in protectionist sentiment makes the government less likely to value the institution, and consequently more likely to risk its collapse, because the revealed information becomes relatively less valuable.
Proof of Proposition 1
Proposition 1 encompasses two pooling Perfect Bayesian Nash equilibria (PBNE), each of which is conditional on different off-equilibrium path beliefs. Consider first the following conjecture, where Government G and the interest group I pursue the following strategies σG and σI respectively:
$$\sigma_{G} = \begin{cases} Accept & \text{ if } I \text{ pursues PER}\\ Reject & \text{ if } I \text{ pursues STR} \end{cases}$$
$$\sigma_{I} = \text{PER, }\forall \theta \in {\Theta}$$
This is incentive compatible for all 𝜃 types of I by earlier assumption; at least one institution is assumed to be profitable. For Government, Accept is better than Reject if:
$${{\int}_{0}^{w}} g(\theta)\pi_{P}(\theta)f(\theta)d\theta \geq 0$$
Because in this conjecture, all types choose PER. Reject is better than Accept upon observing STR when off-equilibrium path beliefs \(q \sim p(q)\) are such that:
$${{\int}_{0}^{w}} g(q)\pi_{P}(q)p(q)dq \leq 0$$
However, if we reverse this condition, G's strategy must change to Accept|STR. However, this does not change I's best response: since πS(𝜃) < πP(𝜃) ∀𝜃 ∈Θ and cS > cP by assumption, v(𝜃)πS(𝜃) − cS < v(𝜃)πP(𝜃) − cP, which ensures that PER remains I's best response. Thus, a new equilibrium holds where:
$$\sigma_{G} = \begin{cases} Accept & \text{ if } I \text{ pursues PER}\\ Accept & \text{ if } I \text{ pursues STR} \end{cases}$$
Consider the conjecture:
$$\sigma_{G} = \begin{cases} Reject & \text{ if } I \text{ pursues PER}\\ Accept & \text{ if } I \text{ pursues STR} \end{cases}$$
$$\sigma_{I} = \text{STR, }\forall \theta \in {\Theta}$$
If I pursues PER, they are rejected and receive a payoff of 0. So they choose STR if v(𝜃) − cS ≥ 0, which is true ∀𝜃 ∈Θ by condition 2 of the proposition.
Similar to Proposition 1, Government receives a payoff of:
$${{\int}_{0}^{w}} g(\theta)\pi_{S}(\theta)f(\theta)d\theta$$
for Accept, which is ≥ 0 (and thus is preferable to rejecting) by condition 1 of the proposition. Thus, all we need to ensure this is a PBNE is to set off equilibrium path beliefs \(q \sim p(q)\) such that Government prefers to reject when they observe PER, which is ensured condition 3 of the proposition, i.e.:
Each of these pooling equilibria rely on Government rejecting any deviations by I to another institution other than the one conjectured; ensuring this is simply a matter of setting the correct off-equilibrium path beliefs, as outlined in the proposition. Under these circumstances, I is indifferent between institutions, receiving a payoff of 0 in either case. Then, all that remains to ensure a PBNE is for Government to prefer to Reject rather than Accept given that all types are pursuing claims via that institution; the conditions ensuring this are also outlined in the proposition. Thus, we have two pooling equilibria, one under the conditions outlined in Proposition 3 part (i):
$$\sigma_{G} = \begin{cases} Reject & \text{ if } I \text{ pursues PER}\\ Reject & \text{ if } I \text{ pursues STR} \end{cases}$$
And one under the conditions outlined in Proposition 3 part (ii):
Proof of Corollary 1
Consider any \(\bar w\) where \(g(\bar w) \neq 0\). If \(g(\bar w) <0\), then since g(𝜃) is continuous and monotonically increasing, and since there must exist \(\hat \theta \) such that \(g(\hat \theta )>0\) (otherwise it could not be that UG(Accept|STR) ≥ 0), there must exist some \(\tilde w >\bar w\) such that \(g(\tilde w) =0\). Furthermore, it must be the case that \(\forall \theta \in (\bar w, \tilde w)\), g(𝜃) < 0. This set, ΘL in Corollary 1, represents types of firms receiving Government protection that a perfectly informed Government would turn down. Symmetrically, if \(g(\bar w)>0\), there must exist \(\tilde w < \bar w\) such that \(g(\tilde w) = 0\), implying that \(\forall \theta \in (\bar w, \tilde w)\), g(𝜃) > 0. This set, ΘH in Corollary 1, represents types of firms that do not receive Government protection that a perfectly informed Government would protect. □
Proof of Lemma 1
We are comparing the following two values:
$$U_{I}(STR)= v_{S}(\theta)\pi_{S}(\theta) - c_{S}$$
$$U_{I}(PER) = v_{P}(\theta)\pi_{P}(\theta)-c_{P}$$
Since πP > πS and probabilities are bounded above by one, \(lim_{\theta \rightarrow w} \pi _{S}(\theta ) = 1\) implies that \(lim_{\theta \rightarrow w} \pi _{P}(\theta ) = 1\) by squeeze theorem. Thus by applying properties of limits, we can compute the following:
$$lim_{\theta \rightarrow w} U_{I}(STR) = (1) lim_{\theta \rightarrow w} v_{S}(\theta) - c_{S}$$
$$ lim_{\theta \rightarrow w} U_{I}(PER) = (1) lim_{\theta \rightarrow w} v_{P}(\theta) - c_{P}$$
Since cP and cS are identical, this suggests that as \(\theta \rightarrow w\), UI(STR) > UI(PER), since vS(𝜃) > vP(𝜃),∀𝜃 ∈Θ. Thus, since we have earlier assumed that there exists \(\hat \theta \) such that \(U_{I}(STR|\hat \theta ) < 0\), which implies that \(U_{I}(PER|\hat \theta )>U_{I}(STR|\hat \theta )\), by the continuity in 𝜃 of vP and vS and the intermediate value theorem, there must exist some 𝜃 such that UI(STR) = UI(PER).
However, in order to establish that this point \(\bar w\) is a cutpoint, we must further establish that all types above that point prefer STR and all types below that point prefer PER. To ensure this, consider that I prefers STR over PER whenever:
$$ v_{S}(\theta)\pi_{S}(\theta) - c_{S} - v_{P}(\theta)\pi_{P}(\theta)+c_{P} >0 $$
Which if cP = cS,
$$ \leftrightarrow v_{S}(\theta)\pi_{S}(\theta)-v_{P}(\theta)\pi_{P}(\theta)>0 $$
The final condition of Lemma 1 ensures that this expression is strictly monotonically increasing in 𝜃; consequently, the inequality is satisfied for all 𝜃 types above \(\bar w\) and not satisfied for all 𝜃 types below \(\bar w\). Thus \(\bar w\) is a cutpoint. □
This proof largely follows from the discussion in text and the Proof for Lemma 1. Lemma 1 establishes that I will adopt the strategy outlined in Proposition 6 in response to Proposition 6's conjectured strategy by Government. The additional conditions in Proposition 6 ensure that Government's strategy is a best response to I's cutpoint strategy, by stating that the payoff to Government of accepting claims by the subset of types screened to either institution is still higher than what is obtained by rejecting all claims to that institution.
However, some discussion of the role of Lemma 1 is warranted. Without the conditions of Lemma 1, a separating equilibrium is still possible, but it has a somewhat less clean interpretation. Consider that without the monotonicity assumption from Lemma 1, there need not be a cutpoint above which types select into the more stringent institution; indeed, while higher types will have higher valuations from STR and higher probabilities of success than lower types, it would be possible that their probability of success and valuations might increase faster for PER, leading to a peculiar situation in which higher types might select into the less stringent institution. In this case, instead of a cutpoint strategy, we can construct the following strategy for I:
$$\sigma_{I} = \begin{cases} STR & \text{ if } v_{S}(\theta)\pi_{S}(\theta)-c_{S} \geq v_{P}(\theta)\pi_{P}(\theta)-c_{P}\\ PER & \text{ if } v_{S}(\theta)\pi_{S}(\theta)-c_{S}< v_{P}(\theta)\pi_{P}(\theta)-c_{P} \end{cases}$$
Noting that depending on the shape of the probability and benefit functions, these two disjoint sets could be any union of subsets of the type space. If we call the STR subset ΘS and the PER subset ΘP, we can consider the following strategy by Government:
$$\sigma_{G} = \begin{cases} \text{Accept } & \text{ if \textit{I} pursues STR}\\ \text{Accept } & \text{ if \textit{I} pursues PER} \end{cases}$$
Which will be a best response whenever the following conditions hold:
$${\int}_{{\Theta}_{P}} g_{P}(\theta)\pi_{P}(\theta) f(\theta)d\theta \geq 0$$
$${\int}_{{\Theta}_{S}} g_{S}(\theta)\pi_{S}(\theta) f(\theta)d\theta \geq 0$$
Thus a separating equilibrium can be constructed if the above conditions hold without relying on Lemma 1. This separating equilibrium does reveal information about the type of I to Government, but in a somewhat less easily interpretable fashion. Nonetheless, the equilibrium described will only hold if a sufficiently positively weighted distribution of types is screened to STR to overcome its relatively low chances of success compared to PER and Government's preference for PER over STR in this variant of the model. □
Consider the pooling conditions from Propositions 1 and 2 respectively.
$$\mathbb{E}[g(\theta)|AllPER] = {{\int}_{0}^{w}} g(\theta)\pi_{P}(\theta)f(\theta)d\theta \geq 0$$
$$\mathbb{E}[g(\theta)|AllSTR] = {{\int}_{0}^{w}} g(\theta)\pi_{S}(\theta)f(\theta)d\theta \geq 0$$
We have defined an upward shift in protectionist sentiment as a shift to g+(𝜃) such that g+(𝜃) ≥ g(𝜃),∀𝜃 ∈Θ, with some positive Lebesgue measure subset \({\Theta }^{\prime }\) such that \(g^{+}(\theta ^{\prime })>g(\theta ^{\prime }), \forall \theta ^{\prime } \in {\Theta }^{\prime }\). We can partition Θ into two sets: \({\Theta }^{\prime }\) and \({\Theta }^{\prime \prime }\), where \(g^{+}(\theta ^{\prime \prime }) =g(\theta ^{\prime \prime }), \forall \theta ^{\prime \prime } \in {\Theta }^{\prime \prime }\). Thus, for both pooling conditions, we can rewrite the relevant integrals, for either institution z as:
$$\mathbb{E}[g(\theta)|z] = \underbrace{{\int}_{{\Theta}^{\prime}} g(\theta^{\prime})\pi_{z}(\theta^{\prime})f(\theta^{\prime})d\theta^{\prime}}_{\alpha} + \underbrace{{\int}_{{\Theta}^{\prime\prime}} g(\theta^{\prime\prime})\pi_{z}(\theta^{\prime\prime})f(\theta^{\prime\prime})d\theta^{\prime\prime}}_{\beta}$$
Which we can compare to the following after a shift in protectionist sentiment:
$$\mathbb{E}[g^{+}(\theta)|z] = \underbrace{{\int}_{{\Theta}^{\prime}} g^{+}(\theta^{\prime})\pi_{z}(\theta^{\prime})f(\theta^{\prime})d\theta^{\prime}}_{A} + \underbrace{{\int}_{{\Theta}^{\prime\prime}} g^{+}(\theta^{\prime\prime})\pi_{z}(\theta^{\prime\prime})f(\theta^{\prime\prime})d\theta^{\prime\prime}}_{B}$$
Because \(g^{+}(\theta ^{\prime \prime })=g(\theta ^{\prime \prime }), \forall \theta ^{\prime \prime } \in {\Theta }^{\prime \prime }\), it must be the case that β = B. Similarly, since \(g^{+}(\theta ^{\prime })>g(\theta ^{\prime }), \forall \theta ^{\prime } \in {\Theta }^{\prime }\), it must be the case that A > α, if either is nonzero. Furthermore, since \({\Theta }^{\prime }\) has positive Lebesgue measure, at least one must be nonzero. Thus we have shown that:
$$\mathbb{E}[g^{+}(\theta)|z] > \mathbb{E}[g(\theta)|z]$$
Which means that the pooling conditions of Propositions 1 and 2 are more likely to be met after an upward shift in protectionist sentiment. □
From the text, note that an institution-induced separating equilibrium is preferred to no institution whenever:
$$U_{G}(\text{Institution}) = {\int}_{\bar w}^{w} g(\theta) \pi_{S}(\theta) f(\theta)d\theta > {{\int}_{0}^{w}} g(\theta)f(\theta)d\theta = U_{G}(\text{No Institution})$$
Now, in a similar fashion to the Proof of Proposition 8, partition Θ into \({\Theta }^{\prime }\) and \({\Theta }^{\prime \prime }\). We want to see which side of the inequality changes more with a shift to g+(𝜃). Following Proposition 8, the integrals will be the same over \({\Theta }^{\prime \prime }\), thus we can compare:
$$ \begin{array}{@{}rcl@{}} {\Delta} U_{G}(\text{Institution}) &=& {\int}_{{\Theta}^{\prime}} g^{+}(\theta^{\prime}) \pi_{S}(\theta^{\prime}) f(\theta^{\prime})d\theta^{\prime} - {\int}_{\Theta '}g(\theta^{\prime})\pi_{S}(\theta^{\prime})f(\theta^{\prime})d\theta^{\prime}\\ &=& {\int}_{{\Theta}^{\prime}} [g^{+}(\theta^{\prime})-g(\theta^{\prime})] \pi_{S}(\theta^{\prime}) f(\theta^{\prime})d\theta^{\prime} \end{array} $$
$$ \begin{array}{@{}rcl@{}} {\Delta} U_{G}(\text{No Institution}) &=& {\int}_{{\Theta}^{\prime}} g^{+}(\theta^{\prime})f(\theta^{\prime})d\theta^{\prime} - {\int}_{{\Theta}^{\prime}} g(\theta^{\prime})f(\theta^{\prime})d\theta^{\prime}\\ &=& {\int}_{{\Theta}^{\prime}} [g^{+}(\theta^{\prime})-g(\theta^{\prime})]f(\theta^{\prime})d\theta^{\prime} \end{array} $$
Since \(\pi _{S}(\theta ^{\prime })\leq 1, \forall \theta ^{\prime } \in {\Theta }^{\prime }\), and since there must exist \(\theta ^{\prime } \in {\Theta }^{\prime }\) such that \(\pi _{S}(\theta ^{\prime })<1\), given that πS(⋅) is strictly monotonically increasing, ΔUG(No Institution) > ΔUG(Institution). Or, in words, an upwards shift in protectionist sentiment has a more significant positive impact on Government's payoff in the "no institution" equilibrium than in a separating equilibrium obtained under an institution, and thus this upwards shift in sentiment makes the institution relatively less attractive. □
Davis, J.S. Screening for losers: Trade institutions and information. Rev Int Organ (2021). https://doi.org/10.1007/s11558-020-09409-7
Trade remedies | CommonCrawl |
Zero-Forcing (ZF) Detection in Massive MIMO Systems
Massive MIMO is one of the defining technologies in 5G cellular systems. In a previous article, we have described spatial matched filtering (or maximum ratio) as the simplest algorithm for signal detection. Here, we explain another linear technique, known as Zero-Forcing (ZF), for this purpose. It was described before in the context of simple MIMO systems here.
Consider the block diagram for uplink of a massive MIMO system as drawn below with $N_B$ base station antennas and $K$ mobiler terminals.
It is evident that the cumulative signal at each base station antenna $j$ is a summation of signals arriving from each user terminal $i$. While the expression below looks complicated, observe from the figure that the signal at each antenna is simply a sum of individual modulation symbols $s_1$, $s_2$, $\cdots$, $s_K$ scaled by channel coefficients.
$$\begin{equation}
\begin{aligned}
r_j = h_{(1\rightarrow j)}\cdot s_1 + h_{(2\rightarrow j)}\cdot s_2 + \cdots + h_{(K\rightarrow j)}\cdot s_{K} +~&~ \text{noise}, \qquad \\
& \qquad j = 1, 2, \cdots,N_B
\end{aligned}
\end{equation}\label{equation-massive-mimo-detection}$$
Here, the flat fading channel gain between $i$-th user terminal ($i=1,2\cdots,K$) and $j$-th base station antenna ($j=1,2,\cdots,N_B$) is denoted by $h_{(i\rightarrow j)}$. Power control is ignored here for simplicity. The reader should keep in mind that power control is important in cellular systems to prevent signals from users with strong channels drowning the signals coming from weak users. However, power control coefficients depend on large-scaling fading that renders them independent of both frequency and fast update rates.
Eq (\ref{equation-massive-mimo-detection}) tells us that the original signal received at the base station is not coming from terminal 1 alone! Instead, all user terminals transmit simultaneously on the uplink and hence the cumulative signal $r_j$ at each antenna $j$ is a superposition of signals from $K$ terminals. As a result, interference from $K-1$ users is added to the desired signal. The main task of the detection algorithms here is to free each modulation symbol $s_i$ sent by a user terminal $i$ from the interference of the other modulation symbols sent by rest of the mobile users.
If maximum ratio or spatial matched filtering is applied to solve this problem, the favorable propagation scenario is approximately true and the relation is not exact. Hence, low amounts of interference from other terminals can still leak into the desired signal causing a degradation in performance. Our goal here is to make up for that performance loss without incurring significant computational complexity. Zero-Forcing (ZF) algorithm provides that solution which is slightly more complex than matched filtering but compensates for the performance loss at the same time.
A proper derivation of Zero-Forcing solution requires dealing with matrices since $K$ user terminals communicate with $N_B$ base station antennas on the uplink. All that data combined results in an $N_B$ $\times$ $K$ matrix of channel gains. However, I will present a simpler scalar derivation that illustrates the basic concept.
A Single Antenna System
One imperfect trick you can often employ is to see the results from a single parameter viewpoint and simply generalize the result into a matrix formulation. Let us apply this trick to understand the general Zero-Forcing philosophy.
For a system with a single antenna both at the Tx and the Rx, we can write the received signal as
\begin{equation}\label{equation-single-flat-channel}
r = h\cdot s + \text{noise}
where $s$ is the modulation symbol sent and $h$ is the flat fading channel gain. As we learned in during the derivation of MRC, the optimal strategy at the Rx is to multiply the incoming signal with a weight $w=h^*$ that has the same magnitude but an opposite phase to the channel gain (which is computed through a channel estimation procedure). Moreover, a scaling factor in proportion to the gain magnitude $|h|^2$ is included to normalize the results. The final expression turns out to be $h^*/|h|^2$ (this is the essence of generalized beamforming). Since $|h|^2=h^*\cdot h$, we have
\begin{equation}\label{equation-noise-zf}
\frac{h^*}{h^*\cdot h}\cdot r = \frac{h^*}{h^*\cdot h} \Big( h\cdot s + \text{noise}\Big) = s + \frac{h^*}{|h|^2}\cdot \text{noise}
Thus, the symbol estimate $\hat s$ can be expressed from left side as
\begin{equation}\label{equation-optimal-weighting}
\hat s = \frac{h^*}{h^*\cdot h}\cdot r = \Big(h^*\cdot h\Big)^{-1}h^*\cdot r
This relation will help lead us towards a general solution. Before that, we address the problem of estimation with multiple observations.
Computing the Slope of a Straight Line
Consider what should have been a straight line $y_j=m\cdot x_j$ where $y_j$ are the set of received data points and $x_j$ is the unknown parameter to be estimated. In the presence of noise, the received points $y$ are scattered around as shown in the figure below. There are several lines with slopes $m$ that can be fit through the points $y_j$ but one of them is the best in some sense. Our task is to find a line through this set of points $y_j$ that forms the best fit. Some of the candidates are also drawn in the same figure.
We start with plotting the error $e_j=y_j-m\cdot x_j$ on the right side of the above figure. Since the noise is Gaussian, the error samples $e_j$ assume both positive and negative values. Owing to this bipolarity, one criterion to find the best fit line is by minimizing the total absolute value squared of the error samples $\sum_j|e_j|^2$. This criterion is known as the Least Squares (LS) solution. Let us find out where it leads.
\min \sum_j|e_j|^2 = \min \sum_j(y_j-m\cdot x_j)^2
The above function forms a parabola which has a unique minimum. This function can be minimized by taking the first derivative and equating it to zero. This first derivative is given by
\sum_j\frac{d}{dm}(y_j-m\cdot x_j)^2 = \sum_j 2(y_j-m\cdot x_j)(-x_j) = -2\sum_j x_j\cdot y_j +2m\sum_j x_j^2
Equating it to zero to find the minimum gives
\begin{equation}\label{equation-line-slope}
-2\sum_j x_j\cdot y_j +2m\sum_j x_j^2 = 0 \qquad \Rightarrow \qquad \hat m = \frac{1}{\sum_jx_j^2}\sum_j x_j\cdot y_j
This is known as the linear least squares solution because it minimizes the sum of squared absolute values of the error terms.
A Single User in a Cell
Turning to our problem, assume that there was only a single terminal in the cell that communicates with all the base station antennas (i.e., there is no interference) such that the channel gains from that user, say 1, to receive antenna $j$ is $h_{(1\rightarrow j)}$. With its modulation symbol denoted by $s_1$, the received signal $r_j$ at antenna $j$ can be written as
r_j = s_1\cdot h_{(1\rightarrow j)} + \text{noise}, \qquad \qquad j = 1, 2, \cdots, N_B
Comparing with the linear equation $y_j=m\cdot x_j$, we have the following corresponding parameters.
y_j \quad &\longrightarrow \quad r_j \\
m \quad &\longrightarrow \quad s_1 \\
x_j \quad &\longrightarrow \quad h_{(1\rightarrow j)} \\
From Eq (\ref{equation-line-slope}), the solution $\hat s_1$ can be correspondingly written as
\hat s_1 = \frac{1}{\sum_j |h_{(1\rightarrow j)}|^2}\sum_j h_{(1\rightarrow j)}^*\cdot r_j
The two differences from the straight line solution, i.e., the absolute value squared and conjugate operation, appear because $h_{(1\rightarrow j)}$ is a complex number (the fading channel coefficient). Since $|h_{(1\rightarrow j)}|^2$ $=$ $h_{(1\rightarrow j)}^*\cdot h_{(1\rightarrow j)}$, we can write
\begin{equation}\label{equation-zf-single}
\hat s_1 = \left(\sum_j h_{(1\rightarrow j)}^*\cdot h_{(1\rightarrow j)}\right)^{-1}\sum_j h_{(1\rightarrow j)}^*\cdot r_j
that is analogous to Eq (\ref{equation-optimal-weighting}). With this result in hand, it is straightforward to understand the Zero-Forcing algorithm for a multi-user scenario.
Multiple Users in a Cell
Now in reality, there is not a single user but multiple users in a cell which communicate with the base station at the same time and frequency thanks to favorable propagation scenario discussed in the last section. In such a case, hidden in the received data samples $r_j$ are not simply the modulation symbols $s_1$ from terminal 1 but also the modulation symbols $s_2$, $\cdots$, $s_K$ from all $K$ users. Therefore, the signal model $r_j$ $=$ $s_1\cdot h_{(1\rightarrow j)}$ becomes multi-dimensional as
\begin{equation}\label{equation-vector-model}
\mathbf{r} = \mathbf{H}\cdot \mathbf{s} + \textbf{noise}
where $\mathbf{r}$ is a vector of received samples, $\mathbf{H}$ is a matrix whose entries $h_{(i\rightarrow j)}$ are channel gains from user $i$ to antenna $j$ and $\mathbf{s}$ is the vector of modulation symbols $s_1$, $s_2$, $\cdots$, $s_K$. Just like a single user where $\sum_j(y_j-m\cdot x_j)^2$ or $\sum_j(r_j-h_{(1\rightarrow j)}\cdot s_1)^2$ was minimized, the least squares solution now focuses on minimizing $||\mathbf{r}-\mathbf{H\cdot s}||^2$. Then, the solution can be straightforwardly written just like Eq (\ref{equation-zf-single}) or Eq (\ref{equation-optimal-weighting}) as
\begin{equation}\label{equation-zf-multiple}
\mathbf{\hat s} = \mathbf{\Big(H^*\:H\Big)}^{-1}~\mathbf{H^*\:r}
where the term before $\mathbf{r}$ is known as a pseudo-inverse of a matrix and $\mathbf{H^*}$ implies both a transpose and a conjugate operation on channel matrix $\mathbf{H}$. This is the expression you would have seen in most research papers and books on 5G physical layer algorithms. While this matrix result seems difficult to understand at first, I believe the derivation of a single user as in Eq (\ref{equation-zf-single}) helps in grasping the underlying basic idea. The enhancement of gains and nullifying the interference in the directions of other users with a massive number of antennas results in a system that is quite different from a simple multi-user system. This is illustrated in the figure below where the cost of additional antennas simplifies the system design in other aspects. Keep in mind that although physical beams are drawn in this figure, the idea stays the same for generalized beamforming scenario.
A few comments are in order here.
Why Zero-Forcing?
In the case of matched filter detector, we relied only on favorable propagation conditions to nullify the interference coming from $K-1$ users. We also mentioned that this only approximately holds true for a large number of antennas $N_B$. In the present instance, the algorithm is known as Zero-Forcing because the decoding vectors are structured in a way to nullify interference among the users, i.e., force zeros on the off-diagonal terms of the matrix. Let us find out how.
Plug in the value of the received samples $\mathbf{r}$ from Eq (\ref{equation-vector-model}) into the Zero-Forcing solution of Eq (\ref{equation-zf-multiple}), we get
\begin{align}
\mathbf{\hat s} &= \mathbf{\Big(H^*\:H\Big)}^{-1}~\mathbf{H^*}\:\Big(\mathbf{H}\cdot \mathbf{s} + \textbf{noise}\Big) \nonumber \\
&= ~~\mathbf{s} ~~+~~ \textbf{modified noise}\label{equation-noise-enhancement}
\end{align}
The operation $\mathbf{\Big(H^*\:H\Big)}^{-1}~\mathbf{H^*}\:\mathbf{H}$ equals $\mathbf{I}$ in the first term, where $\mathbf{I}$ is an identity matrix with ones along the main diagonal and zeros everywhere else. As a result, the signal part in the first term now contains only a vector with each user's modulation symbol free of influence from the other symbols.
Noise Enhancement
One drawback of a Zero-Forcing solution is noise enhancement. Refer back to Eq (\ref{equation-noise-enhancement}) and focus on the effective noise part now. The problem with the multiplicative factor appearing with noise is that it is an inverse of a matrix, much like the expression $\big(\sum_j h_{(1\rightarrow j)}^*\cdot h_{(1\rightarrow j)}\big)^{-1}$ for a single user in Eq (\ref{equation-zf-single}) before. With these channel gains in the denominator, the effective noise can be enhanced at frequencies where channel gains assume low values. This enhanced noise then dominates the signal part and deteriorates the estimation performance.
Regularization Factor
From the above description, a balance between SNR enhancement and interference mitigation is required. One solution is to introduce an additional factor in Eq (\ref{equation-zf-multiple}) that limits the extent of inversion.
\mathbf{\hat s} = \Big(\mathbf{H^*\:H}+\delta \mathbf{I}\Big)^{-1}~\mathbf{H^*\:r}
where $\delta$ is a positive number known as a regularization factor that can be tuned to strike a tradeoff between the two techniques covered before.
When $\delta\rightarrow 0$, the effect of channel dominates and this is clearly the Zero-Forcing solution of Eq (\ref{equation-zf-multiple}), i.e., $\mathbf{\hat s} = \Big(\mathbf{H^*\:H}\Big)^{-1}~\mathbf{H^*\:r}$.
When $\delta\rightarrow\infty$, the identity matrix dominates the channel matrix and the inverse of $\mathbf{I}$ is close to identity $\mathbf{I}$ as well. This is clearly maximum ratio or matching filtering of Eq (\ref{equation-mf-detector}), i.e., $\mathbf{\hat s} = \mathbf{H^*\:r}$.
Regularized Zero-Forcing has proved to be a good candidate between complexity and tradeoff in implementation of massive MIMO in commercial networks.
Finally, on the downlink, a precoding matrix similar to Eq (\ref{equation-zf-multiple}) before data transmission enables the base station to beamform multiple data streams to all user terminals without causing any mutual interference among them. Due to a large number of base station antennas $N_B$, linear processing algorithms described above such as matched filtering and Zero-Forcing are nearly optimal in massive MIMO systems and computationally complex signal processing algorithms are not required.
It must be mentioned that there is a performance gap that exists between all the schemes. Optimal detection is better than Zero-Forcing that in turn performs better than maximum ratio or matched filtering. This makes sense because Zero-Forcing nullifies the interference layers beforehand that results in a significant improvement in SINR.
BeamformingEqualizerMIMO
Gardner Timing Error Detector: A Non-Data-Aided Version of Zero-Crossing Timing Error Detectors
FSK Demodulation in GNU Radio
On Massive MIMO, Channel Hardening and Favorable Propagation
Channel Estimation in Wireless Communication
Diversity in Wireless Communication Systems
Qasim Chaudhari says:
Thanks for your interest. Only some articles are available in pdf format and this is not one of them. | CommonCrawl |
Chapter 1 Study Guide
Mary_McLaughlin39
Probability is used as a basis for inferential statistics
The heights of the mountains in the state of Alaska are an example of a variable
The lowest level of measurement is the nominal level
When the population of college professors is divided into groups according to their rank and then from several from each group to make up a sample, the sample is called a cluster
False it would be a stratified sample
The variable temperature is an example of a quantitive variable
The height of basketball players is considered a continuous variable
The boundary of a value such as 6 inches would be 5.9-6.1 inches
False 5.95-6.05
The number of ads on a one-hour television show is what type of data
What are the boundaries of 25.6 oz
A researcher divided subjects into two groups according to gender and then selected numbers for each group for her sample. What sampling method was the researcher using?
Date that can be classified according to color are measured on what scale?
A study that involves no researcher interventional is called?
A variable that inferences with other variables in the study are called?
The two major branches of statistics are ___________ and __________.
Descriptive; Inferential
The two uses of probability are ___________ and ___________.
Gambling; insurance companies
The group of all subjects under study is called?
A group of subjects selected from the group of all subjects under a study is called?
Three reasons why samples are used in statistics
A) Saves time
B) Saves money
C) When a population is infinitive
The four basic sampling methods are
A) Random Sampling
B) Stratified Sampling
C) Cluster Sampling
D) Systematic Sampling
A study that uses intact groups when it is not possible to randomly assign participants to the group is called?
Quasi- Experiment Study
In a research study, participants should be assigned to groups using _______________ if possible.
Random Methods
The average life expectancy in New zealand is 78.49 years.
A diet high in fruits and vegetables will lower blood pressure.
The total amount of estimated losses for hurricane Katrina was $125 billion dollars.
Researchers stated that the shape of a person's ear is relative to the person aggression.
in 2013 the number of high school graduates will be 3.2 billion students.
Rating a movie as G, PG and R.
Number of candy bars sold on a fund drive.
Classification of automobiles as subcompact, compact, standard or luxury.
Temperatures of hand dryers.
Weights of suitcases on a commercial airline.
Ages of people working in a large factory
Numbers of cups of coffee served at a restaurant.
The amount of drug injections into a guinea pig.
The time it takes a student to drive to school.
The number of gallons of milk sold each day at a grocery store.
Recommended textbook explanations
Elementary Statistics: A Step By Step Approach
9th EditionAllan G. Bluman
2,814 explanations
Elementary Statistics
12th EditionMario F. Triola
10th EditionAllan G. Bluman
Understandable Statistics: Concepts and Methods
12th EditionCharles Henry Brase
AP Bio Test #2
AP BIO unit 1
100 terms
Spanish 2 Culture
Ceramics Exam Review
Other Quizlet sets
PNB Exam II
calubaquibm
Minor Disorders of the Shoulder Complex
kailey_payne
MIDTERM - FUNDAMENTALS OF REAL ESTATE (2)
ellen_isabella2
Health Assessment Ch. 3
bcoll56
Verified questions
Consider the following frequency table of observations on the random variable X: Values 0, 1, 2, 3, 4 Frequency: 4, 21, 10, 13, 2 a. Based on these 50 observations, is a binomial distribution with n = 6 and p = 0.25 an appropriate model? Perform a goodness-of-fit procedure with α = 0.05. b. Calculate the P-value for this test.
The number of gallons of water used when taking a shower is proportional to the time in the shower. A shower lasting 5 minutes uses 30 gallons of water. How much water is used in a shower lasting 11 minutes?
Let W be a gamma random variable with parameters $$ ( t , \beta ) $$ , and suppose that conditional on $$ W = w , X _ { 1 } , X _ { 2 } , \ldots , X _ { n } $$ are independent exponential random variables with rate w. Show that the conditional distribution of W given that $$ X_1=x _ { 1 } , X _ { 2 } = x _ { 2 } , \ldots , X _ { n } = x _ { n } $$ is gamma with parameters $$ \left( t + n , \beta + \sum _ { i = 1 } ^ { n } x _ { i } \right) $$ .
When necessary round your answers to the nearest hundredth. Victoria is buying outdoor carpet for her rectangular lanai, which is 6 yd by 9 yd. The carpeting is sold in square meters. How many square meters of carpeting will she need? | CommonCrawl |
Problems in Mathematics
Problems by Topics
Gauss-Jordan Elimination
Linear Transformation
Vector Space
Eigen Value
Cayley-Hamilton Theorem
Diagonalization
Exam Problems
Abelian Group
Group Homomorphism
Sylow's Theorem
Module Theory
LaTex/MathJax
Login/Join us
Solve later Problems
My Solved Problems
You solved 0 problems!!
Solved Problems / Solve later Problems
Given Eigenvectors and Eigenvalues, Compute a Matrix Product (Stanford University Exam)
Problem 181
Suppose that $\begin{bmatrix}
1 \\
\end{bmatrix}$ is an eigenvector of a matrix $A$ corresponding to the eigenvalue $3$ and that $\begin{bmatrix}
\end{bmatrix}$ is an eigenvector of $A$ corresponding to the eigenvalue $-2$.
Compute $A^2\begin{bmatrix}
\end{bmatrix}$.
(Stanford University Linear Algebra Exam Problem)
Add to solve later
By the given conditions, we have
\[A\begin{bmatrix}
\end{bmatrix}=3\begin{bmatrix}
\end{bmatrix} \text{ and } A \begin{bmatrix}
\end{bmatrix}=-2\begin{bmatrix}
\end{bmatrix}. \tag{*}\]
We express the vector $\begin{bmatrix}
\end{bmatrix}$ as a linear combination of vectors $\begin{bmatrix}
\end{bmatrix}$ and $\begin{bmatrix}
\end{bmatrix}$. Let
\end{bmatrix}+b\begin{bmatrix}
\end{bmatrix}
=\begin{bmatrix}
\end{bmatrix}\] and we want to determine scalars $a$ and $b$. The augmented matrix of the system is reduced as follows:
\left[\begin{array}{rr|r}
1 &1 &3
\end{array}\right] \to
1 & 0& 2 \\
0 &1 & 1
\end{array}\right].
Thus the solution is
\[a=2, b=1\] and hence we obtain the linear combination
\[2\begin{bmatrix}
\end{bmatrix}+\begin{bmatrix}
\end{bmatrix}.\]
Before computing $A^2\begin{bmatrix}
\end{bmatrix}$, we first calculate $A\begin{bmatrix}
\end{bmatrix}$ as follows.
A\begin{bmatrix}
\end{bmatrix}&= A \left(2\begin{bmatrix}
\end{bmatrix} \right)\\
&=2A\begin{bmatrix}
\end{bmatrix}+A\begin{bmatrix}
\end{bmatrix}\\
&=2\cdot 3\begin{bmatrix}
\end{bmatrix}+(-2)\begin{bmatrix}
\end{bmatrix} \text{ by } (*)\\
&=6\begin{bmatrix}
\end{bmatrix}-2\begin{bmatrix}
\end{bmatrix}.
Now, using the result of the above computation, we compute
A^2 \begin{bmatrix}
\end{bmatrix}&= A\left( \begin{bmatrix}
\end{bmatrix}\right)\\
&=A\left( 6\begin{bmatrix}
\end{bmatrix}-2A\begin{bmatrix}
&=6 \cdot 3\begin{bmatrix}
\end{bmatrix}-2(-2)\begin{bmatrix}
&=\begin{bmatrix}
26 \\
Therefore we obtained
\[A^2\begin{bmatrix}
\end{bmatrix}=\begin{bmatrix}
Click here if solved 27
Two Matrices with the Same Characteristic Polynomial. Diagonalize if Possible. Let \[A=\begin{bmatrix} 1 & 3 & 3 \\ -3 &-5 &-3 \\ 3 & 3 & 1 \end{bmatrix} \text{ and } B=\begin{bmatrix} 2 & 4 & 3 \\ -4 &-6 &-3 \\ 3 & 3 & 1 \end{bmatrix}.\] For this problem, you may use the fact that both matrices have the same characteristic […]
True of False Problems on Determinants and Invertible Matrices Determine whether each of the following statements is True or False. (a) If $A$ and $B$ are $n \times n$ matrices, and $P$ is an invertible $n \times n$ matrix such that $A=PBP^{-1}$, then $\det(A)=\det(B)$. (b) If the characteristic polynomial of an $n \times n$ matrix $A$ […]
Is an Eigenvector of a Matrix an Eigenvector of its Inverse? Suppose that $A$ is an $n \times n$ matrix with eigenvalue $\lambda$ and corresponding eigenvector $\mathbf{v}$. (a) If $A$ is invertible, is $\mathbf{v}$ an eigenvector of $A^{-1}$? If so, what is the corresponding eigenvalue? If not, explain why not. (b) Is $3\mathbf{v}$ an […]
Diagonalizable Matrix with Eigenvalue 1, -1 Suppose that $A$ is a diagonalizable $n\times n$ matrix and has only $1$ and $-1$ as eigenvalues. Show that $A^2=I_n$, where $I_n$ is the $n\times n$ identity matrix. (Stanford University Linear Algebra Exam) See below for a generalized problem. Hint. Diagonalize the […]
Given All Eigenvalues and Eigenspaces, Compute a Matrix Product Let $C$ be a $4 \times 4$ matrix with all eigenvalues $\lambda=2, -1$ and eigensapces \[E_2=\Span\left \{\quad \begin{bmatrix} 1 \\ 1 \\ 1 \\ 1 \end{bmatrix} \quad\right \} \text{ and } E_{-1}=\Span\left \{ \quad\begin{bmatrix} 1 \\ 2 \\ 1 \\ 1 […]
Given the Characteristic Polynomial of a Diagonalizable Matrix, Find the Size of the Matrix, Dimension of Eigenspace Suppose that $A$ is a diagonalizable matrix with characteristic polynomial \[f_A(\lambda)=\lambda^2(\lambda-3)(\lambda+2)^3(\lambda-4)^3.\] (a) Find the size of the matrix $A$. (b) Find the dimension of $E_4$, the eigenspace corresponding to the eigenvalue […]
If the Kernel of a Matrix $A$ is Trivial, then $A^T A$ is Invertible Let $A$ be an $m \times n$ real matrix. Then the kernel of $A$ is defined as $\ker(A)=\{ x\in \R^n \mid Ax=0 \}$. The kernel is also called the null space of $A$. Suppose that $A$ is an $m \times n$ real matrix such that $\ker(A)=0$. Prove that $A^{\trans}A$ is […]
Eigenvalues of a Hermitian Matrix are Real Numbers Show that eigenvalues of a Hermitian matrix $A$ are real numbers. (The Ohio State University Linear Algebra Exam Problem) We give two proofs. These two proofs are essentially the same. The second proof is a bit simpler and concise compared to the first one. […]
Tags: augmented matrixeigenvalueeigenvectorexamlinear algebralinear combinationmatrixStanfordStanford.LAvector
Next story Linear Transformation and a Basis of the Vector Space $\R^3$
Previous story Determine Eigenvalues, Eigenvectors, Diagonalizable From a Partial Information of a Matrix
The Matrix $[A_1, \dots, A_{n-1}, A\mathbf{b}]$ is Always Singular, Where $A=[A_1,\dots, A_{n-1}]$ and $\mathbf{b}\in \R^{n-1}$.
by Yu · Published 09/10/2017
Compute the Product $A^{2017}\mathbf{u}$ of a Matrix Power and a Vector
by Yu · Published 09/17/2016 · Last modified 08/29/2017
A Matrix Similar to a Diagonalizable Matrix is Also Diagonalizable
This website's goal is to encourage people to enjoy Mathematics!
This website is no longer maintained by Yu. ST is the new administrator.
Linear Algebra Problems by Topics
The list of linear algebra problems is available here.
Introduction to Matrices
Elementary Row Operations
Gaussian-Jordan Elimination
Solutions of Systems of Linear Equations
Linear Combination and Linear Independence
Nonsingular Matrices
Inverse Matrices
Subspaces in $\R^n$
Bases and Dimension of Subspaces in $\R^n$
General Vector Spaces
Subspaces in General Vector Spaces
Linearly Independency of General Vectors
Bases and Coordinate Vectors
Dimensions of General Vector Spaces
Linear Transformation from $\R^n$ to $\R^m$
Linear Transformation Between Vector Spaces
Orthogonal Bases
Determinants of Matrices
Computations of Determinants
Introduction to Eigenvalues and Eigenvectors
Eigenvectors and Eigenspaces
Diagonalization of Matrices
The Cayley-Hamilton Theorem
Dot Products and Length of Vectors
Eigenvalues and Eigenvectors of Linear Transformations
Jordan Canonical Form
Elementary Number Theory (1)
Field Theory (27)
Group Theory (126)
Linear Algebra (485)
Math-Magic (1)
Module Theory (13)
Probability (33)
Ring theory (67)
Mathematical equations are created by MathJax. See How to use MathJax in WordPress if you want to write a mathematical blog.
How to Prove Markov's Inequality and Chebyshev's Inequality
How to Use the Z-table to Compute Probabilities of Non-Standard Normal Distributions
Expected Value and Variance of Exponential Random Variable
Condition that a Function Be a Probability Density Function
Conditional Probability When the Sum of Two Geometric Random Variables Are Known
A Maximal Ideal in the Ring of Continuous Functions and a Quotient Ring
Find a Basis for a Subspace of the Vector Space of $2\times 2$ Matrices
Can a Student Pass By Randomly Answering Multiple Choice Questions?
Coupon Collecting Problem: Find the Expectation of Boxes to Collect All Toys
Determine Whether Each Set is a Basis for $\R^3$
How to Diagonalize a Matrix. Step by Step Explanation.
Range, Null Space, Rank, and Nullity of a Linear Transformation from $\R^2$ to $\R^3$
How to Find a Basis for the Nullspace, Row Space, and Range of a Matrix
The Intersection of Two Subspaces is also a Subspace
Rank of the Product of Matrices $AB$ is Less than or Equal to the Rank of $A$
Show the Subset of the Vector Space of Polynomials is a Subspace and Find its Basis
Find a Basis and the Dimension of the Subspace of the 4-Dimensional Vector Space
Find a Basis for the Subspace spanned by Five Vectors
Prove a Group is Abelian if $(ab)^2=a^2b^2$
abelian group augmented matrix basis basis for a vector space characteristic polynomial commutative ring determinant determinant of a matrix diagonalization diagonal matrix eigenvalue eigenvector elementary row operations exam finite group group group homomorphism group theory homomorphism ideal inverse matrix invertible matrix kernel linear algebra linear combination linearly independent linear transformation matrix matrix representation nonsingular matrix normal subgroup null space Ohio State Ohio State.LA probability rank ring ring theory subgroup subspace symmetric matrix system of linear equations transpose vector vector space
Search More Problems
Membership Level Free
If you are a member, Login here.
Problems in Mathematics © 2020. All Rights Reserved.
More in Linear Algebra
Determine Eigenvalues, Eigenvectors, Diagonalizable From a Partial Information of a Matrix
Suppose the following information is known about a $3\times 3$ matrix $A$. \[A\begin{bmatrix} 1 \\ 2 \\ 1 \end{bmatrix}=6\begin{bmatrix} 1... | CommonCrawl |
Geographical and socioeconomic inequalities in the utilization of maternal healthcare services in Nigeria: 2003–2017
Chijioke Okoli ORCID: orcid.org/0000-0002-6912-72911,2,
Mohammad Hajizadeh3,
Mohammad Mafizur Rahman1 &
Rasheda Khanam1
Maternal mortality has remained a challenge in many low-income countries, especially in Africa and in Nigeria in particular. This study examines the geographical and socioeconomic inequalities in maternal healthcare utilization in Nigeria over the period between 2003 and 2017.
The study used four rounds of Nigeria Demographic Health Surveys (DHS, 2003, 2008, 2013, and 2018) for women aged 15–49 years old. The rate ratios and differences (RR and RD) were used to measure differences between urban and rural areas in terms of the utilization of the three maternal healthcare services including antenatal care (ANC), facility-based delivery (FBD), and skilled-birth attendance (SBA). The Theil index (T), between-group variance (BGV) were used to measure relative and absolute inequalities in the utilization of maternal healthcare across the six geopolitical zones in Nigeria. The relative and absolute concentration index (RC and AC) were used to measure education-and wealth-related inequalities in the utilization of maternal healthcare services.
The RD shows that the gap in the utilization of FBD between urban and rural areas significantly increased by 0.3% per year over the study period. The Theil index suggests a decline in relative inequalities in ANC and FBD across the six geopolitical zones by 7, and 1.8% per year, respectively. The BGV results do not suggest any changes in absolute inequalities in ANC, FBD, and SBA utilization across the geopolitical zones over time. The results of the RC and the AC suggest a persistently higher concentration of maternal healthcare use among well-educated and wealthier mothers in Nigeria over the study period.
We found that the utilization of maternal healthcare is lower among poorer and less-educated women, as well as those living in rural areas and North West and North East geopolitical zones. Thus, the focus should be on implementing strategies that increase the uptake of maternal healthcare services among these groups.
Despite continual efforts to reduce maternal mortality burden globally, it has remained an ongoing tragedy in many low-income countries, especially in Africa [1,2,3,4], which has the highest rate of maternal deaths in the world and sub-Saharan Africa as a primary contributor has a maternal death of 1 in every 16 pregnant women compared with 1 in 2800 in the developed countries [5]. This substantial difference is one of the largest inequalities of any public health statistics [6].
Social inequalities that prevail in the health sector especially between the poor and the rich continue to be a cause for concern, particularly in the developing worlds [7]. These inequalities are manifested in health outcomes as studies in developing countries show that maternal health service utilization is higher among wealthier women than their poorer counterparts [7,8,9], mostly residing in rural areas [10]. Living in rural areas in developing countries mean residing in deprived communities in terms of social amenities and infrastructure [8].
The rural-urban place of residence accounts for differences in the use of health services, especially as this relates to the level of maternal education and socioeconomic status [5, 8]. Studies show a positive association between education level and the use of antenatal care (ANC), delivery in health facilities (FBD), and skilled birth assistance (SBA) [8]. Of equal importance, is socioeconomic status, which influences the use of health services as the wealthier urban women access healthcare more compared to their poorer rural counterparts.
In Nigeria, there has been some decline in maternal mortality from 576 per 100,000 live births in 2013 to 512 per 100,000 live births in 2018 [11]. The pace of reduction and geographical inequalities in the distribution remains a huge concern. There are inequities in maternal mortality rate across the six geopolitical zones in Nigeria with North-East and North-West zones of the country having almost 10 and 6 times, respectively, higher mortality rates than that of the South-West zone of the country [11]. Women from northern Nigeria, especially in rural areas, are at higher risk of maternal death compared to those from the southern part of the country [11]. Lower access to health care services is most common in the Northern zones of the country, particularly in rural areas, among low socioeconomic status (SES) individuals [11]. This is due to distance to facility, limited means of transportation, poor staffing of the health facilities, poor attitude/unprofessional conduct of healthcare providers, and lower levels of education [12,13,14,15].
To date, most studies in Nigeria focus mainly on socioeconomic inequalities in maternal mortality rates [5, 16]. There is a paucity of studies in the literature assessing geographical and socioeconomic inequalities in maternal healthcare use in Nigeria. Using information collected from the four cycles of the Nigeria Demographic Health Surveys (DHS, 2003, 2008, 2013 and 2018), this study examines trends in the geographical and socioeconomic inequalities in maternal healthcare services utilization over the period between 2003 and 2017. The results of this study will provide useful information for policymakers to address geopolitical socioeconomic inequalities in maternal healthcare services that determine health outcomes in the country.
Study setting
The study setting is in Nigeria, with an estimated population of 198 million as of 2018 [11]. The country comprises 36 states and a Federal Capital Territory, Abuja. The country is divided into six geopolitical zones for administrative and political purposes (North-Central, North-East, North-West, South-East, South-West, and South-South). These geopolitical zones comprise states with a similar culture, ethnic groups, and common history [1, 11].
The country has a three-tiered health system; primary, secondary, and tertiary based on the three tiers of government – local, state, and federal. More health services providers are located in the southern than in the northern states of Nigeria, [17], owing to widespread poverty in the North than in the South [18], but there are some other significant issues: for example, fewer than 20% of healthcare facilities in the country offer emergency obstetric care [11]. In terms of levels of socioeconomic development, wide differences exist between the northern and the southern parts of the country and across the geopolitical zones [10]. Approximately 62% of Nigerians live below the poverty line [10], with northern geopolitical zones having the highest poverty rates in the country [19].
Of the available five rounds of the Nigeria demographic and health survey (1990, 2003, 2008, 2013 and 2018), this study used the latest four. The 1990 DHS was not included because the survey was limited to four (North-East, North-West, South-East, and South-West) of the six geopolitical zones of Nigeria. The Nigerian DHS is part of the DHS program designed to collect nationally representative information using three types of structured questionnaires: household questionnaire, women's questionnaire, and, men's questionnaire [10, 20]. The survey used a three-stage cluster sampling design and covered all the six geopolitical zones of the country. The sampling frame was based on the list of enumeration areas prepared for the 1991 and 2006 Population Census of the Federal Republic of Nigeria. Details of the survey have been provided elsewhere [21]. This study utilizes the information collected through the women's questionnaire on issues related to maternal and child health, fertility, and family planning for women aged 15–49.
The outcome variables of the study are three key aspects of maternal healthcare ANC, FBD, and SBA. Based on the recommendations of the World Health Organization (WHO), an ANC visit is defined as a pregnant woman having at least four antenatal assessments by or under the supervision of a skilled attendant [22]. Although the 2016 WHO guideline stipulates eight ANC visits [23], we used the old guidelines as data came mostly from the period with four ANC visits.
The FBD is defined as giving birth at a permanent health-facility such as primary health centers, hospitals, or a private clinic. The SBA is defined as delivery assisted by an accredited health professional such as a doctor, nurse, midwife, or an auxiliary nurse/midwife [20, 21].
Socioeconomic variables
Maternal education and household wealth index (WI) were used as socioeconomic variables in the study. The WI was measured using household asset ownership, household characteristics, household source of drinking water, and household sanitary facilities as contained in DHS datasets [21, 24]. The WI is generally used as an indicator for household SES when income or expenditure data is unavailable [25]. The WI is constructed using principal components analysis (PCA) technique that assigns a score to each household based on selected household assets. The first principal component of a set of variables captures the largest amount of information that is common to all the variables [26, 27]. The mother's education level (in years) was used as another measure of SES in the study [20].
Our statistical analysis involved measuring geographic, education, and wealth-related inequalities. We calculated geographic inequalities in the utilization of maternal healthcare services (ANC, FBD, and SBA) between urban and rural areas and across the six geopolitical zones of Nigeria. Education and wealth-related inequalities in access to maternal healthcare were also estimated for the study period. The chi-square test was set at 0.05% level of significance. Weights were applied to ensure the representativeness of the actual population.
Measuring inequalities between urban and rural and across geopolitical zones
Absolute and relative inequalities between urban and rural areas were calculated using rate ratio (RR) and rate difference (RD). The Theil index (T) was employed to estimate relative inequalities in maternal healthcare utilization between the six geopolitical zones [20, 28]. The T can be estimated as follows:
$$ T={\sum}_{i=1}^i{GZ}_{ih}\left[\ln \left(\frac{GZ_{ih}\ }{GZ_{ip}\ }\right)\right], $$
where GZih is the geopolitical zone's share of the population's health and GZip is the i th zone's population share. The T ranges from zero, indicating an equal distribution, while a higher value suggests a more unequal distribution. Moreover, the between-group variance (BGV) was used to summarize absolute inequality across the geopolitical zones [20, 28]. The BGV was calculated as:
$$ BGV={\sum}_{i=1}^i{GZP}_i{\left({GZH}_i-\mu \right)}^2 $$
Where GZPi is geopolitical zone 's population size (i.e., number of women who gave birth in each year), GZHi is geopolitical zone i's average health outcome, μ is the average health outcome across all the geopolitical zones.
Measuring socioeconomic inequalities
The concentration index (C index) approach was used to calculate socioeconomic related inequalities in the utilization of maternal healthcare services. The index is a widely used measure of socio-economic health inequalities as it fulfills three qualities for a valid socioeconomic inequality index. The index should: a) reflect the health inequalities that arise from the socioeconomic characteristics; b) be representative of the whole population; and c) be sensitive to the subpopulation group sizes [29, 30]. The C index quantifies the extent of socioeconomic inequality in health, which is useful in tracing inequalities over time across different groups [29].
The relative concentration index (RC) is based on the relative concentration curve which graphs the cumulative share of maternal healthcare use (e.g., ANC), on its y-axis, against the cumulative share of the population, ranked in ascending order of an SES indicator (e.g. the WI) on its x-axis. The RC is calculated as twice the area between the relative concentration curve and the perfect equality line. The RC is negative (positive) if the concentration curve lies above (below) the line of equality, indicating that the utilization of maternal healthcare service is concentrated among poorer (richer) women [31, 32]. The RC ranges from − 1 to 1, with a value of zero signifying "perfect equality" [29]. The convenient regression method can be used to compute the RC index as follows [32]:
$$ 2{\sigma}_r^2\left(\frac{y_i}{\mu}\right)=\alpha +\varphi {r}_i+{\varepsilon}_i, $$
where yi is the healthcare variable of interest (e.g. ANC) for women i, μ is the mean of the healthcare utilization variable for the whole sample, ri = i/N, is the fractional rank of individual i in the distribution from the lowest SES woman (i = 1) to the highest SES woman (i = N), and \( {\sigma}_r^2 \) is the variance of fractional rank. The RC is calculated as the ordinary least squares (OLS) estimate of φ [33].
Since our outcome variable of interest is binary, the minimum and maximum values of the RC are not − 1 and + 1, thus, the RC was normalized by multiplying the estimated index by 1/1-μ, where μ indicates the mean of outcome variable of interest [34, 35]. The generalized concentration index (RC × μ) can be used to calculate absolute socioeconomic inequality in healthcare utilization [31]. Since the generalized concentration index does not satisfy this condition, the Erreygers modified the generalized/absolute concentration index (hereafter the =RC × 4μ) [34, 36] was used to calculate absolute socioeconomic inequality in healthcare utilization. The AC ranges from − 1 to + 1, with zero suggesting perfect equality [34]. All analyses were weighted to account for individual survey sample designs. All analyses were conducted using version 13 of the STATA software package (Stata Corp, College Station, Tex).
Table 1 shows maternal healthcare utilization by the sample characteristics. Of the three age groups, women aged 25–34 years, on average use more maternal ANC, FBD, and SBA over the four-year survey periods. Those with secondary education levels on average utilizes more maternal healthcare services than those with no formal education, or education at primary or tertiary education levels. Expectedly, married women use more ANC, FBD, and SBA than the never married and others (divorced, living together, not living together, and widowed). In the same vein, those employed or working on average use more maternal healthcare than their employed counterparts.
Table 1 Maternal healthcare utilization in Nigeria by mother's characteristics and geographic regions (2003–2018)
The results show Christians utilize more maternal healthcare services compared to Muslims and other religions. For the place of residence, urban residents used more maternal care services than rural residents. However, the wealth index shows a positive relationship in maternal healthcare utilization. Of the six geopolitical zones, the average utilization of maternal care use was higher in South-West followed by North-Central zones while it was lower in North-West and North-East zones.
Table 2 reports the survey year, sample size, and average utilization rates for ANC, FBD, and SBA for the total population (the six geopolitical zones) and urban and rural areas for each year within the survey periods. The total measures of maternal healthcare utilization increased for ANC, FBD, and SBA among women who gave birth between 1998 and 2017. The results show that only 58, 32 and 14% of women who gave birth in 1998 used ANC, FBD, and SBA respectively, while these figures increased to 58, 42, and 45%, respectively in 2017. The utilization of maternal healthcare services also increased in urban and rural areas in Nigeria.
Table 2 Survey year, sample size, and maternal care use (mean) in Nigeria, 2003–2018
Figure 1a shows that all the southern geopolitical zones use ANC services more than their northern counterpart. Within the northern zone, the utilization of maternal care is lowest in the North-West zone. As shown in Fig. 1b, South-East and South-West zones use more FBD over the four survey years than the other geopolitical zones. As reported in Fig. 1c the South West, South-East, and North-Central zones have higher utilization of the SBA rate, while the North-West and North-East zones make less use of SBA.
The proportion of antenatal care (ANC), facility-based delivery (FBD) and skilled-birth attendance (SBA) use across the six geopolitical zones of Nigeria 2003–2018
Figure 2 shows the proportion of maternal healthcare use across the six geopolitical zones by four survey periods. The results indicate a pronounced increase in ANC use from 49 to 59 over the survey periods. However, this was not the case for SBA and FBD, which increased marginally from 31 to 35% and 33 to 40%, respectively, over the study period.
The proportion of antenatal (ANC), facility-based delivery (FBD), and Skilled-birth attendance (SBA) use across the survey period
Geographical inequalities in maternal healthcare utilization
Table 3 reports geographical inequalities in maternal healthcare use between rural and urban and across the geopolitical zones of Nigeria. The urban-rural rate ratios (RR) increased for ANC while it decreased for FBD and SBA over the study period. The relative advantage of urban women compared to rural women in ANC increased from 1998 (RR = 1.552) to 2017 (RR = 1.635). The relative inequality in FBD and SBA decreased from 1998 (RR = 2.980) to 2017 (RR = 2.371) and from 1998 (RR = 3.717) to 2017 (RR = 2.478), respectively. The magnitude of these changes was not statistically significant.
Table 3 Geographic inequalities in maternal healthcare use between the rural and urban area and across the six geopolitical zones of Nigeria: 2003–2018
The urban-rural rate differences (RD) indicate that women in urban areas use more maternal healthcare compared to their rural counterparts. In contrast to the RR results, the RDs show that absolute inequalities in maternal healthcare use between urban-rural areas increased for the whole study period. The increasing time trend coefficients of rate difference was significant for FBD. The estimated coefficient shows that the absolute gap in the utilization of FBD between urban and rural areas increased by 0.3% per year, over the period between 1998 and 2017 (Table 3). Both the T and BGV suggest that inequalities exist in maternal healthcare use across geopolitical zones in Nigeria. The T shows that relative inequalities in ANC, FBD across geopolitical zones declined by 7, and 1.8% per year, respectively. The BGV results do not suggest any changes in absolute inequalities in ANC, FBD, and SBA utilization across the geopolitical zones over time.
Socio-economic inequalities in maternal care
Table 4 reports the relative and absolute education-related inequalities in maternal healthcare utilization among women of childbearing age for the survey period in Nigeria. The positive values of the RC and AC suggest a consistent concentration of all the three maternal healthcare services among well-educated women over the study period of 2003–2017. The extent of relative and absolute education-related inequalities in maternal healthcare utilization did not change over time.
Table 4 Education-related inequalities in maternal healthcare utilization among women aged 15–49 years in Nigeria: 2003–2018
Table 5 reports the relative and absolute measure of wealth-related inequalities in maternal healthcare utilization in Nigeria. The positive values of the RC and AC indicate consistent pro-rich inequality in the utilization of ANC, FBD, and SBA in Nigeria over the survey period. Similar to the results of education-related inequalities, we did not find any change in the magnitude of wealth-related inequalities in maternal healthcare use in Nigeria.
Table 5 Wealth-related inequalities in maternal healthcare services among women aged 15–49 years in Nigeria: 2003–2018
This study examined the geographical and socioeconomic inequalities in maternal healthcare services in Nigeria over the past twenty years. The results highlighted geographical inequalities in maternal healthcare services, especially for SBA and FBD across the six geopolitical zones in Nigeria. The results also suggest that women living in urban areas use more maternal healthcare compared to their rural counterparts. Essentially, the gap in the utilization of FBD between urban and rural areas increased/widened per year.
The results suggest inequalities in maternal care across the geopolitical zones in Nigeria. The finding highlights the perennial entrenchment of North-South differences despite maternal healthcare interventions [37] The intermittent geographic inequalities in the SBA and FBD could be because of the perennial poor socioeconomic development of the northern part of Nigeria [10, 19] which may result in lower utilization of maternal care in northern zones.
Results also indicate consistent socioeconomic inequalities in ANC, FBD, and SBA. Both relative and absolute measure of inequalities indicated higher concentration of maternal healthcare services among the better-off and well-educated women over the four survey years despite the concerted efforts of government interventions such as the introduction of free maternal and child health [38] to contain the abysmal maternal mortality ratio in the country.
The later findings are similar to earlier studies that show pro-rich inequalities in maternal healthcare utilization in Ghana [39] and Nigeria [40]. These results provide important evidence that may assist the health stakeholders to redouble their efforts toward achieving the Sustainable Development Goals (SDGs) three targets of reducing the global maternal mortality ratio to less than 70 per 100,000 live births by 2030 [41]. With the government Free Maternal and Child Health Program aimed at decreasing the high maternal mortality by increasing access to maternal health services, evidence indicates that such intervention leads to an increased percentage of access to SBA thereby reducing maternal mortality [38, 42].
Further, findings show that the northern geopolitical zones especially the North-West zone compared with their southern counterparts lag in the utilization of maternal healthcare services. This is not surprising because of the wide gap in socio-economic development between the northern and southern parts of the country [10]. Studies by Obiyan and Kumar [5] and Nghargbu and Olaniyan [40] also emphasized that wealth status and education were the major factors driving inequality in maternal healthcare utilization in Nigeria. Nghargbu and Olaniyan [40], shows that SES rather than the need for healthcare mainly determine demand for maternal healthcare.
The pronounced inequalities in maternal healthcare services in the northern geopolitical zone are exacerbated by several supply-side factors (lack of accessibility, availability, quality, and comprehensiveness of health services) and demand-side factors (social, economic, and cultural) as confirmed by Obiyan and Kumar [5]. As healthcare costs, transportation, and quality of services were identified as barriers for women seeking maternal health services in Nigeria [37], addressing supply-side barriers alongside demand-side factors may lead to an improvement in the maternal care use in Nigeria, especially among low SES women [6].
To address inequalities in maternal care in Nigeria, the political will of both sub-national and national governments is needed for context-specific interventions. National health systems are key in addressing health inequalities and no state or geopolitical zone should face levels of health inequalities that are avoidable [43]. The northern geopolitical zone should give special attention to the upgrade of hospitals for the uptake of obstetric care [44, 45] so that during an emergency, pregnant women should have access to an appropriately equipped health service. As distance is an important barrier to seeking healthcare, especially in rural areas [46], obstetric care must be located within reasonable reach of the people who should benefit from it [46, 47].
This study shows a positive education gradient in the utilization of maternal healthcare services. The education level of women has been found to affect their use of healthcare facilities in other studies [45]. Thaddeus and Maine [48] also found a significant positive association between the use of prenatal care services and the level of women's education. This is important, especially for the North-West and North-East geo-political zones where the female literacy rate is as low as 38% [19], which calls for action to address the trend and increase maternal healthcare services uptake.
Our descriptive results indicate that women of the Christian religion utilize more key maternal healthcare services compare with their Muslim counterparts. The higher use of maternal healthcare services by the Christian women in the South could be due to their higher level of education compared with the Muslim women in the North [49]. This may explain the lower utilization of the maternal healthcare services in the North-East and North-West geopolitical zones where Islam is the main religion. Evidence shows that most husbands practicing Islam discourage their wives from going out without their permission [50]. This presents a barrier to use maternal healthcare for Muslim women, especially when the husband is away from home [48].
One of the strengths of this paper is that the study used nationally representative data that allows the generalization of findings to the entire country. The use of several measures of inequality to assess geographical and socioeconomic inequalities in maternal healthcare is another strength of the study. This study, however, is subject to some limitations. First, the self-reported maternal healthcare use in DHS may be subject to recall bias. Second, although information on maternal healthcare utilization is obtained from pregnancy and delivery occurred between two to four years before the survey year, the WI as one of SES indicators is constructed from information collected for the survey year. As changes in household wealth occur in the long-run, we considered the WI for the survey year to be a reasonable proxy for recent years.
Geographical and socioeconomic inequalities in maternal healthcare utilization prevail in Nigeria. Specifically, the results of this study demonstrated that the utilization of maternal healthcare is lower among poorer and less-educated women, as well as those living in rural areas and North-West and North-East geopolitical zones. Thus, priority focus should be on implementing strategies that increase the uptake of maternal healthcare services among these groups in Nigeria.
Data for this study is publicly accessible at the DHS website: https://www.dhsprogram.com/data/available-datasets.cfm
ANC:
DHS:
Demographic Health Survey
FBD:
Facility-based delivery
SBA:
Skilled birth attendance
RR:
Rate difference
RC:
Relative concentration index
Absolute concentration index
Theil index
BGV:
Between-group variance
SES:
SSA:
Akinyemi JO, Bolajoko I, Gbadebo BM. Death of preceding child and maternal healthcare services utilisation in Nigeria: investigation using lagged logit models. J Health Popul Nutr. 2018;37(1):23.
Jayasundara DS, Panchanadeswaran S. Maternal mortality in developing countries: applicability of Amartya Sen's theoretical perspectives. J Comp Soc Welfare. 2011;27(3):221–31.
Shabnam J, Gifford M, Dalal K. Socioeconomic inequalities in the use of delivery care services in Bangladesh: a comparative study between 2004 and 2007. Health. 2011;03(12):762–71.
Ononokpono DN, Odimegwu CO, Imasiku E, Adedini S. Contextual determinants of maternal health care service utilization in Nigeria. Women Health. 2013;53(7):647–68.
Obiyan MO, Kumar A. Socioeconomic Inequalities in the Use of Maternal Health Care Services in Nigeria. SAGE Open. 2015;5(4):1–11.
Knight HE, Self A, Kennedy SH. Why are women dying when they reach hospital on time? A systematic review of the 'third delay'. PLoS One. 2013;8(5):e63846.
Wagstaff A, Van Doorslaer E, Watanabe N. On decomposingthe causes of health sector inequalities with an application to malnutrition inequalities in Vietnam. J Econ. 2003;112:207–23.
Mezmur M, Navaneetham K, Letamo G, Bariagaber H. Socioeconomic inequalities in the uptake of maternal healthcare services in Ethiopia. BMC Health Serv Res. 2017;17(1):367.
Wagstaff A, Watanabe N. What difference does the choice of SES make in health inequality measurement? Health Econ. 2003;12(10):885–90.
Ejembi CL, Dahiru T, Aliyu AA. Contextual Factors Influencing Modern Contraceptive Use in Nigeria: DHS Working Papers No. 120. Rockville: ICF International; 2015.
FMoH Nigeria. Second National Strategic Health Development Plan 2018–2022. Abuja, Nigeria: Federal Government of Nigeria, Health Planning RS; 2018.
Al-Mujtaba M, Cornelius LJ, Galadanci H, Erekaha S, Okundaye JN, Adeyemi OA, et al. Evaluating religious influences on the utilization of maternal health services among Muslim and Christian women in north-Central Nigeria. Biomed Res Int. 2016;2016:8.
Babalola S, Fatusi A. Determinants of use of maternal health services in Nigeria--looking beyond individual and household factors. BMC Pregnancy Childbirth. 2009;9:43.
Iliyasu Z, Gajida AU, Galadanci HS, Abubakar IS, Baba AS, Jibo AM, et al. Adherence to intermittent preventive treatment for malaria in pregnancy in urban Kano, northern Nigeria. Pathogens Global Health. 2012;106(6):323–9.
Koce F, Randhawa G, Ochieng B. Understanding healthcare self-referral in Nigeria from the service users' perspective: a qualitative study of Niger state. BMC Health Serv Res. 2019;19(1):209.
Ayoade MA. Spatial and socioeconomic inequalities in under 5 mortality in Nigeria. Afr Geogr Rev. 2019:1–16. https://doi.org/10.1080/19376812.2019.1605913.
Bassey PE, Ejemot-Nwadiaro RI, Esu EB, Ndep AO. Determinants and Differentials of Maternal Reproductive Health Outcomes in Nigeria: A Review of National Demographic Health Survey Data from 1999 to 2013. Res Hum Soc Sci. 2016;6(22):141–5.
Olanrewaju O, Akanni OL. Health Expenditure and Health Status in Northern and Southern Nigeria: A Comparative Analysis Using NHA Framework. CSAE conference; St Catherine College, University of Oxford, Oxford, UK. Oxford, UK 2010.
Nwosu CO, Ataguba JE. Socioeconomic inequalities in maternal health service utilisation: a case of antenatal care in Nigeria using a decomposition approach. BMC Public Health. 2019;19(1):1493.
Hajizadeh M, Alam N, Nandi A. Social inequalities in the utilization of maternal care in Bangladesh: have they widened or narrowed in recent years? Int J Equity Health. 2014;13:120.
National Population Commission, ICF International. Nigeria Demographic and Health Survey 2013. Abuja and Rockville: NPC and ICF International; 2014.
WHO. Provision of effective antenatal care: integrated management of pregnancy and child birth (IMPAC). Geneva, Switzerland: World Health Organization, Safer DoMP; 2006.
WHO. WHO recommendations on antenatal care for a positive pregnancy experience. Geneva, Switzerland: World Health Organization; 2016.
National Population Commission, ICF Macro. Nigeria Demographic and Health Survey 2008. Abuja and Rockville: NPC and ICF International; 2009.
Pulok MH, Uddin J, Enemark U, Hossin MZ. Socioeconomic inequality in maternal healthcare: an analysis of regional variation in Bangladesh. Health Place. 2018;52:205–14.
Filmer D, Pritchett LH. Estimating wealth effects without expenditure data or tears: an application to education enrollments in states of India. Demography. 2001;38(1):115–32.
Vyas S, Kumaranayake L. Constructing socio-economic status indices: how to use principal components analysis. Health Policy Plan. 2006;21(6):459–68.
Health Equity Assessment Toolkit. Software for exploring and comparing health inequalities in countries: built-in database edition version 2.0. Geneva: World Health Organization; 2017.
Hajizadeh M, Hu M, Bombay A, Asada Y. Socioeconomic inequalities in health among indigenous peoples living off-reserve in Canada: trends and determinants. Health Policy. 2018;122(8):854–65.
Wagstaff A, Pact P, Van Doorslaer E. On the measurement of inequalities in health. Soc Sci Med. 1991;33(5):545–57.
Alam N, Hajizadeh M, Dumont A, Fournier P. Inequalities in maternal health care utilization in sub-Saharan African countries: a multiyear and multi-country analysis. PLoS One. 2015;10(4):e0120922.
Kakawani N, Wagstaff A, Van Doorslaer E. Socioeconomic inequalities in health: measurement, computation, and statistical inference. J Econ. 1997;77:87–103.
O'Donnell O, van Doorslaer E, Wagstaff A, Lindelow M. Analyzing health equity using household survey data: a guide to techniques and their implementation. Washington, D.C.: The World Bank; 2008.
O'Donnell O, O'Neill S, Van Ourti T, Walsh B. Conindex: estimation of concentration indices. Stata J. 2016;16(1):112–38.
Wagstaff A. The bounds of the concentration index when the variable of interest is binary, with an application to immunization inequality. Health Econ. 2005;14(4):429–32.
Erreygers G. Correcting the concentration index. J Health Econ. 2009;28(2):504–15.
Wollum A, Burstein R, Fullman N, Dwyer-Lindgren L, Gakidou E. Benchmarking health system performance across states in Nigeria: a systematic analysis of levels and trends in key maternal and child health interventions and outcomes, 2000-2013. BMC Med. 2015;13:208.
Onwujekwe O, Obi F, Ichoku H, Ezumah N, Okeke C, Ezenwaka U, et al. Assessment of a free maternal and child health program and the prospects for program re-activation and scale-up using a new health fund in Nigeria. Niger J Clin Pract. 2019;22(11):1516–29.
Novignon J, Ofori B, Tabiri KG, Pulok MH. Socioeconomic inequalities in maternal health care utilization in Ghana. Int J Equity Health. 2019;18(1):141.
Nghargbu R, Olaniyan O. Inequity in maternal and child health care utilization in Nigeria. Afr Dev Rev. 2017;29(4):630–47.
United Nations. Transforming Our World: The 2030 Agenda for Sustainable Development: United Nations. Contract No.: A/RES/70/1. New York: United Nations; 2015.
Ogbuabor DC, Onwujekwe OE. Implementation of free maternal and child healthcare policies: assessment of influence of context and institutional capacity of health facilities in south-East Nigeria. Glob Health Action. 2018;11(1):1535031.
Marmot M. Achieving health equity: from root causes to fair outcomes. Lancet. 2007;370(9593):1153–63.
Adedokun ST, Uthman OA. Women who have not utilized health Service for Delivery in Nigeria: who are they and where do they live? BMC Pregnancy Childbirth. 2019;19(1):93.
Buor D, Bream K. An analysis of the determinants of maternal mortality in sub-Saharan Africa. J Women's Health. 2004;13(8):926–38.
Tanahashi T. Health service coverage and its evaluation. Bull World Health Organ. 1978;56(2):295–303.
Brouwere VD, Tonglet R, Lerberghe WV. Strategies for reducing maternal mortality in developing countries: what can we learn from the history of the industrialized west? Trop Med Int Health. 1998;3(10):771–82.
Thaddeus S, Maine D. Too far to walk: maternal mortality in context. Soc Sci Med. 1994;38(8):1091–110.
Solanke BL, Oladosu OA, Akinlo A, Olanisebe SO. Religion as a social determinant of maternal health care service utilisation in Nigeria. Afr Popul Stud. 2015;29(2):1868–81.
Fagbamigbe AF, Idemudia ES. Barriers to antenatal care use in Nigeria: evidences from non-users and implications for maternal health programming. BMC Pregnancy Childbirth. 2015;15:95.
This research paper is part of the first author's Ph.D. thesis at the University of Southern Queensland, Toowoomba Campus, Australia. The authors are grateful to ICF International for the authorization to use the DHS data.
The authors have not received any funding to conduct this study.
School of Commerce, and Centre for Health Research, University of Southern Queensland, Toowoomba, QLD, 4350, Australia
Chijioke Okoli, Mohammad Mafizur Rahman & Rasheda Khanam
Department of Health Administration and Management, Faculty of Health Sciences Technology, College of Medicine, University of Nigeria, Enugu Campus, Enugu, Enugu State, Nigeria
Chijioke Okoli
School of Health Administration, Dalhousie University, Halifax, Canada
Mohammad Hajizadeh
Mohammad Mafizur Rahman
Rasheda Khanam
CO designed the study, conducted the statistical analysis, and prepared the first draft of the manuscript. MH and RK assisted in designing the study, supervised data analysis, and writing of the manuscript. MMR reviewed data analysis and the article. All the authors read and approved the final manuscript.
Correspondence to Chijioke Okoli.
Approval letter to use the DHS dataset for this study was obtained from the Demographic and Health Surveys (DHS) Program. The DHS dataset is a secondary data, hence, this study did not require a formal ethics approval. However, we observed anonymity and confidentiality under the data terms of use.
There is no conflict of interest.
Okoli, C., Hajizadeh, M., Rahman, M.M. et al. Geographical and socioeconomic inequalities in the utilization of maternal healthcare services in Nigeria: 2003–2017. BMC Health Serv Res 20, 849 (2020). https://doi.org/10.1186/s12913-020-05700-w
Geographical inequalities; socioeconomic inequalities
Maternal healthcare | CommonCrawl |
PN-PAM scheme for short range optical transmission over SI-POF — an alternative to Discrete Multi-Tone (DMT) scheme
Linning Peng1,
Ming Liu2,
Maryline Hélard3 &
Sylvain Haese3
How to deal with the time-dispersive channel is the main challenge faced by the short-range optical communication systems. In this work a novel pseudo-noise sequence (PN) assisted pulse-amplitude modulated (PN-PAM) transmission scheme for short-range optical communication systems is proposed in this work. With the help of the PN based channel estimation, minimum-phase pre-filter and reduced-state sequence estimation based equalizer, the proposed PAM transmission scheme can significantly reduce the training overhead for channel estimation in the classical PAM systems using decision feedback equalizer (DFE). In addition, the proposed PAM transmission scheme can effectively avoid the error propagation phenomenon in the classical DFE.
Theoretical study shows that the proposed PAM scheme can achieve a 1.5 dB SNR gain with PAM-8 modulation over 50 m step-index polymer optical fiber (SI-POF) channel at a desired BER level of 1×10−3 and 1.2 Gbps transmission rate. Furthermore the hardware experiment using commercially available components proves the improvements in the proposed PAM transmission scheme.
The novel PAM transmission scheme is compared to the optimized discrete multi-tone (DMT) transmission with bit-loading. The experimental results show that for a transmission distance less than 50 m over SI-POF, DMT systems outperform the PAM systems. However, for a SI-POF transmission over the distance longer than 50 m, the proposed scheme can reach a better performance than the DMT systems thanks to the advantage of a lower peak-to-average-power ratio.
Recently, high-speed transmission over plastic optical fiber (POF) has attracted many research interests [1, 2]. POF owns the advantages of easier connection and band insensitive, which could be an economic solution for home networking. However, the available transmission bandwidth in POF is limited due to the significant modal dispersion in large core diameter POF. The intensive modal dispersion could be modeled as multi-path channel delay which causes low-pass channel frequency response [1, 2]. In addition, for different types of short range optical communication systems, such as single-mode fiber (SMF), multi-mode fiber (MMF), and optical wireless with visible light communications (VLC), there have similar channel characteristics as POF's, which can be modeled as a low-pass frequency response with very high signal-to-noise ratio (SNR) [3–6]. Therefore, the increasing traffic demands require better bandwidth utilization in the existing short range systems. In the state-of-the-art short range optical transmission systems, the used transmission bandwidth is far wider than the system's 3 dB bandwidth [3–6]. In order to explore the best transmission performance in these situations, several advanced modulation schemes have been investigated in recent works [7–9].
Multi-carrier modulation (MCM) schemes are widely used for the short range optical transmission systems. The discrete multi-tone (DMT) with bit-loading technique can effectively approach the channel capacity. However, MCM schemes have the drawbacks of high peak-to-average-power ratio (PAPR) and computational complexity [9, 10]. Compared to the MCM schemes, single carrier modulation (SCM) schemes enjoy the advantages of computational simplicity and low PAPR. The Not-Return-to-Zero (NRZ) coding with equalization offers satisfactory achievable link power budget margin [8, 9]. The pulse-amplitude modulation (PAM) is another SCM scheme that provides better spectrum efficiency than NRZ coding. As the short range optical transmission systems usually have high SNR, the PAM transmission scheme shows notable advantages over the classical NRZ transmission scheme [8, 11].
However, sophisticated equalization techniques are needed for most SCM schemes in order to restore the distorted SCM signal after the transmission over the bandwidth-limited channels [8]. An equalizer is commonly adopted at the receiver side to equalize the received signal. In addition, the decision-feedback equalizer (DFE) is proved to outperform the feed-forward equalizer (FFE) [12]. Moreover, in case of adaptive equalization, long training sequences are required for good convergence, which consequently reduces the overall system efficiency. Moreover, DFE has the drawback of the error propagation which reduces the system performance in the practical implementations. Although some works show that the Tomlinson-Harashima precoding technique can resolve the error propagation problems in DFE [13], it requires a prior information at transmitter side and increases the overall system complexity [13].
Concerning practical PAM transmissions over SI-POF, [14] and [15] summarized available transmission rates with different SCM schemes, such as 1 Gbps over 20 m SI-POF, 400 Mbps over 50 m SI-POF, and 170 Mbps over 115 m SI-POF in [15] and 10 Mbps over 425 m SI-POF, 100 Mbps over 275 m SI-POF and 1 Gbps over 75 m SI-POF in [14]. Additionally, recent works reported higher transmission rate over 50 m SI-POF with new designed front-end receivers [16, 17]. In this work, we focus on a system architecture research of increasing SI-POF transmission rate with existing off-the-shelf components. In order to improve the transmission efficiency of the PAM transmission and avoid the error propagation problem in DFE, we propose a novel pseudo-noise sequence assisted pulse-amplitude modulated (PN-PAM) transmission scheme for short range optical communication systems. This novel scheme is a SCM in nature and is incorporated with a minimum phase pre-filter and a simplified trellis-based equalizer at the receiver side. The coefficients of minimum phase pre-filter could be obtained from a pseudo noise (PN) sequence-based channel estimation with very short training symbol length. A comparison between the capacities of the novel PAM scheme and the existing DMT scheme over SI-POF is carried out with the same experimental setups. It is shown that this proposed PAM transmission scheme is suitable for other short range optical communication systems due to its advantage of low PAPR.
The remainder of this paper is organized as follows: In "Methods" section, the method of PN-PAM transmission scheme is introduced. In "Theoretical analysis of the PN-PAM transmission" section, a theoretical analysis for PAM transmission over short range step index-POF (SI-POF) system which is modeled as Gaussian low-pass filter. The PAPR of PAM transmission with root-raised-cosine (RRC) filters is also evaluated. In "Numerical analysis of the PN-PAM transmission" section, the proposed PAM transmission scheme is compared with the classical one via simulations. In "Results and discussion" section, a real SI-POF transmission system with commercially available components is used to further prove the merits of the proposed scheme. The comparisons between the PAM and DMT transmissions over practical channels are also presented. Finally, conclusions are highlighted in "Conclusion" section.
In optical fiber communication systems, PAM transmission with adaptive DFE has been widely used. However, as the optical fiber channels are quite stable, it is possible to obtain the optimal DFE coefficients with a reduced transmission overhead. Furthermore, as DFE has the drawback of the error propagation, it is necessary to introduce a novel decision mechanism to replace the direct decision in DFE. In this section we propose a novel PAM transmission scheme for optical fiber communications. To achieve satisfactory performance, the reception of this novel scheme includes three main components: the PN sequence based channel estimator, a minimum-phase receiver filter, and a reduced-state sequence estimation(RSSE) based equalizer. More details of the proposed scheme is presented in following part of the section.
PN sequence based channel estimation
The SCM based transmissions enjoy the advantage of low PAPR over MCM ones and are therefore attractive for optical fiber transmissions. In the meantime they normally require high channel estimation accuracy in order to prevent the error propagation phenomenon in the reception. The PN sequence-based channel estimation was known for its merits of low complexity and high accuracy in wireless communication scenarios [18]. It was recently proved to be very efficient for in DMT transmission over optical fiber [19]. This motivates us to investigate the application of PN sequence based channel estimation for SCM-based optical fiber transmissions.
In classical PAM systems, the transmitted symbols are expressed as:
$$ \begin{aligned} \bar{S}_{\text{PAM}}&=\left[\bar{S}_{\mathrm{T}},\bar{S}_{\mathrm{D}}\right]^{T}=\left[S_{\mathrm{T}}(0), \cdots S_{\mathrm{T}}\left(N_{\mathrm{T}}-1\right),S_{\mathrm{D}}(0), \cdots\right.\\&\qquad\qquad\qquad\quad\left.S_{\mathrm{D}}(N_{\mathrm{D}}-1)\right]^{T}, \end{aligned} $$
where \(\bar {S}_{\mathrm {T}}\) is the length- N T vector of training symbols for the equalizer; \(\bar {S}_{\mathrm {D}}\) is the length- N D vector of PAM data symbols.
When the PN sequence is inserted to the PAM symbols to assist the channel estimation, the transmitted PN-PAM symbols are written as:
$$ \begin{aligned} \bar{S}_{\mathrm{PN-PAM}}=\left[\bar{\rho}_{\text{PN}},\bar{S}_{\mathrm{D}}\right]^{T}&=\left[\rho_{\text{PN}}(0),\cdots \rho_{\text{PN}}\left(N_{\text{PN}}-1\right),\right.\\ &\left.\quad S_{\mathrm{D}}(0),\cdots S_{\mathrm{D}}\left(N_{\mathrm{D}}-1\right)\right]^{T}, \end{aligned} $$
where \(\bar {\rho }_{\text {PN}}\) is the vector of PN sequence for channel estimation. The length of \(\bar {\rho }_{\text {PN}}\) is N PN.
At the receiver side, the received PN sequence is used to perform channel estimation. The PN sequence based channel estimation for optical communications has been initially introduced in [19]. The m-sequences are selected as the PN sequences for channel estimations due to their ease of generation and their associated low complexity. The most significant benefit of using m-sequence for channel estimation is its special circular autocorrelation property. The circular autocorrelation of the m-sequence is known as:
$$ \text{CR}_{j}=\frac{1}{N_{\text{PN}}}\sum_{i=0}^{N_{\text{PN}}-1}m_{i}m^{*}_{[i+j]_{N_{\text{PN}}}}= \left\{ \begin{array}{cl} 1 &j=0\\ -\frac{1}{N_{\text{PN}}} &else\\ \end{array}\right. $$
where m is the m-sequence, (·)∗ is the complex conjugate, \(\left [\cdot \right ]_{N_{\text {PN}}}\) denotes modulo- N PN operation. With the help of circular autocorrelation property shown in (3), the channel estimation can be simply obtained by performing time domain correlation of known and received PN sequences:
$$ \widetilde{\bar{h}}=\frac{1}{N_{\text{PN}}}\sum_{i=0}^{N_{\text{PN}}-1}\left(\sum_{l=0}^{N_{\mathrm{H}}-1}h_{l}\rho_{i-l}+w_{i}\right)\cdot m^{*}_{[i+j]_{N_{\text{PN}}}} $$
where w is the noise, N H is the channel length. In POF channel model, the massive multi-path delay could be modeled as discrete filter taps. Therefore, the maximal channel multi-path delay in real POF channel could be denoted by channel length N H with number of filter taps.
Finally, the accurate estimate of the channel impulse response (CIR) \(\widetilde {\bar {h}}=[\widetilde {h}_{0},\widetilde {h}_{1},\cdots \widetilde {h}_{N_{\mathrm {H}}-1}]^{T}\) can be easily obtained at a very low complexity cost [20]. According to the analysis carried out in [19], the overall complexity of the PN sequence-based channel estimation is \(\mathcal {O}(N_{\text {PN}}\cdot \log N_{\text {PN}})\), which is determined by the PN sequence length.
Minimum-phase pre-filtering
In communication systems, trellis-based equalizer can effectively eliminate the inter-symbol interference (ISI) after transmission over the channel. The maximum-likelihood sequence estimation (MLSE) is recognized as the optimal equalization algorithm in the sense of sequence detection. As the decision is based on a sequence of symbols, it can effectively avoid the error propagation problem of DFE. However, it is worth noting that for PAM with high orders modulations, the computational complexity of MLSE equalizer dramatically increases. The full MLSE equalizer becomes computationally prohibitive when the modulation order is high and/or when the channel length is long. To avoid the prohibitive complexity, a sub-optimal trellis-search based equalizer, namely RSSE, is commonly used for its simplicity in the hardware implementation.
Studies in [21, 22] show that, in order to obtain the sub-optimal performance after trellis-based equalization, discrete time minimum-phase overall impulse response needs to be carried out previously. We employ an FFE pre-filter to achieve the minimum-phase overall impulse response. As an accurate CIR is obtained directly from the PN sequence-based channel estimation, it is feasible to calculate the filter coefficients from the estimated CIR. The coefficients of the pre-filter can be calculated in closed-form from the estimated CIR \(\widetilde {\bar {h}}\).
In [22], the coefficients of the minimum-phase pre-filter are calculated by the linear prediction from the estimated CIR. The linear prediction is realized by the well-known Levinson-Durbin algorithms. Concretely, the pre-filter is determined as follows:
$$ \widetilde{F}(z)=z^{-N_{\mathrm{H}}}H^{\ast}\left(1/z^{\ast}\right)(1-P(z)), $$
where H ∗(1/z ∗) is the time-reversed conjugated CIR, (1−P(z)) is the calculated linear prediction filter, \(\phantom {\dot {i}\!}z^{-N_{\mathrm {H}}}\) introduces a delay of N H samples.
The analysis of this minimum-phase pre-filter calculation shows that the overall computational complexity of linear prediction method is significantly lower than that of the minimum mean-squared error (MMSE)-DFE method [22].
RSSE based equalization
In contrast to the MLSE equalizer where all possible combinations of symbol sequences are compared with received signal sequence, RSSE dramatically reduces the number of candidates to be compared by applying constellation partitioning and decision-feedback with early decisions [23]. With a proper choice of the number of survivor states, the RSSE based equalizer can approach the optimal performance offered by the MLSE equalizer.
More concretely, the entire symbol alphabet is divided into subsets, and the search trellis is built based on these subsets. The subsets need to be chosen such that the Euclidean distance of symbols within each subset is maximized. Once the survival path is determined, the hard decision within the subset is made directly so that only one survival candidate is reserved in each set, while others are simply discarded for the following search. The selection among subsets is not taken in the current step. Therefore, the number of overall trellis states involved in the search is reduced to \(Z=\prod ^{N_{\mathrm {C}}}_{k=1}J_{k}\), where J k is the number of subsets preserved for the symbol k steps before the currently detecting symbol, N C is the constraint length which is chosen according to the number of significant channel paths, and can be less than the overall channel length N H. It is worth noting that through the choice of J k , the performance and complexity of RSSE equalizer can achieve arbitrary trade-off between the optimal MLSE equalizer and the simple DFE equalizer [22]. For example, when J k =M, 1≤k≤N C, the RSSE equalizer becomes the MLSE equalizer for PAM-M modulation. Similarly, when J k =1, 1≤k≤N C, since there is only one subset preserved for decision, the RSSE equalizer is turned into a DFE equalizer.
Theoretical analysis of the PN-PAM transmission
Gaussian low-pass filter channel model
In most short range optical transmission systems, the channels show similar features such as a low-pass frequency response and very good channel condition (very high SNR) at low frequency part [3–5]. The Gaussian low-pass filter channel model has been proved to be suitable for the POF systems [24]. In this section, it will be used to model a 50-m SI-POF system for the theoretical investigation of the proposed PN-PAM transmission.
The channel frequency response (CFR) of the Gaussian low-pass filter channel model is written as:
$$ H(f)=A\cdot \exp\left[{-\left(\frac{f}{f_{0}}\right)^{2}}\right],\quad f_{0}=\frac{f_{\mathrm{3dB}}}{\sqrt{\ln(2)}}, $$
where H(f) is the CFR at f Hz; A is the optical fiber loss; f 3dB is the 3 dB bandwidth of the considered 50-m SI-POF system.
PAM transmission over Gaussian low-pass filter channel
Using the Gaussian low-pass filter channel model introduced in (6), we can theoretically analyze the PAM transmission over a 50-m SI-POF with different equalizers. It is well known that in additive white Gaussian noise (AWGN) channel, channel capacity is calculated as:
$$ C=W \cdot \log_{2}\left(1+\frac{P}{N_{0}W}\right), $$
where W is the used bandwidth, P is the signal power, N 0 is the power spectral density of the noise. When signal is transmitted over a multi-path channel, ISI will be introduced among consecutive symbols due to the time dispersion of signal. At the receiver side, noise can be boosted after the equalization depending on the equivalent SNR over the whole signal band. Therefore, the performance of the PAM system can be determined through the corresponding SNR after equalization [25]. Based on the post-equalization SNR, we can derive the achievable rate of the PN-PAM transmission in the Gaussian low-pass filter channel.
As the RSSE equalization used in the proposed scheme is a non-linear process, it is difficult to derive the capacity of the proposed PN-PAM scheme in a straightforward manner. Alternatively, we analytically investigate the PAM transmission system using DFE which is an extreme case of the RSSE equalizer. For PAM transmission system using DFE, we assume that no incorrect decision is fed back. Following the results given in [25], the post-equalization SNR of PN-PAM transmission system is written as:
$$ SNR_{\text{DFE}}=\frac{1-\xi_{\text{DFE}}}{\xi_{\text{DFE}}}, $$
$$ \xi_{\text{DFE}}=\exp\left[\frac{T}{2\pi}\int_{-\pi/T}^{\pi/T}\ln\frac{N_{0}}{H\left(e^{j\omega T}+N_{0}\right)}d\omega\right]. $$
The integral in the expression of ξ DFE in (9) can be mathematically approximated by discrete summation. Employing (6), ξ DFE is estimated by:
$$ \begin{aligned} \xi_{\text{DFE}}\approx \exp\left[\frac{1}{N_{p}}\sum_{i=1}^{N_{p}}\ln\frac{N_{0}\cdot N_{p}}{A\cdot \exp\left[-\left(\frac{i\cdot \Delta f}{\sqrt{\ln(2)}\cdot f_{\mathrm{3dB}}}\right)^{2}\right]+N_{0}\cdot N_{p}}\right], \end{aligned} $$
where Δ f is the frequency spacing of the discrete calculation; N p is the number of intervals in order to approximate the integral function. The bandwidth of the PAM system is therefore W PAM=Δ f·N p . The normalized noise energy within the Δ f frequency spacing is N 0.
We assume that the Nyquist bandwidth (1/2T) is used. Introducing the post-equalization SNR in (8) and the channel capacity in (7), we can obtain the capacity of PAM transmission with DFE equalization:
$$ C=2\cdot W_{\text{PAM}} \cdot \log_{2}\left(1+SNR_{\text{DFE}}\right). $$
Introducing the linear approximation method proposed in [26], we can compute the achievable PAM modulation order b as:
$$ b=\frac{SNR(\text{dB})-A_{2}}{A_{1}}, $$
where A 1 and A 2 are coefficients defined in the linear approximation. The exact values of A 1 and A 2 for PAM modulation can be obtained by following similar manipulations as in [26] for different desired BER levels. The obtained A 1 and A 2 are listed in Table 1.
Table 1 Parameters for the relationship between SNR and available PAM modulation order with different desired BER
Applying (11) and (12), the available transmission rate can be calculated as:
$$ R_{s}=2\cdot W_{\text{PAM}}\cdot \frac{10\cdot \log_{10}\left(\frac{1-\xi_{\text{DFE}}}{\xi_{\text{DFE}}}\right)-A_{2}}{A_{1}}. $$
Take the 50-m SI-POF transmission system as an example, where the channel model parameters are the same as in [26]. We can get that f 3dB is 90 MHz and the measured noise power spectral density is −113.7 dBm/Hz. We numerically calculate the PAM transmission rate with the frequency spacing Δ f of 1 MHz and number of intervals N p equal to 1000. With a target BER of 1×10−3 (a level that the residual error can be effectively corrected by channel coding), the relationship between PAM transmission rate and used bandwidth is depicted in Fig. 1.
Comparison of PAM modulation order (upper) and transmission rate (lower) with different used bandwidths
As shown in the figure, the narrower bandwidth, the higher PAM modulation orders. However, concerning transmission rate, there is an optimized used bandwidth and PAM modulation order. For instance, in our POF system model, the optimal used bandwidth in Fig. 1 b is around 220 MHz. The achievable PAM modulation order with this bandwidth is PAM-8 accordingly in Fig. 1 a.
RRC filters for PAM transmissions
In practical communication systems, the square RRC filters are normally used at the transmitter and receiver in order to reduce the required bandwidth for the transmission. For the RRC filters, a roll-off factor β is a measure of the excess bandwidth of the filter, which represents the bandwidth occupied beyond the Nyquist bandwidth of 1/2T. β can be chosen between 0 and 1. Therefore in a practical system, the real required bandwidth W PAM is denoted as:
$$ W_{\text{PAM}}=\frac{1}{2}R_{s}(1+\beta), $$
where R s is the PAM symbol rate.
In a pure PAM system without the RRC filter, the PAPR is directly related to the PAM modulation order. However, the use of RRC filter at the transmitter will increase the PAPR with a reduced excess bandwidth or increased filter length [27]. The relationship between the PAPR of the QAM modulation and the RRC filter roll-off factor was studied for PAM-2 and QAM-32 in [27]. Here we investigate the relationship between β and PAPR for PAM-2, PAM-4, PAM-8, PAM-16, and PAM-32. The maximal PAPR of the PAM signal after the RRC filtering is evaluated by the following equation:
$$ \text{PAPR}_{\text{max}}=10\cdot \log_{10}\left(\frac{x_{\text{max}}^{2}}{\mathbb{E}[x^{2}]}\right), $$
where x max is the maximal amplitude of the PAM-M signal. \(\mathbb {E}[x^{2}]\) is the average power of the generated signal. The measured results with a RRC filter length of 8 taps are presented in Fig. 2. From the figure, we can find that the PAPR of the PAM modulated signal after RRC filtering significantly increases when the roll-off factor is lower than 0.4. The PAPR of the PAM-2, PAM-4 and PAM-8 with a RRC filter roll-off factor of 0.2 is obtained around 4.3, 6.9 and 8.0 dB, respectively.
Relationship between the PAM modulation order and RRC filter roll-off factor
Numerical analysis of the PN-PAM transmission
In this section, we simulate the PN-PAM transmission over the 50-m SI-POF system. The modulation is chosen to be PAM-8 which has been shown to be the best modulation scheme for the given channel condition. The symbol rate is set to be 440 Mega symbols per second. Therefore the theoretically minimal required bandwidth is 220 MHz when roff-off factor in RRC filter is assumed at 0. In the practical simulation system, we use a square RRC transceiver filter to reduce the used bandwidth of the PAM transmissions. The roll-off factor is set to be 0.2. Therefore, the actual used bandwidth in simulations is 264 MHz. The estimated SNR with the noise PSD of −113.7 dBm/Hz is about 29.5 dB.
PN-PAM transmission with different equalization methods
Firstly, in Fig. 3, we present the simulation results of PAM-8 transmission over the 50-m SI-POF channel with different equalization methods. For the classical adaptive DFE equalizations, two typical algorithms referred to as recursive least square (RLS) and least mean square (LMS) are adopted. In genie-aided mode, we initially transmit 10,000 training symbols to get the DFE coefficients and subsequently using the known symbols as the decided symbols for the DFE feedback. Alternatively, in direct-decision mode, we use decided symbols for the DFE feedback. In both cases, the number of decision feedback taps is 6 and the number of FFE taps is 24. The simulation results show that DFE-RLS and DFE-LMS provide similar performance in the 50-m SI-POF system with PAM-8 transmission. However, in both DFE-RLS and DFE-LMS schemes, due to the error propagation in direct-decision mode, there is an approximate 1.5 dB degradation at the BER level of 1×10−3 compared to the genie-aided mode. Therefore it is crucial to avoid the error propagation problem in the practical systems.
Illustration of multi-path CIR in Gaussian low-pass filter channel model (upper) and after pre-ltering (lower)
Then we simulate the proposed PN-PAM transmission scheme with RSSE. The PN sequence length for channel estimation is set to be 255 symbols and a cyclic-prefix with the length of 33 symbols is added to the PN sequence in order to prevent the ISI from previous transmitted symbols. The length of the estimated CIR is 7 taps. The first 6 most significant taps are used to calculate the minimum-phase pre-filter. An illustration of the multi-path CIR in original Gaussian low-pass filter channel model and after pre-filtering is presented in Fig. 4. As shown in the figure, a main path is recovered at the first tap after pre-filtering. Then the most significant multi-path component is located at the second tap, which owns an amplitude about 0.86. Therefore, we design and compare two RSSE structures in 50-m POF transmissions. The first RSSE structure uses the first 2 most significant delay taps for symbols decision. Hence the length of the RSSE trellis is selected to 2. The number of subsets for the first delay tap J 1 is set to 2 and the number of subsets for the second delay tap J 2 is set to 1. The second RSSE structure uses all of the 5 delay taps for symbols decision. For each delay tap, the number of subsets J k is set to 1. In the second RSSE structure, as each delay tap only has one subset, the RSSE equalizer turns into a DFE equalizer with 5 taps. Obviously, for both of the RSSE structure, the overall complexity is very low.
Simulation results of the PAM transmission over 50 meters SI-POF with different equalization methods
After simulations of the transmission over 50-m SI-POF channel, performances of RSSE equalizers are depicted in Fig. 3. As been shown in the figure, the RSSE (2,1) equalizer can achieve similar performance to classical DFE equalizers in genie-aided mode, which has 1.5 dB improvement with the practical DFE equalizers in direct-decision mode. Additionally, the RSSE (1,1,1,1,1) equalizer has a very close performance to classical DFE equalizers. Therefore, it is clear that in the 50-m SI-POF channel, using RSSE (2,1) equalizer can solve the error propagation problem in classical DFE equalizers.
PAM transmission with respect to different training sequence lengths
In addition, as mentioned in "Methods" section, the novel PAM transmission scheme leads to an improved transmission efficiency. The training sequence takes up a certain amount of transmission energy and hence reduces the overall system efficiency. For the classical DFE-RLS and DFE-LMS equalizers, the predefined training sequence is inserted before the data symbols. The equalizers work in training mode when the training symbols are received and then switch to the equalization mode when data symbols are received. In equalization mode, there are two feed-back methods. In general transmissions, the feed-back bits are obtained from decisions, which is called as direct-decision mode. However, in this mode, decision error will be propagated and cause penalties. Besides, it is also possible to use known pilot bits as the feed-back bits. In this mode, error propagation could be avoided due to the known pilot bits at receiver. This mode is called as genie-aided mode. In practical system, the known pilot bits cannot be used to transmit message. Therefore, the genie-aided mode is only used to theoretical optimal performance evaluations.
For the proposed scheme, the training sequence is the PN sequence inserted before the data symbols. We simulate the PAM-8 transmission over the 50-m SI-POF channel with different training sequence lengths for both classical DFE and the proposed scheme. The SNR is fixed to 29.5 dB. The BER performance is depicted in Fig. 5.
Simulation results of the PN-PAM transmission over 50-m SI-POF with different training sequence lengths
With a PN sequence length longer than 255 symbols, the proposed system achieves the best BER performance of around 4.6×10−4. However, the classical DFE based equalizers require much longer training sequences. Simulation results show that even in the genie-aided mode, in order to get converged BER performance, the DFE-RLS requires a training sequence longer than 4096 symbols and the DFE-LMS requires a training sequence longer than 32,768 symbols. Moreover, when DFE works in direct-decision mode, even extremely long training sequence is adopted, they can only reach the best BER performance of around 2.0×10−3.
From simulations shown above, it is obvious that the proposed PN-PAM transmission scheme can achieve higher system efficiency. The improvement comes from two aspects. On the one hand, the PN-based channel estimation requires very little training overhead, roughly 0.01 to 0.05 compared to the classical DFE schemes. On the other hand, the RSSE equalization leads to an improved BER performance with the help of the reduced error propagation compared to classical DFE schemes.
In order to verify the proposed PAM transmission schemes, we setup a practical system for experimental comparisons. We also compared PAM transmissions to DMT transmissions with different POF lengths.
Experimental system setups
In contrast to most experimental POF transmission systems, we use a commercially available digital to analog convertor (DAC) and analog to digital convertor (ADC). Both DAC and ADC are provided from Texas Instruments. The DAC (DAC5681) has 1 Giga samples per second sampling rate and 16 bits resolution. The ADC (ADC12D1800RFRB) has 1.8 Giga samples per second sampling rate and 12 bits resolution. In order to drive the resonant-cavity light emitting diode (RCLED), we designed an amplifying circuit at the transmitter using a commercially available amplifier (OPA695) also from Texas Instruments. The designed transmission bandwidth is 250 MHz.
At the transmitter, RCLED is provided from Firecomms (FC300R-120) with a 3 dB bandwidth of 100 MHz. The biasing current is 20 mA and the coupled power into the SI-POF is −0.2 dBm. PMMA Φ 1 mm SI-POFs (Eska MEGA) are prepared with different lengths (15, 30, 50, 75 and 100 m). At the receiver, a photodiode combined with a trans-impedance amplifier (FC-1000D-120) is employed to detect the received optical signal. The 3 dB bandwidth of the receiver is 625 MHz. The block diagram of the experimental system is presented in Fig. 6.
Both the novel PN-PAM transmission scheme and classical PAM transmission scheme is generated off-line in computer. For the novel PN-PAM transmission scheme, the PN length is set to be 255 symbols and for classical PAM transmission scheme, the training sequence length is chosen as 5000 symbols. The roll-off factor of the RRC filter is selected as 0.25. Therefore, PAM symbol rate is set to 400 Mega symbols per second. The total used bandwidth is 400÷2×1.25=250 MHz. As 2 times oversampling is adopted at the transmitter, the DAC sampling rate is 800 Mega samples per second. The ADC works at 1.8 Giga samples per second. At the receiver, for classical PAM transmission with DFE, the number of decision feedback taps is 6 and the number of FFE taps is 24. For the proposed PN-PAM transmission scheme, the first 13 prominent taps in the CIR estimate are used for the calculation of minimum-phase pre-filter. The performance is evaluated with 20 frames, each containing 14,500 symbols. Therefore, in our experimental systems, the overall training overhead is approximately 25.6% for PAM with DFE (5000 training symbols, 14,500 data symbols) and 1.7% for the proposed PAM transmission scheme (255 PN symbols, 14,500 data symbols).
In the meantime, the DMT transmission signals are also generated for the comparison. For the DMT system, we setup the system with the same 250 MHz used bandwidth as the PAM system. The DAC sampling rate is set to 1 Giga samples per second indicating 4 times oversampling. The number of available subcarrier is 512. The first subcarrier is closed to avoid the direct current component. Bit-loading algorithm with linear approximation [26] is employed to allocate bits and power to each subcarrier. The DMT signal is digitally clipped with an optimal clipping ratio of 10 dB. The hybrid pseudo-noise and zero-padding DMT scheme [19] is adopted for its advantages compared to the classical DMT scheme. The PN sequence length is 255 symbols and the ZP length is 32 symbols. The ADC works at 1.8 Giga samples per second. The performance is evaluated with 20 frames, each consisting of 7 DMT symbols.
Experimental results
For the proposed PN-PAM transmission scheme and DMT transmission scheme, we can estimate channel response using the received PN sequence. The estimated CIR of 15, 30, 50, 75 and 100 m SI-POF for the PAM transmissions are presented in Fig. 7. As shown in the figure, the CIRs exhibit significant time dispersion which causes ISI among consecutive symbols. In addition, the system overall non-linearity causes multi-path delay spreading, which is shown as the additional delay path at 9th and 10th taps in Fig. 7. Based on the CIR, we can calculate the coefficients of the minimum-phase pre-filter using (5). The after pre-filtering are presented in Fig. 8. As we can see from the figure, the normalized impulse responses have significantly reduced the pre-interference before the main path. This is essential for the subsequent DFE or RSSE equalizations.
Channel impulse response of 15, 30, 50, 75 and 100 m SI-POF transmission
Normalized impulse responses of 15, 30, 50, 75 and 100 m SI-POF transmission after pre-filtering
According to the channel conditions, we evaluate several PAM modulations for each transmission length. Both classical PAM with DFE scheme and the proposed PN-PAM transmission scheme are tested. The comparison of the BER performances is presented in Fig. 9. In addition, the BER performance of PAM-4 transmission over 15, 30 and 50 m SI-POF, the PAM-2 transmission over 15, 30, 50, 75 and 100 m SI-POF is measured with error-free (i.e., BER <1×10−6). Therefore, these results are not depicted in Fig. 9. For PAM-8 transmissions, the proposed PN-PAM scheme can achieve the BER performance of around 1×10−3 over 15, 30 and 50 m SI-POF. However, for classical PAM with DFE, the BER performance is only around 1×10−2 with the same conditions. This BER degradation is mainly due to the error propagation when DFE switches to the direct-decision mode after 5000 training symbols. In addition, it is worth noting that in the proposed PAM scheme, the length of the training sequence is only 255 symbols.
Experimental comparisons of PN-PAM and DMT transmission over different length of SI-POFs
In summary, it can be concluded that using the proposed PN-PAM transmission scheme, PAM-8 is suitable for 15, 30 and 50 m SI-POF transmission with a desired BER around 1×10−3. As the symbol rate of the PAM transmission is 400 Mega symbols per second, the total achievable bit rate is 1.2 Gbps. For 75 m SI-POF, PAM-4 is a reasonable choice and 800 Mbps can be achieved. Finally, PAM-2 can support a quasi-error-free transmission (BER <1×10−6) over 100 m SI-POF, which leads to a transmission rate of 400 Mbps.
Comparison and discussion
In this section, we introduce the DMT transmissions for comparisons. In order to implement a fair comparison with the PAM transmissions, we employ bit-loading algorithms and allocate bits for total transmission rates of the DMT system at 1.2 Gbps over 15, 30, and 50 m SI-POF, 800 Mbps over 75 m SI-POF and 400 Mbps over 100 m SI-POF.
The BER performances of DMT are also depicted in Fig. 9 and a summary of experimental results in different transmission schemes with fixed transmission bit rate is presented in Table 2. As shown in the results, we can find that the proposed PN-PAM transmission scheme achieves similar performance to the DMT transmission in the 50-m SI-POF system.
Table 2 Summary of experimental results in different transmission schemes with fixed transmission bit rate
In addition, for the transmission length shorter than 50 m, the DMT systems present better performance. This is mainly due to the fact that for transmission lengths shorter than 50 m, due to the high SNR at receiver, DMT can fully approach the channel capacity with the help of bit-loading. However, when high order PAM modulations are employed for short range communications, the transmitter non-linearity distortion will seriously affect overall performance.
Furthermore, for the transmission lengths longer than 50 m, PN-PAM transmission systems achieve better performance. From the aforementioned PAPR results in Fig. 2, we can find that PAM-2 and PAM-4 present lower PAPR than DMT with 10 dB clipping. Therefore, with the fixed DAC output dynamic range, the PN-PAM-based transmission systems can achieve higher transmitting power and obtain better performance.
In this paper, we introduced a novel PAM transmission scheme for short range optical transmission systems. The novel PN-PAM transmission scheme includes PN sequence-based channel estimation, minimum-phase receiver filter and RSSE based equalizer. A theoretical analysis for the PN-PAM transmission over Gaussian low-pass frequency response channel was also presented. From the theoretical analysis, the PAM-8 modulation is proved to be the best modulation choice for the 50-m SI-POF system.
The simulation results show that, compared to the classical PAM transmission with DFE equalization, the proposed PN-PAM transmission scheme can totally achieve 1.5 dB gain in a 50-m SI-POF system with an affordable complexity increase. Furthermore, simulation results reveal that the proposed PAM scheme requires less than 0.01 to 0.05 cost of system training symbol overhead compared to the classical DFE schemes, and can largely increase overall system efficiency.
Experimental systems with commercially available components are also investigated for both PN-PAM and DMT transmissions with the same used bandwidths. Experimental results show that, for the SI-POF lengths longer than 50 m, the proposed PN-PAM transmission scheme outperforms the classical PAM transmission with DFE equalization as well as the DMT transmissions that has been optimized in a previous work [19]. In the meantime, for the transmission lengths shorter than 50 m, the proposed PN-PAM transmission scheme performs better than the classical PAM with DFE equalization but worse than the DMT transmissions. This degradation can be understood by the fact that in order to achieve the same transmission rate as DMT, the PN-PAM based systems need to employ higher order modulations when the channel condition is good. However, the higher order modulations are more vulnerable to the non-linearity of the SI-POF system.
Therefore, it can be concluded that the proposed PN-PAM transmission scheme outperforms the classical PAM with DFE equalization in terms of both BER performance and overall system throughput. The complexity increase due to the use of RSSE equalizer is also acceptable. For short range optical transmissions with POF length longer than 50 m, the proposed PN-PAM transmission scheme is a better choice than the DMT transmission scheme.
ADC:
Analog to digital convertor
AWGN:
Additive white Gaussian noise
CFR:
Channel frequency response
CIR:
Channel impulse response
DFE:
Decision feedback equalizer
Digital to analog convertor
DMT:
Discrete multi-tone
FFE:
Feed-forward equalizer
Inter-symbol interference
LMS:
Least mean square
MCM:
Multi-carrier modulation
MLSE:
Maximum- likelihood sequence estimation
MMF:
Multi-mode fiber
MMSE:
Minimum mean-squared error
NRZ:
Not-return-to-zero
PAM:
Pulse-amplitude modulated
PAPR:
Peak-to-average-power ratio
PN:
Pseudo-noise
PN-PAM:
Pseudo-noise sequence assisted pulse-amplitude modulated
RCLED:
Resonant-cavity light emitting diode
RLS:
Recursive least square
RRC:
Root-raised-cosine
RSSE:
Reduced-state sequence estimation
SCM:
Single carrier modulation
SI-POF:
Step-index polymer optical fiber
SMF:
Single-mode fiber
SNR:
VLC:
Visible light communications
Okonkwo, CM, Tangdiongga, E, Yang, H, Visani, D, Loquai, S, Kruglov, R, Charbonnier, B, Ouzzif, M, Greiss, I, Ziemann, O, Gaudino, R, Koonen, AMJ: Recent Results from the EU POF-PLUS Project: Multi-Gigabit Transmission over 1 mm Core Diameter Plastic Optical Fibers. IEEE/OSA J. Light. Tech. 29(2), 186–193 (2011).
Popov, M: Recent Progress in Optical Access and Home Networks: Results from the ALPHA Project. In: Proc. ECOC. IEEE, Geneva (2011).
Kai, Y, Nishihara, M, Tanaka, T, Takahara, T, Lei, L, Zhenning, T, Bo, L, Rasmussen, JC, Drenski, T: Experimental comparison of pulse amplitude modulation (PAM) and discrete multi-tone (DMT) for short-reach 400-Gbps data communication. In: Proc. ECOC. IEEE, London (2013).
Lee, SCJ, Breyer, F, Randel, S, Cardenas, D, van den Boom, HPA, Koonen, AMJ: Discrete multitone modulation for high-speed data transmission over multimode fibers using 850-nm VCSEL. In: Proc. OSA/OFC/NFOEC. IEEE, USA (2009).
Kottke, C, Hilt, J, Habel, K, Vucic, J, Langer, KD: 1.25 Gbit/s visible light WDM link based on DMT modulation of a single RGB LED luminary. In: Proc. ECOC. IEEE, Amsterdam (2012).
Joncic, M, Kruglov, R, Haupt, M, Caspary, R, Vinogradov, J, Fischer, UHP: Four-Channel WDM Transmission Over 50 m SI-POF at 14.77 Gb/s Using DMT Modulation. IEEE Photonics. Tech. Letters. 26(13), 1328–1331 (2014).
Randel, S, Breyer, F, Lee, SCJ, Walewski, JW: Advanced Modulation Schemes for Short-Range Optical Communications. IEEE Sel. Top. Quant. Electron. 16(5), 1280–1289 (2010).
Loquai, S, Kruglov, R, Schmauss, B, Bunge, C-A, Winkler, F, Ziemann, O, Hartl, E, Kupfer, T: Comparison of Modulation Schemes for 10.7 Gb/s Transmission Over Large-Core 1 mm PMMA Polymer Optical Fiber. IEEE/OSA J. Light. Tech. 31(13), 2170–2176 (2013).
Schmogrow, R, Winter, M, Meyer, M, Hillerkuss, D, Wolf, S, Baeuerle, B, Ludwig, A, Nebendahl, B, Ben-Ezra, S, Meyer, J, Dreschmann, M, Huebner, M, Becker, J, Koos, C, Freude, W, Leuthold, J: Real-time Nyquist pulse generation beyond 100 Gbit/s and its relation to OFDM. Optics Express. 20(1), 317–337 (2012).
Armstrong, J: OFDM for Optical Communications. IEEE/OSA J. Light. Tech. 27(3), 189–204 (2009).
Szczerba, K, Westbergh, P, Agrell, E, Karlsson, M, Andrekson, PA, Larsson, A: Comparison of Inter symbol Interference Power Penalties for OOK and 4-PAM in Short-Range Optical Links. IEEE/OSA J. Light. Tech. 31(22), 3525–3534 (2013).
Zeolla, D, Antonino, A, Bosco, G, Gaudino, R: DFE Versus MLSE Electronic Equalization for Gigabit/s SI-POF Transmission Systems. IEEE Photon. Technol. Lett. 23(8), 510–512 (2011).
Rath, R, Rosenkranz, W: Tomlinson-Harashima Precoding for Fiber-Optic Communication Systems. In: Proc. of ECOC. IEEE, London (2013).
Straullu, S, Abrate, S: Overview of the performances of PMMA-SI-POF communication systems. In: Proc. SPIE 8645, Broadband Access Communication Technologies VII. SPIE, San Francisco (2013).
Atef, M, Zimmermann, H: Optical Communication over Plastic Optical Fibers, Springer Series in Optical Sciences, Vol. 172. Springer-Verlag, New York (2013).
Gimeno, C, Guerrero, E, Sanchez-Azqueta, C, Royo, G, Aldea, C, Celma S: A new equalizer for 2 Gb/s short-reach SI-POF links. In: Proc. SPIE 9520, Integrated Photonics: Materials, Devices, and Applications III. SPIE, Barcelona (2015).
Gimeno, C, Guerrero, E, Sanchez-Azqueta, C, Aguirre, J, Aldea, C, Celma, S: Multi-Rate Adaptive Equalizer for Transmission Over Up to 50-m SI-POF. IEEE Photon. Technol. Lett. 29(7), 587–590 (2017).
Song, J, Yang, Z, Yang, L, Gong, K, Pan, C, Wang, J, Wu, Y: Technical Review on Chinese Digital Terrestrial Television Broadcasting Standard and Measurements on Some Working Modes. IEEE Trans. Broadcast. 53(1), 1–7 (2007).
Peng, L, Hélard, M, Haese, S, Liu, M, Hélard, J-F: Hybrid PN-ZP-DMT Scheme for Spectrum-Efficient Optical Communications and Its Application to SI-POF. IEEE/OSA J. Light. Technol. 32(18), 3149–3160 (2014).
Liu, M, Crussière, M, Hélard, J-F: Improved Channel Estimation Methods based on PN sequence for TDS-OFDM. In: Proc. International Conference on Telecommunications (ICT). Jounieh (2012).
Gerstackerand, WH, Schober, R: Equalization Concepts for EDGE. IEEE Trans. Wirel. Commun. 1(1), 190–199 (2002).
Gerstacker, WH, Obernosterer, F, Meyer, R, Huber, JB: On Prefilter Computation for Reduced-State Equalization. IEEE Trans. Wirel. Commun. 1(4), 793–800 (2002).
Eyuboglu, MV, Qureshi, SUH: Reduced-State Sequence Estimation with Set Partitioning and Decision Feedback. IEEE Trans. Commun. 36(1), 13–20 (1988).
Ziemann, O, Krauser, J, Zamzow, PE, Daum, W: POF Handbook: Optical Short Range Transmission Systems. 2nd Edition. Springer, Heidelberg (2008).
Proakis, J: Digital Communications. Fourth Edition. McGraw Hill, New York (2001).
Peng, L, Hélard, M, Haese, S: On Bit-loading for Discrete Multi-tone Transmission over Short Range POF Systems. IEEE/OSA J. Light. Technol. 31(24), 4155–4165 (2013).
Chatelain, B, Gagnon, F: Peak-to-average power ratio and inter symbol interference reduction by Nyquist pulse optimization. In: Proc. of IEEE 60th Vehicular Technology Conference. vol. 2, pp. 954–958. SPIE, Los Angeles (2004).
Peng's work is supported by the National Natural Science Foundation of China (Grant No. 61601114) and the Natural Science Foundation of Jiangsu Province (BK20160692). Liu's work is supported by the National Natural Science Foundation of China (Grant No. 61501022) and the Fundamental Research Funds for the Central Universities (2017JBM028).
Institute of Information Science and Engineering, Southeast University, No.2 SiPaiLou, Nanjing, 210096, China
Linning Peng
School of Computer and Information Technology, Beijing Jiaotao University, No.3 ShangYuanCun, Beijing, 100044, China
Ming Liu
IETR (Institute of Electronic and Telecommunications in Rennes), INSA-Rennes (Institut National des Sciences Appliquées de Rennes), 20 Avenue des Buttes de Coësmes, Rennes, 35708, France
Maryline Hélard & Sylvain Haese
Maryline Hélard
Sylvain Haese
LP contributed to entire studies of this work, manuscript preparation and manuscript editing. ML contributed to system design, manuscript revision and manuscript editing. MH contributed to theoretical studies and manuscript revision. SH contributed to experimental studies and manuscript revision. All authors read and approved the final manuscript.
Correspondence to Ming Liu.
Authors' information
Linning Peng received his PhD degrees from IETR (Electronics and Telecommunications Institute of Rennes) laboratory at INSA (National Institute of Applied Sciences) of Rennes, France, in 2014. From 2014, he is a research associate at Southeast University. His research interests are in design and optimization for communication systems.
Ming Liu received the B.Eng. and M.Eng. degrees from the Xi'an Jiaotong University, China, in 2004 and 2007, respectively, and the Ph.D. degree from the National Institute of Applied Sciences (INSA), Rennes, France, in 2011, all in electrical engineering. He was with the Institute of Electronics and Telecommunications of Rennes (IETR) as a postdoctoral researcher from 2011 to 2015. He is now with Beijing Jiaotong University, China, as an Associate Professor. His main research interests include multicarrier transmissions, MIMO techniques, space-time coding and Turbo receiver.
Maryline Hélard received the M.Sc and PhD degrees from INSA (National Institute of Applied Sciences) of Rennes and the Habilitation degree from Rennes 1 University in 1981, 1884 and 2004 respectively. In 1985, she joined France Telecom Research Laboratory as a research engineer and since 1991 she carried out physical layer studies in the field of digital television and wireless communications. In 2007, she joined INSA as a professor and she is now the co-director of the Communication Department at IETR (Electronics and Telecommunications Institute of Rennes). She is co-author of 22 patents and several papers (Journal and conferences). Her current research interests are in the areas of digital communications such as equalization, synchronization, iterative processing, OFDM, MC-CDMA, channel estimation, and MIMO techniques applied to wireless communications and more recently to wire communications (ADSL, optical).
Sylvain Haese received the engineer and PhD degrees in electrical engineering from INSA (National Institute of Applied Sciences) Rennes, France, in 1983 and 1997 respectively. From 1984 to 1993 he was an analog IC designer for automotive and RF circuits. In 1993, he joined INSA and carried out research activity at IETR laboratory where he conducted research for automotive powerline applications and for RF wideband channel sounder circuitry. He is currently involved in hardware analog implementation for RF and optical circuits with the Communication Department at IETR (Electronics and Telecommunications Institute of Rennes).
Peng, L., Liu, M., Hélard, M. et al. PN-PAM scheme for short range optical transmission over SI-POF — an alternative to Discrete Multi-Tone (DMT) scheme. J. Eur. Opt. Soc.-Rapid Publ. 13, 21 (2017). https://doi.org/10.1186/s41476-017-0048-6
Single-carrier modulation
PN sequence
Minimum-phase pre-filter | CommonCrawl |
Hysteresis-driven pattern formation in reaction-diffusion-ODE systems
DCDS Home
On the limiting system in the Shigesada, Kawasaki and Teramoto model with large cross-diffusion rates
June 2020, 40(6): 3571-3593. doi: 10.3934/dcds.2020043
Asymmetric dispersal and evolutional selection in two-patch system
Yong-Jung Kim 1, , Hyowon Seo 2, and Changwook Yoon 3,,
Department of Mathematical Sciences, KAIST, 291 Daehak-ro, Yuseong-gu, Daejeon, 305-701, Korea
Department of Applied Mathematics and the Institute of Natural Sciences, Kyung Hee University, Yongin, 446-701, South Korea
College of Science & Technology, Korea University, Sejong 30019, Republic of Korea
* Corresponding author: Changwook Yoon
Received March 2019 Revised May 2019 Published October 2019
Full Text(HTML)
Figure(6)
Biological organisms leave their habitat when the environment becomes harsh. The essence of a biological dispersal is not in the rate, but in the capability to adjust to the environmental changes. In nature, conditional asymmetric dispersal strategies appear due to the spatial and temporal heterogeneity in the environment. Authors show that such a dispersal strategy is evolutionary selected in the context two-patch problem of Lotka-Volterra competition model. They conclude that, if a conditional asymmetric dispersal strategy is taken, the dispersal is not necessarily disadvantageous even for the case that there is no temporal fluctuation of environment at all.
Keywords: Two-patch system, mega-patch, competition model, asymmetric dispersal, steady state.
Mathematics Subject Classification: Primary: 35F50, 92D25, 97M60, 74G30, 34D20; Secondary: 34D05.
Citation: Yong-Jung Kim, Hyowon Seo, Changwook Yoon. Asymmetric dispersal and evolutional selection in two-patch system. Discrete & Continuous Dynamical Systems - A, 2020, 40 (6) : 3571-3593. doi: 10.3934/dcds.2020043
R. Arditi, L.-F. Bersier and R. P. Rohr, The perfect mixing paradox and the logistic equation: Verhulst vs. Lotka, Ecosphere, 7 (2016), e01599. doi: 10.1002/ecs2.1599. Google Scholar
R. Arditi, C. Lobry and T. Sari, Asymmetric dispersal in the multi-patch logistic equation, Theoret. Popul. Biol., 120 (2018), 11-15. doi: 10.1016/j.tpb.2017.12.006. Google Scholar
R. S. Cantrell, C. Cosner, D. L. Deangelis and V. Padron, The ideal free distribution as an evolutionarily stable strategy, J. Biol. Dynam., 1 (2007), 249-271. doi: 10.1080/17513750701450227. Google Scholar
R. S. Cantrell and C. Cosner, Spatial Ecology via Reaction-Diffusion Equations, Wiley Series in Mathematical and Computational Biology, John Wiley & Sons, Ltd., Chichester, 2003. doi: 10.1002/0470871296. Google Scholar
E. Cho and Y.-J. Kim, Starvation driven diffusion as a survival strategy of biological organisms, Bull. Math. Biol., 75 (2013), 845-870. doi: 10.1007/s11538-013-9838-1. Google Scholar
W. Choi, S. Baek and I. Ahn, Intraguild predation with evolutionary dispersal in a spatially heterogeneous environment, J. Math. Biol., 78 (2019), 2141-2169. doi: 10.1007/s00285-019-01336-5. Google Scholar
D. Cohen and S. A. Levin, Dispersal in patchy environments: The effects of temporal and spatial structure, Theoret. Popul. Biol., 39 (1991), 63-99. doi: 10.1016/0040-5809(91)90041-D. Google Scholar
R. Cressman, V. Křivan and J. Garay, Ideal free distributions, evolutionary games, and population dynamics in multiple-species environments, The American Naturalist, 164 (2004), 473-489. doi: 10.1086/423827. Google Scholar
D. L. DeAngelis, W.-M. Ni and B. Zhang, Effects of diffusion on total biomass in heterogeneous continuous and discrete-patch systems, Theoretical Ecology, 9 (2016), 443-453. doi: 10.1007/s12080-016-0302-3. Google Scholar
D. L. DeAngelis, C. C. Travis and W. M. Post, Persistence and stability of seeddispersed species in a patchy environment, J. Theoret. Biol., 16 (1979), 107-125. doi: 10.1016/0040-5809(79)90008-x. Google Scholar
U. Dieckman, B. O'Hara and W. Weisser, The evolutionary ecology of dispersal, Trends Ecol. Evol., 14 (1999), 88-90. doi: 10.1016/S0169-5347(98)01571-7. Google Scholar
J. Dockery, V. Hutson, K. Mischaikow and M. Pernarowski, The evolution of slow dispersal rates: A reaction diffusion model, J. Math. Biol., 37 (1998), 61-83. doi: 10.1007/s002850050120. Google Scholar
A. Hastings, Can spatial variation alone lead to selection for dispersal?, Theoret. Popul. Biol., 24 (1983), 244-251. doi: 10.1016/0040-5809(83)90027-8. Google Scholar
P. H. Joachim and H. Thomas, Evolution of density-and patch-size-dependent dispersal rates, Proc. R. Soc. Lond. B, 269 (2002). doi: 10.1098/rspb.2001.1936. Google Scholar
M. L. Johnson and M. S. Gaines, Evolution of dispersal: Theoretical models and empirical tests using birds and mammels, Ann. Rev. Ecol. Syst., 21 (1990), 449-480. doi: 10.1146/annurev.es.21.110190.002313. Google Scholar
Y.-J. Kim and O. Kwon, Evolution of dispersal with starvation measure and coexistence, Bull. Math. Biol., 78 (2016), 254-279. doi: 10.1007/s11538-016-0142-8. Google Scholar
Y.-J. Kim, O. Kwon and F. Li, Evolution of dispersal toward fitness, Bull. Math. Biol., 75 (2013), 2474-2498. doi: 10.1007/s11538-013-9904-8. Google Scholar
Y.-J. Kim, O. Kwon and F. Li, Global asymptotic stability and the ideal free distribution in a starvation driven diffusion, J. Math. Biol., 68 (2014), 1341-1370. doi: 10.1007/s00285-013-0674-6. Google Scholar
Y.-J. Kim, S. Seo and C. Yoon, Asymmetric dispersal and ecological coexistence in two-patch system, preprint. Google Scholar
Y.-J. Kim, S. Seo and C. Yoon, Two-patch system revisited: New perspectives, Bull. Math. Biol., submitted. Google Scholar
Y. Lou, On the effects of migration and spatial heterogeneity on single and multiple species, J. Differential Equations, 223 (2006), 400-426. doi: 10.1016/j.jde.2005.05.010. Google Scholar
M. A. McPeek and R. D. Holt, The evolution of dispersal in spatially and temporally varying environments, The American Naturalist, 140 (1992), 1000-1009. doi: 10.1086/285453. Google Scholar
T. Nagylaki, Introduction to Theoretical Population Genetics, Biomathematics, 21. Springer-Verlag, Berlin, 1992. doi: 10.1007/978-3-642-76214-7. Google Scholar
W.-M. Ni, The Mathematics of Diffusion, CBMS-NSF Regional Conference Series in Applied Mathematics, 82. Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 2011. doi: 10.1137/1.9781611971972. Google Scholar
A. Okubo and S. A. Levin, Diffusion and Ecological Problems: Modern Perspectives, 2$^nd$ edition, Interdisciplinary Applied Mathematics, 14. Springer-Verlag, New York, 2001. doi: 10.1007/978-1-4757-4978-6. Google Scholar
R. Ramos-Jiliberto and P. M. de Espans, The perfect mixing paradox and the logistic equation: Verhulst vs. Lotka: Comment, Ecosphere, 8 (2017), e01895. doi: 10.1002/ecs2.1895. Google Scholar
A. M. M. Rodrigues and R. A. Johnstone, Evolution of positive and negative density-dependent dispersal, Proc. R. Soc. B, 281 (2014). doi: 10.1098/rspb.2014.1226. Google Scholar
L. L. Sullivan, B. Li, T. E. Miller, M. G. Neubert and A. K. Shaw, Density dependence in demography and dispersal generates fluctuating invasion speeds, Proceedings of the National Academy of Sciences, 114 (2017), 5053-5058. doi: 10.1073/pnas.1618744114. Google Scholar
J. M. J. Travis and C. Dytham, Habitat persistence, habitat availability and the evolution of dispersal, Proceedings of the Royal Society of London. Series B: Biological Sciences, 266 (1999), 723-728. doi: 10.1098/rspb.1999.0696. Google Scholar
Figure 5. Asymptotic behavior of numerical computation of (31)-(32) with $ \epsilon = 0.02 $. The legends are ordered by the size of asymptotic limits
Figure Options
Download as PowerPoint slide
Figure 1. A mega patch is a collection of many smaller patches. Dispersal across mega patches are counted in a two-patch system
Figure 2. Steady state solutions of (14). In the left figure, $ (K_1,K_2) = (2,5) $ and $ \theta_i $'s are monotone. In the right one, $ (K_1,K_2) = (0.2,5) $ and $ \theta_1 $ has maximum at $ d = 0.6613 $
Figure 3. Diagrams for $ y = -x(1-\frac{x}{K_1}) $ and $ y = x(1-\frac{x}{K_2}) $. Steady states are intersection points with $ y = R $. See (19)
Figure 4. The graph of motility function $ \gamma(s) $ without uniqueness. We have chosen a piecewise linear motility $ \gamma $ which takes the values in (20). Since $ s_i $ and $ \tilde s_i $ are close to each other, $ \gamma $ increases steeply for $ s\in(s_i,\tilde s_i) $
Figure 6. Asymptotic behavior ($ h = 0.1, \ell = 0.01, d = 0.02 $). The legends are ordered by the size of asymptotic limits
Mengting Fang, Yuanshi Wang, Mingshu Chen, Donald L. DeAngelis. Asymptotic population abundance of a two-patch system with asymmetric diffusion. Discrete & Continuous Dynamical Systems - A, 2020, 40 (6) : 3411-3425. doi: 10.3934/dcds.2020031
Yuanshi Wang. Asymmetric diffusion in a two-patch mutualism system characterizing exchange of resource for resource. Discrete & Continuous Dynamical Systems - B, 2021, 26 (2) : 963-985. doi: 10.3934/dcdsb.2020149
Ténan Yeo. Stochastic and deterministic SIS patch model. Discrete & Continuous Dynamical Systems - B, 2020 doi: 10.3934/dcdsb.2021012
Qing Li, Yaping Wu. Existence and instability of some nontrivial steady states for the SKT competition model with large cross diffusion. Discrete & Continuous Dynamical Systems - A, 2020, 40 (6) : 3657-3682. doi: 10.3934/dcds.2020051
Bilel Elbetch, Tounsia Benzekri, Daniel Massart, Tewfik Sari. The multi-patch logistic equation. Discrete & Continuous Dynamical Systems - B, 2021 doi: 10.3934/dcdsb.2021025
Zexuan Liu, Zhiyuan Sun, Jerry Zhijian Yang. A numerical study of superconvergence of the discontinuous Galerkin method by patch reconstruction. Electronic Research Archive, 2020, 28 (4) : 1487-1501. doi: 10.3934/era.2020078
Yan'e Wang, Nana Tian, Hua Nie. Positive solution branches of two-species competition model in open advective environments. Discrete & Continuous Dynamical Systems - B, 2020 doi: 10.3934/dcdsb.2021006
Mohamed Dellal, Bachir Bar. Global analysis of a model of competition in the chemostat with internal inhibitor. Discrete & Continuous Dynamical Systems - B, 2021, 26 (2) : 1129-1148. doi: 10.3934/dcdsb.2020156
Pan Zheng. Asymptotic stability in a chemotaxis-competition system with indirect signal production. Discrete & Continuous Dynamical Systems - A, 2021, 41 (3) : 1207-1223. doi: 10.3934/dcds.2020315
Hirofumi Izuhara, Shunsuke Kobayashi. Spatio-temporal coexistence in the cross-diffusion competition system. Discrete & Continuous Dynamical Systems - S, 2021, 14 (3) : 919-933. doi: 10.3934/dcdss.2020228
Lin Niu, Yi Wang, Xizhuang Xie. Carrying simplex in the Lotka-Volterra competition model with seasonal succession with applications. Discrete & Continuous Dynamical Systems - B, 2020 doi: 10.3934/dcdsb.2021014
Sze-Bi Hsu, Yu Jin. The dynamics of a two host-two virus system in a chemostat environment. Discrete & Continuous Dynamical Systems - B, 2021, 26 (1) : 415-441. doi: 10.3934/dcdsb.2020298
Xianyong Chen, Weihua Jiang. Multiple spatiotemporal coexistence states and Turing-Hopf bifurcation in a Lotka-Volterra competition system with nonlocal delays. Discrete & Continuous Dynamical Systems - B, 2020 doi: 10.3934/dcdsb.2021013
Sebastian J. Schreiber. The $ P^* $ rule in the stochastic Holt-Lawton model of apparent competition. Discrete & Continuous Dynamical Systems - B, 2021, 26 (1) : 633-644. doi: 10.3934/dcdsb.2020374
Manil T. Mohan. First order necessary conditions of optimality for the two dimensional tidal dynamics system. Mathematical Control & Related Fields, 2020 doi: 10.3934/mcrf.2020045
Helmut Abels, Andreas Marquardt. On a linearized Mullins-Sekerka/Stokes system for two-phase flows. Discrete & Continuous Dynamical Systems - S, 2020 doi: 10.3934/dcdss.2020467
Zhouchao Wei, Wei Zhang, Irene Moroz, Nikolay V. Kuznetsov. Codimension one and two bifurcations in Cattaneo-Christov heat flux model. Discrete & Continuous Dynamical Systems - B, 2020 doi: 10.3934/dcdsb.2020344
Caterina Balzotti, Simone Göttlich. A two-dimensional multi-class traffic flow model. Networks & Heterogeneous Media, 2020 doi: 10.3934/nhm.2020034
Yanhong Zhang. Global attractors of two layer baroclinic quasi-geostrophic model. Discrete & Continuous Dynamical Systems - B, 2021 doi: 10.3934/dcdsb.2021023
Yuxin Zhang. The spatially heterogeneous diffusive rabies model and its shadow system. Discrete & Continuous Dynamical Systems - B, 2020 doi: 10.3934/dcdsb.2020357
PDF downloads (188)
HTML views (316)
Yong-Jung Kim Hyowon Seo Changwook Yoon | CommonCrawl |
Locally available agroresidues as potential sorbents: modelling, column studies and scale-up
Arth Jayesh Shah1,
Bhavin Soni1 &
Sanjib Kumar Karmee ORCID: orcid.org/0000-0002-0989-36481
Sawdust, cotton stalk and groundnut shell were used for removal of methylene blue from aqueous solution using batch sorption. Effect of initial dye concentration, temperature, and particle size of sorbents on methylene blue removal was investigated. Sorption capacity increases with rise in initial dye concentration and temperature. Impact of particle size on sorption of methylene blue was investigated and indicated that removal of dye increases with decrease in particle size of sorbents. Maximum sorption for sawdust, cotton stalks and groundnut shell were 9.22 mg g−1, 8.37 mg g−1 and 8.20 mg g−1 respectively; at 60 °C and 100 ppm initial dye concentration. Sorption isotherms were analyzed using fundamental Freundlich isotherm. Subsequently, sips isotherm model was employed for better fitting. Kinetic study shows that, biosorption process is pseudo-second-order in nature. During the course of this study, adsorption dynamics revealed that film diffusion was key step for biosorption. In addition, thermodynamics of sorption was studied; and it was found that Gibbs free energy (∆G°) decreases with increase in temperature. Sawdust was found to be best among all the sorbents. Therefore, column studies and breakthrough curve modelling were performed using sawdust. Furthermore, it was estimated that a scaled-up column using sawdust can treat 6672 L of wastewater in 24 h with 80% efficiency.
In general, stringent norms are laid down by monitoring and control authorities for chemical process industries (CPIs) for releasing effluents into the environment. To strictly follow the environmental policies, CPIs are developing and adopting different novel pollution controlling technologies for effluent release to control the deteriorating quality of water bodies. Removal of pollutant-dyes has always been a major concern for researchers involved in waste management; since their effective removal using conventional treatment processes is challenging. In this regard, modifications were performed in sewage treatment plants and wastewater treatment plants of CPIs to curb the dye contamination in the liquid effluent released by industries into the water bodies. Different dyes are released by industries processing papers, pulp, and paints. Many of these are carcinogenic in nature and toxic to humans and aquatic ecosystem (Acemioǧlu 2004). In addition, CPI's man-made disasters like oil spills are known to cause devastating impacts on holistic biodiversity. Therefore, adequate measures needs to be taken to control these disastrous environmental consequences.
In the above context, activated carbon sorption, ion exchange, chemical coagulation and electrolysis are some of the potential techniques often adopted for dye removal from effluents (Nigam et al. 2000; An et al. 2001). Amongst these, activated carbon sorption is one of the most effective and commercially viable technology used extensively in waste water treatment plants of CPIs to remove dyes (McKay 1996; Mohan and Karthikeyan 1997; Chen et al. 2018). Nevertheless, activated carbon is expensive; therefore, it may be difficult for developing and underdeveloped countries to implement technologies based on activated carbons. Hence, there is an urgent need to develop technologies/processes for waste removal using low cost and readily available sorbents. Along this line, search for effective low-cost sorbents which can have similar effect as that of activated carbon became area of research for many researchers. In this regard, cotton stalks, cotton waste, cotton dust (Ertaş et al. 2010), sawdust (Garg et al. 2004; Azlina et al. 2013), orange peel (Namasivayam et al. 1996), banana peel (Annadurai et al. 2002), wood (Asfour et al. 1985; Ho and McKay 1998), bagasse pith (Nassar and El‐Geundi 1991), chitosan (Sakkayawong et al. 2005), and algae biochar (Chen et al. 2020a; Tan et al. 2020) are a few low-cost sorbents previously reported for dye removal and pollution control.
India is an agriculturally rich nation. Among various provinces of India; in particular, Gujarat is an agrarian state whose main crops include cotton, groundnut shell, rice, sugar cane, castor, tobacco and corn (Soni and Karmee 2020). These crops generate substantial amounts of residues. Around 5.5 million tonnes of surplus sawdust is generated annually in India and due to its easy availability, it can be employed as a sorbent (Soni and Karmee 2020). Similarly, ~ 8 lakh tonnes of groundnut shell and ~ 41 lakh tonnes of cotton stalks are produced annually in Gujarat (Kumari et al. 2020). These are low-cost, locally produced and readily available resources. Utilization of these locally available biomass residues as sorbents is important from circular economy, waste management, and sustainability point of views. Therefore, in this research sawdust, groundnut shell and cotton stalks were examined as low-cost bio-sorbents.
As mentioned earlier, several studies have been carried out in this area; however, a holistic approach that engrosses waste management and sustainable development strategies has not been applied widely yet at an industrial scale using locally available bioresidues. Hence, here, an effort towards implementation of this technology has been made by analyzing the sorbents behavior. In addition, emphasize is given on a scaled-up column design, which has the potential to cater future industrial needs.
A cationic dye methylene blue (MB) (microscopy grade) was procured from LOBA Chemie. The chemical structure of MB (a basic dye) containing secondary amine is presented in Fig. 1. Sawdust (SD), cotton stalks (CS) and groundnut shell (GNS) used for all experimental purposes were procured from Raghuvir Timbers, Anand, Gujarat, India; from Sherdi village of Anand, Gujarat, India and from 'Darshan Seeds Industries', Modasa, Gujarat, India respectively. The procured materials were grinded and sun-dried for 2 days. The sun dried materials were screened and then used for further experiments and analyses.
Chemical structure of methylene blue dye
Batch sorption
For the experiments, different stock solutions containing 25 mg l−1, 50 mg l−1, 75 mg l−1, and 100 mg l−1 MB were prepared by dissolving appropriate amount of MB in deionized water. Since biomass has lower sorption capacity as compared to activated carbon and also it is easily available at cheaper rates, 1 g of sorbent was taken for experimental purposes (Gupta and Suhas 2009). MB solution (100 ml) with requisite concentration was taken in a beaker and biomass (1 g) was added into it. The prepared solution was isothermally stirred for 180 min at 400 rpm. Afterwards, it was filtered through suction filtration. The filtrate samples were then taken for absorbance measurement using UV–Vis Spectrophotometer (Shimadzu UV-1700 PharmaSpec) at 665 nm wavelength.
Amount of dye removed by sorbents at equilibrium, qe can be calculated using following equation (Ertaş et al. 2010):
$$q_{e} = \frac{{\left( {C_{0} - C_{e} } \right)V}}{W},$$
where qe is the amount of dye sorbed (mg g−1). Furthermore, C0 and Ce are the initial and equilibrium liquid phase concentration of dye (mg l−1), respectively. Ce is obtained using absorbance measured from UV–Vis Spectrophotometer during experiments and further using it in the equation obtained from Beer–Lamberts law. V (l) is the volume of solution used for experiment and W (g) is the weight of sorbent used.
Effects of change in various parameters affecting batch sorption was studied and best sorbent was determined. Furthermore, isotherm study, thermodynamic study, kinetic study and dynamic study of batch sorption was carried out to analyze the biosorption process.
Column studies
Column studies were performed for SD (0.15–0.3 mm), because it is the best sorbent among the screened biomass resources. Required amount (1 g, 2 g) of SD was loaded into the column for preparing the bed (Fig. 2). The study was carried out at 30 °C in a borosilicate cylindrical column with 1 cm diameter, 1.2 mm thickness and 27 cm height. MB solution (100 ppm) was prepared and filled in the repository arranged above the column. Flowrate (1.5 ml min−1, 1.8 ml min−1) was measured by adjusting the knob of repository and then it was kept on the top of column; so that, drops fell directly into the bed in-side the column. Non adsorbing cotton was plugged at one end of column to support the SD bed and a sample collector was placed at the bottom of it to collect samples in a fixed time interval. The pictorial representation of the setup is presented in Fig. 2. Column studies were conducted to estimate the breakthrough curve and to ease the scale up procedure. In addition, breakthrough curve modelling was done for predicting breakthrough curve parameters.
Experimental setup used for column studies
Characterization of sorbents
Proximate analysis
Proximate analysis (wt%) of the biomass-based sorbents was performed following ASTM standards viz. D-871-82, ASTM E-1755-01 and ASTM E-872 for determination of moisture content, ash content, and volatile matter respectively. In addition, fixed carbon was calculated by difference. These calculations were done on dry basis and the results were obtained for all the sorbents are presented in Table 1.
Table 1 Proximate analysis of CS, SD and GNS on dry basis
Batch sorption studies
Effect of initial concentration on dye removal in batch sorption studies
Effect of initial dye concentration on the dye removal for 1 g (0.15–0.3 mm) sorbent at 30 °C, 45 °C and 60 °C is studied here. With increase of the initial dye concentration (C0) driving force acting on dye molecules moving towards sorbent increases and it can overcome resistance offered by the film easily. In addition, increase in initial dye concentration will lead to better occupancy of active sites which might be empty at low dye concentrations.
From the experiments it was revealed that equilibrium sorption capacity of SD, CS and GNS changed from 1.88 mg g−1 to 8.7 mg g−1, 1.47 mg g−1 to 7.98 mg g−1 and 0.897 mg g−1 to 7.96 mg g−1 as initial concentrations were changed from 25 to 100 ppm at 30 °C (Fig. 3a). Similar trends were observed for impact of initial dye concentration on MB sorption capacity at 45 °C (Fig. 3b) and 60 °C (Fig. 3c). The data for all set of variations in initial dye concentration at different temperatures has been quantified and visualized in Fig. 3a–c. Similar trend has been observed by other authors for sorption of methylene blue on activated carbon (Hameed et al. 2007), fly-ash (Basava Rao and Ram Mohan Rao 2006) and cotton stalks (Ertaş et al. 2010).
a Impact of initial dye concentration on dye removal at 30 °C for SD, CS and GNS; b Impact of initial dye concentration on dye removal at 45 °C for SD, CS and GNS; c Impact of initial dye concentration on MB removal at 60 °C for SD, CS and GNS
Effect of temperature on dye removal in batch sorption studies
Effect of temperature on dye removal was studied using 1 g of SD, CS and GNS, whose particle size falls in 0.15–0.3 mm, as sorbents. Studies were carried out at 30 °C, 45 °C and 60 °C. The sorption capacity increased with increase in temperature. Therefore, dye sorption was an endothermic process. Increasing temperature enhances the rate of diffusion of sorbate molecules across the boundary layer and further towards the pores of sorbent material. Moreover, decrease in viscosity with the temperature in liquids can make the diffusion movement fast by reducing the shear observed by molecules of adsorbate during mass transfer. In addition, it can be said that altering the temperature will lead to change in equilibrium concentration (Ce) of adsorbent for specific adsorbate.
It was noted that sorption capacity of SD, CS and GNS changed from 8.72 to 9.22 mg g−1, 7.89 mg g−1 to 8.37 mg g−1 and 7.8 mg g−1 to 8.2 mg g−1, respectively, as the temperature was raised from 30 to 60 °C for 100 ppm MB solution. Similar trend was obtained for all set of initial dye concentration for all sorbents as temperature was changed from 30 to 60 °C. Results obtained for different sorbents were quantified and presented in Fig. 4a–c. Other authors also observed similar trend for bamboo charcoal (Zhu et al. 2009), sepiolite (Doǧan et al. 2007) and cotton waste (Doǧan et al. 2007; Ertaş et al. 2010).
a Impact of temperature on the MB removal for SD at 30 °C, 45 °C and 60 °C; b Impact of temperature on the MB removal for CS at 30 °C, 45 °C and 60 °C; c Impact of temperature on the MB removal for GNS at 30 °C, 45 °C and 60 °C
Effect of particle size on dye removal in batch sorption studies
Intra-particle diffusion rate constant (Kd) and intra-particle diffusivity (D) are related in the following way:
$$K_{d} = \frac{{6 q_{e} }}{R}\sqrt {\frac{D}{\pi }} ,$$
where R (cm) is the particle radius and qe (mg g−1) is the solid phase concentration at equilibrium. The equation clearly states that Kd is inversely dependent on adsorbent particle's radius (R). The increase in dye removal with decreasing particle size/radius is expected as small particles (0.15–0.3 mm) have larger external surface area; this increases adsorption probability of adsorbent on adsorbate. As a result, it causes higher dye removal for small particle sizes as compared to large particles (0.85–2 mm).
We have examined the effect with biomass particles obtained after sieving from four different mesh size (ASTM) namely 10, 20, 50 and 100. The particles were divided on the basis of their particle size into three different classes 0.85–2 mm, 0.3–0.85 mm and 0.15–0.3 mm. Experiments were performed for biomass particle collected in above mentioned ranges of particle size. Taking 1 g biomass particle as sorbent with 100 ppm MB solution, experiments were carried out at 30 °C, 45 °C and 60 °C. Keeping the rest of the parameters constant as mentioned in the batch sorption methods, the results we obtained are as follows:
Sorption increases with deceasing in particle size as presented in Fig. 5 for SD particles falling in 0.15–0.3 mm, it is 9.21 mg g−1 which is 7.5% more than SD particles falling in 0.85–0.2 mm at similar conditions. For CS particles falling in 0.15–0.3 mm sorption is 8.37 mg g−1 at 60 °C; whereas, it is 8.16 mg g−1 for CS particles falling in 0.85–0.2 mm under similar experimental conditions (Fig. 9). The dye sorption observed for GNS particles falling in 0.85–0.2 mm at 60 °C is 6.864 mg g−1; whereas, 7.96 mg g−1 was obtained for GNS particles falling in 0.15–0.3 mm at same conditions (Fig. 9). Moreover, we can see 6–8% rise in sorption capacity as particle size decreases. This supports the fact that surface area of sorbent plays an important role in sorption of dye molecules. In addition, small particles move faster in solution while stirring as compared to larger particles; thus, increasing mass transfer. Moreover, from the studies it has been confirmed that the boundary layer thickness is lesser for small particles which shows lesser resistance to mass transfer (Ong et al. 2007). Other authors reported similar trend while performing experiments on rice hull (Ong et al. 2007) and on bamboo charcoal (Zhu et al. 2009).
Sorption of MB on various particle sizes of SD, CS and GNS at 30 °C, 45 °C and 60 °C
BET analysis
Brunauer–Emmett–Teller (BET) analysis was carried out to determine the pore size and pore volume of the sorbents used (Table 2). As discussed previously, intra-particle diffusion rate constant (Kd) is inversely proportional to the radius of sorbent used. From BET analysis, SD was seen having the lowest pore diameter and surface area. It can be inferred that low pore diameter will accommodate more pores for a given surface area which will add to diffusion rate. In addition, the small size of SD compared to CS and GNS will have lesser boundary layer thickness which will not obstruct the movement of sorbate.
Table 2 BET analysis results for SD, CS and GNS
Isotherms study
Freundlich isotherm
The Freundlich adsorption isotherm explains the reversible and non-ideal adsorption process. Unlike Langmuir isotherm, Freundlich isotherm is not restricted to monolayer adsorption. This empirical relationship describes multilayer adsorption of heterogeneous systems and assumes that specific site has specific adsorption energy involved. The Freundlich isotherm can be expressed as
$$q_{e} = kC_{e}^{{\left( \frac{1}{n} \right)}} .$$
Linear equation can be obtained by taking natural logarithm on both sides:
$$\ln q_{e} = \ln k + \frac{1}{n}\ln \left( {C_{e} } \right),$$
where qe is the amount of dye sorbed at equilibrium (mg g−1), Ce is the equilibrium concentration of dye in solution (mg l−1), k and n are Freundlich constants which depicts capacity and intensity of sorption, respectively.
Figure 6a–c shows the Freundlich adsorption isotherm for SD, CS and GNS at three different temperatures, namely, 30 °C, 45 °C and 60 °C for 100 ppm MB solution and 1 g (0.15–0.3 mm) of biomass sorbent. As seen in figures the value of R2 was noted to check the fitting of Freundlich isotherm. R2 value ranges from 0.60 to 0.87 for isotherms at 30 °C, 0.76 to 0.96 for isotherms at 45 °C and 0.86 to 0.99 for isotherms at 60 °C (Table 3).
a Freundlich isotherm at 30 °C for SD, CS and GNS; b Freundlich isotherm at 45 °C for SD, CS and GNS; c Freundlich isotherm at 60 °C for SD, CS and GNS
Table 3 Values of Freundlich constants k, 1/n and R2 for SD, CS and GNS at 30 °C, 45 °C and 60 °C
The values of parameters k and 1/n were derived from isotherms plotted and tabulated as below. Freundlich isotherm being one of the simplest models to represent the adsorption phenomena, many times it is not able to determine the constants properly as in the case of GNS at 30 °C. In this case, value of k tends to zero as the value of 1/n is very high and it is difficult to visualize such processes using simple isotherms. Hence, to obtain a better fit we used Sips isotherm model which has three parameters and tried to obtain results from it.
Sips isotherm
The Sips isotherm was derived from limiting behavior of Langmuir and Freundlich isotherms. This model is valid for localized adsorption without adsorbate–adsorbate interaction (Al-Ghouti and Da'ana 2020). When Ce approaches low value, Sips isotherm reduces to Freundlich, whereas for high values of Ce, it reduces to a monolayer Langmuir isotherm. Operating conditions such as altering of concentration and temperature governs the parameters of Sips isotherm. The sips linear model equation is presented below as
$$\frac{1}{{q_{e} }} = \frac{1}{{Q_{\max } \cdot K_{s} }}(\frac{1}{{C_{e} }})^{{\left( \frac{1}{n} \right)}} + \frac{1}{{Q_{\max } }},$$
where Ks (mg−1) and Qmax (mg g−1) are the sips equilibrium constant and maximum adsorption capacity values, respectively. n whose value ranges from 0 to 1 is dimensionless heterogeneity factor which describe systems heterogeneity. When n = 1 Sips isotherm reduces to Langmuir isotherm, and it implies a homogenous adsorption process. Since Sips model can have many solutions, it is difficult to find the exact solution but most probable solution can be obtained by varying n from 0 to 1 and finding the best fit line.
The main motive of using Sips model was to better fit the isotherm process happening here; and it can be seen by improvement in the value of R2. Here, R2 (sip) is the value of R2 obtained from Sips model; whereas, R2 (Freundlich) is the value of R2 obtained from Freundlich isotherm model. % Improvement is defined as
$$\% {\text{Improvement}} = \frac{{\left( {R^{2} \left( {{\text{sips}}} \right) - R^{2} \left( {{\text{freundlich}}} \right)} \right)}}{{R^{2} \left( {{\text{freundlich}}} \right)}} \times 100.$$
As tabulated the %Improvement values is greater than 1 in all the cases except one, which shows that Sips isotherm model is better fit as compared to Freundlich isotherm model (Table 4). Sips isotherm for SD and CS are shown in Figs. 7 and 8, respectively.
Table 4 Value of Sips constants for SD, CS and GNS at 30 °C, 45 °C and 60 °C and %Improvement due to Sips isotherm
Sips isotherm for SD at 30 °C, 45 °C and 60 °C
Sips isotherm for CS at 30 °C, 45 °C and 60 °C
The values of Qmax, Ks, R2 and 1/n obtained from Sips model for all the isotherms were quantified and tabulated below (Table 4).
Thermodynamics of sorption
Sorption thermodynamics were determined using thermodynamic equilibrium coefficient obtained at different temperature and concentration to obtain various thermodynamic parameters. The value of Gibs free energy (∆G°) for sorption can be calculated as
$$\Delta G^{0} = - RT\ln K_{c} ,$$
where Kc is thermodynamic equilibrium constant (l/g) for sorption process. According to (Niwas et al. 2000), Kc can be obtained by plotting (qe/Ce) vs qe (Fig. 9) and extrapolating qe to 0. Van't Hoff equation which is mentioned below establishes relation between ∆H°, ∆S° and Kc was used to obtain ∆H° and ∆S° for the sorption (Yadava et al. 1991; Namasivayam and Kavitha 2002; Hameed and El-Khaiary 2008):
$$\ln K_{c} = \frac{{ - \Delta H^{0} }}{{{\text{RT}}}} + \frac{{\Delta S^{0} }}{R}.$$
(qe/Ce) vs qe plot to obtain Kc for sorption of MB on SD, CS and GNS
ln (Kc) vs (1/T) was plotted in Fig. 10 and slope of the line obtained was used to find ∆H° and intercept was used to find ∆S°. The thermodynamic parameters obtained from the calculations are shown in Table 5 and R2 mentioned there is the square of correlation coefficient for ln (Kc) vs (1/T). It was observed that ∆H° > 0 which indicates that the sorption process is endothermic in nature. In addition, the value of Kc increases with increase in temperature which too corroborates that process is endothermic in nature (Table 5). Moreover, the value of ∆G° was found to be decreasing with increase in temperature which shows that spontaneity increases with temperature. The positive value of ∆S° shows increased randomness at solid/liquid interface during the sorption of dye on SD, CS and GNS. Similar trend in thermodynamic parameters have been described for adsorption of Congo red onto activated carbon prepared from coirpith (Namasivayam and Kavitha 2002).
Van't hoff plots for MB sorption onto SD, CS and GNS
Table 5 Values of thermodynamic parameters and equilibrium constants for sorption of MB onto SD, CS and GNS at 30 °C, 45 °C and 60 °C
Kinetics of sorption
A kinetic study provides the idea about reaction time and estimates the parameter affecting reaction equilibrium. Various authors studied kinetics of MB sorption on different sorbents including activated carbon and concluded that pseudo-second-order kinetic model is the most suitable kinetic model for biosorption (Bello et al. 2008; Chowdhury and Saha 2010; Simonin 2016; Guarín et al. 2018). Kinetic studies were performed at 30 °C using 1 g (0.15–0.3 mm) of sorbent and keeping rest of the condition same as discussed in the methods section.
Pseudo-second-order Kinetics
Pseudo-second-order kinetics being the widely applicable kinetic model for biosorption processes is discussed here. (Ho and McKay 1999) proposed linear form of pseudo-second-order kinetic equation which is represented as
$$\frac{t}{q} = \frac{t}{{q_{e} }} + \frac{1}{{k_{2} q_{e}^{2} }},$$
where q is the sorption rate (mg g−1 of MB) on sorbent at any time t and qe is the concentration when the sorption reaches equilibrium. (t/q) vs t was plotted in Fig. 11 and the value of qe is obtained which is shown in the Table 6.
Plot of (t/q) vs t for 1 g SD, CS and GNS at 30 °C
Table 6 qe and R2 values obtained for SD, CS and GNS from pseudo second order model
Values of qe were obtained from the line plotted in Fig. 11 which are near to the ones obtained previously in batch sorption and also the R2 value is 0.9999 which shows that this model is best fit for biosorption processes. 9.81 mg g−1, 9.04 mg g−1 and 7.98 mg g−1 are the equilibrium concentration obtained for SD, CS and GNS, respectively, while it was 8.75 mg g−1, 7.982 mg g−1 and 7.92 mg g−1, respectively, as obtained experimentally for the same.
Sorption dynamics
When sorbent is added into MB solution the mass transfer occurred can be conveyed explicitly in four stages (Chen et al. 2020b; Li et al. 2018; Zhou et al. 2019; Zhang et al. 2018)—(i) Diffusion of dye molecules from liquid bulk to the liquid film surrounding adsorbent. (ii) Diffusion from film to adsorbent surface. (iii) Diffusion through pores of the adsorbent. (iv) Uptake of adsorbate on the active sites. Based on the resistance offered in different steps kinetic modelling of diffusion can be done. Steps (i) and (ii) are combined known as film diffusion, whereas (iii) and (iv) are comes under particle diffusion.
To determine the governing diffusion mathematically Boyd et al. (Mittal et al. 2009) suggested a mathematical treatment, where fractional attainment F of equilibrium at any time t was required and the relations given below were proposed:
$$F = 1 - \frac{6}{{\pi^{2} }}\mathop \sum \limits_{1}^{\infty } \frac{1}{{n^{2} }}\exp \left( { - n^{2} \cdot B_{t} } \right)$$
$$F = \frac{{q_{t} }}{{q_{e} }},$$
where qt and qe are the amount sorbed after time t and amount sorbed at equilibrium, respectively:
$$B_{t} = \frac{{\pi^{2} D_{i} }}{{r_{0}^{2} }} = {\text{time constant,}}$$
where Di is diffusion coefficient, Bt is time constant and r0 is the radius of spherical sorbent particle. Bt values were obtained from F values using table proposed by Reichenberg (1953). Rate controlling diffusion step can be determined using Bt vs t graphs. Bt vs t graph was plotted for SD, CS and GNS, as shown in Fig. 12. The Bt vs t graph shows that the nature of change can be better represented by line which does not passes through origin for SD, CS and GNS. As studied by Reichenberg, it can be inferred from the nature of curve that governing diffusion process is film diffusion which depicts that maximum resistance is observed by sorbate while reaching the surface of sorbent. Mittal et al. (2009) obtained similar results for sorption of anionic dye congo-red using waste material.
Bt vs t at 30 °C for 1 g of SD, CS and GNS
Breakthrough curves and modelling of column studies
From the studies we obtained that SD has the highest sorption capacity for MB compared to CS and GNS. It is well known that column studies are more effective compared to batch systems as exhaustion capacity of column is usually relatively higher. Moreover, fixed bed column studies are easy to perform and can be effectively scaled up for further usages. Breakthrough curves were plotted to check the applicability of SD as sorbent on higher scale. Column studies give clear idea about the behavior of sorbent when exposed to a continuous system. Hence column studies were performed with SD as sorbent to describe fixed bed column behavior and to scale up it for industrial purposes. Three models namely Thomas, Adam–Bohart and Yoon–Nelson were used to obtain kinetic model of column studies and predict breakthrough curves.
Breakthrough curves
Breakthrough curves are the plots which help to analyze the behavior of bed with respect to time. Two beds containing 1 g SD and 2 g SD were taken for column studies and the flow rates were kept 1.5 ml min−1 and 1.8 ml min−1, respectively. C is the effluent concentration at any time t and C0 is the influent concentration. Here we have plotted (C/C0) vs time and the results obtained are shown in Fig. 13 for 1 g SD and 2 g SD. From Fig. 13, it can be seen that there is a sharp change in C/C0 after 145 min and 200 min for bed with 1 g SD and 2 g SD, respectively, which shows that the bed is on the threshold of saturation. The point of sharp change is called breakthrough point, the effluent concentration at breakthrough point is called breakthrough concentration (Cb) and the time at which it happens is called breakthrough time (Tb). C vs t was plotted for columns with 1 g SD and 2 g SD and area of curve was measured to obtain the amount of MB sorbed by the column. 24.02 mg and 34.5 mg MB was sorbed by columns with 1 g SD and 2 g SD, respectively. Breakthrough time for 1 g SD and 2 g SD bed obtained at C/C0 = 0.1 was found to be 145 min and 200 min, respectively. 200 ml and 350 ml MB solution was treated by bed till breakthrough by 1 g SD bed and 2 g SD bed, respectively.
Breakthrough curves obtained from column study of 1 g and 2 g SD beds
Thomas model
Thomas Model is one of the most general and widely used models for describing the behavior of sorbents in biosorption process. It assumes plug flow behavior in bed and the equation employed is expressed as
$$\ln \left( { \frac{{C_{0} }}{{C_{t} }} - 1} \right) = \frac{{K_{Th} q_{0} m}}{Q} - K_{Th} C_{0} t,$$
where Kth is Thomas model constant (ml min−1 g−1), qo (mg g−1) is the sorption capacity of sorbent, m is the mass of sorbent in the column and Q (ml min−1) is the flow rate of MB solution being poured from the top into the column. \(\mathrm{Ln}\left( \frac{{C}_{0}}{{C}_{t}}-1\right)\) vs t was plotted and the line equation was used to obtain Kth and q0. The values of q0 increases with decrease in flow rate and bed height. The value of q0 was observed to be 28.93 mg g−1 and 19.44 mg g−1 for 1 g SD column and 2 g SD column, respectively (Table 7). It can be seen that column studies are effective compared to batch sorption methods as sorption capacity observed for SD is more in column studies setup (19–29 mg g−1) compared to batch sorption setup (7–10 mg g−1). (Lakshmipathy and Sarada 2016) obtained the similar trend for Thomas model.
Table 7 Values of parameters obtained from Thomas model, Yoon–Nelson model and Adam–Bohart model
Yoon–Nelson model
Yoon–Nelson developed a simplistic model which assumes that the rate of decrease in the probability of adsorption for each adsorbate molecule is proportional to the probability of sorbate sorption and the probability of sorbate breakthrough on sorbent (Lakshmipathy and Sarada 2016). The linear form of the equation employed in model is as follows:
$$\ln \left( {\frac{{C_{t} }}{{C_{0} - C_{t} }}} \right) = K_{{{\text{YN}}}} - \tau K_{{{\text{YN}}}} ,$$
where KYN (min−1) is Yoon–Nelson proportionality constant and \(\tau\) is time required for retaining 50% of initial sorbate. The values of KYN and \(\tau\) can be obtained by plotting \(\mathrm{ln}\left(\frac{{C}_{t}}{{C}_{0}-{C}_{t}}\right)\) vs t. The values of KYN and \(\tau\) obtained for all breakthrough curves are tabulated in Table 7. The values of \(\tau\) were found to increase with increase in flowrate and bed height. Here the value of \(\tau\) was found to be 195 min for bed with height 5.7 cm and 252 min for bed with height 10.5 cm. The values of \(\tau\) obtained from breakthrough curves (192 min and 238 min) and Yoon–Nelson model (195 min and 252 min) are comparable. (Lakshmipathy and Sarada 2016; Chatterjee et al. 2018) obtained similar trend in results of Yoon–Nelson model.
Adams–Bohart model
Adams–Bohart model is widely used for prediction of breakthrough curves obtained from column studies. According to this model equilibrium is not instantaneous and rate of sorption is proportional to the fraction of sorption capacity. It is mainly useful in predicting the initial part of breakthrough curve. The linearized equation employed in the model is
$$\ln \frac{{C_{t} }}{{C_{0} }} = k_{{{\text{AB}}}} C_{0} t - k_{{{\text{AB}}}} N_{0} \frac{z}{{\mu_{0} }},$$
where C0 is the influent MB concentration, Ct is the effluent MB concentration at any time t, kAB is the kinetic constant (L mg−1 min−1), N0 is the saturation concentration (mg l−1), z is the bed height (cm) and \({\mu }_{0}\) is superficial velocity (cm min−1). \(ln\frac{{C}_{t}}{{C}_{0}}\) vs t was plotted to obtain the model parameters. The calculated parameters N0 and kAB are tabulated in Table 7. It was observed that the value of N0 decreases with increase in bed height and flow rate. Here the value of N0 was obtained to be 7249.89 mg l−1 in case of bed height 5.7 cm and 6909.366 mg l−1 in case of bed height 10.5 cm.
Scale-up procedure
A column that can run with SD as a sorbent was considered to remove MB (or similar) dyes from the waste water/aqueous solution assuming that the column behaves similarly to the column used in the experiments. The widely used column size for water treatment using activated carbon as a sorbent in medium scale industry has diameter in the range 50 cm–100 cm and generally selected by customers as per their requirement.
An up-scaled cylindrical sorption column with 50 cm diameter and 300 cm height containing SD bed of height 100 cm was designed. Clearance of 200 cm (300–100 = 200 cm) above bed is necessary as wastewater may stagnate on top of the bed while starting the column. The idea for scaling up is shown in the figure, where small columns are used as a building block for up-scaling (Fig. 14).
Proposed scaled-up column design along with dimensions
Bed height of small column (H1) = 10.5 cm
Diameter of small column (D1) = 1 cm
Height of small column (L1) = 27 cm
Weight of SD used in small column (W1) = 2 g
Volume of small column (V1) = 8.24 cm3
Cross sectional area of small column (C1) = 0.78 cm2
Flow rate in small column (F1) = 1.8 ml min−1
Breakthrough time for small column (Tb1) = 200 min = 3.33 h
Maximum volume of water treatment possible in small column (CA1) = 350 ml
Bed height of scaled up column (H2) = 100 cm
Diameter of scaled up column (D2) = 50 cm
Height of scaled up column (L2) = 300 cm
Volume of scaled up column (V2) = 196,349 cm3
Cross sectional area of scaled up column (C2) = 1963.49 cm2:
$$\text{Volume factor }\,\left({V}_{f}\right)=\frac{{V}_{2}}{{V}_{1}}=23,829$$
$${\text{Therefore}},V_{1} { } = 23829{ }V_{2} .$$
Thus, a cylindrical column with 50 cm diameter and 100 cm height is similar to 23,829 nos of column with 2 g SD with 10 cm bed height as both of them provide same surface area.
Flow rate of small column = 1.8 ml min−1:
$${\text{Area}}\;{\text{factor }}\left( {A_{f} } \right) = \frac{{C_{2} }}{{C_{1} }} = 2500.$$
Let flowrate in scaled up column be F2. Then,
$$F_{2} = A_{f} \times F_{1} = 4500\frac{{{\text{ml}}}}{{{\text{min}}}}$$
Hence, the scaled-up column is capable of treating 4500 ml min−1 of wastewater.
Let maximum volume of water treatment possible in scaled up column be (CA2). Then
$${\text{CA}}_{2} = V_{f} \times {\text{CA}}_{1} = 8340150{\text{ ml}}{.}$$
\(\mathrm{C}\) Breakthrough time of scaled up column can be obtained in two ways as follows:
$$T_{b2 - A} = \frac{{{\text{CA}}_{2} }}{{F_{2} }} = 30.89{\text{ h}}$$
$$T_{b2 - B} = T_{b1} \times \frac{{H_{2} }}{{H_{1} }} = 31.71{\text{ h}}{.}$$
Smaller of the \({T}_{b2-A}\) and \({T}_{b2-B}\) was considered for calculation.
Let the amount of SD required for scaled up column be W2.
$$W_{2} = V_{f} \times W_{1} = 47{,}658{\text{ g}}{.}$$
Rate of SD = 3–5 INR per kg (0.04–0.07 USD per kg as on November 6, 2020).
Therefore, ~ 150–250 INR would be the cost of SD required in one cycle of operation.
Assuming 80% efficiency the scale-up column can run for 1 day (30.89 × 0.8 = 24.71 h) and treat 6672 L (8340.15 × 0.8 = 6672 L) wastewater containing dyes which can be used in textile industries. In addition, columns can be designed accordingly for lesser flowrates or arranged in parallel to treat more wastewater. Column regeneration is required after 24 h for maintaining 80% efficiency and the waste SD obtained from used bed can be regenerated using weak (mild) acid as MB is a basic dye. However, regeneration is not advisable for bio-sorbents, because the activity of sorbents reduces after one run and also it is not cost effective, since operational cost for regeneration column is more than purchase cost of SD in bulk. Different strategies involving catalytic degradation can be employed for the removal of MB as an alternative to land filling.
From the performed experiments it can be said that SD, CS and GNS can be successfully used for removal of MB (basic dye) from aqueous solution. Optimization of experimental conditions shows that dye removal increases with increase in temperature and initial dye concentration, whereas decreases with increase in particle size of adsorbent. The maximum dye removal for SD, CS and GNS follows the trend SD > CS > GNS amongst all the variation studied in experiments. SD, CS and GNS follow Freundlich isotherm; but didn't follow Langmuir isotherm, which is applicable only for mono-layer adsorption. This indicates that MB sorption onto biomass is a multi-layer adsorption phenomenon. The values of ∆H° and ∆S° were found to be positive for all sorbents. In addition, the increase in Kc with temperature shows that sorption is endothermic in nature. Decrease in ∆G° with temperature depicts that spontaneity decreases with decrement in temperature. Kinetic studies of sorption shows that sorption follows pseudo-second-order kinetics. Adsorption dynamics study concluded that film diffusion is the governing diffusion. Column studies done with SD depicted that it can work better in column rather than batch. Breakthrough curve studies have revealed the potential of SD as a sorbent and it can be used at an industrial scale. Application based scaled-up column design is proposed with SD as a sorbent which can treat 6.67 tonnes of water in 24 h assuming 80% efficiency. As a result, it can be suggested to use low cost biomass SD over CS and GNS for dye removal from effluents released by textile industries. Preparing a bed of SD and installing it at the output of existing treatment unit can also be better alternative of activated carbon filter (ACF). Not only this, it may be applied in loose form to control small oil/dye spills and to manage the leftover traces of larger oil spills.
The data that supports the findings of this study are available from the corresponding author upon reasonable request.
CPIs:
Chemical process industries
CS:
Cotton stalks
GNS:
Groundnut shell
MB:
Methylene blue
BET:
Brunauer–Emmett–Teller
ACF:
Acemioǧlu B (2004) Adsorption of Congo red from aqueous solution onto calcium-rich fly ash. J Colloid Interface Sci. https://doi.org/10.1016/j.jcis.2004.03.019
Al-Ghouti MA, Da'ana DA (2020) Guidelines for the use and interpretation of adsorption isotherm models: a review. J Hazard Mater 393:122383
An HK, Park BY, Kim DS (2001) Crab shell for the removal of heavy metals from aqueous solution. Water Res. https://doi.org/10.1016/S0043-1354(01)00099-9
Annadurai G, Juang RS, Lee DJ (2002) Use of cellulose-based wastes for adsorption of dyes from aqueous solutions. J Hazard Mater. https://doi.org/10.1016/S0304-3894(02)00017-1
Asfour HM, Fadali OA, Nassar MM, El-Geundi MS (1985) Equilibrium studies on adsorption of basic dyes on hardwood. J Chem Technol Biotechnol Chem Technol. https://doi.org/10.1002/jctb.5040350105
Azlina W, Ab W, Ghani K et al (2013) adsorption of methylene blue on sawdust-derived biochar and its adsorption isotherms. J Purity, Util React Environ 2:34–50
Basava Rao VV, Ram Mohan Rao S (2006) Adsorption studies on treatment of textile dyeing industrial effluent by flyash. Chem Eng J. https://doi.org/10.1016/j.cej.2005.09.029
Bello OS, Adeogun IA, Ajaelu JC, Fehintola EO (2008) Adsorption of methylene blue onto activated carbon derived from periwinkle shells: kinetics and equilibrium studies. Chem Ecol. https://doi.org/10.1080/02757540802238341
Chatterjee S, Mondal S, De S (2018) Design and scaling up of fixed bed adsorption columns for lead removal by treated laterite. J Clean Prod. https://doi.org/10.1016/j.jclepro.2017.12.249
Chen YD, Lin YC, Ho SH et al (2018) Highly efficient adsorption of dyes by biochar derived from pigments-extracted macroalgae pyrolyzed at different temperature. Bioresour Technol. https://doi.org/10.1016/j.biortech.2018.02.094
Chen YD, Liu F, Ren NQ, Ho SH (2020a) Revolutions in algal biochar for different applications: State-of-the-art techniques and future scenarios. Chinese Chem Lett. https://doi.org/10.1016/j.cclet.2020.08.019
Chen H, Zhou Y, Wang J et al (2020b) Polydopamine modified cyclodextrin polymer as efficient adsorbent for removing cationic dyes and Cu2+. J Hazard Mater. https://doi.org/10.1016/j.jhazmat.2019.121897
Chowdhury S, Saha P (2010) Pseudo-second-order kinetic model for biosorption of methylene blue onto tamarind fruit shell: Comparison of linear and nonlinear methods. Bioremediat J. https://doi.org/10.1080/10889868.2010.514966
Doǧan M, Özdemir Y, Alkan M (2007) Adsorption kinetics and mechanism of cationic methyl violet and methylene blue dyes onto sepiolite. Dye Pigment. https://doi.org/10.1016/j.dyepig.2006.07.023
Ertaş M, Acemioĝlu B, Alma MH, Usta M (2010) Removal of methylene blue from aqueous solution using cotton stalk, cotton waste and cotton dust. J Hazard Mater. https://doi.org/10.1016/j.jhazmat.2010.07.041
Garg VK, Amita M, Kumar R, Gupta R (2004) Basic dye (methylene blue) removal from simulated wastewater by adsorption using Indian Rosewood sawdust: a timber industry waste. Dye Pigment. https://doi.org/10.1016/j.dyepig.2004.03.005
Guarín JR, Moreno-Pirajan JC, Giraldo L (2018) Kinetic study of the bioadsorption of methylene blue on the surface of the biomass obtained from the Algae D. antarctica. J Chem. https://doi.org/10.1155/2018/2124845
Gupta VK, Suhas (2009) Application of low-cost adsorbents for dye removal - A review. J Environ Manage. 90:2313–2342
Hameed BH, El-Khaiary MI (2008) Removal of basic dye from aqueous medium using a novel agricultural waste material: pumpkin seed hull. J Hazard Mater. https://doi.org/10.1016/j.jhazmat.2007.11.102
Hameed BH, Din ATM, Ahmad AL (2007) Adsorption of methylene blue onto bamboo-based activated carbon: kinetics and equilibrium studies. J Hazard Mater. https://doi.org/10.1016/j.jhazmat.2006.07.049
Ho YS, McKay G (1998) Kinetic models for the sorption of dye from aqueous solution by wood. Process Saf Environ Prot. https://doi.org/10.1205/095758298529326
Ho YS, McKay G (1999) Pseudo-second order model for sorption processes. Process Biochem. https://doi.org/10.1016/S0032-9592(98)00112-5
Kumari G, Soni B, Karmee SK (2020) Synthesis of activated carbon from groundnut shell via chemical activation. J Inst Eng Ser E. https://doi.org/10.1007/s40034-020-00176-z
Lakshmipathy R, Sarada NC (2016) Methylene blue adsorption onto native watermelon rind: batch and fixed bed column studies. Desalin Water Treat. https://doi.org/10.1080/19443994.2015.1040462
Li Y, Zhou Y, Zhou Y et al (2018) Cyclodextrin modified filter paper for removal of cationic dyes/Cu ions from aqueous solutions. Water Sci Technol. https://doi.org/10.2166/wst.2019.009
McKay G (1996) Use of sorbents for removal of pollutants from wastewater. CRC Press
Mittal A, Mittal J, Malviya A, Gupta VK (2009) Adsorptive removal of hazardous anionic dye "Congo red" from wastewater using waste materials and recovery by desorption. J Colloid Interface Sci. https://doi.org/10.1016/j.jcis.2009.08.019
Mohan SV, Karthikeyan J (1997) Removal of lignin and tannin colour from aqueous solution by adsorption onto activated charcoal. Environ Pollut. https://doi.org/10.1016/S0269-7491(97)00025-0
Namasivayam C, Kavitha D (2002) Removal of Congo Red from water by adsorption onto activated carbon prepared from coir pith, an agricultural solid waste. Dye Pigment. https://doi.org/10.1016/S0143-7208(02)00025-6
Namasivayam C, Muniasamy N, Gayatri K et al (1996) Removal of dyes from aqueous solutions by cellulosic waste orange peel. Bioresour Technol. https://doi.org/10.1016/0960-8524(96)00044-2
Nassar MM, El-Geundi MS (1991) Comparative cost of colour removal from textile effluents using natural adsorbents. J Chem Technol Biotechnol. https://doi.org/10.1002/jctb.280500210
Nigam P, Armour G, Banat IM et al (2000) Physical removal of textile dyes from effluents and solid-state fermentation of dye-adsorbed agricultural residues. Bioresour Technol. https://doi.org/10.1016/S0960-8524(99)00123-6
Niwas R, Gupta U, Khan AA, Varshney KG (2000) The adsorption of phosphamidon on the surface of styrene supported zirconium (IV) tungstophosphate: a thermodynamic study. Colloids Surf A Physicochem Eng Asp. https://doi.org/10.1016/S0927-7757(99)00247-2
Ong ST, Lee CK, Zainal Z (2007) Removal of basic and reactive dyes using ethylenediamine modified rice hull. Bioresour Technol. https://doi.org/10.1016/j.biortech.2006.05.011
Reichenberg D (1953) Properties of Ion excahnge resins in relation to structure. J Am Chem Soc 75:589–597
Sakkayawong N, Thiravetyan P, Nakbanpote W (2005) Adsorption mechanism of synthetic reactive dye wastewater by chitosan. J Colloid Interface Sci. https://doi.org/10.1016/j.jcis.2005.01.020
Simonin JP (2016) On the comparison of pseudo-first order and pseudo-second order rate laws in the modeling of adsorption kinetics. Chem Eng J. https://doi.org/10.1016/j.cej.2016.04.079
Soni B, Karmee SK (2020) Towards a continuous pilot scale pyrolysis based biorefinery for production of biooil and biochar from sawdust. Fuel. https://doi.org/10.1016/j.fuel.2020.117570
Tan X, Zhu S, Show PL et al (2020) Sorption of ionized dyes on high-salinity microalgal residue derived biochar: electron acceptor-donor and metal-organic bridging mechanisms. J Hazard Mater. https://doi.org/10.1016/j.jhazmat.2020.122435
Yadava KP, Tyagi BS, Singh VN (1991) Effect of temperature on the removal of lead(II) by adsorption on China clay and wollastonite. J Chem Technol Biotechnol. https://doi.org/10.1002/jctb.280510105
Zhang Y, Lin S, Qiao J et al (2018) Malic acid-enhanced chitosan hydrogel beads (mCHBs) for the removal of Cr(VI) and Cu(II) from aqueous solution. Chem Eng J. https://doi.org/10.1016/j.cej.2018.06.143
Zhou Y, Lu J, Zhou Y, Liu Y (2019) Recent advances for dyes removal using novel adsorbents: a review. Environ Pollut 252:352–365
Zhu Y, Wang D, Zhang X, Qin H (2009) Adsorption removal of methylene blue from aqueous solution by using bamboo charcoal. Fresenius Environ Bull 18:369–376
The authors are thankful to the Sardar Patel Renewable Energy Research Institute (SPRERI), Vallabh Vidyanagar, Anand, Gujarat, India for providing infrastructure and for supporting this piece of research.
This piece of research is financially supported by the Indian Council of Agricultural Research (ICAR), New Delhi, Govt. of India (GoI) and Govt of Gujarat (GoG), Gujarat, India.
Thermo-Chemical Conversion Technology Division, Sardar Patel Renewable Energy Research Institute (SPRERI), Vallabh Vidyanagar, 388 120, Anand, Gujarat, India
Arth Jayesh Shah, Bhavin Soni & Sanjib Kumar Karmee
Arth Jayesh Shah
Bhavin Soni
Sanjib Kumar Karmee
AJS: Experimental investigation, Data analysis, Manuscript writing; BS: Data analysis, supervision, manuscript writing; SKK: Conceptualization, visualization, supervision, project administration, manuscript writing, revision and editing of the manuscript. All authors read and approved the final manuscript.
Correspondence to Sanjib Kumar Karmee.
The authors declare that no animals were used in this study. Informed consent was obtained from all the individual participants included in the study.
All the authors agree for this publication and give consent for it.
The author states that there is no conflict of interest.
Shah, A.J., Soni, B. & Karmee, S.K. Locally available agroresidues as potential sorbents: modelling, column studies and scale-up. Bioresour. Bioprocess. 8, 34 (2021). https://doi.org/10.1186/s40643-021-00387-1
Biosorbents
Column study | CommonCrawl |
Signal Processing Meta
Signal Processing Stack Exchange is a question and answer site for practitioners of the art and science of signal, image and video processing. It only takes a minute to sign up.
Even and odd signal energy property
In Signals and Systems by A. V. Oppenheim, A. S. Willsky, S. Hamid Nawab, 2nd Edition, and Signals and Systems, Simon Haykins, Barry Van Veen, 2nd Edition there is a problem related to energy of real-valued even and odd signal.
Energy of an arbitrary real-valued signal $x(t)$ is equal to the sum of the energy of the even component $x_{e}(t)$ and energy of the odd component $x_{o}(t)$ i.e. \begin{equation} \int_{-\infty}^{\infty}x^2(t)dt = \int_{-\infty}^{\infty}x_{e}^2(t)dt + \int_{-\infty}^{\infty}x_{o}^2(t)dt\notag \end{equation} Which can be proved very easily by expressing $x(t) = x_{e}(t) + x_{o}(t)$ and evaluating its energy as \begin{align} \int_{-\infty}^{\infty}x^2(t)dt &= \int_{-\infty}^{\infty}\big(x_{e}(t) + x_{o}(t)\big)^2dt\notag\\ &= \int_{-\infty}^{\infty}x_{e}^{2}(t)dt + \int_{-\infty}^{\infty}x_{o}^{2}(t)dt +2\int_{-\infty}^{\infty}x_{e}(t)x_{o}(t)dt\notag. \end{align} The term $x_{e}(t)x_{o}(t)$ in the last integration corresponds to an odd signal (multiplication of even and odd signal results into odd signal) and its integration (joint energy) is equal to zero (area under an odd signal over symmetrical limits is zero). Hence \begin{align} \int_{-\infty}^{\infty}x^2(t)dt = \int_{-\infty}^{\infty}x_{e}^{2}(t)dt + \int_{-\infty}^{\infty}x_{o}^{2}(t)dt\notag \end{align}
I was wondering, what if I consider $x(t)$ to be a complex signal, will above property still be valid. I tried as \begin{equation} \int_{-\infty}^{\infty}|x(t)|^2dt = \int_{-\infty}^{\infty}|x_{e}(t)|^2dt + \int_{-\infty}^{\infty}|x_{o}(t)|^2dt\notag \end{equation} Expressing $x(t) = x_{e}(t) + x_{o}(t)$ and evaluating its energy as \begin{align} \int_{-\infty}^{\infty}|x(t)|^2dt &= \int_{-\infty}^{\infty}\big|x_{e}(t) + x_{o}(t)\big|^2dt\notag\\ &= \int_{-\infty}^{\infty}|x_{e}(t)|^{2}dt + \int_{-\infty}^{\infty}|x_{o}(t)|^{2}dt +\int_{-\infty}^{\infty}[x_{e}(t)x_{o}^{*}(t) + x_{o}(t)x_{e}^{*}(t)]dt\notag \end{align}
On expanding the term \begin{align} x_{e}(t)x_{o}^{*}(t) &= \big(x_{er}(t) + jx_{ei}(t)\big)\big(x_{or}(t) - jx_{oi}(t)\big)\\ &= x_{er}(t)x_{or}(t) + x_{ei}(t)x_{oi}(t) - jx_{er}(t)x_{oi}(t) + jx_{ei}(t)x_{or}(t)\\ x_{o}(t)x_{e}^{*}(t) &= \big(x_{or}(t) + jx_{oi}(t)\big)\big(x_{er}(t) - jx_{ei}(t)\big)\\ &= x_{er}(t)x_{or}(t) + x_{ei}(t)x_{oi}(t) - jx_{ei}(t)x_{or}(t) + jx_{er}(t)x_{oi}(t) \end{align} Further on adding this terms results into \begin{align} \int_{-\infty}^{\infty}|x(t)|^2dt &= \int_{-\infty}^{\infty}|x_{e}(t)|^{2}dt + \int_{-\infty}^{\infty}|x_{o}(t)|^{2}dt +2\int_{-\infty}^{\infty}\big(x_{er}(t)x_{or}(t) + x_{oi}(t)x_{ei}(t)\big)dt\notag \end{align} The terms $x_{er}(t)x_{or}(t)$ and $x_{oi}(t)x_{ei}(t)$ in the last integration corresponds to an odd signal and its integration (joint energy) is equal to zero. Hence \begin{equation} \int_{-\infty}^{\infty}|x(t)|^2dt = \int_{-\infty}^{\infty}|x_{e}(t)|^2dt + \int_{-\infty}^{\infty}|x_{o}(t)|^2dt\notag \end{equation} I would appreciate if anyone here can validate the proof. Is it correct to say that the same property too holds for complex signal.
proof complex signal-energy symmetry
MeetMeet
$\begingroup$ deconstruct $x_e$ and $x_o$ into real and imaginary part; fully execute the the $x_ex_o^*$ and $x_e^*x_o$ products :) $\endgroup$ – Marcus Müller Mar 13 '18 at 14:15
$\begingroup$ @MarcusMüller, I have expanded them... $\endgroup$ – Meet Mar 13 '18 at 14:57
$\begingroup$ I appreciate you remind me this property $\endgroup$ – Laurent Duval Mar 13 '18 at 17:27
Your result is correct but note that for complex signals, the even and odd parts are defined by
$$x_e(t)=\frac12\left[x(t)+x^*(-t)\right]\tag{1}$$ and $$x_o(t)=\frac12\left[x(t)-x^*(-t)\right]\tag{2}$$
where $^*$ denotes complex conjugation.
From $(1)$ and $(2)$ it follows that the real part of $x_e(t)$ is even and its imaginary part is odd, whereas $x_o(t)$ has an odd real part and an even imaginary part.
We get
$$|x(t)|^2=|x_e(t)+x_o(t)|^2=|x_e(t)|^2+|x_o(t)|^2+2\,\text{Re}\{x_e(t)x_o^*(t)\}\tag{3}$$
$$\begin{align}x_e(t)x_o^*(t)&=\frac14\left[x(t)+x^*(-t)\right]\left[x^*(t)-x(-t)\right]\\&=\frac14\left[|x(t)|^2-x(t)x(-t)+x^*(t)x^*(-t)-|x(-t)|^2\right]\end{align}\tag{4}$$
we see that $x_e(t)x_o^*(t)$ is an odd signal according to definition $(2)$ (it is the odd part of $\frac12 \left[|x(t)|^2-x(t)x(-t)\right]$), and, consequently, its real part is odd. This implies that the integral over the last term in $(3)$ is zero, and the stated property holds.
Matt L.Matt L.
$\begingroup$ Good explanation. $\endgroup$ – QMC Mar 16 '18 at 4:50
$\begingroup$ Please correct me. The equation in $(1)$ and $(2)$ are known as conjugate-symmetric (CS) and conjugate-antisymmetric (CA) part of the complex signal. Where in general by the definition of CS i.e. $\mathbf{x}(-t) = \mathbf{x}^{*}(t)$, where $\operatorname{\mathbb{R}e}\{\mathbf{x}(t)\}$ has even symmetry and $\operatorname{\mathbb{I}m}\{\mathbf{x}(t)\}$ has odd symmetry. Whereas, CA is defined as $\mathbf{x}(-t) = -\mathbf{x}^{*}(t)$, where $\operatorname{\mathbb{R}e}\{\mathbf{x}(t)\}$ has odd symmetry and $\operatorname{\mathbb{I}m}\{\mathbf{x}(t)\}$ has even symmetry. $\endgroup$ – Meet Mar 18 '18 at 11:53
$\begingroup$ @Meet: Yes, also know as Hermitian (anti-)symmetry. $\endgroup$ – Matt L. Mar 18 '18 at 12:05
$\begingroup$ @MattL.: How can you say its even and odd signals decomposition are given as in $(1)$ and $(2)$. Or there is no difference in Hermitian and even. And skew-Hermitian and odd regarding complex signal. $\endgroup$ – Meet Mar 18 '18 at 12:16
$\begingroup$ @Meet: Because that's how even (symmetric) and odd (anti-symmetric) are usually defined for complex signals. $\endgroup$ – Matt L. Mar 18 '18 at 12:17
Sometimes, notations can simplify the computations.
Let us write $\underline{x} = \overline{x(-t)}$, where $\overline{\cdot} $ is the complex conjugate. In the complex case, it is more often called Hermitian/skew-Hermitian decomposition
$$\frac{x+\underline{x}}{2} (\textrm{hermitian})+\frac{x-\underline{x}}{2} (\textrm{skew-hermitian})$$
then under the integral, the second term is:
$$\frac{x+\underline{x}}{2}\overline{\frac{x+\underline{x}}{2}}+\frac{x-\underline{x}}{2}\overline{\frac{x-\underline{x}}{2}}$$
Multiplying by 4, one gets:
$$(x+\underline{x})\cdot(\overline{x+\underline{x}})+(x-\underline{x})\cdot(\overline{x-\underline{x}})$$
and cross terms cancel nicely.
Laurent DuvalLaurent Duval
Thanks for contributing an answer to Signal Processing Stack Exchange!
Not the answer you're looking for? Browse other questions tagged proof complex signal-energy symmetry or ask your own question.
Finding the Energy & Power of a Composition of Odd and Even Signal
Proof of properties of Fourier series in CT
Hilbert transform from analytic signal
Power spectral density of a PAM signal
How to derive $r(t) = c(t) \circledast \frac{1}{2} h_b(t, \tau)$?
Downsampling: Mathematical derivation
Find autocorrelation of exponential signal $a^nu[n]$
how to evaluate derivative of convolution integral?
Continuous vs discrete signal energy
Partitioning the energy of a signal between its components | CommonCrawl |
A novel phantom technique for evaluating the performance of PET auto-segmentation methods in delineating heterogeneous and irregular lesions
B Berthon1,
C Marshall1,
R Holmes2 &
E Spezi3
Positron Emission Tomography (PET)-based automatic segmentation (PET-AS) methods can improve tumour delineation for radiotherapy treatment planning, particularly for Head and Neck (H&N) cancer. Thorough validation of PET-AS on relevant data is currently needed. Printed subresolution sandwich (SS) phantoms allow modelling heterogeneous and irregular tracer uptake, while providing reference uptake data. This work aimed to demonstrate the usefulness of the printed SS phantom technique in recreating complex realistic H&N radiotracer uptake for evaluating several PET-AS methods.
Ten SS phantoms were built from printouts representing 2mm-spaced slices of modelled H&N uptake, printed using black ink mixed with 18F-fluorodeoxyglucose, and stacked between 2mm thick plastic sheets. Spherical lesions were modelled for two contrasted uptake levels, and irregular and spheroidal tumours were modelled for homogeneous, and heterogeneous uptake including necrotic patterns. The PET scans acquired were segmented with ten custom PET-AS methods: adaptive iterative thresholding (AT), region growing, clustering applied to 2 to 8 clusters, and watershed transform-based segmentation. The difference between the resulting contours and the ground truth from the image template was evaluated using the Dice Similarity Coefficient (DSC), Sensitivity and Positive Predictive value.
Realistic H&N images were obtained within 90 min of preparation. The sensitivity of binary PET-AS and clustering using small numbers of clusters dropped for highly heterogeneous spheres. The accuracy of PET-AS methods dropped between 4% and 68% for irregular lesions compared to spheres of the same volume. For each geometry and uptake modelled with the SS phantoms, we report the number of clusters resulting in optimal segmentation. Radioisotope distributions representing necrotic uptakes proved most challenging for most methods. Two PET-AS methods did not include the necrotic region in the segmented volume.
Printed SS phantoms allowed identifying advantages and drawbacks of the different methods, determining the most robust PET-AS for the segmentation of heterogeneities and complex geometries, and quantifying differences across methods in the delineation of necrotic lesions. The printed SS phantom technique provides key advantages in the development and evaluation of PET segmentation methods and has a future in the field of radioisotope imaging.
Positron emission tomography (PET) imaging using 18F-fluorodeoxyglucose (18F-FDG) allows the observation of metabolic pathways in the human body and is therefore increasingly used for gross tumour volume (GTV) delineation for a number of cancers, including head and neck (H&N). The use of PET-based automatic segmentation (PET-AS) methods could be useful in radiotherapy treatment planning and in the prediction of response to therapy, for which accurate segmentation of the tumours is crucial. Some studies have shown that PET-AS methods which perform well with homogeneous lesions show poor accuracy in the case of more realistic inhomogeneous and irregular clinical lesions, using clinical or simulated data [1, 2], in particular when using fixed thresholding methods, which are highly dependent on the image type [3]. The use of advanced PET-AS beyond thresholding was recommended to reduce dosimetry errors, especially in the case of heterogeneous tumours [4]. Although an increasingly large number of studies have investigated and compared the performance of existing PET segmentation methods, the target objects used are most frequently obtained with plastic fillable phantoms, including inserts of spherical geometry [5, 6]. Plastic phantoms combine the advantage of a known ground truth and a physical object, which can be scanned using patient protocols. However, these phantoms are limited to modelling simplified and clinically unrealistic uptake patterns. Furthermore, due to their fixed regular geometry, they do not allow modelling intra-tumour heterogeneity, which is a key element of clinical lesions. In addition, we have shown in a previous work that the presence of thick plastic walls encompassing the target object has an important effect on the evaluation of PET-AS methods [7]. Therefore, such phantoms are not adequate for studies requiring accurate modelling of patient metabolic uptake [8, 9], particularly in the H&N where the intricate anatomy and heterogeneity occurring in both background and tumour make the task of delineating the GTV very challenging. A small number of phantom studies have used deformed objects or molecular sieves to model non-spherical lesions [10–13] or have included absorbent material into their inserts to model inhomogeneities [14]. However, these techniques did not allow modelling combined heterogeneity and geometrical complexity in a controlled and reproducible manner and most still included the presence of glass or plastic walls. To our knowledge, heterogeneity and complex geometry have not yet been modelled in combination in realistic phantoms.
The use of printed radioactive uptake patterns has been investigated in the literature as a promising technique for generating radioactive sources for PET [15–17]. This allows modelling any desired tracer distribution while providing reference data or ground truth useful for a number of quality assurance purposes. A quantitative calibration study of the printing method was described in detail by Markiewicz et al. [17] for generating single-slice patterns with applications to brain imaging studies. However, the stacking of several printed patterns to produce a 3D object for quantitative applications was not investigated. Recent work by Holmes et al. used a 3D-printed phantom, named subresolution sandwich (SS) phantom, for the generation of realistic SPECT brain images [18]. However, to our knowledge, the use of stacked 18F-FDG-printed uptake patterns to generate a 3D PET phantom has not yet been investigated nor used for the evaluation of PET segmentation techniques.
This work aimed at demonstrating the advantages of using irregular and heterogeneous target objects to evaluate and compare the performance of PET-AS methods. For this purpose, we calibrated and used a novel 3D-printed SS phantom technique to acquire realistic image data. We used the PET images obtained by scanning the 3D-printed SS phantoms to evaluate and compare a set of ten PET-AS methods representing different medical image segmentation approaches. We have investigated the benefits of using the printed SS phantom compared to a standard plastic fillable phantom for testing PET-AS methods intended for radiotherapy treatment planning.
Experimental method and reproducibility
Preparation of the SS phantom
The printed SS phantom structure consists of 120 oval poly(methyl methacrylate) (PMMA) sheet of 2-mm thickness, corresponding to axial slices, which can be assembled using three plastic rods attached to a cylindrical PMMA support. The radioactive part of the phantom, when containing radioactive printouts, can reach a maximum length of 240 mm. The paper and PMMA are held together by a thick plastic sheet, which is screwed on top of the phantom once assembled, allowing it to be scanned as a 3D physical object. A picture of the assembled 3D phantom is shown on Fig. 1a, along with the position of the phantom in the scanner on Fig. 1b.
a Partially assembled printed SS phantom and b assembled phantom positioned on the scanner bed
Plain A4 80-mg paper was used, cut to 168 mm × 197 mm to fit into the phantom and hole punched in order for it to be assembled on the rods. Uptake printouts were generated as grey-level 3D images in Matlab (The MathWorks Inc., Natick, USA), resampled to 2-mm slices and printed on a HP deskjet 990 cxi, using drop-on-demand thermal inkjet printing. The advantage of this type of equipment is its use of refillable ink cartridges, making it possible to add the desired quantity of radiotracer to the same cartridge before each set of experiments. The printing settings "normal" and "black & white" were chosen in order to minimise the printing time (and therefore the radiotracer decay and user exposure to gamma emissions) while ensuring a good printing quality. The corresponding printing speed is 6.5 pages per minute. The printing resolution used throughout this work was 600 × 600 dpi.
The cartridge was filled with the desired 18F-FDG volume and topped with black ink. Various 18F-FDG activity concentrations were used for the different experiments. The images were printed in a hot cell (Gravatom Engineering Systems Ltd, Southampton, UK), after leaving the cartridge with its dispensing head down for 20 min to homogenize its contents, as recommended by the manufacturer. All operations including filling the ink cartridge and assembling the phantom were done behind a lead glass shield (Bright Technologies Ltd, Sheffield, UK). Any inaccuracy in the positioning of the pattern on the paper was corrected for by aligning markers printed as part of the pattern to reference markers drawn on the PMMA sheet. The cross-shaped markers were printed with the same radioactive ink as the printout and were visible on the PET image obtained. The phantom was scanned immediately after assembling on a GE 690 Discovery PET/CT scanner for two bed positions with the protocol used for clinical whole body diagnostic scans, given in Table 1. Both low-dose CT (used for attenuation correction) and high-resolution CT were acquired. Operator exposure to the radioactive tracer was controlled using standard safety equipment (e.g. lead glass shields, shielded syringe carriers, hot cell) and monitored with electronic portable dosimeters (RAD-60S, RADOS Technology, Oy, Finland). We assessed the homogeneity and reproducibility of the printing to ensure reliable printing of the desired uptake distributions.
Table 1 Parameters used for the acquisition and reconstruction of PET scans
The printing, assembling and scanning of the SS phantom took approximately 80 min for each experiment. This included (a) filling the cartridge (10 min), (b) leaving the contents of the cartridge to homogenize (10 min), (c) printing (30 min), (d) assembling (20 min) and (e) scanning (10 min). The whole body radiation dose to the operator for one session with a single scan was 4 μSv.
Printing quality
To assess the printing homogeneity, we printed two 30 mm × 200 mm stripes with a mixture of black ink and radiotracer along both width and length of an A4 paper. The number of counts was measured along these stripes, using thin layer chromatography (TLC) (iScan, Canberra, Uppsala, Sweden) at a speed of 1 mm/s.
The printing reproducibility was assessed using a 100 × 100 mm homogeneous square. This was printed with the same grey level and radioactive ink mixture 66 consecutive times. The phantom obtained by stacking these printouts was then scanned, and the resulting PET image was analysed. A region of interest (ROI) positioned at the centre of each square was reproduced on 60 consecutive slices (the superior and inferior edges of the phantom were excluded) of the PET image and the mean intensity of each ROI was measured.
Printer calibration
Additional experiments aimed at determining the relationship between grey levels specified to the printer and obtained on the PET image and derive an adequate calibration to ensure that the desired tissue uptake ratios were carried out. In this case, ten grey levels ranging from 10 to 100 % of the maximum printed intensity were defined and for each grey level, a 140 mm × 160 mm homogeneous rectangle was printed five times with the same mixture of black ink and 18F-FDG. The paper was weighed before and after printing to measure the amount of ink added by the printer. The weight of ink printed for each grey level, averaged over the five instances, was then plotted against the grey-level values specified. Furthermore, 20 distinct homogeneous 30 mm × 30 mm squares of grey-level values evenly spaced within 5 and 100 % were printed with the radioactive ink mixture. The number of counts detected across the different rectangles was then measured using the iScan TLC. Correction for radioactive decay was applied to compare all readings at the same time point. This process was repeated with three different activity concentrations in the ink at the time of measurement corresponding to different volumes of black ink added to 2 mL of the same radiotracer solution. The relationship between counts and the amount of ink printed on the paper was then derived.
In all experiments, the accuracy of the paper positioning in the phantom was assessed using radioactive cross-shaped markers printed at the top (T), left (L) and right (R) of the printout. The markers' position on the acquired PET image was determined for each slice, as the highest intensity voxel in a 5 × 5 voxel square drawn around the imaged marker. For each one of the T, L and R markers, the difference in positioning with the average marker position was measured.
Generation of realistic 3D uptake maps
A first uptake map was generated to model six spherical tumours of diameters 10, 13, 17, 22, 28 and 38 mm, named S1, S2, S3, S4, S5 and S6, respectively, with two levels of intensity, with the difference between the highest (central) uptake and lowest uptake equal to the difference between the lowest tumour uptake and background. This uptake pattern is shown on Fig. 2b. The methods described in the next section were applied to the six images obtained.
Modelled tumour patterns shown in a transverse slice of the irregular lesion. a Homogeneous. b 2-level uptake. c Gaussian. d Necrotic. e Necrotic Gaussian
We further aimed at using the printed SS phantom to generate realistic irregular and heterogeneous target lesions. For this purpose, a clinical tumour outline was extracted from an available H&N PET/CT scan using manual delineation. The background uptake was modelled by segmenting normal anatomical structures on the CT scan and assigning to each structure a grey-level value corresponding to its mean 18F-FDG uptake, measured on the PET image. Ellipsoidal outlines were also used for different experiments at the same locations as the irregular tumour outlines on the background printout template. These target lesions were modelled with a volume of 11 mL, which is large enough to allow better investigation of highly heterogeneous uptake patterns, such as necrotic centres encountered in large lymph nodes. The different images printed corresponded to the background image, in which one of the volumes (irregular tumour or ellipsoid) was inserted with a grey-level value representing the desired 18F-FDG uptake. The resulting templates were resampled to 2-mm slices in the superior-inferior direction of the H&N scan, in order to match the thickness of the PMMA sheets. This process allowed the retrieval of the modelled tumour contour from the final printout template, providing a ground truth for the evaluation of segmentation results on the PET image. Various tumour uptake distributions of the irregular and ellipsoidal lesions were modelled for a tumour-to-background ratio (TBR) of 4. These are shown for the irregular lesion on Fig. 2. The different uptake patterns included:
Homogeneous uptake
Two-level uptake as described above for the spherical lesions (only used for the irregular lesion)
Heterogeneous Gaussian smoothed uptake: addition to the background uptake map of a homogeneous uptake smoothed with a Gaussian filter to model higher uptake at the centre
Necrotic: homogeneous high uptake with no uptake at the centre of the tumour
Necrotic Gaussian: necrotic uptake smoothed with a Gaussian filter
The phantoms obtained for each case were scanned with an activity concentration in the cartridge of about 6000 kBq/mL, as this provided a PET image with activities corresponding to the original PET scan.
Evaluation of PET-AS methods
In order to evaluate the performance of state-of-the-art PET-AS methods on heterogeneous target objects of complex geometry, we selected four advanced PET-AS approaches (Table 2) from the recent literature to represent some of the categories described by Bankman et al. [19]. One or more custom implementation of these approaches was written and optimised in house into a common framework using the Matlab package, with the Image Processing Toolbox available for testing. All approaches were implemented as fully automatic 3D algorithms except for WT, since previous work had shown better performance when implemented in 2D [20, 21]. The resulting segmentation methods have been described in more details in the previous work [22]. The clustering approach was implemented for a total number of clusters ranging between 2 and 8, leading to PET-AS methods named GCM2, GCM3, GCM4, GCM5, GCM6, GCM7 and GCM8 in this work. Each of these individual clustering algorithms identifies the lowest intensity cluster as the background and the remaining clusters as the tumour in a final step and provides a single contour for the tumour. This method is used because the aim of the segmentation in this study is to identify the whole lesion outline and because no heterogeneities are modelled in the close neighbourhood of the lesions.
Table 2 Description and name of PET-AS methods used in this study. The references correspond to recent publications using similar PET-AS algorithms
The resulting ten PET-AS methods were applied for all target lesions to the region of the original scan corresponding to an extension of 10-mm margin of the true contour's bounding box. The segmentation accuracy of each PET-AS was assessed by comparing the contour obtained to the true contour (extracted from the printout template) using the dice similarity coefficient (DSC) [23] which quantifies the similarity between reference and evaluated volume returning a score between 0 and 1. We used a DSC above 0.7 as an indicator of good overlap:
$$ \mathrm{D}\mathrm{S}\mathrm{C}=\frac{2*\left|A{\displaystyle \cap }B\right|}{\left|A\right|+\left|B\right|} $$
where A is the set of voxels in the reference volume and B is the set of voxels in the evaluated volume.
In addition, the sensitivity (S) and positive predictive value (PPV) were calculated with the following equations:
$$ S=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{F}\mathrm{N}}=\frac{A{\displaystyle \cap }B}{A} $$
$$ \mathrm{P}\mathrm{P}\mathrm{V}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{F}\mathrm{P}}=\frac{A{\displaystyle \cap }B}{B} $$
with TP the true positives (voxels accurately classified), FN the false negatives (voxels in true contour A not included in B) and FP the false positives (voxels in contour B not included in true contour A).
For comparison purposes, the performance of the PET-AS methods was also evaluated using the commonly used NEMA IEC body phantom with spherical plastic inserts. In particular, the results obtained for the irregular lesion which had a volume of 5.9 mL were compared with the segmentation results obtained for the 5.6 mL sphere of the NEMA IEC body phantom scanned at a TBR of 4.
In the homogeneity test, the number of counts measured with the TLC along the stripes of paper printed in both directions was within ± √ μ (with μ as the mean value measured). This is in line with a Poisson distribution expected for the decay of 18F atoms. The resulting curves followed a horizontal trend, showing that there was no variation in the number of counts across the stripes.
For the 60 ROIs drawn on consecutive slices corresponding to the same homogeneous grey-level square, the average difference to the mean ROI value was 4.2 %, with a variation range of 0.27–12.8 %.
Figure 3a shows an example of the grey-level pattern printed and scanned in this experiment. Figure 3b shows the non-linear relationship linking the grey levels specified and the amount of ink deposited on the paper when printing with a mixture of black ink and 18F-FDG. The curve was best fitted to a third-degree polynomial (R 2 > 0.99). The corresponding equation was used to transform grey-level values specified to the amount of ink deposited on the paper. Figure 3c shows the relationship linking the amount of ink deposited on the paper and the number of counts measured from the grey-level ROIs, for the three activity concentrations considered. The combined data obtained for all activity concentrations showed a good fit to a linear curve (R 2 > 0.98).
a Example of grey-level patterns printed and associated PET image with ROIs, b average measured weight of deposited ink and associated standard deviations, c average ROI measured counts for printing with black ink and 18F-FDG
The error in the position of the alignment markers, measured on the PET images at three different locations in the image, was systematically smaller than 2.3 mm, which corresponds to a displacement of one voxel. This was expected since the measurements were made on the PET image and were therefore limited by the voxel size. No systematic error was observed.
Figure 4a, b shows a sagittal view of the images obtained with the printed SS phantom modelling a homogeneous irregular and spheroidal H&N lesion, respectively. A total of nine test images were obtained for the spheroidal and irregular lesions modelled with four and five different uptake distributions. Figure 4c depicts a necrotic spheroidal lesion. The corresponding ground truth contour is shown in black.
Sagittal view of the images obtained with the printed SS phantom for a the irregular homogeneous lesion, b the spheroidal homogeneous lesion and c the necrotic spheroidal lesion
Figure 5 depicts the DSC values obtained by the different PET-AS methods when delineating spheres S1–S6 modelled with a two-level uptake. The corresponding S and PPV are given in Table 3. It can be noticed that binary methods such as AT, RG and WT failed to accurately delineate the largest sphere (DSC<0.6). The DSC values of these binary methods decreased with sphere size, which was correlated to a low S value. On the other hand, PPV for these methods was higher than 0.9 for all spheres larger than S2. The GCM method reached DSC values close to 0.9 for S6, when used with 7 clusters. In the case of small spheres, the accuracy of GCM was higher for small numbers of clusters. When increasing the sphere size, the DSC obtained with GCM was gradually higher for larger numbers of clusters. This was due to (a) decreased S of methods with small number of clusters and (b) increased PPV with sphere size for methods with larger number of cluster. The optimal number of clusters to use was 3, 2, 5, 5, 6 and 7 for spheres S1, S2, S3, S4, S5 and S6, respectively. Following these results and since the lesion size in the next experiments was smaller than 11.5 mL, we used a maximum of 6 clusters with the GCM method in the rest of the work.
DSC obtained by the PET-AS methods for 6 spheres modelled with a two-level uptake
Table 3 S and PPV obtained by the PET-AS methods for 6 spheres modelled with 2 uptake levels
Figure 6 shows the accuracy (DSC) obtained by the different PET-AS methods listed in Table 2 when delineating the irregular lesion modelled with the printed SS phantom, with the results obtained for the 5.6 mL sphere of the NEMA IEC body phantom shown for comparison. The error bars represent the estimated error on the DSC due to errors in the experimental setup. In particular, the reproducibility error in the measurement of the activity injected in the phantom or the cartridge was within 2 % of the true value according to standard calibration test carried out in our centre. Consequently, the error bars were derived as ±4 % of the value of (1−DSC), to account for the fact that the most accurate methods are expected to be the least sensitive to variations in the TBR and image quality. Lower accuracy was obtained for the irregular lesion compared to the NEMA sphere for all methods except GCM3. Differences were larger than the 4 % error estimate for all methods except AT and GCM3, with the largest differences observed for the remaining clustering (GCM) methods and WT (68 % difference). The accuracy of GCM versions peaked for an optimal number of clusters, which was 4 in the case of the NEMA sphere and 3 for the irregular lesion.
Comparison of DSC values obtained for each PET-AS method tested on the regular NEMA sphere S5 and H&N irregular lesion of same volume. The error bars represent an estimate of the effect of the experimental error on DSC
Figure 7a shows the DSC values obtained by the different PET-AS methods for the spheroidal lesion. The corresponding S values and PPV are given in Table 4. For the non-necrotic uptake distributions (homogeneous and Gaussian), DSC values were within 5 % of each other for all methods except for GCM with more than 3 clusters. The DSC values for non-necrotic uptake obtained by AT, RG, GCM2 and GCM3 were also within 5 % of each other and within 10 % of the values obtained by WT. These high DSC values (DSC>0.8) were linked to S values higher than 0.9 for WT, PPV values higher than 0.9 for AT, and PPV and S values just below 0.9 for RG. GCM methods had increasing S and decreasing PPV with an increasing number of clusters. For necrotic lesions, differences between DSC values reached by the different methods were as high as 25 %. The S for necrotic lesions was higher than 0.9 for the necrotic uptakes, with a PPV lower than 0.7 for all methods except AT. The accuracy of GCM versions peaked at 3, 4 and 2 clusters for homogeneous, Gaussian and necrotic uptakes, respectively. The difference between DSCs obtained by the different GCM methods was largest for necrotic uptakes and smallest for the Gaussian uptake.
DSC obtained by the PET-AS tested with different uptake patterns for a the spheroidal lesion and b the heterogeneous lesion
Table 4 S and PPV obtained by the PET-AS methods for the spheroidal and irregular H&N lesion for different uptake patterns (cf. Fig. 7)
Figure 7b shows the DSC values obtained by the different PET-AS methods tested for the segmentation of the irregular lesion. S values and PPV are shown in Table 4. Large differences in accuracy between PET-AS methods are visible, with AT performing 8 and 22 % better than RG and WT, respectively, for homogeneous uptake. Again, the DSC values reached for the GCM methods varied between the different versions implemented for 2 to 6 clusters. This effect was larger than for spheroidal lesions, particularly for non-necrotic uptakes, and was largest for necrotic uptakes. Method GCM3 achieved the highest DSC for all uptake distributions. The S was high (S>0.9) for all uptakes except the Gaussian uptake. PPVs were remarkably lower than for the spheroidal lesion, except for GCM3, and were particularly low for binary methods for highly heterogeneous (two-level and necrotic) uptakes. The largest drop in DSC between the lesions of 31 % of the value for the spheroid was obtained among the binary methods for WT for Gaussian uptake. For the GCM methods, the largest drop in DSC between the lesions was 35 % obtained for GCM3 for homogeneous uptake.
Figure 8 illustrates the fact that different methods included (RG and GCM2-6) or did not include (AT and WT) the necrotic area in the segmented contour for spheroidal lesions. This is shown with the examples of methods AT and RG. Method RG, which did include the necrotic region in the delineated volume, reached 9 and 14 % lower DSC than AT for necrotic and necrotic Gaussian uptakes, respectively, in the spheroidal lesion.
Result of the segmentation (white) of a necrotic spheroidal lesion for a AT and b RG. The black line corresponds to the reference contour
This work aimed at evaluating a variety of promising advanced PET-AS methods for segmenting target objects of complex geometry and heterogeneous or necrotic uptake. For this purpose, we have developed a printed SS phantom technique, which allows generating a physical 3D object modelling any desired tracer uptake distribution with a known ground truth, which is the printout template. The feasibility of producing radioactive two-dimensional PET sources by printing a mixture of ink and 18F-FDG had been demonstrated by Markiewicz et al. [17] previously. In this work, we have taken this idea forward by generating a 3D object from a large number of printed sheets and showed its usefulness for evaluating the performance of PET segmentation algorithms. We obtained a good homogeneity and reproducibility of the grey-level printing, with the equipment used for this work (cf. 3.A.2.). The technique was also calibrated for the accurate modelling of uptake values, to ensure that the tumour-to-tissue ratios printed corresponded to the values modelled. A non-linear relationship between the intensities specified and those measured on the PET scan was found and accounted for through a parametric calibration curve. This is in line with the observation made by Markiewicz et al. with different equipment [17], but in addition, we have also shown that this effect is due to the non-linear deposition of ink on the paper. The use of radioactive cross-marks printed on the paper allowed good alignment of the printouts, with small measured errors likely to be due to noise in the PET image obtained. The distance between the markers and the printout was set to 20 mm on average, to ensure that the signal from the markers did not affect the signal from the lesions or neighbouring background. The protocol and calibration procedure described in this work may be applicable to other equipment. The amount of time necessary for a single operator to prepare the phantom was small enough to allow scanning the phantom within one half-life of the 18F decay. The total exposure to the radioactive tracer for one session with a single scan was comparable to the exposure of manipulating a conventional fillable phantom.
Our phantom technique allowed modelling non-spherical target objects and large heterogeneities in both background and lesion, which would not have been possible in a controlled and reproducible way with a standard fillable phantom. The examples of PET images obtained given on Fig. 4 show that realistic H&N uptake modelling was achieved, without using walls to separate lesion and background 18F-FDG uptakes as in fillable phantoms. In this work, phantom production was limited to oropharynx tumours. However, a printout template could easily be derived for any other site of the body for which a CT scan is available. The printout could also be made more realistic by including a larger number of 18F-FDG uptake levels if needed.
The 15 PET scans of the printed SS phantom including both regular and irregular lesions modelled with different uptake patterns allowed a systematic evaluation of the advantages and disadvantage of the different PET-AS algorithms. Binary methods AT, RG and WT, as well as GCM2 clearly lacked sensitivity for the highly heterogeneous spheres (cf. Fig. 5 and Table 3). In these heterogeneous cases, the methods only delineated the high uptake level in the lesion. This can be sufficient when delineating a tumour subvolume for dose escalation. However, our data shows that multiple clustering methods may be preferred when delineating the whole PET-avid tumour. This lack of sensitivity was not observed for the irregular lesion, even when modelled with two uptake levels. In this case, the smaller size of the lesion and its irregular contours had a larger impact than the heterogeneous uptake and led to high S values and low PPVs for the binary methods (cf. Table 4).
Table 3 also showed that GCM increased in sensitivity (and decreased in PPV) with increasing numbers of clusters, which was observed for spheroidal and irregular modelled H&N lesions as well (cf. Fig. 7 and Table 4). This is due to the inclusion of more clusters in the tumour contour when a higher number of clusters is used in the algorithm. Our results are in line with work by Hatt et al. [2] which showed the superiority of their clustering algorithm using 3 clusters compared to binary segmentation in the case of heterogeneous lesions. Hatt et al.'s method still differs from GCM in that it uses fuzzy levels and a variety of cluster intensity distribution models, which may explain their use of only 3 hard classes. The images obtained with our printed SS phantom showed the need to use of a number of clusters higher than 2 for heterogeneous lesions to delineate the whole tumour and allowed us to identify the optimal number of clusters to apply in different cases.
The comparison between the segmentation of the irregular lesion modelled with homogeneous uptake and the sphere from the NEMA IEC body phantom (cf. Fig. 6) showed a visible decrease in performance of all segmentation methods. This can be explained by the more complex geometry and by the absence of plastic walls in the printed SS phantom. In fact, we have previously shown that inactive walls lead to a lower activity recovery [9, 20, 24] and can influence the accuracy of image segmentation. The comparison of spheroidal and irregular lesions (cf. Fig. 7, Tables 3 and 4) showed that larger differences in accuracy between methods as well as between uptake patterns for the same method could be observed when testing the method on the smaller and irregular lesions. Our data also highlighted the robustness of the AT method to lesion geometry (Fig. 6) and to necrotic areas in the tumour (Fig. 7, Tables 3 and 4) compared to the other binary methods. This may be due to the fact that AT does not include any spatial connectivity aspect in the segmentation, compared to methods using the region-growing process which penalises complex shapes for RG and WT.
In the case of large necrotic lesions, our results showed that some PET-AS methods generated a volume enclosing the central necrotic region in the final contour, while others (AT and WT) did not include this region, and considered it as part of the background (cf. Fig. 8). In this work, we decided not to include the necrotic volume in the ground truth contour and evaluated the performance of the PET-AS algorithms accordingly. Although no uptake was modelled in the necrotic area, the PET intensity was similar to the background intensity due to noise and spill-out effects. This led to low PPV for the methods including the necrotic area, while PPV for AT remained above 0.6 (cf. Table 4). For RG, this can be explained by the growing process used with one seed only, searching for neighbouring voxels in all directions, and making the method unable to delineate annular shapes. GCM used with more than 3 clusters also included the necrotic area, because the large number of clusters, inadequate for such a homogeneous tumour (when excluding the necrotic centre), makes it likely to add low uptake regions to the tumour.
It should be noted that although we covered a wide range of different segmentation methods, more advanced PET-AS algorithms could be evaluated using the printed SS technique presented in this work. In particular the use of image pre-processing tools to denoise and deblur PET images as suggested by Geets et al. [25] and the application of other recently published promising methods such as GMM [26] and FLAB [27, 28] could provide and even more exhaustive set of data in evaluating the performance of PET-AS methods in delineating heterogeneous and irregular lesions.
This study was conducted using the acquisition and scanning parameters routinely used for clinical scans at our centre so that the results could be readily applicable to routine clinical practice. Parameters such as image noise, reconstruction voxel size, post-filtering and TOF correction have been shown in previous studies [29, 30] to have a potentially important impact on image segmentation. Since this work mainly focused on the use of a novel printed SS phantom technique to produce realistic heterogeneous and irregular lesions, we did not evaluate the dependence of the performance of each PET-AS method with image noise and other parameters used in image reconstruction. This topic could be the subject of future work using the printed SS phantom technique.
The flexibility in the design of 18F-FDG uptake patterns provided by the printed SS phantom allowed lesions to be represented with any geometry or uptake distribution, modelling heterogeneities, necrotic regions and, theoretically, microscopic tumour extension. Our work has shown the information that can be extracted using such images compared to homogeneous spherical uptake images. This is a key advantage, in the light of recent studies showing the high impact of segmentation inaccuracies on the dosimetry during radiotherapy treatment in the case of heterogeneous or low intensity lesions [4]. The printed SS phantom technique could be used for many other applications beyond the evaluation of PET segmentation algorithms, such as the assessment and characterisation of combined PET and computed tomography (CT) scanners and the investigation of PET-reconstruction and post-processing methods. Although 3D printing of hollow objects has been used to produce patient-specific plastic inserts [31], such techniques did not provide any flexibility in modifying the phantom and do not allow modelling any heterogeneity as was done in this study. In addition, the printed SS phantom does not use any physical separation (i.e. plastic walls) between the model tumour and background uptake in the transverse plane, which makes it again more realistic than the use of fillable inserts. Although we have shown that the printed SS phantom can be extremely useful in generating realistic target images for segmentation evaluation purposes, the current technique may not yet be adequate for fully quantitative studies. The presence of plastic sheets limits the modelling to details larger than 2 mm in superior-inferior direction, and the scatter and attenuation properties of the plastic, which is the main material in the phantom, do not currently allow modelling human tissue appropriately. The use of a 3D printer to generate PET phantoms was investigated by Miller et al. [32], but the authors acknowledge that the technique does not currently allow printing non-uniform areas of tracer uptake. Work is in progress at our centres to further develop the technique to make it applicable to other quantitative studies.
This work presents a novel phantom technique for the evaluation the performance of PET auto-segmentation methods in delineating heterogeneous and irregular lesions. We developed a method to print a subresolution sandwich phantom with radioactive 18F-FDG maps. We have shown that our method can be successfully used to design, print and acquire PET images of complex and realistic H&N uptake with ground truth data. We have also demonstrated the usefulness of the printed subresolution sandwich phantom technique in assessing the performance of advanced PET automatic segmentation methods when delineating target objects with highly heterogeneous uptake and complex geometry. The printed subresolution sandwich phantom technique has the potential of playing a key role in future 3D quantitative methods in radionuclide imaging.
Nestle U, Kremp S, Schaefer-Schuler A, Sebastian-Welsch C, Hellwig D, Ru C. Comparison of different methods for delineation of 18F-FDG PET-positive tissue for target volume definition in radiotherapy of patients with non-small cell lung cancer. J Nucl Med. 2005;46(8):1342–8.
Hatt M, Cheze le Rest C, Descourt P, Dekker A, De Ruysscher D, Oellers M, et al. Accurate automatic delineation of heterogeneous functional volumes in positron emission tomography for oncology applications. Int J Radiat Oncol Biol Phys. 2010;77(1):301–8.
Cheebsumon P, Yaqub M, van Velden FHP, Hoekstra OS, Lammertsma AA, Boellaard R. Impact of [18F]FDG PET imaging parameters on automatic tumour delineation: need for improved tumour delineation methodology. Eur J Nucl Med Mol Imaging. 2011;38:2136–44.
PubMed Central PubMed Article Google Scholar
Le Maitre A, Hatt M, Pradier O, Cheze-le Rest C, Visvikis D. Impact of the accuracy of automatic tumour functional volume delineation on radiotherapy treatment planning. Phys Med Biol. 2012;57(17):5381–97.
(NEMA) National Electrical Manufacturers Association, Performance measurements of scintillation cameras, Washington DC. Standards Publication No NU1. Wasgington, DC: National Electrical Manufacturers Association; 2001
J. A. Siegel, A. R. Benedetto, R. J. Jaszczak, J. L. Lancaster, M. T. Madsen, W. W. Woodsen, and R. E. Zimmerman, Rotating scintillation camera SPECT acceptance testing and quality control. AAPM report no. 22. NY, New York: American Institute of Physics; 1987
Berthon B, Marshall C, Evans M, Spezi E. Evaluation of advanced automatic PET segmentation methods using non-spherical thin-wall inserts. Med Phys. 2014;41(2):022502.
T. G. Turkington, T. R. Degrado, W. H. Sampson, Small spheres for lesion detection phantoms, in IEEE Nucl. Sci. Symp. Conf. Rec. 2001, 4, pp. 2234–2237.
Bazañez-Borgert M, Bundschuh R a, Herz M, Martínez M-J, Schwaiger M, Ziegler SI. Radioactive spheres without inactive wall for lesion simulation in PET. Z Med Phys. 2008;18(1):37–42.
Drever L a, Roa W, McEwan A, Robinson D. Comparison of three image segmentation techniques for target volume delineation in positron emission tomography. J Appl Clin Med Phys. 2007;8(2):93–109.
Nehmeh SA, El-Zeftawy H, Greco C, Schwartz J, Erdi YE, Kirov A, et al. An iterative technique to segment PET lesions using a Monte Carlo based mathematical model. Med Phys. 2009;36(10):4803.
Zito F, De Bernardi E, Soffientini C, Canzi C, Casati R, Gerundini P, et al. The use of zeolites to generate PET phantoms for the validation of quantification strategies in oncology. Med Phys. 2012;39(9):5353–61.
Shepherd T, Teras M, Beichel R, Boellaard R, Bruynooghe M, Dicken V, et al. Comparative study with new accuracy metrics for target volume contouring in PET image guided radiation therapy. IEEE Trans Med Imaging. 2012;31(11):2006–24.
P. Tylski, G. Bonniaud, E. Decencière, J. Stawiaski, J. Coulot, and D. Lefkopoulos, F-FDG PET images segmentation using morphological watershed : a phantom study, Nucl. Sci. Symp. Conf. Rec. 2006, IEEE, vol. 4. IEEE, pp. 2063–2067, 2006
Larsson SA, Jonsson C, Pagani M, Johansson L, Jacobsson H. A novel phantom design for emission tomography enabling scatter- and attenuation-'free' single-photon emission tomography imaging. Eur J Nucl Med. 2000;27(2):131–9.
Sossi V, Buckley KR, Piccioni P, Rahmim A, Member S, Camborde M, et al. Printed sources for positron emission tomography. IEEE Trans Nucl Sci. 2005;52(1):114–8.
Markiewicz PJ, Angelis GI, Kotasidis F, Green M, Lionheart WR, Reader AJ, et al. A custom-built PET phantom design for quantitative imaging of printed distributions. Phys Med Biol. 2011;56(21):N247–61.
Holmes RB, Hoffman SMa, Kemp PM. Generation of realistic HMPAO SPECT images using a subresolution sandwich phantom. Neuroimage. 2013;81:8–14.
Bankman I. Handbook of medical image processing and analysis. Part II. Segmentation. Baltimore, MD, USA: Academic; 2000.
B. Berthon Optimisation of positron emission tomography segmentation for head and neck radiotherapy treatment planning. PhD thesis, Cardiff University, Cardiff, UK, 2015
Ray S, Hagge R, Gillen M, Cerejo M, Shakeri S, Beckett L, et al. Comparison of two-dimensional and three-dimensional iterative watershed segmentation methods in hepatic tumor volumetrics. Med Phys. 2008;35(12):5869–81.
Berthon B, Marshall C, Edwards A, Evans M, Spezi E. Influence of cold walls on PET image quantification and volume segmentation. Med Phys. 2013;40(8):1–13.
Dice L. Measures of the amount of ecologic association between species. Ecology. 1945;26:297–302.
Hofheinz F, Dittrich S, Potzsch C, van den Hoff J. Effects of cold sphere walls in PET phantom measurements on the volume reproducing threshold. Phys Med Biol. 2010;55(4):1099–113.
Geets X, Lee J a, Bol A, Lonneux M, Grégoire V. A gradient-based method for segmenting FDG-PET images: methodology and validation. Eur J Nucl Med Mol Imaging. 2007;34(9):1427–38.
Aristophanous M, Penney BC, Martel MK, Pelizzari CA. A Gaussian mixture model for definition of lung tumor volumes in positron emission tomography. Med Phys. 2007;34(11):4223.
Hatt M, Cheze C, Turzo A, Roux C, Oncology IT. A fuzzy locally advanced bayesian segmentation approach for volume determination in PET. IEEE Trans Med Imaging. 2009;28(6):881–93.
E. De Bernardi, C. Soffientini, F. Zito, and G. Baselli, Joint segmentation and quantification of oncological lesions in PET/CT: preliminary evaluation on a zeolite phantom, presented at Anaheim, USA 2012 IEEE Nuclear Science Symposium and Medical Imaging Conference Record (NSS/MIC), 2012, no. 1, pp. 3306–3310.
Daisne J-F, Sibomana M, Bol A, Doumont T, Lonneux M, Grégoire V. Tri-dimensional automatic segmentation of PET volumes based on measured source-to-background ratios: influence of reconstruction algorithms. Radiother Oncol. 2003;69(3):247–50.
Hatt M, Cheze Le Rest C, Albarghach N, Pradier O, Visvikis D. PET functional volume delineation: a robustness and repeatability study. Eur J Nucl Med Mol Imaging. 2011;38(4):663–72.
Gear JI, Long C, Rushforth D, Chittenden SJ, Cummings C, Flux GD. Development of patient-specific molecular imaging phantoms using a 3D printer. Med Phys. 2014;41(8):082502.
Miller M a, Hutchins GD. Development of anatomically realistic PET and PET/CT phantoms with rapid prototyping technology. IEEE Nucl Sci Symp Conf Rec. 2007;2007:4252–7.
The authors acknowledge Dr Sudar Jayaprakasam's input in the design of the H&N template and lesions.
This work was carried out as part of the POSITIVE project (Optimization of Positron Emission Tomography based Target Volume Delineation in Head and Neck Radiotherapy), which is funded through Cancer Research Wales grant No. 7061.
Wales Research and Diagnostic Positron Emission Tomography Imaging Centre, Cardiff University - PETIC, room GF705 Ground floor 'C' Block, Heath Park, CF14 4XN, Cardiff, UK
B Berthon & C Marshall
Department of Medical Physics and Bioengineering, University Hospitals Bristol, BS2 8HW, Bristol, UK
R Holmes
School of Engineering, Cardiff University, Cardiff, Wales, UK
E Spezi
B Berthon
C Marshall
Correspondence to B Berthon.
RH developed the concept of radioisotope printing, provided the equipment and participated in the acquisition of the data. BB carried out the experimental set-up, data acquisition and analysis. ES and CM participated in the development of the concept and data analysis. All authors read and approved the final manuscript.
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (https://creativecommons.org/licenses/by/4.0), which permits use, duplication, adaptation, distribution, and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Berthon, B., Marshall, C., Holmes, R. et al. A novel phantom technique for evaluating the performance of PET auto-segmentation methods in delineating heterogeneous and irregular lesions. EJNMMI Phys 2, 13 (2015). https://doi.org/10.1186/s40658-015-0116-1
18F-fluorodeoxyglucose
Imaging phantoms
Image segmentation | CommonCrawl |
•https://doi.org/10.1364/OL.446534
Resonance-order-dependent plasmon-induced transparency in orthogonally arranged nanocavities
Naoki Ichiji and Atsushi Kubo
Naoki Ichiji1 and Atsushi Kubo2,*
1Graduate School of Pure and Applied Sciences, University of Tsukuba, 1-1-1 Tennodai, Tsukuba-shi, Ibaraki 305-8573, Japan
2Faculty of Pure and Applied Sciences, University of Tsukuba, 1-1-1 Tennodai, Tsukuba-shi, Ibaraki 305-8573, Japan
*Corresponding author: [email protected]
Naoki Ichiji https://orcid.org/0000-0001-5910-2405
Atsushi Kubo https://orcid.org/0000-0003-2151-5081
N Ichiji
A Kubo
Naoki Ichiji and Atsushi Kubo, "Resonance-order-dependent plasmon-induced transparency in orthogonally arranged nanocavities," Opt. Lett. 47, 265-268 (2022)
Tunable and switchable bifunctional meta-surface for plasmon-induced transparency and perfect...
Shuaizhao Wang, et al.
Opt. Mater. Express 12(2) 560-572 (2022)
Photochromic switching of narrow-band lattice resonances
Shuai Chen, et al.
Opt. Lett. 47(2) 337-340 (2022)
Effect of roughness on surface plasmons propagation along deep and shallow metallic diffraction...
Hugo Bruhier, et al.
Plasmonics and Optics at Surfaces
Effective refractive index
Nanocavities
Resonant modes
Original Manuscript: October 24, 2021
Revised Manuscript: December 3, 2021
Manuscript Accepted: December 13, 2021
We investigate plasmon-induced transparency (PIT) in a resonator structure consisting of two orthogonally arranged metal-insulator-metal nanocavities. Finite–difference time– domain simulations reveal that when both cavities in this structure resonate at the same frequency, the PIT effect can be used to induce spectral modulation. This spectral modulation depends on the resonance order of the cavity coupled directly to the external field, as it occurs when first-order resonance is exhibited but not with second-order resonance. We confirmed that this behavior is caused by the discrepancies between odd-order and even-order resonances using classical mechanical models analogous to nanocavities. By tuning the resonance frequency and resonance order of the cavities, one can modulate the spectrum of the resonator structure in an order-selective manner. The resonant order-dependent PIT provides insight into the development of metamaterials that function only at specific resonant orders for incident waves of various bands.
© 2022 Optica Publishing Group under the terms of the Optica Open Access Publishing Agreement
The creation of metamaterials composed of engineered nanoscale resonator structures (also known as meta-atoms) has led to significant advances in optical manipulation [1]. The control of optical properties enabled by metamaterials is one of the foundations for controlling light in free space and of surface plasmon polaritons (SPPs) [2,3]. The unique properties of metamaterials are attributed to the dispersion relations near the resonant frequencies of the meta-atoms. The development of modulation techniques and explanation of the resonant spectrum of meta-atoms are fundamental topics in the study of metamaterials. The resonant wavelengths of many meta-atoms, such as Fabry–Pérot-type resonators, are due to the reflection of free electrons or SPPs at their physical boundaries [4]. When the incident wave has a broad spectral range, resonance spectra exhibit multiple peaks originating from multiple resonance orders [5]. However, as it is difficult to suppress or modulate resonances of a specific order exclusively, the working band of a metamaterial is limited to the resolution of the constituent meta-atoms.
The electromagnetically induced transparency (EIT) effect is a quantum phenomenon that arises from the interference between different excitation pathways in a three-level atomic system. An EIT-like effect known as plasmon-induced transparency (PIT) [6,7] can be used to modulate the spectrum of a plasmonic resonator. As it is a plasmonic analog of EIT, PIT occurs due to the interference between plasmonic structures with electric or magnetic resonances [8–10]. The coupling between the resonator excited directly by external light (the bright resonator) and the indirectly excited resonator (the dark resonator) generates significant modulation in the resonance spectrum [11–13]. Owing to its large spectral modulation effect and high sensitivity, the PIT phenomenon has been applied in many fields, such as slow-light generation [14], sensing [15], and waveguide development [16].
In this study, we investigate the resonance interaction between the two metal-insulator-metal (MIM) cavities in an orthogonally arranged resonator structure to realize spectral modulation depending on the resonance order. Only one of the cavities in this structure is directly excited by SPP wave packets (WPs), which are injected next to the resonator structure on the metal surface. This cavity thus functions as a bright resonator directly coupled to the external field, while the other cavity functions as a dark resonator that is excited indirectly via the bright resonator. A finite–difference time–domain (FDTD) simulation revealed that the spectral modulation due to the PIT phenomenon, which occurs when the two cavities have similar resonance wavelengths, depends on the resonance order of the bright resonator. The mode-splitting characteristic of PIT was observed when the bright resonator exhibited first-order resonance, while the modulation of spectral shape was dependent on the resonance wavelength of the dark resonator. Conversely, no mode splitting was observed when the bright resonator exhibited a second-order resonance, and the effect of the dark resonator on the resonance spectrum was marginal. Analysis of a classical mechanical model analogous to the nanocavities confirms that the difference in the symmetry of the magnetic distribution of the bright resonator induces the order-dependent PIT phenomenon. We believe that explaining the order-selective PIT phenomenon by modeling the effect of spatial symmetry on resonance–order–dependent mode couplingprovides insights into advanced optical control with structures that combine multiple resonators.
Figure 1(a) shows a schematic of the resonator structure studied in this work, as defined in the FDTD simulation. A commercial FDTD software package (FDTD Solution, Lumerical, Inc.) was used for all simulations. Here, we placed a Au block on an Al2O3 (thickness a: 16 nm)/Au (thickness t: 100 nm) layer to form an open-ended horizontal MIM cavity (hereafter called the "open cavity") [17,18]. The resonant modes of this open cavity are given by the following equation [5,18,19]:
(1)$$L{k_0}{n_{OC}} + {\phi _{OC}} = N\pi ,$$
where k0 is the vacuum wavenumber, nOC is the real component of the effective refractive index of the MIM nanocavity, N is the integer defining the order of the resonant mode, and ϕOC is the additional phase shift resulting from the opening edge. A thinner a provides a larger nOC [18]. We used values of a and L such that the open cavity exhibited first- and second-order resonances in the near-infrared region.
Fig. 1. Schematic of the multilayered structure used in the FDTD simulation. (a) Illustration of the orthogonally arranged resonator and individual cavities. (b) Illustration of the resonator in the simulation area.
We defined the second cavity by cutting a narrow slit of width w and depth d into the Au block. Thus, the Au block had the same geometry as a U-shaped resonator, which is a typical magnetic resonator structure [20,21]. When the slit width of this structure is sufficiently thin, it can be regarded as a half-closed MIM nanocavity (hereafter termed the "closed cavity") [19,22,23]. The resonant mode for the closed cavity is given by the following equation [19]:
(2)$$d{k_0}{n_{CC}} + {\phi _{CC}} = \left( {N - \frac{1}{2}} \right)\pi ,$$
where nCC is the real component of the effective refractive index of the closed MIM nanocavity and ϕCC is the additional phase shift resulting from the opening edge. From Eqs. (1) and (2), the resonance frequency of each cavity is connected either to the cavity length L or the slit depth d. Therefore, the resonance wavelengths of the two cavities constituting the resonator can be defined independently.
We placed an Au ridge structure 25 μm from the resonator [Fig. 1(b)], to act as an SPP excitation source. SPP WPs with a broad spectral range were excited by injecting the ridge with ultrashort 1.2 fs pulses with a peak wavelength of 600 nm. These WPs propagate on the metal surface, entering the open cavity from the side. In this configuration, the open cavity can be regarded as the bright resonator, as it is directly excited by the SPP WP, while the closed cavity can be regarded as the dark resonator, as it is excited indirectly via the resonance of the open cavity.
To determine the resonator's spectral response, we prepared a reference model without meta-atoms that was otherwise identical in construction to our initial model. The time evolution of the vertical component of the electric field (Ez(t)) was subsequently recorded at point P, located at the right-hand edge of the resonator structure. Then, we evaluated R(ω), the spectral response, as
(3)$$R(\omega ) = \frac{{|{F_{res}}(\omega ){|^2}}}{{|{F_{ref}}(\omega ){|^2}}},$$
where Fres(ω) and Fref(ω) are the fast Fourier transforms (FFTs) of the Ez(t) waveform recorded at point P in the resonator model and reference model, respectively.
Figure 2(a) depicts the spectra obtained for the resonator structures with L fixed at 200 nm and w fixed at 2 nm. Peaks can be observed at 1630 and 880 nm in the spectrum for a resonator with no slit in the open cavity (d = 0 nm, dashed black line), corresponding to its first and second Fabry–Perot resonant modes, respectively. As the resonance wavelength of the closed cavity is determined by slit depth, this parameter can be adjusted such that both cavities in the structure are resonant at the same wavelength. With d = 64 nm, both cavities exhibit first-order resonances at 1630 nm. Because of the resulting mode coupling, splitting can be observed in the spectrum for this structure (solid blue line). In contrast, although both cavities resonate at 880 nm with d = 22 nm, in this case the closed cavity exhibits first-order resonance while the open cavity exhibits second-order resonance. Hence, no modulation is observed in the spectrum for this structure (solid red line), which is similar in shape to the spectrum of the open cavity without a slit. The mode coupling strength between open and closed cavities varies with the distance between the two cavities. Upon lowering the height h below 100 nm and decreasing the separation of the two cavities, the dip in the resonant spectrum due to the coupling becomes more prominent, as shown in Fig. 2(b).
Fig. 2. (a) Spectral responses of orthogonally arranged resonators (L= 200 nm, h = 100 nm, and w= 2 nm) with differing slit depths. (b) Variation of the resonance spectrum with cavity height. (L = 200 nm, d = 64 nm, w = 2 nm). (c) Magnetic field (Hy) distribution in a resonator with a slit depth of 22 nm at a wavelength of 880 nm. Under these conditions, the open cavity exhibits second-order resonance while the closed cavity exhibits first-order resonance. (d) Magnetic field distribution in a resonator with a slit depth of 64 nm at a wavelength 1630 nm. Under these conditions, both cavities exhibit first-order resonance.
The magnetic distributions shown in Figs. 2(c) and 2(d) indicate that the line symmetry of the magnetic field of the open cavity with x = L/2 as an axis depends on the resonance order. The magnetic field of the open cavity is antisymmetric with respect to the closed cavity when the open cavity exhibits even-order resonance. In such cases (e.g., for second-order resonance), the magnetic field in the region of the closed cavity originating from the open cavity is canceled out, and the closed cavity is excited predominantly by diffraction from the Au block. In contrast, when the open cavity exhibits odd-order resonance, such as first-order resonance, the induced magnetic field excites the closed cavity. The mutual inductance of the magnetic fields of the open and closed cavities results in mode coupling [8].
Figures 3(a), 3(b), and 3(c) show color maps of the spectra of resonators with slit widths of 2, 4, and 6 nm, respectively. The color in these images indicates the spectral responses of the resonators, while the slit depth is given by the vertical axis. Here, h was fixed at 100 nm and L was fixed at 100 nm, such that the open cavity exhibited first-order resonance at a wavelength of 1000 nm. The dashed white lines in each graph indicate the theoretical evaluation of the resonance wavelength of the closed cavity, obtained by setting ϕCC = 0 in Eq. (2), according to the dispersion calculation for an MIM waveguide [5,18]. The three graphs show large modulations in the resonance spectra along the resonance wavelength curves, with the slope of the modulation depending on the slit width. There are shifts between the resonance curves indicated by the white lines and slit depths where the mode modulations are maximized. These shifts in the y direction are explained by the additional phase shift, ϕCC, in Eq. (2). Spectral splitting due to the mode coupling of resonators with the same resonance wavelength is a typical feature of PIT, while the calculated peak splitting is up to approximately 470 meV (w: 2 nm, d: 100 nm), which is comparable to that seen in previous studies [9,24,25]. In addition, the shift of each split peak with respect to the resonance wavelength of the dark resonator is also consistent with the study by Zhang et al. [26]. In contrast, the resonance spectrum for the structure where L = 240 nm, which exhibited second-order resonance at 1000 nm, was minimally affected by the slit depth of the closed cavity, as shown in Fig. 3(d).
Fig. 3. Variation of the resonance spectrum with slit depth for a resonator with L = 100 nm and a slit width of (a) 2 nm, (b) 4 nm, or (c) 6 nm. (d) Variation of the resonance spectrum with slit depth for a resonator with L = 240 nm and a slit width of 2 nm. The dashed white lines in these images indicate the predicted resonance wavelength of the closed cavity at the corresponding slit depth, while the shading indicates the intensity of the spectral response.
The PIT phenomenon that occurs in this structure does not depend on the resonance order of the closed cavity. Figure 3(a) confirms that there was large PIT-induced mode splitting along the second-order resonance curve at around d = 100 nm, whereas there is no mode splitting in Fig. 3(d) at the same d. The resonant order of the open cavity affects the line symmetry of the magnetic field with x = L/2 as an axis. However, the resonant order of the closed cavity does not affect the symmetry in the x direction. Therefore, the PIT phenomenon in this configuration of the resonator structure depends only on the resonant order of the open cavity.
To verify the order dependence of the spectral modulation, we constructed numerical models based on a classical mechanical analog to PIT. First, we defined a system consisting of two magnetic dipoles, each representing the open and closed cavities (PO and PC, respectively), as a model for the case where both exhibit first-order resonance ("first-order model"), as shown in Fig. 4(a). The dynamic equation for this is described by that of a system of linearly-coupled Lorentzian oscillators [6,11,26,27]:
(4)$$\left( {\begin{array}{@{}c@{}} {{P_C}}\\ {{P_O}} \end{array}} \right) = {\left( {\begin{array}{@{}cc@{}} {\omega_C^2 - {\omega^2} - i{\gamma_C}\omega }&{ - {\Omega ^2}}\\ { - {\Omega ^2}}&{\omega_O^2 - {\omega^2} - i{\gamma_O}\omega } \end{array}} \right)^{ - 1}} \times \left( {\begin{array}{@{}c@{}} {{g_C}{E_I}}\\ {{g_O}{E_I}} \end{array}} \right), $$
where c and o indicate the closed and open cavities, respectively, ωO and ωC are resonant frequencies, γ is the damping constant for a dipole, EI is the incident field, and g is a coupling constant between a dipole and the incident field. Ω is the constant for the coupling between the two dipoles.
Fig. 4. (a) and (b) Schematics of the linearly coupled Lorentzian oscillators. (a) First-order system in which both cavities exhibit first-order resonance. (b) Second-order system in which the open cavity exhibits second-order resonance. Variation in susceptibility with the resonance wavelength of the dipole corresponding to the closed cavity (Pc) calculated using the (c) first-order model and (d) second-order model.
In addition, we constructed a second-order model consisting of a single dipole representing the closed cavity (PC) and two dipoles representing the open cavity (PO1, PO2), as shown in Fig. 4(b). Here, PO1 and PO2 represent the two peaks of the magnetic distribution when the open cavity exhibits second-order resonance, as shown in Fig. 2(c). The dynamic equations for this model can be defined in a similar form to Eq. (4) as follows [28,29]:
(5)$$\begin{aligned} &\left( {\begin{array}{@{}c@{}} {{P_C}}\\ {P_{{O1}}}\\ {P_{{O2}}} \end{array}} \right) \\&\quad= {\left( {\begin{array}{@{}ccc@{}} {\omega_C^2 - {\omega^2} - i{\gamma_C}\omega }&{ - {\Omega ^2}}&{ - {\Omega ^2}}\\ { - {\Omega ^2}}&{\omega_C^2 - {\omega^2} - i{\gamma_C}\omega }&0\\ { - {\Omega ^2}}&0&{\omega_O^2 - {\omega^2} - i{\gamma_O}\omega } \end{array}} \right)^{ - 1}}\\ &\qquad\times \left( {\begin{array}{@{}c@{}} {{g_C}{E_I}}\\ {g_{{O1}}}{E_I}\\ {g_{{O2}}}{E_I} \end{array}} \right). \end{aligned} $$
Here, we set gO2, the coupling constant between PO2 and the incident field, equal to –gO1 to represent the π-phase shift between the two magnetic oscillations observed with second-order resonance. To simplify the calculation, we assume that the closed cavity is not coupled to the external field at all. Hence, gC = 0. In practice, this coupling constant would have a finite value because of diffraction over the top of the Au block. The values of the remaining parameters were defined as follows: ωO = ωO1 = ωO2 = 300 THz, γC = 25, γO = 12.5, Ω = 75, gO1 = –gO2 = 1, and EI = 1.
The susceptibility of the dipole response can be obtained from Eqs. (4) and (5), χO = PO/EI and χO1 = PO1/EI. Figures 4(c) and 4(d) show color maps of the imaginary parts of χO and χO1, representing the energy dissipation of the model. Here, the resonance wavelength of the open cavity, λO = 2πc/ωO, was fixed at 1000 nm, while the vertical axis corresponds to the resonance wavelength of the closed cavity (λC= 2πc/ωC) as determined by the slit depth. As with the FDTD simulations, mode splitting was observed with the first-order model when the resonance frequencies of the two dipoles coincided (λC = λO), and the peaks shifted according to λC. In contrast, uniform spectra were observed with the second-order model regardless of the value of ωC, as shown in Fig. 4(d). These calculation results are consistent with the FDTD simulation results shown in Fig. 2 and Fig. 3.
In conclusion, we investigated the spectral modulation of a resonator consisting of an orthogonal arrangement of two types of MIM nanocavity. FDTD simulations revealed mode splitting in the resonance spectra due to the PIT phenomenon, and peak shifts according to the resonance frequency of the cavity acting as the dark resonator. The PIT phenomenon was highly dependent on the resonance order of the cavity acting as a bright resonator. The dependence of the mode splitting and peak shift on the resonance order was confirmed using a classical mechanical model. The shape of the resonance spectrum of the resonator structure used in this study is determined by the cavity geometry, the materials used for each cavity (through the effective refractive index), the alignment of the resonator with the external field, and the distance between the cavities. This demonstrates that resonance spectra design, including the narrowing of line widths, the shifting of peak positions, and the generation of multiple peaks, can be enabled by the fabrication of composite meta-atoms consisting of bright and dark resonators. Changing the number and positions of the slits makes it possible to modulate a specific resonance order. The fabrication of the meta-atoms studied in this study could be achieved by cutting slits in a standard MIM nanocavity fabricated by the EB lithography technique using helium ion etching. In addition, the dependence of mode coupling on the mismatch between even and odd resonance orders offers the potential to modulate a specific resonant order of a meta-atom. Such meta-atoms are the building blocks of metamaterials for broadband incident waves such as femtosecond pulses and supercontinuum waves.
Ministry of Education, Culture, Sports, Science and Technology, Q-LEAP ATTO (JPMXS0118068681); Core Research for Evolutional Science and Technology (JPMJCR14F1); Japan Society for the Promotion of Science (JP18967972, JP20J21825).
The authors thank H. T. Miyazaki for advice and valuable discussions.
Data underlying the results may be obtained from the authors upon reasonable request.
1. N. Meinzer, W. L. Barnes, and I. R. Hooper, Nat. Photonics 8, 889 (2014). [CrossRef]
2. N. Yu and F. Capasso, Nat. Mater. 13, 139 (2014). [CrossRef]
3. Y. Liu, S. Palomba, Y. Park, T. Zentgraf, X. B. Yin, and X. Zhang, Nano Lett. 12, 4853 (2012). [CrossRef]
4. N. Ismail, C. C. Kores, D. Geskus, and M. Pollnau, Opt. Express 24, 16366 (2016). [CrossRef]
5. N. Ichiji, Y. Otake, and A. Kubo, Opt. Express 27, 22582 (2019). [CrossRef]
6. S. Zhang, D. A. Genov, Y. Wang, M. Liu, and X. Zhang, Phys. Rev. Lett. 101, 047401 (2008). [CrossRef]
7. R. Taubert, M. Hentschel, J. Kastel, and H. Giessen, Nano Lett. 12, 1367 (2012). [CrossRef]
8. P. C. Wu, W. T. Chen, K. Y. Yang, C. T. Hsiao, G. Sun, A. Q. Liu, N. I. Zheludev, and D. P. Tsai, Nanophotonics 1, 131 (2012). [CrossRef]
9. R. Yahiaoui, J. A. Burrow, S. M. Mekonen, A. Sarangan, J. Mathews, I. Agha, and T. A. Searles, Phys. Rev. B 97, 155403 (2018). [CrossRef]
10. M. Wan, Y. Song, L. Zhang, and F. Zhou, Opt. Express 23, 27361 (2015). [CrossRef]
11. X. Hu, S. Yuan, A. Armghan, Y. Liu, Z. Jiao, H. Lv, C. Zeng, Y. Huang, Q. Huang, Y. Wang, and J. Xia, J. Phys. D: Appl. Phys. 50, 025301 (2017). [CrossRef]
12. Z. Ye, S. Zhang, Y. Wang, Y. Park, T. Zentgraf, G. Bartal, X. Yin, and X. Zhang, Phys. Rev. B 86, 155148 (2012). [CrossRef]
13. K. M. Devi, D. R. Chowdhury, G. Kumar, and A. K. Sama, J. Appl. Phys. 124, 063103 (2018). [CrossRef]
14. B. Zhang, H. Li, H. Xu, M. Zhao, C. Xiong, C. Liu, and K. Wu, Opt. Express 27, 3598 (2019). [CrossRef]
15. N. Liu, T. Weiss, M. Mesch, L. Langguth, U. Eigenthaler, M. Hirscher, C. Sonnichsen, and H. Giessen, Nano Lett. 10, 1103 (2010). [CrossRef]
16. C. Xiong, H. Li, H. Xu, M. Zhao, B. Zhang, C. Liu, and K. Wu, Opt. Express 27, 17718 (2019). [CrossRef]
17. F. Ding, Y. Yang, R. A. Deshpande, and S. I. Bozhevolnyi, Nanophotonics 7, 1129 (2018). [CrossRef]
18. Y. Kurokawa and H. T. Miyazaki, Phys. Rev. B 75, 035411 (2007). [CrossRef]
19. H. T. Miyazaki and Y. Kurokawa, Appl. Phys. Lett. 89, 211126 (2006). [CrossRef]
20. W. L. Hsu, P. C. Wu, J. W. Chen, T. Y. Chen, B. H. Cheng, W. T. Chen, Y. W. Huang, C. Y. Liao, G. Sun, and D. P. Tsai, Sci. Rep. 5, 11226 (2015). [CrossRef]
21. J. Chen, S. Qi, X. Hong, P. Gu, R. Wei, C. Tang, Y. Huang, and C. Zhao, Results Phys. 15, 102791 (2019). [CrossRef]
22. L. Emeric, C. Deeb, F. Pardo, and J. L. Pelouard, Opt. Lett. 44, 4761 (2019). [CrossRef]
23. S. J. Park, Y. B. Kim, Y. J. Moon, J. W. Cho, and S. K. Kim, Opt. Express 28, 15472 (2020). [CrossRef]
24. K. M. Devi, A. K. Sama, D. R. Chowdhury, and G. Kumar, Opt. Express 25, 10484 (2017). [CrossRef]
25. X. Niu, X. Hu, Q. Yan, J. Zhu, H. Cheng, Y. Huang, C. Lu, Y. Fu, and Q. Gong, Nanophotonics 8, 1125 (2019). [CrossRef]
26. J. X. Zhang, J. Zhang, and Y. F. Li, Plasmonics 16, 2305 (2021). [CrossRef]
27. C. L. G. Alzar, M. A. G. Martinez, and P. Nussenzveig, Am. J. Phys. 70, 37 (2002). [CrossRef]
28. K. Zhang, C. Wang, L. Qin, R. W. Peng, D. H. Xu, X. Xiong, and M. Wang, Opt. Lett. 39, 3539 (2014). [CrossRef]
29. J. A. Souza, L. Cabral, R. R. Oliveira, and C. J. Villas-Boas, Phys. Rev. A 92, 023818 (2015). [CrossRef]
N. Meinzer, W. L. Barnes, and I. R. Hooper, Nat. Photonics 8, 889 (2014).
[Crossref]
N. Yu and F. Capasso, Nat. Mater. 13, 139 (2014).
Y. Liu, S. Palomba, Y. Park, T. Zentgraf, X. B. Yin, and X. Zhang, Nano Lett. 12, 4853 (2012).
N. Ismail, C. C. Kores, D. Geskus, and M. Pollnau, Opt. Express 24, 16366 (2016).
N. Ichiji, Y. Otake, and A. Kubo, Opt. Express 27, 22582 (2019).
S. Zhang, D. A. Genov, Y. Wang, M. Liu, and X. Zhang, Phys. Rev. Lett. 101, 047401 (2008).
R. Taubert, M. Hentschel, J. Kastel, and H. Giessen, Nano Lett. 12, 1367 (2012).
P. C. Wu, W. T. Chen, K. Y. Yang, C. T. Hsiao, G. Sun, A. Q. Liu, N. I. Zheludev, and D. P. Tsai, Nanophotonics 1, 131 (2012).
R. Yahiaoui, J. A. Burrow, S. M. Mekonen, A. Sarangan, J. Mathews, I. Agha, and T. A. Searles, Phys. Rev. B 97, 155403 (2018).
M. Wan, Y. Song, L. Zhang, and F. Zhou, Opt. Express 23, 27361 (2015).
X. Hu, S. Yuan, A. Armghan, Y. Liu, Z. Jiao, H. Lv, C. Zeng, Y. Huang, Q. Huang, Y. Wang, and J. Xia, J. Phys. D: Appl. Phys. 50, 025301 (2017).
Z. Ye, S. Zhang, Y. Wang, Y. Park, T. Zentgraf, G. Bartal, X. Yin, and X. Zhang, Phys. Rev. B 86, 155148 (2012).
K. M. Devi, D. R. Chowdhury, G. Kumar, and A. K. Sama, J. Appl. Phys. 124, 063103 (2018).
B. Zhang, H. Li, H. Xu, M. Zhao, C. Xiong, C. Liu, and K. Wu, Opt. Express 27, 3598 (2019).
N. Liu, T. Weiss, M. Mesch, L. Langguth, U. Eigenthaler, M. Hirscher, C. Sonnichsen, and H. Giessen, Nano Lett. 10, 1103 (2010).
C. Xiong, H. Li, H. Xu, M. Zhao, B. Zhang, C. Liu, and K. Wu, Opt. Express 27, 17718 (2019).
F. Ding, Y. Yang, R. A. Deshpande, and S. I. Bozhevolnyi, Nanophotonics 7, 1129 (2018).
Y. Kurokawa and H. T. Miyazaki, Phys. Rev. B 75, 035411 (2007).
H. T. Miyazaki and Y. Kurokawa, Appl. Phys. Lett. 89, 211126 (2006).
W. L. Hsu, P. C. Wu, J. W. Chen, T. Y. Chen, B. H. Cheng, W. T. Chen, Y. W. Huang, C. Y. Liao, G. Sun, and D. P. Tsai, Sci. Rep. 5, 11226 (2015).
J. Chen, S. Qi, X. Hong, P. Gu, R. Wei, C. Tang, Y. Huang, and C. Zhao, Results Phys. 15, 102791 (2019).
L. Emeric, C. Deeb, F. Pardo, and J. L. Pelouard, Opt. Lett. 44, 4761 (2019).
S. J. Park, Y. B. Kim, Y. J. Moon, J. W. Cho, and S. K. Kim, Opt. Express 28, 15472 (2020).
K. M. Devi, A. K. Sama, D. R. Chowdhury, and G. Kumar, Opt. Express 25, 10484 (2017).
X. Niu, X. Hu, Q. Yan, J. Zhu, H. Cheng, Y. Huang, C. Lu, Y. Fu, and Q. Gong, Nanophotonics 8, 1125 (2019).
J. X. Zhang, J. Zhang, and Y. F. Li, Plasmonics 16, 2305 (2021).
C. L. G. Alzar, M. A. G. Martinez, and P. Nussenzveig, Am. J. Phys. 70, 37 (2002).
K. Zhang, C. Wang, L. Qin, R. W. Peng, D. H. Xu, X. Xiong, and M. Wang, Opt. Lett. 39, 3539 (2014).
J. A. Souza, L. Cabral, R. R. Oliveira, and C. J. Villas-Boas, Phys. Rev. A 92, 023818 (2015).
Agha, I.
Alzar, C. L. G.
Armghan, A.
Bartal, G.
Bozhevolnyi, S. I.
Burrow, J. A.
Cabral, L.
Capasso, F.
Chen, J.
Chen, J. W.
Chen, T. Y.
Chen, W. T.
Cheng, B. H.
Cho, J. W.
Chowdhury, D. R.
Deeb, C.
Deshpande, R. A.
Devi, K. M.
Ding, F.
Eigenthaler, U.
Emeric, L.
Fu, Y.
Genov, D. A.
Geskus, D.
Giessen, H.
Gong, Q.
Gu, P.
Hentschel, M.
Hirscher, M.
Hong, X.
Hooper, I. R.
Hsiao, C. T.
Hsu, W. L.
Hu, X.
Huang, Q.
Huang, Y.
Huang, Y. W.
Ichiji, N.
Ismail, N.
Jiao, Z.
Kastel, J.
Kim, S. K.
Kim, Y. B.
Kores, C. C.
Kubo, A.
Kumar, G.
Kurokawa, Y.
Langguth, L.
Li, H.
Li, Y. F.
Liao, C. Y.
Liu, A. Q.
Liu, C.
Liu, M.
Liu, N.
Lu, C.
Lv, H.
Martinez, M. A. G.
Mathews, J.
Meinzer, N.
Mekonen, S. M.
Mesch, M.
Miyazaki, H. T.
Moon, Y. J.
Niu, X.
Nussenzveig, P.
Oliveira, R. R.
Otake, Y.
Palomba, S.
Pardo, F.
Park, S. J.
Park, Y.
Pelouard, J. L.
Peng, R. W.
Pollnau, M.
Qi, S.
Qin, L.
Sama, A. K.
Sarangan, A.
Searles, T. A.
Song, Y.
Sonnichsen, C.
Souza, J. A.
Sun, G.
Tang, C.
Taubert, R.
Tsai, D. P.
Villas-Boas, C. J.
Wan, M.
Wang, M.
Wang, Y.
Wei, R.
Weiss, T.
Wu, K.
Wu, P. C.
Xia, J.
Xiong, C.
Xiong, X.
Xu, D. H.
Xu, H.
Yahiaoui, R.
Yan, Q.
Yang, K. Y.
Yang, Y.
Ye, Z.
Yin, X.
Yin, X. B.
Yu, N.
Yuan, S.
Zeng, C.
Zentgraf, T.
Zhang, B.
Zhang, J. X.
Zhang, K.
Zhang, L.
Zhang, S.
Zhao, C.
Zhao, M.
Zheludev, N. I.
Zhou, F.
Zhu, J.
Am. J. Phys. (1)
Appl. Phys. Lett. (1)
J. Phys. D: Appl. Phys. (1)
Nano Lett. (3)
Nanophotonics (3)
Nat. Mater. (1)
Nat. Photonics (1)
Plasmonics (1)
Results Phys. (1)
Sci. Rep. (1)
(1) Lk0nOC+ϕOC=Nπ,
(2) dk0nCC+ϕCC=(N−12)π,
(3) R(ω)=|Fres(ω)|2|Fref(ω)|2,
(4) (PCPO)=(ωC2−ω2−iγCω−Ω2−Ω2ωO2−ω2−iγOω)−1×(gCEIgOEI),
(5) (PCPO1PO2)=(ωC2−ω2−iγCω−Ω2−Ω2−Ω2ωC2−ω2−iγCω0−Ω20ωO2−ω2−iγOω)−1×(gCEIgO1EIgO2EI). | CommonCrawl |
arXiv.org > physics > arXiv:1409.6469
Physics > Fluid Dynamics
arXiv:1409.6469 (physics)
[Submitted on 23 Sep 2014 (v1), last revised 1 Feb 2016 (this version, v2)]
Title:Geostrophic convective turbulence: The effect of boundary layers
Authors:Rudie P. J. Kunnen, Rodolfo Ostilla-Mónico, Erwin P. van der Poel, Roberto Verzicco, Detlef Lohse
Abstract: Rayleigh--Bénard (RB) convection, the flow in a fluid layer heated from below and cooled from above, is used to analyze the transition to the geostrophic regime of thermal convection. In the geostrophic regime, which is of direct relevance to most geo- and astrophysical flows, the system is strongly rotated while maintaining a sufficiently large thermal driving to generate turbulence. We directly simulate the Navier--Stokes equations for two values of the thermal forcing, i.e. $Ra=10^{10}$ and $Ra=5\cdot10^{10}$, a constant Prandtl number~$Pr=1$, and vary the Ekman number in the range $Ek=1.3\cdot10^{-7}$ to $Ek=2\cdot10^{-6}$ which satisfies both requirements of super-criticality and strong rotation. We focus on the differences between the application of no-slip vs. stress-free boundary conditions on the horizontal plates. The transition is found at roughly the same parameter values for both boundary conditions, i.e. at~$Ek\approx 9\times 10^{-7}$ for~$Ra=1\times 10^{10}$ and at~$Ek\approx 3\times 10^{-7}$ for~$Ra=5\times 10^{10}$. However, the transition is gradual and it does not exactly coincide in~$Ek$ for different flow indicators. In particular, we report the characteristics of the transitions in the heat transfer scaling laws, the boundary-layer thicknesses, the bulk/boundary-layer distribution of dissipations and the mean temperature gradient in the bulk. The flow phenomenology in the geostrophic regime evolves differently for no-slip and stress-free plates. For stress-free conditions the formation of a large-scale barotropic vortex with associated inverse energy cascade is apparent. For no-slip plates, a turbulent state without large-scale coherent structures is found; the absence of large-scale structure formation is reflected in the energy transfer in the sense that the inverse cascade, present for stress-free boundary conditions, vanishes.
Comments: Submitted to JFM
Subjects: Fluid Dynamics (physics.flu-dyn)
DOI: 10.1017/jfm.2016.394
Cite as: arXiv:1409.6469 [physics.flu-dyn]
(or arXiv:1409.6469v2 [physics.flu-dyn] for this version)
From: Rodolfo Ostilla Mónico [view email]
[v1] Tue, 23 Sep 2014 10:07:36 UTC (3,815 KB)
[v2] Mon, 1 Feb 2016 19:04:49 UTC (18,124 KB)
physics.flu-dyn | CommonCrawl |
Global and cross-country analysis of exposure of vulnerable populations to heatwaves from 1980 to 2018
Jonathan Chambers ORCID: orcid.org/0000-0002-2332-81431
Climatic Change volume 163, pages 539–558 (2020)Cite this article
Heatwaves have become more frequent and intense due to anthropogenic global warming and have serious and potentially life-threatening impacts on human health, particularly for people over 65 years old. While a range of studies examine heatwave exposures, few cover the whole globe and very few cover key areas in Africa, South America, and East Asia. By using global gridded climate reanalysis, population, and demographic data, this work analyses trends in change in exposure of vulnerable populations to heatwaves, providing global and per-country aggregate statistics. The difference between the global mean of heatwave indexes and the mean weighted by vulnerable population found that these populations are experiencing up to five times the number of heatwave days relative to the global average. The total exposures, measured in person-days of heatwave, highlight the combined effect of increased heatwaves and aging populations. In China and India, heatwave exposure increased by an average of 508 million person-days per year in the last decade. Mapping of changes per country highlighted significant exposure increases, particularly in the Middle East and in South East Asia. Major disparities were found between the heatwave exposures, country income group, and country health system capacity, thus highlighting the significant inequalities in global warming impacts and response capacities with respect to health across countries. It is therefore of prime importance that health development and response are coordinated with climate change mitigation and adaptation work.
Avoid the common mistakes
Anthropogenic global warming is driving an observed increase in the frequency, intensity, and duration of global heatwaves and warm spells, with these trends projected to continue in the future (IPCC 2013a; Perkins-Kirkpatrick and Gibson 2017; Perkins et al. 2012). The World Health Organization (WHO) has identified climate change as a global risk factor for health (WHO 2009), with heatwaves presenting a particularly acute risk. Furthermore, vulnerability to heatwaves is not uniform—certain age groups are more susceptible to ill effects, while other factors including prevalence of certain diseases, condition of infrastructure, and health system status all contribute to the overall risk factor (Watts et al. 2019, 2018, 2017, 2016).
Health impacts of heatwaves
Heatwaves have been shown to have serious and potentially life-threatening impacts on human health (Anderson and Bell 2009; Basu and Samet 2002; Campbell et al. 2018; Hajat and Kosatky 2010; Krau 2013), with specific events noted as public health disasters such as in Chicago during July 1995 and in France during August 2003 (Krau 2013). High temperatures can cause heat stroke, heat exhaustion, heat syncope, and heat cramps, with heat stroke being particularly associated with sedentary elderly people (Kilbourne 1997). It has been observed that health effects increase as temperatures rise above certain heatwave thresholds (Lin et al. 2009). Although there is evidence of acclimatisation to local hot climates, all persons are negatively affected by temperatures in the extreme percentiles of their local climatologies (Anderson and Bell 2009), with statistically significant effects on mortality when temperatures surpass the 99th percentile even in locations which display evidence of adaptation to heatwaves (Gasparrini et al. 2015a). It has been noted that high night-time (minimum) temperatures in particular have high health impacts because of a lack of night-time relief from excessive heat, which would allow the human body to rest and recover from heat stress (Smith and Levermore 2008; Watts et al. 2015).
The health risks associated with heatwaves have been shown to be higher for certain groups of people. Increased risk has been associated with those living in urban areas (with high population density), possible due to urban heat island effects (Basu and Samet 2002; Watts et al. 2018). Persons with pre-existing cardiovascular and chronic respiratory conditions, as well as those with diabetes, have been found to have higher mortality due to heatwaves (mainly due to stress on the cardiovascular and respiratory systems) (Basu and Samet 2002; Gasparrini et al. 2015b; Kenney and Hodgson 1987). Older persons, generally identified in studies as those over 65 years old, are also at increased risk (Anand and Bärnighausen 2007; Campbell et al. 2018; Guo et al. 2017; Li et al. 2015; Oudin Åström et al. 2011). Causes for this include their lower ability to thermoregulate body temperatures (Basu and Samet 2002; Kenney and Hodgson 1987), the prevalence of the aforementioned pre-existing medical conditions within this age group, and possibly increased social isolation which has been identified as a risk factor (Buscail et al. 2012).
Studies have considered the health impacts of past heatwaves by comparing health outcomes from heatwave events with local or global heatwave indexes. In general, this has been performed for a selection of cities or regions (Anderson and Bell 2009; Campbell et al. 2018; Li et al. 2015; Russo et al. 2015; Scalley et al. 2015; Zhao et al. 2019, 2018) or by collecting many individual studies (Mora et al. 2017). Guo et al. (2018, 2017) combined mortality and climate data to estimate heatwave impacts for 412 communities in 20 regions.
However, while there has been extensive research on heatwaves and health in Europe, North America, and Australia, significant geographical areas have limited coverage. For example, in reviews of case studies, by Campbell et al. (2018) and Mora et al. (2017), four studies were found for Africa and seven for South America. More recent works include studies for South Africa (Wright et al. 2019) Senegal (Sarr et al. 2019), and Brazil (Zhao et al. 2018). The dataset developed by Guo et al. (2018) included no data for Africa and limited data for Brazil, Chile, and Columbia. In these regions, data challenges currently make it difficult to estimate deaths attributable to heatwaves (Wright et al. 2019). Gaps in coverage mean that at-risk areas may not be identified and make it difficult to compare trends globally. Using a case-study based methodology limits the geographic coverage.
Campbell et al. (2018) highlighted that areas with the least coverage also have lower wealth per adult, while Herold et al. (2017) found that temperature extremes increased more in low- versus high-income countries. Numerous studies show evidence that countries with lower levels of wealth tend to have reduced numbers of health workers, which leads to worse health outcomes (Anand and Bärnighausen 2007; Speybroeck et al. 2006). WHO regions with poor coverage of heatwave impact studies also have lower numbers of health workers per population, notably the Africa region with an average of 2.5 medical doctors per 10,000 people (compared with 34 per 10,000 for the Europe region). Indeed, Guo et al. (2016) found a decrease in heatwave-related mortality over the period 1993–2006 in Australia, Canada, Japan, South Korea, Spain, the UK, and the USA, which all have high numbers of health workers and therefore the capacity to develop improved heatwave response measures. This highlights the need for research covering underserved regions.
Heatwave indicators
No single internationally accepted definition of heatwave index exists. The World Meteorological Organization (WMO), following a survey of country practices, suggests heatwaves be defined as "A marked unusual hot weather (Max, Min and daily average) over a region persisting at least two consecutive days during the hot period of the year based on local climatological conditions, with thermal conditions recorded above given thresholds" (WMO 2015).
Existing heatwave indexes follow the WMO guideline but differ significantly in the details, such as the thresholds (number of days required, threshold values or percentiles, normalisation approach). A range of climate extreme indicators have been proposed by the Expert Team on Climate Change Detection and Indices, notably the warm spell duration indicator (WSDI) defined as count of days part of a 6-day window when maximum temperature is above the 90th percentile. Maximum temperature has been used to define heatwave conditions as it approximates the maximum thermal stress on the body (Basagaña et al. 2011; Campbell et al. 2018; Kilbourne 1997; Perkins 2015). However, a study of mortality during the 2003 Paris heatwave found that high minimum temperature had more impact on increased probability of death in people over 65 than mean or maximum temperatures (Laaidi et al. 2012; Xu et al. 2018), highlighting the importance of night-time respite for the body to recover during heatwave periods (Basu and Samet 2002).
In the author's previous work by Watts et al. (2017, 2018, 2019), a heatwave was defined as a period of four or more days at a given location where the minimum daily temperature was greater than the 99th percentile of the distribution of minimum daily temperature at that location over the 1986–2005 reference period for the summer months (June, July, August in the northern hemisphere, December, January, February in the southern hemisphere). However, this definition may fail to suitably reflect conditions in countries or regions where the hottest months do not coincide with the summer period defined above, for example northern India typically experiences its yearly maximum temperatures in May.
There are several aspects of heatwaves to be measured such as frequency, length, and magnitude, and there are any number of formulations of indexes to measure these (Perkins 2015). With respect to health, there is a need to determine from what duration of heatwave the effects start to be felt. Epidemiological evidence found that a run of at least three consecutive days of high temperatures was associated with increased mortality (Basu and Samet 2002; Nairn and Fawcett 2013). Furthermore, heatwave indexes based on local temperature percentiles, rather than absolute thresholds, are more relevant because they can be applied globally and also help reflect a degree of local acclimatisation to regional conditions (Nairn and Fawcett 2013; Perkins 2015). These factors have notably been considered in the Australian Bureau of Meteorology's heatwave indicators for Australia (Nairn and Fawcett 2013).
Research aims
Previous studies were not able to assess heatwave impacts in all locations, which is mainly due to the use of case-study based methods which limit their geographic scope. They are therefore limited in giving a global overview, particularly for lower-income countries which have been shown to be more exposed to increasing temperature extremes.
This study aims at providing a global and cross-country analysis of exposure of vulnerable persons to heatwaves. We build on our previous work in the Lancet Climate Countdown, which developed indicators of heatwave health risk through the exposure of persons over 65 to change in heatwaves based on global climate and demographic datasets (Watts et al. 2015, 2016, 2017, 2018). This study aims at further exploring the factors of vulnerability and variation of vulnerability across countries by combining heatwave exposure with country wealth and health system metrics. Global and per-country values are presented to assess the variability in heatwave exposure across different regions.
This section presents the definitions of the heatwave indices used for the study and the method of calculating the change and trends. The method combines heatwave indexes with global population, demographic, and health data covering the period from 1980 to 2018. This enables a global and cross-country analysis of heatwave exposure trends among vulnerable people. Table 1 summarises the datasets used; further details are given in the following section. The method was implemented in Python using the Xarray package (Hoyer and Hamman 2016). Note: a grid cell in the rectangular gridded data is denoted by its coordinates (i, j).
Table 1 Summary of datasets used
This work used climate reanalysis data from the ERA-5 project at 0.5° grid resolution for the years 1980–2018. Temperature at 2 m from the earth's surface was acquired at hourly time resolution, and daily summaries of mean, min, and max temperature were generated from the hourly data. Percentiles of mean, min, and max temperature were computed for the period 1986–2005. The daily values and percentiles are available as open access datasetsFootnote 1 (Chambers 2019a, b).
Gridded population and demographic data at 0.5° grid resolution were obtained from the NASA Socioeconomic Data and Applications Center (SEDAC) Global Population of the World version 4 (GPWv4) (NASA SEDAC and CIESIN 2016) for the years 2000–2018. For the years 1980–2000, historical 0.5° resolution population data from the Inter-Sectoral Impact Model Intercomparison Project (ISIMIP) were used (Goldewijk et al. 2017). These datasets were readily combined as they share a common coordinate system and it was found that population totals were continuous across them.
NASA SEDAC GPWv4 provided gridded demographic data for 2010 as a set of grids of total population per 5-year age band. The UN World Population Program (WPP) provides country-level demographic statistics for 1950 onwards (extended through modelling until 2100), and the values for the median scenario were retained (UN 2019). The gridded demographic data was adjusted for each year from 1980 to 2018 such that the mean demographic distribution for the grid cells corresponding to each country matched the country-level values. This allowed to maintain the high spatial resolution data from 2010 for all years studied, under the simplifying assumption that the relative spatial distribution of population for each age band within each country remained approximately constant. This was achieved as follows:
The GPWv4 gridded demographic age band totals per grid cell for 2010 were converted to fractions such that the sum over age bands per grid cell equals 1.
The WPP demographic age band totals per country per year were converted into fractions per age band per year, such that the sum over age bands per country per year equals 1.
For each country, the appropriate section of gridded data was selected using the gridded country codes provided by the GPWv4 dataset.
For each year, for each 5-year age band, the ratio \( {\delta}_{\mathrm{age}}^y \) of the fraction per age band for that year to the fraction per age band for 2010 was calculated (Eq. 1).
$$ {\delta}_y^{\mathrm{age}}={f}_y^{\mathrm{age}}/{f}_{2010}^{age} $$
To obtain the adjusted grid cell value, the value for 2010 was multiplied by \( {\delta}_{\mathrm{age}}^y \) for each year for each grid cell (Eq. 2).
$$ {f}_{y,i,j}^{\mathrm{age}}={\delta}_y^{\mathrm{age}}{f}_{2010,i,j}^{\mathrm{age}} $$
The output grids of fraction of population per age band for each year were assembled by merging the individual grids for each country.
For each year, the total population over 65 per grid cell \( {P}_{y,i,j}^{65+} \) was calculated using Eq. 3:
$$ {P}_{y,i,j}^{65+}={f}_{y,i,j}^{65+}\times {P}_{y,i,j}^{\mathrm{total}} $$
Health and economic data
Country-level health metrics were obtained from the WHO Global Health Observatory data repository ("WHO Global Health Observatory," 2019) and associated with other country data. World Bank Income groups (low income, lower-middle income, upper-middle income, high income) were associated with each country (World Bank 2018).
Definition of heatwave indexes
In this work, a heatwave was defined as a period of 4 or more days at a given location where the minimum daily temperature was greater than the 99th percentile of the distribution of minimum daily temperatures at that location for all months of the year over the 1986–2005 baseline period (thereby relaxing the restriction to summer months used in (Watts et al. 2019, 2018, 2017)). The baseline period was chosen in accordance with the practice of the Intergovernmental Panel on Climate Change (IPCC 2013b).
Five descriptive indexes were calculated based on the heatwave definition to evaluate trends in heatwave frequency and intensity in terms of duration and temperature anomaly (Table 2).
Table 2 Summary of descriptive indexes
Heatwave count, days, and degree days
To calculate the heatwave count, heatwave days, and heatwave degree days metrics for a given year, we extract for each grid cell the sequences of days which correspond to the heatwave definition above. For each day d and grid cell (i, j), the threshold exceedance Ed, i, j is calculated according to Eq. 4:
$$ {E}_{d,i,j}=\left\{\begin{array}{c}1\ if\ T{\mathit{\min}}_{d,i,j}>T{99}_{i,j}\\ {}0\ otherwise\end{array}\right. $$
where Tmind, i, j is the daily minimum temperature and T99i, j is the 99th percentile of daily minimum temperatures. The degree difference DDd, i, j is calculated for each day between Tmind, i, j and T99i, j, where the difference is positive (Eq. 5):
$$ {DD}_{d,i,j}=\max \left(T{\min}_{d,i,j}\hbox{--} T{99}_{i,j},0\right) $$
This produces two time series vectors per grid cell, \( {\overline{E}}_{i,j} \) and \( {\overline{DD}}_{i,j} \). These are split into sets of continuous sequences of days where Ed, i, j = 1 and the length of each sequence is ≥ 4, i.e., where heatwave conditions occur for 4 or more consecutive days. The sequence information from \( {\overline{E}}_{i,j} \) is used to split the degree difference vector \( {\overline{DD}}_{i,j} \) (see supplementary information for further details). From these sets of sequences, we calculate for each year y:
Heatwave County, i, j equals the count of the number of distinct sequences of days for a grid cell for a year.
Heatwave Daysy, i, j equals the sum of lengths of the sequences for a grid cell for a year.
Heatwave Degree Daysy, i, j equals the sum of all degree difference sequences for a grid cell for a year.
Heatwave mean length
The heatwave mean length is the mean number of days per heatwave for a given year, calculated as the number of heatwave days divided by the number of individual heatwaves for a grid cell (i, j) (Eq. 6).
$$ Heatwave\ {Mean\ Length}_{y,i,j}={Heatwave\ Days}_{y,i,j}/{Heatwave\ Count}_{y,i,j} $$
Heatwave mean degrees over threshold
The heatwave mean degrees metric is the mean °C above the threshold value for each grid cell and is calculated yearly as heatwave degree days divided by the heatwave days for grid cell (i, j) (Eq. 7). It provides a measure of the intensity of the heatwave.
$$ Heatwave\ {Mean\ Degrees}_{y,i,j}={Heatwave\ Degrees}_{y,i,j}/{Heatwave\ Days}_{y,i,j} $$
Heatwave indexes change
To observe trends that deviate from the historical mean and to make it possible to compare values across locations, we calculate the change in index compared with a baseline, defined as the mean of each index across years for the period 1986–2005. For each index and for each year from 1980 to 2018, the difference was calculated relative to the baseline. Since this calculation is the same for all heatwave indexes, we summarise the change calculation for a given year for any of the heatwave indexes as Eq. 8:
$$ heatwave\ {index\ change}_{y,i,j}={heatwave\ index}_{y,i,j}- heatwave\ {index\ baseline}_{i,j} $$
where heatwave indexy, i, j is any given heatwave index from Table 2, heatwave index baselinei, j is the baseline mean of that index, and heatwave index changey, i, j is the change relative to the baseline for that year.
Exposure of vulnerable population to change in heatwaves
Exposure to heatwaves is used as an index of the human health risk factor. It provides a method of aggregated risk tracking that can be applied globally by using high-resolution population and demographic datasets. The vulnerable population was defined as people over 65. The exposure for a given year is calculated in the same way for each index, which we summarise as Eq. 9:
$$ exposure\ to\ change\ {in\ index}_{y,i,j}={P}_{y,i,j}^{65+}\times heatwave\ {in dex\ change}_{y,i,j} $$
where exposure to change in indexy, i, j is the yearly exposure for a given heatwave index in Table 2, \( {P}_{y,i,j}^{65+} \) is the number of people over the age of 65, and heatwave index changey, i, j is the change relative to baseline for the selected index.
Global and exposure weighted means of heatwaves and exposures
Global mean
The global mean values take into account all grid cells (land and sea), weighted by grid cell area.
Exposure weighted mean
Exposure weighted mean values for each index are calculated by weighting the chosen heatwave index change by the relative fraction of the relevant population in each grid cell, as shown in Eq. 10, where total population in the age band \( {P}_y^{65+}={\sum}_{i,j}{P}_{y,i,j}^{65+} \) . Trends over time of the exposure weighted mean will only reflect the (change in) spatial distribution of vulnerable population and not change in the total vulnerable population, because the values are normalised by the totals for each year.
$$ exposure\ {weighted\ mean}_y={\sum}_{i,j}\ \frac{P_{y,i,j}^{65+}}{P_y^{65+}}\times heatwave\ {index\ change}_{y,i,j} $$
The global exposure weighted mean by definition considers only land grid cells. For country exposures, the grid cells for the corresponding country are selected based on a country mask and the same calculation is applied, using the total vulnerable population of that country as the divisor. As a result, per-country values are only affected by changes in spatial distribution of vulnerable population within each country. Differences in population growth and demographic changes between countries are thereby factored out (e.g., strong population growth in one country will not skew the weighted mean for other countries).
Population and demographic trends
This work merged gridded historical population data with UN WPP demographic data to produce gridded time series. It has been noted that the world's population is aging rapidly (United Nations 2015). Figure 1 summarises the global totals by age band and highlights the very rapid increase in the population over 65 from 277 million to 702 million, making it the largest single age group in 2018.
Total population by age band, age band for people over 65 highlighted (solid black line)
Figure 2 shows the global distribution of the change in percentage of people over 65 between 1980 and 2018. It highlights that there has been an increase of over 10 percentage points in Japan and some regions of Europe. Sub-Saharan Africa shows a slight decrease in percentage of over-65s, due to a combination of lower life expectancy and higher population growth in the study period. As a result, the population is becoming younger on average and over-65s represent a relatively smaller percentage of the total.
Global distribution of the change in percentage points of the percentage of population over 65 between 1980 and 2018 (start and end of the period studied)
Global changes
Two aspects of global change are considered: the comparison between the global mean and the exposure weighted mean, and the total exposure values. The exposure weighted mean factors out population growth and net change in demographic distributions (i.e., the net increase in over-65 s due to aging population), and instead reflects only the changes in spatial distribution of vulnerable population relative to the spatial distribution of heatwaves. This highlights the difference between global trends and how those trends are experienced by the population. Conversely, the total exposure values capture both change in heatwave conditions and increases in both total global population and fraction of the total population over 65. This captures the absolute change in the risk factor, which is relevant as the total need for adaptation and (medical) response measures is related to the absolute exposures rather than the mean.
The heatwave indicators are available as open access datasetsFootnote 2 (Chambers 2019c).
Global mean changes
Figure 3 summarises the heatwave indicator global mean and exposure weighted mean (tabulated numerical values may be found in the supplementary material). The change in heatwave degree days combines all the effects of change in heatwave occurrences, length, and intensity. We observe a dramatically stronger trend in the exposure weighted values than the global average; this indicates that heatwaves are occurring more often and with higher intensity in areas with high population. Across all grid cells in 2018, there were an average of 0.7 days of heatwave, while the vulnerable population experienced an average 3.6 days (five times higher).
Global and exposure weighted means of heatwave indicators change relative to the 1986–2005 reference period
The components of this trend can be better understood by inspecting the plots of the number of heatwave days per year, mean length of heatwave in days, and intensity of heatwave. The total number of days of heatwave shows a stronger trend in the exposure weighted mean than the global mean, while the mean length of heatwaves and the intensity of heatwaves appear in line with global trend, although in 2018 the global mean length was 0.2 days while the exposure weighted mean was 0.5 days. The spike in 2010 is mainly due to the June–August Russian heatwave which covered a very large area (Trenberth and Fasullo 2012).
Global absolute change in exposure
We compare global absolute change in exposure for the heatwave degree days indicator (which combines length and intensity) and the heatwave days indicator.
Figure 4 shows the time series of total exposures for degree days and days of heatwave, highlighting a significant increase in exposures in the past decade. Although minor differences in the year-on-year patterns exist between these two, there are no differences in the overall trend as highlighted by the 10-year moving mean line. The 10-year moving mean for 2014 (covering the period 2008–2018) gave an increase of 1.4 billion person-days exposure, while the maximum value recorded in 2018 was 2.5 billion person-days. There appears to be an acceleration of the trend of increase in exposure rates in the 2010–present period. This is driven by a combination of increasing heatwave days in populated areas and an increase in the total population and fraction of total population over 65—particularly in India and China. The increases in total exposures are important for health systems, as they drive the need for increased capacity to provide sufficient prevention and response services.
Exposure to change in heatwave degree days and number of days per year relative to the mean for 1986–2005. The 10-year moving mean of values indicates the longer-term trend
Given the minor differences in trends between heatwave degree days and heatwave days, we focus on the latter indicator for the remaining analysis, as we consider this metric to offer a more intuitive interpretation of the trends.
Exposure by country
Figure 5 shows the trend in total exposure of vulnerable people to heatwave days. The top five countries by total mean exposure over the past decade are China, India, Japan, the USA, and Indonesia; these are identified separately on the figure, highlighting in particular the large contribution from India and China in absolute terms (227 and 281 million person-days in 2010–2018, respectively). The 10-year moving mean clearly shows the long-term trend in increasing exposure in the five countries highlighted. Tables of decadal averages may be found in the supplementary material.
Exposure to change in number of heatwave days per year relative to the reference period: a yearly, b 10-year centred moving average. The top 5 countries by total exposure over the last decade are highlighted: China (CHN), India (IND), Japan (JPN), United States of America (USA), and Indonesia (IDN)
The presence of Indonesia in the top five is interesting to note, as little literature was found concerning heatwaves for this country. Further research would be needed to determine whether heatwave exposures are having significant impacts in Indonesia or whether particular features of the local climate contribute to abnormally high heatwave index values.
Figure 6 summarises the decadal change weighted mean exposures per country for days of heatwave conditions per year, relative to the reference period. Figure 6 d covers 9 instead of 10 years as 2019 data is not yet available. These values are available in a tabular form in the supplementary material. There is a clear trend of increasing exposure to heatwave conditions over the period studied. In the 2000–2009 period, most countries displayed increased exposure, this trend being strongly reinforced in the 2010–2018 period with almost all countries experiencing a significant positive increase in exposures. In this latter period, vulnerable populations in Bhutan, Egypt, Israel, and Yemen experienced on average over a week (7 days) more heatwave than in the reference period. Particularly high increases are apparent in the Middle East and Arabian Peninsula, as well as in the Caribbean. Note that these weighted averages are not affected by total population growth within countries or differences in population growth between countries, as discussed in the "Exposure weighted mean" section. The observed changes therefore reflect the concentration of population in locations with high increases in heatwave occurrences.
Decadal averages of mean exposure of vulnerable population to changes in the number of heatwave days per year by country. Plot d covers 9 instead of 10 years. Where the colour scale ends in an arrow at the top, this indicates an open range (values may exceed that displayed on the scale)
A comparison was made of the different parameter choices used for the chosen definition of the heatwave. Figure 7 shows the comparison of the heatwave time series when the calculation is applied with daily mean and maximum temperature instead of minimum temperature. All indicators follow similar trends. For the global mean changes, the mean and maximum temperature–based time series are almost identical while the minimum temperatures show reduced min/max values. Conversely, the exposure weighted values show the mean and minimum based curves being near identical while the maximum temperature based heatwave index shows reduced min/max values.
Heatwave days trend calculated using the 99th percentile of daily minimum, maximum, and mean temperature
These results suggest that relatively little change in overall trends would be expected if different temperature values were used, while evidence from health research supports the use of minimum temperatures to account for effects of lack of respite from high temperatures on health (Laaidi et al. 2012; Xu et al. 2018).
Health system indicators
The ability to respond to heatwave effects is related to the robustness of a country's health system. As previously noted, there is a strong relation between medical staffing levels and health outcomes; therefore, we may use the number of doctors per 10,000 inhabitants provided by the WHO as an indicator of health system capacity. Figure 8 aims at summarising the change in both heatwave effects (measured as exposure weighted mean heatwave days per country) and the medical staffing levels over the past decades. Decadal averages as calculated for Fig. 6 are plotted against mean number of doctors per 10,000 inhabitants for the corresponding decades, the most recent data point is highlighted. As this analysis required data for both heatwaves and doctors, it was only possible to plot values for 2000–2009 and 2010–2018 due to limited data availability.
Overview of decadal mean trends in heatwave exposure against medical staffing, measured as doctors per 10,000 persons. Points indicate latest data for 2010–2018, and lines indicate trends since 2000 for the corresponding point. Point sizes are proportional to country total population. Colours indicate the World Bank country income group
We see that while significant increases in exposure have occurred for most countries, we do not observe strong trends in medical staffing. This is particularly true of low- and low-middle-income countries (as defined by World Bank income groups). While it is not expected that heatwave occurrences should directly drive staffing levels, this does highlight a further aspect of vulnerability to heatwaves. Countries with less income are experiencing increased heatwave occurrences but do not have the high medical staff levels to help cope with the impacts, and increasing these will be challenging.
In this context, we can contrast the cases of Egypt and Cuba, being lower- and upper-middle-income countries, respectively, but in very different situations. Cuba has a very high level of doctors per inhabitant of over 70 per 10,000, while Egypt has 8 per 10,000. Conversely, vulnerable populations in Egypt have experienced a mean increase of 12 days heatwave (exposure weighted), while in Cuba, the increase is 0.7 days. This highlights that both effects of heatwaves and response capacity with respect to heatwaves vary very significantly between countries and are affected both by changes in climate- and country-specific socioeconomic conditions. This is likely to further exacerbate global inequalities with respect to which countries experience the largest climate change impacts, in terms of direct climate effects, the vulnerability of populations to those effects, and the capacity of providing adequate health responses.
In general, we note that both low- and lower-middle-income countries have nearly uniformly low medical staffing levels, while there is a much broader range in upper-middle- and high-income countries. The former groups therefore are likely to face challenges to develop preparation and response measures. For the latter groups, it seems that country policies have a larger role in determining health coverage. Therefore, country policies could have a significant impact on heatwave preparedness by focusing efforts on preparation and response measures.
A known issue with the use of ERA5 for population-focused studies is that in coastal areas, the temperatures will tend to be an average of land and sea temperatures. This will underestimate the temperatures in coastal areas, which include a large portion of the world's population. As a result, the heatwave exposures are likely to be somewhat underestimated. Future work could use the upcoming ERA5-Land dataset, which restricts the climate reanalysis to land pixels only, resulting in higher resolution data which is also more accurate over land. This study followed standard practice in calculating change values relative to the 1986–2005 reference period, thereby minimizing any potential climate reanalysis data mean bias errors. Overall, we consider the uncertainty contribution from the climate data to be low.
This study considered only ambient air temperature, while it is known that the combination of high heat and humidity also has significant health impact (Lin et al. 2009). A reliable index combining temperature and humidity is not straightforward (Kjellstrom et al. 2017; Watts et al. 2018); this should be a topic of future research. Nevertheless, as humidity is an aggravating factor for health impacts, we can consider that our results set an exposure baseline. If humidity were to be included, we would likely expect higher exposures overall.
The generation of gridded population data is complex, and the resulting data includes a level of uncertainty that is difficult to quantify. In order to maintain consistency, the "UN WPP adjusted" variant of the NASA GPWv4 data was used together with other UN WPP demographic data thereby defining the UN provided values as the authoritative baseline for the analysis. Nevertheless, there remains significant uncertainty in the population values particularly in areas with poor data collection (e.g., conflict zones). However, it was not feasible to address all of these in the context of this global study.
For demographic data, a simplifying assumption was made that the relative spatial distribution of population for each age band within each country remained approximately constant while the per-country totals per age band were adjusted to match the UN data. It is possible that demographic distributions within countries change over time due to population movements and other factors. While the total population movements over time are captured by the population data, we cannot know if such movements are caused mainly by particular subsets of age groups (e.g., young people moving to cities). Other factors include lifestyles, wealth, or health care which may evolve differently in different parts of a country resulting in changes in demographic makeup over the period studied. By calibrating to UN data, we aim for consistency at the country level. Extending this to sub-national units would be extremely challenging and likely explains why no such dataset already exists covering the time span considered.
Finally, this study considered the dimensions of vulnerability the age group, healthcare staffing, and income group. There is a large range of potential vulnerability factors that could be considered such as gender and income inequality. Consequently, there is considerable scope for further work on these topics.
This study developed heatwave indexes from global climate reanalysis data and combined these with global population, demographic, and health data covering the period from 1980 to 2018. This enabled a global and cross-country analysis of heatwave exposure trends among vulnerable people. We demonstrated that there is a clear trend in increasing heatwave days globally, in accordance with climate model predictions for the effects of anthropogenic climate change. Heatwaves are being experienced by vulnerable populations at a higher rate than the global average. Furthermore, heatwave exposures in absolute terms are increasing rapidly, driven by a combination of increasing heatwave frequency, growing population, and aging of the population resulting in a larger number of people over 65 years old.
These results are significant in that they are produced from observational data of the recent past, rather than based on future projections, and therefore highlight the reality of climate change impacts that have already happened. Ongoing work aims at maintaining updates of these indicators as new data becomes available.
Heatwave index trends were combined with country health system metrics and economic metrics (World Bank income group). This highlighted the large disparities in health and wealth relative to heatwave trends. While heatwaves affect all countries irrespective of wealth, this study highlights that certain countries are at additional risk of negative impacts due to the combination of high heatwave exposure, low medical staffing, and low income. These factors exacerbate inequalities between countries with respect to climate change impacts. By tabulating these indicators per country, further work can be performed to explore other factors of vulnerability, to determine the relation between vulnerability and excess mortality, and to consider response strategies.
The increasing exposure of vulnerable people to heatwaves indicates the importance of considering climate change impacts in healthcare, in terms of both national planning and international development. We recommend that healthcare entities be fully engaged in climate mitigation and adaptation efforts to address this growing risk factor. The large increases in absolute exposures highlight the need for capacity building to match the increased needs. This paper provides a suitable statistical background which can be used to inform further policy development in national and international agencies.
https://zenodo.org/record/3403951; https://zenodo.org/record/3403963
https://zenodo.org/record/3403922
Anand S, Bärnighausen T (2007) Health workers and vaccination coverage in developing countries: an econometric analysis. Lancet 369:1277–1285. https://doi.org/10.1016/S0140-6736(07)60599-6
Anderson BG, Bell ML (2009) Weather-related mortality: how heat, cold, and heat waves affect mortality in the United States. Epidemiology 20:205–213. https://doi.org/10.1097/EDE.0b013e318190ee08
Basagaña X, Sartini C, Barrera-Gómez J, Dadvand P, Cunillera J, Ostro B, Sunyer J, Medina-Ramón M (2011) Heat waves and cause-specific mortality at all ages. Epidemiology 22:765–772. https://doi.org/10.1097/ede.0b013e31823031c5
Basu R, Samet JM (2002) Relation between elevated ambient temperature and mortality: a review of the epidemiologic evidence. Epidemiol Rev 24:190–202. https://doi.org/10.1093/EPIREV/MXF007
Buscail C, Upegui E, Viel J-F (2012) Mapping heatwave health risk at the community level for public health action. Int J Health Geogr 11:38. https://doi.org/10.1186/1476-072X-11-38
Campbell S, Remenyi TA, White CJ, Johnston FH (2018) Heatwave and health impact research: a global review. Health Place 53:210–218. https://doi.org/10.1016/J.HEALTHPLACE.2018.08.017
Chambers J (2019a). ERA5-derived daily temperature summary 1980–2018. https://doi.org/10.5281/ZENODO.3403963
Chambers J (2019b). Percentiles of daily mean, min, and max temperature 1986–2005. https://doi.org/10.5281/ZENODO.3403951
Chambers J (2019c). Heatwave indexes 1980–2018. https://doi.org/10.5281/ZENODO.3403922
Gasparrini A, Guo Y, Hashizume M, Kinney PL, Petkova EP, Lavigne E, Zanobetti A, Schwartz JD, Tobias A, Leone M, Tong S, Honda Y, Kim H, Armstrong BG (2015a) Temporal variation in heat–mortality associations: a multicountry study. Environ Health Perspect 123:1200–1207. https://doi.org/10.1289/ehp.1409070
Gasparrini A, Guo Y, Hashizume M, Lavigne E, Zanobetti A, Schwartz J, Tobias A, Tong S, Rocklöv J, Forsberg B, Leone M, De Sario M, Bell ML, Armstrong B et al (2015b) Mortality risk attributable to high and low ambient temperature: a multicountry observational study. Lancet 386:369–375. https://doi.org/10.1016/S0140-6736(14)62114-0
Goldewijk KK, Beusen A, Doelman J, Stehfest E, Hague T (2017) Anthropogenic land use estimates for the Holocene – 927–953
Guo Y, Gasparrini A, Armstrong BG, Tawatsupa B, Tobias A, Lavigne E, Coelho M d SZS, Pan X, Kim H, Hashizume M, Honda Y, Guo YL et al (2016) Temperature variability and mortality: a multi-country study. Environ. Health Perspect 124:1554–1559. https://doi.org/10.1289/EHP149
Guo Y, Gasparrini A, Armstrong BG, Tawatsupa B, Tobias A, Lavigne E, Coelho M d SZS, Pan X, Kim H, Hashizume M, Honda Y, Guo Y-LL et al (2017) Heat wave and mortality: a multicountry. Multicommunity Study Environ Health Perspect 125:087006. https://doi.org/10.1289/EHP1026
Guo Y, Gasparrini A, Li S, Sera F, Vicedo-Cabrera AM, de Sousa Zanotti Stagliorio Coelho M, Saldiva PHN, Lavigne E, Tawatsupa B, Punnasiri K et al (2018) Quantifying excess deaths related to heatwaves under climate change scenarios: a multicountry time series modelling study. PLoS Med 15:e1002629. https://doi.org/10.1371/journal.pmed.1002629
Hajat S, Kosatky T (2010) Heat-related mortality: a review and exploration of heterogeneity. J Epidemiol Community Health 64:753–760. https://doi.org/10.1136/jech.2009.087999
Herold N, Alexander L, Green D, Donat M (2017) Greater increases in temperature extremes in low versus high income countries. Environ Res Lett 12. https://doi.org/10.1088/1748-9326/aa5c43
Hoyer S, Hamman J (2016) Xarray: N-D labeled arrays and datasets in Python. prep, J. Open Res. Softw
IPCC (2013a) Fifth Assessment Report - Climate Change 2013 [WWW Document]. URL http://www.ipcc.ch/report/ar5/wg1/ (accessed 5.10.16)
IPCC (2013b) Climate Change 2013: The Physical Science Basis. Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change. Cambridge University Press, Cambridge, UK
Kenney WL, Hodgson JL (1987) Heat tolerance, thermoregulation and ageing. Sport Med 4:446–456. https://doi.org/10.2165/00007256-198704060-00004
Kilbourne EM (1997) Heat waves and hot environments. public Heal. Conseq. disasters 245–69
Kjellstrom T, Freyberg C, Lemke B, Otto M, Briggs D (2017) Estimating population heat exposure and impacts on working people in conjunction with climate change. Int J Biometeorol 62:291–306. https://doi.org/10.1007/s00484-017-1407-0
Krau SD (2013) The impact of heat on morbidity and mortality. Crit Care Nurs Clin North Am 25:243–250. https://doi.org/10.1016/j.ccell.2013.02.009
Laaidi K, Zeghnoun A, Dousset B, Bretin P, Vandentorren S, Giraudet E, Beaudeau P (2012) The impact of heat islands on mortality in Paris during the august 2003 heat wave. Environ Health Perspect 120:254–259. https://doi.org/10.1289/ehp.1103532
Li M, Gu S, Bi P, Yang J, Liu Q (2015) Heat waves and morbidity: current knowledge and further direction-a comprehensive literature review. Int. J. Environ. Res. Public Health 12:5256–5283. https://doi.org/10.3390/ijerph120505256
Lin S, Luo M, Walker RJ, Liu X, Hwang SA, Chinery R (2009) Extreme high temperatures and hospital admissions for respiratory and cardiovascular diseases. Epidemiology 20:738–746. https://doi.org/10.1097/EDE.0b013e3181ad5522
Mora C, Dousset B, Caldwell IR, Powell FE, Geronimo RC, Bielecki CR, Counsell CWW, Dietrich BS, Johnston ET, Louis LV, Lucas MP et al (2017) Global risk of deadly heat. Nat Clim Chang 7:501–506. https://doi.org/10.1038/nclimate3322
Nairn J, Fawcett R (2013) Defining heatwaves: heatwave defined as a heat-impact event servicing all communiy and business sectors in Australia, CAWCR technical report 551.5250994
NASA SEDAC, CIESIN (2016). Gridded population of the world, version 4 (GPWv4): population count
Oudin Åström D, Bertil F, Joacim R (2011). Heat wave impact on morbidity and mortality in the elderly population: a review of recent studies. Maturitas. https://doi.org/10.1016/j.maturitas.2011.03.008
Perkins SE (2015) A review on the scientific understanding of heatwaves—their measurement, driving mechanisms, and changes at the global scale. Atmos Res 164–165:242–267. https://doi.org/10.1016/J.ATMOSRES.2015.05.014
Perkins SE, Alexander LV, Nairn JR (2012) Increasing frequency, intensity and duration of observed global heatwaves and warm spells. Geophys. Res. Lett. 39:2012GL053361. https://doi.org/10.1029/2012GL053361
Perkins-Kirkpatrick SE, Gibson PB (2017) Changes in regional heatwave characteristics as a function of increasing global temperature. Sci Rep 7:12256. https://doi.org/10.1038/s41598-017-12520-2
Russo S, Sillmann J, Fischer EM (2015) Top ten European heatwaves since 1950 and their occurrence in the coming decades. Environ Res Lett 10:124003. https://doi.org/10.1088/1748-9326/10/12/124003
Sarr AB, Diba I, Basse J, Sabaly HN, Camara M (2019) Future evolution of surface temperature extremes and the potential impacts on the human health in Senegal. African J Environ Sci Technol 13:482–510. https://doi.org/10.5897/ajest2019.2757
Scalley BD, Spicer T, Jian L, Xiao J, Nairn J, Robertson A, Weeramanthri T (2015) Responding to heatwave intensity: excess heat factor is a superior predictor of health service utilisation and a trigger for heatwave plans. Aust. N. Z. J. Public Health 39:582–587. https://doi.org/10.1111/1753-6405.12421
Smith C, Levermore G (2008) Designing urban spaces and buildings to improve sustainability and quality of life in a warmer world. Energy Policy 36:4558–4562. https://doi.org/10.1016/J.ENPOL.2008.09.011
Speybroeck N, Kinfu Y, Poz MRD, Evans DB (2006). Reassessing the relationship between human resources for health , intervention coverage and health outcomes
Trenberth KE, Fasullo JT (2012) Climate extremes and climate change: the Russian heat wave and other climate extremes of 2010. J. Geophys. Res. Atmos. 117, n/a-n/a. https://doi.org/10.1029/2012JD018020
UN (2019) World Population Prospects 2019: Data Booklet
United Nations (2015) World population ageing. New York, USA, New York
Watts N, Adger WN, Agnolucci P, Blackstock J, Byass P, Cai W, Chaytor S, Colbourn T, Collins M, Cooper A, Cox PM, Depledge J, Drummond et al (2015) Health and climate change: policy responses to protect public health. Lancet 386:1861–1914. https://doi.org/10.1016/S0140-6736(15)60854-6
Watts N, Adger WN, Ayeb-Karlsson S, Bai Y, Byass P, Campbell-Lendrum D, Colbourn T, Cox P, Davies M, Depledge M, Depoux A et al (2016) The Lancet Countdown: tracking progress on health and climate change. Lancet 0:1693–1733. https://doi.org/10.1016/S0140-6736(16)32124-9
Watts N, Amann M, Ayeb-Karlsson S, Belesova K, Bouley T, Boykoff M, Byass P, Cai W, Campbell-Lendrum D, Chambers J et al (2017) The Lancet Countdown on health and climate change: from 25 years of inaction to a global transformation for public health. Lancet 391:581–630. https://doi.org/10.1016/S0140-6736(17)32464-9
Watts N, Amann M, Arnell N, Ayeb-Karlsson S, Belesova K, Berry H, Bouley T, Boykoff M, Byass P, Cai W, Campbell-Lendrum D, Chambers J, Costello A et al (2018) The 2018 report of the Lancet Countdown on health and climate change: shaping the health of nations for centuries to come. Lancet 392:2479–2514. https://doi.org/10.1016/S0140-6736(18)32594-7
Watts N, Amann M, Arnell N, Ayeb-Karlsson S, Belesova K, Boykoff M, Byass P, Cai W, Campbell-Lendrum D, Capstick S, Chambers J, et al. (2019) The 2019 report of the Lancet Countdown on health and climate change: ensuring that the health of a child born today is not defined by a changing climate. Lancet. https://doi.org/10.1016/S0140-6736(19)32596-6
WHO (2009) Global Health Risks
WHO Global Health Observatory [WWW Document] (2019) WHO. URL https://www.who.int/gho/about/en/ (accessed 9.4.19)
WMO (2015) Guidelines on the definition and monitoring of extreme weather and climate events. Task Team Defin Extrem Weather Clim Events 62. https://doi.org/10.1016/j.corsci.2014.12.017
World Bank (2018). GDP per capita PPP - current international $
Wright CY, Kapwata T, Wernecke B, Garland RM, Nkosi V, Shezi B, Landman WA, Mathee A (2019) Gathering the evidence and identifying opportunities for future research in climate, heat and health in South Africa: the role of the South African Medical Research Council. South African Med J 109:20–24. https://doi.org/10.7196/SAMJ.2019.v109i11b.14253
Xu Z, Cheng J, Hu W, Tong S (2018) Heatwave and health events: a systematic evaluation of different temperature indicators, heatwave intensities and durations. Sci Total Environ 630:679–689. https://doi.org/10.1016/J.SCITOTENV.2018.02.268
Zhao Q, Coelho MSZS, Li S, Saldiva PHN, Hu K, Abramson MJ, Huxley RR, Guo Y (2018) Spatiotemporal and demographic variation in the association between temperature variability and hospitalizations in Brazil during 2000-2015: a nationwide time-series study. Environ Int 120:345–353. https://doi.org/10.1016/j.envint.2018.08.021
Zhao Q, Li S, Coelho MSZS, Saldiva PHN, Hu K, Huxley RR, Abramson MJ, Guo Y (2019) The association between heatwaves and risk of hospitalization in Brazil: a nationwide time series study between 2000 and 2015. PLoS Med 16:e1002753. https://doi.org/10.1371/journal.pmed.1002753
Open access funding provided by University of Geneva.
Chair for Energy Efficiency, Institute for Environmental Sciences and Forel Institute, University of Geneva, Boulevard Carl-Vogt 66, 1205, Geneva, Switzerland
Jonathan Chambers
Correspondence to Jonathan Chambers.
ESM 1
(XLSX 16 kb)
Chambers, J. Global and cross-country analysis of exposure of vulnerable populations to heatwaves from 1980 to 2018. Climatic Change 163, 539–558 (2020). https://doi.org/10.1007/s10584-020-02884-2
Issue Date: November 2020 | CommonCrawl |
FSH: fast spaced seed hashing exploiting adjacent hashes
Samuele Girotto1,
Cinzia Pizzi ORCID: orcid.org/0000-0002-6616-40031
Patterns with wildcards in specified positions, namely spaced seeds, are increasingly used instead of k-mers in many bioinformatics applications that require indexing, querying and rapid similarity search, as they can provide better sensitivity. Many of these applications require to compute the hashing of each position in the input sequences with respect to the given spaced seed, or to multiple spaced seeds. While the hashing of k-mers can be rapidly computed by exploiting the large overlap between consecutive k-mers, spaced seeds hashing is usually computed from scratch for each position in the input sequence, thus resulting in slower processing.
The method proposed in this paper, fast spaced-seed hashing (FSH), exploits the similarity of the hash values of spaced seeds computed at adjacent positions in the input sequence. In our experiments we compute the hash for each positions of metagenomics reads from several datasets, with respect to different spaced seeds. We also propose a generalized version of the algorithm for the simultaneous computation of multiple spaced seeds hashing. In the experiments, our algorithm can compute the hashing values of spaced seeds with a speedup, with respect to the traditional approach, between 1.6\(\times\) to 5.3\(\times\), depending on the structure of the spaced seed.
Spaced seed hashing is a routine task for several bioinformatics application. FSH allows to perform this task efficiently and raise the question of whether other hashing can be exploited to further improve the speed up. This has the potential of major impact in the field, making spaced seed applications not only accurate, but also faster and more efficient.
The software FSH is freely available for academic use at: https://bitbucket.org/samu661/fsh/overview.
The most frequently used tools in bioinformatics are those searching for similarities, or local alignments, between biological sequences. k-mers, i.e. words of length k, are at the basis of many sequence comparison methods, among which the most widely used and notable example is BLAST [1].
BLAST uses the so-called "hit and extend" method, where a hit consists of a match of a 11-mers between two sequences. Then these matches are potential candidates to be extended and to form a local alignment. It can be easily noticed that not all local alignments include an identical stretch of length 11. As observed in [2] allowing for not consecutive matches increases the chances of finding alignments. The idea of optimizing the choice of the positions for the required matches, in order to design the so called spaced seeds, has been investigated in many studies, and it was used in PatternHunter [3], another popular similarity search software.
In general contiguous k-mers counts are a fundamental step in many bioinformatics applications [4,5,6,7,8,9,10]. However, spaced seeds are now routinely used, instead of contiguous k-mers, in many problems involving sequence comparison like: multiple sequence alignment [11], protein classification [12], read mapping [13] and for alignment-free phylogeny reconstruction [14]. More recently, it was shown that also metagenome reads clustering and classification can benefit from the use of spaced seeds [15,16,17].
A spaced seed of length k and weight \(w<k\) is a string over the alphabet \(\{1,0\}\) that contains w '1' and \((k-w)\) '0' symbols. A spaced seed is a mask where the symbols '1' and '0' denote respectively match and don't care positions. The design of spaced seeds is a challenging problem itself, tackled by several studies in the literature [3, 18, 19]. Ideally, one would like to maximize the sensitivity of the spaced seeds, which is however an NP-hard problem [20].
The advantage of using spaced seeds, rather than contiguous k-mers, in biological sequence analysis, comes from the ability of such pattern model to account for mutations, allowing for some mismatches in predefined positions. Moreover, from the statistical point of view, the occurrences of spaced seeds at neighboring sequence positions are statistically less dependent than occurrences of contiguous k-mers [20]. Much work has been dedicated to spaced seeds over the years, we refer the reader to [21] for a survey on the earlier work.
Large-scale sequence analysis often relies on cataloging or counting consecutive k-mers in DNA sequences for indexing, querying and similarity searching. An efficient way of implementing such operations is through the use of hash based data structures, e.g. hash tables. In the case of contiguous k-mers this operation is fairly simple because the hashing value can be computed by extending the hash computed at the previous position, since they share \(k-1\) symbols [22]. For this reason, indexing all contiguous k-mers in a string can be a very efficient process.
However, when using spaced seeds these observations do not longer hold. As a consequence, the use of spaced seeds within a string comparison method generally produces a slow down with respect to the analogous computation performed using contiguous k-mers. Therefore, improving the performance of spaced seed hashing algorithms would have a great impact on a wide range of bioinformatics tools.
For example, from a recent experimental comparison among several metagenomic read classifiers [23], Clark [7] emerged as one of the best performing tools for such a task. Clark is based on discriminative contiguous k-mers, and it is capable of classifying about 3.5M reads/min. When contiguous k-mers are replaced by spaced seeds, as in Clark-S [17], while the quality of the classification improves, the classification rate is reduced to just 200K reads/min.
The authors of Clark-S attributed such a difference to the use of spaced seeds. In particular, the possible sources of slowdown are two: the hashing of spaced seeds, and the use of multiple spaced seeds. In fact, Clark-S uses three different spaced seeds simultaneously in its processing. However, while the number of spaced seeds used could explain a 3\(\times\) slowdown, running Clark-S is 17\(\times\) slower than the original k-mer based Clark. Thus, the main cause of loss of speed performances can be ascribe to the use of spaced seed instead of contiguous k-mers. A similar reduction in time performance when using spaced seeds is reported also in other studies [12, 13, 15]. We believe that one of the causes of the slowdown is the fact that spaced seeds can not be efficiently hashed, as opposed to contiguous k-mers, raising the question of whether faster algorithms can be designed for this purpose.
In this paper we address the problem of the computation of spaced seed hashing for all the positions in an given input sequence, and present an algorithm that is faster than the standard approach to solve this problem. Moreover, since using multiple spaced seeds simultaneously on the same input string can increase the sensitivity [14], we also developed a variant of our algorithm for simultaneous hashing of multiple spaced seeds. Although faster implementations of specific methods that exploits spaced seeds are desirable, the main focus of this paper is the fast computation of spaced seed hashing.
In general, when computing a hash function there are also other properties of the resulting hash that might be of interest like: bit dependencies, hash distributions, collisions etc. However, the main focus of this paper is the fast computation of spaced seed hashing, using the simple Rabin-Karp rolling hash function. It is important to observe that many hashing functions can be efficiently computed from the Rabin-Karp rolling hash. For example, our method can be extended to implement the cyclic polynomial hash used in [22] with no extra costs.
In the "Methods" section we briefly summarize the properties of spaced seeds and describe our algorithm, FSH,Footnote 1 together with a variant for handling multiple seed hashing. Then, experimental results on NGS reads hashing for various spaced seeds are reported and discussed.
A spaced-seed S (or just a seed) is a string over the alphabet \(\{1,0\}\) where the 1s correspond to matching positions. The weight of a seed corresponds to the number of 1s, while the overall length, or span, is the sum of the number of 0s and 1s.
Another way to denote a spaced seed is through the notation introduced in [25]. A spaced seed can be represented by its shape Q that is the set of non negative integers corresponding to the positions of the 1s in the seed. A seed can be described by its shape Q where its weight W is denoted as |Q|, and its span s(Q) is equal to \(\max Q + 1\). For any integer i and shape Q, the positioned shape \(i+Q\) is defined as the set \(\{i+k, k \in Q\}\). Let us consider the positioned shape \(i+Q=\{i_0,i_1,\dots ,i_{W-1}\}\), where \(i=i_0<i_1<...<i_{W-1}\), and let \(x=x_0 x_1 \dots x_{n-1}\) be a string over the alphabet \(\mathcal {A}\). For any position i in the string x, with \(0\le i \le n-s(Q)\), the positioned spaced seed \(i+Q\) identifies a string of length |Q| that we call Q-gram. A Q-gram at position i in x is the string \(x_{i_0} x_{i_1} \dots x_{i_{W-1}}\) and it is denoted by \(x[i+Q]\).
Let \(Q=\{0,2,3,4,6,7\}\), then Q is the seed 10111011, its weight is \(|Q|=6\) and its span is \(s(Q)=8\). Let us consider the string \(x=ACTGACTGGA\), then the Q-gram \(x[0+Q]=ATGATG\) can be defined as:
$$\begin{aligned} \begin{array}{lllllllllll} {\text {x}} &{} ~~{\text {A}} &{} ~~{\text {C}} &{} ~~{\text {T}} &{} ~~{\text {G}} &{} ~~{\text {A}} &{} ~~{\text {C}} &{} ~~{\text {T}} &{} ~~{\text {G}} &{} ~~{\text {G}} &{} ~~{\text {A}} \\ {\text {Q}} &{} ~~{\text {1}} &{} ~~{\text {0}} &{} ~~{\text {1}} &{} ~~{\text {1}} &{} ~~{\text {1}} &{} ~~{\text {0}} &{} ~~{\text {1}} &{} ~~{\text {1}} &{} ~~{} &{} ~~{} \\ {{\text {x[0 + Q]}}} &{} ~~{\text {A}} &{} {} &{} ~~{\text {T}} &{} ~~{\text {G}} &{} ~~{\text {A}} &{} ~~{} &{} ~~{\text {T}} &{} ~~{\text {G}} &{} ~~{} &{} ~~{} \end{array} \end{aligned}$$
Similarly all other Q-grams are \(x[1+Q]=CGACGG\), and \(x[2+Q]=TACTGA\).
Spaced seed hashing
In order to hash any string, first we need to have a coding function from the alphabet \(\mathcal {A}\) to a binary codeword. For example let us consider the function \(encode: \mathcal {A} \rightarrow \{0,1\}^{log_2|\mathcal {A}|}\), with the following values \(encode(A)=00, encode(C)=01, encode(G)=10, encode(T)=11\). Based on this function we can compute the encodings of all symbols of the Q-gram \(x[0+Q]\) as follows:
$$\begin{aligned} \begin{array}{lllllll} {x{\text {[0 + Q]}}} &{} ~~{\text {A}} &{} ~~{\text {T}} &{} ~~{\text {G}} &{} ~~{\text {A}} &{} ~~{\text {T}} &{} ~~{\text {G}}\\ {encodings} &{} ~~{{\text {00}}} &{} ~~{{\text {11}}} &{} ~~{{\text {10}}} &{} ~~{{\text {00}}} &{} ~~{{\text {11}}} &{} ~~{{\text {10}}}\\ \end{array} \end{aligned}$$
There exist several hashing functions, in this paper we consider the Rabin-Karp rolling hash, defined as \(h(x[0+Q])=encode(A)*|\mathcal {A}|^0+encode(T)*|\mathcal {A}|^1+encode(G)*|\mathcal {A}|^2+encode(A)*|\mathcal {A}|^3+encode(T)*|\mathcal {A}|^4+encode(G)*|\mathcal {A}|^5\). In the original Rabin-Karp rolling hash all math is done in modulo n, here for simplicity we avoid that. In the case of DNA sequences \(|\mathcal {A}|=4\), that is a power of 2 and thus the multiplications can be implemented with a shift. In the above example, the hashing value associated to the Q-gram ATGATG simply corresponds to the list of encoding in Little-endian: 101100101100.
To compute the hashing value of a Q-gram from its encodings one can define the function \(h(x[i+Q])\), for any given position i of the string x, as:
$$\begin{aligned} h(x[i+Q]) = \bigvee _{k \in Q} ( encode(x_{i+k}) \ll m(k)*log_2|\mathcal {A}| ) \end{aligned}$$
Where m(k) is the number of shifts to be applied to the encoding of the k-th symbols. For a spaced seed Q the function m is defined as \(m(k)=|\{i\in Q, \text{ such } \text{ that } i < k\}|\). In other words, given a position k in the seed, m stores the number of matching positions that appear to the left of k. The vector m is important for the computation of the hashing value of a Q-gram.
In the following we report an example of hashing value computation for the Q-gram \(x[0+Q]\).
Q 1 0 1 1 1 0 1 1
m 0 1 1 2 3 4 4 5
Shifted-encodings 00 11 \(\ll\) 2 10 \(\ll\) 4 00 \(\ll\) 6 11 \(\ll\) 8 10 \(\ll\) 10
Hashing value 101100101100
The hashing values for the others Q-grams can be determined through the function \(h(x[i+Q])\) with a similar procedure. Following the above example the hashing values for the Q-grams \(x[1+Q]=CGACGG\) and \(x[2+Q]=TACTGA\) are respectively 101001001001 and 001011010011.
In this paper we decided to use the Rabin-Karp rolling hash, because it is very intuitive. There are other hashing functions, like the cyclic polynomial hash, that are usually more appropriate because of some desirable properties like uniform distribution in the output space, universality, higher-order independence [22]. In this paper we will focus on the efficient computation of the Rabin-Karp rolling hash. However, with the same paradigm proposed in the following sections, one can compute also the cyclic polynomial hash by replacing: shifts with rotations, OR with XOR, and the function encode(A) in Eq. (1) with a seed table where the letters of the DNA alphabet are assigned different random 64-bit integers.
Fast spaced seed hashing
In many applications [11,12,13,14,15, 17] it is important to scan a given string x and to compute the hashing values over all positions. In this paper we want to address the following problem.
Let us consider a string \(x= x_0 x_1 \ldots x_i \ldots x_{n-1}\), of length n, a spaced seed Q and an hash function h that maps strings into a binary codeword. We want to compute the hashing values \(\mathcal {H}(x,Q)\) for all the Q-grams of x, in the natural order starting from the first position 0 of x to the last \(n-s(Q)\).
$$\begin{aligned} \mathcal {H}(x,Q) = \langle h(x[0+Q]), h(x[1+Q]), \dots h(x[n-s(Q)]) \rangle \end{aligned}$$
Clearly, in order to address Problem 1, it is possible to use Eq. 1 for each position of x. Note that, in order to compute the hashing function \(h(x[i+Q])\) for a given position, the number of symbols that have to be extracted from x and encoded into the hash is equal to the weight of the seed |Q|. Thus such an approach can be very time consuming, requiring the encoding of \(|Q|(n-s(Q))\) symbols. In summary, loosely speaking, in the above process each symbol of x is read and encoded into the hash |Q| times.
In this paper we present a solution for Problem 1 that is optimal in the number of encoded symbols. The scope of this study is to minimize the number of times that a symbol needs to be read and encoded for the computation of \(\mathcal {H}(x,Q)\). Since the hashing values are computed in order, starting from the first position, the idea is to speed up the computation of the hash at a position i by reusing part of the hashes already computed at previous positions.
As mentioned above, using Eq. 1 in each position of an input string x is a simple possible way to compute the hashing values \(\mathcal {H}(x,Q)\). However, we can study how the hashing values are built in order to develop a better method. For example, let us consider the simple case of a contiguous k-mers. Given the hashing value at position i it is possible to compute the hashing for position \(i+1\), with three operations: a rotation, the deletion of the encoding of the symbol at position i, and the insertion of the encoding of the symbol at position \(i+k\), since the two hashes share \(k-1\) symbols. In fact in [22] the authors showed that this simple observation can speed up the hashing of a string by recursively applying these operations. However, if we consider the case of a spaced seed Q, we can clearly see that this observation does not hold. In fact, in the above example, two consecutive Q-grams, like \(x[0+Q]=ATGATG\) and \(x[1+Q]=CGACGG\), do not necessarily have much in common.
In the case of spaced seeds the idea of reusing part of the previous hash to compute the next one needs to be further developed. More precisely, because of the shape of a spaced seed, we need to explore not only the hash at the previous position, but all the \(s(Q)-1\) previous hashes.
Let us assume that we want to compute the hashing value at position i and that we already know the hashing value at position \(i-j\), with \(j<s(Q)\). We can introduce the following definition of \(\mathcal {C}_j = \{k-j \in Q: k \in Q \wedge m(k-j) = m(k)-m(j)\}\) as the positions in Q that after j shifts are still in Q with the propriety of \(m(k-j) = m(k)-m(j)\). In other words, if we are processing the position i of x and we want to reuse the hashing value already computed at position \(i-j\), \(\mathcal {C}_j\) represents the symbols of \(h(x[i-j+Q])\) that we can keep while computing \(h(x[i+Q])\). More precisely, we can keep the encoding of \(|\mathcal {C}_j|\) symbols from that hash and insert the remaining \(|Q| - |\mathcal {C}_j|\) symbols at positions Q \(\backslash\) \(C_j\).
If we know the first hashing value \(h(x[0+Q])\) and we want to compute the second hash \(h(x[1+Q])\), the following example show how to construct \(C_1\).
k 0 1 2 3 4 5 6 7
Q\(\ll\)1 1 0 1 1 1 0 1 1
m(k) 0 1 1 2 3 4 4 5
m(k) − m(1) − 1 0 0 1 2 3 3 4
\(C_1\) 2 3 6
The symbols at positions \(C_1=\{2,3,6\}\) of the hash \(h(x[1+Q])\) have already been encoded in the hash \(h(x[0+Q])\) and we can keep them. In order to complete \(h(x[1+Q])\), the remaining \(|Q| - |\mathcal {C}_1|= 3\) symbols need to be read from x at positions \(i+k\), where \(i=1\) and \(k \in Q \backslash C_1 = \{0,4,7\}\).
x A C T G A C T G G A
\(x[0+Q]\) A T G A T G
\(Q \backslash C_1\) 0 4 7
\(x[1+Q]\) C G A C G G
Note that the definition of \(|\mathcal {C}_j|\) is not equivalent to the overlap complexity of two spaced seeds, as defined in [19]. In some cases, like the one presented above, the overlap complexity coincides with \(|\mathcal {C}_1|=3\). However, there are other cases where \(|\mathcal {C}_j|\) is smaller than the overlap complexity.
Let us consider the hash at position 2 \(h(x[2+Q])\), and the hash at position 0 \(h(x[0+Q])\). In this case we are interested in \(\mathcal {C}_2\).
Q \(\ll\) 2 1 0 1 1 1 0 1 1
\(C_2\) 0 4
The only symbols that can be preserved from \(h(x[0+Q])\) in order to compute \(h(x[2+Q])\) are those at positions 0 and 4, whereas the overlap complexity is 3.
For completeness we report all values of \(\mathcal {C}_j\):
$$\begin{aligned} \mathcal {C}&=\langle \mathcal {C}_1, \ldots , \mathcal {C}_7\rangle \\ &= \langle\{2,3,6\}, \{0,4\}, \{0,3,4\}, \{0,2,3\}, \{2\}, \{0\}, \{0\}\rangle \end{aligned}$$
In order to address Problem 1, we need to find, for a given position i, the best previous hash that ensures to minimize the number of times that a symbol needs to be read and encoded, in order to compute \(h(x[i+Q])\). We recall that \(|\mathcal {C}_j|\) represents the number of symbols that we can keep from the previous hash at position \(i-j\), and thus the number of symbols that needs to be read and encoded are |Q \(\backslash\) \(C_j|\). To solve Problem 1 and to minimize the number of symbols that needs to be read, |Q \(\backslash\) \(C_j|\), it is enough to search for the j that maximizes \(|\mathcal {C}_j|\). The best previous hash can be detected with the following function:
$$\begin{aligned} ArgBH(s)= \arg \max _{j\in [1,s]} |\mathcal {C}_j| \end{aligned}$$
If we have already computed the previous j hashes, the best hashing value can be found at position \(i-ArgBH(j)\), and will produce the maximum saving \(|\mathcal {C}_{ArgBH(j)}|\) in terms of symbols that can be kept. Following the above observation we can compute all hashing values \(\mathcal {H}(x, Q)\) incrementally, by using dynamic programming as described by the pseudocode of FSH.
The above dynamic programming algorithm, FSH, scans the input string x and computes all hashing value according to the spaced seed Q. In order to better understand the amount of savings we evaluate the above algorithm by counting the number of symbols that are read and encoded. First, we can consider the input string to be long enough so that we can discard the transient of the first \(s(Q)-1\) hashes. Let us continue to analyze the spaced seed 10111011. If we use the standard function \(h(x[i+Q])\) to compute all hashes, each symbol of x is read \(|Q|=6\) times. With our algorithm, we have that \(|\mathcal {C}_{ArgBH(7)}|=3\) and thus half of the symbols do need to be encoded again, overall each symbol is read three times. The amount of saving depends on the structure of the spaced seed. For example, the spaced seed 10101010101, with the same weight \(|Q|=6\), is the one that ensures the best savings (\(|\mathcal {C}_{ArgBH(10)}|=5\)). In fact, with our algorithm, we can compute all hashing values while reading each symbol of the input string only once, as with contiguous k-mers. To summarize, if one needs to scan a string with a spaced seed and to compute all hashing values, the above algorithm guarantees to minimize the number of symbols to read.
Fast multiple spaced seed hashing
Using multiple spaced seeds, instead of just one spaced seed, is reported to increase the sensitivity [14]. Therefore, applications that exploit such an observation (for example [15,16,17, 26]) will benefit from further speedup that can be obtained from the information already computed from multiple spaced seeds.
Our algorithm, FSH, can be extended to accommodate the need of hashing multiple spaced seeds simultaneously, without backtracking. Let us assume that we have a set \(S={s_1,s_2,..., s_{|S|}}\) of spaced seeds, all of the same length L, from which we can compute the corresponding vectors \(m_{s_i}\). To this purpose, FSH needs to be modified as follows. First of all, a new cycle (between steps 2 and 14) is needed to iterate the processing among the set of all spaced seeds. Next, \(\mathcal {C}_j\) needs to be redefined so that it compares not only a given spaced seed with itself, but all spaced seeds vs all:
$$\begin{aligned} \mathcal {C}^{yz}_j = \{k-j \in s_y: k \in s_z \wedge m_{s_y}(k-j) = m_{s_z}(k)-m_{s_z}(j)\} \end{aligned}$$
In the new definition \(\mathcal {C}^{yz}_j\) evaluates the number of symbols in common between the seed \(s_y\) and the j-th shift of the seed \(s_z\). The function \(\mathcal {C}^{yz}_j\) allows to identify, while computing the hash of \(s_y\), the number of symbols in common with the j-th shift of seed \(s_z\). Similarly, we need to redefine ArgBH(i) so that it detects not only the best previous hash, but also the best seed. We define
$$\begin{aligned} ArgBSH(y,s)= \arg \max _{z \in [1,|S|], j\in [1,s] } |\mathcal {C}^{yz}_j| \end{aligned}$$
that returns, for the seed \(s_y\), the pair \((s_z,p)\) representing the best seed \(s_z\) and best hash p. With these new definitions we can now adjust our algorithm so that, while computing the hash of \(s_y\) for a given position i, it can start from the best previous hash identified by the pair \(ArgBSH(y,s)=(s_z,p)\). The other steps for the insertion of the remaining symbols do not need to be modified.
In this section we will discuss the improvement in terms of time speedup of our approach (\(T_{FSH}\)) with respect to the time \(T_{Eq1}\) needed for computing spaced seeds hashing repeatedly using Eq. 1: \(\text{ speedup } = \frac{T_{Eq1}}{T_{FSH}}\).
Spaced seeds and datasets description
The spaced seeds we used have been proposed in literature as maximizing the hit probability [17], minimizing the overlap complexity [18] and maximizing the sensitivity [18]. We tested nine of such spaced seeds, three for each category. The spaced seeds are reported in Table 1 and labeled Q1, Q2, ...,Q9. Besides these spaced seeds, we also tested Q0, which corresponds to an exact match with a 22mer (all 22 positions are set to 1), and Q10, a spaced seed with repeated '10' and a total of 22 symbols equal to '1'. All spaced seeds \(Q0-Q10\) have the same weight \(|Qi|=22\). Furthermore, in order to compare seeds with different density, we computed with rasbhari several sets of seeds with weights from 11 to 32 and lengths from 16 to 45.
Table 1 The nine spaced seeds used in the experiments grouped according to their type
The datasets we used were taken from previous scientific papers on metagenomic read binning and classification [6, 27]. We considered both simulated datasets (S,L,R), and synthetic datasets (MiSeq, HiSeq, MK_a1, MK_a2, and simBA5). The datasets \(S_x\) and \(L_x\) contain sets of paired-end reads of length approximately 80 bp generated according to the Illumina error profile with an error rate of 1%, while the datasets \(R_x\) contain Roche 454 single-end long reads of length approximately 700bp, and a sequencing error of 1%. The synthetic datasets represent mock communities built from real shotgun reads of various species. Table 2 shows, for each dataset, the number of reads and their average length.
Table 2 Number of reads and average lengths for each of the dataset used in our experiments
All the experiments where run on a laptop equipped with an Intel i74510U cpu at 2 GHz, and 16 GB RAM.
Analysis of the time performances
Figure 1 plots, for each spaced seed, the speedup that is obtainable with our approach with respect to the standard hashing computation. As a reference, the baseline given by the standard approach is about 17 min to compute the hash for a given seed on all datasets.
The speedup of our approach with respect to the standard hashing computation, as a function of the spaced seeds used in our experiments
First of all it can be noticed that our approach improves over the standard algorithm for all of the considered spaced seeds. The smallest improvements are for the spaced seeds Q2 and Q3, both belonging to the class of spaced seeds maximizing the hit probability, for which the speedup is almost 1.2\(\times\), and the running time is about 15 min. For all the other spaced seeds the speedup is close to 1.6\(\times\), thus saving about 40% of the time required by the standard computation, and ending the computation in less than 11 min on average.
Figure 2 shows the performances of our approach with respect to the single datasets. In this experiment we considered the best performing spaced seed in each of the classes that we considered, namely Q1, Q6, and Q9, and the two additional special cases Q0 and Q10.
Details of the speedup on each of the considered datasets. Q0 is the solid 22mer, Q10 is the spaced seed with repeated 10. The other reported spaced seeds are the ones with the best performances for each class: Q1 (maximizing the hit probability), Q6 (minimizing the overlap complexity) and Q9 (maximizing the sensitivity)
We notice that for the spaced seeds Q0 and Q10 the standard approach requires respectively, 12 and 10 min, to process all datasets. This is already an improvement of the standard method with respect to the 17 min required with the other seeds \(Q1-Q9\). Nevertheless, with our algorithm the hashing of all dataset can be completed in just 2.7 min for Q0 e 2.5 min for Q10, with a speedup of 4.5\(\times\) and 4.2\(\times\).
We observe that while the speedup for the spaced seeds Q1, Q6, and Q9 is basically independent on the dataset and about 1.6\(\times\), the speedup for both the 22-mer Q0 and the 'alternate' spaced seed Q10 is higher, spanning from 4.3\(\times\) to 5.3\(\times\), depending on the seed and on the dataset. In particular, the speedup increases with the length of the reads and it achieves the highest values for the long read datasets \(R_7, R_8\) and \(R_9\). This behavior is expected, as these datasets have longer reads with respect to the others, thus the effect of the initial transient is mitigated.
Multiple spaced seed hashing
When the analysis of biological data to perform requires the use of multiple spaced seeds, it is possible to compute the hash of all seeds simultaneously while reading the input string with the method described in Section.
In Fig. 3 we report the comparison between the speedup we obtained when computing the hash for each spaced seed Q1,...,Q9 independently (light grey), and the speedup we obtained when using the multiple spaced seeds approach (dark grey).
Details of the time speedup of our approach with the multiple spaced seeds hashing (dark grey) and of our approach with each spaced seed hashed independently (light grey)
In most cases, multiple spaced seed hashing allows for a further improvement of about 2–5%, depending on the dataset. In terms of absolute values, the standard computation to hash all datasets requires 159 min, the computation of all seeds independently with the approach described in Section takes 109 min, while the simultaneous computation of multiple spaced seeds with our method takes 107 min. When considering all datasets the average speedup increases from 1.45\(\times\) (independent computation) to 1.49\(\times\) (simultaneous computation). The small improvement can be justified by the fact that the spaced seeds considered are by construction with minimal overlap.
Predicted speedup vs real speedup
In Fig. 4 are reported the average speedup (Real), over all datasets, for the three different groups of nine seeds with the same density (W/L), generated with rasbhari [18]. In the same Figure we include also the speedup when all nine seeds are used simultaneously (Multi) and the theoretical speedup predicted by our method (Predicted).
The theoretical and real speedup of our approach with respect to the standard hashing computation, as a function of the spaced seeds weight
As, for the theoretical predicted speedups, these are usually in line with the real speedups even if the absolute values are not necessarily close. We suspect that the model we use, where shifts and insertions have the same cost, is too simplistic. Probably, the real computational cost for the insertion of a symbol is greater than the cost for shifting, and also cache misses might play a role.
If the theoretical speedup for multiple seeds is greater than the theoretical speedup for independent seeds, this indicates that in principle, with multiple seeds, it is possible to improve with respect to the computation of seeds independently. It is interesting to note that the real results confirm these predictions. For example, in the multiple seeds with weights 32, it is impossible to improve both theoretically and in practice. In the other two cases, the computation of multiple seeds is faster in practice as correctly predicted by the theoretical speedup.
The effect of spaced seeds weight and reads length
To better understand the impact of reads length and density of spaced seeds on the speedup, in this section we report a series of experiments under various conditions. In order to compare the performance of our method on spaced seeds with different weights we generated several sets of nine spaced seeds with rasbhari [18] with weights from 11 to 32 and lengths from 16 to 45. First, we test how the reads length affects the speedup. In Fig. 5 we report the speedup as a function of the reads length, for various spaced seeds with the same density (W / L).
The speedup of our approach with respect to the standard hashing computation as a function of reads length and the spaced seeds weight (all with the same density)
We can observe that the speedup increases as a function of the reads length. This is expected, in fact the effect of the initial transient of our hashing computation is mitigated on longer reads. Another interesting behavior is the fact that, although the spaced seeds have all the same density, longer spaced seeds have the highest speedup. A possible explanation lies in the way our algorithm works. Since our hashing computation explores the previous L hashes searching for redundancies, as the length of the spaced seed increases, also our ability to reuse the previous hashes increases, and similarly it does the speedup.
In Fig. 6 we compare the speedup of various spaced seeds as a function of the weight W, while the length \(L=31\) remains constant.
The speedup of our approach with respect to the standard hashing computation as a function of reads length and the spaced seeds density (L=31 and W varies)
We can note that if the weight of the seeds grows then also the speedup grows. This behavior is observed for various reads length. This phenomenon can be explained as follows, if a spaced seed has more 1s (higher weight), then the chances to reuse part of the seed increase, and consequently the speedup of FSH increases.
Conclusions and future work
In this paper we tackle the problem of designing faster algorithms for the computation of spaced seed hashing. We presented a new approach, FSH, for spaced seeds hashing that exploits the information from adjacent hashes, in order to minimize the operations that need to be performed to compute the next hash. In summary, FSH can speedup spaced seed hashing on various conditions. The experiments we performed, on short NGS reads, showed that FSH has a speedup of 1.6\(\times\), with respect to the standard approach, for several kind of spaced seeds defined in the literature. Furthermore, the gain greatly improved in special cases, where seeds show a high autocorrelation, and for which a speed up of about 4\(\times\) to 5\(\times\) can be achieved. The benefit in terms of computation time increases as the length of the reads grows, like in modern sequencing technologies, or when long and complex spaced seeds are needed.
Another contribution of this work is to open the way to the development of further research on methods for speeding up spaced seed hashing computation. In the future, we plan to investigate alternative ways to compute spaced seed hashing based on indexing strategies. Another interesting direction of research is to experimentally evaluate the impact of fast spaced seed hashing in different bioinformatics contexts where tools based on spaced seeds are used.
a preliminary version of this manuscript was published in [24].
Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ. Basic local alignment search tool. J Mol Biol. 1990;215(3):403–10.
Buhler J. Efficient large-scale sequence comparison by locality-sensitive hashing. Bioinformatics. 2001;17(5):419.
Ma B, Tromp J, Li M. Patternhunter: faster and more sensitive homology search. Bioinformatics. 2002;18(3):440.
Comin M, Antonello M. Fast entropic profiler: an information theoretic approach for the discovery of patterns in genomes. IEEE/ACM Trans Comput Biol Bioinformatics. 2014;11(3):500–9.
Comin M, Leoni A, Schimd M. Clustering of reads with alignment-free measures and quality values. Algorithms Mol Biol. 2015;10(1):4.
Girotto S, Pizzi C, Comin M. MetaProb: accurate metagenomic reads binning based on probabilistic sequence signatures. Bioinformatics. 2016;32(17):567–75. https://doi.org/10.1093/bioinformatics/btw466.
Ounit R, Wanamaker S, Close TJ, Lonardi S. Clark: fast and accurate classification of metagenomic and genomic sequences using discriminative k-mers. BMC Genomics. 2015;16(1):1–13.
Pizzi C, Ukkonen E. Fast profile matching algorithms-a survey. Theor Comput Sci. 2008;395(2):137–57.
Parida L, Pizzi C, Rombo SE. Irredundant tandem motifs. Theor Comput Sci. 2014;525:89–102.
Shajii A, Yorukoglu D, William Yu Y, Berger B. Fast genotyping of known snps through approximate k -mer matching. Bioinformatics. 2016;32(17):538.
Darling AE, Treangen TJ, Zhang L, Kuiken C, Messeguer X, Perna NT. In: Bücher P, Moret BME, editors. Procrastination leads to efficient filtration for local multiple alignment. Berlin: Springer; 2006. p. 126–37.
Onodera T, Shibuya T. The gapped spectrum kernel for support vector machines. In: Proceedings of the 9th international conference on machine learning and data mining in pattern recognition. MLDM'13, pp. 1–15. Springer, Berlin, Heidelberg 2013.
Rumble SM, Lacroute P, Dalca AV, Fiume M, Sidow A, Brudno M. Shrimp: accurate mapping of short color-space reads. PLOS Comput Biol. 2009;5(5):1–11.
Leimeister C-A, Boden M, Horwege S, Lindner S, Morgenstern B. Fast alignment-free sequence comparison using spaced-word frequencies. Bioinformatics. 2014;30(14):1991.
Bainda K, Sykulski M, Kucherov G. Spaced seeds improve k-mer-based metagenomic classification. Bioinformatics. 2015;31(22):3584.
Girotto S, Comin M, Pizzi C. Metagenomic reads binning with spaced seeds. Theor Comput Sci. 2017;698:88–99.
Ounit R, Lonardi S. Higher classification sensitivity of short metagenomic reads with clark-s. Bioinformatics. 2016;32(24):3823.
Hahn L, Leimeister C-A, Ounit R, Lonardi S, Morgenstern B. Rasbhari: optimizing spaced seeds for database searching, read mapping and alignment-free sequence comparison. PLOS Comput Biol. 2016;12(10):1–18.
Ilie L, Ilie S, Mansouri Bigvand A. Speed: fast computation of sensitive spaced seeds. Bioinformatics. 2011;27(17):2433.
Ma B, Li M. On the complexity of the spaced seeds. J Comput Syst Sci. 2007;73(7):1024–34.
Brown DG, Li M, Ma B. A tutorial of recent developments in the seeding of local alignment. J Bioinformatics Comput Biol. 2004;02(04):819–42.
Mohamadi H, Chu J, Vandervalk BP, Birol I. ntHash: recursive nucleotide hashing. Bioinformatics. 2016;32(22):3492–4. https://doi.org/10.1093/bioinformatics/btw397.
Lindgreen S, Adair KL, Gardner P. An evaluation of the accuracy and speed of metagenome analysis tools. Sci Rep. 2016;6:19233.
Girotto S, Comin M, Pizzi C. Fast spaced seed hashing. In: Schwartz R, Reinert K, editors. In: 17th international workshop on algorithms in bioinformatics (WABI 2017), vol 88. Leibniz international proceedings in informatics (LIPIcs)Dagstuhl: Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik; 2017. pp. 7–1714.
Keich U, Li M, Ma B, Tromp J. On spaced seeds for similarity search. Dis Appl Math. 2004;138(3):253–63.
Girotto S, Comin M, Pizzi C. Binning metagenomic reads with probabilistic sequence signatures based on spaced seeds. In: 2017 IEEE conference on computational intelligence in bioinformatics and computational biology (CIBCB). pp. 1–8. 2017.
Wood DE, Salzberg SL. Kraken: ultrafast metagenomic sequence classification using exact alignments. Genome Biol. 2014;15:46.
All authors contributed to the design of the approach, the analysis of the results, and the writing of the paper. CP and MC conceived the study. SG implemented the FSH software tool. SG and MC performed the experiments. CP coordinated and supervised the work. All authors read and approved the final manuscript.
This work was supported by the Italian MIUR project "Compositional Approaches for the Characterization and Mining of Omics Data" (PRIN20122F87B2).
Department of Information Engineering, University of Padova, via Gradenigo 6/A, Padova, Italy
Samuele Girotto, Matteo Comin & Cinzia Pizzi
Samuele Girotto
Cinzia Pizzi
Correspondence to Matteo Comin or Cinzia Pizzi.
Girotto, S., Comin, M. & Pizzi, C. FSH: fast spaced seed hashing exploiting adjacent hashes. Algorithms Mol Biol 13, 8 (2018). https://doi.org/10.1186/s13015-018-0125-4
Spaced seeds
K-mers
Efficient hashing | CommonCrawl |
Quasi-effective stability for nearly integrable Hamiltonian systems
Global behavior of delay differential equations model of HIV infection with apoptosis
January 2016, 21(1): 81-102. doi: 10.3934/dcdsb.2016.21.81
Global existence and boundedness in a parabolic-elliptic Keller-Segel system with general sensitivity
Kentarou Fujie 1, and Takasi Senba 2,
Department of Mathematics, Tokyo University of Science, Tokyo 162-8601
Department of Mathematics, Kyushu Institute of Technology, Sensuicho, Tobata, Kitakyushu 804-8550
Received June 2015 Revised July 2015 Published November 2015
This paper is concerned with the parabolic-elliptic Keller-Segel system with signal-dependent sensitivity $\chi(v)$, \begin{align*} \begin{cases} u_t=\Delta u - \nabla \cdot ( u \nabla \chi(v)) &\mathrm{in}\ \Omega\times(0,\infty), \\ 0=\Delta v -v+u &\mathrm{in}\ \Omega\times(0,\infty), \end{cases} \end{align*} under homogeneous Neumann boundary condition in a smoothly bounded domain $\Omega \subset \mathbb{R}^2$ with nonnegative initial data $u_0 \in C^{0}(\overline{\Omega})$, $\not\equiv 0$.
In the special case $\chi(v)=\chi_0 \log v\, (\chi_0>0)$, global existence and boundedness of the solution to the system were proved under some smallness condition on $\chi_0$ by Biler (1999) and Fujie, Winkler and Yokota (2015). In the present work, global existence and boundedness in the system will be established for general sensitivity $\chi$ satisfying $\chi'>0$ and $\chi'(s) \to 0 $ as $s\to \infty$. In particular, this establishes global existence and boundedness in the case $\chi(v)=\chi_0\log v$ with large $\chi_0>0$. Moreover, although the methods in the previous results are effective for only few specific cases, the present method can be applied to more general cases requiring only the essential conditions. Actually, our condition is necessary, since there are many radial blow-up solutions in the case $\inf_{s>0} \chi^\prime (s) >0$.
Keywords: logarithmic sensitivity, $\varepsilon$-regularity., boundedness, global existence, Chemotaxis.
Mathematics Subject Classification: Primary: 35B45, 35K55; Secondary: 92C1.
Citation: Kentarou Fujie, Takasi Senba. Global existence and boundedness in a parabolic-elliptic Keller-Segel system with general sensitivity. Discrete & Continuous Dynamical Systems - B, 2016, 21 (1) : 81-102. doi: 10.3934/dcdsb.2016.21.81
P. Biler, Global solutions to some parabolic-elliptic systems of chemotaxis,, Adv. Math. Sci. Appl., 9 (1999), 347. Google Scholar
H. Brézis and W. Strauss, Semi-linear second-order elliptic equations in $L^1$,, J. Math. Soc. Japan, 25 (1973), 565. doi: 10.2969/jmsj/02540565. Google Scholar
S. Y. A. Chang and P. Yang, Conformal deformation of metrics on $S^2$,, J. Differential Geom., 27 (1988), 259. Google Scholar
K. Fujie, Boundedness in a fully parabolic chemotaxis system with singular sensitivity,, J. Math. Anal. Appl., 424 (2015), 675. doi: 10.1016/j.jmaa.2014.11.045. Google Scholar
K. Fujie, M. Winkler and T. Yokota, Boundedness of solutions to parabolic-elliptic Keller-Segel systems with signal-dependent sensitivity,, Math. Methods Appl. Sci., 38 (2015), 1212. doi: 10.1002/mma.3149. Google Scholar
K. Fujie and T. Yokota, Boundedness in a fully parabolic chemotaxis system with strongly singular sensitivity,, Appl. Math. Lett., 38 (2014), 140. doi: 10.1016/j.aml.2014.07.021. Google Scholar
M. A. Herrero and J. J. L. Velázquez, A blow-up mechanism for a chemotaxis model,, Ann. Scuola Norm. Sup. Pisa Cl. Sci., 24 (1997), 663. Google Scholar
T. Hillen and K. Painter, A user's guide to PDE models for chemotaxis,, J. Math. Biol., 58 (2009), 183. doi: 10.1007/s00285-008-0201-3. Google Scholar
D. Horstmann, From 1970 until present: The Keller-Segel model in chemotaxis and its consequences. I,, Jahresber. Deutsch. Math.-Verein., 105 (2003), 103. Google Scholar
W. Jäger and S. Luckhaus, On explosions of solutions to a system of partial differential equations modelling chemotaxis,, Trans. Amer. Math. Soc., 329 (1992), 819. doi: 10.1090/S0002-9947-1992-1046835-6. Google Scholar
E. F. Keller and L. A. Segel, Initiation of slime mold aggregation viewed as an instability,, J. Theor. Biol., 26 (1970), 399. doi: 10.1016/0022-5193(70)90092-5. Google Scholar
E. F. Keller and L. A. Segel, Traveling bands of chemotactic bacteria: A theoretical analysis,, J. Theor. Biol., 30 (1971), 235. doi: 10.1016/0022-5193(71)90051-8. Google Scholar
T. Nagai, Blow-up of radially symmetric solutions to a chemotaxis system,, Adv. Math. Sci. Appl., 5 (1995), 581. Google Scholar
T. Nagai, Blow-up of nonradial solutions to parabolic-elliptic systems modeling chemotaxis in two dimensional domains,, J. Inequal. Appl., 6 (2001), 37. doi: 10.1155/S1025583401000042. Google Scholar
T. Nagai and T. Senba, Global existence and blow-up of radial solutions to a parabolic-elliptic system of chemotaxis,, Adv. Math. Sci. Appl., 8 (1998), 145. Google Scholar
T. Nagai, T. Senba and K. Yoshida, Application of the Trudinger-Moser inequality to a parabolic system of chemotaxis,, Funkc. Ekvacioj, 40 (1997), 411. Google Scholar
V. Nanjundiah, Chemotaxis, signal relaying and aggregation morphology,, J. Theor. Biol., 42 (1973), 63. doi: 10.1016/0022-5193(73)90149-5. Google Scholar
T. Senba and T. Suzuki, Chemotactic collapse in a parabolic-elliptic system of mathematical biology,, Adv. Differential Equations, 6 (2001), 21. Google Scholar
Y. Sugiyama, On $\varepsilon$-regularity theorem and asymptotic behaviors of solutions for Keller-Segel systems,, SIAM J. Math. Anal., 41 (2009), 1664. doi: 10.1137/080721078. Google Scholar
M. Winkler, Absence of collapse in a parabolic chemotaxis system with signal-dependent sensitivity,, Math. Nachr., 283 (2010), 1664. doi: 10.1002/mana.200810838. Google Scholar
M. Winkler, Global solutions in a fully parabolic chemotaxis system with singular sensitivity,, Math. Methods Appl. Sci., 34 (2011), 176. doi: 10.1002/mma.1346. Google Scholar
Wei Wang, Yan Li, Hao Yu. Global boundedness in higher dimensions for a fully parabolic chemotaxis system with singular sensitivity. Discrete & Continuous Dynamical Systems - B, 2017, 22 (10) : 3663-3669. doi: 10.3934/dcdsb.2017147
Sachiko Ishida. Global existence and boundedness for chemotaxis-Navier-Stokes systems with position-dependent sensitivity in 2D bounded domains. Discrete & Continuous Dynamical Systems - A, 2015, 35 (8) : 3463-3482. doi: 10.3934/dcds.2015.35.3463
Johannes Lankeit, Yulan Wang. Global existence, boundedness and stabilization in a high-dimensional chemotaxis system with consumption. Discrete & Continuous Dynamical Systems - A, 2017, 37 (12) : 6099-6121. doi: 10.3934/dcds.2017262
Qi Wang. Boundary spikes of a Keller-Segel chemotaxis system with saturated logarithmic sensitivity. Discrete & Continuous Dynamical Systems - B, 2015, 20 (4) : 1231-1250. doi: 10.3934/dcdsb.2015.20.1231
Ling Liu, Jiashan Zheng. Global existence and boundedness of solution of a parabolic-parabolic-ODE chemotaxis-haptotaxis model with (generalized) logistic source. Discrete & Continuous Dynamical Systems - B, 2019, 24 (7) : 3357-3377. doi: 10.3934/dcdsb.2018324
Qi Wang. Global solutions of a Keller--Segel system with saturated logarithmic sensitivity function. Communications on Pure & Applied Analysis, 2015, 14 (2) : 383-396. doi: 10.3934/cpaa.2015.14.383
Alexandre Montaru. Wellposedness and regularity for a degenerate parabolic equation arising in a model of chemotaxis with nonlinear sensitivity. Discrete & Continuous Dynamical Systems - B, 2014, 19 (1) : 231-256. doi: 10.3934/dcdsb.2014.19.231
Hao Yu, Wei Wang, Sining Zheng. Global boundedness of solutions to a Keller-Segel system with nonlinear sensitivity. Discrete & Continuous Dynamical Systems - B, 2016, 21 (4) : 1317-1327. doi: 10.3934/dcdsb.2016.21.1317
Youshan Tao, Lihe Wang, Zhi-An Wang. Large-time behavior of a parabolic-parabolic chemotaxis model with logarithmic sensitivity in one dimension. Discrete & Continuous Dynamical Systems - B, 2013, 18 (3) : 821-845. doi: 10.3934/dcdsb.2013.18.821
Masaaki Mizukami. Boundedness and asymptotic stability in a two-species chemotaxis-competition model with signal-dependent sensitivity. Discrete & Continuous Dynamical Systems - B, 2017, 22 (6) : 2301-2319. doi: 10.3934/dcdsb.2017097
Youshan Tao. Global dynamics in a higher-dimensional repulsion chemotaxis model with nonlinear sensitivity. Discrete & Continuous Dynamical Systems - B, 2013, 18 (10) : 2705-2722. doi: 10.3934/dcdsb.2013.18.2705
Hua Zhong, Chunlai Mu, Ke Lin. Global weak solution and boundedness in a three-dimensional competing chemotaxis. Discrete & Continuous Dynamical Systems - A, 2018, 38 (8) : 3875-3898. doi: 10.3934/dcds.2018168
Chunhua Jin. Boundedness and global solvability to a chemotaxis-haptotaxis model with slow and fast diffusion. Discrete & Continuous Dynamical Systems - B, 2018, 23 (4) : 1675-1688. doi: 10.3934/dcdsb.2018069
Mengyao Ding, Wei Wang. Global boundedness in a quasilinear fully parabolic chemotaxis system with indirect signal production. Discrete & Continuous Dynamical Systems - B, 2019, 24 (9) : 4665-4684. doi: 10.3934/dcdsb.2018328
Marcel Freitag. Global existence and boundedness in a chemorepulsion system with superlinear diffusion. Discrete & Continuous Dynamical Systems - A, 2018, 38 (11) : 5943-5961. doi: 10.3934/dcds.2018258
T. Hillen, K. Painter, Christian Schmeiser. Global existence for chemotaxis with finite sampling radius. Discrete & Continuous Dynamical Systems - B, 2007, 7 (1) : 125-144. doi: 10.3934/dcdsb.2007.7.125
Shuguang Shao, Shu Wang, Wen-Qing Xu. Global regularity for a model of Navier-Stokes equations with logarithmic sub-dissipation. Kinetic & Related Models, 2018, 11 (1) : 179-190. doi: 10.3934/krm.2018009
Pan Zheng. Global boundedness and decay for a multi-dimensional chemotaxis-haptotaxis system with nonlinear diffusion. Discrete & Continuous Dynamical Systems - B, 2016, 21 (6) : 2039-2056. doi: 10.3934/dcdsb.2016035
Sainan Wu, Junping Shi, Boying Wu. Global existence of solutions to an attraction-repulsion chemotaxis model with growth. Communications on Pure & Applied Analysis, 2017, 16 (3) : 1037-1058. doi: 10.3934/cpaa.2017050
Radek Erban, Hyung Ju Hwang. Global existence results for complex hyperbolic models of bacterial chemotaxis. Discrete & Continuous Dynamical Systems - B, 2006, 6 (6) : 1239-1260. doi: 10.3934/dcdsb.2006.6.1239
Kentarou Fujie Takasi Senba | CommonCrawl |
Physics Meta
Physics Stack Exchange is a question and answer site for active researchers, academics and students of physics. It only takes a minute to sign up.
Is all angular momentum quantized?
Angular momentum is definitely quantized in elementary particles and electrons in atoms. Molecules also have characteristic rotation spectra.
Is it true that all angular momentum is quantized, including big things like automobile tires, flywheels and planets?
If so what is the largest object for which this quantized rotation has been verified/observed/measured?
quantum-mechanics angular-momentum rotation discrete
Qmechanic♦
Jim GraberJim Graber
$\begingroup$ I'm quite sure it's true even for macroscopic objects, albeit obviously not measurable since $\hbar\ll L$. But what's the biggest objects for which it is measurable would be interesting to know $\endgroup$
– leftaroundabout
$\begingroup$ I would submit the angular momentum of neutron stars as the answer, but someone who really knows (I worry it might be apocryphal) should write it up. Most of the neutron star should be some form of superfluid, in which angular momentum must be contained in vortices (similar to en.wikipedia.org/wiki/Abrikosov_vortex). As the rotation slows due to radiation/energy loss the vortices leave one by one from the core, and it is possible to observe the spikes in the rotation rate: en.wikipedia.org/wiki/Glitch_(astronomy) $\endgroup$
– genneth
$\begingroup$ Also, in 2D there is no need for quantised angular momentum. $\endgroup$
The angular momentum only has quantized eigenvalues; this statement is valid quite generally for all bodies. For example, $J_z$ has to be a multiple of $\hbar/2$ because $$ U = \exp(4\pi i J_z) $$ is the rotation by $4\pi$ and such a rotation brings every state to itself and has to be identity. (For a $2\pi$ rotation, the state changes the sign if it contains an odd number of fermions.) Therefore, we have $$\exp(4\pi i j_z) = 1\quad \Rightarrow\quad j_z\in\{0,\frac 12, 1, \frac 32, \dots\}$$ Can the quantization of $j_z$ be actually measured? Well, one may only measure a sharp value of $j_z$ if the object is an eigenstate. Eigenstates of $j_z$ are rotationally symmetric with respect to rotations around the $z$-axis, up to an overall phase. So if we have a non-axially-symmetric object, its sharp $j_z$ eigenvalue obviously can't be observed because it's a linear superposition of many states with different $j_z$ eigenvalues.
For atoms, the angular momentum may be observed; these are the usual quantum numbers associated with the electrons. In the same way, the total angular momentum may obviously be measured and shown to be quantized for nuclei.
Larger systems are molecules. For some molecules, the quantized nature of the angular momentum may be measured. To add some terminology, we measure the rotational quantum numbers of these molecules by observing transitions in the rotational spectrum and the method is the rotational spectroscopy:
http://en.wikipedia.org/wiki/Rotational_spectroscopy
It only applies to molecules in gases because in solids and liquids, collisions constantly distort the angular momentum. Also, one can't have a well-defined quantized $j_z$ for "true solids" i.e. crystals because crystals aren't symmetric under continuous rotations; they're only kept invariant by the discrete crystalline subgroup of the rotational group.
So the maximum size for which the quantization may be verified are "rather large" molecules of gases and the maximum size is getting larger as the progress goes on (and as people are able to reduce the temperature and improve the accuracy).
Luboš MotlLuboš Motl
$\begingroup$ I did find halexandria.org/dward156.htm about superconductors: "Although quantum mechanical behavior is usually thought of as being restricted to the microscopic scale of an atom or molecule, superconductivity operates at a macroscopic quantum level; pairs condense into a single large-scale quantum state, which has long-range order and can be described as if it was a giant molecule with a single wavefunction." $\endgroup$
– anna v
$\begingroup$ That's surely right and excitations in superconductors may have quantized spin. Still, it is hard to find that the background superconducting "medium" would be an angular momentum eigenstate. This won't really happen easily. $\endgroup$
– Luboš Motl
For those interested in an algebraic approach to this problem, it is possible to prove that angular momentum is quantized using only the commutation relations $$\mathbf{J}\times\mathbf{J}=i\hbar\mathbf{J}.$$ From these, one can build the operator $\mathbf{J}^2$, called the total angular momentum operator. One can also build the raising and lowering operators $$J_{\pm} = J_x \pm iJ_y.$$ These operators commute with $\mathbf{J}^2$ (and therefore leave its eigenvalue unchanged), and raise/lower the eigenvalue of $J_z$ by one unit of $\hbar$ (all this can be proved from the commutation relations). It is conventional to define the eigenvalue $j$ using $\hbar^2 j(j+1)=a$, where $a$ is the actual eigenvalue $\mathbf{J}^2$. It is also conventional to use $m=b/\hbar$, where $b$ is the eigenvalue of $J_z$.
With these definitions, and the commutation relations, we can prove the inequality $j(j+1)\geq m^2$ must hold for any simultaneous eigenstate of $\mathbf{J}^2$ and $J_z$. Intuitively, this just the quantum mechanics version of the fact that the $z$-component of angular momentum cannot be bigger than the total angular momentum.
Suppose $|\psi\rangle$ is an eigenstate of $\mathbf{J}^2$ and $J_z$. Then $(J_+)^n|\psi\rangle$ is also an eigenstate of these operators with the same value of $j$, but with $m$ increased by $n$. Therefore, for the inequality to always hold, we must eventually reach a termination point where $(J_+)^n|\psi\rangle=0$. Let $|\psi_\text{max}\rangle$ be the state such that $J_+|\psi_\text{max}\rangle=0$. We can determine the eigenvalues of this state using the fact that $$J_-J_+|\psi_\text{max}\rangle=J_-0=0.$$ You can show that $J_-J_+=\mathbf{J}^2-J_z^2-\hbar J_z$. Therefore, we have $$(\mathbf{J}^2-J_z^2-\hbar J_z)|\psi_\text{max}\rangle=(\hbar^2 j(j+1)-\hbar^2 m_\text{max}^2-\hbar^2 m_\text{max})|\psi_\text{max}\rangle=0$$ $$\implies j(j+1)=m_\text{max}(m_\text{max}+1)\implies j=m_\text{max}.$$ Now we just need to use the fact that $m$ cannot be lowered indefinitely without violating the inequality. This implies there is $|\psi_\text{min}\rangle$ with $$0=J_+J_-|\psi_\text{min}\rangle=(\mathbf{J}^2-J_z^2+\hbar J_z)|\psi_\text{min}\rangle=(\hbar^2j(j+1)-\hbar^2m^2_\text{min}+\hbar^2m_\text{min})|\psi_\text{min}\rangle$$ $$\implies j(j+1)=m_\text{min}(m_\text{min}-1).$$ Combining this with the relation we got above, we get $$m_\text{min}^2-m_\text{min}=m_\text{max}^2+m_\text{max}.$$ From this, we infer $m_\text{max}=-m_\text{min}$. Now if we start raising the minimum state, we must eventually get to the maximum state or we will be able to raise $m$ indefinately, violating the inequality. Therefore, $m_\text{max}=m_\text{min}+n$ for some integer $n$. Combining this with the previous equation gives $$j=m_\text{max}=\frac{n}{2}.$$ Therefore, $j$ can only be an integer or a half-integer.
YachsutYachsut
I'm going to disagree with the other answers: I think that the angular momentum of macroscopic "classical" objects is not quantized.
Consider an automobile tire spinning in a wheel well. On the tire is a device that triggers whenever a certain point on the wheel crosses a certain point on the well, adding one to an internal counter if it passes it clockwise and subtracting one if it crosses it counterclockwise. (Alternately, you could dispense with the wheel well and say that the device tracks its own position by inertial navigation.) The state of this system can be described by a value $θ\in\mathbb R$, where the current value of the counter is $\lfloor θ/2π\rfloor$ and the angle of the wheel is $θ\text{ (mod }2π\text{)}$. In the absence of external forces, the Hamiltonian of the system is essentially that of a free particle in $\mathbb R$, and the spectrum of angular momenta is continuous just like the free particle's momentum spectrum.
That's a 2+1 dimensional system. In 3+1 dimensions, there's the Dirac belt trick to worry about. Does it matter? I don't think so. There's no reason to limit the device to holding a single integer, or to being reversible. It could simply store the entire history of its orientation readings internally, or broadcast them by radio, indelibly recording them in the universal wave function. That's a very noncompact state space, and it's an accurate enough model of bodies like the earth.
The angular momentum operator on this monstrosity obviously violates the assumptions of any proof of the quantization of angular momentum, but that's no reason not to call it angular momentum. We do call it angular momentum, and it's what the question was about.
In response to comments I'll try to clarify my answer.
These are quantum systems, but the earth system is "classical" in the sense of being a quantum system with emergent classical behavior.
The reason that high temperature systems behave classically is that they constantly leak which-path information into the environment. If you do a double-slit experiment with the earth, it will emit different patterns of light going through one slit than through the other. You can literally see which slit it goes through, but even if you don't look, the which-path information is there in the patterns of light, or in patterns of heat if the light is absorbed by the walls of the lab, and that's all that's necessary to make the final states orthogonal and destroy the interference pattern.
It's sometimes said that you can't see an interference pattern in the earth double-slit experiment simply because its de Broglie wavelength is so small. That would be correct for a supermassive stable particle that doesn't radiate, but it's wrong for the earth. For the earth there's no interference pattern at all, for the same reason there's no interference pattern when there's a detector at one of the slits. Earth's thermal radiation is the "detector".
The case of rotation is similar. Different rotations are different paths through the state space (it's the state space, not physical 3D space, that the wave function is defined on and which matters here). If you consider two different paths ending in the same physical orientation (analogous to the same position on the screen in the double-slit case), these paths will interfere if no information about which path was taken is recorded anywhere. In the case of the earth, this means they'll interfere if there's no way for anyone to tell whether the earth rotated around its axis or not. If there's any record of it – if any animals remember the day-night cycle, or don't but could in principle, or if aliens see it rotate through a telescope, or don't but could in principle – then there's no interference.
The proof that angular momentum is quantized depends on the compactness of the space of orientations. This is fine if the space of orientations is the phase space, i.e., if the system is memoryless. If it has a memory, rotating the system through $2π$ or $4π$ doesn't leave it in the same state as not rotating it.
The tire example in the second paragraph may have been a mistake since it seems to have only caused confusion. But it's a perfectly good quantum system in the abstract, and its state space is $\mathbb R$, not $S^1$.
benrgbenrg
$\begingroup$ Quantization is a quantum effect, so you are completely correct that it doesn't happen if we take the classical limit. However, every object should be treated, technically speaking, with the laws of quantum mechanics, so all angular momentum is quantized, even if those effects are not noticeable. $\endgroup$
– Yachsut
$\begingroup$ The system you've described is not essentially like a free particle in $\mathbb R$, it's essentially like a free particle in a loop (i.e. in $S^1$ rather than $\mathbb R$). The momentum spectrum of a free particle in a loop is not continuous, and neither is the angular momentum spectrum here. $\endgroup$
– Chris ♦
$\begingroup$ @JoshuaTS I am treating these objects as quantum mechanical. $\endgroup$
– benrg
$\begingroup$ @Chris Every value of $θ\in\mathbb R$ maps to a distinct state of the system. The system includes the counter and its stored count. $\endgroup$
$\begingroup$ @benrg The stored count clearly has nothing to do with the physical motion of the wheel. Keeping a count of that would require an extra term in the Hamiltonian anyway- if it's truly a free particle there's no way to update the count. $\endgroup$
Thanks for contributing an answer to Physics Stack Exchange!
Not the answer you're looking for? Browse other questions tagged quantum-mechanics angular-momentum rotation discrete or ask your own question.
Proof for quantized angular momentum
Discreteness of the general angular momentum in quantum mechanics
How does angular momentum get quantized?
Why does spin have a discrete spectrum?
A universe of angular momentum?
Angular momentum needn't always change in multiples of $\hbar$?
Why must a fundamental particle's spin be a multiple of $\frac 1 2$?
What all has intrinsic spin?
Is the angular momentum of the ceiling fan quantized?
Can centrifugal force overcome other forces (in a singularity/Kerr metric)?
What is the evidence (experimental observation) that elementary particles have spin angular momentum?
Angular velocity across different reference frames | CommonCrawl |
How to "set" the lightsail?
This question asks for hard science. All answers to this question should be backed up by equations, empirical evidence, scientific papers, other citations, etc. Answers that do not satisfy this requirement might be removed. See the tag description for more information.
Suppose a starship is being powered by a lasers beamed first from the departure star, and then from the destination which is a moving base. The ship is moving in the regime of 10–30% of light speed.
Picture a letter "T". The ship is accelerated up the vertical line from the source at the bottom of the T, into the path of the horizontal cross-line. A mobile base (the destination) moving on this horizontal line at 10% lightspeed will supply a laser too.
That is, the home system will push a lightsail craft into the path of a base moving at relativistic speeds. That base would pass home with a closest approach of several light years.
Let me try another mental picture: you are a mile back on a path that intersects with a main road at a right angle. A mobile home is travelling down the main road at 70 miles per hour. The beam from home pushes you into the main road, and the beam from the mobile home needs to get you going in that direction instead for eventual rendezvous.
The mobile base needs to accelerate the incoming craft to its own oncoming speed and kill the transverse velocity.
What would the maneuver look like? I'm supposing that the angle at which it presents the sail will be significantly affected by relativistic effects and aberration of moving source.
Also, the mobile base (from a more advanced civilization) can do any advanced tricks you can imagine, such as synthetic aperture beamforming to make the wavefronts come from a different direction than the actual source, and impart orbital angular momentum to the photons.
The home beam has just enough power and focus for the maneuver it is designed for. The base beam can be more powerful and amazingly well-focused. But the base won't aim the beam directly at the home; they will require the ship to be some distance out (like a light year) before offering.
Peregrine Rook's sketch is nicer ☺.
I think the sail would be tipped the other way when catching the beam from the base, though, to slow the "up" component.
hard-science space-travel spaceships
JDługosz
JDługoszJDługosz
$\begingroup$ Must the two beams be (roughly) orthogonal or can either of them be "aimed" off of their primary axes? $\endgroup$ – Nolo Aug 24 '16 at 5:20
$\begingroup$ @nilo the beams can be aimed anywhere. One from "home" that's a straight laser. One from "base" which is more powerful and fancy in any imaginable way. $\endgroup$ – JDługosz Aug 24 '16 at 7:16
$\begingroup$ @PeregrineRook yes, your sketch is nicer than mine! $\endgroup$ – JDługosz Aug 24 '16 at 7:17
$\begingroup$ «impart orbital angular momentum to the photons» I don't know if that would help with this beam, but it's something I introduced earlier in the story for communications. I'll try and dig up a link. $\endgroup$ – JDługosz Aug 24 '16 at 7:20
$\begingroup$ This is all pretty beyond be science wise, but as someone who used to sail a lot, remember that you need a keel (or dagger/centreboard on smaller boats) to go reliably in any direction other than away from the wind. A keel is essentially a surface for the force imparted to the sail by the wind to push against and an underwater wing at the same time. It turns movement imparted by the sail into forward movement. My (admittedly limited) knowledge of solar sails would suggest that you'd be completely at the mercy of the "Pushing" of the solar winds, and find it hard to do much manoeuvring! $\endgroup$ – Miller86 Aug 24 '16 at 8:33
First, let's look at the different types of trajectories a solar sail can take. They differ mainly based on something called the lightness number, $\beta$, which depends on the composition and structure of the sail. $\beta$ can be used to determine the type of trajectory the solar sail will follow: $$\begin{array}{|c|c|} \hline \text{Value of }\beta & \text{Type of trajectory} \\ \hline \beta=0 & \text{circular Keplerian} \\ \hline 0<\beta<\frac{1}{2} & \text{elliptical} \\ \hline \beta=\frac{1}{2} & \text{parabolic} \\ \hline \frac{1}{2}<\beta<1 & \text{hyperbolic} \\ \hline \beta=1 & \text{rectilinear} \\ \hline 1<\beta & \text{flipped hyperbolic} \\ \hline \end{array}$$ This is also evident in Figure 4.8 (page 123) of Colin McInnes' Solar Sailing: Technology, Dynamics and Mission Applications, which is my primary reference in this answer:
Now, you can see that a hyperbolic trajectory of some sort may be exactly what you're looking for - and, in fact, it requires no assistance from the base it is rendezvousing with! Parabolic trajectories, too, are escape trajectories, but a hyperbolic trajectory might be more efficient. Plus, having a greater lightness number results in a greater characteristic acceleration (see Seboldt & Dachwald (2003)), because $a_c\propto\beta$. Therefore, I'd prefer to work with a flipped hyperbolic trajectory; I'll choose $\beta\approx2$.
There are two equations of motion for polar coordinates $(r,\theta)$: $$\frac{\mathrm{d}^2r}{\mathrm{d}t^2}-r\left(\frac{\mathrm{d}\theta}{\mathrm{d}t}\right)^2=-\overbrace{\frac{\mu}{r^2}}^{\text{gravitational}}+\overbrace{\beta\frac{\mu}{r^2}\cos^3\alpha}^{\text{radiation}}\tag{4.37a}$$ $$r\frac{\mathrm{d}^2\theta}{\mathrm{d}t^2}+2\left(\frac{\mathrm{d}r}{\mathrm{d}t}\right)\left(\frac{\mathrm{d}\theta}{\mathrm{d}t}\right)=\beta\frac{\mu}{r^2}\cos\alpha^2\sin\alpha\tag{4.37b}$$ where $\mu$ is the standard gravitational parameter and $\alpha$ is the angle between a vector normal to the sail and a vector pointing from the star to the sail. Compare McInnis' $(\text{4.37a})$ to $(\text{346})$ here, with the substitution of $h=r^2\dot{\theta}$. The two are identical, with the addition of the radiation term in the solar sail reformulation. Let's have $\alpha\approx0$. This means that the right-hand side of $(\text{4.37a})$ becomes $(\beta-1\frac{\mu}{r^2}$, and the right-hand side of $(\text{4.37b})$ becomes $0$.
We can arrive at a simple analytical solution if we assume that the solar sail takes the path of a logarithmic spiral, i.e. a path of the form $$r(\theta)=r_0\exp(\theta\tan\gamma)$$ where $r_0$ is the initial radius and $\gamma$ is the spiral angle, the angle between the velocity vector and the transverse direction of the sail's path. So let's step back a little, and let's assume that
$\beta\approx0.75$ (I've chosen a value for a normal hyperbolic trajectory)
$\alpha\neq0^{\circ}$. It could, but that might not be optimal.
McInnes goes through several substitutions, leading to $$r^3\left(\frac{\mathrm{d}\theta}{\mathrm{d}t}\right)^2=\mu\left[1-\beta\cos^2\alpha(\cos\alpha-\tan\gamma\sin\alpha)\right]\cos^2\gamma\tag{4.41}$$ From this and earlier substitutions, we can derive expressions for the radial velocity $v_r(r)$ and angular velocity $v_{\theta}(r)$. The equation for the former is $$v(r)=\sqrt{\frac{\mu}{r}}\left[1-\beta\cos^2\alpha(\cos\alpha-\sin\alpha\tan\gamma)\right]^{1/2}\tag{4.44}$$ There's a fairly complicated relationship between $\gamma$ and $\alpha$, but it can be simplified for small $\gamma$: $$\frac{\beta\cos^2\alpha\sin\alpha}{1-\beta\cos^3\alpha}=\frac{\sin\gamma\cos\gamma}{2-\sin^2\gamma}\approx\frac{1}{2}\tan\gamma\tag{4.45,4.48}$$ This integration is important when we try to find a relationship between $r$ and $t$. We integrate $(\text{4.44})$: $$\int_{r_0}^r\sqrt{r}\mathrm{d}r=\int_{t_0}^t\left(2\beta\mu\sin\alpha\cos^2\alpha\tan\gamma\right)^{1/2}\mathrm{d}t\tag{4.46}$$ Integrating this and substituting in $(\text{4.48})$ yields $$t-t_0=\frac{1}{3}\left(r^{3/2}-r_0^{3/2}\right)\left(\frac{1-\beta\cos^3\alpha}{\beta^2\mu\cos^4\alpha\sin^2\alpha}\right)^{1/2}\tag{4.49}$$ However, we can simplify this by letting $t_0=0$ and focusing on cases where $r_0\ll r$ for most $r$, which is the case here when $r=r_f$. We can then find when the function of $\alpha$ in $(\text{4.49})$ is maximized; it turns out that for small $\beta$ (i.e. $\beta<0.5$), $\alpha_{\text{max}}\approx35.26^{\circ}$. However, I chose $\beta=0.75$, and so it turns out that $\alpha$ is maximized at about $35.26^{\circ}$. Plugging this back into our approximation for $\tan\gamma$, we find that $\tan\gamma\approx1.362$, which gives us $\gamma\approx53.7^{\circ}$. This likely makes our small angle approximation for $\tan\gamma$ less accurate, but it will do for now. Plugging this in, and assuming once again that $t_0=0$ and $r_0\ll r$, $(\text{4.49})$ gives us $$t=r^{3/2}\times1.23\times10^{-10}$$ and for a final radius of three light-years ($2.838\times10^{16}$ meters), we find that $t\approx5.88\times10^{14}$ seconds, or about 19 million years. That might seem like it can't be correct, but Centauri Dreams cites Matloff et al. that it could take a really good solar sail 30 years just to reach the Oort Cloud, 500 AU away - and one light-year is about 60,000 AU. Clearly, a simple logarithmic spiral quite like this won't work.
In fact, this means that you absolutely need to give the solar sail a very fast initial boost to make interstellar travel on these scales even remotely feasible. This makes the equations a little harder, and it means that yyou might not see an easy analytical solution pop up.
Let's go back to our original coupled equations $(\text{4.37a})$ and $\text{4.37b})$, where we've set $\beta=2$ and $\alpha=0$. This becomes a simple central force problem, which has one equation of the form $$\frac{\mathrm{d}^2r}{\mathrm{d}t^2}-\frac{h^2}{r^3}=\frac{F(r)}{m}$$ where I've defined $h\equiv r^2\dot{\theta}$, which is conserved. $F(r)$ is the central force as a function of $r$; normally, in orbital mechanics, it's simply $$F(r)=-\frac{GMm}{r^2}$$ as is the case in $(\text{346})$; here, as I noted before, we also have to account for the force from radiation pressure. With $\beta=2$, it just so happens that the two forces add up to $$F(r)=\frac{-GMm}{r^2}+\frac{(2)GMm}{r^2}=\frac{GMm}{r^2}$$ which is repulsive, unlike $(\text{346})$. That pdf shows a good derivation of the orbital equation from the central force law, which I'm not going to go through again, as it's pretty standard. For a generic central force of the form $$F(r)=-\frac{k}{r^2}$$ we arrive at an orbit of the form $$r(\theta)=\frac{l}{1+\varepsilon\cos\theta}\tag{355}$$ where $k=-GM$ (in general, $k=(\beta-1)GM$), and $$l\equiv\frac{mh^2}{k},\quad\varepsilon\equiv\frac{l}{a}-1\tag{356}$$ I'm no expert when it comes to solar sail construction, so I read through McInnes et al. (2001) and came up with a conservative estimate of 2,000 kg. The authors estimated that you could send a 900 kg solar sail to solar orbit, with much of that mass being payload. My guess could be way off, so I'd appreciate it if an expert has better figures.
I assumed that the solar sail starts out on a circular orbit around a sun-like star at roughly Earth's semi-major axis. From this, I calculated $$v_0=\sqrt{\frac{\mu}{r}}=2.97\times10^4\text{ m/s}$$ $$h=\frac{|L|}{m}=\frac{rmv}{m}=rv=4.46\times10^{15}\text{ m}^2\text{/s}$$ $$k=(\beta-1)GM=1.327\times10^{20}\text{ m}^3\text{/s}^2$$ $$l\equiv\frac{mh^2}{k}=3\times10^{14}$$ $$\varepsilon\equiv\frac{l}{a}-1=2000$$ From this, I get $$r=\frac{3\times10^{14}}{1+2000\cos\theta}$$ $\varepsilon>1$ (as was expected, given that $\beta>1$), and in fact $\varepsilon\gg1$.
I used modified code from this page to solve $(\text{4.37a})$ in Mathematica and plot the motion of the solar sail over the course of one year:
M = 1.99 10^30 (*mass of Sun*)
G = 6.67 10^-11 (*Newton's constant*)
x0 = 1.50*10^11 (*apsidal distance*)
y0 = 0; vx0 = 0;(*on x axis with velocity in y direction*)
vCirc = Sqrt[G M/x0] (*apsidal speed for circular orbit*)
vy0 = 0.8 vCirc (*smaller speed gives elliptical orbit*)
a = 1/(2/x0 - vy0^2/(G M)) (*semimajor axis from E=T+V*)
T = 2 Pi Sqrt[a^3/(G M)] (*period from Kepler's third law*)
beta = 2 (*accounts for radiation pressure*)
r[t_] := {x[t], y[t]} (*position vector*)
equation = Thread[r''[t] == (beta-1) G M r[t]/Dot[r[t], r[t]]^(3/2)]
initial = Join[Thread[r[0] == {x0, y0}], Thread[r'[0] == {vx0, vy0}]]
solution = NDSolve[Join[equation, initial], r[t], {t, 0, T}]
orbit = ParametricPlot[r[t] /. solution, {t, 0, T}];
Show[orbit]
This is the orbit:
As you can see, it travels in essentially a straight line, going at a little over 5 Au per year, at first. That's not bad at all. It's still going to take a long time to reach the base, but this is likely going to be on the order of thousands of years, not millions of years.
HDE 226868♦HDE 226868
$\begingroup$ «figure out if we even need to take special relativistic effects into account in the case of the lightsail.» I seem to have missed that in the end. What's the punchline? $\endgroup$ – JDługosz Sep 5 '16 at 16:21
$\begingroup$ I would think that with distances > 500AU and into interstellar space, and speeds at 10%C, that orbital mechanics is not applicable. Other stars and galatic tides will make larger peturbations than the sun of the launch site, and the accelerations will render g unimportant. $\endgroup$ – JDługosz Sep 5 '16 at 16:24
$\begingroup$ That is, model it in free space without gravity. Incoming beam is a momentum source subject to aberation of motion, and reflection gives large percent of same momentum in a chosen direction. I'm guessing* that the apparent position of the beam source is what matters but with both source and receiver moving at relativistic speeds I don't know how the wavefront direction will look. $\endgroup$ – JDługosz Sep 5 '16 at 16:28
$\begingroup$ @JDługosz Regarding the first comment: I was going to calculate the speeds of the trajectories; I haven't gotten around to that yet. Regarding the second comment: Orbital mechanics is most definitely valid at distances greater than 500 AU. It's valid in the Oort Cloud, which starts ten time as far away! $\endgroup$ – HDE 226868♦ Sep 7 '16 at 18:00
$\begingroup$ «5 Au per year» that's nowhere near the 10 to 30% of c I need. Voyage time should be decades. Remember, it's a high-thrust lightsail, not an ambient solar flux sail. $\endgroup$ – JDługosz Sep 7 '16 at 22:03
I believe the desired outcome can be achieved with relatively simple means. The trick with solar sails is that although the incoming light can only push the sail directly, the reflection of that light can push the sail in a different direction. The resulting net thrust is the combination of the incident light and the reflected light. For a solar sail being pushed by lasers at significant fractions of C it's safe to assume that the the sail will have near 100% reflectivity (otherwise the non-reflected light would incinerate the ship) so the magnitudes of the incident and reflected light will be approximately equal. Since from basic geometry we know that the angle of incident light and the angle of reflection will be equal, then the angle of thrust, or net acceleration will always be directly orthogonal to the plane of the sail. This means the solar sail will always accelerate straight ahead. If we want to accelerate in a different direction, we simply have to turn our sail to face directly away from that direction, treating the sail as if it were any other conventional source of thrust. The caveat though is that changing the orientation of the sail changes the magnitude of the experienced thrust. The acceleration of the sail can be computed by the following functions:
Since all the variables in the above equations are constants with the exception of B, the angle of the sail with respect to the laser, we can deduce the relationship between the acceleration of the ship and the angle B to be Accel = cos(B)^2. That is to say when B is 0 and the sail is facing the laser directly it will experience maximal acceleration and when B is 90 degrees and the sail is sideways to the laser is will experience 0 acceleration.
It follows that if we want our trip to be efficient we need to minimize B. Of course, if you want to make the whole thing much simpler you can simply say the light comes from directly behind the craft at all times due to some fancy technology. In that situation the force experienced by the ship will always be constant. But that also takes all the fun out of solar sails doesn't it?
So with this system we can accelerate in any direction away from the laser source, but never back towards it. However, the efficiency of our acceleration decreases rapidly the harder we try to turn. One consequence of this is that it will be difficult to ever use both lasers simultaneously with any efficiency since they are ~90 degrees apart. This means for the first leg of our journey we are going to want to accelerate directly away from our home laser towards some far off rendezvous point and ignore the station laser. By accelerating directly away and keeping B equal to 0 we maximize our acceleration. At some point though we will need to reduce our velocity towards the oncoming station in order not to overshoot it. We have to use the station laser to do this. Ideally by this time we are closing with the station and thus the angle we must thrust to match velocities with the station is close to that of the laser making our thrust once again efficient.
The below schematic isn't exactly what I am describing above, it was made before I realized how inefficient the angled thrusting would be, but it still gets the general concept across.
With regards to the effects of relativity. Obviously the lasers from both parties will need to be aimed light-years ahead of the ship's path with absurdly precise calculations and a predetermined course. Even a slight error would compound and eventually throw the ship out of the path of the lasers which had been fired years in advance. Even with faster than light communications this would be a remarkable feat.
To specifically address your concerns regarding relativity and the angle of the sail:
I'm supposing that the angle at which it presents the sail will be significantly affected by relativistic effects and aberration of moving source.
The aberration of light due to the movement of the station will not change the direction the ship accelerates since we determined above that the ship always accelerates orthogonal to the plane of the sail. The aberration of light will however change the magnitude of that thrust by influencing the projected area of the sail (and therefore the amount of light that hits the sail) and the proportion of the incident and reflected thrust vectors that are productive (how much of those vectors cancel each other out).
This answer doesn't include a precise plot of an optimal course for the ship to take. This is because there are many possible courses and they differ drastically based on the relative strengths of the lasers and the distances and velocities involved. For instance, if the station laser is significantly more powerful than the home laser we will want a course that lets us flip over to utilize it as soon as possible. But that course is very different from one in which the home laser is preferred. Based on the distances and velocities and maximal accelerations involved the ship might have to begin accelerating on a course nearly parallel to that of the station to ensure it matches velocities before the station passes. Or if the station is very far off maybe it can simply accelerate directly into the path of the station and then be brought up to speed by the maximal effectiveness of the station's laser pushing the ship directly in front of it. I see no way to simply compute a single optimal course even if those missing constants were defined. I do think that this answer provides insight into the principles of the laser-powered lightsail's operations and the equations necessary to calculate the time a given course will take.
Mike NicholsMike Nichols
$\begingroup$ +1 for the illustrations. What did you use to draw? But this elementary primer is not hard-science—you didn't even mention cosine, and the relativistic effects are not just time delay in aiming but complicating factors to know how to handle. $\endgroup$ – JDługosz Sep 7 '16 at 21:57
$\begingroup$ @JDługosz It seems to me that without specifics on the exact distances involved, the relative velocities of the star and station, and the relative strengths of the each point's lasers one can't actually apply the geometry and calculus to compute an exact course. The fundamental concept here is that regardless of where the lasers are the solar sail will accelerate in the direction it is facing. This means the solar sail craft is can be treated approximately as any other conventionally propelled ship. The differences being direction influencing magnitude of thrust and no change in mass. $\endgroup$ – Mike Nichols Sep 7 '16 at 22:36
$\begingroup$ I used google drawings as part of google drive to generate the schematic. $\endgroup$ – Mike Nichols Sep 7 '16 at 22:38
$\begingroup$ I didn't give too much detail because I will adjust to suit the timeline of the plot, once I know what's possible. That is, I'm working backwards from the narrative. $\endgroup$ – JDługosz Sep 7 '16 at 22:43
There are some ways to break this problem into simpler ones.
One laser at a time
Since both the thrust sources are lasers, they're coherent. And since managing their relative phases at distances of light-years is basically impossible, you want to have just one active at a time, to prevent interference and loss of thrust.
Look at it as two separate voyages
It's a basic physics trick to break down problems in forces to two separate problems at right angles. Since there is essentially no friction in this system, that's quite accurate for this problem. So we can look at this as two separate problems:
Leaving the starting point, accelerating, making turnover, decelerating and stopping at the right distance from the start.
Accelerating from zero velocity on the course parallel to the station to match its actual velocity.
I'm not suggesting that the first voyage should be completed, and then the second started, just that it's easier to think about the problem in two pieces.
Managing the sail
Start out with the sail pointing backwards towards the start point. Leave it there until you reach turnover. Then angle it at $arctan(y/x)$ to your course, where $y$ is your velocity away from the start, which you have to shed, and $x$ is the velocity of the station, which you have to acquire. Leave it to the cunning laser on the station's ability to come from a different effective direction to its actual direction to supply thrust from a constant direction relative to you.
This is not the most power-efficient way to do the voyage, but it makes the least demands on the laser at the start point and on the ship. Light-sail ships are even more weight-critical than ordinary spacecraft, and swinging your sail around continuously while you're riding the station's beam takes (a) reaction mass and (b) keeping the engines and control system that use that reaction mass working. All of that costs weight. Avoiding the need to do those things makes the voyage more likely to succeed.
John DallmanJohn Dallman
$\begingroup$ You bring up a good point! For your numbered list I can't tell if #1 is meant as a way of composing the problem only or you plan to actually do that. $\endgroup$ – JDługosz Sep 3 '16 at 9:12
$\begingroup$ Edited to clarify. $\endgroup$ – John Dallman Sep 3 '16 at 9:28
$\begingroup$ You can easily avoid interference between the lasers by just using lasers of different wavelength. Not that it matters much, given that the solar sail is going to be much larger than the wavelength of the laser (meters vs. nanometers), so the light arriving some hundred nanometers displaced won't matter. $\endgroup$ – celtschk Sep 7 '16 at 7:59
Not the answer you're looking for? Browse other questions tagged hard-science space-travel spaceships or ask your own question.
Alien message: "Invitation"
Defending against directed Gamma Ray weaponry
Designing a binary asteroid pair
How to get across the galaxy moving slower than light - in a single lifetime?
Runaway Starship Ramps
How would two generational ships traveling at point eight cee communicate with each other?
How well will interstellar ploughs work?
The Colonist - Part II: Landing
Is this a plausible interstellar propulsion system?
Is there anything about photons and/or space-time that would allow the detection of an energy-based attack from a distance of ten light seconds?
Ability of frozen embryos to withstand many Gs, and the cosmological event horizon for a laser-powered sail ship? | CommonCrawl |
Assessing whether universal coverage with insecticide-treated nets has been achieved: is the right indicator being used?
Hannah Koenker1Email authorView ORCID ID profile,
Fred Arnold2,
Fatou Ba3,
Moustapha Cisse3,
Lamine Diouf3,
Erin Eckert4,
Marcy Erskine5,
Lia Florey4,
Megan Fotheringham4,
Lilia Gerberg4,
Christian Lengeler6, 7,
Matthew Lynch1,
Abraham Mnzava8,
Susann Nasr9,
Médoune Ndiop3,
Stephen Poyer10,
Melanie Renshaw11,
Estifanos Shargie9,
Cameron Taylor2,
Julie Thwing12,
Suzanne Van Hulle13,
Yazoumé Ye2,
Josh Yukich14 and
Albert Kilian15
Background/methods
Insecticide-treated nets (ITNs) are the primary tool for malaria vector control in sub-Saharan Africa, and have been responsible for an estimated two-thirds of the reduction in the global burden of malaria in recent years. While the ultimate goal is high levels of ITN use to confer protection against infected mosquitoes, it is widely accepted that ITN use must be understood in the context of ITN availability. However, despite nearly a decade of universal coverage campaigns, no country has achieved a measured level of 80% of households owning 1 ITN for 2 people in a national survey. Eighty-six public datasets from 33 countries in sub-Saharan Africa (2005–2017) were used to explore the causes of failure to achieve universal coverage at the household level, understand the relationships between the various ITN indicators, and further define their respective programmatic utility.
The proportion of households owning 1 ITN for 2 people did not exceed 60% at the national level in any survey, except in Uganda's 2014 Malaria Indicator Survey (MIS). At 80% population ITN access, the expected proportion of households with 1 ITN for 2 people is only 60% (p = 0.003 R2 = 0.92), because individuals in households with some but not enough ITNs are captured as having access, but the household does not qualify as having 1 ITN for 2 people. Among households with 7–9 people, mean population ITN access was 41.0% (95% CI 36.5–45.6), whereas only 6.2% (95% CI 4.0–8.3) of these same households owned at least 1 ITN for 2 people. On average, 60% of the individual protection measured by the population access indicator is obscured when focus is put on the household "universal coverage" indicator. The practice of limiting households to a maximum number of ITNs in mass campaigns severely restricts the ability of large households to obtain enough ITNs for their entire family.
The two household-level indicators—one representing minimal coverage, the other only 'universal' coverage—provide an incomplete and potentially misleading picture of personal protection and the success of an ITN distribution programme. Under current ITN distribution strategies, the global malaria community cannot expect countries to reach 80% of households owning 1 ITN for 2 people at a national level. When programmes assess the success of ITN distribution activities, population access to ITNs should be considered as the better indicator of "universal coverage," because it is based on people as the unit of analysis.
Universal coverage
Bed net coverage
Insecticide-treated nets (ITNs), which today are almost exclusively comprised of long-lasting insecticidal nets (LLINs), are the primary tool for malaria vector control in sub-Saharan Africa, and have been responsible for an estimated two-thirds of the reduction in the global burden of malaria in recent years [1]. Over 1.5 billion ITNs have been distributed since the UN Secretary General called for a scale-up of ITN coverage in 2008, primarily through mass campaigns aiming at reaching universal coverage [2]. In line with the definition of "universal health coverage", the World Health Organization (WHO), in the 2017 update of its recommendations on achieving universal coverage with LLINs, defines "universal coverage" as "universal access to, and use of, LLINs" for the entire population at risk of malaria targeted in the control or elimination strategy [3]. Usually the minimum target for universal coverage to be considered achieved is 80% both for access (ownership) and use. This definition of "universal coverage with ITNs" is not disputed, and there is general agreement how to quantify the need for ITNs.
Universal coverage campaigns use an algorithm to calculate the number of ITNs needed for procurement based on population. The definition applies the observation that on average two people share a net, meaning that if one net is given for every two people in a household, all members have a chance to use an ITN [4]. For quantification of the number of ITNs needed for a national mass distribution campaign, the population is divided by 1.8 (and not by 2), to account for households with an odd number of members in which an additional net would be needed [3, 5]. Campaigns also tend not to count existing ITNs in the household, as these are most often older ITNs, with a limited useful life, and the effort of counting and including these in distribution planning would be intensive, and possibly of limited utility [6].
The 2013 revision of malaria indicators by the Roll Back Malaria Monitoring and Evaluation Reference Group [7] recommended four indicators for measuring ITN availability and use (Table 1). Two are calculated at the household level, and two are calculated at the individual (population) level. The two household level indicators are (i) the proportion of households that own at least 1 ITN and (ii) the proportion of households that own at least 1 ITN for 2 people. The two population-level indicators are (iii) the proportion of the population with access to an ITN within the household and (iv) the proportion of the population that used an ITN the previous night. While the ultimate goal is of course high levels of ITN use to confer protection against infected mosquitoes, it is widely accepted that ITN use must be understood in the context of ITN availability [8–11]. Ownership and access indicators are, therefore, useful for malaria programmes to understand the reach and breadth of their ITN distribution activities.
ITN indicators: advantages and limitations
What it measures
% HHs owning at least 1 ITN
Measures what proportion of households has 1 (or more) ITNs
Demonstrates the basic 'reach' of ITN distribution activities
Does not indicate the extent to which individuals have the opportunity to use an ITN—as 1 ITN is nearly always insufficient to enable ITN use by all household members
% HHs owning at least 1 ITN for 2 people
Measures what proportion of households has enough ITNs to protect all individuals in the household assuming 2 persons use each ITN
Correlates with WHO and mass campaigns goals of providing 1 ITN for every 2 people; easy to communicate with a broader audience
Underestimates coverage by totally ignoring households that have ITNs to cover a significant portion, but not all, of the individuals in the household
% population that used an ITN the night before the survey
Measures the level of ITN use of all age groups at the time of the survey
Provides an exact picture of what proportion of the population is individually protected by an ITN the night before the survey
Low ITN use often assumed to be a behavioural problem, but use is highly driven by ITN access, which is not accounted for by this indicator
% population with access to an ITN within the households
Provides an estimate of the proportion of the total population that could have slept under an ITN. Assuming two people share one ITN
Accounts for ITNs in all households and precisely counts all individuals that could use an ITN. Can be directly compared with ITN use to identify specific behavioural gaps
Can be challenging to conceptualize
The three indicators measuring ownership and access provide different viewpoints into ITN 'coverage'. Previous work has shown they are mathematically related [6, 11]; the present work focuses on the programmatic utility of the indicators. The proportion of households that own at least 1 ITN provides a sense of the spatial reach of ITN distribution activities, at a minimal depth of coverage. The proportion of households that own at least 1 ITN for every 2 household members is often referred to as "universal coverage", and may be reworded as the proportion of households with 'enough' or 'sufficient' ITNs. This seems intuitively to be the best choice for a summary indicator as the algorithm for allocating nets to households to achieve universal coverage and it is also part of the definition of the indicator. Most of the time, country programmes set targets for all ITN indicators at 80% or above in line with WHO recommendations. However, despite 7 years of universal coverage campaigns, no country has achieved a measured level of 80% of households with 1 ITN for 2 people [12] in a national survey, even immediately after a universal coverage distribution campaign. National-level results for the proportion of households owning at least 1 ITN for every 2 people consistently lag behind results for the third indicator, the proportion of the population with access to an ITN within the household (Fig. 1) [12]. This third indicator of 'coverage', often referred to as 'population ITN access' or 'ITN access', provides a population level estimate of individuals who could use an ITN, again based on the assumption that two people can share a net. It is calculated by multiplying the number of ITNs owned by the household by 2, creating a number of 'potential ITN users' in the household. Then the number of potential ITN users is divided by the number of household members who stayed in the house the night before the survey (de jure members). Values over 1.00 are set to 1.00, as households cannot have more than 100% access. Each member of the household is then assigned that value in the household member dataset, and the mean is calculated across the population [7, 9]. In the 2017 World Malaria Report, the proportion of households owning any ITN was modelled at 79.7%, population ITN access at 61.2%, population ITN use at 54.1%, and proportion of households that own at least 1 ITN for 2 people in last position at 43.4%.
National level population access to ITN (green) and household ownership of ≥ 1 ITN for 2 people (black) plotted against household ownership of ≥ 1 ITN from 86 surveys. Shaded area = 95% CI of fitted values)
The objective of this study is to explore reasons why the indicator "the proportion of households owning at least 1 ITN for 2 people" falls consistently far below target levels, and to evaluate the three ITN ownership coverage indicators to see which one is the right indicator to assess whether universal coverage has been achieved.
Eighty-six publicly available datasets from Demographic and Health Surveys (DHS) and Malaria Indicator Surveys (MIS) in 33 countries in sub-Saharan Africa (2005–2017) representing all available data sets for this period were downloaded with permission from dhsprogram.com. The proportion of households owning at least 1 ITN for 2 people (enough ITNs) and population access to an ITN within the household were calculated at the national level, according to standard RBM Monitoring and Evaluation Reference Group procedures [7]. Mean household size was calculated using de jure (usual) members. All data preparations and analyses were done using Stata 14 software (Stata Corp, College Station, Texas, USA) and applying the sampling weights as provided in the data sets.
To provide data points at the higher end of the range of access and ownership, 12 surveys from eight countries were identified where national-level ownership of at least 1 ITN within the household exceeded 80%. A total of 121 regional or provincial estimates of the same indicators were calculated for these 12 surveys. For 59 surveys conducted in 2010–2016, ITN indicators were calculated by household size (a categorical variable of 1–3, 4–6, 7–10, and ≥ 11 de jure members) and extracted with their standard errors and confidence intervals adjusting for the cluster sampling design.
Country results for all described variables were then extracted into a new data set that also included country and region (where applicable), year and type of survey (MIS, DHS). Multivariable regression analysis was then used to analyse trends and relationships within this data set either as linear regression models or fractional polynomial models, using Stata's fp command to identify the best fit. Analytical weights were created and applied to adjust for differences in size and variation of data sets. Unless otherwise indicated, statistical significance testing applied the Pearson design-based F-statistic for proportions and ordinary least squares linear regression for multivariable analysis.
In a simple plot of the national results for each of the three ITN coverage indicators plotted against household ownership of at least 1 ITN, it is observed that household ownership of at least 1 ITN for 2 people is consistently below population ITN access, which itself falls consistently below household ownership of at least 1 ITN (Fig. 1).
Even immediately following universal coverage campaigns, the highest result for the proportion of households owning at least 1 ITN for 2 people was only 62.0% at the national level, in Uganda's 2014 MIS. Among the regional data points, the highest result was 81.0% in Lindi, Tanzania, in the 2011–2012 Tanzania HIV/AIDS and Malaria Indicator Survey (Fig. 2).
National (blue circles, from 86 surveys) and selected regional estimates (green triangles, from 12 surveys where national-level ownership of at least 1 ITN was > 80%; offset for readability) for household ownership of at least 1 ITN for every 2 people, 2005–2016. Target line of 80% indicated in dashed red
In the 12 surveys where household ownership of at least 1 ITN exceeded 80%, population ITN access ranged from 57.3% in Madagascar 2011 to 78.8% in Uganda 2014 (Table 2). In these same surveys, the proportion of households owning at least 1 ITN for 2 people ranged from 31.1% in Madagascar 2011 to 62.0% in Uganda 2014.
ITN indicators in household surveys conducted shortly after universal coverage campaigns
% households owning ≥ 1 ITN
% households owning ≥ 1 ITN per 2 people
% population with access to an ITN
Mean household size (de jure)
Population ITN access and household ownership of sufficient ITNs were highly correlated, with household ownership of 1 ITN for 2 people on average estimated to be 67.0% that of population ITN access (coef. 0.67 95% CI 0.65–0.69; p < 0.0001; R2 = 0.97) in a linear model when the no-constant option was specified to force the intercept at zero for the two indicators. However, as shown in Fig. 3, the fractional polynomial model was a better fit than the linear model (p = 0.003), demonstrating that at 80% population ITN access, the proportion of households owning ≥ 1 ITN for 2 people is estimated to be approximately 60%. Models for each indicator are presented in Additional file 1.
Household ownership of ≥ 1 ITN for 2 people vs population ITN access with national and regional results. Fitted values use a best-fit fractional polynomial
Household size was a key determinant of all three ITN coverage indicators. Among surveys conducted in 2010–2016, ownership of at least 1 ITN increased as household size increased (coef. = 1.36; p < 0.001). However, increasing household size was significantly associated with lower levels of household ownership of at least 1 ITN for 2 people (coef. = − 2.24; p < 0.001), with only 6.2% (95% CI 4.0–8.3) of households of 7–9 people reaching this threshold. Larger households also had reduced levels of population ITN access, but the decline was less pronounced (coef. = − 0.66; p = 0.010). Across the 2010–2016 surveys, population ITN access was 41.0% (95% CI 36.5–45.6) among those in households with 7–9 people, whereas these same households only had rates of 6.2% of owning at least 1 ITN for 2 people (Fig. 4).
Mean ITN coverage for the three ITN coverage indicators for households of varying sizes, across 59 household surveys (2010–2016)
To provide a simplified illustration of the individual protection that is obscured by the household indicator of owning at least 1 ITN for 2 people, compared to the population access indicator, Fig. 5 depicts five households, in which a total of 30 people reside, with 10 ITNs. All five households own at least 1 ITN (Fig. 5a), but only one (the smallest household) owns at least 1 ITN for every 2 people (green house in Fig. 5b). However, as illustrated with the green stick figures in Fig. 5c, 19 people have access to an ITN within their household, out of 30 (63%). Ultimately, 18 of those 19 individuals with access slept under an ITN the previous night (green figures in Fig. 5d), giving a total population use of 60%.
Illustrative depiction of ITN indicators using 5 households, 30 individuals, and 10 ITNs. The top row a, b demonstrate household ownership indicators, while the bottom row c, d shows population-level indicators. ITNs are depicted in tall trapezoids and individuals with stick figures. Households meeting the indicator criteria for ownership are identified in green/darker color. Individuals meeting the indicator criteria are identified with solid green color
If one looks at the number of people that are assumed to be protected with the indicator of proportion of households owning at least 1 ITN for 2 people, only three individuals (10%) are counted. Compare this with the 19 people that are counted under the population access indicator. In effect, 16 individuals out of the 30 in this hypothetical village—53%—have access to an ITN that is ignored when looking only at the indicator of households with enough ITNs. This is the same as the crude difference between 63% population ITN access and 10% (3 of 30) population living in households that own enough ITNs. The ignored population can also be expressed as a percentage of population access: 16 individuals out of the 19 individuals with access to an ITN in this village are ignored by the indicator of households that own at least 1 ITN for 2 people, or 84%.
Expanding this analysis to the 86 datasets (Fig. 6), the average difference between the population with access to an ITN and the population living in households that own enough ITNs is 21%. This is the overall percentage of the population that has access to an ITN within their household that is ignored when looking solely at the indicator of proportion of households that own at least 1 ITN for 2 people. But because this crude difference is smaller at lower levels of population access, and higher at high levels of access, it is better expressed as a percentage. The percentage of population access that is ignored, out of the total population with access, can be expressed as
$$\% population\;whose\;ITN\;access\;is\;ignored\;by\;the\;indicator\;of\; ``\% \;households\;owing\;at\;least\;1\;ITN\;for\;2\;people" = 1 - \left( {\frac{\% \;population\;living\;in\;households\;with\;enough\;ITNs}{\% \;population\;with\;access\;to\;an\;ITN}} \right)$$
The proportion of people with access to an ITN (green) and the proportion of people living in households with enough ITNs (yellow) as a function of household ownership of any ITN. The difference between the green and yellow plots is 20 percentage points on average, and the gap is on average 60% of the percentage of population ITN access
On average, across the 86 national surveys reviewed in this study, out of all the people with access to an ITN, 60% (95% CI 23–89%) are ignored when planners focus solely on the indicator of households owning at least 1 ITN for 2 people.
Currently, targets in national strategic plans or donor documents for all three ITN coverage indicators are usually set at 80% or above. This gives a perhaps unintended implication that the three indicators should increase together at the same rates. Moreover, universal coverage guidance from WHO and others calls for procuring ITNs with the goal of providing each household with 1 ITN for 2 people, again implying that by doing so, countries should expect to achieve 100% of households owning enough ITNs immediately after a mass campaign. These implied expectations contribute to confusion and frustration when post-campaign results—particularly for the indicator of households owning at least 1 ITN for 2 people—are far below target levels. This also has significant implications for donor funding. Performance frameworks, typically aligned to the household ownership indicators, may inadvertently set national programmes up for failure, and countries may be unnecessarily penalized based on the indicator targets, not all of which are achievable.
This work builds on previous work describing the utility of the ITN indicators and exploring the mathematical relationships between the indicators in order to model ITN coverage in years between surveys [6, 9, 11]. However, in terms of programmatic utility, each indicator must be considered with its advantages and limitations, in terms of interpreting the extent of ITN protection in a given population. The two household indicators can be compared to provide an 'ownership gap', and the two population indicators can be compared to provide a 'use gap' [9, 11].
The proportion of households owning at least 1 ITN is a minimal threshold that essentially describes the spatial reach of ITN distribution activities, but not the degree to which the population is protected. (The vast majority (80%) of households in endemic countries require more than a single ITN to protect all persons in the household—see Additional file 2). At the other end of the spectrum, the proportion of households owning at least 1 ITN for 2 people is an indicator of 'perfect' household coverage, and has never been reached at a national or even a subregional level. Households may miss qualifying as having 'enough' nets by only 1–2 nets, and this is often misinterpreted as these households not having any protection. The two household-level indicators—one representing minimal coverage, the other only 'universal' coverage—thus provide an incomplete and potentially misleading picture of personal protection and the success of an ITN distribution programme.
Larger households were far less likely than smaller households to own enough ITNs for all their household members. In fact, many individuals in these households that own some but not enough ITNs had access to a net, and (in most cases) were sleeping under one, as illustrated in Fig. 6. This individual protection is obscured when programme planners focus only on the household-level indicator.
Given these limitations of the household level indicators, the population ITN access indicator is a far better indicator of 'universal coverage' because it is based on individual people. It provides a clear picture of the proportion of individuals in a given setting that have the opportunity to use an ITN. It can also be directly compared to the proportion of the population that used an ITN the previous night, which enables detailed analysis of specific behavioral gaps nationally as well as among population subgroups. Ultimately, of course, ITN use is the key behavior required for malaria control, but people cannot use an ITN to which they do not have access. Recent research demonstrates clearly that rates of ITN use among those with access to an ITN with few exceptions are at or above an 80% target [10–13]. Therefore, increasing ITN access will lead directly to increases in ITN use.
It is important to consider and address the programmatic and policy factors that prevent households from obtaining enough ITNs. The primary programmatic reason is that larger households rarely receive the necessary number of ITNs during mass campaigns. During the process of household registration, programmes often put a cap on the number of ITNs any given household can receive to reduce the opportunity for fraud due to inflated numbers of household members. Second, during the process of distribution itself, campaign staff may also pragmatically ration ITNs if they think not enough are available, to remain certain that all households in their catchment area will receive at least some ITNs. Third, larger households, which tend to have more children than smaller households, may have some sleeping spaces in which more than 2 people are sharing an ITN [4] and, therefore, may not require (or be motivated to acquire) ITNs in the 1:2 ratio.
Policy decisions are also likely affecting the ability of large households to receive enough ITNs. The current guidance from the WHO recommends that mass campaigns be planned with a quantification algorithm of "population divided by 1.8," which is intended to account for the odd-numbered households that require an additional 'half net' according to the 1 for 2 ratio. In 2017 the algorithm was updated by the WHO to allow a 10% buffer accounting for outdated census projections [14]. However, when looking more closely at sleeping space patterns, researchers have found reasons to question the current quantification guidance. Analysis of discordant ITN-person pairs (e.g., two roommates in a household who do not share a sleeping space) as well as the trend that with increasing wealth and also increasing ITN access, the number of people per ITN decreases, imply that a more accurate expectation would be that each ITN only protects on average 1.6 people [4]. Whether inaccurate population estimates or an inadequate quantification factor are the greater determinant of ITN gaps during mass campaigns remains to be explored.
Three possible solutions to these supply challenges can be considered. First, if the current levels of ITN access are considered sufficient in epidemiological terms to maintain malaria control, then no changes in distribution strategy are required. Rather, the current targets could be adjusted to be more appropriate for each indicator. Enormous reductions in malaria morbidity and mortality have been observed over the past decade, during which ITN coverage has not been at target levels and yet this 'insufficient' ITN coverage has been credited with two-thirds of the observed reductions in morbidity [1]. Modeling work also indicates that community-level protection can be achieved at lower-than-universal coverage levels of 35–65% population use of ITNs [15]. On this basis, the target levels for each ITN coverage indicator might be adjusted to be more pragmatic—i.e. a 95% target for household ownership of any ITN, which corresponds roughly to an 80% target for population ITN access, 70% population ITN use, and a 55% target for household ownership of at least 1 ITN for 2 people.
Second, if current levels of ITN access are not considered sufficient for malaria control, and targets for ITN use should be 80%, as outlined in the WHO Global Technical Strategy (implying a population ITN access target of 90%) [16], then it follows that additional ITNs would need to be procured, potentially using a 10% buffer for mass campaigns, and/or by increasing ITN distribution through ongoing school or community based channels. The WHO currently calls for mass campaigns every 3 years using the population/1.8 quantification factor with an optional 10% buffer, which is equivalent to a population/1.6 quantification. The guidelines further recommend additional ITN distribution as needed to maintain target levels [14], but there is no robust guidance on how many additional ITNs might be needed, nor the most efficient combination of distribution strategies, which inhibits programmes from moving away from triennial mass campaigns. Additional research to provide more specific estimates, including cost-effective options for optimizing ITN coverage over time and space, would likely ease this process for programme planners and donors.
Third, there is some scope for increasing programmatic efficiency in ITN distribution and attempting to use existing quantities of ITNs to achieve higher rates of coverage. This can be done regardless of whether the above two solutions are implemented. First, programmes must acknowledge that large households require more nets, and either avoid setting caps, or set them taking into account regional demographic variations in household sizes. Data on household size are regularly reported in large national surveys such as DHS and MIS, and are summarized here in Additional file 2. Caps currently serve both to limit the negative impact of respondents inflating household size during registration and to ensure that in situations where not enough ITNs are available, all households receive at least a few ITNs. Some regions may indeed have only a small percentage of households that are larger than 8 people; a cap of four ITNs per household might work well. However, in other regions, a cap of four ITNs per household may automatically exclude 15% of households from reaching the target of 1 ITN for 2 people, as in Ghana's northern regions where the average household size is larger than the rest of the country [17]. Obviously, additional mechanisms to avoid inflation of the numbers of household members during the campaign's registration phase are and should be put in place. In areas where caps have been used, 'deflation' of household size has also been observed—splitting larger households into two or more smaller households to avoid the cap. Second, it has been shown previously that the quality of census and household registration data contribute much more to successful campaigns than other factors [18]. Therefore, investing in household registration and its supervision will help to ensure that all households—whether large, small, or hard to reach—are reached and accurately served. Additional research will be needed to thoroughly assess cost-effective strategies for capping.
There are some minor methodological factors related to achieving universal coverage (based on either indicator) that should be noted. The standard MIS/DHS net roster only lists up to seven ITNs, ignoring any additional nets in the household. In the Mali 2015 MIS, 13% of households owned 7 ITNs, and it is likely that many households own 8 or more nets. These additional nets, however, are not counted and, therefore, these households (if large) may miss reaching the threshold of owning 1 ITN for 2 people solely as a result of this approach. Other countries, including Senegal, have modified the standard net roster to allow for additional ITNs to fit their context. Likewise, the definition of a household—whether for household survey purposes or for mass campaign planning and registration—is certain to be problematic if not done consistently.
Based on the above findings, the authors recommend that national programmes, donors, and implementing partners focus on the proportion of the population with access to an ITN within the household as the key indicator of universal coverage. Use of this population-level indicator as the primary measure of ITN coverage will strengthen national strategies, implementation plans, policy documents, and DHS, MIS, and MICS reports. The household-level indicator of owning at least 1 ITN for 2 people can be retained, but serve as a secondary indicator. Programmes will need to understand its limitations, and set targets accordingly. Under current ITN quantification and distribution strategies, an 80% target for households owning at least 1 ITN for 2 people is not achievable at a national or even subnational level. This disconnect may inadvertently lead to countries being penalized for continued malaria funding that is contingent upon performance.
This indicator is highly sensitive to average household size, and it masks significant individual protection—on average, 60% of the individual protection measured by the population access indicator is ignored when focus is put on the household "universal coverage" indicator. Given individual ITN use is only possible when a person has access to an ITN within their household, measuring actual ITN access in targeted geographical areas is the more programmatically useful indicator. Population access to ITNs, because it is based on persons as the unit of analysis, should be considered as the primary indicator of ITN coverage when assessing the success of ITN distributions.
HK and AK analysed the data and HK drafted the paper in consultation with other co-authors. All authors read and approved the final manuscript.
The authors are grateful for the many productive discussions on this topic held with Roll Back Malaria partners.
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
This publication is made possible by the generous support of the American people through the United States Agency for International Development (USAID) and the US President's Malaria Initiative (PMI) under the terms of USAID/JHU Cooperative Agreement No AID-OAA-A-14-00057. The contents do not necessarily reflect the views of PMI or the US Government.
12936_2018_2505_MOESM1_ESM.pdf Additional file 1. Each of the four ITN indicators discussed in this paper are presented plotted against each other. Plots were made using Stata's "aaplot" function, in which linear (gray lines), quadratic (pink lines), and fractional polynomial fits (shaded gray) can be compared. For each plot the equations for the quadratic and the linear models are listed, with the R2 value, describing the proportion of the variance attributable to the included variables. Equations may be useful to inform modeling of these indicators.
12936_2018_2505_MOESM2_ESM.xlsx Additional file 2. For the most recent DHS or MIS survey available in each country, the proportion of households with at least 7, 9, 11, 13, and 15 usual residents was calculated, for each region or province. These represent the proportion of households that would be prevented from receiving 1 ITN for 2 people if caps are set during mass ITN campaigns at 3, 4, 5, 6, or 7 ITNs, respectively. Programme planners may wish to consult these tables when considering setting caps for each region where ITNs will be distributed. This assumes that the definition of a 'household' remains the same during the campaign as in the surveys, generally 'people eating from the same pot'.
PMI Vectorworks Project, Johns Hopkins Bloomberg School of Public Health Center for Communication Programs, Baltimore, MD, USA
ICF, Rockville, MD, USA
National Malaria Control Programme, Ministry of Health, Dakar, Senegal
U.S. President's Malaria Initiative, U.S. Agency for International Development, Washington, DC, USA
International Federation of the Red Cross and Red Crescent Societies, Geneva, Switzerland
Swiss Tropical and Public Health Institute, Basel, Switzerland
University of Basel, Basel, Switzerland
African Leaders' Malaria Alliance, Arusha, Tanzania
The Global Fund to Fight AIDS, Tuberculosis, and Malaria, Geneva, Switzerland
Population Services International, Washington, DC, USA
African Leaders' Malaria Alliance, Nairobi, Kenya
U.S. President's Malaria Initiative, U.S. Centers for Disease Control and Prevention, Atlanta, GA, USA
Catholic Relief Services, Baltimore, MD, USA
PMI VectorWorks Project, Centre for Applied Malaria Research, Tulane University School of Public Health, New Orleans, LA, USA
PMI VectorWorks Project, Tropical Health LLP, Montagut, Spain
Bhatt S, Weiss DJ, Cameron E, Bisanzio D, Mappin B, Dalrymple U, et al. The effect of malaria control on Plasmodium falciparum in Africa between 2000 and 2015. Nature. 2015;526:207–11.View ArticleGoogle Scholar
Milliner J. Net mapping project. 2016. http://allianceformalariaprevention.com/working-groups/net-mapping-project/. Accessed 7 May 2018.
WHO. Recommendations for achieving universal coverage with long-lasting insecticidal nets in malaria control. Geneva: World Health Organization; 2013.Google Scholar
Kilian A, Koenker H, Paintain L. Estimating population access to insecticide-treated nets from administrative data: correction factor is needed. Malar J. 2013;12:259.View ArticleGoogle Scholar
Kilian A, Boulay M, Koenker H, Lynch M. How many mosquito nets are needed to achieve universal coverage? Recommendations for the quantification and allocation of long-lasting insecticidal nets for mass campaigns. Malar J. 2010;9:330.PubMedPubMed CentralGoogle Scholar
Yukich J, Bennett A, Keating J, Yukich RK, Lynch M, Eisele TP, et al. Planning long lasting insecticide treated net campaigns: should households' existing nets be taken into account? Parasites Vectors. 2013;6:174.View ArticleGoogle Scholar
MEASURE Evaluation, MEASURE DHS, President's Malaria Initiative, Roll Back Malaria Partnership, UNICEF, World Health Organization. Household survey indicators for malaria control. 2013.Google Scholar
Eisele TP, Keating J, Littrell M, Larsen D, Macintyre K. Assessment of insecticide-treated bednet use among children and pregnant women across 15 countries using standardized national surveys. Am J Trop Med Hyg. 2009;80:209–14.View ArticleGoogle Scholar
Kilian A, Koenker H, Baba E, Onyefunafoa EO, Selby RA, Lokko K, et al. Universal coverage with insecticide-treated nets—applying the revised indicators for ownership and use to the Nigeria 2010 malaria indicator survey data. Malar J. 2013;12:314.View ArticleGoogle Scholar
Koenker H, Kilian A. Recalculating the net use gap: a multi-country comparison of ITN use versus ITN access. PLoS ONE. 2014;9:e97496.View ArticleGoogle Scholar
Bhatt S, Weiss DJ, Mappin B, Dalrymple U, Cameron E. Coverage and system efficiencies of insecticide-treated nets in Africa from 2000 to 2017. eLife. 2015;4:e09672.View ArticleGoogle Scholar
WHO. World malaria report 2017. Geneva: World Health Organization; 2017.Google Scholar
ITN Access and Use—VectorWorks. 2016. p. 1–107. http://www.vector-works.org/resources/itn-access-and-use/. Accessed 7 May 2018.
WHO. Achieving and maintaining universal coverage with long-lasting insecticidal nets for malaria control. Geneva: World Health Organization; 2017.Google Scholar
Killeen GF, Smith TA, Ferguson HM, Mshinda H, Abdulla S, Lengeler C, et al. Preventing childhood malaria in Africa by protecting adults from mosquitoes with insecticide-treated nets. PLoS Med. 2007;4:e229.View ArticleGoogle Scholar
WHO. Global technical strategy for malaria 2016–2030. Geneva: World Health Organization; 2015.Google Scholar
Ghana Statistical Service, Ghana Health Service, ICF. Ghana malaria indicator survey 2016. Accra, Ghana and Rockville, Maryland; 2017.Google Scholar
de Beyl CZ, Koenker H, Acosta A, Onyefunafoa EO, Adegbe E, McCartney-Melstad A, et al. Multi-country comparison of delivery strategies for mass campaigns to achieve universal coverage with insecticide-treated nets: what works best? Malar J. 2016;15:58.View ArticleGoogle Scholar | CommonCrawl |
Span of an empty set is the zero vector
I am reading Nering's book on Linear Algebra and in the section on vector spaces he makes the comment, "We also agree that the empty set spans the set consisting of the zero vector alone".
Is Nering defining the span of the empty set to be the set containing the zero vector or is this something you can prove from the definition of span? I sense it is the latter, but the proof seems a bit tricky since you would be saying that {0} = Span of the indexed set of vectors in the empty set. But since the empty set has no vectors, it is not clear to me what its span would be.
linear-algebra matrices vector-spaces span
Matt BrennemanMatt Brenneman
$\begingroup$ The sum of no vectors is zero. $\endgroup$ – Rahul Aug 22 '12 at 0:50
$\begingroup$ In addition to other useful and explanatory answers, observe that Nering says "we agree...". That is, to my interpretation, he expresses disinterest in whether or not this could be proven, or should be a definition, or whatever, ... probably because he sees that it doesn't much matter, and I agree with this. So he is asserting neither, although, as in the answers, your questions can be reasonably addressed, also. In particular, again, in effect he asserts that there is no reason to care much about it, and I agree. $\endgroup$ – paul garrett Aug 21 '14 at 18:14
$\begingroup$ At the risk of pushing up an already answered question, I'd like to add that since linear span of a set of vectors $S$ is always a vector space and since every vector space contains the $\mathbf{0}$ vector, the linear span of $\mathbf{\phi}$ has to contain $\mathbf{0}$. To prove that it contains only $\mathbf{0}$, it is enough to show it can't contain any other element since those elements aren't present in the set $S$. $\endgroup$ – Aritra Das Feb 5 '17 at 10:04
Depending on how you define the span, this is either a definition or it follows from the definition of span (and judging by the wording it is probably the former). What's Nering's definition of span?
(One definition of span is the following: the span of a collection of vectors is the intersection of all subspaces containing them. The span of no vectors is therefore the intersection of all subspaces, which is $\{ 0 \}$.)
Qiaochu YuanQiaochu Yuan
$\begingroup$ This is the definition Nering gives for the span of a subset A of the vector space V: "For any subset A of V the set of all linear combinations of vectors in A is called the set spanned by A, and we denote it by <A>. We also say that A spans <A>." $\endgroup$ – Matt Brenneman Aug 22 '12 at 0:55
$\begingroup$ BTW, I like your definition. Technically that would solve my problem, but I still wouldn't understand my problem ;>) $\endgroup$ – Matt Brenneman Aug 22 '12 at 0:59
$\begingroup$ @Matt: that definition is ambiguous unless Nering has also defined what a linear combination of no vectors is (as Rahul says in the comments, the correct definition is that it is $0$). I am guessing that Nering has not defined a linear combination of no vectors, and so this is an additional definition. $\endgroup$ – Qiaochu Yuan Aug 22 '12 at 1:00
$\begingroup$ @Matt: yes, the problem is that most authors do not define the empty sum. The empty sum should be $0$. $\endgroup$ – Qiaochu Yuan Aug 22 '12 at 1:10
$\begingroup$ @LVK: yes, or you can recognize that addition isn't a binary operation; it's a family of $n$-ary operations for every $n \ge 0$, and it just so happens that they can all be defined in terms of the additive identity, the identity operation, and the $n = 2$ operation because of associativity... $\endgroup$ – Qiaochu Yuan Aug 22 '12 at 16:56
The span of a set D is the smallest subspace containing the elements of D. Now, every subspace contains 0. Thus if D is a null set the span of D can only be the subspace containing 0.
C. RavishankarC. Ravishankar
linear span of an empty set i.e L(0) is taken as the set (O),this is confusing because L(0) is the set of all linear combinations of the elements of 0 but to make a linear combination we need to have at least one vector of the set and empty set contains no vectors in it. Thus it it should have been 0 and not (O).
On the other hand, if possible, let L(0) be a set other than (O). Then then it* either contains at least one non zero element (i.e a vector of V) which is a linear combination of the elements of 0.This leads us to a contradiction that 0 is not empty.Hence the possibility of L(0) to be other than (O) is ruled out.
or is it self 0.Now if this possibility can be ruled out then the proof becomes complete. reader may please comment.**
Narinder Kumar DharNarinder Kumar Dhar
Looking at the problem from a programatic perspective, if ever I'd like to represent (or generate maybe?) the span of a set of vectors using the linear combinations of vectors definition. I'd always start with a sum variable equating to zero and then iteratively keep on adding to the sum.
If the set would be empty, the script would return the zero vector.
So, Span of an empty set is the zero vector, makes some sense.
Karanv.10111Karanv.10111
Not the answer you're looking for? Browse other questions tagged linear-algebra matrices vector-spaces span or ask your own question.
Empty Set $\{\}$ is the Only Basis of the Zero Vector Space $\{0\}$
what does the set containing only the zero vector actually span?
Two subsets with the same span?
Help understanding the span of a set in $R^2$
Is $span(v_1, . . . ,v_m)$ a linearly dependent or linearly independent set of vectors? Also, what will happen if we take span of span?
If the det of a set of vectors is zero, why does not span a vector space?
linear independance of a span
Vector subspaces of zero dimension
Span of a set of vectors containing the zero vector
Problems with the linear span of the empty set | CommonCrawl |
Unsupervised domain adaptation for lip reading based on cross-modal knowledge distillation
Yuki Takashima1,
Ryoichi Takashima ORCID: orcid.org/0000-0002-9808-02501,
Ryota Tsunoda1,
Ryo Aihara2,
Tetsuya Takiguchi1,
Yasuo Ariki1 &
Nobuaki Motoyama2
We present an unsupervised domain adaptation (UDA) method for a lip-reading model that is an image-based speech recognition model. Most of conventional UDA methods cannot be applied when the adaptation data consists of an unknown class, such as out-of-vocabulary words. In this paper, we propose a cross-modal knowledge distillation (KD)-based domain adaptation method, where we use the intermediate layer output in the audio-based speech recognition model as a teacher for the unlabeled adaptation data. Because the audio signal contains more information for recognizing speech than lip images, the knowledge of the audio-based model can be used as a powerful teacher in cases where the unlabeled adaptation data consists of audio-visual parallel data. In addition, because the proposed intermediate-layer-based KD can express the teacher as the sub-class (sub-word)-level representation, this method allows us to use the data of unknown classes for the adaptation. Through experiments on an image-based word recognition task, we demonstrate that the proposed approach can not only improve the UDA performance but can also use the unknown-class adaptation data.
Lip reading is a technique of understanding utterances by visually interpreting the movements of a person's lips, face, and tongue when the spoken sounds cannot be heard. For example, for people with hearing problems, lip reading is one communication skill that can help them communicate better. McGurk et al. [1] reported that we human beings perceive a phoneme not only from the auditory information of the voice but also from visual information associated with the movement of the lips and face. Moreover, it is reported that we try to catch the movement of lips in a noisy environment and we misunderstand the utterance when the movements of the lips and the voice are not synchronized. Therefore, understanding the relationship between the voice and the movements of the lips is very important for speech perception. In the field of automatic speech recognition (ASR), visual information is used to assist the performance of speech recognition in a noisy environment [2]. In this work, lip reading has the goal of classifying words from the movements of the lips.
Recently, deep learning-based models have improved the performance of audio-visual automatic speech recognition (AV-ASR) or lip reading [3–7] where a large amount of training data is available. However, in a variety of real-life situations, there is often a mismatch between the training environment and the real environment where a user utilizes the system, and it is not easy to collect a sufficient amount of training data in a specific environment. Therefore, an effective way to adapt the model to a new environment is required. This is known as the domain adaptation (DA) problem.
The purpose of DA is to adapt a model trained on a source domain (source model) to a new target domain by using a relatively small amount of additional training (adaptation) data. Especially, in the case when all the adaptation data are not labeled, it is called "unsupervised domain adaptation" (UDA). Various UDA approaches have been proposed [8–10]. However, most of them assume that all the adaptation data belong to classes that are defined in the source model. This means that we cannot use the real environment data for the adaptation if that data is out-of-class (e.g., out-of-vocabulary (OOV) words in speech recognition). For more practical adaptation, it is preferable if out-of-class (unknown class) data can also be used. With this in mind, in this paper, we investigate an unknown-class-driven UDA method. Although there has been research carried out to tackle a similar issue [10, 11], the UDA on the unknown-class data is an extremely challenging task because we cannot use any conventional training policies, such as maximizing the output probability of the correct class.
In this paper, we propose a UDA method based on a model for cross-modal knowledge distillation (KD) for lip reading. There are two key factors: cross-modal KD and its application to UDA. KD [12] was originally introduced as model compression, in which a small model (student model) is trained to imitate an already-trained larger model (teacher model). Based on the idea that KD can transfer the knowledge of the teacher model to the student model, this technique has been applied to various tasks [13–15]. In this paper, we investigate cross-modal KD, where the student and teacher model are a lip-reading model and an audio-based speech recognition model (ASR model), respectively. Our proposed method uses audio-visual data for training and adapting the lip-reading model. Before training the lip-reading model, we train the ASR model using audio data. In our research, we use an ASR model based on an artificial neural network. Then, we train the lip-reading model by using the output from the intermediate layer of the ASR model. Typically, the audio data has more information for recognizing speech and shows better recognition accuracy than the visual data. For this reason, the use of the output from the ASR model can be a powerful teacher.
Another important factor is the use of the data of the unknown class for UDA. The basic KD that minimizes the distance between the output probabilities (i.e., output of the final layer) of the teacher and student models cannot be applied to unknown class UDA because the output labels of the source model do not contain the target class. To solve this problem, we use the output of the intermediate layer for the KD instead of that of the final layer. This approach is advantageous because, unlike basic final-layer-based KD, our intermediate-layer-based KD can construct the sub-class (e.g., sub-word in speech recognition) representation implicitly inside the network. By using this sub-class representation as an adaptation objective, we can use the unknown class data for the adaptation.
Our approach, which utilizes an audio signal to enhance the lip-reading performance, is suitable for applications having a video camera, such as car navigation systems using in-vehicle cameras and service robots. In these applications, we can use both audio and video signals, and improving the lip-reading performance is expected to contribute to the improvement of audio-visual speech recognition performance. In the experiment, we demonstrate that our proposed method can improve the UDA performance on a word recognition task.
There have been many studies carried out on AV-ASR over the years, and most of them discuss how to integrate multimodal features [3, 15, 16]. We expect that to improve the performance of the lip reading can contribute to improving the performance of AV-ASR. LipNet [17] performs end-to-end sentence-level lip reading. This model consists of spatiotemporal convolutions and recurrent operations, and that is trained by a connectionist temporal classification loss [18]. MobiLipNet [19] has been proposed to achieve computationally efficient lip reading, and that uses the depthwise convolution and the pointwise convolution. There are some prior works based on a generative adversarial network (GAN) [20] for lip reading. Wand et al. [21] proposed a speaker-independent lip-reading system using domain-adversarial training that trains a model that can extract the speaker-invariant feature representation. Oliveira et al. [22] investigated a method to recognize viseme, that is the visual correspondent of a phoneme, using GAN-based mapping to alleviate a head-pose variation problem.
There have been some studies on cross-modal KD [15, 23, 24] for the purpose of transferring the knowledge of a modal having rich training data to a modal having poor training data. This technique has also been applied to the AV-ASR task [15], where the knowledge of the audio trained from a large amount of speech data is transferred to the AV-ASR model. In that study, they focused only on the case in which the audio data is corrupted by noise, and did not discuss the environmental mismatch in the image data, which is our target issue. For lip reading, a similar approach to our proposed method was used more recently as multi-granularity KD from a speech recognizer to a lip reader (LIBS) [25] where a frame-level KD corresponds to our intermediate-layer-based KD. In order to take account of the difference between the audio and video sampling rates, LIBS employs an attention mechanism. Different from LIBS, our method uses a pyramid structure to obtain the audio and video sequences of the same length. Moreover, our method is evaluated on a word-level recognition task, while LIBS was evaluated on a sequence-level utterance recognition task.
The recent UDA approach involves finding a common representation for the two domains. Deep domain confusion [26] learns the meaningful and domain-invariant representation with an additional adaptive layer and loss function. GAN-based UDA approaches [27, 28] aim to learn the intermediate representation that cannot be used to distinguish the domain. Saito et al. [10] proposed a method to maximize the discrepancy between two classifier outputs considering the task-specific-design boundaries. Sohn et al. [29] proposed a feature-level UDA method using unlabeled video data that distills knowledge from a still image network to a video adaptation network. Afoura et al. [24] proposed a cross-modal KD method to improve the performance of lip reading using an ASR model. In our study, we investigate the use of cross-modal KD to adapt a model to the target environment.
Despite the recent progress of UDA, these conventional methods assume that all the adaptation data belong to classes that are defined in the source model, and none of the data can be used for the adaptation if that data is out-of-class. In the field of voice conversion, some approaches that do not require any context information have been proposed (e.g., [30]). Similar to these works, a context-independent (i.e., class-independent) approach for training the lip-reading model is required. In this work, we focus on the scenario where only the data of the unknown class is available during adaptation.
Proposed method
We aim to achieve UDA using the data of the unknown class on lip reading, which estimates the word label from an image input. In our proposed method, we use audio-visual data for training and adapting the lip-reading model, and for evaluating, we use only visual data. First, we explain the basic idea of the cross-modal KD on which our method is based. Then, we describe our proposed UDA method, which is based on the cross-modal KD using the data of the unknown class.
Cross-modal KD
Figure 1 shows an overview of the basic procedure of cross-modal KD, where the speech and the image are given from the same utterance. In our lip-reading task, the output is defined by the word. First, in advance, we train the audio model, which estimates the probability of the word from the acoustic feature using the cross entropy loss with the correct label. Given an acoustic feature xaud and an image feature xvis, the basic KD loss is defined as follows:
$$\begin{array}{*{20}l} -\sum_{l} p_{\text{aud}}(l|x_{\text{aud}}) \ln p_{\text{vis}}(l|x_{\text{vis}}), \end{array} $$
Basic procedure of cross-modal knowledge distillation
where pvis(l|xvis) and paud(l|xaud) denote the probabilities of a label l estimated from the visual model based on xvis and estimated from the audio model based on the input xaud, respectively. Here, the acoustic feature and the image feature are extracted from the same utterance. When training the visual model, the parameters of the audio model are fixed. This loss function forces the visual model to imitate the outputs extracted from the audio model. Practically speaking, the softmax loss using the correct label (hard loss) is often used for stable training with the linear interpolation parameter λ. Li et al. [15] demonstrate that KD between the ASR model and the AV-ASR model improves the recognition performance when the speech data is corrupted by noise. Therefore, it is expected that KD between the audio model (ASR model) and the visual model (lip-reading model) also contributes to improving the performance in our task.
Cross-modal KD-based UDA for the unknown class
Before describing our method, we first want to highlight the fact that the adaptation data does not belong to any class of the source domain. Considering the domain, let \(\mathcal {D}\) be the joint distribution over sequences of audio features and visual features, and the corresponding label. The output of the network is defined by the word.
Our model consists of two parts: an encoder and a classifier, as shown in Fig. 2. The encoder is a stacked convolution layer. The two encoders of the audio and visual modal can be defined as follows:
$$\begin{array}{*{20}l} \boldsymbol{h}^{a} &= f_{\text{aud}}(\boldsymbol{a}), \end{array} $$
Overview of our proposed UDA
$$\begin{array}{*{20}l} \boldsymbol{h}^{v} &= f_{\text{vis}}(\boldsymbol{v}), \end{array} $$
where \(\phantom {\dot {i}\!}\boldsymbol {a}=(a_{1},...,a_{t},...,a_{T_{a}})\) and \(\phantom {\dot {i}\!}\boldsymbol {v}=(v_{1},...,v_{t^{\prime }},...,v_{T_{v}})\) are input sequences of acoustic features and of visual features, respectively. \(\boldsymbol {h}^{a}=(h^{a}_{1},...,h^{a}_{u},...,h^{a}_{U})\) and \(\boldsymbol {h}^{v}=(h^{v}_{1},...,h^{v}_{u},...,h^{v}_{U})\) are the sequences of high-level representations. Here \(\phantom {\dot {i}\!}a_{t}, v_{t^{\prime }}, h^{a}_{u}\in \mathbb {R}^{d}\), and \(h^{v}_{u}\in \mathbb {R}^{d}\) are the input acoustic feature frame, the input visual feature frame, and the d-dimensional encoder features of both modalities, respectively. Ta,Tv and U≤ min(Ta,Tv) denote the numbers of the input acoustic features and the input visual features, and the number of the encoder output features, respectively. The number of steps of encoded features is the same between the two modalities. The classifier consists of fully connected layers to estimate the corresponding word label.
During adaptation, our method minimizes the mean square error (MSE) between the hidden representations as follows:
$$\begin{array}{*{20}l} \mathcal{L}_{{MSE}}(\mathcal{D}) = \mathbb{E}_{\{\boldsymbol{v},\boldsymbol{a},\boldsymbol{y}\}\sim \mathcal{D}} [|| \boldsymbol{h}^{a} - \boldsymbol{h}^{v} ||_{2}^{2}], \end{array} $$
where y is the label and is ignored. Unlike the generally used KD loss (Eq. (1)), we use the hidden representation in the intermediate layer for distillation. In the output layer and layers in the classifier, the frame-level information is lost and the feature representation is specialized to word-level (i.e., class-level) information. For this reason, the simple KD formulation cannot be applied to the adaptation if the adaptation data is out-of-class. On the other hand, the layers in the encoder have sub-word or phoneme-like representation that is independent of the class because they still retain the frame-level information. For this reason, our proposed method realizes UDA using the data of the unknown class.
Training procedure
Considering the source domain, let \(\mathcal {D}_{\text {src}}\) be the joint distribution over sequences of audio features and visual features, and the corresponding label. \(\mathcal {D}_{\text {trg}}\) is analogously defined for the target domain.
The first step is to train the models on the source domain. In this step, we expect that the hidden representation in the visual model is similar to that of the audio model. First, in advance, we train the audio model using the cross entropy loss with the correct label as follows:
$$\begin{array}{*{20}l} \mathbb{E}_{\{\boldsymbol{v},\boldsymbol{a},\boldsymbol{y}\}\sim \mathcal{D}_{\text{src}}} [-\log (g_{\text{aud}}(\boldsymbol{y}|\boldsymbol{h}^{a}))], \end{array} $$
where v is not used and gaud(y|ha) denotes the output probability of the label y estimated by the classifier of the audio model from the encoded feature h. Then, we train the visual model using the KD loss and the cross entropy loss as follows:
$$\begin{array}{*{20}l} &\mathcal{L}_{{MSE}}(\mathcal{D}_{\text{src}}) + \mathcal{L}_{{CE}}(\mathcal{D}_{\text{src}})\\ &= \mathcal{L}_{{MSE}}(\mathcal{D}_{\text{src}}) + \mathbb{E}_{\{\boldsymbol{v},\boldsymbol{a},\boldsymbol{y}\}\sim \mathcal{D}_{\text{src}}} [-\log (g_{\text{vis}}(\boldsymbol{y}|\boldsymbol{h}^{v}))], \end{array} $$
where gvis(y|hv) is the output probability estimated by the visual classifier.
Next, we adapt the visual model using the data of the unknown class based on the UDA scheme as described in Section 3.2. For more stable adaptation, we also use the data of the source domain. In addition to the loss in Eq. (4), we calculate losses for the source domain that has the correct label. This works as a regularization to prevent overfitting to the target distribution in the audio modality. Finally, our UDA approach for an unknown class minimizes the loss as follows:
$$\begin{array}{*{20}l} \mathcal{L} = \mathcal{L}_{{MSE}}(\mathcal{D}_{\text{trg}}) + \alpha\mathcal{L}_{{MSE}}(\mathcal{D}_{\text{src}}) + (1-\alpha)\mathcal{L}_{{CE}}(\mathcal{D}_{\text{src}}), \end{array} $$
where α indicates a weight parameter used to adapt the model stably, and we employ 0.5 in this paper. All parameters of the visual model are fine-tuned to minimize this loss function.
The proposed method was evaluated in a word recognition task on the lip reading in the wild (LRW) dataset [5]. LRW is a large-scale lip-reading dataset that consists of sounds and face images, where some works on AV-ASR or lip reading [31, 32] have been verified. All the videos are clipped to 29 frames (1.16 s) in length. Note that the length of each utterance is completely fixed.
LRW consists of up to 1000 utterances of 500 different words spoken by hundreds of different speakers. From the whole of the dataset, we picked out 800 utterances of 500 words (a total of 400,000 utterances) and divided them into several subsets, as shown in Fig. 3. We randomly divided 500 words into two sets of classes: the known class set of 400 words and the unknown class set of 100 words. For each of the 400 known words, we picked out (a) 500 utterances (a total of 200,000 utterances) and (b) another 50 utterances (a total of 20,000 utterances) as the training set of the source domain and the evaluation set of the target domain, respectively. For evaluating the UDA method, we used two different adaptation sets: the known class set and the unknown class set. The unknown class set (d) consisted of 250 utterances of 100 unknown words (a total of 25,000 utterances). For known class set (c), we randomly selected 100 words from 400 known words in order to match the condition with the unknown class set. Then, we created the known class set using 250 utterances of the selected 100 known words (a total of 25,000 utterances) which were not used for either the training set or the evaluation set. The evaluation set and the two adaptation sets were in the target domain while the training set was in the source domain. For creating the target domain data, we changed the brightness of the image (no transformation was carried out on the sound signal of the video) because changes in brightness are one of the most likely situations in real environments (e.g., daytime and night, or a car navigation system when driving through a tunnel).
Graphical representation of the division of the words, (a) source training set of the known words, (b) target evaluation set of the known words, (c) target adaptation set of the known words, and (d) target adaptation set of the unknown words
For the acoustic features, we calculated 40-dimensional log-mel filter bank features computed every 10 ms over a 25 ms window. Then, we stacked their delta and acceleration along the channel. The number of frames was 116. For the visual feature, the images are transformed to grayscale and resized to 112 ×112. The number of frames was 28. The encoder configuration is shown in Table 1. We used a pyramid structure that takes every two consecutive frames of the output from the previous layer without overlap as input. This structure allows the subsequent module to extract the relevant information from a smaller number of time steps. For the classifier, we use the three fully connected layers (4096 → 4096 → 400). We construct the individual model for the two modalities. The network was optimized using an Adam optimizer [33]. The batch size was 24, and the learning rate was set to 1e −4. When training models on the source domain, the number of epochs was 20 with early stopping. When adapting models to the target domain, the number of epochs was 10.
Table 1 Network architecture of the encoder
Our experiments were conducted using an Intel(R) Core(TM) i9-7900X CPU @ 3.30 GHz and single GeForce GTX 1080 Ti. Our proposed model took about 1.5 hours and 10 minutes per epoch for training and adaptation, respectively.
First, we evaluated the performance of cross-modal KD on the training data of the source domain model. Here, we use the test data without modifying the brightness of the image and do not consider UDA. Table 2 shows the word recognition accuracy corresponding to each method. "Baseline" indicates the baseline model that was trained using the face image only. In our proposed method, we adopt a dimension reduction in the model (the 4th layer in Table 1) to calculate the KD loss efficiently. However, the dimension reduction is removed here for evaluating the baseline model because it degraded the recognition accuracy of the baseline model. From this table, when using 250 utterances per word to train the model, our proposed model achieved a relative improvement of 3.57% compared to the baseline model, despite the comparable performance when using 500 utterances per word. Typically, the audio data has more information for recognizing the speech and shows better recognition accuracy than the use of the visual data. This result shows that the output from the ASR model worked as a powerful teacher. We also assume that KD affects the regularization because we obtained more improvement with less training data.
Table 2 Word recognition accuracy [%] for each method on the source domain
Next, we confirmed the effectiveness of our proposed method for UDA. For the baseline adaptation, we updated parameters using two losses: the cross entropy loss of the source domain (the third term of Eq. (7)) and the pseudo label of the target domain estimated by the source model itself. Table 3 shows the word recognition accuracy corresponding to each method. Our proposed method outperformed conventional UDA in the setting that uses the known class. The relative improvements compared to no adaptation are 12.53% for the baseline method and 21.88% for our method, respectively. Moreover, our proposed method also improved the classification accuracy compared to no adaptation by relatively 21.48% even when we used unknown class adaptation data. These results show that the intermediate-layer-based KD approach can transfer the sub-class representation that does not depend on the class. Therefore, by using such representation as an objective of the adaptation, it is possible to use the unknown class data for UDA.
Table 3 Word recognition accuracy [%] for each method
Moreover, we measured the performance of our UDA approach as a function of the number of adaptation utterances. As shown in Fig. 4, we observed that the accuracy decreases as the number of adaptation utterances decreases. We can see that the accuracies are saturated when using about 200 utterances for adaptation. Moreover, even when we use a smaller amount of the adaptation data, our method can adapt the model more effectively than the baseline method using all of the adaptation data (the fourth row in Table 3). These results demonstrate that our method can achieve stable and effective adaptation for UDA using the data of the unknown class.
The correlation between word recognition accuracies and the number of adaptation utterances. "Known class" and "Unknown class" indicate adaptation using the data of the known class and of the unknown class, respectively
Finally, we calculated the real time factor (RTF) that is the ratio of the recognition response to the utterance duration. Generally, RTF <1 is required for real-time scenarios. Here, decoding was performed on an Intel(R) Core(TM) i9-7900X CPU @ 3.30 GHz. The RTF of our system was 1.16. We consider that using a more efficient network architecture, such as MobileNet [34, 35], could improve the RTF while maintaining the performance.
Changing the division of the known/unknown words
In the experiments mentioned above, we used the fixed split for the known/unknown words. To evaluate the robustness of the variety of division pattern of the known/unknown words, we conducted 5-fold cross-validation for our proposed method. For this purpose, we split 500 words in LRW into 5 consecutive folds. Then, we used 100 words as the unknown class and the remaining 400 words as the known class. Table 4 shows the word recognition accuracy corresponding to each fold. The rightmost column in the table shows the mean value and the standard deviation. Our proposed method had a small standard deviation. This means that our method has high robustness for the selection of the words.
Table 4 Word recognition accuracy [%] for the 5-fold cross-validation
Noisy audio
To demonstrate the potential of our proposed method, we conducted the experiments in a more realistic scenario. For this purpose, we introduced acoustic noise for the audio in addition to brightness for the image during adaptation. White noise was added to audio signals, and their SNR was set to 30dB, 20dB, 10dB, and 0dB. As shown in Table 5, although the performance of our proposed method hardly varies among different SNRs (less than 1%), the use of the noisy audio signal significantly degraded the adaptation performance compared to using a clean audio signal.
Table 5 Word recognition accuracy [%] corresponding to each SNR
By comparing the results of "clean" and "30dB" in Table 5, we see that the recognition accuracy greatly degraded even though "30dB" was a small noise condition. In order to analyze these results, we measured how greatly the hidden representation of the audio signal ha, which is used as a teacher in our proposed cross-modal KD for UDA (see Eq. 4), is distorted by noise under each condition. For this measurement, we calculated the SNR under the hidden representation space as follows:
$$\begin{array}{*{20}l} \text{SNR} = 10\log_{10} \frac{||\boldsymbol{h}_{\text{clean}}^{a}||_{2}^{2}}{||\boldsymbol{h}_{\text{noisy}}^{a} - \boldsymbol{h}_{\text{clean}}^{a}||_{2}^{2}}, \end{array} $$
where \(\boldsymbol {h}_{\text {clean}}^{a}\) and \(\boldsymbol {h}_{\text {noisy}}^{a}\) denote the hidden representations ha obtained under clean and noisy (SNR = 30, 20, 10, 0dB) conditions, respectively. Table 6 shows the SNR of ha for each SNR of the input audio signal. As shown in this table, even when the SNR of the input audio signal was 30dB, the SNR of the hidden representation degraded to 14.14dB. Because this distorted hidden representation was used as a teacher in our proposed cross-modal KD, this result means that the proposed method is sensitive to the noise in the input audio signal. One possible reason for this sensitivity is that the audio model was trained using clean speech data and overfitted to the clean condition. Therefore, this degradation might be reduced if we use noisy audio data to train the noise-robust audio model. Nevertheless, the performance of our proposed system using the noisy audio signal still outperformed the baseline system (44.10, Known class adap. in Table 3) and the proposed system without adaptation (42.84 in Table 3) which do not use the audio signal.
Table 6 SNR of the hidden representation ha for each SNR of the input audio signal
In this paper, we proposed the intermediate-layer-based KD approach for UDA, which can effectively transfer the knowledge of the ASR model to the lip-reading model. Our method allows us to use the data of the unknown class to adapt the model from the source domain to the target domain. Experimental results show that our proposed method can adapt the model effectively regardless of whether the class of the adaptation data is known or unknown.
We used a simple network architecture based on stacked convolution layers because we assume an isolated word recognition task. In order to extend our approach for a continuous speech recognition task (i.e., sentence recognition task), we will investigate the use of recurrent neural network-based models which are suitable for this task, such as LipNet [17], in the future. In addition, we will demonstrate the effectiveness of our method in more complex transformations or more realistic environments. Our proposed method can use the audio-only database because the ASR model and the lip reading model are trained separately. Therefore, we will further investigate the combination with large audio databases. Our future work will also include the further investigation of its potential, focusing particularly on multi-modal tasks.
All data used in this study are included in the lip reading in the wild (LRW) dataset [5].
ASR:
GAN:
Generative adversarial network
KD:
Knowledge distillation
LRW:
Lip reading in the wild
OOV:
Out of vocabulary
RTF:
Real time factor
UDA:
Unsupervised domain adaptation
H. McGurk, J. MacDonald, Hearing lips and seeing voices. Nature. 264:, 746–748 (1976).
M. J. Tomlinson, M. J. Russell, N. M. Brooke, in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Integrating audio and visual information to provide highly robust speech recognition, (1996), pp. 821–824.
A. Verma, T. Faruquie, C. Neti, S. Basu, A. Senior, in Proc. IEEE Automatic Speech Recognition and Understanding (ASRU), 1. Late integration in audio-visual continuous speech recognition, (1999), pp. 71–74.
K. Palecek, J. Chaloupka, in Proc. International Conference on Telecommunications and Signal Processing (TSP). Audio-visual speech recognition in noisy audio environments, (2013), pp. 484–487.
J. S. Chung, A. Zisserman, in Proc. Asian Conference on Computer Vision (ACCV). Lip reading in the wild, (2016), pp. 87–103.
J. S. Chung, A. Senior, O. Vinyals, A. Zisserman, in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Lip reading sentences in the wild, (2017), pp. 3444–3453.
J. Yu, S. Zhang, J. Wu, S. Ghorbani, B. Wu, S. Kang, S. Liu, X. Liu, H. Meng, D. Yu, in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Audio-visual recognition of overlapped speech for the LRS2 dataset, (2020), pp. 6984–6988.
Y. Ganin, V. S. Lempitsky, in Proc. International Conference on Machine Learning (ICML). Unsupervised domain adaptation by backpropagation, (2015), pp. 1180–1189.
M. Ghifary, W. B. Kleijn, M. Zhang, D. Balduzzi, W. Li, in Proc. European Conference on Computer Vision (ECCV), 9908. Deep reconstruction-classification networks for unsupervised domain adaptation, (2016), pp. 597–613.
K. Saito, K. Watanabe, Y. Ushiku, T. Harada, in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Maximum classifier discrepancy for unsupervised domain adaptation, (2018), pp. 3723–3732.
P. P. Busto, J. Gall, in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Open set domain adaptation, (2017), pp. 754–763.
G. Hinton, O. Vinyals, J. Dean, in Proc. NIPS Deep Learning Workshop. Distilling the knowledge in a neural network, (2014).
T. Asami, R. Masumura, Y. Yamaguchi, H. Masataki, Y. Aono, in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Domain adaptation of DNN acoustic models using knowledge distillation, (2017), pp. 5185–5189.
G. Chen, W. Choi, X. Yu, T. X. Han, M. Chandraker, in NIPS. Learning efficient object detection models with knowledge distillation, (2017), pp. 742–751.
W. Li, S. Wang, M. Lei, S. M. Siniscalchi, C. H. Lee, in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Improving audio-visual speech recognition performance with cross-modal student-teacher training, (2019), pp. 6560–6564.
H. Ninomiya, N. Kitaoka, S. Tamura, Y. Iribe, K. Takeda, in Proc. ISCA Interspeech. Integration of deep bottleneck features for audio-visual speech recognition, (2015), pp. 563–567.
Y. M. Assael, B. Shillingford, S. Whiteson, N. de Freitas, LipNet: Sentence-level lipreading (2016). arXiv preprint arXiv:1611.01599.
A. Graves, S. Fernández, F. J. Gomez, J. Schmidhuber, in Proc. International Conference on Machine Learning (ICML). Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks, (2006), pp. 369–376.
A. Koumparoulis, G. Potamianos, in Proc. ISCA Interspeech. MobiLipNet: Resource-efficient deep learning based lipreading, (2019), pp. 2763–2767.
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, Y. Bengio, in NIPS. Generative adversarial nets, (2014), pp. 2672–2680.
M. Wand, J. Schmidhuber, in Proc. ISCA Interspeech. Improving speaker-independent lipreading with domain-adversarial training, (2017), pp. 3662–3666.
D. A. B. Oliveira, A. B. Mattos, E. D. S. Morais, in Proc. European Conference on Computer Vision (ECCV) Workshops. Improving viseme recognition using GAN-based frontal view mapping, (2018), pp. 2148–2155.
S. Gupta, J. Hoffman, J. Malik, in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Cross modal distillation for supervision transfer, (2016), pp. 2827–2836.
T. Afouras, J. S. Chung, A. Zisserman, in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). ASR is all you need: Cross-modal distillation for lip reading, (2020), pp. 2143–2147.
Y. Zhao, R. Xu, X. Wang, P. Hou, H. Tang, M. Song, in Proc. The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI). Hearing lips: Improving lip reading by distilling speech recognizers, (2020), pp. 6917–6924.
E. Tzeng, J. Hoffman, N. Zhang, K. Saenko, T. Darrell, Deep domain confusion: Maximizing for domain invariance (2014). arXiv preprint arXiv:1412.3474.
E. Tzeng, J. Hoffman, K. Saenko, T. Darrell, in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Adversarial discriminative domain adaptation, (2017), pp. 2962–2971.
R. Shu, H. H. Bui, H. Narui, S. Ermon, in Proc. International Conference on Learning Representations (ICLR). A DIRT-T approach to unsupervised domain adaptation, (2018).
K. Sohn, S. Liu, G. Zhong, X. Yu, M. -H. Yang, M. Chandraker, in Proc. IEEE International Conference on Computer Vision (ICCV). Unsupervised domain adaptation for face recognition in unlabeled videos, (2017), pp. 5917–5925.
A. Mouchtaris, J. V. der Spiegel, P. Mueller, Nonparallel training for voice conversion based on a parameter adaptation approach. IEEE Trans. Audio Speech Lang. Process.14(3), 952–963 (2006).
S. Petridis, T. Stafylakis, P. Ma, F. Cai, G. Tzimiropoulos, M. Pantic, in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). End-to-end audiovisual speech recognition, (2018), pp. 6548–6552.
T. Stafylakis, G. Tzimiropoulos, in Proc. ISCA Interspeech. Combining residual networks with LSTMs for lipreading, (2017), pp. 3652–3656.
D. P. Kingma, J. Ba, in Proc. International Conference on Learning Representations (ICLR). Adam: A method for stochastic optimization, (2015).
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, H. Adam, MobileNets: Efficient convolutional neural networks for mobile vision applications (2017). arXiv preprint arXiv:1704.04861.
M. Sandler, A. G. Howard, M. Zhu, A. Zhmoginov, L. -C. Chen, in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). MobileNetV2: Inverted residuals and linear bottlenecks, (2018), pp. 4510–4520.
Graduate School of System Informatics, Kobe University, Kobe, Japan
Yuki Takashima, Ryoichi Takashima, Ryota Tsunoda, Tetsuya Takiguchi & Yasuo Ariki
Information Technology R&D Center, Mitsubishi Electric Corporation, Ofuna, Japan
Ryo Aihara & Nobuaki Motoyama
Yuki Takashima
Ryoichi Takashima
Ryota Tsunoda
Ryo Aihara
Tetsuya Takiguchi
Yasuo Ariki
Nobuaki Motoyama
The first author mainly performed the experiments and wrote the paper, and the other authors reviewed and edited the manuscript. All of the authors discussed the final results. All of the authors read and approved the final manuscript.
Correspondence to Ryoichi Takashima.
Takashima, Y., Takashima, R., Tsunoda, R. et al. Unsupervised domain adaptation for lip reading based on cross-modal knowledge distillation. J AUDIO SPEECH MUSIC PROC. 2021, 44 (2021). https://doi.org/10.1186/s13636-021-00232-5
Lip reading | CommonCrawl |
A logarithm is the inverse function to an exponential function. It is defined as the exponent to which a fixed base must be raised to yield a given number.
Conversion between Logarithmic and Exponential Form
There is actually a simple way to solve difficult questions that involve logarithmic or exponential equations. The key is to remember that an exponential equation is just a special case of a logarithmic equation, so it's possible to convert an exponential equation into a logarithmic equation. So how do we convert the equation?
${{a}^{b}}=c\underset{{}}{\longleftrightarrow}b={{\log }_{a}}c$
$a$: base
$b$: index
$a>0,c>0$
Base of $10$
Natural Base
${{\log }_{10}}x=\lg x$
${{\log }_{e}}x=\ln x$
Question 1 – Conversion to Logarithmic Form
Convert each of the following to logarithmic form.
${{x}^{2y}}=4$
(a) ${{x}^{2y}}=4$
${{5}^{x}}=12$
(b) ${{5}^{x}}=12$
${{\left( 4x \right)}^{5-p}}=a$
(c) ${{\left( 4x \right)}^{5-p}}=a$
{{x}^{2y}}&=4 \\
& \Downarrow \\
2y&={{\log }_{x}}4
{{5}^{x}}&=12 \\
x&={{\log }_{5}}12
{{\left( 4x \right)}^{5-p}}&=a \\
5-p&={{\log }_{4x}}a
Question 2 – Conversion to Exponential Form
Solve each of the following equations.
$\ln 4x=5$
(a) $\ln 4x=5$
${{\log }_{x}}16=4$
(b) ${{\log }_{x}}16=4$
$\ln (3x)=6$
(c) $\ln (3x)=6$
${{\log }_{k}}81=2$
(d) ${{\log }_{k}}81=2$
\ln 4x&=5 \\
{{\log }_{\text{e}}}4x&=5 \\
4x&={{\text{e}}^{5}} \\
x&=\frac{1}{4}{{\text{e}}^{5}}
{{\log }_{x}}16&=4 \\
{{x}^{4}}&=16 \\
x&=\pm \sqrt[4]{16} \\
x&=2\,\,\text{or}\,\,-2
$x=-2$ (rej, as $x>0$)
$\therefore x=2$
\ln \left( 3x \right)&=6 \\
{{\log }_{\text{e}}}\left( 3x \right)&=6 \\
{{\text{e}}^{6}}&=3x \\
{{\log }_{k}}81&=2 \\
{{k}^{2}}&=81 \\
k&=\pm \sqrt{81} \\
& =9\,\,\text{or}-9
$k=-9$ (rej, as $k>0$)
$\therefore k=9$
Special Properties to Take Note
Property I
Property II
The logarithm of $1$ to the any base will always yield $0$.
${{\log }_{a}}1=0$
${{\log }_{5}}1=0$ ${{\log }_{17.5}}1=0$ $\ln 1=0$
The logarithm of any number to the same base will always yield $1$.
${{\log }_{a}}a=1$
${{\log }_{11}}11=1$ ${{\log }_{20.5}}20.5=1$ $\ln e=1$
Product Law and Its Proof
The product law for logarithms can be applied to simplify a logarithm of a product of many terms. The product law for logarithms states that the sum of the logs of two numbers is equal to the log of the product of two numbers.
${{\log }_{a}}b+{{\log }_{a}}c={{\log }_{a}}\left( b\times c \right)$
${{\log }_{a}}(p+q)\ne \left( {{\log}_{a}}p \right)\left( {{\log}_{a}}q \right)$
${{\log }_{a}}(p+q)\ne {{\log}_{a}}p+{{\log}_{a}}q$
$\ln 2+\ln5=\ln10$
${{\log }_{3}}2+{{\log }_{3}}20={{\log }_{3}}40$
${{\log }_{2}}3+{{\log }_{2}}7+{{\log }_{2}}2={{\log }_{2}}42$
Simplify ${{\lg }_{6}}2+{{\lg }_{6}}3$ if possible.
& {{\lg }_{6}}2+{{\lg }_{6}}3 \\
& ={{\log }_{6}}\left( 2\times 3 \right) \\
& ={{\log }_{6}}6 \\
& =1 \\
Quotient Law and Its Proof
The quotient law for logarithms is also often used when simplifying logs. The quotient law for logarithms states that the difference between the logs of two numbers is equal to the log of the quotient of two numbers.
${{\log }_{a}}b-{{\log }_{a}}c={{\log }_{a}}\left( \frac{b}{c} \right)$
${{\log }_{a}}(p-q)\ne \frac{{{\log}_{a}}p}{{{\log}_{a}}q}$
$\ln 2-\ln5=\ln\frac{2}{5}$
${{\log }_{3}}2-{{\log }_{3}}20={{\log }_{3}}\frac{1}{10}$
${{\log }_{2}}16-{{\log }_{2}}5+{{\log }_{2}}2={{\log }_{2}}\frac{16\times 2}{5}$
Simplify ${{\log }_{5}}25-{{\log }_{5}}5$ if possible.
& {{\log }_{5}}25-{{\log }_{5}}5 \\
& ={{\log }_{5}}\left( \frac{25}{5} \right) \\
Power Law and Its Proof
The power law for logarithms can be applied for expanding or simplifying logarithms. The power law of logarithms allows us to move the exponent to the front of the logarithm if the logarithmic term has an exponent.
${{\log }_{a}}{{b}^{r}}=r{{\log }_{a}}b$
${{\left( {{\log }_{a}}x \right)}^{3}}\ne 3{{\log }_{a}}x$
But ${{\left( {{\log }_{a}}x \right)}^{3}}=\left( {{\log }_{a}}x \right)\left( {{\log }_{a}}x \right)\left( {{\log }_{a}}x \right)$
${{\log }_{2}}{{5}^{x}}=x{{\log }_{2}}5$
${{\log }_{3}}\sqrt{2}=\frac{1}{2}{{\log }_{3}}2$
Evaluate each of the following without using the calculator.
${{\log }_{8}}64$
(a) ${{\log }_{8}}64$
${{\log }_{2}}\sqrt{4}+{{\log }_{2}}\sqrt{3}-{{\log }_{2}}\sqrt{6}$
(b) ${{\log }_{2}}\sqrt{4}+{{\log }_{2}}\sqrt{3}-{{\log }_{2}}\sqrt{6}$
{{\log }_{8}}64&={{\log }_{8}}{{8}^{2}} \\
& =2{{\log }_{8}}8 \\
& =2\left( 1 \right) \\
& {{\log }_{2}}\sqrt{4}+{{\log }_{2}}\sqrt{3}-{{\log }_{2}}\sqrt{6} \\
& ={{\log }_{2}}\left( \sqrt{4}\cdot \sqrt{3} \right)-{{\log }_{2}}\sqrt{6} \\
& ={{\log }_{2}}\frac{\sqrt{4}\cdot \sqrt{3}}{\sqrt{6}} \\
& ={{\log }_{2}}\sqrt{\frac{4\cdot 3}{6}} \\
& ={{\log }_{2}}\sqrt{2} \\
& ={{\log }_{2}}{{2}^{\frac{1}{2}}} \\
& =\frac{1}{2}{{\log }_{2}}2 \\
& =\frac{1}{2} \\
Change of Base and Its Proof
From the previous section, we know that the common logarithm is also called the "logarithm with a base of $10$," and the natural logarithm is referred to as the "logarithm with a base of $\text{e}$". Although both logarithms are commonly called the logarithm, they are actually two separate calculations. Most graphing calculators have keys that allow you to work with logarithms: LOG for common logarithms and LN for natural logarithms.
What happens if we have questions involving logarithms with a base other than $10$ and $\text{e}$? The change-of-base formula allows us to convert any logarithm into another logarithm with a different base, which can be very useful in solving certain types of questions.
${{\log }_{a}}b=\frac{{{\log }_{c}}b}{{{\log }_{c}}a}$
${{\log }_{x}}y=\frac{1}{{{\log }_{y}}x}$
Converting the logarithm into another logarithm with base $7$:
${{\log }_{2}}5=\frac{{{\log }_{7}}5}{{{\log }_{7}}2}$
Converting the logarithm into another logarithm with base $p$:
${{\log }_{11}}2=\frac{{{\log }_{p}}2}{{{\log }_{p}}11}$
Given that $p={{\log }_{a}}9$, find ${{\log }_{3}}a$ in terms of $p$.
(a) Given that $p={{\log }_{a}}9$, find ${{\log }_{3}}a$ in terms of $p$.
If $p=\lg 14$, ${{\log }_{14}}1\frac{2}{5}$ in terms of $p$.
(b) If $p=\lg 14$, ${{\log }_{14}}1\frac{2}{5}$ in terms of $p$.
p&={{\log }_{a}}9 \\
p&=\frac{{{\log }_{3}}9}{{{\log }_{3}}a} \\
{{\log }_{3}}a&=\frac{{{\log }_{3}}{{3}^{2}}}{p} \\
& =\frac{2{{\log }_{3}}3}{p} \\
& =\frac{2}{p}
p&=\lg 14\\&={{\log }_{10}}14\\&=\frac{{{\log }_{14}}14}{{{\log }_{14}}10}\\&=\frac{1}{{{\log }_{14}}10} \\
{{\log }_{14}}10&=\frac{1}{p}
& {{\log }_{14}}\left( 1\frac{2}{5} \right)\\&={{\log }_{14}}\left( \frac{7}{5} \right) \\
& ={{\log }_{14}}\left( \frac{7\cdot 2}{5\cdot 2} \right) \\
& ={{\log }_{14}}\left( \frac{14}{10} \right) \\
& ={{\log }_{14}}14-{{\log }_{14}}10 \\
& =1-\frac{1}{p}
Simultaneous Logarithm Equations
Suppose we have a system of equations that contains multiple logarithmic equations and multiple unknown variables, how do we address them? In this section, we will learn how to solve systems of logarithmic equations by substitution.
Solve the simultaneous equations.
{{\log }_{4}}x-{{\log }_{2}}y&=2 \\
{{3}^{x}}&=81\left( {{9}^{\frac{3}{2}-3y}} \right)
{{\log }_{4}}x-{{\log }_{2}}y&=2—(1) \\
{{3}^{x}}&=81\left( {{9}^{\frac{3}{2}-3y}} \right)—(2)
From (2):
{{3}^{x}}&={{3}^{4}}\left( {{\left( {{3}^{2}} \right)}^{\frac{3}{2}-3y}} \right) \\
{{3}^{x}}&={{3}^{4}}\cdot {{3}^{3-6y}} \\
{{3}^{x}}&={{3}^{4+3-6y}} \\
x&=4+3-6y \\
x&=7-6y—(3)
Substitute (3) into (1):
{{\log }_{4}}\left( 7-6y \right)-{{\log }_{2}}y&=2 \\
\frac{{{\log }_{2}}\left( 7-6y \right)}{{{\log }_{2}}{{2}^{2}}}-{{\log }_{2}}y&=2 \\
\frac{{{\log }_{2}}\left( 7-6y \right)}{2}-{{\log }_{2}}y&=2 \\
{{\log }_{2}}\left( 7-6y \right)-2{{\log }_{2}}y&=4 \\
{{\log }_{2}}\left( 7-6y \right)-{{\log }_{2}}{{y}^{2}}&=4 \\
{{\log }_{2}}\frac{7-6y}{{{y}^{2}}}&=4 \\
\frac{7-6y}{{{y}^{2}}}&={{2}^{4}} \\
7-6y&=16{{y}^{2}} \\
16{{y}^{2}}+6y-7&=0\\
\left( 2y-1 \right)\left( 8y+7 \right)&=0 \\
y&=\frac{1}{2}\,\,\text{or}\,\,-\frac{7}{8}
$y=-\frac{7}{8}$ (rej, as ${{\log }_{2}}\left( -\frac{7}{8} \right)$ is undefined)
Substitute $y=\frac{1}{2}$ into (3):
x&=7-6\left( \frac{1}{2} \right) \\
$\therefore y=\frac{1}{2},\,\,x=4$
Applications of Logarithms
The logarithm is a very common and useful way to measure the relative magnitudes of things. Here are a few examples of logarithms in real-life:
The Richter scale – a measure of the energy released in an earthquake, with each level 10 times more powerful than the last.
Decibel – a logarithmic measure of the intensity of a sound.
pH value – a measure of acidity and alkalinity on a scale of 0 to 14, with 7 being neutral.
The mass, $m$ grams, of a radioactive substance, present at time t days after first being observed, is given by the formula $m=28{{e}^{-0.00072t}}$.
Find the value of $m$ when $t=20$.
(a) Find the value of $m$ when $t=20$.
Find the value of $t$ when the mass is half of its value at $t=0$.
(b) Find the value of $t$ when the mass is half of its value at $t=0$.
State the value which $m$ approaches as $t$ becomes very large.
(c) State the value which $m$ approaches as $t$ becomes very large.
Sketch the graph of $m$ against $t$.
(d) Sketch the graph of $m$ against $t$.
When $t=20$,
m&=28{{\text{e}}^{-0.00072\left( 20 \right)}} \\
& =27.5996 \\
& =27.6\,\text{grams }\left( 3\,\,\text{s}\text{.f}\text{.} \right)
When $t=0$,
m&=28{{\text{e}}^{-0.00072\left( 0 \right)}} \\
& =28{{\text{e}}^{0}} \\
& =28\,\text{grams}
New $m=\frac{28}{2}=14$
m&=28{{\text{e}}^{-0.00072t}} \\
14&=28{{\text{e}}^{-0.00072t}} \\
\frac{1}{2}&={{\text{e}}^{-0.00072t}} \\
\ln \frac{1}{2}&=\ln {{\text{e}}^{-0.00072t}} \\
\ln \frac{1}{2}&=-0.00072t \\
t&=\frac{\ln \frac{1}{2}}{-0.00072} \\
& =962.7 \\
& =963\,\,\text{days}\,\left( 3\,\,\text{s}\text{.f}\text{.} \right)
$t\to \infty ,m\to 0$
$m$ approaches $0$ gram.
Click image to view in full size | CommonCrawl |
What does it mean for a probability distribution to not have a density function?
I understand the distinction between probability mass and density functions. But I don't understand what it means for a continuous random variable to have a probability distribution but not a density. I am reading this paper where the author consistently refers to the possibility that the probability density $P_{\theta}$ may or may not exist for a probability distribution $\mathbb{P}_{\theta}$. Can anyone explain what it meant by this? I would have thought that if $P_{\theta}$ did not exist, neither would $\mathbb{P}_{\theta}$.
distributions pdf
gwggwg
$\begingroup$ The answer is prominently posted on the first page of the paper: "We need the model density $\mathbb{P}_\theta$ to exist. This is not the case in the rather common situation where we are dealing with distributions supported by low dimensional manifolds. It is then unlikely that the model manifold and the true distribution's support have a non-negligible intersection (see [1]), and this means that the KL distance is not defined (or simply infinite)." The distinction looks rather important to me--it certainly isn't "completely useless" (to quote a now deleted comment). $\endgroup$ – whuber♦ Jun 22 '17 at 20:36
$\begingroup$ Just so we're on the same page, you have the notation in the paper wrong. He uses $\mathbb{P}_{\theta}$ to denote the distribution and $P_{\theta}$ to denote the density. Anyway, I do not understand that answer because the distinction in terms does not seem necessary to make his point. For example, why can't we also say that we need the model distribution to exist? And if the model density $P_{\theta}$ does not exist, how can $\mathbb{P}_{\theta}$ exist? $\endgroup$ – gwg Jun 22 '17 at 22:16
$\begingroup$ Sorry about not picking up on that typographical distinction--but isn't the quotation perfectly clear? Distributions always exist but densities need not exist. A good example is the Bernoulli$(p)$ distribution: its distribution function at $x$ equals $1-p$ when $0\le x\lt 1$ and otherwise is $0$ when $X\lt 0$ or $1$ when $X\ge 1$. It has no density. The paper is concerned about situations like a bivariate random variable $(X,Y)$ where $X$ has a standard Normal distribution and $Y=X$. This is perfectly well defined; it has a distribution function; but it cannot have a density. $\endgroup$ – whuber♦ Jun 22 '17 at 22:21
$\begingroup$ In case you haven't encountered the definition of multivariate distributions, they are like the univariate one: $F(x,y) = \Pr(X\le x\text{ and }Y \le y)$. For instance, if $\Phi$ is the standard Normal distribution, then the distribution function for the $(X,Y)$ defined in my previous comment is $$F(x,y)=\Phi(\min(x,y)).$$The corresponding density function, if it exists, will equal $\frac{\partial^2}{\partial x\partial y}F$. However, this $F$ is not differentiable anywhere where $x=y$--the graph of $F$ has a sharp "ridge" there--and otherwise the mixed partials are zero. $\endgroup$ – whuber♦ Jun 22 '17 at 22:27
$\begingroup$ Sorry if I am missing something obvious. I think I follow everything you've said so far. For example, the Bernoulli distribution does not have a density because a Bernoulli r.v. is discrete. But the paper seems to suggest there is something deeper here (maybe I am just reading into it): "The problem this paper is concerned with is that of unsupervised learning. Mainly, what does it mean to learn a probability distribution? The classical answer to this is to learn a probability density." Why a density? Why not just say distribution? $\endgroup$ – gwg Jun 22 '17 at 23:39
Browse other questions tagged distributions pdf or ask your own question.
What is the meaning of superscript in $p_{\theta}(x)$ and ${\mathbb E}_{\theta}\left[S(\theta)\right]$?
Some basic questions related to the moments of a probability distribution
What is 'probability of correct selection'?
How to calculate the probability of the parameters?
Distribution vs Distribution Function | CommonCrawl |
SciPost Physics Vol. 8 issue 1
SciPost Physics Core Vol. 1 issue 1
Order by: publication date number of citations
Exact correlations in the Lieb-Liniger model and detailed balance out-of-equilibrium
Jacopo De Nardis, Miłosz Panfil
SciPost Phys. 1, 015 (2016) · published 30 December 2016 |
Toggle abstract
· pdf
We study the density-density correlation function of the 1D Lieb-Liniger model and obtain an exact expression for the small momentum limit of the static correlator in the thermodynamic limit. We achieve this by summing exactly over the relevant form factors of the density operator in the small momentum limit. The result is valid for any eigenstate, including thermal and non-thermal states. We also show that the small momentum limit of the dynamic structure factors obeys a generalized detailed balance relation valid for any equilibrium state.
Viktor Eisler, Florian Maislinger, Hans Gerd Evertz
We study the melting of domain walls in the ferromagnetic phase of the transverse Ising chain, created by flipping the order-parameter spins along one-half of the chain. If the initial state is excited by a local operator in terms of Jordan-Wigner fermions, the resulting longitudinal magnetization profiles have a universal character. Namely, after proper rescalings, the profiles in the noncritical Ising chain become identical to those obtained for a critical free-fermion chain starting from a step-like initial state. The relation holds exactly in the entire ferromagnetic phase of the Ising chain and can even be extended to the zero-field XY model by a duality argument. In contrast, for domain-wall excitations that are highly non-local in the fermionic variables, the universality of the magnetization profiles is lost. Nevertheless, for both cases we observe that the entanglement entropy asymptotically saturates at the ground-state value, suggesting a simple form of the steady state.
Xinyi Chen-Lin
We study the circular Wilson loop in the symmetric representation of U(N) in $\mathcal{N} = 4$ super-Yang-Mills (SYM). In the large N limit, we computed the exponentially-suppressed corrections for strong coupling, which suggests non-perturbative physics in the dual holographic theory. We also computed the next-to-leading order term in 1/N, and the result matches with the exact result from the k-fundamental representation.
Jan de Gier, Jesper Lykke Jacobsen, Anita Ponsaing
We compute the boundary entropy for bond percolation on the square lattice in the presence of a boundary loop weight, and prove explicit and exact expressions on a strip and on a cylinder of size $L$. For the cylinder we provide a rigorous asymptotic analysis which allows for the computation of finite-size corrections to arbitrary order. For the strip we provide exact expressions that have been verified using high-precision numerical analysis. Our rigorous and exact results corroborate an argument based on conformal field theory, in particular concerning universal logarithmic corrections for the case of the strip due to the presence of corners in the geometry. We furthermore observe a crossover at a special value of the boundary loop weight.
One step replica symmetry breaking and extreme order statistics of logarithmic REMs
Xiangyu Cao, Yan V. Fyodorov, Pierre Le Doussal
Building upon the one-step replica symmetry breaking formalism, duly understood and ramified, we show that the sequence of ordered extreme values of a general class of Euclidean-space logarithmically correlated random energy models (logREMs) behave in the thermodynamic limit as a randomly shifted decorated exponential Poisson point process. The distribution of the random shift is determined solely by the large-distance ("infra-red", IR) limit of the model, and is equal to the free energy distribution at the critical temperature up to a translation. the decoration process is determined solely by the small-distance ("ultraviolet", UV) limit, in terms of the biased minimal process. Our approach provides connections of the replica framework to results in the probability literature and sheds further light on the freezing/duality conjecture which was the source of many previous results for log-REMs. In this way we derive the general and explicit formulae for the joint probability density of depths of the first and second minima (as well its higher-order generalizations) in terms of model-specific contributions from UV as well as IR limits. In particular, we show that the second min statistics is largely independent of details of UV data, whose influence is seen only through the mean value of the gap. For a given log-correlated field this parameter can be evaluated numerically, and we provide several numerical tests of our theory using the circular model of $1/f$-noise.
Piero Naldesi, Elisa Ercolessi, Tommaso Roscilde
SciPost Phys. 1, 010 (2016) · published 27 October 2016 |
The many-body localization (MBL) transition is a quantum phase transition involving highly excited eigenstates of a disordered quantum many-body Hamiltonian, which evolve from "extended/ergodic" (exhibiting extensive entanglement entropies and fluctuations) to "localized" (exhibiting area-law scaling of entanglement and fluctuations). The MBL transition can be driven by the strength of disorder in a given spectral range, or by the energy density at fixed disorder - if the system possesses a many-body mobility edge. Here we propose to explore the latter mechanism by using "quantum-quench spectroscopy", namely via quantum quenches of variable width which prepare the state of the system in a superposition of eigenstates of the Hamiltonian within a controllable spectral region. Studying numerically a chain of interacting spinless fermions in a quasi-periodic potential, we argue that this system has a many-body mobility edge; and we show that its existence translates into a clear dynamical transition in the time evolution immediately following a quench in the strength of the quasi-periodic potential, as well as a transition in the scaling properties of the quasi-stationary state at long times. Our results suggest a practical scheme for the experimental observation of many-body mobility edges using cold-atom setups.
Marco Picco, Sylvain Ribault, Raoul Santachiara
We study four-point functions of critical percolation in two dimensions, and more generally of the Potts model. We propose an exact ansatz for the spectrum: an infinite, discrete and non-diagonal combination of representations of the Virasoro algebra. Based on this ansatz, we compute four-point functions using a numerical conformal bootstrap approach. The results agree with Monte-Carlo computations of connectivities of random clusters.
Correlations of zero-entropy critical states in the XXZ model: integrability and Luttinger theory far from the ground state
R. Vlijm, I. S. Eliëns, J. -S. Caux
Pumping a finite energy density into a quantum system typically leads to `melted' states characterized by exponentially-decaying correlations, as is the case for finite-temperature equilibrium situations. An important exception to this rule are states which, while being at high energy, maintain a low entropy. Such states can interestingly still display features of quantum criticality, especially in one dimension. Here, we consider high-energy states in anisotropic Heisenberg quantum spin chains obtained by splitting the ground state's magnon Fermi sea into separate pieces. Using methods based on integrability, we provide a detailed study of static and dynamical spin-spin correlations. These carry distinctive signatures of the Fermi sea splittings, which would be observable in eventual experimental realizations. Going further, we employ a multi-component Tomonaga-Luttinger model in order to predict the asymptotics of static correlations. For this effective field theory, we fix all universal exponents from energetics, and all non-universal correlation prefactors using finite-size scaling of matrix elements. The correlations obtained directly from integrability and those emerging from the Luttinger field theory description are shown to be in extremely good correspondence, as expected, for the large distance asymptotics, but surprisingly also for the short distance behavior. Finally, we discuss the description of dynamical correlations from a mobile impurity model, and clarify the relation of the effective field theory parameters to the Bethe Ansatz solution.
1 citation
Role of fluctuations in the phase transitions of coupled plaquette spin models of glasses
Giulio Biroli, Charlotte Rulquin, Gilles Tarjus, Marco Tarzia
We study the role of fluctuations on the thermodynamic glassy properties of plaquette spin models, more specifically on the transition involving an overlap order parameter in the presence of an attractive coupling between different replicas of the system. We consider both short-range fluctuations associated with the local environment on Bethe lattices and long-range fluctuations that distinguish Euclidean from Bethe lattices with the same local environment. We find that the phase diagram in the temperature-coupling plane is very sensitive to the former but, at least for the $3$-dimensional (square pyramid) model, appears qualitatively or semi-quantitatively unchanged by the latter. This surprising result suggests that the mean-field theory of glasses provides a reasonable account of the glassy thermodynamics of models otherwise described in terms of the kinetically constrained motion of localized defects and taken as a paradigm for the theory of dynamic facilitation. We discuss the possible implications for the dynamical behavior.
Dispersive hydrodynamics of nonlinear polarization waves in two-component Bose-Einstein condensates
T. Congy, A. M. Kamchatnov, N. Pavloff
We study one dimensional mixtures of two-component Bose-Einstein condensates in the limit where the intra-species and inter-species interaction constants are very close. Near the mixing-demixing transition the polarization and the density dynamics decouple. We study the nonlinear polarization waves, show that they obey a universal (i.e., parameter free) dynamical description, identify a new type of algebraic soliton, explicitly write simple wave solutions, and study the Gurevich-Pitaevskii problem in this context. | CommonCrawl |
Chemistry Stack Exchange is a question and answer site for scientists, academics, teachers, and students in the field of chemistry. It only takes a minute to sign up.
Is diamond transparent to X-rays?
Why is diamond said to be transparent to X-rays? Does this statement mean that X-rays can pass through diamond? If that is the case, then how does one explain this phenomenon?
inorganic-chemistry
getafix
AksaKAksaK
$\begingroup$ You are transparent to X-rays. (Your bones are not, though.) It is all about atomic number, nothing more. $\endgroup$
– Ivan Neretin
$\begingroup$ Atoms do absorb x-rays , but this depends on the wavelength and is different for different elements. So the answer to your question is yes to some x-rays diamonds are transparent. However, the main interaction of a crystal (which diamond has to be) is to diffract x-rays. See en.wikipedia.org/wiki/X-ray_absorption_spectroscopy for absorption $\endgroup$
– porphyrin
There are x-rays (Li K-$\alpha$ is 50 eV) and there are x-rays (Uranium K-$\alpha$ 98 keV).
In reality all electromagnetic radiation tries to pass through everything. Let $\rm I_0$ be the intensity of the beam at the surface and $\rm I_x$ be the fraction that gets through to depth $x$, then:
$\rm I_x = \rm I_0 e^{-\mu\rho x}$
$\mu$ is the mass absorption coefficient, units = $\rm{cm}^2/\rm g$
$\rho$ is the density of the material, units $\rm g/\rm{cm}^3$
$x$ depth of radiation, units = $\rm{cm}$
As a gross generality as the energy of the radiation increases (wavelength shorter) the transparency of matter increases. So a thin slice of carbon, be it graphite or diamond, will stop the vast major of Li K-alpha x-rays, but very few U K-alpha x-rays.
Note with some rearrangements and variable substitution this gives the Beer-Lambert Law used in UV-Vis spectroscopy.
MaxWMaxW
Your diamond will absorb x-rays at all x-ray wavelengths, but the extent of absorption changes, and is far less at shorter wavelengths (or higher energy) than at longer ones. The measured absorption is both due to true absorption and scattering of the x-rays off an atom's electrons. The 'background' absorption in an atom is due to an electron in an occupied level being excited to a virtual (unoccupied) level. Absorption spectra are typically recoded in the range of approximately 0.01 to 1 nm or 123.9 keV to 1.239 keV respectively.
As pointed out in another answer (@MaxW) the attenuation due to absorption experienced through any material depends in the Beer-Lambert law $I=I_0 $exp$(-\mu x)$ for path length x . The linear absorption coefficient, $\mu$, however, depends on wavelength.
As the wavelength is decreased (energy increase) there is a general decrease in absorption until certain critical energies are reached, then there is a sudden and significant increase in absorption, see figure. (This is a generic sketch and does not refer to any atom) These features are called absorption edges and occur when a core electron is ejected into the continuum as a photo-electron.The minimum energy to eject an electron is the threshold energy, which is equal to the binding energy of the electron.
The probability of ejecting an electron is greatest just when the energy is just enough to eject a core electron from the atom. This corresponds to the absorption edge. As this energy depends on the energy levels in each type of atom these edges occur at different energies in different types of atoms. As the atomic number gets larger these jumps in absorption (edges) shift to higher energy but become smaller. For example,$\ce{C \approx 0.28, Al \approx 1.5, Cu \approx 8.9, Pb \approx 88 } $ keV. (This difference means that, in practice, one element can act as an absorber to filter and or isolate another element's x-ray emission lines. This is particularly true of elements with Z values that are close to one another.)
The highest energy absorption edge is for K shell electron ejection then L and M etc. to lower energies. The K absorption corresponds to ejecting an electron with principal quantum number $n=1$ thus from a 1s orbital ($^2S_{1/2}$) into the continuum. The L absorption ($n=2$) has three closely spaced levels because orbitals with angular momentum (p orbitals in this case) are split in energy due to coupling of electron spin and orbital angular momentum (spin-orbit coupling), the levels are labelled ${^2S_{1/2}, ^2P_{1/2}, ^2S_{3/2}}$ . The M transitions involve $n=3$, involve s, p & d orbitals and are also split.
The absorption here refers to the photoelectric effect when a core electron is ejected and energy is carried away by the photoelectron as kinetic energy. The atom is left in an excited state and the 'hole' left in the atom, is very rapidly ($\le 10^{-15} $ s) filled by an other electron moving down in energy and the release of an photon of x-ray fluorescence or of an electron (Auger process).
The attenuation depends on the amount and type of matter traversed, and it is found that absorption coefficient can be expressed as $\mu \approx \rho Z^4 \lambda ^3/A $, where $\rho$ is the density, A the atomic mass and Z the atomic number; $\lambda $ is the wavelength. Thus as $\mu$ depends of density and atomic number it is easy to see why metals show up in medical x-ray images more than does bone or soft tissue.
(The reason for the $z^4$ dependence is that the matrix element for an electric-dipole transition (bound to unbound / continuum) depends on $Z^2$ and the transition probability depends on the transition matrix squared).
If the excited atom is in a molecule, when the photoelectron is released it has wavelike properties, and can be diffracted off electrons in neighbouring atoms causing constructive and destructive interference. This behaviour adds a sinusoidal-like feature on, and just past, the absorption edge (in the direction of higher energy, but to small to show in the figure) and is very useful in determining structure of small molecules when diffraction cannot be used. The phenomena are called XANES (x-ray absorption near edge structure) and EXAFS (Extended x-ray absorption fine structure).
porphyrinporphyrin
Thanks for contributing an answer to Chemistry Stack Exchange!
Not the answer you're looking for? Browse other questions tagged inorganic-chemistry or ask your own question.
Classical reason for good heat conductance in diamond?
Structure of diamond
Ashes to diamonds --- How?
Shapes of ionic compound
Classification of oxides,transition elements
What is Drago's rule? Does it really exist?
Trend in reducing property of dioxides
Why is graphite brittle?
Why does an mercury ore exist as HgS? | CommonCrawl |
Corporate Finance & Accounting Financial Ratios
What Is Return on Investment (ROI)?
Return on Investment (ROI) is a performance measure used to evaluate the efficiency of an investment or compare the efficiency of a number of different investments. ROI tries to directly measure the amount of return on a particular investment, relative to the investment's cost. To calculate ROI, the benefit (or return) of an investment is divided by the cost of the investment. The result is expressed as a percentage or a ratio.
How to Calculate ROI
The return on investment formula is as follows:
ROI=Current Value of Investment−Cost of InvestmentCost of Investment\begin{aligned} &\text{ROI} = \dfrac{\text{Current Value of Investment}-\text{Cost of Investment}}{\text{Cost of Investment}}\\ \end{aligned}ROI=Cost of InvestmentCurrent Value of Investment−Cost of Investment
"Current Value of Investment" refers to the proceeds obtained from the sale of the investment of interest. Because ROI is measured as a percentage, it can be easily compared with returns from other investments, allowing one to measure a variety of types of investments against one another.
How To Calculate Return On Investment (ROI)
Understanding Return on Investment (ROI)
ROI is a popular metric because of its versatility and simplicity. Essentially, ROI can be used as a rudimentary gauge of an investment's profitability. This could be the ROI on a stock investment, the ROI a company expects on expanding a factory, or the ROI generated in a real estate transaction. The calculation itself is not too complicated, and it is relatively easy to interpret for its wide range of applications. If an investment's ROI is net positive, it is probably worthwhile. But if other opportunities with higher ROIs are available, these signals can help investors eliminate or select the best options. Likewise, investors should avoid negative ROIs, which imply a net loss.
For example, suppose Joe invested $1,000 in Slice Pizza Corp. in 2017 and sold his stock shares for a total of $1,200 one year later. To calculate his return on his investment, he would divide his profits ($1,200 - $1,000 = $200) by the investment cost ($1,000), for a ROI of $200/$1,000, or 20 percent.
With this information, he could compare his investment in Slice Pizza with his other projects. Suppose Joe also invested $2,000 in Big-Sale Stores Inc. in 2014 and sold his shares for a total of $2,800 in 2017. The ROI on Joe's holdings in Big-Sale would be $800/$2,000, or 40 percent. (See Limitations of ROI below for potential issues arising from contrasting time frames.)
Limitations of ROI
Examples like Joe's (above) reveal some limitations of using ROI, particularly when comparing investments. While the ROI of Joe's second investment was twice that of his first investment, the time between Joe's purchase and sale was one year for his first investment and three years for his second.
Joe could adjust the ROI of his multi-year investment accordingly. Since his total ROI was 40 percent, to obtain his average annual ROI, he could divide 40 percent by 3 to yield 13.33 percent. With this adjustment, it appears that although Joe's second investment earned him more profit, his first investment was actually the more efficient choice.
ROI can be used in conjunction with Rate of Return, which takes into account a project's time frame. One may also use Net Present Value (NPV), which accounts for differences in the value of money over time, due to inflation. The application of NPV when calculating rate of return is often called the Real Rate of Return.
Developments in ROI
Recently, certain investors and businesses have taken an interest in the development of a new form of the ROI metric, called "Social Return on Investment," or SROI. SROI was initially developed in the early 2000s and takes into account broader impacts of projects using extra-financial value (i.e., social and environmental metrics not currently reflected in conventional financial accounts). SROI helps understand the value proposition of certain ESG (Environmental Social & Governance) criteria used in socially responsible investing (SRI) practices. For instance, a company may undertake to recycle water in its factories and replace its lighting with all LED bulbs. These undertakings have an immediate cost which may negatively impact traditional ROI—however, the net benefit to society and the environment could lead to a positive SROI
There are several other new flavors of ROI that have been developed for particular purposes. Social media statistics ROI pinpoints the effectiveness of social media campaigns—for example how many clicks or likes are generated for a unit of effort. Similarly, marketing statistics ROI tries to identify the return attributable to advertising or marketing campaigns. So-called learning ROI relates to the amount of information learned and retained as return on education or skills training. As the world progresses and the economy changes, several other niche forms of ROI are sure to be developed in the future. (For related reading, see "How to Calculate the ROI on a Rental Property")
Investopedia requires writers to use primary sources to support their work. These include white papers, government data, original reporting, and interviews with industry experts. We also reference original research from other reputable publishers where appropriate. You can learn more about the standards we follow in producing accurate, unbiased content in our editorial policy.
World Health Organization. "Social Return on Investment," Page 4. Accessed Sept. 25, 2019.
Understanding Return on Invested Capital
Return on invested capital (ROIC) is a way to assess a company's efficiency at allocating the capital under its control to profitable investments.
Return on Total Assets (ROTA) Definition
Return on total assets is a ratio that measures a company's earnings before interest and taxes (EBIT) against its total net assets.
Internal Rate of Return – IRR
The internal rate of return (IRR) is a metric used in capital budgeting to estimate the profitability of potential investments.
Understanding the Rate of Return on an Investment
A rate of return is the gain or loss on an investment over a specified time period, expressed as a percentage of the investment's cost.
What Semi-Deviation Measures
Semi-deviation is a method of evaluating the below-mean fluctuations in the returns on investment. It is used as an alternative to standard deviation.
Capital Asset Pricing Model (CAPM)
The Capital Asset Pricing Model is a model that describes the relationship between risk and expected return.
How to Calculate Return on Investment – ROI
The Difference Between ROI and ROCE
The ROI Of Space Exploration
What is the formula for calculating net present value (NPV) in Excel?
How do you calculate IRR in Excel? | CommonCrawl |
Communications in Mathematical Physics
Renormalisation of Pair Correlation Measures for Primitive Inflation Rules and Absence of Absolutely Continuous Diffraction
Michael Baake
Franz Gähler
Neil Mañibo
The pair correlations of primitive inflation rules are analysed via their exact renormalisation relations. We introduce the inflation displacement algebra that is generated by the Fourier matrix of the inflation and deduce various consequences of its structure. Moreover, we derive a sufficient criterion for the absence of absolutely continuous diffraction components, as well as a necessary criterion for its presence. This is achieved via estimates for the Lyapunov exponents of the Fourier matrix cocycle of the inflation rule. We also discuss some consequences for the spectral measures of such systems. While we develop the theory first for the classic setting in one dimension, we also present its extension to primitive inflation rules in higher dimensions with finitely many prototiles up to translations.
Communicated by J. Marklof
It is a pleasure to thank Frederic Alberti, Alan Bartlett, Scott Balchin, Natalie Frank, Uwe Grimm, Andrew Hubery, Robbie Robinson, Boris Solomyak and Nicolae Strungaru for helpful discussions. We also thank two anonymous reviewers for their thoughtful comments. This work was supported by the German Research Foundation (DFG), within the CRC 1283.
Appendix: The (Skew) Kronecker Product Algebra
The structure of the correlation measures relies on some properties of the Kronecker product matrices
$$\begin{aligned} \varvec{A} (k) \, {:}{=}\, B(k) \otimes \overline{B(k)} , \end{aligned}$$
defined for \(k\in \mathbb {R}\). Obviously, one has \(\overline{\varvec{A} (k)} = \varvec{A} (-k)\) and \(\det (\varvec{A} (k)) = |\det (B(k))|^{2 n_{a}}\).
In view of the structure of Eq. (36), let us now consider the \(\mathbb {R}\)-algebra \(\varvec{\mathcal {A}}\) that is generated by the matrix family \(\{ \varvec{A} (k) \mid k\in \mathbb {R}\}\). Due to the Kronecker product structure, \(\varvec{\mathcal {A}}\) fails to be irreducible, no matter what the structure of the IDA \(\mathcal {B}\) is. Let us explore this in some more detail. Let \(V=\mathbb {C}^{n_{a}}\) and consider \(W{:}{=}V \otimes ^{}_{\mathbb {C}} V\), the (complex) tensor product, which is a vector space over \(\mathbb {C}\) of dimension \(n_{a}^{2}\), but also one over \(\mathbb {R}\), then of dimension \(2n_{a}^{2}\). In the latter setting, consider the involution \(C \! : \, W \!\longrightarrow W\) defined by
$$\begin{aligned} x \otimes y \; \longmapsto \; C (x \otimes y) \, {:}{=}\, \overline{y \otimes x} \, = \, {\bar{y}} \otimes {\bar{x}} \end{aligned}$$
together with its unique extension to an \(\mathbb {R}\)-linear mapping on W. Observe that there is no \(\mathbb {C}\)-linear extension, because \(C \bigl (a (x \otimes y)\bigr ) = {\bar{a}}\; C (x\otimes y)\) for \(a \in \mathbb {C}\). With this definition of C, one finds for an arbitrary \(k\in \mathbb {R}\) that
$$\begin{aligned} \begin{aligned} \varvec{A} (k)\, C(x\otimes y) \,&= \, \bigl (B(k) \otimes \,\overline{\! B(k)\! }\, \bigr ) ( {\bar{y}} \otimes {\bar{x}} ) \, = \, \bigl (B(k){\bar{y}}\bigr ) \otimes \bigl (\, \overline{\! B(k)x } \, \bigr ) \\&= \, C \bigl ( \bigl (B(k) \otimes \, \overline{\! B(k)\! }\, \bigr ) (x \otimes y ) \bigr ) \, = \, C \bigl ( \varvec{A} (k) \, ( x \otimes y ) \bigr ), \end{aligned} \end{aligned}$$
so C commutes with the linear map defined by \(\varvec{A} (k)\), for any \(k\in \mathbb {R}\). The \(\mathbb {R}\)-linear mapping C has eigenvalues \(\pm 1\) and is diagonalisable, as follows from the unique splitting of an arbitrary \(w\in W\) as \(w = \frac{1}{2} \bigl ( w + C(w)\bigr ) + \frac{1}{2} \bigl ( w - C(w)\bigr )\). So, our vector space splits as \(W \! = W_{\! +} \oplus W_{\! -}\) into real vector spaces that are eigenspaces of C. Their dimensions are
$$\begin{aligned} \dim ^{}_{\mathbb {R}} (W_{\! +}) \, = \, \dim ^{}_{\mathbb {R}} (W_{\! -}) \, = \, n_{a}^{2} \end{aligned}$$
since \(W_{\! -} = \mathrm {i}W_{\! +}\) with \(W_{\! +} \cap W_{\! -} = \{ 0 \}\). It is thus clear that \(W_{\! +}\) and \(W_{\! -}\) are invariant (real) subspaces for the \(\mathbb {R}\)-algebra \(\varvec{\mathcal {A}}\).
Observe next that we have
$$\begin{aligned} \varvec{A} (k) \, = \, B(k) \otimes \overline{B (k)} \; = \! \sum _{x,y \in S_{T}}\! \mathrm {e}^{2 \pi \mathrm {i}k (x-y)} \, D_{x} \otimes D_{y} \; = \sum _{z\in \triangle _{T}} \mathrm {e}^{2 \pi \mathrm {i}k z}\, F_{z} \end{aligned}$$
where \(\triangle _{T} {:}{=}S_{T} - S_{T}\) is the Minkowski difference, with \(-\triangle _{T}=\triangle _{T}\), and
$$\begin{aligned} F_{z} \; = \sum _{\begin{array}{c} x,y \in S_{T} \\ x-y = z \end{array}} D_{x} \otimes D_{y} . \end{aligned}$$
In analogy to before, \(F_{z} = F_{z'}\) is possible for \(z\ne z'\). For instance, if \(z=x-y\) with \(x\ne y\) and \(D_{x} = D_{y}\), one can get \(F_{z} = F_{-z}\) if there is no other way to write z as a difference of two numbers in \(S_{T}\).
For \(a\in \mathbb {C}\), one easily checks that \(C \circ (a F_{z}) = {\bar{a}} C \circ F_{z} = {\bar{a}} F_{-z} \circ C\), which implies \([C, \varvec{A}(k)]=0\) for all \(k\in \mathbb {R}\), in line with our previous derivation. It is immediate that \(\varvec{\mathcal {A}}\) is contained in the \(\mathbb {R}\)-algebra \(\varvec{\mathcal {A}}_{F}\) that is generated by the matrices \(\{ F_{z}+F_{-z} \mid 0 \leqslant z\in \triangle _{T}\}\) together with \(\{ \mathrm {i}( F_{z} - F_{-z}) \mid 0 \leqslant z\in \triangle _{T}\}\), and an argument similar to the one previously used for \(\mathcal {B}\) shows that \( \varvec{\mathcal {A}}_{F} \subseteq \varvec{\mathcal {A}}\), hence \(\varvec{\mathcal {A}} = \varvec{\mathcal {A}}_{F}\). Since \(\dim ^{}_{\mathbb {C}} (\mathcal {B}) \leqslant n_{a}^{2}\), and since we generate the real algebra only after taking the Kronecker product, one has
$$\begin{aligned} \dim ^{}_{\mathbb {R}} (\varvec{\mathcal {A}}) \, \leqslant \, n_{a}^{4} , \end{aligned}$$
which is also clear from \(\dim ^{}_{\mathbb {R}} (W_{\! +}) = n_{a}^{2}\). Moreover, one has the following result.
Lemma 5.15
Let \(\varrho \) be a primitive inflation rule on an alphabet with \(n_{a}\) letters, and assume that the IDA \(\mathcal {B}\) of \(\varrho \) is irreducible over \(\mathbb {C}\). Then, the induced \(\mathbb {R}\)-algebra \(\varvec{\mathcal {A}}\) is isomorphic with \({{\,\mathrm{Mat}\,}}(n_{a}^2, \mathbb {R})\), and its action on the subspace \(W_{\! +}\) is irreducible as well, this time over \(\mathbb {R}\).
Here, \(\mathcal {B}\) irreducible over \(\mathbb {C}\) means \(\mathcal {B}= {{\,\mathrm{Mat}\,}}(n_{a}, \mathbb {C})\). With \(\varGamma {:}{=}\mathcal {B}\otimes ^{}_{\mathbb {C}} \mathcal {B}\), where \(\otimes ^{}_{\mathbb {C}}\) denotes the tensor product over \(\mathbb {C}\), one has \(\varGamma \simeq {{\,\mathrm{Mat}\,}}(n_{a}^{2}, \mathbb {C})\) by standard arguments. Clearly, \(\varGamma \) is a \(\mathbb {C}\)-algebra of dimension \(n_{a}^{4}\), but also an \(\mathbb {R}\)-algebra, then of dimension \(2 n_{a}^{4}\). Now, using the Kronecker product as representation of the tensor product, the mapping defined by \(M\otimes N \mapsto \overline{N}\otimes \overline{M}\) has a unique extension to an automorphism \(\sigma \) of \(\varGamma \) as an \(\mathbb {R}\)-algebra.
Our \(\mathbb {R}\)-algebra \(\varvec{\mathcal {A}}\) consists of all fixed points of \(\sigma \), so \(\varvec{\mathcal {A}} = \{ Q \in \varGamma \mid \sigma (Q) = Q \}\). Employing the elementary matrices \(E_{ij}\) from \({{\,\mathrm{Mat}\,}}(n_{a}, \mathbb {R})\) with \(E_{ij,k\ell } {:}{=}E_{ik} \otimes E_{j \ell }\), we can give a basis of \(\varvec{\mathcal {A}}\), seen as a vector space over \(\mathbb {R}\), by
$$\begin{aligned} \big \{ \tfrac{1}{2} (E_{ij,k\ell } + E_{k\ell ,ij}) \mid (i,j) \leqslant (k,\ell ) \big \} \cup \big \{ \tfrac{\mathrm {i}}{2} (E_{ij,k\ell } - E_{k\ell ,ij}) \mid (i,j) < (k,\ell ) \big \} , \end{aligned}$$
where lexicographic ordering is used for the double indices. Note that the cardinalities are \(\frac{1}{2} n_{a}^{2} (n_{a}^{2} + 1)\) and \(\frac{1}{2} n_{a}^{2} (n_{a}^{2} - 1)\), which add up to \(\dim ^{}_{\mathbb {R}} (\varvec{\mathcal {A}}) = n_{a}^{4}\).
Next, observe that we can get \(E_{ij,k\ell }\) and \(E_{k\ell ,ij}\) by a simple (complex) linear combination of \( \tfrac{1}{2} (E_{ij,k\ell } + E_{k\ell ,ij})\) and \(\tfrac{\mathrm {i}}{2} (E_{ij,k\ell } - E_{k\ell ,ij})\), and vise versa. Put together, this defines a (complex) inner automorphism of \(\varGamma \). Observing that \({{\,\mathrm{Mat}\,}}(n_{a}^{2}, \mathbb {R}) = \{ Q \in \varGamma \mid {\overline{Q}} = Q \}\), this construction can now be used to show that \(\varvec{\mathcal {A}} \simeq {{\,\mathrm{Mat}\,}}(n_{a}^{2}, \mathbb {R})\), which is a central simple algebra. Since \(\varvec{\mathcal {A}} W_{\! +} \subseteq W_{\! +}\) and \(\dim ^{}_{\mathbb {R}} (W_{\! +}) = n_{a}^{2}\), the claimed irreducibility over the reals follows. \(\quad \square \)
Note that all \(F_{z}\) are non-negative, integer matrices. They clearly satisfy the relation \(\sum _{z\in \triangle _{T}} F_{z} = \varvec{A} (0) = M_{\varrho } \otimes M_{\varrho }\). Moreover, under some mild conditions, the spectral radius of \(F^{}_0\) is \(\lambda \), while the other matrices \(F_z\) have smaller spectral radius.
Let us come back to Eq. (36), which implies
$$\begin{aligned} \Vert \varvec{A} (k) \Vert ^{}_{\mathrm {F}} \, = \, \Vert B (k) \Vert ^{2}_{\mathrm {F}} . \end{aligned}$$
If we consider the matrix cocycle defined by \(\varvec{A}^{(n)} (k) = B^{(n)} (k) \otimes \overline{B^{(n)} (k)}\), it is immediate that the maximal Lyapunov exponents, for all \(k\in \mathbb {R}\), are related by
$$\begin{aligned} \chi ^{\varvec{A}} (k) \, = \, 2 \chi ^{B} (k) , \end{aligned}$$
which also holds for the higher-dimensional case with \(k\in \mathbb {R}^d\). Clearly, one can now reformulate Theorems 3.28 and 5.7 in terms of \(\chi ^{\varvec{A}}\). In particular, one has the following reformulation of Theorem 3.34 and Corollary 3.35 and their higher-dimensional analogues.
Corollary 5.16
Let \(\varrho \) be a primitive inflation rule in \(\mathbb {R}^d\) with finitely many translational prototiles and expansive map Q. Let \(B^{(n)} (.)\) be its Fourier matrix cocycle, with \(\det (B(k))\ne 0\) for at least one \(k\in \mathbb {R}^d\), and \(\varvec{A}^{(n)} (.) = B^{(n)} (.) \otimes \overline{B^{(n)} (.)}\) the corresponding Kronecker product cocycle. If the diffraction measure of the hull defined by \(\varrho \) contains a non-trivial absolutely continuous component, one has \(\chi ^{\varvec{A}} (k) = \log |\det (Q) |\) for a subset of \(\mathbb {R}^d\) of positive measure, which has full measure when \(\chi ^{\varvec{A}} (k)\) is constant for a.e. \(k\in \mathbb {R}^d\). \(\quad \square \)
Akiyama, S., Barge, M., Berthé, V., Lee, J.-Y., Siegel, A.: On the Pisot substitution conjecture. In: Kellendonk, J., Lenz, D., Savinien, J. (eds.) Mathematics of Aperiodic Order, Birkhäuser, Basel (2015)Google Scholar
Baake, M., Frank, N.P., Grimm, U., Robinson, E.A.: Geometric properties of a binary non-Pisot inflation and absence of absolutely continuous diffraction. Stud. Math. 247, 109–154 (2019). arXiv:1706.03976
Baake, M., Gähler, F.: Pair correlations of aperiodic inflation rules via renormalisation: some interesting examples. Topol. Appl. 205, 4–27 (2016). arXiv:1511.00885
Baake, M., Grimm, U.: Squirals and beyond: substitution tilings with singular continuous spectrum. Ergod. Theory Dyn. Syst. 34, 1077–1102 (2014). arXiv:1205.1384
Baake, M., Grimm, U.: Aperiodic Order, vol. 1: A Mathematical Invitation. Cambridge University Press, Cambridge (2013)Google Scholar
Baake, M., Grimm, U. (eds.): Aperiodic Order, vol. 2: Crystallography and Almost Periodicity. Cambridge University Press, Cambridge (2017)Google Scholar
Baake, M., Grimm, U.: Renormalisation of pair correlations and their Fourier transforms for primitive block substitutions. In: Akiyama, S., Arnoux, P. (eds.), Tiling and Discrete Geometry, Springer, Berlin (in press) (2018). arXiv:1906.10484
Baake, M., Grimm, U., Mañibo, N.: Spectral analysis of a family of binary inflation rules. Lett. Math. Phys. 108, 1783–1805 (2018). arXiv:1709.09083
Baake, M., Haynes, A., Lenz, D.: Averaging almost periodic functions along exponential sequences. In: Baake, M., Grimm, U. (eds.): Aperiodic Order, vol. 2: Crystallography and Almost Periodicity, pp. 343–362. Cambridge University Press, Cambridge (2017)Google Scholar
Baake, M., Lenz, D.: Dynamical systems on translation bounded measures: pure point dynamical and diffraction spectra. Ergod. Theory Dyn. Syst. 24, 1867–1893 (2004). arXiv:math.DS/0302231
Baake, M., Lenz, D.: Spectral notions of aperiodic order. Discr. Cont. Dynam. Syst. S 10, 161–190 (2017). arXiv:1601.06629
Baake, M., Lenz, D., van Enter, A.C.D.: Dynamical versus diffraction spectrum for structures with finite local complexity. Ergod. Theory Dyn. Syst. 35, 2017–2043 (2015). arXiv:1307.7518
Baake, M., Moody, R.V.: Weighted Dirac combs with pure point diffraction. J. Reine Angew. Math. (Crelle) 573, 61–94 (2004). arXiv:math.MG/0203030
Barreira, L., Pesin, Y.: Nonuniform Hyperbolicity. Cambridge University Press, Cambridge (2007)CrossRefzbMATHGoogle Scholar
Bartlett, A.: Spectral theory of \({\mathbb{Z}}^d\) substitutions. Ergod. Theory Dyn. Syst. 38, 1289–1341 (2018). arXiv:1410.8106
Berg, C., Forst, G.: Potential Theory on Locally Compact Abelian Groups. Springer, Berlin (1975)CrossRefzbMATHGoogle Scholar
Berlinkov, A., Solomyak, B.: Singular substitutions of constant length. Ergod. Theory Dyn. Syst. (in press). arXiv:1705.00899
Bufetov, A.I., Solomyak, B.: On the modulus of continuity for spectral measures in substitution dynamics. Adv. Math. 260, 84–129 (2014). arXiv:1305.7373
Bufetov, A.I., Solomyak, B.: A spectral cocycle for substitution systems and translation flows. (preprint). arXiv:1802.04783
Chan, L., Grimm, U.: Spectrum of a Rudin–Shapiro-like sequence. Adv. Appl. Math. 87, 16–23 (2017). arXiv:1611.04446
Chan, L., Grimm, U., Short, I.: Substitution-based structures with absolutely continuous spectrum. Indag. Math. 29, 1072–1086 (2018). arXiv:1706.05289
Clark, A., Sadun, L.: When size matters: subshifts and their related tiling spaces. Ergod. Theory Dyn. Syst. 23, 1043–57 (2003). arXiv:math.DS/0201152
Damanik, D., Sims, R., Stolz, G.: Localization for one-dimensional, continuum, Bernoulli–Anderson models. Duke Math. J. 114, 59–100 (2002). arXiv:math-ph/0010016
Dekking, F.M.: The spectrum of dynamical systems arising from substitutions of constant length. Z. Wahrscheinlichkeitsth. Verw. Geb. 41, 221–239 (1978)MathSciNetCrossRefzbMATHGoogle Scholar
Durand, F.: A characterization of substitutive sequences using return words. Discr. Math. 179, 89–101 (1998). arXiv:0807.3322
Einsiedler, M., Ward, T.: Ergodic Theory—With a View Towards Number Theory, GTM 259. Springer, London (2011)zbMATHGoogle Scholar
Everest, G., Ward, T.: Heights of Polynomials and Entropy in Algebraic Dynamics. Springer, London (1999)CrossRefzbMATHGoogle Scholar
Fan, A.-H., Saussol, B., Schmeling, J.: Products of non-stationary random matrices and multiperiodic equations of several scaling factors. Pac. J. Math. 214, 31–54 (2004). arXiv:math.DS/0210347
Frank, N.P.: Substitution sequences in \({\mathbb{Z}}^d\) with a nonsimple Lebesgue component in the spectrum. Ergod. Theory Dyn. Syst. 23, 519–532 (2003)CrossRefGoogle Scholar
Frank, N.P.: Multi-dimensional constant-length substitution sequences. Topol. Appl. 152, 44–69 (2005)CrossRefzbMATHGoogle Scholar
Frank, N.P.: Introduction to hierarchical tiling dynamical systems. In: Akiyama, S, Arnoux, P. (eds.), Tiling and Discrete Geometry, Springer, Berlin (in press; preprint) (2018). arXiv:1802.09956
Frettlöh, D.: More inflation tilings. In: Baake, M., Grimm, U. (eds.): Aperiodic Order, vol. 2: Crystallography and Almost Periodicity, pp. 1–37. Cambridge University Press, Cambridge (2017)Google Scholar
Frettlöh, D., Richard, C.: Dynamical properties of almost repetitive Delone sets. Discr. Contin. Dyn. Syst. A 34, 531–556 (2014). arXiv:1210.2955
Gantmacher, F.: Matrizentheorie. Springer, Berlin (1986)CrossRefGoogle Scholar
Gil de Lamadrid, J., Argabright, L.N.: Almost Periodic Measures, Memoirs AMS, vol. 428. AMS, Providence (1990)Google Scholar
Godrèche, C., Lançon, F.: A simple example of a non-Pisot tiling with fivefold symmetry. J. Phys. I (Fr.) 2, 207–220 (1992)CrossRefGoogle Scholar
Hof, A.: On diffraction by aperiodic structures. Commun. Math. Phys. 169, 25–43 (1995)ADSMathSciNetCrossRefzbMATHGoogle Scholar
James, G., Liebeck, M.: Representations and Characters of Groups, 2nd edn. Cambridge University Press, Cambridge (2001)CrossRefzbMATHGoogle Scholar
Kellendonk, J., Lenz, D., Savinien, J. (eds.): Mathematics of Aperiodic Order. Birkhäuser, Basel (2015)zbMATHGoogle Scholar
Lançon, F., Billiard, L.: Two-dimensional system with a quasicrystalline ground state. J. Phys. (Fr.) 49, 249–256 (1988)MathSciNetCrossRefGoogle Scholar
Lang, S.: Algebra, 3rd, revised edn. Springer, New York (2002)CrossRefzbMATHGoogle Scholar
Lee, J.-Y., Moody, R.V., Solomyak, B.: Pure point dynamical and diffraction spectra. Ann. Henri Poincaré 3, 1003–1018 (2002). arXiv:0910.4809
Lenz, D.: Continuity of eigenfunctions of uniquely ergodic dynamical systems and intensity of Bragg peaks. Commun. Math. Phys. 287, 225–258 (2009). arXiv:math-ph/0608026
Lenz, D., Strungaru, N.: Pure point spectrum for measure dynamical systems on locally compact Abelian groups. J. Math. Pures Appl. 92, 323–341 (2009). arXiv:0704.2498
Lomonosov, V., Rosenthal, P.: The simplest proof of Burnside's theorem on matrix algebras. Linear Algebra Appl. 383, 45–47 (2004)MathSciNetCrossRefzbMATHGoogle Scholar
Mañibo, N.: Lyapunov exponents for binary substitutions of constant length. J. Math. Phys. 58(113504), 1–9 (2017). arXiv:1706.00451
Mañibo, N.: Spectral analysis of primitive inflation rules. Oberwolfach Rep. 14, 2830–2832 (2017)Google Scholar
Mañibo, N.: Lyapunov Exponents in the Spectral Theory of Primitive Inflation Systems. PhD Thesis, Bielefeld University (2019). https://pub.uni-bielefeld.de/record/2935972
Moody, R.V., Strungaru, N.: Almost periodic measures and their Fourier transforms. In: Baake, M., Grimm, U. (eds.): Aperiodic Order, vol. 2: Crystallography and Almost Periodicity, pp.173–270. Cambridge University Press, Cambridge (2017)Google Scholar
Müller, P., Richard, C.: Ergodic properties of randomly coloured point sets. Can. J. Math. 65, 349–402 (2013). arXiv:1005.4884
Queffélec, M.: Substitution Dynamical Systems: Spectral Analysis, 2nd edn., LNM 1294, Springer, Berlin (2010)Google Scholar
Robinson Jr., E.A.: Symbolic dynamics and tilings of \({\mathbb{R}}^{d}\). Proc. Symp. Appl. Math. 60, 81–119 (2004)CrossRefzbMATHGoogle Scholar
Rudin, W.: Fourier Analysis on Groups. Wiley, New York (1962)zbMATHGoogle Scholar
Scott, W.R.: Group Theory. Prentice Hall, Englewood Cliffs (1964)zbMATHGoogle Scholar
Sing, B.: Pisot Substitutions and Beyond. PhD Thesis, Bielefeld University (2006). https://pub.uni-bielefeld.de/record/2302336
Solomyak, B.: Dynamics of self-similar tilings. Ergod. Theory Dyn. Syst. 17, 695–738 (1997) and Ergod. Theory Dyn. Syst. 19, 1685 (1999) (erratum)Google Scholar
Solomyak, B.: Nonperiodicity implies unique composition for self-similar translationally finite tilings. Discr. Comput. Geom. 20, 265–278 (1998)MathSciNetCrossRefzbMATHGoogle Scholar
Strungaru, N.: On the Fourier analysis of measures with Meyer set support (preprint). arXiv:1807.03815
Trebin, H.R. (ed.): Quasicrystals: Structure and Physical Properties. Wiley-VCH, Weinheim (2003)Google Scholar
Viana, M.: Lectures on Lyapunov Exponents. Cambridge University Press, Cambridge (2013)zbMATHGoogle Scholar
Vince, A.: Digit tiling of Euclidean space. In: Baake, M., Moody, R.V. (eds.) Directions in Mathematical Quasicrystals, CRM Monograph Series, vol. 13, pp. 329–370. AMS, Providence (2000)CrossRefGoogle Scholar
© Springer-Verlag GmbH Germany, part of Springer Nature 2019
1.Fakultät für MathematikUniversität BielefeldBielefeldGermany
Baake, M., Gähler, F. & Mañibo, N. Commun. Math. Phys. (2019). https://doi.org/10.1007/s00220-019-03500-w
Accepted 02 May 2019
DOI https://doi.org/10.1007/s00220-019-03500-w | CommonCrawl |
What is the Maclaurin series representation of $(1 - \frac{x}{5})^{-4}$
Question: Find the Maclaurin series representation of $(1 - \frac{x}{5})^{-4}$ using the definition of the Maclaurin series $\sum_{n=0}^{\infty} \frac{F^{n}(a)}{n!}(x-a)^n$
My approach:
Find $F^n(0) = \frac{(n+3)!}{5^n}$
Input $F^n(0)$ into formula.
Final Result: $\sum_{n=0}^{\infty} \frac{(n+3)!}{5^n * n!} * x^n$
However, answer is marked as wrong. Can someone please explain the reason for this. Also any tips to help me understand the Taylor / Maclaurin series would be much appreciated.
sequences-and-series taylor-expansion
J. W. Tanner
UrmzdUrmzd
$\begingroup$ Just as a sanity check, did you remember to include the $x^n$ terms? As is written now you have calculated a series representation of $(1-\frac{1}{5})^{-4}$... $\endgroup$
– Theo Diamantakis
$$(1 - \frac{x}{5})^{-4}=\frac{1}{(1-\frac{x}{5})^4}$$ use $$\frac{1}{1-x}=\sum_{n=0}^{\infty}x^n$$ $$(\frac{1}{1-x})'''=\sum_{n=3}^{\infty}n(n-1)(n-2)x^{n-3}$$ $$\frac{6}{(1-x)^4}=\sum_{n=3}^{\infty}n(n-1)(n-2)x^{n-3}$$ or $$\frac{1}{(1-x)^4}=\frac{1}{6}\sum_{n=3}^{\infty}n(n-1)(n-2)x^{n-3}$$ $$\frac{1}{(1-x)^4}=\frac{1}{6}\sum_{n=0}^{\infty}(n+1)(n+2)(n+3)x^{n}$$
now let $x\rightarrow \frac{x}{5}$
E.H.EE.H.E
$\begingroup$ +1: I really like this approach! $\endgroup$
– Cameron Buie
$\begingroup$ Thanks ...... . $\endgroup$
– E.H.E
The Maclaurin series definition isn't quite right. Instead, it should be $$\sum_{n=0}^\infty\frac{F^{(n)}(0)}{n!}x^n.$$ Consequently, we should have $$\left(1-\frac{x}{5}\right)^{-4}=\sum_{n=0}^\infty\frac{(n+3)!}{5^n\cdot n!}x^n$$ by the work that you've already done.
However, noting that $$(n+3)!=(n+3)\cdot(n+2)\cdot(n+1)\cdot n!,$$ we can write it instead as $$\left(1-\frac{x}{5}\right)^{-4}=\sum_{n=0}^\infty\frac{(n+3)(n+2)(n+1)}{5^n}x^n.$$
One way we can see that there must be something involving $x$ in the series is that $\left(1-\frac{x}{5}\right)^{-4}$ varies in value with different $x$ values, while $\sum_{n=0}^\infty\frac{(n+3)!}{5^n\cdot n!}$ is simply a constant--in particular, it turns out to be $$\left(1-\frac{1}{5}\right)^{-4}=\left(\frac45\right)^{-4}=\left(\frac54\right)^4=\frac{5^4}{4^4}=\frac{625}{256}.$$
Added: It seems that you've made an error in calculating the derivatives, unfortunately.
$$F'(x)=-4\cdot\left(1-\frac{x}{5}\right)^{-5}\cdot\frac{d\left(1-\frac{x}{5}\right)}dx=\frac15\cdot 4\cdot\left(1-\frac{x}{5}\right)^{-5}$$
$$F''(x)=-5\cdot\frac15\cdot 4\cdot\left(1-\frac{x}{5}\right)^{-6}\cdot\frac{d\left(1-\frac{x}{5}\right)}{dx}=\frac1{5^2}\cdot 5\cdot 4\cdot\left(1-\frac{x}{5}\right)^{-6}$$
$$F'''(x)=-6\cdot\frac15\cdot 5\cdot 4\cdot\left(1-\frac{x}{5}\right)^{-7}\cdot\frac{d\left(1-\frac{x}{5}\right)}{dx}=\frac1{5^3}\cdot 6\cdot 5\cdot 4\cdot\left(1-\frac{x}{5}\right)^{-7}$$
and more generally, for $n\ge 4,$ we have $$F^{(n)}(x)=\frac1{5^n}\cdot(n+3)\cdot(n+2)\cdots 5\cdot 4\cdot\left(1-\frac{x}{5}\right)^{-(n+4)}=\frac{1}{5^n}\cdot\frac{(n+3)!}{3!}\cdot \left(1-\frac{x}{5}\right)^{-(n+4)}.$$
Thus, $$F^{(n)}(0)=\frac{(n+3)!}{5^n\cdot 3!}$$ for each $n,$ and so the Maclaurin series is $$\left(1-\frac{x}{5}\right)^{-4}=\sum_{n=0}^\infty\frac{(n+3)!}{5^n\cdot 3!\cdot n!}x^n=\sum_{n=0}^\infty\frac{(n+3)(n+2)(n+1)}{5^n\cdot 3!}x^n.$$
Cameron BuieCameron Buie
$\begingroup$ Would the same concept apply to something like (1-x/3)^(-5), following your logic, I got (n+4)(n+3)(n+2)(n+1)/3^n * x^n. However, I keep getting an error. Im still new to series and sequences so my logic is incomplete, is there something wrong with what was stated? $\endgroup$
– Urmzd
$\begingroup$ It looks like you made an error calculating the derivatives. I've adjusted my answer accordingly. $\endgroup$
$\begingroup$ Thank you. I'm still slightly confused as to why there is a 3!, what's the reasoning behind this? $\endgroup$
$\begingroup$ It's because $$\begin{eqnarray}(n+3)\cdot(n+2)\cdots5\cdot 4 &=&(n+3)\cdot(n+2)\cdots5\cdot 4\cdot\frac33\cdot\frac22\cdot\frac11\\ &=& \frac{(n+3)\cdot(n+2)\cdots 2\cdot 1}{3\cdot 2\cdot 1}\\ &=& \frac{(n+3)!}{3!}.\end{eqnarray}$$ $\endgroup$
Let $F(x)=\left(1 - \dfrac{x}{5}\right)^{-4}.$
Using your approach,
$$(1)\quad F^{(n)}(0) = \frac{(n+3)!}{5^n3!}.$$
$(2)$ The formula for Maclaurin series is $$\sum_{n=0}^{\infty} \frac{F^{(n)}(0)}{n!}x^n.$$
$(3)$ The final result should be $$\sum_{n=0}^{\infty} \frac{(n+3)(n+2)(n+1)}{5^n 3!}x^n.$$
J. W. TannerJ. W. Tanner
$\begingroup$ Can you explain why there is a 3! in step 1? $\endgroup$
$\begingroup$ You should be able to prove it by induction, but note that when $n=0$ it's just $1$; the first derivative gets a factor of $4$ from the exponent and the exponent becomes $-5,$ so the second derivative has a coefficient $4\times5$ and exponent $-6$, the third derivative has coefficient $4\times5\times6$...the $n^{th}$ derivative has coefficient $4\times5\times6\times...\times (n+3)$, which is $(n+3)!/3!$ $\endgroup$
– J. W. Tanner
Not the answer you're looking for? Browse other questions tagged sequences-and-series taylor-expansion or ask your own question.
Question about Maclaurin Series for $\cos x$
Proofs using Taylor Series Expansion
Finding a Taylor Series representation of $f(x)=\ln(\frac{1+2x}{1-2x})$ centered at $0$.
Taylor/Maclaurin Series vs Taylor/Maclaurin Polynomial
Power Series Representation of $\frac{1}{(1+3x)^2}$
Finding the approximate value given Taylor series representation and relative approximate error
MacLaurin Series of $\tan(x)$
Maclaurin series is the geometric series, question | CommonCrawl |
Only $35.99/year
SHRM-CP Definitions
ClaireReff
Money an organization owes its vendors and suppliers.
Money an organization's customers owe the organization.
Communication technique to increase the engagement between communicators and their audiences. It involves two-way communication and attention to nonverbal signs that indicate interest and reactions to the message and speaker.
Data-sorting technique in which a group categorizes and subcategorizes data until relationships are clearly drawn.
Affinity Diagramming
Financial, physical, and sometimes intangible properties an organization owns.
Statement of an organization's financial position at a specific point in time, showing assets, liabilities, and shareholder equity.
Exchange of anything of value to gain greater influence or preference.
Presentation to management that establishes that a specific problem exists and argues for a proposed solution.
Ability to use information to gain a deeper understanding of an organization and make sound business decisions
Statement of an organization's ability to meet its current and short-term obligations, showing incoming and outgoing cash and cash reserves in operations, investments, and financing.
Legal system based on written codes (laws, rules, or regulations).
Principles that guide decision making and behavior in an organization.
Legal system in which each case is considered in terms of how it relates to legal decisions that have already been made; evolves through judicial decisions over time.
Treatment of personal information that has been disclosed to another person or organization.
Situation in which a person or organization may benefit from undue influence due to involvement in outside activities, relationships, or investments that conflict with or have an impact on the employment relationship or its outcomes.
Capacity to recognize, interpret, and behaviorally adapt to multicultural situations and contexts.
Cultural Intelligence
Basic beliefs, attitudes, values, behaviors, and customs shared and followed by members of a group, which give rise to the group's sense of identity.
Technique that progressively collects information from a group of anonymous respondents.
Concept that laws are enforced only through accepted, codified procedures.
Ability to be sensitive to and understand one's own and others' emotions and impulses.
Business management software, usually a suite of integrated applications, that a company can use to collect, store, manage and interpret data from many business activities.
Amount of owners' or shareholders' portion of a business.
Extension of the power of a country's laws over its citizens outside that country's sovereign national boundaries.
Extraterritoriality
In communication, structuring a message to include opportunities for correction or clarification. This requires two-way communication
Small group of invited persons (typically six to twelve) who actively participate in a structured discussion, led by a facilitator, for the purpose of eliciting their input.
Group decision-making tool designed to analyze the forces favoring and opposing a particular change. A factor is weighted, and the factors on each side are summed and compared.
Process of constructing a message so that an audience sees communicated facts in a certain way and is persuaded to take a certain action.
Ability to take an international perspective, inclusive of other cultures' views.
Global Mindset
Ratio of gross profit to net sales.
Societies or groups characterized by complex, usually long-standing networks of relationships; members share a rich history of common experience, so the way they interact and interpret events is often not apparent to outsiders.
High Context Cultures
Statement that reports revenues, expenses, and profits for a specified period of time, for example, quarterly or annually
Visualization of the impact of change on productivity. When change is introduced, there is typically a decrease in productivity and then a gradual return to—or, ideally, a surpassing of— previous levels of productivity.
J Curve
Right of a legal body to exert authority over a given geographical territory, subject matter, or persons or institutions.
Organization's debts and other financial obligations.
Societies in which relationships have less history; individuals know each other less well and don't share a common database of experience, so communication must be very explicit.
Low Context Cultures
Average score or value
Middle value in a range of values.
Data-sorting technique in which group members add related ideas and indicate logical connections, eventually grouping similar ideas.
Value that occurs most frequently in a set of data.
Factors that initiate, direct, and sustain human behavior over time.
Group decision-making tool in which the group defines the characteristics of a successful decision and then scores each alternative against those criteria.
Multi-criteria decision analysis (MCDA)
Process by which two or more parties work together to reach agreement on a matter.
Ratio of net income (gross sales minus expenses and taxes) to net sales.
Process of developing mutually beneficial contacts through the exchange of information.
In communication, any factor that can disrupt the sending and receipt of a message—for example, physical factors such as loud environments, cultural factors such as a distinctive accent, or cognitive factors such as the use of unfamiliar jargon.
Technique in which participants each suggest ideas through a series of rounds and then discuss the items, eliminate redundancies and irrelevancies, and agree on the importance of the remaining items.
Nominal group technique (NGT)
Components of a message apart from its words. This could include physical gestures and posture and vocal tones, volume, and speed.
Nonverbals
Processing applications that store data in a multidimensional "cube," which enables users to analyze data quickly in a variety of different ways.
Online analytical processing (OLAP)
Process in which negotiators aim for mutual gain, emphasizing the need to focus on the problem instead of personal differences and on mutually beneficial outcomes.
Comparing the sizes of two variables to produce an index or percentage; commonly used to analyze financial statements.
Ratio Analysis
Extent to which a measurement instrument provides consistent results.
Type of analysis that starts with a result and then works backward to identify fundamental cause.
Root-Cause Analysis
Concept that stipulates that no individual is beyond the reach of the law and that authority is exercised only in accordance with written and publicly disclosed laws.
Statistical method used to test the possible effects of altering the details of a strategy to see if the likely outcome can be improved.
Scenerio-What/If analysis
Ability to create connections or rapport with others
Concept that proposes that any organization operates within a complex environment in which it affects and is affected by a variety of forces or stakeholders who all share in the value of the organization and its activities.
Stakeholder Concept
Distance of any data point from the center of a distribution when data is distributed in a "normal" or expected pattern.
Extent to which an organization's agreements, dealings, information, practices, and transactions are open to disclosure and review by relevant persons.
Statistical method that examines data from different points in time to determine if a variance is an isolated event or if it is part of a longer trend.
Raw average of data that gives equal weight to all values, with no regard for other factors.
Unweighted Mean
Extent to which a measurement instrument measures what it is intended to measure.
The benefit created when an organization meets its strategic goals; measure of usefulness, worth, or importance.
The process by which an organization creates the product or service it offers to the customer.
Statistical method for identifying the degree of difference between planned and actual performance or outcomes.
Variance analysis
Average of data that adds factors to reflect the importance of different values.
Weighted Mean
SHRM-CP Vocabulary
398 terms
Hanfee
Competencies -CPS HR
Jesslaura13
SHRM Cases
4 terms
SHRM Extras
IM AI Machine Learning
IM IOT
Suppose selected financial data of **Edgewater Company** and **The Ritter Company** for 2014 are presented here (in millions). $$ \begin{array}{c} \textbf{Income Statement Data for Year}\\ \end{array} $$ $$ \begin{array}{lcc} &\underline{\textbf{Edgewater}}&\underline{\textbf{Ritter}}\\[5pt] \text{Net sales}&\text{\$\hspace{2pt}1,356.0}&\text{\$\hspace{2pt}1,436.5}\\ \text{Cost of goods sold}&\text{\hspace{15pt}776.3}&\text{\hspace{15pt}771.7}\\ \text{Selling and administrative expenses}&\text{\hspace{15pt}380.6}&\text{\hspace{15pt}605.5}\\ \text{Interest expense}&\text{\hspace{25pt}0.1}&\text{\hspace{25pt}0.1}\\ \text{Other income (expense)}&\text{\hspace{25pt}9.0}&\text{\hspace{30pt}.5}\\ \text{Income tax expense}&\underline{\text{\hspace{20pt}63.6}}&\underline{\text{\hspace{20pt}19.7}}\\ \text{Net income}&\underline{\underline{\text{\$\hspace{10pt}144.4}}}&\underline{\underline{\text{\$\hspace{15pt}40.0}}}\\ \end{array} $$ $$ \begin{array}{c} \textbf{Balance Sheet Data (End of Year)}\\ \end{array} $$ $$ \begin{array}{lcc} &\underline{\textbf{Edgewater}}&\underline{\textbf{Ritter}}\\[5pt] \text{Current assets}&\text{\$\hspace{10pt}885.7}&\text{\$\hspace{1pt}617.2}\\ \text{Noncurrent assets}&\underline{\text{\hspace{15pt}280.8}}&\underline{\text{\hspace{6pt}219.1}}\\ \text{Total assets}&\underline{\underline{\text{\$\hspace{2pt}1,166.5}}}&\underline{\underline{\text{\$\hspace{1pt}836.3}}}\\[5pt] \text{Current liabilities}&\text{\$\hspace{10pt}166.5}&\text{\$\hspace{1pt}218.0}\\ \text{Long-term debt}&\text{\hspace{20pt}29.9}&\text{\hspace{11pt}41.1}\\ \text{Total stockholders' equity}&\underline{\text{\hspace{15pt}970.1}}&\underline{\text{\hspace{6pt}577.2}}\\ \text{Total liabilities and stockholders' equity}&\underline{\underline{\text{\$\hspace{2pt}1,166.5}}}&\underline{\underline{\text{\$\hspace{1pt}836.3}}}\\ \end{array} $$ $$ \begin{array}{c} \textbf{Beginning-of-Year Balances}\\ \end{array} $$ $$ \begin{array}{lcc} &\underline{\textbf{Edgewater}}&\underline{\textbf{Ritter}}\\[5pt] \text{Total assets}&\text{\$\hspace{3pt}1,027.3}&\text{\$\hspace{1pt}860.4}\\ \text{Total stockholders' equity}&\text{\hspace{15pt}830.7}&\text{\hspace{5pt}561.7}\\ \text{Current liabilities}&\text{\hspace{15pt}187.9}&\text{\hspace{5pt}285.6}\\ \text{Total liabilities}&\text{\hspace{15pt}196.6}&\text{\hspace{5pt}298.7}\\ \end{array} $$ $$ \begin{array}{c} \textbf{Other Data}\\ \end{array} $$ $$ \begin{array}{lcc} &\underline{\textbf{Edgewater}}&\underline{\textbf{Ritter}}\\[5pt] \text{Average net accounts receivable}&\text{\$\hspace{1pt}293.2}&\text{\$\hspace{1pt}196.1}\\ \text{Average inventory}&\text{\hspace{5pt}239.1}&\text{\hspace{5pt}194.3}\\ \text{Net cash provided by operating activities}&\text{\hspace{5pt}124.5}&\text{\hspace{10pt}38.6}\\ \text{Capital expenditures}&\text{\hspace{10pt}34.3}&\text{\hspace{10pt}30.5}\\ \text{Dividends}&\text{\hspace{10pt}20.9}&\text{\hspace{22pt}0}\\ \end{array} $$ ***Instructions*** (a) For each company, compute the following ratios. (1) Current ratio. (8) Return on assets. (2) Accounts receivable turnover. (9) Return on common stockholders' equity. (3) Average collection period. (10) Debt to assets ratio. (4) Inventory turnover. (11) Times interest earned. (5) Days in inventory. (12) Current cash debt coverage. (6) Profit margin. (13) Cash debt coverage. (7) Asset turnover. (14) Free cash flow. (b) Compare the liquidity, solvency, and profitability of the two companies.
Define the following terms: Preferred stock
For the following loans, make a table (as in discussed example) showing the amount of each monthly payment that goes toward principal and interest for the first three months of the loan. A student loan of $\$ 24,000$ at a fixed $\mathrm{APR}$ of $8 \%$ for $15$ years
Journalize entries for the following related transactions of Platypus Company: d. Purchased $9,000 of merchandise from Sitwell Co. on account, terms n/30. e. Received a check for the balance owed from the return in (c), after deducting for the purchase in (d).
Operations Management: Sustainability and Supply Chain Management
12th Edition•ISBN: 9780134163451 (3 more)Barry Render, Chuck Munson, Jay Heizer
Information Technology Project Management: Providing Measurable Organizational Value
5th Edition•ISBN: 9781118898208Jack T. Marchewka
12th Edition•ISBN: 9780134165325Barry Render, Chuck Munson, Jay Heizer
5th Edition•ISBN: 9781118911013 (2 more)Jack T. Marchewka
test 2 review
kathleen_nguyen2
Mini test ss1+ ss2 psychopathology
Grace1234642
Exam 6- BCH 403
Michael_Kaczor3
MICR3001 L2: Neisseria meningitidis
Haybales1462 | CommonCrawl |
Arranging letters to make a word in a regular language
Fix a regular language $L$ on the alphabet $\{a, b\}$, and consider the following problem. I am given as input:
some number $m \in \mathbb{N}$ of copies of the letter $a$, and
some number $n \in \mathbb{N}$ of copies of the letter $b$ but each copy $1 \leq i \leq n$ comes with a constraint expressed as a pair of integers $(p_i, q_i)$ which means: "there must be at least $p_i$ $a$'s to the left of this $b$ and at least $q_i$ $a$'s to the right of this $b$".
My goal is to decide if I can construct a word of length $m + n$ with $m$ letters $a$ and $n$ letters $b$ that falls in the language $L$ and where every copy of $b$ was put at a position that satisfies its constraints. (Formally: there is an injective function $f$ from $\{1, \ldots, n\}$ to $\{1, \ldots, n+m\}$ such that, letting $A$ be the elements of $\{1, \ldots, n+m\}$ that are not in the image of $f$, for each $1 \leq i \leq n$, the set $A$ contains at least $p_i$ integers that are $< f(i)$ and at least $q_i$ integers that are $> f(i)$.) Note that the $b$'s can be put in any order (as long as their constraints are satisfied), they needn't be put in the order in which they are in the input. In other words, $f$ need not be an increasing function.
Is this problem in polynomial time for every regular language $L$, or is there a language $L$ for which the problem is NP-hard?
I have a PTIME greedy algorithm that works if $L$ has only one word of every length, e.g., it is something like $(ab)^*$. In this case, you should go over the even positions (where $b$'s must go) and at each position put a copy of $b$ which is available and which is as constrained as possible, i.e., the constraint $p_i$ is satisfied, and the constraint $q_i$ is as large as possible. It is clear that this algorithm respects the constraints if it succeeds, and that this is always the best way to place the $b$'s. However when $L$ contains multiple words of length $m+n$ then this no longer works and I can't see a dynamic algorithm to solve the problem.
(This question relates to this earlier question of mine but the main difference that the alphabet is now restricted to be $\{a, b\}$ so the previous proof does not work. The problem can also be equivalently phrased in terms of topological sorts in which case it is a rephrasing of a problem in this list.)
cc.complexity-theory ds.algorithms fl.formal-languages regular-language
a3nm
a3nma3nm
With an idea by Louis Jachiet, we managed to design a PTIME algorithm for this task. Long story short, it's a dynamic programming algorithm where you sort the $b$'s by decreasing "ending time" (i.e., by increasing $q_i$ above), consider the $b$'s by intervals of "starting time" (the $p_i$ above), and restrict the search to greedy schedulings that follow the idea for $(ab)^*$ given in the question. Somewhat surprisingly, the problem is in PTIME even if the target regular language is also given as part of the input (i.e., not fixed). Also, the algorithm would also work if, instead of copies of the letter $a$, we had a fixed word on some alphabet; however all the $b$'s should be the same symbol.
I'll rephrase the problem of my question to a problem where each $b$ comes with a pair $(s_i, e_i)$ saying that this $b$ must be inserted with at least $s_i$ $a$'s to the left, and strictly less than $e_i$ $a$'s to the left. This is equivalent to the original problem phrasing in the question (take $s_i := p_i$ and $e_i := m + 1 - q_i$ where $m$ is the number of $a$'s), but it is a bit easier to reason with: we can now see the constraints as defining an interval $[s_i, e_i[$ of positions where the insertion can take place. By a position $p$, I mean a position in the word of $a$, i.e., $0 \leq p \leq m$; when we insert multiple $b$'s then they do not change positions of other $b$'s in the word of $a$'s. Besides, since all $b$'s are the same symbol, it suffices to know the position where we insert them; we don't care about the relative positions of the $b$'s that are all inserted at the same position in the word of $a$'s.
I will need to talk about state pair sets of the automaton, which are just sets $S$ containing pairs $(q, q')$ of states. Given a word $w$ over $\{a, b\}$, I will write $\phi(w)$ for the state pair set that it achieves, i.e., all $(q, q')$ such that there is a path from $q$ to $q'$ labeled by $w$, which can clearly be computed in PTIME from $w$ and an automaton representation of the word. Given two state pair sets $S$ and $S'$, I define $S \odot S'$ to be the set of all state pairs $(q, q'')$ that can be obtained by combining a pair of $S$ and of $S'$, formally $S \odot S' = {(q, q'') \mid \exists q', (q, q') \in S \land (q', q'') \in S'}$. Notice that we have $\phi(w w') = (\phi(w)) \odot (\phi(w'))$ for any words $w$ and $w'$. What is more, the question of whether a word is accepted or not boils down to checking whether $\phi(w)$ contains a pair $(q_0, q_f)$ for a final state $q_f$. (What I'm redefining here is basically the transition monoid of the automaton, for those familiar with it.)
I will consider the $b$'s by decreasing ending time $e_i$, and break ties in some arbitrary but consistent way, so when I talk about the $i$-th $b$, with constraints $(s_i, e_i)$, then it is the $i$-th $b$ according to this order that I fixed.
Let me now claim that, if we can achieve a word $w$ by insertions of $b$'s into the $a$'s, then we can achieve the same word $w$ by doing insertions following a greedy strategy: when I insert the $i$-th $b$ at a position $p$ in the word of $a$'s, then all subsequent $b$'s that could also go at that position (i.e., $s_j \leq p < e_j$ for some $j$) are inserted to the left of that position, i.e., their position is $p'$ with $p' \leq p$. Let's see why we can always restrict to greedy strategies without loss of generality. Consider a stategy to do insertions to achieve $w$, and let's see that we can change it into a greedy strategy that achieves the same word. Consider a violation in the current strategy where we insert the $i$-th $b$ at position $p$ (so $p_i \leq p < e_i$) and the $j$-th $b$ (with $j > i$) could also go at that position (so $p_j \leq p < e_j$) but it was inserted to the right, i.e., $p' > p$. Let's see why the $i$-th $b$ can also be inserted at $p'$, which justifies that we can fix that violation by swapping the two insertions, and thus iteratively repair any strategy to a greedy strategy. By definition of the order, we have $e_j \leq e_i$, so as $p' < e_j$ we have $p' < e_i$. Now, as $p_i \leq p$ and $p < p'$, we have $p_i \leq p'$. So indeed $p \in [p_i, e_i[$ and we can indeed fix the violation by inserting the $i$-th $b$ at $p'$ and the $j$-th $b$ at $p$.
Now I can explain the dynamic algorithm. We will compute, for all $0 \leq i \leq j \leq m$, for all $0 \leq s \leq s' \leq m$, for all $0 \leq k \leq n$ (with $n$ the number of intervals), the set $S(i, j, s, s', k)$ which is the union of the state pair sets over all words that can be obtained by taking the subword of $a$'s from the $i$-th $a$ (included) to the $j$-th $a$ (excluded), performing insertions of $b$'s using exactly the $b$'s with position $i \geq k$ in the order (numbering them from $0$ to $n-1$) and with starting time $s \leq s_i < s'$, and considering the word obtained in this fashion (containing $j - i$ $a$'s and some $b$'s inserted before, after, or between them).
The quantity that we wish to compute to solve our problem is $S(0, m, 0, m, 0)$, telling us what can be achieved by inserting all intervals in the whole word of $m$ $a$'s; we then simply check if there is a pair of the form $(q_0, q_f)$ in the result, with $q_0$ the initial state and $q_f$ a final state.
The base case is the $S(i, j, s, s', n)$, where we ask what can be achieved without any insertions: this is simply the effect of the $a$'s on their own, formally, it is $\phi(a^{j-i})$.
Now, for the inductive step, consider $S(i, j, s, s', k)$ with $k < n$. Consider the $k$-th copy of $b$ and its interval $[s_k, e_k[$. If we don't have $s \leq s_k < s'$, then we are not considering this $b$, so we simply have $S(i, j, s, s', k) = S(i, j, s, s', k+1)$. Otherwise, we are considering the $k$-th $b$, and we claim that:
$$S(i, j, s, s', k) = \hspace{-1cm} \bigcup_{\max(i, s_k) \leq p \leq \min(j, e_k-1)}\hspace{-1cm} S(i, p+1, s, p+1, k+1) \odot \phi(b) \odot S(p+1, j, p+1, s', k+1).$$
In particular, if the interval for the $k$-th $b$ does not overlap with $[i, j[$, then $S(i, j, s, s', k) = \emptyset$ (meaning that we cannot perform the insertions).
To see why this formula holds, observe that we must insert the $k$-th $b$ as we are considering it, and this insertion must be at a position $p$ such that $s_k \leq p < e_k$, so $s_k \leq p \leq e_k-1$, and also we are considering insertions in the subword from the $i$-th $a$ (included) and the $j$-th $a$ (excluded) so $i \leq p \leq j$ (we can insert immediately after the end of this subword of $a$). Now, all remaining $b$'s (strictly after $k$) with starting position in $[s, s'[$ are partitioned between those with starting position in $[s, p+1[$ and those with starting position in $[p+1, s'[$. Let's argue that these $b$'s must be inserted as we claim, i.e., the first ones in the subword of $a$ between $i$ included and $p+1$ excluded (so at or before $p$) and the second ones between $p+1$ included and $j$ excluded (so strictly after $p$). For the second ones, this is clear, as their starting position is $\geq p+1$ so they must be inserted at position $p+1$ or later. For the first $b$'s, either their ending time is $\leq p+1$, in which case they must necessarily be inserted strictly before position $p+1$; or their ending time is $> p+1$, but in this case, as their starting position is $< p+1$, this means that they could legally be inserted at position $p$ where we inserted the $k$-th copy of $b$; now by definition of a greedy strategy, since they come after this $k$-th $b$ in the order which we inserted at a position $p$, then they must be inserted at a position $\leq p$.
Formally, correctness can be shown by showing inductively that the $S(i, j, s, s', k)$ contains the right state pair set: one direction is because what we compute really corresponds to a way to perform the insertions; the other is because any way to perform the insertions is equivalent to a greedy strategy, and all greedy strategies are represented by the above reasoning.
This algorithm clearly establishes that the problem is in PTIME, with complexity like $O(n \times n^4 \times m \times \mathrm{Poly}(A))$ where $A$ is the automaton. We're not claiming that this is optimal. :)
Not the answer you're looking for? Browse other questions tagged cc.complexity-theory ds.algorithms fl.formal-languages regular-language or ask your own question.
Testing whether letters can be scheduled to achieve a word in a regular language
Hardness of finding a word of length at most $k$ accepted by a nondeterministic pushdown automaton
Measurability of an $\omega$-regular language
Bounds on the size of NFA for $r$-skip $k$-distinct language
What is the state complexity of the copy language?
Complexity of the problem of words with fewest distinct letters accepted by a finite automaton
Maximum shortest word accepted by pushdown automata | CommonCrawl |
Curious Properties of 33
Because my explanation has so many words, I'll start with my question and then you can read the explanation if you need to:
The Bernstein Hash method uses the number 33 as a multiplier. From what I've read Bernstein himself has no reasonable explanation as to why 33 has such useful properties. I'm wondering if the mathematics community has any theories on the matter.
I'm a software engineer and I was recently working on a blog post about a hash function I was writing. In the process of designing my hash function, I looked at a lot of implementations of other hash functions.
For non-programmers, the gist is that the hashcodes produced by objects should be well distributed throughout the range of values in a 32 bit integer (-2,147,483,648 through 2,147,483,647).
Let's say I have the string "ABCD." A hash function would loop through each character, get the ASCII value of it, do something to it and aggregate it into a composite hashcode.
For example, in a lot of implementations, they'd take a hashcode initialized to a large prime, multiply it by another prime and the XOR it with the value of 'A' which is 65. Then, they'd take that and multiply it by the same prime and XOR that with the value of 'B'. They'd do this until the end of the string is reached.
I found a clever implementation in the Java framework code that loops over each item and effectively applies this: $i = ((i \ll 5) - i) \oplus j$. I was confused at first until I worked out that $(i \ll 5) - i = 31i$. For a computer, bit shifting is faster than multiplying so this is a clever way to multiply by a prime number.
So, I looked in Microsoft's .Net framework and I found that they do it a little differently. They use $(i \ll 5) + i$ instead! I couldn't figure out for the life of me why they used 33 instead of 31 because from what I understand multiplying by prime numbers is the foundation of many hashing and cryptographic functions.
I found out that this technique is called the Bernstein Hash and that Bernstein himself doesn't know why 33 produces such a good distribution of values as a multiplier in hashing functions.
number-theory computer-science hash-function
D. PatrickD. Patrick
$\begingroup$ I wish I could distribute credit among the several answers I've gotten. They've all produced interesting speculation and they seem to be in line with the research I did when first investigating this topic. One interesting thing to note, the hash functions which use 31 or 33 as factors aren't just for strings. Does that make the entropy with regard to ASCII characters less relevant? Further, both 31 and 33 as factors involve the same bitshift operation so I don't know that the "lowest 5 bits" explanation is fundamentally at play here. $\endgroup$
– D. Patrick
I've always assumed that the factor 33 (which amounts to a 5-bit shift plus a addition, as you note) was chosen because 5 bits is roughly the significant content of (ASCII) text, hence the "spreading" is rather optimal for typical textual keys. I doubt something more can be said from the strictly mathematical point of view.
"from what I understand multiplying by prime numbers is the foundation of many hashing and cryptographic functions." That sounds rather vague to me: for example, for linear congruential generators, the multiplicator is frequently not prime. Empirically, it's seen that 31 or 33 make very little difference. Bear in mind that hashing functions usually relax the strict requirements of cryptographic functions, in favour of simplicity and performance.
Some reasonable heuristics and experimental results are given here.
See also this old discussion about the 33 vs 31 thing.
leonbloyleonbloy
$\begingroup$ Note that the experimental results you link to use addition where the question has XOR. See my answer about why that might make a difference. $\endgroup$
– joriki
I'm not really familiar with this particular hash function, but I decided to try going for the source, which in this case seems to be the Usenet newsgroup comp.lang.c. In this message, Phong Vo[drew] points out that one advantage of 33 over 31 is that it is congruent to 1 modulo 4, so that $k \mapsto 33*k + c \pmod{2^n}$, for a given $c \ne 0$, is a cyclic permutation on $\mathbb Z / 2^n \mathbb Z$. In particular, this means that, if you feed the hash function constant (non-zero) input, it behaves like a full-period LCRNG.
Of course, this doesn't really prove anything; it's just suggestive. Also note that this explanation doesn't directly apply to the version using XOR instead of addition to mix in the data. (Both seem to have been recommended by Bernstein at various times.) In practice, of course, I wouldn't expect much difference between the XOR and addition variants anyway; they are very similar operations, and either should mix in the input just about as well.
Like leonbloy, I also suspect that part of the reason why 33 (or 31) works so well in practice may be that the typical input to such functions is often ASCII text, which tends to have most of its entropy in the lowest five bits. Thus, shifting the hash value left by five bits per round should diffuse this entropy particularly efficiently across all its bits.
Also, it's worth noting that this function was never intended to be a particularly good hash; it was designed to be a fast, yet still acceptably good, hash for applications where the speed of hashing strings is a limiting factor.
$\begingroup$ I think it should be "congruent to $1$ modulo $4$"? $\endgroup$
$\begingroup$ @joriki: Oops, yes, thanks! Corrected. $\endgroup$
– Ilmari Karonen
$\begingroup$ It seems the experimental results that leonbloy linked don't bear out the advantage of the multiplier being congruent to 1 mod 4? (See the remark near the end of my answer about that and also about why there might be a difference between XOR and addition.) $\endgroup$
Ilmari and leonbloy have already said quite a bit and provided pertinent links; here are some more thoughts:
First, about the primes: the accepted answer to this question at stackoverflow sounds right to me. It's not that either the multiplier or the hash table size need to be primes; they should just be coprime. If you're writing the code for both, there's no reason for them to be prime, but if you're writing the code for only one of them (which often happens in practice), you might want to choose primes, or at least numbers with large prime factors, to reduce the chances of a "prime collision" between the multiplier and the hash table size.
Second, about hashcodes being "well distributed" or "optimally spread": That's only part of the story. For long strings, where injectivity is not an option, random spread is good, but for short strings, injectivity is even better than random spread. Ideally, a multiplier-based hash function should have a random spread for initial inputs but be injective with respect to the last few inputs.
ASCII codes for letters of the same case differ only in the low $5$ bits. So for strings ending in lowercase letters and $32$-bit hash values, you can get injectivity with respect to the last six characters if the multiplier is greater than $32$, whereas for multipliers less than $32$ the lowest bit of the penultimate input influences at most the last $5$ bits and thus its contribution isn't linearly independent from the contributions of all the other bits. In that case you're only using half the available hash values, and the values for the last six inputs form pairs that are mapped to the same hash values.
If the multiplier is greater than $32$ and the multiplication doesn't overflow, injectivity with respect to the last $6$ lowercase characters is guaranteed. This is the case up to a multiplier of $47$ (since $2^4\cdot47^5\lesssim2^{32}$), but even beyond that, the contributions from different bits are usually linearly independent (there's a good chance for $30$ random vectors in $\mathbb F_2^{32}$ to be linearly independent); the first odd multiplier for which they aren't is $95$.
So it's not immediately clear why $33$ should be better for ASCII strings than any other odd multiplier greater than $32$ with remainder $1$ mod $4$ (see Ilmari's answer). However, more generally speaking, the lower the multiplier, the more final inputs get mapped injectively before they start getting scrambled by the overflow. So it could well be that the $33$ is a good trade-off between getting the lower $5$ bits of ASCII characters out of each other's way (which requires $f\ge32$) and delaying the onset of scrambling by overflow (which requires low $f$).
A note on the difference between the XOR variant and the one where $j$ is added instead: My considerations above about linear independence apply only to the XOR case, in which we can treat the hash value as a vector in $\mathbb F_2^{32}$ and the hash function as an affine transform on that space. In the case of addition, we don't need the multiplier to be greater than $32$ for the hash to be injective with respect to the last six inputs, just greater than the number of lowercase letters, which is $26$, so in that case there's no particular advantage to $33$. That's borne out by the experimental results that leonbloy linked to, where $31$ (labeled "K&R") even does slightly better on words than $33$ (labeled "Bernstein"); you can see near the top of the page or by following the Bernstein link that these results refer to the case with addition. (This is consistent with the idea that lower multipliers are generally better as long as they map the lowercase letters injectively, but it seems to cast some doubt on Ilmari's point about the remainder mod $4$?)
Examples where the combination of $31$ and XOR fails to be injective already occur with $3$ letters; for instance, "rox" and "rng" are both mapped to 1A607.
This is all just about the advantages of a multiplier with respect to avoiding hash collisions. Often the speed of computing the hash function is at least as important as avoiding collisions, and in that respect $33$ has the advantage over most other multipliers (though not over $31$) that it can easily be computed with a shift and an addition, as you explained.
jorikijoriki
Not the answer you're looking for? Browse other questions tagged number-theory computer-science hash-function or ask your own question.
Help in understanding the properties of prime numbers
Engineering notation algorithm, i.e. 1000 -> 1k, 0.001 -> 1m
What other types of distributivity are there?
A question about r-universal hash family definition
Hash function that can determine set similarity
Why Proof of Work is Hard
Prove that if hash function $h_2(k)$ and $m$ are coprimes, then they produce a probe sequence that is a permutation of $(0, \cdots, ,m-1)$
What system has modular inverses for non primes too? | CommonCrawl |
Fertility Research and Practice
Risk profile of Qatari women treated for infertility in a tertiary hospital: a case-control study
Sarah Musa ORCID: orcid.org/0000-0002-3106-62781 &
Sherif Osman2,3
Fertility Research and Practice volume 6, Article number: 12 (2020) Cite this article
Female infertility is a multifactorial condition constituting a worldwide public health problem. The ability to reproduce is an important product of any marriage, hence infertility may exert a negative impact on physical, financial, social and emotional wellbeing of affected couples. The cornerstone to the management of any disease, including infertility, is prevention. Identifying the modifiable risk factors of female infertility will aid at prevention, early detection, and treatment of medical conditions that can threaten fertility as well as promoting healthy behaviours that can preserve it.
To explore the risk profile of infertility among Qatari women and compare risk factors distribution among primary vs. secondary infertility.
A hospital-based case control study was conducted from September 17th, 2017- February 10th, 2018. Cases (n = 136) were enrolled from infertility clinic and controls (pregnant women, n = 272), were enrolled from antenatal clinic, Women Hospital, Hamad Medical Corporation (HMC). Interview questionnaire was utilized to collect data about sociodemographic, risk factors related to infertility and patient health Questionnaire (PHQ)-2. Body Mass Index (BMI) was calculated. Logistic regression was used to identify the associated factors to infertility. Statistical significance was set at 0.05.
Forty three primary and ninety three secondary infertility cases were included. Risk factors were age > 35 years (OR = 3.7, 95% CI: 1.41–9.83), second-hand smoking (OR = 2.44, 95% CI:1.26–4.73), steady weight gain (OR = 4.65,, 95% CI: 2.43–8.91), recent weight gain (OR = 4.87, 95% CI: 2.54–9.32), menstrual cycle irregularities (OR = 4.20, 95% CI:1.14–15.49), fallopian tube blockage (OR = 5.45, 95% CI: 1.75–16.95), and symptoms suggestive of sexually transmitted infections (STIs) including chronic lower abdominal/pelvic pain (OR = 3.46, 95% CI: 1.57–7.63), abnormal vaginal discharge (OR = 3.32, 95% CI:1.22–9.03) and dyspareunia (OR = 7.04, 95% CI: 2.76–17.95). Predictive factors for secondary infertility were; longer time from previous conception (OR = 5.8, 95% CI: 3.28–10.21), history of stillbirth (OR = 2.63, 95% CI: 1.04–6.67) or miscarriage (OR = 2.11, 95% CI: 1.21–3.68) and postpartum infection (OR = 3.75, 95% CI: 1.27–11.06). Protective factors were higher education level (OR = 0.44, 95% CI: 0.25–0.78), higher income (OR = 0.17, 95% CI: 0.06–0.49), and awareness/loyalty to fertility window (OR = 0.33, 95% CI: 0.21–0.52 and OR = 0.29, 95% CI: 0.19–0.44, consequently).
This study highlighted the opportunities to strengthen public health as well as hospital-based health promotion programs importantly toward behavioural-related risk factors (e.g. smoking, obesity, STIs etc.). Moreover, detecting, preventing, and managing modifiable risk factors through awareness, screening and early management of chronic diseases, may contribute at reduction of incidence and severity of infertility. Such interventions can be delivered at premarital, family planning, post-natal and antenatal clinics at primary health care with early referral to secondary care if required.
Plain English summary
Infertility is defined by the failure to conceive after 1 year or more of regular unprotected sexual intercourse. It is considered as a stigmatizing condition more pronounced in Arab communities. Couples are distracted by the physical, financial, social and emotional hardship of the disease. It can also affects marriage stability, family relationships and job performance. Although male and female are attributed equally to infertility (third of cases each), it appears that women is consistently held responsible and she is often impacted psychologically and socially as a consequence. Several risk factors of female infertility might be preventable particularly the ones related to behaviour and lifestyle.
This study attempts to explore the risk factors of female infertility to provide guidance for prevention and early management. We have interviewed infertile females (136) and fertile pregnant females (272) using questionnaires individually. We have classified infertility as primary (women with no previous conception) or secondary (women with previous conception).
Of the 136 infertile cases, 43 had primary infertility and 93 had secondary infertility. We found that the most associated risk factors to female infertility were age > 35 year, second hand smoking, steady weight gain since marriage, recent weight gain, irregular menstrual cycle, fallopian tube blockage, some symptoms that can be related to sexual transmitted infections including chronic lower abdominal pain, abnormal vaginal discharge, and pain during sexual intercourse. Risk factors for secondary infertility were identified as the following; history of stillbirth/miscarriage, postpartum infection or previous caesarean section. Higher education/income as well as awareness/loyalty to fertility window, were found to be protective against infertility.
In conclusion, infertility is a multifactorial disease that remain a significant burden for individuals, families and communities. Several modifiable risk factors were found to be associated with female infertility, which may be considered for planning of better reproductive healthcare in Qatar.
Key message points
Lifestyle pattern mainly obesity and second-hand smoking, is contributed to the occurrence of female infertility among Qatari women.
Screening for symptoms suggestive of sexual transmitted disease is an essential step for prevention of female infertility.
Secondary female infertility is found to be linked to the rate of caesarean section, stillbirth and miscarriages.
Infertility is a disease of the reproductive system defined by the failure to achieve a clinical pregnancy after 12 months or more of regular unprotected sexual intercourse [1, 2]. Primary infertility is defined as the inability to conceive after 1 year of unprotected sexual intercourse, with no previous conceptions, while secondary infertility is referred to couples who are unable to conceive after 1 year of unprotected intercourse following a previous pregnancy [3, 4]. About one-third or more of all infertility cases are related to women's causes, another third due to male causes, the remaining are caused by mixed or by unknown factors [5]. Globally, every year, 60–80 million new couples suffer from infertility [6]. A systematic analysis published by the World Health Organization (WHO) in 2012, revealed that one in every four couples in developing countries are affected with infertility [2]. Infertility affects between 8 and 12% of reproductive-aged couples worldwide [6, 7]. However, in some regions, the rates are much higher, reaching up to 30% in some populations such as Middle East and North Africa (MENA) region [7,8,9]. Infertility is a cause of instability in the lives of couples, particularly women, raising chances of divorce, lowering chances of entering into marriage, put her at risk of family violence, and increasing the chances that her husband will marry another wife, in religions where polygyny is permitted, as in the Islamic Arab world [10]. Treatment of infertility can be medically invasive, associated with adverse health problems and my cause psychological stress, anxiety or depression. A serious risk of ovulation induction is ovarian hyperstimulation syndrome (OHSS). Some published research suggests that infertility treatments may be associated with an increased risk of gynaecologic or breast cancer. Infertility treatments have increased the rate of twin and higher-order multiple births, which put both mother and infants at higher risk of adverse health outcomes. Even singleton births resulting from Assisted Reproductive Technology (ART) are associated with increased risk of low birth weight (LBW) and even at higher risk of birth defects. Lack of access to public health care, traditional means of self-cure (e.g. unprotected sex with multiple partners to achieve the goal of a wanted pregnancy) can result in the spread of HIV and other STIs, with the potential to contribute further to the disease burden [11]. Female infertility risk factors ranges from non-modifiable such as older age, ethnic background, congenital anomalies of reproductive organ, certain genetic conditions, family history [12,13,14], and modifiable factors that include sociodemographic, STIs, post-abortal or postpartum infections leading to fallopian tube blockage, high risk sexual behaviour (e.g. early age at first sexual intercourse, multiple marriages/relations), environmental hazards (e.g. radiation exposure, chemotherapeutic and toxic agents), lifestyle factors (e.g. obesity, tobacco smoking, alcohol intake, emotional stress, etc.), some medical conditions (as menstrual cycle abnormalities, thyroid diseases, polycystic ovarian syndrome (PCOS)), and prior history of pelvic surgeries (e.g. caesarean section, appendectomy) [15,16,17,18]. According to the United Nation's (UN) "World Population Prospects": The 2015 Revision; total fertility rate in Qatar has dropped from 6.11 children per woman in 1965–1980 to 2.1 in 2010–2015. Projections show that total fertility will decline further to reach 1.76 in 2020–2025, which is below the replacement level fertility. The most important factors they unveiled are as increased age at first marriage, increased educational level of Qatari women, and more women integrated in the labour force [19]. The aim of the present study was to explore infertility risk profile among Qatari females that will aid in planning preventive and management strategies to mitigate its burden, and consequently maternal and foetal morbidity, mortality and economic cost on families and on the healthcare system.
An analytical case-control study was conducted.
Study settings and duration
Cases were recruited from infertility clinics, Women Hospital-HMC, Doha. It is the main governmental hospital providing infertility counselling and management services in the State of Qatar, where most cases are served on the national level coverage. The clinic serves around 3500 patients annually, at an average rate of 300 patients per month. For the year 2017, the clinics covered 1486 new cases as well as 1973 follow up cases. Among those, 42% were Qatari women. Controls were recruited from the antenatal clinic, Women Hospital-HMC, Doha. Antenatal clinics at Women Hospital are the main provider of such service within secondary care level in Qatar, parallel to Primary Health Care Corporation (PHCC). The clinic serves around 60,000 patients annually, at an average rate of 5000 patients per month. For the year 2017, the clinics covered 10,657 new cases and 48,503 follow-up cases. Among those, 40% were Qatari women. The study was conducted during the period from 17th September 2017 to 10th February 2018.
Defined as; any Qatari women within the reproductive age (15–49 years), who reports failure to achieve a clinical pregnancy after 12 months or more of regular unprotected sexual intercourse, attending infertility clinic at Women's Hospital - HMC. Controls: Defined as; any Qatari pregnant woman within the reproductive age (15–49 years), attending antenatal clinic at Women Hospital - HMC. Controls are supposed to be those seeking healthcare (antenatal care) at the same setting (Women's Hospital) and mostly attributed to the same population pool where cases came from. A ratio of 2:1 was utilized for controls to cases.
For cases
Those with clinical diagnosis of infertility due to male or combined causes.
For controls
Those with prior complain/history of infertility or previously managed to treat infertility and those with the current pregnancy being a product of infertility management.
Sample size calculation and sampling technique
Sample size of 408 (136 cases and 272 controls) was calculated using the following case-control study formula [20]:
n = \( \frac{\left(r+1\right)}{r}X\frac{\left(\ P\ \right)\ x\ \left(\ 1-P\ \right)\ x\ \left(\ Z\beta + Z\alpha\ \right)2}{\left(P1-P2\right)2.} \)
n: Minimum sample size required [for the cases group]
r: Ratio of control to cases [i.e. 2: 1] = 2
Zα: Standard normal variant for the selected significance level [i.e. 95%] = 1.96
Zβ: Standard normal variant for the desired 80% power = 0.84
OR: The assumed least Odds Ratio foreseen = 2
P: Average proportion exposed
P1: The assumed proportion exposed in the case group that is calculated as the following:
$$ P\; cases\;\mathit{\exp}o=\frac{OR\times P\; controls\kern0.17em expo}{p\; controls\kern0.17em expo\;\left( OR-1+1\right)} $$
P2: The assumed proportion exposed in the control group, where three different proposed risk factors of infertility were reviewed in literature to acquire their prevalence in the studied community. They were the following; Qatari women suffering chlamydial infection (5.3) [21], polycystic ovarian syndrome (18.33%) [22] and, obesity (36.4%) [23]
The average for the three was calculated to be 20%.
Sampling technique
Cases were recruited using a convenient non-probability sampling technique. Controls were selected from those pregnant women attending the antenatal clinic, using probability systematic random sampling technique. List of attendees at the daily appointment sheet was used as a sampling frame where participants were selected systematically each fourth listed, after selecting the first one randomly. The average Qatari women attending the clinic /month = 2000. The clinic runs AM/PM shifts 5 days a week. Average daily attendance AM shift = 50 (two stations each 25 cases/station/shift). The sampling interval (k) was calculated based on the following formula [k = N/n], where N is the population size = 2000/2 shits = 1000 divided by n = 272 = 3.67 rounded into 4.
Data were collected using predesigned interview questionnaire consisting of the following components; Sociodemographic characteristics (age, education level, occupation, and income), marriage history (consanguinity, age at first marriage, recurrent marriage, duration of marriage, husband's absence), lifestyle history (smoking, alcohol, vigorous exercise, weight gain), menstrual history (age of menarche, regularity of menstrual cycle, duration of menstrual cycle, number of menstrual flow days, menorrhagia, intermenstrual bleeding, dysmenorrhea, secondary amenorrhoea, obstetric history (previous and time of previous conception, stillbirth, miscarriage, ectopic pregnancy, antenatal care, post-partum/abortal infection, gynaecologic history (chronic pelvic pain, abnormal vaginal discharge, painful urination, dyspareunia, gynaecological related fever, pelvic inflammatory disease (PVD), tubal blockage, fibroid uterus, endometriosis or congenital anomaly of the reproductive organ, medical history (diabetes mellitus (DM), thyroid disease, hyperprolactinemia), medication history (cancer treatment, prolonged use of steroid, hormonal therapy, prolonged high dose of nonsteroidal anti-inflammatory drugs (NSAIDs), certain antihypertensive, anti-obesity, antidepressant/antipsychotic), surgical history (caesarean section, dilatation & curettage, appendectomy, pelvic or abdominal surgery), birth control history (contraception use and methods; oral contraceptive pills, intrauterine device, natural/barrier methods), family history (female infertility, menstrual cycle irregularity, early menopause, PCOS, fibroid uterus, DM, thyroid disease), sexual history (knowledge & loyalty to fertility window, coital frequency). The second component of the questionnaire was PHQ – 2 and any patients who scored positive were advised to get referral into a specialized care for further evaluation with the more explicit and specific PHQ-9. Medical review was performed as well as anthropometric measurement of weight, height and body mass index (BMI).
Study variables
Dependent (outcome)
Primary infertility
Women in the reproductive age group who are unable to conceive after 1 year of unprotected sexual intercourse with no previous conceptions.
Women in the reproductive age group who are unable to conceive after 1 year of unprotected intercourse following a previous pregnancy.
Included sociodemographic characteristics, history of marriage, lifestyle, menstrual, obstetric, gynaecological, medical, medication, surgical, birth-control, sexual and family, depression screening using patient health questionnaire (PHQ)-2 score, and anthropometric measurements. BMI was calculated and classified according to the World Health Organization (WHO).
Formal approvals were obtained prior to field work from the Arab Board of Medical Specialization, Research Ethics Committee of Women Hospital, Medical Research Center (MRC)-HMC and Institutional Review Board (IRB)-HMC. Informed consent was taken from the willing participants after explaining the aim, objectives and possible benefits from the study following the HMC-IRB standard template of informed consent. All eligible clients were participating totally voluntarily and given the chance to clarify any concerns. The study was conducted with no negative effect on the relationship between the clients and the healthcare provider. Clients were instructed that they could withdraw at any time without any adverse consequences. Confidentiality of the information and privacy have been assured throughout the study. Those screened as positive by the PHQ-2 were advised to go further with the PHQ-9 testing at specialized secondary care.
Quality control measures
Content and face validity of the constructed questionnaire were established by extensive literature review, consultation of experts in the fields of community medicine, maternal health, primary health care and consultants in obstetrics and gynaecology specializing in infertility. The principle investigator performed data collection with the assistance of an assigned data collector (physician). Adequate training of the data collector was done through explaining in details all sections of the questionnaire, as well as, interviewing few clients in front of the assigned physician. The researcher reviewed the questionnaires to ensure completion and consistency, together with extracting the pre-conception weight from electronic medical records to calculate BMI. Prior to data collection, the questionnaire was piloted using a convenient sample of 10 eligible cases and 10 controls to test for the clarity, understandability, feasibility and timeliness to complete the questionnaire. Those piloted participants were later omitted. The completed questionnaires were reviewed on daily basis and revised for data completion and consistency by the PI.
Data entry was done using Statistical Package of Social Science IBM-SPSS© version 22. Student t-test and chi square test were used to compare (mean + standard deviation) and (observed frequency) for numerical and categorical variables, consequently. Crude and adjusted odd ratios (OR) were calculated to examine the risk association between two variables. Variables having p-value equal or less than 0.05 at the bi-variable analysis were considered as statistically significant and were further included in the multivariate logistic regression. Two regression model using forward stepwise method were used; Model I was to obtain risk factors of primary and secondary infertility compared to controls, while Model II was to obtain risk factors of secondary infertility compared to controls with previous conception.
Patient and public involvmement
Patients were involved in identifying research priorities. They were interviewed during rotations at infertility clinic to identify the most important and relevant outcome measures. Patients worked with us in formulating the research questions, however it was difficult to involve patients in other areas of the study design due to data protection restriction and ethical considerations. Dissemination strategies will include raising awareness of preventive risk factors of female infertility among Qatari through media such as television programmes, newspaper and social media. Moreover, leaflets will be designed for Primary Health Care Centers to be available at premarital clinics, post-natal clinic and well-women clinic, as well as infertility clinics related to Hamad Medical Corporation.
It was found that 68.4% of infertile participants were suffering from secondary infertility, while the remainder (36.6%) had primary infertility. Fig. 1.
Distributions of infertile participants according to fertility type, Women Hospital-Hamad Medical Corporation, 2018
Table 1 shows the distribution of cases and controls according to their sociodemographic characteristics. The mean age of cases and controls was 32.5 + 6.6 years and 30.2 + 5.5 years, subsequently. Regarding the educational level, majority of participants in both groups have completed secondary and/or university education or higher. More than half of cases and more than three quarter of controls had their average monthly income in the high category (> 25.000 Qatari Riyals). Occupation showed no statistical difference between the two groups. Regarding the age at first marriage, 11.7% of infertile women got married at an age of 30 year or above as compared to only 5.1% of controls (p = 0.024). In respect to husband's absence, only 14.7% of control reported their husbands being absent from home, compared to as high as 31.6% of infertile participants, the difference was statistically significant (p = 0.001). However, consanguinity, recurrent marriage and duration of menstrual cycle had no statistical significance between groups.
Table 1 Distribution of study participants according to their socio-demographic characteristics, Women Hospital-Hamad Medical Corporation, 2018
Table 2 shows the distribution of study participants according to their lifestyle history. Only 2.2% of cases are currently cigarette smokers, compared to none of their fertile counterparts, who reported never being smokers either currently or previously. Similarly, nine cases (6.6%) are currently or previously smoked water pipe tobacco, while only 1.5% of controls have similar exposure, the difference was statistically significant (p = 0.006). Around 58.1% of cases reported exposure to second hand smoke, the figure was significantly higher than their controls (p = 0.014). None of the study participants reported alcohol consumption. Infertile participants reported practicing vigorous exercise (as swimming, fixed cycling and jugging) more commonly that their controls, 8.8 and 3.3% respectively (p = 0.017). Around one fourth of cases had history of childhood obesity, while the majority of them reported steady weight gain since the start of marriage and/or recently during the last 6 months. On the other hand, controls significantly showed much lower figures.
Table 2 Distribution of study participants according to their lifestyle-related characteristics, Women Hospital-Hamad Medical Corporation, 2018
Table 3 demonstrates the distribution of study participants according to gynaecological history. Majority of the cases and controls had normal age of menarche. Cases were more likely to report history of mensural cycle irregularity of duration more than 6 months, as well as history of menorrhagia, intermenstrual bleeding, dysmenorrhea and secondary amenorrhea, with statistical significance differences. Symptoms suggestive of STIs (chronic pelvic pain, abnormal vaginal discharge, painful urination, dyspareunia) were highly significant among cases as compared to controls. Gynaecological related-fever had no statistical significance difference.
Table 3 Distribution of study participants according to gynaecological history, Women Hospital-Hamad Medical Corporation, 2018
Table 4 shows the distribution of secondary infertility participants and controls according to their obstetric history. Most of secondary infertile cases and controls had their previous pregnancy within last 5 years. Secondary infertile women were more likely to report history of stillbirth, recurrent miscarriage, post-partum/abortal infection, caesarean section, while history of ectopic pregnancy or dilatation & curettage were not found to be statistically significant. Around 15% of secondary infertile cases reported not having antenatal care in their previous pregnancies, compared to only 7.8% of controls, the difference reached statistical significance.
Table 4 Distribution of secondary infertility participants and controls according to their obstetric history, Women Hospital-Hamad Medical Corporation, 2018
Table 5 demonstrates the distribution of study participants according to medical/medication history. Hypothyroidism, hyperprolactinemia, depression were reported significantly higher among cases. More than half of the infertility cases were suffering from PCOS, versus 19.1% of their controls. Furthermore, around 17% of cases had fallopian tube blockage, compared to only 2.6% of their fertile controls. Secondary infertile women tended to have higher rate of fallopian tube blockage than women with primary infertility (20.4% vs. 9.3% respectively). Fibroid uterus was reported among 19.6% of cases compared to only 4.0% of controls. Endometrioses and reproductive congenital anomalies showed no statistical significance. More cases reported history of appendectomy compared to controls (8.3% vs. 3.3% respectively). Furthermore, the rate of surgical management of obesity (most commonly sleeve gastrectomy and/or liposuction) was significantly higher among cases compared to their controls (24.3% vs. 13.6% respectively). History of other pelvic surgeries was statistically more frequent amongst cases than controls (18.4% vs. 15.1% respectively). Cases were more likely to have history of prolonged use of steroid, hormonal therapy, prolonged high dose of NSAID, and anti-obesity. However, cancer treatment, anti-hypertensive and antidepressant showed no statistical significant difference.
Table 5 Distribution of study participants according medical/medication history, Women Hospital-Hamad Medical Corporation, 2018
Table 6 shows the distribution of study participants according to their birth-control/sexual history. Among contraception users, hormonal control was the most commonly adopted method (71.7 and 50% among cases and controls subsequently), followed by natural/barrier method. However, the use of intrauterine devices as well as duration of birth control use, showed no statistical significant difference between the two groups. Controls were more likely to be aware and loyal to fertility window, while coital frequency showed no statistical significance difference.
Table 7 Distribution of study participants according to their family history, Women Hospital-Hamad Medical Corporation, 2018
Table 7 demonstrates the distribution of study participants according to their family history. Family history of female infertility was observed in 41.9% of cases compared to 27.6% of controls. Moreover, family history of menstrual cycle irregularity, PCOS, fibroid, DM and thyroid disease were all more distributed among cases, with a significant statistical difference.
Table 8 illustrates the distribution of study participants according to their WHO-BMI classification/ PHQ-2 results. The mean BMI values for cases was higher compared to their controls (mean + standard deviation = 31.4 + 6.4 Kg/m2 and 28.7 + 6.1 Kg/m2, respectively Infertile women were more likely to be obese as compared to controls with statistical significance difference. With regard PHQ-2 results, 14% of infertile women screened positive against depression compared to only 5.5% of their controls, with a statistical significant difference.
Table 8 Distribution of study participants according to their WHO-BMI classification/ PHQ-2 score, Women Hospital-Hamad Medical Corporation, 2018
Comparing the distribution of selected significant risk factors between primary and secondary infertility in bivariate analysis, it was found that husband's absence, older age, abnormal vaginal discharge, fallopian tube blockage, history of appendectomy and older age at first marriage, were more commonly found among secondary infertile women. Fig. 2. The most predictive factors of infertility obtained after bivariate analysis, illustrated with crude OR and 95% confidence interval (CI) are shown in Fig. 3.
Distribution of some risk factors among primary and secondary infertile participants, Women Hospital-Hamad Medical Corporation, 2018
Main significant risk factors of infertility among Qatari women derived from the bivariate analysis, Women Hospital-Hamad Medical Corporattion, 2018
Table 9 describes the result of multivariate logistic regression analysis. Among the forty two entered significant factors only nine were found to be predictors of infertility [Model I: X2 (12) = 264, p < 0.001] including; age > 35 years, second hand smoking, steady weight since marriage, recent weight gain, menstrual cycle irregularity, chronic lower abdominal pain, abnormal vaginal discharge, dyspareunia and fallopian tube blockage. Furthermore, four variables were found to be predictors of secondary infertility (among those with history of previous conception) [Model II: X2 (4) = 57.3, p < 0.001], including duration of 5 years or more from previous conception, stillbirth, recurrent miscarriage and post-partum/abortal infection.
Table 9 Infertility risk factors: Results of the bivariate and multivariate logistic regression analysis, Women Hospital-Hamad Medical Corporation, 2018
The studied sample revealed that 68.4% had secondary infertility, while 31.6% had primary infertility. Similarly, a systematic analysis [2] of national health surveys conducted among 190 countries by Mascarenhas MN et al. (2012) found that secondary infertility was more prevalent than primary (10.5% vs. 1.9% respectively). However, regionally, a study in Kuwait [24] conducted by Omu FE and Omu AE (2002–2007), revealed that among 268 women attending infertility clinic, the rate of primary and secondary infertility were 65.7 and 34.3%, respectively. As compared to our study, the variation in the distribution of primary and secondary infertility could be related to the selection of different population and exclusion of cases with male factor, where many primary infertility exists.
Female infertility risk factors
In the current study, It was found that age > 35 years significantly increased the risk of infertility by around four times, (OR = 3.72, 95% CI: 1.41–9.83, p = 0.008). It also revealed that with increasing age, the trend of infertility risk increases in a step manner. This is in consonance with a case-control study conducted in Lusaka, Zambia by Kalima-Munalula MN et al. (2017) who found a significant association between age and female infertility. There was an increasing trend of infertility risk, with increasing age, at age group 20 - 29y, the OR was 2.39; and OR of 8.42 at 30 - 39y [25]. Decreased fecundity with increasing female age has long been recognized from demographic and epidemiological studies, which consistently found that fertility declined beginning as early as the middle of the third decade. The biological basis of this decline include decline in the number of oocytes from birth to menopause, the quality of existing oocytes diminishes with age and on an average, intercourse frequency declines with age [26].
This study found that second hand smoking (aOR = 2.44, 95% CI = 1.26–4.73, p = 0.008) and water-pipe smoking were significantly associated with female infertility (OR = 4.75, 95% CI = 1.44–15.71, p = 0.01). In agreement to our study, the association between second-hand smoking and infertility was assessed in a prospective cohort of postmenopausal women by Hyland A. et al. (1993–1998). The study established that active-smokers were 1.14 times more likely to have infertility and 1.26 times more likely for earlier menopause than never-smoking women [27]. Second hand smoking was linked to early menopause in several studies that may contribute to female infertility. Moreover, the present study showed that obesity is a significant risk factors for female infertility. This was consistent with the results of a case-control study of 582 women, Algeria by MAÏ HA et al. (2015). It reported that women with BMI greater than 30 m2/kg were 3.26 times more likely to have infertility (OR = 3.26) [28]. Similarly, a study conducted in Saudi Arabia, King Fahad Medical City by Rafique M. et al. (2016), revealed that among 127 cases of female infertility, 33.2% were overweight and 48% were obese. In addition, PCOS was present in 30.8% of overweight and 38.7% of obese women [29]. This is not surprising, because obesity is associated with anovulation, menstrual disorders, miscarriage, and adverse pregnancy outcomes, all of which could contribute to the infertile status.
In the current study, it was found that menstrual cycle irregularity is a significant risk of female infertility (aOR = 4.20, 95% CI = 1.14–15.49, p = 0.031) including oligomenorrhea, menorrhagia, dysmenorrhea and intermenstrual bleeding. Similarly, Shamila S et al. (2011) in their survey found that menstrual cycle irregularity was a common observation reported among infertile females in the three study areas (40, 44.85 and 44.11% respectively) and was positively correlated with female infertility [30]. Likewise, a case-control study in south-eastern Iran conducted by Ansari H et al. (2016), reported that women with irregular menstruation were nearly 4 times more likely to have secondary infertility, compared to their regular cycle counterparts (aOR = 3.91) [31]. A study conducted in Korea by Kwon SK et al. (2014), found that among the studied 1080 women suffering secondary amenorrhea, PCOS was the most common cause (48.4%) [32]. It was also found in this study that PCOS increased the risk of female infertility by nearly 5 times and these results correlate with the studies concerning the percentage of women suffering infertility problems due to PCOS by Wendy A et al. (54.6%) [33], Susan M. et al. (40%) [34] and Kristi P et al. (56%) [35]. In PCOS, levels of hormones including androgens and testosterone increase due to high levels of luteinizing hormone (LH) and low levels of the follicular-stimulating hormone (FSH), so follicles in these individuals are prevented from producing a mature egg. Furthermore, PCOS increases the risk of insulin resistance, along with type 2 diabetes, which is one of the causes of infertility [36].
The present study found that symptoms suggestive of STIs were highly correlated with female infertility; dyspareunia (OR = 7.04, 95% CI = 2.76–17.95, p = 0.001), while chronic lower abdominal pain or abnormal vaginal discharge increased the risk of infertility by more than three times. In Nigeria, Ogbu GI. et al. (2017) studied the relationship between Chlamydia trachomatis infection and tubal infertility found a statistically significant association between positive C. trachomatis antibody titre among cases with tubal factor infertility (75.0%) compared with controls (22.2%). They concluded that the clinical feature having the potential of identifying woman at high risk for Chlamydia infection were vaginal discharge (24.5%), followed by dysmenorrhea (24.5%) and lower abdominal pain (23.1%) [37]. The present study also demonstrated that fallopian tube blockage is a risk factor for female infertility (OR = 5.45, 95% CI = 1.75–16.95, p = 0.003). Fallopian tube blockage was much more common in secondary infertile females (20.4%) compared to only 9.3% of primary infertile. Tubal blockage is usually associated with chronic untreated STIs/PID or could be related to history of adverse pregnancy outcome, both of which, calls for the urgency of implementing STIs screening program and appropriate antenatal and post-natal care consequently.
In this study, hypothyroidism and hyperprolactinemia were found to be predictors for female infertility. This was also seen in a study by Hymavathi k et al. (2016), India to investigate the correlation of thyroid and prolactin hormones levels with female infertility. The study found that 27% of women with primary infertility were hypothyroid and 7% were hyperthyroid. Among those with secondary infertility the corresponding figures were 5 and 2% respectively. Additionally, hyperprolactinemia was detected in 37% of infertile cases, more commonly among primary infertile women (79.4%) as compared to 20.6% secondary infertile [38]. Thyroid dysfunction have been found to be associated with anovulatory cycles, decreased fecundity, and increased morbidity during pregnancy. Hyperprolactinemia also adversely affects the fertility potential by disturbing pulsatile secretion of GnRH and hence interfering with ovulation. It may result in menstrual and ovulatory dysfunctions like anovulation, amenorrhea and galactorrhoea. In addition, history of appendectomy was found to be an independent risk factor for female infertility, in present study. On contrary, a meta-analysis by Elraiyah T et al. (2014) showed that previous appendectomy is not significantly associated with increased incidence of infertility in women, (OR = 1.03) [39]. Complicated, ruptured appendicitis has been implicated in causing scarring, which can lead to infertility and/or ectopic pregnancy.
Awareness and loyalty to fertility window were found in the current study to be protective against infertility. A cross-sectional study of fertility-awareness among women seeking fertility assistance in Australia by Hampton KD et al. (2013) found that 68.2% believed they had timed intercourse mainly within the fertile, but only 12.7% could accurately identify this window. Most infertile women were graded by the study as having either no fertility-awareness (11.8%) or poor fertility-awareness (52.5%) [40]. Additionally, another study by Blake D et al. (1997), has investigated the fertility-awareness of infertile women seeking fertility assistance, they found that 74% of participants could not accurately identify the fertile window [41]. There is a compelling need to educate women about their fertility awareness. Primary care providers need to integrate fertility health literacy into health promotion of women of reproductive age.
Secondary infertility risk factor
The current study revealed that history of recurrent miscarriages/stillbirth was as twice as common among female with secondary infertility. History of post-partum / post-abortal infection and caesarean section were also found to be significant predictors of secondary infertility in this study. In agreement, Dhont N et al. (2009) in their study conducted in Rwanda, found that secondary infertile women were two times more likely to have history of an adverse pregnancy outcome (miscarriage / ectopic pregnancy, (aOR =1.89), history of stillbirth (aOR = 7.52), history of postpartum infection (aOR = 11.49) or history of caesarean section (aOR = 11.49) compared to their controls [42]. The decision for caesarean intervention should not be taken lightly and should be clinically justified.
Study strengths
This is the first study in Qatar to explore the risk factors of female infertility among Qatari women. Controls were selected from the same population where cases came from, and screening for male factors was done using semen analysis, both of which would minimize selection bias. Since this is unmatched case-control study, multiple logistic regression was applied to overcome the effect of confounders. A ratio of 2:1 (controls to cases) was utilized to increase the statistical power of the study.
The findings of this study should be considered with the following limitations. First, this is a hospital-based study and findings may not be representative for the general population. Furthermore, controls were selected by probability systematic random sampling technique, while cases were selected via convenient non-probability technique. As a result, the study can be subjected to selection bias which affect the generalizability and the statistical significance of the results. Due to the retrospective nature of case-control studies, recall bias could increase the likelihood that infertile women recall and report exposures compared to their controls, pregnant women. Moreover, temporal relationships between studied risk factors and female infertility cannot be ascertained.
Infertility is a multifactorial complex disease that remains a significant burden for the individuals, families and communities. Several modifiable risk factors were found to be predictors of female infertility among Qatari females that maybe be considered for planning of better reproductive health care. Older age and delayed age at first marriage beyond 30 years were found to be independent risk factors for infertility. Lifestyle pattern including smoking whether water pipe of second hand, obesity, as well as symptoms suggestive of STIs can contribute significantly to infertile status. Furthermore, menstrual cycle abnormalities, PCOS, tubal blockage, fibroid, hyperthyroidism, hyperprolactinemia, appendectomy, post-partum infection, caesarean section, recurrent miscarriage, stillbirth, were all found to be risk factors of female infertility. Conversely, higher education/income and fertility window awareness were found to be protective against infertility. Therefore, primary prevention as well as screening and early management using cost-effective interventions targeting mainly modifiable risk factors are essential components of reproductive health care planning. Moreover, delivering integrated care through utilization of premarital, well women, antenatal, postnatal, and family planning clinics to raise awareness and screen for related risk factors.
The data that support the findings of this study are available from Hamad Medical Corporation (HMC) but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of Medical Research Center-HMC.
HMC:
PHCC:
Primary Health Care Corporation
PHQ-2:
Patient health questionnaire
STIs:
Assisted Reproductive Technology
LBW:
Low birth weigh
MENA:
PCOS:
LH:
FSH:
Follicular-stimulating hormone
UN:
PVD:
NSAIDs:
Nonsteroidal anti-inflammatory drugs
IBM-SPSS:
Statistical Package of Social Science
Egers-Hochschild F, Adamson GD, de Mouzon J, Ishihara O, Mansour R, Nygren K, et al. International committee for monitoring assisted reproductive technology (ICMART) and the World Health Organization (WHO) revised glossary of assisted reproductive technology (ART) terminology, 2009. Fertil Steril. 2009;92:1520–4.
Mascarenhas MN, Flaxman SR, Boerma T, Vanderpoel S, Stevens GA. National, regional, and global trends in infertility prevalence since 1990: a systematic analysis of 277 health surveys. PLoS Med. 2012;12(9):1–12.
World Health Organization. Gender and genetics: assisted reproductive technologies (ARTs). Geneva: World Health Organization; 2003. Available from: http://www.who.int/genomics/gender/en/index6.html.
World Health Organization. Infertility: a tabulation of available data on prevalence of primary and secondary infertility. In: Programme on maternal and child health and family planning, division of family health. Geneva: WHO; 1991. Available from: http://apps.who.int/iris/bitstream/10665/59769/1/WHO_MCH_91.9.pdf.
Peterson BD, Gold L, Feingold T. The experience and influence of infertility: considerations for couple counselors. Fam J. 2007;15(3):251–7.
Mallikarjuna M, Rajeshwari B. Selected risk factors of infertility in women: case control study. Int J Reprod Contracept Obstet Gynecol. 2015;4(6):1714–9.
Ombelet W, Cooke I, Dyer S, Serour G, Devroey P. Infertility and the provision of infertility medical services in developing countries. Hum Reprod Update. 2008;14(6):605–62.
Ombelet W, Devroey P, Gianardi L, te Velde E. Developing countries and infertility. Spec Issue Hum Reprod. 2008b:1–117.
Nachtigall RD. International disparities in access to infertility services. Fertil Steril. 2006;85(4):871–5.
Inhorn M, Patrizio P. Infertility around the globe: new thinking on gender, reproductive technologies and global movements in the 21st century. Hum Reprod Update. 2015;21(4):411–26.
Centers for Disease Control and Prevention. National Public Health Action Plan for the detection, prevention, and Management of Infertility. Atlanta: Centers for Disease Control and Prevention; 2014. p. 23.
Cooke L, Nelson SM. Reproductive ageing and fertility in an ageing population. Obstetrician Gynaecol. 2011;13:161–16.
Osman AA. Aetiology of female infertility in Gezira (central of Sudan). J Appl Sci. 2010;10(19):2333–7.
Zorrilla M, Yatsenko AN. The genetics of infertility: current status of the field. Curr Genet Med Rep. 2013;1(4).
Romero R, Romero G, Abortes I, Medina HG. Risk factors associated to female infertility. Ginecol Obstet Mex. 2008;76(12):717–21.
Saoji AV. Primary infertility problems among female have been a source of concern in India lately. Innovative J Med Health Sci. 2014;4(1):332–40.
Jejeebhoy SJ. Infertility in India - levels, patterns and consequences: priorities for social science research. J Fam Welf. 1998 June;44(2):15–24.
Melo AS, Ferriani RA, Navarro PA. Treatment of infertility in women with polycystic ovary syndrome: approach to clinical practice. Clinics (Sao Paulo). 2015;70(11):765–9.
United Nations. World population prospects: the 2012 revision. New York: Population Division, Dept. of Economic and Social Affairs. United Nation; 2013. Available from: https://esa.un.org/unpd/wpp/publications/Files/WPP2012_HIGHLIGHTS.pdf.
Charan J, Biswas T. How to calculate sample size for different study designs in medical research. Indian J Pschol Med. 2013;45(2):121–6.
Al-Thani A, Abdul-Rahim H, Alabsi E, Nsaisu H, Haddad P, Mumtaz G, et al. Prevalence of chlamydia trachomatis infection in the general population of women in Qatar. Sex Transm Infect. 2013;89(3):57–60.
Sharif E, Rahman S, Zia Y, Rizk NM. The frequency of polycystic ovary syndrome in young reproductive females in Qatar. In J Womens Health. 2016;9:1–9.
Haj Bakri A, Al-Thani A. Qatar STEPwise report 2012: chronic disease risk factor surveillance. Doha: Supreme Council of Health; 2013. p. 124.
Omu FE, Omu AE. Emotional reaction to diagnosis of infertility in Kuwait and successful clients' perception of nurses' role during treatment. BMC Nurs. 2010;9(5):1–10.
Kalima-Munalula MN, Ahmed Y, Vwalika B. Factors associated with infertility among women attending the Gynaecology Clinic at University Teaching Hospital, Lusaka, Zambia. Med J Zambia. 2017;44(1):41–4.
ESHRE Capri Workshop Group (2005). Fertility and aging. Hum Reprod Update. 2005;11(3):261–76.
Hyland A, Piazza K, Hovey KM, Tindle HA, Manson AE, Messina C, et al. Associations between lifetime tobacco exposure with infertility and age at natural menopause: the Women's health initiative observational study. Tob Control. 2016;25:706–14.
MAÏ HA, Demmouche A. A case-control study of body mass index and infertility in Algerian women (Sidi Bel Abbes, west of Algeria). Int J Infertility Fetal Med. 2015;6(3):103–7.
Rafique M, Nuzhat A. Role of obesity in female infertility and assisted reproductive technology (ART) outcomes. Saudi J Obes. 2016;4(2):75–9.
Shamila S, Sasikala SL. Primary report on the risk factors affecting female infertility in south Indian districts of Tamil Nadu and Kerala. Indian J Community Med. 2011;36(1):59–61.
Ansari H, Azarkish F, Rigi SN, Rouhandeh R, Mohammadi Y. Menstrual-reproductive and socio-demographic factors of secondary infertile and fertile women in Zahedan: a case-control study in southeastern Iran. Pharm Lett. 2016;8(1):348–53.
Kwon SK, Chae HD, Lee KH, Kim SH, Kim CH, Kang BM. Causes of amenorrhea in Korea: experience of a single large center. Clin Exp Reprod Med. 2014;41(1):29–32.
March WA, Moore VM, Willson KJ, Phillips DI, Norman RJ, Davies MJ. The prevalence of polycystic ovary syndrome in a community sample assessed under contrasting diagnostic criteria. Hum Reprod. 2010;25(2):544–51.
Susan M, Kristen A. Pate. Epidemiology, diagnosis, and management of polycystic ovary syndrome. Clin Epidemiol. 2014;6:1–13.
Panchuk K, Lynam MJ. Polycystic ovary syndrome: appreciating the complexities and implications of diagnosis for primary care. UBCMJ. 2012;4(1):10–5.
Moridi A, Roozbeh H, Yaghoobi H, Soltani S, et al. Etiology and risk factors associated with infertility. Int J Women's Health Reprod Sci. 2019 July;7(3):346–53.
Ogbu GI, Anzaku SA, Aimakhu C. Burden of chlamydia trachomatis infection amongst infertile women compared with pregnant controls in north-Central Nigeria. Int J Res Med Sci. 2017;5(9):3819–26.
Hymavathi K, Tadisetti S, Pusarla D, Pambadi P. Correlation of serum thyroid hormones and prolactin levels to female infertility. Int J Reprod Contraception Obstet Gynaecol. 2016 Nov;5(11):4018–24.
Elraiyah T, Hashim Y, Elamin M, Erwin PJ, Zarroug AE. The effect of appendectomy in future tubal infertility and ectopic pregnancy: a systematic review and meta-analysis. J Surg Res. 2014;192(2):368–74.
Hampton KD, Mazza D, Newton JM. Fertility-awareness knowledge, attitudes and practices of women seeking fertility assistance. J Adv Nurs. 2013;69(5):1076–84.
Blake D, Smith D, Bargiacchi A, France M, Gudex G. Fertility awareness in women attending a fertility clinic. Aust New Zealand J Obstetrics Gynaecol. 1997;37(3):350–2.
Dhont N, Luchters S, Muvunyi C, Vyankandondera J. The risk factor profile of women with secondary infertility: an unmatched case-control study in Kigali, Rwanda. BMC Womens Health. 2011;11(32):1–7.
I would like to convey thanks to all participants of this study, who sacrificed their precious limited time and valuable information. I would like to express my appreciative and honest thanks to my academic supervisor Dr. Sherif Omar Osman for his sincere help and for the offered precious time, assistance, support and guidance. I would like also to thank my co-supervisors Dr. Noora Al Kubaisi and Dr. Hessa Shahbic for their assistance and guidance. Their comments, advices, and efforts were invaluable. I would like also to express my warm appreciation for Dr. Rajvir Singh, the Senior Consultant of Biostatistics in Hamad Medical Corporation for his sincere assistance, professional guidance, truthful encouragement and continuous support. My thanks are extended to Dr. Noora Al Malki, for her dedicated genuine help, and for the time she devoted to timely and perfectly accomplish the data collection part of this work.
Consent to participate
Informed consent, following the HMC-IRB standard template, was obtained from all participants. Patients were explained that participation is anonymous and results will be collectively presented and disseminated as educational materials and/or publication.
The author disclosed receipt of the following financial support for the research, and publication.
A. Personal cost: data collector.
B. Supplies & Equipment: Laptop
C. Conference
D. Publication fees
Department of Family & Community Medicine, Hamad Medical Corporation, Doha, Qatar
Sarah Musa
Department of Tropical Health, High Institute of Public Health, Alexandria University, Alexandria, Egypt
Sherif Osman
Department of Family & Community Medicine, Primary Health Care Corporation, Doha, Qatar
SM (principle investigator). Conceptualization, designing, coordination of this study. Developed the theoretical framework of the study. Developed and validated the data collection tool. Performed data collection and entry. Conducted data analysis. Took the lead in writing the manuscript with input from co-author. Wrote the results and designed tables and figures with the assistance of co-author. SO (Co Author) Assist in designing and conceptualization of the study. Contributed to development of data collection tool. Assist in data analysis and interpretation of the results. Assist in drafting and critical revision of the article. Contributed to the final version of the manuscript. In charge of overall direction and planning. All authors read and approved the final manuscript.
Authors' information
Dr. Sarah Rashid Musa
Community medicine specialist/ Health Center Wellness In-Charge, Primary Health Care Corporation (PHCC), Doha-Qatar
Bachelor of Medicine (MB), Bachelor of Surgery (BCh), Bachelor of Obstetrics (BAO), Royal College of surgeons in Ireland, 2011.
Arab Board of Health specialization of community medicine (Part I & II)
Correspondence to Sherif Osman.
Approvals were obtained from Research Ethics Committee of Women Hospital, Medical Research Centre and IRB-HMC.
Director of obstetrics and gynaecology department was informed and permission was obtained.
Participation was voluntarily and clients were instructed that they could withdraw at any time without any adverse consequences.
Confidentiality and privacy have been assured throughout the study.
Participants scored positive in PHQ-2 were advised for further assessment and referral.
The following approvals were obtained:
A. Women's Hospital- HMC.
B. Medical Research Center- HMC.
C. Institutional Review Board (IRB)- HMC
The author declare that they have no competing interests.
Musa, S., Osman, S. Risk profile of Qatari women treated for infertility in a tertiary hospital: a case-control study. Fertil Res and Pract 6, 12 (2020). https://doi.org/10.1186/s40738-020-00080-5
Sexual transmitted disease
Submission enquiries: [email protected] | CommonCrawl |
Only show content I have access to (58)
Only show open access (10)
Chapters (6)
Last 12 months (12)
Last 3 years (40)
Over 3 years (211)
Materials Research (124)
Earth and Environmental Sciences (16)
MRS Online Proceedings Library Archive (114)
Epidemiology & Infection (18)
Psychological Medicine (11)
The Journal of Agricultural Science (11)
Journal of Materials Research (8)
Proceedings of the International Astronomical Union (7)
Microscopy and Microanalysis (6)
High Power Laser Science and Engineering (4)
Journal of Developmental Origins of Health and Disease (4)
The European Physical Journal - Applied Physics (4)
British Journal of Nutrition (3)
European Journal of Anaesthesiology (3)
Journal of Fluid Mechanics (3)
Journal of Helminthology (3)
Journal of Mechanics (3)
Journal of Plasma Physics (3)
Bulletin of Entomological Research (2)
International Journal of Astrobiology (2)
Powder Diffraction (2)
Cambridge University Press (6)
Materials Research Society (122)
BSAS (9)
International Astronomical Union (9)
Brazilian Society for Microscopy and Microanalysis (SBMM) (6)
Nestle Foundation - enLINK (4)
Nutrition Society (4)
International Glaciological Society (3)
Testing Membership Number Upload (3)
Mineralogical Society (2)
Ryan Test (2)
Canadian Neurological Sciences Federation (1)
European Microwave Association (1)
International Psychogeriatric Association (1)
Neuroscience Education Institute (1)
Royal Aeronautical Society (1)
Society for Healthcare Epidemiology of America (SHEA) (1)
test society (1)
Cambridge Handbooks in Psychology (2)
International Hydrology Series (1)
Cambridge Handbooks (2)
Cambridge Handbooks of Psychology (2)
Gridded and direct Epoch of Reionisation bispectrum estimates using the Murchison Widefield Array
Cathryn M. Trott, Catherine A. Watkinson, Christopher H. Jordan, Shintaro Yoshiura, Suman Majumdar, N. Barry, R. Byrne, B. J. Hazelton, K. Hasegawa, R. Joseph, T. Kaneuji, K. Kubota, W. Li, J. Line, C. Lynch, B. McKinley, D. A. Mitchell, M. F. Morales, S. Murray, B. Pindor, J. C. Pober, M. Rahimi, J. Riding, K. Takahashi, S. J. Tingay, R. B. Wayth, R. L. Webster, M. Wilensky, J. S. B. Wyithe, Q. Zheng, David Emrich, A. P. Beardsley, T. Booler, B. Crosse, T. M. O. Franzen, L. Horsley, M. Johnston-Hollitt, D. L. Kaplan, D. Kenney, D. Pallot, G. Sleap, K. Steele, M. Walker, A. Williams, C. Wu
Published online by Cambridge University Press: 18 July 2019, e023
We apply two methods to estimate the 21-cm bispectrum from data taken within the Epoch of Reionisation (EoR) project of the Murchison Widefield Array (MWA). Using data acquired with the Phase II compact array allows a direct bispectrum estimate to be undertaken on the multiple redundantly spaced triangles of antenna tiles, as well as an estimate based on data gridded to the uv-plane. The direct and gridded bispectrum estimators are applied to 21 h of high-band (167–197 MHz; z = 6.2–7.5) data from the 2016 and 2017 observing seasons. Analytic predictions for the bispectrum bias and variance for point-source foregrounds are derived. We compare the output of these approaches, the foreground contribution to the signal, and future prospects for measuring the bispectra with redundant and non-redundant arrays. We find that some triangle configurations yield bispectrum estimates that are consistent with the expected noise level after 10 h, while equilateral configurations are strongly foreground-dominated. Careful choice of triangle configurations may be made to reduce foreground bias that hinders power spectrum estimators, and the 21-cm bispectrum may be accessible in less time than the 21-cm power spectrum for some wave modes, with detections in hundreds of hours.
Substituting brown rice for white rice on diabetes risk factors in India: a randomised controlled trial
V. S. Malik, V. Sudha, N. M. Wedick, M. RamyaBai, P. Vijayalakshmi, N. Lakshmipriya, R. Gayathri, A. Kokila, C. Jones, B. Hong, R. Li, K. Krishnaswamy, R. M. Anjana, D. Spiegelman, W. C. Willett, F. B. Hu, V. Mohan
Journal: British Journal of Nutrition , First View
Published online by Cambridge University Press: 22 April 2019, pp. 1-9
India has the second largest number of people with type 2 diabetes (T2D) globally. Epidemiological evidence indicates that consumption of white rice is positively associated with T2D risk, while intake of brown rice is inversely associated. Thus, we explored the effect of substituting brown rice for white rice on T2D risk factors among adults in urban South India. A total of 166 overweight (BMI ≥ 23 kg/m2) adults aged 25–65 years were enrolled in a randomised cross-over trial in Chennai, India. Interventions were a parboiled brown rice or white rice regimen providing two ad libitum meals/d, 6 d/week for 3 months with a 2-week washout period. Primary outcomes were blood glucose, insulin, glycosylated Hb (HbA1c), insulin resistance (homeostasis model assessment of insulin resistance) and lipids. High-sensitivity C-reactive protein (hs-CRP) was a secondary outcome. We did not observe significant between-group differences for primary outcomes among all participants. However, a significant reduction in HbA1c was observed in the brown rice group among participants with the metabolic syndrome (−0·18 (se 0·08) %) relative to those without the metabolic syndrome (0·05 (se 0·05) %) (P-for-heterogeneity = 0·02). Improvements in HbA1c, total and LDL-cholesterol were observed in the brown rice group among participants with a BMI ≥ 25 kg/m2 compared with those with a BMI < 25 kg/m2 (P-for-heterogeneity < 0·05). We observed a smaller increase in hs-CRP in the brown (0·03 (sd 2·12) mg/l) compared with white rice group (0·63 (sd 2·35) mg/l) (P = 0·04). In conclusion, substituting brown rice for white rice showed a potential benefit on HbA1c among participants with the metabolic syndrome and an elevated BMI. A small benefit on inflammation was also observed.
Neutron Diffraction Study of the Pseudo-Macro Residual Stresses in ZrO2(CeO2)/Al2O3 Ceramic Composites
Xun-Li Wang, C. R. Hubbard, K. B. Alexander, P. F. Becher, J. A. Fernandez-Baca, S. Spooner
Journal: Advances in X-ray Analysis / Volume 36 / 1992
Published online by Cambridge University Press: 06 March 2019, pp. 499-504
Print publication: 1992
Neutron powder diffraction techniques have been used to characterize the pseudo-macro (PM) residual stresses in ZrO2(CeO2)/Al2O3 ceramic composites as a function of ZrO2(CeO2) volume fraction and fabrication procedures. The diffraction data were analyzed using the Rietveld structure refinement technique. From the refinement, we found that the CeO2 stabilized tetragonal ZrO2 particles were in tension and the Al2O3 matrix was in compression. Different sintering time had little impact on the PM stresses. On the other hand, the magnitude of the PM stresses in both ZrO2 and Al2O3 decreased linearly with the increase of their volume fractions.
49 Combinatorial Pharmacogenomics to Guide Treatment Selection for Major Depressive Disorder: A Large, Blinded, Randomized Controlled Trial
John F. Greden, Anthony J. Rosthschild, Michael Thase, Boadie W. Dunlop, DMH Charles DeBattista, Charles R. Conway, Brent P. Forester, Francis M. Mondimore, Richard C. Shelton, James Li, Alexa Gilbert, Lindsey Burns, Michael Jablonski, Bryan Dechairo, Sagar Parikh
Journal: CNS Spectrums / Volume 24 / Issue 1 / February 2019
Print publication: February 2019
Major depressive disorder (MDD) is a leading cause of disease burden worldwide, with lifetime prevalence in the United States of 17%. Here we present the results of the first prospective, large-scale, patient- and rater-blind, randomized controlled trial evaluating the clinical importance of achieving congruence between combinatorial pharmacogenomic (PGx) testing and medication selection for MDD.
1,167 outpatients diagnosed with MDD and an inadequate response to ≥1 psychotropic medications were enrolled and randomized 1:1 to a Treatment as Usual (TAU) arm or PGx-guided care arm. Combinatorial PGx testing categorized medications in three groups based on the level of gene-drug interactions: use as directed, use with caution, or use with increased caution and more frequent monitoring. Patient assessments were performed at weeks 0 (baseline), 4, 8, 12 and 24. Patients, site raters, and central raters were blinded in both arms until after week 8. In the guided-care arm, physicians had access to the combinatorial PGx test result to guide medication selection. Primary outcomes utilized the Hamilton Depression Rating Scale (HAM-D17) and included symptom improvement (percent change in HAM-D17 from baseline), response (50% decrease in HAM-D17 from baseline), and remission (HAM-D17<7) at the fully blinded week 8 time point. The durability of patient outcomes was assessed at week 24. Medications were considered congruent with PGx test results if they were in the 'use as directed' or 'use with caution' report categories while medications in the 'use with increased caution and more frequent monitoring' were considered incongruent. Patients who started on incongruent medications were analyzed separately according to whether they changed to congruent medications by week8.
At week 8, symptom improvement for individuals in the guided-care arm was not significantly different than TAU (27.2% versus 24.4%, p=0.11). However, individuals in the guided-care arm were more likely than those in TAU to achieve remission (15% versus 10%; p<0.01) and response (26% versus 20%; p=0.01). Remission rates, response rates, and symptom reductions continued to improve in the guided-treatment arm until the 24week time point. Congruent prescribing increased to 91% in the guided-care arm by week 8. Among patients who were taking one or more incongruent medication at baseline, those who changed to congruent medications by week 8 demonstrated significantly greater symptom improvement (p<0.01), response (p=0.04), and remission rates (p<0.01) compared to those who persisted on incongruent medications.
Combinatorial PGx testing improves short- and long-term response and remission rates for MDD compared to standard of care. In addition, prescribing congruency with PGx-guided medication recommendations is important for achieving symptom improvement, response, and remission for MDD patients.
Funding Acknowledgements: This study was supported by Assurex Health, Inc.
Transgenerational effects of maternal bisphenol A exposure on offspring metabolic health – Erratum
A. Bansal, C. Li, F. Xin, A. Duemler, W. Li, C. Rashid, M. S. Bartolomei, R. A. Simmons
Journal: Journal of Developmental Origins of Health and Disease / Volume 10 / Issue 1 / February 2019
Published online by Cambridge University Press: 15 January 2019, p. 138
Consistent improvements in soil biochemical properties and crop yields by organic fertilization for above-ground (rapeseed) and below-ground (sweet potato) crops
X. P. Li, C. L. Liu, H. Zhao, F. Gao, G. N. Ji, F. Hu, H. X. Li
Journal: The Journal of Agricultural Science / Volume 156 / Issue 10 / December 2018
Published online by Cambridge University Press: 19 March 2019, pp. 1186-1195
Print publication: December 2018
Although application of organic fertilizers has become a recommended way for developing sustainable agriculture, it is still unclear whether above-ground and below-ground crops have similar responses to chemical fertilizers (CF) and organic manure (OM) under the same farming conditions. The current study investigated soil quality and crop yield response to fertilization of a double-cropping system with rapeseed (above-ground) and sweet potato (below-ground) in an infertile red soil for 2 years (2014–16). Three fertilizer treatments were compared, including CF, OM and organic manure plus chemical fertilizer (MCF). Organic fertilizers (OM and MCF) increased the yield of both above- and below-ground crops and improved soil biochemical properties significantly. The current study also found that soil-chemical properties were the most important and direct factors in increasing crop yields. Also, crop yield was affected indirectly by soil-biological properties, because no significant effects of soil-biological activities on yield were detected after controlling the positive effects of soil-chemical properties. Since organic fertilizers could not only increase crop yield, but also improve soil nutrients and microbial activities efficiently and continuously, OM application is a reliable agricultural practice for both above- and below-ground crops in the red soils of China.
Transgenerational effects of maternal bisphenol: a exposure on offspring metabolic health
Journal: Journal of Developmental Origins of Health and Disease / Volume 10 / Issue 2 / April 2019
Published online by Cambridge University Press: 26 October 2018, pp. 164-175
Print publication: April 2019
Exposure to the endocrine disruptor bisphenol A (BPA) is ubiquitous and associated with health abnormalities that persist in subsequent generations. However, transgenerational effects of BPA on metabolic health are not widely studied. In a maternal C57BL/6J mice (F0) exposure model using BPA doses that are relevant to human exposure levels (10 μg/kg/day, LowerB; 10 mg/kg/day, UpperB), we showed male- and dose-specific effects on pancreatic islets of the first (F1) and second generation (F2) offspring relative to controls (7% corn oil diet; control). In this study, we determined the transgenerational effects (F3) of BPA on metabolic health and pancreatic islets in our model. Adult F3 LowerB and UpperB male offspring had increased body weight relative to Controls, however glucose tolerance was similar in the three groups. F3 LowerB, but not UpperB, males had reduced β-cell mass and smaller islets which was associated with increased glucose-stimulated insulin secretion. Similar to F1 and F2 BPA male offspring, staining for markers of T-cells and macrophages (CD3 and F4/80) was increased in pancreas of F3 LowerB and UpperB male offspring, which was associated with changes in cytokine levels. In contrast to F3 BPA males, LowerB and UpperB female offspring had comparable body weight, glucose tolerance and insulin secretion as Controls. Thus, maternal BPA exposure resulted in fewer metabolic defects in F3 than F1 and F2 offspring, and these were sex- and dose-specific.
Discovery of Se-rich canfieldite, Ag8Sn(S,Se)6, from the Shuangjianzishan Ag–Pb–Zn deposit, NE China: A multimethodic chemical and structural study
Degao Zhai, Luca Bindi, Panagiotis C. Voudouris, Jiajun Liu, Stylianos F. Tombros, Kuan Li
Journal: Mineralogical Magazine / Volume 83 / Issue 3 / June 2019
Print publication: June 2019
During a study of the ore minerals belonging to the recently discovered Shuangjianzishan Ag–Pb–Zn deposit in NE China, we have discovered exceptional selenium enrichment in canfieldite (up to 11.6 wt.% of Se). Incorporation of Se into canfieldite has been investigated by an integrated approach using field emission scanning electron microscopy, electron microprobe and single-crystal X-ray diffraction. Canfieldite has been identified as one of the dominant Ag-bearing ore minerals in the studied deposit, which occurs mostly in slate-hosted vein type Ag–Pb–Zn ore bodies. Selenium is either homogeneously or, remarkably, heterogeneously distributed in the different canfieldite fragments studied. Chemical variations of Se are mostly attributable to a series of retrograde reactions resulting in diverse decomposition and exsolution of primary phases during cooling, or alternatively, related to influxes of Se-rich fluids during the formation of canfieldite. To evaluate the effects of the Se-for-S substitution in the structure, a crystal of Se-rich canfieldite [Ag7.98Sn1.02(S4.19Se1.81)Σ6.00] was investigated. The unit-cell parameters are: a = 10.8145(8) Å and V = 1264.8(3) Å3. The structure was refined in the space group F $\bar{4}$ 3m to R1 = 0.0315 for 194 independent reflections, with 20 parameters. The crystal structure of Se-rich canfieldite was found to be topologically identical to that of pure canfieldite. If the short Ag–Ag contacts are ignored (due to the disorder), the two Ag atoms in the structure can be considered as three-fold (Ag1) and four-fold (Ag2) coordinated. Tin adopts a regular tetrahedral coordination. As in the case of Te-rich canfieldite, the refinement of the site-occupancy factor indicates that Se is disordered over the three anion positions.
Clutter removal for measuring low-frequency narrow-band antenna using spectral estimation
C. F. Hu, N. J. Li
Journal: International Journal of Microwave and Wireless Technologies / Volume 11 / Issue 3 / April 2019
Published online by Cambridge University Press: 13 September 2018, pp. 215-219
The measurement accuracy of low-frequency narrow-band antenna is heavily influenced by its environment, which is also difficult to remove the clutter with a time gating. This paper proposes a method to improve the measurement accuracy of low-frequency narrow-band antenna using signal processing technique. The method is to predict the unknown value out of received original signal with an auto-regressive model (AR model) based on modern spectral estimation theory, and the parameters in AR model are calculated by maximum entropy spectral estimation algorithm. Thus, a wideband signal compared with the original band is obtained, and then the time-domain resolution is enhanced. The time gating is more exactly to separate the antenna radiation signal from multipath signals. The simulation and experimental results show that about 50% extended data for each ends of original band can be obtained after spectral extrapolation, and the time-domain resolution after extrapolation is twice than the original narrow-band signal, and the influence of measurement environment can be eliminated effectively. The method can be used to improve accuracy in actual antenna measurement.
Effect of stocking rate on grazing behaviour and diet selection of goats on cultivated pasture
L. Q. Wan, K. S. Liu, W. Wu, J. S. Li, T. C. Zhao, X. Q. Shao, F. He, H. Lv, X. L. Li
Journal: The Journal of Agricultural Science / Volume 156 / Issue 7 / September 2018
Cultivated pastures in southern China are being used to improve forage productivity and animal performance, but studies on grazing behaviour of goats in these cultivated pastures are still rare. In the current study, the grazing behaviour of Yunling black goats under low (5 goats/ha) and high (15 goats/ha) stocking rates (SRs) was evaluated. Data showed that the proportion of time goats spent on activities was: eating (0.59–0.87), ruminating (0.05–0.35), walking (0.03–0.06) and resting (0.01–0.03). Compared with low SR, goats spent more time eating and walking, and less time ruminating and resting under high SR. Goats had similar diet preferences under both SR and preferred to eat grasses (ryegrass and cocksfoot) more than a legume (white clover). The distribution of eating time on each forage species was more uniform under high v. low SR. Bites/step, bite weight and daily intake were greater under low than high SR. Results suggest that the SR affects grazing behaviour of goats on cultivated pasture, and identifying an optimal SR is critical for increasing bite weight and intake.
The Maia Detector Journey: Development, Capabilities and Applications
C G Ryan, D P Siddons, R Kirkham, A J Kuczewski, P A Dunn, G De Geronimo, A. Dragone, Z Y Li, G F Moorhead, M Jensen, D J Paterson, M D de Jonge, D L Howard, R Dodanwela, G A Carini, R Beuttenmuller, D Pinelli, L Fisher, R M Hough, A Pagès, S A James, P Davey
Journal: Microscopy and Microanalysis / Volume 24 / Issue S1 / August 2018
Published online by Cambridge University Press: 01 August 2018, pp. 720-721
Print publication: August 2018
Experimental platform for the investigation of magnetized-reverse-shock dynamics in the context of POLAR
HPL Laboratory Astrophysics
B. Albertazzi, E. Falize, A. Pelka, F. Brack, F. Kroll, R. Yurchak, E. Brambrink, P. Mabey, N. Ozaki, S. Pikuz, L. Van Box Som, J. M. Bonnet-Bidaud, J. E. Cross, E. Filippov, G. Gregori, R. Kodama, M. Mouchet, T. Morita, Y. Sakawa, R. P. Drake, C. C. Kuranz, M. J.-E. Manuel, C. Li, P. Tzeferacos, D. Lamb, U. Schramm, M. Koenig
Journal: High Power Laser Science and Engineering / Volume 6 / 2018
Published online by Cambridge University Press: 16 July 2018, e43
The influence of a strong external magnetic field on the collimation of a high Mach number plasma flow and its collision with a solid obstacle is investigated experimentally and numerically. The laser irradiation ( $I\sim 2\times 10^{14}~\text{W}\cdot \text{cm}^{-2}$ ) of a multilayer target generates a shock wave that produces a rear side plasma expanding flow. Immersed in a homogeneous 10 T external magnetic field, this plasma flow propagates in vacuum and impacts an obstacle located a few mm from the main target. A reverse shock is then formed with typical velocities of the order of 15–20 $\pm$ 5 km/s. The experimental results are compared with 2D radiative magnetohydrodynamic simulations using the FLASH code. This platform allows investigating the dynamics of reverse shock, mimicking the processes occurring in a cataclysmic variable of polar type.
P.054 Clinical characteristics and outcomes of patients treated for acromegaly at The Ottawa Hospital
F Alkherayf, T Li, J Malcolm, A Arnaout, H Lochnan, E Keely, C Agbi, M Doyle
Journal: Canadian Journal of Neurological Sciences / Volume 45 / Issue s2 / June 2018
Published online by Cambridge University Press: 27 June 2018, p. S30
Background: Acromegaly is associated with significant morbidity. The purpose of this study was to establish characteristics and outcomes of patients treated for acromegaly at The Ottawa Hospital, to compare our results with published reports from other centers and to identify opportunities to improve patient care. Methods: A retrospective chart review of patients surgically and medically treated for acromegaly between January 1, 2007 and December 31, 2016 was completed. Demographic information, biochemical data, presenting features, disease comorbidities, treatment interventions, and were collected. Results: Fifty-one patients were identified using CCI/ICD-10 codes and IGF-1 levels. Similar to other centers, the majority of patients had a macroadenoma (78.4% vs 11.8%) with a high percentage invading the cavernous sinus (57.5%). While surgical intervention was performed in 90% of patients, only 23.3% of patient achieved surgical cure (IGF-1 normalization within reference range). Approximately 30% of patients were controlled with adjuvant medical therapy while more than 40 % had elevated IGF-1 levels at last follow-up. Radiotherapy was less commonly used. Conclusions: Despite a multi-modal treatment approach for acromegaly, outcomes are variable. This study highlights the need for further research to better understand factors associated with surgical cure, response to medical therapy and the role of radiotherapy.
EMP control and characterization on high-power laser systems
P. Bradford, N. C. Woolsey, G. G. Scott, G. Liao, H. Liu, Y. Zhang, B. Zhu, C. Armstrong, S. Astbury, C. Brenner, P. Brummitt, F. Consoli, I. East, R. Gray, D. Haddock, P. Huggard, P. J. R. Jones, E. Montgomery, I. Musgrave, P. Oliveira, D. R. Rusby, C. Spindloe, B. Summers, E. Zemaityte, Z. Zhang, Y. Li, P. McKenna, D. Neely
Published online by Cambridge University Press: 21 May 2018, e21
Giant electromagnetic pulses (EMP) generated during the interaction of high-power lasers with solid targets can seriously degrade electrical measurements and equipment. EMP emission is caused by the acceleration of hot electrons inside the target, which produce radiation across a wide band from DC to terahertz frequencies. Improved understanding and control of EMP is vital as we enter a new era of high repetition rate, high intensity lasers (e.g. the Extreme Light Infrastructure). We present recent data from the VULCAN laser facility that demonstrates how EMP can be readily and effectively reduced. Characterization of the EMP was achieved using B-dot and D-dot probes that took measurements for a range of different target and laser parameters. We demonstrate that target stalk geometry, material composition, geodesic path length and foil surface area can all play a significant role in the reduction of EMP. A combination of electromagnetic wave and 3D particle-in-cell simulations is used to inform our conclusions about the effects of stalk geometry on EMP, providing an opportunity for comparison with existing charge separation models.
HIV and viral hepatitis coinfection analysis using surveillance data from 15 US states and two cities
K. A. Bosh, J. R. Coyle, V. Hansen, E. M. Kim, S. Speers, M. Comer, L. M. Maddox, S. Khuwaja, W. Zhou, A. Jatta, R. Mayer, A. D. Brantley, N. W. Muriithi, R. Bhattacharjee, C. Flynn, L. Bouton, B. John, J. Keusch, C. A. Barber, K. Sweet, C. Ramaswamy, E. F. Westheimer, L. VanderBusch, A. Nishimura, A. Vu, L. Hoffman-Arriaga, E. Rowlinson, A. O. Carter, L. E. Yerkes, W. Li, J. R. Reuer, L. J. Stockman, T. Tang, J. T. Brooks, E. H. Teshale, H. I. Hall
Journal: Epidemiology & Infection / Volume 146 / Issue 7 / May 2018
Published online by Cambridge University Press: 11 April 2018, pp. 920-930
Coinfection with human immunodeficiency virus (HIV) and viral hepatitis is associated with high morbidity and mortality in the absence of clinical management, making identification of these cases crucial. We examined characteristics of HIV and viral hepatitis coinfections by using surveillance data from 15 US states and two cities. Each jurisdiction used an automated deterministic matching method to link surveillance data for persons with reported acute and chronic hepatitis B virus (HBV) or hepatitis C virus (HCV) infections, to persons reported with HIV infection. Of the 504 398 persons living with diagnosed HIV infection at the end of 2014, 2.0% were coinfected with HBV and 6.7% were coinfected with HCV. Of the 269 884 persons ever reported with HBV, 5.2% were reported with HIV. Of the 1 093 050 persons ever reported with HCV, 4.3% were reported with HIV. A greater proportion of persons coinfected with HIV and HBV were males and blacks/African Americans, compared with those with HIV monoinfection. Persons who inject drugs represented a greater proportion of those coinfected with HIV and HCV, compared with those with HIV monoinfection. Matching HIV and viral hepatitis surveillance data highlights epidemiological characteristics of persons coinfected and can be used to routinely monitor health status and guide state and national public health interventions.
Waterborne Norovirus outbreak at a seaside resort likely originating from municipal water distribution system failure
G. M. Giammanco, F. Bonura, N. Urone, G. Purpari, M. Cuccia, A. Pepe, S. Li Muli, V. Cappa, C. Saglimbene, G. Mandolfo, A. Marino, A. Guercio, I. Di Bartolo, S. De Grazia
In May 2016 a Norovirus (NoV) gastroenteritis outbreak involved a high school class visiting a seaside resort near Taormina (Mascali, Sicily). Twenty-four students and a teacher were affected and 17 of them showed symptoms on the second day of the journey, while the others got ill within the following 2 days. Symptoms included vomiting, diarrhoea and fever, and 12 students required hospitalisation. Stool samples tested positive for NoV genome by Real-Time polymerase chain reaction assay in all 25 symptomatic subjects. The GII.P2/GII.2 NoV genotype was linked to the outbreak by ORF1/ORF2 sequence analysis. The epidemiological features of the outbreak were consistent with food/waterborne followed by person-to-person and/or vomit transmission. Food consumed at a shared lunch on the first day of the trip was associated to illness and drinking un-bottled tap water was also considered as a risk factor. The analysis of water samples revealed the presence of bacterial indicators of faecal contamination in the water used in the resort as well as in other areas of the municipal water network, linking the NoV gastroenteritis outbreak to tap water pollution from sewage leakage. From a single water sample, an amplicon whose sequence corresponded to the capsid genotype recovered from patients could be obtained.
Studies of the relationship between rice stem composition and lodging resistance
M. Y. Gui, D. Wang, H. H. Xiao, M. Tu, F. L. Li, W. C. Li, S. D. Ji, T. X. Wang, J. Y. Li
Journal: The Journal of Agricultural Science / Volume 156 / Issue 3 / April 2018
Published online by Cambridge University Press: 25 May 2018, pp. 387-395
Plant height and lodging resistance can affect rice yield significantly, but these traits have always conflicted in crop cultivation and breeding. The current study aimed to establish a rapid and accurate plant type evaluation mechanism to provide a basis for breeding tall but lodging-resistant super rice varieties. A comprehensive approach integrating plant anatomy and histochemistry was used to investigate variations in flexural strength (a material property, defined as the stress in a material just before it yields in a flexure test) of the rice stem and the lodging index of 15 rice accessions at different growth stages to understand trends in these parameters and the potential factors influencing them. Rice stem anatomical structure was observed and the lignin content the cell wall was determined at different developmental stages. Three rice lodging evaluation models were established using correlation analysis, multivariate regression and artificial radial basis function (RBF) neural network analysis, and the results were compared to identify the most suitable model for predicting optimal rice plant types. Among the three evaluation methods, the mean residual and relative prediction errors were lowest using the RBF network, indicating that it was highly accurate and robust and could be used to establish a mathematical model of the morphological characteristics and lodging resistance of rice to identify optimal varieties.
Effects of tributyrin supplementation on short-chain fatty acid concentration, fibrolytic enzyme activity, nutrient digestibility and methanogenesis in adult Small Tail ewes
Q. C. Ren, J. J. Xuan, Z. Z. Hu, L. K. Wang, Q. W. Zhan, S. F. Dai, S. H. Li, H. J. Yang, W. Zhang, L. S. Jiang
Published online by Cambridge University Press: 19 June 2018, pp. 465-470
In vivo and in vitro trials were conducted to assess the effects of tributyrin (TB) supplementation on short-chain fatty acid (SFCA) concentrations, fibrolytic enzyme activity, nutrient digestibility and methanogenesis in adult sheep. Nine 12-month-old ruminally cannulated Small Tail ewes (initial body weight 55 ± 5.0 kg) without pregnancy were used for the in vitro trial. In vitro substrate made to offer TB at 0, 2, 4, 6 and 8 g/kg on a dry matter (DM) basis was incubated by ruminal microbes for 72 h at 39°C. Forty-five adult Small Tail ewes used for the in vivo trial were randomly assigned to five treatments with nine animals each for an 18-d period according to body weight (55 ± 5.0 kg). Total mixed ration fed to ewes was also used to offer TB at 0, 2, 4, 6 and 8 g/kg on a DM basis. The in vitro trial showed that TB supplementation linearly increased apparent digestibility of DM, crude protein, neutral detergent fibre and acid detergent fibre, and enhanced gas production and methane emissions. The in vivo trial showed that TB supplementation decreased DM intake, but enhanced ruminal fermentation efficiency. Both in vitro and in vivo trials showed that TB supplementation enhanced total SFCA concentrations and carboxymethyl cellulase activity. The results indicate that TB supplementation might exert advantage effects on rumen microbial metabolism, despite having an enhancing effect on methanogenesis.
Follow Up of GW170817 and Its Electromagnetic Counterpart by Australian-Led Observing Programmes
Gravitational Wave Astronomy
I. Andreoni, K. Ackley, J. Cooke, A. Acharyya, J. R. Allison, G. E. Anderson, M. C. B. Ashley, D. Baade, M. Bailes, K. Bannister, A. Beardsley, M. S. Bessell, F. Bian, P. A. Bland, M. Boer, T. Booler, A. Brandeker, I. S. Brown, D. A. H. Buckley, S.-W. Chang, D. M. Coward, S. Crawford, H. Crisp, B. Crosse, A. Cucchiara, M. Cupák, J. S. de Gois, A. Deller, H. A. R. Devillepoix, D. Dobie, E. Elmer, D. Emrich, W. Farah, T. J. Farrell, T. Franzen, B. M. Gaensler, D. K. Galloway, B. Gendre, T. Giblin, A. Goobar, J. Green, P. J. Hancock, B. A. D. Hartig, E. J. Howell, L. Horsley, A. Hotan, R. M. Howie, L. Hu, Y. Hu, C. W. James, S. Johnston, M. Johnston-Hollitt, D. L. Kaplan, M. Kasliwal, E. F. Keane, D. Kenney, A. Klotz, R. Lau, R. Laugier, E. Lenc, X. Li, E. Liang, C. Lidman, L. C. Luvaul, C. Lynch, B. Ma, D. Macpherson, J. Mao, D. E. McClelland, C. McCully, A. Möller, M. F. Morales, D. Morris, T. Murphy, K. Noysena, C. A. Onken, N. B. Orange, S. Osłowski, D. Pallot, J. Paxman, S. B. Potter, T. Pritchard, W. Raja, R. Ridden-Harper, E. Romero-Colmenero, E. M. Sadler, E. K. Sansom, R. A. Scalzo, B. P. Schmidt, S. M. Scott, N. Seghouani, Z. Shang, R. M. Shannon, L. Shao, M. M. Shara, R. Sharp, M. Sokolowski, J. Sollerman, J. Staff, K. Steele, T. Sun, N. B. Suntzeff, C. Tao, S. Tingay, M. C. Towner, P. Thierry, C. Trott, B. E. Tucker, P. Väisänen, V. Venkatraman Krishnan, M. Walker, L. Wang, X. Wang, R. Wayth, M. Whiting, A. Williams, T. Williams, C. Wolf, C. Wu, X. Wu, J. Yang, X. Yuan, H. Zhang, J. Zhou, H. Zovaro
The discovery of the first electromagnetic counterpart to a gravitational wave signal has generated follow-up observations by over 50 facilities world-wide, ushering in the new era of multi-messenger astronomy. In this paper, we present follow-up observations of the gravitational wave event GW170817 and its electromagnetic counterpart SSS17a/DLT17ck (IAU label AT2017gfo) by 14 Australian telescopes and partner observatories as part of Australian-based and Australian-led research programs. We report early- to late-time multi-wavelength observations, including optical imaging and spectroscopy, mid-infrared imaging, radio imaging, and searches for fast radio bursts. Our optical spectra reveal that the transient source emission cooled from approximately 6 400 K to 2 100 K over a 7-d period and produced no significant optical emission lines. The spectral profiles, cooling rate, and photometric light curves are consistent with the expected outburst and subsequent processes of a binary neutron star merger. Star formation in the host galaxy probably ceased at least a Gyr ago, although there is evidence for a galaxy merger. Binary pulsars with short (100 Myr) decay times are therefore unlikely progenitors, but pulsars like PSR B1534+12 with its 2.7 Gyr coalescence time could produce such a merger. The displacement (~2.2 kpc) of the binary star system from the centre of the main galaxy is not unusual for stars in the host galaxy or stars originating in the merging galaxy, and therefore any constraints on the kick velocity imparted to the progenitor are poor.
Acetate alters the process of lipid metabolism in rabbits
C. Fu, L. Liu, F. Li
Journal: animal / Volume 12 / Issue 9 / September 2018
Published online by Cambridge University Press: 04 December 2017, pp. 1895-1902
An experiment was conducted to investigate the effect of acetate treatment on lipid metabolism in rabbits. New Zealand Rabbits (30 days, n=80) randomly received a subcutaneous injection (2 ml/injection) of 0, 0.5, 1.0 or 2.0 g/kg per day body mass acetate (dissolved in saline) for 4 days. Our results showed that acetate induced a dose-dependent decrease in shoulder adipose (P<0.05). Although acetate injection did not alter the plasma leptin and glucose concentration (P>0.05), acetate treatment significantly decreased the plasma adiponectin, insulin and triglyceride concentrations (P<0.05). In adipose, acetate injection significantly up-regulated the gene expression of peroxisome proliferator-activated receptor gamma (PPARγ), CCAAT/enhancer-binding protein α (C/EBPα), differentiation-dependent factor 1 (ADD1), adipocyte protein 2 (aP2), carnitine palmitoyltransferase 1 (CPT1), CPT2, hormone-sensitive lipase (HSL), G protein-coupled receptor (GPR41), GPR43, adenosine monophosphate-activated protein kinase α1 (AMPKα1), adiponectin receptor (AdipoR1), AdipoR2 and leptin receptor. In addition, acetate treatment significantly increased the protein levels of phosphorylated AMPKα, extracellular signaling-regulated kinases 1 and 2 (ERK1/2), p38 mitogen-activated protein kinase (P38 MAPK) and c-jun amino-terminal kinase (JNK). In conclusion, acetate up-regulated the adipocyte-specific transcription factors (PPARγ, C/EBPα, aP2 and ADD1), which were associated with the activated GPR41/43 and MAPKs signaling. Meanwhile, acetate decreased fat content via the upregulation of the steatolysis-related factors (HSL, CPT1 and CPT2), and AMPK signaling may be involved in the process. | CommonCrawl |
Home » Mechanics » Work Done Quiz with answers
Work Done Quiz with answers
The concept of work done is fundamental in physics. Whether you are studying physics as a pastime or preparing for tests such as the MCAT, AP Physics, GCSE, or IB, you must track your progress.
You can test your concepts in this Work done quiz by taking this online practice quiz. Concepts you must be comfortable with before taking this quiz are
Motion (Kinematics 1D and 2D)
Work Done and
This quiz only includes algebra-based questions on the concept of work.
Work Done Quiz Questions and Answers
Question 1 Product of force and displacement is called
(a) work done
(b) energy
(c) acceleration
(d) power
Question 2 What is the metric unit of work?
(a) meter
(b) Joule
(c) Watt
(d) horsepower
Question 3 Calculate the work done in moving a block of 15 Kg by a distance of 4 m when 50 N of force is being applied to it.
(a) 200 Joules
(b) 2000 Joules
(c) 300 Joules
(d) 3000 Joules
Work done, $W= F\times d = 50\times 4=200Joules$
It is important to note that when we are calculating work, the mass of the object that is being displaced is irrelevant.
Question 4 Consider the diagram below, which depicts a force of $10N$ being applied to a box of mass $20 Kg$ at an angle of $60^0$. This force moves the box $20m$ across the smooth table horizontally. The work done by the force is
(a) 100 J
(b) 150 J
(c) 10 J
(d) 200 J
From the figure, we can see that force is acting at an angle of 60 degrees with the direction of the displacement. Here force would have two components
The component of force along the y-axis does not contribute to the work done by the force. Only a component of force along the direction of displacement is effective. So we have,
$W=(F\cos\theta)d$
The force is applied at a $60$ angle from the direction of displacement, so $\theta = 60^0$
$W=(10N)(\cos60^0)(20m)=(10N)(0.5)(20m)$
$W=100J$
Question 5 A porter lifts a 15 Kg box from the ground to a height of 2.0 m. The work done by the porter on the box would be equal. ($g=9.8 m/s^2$)
(a) 300 N
(b) 290 N
(c) 294 N
(d) 297 N
It is given in the question that
$m=15 Kg$; $distance\;\;s= 2.0m$ ; $g=9.8 m/s^2$ and we have to calculate work $W=?$
Now, Force applied $=F=mg$ (weight of the box)
$F=15Kg\times9.8m/s^2=147N$
Work done $W=F\cdot s=147N\cdot 2.0 m = 294N$
Question 6 Work is done on a body when
a. force acts on the body, but the body is not displaced.
b. force does not act on the body, but it is displaced.
c. force acts on the body in the direction perpendicular to the direction of the displacement of the body.
d. force acts on the body and the body is either displaced in the direction of force or opposite to the direction of the force.
We know that work done,
$W=F\cdot s=Fs\cos\theta$
When the force and displacement are both in the same direction, $theta = 0$. As a result, the work done would be
$W=Fs\cos0^0 = FS$
in a case when force and displacement happen to be opposite to each other $\theta = 180^0$. So, the work done would be
$W=Fs\cos180^0=-Fs$
This is the case of negative work done. The work done by frictional force when pushing a block on a hard surface is an example of negative work.
Question 7 In case of negative work, the angle between force and displacement is
a. $0^0$
b. $45^0$
c. $90^0$
d. $180^0$
Question 8. In a tug of war, work done by a winning team is
a. zero
b. positive
d. negative
Work done by the winning team is positive because
In a tug of war, the winning team exerts a force on the opposing team and successfully moves it over a distance.
The losing team goes toward the winning team as the winning team tugs the rope in its direction.
Because the applied force is in the same direction as the motion, the work done is positive.
Question 9. What is the work done by gravity if a 90 kg block is pushed along a 100 m track?
a. 10 J
b. 0 J
c. 90 J
d. 100 J
The work done by any force that is perpendicular to the direction of displacement is equal to zero.
Question 10. A child builds a tower from three blocks. The blocks are uniform cubes of side 2 cm. The blocks are initially all lying on the same horizontal surface, and each block has a mass of 0.1 kg. The work done by the child is
(a) 4J
(b) 0.04 J
(c) 6J
(d) 0.06 J
The blocks are uniform cubes of side =2 cm = .02 m
Mass of block $0.1 Kg$
Total work done is a change in kinetic energy plus the change in potential energy. Since the change in kinetic energy is zero. So the total work done by the child would be equal to the total change in the potential energy of blocks.
Potential Energy $=mg\Delta h$
Potential Energy of block 1 $=0.1 \times 10 \times 0$
Potential Energy of block 2 $=0.1 \times 10 \times .02 = 0.02 J$
Thus, the total potential energy is,
$P.E. = 0+0.02+0.04=0.06 J$
Question 11. A certain force acting on a body of mass 2 kg increases its velocity from 6 m/s to 15 m/s in 2 s. The work done by the force during this interval is
c. 94.5 J
we know that
$v=u+at$
$15=6+a(2)$
$a=4.5m/s^2$
$s=ut+\frac{1}{2}at^2=6(2)+0.5(4.5)(4)=21m$
$W=F\cdot s=2(4.5)(21)=189J$
Question 12 In which of the following cases work done would be maximum
$W=Fs\cos\theta$
In the case of option d $\theta=0^0$
therefore work done is maximum
Question 13 A man raises a box of mass 50 Kg to a height of 3 m in 2 minutes, while another man raises the same box to the same height in 4 minutes. What is the ratio of work done by them?
a. 1:1
b. 2:1
c. 1:2
d. 4:1
Work done, $W=Fs\cos\theta$
where $F$ is the force applied, $s$ is the displacement and $\theta$ is the angle between force and displacement.
This shows that work done is independent of time.
According to our question, both forces are applied and the direction of movement of the box is the same. So we have $\theta = 0^0$
Both men are raising mass 50 kg to a height of 3 m.
Work done by first man $= mgh$
$=50\times 10\times 3$
$= 1500 J$
Work done by second man $= mgh$
Hence work done is in the ratio of $1500:1500=1:1$
Question 14 A bullet of mass 10 g leaves a rifle at an initial velocity
of 1000 m/s and strikes the earth at the same level with a velocity of 500 m/s. The work done in joule for overcoming the resistance of the air will be
(a) 375
(d) 500
Work done = change in kinetic energy
$W=\frac{1}{2}\times 0.01[(1000)^2-(500)^2]=3750J$
Question 15 A body moves a distance of 10 m along a straight line under the action of a 5 N force. If the work done is 25 J, then the angle between the force and direction of motion of the body is
(a) 60°
(b) 75°
(c) 30°
(d) 45°
Distance $s=10m$ ; Force $F=5N$ ; and work done $W=25 J$
Work done is given by relation $W=Fs\cos\theta$
$25=5\times 10\cos\theta = 20\cos \theta$
$\cos\theta=\frac{25}{50}=0.5$
or, $\theta=60^0$
Question 16 When a body moves with a constant speed along a circle
(a) no work is done on it
(b) no acceleration is produced in it
(c) its velocity remains constant
(d) no force acts on it.
When speed is constant in a circular motion, it means the work done by the centripetal force is zero.
Categories Mechanics
What unit of measurement is used for mass?
Distance and displacement questions
Vectors in physics
Force and Laws of Motion
Current Electricity (3)
Electromagnetism (3)
Electrostatics (11)
physics formula (3)
Simple Harmonic Motion (1)
Units And Measurement (11)
Vectors (4)
How to get velocity from acceleration?
How are mass and weight related?
Centre of mass formulas list with solved examples and problems
© 2023 PhysicsGoEasy • Built with GeneratePress | CommonCrawl |
Conditional distribution of $(X_1,\cdots,X_n)\mid X_{(n)}$ where $X_i$'s are i.i.d $\mathcal U(0,\theta)$ variables
Let $(X_1,X_2,\cdots,X_n)$ be a random sample drawn from $\mathcal U(0,\theta)$ distribution. It is a common exercise to prove that the maximum order statistic $X_{(n)}$ is sufficient for $\theta$ as an application of the Fisher-Neyman Factorization theorem. However, I am trying to prove this fact from the definition of a sufficient statistic.
Indeed, for some discrete distributions we can prove sufficiency of a given statistic from definition without using the Factorization theorem. But for continuous distributions like this one, I guess it is not that straightforward.
Joint density of the sample $\mathbf X=(X_1,\cdots,X_n)$ is given by
\begin{align} f_{\theta}(\mathbf x)&=\prod_{i=1}^n\frac{1}{\theta}\mathbf1_{0<x_i<\theta} \\&=\frac{1}{\theta^n}\mathbf1_{0<x_{(1)},x_{(n)}<\theta} \end{align}
It is clear from the Factorization theorem that $T(\mathbf X)=X_{(n)}$ is sufficient for $\theta$.
But from the definition of sufficiency, I have to show that the conditional distribution of $\mathbf X\mid T$ is independent of $\theta$. I don't think I can say the following:
\begin{align} f_{\mathbf X\mid T}(\mathbf x\mid t)f_T(t)&=f_{T\mid\mathbf X}(t\mid\mathbf x)f_{\theta}(\mathbf x) \\\implies f_{\mathbf X\mid T}(\mathbf x\mid t)&=\frac{f_{\theta}(\mathbf x)}{f_T(t)}f_{T\mid\mathbf X}(t\mid\mathbf x) \end{align}
We know that the density of $T$ is $$f_T(t)=\frac{n\,t^{n-1}}{\theta^n}\mathbf1_{0<t<\theta}$$
But I don't know what $f_{T\mid\mathbf X}(\cdot)$ is because it looks like $T\mid\mathbf X$ has a singular distribution.
If I knew the joint distribution of $(\mathbf X,T)$, then maybe I could have said that $$f_{\mathbf X\mid T}(\mathbf x\mid t)=\frac{f_{\mathbf X,T}(\mathbf x,t)}{f_T(t)}$$
Also tried working with the conditional distribution function $$P\left[X_1\le x_1,\cdots,X_n\le x_n\mid T=t\right]=\lim_{\varepsilon\to0}\frac{P\left[X_1\le x_1,\cdots,X_n\le x_n, t-\varepsilon\le T\le t+\varepsilon\right]}{P(t-\varepsilon\le T\le t+\varepsilon)}$$
I have gone through this related post but could not come up with an answer. Is it also true that $\mathbf X\mid T$ has a mixed distribution?
I also have this equivalent definition of sufficiency at hand, which says that if $T$ is sufficient for $\theta$, then for any other statistic $T'$, the conditional distribution of $T'\mid T$ is also independent of $\theta$. Maybe for a suitable choice of $T'$ I can prove the required fact, but I prefer to do it from the first definition. Any hints will be great.
It looks like what I am looking for is basically a proof of the Factorisation theorem for continuous distributions, which I did find in Hogg and Craig's Mathematical Statistics.
Here is an extract from Theory of Point Estimation by Lehmann-Casella (2nd edition) that gives a hint of a probabilistic argument for sufficiency of $T=X_{(n)}$:
Let $X_1,\cdots,X_n$ be independently distributed according to the uniform distribution $U(0,\theta)$. Let $T$ be the largest of the $n$ $X$'s, and consider the conditional distribution of the remaining $n − 1$ $X$'s given $t$ . Thinking of the $n$ variables as $n$ points on the real line, it is intuitively obvious and not difficult to see formally (Problem 6.2) that the remaining $n − 1$ points (after the largest is fixed at $t$ ) behave like $n − 1$ points selected at random from the interval $(0, t)$. Since this conditional distribution is independent of $\theta$, $T$ is sufficient. Given only $T = t$ , it is obvious how to reconstruct the original sample: Select $n − 1$ points at random on $(0, t)$.
Problem 6.2 says
Let $X_1,\cdots,X_n$ be iid according to a distribution $F$ and probability density $f$ . Show that the conditional distribution given $X_{(i)} = a$ of the $i−1$ values to the left of $a$ and the $n−i$ values to the right of $a$ is that of $i−1$ variables distributed independently according to the probability density $f(x)/F(a)$ and $n−i$ variables distributed independently with density $f(x)/[1 − F(a)]$, respectively, with the two sets being (conditionally) independent of each other.
So for a 'formal' proof of the sufficiency of $T$ without applying the Factorization theorem, do I have to prove the theorem itself for this particular problem or is there another option as highlighted in the above extract?
distributions mathematical-statistics estimation sufficient-statistics
StubbornAtom
StubbornAtomStubbornAtom
$\begingroup$ In what sense does $T\mid X$ have a "singular" distribution? $\endgroup$ – whuber♦ Aug 7 '18 at 12:06
$\begingroup$ @whuber I might be wrong, but I think $T\mid X$ does not have a density, i.e not absolutely continuous. That's what I meant. $\endgroup$ – StubbornAtom Aug 7 '18 at 15:53
$\begingroup$ The quotation after "Problem 6.2 says" refers explicitly to a density. $\endgroup$ – whuber♦ Aug 9 '18 at 18:35
$\begingroup$ @whuber Not sure I follow. No specific density is mentioned. Except perhaps it was referring to the Uniform density in the previous quotation. $\endgroup$ – StubbornAtom Aug 9 '18 at 18:40
$(X_1, ..., X_n) \vert X_{(n)}$ can be expressed as the mixture distribution of $(Y_{1}, ,Y_{n})$ with $$Y_{i} \quad\begin{cases} &\sim U(0,X_{(n)}) & \qquad \text{for $i \neq j$} \\ &= X_{(n)} & \qquad \text{for $i=j$} \end{cases}$$
where the mixture is due to using $n$ different values for $j$ giving $n$ different distributions for $(Y_1,...,Y_n)$.
You can see it is independent from $\theta$.
It gives a bit strange density function. You get (where for simplicity of notation $\eta = X_{(n)}$):
$$g_\eta(\mathbf{x}) = \frac{1}{\eta^{n-1}} \mathbf{1}_{0\leq x_{(1)},x_{(n-1)} \leq x_{(n)}=\eta}$$
and this indicator function $\mathbf{1}_{0\leq x_{(1)},x_{(n-1)} \leq x_{(n)}=\eta}$ is not equal to 1 inside the hypercube, but only on $n$ of its facets (here you see the facets for $n=2$ as an L-shape, the 2 facets of a 2d-hypercube are sides of a square.)
The above is a bit intuitive. I actually don't know how to correctly describe the pdf/cdf. For comparison an example in two dimensions: the conditional variable $(X_1,X_2)_{ \max(X_1,X_2) = t}$, with $X_1$ and $X_2$ i.i.d uniform, is a uniform distribution on the two line pieces $X_1=t , 0\leq X_2 \leq t$ and $0 \leq X_1 \leq t, X_2=t$ in 2D space.
Maybe you can resolve this by using $(X_1, ..., X_n) \vert (X_{(n)} \leq t)$ which is the $(Y_1, ..., Y_n)$ where the $Y_i \sim U(0,t)$
Sextus EmpiricusSextus Empiricus
$\begingroup$ I wonder if I can say the following like in discrete cases by introducing an indicator variable: \begin{align} f_{\mathbf X\mid T}(\mathbf x\mid t)&=\frac{f_{\theta}(\mathbf x)}{f_T(t)}\mathbf1_{\mathbf x\in A_t} \\&=\frac{1/\theta^n}{nt^{n-1}/\theta^n}\mathbf1_{\mathbf x\in A_t} \\&=\frac{\mathbf1_{\mathbf x\in A_t}}{nt^{n-1}} \end{align} where $$A_t=\{\mathbf x:x_{(n)}=t\},\quad0<t<\theta$$ $\endgroup$ – StubbornAtom Aug 28 '18 at 21:35
Not the answer you're looking for? Browse other questions tagged distributions mathematical-statistics estimation sufficient-statistics or ask your own question.
What is the probability that $X<Y$ given $\min(X,Y)$?
Conditional Distribution of uniform random variable given Order statistic
Puzzled by definition of sufficient statistics
Can the Fisher factorization theorem be understood as a product of densities?
How to find sufficient statistic?
Equivalent definitions of a sufficient statistic
UMVUE of $\frac{\theta}{1+\theta}$ while sampling from $\text{Beta}(\theta,1)$ population
Verification of sufficiency of a linear combination of the sample $(X_i)_{i\ge1}$ where $X_i\stackrel{\text{i.i.d}}\sim\text{Ber}(\theta)$
UMVUE of distribution function $F$ when $X_i\sim F$ are i.i.d random variables
Finding UMVUE of $\theta e^{-\theta}$ where $X_i\sim\text{Pois}(\theta)$
If $X_1,\cdots,X_n \sim \mathcal{N}(\mu, 1)$ are IID, then compute $\mathbb{E}\left( X_1 \mid T \right)$, where $T = \sum_i X_i$
Sufficient Statistic of Uniform $(-\theta,0)$
What is the intuition behind the factorization theorem? (Sufficient statistics)
How can I show that $\sum X_i$ is not a sufficient statistic for $\theta$? | CommonCrawl |
Diffeomorphisms with a generalized Lipschitz shadowing property
Strong blow-up instability for standing wave solutions to the system of the quadratic nonlinear Klein-Gordon equations
Well-posedness of renormalized solutions for a stochastic $ p $-Laplace equation with $ L^1 $-initial data
Niklas Sapountzoglou and Aleksandra Zimmermann ,
University of Duisburg-Essen, Thea-Leymann-Strasse 9, 45127 Essen, Germany
Received December 2019 Revised August 2020 Published November 2020
We consider a $ p $-Laplace evolution problem with stochastic forcing on a bounded domain $ D\subset\mathbb{R}^d $ with homogeneous Dirichlet boundary conditions for $ 1<p<\infty $. The additive noise term is given by a stochastic integral in the sense of Itô. The technical difficulties arise from the merely integrable random initial data $ u_0 $ under consideration. Due to the poor regularity of the initial data, estimates in $ W^{1,p}_0(D) $ are available with respect to truncations of the solution only and therefore well-posedness results have to be formulated in the sense of generalized solutions. We extend the notion of renormalized solution for this type of SPDEs, show well-posedness in this setting and study the Markov properties of solutions.
Keywords: Stochastic p-Laplace equation, integrable random initial data, renormalized solutions.
Mathematics Subject Classification: 35K92, 60H15.
Citation: Niklas Sapountzoglou, Aleksandra Zimmermann. Well-posedness of renormalized solutions for a stochastic $ p $-Laplace equation with $ L^1 $-initial data. Discrete & Continuous Dynamical Systems - A, doi: 10.3934/dcds.2020367
S. Attanasio and F. Flandoli, Renormalized solutions for stochastic transport equations and the regularization by bilinear multiplication noise, Comm. Partial Differential Equations, 36 (2011), 1455-1474. doi: 10.1080/03605302.2011.585681. Google Scholar
P. Baldi, Stochastic Calculus, An Introduction Through Theory and Exercises. Universitext, Springer, 2017. doi: 10.1007/978-3-319-62226-2. Google Scholar
G. I. Barenblatt, Similarity, Self-Similarity, and Intermediate Asymptotics, New York, London, 1979. Google Scholar
P. Bénilan, L. Boccardo, T. Gallouët, R. Gariepy, M. Pierre and J. L. Vázquez, An $L^1$-theory of existence and uniqueness of solutions of nonlinear elliptic equations, Ann. Scuola Norm. Sup. Pisa Cl. Sci., 22 (1995), 241-273. Google Scholar
D. Blanchard and H. Redwane, Renormalized solutions for a class of nonlinear evolution problems, J. Math. Pures Appl., 77 (1998), 117-151. doi: 10.1016/S0021-7824(98)80067-6. Google Scholar
D. Blanchard, Truncations and monotonicity methods for parabolic equations, Nonlinear Anal., 21 (1993), 725-743. doi: 10.1016/0362-546X(93)90120-H. Google Scholar
D. Blanchard and F. Murat, Renormalised solutions of nonlinear parabolic problems with $L^1$ data: Existence and uniqueness, Proc. Roy. Soc. Edinburgh Sect. A, 127 (1997), 1137-1152. doi: 10.1017/S0308210500026986. Google Scholar
D. Blanchard, F. Murat and H. Redwane, Existence and uniqueness of a renormalized solution of a fairly general class of nonlinear parabolic problems, Journal of Differential Equations, 177 (2001), 331-374. doi: 10.1006/jdeq.2000.4013. Google Scholar
D. Breit, Regularity theory for nonlinear systems of SPDEs, Manuscripta Math., 146 (2015), 329-349. doi: 10.1007/s00229-014-0704-8. Google Scholar
D. Breit, E. Feireisl and M. Hofmanová, Stochastically Forced Compressible Fluid Flows, De Gruyter, Berlin, 2018. Google Scholar
P. Catuogno and C. Olivera, $L^p$-solutions of the stochastic transport equation, Random Oper. Stoch. Equ., 21 (2013), 125-134. doi: 10.1515/rose-2013-0007. Google Scholar
[12] G. Da Prato and J. Zabczyk, Stochastic Equations in Infinite Dimensions. 2. Edition, Encyclopedia of Mathematics and Its Applications, Cambridge University Press, Cambridge, 1992. doi: 10.1017/CBO9780511666223. Google Scholar
B. Delamotte, A hint of renormalization, Am. J. Phys., 72 (2004), 170-184. Google Scholar
J. I. Diaz and F. de Thélin, On a nonlinear parabolic problem arising in some models related to turbulent flows, SIAM J. Math. Anal., 25 (1994), 1085-1111. doi: 10.1137/S0036141091217731. Google Scholar
R. J. DiPerna and P.-L. Lions, On the Cauchy problem for Boltzmann equations: Global existence and weak stability, Ann. Math., 130 (1989), 321-366. doi: 10.2307/1971423. Google Scholar
E. Feireisl, Dynamics of Viscous Compressible Fluids. Volume 26 of Oxford Lecture Series in Mathematics and its Applications, Oxford University Press, Oxford 2004. Google Scholar
D. Fellah and É. Pardoux, Une formule d'Itô dans des espaces de Banach, et Application, In: Körezlioǧlu H., Üstünel A.S. (eds) Stochastic Analysis and Related Topics. Progress in Probability, vol. 31. Birkhäuser, Boston, MA, 1992. Google Scholar
B. Gess and M. Hofmanová, Well-posedness and regularity for quasilinear degenerate parabolic-hyperbolic SPDE, Ann. Probab., 46 (2018), 2495-2544. doi: 10.1214/17-AOP1231. Google Scholar
M. Gubinelli, P. Imkeller and N. Perkowski, Paracontrolled distributions and singular PDEs, Forum Math. Pi, 3 (2015), e6, 75 pp. doi: 10.1017/fmp.2015.2. Google Scholar
M. Hairer, A theory of regularity structures, Invent. Math., 198 (2014), 269-504. doi: 10.1007/s00222-014-0505-4. Google Scholar
L. Hörmander, The Analyis of Linear Partial Differential Operators I. Distribution Theory and Fourier Analysis., Springer-Verlag, Berlin, 1990. doi: 10.1007/978-3-642-61497-2. Google Scholar
T. Komorowski, S. Peszat and T. Szarek, On ergodicity of some Markov processes, Ann. Probab., 38 (2010), 1401-1443. doi: 10.1214/09-AOP513. Google Scholar
N. V. Krylov and B. L. Rozovski${\rm{\mathord{\buildrel{\lower3pt\hbox{$\scriptscriptstyle\smile$}} \over i} }}$, Stochastic evolution equations, J. Soviet Math., 16 (1981), 1233-1277. Google Scholar
W. Liu and M. Röckner, Stochastic Partial Differential Equations: An Introduction, Universitext, Springer, Cham, 2015. doi: 10.1007/978-3-319-22354-4. Google Scholar
M. Ondreját, Uniqueness for stochastic evolution equations in Banach spaces, Dissertationes Math. (Rozprawy Mat.), 426 (2004), 1-63. doi: 10.4064/dm426-0-1. Google Scholar
E. Pardoux, Equations aux Dérivées Partielles Stochastiques non Linéaires Monotones, University of Paris, 1975. PhD-thesis. Google Scholar
S. Punshon-Smith and S. Smith, On the Boltzmann equation with stochastic kinetic transport: Global existence of renormalized martingale solutions, Arch. Rational Mech. Anal., 229 (2018), 627-708. doi: 10.1007/s00205-018-1225-5. Google Scholar
G. Vallet and A. Zimmermann, Well-posedness for a pseudomonotone evolution problem with multiplicative noise, J. Evol. Equ., 19 (2019), 153-202. doi: 10.1007/s00028-018-0472-0. Google Scholar
[29] J. Wloka, Partial Differential Equations, Cambridge University Press, Cambridge, 1987. doi: 10.1017/CBO9781139171755. Google Scholar
Haruki Umakoshi. A semilinear heat equation with initial data in negative Sobolev spaces. Discrete & Continuous Dynamical Systems - S, 2021, 14 (2) : 745-767. doi: 10.3934/dcdss.2020365
Van Duong Dinh. Random data theory for the cubic fourth-order nonlinear Schrödinger equation. Communications on Pure & Applied Analysis, , () : -. doi: 10.3934/cpaa.2020284
Bixiang Wang. Mean-square random invariant manifolds for stochastic differential equations. Discrete & Continuous Dynamical Systems - A, 2021, 41 (3) : 1449-1468. doi: 10.3934/dcds.2020324
Yi Zhou, Jianli Liu. The initial-boundary value problem on a strip for the equation of time-like extremal surfaces. Discrete & Continuous Dynamical Systems - A, 2009, 23 (1&2) : 381-397. doi: 10.3934/dcds.2009.23.381
Stanislav Nikolaevich Antontsev, Serik Ersultanovich Aitzhanov, Guzel Rashitkhuzhakyzy Ashurova. An inverse problem for the pseudo-parabolic equation with p-Laplacian. Evolution Equations & Control Theory, 2021 doi: 10.3934/eect.2021005
Yangrong Li, Shuang Yang, Qiangheng Zhang. Odd random attractors for stochastic non-autonomous Kuramoto-Sivashinsky equations without dissipation. Electronic Research Archive, 2020, 28 (4) : 1529-1544. doi: 10.3934/era.2020080
Wenlong Sun, Jiaqi Cheng, Xiaoying Han. Random attractors for 2D stochastic micropolar fluid flows on unbounded domains. Discrete & Continuous Dynamical Systems - B, 2021, 26 (1) : 693-716. doi: 10.3934/dcdsb.2020189
Sebastian J. Schreiber. The $ P^* $ rule in the stochastic Holt-Lawton model of apparent competition. Discrete & Continuous Dynamical Systems - B, 2021, 26 (1) : 633-644. doi: 10.3934/dcdsb.2020374
Peter H. van der Kamp, D. I. McLaren, G. R. W. Quispel. Homogeneous darboux polynomials and generalising integrable ODE systems. Journal of Computational Dynamics, 2021, 8 (1) : 1-8. doi: 10.3934/jcd.2021001
Shang Wu, Pengfei Xu, Jianhua Huang, Wei Yan. Ergodicity of stochastic damped Ostrovsky equation driven by white noise. Discrete & Continuous Dynamical Systems - B, 2021, 26 (3) : 1615-1626. doi: 10.3934/dcdsb.2020175
Tetsuya Ishiwata, Young Chol Yang. Numerical and mathematical analysis of blow-up problems for a stochastic differential equation. Discrete & Continuous Dynamical Systems - S, 2021, 14 (3) : 909-918. doi: 10.3934/dcdss.2020391
Lihong Zhang, Wenwen Hou, Bashir Ahmad, Guotao Wang. Radial symmetry for logarithmic Choquard equation involving a generalized tempered fractional $ p $-Laplacian. Discrete & Continuous Dynamical Systems - S, 2020 doi: 10.3934/dcdss.2020445
Fuensanta Andrés, Julio Muñoz, Jesús Rosado. Optimal design problems governed by the nonlocal $ p $-Laplacian equation. Mathematical Control & Related Fields, 2021, 11 (1) : 119-141. doi: 10.3934/mcrf.2020030
Zaizheng Li, Qidi Zhang. Sub-solutions and a point-wise Hopf's lemma for fractional $ p $-Laplacian. Communications on Pure & Applied Analysis, , () : -. doi: 10.3934/cpaa.2020293
Raffaele Folino, Ramón G. Plaza, Marta Strani. Long time dynamics of solutions to $ p $-Laplacian diffusion problems with bistable reaction terms. Discrete & Continuous Dynamical Systems - A, 2020 doi: 10.3934/dcds.2020403
Peter Poláčik, Pavol Quittner. Entire and ancient solutions of a supercritical semilinear heat equation. Discrete & Continuous Dynamical Systems - A, 2021, 41 (1) : 413-438. doi: 10.3934/dcds.2020136
Niklas Sapountzoglou Aleksandra Zimmermann
\begin{document}$ p $\end{document}-Laplace equation with \begin{document}$ L^1 $\end{document}-initial data" readonly="readonly"> | CommonCrawl |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.